This the multi-page printable view of this section. Click here to print.
JVM 深入理解 V2
- 1: CH01-走近 Java
- 2: CH02-内存区域与溢出
- 3: CH03-垃圾收集与分配策略
- 4: CH04-性能监控与故障处理
- 5: CH05-调优案例
- 6: CH06-类文件结构
- 7: CH07-类加载
- 8: CH08-字节码执行引擎
- 9: CH09-案例与实战
- 10: CH10-编译期优化
- 11: CH11-运行时优化
- 12: CH12-内存模型与线程
- 13: CH13-线程安全与锁优化
- 14: Endix-B-字节码指令
- 15: Endix-C-虚拟机参数
1 - CH01-走近 Java
Java 技术体系
Java 技术体系包括以下几个组成部分:
- Java程序设计语言
- 各种硬件平台上的Java虚拟机
- Class文件格式
- Java API类库
- 来自商业机构和开源社区的第三方Java类库
我们可以把Java程序设计语言、Java虚拟机、Java API类库这三部分统称为JDK(Java Development Kit),JDK是用于支持Java程序开发的最小环境,在后面的内容中,为了讲解方便,有一些地方会以JDK来代替整个Java技术体系。另外,可以把Java API类库中的Java SE API子集和Java虚拟机这两部分统称为JRE(Java Runtime Environment),JRE是支持Java程序运行的标准环境。图1-2展示了Java技术体系所包含的内容,以及JDK和JRE所涵盖的范围。
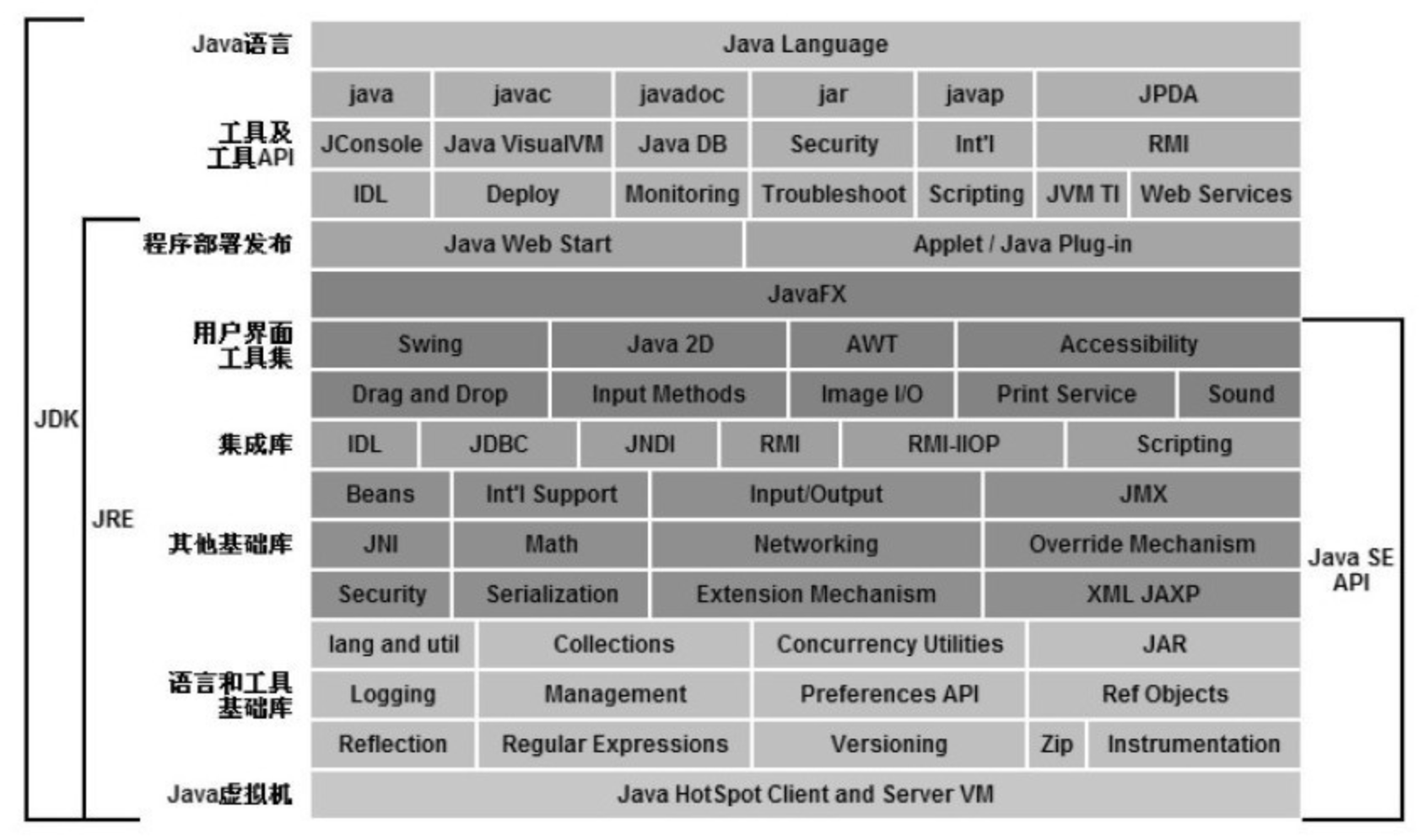
以上是根据各个组成部分的功能来进行划分的,如果按照技术所服务的领域来划分,或者说按照Java技术关注的重点业务领域来划分,Java技术体系可以分为4个平台,分别为:
- Java Card:支持一些Java小程序(Applets)运行在小内存设备(如智能卡)上的平台。
- Java ME(Micro Edition):支持Java程序运行在移动终端(手机、PDA)上的平台,对Java API有所精简,并加入了针对移动终端的支持,这个版本以前称为J2ME。
- Java SE(Standard Edition):支持面向桌面级应用(如Windows下的应用程序)的Java平台,提供了完整的Java核心API,这个版本以前称为J2SE。
- Java EE(Enterprise Edition):支持使用多层架构的企业应用(如ERP、CRM应用)的Java平台,除了提供Java SE API外,还对其做了大量的扩充并提供了相关的部署支持,这个版本以前称为J2EE。
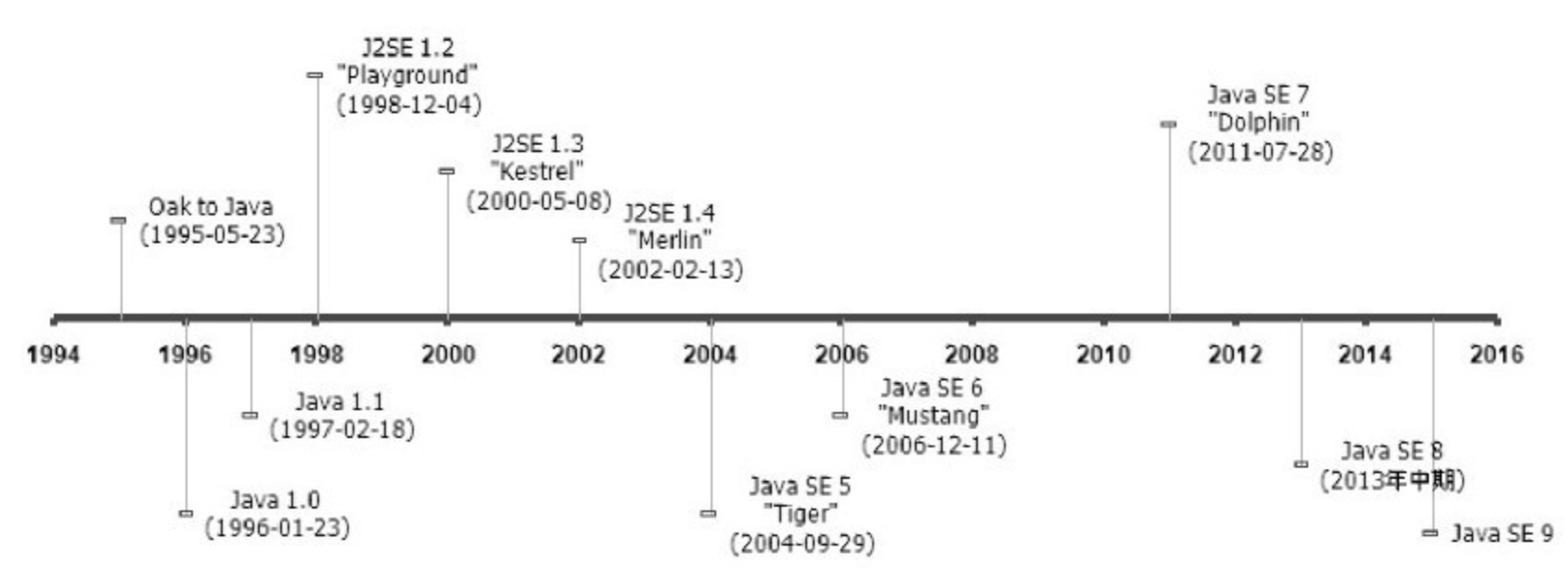
虚拟机发展史
- Sun Classic/Exact VM,只能使用纯解释方式来执行 Java 代码,如果需要使用 JIT 编译期,就需要进行外挂。一旦外挂 JIT,解释器便被完全接管。
- Exact VM,已具备现代高性能虚拟机的雏形,具备两级即时编译期、编译期与解释器混合工作模式,使用精准式内存管理。
- HotSpot,名称指的是热点代码探测技术,准确式 GC。
- Sun Mobile-Embedded VM/Meta-Circular VM
- JRockit VM,专注于服务器端应用,它可以不太关注程序启动速度,因此内部不包含解析器实现,全部代码都靠即时编译器编译后执行。除此之外,J垃圾收集器和MissionControl服务套件等部分的实现,在众多Java虚拟机中也一直处于领先水平。
- IBM J9 VM,它是一款设计上从服务器端到桌面应用再到嵌入式都全面考虑的多用途虚拟机,J9的开发目的是作为IBM公司各种Java产品的执行平台,它的主要市场是和IBM产品(如IBM WebSphere等)搭配以及在IBM AIX和z/OS这些平台上部署Java应用。
- Azul VM,基于 HotSpot 改进,用于专有硬件Vega系统上的 Java 虚拟机,每个 Azul 实例可与管理至少数十个 CPU 和数百GB内存的硬件资源,并提供在巨大内存范围内实现可供 GC 时间的垃圾回收器,为专有硬件优化的线程调度。
- BEA Liquid VM,即现在的 JRockit VE,不需要操作系统的支持,自身实现了一个专用操作系统的必要功能。由虚拟机越过通用操作系统直接控制硬件可以获得很多好处,如在线程调度时不需要进程内核态/用户态的切换等,以最大限度的发挥硬件的能力。
- Apache Harmony,很多优秀代码被吸纳进 JDK 7 和 Google Android SDK 中,尤其对 Android 的发展起到了很大的推动作用。
- Google Android Dalvik VM,Andriod 平台的核心组件,不遵循 JVM 规范,不能直接执行 Class 文件,使用的是寄存器架构而非 JVM 中常见的架构。其执行文件可以通过 Class 文件转化而来,可以使用 Java 来编写应用并调用大部分的 Java API。随着 Android 的迅猛发展得以快速发展。
- Microsoft JVM,Windows 平台特定 JVM,最终因侵权终止。
- GraalVM,支持多种编程语言的通用虚拟机,低负载、高性能。
热点代码探测能力可以通过执行计数器找出最具有编译价值的代码,然后通知JIT编译器以方法为单位进行编译。 如果一个方法被频繁调用,或方法中有效循环次数很多,将会分别触发标准编译和OSR(栈上替换)编译动作。通过编译器与解释器恰当地协同工作,可以在最优化的程序响应时间与最佳执行性能中取得平衡,而且无须等待本地代码输出才能执行程序,即时编译的时间压力也相对减小,这样有助于引入更多的代码优化技术,输出质量更高的本地代码。
未来展望
- 模块化。解决应用系统与技术平台越来越复杂、越来越庞大的一个重要功能。
- 混合语言。当单一的Java开发已经无法满足当前软件的复杂需求时,越来越多基于Java虚拟机的语言开发被应用到软件项目中,Java平台上的多语言混合编程正成为主流,每种语言都可以针对自己擅长的方面更好地解决问题。
- 多核并行。ForkJoin 和 Lambda 帮助 Java 顺利过渡到多核,对多核的深入支持有助于稳定 Java 的引领低位。
- 丰富语法。
- 64 位虚拟机。由于指针膨胀和各种数据类型对齐补白的原因,运行于64位系统上的Java应用需要消耗更多的内存,通常要比32位系统额外增加10%~30%的内存消耗;其次,多个机构的测试结果显示,64位虚拟机的运行速度在各个测试项中几乎全面落后于32位虚拟机,两者大约有15%左右的性能差距。
源码结构
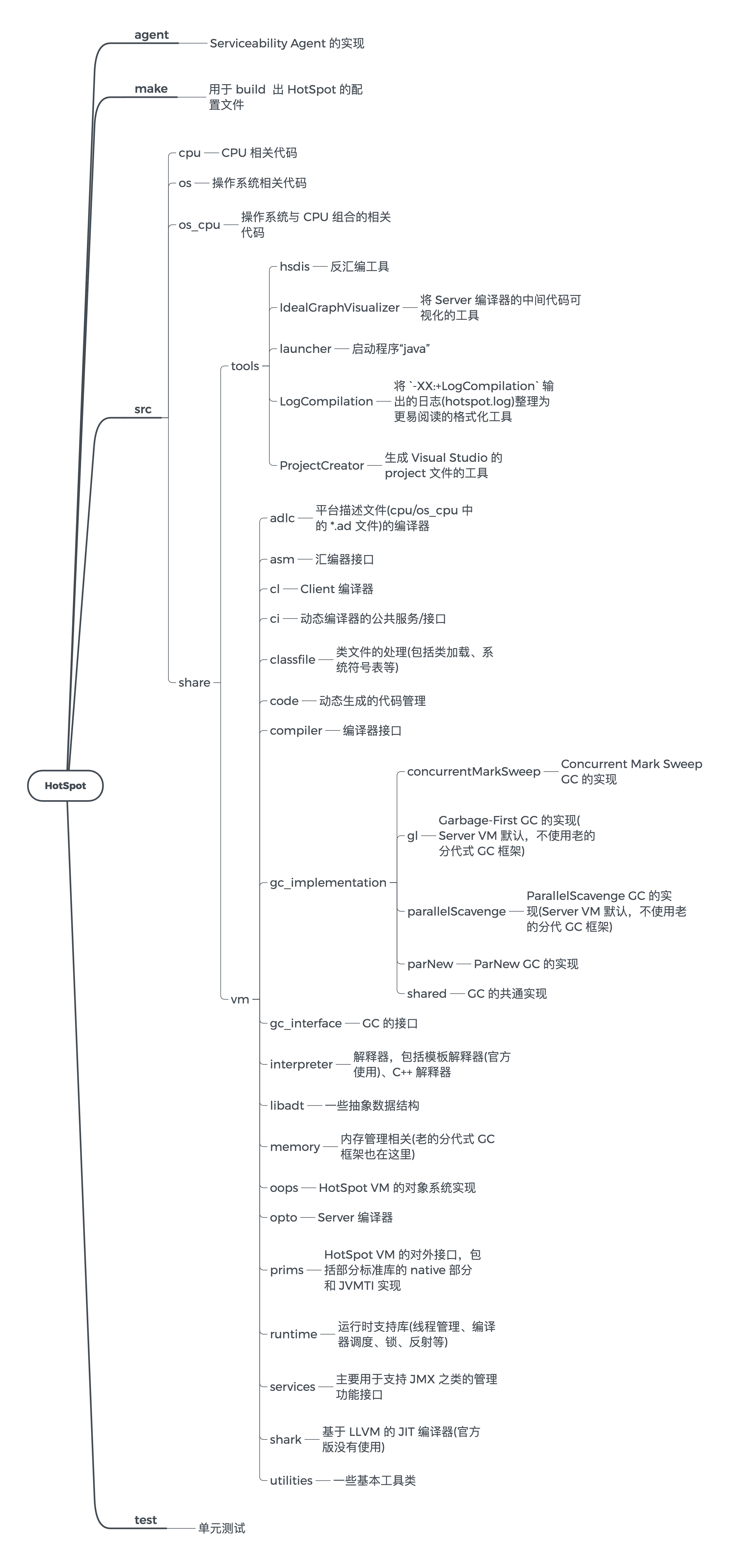
如何阅读 HotSpot 源码
什么时候不读 HotSpot 源码
- 不同 JVM 具体实现相当复杂。
- 基础概念不扎实时。
- 硬读实现复杂的源码对理解基础概念的帮助不大。
- 繁琐的实现细节反而会掩盖一些抽象概念。
- 已有现成的阅读资料时。
- 读资料比读源码更容易吸收自己需要的信息。
- 因人而异。
不明就里读源码的坏处
- 加深误解
- 浪费时间/精力
- 读了但全然无法理解,还不如先不读
- 有些细节知道了也没用
在读源码之前
- 仅为理解 Java 程序的行为?
- 是否已经了解 Java 语言层面的规定?
- Java 语言规范
- 是否已经了解 JVM 的抽象概念?
- JVM 规范
- 已确定需要关注的行为是特定与某个实现?
- 回到上面两点
- 是否有关于该实现的内部细节的文字描述?
- 优先选择阅读文字描述。
- 是否已经了解 Java 语言层面的规定?
- 仍然想深入学习 VM 的内部知识?
- 阅读相关背景知识的书、论文、博客等。
- 能够在阅读源码之前事先了解术语。
- 知道术语便于找到更多资料。
- 阅读一些更加简单的 VM 实现的源码。
- 循序渐进。
- 自己动手编写简单的编译器、VM
- 实践是检验真理最有效途径。
- 最后,如果真的有空才去读 HotSpot 源码。
- 阅读相关背景知识的书、论文、博客等。
- 工作的内容就是开发 HotSpot VM?
- 需要非常仔细的阅读。
- 优先选择动态调试。
- 上手顺序:文档——读代码——做实验——调试。
其他 VM
- KVM:简单小巧的 JVM 实现。
- 优点:
- 包含 JVM 的最核心组件
- 实现方式与 JVM 规范所描述的抽象比较接近
- 缺点:
- 是 Java ME CLDC VM,而不是 Java SE VM
- 未实现反射、浮点计算等功能
- 优点:
- Maxine VM:纯 Java 实现的 JVM。
- 可在 IDE 中开发调试
- 二进制兼容性,可使用 Oracle JDK/OpenJDK 的类库,兼容主流的 Java 应用。
- VMKit/J3:使用线程组件搭建的 JVM。
其他资源
2 - CH02-内存区域与溢出
Java 与 C++ 之间有一堵由内存动态分配和垃圾收集技术所围成的“高墙”,墙外面的人想进去,墙里面的人却想出来。
2.1 概述
在 C/C++ 中,开发人员即拥有每一个对象的“所有权”,又负担着每个对象生命开始到终结的维护责任。
在 Java 中,在虚拟机自动内存管理机制的帮助下,开发人员不需要为每个 new 操作去编写与之配对的 delete/free 代码,不容易出现内存泄露和内存溢出问题。
2.2 运行时数据区域
JVM 在执行 Java 程序时会将它所管理的内存划分为不若干个不同的数据区域。这些区域都有各自的用途、创建和销毁实现,有的区域随着虚拟机进程的启动而存在,有些则依赖于用户线程的启动和结束而创建和销毁。

2.2.1 程序计数器
程序计数器是一块较小的内存空间,可以被看作是当前线程所执行字节码的“行号指示器”。在虚拟机的概念模型中,字节码解释器工作时就是通过改变该计数器的值来选取下一条要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖于该计数器来完成。
由于 JVM 的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说指一个核)都只会执行一个条线程中的指令。因此,为了线程切换后恢复到正确的执行位置,每条线程都需要一个独立的程序计数器,各条线程之间的程序计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
如果线程正在执行的是一个 Java 方法,该计数器记录的是正在执行的虚拟机字节码指令的地址:如果正在执行的是 Native 方法,该计数器值则为空(undefined)。此内存区域是唯一一个在 JVM 规范中没有规定任何 OOM 情况的区域。
2.2.2 JVM 栈
与程序计数器一样,JVM 栈(stack)也是线程私有的,其声明周期与线程相同。它描述的是 Java 方法执行的内存模型:每个方法在执行的同时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每个方法从调用直至执行完成的过程,就对应这一个栈帧在 JVM 栈中入栈到出栈的过程。
经常有人把 Java 内存区域分为堆内存和栈内存,这种分类方式比较粗糙,Java 内存区域的划分实际上远比这复杂。这种划分方式的流行只能说明大多数程序员最关注的、与对象内存分配关系最密切的区域是这两块。其中所指的“栈”就是这里所讲的 JVM 栈,或者说是局部变量表部分。
局部变量表存放了编译期可知的各种数据类型(8 种基本类型)、对象引用(引用类型,不等同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与该对象相关的位置)、returnAddress 类型(指向一条字节码指令的地址)。
其中 64 位长度的 long 和 double 型数据会占用 2 个局部两两空间(slot),其余的数据类型仅占用一个。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,该方法需要在帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。
在 JVM 规范中,对该区域规定了两种异常情况:
- 如果线程请求的栈深度大于虚拟机所允许的深度,将抛出栈溢出异常。
- 如果虚拟机栈可以动态扩展,当扩展时无法申请到足够的内存,将抛出内存溢出异常。
当前大部分虚拟机实现都可以动态扩展,只不过规范中也允许固定长度的虚拟机栈。
2.2.3 本地方法栈
本地方法栈(Native Method Stack)与虚拟机栈相似,区别在于:
- 虚拟机栈用于虚拟机执行 Java 方法,为字节码服务。
- 本地方法栈用于为虚拟机本身用到的 Native 方法服务。
虚拟机规范中没有强制规定本地方法栈中方法需要使用的语言、使用方式、数据结构,因此具体的虚拟机可以自由实现。甚至有虚拟机把直接把本地方法栈和虚拟机栈合二为一,如 Sun HotSpot 虚拟机。
可能会抛出栈溢出或内存溢出异常。
Java 堆
Java Heap 是 JVM 所管理内存中最大的一块,是被所有线程共享的一块内存区域,在虚拟机启动时创建,用于存放对象实例,几乎所有的对象实例都在这里分配内存。
规范中的描述为:所有的对象实例和数组都要在堆上分配。但是随着 JIT 编译器的发展与逃逸分析技术的逐渐成熟,栈上分配、标量替换等优化技术将会带来一些微秒的变化,所有对象都在堆上分配也慢慢变得不那么“绝对”了。
堆是 GC 管理的主要区域。从内存回收的角度来看,由于现在收集器基本都采用分代收集算法,所以堆可以被细分为新生代和老年代,再细致一点的有 Eden 空间、From Survivor 空间、To Survivor 空间等。从内存分配的角度来看,线程共享的堆中可能划分出多个线程私有的分配缓冲区。不过无论如何划分,都与存放的内容无关,无论哪个区域,存储依然都是对象实例,进一步划分的目的是为了更好的回收内存,或者更快的分配内存。
根据虚拟机规范的规定,堆可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可,这类似于磁盘空间。在实现时,既可以实现为固定大小的、也可以是可扩展的,不过当前主流的虚拟机都是按照可扩展的方式来实现的(通过 -Xmx 和 -Xms 控制)。如果在堆中没有内存完成实例分配,并且堆也无法再进行扩展时,将抛出内存溢出异常。
2.2.5 方法区
方法区与堆一样,被各个线程共享,用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译后的代码等数据。虽然规范中将方法区描述为堆的一个逻辑部分,但是他却有一个别名叫做“非堆(Non-Heap)”,目的应该是为了与堆进行区分。
对于习惯于在 HotSpot 虚拟机实现上开发的程序员来说,很多人更愿意称方法区为“永久带”,本质上两者并不等价,仅仅是因为 HotSpot 的设计团队选择把 GC 分代收集扩展至方法区,或者说使用永久带来实现方法区而已,这样 HotSpot 的垃圾收集器可以像管理堆一样来管理这部分内存,这能够省去专门为方法区编写内存管理代码的工作。其他虚拟机(JRockit/J9)则不存在永久带的概念。原则上,如何实现方法区属于虚拟机的实现细节,不受规范的约束,但是用永久带来实现方法区,现在看来并非一个好主意,因为这样更容易遇到内存溢出问题,而且极少有方法会因为这个原因导致不同虚拟机下出现不同的表现。因此对于 HotSpot 来说,根据官方发布的路线图信息,目前也有放弃永久带并逐步改为采用 Native Memory 来实现方法区的规划了。在目前已经发布的 JDK 1.7 中,已经把原本放在永久带的字符串常量池移出。
规范对方法区的限制非常宽松,除了和堆一样不需要连续的内存、可以选择固定大小和可扩展之外,还可以选择实现垃圾收集机制。相对堆而言,垃圾收集行为在该区域较少出现,但并非数据进入了方法区就如永久代的名字一样“永久”存在了。该区域的内存回收目标主要是针对常量池和类的卸载,一般来说,该区域的回收“成绩”比较难以令人满意,尤其是对类的卸载,条件相当苛刻,但是该区域的回收是确实必要的。
根据规范规定,当方法区无法满足内存分配需求时,将抛出内存溢出异常。
2.2.6 运行时常量池
运行时常量池是方法区的一部分。Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项就是常量池,用于存放在编译期生成的各种字面量和符合引用,该部分内容将在类加载后被存放到方法区的运行时常量池。
JVM 对 Class 文件的各个部分的格式都有严格的规定,每个字节用于存放哪种数据都必须符合规范中的要求才会被虚拟机认可、装载和执行,但对于运行时常量池,规范中没有任何细节的要求,不同的供应商实现的虚拟机可以按照自己的需求来实现该内存区域。但一般来说,除了保存 Class 文件中描述的符号引用之外,还会把翻译出来的直接引用也存储在运行时常量池中。
运行时常量池相对于 Class 文件常量池的另外一个重要特征是具备动态性,Java 并不要求常量只能在编译期产生,也就是并非预置入 Class 文件中常量池的内存才能进入方法区运行时常量池,运行区间也可能将新的常量放入池中,这种特性被开发人员利用的比较多的便是 String 类的 intern() 方法。
既然运行时常量池是方法区的一部分,自然受到方法区内存的限制,当常量池中无法申请到内存时将抛出内存溢出异常。
2.2.7 直接内存
直接内存并非虚拟机运行时数据的一部分,也不是 JVM 规范中定义的内存区域。但是这部分内存也被频繁的使用,而且可能导致内存溢出异常,因此有必要介绍。
在 JDK 1.4 中引入例如 NIO 类,引入了一种基于 Channel 和 Buffer 的 IO 方式,可以使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样能在一些场景中显著提升性能,因为避免了在 Java 堆和 Native 堆中来回复制数据。
显然,本机内存的分配不会受到 Java 堆大小的限制,但是会收到本机总内存大小以及处理器寻址空间的限制。服务器管理员在配置虚拟机参数时,会根据实际内存设置 -Xmx 等参数信息,但经常会忽略直接内存,使得各个内存区域的总和大于实际的物理内存限制,从而导致扩展时出现内存溢出异常。
2.3 HotSpot 对象探秘
2.3.1 对象的创建
虚拟机遇到一条 new 指令时,首先回去检查该指令的参数是否能在常量池中定位到一个类的符号引用,并且检查该符号引用代表的类是否已经被加载、解析且初始化。如果没有,必须首先执行对相关类的加载过程。
如果类加载检查通过,接下来虚拟机将为新生对象分配内存。对象所需要的内存大小在类加载时便可以完全确定,为对象分配空间的任务等同于把一块确定大小的内存从堆中划分出来。假设堆中内存是绝对规整的,所有用过的内存都放在一边,空闲的内存放在另一边,中间放着一个指针作为分界点的指示器,所分配的内存就仅仅是把该指针向空闲空间一侧挪动一段与新生对象的大小相等的距离,这种分配方式成为“指针碰撞”。如果堆中的内存是不规整的,已用内存与空闲内存相互交错,虚拟机就需要维护一个列表,记录哪些内存块是可用的,在分配的时候从列表中找到一块足够大的空间来分配给新生对象实例,并更新列表上的记录,这种分配方式称为“空闲列表”。堆是否规整来决定了使用哪种分配方式,而堆是否规整又由所采用的垃圾收集器是否带有压缩整理功能来决定。因此,在使用 Serial、ParNew 等带有 Compact 过程的收集器时,系统采用的分配算法是指针碰撞,而使用 CMS 这种基于 MarkSweep 算法的收集器时,通常会采用空闲列表方式。
除了如何划分可用空间之外,还有另外一个需要考虑的问题是,在虚拟机中对象创建是非常频繁的行为,即使是仅仅修改一个指针所指向的位置,在并发情况下也并不是线程安全的,可能出现正在给对象 A 分配内存,指针还没来得及修改,对象 B 又同时使用了原来的指针来分配内存的情况。解决该问题有两种方案,一种是对内存分配动作进行同步——实际上虚拟机采用 CAS 加上失败重试的方式保证更新操作的原子性;另一种方式是把内存分配的动作按照线程划分在不同的空间之中进行,即每个线程在 Java 堆中预先分配一小块内存,称之为本地线程分配缓冲(TLAB)。哪个线程要分配内存,就在哪个线程的 TLAB 上分配,只有 TLAB 用完并分配新的 TLAB 时,才需要同步。虚拟机是否使用 TLAB,可以通过 -XX:+/-UseTLAB 参数来设定。
内存分配完成后,虚拟机需要将分配的内存空间都初始化为零值(不包括对象头),如果使用 TLAB,这一过程也可以被提前至分配 TLAB 时进行。该操作保证了对象的实例字段在 Java 代码中可以不赋值初始值就能直接被使用,程序将访问到这些字段的类型所对应的零值。
接下来,虚拟机要对对象重新进行必要的设置,比如该对象是哪个类的实例、如何才能找到类的元信息、对象的哈希码、对象的 GC 分代年龄等信息。这些信息存放在对象的对象头之中。根据虚拟机当前的运行状态的不同,如是否启用偏向锁,对象头会有不同的设置方式。
在上面的工作都完成之后,从虚拟机的视角来看,一个新的对象已经产生了,但从 Java 程序的角度来看,对象创建才刚刚开始——init方法还没有执行,所有的字段都还为零值。所以,一般来说(根据字节码中是否跟随 invokespecial 指令所决定),执行 new 指令之后会接着执行 init 方法,把对象安装程序员的意愿进行初始化,这样一个真正可用的对象才算创建完成。
下面的代码清单是 HotSpot 中 butecodeInterpreter.cpp 的片段:
// 确保常量池中存放的是已解释的类
if(!constants->tag_at(index).is_unresolved_kclass()) {
// 断言确保是 klassOop 和 instanceKlassOop
oop entry = (klassOop)*constants->obj_at_addr(index);
assert(entry->is_klass(), "Should be resolved klass");
klassOop k_entry=(klassOop)entry;
assert(k_entry->klass_part()->oop_is_instance(), "Should be instan
instanceKlass * ik=(instanceKlass*)k_entry->klass_part();
// 确保对象所属类型已经经过初始化阶段
if(ik->is_initialized()&&ik->can_be_fastpath_allocated()) {
//取对象长度
size_t obj_size=ik->size_helper();
oop result=NULL;
//记录是否需要将对象所有字段置零值
bool need_zero=!ZeroTLAB;
//是否在TLAB中分配对象
if(UseTLAB){
result=(oop)THREAD->tlab().allocate(obj_size);
}
if(result==NULL){
need_zero=true;
//直接在eden中分配对象
retry:
HeapWord * compare_to=*Universe:heap()->top_addr();
HeapWord * new_top=compare_to+obj_size;
/*cmpxchg是x86中的CAS指令, 这里是一个C++方法, 通过CAS方式分配空间, 如果并发失败, 转到retry中重试, 直至成功分配为止*/
if(new_top<=*Universe:heap()->end_addr()){
if(Atomic:cmpxchg_ptr(new_top,Universe:heap()->top_addr(), compare_to)!=compare_to){
goto retry;
}
result=(oop)compare_to;
}
}
if(result!=NULL){
//如果需要, 则为对象初始化零值
if(need_zero){
HeapWord * to_zero=(HeapWord*)result+sizeof(oopDesc)/oopSize;
obj_size-=sizeof(oopDesc)/oopSize;
if(obj_size>0){
memset(to_zero, 0, obj_size * HeapWordSize);
}
}
//根据是否启用偏向锁来设置对象头信息
if(UseBiasedLocking){
result->set_mark(ik->prototype_header());
}else{
result->set_mark(markOopDesc:prototype());
}
result->set_klass_gap(0);
result->set_klass(k_entry);
//将对象引用入栈, 继续执行下一条指令
SET_STACK_OBJECT(result, 0);
UPDATE_PC_AND_TOS_AND_CONTINUE(3, 1);
}
}
}
2.3.2 对象的内存布局
在 HotSpot 中,对象在内存中存储的布局可以分为三个区域:
- 对象头
- 实例数据
- 对齐填充
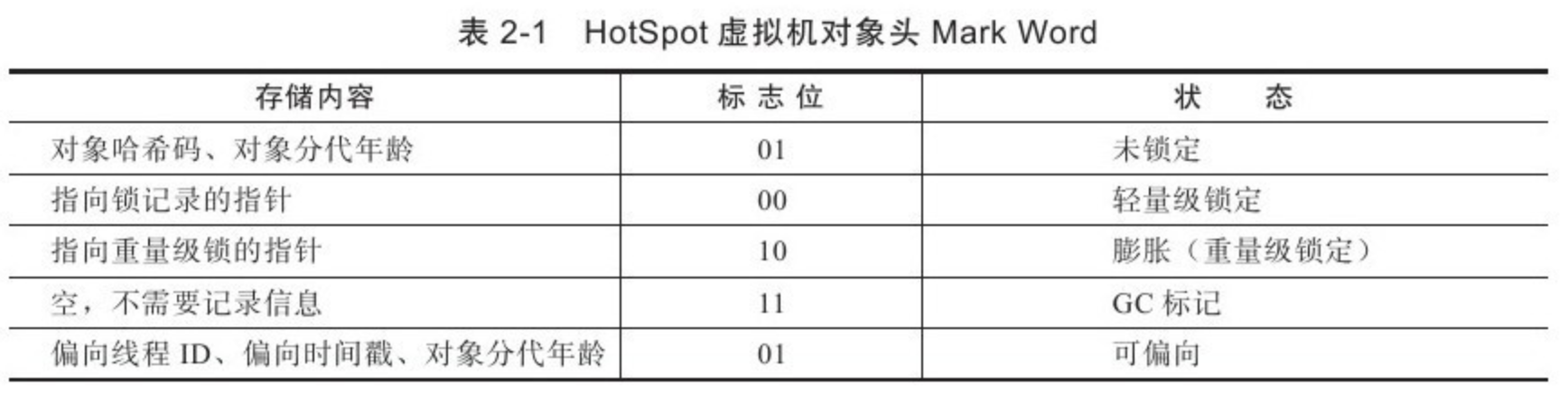
对象头包括两部分。第一部分用于存储对象自身的运行时数据,如哈希值、GC 年龄分代、锁状态标志、线程持有的锁、偏向线程 ID、偏向时间戳等。这部分数据的长度在 32 位和 64 位的虚拟机(未开启压缩指针)中分别为 32 位和 64 位,官方称其为 “Mark Word”。对象需要存储的运行时数据很多,其实已经超出了 32、64 位 Bitmap 结构所能记录的限度,但是对象头信息是与对象自身定义的数据无关的额外存储成本,考虑到虚拟机的空间效率,Mark Word 被设计成一个非固定的数据结构以便在极小的空间内存储尽可能多的信息,它会根据对象的状态复用自己的存储空间。如,在 32 位的 HotSpot 中,如果对象处于未被锁定的状态下,那么 MarkWord 的 32 位存储空间中的 25 位用于存储对象哈希值,4位用于存储对象年龄分代,2位用于存储标志位。1位固定为0,而在其他状态(轻量级锁、重量级锁、GC 标记、可偏向)下对象的存储内容见下表:
对象的另外一部分是类型指针,即对象指向它的类元数据的指针,虚拟机通过该指针来确定这个对象的所属的类。并不是所有虚拟机实现都必须在对象数据上保留类型指针,换句话说,查找对象的元数据信息并不一定要经过对象本身。另外,如果对象是一个数组,拿在对象头中还必须有一块用于记录数组长度的信息,因为虚拟机可以通过普通 Java 对象的元数据信息来确定 Java 的对象的大小,但是从数组的元数据中无法确定数组的大小。
代码清单 2-2 为 HotSpot 中 markOop.cpp 的代码片段,描述了 32 位下 MarkWord 的存储状态:
//Bit-format of an object header(most significant first,big endian layout below):
//32 bits:
//--------
//hash:25------------>|age:4 biased_lock:1 lock:2(normal object)
//JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2(biased object)
//size:32------------------------------------------>|(CMS free block)
//PromotedObject*:29---------->|promo_bits:3----->|(CMS promoted object)
接下来的实例数据部分是对象真正存储的有效信息,也是在程序代码中所定义的各种类型的字段内容。无论是从父类继承而来,而是在子类中定义的,都需要记录下来。这部分的存储顺序会收到虚拟机分配策略参数(FieldsAllocationStyle)和字段在 Java 代码中定义顺序的影响。HotSpot 默认的分配策略为 longs/doubles、ints、shorts/chars、bytes/booleans、oops(Ordinary Object Pointers)。从分配策略可看出,相同宽度的字段总是会被分配在一起。在满足该前提条件的情况下,在父类中定义的字段会出现在子类定义的字段之前。如果 CompactFields 参数为真(默认为真),那么子类中较窄的字段也可能会插入到父类字段的空隙中。
第三部分对齐填充并不是必然存在的,也没有特别的含义,仅仅起着占位符的作用。由于 HotSpot 的自动内存管理系统要求对象起始地址必须是 8 字节的整数倍,即对象的大小必须是 8 字节的整数倍。而对象头部分正好是 8 字节数的倍数,因此当对象实例数据部分没有对齐时,就需要对齐填充来补全。
2.3.3 对象的访问定位
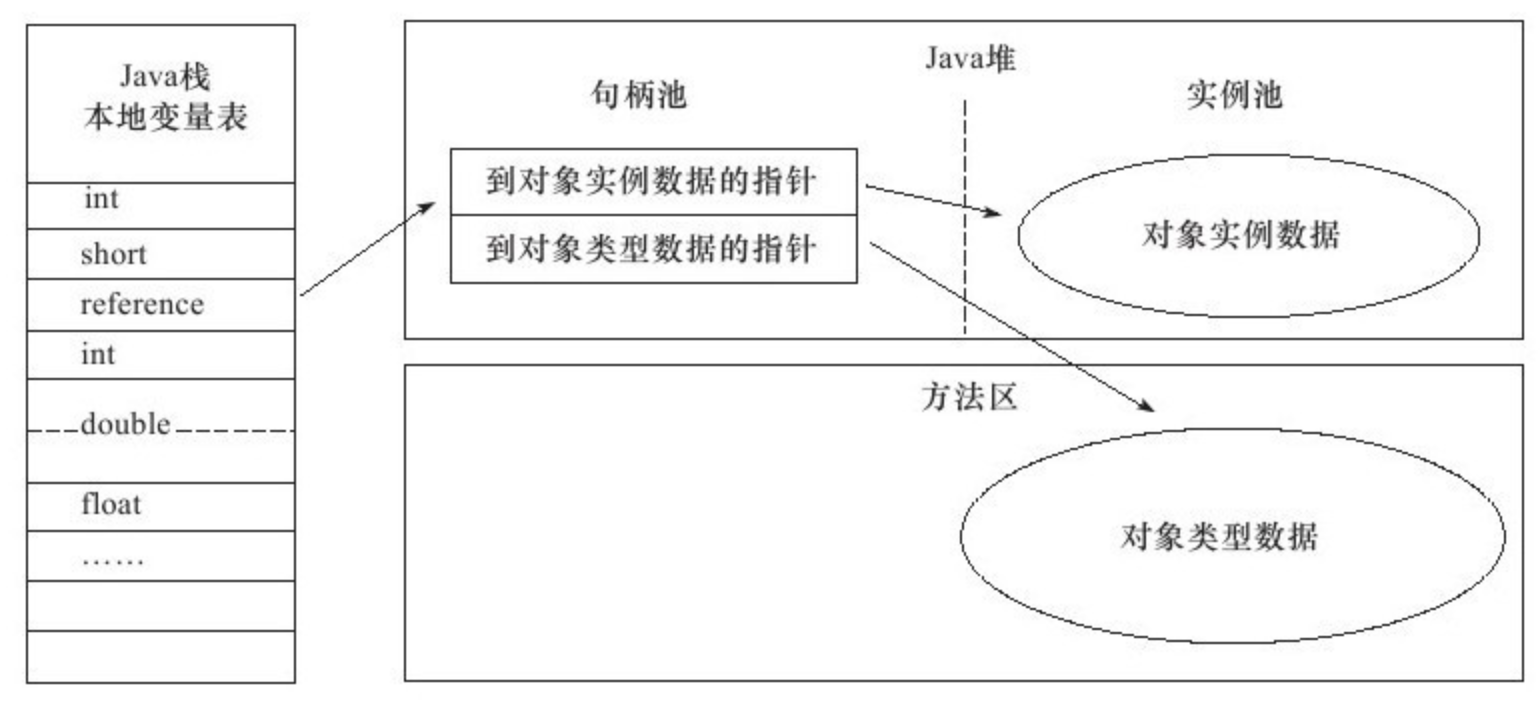
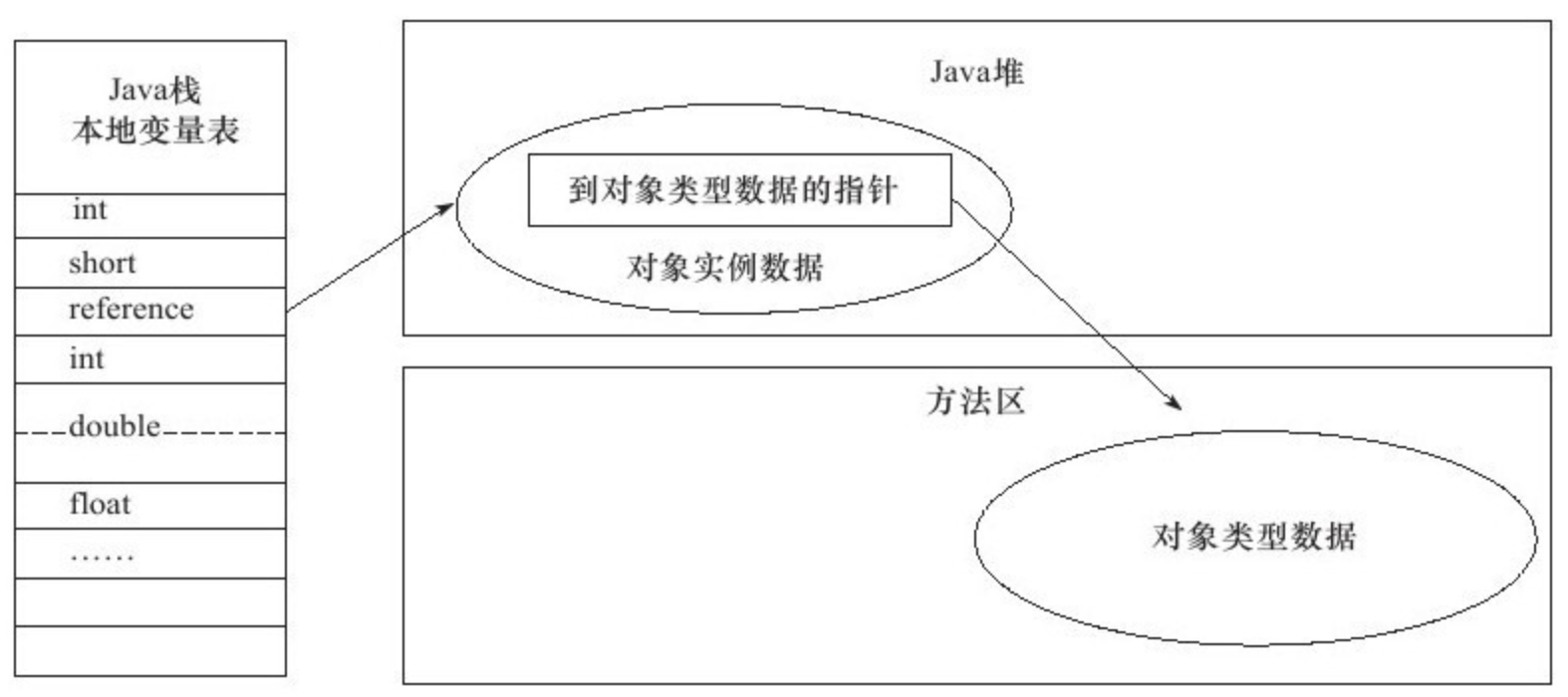
Java 程序需要通过栈上的 reference 数据来操作堆上的具体对象。由于 reference 类型在虚拟机规范中国之规定了一个指向对象的引用,并没有定义该引用应该通过哪种方式去定位、访问堆中对象的具体位置,所以对象访问的方式也取决于具体虚拟机的实现。目前主流的方向是使用句柄或直接指针。
如果使用句柄来访问,那么堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息。如下图:
如果使用直接指针访问,那么堆对象的布局就必须考虑如何放置访问类型数据的相关信息,而 reference 中存储的直接就是对象的地址。如下图:
这两种对象访问方式各有优势,句柄方式访问的最大好处就是 reference 中存储的是稳定的句柄地址,在对象被移动(如垃圾收集时移动对象)时只会改变句柄中的实例数据指针,而 reference 本身不需要修改。
直接指针的方式的最大好处就是速度快,它节省了一次指针定位的时间开销,由于对象的访问在 Java 中非常频繁,因此这类开销积少成多后也是一项非常可观的执行成本。就本书讨论的 HotSpot 而言,它使用直接指针的方式来访问对象,但从整体软件开发的范围来看,各种语言和框架使用句柄来访问的情况也十分常见。
2.4 实战内存溢出异常
2.4.1 堆溢出
堆用于存储对象实例,只要不断创建对象,并且保证 GC Roots 到对象之间的存在可达路径来避免 GC 清除这些对象,那么在对象数量达到堆的最大容量时就会产生堆内存溢出异常。
/**
*VM Args:-Xms20m-Xmx20m-XX:+HeapDumpOnOutOfMemoryError
*@author zzm
*/
public class HeapOOM{
static class OOMObject{
}
public static void main(String[]args){
List<OOMObject>list=new ArrayList<OOMObject>();
while(true){
list.add(new OOMObject());
}
}
}
要解决该区域的内存溢出异常,一般的手段是先通过内存映像分析工具(如 MAT)对 dump 出来的堆转储快照进行分析,重点是确认内存中的对象是否是必要的,即要分清楚到底是出现了内存泄露还是内存溢出。
如果是内存泄露,可以进一步通过工具查看泄露对象到 GC Roots 的引用链。于是就能找到泄露对象是通过怎样的路径与 RC Roots 相关联并导致垃圾收集器无法将其回收。掌握了泄露对象的类型信息及其 GC Roots 引用链就能比较准确的定位出泄露代码的位置。
如果不存在泄露,就是内存中的对象确实都是需要存活的,那么就应当检查虚拟机的堆参数,与机器物理内存相比是否还能调大,从代码上检查是否存在某些对象的生命周期过长、持有状态时间过长的情况,尝试减少程序运行期的内存消耗。
2.4.2 虚拟机栈和本地方法栈溢出
由于在 HotSpot 中并不区分虚拟机栈和本地方法栈,因此对于 HotSpot 来说虽然 -Xoss参数(用于设置本地方法栈的大小)存在,但实际上是无效的,栈容量仅能通过 -Xss 参数来设定。关于虚拟机栈和本地方法栈,JVM 规范中描述了两种异常:
- 如果线程请求的栈深度大于虚拟机所允许的最大深度,将抛出栈溢出异常。
- 如果虚拟机在扩展栈时无法申请到足够的内存空间,则抛出内存溢出异常。
这里把异常分为两种情况看似更加严谨,但却存在着一些互相重叠的地方:当占空间无法继续分配时,到底是内存太小、还是已使用的栈深度太大,其本质上只是对同一件事情的两种描述而已。
在笔者的实验中,将实验范围限定于单线程的操作中,尝试了下面两种方式均无法然虚拟机产生内存溢出异常,尝试的结果都是栈溢出异常:
- 使用
-Xss参数减少栈内存容量,结果抛出栈溢出异常,异常出现时输出的栈深度相应缩小。 - 定义了大量的本地变量,以增大此方法帧中本地变量表的长度。结果抛出栈溢出异常时输出的栈深度相应缩小。
/**
*VM Args:-Xss128k
*@author zzm
*/
public class JavaVMStackSOF{
private int stackLength=1;
public void stackLeak(){
stackLength++;
stackLeak();
}
public static void main(String[]args)throws Throwable{
JavaVMStackSOF oom=new JavaVMStackSOF();
try{
oom.stackLeak();
}catch(Throwable e){
System.out.println("stack length:"+oom.stackLength);
throw e;
}
}
}
实验结果表明,在单个线程中,无论是由于栈帧太大还是虚拟机栈容量太小,当无法分配内存的时候,抛出的都是栈溢出异常。
如果测试时不限于单线程,通过不断创建线程的方式倒是可以产生内存溢出异常。但是这样产生的内存溢出异常与栈空间十分足够大并不存在任何联系,或者准确的说,在这种情况下,为每个线程的栈分配的内存越大,反而越容易产生内存溢出异常。
具体原因不难理解,操作系统分配给每个进程的内存是有限制的,比如 32 位的 Windows 限制为 2GB。虚拟机提供了参数来控制 Java 堆和方法区的内存最大值。剩余的内存为 2GB 减去 Xmx(最大堆容量),再减去 MaxPermSize(最大方法区容量),程序计数器消耗内存很小可以忽略。如果虚拟机进程本身消耗的内存不算在内,剩下的内存就由虚拟机栈和本地方法栈“瓜分”了。每个线程分配到的栈容量越大,可以创建的线程数量就越少,创建新的线程时就越容易把剩下的内存耗尽。
这一点读者需要在开发多线程的应用时特别注意,出现栈溢出异常时有错误堆栈可以阅读,相对来说,比较容易找到问题的所在。而且,如果使用虚拟机默认参数,栈深度在大多数情况下(因为每个方法压入栈的帧大小并不是一样的,所以只能说在大多数情况下)达到1000~2000完全没有问题,对于正常的方法调用(包括递归),这个深度应该完全够用了。但是,如果是建立过多线程导致的内存溢出,在不能减少线程数或者更换64位虚拟机的情况下,就只能通过减少最大堆和减少栈容量来换取更多的线程。如果没有这方面的处理经验,这种通过“减少内存”的手段来解决内存溢出的方式会比较难以想到。
代码清单 2-5 创建线程导致内存溢出异常:
/**
*VM Args:-Xss2M(这时候不妨设置大些)
*@author zzm
*/
public class JavaVMStackOOM{
private void dontStop(){
while(true){
}
}
public void stackLeakByThread(){
while(true){
Thread thread=new Thread(new Runnable(){
@Override
public void run(){
dontStop();
}
});
thread.start();
}
}
public static void main(String[]args)throws Throwable{
JavaVMStackOOM oom=new JavaVMStackOOM();
oom.stackLeakByThread();
}
}
2.4.3 方法区和运行时常量池溢出
由于运行时常量池是方法区的一部分,因此这两个区域的溢出测试就放在一起进行。前面提到JDK 1.7开始逐步“去永久代”的事情,在此就以测试代码观察一下这件事对程序的实际影响。
String.intern() 是一个 Native 方法,它的作用是:如果字符串常量池中已经包含一个等于此 String 对象的字符串,则返回代表池中这个字符串的 String 对象;否则,将此 String 对象包含的字符串添加到常量池中,并且返回此 String 对象的引用。在 JDK 1.6 及之前的版本中,由于常量池分配在永久代内,我们可以通过 -XX:PermSize 和 -XX:MaxPermSize 限制方法区大小,从而间接限制其中常量池的容量,如代码清单 2-6 所示。
/**
*VM Args:-XX:PermSize=10M-XX:MaxPermSize=10M
*@author zzm
*/
public class RuntimeConstantPoolOOM{
public static void main(String[]args){
//使用List保持着常量池引用, 避免Full GC回收常量池行为
List<String>list=new ArrayList<String>();
//10MB的PermSize在integer范围内足够产生OOM了
int i=0;
while(true){
list.add(String.valueOf(i++).intern());
}
}
}
而使用 JDK 1.7 运行这段程序就不会得到相同的结果,while 循环将一直进行下去。关于这个字符串常量池的实现问题,还可以引申出一个更有意思的影响,如代码清单 2-7 所示。
public class RuntimeConstantPoolOOM{
public static void main(String[]args){
public static void main(String[]args){
String str1=new StringBuilder("计算机").append("软件").toString();
System.out.println(str1.intern()==str1);
String str2=new StringBuilder("ja").append("va").toString();
System.out.println(str2.intern()==str2);
}
}
}
这段代码在 JDK 1.6 中运行,会得到两个 false,而在 JDK 1.7 中运行,会得到一个 true 和一个 false。产生差异的原因是:在 JDK 1.6中,intern() 方法会把首次遇到的字符串实例复制到永久代中,返回的也是永久代中这个字符串实例的引用,而由StringBuilder 创建的字符串实例在 Java 堆上,所以必然不是同一个引用,将返回false。而 JDK 1.7(以及部分其他虚拟机,例如JRockit)的 intern() 实现不会再复制实例,只是在常量池中记录首次出现的实例引用,因此 intern() 返回的引用和由 StringBuilder 创建的那个字符串实例是同一个。对 str2 比较返回 false 是因为"java"这个字符串在执行 StringBuilder.toString() 之前已经出现过,字符串常量池中已经有它的引用了,不符合“首次出现”的原则,而“计算机软件”这个字符串则是首次出现的,因此返回 true。
方法区用于存放 Class 的相关信息,如类名、访问修饰符、常量池、字段描述、方法描述等。对于这些区域的测试,基本的思路是运行时产生大量的类去填满方法区,直到溢出。虽然直接使用 Java SE API 也可以动态产生类(如反射时的 GeneratedConstructorAccessor 和动态代理等),但在本次实验中操作起来比较麻烦。在代码清单 2-8中,笔者借助 CGLib 直接操作字节码运行时生成了大量的动态类。
/**
*VM Args:-XX:PermSize=10M-XX:MaxPermSize=10M
*@author zzm
*/
public class JavaMethodAreaOOM{
public static void main(String[]args){
while(true){
Enhancer enhancer=new Enhancer();
enhancer.setSuperclass(OOMObject.class);
enhancer.setUseCache(false);
enhancer.setCallback(new MethodInterceptor(){
public Object intercept(Object obj,Method method,Object[]args,MethodProxy proxy)throws Throwable{
return proxy.invokeSuper(obj,args);
}
});
enhancer.create();
}
}
static class OOMObject{
}
}
值得特别注意的是,我们在这个例子中模拟的场景并非纯粹是一个实验,这样的应用经常会出现在实际应用中:当前的很多主流框架,如 Spring、Hibernate,在对类进行增强时,都会使用到 CGLib 这类字节码技术,增强的类越多,就需要越大的方法区来保证动态生成的 Class 可以加载入内存。另外,JVM 上的动态语言(例如Groovy等)通常都会持续创建类来实现语言的动态性,随着这类语言的流行,也越来越容易遇到与代码清单 2-8 相似的溢出场景。
方法区溢出也是一种常见的内存溢出异常,一个类要被垃圾收集器回收掉,判定条件是比较苛刻的。在经常动态生成大量 Class 的应用中,需要特别注意类的回收状况。这类场景除了上面提到的程序使用了 CGLib 字节码增强和动态语言之外,常见的还有:大量JSP 或动态产生 JSP 文件的应用(JSP第一次运行时需要编译为Java类)、基于 OSGi 的应用(即使是同一个类文件,被不同的加载器加载也会视为不同的类)等。
2.4.4 本机直接内存溢出
DirectMemory 容量可通过 -XX:MaxDirectMemorySize 指定,如果不指定,则默认与 Java 堆最大值(-Xmx指定)一样,代码清单 2-9 越过了 DirectByteBuffer 类,直接通过反射获取 Unsafe 实例进行内存分配(Unsafe 类的 getUnsafe() 方法限制了只有引导类加载器才会返回实例,也就是设计者希望只有 rt.jar 中的类才能使用 Unsafe 的功能)。因为,虽然使用 DirectByteBuffer 分配内存也会抛出内存溢出异常,但它抛出异常时并没有真正向操作系统申请分配内存,而是通过计算得知内存无法分配,于是手动抛出异常,真正申请分配内存的方法是 unsafe.allocateMemory()。
/**
*VM Args:-Xmx20M-XX:MaxDirectMemorySize=10M
*@author zzm
*/
public class DirectMemoryOOM{
private static final int_1MB=1024*1024;
public static void main(String[]args)throws Exception{
Field unsafeField=Unsafe.class.getDeclaredFields()[0];
unsafeField.setAccessible(true);
Unsafe unsafe=(Unsafe)unsafeField.get(null);
while(true){
unsafe.allocateMemory(_1MB);
}
}
}
由 DirectMemory 导致的内存溢出,一个明显的特征是在 Heap Dump 文件中不会看见明显的异常,如果读者发现 OOM 之后 Dump 文件很小,而程序中又直接或间接使用了 NIO,那就可以考虑检查一下是不是这方面的原因。
2.5 本章小结
通过本章的学习,我们明白了虚拟机中的内存是如何划分的,哪部分区域、什么样的代码和操作可能导致内存溢出异常。虽然 Java 有垃圾收集机制,但内存溢出异常离我们仍然并不遥远,本章只是讲解了各个区域出现内存溢出异常的原因,第3章将详细讲解 Java 垃圾收集机制为了避免内存溢出异常的出现都做了哪些努力。
3 - CH03-垃圾收集与分配策略
3.1 概述
当需要排查各种内存溢出、内存泄漏问题时,当垃圾收集成为系统达到更高并发量的瓶颈时,我们就需要对这些“自动化”的(动态内存分配与内存回收)技术实施必要的监控和调节。
第 2 章介绍了 Java 内存运行时区域的各个部分,其中程序计数器、虚拟机栈、本地方法栈 3 个区域随线程而生,随线程而灭;栈中的栈帧随着方法的进入和退出而有条不紊地执行着出栈和入栈操作。每一个栈帧中分配多少内存基本上是在类结构确定下来时就已知的(尽管在运行期会由 JIT 编译器进行一些优化,但在本章基于概念模型的讨论中,大体上可以认为是编译期可知的),因此这几个区域的内存分配和回收都具备确定性,在这几个区域内就不需要过多考虑回收的问题,因为方法结束或者线程结束时,内存自然就跟随着回收了。
而 Java 堆和方法区则不一样,一个接口中的多个实现类需要的内存可能不一样,一个方法中的多个分支需要的内存也可能不一样,我们只有在程序处于运行期间时才能知道会创建哪些对象,这部分内存的分配和回收都是动态的,垃圾收集器所关注的是这部分内存,本章后续讨论中的“内存”分配与回收也仅指这一部分内存。
3.2 对象已死?
在堆里面存放着 Java 世界中几乎所有的对象实例,垃圾收集器在对堆进行回收前,第一件事情就是要确定这些对象之中哪些还“存活”着,哪些已经“死去”(即不可能再被任何途径使用的对象)。
引用技术法
很多教科书判断对象是否存活的算法是这样的:给对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加1;当引用失效时,计数器值就减1;任何时刻计数器为0的对象就是不可能再被使用的。作者面试过很多的应届生和一些有多年工作经验的开发人员,他们对于这个问题给予的都是这个答案。
客观地说,引用计数算法(Reference Counting)的实现简单,判定效率也很高,在大部分情况下它都是一个不错的算法,也有一些比较著名的应用案例,例如微软公司的 COM(Component Object Model)技术、使用 ActionScript 3 的FlashPlayer、Python 语言和在游戏脚本领域被广泛应用的 Squirrel 中都使用了引用计数算法进行内存管理。但是,至少主流的Java虚拟机里面没有选用引用计数算法来管理内存,其中最主要的原因是它很难解决 对象之间相互循环引用 的问题。
举个简单的例子,请看代码清单 3-1 中的 testGC() 方法:对象 objA 和 objB 都有字段 instance,赋值令 objA.instance=objB 及 objB.instance=objA,除此之外,这两个对象再无任何引用,实际上这两个对象已经不可能再被访问,但是它们因为互相引用着对方,导致它们的引用计数都不为 0,于是引用计数算法无法通知 GC 收集器回收它们。
/**
*testGC()方法执行后, objA和objB会不会被GC呢?
*@author zzm
*/
public class ReferenceCountingGC{
public Object instance=null;
private static final int_1MB=1024*1024;
/**
*这个成员属性的唯一意义就是占点内存, 以便能在GC日志中看清楚是否被回收过
*/
private byte[]bigSize=new byte[2*_1MB];
public static void testGC(){
ReferenceCountingGC objA=new ReferenceCountingGC();
ReferenceCountingGC objB=new ReferenceCountingGC();
objA.instance=objB;
objB.instance=objA;
objA=null;
objB=null;
//假设在这行发生GC,objA和objB是否能被回收?
System.gc();
}
}
从运行结果中可以清楚看到,GC 日志中包含"4603K->210K",意味着虚拟机并没有因为这两个对象互相引用就不回收它们,这也从侧面说明虚拟机并不是通过引用计数算法来判断对象是否存活的。
3.2.2 可达性分析算法
在主流的商用程序语言(Java、C#,甚至包括前面提到的古老的Lisp)的主流实现中,都是称通过可达性分析(Reachability Analysis)来判定对象是否存活的。这个算法的基本思路就是通过一系列的称为"GC Roots"的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到 GC Roots 没有任何引用链相连(用图论的话来说,就是从 GC Roots 到这个对象不可达)时,则证明此对象是不可用的。如图 3-1 所示,对象 object 5、object 6、object 7 虽然互相有关联,但是它们到 GC Roots 是不可达的,所以它们将会被判定为是可回收的对象。
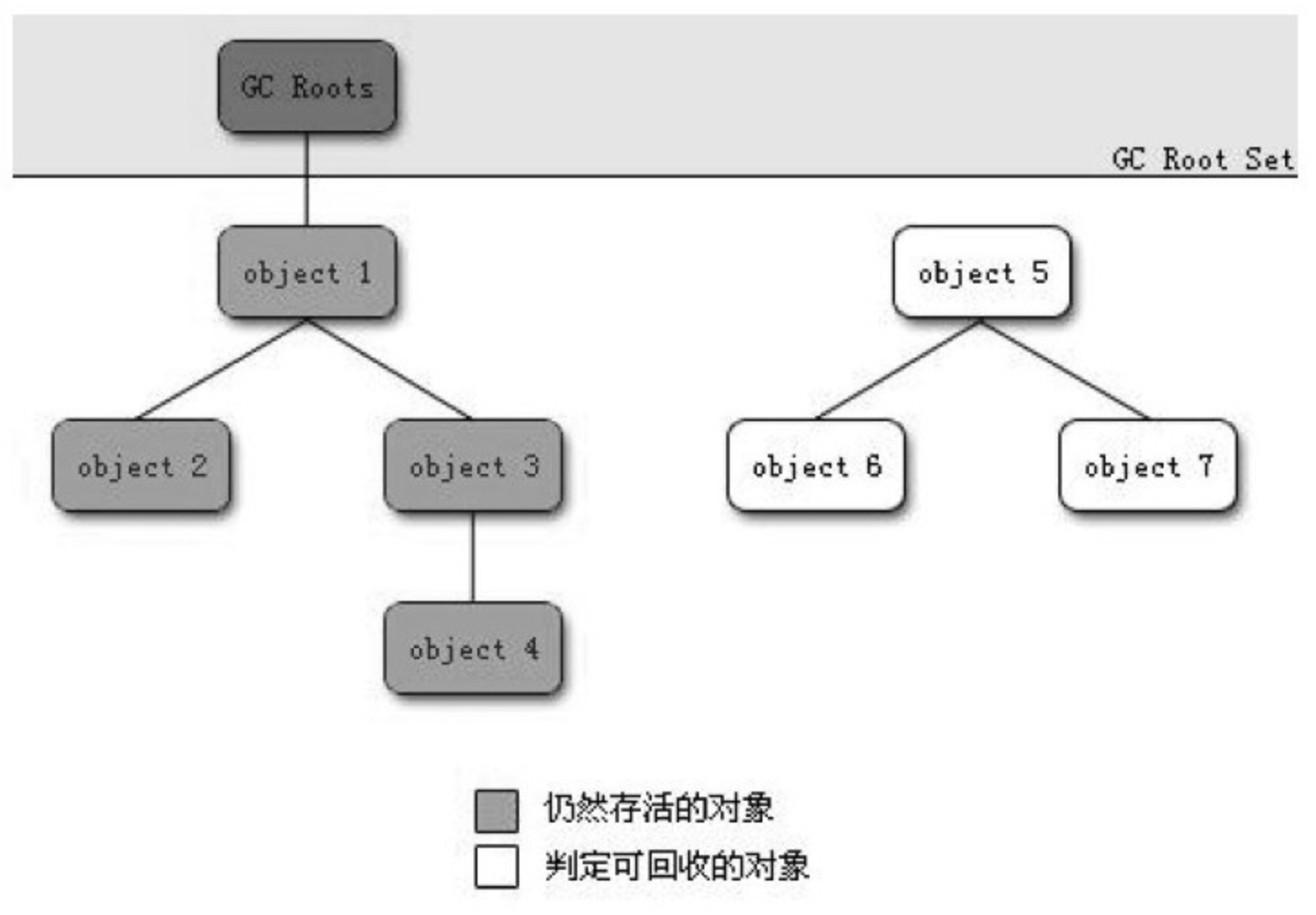
在Java语言中,可作为 GC Roots 的对象包括下面几种:
- 虚拟机栈(栈帧中的本地变量表)中引用的对象。
- 方法区中类静态属性引用的对象。
- 方法区中常量引用的对象。
- 本地方法栈中 JNI(即一般说的Native方法)引用的对象。
3.2.3 再谈引用
无论是通过引用计数算法判断对象的引用数量,还是通过可达性分析算法判断对象的引用链是否可达,判定对象是否存活都与“引用”有关。在 JDK 1.2 以前,Java 中的引用的定义很传统:如果 reference 类型的数据中存储的数值代表的是另外一块内存的起始地址,就称这块内存代表着一个引用。这种定义很纯粹,但是太过狭隘,一个对象在这种定义下只有被引用或者没有被引用两种状态,对于如何描述一些“食之无味,弃之可惜”的对象就显得无能为力。我们希望能描述这样一类对象:当内存空间还足够时,则能保留在内存之中;如果内存空间在进行垃圾收集后还是非常紧张,则可以抛弃这些对象。很多系统的缓存功能都符合这样的应用场景。
在 JDK 1.2 之后,Java 对引用的概念进行了扩充,将引用分为强引用(Strong Reference)、软引用(Soft Reference)、弱引用(Weak Reference)、虚引用(Phantom Reference)4种,这 4 种引用强度依次逐渐减弱。
强引用就是指在程序代码之中普遍存在的,类似"Object obj=new Object()“这类的引用,只要强引用还存在,垃圾收集器永远不会回收掉被引用的对象。
软引用是用来描述一些还有用但并非必需的对象。对于软引用关联着的对象,在系统将要发生内存溢出异常之前,将会把这些对象列进回收范围之中进行第二次回收。如果这次回收还没有足够的内存,才会抛出内存溢出异常。在 JDK 1.2 之后,提供了 SoftReference 类来实现软引用。
弱引用也是用来描述非必需对象的,但是它的强度比软引用更弱一些,被弱引用关联的对象只能生存到下一次垃圾收集发生之前。当垃圾收集器工作时,无论当前内存是否足够,都会回收掉只被弱引用关联的对象。在 JDK 1. 2之后,提供了 WeakReference 类来实现弱引用。
虚引用也称为幽灵引用或者幻影引用,它是最弱的一种引用关系。一个对象是否有虚引用的存在,完全不会对其生存时间构成影响,也无法通过虚引用来取得一个对象实例。为一个对象设置虚引用关联的唯一目的就是能在这个对象被收集器回收时收到一个系统通知。在 JDK 1.2 之后,提供了 PhantomReference 类来实现虚引用。
3.2.4 生存还是死亡
即使在可达性分析算法中不可达的对象,也并非是“非死不可”的,这时候它们暂时处于“缓刑”阶段,要真正宣告一个对象死亡,至少要经历两次标记过程:如果对象在进行可达性分析后发现没有与 GC Roots 相连接的引用链,那它将会被第一次标记并且进行一次筛选,筛选的条件是此对象是否有必要执行 finalize() 方法。当对象没有覆盖 finalize() 方法,或者 finalize() 方法已经被虚拟机调用过,虚拟机将这两种情况都视为“没有必要执行”。
如果这个对象被判定为有必要执行 finalize() 方法,那么这个对象将会放置在一个叫做 F-Queue 的队列之中,并在稍后由一个由虚拟机自动建立的、低优先级的 Finalizer 线程去执行它。这里所谓的“执行”是指虚拟机会触发这个方法,但并不承诺会等待它运行结束,这样做的原因是,如果一个对象在 finalize() 方法中执行缓慢,或者发生了死循环(更极端的情况),将很可能会导致 F-Queue 队列中其他对象永久处于等待,甚至导致整个内存回收系统崩溃。finalize() 方法是对象逃脱死亡命运的最后一次机会,稍后 GC 将对 F-Queue 中的对象进行第二次小规模的标记,如果对象要在 finalize() 中成功拯救自己——只要重新与引用链上的任何一个对象建立关联即可,譬如把自己(this关键字)赋值给某个类变量或者对象的成员变量,那在第二次标记时它将被移除出“即将回收”的集合;如果对象这时候还没有逃脱,那基本上它就真的被回收了。从代码清单 3-2 中我们可以看到一个对象的 finalize() 被执行,但是它仍然可以存活。
/**
*此代码演示了两点:
*1.对象可以在被 GC 时自我拯救。
*2.这种自救的机会只有一次, 因为一个对象的 finalize() 方法最多只会被系统自动调用一次
*@author zzm
*/
public class FinalizeEscapeGC{
public static FinalizeEscapeGC SAVE_HOOK=null;
public void isAlive(){
System.out.println("yes,i am still alive:)");
}
@Override
protected void finalize()throws Throwable{
super.finalize();
System.out.println("finalize mehtod executed!");
FinalizeEscapeGC.SAVE_HOOK=this;
}
public static void main(String[]args)throws Throwable{
SAVE_HOOK=new FinalizeEscapeGC();
//对象第一次成功拯救自己
SAVE_HOOK=null;
System.gc();
//因为finalize方法优先级很低, 所以暂停0.5秒以等待它
Thread.sleep(500);
if(SAVE_HOOK!=null){
SAVE_HOOK.isAlive();
}else{
System.out.println("no,i am dead:(");
}
//下面这段代码与上面的完全相同, 但是这次自救却失败了
SAVE_HOOK=null;
System.gc();
//因为finalize方法优先级很低, 所以暂停0.5秒以等待它
Thread.sleep(500);
if(SAVE_HOOK!=null){
SAVE_HOOK.isAlive();
}else{
System.out.println("no,i am dead:(");
}
}
}
从代码清单3-2的运行结果可以看出,SAVE_HOOK 对象的 finalize() 方法确实被 GC 收集器触发过,并且在被收集前成功逃脱了。
另外一个值得注意的地方是,代码中有两段完全一样的代码片段,执行结果却是一次逃脱成功,一次失败,这是因为任何一个对象的 finalize() 方法都只会被系统自动调用一次,如果对象面临下一次回收,它的 finalize() 方法不会被再次执行,因此第二段代码的自救行动失败了。
需要特别说明的是,上面关于对象死亡时 finalize() 方法的描述可能带有悲情的艺术色彩,笔者并不鼓励大家使用这种方法来拯救对象。相反,笔者建议大家尽量避免使用它,因为它不是 C/C++ 中的析构函数,而是 Java 刚诞生时为了使 C/C++ 程序员更容易接受它所做出的一个妥协。它的运行代价高昂,不确定性大,无法保证各个对象的调用顺序。有些教材中描述它适合做“关闭外部资源”之类的工作,这完全是对这个方法用途的一种自我安慰。finalize() 能做的所有工作,使用 try-finally 或者其他方式都可以做得更好、更及时,所以笔者建议大家完全可以忘掉 Java 语言中有这个方法的存在。
3.2.5 回收方法区
很多人认为方法区(或者HotSpot虚拟机中的永久代)是没有垃圾收集的,Java 虚拟机规范中确实说过可以不要求虚拟机在方法区实现垃圾收集,而且在方法区中进行垃圾收集的“性价比”一般比较低:在堆中,尤其是在新生代中,常规应用进行一次垃圾收集一般可以回收 70%~95% 的空间,而永久代的垃圾收集效率远低于此。
永久代的垃圾收集主要回收两部分内容:废弃常量和无用的类。回收废弃常量与回收 Java 堆中的对象非常类似。以常量池中字面量的回收为例,假如一个字符串"abc"已经进入了常量池中,但是当前系统没有任何一个 String 对象是叫做"abc"的,换句话说,就是没有任何 String 对象引用常量池中的"abc"常量,也没有其他地方引用了这个字面量,如果这时发生内存回收,而且必要的话,这个"abc"常量就会被系统清理出常量池。常量池中的其他类(接口)、方法、字段的符号引用也与此类似。
判定一个常量是否是“废弃常量”比较简单,而要判定一个类是否是“无用的类”的条件则相对苛刻许多。类需要同时满足下面 3 个条件才能算是“无用的类”:
- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
- 加载该类的 ClassLoader 已经被回收。
- 该类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
虚拟机可以对满足上述 3 个条件的无用类进行回收,这里说的仅仅是“可以”,而并不是和对象一样,不使用了就必然会回收。是否对类进行回收,HotSpot 虚拟机提供了-Xnoclassgc参数进行控制,还可以使用-verbose:class以及-XX:+TraceClassLoading、-XX:+TraceClassUnLoading查看类加载和卸载信息,其中-verbose:class和-XX:+TraceClassLoading可以在 Product 版的虚拟机中使用,-XX:+TraceClassUnLoading参数需要 FastDebug 版的虚拟机支持。
在大量使用反射、动态代理、CGLib 等 ByteCode 框架、动态生成 JSP 以及 OSGi 这类频繁自定义 ClassLoader 的场景都需要虚拟机具备类卸载的功能,以保证永久代不会溢出。
3.3 垃圾回收算法
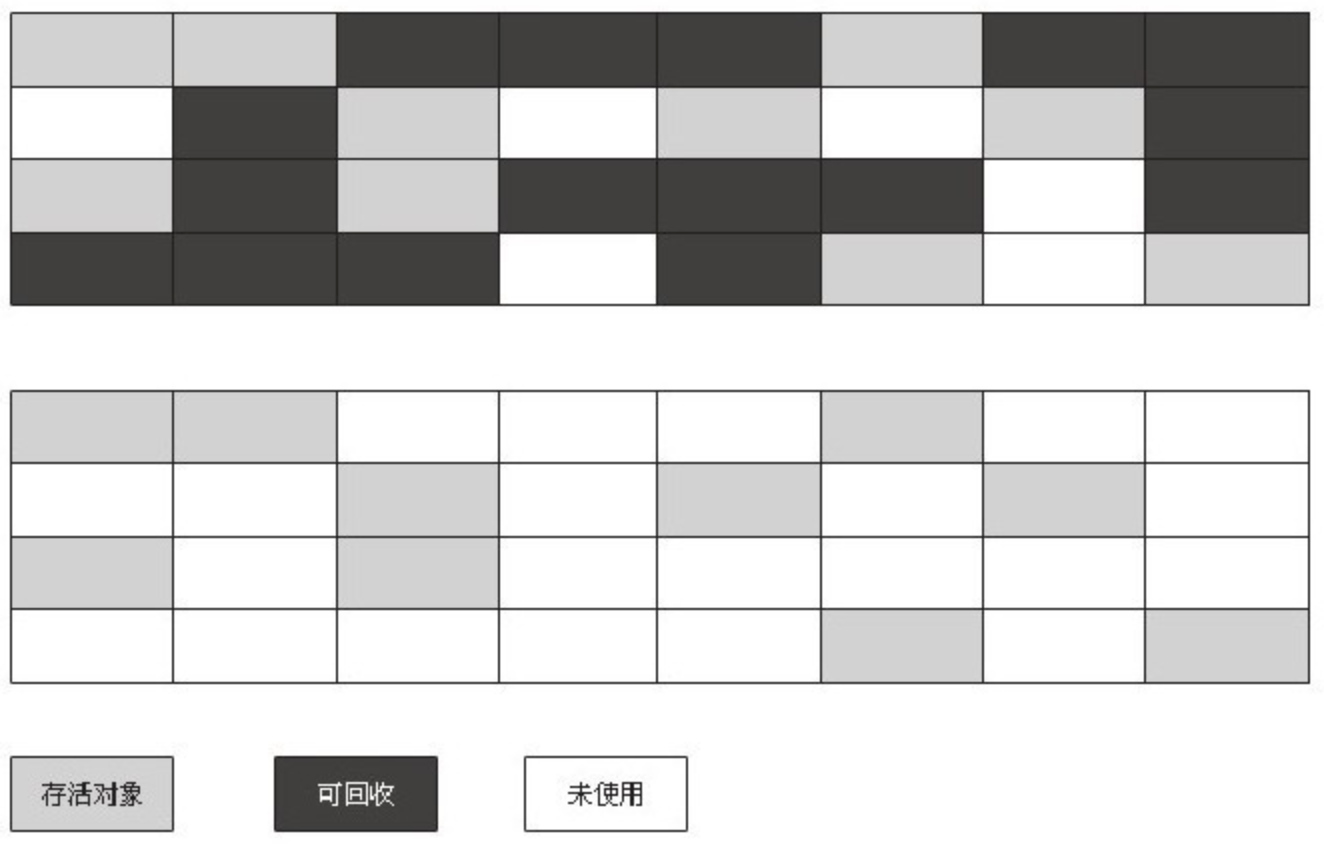
3.3.1 标记-清除算法
最基础的收集算法是“标记-清除”(Mark-Sweep)算法,如同它的名字一样,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象,它的标记过程其实在前一节讲述对象标记判定时已经介绍过了。之所以说它是最基础的收集算法,是因为后续的收集算法都是基于这种思路并对其不足进行改进而得到的。它的主要不足有两个:一个是效率问题,标记和清除两个过程的效率都不高;另一个是空间问题,标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行过程中需要分配较大对象时,无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。标记—清除算法的执行过程如图 3-2 所示。
3.3.2 复制算法
为了解决效率问题,一种称为“复制”(Copying)的收集算法出现了,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。这样使得每次都是对整个半区进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将内存缩小为了原来的一半,代价未免太高了一点。复制算法的执行过程如图3-3所示。
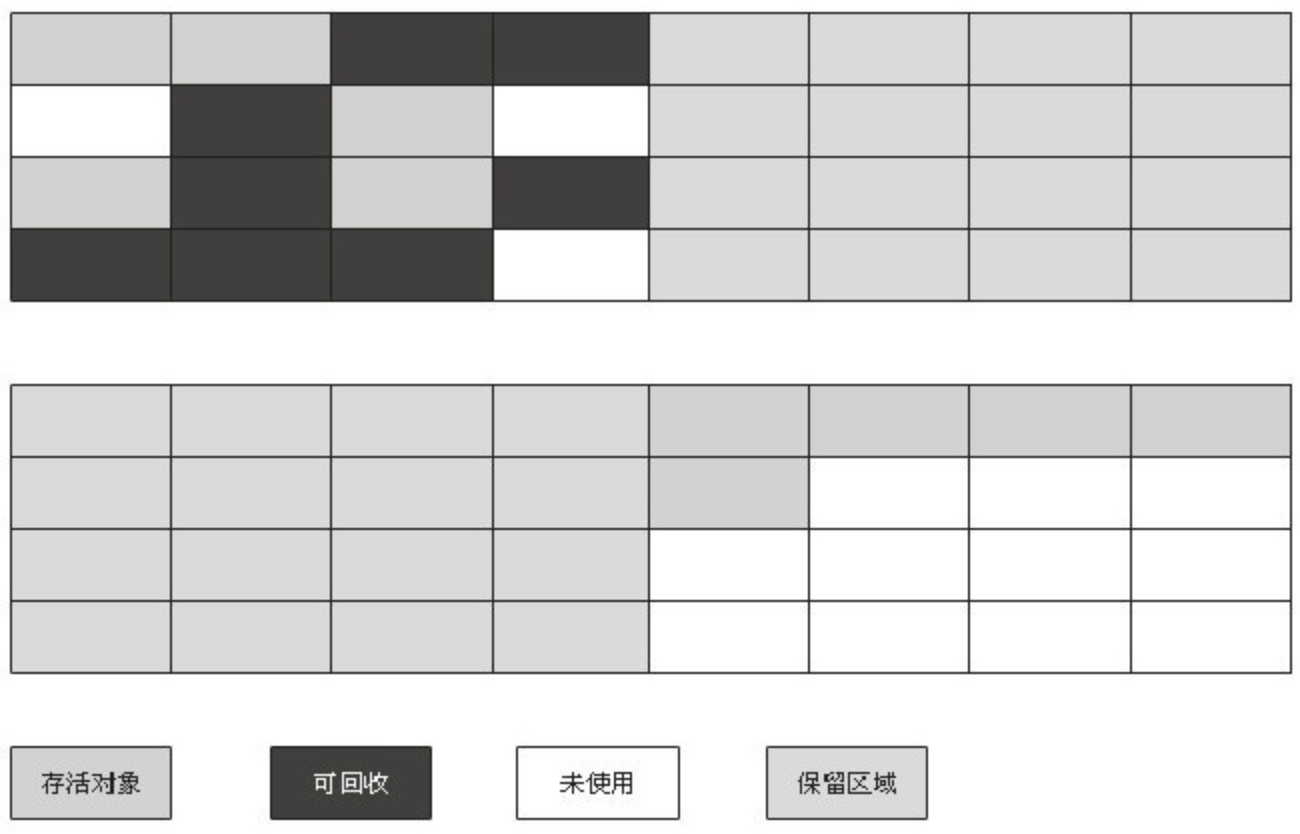
现在的商业虚拟机都采用这种收集算法来回收新生代,IBM 公司的专门研究表明,新生代中的对象 98% 是“朝生夕死”的,所以并不需要按照 1:1 的比例来划分内存空间,而是将内存分为一块较大的 Eden 空间和两块较小的 Survivor 空间,每次使用 Eden 和其中一块 Survivor。当回收时,将 Eden 和 Survivor 中还存活着的对象一次性地复制到另外一块 Survivor 空间上,最后清理掉Eden和刚才用过的 Survivor 空间。HotSpot 虚拟机默认 Eden 和 Survivor 的大小比例是 8:1,也就是每次新生代中可用内存空间为整个新生代容量的 90%(80%+10%),只有 10% 的内存会被“浪费”。当然,98% 的对象可回收只是一般场景下的数据,我们没有办法保证每次回收都只有不多于 10% 的对象存活,当 Survivo r空间不够用时,需要依赖其他内存(这里指老年代)进行分配担保(Handle Promotion)。
内存的分配担保就好比我们去银行借款,如果我们信誉很好,在 98% 的情况下都能按时偿还,于是银行可能会默认我们下一次也能按时按量地偿还贷款,只需要有一个担保人能保证如果我不能还款时,可以从他的账户扣钱,那银行就认为没有风险了。内存的分配担保也一样,如果另外一块 Survivor 空间没有足够空间存放上一次新生代收集下来的存活对象时,这些对象将直接通过分配担保机制进入老年代。关于对新生代进行分配担保的内容,在本章稍后在讲解垃圾收集器执行规则时还会再详细讲解。
3.3.3 标记-整理算法
复制收集算法在对象存活率较高时就要进行较多的复制操作,效率将会变低。更关键的是,如果不想浪费 50% 的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都 100% 存活的极端情况,所以在老年代一般不能直接选用这种算法。
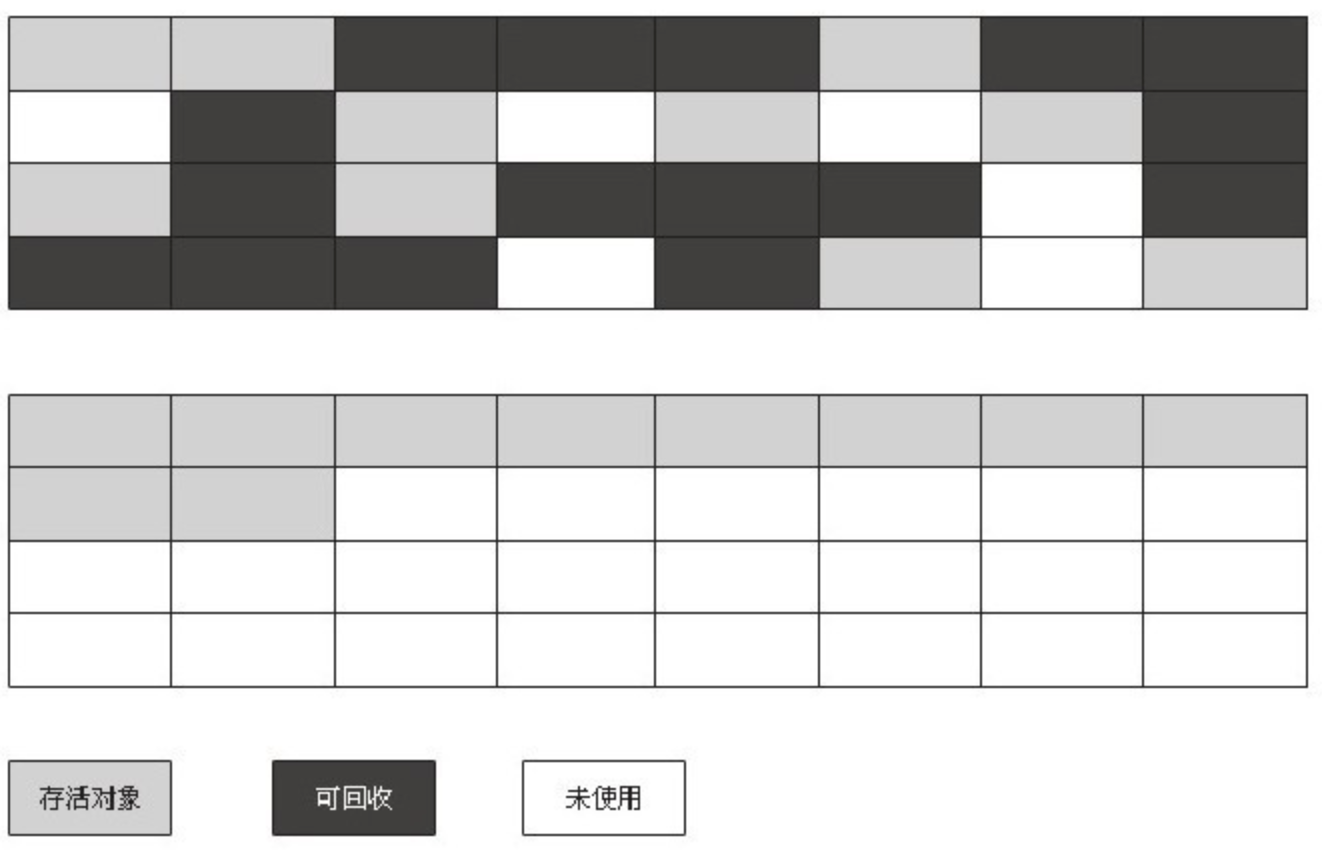
根据老年代的特点,有人提出了另外一种“标记-整理”(Mark-Compact)算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存,“标记-整理”算法的示意图如图3-4所示。
3.3.4 分代收集算法
当前商业虚拟机的垃圾收集都采用“分代收集”(Generational Collection)算法,这种算法并没有什么新的思想,只是根据对象存活周期的不同将内存划分为几块。一般是把 Java 堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记—清理”或者“标记—整理”算法来进行回收。
3.4 HotSpot 算法实现
3.2 节和 3.3 节从理论上介绍了对象存活判定算法和垃圾收集算法,而在 HotSpot 虚拟机上实现这些算法时,必须对算法的执行效率有严格的考量,才能保证虚拟机高效运行。
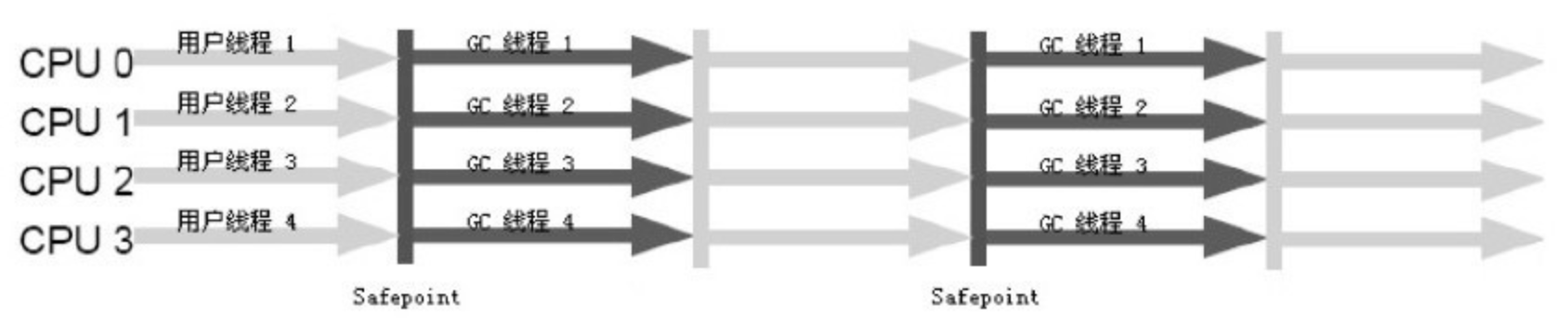
3.4.1 枚举根节点
从可达性分析中从 GC Roots 节点找引用链这个操作为例,可作为 GC Roots 的节点主要在全局性的引用(例如常量或类静态属性)与执行上下文(例如栈帧中的本地变量表)中,现在很多应用仅仅方法区就有数百兆,如果要逐个检查这里面的引用,那么必然会消耗很多时间。
另外,可达性分析对执行时间的敏感还体现在 GC 停顿上,因为这项分析工作必须在一个能确保一致性的快照中进行——这里“一致性”的意思是指在整个分析期间整个执行系统看起来就像被冻结在某个时间点上,不可以出现分析过程中对象引用关系还在不断变化的情况,该点不满足的话分析结果准确性就无法得到保证。这点是导致 GC 进行时必须停顿所有 Java 执行线程(Sun将这件事情称为"Stop The World”)的其中一个重要原因,即使是在号称(几乎)不会发生停顿的 CMS 收集器中,枚举根节点时也是必须要停顿的。
由于目前的主流 Java 虚拟机使用的都是准确式 GC(这个概念在第 1 章介绍Exact VM对 Classic VM 的改进时讲过),所以当执行系统停顿下来后,并不需要一个不漏地检查完所有执行上下文和全局的引用位置,虚拟机应当是有办法直接得知哪些地方存放着对象引用。在 HotSpot 的实现中,是使用一组称为 OopMap 的数据结构来达到这个目的的,在类加载完成的时候,HotSpot 就把对象内什么偏移量上是什么类型的数据计算出来,在 JIT 编译过程中,也会在特定的位置记录下栈和寄存器中哪些位置是引用。这样,GC 在扫描时就可以直接得知这些信息了。下面的代码清单 3-3 是 HotSpot Client VM 生成的一段 String.hashCode() 方法的本地代码,可以看到在 0x026eb7a9 处的 call 指令有 OopMap 记录,它指明了 EBX 寄存器和栈中偏移量为 16 的内存区域中各有一个普通对象指针(Ordinary Object Pointer)的引用,有效范围为从 call 指令开始直到 0x026eb730(指令流的起始位置)+142(OopMap记录的偏移量)=0x026eb7be,即 hlt 指令为止。
[Verified Entry Point]
0x026eb730:mov%eax, -0x8000(%esp)
……
;ImplicitNullCheckStub slow case
0x026eb7a9:call 0x026e83e0
;OopMap{ebx=Oop[16]=Oop off=142}
;*caload
;-java.lang.String:hashCode@48(line 1489)
;{runtime_call}
0x026eb7ae:push$0x83c5c18
;{external_word}
0x026eb7b3:call 0x026eb7b8
0x026eb7b8:pusha
0x026eb7b9:call 0x0822bec0;{runtime_call}
0x026eb7be:hlt
3.4.2 安全点
在 OopMap 的协助下,HotSpot 可以快速且准确地完成 GC Roots 枚举,但一个很现实的问题随之而来:可能导致引用关系变化,或者说 OopMap 内容变化的指令非常多,如果为每一条指令都生成对应的 OopMap,那将会需要大量的额外空间,这样 GC 的空间成本将会变得很高。
实际上,HotSpot 也的确没有为每条指令都生成 OopMap,前面已经提到,只是在“特定的位置”记录了这些信息,这些位置称为安全点(Safepoint),即程序执行时并非在所有地方都能停顿下来开始 GC,只有在到达安全点时才能暂停。Safepoint 的选定既不能太少以致于让 GC 等待时间太长,也不能过于频繁以致于过分增大运行时的负荷。所以,安全点的选定基本上是以程序“是否具有让程序长时间执行的特征”为标准进行选定的——因为每条指令执行的时间都非常短暂,程序不太可能因为指令流长度太长这个原因而过长时间运行,“长时间执行”的最明显特征就是指令序列复用,例如方法调用、循环跳转、异常跳转等,所以具有这些功能的指令才会产生 Safepoint。
对于 Sefepoint,另一个需要考虑的问题是如何在 GC 发生时让所有线程(这里不包括执行 JNI 调用的线程)都“跑”到最近的安全点上再停顿下来。这里有两种方案可供选择:抢先式中断(Preemptive Suspension)和主动式中断(Voluntary Suspension),其中抢先式中断不需要线程的执行代码主动去配合,在 GC 发生时,首先把所有线程全部中断,如果发现有线程中断的地方不在安全点上,就恢复线程,让它“跑”到安全点上。现在几乎没有虚拟机实现采用抢先式中断来暂停线程从而响应 GC 事件。
而主动式中断的思想是当 GC 需要中断线程的时候,不直接对线程操作,仅仅简单地设置一个标志,各个线程执行时主动去轮询这个标志,发现中断标志为真时就自己中断挂起。轮询标志的地方和安全点是重合的,另外再加上创建对象需要分配内存的地方。下面代码清单 3-4 中的 test 指令是 HotSpot 生成的轮询指令,当需要暂停线程时,虚拟机把 0x160100 的内存页设置为不可读,线程执行到 test 指令时就会产生一个自陷异常信号,在预先注册的异常处理器中暂停线程实现等待,这样一条汇编指令便完成安全点轮询和触发线程中断。
0x01b6d627:call 0x01b2b210;OopMap{[60]=Oop off=460}
;*invokeinterface size
;-Client1:main@113(line 23)
;{virtual_call}
0x01b6d62c:nop
;OopMap{[60]=Oop off=461}
;*if_icmplt
;-Client1:main@118(line 23)
0x01b6d62d:test%eax, 0x160100;{poll}
0x01b6d633:mov 0x50(%esp), %esi
0x01b6d637:cmp%eax, %esi
3.4.3 安全区域
使用 Safepoint 似乎已经完美地解决了如何进入 GC 的问题,但实际情况却并不一定。Safepoint 机制保证了程序执行时,在不太长的时间内就会遇到可进入 GC 的 Safepoint。但是,程序“不执行”的时候呢?所谓的程序不执行就是没有分配 CPU 时间,典型的例子就是线程处于 Sleep 状态或者 Blocked 状态,这时候线程无法响应 JVM 的中断请求,“走”到安全的地方去中断挂起,JVM 也显然不太可能等待线程重新被分配 CPU 时间。对于这种情况,就需要安全区域(Safe Region)来解决。
安全区域是指在一段代码片段之中,引用关系不会发生变化。在这个区域中的任意地方开始 GC 都是安全的。我们也可以把 Safe Region 看做是被扩展了的 Safepoint。
在线程执行到 Safe Region 中的代码时,首先标识自己已经进入了 Safe Region,那样,当在这段时间里 JVM 要发起 GC 时,就不用管标识自己为 Safe Region 状态的线程了。在线程要离开 Safe Region 时,它要检查系统是否已经完成了根节点枚举(或者是整个 GC 过程),如果完成了,那线程就继续执行,否则它就必须等待直到收到可以安全离开 Safe Region 的信号为止。
到此,笔者简要地介绍了 HotSpot 虚拟机如何去发起内存回收的问题,但是虚拟机如何具体地进行内存回收动作仍然未涉及,因为内存回收如何进行是由虚拟机所采用的 GC 收集器决定的,而通常虚拟机中往往不止有一种 GC 收集器。下面继续来看 HotSpot 中有哪些 GC 收集器。
3.5 垃圾收集器
如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。Java 虚拟机规范中对垃圾收集器应该如何实现并没有任何规定,因此不同的厂商、不同版本的虚拟机所提供的垃圾收集器都可能会有很大差别,并且一般都会提供参数供用户根据自己的应用特点和要求组合出各个年代所使用的收集器。这里讨论的收集器基于 JDK 1.7 Update 14 之后的 HotSpot 虚拟机(在这个版本中正式提供了商用的 G1 收集器,之前 G1 仍处于实验状态),这个虚拟机包含的所有收集器如图 3-5 所示。
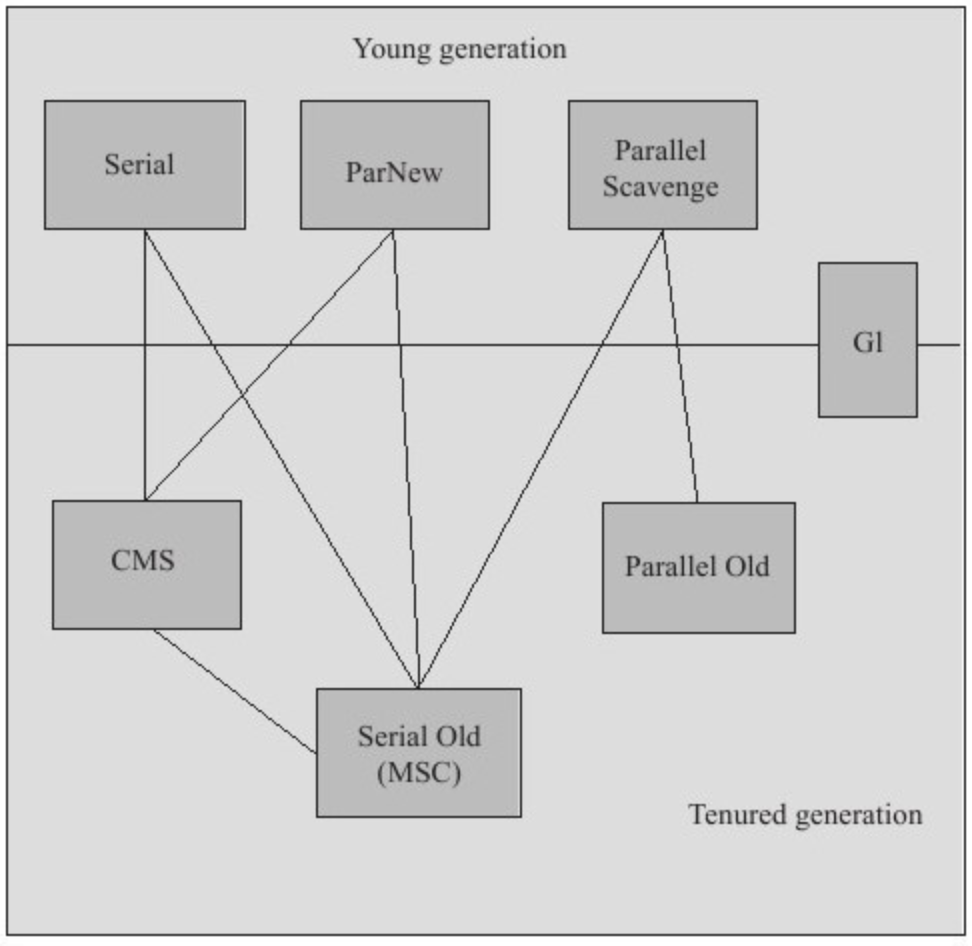
图 3-5 展示了 7 种作用于不同分代的收集器,如果两个收集器之间存在连线,就说明它们可以搭配使用。虚拟机所处的区域,则表示它是属于新生代收集器还是老年代收集器。接下来笔者将逐一介绍这些收集器的特性、基本原理和使用场景,并重点分析 CMS 和 G1 这两款相对复杂的收集器,了解它们的部分运作细节。
在介绍这些收集器各自的特性之前,我们先来明确一个观点:虽然我们是在对各个收集器进行比较,但并非为了挑选出一个最好的收集器。因为直到现在为止还没有最好的收集器出现,更加没有万能的收集器,所以我们选择的只是对具体应用最合适的收集器。这点不需要多加解释就能证明:如果有一种放之四海皆准、任何场景下都适用的完美收集器存在,那 HotSpot 虚拟机就没必要实现那么多不同的收集器了。
3.5.1 Serial 收集器
Serial 收集器是最基本、发展历史最悠久的收集器,曾经(在 JDK 1.3.1 之前)是虚拟机新生代收集的唯一选择。大家看名字就会知道,这个收集器是一个单线程的收集器,但它的“单线程”的意义并不仅仅说明它只会使用一个 CPU 或一条收集线程去完成垃圾收集工作,更重要的是在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束。“Stop The World"这个名字也许听起来很酷,但这项工作实际上是由虚拟机在后台自动发起和自动完成的,在用户不可见的情况下把用户正常工作的线程全部停掉,这对很多应用来说都是难以接受的。读者不妨试想一下,要是你的计算机每运行一个小时就会暂停响应 5 分钟,你会有什么样的心情?图 3-6 示意了 Serial/Serial Old 收集器的运行过程。

