CH02-简介
导致并行编程困难的历史原因
困难的分类:
- 并行系统在历史上的高价格与稀缺性。
- 研究者和从业人员对并行系统的经验欠缺。
- 缺少公开的并行代码。
- 并行编程缺少被广泛了解的工程准则。
- 相对于处理本身,通信的代价高昂,即使在紧凑的 共享内存系统 中也是如此。
目前这些问题的现状:
- 基于摩尔定律,并行系统的价格降低。
- 研究者和从业人员开始广泛接触并行系统。
- 大量开源的并行软件项目出现。
- 开发者社区形成,这些开发者知道产品级的并行代码需要什么样的准则。
- 通信、处理代价高昂的问题依然存在,而光的有限速度及原子特性会限制该领域的进展,但方法总是有的。
并行编程的目标
性能
大多并行编程的尝试都是为了提升性能。摩尔定律仍然在晶体管密度方面有效,但在单线程性能方面已经不再有效,因此 对性能的关注点从硬件转移到了并行软件。这意味着先编写单线程代码,再通过升级 CPU 来提升性能已不再可行。因此首先要考虑的是性能而不是扩展性。
即使拥有多个 CPU,也不必全部都用起来。并行编程主要是为了性能优化,但这只是众多优化措施中的一种。 如果程序够快则无需优化或并行化,亦或是基于单线程方式的优化。如果需要基于并行的方式进行优化,则需要与最好的串行算法进行比较,已确定并行化的必要性。
生产率
硬件的价格已远低于软件的开发与维护成本。仅仅高效的使用硬件已经不再足够,高效的利用开发者已经变得同等重要。
通用性
要想减少开发并行程序的高昂成本,一种方式是 让程序尽量通用。如果其他影响因素一样,通用的软件能获得更多用户从而摊薄成本。但通用性会带来更大的性能损失和生产率损失。如下是一些典型的并行开发环境。
- C/C++ 锁与线程:包含 POSIX 线程(pthreads)、Windows 线程以及众多系统内核环境。性能优秀、通用性良好,但生产率低。
- Java:生产率比 C/C++ 要高,虽然性能不断进步但仍低于 C/C++。
- MPI:该消息传递接口向大量的科学和技术计算提供能力,提供了无与伦比的性能和扩展性。虽然通用但主要面向科学计算。生产率低于 C/C++。
- OpenMP:该编译指令集用于并行循环,因此用于特定任务从而限制了其性能。比 MPI、C/C++ 要简单。
- SQL:结构化编程语言 SQL 仅用于数据库查询,性能出色、生产率优秀。
同时满足性能、生产率、通用性要求的并行编程环境仍不存在,因此必须在三者之间进行权衡。 越往上层,生成率越重要;越往下层,性能和通用性越重要。大量的开发工作消耗在上层,必须提高通用性以降低成本;下层的性能损失很难在上层得到恢复。越往上层,采用额外的硬件比采用额外的开发者更划算。
本书面向底层开发,因此主要关心 性能和通用性。
并行编程的替代方案
并行编程只是提升性能的方案之一,以下是一些其他流行的方案:
