CH05-计数
计数概念的简单性让我们在探索并发中的基本问题时,无需被繁复的数据结构或复杂的同步原语干扰,因此可以作为并行编程的极佳切入对象。
并发计数并不简单
1 long counter = 0;
2
3 void inc_count(void)
4 {
5 counter++;
6 }
7
8 long read_count(void)
9 {
10 return counter;
11 }
- 1,声明一个计数器
- 5,将计数器加 1
- 10,读取计数器的值
当计数器不停读取计数但又几乎不增加计数时,计算性能非常好。但存在计数丢失。精确计数的最简单方式是使用原子操作:
1 atomic_t counter = ATOMIC_INIT(0);
2
3 void inc_count(void)
4 {
5 atomic_inc(&counter);
6 }
7
8 long read_count(void)
9 {
10 return atomic_read(&counter);
11 }
- 1,声明一个原子计数器
- 5,将计数器原子加 1
- 10,原子读取计数器的值
以上都是原子操作,因此非常精确,单线程时速度是非原子方式的 1/6,两个线程时速度是非原子方式的 1/10,即原子计数的性能随着 CPU 和线程数的增加而下降。
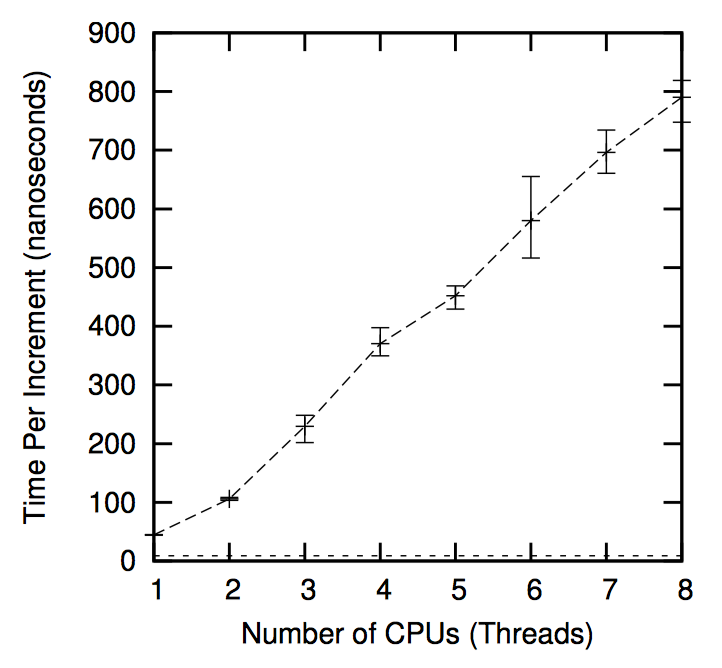
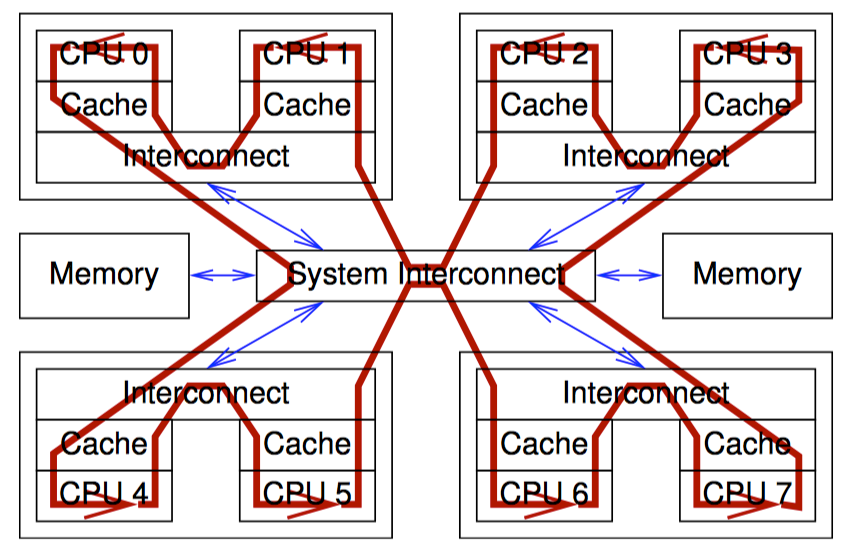
下图以 CPU 视角展示了原子操作带来的性能损耗,为了让每个 CPU 得到机会来增加一个全局变量,包含变量的缓存行需要在所有 CPU 间传播,沿下图中箭头所示的方向。这种传播相当耗时,从而导致了上图中糟糕的性能。
统计计数器
常见的统计计数器场景中,计数器更新频繁但很少被读,或者甚至完全不读。
设计
统计计数器一般以每个线程一个计数器的方式实现(或者在内核运行时以每个 CPU 一个),所以每个线程仅更更新自己的计数。而总的计数值就是所有线程计数值的和。
基于数组的实现
分配一个数组,数组每个元素对应一个线程(假设数组已经按缓存行对其并且被填充,以防止出现假共享)。
该数组可以用一个“每线程”原语来表示:
1 DEFINE_PER_THREAD(long, counter);
2
3 void inc_count(void)
4 {
5 __get_thread_var(counter)++;
6 }
7
8 long read_count(void)
9 {
10 int t;
11 long sum = 0;
12
13 for_each_thread(t)
14 sum += per_thread(counter, t);
15 return sum;
16 }
- 1,定义了一个数组,包含一套类型为 long 的每线程计数器 counter。
- 3~6,增加计数的函数,使用
__get_thread_var()原语来定位当前运行线程对应 counter 数组的元素。因为该元素仅能由对应的线程修改,因此使用非原子自增即可。 - 8~16,读取总计数的函数,使用
for_each_thread()原语遍历当前运行的所有线程,使用per_thread()原语获取指定线程的计数。因为硬件可以原子地存取正确对齐的 long 型数据,并且 GCC 充分利用了这一点,所以使用非原子读取操作即可。
