CH23-LinkedList
分析完了 List 与 Queue 之后,终于可以看看 LinkedList 的实现了。LinkedList 弥补了 ArrayList 增删较慢的问题,但在查找方面又逊色于 ArrayList,所以在使用时需要根据场景灵活选择。对于这两个频繁使用的集合类,掌握它们的源码并正确使用,可以让我们的代码更高效。
LinkedList 既实现了 List,又实现了 Deque,前者使它能够像使用 ArrayList 一样使用,后者又使它能够承担队列的职责。LinkedList 内部结构是一个双向链表,我们在分析 ArrayDeque 时提到过这个概念,就是扩充单链表的指针域,增加一个指向前一个元素的指针 previous。
AbstractSequentialList
AbstractSequentialList 是 LinkedList 的父级,它继承自 AbstractList,并且是一个抽象类,它主要为顺序表的链式实现提供一个骨架:
This class provides a skeletal implementation of the List interface to minimize the effort required to implement this interface backed by a “sequential access” data store (such as a linked list). For random access data (such as an array), AbstractList should be used in preference to this class.
意思是它的主要作用是提供一个实现 List 接口的骨架,来减少我们实现基于链式存储的实现类时所需的工作量。AbstractSequentialList 并没有做很多特殊的事情,其中最主要的是提供一个方法的默认实现,并将以下方法抽象,以期有更符合场景的实现:
public abstract ListIterator<E> listIterator(int index);
其他一些方法的实现都利用了这个 listIterator 方法,我们不再一一查看了。下面我们分析 LinkedList 的实现。
LinkedList 的结构
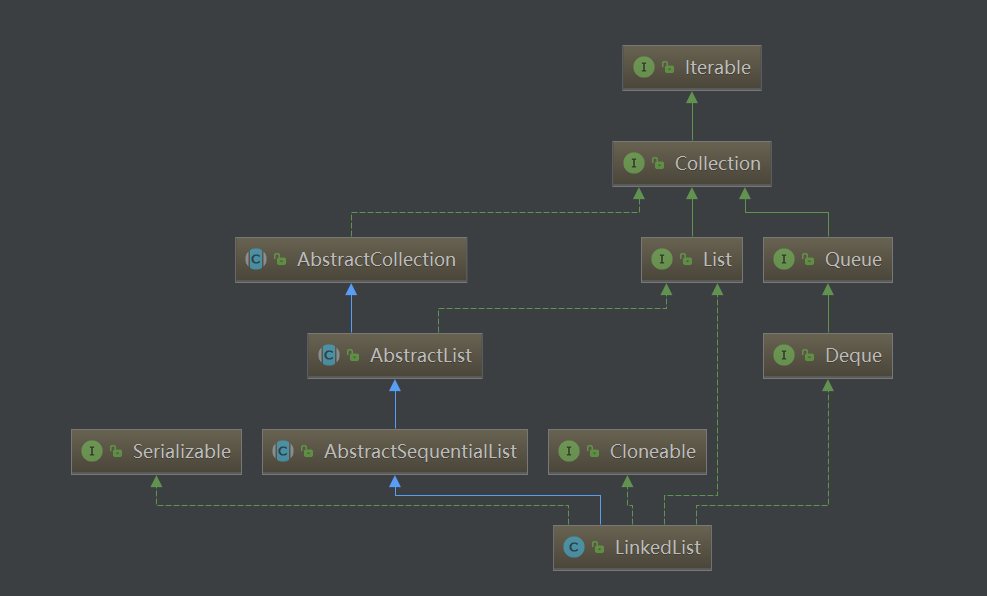
可以看到,LinkedList 也实现了 Cloneable、java.io.Serializable 等方法,借鉴于 ArrayList 的经验,我们可以想到它的 Clone 也是浅克隆,在序列化方法也采用了同样的方式,我们就不再赘述了。
构造方法与成员变量
数据单元 Node
在介绍链表结构时提到过,其数据单元分为数据域和指针域,分别存储数据和指向下一个元素的位置,在 Java 中只要定义一个实体类就可以解决了。
private static class Node<E> {
E item; //数据
Node<E> next; //下一个元素
Node<E> prev; //上一个元素
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
成员变量
LinkedList 成员变量主要有三个,而且其意义清晰可见。
// 记录当前链表的长度
transient int size = 0;
// 第一个节点
transient Node<E> first;
// 最后一个节点
transient Node<E> last;
构造函数
因为链表没有长度方面的问题,所以也不会涉及到扩容等问题,其构造函数也十分简洁了。
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
一个默认的构造函数,什么都没有做,一个是用其他集合初始化,调用了一下 addAll 方法。addAll 方法我们就不再分析了,它应该是和添加一个元素的方法是一致的。
重要方法
LinkedList 既继承了 List,又继承了 Deque,那它必然有一堆 add、remove、addFirst、addLast 等方法。这些方法的含义也相差不大,实现也是类似的,因此 LinkedList 又提取了新的方法,来简化这些问题。我们看看这些不对外的方法,以及它们是如何与上述函数对应的。
//将一个元素链接到首位
private void linkFirst(E e) {
//先将原链表存起来
final Node<E> f = first;
//定义一个新节点,其next指向原来的first
final Node<E> newNode = new Node<>(null, e, f);
//将first指向新建的节点
first = newNode;
//原链表为空表
if (f == null)
//把last也指向新建的节点,现在first与last都指向了它
last = newNode;
else
//把原链表挂载在新建节点,也就是现在的first之后
f.prev = newNode;
size++;
modCount++;
}
//与linkFirst类似
void linkLast(E e) {
//...
}
//在某个非空节点之前添加元素
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
//先把succ节点的前置节点存起来
final Node<E> pred = succ.prev;
//新节点插在pred与succ之间
final Node<E> newNode = new Node<>(pred, e, succ);
//succ的prev指针移到新节点
succ.prev = newNode;
//前置节点为空
if (pred == null)
//说明插入到了首位
first = newNode;
else
//把前置节点的next指针也指向新建的节点
pred.next = newNode;
size++;
modCount++;
}
//删除首位的元素,元素必须非空
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
private E unlinkLast(Node<E> l) {
//...
}
//删除一个指定的节点
E unlink(Node<E> x) {
//...
}
可以看到,LinkedList 提供了一系列方法用来插入和删除,但是却没有再实现一个方法来进行查询,因为对链表的查询是比较慢的,所以它是通过另外的方法来实现的,我们看一下:
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
//可以说尽力了
Node<E> node(int index) {
// assert isElementIndex(index);
//size>>1就是取一半的意思
//折半,将遍历次数减少一半
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
最后,我们看下它如何对应那些继承来的方法:
//引用了node方法,需要遍历
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
//也可能需要遍历
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
//也要遍历
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
public E element() {
return getFirst();
}
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
public E remove() {
return removeFirst();
}
public boolean offer(E e) {
return add(e);
}
public boolean offerFirst(E e) {
addFirst(e);
return true;
}
//...
总结
LinkedList 非常适合大量数据的插入与删除,但其对处于中间位置的元素,无论是增删还是改查都需要折半遍历,这在数据量大时会十分影响性能。在使用时,尽量不要涉及查询与在中间插入数据,另外如果要遍历,也最好使用 foreach,也就是 Iterator 提供的方式。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.