对于"Stop The World"带给用户的不良体验,虚拟机的设计者们表示完全理解,但也表示非常委屈:“你妈妈在给你打扫房间的时候,肯定也会让你老老实实地在椅子上或者房间外待着,如果她一边打扫,你一边乱扔纸屑,这房间还能打扫完?”这确实是一个合情合理的矛盾,虽然垃圾收集这项工作听起来和打扫房间属于一个性质的,但实际上肯定还要比打扫房间复杂得多啊!
从 JDK 1.3 开始,一直到现在最新的 JDK 1.7,HotSpot 虚拟机开发团队为消除或者减少工作线程因内存回收而导致停顿的努力一直在进行着,从 Serial 收集器到 Parallel 收集器,再到 Concurrent Mark Sweep(CMS)乃至 GC 收集器的最前沿成果 Garbage First(G1)收集器,我们看到了一个个越来越优秀(也越来越复杂)的收集器的出现,用户线程的停顿时间在不断缩短,但是仍然没有办法完全消除(这里暂不包括 RTSJ 中的收集器)。寻找更优秀的垃圾收集器的工作仍在继续!
写到这里,笔者似乎已经把 Serial 收集器描述成一个“老而无用、食之无味弃之可惜”的鸡肋了,但实际上到现在为止,它依然是虚拟机运行在 Client 模式下的默认新生代收集器。它也有着优于其他收集器的地方:简单而高效(与其他收集器的单线程比),对于限定单个 CPU 的环境来说,Serial 收集器由于没有线程交互的开销,专心做垃圾收集自然可以获得最高的单线程收集效率。在用户的桌面应用场景中,分配给虚拟机管理的内存一般来说不会很大,收集几十兆甚至一两百兆的新生代(仅仅是新生代使用的内存,桌面应用基本上不会再大了),停顿时间完全可以控制在几十毫秒最多一百多毫秒以内,只要不是频繁发生,这点停顿是可以接受的。所以,Serial 收集器对于运行在 Client 模式下的虚拟机来说是一个很好的选择。
3.5.2 ParNew 收集器
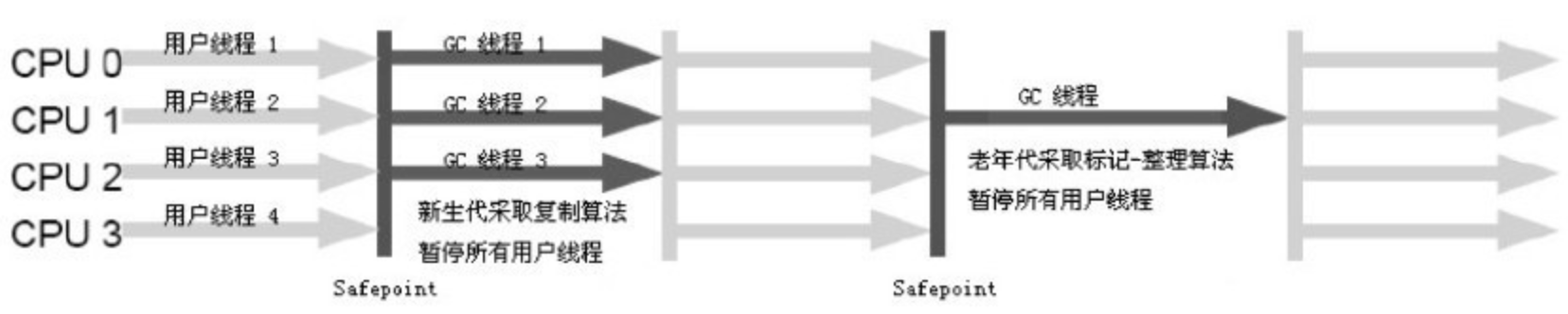
ParNew 收集器其实就是 Serial 收集器的多线程版本,除了使用多条线程进行垃圾收集之外,其余行为包括 Serial 收集器可用的所有控制参数(例如:-XX:SurvivorRatio、-XX:PretenureSizeThreshold、-XX:HandlePromotionFailure 等)、收集算法、Stop The World、对象分配规则、回收策略等都与 Serial 收集器完全一样,在实现上,这两种收集器也共用了相当多的代码。ParNew 收集器的工作过程如图 3-7 所示。
ParNew 收集器除了多线程收集之外,其他与 Serial 收集器相比并没有太多创新之处,但它却是许多运行在 Server 模式下的虚拟机中首选的新生代收集器,其中有一个与性能无关但很重要的原因是,除了 Serial 收集器外,目前只有它能与 CMS 收集器配合工作。在 JDK 1.5 时期,HotSpot 推出了一款在强交互应用中几乎可认为有划时代意义的垃圾收集器——CMS 收集器(Concurrent Mark Sweep,本节稍后将详细介绍这款收集器),这款收集器是 HotSpot 虚拟机中第一款真正意义上的并发(Concurrent)收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作,用前面那个例子的话来说,就是做到了在你的妈妈打扫房间的时候你还能一边往地上扔纸屑。
不幸的是,CMS 作为老年代的收集器,却无法与 JDK 1.4.0 中已经存在的新生代收集器 Parallel Scavenge 配合工作,所以在 JDK 1.5 中使用 CMS 来收集老年代的时候,新生代只能选择 ParNew 或者 Serial 收集器中的一个。ParNew 收集器也是使用 -XX:+UseConcMarkSweepGC 选项后的默认新生代收集器,也可以使用 -XX:+UseParNewGC 选项来强制指定它。
ParNew 收集器在单 CPU 的环境中绝对不会有比 Serial 收集器更好的效果,甚至由于存在线程交互的开销,该收集器在通过超线程技术实现的两个 CPU 的环境中都不能百分之百地保证可以超越 Serial 收集器。当然,随着可以使用的 CPU 的数量的增加,它对于 GC 时系统资源的有效利用还是很有好处的。它默认开启的收集线程数与 CPU 的数量相同,在 CPU 非常多(譬如32个,现在 CPU 动辄就4核加超线程,服务器超过 32 个逻辑 CPU 的情况越来越多了)的环境下,可以使用 -XX:ParallelGCThreads 参数来限制垃圾收集的线程数。
注意 从 ParNew 收集器开始,后面还会接触到几款并发和并行的收集器。在大家可能产生疑惑之前,有必要先解释两个名词:并发和并行。这两个名词都是并发编程中的概念,在谈论垃圾收集器的上下文语境中,它们可以解释如下。
- 并行(Parallel):指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
- 并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行的,可能会交替执行),用户程序在继续运行,而垃圾收集程序运行于另一个 CPU 上。
3.5.3 Parallel Scavenge 收集器
Parallel Scavenge 收集器是一个新生代收集器,它也是使用复制算法的收集器,又是并行的多线程收集器……看上去和 ParNew 都一样,那它有什么特别之处呢?
Parallel Scavenge 收集器的特点是它的关注点与其他收集器不同,CMS 等收集器的关注点是尽可能地缩短垃圾收集时用户线程的停顿时间,而 Parallel Scavenge 收集器的目标则是达到一个可控制的吞吐量(Throughput)。所谓吞吐量就是 CPU 用于运行用户代码的时间与 CPU 总消耗时间的比值,即吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间),虚拟机总共运行了 100 分钟,其中垃圾收集花掉 1 分钟,那吞吐量就是 99%。
停顿时间越短就越适合需要与用户交互的程序,良好的响应速度能提升用户体验,而高吞吐量则可以高效率地利用 CPU 时间,尽快完成程序的运算任务,主要适合在后台运算而不需要太多交互的任务。
Parallel Scavenge 收集器提供了两个参数用于精确控制吞吐量,分别是控制最大垃圾收集停顿时间的 -XX:MaxGCPauseMillis 参数以及直接设置吞吐量大小的 -XX:GCTimeRatio 参数。
MaxGCPauseMillis 参数允许的值是一个大于 0 的毫秒数,收集器将尽可能地保证内存回收花费的时间不超过设定值。不过大家不要认为如果把这个参数的值设置得稍小一点就能使得系统的垃圾收集速度变得更快,GC 停顿时间缩短是以牺牲吞吐量和新生代空间来换取的:系统把新生代调小一些,收集 300MB 新生代肯定比收集 500MB 快吧,这也直接导致垃圾收集发生得更频繁一些,原来 10 秒收集一次、每次停顿 100 毫秒,现在变成 5 秒收集一次、每次停顿 70 毫秒。停顿时间的确在下降,但吞吐量也降下来了。
GCTimeRatio 参数的值应当是一个大于 0 且小于 100 的整数,也就是垃圾收集时间占总时间的比率,相当于是吞吐量的倒数。如果把此参数设置为 19,那允许的最大GC时间就占总时间的 5%(即1/(1+19)),默认值为 99,就是允许最大 1%(即1/(1+99))的垃圾收集时间。
由于与吞吐量关系密切,Parallel Scavenge 收集器也经常称为“吞吐量优先”收集器。除上述两个参数之外,Parallel Scavenge 收集器还有一个参数 -XX:+UseAdaptiveSizePolicy 值得关注。这是一个开关参数,当这个参数打开之后,就不需要手工指定新生代的大小(-Xmn)、Eden 与 Survivor 区的比例(-XX:SurvivorRatio)、晋升老年代对象年龄(-XX:PretenureSizeThreshold)等细节参数了,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或者最大的吞吐量,这种调节方式称为 GC 自适应的调节策略(GC Ergonomics)。如果读者对于收集器运作原来不太了解,手工优化存在困难的时候,使用 Parallel Scavenge 收集器配合自适应调节策略,把内存管理的调优任务交给虚拟机去完成将是一个不错的选择。只需要把基本的内存数据设置好(如 -Xmx 设置最大堆),然后使用 MaxGCPauseMillis 参数(更关注最大停顿时间)或 GCTimeRatio(更关注吞吐量)参数给虚拟机设立一个优化目标,那具体细节参数的调节工作就由虚拟机完成了。自适应调节策略也是 Parallel Scavenge 收集器与 ParNew 收集器的一个重要区别。
3.5.4 Serial Old 收集器
Serial Old 是 Serial 收集器的老年代版本,它同样是一个单线程收集器,使用“标记-整理”算法。这个收集器的主要意义也是在于给 Client 模式下的虚拟机使用。如果在 Server 模式下,那么它主要还有两大用途:一种用途是在 JDK 1.5 以及之前的版本中与 Parallel Scavenge 收集器搭配使用,另一种用途就是作为 CMS 收集器的后备预案,在并发收集发生 Concurrent Mode Failure 时使用。这两点都将在后面的内容中详细讲解。Serial Old 收集器的工作过程如图 3-8 所示。

3.5.5 Parallel Old 收集器
Parallel Old 是 Parallel Scavenge 收集器的老年代版本,使用多线程和“标记-整理”算法。这个收集器是在 JDK 1.6 中才开始提供的,在此之前,新生代的 Parallel Scavenge 收集器一直处于比较尴尬的状态。原因是,如果新生代选择了 Parallel Scavenge 收集器,老年代除了 Serial Old(PS MarkSweep)收集器外别无选择(还记得上面说过 Parallel Scavenge 收集器无法与 CMS 收集器配合工作吗?)。由于老年代 Serial Old 收集器在服务端应用性能上的“拖累”,使用了 Parallel Scavenge 收集器也未必能在整体应用上使用了 Parallel Scavenge 收集器也未必能在整体应用上获得吞吐量最大化的效果,由于单线程的老年代收集中无法充分利用服务器多 CPU 的处理能力,在老年代很大而且硬件比较高级的环境中,这种组合的吞吐量甚至还不一定有 ParNew 加 CMS 的组合“给力”。
直到 Parallel Old 收集器出现后,“吞吐量优先”收集器终于有了比较名副其实的应用组合,在注重吞吐量以及 CPU 资源敏感的场合,都可以优先考虑 Parallel Scavenge 加 Parallel Old 收集器。Parallel Old 收集器的工作过程如图3-9所示。
3.5.6 CMS 收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。目前很大一部分的 Java 应用集中在互联网站或者 B/S 系统的服务端上,这类应用尤其重视服务的响应速度,希望系统停顿时间最短,以给用户带来较好的体验。CMS 收集器就非常符合这类应用的需求。
从名字(包含"Mark Sweep”)上就可以看出,CMS 收集器是基于“标记—清除”算法实现的,它的运作过程相对于前面几种收集器来说更复杂一些,整个过程分为 4 个步骤,包括:
- 初始标记(CMS initial mark)
- 并发标记(CMS concurrent mark)
- 重新标记(CMS remark)
- 并发清除(CMS concurrent sweep)
其中,初始标记、重新标记这两个步骤仍然需要"Stop The World"。初始标记仅仅只是标记一下 GC Roots 能直接关联到的对象,速度很快,并发标记阶段就是进行 GC Roots Tracing 的过程,而重新标记阶段则是为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间短。
由于整个过程中耗时最长的并发标记和并发清除过程收集器线程都可以与用户线程一起工作,所以,从总体上来说,CMS 收集器的内存回收过程是与用户线程一起并发执行的。通过图 3-10 可以比较清楚地看到 CMS 收集器的运作步骤中并发和需要停顿的时间。
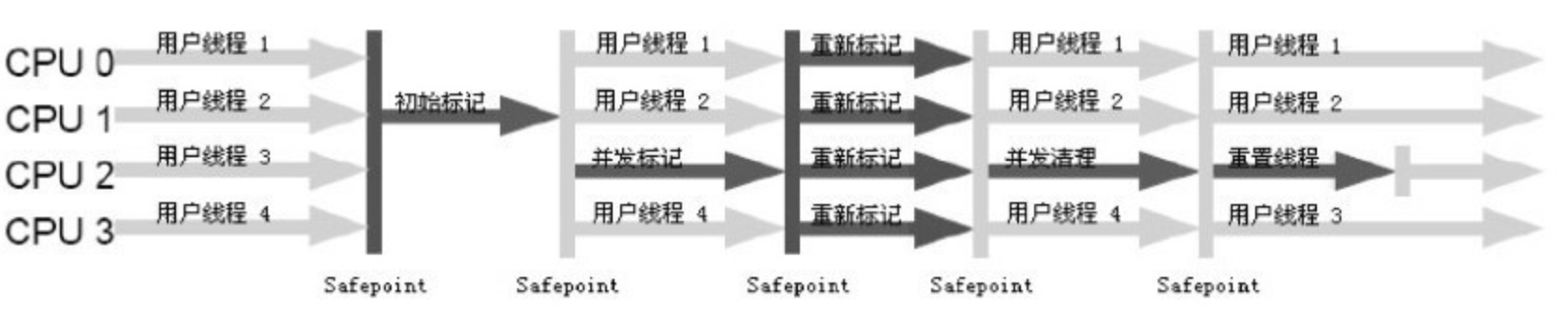
CMS 是一款优秀的收集器,它的主要优点在名字上已经体现出来了:并发收集、低停顿,Sun 公司的一些官方文档中也称之为并发低停顿收集器(Concurrent Low Pause Collector)。但是 CMS 还远达不到完美的程度,它有以下 3 个明显的缺点:
CMS 收集器对 CPU 资源非常敏感。其实,面向并发设计的程序都对 CPU 资源比较敏感。在并发阶段,它虽然不会导致用户线程停顿,但是会因为占用了一部分线程(或者说 CPU 资源)而导致应用程序变慢,总吞吐量会降低。CMS 默认启动的回收线程数是(CPU数量+3)/4,也就是当 CPU 在 4 个以上时,并发回收时垃圾收集线程不少于 25% 的 CPU 资源,并且随着 CPU 数量的增加而下降。但是当 CPU 不足 4 个(譬如2个)时,CMS 对用户程序的影响就可能变得很大,如果本来 CPU 负载就比较大,还分出一半的运算能力去执行收集器线程,就可能导致用户程序的执行速度忽然降低了 50%,其实也让人无法接受。为了应付这种情况,虚拟机提供了一种称为“增量式并发收集器”(Incremental Concurrent Mark Sweep/i-CMS)的 CMS 收集器变种,所做的事情和单 CPU 年代 PC 机操作系统使用抢占式来模拟多任务机制的思想一样,就是在并发标记、清理的时候让 GC 线程、用户线程交替运行,尽量减少 GC 线程的独占资源的时间,这样整个垃圾收集的过程会更长,但对用户程序的影响就会显得少一些,也就是速度下降没有那么明显。实践证明,增量时的 CMS 收集器效果很一般,在目前版本中, i-CMS 已经被声明为 “deprecated”,即不再提倡用户使用。
CMS 收集器无法处理浮动垃圾(Floating Garbage),可能出现"Concurrent Mode Failure"失败而导致另一次 Full GC 的产生。由于 CMS 并发清理阶段用户线程还在运行着,伴随程序运行自然就还会有新的垃圾不断产生,这一部分垃圾出现在标记过程之后,CMS 无法在当次收集中处理掉它们,只好留待下一次 GC 时再清理掉。这一部分垃圾就称为“浮动垃圾”。也是由于在垃圾收集阶段用户线程还需要运行,那也就还需要预留有足够的内存空间给用户线程使用,因此 CMS 收集器不能像其他收集器那样等到老年代几乎完全被填满了再进行收集,需要预留一部分空间提供并发收集时的程序运作使用。在 JDK 1.5 的默认设置下,CMS 收集器当老年代使用了 68% 的空间后就会被激活,这是一个偏保守的设置,如果在应用中老年代增长不是太快,可以适当调高参数 -XX:CMSInitiatingOccupancyFraction 的值来提高触发百分比,以便降低内存回收次数从而获取更好的性能,在 JDK 1.6 中,CMS 收集器的启动阈值已经提升至 92%。要是 CMS 运行期间预留的内存无法满足程序需要,就会出现一次"Concurrent Mode Failure"失败,这时虚拟机将启动后备预案:临时启用 Serial Old 收集器来重新进行老年代的垃圾收集,这样停顿时间就很长了。所以说参数 -XX:CM SInitiatingOccupancyFraction 设置得太高很容易导致大量"Concurrent Mode Failure"失败,性能反而降低。
还有最后一个缺点,在本节开头说过,CMS 是一款基于“标记—清除”算法实现的收集器,如果读者对前面这种算法介绍还有印象的话,就可能想到这意味着收集结束时会有大量空间碎片产生。空间碎片过多时,将会给大对象分配带来很大麻烦,往往会出现老年代还有很大空间剩余,但是无法找到足够大的连续空间来分配当前对象,不得不提前触发一次 Full GC。为了解决这个问题,CMS 收集器提供了一个 -XX:+UseCMSCompactAtFullCollection 开关参数(默认就是开启的),用于在 CMS 收集器顶不住要进行 FullGC 时开启内存碎片的合并整理过程,内存整理的过程是无法并发的,空间碎片问题没有了,但停顿时间不得不变长。虚拟机设计者还提供了另外一个参数 -XX:CMSFullGCsBeforeCompaction,这个参数是用于设置执行多少次不压缩的 Full GC 后,跟着来一次带压缩的(默认值为 0,表示每次进入 Full GC 时都进行碎片整理)。
3.5.7 G1 收集器
G1(Garbage-First)收集器是当今收集器技术发展的最前沿成果之一,早在 JDK 1.7 刚刚确立项目目标,Sun 公司给出的 JDK 1.7 RoadMap 里面,它就被视为 JDK 1.7 中 HotSpot 虚拟机的一个重要进化特征。从 JDK 6u14 中开始就有 Early Access 版本的 G1 收集器供开发人员实验、试用,由此开始 G1 收集器的"Experimental"状态持续了数年时间,直至 JDK 7u4,Sun 公司才认为它达到足够成熟的商用程度,移除了"Experimental"的标识。
G1 是一款面向服务端应用的垃圾收集器。HotSpot 开发团队赋予它的使命是(在比较长期的)未来可以替换掉 JDK 1.5 中发布的 CMS 收集器。与其他 GC 收集器相比,G1 具备如下特点。
并行与并发:G1 能充分利用多 CPU、多核环境下的硬件优势,使用多个 CPU(CPU 或者 CPU 核心)来缩短 Stop-The-World 停顿的时间,部分其他收集器原本需要停顿 Java 线程执行的 GC 动作,G1 收集器仍然可以通过并发的方式让 Java 程序继续执行。
分代收集:与其他收集器一样,分代概念在 G1 中依然得以保留。虽然 G1 可以不需要其他收集器配合就能独立管理整个 GC 堆,但它能够采用不同的方式去处理新创建的对象和已经存活了一段时间、熬过多次 GC 的旧对象以获取更好的收集效果。
空间整合:与 CMS 的“标记—清理”算法不同,G1 从整体来看是基于“标记—整理”算法实现的收集器,从局部(两个 Region 之间)上来看是基于“复制”算法实现的,但无论如何,这两种算法都意味着 G1 运作期间不会产生内存空间碎片,收集后能提供规整的可用内存。这种特性有利于程序长时间运行,分配大对象时不会因为无法找到连续内存空间而提前触发下一次 GC。
可预测的停顿:这是 G1 相对于 CMS 的另一大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内,消耗在垃圾收集上的时间不得超过 N 毫秒,这几乎已经是实时 Java(RTSJ)的垃圾收集器的特征了。
在 G1 之前的其他收集器进行收集的范围都是整个新生代或者老年代,而 G1 不再是这样。使用 G1 收集器时,Java 堆的内存布局就与其他收集器有很大差别,它将整个 Java 堆划分为多个大小相等的独立区域(Region),虽然还保留有新生代和老年代的概念,但新生代和老年代不再是物理隔离的了,它们都是一部分 Region(不需要连续)的集合。
G1 收集器之所以能建立可预测的停顿时间模型,是因为它可以有计划地避免在整个 Java 堆中进行全区域的垃圾收集。G1 跟踪各个 Region 里面的垃圾堆积的价值大小(回收所获得的空间大小以及回收所需时间的经验值),在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的 Region(这也就是 Garbage-First 名称的来由)。这种使用 Region 划分内存空间以及有优先级的区域回收方式,保证了 G1 收集器在有限的时间内可以获取尽可能高的收集效率。
G1 把内存“化整为零”的思路,理解起来似乎很容易,但其中的实现细节却远远没有想象中那样简单,否则也不会从 2004 年 Sun 实验室发表第一篇 G1 的论文开始直到今天(将近10年时间)才开发出 G1 的商用版。笔者以一个细节为例:把 Java 堆分为多个 Region 后,垃圾收集是否就真的能以 Region 为单位进行了?听起来顺理成章,再仔细想想就很容易发现问题所在:Region 不可能是孤立的。一个对象分配在某个 Region 中,它并非只能被本 Region 中的其他对象引用,而是可以与整个 Java 堆任意的对象发生引用关系。那在做可达性判定确定对象是否存活的时候,岂不是还得扫描整个 Java 堆才能保证准确性?这个问题其实并非在 G1 中才有,只是在 G1 中更加突出而已。在以前的分代收集中,新生代的规模一般都比老年代要小许多,新生代的收集也比老年代要频繁许多,那回收新生代中的对象时也面临相同的问题,如果回收新生代时也不得不同时扫描老年代的话,那么 Minor GC 的效率可能下降不少。
在 G1 收集器中,Region 之间的对象引用以及其他收集器中的新生代与老年代之间的对象引用,虚拟机都是使用 Remembered Set 来避免全堆扫描的。G1 中每个 Region 都有一个与之对应的 Remembered Set,虚拟机发现程序在对 Reference 类型的数据进行写操作时,会产生一个 Write Barrier 暂时中断写操作,检查 Reference 引用的对象是否处于不同的 Region 之中(在分代的例子中就是检查是否老年代中的对象引用了新生代中的对象),如果是,便通过 CardTable 把相关引用信息记录到被引用对象所属的 Region 的 Remembered Set 之中。当进行内存回收时,在 GC 根节点的枚举范围中加入 Remembered Set 即可保证不对全堆扫描也不会有遗漏。
如果不计算维护 Remembered Set 的操作,G1 收集器的运作大致可划分为以下几个步骤:
- 初始标记(Initial Marking)
- 并发标记(Concurrent Marking)
- 最终标记(Final Marking)
- 筛选回收(Live Data Counting and Evacuation)
对 CMS 收集器运作过程熟悉的读者,一定已经发现 G1 的前几个步骤的运作过程和 CMS 有很多相似之处。初始标记阶段仅仅只是标记一下 GC Roots 能直接关联到的对象,并且修改 TAMS(Next Top at Mark Start)的值,让下一阶段用户程序并发运行时,能在正确可用的 Region 中创建新对象,这阶段需要停顿线程,但耗时很短。并发标记阶段是从 GC Root 开始对堆中对象进行可达性分析,找出存活的对象,这阶段耗时较长,但可与用户程序并发执行。而最终标记阶段则是为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程 Remembered Set Logs 里面,最终标记阶段需要把 Remembered Set Logs 的数据合并到 Remembered Set 中,这阶段需要停顿线程,但是可并行执行。最后在筛选回收阶段首先对各个 Region 的回收价值和成本进行排序,根据用户所期望的 GC 停顿时间来制定回收计划,从 Sun 公司透露出来的信息来看,这个阶段其实也可以做到与用户程序一起并发执行,但是因为只回收一部分 Region,时间是用户可控制的,而且停顿用户线程将大幅提高收集效率。通过图 3-11 可以比较清楚地看到 G1 收集器的运作步骤中并发和需要停顿的阶段。

由于目前 G1 成熟版本的发布时间还很短,G1 收集器几乎可以说还没有经过实际应用的考验,网络上关于 G1 收集器的性能测试也非常贫乏,到目前为止,笔者还没有搜索到有关的生产环境下的性能测试报告。强调“生产环境下的测试报告”是因为对于垃圾收集器来说,仅仅通过简单的 Java 代码写个 Microbenchmark 程序来创建、移除 Java 对象,再用 -XX:+PrintGCDetails 等参数来查看 GC 日志是很难做到准确衡量其性能的。因此,关于 G1 收集器的性能部分,笔者引用了 Sun 实验室的论文《Garbage-First Garbage Collection》中的一段测试数据。
此处略去对 G1 的性能度量部分。
3.5.8 理解 GC 日志
阅读 GC 日志是处理 Java 虚拟机内存问题的基础技能,它只是一些人为确定的规则,没有太多技术含量。在本书的第 1 版中没有专门讲解如何阅读分析 GC 日志,为此作者收到许多读者来信,反映对此感到困惑,因此专门增加本节内容来讲解如何理解 GC 日志。
每一种收集器的日志形式都是由它们自身的实现所决定的,换而言之,每个收集器的日志格式都可以不一样。但虚拟机设计者为了方便用户阅读,将各个收集器的日志都维持一定的共性,例如以下两段典型的 GC 日志:
33.125:[GC[DefNew:3324K->152K(3712K), 0.0025925 secs]3324K->152K(11904K), 0.0031680 secs]
100.667:[Full GC[Tenured:0 K->210K(10240K), 0.0149142secs]4603K->210K(19456K), [Perm:2999K->2999K(21248K)], 0.0150007 secs][Times:user=0.01 sys=0.00, real=0.02 secs]
最前面的数字“33.125:”和“100.667:”代表了 GC 发生的时间,这个数字的含义是从 Java 虚拟机启动以来经过的秒数。
GC日志开头的 [GC 和 [Full GC 说明了这次垃圾收集的停顿类型,而不是用来区分新生代 GC 还是老年代 GC 的。如果有"Full",说明这次 GC 是发生了 Stop-The-World 的,例如下面这段新生代收集器 ParNew 的日志也会出现 [Full GC(这一般是因为出现了分配担保失败之类的问题,所以才导致 STW)。如果是调用System.gc() 方法所触发的收集,那么在这里将显示 [Full GC(System)。
[Full GC 283.736:[ParNew:261599K->261599K(261952K), 0.0000288 secs]
接下来的 [DefNew、[Tenured、[Perm 表示 GC 发生的区域,这里显示的区域名称与使用的 GC 收集器是密切相关的,例如上面样例所使用的 Serial 收集器中的新生代名为"Default New Generation",所以显示的是 [DefNew。如果是 ParNew 收集器,新生代名称就会变为 [ParNew,意为"Parallel New Generation"。如果采用 Parallel Scavenge 收集器,那它配套的新生代称为"PSYoungGen",老年代和永久代同理,名称也是由收集器决定的。
后面方括号内部的"3324K->152K(3712K)“含义是“GC 前该内存区域已使用容量->GC 后该内存区域已使用容量(该内存区域总容量)”。而在方括号之外的"3324K->152K(11904K)“表示“ GC 前 Java 堆已使用容量->GC 后 Java 堆已使用容量(Java 堆总容量)”。
再往后,“0.0025925 secs"表示该内存区域 GC 所占用的时间,单位是秒。有的收集器会给出更具体的时间数据,如 [Times:user=0.01 sys=0.00,real=0.02 secs],这里面的 user、sys 和 real 与 Linux 的 time 命令所输出的时间含义一致,分别代表用户态消耗的 CPU 时间、内核态消耗的 CPU 时间和操作从开始到结束所经过的墙钟时间(Wall Clock Time)。CPU 时间与墙钟时间的区别是,墙钟时间包括各种非运算的等待耗时,例如等待磁盘 I/O、等待线程阻塞,而 CPU 时间不包括这些耗时,但当系统有多 CPU 或者多核的话,多线程操作会叠加这些 CPU 时间,所以读者看到 user 或 sys 时间超过 real 时间是完全正常的。
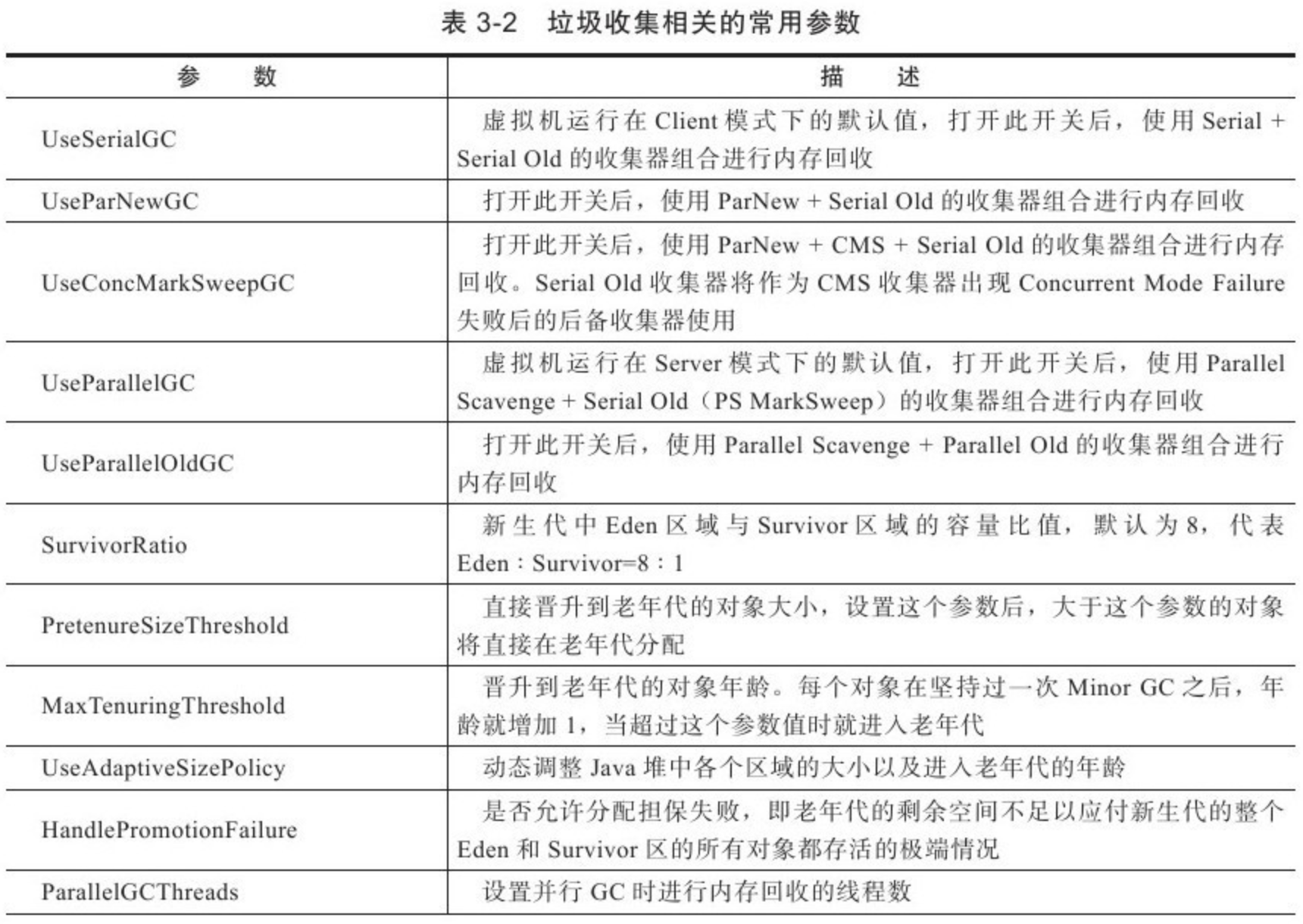
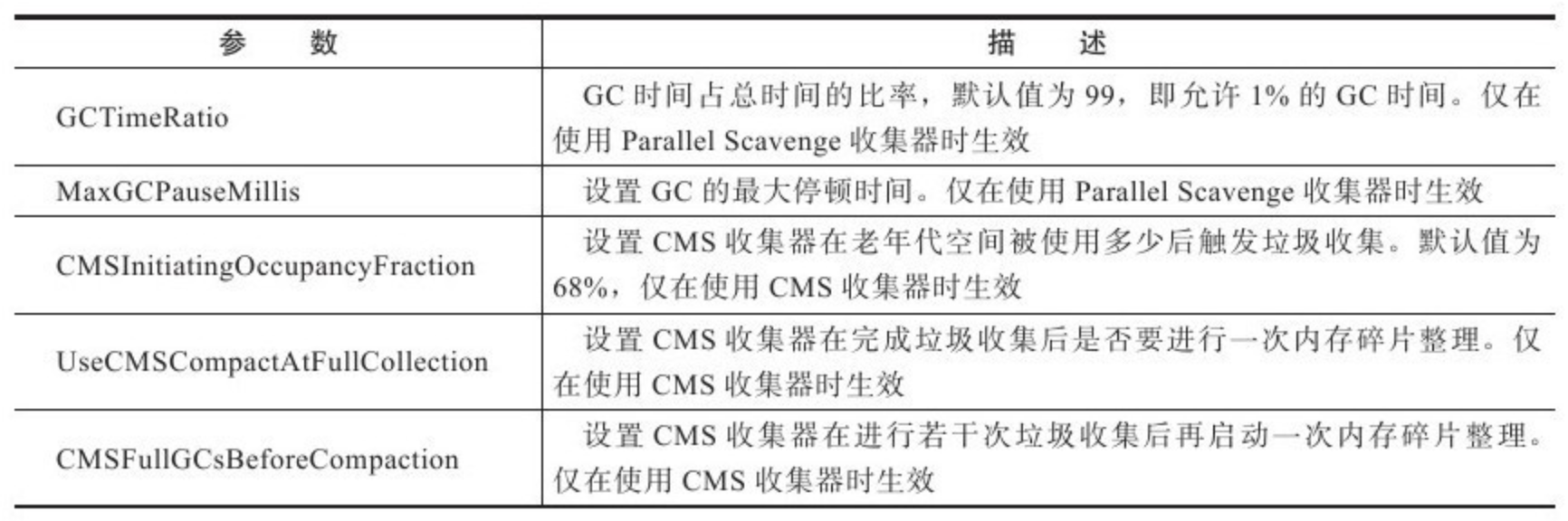
3.5.9 垃圾收集器参数总结
JDK 1.7 中的各种垃圾收集器到此已全部介绍完毕,在描述过程中提到了很多虚拟机非稳定的运行参数,在表 3-2 中整理了这些参数供读者实践时参考。
3.6 内存分配与回收策略
Java 技术体系中所提倡的自动内存管理最终可以归结为自动化地解决了两个问题:给对象分配内存以及回收分配给对象的内存。关于回收内存这一点,我们已经使用了大量篇幅去介绍虚拟机中的垃圾收集器体系以及运作原理,现在我们再一起来探讨一下给对象分配内存的那点事儿。
对象的内存分配,往大方向讲,就是在堆上分配(但也可能经过 JIT 编译后被拆散为标量类型并间接地栈上分配),对象主要分配在新生代的 Eden 区上,如果启动了本地线程分配缓冲,将按线程优先在 TLAB 上分配。少数情况下也可能会直接分配在老年代中,分配的规则并不是百分之百固定的,其细节取决于当前使用的是哪一种垃圾收集器组合,还有虚拟机中与内存相关的参数的设置。
接下来我们将会讲解几条最普遍的内存分配规则,并通过代码去验证这些规则。本节下面的代码在测试时使用 Client 模式虚拟机运行,没有手工指定收集器组合,换句话说,验证的是在使用 Serial/Serial Old 收集器下(ParNew/Serial Old 收集器组合的规则也基本一致)的内存分配和回收的策略。读者不妨根据自己项目中使用的收集器写一些程序去验证一下使用其他几种收集器的内存分配策略。
3.6.1 对象优先在 Eden 分配
大多数情况下,对象在新生代 Eden 区中分配。当 Eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC。
虚拟机提供了 -XX:+PrintGCDetails 这个收集器日志参数,告诉虚拟机在发生垃圾收集行为时打印内存回收日志,并且在进程退出的时候输出当前的内存各区域分配情况。在实际应用中,内存回收日志一般是打印到文件后通过日志工具进行分析,不过本实验的日志并不多,直接阅读就能看得很清楚。
代码清单 3-5 的 testAllocation() 方法中,尝试分配 3 个 2MB 大小和 1 个 4MB 大小的对象,在运行时通过 -Xms20M、-Xmx20M、-Xmn10M 这 3 个参数限制了 Java 堆大小为 20MB,不可扩展,其中 10MB 分配给新生代,剩下的 10MB 分配给老年代。-XX:SurvivorRatio=8 决定了新生代中 Eden 区与一个 Survivor 区的空间比例是 8:1,从输出的结果也可以清晰地看到"eden space 8192K、from space 1024K、to space 1024K"的信息,新生代总可用空间为 9216KB(Eden 区+1个 Survivor 区的总容量)。
执行 testAllocation() 中分配 allocation4 对象的语句时会发生一次 Minor GC,这次 GC 的结果是新生代 6651KB 变为 148KB,而总内存占用量则几乎没有减少(因为 allocation1、allocation2、allocation3 三个对象都是存活的,虚拟机几乎没有找到可回收的对象)。这次 GC 发生的原因是给 allocation4 分配内存的时候,发现 Eden 已经被占用了 6MB,剩余空间已不足以分配 allocation4 所需的 4MB 内存,因此发生 Minor GC。GC 期间虚拟机又发现已有的 3 个 2MB 大小的对象全部无法放入 Survivor 空间(Survivor 空间只有 1MB 大小),所以只好通过分配担保机制提前转移到老年代去。
这次 GC 结束后,4MB 的 allocation4 对象顺利分配在 Eden 中,因此程序执行完的结果是 Eden 占用 4MB(被 allocation4 占用),Survivor 空闲,老年代被占用 6MB(被 allocation1、allocation2、allocation3 占用)。通过 GC 日志可以证实这一点。
注意:作者多次提到的 Minor GC 和 Full GC 有什么不一样吗?
- 新生代 GC(Minor GC):指发生在新生代的垃圾收集动作,因为 Java 对象大多都具备朝生夕灭的特性,所以 Minor GC 非常频繁,一般回收速度也比较快。
- 老年代 GC(Major GC/Full GC):指发生在老年代的 GC,出现了 Major GC,经常会伴随至少一次的 Minor GC(但非绝对的,在 Parallel Scavenge 收集器的收集策略里就有直接进行 Major GC 的策略选择过程)。Major GC 的速度一般会比 Minor GC 慢 10 倍以上。
代码清单3-5 新生代 Minor GC:
private static final int_1MB=1024*1024;
/**
*VM参数:-verbose:gc-Xms20M-Xmx20M-Xmn10M-XX:+PrintGCDetails
-XX:SurvivorRatio=8
*/
public static void testAllocation(){
byte[]allocation1, allocation2, allocation3, allocation4;
allocation1=new byte[2*_1MB];
allocation2=new byte[2*_1MB];
allocation3=new byte[2*_1MB];
allocation4=new byte[4*_1MB];//出现一次Minor GC
}
执行结果:
[GC[DefNew:6651K->148K(9216K), 0.0070106 secs]6651K->6292K(19456K),
0.0070426 secs][Times:user=0.00 sys=0.00, real=0.00 secs]
Heap
def new generation total 9216K,used 4326K[0x029d0000, 0x033d0000, 0x033d0000)
eden space 8192K, 51%used[0x029d0000, 0x02de4828, 0x031d0000)
from space 1024K, 14%used[0x032d0000, 0x032f5370, 0x033d0000)
to space 1024K, 0%used[0x031d0000, 0x031d0000, 0x032d0000)
tenured generation total 10240K,used 6144K[0x033d0000, 0x03dd0000, 0x03dd0000)
the space 10240K, 60%used[0x033d0000, 0x039d0030, 0x039d0200, 0x03dd0000)
compacting perm gen total 12288K,used 2114K[0x03dd0000, 0x049d0000, 0x07dd0000)
the space 12288K, 17%used[0x03dd0000, 0x03fe0998, 0x03fe0a00, 0x049d0000)
No shared spaces configured.
3.6.2 大对象直接进入老年代
所谓的大对象是指,需要大量连续内存空间的 Java 对象,最典型的大对象就是那种很长的字符串以及数组(笔者列出的例子中的 byte[] 数组就是典型的大对象)。大对象对虚拟机的内存分配来说就是一个坏消息(替 Java 虚拟机抱怨一句,比遇到一个大对象更加坏的消息就是遇到一群“朝生夕灭”的“短命大对象”,写程序的时候应当避免),经常出现大对象容易导致内存还有不少空间时就提前触发垃圾收集以获取足够的连续空间来“安置”它们。
虚拟机提供了一个 -XX:PretenureSizeThreshold 参数,令大于这个设置值的对象直接在老年代分配。这样做的目的是避免在 Eden 区及两个 Survivor 区之间发生大量的内存复制(复习一下:新生代采用复制算法收集内存)。
执行代码清单 3-6 中的 testPretenureSizeThreshold() 方法后,我们看到 Eden 空间几乎没有被使用,而老年代的 10MB 空间被使用了 40%,也就是 4MB 的 allocation 对象直接就分配在老年代中,这是因为 PretenureSizeThreshold 被设置为 3MB(就是 3145728,这个参数不能像 -Xmx 之类的参数一样直接写 3MB),因此超过 3MB 的对象都会直接在老年代进行分配。注意 PretenureSizeThreshold 参数只对 Serial 和 ParNew 两款收集器有效,Parallel Scavenge 收集器不认识这个参数,Parallel Scavenge 收集器一般并不需要设置。如果遇到必须使用此参数的场合,可以考虑 ParNew 加 CMS 的收集器组合。
代码清单 3-6 大对象直接进入老年代:
private static final int_1MB=1024*1024;
/**
*VM参数:-verbose:gc-Xms20M-Xmx20M-Xmn10M-XX:+PrintGCDetails-XX:SurvivorRatio=8
*-XX:PretenureSizeThreshold=3145728
*/
public static void testPretenureSizeThreshold(){
byte[]allocation;
allocation=new byte[4*_1MB];//直接分配在老年代中
}
运行结果:
Heap
def new generation total 9216K,used 671K[0x029d0000, 0x033d0000, 0x033d0000)
eden space 8192K, 8%used[0x029d0000, 0x02a77e98, 0x031d0000)
from space 1024K, 0%used[0x031d0000, 0x031d0000, 0x032d0000)
to space 1024K, 0%used[0x032d0000, 0x032d0000, 0x033d0000)
tenured generation total 10240K,used 4096K[0x033d0000, 0x03dd0000, 0x03dd0000)
the space 10240K, 40%used[0x033d0000, 0x037d0010, 0x037d0200, 0x03dd0000)
compacting perm gen total 12288K,used 2107K[0x03dd0000, 0x049d0000, 0x07dd0000)
the space 12288K, 17%used[0x03dd0000, 0x03fdefd0, 0x03fdf000, 0x049d0000)
No shared spaces configured.
3.6.3 长期存活的对象将进入老年代
既然虚拟机采用了分代收集的思想来管理内存,那么内存回收时就必须能识别哪些对象应放在新生代,哪些对象应放在老年代中。为了做到这点,虚拟机给每个对象定义了一个对象年龄(Age)计数器。如果对象在 Eden 出生并经过第一次 Minor GC 后仍然存活,并且能被 Survivor 容纳的话,将被移动到 Survivor 空间中,并且对象年龄设为 1。对象在 Survivor 区中每“熬过”一次 Minor GC,年龄就增加 1 岁,当它的年龄增加到一定程度(默认为15岁),就将会被晋升到老年代中。对象晋升老年代的年龄阈值,可以通过参数 -XX:MaxTenuringThreshold 设置。
读者可以试试分别以 -XX:MaxTenuringThreshold=1 和 -XX:MaxTenuringThreshold=15 两种设置来执行代码清单 3-7 中的 testTenuringThreshold() 方法,此方法中的 allocation1 对象需要 256KB 内存,Survivor 空间可以容纳。当 MaxTenuringThreshold=1 时,allocation1 对象在第二次 GC 发生时进入老年代,新生代已使用的内存 GC 后非常干净地变成 0KB。而 MaxTenuringThreshold=15 时,第二次 GC 发生后,allocation1 对象则还留在新生代 Survivor 空间,这时新生代仍然有 404KB 被占用。
代码清单3-7 长期存活的对象进入老年代:
private static final int_1MB=1024*1024;
/**
*VM参数:-verbose:gc-Xms20M-Xmx20M-Xmn10M-XX:+PrintGCDetails-XX:SurvivorRatio=8-XX:MaxTenuringThreshold=1
*-XX:+PrintTenuringDistribution
*/
@SuppressWarnings("unused")
public static void testTenuringThreshold(){
byte[]allocation1, allocation2, allocation3;
allocation1=new byte[_1MB/4];
//什么时候进入老年代取决于XX:MaxTenuringThreshold设置
allocation2=new byte[4*_1MB];
allocation3=new byte[4*_1MB];
allocation3=null;
allocation3=new byte[4*_1MB];
}
以 MaxTenuringThreshold=1 参数来运行的结果:
[GC[DefNew Desired Survivor size 524288 bytes,new threshold 1(max 1) -age 1:414664 bytes, 414664 total :4859K->404K(9216K), 0.0065012 secs]4859K->4500K(19456K), 0.0065283 secs [Times:user=0.02 sys=0.00, real=0.02 secs]
[GC[DefNew Desired Survivor size 524288 bytes,new threshold 1(max 1):4500K->0K(9216K), 0.0009253 secs]8596K->4500K(19456K),0.0009458 secs][Times:user=0.00 sys=0.00,real=0.00 secs]
Heap
def new generation total 9216K,used 4178K[0x029d0000,0x033d0000, 0x033d0000)
eden space 8192K, 51%used[0x029d0000, 0x02de4828, 0x031d0000)
from space 1024K, 0%used[0x031d0000, 0x031d0000, 0x032d0000)
to space 1024K, 0%used[0x032d0000, 0x032d0000, 0x033d0000)
tenured generation total 10240K,used 4500K[0x033d0000, 0x03dd0000, 0x03dd0000)
the space 10240K, 43%used[0x033d0000, 0x03835348, 0x03835400, 0x03dd0000)
compacting perm gen total 12288K,used 2114K[0x03dd0000, 0x049d0000, 0x07dd0000)
the space 12288K, 17%used[0x03dd0000, 0x03fe0998, 0x03fe0a00, 0x049d0000)
No shared spaces configured.
以MaxTenuringThreshold=15参数来运行的结果:
[GC[DefNew Desired Survivor size 524288 bytes,new threshold 15(max 15) -age 1:414664 bytes, 414664 total:4859K->404K(9216K), 0.0049637 secs]4859K->4500K(19456K), 0.0049932 secs][Times:user=0.00 sys=0.00, real=0.00 secs]
[GC[DefNew Desired Survivor size 524288 bytes,new threshold 15(max 15) -age 2:414520 bytes, 414520 total :4500K->404K(9216K), 0.0008091 secs]8596K->4500K(19456K), 0.0008305 secs][Times:user=0.00 sys=0.00, real=0.00 secs]
Heap
def new generation total 9216K,used 4582K[0x029d0000, 0x033d0000, 0x033d0000)
eden space 8192K, 51%used[0x029d0000, 0x02de4828, 0x031d0000)
from space 1024K, 39%used[0x031d0000, 0x03235338, 0x032d0000)
to space 1024K, 0%used[0x032d0000, 0x032d0000, 0x033d0000)
tenured generation total 10240K,used 4096K[0x033d0000, 0x03dd0000, 0x03dd0000)
the space 10240K, 40%used[0x033d0000, 0x037d0010, 0x037d0200, 0x03dd0000)
compacting perm gen total 12288K,used 2114K[0x03dd0000, 0x049d0000, 0x07dd0000)
the space 12288K, 17%used[0x03dd0000, 0x03fe0998, 0x03fe0a00, 0x049d0000)
No shared spaces configured.
3.6.4 动态对象年龄判定
为了能更好地适应不同程序的内存状况,虚拟机并不是永远地要求对象的年龄必须达到了 MaxTenuringThreshold 才能晋升老年代,如果在 Survivor 空间中相同年龄所有对象大小的总和大于 Survivor 空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代,无须等到 MaxTenuringThreshold 中要求的年龄。
执行代码清单 3-8 中的 testTenuringThreshold2() 方法,并设置 -XX:MaxTenuringThreshold=15,会发现运行结果中 Survivor 的空间占用仍然为 0%,而老年代比预期增加了 6%,也就是说,allocation1、allocation2 对象都直接进入了老年代,而没有等到 15 岁的临界年龄。因为这两个对象加起来已经到达了 512KB,并且它们是同年的,满足同年对象达到 Survivor 空间的一半规则。我们只要注释掉其中一个对象 new 操作,就会发现另外一个就不会晋升到老年代中去了。
代码清单3-8 动态对象年龄判定:
private static final int_1MB=1024*1024;
/**
*VM参数:-verbose:gc-Xms20M-Xmx20M-Xmn10M-XX:+PrintGCDetails-XX:SurvivorRatio=8-XX:MaxTenuringThreshold=15
*-XX:+PrintTenuringDistribution
*/
@SuppressWarnings("unused")
public static void testTenuringThreshold2(){
byte[]allocation1, allocation2, allocation3, allocation4;
allocation1=new byte[_1MB/4];
//allocation1+allocation2大于survivo空间一半
allocation2=new byte[_1MB/4];
allocation3=new byte[4*_1MB];
allocation4=new byte[4*_1MB];
allocation4=null;
allocation4=new byte[4*_1MB];
}
运行结果:
[GC[DefNew
Desired Survivor size 524288 bytes,new threshold 1(max 15)
-age 1:676824 bytes, 676824 total
:5115K->660K(9216K), 0.0050136 secs]5115K->4756K(19456K), 0.0050443 secs][Times:user=0.00 sys=0.01, real=0.01 secs]
[GC[DefNew
Desired Survivor size 524288 bytes,new threshold 15(max 15)
:4756K->0K(9216K), 0.0010571 secs]8852K->4756K(19456K), 0.0011009 secs][Times:user=0.00 sys=0.00, real=0.00 secs]
Heap
def new generation total 9216K,used 4178K[0x029d0000, 0x033d0000, 0x033d0000)
eden space 8192K, 51%used[0x029d0000, 0x02de4828, 0x031d0000)
from space 1024K, 0%used[0x031d0000, 0x031d0000, 0x032d0000)
to space 1024K, 0%used[0x032d0000, 0x032d0000, 0x033d0000)
tenured generation total 10240K,used 4756K[0x033d0000, 0x03dd0000, 0x03dd0000)
the space 10240K, 46%used[0x033d0000, 0x038753e8, 0x03875400, 0x03dd0000)
compacting perm gen total 12288K,used 2114K[0x03dd0000, 0x049d0000, 0x07dd0000)
the space 12288K, 17%used[0x03dd0000, 0x03fe09a0, 0x03fe0a00, 0x049d0000)
No shared spaces configured.
空间分配担保
在发生 Minor GC 之前,虚拟机会先检查老年代最大可用的连续空间是否大于新生代所有对象总空间,如果这个条件成立,那么 Minor GC 可以确保是安全的。如果不成立,则虚拟机会查看 HandlePromotionFailure 设置值是否允许担保失败。如果允许,那么会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试着进行一次 Minor GC,尽管这次 Minor GC 是有风险的;如果小于,或者 HandlePromotionFailure 设置不允许冒险,那这时也要改为进行一次 Full GC。
下面解释一下“冒险”是冒了什么风险,前面提到过,新生代使用复制收集算法,但为了内存利用率,只使用其中一个 Survivor 空间来作为轮换备份,因此当出现大量对象在 Minor GC 后仍然存活的情况(最极端的情况就是内存回收后新生代中所有对象都存活),就需要老年代进行分配担保,把 Survivor 无法容纳的对象直接进入老年代。与生活中的贷款担保类似,老年代要进行这样的担保,前提是老年代本身还有容纳这些对象的剩余空间,一共有多少对象会活下来在实际完成内存回收之前是无法明确知道的,所以只好取之前每一次回收晋升到老年代对象容量的平均大小值作为经验值,与老年代的剩余空间进行比较,决定是否进行 Full GC 来让老年代腾出更多空间。
取平均值进行比较其实仍然是一种动态概率的手段,也就是说,如果某次 Minor GC 存活后的对象突增,远远高于平均值的话,依然会导致担保失败(Handle Promotion Failure)。如果出现了 HandlePromotionFailure 失败,那就只好在失败后重新发起一次 Full GC。虽然担保失败时绕的圈子是最大的,但大部分情况下都还是会将HandlePromotionFailure 开关打开,避免 Full GC 过于频繁,参见代码清单3-9,请读者在 JDK 6 Update 24 之前的版本中运行测试。
代码清单3-9 空间分配担保:
private static final int_1MB=1024*1024;
/**
*VM参数:-Xms20M-Xmx20M-Xmn10M-XX:+PrintGCDetails-XX:SurvivorRatio=8-XX:-HandlePromotionFailure
*/
@SuppressWarnings("unused")
public static void testHandlePromotion(){
byte[]allocation1, allocation2, allocation3, allocation4, allocation5, allocation6, allocation7;
allocation1=new byte[2*_1MB];
allocation2=new byte[2*_1MB];
allocation3=new byte[2*_1MB];
allocation1=null;
allocation4=new byte[2*_1MB];
allocation5=new byte[2*_1MB];
allocation6=new byte[2*_1MB];
allocation4=null;
allocation5=null;
allocation6=null;
allocation7=new byte[2*_1MB];
}
以HandlePromotionFailure=false参数来运行的结果:
[GC[DefNew:6651K->148K(9216K), 0.0078936 secs]6651K->4244K(19456K), 0.0079192 secs][Times:user=0.00 sys=0.02, real=0.02 secs]
[GC[DefNew:6378K->6378K(9216K), 0.0000206secs][Tenured:4096K->4244K(10240K), 0.0042901 secs]10474K->4244K(19456K), [Perm:2104K->2104K(12288K)], 0.0043613 secs][Times:user=0.00 sys=0.00, real=0.00 secs]
以HandlePromotionFailure=true参数来运行的结果:
[GC[DefNew:6651K->148K(9216K), 0.0054913 secs]6651K->4244K(19456K), 0.0055327 secs][Times:user=0.00 sys=0.00, real=0.00 secs]
[GC[DefNew:6378K->148K(9216K), 0.0006584 secs]10474K->4244K(19456K), 0.0006857 secs][Times:user=0.00 sys=0.00, real=0.00 secs]
在 JDK 6 Update 24 之后,这个测试结果会有差异,HandlePromotionFailure 参数不会再影响到虚拟机的空间分配担保策略,观察 OpenJDK 中的源码变化(见代码清单3-10),虽然源码中还定义了 HandlePromotionFailure 参数,但是在代码中已经不会再使用它。JDK 6 Update 24 之后的规则变为只要老年代的连续空间大于新生代对象总大小或者历次晋升的平均大小就会进行 Minor GC,否则将进行 Full GC。
代码清单3-10 HotSpot中空间分配检查的代码片段:
bool TenuredGeneration:promotion_attempt_is_safe(size_t
max_promotion_in_bytes)const{
//老年代最大可用的连续空间
size_t available=max_contiguous_available();
//每次晋升到老年代的平均大小
size_t av_promo=(size_t)gc_stats()->avg_promoted()->padded_average();
//老年代可用空间是否大于平均晋升大小, 或者老年代可用空间是否大于当此GC时新生代所有对象容量
bool res=(available>=av_promo)||(available>=
max_promotion_in_bytes);
return res;
}
3.7 本章小结
本章介绍了垃圾收集的算法、几款 JDK 1.7 中提供的垃圾收集器特点以及运作原理。通过代码实例验证了 Java 虚拟机中自动内存分配及回收的主要规则。
内存回收与垃圾收集器在很多时候都是影响系统性能、并发能力的主要因素之一,虚拟机之所以提供多种不同的收集器以及提供大量的调节参数,是因为只有根据实际应用需求、实现方式选择最优的收集方式才能获取最高的性能。没有固定收集器、参数组合,也没有最优的调优方法,虚拟机也就没有什么必然的内存回收行为。因此,学习虚拟机内存知识,如果要到实践调优阶段,那么必须了解每个具体收集器的行为、优势和劣势、调节参数。在接下来的两章中,作者将会介绍内存分析的工具和调优的一些具体案例。
4 - CH04-性能监控与故障处理
4.1 概述
给一个系统定位问题的时候,知识、经验是关键基础,数据是依据,工具是运用知识处理数据的手段。这里说的数据包括:运行日志、异常堆栈、GC 日志、线程快照(threaddump/javacore文件)、堆转储快照(heapdump/hprof文件)等。经常使用适当的虚拟机监控和分析的工具可以加快我们分析数据、定位解决问题的速度,但在学习工具前,也应当意识到工具永远都是知识技能的一层包装,没有什么工具是“秘密武器”,不可能学会了就能包治百病。
4.2 JDK 命令行工具
Java 开发人员肯定都知道 JDK 的 bin 目录中有"java.exe"、“javac.exe"这两个命令行工具,但并非所有程序员都了解过JDK的bin目录之中其他命令行程序的作用。每逢JDK更新版本之时,bin 目录下命令行工具的数量和功能总会不知不觉地增加和增强。bin目录的内容如图 4-1 所示。
说起 JDK 的工具,比较细心的读者,可能会注意到这些工具的程序体积都异常小巧。假如以前没注意到,现在不妨再看看图 4-1 中的最后一列“大小”,几乎所有工具的体积基本上都稳定在 27KB 左右。并非 JDK 开发团队刻意把它们制作得如此精炼来炫耀编程水平,而是因为这些命令行工具大多数是 jdk/lib/tools.jar 类库的一层薄包装而已,它们主要的功能代码是在 tools 类库中实现的。读者把图 4-1 和图 4-2 两张图片对比一下就可以看得很清楚。
假如读者使用的是Linux版本的JDK,还会发现这些工具中很多甚至就是由Shell脚本直接写成的,可以用vim直接打开它们。
JDK开发团队选择采用Java代码来实现这些监控工具是有特别用意的:当应用程序部署到生产环境后,无论是直接接触物理服务器还是远程Telnet到服务器上都可能会受到限制。借助tools.jar类库里面的接口,我们可以直接在应用程序中实现功能强大的监控分析功能。
需要特别说明的是,本章介绍的工具全部基于Windows平台下的JDK 1.6 Update 21,如果JDK版本、操作系统不同,工具所支持的功能可能会有较大差别。大部分工具在JDK 1.5中就已经提供,但为了避免运行环境带来的差异和兼容性问题,建议读者使用JDK 1.6来验证本章介绍的内容,因为JDK 1.6的工具可以正常兼容运行于JDK 1.5的虚拟机之上的程序,反之则不一定。表4-1中说明了JDK主要命令行监控工具的用途。
注意 如果读者在工作中需要监控运行于JDK 1.5的虚拟机之上的程序,在程序启动时请添加参数”-Dcom.sun.management.jmxremote"开启JMX管理功能,否则由于部分工具都是基于JMX(包括4.3节介绍的可视化工具),它们都将会无法使用,如果被监控程序运行于JDK 1.6的虚拟机之上,那JMX管理默认是开启的,虚拟机启动时无须再添加任何参数。
- jps:JVM Process Status Tool,显示指定系统内所有的 HotSpot 进程。
- jstat:JVM Statiistics Monitoring Tool,用于收集 HotSpot 各方面的运行数据。
- jinfo:Configuration Info for Java,显示虚拟机配置信息。
- jmap:Memory Map for Java,生成虚拟机的内存转储快照。
- jhat:JVM Heap Dump Browser,用于分析 heandump 文件。
- jstack:Stack Trace for Java,显示虚拟机的线程快照。
4.2.1 jps:虚拟机进程状况工具
可以列出正在运行的虚拟机进程,并显示虚拟机执行主类(Main Class,main()函数所在的类)名称以及这些进程的本地虚拟机唯一ID(Local Virtual Machine Identifier,LVMID)。虽然功能比较单一,但它是使用频率最高的JDK命令行工具,因为其他的JDK工具大多需要输入它查询到的LVMID来确定要监控的是哪一个虚拟机进程。对于本地虚拟机进程来说,LVMID与操作系统的进程ID(Process Identifier,PID)是一致的,使用Windows的任务管理器或者UNIX的ps命令也可以查询到虚拟机进程的LVMID,但如果同时启动了多个虚拟机进程,无法根据进程名称定位时,那就只能依赖jps命令显示主类的功能才能区分了。
执行方式:
jps[options][hostid]
jps可以通过RMI协议查询开启了RMI服务的远程虚拟机进程状态,hostid为RMI注册表中注册的主机名。jps的其他常用选项见表4-2。

4.2.2 jstat:虚拟机统计信息显示工具
jstat 是用于监视虚拟机各种运行状态信息的命令行工具。它可以显示本地或者远程虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据,在没有GUI图形界面,只提供了纯文本控制台环境的服务器上,它将是运行期定位虚拟机性能问题的首选工具。
命令格式为:
jstat[option vmid[interval[s|ms][count]]]
对于命令格式中的VMID与LVMID需要特别说明一下:如果是本地虚拟机进程,VMID与LVMID是一致的,如果是远程虚拟机进程,那VMID的格式应当是:
[protocol:][//]lvmid[@hostname[:port]/servername]
参数interval和count代表查询间隔和次数,如果省略这两个参数,说明只查询一次。假设需要每250毫秒查询一次进程2764垃圾收集状况,一共查询20次,那命令应当是:
jstat-gc 2764 250 20
选项option代表着用户希望查询的虚拟机信息,主要分为3类:类装载、垃圾收集、运行期编译状况,具体选项及作用请参考表4-3中的描述。

4.2.3 jinfo:Java配置信息工具
作用是实时地查看和调整虚拟机各项参数。使用jps命令的-v参数可以查看虚拟机启动时显式指定的参数列表,但如果想知道未被显式指定的参数的系统默认值,除了去找资料外,就只能使用jinfo的-flag选项进行查询了(如果只限于JDK 1.6或以上版本的话,使用java-XX:+PrintFlagsFinal查看参数默认值也是一个很好的选择),jinfo还可以使用-sysprops选项把虚拟机进程的System.getProperties()的内容打印出来。这个命令在JDK 1.5时期已经随着Linux版的JDK发布,当时只提供了信息查询的功能,JDK 1.6之后,jinfo在Windows和Linux平台都有提供,并且加入了运行期修改参数的能力,可以使用-flag[+|-]name或者-flag name=value修改一部分运行期可写的虚拟机参数值。JDK 1.6中,jinfo对于Windows平台功能仍然有较大限制,只提供了最基本的-flag选项。
命令格式:
jinfo[option]pid
执行样例:查询CMSInitiatingOccupancyFraction参数值。
C:\>jinfo-flag CMSInitiatingOccupancyFraction 1444
-XX:CMSInitiatingOccupancyFraction=85
4.2.4 jmap:Java内存映像工具
用于生成堆转储快照(一般称为heapdump或dump文件)。如果不使用jmap命令,要想获取Java堆转储快照,还有一些比较“暴力”的手段:譬如在第2章中用过的-XX:+HeapDumpOnOutOfMemoryError参数,可以让虚拟机在OOM异常出现之后自动生成dump文件,通过-XX:+HeapDumpOnCtrlBreak参数则可以使用 Ctrl+Break 键让虚拟机生成dump文件,又或者在Linux系统下通过Kill-3命令发送进程退出信号“吓唬”一下虚拟机,也能拿到dump文件。
jmap的作用并不仅仅是为了获取dump文件,它还可以查询finalize执行队列、Java堆和永久代的详细信息,如空间使用率、当前用的是哪种收集器等。
和jinfo命令一样,jmap有不少功能在Windows平台下都是受限的,除了生成dump文件的-dump选项和用于查看每个类的实例、空间占用统计的-histo选项在所有操作系统都提供之外,其余选项都只能在Linux/Solaris下使用。
命令格式:
jmap[option]vmid
option选项的合法值与具体含义见表4-4。
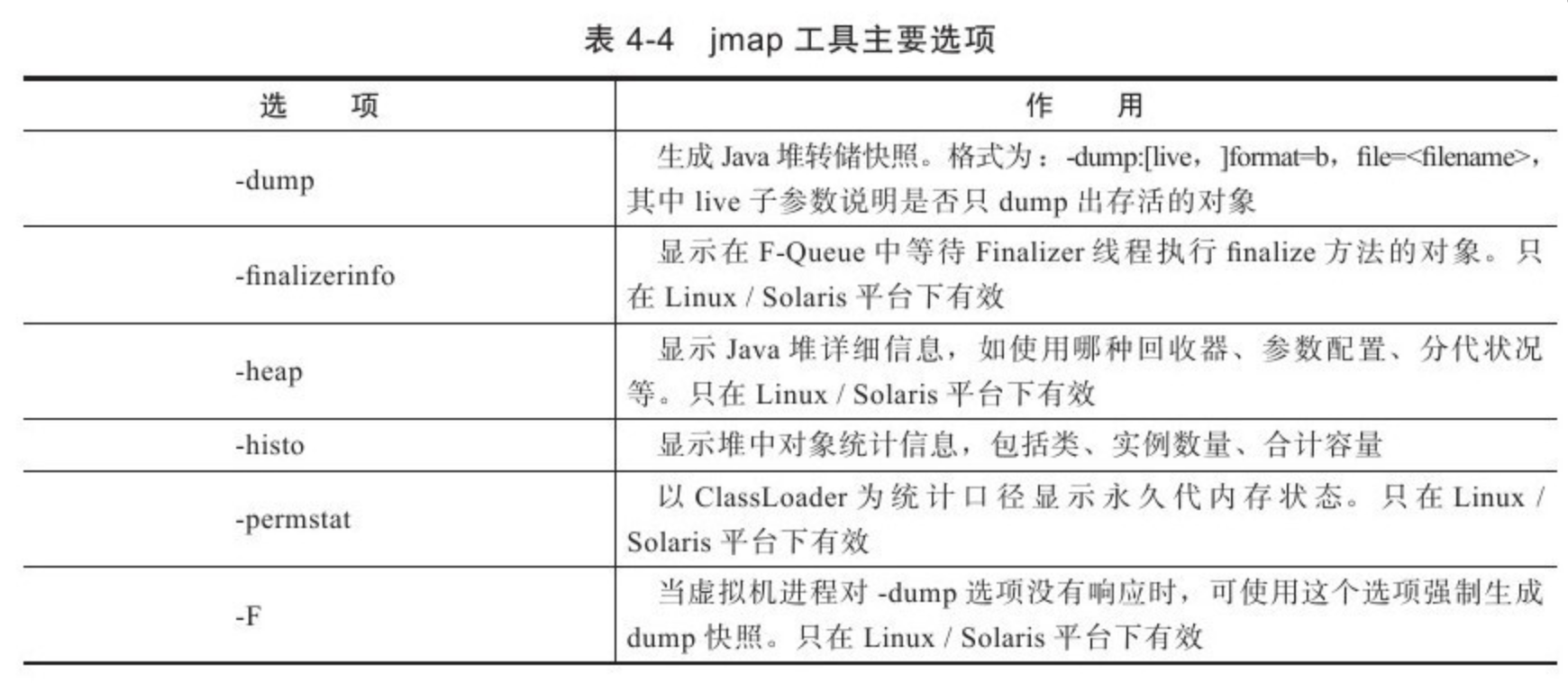
代码清单4-2是使用jmap生成一个正在运行的Eclipse的dump快照文件的例子,例子中的3500是通过jps命令查询到的LVMID。
C:\Users\IcyFenix>jmap-dump:format=b,file=eclipse.bin 3500
Dumping heap to C:\Users\IcyFenix\eclipse.bin……
Heap dump file created
4.2.5 jhat:虚拟机堆转储快照分析工具
Sun JDK提供jhat(JVM Heap Analysis Tool)命令与jmap搭配使用,来分析jmap生成的堆转储快照。jhat内置了一个微型的HTTP/HTML服务器,生成dump文件的分析结果后,可以在浏览器中查看。不过实事求是地说,在实际工作中,除非笔者手上真的没有别的工具可用,否则一般都不会去直接使用jhat命令来分析dump文件,主要原因有二:一是一般不会在部署应用程序的服务器上直接分析dump文件,即使可以这样做,也会尽量将dump文件复制到其他机器上进行分析,因为分析工作是一个耗时而且消耗硬件资源的过程,既然都要在其他机器进行,就没有必要受到命令行工具的限制了;另一个原因是jhat的分析功能相对来说比较简陋,后文将会介绍到的VisualVM,以及专业用于分析dump文件的Eclipse Memory Analyzer、IBM HeapAnalyzer等工具,都能实现比jhat更强大更专业的分析功能。
命令格式:
jhat[heapdump.file]
4.2.6 jstack:Java堆栈跟踪工具
jstack(Stack Trace for Java)命令用于生成虚拟机当前时刻的线程快照(一般称为threaddump或者javacore文件)。线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等都是导致线程长时间停顿的常见原因。线程出现停顿的时候通过jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做些什么事情,或者等待着什么资源。
命令格式:
jstack[option]vmid
option选项的合法值与具体含义见表4-5。