该方法随着 inc_count() 函数的更新者线程增加而线性扩展,原因是每个 CPU 可以快速的增加自己线程的变量值,不再需要代价高昂的、跨越整个计算机系统的通信,如下图所示:
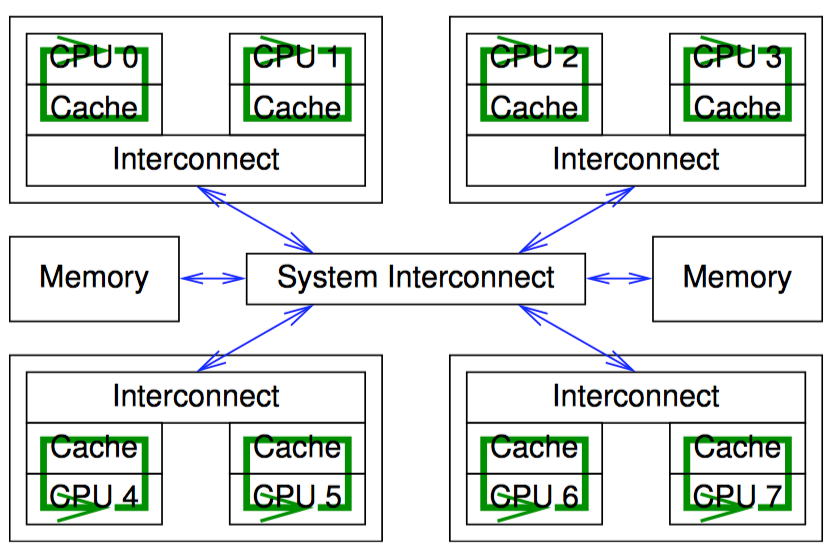
但这种在“更新端”扩展极佳的方式在存在大量线程时会给“读取端”带来极大代价。接下来将介绍另一种方式,能在保留更新端扩展性的同时,减少读取端产生的代价。
最终结果一致的实现
一种保留更新端扩展性的同时又能提升读取端性能的方式是:削弱一致性要求。
前面介绍的计数算法要求保证返回的值在 read_count() 执行前一刻的理想计数值和 read_count() 执行完毕时的理想计数值之间。最终一致性方式提供了弱一些的保证:当不调用 inc_count() 时,调用 read_count() 最终会返回正确的值。
我们维护一个全局计数来利用”最终结果一致性“。但是因为写者只操作自己线程的每线程计数,我们需要一个单独的线程负责将每线程计数的计数值传递给全局计数,而读者仅需访问全局计数值。如果写者正在更新计数,读者读取的全局计数值将不是最新的,不过一旦写者更新完毕,全局计数最终会回归正确的值。
1 DEFINE_PER_THREAD(unsigned long, counter);
2 unsigned long global_count;
3 int stopflag;
4
5 void inc_count(void)
6 {
7 ACCESS_ONCE(__get_thread_var(counter))++;
8 }
9
10 unsigned long read_count(void)
11 {
12 return ACCESS_ONCE(global_count);
13 }
14
15 void * eventual(void * arg)
16 {
17 int t;
18 int sum;
19
20 while (stopflag < 3) {
21 sum = 0;
22 for_each_thread(t)
23 sum += ACCESS_ONCE(per_thread(counter, t));
24 ACCESS_ONCE(global_count) = sum;
25 poll(NULL, 0, 1);
26 if (stopflag) {
27 smp_mb();
28 stopflag++;
29 }
30 }
31 return NULL;
32 }
33
34 void count_init(void)
35 {
36 thread_id_t tid;
37
38 if (pthread_create(&tid, NULL, eventual, NULL)) {
39 perror("count_init:pthread_create");
40 exit(-1);
41 }
42 }
43
44 void count_cleanup(void)
45 {
46 stopflag = 1;
47 while (stopflag < 3)
48 poll(NULL, 0, 1);
49 smp_mb();
50 }
- 1~2,定义了跟踪计数值的没线程变量和全局变量。
- 3,定义了 stopflag,用于控制程序结束。
- 5~8,增加计数函数
- 10~13,读取计数函数
- 34~42,
