CH02-哈希表
无论是数组还是链表,其对数据的查询表现都比较无力,要想知道一个元素是否在数组或链表中,只能从前向后挨个对比。出现这个问题的根源在于,我们没有办法直接根据一个元素找到它存储的位置,那有没有办法消除这个对比的过程呢?
哈希表就是解决查询问题的一种方案。在后续将会分析的二叉排序树中,还会将数据排序以进行二分查找,将时间复杂度从 O(n) 降低到 O(lg n)。
哈希表与 hash 函数
通俗来讲,哈希表就是通过关键字来获取数据的一种数据结构,它通过把关键字映射为表中的位置来获取元素,这种映射主要是使用 Hash 函数。
Hash 函数,实际上是建立起 key 值与 int 值映射关系的函数。这就好比我们每个人都有一个身份证号一样,无论是男是女,出生在何处,都可以通过身份证号来分辨,这就是把人的信息映射成一串数字的典型做法。Hash 函数和此类似,不过是把任意的 Java 对象,映射成一个 int 数值,供哈希表使用。
而哈希表,就是一个数组,只是其元素不是按照数组的规则排列的。任何一个元素要放进哈希表中,都必须先通过 Hash 函数获取到一个 int 数值,这个数值经过处理后将作为它的存放位置,然后这个元素才能放进哈希表中。
可以发现,数组与哈希表的操作不同之处主要在于,前者是直接插入,后者需要通过 Hash 函数计算后再插入。可以通过下图对比来理解:

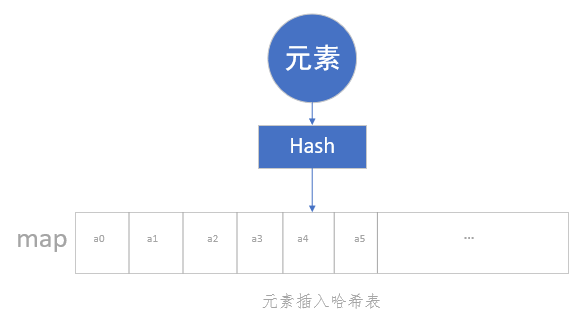
哈希表完全继承了数组的优点,又显著的提高了查询的速度,通过 Hash 函数使得查询速度达到了 O(1)。既然有了哈希表,它这么优秀,为何还需要数组的存在呢?那是因为 Hash 表是有缺陷的,这个缺陷就是哈希碰撞。
哈希碰撞
Hash 函数所做的事,就是无论什么对象,都根据一个规则映射为一个 int 值。被转换的对象有无数种可能,但是 int 的值是有限的,它只有 2^32 个,这样一来,必然会有不同的对象,映射得到相同的 int 值,这就是所谓的哈希碰撞。发生碰撞之后,就要把不同的元素插入到相同的位置,这时候单纯的使用一维数组已经无法满足需求了。
解决哈希碰撞
要解决哈希碰撞,我们可以想到多种解决方案。例如使用二维数组,将碰撞的元素按顺序存储起来,类似下图:
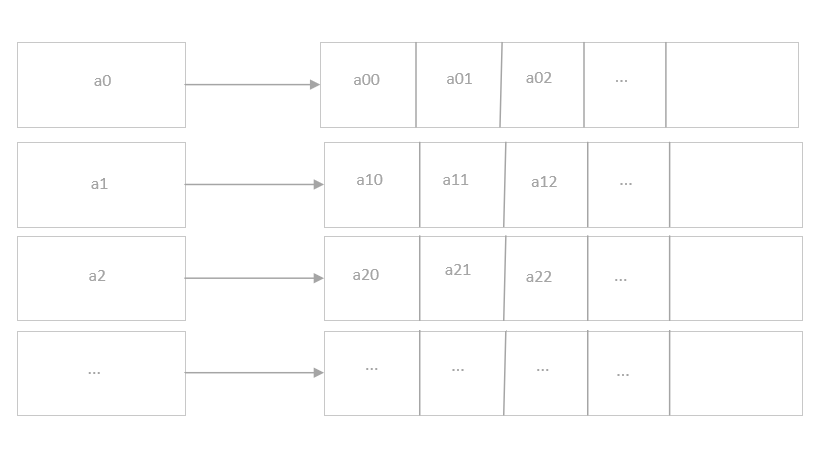
这样的方式有一个很大的诟病,因为数组大小是固定的,所以第二维的数组长度都是一样的,但是哈希碰撞一定是比较少发生的情况,也就是我们声明了一个很大的数组,但是其中大部分都是闲置的,这就浪费了大量的内存。
还有一些方案是考虑了哈希表的散列化,将元素插入到空闲的位置去。因为哈希表基本不会像数组一样每个位置都有元素,这样就可以将碰撞的元素插入到这些空闲的位置中区,这种方案称为定址法。但是这个方法在扩展性上表现不佳,我们这里就不再浪费篇幅来解释它了。
目前比较通用的方法,就是使用数组+链表组合的方式。当出现哈希碰撞时,在该位置的数据就通过链表的方式链接起来,如下图所示:
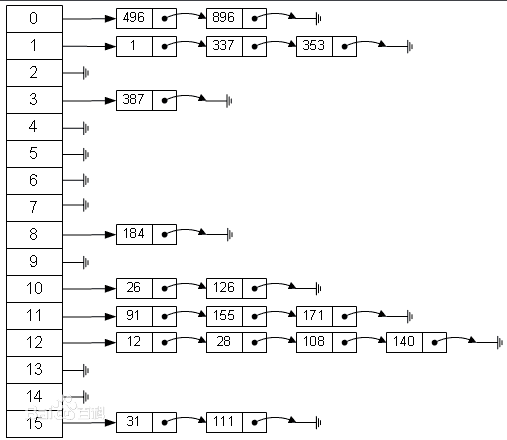
这是当前比较理想的方法,既继承了数组的优点,又在碰撞时继承了链表的优点,这也是哈希表强大的地方之一。
在 JDK1.7 及之前的版本中,HashMap 的存储结构和上图是一致的,在 JDK1.8 之后还加入了红黑树以进一步优化,在后续文章中我们会对其进行详尽的分析。
哈希表的优缺点
哈希表是一种优化存储的思想,具体存储元素的依然是其他的数据结构。设计良好的哈希表,能同时兼备数组和链表的优点,它能在插入和查找时都具备良好的性能。然而设计不好的哈希表,有可能会出现较多的哈希碰撞,导致链表过长,从而哈希表会更像一个链表。还有当数据量很大时,为防止链表过长,就需要对数组进行扩容,这时就涉及到了数组的拷贝,其对性能的影响也很严重,所以需要提前对可能的情况有良好的预测,才能真正发挥哈希表的优势。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.