4.2.7 HSDIS:JIT生成代码反汇编
在Java虚拟机规范中,详细描述了虚拟机指令集中每条指令的执行过程、执行前后对操作数栈、局部变量表的影响等细节。这些细节描述与Sun的早期虚拟机(Sun Classic VM)高度吻合,但随着技术的发展,高性能虚拟机真正的细节实现方式已经渐渐与虚拟机规范所描述的内容产生了越来越大的差距,虚拟机规范中的描述逐渐成了虚拟机实现的“概念模型”——即实现只能保证规范描述等效。基于这个原因,我们分析程序的执行语义问题(虚拟机做了什么)时,在字节码层面上分析完全可行,但分析程序的执行行为问题(虚拟机是怎样做的、性能如何)时,在字节码层面上分析就没有什么意义了,需要通过其他方式解决。
分析程序如何执行,通过软件调试工具(GDB、Windbg等)来断点调试是最常见的手段,但是这样的调试方式在Java虚拟机中会遇到很大困难,因为大量执行代码是通过JIT编译器动态生成到CodeBuffer中的,没有很简单的手段来处理这种混合模式的调试(不过相信虚拟机开发团队内部肯定是有内部工具的)。因此,不得不通过一些特别的手段来解决问题,基于这种背景,本节的主角——HSDIS插件就正式登场了。
HSDIS是一个Sun官方推荐的HotSpot虚拟机JIT编译代码的反汇编插件,它包含在HotSpot虚拟机的源码之中,但没有提供编译后的程序。在Project Kenai的网站也可以下载到单独的源码。它的作用是让HotSpot的-XX:+PrintAssembly指令调用它来把动态生成的本地代码还原为汇编代码输出,同时还生成了大量非常有价值的注释,这样我们就可以通过输出的代码来分析问题。读者可以根据自己的操作系统和CPU类型从Project Kenai的网站上下载编译好的插件,直接放到JDK_HOME/jre/bin/client和JDK_HOME/jre/bin/server目录中即可。如果没有找到所需操作系统(譬如Windows的就没有)的成品,那就得自己使用源码编译一下。
还需要注意的是,如果读者使用的是Debug或者FastDebug版的HotSpot,那可以直接通过-XX:+PrintAssembly指令使用插件;如果使用的是Product版的HotSpot,那还要额外加入一个-XX:+UnlockDiagnosticVMOptions参数。笔者以代码清单4-6中的简单测试代码为例演示一下这个插件的使用。
测试代码:
public class Bar{
int a=1;
static int b=2;
public int sum(int c){
return a+b+c;
}
public static void main(String[]args){
new Bar().sum(3);
}
}
编译这段代码,并使用以下命令执行。
java-XX:+PrintAssembly-Xcomp-XX:CompileCommand=dontinline, *Bar.sum-XX:Compi leCommand=compileonly, *Bar.sum test.Bar
其中,参数-Xcomp是让虚拟机以编译模式执行代码,这样代码可以“偷懒”,不需要执行足够次数来预热就能触发JIT编译。两个 -XX:CompileCommand 意思是让编译器不要内联sum()并且只编译sum(),-XX:+PrintAssembly 就是输出反汇编内容。如果一切顺利的话,那么屏幕上会出现类似下面代码清单4-7所示的内容。
[Disassembling for mach='i386']
[Entry Point]
[Constants]
#{method}'sum''(I)I'in'test/Bar'
#this:ecx='test/Bar'
#parm0:edx=int
#[sp+0x20](sp of caller)
……
0x01cac407:cmp 0x4(%ecx), %eax
0x01cac40a:jne 0x01c6b050;{runtime_call}
[Verified Entry Point]
0x01cac410:mov%eax, -0x8000(%esp)
0x01cac417:push%ebp
0x01cac418:sub$0x18, %esp;*aload_0
;-test.Bar:sum@0(line 8)
;block B0[0, 10]
0x01cac41b:mov 0x8(%ecx), %eax;*getfield a
;-test.Bar:sum@1(line 8)
0x01cac41e:mov$0x3d2fad8, %esi;{oop(a
'java/lang/Class'='test/Bar')}
0x01cac423:mov 0x68(%esi), %esi;*getstatic b
;-test.Bar:sum@4(line 8)
0x01cac426:add%esi, %eax
0x01cac428:add%edx, %eax
0x01cac42a:add$0x18, %esp
0x01cac42d:pop%ebp
0x01cac42e:test%eax, 0x2b0100;{poll_return}
0x01cac434:ret
上段代码并不多,下面一句句进行说明。
- mov%eax,-0x8000(%esp):检查栈溢。
- push%ebp:保存上一栈帧基址。
- sub$0x18,%esp:给新帧分配空间。
- mov 0x8(%ecx),%eax:取实例变量a,这里0x8(%ecx)就是ecx+0x8的意思,前面"Constants"节中提示了"this:ecx=‘test/Bar’",即ecx寄存器中放的就是this对象的地址。偏移0x8是越过this对象的对象头,之后就是实例变量a的内存位置。这次是访问“Java堆”中的数据。
- mov$0x3d2fad8,%esi:取test.Bar在方法区的指针。
- mov 0x68(%esi),%esi:取类变量b,这次是访问“方法区”中的数据。
- add%esi,%eax和add%edx,%eax:做两次加法,求a+b+c的值,前面的代码把a放在eax中,把b放在esi中,而c在 Constants 中提示了,“parm0:edx=int”,说明c在edx中。
- add$0x18,%esp:撤销栈帧。
- pop%ebp:恢复上一栈帧。
- test%eax,0x2b0100:轮询方法返回处的SafePoint。
- ret:方法返回。
4.3 JDK的可视化工具
4.3.1 JConsole:Java监视与管理控制台
JConsole 是一种基于JMX的可视化监视、管理工具。它管理部分的功能是针对JMX MBean进行管理,由于MBean可以使用代码、中间件服务器的管理控制台或者所有符合JMX规范的软件进行访问,所以本节将会着重介绍JConsole监视部分的功能。
4.3.2 VisualVM:多合一故障处理工具
VisualVM(All-in-One Java Troubleshooting Tool)是到目前为止随JDK发布的功能最强大的运行监视和故障处理程序,并且可以预见在未来一段时间内都是官方主力发展的虚拟机故障处理工具。官方在VisualVM的软件说明中写上了"All-in-One"的描述字样,预示着它除了运行监视、故障处理外,还提供了很多其他方面的功能。如性能分析(Profiling),VisualVM的性能分析功能甚至比起JProfiler、YourKit等专业且收费的Profiling工具都不会逊色多少,而且VisualVM的还有一个很大的优点:不需要被监视的程序基于特殊Agent运行, 不需要被监视的程序基于特殊Agent运行,因此它对应用程序的实际性能的影响很小,使得它可以直接应用在生产环境中。这个优点是JProfiler、YourKit等工具无法与之媲美的。
4.4 本章小结
本章介绍了随JDK发布的6个命令行工具及两个可视化的故障处理工具,灵活使用这些工具可以给问题处理带来很大的便利。
除了JDK自带的工具之外,常用的故障处理工具还有很多,如果读者使用的是非Sun系列的JDK、非HotSpot的虚拟机,就需要使用对应的工具进行分析,如:
- IBM的Support Assistant、Heap Analyzer、Javacore Analyzer、Garbage Collector Analyzer适用于IBM J9 VM。
- HP的HPjmeter、HPjtune适用于HP-UX、SAP、HotSpot VM。
- Eclipse的Memory Analyzer Tool(MAT)适用于HP-UX、SAP、HotSpot VM,安装IBM DTFJ插件后可支持IBM J9 VM。
- BEA的JRockit Mission Control适用于JRockit VM。
5 - CH05-调优案例
5.1 概述
除了知识与工具外,经验同样是一个很重要的因素。
5.2 案例分析
5.2.1 高性能硬件上的程序部署策略
例如,一个 15 万PV/天左右的在线文档类型网站最近更换了硬件系统,新的硬件为 4 个 CPU、16GB 物理内存,操作系统为 64 位 CentOS 5.4,Resin 作为 Web 服务器。整个服务器暂时没有部署别的应用,所有硬件资源都可以提供给这访问量并不算太大的网站使用。管理员为了尽量利用硬件资源选用了 64 位的 JDK 1.5,并通过 -Xmx 和 -Xms 参数将 Java 堆固定在 12GB。使用一段时间后发现使用效果并不理想,网站经常不定期出现长时间失去响应的情况。
监控服务器运行状况后发现网站失去响应是由 GC 停顿导致的,虚拟机运行在 Server 模式,默认使用吞吐量优先收集器,回收 12GB 的堆,一次 Full GC 的停顿时间高达 14 秒。并且由于程序设计的关系,访问文档时要把文档从磁盘提取到内存中,导致内存中出现很多由文档序列化产生的大对象,这些大对象很多都进入了老年代,没有在 Minor GC 中清理掉。这种情况下即使有 12GB 的堆,内存也很快被消耗殆尽,由此导致每隔十几分钟出现十几秒的停顿,令网站开发人员和管理员感到很沮丧。
这里先不延伸讨论程序代码问题,程序部署上的主要问题显然是过大的堆内存进行回收时带来的长时间的停顿。硬件升级前使用 32 位系统 1.5GB 的堆,用户只感觉到使用网站比较缓慢,但不会发生十分明显的停顿,因此才考虑升级硬件以提升程序效能,如果重新缩小给 Java 堆分配的内存,那么硬件上的投资就显得很浪费。
在高性能硬件上部署程序,目前主要有两种方式:
- 通过 64 位 JDK 来使用大内存。
- 使用若干个 32 位虚拟机建立逻辑集群来利用硬件资源。
此案例中的管理员采用了第一种部署方式。对于用户交互性强、对停顿时间敏感的系统,可以给 Java 虚拟机分配超大堆的前提是有把握把应用程序的 Full GC 频率控制得足够低,至少要低到不会影响用户使用,譬如十几个小时乃至一天才出现一次 Full GC,这样可以通过在深夜执行定时任务的方式触发 Full GC 甚至自动重启应用服务器来保持内存可用空间在一个稳定的水平。
控制 Full GC 频率的关键是看应用中绝大多数对象能否符合“朝生夕灭”的原则,即大多数对象的生存时间不应太长,尤其是不能有成批量的、长生存时间的大对象产生,这样才能保障老年代空间的稳定。
在大多数网站形式的应用里,主要对象的生存周期都应该是请求级或者页面级的,会话级和全局级的长生命对象相对很少。只要代码写得合理,应当都能实现在超大堆中正常使用而没有 Full GC,这样的话,使用超大堆内存时,网站响应速度才会比较有保证。除此之外,如果读者计划使用 64 位 JDK 来管理大内存,还需要考虑下面可能面临的问题:
- 内存回收导致的长时间停顿。
- 现阶段,64 位 JDK 的性能测试结果普遍低于 32 位 JDK。
需要保证程序足够稳定,因为这种应用要是产生堆溢出几乎就无法产生堆转储快照(因为要产生十几 GB 乃至更大的 HeapDump 文件),哪怕产生了快照也几乎无法进行分析。
相同程序在 64 位 JDK 消耗的内存一般比 32 位 JDK 大,这是由于指针膨胀,以及数据类型对齐补白等因素导致的。
上面的问题听起来有点吓人,所以现阶段不少管理员还是选择第二种方式:使用若干个 32 位虚拟机建立逻辑集群来利用硬件资源。具体做法是在一台物理机器上启动多个应用服务器进程,每个服务器进程分配不同端口,然后在前端搭建一个负载均衡器,以反向代理的方式来分配访问请求。读者不需要太过在意均衡器转发所消耗的性能,即使使用 64 位 JDK,许多应用也不止有一台服务器,因此在许多应用中前端的均衡器总是要存在的。
考虑到在一台物理机器上建立逻辑集群的目的仅仅是为了尽可能利用硬件资源,并不需要关心状态保留、热转移之类的高可用性需求,也不需要保证每个虚拟机进程有绝对准确的均衡负载,因此使用无 Session 复制的亲合式集群是一个相当不错的选择。我们仅仅需要保障集群具备亲合性,也就是均衡器按一定的规则算法(一般根据 SessionID 分配)将一个固定的用户请求永远分配到固定的一个集群节点进行处理即可,这样程序开发阶段就基本不用为集群环境做什么特别的考虑了。
当然,很少有没有缺点的方案,如果读者计划使用逻辑集群的方式来部署程序,可能会遇到下面一些问题:尽量避免节点竞争全局的资源,最典型的就是磁盘竞争,各个节点如果同时访问某个磁盘文件的话(尤其是并发写操作容易出现问题),很容易导致 IO 异常。
很难最高效率地利用某些资源池,譬如连接池,一般都是在各个节点建立自己独立的连接池,这样有可能导致一些节点池满了而另外一些节点仍有较多空余。尽管可以使用集中式的 JNDI,但这个有一定复杂性并且可能带来额外的性能开销。
各个节点仍然不可避免地受到 32 位的内存限制,在 32 位 Windows 平台中每个进程只能使用 2GB 的内存,考虑到堆以外的内存开销,堆一般最多只能开到 1.5GB。在某些 Linux 或 UNIX 系统(如 Solaris)中,可以提升到 3GB 乃至接近 4GB 的内存,但 32 位中仍然受最高 4GB(2^{32})内存的限制。
大量使用本地缓存(如大量使用 HashMap 作为 K/V 缓存)的应用,在逻辑集群中会造成较大的内存浪费,因为每个逻辑节点上都有一份缓存,这时候可以考虑把本地缓存改为集中式缓存。
介绍完这两种部署方式,再重新回到这个案例之中,最后的部署方案调整为建立 5 个 32 位 JDK 的逻辑集群,每个进程按 2GB 内存计算(其中堆固定为1.5GB),占用了 10GB 内存。另外建立一个 Apache 服务作为前端均衡代理访问门户。考虑到用户对响应速度比较关心,并且文档服务的主要压力集中在磁盘和内存访问,CPU 资源敏感度较低,因此改为 CMS 收集器进行垃圾回收。部署方式调整后,服务再没有出现长时间停顿,速度比硬件升级前有较大提升。
5.2.2 集群间同步导致的内存溢出
例如,有一个基于 B/S 的 MIS 系统,硬件为两台 2 个 CPU、8GB 内存的 HP 小型机,服务器是 WebLogic 9.2,每台机器启动了 3 个 WebLogic 实例,构成一个 6 个节点的亲合式集群。由于是亲合式集群,节点之间没有进行 Session 同步,但是有一些需求要实现部分数据在各个节点间共享。开始这些数据存放在数据库中,但由于读写频繁竞争很激烈,性能影响较大,后面使用 JBossCache 构建了一个全局缓存。全局缓存启用后,服务正常使用了一段较长的时间,但最近却不定期地出现了多次的内存溢出问题。
在内存溢出异常不出现的时候,服务内存回收状况一直正常,每次内存回收后都能恢复到一个稳定的可用空间,开始怀疑是程序某些不常用的代码路径中存在内存泄漏,但管理员反映最近程序并未更新、升级过,也没有进行什么特别操作。只好让服务带着 -XX:+HeapDumpOnOutOfMemoryError 参数运行了一段时间。在最近一次溢出之后,管理员发回了 heapdump 文件,发现里面存在着大量的 org.jgroups.protocols.pbcast.NAKACK 对象。
JBossCache 是基于自家的 JGroups 进行集群间的数据通信,JGroups 使用协议栈的方式来实现收发数据包的各种所需特性自由组合,数据包接收和发送时要经过每层协议栈的 up() 和 down() 方法,其中的 NAKACK 栈用于保障各个包的有效顺序及重发。JBossCache 协议栈如图5-1所示。

由于信息有传输失败需要重发的可能性,在确认所有注册在 GMS(Group Membership Service)的节点都收到正确的信息前,发送的信息必须在内存中保留。而此 MIS 的服务端中有一个负责安全校验的全局 Filter,每当接收到请求时,均会更新一次最后操作时间,并且将这个时间同步到所有的节点去,使得一个用户在一段时间内不能在多台机器上登录。在服务使用过程中,往往一个页面会产生数次乃至数十次的请求,因此这个过滤器导致集群各个节点之间网络交互非常频繁。当网络情况不能满足传输要求时,重发数据在内存中不断堆积,很快就产生了内存溢出。
这个案例中的问题,既有 JBossCache 的缺陷,也有 MIS 系统实现方式上缺陷。JBossCache 官方的 maillist 中讨论过很多次类似的内存溢出异常问题,据说后续版本也有了改进。而更重要的缺陷是这一类被集群共享的数据要使用类似 JBossCache 这种集群缓存来同步的话,可以允许读操作频繁,因为数据在本地内存有一份副本,读取的动作不会耗费多少资源,但不应当有过于频繁的写操作,那样会带来很大的网络同步的开销。
5.2.3 堆外内存导致的溢出错误
例如,一个学校的小型项目:基于 B/S 的电子考试系统,为了实现客户端能实时地从服务器端接收考试数据,系统使用了逆向 AJAX 技术(也称为 Comet 或者 Server Side Push),选用 CometD 1.1.1 作为服务端推送框架,服务器是 Jetty 7.1.4,硬件为一台普通 PC 机,Core i5 CPU,4GB 内存,运行 32 位 Windows 操作系统。
测试期间发现服务端不定时抛出内存溢出异常,服务器不一定每次都会出现异常,但假如正式考试时崩溃一次,那估计整场电子考试都会乱套,网站管理员尝试过把堆开到最大,而 32 位系统最多到 1.6GB 就基本无法再加大了,而且开大了基本没效果,抛出内存溢出异常好像还更加频繁了。加入 -XX:+HeapDumpOnOutOfMemoryError,居然也没有任何反应,抛出内存溢出异常时什么文件都没有产生。无奈之下只好挂着 jstat 并一直紧盯屏幕,发现 GC 并不频繁,Eden 区、Survivor 区、老年代以及永久代内存全部都表示“情绪稳定,压力不大”,但就是照样不停地抛出内存溢出异常,管理员压力很大。最后,在内存溢出后从系统日志中找到异常堆栈,如代码清单5-1所示。
[org.eclipse.jetty.util.log]handle failed java.lang.OutOfMemoryError:null
at sun.misc.Unsafe.allocateMemory(Native Method)
at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:99)
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:288)
at org.eclipse.jetty.io.nio.DirectNIOBuffer.<init>
……
如果认真阅读过本书的第 2 章,看到异常堆栈就应该清楚这个抛出内存溢出异常是怎么回事了。大家知道操作系统对每个进程能管理的内存是有限制的,这台服务器使用的 32 位 Windows 平台的限制是 2GB,其中划了 1.6GB 给 Java 堆,而 Direct Memory 内存并不算入 1.6GB 的堆之内,因此它最大也只能在剩余的 0.4GB 空间中分出一部分。在此应用中导致溢出的关键是:垃圾收集进行时,虚拟机虽然会对 Direct Memory 进行回收,但是 Direct Memory 却不能像新生代、老年代那样,发现空间不足了就通知收集器进行垃圾回收,它只能等待老年代满了后 Full GC,然后“顺便地”帮它清理掉内存的废弃对象。否则它只能一直等到抛出内存溢出异常时,先 catch 掉,再在 catch 块里面“大喊”一声:“System.gc()!"。要是虚拟机还是不听(譬如打开了 -XX:+DisableExplicitGC 开关),那就只能眼睁睁地看着堆中还有许多空闲内存,自己却不得不抛出内存溢出异常了。而本案例中使用的 CometD 1.1.1 框架,正好有大量的 NIO 操作需要使用到 Direct Memory 内存。
从实践经验的角度出发,除了 Java 堆和永久代之外,我们注意到下面这些区域还会占用较多的内存,这里所有的内存总和受到操作系统进程最大内存的限制。
Direct Memory:可通过 -XX:MaxDirectMemorySize 调整大小,内存不足时抛出 OutOfMemoryError 或者 OutOfMemoryError:Direct buffer memory。
线程堆栈:可通过 -Xss 调整大小,内存不足时抛出 StackOverflowError(纵向无法分配,即无法分配新的栈帧)或者 OutOfMemoryError:unable to create new native thread(横向无法分配,即无法建立新的线程)。
Socket 缓存区:每个 Socket 连接都 Receive 和 Send 两个缓存区,分别占大约 37KB 和 25KB 内存,连接多的话这块内存占用也比较可观。如果无法分配,则可能会抛出 IOException:Too many open files 异常。
JNI 代码:如果代码中使用 JNI 调用本地库,那本地库使用的内存也不在堆中。
虚拟机和 GC:虚拟机、GC 的代码执行也要消耗一定的内存。
5.2.4 外部命令导致系统缓慢
这是一个来自网络的案例:一个数字校园应用系统,运行在一台 4 个 CPU 的 Solaris 10 操作系统上,中间件为 GlassFish 服务器。系统在做大并发压力测试的时候,发现请求响应时间比较慢,通过操作系统的 mpstat 工具发现 CPU 使用率很高,并且系统占用绝大多数的 CPU 资源的程序并不是应用系统本身。这是个不正常的现象,通常情况下用户应用的 CPU 占用率应该占主要地位,才能说明系统是正常工作的。
通过 Solaris 10 的 Dtrace 脚本可以查看当前情况下哪些系统调用花费了最多的 CPU 资源,Dtrace 运行后发现最消耗 CPU 资源的竟然是"fork"系统调用。众所周知,“fork"系统调用是 Linux 用来产生新进程的,在 Java 虚拟机中,用户编写的 Java 代码最多只有线程的概念,不应当有进程的产生。
这是个非常异常的现象。通过本系统的开发人员,最终找到了答案:每个用户请求的处理都需要执行一个外部 shell 脚本来获得系统的一些信息。执行这个 shell 脚本是通过Java 的 Runtime.getRuntime().exec() 方法来调用的。这种调用方式可以达到目的,但是它在 Java 虚拟机中是非常消耗资源的操作,即使外部命令本身能很快执行完毕,频繁调用时创建进程的开销也非常可观。Java 虚拟机执行这个命令的过程是:首先克隆一个和当前虚拟机拥有一样环境变量的进程,再用这个新的进程去执行外部命令,最后再退出这个进程。如果频繁执行这个操作,系统的消耗会很大,不仅是 CPU,内存负担也很重。
用户根据建议去掉这个 Shell 脚本执行的语句,改为使用 Java 的 API 去获取这些信息后,系统很快恢复了正常。
5.2.5 服务器 JVM 进程崩溃
例如,一个基于 B/S 的 MIS 系统,硬件为两台 2 个 CPU、8GB 内存的 HP 系统,服务器是 WebLogic 9.2(就是5.2.2节中的那套系统)。正常运行一段时间后,最近发现在运行期间频繁出现集群节点的虚拟机进程自动关闭的现象,留下了一个 hs_err_pid???.log 文件后,进程就消失了,两台物理机器里的每个节点都出现过进程崩溃的现象。从系统日志中可以看出,每个节点的虚拟机进程在崩溃前不久,都发生过大量相同的异常,见代码清单 5-2。
java.net.SocketException:Connection reset
at java.net.SocketInputStream.read(SocketInputStream.java:168)
at java.io.BufferedInputStream.fill(BufferedInputStream.java:218)
at java.io.BufferedInputStream.read(BufferedInputStream.java:235)
at org.apache.axis.transport.http.HTTPSender.readHeadersFromSocket(HTTPSender.java:583)
at org.apache.axis.transport.http.HTTPSender.invoke(HTTPSender.java:143)……99 more
这是一个远端断开连接的异常,通过系统管理员了解到系统最近与一个 OA 门户做了集成,在 MIS 系统工作流的待办事项变化时,要通过 Web 服务通知 OA 门户系统,把待办事项的变化同步到 OA 门户之中。通过 SoapUI 测试了一下同步待办事项的几个 Web 服务,发现调用后竟然需要长达 3 分钟才能返回,并且返回结果都是连接中断。
由于 MIS 系统的用户多,待办事项变化很快,为了不被 OA 系统速度拖累,使用了异步的方式调用 Web 服务,但由于两边服务速度的完全不对等,时间越长就累积了越多 Web 服务没有调用完成,导致在等待的线程和 Socket 连接越来越多,最终在超过虚拟机的承受能力后使得虚拟机进程崩溃。解决方法:通知 OA 门户方修复无法使用的集成接口,并将异步调用改为生产者/消费者模式的消息队列实现后,系统恢复正常。
5.2.6 不恰当数据结构导致内存占用过大
例如,有一个后台 RPC 服务器,使用 64 位虚拟机,内存配置为 -Xms4g-Xmx8g-Xmn1g,使用 ParNew+CMS 的收集器组合。平时对外服务的 Minor GC 时间约在 30 毫秒以内,完全可以接受。但业务上需要每 10 分钟加载一个约 80MB 的数据文件到内存进行数据分析,这些数据会在内存中形成超过 100 万个 HashMap<Long,Long>Entry,在这段时间里面 Minor GC 就会造成超过 500 毫秒的停顿,对于这个停顿时间就接受不了了,具体情况如下面 GC 日志所示。
{Heap before GC invocations=95(full 4):
par new generation total 903168K,used 803142K[0x00002aaaae770000, 0x00002aaaebb70000, 0x00002aaaebb70000)
eden space 802816K, 100%used[0x00002aaaae770000, 0x00002aaadf770000, 0x00002aaadf770000)
from space 100352K, 0%used[0x00002aaae5970000, 0x00002aaae59c1910, 0x00002aaaebb70000)
to space 100352K, 0%used[0x00002aaadf770000, 0x00002aaadf770000, 0x00002aaae5970000)
concurrent mark-sweep generation total 5845540K,used 3898978K[0x00002aaaebb70000, 0x00002aac507f9000, 0x00002aacae770000)
concurrent-mark-sweep perm gen total 65536K,used 40333K[0x00002aacae770000, 0x00002aacb2770000, 0x00002aacb2770000)
2011-10-28 T11:40:45.162+0800:226.504:[GC226.504:[ParNew:803142K->100352K(903168K), 0.5995670 secs]4702120K->4056332K(6748708K), 0.5997560 secs][Times:user=1.46 sys=0.04, real=0.60 secs]
Heap after GC invocations=96(full 4):
par new generation total 903168K,used 100352K[0x00002aaaae770000, 0x00002aaaebb70000, 0x00002aaaebb70000)
eden space 802816K, 0%used[0x00002aaaae770000, 0x00002aaaae770000, 0x00002aaadf770000)
from space 100352K, 100%used[0x00002aaadf770000, 0x00002aaae5970000,
0x00002aaae5970000)
to space 100352K, 0x00002aaaebb70000)0%used[0x00002aaae5970000, 0x00002aaae5970000,
concurrent mark-sweep generation total 5845540K,used 3955980K[0x00002aaaebb70000, 0x00002aac507f9000, 0x00002aacae770000)
concurrent-mark-sweep perm gen total 65536K,used 40333K[0x00002aacae770000, 0x00002aacb2770000, 0x00002aacb2770000)
}
Total time for which application threads were stopped:0.6070570 seconds
观察这个案例,发现平时的 Minor GC 时间很短,原因是新生代的绝大部分对象都是可清除的,在 Minor GC 之后 Eden 和 Survivor 基本上处于完全空闲的状态。而在分析数据文件期间,800MB 的 Eden 空间很快被填满从而引发 GC,但 Minor GC 之后,新生代中绝大部分对象依然是存活的。我们知道 ParNew 收集器使用的是复制算法,这个算法的高效是建立在大部分对象都“朝生夕灭”的特性上的,如果存活对象过多,把这些对象复制到 Survivor 并维持这些对象引用的正确就成为一个沉重的负担,因此导致 GC 暂停时间明显变长。
如果不修改程序,仅从 GC 调优的角度去解决这个问题,可以考虑将 Survivor 空间去掉(加入参数-XX:SurvivorRatio=65536、-XX:MaxTenuringThreshold=0 或者 -XX:+AlwaysTenure),让新生代中存活的对象在第一次 Minor GC 后立即进入老年代,等到 Major GC 的时候再清理它们。这种措施可以治标,但也有很大副作用,治本的方案需要修改程序,因为这里的问题产生的根本原因是用 HashMap<Long,Long> 结构来存储数据文件空间效率太低。
下面具体分析一下空间效率。在 HashMap<Long,Long> 结构中,只有 Key 和 Value 所存放的两个长整型数据是有效数据,共 16B(2×8B)。这两个长整型数据包装成 java.lang.Long 对象之后,就分别具有 8B 的 MarkWord、8B 的 Klass 指针,在加 8B 存储数据的 long 值。在这两个 Long 对象组成 Map.Entry 之后,又多了 16B 的对象头,然后一个 8B 的 next 字段和 4B 的 int 型的 hash 字段,为了对齐,还必须添加 4B 的空白填充,最后还有 HashMap 中对这个 Entry 的 8B 的引用,这样增加两个长整型数字,实际耗费的内存为(Long(24B)×2)+Entry(32B)+HashMap Ref(8B)=88B,空间效率为 16B/88B=18%,实在太低了。
5.2.7 由 Windows 虚拟内存导致的长时间停顿
例如,有一个带心跳检测功能的 GUI 桌面程序,每 15 秒会发送一次心跳检测信号,如果对方 30 秒以内都没有信号返回,那就认为和对方程序的连接已经断开。程序上线后发现心跳检测有误报的概率,查询日志发现误报的原因是程序会偶尔出现间隔约一分钟左右的时间完全无日志输出,处于停顿状态。
因为是桌面程序,所需的内存并不大(-Xmx256m),所以开始并没有想到是 GC 导致的程序停顿,但是加入参数 -XX:+PrintGCApplicationStoppedTime-XX:+PrintGCDateStamps-Xloggc:gclog.log 后,从 GC 日志文件中确认了停顿确实是由 GC 导致的,大部分 GC 时间都控制在 100 毫秒以内,但偶尔就会出现一次接近 1 分钟的 GC。
Total time for which application threads were stopped:0.0112389 seconds
Total time for which application threads were stopped:0.0001335 seconds
Total time for which application threads were stopped:0.0003246 seconds
Total time for which application threads were stopped:41.4731411 seconds
Total time for which application threads were stopped:0.0489481 seconds
Total time for which application threads were stopped:0.1110761 seconds
Total time for which application threads were stopped:0.0007286 seconds
Total time for which application threads were stopped:0.0001268 seconds
从 GC 日志中找到长时间停顿的具体日志信息(添加了 -XX:+PrintReferenceGC 参数),找到的日志片段如下所示。从日志中可以看出,真正执行 GC 动作的时间不是很长,但从准备开始 GC,到真正开始 GC 之间所消耗的时间却占了绝大部分。
除 GC 日志之外,还观察到这个 GUI 程序内存变化的一个特点,当它最小化的时候,资源管理中显示的占用内存大幅度减小,但是虚拟内存则没有变化,因此怀疑程序在最小化时它的工作内存被自动交换到磁盘的页面文件之中了,这样发生 GC 时就有可能因为恢复页面文件的操作而导致不正常的 GC 停顿。
在 MSDN 上查证后确认了这种猜想,因此,在 Java 的 GUI 程序中要避免这种现象,可以加入参数”-Dsun.awt.keepWorkingSetOnMinimize=true"来解决。这个参数在许多 AWT 的程序上都有应用,例如 JDK 自带的 Visual VM,用于保证程序在恢复最小化时能够立即响应。在这个案例中加入该参数后,问题得到解决。
5.3 实战:Eclipse运行速度调优
很多 Java 开发人员都有这样一种观念:系统调优的工作都是针对服务端应用而言,规模越大的系统,就越需要专业的调优运维团队参与。这个观点不能说不对,5.2 节中笔者所列举的案例确实都是服务端运维、调优的例子,但服务端应用需要调优,并不说明其他应用就不需要了,作为一个普通的 Java 开发人员,前面讲的各种虚拟机的原理和最佳实践方法距离我们并不遥远,开发者身边很多场景都可以使用上面这些知识。下面通过一个普通程序员日常工作中可以随时接触到的开发工具开始这次实战。
5.3.1 调优前的程序运行状态
笔者使用 Eclipse 作为日常工作中的主要 IDE 工具,由于安装的插件比较大(如Klocwork、ClearCase LT等)、代码也很多,启动 Eclipse 直到所有项目编译完成需要四五分钟。一直对开发环境的速度感觉不满意,趁着编写这本书的机会,决定对 Eclipse 进行“动刀”调优。
笔者机器的 Eclipse 运行平台是 32 位 Windows 7 系统,虚拟机为 HotSpot VM 1.5 b64。硬件为 ThinkPad X201,Intel i5 CPU,4GB 物理内存。在初始的配置文件 eclipse.ini 中,除了指定 JDK 的路径、设置最大堆为 512MB 以及开启了JMX 管理(需要在 VisualVM 中收集原始数据)外,未做其他任何改动,原始配置内容如代码清单5-3所示。
-vm
D:/_DevSpace/jdk1.5.0/bin/javaw.exe
-startup
plugins/org.eclipse.equinox.launcher_1.0.201.R35x_v20090715.jar
--launcher.library
plugins/org.eclipse.equinox.launcher.win32.win32.x86_1.0.200.v20090519
-product
org.eclipse.epp.package.jee.product
--launcher.XXMaxPermSize
256M
-showsplash
org.eclipse.platform
-vmargs
-Dosgi.requiredJavaVersion=1.5
-Xmx512m
-Dcom.sun.management.jmxremote
为了要与调优后的结果进行量化对比,调优开始前笔者先做了一次初始数据测试。测试用例很简单,就是收集从 Eclipse 启动开始,直到所有插件加载完成为止的总耗时以及运行状态数据,虚拟机的运行数据通过 VisualVM 及其扩展插件 VisualGC 进行采集。测试过程中反复启动数次 Eclipse 直到测试结果稳定后,取最后一次运行的结果作为数据样本(为了避免操作系统未能及时进行磁盘缓存而产生的影响),数据样本如图5-2所示。
Eclipse 启动的总耗时没有办法从监控工具中直接获得,因为 VisualVM 不可能知道 Eclipse 运行到什么阶段算是启动完成。为了测试的准确性,笔者写了一个简单的 Eclipse 插件,用于统计 Eclipse 的启动耗时。由于代码很简单,并且本书不是 Eclipse RCP 开发的教程,所以只列出代码清单 5-4 供读者参考,不再延伸讲解。如果读者需要这个插件,可以使用下面代码自行编译或者发电子邮件向笔者索取。
ShowTime.java代码:
import org.eclipse.jface.dialogs.MessageDialog;
import org.eclipse.swt.widgets.Display;
import org.eclipse.swt.widgets.Shell;
import org.eclipse.ui.IStartup;
/**
*统计Eclipse启动耗时
*@author zzm
*/
public class ShowTime implements IStartup{
public void earlyStartup(){
Display.getDefault().syncExec(new Runnable(){
public void run(){
long eclipseStartTime=Long.parseLong(System.getProperty("eclipse.startTime"));
long costTime=System.currentTimeMillis()-eclipseStartTime;
Shell shell=Display.getDefault().getActiveShell();
String message="Eclipse启动耗时:"+costTime+"ms";
MessageDialog.openInformation(shell, "Information", message);
}
});
}
}
plugin.xml 代码:
<?xml version="1.0"encoding="UTF-8"?>
<?eclipse version="3.4"?>
<plugin>
<extension
point="org.eclipse.ui.startup">
<startup class="eclipsestarttime.actions.ShowTime"/>
</extension>
</plugin>
上述代码打包成 jar 后放到 Eclipse 的 plugins 目录,反复启动几次后,插件显示的平均时间稳定在 15 秒左右。
根据 VisualGC 和 Eclipse 插件收集到的信息,总结原始配置下的测试结果如下。
- 整个启动过程平均耗时约15秒。
- 最后一次启动的数据样本中,垃圾收集总耗时 4.149 秒,其中:
- Full GC 被触发了 19 次,共耗时 3.166 秒。
- Minor GC 被触发了 378 次,共耗时 0.983 秒。
- 加载类 9115 个,耗时 4.114 秒。
- JIT编译时间为 1.999 秒。
虚拟机 512MB 的堆内存被分配为 40MB 的新生代(31.5 的 Eden 空间和两个 4MB 的 Surviver 空间)以及 472MB 的老年代。
客观地说,由于机器硬件还不错(请读者以 2010 年普通 PC 机的标准来衡量),15秒的启动时间其实还在可接受范围以内,但是从 VisualGC 中反映的数据来看,主要问题是非用户程序时间(图5-2中的 Compile Time、Class Load Time、GC Time)非常之高,占了整个启动过程耗时的一半以上(这里存在少许夸张成分,因为如 JIT 编译等动作是在后台线程完成的,用户程序在此期间也正常执行,所以并没有占用了一半以上的绝对时间)。虚拟机后台占用太多时间也直接导致 Eclipse 在启动后的使用过程中经常有不时停顿的感觉,所以进行调优有较大的价值。
5.3.2 升级 JDK 1.6 的性能变化及兼容问题
对 Eclipse 进行调优的第一步就是先把虚拟机的版本进行升级,希望能先从虚拟机版本身上得到一些“免费的”性能提升。
每次 JDK 的大版本发布时,开发商肯定都会宣称虚拟机的运行速度比上一版本有了很大的提高,这虽然是个广告性质的宣言,经常被人从升级列表或者技术白皮书中直接忽略过去,但从国内外的第三方评测数据来看,版本升级至少某些方面确实带来了一定的性能改善,以下是一个第三方网站对 JDK 1.5、1.6、1.7 三个版本做的性能评测,分别测试了以下4个用例:
- 生成 500 万个的字符串。
- 500 万次
ArrayList<String>数据插入,使用第一点生成的数据。 - 生成 500 万个
HashMap<String,Integer>,每个键-值对通过并发线程计算,测试并发能力。 - 打印 500 万个
ArrayList<String>中的值到文件,并重读回内存。
三个版本的 JDK 分别运行这 3 个用例的测试程序,测试结果如图5-4所示。
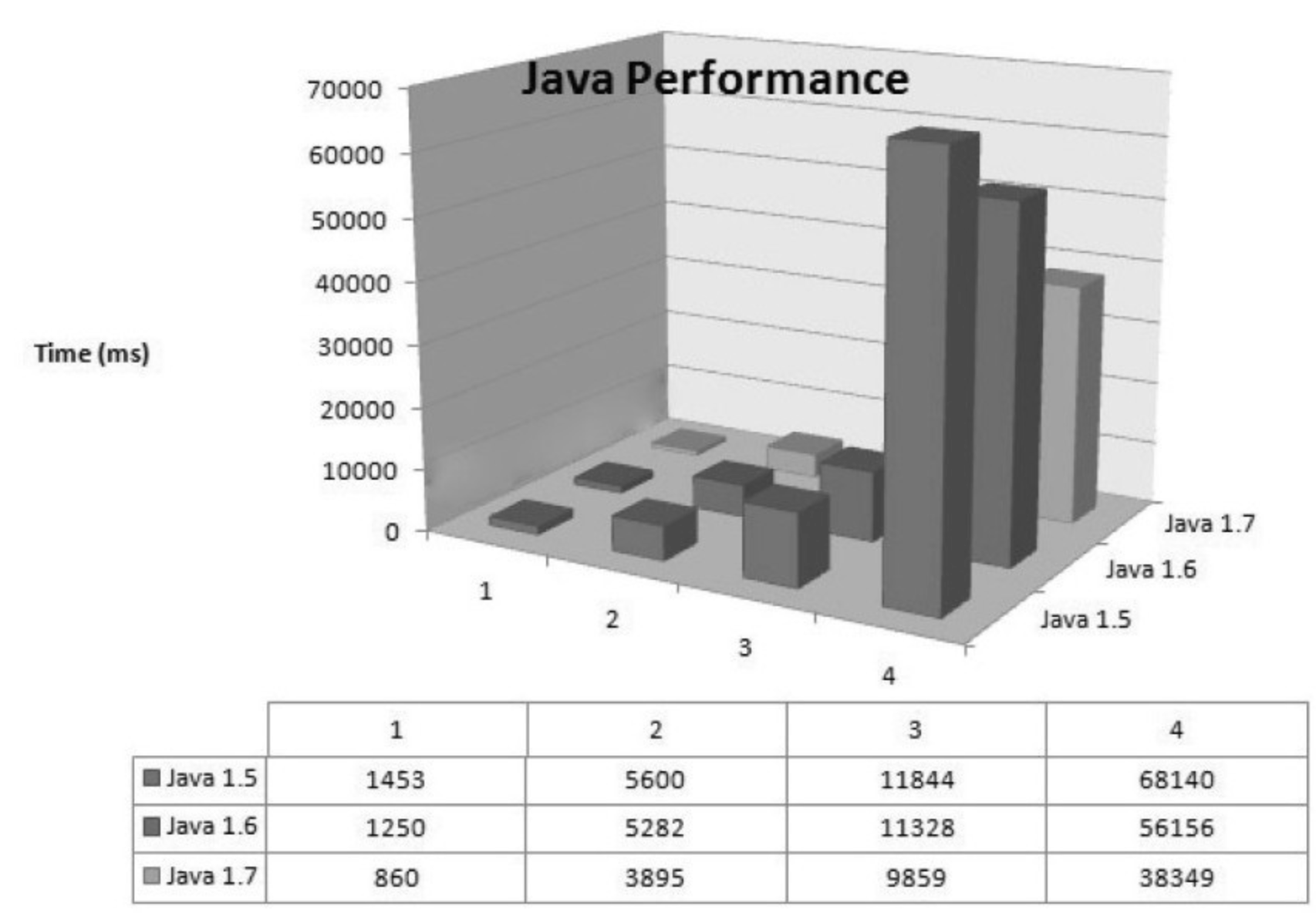
从这 4 个用例的测试结果来看,JDK 1.6 比 JDK 1.5 有大约 15% 的性能提升,尽管对 JDK 仅测试这 4 个用例并不能说明什么问题,需要通过测试数据来量化描述一个 JDK 比旧版提升了多少是很难做到非常科学和准确的(要做稍微靠谱一点的测试,可以使用 SPECjvm2008 来完成,或者把相应版本的 TCK 中数万个测试用例的性能数据对比一下可能更有说服力),但我还是选择相信这次“软广告”性质的测试,把 JDK 版本升级到 1.6 Update 21。
与所有小说作者设计的故事情节一样,获得最后的胜利之前总是要经历各种各样的挫折,这次升级到 JDK 1.6 之后,性能有什么变化先暂且不谈,在使用几分钟之后,笔者的 Eclipse 就和前面几个服务端的案例一样非常“不负众望”地发生了内存溢出。
这次内存溢出完全出乎笔者的意料之外:决定对 Eclipse 做调优是因为速度慢,但开发环境一直都很稳定,至少没有出现过内存溢出的问题,而这次升级除了 eclipse.ini 中的 JVM 路径改变了之外,还未进行任何运行参数的调整,进到 Eclipse 主界面之后随便打开了几个文件就抛出内存溢出异常了,难道 JDK 1.6 Update 21 有哪个 API 出现了严重的泄漏问题吗?
事实上,并不是 JDK 1.6 出现了什么问题,根据前面章节中介绍的相关原理和工具,我们要查明这个异常的原因并且解决它一点也不困难。打开 VisualVM,监视页签中的内存曲线部分如图5-6和图5-7所示。
在 Java 堆中监视曲线中,“堆大小”的曲线与“使用的堆”的曲线一直都有很大的间隔距离,每当两条曲线开始有互相靠近的趋势时,“最大堆”的曲线就会快速向上转向,而“使用的堆”的曲线会向下转向。“最大堆”的曲线向上是虚拟机内部在进行堆扩容,运行参数中并没有指定最小堆(-Xms)的值与最大堆(-Xmx)相等,所以堆容量一开始并没有扩展到最大值,而是根据使用情况进行伸缩扩展。“使用的堆”的曲线向下是因为虚拟机内部触发了一次垃圾收集,一些废弃对象的空间被回收后,内存用量相应减少,从图形上看,Java 堆运作是完全正常的。但永久代的监视曲线就有问题了,“PermGen大小”的曲线与“使用的PermGen”的曲线几乎完全重合在一起,这说明永久代中没有可回收的资源,所以“使用的PermGen”的曲线不会向下发展,永久代中也没有空间可以扩展,所以“PermGen大小”的曲线不能向上扩展。这次内存溢出很明显是永久代导致的内存溢出。
再注意到图 5-7 中永久代的最大容量:“67,108,864个字节”,也就是 64MB,这恰好是 JDK 在未使用 -XX:MaxPermSize 参数明确指定永久代最大容量时的默认值,无论 JDK 1.5 还是 JDK 1.6,这个默认值都是 64MB。对于 Eclipse 这种规模的 Java 程序来说,64MB 的永久代内存空间显然是不够的,溢出很正常,那为何在 JDK 1.5 中没有发生过溢出呢?
在 VisualVM 的“概述-JVM参数”页签中,分别检查使用 JDK 1.5 和 JDK 1.6 运行 Eclipse 时的 JVM 参数,发现使用 JDK 1.6 时,只有以下 3 个 JVM 参数,如代码清单5-5所示。
-Dcom.sun.management.jmxremote
-Dosgi.requiredJavaVersion=1.5
-Xmx512m
而使用 JDK 1.5 运行时,就有 4 条 JVM 参数,其中多出来的一条正好就是设置永久代最大容量的 -XX:MaxPermSize=256M,如代码清单5-6所示。
代码清单5-6 JDK 1.5的Eclipse运行期参数
-Dcom.sun.management.jmxremote
-Dosgi.requiredJavaVersion=1.5
-Xmx512m
-XX:MaxPermSize=256M
为什么会这样呢?笔者从 Eclipse 的 Bug List 网站上找到了答案:使用 JDK 1.5 时之所以有永久代容量这个参数,是因为在 eclipse.ini 中存在”–launcher.XXMaxPermSize 256M"这项设置,当 launcher——也就是 Windows 下的可执行程序 eclipse.exe,检测到假如是 Eclipse 运行在 Sun 公司的虚拟机上的话,就会把参数值转化为 -XX:MaxPermSize 传递给虚拟机进程,因为三大商用虚拟机中只有 Sun 系列的虚拟机才有永久代的概念,也就是只有 HotSpot 虚拟机需要设置这个参数,JRockit 虚拟机和 IBM J9 虚拟机都不需要设置。
在2009年4月20日,Oracle 公司正式完成了对 Sun 公司的收购,此后无论是网页还是具体程序产品,提供商都从 Sun 变为了 Oracle,而 eclipse.exe 就是根据程序提供商判断是否为 Sun 的虚拟机,当 JDK 1.6 Update 21 中 java.exe、javaw.exe 的"Company"属性从"Sun Microsystems Inc.“变为"Oracle Corporation"之后,Eclipse 就完全不认识这个虚拟机了,因此没有把最大永久代的参数传递过去。
了解原因之后,解决方法就简单了,launcher 不认识就只好由人来告诉它,即在 eclipse.ini 中明确指定 -XX:MaxPermSize=256M 这个参数就可以了。
5.3.3 编译时间和类加载时间的优化
从 Eclipse 启动时间上来看,升级到 JDK 1.6 所带来的性能提升是……嗯?基本上没有提升?多次测试的平均值与 JDK 1.5 的差距完全在实验误差范围之内。
各位读者不必失望,Sun JDK 1.6 性能白皮书描述的众多相对于 JDK 1.5 的提升不至于全部是广告,虽然总启动时间没有减少,但在查看运行细节的时候,却发现了一件很值得注意的事情:在 JDK 1.6 中启动完 Eclipse 所消耗的类加载时间比 JDK 1.5 长了接近一倍,不要看反了,这里写的是 JDK 1.6 的类加载比 JDK 1.5 慢一倍,测试结果如代码清单5-7所示,反复测试多次仍然是相似的结果。
使用JDK 1.6的类加载时间:
C:\Users\IcyFenix>jps
3552
6372 org.eclipse.equinox.launcher_1.0.201.R35x_v20090715.jar
6900 Jps
C:\Users\IcyFenix>jstat-class 6372
Loaded Bytes Unloaded Bytes Time
7917 10190.3 0 0.0 8.18
使用JDK 1.5的类加载时间:
C:\Users\IcyFenix>jps
3552
7272 Jps
7216 org.eclipse.equinox.launcher_1.0.201.R35x_v20090715.jar
C:\Users\IcyFenix>jstat-class 7216
Loaded Bytes Unloaded Bytes Time
7902 9691.2 3 2.6 4.34
在本例中,类加载时间上的差距并不能作为一个具有普遍性的测试结果去说明 JDK 1.6 的类加载必然比 JDK 1.5 慢,笔者测试了自己机器上的 Tomcat 和 GlassFish 启动过程,并未没有出现类似的差距。在国内最大的 Java 社区中,笔者发起过关于此问题的讨论,从参与者反馈的测试结果来看,此问题只在一部分机器上存在,而且 JDK 1.6 的各个 Update 版之间也存在很大差异。
多次试验后,笔者发现在机器上两个 JDK 进行类加载时,字节码验证部分耗时差距尤其严重。考虑到实际情况:Eclipse 使用者甚多,它的编译代码我们可以认为是可靠的,不需要在加载的时候再进行字节码验证,因此通过参数 -Xverify:none 禁止掉字节码验证过程也可作为一项优化措施。加入这个参数后,两个版本的 JDK 类加载速度都有所提高,JDK 1.6 的类加载速度仍然比 JDK 1.5 慢,但是两者的耗时已经接近了许多,测试数据如代码清单5-8所示。关于类与类加载的话题,譬如刚刚提到的字节码验证是怎么回事,本书专门规划了两个章节进行详细讲解,在此不再延伸讨论。
使用JDK 1.6的类加载时间:
C:\Users\IcyFenix>jps
5512 org.eclipse.equinox.launcher_1.0.201.R35x_v20090715.jar
5596 Jps
C:\Users\IcyFenix>jstat-class 5512
Loaded Bytes Unloaded Bytes Time
6749 8837.0 0 0.0 3.94
使用JDK 1.5的类加载时间:
C:\Users\IcyFenix>jps
4724 org.eclipse.equinox.launcher_1.0.201.R35x_v20090715.jar
5412 Jps
C:\Users\IcyFenix>jstat-class 4724
Loaded Bytes Unloaded Bytes Time
6885 9109.7 3 2.6 3.10
在取消字节码验证之后,JDK 1.5 的平均启动下降到了 13 秒,而 JDK 1.6 的测试数据平均比 JDK 1.5 快 1 秒,下降到平均 12 秒左右,如图5-8所示。在类加载时间仍然落后的情况下,依然可以看到 JDK 1.6 在性能上比 JDK 1.5 稍有优势,说明至少在 Eclipse 启动这个测试用例上,升级 JDK 版本确实能带来一些“免费的”性能提升。
前面说过,除了类加载时间以外,在 VisualGC 的监视曲线中显示了两项很大的非用户程序耗时:编译时间(Compile Time)和垃圾收集时间(GC Time)。垃圾收集时间读者应该非常清楚了,而编译时间是什么呢?程序在运行之前不是已经编译了吗?虚拟机的 JIT 编译与垃圾收集一样,是本书的一个重要部分,后面有专门章节讲解,这里先简单介绍一下:编译时间是指虚拟机的 JIT 编译器(Just In Time Compiler)编译热点代码(Hot Spot Code)的耗时。我们知道 Java 语言为了实现跨平台的特性,Java 代码编译出来后形成的 Class 文件中存储的是字节码(ByteCode),虚拟机通过解释方式执行字节码命令,比起 C/C++ 编译成本地二进制代码来说,速度要慢不少。为了解决程序解释执行的速度问题,JDK 1.2 以后,虚拟机内置了两个运行时编译器,如果一段Java 方法被调用次数达到一定程度,就会被判定为热代码交给 JIT 编译器即时编译为本地代码,提高运行速度(这就是 HotSpot 虚拟机名字的由来)。甚至有可能在运行期动态编译比 C/C++ 的编译期静态译编出来的代码更优秀,因为运行期可以收集很多编译器无法知道的信息,甚至可以采用一些很激进的优化手段,在优化条件不成立的时候再逆优化退回来。所以 Java 程序只要代码没有问题(主要是泄漏问题,如内存泄漏、连接泄漏),随着代码被编译得越来越彻底,运行速度应当是越运行越快的。Java 的运行期编译最大的缺点就是它进行编译需要消耗程序正常的运行时间,这也就是上面所说的“编译时间”。
虚拟机提供了一个参数 -Xint 禁止编译器运作,强制虚拟机对字节码采用纯解释方式执行。如果读者想使用这个参数省下 Eclipse 启动中那 2 秒的编译时间获得一个“更好看”的成绩的话,那恐怕要失望了,加上这个参数之后,虽然编译时间确实下降到 0,但 Eclipse 启动的总时间剧增到 27 秒。看来这个参数现在最大的作用似乎就是让用户怀念一下 JDK 1.2 之前那令人心酸和心碎的运行速度。
与解释执行相对应的另一方面,虚拟机还有力度更强的编译器:当虚拟机运行在 -client 模式的时候,使用的是一个代号为 C1 的轻量级编译器,另外还有一个代号为 C2 的相对重量级的编译器能提供更多的优化措施,如果使用 -server 模式的虚拟机启动 Eclipse 将会使用到 C2 编译器,这时从 VisualGC 可以看到启动过程中虚拟机使用了超过 15 秒的时间去进行代码编译。如果读者的工作习惯是长时间不关闭 Eclipse 的话,C2 编译器所消耗的额外编译时间最终还是会在运行速度的提升之中赚回来,这样使用 -server 模式也是一个不错的选择。不过至少在本次实战中,我们还是继续选用 -client 虚拟机来运行 Eclipse。
5.3.4 调整内存设置控制垃圾收集频率
三大块非用户程序时间中,还剩下 GC 时间没有调整,而 GC 时间却又是其中最重要的一块,并不只是因为它是耗时最长的一块,更因为它是一个稳定持续的过程。由于我们做的测试是在测程序的启动时间,所以类加载和编译时间在这项测试中的影响力被大幅度放大了。在绝大多数的应用中,不可能出现持续不断的类被加载和卸载。在程序运行一段时间后,热点方法被不断编译,新的热点方法数量也总会下降,但是垃圾收集则是随着程序运行而不断运作的,所以它对性能的影响才显得尤为重要。
在Eclipse启动的原始数据样本中,短短 15 秒,类共发生了 19 次 Full GC 和 378 次 Minor GC,一共 397 次 GC 共造成了超过 4 秒的停顿,也就是超过 1/4 的时间都是在做垃圾收集,这个运行数据看起来实在太糟糕了。
首先来解决新生代中的 Minor GC,虽然 GC 的总时间只有不到 1 秒,但却发生了 378 次之多。从 VisualGC 的线程监视中看到,Eclipse 启动期间一共发起了超过 70 条线程,同时在运行的线程数超过 25 条,每当发生一次垃圾收集动作,所有用户线程都必须跑到最近的一个安全点(SafePoint)然后挂起线程等待垃圾回收。这样过于频繁的 GC 就会导致很多没有必要的安全点检测、线程挂起及恢复操作。
新生代 GC 频繁发生,很明显是由于虚拟机分配给新生代的空间太小而导致的,Eden 区加上一个 Survivor 区还不到 35MB。因此很有必要使用 -Xmn 参数调整新生代的大小。
再来看一看那 19 次 Full GC,看起来 19 次并“不多”(相对于 378 次 Minor GC 来说),但总耗时为 3.166 秒,占了 GC 时间的绝大部分,降低 GC 时间的主要目标就要降低这部分时间。从 VisualGC 的曲线图上可能看得不够精确,这次直接从 GC 日志中分析一下这些 Full GC 是如何产生的,代码清单5-9中是启动最开始的 2.5 秒内发生的 10 次 Full GC 记录。
0.278:[GC 0.278:[DefNew:574K->33K(576K), 0.0012562 secs]0.279:[Tenured:1467K->997K(1536K), 0.0181775 secs]1920K->997K(2112K), 0.0195257 secs]
0.312:[GC 0.312:[DefNew:575K->64K(576K), 0.0004974 secs]0.312:[Tenured:1544K->1608K(1664K), 0.0191592 secs]1980K->1608K(2240K), 0.0197396 secs]
0.590:[GC 0.590:[DefNew:576K->64K(576K), 0.0006360 secs]0.590:[Tenured:2675K->2219K(2684K), 0.0256020 secs]3090K->2219K(3260K), 0.0263501 secs]
0.958:[GC 0.958:[DefNew:551K->64K(576K), 0.0011433 secs]0.959:[Tenured:3979K->3470K(4084K), 0.0419335 secs]4222K->3470K(4660K), 0.0431992 secs]
1.575:[Full GC 1.575:[Tenured:4800K->5046K(5784K), 0.0543136 secs]5189K->5046K(6360K), [Perm:12287K->12287K(12288K)], 0.0544163 secs]
1.703:[GC 1.703:[DefNew:703K->63K(704K), 0.0012609 secs]1.705:[Tenured:8441K->8505K(8540K), 0.0607638 secs]8691K->8505K(9244K), 0.0621470 secs]
1.837:[GC 1.837:[DefNew:1151K->64K(1152K), 0.0020698 secs]1.839:[Tenured:14616K->14680K(14688K), 0.0708748 secs]15035K->14680K(15840K), 0.0730947 secs]
2.144:[GC 2.144:[DefNew:1856K->191K(1856K), 0.0026810 secs]2.147:[Tenured:25092K->24656K(25108K), 0.1112429 secs]26172K->24656K(26964K), 0.1141099 secs]
2.337:[GC 2.337:[DefNew:1914K->0K(3136K), 0.0009697 secs]2.338:[Tenured:41779K->27347K(42056K), 0.0954341 secs]42733K->27347K(45192K), 0.0965513 secs]
2.465:[GC 2.465:[DefNew:2490K->0K(3456K), 0.0011044 secs]2.466:[Tenured:46379K->27635K(46828K), 0.0956937 secs]47621K->27635K(50284K), 0.0969918 secs]
括号中加粗的数字代表老年代的容量,这组 GC 日志显示了 10 次 Full GC 发生的原因全部都是老年代空间耗尽,每发生一次 Full GC 都伴随着一次老年代空间扩容:1536KB->1664KB->2684KB……42056KB->46828KB,10 次 GC 以后老年代容量从起始的 1536KB 扩大到 46828KB,当 15 秒后 Eclipse 启动完成时,老年代容量扩大到了 103428KB,代码编译开始后,老年代容量到达顶峰 473MB,整个 Java 堆到达最大容量 512MB。
日志还显示有些时候内存回收状况很不理想,空间扩容成为获取可用内存的最主要手段,譬如语句"Tenured:25092K->24656K(25108K),0.1112429 secs”,代表老年代当前容量为 25108KB,内存使用到 25092KB 的时候发生 Full GC,花费 0.11 秒把内存使用降低到 24656KB,只回收了不到 500KB 的内存,这次 GC 基本没有什么回收效果,仅仅做了扩容,扩容过程相比起回收过程可以看做是基本不需要花费时间的,所以说这 0.11 秒几乎是白白浪费了。
由上述分析可以得出结论:Eclipse 启动时,Full GC 大多数是由于老年代容量扩展而导致的,由永久代空间扩展而导致的也有一部分。为了避免这些扩展所带来的性能浪费,我们可以把 -Xms 和 -XX:PermSize 参数值设置为 -Xmx 和 -XX:MaxPermSize 参数值一样,这样就强制虚拟机在启动的时候就把老年代和永久代的容量固定下来,避免运行时自动扩展。
根据分析,优化计划确定为:把新生代容量提升到 128MB,避免新生代频繁 GC;把 Java 堆、永久代的容量分别固定为 512MB 和 96MB,避免内存扩展。这几个数值都是根据机器硬件、Eclipse 插件和工程数量来决定的,读者实践的时候应根据 VisualGC 中收集到的实际数据进行设置。改动后的 eclipse.ini 配置如代码清单5-10所示。
-vm
D:/_DevSpace/jdk1.6.0_21/bin/javaw.exe
-startup
plugins/org.eclipse.equinox.launcher_1.0.201.R35x_v20090715.jar
--launcher.library
plugins/org.eclipse.equinox.launcher.win32.win32.x86_1.0.200.v20090519
-product
org.eclipse.epp.package.jee.product
-showsplash
org.eclipse.platform
-vmargs
-Dosgi.requiredJavaVersion=1.5
-Xverify:none
-Xmx512m
-Xms512m
-Xmn128m
-XX:PermSize=96m
-XX:MaxPermSize=96m
现在这个配置之下,GC 次数已经大幅度降低,图5-9是 Eclipse 启动后 1 分钟的监视曲线,只发生了 8 次 Minor GC 和 4 次 Full GC,总耗时为 1.928 秒。
这个结果已经算是基本正常,但是还存在一点瑕疵:从 Old Gen 的曲线上看,老年代直接固定在 384MB,而内存使用量只有 66MB,并且一直很平滑,完全不应该发生 Full GC 才对,那 4 次 Full GC 是怎么来的?使用 jstat-gccause 查询一下最近一次 GC 的原因,见代码清单5-11。
C:\Users\IcyFenix>jps
9772 Jps
4068 org.eclipse.equinox.launcher_1.0.201.R35x_v20090715.jar
C:\Users\IcyFenix>jstat-gccause 4068
S0 S1 E O P YGC YGCT FGC FGCT GCT LGCC GCC
0.00 0.00 1.00 14.81 39.29 6 0.422 20 5.992 6.414
System.gc()No GC
从 LGCC(Last GC Cause)中看到,原来是代码调用 System.gc() 显式触发的 GC,在内存设置调整后,这种显式 GC 已不符合我们的期望,因此在 eclipse.ini 中加入参数 -XX:+DisableExplicitGC 屏蔽掉 System.gc()。再次测试发现启动期间的 Full GC 已经完全没有了,只有 6 次 Minor GC,耗时 417 毫秒,与调优前 4.149 秒的测试样本相比,正好是十分之一。进行 GC 调优后 Eclipse 的启动时间下降非常明显,比整个 GC 时间降低的绝对值还大,现在启动只需要 7 秒多。
5.3.5 选择收集器降低延迟
现在 Eclipse 启动已经比较迅速了,但我们的调优实战还没有结束,毕竟 Eclipse 是拿来写程序的,不是拿来测试启动速度的。我们不妨再在 Eclipse 中测试一个非常常用但又比较耗时的操作:代码编译。图5-11是当前配置下 Eclipse 进行代码编译时的运行数据,从图中可以看出,新生代每次回收耗时约 65 毫秒,老年代每次回收耗时约 725 毫秒。对于用户来说,新生代 GC 的耗时还好,65 毫秒在使用中无法察觉到,而老年代每次 GC 停顿接近 1 秒钟,虽然比较长时间才会出现一次,但停顿还是显得太长了一些。
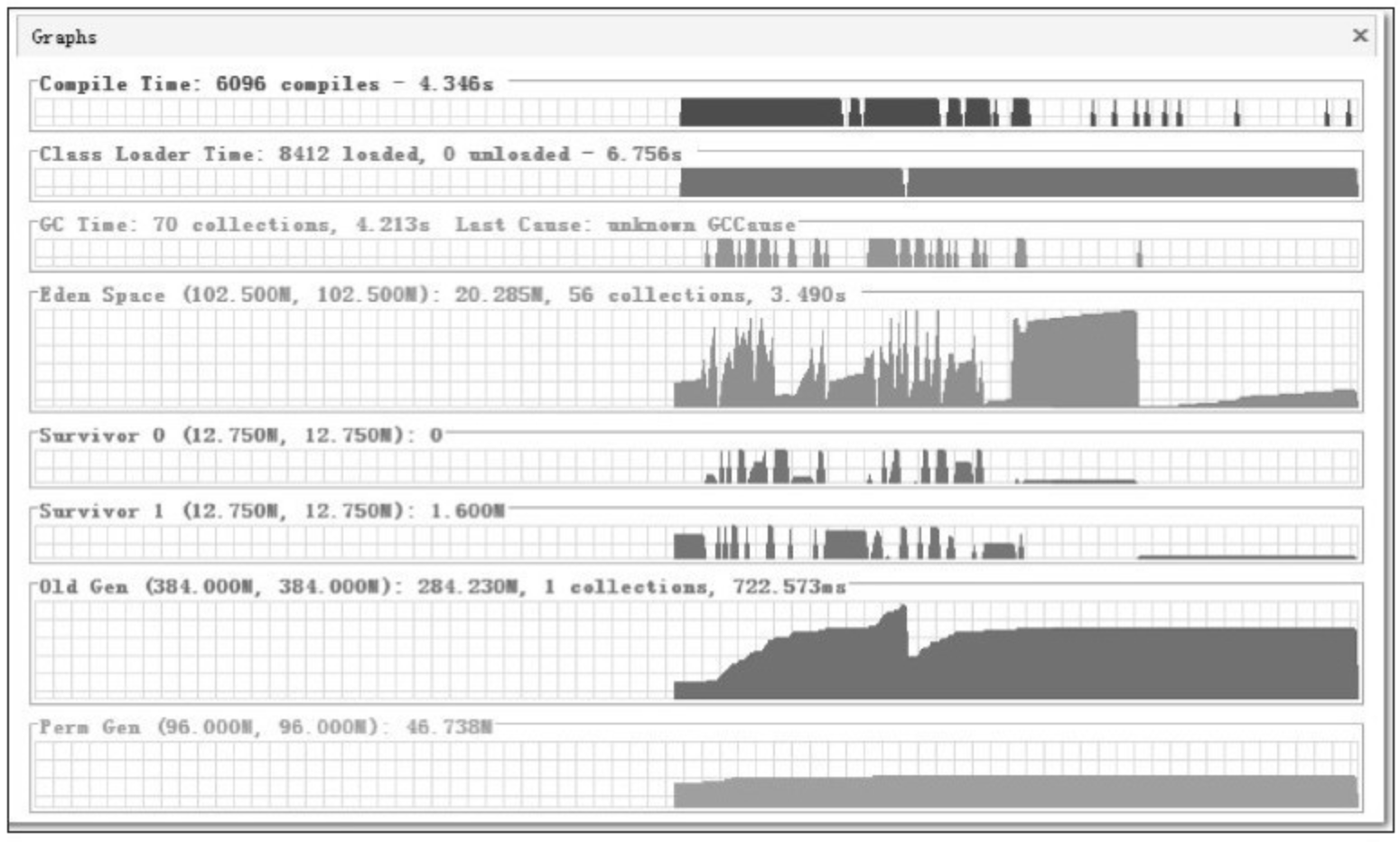
再注意看一下编译期间的 CPU 资源使用状况。图 5-12 是 Eclipse 在编译期间的 CPU 使用率曲线图,整个编译过程中平均只使用了不到 30% 的 CPU 资源,垃圾收集的 CPU 使用率曲线更是几乎与坐标横轴紧贴在一起,这说明 CPU 资源还有很多可利用的余地。
列举 GC 停顿时间、CPU 资源富余的目的,都是为了接下来替换掉 Client 模式的虚拟机中默认的新生代、老年代串行收集器做铺垫。
Eclipse 应当算是与使用者交互非常频繁的应用程序,由于代码太多,笔者习惯在做全量编译或者清理动作的时候,使用"Run in Backgroup"功能一边编译一边继续工作。回顾一下在第 3 章提到的几种收集器,很容易想到 CMS 是最符合这类场景的收集器。因此尝试在 eclipse.ini 中再加入这两个参数 -XX:+UseConcMarkSweepGC、-XX:+UseParNewGC(ParNew 收集器是使用 CMS 收集器后的默认新生代收集器,写上仅是为了配置更加清晰),要求虚拟机在新生代和老年代分别使用 ParNew 和 CMS 收集器进行垃圾回收。指定收集器之后,再次测试的结果如图5-13所示,与原来使用串行收集器对比,新生代停顿从每次 65 毫秒下降到了每次 53 毫秒,而老年代的停顿时间更是从 725 毫秒大幅下降到了 36 毫秒。
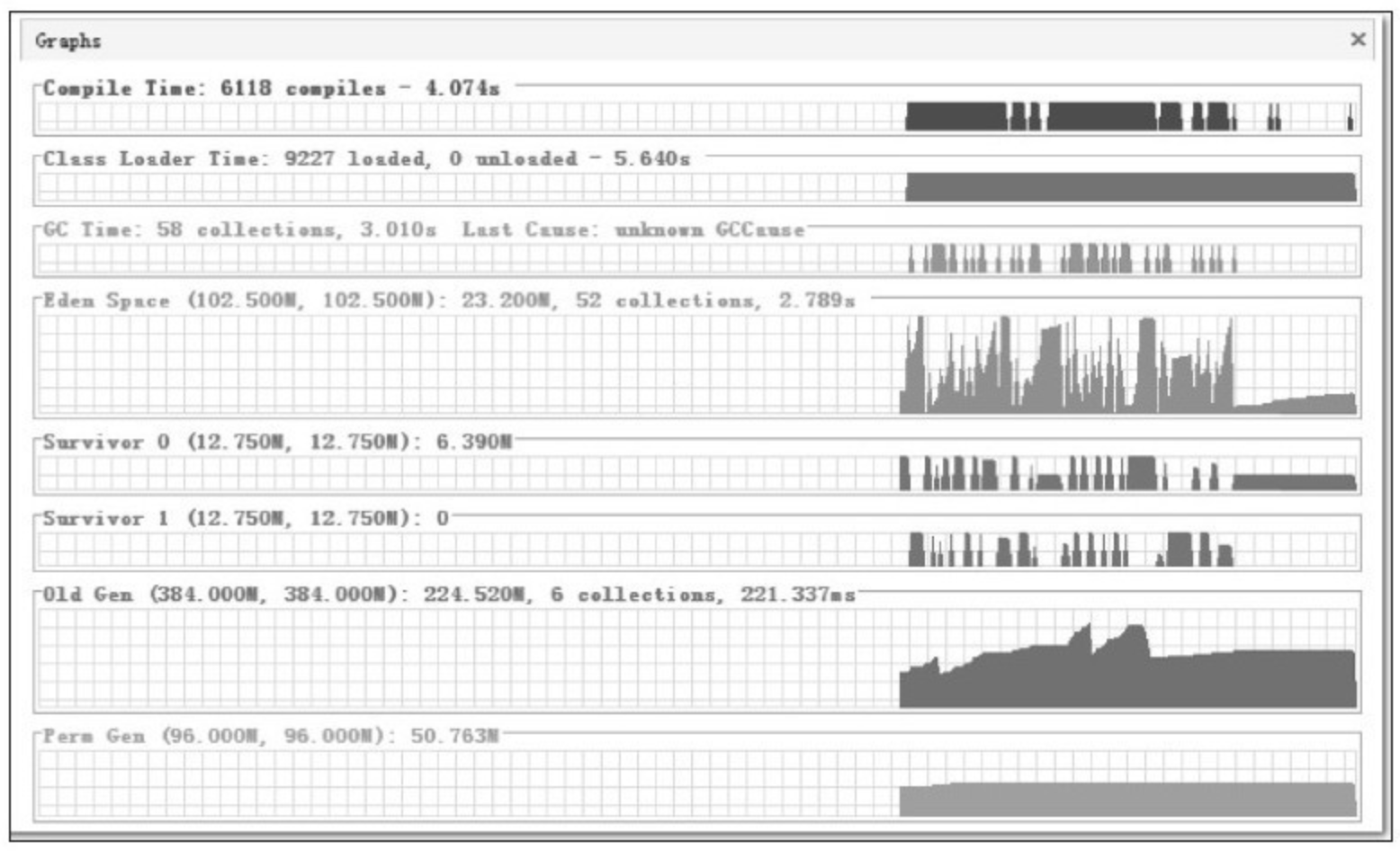
当然,CMS 的停顿阶段只是收集过程中的一小部分,并不是真的把垃圾收集时间从 725 毫秒变成 36 毫秒了。在 GC 日志中可以看到 CMS 与程序并发的时间约为 400 毫秒,这样收集器的运作结果就比较令人满意了。
到此,对于虚拟机内存的调优基本就结束了,这次实战可以看做是一次简化的服务端调优过程,因为服务端调优有可能还会存在于更多方面,如数据库、资源池、磁盘I/O等,但对于虚拟机内存部分的优化,与这次实战中的思路没有什么太大差别。即使读者实际工作中接触不到服务器,根据自己工作环境做一些试验,总结几个参数让自己日常工作环境速度有较大幅度提升也是很划算的。
5.4 本章小结
Java 虚拟机的内存管理与垃圾收集是虚拟机结构体系中最重要的组成部分,对程序的性能和稳定性有非常大的影响,在本书的第 2~5 章中,笔者从理论知识、异常现象、代码、工具、案例、实战等几个方面对其进行了讲解,希望读者有所收获。
本书关于虚拟机内存管理部分到此为止就结束了,后面将开始介绍Class文件与虚拟机执行子系统方面的知识。
6 - CH06-类文件结构
6.1 概述
越来越多的程序语言选择了与操作系统和机器指令集无关的、平台中立的格式作为程序编译后的存储格式。
6.2 无关性的基石
Java在刚刚诞生之时曾经提出过一个非常著名的宣传口号:“一次编写,到处运行(Write Once,Run Anywhere)”,这句话充分表达了软件开发人员对冲破平台界限的渴求。
“与平台无关”的理想最终实现在操作系统的应用层上:Sun公司以及其他虚拟机提供商发布了许多可以运行在各种不同平台上的虚拟机,这些虚拟机都可以载入和执行同一种平台无关的字节码,从而实现了程序的“一次编写,到处运行”。
各种不同平台的虚拟机与所有平台都统一使用的程序存储格式——字节码(ByteCode)是构成平台无关性的基石,但本节标题中刻意省略了“平台”二字,那是因为笔者注意到虚拟机的另外一种中立特性——语言无关性正越来越被开发者所重视。
实现语言无关性的基础仍然是虚拟机和字节码存储格式。Java虚拟机不和包括Java在内的任何语言绑定,它只与“Class文件”这种特定的二进制文件格式所关联,Class文件中包含了Java虚拟机指令集和符号表以及若干其他辅助信息。基于安全方面的考虑,Java虚拟机规范要求在Class文件中使用许多强制性的语法和结构化约束,但任一门功能性语言都可以表示为一个能被Java虚拟机所接受的有效的Class文件。作为一个通用的、机器无关的执行平台,任何其他语言的实现者都可以将Java虚拟机作为语言的产品交付媒介。
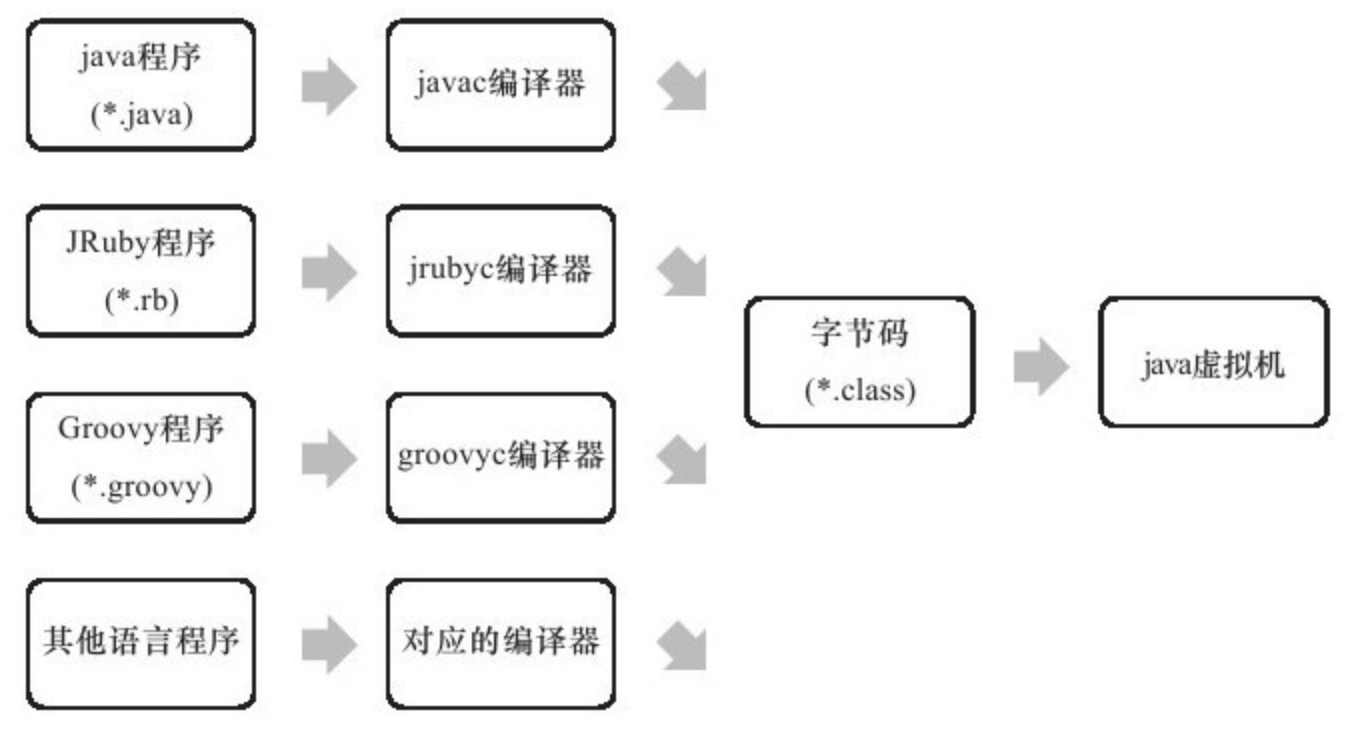
Java语言中的各种变量、关键字和运算符号的语义最终都是由多条字节码命令组合而成的,因此字节码命令所能提供的语义描述能力肯定会比Java语言本身更加强大。因此,有一些Java语言本身无法有效支持的语言特性不代表字节码本身无法有效支持,这也为其他语言实现一些有别于Java的语言特性提供了基础。
6.3 Class 类文件结构
注意 任何一个Class文件都对应着唯一一个类或接口的定义信息,但反过来说,类或接口并不一定都得定义在文件里(譬如类或接口也可以通过类加载器直接生成)。
Class文件是一组以8位字节为基础单位的二进制流,各个数据项目严格按照顺序紧凑地排列在Class文件之中,中间没有添加任何分隔符,这使得整个Class文件中存储的内容几乎全部是程序运行的必要数据,没有空隙存在。当遇到需要占用8位字节以上空间的数据项时,则会按照高位在前的方式分割成若干个8位字节进行存储。
根据Java虚拟机规范的规定,Class文件格式采用一种类似于C语言结构体的伪结构来存储数据,这种伪结构中只有两种数据类型:无符号数和表,后面的解析都要以这两种数据类型为基础,所以这里要先介绍这两个概念。
- 无符号数属于基本的数据类型,以u1、u2、u4、u8来分别代表1个字节、2个字节、4个字节和8个字节的无符号数,无符号数可以用来描述数字、索引引用、数量值或者按照UTF-8编码构成字符串值。
- 表是由多个无符号数或者其他表作为数据项构成的复合数据类型,所有表都习惯性地以
_info结尾。表用于描述有层次关系的复合结构的数据,整个Class文件本质上就是一张表,它由表6-1所示的数据项构成。
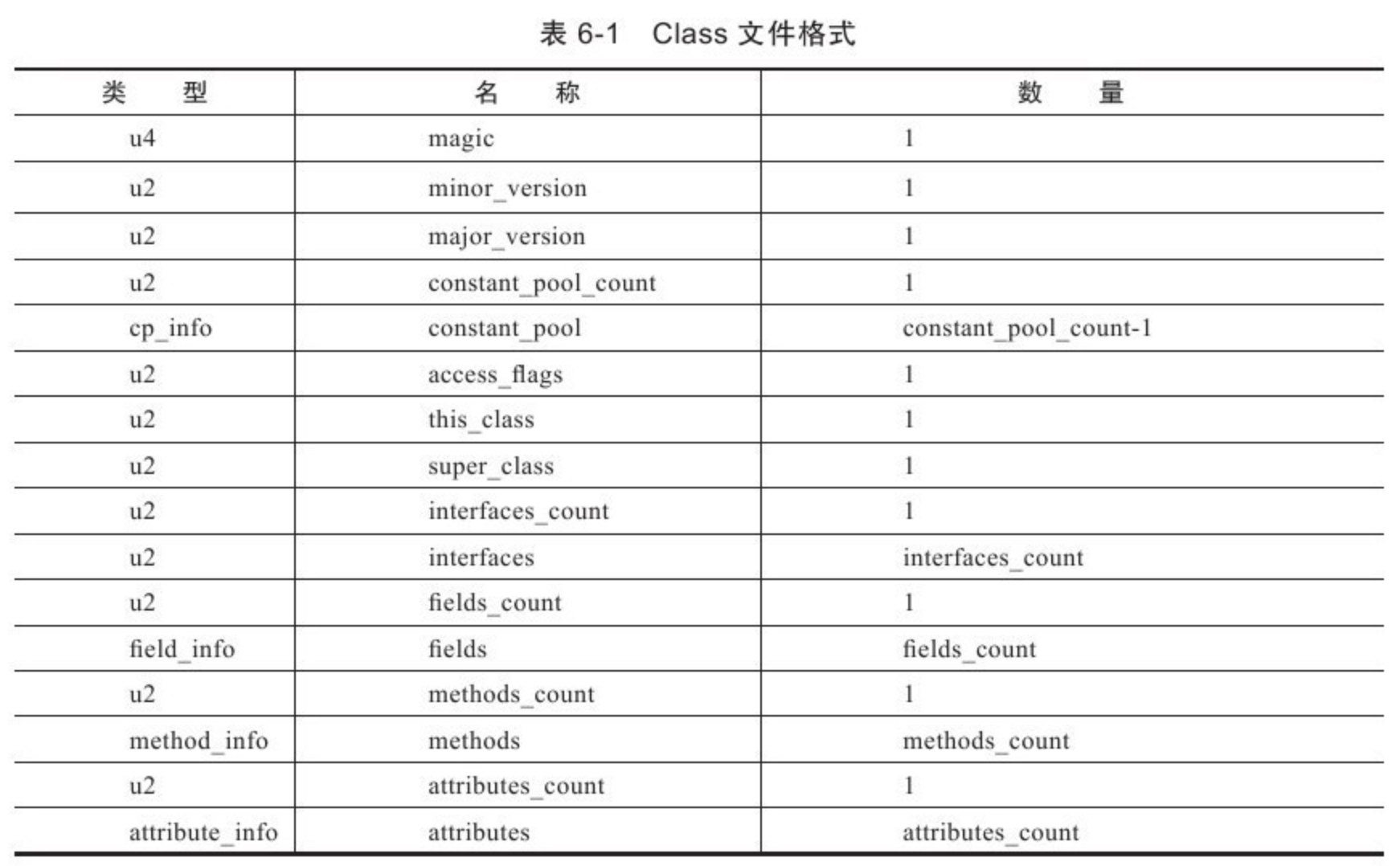
无论是无符号数还是表,当需要描述同一类型但数量不定的多个数据时,经常会使用一个前置的容量计数器加若干个连续的数据项的形式,这时称这一系列连续的某一类型的数据为某一类型的集合。
Class的结构不像XML等描述语言,由于它没有任何分隔符号,所以在表6-1中的数据项,无论是顺序还是数量,甚至于数据存储的字节序(Byte Ordering,Class文件中字节序为Big-Endian)这样的细节,都是被严格限定的,哪个字节代表什么含义,长度是多少,先后顺序如何,都不允许改变。接下来我们将一起看看这个表中各个数据项的具体含义。
6.3.1 魔数与 Class 文件的版本
每个Class文件的头4个字节称为魔数(Magic Number),它的唯一作用是确定这个文件是否为一个能被虚拟机接受的Class文件。很多文件存储标准中都使用魔数来进行身份识别,譬如图片格式,如gif或者jpeg等在文件头中都存有魔数。使用魔数而不是扩展名来进行识别主要是基于安全方面的考虑,因为文件扩展名可以随意地改动。文件格式的制定者可以自由地选择魔数值,只要这个魔数值还没有被广泛采用过同时又不会引起混淆即可。
紧接着魔数的4个字节存储的是Class文件的版本号:第5和第6个字节是次版本号(Minor Version),第7和第8个字节是主版本号(Major Version)。Java的版本号是从45开始的,JDK 1.1之后的每个JDK大版本发布主版本号向上加1(JDK 1.0~1.1使用了45.0~45.3的版本号),高版本的JDK能向下兼容以前版本的Class文件,但不能运行以后版本的Class文件,即使文件格式并未发生任何变化,虚拟机也必须拒绝执行超过其版本号的Class文件。
package org.fenixsoft.clazz;
public class TestClass{
private int m;
public int inc(){
return m+1;
}
}
图6-2显示的是使用十六进制编辑器WinHex打开这个Class文件的结果,可以清楚地看见开头4个字节的十六进制表示是0xCAFEBABE,代表次版本号的第5个和第6个字节值为0x0000,而主版本号的值为0x0032,也即是十进制的50,该版本号说明这个文件是可以被JDK 1.6或以上版本虚拟机执行的Class文件。

表6-2列出了从JDK 1.1到JDK 1.7,主流JDK版本编译器输出的默认和可支持的Class文件版本号。
6.3.2 常量池
紧接着主次版本号之后的是常量池入口,常量池可以理解为Class文件之中的资源仓库,它是Class文件结构中与其他项目关联最多的数据类型,也是占用Class文件空间最大的数据项目之一,同时它还是在Class文件中第一个出现的表类型数据项目。
由于常量池中常量的数量是不固定的,所以在常量池的入口需要放置一项u2类型的数据,代表常量池容量计数值(constant_pool_count)。与Java中语言习惯不一样的是,这个容量计数是从1而不是0开始的,如图6-3所示,常量池容量(偏移地址:0x00000008)为十六进制数0x0016,即十进制的22,这就代表常量池中有21项常量,索引值范围为1~21。在Class文件格式规范制定之时,设计者将第0项常量空出来是有特殊考虑的,这样做的目的在于满足后面某些指向常量池的索引值的数据在特定情况下需要表达“不引用任何一个常量池项目”的含义,这种情况就可以把索引值置为0来表示。Class文件结构中只有常量池的容量计数是从1开始,对于其他集合类型,包括接口索引集合、字段表集合、方法表集合等的容量计数都与一般习惯相同,是从0开始的。