count_init()函数创建了位于 15~32 行的eventual()线程,该线程将遍历所有线程,对每个线程的本地计算 counter 进行累加,将结果放入 global_count。eventual线程在每次循环之间等待 1ms(随便选择的值)。 - 44~50,
count_cleanup()函数用来控制程序结束。
本方法在提供极快的读取端计数性能的同时,仍然保持线性的更新端计数性能曲线。但也带来额额外的开销,即 eventual 线程。
基于每线程变量的实现
GCC 提供了一个用于每线程存储的 _thread 存储类。下面使用该类来实现统计计数器,该实现不仅能扩展,而且相对于简单的非原子自增来说几乎没有性能损失。
1 long __thread counter = 0;
2 long * counterp[NR_THREADS] = { NULL };
3 long finalcount = 0;
4 DEFINE_SPINLOCK(final_mutex);
5
6 void inc_count(void)
7 {
8 counter++;
9 }
10
11 long read_count(void)
12 {
13 int t;
14 long sum;
15
16 spin_lock(&final_mutex);
17 sum = finalcount;
18 for_each_thread(t)
19 if (counterp[t] != NULL)
20 sum += * counterp[t];
21 spin_unlock(&final_mutex);
22 return sum;
23 }
24
25 void count_register_thread(void)
26 {
27 int idx = smp_thread_id();
28
29 spin_lock(&final_mutex);
30 counterp[idx] = &counter;
31 spin_unlock(&final_mutex);
32 }
33
34 void count_unregister_thread(int nthreadsexpected)
35 {
36 int idx = smp_thread_id();
37
38 spin_lock(&final_mutex);
39 finalcount += counter;
40 counterp[idx] = NULL;
41 spin_unlock(&final_mutex);
42 }
- 1~4,定义所需变量,
counter是每线程计数变量,counterp[]数组允许线程访问彼此的计数,finalcount在各个线程退出时将计数值累加到综合,final_mutex协调累加计数总和值的线程和退出的线程。 - 更新者调用
inc_count()函数,见 6~9 行。 - 写者调用
read_count()函数,首先在 16 行获取与正在退出线程互斥的锁,21 行释放锁。17 行初始化已退出线程的每线程计数总和,18~20 将还在运行的线程的每线程计数累加进总和,最后,22 行返回总和。 - 25~32,
count_register_thread()函数,每个线程在访问自己的计数前都要调用它,将本线程对应countp[]数组中的元素指向线程的每线程变量 counter。 - 34~42,
