CH05-调优案例
5.1 概述
除了知识与工具外,经验同样是一个很重要的因素。
5.2 案例分析
5.2.1 高性能硬件上的程序部署策略
例如,一个 15 万PV/天左右的在线文档类型网站最近更换了硬件系统,新的硬件为 4 个 CPU、16GB 物理内存,操作系统为 64 位 CentOS 5.4,Resin 作为 Web 服务器。整个服务器暂时没有部署别的应用,所有硬件资源都可以提供给这访问量并不算太大的网站使用。管理员为了尽量利用硬件资源选用了 64 位的 JDK 1.5,并通过 -Xmx 和 -Xms 参数将 Java 堆固定在 12GB。使用一段时间后发现使用效果并不理想,网站经常不定期出现长时间失去响应的情况。
监控服务器运行状况后发现网站失去响应是由 GC 停顿导致的,虚拟机运行在 Server 模式,默认使用吞吐量优先收集器,回收 12GB 的堆,一次 Full GC 的停顿时间高达 14 秒。并且由于程序设计的关系,访问文档时要把文档从磁盘提取到内存中,导致内存中出现很多由文档序列化产生的大对象,这些大对象很多都进入了老年代,没有在 Minor GC 中清理掉。这种情况下即使有 12GB 的堆,内存也很快被消耗殆尽,由此导致每隔十几分钟出现十几秒的停顿,令网站开发人员和管理员感到很沮丧。
这里先不延伸讨论程序代码问题,程序部署上的主要问题显然是过大的堆内存进行回收时带来的长时间的停顿。硬件升级前使用 32 位系统 1.5GB 的堆,用户只感觉到使用网站比较缓慢,但不会发生十分明显的停顿,因此才考虑升级硬件以提升程序效能,如果重新缩小给 Java 堆分配的内存,那么硬件上的投资就显得很浪费。
在高性能硬件上部署程序,目前主要有两种方式:
- 通过 64 位 JDK 来使用大内存。
- 使用若干个 32 位虚拟机建立逻辑集群来利用硬件资源。
此案例中的管理员采用了第一种部署方式。对于用户交互性强、对停顿时间敏感的系统,可以给 Java 虚拟机分配超大堆的前提是有把握把应用程序的 Full GC 频率控制得足够低,至少要低到不会影响用户使用,譬如十几个小时乃至一天才出现一次 Full GC,这样可以通过在深夜执行定时任务的方式触发 Full GC 甚至自动重启应用服务器来保持内存可用空间在一个稳定的水平。
控制 Full GC 频率的关键是看应用中绝大多数对象能否符合“朝生夕灭”的原则,即大多数对象的生存时间不应太长,尤其是不能有成批量的、长生存时间的大对象产生,这样才能保障老年代空间的稳定。
在大多数网站形式的应用里,主要对象的生存周期都应该是请求级或者页面级的,会话级和全局级的长生命对象相对很少。只要代码写得合理,应当都能实现在超大堆中正常使用而没有 Full GC,这样的话,使用超大堆内存时,网站响应速度才会比较有保证。除此之外,如果读者计划使用 64 位 JDK 来管理大内存,还需要考虑下面可能面临的问题:
- 内存回收导致的长时间停顿。
- 现阶段,64 位 JDK 的性能测试结果普遍低于 32 位 JDK。
需要保证程序足够稳定,因为这种应用要是产生堆溢出几乎就无法产生堆转储快照(因为要产生十几 GB 乃至更大的 HeapDump 文件),哪怕产生了快照也几乎无法进行分析。
相同程序在 64 位 JDK 消耗的内存一般比 32 位 JDK 大,这是由于指针膨胀,以及数据类型对齐补白等因素导致的。
上面的问题听起来有点吓人,所以现阶段不少管理员还是选择第二种方式:使用若干个 32 位虚拟机建立逻辑集群来利用硬件资源。具体做法是在一台物理机器上启动多个应用服务器进程,每个服务器进程分配不同端口,然后在前端搭建一个负载均衡器,以反向代理的方式来分配访问请求。读者不需要太过在意均衡器转发所消耗的性能,即使使用 64 位 JDK,许多应用也不止有一台服务器,因此在许多应用中前端的均衡器总是要存在的。
考虑到在一台物理机器上建立逻辑集群的目的仅仅是为了尽可能利用硬件资源,并不需要关心状态保留、热转移之类的高可用性需求,也不需要保证每个虚拟机进程有绝对准确的均衡负载,因此使用无 Session 复制的亲合式集群是一个相当不错的选择。我们仅仅需要保障集群具备亲合性,也就是均衡器按一定的规则算法(一般根据 SessionID 分配)将一个固定的用户请求永远分配到固定的一个集群节点进行处理即可,这样程序开发阶段就基本不用为集群环境做什么特别的考虑了。
当然,很少有没有缺点的方案,如果读者计划使用逻辑集群的方式来部署程序,可能会遇到下面一些问题:尽量避免节点竞争全局的资源,最典型的就是磁盘竞争,各个节点如果同时访问某个磁盘文件的话(尤其是并发写操作容易出现问题),很容易导致 IO 异常。
很难最高效率地利用某些资源池,譬如连接池,一般都是在各个节点建立自己独立的连接池,这样有可能导致一些节点池满了而另外一些节点仍有较多空余。尽管可以使用集中式的 JNDI,但这个有一定复杂性并且可能带来额外的性能开销。
各个节点仍然不可避免地受到 32 位的内存限制,在 32 位 Windows 平台中每个进程只能使用 2GB 的内存,考虑到堆以外的内存开销,堆一般最多只能开到 1.5GB。在某些 Linux 或 UNIX 系统(如 Solaris)中,可以提升到 3GB 乃至接近 4GB 的内存,但 32 位中仍然受最高 4GB(2^{32})内存的限制。
大量使用本地缓存(如大量使用 HashMap 作为 K/V 缓存)的应用,在逻辑集群中会造成较大的内存浪费,因为每个逻辑节点上都有一份缓存,这时候可以考虑把本地缓存改为集中式缓存。
介绍完这两种部署方式,再重新回到这个案例之中,最后的部署方案调整为建立 5 个 32 位 JDK 的逻辑集群,每个进程按 2GB 内存计算(其中堆固定为1.5GB),占用了 10GB 内存。另外建立一个 Apache 服务作为前端均衡代理访问门户。考虑到用户对响应速度比较关心,并且文档服务的主要压力集中在磁盘和内存访问,CPU 资源敏感度较低,因此改为 CMS 收集器进行垃圾回收。部署方式调整后,服务再没有出现长时间停顿,速度比硬件升级前有较大提升。
5.2.2 集群间同步导致的内存溢出
例如,有一个基于 B/S 的 MIS 系统,硬件为两台 2 个 CPU、8GB 内存的 HP 小型机,服务器是 WebLogic 9.2,每台机器启动了 3 个 WebLogic 实例,构成一个 6 个节点的亲合式集群。由于是亲合式集群,节点之间没有进行 Session 同步,但是有一些需求要实现部分数据在各个节点间共享。开始这些数据存放在数据库中,但由于读写频繁竞争很激烈,性能影响较大,后面使用 JBossCache 构建了一个全局缓存。全局缓存启用后,服务正常使用了一段较长的时间,但最近却不定期地出现了多次的内存溢出问题。
在内存溢出异常不出现的时候,服务内存回收状况一直正常,每次内存回收后都能恢复到一个稳定的可用空间,开始怀疑是程序某些不常用的代码路径中存在内存泄漏,但管理员反映最近程序并未更新、升级过,也没有进行什么特别操作。只好让服务带着 -XX:+HeapDumpOnOutOfMemoryError 参数运行了一段时间。在最近一次溢出之后,管理员发回了 heapdump 文件,发现里面存在着大量的 org.jgroups.protocols.pbcast.NAKACK 对象。
JBossCache 是基于自家的 JGroups 进行集群间的数据通信,JGroups 使用协议栈的方式来实现收发数据包的各种所需特性自由组合,数据包接收和发送时要经过每层协议栈的 up() 和 down() 方法,其中的 NAKACK 栈用于保障各个包的有效顺序及重发。JBossCache 协议栈如图5-1所示。

由于信息有传输失败需要重发的可能性,在确认所有注册在 GMS(Group Membership Service)的节点都收到正确的信息前,发送的信息必须在内存中保留。而此 MIS 的服务端中有一个负责安全校验的全局 Filter,每当接收到请求时,均会更新一次最后操作时间,并且将这个时间同步到所有的节点去,使得一个用户在一段时间内不能在多台机器上登录。在服务使用过程中,往往一个页面会产生数次乃至数十次的请求,因此这个过滤器导致集群各个节点之间网络交互非常频繁。当网络情况不能满足传输要求时,重发数据在内存中不断堆积,很快就产生了内存溢出。
这个案例中的问题,既有 JBossCache 的缺陷,也有 MIS 系统实现方式上缺陷。JBossCache 官方的 maillist 中讨论过很多次类似的内存溢出异常问题,据说后续版本也有了改进。而更重要的缺陷是这一类被集群共享的数据要使用类似 JBossCache 这种集群缓存来同步的话,可以允许读操作频繁,因为数据在本地内存有一份副本,读取的动作不会耗费多少资源,但不应当有过于频繁的写操作,那样会带来很大的网络同步的开销。
5.2.3 堆外内存导致的溢出错误
例如,一个学校的小型项目:基于 B/S 的电子考试系统,为了实现客户端能实时地从服务器端接收考试数据,系统使用了逆向 AJAX 技术(也称为 Comet 或者 Server Side Push),选用 CometD 1.1.1 作为服务端推送框架,服务器是 Jetty 7.1.4,硬件为一台普通 PC 机,Core i5 CPU,4GB 内存,运行 32 位 Windows 操作系统。
