This the multi-page printable view of this section. Click here to print.
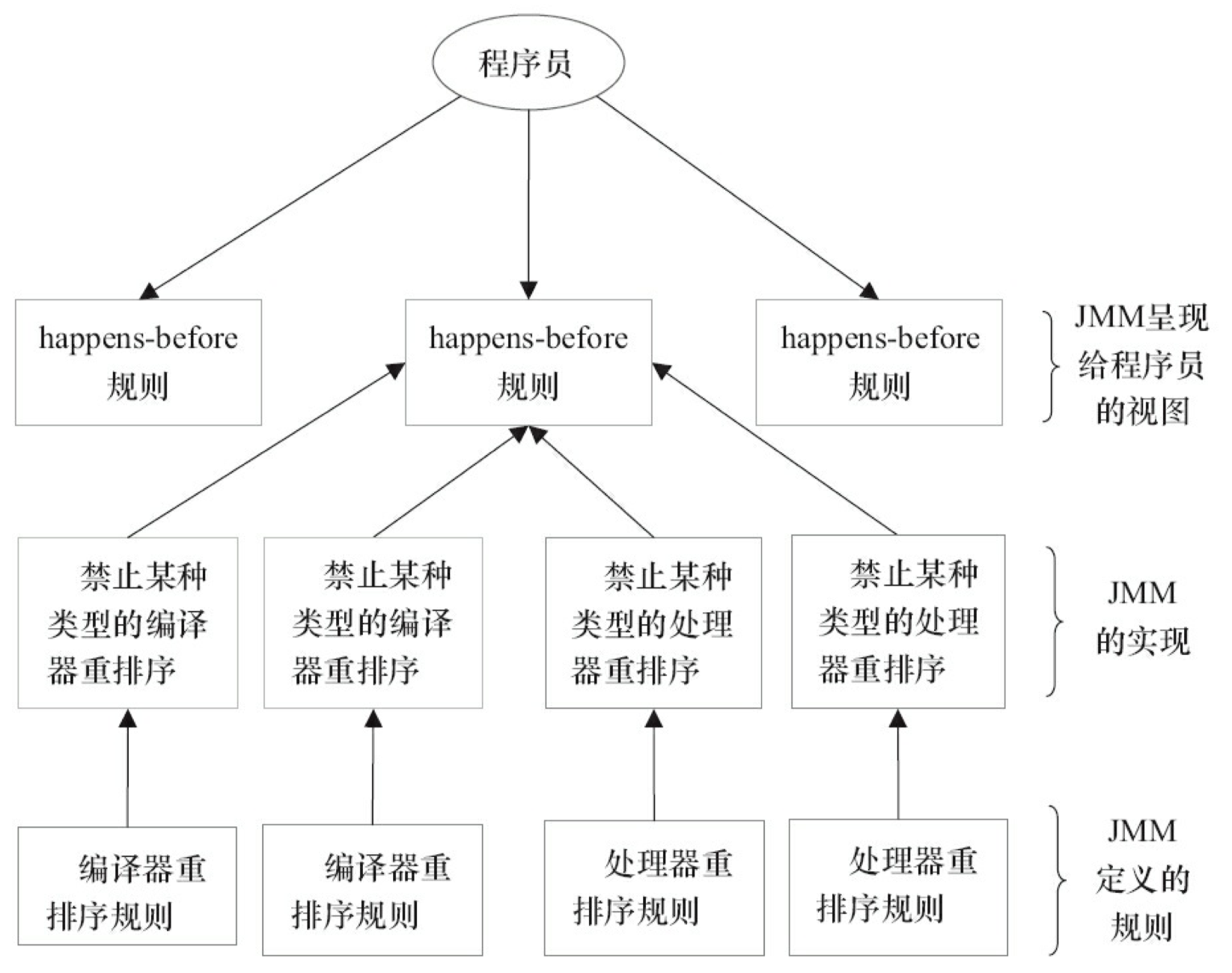
JMM 规范
1 - CH01-JMM规范
The Java ® Language Specification SE 8 - Chapter 17 Threads and Locks
Java 内存模型定义了线程之间如何通过内存进行交互,是深入学习 Java 并发编程的必要前提。
Java 虚拟机可以支持多线程同时执行。这些线程可以独立的对驻留在内存中的值和对象执行操作代码。对这些线程的支持,可以是多硬件处理器,也可以是单硬件处理器的时间片机制,或者是多硬件处理器的时间片机制。
线程由 Thread 类表示。对用户来说,创建线程的唯一方式就是创建该类的对象,每个线程都和一个这样的对象关联。在 Thread 类的对象上调用 start 方法将会启动对应的线程。
在进行不正确的同步操作时,可能会引起线程行为的混淆与反常。本章描述的是多线程的语义,其中包含以下规则:若主存(内存)是由多个线程更新的,那么对主存的读操作可以看到哪些值。 因为这些规范与针对不同硬件架构的“内存模型”类似,因此也被称为“Java 编程语言内存模型”。当不会产生任何混淆时,我们将直接称这些规则为“内存模型”。
这些语义并未规定多线程程序应该如何执行,它们描述的是多线程程序允许展示出来的行为。
同步
Java 语言为线程间通信提供了多种机制,这些方法中最简单的就是“同步(synchronization)”,它是使用“监视器(monitor)”实现的。Java 中每个对象都与一个可以被线程锁定或解锁的监视器相关联。在任何时刻,只有一个线程可以持有某个监视器上的锁。任何其他试图锁定该监视器的线程都将被阻塞,直至它们可以获得该监视器上的锁。一个线程可以多次锁定某个指定的监视器,每个解锁操作都会抵消前一次锁定。
synchronized 语句计算的是对象的引用,然后试图锁定该对象的监视器,并且在锁定动作完成之前,不会执行下一个动作。在锁定动作执行之后,synchronized 语句体被执行。如果该语句体执行结束,无论是正常结束还是猝然结束,都会在之前锁定的监视器上执行解锁操作。
synchronized 方法在被调用时会自动执行锁定动作,它的方法体在该锁定动作完成之前是不会被执行的。如果该方法是实例方法,那么会锁定调用该实例方法的对象所关联的监视器。如果该方法是静态方法,那么它会锁定定义该方法的类的 Class 对象相关联的监视器。如果该方法体执行结束,无论是正常结束还是猝然结束,都会在之前锁定的监视器上执行解锁操作。
Java 编程语言既不阻止也不要求对死锁情况的探测。线程(间接或直接)持有多个对象上的锁的的程序应该使用避免死锁的惯用技术,如果必要的话,可以创建更高级别的不会产生死锁的锁定原语。
其他机制,如 volatile 变量的读写和对 JUC 包中的类的使用,都提供了可替代的同步方式。
等待集合通知
每个对象除了拥有关联的监视器,还拥有关联的“等待集”,即一个线程集。
当对象最先被创建时,它的等待集为空。向等待集中添加或移除线程的基础动作都是原子性的。等待集只能通过 Object.wait、Object.notify、Object.notifyAll 方法进行操作。
等待集的操作还会受到线程的中断和 Thread 类中用于处理中断的方法的影响。另外,Thread 类中用于睡眠和连接其他线程的方法也具有从等待和通知动作中导出的属性。
等待
调用 wait() 时,或者调用具有定时机制的 wait(long millisecs) 和 wait(long millisecs, int nanosecs) 时会发生“等待动作”。
向带有定时机制的 wait 方法传入参数值 0 等同于调用没有定时机制的 wait 方法。
如果线程返回时没有抛出 InterruptedException 异常,那么该线程就是正常返回的。
设线程 t 在对象 m 上执行 wait 方法,n 是线程 t 在对象 m 上尚未解锁的锁定动作的数量,那么将会发生下列动作之一:
- 如果 n 是 0(即线程 t 还没有锁定目标 m),那么会抛出 IllegalMonitorStateException。
- 如果是定时的等待,并且 nanosecs 的范围不在 0~999999 范围内,或者 millisecs 是负数,那么将会抛出 IllegalArgumentException。
- 如果线程 t 被中断,那么会抛出 InterruptedException,并且 t 的中断状态会被设为 false。
- 除此之外,会执行下面的序列:
- 线程 t 被添加到对象 m 的等待集,并且在 m 上执行 n 个解锁动作。
- 线程 t 不执行任何更进一步的指令,直到它从 m 的等待集中移除。线程 t 可以因下列任何一个动作而从等待集中移除,并在之后某个时刻继续执行:
- 在 m 上执行 notify 动作,在该动作中 t 被选中并从等待集中移除。
- 在 m 上执行 notifyAll 动作。
- 在 t 上执行 interrupt 动作。
- 如果是定时等待,那么在从该等到动作开始至少 millisecs 毫秒加上 nanosecs 纳秒的时间流逝之后,一个内部动作将 t 从 m 的等待集中移除。
- 内部动作由 Java 编程语言的实现执行。我们允许但不鼓励 Java 编程语言的实现执行的是“欺骗性唤醒”,即将线程从等待集中移除,由此无需显式指令就可以使得线程能够继续执行。
- 线程 t 在 m 上执行 n 个锁定操作。
- 如果线程 t 在第 2 步因为竞争而从 m 的等待集中被移除,那么 t 的中断状态会被设置为 false,并且 wait 方法会抛出中断异常。
@@@ note
第 2 条款迫使开发者必须循序以下 Java 编码习惯:对于在线程等待某个逻辑条件满足时才会终止的循环,才适合使用 wait。
@@@
每个线程必须确定可以引发从等待集中被移除的事件顺序。该顺序不必与其他排序方式一致,但是线程的行为必须是看起来就像这些事件是按照这个顺序发生的一样。
例如,如果线程 t 在 m 的等待集中,并且 t 的中断和 m 的通知都发生了,那么这些事件必然有一个顺序。如果中断被认为首先发生,那么 t 最终会抛出中断异常而从 wait 返回,并且位于 m 的等待集的另一个线程(如果在发通知时存在的话)必须收到这个通知;如果通知被认为首先发生,那么 t 最终会从 wait 中正常返回,而中断将被悬挂。
通知
调用 notify 或 notifyAll 时发生通知动作。
设线程 t 在对象 m 上执行这两个方法,n 是线程 t 在对象 m 上尚未解锁的锁定动作的数量,那么将会发生下列动作之一:
- 如果 n = 0,将会抛出非法监视器状态异常。这种情况表示线程 t 还没有处理目标 m 的锁。
- 如果 n > 0,并且是 notify 动作,那么如果 m 的等待集不为空,那么作为 m 的当前等待集中的成员线程 u 将被选中并从等待集中移除。不能保证等待集中哪个线程会被选中。从等待集中移除使得 u 可以在等待动作中继续。但是,需要注意 u 在继续执行时的加锁动作只有在 t 完全解锁 m 的监视器之后的某个时刻才能成功。
- 如果 n > 0,并且是 notifyAll 动作,那么所有线程都会从 m 的等待集中移除,因此也就都可以继续执行。
但是需要注意,其中每次仅有一个线程可以在等待过程中锁定所需的监视器。
中断
调用 Thread.interrupt 或 ThreadGoup.interrupt 方法时,发生中断动作。
设 t 是调用 u.interrupt 的线程,其中 u 是某个线程,t 和 u 可以相同。该调用动作会使得 u 的中断状态被设置为 true。
另外,如果存在某个对象 m,其等待集合包含 u,那么 u 会从 m 的等待集合中移除。这使得 u 从等待动作中恢复,在这种情况下,这个等待在重新锁定 m 的监视器之后,会抛出中断异常。
调用 Thread.isInterrupted 可以确定线程的中断状态。静态方法 Thread.interrupted 可以被线程调用以观察和清除自身的中断状态。
等待、通知、中断之间的交互
如果线程在等待时被通知了然后又被中断,那么它可以:
- 从 wait 中正常返回,尽管仍然具有悬挂的中断。
- 从 wait 中抛出中断异常。
线程不可以重置它的中断状态并从对 wait 的调用中返回。类似的,通知不能因中断而丢失。假设线程集 s 在对象 m 的等待集中,另一个线程在 m 上执行另一个 notify,那么:
- s 中至少有一个线程必须从 wait 中正常返回。
- s 中所有线程都必须抛出中断异常并退出 wait。
@@@ note
如果一个线程被 notify 中断和唤醒,并且该线程以抛出中断异常的方式从 wait 返回,那么在等待集中的其他线程必须必通知。
@@@
睡眠与让步
Thread.sleep 会导致当前运行的线程睡眠(暂时中止执行)指定的一段时间,具体时间取决于系统定时器和调度器的精确度。睡眠的线程不会丧失对任何监视器的所有权,而继续执行的时机则依赖于执行该线程的处理器的调度时机和可用性。
注意到这一点很重要:无论是 Thread.sleep 还是 Thread.yield 都没有任何同步语义。特别是,编译器不必在调用 Thread.sleep 或 Thread.yield 之前将寄存器中缓存的写操作冲刷到共享内存中,也不必在调用 Thread.sleep 或 Thread.yield 之后重新加载寄存器中缓存的值。
例如在下面的代码中,假设 this.done 是非 volatile 的 boolean 域:
while(!this.done)
Thread.sleep(1000);
编译器可以只读取 this.done 一次,并且在循环中的每次迭代中重用缓存的值。这意味着即使另一个线程修改了 this.done 的值,该循环永远也不会停止。
内存模型
给定一个程序和该程序的执行轨迹,“内存模型”可以描述该执行轨迹是否是该程序的一次合法执行。Java 编程语言的内存模型是通过以下方式实现的:查验执行轨迹中的每个读操作,并依据特定的规则检查该读操作所观察到的写操作是否有效。
内存模型描述了程序的潜在行为。Java 语言的实现可以按照其喜好来产生任何代码,只要程序的执行过程都会产生内存模型可以预测的结果。
这为 Java 语言的实现者提供了很大的自由度去执行大量的代码转换,包括重排序动作和移除不必要的同步。
示例:不正确的同步程序会展示惊人的行为
Java 编程语言的语义允许编译器和微处理器执行优化,与未正确同步的代码进行交互,而这种交互方式可能会产生看起来很荒谬的行为。下面的几个示例展示了未正确同步的程序可能会展示出惊人的行为。
例如,考虑下表中展示的样例程序轨迹。该程序使用了局部变量 r1 和 r2、共享变量 A 和 B。最初 A==B==0:
| Thread 1 | Thread 2 |
|---|---|
| 1: r2 = A; | 3: r1 = B; |
| 2: B =1; | 4: A = 2; |
看起来好像不可能产生 r2==2 和 r1==1 这样的结果。直觉上,在某次执行中,要么是指令 1,要么是指令 3 先到。如果是指令 1 先到,那么它应该看不到指令 4 的写操作。如果指令 3 先到,那么它应该看不到指令 2 的写操作。
如果某次执行确实展示了这种行为,即产生 r2==2 和 r1==1 这样的结果,那么我们就知道指令的顺序是 4、1、2、3,这表面上看起来很荒谬。
但是,编译器可以对其中一个线程的指令进行重排序,只要重排序不会影响该线程单独执行时的效果即可。如果指令 1、2 进行重排序,就像下表中展示的轨迹顺序,那么就很容易看到 r2==2 和 r1==1 这样的结果。
| Thread 1 | Thread 2 |
|---|---|
| 1: B = A; | 3: r1 = B; |
| 2: r2 =A; | 4: A = 2; |
对有些开发者而言,这种行为看起来像是“受损了”。但是应该注意到,这种代码实际上只是没有进行正确的同步:
- 在一个线程中存在对一个变量的写操作。
- 在另一个线程中存在对同一个变量的读操作。
- 而写操作和读操作并未通过同步进行排序。
这种情况是“数据竞争”的一个实例。当代码包含数据竞争时,经常会产生有悖直觉的结果。
很多机制都可以产生上述重排序。Java 虚拟机实现中的即时编译器(JIT)可以重新安排代码或处理器。另外,对于 Java 虚拟机的实现而言,其架构的内存层次结构使得代码看起来就像是被重排序过一样。在本章中,我们将任何可以重排序代码的事物都归类为“编译器”。
另一个会出现惊人结果的例子可以在下表中看到。最初,p==q 且 p.x==0。该程序也未进行正确的同步,它对其中的写操作没有进行任何强制排序就向共享内存执行了写操作。
| Thread 1 | Thread 2 |
|---|---|
| 1: r1 = P; | 1: r6 = p; |
| 2: r2 = r1.x; | 2: r6.x = |
| 3: r3 = q; | |
| 4: r4 = r3.x; | |
| 4: r5 = r1.x; |
一项常见的编译器优化是,在对 r5 执行读操作时,复用了对 r2 执行读操作后所获得的值,因为它们都是在没有任何具有干扰效果的写操作时对 r1.x 的读操作。
现在请考虑这样的情况:在 Thread 2 中对 r6.x 的赋值发生在 Thread 1 中对 r1.x 的第一次读操作和对 r3.x 的读操作之间。如果编译器决定对 r5 重用 r2 的值,那么 r2 和 r5 的值就都是 0,而 r4 的值将是 3。从开发者的角度看,在 p.x 中存储的值从 0 变成了 3,之后又变回去了。
| Thread 1 | Thread 2 |
|---|---|
| 1: r1 = P; | 1: r6 = p; |
| 2: r2 = r1.x; | 2: r6.x = 3; |
| 3: r3 = q; | |
| 4: r4 = r3.x; | |
| 4: r5 = r1.x; |
线程内语义
内存模型可以确定程序中的每个点可以读取什么值。每个线程单独的动作必须由该线程的语义来管制其行为,但是每个读取操作看到的值是由内存模型决定的。当我们提到这一点时,就称程序遵循“线程内语义”。线程内语义是用于单线程程序的语义,并且允许对线程行为进行完整的预测,而该行为是基于该线程内的读动作所能看到的值的。为了确定在程序执行中线程 t 的动作是否是合法的,我们可以直接计算线程 t 的实现,因为它将在单线程上下文中执行,就像在本规范其他部分中定义的那样。
每当线程 t 的计算会生成线程间动作时,它必须匹配为在程序顺序中紧接着到来的 t 的线程间动作 a。如果 a 是读操作,那么 t 的进一步计算将使用由内存模型确定的 a 所看到的值。
本节将提供 Java 编程语言内存模型的规范,但是不包括处理 final 域的话题,它们将在下一节进行描述。
这里描述的内存模型不基于 Java 编程语言的面向对象特性。为了保持例子的简洁性和简单性,我们经常展示的是没有类或方法定义或显式引用的代码片段。大多数例子都包括两个或多个线程,它们包含对对象的局部变量、共享全局变量、实例域的访问语句。典型情况是,我们将使用 r1 和 r2 这样的变量名来表示方法或线程的局部变量。这种变量对其他线程是不可访问的。
共享变量
可以在线程间共享的内存被称为“共享内存”或“堆内存”。所有实例域、静态域、数组元素都存储在堆内存。在本章,我们将使用“变量”来指代这些域或数组元素。
局部变量、形式方法参数、异常处理参数永远都不会在线程间共享,因此也就不受内存模型的影响。
如果至少有一个访问是写操作,两个对相同变量的访问(读或写)被称为是“冲突的”。
动作
“线程间动作”是指一个线程执行的动作可以被另一个线程探测到或者直接受另一个线程影响。程序可以执行的线程间动作有如下几种:
- 读(正常读或对非 volatile 的读):对变量的读。
- 写(正常写或对非 volatile 的写):对变量的写。
- 同步动作,包括:
- volatile 读:对变量的 volatile 读。
- volatile 写:对变量的 volatile 写。
- 锁定:锁定监视器。
- 解锁:解锁监视器。
- 线程(合成)的第一个和最后一个动作。
- 启动线程或探测线程是否已被终止的动作。
- 外部动作:可以从“执行外部”观察到的动作,其结果基于“执行外部”的环境。
- 线程分岔动作:它只能由在不执行任何内存、同步或外部动作的无限循环中的线程执行。如果一个线程执行了线程分岔动作,那么它后续会跟随无限数量的线程分岔动作。
- 引入线程分岔动作是为了对一个线程可能会如何导致所有其他线程停顿或不能有所进展的情况进行建模。
本规范只关注线程间的动作,我们不需要关心线程内的工作(如将两个局部变量加起来存储到第三个局部变量中)。如前所述,所有线程都需要遵守正确的 Java 程序线程内语义。我们通常将线程间动作更简洁的称为“动作”。
一个动作 a 由元组 <t, k, v, u> 构成,其中:
- t 是执行动作的线程。
- k 是动作的种类。
- v 是动作涉及的变量和监视器。
- 对于锁定动作,v 是被锁定的监视器;对于解锁动作,v 是被解锁的监视器。
- 如果动作是(volatile 或非 volatile)的读,那么 v 就是被读取的变量。
- 如果动作是(volatile 或非 volatile)的写,那么 v 就是被写入的变量。
- u 是该动作的任意唯一的标识符。
外部动作元组还包含额外的组成部分,它包含执行该动作的线程可以感知到的该外部动作的结果,可以是表示该动作成功或失败的信息,以及该动作读取的值。
外部动作的参数(如哪些字节要写到哪些 socket)不是外部动作元组的组成部分。这些参数由线程内的其他动作设置,并且可以通过检查线程内语义而确定。它们在内存模型中没有专门的讨论。
在不终止的执行中,不是所有的外部动作都是可观察的。
程序与程序顺序
在每个线程 t 执行的所有线程动作中,t 的程序顺序是一种全序,反映了这些动作按照 t 的线程内语义执行的顺序。
动作集是连续一致的,如果其所有动作都按照与程序顺序一致的全序(执行顺序)发生,并且每个对变量 v 的读操作 r 都可以看到由对 v 的写操作 w 写入的值,使得:
- w 在执行顺序中在 r 之前到来。
- 没有任何其他写操作 w’ 使得在执行顺序中 w 在 w’ 之前到来、而且 w’ 在 r 之前到来。
连续一致性是对程序执行中的可见性和排序做出的非常强的保障。在连续一致的执行中,在所有单独的动作(如读操作和写操作)之上存在全序(total order),它与程序的顺序一致,并且每个单独的动作都是原子性的,且对每个线程都是立即可见的。
如果程序中没有任何数据竞争,那么程序的所有执行看起来都是连续一致的。
对于由“需要被原子性的感知”和“不需要被原子性的感知”的操作构成的组,连续一致性和不存在的数据竞争仍旧不能保证这样的组中不会产生错误。
@@@ note
如果我们要使用连续一致性作为我们的内存模型,那么我们讨论过的编译器和处理器的很多优化都是非法的。
@@@
同步顺序
每次执行都有一个同步顺序。同步顺序是执行中所有同步动作之上的全序。对于每个线程 t,t 中的同步动作的同步顺序与 t 的程序顺序是一致的。
同步动作可以归纳出动作上的“被同步”关系,定义如下:
- 在监视器 m 上的解锁动作会同步所有后续的在 m 上的锁定动作(其中“后续”是按照同步顺序定义的)。
- 对于 volatile 变量 v 的写操作会同步所有后续由任何线程执行的对 v 的读操作(其中“后续”是按照同步顺序定义的)。
- 启动线程的动作会同步它所启动的线程中的第一个动作。
- 对每个变量写入缺省值(0、false、null)的操作会同步每个线程中的第一个动作。
- 尽管看起来有点怪,在给包含变量的对象分配内存之前就对该变量写入了缺省值,但是在概念上,每个对象是在程序开始时使用缺省的初始化值创建的。
- 线程 T1 中的最后一个动作会与探测到 T1 已经终止的另一个线程 T2 中的任何动作同步。
- T2 可以通过调用 T1.isAlive 或 T1.join 来实现这种探测。
- 如果线程 T1 中断了线程 T2,那么对于代码中的任何点,只要其他任何线程(包含 T2)能够确定 T2 已经被中断(可以通过抛出中断异常、调用 Thread.interrupted、Thread.isInterrupted 方法来实现),那么 T1 执行的中断动作就会在这些点进行同步。
在表示同步关系的边中,源头称为释放,目的地称为获取。
Happens-Before 顺序
两个动作可以通过 “Happens-Before” 关系进行排序。如果一个动作在另一个动作之前发生,那么第一个动作对第二个动作就是可见的,并且排在第二个动作之前。
如果我们有两个动作 x 和 y,那么我们写作 hb(x,y) 来表示 x 在 y 之前发生。
- 如果 x 和 y 是同一个线程的动作,并且按照程序顺序 x 在 y 之前到来,那么 hb(x,y)。
- 从对象的构造器的末尾到该对象的终结器的开头,存在一条表示 “Happens-Before” 的边。
- 如果动作 x 会同步接下来的动作 y,那么我们也可以得出 hb(x,y)。
- 如果 hb(x,y) 且 hb(y,z),那么 hb(x,z)。
Object 类的 wait 方法与其相关联的锁定和解锁动作,它们之间的 “Happens-Before” 关系是由这些关联的动作定义的。
@@@ note
应该注意,两个动作之间存在 “Happens-Before” 关系并不意味着在代码实现中它们必须按照该顺序发生。如果重排序产生的结果与合法的执行是一致的,那么它就并不是非法的。
@@@
例如,对由某线程构造的对象的每个域写入其缺省值的操作,就不必非要在该线程的开始之前发生,只要没有任何读操作可以观察到这个事实即可。
更具体的说,如果两个动作共享 “Happens-Before” 关系,那么对于不和它们共享 “Happens-Before” 关系的任何代码来说,它们不必看起来非要是以该顺序发生的。例如,如果在一个线程中的写操作会与在另一个线程中的读操作产生数据竞争,那么这些写操作对那些读操作来说可以看起来像是乱序发生的。
在数据竞争发生时,需要定义 “Happens-Before” 关系。
由同步的边组成集合 S 是充分的,如果他是一个最小集,使得带有程序顺序的 S 的传递闭包可以确定在执行中的所有 “Happens-Before” 的边。这个集是唯一的。
由上面的定义可以得出下面的内容:
- 在监视器上的解锁动作在每个后续在该监视器上的锁定操作之前发生。
- 对 volatile 域的写操作在每个后续对该域的读操作之前发生。
- 在线程上对 start() 的调用在被启动线程的所有动作之前发生。
- 一个线程中的所有动作在任何其线程成功的从该线程上的 join 发生之前发生。
- 任何对象的缺省值初始化在程序中的其他任何动作(除了缺省的写操作)之前发生。
如果一个程序包含了两个互相冲突且没有 “Happens-Before” 排序关系的访问操作,那么就称该程序包含“数据竞争”。
对于不是线程间动作的操作,例如对数组长度的读操作、受检强制类型转换的执行和对虚拟方法的调用,其语义不受数据竞争的直接影响。
- 因此,数据竞争不能引发不正确的行为,例如返回错误的数组长度。
- 当且仅当所有连续一致的执行都没有数据竞争,程序则是正确同步的。
- 如果程序是正确同步的,那么该程序的所有执行看起来都是连续一致的。
这对开发者来说是很好的保障。开发者不需要推断重排序方式以确定他们的代码是否包含数据竞争,因此也就不需要在确定他们的代码是否被正确的同步时推断重排序方式。一旦确定了代码是正确同步的,开发者就不需要担心重排序是否会影响他们的代码。
程序必须被正确同步以避免各种在代码重排序时会被观察到的反常行为。正确的同步并不能确保程序的整体行为是正确的,但是它使得开发者可以以简单的方式推断程序可能的行为。对于正确同步的程序,其行为对可能的重排序形成的依赖要少的多。没有正确的同步,就可能会产生非常奇怪的、混乱和反常的行为。
我们称变量 v 的读操作 r 允许观察对 v 的写操作 w,如果在执行轨迹的 “Happens-Before” 的偏序(partial-order)关系中:
- r 的排序不在 w 之前,即非 hb(r,w)。
- 中间没有介入任何对 v 的写操作 w’,即没有任何对 v 的写操作 w’ 使得 hb(w,w’) 和 hb(w’,r) 同时成立。
非正式的讲,读操作 r 允许看到写操作 w 结果,如果没有任何 “Happens-Before” 排序会阻止该操作。
如果对该动作集 A 中的每个读操作 r,用 w(r) 表示 r 可以看到的写操作,都不满足 hb(r, w(r)),或 A 中不存在些操作 w 使得 w.v = r.v、hb(w(r), w) 和 hb(w, r) 同时成立,那么动作集 A 具有 “Happens-Before” 一致性。
在具有 “Happens-Before 一致性” 的工作集中,每个读操作看到的写操作都是 “Happens-Before” 排序机制允许看到的写操作。
示例: Happens-Before 一致性
对于下图中的轨迹,初始时 A==B==0。该轨迹可以观察到 r2==0 和 r1==0,并且在 “Happens-Before” 上仍旧保持一致性,因为执行顺序允许每个读操作看到恰当的写操作。
| Thread 1 | Thread 2 |
|---|---|
| 1: B = 1; | 1: A = 2; |
| 2: r2 = A; | 2: r1 = B; |
因为没有任何同步,所有每个读操作都可以看到写入初始值的写操作或由另一线程执行的写操作。下面的执行顺序展示了这种行为:
1: B=1;
2: A=2;
3: r2=A; // seen initial write of 0
4: r1=B; // seen initial write of 0
另一种具有 “Happens-Before 一致性” 的执行顺序为:
1: r2=A; // seen write of A=2
2: r1=B; // seen write of B=1
3: B=1;
4: A=2;
在该执行中,读操作看到的是在执行顺序之后发生的写操作。这看起来很反常,但是是 “Happens-Before一致性” 所允许的。允许读操作看到之后发生的写操作有时可能会产生不可接受的行为。
执行
执行 E 可以用元组 <P, A, po, so, W, V, sw, hb> 表示,其构成为:
- P:程序。
- A:动作集。
- po:程序顺序,对于每个线程 t,是在 A 中由 t 执行的所有动作上的全序。
- so:同步顺序,即 A 中所有同步动作上的全序。
- W:“被看到的写动作”函数,对 A 中的每个读操作 r,会给出 W(r),即在 E 中 r 看到的写动作。
- V:“被写入的值”函数,对 A 中的每个写操作 w,会给出 V(w),即在 E 中 w 写入的值。
- sw:与….同步,即同步关系上的偏序。
- hb:之前发生,即动作上的偏序。
@@@ note
“与….同步”和“之前发生”元素是由执行中的其他组成部分以及有关良构执行的规则唯一确定的。
@@@
执行具有 “Happens-Before 一致性”,如果它的工作集具有“Happens-Before 一致性”。
良构执行
我们只考虑良构(Well-Formed)的执行。如果下面的条件都为 true,则执行 E = <P, A, po, so, W, V, sw, hb> 是良构的:
- 每个读操作看到的都是在该执行中对同一个变量的写操作。
- 所有对 volatile 变量的读操作和写操作都是 volatile 动作。对于 A 中的所有读操作,其 W(r) 都在 A 内,且 W(r).v = r.v。变量 r.v 是 volatile 的,当前仅当 r 是 volatile 读操作;w.v 是 volatile 的,当且仅当 W 是 volatile 的。
- “之前发生”顺序是偏序。
- “之前发生”顺序是由“与….同步”边和程序顺序的传递闭包给出的。它必须是有效的偏序:自反的、传递的且反对称的。
- 该执行遵守线程内一致性。
- 对每个线程 t,在 A 中由 t 执行的动作与该线程在单独执行时的程序顺序中生成的动作相同,如果每个读操作 r 看到的值都是 v(w(r)),那么每个写操作都会写入 v(w)。每个读操作看到的值是由内存模型确定的。所给出的程序顺序必须反映按照 P 的线程内语义执行动作的程序顺序。
- 该执行是 “Happens-Before 一致性”。
- 该执行遵循同步顺序一致性。
- 对所有 A 中的 volatile 读操作,即不存在 so(r, W(t)),也不存在 A 中的写操作 W 使得 w.v = r.v、so(w(r), w) 和 so(w,r)同时成立。
执行和因果关系要求
我们使用 Fd 表示这样的函数:将 F 的域限定为 d。对于所有在 d 中的 x,Fd(x) = F(x),并且对于所有不在 d 中的 x,Fd(x) 无定义。
我们使用 Pd 表示将偏序 P 限定为 d 中的元素。对于所有在 d 中的 x 和 y,P(x,y) 成立当且仅当 Pd(x,y)。如果 x 和 y 不在 d 中,那么就不存在 Pd(x,y)。
良构 E = <P, A, po, so, W, V, sw, hb> 是由 A 中的“提交动作”所验证的。如果 A 中的所有动作都能够提交,那么该执行就满足 Java 编程语言内存模型有关因果关系的要求。
从空集 C0 开始,我们执行一系列步骤,将动作从动作集 A 中取出,并将其添加到提交动作集 Ci 中,以得到新的提交集 C i+1。为了证明这种方式的合理性,对于每个 Ci,我们需要证明包含 Ci 的执行 E 满足特定的条件。
形式化的将,执行 E 满足 Java 编程语言内存模型的因果关系要求当且仅当存在:
- 动作集 C0、Ci、….,使得:
- C0 是空集。
- Ci 是 C i+1 的真子集。
- A = U(C0, C1, …)。
- 如果 A 是有限集,那么 C0、C1、….Cn 序列是有限的,以 Cn=A 结尾。
- 如果 A 是无限集,那么 C0、C1、….Cn、… 序列也可能是无限的,并且必须满足这个无限序列中的所有元素的并集等于 A。
- 良构的执行 E0、…、Ei、…,其中 Ei = <P, Ai, poi, soi, Wi, Vi, swi, hbi>
- 给定这些动作集 C0、… 和执行 Ei、…,每个在 Ci 中的动作必须是 Ei 的动作之一。所有在 Ci 中的动作必须共享与 Ei 和 E 中相同的相对的之前发生顺序和同步顺序。形式化的讲:
- Ci 是 Ai 的子集。
- hbi|ci = hb|ci
- soi|ci = so|ci
- 由 Ci 中的写操作写入的值必须与在 Ei 和 E 中写入的值相同。只有在 Ci-1 中的读操作才要求在 Ei 中看到的写操作与在 E 中看到的写操作相同。形式化的讲:
- Vi|ci = V|ci
- Wi|ci-1 = W|ci-1
- 所有在 Ei 中但不在 Ci-1 中的读操作必须看到在它们知己去哪发生的写操作。每个在 Ci - Ci-1 中的读操作 r 都必须在 Ei 和 E 中看到在 Ci-1 中的写操作,但是在 Ei 中看到的写操作可以在 E 中看到的写操作不同。形式化的讲:
- 对于任何在 Ai - Ci 中的读操作 r,都有 hbi(Wi(r), r)。
- 对于任何在 (Ci - Ci-1) 中的读操作 r,都有 Wi(r) 在 Ci-1 中并且 W(r) 在 Ci-1 中。
- 给定 Ei 的充分的“与…同步”边的集合,如果有一个“释放-获取”对在你正在提交的动作之前发生,那么该操作对必须在所有的 Ej 中都存在,其中 j >= i。形式化的讲:
- 设 SSWi 是在 hbi 的传递归约中但不在 po 中的 SWi 的边。我们称是 SSWi 为 “Ei 的充分的与…同步的边”。如果 SSWi(x,y) 和 hbi(y,z),且 z 在 Ci 中,那么对所有的 j>=i,都有 SWj(x,y)。
- 如果动作 y 被提交,那么所有在 y 之前发生的所有外部动作也都会被提交。
- 如果 y 在 Ci 中,x 是外部动作,且有 hbi(x,y),那么 x 在 Ci 中。
- 给定这些动作集 C0、… 和执行 Ei、…,每个在 Ci 中的动作必须是 Ei 的动作之一。所有在 Ci 中的动作必须共享与 Ei 和 E 中相同的相对的之前发生顺序和同步顺序。形式化的讲:
示例:“Happens-Before 一致性” 是不充分的
“Happens-Before 一致性” 是必要的但不是充分的约束集。仅仅强制实现 “Happens-Before 一致性” 仍旧会允许不可接受的行为发生,这些行为会违反我们已经为程序实现的需求。例如,“Happens-Before 一致性”使得值看起来像是“无中生有”的。通过对下表的轨迹进行详细检查就会看到这一点。
| Thread 1 | Thread 2 |
|---|---|
| 1: r1 = x; | 1: r2 = y |
| 2: if(r1 != 0) y = 1; | 2: if(r2 != 0) x = 1; |
上表中展示的代码是正确同步的。这看起来很令人惊讶,因为它没有执行任何同步动作。但是请记住,当且仅当在它以连续一致的方式执行时程序是正确同步的,不会有任何数据竞争。如果这段代码是以连续一致的方式执行的,每个动作都按照程序顺序发生,每个写操作都不会发生。因为不会发生任何写操作,所以不会有任何数据竞争,因此:该程序是正确同步的。
既然这个程序是正确同步的,那么我们唯一允许其产生的行为只能是连续一致的行为。但是,这个程序存在这样一种执行:它是“Happens-Before 一致”的,但不是连续一致的:
r1 = x; // sees write of x = 1
y = 1;
r2 = y; // sees write of y = 1
x = 1;
这个结果是“Happens-Before 一致”的:没有任何“Happens-Before”关系会阻止它发生。但是很明显,这个结果不可接受:没有任何连续一致性的执行会产生这种行为。因此,由于我们允许读操作看到在执行顺序中之后到来的写操作,所以有时就会产生这种不可接受的行为。
尽管允许“读操作看到在执行顺序中之后到来的写操作”有时并不是我们想要的,但是它有时又是必须的。就像我们在上一个示例的表中看到的,其中的轨迹就要求某些读操作要看到在执行顺序中之后到来的写操作。由于在每个线程中,读操作总是先到,所以在执行顺序中第一个动作必然是读操作。如果该读操作不能看到之后发生的写操作,那么它就看不到它所读取的变量初始值之外的任何其他值。很明显,这将无法反映所有的行为。
我们将“读操作何时可以看到将来的写操作”的问题称为“因果关系”,因为这些问题与上表中所展示的情况类似。在那种情况中,读操作导致写操作发生,而写操作又导致读操作发生。对于这些动作而言,没有“首因”。因此,我们在内存模型中需要一种一致的方式,以确定哪些读操作可以提前看到写操作。
诸如上个示例的表中证明了本规范在描述读操作是否可以看到执行中之后发生的写操作时,必须格外小心(一定要记住,如果一个读操作可以看到执行中之后发生的读操作,那么就表示该写操作实际上是之前就执行过的)。
内存模型将给定的执行和程序作为输入,确定该执行是否是该程序的和合法执行。它是通过渐进的构建“提交”动作集来实现这一目的的,该动作集反映了程序执行了哪些动作。 通常,下一个被提交的动作将表现为在连续一致执行中可以执行的下一个动作。但是,为了表现需要看到之后发生的写操作的读操作,我们允许某些动作的提交时机早于在它们之前发生的工作的提交时机。
很明显,某些动作可以被提早提交,但是某些动作则不行。如本例的表中的某个写操作是在对该变量的读操作之前提交的,那么读操作将看到写操作,因为会产生“无中生有”的结果。非形式化的讲,我们允许某个动作早提交,前提是我们知道该动作的发生不会导致任何数据竞争。在上表中,两个写操作都不能提早执行,因为除非读操作可以看到数据竞争的结果,否则这些写操作就不能发生。
可观察的行为和不终止的执行
对于总是会在某个边界的有限时间内终止的程序,它们的行为可以直接根据它们允许的执行而被(以非形式化的方式)理解。对于不会在有限时间段内终止的程序,会产生更多微妙的问题。
程序的可观察的行为是用该程序可以执行的外部动作的有限集来定义的。例如,只是打印“Hello”的程序可以用这样的行为集描述:对于任何非负整数 i,该行为集包含打印 “Hello” i 次的行为。
“终止”不会被显式的建模为行为,但是程序可以很容易的扩展为生成额外的外部动作 executionTermination,该动作在所有线程被终止时发生。
我们还定义了一个特殊的悬挂(hand)动作。如果行为是用包含悬挂动作的外部动作集描述的,那么它表示的行为是:在外部动作被观察到之后,程序可以在时间上无界的运行,而不需要执行任何额外的外部动作或不需要终止。程序可以悬挂,如果所有线程都被阻塞,或者该程序可以执行在数量上无界的动作,而不需要执行任何外部动作。
线程可以在各种各样的环境中被阻塞,例如当它视图获取锁或者执行依赖于外部数据的外部动作(诸如读操作)时。
执行可以导致某个线程被无限阻塞,并且该执行不会终止。在这种情况下,被阻塞线程所产生的动作必须由该线程到被阻塞时为止所产生的所有动作构成,包括导致该线程被阻塞的动作,并且不包含在导致阻塞的动作之后该线程所产生的动作。
为了推断可观察到的行为,我们需要谈谈可观察动作集。
如果 o 是执行 E 的可以观察动作集,那么 o 必须是 E 的动作集 A 的子集,并且必须包含有限数量的动作,即使 A 包含无限数量的动作也是如此。并且,如果 y 是在 o 中的动作,并且有 hb(x,y) 或 so(x,y),那么 x 在 o 中。
@@@ note
可观察动作集并没有被限制为仅能包含外部动作,但是只有在动作集中的外部动作才会被当做可观察的外部动作。
@@@
行为 B 是程序 P 允许的行为,当且仅当 B 是有限外部动作集,并且:
- 存在 P 的执行 E 和 E 的可观察动作集 O,使得 B 是 O 中的外部动作集(如果 E 中的任何线程都归于阻塞状态,并且 O 包含 E 中的所有动作,那么 B 也可以包含悬挂动作)。
- 存在动作集 O,使得 B 由悬挂动作和所有 O 中的外部动作构成,并且对于所有 k >= |O|,都存在带有动作集 的 P 的执行 E,以及动作集 O’,使得:
- O 和 O’ 都是 A 的子集,且它们满足可观察动作集的要求。
- O <= O’ <= A。
- |O’| >= k。
- O’ - O 不包含任何外部动作。
@@@ note
行为 B 没有描述 B 中的外部动作被观察到的顺序,但是其他外部动作应该如何被生成和执行的(内部)约束条件可以被施加这种限制。
@@@
final 域的语义
声明为 final 的域只会被初始化一次,但是在正常情况下永远都不会再变更。final 域的详细语义与普通域的语义有些不同。特别是,编译器在同步栅栏和对任意或未知方法的调用之间可以有很大的自由度去移动对 final 域必须被重载的场景中,也不会从内存从载它。
final 域还使得开发者无需同步而实现线程安全的不可变对象。线程安全的不可变对象可以被所有线程看做是不可变的,即使数据竞争被用来在线程间传递不可变对象的引用,也是如此。这可以提供安全保障,以防止通过不正确或有恶意的代码误用不可变类。final 域必须被正确使用,以提供不可变性的保障。
对象在其构造器执行完成时被认为是完全初始化的。对于只能在对象完全初始化之后才能看到对该对象的引用的线程,可以保证它看到该对象的 fianl 域是被正确初始化的值。
final 域的使用模型非常简单:在对象的构造器中设置 fianl 域,并且不要在另一个线程可以在该对象的构造器质性完成之前看到它的地方,对该对象的引用执行写操作。如果遵循了这一点,那么当该对象被另一个线程看到时,这个线程就总是会看到该对象的 final 域的正确构造版本,并且对于任何被这些 fianl 域引用的对象或数组,这个线程也会看到它们至少与这些 final 域同样新的版本。
示例:Java 内存模型中的 fianl 域
下面的程序展示了 final 域与普通域的比较:
class FinalFiledExample {
final int x;
int y;
static final FinalFieldExample f;
punlic FinalFieldExample() {
x = 3;
y = 4;
}
static void writer() {
f = new FinalFieldExample();
}
static void reader() {
if(f != null) {
int i = f.x; // guranteed to see 3
int j = f.y; // cound see 0
}
}
}
一个线程可能会执行该类的 wirter 方法,而另一个线程可能会执行其 reader 方法。
因为 writer 方法在该对象构造器执行完成之后会写入 f,因此可以保证 reader 方法能正确看到 f.x 的初始化值:3。但是,f.y 不是 final 的,因此不能保证 reader 方法会看到它的值为 4。
示例:用于安全目的的 final 域
final 域被设计用来保证必要的安全性。请考虑下面的程序,其中一个线程(称为线程 1)会执行:
Global.s = "/tmp/user".substring(4);
而另一个线程(2)执行:
Strin myS = Global.s;
if(myS.equals("/tmp")) System.out.println(myS);
String 对象被设计为不可变的,并且字符串操作也不执行同步。尽管 String 的实现没有任何数据竞争,但是其他涉及使用 String 对象的代码也许会有数据竞争,并且内存模型对具有数据竞争的程序只提供弱保证。特别是,如果 String 类的域不是 final 的,那么它就有可能出现这样的情况(尽管不大可能):线程 2 最初会看到字符串对象的偏移量为缺省值 0,使得可以将它与 “/tmp” 进行比较看它们是否相等。而稍后在 String 对象上的操作可能会看到正确的偏移量 4,使得该 String 对象可以被感知到是 “/usr”。Java 编程语言的很多安全特性都依赖于 String 对象被感知为真的不可变,即使恶意代码可以利用数据竞争在线程间传递 String 引用也是如此。
final 域的语义
设 o 是对象,c 是 o 的构造器,在 c 中 final 域 f 会被写入。在 o 的 final 域上的“冻结”动作会在 c 退出时发生,无论是正常退出还是猝然退出。
注意,如果一个构造器调用了另一个构造器,并且被调用的构造器设置了 final 域,那么该 final 域的冻结就会在被调用的构造器的结尾处发生。
对于每次执行,读操作的行为会受到两个额外的偏序关系影响,即解引用链 dereferences() 和内存链 mc(),它们被认为是执行的一部分(因此被认为对任何特定执行都是不变的)。这些偏序必须满足下面的约束条件(不必有唯一解决方案):
- 解引用链:如果线程 t 没有初始化对象 o,但是动作 a 是由线程 t 执行的对对象 o 的某个域或元素的读操作或写操作,那么必然存在某个由线程 t 执行的可以看到 o 的地址的读操作 r,使得 r dereferences(r,a) 成立。
- 内存链:在内存链排序上有若干约束条件。
- 如果 r 是可以看到写操作 w 的读操作,那么必然有 mc(w,r)。
- 如果 r 和 a 是使得 dereferences(r,a) 成立的动作,那么必然有 mc(r,a)。
- 如果线程 t 没有初始化对象 o,但是 w 是由线程 t 执行的对对象 o 的地址的写操作,那么必然存在某个线程 t 执行的可以看到 o 的地址读操作 r,使得 r mc(r,w) 成立。
假设没有写操作 w、冻结动作 f、动作 a(不是对 final 域的读操作)、对由 f 冻结的 final 域的读操作 r1,以及读操作 r2,使得 hb(w,f)、hb(f,a)、mc(a,r1) 和 dereferences(r1,r2) 成立,那么在确定哪些值可以被 r2 看到时,我们认为 hb(w,r2)。(这个“之前发生”排序与其他的“之前发生”排序没有构成产地闭包)
注意:dereferences 顺序是自反的,并且 r1 可以和 r2 相同。
对于对 final 域的读操作,只有被认为在这个对 final 域的读操作之前到来的写操作才是可以通过 final 域语义导出的操作。
在构造阶段读 final 域
如果某个对象位于构造它的线程中,那么对这个对象的 final 域的读操作是根据通常的 “Happens-Before” 规则,针对该域的初始化而排序的。如果该读操作出现在该域在构造器中被设置之后,那么它就会看到该 final 域已经赋过的值,否则,它会看到缺省值。
对 final 域的后续修改
在某些情况下,例如反序列化,系统需要在对象构造之后修改其 final 域。final 域可以通过反射和其他依赖于 Java 具体实现的方式被修改。唯一能够是这种修改具有合理语义的模式,就是允许先构造对象,然后再修改对象的 fianl 域的模式。这种对象不应该对其其他线程是可见的,而 final 域也不应该被读取,直至所有该对象的 final 域的更新都结束。final 域的冻结可以发生在设置该 fianl 域的构造器的末尾,或者在紧挨每个通过反射或其他特殊机制修改该 final 域的操作之后。
即使如此,还存在大量的复杂性。如果 final 域被初始化为域声明中的编译时常量表达式,那么对该 final 域的修改可能不会被观察到,因为对该 final 域的使用在编译器时就已经替换成了该常量表达式。
另一个问题是本规范允许对 final 域进行积极优化。在线程中,允许重排序对 final 域的读操作和对不再构造器中发生的对该域的修改操作。
示例:对 final 域的积极优化
class A {
final int x;
A() {
x = 1;
}
inf f() {
return d(this,this);
}
int d(A a1, A a2) {
int i = a1.x;
g(a1);
int i = a2.x;
return j - i;
}
static void g(A A) {
// use reflection to change a.x to 2
}
}
在方法 d 中,编译器可以任意对 x 的读操作和对 g 的调用进行重排序。因此,new A().f() 可能会返回 -1、0、1。
Java 编程语言的实现可以提供一种方式,用来在 final 域安全的上下文中执行代码块。如果某个对象是在 final 域安全的上下文中出现的对该 final 域的修改操作进行重排序。
final 域安全的上下文具有额外的保护措施。如果一个线程已经看到了未正确发布的对某个对象的引用,该线程通过该引用可以看到 final 域的缺省值,并且之后在 final 域安全的上下文中读取了正确发布的对该对象的引用,那么可以保证该线程可以看到该 final 域的正确的值。在形式上,在 final 域安全的上下文中执行的代码会被当做单独的线程处理(这种处理仅仅只针对 final 域的语义)。
在 Java 编程语言的实现中,编译器不应该将对 final 域的访问操作移入或移出 final 域安全的上下文(尽管它可以围绕着这种上下文的执行而移动,只要该对象不是在该上下文中构造的)。
有一种场景适合使用 fianl 域安全的上下文,即在执行器或线程池中。通过执行在彼此分离的 final 域安全的上下文中的每一个 Runnable 对象,执行器可以保证某个 Runnable 对象 o 的不正确访问将不会影响对由同一个执行器处理的其他 Runnable 做出的对 final 域的保证。
写受保护的域
正常情况下,是 final 且是 static 的域不能被修改。
但是,因历史遗留问题,System.in、System.out 和 System.err 虽然是 static final 域,但是它们必须通过 System.setIn、System.setOut、System.setErr 方法进行修改。我们将这些域称为“写受保护”的域,以便与普通 final 域区分。
编译器需要将这些域与其他 final 域区别对待。例如,对普通 final 域的读操作对同步是“免疫的”:涉及锁或 volatile 读的屏障不会影响从 final 域中读出的值。但是,由于我们可以看到对写受保护的域的值所做的变更,所以同步事件应该对它们有影响。因此,由于我们可以看到对写受保护的域的值所做的变更,所以同步事件应该对它们有影响。因此,其语义要求这些域应该被当做不能由用户代码修改的普通域进行处理,除非用户代码在 System 类中。
字撕裂
对 Java 虚拟机的实现有一种考虑,即每个域和数组元素都被认为是有区别的,对一个域或元素的更新不必与其他域或元素的读或更新操作交互。特别是,分别更新字节数组中毗邻元素的两个线程必定不会互相干涉或交互,因此也就不需要同步以确保连续的一致性。
某些处理器并不提供对单个字节进行写操作的能力。在这种处理器上通过直接读取整个字、更新恰当的字节,然后将整个字写回内存的方式来实现字节数组的更新是非法的。这个问题有时被称为字撕裂,在不能很容易的单独更新单个字节的处理器上,需要其他的实现方式。
示例:探测字撕裂
public class WordTearing extends Thread {
static final int LENGTH = 8;
static final int ITERS = 1000000;
static byte[] counts = new byte[LENGTH];
static Thread[] threads = new Thread[LENGTH];
final int id;
WordTearing(int i) {
id = i;
}
public void run() {
byte b = 0;
for(int i=0; i < ITERS; i++) {
byte v2 = counts[id];
if(v != v2) {
System.err.pringln("Word-Tearing foung: " +
"counts[" + id + "] =" + v2 +
", shoube be " + v);
return;
}
v++;
counts[id] = v;
}
}
}
这里的关键是字节必须不能被写操作覆盖为毗邻的字节。
double 和 long 的非原子化处理
考虑到 Java 编程语言的内存模型,对非 volatile 的 long 或 double 的单个写操作会当做两个分离的写操作处理:每个操作处理 32 位。这会导致一种情况:一个线程会看到由某个写操作写入的 64 位值的头 32 位、由另一个写操作写入的后 32 位。
对 volatile 的 long 或 double 值的读操作和写操作总是原子性的。
对引用的读操作和写操作总是原子性的,无论它们被实现为 32 位还是 64 位的值。
某些实现会发现将单个对 64 位的 long 或 double 值的写动作分成两个毗邻的 32 位值的写动作会更方便。由于效率的原因,这种行为是实现相关的,Java 虚拟机的实现可以自由选择对 long 或 double 值的写操作是原子性的还是分成两部分。
我们鼓励 Java 虚拟机的实现应该避免将 64 位值分开,并鼓励开发者将共享的 64 位值声明为 volatile 的,或者正确的同步使用它们的程序以避免可能出现的复杂性。
2 - CH02-JMM Explain
多任务和高并发的内存交互
多任务和高并发是衡量一台计算机的处理能力的重要指标之一。一般衡量一个服务器性能的高低好坏,使用每条事务处理数(Transcations Per Second, TPS),该指标比较能够说明问题,它代表着一秒内服务器平均能够响应的请求数,而 TPS 值与程序的并发能力有着非常密切的关系。“物理机”的并发问题与“虚拟机”中的情况有很多相似之处,物理机对并发的处理方案对于虚拟机的实现也有相当大的参考意义。
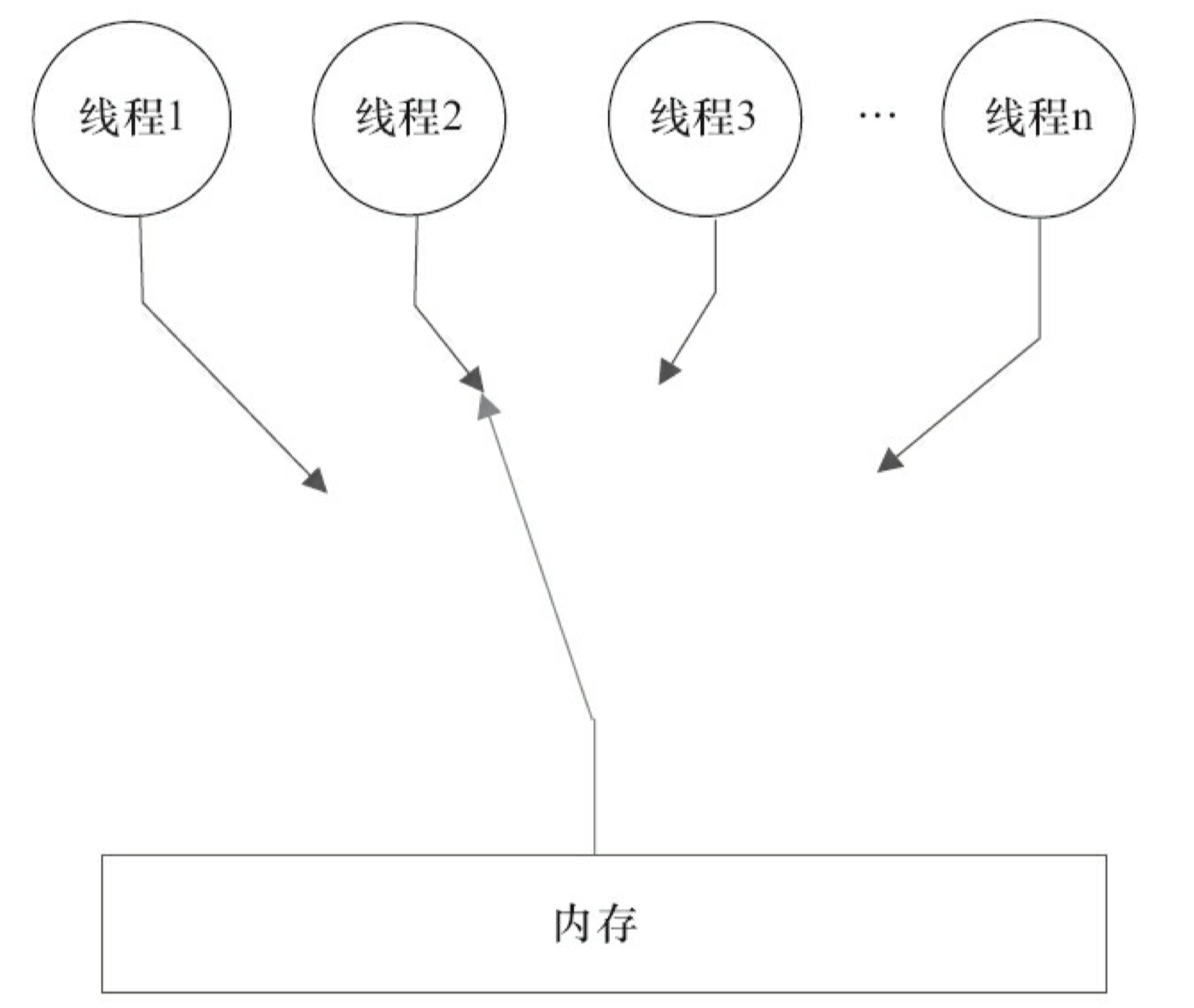
由于计算机的存储设备与处理器的运算能力之间有着几个数量级的差距,所以现代计算机系统都不得不加入一层读写速度尽可能接近处理器运算速度的“高速缓存(cache)”来作为内存与处理器之间的缓冲:将运算需要使用到的数据复制到缓存中,让运算能够快速运行;当运算结束后再将数据从缓存同步会内存之中,这样一来处理器就无需等待缓慢的内存读写了。
基于高速缓存的存储交互很好的解决了处理器与内存的速度矛盾,但是引入了一个新的问题:“缓存一致性(Cache Coherence)”。在多处理器系统中,每个处理器都有自己的高速缓存,而它们又共享同一主存,如下图所示:多个处理器运算任务都涉及同一块主存,需要一种协议可以保障数据的一致性(及多个处理器看到相同的数据),这类协议有 MSI/MESI/MOSI/Dragon Protocl 等。
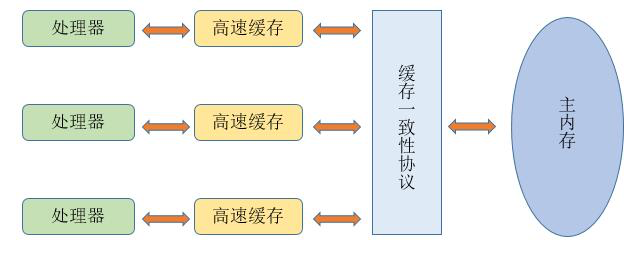
除此之外,为了使得处理器内部的运算单元能尽可能被充分利用,处理器可能会对输入代码进行“乱序执行(Out-Of-Order Execution)”优化,处理器会在计算之后将对乱序执行的代码进行结果重组,以保证结果的准确性。与处理器的乱序执行优化类似,Java 虚拟机的即时编译器(JIT)中也有类似的“指令重排序(Instruction Recorder)”优化。
Java 内存模型
内存模型可以理解为在特定的操作协议下,对特定的内存或告诉缓存进行读写访问的过程抽象,不同架构下的物理机拥有不同的内存模型,Java 虚拟机也有自己的内存模型,即“Java 内存模型(JMM)”。在 C/C++ 语言中则是直接使用物理硬件和操作系统的内存模型,导致不同平台下并发访问出错,需要进行多平台的兼容。而 JMM 的出现,能够屏蔽掉各种硬件和操作系统的内存访问差异,实现平台一致性,使得 Java 程序能够“一次编写,到处运行”。
主内存与工作内存
Java 内存模型的目的主要是“定义程序中各个变量的访问规则”,即在虚拟机中将变量存储到内存和从内存中取出变量这样的底层细节。此处的变量与进行 Java 编程时所说的变量不同,包括了实例字段、静态字段、数组元素,但是不包括局部变量与方法参数,因为后者是线程私有的,永远不会被共享。
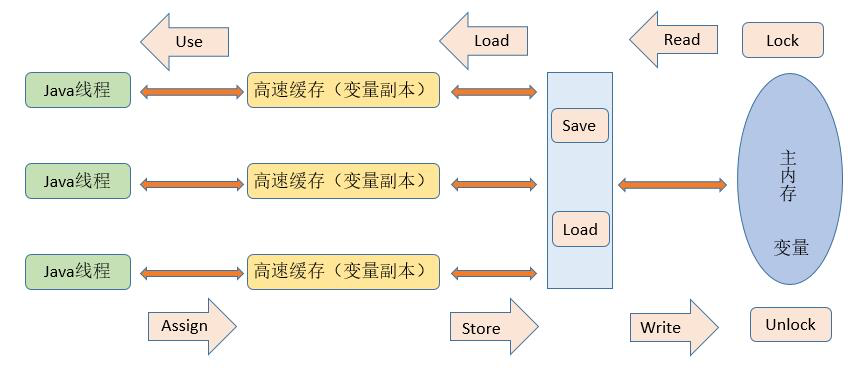
Java 内存模型中规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存(可以与前面所说的处理器的高速缓存类比),线程的工作内存中使用到的变量到主内存副本拷贝,线程对变量的所有操作(读取、赋值)都必须在工作内存中进行,而不能直接读写主内存中的变量。不同线程之间无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成,线程、主内存和工作内存之间的交互关系如下图:
@@@ note
这里的主内存、工作内存与 Java 内存区域的 Java 堆、栈、方法区不是同一层次的内存划分,两者之间没有关系。
@@@
内存交互操作
由上面的交互关系可知,关于主内存与工作内存之间的具体交互协议,即一个变量如何从主内存拷贝到工作内存、如何从工作内存同步到主内存之间的实现细节,Java 内存模型定义了以下 8 种操作来完成:
- lock:作用于主内存的变量,把一个变量标识为由一条线程独占的状态。
- unlock:作用于主内存的变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
- read:作用于主内存的变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的 load 动作使用。
- load:作用于工作内存变量,把 read 操作从主内存得到的变量值放入工作内存的变量副本中。
- use:作用于工作内存变量,把工作内存变量的值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行该操作。
- assign:作用于工作内存变量,它把一个从执行引擎接收到的值赋值给工作内存变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行该操作。
- store:作用于工作内存变量,把工作内存变量值传送给主内存,以便随后的 write 操作。
- write:作用于主内存的变量,它把 store 操作从工作内存中得到的变量值传送到主内存的变量中。
如果要把一个变量从主内存复制到工作内存,就需要按序执行 read 和 load 操作;如果把变量从工作内存中同步到主内存中,就需要按序执行 store 和 write 操作。JMM 只要求上述两个操作“必须按序执行,而没有保证必须是连续执行”。也就是说在 read 和 load 之间、store 和 write 之间可以插入其他指令,如对主内存中的变量 a、b 进行访问时,可能顺序是 read a、read b、load b、load a。JMM 还规定了在执行上述 8 种基本操作时,必须满足如下规则:
- 不允许 read 和 load、store 和 write 操作之一单独出现。
- 不允许一个线程丢弃它最近的 assign 操作,即变量在工作内存中改变了之后必须同步回主内存中。
- 不允许一个线程无原因的(没有发生过任何 assign 操作)把数据从工作内存同步回主内存中。
- 一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(load、assign)的变量。即在对一个变量实施 use 和 store 操作之前,必须已经对该变量执行过了 assign 和 load 操作。
- 一个变量在同一时刻只允许一条线程对其进行 lock 操作,lock 和 unlock 必须成对出现。
- 如果对一个变量执行 lock 操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前需要重新执行 load 或 assign 操作来初始化该变量的值。
- 如果一个变量事先没有被 lock 操作锁定,则不允许对其执行 unlock 从操作;也不允许去 unlock 一个被其他线程锁定的变量。
- 对一个变量执行 unlock 操作之前,必须先把该变量同步到主内存中(执行 store 和 write操作)。
这 8 中内存访问操作很繁琐,后文会使用一个等效判断原则,即先行发生(happens before)原则来确定一个内存访问在并发环境下是否安全。
volatile 变量
关键字 volatile 是 JVM 中最轻量级的同步机制。volatile 变量具有两种特性:
- 保证变量的可见性。对一个 volatile 变量的读,总是能看到(任意线程)该 volatile 变量最后的写入,这个新值对于其他线程来说是立即可见的。
- 屏蔽指令重排序。指令重排序是编译器和处理器为了执行效率而对程序执行的优化手段,后文有详细分析。
volatile 语义并不能保证变量的原子性。对任意单个 volatile 变量的读/写具有原子性,但类似自增、自减这种复合操作不具有原子性,因为自增运算包括取值、加 1、重新赋值这 3 步操作,并不具备原子性。
由于 volatile 只能保证变量的可见性和屏蔽指令重排,只有满足以下两条规则时,才能使用 volatile 来保证并发安全,否则就需要加锁(使用 synchronized、lock、JUC 中的 Atomic 原子类)来保证并发中的原子性:
- 运算结果不存在数据依赖(重排序的数据依赖性),或者仅有单一的线程修改变量的值(重排序的 as-if-serial 语义)。
- 变量不需要与其他的状态变量共同参与不变约束。
因为需要在本地代码中插入许多内存屏障指令来屏蔽特定条件下的重排序,volatile 变量的写操作与读操作相比慢一些,但是其性能开销比锁低很多。
long/double 非原子协定
JMM 要求 lock、unlock、read、load、assign、use、store、write 这 8 个操作都必须具有原子性,但对于 64 位的数据类型 long 和 double,具有非原子协定:允许虚拟机经没有被修饰为 volatile 的 64 位数据的读写操作划分为两次 32 位的操作进行。(于此类似的是,在栈帧结构的局部变量表中,long 和 double 类型的局部变量可以使用 2 个能存储 32 位变量的变量槽来存储,详见“深入理解 Java 虚拟机” 第 8 章)
如果多个线程共享一个没有声明为 volatile 的 long 或 double 变量,并且同时执行存取操作,某些线程可能会读到一个即非原值、又非其他线程修改了的代表了“半个变量”的数值。不过这种情况十分罕见。因为非原子协定换句话说,同样允许 long 和 double 的读写操作实现为原子操作,并且目前绝大多数虚拟机都是这样做的。
原子性、可见性、有序性
原子性
JMM 保证的原子性变量操作包括 read、load、assign、use、store、write,而 long 和 double 非原子协定导致的非原子性操作基本可以忽略。如果需要对更大范围的代码实行原子性操作,则需要使用 JMM 提供的 lock、unlock、synchronized。
可见性
前面分析 volatile 语义时已经提到,可见性是指当一个线程修改了变量的值,其他线程能够立即得知这个修改。JMM 在变量被修改后将新值重新同步回主内存,依赖主内存作为媒介,在变量被线程读取前从内存刷新变量新值,保证变量的可见性。普通变量和 volatile 变量都是如此,只不过 volatile 的特殊规则保证了这种可见性是立即得到的,而普通变量并不具备这样严格的可见性。除了 volatile 外,synchronized 和 final 也能保证可见性。
有序性
JMM 的有序性表现为:如果在本线程内观察,所有操作都是有序的;如果在一个线程中观察另一个线程,所有操作都是无序的。前半句指“线程内表现为串行语义(as-if=serial)”,后半句指“指令重排序”和变量的“工作内存与主内存的同步延迟”现象。
重排序
在执行程序时为了提高性能,编译器和处理器经常会对指令进行重排序。从硬件架构上来说,指令重排序是指 CPU 采用了允许将多条指令不再按照程序规定的顺序,分开发送给相应电路单元处理器,而不是将指令任意重排。重排序分为 3 种类型:
- 编译器优化重排序。编译器在不改变单线程程序语义的前提下,可以重新安排程序的执行顺序。
- 指令级并行重排序。先来处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
- 内存系统重排序。由于处理器使用缓存和读写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。

