CH03-硬件特性
本章主要关注 共享内存系统中的同步和通信开销,仅涉及一些共享内存并行硬件设计的初级知识。
概述
人们容易认为 CPU 的性能就像在一条干净的赛道上赛跑,但事实上更像是一个障碍赛训练场。
流水线 CPU
在 20 世纪 80 年代,典型的微处理器在处理一条指令之前,至少需要取值、解码和执行这三个时钟周期来完成当前指令。到 90 年代之后,CPU 可以同时处理多条指令,通过一条很长的流水线来控制 CPU 内部的指令流。
带有长流水线的 CPU 要想达到最佳性能,需要程序给出高度可预测的控制流。如果程序代码执行的是紧凑循环,那么这种程序就能提供 可预测的控制流,此时 CPU 可以正确预测出在大多数情况下代码循环结束后的分支走向。在这种程序中,流水线可以一直保持在满状态,CPU 高速运行。
如果程序中带有很多循环,且循环计数都比较小,或者面向对象的程序中带有很多虚方法,每个虚方法都可以引用不同的对象实例,而这些对象实例都实现了一些频繁被调用的成员函数,此时 CPU 很难或者完全不可能预测某个分支的走向。这样一来,CPU 要么等待控制流进行到足以知道分支走向的方向,要么干脆猜测,但常常出错。这时流水线会被排空,CPU 需要等待流水线被新指令填充,这将大幅降低 CPU 的性能。
- 分支预测的原理?
内存引用
在 20 世纪 80 年代,微处理器从内存中读取一个值的时间一般比执行一条指令的时间短,即指令执行慢于内存 IO。在 2006 年,同样是读取内存中的一个值的时间,微处理器可以执行上百条甚至千条指令。这源于摩尔定律对 CPU 性能的提升,以及内存容量的增长。
虽然现代微型计算机上的大型缓存极大减少了内存访问延迟,但是只有高度可预测的数据访问模式才能发挥缓存的最大效用。因此对内存的引用也就造成了对 CPU 性能的严重影响。
原子操作
原子操作本身的概念在某种意义上与 CPU 流水线上一次执行多条指令的操作产生了冲突。而现代 CPU 使用了很多手段让这些操作看起来是原子的,即使这些指令实际上并非原子。比如标出所有包含原子操作所需数据的流水线,确保 CPU 在执行原子操作时,所有这些流水线都属于正在执行原子操作的 CPU,并且只有在这些流水线仍归该 CPU 所有时才推进原子操作的执行。这样一来,因为所有数据都只属于该 CPU,即使 CPU 流水线可以同时执行多条指令,其他 CPU 也无法干扰此 CPU 的原子操作执行。但这种方式要求流水线必须能够被延迟或冲刷,这样才能执行让原子操作过程正确完成的一系列操作。
非原子操作则与之相反,CPU 可以从流水线中按照数据出现的顺序读取并把结果放入缓冲区,无需等待流水线的归属切换。
虽然 CPU 设计者已经开始优化原子操作的开销,但原子指令仍频繁对 CPU 性能造成影响。
内存屏障
原子操作通常只用于数据的单个元素,由于许多并行算法都需要在更新多个元素时保证正确的执行顺序,因此大多数 CPU 都提供了内存屏障。
spin_lock(&mylock);
a = a +1;
spin_unlock(&mylock);
像这样一个基于锁的临界区中,锁操作必须包含隐式或显式的内存屏障。内存屏障可以防止 CPU 为了提升性能而进行乱序执行,因此内存屏障也一定会影响性能。
高速缓存未命中
现代 CPU 使用大容量的高速缓存来降低由于低速的内存访问带来的性能惩罚。但是,CPU 高速缓存事实上对多 CPU 间频繁访问的变量起到了反面效果。因为当某个 CPU 想去改变变量的值时,极有可能该变量的值刚被其他 CPU 修改过。这时,变量存在于其他 CPU 的高速缓存中,这将导致代价高昂的高速缓存为命中。