测试期间发现服务端不定时抛出内存溢出异常,服务器不一定每次都会出现异常,但假如正式考试时崩溃一次,那估计整场电子考试都会乱套,网站管理员尝试过把堆开到最大,而 32 位系统最多到 1.6GB 就基本无法再加大了,而且开大了基本没效果,抛出内存溢出异常好像还更加频繁了。加入 -XX:+HeapDumpOnOutOfMemoryError,居然也没有任何反应,抛出内存溢出异常时什么文件都没有产生。无奈之下只好挂着 jstat 并一直紧盯屏幕,发现 GC 并不频繁,Eden 区、Survivor 区、老年代以及永久代内存全部都表示“情绪稳定,压力不大”,但就是照样不停地抛出内存溢出异常,管理员压力很大。最后,在内存溢出后从系统日志中找到异常堆栈,如代码清单5-1所示。
[org.eclipse.jetty.util.log]handle failed java.lang.OutOfMemoryError:null
at sun.misc.Unsafe.allocateMemory(Native Method)
at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:99)
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:288)
at org.eclipse.jetty.io.nio.DirectNIOBuffer.<init>
……
如果认真阅读过本书的第 2 章,看到异常堆栈就应该清楚这个抛出内存溢出异常是怎么回事了。大家知道操作系统对每个进程能管理的内存是有限制的,这台服务器使用的 32 位 Windows 平台的限制是 2GB,其中划了 1.6GB 给 Java 堆,而 Direct Memory 内存并不算入 1.6GB 的堆之内,因此它最大也只能在剩余的 0.4GB 空间中分出一部分。在此应用中导致溢出的关键是:垃圾收集进行时,虚拟机虽然会对 Direct Memory 进行回收,但是 Direct Memory 却不能像新生代、老年代那样,发现空间不足了就通知收集器进行垃圾回收,它只能等待老年代满了后 Full GC,然后“顺便地”帮它清理掉内存的废弃对象。否则它只能一直等到抛出内存溢出异常时,先 catch 掉,再在 catch 块里面“大喊”一声:“System.gc()!"。要是虚拟机还是不听(譬如打开了 -XX:+DisableExplicitGC 开关),那就只能眼睁睁地看着堆中还有许多空闲内存,自己却不得不抛出内存溢出异常了。而本案例中使用的 CometD 1.1.1 框架,正好有大量的 NIO 操作需要使用到 Direct Memory 内存。
从实践经验的角度出发,除了 Java 堆和永久代之外,我们注意到下面这些区域还会占用较多的内存,这里所有的内存总和受到操作系统进程最大内存的限制。
Direct Memory:可通过 -XX:MaxDirectMemorySize 调整大小,内存不足时抛出 OutOfMemoryError 或者 OutOfMemoryError:Direct buffer memory。
线程堆栈:可通过 -Xss 调整大小,内存不足时抛出 StackOverflowError(纵向无法分配,即无法分配新的栈帧)或者 OutOfMemoryError:unable to create new native thread(横向无法分配,即无法建立新的线程)。
Socket 缓存区:每个 Socket 连接都 Receive 和 Send 两个缓存区,分别占大约 37KB 和 25KB 内存,连接多的话这块内存占用也比较可观。如果无法分配,则可能会抛出 IOException:Too many open files 异常。
JNI 代码:如果代码中使用 JNI 调用本地库,那本地库使用的内存也不在堆中。
虚拟机和 GC:虚拟机、GC 的代码执行也要消耗一定的内存。
5.2.4 外部命令导致系统缓慢
这是一个来自网络的案例:一个数字校园应用系统,运行在一台 4 个 CPU 的 Solaris 10 操作系统上,中间件为 GlassFish 服务器。系统在做大并发压力测试的时候,发现请求响应时间比较慢,通过操作系统的 mpstat 工具发现 CPU 使用率很高,并且系统占用绝大多数的 CPU 资源的程序并不是应用系统本身。这是个不正常的现象,通常情况下用户应用的 CPU 占用率应该占主要地位,才能说明系统是正常工作的。
通过 Solaris 10 的 Dtrace 脚本可以查看当前情况下哪些系统调用花费了最多的 CPU 资源,Dtrace 运行后发现最消耗 CPU 资源的竟然是"fork"系统调用。众所周知,“fork"系统调用是 Linux 用来产生新进程的,在 Java 虚拟机中,用户编写的 Java 代码最多只有线程的概念,不应当有进程的产生。
这是个非常异常的现象。通过本系统的开发人员,最终找到了答案:每个用户请求的处理都需要执行一个外部 shell 脚本来获得系统的一些信息。执行这个 shell 脚本是通过Java 的 Runtime.getRuntime().exec() 方法来调用的。这种调用方式可以达到目的,但是它在 Java 虚拟机中是非常消耗资源的操作,即使外部命令本身能很快执行完毕,频繁调用时创建进程的开销也非常可观。Java 虚拟机执行这个命令的过程是:首先克隆一个和当前虚拟机拥有一样环境变量的进程,再用这个新的进程去执行外部命令,最后再退出这个进程。如果频繁执行这个操作,系统的消耗会很大,不仅是 CPU,内存负担也很重。
用户根据建议去掉这个 Shell 脚本执行的语句,改为使用 Java 的 API 去获取这些信息后,系统很快恢复了正常。
5.2.5 服务器 JVM 进程崩溃
例如,一个基于 B/S 的 MIS 系统,硬件为两台 2 个 CPU、8GB 内存的 HP 系统,服务器是 WebLogic 9.2(就是5.2.2节中的那套系统)。正常运行一段时间后,最近发现在运行期间频繁出现集群节点的虚拟机进程自动关闭的现象,留下了一个 hs_err_pid???.log 文件后,进程就消失了,两台物理机器里的每个节点都出现过进程崩溃的现象。从系统日志中可以看出,每个节点的虚拟机进程在崩溃前不久,都发生过大量相同的异常,见代码清单 5-2。
java.net.SocketException:Connection reset
at java.net.SocketInputStream.read(SocketInputStream.java:168)
at java.io.BufferedInputStream.fill(BufferedInputStream.java:218)
at java.io.BufferedInputStream.read(BufferedInputStream.java:235)
at org.apache.axis.transport.http.HTTPSender.readHeadersFromSocket(HTTPSender.java:583)
at org.apache.axis.transport.http.HTTPSender.invoke(HTTPSender.java:143)……99 more
这是一个远端断开连接的异常,通过系统管理员了解到系统最近与一个 OA 门户做了集成,在 MIS 系统工作流的待办事项变化时,要通过 Web 服务通知 OA 门户系统,把待办事项的变化同步到 OA 门户之中。通过 SoapUI 测试了一下同步待办事项的几个 Web 服务,发现调用后竟然需要长达 3 分钟才能返回,并且返回结果都是连接中断。
由于 MIS 系统的用户多,待办事项变化很快,为了不被 OA 系统速度拖累,使用了异步的方式调用 Web 服务,但由于两边服务速度的完全不对等,时间越长就累积了越多 Web 服务没有调用完成,导致在等待的线程和 Socket 连接越来越多,最终在超过虚拟机的承受能力后使得虚拟机进程崩溃。解决方法:通知 OA 门户方修复无法使用的集成接口,并将异步调用改为生产者/消费者模式的消息队列实现后,系统恢复正常。
5.2.6 不恰当数据结构导致内存占用过大
例如,有一个后台 RPC 服务器,使用 64 位虚拟机,内存配置为 -Xms4g-Xmx8g-Xmn1g,使用 ParNew+CMS 的收集器组合。平时对外服务的 Minor GC 时间约在 30 毫秒以内,完全可以接受。但业务上需要每 10 分钟加载一个约 80MB 的数据文件到内存进行数据分析,这些数据会在内存中形成超过 100 万个 HashMap<Long,Long>Entry,在这段时间里面 Minor GC 就会造成超过 500 毫秒的停顿,对于这个停顿时间就接受不了了,具体情况如下面 GC 日志所示。
{Heap before GC invocations=95(full 4):
par new generation total 903168K,used 803142K[0x00002aaaae770000, 0x00002aaaebb70000, 0x00002aaaebb70000)
