CH08-Lambda 架构
如果需要将一大批货物从国家的一端运送到另一端,18 轮的打开车是不二之选。如果紧要运行一个包裹,大卡车就不太适用了,因此综合性的航运公司也会适用一些小型货车进行本地的货物收发。
Lambda 架构采用了类似的方法,既使用了可以进行大规模数据批处理的 MapReduce 技术,也使用了可以快速处理数据并及时反馈的流处理技术,这样混搭能够为大数据问题提供扩展性、响应性、容错性都很优秀的解决方案。
并行计算
不同于传统数据处理,大数据领域广泛使用了并行计算——只要有足够的计算资源就可以处理 TB 级别的数据。Lambda 架构是一种大数据处理技术。
与上一章讨论的 GPGPU 编程类似,Lambda 架构也使用了数据并行技术。与 GPGPU 不同的是,Lambda 架构站在大规模场景的角度来解决问题,它可以将数据和计算分布到几十台或几百台机器构建的集群上运行。这种技术不但解决了之间因为规模庞大而无法解决的问题,还可以构建出对硬件错误和认为错误进行容错的系统。
Lambda 架构包含了很多内如,本章只侧重于其并发和分布式特性(更多内如可以参考 Big Data 一书)。对于 Lambda 架构中的诸多组件,本书侧重介绍两个主要的层:批处理层和加速层。
批处理层使用 MapReduce 这类批处理技术从历史数据中对批处理视图进行预计算。这种计算效率高但延迟也高,所以又增加了一个加速层,使用流处理等低延迟技术从接收到的新数据中计算实时视图。合并这两种视图,就可以获得最终的计算结果。
这是本书中最复杂的专题。它以很多其他技术作为基石,其中最重要的就是 MapReduce。
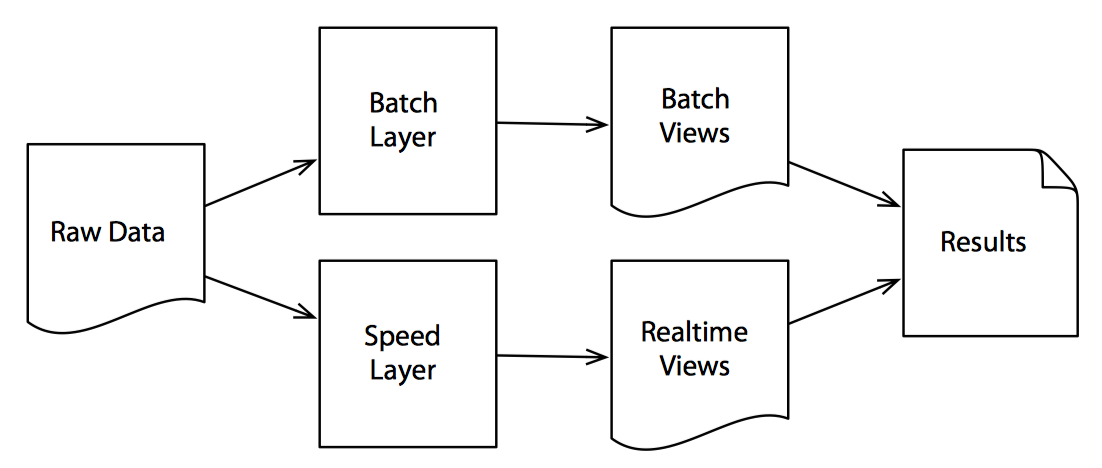
MapReduce