常量池中主要存放两大类常量:字面量(Literal)和符号引用(Symbolic References)。字面量比较接近于Java语言层面的常量概念,如文本字符串、声明为final的常量值等。而符号引用则属于编译原理方面的概念,包括了下面三类常量:
- 类和接口的全限定名(Fully Qualified Name)
- 字段的名称和描述符(Descriptor)
- 方法的名称和描述符
Java代码在进行Javac编译的时候,并不像C和C++那样有“连接”这一步骤,而是在虚拟机加载Class文件的时候进行动态连接。也就是说,在Class文件中不会保存各个方法、字段的最终内存布局信息,因此这些字段、方法的符号引用不经过运行期转换的话无法得到真正的内存入口地址,也就无法直接被虚拟机使用。当虚拟机运行时,需要从常量池获得对应的符号引用,再在类创建时或运行时解析、翻译到具体的内存地址之中。
常量池中每一项常量都是一个表,在JDK 1.7之前共有11种结构各不相同的表结构数据,在JDK 1.7中为了更好地支持动态语言调用,又额外增加了3种(CONSTANT_MethodHandle_info、CONSTANT_MethodType_info和CONSTANT_InvokeDynamic_info)。
这14种表都有一个共同的特点,就是表开始的第一位是一个u1类型的标志位(tag,取值见表6-3中标志列),代表当前这个常量属于哪种常量类型。这14种常量类型所代表的具体含义见表6-3。
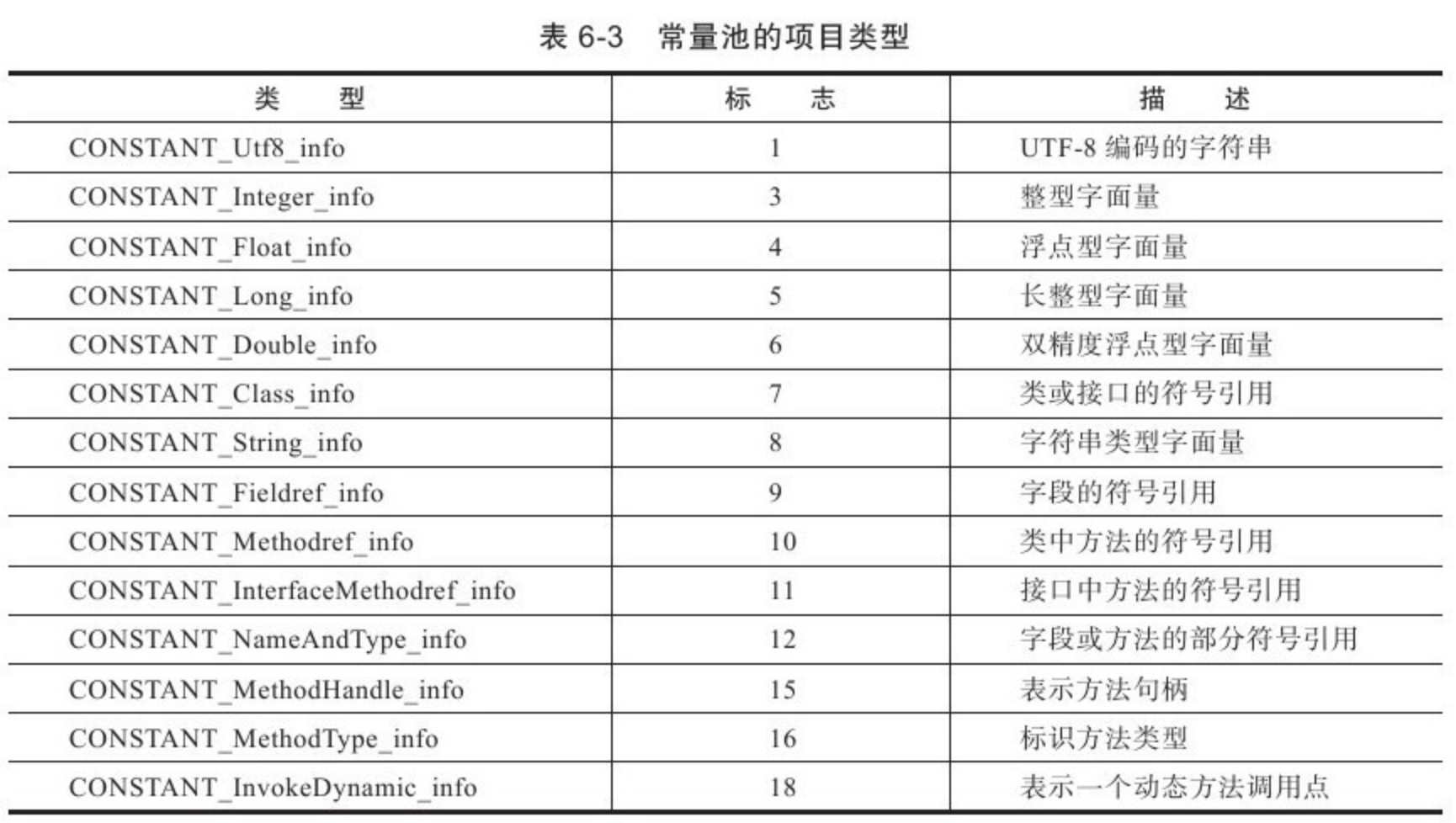
之所以说常量池是最烦琐的数据,是因为这14种常量类型各自均有自己的结构。
回头看看图6-3中常量池的第一项常量,它的标志位(偏移地址:0x0000000A)是0x07,查表6-3的标志列发现这个常量属于CONSTANT_Class_info类型,此类型的常量代表一个类或者接口的符号引用。CONSTANT_Class_info的结构比较简单,见表6-4。

tag是标志位,上面已经讲过了,它用于区分常量类型;name_index是一个索引值,它指向常量池中一个CONSTANT_Utf8_info类型常量,此常量代表了这个类(或者接口)的全限定名,这里name_index值(偏移地址:0x0000000B)为0x0002,也即是指向了常量池中的第二项常量。继续从图6-3中查找第二项常量,它的标志位(地址:0x0000000D)是0x01,查表6-3可知确实是一个CONSTANT_Utf8_info类型的常量。CONSTANT_Utf8_info类型的结构见表6-5。

length值说明了这个UTF-8编码的字符串长度是多少字节,它后面紧跟着的长度为length字节的连续数据是一个使用UTF-8缩略编码表示的字符串。UTF-8缩略编码与普通UTF-8编码的区别是:从’\u0001’到’\u007f’之间的字符(相当于1~127的ASCII码)的缩略编码使用一个字节表示,从’\u0080’到’\u07ff’之间的所有字符的缩略编码用两个字节表示,从’\u0800’到’\uffff’之间的所有字符的缩略编码就按照普通UTF-8编码规则使用三个字节表示。
顺便提一下,由于Class文件中方法、字段等都需要引用CONSTANT_Utf8_info型常量来描述名称,所以CONSTANT_Utf8_info型常量的最大长度也就是Java中方法、字段名的最大长度。而这里的最大长度就是length的最大值,既u2类型能表达的最大值65535。所以Java程序中如果定义了超过64KB英文字符的变量或方法名,将会无法编译。
本例中这个字符串的length值(偏移地址:0x0000000E)为0x001D,也就是长29字节,往后29字节正好都在1~127的ASCII码范围以内,内容为"org/fenixsoft/clazz/TestClass",有兴趣的读者可以自己逐个字节换算一下,换算结果如图6-4选中的部分所示。

到此为止,我们分析了TestClass.class常量池中21个常量中的两个,其余的19个常量都可以通过类似的方法计算出来。为了避免计算过程占用过多的版面,后续的19个常量的计算过程可以借助计算机来帮我们完成。在JDK的bin目录中,Oracle公司已经为我们准备好一个专门用于分析Class文件字节码的工具:javap,代码清单6-2中列出了使用javap工具的-verbose参数输出的TestClass.class文件字节码内容(此清单中省略了常量池以外的信息)。前面我们曾经提到过,Class文件中还有很多数据项都要引用常量池中的常量,所以代码清单6-2中的内容在后续的讲解过程中还要经常使用到。
C:\>javap-verbose TestClass
Compiled from"TestClass.java"
public class org.fenixsoft.clazz.TestClass extends java.lang.Object
SourceFile:"TestClass.java"
minor version:0
major version:50
Constant pool:
const#1=class#2;//org/fenixsoft/clazz/TestClass
const#2=Asciz org/fenixsoft/clazz/TestClass;
const#3=class#4;//java/lang/Object
const#4=Asciz java/lang/Object;
const#5=Asciz m;
const#6=Asciz I;
const#7=Asciz<init>;
const#8=Asciz()V;
const#9=Asciz Code;
const#10=Method#3.#11;//java/lang/Object."<init>":()V
const#11=NameAndType#7:#8;//"<init>":()V
const#12=Asciz LineNumberTable;
const#13=Asciz LocalVariableTable;
const#14=Asciz this;
const#15=Asciz Lorg/fenixsoft/clazz/TestClass;
const#16=Asciz inc;
const#17=Asciz()I;
const#18=Field#1.#19;//org/fenixsoft/clazz/TestClass.m:I
const#19=NameAndType#5:#6;//m:I
const#20=Asciz SourceFile;
const#21=Asciz TestClass.java;
从代码清单6-2中可以看出,计算机已经帮我们把整个常量池的21项常量都计算了出来,并且第1、2项常量的计算结果与我们手工计算的结果一致。仔细看一下会发现,其中有一些常量似乎从来没有在代码中出现过,如"I"、“V”、“<init>”、“LineNumberTable”、“LocalVariableTable"等,这些看起来在代码任何一处都没有出现过的常量是哪里来的呢?
这部分自动生成的常量的确没有在Java代码里面直接出现过,但它们会被后面即将讲到的字段表(field_info)、方法表(method_info)、属性表(attribute_info)引用到,它们会用来描述一些不方便使用“固定字节”进行表达的内容。譬如描述方法的返回值是什么?有几个参数?每个参数的类型是什么?因为Java中的“类”是无穷无尽的,无法通过简单的无符号字节来描述一个方法用到了什么类,因此在描述方法的这些信息时,需要引用常量表中的符号引用进行表达。这部分内容将在后面进一步阐述。最后,笔者将这14种常量项的结构定义总结为表6-6以供读者参考。

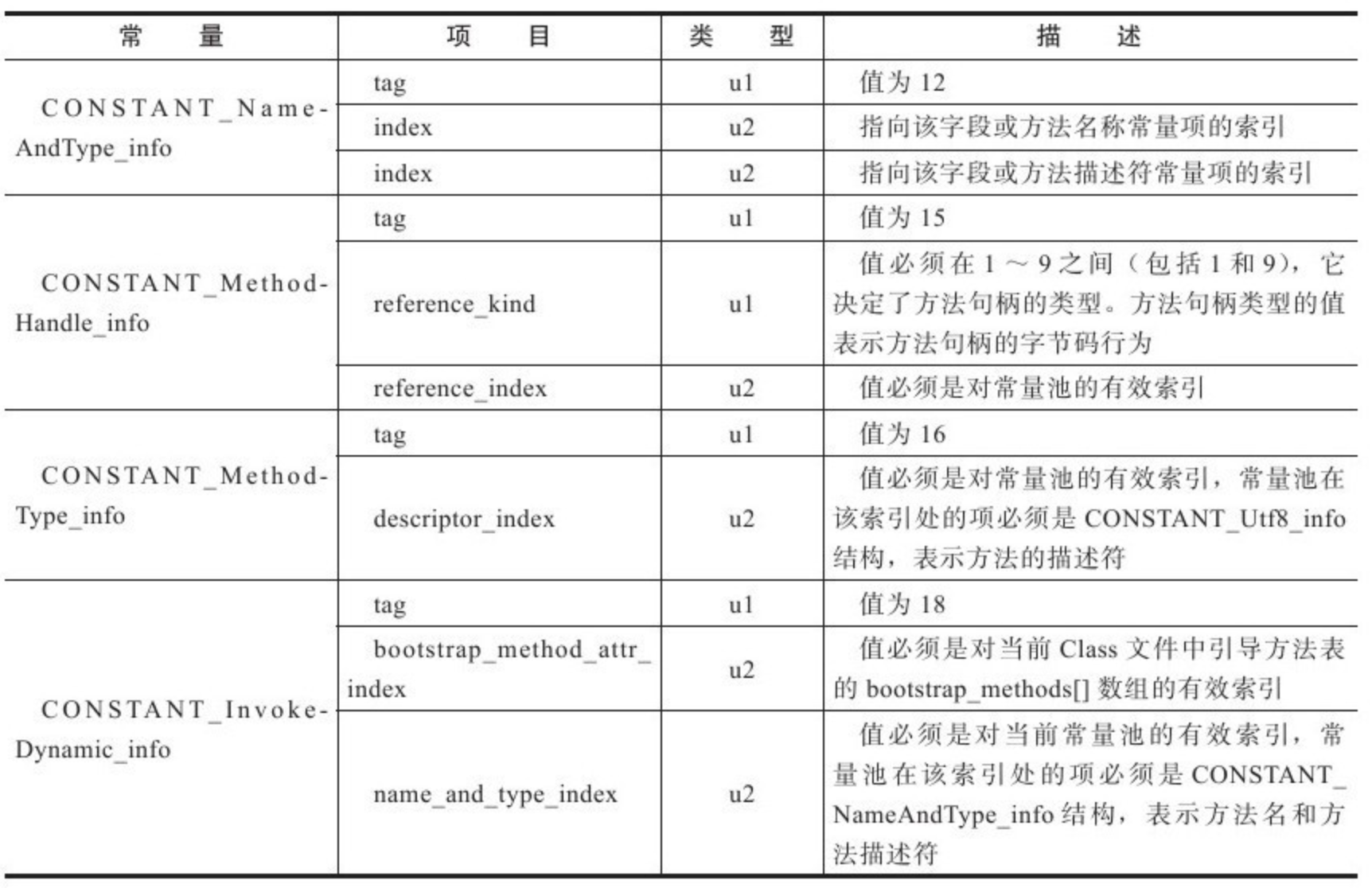
6.3.3 访问标志
在常量池结束之后,紧接着的两个字节代表访问标志(access_flags),这个标志用于识别一些类或者接口层次的访问信息,包括:这个Class是类还是接口;是否定义为public类型;是否定义为abstract类型;如果是类的话,是否被声明为final等。具体的标志位以及标志的含义见表6-7。

access_flags中一共有16个标志位可以使用,当前只定义了其中8个,没有使用到的标志位要求一律为0。以代码清单6-1中的代码为例,TestClass是一个普通Java类,不是接口、枚举或者注解,被public关键字修饰但没有被声明为final和abstract,并且它使用了JDK 1.2之后的编译器进行编译,因此它的ACC_PUBLIC、ACC_SUPER标志应当为真,而ACC_FINAL、ACC_INTERFACE、ACC_ABSTRACT、ACC_SYNTHETIC、ACC_ANNOTATION、ACC_ENUM这6个标志应当为假,因此它的access_flags的值应为:0x0001|0x0020=0x0021。从图6-5中可以看出,access_flags标志(偏移地址:0x000000EF)的确为0x0021。

6.3.4 类索引、父类索引与接口索引集合
类索引(this_class)和父类索引(super_class)都是一个u2类型的数据,而接口索引集合(interfaces)是一组u2类型的数据的集合,Class文件中由这三项数据来确定这个类的继承关系。类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名。由于Java语言不允许多重继承,所以父类索引只有一个,除了java.lang.Object之外,所有的Java类都有父类,因此除了java.lang.Object外,所有Java类的父类索引都不为0。接口索引集合就用来描述这个类实现了哪些接口,这些被实现的接口将按implements语句(如果这个类本身是一个接口,则应当是extends语句)后的接口顺序从左到右排列在接口索引集合中。
类索引、父类索引和接口索引集合都按顺序排列在访问标志之后,类索引和父类索引用两个u2类型的索引值表示,它们各自指向一个类型为CONSTANT_Class_info的类描述符常量,通过CONSTANT_Class_info类型的常量中的索引值可以找到定义在CONSTANT_Utf8_info类型的常量中的全限定名字符串。图6-6演示了代码清单6-1的代码的类索引查找过程。
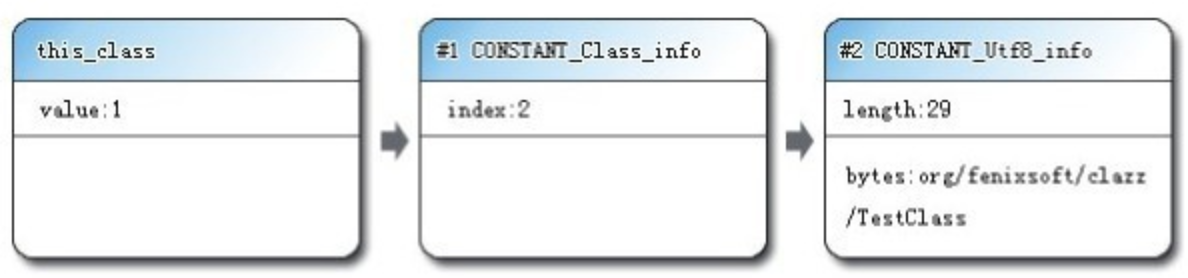
对于接口索引集合,入口的第一项——u2类型的数据为接口计数器(interfaces_count),表示索引表的容量。如果该类没有实现任何接口,则该计数器值为0,后面接口的索引表不再占用任何字节。代码清单6-1中的代码的类索引、父类索引与接口表索引的内容如图6-7所示。

从偏移地址0x000000F1开始的3个u2类型的值分别为0x0001、0x0003、0x0000,也就是类索引为1,父类索引为3,接口索引集合大小为0,查询前面代码清单6-2中javap命令计算出来的常量池,找出对应的类和父类的常量,结果如代码清单6-3所示。
const#1=class#2;//org/fenixsoft/clazz/TestClass
const#2=Asciz org/fenixsoft/clazz/TestClass;
const#3=class#4;//java/lang/Object
const#4=Asciz java/lang/Object;
6.3.5 字段表集合
字段表(field_info)用于描述接口或者类中声明的变量。字段(field)包括类级变量以及实例级变量,但不包括在方法内部声明的局部变量。一个字段可以包括的信息有:字段的作用域(public、private、protected修饰符)、是实例变量还是类变量(static修饰符)、可变性(final)、并发可见性(volatile修饰符,是否强制从主内存读写)、可否被序列化(transient修饰符)、字段数据类型(基本类型、对象、数组)、字段名称。上述这些信息中,各个修饰符都是布尔值,要么有某个修饰符,要么没有,很适合使用标志位来表示。而字段叫什么名字、字段被定义为什么数据类型,这些都是无法固定的,只能引用常量池中的常量来描述。表6-8中列出了字段表的最终格式。

字段修饰符放在access_flags项目中,它与类中的access_flags项目是非常类似的,都是一个u2的数据类型,其中可以设置的标志位和含义见表6-9。
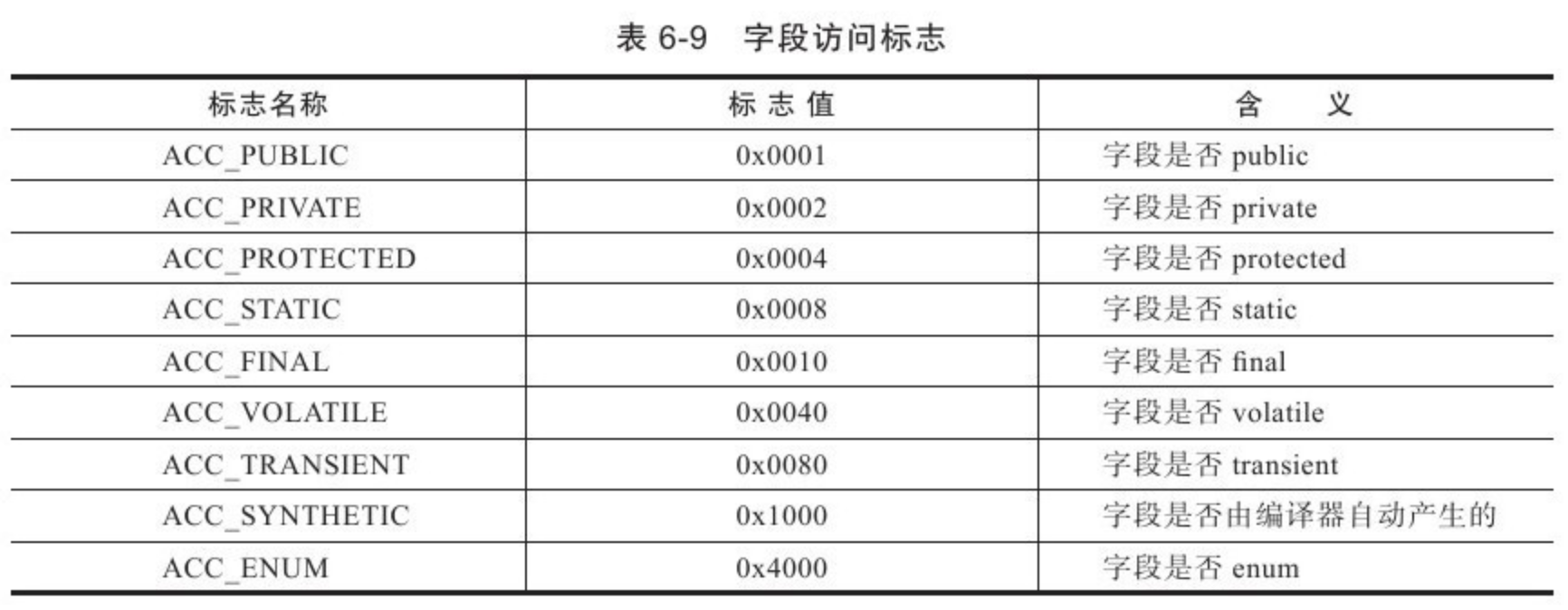
很明显,在实际情况中,ACC_PUBLIC、ACC_PRIVATE、ACC_PROTECTED三个标志最多只能选择其一,ACC_FINAL、ACC_VOLATILE不能同时选择。接口之中的字段必须有ACC_PUBLIC、ACC_STATIC、ACC_FINAL标志,这些都是由Java本身的语言规则所决定的。
跟随access_flags标志的是两项索引值:name_index和descriptor_index。它们都是对常量池的引用,分别代表着字段的简单名称以及字段和方法的描述符。现在需要解释一下“简单名称”、“描述符”以及前面出现过多次的“全限定名”这三种特殊字符串的概念。
全限定名和简单名称很好理解,以代码清单6-1中的代码为例,“org/fenixsoft/clazz/TestClass"是这个类的全限定名,仅仅是把类全名中的“.”替换成了“/”而已,为了使连续的多个全限定名之间不产生混淆,在使用时最后一般会加入一个“;”表示全限定名结束。简单名称是指没有类型和参数修饰的方法或者字段名称,这个类中的inc()方法和m字段的简单名称分别是"inc"和"m”。
相对于全限定名和简单名称来说,方法和字段的描述符就要复杂一些。描述符的作用是用来描述字段的数据类型、方法的参数列表(包括数量、类型以及顺序)和返回值。根据描述符规则,基本数据类型(byte、char、double、float、int、long、short、boolean)以及代表无返回值的void类型都用一个大写字符来表示,而对象类型则用字符L加对象的全限定名来表示,详见表6-10。
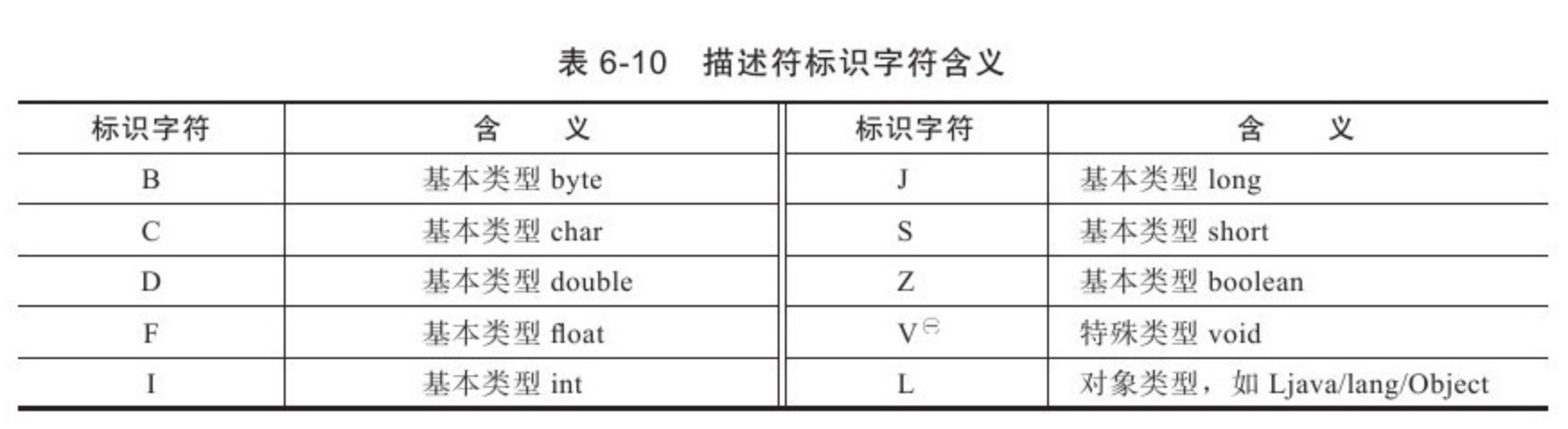
对于数组类型,每一维度将使用一个前置的 [ 字符来描述,如一个定义为 java.lang.String[][] 类型的二维数组,将被记录为:[[Ljava/lang/String;,一个整型数组 int[] 将被记录为 [I。
用描述符来描述方法时,按照先参数列表,后返回值的顺序描述,参数列表按照参数的严格顺序放在一组小括号“()”之内。如方法void inc()的描述符为”()V",方法java.lang.String toString()的描述符为"()Ljava/lang/String;",方法 int indexOf(char[]source,int sourceOffset,int sourceCount,char[]target,int targetOffset,int targetCount,int fromIndex) 的描述符为 ([CII[CIII)I。
对于代码清单6-1中的TestClass.class文件来说,字段表集合从地址0x000000F8开始,第一个u2类型的数据为容量计数器fields_count,如图6-8所示,其值为0x0001,说明这个类只有一个字段表数据。接下来紧跟着容量计数器的是access_flags标志,值为0x0002,代表private修饰符的ACC_PRIVATE标志位为真(ACC_PRIVATE标志的值为0x0002),其他修饰符为假。代表字段名称的name_index的值为0x0005,从代码清单6-2列出的常量表中可查得第5项常量是一个CONSTANT_Utf8_info类型的字符串,其值为"m",代表字段描述符的descriptor_index的值为0x0006,指向常量池的字符串"I",根据这些信息,我们可以推断出原代码定义的字段为:“private int m;"。
字段表都包含的固定数据项目到descriptor_index为止就结束了,不过在descriptor_index之后跟随着一个属性表集合用于存储一些额外的信息,字段都可以在属性表中描述零至多项的额外信息。对于本例中的字段m,它的属性表计数器为0,也就是没有需要额外描述的信息,但是,如果将字段m的声明改为"final static int m=123;",那就可能会存在一项名称为ConstantValue的属性,其值指向常量123。关于attribute_info的其他内容,将在6.3.7节介绍属性表的数据项目时再进一步讲解。
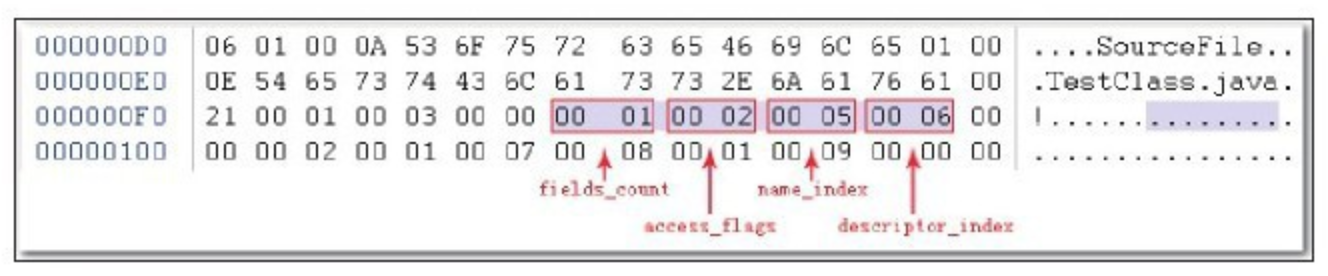
字段表集合中不会列出从超类或者父接口中继承而来的字段,但有可能列出原本Java代码之中不存在的字段,譬如在内部类中为了保持对外部类的访问性,会自动添加指向外部类实例的字段。另外,在Java语言中字段是无法重载的,两个字段的数据类型、修饰符不管是否相同,都必须使用不一样的名称,但是对于字节码来讲,如果两个字段的描述符不一致,那字段重名就是合法的。
6.3.6 方法表集合
如果理解了上一节关于字段表的内容,那本节关于方法表的内容将会变得很简单。Class文件存储格式中对方法的描述与对字段的描述几乎采用了完全一致的方式,方法表的结构如同字段表一样,依次包括了访问标志(access_flags)、名称索引(name_index)、描述符索引(descriptor_index)、属性表集合(attributes)几项,见表6-11。这些数据项目的含义也非常类似,仅在访问标志和属性表集合的可选项中有所区别。

因为volatile关键字和transient关键字不能修饰方法,所以方法表的访问标志中没有了ACC_VOLATILE标志和ACC_TRANSIENT标志。与之相对的,synchronized、native、strictfp和abstract关键字可以修饰方法,所以方法表的访问标志中增加了ACC_SYNCHRONIZED、ACC_NATIVE、ACC_STRICTFP和ACC_ABSTRACT标志。对于方法表,所有标志位及其取值可参见表6-12。
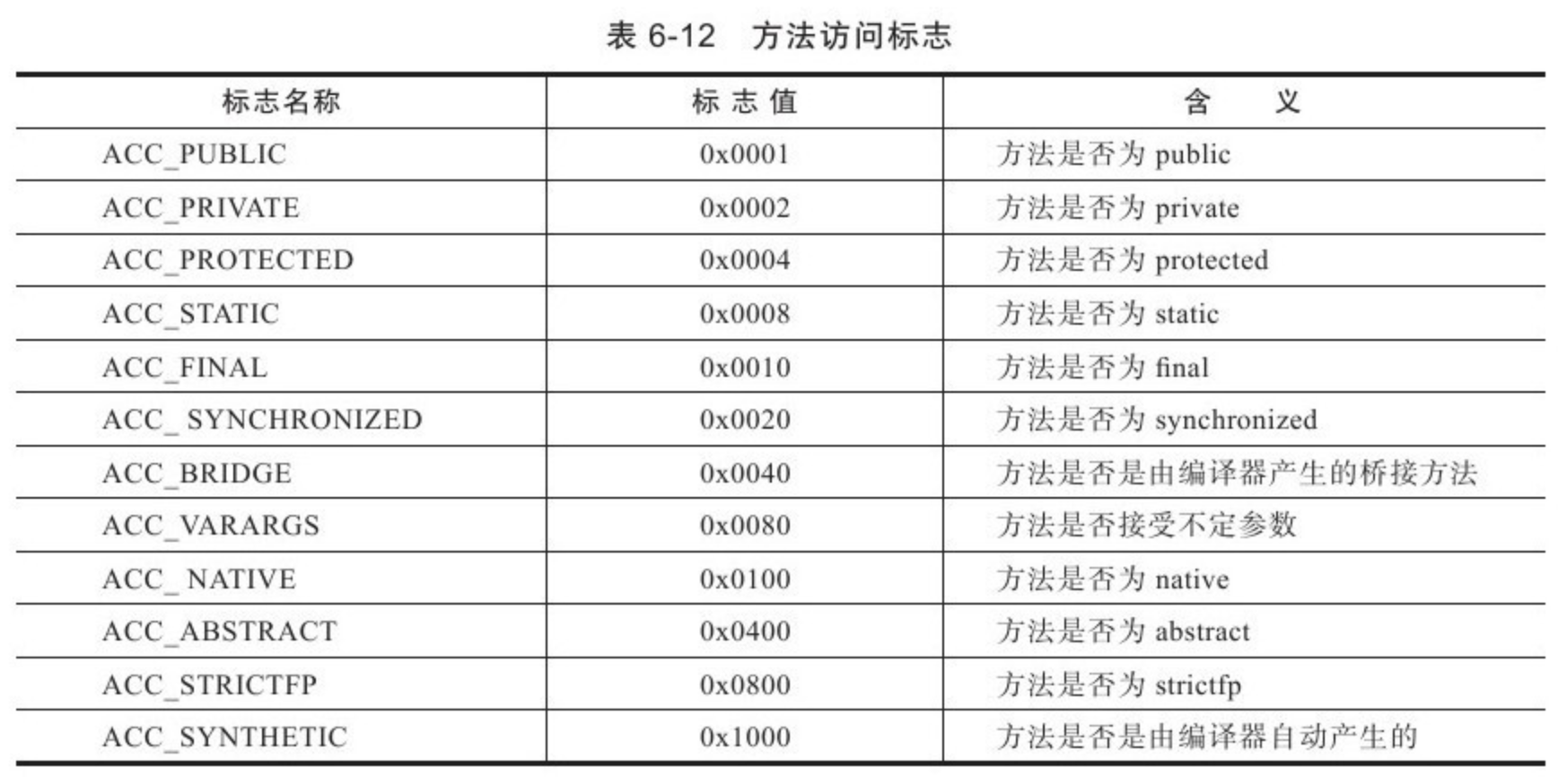
我们继续以代码清单6-1中的Class文件为例对方法表集合进行分析,如图6-9所示,方法表集合的入口地址为:0x00000101,第一个u2类型的数据(即是计数器容量)的值为0x0002,代表集合中有两个方法(这两个方法为编译器添加的实例构造器<init>和源码中的方法inc())。第一个方法的访问标志值为0x001,也就是只有ACC_PUBLIC标志为真,名称索引值为0x0007,查代码清单6-2的常量池得方法名为"<init>”,描述符索引值为0x0008,对应常量为"()V",属性表计数器attributes_count的值为0x0001就表示此方法的属性表集合有一项属性,属性名称索引为0x0009,对应常量为"Code",说明此属性是方法的字节码描述。

与字段表集合相对应的,如果父类方法在子类中没有被重写(Override),方法表集合中就不会出现来自父类的方法信息。但同样的,有可能会出现由编译器自动添加的方法,最典型的便是类构造器"<clinit>"方法和实例构造器"<init>"方法。
在Java语言中,要重载(Overload)一个方法,除了要与原方法具有相同的简单名称之外,还要求必须拥有一个与原方法不同的特征签名,特征签名就是一个方法中各个参数在常量池中的字段符号引用的集合,也就是因为返回值不会包含在特征签名中,因此Java语言里面是无法仅仅依靠返回值的不同来对一个已有方法进行重载的。但是在Class文件格式中,特征签名的范围更大一些,只要描述符不是完全一致的两个方法也可以共存。也就是说,如果两个方法有相同的名称和特征签名,但返回值不同,那么也是可以合法共存于同一个Class文件中的。
6.3.7 属性表集合
属性表(attribute_info)在前面的讲解之中已经出现过数次,在Class文件、字段表、方法表都可以携带自己的属性表集合,以用于描述某些场景专有的信息。
与Class文件中其他的数据项目要求严格的顺序、长度和内容不同,属性表集合的限制稍微宽松了一些,不再要求各个属性表具有严格顺序,并且只要不与已有属性名重复,任何人实现的编译器都可以向属性表中写入自己定义的属性信息,Java虚拟机运行时会忽略掉它不认识的属性。为了能正确解析Class文件,《Java虚拟机规范(第2版)》中预定义了9项虚拟机实现应当能识别的属性,而在最新的《Java虚拟机规范(Java SE 7)》版中,预定义属性已经增加到21项,具体内容见表6-13。下文中将对其中一些属性中的关键常用的部分进行讲解。
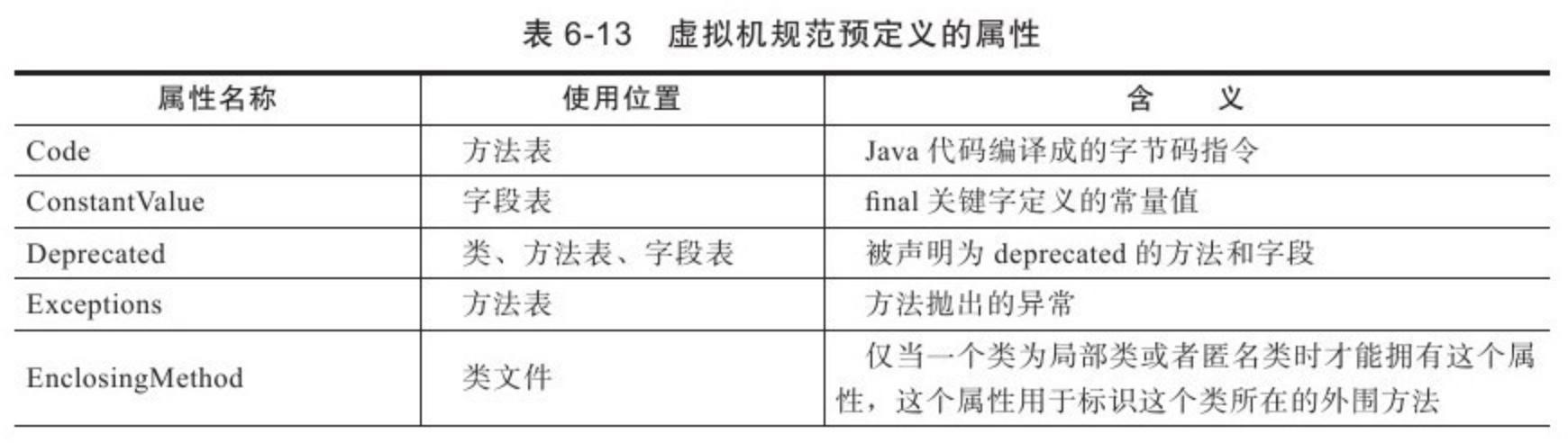
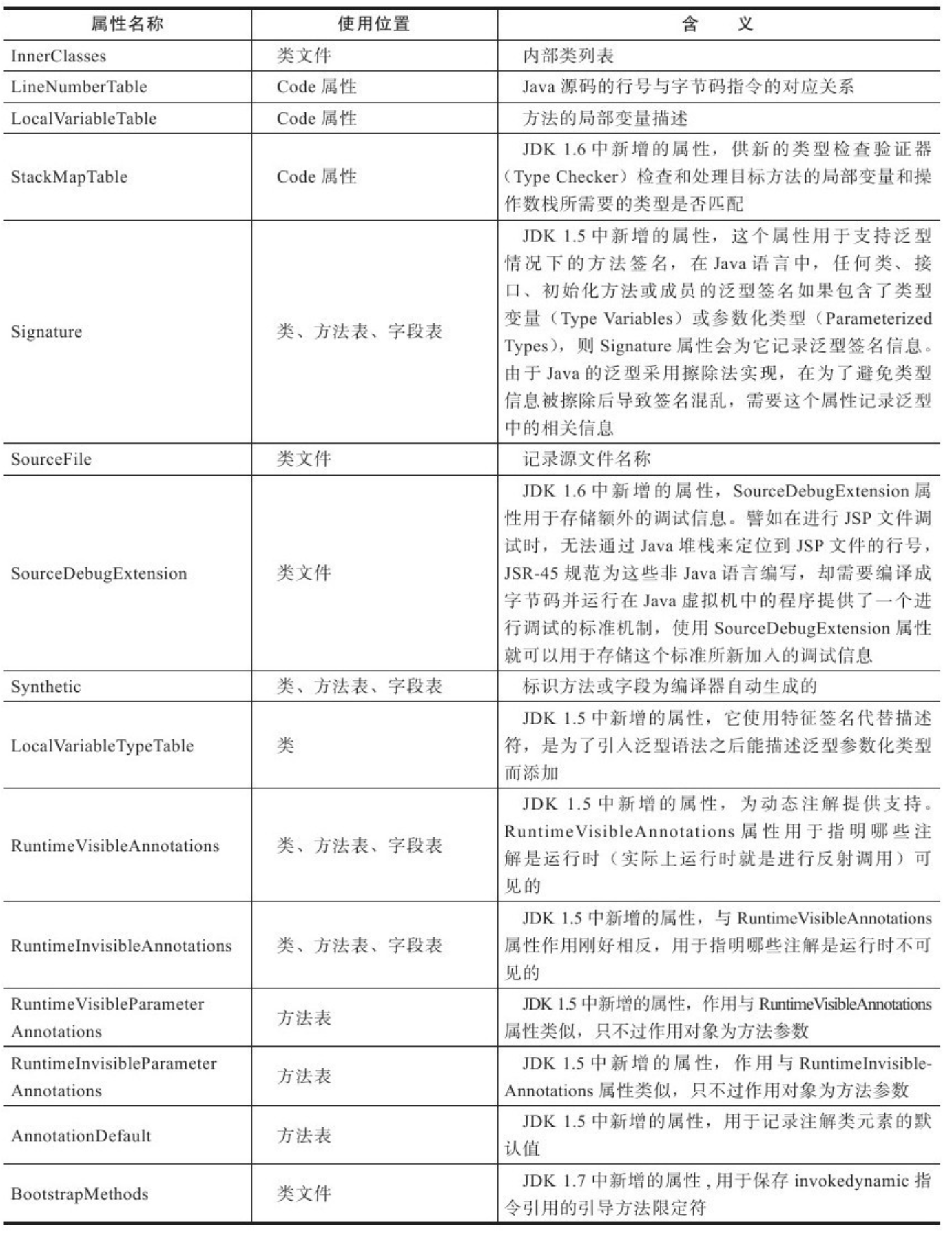
对于每个属性,它的名称需要从常量池中引用一个CONSTANT_Utf8_info类型的常量来表示,而属性值的结构则是完全自定义的,只需要通过一个u4的长度属性去说明属性值所占用的位数即可。一个符合规则的属性表应该满足表6-14中所定义的结构。

Code 属性
Java程序方法体中的代码经过Javac编译器处理后,最终变为字节码指令存储在Code属性内。Code属性出现在方法表的属性集合之中,但并非所有的方法表都必须存在这个属性,譬如接口或者抽象类中的方法就不存在Code属性,如果方法表有Code属性存在,那么它的结构将如表6-15所示。

attribute_name_index是一项指向CONSTANT_Utf8_info型常量的索引,常量值固定为"Code",它代表了该属性的属性名称,attribute_length指示了属性值的长度,由于属性名称索引与属性长度一共为6字节,所以属性值的长度固定为整个属性表长度减去6个字节。
max_stack代表了操作数栈(Operand Stacks)深度的最大值。在方法执行的任意时刻,操作数栈都不会超过这个深度。虚拟机运行的时候需要根据这个值来分配栈帧(Stack Frame)中的操作栈深度。
max_locals代表了局部变量表所需的存储空间。在这里,max_locals的单位是Slot,Slot是虚拟机为局部变量分配内存所使用的最小单位。对于byte、char、float、int、short、boolean和returnAddress等长度不超过32位的数据类型,每个局部变量占用1个Slot,而double和long这两种64位的数据类型则需要两个Slot来存放。方法参数(包括实例方法中的隐藏参数"this")、显式异常处理器的参数(Exception Handler Parameter,就是try-catch语句中catch块所定义的异常)、方法体中定义的局部变量都需要使用局部变量表来存放。另外,并不是在方法中用到了多少个局部变量,就把这些局部变量所占Slot之和作为max_locals的值,原因是局部变量表中的Slot可以重用,当代码执行超出一个局部变量的作用域时,这个局部变量所占的Slot可以被其他局部变量所使用,Javac编译器会根据变量的作用域来分配Slot给各个变量使用,然后计算出max_locals的大小。
code_length和code用来存储Java源程序编译后生成的字节码指令。code_length代表字节码长度,code是用于存储字节码指令的一系列字节流。既然叫字节码指令,那么每个指令就是一个u1类型的单字节,当虚拟机读取到code中的一个字节码时,就可以对应找出这个字节码代表的是什么指令,并且可以知道这条指令后面是否需要跟随参数,以及参数应当如何理解。我们知道一个u1数据类型的取值范围为0x00~0xFF,对应十进制的0~255,也就是一共可以表达256条指令,目前,Java虚拟机规范已经定义了其中约200条编码值对应的指令含义,编码与指令之间的对应关系可查阅本书的附录B“虚拟机字节码指令表”。
关于code_length,有一件值得注意的事情,虽然它是一个u4类型的长度值,理论上最大值可以达到2^{32}-1,但是虚拟机规范中明确限制了一个方法不允许超过65535条字节码指令,即它实际只使用了u2的长度,如果超过这个限制,Javac编译器也会拒绝编译。一般来讲,编写Java代码时只要不是刻意去编写一个超长的方法来为难编译器,是不太可能超过这个最大值的限制。但是,某些特殊情况,例如在编译一个很复杂的JSP文件时,某些JSP编译器会把JSP内容和页面输出的信息归并于一个方法之中,就可能因为方法生成字节码超长的原因而导致编译失败。
Code属性是Class文件中最重要的一个属性,如果把一个Java程序中的信息分为代码(Code,方法体里面的Java代码)和元数据(Metadata,包括类、字段、方法定义及其他信息)两部分,那么在整个Class文件中,Code属性用于描述代码,所有的其他数据项目都用于描述元数据。了解Code属性是学习后面关于字节码执行引擎内容的必要基础,能直接阅读字节码也是工作中分析Java代码语义问题的必要工具和基本技能,因此笔者准备了一个比较详细的实例来讲解虚拟机是如何使用这个属性的。
继续以代码清单6-1的TestClass.class文件为例,如图6-10所示,这是上一节分析过的实例构造器"<init>"方法的Code属性。它的操作数栈的最大深度和本地变量表的容量都为0x0001,字节码区域所占空间的长度为0x0005。虚拟机读取到字节码区域的长度后,按照顺序依次读入紧随的5个字节,并根据字节码指令表翻译出所对应的字节码指令。翻译"2A B7 00 0A B1"的过程为:
- 读入2A,查表得0x2A对应的指令为aload_0,这个指令的含义是将第0个Slot中为reference类型的本地变量推送到操作数栈顶。
- 读入B7,查表得0xB7对应的指令为invokespecial,这条指令的作用是以栈顶的reference类型的数据所指向的对象作为方法接收者,调用此对象的实例构造器方法、private方法或者它的父类的方法。这个方法有一个u2类型的参数说明具体调用哪一个方法,它指向常量池中的一个CONSTANT_Methodref_info类型常量,即此方法的方法符号引用。
- 读入00 0A,这是invokespecial的参数,查常量池得0x000A对应的常量为实例构造器"<init>"方法的符号引用。
- 读入B1,查表得0xB1对应的指令为return,含义是返回此方法,并且返回值为void。这条指令执行后,当前方法结束。
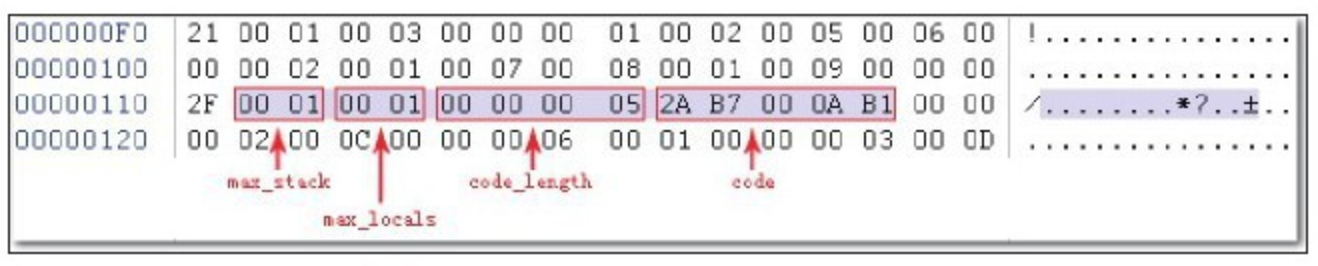
这段字节码虽然很短,但是至少可以看出它的执行过程中的数据交换、方法调用等操作都是基于栈(操作栈)的。我们可以初步猜测:Java虚拟机执行字节码是基于栈的体系结构。但是与一般基于堆栈的零字节指令又不太一样,某些指令(如invokespecial)后面还会带有参数,关于虚拟机字节码执行的讲解是后面两章的重点,我们不妨把这里的疑问放到第8章去解决。
我们再次使用javap命令把此Class文件中的另外一个方法的字节码指令也计算出来,结果如代码清单6-4所示。
//原始Java代码
public class TestClass{
private int m;
public int inc(){
return m+1;
}
}
C:\>javap-verbose TestClass
//常量表部分的输出见代码清单6-1, 因版面原因这里省略掉
{
public org.fenixsoft.clazz.TestClass();
Code:
Stack=1, Locals=1, Args_size=1
0:aload_0
1:invokespecial#10;//Method java/lang/Object."<init>":()V
4:return
LineNumberTable:
line 3:0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lorg/fenixsoft/clazz/TestClass;
public int inc();
Code:
Stack=2, Locals=1, Args_size=1
0:aload_0
1:getfield#18;//Field m:I
4:iconst_1
5:iadd
6:ireturn
LineNumberTable:
line 8:0
LocalVariableTable:
Start Length Slot Name Signature
0 7 0 this Lorg/fenixsoft/clazz/TestClass;
}
如果大家注意到javap中输出的"Args_size"的值,可能会有疑问:这个类有两个方法——实例构造器<init>()和inc(),这两个方法很明显都是没有参数的,为什么Args_size会为1?而且无论是在参数列表里还是方法体内,都没有定义任何局部变量,那Locals又为什么会等于1?如果有这样的疑问,大家可能是忽略了一点:在任何实例方法里面,都可以通过"this"关键字访问到此方法所属的对象。这个访问机制对Java程序的编写很重要,而它的实现却非常简单,仅仅是通过Javac编译器编译的时候把对this关键字的访问转变为对一个普通方法参数的访问,然后在虚拟机调用实例方法时自动传入此参数而已。因此在实例方法的局部变量表中至少会存在一个指向当前对象实例的局部变量,局部变量表中也会预留出第一个Slot位来存放对象实例的引用,方法参数值从1开始计算。这个处理只对实例方法有效,如果代码清单6-1中的inc()方法声明为static,那Args_size就不会等于1而是等于0了。
在字节码指令之后的是这个方法的显式异常处理表(下文简称异常表)集合,异常表对于Code属性来说并不是必须存在的,如代码清单6-4中就没有异常表生成。
异常表的格式如表6-16所示,它包含4个字段,这些字段的含义为:如果当字节码在第start_pc行到第end_pc行之间(不含第end_pc行)出现了类型为catch_type或者其子类的异常(catch_type为指向一个CONSTANT_Class_info型常量的索引),则转到第handler_pc行继续处理。当catch_type的值为0时,代表任意异常情况都需要转向到handler_pc处进行处理。

异常表实际上是Java代码的一部分,编译器使用异常表而不是简单的跳转命令来实现Java异常及finally处理机制。
代码清单6-5是一段演示异常表如何运作的例子,这段代码主要演示了在字节码层面中try-catch-finally是如何实现的。在阅读字节码之前,大家不妨先看看下面的Java源码,想一下这段代码的返回值在出现异常和不出现异常的情况下分别应该是多少?
//Java源码
public int inc(){
int x;
try{
x=1;
return x;
}catch(Exception e){
x=2;
return x;
}finally{
x=3;
}
}
//编译后的ByteCode字节码及异常表
public int inc();
Code:
Stack=1, Locals=5, Args_size=1
0:iconst_1//try块中的x=1
1:istore_1
2:iload_1//保存x到returnValue中, 此时x=1
3:istore 4
5:iconst_3//finaly块中的x=3
6:istore_1
7:iload 4//将returnValue中的值放到栈顶, 准备给ireturn返回
9:ireturn
10:astore_2//给catch中定义的Exception e赋值, 存储在Slot 2中
11:iconst_2//catch块中的x=2
12:istore_1
13:iload_1//保存x到returnValue中, 此时x=2
14:istore 4
16:iconst_3//finaly块中的x=3
17:istore_1
18:iload 4//将returnValue中的值放到栈顶, 准备给ireturn返回
20:ireturn
21:astore_3//如果出现了不属于java.lang.Exception及其子类的异常才会走到这里
22:iconst_3//finaly块中的x=3
23:istore_1
24:aload_3//将异常放置到栈顶, 并抛出
25:athrow
Exception table:
from to target type
0 5 10 Class java/lang/Exception
0 5 21 any
10 16 21 any
编译器为这段Java源码生成了3条异常表记录,对应3条可能出现的代码执行路径。从Java代码的语义上讲,这3条执行路径分别为:
- 如果try语句块中出现属于Exception或其子类的异常,则转到catch语句块处理。
- 如果try语句块中出现不属于Exception或其子类的异常,则转到finally语句块处理。
- 如果catch语句块中出现任何异常,则转到finally语句块处理。
返回到我们上面提出的问题,这段代码的返回值应该是多少?对Java语言熟悉的读者应该很容易说出答案:如果没有出现异常,返回值是1;如果出现了Exception异常,返回值是2;如果出现了Exception以外的异常,方法非正常退出,没有返回值。我们一起来分析一下字节码的执行过程,从字节码的层面上看看为何会有这样的返回结果。
字节码中第0~4行所做的操作就是将整数1赋值给变量x,并且将此时x的值复制一份副本到最后一个本地变量表的Slot中(这个Slot里面的值在ireturn指令执行前将会被重新读到操作栈顶,作为方法返回值使用。为了讲解方便,笔者给这个Slot起了个名字:returnValue)。如果这时没有出现异常,则会继续走到第5~9行,将变量x赋值为3,然后将之前保存在returnValue中的整数1读入到操作栈顶,最后ireturn指令会以int形式返回操作栈顶中的值,方法结束。如果出现了异常,PC寄存器指针转到第10行,第10~20行所做的事情是将2赋值给变量x,然后将变量x此时的值赋给returnValue,最后再将变量x的值改为3。方法返回前同样将returnValue中保留的整数2读到了操作栈顶。从第21行开始的代码,作用是变量x的值赋为3,并将栈顶的异常抛出,方法结束。
尽管大家都知道这段代码出现异常的概率非常小,但并不影响它为我们演示异常表的作用。如果大家到这里仍然对字节码的运作过程比较模糊,其实也不要紧,关于虚拟机执行字节码的过程,本书第8章中将会有更详细的讲解。
Exceptions 属性
这里的Exceptions属性是在方法表中与Code属性平级的一项属性,读者不要与前面刚刚讲解完的异常表产生混淆。Exceptions属性的作用是列举出方法中可能抛出的受查异常(Checked Excepitons),也就是方法描述时在throws关键字后面列举的异常。它的结构见表6-17。

Exceptions属性中的number_of_exceptions项表示方法可能抛出number_of_exceptions种受查异常,每一种受查异常使用一个exception_index_table项表示,exception_index_table是一个指向常量池中CONSTANT_Class_info型常量的索引,代表了该受查异常的类型。
LineNumberTable 属性
LineNumberTable属性用于描述Java源码行号与字节码行号(字节码的偏移量)之间的对应关系。它并不是运行时必需的属性,但默认会生成到Class文件之中,可以在Javac中分别使用-g:none或-g:lines选项来取消或要求生成这项信息。如果选择不生成LineNumberTable属性,对程序运行产生的最主要的影响就是当抛出异常时,堆栈中将不会显示出错的行号,并且在调试程序的时候,也无法按照源码行来设置断点。LineNumberTable属性的结构见表6-18。

line_number_table是一个数量为line_number_table_length、类型为line_number_info的集合,line_number_info表包括了start_pc和line_number两个u2类型的数据项,前者是字节码行号,后者是Java源码行号。
LocalVariableTable 属性
LocalVariableTable属性用于描述栈帧中局部变量表中的变量与Java源码中定义的变量之间的关系,它也不是运行时必需的属性,但默认会生成到Class文件之中,可以在Javac中分别使用-g:none或-g:vars选项来取消或要求生成这项信息。如果没有生成这项属性,最大的影响就是当其他人引用这个方法时,所有的参数名称都将会丢失,IDE将会使用诸如arg0、arg1之类的占位符代替原有的参数名,这对程序运行没有影响,但是会对代码编写带来较大不便,而且在调试期间无法根据参数名称从上下文中获得参数值。LocalVariableTable属性的结构见表6-19。
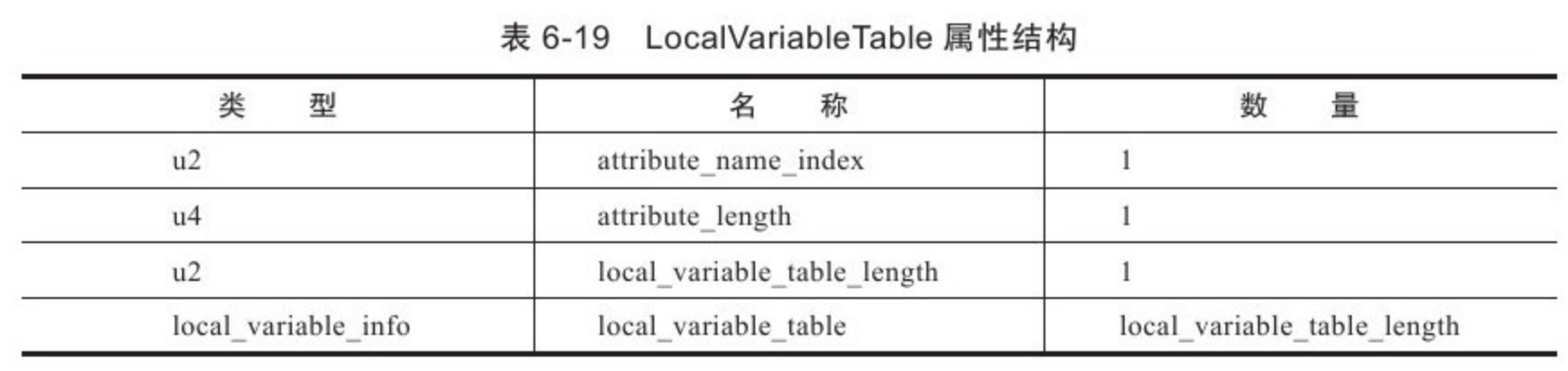
其中,local_variable_info项目代表了一个栈帧与源码中的局部变量的关联,结构见表6-20。

start_pc和length属性分别代表了这个局部变量的生命周期开始的字节码偏移量及其作用范围覆盖的长度,两者结合起来就是这个局部变量在字节码之中的作用域范围。
name_index和descriptor_index都是指向常量池中CONSTANT_Utf8_info型常量的索引,分别代表了局部变量的名称以及这个局部变量的描述符。
index是这个局部变量在栈帧局部变量表中Slot的位置。当这个变量数据类型是64位类型时(double和long),它占用的Slot为index和index+1两个。
顺便提一下,在JDK 1.5引入泛型之后,LocalVariableTable属性增加了一个“姐妹属性”:LocalVariableTypeTable,这个新增的属性结构与LocalVariableTable非常相似,仅仅是把记录的字段描述符的descriptor_index替换成了字段的特征签名(Signature),对于非泛型类型来说,描述符和特征签名能描述的信息是基本一致的,但是泛型引入之后,由于描述符中泛型的参数化类型被擦除掉,描述符就不能准确地描述泛型类型了,因此出现了LocalVariableTypeTable。
SourceFile 属性
SourceFile属性用于记录生成这个Class文件的源码文件名称。这个属性也是可选的,可以分别使用Javac的-g:none或-g:source选项来关闭或要求生成这项信息。在Java中,对于大多数的类来说,类名和文件名是一致的,但是有一些特殊情况(如内部类)例外。如果不生成这项属性,当抛出异常时,堆栈中将不会显示出错代码所属的文件名。这个属性是一个定长的属性,其结构见表6-21。

sourcefile_index数据项是指向常量池中CONSTANT_Utf8_info型常量的索引,常量值是源码文件的文件名。
ConstantValue 属性
ConstantValue属性的作用是通知虚拟机自动为静态变量赋值。只有被static关键字修饰的变量(类变量)才可以使用这项属性。类似"int x=123"和"static int x=123"这样的变量定义在Java程序中是非常常见的事情,但虚拟机对这两种变量赋值的方式和时刻都有所不同。对于非static类型的变量(也就是实例变量)的赋值是在实例构造器<init>方法中进行的;而对于类变量,则有两种方式可以选择:在类构造器<clinit>方法中或者使用ConstantValue属性。目前Sun Javac编译器的选择是:如果同时使用final和static来修饰一个变量(按照习惯,这里称“常量”更贴切),并且这个变量的数据类型是基本类型或者java.lang.String的话,就生成ConstantValue属性来进行初始化,如果这个变量没有被final修饰,或者并非基本类型及字符串,则将会选择在<clinit>方法中进行初始化。
虽然有final关键字才更符合"ConstantValue"的语义,但虚拟机规范中并没有强制要求字段必须设置了ACC_FINAL标志,只要求了有ConstantValue属性的字段必须设置ACC_STATIC标志而已,对final关键字的要求是Javac编译器自己加入的限制。而对ConstantValue的属性值只能限于基本类型和String,不过笔者不认为这是什么限制,因为此属性的属性值只是一个常量池的索引号,由于Class文件格式的常量类型中只有与基本属性和字符串相对应的字面量,所以就算ConstantValue属性想支持别的类型也无能为力。ConstantValue属性的结构见表6-22。

从数据结构中可以看出,ConstantValue属性是一个定长属性,它的attribute_length数据项值必须固定为2。constantvalue_index数据项代表了常量池中一个字面量常量的引用,根据字段类型的不同,字面量可以是CONSTANT_Long_info、CONSTANT_Float_info、CONSTANT_Double_info、CONSTANT_Integer_info、CONSTANT_String_info常量中的一种。
InnerClasses 属性
InnerClasses属性用于记录内部类与宿主类之间的关联。如果一个类中定义了内部类,那编译器将会为它以及它所包含的内部类生成InnerClasses属性。该属性的结构见表6-23。
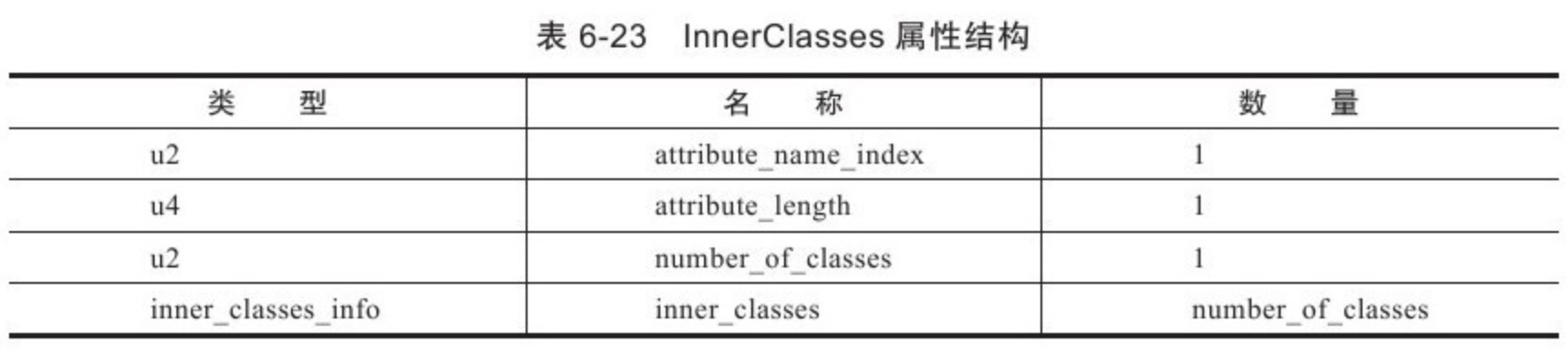
数据项number_of_classes代表需要记录多少个内部类信息,每一个内部类的信息都由一个inner_classes_info表进行描述。inner_classes_info表的结构见表6-24。
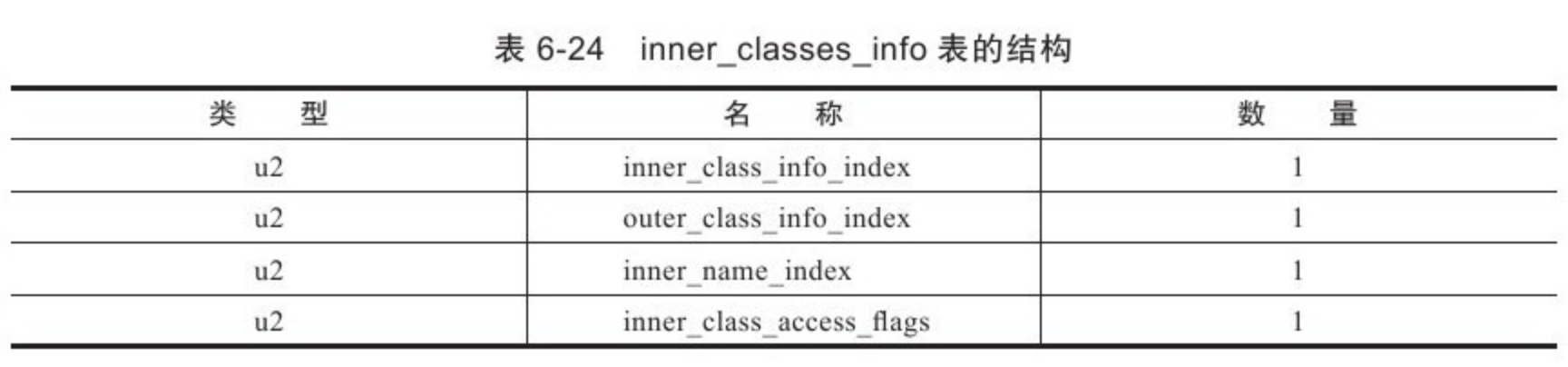
inner_class_info_index和outer_class_info_index都是指向常量池中CONSTANT_Class_info型常量的索引,分别代表了内部类和宿主类的符号引用。
inner_name_index是指向常量池中CONSTANT_Utf8_info型常量的索引,代表这个内部类的名称,如果是匿名内部类,那么这项值为0。
inner_class_access_flags是内部类的访问标志,类似于类的access_flags,它的取值范围见表6-25。
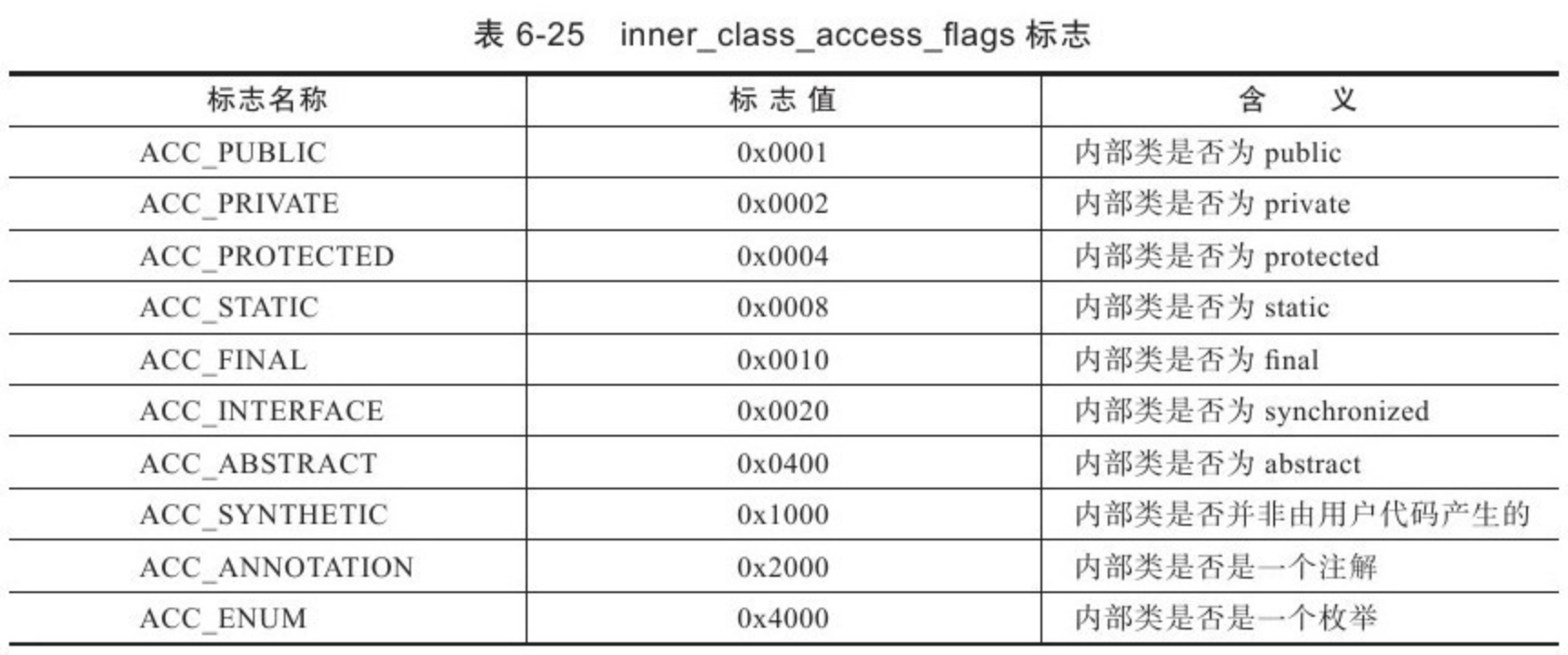
Deprecated/Synthetic 属性
Deprecated和Synthetic两个属性都属于标志类型的布尔属性,只存在有和没有的区别,没有属性值的概念。
Deprecated属性用于表示某个类、字段或者方法,已经被程序作者定为不再推荐使用,它可以通过在代码中使用@deprecated注释进行设置。
Synthetic属性代表此字段或者方法并不是由Java源码直接产生的,而是由编译器自行添加的,在JDK 1.5之后,标识一个类、字段或者方法是编译器自动产生的,也可以设置它们访问标志中的ACC_SYNTHETIC标志位,其中最典型的例子就是Bridge Method。所有由非用户代码产生的类、方法及字段都应当至少设置Synthetic属性和ACC_SYNTHETIC标志位中的一项,唯一的例外是实例构造器"<init>"方法和类构造器"<clinit>"方法。

其中attribute_length数据项的值必须为0x00000000,因为没有任何属性值需要设置。
StackMapTable 属性
StackMapTable属性在JDK 1.6发布后增加到了Class文件规范中,它是一个复杂的变长属性,位于Code属性的属性表中。这个属性会在虚拟机类加载的字节码验证阶段被新类型检查验证器(Type Checker)使用(见7.3.2节),目的在于代替以前比较消耗性能的基于数据流分析的类型推导验证器。
这个类型检查验证器最初来源于Sheng Liang(听名字似乎是虚拟机团队中的华裔成员)为Java ME CLDC实现的字节码验证器。新的验证器在同样能保证Class文件合法性的前提下,省略了在运行期通过数据流分析去确认字节码的行为逻辑合法性的步骤,而是在编译阶段将一系列的验证类型(Verification Types)直接记录在Class文件之中,通过检查这些验证类型代替了类型推导过程,从而大幅提升了字节码验证的性能。这个验证器在JDK 1.6中首次提供,并在JDK 1.7中强制代替原本基于类型推断的字节码验证器。关于这个验证器的工作原理,《Java虚拟机规范(Java SE 7版)》花费了整整120页的篇幅来讲解描述,并且分析证明新验证方法的严谨性,笔者在此不再赘述。
StackMapTable属性中包含零至多个栈映射帧(Stack Map Frames),每个栈映射帧都显式或隐式地代表了一个字节码偏移量,用于表示该执行到该字节码时局部变量表和操作数栈的验证类型。类型检查验证器会通过检查目标方法的局部变量和操作数栈所需要的类型来确定一段字节码指令是否符合逻辑约束。StackMapTable属性的结构见表6-27。
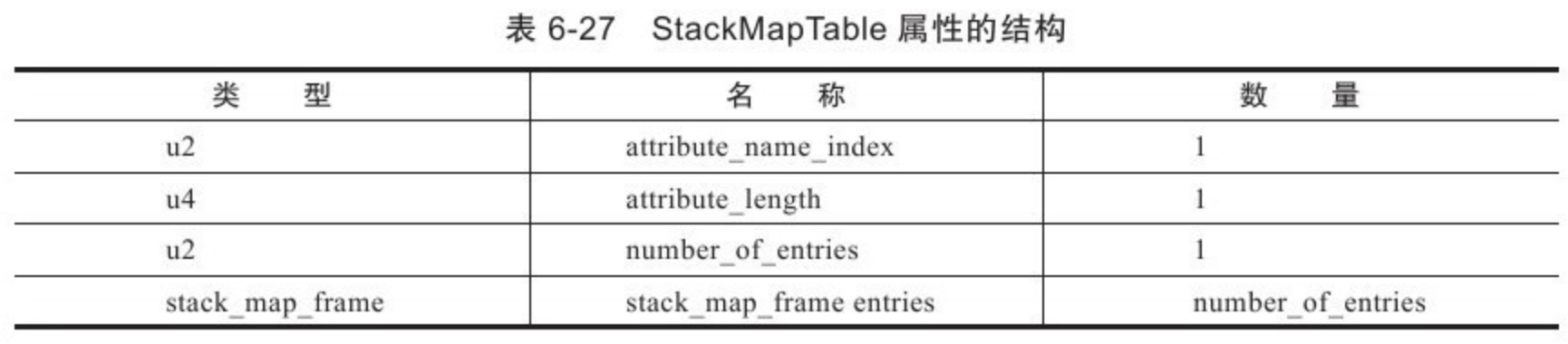
《Java虚拟机规范(Java SE 7版)》明确规定:在版本号大于或等于50.0的Class文件中,如果方法的Code属性中没有附带StackMapTable属性,那就意味着它带有一个隐式的StackMap属性。这个StackMap属性的作用等同于number_of_entries值为0的StackMapTable属性。一个方法的Code属性最多只能有一个StackMapTable属性,否则将抛出ClassFormatError异常。
Signature 属性
Signature属性在JDK 1.5发布后增加到了Class文件规范之中,它是一个可选的定长属性,可以出现于类、属性表和方法表结构的属性表中。在JDK 1.5中大幅增强了Java语言的语法,在此之后,任何类、接口、初始化方法或成员的泛型签名如果包含了类型变量(Type Variables)或参数化类型(Parameterized Types),则Signature属性会为它记录泛型签名信息。之所以要专门使用这样一个属性去记录泛型类型,是因为Java语言的泛型采用的是擦除法实现的伪泛型,在字节码(Code属性)中,泛型信息编译(类型变量、参数化类型)之后都通通被擦除掉。使用擦除法的好处是实现简单(主要修改Javac编译器,虚拟机内部只做了很少的改动)、非常容易实现Backport,运行期也能够节省一些类型所占的内存空间。但坏处是运行期就无法像C#等有真泛型支持的语言那样,将泛型类型与用户定义的普通类型同等对待,例如运行期做反射时无法获得到泛型信息。Signature属性就是为了弥补这个缺陷而增设的,现在Java的反射API能够获取泛型类型,最终的数据来源也就是这个属性。关于Java泛型、Signature属性和类型擦除,在第10章介绍编译器优化的时候会通过一个具体的例子来讲解。Signature属性的结构见表6-28。

其中signature_index项的值必须是一个对常量池的有效索引。常量池在该索引处的项必须是CONSTANT_Utf8_info结构,表示类签名、方法类型签名或字段类型签名。如果当前的Signature属性是类文件的属性,则这个结构表示类签名,如果当前的Signature属性是方法表的属性,则这个结构表示方法类型签名,如果当前Signature属性是字段表的属性,则这个结构表示字段类型签名。
BootstrapMethods 属性
BootstrapMethods属性在JDK 1.7发布后增加到了Class文件规范之中,它是一个复杂的变长属性,位于类文件的属性表中。这个属性用于保存invokedynamic指令引用的引导方法限定符。《Java虚拟机规范(Java SE 7版)》规定,如果某个类文件结构的常量池中曾经出现过CONSTANT_InvokeDynamic_info类型的常量,那么这个类文件的属性表中必须存在一个明确的BootstrapMethods属性,另外,即使CONSTANT_InvokeDynamic_info类型的常量在常量池中出现过多次,类文件的属性表中最多也只能有一个BootstrapMethods属性。BootstrapMethods属性与JSR-292中的InvokeDynamic指令和java.lang.Invoke包关系非常密切,要介绍这个属性的作用,必须先弄清楚InovkeDynamic指令的运作原理,笔者将在第8章专门用1节篇幅去介绍它们,在此先暂时略过。
目前的Javac暂时无法生成InvokeDynamic指令和BootstrapMethods属性,必须通过一些非常规的手段才能使用到它们,也许在不久的将来,等JSR-292更加成熟一些,这种状况就会改变。BootstrapMethods属性的结构见表6-29。
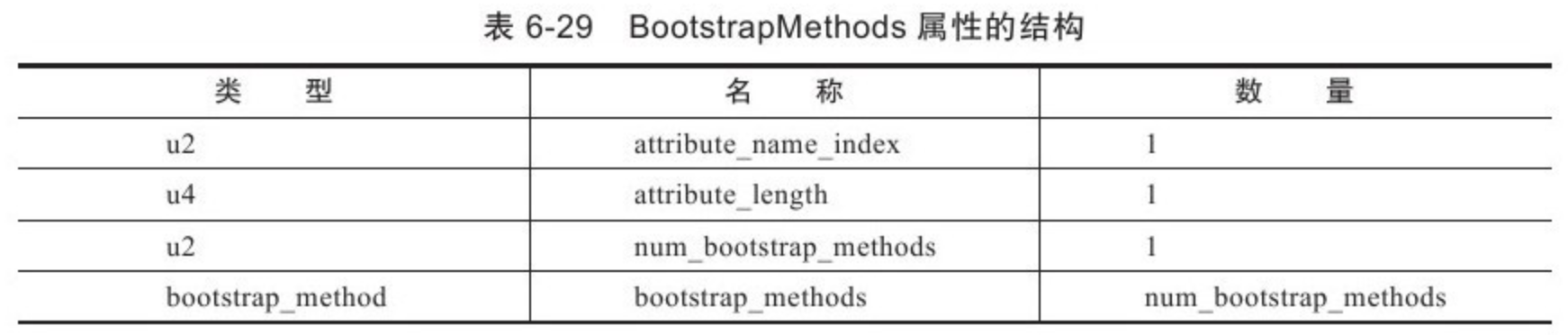
其中引用到的bootstrap_method结构见表6-30。

BootstrapMethods属性中,num_bootstrap_methods项的值给出了bootstrap_methods[]数组中的引导方法限定符的数量。而bootstrap_methods[]数组的每个成员包含了一个指向常量池CONSTANT_MethodHandle结构的索引值,它代表了一个引导方法,还包含了这个引导方法静态参数的序列(可能为空)。bootstrap_methods[]数组中的每个成员必须包含以下3项内容。
bootstrap_method_ref:bootstrap_method_ref项的值必须是一个对常量池的有效索引。常量池在该索引处的值必须是一个CONSTANT_MethodHandle_info结构。
num_bootstrap_arguments:num_bootstrap_arguments项的值给出了bootstrap_arguments[]数组成员的数量。
bootstrap_arguments[]:bootstrap_arguments[]数组的每个成员必须是一个对常量池的有效索引。常量池在该索引处必须是下列结构之一:CONSTANT_String_info、CONSTANT_Class_info、CONSTANT_Integer_info、CONSTANT_Long_info、CONSTANT_Float_info、CONSTANT_Double_info、CONSTANT_MethodHandle_info或CONSTANT_MethodType_info。
6.4 字节码指令简介
Java虚拟机的指令由一个字节长度的、代表着某种特定操作含义的数字(称为操作码,Opcode)以及跟随其后的零至多个代表此操作所需参数(称为操作数,Operands)而构成。由于Java虚拟机采用面向操作数栈而不是寄存器的架构(这两种架构的区别和影响将在第8章中探讨),所以大多数的指令都不包含操作数,只有一个操作码。
字节码指令集是一种具有鲜明特点、优劣势都很突出的指令集架构,由于限制了Java虚拟机操作码的长度为一个字节(即0~255),这意味着指令集的操作码总数不可能超过256条;又由于Class文件格式放弃了编译后代码的操作数长度对齐,这就意味着虚拟机处理那些超过一个字节数据的时候,不得不在运行时从字节中重建出具体数据的结构,如果要将一个16位长度的无符号整数使用两个无符号字节存储起来(将它们命名为byte1和byte2),那它们的值应该是这样的:(byte1<<8)|byte2。
这种操作在某种程度上会导致解释执行字节码时损失一些性能。但这样做的优势也非常明显,放弃了操作数长度对齐,就意味着可以省略很多填充和间隔符号;用一个字节来代表操作码,也是为了尽可能获得短小精干的编译代码。这种追求尽可能小数据量、高传输效率的设计是由Java语言设计之初面向网络、智能家电的技术背景所决定的,并一直沿用至今。
如果不考虑异常处理的话,那么Java虚拟机的解释器可以使用下面这个伪代码当做最基本的执行模型来理解,这个执行模型虽然很简单,但依然可以有效地工作:
do{
自动计算PC寄存器的值加1;
根据PC寄存器的指示位置, 从字节码流中取出操作码;
if(字节码存在操作数)从字节码流中取出操作数;
执行操作码所定义的操作;
}while(字节码流长度>0);
6.4.1 字节码与数据类型
在Java虚拟机的指令集中,大多数的指令都包含了其操作所对应的数据类型信息。例如,iload指令用于从局部变量表中加载int型的数据到操作数栈中,而fload指令加载的则是float类型的数据。这两条指令的操作在虚拟机内部可能会是由同一段代码来实现的,但在Class文件中它们必须拥有各自独立的操作码。
对于大部分与数据类型相关的字节码指令,它们的操作码助记符中都有特殊的字符来表明专门为哪种数据类型服务:i代表对int类型的数据操作,l代表long,s代表short,b代表byte,c代表char,f代表float,d代表double,a代表reference。也有一些指令的助记符中没有明确地指明操作类型的字母,如arraylength指令,它没有代表数据类型的特殊字符,但操作数永远只能是一个数组类型的对象。还有另外一些指令,如无条件跳转指令goto则是与数据类型无关的。
由于Java虚拟机的操作码长度只有一个字节,所以包含了数据类型的操作码就为指令集的设计带来了很大的压力:如果每一种与数据类型相关的指令都支持Java虚拟机所有运行时数据类型的话,那指令的数量恐怕就会超出一个字节所能表示的数量范围了。因此,Java虚拟机的指令集对于特定的操作只提供了有限的类型相关指令去支持它,换句话说,指令集将会故意被设计成非完全独立的(Java虚拟机规范中把这种特性称为"Not Orthogonal",即并非每种数据类型和每一种操作都有对应的指令)。有一些单独的指令可以在必要的时候用来将一些不支持的类型转换为可被支持的类型。
表6-31列举了Java虚拟机所支持的与数据类型相关的字节码指令,通过使用数据类型列所代表的特殊字符替换opcode列的指令模板中的T,就可以得到一个具体的字节码指令。如果在表中指令模板与数据类型两列共同确定的格为空,则说明虚拟机不支持对这种数据类型执行这项操作。例如,load指令有操作int类型的iload,但是没有操作byte类型的同类指令。
注意,从表6-31中可以看出,大部分的指令都没有支持整数类型byte、char和short,甚至没有任何指令支持boolean类型。编译器会在编译期或运行期将byte和short类型的数据带符号扩展(Sign-Extend)为相应的int类型数据,将boolean和char类型数据零位扩展(Zero-Extend)为相应的int类型数据。与之类似,在处理boolean、byte、short和char类型的数组时,也会转换为使用对应的int类型的字节码指令来处理。因此,大多数对于boolean、byte、short和char类型数据的操作,实际上都是使用相应的int类型作为运算类型(Computational Type)。