eden space 802816K, 100%used[0x00002aaaae770000, 0x00002aaadf770000, 0x00002aaadf770000)
from space 100352K, 0%used[0x00002aaae5970000, 0x00002aaae59c1910, 0x00002aaaebb70000)
to space 100352K, 0%used[0x00002aaadf770000, 0x00002aaadf770000, 0x00002aaae5970000)
concurrent mark-sweep generation total 5845540K,used 3898978K[0x00002aaaebb70000, 0x00002aac507f9000, 0x00002aacae770000)
concurrent-mark-sweep perm gen total 65536K,used 40333K[0x00002aacae770000, 0x00002aacb2770000, 0x00002aacb2770000)
2011-10-28 T11:40:45.162+0800:226.504:[GC226.504:[ParNew:803142K->100352K(903168K), 0.5995670 secs]4702120K->4056332K(6748708K), 0.5997560 secs][Times:user=1.46 sys=0.04, real=0.60 secs]
Heap after GC invocations=96(full 4):
par new generation total 903168K,used 100352K[0x00002aaaae770000, 0x00002aaaebb70000, 0x00002aaaebb70000)
eden space 802816K, 0%used[0x00002aaaae770000, 0x00002aaaae770000, 0x00002aaadf770000)
from space 100352K, 100%used[0x00002aaadf770000, 0x00002aaae5970000,
0x00002aaae5970000)
to space 100352K, 0x00002aaaebb70000)0%used[0x00002aaae5970000, 0x00002aaae5970000,
concurrent mark-sweep generation total 5845540K,used 3955980K[0x00002aaaebb70000, 0x00002aac507f9000, 0x00002aacae770000)
concurrent-mark-sweep perm gen total 65536K,used 40333K[0x00002aacae770000, 0x00002aacb2770000, 0x00002aacb2770000)
}
Total time for which application threads were stopped:0.6070570 seconds
观察这个案例,发现平时的 Minor GC 时间很短,原因是新生代的绝大部分对象都是可清除的,在 Minor GC 之后 Eden 和 Survivor 基本上处于完全空闲的状态。而在分析数据文件期间,800MB 的 Eden 空间很快被填满从而引发 GC,但 Minor GC 之后,新生代中绝大部分对象依然是存活的。我们知道 ParNew 收集器使用的是复制算法,这个算法的高效是建立在大部分对象都“朝生夕灭”的特性上的,如果存活对象过多,把这些对象复制到 Survivor 并维持这些对象引用的正确就成为一个沉重的负担,因此导致 GC 暂停时间明显变长。
如果不修改程序,仅从 GC 调优的角度去解决这个问题,可以考虑将 Survivor 空间去掉(加入参数-XX:SurvivorRatio=65536、-XX:MaxTenuringThreshold=0 或者 -XX:+AlwaysTenure),让新生代中存活的对象在第一次 Minor GC 后立即进入老年代,等到 Major GC 的时候再清理它们。这种措施可以治标,但也有很大副作用,治本的方案需要修改程序,因为这里的问题产生的根本原因是用 HashMap<Long,Long> 结构来存储数据文件空间效率太低。
下面具体分析一下空间效率。在 HashMap<Long,Long> 结构中,只有 Key 和 Value 所存放的两个长整型数据是有效数据,共 16B(2×8B)。这两个长整型数据包装成 java.lang.Long 对象之后,就分别具有 8B 的 MarkWord、8B 的 Klass 指针,在加 8B 存储数据的 long 值。在这两个 Long 对象组成 Map.Entry 之后,又多了 16B 的对象头,然后一个 8B 的 next 字段和 4B 的 int 型的 hash 字段,为了对齐,还必须添加 4B 的空白填充,最后还有 HashMap 中对这个 Entry 的 8B 的引用,这样增加两个长整型数字,实际耗费的内存为(Long(24B)×2)+Entry(32B)+HashMap Ref(8B)=88B,空间效率为 16B/88B=18%,实在太低了。
5.2.7 由 Windows 虚拟内存导致的长时间停顿
例如,有一个带心跳检测功能的 GUI 桌面程序,每 15 秒会发送一次心跳检测信号,如果对方 30 秒以内都没有信号返回,那就认为和对方程序的连接已经断开。程序上线后发现心跳检测有误报的概率,查询日志发现误报的原因是程序会偶尔出现间隔约一分钟左右的时间完全无日志输出,处于停顿状态。
因为是桌面程序,所需的内存并不大(-Xmx256m),所以开始并没有想到是 GC 导致的程序停顿,但是加入参数 -XX:+PrintGCApplicationStoppedTime-XX:+PrintGCDateStamps-Xloggc:gclog.log 后,从 GC 日志文件中确认了停顿确实是由 GC 导致的,大部分 GC 时间都控制在 100 毫秒以内,但偶尔就会出现一次接近 1 分钟的 GC。
Total time for which application threads were stopped:0.0112389 seconds
Total time for which application threads were stopped:0.0001335 seconds
Total time for which application threads were stopped:0.0003246 seconds
Total time for which application threads were stopped:41.4731411 seconds
Total time for which application threads were stopped:0.0489481 seconds
Total time for which application threads were stopped:0.1110761 seconds
Total time for which application threads were stopped:0.0007286 seconds
Total time for which application threads were stopped:0.0001268 seconds
从 GC 日志中找到长时间停顿的具体日志信息(添加了 -XX:+PrintReferenceGC 参数),找到的日志片段如下所示。从日志中可以看出,真正执行 GC 动作的时间不是很长,但从准备开始 GC,到真正开始 GC 之间所消耗的时间却占了绝大部分。
除 GC 日志之外,还观察到这个 GUI 程序内存变化的一个特点,当它最小化的时候,资源管理中显示的占用内存大幅度减小,但是虚拟内存则没有变化,因此怀疑程序在最小化时它的工作内存被自动交换到磁盘的页面文件之中了,这样发生 GC 时就有可能因为恢复页面文件的操作而导致不正常的 GC 停顿。
在 MSDN 上查证后确认了这种猜想,因此,在 Java 的 GUI 程序中要避免这种现象,可以加入参数”-Dsun.awt.keepWorkingSetOnMinimize=true"来解决。这个参数在许多 AWT 的程序上都有应用,例如 JDK 自带的 Visual VM,用于保证程序在恢复最小化时能够立即响应。在这个案例中加入该参数后,问题得到解决。
5.3 实战:Eclipse运行速度调优
很多 Java 开发人员都有这样一种观念:系统调优的工作都是针对服务端应用而言,规模越大的系统,就越需要专业的调优运维团队参与。这个观点不能说不对,5.2 节中笔者所列举的案例确实都是服务端运维、调优的例子,但服务端应用需要调优,并不说明其他应用就不需要了,作为一个普通的 Java 开发人员,前面讲的各种虚拟机的原理和最佳实践方法距离我们并不遥远,开发者身边很多场景都可以使用上面这些知识。下面通过一个普通程序员日常工作中可以随时接触到的开发工具开始这次实战。