IO 操作
缓存未命中可被视为 CPU 之间的 IO 操作,也是代价最小的 IO 操作之一。IO 操作涉及网络、大容量存储,或者人类本身(人机交互 IO)。IO 操作对性能的影响也远远大于前面所有提到的所有影响因素。
这也是共享内存并行计算和分布式系统式的并行编程的其中一个不同点:共享内存式并行编程的程序一般不会处理比缓存未命中更糟的情况,而分布式并行编程的程序则会遭遇网络通信延迟。因此,通信的开销占实际执行任务的比率是一项关键的设计参数。
开销
硬件体系结构
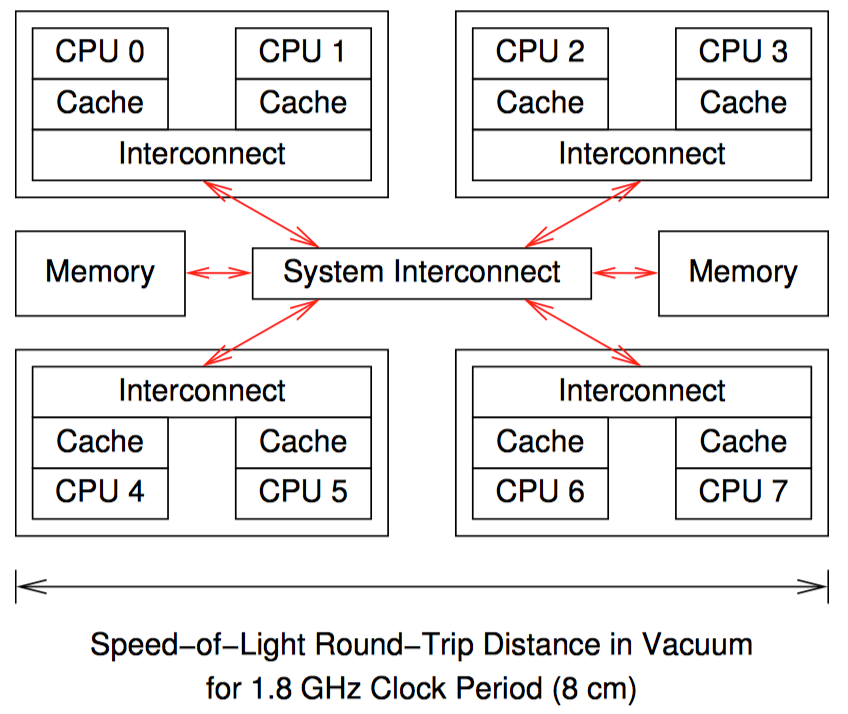
这是一个 8 核计算机概要图:每个芯片上有 2 个核,每个核带有自己的高速缓存,每个芯片内还带有一个互联模块,使芯片内的两个核可以互相通信,图中央的系统互联模块可以让 4 个芯片之间互相通信,并且与主存进行连接。
数据以缓存行(cache line)为单位在系统中传输,缓存行对应内存中一个 2 的乘方大小的字节,大小通常为 32 到 256 之间。当 CPU 从内存中读取一个变量到它的寄存器中时,必须首先将该变量的缓存行读取到 CPU 高速缓存;CPU 寄存器中的一个值存储到内存时,不仅需要将包含了该值的缓存行写入 CPU 高速缓存,还必须确保其他 CPU 没有该缓存行的复制。
比如,如果 CPU0 在对一个变量执行"比较并交换(CAS)“操作,而该变量所在的缓存行存储在 CPU7 的高速缓存中。下面是将要发送的事件序列:
- CPU0 检查本地高速缓存,没有找到缓存行。
- 请求被转发到 CPU0 和 CPU1 的互联模块,检查 CPU1 的高速缓存,没有找到缓存行。
- 请求被转发到系统互联模块,检查其他三个芯片,得知缓存行被 CPU6 和 CPU7 所在的芯片持有。
- 请求被转发到 CPU6 和 CPU7 的互联模块,检查这两个 CPU 的高速缓存,在 CPU7 的高速缓存中找到缓存行。
- CPU7 将缓存行发送到自己所属的互联模块,并且刷新掉自己高速缓存中的缓存行。
- CPU6 和 CPU7 所在芯片的互联模块将缓存行发送给系统互联模块。
- 系统互联模块将缓存行发送给 CPU0 和 CPU1 所在芯片的互联模块。
- CPU0 和 CPU1 所在芯片的互联模块将缓存行发送给 CPU0 的高速缓存。
- CPU0 现在可以对高速缓存中的变量执行 CAS 操作。
操作开销
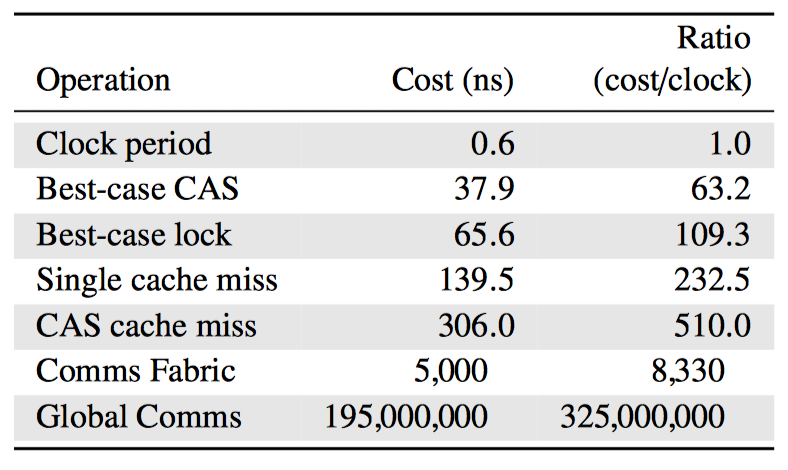
上图是各种同步机制相与 CPU 周期时间的比率。(4-CPU 1.8 GHz AMD Opteron 844 System)
软件设计的启示
并行算法必须将每个线程设计成尽可能独立运行的线程。越少使用线程间的同步通信手段,比如原子操作、锁或其他消息传递方法,应用程序的性能和扩展性就会越好。想要达到优秀的并行性和扩展性,就需要在并行算法和实现中挣扎,小心的选择数据结构和算法,尽量使用现有的并行软件和环境,或者将并行问题转换为已经拥有并行解决方案的问题。
- 好消息是多核系统变得廉价且可靠。
- 另一个好消息是,现在很多同步操作的开销正变得越来越小。
- 坏消息是 高速缓存未命中的开销仍然很高,特别是在大型系统上。 本书剩余部分则会讨论如何解决该问题。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.