- 运行多个串行应用实例:
- 会增加内存消耗、CPU 指令周期浪费在重复计算中间结果上,也会增加数据复制操作。
- 利用现有的并行软件构建应用:
- 通常会牺牲性能,至少会逊色于精心构造的并行程序,但可以显著降低开发难度。
- 对串行应用进行逻辑优化:
- 来自并行计算的速度提升与 CPU 个数大约成正比,而对软件逻辑进行的优化可能会带来指数级的性能提升。
- 不同程序的性能瓶颈不同。
复杂的原因
并行编程需要双向交互:人告诉计算机要做什么;人还需要通过结果的性能和扩展性来评价程序。
我们所要考虑的并行程序开发者的任务,对于串行程序开发者来说是完全不需要的。我们将这些任务分为 4 类:
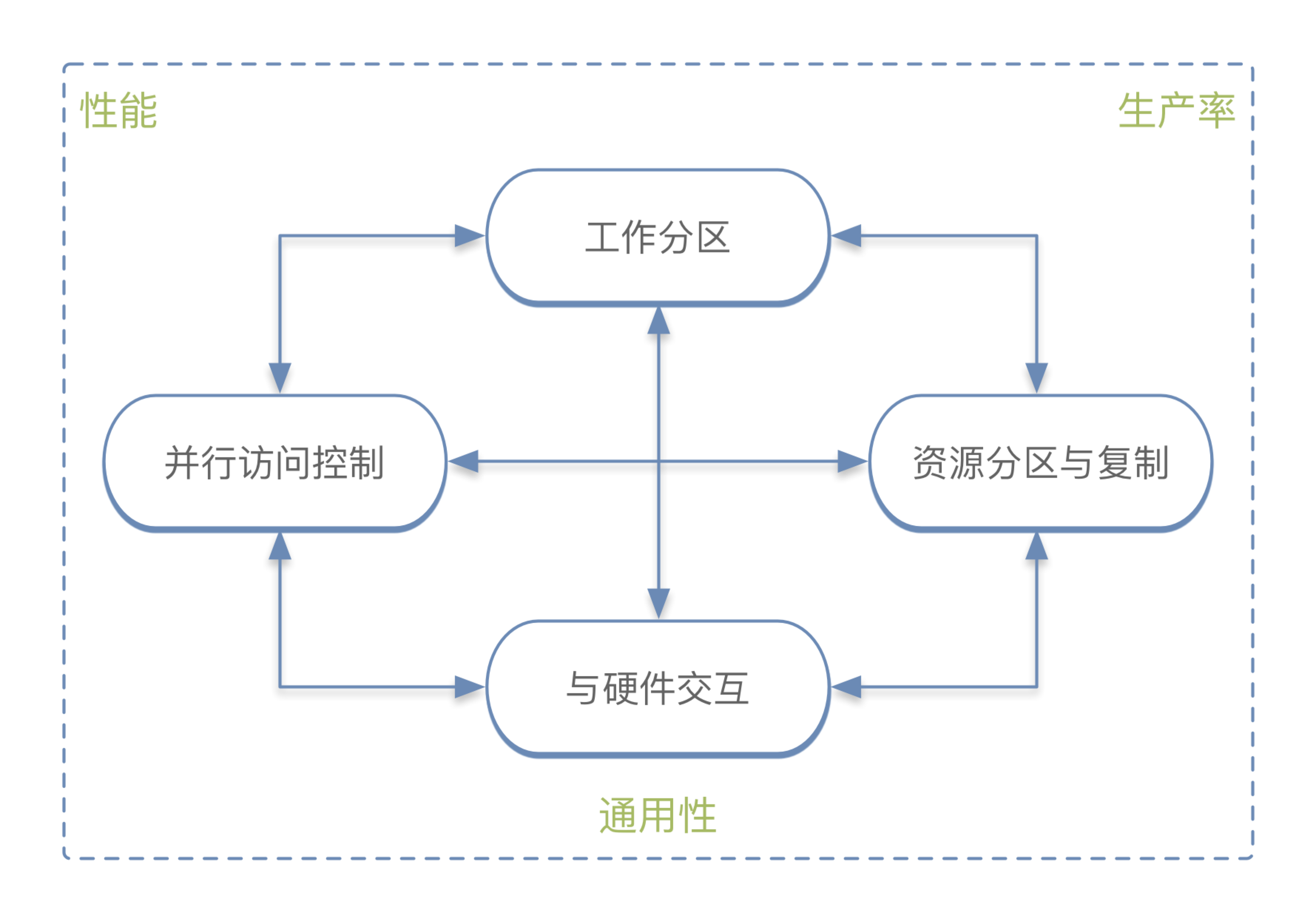
分割任务
合理的对任务进行分割以提升并行度,可以极大提升性能和扩展性,但是也会增加复杂性。 比如,分割任务可能会让全局错误处理和事件处理更复杂,并行程序可能需要一些相当复杂的同步措施来安全的处理这些全局事件。总的来说,每个任务分割都需要一些交互,如果某个线程不存在任何交互,那它的执行对任务本身也就不产生任何影响。但是交互也就意味着额外的、可能降低性能的开销。
如果同时执行太多线程,CPU 缓存将会溢出,引起过高的缓存未命中,降低性能。
运行程序并发执行会大量增加程序的状态集,导致程序难以理解和调试,降低生产率。
并行访问控制
单线程的线性程序对程序的所有资源都有访问权,主要是内存数据结构,但也可能是 CPU、内存、高速缓存、IO 设备、计算加速器、文件等。并行访问控制的问题有:
- 访问特定的资源是否受限于资源的位置。 比如本地或远程、显式或隐式、赋值或消息传递等。
- 线程如何协调对资源的访问。 这种协调由不同的并行语言或环境通过大量同步机制实现,如:消息传递、加锁、事务、引用计数、显式计时、共享原子变量、数据所有权等。因此要面对死锁、活锁、事务回滚等问题。
资源分割与复制
最有效的并行算法和系统都善于对资源进行并行化,所以并行编程的编写最好从分割写密集型资源和复制经常访问的读密集型资源开始。 这里所说的访问频繁的数据,可能是计算机系统、海量存储设备、NUMA节点、CPU、页面、Cache Line、同步原语实例、代码临界区等等多个层次。
与硬件交互
开发者需要根据目标硬件的高速缓存分布、系统的拓扑结果或者内部互联协议来对应用进行量体裁衣。
组合使用
最好的实践会将上述 4 种类型的基础性任务组合应用。比如,数据并行方案首先把数据分割以减少组件内的交互需求,然后分割相应的代码,最后对数据分区并与线程映射,以便提升吞吐、减少线程内交互。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.