JMM 重排序屏障
从 Java 源代码到最终实际执行的指令序列,会经过 3 种重排序。但是为了保证内存的可见性,Java 编译器会在生成的指令序列的适当位置插入内存屏障指令来禁止特定类型的处理器重排序。对于编译器的重排序,JMM 会根据重排序规则禁止特定类型的编译器重排序;对于处理器重排序,JMM 会插入特定类型的内存屏障,通过内存的屏障指令来禁止特定类型的处理器重排序。这里讨论 JMM 对处理器的重排序,为了更深刻理解 JMM 对处理器重排序的处理,先来认识一下常见处理器的重排序规则:
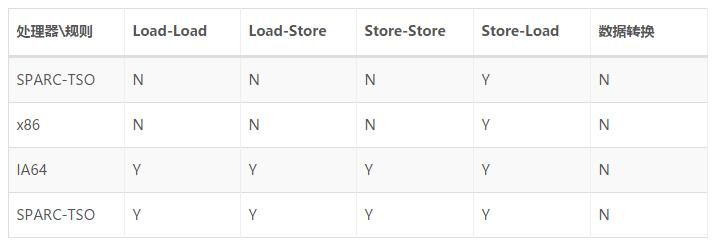
其中的 N 表示处理器不允许两个操作进行重排序,Y 表示允许。可以看出:常见处理器你对 StoreLoad 都是允许重排的,并且常见处理器都不允许对存在数据依赖的操作进行重排序。另外,对应数据转换这一列都为 N,所以处理器均不允许这种重排序。
那么这个结论有什么用呢?比如第一点:处理器允许 StoreLoad 操作的重排序,那么在并发编程中读线程可能读到一个未被初始化或 null 值,出现不可预知的错误,基于这一点,JMM 会在适当的位置插入内存屏障指令来禁止特定类型的处理器重排序。
内存屏障指令共有 4 类:LoadLoad、StoreStore、LoadStore、StoreLoad。详细释义参考 JMM 规范。
数据依赖性
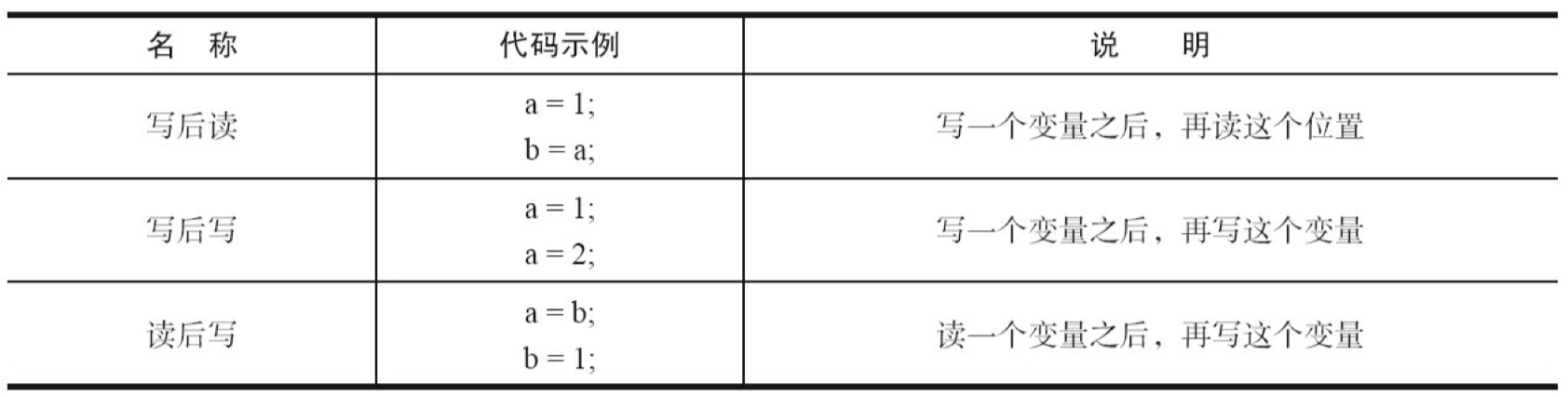
根据上面的表格,处理器不会对存在数据依赖性的操作进行重排序。这里数据依赖性的准确定义是:如果两个操作访问同一个变量,其中一个操作是写,此时两个操作就构成了数据依赖性。常见的具有这种特点的操作有自增、自减。如果改变了具有数据依赖性的两个操作的执行顺序,那么最后的执行结果就会被改变。这也就是不能进行重排序的原因。
- 写后读:
a = 1; b = a; - 写后写:
a = 1; a = 2; - 读后写:
a = b; b = 1;
重排序遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行属性怒。但是这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。
as-if-serial 语义
as-if-serial 语义指的是:“无论怎么重排序,(单线程)程序的执行结果不能被改变”。编译器、runtime 和处理器都必须遵守 as-if-serial 语义。
as-if-serial 语义把单线程程序保护了起来,遵守 as-if-serial 语义的编译器,runtime 和处理器共同为编写单线程程序的开发者穿件了一个幻觉:单线程程序是按程序编写的顺序来执行的。as-if-serial 语义使单线程开发者无需单行重排会干扰他们,也无需担心内存可见性问题。
重排序对多线程的影响
如果代码中存在控制依赖,会影响指令序列执行的并行度。因此,编译器和处理器会采用猜测(speculation)执行来克服控制的相关性。所以重排序破坏了程序的顺序规则(该规则是说指令顺序与实际代码的执行顺序是一致的,但是处理器和编译器会进行重排序,只要最后的结果不变,重排序就是合理的)。
先行发生原则(happens-before)
前面所说的内存交互原则都必须满足一定的规则,而 happens-before 就是定义这些规则时的一个等效判断的原则。happens-before 是 JMM 定义的、两个操作之间的偏序关系:如操作 A 线程发生于操作 B,则 A 产生的影响能够被 B 观察到,“影响”包括了修改了内存中共享变量的值、发送了消息、调用了方法等。如果两个操作满足 happens-before 原则,那么就不需要进行同步操作,JVM 能够保证操作具有顺序性,此时不能随意进行重排序。否则,无法保证顺序性,就能进行指令的重排序。
happens-before 原则主要包括:
- 程序次序原则
- 管理锁定原则
- volatile 变量规则
- 线程启动规则
- 线程终止规则
- 线程中断规则
- 对象终结规则
- 传递性
详细释义参见 JMM 规范。
3 - CH03-JMM原则
Reference
3.1 Java内存模型的基础
3.1.1 并发编程模型的两个关键问题
在并发编程中,需要处理两个关键问题:线程之间的通信与同步。(这里所说的线程是指并发执行的活动实体)。通信是指线程之间如何交换信息。在命命令式编程中,线程之间的通信机制有两种:共享内存与消息传递。
在共享内存的并发模型里,线程之间共享程序的公共状态,通过读写内存中的公共状态进行隐式通信。在消息传递的并发模型里,线程之间没有公共状态,线程之间必须通过发送消息来显式进行通信。
同步是指程序中用于控制不同线程间操作所发生的相对顺序的机制。在共享内存并发模型里,同步是显式进行的。程序员必须显式指定某个方法或某段代码需要在线程之间互斥执行。在消息传递的并发模型里,由于消息的发送操作一定是在消息的接收操作之前,因此同步是隐式进行的。
Java 的并发实现采用的是共享内存模型,Java 线程之间的通信总是隐式进行,整个通信过程对程序员完全透明。如果编写多线程程序的 Java 程序员不理解隐式进行的线程之间通信的工作机制,很可能会遇到各种奇怪的内存可见性问题。
3.1.2 Java 内存模型的抽象结构
在 Java 中,所有实例域、静态域和数组元素都存储在堆内存中,堆内存在线程之间共享(本文使用“共享变量”来代指实例域、静态域和数组元素)。局部变量、方法参数、异常处理器参数不会在线程之间共享(会被保存在对应执行线程的栈上),因此不存在内存可见性问题,也不受内存模型的影响。
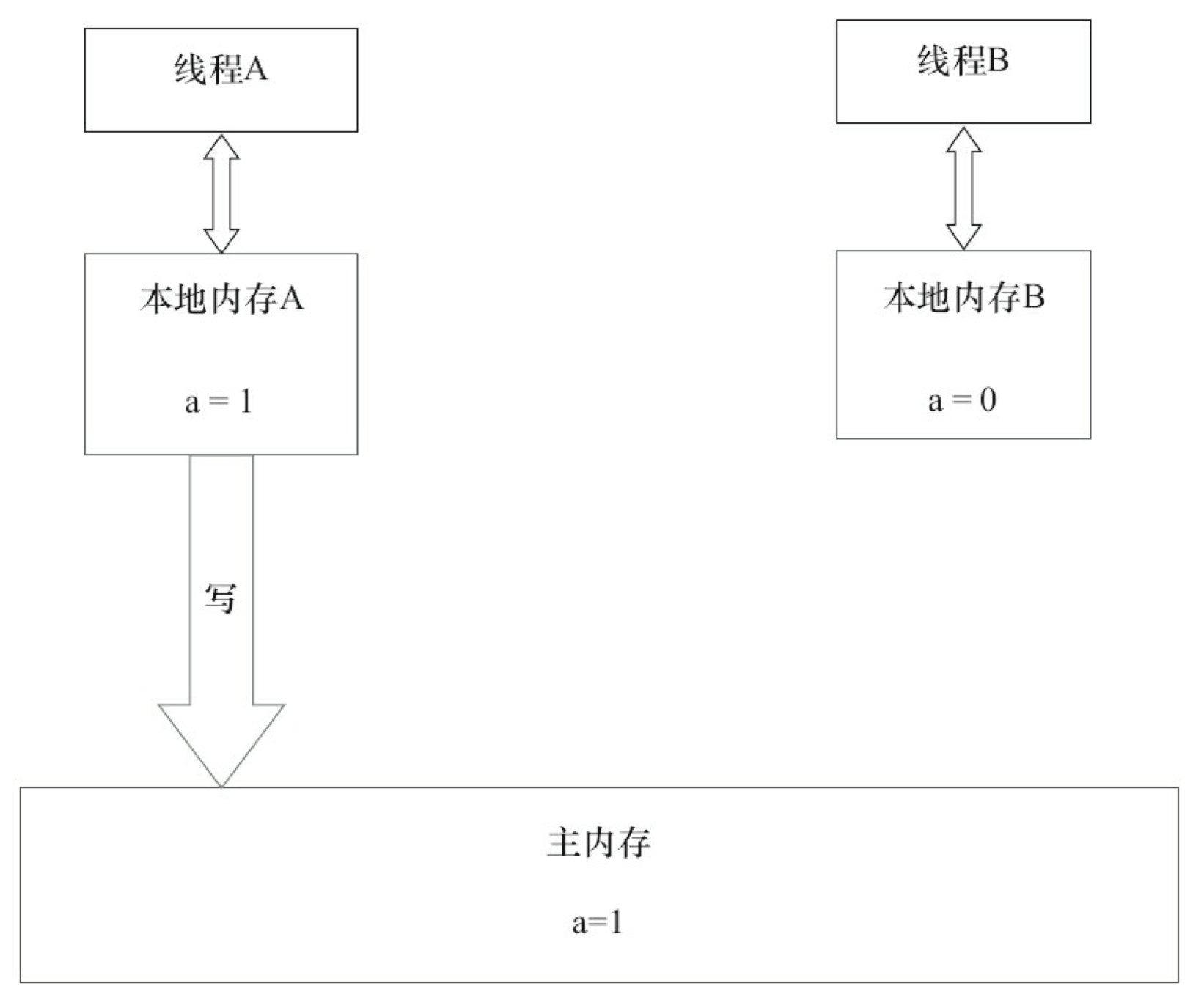
Java 线程之间的通信由 Java 内存模型(JMM)控制,JMM 决定一个线程对共享变量的写入何时对另一个线程可见。从抽象的角度来看,JMM 定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存中,每个线程都自己的私有本地内存,本地内存中存储了该线程用以读/写共享变量的副本。本地内存是 JMM 的一个抽象概念,并不真实存在。它涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。 JMM 的抽象示意如图所示。
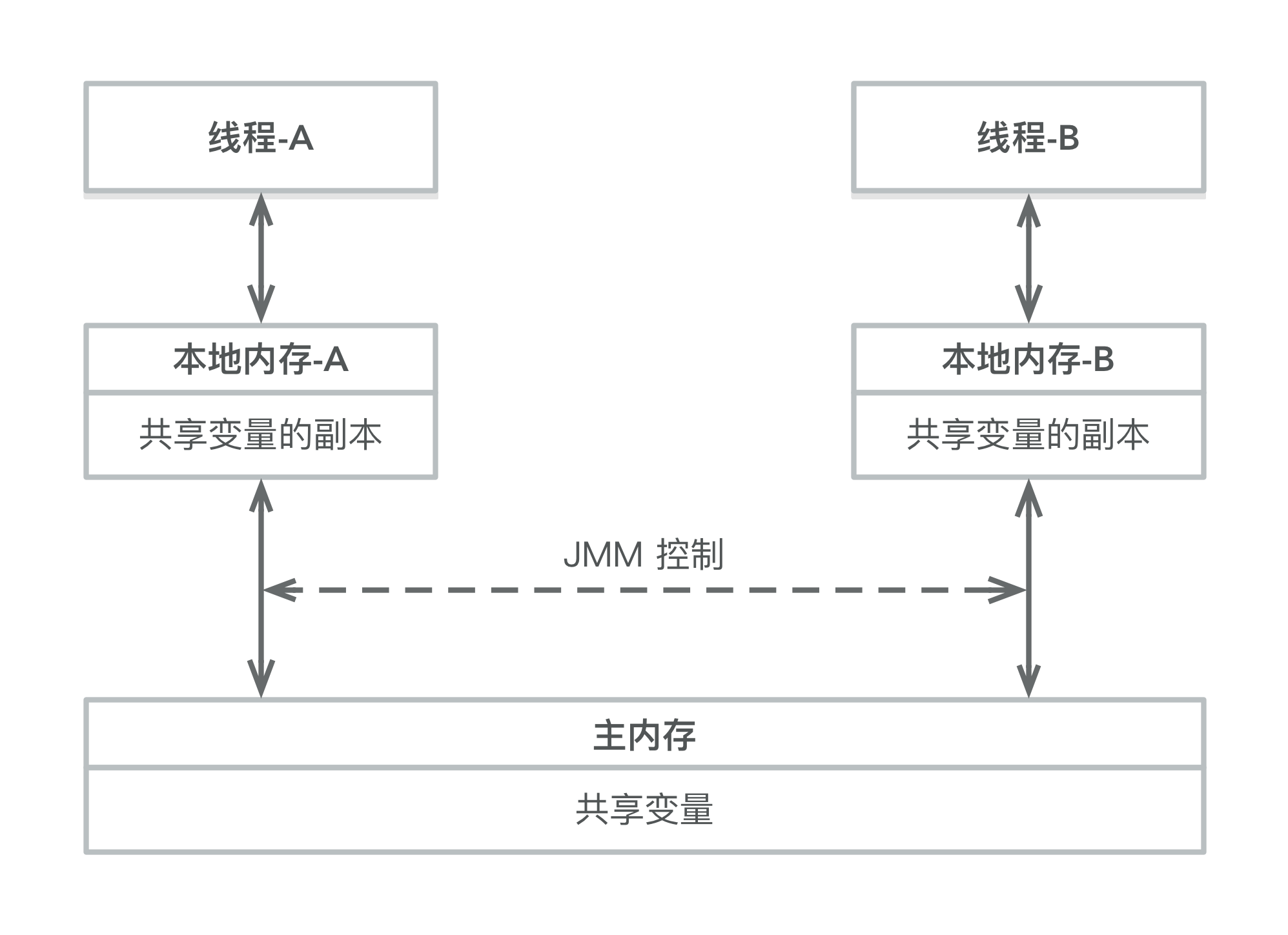
从上图来看,如果线程 A 与线程 B 之间要通信的话,必须要经历下面 2 个步骤:
- 线程 A 将本地内存 A 中被更新过的共享变量刷新到主内存中。
- 线程 B 到主内存中去读取由线程 A 之前更新过的共享变量。
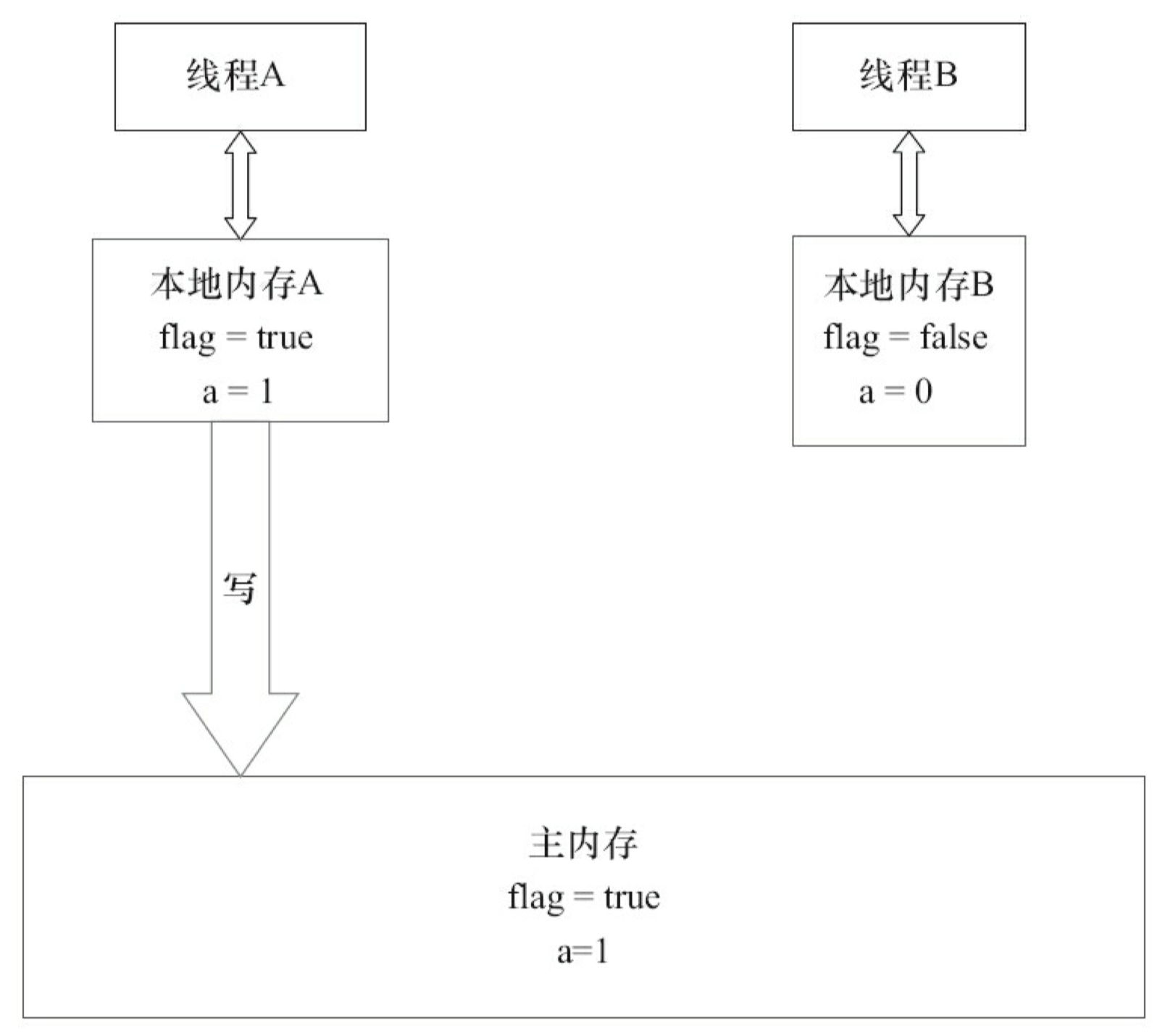
下面通过示意图来说明这两个步骤。
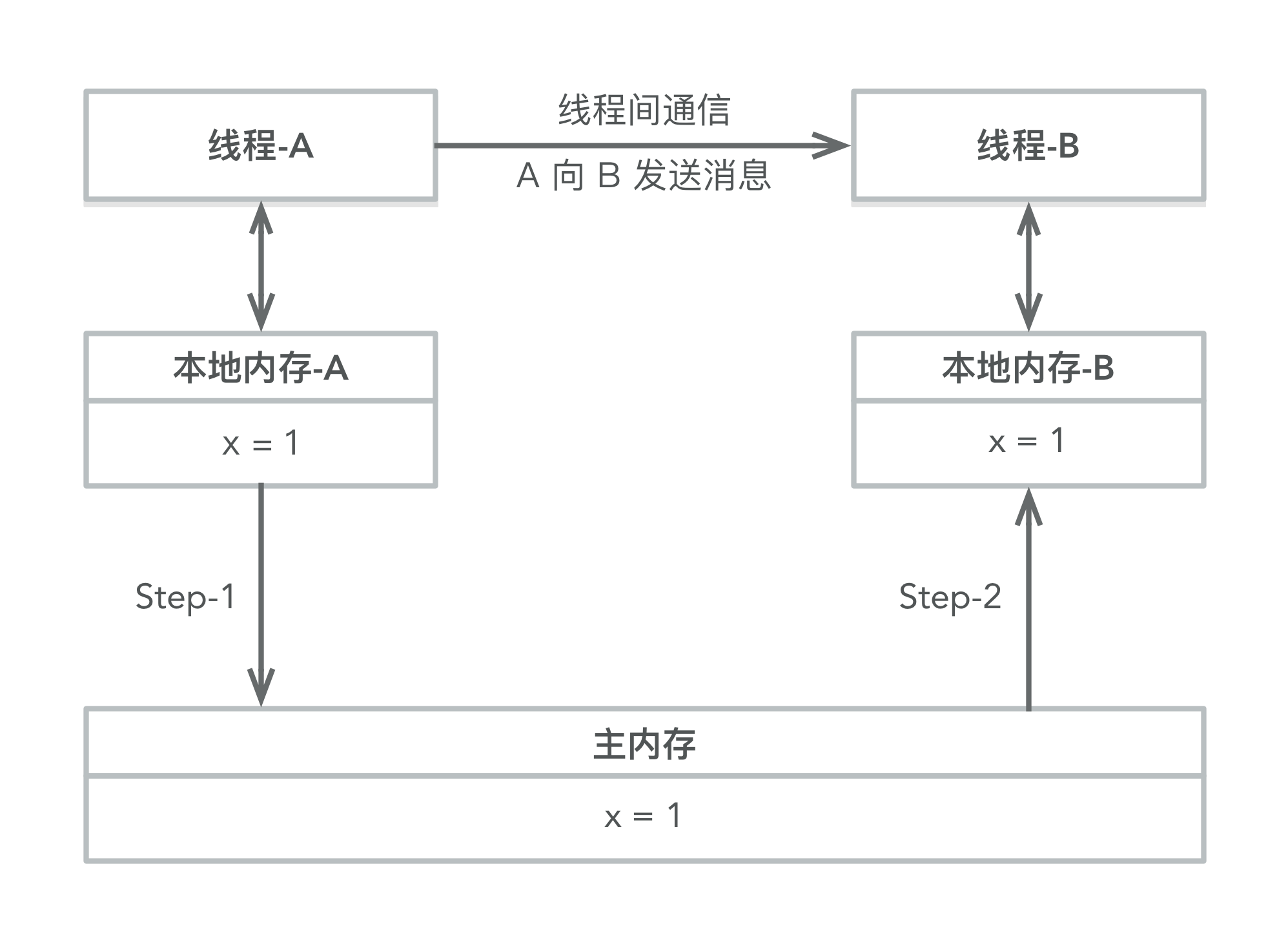
如上图所示,本地内存 A 和本地内存 B 持有主内存中共享变量 x 的副本。假设初始时,这 3 个内存中的 x 值都为 0。线程 A 在执行时,把更新后的 x 值(假设值为1)临时存放在自己的本地内存 A 中。当线程 A 和线程 B 需要通信时,线程 A 首先会把自己本地内存中修改后的 x 值刷新到主内存中,此时主内存中的 x 值变为了 1。随后,线程 B 到主内存中去读取线程 A 更新后的 x 值,此时线程 B 的本地内存的 x 值也变为了 1。
从整体来看,这两个步骤实质上是线程 A 在向线程 B 发送消息,而且这个通信过程必须要经过主内存。JMM 通过控制主内存与每个线程的本地内存之间的交互,来为 Java 程序员提供内存可见性保证。
3.1.3 从源代码到指令序列的重排序
为了在执行程序时提高性能,编译器和处理器常常会对指令做重排序。重排序分 3 种类型:
- 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句 的执行顺序。
- 指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
- 内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上 去可能是在乱序执行。
从 Java 源代码到最终实际执行的指令序列,会分别经历下面3种重排序:

上述第 1 步属于编译器重排序,2~3 步属于处理器重排序。这些重排序可能会导致多线程程序出现内存可见性问题。对于编译器,JMM 的编译器重排序规则会禁止特定类型的编译器重排序(并非所有的编译器重排序都要禁止)。对于处理器重排序,JMM 的处理器重排序规则会要求 Java 编译器在生成指令序列时,插入特定类型的内存屏障(Memory Barriers,Intel 称之为 Memory Fence)指令,通过内存屏障指令来禁止特定类型的处理器重排序。
JMM 属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
3.1.4 并发编程模型的分类
现代的处理器使用写缓冲区临时保存向内存写入的数据。写缓冲区可以保证指令流水线持续运行,它可以避免由于处理器停顿下来等待向内存写入数据而产生的延迟。同时,通过以批处理的方式刷新写缓冲区,以及合并写缓冲区中对同一内存地址的多次写,从而减少对内存总线的占用。虽然写缓冲区有这么多好处,但每个处理器上的写缓冲区,仅仅对它所属的处理器可见。这个特性会对内存操作的执行顺序产生重要的影响:处理器对内存的读/写操作的执行顺序,不一定与内存实际发生的读/写操作顺序一致!为了具体说明,请看下面的表。
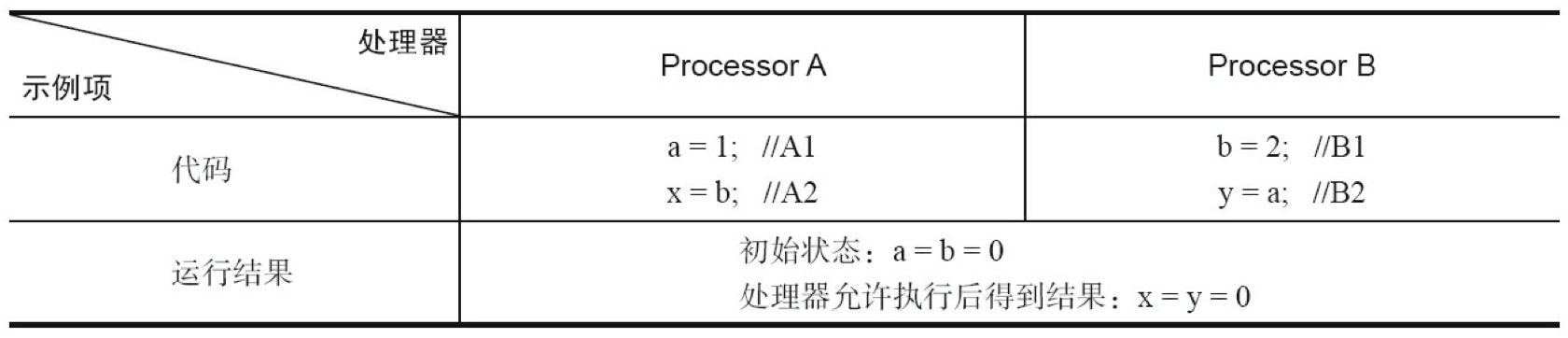
假设处理器 A 和处理器 B 按程序的顺序并行执行内存访问,最终可能得到 x=y=0 的结果。具体的原因如图所示。
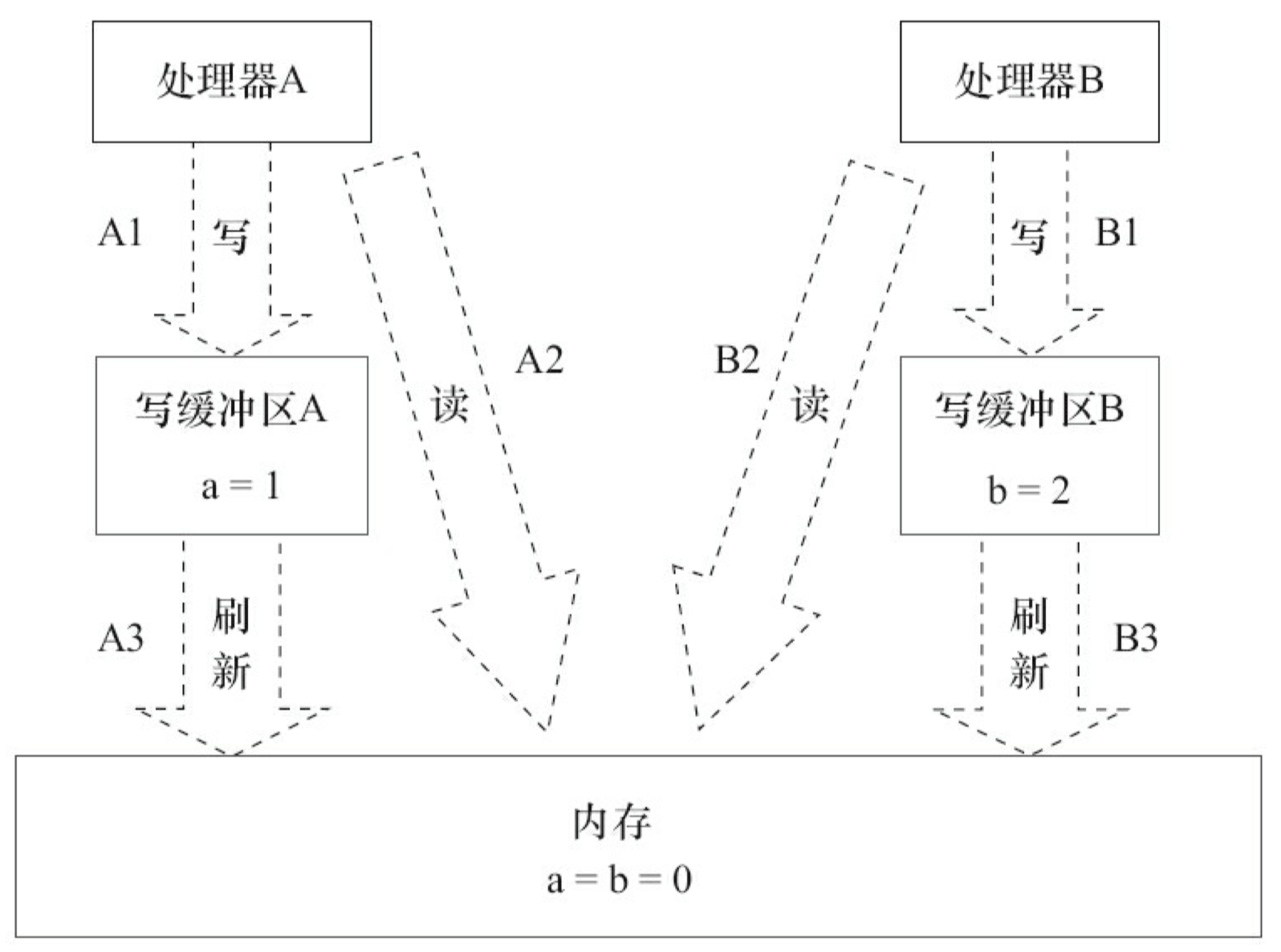
这里处理器 A 和处理器 B 可以同时把共享变量写入自己的写缓冲区(A1,B1),然后从内存中读取另一个共享变量(A2,B2),最后才把自己写缓存区中保存的脏数据刷新到内存中(A3, B3)。当以这种时序执行时,程序就可以得到 x=y=0 的结果。
从内存操作实际发生的顺序来看,直到处理器 A 执行 A3 来刷新自己的写缓存区,写操作 A1 才算真正执行了。虽然处理器 A 执行内存操作的顺序为:A1→A2,但内存操作实际发生的顺序却是 A2→A1。此时,处理器 A 的内存操作顺序被重排序了(处理器 B 的情况和处理器 A 一样)。
这里的关键是,由于写缓冲区仅对自己的处理器可见,它会导致处理器执行内存操作的顺序可能会与内存实际的操作执行顺序不一致。由于现代的处理器都会使用写缓冲区,因此 现代的处理器都会允许对写-读操作进行重排序。
下表是常见处理器允许的重排序类型的列表。
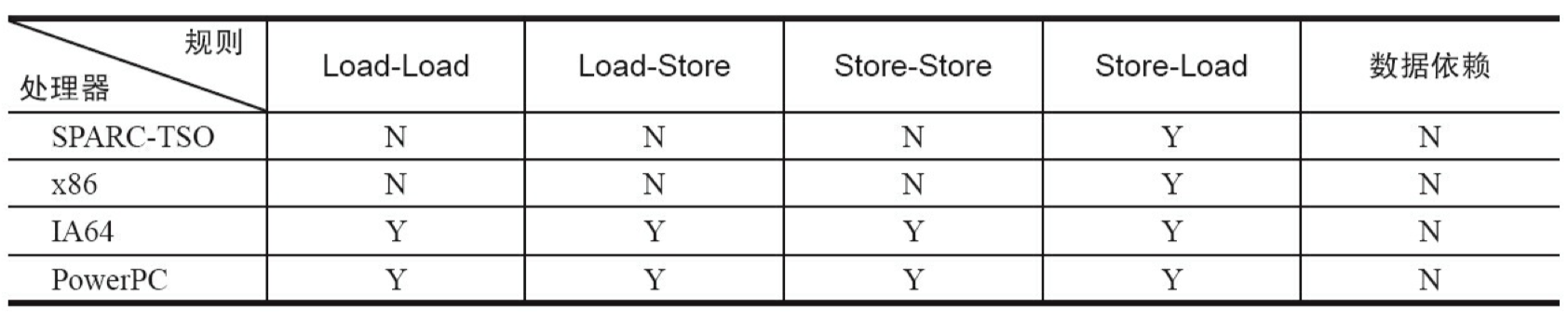
元格中的 “N” 表示处理器不允许两个操作重排序,“Y” 表示允许重排序。
从上表我们可以看出:常见的处理器都允许 Store-Load 重排序;常见的处理器都不允许对存在数据依赖的操作应用重排序。sparc-TSO 和 X86 拥有相对较强的处理器内存模型,它们仅允许对写-读操作做重排序(因为它们都使用了写缓冲区)。
为了保证内存可见性,Java 编译器在所生成指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序。JMM 把内存屏障指令分为4类,如表所示。

StoreLoad Barriers 是一个“全能型”的屏障,它同时具有其他 3 个屏障的效果。现代的多处理器大多支持该屏障(其他类型的屏障不一定被所有处理器支持)。执行该屏障的开销会很昂贵,因为当前处理器通常要把写缓冲区中的数据全部刷新到内存中(Buffer Fully Flush)。
3.1.5 happens-before 简介
从 JDK 5 开始,Java 使用新的 JSR-133 内存模型。JSR-133 使用 happens-before 的概念来阐述操作之间的内存可见性。在 JMM 中,如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须要存在 happens-before 关系。这里提到的两个操作既可以是在一个线程之内,也可以是在不同线程之间。
与程序员密切相关的 happens-before 规则如下:
- 程序顺序规则:一个线程中的每个操作,happens-before 于该线程中的任意后续操作。
- 监视器锁规则:对一个锁的解锁,happens-before 于随后对这个锁的加锁。
- volatile 变量规则:对一个 volatile 域的写,happens-before 于任意后续对这个 volatile 域的读。
- 传递性:如果 A happens-before B,且 B happens-before C,那么 A happens-before C。
注意:两个操作之间具有 happens-before 关系,并不意味着前一个操作必须要在后一个操作之前执行!happens-before 仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前(the first is visible to and ordered before the second)。happens-before 的定义很微妙,后文会具体说明 happens-before 为什么要这么定义。
happens-before 与 JMM 的关系如图所示。
如图所示,一个 happens-before 规则对应于一个或多个编译器和处理器重排序规则。对于 Java 程序员来说,happens-before 规则简单易懂,它避免 Java 程序员为了理解 JMM 提供的内存可见性保证而去学习复杂的重排序规则以及这些规则的具体实现方法。
3.2 重排序
重排序是指编译器和处理器为了优化程序性能而对指令序列进行重新排序的一种手段。
3.2.1 数据依赖性
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。数据依赖分为下列 3 种类型,如表 3-4 所示。
上面 3 种情况,只要重排序两个操作的执行顺序,程序的执行结果就会被改变。
前面提到过,编译器和处理器可能会对操作应用重排序。编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。
这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。
3.2.2 as-if-serial 语义
as-if-serial 语义是:不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。编译器、运行时和处理器都必须遵守 as-if-serial 语义。
为了遵守 as-if-serial 语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。为了具体说明,请看下面计算圆面积的代码示例。
double pi = 3.14; // A
double r = 1.0; // B
double area = pi * r * r; // C
上面 3 个操作的数据依赖关系如图 3-6 所示。
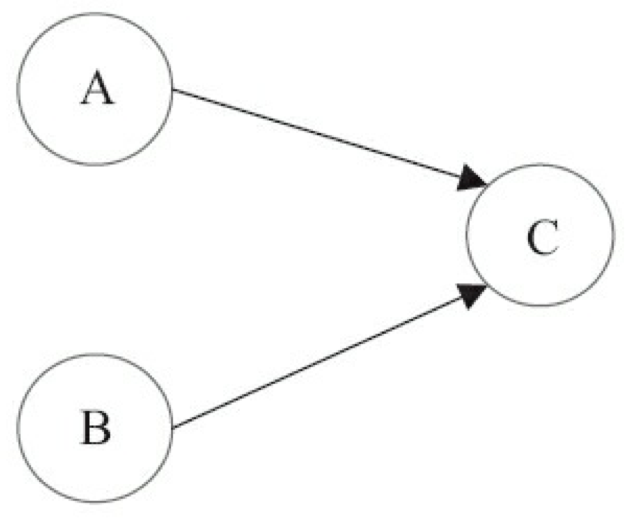
如图 3-6 所示,A 和 C 之间存在数据依赖关系,同时 B 和 C 之间也存在数据依赖关系。因此在最终执行的指令序列中,C 不能被重排序到 A 和 B 的前面(C 排到 A 和 B 的前面,程序的结果将会被改变)。但 A 和 B 之间没有数据依赖关系,编译器和处理器可以重排序 A 和 B 之间的执行顺序。 图 3-7 是该程序的两种执行顺序。
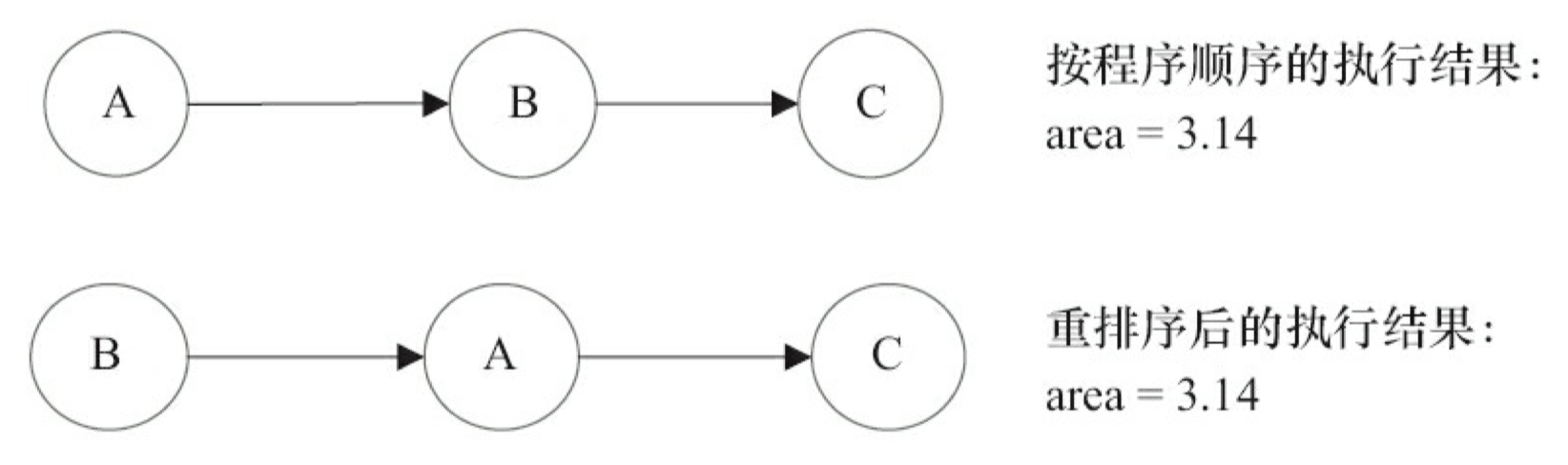
as-if-serial 语义把单线程程序保护了起来,遵守 as-if-serial 语义的编译器、运行时和处理器共同为编写单线程程序的程序员创建了一个幻觉:单线程程序是按程序的顺序来执行的。as-if-serial 语义使单线程程序员无需担心重排序会干扰他们,也无需担心内存可见性问题。
3.2.3 程序顺序规则
根据 happens-before 的程序顺序规则,上面计算圆的面积的示例代码存在 3 个 happens-before 关系:
- A happens-before B。
- B happens-before C。
- A happens-before C。
这里的第 3 个 happens-before 关系,是根据 happens-before 的传递性推导出来的。
这里 A happens-before B,但在实际执行时 B 却可以排在 A 之前执行(看上面的重排序后的执行顺序)。如果 A happens-before B,JMM 并不要求 A 一定要在 B 之前执行。JMM 仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前。这里操作 A 的执行结果不需要对操作 B 可见;而且重排序操作 A 和操作 B 后的执行结果,与操作 A 和操作 B 按 happens-before 顺序执行的结果一致。在这种情况下,JMM 会认为这种重排序合法,因此 JMM 允许这种重排序。
在计算机中,软件技术和硬件技术有一个共同的目标:在不改变程序执行结果的前提下,尽可能提高并行度。编译器和处理器遵从这一目标,从 happens-before 的定义我们可以看出,JMM 同样遵从这一目标。
3.2.4 重排序对多线程的影响
现在让我们来看看,重排序是否会改变多线程程序的执行结果。请看下面的示例代码。
class RecordExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; // 1
flag = true; // 2
}
public void reader() {
if(flag) { // 3
int i = a * a; // 4
}
}
}
flag 变量是个标记,用来标识变量 a 是否已被写入。这里假设有两个线程 A 和 B,A 首先执行 writer 方法,随后 B 线程接着执行 reader 方法。线程 B 在执行操作 4 时,能否看到线程 A 在操作 1 对共享变量 a 的写入呢?答案是不一定。
由于操作 1 和操作 2 没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作 3 和操作 4 没有数据依赖关系(有控制依赖关系),编译器和处理器也可以对这两个操作重排序。让我们先来看看,当操作 1 和操作 2 重排序时,可能会产生什么效果?请看下面的程序执行时序图,如图 38 所示。
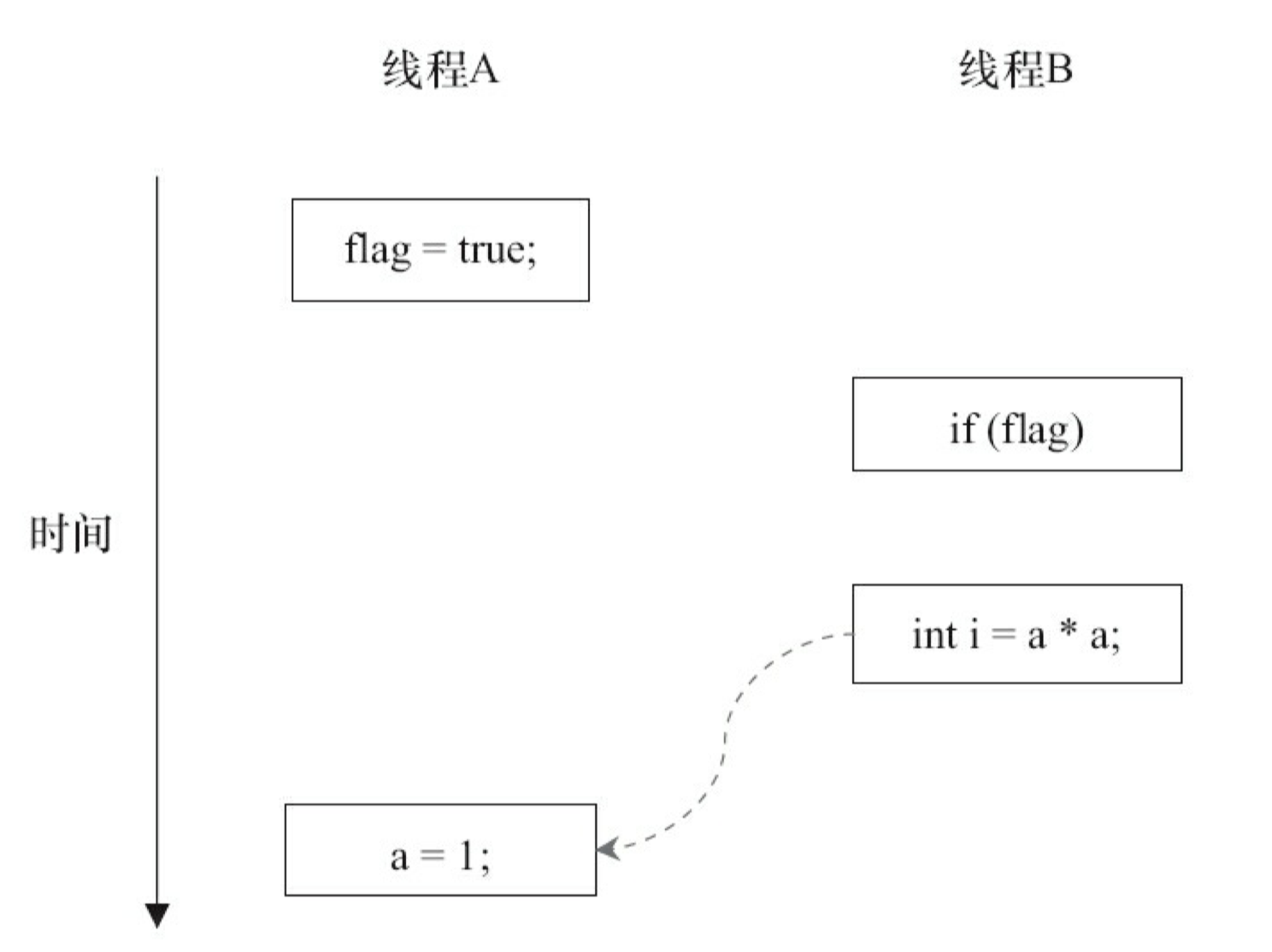
如图 3-8 所示,操作 1 和操作 2 做了重排序。程序执行时,线程 A 首先写标记变量 flag,随后线程 B 读这个变量。由于条件判断为真,线程 B 将读取变量 a。此时,变量 a 还没有被线程 A 写入,在这里多线程程序的语义被重排序破坏了!
下面再让我们看看,当操作 3 和操作 4 重排序时会产生什么效果(借助这个重排序,可以顺便说明控制依赖性)。下面是操作 3 和操作 4 重排序后,程序执行的时序图,如图 3-9 所示。
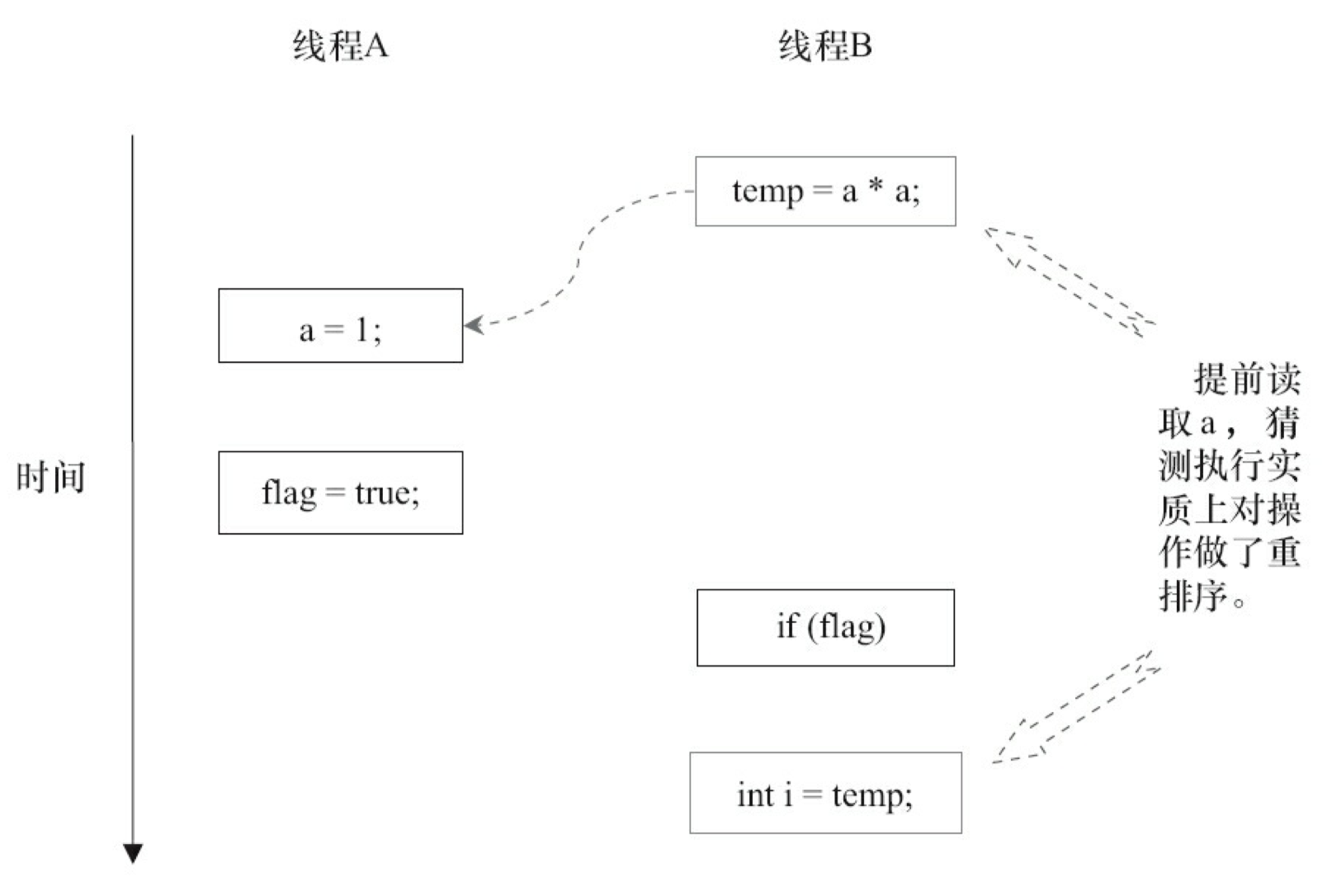
在程序中,操作 3 和操作 4 存在控制依赖关系。当代码中存在控制依赖性时,会影响指令序列执行的并行度。为此,编译器和处理器会采用猜测(Speculation)执行来克服控制相关性对并行度的影响。以处理器的猜测执行为例,执行线程 B 的处理器可以提前读取并计算 a * a,然后把计算结果临时保存到一个名为重排序缓冲(Reorder Buffer,ROB)的硬件缓存中。当操作 3 的条件判断为真时,就把该计算结果写入变量 i 中。
从图 3-9 中我们可以看出,猜测执行实质上对操作 3 和 4 做了重排序。重排序在这里破坏了多线程程序的语义!
在单线程程序中,对存在控制依赖的操作重排序,不会改变执行结果(这也是 as-if-serial 语义允许对存在控制依赖的操作做重排序的原因);但在多线程程序中,对存在控制依赖的操作重排序,可能会改变程序的执行结果。
3.3 顺序一致性
顺序一致性内存模型是一个理论参考模型,在设计的时候,处理器的内存模型和编程语言的内存模型都会以顺序一致性内存模型作为参照。
3.3.1 数据竞争与顺序一致性
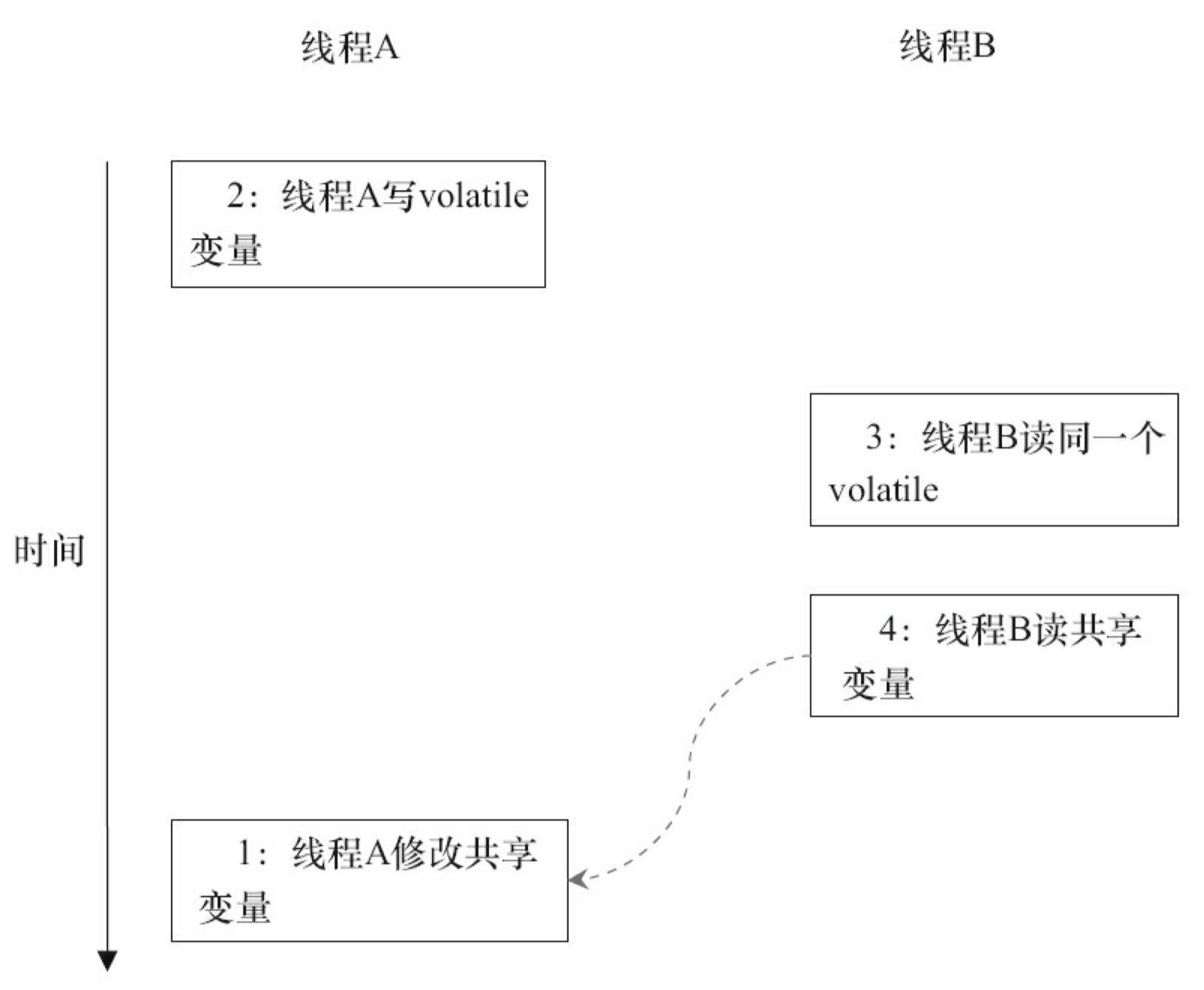
当程序未正确同步时,就可能会存在数据竞争。Java内存模型规范对数据竞争的定义下:
- 在一个线程中写一个变量,在另一个线程读同一个变量,而且写和读没有通过同步来排序。
当代码中包含数据竞争时,程序的执行往往产生违反直觉的结果。如果一个多线程程序能正确同步,这个程序将是一个没有数据竞争的程序。
JMM 对正确同步的多线程程序的内存一致性做了如下保证:
如果程序是正确同步的,程序的执行将具有顺序一致性(Sequentially Consistent)——即程序的执行结果与该程序在顺序一致性内存模型中的执行结果相同。马上我们就会看到,这对于程序员来说是一个极强的保证。这里的同步是指广义上的同步,包括对常用同步原语(synchronized、volatile、final)的正确使用。
顺序一致性内存模型
顺序一致性内存模型是一个被计算机科学家理想化了的理论参考模型,它为程序员提供了极强的内存可见性保证。顺序一致性内存模型有两大特性:
- 一个线程中的所有操作必须按照程序的顺序来执行。
- (不管程序是否同步)所有线程都只能看到一个单一的操作执行顺序。在顺序一致性内 存模型中,每个操作都必须原子执行且立刻对所有线程可见。
顺序一致性内存模型为程序员提供的视图如图 3-10 所示。
在概念上,顺序一致性模型有一个单一的全局内存,该内存通过一个左右摆动的开关可以连接到任意一个线程,同时每一个线程必须按照程序的顺序来执行内存读/写操作。从上 面的示意图可以看出,在任意时间点最多只能有一个线程可以连接到内存。当多个线程并发执行时,图中的开关装置能把所有线程的所有内存读/写操作串行化(即在顺序一致性模型中,所有操作之间具有全序关系)。
为了更好进行理解,下面通过两个示意图来对顺序一致性模型的特性做进一步的说明。
假设有两个线程 A 和 B 并发执行。其中A线程有 3 个操作,它们在程序中的顺序是: A1→A2→A3。B线程也有3个操作,它们在程序中的顺序是:B1→B2→B3。
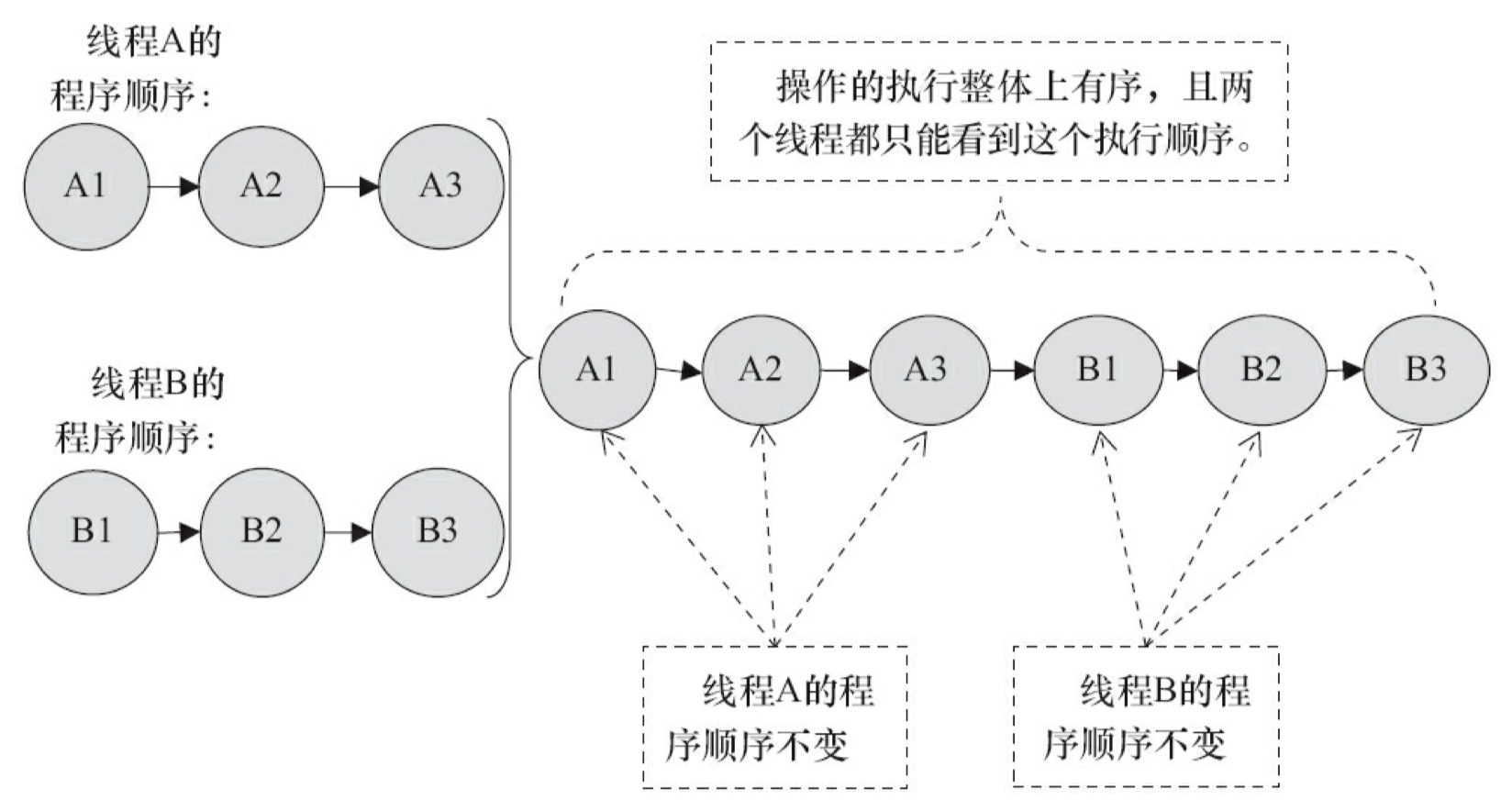
假设这两个线程使用监视器锁来正确同步:A 线程的 3 个操作执行后释放监视器锁,随后 B 线程获取同一个监视器锁。那么程序在顺序一致性模型中的执行效果将如图 3-11 所示。
现在我们再假设这两个线程没有做同步,下面是这个未同步程序在顺序一致性模型中的执行示意图,如图 3-12 所示。
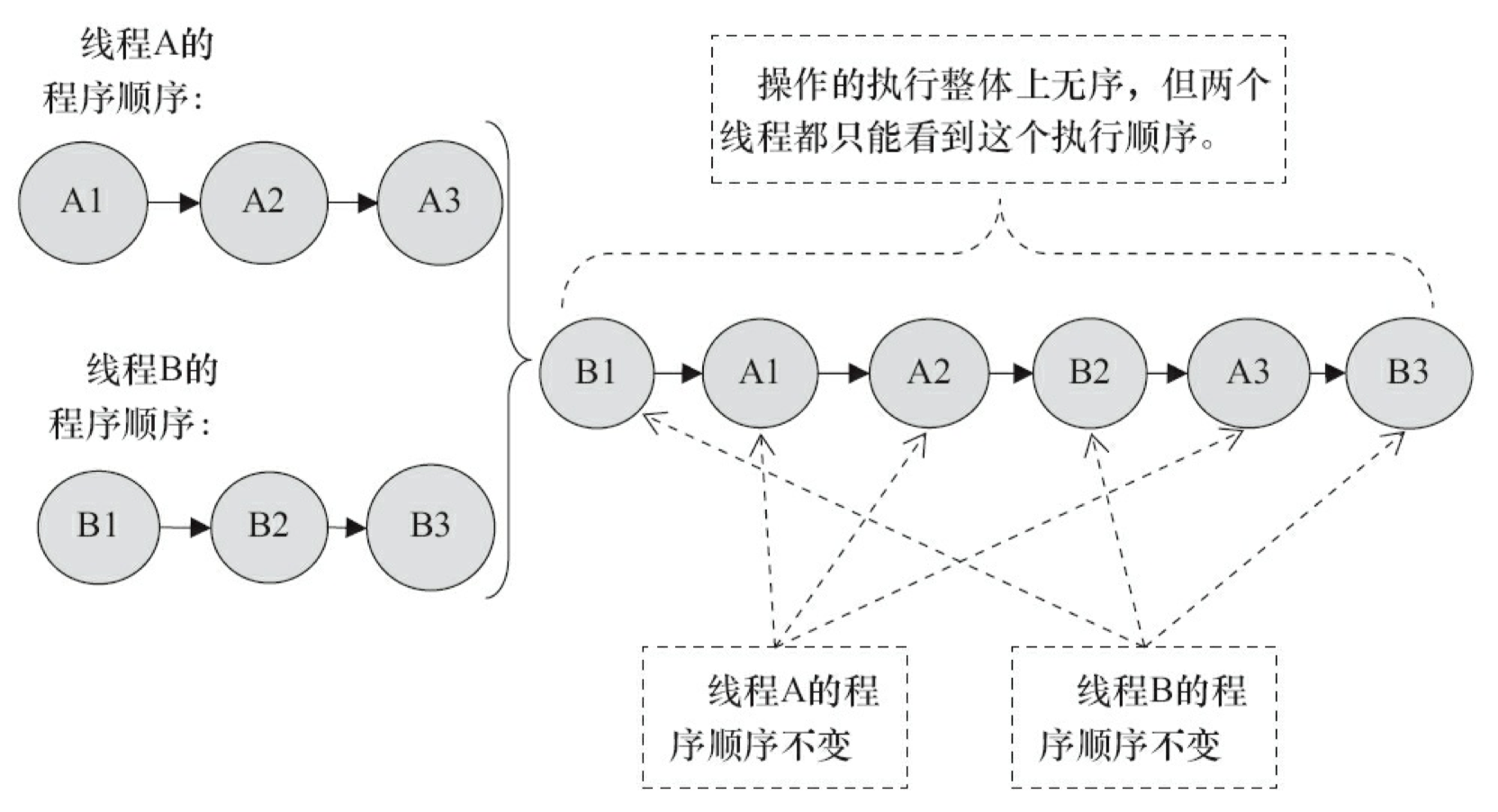
未同步程序在顺序一致性模型中虽然整体执行顺序是无序的,但所有线程都只能看到一个一致的整体执行顺序。以上图为例,线程 A 和 B 看到的执行顺序都是: B1→A1→A2→B2→A3→B3。之所以能得到这个保证是因为顺序一致性内存模型中的每个操 作必须立即对任意线程可见。
但是,在 JMM 中就没有这个保证。未同步程序在 JMM 中不但整体的执行顺序是无序的,而且所有线程看到的操作执行顺序也可能不一致。比如,在当前线程把写过的数据缓存在本地内存中,在没有刷新到主内存之前,这个写操作仅对当前线程可见;从其他线程的角度来观察,会认为这个写操作根本没有被当前线程执行。只有当前线程把本地内存中写过的数据刷新到主内存之后,这个写操作才能对其他线程可见。在这种情况下,当前线程和其他线程看到的操作执行顺序将不一致。
3.3.3 同步程序的顺序一致性效果
下面,对前面的示例程序 ReorderExample 用锁来同步,看看正确同步的程序如何具有顺序一致性。
class SynchronizedExample {
int a = 0;
boolean flag = false;
public synchronized void writer() {
a = 1;
flag = true;
}
public synchronized void reader() {
if(flag) {
int i = a;
...
}
}
}
在上面示例代码中,假设 A 线程执行 writer 方法后,B 线程执行 reader 方法。这是一个正确同步的多线程程序。根据 JMM 规范,该程序的执行结果将与该程序在顺序一致性模型中的执行结果相同。下面是该程序在两个内存模型中的执行时序对比图,如图 3-13 所示。
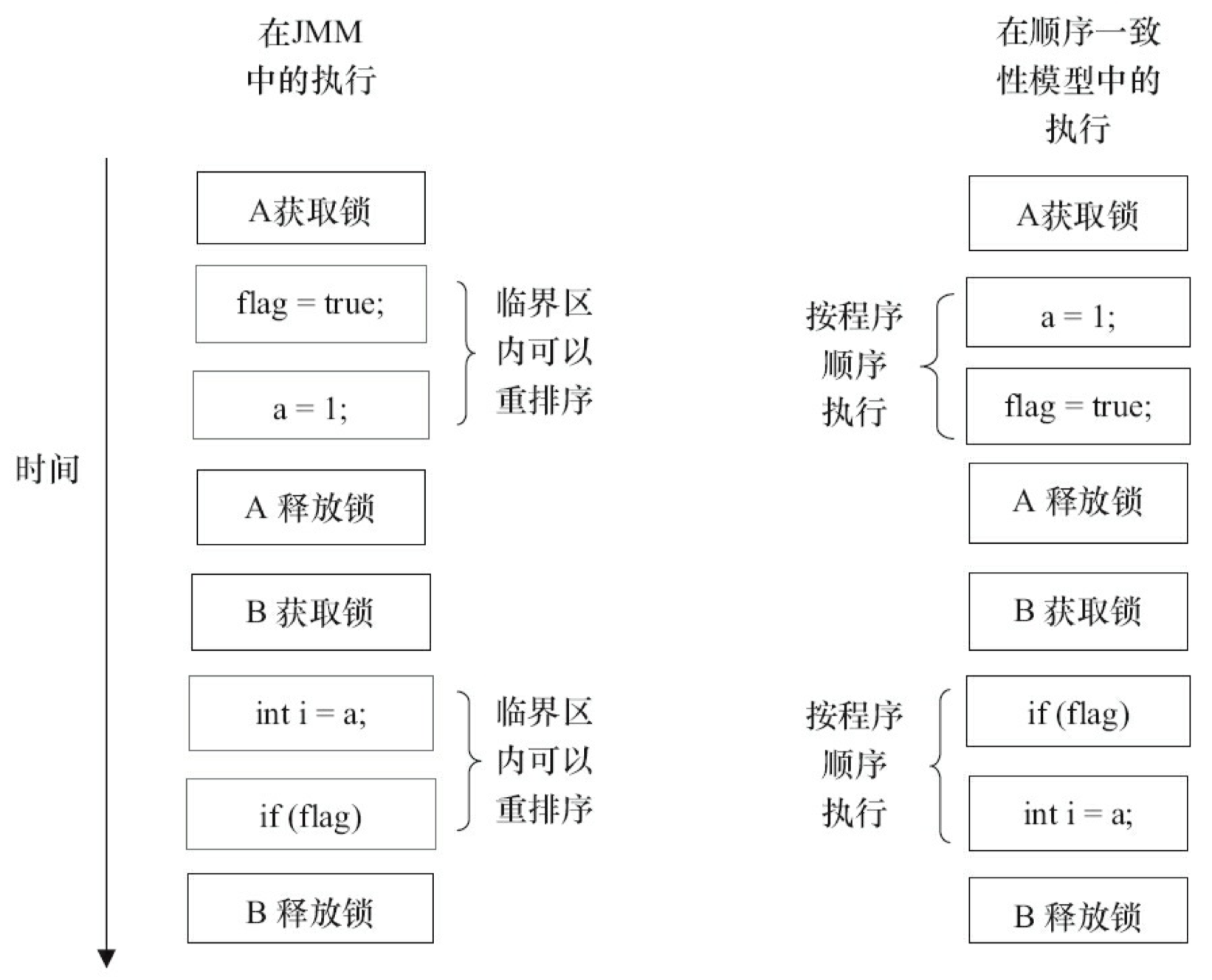
顺序一致性模型中,所有操作完全按程序的顺序串行执行。而在 JMM 中,临界区内的代码可以重排序(但 JMM 不允许临界区内的代码“逸出”到临界区之外,那样会破坏监视器的语义)。JMM 会在退出临界区和进入临界区这两个关键时间点做一些特别处理,使得线程在这两个时间点具有与顺序一致性模型相同的内存视图。虽然线程 A 在临界区内做了重排序,但由于监视器互斥执行的特性,这里的线程 B 根本无法“观察”到线程A在临界区内的重排序。这种重排序既提高了执行效率,又没有改变程序的执行结果。
从这里我们可以看到,JMM 在具体实现上的基本方针为:在不改变(正确同步的)程序执 行结果的前提下,尽可能地为编译器和处理器的优化打开方便之门。
3.3.4 未同步程序的执行特性
对于未同步或未正确同步的多线程程序,JMM 只提供最小安全性:线程执行时读取到的 值,要么是之前某个线程写入的值,要么是默认值(0,Null,False),JMM 保证线程读操作读取到的值不会无中生有的冒出来。为了实现最小安全性,JVM 在堆上分配对象时,首先会对内存空间进行清零,然后才会在上面分配对象(JVM 内部会同步这两个操作)。因此,在已清零的内存空间(Pre-zeroed Memory)分配对象时,域的默认初始化已经完成了。
JMM 不保证未同步程序的执行结果与该程序在顺序一致性模型中的执行结果一致。因为如果想要保证执行结果一致,JMM 需要禁止大量的处理器和编译器的优化,这对程序的执行 性能会产生很大的影响。而且未同步程序在顺序一致性模型中执行时,整体是无序的,其执行结果往往无法预知。而且,保证未同步程序在这两个模型中的执行结果一致没什么意义。
未同步程序在 JMM 中的执行时,整体上是无序的,其执行结果无法预知。未同步程序在两个模型中的执行特性有如下几个差异:
- 顺序一致性模型保证单线程内的操作会按程序的顺序执行,而 JMM 不保证单线程内的操作会按程序的顺序执行(比如上面正确同步的多线程程序在临界区内的重排序)。
- 顺序一致性模型保证所有线程只能看到一致的操作执行顺序,而 JMM 不保证所有线程能看到一致的操作执行顺序。
- 字撕裂。JMM 不保证对 64 位的 long/double 型变量的写操作具有原子性,而顺序一致性模型保证对所有的内存读/写操作都具有原子性。
第 3 个差异与处理器总线的工作机制密切相关。在计算机中,数据通过总线在处理器和内存之间传递。每次处理器和内存之间的数据传递都是通过一系列步骤来完成的,这一系列步骤称之为总线事务(Bus Transaction)。总线事务包括读事务和写事务。读事务从内存传送数据到处理器,写事务从处理器传送数据到内存,每个事务会读/写内存中一个或多个物理上连续的字。这里的关键是,总线会同步试图并发使用总线事务。在一个处理器执行总线事务期间,总线会禁止其他的处理器和 I/O 设备执行内存的读/写。下面,让我们通过一个示意图来说明总线的工作机制,如图3-14所示。
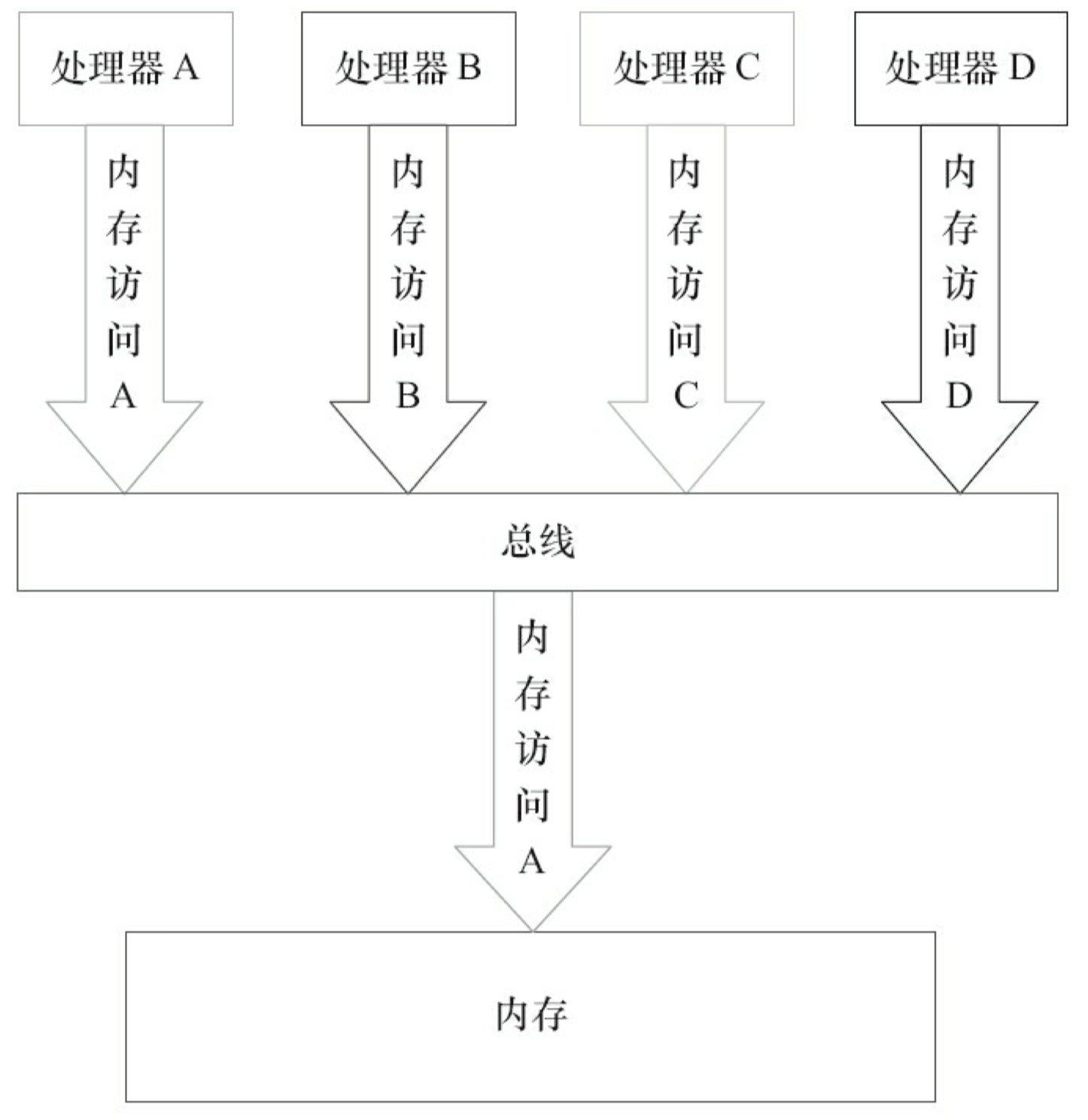
由图可知,假设处理器 A,B 和 C 同时向总线发起总线事务,这时总线仲裁会对竞争做出裁决,这里假设总线在仲裁后判定处理器 A 在竞争中获胜(总线仲裁会确保所有处理器都能公平的访问内存)。此时处理器 A 继续它的总线事务,而其他两个处理器则要等待 处理器 A 的总线事务完成后才能再次执行内存访问。假设在处理器 A 执行总线事务期间(无论读写),处理器 D 向总线发起了总线事务,此时处理器 D 的请求会被总线禁止。
总线的这些工作机制可以把所有处理器对内存的访问以串行化的方式来执行。在任意时间点,最多只能有一个处理器可以访问内存。这个特性确保了单个总线事务之中的内存读/写 操作具有原子性。
在一些 32 位的处理器上,如果要求对 64 位数据的写操作具有原子性,会有比较大的开销。为了照顾这种处理器,Java语 言规范鼓励但不强求 JVM 对 64 位的 long/double 型变量的写操作具有原子性。当 JVM 在这种处理器上运行时,可能会把一个 64 位 long/double 型变量的写操作拆分为两个 32 位的写操作来执行。这两个 32 位的写操作可能会被分配到不同的总线事务中执行,此时对这个 64 位变量的写操作将不具有原子性。
当单个内存操作不具有原子性时,可能会产生意想不到后果。请看示意图,如图 3-15 所示。
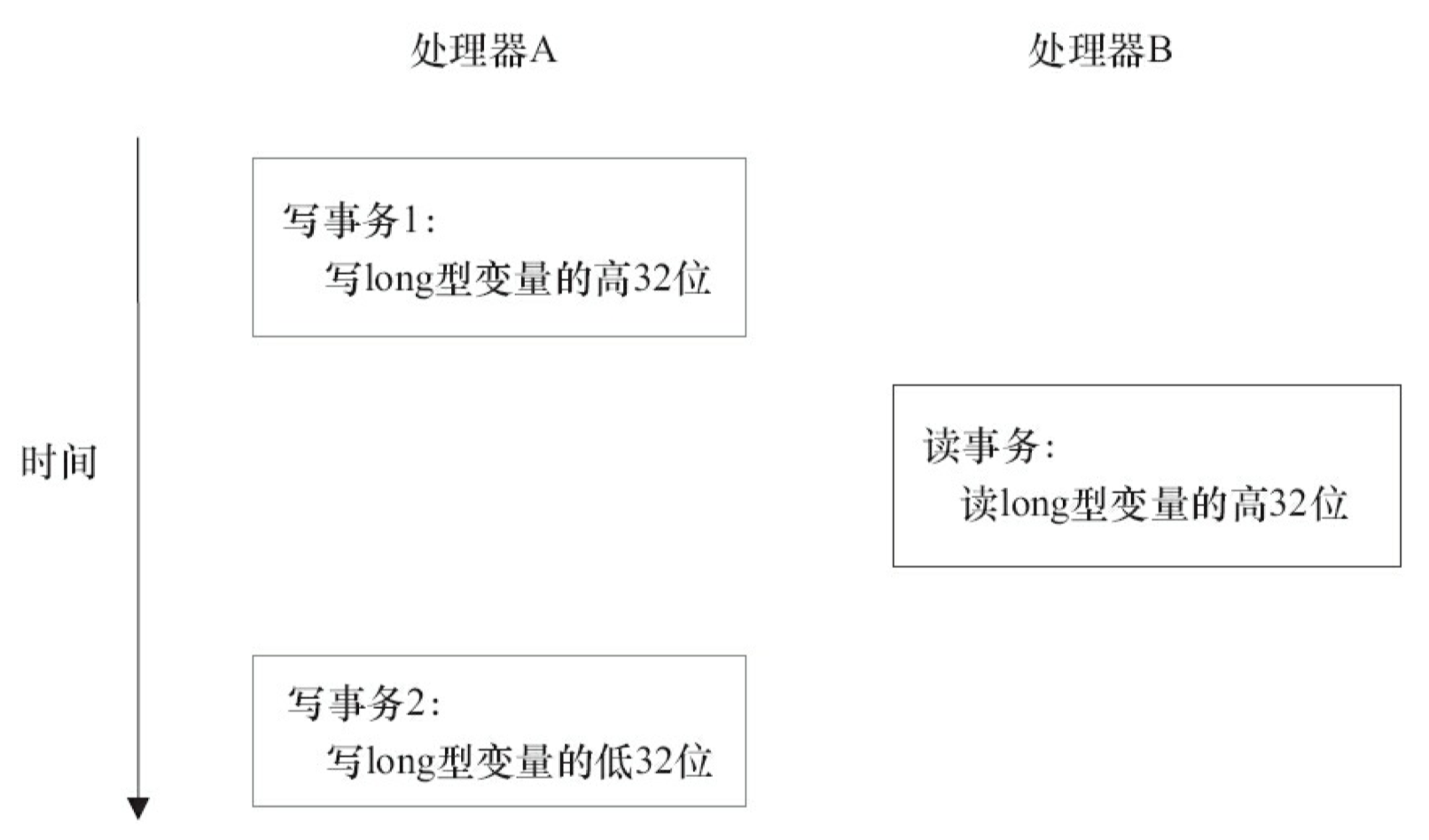
如上图所示,假设处理器 A 写一个 long 型变量,同时处理器 B 要读这个 long 型变量。处理器 A 中 64 位的写操作被拆分为两个 32 位的写操作,且这两个 32 位的写操作被分配到不同的写事务中执行。同时,处理器 B 中 64 位的读操作被分配到单个的读事务中执行。当处理器 A 和 B 按上图的时序来执行时,处理器 B 将看到仅仅被处理器 A “写了一半”的无效值。
注意,在 JSR-133 之前的旧内存模型中,一个 64 位 long/double 型变量的读/写操作可以被拆分为两个 32 位的读/写操作来执行。从 JSR-133 内存模型开始(JDK5),仅仅只允许把一个 64 位l ong/double 型变量的写操作拆分为两个 32 位的写操作来执行,任意的读操作在 JSR133 中都必须具有原子性(即任意读操作必须要在单个读事务中执行)。
3.4 volatile 的内存语义
当声明共享变量为 volatile 后,对这个变量的读/写将会很特别。为了揭开 volatile 的神秘面纱,下面将介绍 volatile 的内存语义及其实现。
3.4.1 volatile 的特性
理解 volatile 特性的一个好方法是把对 volatile 变量的单个读/写,看成是使用同一个锁对这些单个读/写操作做了同步。下面通过具体的示例来说明,示例代码如下。