5.3.1 调优前的程序运行状态
笔者使用 Eclipse 作为日常工作中的主要 IDE 工具,由于安装的插件比较大(如Klocwork、ClearCase LT等)、代码也很多,启动 Eclipse 直到所有项目编译完成需要四五分钟。一直对开发环境的速度感觉不满意,趁着编写这本书的机会,决定对 Eclipse 进行“动刀”调优。
笔者机器的 Eclipse 运行平台是 32 位 Windows 7 系统,虚拟机为 HotSpot VM 1.5 b64。硬件为 ThinkPad X201,Intel i5 CPU,4GB 物理内存。在初始的配置文件 eclipse.ini 中,除了指定 JDK 的路径、设置最大堆为 512MB 以及开启了JMX 管理(需要在 VisualVM 中收集原始数据)外,未做其他任何改动,原始配置内容如代码清单5-3所示。
-vm
D:/_DevSpace/jdk1.5.0/bin/javaw.exe
-startup
plugins/org.eclipse.equinox.launcher_1.0.201.R35x_v20090715.jar
--launcher.library
plugins/org.eclipse.equinox.launcher.win32.win32.x86_1.0.200.v20090519
-product
org.eclipse.epp.package.jee.product
--launcher.XXMaxPermSize
256M
-showsplash
org.eclipse.platform
-vmargs
-Dosgi.requiredJavaVersion=1.5
-Xmx512m
-Dcom.sun.management.jmxremote
为了要与调优后的结果进行量化对比,调优开始前笔者先做了一次初始数据测试。测试用例很简单,就是收集从 Eclipse 启动开始,直到所有插件加载完成为止的总耗时以及运行状态数据,虚拟机的运行数据通过 VisualVM 及其扩展插件 VisualGC 进行采集。测试过程中反复启动数次 Eclipse 直到测试结果稳定后,取最后一次运行的结果作为数据样本(为了避免操作系统未能及时进行磁盘缓存而产生的影响),数据样本如图5-2所示。
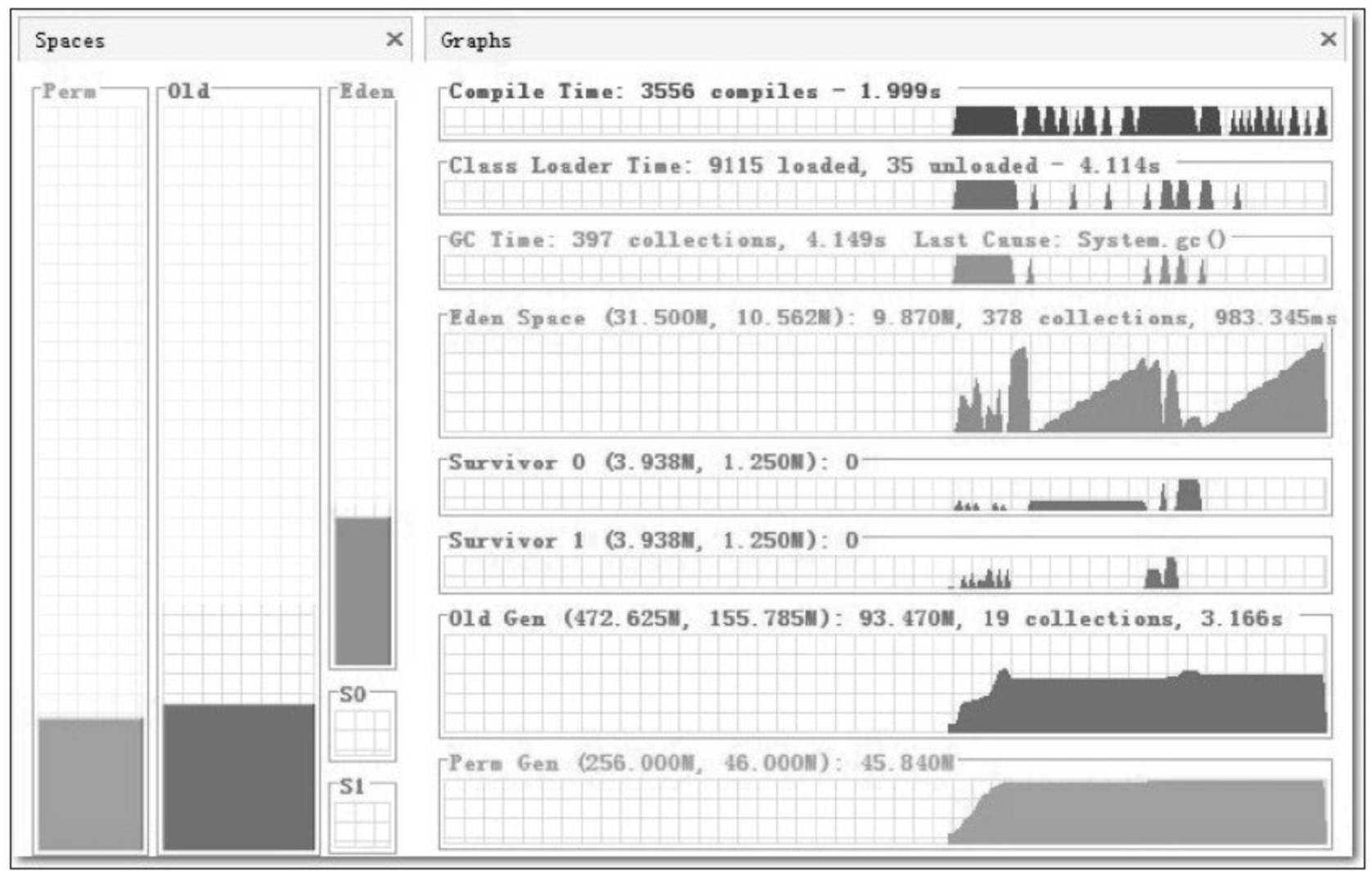
Eclipse 启动的总耗时没有办法从监控工具中直接获得,因为 VisualVM 不可能知道 Eclipse 运行到什么阶段算是启动完成。为了测试的准确性,笔者写了一个简单的 Eclipse 插件,用于统计 Eclipse 的启动耗时。由于代码很简单,并且本书不是 Eclipse RCP 开发的教程,所以只列出代码清单 5-4 供读者参考,不再延伸讲解。如果读者需要这个插件,可以使用下面代码自行编译或者发电子邮件向笔者索取。
ShowTime.java代码:
import org.eclipse.jface.dialogs.MessageDialog;
import org.eclipse.swt.widgets.Display;
import org.eclipse.swt.widgets.Shell;
import org.eclipse.ui.IStartup;
/**
*统计Eclipse启动耗时
*@author zzm
*/
public class ShowTime implements IStartup{
public void earlyStartup(){
Display.getDefault().syncExec(new Runnable(){
public void run(){
long eclipseStartTime=Long.parseLong(System.getProperty("eclipse.startTime"));
long costTime=System.currentTimeMillis()-eclipseStartTime;
Shell shell=Display.getDefault().getActiveShell();
String message="Eclipse启动耗时:"+costTime+"ms";
MessageDialog.openInformation(shell, "Information", message);
}
});
}
}
plugin.xml 代码:
<?xml version="1.0"encoding="UTF-8"?>
<?eclipse version="3.4"?>
<plugin>
<extension
point="org.eclipse.ui.startup">
<startup class="eclipsestarttime.actions.ShowTime"/>
</extension>
</plugin>
上述代码打包成 jar 后放到 Eclipse 的 plugins 目录,反复启动几次后,插件显示的平均时间稳定在 15 秒左右。
根据 VisualGC 和 Eclipse 插件收集到的信息,总结原始配置下的测试结果如下。
- 整个启动过程平均耗时约15秒。
- 最后一次启动的数据样本中,垃圾收集总耗时 4.149 秒,其中:
- Full GC 被触发了 19 次,共耗时 3.166 秒。
- Minor GC 被触发了 378 次,共耗时 0.983 秒。
- 加载类 9115 个,耗时 4.114 秒。
- JIT编译时间为 1.999 秒。
虚拟机 512MB 的堆内存被分配为 40MB 的新生代(31.5 的 Eden 空间和两个 4MB 的 Surviver 空间)以及 472MB 的老年代。
客观地说,由于机器硬件还不错(请读者以 2010 年普通 PC 机的标准来衡量),15秒的启动时间其实还在可接受范围以内,但是从 VisualGC 中反映的数据来看,主要问题是非用户程序时间(图5-2中的 Compile Time、Class Load Time、GC Time)非常之高,占了整个启动过程耗时的一半以上(这里存在少许夸张成分,因为如 JIT 编译等动作是在后台线程完成的,用户程序在此期间也正常执行,所以并没有占用了一半以上的绝对时间)。虚拟机后台占用太多时间也直接导致 Eclipse 在启动后的使用过程中经常有不时停顿的感觉,所以进行调优有较大的价值。
5.3.2 升级 JDK 1.6 的性能变化及兼容问题
对 Eclipse 进行调优的第一步就是先把虚拟机的版本进行升级,希望能先从虚拟机版本身上得到一些“免费的”性能提升。
每次 JDK 的大版本发布时,开发商肯定都会宣称虚拟机的运行速度比上一版本有了很大的提高,这虽然是个广告性质的宣言,经常被人从升级列表或者技术白皮书中直接忽略过去,但从国内外的第三方评测数据来看,版本升级至少某些方面确实带来了一定的性能改善,以下是一个第三方网站对 JDK 1.5、1.6、1.7 三个版本做的性能评测,分别测试了以下4个用例:
- 生成 500 万个的字符串。
- 500 万次
ArrayList<String>数据插入,使用第一点生成的数据。 - 生成 500 万个
HashMap<String,Integer>,每个键-值对通过并发线程计算,测试并发能力。 - 打印 500 万个
ArrayList<String>中的值到文件,并重读回内存。
三个版本的 JDK 分别运行这 3 个用例的测试程序,测试结果如图5-4所示。
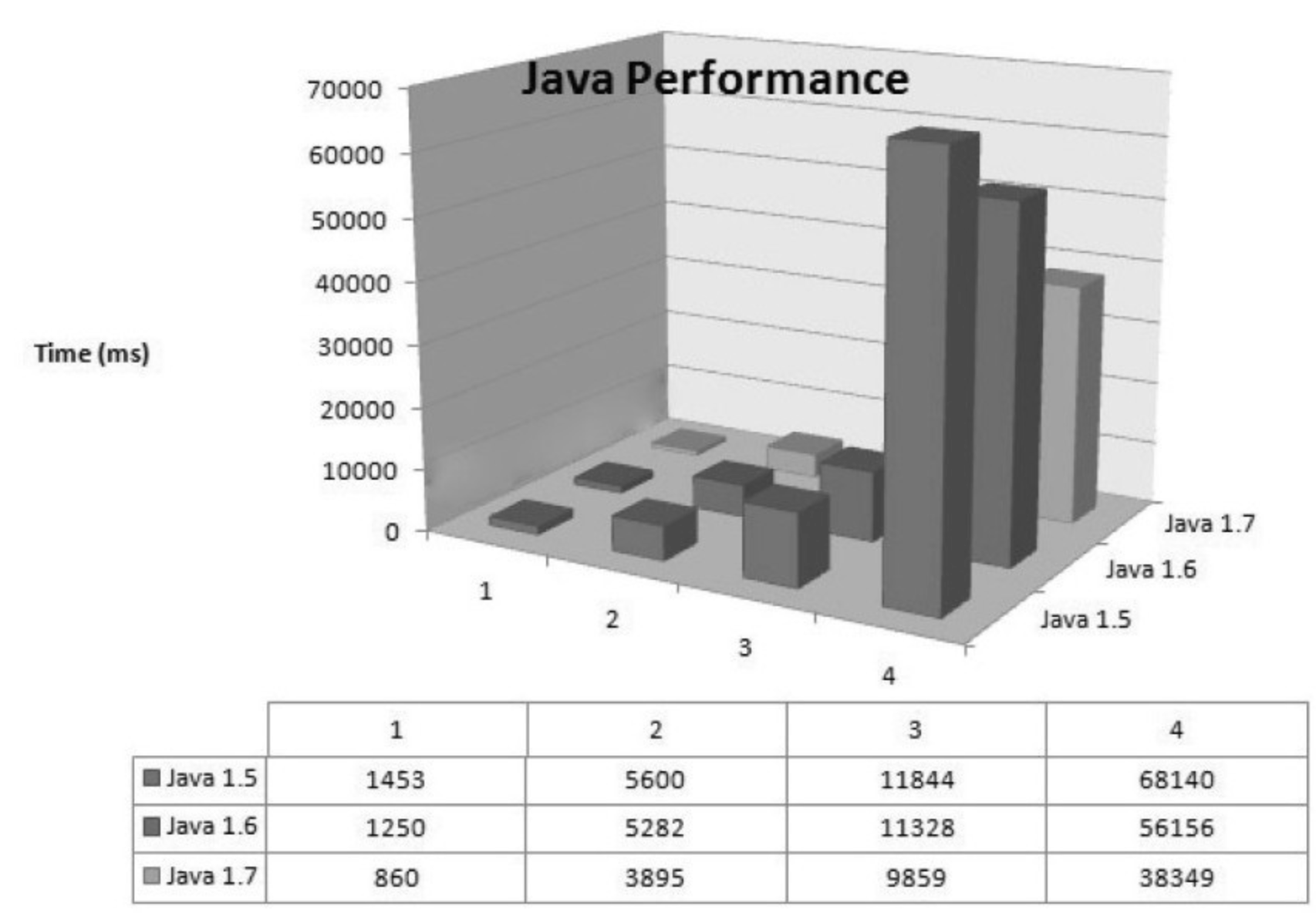
从这 4 个用例的测试结果来看,JDK 1.6 比 JDK 1.5 有大约 15% 的性能提升,尽管对 JDK 仅测试这 4 个用例并不能说明什么问题,需要通过测试数据来量化描述一个 JDK 比旧版提升了多少是很难做到非常科学和准确的(要做稍微靠谱一点的测试,可以使用 SPECjvm2008 来完成,或者把相应版本的 TCK 中数万个测试用例的性能数据对比一下可能更有说服力),但我还是选择相信这次“软广告”性质的测试,把 JDK 版本升级到 1.6 Update 21。
与所有小说作者设计的故事情节一样,获得最后的胜利之前总是要经历各种各样的挫折,这次升级到 JDK 1.6 之后,性能有什么变化先暂且不谈,在使用几分钟之后,笔者的 Eclipse 就和前面几个服务端的案例一样非常“不负众望”地发生了内存溢出。
这次内存溢出完全出乎笔者的意料之外:决定对 Eclipse 做调优是因为速度慢,但开发环境一直都很稳定,至少没有出现过内存溢出的问题,而这次升级除了 eclipse.ini 中的 JVM 路径改变了之外,还未进行任何运行参数的调整,进到 Eclipse 主界面之后随便打开了几个文件就抛出内存溢出异常了,难道 JDK 1.6 Update 21 有哪个 API 出现了严重的泄漏问题吗?