MapReduce 是一个多语义的术语。它可以指代一类算法,这类算法分为两个步骤:对一个数据首先进行映射操作(map),然后进行化简(reduce)操作。
MapReduce 还可以指代一类系统:这类系统使用了上述算法,将计算过程高效的分布到一个集群上。这类系统不仅可以将数据和数据处理过程分不到集群的多台机器上,还可以在一台或多个计算机崩溃时继续运转。
当 MapReduce 指代一类系统时,可以说它是 Google 发明的。除了 Google,最流行的 MapReduce 框架是 Hadoop。
Hadoop 基础
Hadoop 就是用来处理大量数据的工具。如果你的数据不是以 GB 或更大的单位来度量的,那就不适用使用 Hadoop。Hadoop 的效率源自于它将数据分块后分别交给多台计算机进行处理。
我们很容易猜到,一个 MapReduce 任务由两种主要的组件构成:mapper 和 reducer。mapper 负责将某种输入格式映射为许多键值对;reducer 负责将这些键值对转换为最终的输出格式。mapper 和 reducer 可以分布在很多不同的机器上。
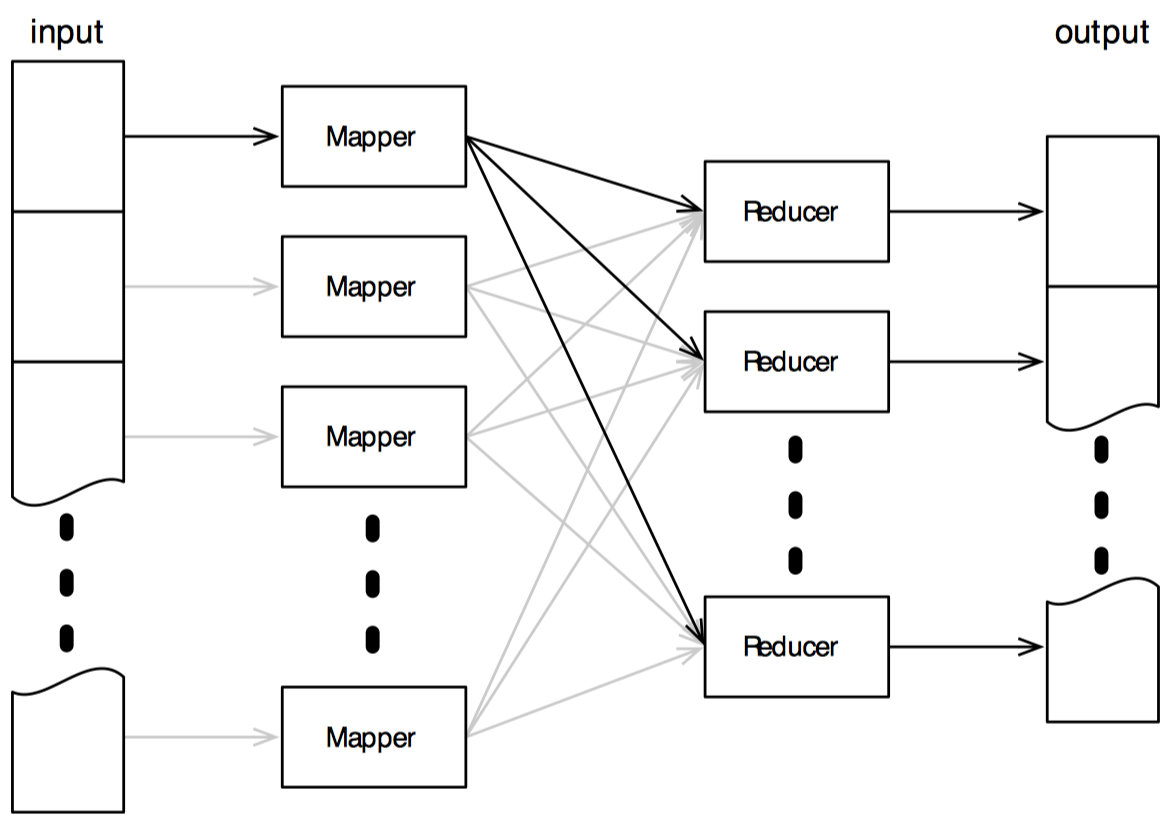
输入通常由一个或多个大文本文件构成。Hadoop 对这些文件进行分片(每一片的大小是可配置的),并将每个分片发送个一个 mapper,mapper 将输出一系列键值对,Hadoop 再将这些键值对发送给 reducer。
一个 mapper 产生的键值对可以发送给多个 reducer。键值对的键决定了那个 reducer 会接收这个键值对——Hadoop 确保具有相同键的键值对(无论由哪个 mapper 产生)都会发送给同一个 reducer 处理。这个阶段通常被称为洗牌(shuffle)。
