CH02-JMM Explain
多任务和高并发的内存交互
多任务和高并发是衡量一台计算机的处理能力的重要指标之一。一般衡量一个服务器性能的高低好坏,使用每条事务处理数(Transcations Per Second, TPS),该指标比较能够说明问题,它代表着一秒内服务器平均能够响应的请求数,而 TPS 值与程序的并发能力有着非常密切的关系。“物理机”的并发问题与“虚拟机”中的情况有很多相似之处,物理机对并发的处理方案对于虚拟机的实现也有相当大的参考意义。
由于计算机的存储设备与处理器的运算能力之间有着几个数量级的差距,所以现代计算机系统都不得不加入一层读写速度尽可能接近处理器运算速度的“高速缓存(cache)”来作为内存与处理器之间的缓冲:将运算需要使用到的数据复制到缓存中,让运算能够快速运行;当运算结束后再将数据从缓存同步会内存之中,这样一来处理器就无需等待缓慢的内存读写了。
基于高速缓存的存储交互很好的解决了处理器与内存的速度矛盾,但是引入了一个新的问题:“缓存一致性(Cache Coherence)”。在多处理器系统中,每个处理器都有自己的高速缓存,而它们又共享同一主存,如下图所示:多个处理器运算任务都涉及同一块主存,需要一种协议可以保障数据的一致性(及多个处理器看到相同的数据),这类协议有 MSI/MESI/MOSI/Dragon Protocl 等。
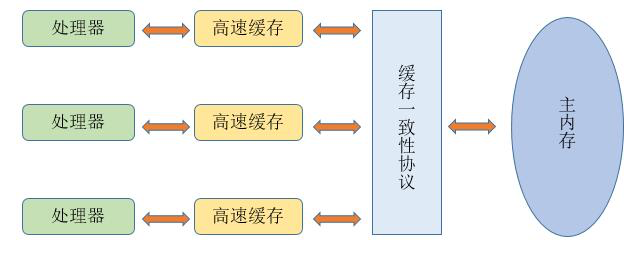
除此之外,为了使得处理器内部的运算单元能尽可能被充分利用,处理器可能会对输入代码进行“乱序执行(Out-Of-Order Execution)”优化,处理器会在计算之后将对乱序执行的代码进行结果重组,以保证结果的准确性。与处理器的乱序执行优化类似,Java 虚拟机的即时编译器(JIT)中也有类似的“指令重排序(Instruction Recorder)”优化。
Java 内存模型
内存模型可以理解为在特定的操作协议下,对特定的内存或告诉缓存进行读写访问的过程抽象,不同架构下的物理机拥有不同的内存模型,Java 虚拟机也有自己的内存模型,即“Java 内存模型(JMM)”。在 C/C++ 语言中则是直接使用物理硬件和操作系统的内存模型,导致不同平台下并发访问出错,需要进行多平台的兼容。而 JMM 的出现,能够屏蔽掉各种硬件和操作系统的内存访问差异,实现平台一致性,使得 Java 程序能够“一次编写,到处运行”。
主内存与工作内存
Java 内存模型的目的主要是“定义程序中各个变量的访问规则”,即在虚拟机中将变量存储到内存和从内存中取出变量这样的底层细节。此处的变量与进行 Java 编程时所说的变量不同,包括了实例字段、静态字段、数组元素,但是不包括局部变量与方法参数,因为后者是线程私有的,永远不会被共享。
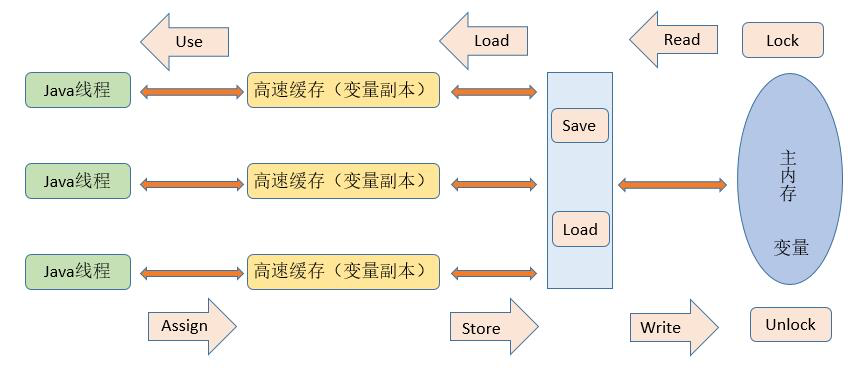
Java 内存模型中规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存(可以与前面所说的处理器的高速缓存类比),线程的工作内存中使用到的变量到主内存副本拷贝,线程对变量的所有操作(读取、赋值)都必须在工作内存中进行,而不能直接读写主内存中的变量。不同线程之间无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成,线程、主内存和工作内存之间的交互关系如下图:
@@@ note
这里的主内存、工作内存与 Java 内存区域的 Java 堆、栈、方法区不是同一层次的内存划分,两者之间没有关系。
@@@
内存交互操作
由上面的交互关系可知,关于主内存与工作内存之间的具体交互协议,即一个变量如何从主内存拷贝到工作内存、如何从工作内存同步到主内存之间的实现细节,Java 内存模型定义了以下 8 种操作来完成:
- lock:作用于主内存的变量,把一个变量标识为由一条线程独占的状态。