事实上,并不是 JDK 1.6 出现了什么问题,根据前面章节中介绍的相关原理和工具,我们要查明这个异常的原因并且解决它一点也不困难。打开 VisualVM,监视页签中的内存曲线部分如图5-6和图5-7所示。
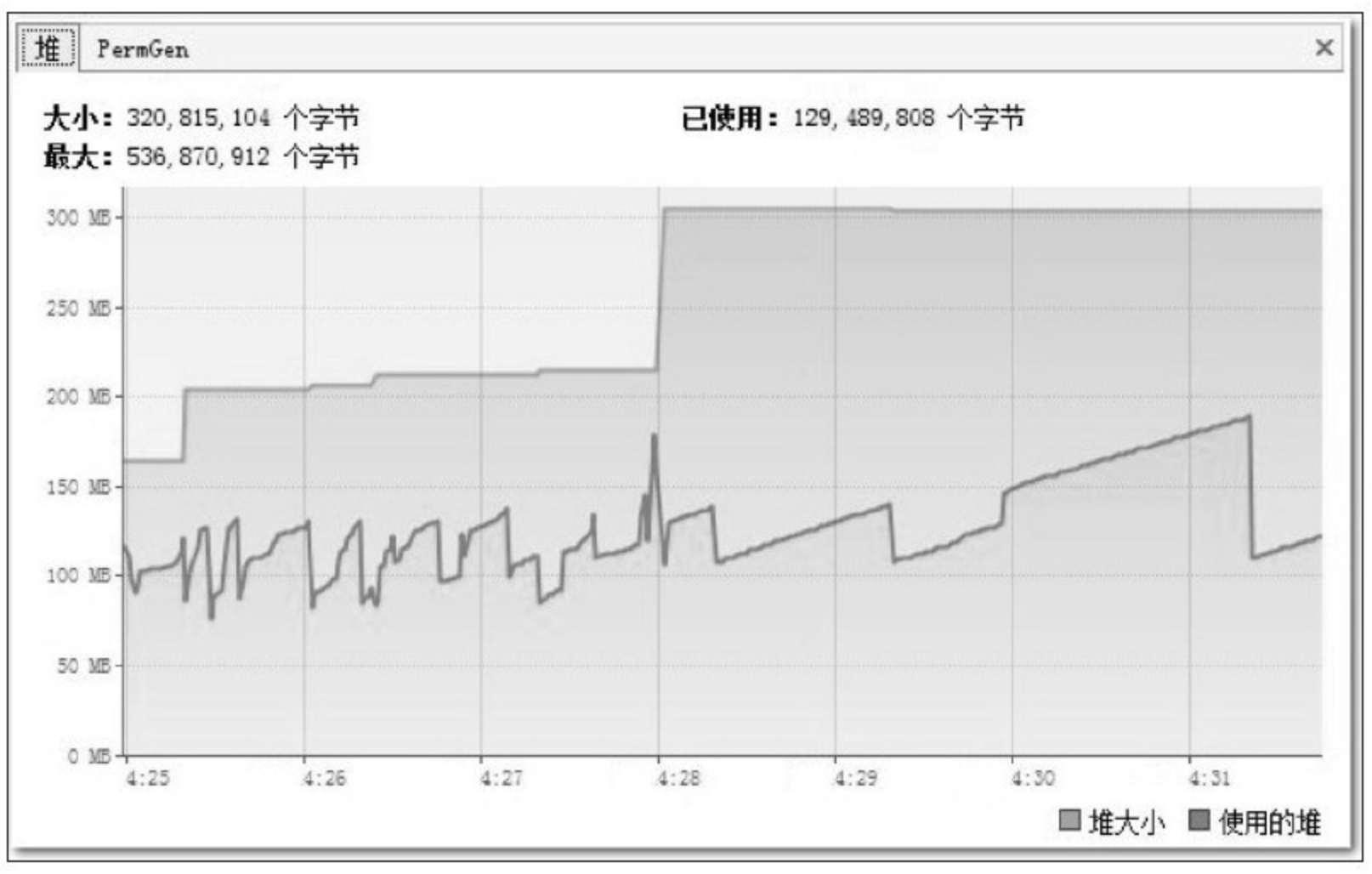
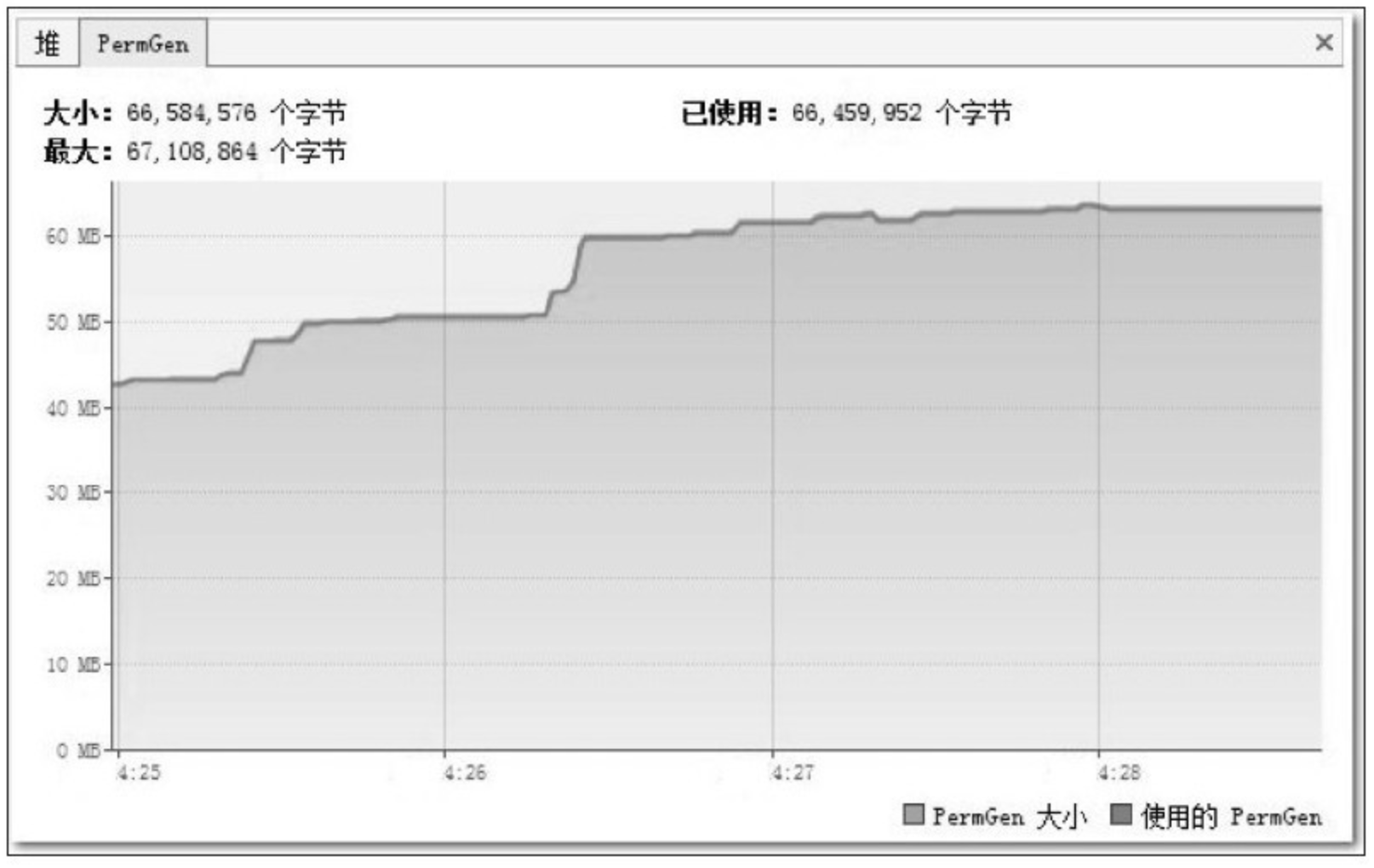
在 Java 堆中监视曲线中,“堆大小”的曲线与“使用的堆”的曲线一直都有很大的间隔距离,每当两条曲线开始有互相靠近的趋势时,“最大堆”的曲线就会快速向上转向,而“使用的堆”的曲线会向下转向。“最大堆”的曲线向上是虚拟机内部在进行堆扩容,运行参数中并没有指定最小堆(-Xms)的值与最大堆(-Xmx)相等,所以堆容量一开始并没有扩展到最大值,而是根据使用情况进行伸缩扩展。“使用的堆”的曲线向下是因为虚拟机内部触发了一次垃圾收集,一些废弃对象的空间被回收后,内存用量相应减少,从图形上看,Java 堆运作是完全正常的。但永久代的监视曲线就有问题了,“PermGen大小”的曲线与“使用的PermGen”的曲线几乎完全重合在一起,这说明永久代中没有可回收的资源,所以“使用的PermGen”的曲线不会向下发展,永久代中也没有空间可以扩展,所以“PermGen大小”的曲线不能向上扩展。这次内存溢出很明显是永久代导致的内存溢出。
再注意到图 5-7 中永久代的最大容量:“67,108,864个字节”,也就是 64MB,这恰好是 JDK 在未使用 -XX:MaxPermSize 参数明确指定永久代最大容量时的默认值,无论 JDK 1.5 还是 JDK 1.6,这个默认值都是 64MB。对于 Eclipse 这种规模的 Java 程序来说,64MB 的永久代内存空间显然是不够的,溢出很正常,那为何在 JDK 1.5 中没有发生过溢出呢?
在 VisualVM 的“概述-JVM参数”页签中,分别检查使用 JDK 1.5 和 JDK 1.6 运行 Eclipse 时的 JVM 参数,发现使用 JDK 1.6 时,只有以下 3 个 JVM 参数,如代码清单5-5所示。
-Dcom.sun.management.jmxremote
-Dosgi.requiredJavaVersion=1.5
-Xmx512m
而使用 JDK 1.5 运行时,就有 4 条 JVM 参数,其中多出来的一条正好就是设置永久代最大容量的 -XX:MaxPermSize=256M,如代码清单5-6所示。
代码清单5-6 JDK 1.5的Eclipse运行期参数
-Dcom.sun.management.jmxremote
-Dosgi.requiredJavaVersion=1.5
-Xmx512m
-XX:MaxPermSize=256M
为什么会这样呢?笔者从 Eclipse 的 Bug List 网站上找到了答案:使用 JDK 1.5 时之所以有永久代容量这个参数,是因为在 eclipse.ini 中存在”–launcher.XXMaxPermSize 256M"这项设置,当 launcher——也就是 Windows 下的可执行程序 eclipse.exe,检测到假如是 Eclipse 运行在 Sun 公司的虚拟机上的话,就会把参数值转化为 -XX:MaxPermSize 传递给虚拟机进程,因为三大商用虚拟机中只有 Sun 系列的虚拟机才有永久代的概念,也就是只有 HotSpot 虚拟机需要设置这个参数,JRockit 虚拟机和 IBM J9 虚拟机都不需要设置。
在2009年4月20日,Oracle 公司正式完成了对 Sun 公司的收购,此后无论是网页还是具体程序产品,提供商都从 Sun 变为了 Oracle,而 eclipse.exe 就是根据程序提供商判断是否为 Sun 的虚拟机,当 JDK 1.6 Update 21 中 java.exe、javaw.exe 的"Company"属性从"Sun Microsystems Inc.“变为"Oracle Corporation"之后,Eclipse 就完全不认识这个虚拟机了,因此没有把最大永久代的参数传递过去。
了解原因之后,解决方法就简单了,launcher 不认识就只好由人来告诉它,即在 eclipse.ini 中明确指定 -XX:MaxPermSize=256M 这个参数就可以了。
5.3.3 编译时间和类加载时间的优化
从 Eclipse 启动时间上来看,升级到 JDK 1.6 所带来的性能提升是……嗯?基本上没有提升?多次测试的平均值与 JDK 1.5 的差距完全在实验误差范围之内。
各位读者不必失望,Sun JDK 1.6 性能白皮书描述的众多相对于 JDK 1.5 的提升不至于全部是广告,虽然总启动时间没有减少,但在查看运行细节的时候,却发现了一件很值得注意的事情:在 JDK 1.6 中启动完 Eclipse 所消耗的类加载时间比 JDK 1.5 长了接近一倍,不要看反了,这里写的是 JDK 1.6 的类加载比 JDK 1.5 慢一倍,测试结果如代码清单5-7所示,反复测试多次仍然是相似的结果。
使用JDK 1.6的类加载时间:
C:\Users\IcyFenix>jps
3552
6372 org.eclipse.equinox.launcher_1.0.201.R35x_v20090715.jar
6900 Jps
C:\Users\IcyFenix>jstat-class 6372
Loaded Bytes Unloaded Bytes Time
7917 10190.3 0 0.0 8.18
使用JDK 1.5的类加载时间:
C:\Users\IcyFenix>jps
3552
7272 Jps
7216 org.eclipse.equinox.launcher_1.0.201.R35x_v20090715.jar
C:\Users\IcyFenix>jstat-class 7216
Loaded Bytes Unloaded Bytes Time
7902 9691.2 3 2.6 4.34
在本例中,类加载时间上的差距并不能作为一个具有普遍性的测试结果去说明 JDK 1.6 的类加载必然比 JDK 1.5 慢,笔者测试了自己机器上的 Tomcat 和 GlassFish 启动过程,并未没有出现类似的差距。在国内最大的 Java 社区中,笔者发起过关于此问题的讨论,从参与者反馈的测试结果来看,此问题只在一部分机器上存在,而且 JDK 1.6 的各个 Update 版之间也存在很大差异。