Hadoop 为每个键调用一次 reducer,并传入所有与该键对应的值。reducer 将这些值合并,再生产最终的输出结果。
批处理层
传统数据系统的缺陷
数据系统不是一个新概念——从计算机发明之初,数据库就一直负责存储和处理数据。传统数据库适用于一台计算机,但随着要处理的数据量越来越大,数据库就必须使用多台机器。
扩展性
利用一些技术(如复制、分片等)可以将传统数据库扩展到多台机器上,但随着计算机数量和数据量的增长,这种方案会变得越来越困难。超过一定程度,增加计算机资源将无法继续提升性能。
维护成本
维护一个跨越多台计算机的数据库的成本是比较高的。如果要求维护时不能停机,那么维护将变得更加困难——比如对数据库进行重新分片。随着数据量和查询数量的增加,容错、备份、确保数据一致性等工作的难度会呈几何级数增长。
复杂度
复制和分片通常要求应用层提供一些支持——应用需要知道将请求发送给哪一台机器,以及应该更行哪一个数据分片。开发者习惯使用的许多特性(比如事务)在数据库分片后将无法使用。也就是说开发者必须显式处理失败的事务并进行重试。这都增加了传统数据库的复杂性,也增加了出错的可能。
认为错误
讨论容错性时很容易被忽略的就是认为错误。许多数据故障不是由于存储故障引起的,而是由于管理员或开发人员的认为错误引起的。如果运气比较好,这类错误可以被快速定位,并通过还原备份来恢复,但不是所有错误都可以被轻易解决。设想一下,如果有一个隐藏了几周的数据错误突然引发了大面积崩溃,我们又该如何修复数据库呢?
有时,我们可以分析错误影响的范围,并使用临时的脚本来修复数据库。有时我们可以通过重放数据库日志来回滚这个错误。有时,我们只能承认运气不佳。每次一来运气可不是长久之计。