- unlock:作用于主内存的变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
- read:作用于主内存的变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的 load 动作使用。
- load:作用于工作内存变量,把 read 操作从主内存得到的变量值放入工作内存的变量副本中。
- use:作用于工作内存变量,把工作内存变量的值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行该操作。
- assign:作用于工作内存变量,它把一个从执行引擎接收到的值赋值给工作内存变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行该操作。
- store:作用于工作内存变量,把工作内存变量值传送给主内存,以便随后的 write 操作。
- write:作用于主内存的变量,它把 store 操作从工作内存中得到的变量值传送到主内存的变量中。
如果要把一个变量从主内存复制到工作内存,就需要按序执行 read 和 load 操作;如果把变量从工作内存中同步到主内存中,就需要按序执行 store 和 write 操作。JMM 只要求上述两个操作“必须按序执行,而没有保证必须是连续执行”。也就是说在 read 和 load 之间、store 和 write 之间可以插入其他指令,如对主内存中的变量 a、b 进行访问时,可能顺序是 read a、read b、load b、load a。JMM 还规定了在执行上述 8 种基本操作时,必须满足如下规则:
- 不允许 read 和 load、store 和 write 操作之一单独出现。
- 不允许一个线程丢弃它最近的 assign 操作,即变量在工作内存中改变了之后必须同步回主内存中。
- 不允许一个线程无原因的(没有发生过任何 assign 操作)把数据从工作内存同步回主内存中。
- 一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(load、assign)的变量。即在对一个变量实施 use 和 store 操作之前,必须已经对该变量执行过了 assign 和 load 操作。
- 一个变量在同一时刻只允许一条线程对其进行 lock 操作,lock 和 unlock 必须成对出现。
- 如果对一个变量执行 lock 操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前需要重新执行 load 或 assign 操作来初始化该变量的值。
- 如果一个变量事先没有被 lock 操作锁定,则不允许对其执行 unlock 从操作;也不允许去 unlock 一个被其他线程锁定的变量。
- 对一个变量执行 unlock 操作之前,必须先把该变量同步到主内存中(执行 store 和 write操作)。
这 8 中内存访问操作很繁琐,后文会使用一个等效判断原则,即先行发生(happens before)原则来确定一个内存访问在并发环境下是否安全。
volatile 变量
关键字 volatile 是 JVM 中最轻量级的同步机制。volatile 变量具有两种特性:
- 保证变量的可见性。对一个 volatile 变量的读,总是能看到(任意线程)该 volatile 变量最后的写入,这个新值对于其他线程来说是立即可见的。
- 屏蔽指令重排序。指令重排序是编译器和处理器为了执行效率而对程序执行的优化手段,后文有详细分析。
volatile 语义并不能保证变量的原子性。对任意单个 volatile 变量的读/写具有原子性,但类似自增、自减这种复合操作不具有原子性,因为自增运算包括取值、加 1、重新赋值这 3 步操作,并不具备原子性。