多次试验后,笔者发现在机器上两个 JDK 进行类加载时,字节码验证部分耗时差距尤其严重。考虑到实际情况:Eclipse 使用者甚多,它的编译代码我们可以认为是可靠的,不需要在加载的时候再进行字节码验证,因此通过参数 -Xverify:none 禁止掉字节码验证过程也可作为一项优化措施。加入这个参数后,两个版本的 JDK 类加载速度都有所提高,JDK 1.6 的类加载速度仍然比 JDK 1.5 慢,但是两者的耗时已经接近了许多,测试数据如代码清单5-8所示。关于类与类加载的话题,譬如刚刚提到的字节码验证是怎么回事,本书专门规划了两个章节进行详细讲解,在此不再延伸讨论。
使用JDK 1.6的类加载时间:
C:\Users\IcyFenix>jps
5512 org.eclipse.equinox.launcher_1.0.201.R35x_v20090715.jar
5596 Jps
C:\Users\IcyFenix>jstat-class 5512
Loaded Bytes Unloaded Bytes Time
6749 8837.0 0 0.0 3.94
使用JDK 1.5的类加载时间:
C:\Users\IcyFenix>jps
4724 org.eclipse.equinox.launcher_1.0.201.R35x_v20090715.jar
5412 Jps
C:\Users\IcyFenix>jstat-class 4724
Loaded Bytes Unloaded Bytes Time
6885 9109.7 3 2.6 3.10
在取消字节码验证之后,JDK 1.5 的平均启动下降到了 13 秒,而 JDK 1.6 的测试数据平均比 JDK 1.5 快 1 秒,下降到平均 12 秒左右,如图5-8所示。在类加载时间仍然落后的情况下,依然可以看到 JDK 1.6 在性能上比 JDK 1.5 稍有优势,说明至少在 Eclipse 启动这个测试用例上,升级 JDK 版本确实能带来一些“免费的”性能提升。
前面说过,除了类加载时间以外,在 VisualGC 的监视曲线中显示了两项很大的非用户程序耗时:编译时间(Compile Time)和垃圾收集时间(GC Time)。垃圾收集时间读者应该非常清楚了,而编译时间是什么呢?程序在运行之前不是已经编译了吗?虚拟机的 JIT 编译与垃圾收集一样,是本书的一个重要部分,后面有专门章节讲解,这里先简单介绍一下:编译时间是指虚拟机的 JIT 编译器(Just In Time Compiler)编译热点代码(Hot Spot Code)的耗时。我们知道 Java 语言为了实现跨平台的特性,Java 代码编译出来后形成的 Class 文件中存储的是字节码(ByteCode),虚拟机通过解释方式执行字节码命令,比起 C/C++ 编译成本地二进制代码来说,速度要慢不少。为了解决程序解释执行的速度问题,JDK 1.2 以后,虚拟机内置了两个运行时编译器,如果一段Java 方法被调用次数达到一定程度,就会被判定为热代码交给 JIT 编译器即时编译为本地代码,提高运行速度(这就是 HotSpot 虚拟机名字的由来)。甚至有可能在运行期动态编译比 C/C++ 的编译期静态译编出来的代码更优秀,因为运行期可以收集很多编译器无法知道的信息,甚至可以采用一些很激进的优化手段,在优化条件不成立的时候再逆优化退回来。所以 Java 程序只要代码没有问题(主要是泄漏问题,如内存泄漏、连接泄漏),随着代码被编译得越来越彻底,运行速度应当是越运行越快的。Java 的运行期编译最大的缺点就是它进行编译需要消耗程序正常的运行时间,这也就是上面所说的“编译时间”。
虚拟机提供了一个参数 -Xint 禁止编译器运作,强制虚拟机对字节码采用纯解释方式执行。如果读者想使用这个参数省下 Eclipse 启动中那 2 秒的编译时间获得一个“更好看”的成绩的话,那恐怕要失望了,加上这个参数之后,虽然编译时间确实下降到 0,但 Eclipse 启动的总时间剧增到 27 秒。看来这个参数现在最大的作用似乎就是让用户怀念一下 JDK 1.2 之前那令人心酸和心碎的运行速度。
与解释执行相对应的另一方面,虚拟机还有力度更强的编译器:当虚拟机运行在 -client 模式的时候,使用的是一个代号为 C1 的轻量级编译器,另外还有一个代号为 C2 的相对重量级的编译器能提供更多的优化措施,如果使用 -server 模式的虚拟机启动 Eclipse 将会使用到 C2 编译器,这时从 VisualGC 可以看到启动过程中虚拟机使用了超过 15 秒的时间去进行代码编译。如果读者的工作习惯是长时间不关闭 Eclipse 的话,C2 编译器所消耗的额外编译时间最终还是会在运行速度的提升之中赚回来,这样使用 -server 模式也是一个不错的选择。不过至少在本次实战中,我们还是继续选用 -client 虚拟机来运行 Eclipse。
5.3.4 调整内存设置控制垃圾收集频率
三大块非用户程序时间中,还剩下 GC 时间没有调整,而 GC 时间却又是其中最重要的一块,并不只是因为它是耗时最长的一块,更因为它是一个稳定持续的过程。由于我们做的测试是在测程序的启动时间,所以类加载和编译时间在这项测试中的影响力被大幅度放大了。在绝大多数的应用中,不可能出现持续不断的类被加载和卸载。在程序运行一段时间后,热点方法被不断编译,新的热点方法数量也总会下降,但是垃圾收集则是随着程序运行而不断运作的,所以它对性能的影响才显得尤为重要。
在Eclipse启动的原始数据样本中,短短 15 秒,类共发生了 19 次 Full GC 和 378 次 Minor GC,一共 397 次 GC 共造成了超过 4 秒的停顿,也就是超过 1/4 的时间都是在做垃圾收集,这个运行数据看起来实在太糟糕了。
首先来解决新生代中的 Minor GC,虽然 GC 的总时间只有不到 1 秒,但却发生了 378 次之多。从 VisualGC 的线程监视中看到,Eclipse 启动期间一共发起了超过 70 条线程,同时在运行的线程数超过 25 条,每当发生一次垃圾收集动作,所有用户线程都必须跑到最近的一个安全点(SafePoint)然后挂起线程等待垃圾回收。这样过于频繁的 GC 就会导致很多没有必要的安全点检测、线程挂起及恢复操作。
