CH21-ArrayQueue
在介绍了 Queue 与 Deque 概念之后,这是要进行分析的第一个实现类。ArrayDeque 可能大家用的都比较少,但其实现里有许多亮点还是值得我们关注的。
Deque 的定义为 double ended queue,也就是允许在两侧进行插入和删除等操作的队列。这个定义看起来很简单,那么我们怎么实现它呢?我们最容易想到的就是使用双向链表。我们在前文介绍过单链表,其每个数据单元都包含一个数据元素和一个指向下一个元素位置的指针 next,这样的链表只能从前向后遍历。如果我们要把它变成双向的,只需要添加一个可以指向上一个元素位置的指针 previous,同时记录下其尾节点即可。LinkedList 的实现就是采用了这一实现方案。
那 ArrayDeque 又是什么,它的结构又是怎样的呢?我们先看下其文档吧:
Resizable-array implementation of the Deque interface. Array deques have no capacity restrictions; they grow as necessary to support usage. They are not thread-safe; in the absence of external synchronization, they do not support concurrent access by multiple threads. Null elements are prohibited. This class is likely to be faster than Stack when used as a stack, and faster than LinkedList when used as a queue.
文档中并没有过多的介绍实现细节,但说它是Resizable-array implementation of the Deque interface,也就是用可动态调整大小的数组来实现了Deque,听起来是不是像ArrayList?但ArrayDeque对数组的操作方式和ArrayList有较大的差别。下面我们就深入其源码看看它是如何巧妙的使用数组的,以及为何说 “faster than Stack when used as a stack, and faster than LinkedList when used as a queue”。
构造函数与重要成员变量
ArrayDeque共有四个成员变量,其中两个我们在分析ArrayList时已经见过了,还有两个我们需要认真研究一下:
//存放元素,长度和capacity一致,并且总是2的次幂
//这一点,我们放在后面解释
transient Object[] elements;
//capacity最小值,也是2的次幂
private static final int MIN_INITIAL_CAPACITY = 8;
//标记队首元素所在的位置
transient int head;
//标记队尾元素所在的位置
transient int tail;
其构造函数共有三个:
//默认构造函数,将elements长度设为16,相当于最小capacity的两倍
public ArrayDeque() {
elements = new Object[16];
}
//带初始大小的构造
public ArrayDeque(int numElements) {
allocateElements(numElements);
}
//从其他集合类导入初始数据
public ArrayDeque(Collection<? extends E> c) {
allocateElements(c.size());
addAll(c);
}
这里看到有两个构造函数都用到了 allocateElements 方法,这是一个非常经典的方法,我们接下来就先重点研究它。
寻找最近的 2 次幂
在定义 elements 变量时说,其长度总是2的次幂,但用户传入的参数并不一定符合规则,所以就需要根据用户的输入,找到比它大的最近的2次幂。比如用户输入13,就把它调整为16,输入31,就调整为32,等等。考虑下,我们有什么方法可以实现呢?
来看下ArrayDeque是怎么做的吧:
private void allocateElements(int numElements) {
int initialCapacity = MIN_INITIAL_CAPACITY;
// Find the best power of two to hold elements.
// Tests "<=" because arrays aren't kept full.
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
if (initialCapacity < 0) // Too many elements, must back off
initialCapacity >>>= 1;// Good luck allocating 2 ^ 30 elements
}
elements = new Object[initialCapacity];
}
看到这段迷之代码了吗?在HashMap中也有一段类似的实现。但要读懂它,我们需要先掌握以下几个概念:
- 在java中,int的长度是32位,有符号int可以表示的值范围是 (-2)31 到 231-1,其中最高位是符号位,0表示正数,1表示负数。
>>>:无符号右移,忽略符号位,空位都以0补齐。|:位或运算,按位进行或操作,逢1为1。
我们知道,计算机存储任何数据都是采用二进制形式,所以一个int值为80的数在内存中可能是这样的:
0000 0000 0000 0000 0000 0000 0101 0000
比80大的最近的2次幂是128,其值是这样的:
0000 0000 0000 0000 0000 0000 1000 0000
我们多找几组数据就可以发现规律:
- 每个2的次幂用二进制表示时,只有一位为 1,其余位均为 0(不包含符合位)。