报表与分析
传统数据库擅长于运营支持,即处理日常的业务数据。如果要处理历史数据,比如生成报表或进行数据分析,传统数据库的效率就比较低了。
典型的解决方案是在独立的数据仓库中使用另一种格式来维护历史数据。数据从业务数据库向数据仓库的迁移过程就是著名的 ETL。这种方案不仅复杂,而且需要准确预测将来需要什么样的信息。有时会碰到这种情况:由于缺乏必要的信息或者信息格式不对,无法生成所需报表或进行某些分析。
永恒的真相
我们可以将信息分为两类——原始数据和(从原始数据生成的)衍生数据。原始数据是永恒的真相,也是 Lambda 架构的基础。
加速层
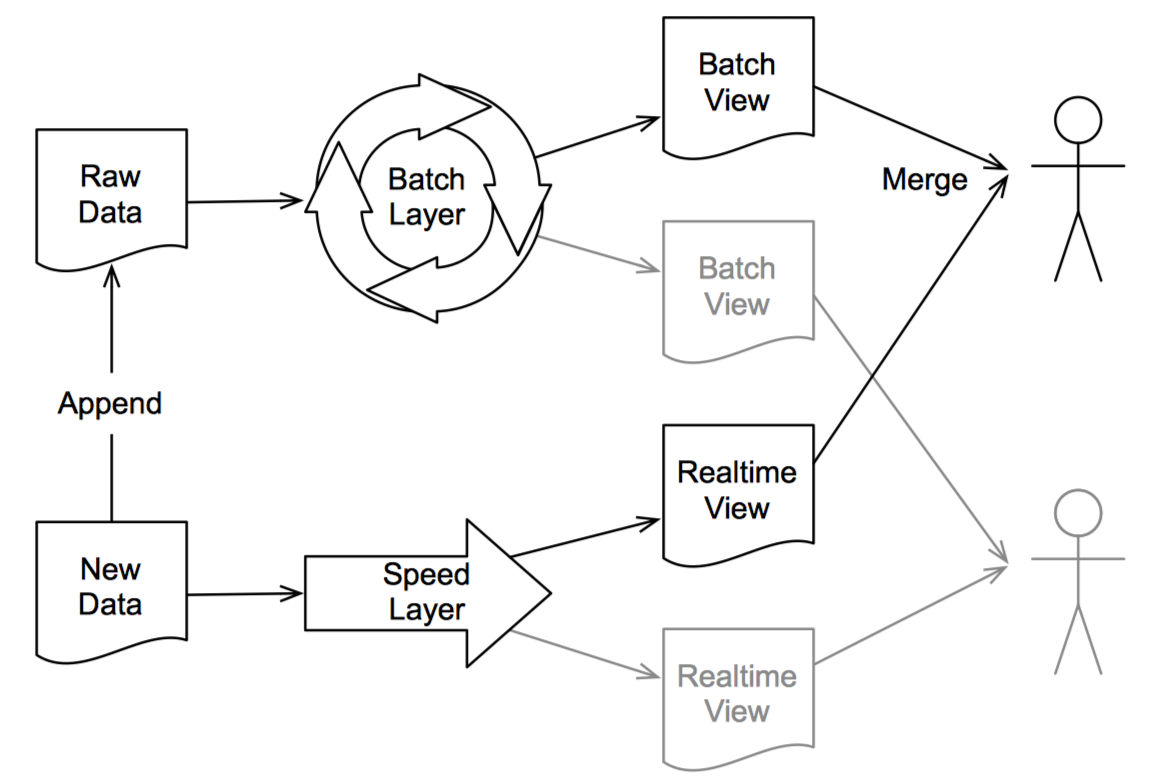
上图展示了批处理层与加速层的协作方式。有新数据生成时,一方面给将其添加到原始数据中,这样批处理层就可以进行处理;另一方面将其传递给加速层,加速层会生成一个实时视图,实时视图会和批处理视图合并来满足对最新数据的查询。
实时视图仅包含最后一次生成批处理视图后产生的原始数据所对应的衍生信息,当这部分数据被批处理层处理后,该实时视图被弃用。
设计加速层
不同的应用对实时性的要求是不同的——有一些要求数据在妙级可用,有些甚至是毫秒。
由于加速层需要使用增量算法,因此要比构建批处理层复杂的多。这意味着加速层不能只处理原始数据,也就享受不到原始数据的原始特性了。我们必须重新面对传统数据库的特性:随机写、复杂的锁机制和事务机制。
从好的方面来看,加速层只需要处理一部分数据,就是那部分还未被批处理层处理的珊瑚橘。一旦批处理层赶上进度,旧的数据就会从加速层移除。
同步与异步
最容易想到的构建加速层的方式是模仿传统的同步数据库。其实可以将传统数据库看做是 Lambda 架构的一种退化特例(没有批处理层)。