假设有多个线程分别调用上面程序的 3 个方法,这个程序在语义上和下面程序等价。

如上面示例程序所示,一个 volatile 变量的单个读/写操作,与一个普通变量的读/写操作都是使用同一个锁来同步,它们之间的执行效果相同。
锁的 happens-before 规则保证释放锁和获取锁的两个线程之间的内存可见性,这意味着对一个 volatile 变量的读,总是能看到(任意线程)对这个 volatile 变量最后的写入值。
锁的语义决定了临界区代码的执行具有原子性。这意味着,即使是 64 位的 long 型和double 型变量,只要它是 volatile 变量,对该变量的读/写就具有原子性。如果是多个 volatile 操作或类似于 volatile++ 这种复合操作,这些操作整体上不具有原子性。
简而言之,volatile 变量自身具有下列特性:
- 可见性。对一个 volatile 变量的读,总是能看到任意线程对这个 volatile 变量最后的写入值。
- 原子性。对任意单个 volatile 变量的读/写具有原子性,但类似于 volatile++ 这种复合操作不具有原子性。
3.4.2 volatile 写-读建立的 happens-before 关系
上面讲的是 volatile 变量自身的特性,对程序员来说,volatile 对线程的内存可见性的影响比 volatile 自身的特性更为重要,也更需要我们去关注。
从 JSR-133 开始,volatile 变量的写-读可以实现线程之间的通信。
从内存语义的角度来说,volatile 的写-读与锁的释放-获取有相同的内存效果:volatile 写和锁的释放有相同的内存语义;volatile 读与锁的获取有相同的内存语义。
请看下面使用 volatile 变量的示例代码。

假设线程 A 执行 writer 方法之后,线程 B 执行 reader 方法。根据 happens-before 规则,这个过程建立的 happens-before 关系可以分为 3 类:
- 根据程序次序规则,1 happens-before 2,3 happens-before 4。
- 根据 volatile 规则,2 happens-before 3。
- 根据 happens-before 的传递性规则,1 happens-before 4。
上述 happens-before 关系的图形化表现形式如下。
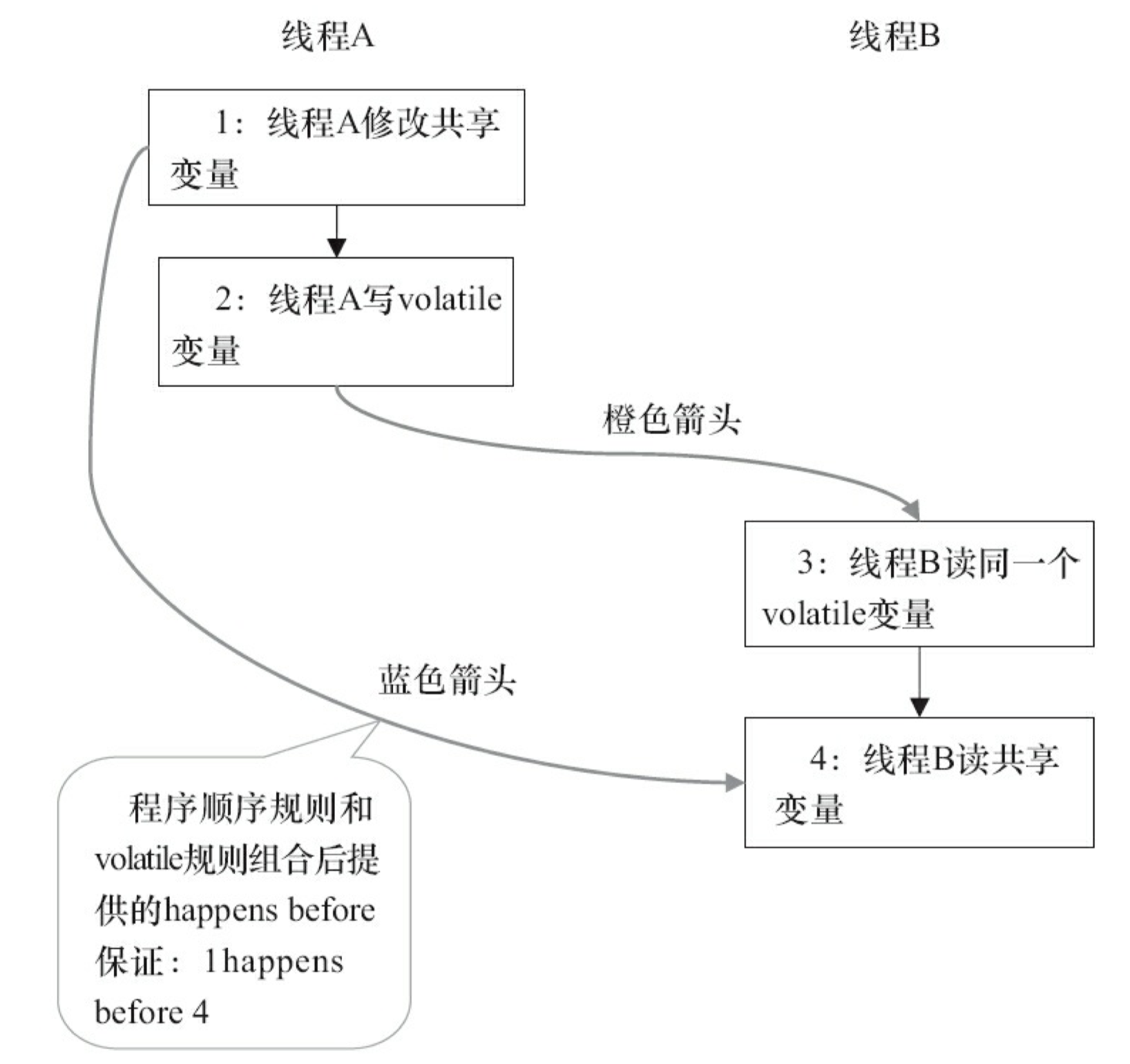
在上图中,每一个箭头链接的两个节点,代表了一个 happens-before 关系。黑色箭头表示 序顺序规则;橙色箭头表示 volatile 规则;蓝色箭头表示组合这些规则后提供的 happens-before 保证。
这里 A 线程写一个 volatile 变量后,B 线程读同一个 volatile 变量。A 线程在写 volatile 变量之前所有可见的共享变量,在 B 线程读同一个 volatile 变量后,将立即变得对 B 线程可见。
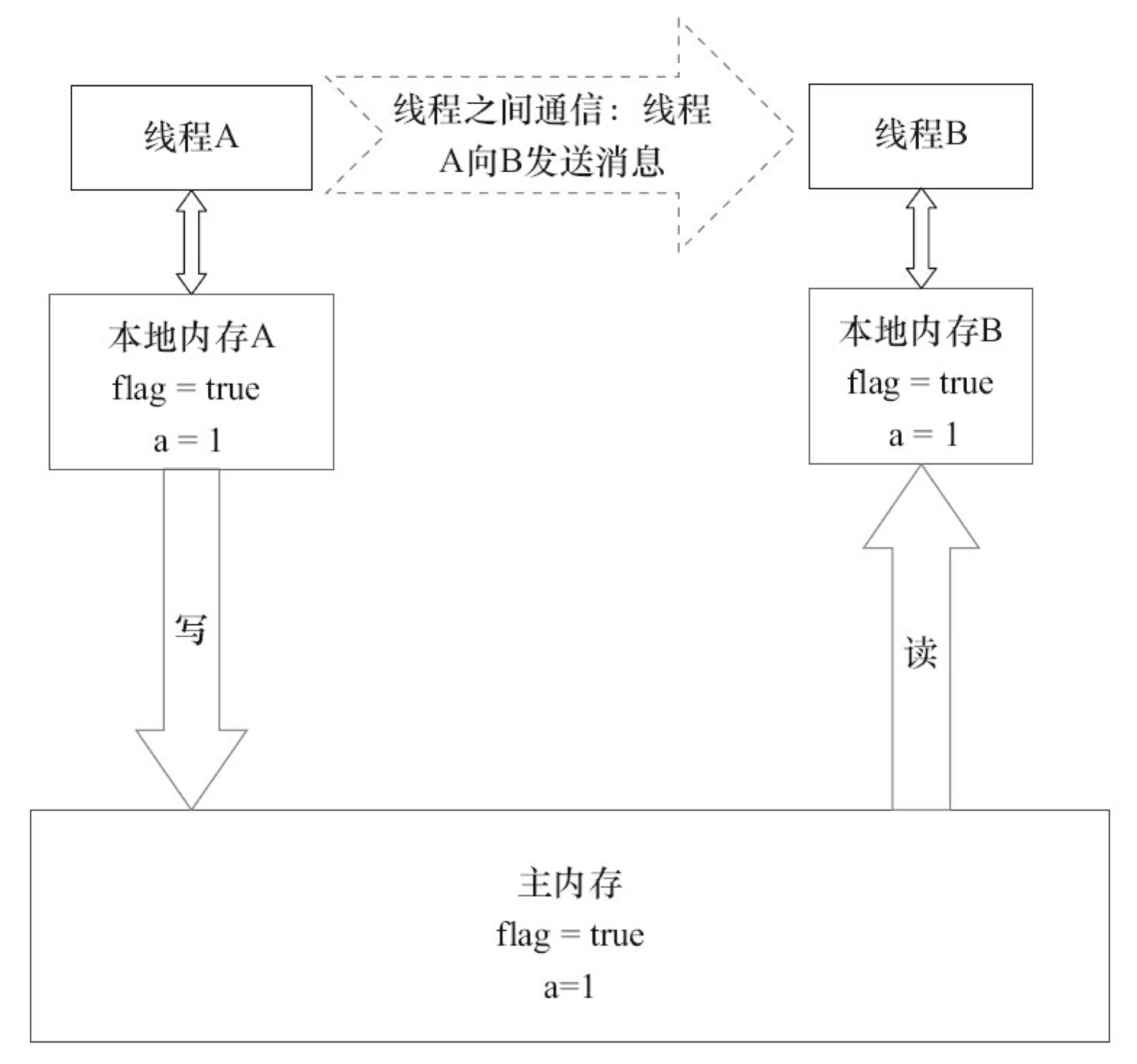
volatile 写-读的内存语义
当写一个 volatile 变量时,JMM 会把该线程对应的本地内存中的共享变量值刷新到主内存。
以上面示例程序 VolatileExample 为例,假设线程 A 首先执行 writer 方法,随后线程 B 执行 reader 方法,初始时两个线程的本地内存中的 flag 和 a 都是初始状态。图 3-17 是线程 A 执行 volatile 写后,共享变量的状态示意图。
如图 3-17 所示,线程 A 在写 flag 变量后,本地内存 A 中被线程 A 更新过的两个共享变量的值被刷新到主内存中。此时,本地内存 A 和主内存中的共享变量的值是一致的。
volatile 读的内存语义如下。
当读一个 volatile 变量时,JMM 会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量。
图 3-18 为线程 B 读同一个 volatile 变量后,共享变量的状态示意图。
如图所示,在读 flag 变量后,本地内存 B 包含的值已经被置为无效。此时,线程 B 必须从主内存中读取共享变量。线程 B 的读取操作将导致本地内存 B 与主内存中的共享变量的值变成一致。
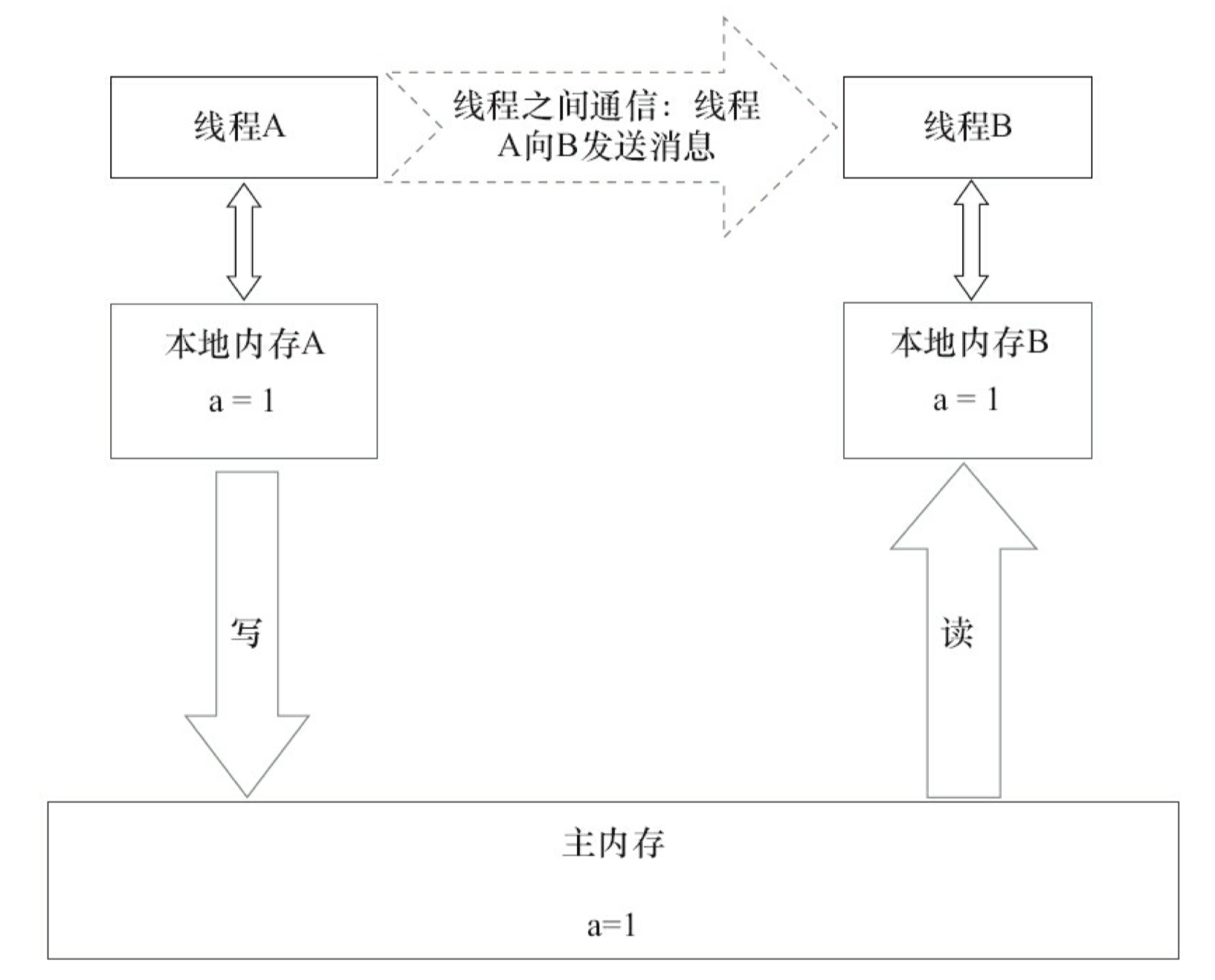
如果我们把 volatile 写和 volatile 读两个步骤综合起来看的话,在读线程 B 读一个 volatile 变量后,写线程 A 在写这个 volatile 变量之前所有可见的共享变量的值都将立即变得对读线程 B 可见。
下面对 volatile 写和 volatile 读的内存语义做个总结。
- 线程 A 写一个 volatile 变量,实质上是线程 A 向接下来将要读这个 volatile 变量的某个线程发出了(其对共享变量所做修改的)消息。
- 线程 B 读一个 volatile 变量,实质上是线程 B 接收了之前某个线程发出的(在写这个 volatile 变量之前对共享变量所做修改的)消息。
- 线程 A 写一个 volatile 变量,随后线程 B 读这个 volatile 变量,这个过程实质上是线程 A 通过主内存向线程B发送消息。
3.4.4 volatile 内存语义的实现
前文提到过重排序分为编译器重排序和处理器重排序。为了实现 volatile 内存语义,JMM 会分别限制这两种类型的重排序类型。表 3-5 是 JMM 针对编译器制定的 volatile 重排序规则表。