- 要找到比一个数大的2的次幂(在正数范围内),只需要将其最高位左移一位(从左往右第一个 1 出现的位置),其余位置 0 即可。
但从实践上讲,没有可行的方法能够进行以上操作,即使通过&操作符可以将某一位置 0 或置 1,也无法确认最高位出现的位置,也就是基于最高位进行操作不可行。
但还有一个很整齐的数字可以被我们利用,那就是 2n-1,我们看下 128-1=127 的表示形式:
0000 0000 0000 0000 0000 0000 0111 1111
把它和80对比一下:
0000 0000 0000 0000 0000 0000 0101 0000 //80
0000 0000 0000 0000 0000 0000 0111 1111 //127
可以发现,我们只要把80从最高位起每一位全置为1,就可以得到离它最近且比它大的 2n-1,最后再执行一次+1操作即可。具体操作步骤为(为了演示,这里使用了很大的数字):
首先是原值:
0011 0000 0000 0000 0000 0000 0000 0010
- 无符号右移1位
0001 1000 0000 0000 0000 0000 0000 0001
- 与原值
|操作:
0011 1000 0000 0000 0000 0000 0000 0011
可以看到最高2位都是1了,也仅能保证前两位为1,这时就可以直接移动两位. 3. 无符号右移2位
0000 1110 0000 0000 0000 0000 0000 0000
- 与原值
|操作:
0011 1110 0000 0000 0000 0000 0000 0011
此时就可以保证前4位为1了,下一步移动4位. 5. 无符号右移4位:
0000 0011 1110 0000 0000 0000 0000 0000
- 与原值
|操作:
0011 1111 1110 0000 0000 0000 0000 0011
此时就可以保证前8位为1了,下一步移动8位 7. 无符号右移8位:
0000 0000 0011 1111 1110 0000 0000 0000
- 与原值
|操作:
0011 1111 1111 1111 1110 0000 0000 0011
此时前16位都是1,只需要再移位操作一次,即可把32位都置为1了。 9. 无符号右移16位:
0000 0000 0000 0000 0011 1111 1111 1111
- 与原值
|操作:
0011 1111 1111 1111 1111 1111 1111 1111
- 进行 +1 操作:
0100 0000 0000 0000 0000 0000 0000 0000
如此经过11步操作后,我们终于找到了合适的2次幂。写成代码就是:
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
不过为了防止溢出,导致出现负值(如果把符号位置为1,就为负值了)还需要一次校验:
if (initialCapacity < 0) // Too many elements, must back off
initialCapacity >>>= 1;// Good luck allocating 2 ^ 30 elements
至此,初始化的过程就完毕了。
重要操作方法
add
Deque主要定义了一些关于First和Last的操作,如add、remove、get等。我们看看它是如何实现的吧。
//在队首添加一个元素,非空
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
elements[head = (head - 1) & (elements.length - 1)] = e;
if (head == tail)
doubleCapacity();
}
//在队尾添加一个元素,非空
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
elements[tail] = e;
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();
}
这里,又有一段迷之代码需要我们认真研究了,这也是ArrayDeque值得我们研究的地方之一,通过位运算提升效率。
elements[head = (head - 1) & (elements.length - 1)] = e;
很明显这是一个赋值操作,而且应该是给head之前的位置赋值,所以head = (head - 1)是合理的操作,那这个& (elements.length - 1)又表示什么呢?
在之前的定义与初始化中,elements.length 要求为2的次幂,也就是 2n 形式,那这个 & (elements.length - 1) 也就是 2n-1 了,在内存中用二进制表示就是从最高位起每一位都是1。我们还以之前的127为例:
0000 0000 0000 0000 0000 0000 0111 1111
& 就是按位与,全1才为1。那么任意一个正数和127进行按位与操作后,都只有最右侧7位被保留了下来,其他位全部置0(除符号位),而对一个负数而言,则会把它的符号位置为0,&操作后会变成正数。比如-1的值是1111 … 1111(32个1),和127按位操作后结果就变成了127 。所以,对于正数它就是取模,对于负数,它就是把元素插入了数组的结尾。所以,这个数组并不是向前添加元素就向前扩展,向后添加就向后扩展,它是循环的,类似这样:
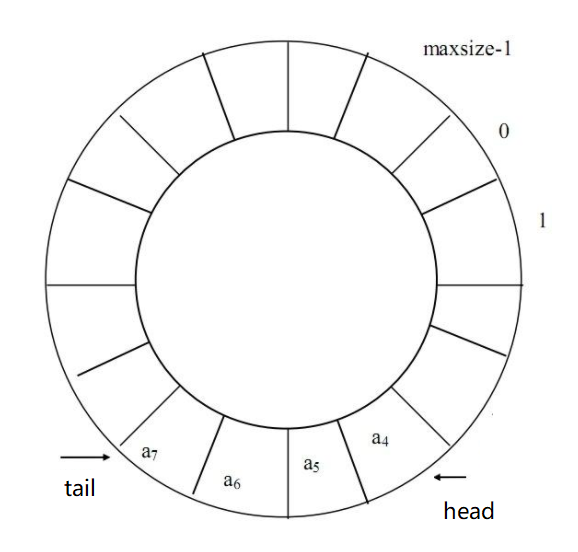
初始时,head 与 tail 都指向 a[0],这时候数组是空的。当执行 addFirst() 方法时,head 指针移动一位,指向 a[elements.length-1],并赋值,也就是给 a[elements.length-1] 赋值。当执行 addLast() 操作时,先给 a[0] 赋值,再将 tail指针移动一位,指向 a[1]。所以执行完之后head指针位置是有值的,而 tail 位置是没有值的。