在本章中,受篇幅所限,无法对字节码指令集中每条指令进行逐一讲解,但阅读字节码作为了解Java虚拟机的基础技能,是一项应当熟练掌握的能力。笔者将字节码操作按用途大致分为9类,按照分类来为读者概略介绍一下这些指令的用法。如果读者需要了解更详细的信息,可以参考阅读笔者翻译的《Java虚拟机规范(Java SE 7版)》的第6章。
6.4.2 加载与存储指令
加载和存储指令用于将数据在栈帧中的局部变量表和操作数栈(见第2章关于内存区域的介绍)之间来回传输,这类指令包括如下内容。
将一个局部变量加载到操作栈:iload、iload_<n>、lload、lload_<n>、fload、fload_<n>、dload、dload_<n>、aload、aload_<n>。
将一个数值从操作数栈存储到局部变量表:istore、istore_<n>、lstore、lstore_<n>、fstore、fstore_<n>、dstore、dstore_<n>、astore、astore_<n>。
将一个常量加载到操作数栈:bipush、sipush、ldc、ldc_w、ldc2_w、aconst_null、iconst_m1、iconst_<i>、lconst_<l>、fconst_<f>、dconst_<d>。
扩充局部变量表的访问索引的指令:wide。
存储数据的操作数栈和局部变量表主要就是由加载和存储指令进行操作,除此之外,还有少量指令,如访问对象的字段或数组元素的指令也会向操作数栈传输数据。
上面所列举的指令助记符中,有一部分是以尖括号结尾的(例如iload_<n>),这些指令助记符实际上是代表了一组指令(例如iload_<n>,它代表了iload_0、iload_1、iload_2和iload_3这几条指令)。这几组指令都是某个带有一个操作数的通用指令(例如iload)的特殊形式,对于这若干组特殊指令来说,它们省略掉了显式的操作数,不需要进行取操作数的动作,实际上操作数就隐含在指令中。除了这点之外,它们的语义与原生的通用指令完全一致(例如iload_0的语义与操作数为0时的iload指令语义完全一致)。这种指令表示方法在本书以及《Java虚拟机规范》中都是通用的。
6.4.3 运算指令
运算或算术指令用于对两个操作数栈上的值进行某种特定运算,并把结果重新存入到操作栈顶。大体上算术指令可以分为两种:对整型数据进行运算的指令与对浮点型数据进行运算的指令,无论是哪种算术指令,都使用Java虚拟机的数据类型,由于没有直接支持byte、short、char和boolean类型的算术指令,对于这类数据的运算,应使用操作int类型的指令代替。整数与浮点数的算术指令在溢出和被零除的时候也有各自不同的行为表现,所有的算术指令如下。
- 加法指令:iadd、ladd、fadd、dadd。
- 减法指令:isub、lsub、fsub、dsub。
- 乘法指令:imul、lmul、fmul、dmul。
- 除法指令:idiv、ldiv、fdiv、ddiv。
- 求余指令:irem、lrem、frem、drem。
- 取反指令:ineg、lneg、fneg、dneg。
- 位移指令:ishl、ishr、iushr、lshl、lshr、lushr。
- 按位或指令:ior、lor。
- 按位与指令:iand、land。
- 按位异或指令:ixor、lxor。
- 局部变量自增指令:iinc。
- 比较指令:dcmpg、dcmpl、fcmpg、fcmpl、lcmp。
Java虚拟机的指令集直接支持了在《Java语言规范》中描述的各种对整数及浮点数操作(参见《Java语言规范(第3版)》中的4.2.2节和4.2.4节)的语义。数据运算可能会导致溢出,例如两个很大的正整数相加,结果可能会是一个负数,这种数学上不可能出现的溢出现象,对于程序员来说是很容易理解的,但其实Java虚拟机规范没有明确定义过整型数据溢出的具体运算结果,仅规定了在处理整型数据时,只有除法指令(idiv和ldiv)以及求余指令(irem和lrem)中当出现除数为零时会导致虚拟机抛出ArithmeticException异常,其余任何整型数运算场景都不应该抛出运行时异常。
Java虚拟机规范要求虚拟机实现在处理浮点数时,必须严格遵循IEEE 754规范中所规定的行为和限制。也就是说,Java虚拟机必须完全支持IEEE 754中定义的非正规浮点数值(Denormalized Floating-Point Numbers)和逐级下溢(Gradual Underflow)的运算规则。这些特征将会使某些数值算法处理起来变得相对容易一些。
在把浮点数转换为整数时,Java虚拟机使用IEEE 754标准中的向零舍入模式,这种模式的舍入结果会导致数字被截断,所有小数部分的有效字节都会被丢弃掉。向零舍入模式将在目标数值类型中选择一个最接近但是不大于原值的数字来作为最精确的舍入结果。
另外,Java虚拟机在处理浮点数运算时,不会抛出任何运行时异常(这里所讲的是Java语言中的异常,请读者勿与IEEE 754规范中的浮点异常互相混淆,IEEE 754的浮点异常是一种运算信号),当一个操作产生溢出时,将会使用有符号的无穷大来表示,如果某个操作结果没有明确的数学定义的话,将会使用NaN值来表示。所有使用NaN值作为操作数的算术操作,结果都会返回NaN。
在对long类型数值进行比较时,虚拟机采用带符号的比较方式,而对浮点数值进行比较时(dcmpg、dcmpl、fcmpg、fcmpl),虚拟机会采用IEEE 754规范所定义的无信号比较(Nonsignaling Comparisons)方式。
6.4.4 类型转换指令
类型转换指令可以将两种不同的数值类型进行相互转换,这些转换操作一般用于实现用户代码中的显式类型转换操作,或者用来处理本节开篇所提到的字节码指令集中数据类型相关指令无法与数据类型一一对应的问题。
Java虚拟机直接支持(即转换时无需显式的转换指令)以下数值类型的宽化类型转换(Widening Numeric Conversions,即小范围类型向大范围类型的安全转换):
- int类型到long、float或者double类型。
- long类型到float、double类型。
- float类型到double类型。
相对的,处理窄化类型转换(Narrowing Numeric Conversions)时,必须显式地使用转换指令来完成,这些转换指令包括:i2b、i2c、i2s、l2i、f2i、f2l、d2i、d2l和d2f。窄化类型转换可能会导致转换结果产生不同的正负号、不同的数量级的情况,转换过程很可能会导致数值的精度丢失。
在将int或long类型窄化转换为整数类型T的时候,转换过程仅仅是简单地丢弃除最低位N个字节以外的内容,N是类型T的数据类型长度,这将可能导致转换结果与输入值有不同的正负号。这点很容易理解,因为原来符号位处于数值的最高位,高位被丢弃之后,转换结果的符号就取决于低N个字节的首位了。
在将一个浮点值窄化转换为整数类型T(T限于int或long类型之一)的时候,将遵循以下转换规则:
- 如果浮点值是NaN,那转换结果就是int或long类型的0。
- 如果浮点值不是无穷大的话,浮点值使用IEEE 754的向零舍入模式取整,获得整数值v,如果v在目标类型T(int或long)的表示范围之内,那转换结果就是v。
- 否则,将根据v的符号,转换为T所能表示的最大或者最小正数。
从double类型到float类型的窄化转换过程与IEEE 754中定义的一致,通过IEEE 754向最接近数舍入模式舍入得到一个可以使用float类型表示的数字。如果转换结果的绝对值太小而无法使用float来表示的话,将返回float类型的正负零。如果转换结果的绝对值太大而无法使用float来表示的话,将返回float类型的正负无穷大,对于double类型的NaN值将按规定转换为float类型的NaN值。
尽管数据类型窄化转换可能会发生上限溢出、下限溢出和精度丢失等情况,但是Java虚拟机规范中明确规定数值类型的窄化转换指令永远不可能导致虚拟机抛出运行时异常。
6.4.5 对象创建与访问指令
虽然类实例和数组都是对象,但Java虚拟机对类实例和数组的创建与操作使用了不同的字节码指令(在第7章会讲到数组和普通类的类型创建过程是不同的)。对象创建后,就可以通过对象访问指令获取对象实例或者数组实例中的字段或者数组元素,这些指令如下。
- 创建类实例的指令:new。
- 创建数组的指令:newarray、anewarray、multianewarray。
- 访问类字段(static字段,或者称为类变量)和实例字段(非static字段,或者称为实例变量)的指令:getfield、putfield、getstatic、putstatic。
- 把一个数组元素加载到操作数栈的指令:baload、caload、saload、iaload、laload、faload、daload、aaload。
- 将一个操作数栈的值存储到数组元素中的指令:bastore、castore、sastore、iastore、fastore、dastore、aastore。
- 取数组长度的指令:arraylength。
- 检查类实例类型的指令:instanceof、checkcast。
6.4.6 操作数栈管理指令
如同操作一个普通数据结构中的堆栈那样,Java虚拟机提供了一些用于直接操作操作数栈的指令,包括:
- 将操作数栈的栈顶一个或两个元素出栈:pop、pop2。
- 复制栈顶一个或两个数值并将复制值或双份的复制值重新压入栈顶:dup、dup2、dup_x1、dup2_x1、dup_x2、dup2_x2。
- 将栈最顶端的两个数值互换:swap。
6.4.7 控制转移指令
控制转移指令可以让Java虚拟机有条件或无条件地从指定的位置指令而不是控制转移指令的下一条指令继续执行程序,从概念模型上理解,可以认为控制转移指令就是在有条件或无条件地修改PC寄存器的值。控制转移指令如下。
- 条件分支:ifeq、iflt、ifle、ifne、ifgt、ifge、ifnull、ifnonnull、if_icmpeq、if_icmpne、if_icmplt、if_icmpgt、if_icmple、if_icmpge、if_acmpeq和if_acmpne。
- 复合条件分支:tableswitch、lookupswitch。
- 无条件分支:goto、goto_w、jsr、jsr_w、ret。
在Java虚拟机中有专门的指令集用来处理int和reference类型的条件分支比较操作,为了可以无须明显标识一个实体值是否null,也有专门的指令用来检测null值。
与前面算术运算时的规则一致,对于boolean类型、byte类型、char类型和short类型的条件分支比较操作,都是使用int类型的比较指令来完成,而对于long类型、float类型和double类型的条件分支比较操作,则会先执行相应类型的比较运算指令(dcmpg、dcmpl、fcmpg、fcmpl、lcmp,见6.4.3节),运算指令会返回一个整型值到操作数栈中,随后再执行int类型的条件分支比较操作来完成整个分支跳转。由于各种类型的比较最终都会转化为int类型的比较操作,int类型比较是否方便完善就显得尤为重要,所以Java虚拟机提供的int类型的条件分支指令是最为丰富和强大的。
6.4.8 方法调用和返回指令
方法调用(分派、执行过程)将在第8章具体讲解,这里仅列举以下5条用于方法调用的指令。
- invokevirtual指令用于调用对象的实例方法,根据对象的实际类型进行分派(虚方法分派),这也是Java语言中最常见的方法分派方式。
- invokeinterface指令用于调用接口方法,它会在运行时搜索一个实现了这个接口方法的对象,找出适合的方法进行调用。
- invokespecial指令用于调用一些需要特殊处理的实例方法,包括实例初始化方法、私有方法和父类方法。
- invokestatic指令用于调用类方法(static方法)。
- invokedynamic指令用于在运行时动态解析出调用点限定符所引用的方法,并执行该方法,前面4条调用指令的分派逻辑都固化在Java虚拟机内部,而invokedynamic指令的分派逻辑是由用户所设定的引导方法决定的。
方法调用指令与数据类型无关,而方法返回指令是根据返回值的类型区分的,包括ireturn(当返回值是boolean、byte、char、short和int类型时使用)、lreturn、freturn、dreturn和areturn,另外还有一条return指令供声明为void的方法、实例初始化方法以及类和接口的类初始化方法使用。
6.4.9 异常处理指令
在Java程序中显式抛出异常的操作(throw语句)都由athrow指令来实现,除了用throw语句显式抛出异常情况之外,Java虚拟机规范还规定了许多运行时异常会在其他Java虚拟机指令检测到异常状况时自动抛出。例如,在前面介绍的整数运算中,当除数为零时,虚拟机会在idiv或ldiv指令中抛出ArithmeticException异常。
而在Java虚拟机中,处理异常(catch语句)不是由字节码指令来实现的(很久之前曾经使用jsr和ret指令来实现,现在已经不用了),而是采用异常表来完成的。
6.4.10 同步指令
Java虚拟机可以支持方法级的同步和方法内部一段指令序列的同步,这两种同步结构都是使用管程(Monitor)来支持的。
方法级的同步是隐式的,即无须通过字节码指令来控制,它实现在方法调用和返回操作之中。虚拟机可以从方法常量池的方法表结构中的ACC_SYNCHRONIZED访问标志得知一个方法是否声明为同步方法。当方法调用时,调用指令将会检查方法的ACC_SYNCHRONIZED访问标志是否被设置,如果设置了,执行线程就要求先成功持有管程,然后才能执行方法,最后当方法完成(无论是正常完成还是非正常完成)时释放管程。在方法执行期间,执行线程持有了管程,其他任何线程都无法再获取到同一个管程。如果一个同步方法执行期间抛出了异常,并且在方法内部无法处理此异常,那么这个同步方法所持有的管程将在异常抛到同步方法之外时自动释放。
同步一段指令集序列通常是由Java语言中的synchronized语句块来表示的,Java虚拟机的指令集中有monitorenter和monitorexit两条指令来支持synchronized关键字的语义,正确实现synchronized关键字需要Javac编译器与Java虚拟机两者共同协作支持,譬如代码清单6-6中所示的代码。
void onlyMe(Foo f){
synchronized(f){
doSomething();
}
}
编译后,这段代码生成的字节码序列如下:
Method void onlyMe(Foo)
0 aload_1//将对象f入栈
1 dup//复制栈顶元素(即f的引用)
2 astore_2//将栈顶元素存储到局部变量表Slot 2中
3 monitorenter//以栈顶元素(即f)作为锁, 开始同步
4 aload_0//将局部变量Slot 0(即this指针)的元素入栈
5 invokevirtual#5//调用doSomething()方法
8 aload_2//将局部变量Slow 2的元素(即f)入栈
9 monitorexit//退出同步
10 goto 18//方法正常结束, 跳转到18返回
13 astore_3//从这步开始是异常路径, 见下面异常表的Taget 13
14 aload_2//将局部变量Slow 2的元素(即f)入栈
15 monitorexit//退出同步
16 aload_3//将局部变量Slow 3的元素(即异常对象)入栈
17 athrow//把异常对象重新抛出给onlyMe()方法的调用者
18 return//方法正常返回
Exception table:
FromTo Target Type
4 10 13 any
13 16 13 any
编译器必须确保无论方法通过何种方式完成,方法中调用过的每条monitorenter指令都必须执行其对应的monitorexit指令,而无论这个方法是正常结束还是异常结束。
从代码清单6-6的字节码序列中可以看到,为了保证在方法异常完成时monitorenter和monitorexit指令依然可以正确配对执行,编译器会自动产生一个异常处理器,这个异常处理器声明可处理所有的异常,它的目的就是用来执行monitorexit指令。
6.5 共有设计和私有实现
Java虚拟机规范描绘了Java虚拟机应有的共同程序存储格式:Class文件格式以及字节码指令集。这些内容与硬件、操作系统及具体的Java虚拟机实现之间是完全独立的,虚拟机实现者可能更愿意把它们看做是程序在各种Java平台实现之间互相安全地交互的手段。
理解公有设计与私有实现之间的分界线是非常有必要的,Java虚拟机实现必须能够读取Class文件并精确实现包含在其中的Java虚拟机代码的语义。拿着Java虚拟机规范一成不变地逐字实现其中要求的内容当然是一种可行的途径,但一个优秀的虚拟机实现,在满足虚拟机规范的约束下对具体实现做出修改和优化也是完全可行的,并且虚拟机规范中明确鼓励实现者这样做。只要优化后Class文件依然可以被正确读取,并且包含在其中的语义能得到完整的保持,那实现者就可以选择任何方式去实现这些语义,虚拟机后台如何处理Class文件完全是实现者自己的事情,只要它在外部接口上看起来与规范描述的一致即可。
虚拟机实现者可以使用这种伸缩性来让Java虚拟机获得更高的性能、更低的内存消耗或者更好的可移植性,选择哪种特性取决于Java虚拟机实现的目标和关注点是什么。虚拟机实现的方式主要有以下两种:
- 将输入的Java虚拟机代码在加载或执行时翻译成另外一种虚拟机的指令集。
- 将输入的Java虚拟机代码在加载或执行时翻译成宿主机CPU的本地指令集(即JIT代码生成技术)。
精确定义的虚拟机和目标文件格式不应当对虚拟机实现者的创造性产生太多的限制,Java虚拟机应被设计成可以允许有众多不同的实现,并且各种实现可以在保持兼容性的同时提供不同的、新的、有趣的解决方案。
6.6 Class 文件结构的发展
Class文件结构自Java虚拟机规范第1版订立以来,已经有十多年的历史。这十多年间,Java技术体系有了翻天覆地的改变,JDK的版本号已经从1.0提升到了1.7。相对于语言、API以及Java技术体系中其他方面的变化,Class文件结构一直处于比较稳定的状态,Class文件的主体结构、字节码指令的语义和数量几乎没有出现过变动,所有对Class文件格式的改进,都集中在向访问标志、属性表这些在设计上就可扩展的数据结构中添加内容。
如果以《Java虚拟机规范(第2版)》为基准进行比较的话,那么在后续Class文件格式的发展过程中,访问标志里新加入了ACC_SYNTHETIC、ACC_ANNOTATION、ACC_ENUM、ACC_BRIDGE、ACC_VARARGS共5个标志。而属性表集合中,在JDK 1.5到JDK 1.7版本之间一共增加了12项新的属性,这些属性大部分用于支持Java中许多新出现的语言特性,如枚举、变长参数、泛型、动态注解等。还有一些是为了支持性能改进和调试信息,譬如JDK 1.6的新类型校验器的StackMapTable属性和对非Java代码调试中用到的SourceDebugExtension属性。
Class文件格式所具备的平台中立(不依赖于特定硬件及操作系统)、紧凑、稳定和可扩展的特点,是Java技术体系实现平台无关、语言无关两项特性的重要支柱。
本章小结
Class文件是Java虚拟机执行引擎的数据入口,也是Java技术体系的基础构成之一。了解Class文件的结构对后面进一步了解虚拟机执行引擎有很重要的意义。
本章详细讲解了Class文件结构中的各个组成部分,以及每个部分的定义、数据结构和使用方法。通过代码清单6-1的Java代码与它的Class文件样例,以实战的方式演示了Class的数据是如何存储和访问的。从第7章开始,我们将以动态的、运行时的角度去看看字节码流在虚拟机执行引擎中是怎样被解释执行的。
7 - CH07-类加载
7.1 概述
虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验、转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这就是虚拟机的类加载机制。
与那些在编译期执行连接过程的语言不同,Java 中类型的加载、连接、初始化过程均在运行时进行。这种类加载机制会为运行时增加一些性能开销,但也给 Java 提供了高度的灵活性:基于这种运行时动态加载和连接的能力,Java 中天生就可以动态扩展语言的特性。
7.2 类加载的时机
类的完整生命周期:加载、验证、准备、解析、初始化、使用、卸载。其中验证、准备、解析这三个部分被合称为连接。
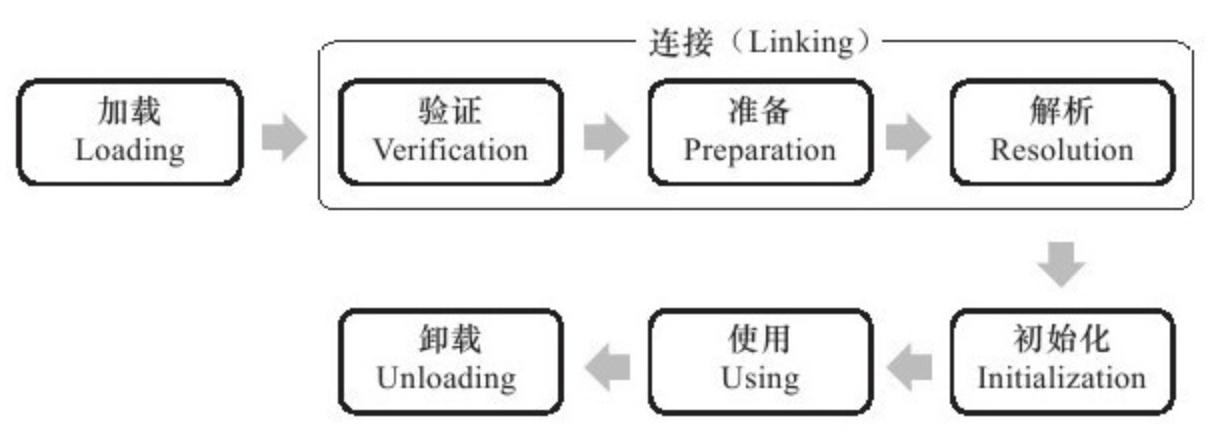
- 大致固定的“开始顺序”:加载、验证、准备、初始化、卸载。
- 各个阶段开始后会以交叉混合方式进行,即在一个阶段的执行过程中调用、激活另一个阶段。
- 解析阶段的开始时机不一定,它在某些情况下可以在初始化节点之后进行,这是为了支持 Java 的运行时绑定(或称动态绑定、晚期绑定)。
JVM 规范并没有定义开始加载一个类的时机,因此取决于具体的 JVM 实现。但对于初始化阶段,JVM 规范严格规定了 有且仅有 5 种情况 必须立即对类执行“初始化”(因此初始化的前置阶段必须在之前开始):
- 遇到 new、getstatic、putstatic、invokestatic 这四种字节码指令时,如果没有对类进行初始化,则需要先触发对应类的初始化。
- 使用
java.lang.reflect中的方法对类进行反射调用。 - 当初始化一个类的时候,发现其父类尚未被初始化。
- 当虚拟机启动时,用户需要制定一个将要执行的主类(包含 main 方法的类)。
- (JDK 7)如果一个
MethodHandle实例最后的解析结果是REF_getStatic、REF_putStatic、REF_invikeStatic的方法句柄对应类类没有被初始化。
这 5 种场景中的行为成为对一个类进行主动引用。除此之外,所有引用类的行为都不会触发初始化,称为被动引用。
被动引用场景
通过子类引用父类的静态字段
不会导致子类初始化。会引起父类的初始化和子类的加载。
通过数组定义来引用类
不会触发此类的初始化。
public class NotInitialization{
public static void main(String[]args){
SuperClass[]sca=new SuperClass[10];
}
}
这段代码不会触发 SuperClass 类的初始化,但会触发一个名为 [Lorg.fenixsoft.classloading.SuperClass 类的初始化,这是一个由 JVM 自动生成的、直接继承于 java.lang.Object 的子类,创建动作由字节码指令 newarray 触发。
在 JVM 内部,自动生成了一个类来封装数组数据(因此数组操作在 Java 中比在 C/C++ 中安全,后者是直接移动指针),该类值暴露了共有的 length 属性和 clone 方法。
应用类的常量字段
public class ConstClass{
static{
System.out.println("ConstClass init!");
}
public static final String HELLOWORLD="hello world";
}
public class NotInitialization{
public static void main(String[]args){
System.out.println(ConstClass.HELLOWORLD);
}
}
该示例中并不会引起类 ConstClass 的加载。因为在编译阶段通过常量传播优化,已经将此常量的值存储到了类 NotInitialization 常量池中,以后 NotInitialization 对该常量的引用实质上是对自身常量池的引用。即,NotInitialization 的 Class 文件中并没有对类 ConstClass 的符号引用入口,这两个类在编译成 Class 之后便不存在任何关联了。
接口初始化
接口也有初始化过程。在类中一般使用静态块来显示初始化信息,而接口中不能使用静态块,但编译器仍然会为接口生成 <clinit>() 类构造器,用于初始化接口中所定义的成员变量。
接口与类真正有所区别的地方在于上面所述 5 种主动引用情况的第 3 种:当一个类在初始化时,要求其父类全部都已经初始化过了;但是一个接口在初始化时,并不要求其父接口全部都完成了初始化,只有在真正使用到父接口时(如引用父接口中的常量)才会将其初始化。
7.3 类的加载过程
7.3.1 加载
加载阶段,虚拟机要完成的 3 件事情:
- 通过一个类的完全限定名来获取该类的二进制字节流。
- 将二进制字节流表示的静态存储结构转化为方法区的运行时数据结构。
- 在内存中生成一个代表该类的
java.lang.Class对象,作为在方法区中该类的各种信息的访问入口。
在 JVM 规范中并没有具体规定一定要从哪获取、怎样获取二进制字节流,因此具有很大的灵活性。基于这一点有很多有意义的实现:
- 从 ZIP 包中获取,这最终成为了日后 JAR/EAR/WAR 格式的基础。
- 从网络中获取,典型应用是 Applet。
- 运行时计算生成,应用最多的就是动态代理技术。
- 由其他文件生成,典型应用是 JSP。
- 从数据库中获取。
- 等等。
相对于类加载过程的其他阶段,一个非数组类在加载阶段的获取二进制字节流操作是可控性最强的,因为既可以使用系统提供的“引导类加载器”来加载,也可以由用户自定义的类加载器来加载,开发人员可以通过自定义的类加载器来控制字节流的获取方式。
数组类本省不能通过类加载器创建,它是由 JVM 直接创建的。但数组类仍与类加载器有着密切的联系,因为数组类的元素类型最终需要靠类加载器来创建。一个数组类(简称 C)的创建过程遵循以下规则:
- 如果数组的元素类型是引用类型,就递归采用本节中定义的加载过程来加载该元素类型,数组 C 将在加载元素类型的类加载器的名称空间上被标识(一个类必须与其加载器来确定唯一性)。
- 如果数组的元素类型不是引用类型,JVM 将会把数组 C 标记位与引导类加载关联。
- 数组类的可见性与元素类型的可见性一致,如果元素类型不是引用类型,则数组类的可见性为 public。
加载阶段与连接阶段是交叉进行的(如一部分字节码文件格式校验动作),加载阶段尚未完成,连接阶段可能已经开始,但这些夹杂在加载阶段的动作仍然属于连接阶段,这两个阶段的开始时间依然保持着固定的先后顺序。
7.3.2 验证
连接节点的第一步,为了确保 Class 文件的字节码中包含的信息符合当前虚拟机的要求,且不会危害虚拟机自身的安全。
Class 文件并不一定由 Java 源码编译而来。在字节码语言层面上,Java 代码无法做到的(比较危险的)事情都是可以实现的。虚拟机如果不检查输入的字节流而对其完全信任的话,很有可能因为载入了有害的字节流而导致系统崩溃。
验证阶段是非常重要的,该阶段是否严谨,决定了 JVM 是否能够承受恶意代码的攻击。从执行性能的角度来看,验证阶段的工作量在类加载子系统中占有相当大一部分。
验证阶段主要可以分为以下 4 个检验动作:
- 文件格式验证
- 元数据验证
- 字节码验证
- 符号引用验证
详细细节可以参考虚拟机规范。
7.3.3 准备
正式为类变量(静态变量)分配内存设置初始值(零值),这些变量所使用的内存将被分配在方法区。
假设一个类变量的定义为 public static int value=123;,那么该字段在准备阶段之后的值仍然为 int 类型的零值,即 0。因为在该阶段尚未开始执行任何 Java 方法,而把 value 赋值为 123 的 putstatic 指令会在程序被编译后放在类构造器的 <clinit>() 方法中,并在初始化节点执行。
一种特殊情况:如果类字段的字段属性表存在 ConstantValue 属性,那么在准备阶段变量 value 就会被初始化为 ConstantValue 属性所指定的值。
假设将上面的定义修改为 public static final int value=123;,这是 Javac 将会为 value 生成 ConstantValue 属性,在准备阶段 JVM 就会根据 ConstantValue 的设置将 value 赋值为 123。
基本数据类型的零值:

7.3.4 解析
将常量池中的符号引用替换为直接引用的过程。
符号引用:以一组符号来描述所引用的目标,符合可以是任何形式的字面量,只要使用时能够无歧义的定位到目标即可。符号引用与虚拟机实现的内存布局无关,引用的目标并不一定已经加载到内存中。各种虚拟机实现的内存布局可以各不相同,但是它们能接受的符号引用必须都是一致的,因为符号引用的字面量形式明确定义在Java虚拟机规范的Class文件格式中。
直接引用:直接引用可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄。直接引用是和虚拟机实现的内存布局相关的,同一个符号引用在不同虚拟机实例上翻译出来的直接引用一般不会相同。如果有了直接引用,那引用的目标必定已经在内存中存在。
JVM 规范中并未规定解析阶段发生的具体时间,只要求在执行 anewarray、checkcast、getfield、getstatic、instanceof、invokedynamic、invokeinterface、invokespecial、invokestatic、invokevirtual、ldc、ldc_w、multianewarray、new、putfield、putstatic 这 16 个用于操作符号引用的字节码指令之前,先对其使用的符号引用进行解析。所有虚拟机实现可以根据需要来判断是要在类加载时就对常量池中的符号引用进行解析,还是等到一个符号引用将要被使用时再去解析。
解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄、调用点,这 7 类符号进行,分别对应于常量池中的 CONSTANT_Class_info、CONSTANT_Fieldref_info、CONSTANT_Methodref_info、CONSTANT_InterfaceMethodref_info、CONSTANT_MethodType_info、CONSTANT_MethodHandle_info和CONSTANT_InvokeDynamic_info 这 7 种常量类型。
这里介绍前 4 种引用的解析过程,后 3 种与动态语言的支持相关,会在第 8 章介绍完 invokedynamic 指令的语义之后再做介绍。
1. 类或接口
假设当前类为 D,如果要把一个未解析过的符号引用 N 解析为一个类或接口 C 的直接引用,虚拟机要完成的解析过程包含以下 3 个步骤:
- 如果 C 不是一个数组类型,虚拟机将会把代表 N 的完全限定名传递给 D 的类加载器来加载这个类 C。在加载过程中,由于元数据验证、字节码验证的需要,又可能触发其他相关类的加载动作,如该类的父类或父接口。一旦该过程出现任何异常,解析过程宣告失败。
- 如果 C 是一个数组类型,并且数组的元素类型为对象,即 N 的描述符会以类似
[Ljava/lang/Integer的形式,那将会按照第一步的规则首先加载素组元素的类型。完成后由虚拟机生成一个代表次数组维度和元素的数组对象。 - 如果上述步骤没有出现任何异常,那么 C 在虚拟机中实际已经称为了一个有效的类或接口了,但在解析完成之前要进行符号引用验证,以确认 D 是否具备对 C 的访问权限。如果不具备访问权限,将抛出
java.lang.IllegalAccessError异常。
2. 字段解析
首先将会对字段表内 class_index 项中索引的 CONSTANT_Class_info 符号引用进行解析,也就是字段所属的类或接口的符号引用。如果该过程中出现异常将会导致本解析过程失败;如果解析成功完成,那么将该字段所属的类或接口用 C 表示,虚拟机规范中要求按照如下步骤对 C 进行后续字段的搜索:
- 如果 C 本身包含了简单名称和字段描述符都与目标相匹配的字段,则返回该字段的直接引用,查找结束。
- 否则,如果在 C 中实现了接口,将会安装继承关系从下往上递归搜索各个接口及父接口,如果接口中包含了简单名称和字段描述符都与目标相匹配的字段,则返回该字段的直接引用,查找结束。
- 否则,如果 C 不是
java.lang.Object的话,将会安装继承关系递归搜索其父类,如果在父类中包含了简单名称和字段描述符都与目标相匹配的字段,则返回该字段的直接引用,查找结束。 - 否则,查找是被,抛出
java.lang.NoSuchFieldError异常。
如果查找过程成功返回了引用,将会对该字段进行权限验证,如果发现不具备对该字段的访问权限,将抛出 java.lang.IllegalAccessError 异常。
在实际应用中,虚拟机的编译器实现可能会比上述规范更加严格,如果一个字段同时出现在 C 的接口和父类中,或者同时出现在自己或父类的多个实现接口中,那么编译器可能会直接拒绝编译。
3. 类方法解析
类方法解析的第一个步骤与字段解析一样,也需要解析出类方法表的 class_index 项中索引的方法所属的类或接口的符号引用,如果解析成功,我们依然用 C 表示该类,接下来虚拟机会按照如下步骤进行后续的类方法搜索:
- 类方法和接口方法符号引用的常量类型定义是分开的,如果在类方法中发现 class_index 中索引的 C 是个接口,那就直接抛出
java.lang.IncompatibleClassChangeError异常。 - 如果通过了第 1 步,在类 C 中查找是否有简单名称和描述符都与目标相匹配的方法,如果有则返回这个方法的直接引用,结束查找。
- 否则,在类 C 的父类中查找是否有简单名称和描述符都与目标相匹配的方法,如果有则返回这个方法的直接引用,查找结束。
- 否则,在类 C 实现的接口列表及它们的父接口之中递归查找是否有简单名称和描述符都与目标相匹配的方法,如果存在匹配的方法,说明类 C 是一个抽象类,这时查找结束,抛出
java.lang.AbstractMethodError异常。 - 否则,宣告方法查找失败,抛出
java.lang.NoSuchMethodError异常。
最后,如果查找过程成功返回了直接引用,将会对这个方法进行权限验证,如果发现不具备对此方法的访问权限,将抛出 java.lang.IllegalAccessError 异常。
4. 接口方法解析
接口方法也需要解析出接口方法表的 class_index 项中索引的方法所属的类或接口的符号引用,如果解析成功,依然用 C 表示这个接口,接下来虚拟机会按照如下步骤进行后续的接口方法搜索:
- 与类解析不同,如果在接口方法表中发现 class_index 中的索引 C 是一个类而不是接口,将直接抛出
java.lang.IncompatibleClassChangeError异常。 - 否则,在接口 C 中查找是否有简单名称和描述符都与目标相匹配的方法,如果有则返回这个方法的直接引用,结束查找。
- 否则,在接口 C 的父接口中递归查找,直到
java.lang.Object类为止(包括该类),查找是否有简单名称和描述符都与目标相匹配的方法,如果有则返回这个方法的直接引用,结束查找。 - 否则,宣告方法查找失败,抛出
java.lang.NoSuchMethodError异常。
由于接口中所有的方法默认都是 public 访问权限,因此不存在访问权限问题,即也不会抛出 java.lang.IllegalAccessError 异常。
7.3.5 初始化
这是类加载过程的最后一步。前面已介绍的过程中,除了在加载阶段用户应用程序可以通过自定义类加载器参与之外,其余动作完全由虚拟机主导和控制。到了初始化阶段,才开始真正执行类中定义的 Java 程序字节码。
在准备阶段,变量已经赋过一次系统要求的初始值,而在初始化阶段,则根据程序员通过程序制定的主观计划去初始化类变量和其他资源,或者可以从另外一个角度来表达:初始化阶段是执行类构造器 <clinit>() 方法的过程。
<clinit>() 方法是由编译器自动收集类中的所有类变量的赋值动作和静态语句块中的语句合并产生的,收集顺序取决于语句在代码源文件中出现的顺序,静态语句块只能访问到定义在静态语句块之前的变量,但可以为定义在其后的变量赋值而不能访问。
<clinit>() 方法与类的构造函数(类实例构造器) <init>() 方法不同,它不需要显式的调用父类构造器,虚拟机会保证在子类的 <clinit>() 方法执行之前,父类的 <clinit>() 方法已经执行完毕。因此在虚拟机中第一个被执行的 <clinit>() 方法一定属于 java.lang.Object。
如果一个类中没有静态语句块会对变量的赋值操作,那么编译器就不会为其生成该方法。
接口中不能使用静态语句块,但仍然有变量初始化的赋值操作,因此接口与类一样都会生成 <clinit>() 方法。但与类不同的是,执行接口的 <clinit>() 方法不需要首先执行父接口的 <clinit>() 方法。因为当父接口中定义的变量使用时,父接口才会初始化。另外,接口的实现类在初始化时也不会执行父接口的 <clinit>() 方法。
虚拟机会保证一个类的 <clinit>() 方法在多线程环境中能够被正确的加锁、同步,如果多个线程同时去初始化一个类,那么只会有一个线程去执行该类的 <clinit>() 方法,其他线程都有阻塞等待,直到活动线程执行 <clinit>() 方法完毕。如果在一个类的 <clinit>() 方法中有耗时很长的操作,就可能会造成多个进程阻塞。
7.4 类加载器
虚拟机设计团队把类加载阶段中:“通过一个类的完全限定名来获取描述此类的二进制字节流”,这样一个动作放到了 JVM 外部来实现,以便让应用程序自己决定如何获取需要的类。实现这个动作的代码模块被称为“类加载器”。
7.4.1 类与类加载器
在一个 JVM 实例内,对于任意一个类,都需要由加载它的类加载器和这个类本身来共同确立其唯一性,每个类加载器都有一个独立的类名称空间。
两个相等的类,意味着由同一个虚拟机加载。相等性包括 Class 对象的 equals 方法、isAssignableFrom 方法、isInstance 方法返回的结果,也包括使用 isinstanceof 关键字对对象所属的类进行关系判定等情况。
7.4.2 双亲委派模型
从 JVM 的角度来看,只有两种不同的类加载器:一种是启动类加载器,由 C++ 语言实现,是 JVM 的一部分;另一种就是所有其他的加载器,均由 Java 语言实现,独立于虚拟机外部,并且全部继承自抽象类 java.lang.ClassLoader。
从应用开发的角度看,绝大部分的 Java 程序都会用到以下 3 种类加载器:
启动类加载器:负责将存放在 <JAVA_HOME>/lib 目录中、或者被 -Xbootclasspath 参数指定的路径中的、并且是虚拟机识别的(以文件名识别,如 rt.jar)类库加载到虚拟机内存中。该加载器无法被 Java 程序直接引用,如果在编写自定义加载器时需要将加载请求委派给引导类加载器,可以直接使用 null 作为自定义加载器的父加载器。
扩展类加载器:由 sun.misc.Launcher$ExtClassLoader 实现,负责加载 <JAVA_HOME>/lib/ext 目录中的、或者被 java.ext.dirs 系统变量指定的路径中的所有类库,可以被开发者直接使用。
应用类加载器:由 sun.misc.Launcher$AppClassloader 实现。是 ClassLoader.getSystemClassLoader 的返回值,一般也称为系统类加载器。负责加载用户类路径(ClassPath)中所有的类库,可以被开发者直接使用。如果应用中没有自定义实现任何加载器,一般情况下就是程序中默认的加载器。
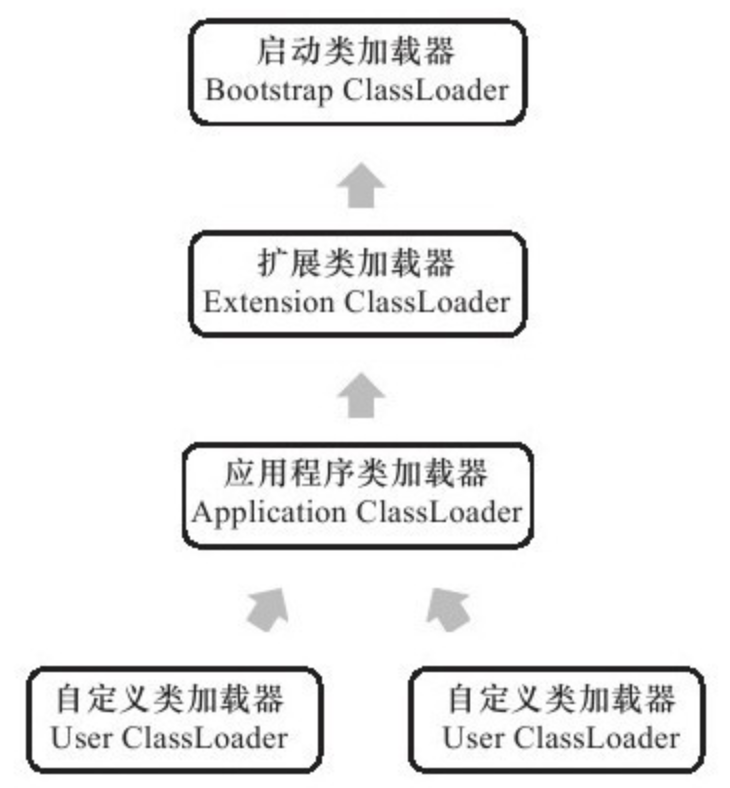
上图展示了这几种加载器之间的关系,称为类加载器的“双亲委派模型”。该模型要求除了顶层的启动类加载器外,其余的类加载器都应当有字节的父类加载器。这里所指的类加载器之间的父子关系不使用类继承形式来实现,而是使用组合关系来将加载请求为派给父类加载器。
双亲委派模型的工作过程是:如果一个类加载器收到了类加载请求,他首先不会自己去尝试执行加载,而是把该请求委派给父加载器去完成加载,每一个层次的加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成该加载请求时(在搜索范围内无法找到需要的类),子加载器才会尝试自己去加载。
这种模型的好处就是,Java 类随着其类加载器一起具备了一种优先级层次关系。比如 Objcet 类,它被存放在 rt.jar 中,无论哪个加载器要加载该类,最终都是委派给处于模型最顶层的启动类加载器进行加载,因此 Object 类在程序的各个类加载器中都是同一个类。如果没有使用双亲委派模型,而是由各个类加载器自己去加载的话,如果用户字节编写了一个名为 java.lang.Object 的类,Java 类型体系中的最基础行为就无法得到保证。
7.4.3 破坏双亲委派模型
双亲委派模型并非一个强制性的约束模型,而 Java 设计者推荐给开发者的类加载器实现方式。
下面是种对这种模型的“破坏(创新)”形式。
1. 历史遗留
第一次“被破坏”其实发生在双亲委派模型出现之前,即 JDK 1.2 发布之前。由于双亲委派模型在 JDK 1.2 之后才被引入,而类加载器和抽象类 java.lang.ClassLoader 在早在 JDK 1.0 时代就已经存在,面对已经存在的用户自定义加载器实现,Java 设计者在引入双亲委派模型时不得不做出一些妥协。为了向前兼容,JDK 1.2 之后的 java.lang.ClassLoader 添加了一个新的 protected 方法 findClass。在此之前,用户继承 ClassLoader 时唯一的目的就是重新 loadClass 方法,因为虚拟机在进行类加载时会调用加载器的私有方法 loadClassInternal,而该方法的唯一逻辑就是调用 loadClass 方法。
在 JDK 1.2 之后已经不提倡覆写 loadClass 方法,而应当把自己的类加载逻辑编写在 findClass 方法中,在 loadClass 方法的逻辑里如果父类记载失败,则会调用自己的 findClass 方法来完成加载,这样就可以保证新编写的类加载器都符合双亲委派模型。
2. 模型缺陷
双亲委派模型很好的解决了各个加载器对基础类的统一问题(越基础的类越由上层的加载器完成加载),基础类之所以被称为“基础”,是因为它们总是作为被用户代码调用的 API。但有时候基础类也需要调用用户代码。
如 JNDI 服务,它的代码由启动类加载器完成加载(rt.jar),但 JNDI 的目的就是对资源进行集中管理和查找,它需要调用由独立厂商实现并部署在应用程序 ClassPath 下的 JNDI 接口提供者(SPI)代码,但启动类加载器并不认识这些代码。
为了解决该问题,Java 设计团队只好引入了一个不太优雅的设计:线程上下文加载器。该加载器可以通过 Thread 类的 setContextClassLoader 方法进行设置,如果线程创建时还未设置,它将会从父线程中继承一个加载器,如果在应用程序的全局范围内都没有设置过,那么就使用应用程序类加载器。
JDNI 使用该加载器来加载所需的 SPI 代码,也就是父类加载器请求子类加载器来完成对类的加载操作,这种行为实际上是打通了双亲委派模型的层次结构来逆向使用类加载器,也违背了双亲委派模型的一般性原则。Java 中的所有 SPI 的加载动作基本都采用这种方式。
3. 动态性
这里所说的动态性指的是:代码热替换、模块热部署等。OSGI 已经成为了业界“事实上”的 Java 模块化标准,而 OSGI 实现模块化热部署的关键就是它自已定义的类加载器机制。每个程序模块(Bundle)都有一个自己的类加载器,当需要更换一个 Bundle 时,就把 Bundle 连同类加载器一起替换掉以实现代码的热替换。
在 OSGI 环境下,类加载器不再是双亲委派模型中的树状结构,而是进一步发展为更加复杂的网状结构,当收到类加载请求时,OSGI 将按照下面的顺序来搜索类:
- 将以
java.*开头的类委派给父类加载器。 - 否则,将委派列表名单内的类委派给父类加载器。
- 否则,将 import 列表中的类委派给 Export 这个类所属的 Bundle 的类加载器。
- 否则,查找当前 Bundle 的 ClassPath,使用自己的类加载器。
- 否则,查找类师傅在自己的 Fragment Bundle 中,如果在,则委派给 Fragment Bundle 的类加载器。
- 否则,查找 Dynamic Import 列表的 Bundle,委派给对应 Bundle 的类加载器。
- 否则,类查找失败。
以上查找顺序中只有开头两点符合双亲委派模型,其余的类查找都在平级的类加载器中机进行。
7.5 本章小结
本章介绍了类加载过程的“加载”、“验证”、“准备”、“解析”和“初始化”5个阶段中虚拟机进行了哪些动作,还介绍了类加载器的工作原理及其对虚拟机的意义。
8 - CH08-字节码执行引擎
8.1 概述
“虚拟机”是一个相对于“物理机”的概念,这两种机器都有代码执行能力,其区别是物理机的执行引擎是直接建立在处理器、硬件、指令集和操作系统层面上的,而虚拟机的执行引擎则是由自己实现的,因此可以自行制定指令集与执行引擎的结构体系,并且能够执行那些不被硬件直接支持的指令集格式。
在Java虚拟机规范中制定了虚拟机字节码执行引擎的概念模型,这个概念模型成为各种虚拟机执行引擎的统一外观。在不同的虚拟机实现里面,执行引擎在执行 Java 代码的时候可能会有解释执行(通过解释器执行)和编译执行(通过即时编译器产生本地代码执行)两种选择,也可能两者兼备,甚至还可能会包含几个不同级别的编译器执行引擎。但从外观上看起来,所有的Java虚拟机的执行引擎都是一致的:输入的是字节码文件,处理过程是字节码解析的等效过程,输出的是执行结果,本章将主要从概念模型的角度来讲解虚拟机的方法调用和字节码执行。
8.2 运行时栈帧结构
栈帧(Stack Frame)是用于支持虚拟机进行方法调用和方法执行的数据结构,是虚拟机运行时数据区中的虚拟机栈的栈元素。每个方法调用从开始到执行完成的过程,都对应着一个栈帧在虚拟机站里面从入栈到出栈的过程。
每个栈帧中都包含了局部变量表、操作数栈、动态连接、方法返回地址等信息。栈帧中需要多大的局部变量表、多深的操作数栈会在 编译期确定,并且写入到方法表的 Code 属性中,因此一个栈帧需要分配多少内存。不会受到程序运行期变量数据的影响,而仅仅取决于具体的虚拟机实现。
一个线程中的方法调用链可能很长,很多方法都同时处于执行状态。对于执行引擎来说,在活动线程中,只有位于栈顶的栈帧才是有效的,称作 当前栈帧,与该栈帧关联的方法称为 当前方法。执行引擎运行的所有字节码指令都只针对当前栈帧进行操作,在概念模型上,典型的栈帧结构如下图所示。
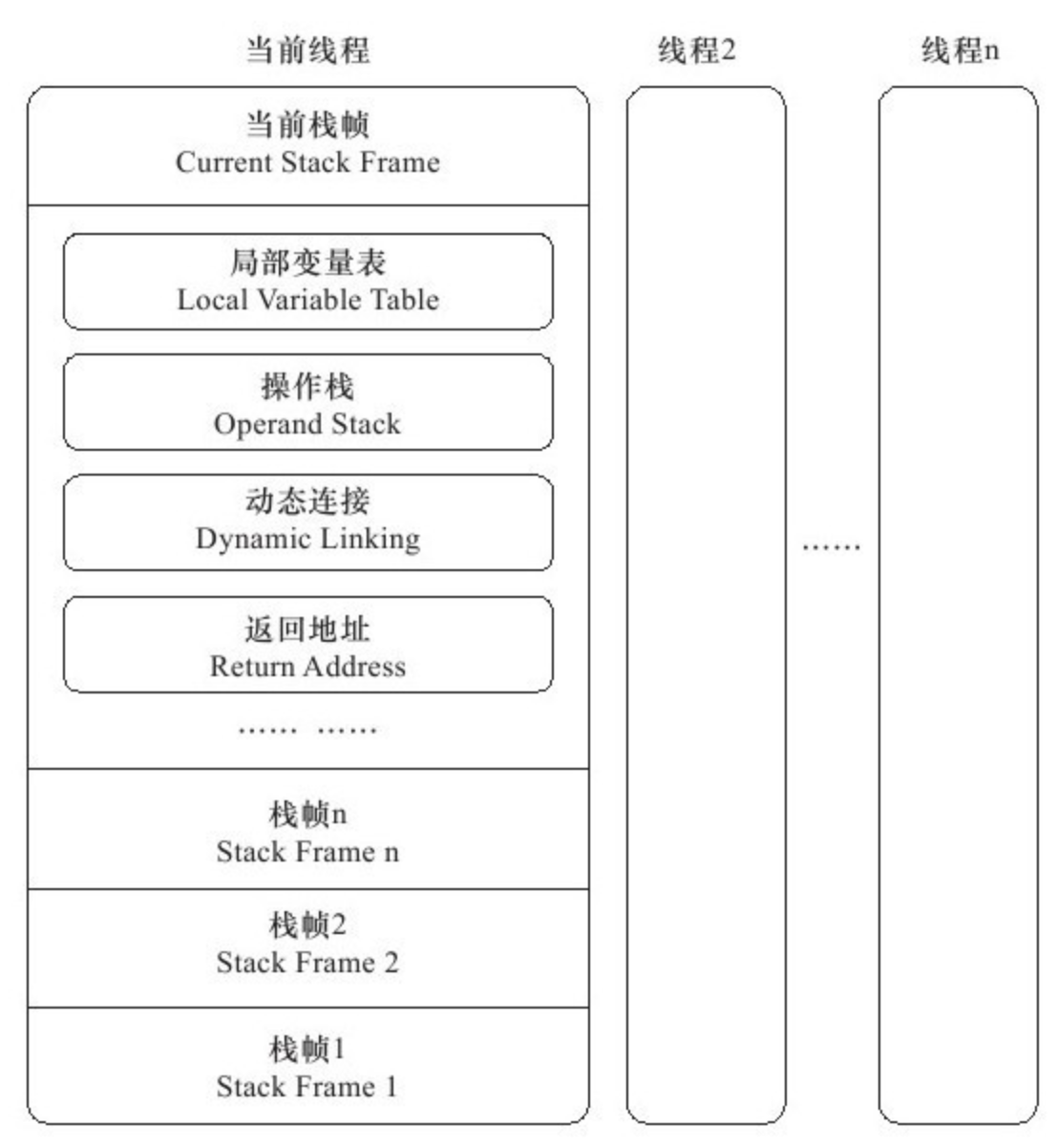
8.2.1 局部变量表
局部变量表是一组 变量值存储空间,用于存放 方法参数 和方法内部定义的 局部变量。在 Java 程序被编译为 Class 文件时,就在方法的 Code 属性中的 max_locals 数据项中确定了该方法需要分配的局部变量表的最大容量。
局部变量表以槽(slot)为最小单位,虚拟机规范中没有明确指定一个 Slot 应该占用多大的内存空间,但是很有导向性的说到每个 Slot 都应该能存放一个 boolean、byte、char、short、int、float、reference、returnAddress 类型的数据,这 8 种数据类型,都可以用 32 位或更小的物理内存来存放,允许 Slot 的长度随着处理器、操作系统或虚拟机的不同而发生变化。只要保证即使在 64 位虚拟机中使用 64 位的物理内存空间来实现一个 slot,虚拟机仍要使用对齐和补白的手段让 slot 在外观上看起来与 32 位的虚拟机中一致。
上面提到的前 6 种数据类型无需多说,而第 7 种 reference 类型表示对一个对象实例的引用,虚拟机规范没有明确说明其长度和结构。但一般来说,虚拟机实现至少都应当能通过该引用做当两点:从此引用中直接或间接的查找到对象在 Java 堆中的数据存放的起始地址索引;此引用中直接或间接的查找到对象所属数据类型在方法区中存储的类型信息,否则无法实现 Java 语言规范中定义语法约束。
第 8 种 returnAddress 类型目前已经很少见了,它为字节码指令 jsr、jsr_w、ret 服务,指向了一条字节码指令的地址,远古 JVM 曾使用这几条指令来实现处理,现在已经由异常表代替。
对于 64 位的数据类型,虚拟机会以高位补齐的方式为其分配两个连续的 Slot 空间。Java 语言中明确的(reference 类型则可能是 32/64 位) 64 位数据类型目前只有 long、double。值得一提的是,这里把 long、double 分割存储的方法与“非原子性协定”中对这两种数据类型分割为两次读写的方式类似。不过,由于局部变量表建立在线程的堆栈上,是线程私有数据,无论读写两个连续的 slot 是否为原子操作,都不会引起数据安全性问题。
虚拟机通过索引定位的方式使用局部变量表,索引值从 0 开始只局部变量表的最大 slot 数量。如果访问的是 32 位数据类型的变量,则索引 N 就表示使用第 N 个 Slot;如果是 64 位的数据类型变量,则会同时使用 N 和 N+1 来表示两个 Slot。对于两个相邻的用于存放一个 64 位数据的 slot,不允许采用任何单独的方式来单独访问其中一个,否则将在类加载的校验阶段抛出异常。
在方法执行时,虚拟机使用局部变量表来完成参数值到参数变量列表的传递过程。如果执行的是实例方法,局部变量表中第 0 位索引的 slot 默认用于传递方法所属对象实例的引用,在方法中可以通过关键字 this 来方法该隐含参数。其余参数则按照参数列表顺序排列,占用从索引值 1 开始的局部变量 slot。参数列表分配完成之后,再根据方法体内部定义的变量顺序和作用域来分配其余的 slot。
为了尽可能的节省栈空间,局部变量表中的 slot 是可以重用的,方法体中定义的变量,其作用域并不一定会覆盖整个方法体。如果当前字节码 PC 计数器的值已经超出了某个变量的作用域,那么该变量对应的 slot 就可以交给其他变量使用。不过,这样的设计出了节省栈帧空间之外,还会伴随着一些额外的副作用,如在某些情况下,slot 的复用会直接影响到系统的垃圾收集行为。
slot 复用如何影响 GC?
“如果当前字节码 PC 计数器的值已经超出了某个变量的作用域,那么该变量对应的 slot 就可以交给其他变量使用。” 但是,如果并没有其他变量复用该 slot,该 slot 中原有的值会继续保持,所以作为 GC-Roots 一部分的局部变量表仍然保持着对该 slot 中的变量值的关联。 这种关联没有被及时打断,在绝大部分情况下影响都很轻微。但如果遇到一个方法,其后面的代码有一些耗时很长的操作,而前面又定义了占用了大量内存、实际上已经不会再使用的变量,手动将其设置为 null 值这会变得有意义。 但赋值为 null 的操作可能被 JIT 优化掉,因此不能依赖这种操作。
局部变量不像前面介绍的类变量那样存在“准备阶段”。通过第 7 章的讲解,我们已经知道类(静态)变量有两次赋初始值的过程,一次在准备阶段,赋予系统初始值;另外一次在初始化阶段,赋予程序员定义的初始值。因此,即使在初始化阶段程序员没有为类变量赋值也没有关系,类变量仍然具有一个确定的初始值。但局部变量就不一样,如果一个局部变量定义了但没有赋初始值是不能使用的,不要认为 Java 中任何情况下都存在诸如整型变量默认为 0,布尔型变量默认为 false 等这样的默认值。编译器会报告这种错误。
8.2.2 操作数栈
即操作栈,是一个 LIFO 栈。与局部变量表一样,其最大深度也在编译期写入到 Code 属性的 max_stacks 数据项中。操作数栈的每个元素可以是任意的 Java 数据类型,包括 long 和 double。32 位数据类型所占的占容量为 1,64 位数据类型所占的栈容量为 2。在方法执行的任何时刻,操作数栈的深度都不会超过 max_stacks 数据项中设定的最大值。
当一个方法刚刚开始执行的时候,该方法的操作数栈是空的,在方法的执行过程中,会有各种字节码指令往操作数栈中写入和提取内容,也就是入栈、出栈操作。比如,在做算术运算的时候是通过操作数栈完成的,又或者在调用其他方法的时候是通过操作数栈完成参数传递的。
举个例子,整数加法的字节码指令 iadd 在运行的时候操作数栈中最接近栈顶的两个元素已经存入了两个 int 型的数值,当执行 iadd 指令时,会将栈顶的两个 int 值出栈并相加,然后再将相加的结果入栈。
操作数栈中元素的数据类型必须与字节码指令的序列严格匹配,在编译程序代码的时候,编译器要严格保证这一点,在类校验的数据流分析中还要再次验证这一点。
再以上面 iadd 指令为例,该指令用于整型加法,它在执行时,最接近栈顶的两个元素的数据类型必须都是 int 型,不能出现一个 long 和一个 float 使用 iadd 命令相加的情况。
另外,在概念模型中,两个栈顶作为虚拟机栈的元素,是完全互相独立的。但在大多虚拟机的实现中会做一些优化处理,使两个栈帧出现一部分重叠。让下面栈帧的部分操作数与上面栈帧的局部变量表重叠在一起,这样在进行方法调用时就可以共用一部分数据,无需进行额外的参数复制传递,重叠的过程如图 8-2 所示。
Java 虚拟机的解释执行引擎称为“基于栈的执行引擎”,其中所指的栈就是操作数栈。
8.2.3 动态链接
每个栈帧都包含一个指向运行时常量池中该栈所属方法的引用,持有该引用是为了支持方法调用过程中的动态连接。通过第六章的讲解,我们知道 Class 文件的常量池中存有大量的符号引用,字节码中的方法调用指令就是以常量池中指向方法的符号引用作为参数。这些符号引用一部分会在类加载阶段或者第一次使用的时候被转换为直接引用,这时候的转换被称为静态解析。另外一部分将在每次运行期间转换为直接引用,这部分称为动态连接。
8.2.4 方法返回地址
当一个方法开始执行后,只有两种方式可以退出该方法。
第一种方式是执行引擎遇到任意一个方法返回的字节码指令,这时候可能会有返回值传递给上层的方法调用者(即调用当前方法的方法),是否有返回值和返回值的类型将根据具体的方法返回指令来确定,这种退出方式称为正常完成出口。
另一种退出方式是在方法执行过程中遇到了异常,并且该异常没有在方法体内得到处理,无论是 JVM 内部产生的异常,还是代码中使用 athrow 字节码指令产生的异常,只要在本方法的异常表中没有搜索到匹配的异常处理器,就会导致方法退出,这种退出方式称为异常完成出口。这种退出方式不会给它的上层调用者产生任何返回值的。
无论采用何种退出方式,在方法退出之后,都需要返回到方法被调用的位置,程序才能继续执行,方法返回时可能需要在栈帧中保存一些信息,用来帮助恢复它上层的方法的执行状态。一般来说,方法正常退出时,调用者的 PC 计数器值可以作为返回地址,栈帧中可能会保存该计数器值。而方法异常退出时,返回地址要通过异常处理器表来确定,栈帧中一般不会保存这部分信息。
方法退出的过程实际上就等同于把当前栈帧出栈,因此退出时可能执行的操作有:恢复上层方法的局部变量表和操作数栈,把返回值(如果有的话)压入调用者栈帧的操作数中,调整 PC 计数器的值以指向方法调用指令后面的一条指令等。
8.2.5 附加信息
虚拟机规范允许具体的虚拟机实现增加一些规范中没有描述的信息到栈帧中,如调试相关的信息,这部分信息完全取决于具体的虚拟机实现,这里不再描述。在实际开发中,一般会把动态连接、方法返回地址与其他附加信息全部归为一类,称为栈帧信息。
8.3 方法调用
方法调用不等同于方法执行,方法调用阶段唯一的任务就是确定被调用方法的版本(即要调用哪个方法),暂时还不涉及方法内部的具体运行过程。在程序运行时,进行方法调用是最普遍、最频繁的操作,但前面已经讲过,Class 文件的编译过程中不包含传统编译中的连接步骤,一切方法调用在 Class 文件中存储的都只是符号引用,而不是方法在实际运行时内存布局中的入口地址(相当于之前说的直接引用)。该特性给 Java 带来了更强大的动态扩展能力,但也使得 Java 方法调用过程变得相对复杂起来,需要在类加载期间,甚至到运行期间才能确定目标方法的直接引用。
8.3.1 解析
所有方法调用中的目标方法在 Class 文件里面都是一个常量池中的符号引用,在类加载的解析阶段,会将其中的一部分符号引用转化为直接引用,这种解析能够成立的前提是:方法在程序真正运行之前就有一个可确定的版本,并且该方法的调用版本在运行期是不可改变的。即,调用目标在程序代码编写完成、编译器进行编译时就必须确定下来。这类方法的调用称为解析(Resolution)。
在 Java 语言中符合“编译期可知、运行期不可变”这种要求的方法,主要包括静态方法和私有方法两大类,前者直接与类相关联,后者不可被外部访问,这两种方法各自的特点都决定了它们都不可能通过继承或别的方式被重写为其他版本,因此它们都适合在类加载阶段完成解析。
与之对应的是,在 JVM 中提供了 5 个方法调用字节码指令,分别是:
- invokestatic:调用静态方法。
- invokespecial:调用实例构造器
<init>方法、私有方法、父类方法。 - invokevirtual:调用所有的虚方法。
- invikeinterface:调用接口方法,会在运行时确定一个实现该接口的对象。
- invokedynamic:先在运行时动态解析出调用点限定符所引用的方法,然后再执行该方法,在此之前的 4 条调用指令,分派逻辑是固化在 JVM 内部的,而 invokedynamic 指令的分派逻辑是由用户指定的引导方法决定的。
只要能被 invokestatic 和 invokespecial 指令调用的方法,都可以在解析阶段中确定唯一的调用版本,符合该条件的只有静态方法、私有方法、实例构造器、父类方法 4 种,它们在类加载的时候就会把符号引用解析为该方法的直接引用。这些方法可以称为非虚方法,与之相反,其他方法则被称为虚方法(final 方法除外)。
Java 中的非虚方法除了使用 invokestatic 和 invokespecial 调用的方法之外还有一种,即被 final 修饰的方法。虽然 final 方法是使用 invokevirtual 指令来调用的,但是由于它无法被覆盖、不会存在其他版本,所以也无需对方法接收者进行多态选择,又或者说多态选择的结果一定是唯一的。在 Java 语言规范中明确说明了 fianl 方法是一种非虚方法。
解析调用移动是一个静态的过程,在编译期间就完全确定,在类装载的解析阶段就会把涉及的符号引用全部转换为可确定的直接引用,不会延迟到运行期再进行。而分派(dispatch)调用则可能是静态或动态的,根据分派所依据的宗量数有但分派和多分派。这两类分派方式来那个量组合就构成了静态但分派、静态多分派、动态单分派、动态多分派这 4 种分派组合的情况。
8.3.2 分派
Java 是一种 OO 语言,因为它具备 OO 的 3 个基本特征:封装、继承、多态。这里讲解的分派调用过程将会揭示多态特性的一些最基本体现,如“重载”和“重写”在 JVM 中是如何实现的,即虚拟机如何确定正确的目标方法。
1. 静态分派
public class StaticDispatch{
static abstract class Human{
}
static class Man extends Human{
}
static class Woman extends Human{
}
public void sayHello(Human guy){
System.out.println("hello,guy!");
}
public void sayHello(Man guy){
System.out.println("hello,gentleman!");
}
public void sayHello(Woman guy){
System.out.println("hello,lady!");
}
public static void main(String[]args){
Human man=new Man();
Human woman=new Woman();
StaticDispatch sr=new StaticDispatch();
sr.sayHello(man);
sr.sayHello(woman);
}
}
// 执行结果:
// hello,guy!
// hello,guy!
可以发现两次方法调用均选择了以 Human 的参数类型的重载方法。要理解该问题,我们先按如下定义来理解两个重要的概念。
Human man = new Man();
我们将上面代码中的 “Human” 称为变量的静态类型,或者叫做外观类型,后面的 “Man” 则称为变量的实际类型,静态类型和实际类型在程序中都可以发生一些变化,区别是静态类型的变化仅仅在使用时发生,变量本身的静态类型不会被改变,并且最终的静态类型是编译期可知的;而实际类型变化的结果在运行期才可以确定,编译器在编译程序的时候并不知道一个对象的实际类型是什么。
再回到最初的例子中。main 中的两次 sayHello 方法调用,在方法接收者已经确定是对象 sr 的前提下,使用哪个重载版本,就完全取决于传入参数的数量的类型。代码中刻意的定义了两个静态类型相同但实际类型不同的变量,但 虚拟机(更准确的说是编译器)在重载时是通过参数的静态类型而非实际类型作为判断依据的。并且静态类型是编译期可知的,因此在编译阶段,Javac 编译器会根据参数的静态类型决定使用哪个重载版本的方法,因此选择了 sayHello(Human) 作为调用目标,并把该方法的符号引用写入到了 main 方法里的两条 invokevirtual 指令的参数中。
所有依赖静态类型进行方法版本定位的分派动作称为静态分派。静态分派的典型应用是方法重载。静态分派发生在编译期,因此确定静态分派的动作实际上不是由虚拟机来执行的。另外,编译器虽然能确定出方法的重载版本,但在很多情况下这个重载版本并不是唯一的,往往只能确定一个“更加合适的”版本。这种模糊的结论在由 0 和 1 构成的计算机世界中算是比较“稀罕”的事情,产生这种模糊结论的主要原因是字面量不需要定义,所以字面量没有显式的静态类型,它的静态类型只能通过语言上的规则来理解和推断。下面的例子演示了“更合适的版本”是什么。
package org.fenixsoft.polymorphic;
public class Overload{
public static void sayHello(Object arg){
System.out.println("hello Object");
}
public static void sayHello(int arg){
System.out.println("hello int");
}
public static void sayHello(long arg){
System.out.println("hello long");
}
public static void sayHello(Character arg){
System.out.println("hello Character");
}
public static void sayHello(char arg){
System.out.println("hello char");
}
public static void sayHello(char……arg){
System.out.println("hello char……");
}
public static void sayHello(Serializable arg){
System.out.println("hello Serializable");
}
public static void main(String[]args){
sayHello('a');
}
}
// 输出
// hello char
这很好理解,'a' 是一个 char 类型的数据,自然会寻找参数类型为 char 的重载方法,如果注释掉对应 char 参数类型的方法 sayHello(char arg),则输出会不变为 hello int。
这时发生了一次自动类型转换,'a' 除了可以代表一个字符串,还可以代表数字 97(a 的 Unicode 数值为十进制的 97)。因此参数类型为 int 的重载也是合适的。如果继续去掉参数类型为 int 的方法 sayHello(int arg),输出则变为 hello long。
这时发生了两次自动类型转换,'a'转型为整数 97 之后,进一步转型为长整型 97L,匹配了参数类型为 long 的重载。例子中没有提供其他类型如 float、double 等重载方法,不过实际上自动转型还能继续发生多次,按照 char、int、long、float、double 的顺序依次转型进行匹配。但不会匹配到 byte 和 short 类型的重载,因为 char 到 byte 或 short 的转型是不安全的。继续注释掉参数类型为 long 的方法 sayHello(long arg),输出则变为 hello character。
这时发生了一次自动装箱操作,'a' 被包装为它的封装类型 java.lang.Character,所以匹配到了参数类型为 Character 的重载,继续注释掉参数类型为 Character 类型的方法 sayHello(Character arg),输出则变为 hello Seralizable。
这个输出可能会让人感到难以理解,一个字符或数字与序列化有什么关系呢?出现这种结果的原因是 java.lang.Serializable 是 java.lang.Character 的一个接口,当它自动装箱之后发现还是找不到装箱类,但是找到了装箱类所实现的接口类型,所以紧接着又发生一次自动转型。char 可以转换为 int,但是 Character 是绝对不会转型为 Integer 的,它只能安全的转型为它实现的接口或父类。Character 还实现了另外一个接口 java.lang.Comparable<Character>,如果同时还出现了两个参数类型分别为 Serializable 和 Comparable<Character> 的重载方法,那它们在此时的优先级是一样的。编译器无法确定要自动转型为哪种类型,因此会提示模糊类型,拒绝编译。程序必须在调用时显式的指定字面量的静态类型,如:sayHello((Comparable<Character>) 'a'),才能编译通过。如果继续将参数类型为 Comparable<Character> 的方法去掉,结果变为:hello Object。
这时是 char 装箱后转型为父类了,如果有多个父类,那将在继承关系中从下往上开始搜索,越接靠上层的优先级越低。即使方法调用传入的参数值为 null,该规则仍然适用。当把参数类型为 Object 的方法去掉之后,输出将变为 hello char...。
7 个重载方法已经被移除的只剩下一个类,可变变长参数的重载优先级是最低的,这时候 'a' 被当做一个数组元素。这里使用的是 char 类型的变长参数,读者在验证时还可以选择 int、Character、Object 类型等的变长参数重载来重新演示上面的例子。但要注意的是,有一些在单个参数中能成立的自动转型,如 char 到 int,在变长参数中是不成立的。
上面的例子演示了编译期间选择静态分派目标的过程,该过程也是 Java 语言实现方法重载的本质。比较容易混淆的是,解析与分派的关系并非二选一的排他关系,它们是在不同层次上去筛选、确定目标方法的过程。如前所述,静态方法会在类加载期间进行解析,而静态方法也可以拥有重载版本,选择重载版本的过程就是通过静态分派完成的。
2. 动态分派
动态分配与多态性的另外一个重要体现——重写(override)有着密切的联系。
public class DynamicDispatch{
static abstract class Human{
protected abstract void sayHello();
}
static class Man extends Human{
@Override
protected void sayHello(){
System.out.println("man say hello");
}
}
static class Woman extends Human{
@Override
protected void sayHello(){
System.out.println("woman say hello");
}
}
public static void main(String[]args){
Human man=new Man();
Human woman=new Woman();
man.sayHello();
woman.sayHello();
man=new Woman();
man.sayHello();
}
}
// 结果
// man say hello
// woman say hello
// woman say hello
这里,虚拟机不再根据静态类型来选择要调用的方法,因为静态类型同样都是 Human 的两个变量 man 和 woman 在调用 sayHello 方法时执行了不同的行为,并且变量 man 在两次调用中执行了不同的方法。导致这个现象的原因很明显,是这两个变量的实际类型不同,JVM 是如何根据实际类型来分派方法执行版本呢?这里使用 javap 命令输出这段代码的字节码,尝试从中寻找答案,输出结果如下:
public static void main(java.lang.String[]);
Code:
Stack=2, Locals=3, Args_size=1
0:new#16;//class org/fenixsoft/polymorphic/Dynamic-
Dispatch $Man
3:dup
4:invokespecial#18;//Method org/fenixsoft/polymorphic/Dynamic-
Dispatch $Man."<init>":()V
7:astore_1
8:new#19;//class org/fenixsoft/polymorphic/Dynamic-
Dispatch $Woman
11:dup
12:invokespecial#21;//Method org/fenixsoft/polymorphic/DynamicDispa
tch $Woman."<init>":()V
15:astore_2
16:aload_1
17:invokevirtual#22;//Method org/fenixsoft/polymorphic/Dynamic-
Dispatch $Human.sayHello:()V
20:aload_2
21:invokevirtual#22;//Method org/fenixsoft/polymorphic/Dynamic-
Dispatch $Human.sayHello:()V
24:new#19;//class org/fenixsoft/polymorphic/Dynamic-
Dispatch $Woman
27:dup
28:invokespecial#21;//Method org/fenixsoft/polymorphic/Dynam
icDispatch $Woman."<init>":()V
31:astore_1
32:aload_1
33:invokevirtual#22;//Method org/fenixsoft/polymorphic/
DynamicDispatch $Human.sayHello:()V
36:return
0~15 行的代码是准备动作,作用是建立 man 和 women 的内存空间、调用 Man 和 Women 类型的实例构造器,将这两个实例的应用存放在 1、2 两个局部变量表的 slot 之中,该动作对应代码中的两行代码:
Human man=new Man();
Human woman=new Woman();
接下来 16~21 行是关键部分,16、20 两行分别把刚刚创建的两个对象的引用压到栈顶,这两个对象是将要执行的 sayHello 方法的持有者,称为接收者;17、21 是方法调用指令,这两条调用指令但从字节码角度来看,无论是指令(都是 invokevirtual)还是参数(都是常量池中第 22 项的常量,注释还显示了该常量是 Human.sayHello 的符号引用)完全一样,但是这两行指令最终执行的目标方法是不同的。原因就需要从 invokevirtual 指令的多态查找过程说起,invokevirtual 指令的运行时解析过程大致分为以下几个步骤:
- 找到操作数栈顶的第一个元素所指向的对象的实际类型,记做 C。
- 如果在类型 C 中找到与常量中的描述符合简单名称都相符的方法,则进行访问权限校验,如果校验通过则返回该方法的直接引用,查找过程结束;如果不通过,则返回非法访问异常。
- 否则,按照继承关系从下往上依次对 C 的各个父类机执行第 2 步的搜索和验证过程。
- 如果始终没有找到合适的方法,则抛出抽象方法异常。
由于 invokevirtual 指令指定的第一步就是在运行期确定接收者的实际类型,所以两次调用中的 invokevirtual 指令把常量池中的类方法符号引用解析到了不同的直接引用上,该过程就是 Java 中方法重写的本质。我们把这种在运行期根据实际类型确定方法执行版本的分派过程称为动态分派。
3. 但分派与多分派
方法的接收者与方法的参数统称为方法的宗量,该定义最早来自《Java 与模式》一书。根据分派基于多少种宗量,可以将分派划分为单分派和多分派两种。单分派是根据一个宗量对目标方法进行选择,多分派则是根据多个宗量对目标方法进行选择。
public class Dispatch{
static class QQ{}
static class_360{}
public static class Father{
public void hardChoice(QQ arg){
System.out.println("father choose qq");
}
public void hardChoice(_360 arg){
System.out.println("father choose 360");
}
}
public static class Son extends Father{
public void hardChoice(QQ arg){
System.out.println("son choose qq");
}
public void hardChoice(_360 arg){
System.out.println("son choose 360");
}
}
public static void main(String[]args){
Father father=new Father();
Father son=new Son();
father.hardChoice(new_360());
son.hardChoice(new QQ());
}
}
// 结果
// father choose 360
// son choose qq
在 main 函数中调用了两次 hardChoice 方法,这两次方法调用的选择结果在程序输出中已经显示的很清晰了。
在编译器编译期间的静态分派过程中,选择方法主要依据两点:一是静态类型是 Father 还是 Son,二是方法参数是 QQ 还是 360。这次选择的最终产物是产生了两条 invokevirtual 指令,两条指令的参数分别是常量池中指向 Father.hardChoice(360) 和 Father.hardChoice(QQ) 方法的符号引用。因为根据两个宗量进行选择,所以 Java 的静态分派属于多分派。
再看看运行时阶段虚拟机的选择,也就是动态分派过程。在执行 son.hardChoice(QQ) 这行代码对应的 invokevirtual 指令时,由于编译器已经决定目标方法的签名必须是 hardChoice(QQ),虚拟机此时不关心传递过来的参数是 QQ 的哪个子类实现,因为这时参数是静态类型、实际类型都对方法的选择不构成影响,唯一可以印象虚拟机选择的因素只有此方法的接收者的实际类型是 Father 还是 Son。意味只有一个宗量作为选择依据,所以 Java 的动态分派属于单分派。
根据上述论证的结果,我们可以总结出:现在的 Java(1.8之前) 是一种静态多分派、动态单分派的语言。
按照目前 Java 语言的发展趋势,它并没有直接变为动态语言的迹象,而是通过内置动态语言(如 JavaScript)执行引擎的方式来满足动态性的需求。但是 JVM 层面上则不同,在 JDK 1.7 中实现的 JSR-292 里面就已经开始提供对动态语言的支持了,JDK 1.7 中新增的 invokedynamic 指令也成为了最复杂的一条方法调用字节码指令。
4. 虚拟机动态分派实现
由于动态分派是非常频繁的动作,而且动态分派的方法版本选择过程需要运行时在类的方法元数据中搜索合适的目标方法,因此在虚拟机的实际实现中基于性能的考虑,大部分实现都不会真正的进行如此频繁的搜索。面对这种情况,最常用的“稳定优化”手段就是为类在方法区中建立一个续方法表(vtable,于此对应,invokeinterface 执行时也会用到接口方法表,即 itable),使用虚方法表索引来代替元数据查找以提高性能。
下图是虚方法表的数据结构示例:
虚方法表中存放着各个方法的实际入口地址。如果某个方法在子类中没有被重写,那子类的虚方法表里面的地址入口和父类相同方法的地址入口是一致的,都指向父类的实现入口。如果子类中重写了父类的方法,子类方法表中的地址将会替换为指向子类实现版本的入口地址。在上图中,Son 重写了来自 Father 的全部方法,因此 Son 的方法表没有指向 Father 类型数据的箭头。但是 Son 和 Father 都没有重写来自 Object 的方法,所以它们的方法表中所有从 Object 继承而来的方法都指向了 Object 的数据类型。
为了程序实现上的方便,具有相同签名的方法,在父类、子类的虚方法表中都应当具有一样的索引序号,这样当类型变换时,仅需要变更查找的方法表,就可以从不同的虚方法表中按索引转换出所需的入口地址。
方法表一般在类加载的连接阶段进行初始化,准备了类的变量初始值之后,虚拟机会把该类的方法表也初始化完成。
上文中说方法表是分派调用的“稳定优化”手段,虚拟机除了使用方法表之外,在条件允许的情况下,还会使用内联缓存和基于“类型继承关系分析”技术的守护内联两种非稳定的“激进优化”手段来获得更高的性能,关于这两种优化技术的原理和运作过程,可参考本书第 11 章。
8.3.3 动态类型语言支持
从 Sun 公司的第一款 JVM 问世至 JDK7 来临之前的十余年时间里,JVM 的字节码指令集的数量一直都没有发生过变化。随着 JDK7 的发布,字节码指令集终于迎来了第一位新成员——invokedynamic 指令。这条新增加的指令是 JDK7 实现“动态类型语言”支持而进行的改进之一,也是为 JDK8 可以顺利实现 Lambda 表达式做出技术准备。
1. 动态类型语言
动态类型语言的关键特征是它的类型检查的主体过程是在运行期而非编译期。相对的,在编译期进行类型检查的过程的语言就是常说的静态类型语言。
静态类型语言在编译期确定类型,最显著的好处是编译器可以提供严谨的类型检查,这样与类型相关的问题在编码时就能发现,利于稳定性以及代码达到较大规模。而动态类型语言在运行期确定类型,这可以为开发人员提供更大的灵活性,某些在静态类型语言中需要大量“臃肿”代码来实现的功能,有动态类型语言来实现可能会更加清晰简洁,这也就意味着开发效率的提升。
2. JDK7 与动态类型
JVM 层面对动态类型语言的支持一直有所欠缺,主要变现在方法调用方面:JDK7 之前的字节码指令集中,4 条方法调用指令的第一个参数都是被调用方法的符号引用。前面已经说过,方法的符号引用在编译时产生,而动态类型语言只有在运行期才能确定接收者类型。这样,在 JVM 上实现的动态类型语言就不得不使用其他方式(如在编译期留一个占位符类型,运行时动态生成字节码实现具体类型到占位符类型的适配)来实现,这样势必会增加动态类型语言的实现难度,也可能会带来额外的性能或内存开销。尽管可以利用一些方法(如 Call site Caching)让这些开销尽可能变小,但这种底层问题终归是应当在虚拟机层次上来解决才最合适,因此在 JVM 层面上提供动态类型的直接支持就成为了 Java 平台的发展趋势之一,这就是 JDK7 中 JSR-292 invokedynamic 指令以及 java.lang.invoke 包出现的技术背景。
3. java.lang.invike 包
JDK7 实现了 JSR-292,新加入的 java.lang.invoke 包就是 JSR-292 的一个重要组成部分,该包的主要目的是在之前单纯依靠符号引用来确定调用的目标方法这种方式之外,提供一种新的动态确定目标方法的机制,称为 MethodHandle。
这类似于 C/C++ 中的函数指针,或者 C# 中的 Delegate 类。比如我们要实现一个带谓词的排序函数,在 C/C++ 中的做法是把谓词定义为函数,用函数指针把谓词传递给排序方法:
void sort(int list[], const int size,int(*compare)(int,int))
Java 无法把方法作为一个参数进行传递。普遍的做法是设计一个带有 compare 方法的 Comparator 接口,以实现了这个接口的对象作为参数,如 Colleciton.sort 就是这样定义的:
void sort(List list,Comparator c)
在拥有 MethodHandle 之后,Java 也可以拥有类似函数指针或委托的方法别名工具了。但在看完 MethodHandle 的用法之后大家可能会有疑惑,相同的事情,反射不是已经早就实现了吗?确实,仅站在 Java 语言的角度来看,MethodHandle 的使用方法和效果与 Reflection 有着众多相似之处,不过,它们还是有以下区别:
从本质上讲,Reflection 和 MethodHandle 都是在模拟方法调用,但 Refection 是在模拟 Java 代码层次的方法调用,而 MethodHandle 是在模拟字节码层次的方法调用。在 MethodHandle.lookup 中的 3 个方法——findStatic、findVirtual、findSpecial 正是为了对应于 invokestatic、invokevirtual/invokeinterface、invokespecial 这几条字节码指令的执行权限校验行为,而这些底层细节在使用 Reflection API 是不需要关心的。
Reflection 中的 java.lang.reflect.Method 对象远比 MethodHandle 机制中的 java.lang.invoke.MethodHandle 对象包含的信息多。前者是在 Java 一端的全面镜像,包含了方法签名、描述符以及方法属性表中各种属性的 Java 端表示方式,还包含执行权限等运行时信息。而后者仅仅包含与执行该方法相关的信息。即,Reflection 属于重量级 API,而 MethodHandle 属于轻量级。
由于 MethodHandle 是对字节码指令指令调用的模拟,所以理论上虚拟机在这方面做得各种优化(如方法内联),在 MethodHandle 上也应当可以采用类似的思路来支持(但目前还不完善)。而通过反射调用则行不通。
MethodHandle 与 Reflection 除了上面列举的区别外,最关键的一点还在于去掉前面讨论事假的前提“仅站在 Java 语言的角度来看”:Reflection API 的设计目标是只为 Java 语言服务的,而 MethodHandle 则设计成客服务于所有 JVM 之上的语言,其中也包含 Java。
4. invokedynamic 指令
在某种程度上,invokedynamic 指令与 MethodHandle 机制的作用一样,都是为了解决原有 4 条 invoke 指令方法分派规则规划在虚拟机中的问题,把如何查找目标方法的决定权从虚拟机转嫁到具体的用户代码中,让用户(或其他语言的设计者)拥有更高的自由度。而且,它们两者的思路也是可类比的,可以把它们想象成为了达成同一个目的,一个采用上层 Java 代码和 API 来实现;另一个用字节码和 Class 中的属性、常量来完成。
每一处含有 invokedynamic 指令的位置都称作“动态调用点”,该指令的第一个参数不再是代表方法符号引用的 CONSTANT_Methodref_info 常量,而是变为 JKD7 新加入的 CONSTANT_InvokeDynamic_info 常量,从这个新常量中可以得到 3 项信息:引导方法(存放在新增的 BootstrapMethods 属性中)、方法类型、方法名称。引导方法有固定的参数,且返回值是 java.lang.invoke.CallSite 对象,该对象代表要真正执行的目标方法调用。根据 CONSTANT_InvokeDynamic_info 中提供的信息,虚拟机可以找到并且执行引导方法,从而获得一个 CallSite 对象,最终滴啊用要执行的目标方法。
前面讲过,由于 invokedynamic 指令面向的使用者并非只有 Java 语言,而是其他 JVM 上的动态语言,因此紧靠 Java 语言的编译器 javac 没有办法生成带有 invokedynamic 指定的字节码,所以需要使用 Java 语言来演示 invokedynamic 指令只能用一些变通办法。John Rose 编写了一个把程序的字节码转换为使用 invokedynamic 指令的简单工具 INDY 来完成这件事情,我们我们可以使用该工具来生成最终需要的字节码。
5. 掌控方法分派规则
invokedynamic 指令与前面 4 条 invoke 指令的最大差别就是它的分派逻辑不是由 JVM 决定的,而是有开发者决定。下面是一个简单的例子:
class GrandFather{
void thinking(){
System.out.println("i am grandfather");
}
}
class Father extends GrandFather{
void thinking(){
System.out.println("i am father");
}
}
class Son extends Father{
void thinking(){
//请读者在这里填入适当的代码(不能修改其他地方的代码)
//实现调用祖父类的thinking()方法, 打印"i am grandfather"
}
}
在 Java 程序中,可以通过 super 关键字来滴啊用父类中的方法,但是如何调用始祖类的方法呢?
在 JDK7 之前,使用纯粹的 Java 语言很难处理这个问题(直接生产字节码很简单,如使用 ASM 字节码生产工具),原因是在 Son 类的 thinking 方法中无法获取一个实际类型是 GrandFather 的对象引用,而 invokevirtual 指令的分派逻辑就是按照方法接收者的实际类型来进行分派的,该逻辑是固化在 JVM 中的,开发者无法改变。在 JDK7 中,可以使用以下代码来解决该问题。
import static java.lang.invoke.MethodHandles.lookup;
import java.lang.invoke.MethodHandle;
import java.lang.invoke.MethodType;
class Test{
class GrandFather{
void thinking(){
System.out.println("i am grandfather");
}
}
class Father extends GrandFather{
void thinking(){
System.out.println("i am father");
}
}
class Son extends Father{
void thinking(){
try{
MethodType mt=MethodType.methodType(void.class);
MethodHandle mh=lookup().findSpecial(GrandFather.class, "thinking", mt,getClass());
mh.invoke(this);
}catch(Throwable e){
}
}
}
public static void main(String[]args){
(new Test().new Son()).thinking();
}
}
8.4 基于栈的字节码解释执行引擎
上面介绍了 JVM 是如何调用方法的,下面接着介绍 JVM 是如何执行方法中的字节码指令的。很多 JVM 的执行引擎在执行 Java 代码时都有解释执行(通过解释器解释字节码来执行)和编译执行(通过编译器将字节码便以为本地代码来执行)两种选择。
8.4.1 解释执行
Java 语言经常被人们定位为解释执行的语言,在 JDK1 时代,这种定义还算是比较准确的,但当主流的虚拟机中都包含了即时编译器之后,Class 文件中的代码到底会被解释执行还是编译执行,就成了只有虚拟机自己才能准确判断问题。再后来,Java 也发展出了可以直接生成本地代码的编译器,而 C/C++ 也出现了通过解释器执行的版本,这时候就再笼统的说解释执行,对于整个 Java 语言来说就成了无意义的概念,只有确定过了谈论对象是某种具体的 Java 实现版本和执行引擎的运行模式时,对解释执行和编译执行的讨论才是有意义的。
无论是解析还是编译,也不论是物理机还是虚拟机,对于应用程序,机器都不可能如人那样阅读、理解,然后就获得了执行能力。大部分程序代码到物理机的目标代码或虚拟机能执行的指令集之前,都需要经过下图中最下面的那条分支,就是传统编译原理中程序代码到目标机器代码的生成过程,而中间的那条分支,自然就是解释执行的过程。
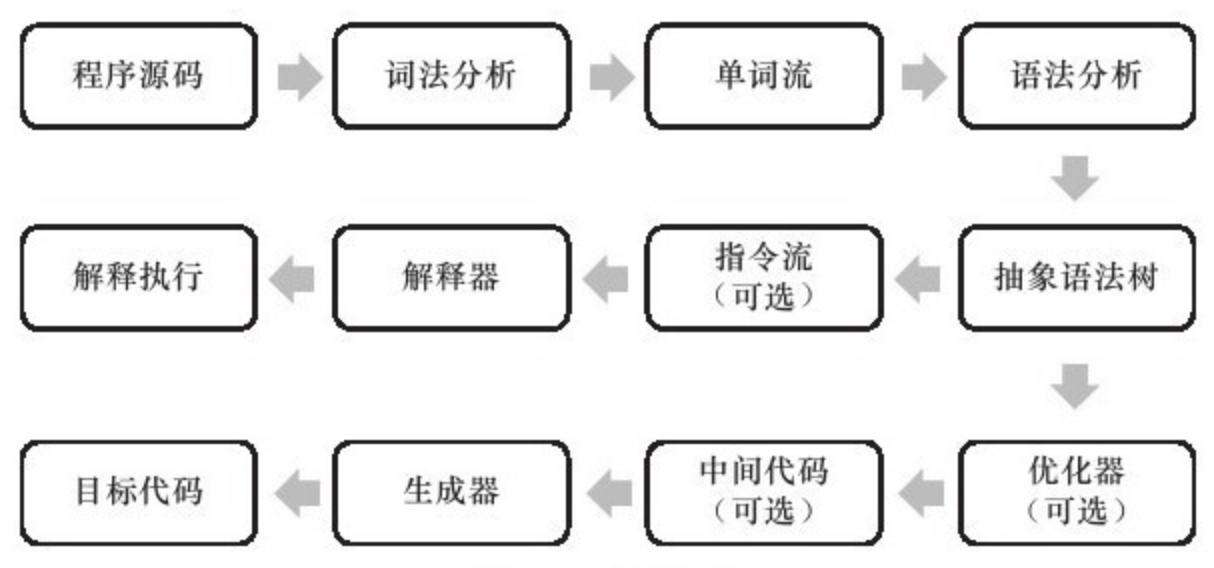
如今,基于物理机、JVM、或者非 Java 的其他高级语言虚拟机的语言,大多都会遵循这种现代编译原理的思路,在执行前先对程序源码进行词法分析和语法分析处理,把源码转化为抽象语法树。对于一门具体语言的实现来说,词法分析、语法分析以及后面的优化器和目标代码生成器都可以选择独立于执行引擎,形成一个完整意义的编译器来实现,这类代表语言是 C/C++。也可以选择把其中一部分步骤(如生成抽象语法树之前的步骤)实现为一个半独立的编译器,这类代表就是 Java。又或者把这些步骤和执行引擎全部集中封装到一个封闭的黑匣子中,如大多数的 JavaScript 执行器。
Java 中,javac 编译器完成了程序代码经过词法分、语法分析到抽象语法树,再遍历语法树生成线性的字节码指令流的过程。因为这部分动作是在 JVM 之外进行的,而解释器位于 JVM 内部,所以 Java 的编译就是半独立实现的。
8.4.2 基于栈的指令集与基于寄存器的指令集
Java 编译器输出的指令流,基本上是一种基于栈的指令集架构,指令流中的指令大部分都是零地址指令,它们依赖操作数栈进行工作。与之相对的另外一套常用的指令集架构是基于寄存器的指令集,最典型的就是 X86 的二地址指令集,通俗的说,就是现在我们主流 PC 机中直接支持的指令集架构,这些指令依赖寄存器进行工作。
举个简单的例子,分别使用两种指令集架构来实现 1+1,基于栈的指令集会是这样:
iconst_1
iconst_1
iadd
istore_0
两条 iconst_1 指令连续把两个常量 1 压入栈,iadd 指令把栈顶的两个值出栈、相加,然后把结果放入栈顶,最后 istore_0 把栈顶的值放到局部变量表的第 0 个 slot 中。
如果是基于寄存器架构,程序会是这种形式:
mov eax, 1
add eax, 1
mov 指令把 EAX 寄存器的值设为 1,然后 add 指令再把该值加 1,结果就保存在 EAX 寄存器中。
基于栈的指令集主要优点是可移植,寄存器由硬件直接提供,程序直接依赖这些硬件寄存器则不可避免的要受到硬件的约束。如,现在 32 位 80x86 体系的处理器中提供了 8 个 32 位的寄存器,而 ARM 体系的 CPU 则提供了 16 个 32 位的通用寄存器。如果使用基于栈的指令集,用户程序不会直接使用这些寄存器,就可以由虚拟机实现来自行决定把一些访问最频繁的数据(程序计数器、栈顶缓存等)放到寄存器中已获得尽量好的性能,这样实现起来也更加简单。栈架构的指令集还有一些其他优点,如代码相对更加紧凑(字节码中每个字节都对应一条指令,而多地址指令集中还需要存放参数)、编译器更加简单(不需要考虑空间分配问题,所需空间都在栈上操作)等。
栈架构指令集的主要缺点是执行速度相对来说会慢一点。所有主流物理机的指令集都是寄存器架构。
虽然栈架构指令集的代码非常紧凑,但是完成相同功能所需的指令数量一般会比寄存器架构多,因为出栈、入栈操作本身就产生了相当多的指令数量。更重要的是,栈实现在内存之中,频繁的栈访问也就意味着频繁的内存访问,相对于处理器来说,内存始终是执行速度的瓶颈。尽管虚拟机可以采取栈顶缓存的手段,把最常用的操作映射到寄存器中避免直接内存访问,但这也只能是优化措施而不是解决本质问题的方法。由于指令数量和内存访问的原因,所以导致了栈架构指令集的执行速度会相对较慢。
8.4.3 基于栈的解释器执行过程
一个简单的算术示例:
public int calc(){
int a=100;
int b=200;
int c=300;
return(a+b)*c;
}
使用 javap 查看其字节码指令:
public int calc();
Code:
Stack=2, Locals=4, Args_size=1
0:bipush 100
2:istore_1
3:sipush 200
6:istore_2
7:sipush 300
10:istore_3
11:iload_1
12:iload_2
13:iadd
14:iload_3
15:imul
16:ireturn
}
字节码指令中显示,需要深度为 2 的操作数栈和 4 个 slot 的局部变量空间,如下一系列的图中,展示了该段代码在执行过程中代码、操作数栈、局部变量表的变化情况。
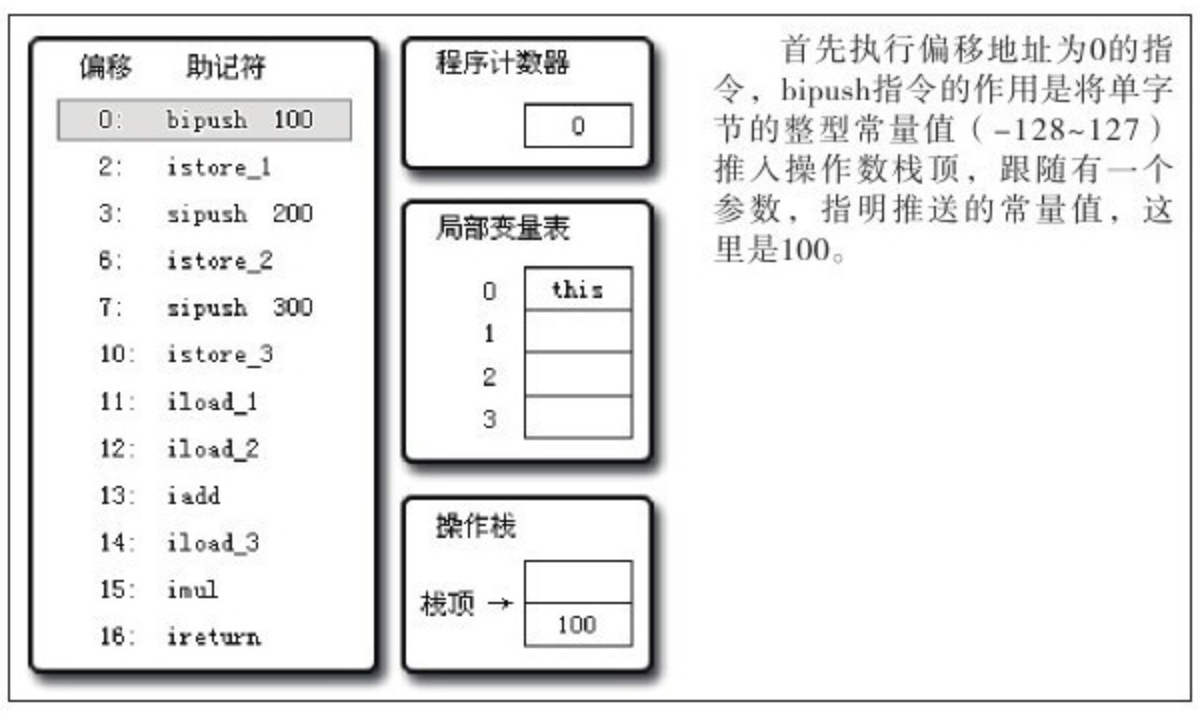
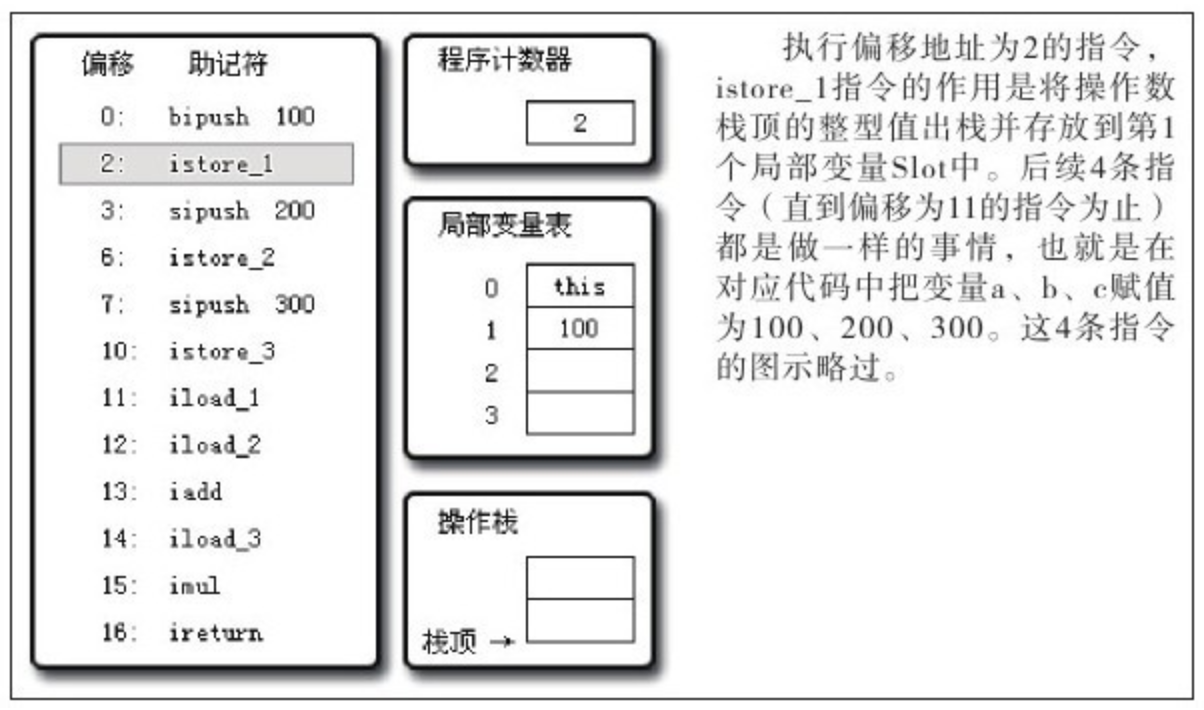
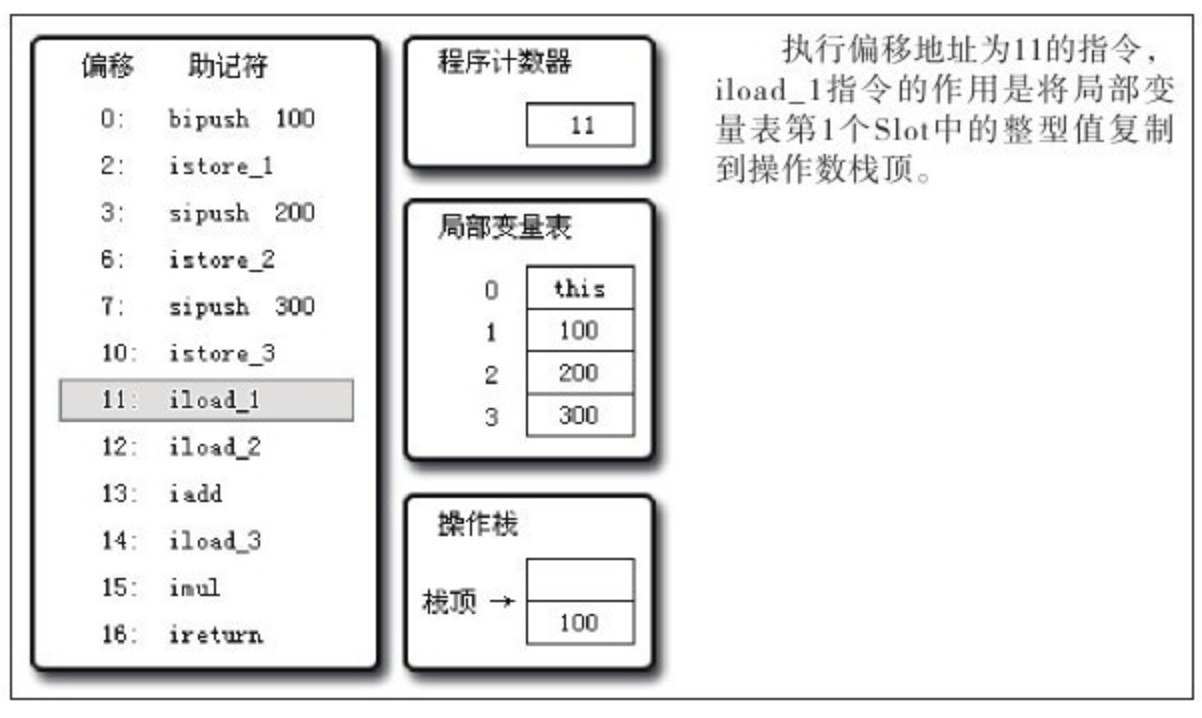