count_unregister_thread()函数,每个之前调用过count_register_thread()函数的线程在退出时都要调用该函数。38 行获取锁,41 行释放锁,因此排除了有线程正在调用read_count()同时又有线程调用count_unregister_thread()函数的情况。39 行将本线程的每线程计数添加到全局 finalcount 中,然后将countp[]数组的对应元素设置为 NULL。随后read_count()调用可以在全局变量 finalcount 里找到已退出线程的计数值,并且顺序访问countp[]数组时可以跳过已退出线程,从而获得正确的总计数结果。
该方式让更新者的性能几乎和非原子计数一样,并且也能线性扩展。另外,并发的读者竞争一个全局锁,因此性能不佳,扩展性差。但是这不是统计计数器要面对的问题,因为统计计数器总是在增加计数,很少读取计数。
近似上限计数器
另一种计数的场景是上限检查,比如需要维护一个已分配数据结构数目的计数器,来防止分配超过一个上限。我们假设这些结构的生命周期很短,数目也极少能超出上限。对近似值上限来说,偶尔超出少许是可以接受的。
设计
一种可能的实现是将近似总数值(10000)平均分配给每个线程,然后每个线程一个固定个数的资源池。假如有 100 个线程,每个线程管理一个有 100 个结构的资源池。这种方式简单,在有些情况下有效,但是无法处理一种常见情况:某个结构由一个结构创建,但由另一个线程释放。一方面,如果线程释放一个结构就得一分的话,那么一直在分配结构的线程很快就会分配光资源池,而一直在释放结构的线程积攒了大量分数却无法使用。另一方面,如果每个被释放的结构都能让分配它的 CPU 加一分,CPU 就需要操纵其他 CPU 的计数,这会带来昂贵的原子操作或其他跨线程通信手段。
因此,在很多重要的情况下我们不能讲计数问题完全分割。对于上限计数,我们可以采用一种分割计数方法的变体,部分地分割计数。比如在四个线程中,每个线程拥有一份每线程变量 counter,但同时每个线程也持有一份每线程的最大值 countermax。
如果某个线程需要增加其 counter,可是此时 counter 等于 countermax,这时该如何处理呢?此时可以把此线程 counter 值的一半转移给 globalcount,然后在增加 counter。举个例子,加入某线程的 counter 和 countermax 都为 10,我们可以执行如下操作:
- 获取全局锁
- 给 globalcount 增加 5
- 当前线程的 couter 减少 5,以抵消全局的增加
- 释放全局锁
- 递增当前线程的 counter,编程 6
虽然该操作中需要全局锁,但是该锁只有在每 5 次增加操作后才获取一次,从而降低了竞争程度,如果我们增大了 countermax 的值,竞争程度还会进一步降低。但是增大 countermax 值的副作用是 globalcount 精确度的降低。假设一台 4 CPU 系统,此时 countermax 值为 10,global 和真实计数值的误差最高可达 40,如果把 countermax 增加到 100,那么 globalcount 和真实计数值的误差可达 400。
因此问题成了我们到底有多在意 globalcount 和真实计数值的偏差。真实计数值由 globalcount 和所有每线程 counter 相加得出。误差取决于真实计数值和计数上限的差值有多大,差值越大,countermax 就越不容易超过 globalcountmax 的上限。这就代表着任何一个线程的 countermax 变量可以根据当前的差值计算取值。当离上限还比较远时,可以给每线程变量 countermax 赋值一个较大的数,这样对性能和扩展性都有好处。当靠近上限时,可以给这些 countermax 赋值一个比较小的数,这样可以降低超过统计上限 globalcountmax 的风险,从而减少误差。