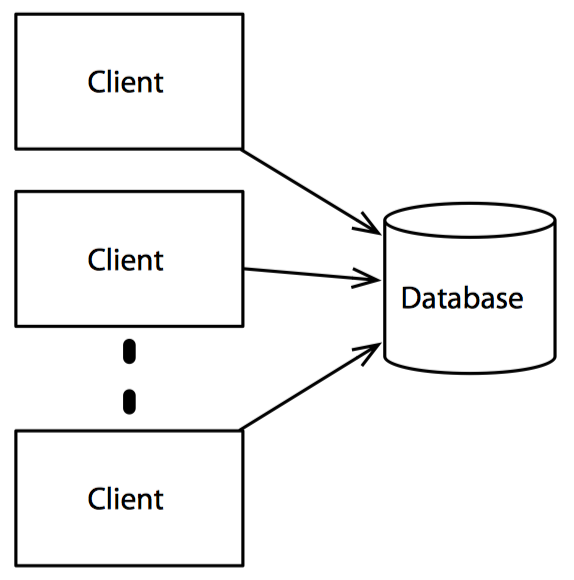
在这种模型中,客户端直接和数据库通信,并在数据库进行更新操作时阻塞。这种模型非常合理,在某些场景下这是唯一能满足特定需求的方法。不过在另一些场景中,异步架构更合适一些。
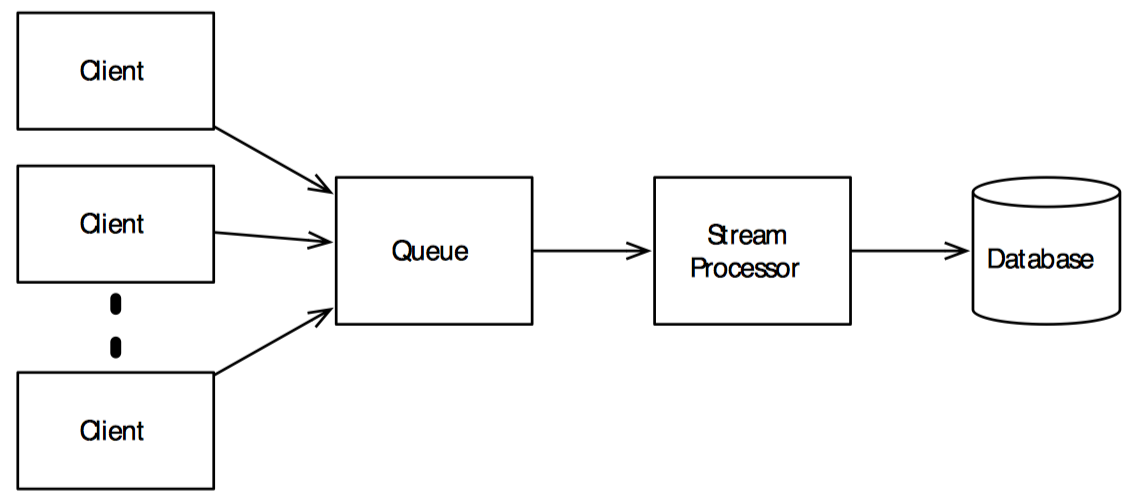
在这种模型中,客户端将更新操作添加到队列(如 Kafka),这一步是无阻塞的。流处理器将串行的处理这些更新操作并对数据库进行更新。
用队列将客户端和数据库解耦,会使更新操作变得更加复杂。不过,根据异步的特性,如果可以接受异步方案,也会获得非常显著的好处:
- 客户端不会阻塞,所以少量的客户端就能处理大量数据,从而提高吞吐。
- 业务压力激增会导致客户端或数据库超载,也会导致同步系统超时或丢失一些更新。而异步系统则不同,只需要将未处理的更新操作保持在队列中,在业务压力恢复稳定后可逐渐赶上进度。
- 稍后我们将了解到:流处理器可以被并行化,也可以在多台计算机上进行分布式计算,即改善了性能也提供了容错。
如何让数据过期
假设批处理层需要两个小时处理数据,那么很容易就会认为加速层需要保留这两个小时以内的数据。实际上加速层需要保留两倍的数据,如下图所示。
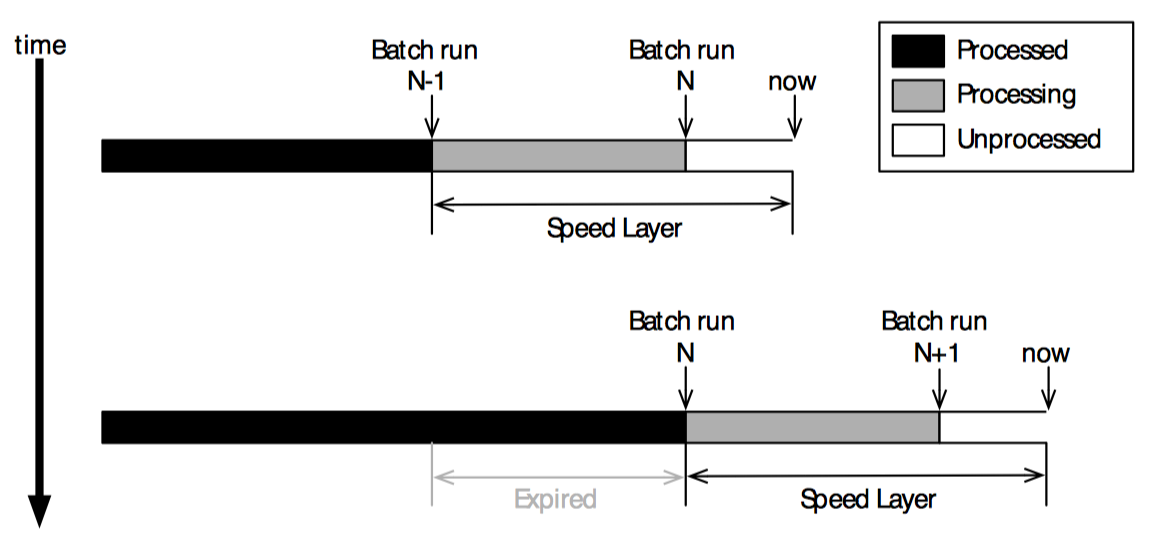
假设 N-1 次批处理刚刚结束,第 N 次批处理正要开始。如果每次批处理需要运行两个小时,这意味着批处理视图会落后两个小时。因此加速层需要保持这落后的两个小时数据,还要保持批处理层运行的两个小时中所有的新数据,总共需要保持 4 个小时的数据。