由于 volatile 只能保证变量的可见性和屏蔽指令重排,只有满足以下两条规则时,才能使用 volatile 来保证并发安全,否则就需要加锁(使用 synchronized、lock、JUC 中的 Atomic 原子类)来保证并发中的原子性:
- 运算结果不存在数据依赖(重排序的数据依赖性),或者仅有单一的线程修改变量的值(重排序的 as-if-serial 语义)。
- 变量不需要与其他的状态变量共同参与不变约束。
因为需要在本地代码中插入许多内存屏障指令来屏蔽特定条件下的重排序,volatile 变量的写操作与读操作相比慢一些,但是其性能开销比锁低很多。
long/double 非原子协定
JMM 要求 lock、unlock、read、load、assign、use、store、write 这 8 个操作都必须具有原子性,但对于 64 位的数据类型 long 和 double,具有非原子协定:允许虚拟机经没有被修饰为 volatile 的 64 位数据的读写操作划分为两次 32 位的操作进行。(于此类似的是,在栈帧结构的局部变量表中,long 和 double 类型的局部变量可以使用 2 个能存储 32 位变量的变量槽来存储,详见“深入理解 Java 虚拟机” 第 8 章)
如果多个线程共享一个没有声明为 volatile 的 long 或 double 变量,并且同时执行存取操作,某些线程可能会读到一个即非原值、又非其他线程修改了的代表了“半个变量”的数值。不过这种情况十分罕见。因为非原子协定换句话说,同样允许 long 和 double 的读写操作实现为原子操作,并且目前绝大多数虚拟机都是这样做的。
原子性、可见性、有序性
原子性
JMM 保证的原子性变量操作包括 read、load、assign、use、store、write,而 long 和 double 非原子协定导致的非原子性操作基本可以忽略。如果需要对更大范围的代码实行原子性操作,则需要使用 JMM 提供的 lock、unlock、synchronized。
可见性
前面分析 volatile 语义时已经提到,可见性是指当一个线程修改了变量的值,其他线程能够立即得知这个修改。JMM 在变量被修改后将新值重新同步回主内存,依赖主内存作为媒介,在变量被线程读取前从内存刷新变量新值,保证变量的可见性。普通变量和 volatile 变量都是如此,只不过 volatile 的特殊规则保证了这种可见性是立即得到的,而普通变量并不具备这样严格的可见性。除了 volatile 外,synchronized 和 final 也能保证可见性。
有序性
JMM 的有序性表现为:如果在本线程内观察,所有操作都是有序的;如果在一个线程中观察另一个线程,所有操作都是无序的。前半句指“线程内表现为串行语义(as-if=serial)”,后半句指“指令重排序”和变量的“工作内存与主内存的同步延迟”现象。
重排序
在执行程序时为了提高性能,编译器和处理器经常会对指令进行重排序。从硬件架构上来说,指令重排序是指 CPU 采用了允许将多条指令不再按照程序规定的顺序,分开发送给相应电路单元处理器,而不是将指令任意重排。重排序分为 3 种类型:
- 编译器优化重排序。编译器在不改变单线程程序语义的前提下,可以重新安排程序的执行顺序。
- 指令级并行重排序。先来处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
- 内存系统重排序。由于处理器使用缓存和读写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。

JMM 重排序屏障