这种设计就是一个并行快速路径的例子,这是一种重要的设计模式,适用于下面的情况:在多数情况下没有线程间的通信和交互开销,对偶尔进行的跨线程通信又使用了静心设计的(但是开销仍然很大的)全局算法。
精确上限计数器
一种实现精确计数的方式是允许线程放弃自己的计数,另一种是采用原子操作。当然,原子操作会减慢快速路径。
原子上限计数
如果想要一个线程减少另一个线程上的计数,需要自动的操作两个线程的 counter 和 countermax 变量。通常的做法是将这两个变量合并成一个变量,比如一个 32 位的变量,高 16 位代表 counter,低 16 位代表 countermax。
这种方式运行计数一直增长直到上限,但是也带来了快速路径上原子操作的开销,让快速路径明显变慢了。虽然在某些场合这种变慢是允许的,但是仍然值得我们去探索让读取端性能更好的算法。而使用信号处理函数从其他线程窃取计数就是一种算法。因为信号处理函数可以运行在收到信号线程的上下文,所以就不需要原子操作了。
Signal-Theft 上限计数
虽然每线程状态只由对应线程修改,但是信号处理函数仍然有必要进行同步。
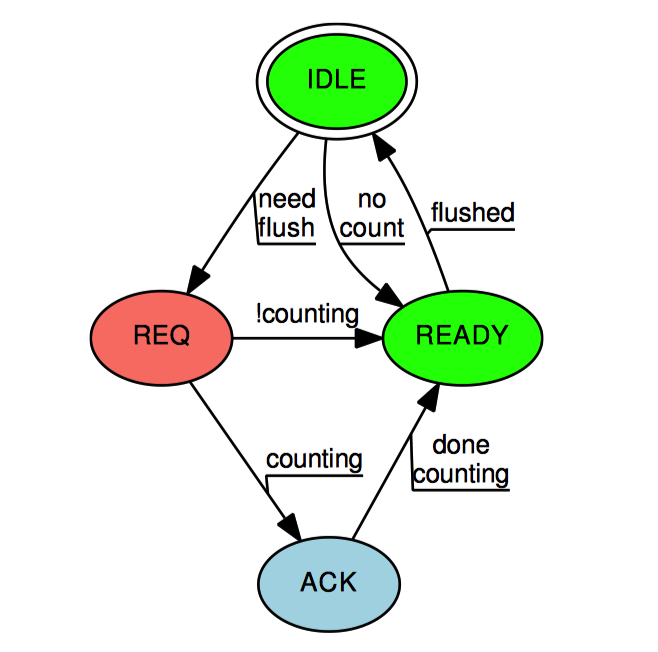
上图中的状态机展示了这种同步机制。Signal-Threft 状态机从”空闲“状态开始,当 add_count() 和 sub_count() 发现线程的本地计数和全局计数之和已经不足以容纳请求的大小时,对应的慢速路径将每线程的 threft 状态设置为”请求”(除非线程没有计数值,这样它就直接转换为“准备完毕”)。只有在慢速路径获得 gblcnt_mutex_lock 之后,才允许从“空闲”状态转换为其他状态。然后慢速路径向每个线程发送一个信号,对应的信号处理函数检查本地线程的 threft 和 counting 状态。如果 threft 状态不为“请求”,则信号处理函数就不能改变其状态,只能直接返回。而 threft 状态为“请求”时,如果设置了 counting 变量,表名当前线程正处于快速路径,信号处理函数将 threft 状态设置为“确认”,而不是“准备完毕”。
如果 threft 状态为“确认”,那么只有快速路径才有权改变 threft 的状态。当快速路径完成时,会将 threft 状态设置为“准备完毕”。
一旦慢速路径发现某个线程的 threft 状态为“准备完毕”,这时慢速路径有权窃取此线程的计数。然后慢速路径将线程的 threft 状态设置为“空闲”。
在一般笔记本电脑上,使用 signal-threft 的实现比原子操作的实现快两倍。由于原子操作的相对缓慢,signal-threft 实现在 Pentium-4 处理器上比原子操作好的多,但是后来,老式的 8086 对称处理器系统在原子操作实现的路径深度更短,原子操作的性能也随之提升。可是,更新端的性能提升是以读取端的高昂开销为代价的,POSIX 信号不是没有开销的。如果考虑最终的性能,则需要在实际部署应用的系统上测试这两种方式。
特殊场合的并行计数