举例来说,第三行最后一个单元格的意思是:在程序中,当第一个操作为普通变量的读或 写时,如果第二个操作为 volatile 写,则编译器不能重排序这两个操作。
从表 3-5 我们可以看出。
- 当第二个操作是 volatile 写时,不管第一个操作是什么,都不能重排序。这个规则确保 volatile 写之前的操作不会被编译器重排序到 volatile 写之后。
- 当第一个操作是 volatile 读时,不管第二个操作是什么,都不能重排序。这个规则确保 volatile 读之后的操作不会被编译器重排序到 volatile 读之前。
- 当第一个操作是 volatile 写,第二个操作是 volatile 读时,不能重排序。
为了实现 volatile 的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。对于编译器来说,发现一个最优布置来最小化插入屏障的总数几乎不可能。为此,JMM 采取保守策略。下面是基于保守策略的 JMM 内存屏障插入策略。
- 在每个 volatile 写操作的前面插入一个 StoreStore 屏障。
- 在每个 volatile 写操作的后面插入一个 StoreLoad 屏障。
- 在每个 volatile 读操作的后面插入一个 LoadLoad 屏障。
- 在每个 volatile 读操作的后面插入一个 LoadStore 屏障。
上述内存屏障插入策略非常保守,但它可以保证在任意处理器平台,任意的程序中都能得到正确的 volatile 内存语义。
下面是保守策略下,volatile 写插入内存屏障后生成的指令序列示意图,如图 3-19 所示。
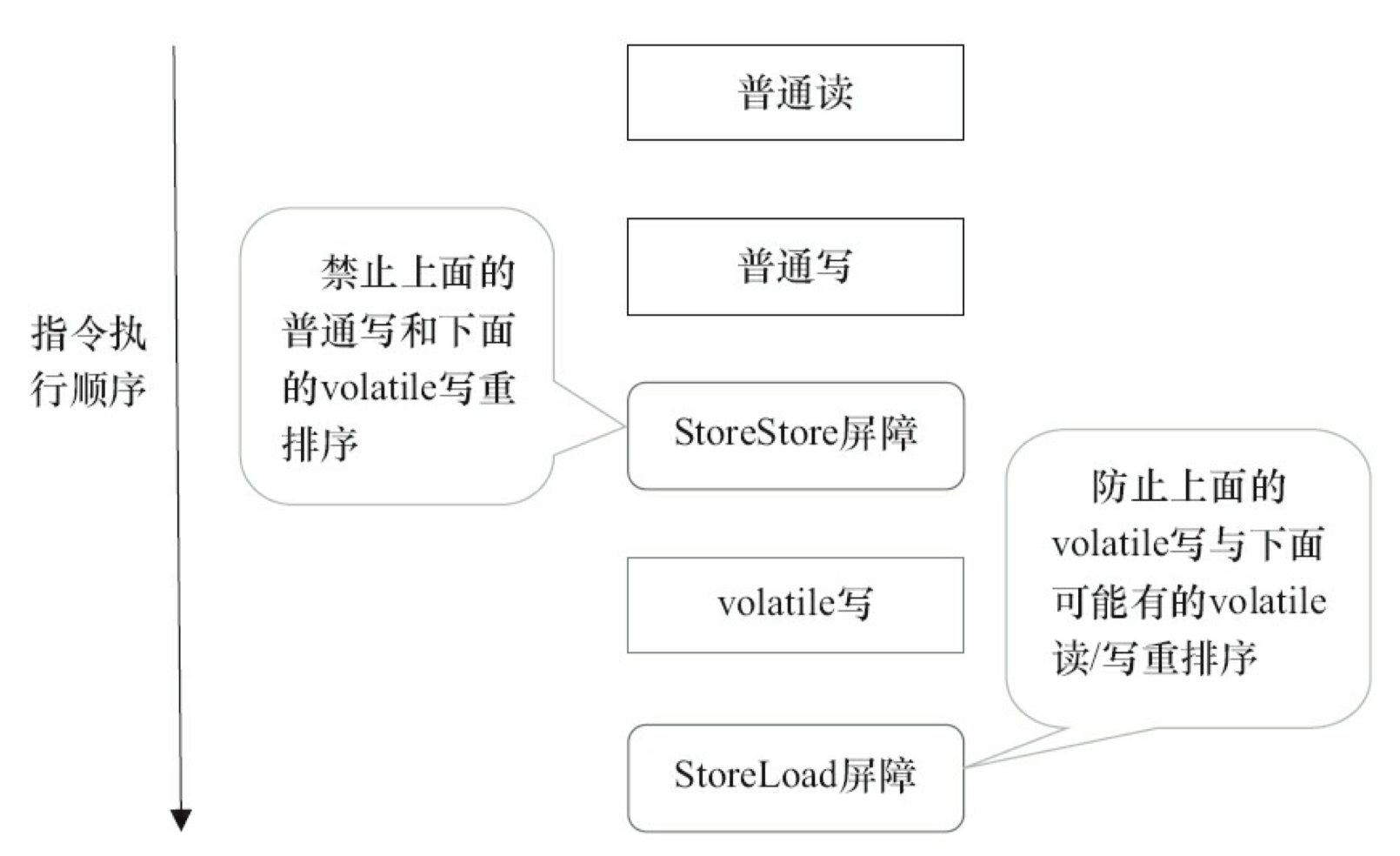
图 3-19 中的 StoreStore 屏障可以保证在 volatile 写之前,其前面的所有普通写操作已经对任意处理器可见了。这是因为 StoreStore 屏障将保障上面所有的普通写在 volatile 写之前刷新到主内存。
这里比较有意思的是,volatile 写后面的 StoreLoad 屏障。此屏障的作用是避免 volatile 写与后面可能有的 volatile 读/写操作重排序。因为编译器常常无法准确判断在一个 volatile 写的后面是否需要插入一个 StoreLoad 屏障(比如,一个volatile写之后方法立即return)。为了保证能正确实现 volatile 的内存语义,JMM 在采取了保守策略:在每个 volatile 写的后面,或者在每个 volatile 读的前面插入一个 StoreLoad 屏障。从整体执行效率的角度考虑,JMM 最终选择了在每个 volatile 写的后面插入一个 StoreLoad 屏障。因为 volatile 写-读内存语义的常见使用模式是:一个写线程写 volatile 变量,多个读线程读同一个 volatile 变量。当读线程的数量大大超过写线程时,选择在 volatile 写之后插入 StoreLoad 屏障将带来可观的执行效率的提升。从这里可以看到 JMM 在实现上的一个特点:首先确保正确性,然后再去追求执行效率。
下面是在保守策略下,volatile 读插入内存屏障后生成的指令序列示意图,如图 3-20 所示。
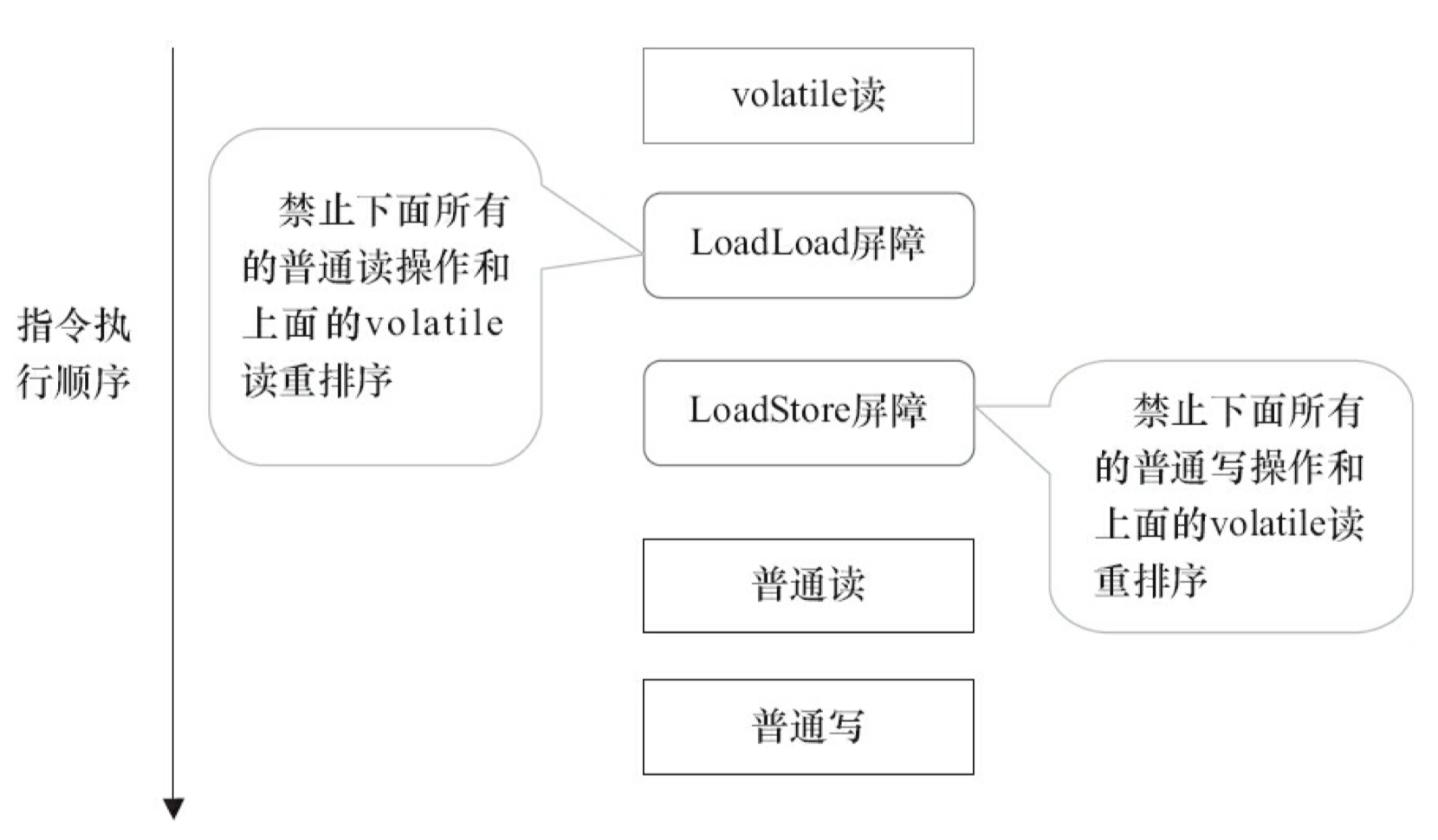
图 3-20 中的 LoadLoad 屏障用来禁止处理器把上面的 volatile 读与下面的普通读重排序。LoadStore 屏障用来禁止处理器把上面的 volatile 读与下面的普通写重排序。
上述 volatile 写和 volatile 读的内存屏障插入策略非常保守。在实际执行时,只要不改变 volatile 写-读的内存语义,编译器可以根据具体情况省略不必要的屏障。下面通过具体的示例代码进行说明。

针对 readAndWrite 方法,编译器在生成字节码时可以做如下的优化。
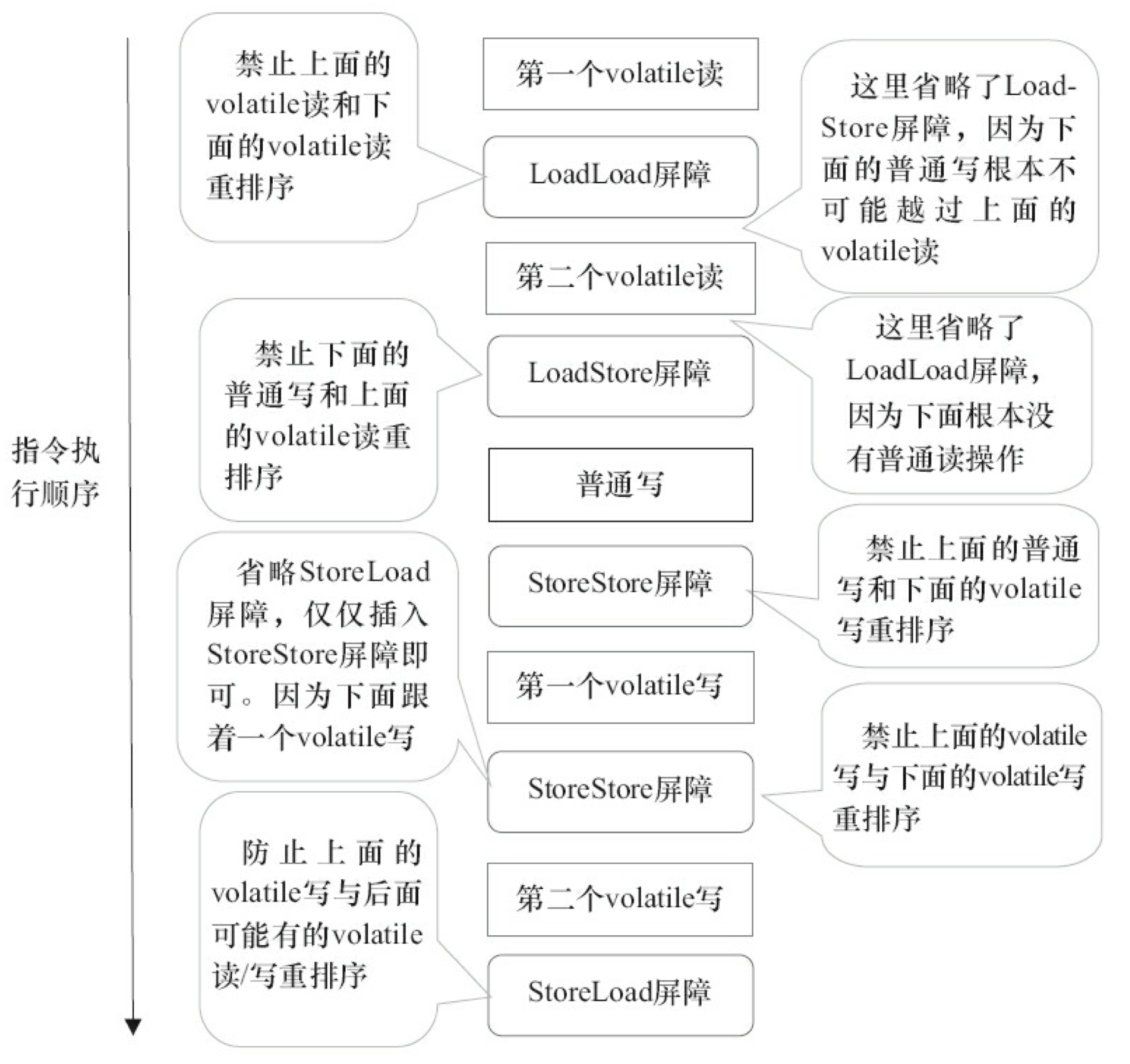
注意,最后的 StoreLoad 屏障不能省略。因为第二个 volatile 写之后,方法立即return。此时编译器可能无法准确断定后面是否会有 volatile 读或写,为了安全起见,编译器通常会在这里插入一个 StoreLoad 屏障。
上面的优化针对任意处理器平台,由于不同的处理器有不同“松紧度”的处理器内存模 型,内存屏障的插入还可以根据具体的处理器内存模型继续优化。以 X86 处理器为例,图 3-21 中除最后的 StoreLoad 屏障外,其他的屏障都会被省略。
前面保守策略下的 volatile 读和写,在 X86 处理器平台可以优化成如图 3-22 所示。
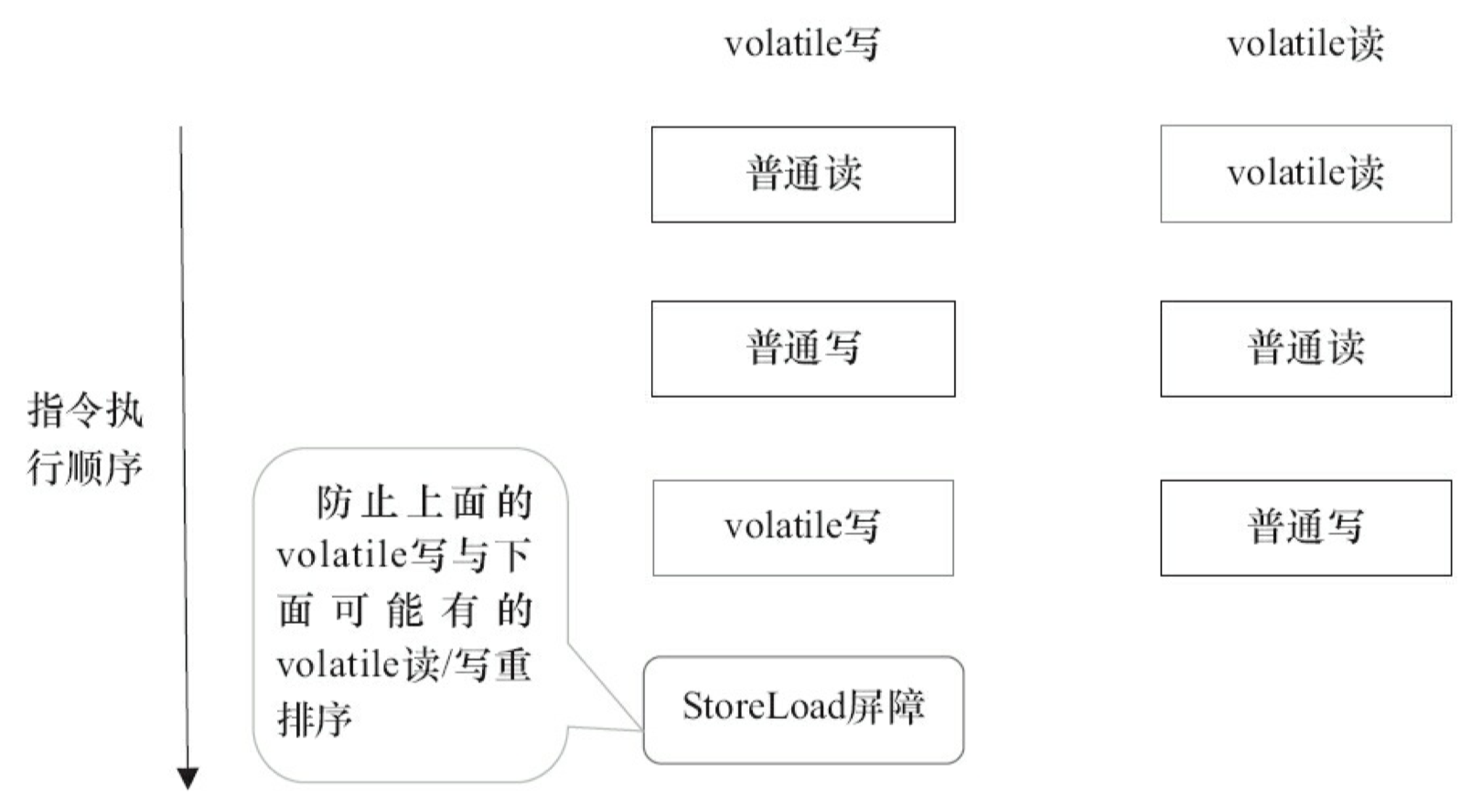
前文提到过,X86 处理器仅会对写-读操作做重排序。X86 不会对读-读、读-写和写-写操作做重排序,因此在 X86 处理器中会省略掉这 3 种操作类型对应的内存屏障。在 X86 中,JMM 仅需在 volatile 写后面插入一个 StoreLoad 屏障即可正确实现 volatile 写-读的内存语义。这意味着在 X86 处理器中,volatile 写的开销比volatile 读的开销会大很多(因为执行StoreLoad屏障开销会比较大)。
JSR-133 为什么要增强 volatile 的内存语义
在 JSR-133 之前的旧 Java 内存模型中,虽然不允许 volatile 变量之间重排序,但旧的 Java 内存模型允许 volatile 变量与普通变量重排序。在旧的内存模型中,VolatileExample 示例程序可能被重排序成下列时序来执行,如图 3-23 所示。
在旧的内存模型中,当 1 和 2 之间没有数据依赖关系时,1 和 2 之间就可能被重排序(3 和 4 类似)。其结果就是:读线程 B 执行 4 时,不一定能看到写线程 A 在执行 1 时对共享变量的修改。
因此,在旧的内存模型中,volatile 的写-读没有锁的释放-获所具有的内存语义。为了提供一种比锁更轻量级的线程之间通信的机制,JSR-133 专家组决定增强 volatile 的内存语义:严格限制编译器和处理器对 volatile 变量与普通变量的重排序,确保 volatile 的写-读和锁的释放-获取具有相同的内存语义。从编译器重排序规则和处理器内存屏障插入策略来看,只要 volatile 变量与普通变量之间的重排序可能会破坏 volatile 的内存语义,这种重排序就会被编译器重排序规则和处理器内存屏障插入策略禁止。
由于 volatile 仅仅保证对单个 volatile 变量的读/写具有原子性,而锁的互斥执行的特性可以确保对整个临界区代码的执行具有原子性。在功能上,锁比 volatile 更强大;在可伸缩性和执行性能上,volatile 更有优势。如果读者想在程序中用 volatile 代替锁,请一定谨慎,具体详情请参 阅 Brian Goetz 的文章。
3.5 锁的内存语义
众所周知,锁可以让临界区互斥执行。这里将介绍锁的另一个同样重要,但常常被忽视的 功能:锁的内存语义。
3.5.1 锁的释放-获取建立的 happens-before 关系
锁是 Java 并发编程中最重要的同步机制。锁除了让临界区互斥执行外,还可以让释放锁的线程向获取同一个锁的线程发送消息。
下面是锁释放-获取的示例代码。

假设线程 A 执行 writer 方法,随后线程 B 执行 reader 方法。根据 happens-before 规则,这个过程包含的 happens-before 关系可以分为 3 类。
- 根据程序次序规则,1 happens-before 2, 2 happens-before 3, 4 happens-before 5, 5 happens-before 6。
- 根据监视器锁规则,3 happens-before 4。
- 根据 happens-before 的传递性,2 happens-before 5。
上述 happens-before 关系的图形化表现形式如图 3-24 所示。
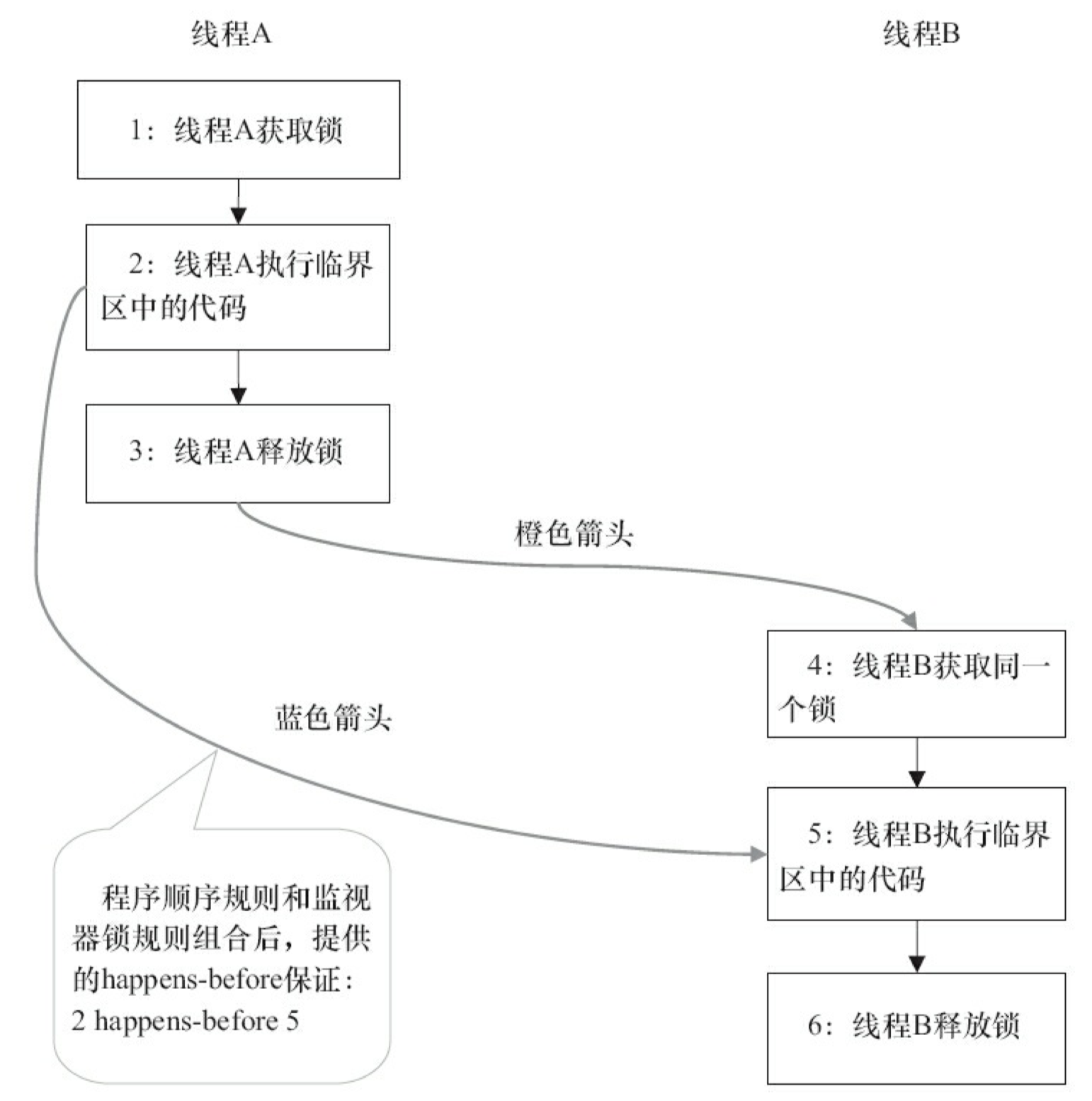
在图 3-24 中,每一个箭头链接的两个节点,代表了一个 happens-before 关系。黑色箭头表示程序顺序规则;橙色箭头表示监视器锁规则;蓝色箭头表示组合这些规则后提供的 happens-before 保证。
图 3-24 表示在线程 A 释放了锁之后,随后线程 B 获取同一个锁。在上图中,2 happens-before 5。因此,线程 A 在释放锁之前所有可见的共享变量,在线程 B 获取同一个锁之后,将立刻变得对 B 线程可见。
3.5.2 锁的释放和获取的内存语义
当线程释放锁时,JMM 会把该线程对应的本地内存中的共享变量刷新到主内存中。以上 面的 MonitorExample 程序为例,A 线程释放锁后,共享数据的状态示意图如图 3-25 所示。
当线程获取锁时,JMM 会把该线程对应的本地内存置为无效。从而使得被监视器保护的 临界区代码必须从主内存中读取共享变量。图 3-26 是锁获取的状态示意图。
对比锁释放-获取的内存语义与 volatile 写-读的内存语义可以看出:锁释放与 volatile 写有着相同的内存语义;锁获取与 volatile 读有相同的内存语义。
下面对锁释放和锁获取的内存语义做个总结。
- 线程 A 释放一个锁,实质上是线程 A 向接下来将要获取这个锁的某个线程发出了(线程 A 对共享变量所做修改的)消息。
- 线程 B 获取一个锁,实质上是线程 B 接收了之前某个线程发出的(在释放这个锁之前对共享变量所做修改的)消息。
- 线程 A 释放锁,随后线程 B 获取这个锁,这个过程实质上是线程 A 通过主内存向线程 B 发送消息。
3.5.3 锁内存语义的实现
本文将借助 ReentrantLock 的源代码,来分析锁内存语义的具体实现机制。请看下面的示例代码。

在 ReentrantLock 中,调用 lock 方法获取锁;调用 unlock 方法释放锁。
ReentrantLock 的实现依赖于 Java 同步器框架AbstractQueuedSynchronizer。AQS 使用一个整型的 volatile 变量(命名为 state)来维护同步状态,马上我们会看到,这个 volatile 变量是 ReentrantLock 内存语义实现的关键。
图 3-27 是 ReentrantLock 的类图(仅画出与本文相关的部分)。
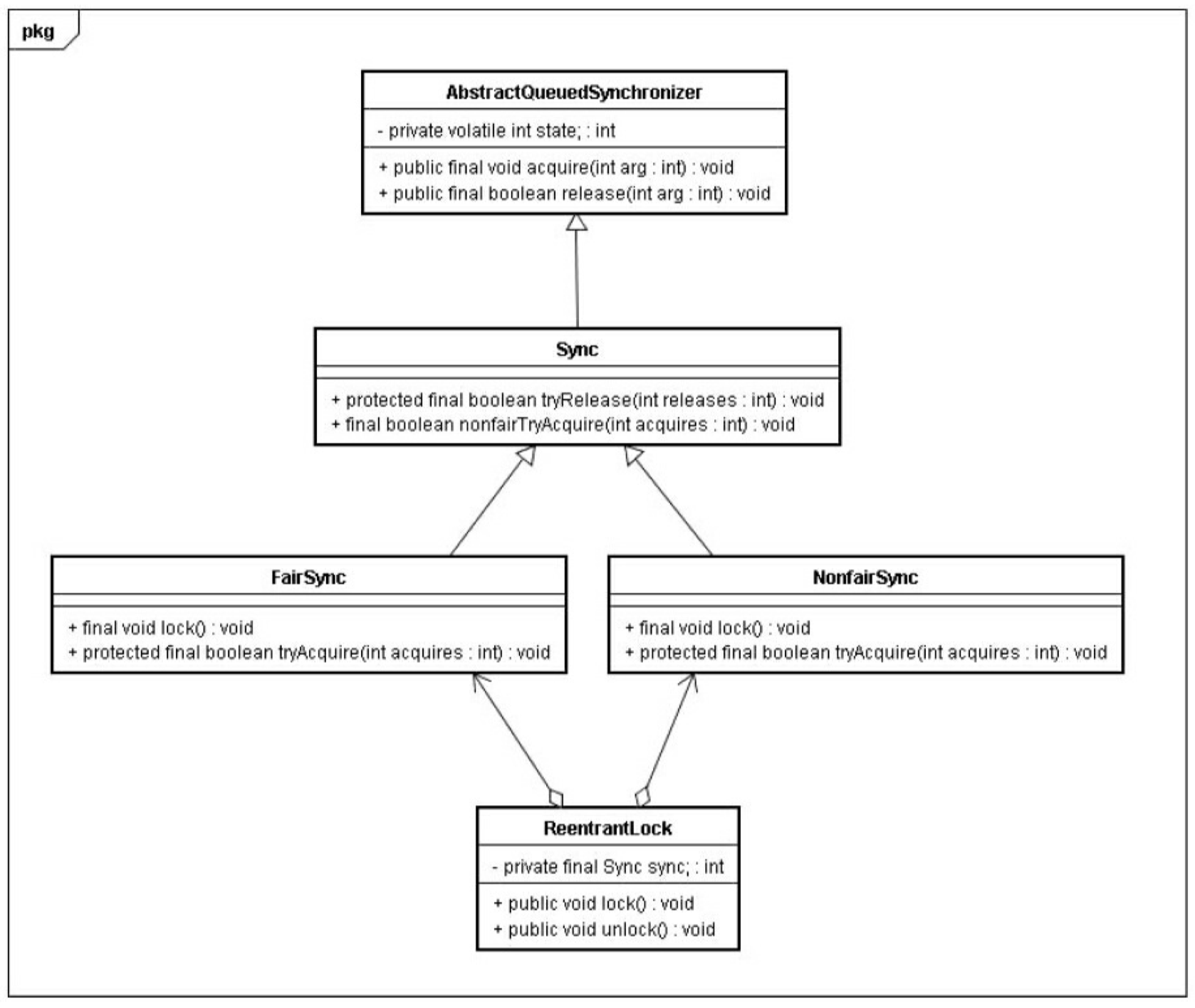
ReentrantLock 分为公平锁和非公平锁,我们首先分析公平锁。使用公平锁时,加锁方法 lock 调用轨迹如下。
- ReentrantLock:lock()。
- FairSync:lock()。
- AbstractQueuedSynchronizer:acquire(int arg)。
- ReentrantLock:tryAcquire(int acquires)。
在第 4 步真正开始加锁,下面是该方法的源代码。

从上面源代码中我们可以看出,加锁方法首先读 volatile 变量 state。在使用公平锁时,解锁方法 unlock 调用轨迹如下。
- ReentrantLock:unlock()。
- AbstractQueuedSynchronizer:release(int arg)。
- Sync:tryRelease(int releases)。
在第 3 步真正开始释放锁,下面是该方法的源代码。

从上面的源代码可以看出,在释放锁的最后写 volatile 变量 state。
公平锁在释放锁的最后写 volatile 变量 state,在获取锁时首先读这个 volatile 变量。根据 volatile 的 happens-before 规则,释放锁的线程在写 volatile 变量之前可见的共享变量,在获取锁的线程读取同一个 volatile 变量后将立即变得对获取锁的线程可见。
现在我们来分析非公平锁的内存语义的实现。非公平锁的释放和公平锁完全一样,所以这里仅仅分析非公平锁的获取。使用非公平锁时,加锁方法 lock 调用轨迹如下。
- ReentrantLock:lock()。
- NonfairSync:lock()。
- AbstractQueuedSynchronizer:compareAndSetState(int expect,int update)。
在第 3 步真正开始加锁,下面是该方法的源代码。

该方法以原子操作的方式更新 state 变量,本文把 Java 的 compareAndSet 方法调用简称为 CAS。JDK 文档对该方法的说明如下:如果当前状态值等于预期值,则以原子方式将同步状态设置为给定的更新值。此操作具有 volatile 读和写的内存语义。
这里我们分别从编译器和处理器的角度来分析,CAS 如何同时具有 volatile 读和 volatile 写的内存语义。
前文我们提到过,编译器不会对 volatile 读与 volatile 读后面的任意内存操作重排序;编译器不会对 volatile 写与 volatile 写前面的任意内存操作重排序。组合这两个条件,意味着为了同时实现 volatile 读和 volatile 写的内存语义,编译器不能对 CAS 与 CAS 前面和后面的任意内存操作重排序。
下面我们来分析在常见的 intel X86 处理器中,CAS 是如何同时具有 volatile 读和 volatile 写的内存语义的。
下面是 sun.misc.Unsafe 类的 compareAndSwapInt() 方法的源代码。
public final native boolean compareAndSwapInt(Object o, long offset)
可以看到,这是一个本地方法调用。
如上面源代码所示,程序会根据当前处理器的类型来决定是否为 cmpxchg 指令添加 lock 前缀。如果程序是在多处理器上运行,就为 cmpxchg 指令加上 lock 前缀(Lock Cmpxchg)。反之,如果程序是在单处理器上运行,就省略 lock 前缀(单处理器自身会维护单处理器内的顺序一致性,不需要 lock 前缀提供的内存屏障效果)。
intel 的手册对 lock 前缀的说明如下。
- 确保对内存的读-改-写操作原子执行。在 Pentium 及 Pentium 之前的处理器中,带有 lock 前缀的指令在执行期间会锁住总线,使得其他处理器暂时无法通过总线访问内存。很显然,这会带来昂贵的开销。从 Pentium 4、Intel Xeon 及 P6 处理器开始,Intel 使用缓存锁定(Cache Locking)来保证指令执行的原子性。缓存锁定将大大降低 lock 前缀指令的执行开销。
- 禁止该指令,与之前和之后的读和写指令重排序。
- 把写缓冲区中的所有数据刷新到内存中。
上面的第 2 点和第 3 点所具有的内存屏障效果,足以同时实现 volatile 读写的内存语义。
经过上面的分析,现在我们终于能明白为什么 JDK 文档说 CAS 同时具有 volatile 读写的内存语义了。
现在对公平锁和非公平锁的内存语义做个总结。
- 公平锁和非公平锁释放时,最后都要写一个 volatile 变量 state。
- 公平锁获取时,首先会去读 volatile 变量。
- 非公平锁获取时,首先会用 CAS 更新 volatile 变量,这个操作同时具有 volatile 读写的内存语义。
从本文对 ReentrantLock 的分析可以看出,锁释放-获取的内存语义的实现至少有下面两种方式。
- 利用 volatile 变量的写-读所具有的内存语义。
- 利用 CAS 所附带的 volatile 读写的内存语义。
3.5.4 JUC 包的实现
由于 Java 的 CAS 同时具有 volatile 读和 volatile 写的内存语义,因此 Java 线程之间的通信现在有了下面 4 种方式。
- A 线程写 volatile 变量,随后 B 线程读这个 volatile 变量。
- A 线程写 volatile 变量,随后 B 线程用 CAS 更新这个 volatile 变量。
- A 线程用 CAS 更新一个 volatile 变量,随后 B 线程用 CAS 更新这个 volatile 变量。
- A 线程用 CAS 更新一个 volatile 变量,随后 B 线程读这个 volatile 变量。
Java 的 CAS 会使用现代处理器上提供的高效机器级别的原子指令,这些原子指令以原子方式对内存执行读-改-写操作,这是在多处理器中实现同步的关键(从本质上来说,能够支持原子性读-改-写指令的计算机,是顺序计算图灵机的异步等价机器,因此任何现代的多处理器都会去支持某种能对内存执行原子性读-改-写操作的原子指令)。同时,volatile 变量的读/写和 CAS 可以实现线程之间的通信。把这些特性整合在一起,就形成了整个 JUC 包得以实现的基石。如果我们仔细分析 JUC 包的源代码实现,会发现一个通用化的实现模式。
- 首先,声明共享变量为 volatile。
- 然后,使用 CAS 的原子条件更新来实现线程之间的同步。
- 同时,配合以 volatile 的读/写和 CAS 所具有的 volatile 读和写的内存语义来实现线程之间的通信。
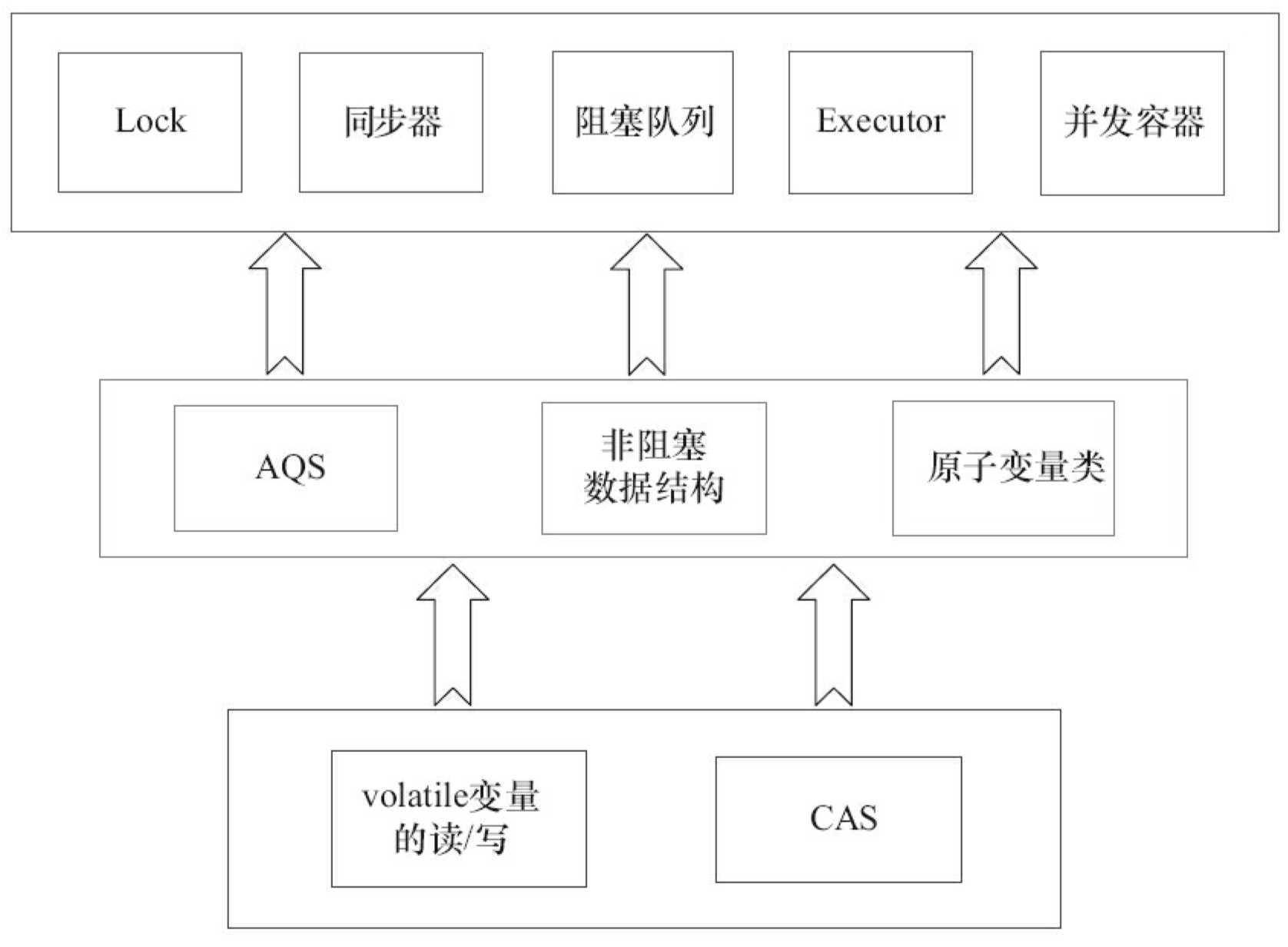
AQS,非阻塞数据结构和原子变量类,这些 JUC 包中的基础类都是使用这种模式来实现的,而 JUC 包中的高层类又是依赖于这些基础类来实现的。从整体来看,JUC 包的实现示意图如 3-28 所示。
3.6 final域的内存语义
与前面介绍的锁和 volatile 相比,对 final 域的读和写更像是普通的变量访问。下面将介绍 final 域的内存语义。
3.6.1 final 域的重排序规则
对于 final 域,编译器和处理器要遵守两个重排序规则。
- 在构造函数内对一个 final 域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
- 初次读一个包含 final 域的对象的引用,与随后初次读这个 final 域,这两个操作之间不能重排序。
下面通过一些示例性的代码来分别说明这两个规则。

这里假设一个线程 A 执行 writer 方法,随后另一个线程 B 执行 reader 方法。下面我们通过这两个线程的交互来说明这两个规则。
3.6.2 写 final 域的重排序规则
写 final 域的重排序规则禁止把 final 域的写重排序到构造函数之外。这个规则的实现包含下面 2 个方面。
- JMM 禁止编译器把 final 域的写重排序到构造函数之外。
- 编译器会在 final 域的写之后,构造函数 return 之前,插入一个 StoreStore 屏障。这个屏障禁止处理器把 final 域的写重排序到构造函数之外。
现在让我们分析 writer 方法。writer 方法只包含一行代码:finalExample=new FinalExample()。这行代码包含两个步骤,如下。
- 构造一个 FinalExample 类型的对象。
- 把这个对象的引用赋值给引用变量 obj。
假设线程 B 读对象引用与读对象的成员域之间没有重排序,图 3-29 是一种可能的执行时序。
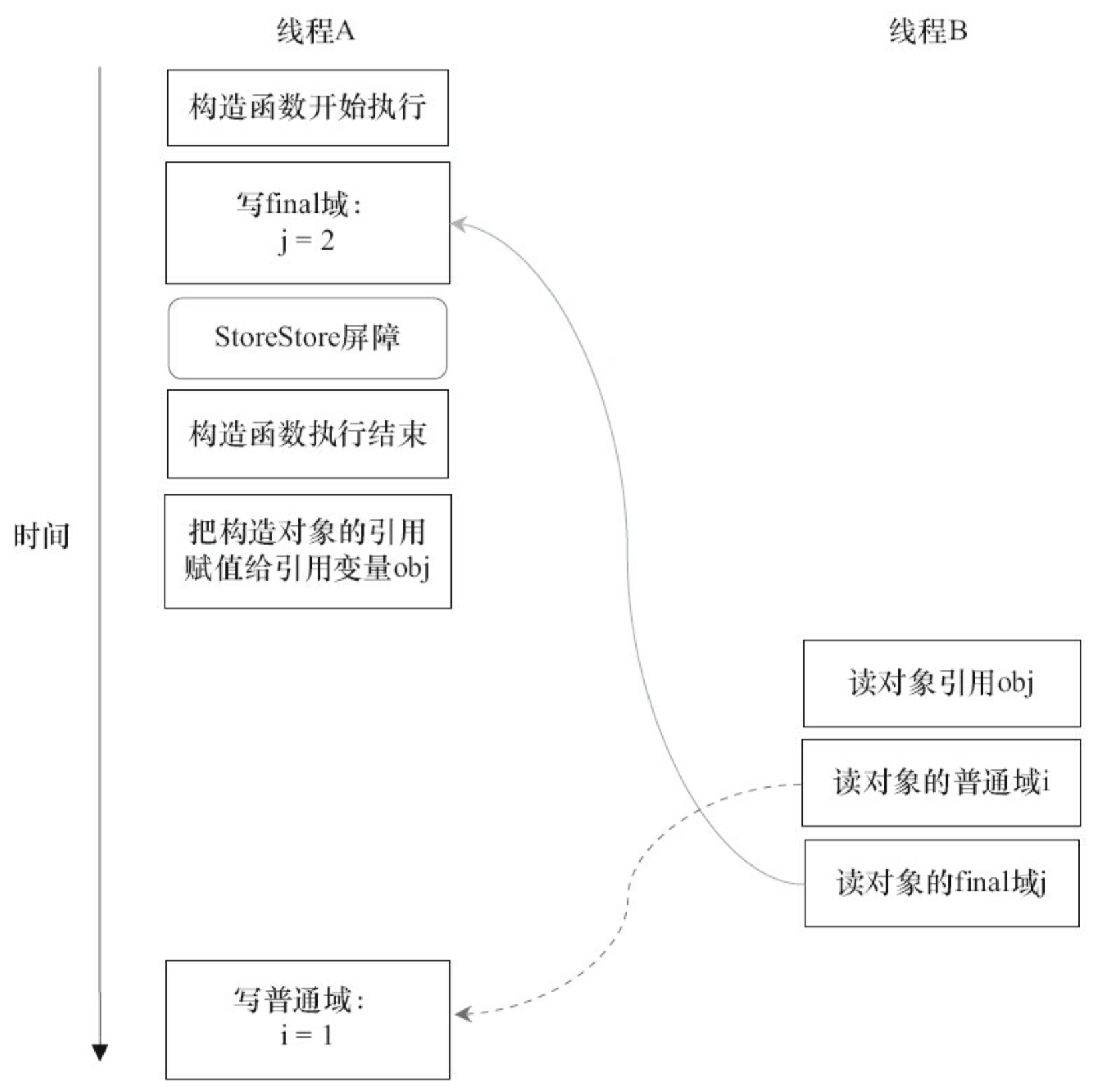
在图 3-29 中,写普通域的操作被编译器重排序到了构造函数之外,读线程 B 错误地读取了普通变量 i 初始化之前的值。而写 final 域的操作,被写 final 域的重排序规则“限定”在了构造函数之内,读线程 B 正确地读取了 final 变量初始化之后的值。
写 final 域的重排序规则可以确保:在对象引用为任意线程可见之前,对象的 final 域已经被正确初始化过了,而普通域不具有这个保障。以上图为例,在读线程 B “看到”对象引用 obj 时,很可能 obj 对象还没有构造完成(对普通域i的写操作被重排序到构造函数外,此时初始值 1 还 没有写入普通域 i)。
3.6.3 读 final 域的重排序规则
读 final 域的重排序规则是,在一个线程中,初次读对象引用与初次读该对象包含的 final 域,JMM 禁止处理器重排序这两个操作(注意,这个规则仅仅针对处理器)。编译器会在读 final 域操作的前面插入一个 LoadLoad 屏障。
初次读对象引用与初次读该对象包含的 final 域,这两个操作之间存在间接依赖关系。由于编译器遵守间接依赖关系,因此编译器不会重排序这两个操作。大多数处理器也会遵守间接依赖,也不会重排序这两个操作。但有少数处理器允许对存在间接依赖关系的操作做重排序(比如 alpha 处理器),这个规则就是专门用来针对这种处理器的。
reader 方法包含 3 个操作。
- 初次读引用变量 obj。
- 初次读引用变量 obj 指向对象的普通域 j。
- 初次读引用变量 obj 指向对象的 final 域 i。
现在假设写线程 A 没有发生任何重排序,同时程序在不遵守间接依赖的处理器上执行,图 3-30 所示是一种可能的执行时序。
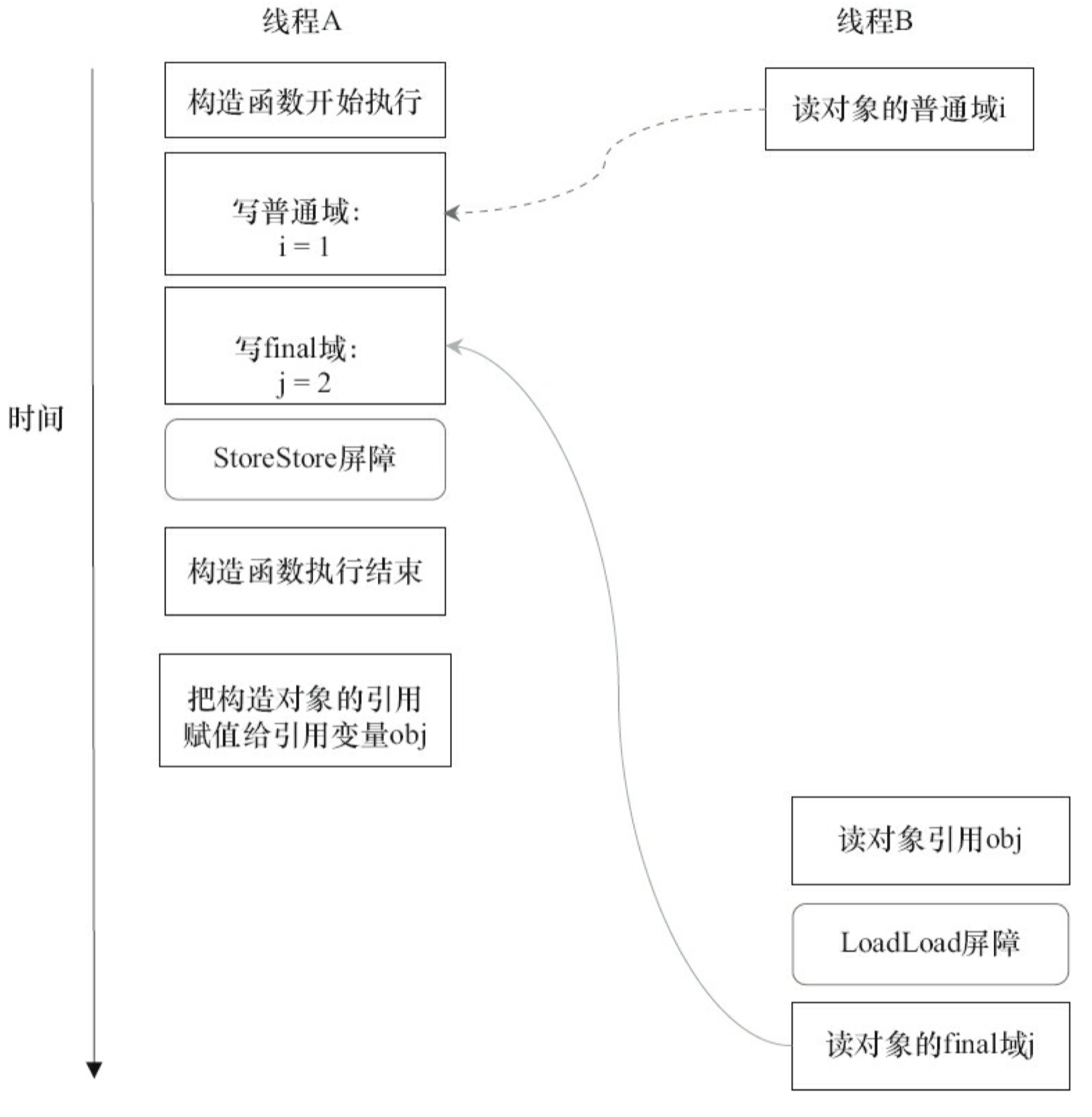
在图 3-30 中,读对象的普通域的操作被处理器重排序到读对象引用之前。读普通域时,该 域还没有被写线程 A 写入,这是一个错误的读取操作。而读 final 域的重排序规则会把读对象 final 域的操作“限定”在读对象引用之后,此时该 final 域已经被 A 线程初始化过了,这是一个正确的读取操作。
读 final 域的重排序规则可以确保:在读一个对象的 final 域之前,一定会先读包含这个 final 域的对象的引用。在这个示例程序中,如果该引用不为 null,那么引用对象的 final 域一定已经被 A 线程初始化过了。
3.6.4 final域为引用类型
上面我们看到的 final 域是基础数据类型,如果 final 域是引用类型,将会有什么效果?请看下列示例代码。