当第 N 次批处理结束时,需要让最早两个小时的数据过期,但仍保存其后两个小时的数据。有多种方法可以达到目的,不过最容易的就是同时维护两个加速层,并交替使用它们,如下图:
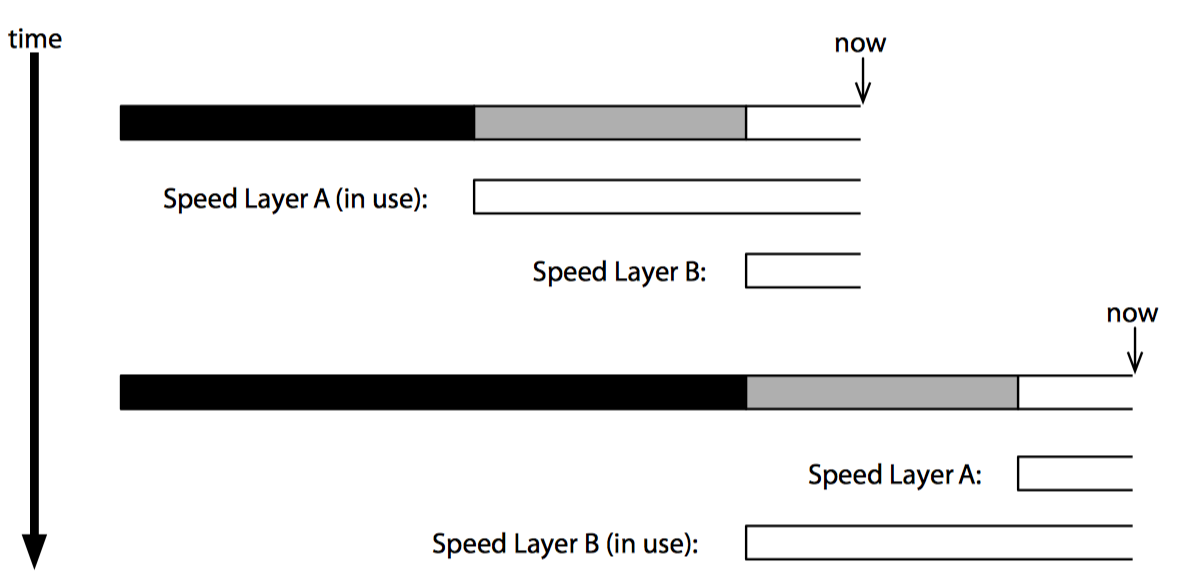
当一次梳理完成时,批处理视图中的新数据就变得可用,就可以将当前用户处理请求的加速层换到另一个加速层上。切换后闲置的加速层会清理其数据库,并在新的批处理开始时重新建立视图。
这种做法的好处是,一方面不需要费心识别加速层的数据库中那些数据需要被过期清理,另一方面由于每次切换后加速层都是从一个空数据库开始运行,因此达到了更好的性能和可靠性。当然为此付出的代价是必须维护两份加速层的数据并且消耗两份计算资源,不过考虑到加速层仅仅处理总数据量中很小的一部分,因此付出的代价不那么大。
总结
Lambda 架构将我们已经学到的一些内容进行了融合:
- 原始数据是永恒的真相,这让我们想到分离状态与标识的做法。
- Hadoop 并行化解问题的方法是先将数据切分,在进行化简操作,这类似于并行函数式编程的做法。
- 类似于 actor 模型,Lambda 架构将处理过程分布大集群上,既改善了性能又提供了容错。
- Storm 的元组流类似于 Actor 和 CSP 中的消息机制。
优点
Lambda 架构非常适合报表与分析——以前则是使用数仓来完成这类任务。
缺点
仅适合大数据量。
显然本书仅涉及了 Lambda 架构,或者说是大数据处理问题的一些皮毛。但好的一点是将其他并发编程模型与 Lambda 架构进行了相似性关联,在构建大数据处理系统时可以借鉴已有的、微观的并发编程模型,从思路上、从形式上。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.