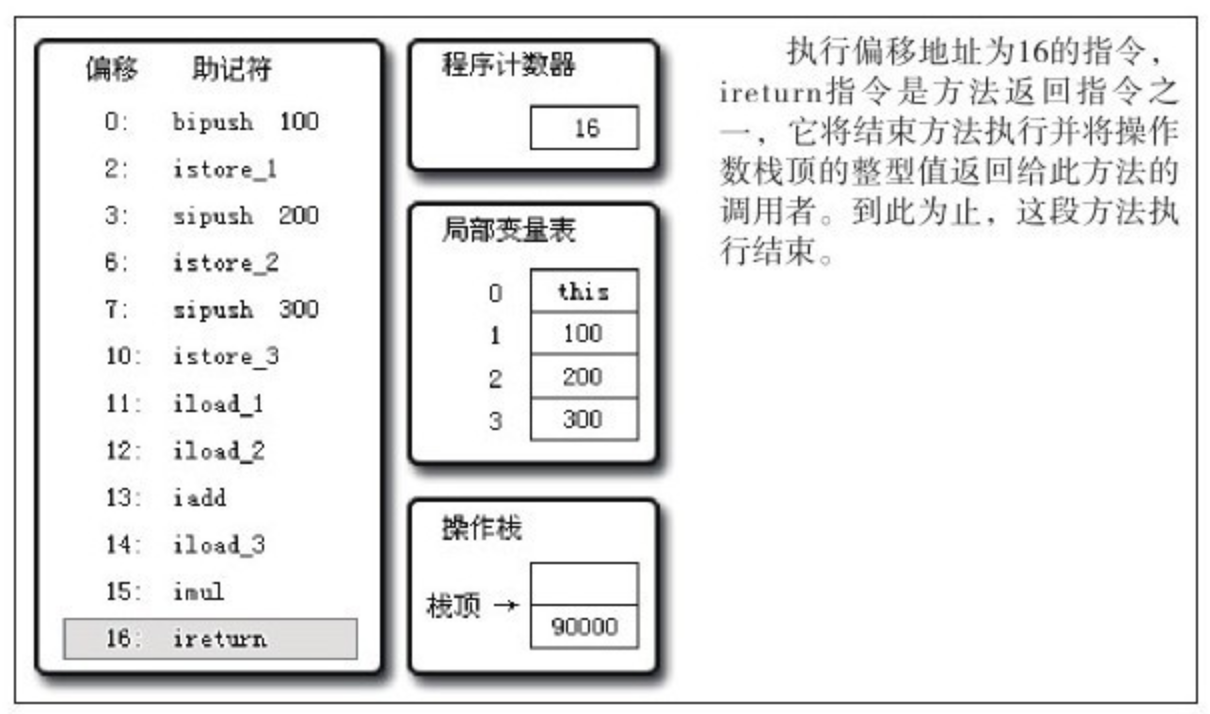
上面的执行过程仅仅是一种概念模型,虚拟机会对执行过程做一些优化来提高运行性能,实际的运作过程不一定完全符合概念模型的描述。更加准确的说,实际情况会和上面描述的概念模型差距非常大,这种差距产生的原因是虚拟机中解析器和即时编译器对输入的字节码进行优化,如,在 HotSpot 虚拟机中,有很多以 “fast_” 开头的非标准字节码指令用于合并、替换输入的字节码以提升解释执行性能,而即时编译器的优化手段更加花样繁多。
不过,我们从这段程序的执行中也可以看出站结构指令集的一般运行过程,整个运算过程的中间变量都以操作数出入栈为信息交换途径,符合我们在前面分析的特点。
8.5 本章小结
本章中,我们分析了虚拟机在执行代码时,如何找到正确的方法、如何执行方法中的字节码,以及执行代码时涉及的数据结构。
9 - CH09-案例与实战
9.1 概述
在Class文件格式与执行引擎这部分中,用户的程序能直接影响的内容并不太多,Class文件以何种格式存储,类型何时加载、如何连接,以及虚拟机如何执行字节码指令等都是由虚拟机直接控制的行为,用户程序无法对其进行改变。能通过程序进行操作的,主要是字节码生成与类加载器这两部分的功能,但仅仅在如何处理这两点上,就已经出现了许多值得欣赏和借鉴的思路,这些思路后来成为了许多常用功能和程序实现的基础。
9.2 案例分析
四个分别关于类加载器和字节码的案例。
9.2.1 Tomcat:正统的类加载器架构
主流的 Java Web 服务器都实现了自定义加载器,因为一个功能健全的 Web 服务器要解决如下几个问题。
部署在同一个服务器上的两个 Web 应用程序所使用的 Java 类库可以实现相互隔离。这是最基本的要求,两个不同的应用程序可能会依赖同一个第三方类库的不同版本,不能要求一个类库在一个服务器中只有一份,服务器应该保证两个应用程序的类库可以互相独立使用。
部署在同一个服务器上的两个 Web 应用程序所使用的 Java 类库可以互相共享。这个需求也很常见,如,用户可能有 10 个使用 Spring 组织的应用程序部署在同一台服务器上,如果把 10 份 Spring 分别存放在各个应用程序的隔离目录中,将会有很大的资源浪费——主要不是浪费磁盘的问题,而是指类库在使用时要被加载器服务器内存,如果类库不能共享,虚拟机的方法区很容易出现过度膨胀的风险。
服务器要尽可能的保证自身的安全,而不受所部署的 Web 应用程序的影响。目前,很多主流的 Java Web 服务器自身也是使用 Java 语言实现的。因此,服务器本身也有类库依赖的问题,一般基于安全因素考虑,服务器所使用的类库应该与应用程序使用的类库相互独立。
支持 JSP 应用的 Web 服务器,大多都需要支持 HotSwap 功能。我们知道,JSP 文件最终要编译成 Java Class 才能由虚拟机执行,但 JSP 文件由于其纯文本存储的特性,运行时修改的概率要远远大于第三方类库或程序自身的 Class 文件。而且 ASP、PHP、JSP 这些网页应用也把修改后无需重启作为一个很大的优势来看待,因此“主流”的 Web 服务器都会支持 JSP 生成类的热替换,当然也有非主流的,如运行在生产模式下的 WebLogic 服务器默认就不会处理 JSP 文件的变化。
由于上述问题的存在,在部署 Web 应用时,单独的一个 ClassPath 就无法满足需求了,所以各种 Web 服务器都“不约而同”的提供了好几个 ClassPath 路径来供用户存放第三方类库,这些路径一般都以 lib 或 classes 命名。被放置到不同路径中的类库,具备不同的访问范围和服务对象,通常,每个目录都会有一个相应的自定义类加载器来加载放置在其中的 Java 类库。以下以 Tomcat 服务器为例来介绍它是如何规划用户类库结构和类加载器的。
在 Tomcat 目录结构中,有 3 组目录(/common/*, /server/*, /shared/*)可以用来存放 Java 类库,另外还可以加上 Web 应用程序自身目录的 /WEB-INF/*,一共 4 组,把 Java 类库放置在这些目录中的含义分别如下。
- common:类库可以被 Tomcat 和所有 Web 应用共同使用。
- server:类库可以被 Tomcat 使用,对所有的 Web 应用都不可见。
- shared:类库可以被所有 Web 应用使用,但对 Tomcat 自己不可见。
- WEB-INF:尽可以被指定 Web 应用可见,但对 Tomcat 和其他所有 Web 应用都不可见。
为了支持这套目录结构,并对目录中的类库进行加载和隔离,Tomcat 定义了多个类加载器,这些类加载器按照经典的双亲委派模型来实现,其关系如下图所示:
灰色部分为 JDK 默认提供的类加载器,这里不再赘述。而 CommonClassLoader、CatalinaClassLoader、SharedClassLoader 和 WebappClassLoader 则是 Tomcat 自己定义的类加载器,它们分别用于加载上面介绍的 4 个目录中的类库。通常 WebApp 和 JSP 类加载器会存在多个实例,每个 Web 应用对应一个 WebApp 类加载器,每个 JSP 文件对应一个 JSP 类加载器。
从上图中的委派模型可以看出,CommonClassLoader 能加载的类都可以被 CatalinaClassLoader 和 SharedClassLoader 使用,而 CatalinaClassLoader 和 SharedClassLoader 自己能加载的类则与对方相互隔离。WebappClassLoader 可以使用 SharedClassLoader 加载到的类,但各个 WebappClassLoader 实例之间相互隔离。而 JasperLoader 的加载范围仅仅是该 JSP 文件所编译出来的那个 Class,它出现的目的就是为了被丢弃:当服务器检测到 JSP 文件被修改时,会替换掉目前的 JasperLoader 的实例,并通过在建立一个新的 JSP 类加载器来实现 JSP 文件的 HotSwap 功能。
9.2.2 OSGI:灵活的类加载器架构
OSGI 中的每个模块(Bundle)与普通的 Java 类库区别并不大,两者一般都以 Jar 格式进行封装,并且内部存储的都是 Java Package 和 Class。但是一个 Bundle 可以声明它所依赖的 Java Package,也可以声明它允许导出发布的 Java Package。在 OSGI 里面,Bundle 之间的依赖关系从传统的上层模块依赖底层模块转换为平级别模块之间的依赖(之上表面上看是如此),而且类库的可见性能得到非常精确的控制,一个模块里只有被 Export 过的 Package 才能被外界访问,其他的 Package 和 Class 会隐藏起来。除了更加精确的模块划分和可见性控制之外,引入 OSGI 的另外一个重要的理由是,基于 OSGI 的程序很可能(并不一定会)可以实现模块级的热插拔功能,当程序升级或者调试除错时,可以只停用、重新安装然后启用程序的其中一部分,这对企业级程序开发来说是一个非常有诱惑力的特性。
OSGI 之所以能有上述优点,要归功于它灵活的类加载器架构。OSGI 和 Bundle 类加载器之间只有规则,没有固定的委派关系。如,某个 Bundle 声明了一个它依赖的 Package,如果有其它 Bundle 声明发布了这个 Package,那么所有对这个 Package 的类加载动作都会委派给发布它的 Bundle 类加载器来完成。当不涉及摸个具体的 Package 时,各个 Bundle 加载器都是平级关系,只有具体使用某个 Package 和 Class 时,才会根据 Package 的导入导出定义来构造 Bundle 之间的委派和依赖关系。
另外,一个 Bundle 类加载器为其他 Bundle 提供服务时,会根据 Export-Package 列表严格控制访问范围。如果一个类存在于 Bundle 的类库中但是没有被 Export,那么该 Bundle 的类加载器能找到这个类,但是不会提供给其他 Bundle 使用,而 OSGI 平台也不会该其他 Bundle 的类加载请求分配给这个 Bundle 来处理。
我们可以举一个更具体一些的简单例子,假设存在 Bundle A、B、C 三个模块,并且这三个 Bundle 定义的依赖关系如下:
- A:声明发布了 PackageA,依赖了 java.* 包。
- B:声明依赖了 PackageA 和 PackageC,同时也依赖了 java.* 包。
- C:声明发布了 PackageC,依赖了 PackageA。
那么,这三个 Bundle 之间的类加载器以及父类加载器之间的关系如图所示:

由于没有牵扯到具体 OSGI 实现,上图中没有指明具体的类加载器实现,只是一个体现了加载器之间关系的概念模型,并且只是体现了 OSGI 中最简单的加载器委派关系。一般来说,在 OSGI 中,加载一个类可能发生的查找行为和委派发生关系会比上图中显示的过程复杂的多,类加载时可能进行的查找规则如下。
- 以 java.* 开头的类,委派给父类加载器。
- 否则,委派列表名单内的类,委派给父类加载器加载。
- Import 列表中的类,委派给 Export 这个类的 Bundle 的类加载器加载。
- 否则,查找当前 Bundle 的 ClassPath,使用自己的类加载器加载。
- 否则,查找是否在自己的 Fragment Bundle 中,如果是,则委派给 Fragment Bundle 的类加载器来加载。
- 否则,查找 Dynamic Import 列表中的 Bundle,委派给对应 Bundle 的类加载器加载。
- 否则,类查找失败。
从上图中可以看出,在 OSGI 中,加载器之间的关系不再是双亲委派模型的树形结构,而是已经进一步发展成了一种更为复杂的、运行时才能确定的网状结构。这种网状的类加载器架构在带来更好的灵活性的同时,也可能会产生很多新的隐患。
9.2.3 字节码生成技术与动态代理实现
“字节码生成”并不是什么高深的技术,读者在看到“字节码生成”这个标题时也先不必去想诸如 Javassist、CGLib、ASM 之类的字节码类库,因为 JDK 里面的 javac 命令就是字节码生成技术的“老祖宗”,并且 javac 也是一个由 Java 语言写成的程序,它的代码存放在 OpenJDK 的 langtools/src/share/classes/com/sun/tools/javac 目录中。要深入了解字节码生成,阅读 javac 的源码是个很好的途径,不过 javac 对于我们这个例子来说太过庞大了。在 Java 里面除了 javac 和字节码类库外,使用字节码生成的例子还有很多,如 Web 服务器中的 JSP 编译器,编译时植入的 AOP 框架,还有很常用的动态代理技术,甚至在使用反射的时候虚拟机都有可能会在运行时生成字节码来提高执行速度。
相信许多Java开发人员都使用过动态代理,即使没有直接使用过 java.lang.reflect.Proxy 或实现过 java.lang.reflect.InvocationHandler 接口,应该也用过 Spring 来做过 Bean 的组织管理。如果使用过 Spring,那大多数情况都会用过动态代理,因为如果 Bean 是面向接口编程,那么在 Spring 内部都是通过动态代理的方式来对 Bean 进行增强的。动态代理中所谓的“动态”,是针对使用 Java 代码实际编写了代理类的“静态”代理而言的,它的优势不在于省去了编写代理类那一点工作量,而是 实现了可以在原始类和接口还未知的时候,就确定代理类的代理行为,当代理类与原始类脱离直接联系后,就可以很灵活地重用于不同的应用场景之中。
下面展示了一个简单的动态代理用法,原始的逻辑是打印一句"hello world",代理类的逻辑是在原始类方法执行前打印一句"welcome"。
public class DynamicProxyTest{
interface IHello{
void sayHello();
}
static class Hello implements IHello{
@Override
public void sayHello(){
System.out.println("hello world");
}
}
static class DynamicProxy implements InvocationHandler{
Object originalObj;
Object bind(Object originalObj){
this.originalObj=originalObj;
return
Proxy.newProxyInstance(originalObj.getClass().getClassLoader(), originalObj.getClass().getInterfaces(), this);
}
@Override
public Object invoke(Object proxy,Method method,Object[]args)throws Throwable{
System.out.println("welcome");
return method.invoke(originalObj,args);
}
}
public static void main(String[]args){
IHello hello=(IHello)new DynamicProxy().bind(new Hello());
hello.sayHello();
}
}
上述代码里,唯一的“黑匣子”就是 Proxy.newProxyInstance() 方法,除此之外再没有任何特殊之处。该方法返回一个实现了 IHello 接口、且代理了 new Hello() 实例的行为的对象。跟踪该方法的源码,可以看到程序进行了验证、优化、缓存、同步、生成字节码、显式类加载等操作,前面的步骤并不是我们关注的重点,而在最后它调用了 sun.misc.ProxyGenerator.generateProxyClass() 方法来完成字节码的生成动作,该方法可以在运行时产生一个描述代理类的字节码 byte[] 数组。如果想看一看这个在运行时产生的代理类的内容,可以在 main 方法中添加如下代码:
System.getProperties().put(
"sun.misc.ProxyGenerator.saveGeneratedFiles", "true");
加入该代码后再次运行,磁盘中将会产生一个名为 $Proxy().class 的代理类 Class 文件,反编译后可以看见如下清单中的内容:
package org.fenixsoft.bytecode;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
import java.lang.reflect.UndeclaredThrowableException;
public final class $Proxy0 extends Proxy implements DynamicProxyTest.IHello{
private static Method m3;
private static Method m1;
private static Method m0;
private static Method m2;
public $Proxy0(InvocationHandler paramInvocationHandler)
throws
{
super(paramInvocationHandler);
}
public final void sayHello()
throws
{
try
{
this.h.invoke(this,m3, null);
return;
}
catch(RuntimeException localRuntimeException)
{
throw localRuntimeException;
}
catch(Throwable localThrowable)
{
throw new UndeclaredThrowableException(localThrowable);
}
}
//此处由于版面原因, 省略equals()、hashCode()、toString()三个方法的代码
//这3个方法的内容与sayHello()非常相似。
static
{
try
{
m3=Class.forName("org.fenixsoft.bytecode.DynamicProxyTest $IHello").getMethod("sayHello", new Class[0]);
m1=Class.forName("java.lang.Object").getMethod("equals", new Class[]{Class.forName("java.lang.Object")});
m0=Class.forName("java.lang.Object").getMethod("hashCode", new Class[0]);
m2=Class.forName("java.lang.Object").getMethod("toString", new Class[0]);
return;
}
catch(NoSuchMethodException localNoSuchMethodException)
{
throw new NoSuchMethodError(localNoSuchMethodException.getMessage());
}
catch(ClassNotFoundException localClassNotFoundException)
{
throw new NoClassDefFoundError(localClassNotFoundException.getMessage());
}
}
}
该代理类的实现很简单,它为传入接口中的每个方法,以及从 java.lang.Object 中继承来的 equals/hashCode/toString 方法都生成了对应的实现,并且统一调用了 InvocationHandler 对象的 invoke 方法(代码中的 this.h 即使父类 Proxy 中保存的 InvocationHandler 实例变量)来实现这些方法的内容,各个方法的区别不过是传入的参数和 Method 对象有所不同而已,所以无论调用动态代理的哪一个方法,实际上都是在执行 InvocationHandler.invoke 中的代理逻辑。
这个例子中并没有讲到 generateProxyClass() 方法具体是如何产生代理类 “$Proxy0.class” 的字节码的,大致的生成过程其实就是根据 Class 文件的格式规范去拼装字节码,但在实际开发中,以 byte 为单位直接拼装出字节码的应用场合很少见,这种生成方式也只能产生一些高度模板化的代码。对于用户的程序代码来说,如果有要大量操作字节码的需求,还是使用封装好的字节码类库比较合适。如果读者对动态代理的字节码拼装过程很感兴趣,可以在 OpenJDK 的 jdk/src/share/classes/sun/misc 目录下找到 sun.misc.ProxyGenerator 的源码。
9.2.4 Retrotanslator:跨越 JDK 版本
Retrotranslator 的作用是将 JDK 1.5 编译出来的 Class 文件转变为可以在 JDK 1.4 或 1.3 上部署的版本,它可以很好地支持自动装箱、泛型、动态注解、枚举、变长参数、遍历循环、静态导入这些语法特性,甚至还可以支持 JDK 1.5 中新增的集合改进、并发包以及对泛型、注解等的反射操作。了解了 Retrotranslator 这种逆向移植工具可以做什么以后,现在关心的是它是怎样做到的?
要想知道 Retrotranslator 如何在旧版本JDK中模拟新版本JDK的功能,首先要弄清楚 JDK 升级中会提供哪些新的功能。JDK 每次升级新增的功能大致可以分为以下 4 类:
在编译器层面做的改进。如自动装箱拆箱,实际上就是编译器在程序中使用到包装对象的地方自动插入了很多 Integer.valueOf()、Float.valueOf() 之类的代码;变长参数在编译之后就自动转化成了一个数组来完成参数传递;泛型的信息则在编译阶段就已经擦除掉了(但是在元数据中还保留着),相应的地方被编译器自动插入了类型转换代码。
对 Java API 的代码增强。譬如 JDK 1.2 时代引入的 java.util.Collections 等一系列集合类,在 JDK 1.5 时代引入的 java.util.concurrent 并发包等。
需要在字节码中进行支持的改动。如 JDK 1.7 里面新加入的语法特性:动态语言支持,就需要在虚拟机中新增一条 invokedynamic 字节码指令来实现相关的调用功能。不过字节码指令集一直处于相对比较稳定的状态,这种需要在字节码层面直接进行的改动是比较少见的。
虚拟机内部的改进。如 JDK5 中实现的 JSR-133 规范重新定义的 Java 内存模型、CMS 收集器之类的改动。这类改动对于程序员编写的代码来说基本是透明的,但会对程序运行时产生影响。
上述 4 种功能中,Retrotranslator 只能模拟前两类,对于后面两类直接在虚拟机内部实现的改进,一般所有的逆向移植工具都是无能为力的,至少不能完整的或者在可接收的效率上完成全部模拟,否则虚拟机设计团队也没有必要舍近求远的改动处于 JDK 底层的虚拟机。在可以模拟的两类功能中,第二类模拟相对容易实现一些,如 JDK5 引入 JUC 包,实际上是由多线程大师 Doug Lea 开发的一套并发包,在 JDK5 出现之前就已经存在,所以要在旧 JDK 中支持这部分功能,以独立类库的方式便可实现。Retrotranslator 中附带了一个名为 “backport-util-concurrent.jar” 的类库来代替 JDK5 并发包。
至于JDK在编译阶段进行处理的那些改进,Retrotranslator 则是使用 ASM 框架直接对字节码进行处理。由于组成 Class 文件的字节码指令数量并没有改变,所以无论是 JDK 1.3、JDK 1.4 还是 JDK 1.5,能用字节码表达的语义范围应该是一致的。当然,肯定不可能简单地把 Class 的文件版本号从 49.0 改回 48.0 就能解决问题了,虽然字节码指令的数量没有变化,但是元数据信息和一些语法支持的内容还是要做相应的修改。以枚举为例,在 JDK 1.5 中增加了 enum 关键字,但是 Class 文件常量池的 CONSTANT_Class_info 类型常量并没有发生任何语义变化,仍然是代表一个类或接口的符号引用,没有加入枚举,也没有增加过 “CONSTANT_Enum_info” 之类的“枚举符号引用”常量。所以使用 enum 关键字定义常量,虽然从 Java 语法上看起来与使用 class 关键字定义类、使用 interface 关键字定义接口是同一层次的,但实际上这是由 Javac 编译器做出来的假象,从字节码的角度来看,枚举仅仅是一个继承于 java.lang.Enum、自动生成了 values() 和 valueOf() 方法的普通 Java 类而已。
Retrotranslator 对枚举所做的主要处理就是把枚举类的父类从 java.lang.Enum 替换为它运行时类库中包含的 “net.sf.retrotranslator.runtime.java.lang.Enum_",然后再在类和字段的访问标志中抹去 ACC_ENUM 标志位。当然,这只是处理的总体思路,具体的实现要复杂得多。可以想象既然两个父类实现都不一样,values 和 valueOf 方法自然需要重写,常量池需要引入大量新的来自父类的符号应用,这些都是实现细节。下图使用 JDK5 编译的枚举类与被 Retrotranslator 转换处理后的字节码进行对比。
9.3 实战:实现远程执行功能
不知道读者在编写程序时是否遇到过如下情景:在排查问题过程中,想查看内存中的一些参数值,却又没有方法把这些值输出到界面或日志中,又或者定位到某个缓存数据有问题,但缺少缓存的统一万里界面,不得不重启服务才能清理该缓存。类似的需求有一个共同的特点,就是只要在服务中执行一段程序代码,就可以定位或排除问题,但就是找不到可以让服务器执行代码的途径,这时候就会希望 Java 服务器中也有提供类似 Groovy Console 的功能。
JDK6 之后提供了 Compiler API,可以动态的编译 Java 程序,虽然这样达不到动态语言的灵活度,但让服务器执行临时代码的需求就可以得到解决了。在 JDK6 之前,也可以通过其他方式实现,比如编写一个 JSP 文件上传到服务器,然后在浏览器中运行,或者在服务器程序中插入一个额 BeanShell Script、JavaScript 等语言的执行引擎来执行动态脚本。
9.3.1 目标
首先,在实现“在服务端执行临时代码”这个需求之前,先来明确一下本次实战的具体目标,我们希望最终的产品是这样的:
- 不依赖具体的 JDK 版本,能在目前普遍使用的 JDK 中部署,也能在 JDK 4~7 中部署。
- 不改变原有服务端程序的部署方式,不依赖任何三方类库。
- 不侵入原有程序,即无需改动原有程序的任何代码,也不会对原有程序的运行带来任何影响。
- 考虑到 BeanShell Script 或 JavaScript 等脚本编写起来不太方便,“临时代码”需要直接支持 Java 语言。
- “临时代码”应当具备足够的自由度,不需要依赖特定的类或实现特定的接口。这里写的是“不需要”而不是“不可以”,当“临时代码”需要引用其他类库的时也没有限制,只要服务端程序能够使用,临时代码应当都能被直接引用。
- “临时代码”的执行结果能够返回客户端,执行结果可以包括程序中输出的信息以及抛出的异常等等。
9.3.2 思路
在程序实现的过程中,我们需要解决如下 3 个问题:
- 如何编译提交到服务器的 Java 代码?
- 如何执行编译之后的 Java 代码?
- 如何收集 Java 代码的执行结果?
对于第一个问题,我们有两种思路可供选择,一种是使用 tools.jar 中的 com.sun.tools.javac.Main 类来编译 Java 文件,这其实和使用 javac 命令编译一行。这种思路的缺点是引入了额外的 Jar 包,而且把程序“绑死”在了 Sun 的 JDK 上,要部署到其他公司的 JDK 中还得把这个 tools.jar 带上。另外一种思路是直接在客户端编译好,把字节码而不是 Java 源代码直接传到服务端,这听起来有点投机取巧,一般来说确实不应该假设客户端一定具有编译代码的能力,但是然程序员会写 Java 代码给服务端来排查问题,那么很难想象他的机器上会连编译 Java 代码的环境都没有。
对于第二个问题,简单的一想:要执行编译后的 Java 代码,让类加载器加载这个类生成一个 Class 对象,然后反射代用某个方法就可以了。但我们还应该考虑的周全一点:一段程序往往不是编写、运行一次就能达到效果,同一个类可能要反复的修改、提交、执行。提交上去的类还有可能需要访问其他的类库。此外,既然提交的是临时代码,那么提交的类应该在执行完成后卸载并回收。
最后一个问题,我们想把程序往标准输出和标准错误输出中但因的信息收集起来,但标准输出是整个虚拟机进程全局共享的资源,如果使用 System.setout、System.setErr 方法把输出流重定向到自定义的 PrintStream 对象上固然可以收集到输出信息,但也会对原有程序产生影响:会把其他线程输出的信息也一并收集。虽然这并不是不能解决问题,不过为了达到完全不影响原有程序的目的,我们可以采用另外一种办法,即直接在执行的类中把 System.out 的符号引用替换为我们准备好的 PrintStream 符号引用,基于前面学习的知识,做到这一点并不难。
9.3.3 实现
首先看看实现过程中需要用到的 4 个支持类。第一个类用于实现“同一个类的代码可以被加载多次”这个需求:
/**
*为了多次载入执行类而加入的加载器<br>
*把 defineClass 方法开放出来, 只有外部显式调用的时候才会使用到loadByte方法
*由虚拟机调用时, 仍然按照原有的双亲委派规则使用loadClass方法进行类加载
*/
public class HotSwapClassLoader extends ClassLoader{
public HotSwapClassLoader(){
super(HotSwapClassLoader.class.getClassLoader());
}
public Class loadByte(byte[]classByte){
return defineClass(null,classByte, 0, classByte.length);
}
}
HotSwapClassLoader 完成的工作仅仅是公开父类中的 protected 方法 defineClass,我们将使用该方法来把提交执行的 Java 类的字节数组转换为 Class 对象。HotSwapClassLoader 中并没有重写 loadClass 或 findClass 方法,因此如果不算外部手动调用 loadByte 的话,该类加载器的类查找范围与其父类加载器是完全一致的,在被虚拟机调用时,它会按照双亲委派模型交给父类加载。构造函数中指定为加载 HotSwapClassLoader 类的类加载器作为父类加载器,这一步是实现提交的执行代码可以访问服务端引用类库的关键。
第二个类是实现 java.lang.System 替换为自定义的 PrintStream 类的过程,它直接修改符合 Class 文件格式的字节数组中的常量池部分,将常量池中指定内容的 CONSTANT_Utf8_info 常量替换为新的字符串,具体代码如代码清单所示。ClassModifier 中涉及对字节数组操作的部分,主要是将字节数组与 int 和 String 互相转换,以及把对字节数组的替换操作封装在代码清单所示的 ByteUtils 中。
/**
*修改Class文件, 暂时只提供修改常量池常量的功能
*@author zzm
*/
public class ClassModifier{
/**
*Class文件中常量池的起始偏移
*/
private static final int CONSTANT_POOL_COUNT_INDEX=8;
/**
*CONSTANT_Utf8_info常量的tag标志
*/
private static final int CONSTANT_Utf8_info=1;
/**
*常量池中11种常量所占的长度, CONSTANT_Utf8_info型常量除外, 因为它不是定长的
*/
private static final int[]CONSTANT_ITEM_LENGTH={-1, -1, -1, 5, 5, 9, 9, 3, 3, 5, 5, 5, 5};
private static final int u1=1;
private static final int u2=2;
private byte[]classByte;
public ClassModifier(byte[]classByte){
this.classByte=classByte;
}
/**
*修改常量池中CONSTANT_Utf8_info常量的内容
*@param oldStr修改前的字符串
*@param newStr修改后的字符串
*@return修改结果
*/
public byte[]modifyUTF8Constant(String oldStr,String newStr){
int cpc=getConstantPoolCount();
int offset=CONSTANT_POOL_COUNT_INDEX+u2;
for(int i=0;i<cpc;i++){
int tag=ByteUtils.bytes2Int(classByte,offset,u1);
if(tag==CONSTANT_Utf8_info){
int len=ByteUtils.bytes2Int(classByte,offset+u1, u2);
offset+=(u1+u2);
String str=ByteUtils.bytes2String(classByte,offset,len);
if(str.equalsIgnoreCase(oldStr)){
byte[]strBytes=ByteUtils.string2Bytes(newStr);
byte[]strLen=ByteUtils.int2Bytes(newStr.length(), u2);
classByte=ByteUtils.bytesReplace(classByte,offset-u2, u2, strLen);
classByte=ByteUtils.bytesReplace(classByte,offset,len,strBytes);
return classByte;
}else{
offset+=len;
}
}else{
offset+=CONSTANT_ITEM_LENGTH[tag];
}
}
return classByte;
}
/**
*获取常量池中常量的数量
*@return常量池数量
*/
public int getConstantPoolCount(){
return ByteUtils.bytes2Int(classByte,CONSTANT_POOL_COUNT_INDEX,u2);
}
}
/**
*Bytes数组处理工具
*@author
*/
public class ByteUtils{
public static int bytes2Int(byte[]b,int start,int len){
int sum=0;
int end=start+len;
for(int i=start;i<end;i++){
int n=((int)b[i])&0xff;
n<<=(--len)*8;
sum=n+sum;
}
return sum;
}
public static byte[]int2Bytes(int value,int len){
byte[]b=new byte[len];
for(int i=0;i<len;i++){
b[len-i-1]=(byte)((value>>8*i)&0xff);
}
return b;
}
public static String bytes2String(byte[]b,int start,int len){
return new String(b,start,len);
}
public static byte[]string2Bytes(String str){
return str.getBytes();
}
public static byte[]bytesReplace(byte[]originalBytes,int offset,int len,byte[]replaceBytes){
byte[]newBytes=new byte[originalBytes.length+(replaceBytes.length-len)];
System.arraycopy(originalBytes, 0, newBytes, 0, offset);
System.arraycopy(replaceBytes, 0, newBytes,offset,replaceBytes.length);
System.arraycopy(originalBytes,offset+len,newBytes,offset+replaceBytes.length,originalBytes.length-offset-len);
return newBytes;
}
}
经过 ClassModifer 处理后的字节数组才会传给 HotSwapClassLoader.loadByte 方法来执行类加载,字节数组在这里替换符号引用之后,与客户端直接在 Java 代码中引用 HackSystem 类在编译生成的 Class 完全一样。这样的实现避免了客户端编写临时代码时要依赖特定的类,又避免了服务端修改标准输出后影响其他程序的输出。
最后一个类是前面提到过的用来替换 java.lang.System 的 HackSystem,该类中的方法看起来不少,但其实除了把 out 和 err 两个静态变量替换为使用 ByteArrrayOutputStream 作为打印目标的同一个 PrintStream 对象,以及增加了读取、清理 ByteArrayOutputStream 中内容的 getBufferString 和 clearBuffer 方法外,就再没有其他新鲜的内容了。其余的方法全部都来自于 System 类的 public 方法,方法名称、参数、返回值都完全一样,并且实现也是直接调转了 System 类的对应方法而已。保留这些方法的目的是为了在 System 在被替换为 HackSystem 之后,执行代码中调用的 System 的其余方法仍然可以继续使用,HackSystem 的实现如下所示。
/**
*为JavaClass劫持java.lang.System提供支持
*除了out和err外, 其余的都直接转发给System处理
*
*@author zzm
*/
public class HackSystem{
public final static InputStream in=System.in;
private static ByteArrayOutputStream buffer=new ByteArrayOutputStream();
public final static PrintStream out=new PrintStream(buffer);
public final static PrintStream err=out;
public static String getBufferString(){
return buffer.toString();
}
public static void clearBuffer(){
buffer.reset();
}
public static void setSecurityManager(final SecurityManager s){
System.setSecurityManager(s);
}
public static SecurityManager getSecurityManager(){
return System.getSecurityManager();
}
public static long currentTimeMillis(){
return System.currentTimeMillis();
}
public static void arraycopy(Object src,int srcPos,Object dest,int destPos,int length){
System.arraycopy(src,srcPos,dest,destPos,length);
}
public static int identityHashCode(Object x){
return System.identityHashCode(x);
}
//下面所有的方法都与java.lang.System的名称一样
//实现都是字节转调System的对应方法
//因版面原因, 省略了其他方法
}
我们来看看最后一个类 JavaClassExecutor,它是提供给外部调用的入口,调用前面几个直接类组装逻辑,完成类加载工作。JavaClassExecutor 只有一个 execute 方法,用输入的符合 Class 文件格式的字节数组替换 java.lang.System 的符号引用后,使用 HotSwapClassLoader 加载生成一个 Class 对象,由于每次执行 execute 方法都会生成一个新的类加载器实例,因此同一个类可以实现重复加载。然后,发射调用这个 Class 对象的 main 方法,如果期间出现任何异常,将异常信息打印到 HackSystem.out 中,最后把缓冲区中的信息作为方法的结果返回。JavaClassExecutor 的实现代码如代码清单所示。
/**
*JavaClass执行工具
*
*@author zzm
*/
public class JavaClassExecuter{
/**
*执行外部传过来的代表一个Java类的byte数组<br>
*将输入类的byte数组中代表java.lang.System的CONSTANT_Utf8_info常量修改为劫持后的HackSystem类
*执行方法为该类的static main(String[]args)方法, 输出结果为该类向System.out/err输出的信息
*@param classByte代表一个Java类的byte数组
*@return执行结果
*/
public static String execute(byte[]classByte){
HackSystem.clearBuffer();
ClassModifier cm=new ClassModifier(classByte);
byte[]modiBytes=cm.modifyUTF8Constant("java/lang/System", "org/fenixsoft/classloading/execute/HackSystem");
HotSwapClassLoader loader=new HotSwapClassLoader();
Class clazz=loader.loadByte(modiBytes);
try{
Method method=clazz.getMethod("main", new Class[]{String[].class});
method.invoke(null,new String[]{null});
}catch(Throwable e){
e.printStackTrace(HackSystem.out);
}
return HackSystem.getBufferString();
}
}
9.3.4 验证
如果只是测试的话,那么可以任意下一个 Java 类,内容无所谓,只要向 System.out 输出信息即可,取名为 TestClass,同时放到服务器 C 盘的根目录中,然后建立一个 JSP 文件并加入如下清单中的代码,就可以在浏览器中看到这个类的运行效果了。
<%@page import="java.lang.*"%>
<%@page import="java.io.*"%>
<%@page import="org.fenixsoft.classloading.execute.*"%>
<%
InputStream is=new FileInputStream("c:/TestClass.class");
byte[]b=new byte[is.available()];
is.read(b);
is.close();
out.println("<textarea style='width:1000;height=800'>");
out.println(JavaClassExecuter.execute(b));
out.println("</textarea>");
%>
当然,上面的做法只是用于测试和演示,实际使用这个 JavaExecutor 执行器的时候,如果还要手工复制一个 Class 文件到服务器上就没有什么意义了。笔者给这个执行器写了一个外壳,是一个 Eclipse 插件,可以把 Java 文件编译后传输到服务器中,然后把执行器的返回结果输出到 Eclipse 的 Console 窗口中,这样就可以在有灵感的时候随时写几行调试代码,当道测试环境的服务器上立即运行了。虽然实现简单,但效果很不错,对调试问题也非常有帮助,如下图所示:
9.4 本章小结
本书 6~9 章介绍了 Class 文件格式、类加载和虚拟机执行引擎,这些内容是虚拟机中必不可少的组成部分,只有了解了虚拟机如何执行程序,才能更好的理解怎样才能写出优秀的代码。
10 - CH10-编译期优化
从计算机程序出现的第一天起,对效率的追求就是程序员天生的鉴定信仰,这个过程犹如一场没有终点、永不停歇的 F1 方程式竞赛,程序员是车手,技术平台则是在赛道上飞驰的赛车。
10.1 概述
Java 语言的“编译期”其实是一段不确定的操作过程,因为它可能是指一个前端编译器把 java 文件转变成 class 文件的过程;也可能是值虚拟机的后端运行时编译器把字节码转换为机器码的过程;还可能是指使用静态提前编译器(AOT 编译器)直接把 java 文件编译为本地机器码的过程。下面列举了这 3 类编译过程中一些比较有代表性的编译器。
- 前端编译器:Sun 的 javac、Eclipse JDT 中的增量式编译器 ECJ。
- JIT 编译器:HotSpot VM 的 C1/C2 编译器。
- AOT 编译器:GNU Compiler for the Java(GCJ)、Excelsior JET。
这 3 类过程中最符合大家对 Java 程序编译认知的应该是第一类,在本章的后续介绍中,笔者提到的编译期和编译器都仅限于第一类编译过程,把第二类编译过程留到下一章中讨论。限制了编译范围后,我们对于“优化”二字的定义就需要宽松一些,因为 javac 这类编译器对代码的运行效率几乎没有任何优化措施。虚拟机设计团队把对性能的优化集中到了后端的即时编译器中,这样可以让那些不是由 javac 产生的 Class 文件也同样能够享受到编译器优化带来的好处。但是 javac 做了很多针对 Java 语言编码过程的优化措施来改善程序员的编码风格和编码效率。相当多新生的 Java 语法特性,都是靠编译器的语法糖来实现的,而不是依赖虚拟机的底层改进来支持的,可以说,Java 中即时编译器在运行期的优化过程对于程序运行来说更重要,而前端编译器在编译期的优化对于程序编码来说关系更加密切。
10.2 Javac 编译器
分析源码是了解一项技术实现内幕的最有效手段,Javac 编译器不像 HotSpot 虚拟机那样使用 C++ 实现,他本身就是一个由 Java 语言编写的程序,这位纯 Java 程序员了解它的编译过程带来了很大的便利。
10.2.1 Javac 的源码与调试
Javac 的源码存放在 JDK_SRC_HOME/langtools/src/share/classes/com/sun/tools/javac 中,除了 JDK 自身的 API 外,就只引用了 JDK_SRC_HOME/langtools/src/share/classes/com/sun/* 里面的代码,调试环境建立起来简单方便,因为基本上不需要处理依赖关系。
虚拟机规范严格定义了 Class 文件的格式,但是“JVM 规范 2”中,虽然有专门的一章“Compiling for the Java Virtual Machine”,但多是以举例的形式描述,并没有对如何把 Java 源文件编译为 Class 文件的编译过程进行十分严格的定义,这导致 Class 文件编译在某种程度上与具体 JDK 实现相关,在一些极端情况下,可能出现对于同一段代码, Javac 编译器可以编译,而 ECJ 编译器就无法编译的问题。从 Sun Javac 的代码来看,编译过程大致可以分为 3 个过程,分别是:
- 解析与填充符号表过程。
- 插入式注解处理器的注解处理过程。
- 分析与字节码生成过程。
这 3 个步骤之间的关系与交互顺序如下图所示:

Javac 编译动作的入口是 com.sun.tools.javac.main.JavaCompiler 类,上述 3 个过程的代码逻辑集中在这个类的 compile 和 compile2 方法中,其中主体代码如下图所示,真个编译最关键的处理就是图中标注的 8 个方法来完成,下面我们具体看一下这 8 个方法实现了什么功能。

10.2.2 解析与填充符号表
解析步骤由上图中的 parseFiles 方法完成,解析步骤包括了经典程序编译原理中的词法分析和语法分析两个过程。
1. 词法分析,语法分析
词法分析是将源代码的字符流转换为标记(token)集合,单个字符是程序编写过程的最小元素,而标记则是编译过程的最小元素,关键字、变量名、字面量、运算符都可以称为标记。如“int a = b + 2” 这个语句包含了 6 个标记,分别是 int、a、=、b、+、2,虽然关键字 int 由 3 个字符构成,但它只是一个 token,不可在被拆分。在 Javac 源码中,词法分析过程由 com.sun.tools.javac.parser.Scanner 类来实现。
语法分析是根据 token 序列构造抽象语法树的过程,抽闲语法树是一种用来描述程序代码语法及饿哦股的树形表示方式,语法树的每个节点都代表着程序代码中的一个语法结构,如包、类型、修饰符、运算符、接口、返回值甚至代码注释等都可以是一个语法结构。
下图根据 Eclipse AST View 插件分析出来的某段代码的抽象语法树视图,读者可以通过这张图对抽象语法树有一个直观的认识。在 Javac 源码中,语法分析过程由 com.sun.tools.javac.parser.Parser 类实现,这个阶段产生的抽象语法树由 com.sun.tools.javac.tree.JCTree 类表示,经过这个步骤之后,编译器就基本不会再对代码的源文件进行操作了,后续的操作都建立在该抽象语法树之上。
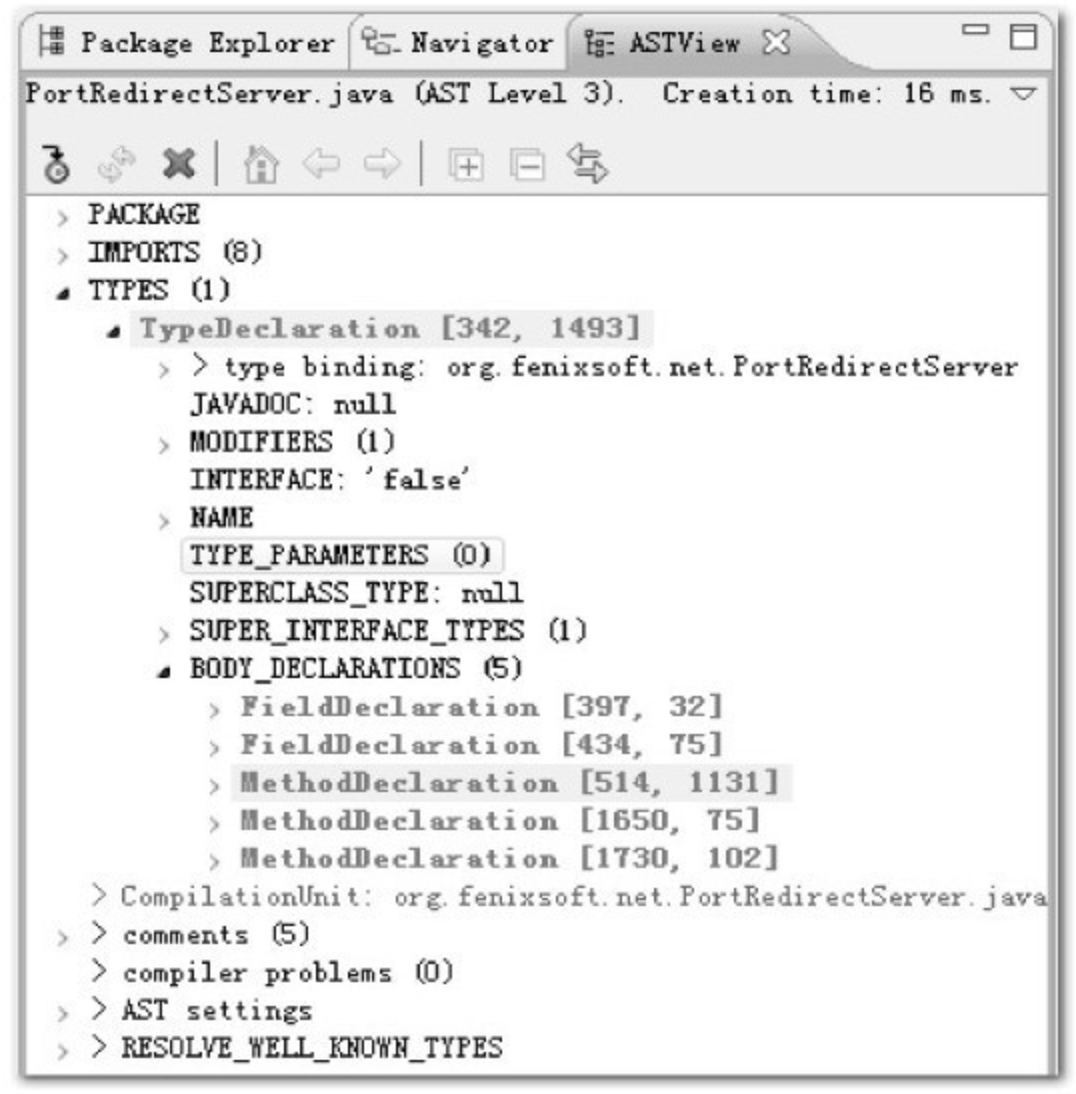
2. 填充符号表
完成了语法分析和词法分析之后,下一步就是填充符号表的过程,也就是 enterTrees 方法完成的工作。符号表是由一组符号地址和符号信息构成的表格,可以把它想象成哈希表中 KV 对的形式。符号表中所记录的信息在编译的不同阶段都要用到。在语义分析中,符号表锁记录的内容将用于语义检查和产生中间代码。在目标代码生成阶段,当对符号名进行地址分配时,符号表是地址分配的依据。
在 Javac 源码中,填充符号表的过程由 com.sun.tools.javac.comp.Enter 类实现,此过程的出口是一个待处理列表,包含了一个编译单元的抽象语法树的顶级节点,以及 package-info.java 的顶级节点(如果有的话)。
10.2.3 注解处理器
在 JDK5 之后,Java 语言提供了对注解的支持,这些注解与普通的 Java 代码一样,是在运行期间发挥作用的。在 JDK6 中实现了 JSR-269 规范,提供了一组插入式注解处理器的标准 API 在编译期间对注解进行处理,可以把它看做是一组编译器插件,在这些插件里面,可以读取、修改、添加抽象语法树中的任意元素。如果这些插件在处理注解期间对语法树进行了修改,编译器将会回到解析及填充符号表的过程重新处理,每次循环称为一个 Round,也就是前面图示中的回环过程。
有了编译器注解处理器的标准 API 之后,我们的代码才有可能干涉编译器的行为,由于语法树中的任意元素,甚至包括代码注释都可以在插件之中访问到,所以通过插入式注解处理器实现的插件在功能上有很大的发挥空间。只要有足够的创意,程序员可以使用插入式注解处理器来实现很多原本只能在编码中完成的事情,本章最后会给出一个使用插入式注解处理器的简单实战。
在 Javac 源码中,插入式注解处理器的初始化过程是在 initPorcessAnnotations 方法中完成的,而它的执行过程则是在 processAnnotations 方法中完成的,该方法判断是否还有新的注解处理器需要执行,如果有的话,通过 com.sun.tools.javac.processing.JavacProcessingEnvironment 类的 doProcessing 方法生成一个新的 JavaCompiler 对象对编译的后续步骤进行处理。
10.2.4 语义分析与字节码生成
语法分析之后,编译器获得了程序代码的抽象语法树表示,语法树能表示一个结构正确的源程序的抽象,但无法保证源程序是符合逻辑的。而语义分析的主要任务是对结构上正确的源程序进行上下文有关性质的审查,如进行类型审查。举个例子,假设有如下 3 个变量定义语句:
int a=1;
boolean b=false;
char c=2;
后续可能出现的赋值运算:
int d=a+c;
int d=b+c;
char d=a+c;
后续代码中如果出现了如上 3 种赋值运算的话,那它们都能构成结构正确的语法树,但是只有第 1 种的写法在语义上是没有问题的,能够通过编译,其余两种在 Java 语言中是不合逻辑的,无法编译。
1. 标注检查
Javac 在编译过程中,语义分析过程中分为标注检查和数据与控制流分析两个步骤,分别由 attribute 和 flow 方法完成。
标注检查步骤检查的内容包括诸如变量使用前是否已被声明、变量与赋值之间的数据类型是否能够匹配等。在标注检查步骤中,还有一个重要的动作称为常量折叠,如果我们在代码中写了如下定义:
int a=1+2;
那么在语法树上仍然能看到字面量 1、2 和操作符 +,但是在经过常量折叠之后,它们将会被折叠为字面量 3,如下图所示,这个插入式表达式的值已经在语法树上标注出来了。由于编译期进行了常量折叠,所以在代码中的定位直接变为a=3,并不会增加程序运行期间哪怕是仅仅一个 CPU 指令的运算量。
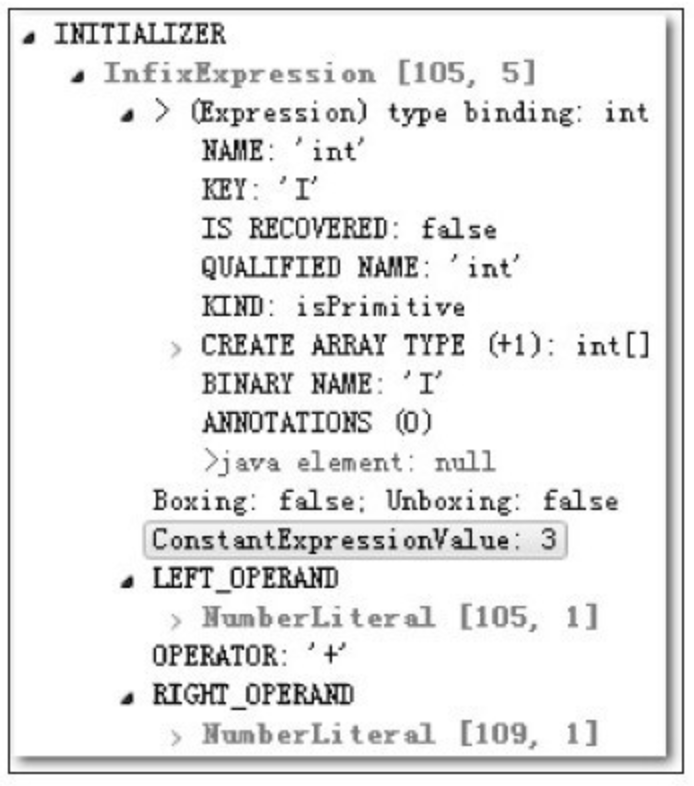
标注检查步骤在 Javac 源码中的实现类是 com.sun.tools.javac.comp.Attr 类和 com.sun.tools.javac.comp.Check 类。
2. 数据及控制流分析
数据及控制流分析是对程序上下文逻辑更进一步的验证,它可以检查出诸如程序局部变量在使用前是否有赋值、方法的每条路径是否都有返回值、是否所有的受查异常都被正确处理了等问题。编译时期的数据及控制流分析与类加载时的数据及控制流分析的目的基本上是一致的,但校验范围有所区别,有一些校验项只有在编译期或运行期才能进行。下面举一个关于 final 修饰符的数据及控制流分析的例子,见如下代码清单。
//方法一带有final修饰
public void foo(final int arg){
final int var=0;
//do something
}
//方法二没有final修饰
public void foo(int arg){
int var=0;
//do something
}
在这两个 foo 方法中,第一种方法的参数和局部变量定义使用了 final 修饰符,而第二种方法则没有,在代码编写时程序肯定会受到 final 修饰符的影响,不能再改变 arg 和 var 变量的值,但是这两段代码编译出来的 Class 文件没有任何区别,通过第 6 章的学习我们已经知道,局部变量与字段是有区别的,它在常量池中没有 CONSTANT_Fieldref_info 的符号引用,自然就没有访问标志信息,甚至可能连名称都不会保留下来,自然在 Class 文件中不能知道一个局部变量是不是声明为 fianl 了。因此,将局部变量声明为 final,对运行期是没有影响的,变量的不变性仅仅由编译器在编译期保障。在 Javac 源码中,数据以及控制流分析的入口是 flow 方法,具体操作由 com.sun.tools.javac.comp.Flow 类来完成。
3. 解语法糖
语法糖是由英国计算机科学家 Peter J.Landin 发明的一个术语,指在计算机语言中添加的某种语法,这种语法对语言的功能没有影响,但是更方便程序员的使用。通常来说,使用语法糖能够增加程序的可读性,从而减少程序代码出错的几乎。
Java 中最常用的语法糖主要是前面提到过的泛型、变长参数、自动装拆箱,虚拟机运行时不支持这些语法,它们在编译阶段还原回简单的基础语法结构,这个过程称为解语法糖。Java 的这些语法糖被解除后是什么样子,将在 10.3 节详细描述。
在 Javac 的源码中,解语法糖的过程是由 desugar 方法触发,在 com.sun.tools.javac.comp.TransTypes 类和 com.sun.tools.javac.comp.Lower 中完成。
4. 字节码生成
字节码生成是 Javac 编译过程的最后一个阶段,在 Javac 源码里面由 com.sun.tools.javac.jvm.Gen 类完成。字节码生成阶段不仅仅是把前面各个步骤生成的信息(语法树、符号表)转换成字节码写到磁盘中,编译器还进行了少量的代码添加和转换工作。
例如,前面章节中多次提到的实例构造器 <init>() 方法和类构造器 <clinit>() 方法就是在该阶段添加到语法树之中的,这两个构造器的产生过程实际上是一个代码收敛的过程,编译器会把语句块(对于实例构造器而言是 {} 块,对于类构造器而言是 static{} 块)、变量初始化、调用父类的实例构造器等操作收敛到 <init>() 和 <clinit>() 方法之中,并且保证一定是按先执行父类的实例构造器,然后初始化变量,最后再执行语句块的顺序进行,上面所述的动作由 Gen.normalizeDefs() 方法来实现。除了生成构造器之外,还有其他的一些代码替换工作用于优化程序的实现逻辑,如把字符串的加发操作替换为 StringBuilder 的 append 操作。
完成了对语法树的遍历和调整之后,就会把填充了所有所需信息的符号表交给 com.sun.tools.javac.jvm.ClassWriter 类,由这个类的 writeClass 方法输出字节码,生成最终的 Class 文件,到此为止整个编译过程宣告结束。
10.3 Java 语法糖的味道
几乎各种语言或多或少都提供过一些语法糖来方便程序员的代码开发,这些语法糖虽然不会提供实质性的功能改进,但是它们或能提高效率,或能提升语法的严谨性,或能减少编码出错的机会。不过也有一种观点认为语法糖并不一定都是有益的,大量添加和使用“含糖”的语法,容易让程序员产生依赖,无法看清语法糖的糖衣背后,程序代码的真实面目。
总而言之,语法糖可以看做是编译器实现的一些“小把戏”,这些“小把戏”可能会使得效率“大提升”,但我们也应该去了解这些“小把戏”背后的真实世界,那样才能利用好它们,而不是被它们所迷惑。
10.3.1 泛型与类型擦除
泛型是 JDK 1.5 的一项新增特性,它的本质是参数化类型的应用,也就是说所操作的数据类型被指定为一个参数。这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口和泛型方法。
泛型思想早在 C++ 语言的模板中就开始生根发芽,在 Java 语言处于还没有出现泛型的版本时,只能通过 Object 是所有类型的父类和类型强制转换两个特点的配合来实现类型泛化。例如,在哈希表的存取中,JDK 1.5 之前使用HashMap 的 get() 方法,返回值就是一个 Object 对象,由于 Java 语言里面所有的类型都继承于 java.lang.Object,所以 Object 转型成任何对象都是有可能的。但是也因为有无限的可能性,就只有程序员和运行期的虚拟机才知道这个 Object 到底是个什么类型的对象。在编译期间,编译器无法检查这个 Object 的强制转型是否成功,如果仅仅依赖程序员去保障这项操作的正确性,许多 ClassCastException 的风险就会转嫁到程序运行期之中。
泛型技术在 C# 和 Java 之中的使用方式看似相同,但实现上却有着根本性的分歧,C# 里面泛型无论在程序源码中、编译后的 IL 中,或是运行期的 CLR 中,都是切实存在的,List<int> 与 List<String> 就是两个不同的类型,它们在系统运行期生成,有自己的虚方法表和类型数据,这种实现称为类型膨胀,基于这种方法实现的泛型称为真实泛型。
Java 语言中的泛型则不一样,它只在程序源码中存在,在编译后的字节码文件中,就已经替换为原来的原生类型了,并且在相应的地方插入了强制转型代码,因此,对于运行期的 Java 语言来说,ArrayList<int> 与 ArrayList<String> 就是同一个类,所以泛型技术实际上是 Java 语言的一颗语法糖,Java 语言中的泛型实现方法称为类型擦除,基于这种方法实现的泛型称为伪泛型。
当初 JDK 设计团队为什么选择类型擦除的方式来实现 Java 语言的泛型支持呢?是因为实现简单、兼容性考虑还是别的原因?我们已不得而知,但确实有不少人对 Java 语言提供的伪泛型颇有微词,当时甚至连《Thinking in Java》一书的作者 Bruce Eckel 也发表了一篇文章《这不是泛型!》来批评 JDK 1.5 中的泛型实现。
在当时众多的批评之中,有一些是比较表面的,还有一些从性能上说泛型会由于强制转型操作和运行期缺少针对类型的优化等从而导致比 C# 的泛型慢一些,则是完全偏离了方向,姑且不论 Java 泛型是不是真的会比 C# 泛型慢,选择从性能的角度上评价用于提升语义准确性的泛型思想就不太恰当。但笔者也并非在为 Java 的泛型辩护,它在某些场景下确实存在不足,笔者认为通过擦除法来实现泛型丧失了一些泛型思想应有的优雅,例如代码清单 10-4 的例子。
public class GenericTypes{
public static void method(List<String>list){
System.out.println("invoke method(List<String>list)");
}
public static void method(List<Integer>list){
System.out.println("invoke method(List<Integer>list)");
}
}
请想一想,上面这段代码是否正确,能否编译执行?也许你已经有了答案,这段代码是不能被编译的,因为参数 List<Integer> 和 List<String> 编译之后都被擦除了,变成了一样的原生类型 List<E>,擦除动作导致这两种方法的特征签名变得一模一样。初步看来,无法重载的原因已经找到了,但真的就是如此吗?只能说,泛型擦除成相同的原生类型只是无法重载的其中一部分原因,请再接着看一看代码清单 10-5 中的内容。
public class GenericTypes{
public static String method(List<String>list){
System.out.println("invoke method(List<String>list)");
return"";
}
public static int method(List<Integer>list){
System.out.println("invoke method(List<Integer>list)");
return 1;
}
public static void main(String[]args){
method(new ArrayList<String>());
method(new ArrayList<Integer>());
}
}
// result
// invoke method(List<String>list)
// invoke method(List<Integer>list)
代码清单 10-5 与代码清单 10-4 的差别是两个 method 方法添加了不同的返回值,由于这两个返回值的加入,方法重载居然成功了,即这段代码可以被编译和执行了。这是对 Java 语言中返回值不参与重载选择的基本认知的挑战吗?
代码清单 10-5 中的重载当然不是根据返回值来确定的,之所以这次能编译和执行成功,是因为两个 method() 方法加入了不同的返回值后才能共存在一个 Class 文件之中。第 6 章介绍 Class 文件方法表的数据结构时曾经提到过,方法重载要求方法具备不同的特征签名,返回值并不包含在方法的特征签名之中,所以返回值不参与重载选择,但是在 Class 文件格式之中,只要描述符不是完全一致的两个方法就可以共存。也就是说,两个方法如果有相同的名称和特征签名,但返回值不同,那它们也是可以合法地共存于一个 Class 文件中的。
由于 Java 泛型的引入,各种场景(虚拟机解析、反射等)下的方法调用都可能对原有的基础产生影响和新的需求,如在泛型类中如何获取传入的参数化类型等。因此,JCP 组织对虚拟机规范做出了相应的修改,引入了诸如 Signature、LocalVariableTypeTable 等新的属性用于解决伴随泛型而来的参数类型的识别问题,Signature 是其中最重要的一项属性,它的作用就是存储一个方法在字节码层面的特征签名,这个属性中保存的参数类型并不是原生类型,而是包括了参数化类型的信息。修改后的虚拟机规范要求所有能识别 49.0 以上版本的 Class 文件的虚拟机都要能正确地识别 Signature 参数。
从上面的例子可以看到擦除法对实际编码带来的影响,由于 List<String> 和 List<Integer> 擦除后是同一个类型,我们只能添加两个并不需要实际使用到的返回值才能完成重载,这是一种毫无优雅和美感可言的解决方案,并且存在一定语意上的混乱,譬如上面脚注中提到的,必须用 Sun JDK 1.6 的 Javac 才能编译成功,其他版本或者 ECJ 编译器都可能拒绝编译。
另外,从 Signature 属性的出现我们还可以得出结论,擦除法所谓的擦除,仅仅是对方法的 Code 属性中的字节码进行擦除,实际上元数据中还是保留了泛型信息,这也是我们能通过反射手段取得参数化类型的根本依据。
10.3.2 自动装箱、拆箱与遍历循环
从纯技术的角度来讲,自动装箱、自动拆箱与遍历循环(Foreach循环)这些语法糖,无论是实现上还是思想上都不能和上文介绍的泛型相比,两者的难度和深度都有很大差距。专门拿出一节来讲解它们只有一个理由:毫无疑问,它们是 Java 语言里使用得最多的语法糖。我们通过代码清单 10-6 和代码清单 10-7 中所示的代码来看看这些语法糖在编译后会发生什么样的变化。
public static void main(String[]args){
List<Integer>list=Arrays.asList(1, 2, 3, 4);
//如果在JDK 1.7中, 还有另外一颗语法糖[1]
//能让上面这句代码进一步简写成List<Integer>list=[1, 2, 3, 4];
int sum=0;
for(int i:list){
sum+=i;
}
System.out.println(sum);
}
public static void main(String[]args){
List list=Arrays.asList(new Integer[]{
Integer.valueOf(1),
Integer.valueOf(2),
Integer.valueOf(3),
Integer.valueOf(4)});
int sum=0;
for(Iterator localIterator=list.iterator();localIterator.hasNext();){
int i=((Integer)localIterator.next()).intValue();
sum+=i;
}
System.out.println(sum);
}
代码清单 10-6 中一共包含了泛型、自动装箱、自动拆箱、遍历循环与变长参数 5 种语法糖,代码清单 10-7 则展示了它们在编译后的变化。泛型就不必说了,自动装箱、拆箱在编译之后被转化成了对应的包装和还原方法,如本例中的 Integer.valueOf() 与 Integer.intValue() 方法,而遍历循环则把代码还原成了迭代器的实现,这也是为何遍历循环需要被遍历的类实现 Iterable 接口的原因。最后再看看变长参数,它在调用的时候变成了一个数组类型的参数,在变长参数出现之前,程序员就是使用数组来完成类似功能的。
这些语法糖虽然看起来很简单,但也不见得就没有任何值得我们注意的地方,代码清单 10-8 演示了自动装箱的一些错误用法。
public static void main(String[]args){
Integer a=1;
Integer b=2;
Integer c=3;
Integer d=3;
Integer e=321;
Integer f=321;
Long g=3L;
System.out.println(c==d);
System.out.println(e==f);
System.out.println(c==(a+b));
System.out.println(c.equals(a+b));
System.out.println(g==(a+b));
System.out.println(g.equals(a+b));
}
阅读完代码清单 10-8,读者不妨思考两个问题:一是这 6 句打印语句的输出是什么?二是这 6 句打印语句中,解除语法糖后参数会是什么样子?这两个问题的答案可以很容易试验出来,笔者就暂且略去答案,希望读者自己上机实践一下。无论读者的回答是否正确,鉴于包装类的“==”运算在不遇到算术运算的情况下不会自动拆箱,以及它们 equals() 方法不处理数据转型的关系,笔者建议在实际编码中尽量避免这样使用自动装箱与拆箱。
10.3.3 条件编译
许多程序设计语言都提供了条件编译的途径,如 C/C++ 中使用预处理器指示符(#ifdef)来完成条件编译。C/C++ 的预处理器最初的任务是解决编译时的代码依赖关系(如非常常用的 #include 预处理命令),而在 Java 语言之中并没有使用预处理器,因为 Java 语言天然的编译方式(编译器并非一个个地编译 Java 文件,而是将所有编译单元的语法树顶级节点输入到待处理列表后再进行编译,因此各个文件之间能够互相提供符号信息)无须使用预处理器。那 Java 语言是否有办法实现条件编译呢?
Java 语言当然也可以进行条件编译,方法就是使用条件为常量的 if 语句。如代码清单 10-9 所示,此代码中的 if 语句不同于其他 Java 代码,它在编译阶段就会被“运行”,生成的字节码之中只包括 System.out.println("block 1"); 一条语句,并不会包含 if 语句及另外一个分子中的 System.out.println("block 2");。
public static void main(String[]args){
if(true){
System.out.println("block 1");
}else{
System.out.println("block 2");
}
}
上述代码编译后 Class 文件的反编译效果:
public static void main(String[]args){
System.out.println("block 1");
}
只能使用条件为常量的 if 语句才能达到上述效果,如果使用常量与其他带有条件判断能力的语句搭配,则可能在控制流分析中提示错误,被拒绝编译,如代码清单 10-10 所示的代码就会被编译器拒绝编译。
public static void main(String[]args){
//编译器将会提示"Unreachable code"
while(false){
System.out.println("");
}
}
Java 语言中条件编译的实现,也是 Java 语言的一颗语法糖,根据布尔常量值的真假,编译器将会把分支中不成立的代码块消除掉,这一工作将在编译器解除语法糖阶段(com.sun.tools.javac.comp.Lower 类中)完成。由于这种条件编译的实现方式使用了 if 语句,所以它必须遵循最基本的 Java 语法,只能写在方法体内部,因此它只能实现语句基本块级别的条件编译,而没有办法实现根据条件调整整个 Java 类的结构。
除了本节中介绍的泛型、自动装箱、自动拆箱、遍历循环、变长参数和条件编译之外,Java 语言还有不少其他的语法糖,如内部类、枚举类、断言语句、对枚举和字符串的 switch 支持、try 语句中定义和关闭资源等,读者可以通过跟踪 Javac 源码、反编译 Class 文件等方式了解它们的本质实现,囿于篇幅,笔者就不再一一介绍了。
10.4 实战:插入式注解处理器
JDK 编译优化部分在本书中并没有设置独立的实战章节,因为我们开发程序,考虑的主要是程序会如何运行,很少会有针对程序编译的需求。也因为这个原因,在 JDK 的编译子系统里面,提供给用户直接控制的功能相对较少,除了第 11 章会介绍的虚拟机 JIT 编译的几个相关参数以外,我们就只有使用 JSR-296 中定义的插入式注解处理器 API 来对 JDK 编译子系统的行为产生一些影响。
但是笔者并不认为相对于前两部分介绍的内存管理子系统和字节码执行子系统,JDK 的编译子系统就不那么重要。一套编程语言中编译子系统的优劣,很大程度上决定了程序运行性能的好坏和编码效率的高低,尤其在 Java 语言中,运行期即时编译与虚拟机执行子系统非常紧密地互相依赖、配合运作。了解 JDK 如何编译和优化代码,有助于我们写出适合 JDK 自优化的程序。下面我们回到本章的实战中,看看插入式注解处理器 API 能实现什么功能。
10.4.1 实战目标
通过阅读 Javac 编译器的源码,我们知道编译器在把 Java 程序源码编译为字节码的时候,会对 Java 程序源码做各方面的检查校验。这些校验主要以程序“写得对不对”为出发点,虽然也有各种 WARNING 的信息,但总体来讲还是较少去校验程序“写得好不好”。有鉴于此,业界出现了许多针对程序“写得好不好”的辅助校验工具,如 CheckStyle、FindBug、Klocwork 等。这些代码校验工具有一些是基于 Java 的源码进行校验,还有一些是通过扫描字节码来完成,在本节的实战中,我们将会使用注解处理器 API 来编写一款拥有自己编码风格的校验工具:NameCheckProcessor。
当然,由于我们的实战都是为了学习和演示技术原理,而不是为了做出一款能媲美 CheckStyle 等工具的产品来,所以 NameCheckProcessor 的目标也仅定为对 Java 程序命名进行检查,根据《Java语言规范(第3版)》中第 6.8 节的要求,Java 程序命名应当符合下列格式的书写规范。
- 类:符合驼峰命名法,首字母大写。
- 方法:符合驼式命名法,首字母小写。
- 类或实例变量:符合驼式命名法,首字母小写。
- 常量:要求全部由大写字母或下划线构成,并且第一个字符不能是下划线。
10.4.2 代码实现
要通过注解处理器 API 实现一个编译器插件,首先需要了解这组 API 的一些基本知识。
我们实现注解处理器的代码需要继承抽象类 javax.annotation.processing.AbstractProcessor,这个抽象类中只有一个必须覆盖的 abstract 方法:“process()",它是 Javac 编译器在执行注解处理器代码时要调用的过程,我们可以从这个方法的第一个参数"annotations"中获取到此注解处理器所要处理的注解集合,从第二个参数"roundEnv"中访问到当前这个 Round 中的语法树节点,每个语法树节点在这里表示为一个 Element。在 JDK 1.6 新增的 javax.lang.model 包中定义了 16 类 Element,包括了 Java 代码中最常用的元素,如:
- PACKAGE
- ENUM
- CLASS
- ANNOTATION_TYPE
- INTERFACE
- ENUM_CONSTANT
- FIELD
- PARAMETER
- LOCAL_VARIABLE
- EXCEPTION_PARAMETER
- METHOD
- CONSTRUCTOR
- STATIC_INIT
- INSTANCE_INIT
- TYPE_PARAMETER
- OTHER
除了 process() 方法的传入参数之外,还有一个很常用的实例变量"processingEnv”,它是 AbstractProcessor 中的一个 protected 变量,在注解处理器初始化的时候(init() 方法执行的时候)创建,继承了 AbstractProcessor 的注解处理器代码可以直接访问到它。它代表了注解处理器框架提供的一个上下文环境,要创建新的代码、向编译器输出信息、获取其他工具类等都需要用到这个实例变量。
注解处理器除了 process() 方法及其参数之外,还有两个可以配合使用的 Annotations:@SupportedAnnotationTypes 和 @SupportedSourceVersion,前者代表了这个注解处理器对哪些注解感兴趣,可以使用星号 * 作为通配符代表对所有的注解都感兴趣,后者指出这个注解处理器可以处理哪些版本的 Java 代码。
每一个注解处理器在运行的时候都是单例的,如果不需要改变或生成语法树的内容,process() 方法就可以返回一个值为 false 的布尔值,通知编译器这个 Round 中的代码未发生变化,无须构造新的 JavaCompiler 实例,在这次实战的注解处理器中只对程序命名进行检查,不需要改变语法树的内容,因此 process() 方法的返回值都是 false。关于注解处理器的 API,笔者就简单介绍这些,对这个领域有兴趣的读者可以阅读相关的帮助文档。下面来看看注解处理器 NameCheckProcessor 的具体代码,如代码清单 10-11 所示。
//可以用"*"表示支持所有Annotations
@SupportedAnnotationTypes("*")
//只支持JDK 1.6的Java代码
@SupportedSourceVersion(SourceVersion.RELEASE_6)
public class NameCheckProcessor extends AbstractProcessor{
private NameChecker nameChecker;
/**
*初始化名称检查插件
*/
@Override
public void init(ProcessingEnvironment processingEnv){
super.init(processingEnv);
nameChecker=new NameChecker(processingEnv);
}
/**
*对输入的语法树的各个节点进行名称检查
*/
@Override
public boolean process(Set<?extends TypeElement>annotations,RoundEnvironment roundEnv){
if(!roundEnv.processingOver()){
for(Element element:roundEnv.getRootElements())
nameChecker.checkNames(element);
}
return false;
}
}
从上面代码可以看出,NameCheckProcessor 能处理基于 JDK 1.6 的源码,它不限于特定的注解,对任何代码都“感兴趣”,而在 process() 方法中是把当前 Round 中的每一个 RootElement 传递到一个名为 NameChecker 的检查器中执行名称检查逻辑,NameChecker 的代码如代码清单 10-12 所示。
/**
*程序名称规范的编译器插件:<br>
*如果程序命名不合规范, 将会输出一个编译器的WARNING信息
*/
public class NameChecker{
private final Messager messager;
NameCheckScanner nameCheckScanner=new NameCheckScanner();
NameChecker(ProcessingEnvironment processsingEnv){
this.messager=processsingEnv.getMessager();
}
/**
*对Java程序命名进行检查, 根据《Java语言规范(第3版)》第6.8节的要求, Java程序命名应当符合下列格式:
*
*<ul>
*<li>类或接口:符合驼式命名法, 首字母大写。
*<li>方法:符合驼式命名法, 首字母小写。
*<li>字段:
*<ul>
*<li>类、实例变量:符合驼式命名法, 首字母小写。
*<li>常量:要求全部大写。
*</ul>
*</ul>
*/
public void checkNames(Element element){
nameCheckScanner.scan(element);
}
/**
*名称检查器实现类, 继承了JDK 1.6中新提供的ElementScanner6<br>
*将会以Visitor模式访问抽象语法树中的元素
*/
private class NameCheckScanner extends ElementScanner6<Void,Void>{
/**
*此方法用于检查Java类
*/
@Override
public Void visitType(TypeElement e,Void p){
scan(e.getTypeParameters(), p);
checkCamelCase(e,true);
super.visitType(e,p);
return null;
}
/**
*检查方法命名是否合法
*/
@Override
public Void visitExecutable(ExecutableElement e,Void p){
if(e.getKind()==METHOD){
Name name=e.getSimpleName();
if
(name.contentEquals(e.getEnclosingElement().getSimpleName()))
messager.printMessage(WARNING, "一个普通方法""+name+""不应当与类名重复, 避免与构造函数产生混淆", e);
checkCamelCase(e,false);
}
super.visitExecutable(e,p);
return null;
}
/**
*检查变量命名是否合法
*/
@Override
public Void visitVariable(VariableElement e,Void p){
//如果这个Variable是枚举或常量, 则按大写命名检查, 否则按照驼式命名法规则检查
if(e.getKind()==ENUM_CONSTANT||e.getConstantValue()!=null||heuristicallyConstant(e))
checkAllCaps(e);
else
checkCamelCase(e,false);
return null;
}
/**
*判断一个变量是否是常量
*/
private boolean heuristicallyConstant(VariableElement e){
if(e.getEnclosingElement().getKind()==INTERFACE)
return true;
else if(e.getKind()==FIELD&&e.getModifiers().containsAll(EnumSet.of(PUBLIC,STATIC,FINAL)))
return true;
else{
return false;
}
}
/**
*检查传入的Element是否符合驼式命名法, 如果不符合, 则输出警告信息
*/
private void checkCamelCase(Element e,boolean initialCaps){
String name=e.getSimpleName().toString();
boolean previousUpper=false;
boolean conventional=true;
int firstCodePoint=name.codePointAt(0);
if(Character.isUpperCase(firstCodePoint)){
previousUpper=true;
if(!initialCaps){
messager.printMessage(WARNING, "名称""+name+""应当以小写字母开头", e);
return;
}
}else if(Character.isLowerCase(firstCodePoint)){
if(initialCaps){
messager.printMessage(WARNING, "名称""+name+""应当以大写字母开头", e);
return;
}
}else
conventional=false;
if(conventional){
int cp=firstCodePoint;
for(int i=Character.charCount(cp);i<name.length();i+=Character.charCount(cp)){
cp=name.codePointAt(i);
if(Character.isUpperCase(cp)){
if(previousUpper){
conventional=false;
break;
}
previousUpper=true;
}else
previousUpper=false;
}
}
if(!conventional)
messager.printMessage(WARNING, "名称""+name+""应当符合驼式命名法(Camel Case Names)", e);
}
/**
*大写命名检查, 要求第一个字母必须是大写的英文字母, 其余部分可以是下划线或大写字母
*/
private void checkAllCaps(Element e){
String name=e.getSimpleName().toString();
boolean conventional=true;
int firstCodePoint=name.codePointAt(0);
if(!Character.isUpperCase(firstCodePoint))
conventional=false;
else{
boolean previousUnderscore=false;
int cp=firstCodePoint;
for(int i=Character.charCount(cp);i<name.length();i+=Character.charCount(cp)){
cp=name.codePointAt(i);
if(cp==(int)'_'){
if(previousUnderscore){
conventional=false;
break;
}
previousUnderscore=true;
}else{
previousUnderscore=false;
if(!Character.isUpperCase(cp)&&!Character.isDigit(cp))
{
conventional=false;
break;
}
}
}
}
if(!conventional)
messager.printMessage(WARNING, "常量""+name+""应当全部以大写字母或下划线命名, 并且以字母开头", e);
}
}
}
NameChecker 的代码看起来有点长,但实际上注释占了很大一部分,其实即使算上注释也不到 190 行。它通过一个继承于 javax.lang.model.util.ElementScanner6 的 NameCheckScanner 类,以 Visitor 模式来完成对语法树的遍历,分别执行 visitType()、visitVariable() 和 visitExecutable() 方法来访问类、字段和方法,这 3 个 visit 方法对各自的命名规则做相应的检查,checkCamelCase() 与 checkAllCaps() 方法则用于实现驼式命名法和全大写命名规则的检查。
整个注解处理器只需 NameCheckProcessor 和 NameChecker 两个类就可以全部完成,为了验证我们的实战成果,代码清单 10-13 中提供了一段命名规范的“反面教材”代码,其中的每一个类、方法及字段的命名都存在问题,但是使用普通的Javac编译这段代码时不会提示任何一个 Warning 信息。
public class BADLY_NAMED_CODE{
enum colors{
red,blue,green;
}
static final int_FORTY_TWO=42;
public static int NOT_A_CONSTANT=_FORTY_TWO;
protected void BADLY_NAMED_CODE(){
return;
}
public void NOTcamelCASEmethodNAME(){
return;
}
}
10.4.3 运行与测试
我们可以通过 Javac 命令的"-processor"参数来执行编译时需要附带的注解处理器,如果有多个注解处理器的话,用逗号分隔。还可以使用 -XprintRounds 和 -XprintProcessorInfo 参数来查看注解处理器运作的详细信息,本次实战中的 NameCheckProcessor 的编译及执行过程如代码清单 10-14 所示。
D:\src>javac org/fenixsoft/compile/NameChecker.java
D:\src>javac org/fenixsoft/compile/NameCheckProcessor.java
D:\src>javac-processor org.fenixsoft.compile.NameCheckProcessor org/fenixsoft/compile/BADLY_NAMED_CODE.java
org\fenixsoft\compile\BADLY_NAMED_CODE.java:3:警告:名称"BADLY_NAMED_CODE"应当符合驼式命名法(Camel Case Names)
public class BADLY_NAMED_CODE{
^
org\fenixsoft\compile\BADLY_NAMED_CODE.java:5:警告:名称"colors"应当以大写字母开头
enum colors{
^
org\fenixsoft\compile\BADLY_NAMED_CODE.java:6:警告:常量"red"应当全部以大写字母或下划线命名, 并且以字母开头
red,blue,green;
^
org\fenixsoft\compile\BADLY_NAMED_CODE.java:6:警告:常量"blue"应当全部以大写字母或下划线命名, 并且以字母开头
red,blue,green;
^
org\fenixsoft\compile\BADLY_NAMED_CODE.java:6:警告:常量"green"应当全部以大写字母或下划线命名, 并且以字母开头
red,blue,green;
^
org\fenixsoft\compile\BADLY_NAMED_CODE.java:9:警告:常量"_FORTY_TWO"应当全部以大写字母或下划线命名, 并且以字母开头
static final int_FORTY_TWO=42;
^
org\fenixsoft\compile\BADLY_NAMED_CODE.java:11:警告:名称"NOT_A_CONSTANT"应当以小写字母开头
public static int NOT_A_CONSTANT=_FORTY_TWO;
^
org\fenixsoft\compile\BADLY_NAMED_CODE.java:13:警告:名称"Test"应当以小写字母开头
protected void Test(){
^
org\fenixsoft\compile\BADLY_NAMED_CODE.java:17:警告:名称"NOTcamelCASEmethodNAME"应当以小写字母开头
public void NOTcamelCASEmethodNAME(){
^
10.4.4 其他应用案例
NameCheckProcessor 的实战例子只演示了 JSR-269 嵌入式注解处理器 API 中的一部分功能,基于这组 API 支持的项目还有用于校验 Hibernate 标签使用正确性的Hibernate Validator Annotation Processor、自动为字段生成 getter 和 setter 方法的 Project Lombok 等,读者有兴趣的话可以参考它们官方站点的相关内容。
10.5 本章小结
在本章中,我们从编译器源码实现的层次上了解了 Java 源代码编译为字节码的过程,分析了 Java 语言中泛型、主动装箱/拆箱、条件编译等多种语法糖的前因后果,并实战练习了如何使用插入式注解处理器来完成一个检查程序命名规范的编译器插件。如本章概述中所说的那样,在前端编译器中,“优化”手段主要用于提升程序的编码效率,之所以把 Javac 这类将 Java 代码转变为字节码的编译器称做“前端编译器”,是因为它只完成了从程序到抽象语法树或中间字节码的生成,而在此之后,还有一组内置于虚拟机内部的“后端编译器”完成了从字节码生成本地机器码的过程,即前面多次提到的即时编译器或JIT编译器,这个编译器的编译速度及编译结果的优劣,是衡量虚拟机性能一个很重要的指标。
11 - CH11-运行时优化
11.1 概述
在部分的商用虚拟机(Sun HotSpot、IBM J9)中,Java 程序最初是通过解释器(Interpreter)进行解释执行的,当虚拟机发现某个方法或代码块的运行特别频繁时,就会把这些代码认定为“热点代码”(Hot Spot Code)。为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各种层次的优化,完成这个任务的编译器称为即时编译器(JIT)。
即时编译器并不是虚拟机必需的部分,Java 虚拟机规范并没有规定 Java 虚拟机内必须要有即时编译器存在,更没有限定或指导即时编译器应该如何去实现。但是,即时编译器编译性能的好坏、代码优化程度的高低却是衡量一款商用虚拟机优秀与否的最关键的指标之一,它也是虚拟机中最核心且最能体现虚拟机技术水平的部分。在本章中,我们将走进虚拟机的内部,探索即时编译器的运作过程。
由于 Java 虚拟机规范没有具体的约束规则去限制即时编译器应该如何实现,所以这部分功能完全是与虚拟机具体实现相关的内容,如无特殊说明,本章提及的编译器、即时编译器都是指 HotSpot 虚拟机内的即时编译器,虚拟机也是特指 HotSpot 虚拟机。不过,本章的大部分内容是描述即时编译器的行为,涉及编译器实现层面的内容较少,而主流虚拟机中即时编译器的行为又有很多相似和相通之处,因此,对其他虚拟机来说也具有较高的参考意义。
11.2 HotSpot VM 内的即时编译器
在本节中,我们将要了解 HotSpot 虚拟机内的即时编译器的运作过程,同时,还要解决以下几个问题:
- 为何 HotSpot 虚拟机要使用解释器与编译器并存的架构?
- 为何 HotSpot 虚拟机要实现两个不同的即时编译器?
- 程序何时使用解释器执行?何时使用编译器执行?
- 哪些程序代码会被编译为本地代码?如何编译为本地代码?
- 如何从外部观察即时编译器的编译过程和编译结果?
11.2.1 解释器与编译器
尽管并不是所有的 Java 虚拟机都采用解释器与编译器并存的架构,但许多主流的商用虚拟机,如 HotSpot、J9 等,都同时包含解释器与编译器。解释器与编译器两者各有优势:当程序需要迅速启动和执行的时候,解释器可以首先发挥作用,省去编译的时间,立即执行。在程序运行后,随着时间的推移,编译器逐渐发挥作用,把越来越多的代码编译成本地代码之后,可以获取更高的执行效率。当程序运行环境中内存资源限制较大(如部分嵌入式系统中),可以使用解释执行节约内存,反之可以使用编译执行来提升效率。同时,解释器还可以作为编译器激进优化时的一个“逃生门”,让编译器根据概率选择一些大多数时候都能提升运行速度的优化手段,当激进优化的假设不成立,如加载了新类后类型继承结构出现变化、出现“罕见陷阱”时可以通过逆优化退回到解释状态继续执行(部分没有解释器的虚拟机中也会采用不进行激进优化的 C1 编译器担任“逃生门”的角色),因此,在整个虚拟机执行架构中,解释器与编译器经常配合工作,如图 11-1 所示。
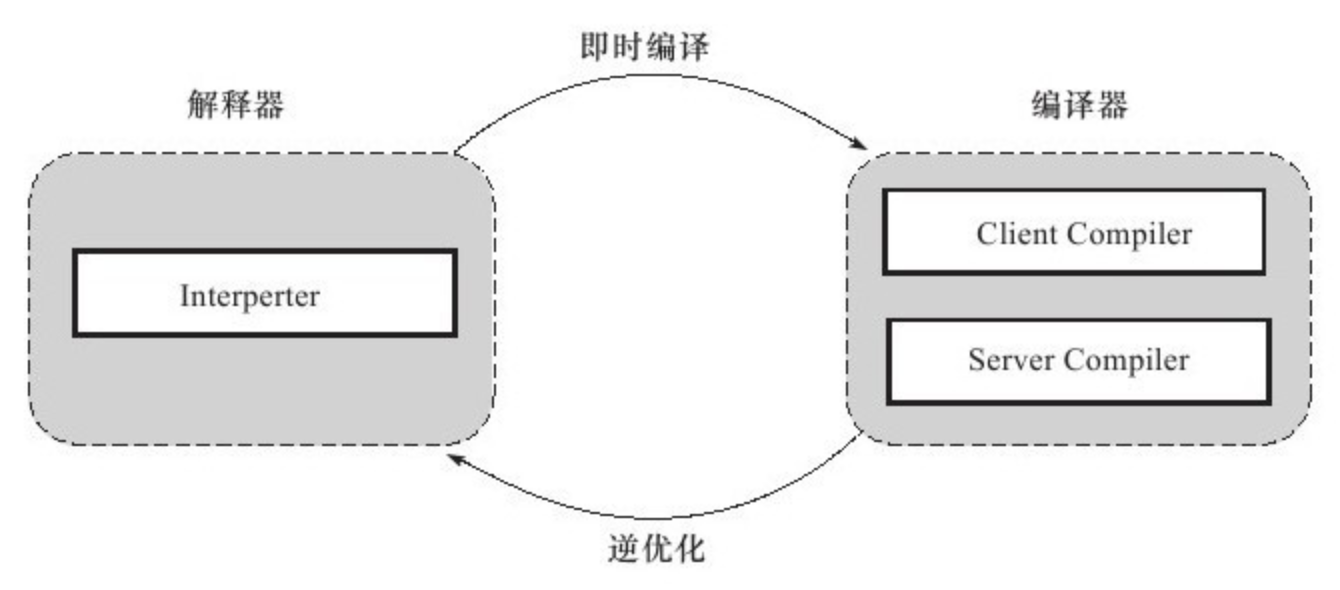
HotSpot 虚拟机中内置了两个即时编译器,分别称为 Client Compiler 和 Server Compiler,或者简称为 C1 编译器和 C2 编译器(也叫Opto编译器)。目前主流的 HotSpot 虚拟机(Sun系列JDK 1.7及之前版本的虚拟机)中,默认采用解释器与其中一个编译器直接配合的方式工作,程序使用哪个编译器,取决于虚拟机运行的模式,HotSpot 虚拟机会根据自身版本与宿主机器的硬件性能自动选择运行模式,用户也可以使用"-client"或"-server"参数去强制指定虚拟机运行在 Client 模式或 Server 模式。
无论采用的编译器是 Client Compiler 还是 Server Compiler,解释器与编译器搭配使用的方式在虚拟机中称为“混合模式”,用户可以使用参数"-Xint"强制虚拟机运行于“解释模式”,这时编译器完全不介入工作,全部代码都使用解释方式执行。另外,也可以使用参数"-Xcomp"强制虚拟机运行于“编译模式”,这时将优先采用编译方式执行程序,但是解释器仍然要在编译无法进行的情况下介入执行过程,可以通过虚拟机的"-version"命令的输出结果显示出这3种模式,如代码清单 11-1 所示,请注意黑体字部分。
C:\>java-version
java version"1.6.0_22"
Java(TM)SE Runtime Environment(build 1.6.0_22-b04)
Dynamic Code Evolution 64-Bit Server VM(build 0.2-b02-internal, 19.0-b04-internal,mixed mode)
C:\>java-Xint-version
java version"1.6.0_22"
Java(TM)SE Runtime Environment(build 1.6.0_22-b04)
Dynamic Code Evolution 64-Bit Server VM(build 0.2-b02-internal, 19.0-b04-internal,interpreted mode)
C:\>java-Xcomp-version
java version"1.6.0_22"
Java(TM)SE Runtime Environment(build 1.6.0_22-b04)
Dynamic Code Evolution 64-Bit Server VM(build 0.2-b02-internal, 19.0-b04-internal,compiled mode)
由于即时编译器编译本地代码需要占用程序运行时间,要编译出优化程度更高的代码,所花费的时间可能更长;而且想要编译出优化程度更高的代码,解释器可能还要替编译器收集性能监控信息,这对解释执行的速度也有影响。为了在程序启动响应速度与运行效率之间达到最佳平衡,HotSpot 虚拟机还会逐渐启用分层编译的策略,分层编译的概念在 JDK 1.6 时期出现,后来一直处于改进阶段,最终在 JDK 1.7 的 Server 模式虚拟机中作为默认编译策略被开启。分层编译根据编译器编译、优化的规模与耗时,划分出不同的编译层次,其中包括:
- 0,程序解释执行,解释器不开启性能监控功能(Profiling),可触发第 1 层编译。
- 1,也称为 C1 编译,将字节码编译为本地代码,进行简单、可靠的优化,如有必要将加入性能监控的逻辑。
- 2,也称为 C2 编译,也是将字节码编译为本地代码,但是会启用一些编译耗时较长的优化,甚至会根据性能监控信息进行一些不可靠的激进优化。
实施分层编译后,Client Compiler 和 Server Compiler 将会同时工作,许多代码都可能会被多次编译,用 Client Compiler 获取更高的编译速度,用 Server Compiler 来获取更好的编译质量,在解释执行的时候也无须再承担收集性能监控信息的任务。
11.2.2 编译对象与触发条件
上文中提到过,在运行过程中会被即时编译器编译的“热点代码”有两类,即:
- 被多次调用的方法。
- 被多次执行的循环体。
前者很好理解,一个方法被调用得多了,方法体内代码执行的次数自然就多,它成为“热点代码”是理所当然的。而后者则是为了解决一个方法只被调用过一次或少量的几次,但是方法体内部存在循环次数较多的循环体的问题,这样循环体的代码也被重复执行多次,因此这些代码也应该认为是“热点代码”。
对于第一种情况,由于是由方法调用触发的编译,因此编译器理所当然地会以整个方法作为编译对象,这种编译也是虚拟机中标准的 JIT 编译方式。而对于后一种情况,尽管编译动作是由循环体所触发的,但编译器依然会以整个方法(而不是单独的循环体)作为编译对象。这种编译方式因为编译发生在方法执行过程之中,因此形象地称之为栈上替换(On Stack Replacement,简称为 OSR 编译,即方法栈帧还在栈上,方法就被替换了)。
读者可能还会有疑问,在上面的文字描述中,无论是“多次执行的方法”,还是“多次执行的代码块”,所谓“多次”都不是一个具体、严谨的用语,那到底多少次才算“多次”呢?还有一个问题,就是虚拟机如何统计一个方法或一段代码被执行过多少次呢?解决了这两个问题,也就回答了即时编译被触发的条件。
判断一段代码是不是热点代码,是不是需要触发即时编译,这样的行为称为热点探测(Hot Spot Detection),其实进行热点探测并不一定要知道方法具体被调用了多少次,目前主要的热点探测判定方式有两种,分别如下。
基于采样的热点探测(Sample Based Hot Spot Detection):采用这种方法的虚拟机会周期性地检查各个线程的栈顶,如果发现某个(或某些)方法经常出现在栈顶,那这个方法就是“热点方法”。基于采样的热点探测的好处是实现简单、高效,还可以很容易地获取方法调用关系(将调用堆栈展开即可),缺点是很难精确地确认一个方法的热度,容易因为受到线程阻塞或别的外界因素的影响而扰乱热点探测。
基于计数器的热点探测(Counter Based Hot Spot Detection):采用这种方法的虚拟机会为每个方法(甚至是代码块)建立计数器,统计方法的执行次数,如果执行次数超过一定的阈值就认为它是“热点方法”。这种统计方法实现起来麻烦一些,需要为每个方法建立并维护计数器,而且不能直接获取到方法的调用关系,但是它的统计结果相对来说更加精确和严谨。
在 HotSpot 虚拟机中使用的是第二种——基于计数器的热点探测方法,因此它为每个方法准备了两类计数器:方法调用计数器(Invocation Counter)和回边计数器(Back Edge Counter)。
在确定虚拟机运行参数的前提下,这两个计数器都有一个确定的阈值,当计数器超过阈值溢出了,就会触发 JIT 编译。
我们首先来看看方法调用计数器。顾名思义,这个计数器就用于统计方法被调用的次数,它的默认阈值在 Client 模式下是 1500 次,在 Server 模式下是 10 000 次,这个阈值可以通过虚拟机参数 -XX:CompileThreshold 来人为设定。当一个方法被调用时,会先检查该方法是否存在被 JIT 编译过的版本,如果存在,则优先使用编译后的本地代码来执行。如果不存在已被编译过的版本,则将此方法的调用计数器值加 1,然后判断方法调用计数器与回边计数器值之和是否超过方法调用计数器的阈值。如果已超过阈值,那么将会向即时编译器提交一个该方法的代码编译请求。
如果不做任何设置,执行引擎并不会同步等待编译请求完成,而是继续进入解释器按照解释方式执行字节码,直到提交的请求被编译器编译完成。当编译工作完成之后,这个方法的调用入口地址就会被系统自动改写成新的,下一次调用该方法时就会使用已编译的版本。整个 JIT 编译的交互过程如图 11-2 所示。
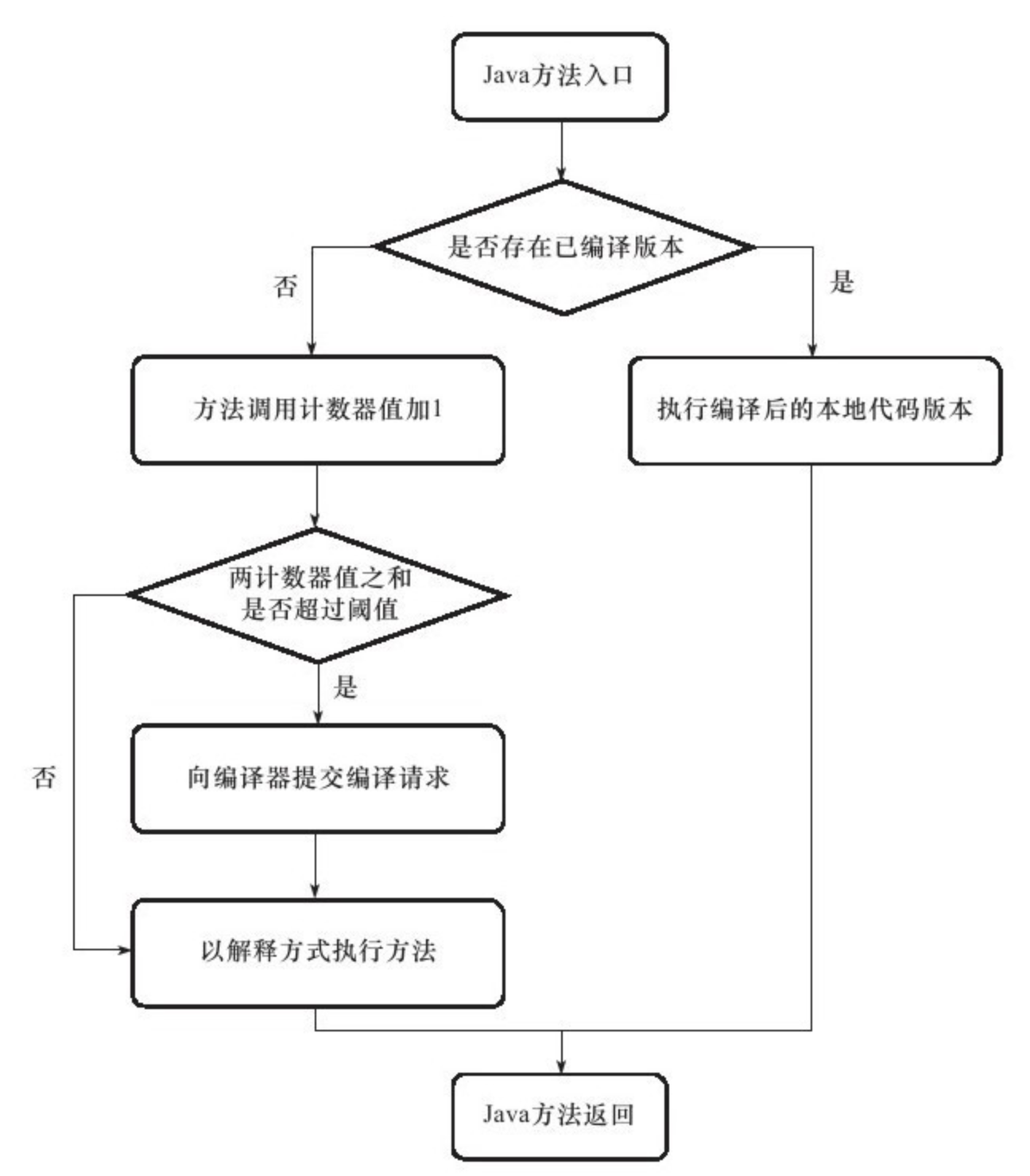
如果不做任何设置,方法调用计数器统计的并不是方法被调用的绝对次数,而是一个相对的执行频率,即一段时间之内方法被调用的次数。当超过一定的时间限度,如果方法的调用次数仍然不足以让它提交给即时编译器编译,那这个方法的调用计数器就会被减少一半,这个过程称为方法调用计数器热度的衰减,而这段时间就称为此方法统计的半衰周期。进行热度衰减的动作是在虚拟机进行垃圾收集时顺便进行的,可以使用虚拟机参数 -XX:-UseCounterDecay 来关闭热度衰减,让方法计数器统计方法调用的绝对次数,这样,只要系统运行时间足够长,绝大部分方法都会被编译成本地代码。另外,可以使用 -XX:CounterHalfLifeTime 参数设置半衰周期的时间,单位是秒。
现在我们再来看看另外一个计数器——回边计数器,它的作用是统计一个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令称为“回边”。显然,建立回边计数器统计的目的就是为了触发 OSR 编译。
关于回边计数器的阈值,虽然 HotSpot 虚拟机也提供了一个类似于方法调用计数器阈值 -XX:CompileThreshold 的参数 -XX:BackEdgeThreshold 供用户设置,但是当前的虚拟机实际上并未使用此参数,因此我们需要设置另外一个参数 -XX:OnStackReplacePercentage 来间接调整回边计数器的阈值,其计算公式如下。
虚拟机运行在 Client 模式下,回边计数器阈值计算公式为:方法调用计数器阈值(CompileThreshold) × OSR 比率(OnStackReplacePercentage) /100。
其中 OnStackReplacePercentage 默认值为 933,如果都取默认值,那 Client 模式虚拟机的回边计数器的阈值为 13995。
虚拟机运行在 Server 模式下,回边计数器阈值的计算公式为:
方法调用计数器阈值(CompileThreshold) × (OSR比率(OnStackReplacePercentage) - (解释器监控比率(InterpreterProfilePercentage) / 100。
其中 OnStackReplacePercentag e默认值为 140,InterpreterProfilePercentage 默认值为 33,如果都取默认值,那 Server 模式虚拟机回边计数器的阈值为 10700。
当解释器遇到一条回边指令时,会先查找将要执行的代码片段是否有已经编译好的版本,如果有,它将会优先执行已编译的代码,否则就把回边计数器的值加 1,然后判断方法调用计数器与回边计数器值之和是否超过回边计数器的阈值。当超过阈值的时候,将会提交一个 OSR 编译请求,并且把回边计数器的值降低一些,以便继续在解释器中执行循环,等待编译器输出编译结果,整个执行过程如图 11-3 所示。
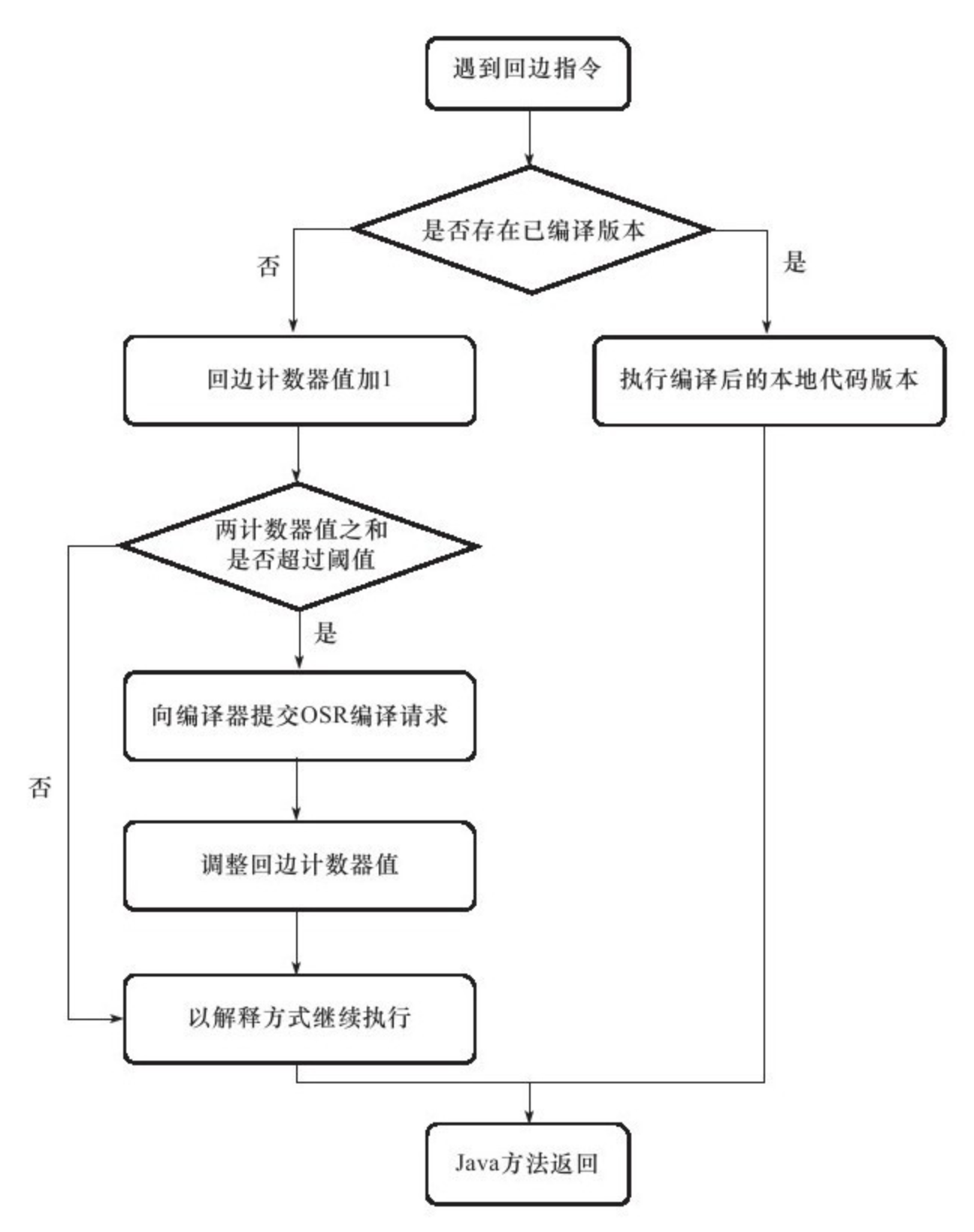
与方法计数器不同,回边计数器没有计数热度衰减的过程,因此这个计数器统计的就是该方法循环执行的绝对次数。当计数器溢出的时候,它还会把方法计数器的值也调整到溢出状态,这样下次再进入该方法的时候就会执行标准编译过程。
最后需要提醒一点,图 11-2 和图 11-3 都仅仅描述了 Client VM 的即时编译方式,对于 Server VM 来说,执行情况会比上面的描述更复杂一些。从理论上了解过编译对象和编译触发条件后,我们再从 HotSpot 虚拟机的源码中观察一下,在 MethodOop.hpp (一个methodOop对象代表了一个Java方法)中,定义了 Java 方法在虚拟机中的内存布局,如下所示:

11.2.3 编译过程
在默认设置下,无论是方法调用产生的即时编译请求,还是 OSR 编译请求,虚拟机在代码编译器还未完成之前,都仍然将按照解释方式继续执行,而编译动作则在后台的编译线程中进行。用户可以通过参数 -XX:-BackgroundCompilation 来禁止后台编译,在禁止后台编译后,一旦达到 JIT 的编译条件,执行线程向虚拟机提交编译请求后将会一直等待,直到编译过程完成后再开始执行编译器输出的本地代码。
那么在后台执行编译的过程中,编译器做了什么事情呢?Server Compiler 和 Client Compiler 两个编译器的编译过程是不一样的。对于 Client Compiler 来说,它是一个简单快速的三段式编译器,主要的关注点在于局部性的优化,而放弃了许多耗时较长的全局优化手段。
在第一个阶段,一个平台独立的前端将字节码构造成一种高级中间代码表示(High-Level Intermediate Representaion, HIR)。HIR 使用静态单分配(Static Single Assignment, SSA)的形式来代表代码值,这可以使得一些在 HIR 的构造过程之中和之后进行的优化动作更容易实现。在此之前编译器会在字节码上完成一部分基础优化,如方法内联、常量传播等优化将会在字节码被构造成 HIR 之前完成。
在第二个阶段,一个平台相关的后端从 HIR 中产生低级中间代码表示(Low-Level Intermediate Representation, LIR),而在此之前会在 HIR 上完成另外一些优化,如空值检查消除、范围检查消除等,以便让 HIR 达到更高效的代码表示形式。
最后阶段是在平台相关的后端使用线性扫描算法(Linear Scan Register Allocation)在 LIR 上分配寄存器,并在 LIR 上做窥孔(Peephole)优化,然后产生机器代码。Client Compiler 的大致执行过程如图 11-4 所示。
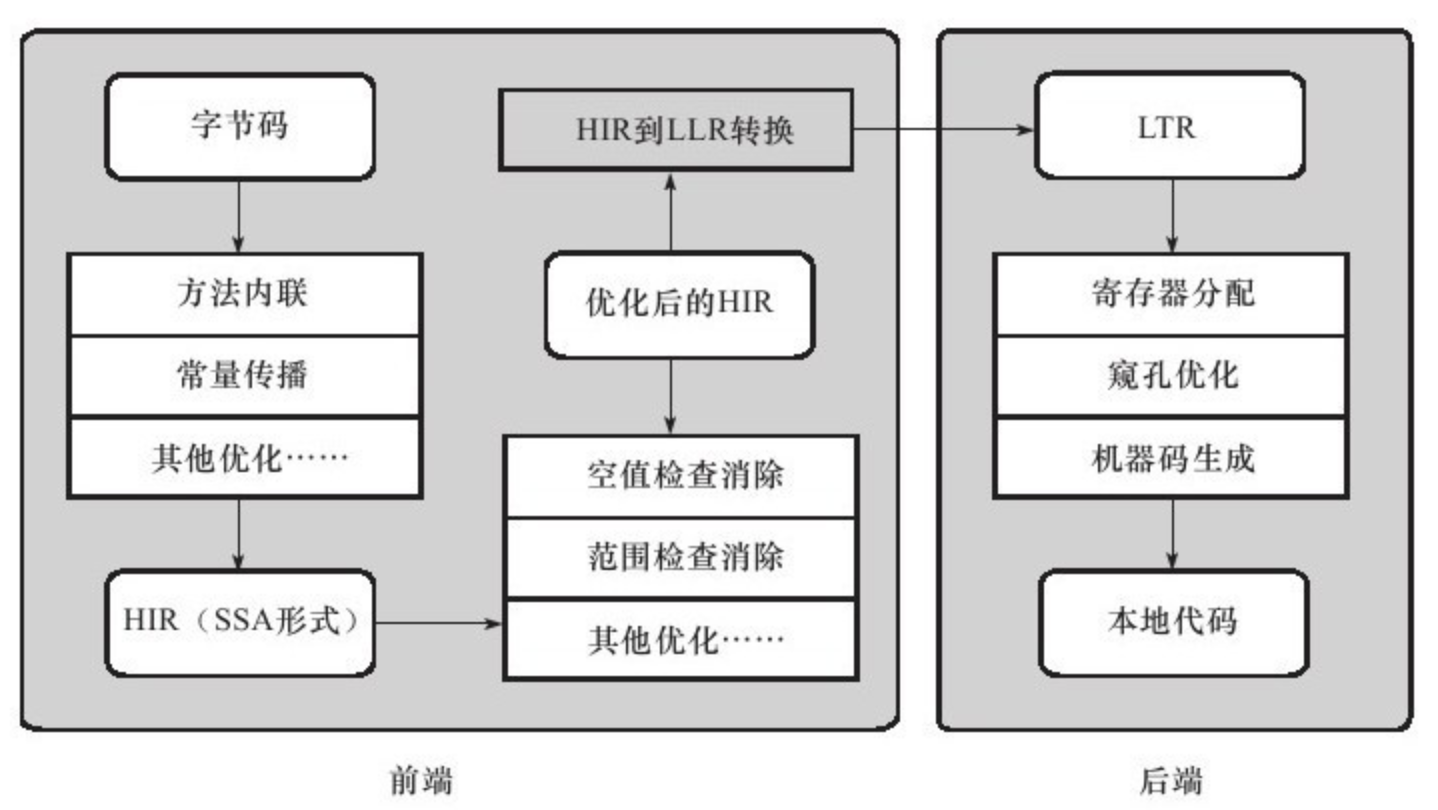
而 Server Compiler 则是专门面向服务端的典型应用并为服务端的性能配置特别调整过的编译器,也是一个充分优化过的高级编译器,几乎能达到 GNU C++ 编译器使用 -O2 参数时的优化强度,它会执行所有经典的优化动作,如无用代码消除、循环展开、循环表达式外提、消除公共子表达式、常量传播、基本块重排序等,还会实施一些与 Java 语言特性密切相关的优化技术,如范围检查消除、空值检查消除等。另外,还可能根据解释器或 Client Compiler 提供的性能监控信息,进行一些不稳定的激进优化,如守护内联、分支频率预测等。本章的下半部分将会挑选上述的一部分优化手段进行分析和讲解。
Server Compiler 的寄存器分配器是一个全局图着色分配器,它可以充分利用某些处理器架构(如RISC)上的大寄存器集合。以即时编译的标准来看,Server Compiler 无疑是比较缓慢的,但它的编译速度依然远远超过传统的静态优化编译器,而且它相对于Client Compiler 编译输出的代码质量有所提高,可以减少本地代码的执行时间,从而抵消了额外的编译时间开销,所以也有很多非服务端的应用选择使用 Server 模式的虚拟机运行。
在本节中,涉及了许多编译原理和代码优化中的概念名词,没有这方面基础的读者,阅读起来会感觉到抽象和理论化。有这种感觉并不奇怪,JIT 编译过程本来就是一个虚拟机中最体现技术水平也是最复杂的部分,不可能以较短的篇幅就介绍得很详细,另外,这个过程对 Java 开发来说是透明的,程序员平时无法感知它的存在,还好 HotSpot 虚拟机提供了两个可视化的工具,让我们可以“看见” JIT 编译器的优化过程,在稍后笔者将演示这个过程。
11.2.4 查看及分析即时编译结果
一般来说,虚拟机的即时编译过程对用户程序是完全透明的,虚拟机通过解释执行代码还是编译执行代码,对于用户来说并没有什么影响(执行结果没有影响,速度上会有很大差别),在大多数情况下用户也没有必要知道。但是虚拟机也提供了一些参数用来输出即时编译和某些优化手段(如方法内联)的执行状况,本节将介绍如何从外部观察虚拟机的即时编译行为。
本节中提到的运行参数有一部分需要 Debug 或 FastDebug 版虚拟机的支持,Product 版的虚拟机无法使用这部分参数。如果读者使用的是根据本书第 1 章的内容自己编译的 JDK,注意将 SKIP_DEBUG_BUILD 或 SKIP_FASTDEBUG_BUILD 参数设置为 false,也可以在 OpenJDK 网站上直接下载 FastDebug 版的 JDK。注意,本节中所有的测试都基于代码清单 11-2 所示的 Java 代码。
public static final int NUM=15000;
public static int doubleValue(int i){
//这个空循环用于后面演示JIT代码优化过程
for(int j=0;j<100000;j++);
return i*2;
}
public static long calcSum(){
long sum=0;
for(int i=1;i<=100;i++){
sum+=doubleValue(i);
}
return sum;
}
public static void main(String[]args){
for(int i=0;i<NUM;i++){
calcSum();
}
}
首先运行这段代码,并且确认这段代码是否触发了即时编译,要知道某个方法是否被编译过,可以使用参数 -XX:+PrintCompilation 要求虚拟机在即时编译时将被编译成本地代码的方法名称打印出来,如代码清单 11-3 所示(其中带有“%”的输出说明是由回边计数器触发的 OSR 编译)。
VM option'+PrintCompilation'
310 1 java.lang.String:charAt(33 bytes)
329 2 org.fenixsoft.jit.Test:calcSum(26 bytes)
329 3 org.fenixsoft.jit.Test:doubleValue(4 bytes)
332 1%org.fenixsoft.jit.Test:main@5(20 bytes)
从代码清单 11-3 输出的确认信息中可以确认 main()、calcSum() 和 doubleValue() 方法已经被编译,我们还可以加上参数 -XX:+PrintInlining 要求虚拟机输出方法内联信息,如代码清单 11-4 所示。
VM option'+PrintCompilation'
VM option'+PrintInlining'
273 1 java.lang.String:charAt(33 bytes)
291 2 org.fenixsoft.jit.Test:calcSum(26 bytes)
@9 org.fenixsoft.jit.Test:doubleValue inline(hot)
294 3 org.fenixsoft.jit.Test:doubleValue(4 bytes)
295 1%org.fenixsoft.jit.Test:main@5(20 bytes)
@5 org.fenixsoft.jit.Test:calcSum inline(hot)
@9 org.fenixsoft.jit.Test:doubleValue inline(hot)
从代码清单 11-4 的输出中可以看到方法 doubleValue() 被内联编译到 calcSum() 中,而 calcSum() 又被内联编译到方法 main() 中,所以虚拟机再次执行 main() 方法的时候(举例而已,main()方法并不会运行两次),calcSum() 和 doubleValue() 方法都不会再被调用,它们的代码逻辑都被直接内联到 main() 方法中了。
除了查看哪些方法被编译之外,还可以进一步查看即时编译器生成的机器码内容,不过如果虚拟机输出一串 0 和 1,对于我们的阅读来说是没有意义的,机器码必须反汇编成基本的汇编语言才可能被阅读。虚拟机提供了一组通用的反汇编接口,可以接入各种平台下的反汇编适配器来使用,如使用 32 位 80x86 平台则选用 hsdis-i386 适配器,其余平台的适配器还有 hsdis-amd64、hsdis-sparc 和 hsdis-sparcv9 等,可以下载或自己编译出反汇编适配器,然后将其放置在 JRE/bin/client 或 /server 目录下,只要与 jvm.dll 的路径相同即可被虚拟机调用。在为虚拟机安装了反汇编适配器之后,就可以使用 -XX:+PrintAssembly 参数要求虚拟机打印编译方法的汇编代码了,具体的操作可以参考本书 4.2.7 节。
如果没有 HSDIS 插件支持,也可以使用 -XX:+PrintOptoAssembly(用于Server VM)或 -XX:+PrintLIR(用于Client VM) 来输出比较接近最终结果的中间代码表示,代码清单 11-2 被编译后部分反汇编(使用 -XX:+PrintOptoAssembly)的输出结果如代码清单 11-5 所示。从阅读角度来说,使用 -XX:+PrintOptoAssembly 参数输出的伪汇编结果包含了更多的信息(主要是注释),利于阅读并理解虚拟机 JIT 编译器的优化结果。
……
000 B1:#N1<-BLOCK HEAD IS JUNK Freq:1
000 pushq rbp
subq rsp, #16#Create frame
nop#nop for patch_verified_entry
006 movl RAX,RDX#spill
008 sall RAX, #1
00a addq rsp, 16#Destroy frame
popq rbp
testl rax, [rip+#offset_to_poll_page]#Safepoint:poll for GC
……
前面提到的使用 -XX:+PrintAssembly 参数输出反汇编信息需要 Debug 或者 FastDebug 版的虚拟机才能直接支持,如果使用 Product 版的虚拟机,则需要加入参数 -XX:+UnlockDiagnosticVMOptions 打开虚拟机诊断模式后才能使用。
如果除了本地代码的生成结果外,还想再进一步跟踪本地代码生成的具体过程,那还可以使用参数 -XX:+PrintCFGToFile(使用Client Compiler) 或 -XX:PrintIdealGraphFile(使用Server Compiler) 令虚拟机将编译过程中各个阶段的数据(例如,对 C1 编译器来说,包括字节码、HIR 生成、LIR 生成、寄存器分配过程、本地代码生成等数据)输出到文件中。然后使用 Java HotSpot Client Compiler Visualizer(用于分析Client Compiler) 或 Ideal Graph Visualizer(用于分析Server Compiler) 打开这些数据文件进行分析。以 Server Compiler 为例,笔者分析一下 JIT 编译器的代码生成过程。
Server Compiler 的中间代码表示是一种名为 Ideal 的 SSA 形式程序依赖图,在运行 Java 程序的 JVM 参数中加入 -XX:PrintIdealGraphLevel=2-XX:PrintIdealGraphFile=ideal.xml,编译后将产生一个名为 ideal.xml 的文件,它包含了 Server Compiler 编译代码的过程信息,可以使用 Ideal Graph Visualizer 对这些信息进行分析。
Ideal Graph Visualizer 加载 ideal.xml 文件后,在 Outline 面板上将显示程序运行过程中编译过的方法列表,如图 11-5 所示。这里列出的方法是代码清单 11-2 中的测试代码,其中 doubleValue() 方法出现了两次,这是由于该方法的编译结果存在标准编译和 OSR 编译两个版本。在代码清单 11-2 中,笔者特别为 doubleValue() 方法增加了一个空循环,这个循环对方法的运算结果不会产生影响,但如果没有任何优化,执行空循环会占用 CPU 时间,到今天还有许多程序设计的入门教程把空循环当做程序延时的手段来介绍,在 Java 中这样的做法真的能起到延时的作用吗?
展开方法根节点,可以看到下面罗列了方法优化过程的各个阶段(根据优化措施的不同,每个方法所经过的阶段也会有所差别)的 Ideal 图,我们先打开"After Parsing"这个阶段。上文提到,JIT 编译器在编译一个 Java 方法时,首先要把字节码解析成某种中间表示形式,然后才可以继续做分析和优化,最终生成代码。“After Parsing"就是 Server Compiler 刚完成解析,还没有做任何优化时的 Ideal 图表示。在打开这个图后,读者会看到其中有很多有颜色的方块,如图 11-6 所示。每一个方块就代表了一个程序的基本块,基本块的特点是只有唯一的一个入口和唯一的一个出口,只要基本块中第一条指令执行了,那么基本块内所有执行都会按照顺序仅执行一次。
代码清单 11-2 的 doubleValue() 方法虽然只有简单的两行字,但是按基本块划分后,形成的图形结构要比想象中复杂得多,这一方面是要满足 Java 语言所定义的安全需要(如类型安全、空指针检查)和 Java 虚拟机的运作需要(如 Safepoint 轮询),另一方面是由于有些程序代码中一行语句就可能形成好几个基本块(例如循环)。对于例子中的 doubleValue() 方法,如果忽略语言安全检查的基本块,可以简单理解为按顺序执行了以下几件事情:
- 程序入口,建立帧栈。
- 设置 j=0,进行 Safepoint 轮询,跳转到 4 的条件检查。
- 执行 j++。
- 条件检查,如果 j<100000,跳转到 3。
- 设置
i=i*2,进行 SafePoint 检查,函数返回。
以上几个步骤,反映到 Ideal Graph Visualizer 的图上,就是如图 11-7 所示的内容。这样我们要看空循环是否优化,或者何时优化,只要观察代表循环的基本块是否消除,或者何时消除就可以了。
要观察到这一点,可以在 Outline 面板上右键点击"Difference to current graph”,让软件自动分析指定阶段与当前打开的Ideal图之间的差异,如果基本块被消除了,将会以红色显示。对"After Parsing"和"PhaseIdealLoop 1"阶段的 Ideal 图进行差异分析,发现在"PhaseIdealLoop 1"阶段循环操作被消除了,如图 11-8 所示,这也就说明空循环实际上是不会被执行的。
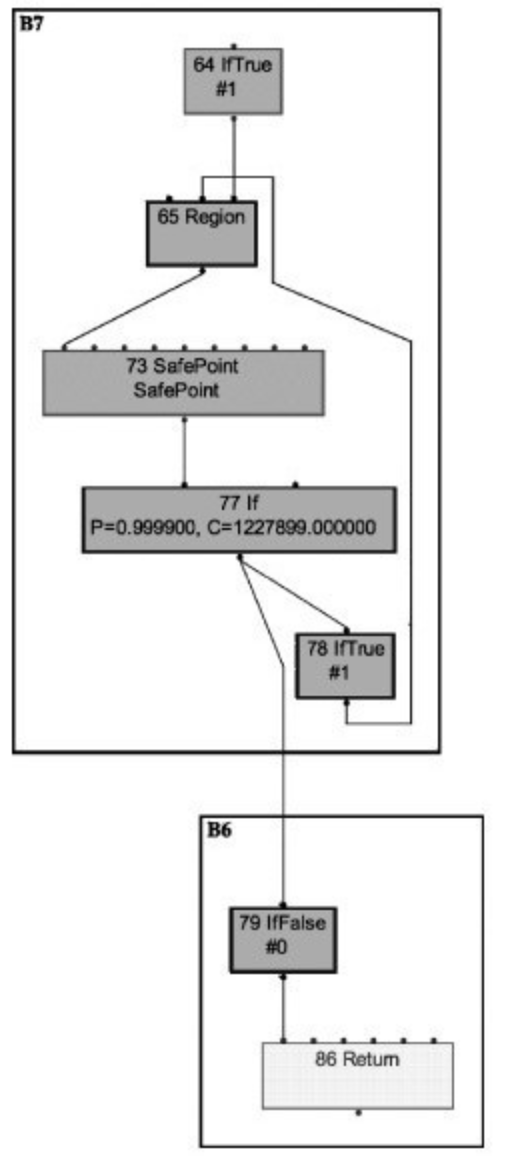
从"After Parsing"阶段开始,一直到最后的"Final Code"阶段,可以看到 doubleValue() 方法的 Ideal 图从繁到简的变迁过程,这也是 Java 虚拟机在尽力优化代码的过程。到了最后的"Final Code"阶段,不仅空循环的开销消除了,许多语言安全和 Safepoint 轮询的操作也一起消除了,因为编译器判断即使不做这些安全保障,虚拟机也不会受到威胁。
最后提醒一下读者,要输出 CFG 或 IdealGraph 文件,需要一个 Debug 版或 FastDebug 版的虚拟机支持,Product 版的虚拟机无法输出这些文件。
11.3 编译优化技术
Java 程序员有一个共识,以编译方式执行本地代码比解释方式更快,之所以有这样的共识,除去虚拟机解释执行字节码时额外消耗时间的原因外,还有一个很重要的原因就是虚拟机设计团队几乎把对代码的所有优化措施都集中在了即时编译器之中,因此一般来说,即时编译器产生的本地代码会比 Javac 产生的字节码更加优秀。下面,笔者将介绍一些 HotSpot 虚拟机的即时编译器在生成代码时采用的代码优化技术。
11.3.1 优化技术概览
在 Sun 官方的 Wiki 上,HotSpot 虚拟机设计团队列出了一个相对比较全面的、在即时编译器中采用的优化技术列表(见表 11-1),其中有不少经典编译器的优化手段,也有许多针对 Java 语言(准确地说是针对运行在 Java 虚拟机上的所有语言)本身进行的优化技术,本节将对这些技术进行概括性的介绍,在后面几节中,再挑选若干重要且典型的优化,与读者一起看看优化前后的代码产生了怎样的变化。


上述的优化技术看起来很多,而且从名字看都显得有点“高深莫测”,虽然实现这些优化也许确实有些难度,但大部分技术理解起来都并不困难。为了消除读者对这些优化技术的陌生感,笔者举一个简单的例子,即通过大家熟悉的 Java 代码变化来展示其中几种优化技术是如何发挥作用的(仅使用Java代码来表示而已)。首先从原始代码开始,如代码清单 11-6 所示。
static class B{
int value;
final int get(){
return value;
}
}
public void foo(){
y=b.get();
//……do stuff……
z=b.get();
sum=y+z;
}
首先需要明确的是,这些代码优化变换是建立在代码的某种中间表示或机器码之上,绝不是建立在 Java 源码之上的,为了展示方便,笔者使用了 Java 语言的语法来表示这些优化技术所发挥的作用。
代码清单 11-6 的代码已经非常简单了,但是仍有许多优化的余地。第一步进行方法内联,方法内联的重要性要高于其他优化措施,它的主要目的有两个,一是去除方法调用的成本(如建立栈帧等),二是为其他优化建立良好的基础,方法内联膨胀之后可以便于在更大范围上采取后续的优化手段,从而获取更好的优化效果。因此,各种编译器一般都会把内联优化放在优化序列的最靠前位置。内联后的代码如代码清单 11-7 所示。
public void foo(){
y=b.value;
//……do stuff……
z=b.value;
sum=y+z;
}
第二步进行冗余访问消除,假设代码中间注释掉的"dostuff……“所代表的操作不会改变 b.value 的值,那就可以把"z=b.value"替换为"z=y”,因为上一句"y=b.value"已经保证了变量 y 与 b.value 是一致的,这样就可以不再去访问对象 b 的局部变量了。如果把 b.value 看做是一个表达式,那也可以把这项优化看成是公共子表达式消除,优化后的代码如代码清单 11-8 所示。
public void foo(){
y=b.value;
//……do stuff……
z=y;
sum=y+z;
}
第三步我们进行复写传播,因为在这段程序的逻辑中并没有必要使用一个额外的变量"z",它与变量"y"是完全相等的,因此可以使用"y"来代替"z"。复写传播之后程序如代码清单 11-9 所示。
public void foo(){
y=b.value;
//……do stuff……
y=y;
sum=y+y;
}
第四步我们进行无用代码消除。无用代码可能是永远不会被执行的代码,也可能是完全没有意义的代码,因此,它又形象地称为"Dead Code",在代码清单 11-9 中,“y=y"是没有意义的,把它消除后的程序如代码清单 11-10 所示。
public void foo(){
y=b.value;
//……do stuff……
sum=y+y;
}
经过四次优化之后,代码清单 11-10 与代码清单 11-6 所达到的效果是一致的,但是前者比后者省略了许多语句(体现在字节码和机器码指令上的差距会更大),执行效率也会更高。编译器的这些优化技术实现起来也许比较复杂,但是要理解它们的行为对于一个普通的程序员来说是没有困难的,接下来,我们将继续查看如下的几项最有代表性的优化技术是如何运作的,它们分别是:
- 语言无关的经典优化技术之一:公共子表达式消除。
- 语言相关的经典优化技术之一:数组范围检查消除。
- 最重要的优化技术之一:方法内联。
- 最前沿的优化技术之一:逃逸分析。
11.3.2 公共子表达式消除
公共子表达式消除是一个普遍应用于各种编译器的经典优化技术,它的含义是:如果一个表达式 E 已经计算过了,并且从先前的计算到现在 E 中所有变量的值都没有发生变化,那么 E 的这次出现就成为了公共子表达式。对于这种表达式,没有必要花时间再对它进行计算,只需要直接用前面计算过的表达式结果代替 E 就可以了。如果这种优化仅限于程序的基本块内,便称为局部公共子表达式消除,如果这种优化的范围涵盖了多个基本块,那就称为全局公共子表达式消除。举个简单的例子来说明它的优化过程,假设存在如下代码:
int d=(c * b)*12+a+(a+b * c);
如果这段代码交给 Javac 编译器则不会进行任何优化,那生成的代码将如代码清单 11-11 所示,是完全遵照 Java 源码的写法直译而成的。
iload_2//b
imul//计算b * c
bipush 12//推入12
imul//计算(c * b)*12
iload_1//a
iadd//计算(c * b)*12+a
iload_1//a
iload_2//b
iload_3//c
imul//计算b * c
iadd//计算a+b * c
iadd//计算(c * b)*12+a+(a+b * c)
istore 4
当这段代码进入到虚拟机即时编译器后,它将进行如下优化:编译器检测到 c * b 与 b * c 是一样的表达式,而且在计算期间 b 与 c 的值是不变的。因此,这条表达式就可能被视为:
int d=E*12+a+(a+E);
这时,编译器还可能(取决于哪种虚拟机的编译器以及具体的上下文而定)进行另外一种优化:代数化简,把表达式变为:
int d=E*13+a*2;
表达式进行变换之后,再计算起来就可以节省一些时间了。如果读者还对其他的经典编译优化技术感兴趣,可以参考《编译原理》中对应的章节。
11.3.3 数组边界检查消除
数组边界检查消除是即时编译器中的一项语言相关的经典优化技术。我们知道 Java 语言是一门动态安全的语言,对数组的读写访问也不像 C、C++ 那样在本质上是裸指针操作。如果有一个数组 foo[],在 Java 语言中访问数组元素 foo[i] 的时候系统将会自动进行上下界的范围检查,即检查 i 必须满足 i>=0 && i<foo.length 这个条件,否则将抛出一个数组越界异常。这对软件开发者来说是一件很好的事情,即使程序员没有专门编写防御代码,也可以避免大部分的溢出攻击。但是对于虚拟机的执行子系统来说,每次数组元素的读写都带有一次隐含的条件判定操作,对于拥有大量数组访问的程序代码,这无疑也是一种性能负担。
无论如何,为了安全,数组边界检查肯定是必须做的,但数组边界检查是不是必须在运行期间一次不漏地检查则是可以“商量”的事情。例如下面这个简单的情况:数组下标是一个常量,如 foo[3],只要在编译期根据数据流分析来确定 foo.length 的值,并判断下标“3”没有越界,执行的时候就无须判断了。更加常见的情况是数组访问发生在循环之中,并且使用循环变量来进行数组访问,如果编译器只要通过数据流分析就可以判定循环变量的取值范围永远在区间 [0,foo.length) 之内,那在整个循环中就可以把数组的上下界检查消除,这可以节省很多次的条件判断操作。
将这个数组边界检查的例子放在更高的角度来看,大量的安全检查令编写 Java 程序比编写 C/C++ 程序容易很多,如数组越界会得到数组越界异常,空指针访问会得到空指针异常,除数为零会得到除零异常等,在 C/C++ 程序中出现类似的问题,一不小心就会出现 Segment Fault 信号或者 Windows 编程中常见的“xxx内存不能为Read/Write”之类的提示,处理不好程序就直接崩溃退出了。但这些安全检查也导致了相同的程序,Java 要比 C/C++ 做更多的事情(各种检查判断),这些事情就成为一种隐式开销,如果处理不好它们,就很可能成为一个 Java 语言比 C/C++ 更慢的因素。要消除这些隐式开销,除了如数组边界检查优化这种尽可能把运行期检查提到编译期完成的思路之外,另外还有一种避免思路——隐式异常处理,Java 中空指针检查和算术运算中除数为零的检查都采用了这种思路。举个例子,例如程序中访问一个对象(假设对象叫 foo)的某个属性(假设属性叫 value),那以 Java 伪代码来表示虚拟机访问 foo.value 的过程如下。
if(foo!=null){
return foo.value;
}else{
throw new NullPointException();
}
在使用隐式异常优化之后,虚拟机会把上面伪代码所表示的访问过程变为如下伪代码。
try{
return foo.value;
}catch(segment_fault){
uncommon_trap();
}
虚拟机会注册一个 Segment Fault 信号的异常处理器(伪代码中的 uncommon_trap()),这样当 foo 不为空的时候,对 value 的访问是不会额外消耗一次对 foo 判空的开销的。代价就是当 foo 真的为空时,必须转入到异常处理器中恢复并抛出 NPE,这个过程必须从用户态转到内核态中处理,结束后再回到用户态,速度远比一次判空检查慢。当 foo 极少为空的时候,隐式异常优化是值得的,但假如 foo 经常为空的话,这样的优化反而会让程序更慢,还好 HotSpot 虚拟机足够“聪明”,它会根据运行期收集到的 Profile 信息自动选择最优方案。
与语言相关的其他消除操作还有不少,如自动装箱消除、安全点消除、消除反射等,笔者就不再一一介绍了。
11.3.4 方法内联
在前面的讲解之中我们提到过方法内联,它是编译器最重要的优化手段之一,除了消除方法调用的成本之外,它更重要的意义是为其他优化手段建立良好的基础,如代码清单 11-12 所示的简单例子就揭示了内联对其他优化手段的意义:事实上 testInline() 方法的内部全部都是无用的代码,如果不做内联,后续即使进行了无用代码消除的优化,也无法发现任何"Dead Code”,因为如果分开来看,foo() 和 testInline() 两个方法里面的操作都可能是有意义的。
public static void foo(Object obj){
if(obj!=null){
System.out.println("do something");
}
}
public static void testInline(String[]args){
Object obj=null;
foo(obj);
}
方法内联的优化行为看起来很简单,不过是把目标方法的代码“复制”到发起调用的方法之中,避免发生真实的方法调用而已。但实际上 Java 虚拟机中的内联过程远远没有那么简单,因为如果不是即时编译器做了一些特别的努力,按照经典编译原理的优化理论,大多数的 Java 方法都无法进行内联。
无法内联的原因其实在第 8 章中讲解 Java 方法解析和分派调用的时候就已经介绍过。只有使用 invokespecial 指令调用的私有方法、实例构造器、父类方法以及使用 invokestatic 指令进行调用的静态方法才是在编译期进行解析的,除了上述 4 种方法之外,其他的 Java 方法调用都需要在运行时进行方法接收者的多态选择,并且都有可能存在多于一个版本的方法接收者(最多再除去被 final 修饰的方法这种特殊情况,尽管它使用 invokevirtual 指令调用,但也是非虚方法,Java 语言规范中明确说明了这点),简而言之,Java 语言中默认的实例方法是虚方法。
对于一个虚方法,编译期做内联的时候根本无法确定应该使用哪个方法版本,如果以代码清单 11-7 中把"b.get()“内联为"b.value"为例的话,就是不依赖上下文就无法确定 b 的实际类型是什么。假如有 ParentB 和 SubB 两个具有继承关系的类,并且子类重写了父类的 get() 方法,那么,是要执行父类的 get() 方法还是子类的 get() 方法,需要在运行期才能确定,编译期无法得出结论。
由于 Java 语言提倡使用面向对象的编程方式进行编程,而 Java 对象的方法默认就是虚方法,因此 Java 间接鼓励了程序员使用大量的虚方法来完成程序逻辑。根据上面的分析,如果内联与虚方法之间产生“矛盾”,那该怎么办呢?是不是为了提高执行性能,就要到处使用 final 关键字去修饰方法呢?
为了解决虚方法的内联问题,Java 虚拟机设计团队想了很多办法,首先是引入了一种名为“类型继承关系分析”(CHA)的技术,这是一种基于整个应用程序的类型分析技术,它用于确定在目前已加载的类中,某个接口是否有多于一种的实现,某个类是否存在子类、子类是否为抽象类等信息。
编译器在进行内联时,如果是非虚方法,那么直接进行内联就可以了,这时候的内联是有稳定前提保障的。如果遇到虚方法,则会向 CHA 查询此方法在当前程序下是否有多个目标版本可供选择,如果查询结果只有一个版本,那也可以进行内联,不过这种内联就属于激进优化,需要预留一个“逃生门”(Guard条件不成立时的Slow Path),称为守护内联。如果程序的后续执行过程中,虚拟机一直没有加载到会令这个方法的接收者的继承关系发生变化的类,那这个内联优化的代码就可以一直使用下去。但如果加载了导致继承关系发生变化的新类,那就需要抛弃已经编译的代码,退回到解释状态执行,或者重新进行编译。
如果向 CHA 查询出来的结果是有多个版本的目标方法可供选择,则编译器还将会进行最后一次努力,使用内联缓存来完成方法内联,这是一个建立在目标方法正常入口之前的缓存,它的工作原理大致是:在未发生方法调用之前,内联缓存状态为空,当第一次调用发生后,缓存记录下方法接收者的版本信息,并且每次进行方法调用时都比较接收者版本,如果以后进来的每次调用的方法接收者版本都是一样的,那这个内联还可以一直用下去。如果发生了方法接收者不一致的情况,就说明程序真正使用了虚方法的多态特性,这时才会取消内联,查找虚方法表进行方法分派。
所以说,在许多情况下虚拟机进行的内联都是一种激进优化,激进优化的手段在高性能的商用虚拟机中很常见,除了内联之外,对于出现概率很小(通过经验数据或解释器收集到的性能监控信息确定概率大小)的隐式异常、使用概率很小的分支等都可以被激进优化“移除”,如果真的出现了小概率事件,这时才会从“逃生门”回到解释状态重新执行。
11.3.5 逃逸分析
逃逸分析是目前 Java 虚拟机中比较前沿的优化技术,它与类型继承关系分析一样,并不是直接优化代码的手段,而是为其他优化手段提供依据的分析技术。
逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他方法中,称为方法逃逸。甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。
如果能证明一个对象不会逃逸到方法或线程之外,也就是别的方法或线程无法通过任何途径访问到这个对象,则可能为这个变量进行一些高效的优化,如下所示。
栈上分配:Java 虚拟机中,在 Java 堆上分配创建对象的内存空间几乎是 Java 程序员都清楚的常识了,Java 堆中的对象对于各个线程都是共享和可见的,只要持有这个对象的引用,就可以访问堆中存储的对象数据。虚拟机的垃圾收集系统可以回收堆中不再使用的对象,但回收动作无论是筛选可回收对象,还是回收和整理内存都需要耗费时间。如果确定一个对象不会逃逸出方法之外,那让这个对象在栈上分配内存将会是一个很不错的主意,对象所占用的内存空间就可以随栈帧出栈而销毁。在一般应用中,不会逃逸的局部对象所占的比例很大,如果能使用栈上分配,那大量的对象就会随着方法的结束而自动销毁了,垃圾收集系统的压力将会小很多。
同步消除:线程同步本身是一个相对耗时的过程,如果逃逸分析能够确定一个变量不会逃逸出线程,无法被其他线程访问,那这个变量的读写肯定就不会有竞争,对这个变量实施的同步措施也就可以消除掉。
标量替换:标量(Scalar)是指一个数据已经无法再分解成更小的数据来表示了,Java 虚拟机中的原始数据类型(int、long 等数值类型以及 reference 类型等)都不能再进一步分解,它们就可以称为标量。相对的,如果一个数据可以继续分解,那它就称作聚合量(Aggregate),Java 中的对象就是最典型的聚合量。如果把一个 Java 对象拆散,根据程序访问的情况,将其使用到的成员变量恢复原始类型来访问就叫做标量替换。如果逃逸分析证明一个对象不会被外部访问,并且这个对象可以被拆散的话,那程序真正执行的时候将可能不创建这个对象,而改为直接创建它的若干个被这个方法使用到的成员变量来代替。将对象拆分后,除了可以让对象的成员变量在栈上(栈上存储的数据,有很大的概率会被虚拟机分配至物理机器的高速寄存器中存储)分配和读写之外,还可以为后续进一步的优化手段创建条件。
关于逃逸分析的论文在 1999 年就已经发表,但直到 Sun JDK 1.6 才实现了逃逸分析,而且直到现在这项优化尚未足够成熟,仍有很大的改进余地。不成熟的原因主要是不能保证逃逸分析的性能收益必定高于它的消耗。如果要完全准确地判断一个对象是否会逃逸,需要进行数据流敏感的一系列复杂分析,从而确定程序各个分支执行时对此对象的影响。这是一个相对高耗时的过程,如果分析完后发现没有几个不逃逸的对象,那这些运行期耗用的时间就白白浪费了,所以目前虚拟机只能采用不那么准确,但时间压力相对较小的算法来完成逃逸分析。还有一点是,基于逃逸分析的一些优化手段,如上面提到的“栈上分配”,由于 HotSpot 虚拟机目前的实现方式导致栈上分配实现起来比较复杂,因此在 HotSpot 中暂时还没有做这项优化。
在测试结果中,实施逃逸分析后的程序在 MicroBenchmarks 中往往能运行出不错的成绩,但是在实际的应用程序,尤其是大型程序中反而发现实施逃逸分析可能出现效果不稳定的情况,或因分析过程耗时但却无法有效判别出非逃逸对象而导致性能(即时编译的收益)有所下降,所以在很长的一段时间里,即使是 Server Compiler,也默认不开启逃逸分析,甚至在某些版本(如 JDK 1.6 Update 18)中还曾经短暂地完全禁止了这项优化。
如果有需要,并且确认对程序运行有益,用户可以使用参数 -XX:+DoEscapeAnalysis 来手动开启逃逸分析,开启之后可以通过参数 -XX:+PrintEscapeAnalysis 来查看分析结果。有了逃逸分析支持之后,用户可以使用参数 -XX:+EliminateAllocations 来开启标量替换,使用 +XX:+EliminateLocks 来开启同步消除,使用参数 -XX:+PrintEliminateAllocations 查看标量的替换情况。
尽管目前逃逸分析的技术仍不是十分成熟,但是它却是即时编译器优化技术的一个重要的发展方向,在今后的虚拟机中,逃逸分析技术肯定会支撑起一系列实用有效的优化技术。
11.4 Java 与 C/C++ 的编译器对比
大多数程序员都认为 C/C++ 会比 Java 语言快,甚至觉得从 Java 语言诞生以来“执行速度缓慢”的帽子就应当扣在它的头顶,这种观点的出现是由于 Java 刚出现的时候即时编译技术还不成熟,主要靠解释器执行的 Java 语言性能确实比较低下。但目前即时编译技术已经十分成熟,Java 语言有可能在速度上与 C/C++ 一争高下吗?要想知道这个问题的答案,让我们从两者的编译器谈起。
Java 与 C/C++ 的编译器对比实际上代表了最经典的即时编译器与静态编译器的对比,很大程度上也决定了 Java 与 C/C++ 的性能对比的结果,因为无论是 C/C++ 还是 Java 代码,最终编译之后被机器执行的都是本地机器码,哪种语言的性能更高,除了它们自身的 API 库实现得好坏以外,其余的比较就成了一场“拼编译器”和“拼输出代码质量”的游戏。当然,这种比较也是剔除了开发效率的片面对比,语言间孰优孰劣、谁快谁慢的问题都是很难有结果的争论,下面我们就回到正题,看看这两种语言的编译器各有何种优势。
Java 虚拟机的即时编译器与 C/C++ 的静态优化编译器相比,可能会由于下列这些原因而导致输出的本地代码有一些劣势:
第一,因为即时编译器运行占用的是用户程序的运行时间,具有很大的时间压力,它能提供的优化手段也严重受制于编译成本。如果编译速度不能达到要求,那用户将在启动程序或程序的某部分察觉到重大延迟,这点使得即时编译器不敢随便引入大规模的优化技术,而编译的时间成本在静态优化编译器中并不是主要的关注点。
第二,Java 语言是动态的类型安全语言,这就意味着需要由虚拟机来确保程序不会违反语言语义或访问非结构化内存。从实现层面上看,这就意味着虚拟机必须频繁地进行动态检查,如实例方法访问时检查空指针、数组元素访问时检查上下界范围、类型转换时检查继承关系等。对于这类程序代码没有明确写出的检查行为,尽管编译器会努力进行优化,但是总体上仍然要消耗不少的运行时间。
第三,Java 语言中虽然没有 virtual 关键字,但是使用虚方法的频率却远远大于 C/C++ 语言,这意味着运行时对方法接收者进行多态选择的频率要远远大于 C/C++ 语言,也意味着即时编译器在进行一些优化(如前面提到的方法内联)时的难度要远大于 C/C++ 的静态优化编译器。
第四,Java 语言是可以动态扩展的语言,运行时加载新的类可能改变程序类型的继承关系,这使得很多全局的优化都难以进行,因为编译器无法看见程序的全貌,许多全局的优化措施都只能以激进优化的方式来完成,编译器不得不时刻注意并随着类型的变化而在运行时撤销或重新进行一些优化。
第五,Java 语言中对象的内存分配都是堆上进行的,只有方法中的局部变量才能在栈上分配。而 C/C++ 的对象则有多种内存分配方式,既可能在堆上分配,又可能在栈上分配,如果可以在栈上分配线程私有的对象,将减轻内存回收的压力。另外,C/C++ 中主要由用户程序代码来回收分配的内存,这就不存在无用对象筛选的过程,因此效率上(仅指运行效率,排除了开发效率)也比垃圾收集机制要高。
上面说了一大堆 Java 语言相对 C/C++ 的劣势,不是说 Java 就真的不如 C/C++ 了,相信读者也注意到了,Java 语言的这些性能上的劣势都是为了换取开发效率上的优势而付出的代价,动态安全、动态扩展、垃圾回收这些“拖后腿”的特性都为 Java 语言的开发效率做出了很大贡献。
何况,还有许多优化是 Java 的即时编译器能做而 C/C++ 的静态优化编译器不能做或者不好做的。例如,在 C/C++ 中,别名分析的难度就要远高于 Java。Java 的类型安全保证了在类似如下代码中,只要 ClassA 和 ClassB 没有继承关系,那对象 objA 和 objB 就绝不可能是同一个对象,即不会是同一块内存两个不同别名。
void foo(ClassA objA,ClassB objB){
objA.x=123;
objB.y=456;
//只要objB.y不是objA.x的别名, 下面就可以保证输出为123
print(objA.x);
}
确定了 objA 和 objB 并非对方的别名后,许多与数据依赖相关的优化才可以进行(重排序、变量代换)。具体到这个例子中,就是无须担心 objB.y 其实与 objA.x 指向同一块内存,这样就可以安全地确定打印语句中的 objA.x 为 123。
Java 编译器另外一个红利是由它的动态性所带来的,由于 C/C++ 编译器所有优化都在编译期完成,以运行期性能监控为基础的优化措施它都无法进行,如调用频率预测、分支频率预测、裁剪未被选择的分支等,这些都会成为 Java 语言独有的性能优势。
11.5 本章小结
第 10~11 两章分别介绍了 Java 程序从源码编译成字节码和从字节码编译成本地机器码的过程,Javac 字节码编译器与虚拟机内的 JIT 编译器的执行过程合并起来其实就等同于一个传统编译器所执行的编译过程。
本章中,我们着重了解了虚拟机的热点探测方法、HotSpot 的即时编译器、编译触发条件,以及如何从虚拟机外部观察和分析JIT编译的数据和结果,还选择了几种常见的编译期优化技术进行讲解。对 Java 编译器的深入了解,有助于在工作中分辨哪些代码是编译器可以帮我们处理的,哪些代码需要自己调节以便更适合编译器的优化。
12 - CH12-内存模型与线程
12.1 概述
多任务处理在现代计算机操作系统中几乎已经以必备功能了。在许多情况下,让计算机同时去做几件事情,不仅是因为计算机的运算能力变得强大了,还有一个很重要的原因是计算机的运算速度,与它的存储和通讯子系统的速度,两者之间的差距越来越大:大部分时间都花在了磁盘 IO、网络通讯和数据库访问上。如果不希望处理器在大部分时间里都处于等待其他资源的状态,就必须使用一些手段去把处理器的运算能力压榨出来,否则就会造成很大的浪费,而让计算机同时处理几项任务则是最容易想到、也被证明是非常有效的“压榨”手段。
除了充分利用计算机处理器的能力之外,一个服务端同时对多个客户端提供服务则是另一个更加具体的并发应用场景。衡量一个服务的性能的高低好坏,每秒事务处理数(TPS)是最重要的指标之一,它代表着一秒内服务平均能够响应的请求总数,而 TPS 值与程序的并发能力又有着密切的关系。对于计算量相同的任务,程序并发协调的越有条不紊,效率自然就会越高;反之,线程之间频繁阻塞甚至死锁,将会大大降低程序的并发能力。
服务端是 Java 语言最擅长的领域之一,这个领域占有了 Java 应用中最大的一块份额,不过如何写好并发应用程序却是程序开发的难点之一,处理好并发方面的问题通常需要很多经验。幸好 Java 语言和虚拟机提供了很多工具,把并发编程的门槛降低了不少。另外,各种中间件服务器、各类框架都努力的替程序员处理尽可能多的线程并发细节,使得程序员在编码时能更关注业务逻辑,而不是花费大部分时间来关注服务会同时被多少人调用。但是无论语言、中间件和框架如何先进,我们都不能期望它们能够独立完成并发处理的所有事情,了解并发的内幕也是称为一个高级程序员不可缺少的课程。
12.2 硬件效率与一致性
在正式讲解 JVM 并发相关的知识之前,我们先花费一点时间来了解物理计算机中的并发问题,物理机遇到的并发问题与 JVM 中的情况有不少相似之处,物理机解决并发的方式对 JVM 的实现由很大的参考意义。
“让计算机并发执行多个运算任务”与“充分利用计算机处理器的效能”之间的因果关系看起来顺理成章,实际上并没有想象中那么容易实现,因为所有的运算任务都不可能仅靠处理器的“计算”就能完成,至少要与内存交互,如读取运算数据、存储运算结果等,仅靠寄存器也无法实现。由于计算机存储设备的访问速度与处理器的运算速度之间有着几个数量级的差距,所以现代计算机系统都不得不加入一层读写速度尽可能接近处理器运算速度的高速缓存来作为处理器与内存之间的缓冲:将运算中用到的数据复制到缓存中以加速运算,当运算结束后在从缓存同步回内存,以避免处理器等待缓慢的内存访问。
基于高速缓存的存储交互很好的解决了处理器与内存之间的速度矛盾,但是也引入了新的问题:缓存一致性。在多处理器系统中,每个处理器都有自己的高速缓存,而它们又都共享同一内存,如下图所示。当多个处理器的运算任务都涉及同一块内存区域时,将可能导致搁置的缓存数据不一致,如果真的发生这种情况,将各个处理器缓存中的数据同步回内存时又以谁的缓存为准呢?为了解决一致性问题,需要各个处理器访问缓存时都遵循一定的协议,在读写时要根据协议来进程操作,这类协议有 MSI、MESI、MOSI、Firefly、Dragon Protocol 等。JVM 内存模型中定义的内存访问操作与硬件的缓存访问操作是具有可比性的。
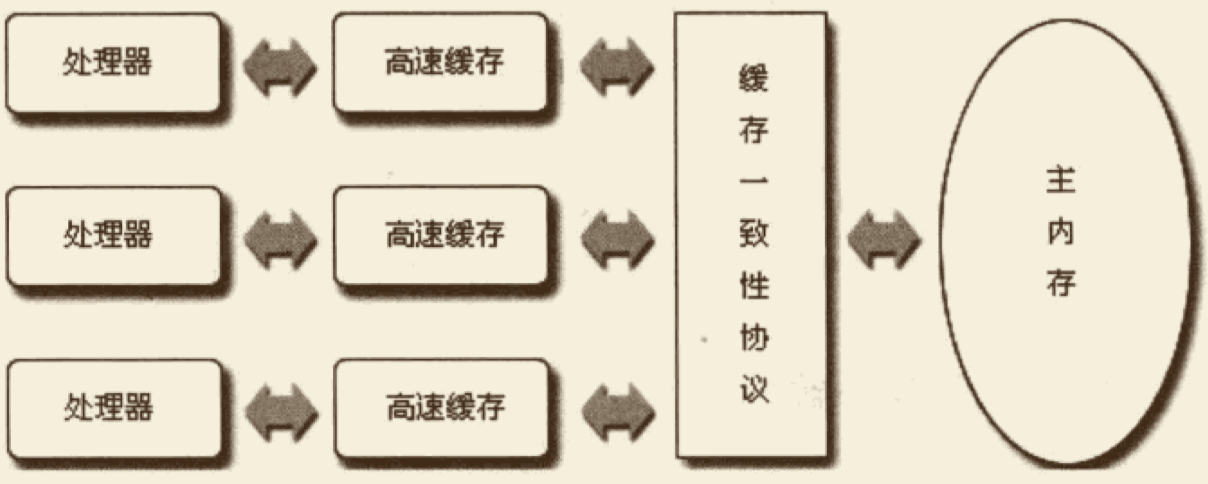
除此之外,为了使得处理器内部的运算单元能够尽量被充分利用,处理器可能会对输入代码进行乱序执行优化,处理器会在计算之后将乱序执行的结果重组,保证该结果与顺序执行的结构一致,但并不保证程序中各个语句计算的顺序与代码输入时的顺序一致,因此如果一个计算任务依赖于另一个计算任务的中间结果,那么其顺序性并不能靠代码的先后顺序来保证。与处理器的乱序执行优化类似,JVM 的即时编译器中也有类似的指令重排优化。
12.3 Java 内存模型
JVM 规范中试图定义一种内存模型(JMM,JSR-133)来屏蔽掉各种硬件和操作系统在内存访问上的差异,以实现 Java 程序在各种平台下都保持一致的并发效果。在此之前,主流语言(如 C/C++)直接使用物理硬件(或者说是操作系统的内存模型),因此,会由于不同平台的内存差异导致程序在一些平台上的并发效果正常,但在另一些平台上出现非预期的并发效果,因此需要经常针对不同的平台来编写程序。
定义 JMM 并非易事,该模型必须定义的足够严谨,才能让 Java 的并发操作不会产生歧义:但是,也必须定义的足够宽松,使得虚拟机的实现能够由足够的自由空间去利用硬件的各种特性(如寄存器、高速缓存等)来获得更好的执行速度。经过长时间的验证和修补,在 JDK 1.5(实现了 JSR-133)发布后,JMM 就已经成熟和完善起来了。
12.3.1 主内存与工作内存
JMM 的主要目标是定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样的底层细节。这里所说的变量与 Java 编程中所说的变量略有区别,它包括实例字段、静态字段和构造数组对象的元素,不包括局部变量和方法参数,因为后者是“线程私有”的,不会在线程间共享,自然也就不存在竞争问题。为了获得更好的执行效能,JMM 并没有限制执行引擎使用处理器的特定寄存器或缓存来和主内存进行交互,也没有限制 JIT 调整代码执行顺序的这类权利。
线程私有:如果局部变量是一个引用类型,它引用的对象在堆中可被各个线程共享,但是引用本身位于 Java 栈的局部变量表中,它是线程私有的。
JMM 规定了所有的变量都存储在主内存中(这里是 JVM 内存的一部分,类似于物理机中的内存)。每条线程还有自己的工作内存(类比于 CPU 的高速缓存,但属于线程所有),线程的工作内存中保存了被该线程使用到的变量,这些变量是来自主内存的副本拷贝,线程对变量的所有操作(读取、赋值)都必须在工作内存中进行,而不能直接读写“主内存中的变量”。不同线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成,线程、主内存、工作内存之间的交互关系如下图。
主内存中的变量:根据 JVM 规范,volatile 变量依然用工作内存的拷贝,但是由于它特殊的操作顺序性规定,所以看起来如图直接操作主内存一样。但 volatile 并不例外。
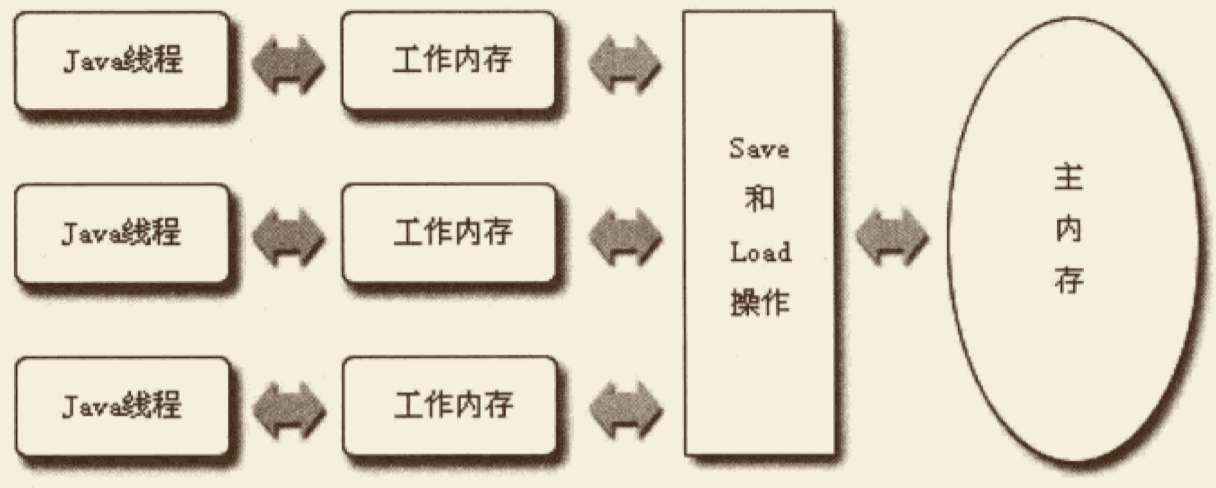
这里所讲的主内存、工作内存与本书第二章所讲的 Java 内存区域中的 Java 堆、栈、方法区等并非同一层次的内存划分。如果两者一定要勉强对应起来,那从变量、主内存、工作内存的定义来看,主内存主要是对应于 Java 堆中对象的实例数据部分,而工作内存则对应于 JVM 栈中的部分区域。从更低的层次来说,主内存就是硬件的内存,而为了获得更好的运行速度,JVM 及硬件系统可能会让工作内存优先存储在寄存器或高速缓存中。
12.3.2 内存间交互操作
关于主内存与工作内存之间具体的交互协议,即一个变量如何从主内存拷贝到工作内存、如何从工作内存同步回主内存之类的实现细节,JMM 中定义了以下 8 种“操作”来完成:
- lock:作用于主内存中的变量,将变量标识为被一条线程独占。
- unlock:作用于主内存中的变量,将被标识为被一条线程独占状态的变量从该线程释放,释放后该变量可以被其他线程 lock。
- read:作用于主内存中的变量,将变量的值从主内存传输到工作内存,以便后续的 load 使用。
- load:作用于工作内存中的变量,将 read 操作从主内存中得到的变量值放入工作内存的变量副本中。
- use:作用于工作内存中的变量,将工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量值的字节码指令时将执行该操作。
- assign:作用于工作内存中的变量,将一个从执行引擎接收到的值赋值给工作内存变量,每当虚拟机遇到一个给变量赋值的字节码指令时将执行该操作。
- store:作用于主内存中的变量,将工作内存中一个变量的值传送到主内存,以便随后的 write 操作使用。
- write:作用于主内存中的变量,将 store 操作从工作内存中得到的变量值放入主内存的变量中。
操作:实现虚拟机时必须保证每一种“操作”都是原子的、不可再分的。对于 double 和 long 类型的变量来说,在操作主内存时会出现字撕裂。
如果要把一个变量从主内存复制到工作内存,就要按顺序执行 read、load 操作;如果要把变量从工作内存同步回主内存,就要按顺序执行 store、write 操作。注意,JMM 只要求上述两个操作必须按顺序执行,而没有要求必须是连续执行,即 read 和 load 之间、store 和 write 之间是可以插入其他指令的(如对另外一些变量的存取操作指令)。除此之外,JMM 还规定了在执行上述 8 种基本操作时必须满足以下规则:
- read 和 laod、store 和 write 必须成对出现。
- 不允许一个线程丢弃它最近的 assign 操作,即变量在工作内存中改变了之后必须把该变化同步回主内存。
- 不允许一个线程无故(没有发生过任何 assign 操作)把数据从线程的工作内存同步回主内存。
- 一个新的变量必须在主内存中“诞生”,不允许在工作内存中直接使用一个未被初始化(load/assign)的变量,即,对一个变量实施 use 和 store 操作之前,必须已经执行过 assign 和 load 操作。
- 一个变量在同一时刻仅允许一个线程对其进行 lock,但 lock 可以被同一线程重复执行多次,多次执行 lock 之后,只有执行相同次数的 unlock 才能完成解锁。
- 如果对一个变量执行 lock,将会清空工作内存中该变量的值而直接使用主内存中该变量的值(lock 引用在主内存),在执行引擎使用该变量前,需要重新执行 load 或 assign 来初始化变量的值。
- 如果一个变量事先没有被 lock 操作锁定,则不允许对其执行 unlock;也不允许 unlock 一个被其他线程锁定的变量。
- 对一个变量执行 unlock 前,必须先把此变量同步回主内存。
12.3.3 volatile 变量的特殊规则
关键字 volatile 可以说是 JVM 提供的最轻量级的同步机制,但是它并不容易被正确完整的理解。
当一个变量被定义为 volatile,它将具备两种特性,第一是保证此变量对所有线程可见:一旦一条线程修改了该变量,新值对于所有其他线程来说是可以立即得知的。而普通变量无法做到这一点,变量值在线程间的传递需要通过主内存来完成,如:线程 A 修改一个普遍变量的值,然后向主内存进行回写,另外一条线程 B 在线程 A 回写完成之后再从主内存读取该变量的新值,这时新值才对线程 B 可见。
这种可见性经常被误解,认为以下描述成立:“volatile 对所有线程是立即可见的,对 volatile 变量的所有写操作都能立即反应到其他线程之中,换句话说,volatile 变量在各个线程中是一致的,所以基于 volatile 变量的运算在并发下是安全的”。这句话的论据部分没有错,但是其论据并不能得出“基于 volatile 变量的运算在并发下是安全的”这个结论。volatile 变量在各个线程的工作内存中不存在一致性的问题(在各个线程的工作内存中 volatile 变量也会存在不一致的情况,由于每次使用 volatile 变量之前都会先进行刷新,执行引擎看不到不一致的情况,因此可以认为不存在一致性问题),“但是 Java 中的运算并非原子操作”,导致 volatile 变量的运算在并发下变得不安全。下面看一个例子。
public class VolatileTest {
public static volatile int race = 0;
public static void increase() {
race++;
}
private static final int THREADS_COUNT = 20;
public static void main(String...args) {
Thread[] threads = new Thread[THREADS_COUNT];
for(int i=0; i<THREADS_COUNT; i++) {
threads[i] = new Thread(new Runnable(){
@Override
public void run() {
for(int i=0; i<10000; i++){
increase();
}
}
});
threads[i].start();
}
while(Thread.activeCount() > 1) {
Thread.yield();
}
System.out.println(race);
}
}
如果上述代码正确的话,最终的输出结果应该是 200000。但实际的运行结果并非如此。问题就出现在自增运算 race++ 之中,我们用 javap 反编译这段代码后会得到下面的代码清单,发现只有一行代码的 increase() 方法在 Class 文件中是由 4 条字节码指令构成的,从字节码层面很容易就分析出并发失败的原因了:当 getstatic 指令把 race 的值取到操作栈顶时,volatile 关键字保证了 race 的值在此时是正确的,但是在执行 iconst_1、iadd 这些指令的时候,其他线程就可能已经把 race 的值增加了,而在操作栈顶的值就成了过期数据,所以 putstatic 指令执行后就可能把较小的 race 值同步回主内存中。
public static void increase();
Code:
Stack=2, Locals=0, Args_size=0
0: getstatic #13; //Field race: I
3: iconst_1
4: iadd
5: putstatic #13: //field race: I
8: return
LineNumberTable:
line 14: 0
line 15: 8
实事求是的说,笔者在此使用字节码来分析并发问题,仍然是不严谨的,因为即便编译出来只有一条字节码指令,也并不意味着执行这条指令就是原子操作。一条字节码指令在解释执行时,解释器将要运行许多代码才能实现它的语义,如果是编译执行,一条字节码指令也可能转换成若干条本地机器码指令,此处使用 -XX:+PrintAssembly 参数输出反汇编来分析会更加严谨一些,但是考虑到读者阅读的方便,并且字节码已经能够说明问题,所以此处使用字节码来分析。
由于 volatile 变量只能保证可见性,在不符合以下两条规则的运算场景中,我们仍然要通过加锁(会用 synchronized 或 JUC 中的原子类)来保证原子性。
- 运算结果并不依赖变量的当前值,或者能够保证只有单一的线程修改变量的值。
- 变量不需要与其他状态变量共同参与不变约束。
而在像如下代码清单中所示的这类场景就很适合使用 volatile 变量来控制并发,当 shutdown() 方法被调用时,能够保证所有线程中执行的 doWork() 方法都立即停下来。
volatile boolean shutdownRequested;
public void shutdown() {
shutdownRequested = true;
}
public void doWork() {
while(!shutdownRequested) {
// do stuff
}
}
使用 volatile 变量的第二个语义是禁止指令重排序优化,普通变量仅仅会保证在该方法执行过程中所有依赖赋值结果的地方都能获得正确的结果,而不能保证变量赋值操作的顺序与程序代码中执行顺序一致。因为在一个线程的方法执行过程中无法感知到这一点,这也就是 JMM 中描述的所谓“线程内表现为串行的语义”。
如下伪代码所示:
Map configOptions;
char[] configText;
// 此时变量必须定义为 volatile
volatile boolean initialized = false;
// 假设以下代码在线程 A 中执行
// 模拟读取配置信息,当读取完成后
// 将 initialized 设置为 true 来通知其他线程配置已经可用
configOptions = new HashMap();
configText = readConfigFile(fileName);
processConfigOptions(configText, configOptions);
inintialized = true;
// 假设以下代码在线程 B 中执行
// 等待 initialized 为 true,代表线程 A 已经把配置信息初始化完成
while (!initialized) {
sleep();
}
// 使用线程 A 初始化好的配置信息
doSomethingWithConfig();
以上描述的场景十分常见,只是我们在处理配置文件时一般不会出现并发而已。如果定义 initialized 变量时没有使用 volatile 修饰,就可能由于指令重排的优化,导致位于线程 A 中最后一句的代码“initialized = true”被提前执行,这样在线程 B 中使用配置信息的代码就可能出现问题,而 volatile 关键字则可以避免此类请求的发生。
解决了 volatile 语义的问题,再来看看在众多保障并发安全的工具中选用 volatile 的意义——它能让我们的代码比使用其他同步工具时更快吗?确实在某些情况下,volatile 同步机制的性能要优于锁(即 synchronized 或 JUC 中的锁),但是由于虚拟机对锁实行的很多消除和优化,使得我们很难量化的说 volatile 就是会比 synchronized 快上多少。如果让 volatile 自己与自己比较,则可以确定一个原则:volatile 变量读操作的性能消耗与普通变量几乎没有什么差别,但是写操作可能会满上一些,因为它需要在本地代码中插入许多内存屏障(Memory Barrier)指令来保证处理器不会发生乱序执行。不过即便如此,大多数场景下 volatile 的总开销仍然要比锁低,我们在 volatile 与锁中选择的唯一判断依据仅仅是 volatile 的语义能否满足使用场景的需求。
本节的最后,我们再来看看 JMM 中对 volatile 变量定义的特殊规则。假设 T 表示一个线程,V 和 W 分别表示两个 volatile 变量,那么在执行 read、load、use、assign、store、write 操作时需要满足如下规则:
- 只有线程 T 对变量 V 执行的前一个动作是 load 的时候,T 才能对 V 执行 use 操作;并且,只有当 T 对 V 执行的后一个动作是 use 时,T 才能对 V 执行 load 动作。T 对 V 的 use 动作可以认为是与 T 对变量 V 的 load 和 read 动作是相关联的,必须一起“连续出现”。(该规则要求在工作内存中,每次使用 V 之前都先从主内存刷新最新值,用于保证能看见其他线程对 B 执行修改后的值)
- 只有当线程 T 对变量 V 执行的前一个操作是 assign 时,T 才能对 V 执行 store 操作;并且,只有当 T 对 V 执行的后一个动作是 store 时,T 才能对 V 执行 assign 操作。T 对 V 的 assign 动作可以认为是 T 对 V 的 store 和 write 动作相关联的,必须一起连续出现。(该规则要求在工作内存中,每次修改 V 后都必须立刻将其同步回主内存,用于保证其他线程可以看到当前线程对 V 所做的修改)
- 假定动作 A 是线程 T 对变量 V 实施的 use 或 assign 动作,假定动作 F 是与动作 A 相关联的 load 或 store 操作,假定动作 P 是与动作 F 相应的对变量 V 的 read 或 write 动作;类似的,假定动作 B 是线程 T 对变量 W 实施的 use 或 assign 动作,假定动作 G 是与动作 B 相关联的 load 或 store 操作,假定动作 Q 是与动作 G 相关联的对变量 W 的 read 或 write 动作。如果 A 先于 B,那么 P 先于 Q。(这条规则要求 volatile 修饰的变量不会被指令重排序优化,保证代码执行的顺序与程序代码的顺序相同)
12.3.4 对于 long 和 double 型变量的特殊规则
JMM 要求 lock、unlock、read、load、assign、use、store、write 这 8 种操作都具有原子性,但是对于 64 位的数据类型,在模型中特别定义了一条宽松的规定:允许虚拟机将没有被 volatile 修饰的 64 位数据的读写操作划分为两次 32 位的操作来进行,即允许虚拟机实现选择可以不保证数据类型为 long 和 double 的非原子性协定。
如果有多个线程共享一个并未声明为 volatile 的 long 或 double 类型的变量,并且同时对它们进行读取和修改操作,那么某些线程可能会读到一个即非原值又非其他线程修改值的“半个变量”数值。
不过这种读取到“半个变量”的情况非常罕见,因为 JMM 虽然允许虚拟机不把 long 和 double 变量的读写操作实现成原子操作,但允许虚拟机选择把这些操作实现为具有原子性的操作,而且还“强烈建议”虚拟机这么做。在实际开发中,目前各种平台下的商用虚拟机几乎都选择把 64 位数据的读写操作实现为原子操作,因此我们在编写代码时一般不需要把 long 的 double 变量专门声明为 volatile。
12.3.5 原子性、可见性、有序性
介绍完 JMM 相关的操作和规则,我们再整体回顾一下该模型的特征。JMM 是围绕着在并对过程中如何处理原子性、可见性、有序性这三个特征来建立的,我们逐个来看一下哪些操作实现了这三个特性。
“原子性(Atomicity)”:由 JMM 来直接保证的原子性变量操作包括 read、load、assign、use、store、write 这 6 个,我们大致认为基本数据类型的访问读写是具备原子性的(long 和 double 除外)。
如果应用场景需要一个更大范围的原子性保证,JMM 还提供了 lock 和 unlock 操作来满足这种需求,尽管虚拟机未把 lock 和 unlock 直接开放给用户使用,但是却提供了更高层次的字节码指令 monitorenter 和 monitorexit 来隐式的使用这两个操作,这两个字节码指令反映到 Java 代码中就是同步块——synchronized 关键字,因此在 synchronized 块之间的操作也具备原子性。
“可见性(Visibility)”:可见性就是指当一个线程修改了共享变量的值,其他线程能够立即获得这些最新的值。上文在讲解 volatile 变量的时候我们已经详细讨论过这一点。JMM 是通过在变量修改后将新值同步回主内存、在变量去读前从主内存刷新变量值这个种依赖主内存作为传递媒介的方式来实现可见性的,无论是普通变量还是 volatile 变量都是如此,普通变量与 volatile 变量的区别在于 volatile 的特殊规则保证了新值能够立即同步主内存,以及每次使用前立即从主内存刷新。因此我们可以说 volatile 保证了多线程操作时变量的可见性,而普通变量则不能保证这一点。
除了 volatile 之外,Java 还提供了两个关键字实现可见性,即 synchronized 和 final。同步块的可见性是由“对一个变量执行 unlock 操作前,必须先把此变量同步回主内存中(store & write)”这条规则获得的;而 final 关键字的可见性是指:被 final 修饰的字段在构造器中一旦被初始化完成,并且构造器没有把“this”的引用传递出去(this 引用逸出是一件很危险的事情,其他线程可能通过这个引用访问到“初始化了一半”的对象),那么在其他线程中就能看到final 字段的值。如下代码所示,变量 i 与 j 都具备可见性,它们无需同步就能被其他线程正确的访问。
public static final int i;
public finl int j;
static {
i = 0;
j = 0; // 也可以选择则构造函数中初始化 j
}
“有序性(Ordering)”:JMM 的有序性前面讲解 volatile 时也详细讨论过,Java 程序中天然的有序性可以总结为一句话:如果在本线程内观察,所有的操作都是有序的;如果在另一个线程中观察,所有的操作都是无序的。前半句是指“线程内表现为串行的语义”,后半句是指“指令重排序”现象和“工作内存与主内存同步延迟”现象。
Java 语言提供了 volatile 和 synchronized 两个关键字来保证线程之间操作的有序性,volatile 关键字本身就包含了禁止指令重排序的语义,而 synchronized 则是由“一个变量在同一时刻仅允许一条线程对其进行 lock 操作”这条规则获得的,这个规则决定了持有同一个锁的两个同步块只能串行的进入。
介绍完并发的三种重要特性,读者有没有发现 synchronized 关键字在需要这三种特性时都可以作为一种解决方案?看起来是万能的?的确,大部分的开发控制操作都能通过使用 synchronized 来完成。synchronized 的“万能”间接造就了它被开发者滥用的局面,越“万能”的并发控制,通常也伴随着越大的性能影响。
12.3.6 先行发生(happens-before)原则
如果 JMM 中所有的有序性都只靠 volatile 和 synchronized 来完成,那么有一些操作就会变得很啰嗦,但是我们在编写 Java 并发代码的时候并没有感觉到这一点,这是因为 Java 语言中有一个“先行发生”原则。该原则非常重要,它是判断数据是否存在竞争、线程是否安全的主要依据。基于该原则,我们可以通过几条规则一揽子解决并发环境下两个操作之间是否可能存在冲突的所有问题。
先行发生是 JMM 中定义的两项操作之间的偏序关系,如果说操作 A 先行发生于操作 B,其实就是说在发生 B 之前,操作 A 产生的影响能被操作 B 观察到,“影响”包括对内存中共享变量值的修改、发送了消息、调用了方法等。这句话不难理解,但它意味着什么呢?我们可以举个例子来说明,如下所示的三行伪代码:
// 线程 A
i = 1;
// 线程 B
j = i;
// 线程 C
i = 2;
假设线程 A 中的操作线性发生于线程 B 中的操作,那么我们就可以确定在线程 B 的操作执行之后,变量 j 的值一定为 1。得出该结论的依据有两个,一是根据现行发生原则,“i=1”的结果可以被观察到;二是线程 C 登场之前,线程 A 操作结束之后没有其他线程会修改变量 i 的值。现在再来考虑线程 C,我们依然保持线程 A 和 B 之前的线性发生关系,而 C 出现在线程 A 和 B 的操作之间,但是 C 与 B 没有先行发生关系,那么 j 的值会是多少呢?答案是不确定。1 或是 2,因为线程 C 对变量 i 的影响可能会被线程 B 观察到,也可能不会,这时候线程 B 就存在读取到过期数据的风险,不具备多线程安全性。
下面是 JMM 中一些“天然的”线性发生关系,这些线性发生关系无需任何同步协助就已经存在,可以直接在编码时使用。如果两个操作之间的关系不在次列,并且也无法从下列规则中推导出来的话,它们就没有顺序性保证,虚拟机可以对他们进行随意重排。
- 程序次序规则:在一个线程内,按照程序代码顺序,书写在前面的操作先行发生于发生在后面的操作。准确的说应该是控制流程序而不是程序代码顺序,因为要考虑分支、循环等结构。
- 管理锁定规则:一个 unlock 操作先行发生于后面对同一个锁的 lock 操作。这里必须强调的是同一个锁,而“后面”是指时间上的先后顺序。
- volatile 变量规则:对一个 volatile 变量的写操作先行发生于后面对这个变量的读操作,这里的“后面”同样指的是时间上的先后顺序。
- 线程启动规则:Thread 对象的 start 方法先行发生于此线程内的所有动作。
- 线程终止规则:线程内的所有操作都先行发生于对此线程的终止检测,我们可以通过 Thread.join() 方法结束、Thread.isAlive() 的返回值等手段检测到线程已经终止执行。
- 线程中断规则:对线程 interrupt() 方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过 Thread.interrupted() 方法检测到是否有中断发生。
- 对象终结规则:一个对象的初始化完成(构造函数执行结束)先行发生于它的 finalize 方法的开始。
- 传递性:如果操作 A 先行发生于操作 B,操作 B 先行发生于操作 C,则操作 A 先行发生于操作 C。
Java 语言无需任何同步手段保障就能成立的先行发生规则就只有上面这些了,笔者演示一下如何使用这些规则去判定操作间是否具有顺序性,对于读写共享变量的操作来说,就是线程是否安全,读者还可以从下面的例子中感受一下“时间上的先后顺序”与“先行发生”之间有什么不同。
private int value = 0;
public void setValue(int value) {
this.value = value;
}
public int getValue() {
return value;
}
上述代码显示的是一组再普通不过的 getter/setter 方法,假设存在线程 A 和 B,线程 A 先(时间上的先后)调用了 setValue(1),然后线程 B 调用了同一个对象的 getValue(),那么线程 B 收到的返回值是什么?
我们依次分析一下先行发生规则,由于两个方法分别是由线程 A 和 B 调用,不再一个线程中,所以程序次序在这里不适用;由于没有同步块,自然就不会发生 lock 和 unlock 操作,所以管理程序规则不适用;由于 value 变量没有被 volatile 修饰,所以 volatile 变量规则不适用;后面的线程启动、终止、中断规则和对象终结规则也和代码中的操作扯不上关系。因为没有一个适用的先行发生规则,所以最后一条传递性也无从谈起,因此我们可以判定尽管线程 A 的操作在时间上先于线程 B,但是无法确定 B 中 getValue 的返回结果,换句话说,这里的操作不是线程安全的。
那么如何修复这个问题呢?我们至少有两种比较简单的方案可供选择:呀么把 getter/setter 方法都定义为 synchronized 方法,这样就可以套用管程锁定规则;要么把 value 定义为 volatile 变量,由于 setter 方法对 value 的修改不依赖于 value 的原值,满足了 volatile 关键字使用场景,这样就可以套用 volatile 变量规则来实现先行发生关系。
通过上面的例子,我们可以得出一个结论:一个操作“时间上先行发生”不代表这个操作会是“先行发生”,那么如果一个操作“先行发生”是否就能推导出这个操作必定是“时间上的先发生”呢?很遗憾,这个推论也是不成立的,一个典型的场景就是多次提到的“指令重排序”,如下代码所示:
// 以下操作在同一个线程中执行
int i = 1;
int j = 2;
根据程序次序规则,第一行的操作先先行发生于第二行的操作,但是第二行代码完全可能先被处理器执行,这并不影响先行发生原则的正确性,因为我们在这条线程中没有办法感知到这一点。
上面两个例子综合得出一个结论:时间上的先后顺序与先行发生原则之间基本没有太大关系,所以我们衡量并发安全问题的时候不要受到时间顺序的干扰,一切必须以先行发生原则为准。
12.4 Java 与线程
并发不一定要依赖多线程(如 PHP 中很常见的多进程并发),但是在 Java 里面谈论并发,大多数与线程脱不开关系。因此我们就从 Java 线程在虚拟机中的实现讲起。
12.4.1 线程的实现
我们知道,线程是比进程更轻量级的调度执行单位,线程的引入,可以把一个进程的资源分配和执行调度分开,各个线程可以共享进程资源(内存地址、文件 IO 等),又可以独立调度(线程是 CPU 调度的最基本单位)。
主流的操作系统都提供了线程实现,Java 语言则提供了在不同硬件和操作系统平台下对线程操作的统一处理,每个 java.lang.Thread 类的实例就代表了一个线程。不过 Thread 类与大部分的 Java API 有着显著的区别,它的所有关键方法都被实现为 Native。在 Java API 中一个 Native 方法可能意味着这个方法没有使用或无法使用平台无关的手段来实现(当然也可能为了执行效率而使用 Native 方法,不过通常最高效率的手段也就是平台相关的手段)。正因为如此,作者把本节标题定位“线程的实现”,而非“Java 线程的实现”。
实现线程主要有三种方式:使用内核线程实现、使用用户线程实现、使用用户线程加轻量级进程混合实现。
1. 使用内核线程实现
内核线程(KLT)就是直接由操作系统内核支持的线程,这些线程由内核来完成线程切换,内核通过操纵调度器对线程进行调度,并负责将线程的任务映射到各个处理器上。每个内核线程都可以看做是内核的一个分身,这样操作系统就有能力同时处理多件事情,支持多线程的内核就叫做多线程内核。
程序一般不会直接使用内核线程,而是使用内核线程的一种高级接口——轻量级进程(LWP)。轻量级进程就是我们通常意义上所说的线程,由于每个轻量级进程都有一个内核线程支持,因此只有先支持内核线程,才能有轻量级进程。这种轻量级进程与内核线程之间 1:1 的冠以称为“一对一的线程模型”,如下图所示:
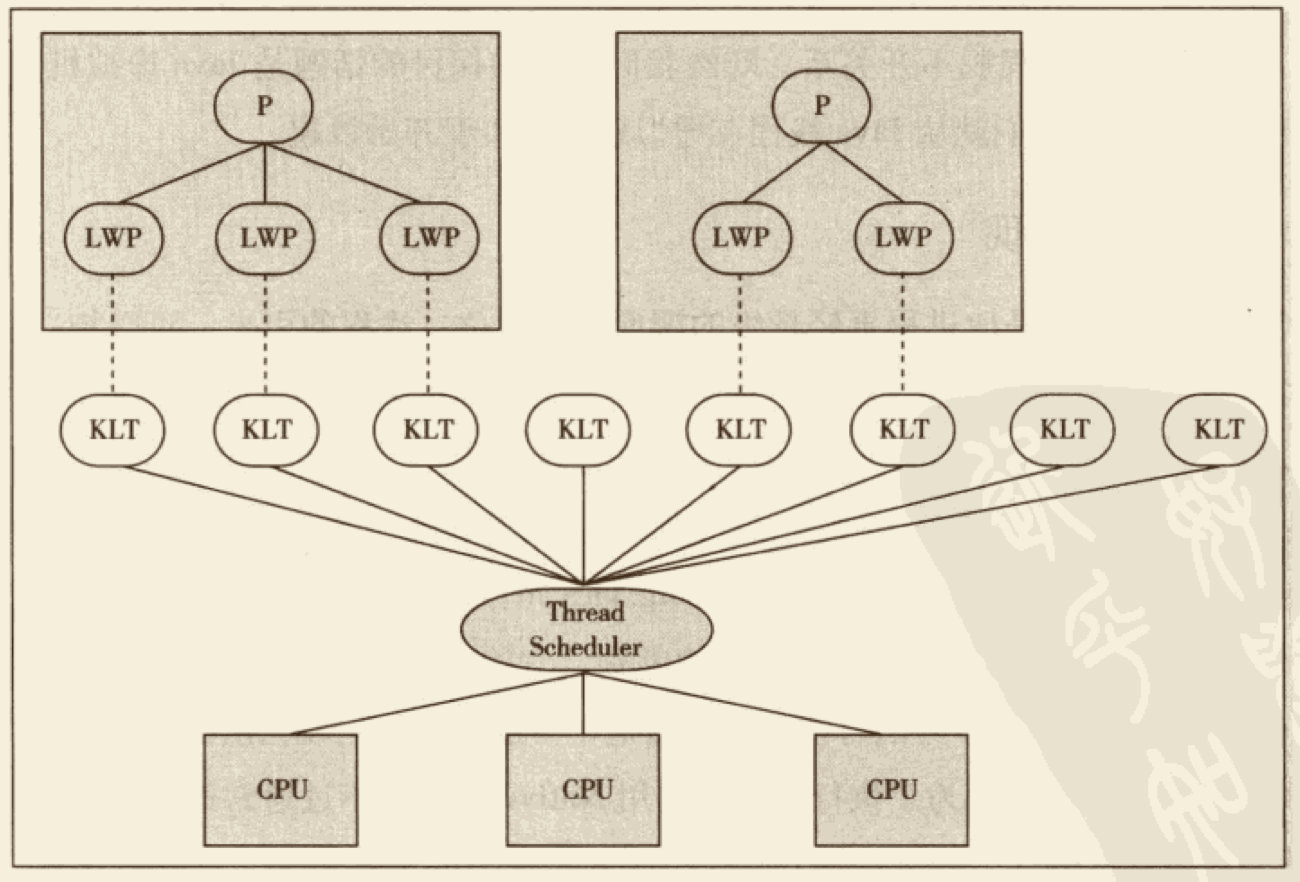
由于内核线程的支持,每个轻量级进程都称为一个独立的调度单元,即使有一个轻量级进程在系统调用中阻塞了,也不会影响整个进程继续工作,但是轻量级进程具有它的局限性:首先,由于是基于内核线程实现的,所以各种进程操作,如创建、撤销及同步都需要进行系统调用。而系统调用的代价相对较高,需要在用户态和内核态中来回切换。其次,每个轻量级进程都需要一个内核线程的支持,因此轻量级进程要消耗一定的内核资源(如内核线程的栈空间),因此一个系统支持轻量级进程的数量是有限的。
2. 使用用户线程实现
广义来讲,一个线程只要不是内核线程,就可以被认为是用户线程(UT),因此从这个定义上来讲轻量级进程也属于用户线程,但轻量级进程的实现始终是建立在内核线程之上的,许多操作都需要使用系统调用,因此效率也会受限制。
而狭义上的用户线程值得是完全建立在用户空间的线程库上,系统内核不能感知到线程存在的实现。用户线程的建立、同步、销毁和调度完全在用户态中完成,不需要内核的帮助。如果程序实现得当,这种线程不需要切换到内核态,因此操作可以是非常快且低消耗的,也可以支持规模更大的线程数量,部分高性能数据库中的多线程就是由用户线程实现的。这种进程与用户线程之前是 1:N 的关系称为 “一对多的线程模型”,如下图:
使用用户线程的优势在于不需要内核支援,劣势在于没有系统内核的支援,所有的线程操作都需要用户程序自己处理。线程的创建、切换、调度都是需要考虑的问题,而且由于操作系统只能把处理器资源分配到进程级别,那些诸如“阻塞如何处理”、“多处理器系统中如何将线程映射到其它处理器上”这类问题解决起来都会异常困难,甚至不可能完成。因而使用用户线程实现的程序一般都比较复杂,处理以前在不支持多线程的操作系统中的多线程程序与少数具有特殊需求的程序之外,现在使用用户线程的程序越来越少了,Java、Ruby 等语言都曾经使用过用户线程,但最终都放弃了。
3. 混合实现
线程除了依赖内核线程实现和完全由用户程序自己实现外,还有一种将内核线程与用户线程结合的实现方式。在这种混合实现中,既存在用户线程,也存在轻量级继承。用户线程还是完全建立在用户空间中,因此用户线程的创建、切换、销毁等操作依然廉价,并且可以支持大规模的用户级线程并发。而操作系统提供支持的轻量级进程则作为用户线程和内核线程之间的桥梁,这样可以利用内核提供的线程调度功能及处理器映射功能,并且用户线程的系统调用要通过轻量级进程来完成,大大降低了进程被阻塞的风险。在这种混合模式中,用户线程与轻量级进程的数量比例是不一定的,是 M:N 的关系,被称为“多对多线程模型”,如下图:
许多 UNIX 系列的操作系统,如 Solaris、HP-UX 等都提供了 M:N 的线程模型实现。
4. Java 线程的实现
Java 线程在 JDK 1.2 之前,是基于名为“绿色线程(Green Threads)” 的用户线程实现的,而在 JDK 1.2 中,线程模型被替换为基于操作系统原生线程模型来实现。因此在目前版本的 JDK 中,操作系统支持怎样的线程模型,在很大程度上决定了 JVM 虚拟机的线程是怎样的映射的,这点在不同平台上没有办法达成一致,虚拟机规范中也并未限定 Java 线程需要使用哪些线程模型来实现。线程模型只对线程的并发规模和操作成本产生影响,对 Java 程序的编码和运行过程来说,这些差异都是透明的。
对于 Sun JDK 来说,它的 Windows 与 Linux 版都是使用一对一的线程模型来实现的,一条 Java 线程就映射到一条轻量级线程之中,因为 Windows 和 Linux 系统提供的线程模型就是一对一的(尽管存在一些多对多模型的实现,但没有成为主流)。
而在 Solaris 平台中,由于操作系统的线程特性可以同时支持一对一(通过 Bound Threads 或 Alternate Libthread)和多对多(通过 LMP/Thread Based Synchronization 实现)的线程模型,因此在 Solaris 版的 JDK 中也对应提供了两个平台专有的虚拟机参数:-XX:+UseLWPSynchronization(默认值) 和 -XX:+UseBoundThreads 来明确指定虚拟机要使用的线程模型。
12.4.2 Java 线程调度
线程调度是指系统为线程分配处理器使用权的过程,主要调度方式有两种,协同式(Cooperative)和抢占式(Preemptive)。
如果使用协同式调度的多线程系统,线程的执行时间由线程本身来控制,线程把自己的工作执行完了之后,要主动通知系统切换到另外一个线程上去。协同式多线程的最大好处是实现简单,而且由于线程要把自己的事情完成之后才会进行线程切换,切换操作对线程自己来说是可以预知的,所以没有什么线程同步的问题。Lua 语言中的“协同例程”就是这类实现。它的缺点很明显:线程执行时间不可控,甚至如果一个线程编写有问题,一直不告诉系统进行线程切换,那么程序会一直阻塞在那里。很久以前的 Windows 3.x 系统就是使用协同式来实现多进程多任务的,那是相当的不稳定,一个进程坚持不让出 CPU 执行时间就会导致整个系统崩溃。
如果使用抢占式调度的多线程系统,那么每个线程将由系统来分配执行时间,线程的切换不由线程本身来决定(在 Java 中,Thread.yield 可以让出执行时间,但是线程本身没办法主动获得执行时间)。在这种实现线程调度的方式下,线程的执行实现是系统可控的,也不会有一个线程导致整个进程阻塞的问题,Java 使用的线程调度方式就是抢占式调度。与前面所说的 Windows 3.x 的例子相对,在 Windows 9x/NT 内核中就是使用抢占式来实现的多进程,当一个进程出了问题,我们还可以使用任务管理器来把这个进程杀掉,而不至于导致系统崩溃。
虽然说 Java 多线程调度是由系统自动完成的,但是我们还是可以“建议”系统给某些线程多分配一些执行时间,另外的一些线程多则可以少分配一些——这项操作可以通过设置线程优先级来完成。Java 语言一共设置了 10 个级别的线程优先级,在两个线程同时处于 Read 状态时,优先级越高的线程越容易被系统选择执行。
但是线程优先级并不是很靠谱,原因是 Java 的线程是被映射到系统的原生线程(内核线程)上来实现的,所以线程调度最终还是由操作系统说了算,虽然现在很多操作系统都提供线程优先级的概念,但是并不见得能与 Java 线程的优先级实现一一对应,如 Solaris 中有 2147483648 种优先级,但 Windows 中仅有 7 种,比 Java 线程优先级多的系统还好说,中间留下一点空位就是了,但比 Java 线程优先级少的系统,就不得不出现几个优先级相同的情况了,下表展示了 Java 线程优先级与 Window 线程优先级之间的对应关系,Windows 平台的 JDK 中使用了除 THREAD_PRIORITY_IDLE 之外的其余 6 种线程优先级。