本例 final 域为一个引用类型,它引用一个 int 型的数组对象。对于引用类型,写 final 域的重排序规则对编译器和处理器增加了如下约束:在构造函数内对一个 final 引用的对象的成员域的写入,与随后在构造函数外把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
对上面的示例程序,假设首先线程 A 执行 writerOne() 方法,执行完后线程 B 执行 writerTwo() 方法,执行完后线程 C 执行 reader() 方法。图 3-31 是一种可能的线程执行时序。
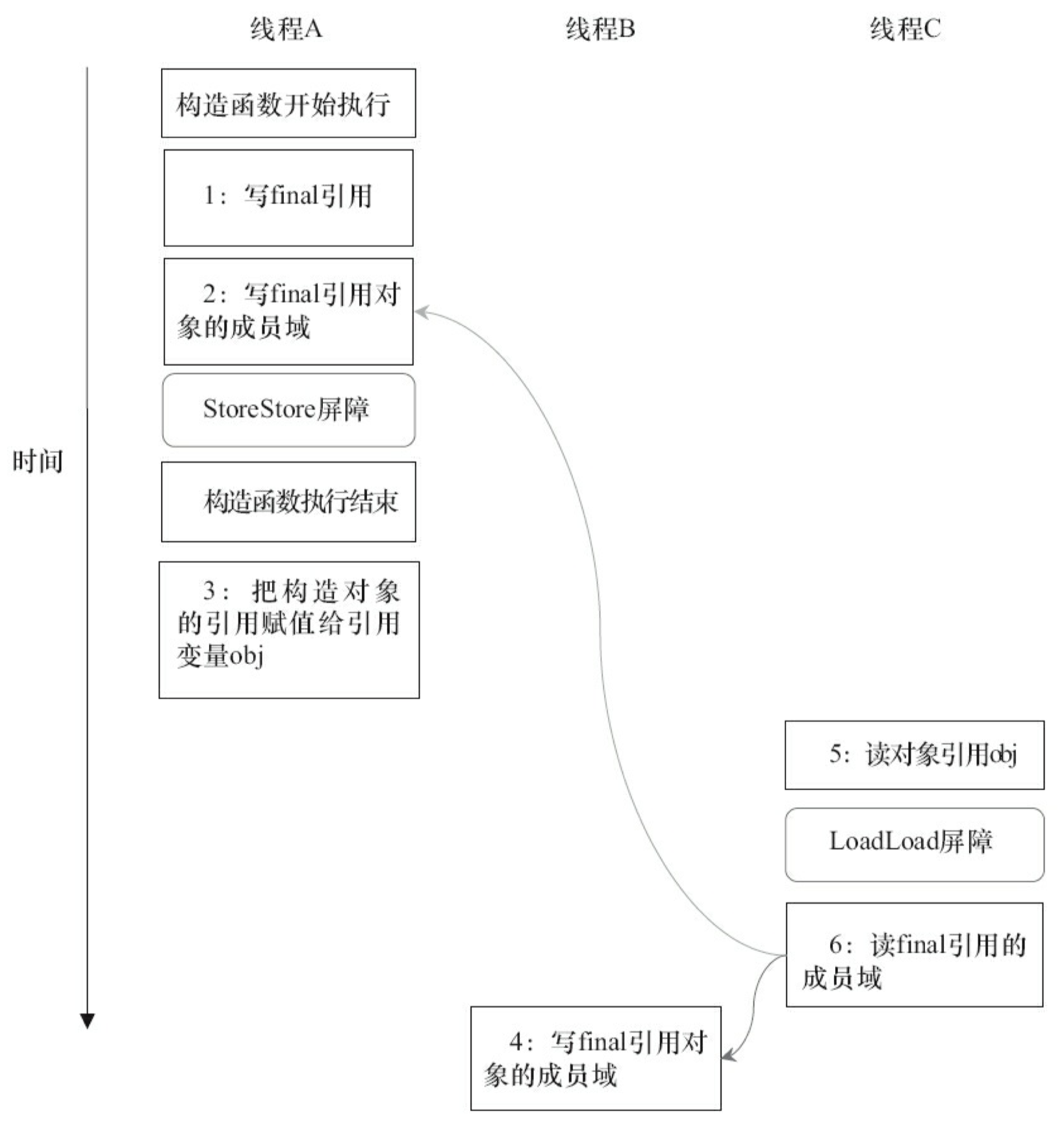
在图 3-31 中,1 是对 final 域的写入,2 是对这个 final 域引用的对象的成员域的写入,3 是把被构造的对象的引用赋值给某个引用变量。这里除了前面提到的 1 不能和 3 重排序外,2 和 3 也不能重排序。
JMM 可以确保读线程 C 至少能看到写线程 A 在构造函数中对 final 引用对象的成员域的写入。即 C 至少能看到数组下标 0 的值为 1。而写线程 B 对数组元素的写入,读线程 C 可能看得到,也可能看不到。JMM 不保证线程 B 的写入对读线程 C 可见,因为写线程 B 和读线程 C 之间存在数据竞争,此时的执行结果不可预知。
如果想要确保读线程 C 看到写线程B对数组元素的写入,写线程B和读线程 C 之间需要使用同步原语(lock/volatile)来确保内存可见性。
3.6.5 为什么 final 引用不能从构造函数内“溢出”
前面我们提到过,写 final 域的重排序规则可以确保:在引用变量为任意线程可见之前,该引用变量指向的对象的 final 域已经在构造函数中被正确初始化过了。其实,要得到这个效果,还需要一个保证:在构造函数内部,不能让这个被构造对象的引用为其他线程所见,也就是对象引用不能在构造函数中“逸出”。为了说明问题,让我们来看下面的示例代码。

假设一个线程 A 执行 writer() 方法,另一个线程 B 执行 reader() 方法。这里的操作 2 使得对象还未完成构造前就为线程 B 可见。即使这里的操作 2 是构造函数的最后一步,且在程序中操作 2 排在操作 1 后面,执行 read() 方法的线程仍然可能无法看到 final 域被初始化后的值,因为这里的操作 1 和操作 2 之间可能被重排序。实际的执行时序可能如图 3-32 所示。
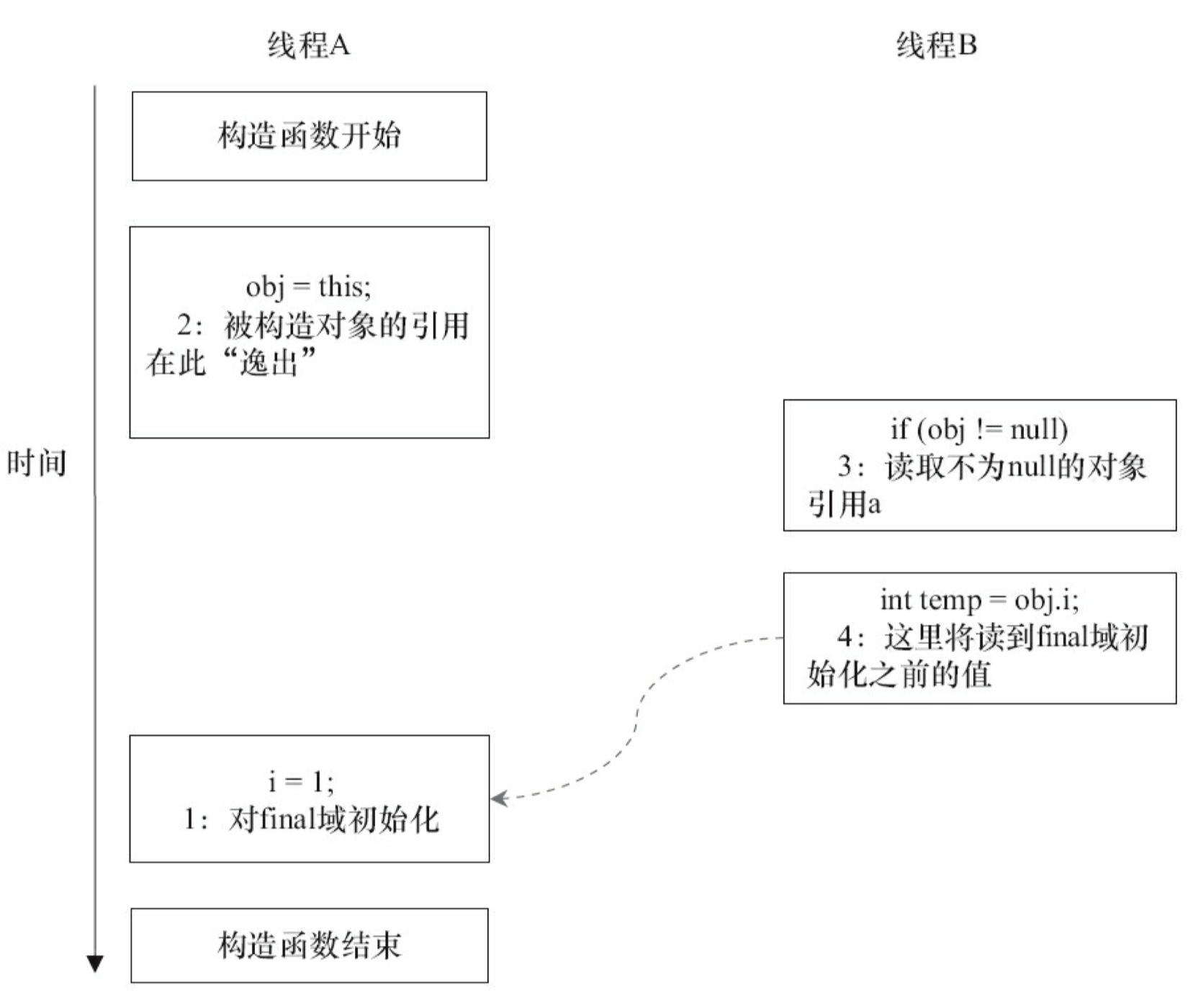
从图 3-32 可以看出:在构造函数返回前,被构造对象的引用不能为其他线程所见,因为此时的 final 域可能还没有被初始化。在构造函数返回后,任意线程都将保证能看到 final 域正确初始化之后的值。
3.6.6 final 语义在处理器中的实现
现在我们以 X86 处理器为例,说明 final 语义在处理器中的具体实现。
上面我们提到,写 final 域的重排序规则会要求编译器在 final 域的写之后,构造函数 return 之前插入一个 StoreStore 障屏。读 final 域的重排序规则要求编译器在读 final 域的操作前面插入一个 LoadLoad 屏障。
由于 X86 处理器不会对写-写操作做重排序,所以在 X86 处理器中,写 final 域需要的 StoreStore 障屏会被省略掉。同样,由于 X86 处理器不会对存在间接依赖关系的操作做重排序,所以在 X86 处理器中,读 final 域需要的 LoadLoad 屏障也会被省略掉。也就是说,在 X86 处理器中,final 域的读/写不会插入任何内存屏障!
3.6.7 JSR-133 为什么要增强 final 的语义
在旧的 Java 内存模型中,一个最严重的缺陷就是线程可能看到 final 域的值会改变。比如,一个线程当前看到一个整型 final 域的值为 0(还未初始化之前的默认值),过一段时间之后这个线程再去读这个 final 域的值时,却发现值变为 1(被某个线程初始化之后的值)。最常见的例子就是在旧的 Java 内存模型中,String 的值可能会改变。
为了修补这个漏洞,JSR-133 专家组增强了 final 的语义。通过为 final 域增加写和读重排序规则,可以为 Java 程序员提供初始化安全保证:只要对象是正确构造的(被构造对象的引用在构造函数中没有“逸出”),那么不需要使用同步(指 lock 和 volatile 的使用)就可以保证任意线程都能看到这个 final 域在构造函数中被初始化之后的值。
3.7 happens-before
happens-before 是 JMM 最核心的概念。对应 Java 程序员来说,理解 happens-before 是理解 JMM 的关键。
3.7.1 JMM 的设计
首先,让我们来看 JMM 的设计意图。从 JMM 设计者的角度,在设计 JMM 时,需要考虑两个关键因素。
- 程序员对内存模型的使用。程序员希望内存模型易于理解、易于编程。程序员希望基于 一个强内存模型来编写代码。
- 编译器和处理器对内存模型的实现。编译器和处理器希望内存模型对它们的束缚越少越 好,这样它们就可以做尽可能多的优化来提高性能。编译器和处理器希望实现一个弱内存模型。
由于这两个因素互相矛盾,所以 JSR-133 专家组在设计 JMM 时的核心目标就是找到一个好的平衡点:一方面,要为程序员提供足够强的内存可见性保证;另一方面,对编译器和处理器的限制要尽可能地放松。下面让我们来看 JSR-133 是如何实现这一目标的。

上面计算圆的面积的示例代码存在 3 个 happens-before 关系,如下。
- A happens-before B。
- B happens-before C。
- A happens-before C。
在 3 个 happens-before 关系中,2 和 3 是必需的,但 1 是不必要的。因此,JMM 把 happens-before 要求禁止的重排序分为了下面两类。
- 会改变程序执行结果的重排序。
- 不会改变程序执行结果的重排序。
JMM对这两种不同性质的重排序,采取了不同的策略,如下。
- 对于会改变程序执行结果的重排序,JMM 要求编译器和处理器必须禁止这种重排序。
- 对于不会改变程序执行结果的重排序,JMM 对编译器和处理器不做要求(JMM 允许这种 重排序)。
图 3-33 是 JMM 的设计示意图。
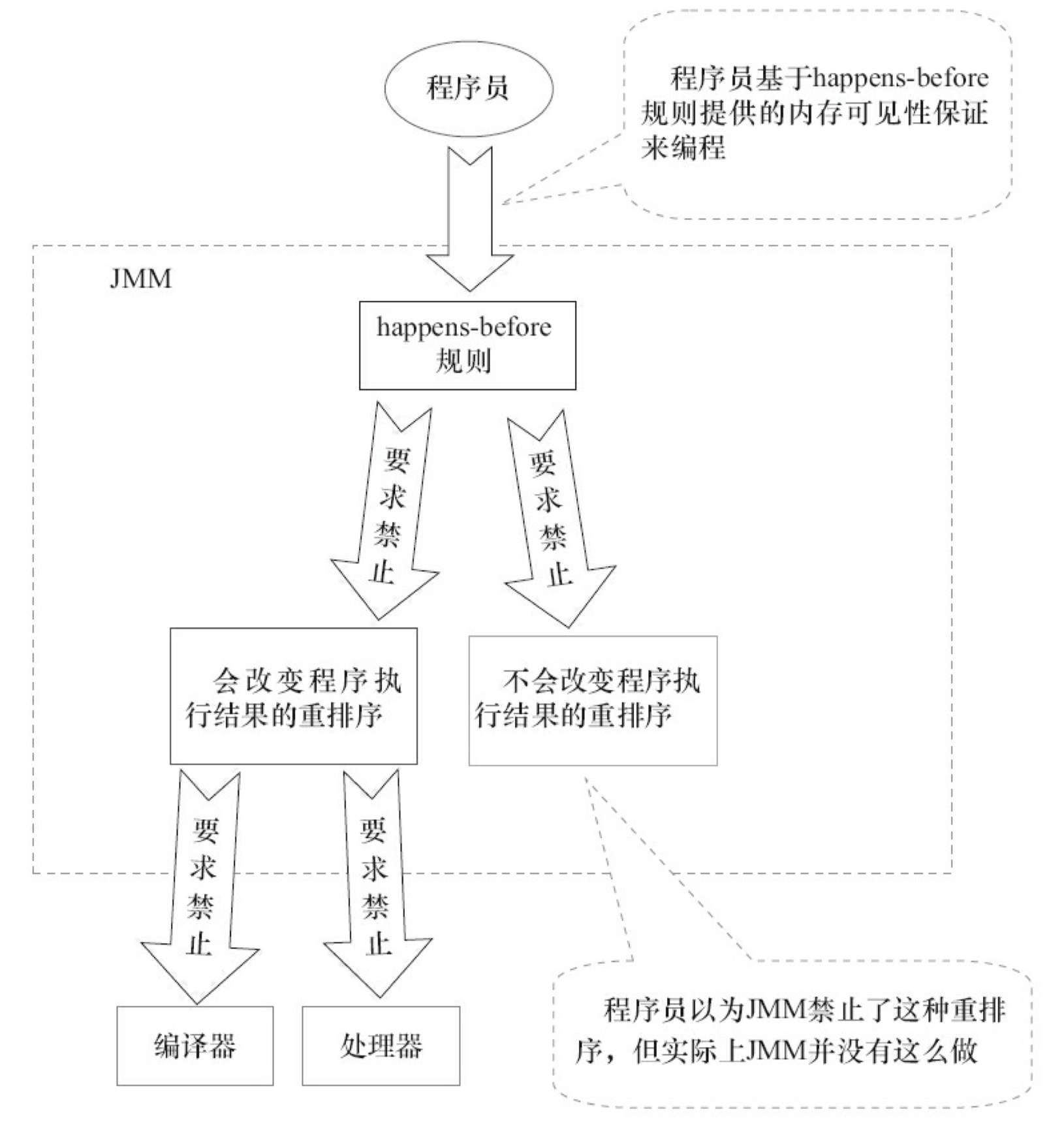
从图 3-33 可以看出两点,如下。
- JMM 向程序员提供的 happens-before 规则能满足程序员的需求。JMM 的happens-before 规则不但简单易懂,而且也向程序员提供了足够强的内存可见性保证(有些内存可见性保证其实并不一定真实存在,比如上面的 A happens-before B)。
- JMM 对编译器和处理器的束缚已经尽可能少。从上面的分析可以看出,JMM 其实是在遵循一个基本原则:只要不改变程序的执行结果(指的是单线程程序和正确同步的多线程程序),编译器和处理器怎么优化都行。例如,如果编译器经过细致的分析后,认定一个锁只会被单个线程访问,那么这个锁可以被消除。再如,如果编译器经过细致的分析后,认定一个 volatile 变量只会被单个线程访问,那么编译器可以把这个 volatile 变量当作一个普通变量来对待。这些 优化既不会改变程序的执行结果,又能提高程序的执行效率。
3.7.2 happens-before 的定义
happens-before 的概念最初由 Leslie Lamport 在其一篇影响深远的论文(Time,Clocks and the Ordering of Events in a Distributed System)中提出。Leslie Lamport 使用 happens-before 来定义分布式系统中事件之间的偏序关系(partial ordering)。Leslie Lamport 在这篇论文中给出了一个分布式算法,该算法可以将该偏序关系扩展为某种全序关系。
JSR-133 使用 happens-before 的概念来指定两个操作之间的执行顺序。由于这两个操作可以在一个线程之内,也可以是在不同线程之间。因此,JMM 可以通过 happens-before 关系向程序员提供跨线程的内存可见性保证(如果 A 线程的写操作 a 与 B 线程的读操作 b 之间存在 happens-before 关系,尽管 a 操作和 b 操作在不同的线程中执行,但 JMM 向程序员保证 a 操作将对 b 操作可见)。
JSR-133 对 happens-before 关系的定义如下:
- 如果一个操作 happens-before 另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
- 两个操作之间存在 happens-before 关系,并不意味着 Java 平台的具体实现必须要按照 happens-before 关系指定的顺序来执行。如果重排序之后的执行结果,与按 happens-before 关系来执行的结果一致,那么这种重排序并不非法(也就是说,JMM允许这种重排序)。
上面的第一点是 JMM 对程序员的承诺。从程序员的角度来说,可以这样理解 happens-before 关系:如果 A happens-before B,那么 Java 内存模型将向程序员保证—— A 操作的结果将对 B 可见, 且A的执行顺序排在 B 之前。注意,这只是 Java 内存模型向程序员做出的保证!
上面的第二点是 JMM 对编译器和处理器重排序的约束原则。正如前面所言,JMM 其实是在遵循一个基本原则:只要不改变程序的执行结果(指的是单线程程序和正确同步的多线程程序),编译器和处理器怎么优化都行。JMM 这么做的原因是:程序员对于这两个操作是否真的被重排序并不关心,程序员关心的是程序执行时的语义不能被改变(即执行结果不能被改变)。因此,happens-before 关系本质上和 as-if-serial 语义是一回事。
- as-if-serial 语义保证单线程内程序的执行结果不被改变,happens-before 关系保证正确同步的多线程程序的执行结果不被改变。
- as-if-serial 语义给编写单线程程序的程序员创造了一个幻境:单线程程序是按程序的顺序来执行的。happens-before 关系给编写正确同步的多线程程序的程序员创造了一个幻境:正确同步的多线程程序是按 happens-before 指定的顺序来执行的。
as-if-serial 语义和 happens-before 这么做的目的,都是为了在不改变程序执行结果的前提下,尽可能地提高程序执行的并行度。
3.7.3 happens-before 规则
JSR-133 定义了如下 happens-before 规则。
- 程序顺序规则:一个线程中的每个操作,happens-before 于该线程中的任意后续操作。
- 监视器锁规则:对一个锁的解锁,happens-before 于随后对这个锁的加锁。
- volatile 变量规则:对一个 volatile 域的写,happens-before 于任意后续对这个 volatile 域的读。
- 传递性:如果 A happens-before B,且 B happens-before C,那么 A happens-before C。
- start() 规则:如果线程A执行操作 ThreadB.start()(启动线程B),那么 A 线程的 ThreadB.start() 操作 happens-before 于线程B中的任意操作。
- join() 规则:如果线程 A 执行操作 ThreadB.join() 并成功返回,那么线程 B 中的任意操作 happens-before 于线程 A 从 ThreadB.join() 操作成功返回。
这里的规则 1~4 前面都讲到过,这里再做个总结。由于 2 和 3 情况类似,这里只以1、3 和 4 为例来说明。图 3-34 是 volatile 写-读建立的 happens-before 关系图。
结合图 3-34,我们做以下分析。
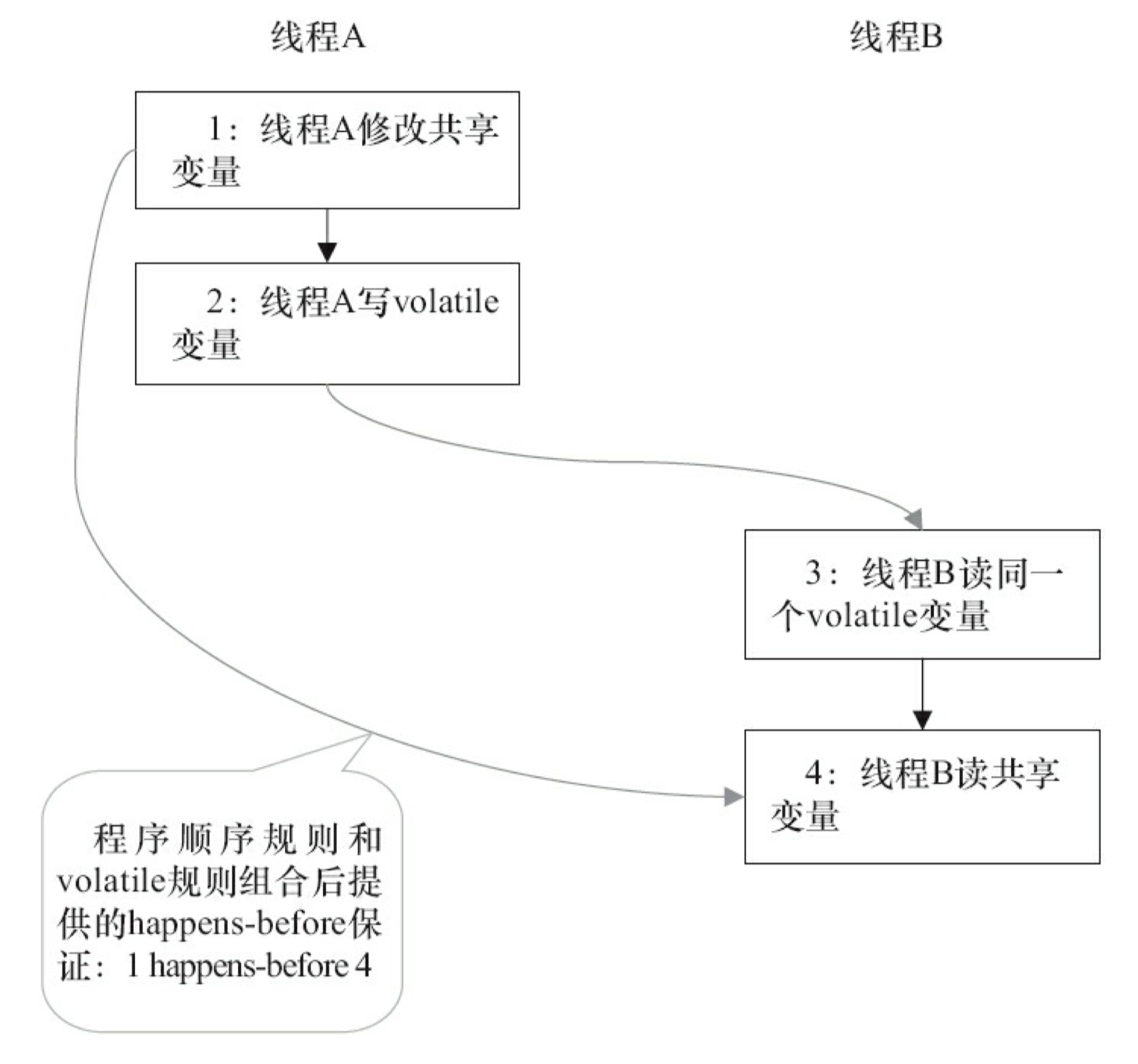
- 1 happens-before 2 和 3 happens-before 4 由程序顺序规则产生。由于编译器和处理器都要遵守 as-if-serial 语义,也就是说,as-if-serial 语义保证了程序顺序规则。因此,可以把程序顺序规则看成是对 as-if-serial 语义的“封装”。
- 2 happens-before 3 是由 volatile 规则产生。前面提到过,对一个 volatile 变量的读,总是能看到“任意线程”之前对这个 volatile 变量最后的写入。因此,volatile 的这个特性可以保证实现 volatile 规则。
- 1 happens-before 4 是由传递性规则产生的。这里的传递性是由 volatile 的内存屏障插入策略和 volatile 的编译器重排序规则共同来保证的。
下面我们来看 start() 规则。假设线程 A 在执行的过程中,通过执行 ThreadB.start() 来启动线程 B;同时,假设线程 A 在执行 ThreadB.start() 之前修改了一些共享变量,线程 B 在开始执行后会 读这些共享变量。图 3-35 是该程序对应的 happens-before 关系图。
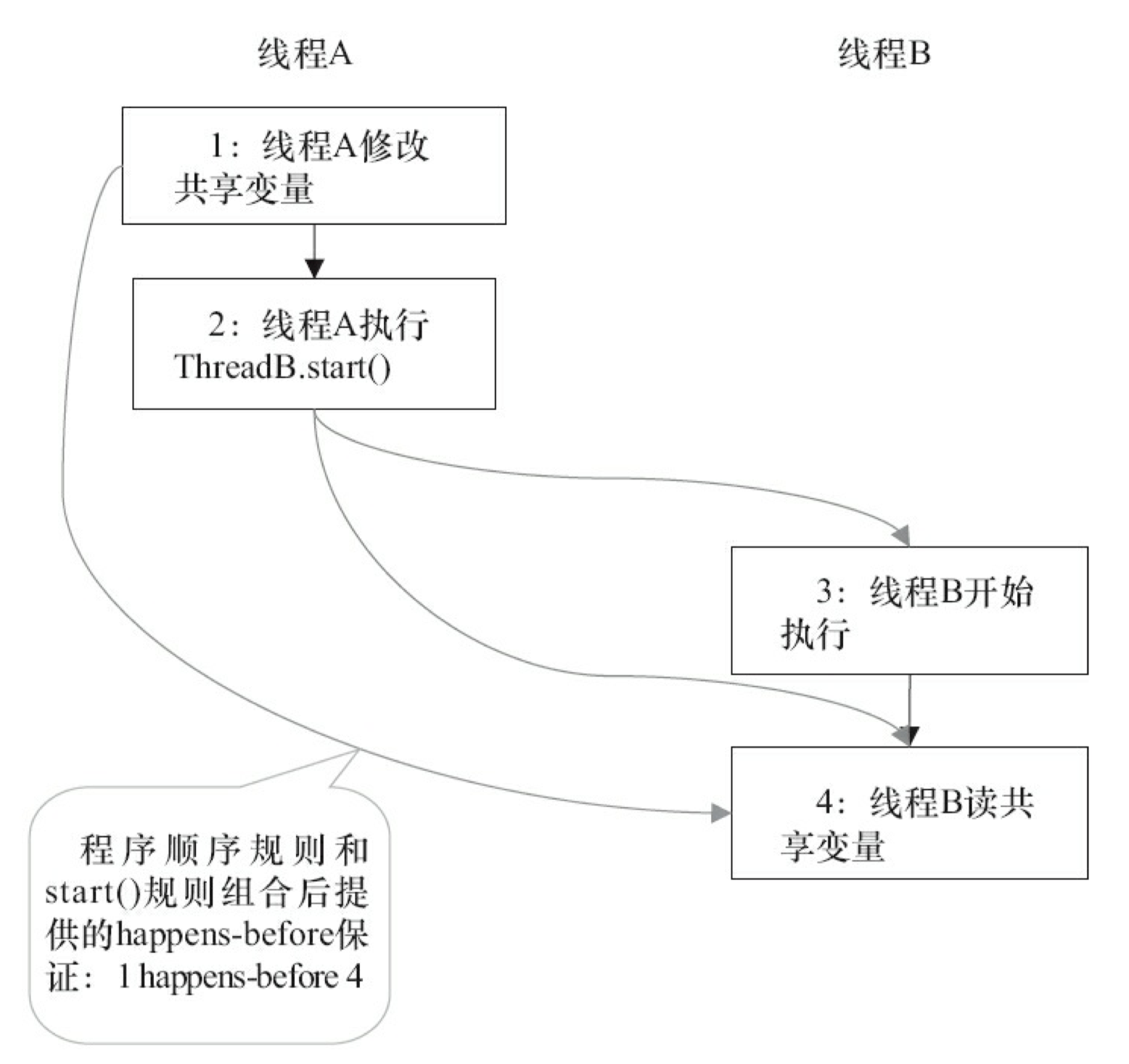
在图 3-35 中,1 happens-before 2 由程序顺序规则产生。2 happens-before 4 由 start() 规则产 生。根据传递性,将有 1 happens-before 4。这实意味着,线程 A 在执行 ThreadB.start() 之前对共享变量所做的修改,接下来在线程 B 开始执行后都将确保对线程B可见。
下面我们来看 join() 规则。假设线程A在执行的过程中,通过执行 ThreadB.join() 来等待线程 B 终止;同时,假设线程 B 在终止之前修改了一些共享变量,线程 A 从 ThreadB.join() 返回后会 读这些共享变量。图 3-36 是该程序对应的 happens-before 关系图。
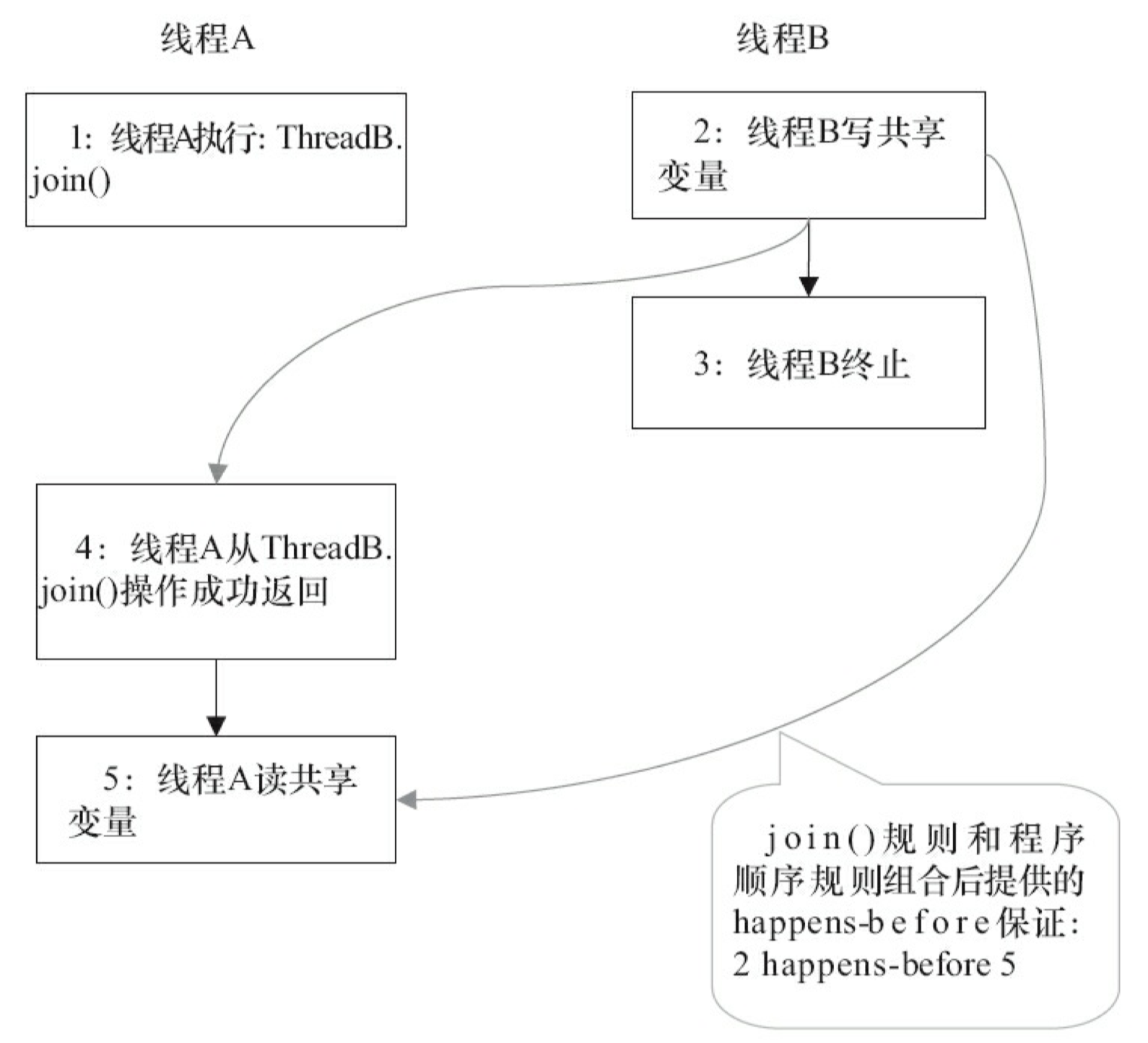
在图 3-36 中,2 happens-before 4 由 join() 规则产生;4 happens-before 5 由程序顺序规则产生。根据传递性规则,将有 2 happens-before 5。这意味着,线程 A 执行操作 ThreadB.join() 并成功返回后,线程 B 中的任意操作都将对线程 A 可见。
3.8 双重检查锁定与延迟初始化
在 Java 多线程程序中,有时候需要采用延迟初始化来降低初始化类和创建对象的开销。双重检查锁定是常见的延迟初始化技术,但它是一个错误的用法。本文将分析双重检查锁定的错误根源,以及两种线程安全的延迟初始化方案。
3.8.1 双重检查锁定的由来
在 Java 程序中,有时候可能需要推迟一些高开销的对象初始化操作,并且只有在使用这些对象时才进行初始化。此时,程序员可能会采用延迟初始化。但要正确实现线程安全的延迟初始化需要一些技巧,否则很容易出现问题。比如,下面是非线程安全的延迟初始化对象的示例代码。

在 UnsafeLazyInitialization 类中,假设A线程执行代码 1 的同时,B 线程执行代码 2。此时,线程 A 可能会看到 instance 引用的对象还没有完成初始化。
对于 UnsafeLazyInitialization 类,我们可以对 getInstance() 方法做同步处理来实现线程安全的延迟初始化。示例代码如下。

由于对 getInstance() 方法做了同步处理,synchronized 将导致性能开销。如果 getInstance() 方法被多个线程频繁的调用,将会导致程序执行性能的下降。反之,如果 getInstance() 方法不会被多个线程频繁的调用,那么这个延迟初始化方案将能提供令人满意的性能。
在早期的 JVM 中,synchronized(甚至是无竞争的 synchronized)存在巨大的性能开销。因此,人们想出了一个“聪明”的技巧:双重检查锁定(Double-Checked Locking)。人们想通过双重检查锁定来降低同步的开销。下面是使用双重检查锁定来实现延迟初始化的示例代码。

如上面代码所示,如果第一次检查 instance 不为 null,那么就不需要执行下面的加锁和初始化操作。因此,可以大幅降低 synchronized 带来的性能开销。上面代码表面上看起来,似乎两全其美。
- 多个线程试图在同一时间创建对象时,会通过加锁来保证只有一个线程能创建对象。
- 在对象创建好之后,执行 getInstance() 方法将不需要获取锁,直接返回已创建好的对象。
双重检查锁定看起来似乎很完美,但这是一个错误的优化!在线程执行到第 4 行,代码读取到 instance 不为 null 时,instance 引用的对象有可能还没有完成初始化。
3.8.2 问题的根源
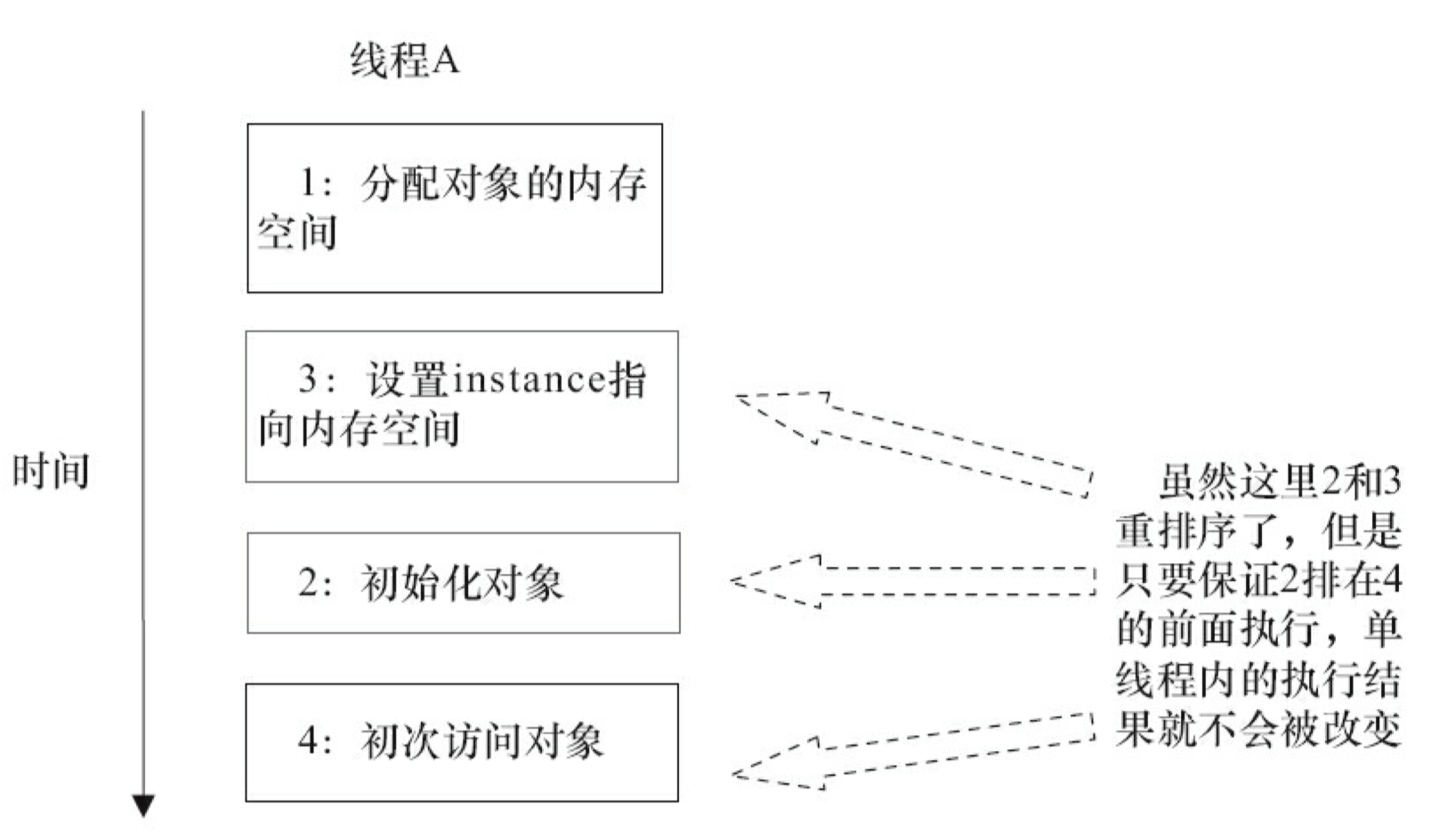
前面的双重检查锁定示例代码的第 7 行创建了一个对象。这一行代码可以分解为如下的 3 行伪代码。