新生代 GC 频繁发生,很明显是由于虚拟机分配给新生代的空间太小而导致的,Eden 区加上一个 Survivor 区还不到 35MB。因此很有必要使用 -Xmn 参数调整新生代的大小。
再来看一看那 19 次 Full GC,看起来 19 次并“不多”(相对于 378 次 Minor GC 来说),但总耗时为 3.166 秒,占了 GC 时间的绝大部分,降低 GC 时间的主要目标就要降低这部分时间。从 VisualGC 的曲线图上可能看得不够精确,这次直接从 GC 日志中分析一下这些 Full GC 是如何产生的,代码清单5-9中是启动最开始的 2.5 秒内发生的 10 次 Full GC 记录。
0.278:[GC 0.278:[DefNew:574K->33K(576K), 0.0012562 secs]0.279:[Tenured:1467K->997K(1536K), 0.0181775 secs]1920K->997K(2112K), 0.0195257 secs]
0.312:[GC 0.312:[DefNew:575K->64K(576K), 0.0004974 secs]0.312:[Tenured:1544K->1608K(1664K), 0.0191592 secs]1980K->1608K(2240K), 0.0197396 secs]
0.590:[GC 0.590:[DefNew:576K->64K(576K), 0.0006360 secs]0.590:[Tenured:2675K->2219K(2684K), 0.0256020 secs]3090K->2219K(3260K), 0.0263501 secs]
0.958:[GC 0.958:[DefNew:551K->64K(576K), 0.0011433 secs]0.959:[Tenured:3979K->3470K(4084K), 0.0419335 secs]4222K->3470K(4660K), 0.0431992 secs]
1.575:[Full GC 1.575:[Tenured:4800K->5046K(5784K), 0.0543136 secs]5189K->5046K(6360K), [Perm:12287K->12287K(12288K)], 0.0544163 secs]
1.703:[GC 1.703:[DefNew:703K->63K(704K), 0.0012609 secs]1.705:[Tenured:8441K->8505K(8540K), 0.0607638 secs]8691K->8505K(9244K), 0.0621470 secs]
1.837:[GC 1.837:[DefNew:1151K->64K(1152K), 0.0020698 secs]1.839:[Tenured:14616K->14680K(14688K), 0.0708748 secs]15035K->14680K(15840K), 0.0730947 secs]
2.144:[GC 2.144:[DefNew:1856K->191K(1856K), 0.0026810 secs]2.147:[Tenured:25092K->24656K(25108K), 0.1112429 secs]26172K->24656K(26964K), 0.1141099 secs]
2.337:[GC 2.337:[DefNew:1914K->0K(3136K), 0.0009697 secs]2.338:[Tenured:41779K->27347K(42056K), 0.0954341 secs]42733K->27347K(45192K), 0.0965513 secs]
2.465:[GC 2.465:[DefNew:2490K->0K(3456K), 0.0011044 secs]2.466:[Tenured:46379K->27635K(46828K), 0.0956937 secs]47621K->27635K(50284K), 0.0969918 secs]
括号中加粗的数字代表老年代的容量,这组 GC 日志显示了 10 次 Full GC 发生的原因全部都是老年代空间耗尽,每发生一次 Full GC 都伴随着一次老年代空间扩容:1536KB->1664KB->2684KB……42056KB->46828KB,10 次 GC 以后老年代容量从起始的 1536KB 扩大到 46828KB,当 15 秒后 Eclipse 启动完成时,老年代容量扩大到了 103428KB,代码编译开始后,老年代容量到达顶峰 473MB,整个 Java 堆到达最大容量 512MB。
日志还显示有些时候内存回收状况很不理想,空间扩容成为获取可用内存的最主要手段,譬如语句"Tenured:25092K->24656K(25108K),0.1112429 secs”,代表老年代当前容量为 25108KB,内存使用到 25092KB 的时候发生 Full GC,花费 0.11 秒把内存使用降低到 24656KB,只回收了不到 500KB 的内存,这次 GC 基本没有什么回收效果,仅仅做了扩容,扩容过程相比起回收过程可以看做是基本不需要花费时间的,所以说这 0.11 秒几乎是白白浪费了。
由上述分析可以得出结论:Eclipse 启动时,Full GC 大多数是由于老年代容量扩展而导致的,由永久代空间扩展而导致的也有一部分。为了避免这些扩展所带来的性能浪费,我们可以把 -Xms 和 -XX:PermSize 参数值设置为 -Xmx 和 -XX:MaxPermSize 参数值一样,这样就强制虚拟机在启动的时候就把老年代和永久代的容量固定下来,避免运行时自动扩展。
根据分析,优化计划确定为:把新生代容量提升到 128MB,避免新生代频繁 GC;把 Java 堆、永久代的容量分别固定为 512MB 和 96MB,避免内存扩展。这几个数值都是根据机器硬件、Eclipse 插件和工程数量来决定的,读者实践的时候应根据 VisualGC 中收集到的实际数据进行设置。改动后的 eclipse.ini 配置如代码清单5-10所示。
-vm