即便如此,如果计数的值总是在 0 附近变动,精确计数就没什么用了,正如统计对 IO 设备的访问计数一样。如果我们并不关心当前有多少计数,这种统计值总是在 0 附近变动的计数开销很大。比如在可移除 IO 设备的访问计数问题,除非有人想移除设备,否则访问次数完全不重要,而移除设备这种情况本身又很少见。
一种简单的解决办法是,为计数增加一个很大的“偏差值”(比如 10 亿),确保计数的值远离 0,让计数可以有效工作。当有人想拔出设备时,计数又减去偏差值。计数最后几次的增长将是非常低效的,但是对之前的所有计数去可以全速运行。
虽然带偏差的计数有用且有效,但这只是可插拔 IO 设备访问计数问题的部分解决办法。当尝试移除设备时,我们不仅需要当前精确的 IO 访问计数,还需要从现在开始阻止未来的访问请求。一种方式是在更新计数时使用读写锁的读锁,在读取计数时使用同一把读写锁的写锁。
并行计数讨论
本章展示了传统计数原语会遇见的问题:可靠性、性能、扩展性。C 语言的 ++ 操作符不能在多线程代码中保证函数的可靠性,对单个变量的原子操作性能不好,可扩展性也差。
并行计数性能
统计计数算法性能:
| 算法 | 写延迟 | 延迟(1核) | 读延迟(32核) |
|---|---|---|---|
| 数组快速通道 | 11.5ns | 308ns | 409ns |
| 最终一致 | 11.6ns | 1ns | 1ns |
| 每线程变量 | 6.3ns | 389ns | 51,200ns |
| RCU | 5.7ns | 354ns | 501ns |
上限计数算法性能:
| 算法 | 是否精确 | 写延迟 | 读延迟(1核) | 读延迟(32核) |
|---|---|---|---|---|
| 每线程变量-1 | 否 | 3.6ns | 375ns | 50,700ns |
| 每线程变量-2 | 否 | 11.7ns | 369ns | 51,000ns |
| 原子方式 | 是 | 51.4ns | 427ns | 49,400ns |
| 信号方式 | 是 | 10.2ns | 370ns | 54,000ns |
并行计算的专门化
上述算法仅在各自的问题领域性能出色,这可以说是并行计算的一个主要问题。毕竟 C 语言的 ++ 操作符在所有单线程程序中性能都不错,不仅仅是个别领域。
我们提到的问题不仅是并行性,更是扩展性。我们提到的问题也不专属于算术问题,假设你还要存储和查询数据库,是不是还会用 ASCII 文件、XML、关系型数据库、链表、紧凑数组、B 树、基树或其他什么数据结构和环境来存取数据,这取决于你需要做什么、做多快、数据集有多大。
同样,如果需要计数,合适的方案取决于统计的数有多大、有多少个 CPU 并发操纵计数、如何使用计数,以及需要的性能和可扩展性程度。
总结
本章的例子显示,分割是提升可扩展性和性能的重要工具。计数有时可以被完全分割,或者被部分分割。
- 分割能够提升性能和可扩展性。
- 部分分割,也就是仅分割主要情况的代码路径,性能也很出色。
- 部分分割可以应用在代码上,但是也可以应用在时间空间上。
- 读取端的代码路径应该保持只读,对共享内存的“伪同步写”严重降低性能和扩展性。
- 经过审慎思考的延迟处理能够提升性能和扩展性。
- 并行性能和扩展性通常是跷跷板的两端,达到某种程度后,对代码的优化反而会降低另一方的表现。
- 对性能和可扩展性的不同需求及其他很多因素,会影响算法、数据结构的设计。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.