上面 3 行伪代码中的 2 和 3 之间,可能会被重排序(在一些 JIT 编译器上,这种重排序是真实发生的,详情见参考文献 1 的“Out-of-order writes”部分)。2 和 3 之间重排序之后的执行时序如下。

根据 JLS,所有线程在执行 Java 程序时必须要遵守 intra-thread semantics。intra-thread semantics 保证重排序不会改变单线程内的程序执行结果。换句话说,intra-thread semantics 允许那些在单线程内、不会改变单线程程序执行结果的重排序。上面 3 行伪代码的 2 和 3 之间虽然被重排序了,但这个重排序并不会违反 intra-thread semantics。这个重排序在没有改变单线程程序执行结果的前提下,可以提高程序的执行性能。
为了更好地理解 intra-thread semantics,请看如图 3-37 所示的示意图(假设一个线程 A 在构造对象后,立即访问这个对象)。
如图 3-37 所示,只要保证 2 排在 4 的前面,即使 2 和 3 之间重排序了,也不会违反 intra-thread semantics。
下面,再让我们查看多线程并发执行的情况。如图 3-38 所示。
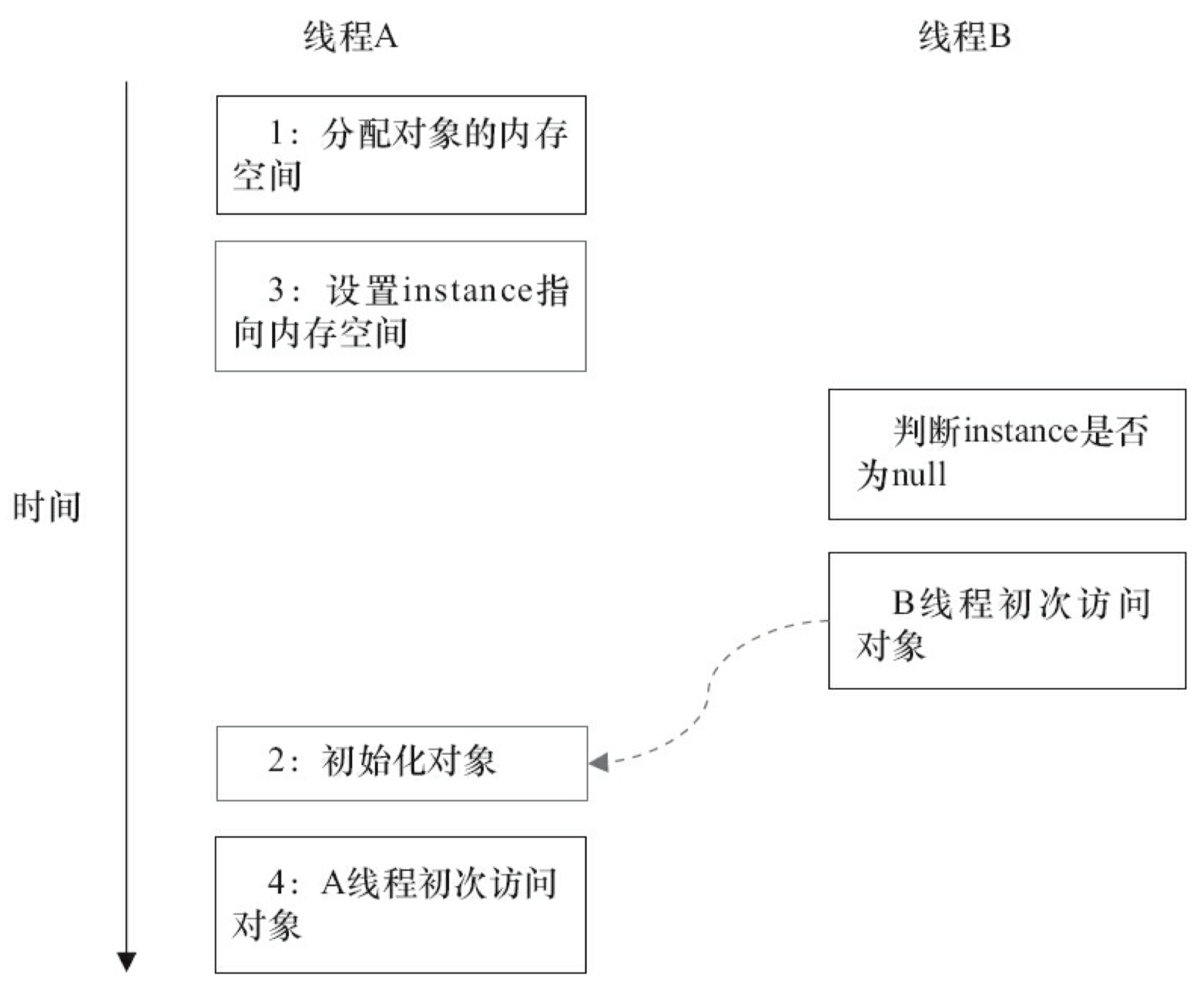
由于单线程内要遵守 intra-thread semantics,从而能保证 A 线程的执行结果不会被改变。但是,当线程 A 和 B 按图 3-38 的时序执行时,B 线程将看到一个还没有被初始化的对象。
回到本文的主题,DoubleCheckedLocking 示例代码的第 7 行如果发生重排序,另一个并发执行的线程B就有可能在第 4 行判断 instance 不为 null。线程 B 接下来将 访问 instance 所引用的对象,但此时这个对象可能还没有被 A 线程初始化!表 3-6 是这个场景的具体执行时序。
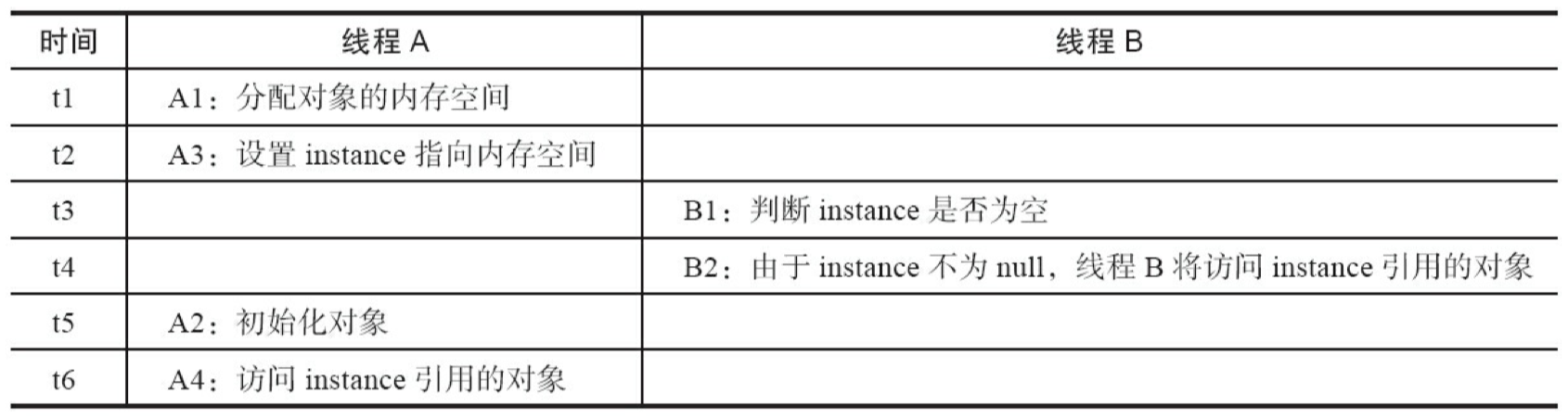
这里 A2 和 A3 虽然重排序了,但 Java 内存模型的 intra-thread semantics 将确保 A2 一定会排在 A4 前面执行。因此,线程 A 的 intra-thread semantics 没有改变,但 A2 和 A3 的重排序,将导致线程 B 在 B1 处判断出 instance 不为空,线程 B 接下来将访问 instance 引用的对象。此时,线程 B 将会访问到一个还未初始化的对象。
在知晓了问题发生的根源之后,我们可以想出两个办法来实现线程安全的延迟初始化。
- 不允许 2 和 3 重排序。
- 允许 2 和 3 重排序,但不允许其他线程“看到”这个重排序。
后文介绍的两个解决方案,分别对应于上面这两点。
3.8.3 基于volatile的解决方案
对于前面的基于双重检查锁定来实现延迟初始化的方案,只需要做一点小的修改(把 instance 声明为 volatile 型),就可以实现线程安全的延迟初始化。请看下面的示例代码。
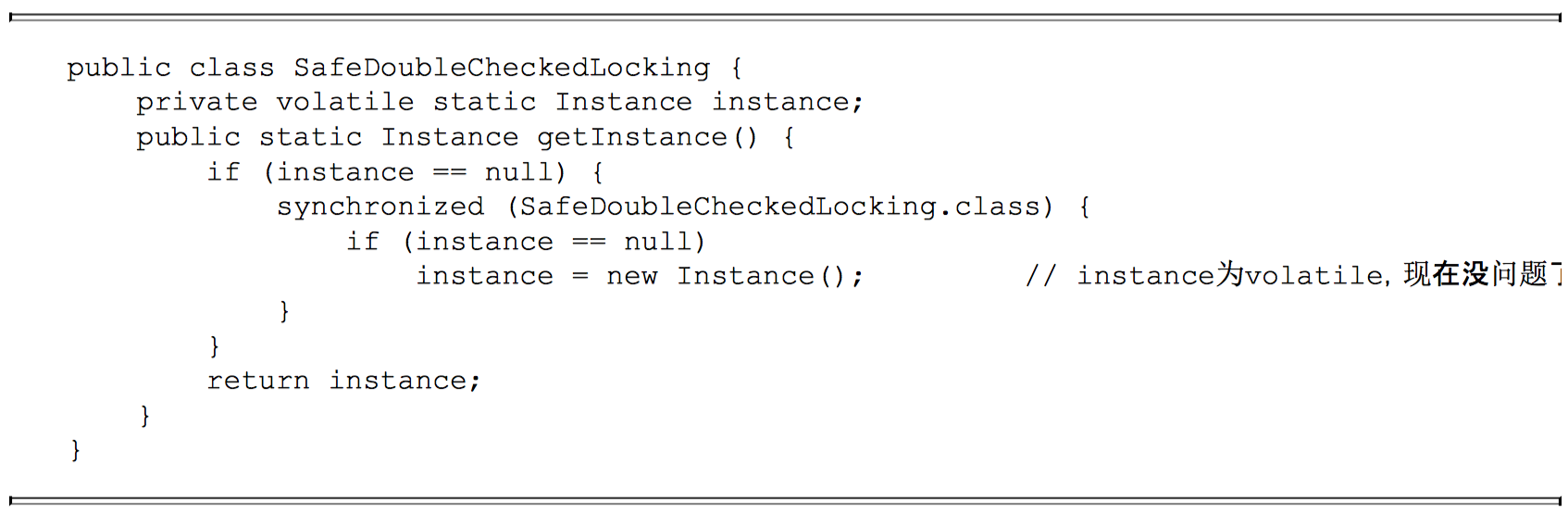
当声明对象的引用为 volatile 后,3.8.2 节中的 3 行伪代码中的 2 和 3 之间的重排序,在多线程环境中将会被禁止。上面示例代码将按如下的时序执行,如图 3-39 所示。
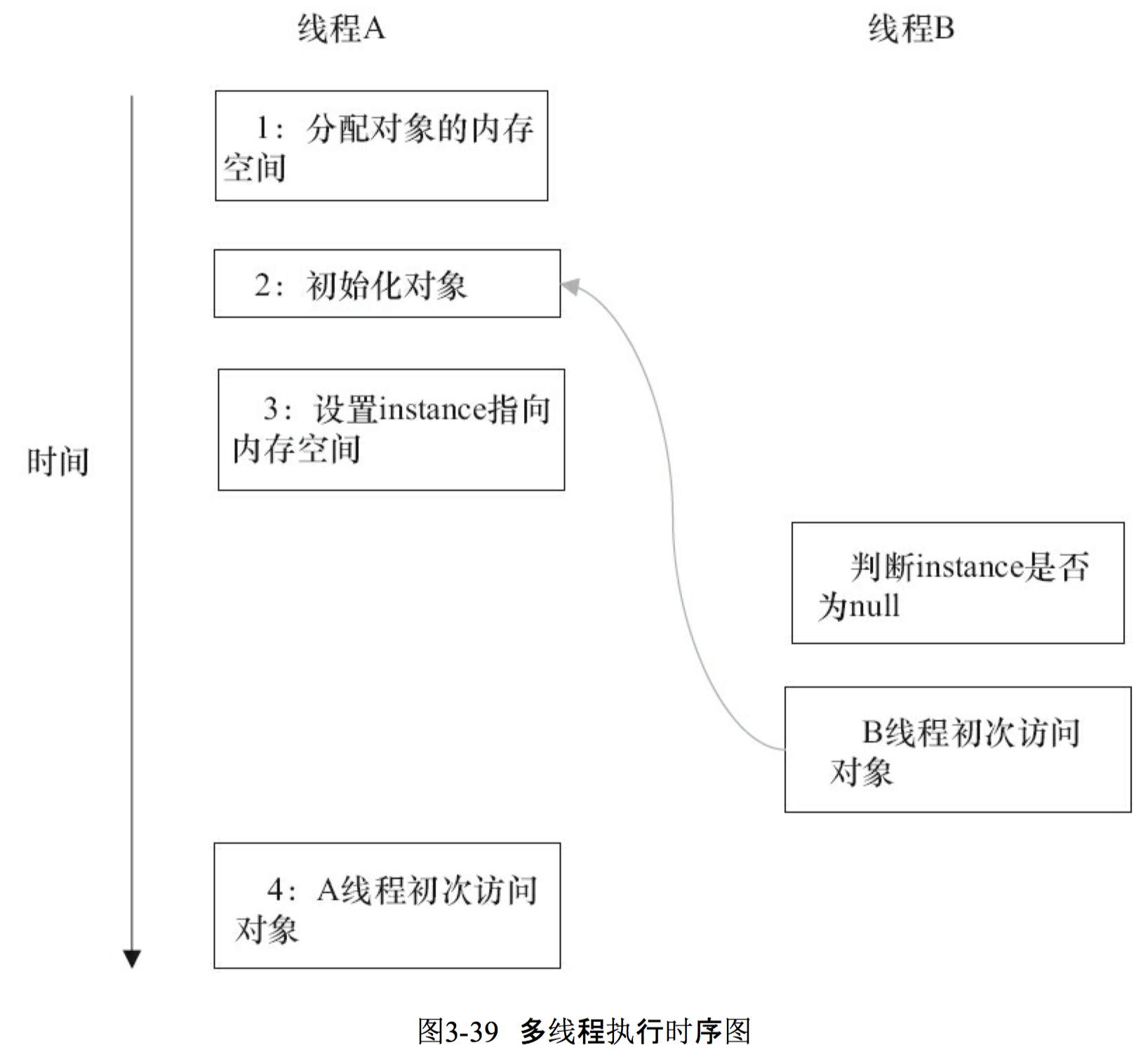
这个方案本质上是通过禁止图 3-39 中的 2 和 3 之间的重排序,来保证线程安全的延迟初始化。
3.8.4 基于类初始化的解决方案
JVM 在类的初始化阶段(即在 Class 被加载后,且被线程使用之前),会执行类的初始化。在执行类的初始化期间,JVM 会去获取一个锁。这个锁可以同步多个线程对同一个类的初始化。
基于这个特性,可以实现另一种线程安全的延迟初始化方案(这个方案被称之为 Initialization On Demand Holder idiom)。

假设两个线程并发执行 getInstance() 方法,下面是执行的示意图,如图 3-40 所示。
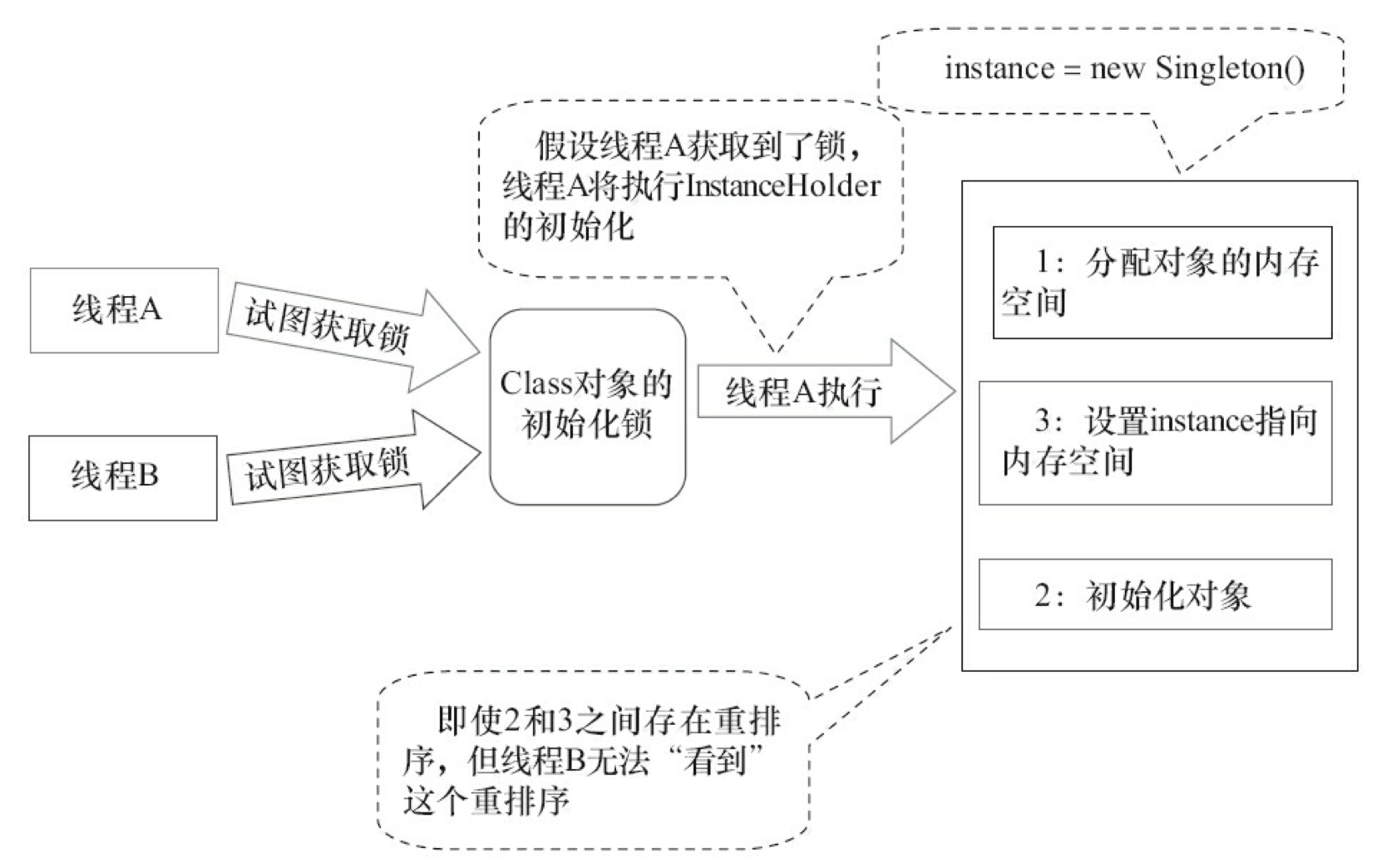
这个方案的实质是:允许 3.8.2 节中的 3 行伪代码中的 2 和 3 重排序,但不允许非构造线程(这里指线程 B)“看到”这个重排序。
初始化一个类,包括执行这个类的静态初始化和初始化在这个类中声明的静态字段。根据 Java 语言规范,在首次发生下列任意一种情况时,一个类或接口类型 T 将被立即初始化。
- T 是一个类,而且一个T类型的实例被创建。
- T 是一个类,且 T 中声明的一个静态方法被调用。
- T 中声明的一个静态字段被赋值。
- T 中声明的一个静态字段被使用,而且这个字段不是一个常量字段。
- T 是一个顶级类(Top Level Class),而且一个断言语句嵌套在 T 内部被执行。
在 InstanceFactory 示例代码中,首次执行 getInstance() 方法的线程将导致 InstanceHolder 类被初始化(符合情况 4)。
由于 Java 语言是多线程的,多个线程可能在同一时间尝试去初始化同一个类或接口(比如这里多个线程可能在同一时刻调用 getInstance() 方法来初始化 InstanceHolder 类)。因此,在Java 中初始化一个类或者接口时,需要做细致的同步处理。
Java 语言规范规定,对于每一个类或接口 C,都有一个唯一的初始化锁 LC 与之对应。从 C 到 LC 的映射,由 JVM 的具体实现去自由实现。JVM 在类初始化期间会获取这个初始化锁,并且每个线程至少获取一次锁来确保这个类已经被初始化过了(事实上,Java 语言规范允许 JVM 的具体实现在这里做一些优化,见后文的说明)。
对于类或接口的初始化,Java 语言规范制定了精巧而复杂的类初始化处理过程。Java 初始化一个类或接口的处理过程如下。这里对类初始化处理过程的说明,省略了与本文无关的部分;同时为了更好的说明类初始化过程中的同步处理机制,笔者人为的把类初始化的处理过程分为了 5 个阶段。
第1阶段:通过在 Class 对象上同步(即获取Class对象的初始化锁),来控制类或接口的初始化。这个获取锁的线程会一直等待,直到当前线程能够获取到这个初始化锁。
假设 Class 对象当前还没有被初始化(初始化状态 state,此时被标记为 state=noInitialization),且有两个线程 A 和 B 试图同时初始化这个 Class 对象。图 3-41 是对应的示意图。
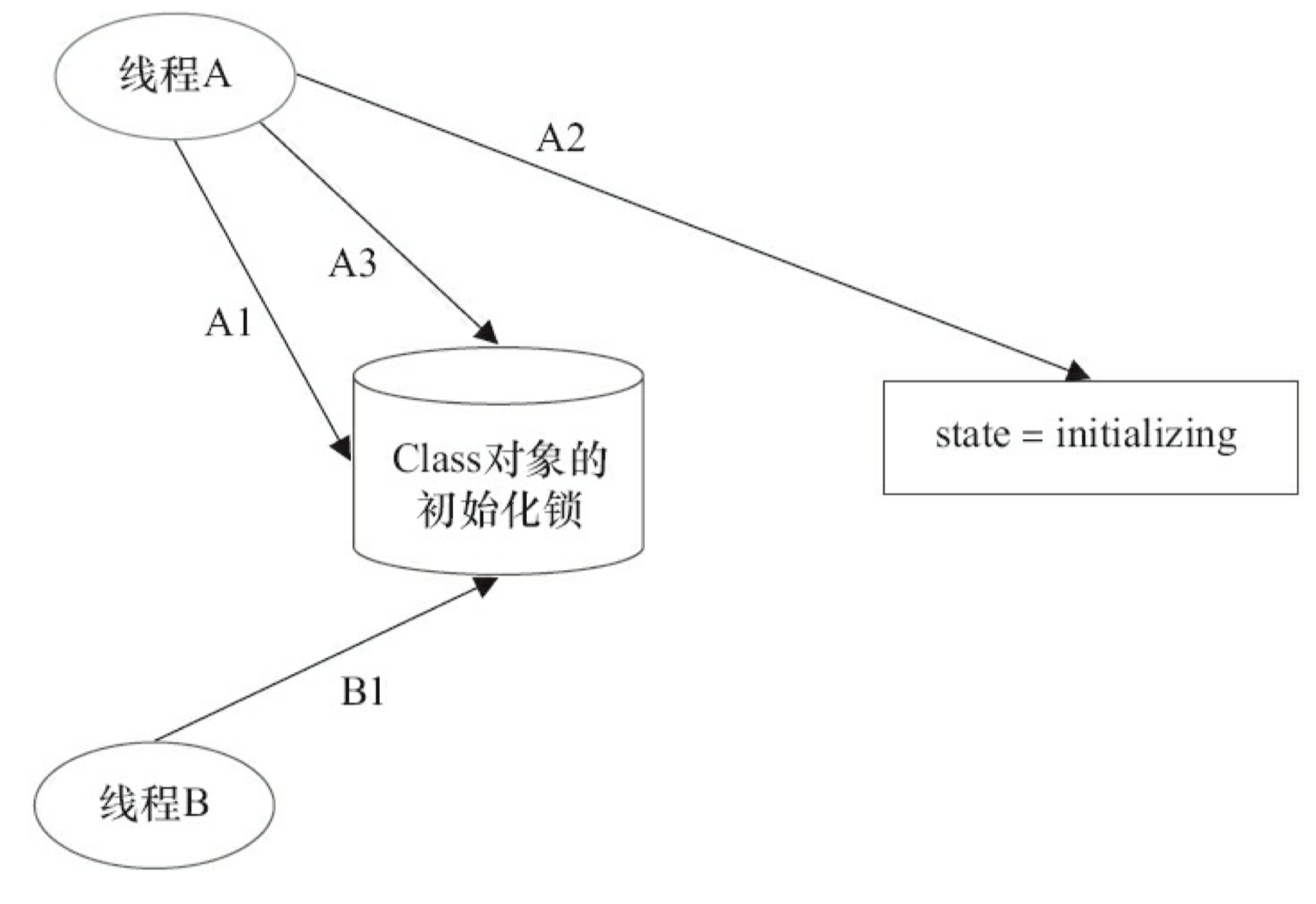
表 3-7 是这个示意图的说明。
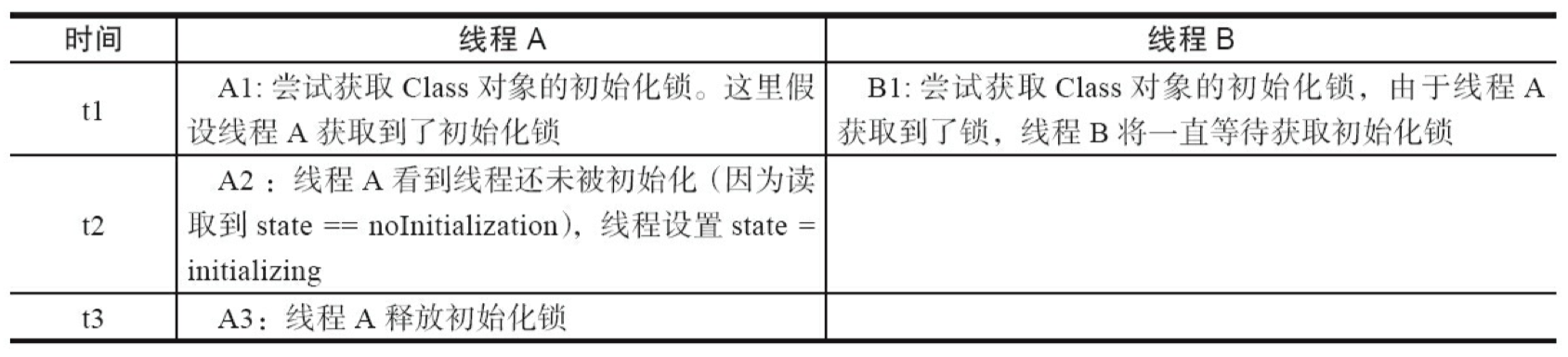
第 2 阶段:线程 A 执行类的初始化,同时线程 B 在初始化锁对应的 condition 上等待。
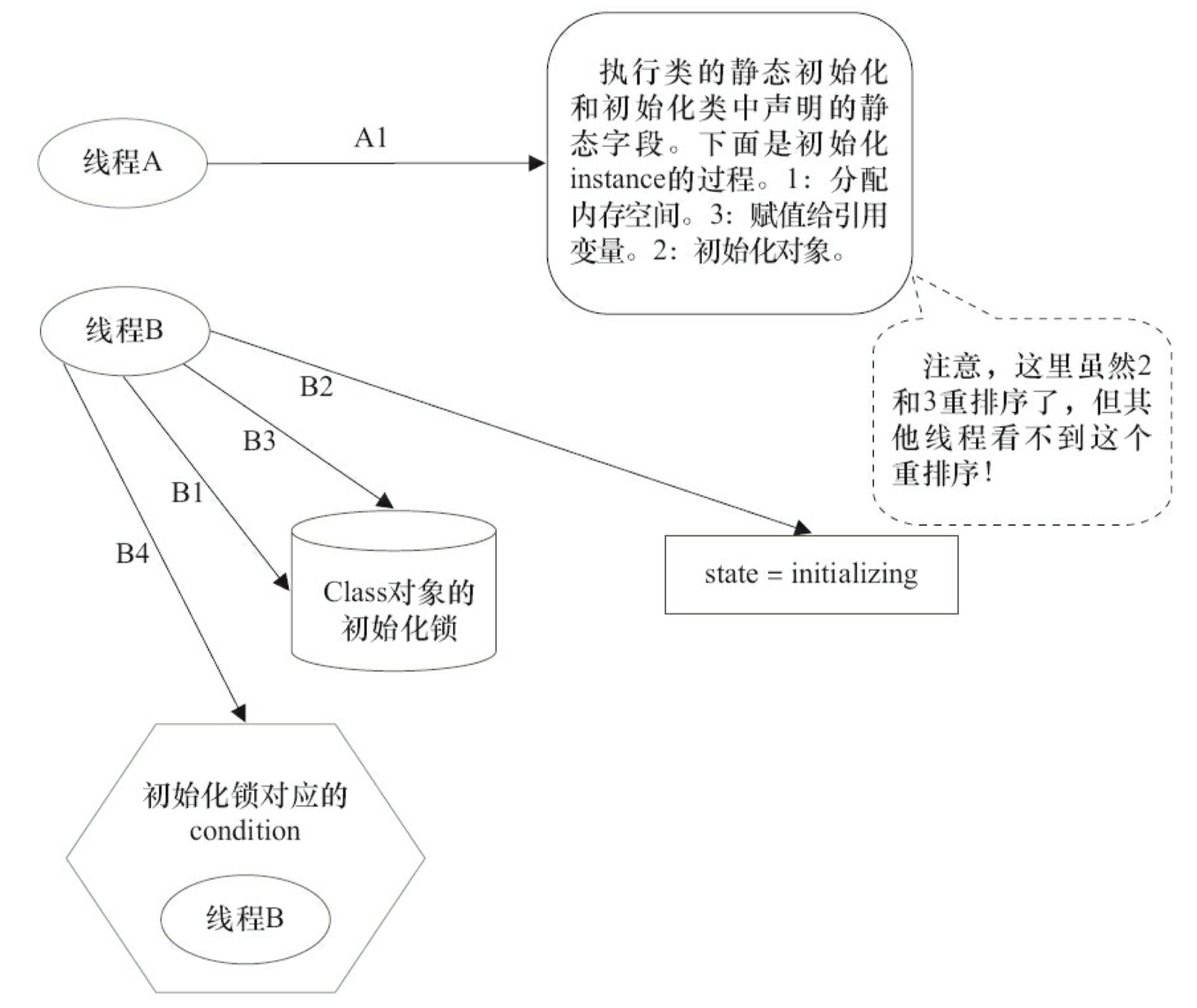
表 3-8 是这个示意图的说明。

第 3 阶段:线程 A 设置 state=initialized,然后唤醒在 condition 中等待的所有线程。
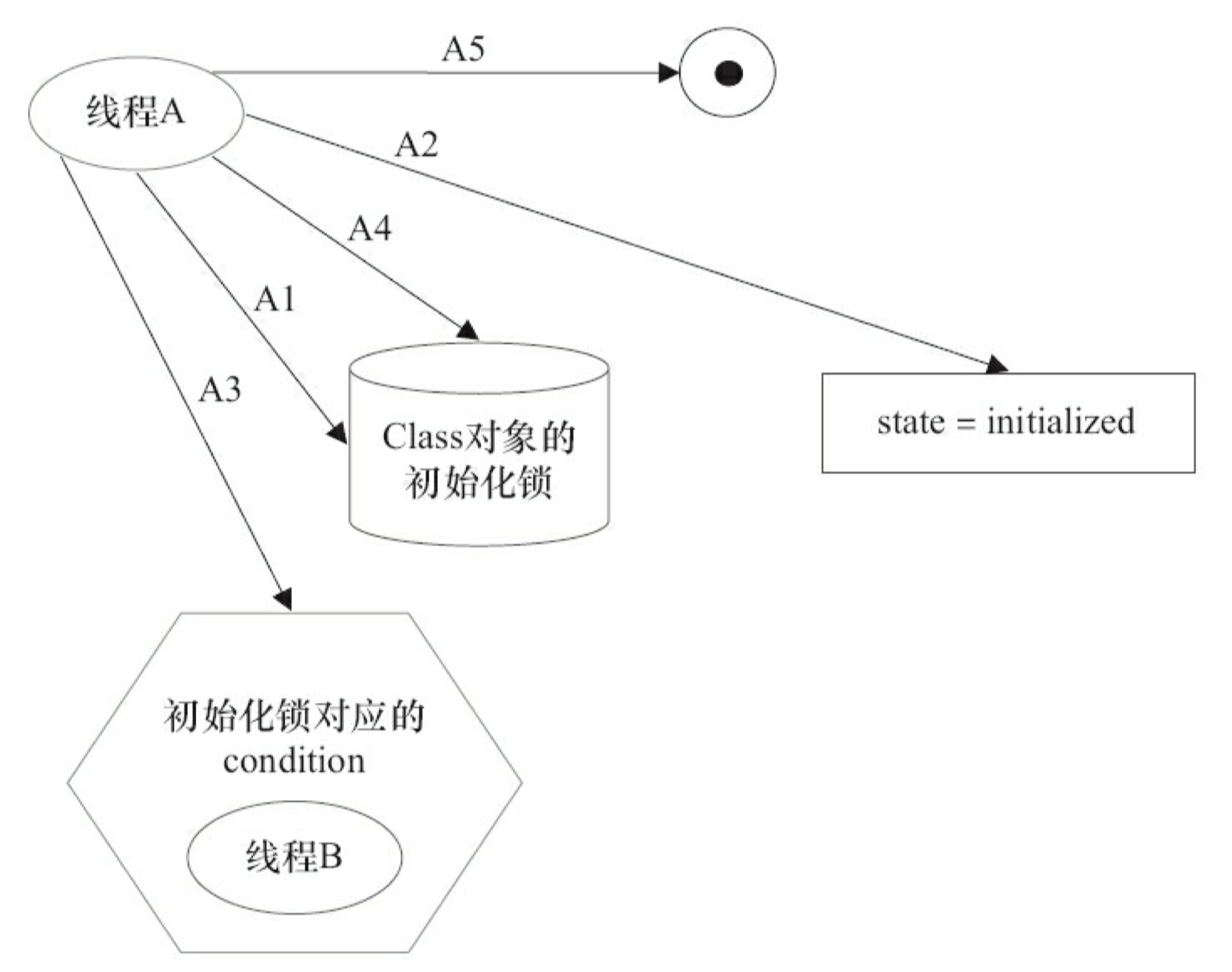
表 3-9 是这个示意图的说明。

第 4 阶段:线程B结束类的初始化处理。


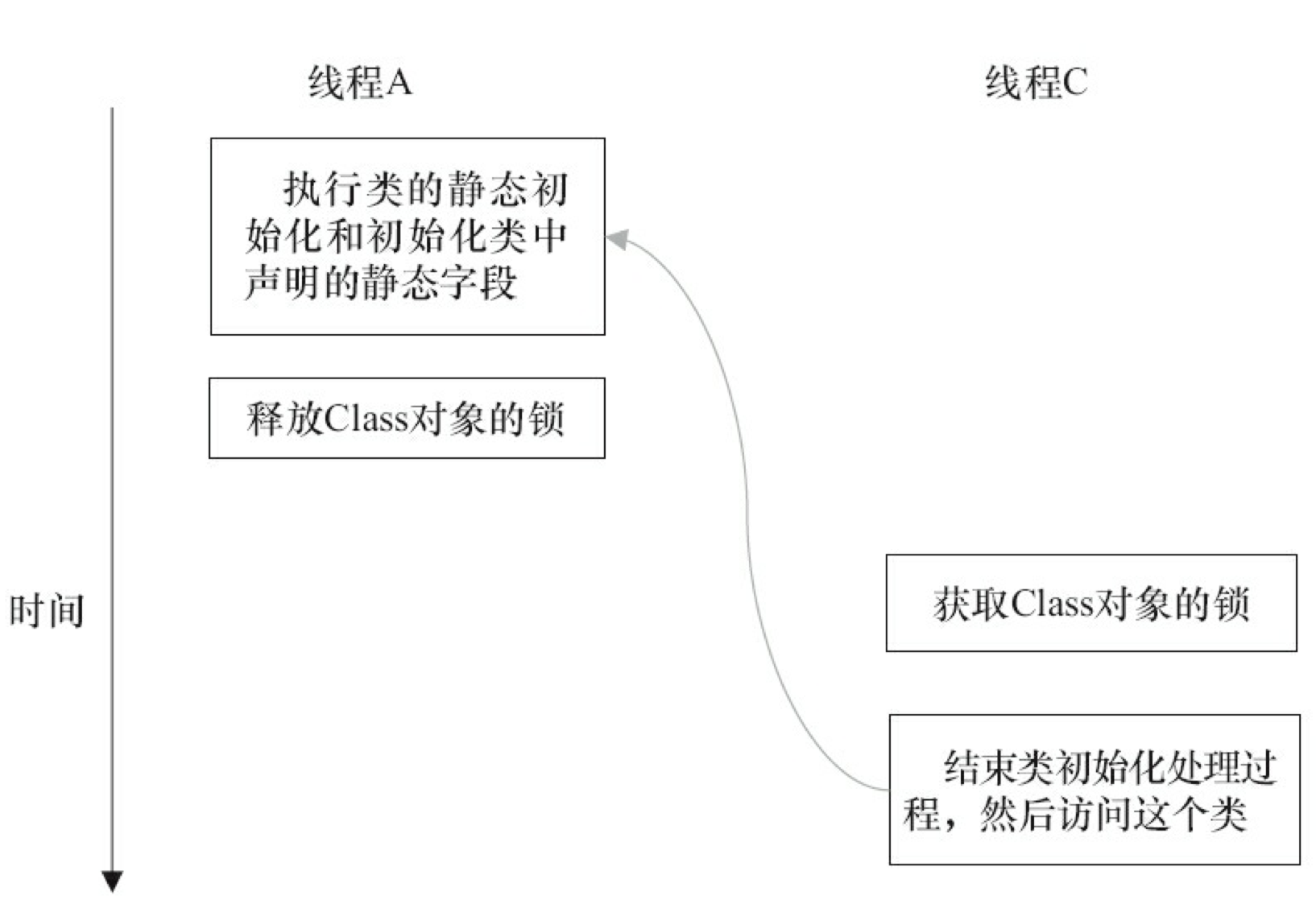
线程 A 在第 2 阶段的 A1 执行类的初始化,并在第 3 阶段的 A4 释放初始化锁;线程 B 在第 4 阶段的 B1 获取同一个初始化锁,并在第 4 阶段的 B4 之后才开始访问这个类。根据 Java 内存模型规范的锁规则,这里将存在如下的 happens-before 关系。
这个 happens-before 关系将保证:线程 A 执行类的初始化时的写入操作(执行类的静态初始化和初始化类中声明的静态字段),线程 B 一定能看到。
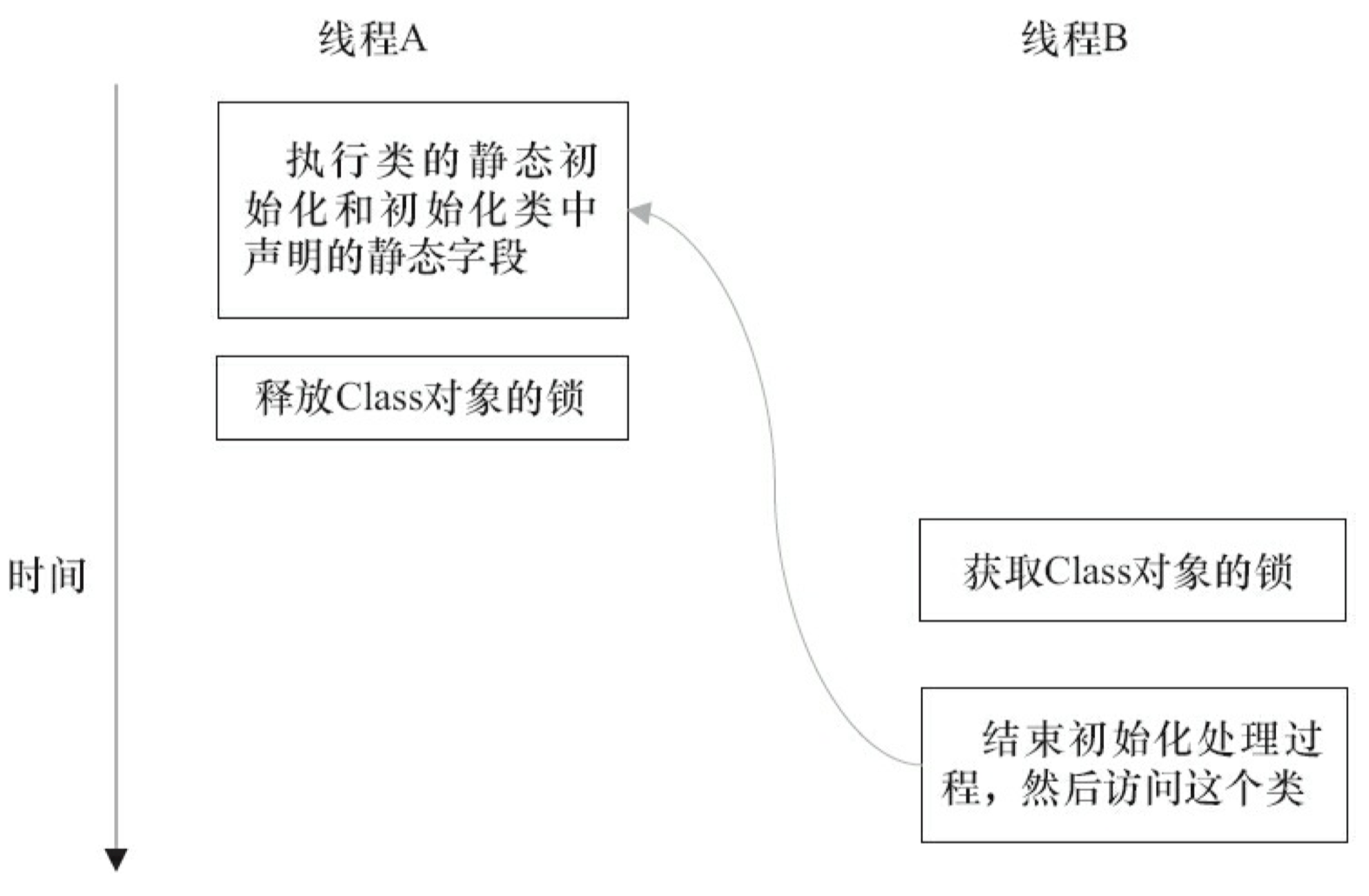
第 5 阶段:线程 C 执行类的初始化的处理。
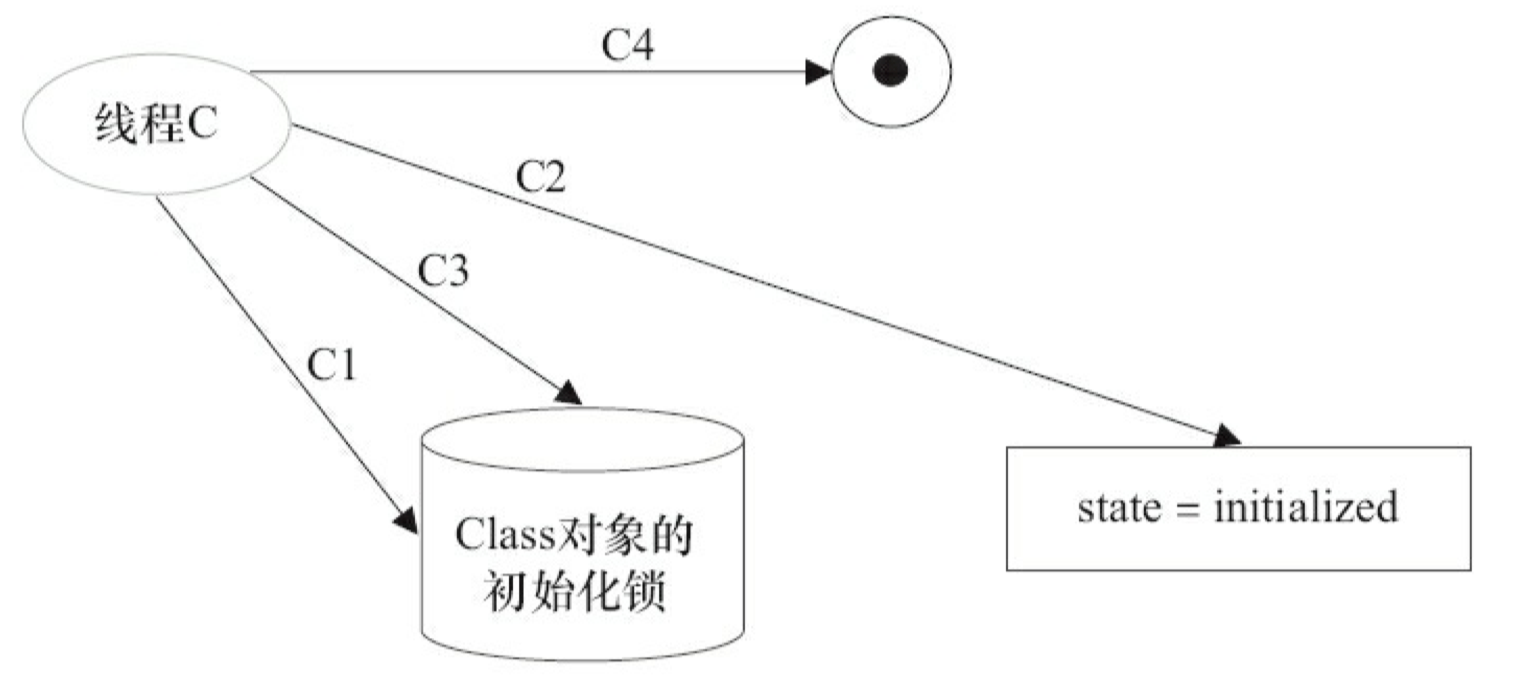
表 3-11 是这个示意图的说明。