D:/_DevSpace/jdk1.6.0_21/bin/javaw.exe
-startup
plugins/org.eclipse.equinox.launcher_1.0.201.R35x_v20090715.jar
--launcher.library
plugins/org.eclipse.equinox.launcher.win32.win32.x86_1.0.200.v20090519
-product
org.eclipse.epp.package.jee.product
-showsplash
org.eclipse.platform
-vmargs
-Dosgi.requiredJavaVersion=1.5
-Xverify:none
-Xmx512m
-Xms512m
-Xmn128m
-XX:PermSize=96m
-XX:MaxPermSize=96m
现在这个配置之下,GC 次数已经大幅度降低,图5-9是 Eclipse 启动后 1 分钟的监视曲线,只发生了 8 次 Minor GC 和 4 次 Full GC,总耗时为 1.928 秒。
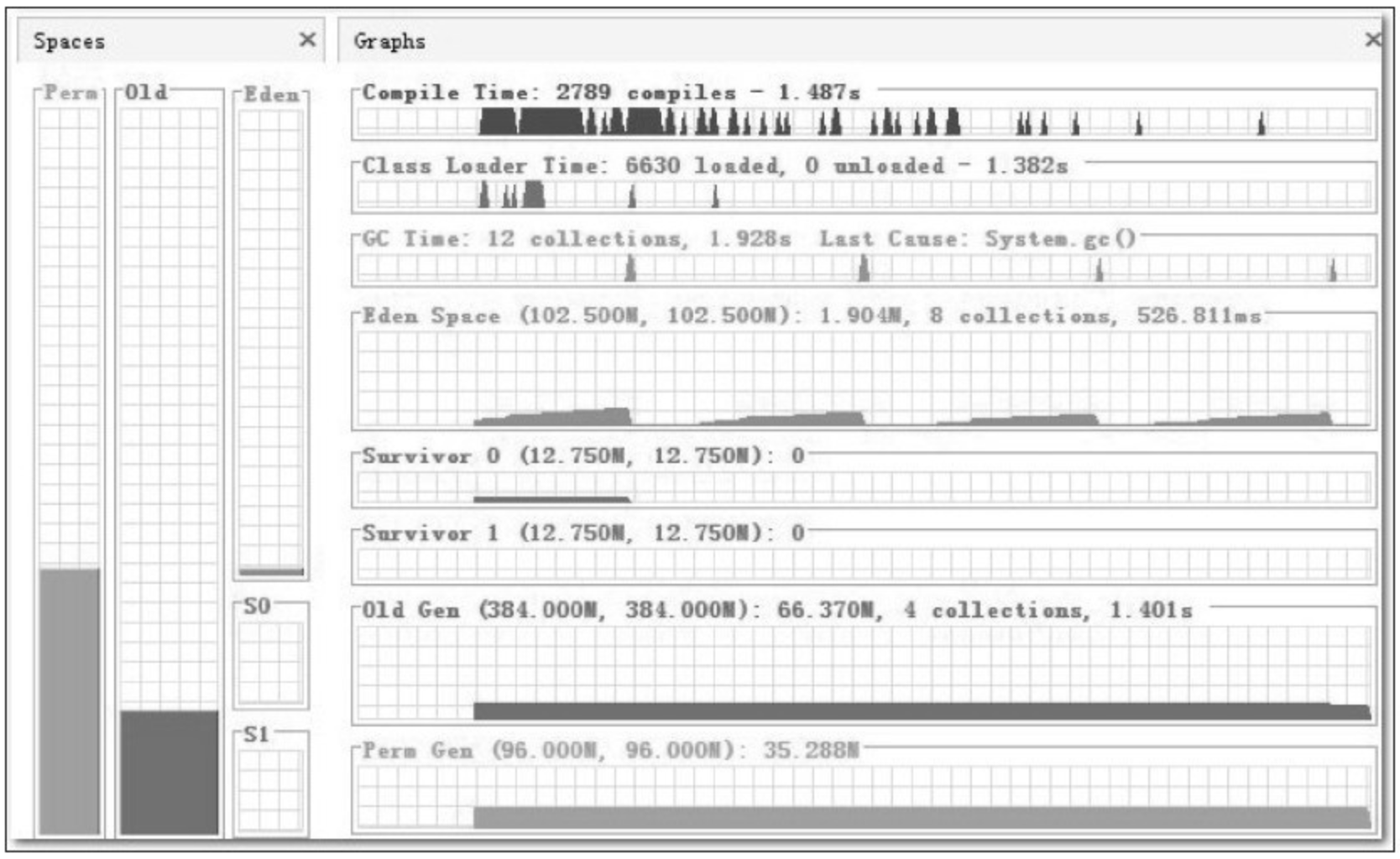
这个结果已经算是基本正常,但是还存在一点瑕疵:从 Old Gen 的曲线上看,老年代直接固定在 384MB,而内存使用量只有 66MB,并且一直很平滑,完全不应该发生 Full GC 才对,那 4 次 Full GC 是怎么来的?使用 jstat-gccause 查询一下最近一次 GC 的原因,见代码清单5-11。
C:\Users\IcyFenix>jps
9772 Jps
4068 org.eclipse.equinox.launcher_1.0.201.R35x_v20090715.jar
C:\Users\IcyFenix>jstat-gccause 4068
S0 S1 E O P YGC YGCT FGC FGCT GCT LGCC GCC
0.00 0.00 1.00 14.81 39.29 6 0.422 20 5.992 6.414
System.gc()No GC
从 LGCC(Last GC Cause)中看到,原来是代码调用 System.gc() 显式触发的 GC,在内存设置调整后,这种显式 GC 已不符合我们的期望,因此在 eclipse.ini 中加入参数 -XX:+DisableExplicitGC 屏蔽掉 System.gc()。再次测试发现启动期间的 Full GC 已经完全没有了,只有 6 次 Minor GC,耗时 417 毫秒,与调优前 4.149 秒的测试样本相比,正好是十分之一。进行 GC 调优后 Eclipse 的启动时间下降非常明显,比整个 GC 时间降低的绝对值还大,现在启动只需要 7 秒多。
5.3.5 选择收集器降低延迟
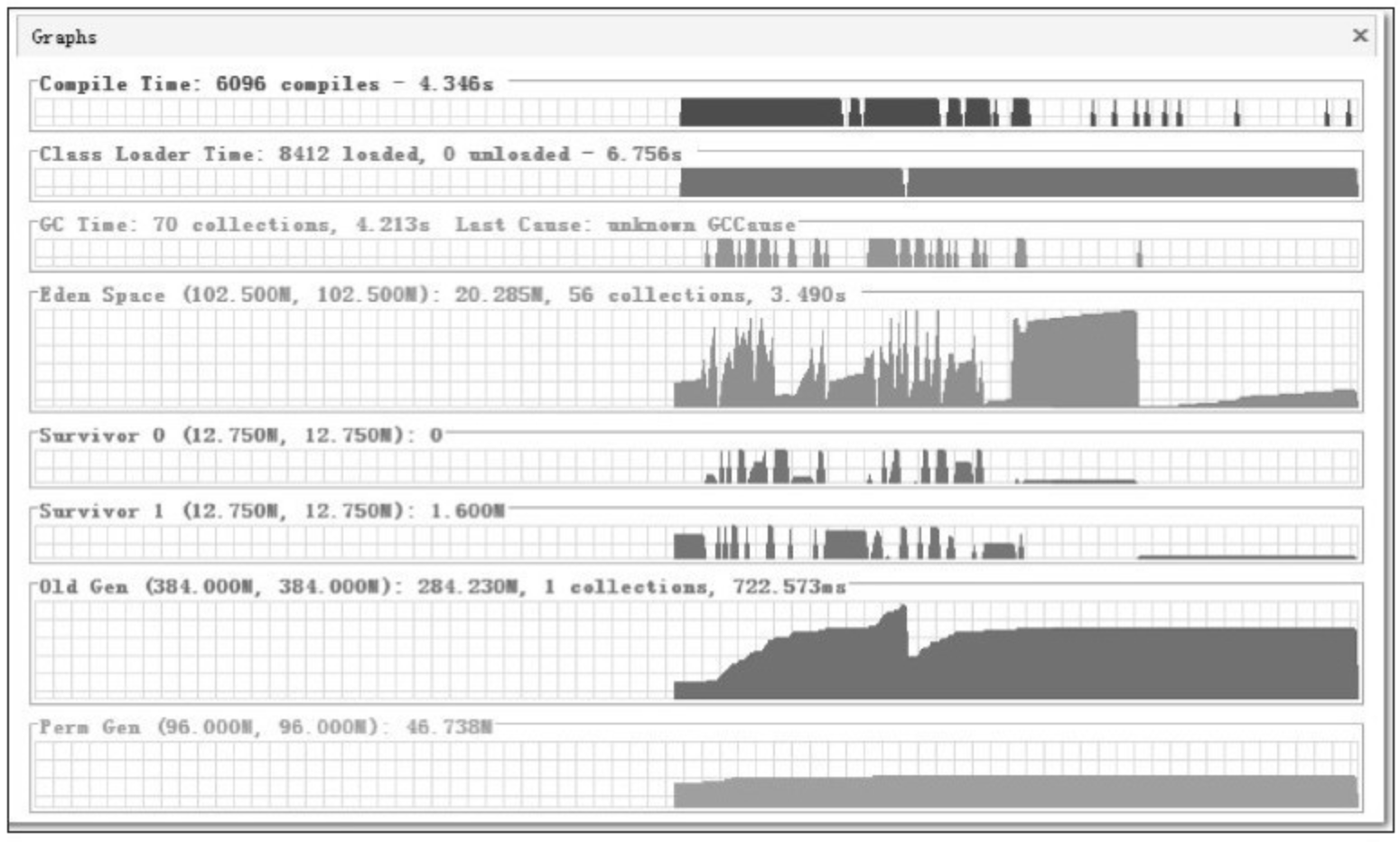
现在 Eclipse 启动已经比较迅速了,但我们的调优实战还没有结束,毕竟 Eclipse 是拿来写程序的,不是拿来测试启动速度的。我们不妨再在 Eclipse 中测试一个非常常用但又比较耗时的操作:代码编译。图5-11是当前配置下 Eclipse 进行代码编译时的运行数据,从图中可以看出,新生代每次回收耗时约 65 毫秒,老年代每次回收耗时约 725 毫秒。对于用户来说,新生代 GC 的耗时还好,65 毫秒在使用中无法察觉到,而老年代每次 GC 停顿接近 1 秒钟,虽然比较长时间才会出现一次,但停顿还是显得太长了一些。
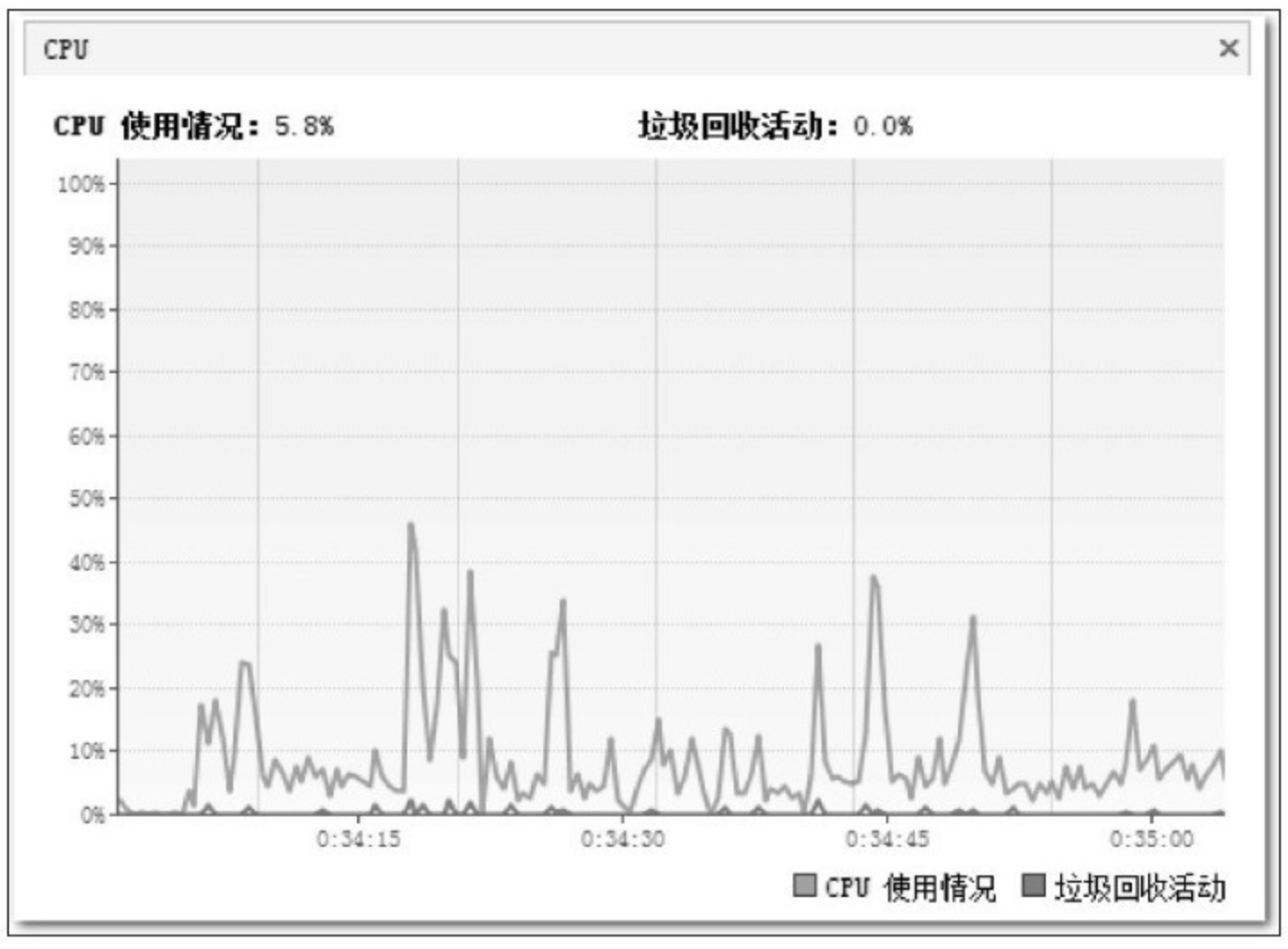
再注意看一下编译期间的 CPU 资源使用状况。图 5-12 是 Eclipse 在编译期间的 CPU 使用率曲线图,整个编译过程中平均只使用了不到 30% 的 CPU 资源,垃圾收集的 CPU 使用率曲线更是几乎与坐标横轴紧贴在一起,这说明 CPU 资源还有很多可利用的余地。
列举 GC 停顿时间、CPU 资源富余的目的,都是为了接下来替换掉 Client 模式的虚拟机中默认的新生代、老年代串行收集器做铺垫。
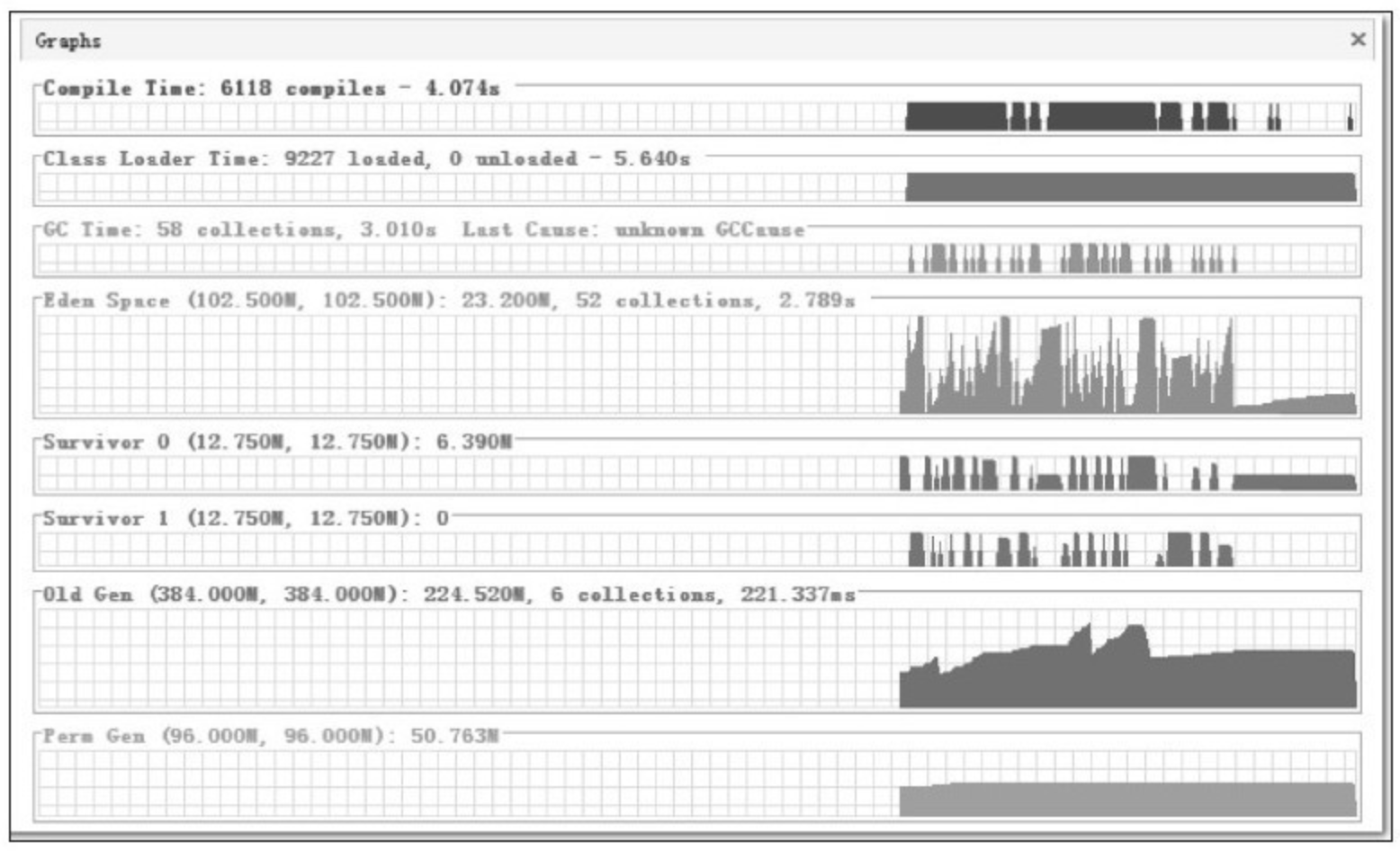
Eclipse 应当算是与使用者交互非常频繁的应用程序,由于代码太多,笔者习惯在做全量编译或者清理动作的时候,使用"Run in Backgroup"功能一边编译一边继续工作。回顾一下在第 3 章提到的几种收集器,很容易想到 CMS 是最符合这类场景的收集器。因此尝试在 eclipse.ini 中再加入这两个参数 -XX:+UseConcMarkSweepGC、-XX:+UseParNewGC(ParNew 收集器是使用 CMS 收集器后的默认新生代收集器,写上仅是为了配置更加清晰),要求虚拟机在新生代和老年代分别使用 ParNew 和 CMS 收集器进行垃圾回收。指定收集器之后,再次测试的结果如图5-13所示,与原来使用串行收集器对比,新生代停顿从每次 65 毫秒下降到了每次 53 毫秒,而老年代的停顿时间更是从 725 毫秒大幅下降到了 36 毫秒。
当然,CMS 的停顿阶段只是收集过程中的一小部分,并不是真的把垃圾收集时间从 725 毫秒变成 36 毫秒了。在 GC 日志中可以看到 CMS 与程序并发的时间约为 400 毫秒,这样收集器的运作结果就比较令人满意了。
到此,对于虚拟机内存的调优基本就结束了,这次实战可以看做是一次简化的服务端调优过程,因为服务端调优有可能还会存在于更多方面,如数据库、资源池、磁盘I/O等,但对于虚拟机内存部分的优化,与这次实战中的思路没有什么太大差别。即使读者实际工作中接触不到服务器,根据自己工作环境做一些试验,总结几个参数让自己日常工作环境速度有较大幅度提升也是很划算的。
5.4 本章小结
Java 虚拟机的内存管理与垃圾收集是虚拟机结构体系中最重要的组成部分,对程序的性能和稳定性有非常大的影响,在本书的第 2~5 章中,笔者从理论知识、异常现象、代码、工具、案例、实战等几个方面对其进行了讲解,希望读者有所收获。
本书关于虚拟机内存管理部分到此为止就结束了,后面将开始介绍Class文件与虚拟机执行子系统方面的知识。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.