随着添加操作执行,数组总会占满,那么怎么判断它满了然后扩容呢?首先,如果 head==tail,则说明数组是空的,所以在添加元素时必须保证 head 与 tail 不相等。假如现在只有一个位置可以添加元素了,类似下图:

此时,tail 指向了 a[8],head已经填充到 a[9] 了,只有 a[8] 是空闲的。很显然,不管是 addFirst 还是 addLast,再添加一个元素后都会导致 head==tail。这时候就不得不扩容了,因为 head==tail 是判断是否为空的条件。扩容就比较简单了,直接翻倍,我们看代码:
private void doubleCapacity() {
//只有head==tail时才可以扩容
assert head == tail;
int p = head;
int n = elements.length;
//在head之后,还有多少元素
int r = n - p; // number of elements to the right of p
//直接翻倍,因为capacity初始化时就已经是2的倍数了,这里无需再考虑
int newCapacity = n << 1;
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
Object[] a = new Object[newCapacity];
//左侧数据拷贝
System.arraycopy(elements, p, a, 0, r);
//右侧数据拷贝
System.arraycopy(elements, 0, a, r, p);
elements = a;
head = 0;
tail = n;
}
分析完add,那么get以及remove等都大同小异,感兴趣可以查看源码。我们还要看看在Deque中定义的removeFirstOccurrence和removeLastOccurrence方法的具体实现。
Occurrence 相关
removeFirstOccurrence 和 removeLastOccurrence 分别用于找到元素在队首或队尾第一次出现的位置并删除。其实现原理是一致的,我们分析一个即可:
public boolean removeFirstOccurrence(Object o) {
if (o == null)
return false;
int mask = elements.length - 1;
int i = head;
Object x;
while ( (x = elements[i]) != null) {
if (o.equals(x)) {
delete(i);
return true;
}
i = (i + 1) & mask;
}
return false;
}
这里就是遍历所有元素,然后通过delete方法删除,我们看看delete实现:
private boolean delete(int i) {
//检查
checkInvariants();
final Object[] elements = this.elements;
final int mask = elements.length - 1;
final int h = head;
final int t = tail;
//待删除元素前面的元素个数
final int front = (i - h) & mask;
//待删除元素后面的元素个数
final int back = (t - i) & mask;
// Invariant: head <= i < tail mod circularity
//确认 i 在head和tail之间
if (front >= ((t - h) & mask))
throw new ConcurrentModificationException();
// Optimize for least element motion
//尽量最少操作数据
//前面数据比较少
if (front < back) {
if (h <= i) {
//这时 h 和 i 之间最近距离没有跨过位置0
System.arraycopy(elements, h, elements, h + 1, front);
} else { // Wrap around
System.arraycopy(elements, 0, elements, 1, i);
elements[0] = elements[mask];
System.arraycopy(elements, h, elements, h + 1, mask - h);
}
elements[h] = null;
head = (h + 1) & mask;
return false;
} else {
if (i < t) { // Copy the null tail as well
//这时 t 和 i 之间最近距离没有跨过位置0
System.arraycopy(elements, i + 1, elements, i, back);
tail = t - 1;
} else { // Wrap around
System.arraycopy(elements, i + 1, elements, i, mask - i);
elements[mask] = elements[0];
System.arraycopy(elements, 1, elements, 0, t);
tail = (t - 1) & mask;
}
return true;
}
}
总结
ArrayDeque 通过循环数组的方式实现的循环队列,并通过位运算来提高效率,容量大小始终是2的次幂。当数据充满数组时,它的容量将翻倍。作为Stack,因为其非线程安全所以效率高于 java.util.Stack,而作为队列,因为其不需要结点支持所以更快(LinkedList使用Node存储数据,这个对象频繁的new与clean,使得其效率略低于ArrayDeque)。但队列更多的用来处理多线程问题,所以我们更多的使用 BlockingQueue,关于多线程的问题,以后再认真研究。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.