在第 3 阶段之后,类已经完成了初始化。因此线程 C 在第 5 阶段的类初始化处理过程相对简单一些(前面的线程 A 和 B 的类初始化处理过程都经历了两次锁获取-锁释放,而线程 C 的类初始化处理只需要经历一次锁获取-锁释放)。
线程 A 在第 2 阶段的 A1 执行类的初始化,并在第 3 阶段的 A4 释放锁;线程 C 在第 5 阶段的 C1 获取同一个锁,并在在第 5 阶段的 C4 之后才开始访问这个类。根据 Java 内存模型规范的锁规则,将存在如下的 happens-before 关系。
这个 happens-before 关系将保证:线程 A 执行类的初始化时的写入操作,线程 C 一定能看到。
通过对比基于 volatile 的双重检查锁定的方案和基于类初始化的方案,我们会发现基于类初始化的方案的实现代码更简洁。但基于 volatile 的双重检查锁定的方案有一个额外的优势:除了可以对静态字段实现延迟初始化外,还可以对实例字段实现延迟初始化。
字段延迟初始化降低了初始化类或创建实例的开销,但增加了访问被延迟初始化的字段的开销。在大多数时候,正常的初始化要优于延迟初始化。如果确实需要对实例字段使用线程安全的延迟初始化,请使用上面介绍的基于 volatile 的延迟初始化的方案;如果确实需要对静态字段使用线程安全的延迟初始化,请使用上面介绍的基于类初始化的方案。
3.9 Java 内存模型综述
前面对 Java 内存模型的基础知识和内存模型的具体实现进行了说明。下面对 Java 内存模型的相关知识做一个总结。
3.9.1 处理器的内存模型
顺序一致性内存模型是一个理论参考模型,JMM 和处理器内存模型在设计时通常会以顺 序一致性内存模型为参照。在设计时,JMM 和处理器内存模型会对顺序一致性模型做一些放松,因为如果完全按照顺序一致性模型来实现处理器和 JMM,那么很多的处理器和编译器优化都要被禁止,这对执行性能将会有很大的影响。
根据对不同类型的读/写操作组合的执行顺序的放松,可以把常见处理器的内存模型划分 为如下几种类型。
- 放松程序中写-读操作的顺序,由此产生了 Total Store Ordering 内存模型,简称为TSO。
- 在上面的基础上,继续放松程序中写-写操作的顺序,由此产生了 Partial Store Order 内存模型,简称为PSO。
- 在前面两条的基础上,继续放松程序中读-写和读-读操作的顺序,由此产生了 Relaxed Memory Order 内存模型(简称为 RMO)和 PowerPC 内存模型。
注意,这里处理器对读/写操作的放松,是以两个操作之间不存在数据依赖性为前提的。因 为处理器要遵守 as-if-serial 语义,处理器不会对存在数据依赖性的两个内存操作做重排序。
表 3-12 展示了常见处理器内存模型的细节特征如下。
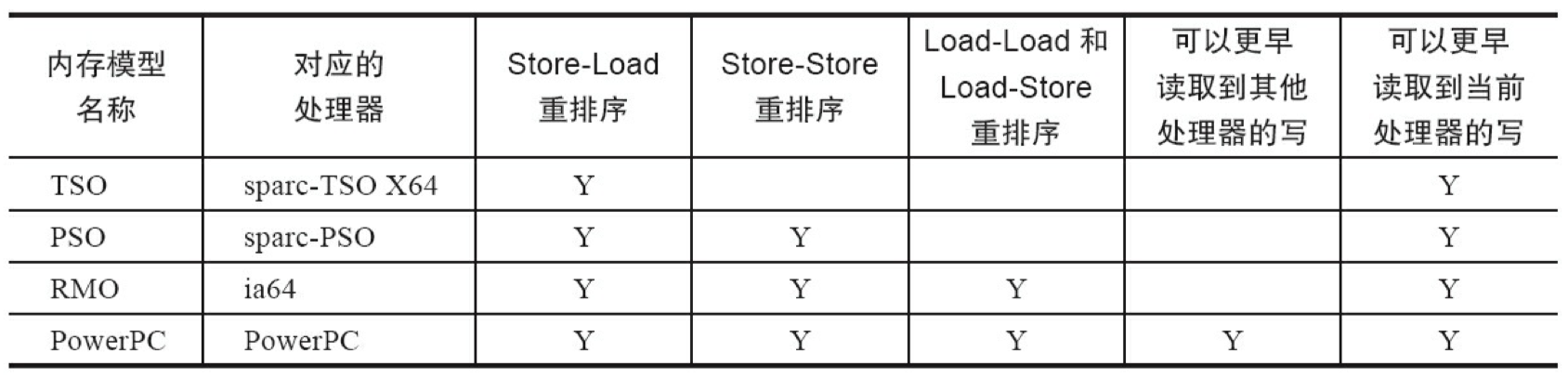
从表 3-12 中可以看到,所有处理器内存模型都允许写-读重排序,原因在第 1 章已经说明过:它们都使用了写缓存区。写缓存区可能导致写-读操作重排序。同时,我们可以看到这些处理器内存模型都允许更早读到当前处理器的写,原因同样是因为写缓存区。由于写缓存区仅对当前处理器可见,这个特性导致当前处理器可以比其他处理器先看到临时保存在自己写缓存区中的写。
表 3-12 中的各种处理器内存模型,从上到下,模型由强变弱。越是追求性能的处理器,内存模型设计得会越弱。因为这些处理器希望内存模型对它们的束缚越少越好,这样它们就可以做尽可能多的优化来提高性能。
由于常见的处理器内存模型比JMM要弱,Java 编译器在生成字节码时,会在执行指令序 列的适当位置插入内存屏障来限制处理器的重排序。同时,由于各种处理器内存模型的强弱不同,为了在不同的处理器平台向程序员展示一个一致的内存模型,JMM 在不同的处理器中需要插入的内存屏障的数量和种类也不相同。图 3-48 展示了 JMM 在不同处理器内存模型中需要插入的内存屏障的示意图。
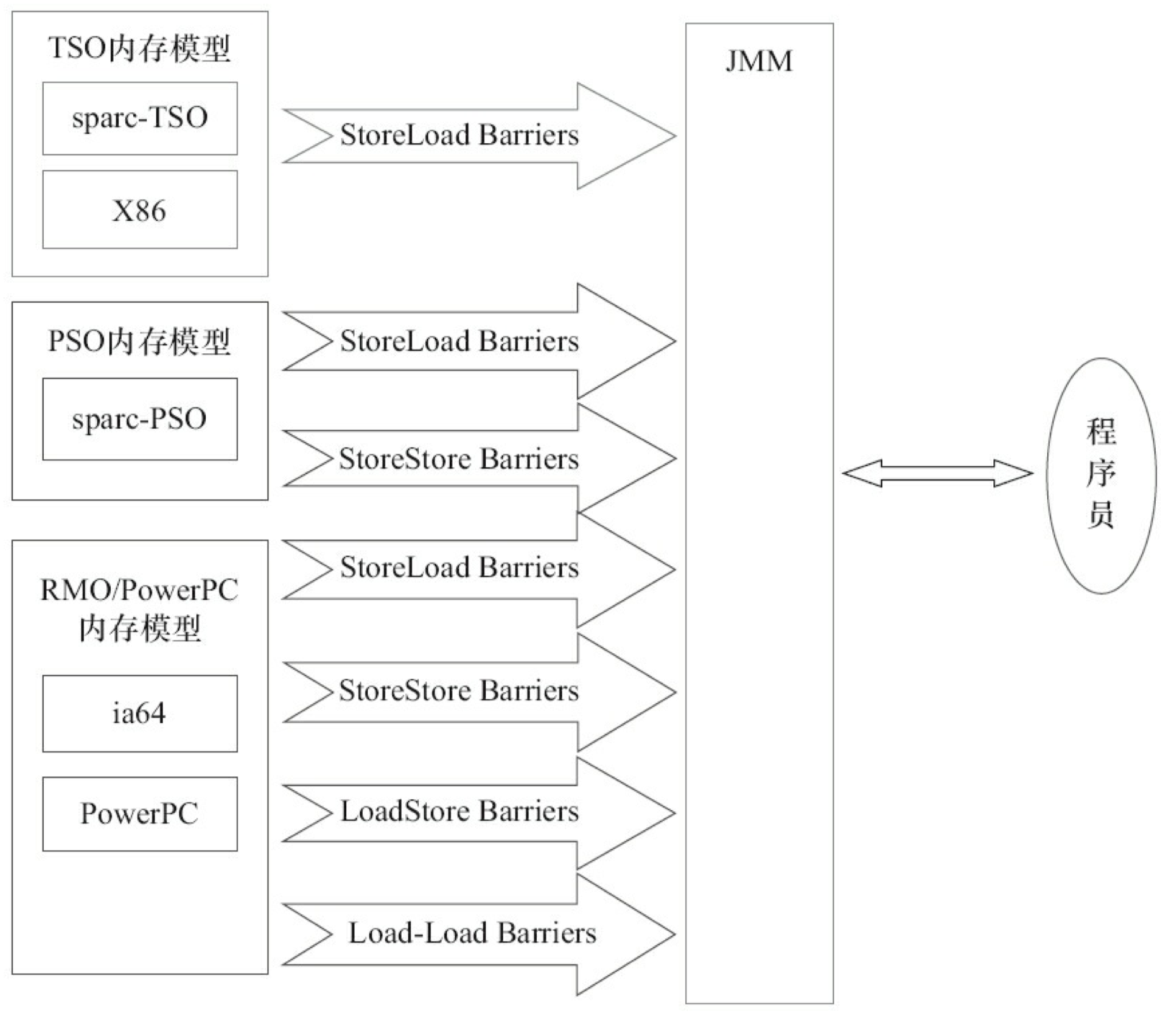
JMM 屏蔽了不同处理器内存模型的差异,它在不同的处理器平台之上为 Java 程序员呈现了一个一致的内存模型。
3.9.2 各种内存模型之间的关系
JMM 是一个语言级的内存模型,处理器内存模型是硬件级的内存模型,顺序一致性内存 模型是一个理论参考模型。下面是语言内存模型、处理器内存模型和顺序一致性内存模型的 强弱对比示意图,如图 3-49 所示。

从图中可以看出:常见的 4 种处理器内存模型比常用的 3 中语言内存模型要弱,处理器内存模型和语言内存模型都比顺序一致性内存模型要弱。同处理器内存模型一样,越是追求执行性能的语言,内存模型设计得会越弱。
3.9.3 JMM 的内存可见性保证
按程序类型,Java 程序的内存可见性保证可以分为下列 3 类。
- 单线程程序。单线程程序不会出现内存可见性问题。编译器、运行时和处理器会共同确 保单线程程序的执行结果与该程序在顺序一致性模型中的执行结果相同。
- 正确同步的多线程程序。正确同步的多线程程序的执行将具有顺序一致性(程序的执行 结果与该程序在顺序一致性内存模型中的执行结果相同)。这是 JMM 关注的重点,JMM 通过限制编译器和处理器的重排序来为程序员提供内存可见性保证。
- 未同步/未正确同步的多线程程序。JMM 为它们提供了最小安全性保障:线程执行时读取到的值,要么是之前某个线程写入的值,要么是默认值(0、null、false)。
注意,最小安全性保障与 64 位数据的非原子性写并不矛盾。它们是两个不同的概念,它 们“发生”的时间点也不同。最小安全性保证对象默认初始化之后(设置成员域为0、null或 false),才会被任意线程使用。最小安全性“发生”在对象被任意线程使用之前。64 位数据的非原子性写“发生”在对象被多个线程使用的过程中(写共享变量)。当发生问题时(处理器 B 看到仅仅被处理器 A “写了一半”的无效值),这里虽然处理器 B 读取到一个被写了一半的无效值,但这个值仍然是处理器 A 写入的,只不过是处理器 A 还没有写完而已。最小安全性保证线程读取到的值,要么是之前某个线程写入的值,要么是默认值(0、null、false)。但最小安全性并不保证 线程读取到的值,一定是某个线程写完后的值。最小安全性保证线程读取到的值不会无中生有的冒出来,但并不保证线程读取到的值一定是正确的。
图 3-50 展示了这 3 类程序在 JMM 中与在顺序一致性内存模型中的执行结果的异同。
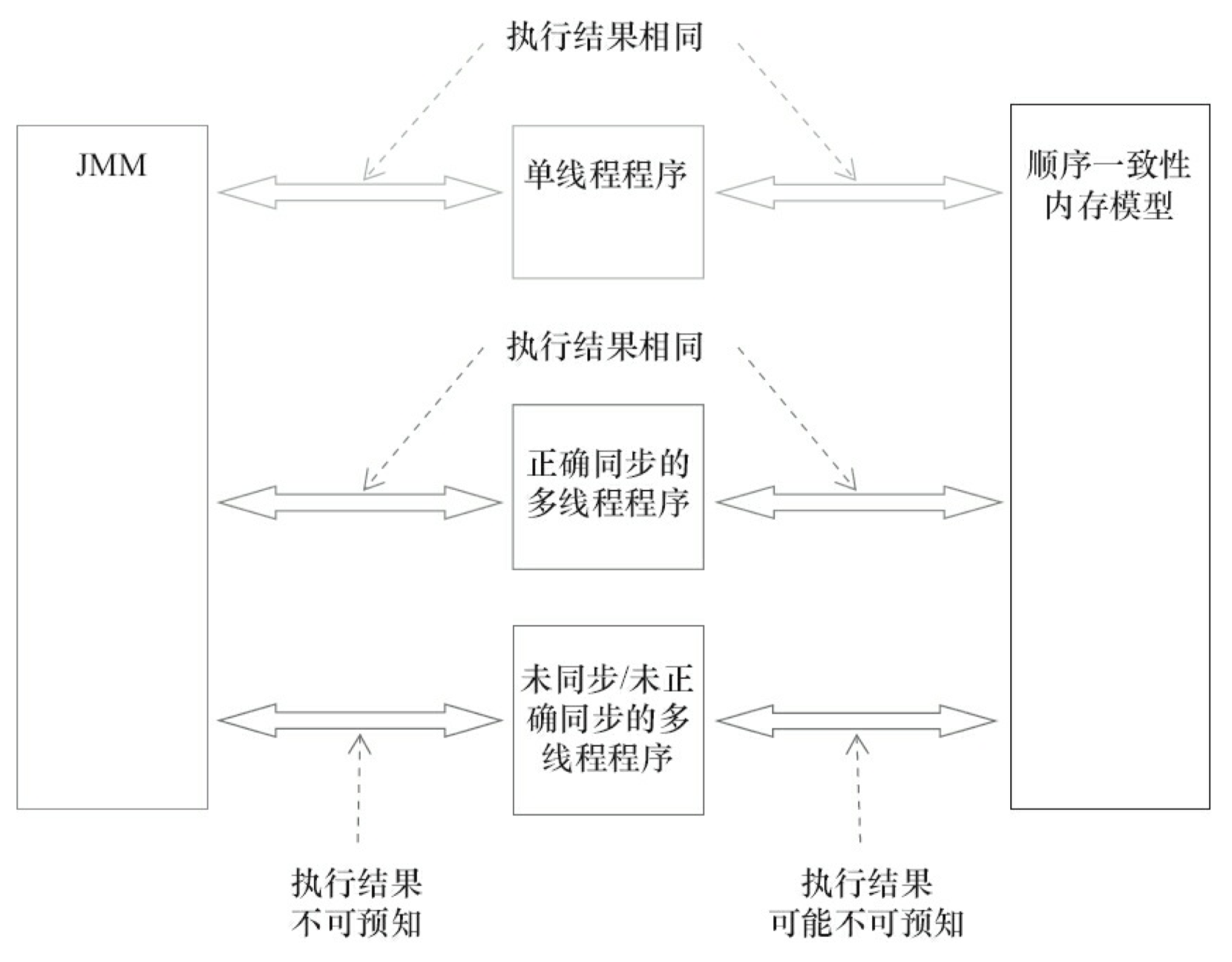
只要多线程程序是正确同步的,JMM 保证该程序在任意的处理器平台上的执行结果,与 该程序在顺序一致性内存模型中的执行结果一致。
3.9.4 JSR-133 对旧内存模型的修补
JSR-133 对 JDK 5 之前的旧内存模型的修补主要有两个。
- 增强 volatile 的内存语义。旧内存模型允许 volatile 变量与普通变量重排序。JSR-133 严格限制 volatile 变量与普通变量的重排序,使 volatile 的写-读和锁的释放-获取具有相同的内存语义。
- 增强 final 的内存语义。在旧内存模型中,多次读取同一个 final 变量的值可能会不相同。为此,JSR-133 为 final 增加了两个重排序规则。在保证 final 引用不会从构造函数内逸出的情况下,final 具有了初始化安全性。
4 - CH04-JSR133-FAQ
什么是内存模型
在多核系统中,处理器一般拥有一层或多层缓存,这些缓存通过加速数据访问(因为数据距离处理器更近)和减少共享内存在总线上的通讯(因为通过本地缓存来满足许多内存操作)来提高 CPU 性能。缓存能够大大提升性能,但同时也带来了很多挑战。例如,当两个 CPU 同时检查相同的内存地址时会发生什么呢?在什么样的条件下它们能够看到相同的值?
在处理器层面,内存模型定义了一个充要条件,“让当前的处理器可以看到其他处理器写入到内存的数据”,以及“其他处理器可以看到当前处理器写入到内存的数据”。有些处理器拥有很强的内存模型(strong memory model),能够让所有处理器在任何时候从任何指定的内存地址上看到完全相同的值。而另外一些处理器则有较弱的内存模型(weaker memory model),在这种处理器中,必须使用内存屏障(一种特殊的指令)来刷新本地处理器缓存并使本地处理器缓存无效,目的是为了让当前处理器能够看到其他处理器的写操作,或者让其他处理器看到当前处理器的写操作。这些内存屏障通常在 lock 和 unlock 操作的时候完成。内存屏障在高级语言中对开发者是不可见的。
在强内存模型下,编写程序有时会很容易,因为减少了对内存屏障的依赖。但是即使在一些最强的内存模型下,内存屏障仍然是必须的。设置内存屏障往往与我们的直觉并不一致。近来处理器设计的趋势更偏向于弱的内存模型,因为弱内存模型削弱了缓存一致性,所以在多处理器平台和更大容量的内存下可以实现更好的可伸缩性。
“一个线程的写操作对其他线程可见”,该问题是因为编译器对代码进行重排序导致的。例如,只要代码的移动不会改变程序的语义,当编译器认为向下移动一个写操作会更有效的时候,编译器就会对代码执行移动。如果编译器推迟执行一个操作,其他线程可以能在这个操作执行完成之前都不会看到该操作的结果,这反映了缓存的影响。
此外,写入内存的操作能够被移动到程序中更靠前的位置。这种情况下,其他线程在程序中可能看到一个比实际发生更早的写操作。所有这些灵活性的设计都是为了通过给编译器、运行时或硬件提供灵活性以使其能够在最佳顺序的情况下来执行操作。在内存模型的限定下,我们能够获得更高的性能。
考虑如下示例:
ClassReordering {
int x = 0, y = 0;
public void writer() {
x = 1;
y = 2;
}
public void reader() {
int r1 = y;
int r2 = x;
}
}
假设在两个并发线程中执行这段代码,读取变量 Y 将会得到 2。因为这个写入比写入到变量 X 的操作更晚一些,程序员可能认为读取变量 X 将一定会得到 1。但是,写入操作可能被重排序。如果发生了重排序,那么,就能发生对变量 Y 的写入操作,读取两个变量的操作紧随其后,而且写入到变量 X 的操作能够发生。程序的结果可能是 r1==2, r2==0。
Java 内存模型描述了在多线程中哪些行为是合法的,以及线程如果通过内存进行交互。它描述了“程序中的变量”与“从内存或寄存器获取或存储它们的底层细节”之间的关系。Java 内存模型通过使用各种硬件和编译器优化来正确实现以上能力。
Java 包含了几个语言级别的关键字,包括:volatile、final、synchronized,目的是为了帮助开发者向编译器描述一个程序的并发需求。Java 内存模型定义了 volatile 和 synchronized 的行为,更重要的是,保证了通过的 Java 程序在所有测处理器架构下都能正确运行。
其他语言有内存模型吗
大部分其他的语言,如 C/C++,都没有被设计成直接支持多线程。这些语言对于发生在编译器和处理器平台架构的重排序行为的保护机制会严重依赖于程序中使用的线程库(如 pthreads)、编译器,以及代码所运行的硬件平台所提供的保障,尤其是 CPU 架构。
JSR 133 是什么
从 1997 年以来,人们不断发现 Java 语言规范的第 17 章定义的 Java 内存模型中存在一些严重的缺陷。这些缺陷会导致一些使人迷惑的行为(如 final 字段会被观察到值的变化)和破坏编译器常见的优化功能。
Java 内存模型是一个雄心勃勃的计划,它是编程语言规第一次尝试合并一个能够在各种处理器架构中为并发提供一致语义的内存模型。不过,定义一个既一致又直观的内存模型远比想象的要难。JSR 133 和 Java 语言定义了一个新的内存模型,它修复了早期内存模型中的缺陷。为了实现 JSR133,final 和 volatile 的语义需要被重新定义。
完整的定义见文档,但是正式的语义不是小心翼翼的,它是令人惊讶的清醒的,目的是让人们意识到一些看似简单的概念(如同步)其实有多复杂。幸运的是,你不需要懂得这些正式定义的细节——JSR 133 的目的是创建一组正式语义,这些语义提供了描述 volatile、synchronized、final 如何正确工作的直观框架。
JSR 133 的目标包括:
- 保留已经存在的安全保证(如类型安全)并强化其他的安全保证。例如,变量值不能凭空创建:线程观察到的每个变量的值必须是被其他线程合理创建的。
- 正确同步的程序的语义应该尽量简单和直观。
- 应该定义未完成或为正确同步的程序的语义,主要是为了把潜在的安全危害降到最低。
- 开发者应该能够自信的推断多线程如何与内存进行交互。
- 能够在现在许多流行的硬件架构中设计正确且高性能的 JVM 实现。
- 应该能够提供“安全初始化”保证。如果一个对象正确的进行了构建(指它的引用没有在构建时逸出),那么所有能够看到该对象的引用的线程,在不进行同步的情况下,也将能够看到在构造方法中设置的 fianl 字段的值。
- 应该尽量不影响现有的代码。
重排序意味着什么
在很多情况下,访问一个程序变量(对象实例字段、类静态字段、数组元素)可能会使用不同的执行顺序,而不是程序语义所指定的顺序执行。编译器能够自由的以优化的名义去改变指令顺序。在特定环境下,处理器可能会次序颠倒的执行指令。数据可能在寄存器、缓冲区或主存中以不同的次序移动,而不是按照程序指定的顺序。
例如,如果一个线程写入值到字段 a、然后写入值到字段 b,并且 b 的值不依赖于 a 的值,那么,处理器能够自由的调整它们的执行顺序,而且缓冲区能够在 a 之前刷新 b 的值到主内存。有许多潜在的重排序来源,例如编译器、JIT 及缓冲区。
编译器、运行时和硬件被期望一起协力创建看似是按顺序执行的语义的假象,这意味着在单线程程序中,程序应该不能观察到重排序的影响。但是,重排序在没有正确同步的多线程程序中会产生作用,在这些多线程程序中,一个线程能够观察到其他线程的影响,也可能检测到其他线程将会以一种不同于程序语义所规定的执行顺序来访问变量。
大部分情况下,一个线程不会关注到其他线程在做什么,但是当它需要关注的时候,就需要使用(正确的)同步了。
旧内存模型的缺陷有哪些?
旧的内存模型中有几个严重的问题。这些问题很难理解,因此被广泛的违背。例如,旧的存储模型在许多情况下,不允许 JVM 发生各种重排序行为。旧的内存模型中让人产生困惑的因素造就了 JSR 133 的诞生。
例如,一个被广泛认可的概念就是:如果使用 final 字段,那么就没有必要在多个线程间使用同步来保证其他线程能够看到这个字段的值。尽管这是一个合理的假设和明显的行为,也是我们所期待的结果。实际上,在旧的内存模型中,我们想让程序正确运行起来却是不行的。在旧的内存模型中,final 字段并没有同其他字段进行区别对待——这意味着同步是保证所有线程看到一个在构造方法中初始化为 final 字段的唯一方法。结果——如果没有正确进行同步,对一个线程来说,它可能看到一个(final)字段的默认值,然后在稍后的时间里,又能看到构造方法中设置的值。这意味着,一些不可变的对象,例如 String,能够改变它们的值——这是在是让人很郁闷。
旧的内存模型允许 volatile 变量的写操作和非 volatile 变量的读写操作一起进行重排序,这和大多数的开发人员对于 volatile 变量的直观感受是不一致的,因此会造成迷惑。
最后,我们将看到的是,开发者对于“程序没有被正确同步的情况下将会发生什么”的直观感受通常是错误的。JSR 133 的目的之一就是要引起这方面的注意。
没有正确同步的含义是什么
没有正确同步的代码对于不同的人来说可能会有不同的理解。在 Java 内存模型这个语义环境下,我们谈到“没有正确同步”时指的是:
- 一个线程中存在对一个变量的写操作。
- 另外一个线程存在对该变量的读操作。
- 而且写操作和读操作之间没有通过同步来保证顺序。
当违反这些规则时,我们就说在这个变量上有一个“数据竞争”。一个拥有数据竞争的程序就是一个没有正确同步的程序。
同步会做些什么
同步有几个方面的作用。最广为人知的就是“互斥”——一次只有一个线程能够获得一个监视器,因此,在一个监视器上同步意味着一旦一个线程进入到该监视器保护的同步块中,其他的线程都不能进入到同一个监视器保护的块中间,除非第一个线程退出了同步块。
但是同步的含义比互斥更广。同步保证了一个线程在同步块之前或之中的一个内存写入操作以可预知的方式对其他拥有相同监视器的线程可见。当我们退出了同步块,我们就释放了这个监视器,该监视器拥有刷新缓冲区到主内存的效果,因此该线程的写入操作能够为其他线程所见。在我们进入一个同步块之前,我们需要获取监视器,监视器拥有使本地处理器缓存失效的功能,因此变量会从主存重新加载,于是其他线程对共享变量的修改对当前线程来说就变得可见了。
基于缓存来讨论同步,可能听起来这些观点仅仅会影响到多处理器的系统。但是,重排序效果能够在单一处理器上很容易的观察到。对于编译器来说,在获取之前或者释放之后移动你的代码是不可能的。当我们谈到在缓冲区上面进行的获取和释放操作时,我们使用了简述的方式来描述大量可能的影响。
新的内存模型语义在内存操作(读写字段、加解锁)以及其他线程的操作(start/join)中创建了一个部分(partial,相对于整个程序的语义顺序)排序,在这些操作中,一些操作被称为 happens before 其他操作。当一个操作在另一个操作之前发生,第一个操作保证能够被排到前面并且对第二个操作可见。这些排序的规则如下:
- 线程中的每个操作 happenns before 该线程中在程序顺序上后续的每个操作。
- 解锁一个监视器的操作 happens before 随后对相同监视器进行的解锁操作。
- 对 volatile 字段的写操作 happens before 后续对相同 volatile 字段的读取操作。
- 在线程上调用 start 方法 happens before 这个线程启动后的任何操作。
- 一个线程中的所有操作都 happens before 从这个线程的 join 方法成功返回的任何其他线程。(即其他线程等待一个线程的 join 方法完成,那么,这个线程中的所有操作 happens before 其他线程中的所有操作)
这意味着:对于任何内存操作,该内存操作在退出一个同步块之前对一个线程是可见的,对任何线程在它进入一个被相同的监视器保护的同步块之后都是可见的,因为所有内存操作 happens before 释放监视器、(当前线程)释放监视器 happens before (其他线程)获取监视器。
其他类似如下模式的实现,被一些人用来强迫实现一个内存屏障,不会生效:
synchronized (new Object()) {}
这段代码其实不会执行任何操作,编译器会将其完全移除,因为编译器知道没有其他线程会使用相同监视器进行同步。要看到其他线程的结果,你必须为一个线程建立 happens before 关系。
@@@ note
对两个线程来说,为了正确建立 happens before 关系而在相同监视器上面进行同步是非常重要的。以下观点是错误的:当线程 A 在对象 X 上面同步的时候,所有东西对线程 A 可见,线程 B 在对象 Y 上面进行同步的时候,所有东西对线程 B 也是可见的。释放监视器和获取监视器必须匹配(即要在相同监视器上面完成这两个操作),否则,代码就会存在数据竞争。
@@@
final 字段是如何改变其值的
我们可以通过分析 String 类的实现细节来展示一个 final 变量是如何可以改变的。
String 对象包含 3 个字段:一个 character 数组、一个数据的 offset、一个 length。实现 String 类的基本原理是:它不仅仅拥有 character 数组,而且为了避免多余的对象分配和拷贝,多个 String 和 StringBuffer 对象都会共享相同的 character 数组。因此,String.substring 方法能够通过改变 length 和 offset,通过共享原始的 character 数组来创建一个新的 String 对象。对于一个 String 来说,这些字段都是 final 型的字段。
String s1 = "/usr/tmp";
String s2 = s1.substring(4);
s2 的 offset 值为 4,length 的值为 4。但是,在旧的内存模型下,对于其他线程来说,有机会看到 offset 拥有默认的值 0,而且,在稍后一点时间会看到正确的值 4,好像字符串的值从 “/usr” 变成了 “/tmp” 一样。
旧的 Java 内存模型允许这些行为,部分 JVM 已经展现出这样的行为了。而在新的 Java 内存模型中,这是非法的。
在新的 JMM 下 final 是如何工作的
一个对象的 final 字段值是在对象的构造方法中设置的。假设对象被正确的构造了,一旦对象被构造,在构造方法里面设置 final 字段的值在没有同步的情况下会对所有其他线程可见。另外,引用这些 final 字段的对象或数组都会看到其最新值。
对于一个对象来说,被正确构造又是什么意思?简单来说,它意味着这个正在构造的对象的引用在构造期间没有被允许逸出(参见安全构造技术)。换句话说,不要让其他线程在其他地方能够看见一个处于构造期的对象引用。不要指派给一个静态字段,不要作为一个 listener 注册给其他对象等。这些操作应该在构造方法完成之后进行,而不是构造方法中进行。
class FinalFieldExample {
final int x;
int y;
static FinalFieldExample f;
public FinalFieldExample() {
x = 3;
y = 4;
}
static void writer() {
f = new FinalFieldExample();
}
static void reader() {
if (f != null) {
int i = f.x;
int j = f.y;
}
}
}
上面的类展示了 fianl 字段应该如何使用。一个正在执行 reader 方法的线程保证看到 f.x 的值为 3,因为它是 final 字段。它不保证看到 f.y 的值为 4,因为 f.y 不是 final 字段。如果 FinalFieldExample 的构造方法是如下这样:
public FinalFieldExample() { // bad!
x = 3;
y = 4;
// bad construction - allowing this to escape
global.obj = this;
}
那么从 global.obj 中读取 this 引用线程不会保证读取到的 x 的值 3。
能够看到字段的正确构造的值固然不错,但是,如果字段本身就是一个引用,那么,你还是希望你的代码能够看到引用所指向的这个对象(或数组)的最新值。如果你的字段是 final 字段,那就就是能够保证的。因此,当一个 final 指针指向一个数组,你无需担心线程能够看到引用的最新值却看不到引用所指向的数组的最新值。重复一下,这里的“正确的”是指“对象构造方法结尾的最新的值”而不是“最新可用的值”。
现在,在讲了如上的片段之后,如果在一个线程构造了一个不可变对象之后(对象仅包含 final 字段),你希望保证该对象被其他线程正确的查看,你仍然需要使用同步才行。例如,没有其他的方式可以保证不可变对象的引用将被第二个线程看到。使用 final 字段的程序应该仔细调试,这需要深入而且仔细的理解并发在你的代码中是如被被管理的。
如果你使用 JNI 来改变你的 final 字段,这方面的行为是没有定义的。
volatile 的作用
Volatile 字段是用于线程间通讯的特殊字段。每次读 volatile 字段都会看到其他线程写入该字段的最新值;实际上,开发者之所以要定义 volatile 字段是因为在某些情况下由于缓存和重排序所看到的陈旧的变量值是不可接受的,编译器和运行时禁止在寄存器里分配它们。它们还必须保证,在它们被写好之后,它们被从缓冲区刷新到主存中,因此,它们能够对其他线程立即可见。同样,在读取一个 volatile 字段之前,缓冲区必须失效,因为值是存在于主存中而不是本地处理器的缓冲区。在重排序访问 volatile 变量的时候还有其他的限制。
在旧的内存模型下,访问 volatile 变量不能被重排序,但是,它们可能和访问非 volatile 变量一起被重排序。这破坏了 volatile 字段从一个线程到另一个线程作为一个信号条件的手段。
下新的内存模型下,volatile 变量仍然不能彼此重排序。和旧模型不同的是,volatile 周围的普通字段也不再能随便的重排序了。写入一个 volatile 字段和释放监视器拥有相同的内存影响,而且读取 volatile 字段和获取监视器也有相同的内存影响。事实上,因为新的内存模型在重排序 volatile 字段访问上面和其他字段(volatile 或非 volatile)访问上面拥有更加严格的约束。当线程 A 写入一个 volatile 字段 f 的时候,如果这时线程 B 读取 f 的值,那么对线程 A 可见的任何东西都变得对线程 B 可见了。
下面的例子展示了应该如何使用 volatile 字段:
class VolatileExample {
int x = 0;
volatile boolean v = false;
public void writer() {
x = 42;
v = true;
}
public void reader() {
if (v == true) {
//uses x - guaranteed to see 42.
}
}
}
假设一个名为 “writer” 的线程和一个名为 “reader” 的线程。对变量 v 的写操作会等到变量 x 被写入到内存之后,然后读线程才能看到 v 的值。因此,如果 reader 线程看到了 v 的值为 true,那么,这也保证能够看到之前发生的“向 x 写入 42”这个操作。而在旧的内存模型中未必如此。如果 v 不是 volatile 变量,那么,编译器可以在 writer 线程中重排序写入操作,然后 reader 线程中读取 x 变量的操作可能会看到其值为 0。
实际上,volatile 的语义已经被加强了,已经块达到同步的级别了。为了可见性的原因,每次读取和写入一个 volatile 字段已经像是半个同步操作了。
@@@ note
对于两个线程来说,为了正确的设置 happens before 关系,访问相同的 volatile 变量是很重要的。以下结论是不正确的:当线程 A 写 volatile 字段 f 的时候,线程 A 可见的所有东西,在线程 B 读取字段 g 的时候,都变得对线程 B 可见了。释放操作和获取操作必须匹配(也就是在同一个 volatile 字段上完成)。
@@@
新的 JMM 是否修复了双重锁检查问题
臭名昭著的双重锁检查(也称多线程单例模式)是一个骗人的把戏,它用来支持 lazy 初始化,同时避免过度使用同步。在非常早的 JVM 中,同步非常慢,开发人员非常系统删掉它。双重锁检查代码如下:
// double-checked-locking - don't do this!
private static Something instance = null;
public Something getInstance() {
if (instance == null) {
synchronized (this) {
if (instance == null)
instance = new Something();
}
}
return instance;
}
这看起来好像非常聪明——在公用代码中避免了同步。这段代码只有一个问题——它不能正常工作。为什么呢?最明显的原因是,初始化实例的写入操作和实例字段的写入操作能够被编译器或缓冲区重排序,重排序可能会导致返回部分构造的一些东西。就是我们会读取到一个没有被初始化的对象。这段代码还有很多其他的错误,以及为什么对这段代码的算法修正是错误的。在旧的内存模型下无法将其修复。更多深入的信息参见:Double-checkedlocking: Clever but broken 和 The “Double-Checked Locking is Broken” Declaration。
很多人认为使用 volatile 关键字能够消除双重锁检查模式的问题。在 1.5 的 JVM 之前,volatile 并不能保证这段代码能够正常工作(因环境而定)。在新的内存模型中,实例字段使用 volatile 可以解决双重锁检查问题,因为在构造线程来初始化一些东西和读取线程返回它的值之间有 happens before 关系。
然后,对于喜欢使用双重锁检查的人来说(我们真的希望没有人喜欢这么用),仍然不是好消息。双重锁检查的重点是为了避免过度使用同步导致性能问题。从 Java 1.0 开始,同步不仅会有昂贵的性能开销,而在新的内存模型下,使用 volatile 的性能开销也有所上升,几乎达到了和同步一样的性能开销。因此,使用双重锁检查来实现单例模式仍然不是一个好的选择(注意这里需要修正,在大多数平台下,volatile 的性能开销还是比较低的)。
使用 IODH 来实现多线程模式下的单例会更加易读:
private static class LazySomethingHolder {
public static Something something = new Something();
}
public static Something getInstance() {
return LazySomethingHolder.something;
}
这段代码是正确的,因为初始化由 static 字段来保证。如果一个子弹设置在 static 舒适化中,对其他访问这个类的线程来说是能够正确的保证其可见性的。
如何实现一个 VM
参考 The JSR-133 Cookbook for Compiler Writers。
为什么要关注 JMM
为什么你需要关注java内存模型?并发程序的bug非常难找。它们经常不会在测试中发生,而是直到你的程序运行在高负荷的情况下才发生,非常难于重现和跟踪。你需要花费更多的努力提前保证你的程序是正确同步的。这不容易,但是它比调试一个没有正确同步的程序要容易的多。
Reference
5 - CH05-JSR133-Cook
从最初的探索至今已经有十年了。在此期间,很多关于处理器和语言的内存模型的规范和问题变得更清楚,更容易理解,但还有一些没有研究清楚。本指南一直在修订、完善来保证它的准确性,然而本指南部分内容展开的细节还不是很完整。想更全面的了解, 可以特别关注下 Peter Sewell 和 Cambridge Relaxed Memory Concurrency Group 的研究工作。
这是一篇用于说明在 JSR 133 中制定的新 Java 内存模型(JMM) 的非官方指南。这篇指南提供了在最简单的背景下各种规则存在的原因,而不是这些规则在指令重排、多核处理器屏障指令和原子操作等方面对编译器和 JVM 所造成的影响。它还包括了一系列如何遵守 JSR 133 的指南。本指南是“非官方”的文档,因为它还包括特定处理器性能和规范的解释,我们不能保证所有的解释都是正确的。此外,处理器的规范和实现也可能会随时改变。