从 Java 源代码到最终实际执行的指令序列,会经过 3 种重排序。但是为了保证内存的可见性,Java 编译器会在生成的指令序列的适当位置插入内存屏障指令来禁止特定类型的处理器重排序。对于编译器的重排序,JMM 会根据重排序规则禁止特定类型的编译器重排序;对于处理器重排序,JMM 会插入特定类型的内存屏障,通过内存的屏障指令来禁止特定类型的处理器重排序。这里讨论 JMM 对处理器的重排序,为了更深刻理解 JMM 对处理器重排序的处理,先来认识一下常见处理器的重排序规则:
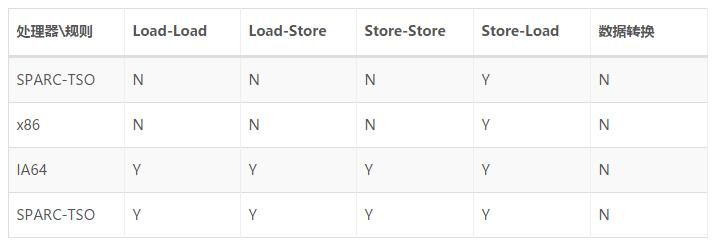
其中的 N 表示处理器不允许两个操作进行重排序,Y 表示允许。可以看出:常见处理器你对 StoreLoad 都是允许重排的,并且常见处理器都不允许对存在数据依赖的操作进行重排序。另外,对应数据转换这一列都为 N,所以处理器均不允许这种重排序。
那么这个结论有什么用呢?比如第一点:处理器允许 StoreLoad 操作的重排序,那么在并发编程中读线程可能读到一个未被初始化或 null 值,出现不可预知的错误,基于这一点,JMM 会在适当的位置插入内存屏障指令来禁止特定类型的处理器重排序。
内存屏障指令共有 4 类:LoadLoad、StoreStore、LoadStore、StoreLoad。详细释义参考 JMM 规范。
数据依赖性
根据上面的表格,处理器不会对存在数据依赖性的操作进行重排序。这里数据依赖性的准确定义是:如果两个操作访问同一个变量,其中一个操作是写,此时两个操作就构成了数据依赖性。常见的具有这种特点的操作有自增、自减。如果改变了具有数据依赖性的两个操作的执行顺序,那么最后的执行结果就会被改变。这也就是不能进行重排序的原因。
- 写后读:
a = 1; b = a; - 写后写:
a = 1; a = 2; - 读后写:
a = b; b = 1;
重排序遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行属性怒。但是这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。
as-if-serial 语义
as-if-serial 语义指的是:“无论怎么重排序,(单线程)程序的执行结果不能被改变”。编译器、runtime 和处理器都必须遵守 as-if-serial 语义。
as-if-serial 语义把单线程程序保护了起来,遵守 as-if-serial 语义的编译器,runtime 和处理器共同为编写单线程程序的开发者穿件了一个幻觉:单线程程序是按程序编写的顺序来执行的。as-if-serial 语义使单线程开发者无需单行重排会干扰他们,也无需担心内存可见性问题。
重排序对多线程的影响
如果代码中存在控制依赖,会影响指令序列执行的并行度。因此,编译器和处理器会采用猜测(speculation)执行来克服控制的相关性。所以重排序破坏了程序的顺序规则(该规则是说指令顺序与实际代码的执行顺序是一致的,但是处理器和编译器会进行重排序,只要最后的结果不变,重排序就是合理的)。
先行发生原则(happens-before)
前面所说的内存交互原则都必须满足一定的规则,而 happens-before 就是定义这些规则时的一个等效判断的原则。happens-before 是 JMM 定义的、两个操作之间的偏序关系:如操作 A 线程发生于操作 B,则 A 产生的影响能够被 B 观察到,“影响”包括了修改了内存中共享变量的值、发送了消息、调用了方法等。如果两个操作满足 happens-before 原则,那么就不需要进行同步操作,JVM 能够保证操作具有顺序性,此时不能随意进行重排序。否则,无法保证顺序性,就能进行指令的重排序。
happens-before 原则主要包括:
- 程序次序原则
- 管理锁定原则
- volatile 变量规则
- 线程启动规则
- 线程终止规则
- 线程中断规则
- 对象终结规则
- 传递性
详细释义参见 JMM 规范。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.