上文说到“线程优先级并不是很靠谱”,不仅仅是说在一些平台上不同的优先级实际会变得相同这一点,还有其他情况让我们不能太依赖优先级:优先级可能会被系统自动改变。例如在 Windows 系统中存在一个名为“优先级推进器”的功能,它的大致作用即使当系统发现一个线程被执行的“特别勤奋努力”的话,可能会越过线程优先级来为其分配执行时间。因此我们不能在程序中通过优先级来完全准确的判断一组状态都为 Ready 的线程中哪个会先执行。
12.4.3 状态转换
Java 语言定义了 5 种线程状态,在任意一个时间点,一个线程只能有且只有其中一种状态:
- New:创建后但尚未启动。
- Runnable:包括了操作系统线程状态的 Running 和 Ready,也就是处于这种状态的线程有可能在执行,也可能正在等着操作系统为其分配执行时间。
- Waiting:无限期等待,不会被分配 CPU 执行时间,需要等待被其他线程显式的唤醒。以下方法会让线程陷入 Waiting 状态:
- Object.wait()
- Thread.join()
- LockSupport.park()
- Timed Waiting:期限等待,不会被分配 CPU 执行时间,在一定时间后它们会由操作系统自动唤醒。以下方法会让线程陷入 Timed Waiting 状态:
- Thread.sleep()
- Object.wait(time)
- Thread.join(time)
- LockSupport.parkNanos(nanos)
- LockSupport.parkUntil(time)
- Blocked:线程被阻塞。“阻塞状态”与“等待状态”的区别是,“阻塞状态”在等着获得一个排他锁,这个事件将在另一个线程放弃该锁的时候发生;而“等待状态”则是在等待一段时间、发生唤醒动作。在程序等待进入同步区域的时候,线程将进入这种状态。
- Terminated:线程已被终止,线程已被结束执行。
上述 5 种状态在约到特定事件时会发生切换,它们之间的转换关系如下图:
12.5 总结
本章中,我们了解了虚拟机 JMM 的结构及操作,并讲解了原子性、可见性、有序性在 JMM 中的体现,介绍了先行发生原则的规则及应用。另外,我们还了解了线程在 Java 语言中的实现方式。
13 - CH13-线程安全与锁优化
13.1 概述
在软件业发展的初期,程序的编写都是以算法为核心,程序员会把数据和过程分别作为独立的部分来考虑,数据代表问题空间中的客体,程序代码则用于处理这些数据,这种思维方式是直接站在计算机的角度去抽象和解决问题,称为面向过程的编程思想。于此相对,面向对象的思想则是站在现实世界的角度去抽象和解决问题,它把数据和行为都看作是对象的一部分,这样可以让程序员以符合现实世界的思维方式来编写和组织程序。
面向过程的编程思想极大的提升了现代软件开发的生产效率和软件可以达到的规模,但是现实世界与计算机世界之间不可避免的存在一些差异。例如,人们很难想象现实中的对象在一项工作进行期间,会被不停的中断可切换,对象的属性可能会在中断期间被修改和变脏,而这些事件在计算机世界中则是很正常的现象。有时候,良好的设计原则不得不向现实做出一些让步,我们必须让程序在计算机中正确无误的运行,然后在考虑如何将代码组织的更好,让程序运行的更快。对于这部分的主题“高效并发”来将,首先需要保证并发的正确性,然后在此基础上实现高效。
13.2 线程安全
“线程安全”这个名词,相信稍有经验的开发者都有听过,甚至在编写和走查代码的时候还会经常挂在嘴边,但是如何找到一个不太拗口的概念来定义线程安全却不是一件容易的事情。
笔者认为 “Java Concurrency In Practice” 的作者 Brian Goetz 对“线程安全”有一个比较恰当的定义:“当多个线程访问一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替执行,也不需要进行额外同步,或者在调用方进行任务其他的协调操作,调用这个对象的行为都可以获得正确的结果,那这个对象就是线程安全的”。
这个定义很严谨,它要求了线程安全的代码必须都具备一个特征:代码本身封装了所有必要的正确性保障手段(如互斥同步等),令调用者无需关心多线程问题,更无须自己实现任何措施来保证多线程的正确调用。这点并不容易做到,在大多数场景中,我们都会将这个定义弱化一些,如果把“调用这个对象的行为”限定为“单次调用”,这个定义的其他描述也能成立的话,我们就可以称之为线程安全了。
13.2.1 Java 中的线程安全
为了更深入理解线程安全,我们可以不把线程安全当做一个非真即假的二元排他选项来看待,安装线程安全的“安全程度”由强至弱来排序,我们可以将 Java 语言中各种操作共享的数据分为以下五类:
1. 不可变
在 Java 语言里面,不可变对象一定是线程安全的,无论是对象的方法实现还是方法的调用者,都不再需要进行任何的线程安全保障措施,在上一章中我们谈到的 final 关键字带来的可见性时曾提到过这一点,只要一个不可变的对象被正确的构建出来(没有发生 this 引用逸出的情况),则其外部的可见状态永远都不会改变,永远也不会看到它在多个线程之中处于不一致的状态。“不可变”带来的安全性也是最简单最纯粹的。
Java 语言中,如果共享的数据是一个基本数据类型,那么只要在定义时使用 final 关键字修饰它就可以保证它是不可变的。如果共享数据是一个对象,那就需要保证对象的行为不会对其状态产生任何影响才行,比如 String 类。
保证对象行为不影响自身状态的途径有很多种,其中最简单的就是把对象中带有状态的变量都声明为 final,这样在构造函数结束之后它就是不可变的。
在 Java API 中符合不可变要求的类型,除了上面提到的 String 之外,常用的还有枚举类型,以及 java.lang.Number 的部分子类,如 Long 和 Double 等数值包装类型,BigInteger 和 BigDecimal 等大数据类型;但同为 Number 子类的原子类 AtomicInteger 和 AtomicLong 则是可变的。
2. 绝对线程安全
绝对的线程安全完全满足 Brian Goetz 对线程安全的定义,一个类要达到“不管运行时环境如何,调用者都不需要任何额外的同步措施”通常需要付出很大的代价。在 Java API 中标注为线程安全的类中,大多数都不是绝对的线程安全。我们可以通过 Java API 中一个不是“绝对线程安全”的线程安全类来看看这类的“绝对”是什么意思。
java.util.Vector 是一个线程安全的容器,因为它所有类似 add、get 的方法都被 synchronized 修饰,尽管这样效率很低,但是确实是安全的。但是,即使它所有的方法都被修饰为同步,也不意味着调用它的时候就无需考虑同步了,如下代码示例:
private static Vector<Integer> vector = new Vector<>();
public static void main(String...args) {
while(true) {
for(int i=0; i<10; i++) {
vector.add(i);
}
Thread removeThread = new Thread(new Runnable() {
@Override
public void run() {
for(int i=0; i<vector.size(); i++) {
vector.remove(i);
}
}
});
Thread printThread = new Thread(new Runnable() {
@Override
public void run() {
for(int i=0; i<vector.size(); i++) {
System.out.println(vector.get(i));
}
}
});
removeThread.start();
printThread.start();
// 避免同时产生过多线程后操作系统假死
while(Thread.activeCount() > 20);
}
}
运行后将会抛出数组索引越界异常。很明显,尽管这里使用到的 get、remove、size 方法都是同步的,但是在多线程环境中,如果不再方法调用端做任何同步措施,使用这段代码仍然不安全,因为如果另一个线程恰好的时间删除了一个元素,导致序号 i 已经不再可用的话,get(i) 将会抛出数组越界异常。如果要保证这段代码能够正确运行,则要进行如下修改:
Thread removeThread = new Thread(new Runnable() {
@Override
public void run() {
synchronized(vector) {
for(int i=0; i<vector.size(); i++) {
vector.remove(i);
}
}
}
});
Thread printThread = new Thread(new Runnable() {
@Override
public void run() {
synchronized(vector) {
for(int i=0; i<vector.size(); i++) {
System.out.println(vector.get(i));
}
}
}
});
3. 相对线程安全
相对线程安全就是我们通常意义上所说的线程安全,它需要保证对这个对象单独的操作是线程安全的,我们在调用的时候不需要做额外的保障措施,但是对于一些特定顺序的连续调用,就可能需要在调用端使用额外的同步手段来保证调用的正确性。上面的例子可以作为说明。
在 Java 语言中,大部分的线程安全类都属于这种类型,例如 Vector、HashTable、Collections 的 synchronizedCollection() 方法包装的集合等。
4. 线程兼容
线程兼容指的是对象本身并不是线程安全的,但是可以通过在调用端正确的使用同步手段来保证对象在并发环境中安全的使用,我们平常说一个类不是线程安全的,绝大多数指的是这种情况。Java API 中大部分类都是线程兼容的,如与前面的 Vector 和 HashTable 相对应的集合类 ArrayList 和 HashMap。
4. 线程对立
线程对立这得是不管调用段是否采取了同步措施,都无法在多线程环境中并发使用的代码。由于 Java 语言天生就具有多线程特性,线程对立这种排斥多线程的代码是很少出现的,而且通常是有害的,应当尽量避免。
一个线程对立的例子是 Thread 类的 suspend 和 resume 方法,如果有两个线程同时持有一个 Thread 对象,一个尝试去中断线程、一个尝试去恢复线程,如果并发执行这种操作,无论调用时是否进行了同步,目标线程都会存在死锁风险。如果 suspend 中断的线程就是即将要执行 resume 的那个线程,那就肯定要产生死锁了。常见的线程对立的操作还有 System.setIn()、System.setOut()、System.runFinalizersOnExit() 等。
13.2.2 实现线程安全
1. 互斥同步
互斥同步是最常见的一种并发正确性保障手段,同步是指在多个线程并发访问共享数据时,保证共享数据在同一时刻只被一条(或者是一些,使用信号量的时候)线程使用。而互斥是实现同步的一种手段,临界区、互斥量、信号量都是主要的互斥实现方式。因此在这四个字面中,互斥是因,通过是果,互斥是方法,同步是目的。
在 Java 中,最基本的互斥同步手段就是 synchronized 关键字,经过编译之后,会在同步块的前后分别形成 monitorenter 和 monitorexit 这两个字节码指令,这两个指令都需要一个 reference 类型的参数来指明要锁定和解锁的对象。如果 Java 程序中的 synchronized 明确指定了对象参数,那就是这个对象的 reference;如果没有明确指定,那就根据 synchronized 修饰的是实例方法还是类方法,来取对应的对象实例或 Class 对象作为对象锁。
根据 JVM 规范的要求,在执行 monitorenter 指令时,首先要尝试获取对象的锁。如果这个对象没有被锁定,或者当前线程已经持有了该对象的锁,把锁的计数器加 1;相应的,在执行 monitorexit 指令时会将锁的计数器减 1,当计数器为 0 时,所就被释放了。如果获取对象锁失败,那当前线程就要阻塞等待,直到对象锁被另一个线程释放为止。
在 JVM 规范对 monitorenter 和 monitorexit 的行为描述中,有两点是需要特别关注的。首先,synchronized 同步块对同一条线程来说是可重入的,不会出现自己把自己锁死的问题。其次,同步块在已进入的线程执行完之前,会阻塞后面其他线程的进入。上一章讲过,Java 线程是映射到操作系统原生线程上的,如果要阻塞或唤醒一条线程,都需要依赖操作系统调用,这就需要从用户态切换到内核态,因此状态转换需要耗费很多处理器时间。对于代码中简单的同步块(如被 synchronized 修饰的 getter/setter 方法),状态切换消耗的时间可能比用户代码执行的时间还要长。所以 synchronized 是 Java 语言中一个重量级操作,有经验的程序员都会在确实必要的情况才使用这种操作。而虚拟机本身也会进行一些优化,比如在通知操作系统阻塞线程之前先加入一段自旋等待过程,避免频繁的切入内核态。
除了 synchronized 之外,我们还可以使用 JUC 中的重入锁来实现同步,在基本用法上,重入锁与 synchronized 很相似,它们都具备一样的线程重入特性,只是代码写法上有些区别,一个表现为 API 层面的互斥锁(lock 和 unlock 方法配合 try/finally 语句块来完成),一个表现为原生语法层面的互斥锁。不过重入锁比 synchronized 增加了一些高级功能,主要有以下三项:
- “等待可中断”是指当持有锁的线程长期不释放锁的时候,正在等待的线程可以选择放弃等待,改为处理器其他任务,可中断特性对处理的执行时间非常长的同步块很有帮助。
- “公平锁”是指多个线程在等待同一个锁时,必须按照申请锁的时间顺序来依次获得锁;而非公平锁则不保证这一点,在锁被释放时,任何一个等待锁的线程都有机会获得锁。synchronized 中的锁是非公平的,重入锁默认情况下也是非公平的,但可以通过构造参数设置。
- “锁绑定多个条件”是指一个重入锁对象可以同时绑定多个 Condition 对象,而在 synchronized 中,锁对象的 wait 和 notify、notifyAll 方法可以实现一个隐含的条件,如果要和多于一个的条件关联的时候,就不得不额外的添加一个锁,而重入锁无需这么做,只需要多次调用 newCondition 方法即可。
如果需要使用到上述功能,选用重入锁是一个很好的选择,那如果是基于性能考虑呢?关于 synchronized 和重入锁的性能问题,Brian Goetz 对这两种锁在 JDK 1.5、单核处理器及双 Xeon 处理器环境做了一组吞吐量对比试验,如下图:
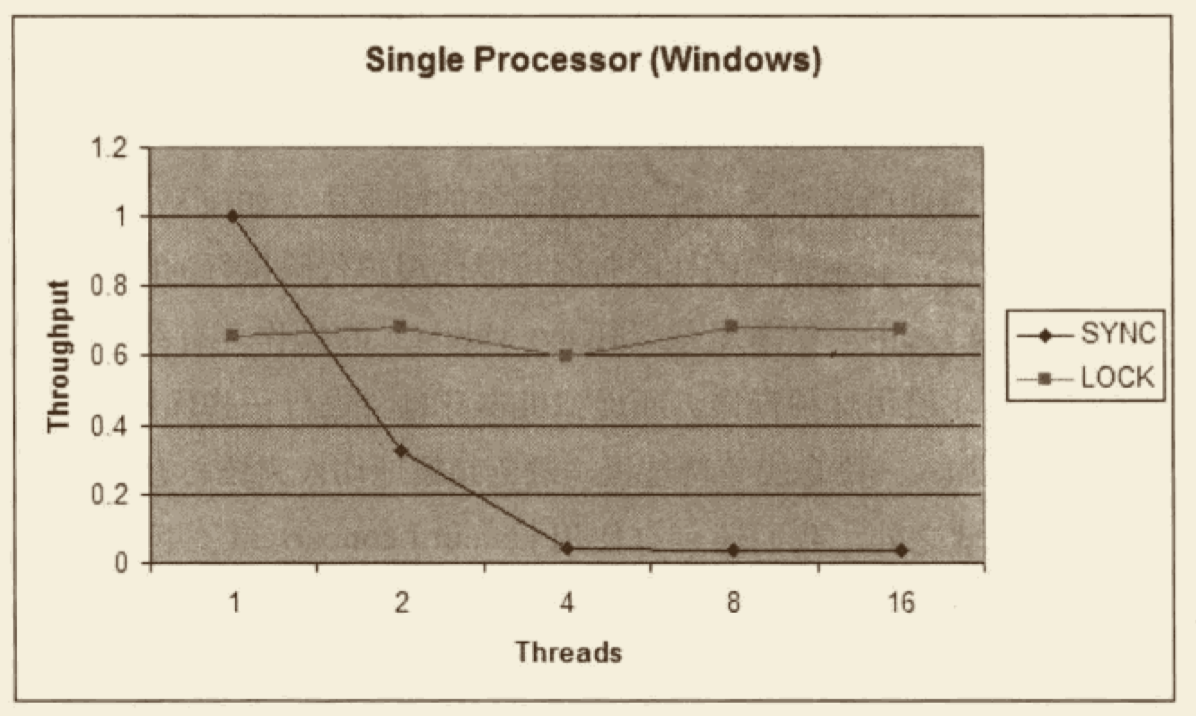
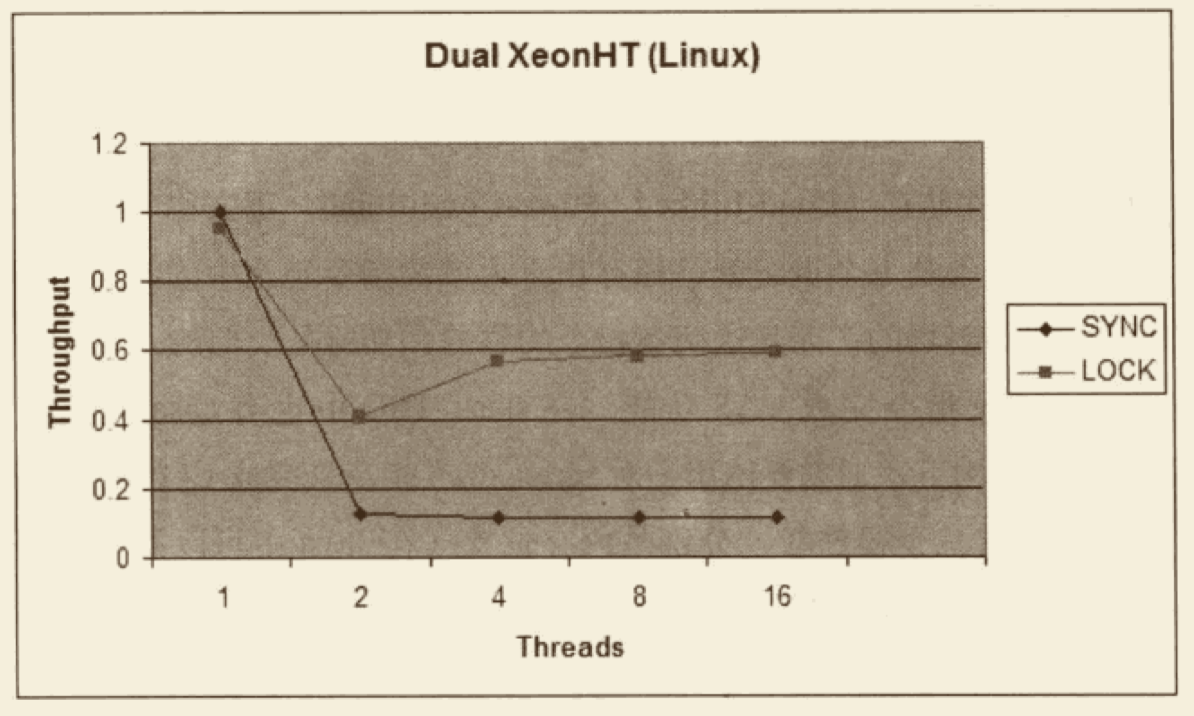
从上面两组试验结构可以看出,多线程环境下 synchronized 的吞吐量下降的非常严重,而重入锁则能基本保持在同一个比较稳定的水平上。与其说重入锁性能好,倒不如说 synchronized 还有非常大的优化空间。后续的技术发展也证明了这一点,JDK 1.6 中加入了很多针对锁的优化措施,这时两者的性能基本持平。因此性能因素不再是选择重入锁的理由了,JVM 在未来的性能改进中肯定也会更加偏向于原生的 synchronized,所以还是提倡在 synchronized 能够实现需求的情况下有限选择。
2. 非阻塞同步
互斥同步最主要的问题就是进行线程阻塞和换新所带来的性能问题,因此这种同步也被称为阻塞同步。另外,它属于一种悲观的并发策略,总是认为只要不去做正确的同步措施(即加锁),那就肯定会出问题,无论共享数据是否真的会出现竞争,它都要求进行加锁(这里说的是概念模型,实际上虚拟机会优化掉很大一部分不必要的加锁)、用户态与内核态切换、维护锁计数器和检查是否有被阻塞的线程需要被唤醒等操作。随着硬件指令集的发展,我们有了另一种选择:基于冲突检测的乐观并发策略,通俗的说就是先进行操作,如果没有其他线程争用共享数据,那操作就成功了;如果共享数据被争用,这时就产生了冲突,然后再进行其他补偿措施(最常见的补偿措施就是不断重试直到成功),这种乐观的并发策略的许多实现都不需要把线程挂起,因此这种同步操作被称为非阻塞同步。
为什么说使用乐观并发策略需要“硬件指令集的发展”才能进行呢?因为我们需要操作和冲突检测这两个步骤具有原子性,靠什么来保证呢?如果这里再使用互斥同步来保证就是去意义了,所以我们只能靠硬件来完成这件事情,硬件保证一个从语义上看起来需要多次操作的行为只通过一条处理器指令就能完成,这类指令常用的有:
- 测试并设置,TAS
- 获取并增加,FAI
- 交换,Swap
- 比较并交换,CAS
- 加载链接/条件存储,LL/SC
其中,前面的三条是上个世纪就存在于大多数指令集中的处理器指令,后面的两条是现代处理器新增的,而且这两条指令的目的和功能是类似的。在 IA64、x86 指令集中通过 cmpxchg 指令完成 CAS 功能,在 sparc-STO 中也有 casa 指令实现,而在 ARM 和 PowerPC 架构下,则需要使用一对 ldrex/strex 指令来完成 LL/SC 功能。
CAS 指令需要有三个操作数,分别是内存位置(即 Java 中变量的内存地址,V)、旧的预期值(A)、新值(B)。CAS 指令执行时,当且仅当 V 符合旧的预期值 A 时,处理器用新值 B 更新 V 的值,否知它就不执行更新,但是不管是否更新了 V 的值,都会返回 旧 V 的值,上述的处理过程是一个原子操作。
在 JDK 1.5 之后,Java 程序中才可以使用 CAS 操作,该操作由 sun.misc.Unsafe 类中的 compareAndSwap 和 compareAndSwapLong 等几个方法提供,JVM 内部对这些方法做了特殊处理,即时编译出来的结果就是一条平台相关的处理器 CAS 指令,没有方法调用的过程,或者可以认为是无条件内联进去了。
由于 Unsafe 类不是提供给用户程序调用的类(Unsafe.getUnsafe 的代码中限制了只有启动类加载器加载的类才可以访问它),如果不采用反射手段,我们只能通过其他 Java API 来间接访问它,如 JUC 包中的整数原子类。
尽管 CAS 看起来很美,但显然这种操作无法涵盖互斥同步的所有使用场景,并且 CAS 从语义上来说并不完美,存在这样一个逻辑漏洞:如果一个变量 V 初次读取的时候是 A 值,并且在准备赋值的时候检查它仍然是 A 值,那我们就能说它的值没有被其他线程改变过吗?如果在这段时间内它的值曾经被改为了 B,后来又被改回了 A,那 CAS 操作就会误认为它从来没有被改变过。该漏洞被称为 CAS 操作的 ABA 问题。JUC 为了解决该问题,提供了一个带有标记的原子引用类 AtomicStampedReference,它可以通过控制变量值的版本来保证 CAS 的正确性。不过目前来说这个类比较鸡肋,大部分情况下 ABA 问题不会影响程序并发的正确性,如果需要解决 ABA 问题,改用传统的互斥同步可能会比原子类更有效。
3. 无同步方案
要保证线程安全,并不是一定就要进行同步,两者没有因果关系。同步只是保障共享数据争用时的正确性手段,如果一个方法本来就不涉及共享数据,那它自然就无需任何同步措施来保证正确性,因此会有一些代码天生就是线程安全的。
“可重入代码”:这种代码也叫纯代码,可以在代码执行的任何时刻中断它,转而去执行另外一段代码(包括递归调用它自身),而在控制权返回后,原来的程序不会出现任何错误。相对线程安全来说,可重入性是更基本的特性,它可以保证线程安全,即所有的可重入代码都是线程安全的,但是并非所有的线程安全的代码都是可重入的。
可重入代码有一些共同的特征:比如不依赖存储在堆上的数据和公共的系统资源、用到的状态都由参数传入、内部不调用非可重入的方法等。我们可以通过一个简单的原则来判断代码是否具有可重入性:如果一个方法,它的返回结果是可以预测的,只要输入了相同的数据,就能返回相同的结果,那它就满足可重入性的要求,当然它就是线程安全的。
“线程本地存储”:如果一段代码中所需要的数据必须与其他代码共享,那就看看这些共享数据的代码是否能保证在同一个线程中执行?如果能保证,我们就可以把共享数据的可见范围限制在同一个线程内,这样,无需同步也能保证线程间不出现数据争用的问题。
符合这种特点的应用很常见,大部分使用消费队列的架构模式(如生产者——消费者)都会将产品的消费过程尽量在一个线程中消费完,其中最重要的一个应用实例就是经典 Web 交互模式中的“一个请求对应一个服务器线程(Thread-per-Request)”的处理方式,这种处理方式的广泛应用使得 Web 服务器的很多应用都可以使用线程本地存储来解决线程安全问题。
Java 语言中,如果一个变量要被多线程访问,可以使用 volatile 关键字声明它为“易变的”;如果一个变量要被某个线程独享,因为 Java 中没有类似 C++ 中 __declspec(thread) 这样的关键字,不过可以通过 java.lang.ThreadLocal 类来实现线程本地存储的功能。每一个线程的 Thread 对象中都有一个 ThreadLocalMap 对象,这个对象存储了一组以 ThreadLocal.threadLocalHashCode 为键,以本地线程变量为值的 K-V 键值对,ThreadLocal 对象就是当前线程的 ThreadLocalMap 的访问入口,每一个 ThreadLocal 对象都包含了一个独一无二的 threadLocalHashCode 值,使用这个值就可以在线程 K-V 键值对中找回对应的本地线程变量。
13.3 锁优化
HotSpot JVM 开发团队在 JDK 1.6 版本上花费了大量精力来实现各种锁的优化技术,所有这些优化都是为了在线程间更加高效的共享数据,以解决竞争问题,从而提高程序的执行效率。
13.3.1 自旋锁与自适应自旋
前面我们讨论同步的时候,提到了互斥同步对性能影响最大的是阻塞式的实现,挂起线程和恢复线程的操作都需要转入内核态中完成,这些操作给系统并发性带来了很大的压力。同时,虚拟机开发团队也注意到在很多应用上,共享数据的锁定状态一般会持续很短一段时间,为了这段很短的时间去挂起和恢复线程很不值得。如果物理机有一个以上的处理器,能让两个或两个以上的线程同时并行执行,我们就可以让后面请求锁的线程“稍等一会”,但不放弃处理器的执行时间,看看持有锁的线程是否很快就能释放锁。为了让线程等待,我们只需让线程执行一个忙循环(自旋),这就是所谓的自旋锁。
自旋锁自 JDK 1.4.2 引入,只不过是默认关闭的,可以使用 -XX:UseSpinning 参数来开启,到了 1.6 就已经改为默认开启了。自旋锁不能代替阻塞,且先不说对处理器数量的要求,自旋等待本身虽然避免了线程切换的开销,但它要是要占用处理器执行时间的,所以如果被占用的时间很短,自旋等待的效果会很好,反之,自旋的线程只会白白消耗掉处理器资源,造成性能浪费。因此自旋等待的时间必须要有一个限度,如果自旋超过了限定次数仍然没有获得锁,那就应当使用传统的方式去挂起线程。自旋次数的默认值是 10,用户可以使用参数 -XX:PreBlockSpin 来修改。
在 JDK 1.6 中引入了自适应自旋锁。自适应意味着自旋的次数不再固定,而是由前一次在同一个锁上自旋的时间及锁的拥有者线程的状态来决定的。如果在同一个锁对象上,自旋等待刚刚成功获得锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋很有可能会再次成功,进而它将允许自旋等待持续相对更长的时间,比如 100 个循环。另一方面,如果对于某个锁,自旋很少获得成功,那在以后要获取这个锁时将可能省略掉自旋过程,以避免浪费处理器时间。有了自适应自旋,随着程序运行和性能监控信息的不断完善,虚拟机对程序锁的状况监控就会越来越准确,虚拟机就会变得越来越聪明了。
13.3.2 锁消除
锁消除指的是虚拟机即时编译器在运行时,对一些代码上要求同步,但是被检测到不可能存在数据竞争的锁进行消除。锁消除的主要判断依据来自逃逸分析和数据支持,如果判断到一段代码中,在堆上的所有数据都不会逃逸出去被其他线程访问到,那就可以把它们当做栈上数据对待,认为它们是线程私有的,同步加锁自然也就无需运行。
也许读者会有疑问,变量是否逃逸,对于虚拟机来说需要使用数据流分析来确定,但是程序员自己应该是很清楚的,怎么会在明知道不存在数据竞争的情况下要求同步呢?答案是有许多同步措施并非由程序员加入,同步代码在 Java 程序中的普遍程度也许超过了大部分读者的想象。比如下面一段代码:
public String concatString(String s1, String s2, String s3) {
return s1 + s2 + s3;
}
由于 String 是一个不可变类,对字符串的连接操作总是通过生成新的 String 对象进行的,因此 javac 编译器会对 String 连接做自动优化。在 JDK 1.5 之前,会转换为 StringBuffer 对象的连续 append 操作,在 JDK 1.5 及之后的版本中,会转换为 StringBuilder 对象的连续 append 操作。
public String concatString(String s1, String s2, String s3) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}
现在大家还认为这段代码没有涉及同步吗?每个 StringBuffer.append 方法中都有一个同步块,锁就是 sb 对象。虚拟机观察变量 sb,很快就发现它的动态作用域被限制在 concatString 方法内部。即 sb 的所有引用永远不会逃逸到 concatString 方法的外部,其他线程也就无法访问它,所以这里虽然有锁,但是可以被安全的消除掉,在即时编译之后,这段代码就会忽略掉所有的同步而直接执行了。
13.3.3 锁粗化
原则上,我们在编写代码的时候,总是推荐将同步块的作用范围限制的尽量小——只在共享数据的实际作用域中才进行同步,这样是为了使得需要同步的操作数量尽可能变小,如果存在锁竞争,那等待锁的线程也可以尽快得到锁。
大部分情况下,上面的原则都是正确的,但是如果一系列的连续读操作都对同一个对象反复加锁和解锁,甚至加锁操作是出现在循环体中,那即使没有线程竞争,频繁的进行同步操作也会带来不必要的性能损耗。
上述代码中连续 append 方法就属于这类情况。如果虚拟机探测到有这样一串零碎的操作都对同一个对象加锁,将会把加锁同步的范围扩展(粗化)到整个操作序列的外部,以上述字符串连接为例,就是扩展到第一个 append 操作之前直至最后一个 append 操作之后,这样一来仅需加锁一次就够了。
13.3.4 轻量级锁
轻量级锁是 JDK 1.6 中加入的新型锁机制,“轻量级”是相对于使用操作系统互斥量来实现的传统锁而言的,因此后者也可以被称为“重量级锁”。首先需要强调的一点是,轻量级锁并非用来替代重量级锁,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用系统互斥量带来的性能损耗。
要理解轻量级锁,以及后面会讲到的偏向锁的原理和运作过程,必须从 HotSpot 虚拟机的对象(对象头部分)的内存布局开始介绍。HotSpot 虚拟机的对象头分为两部分信息,第一部分用于存储对象自身的运行时数据,如哈希码、GC 分代年龄等,这部分数据的长度在 32 位和 64 位的虚拟机中分别为 32 个和 64 个 Bits,官方称它为“Mark Word”,它是实现轻量级锁和偏向锁的关键。另外一部分用于存储指向方法区对象的类型数据的指针,如果是数组对象的话,还会有一个额外的部分用于存储数组长度。
对象头信息是与对象自身定义的数据无关的额外存储成本,考虑到虚拟机的空间效率,Mark Word 被设计成一个非固定数据及饿哦股以便在极小的空间内存储尽可能多的信息,它会根据对象的状态复用自己的存储空间。例如在 32 位的 HotSpot 虚拟机中对象未被锁定的状态下,Mark Word 的 32 个 Bits 空间中的 25 Bits 用于存储对象哈希码,4 Bits 用于存储对象的分代年龄,2 Bits 用于存储锁标志位,1 Bit 固定为 0,在其他状态(轻量级锁定、重量级锁定、GC 标记、可偏向)下对象的存储内容如下表:

在代码进入同步块时,如果此同步对象没有被锁定(锁标志位为 01 状态),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的 Mark Word 的拷贝(官方把这分拷贝加了一个 Displaced 前缀,即 Displaced Mark Word),这时候线程堆栈与对象头的状态如下图所示。
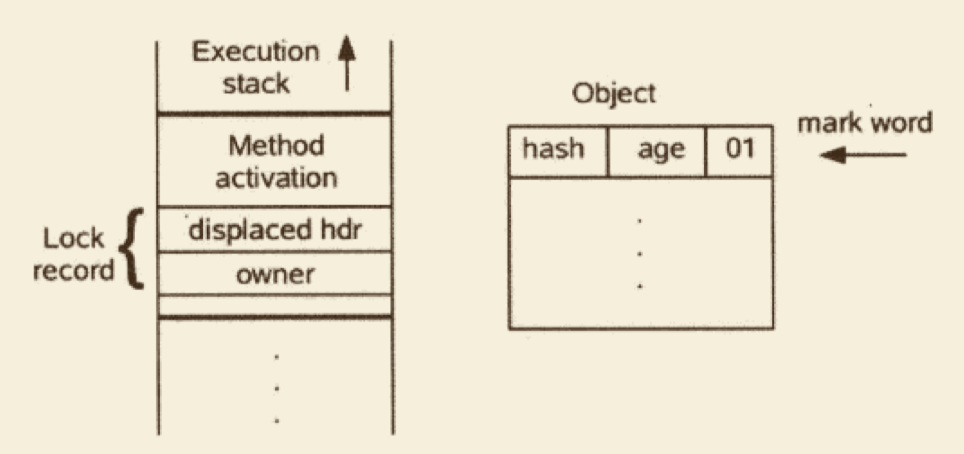
然后,虚拟机将使用 CAS 操作尝试将对象的 Mark Word 更新为指向 Lock Record 的指针。如果该更新动作成功,那么这个线程就拥有了该对象的锁,并且对象 Mark Word 的锁标志位(Mark Word 的最后两 Bits)将转变为 “00”,即表示此对象处于轻量级锁定状态,这时候线程堆栈及对象头的状态如下图所示。
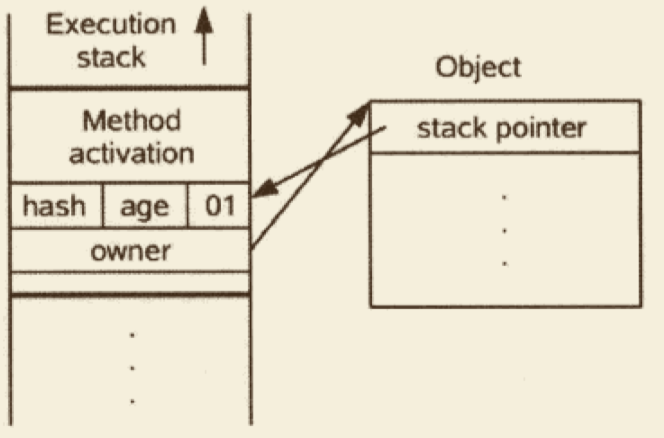
如果这个更新操作失败了,虚拟机首先会检查对象的 Mark Word 是否指向当前线程的栈帧,如果是,就说明当前线程已经拥有了这个对象的锁,可以直接进入同步块继续执行,否则说明这个锁对象已经被其他线程抢占了。如果有两个以上的线程争用同一个锁,那轻量级锁就不再有效,要膨胀为重量级锁,锁标志的状态变为“10”,Mark Word 中存储的就是指向重量级锁(互斥量)的指针,后面等待锁的线程也要进入阻塞状态。
上面买描述的是轻量级锁的加锁过程,它的解锁过程也是通过 CAS 操作来进行的,如果对象的 Mark Word 仍然指向着线程的锁记录,那就用 CAS 操作把对象当前的 Mark Word 和线程中复制的 Displaced Mark Word 替换回来,如果替换成功,整个同步过程就完成了。如果替换失败,说明其他线程尝试过获取该锁,那就要在释放锁的同时,唤醒被挂起的线程。
轻量级锁能够提高程序同步性能的依据是,“对于绝大部分的锁,在整个同步周期内都是不存在竞争的”,这是一条经验数据。如果没有竞争,轻量级锁使用 CAS 操作就避免了使用互斥量的开销,但如果存在锁竞争,除了互斥量的开销外,还额外发生了 CAS 操作,因此在有竞争的情况下,轻量级锁会比传统的重量级锁更慢。
13.3.5 偏向锁
偏向锁也是 JDK 1.6 引入的一项锁优化,它的目的是消除数据在无竞争情况下的同步原语,进一步提高程序的执行性能。如果说轻量级锁是在无竞争情况下使用 CAS 操作来消除同步使用的互斥量,那偏向锁就是在无竞争的情况下把整个同步都消除掉,连 CAS 操作都不做了。
偏向锁的“偏”类似于“偏心”、“偏袒”中的“偏”。它的意思是这个锁会偏向于第一个获得它的线程,如果在接下来的执行过程中,该锁没有被其他线程获取,则持有偏向锁的线程将永远不需要再次进行同步。
如果读者读懂了前面轻量级锁中关于对象头 Mark Word 与线程之前的操作过程,那偏向锁的原理理解起来就会很简单。假设当前虚拟机启用了偏向锁,那么,当锁对象第一次被线程获取时,虚拟机就会把对象头中的标志位设置为 “01”,即偏向模式。同时使用 CAS 操作把获取到该锁的线程 ID 记录在对象头 Mark Word 中,如果 CAS 操作成功,持有偏向锁的线程以后每次进入这个锁相关的同步块时,虚拟机都可以不再进行任何同步操作(如 Locking、Unlocking 及对 Mark Word 的 Update 等)。
当另外一个线程去尝试获取这个锁时,偏向模式就宣告结束。根据锁定对象目前是否处于被锁定的状态,撤销偏向后恢复到未锁定(标志位为“01”)或轻量级锁定状态(标志位为“00”)的状态,后续的同步操作就如上面介绍的轻量级锁那样执行。偏向锁、轻量级锁的状态转换及对象 Mark Word 的关系如下图所示。
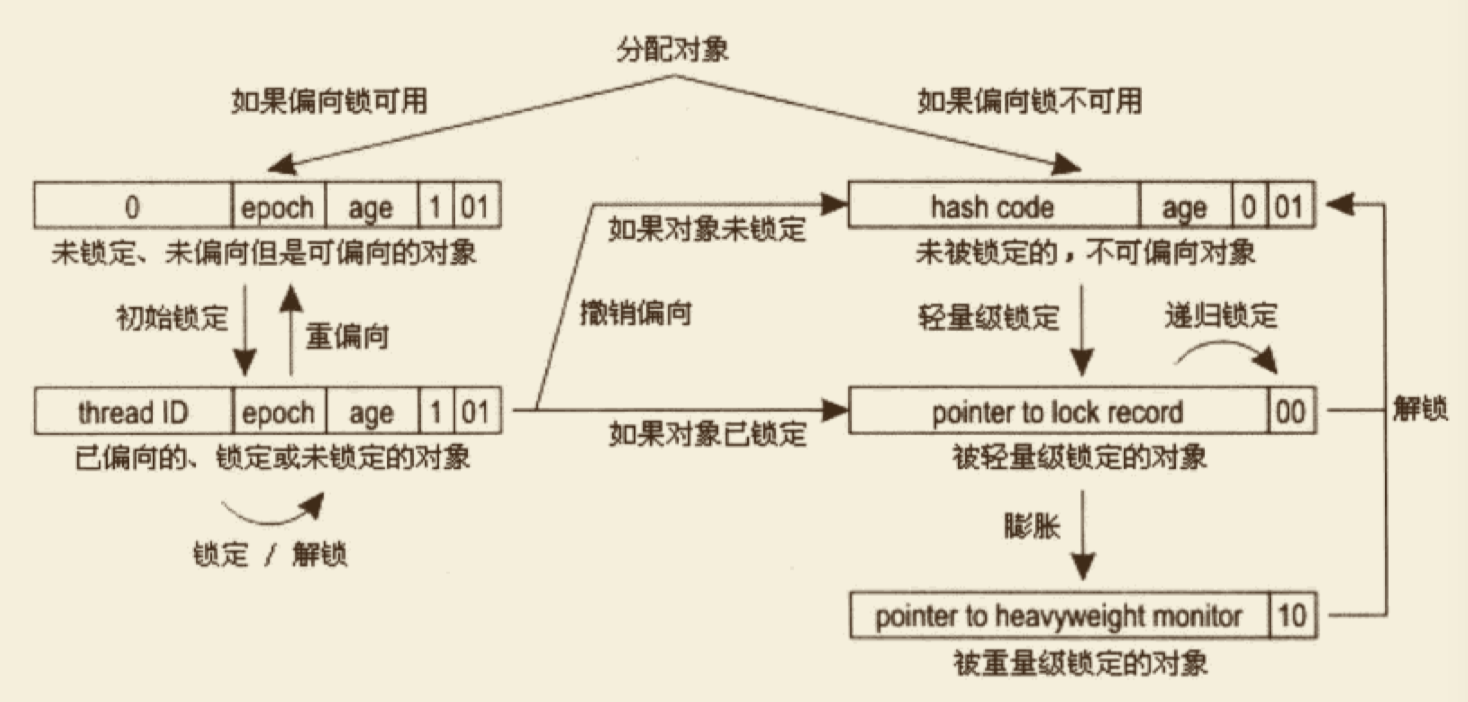
偏向锁可以提高带有同步但无竞争的程序性能。它同样是一个带有效益权衡性质的优化,即并不一定总是对程序的运行有利,如果程序中大多数的锁总是被多个不同的线程访问,那偏向模式就是多余的。在具体问题具体分析的前提下,有时候使用参数 -XX:UseBiasedLocking 来禁止偏向锁优化反而可以提升性能。
13.4 本章小结
本章介绍了线程安全所涉及的概念和分类、同步实现的方式及虚拟机的底层运作原理,并且介绍了虚拟机为了实现高效并发所采取的一系列锁优化措施。
许多资深的程序员都说过,能够写出高伸缩性的并发程序是一门艺术,而了解并发在系统底层是如何实现的,则是掌握这门艺术的前提条件,也是成长为高级程序员的必备知识之一。
14 - Endix-B-字节码指令

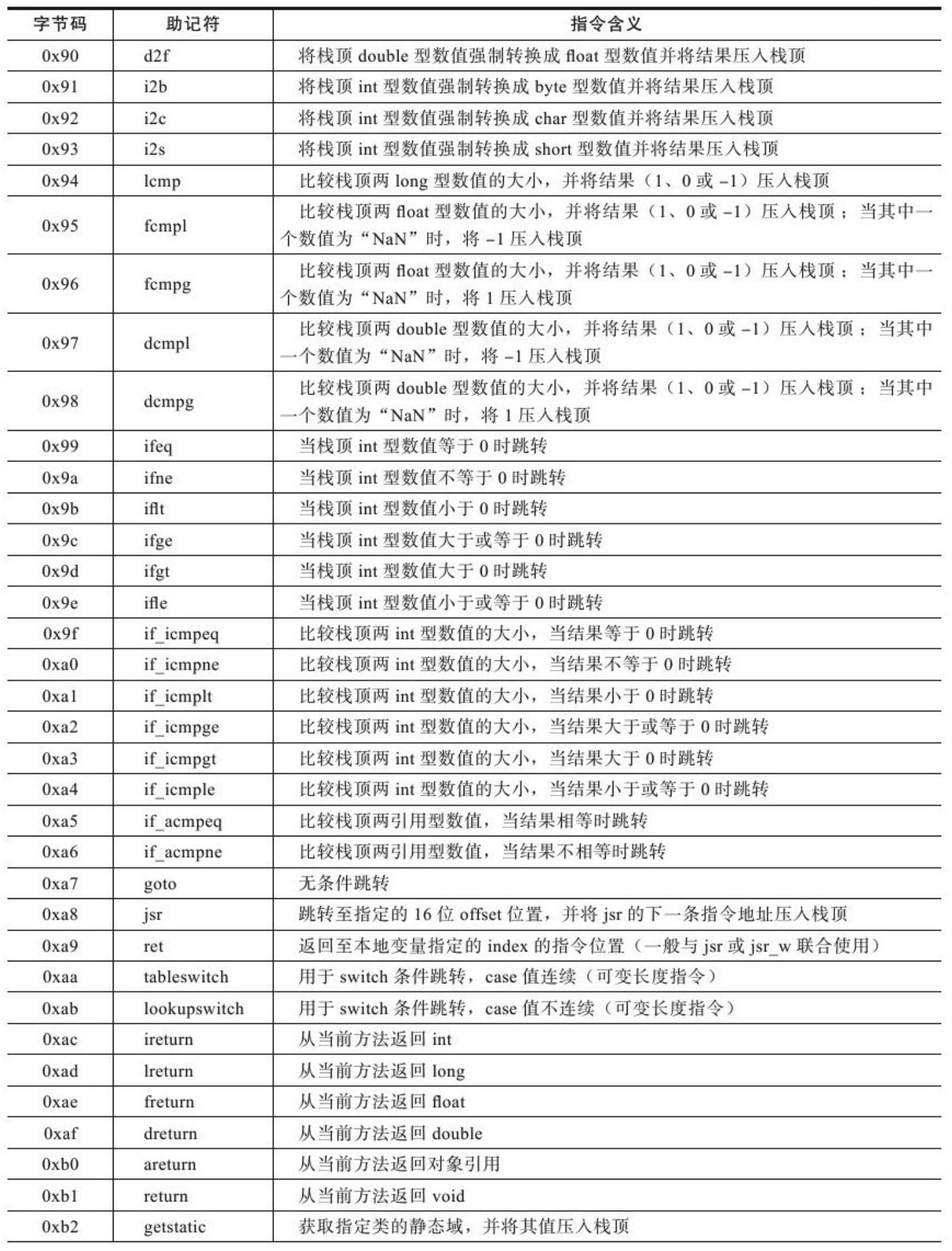
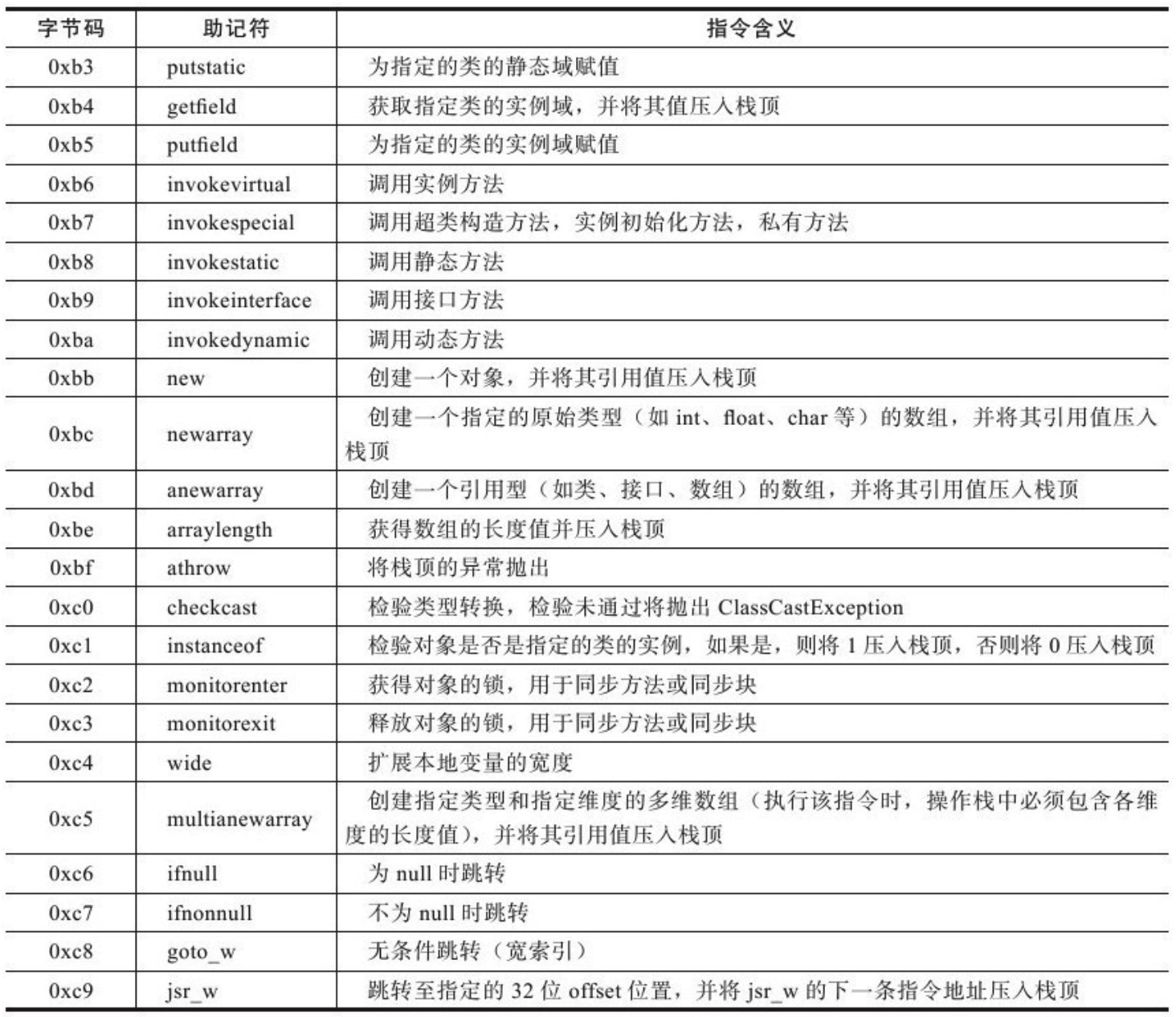
15 - Endix-C-虚拟机参数
使用 -XX:+PrintFlagsFinal 可以输出所有参数的名称和默认值。应用参数的方式有以下 3 种:
-XX:+<option>开启option参数-XX:-<option>关闭option参数-XX:<option>=<value>将option参数的值设置为value
以下是 JDK6 中常用的参数。
内存管理参数
| 参数 | 默认值 | 使用介绍 |
|---|---|---|
| DisableExplicitGC | 默认关闭 | 忽略来自 System.gc() 方法触发的垃圾回收 |
| ExplicitGCInvokesConcurrent | 默认关闭 | 当收到 System.gc() 方法提交的垃圾回收申请时,使用 CMS 收集器进行收集 |
| UseSerialGC | Client 模式 的虚拟机默认开启,其他模式默认关闭 | 虚拟机运行在 Client 模式下的默认值,打开此开关后,使用 Serial+Serial Old 的收集器组合进行内存回收 |
| UseParNewGC | 默认关闭 | 打开此开关后,使用 ParNew+Serial Old 的收集器组合进行内存回收 |
| UserConcMarkSweepGC | 默认关闭 | 打开此开关后,使用 ParNew+CMS+Serial Old 的收集器组合进行内存回收。如果 CMS 收集器出现 Concurrent Mode Failure,则 Serial Old 收集器将作为后备收集器 |
| UserParallelGC | Server 模式的虚拟机默认开启,其他模式默认关闭 | 虚拟机运行在 Server 模式下的默认值,打开此开关后,使用 Parallel Scavenge+Serial Old 的收集器组合进行内存回收 |
| UseParallelOldGC | 默认关闭 | 打开此开关后,使用 Parallel Scavenge+Parallel Old 的收集器组合进行内存回收 |
| ServivorRatio | 默认为 8 | 新生代中 Eden 区域与 Survivor 区域的容量比值 |
| PretenureSizeThreshold | 无默认值 | 直接晋升到老年代的对象大小,设置该参数后,大于这个参数的对象将直接在老年代分配 |
| MaxTenuringThreshold | 默认为 15 | 晋升到老年代的对象年龄。每个对象在坚持过一次 Mirror GC 之后,年龄就加 1,当超过该参数值时进入老年代 |
| UseAdaptiveSizePolicy | 默认开启 | 动态调整 Java 堆中各个区域的大小及进入老年代的年龄 |
| HandlePromotionFailure | JDK 1.5 及之前的版本默认关闭,JDK 1.6 之后默认开启 | 是否允许分配担保失败,即老年代的剩余空间不足以应付新生代的整个 Eden 和 Survivor 区的所有对象都存活的极端情况 |
| ParallelGCThreads | 少于或等于 8 个 CPU 时默认为 CPU 的数量值,多余 8 个 CPU 时比 CPU 的数量之小 | 设置并行 GC 时进行内存回收的线程数 |
| GCTimeRatio | 默认为 99 | GC 时间占总时间的比例,默认允许 1% 的 GC 时间。仅在使用 Parallel Scavenge 收集器时生效 |
| MaxGCPauseMillis | 无默认值 | 设置 GC 的最大停顿时间。仅在使用 Parallel Scavenge 收集器时生效 |
| CMSInitiatingOccupancyFraction | 默认 68 | 设置 CMS 收集器在老年代空间被使用多少后触发垃圾回收,仅在使用 CMS 收集器时生效 |
| UseCMSCompactAtFullCollection | 默认开启 | 设置 CMS 收集器在完成垃圾收集后是否需要进行一次内存碎片整理。仅在使用 CMS 收集器时生效 |
| CMSFullGCsBeforeCompaction | 无默认值 | 设置 CMS 收集器在进行若干次垃圾收集后在启动一次内存碎片整理。仅在使用 CMS 收集器时生效 |
| ScavengeBeforeFullGC | 默认开启 | 在 Full GC 发生之前触发一次 Mirror GC |
| UseGCOverheadLimit | 默认开启 | 禁止 GC 过程无限制的执行,如果过于频繁,就直接发生 OutOfMemory 异常 |
| UseTLAB | Server 模式默认开启 | 优先在本地线程缓冲区中分配对象,避免分配内存时的锁定过程 |
| MaxHeapFreeRatio | 默认为 70 | 当 Xmx 比 Xms 值大时,堆可以动态收缩和扩展,该参数控制当堆空闲大于指定比例时自动收缩 |
| MinHeapFreeRatio | 默认为 70 | 当 Xmx 比 Xms 值小时,对可以动态收缩或扩展,该参数控制当对空闲小于指定比率时自动扩展 |
| MaxPermSize | 大部分情况下默认为 64MB | 永久代的最大值 |
即时编译参数
| 参数 | 默认值 | 使用介绍 |
|---|---|---|
| CompileThreshold | Client 模式下默认为 1500,Server 模式下为 1000 | 触发方法即时编译的阈值 |
| OnStackReplaceRercentage | Client 模式下为 933,Server 模式下为 140 | OSR 比率,它是 OSR 即时编译阈值计算公式的一个参数,用于代替 BckEdgeThreshold 参数控制回边计数器的实际溢出阈值 |
| ReversedCodeCacheSize | 大部分情况下是 32MB | 即时编译器编译的代码缓存的最大值 |
类型加载参数
| 参数 | 默认值 | 使用介绍 |
|---|---|---|
| UseSplitVerifer | 默认开启 | 使用依赖 StackMapTable 信息的类型检查代替数据流分析,以加快字节码校验速度 |
| FailOverToOldVerifier | 默认开启 | 当类型校验失败时,是否允许回到老的类型推导校验方式重新校验,如果开启则允许 |
| RelaxAccessControlCheck | 默认关闭 | 在检验阶段放松对类型访问性的限制 |
多线程相关参数
| 参数 | 默认值 | 使用介绍 |
|---|---|---|
| UseSpinning | JDK 1.6 默认开启,JDK 1.5 默认关闭 | 开启自旋锁以避免线程频繁挂起和唤醒 |
| PreBlockSpin | 默认为 10 | 使用自旋锁时默认的自旋次数 |
| UseThreadPriorities | 默认开启 | 使用本地线程优先级 |
| UseBiasedLocking | 默认开启 | 使用使用偏向锁 |
| UseFastAccessorMethods | 默认开启 | 当频繁反射执行某个方法时,生成字节码来加快反射的执行速度 |
性能参数
| 参数 | 默认值 | 使用介绍 |
|---|---|---|
| AggressiveOpts | JDK 1.6 默认开启,JDK 1.5 默认关闭 | 使用激进的优化特性,这些特性一般是具备正面和负面双重影响的,需要根据具体应用特点来分析才能判定是否对性能有益 |
| UseLargePages | 默认开启 | 如果可能,使用大内存分页,该特性需要操作系统的支持 |
| LargePageSizeInBytes | 默认为 4MB | 使用指定大小的内存分页,该特性需要操作系统的支持 |
| StringCache | 默认开启 | 使用使用字符串缓存 |
调试参数
| 参数 | 默认值 | 使用介绍 |
|---|---|---|
| HeapDumpOnOutOfMemoryError | 默认关闭 | 在发生内存溢出时是否生成堆转储快照 |
| OnOutOfMemoryError | 无默认值 | 当虚拟机抛出内存溢出异常时,执行指定的命令 |
| OnError | 无默认值 | 当虚拟机抛出 ERROR 异常时,执行指定的命令 |
| PrintClassHistogram | 默认关闭 | 使用 [ctrl]-[break] 快捷键输出类统计状态,相当于 jmap-histo 的功能 |
| PrintConcurrentLocks | 默认关闭 | 打印 JUC 中锁的状态 |
| PrintCommandLineFlags | 默认关闭 | 打印启动虚拟机时输入的非稳定参数 |
| PrintCompilation | 默认关闭 | 打印方法的即时编译信息 |
| PrintGC | 默认关闭 | 打印 GC 信息 |
| PrintGCDetails | 默认关闭 | 打印 GC 详细信息 |
| PrintGCtimeStamps | 默认关闭 | 打印 GC 停顿耗时 |
| PrintTenuringDistribution | 默认关闭 | 打印 GC 后新生代各个年龄对象的大小 |
| TracClassLoading | 默认关闭 | 打印类加载信息 |
| TraceClassUnloading | 默认关闭 | 打印类卸载信息 |
| PringInlining | 默认关闭 | 打印方法的内联信息 |
| PrintCFGToFile | 默认关闭 | 将 CFG 图信息输出到文件,只有 DEBUG 版虚拟机才支持该参数 |
| PrintIdealGraphFile | 默认关闭 | 将 Ideal 图信息输出到文件,只有 DEBUG 版虚拟机才支持该参数 |
| UnlockDiagnosticVM Options | 默认关闭 | 让虚拟机进入诊断模式,一些参数(如 PrintAssembly)需要在诊断模式下才能使用 |
| PrintAssembly | 默认关闭 | 打印即时编译后的二进制信息 |