This the multi-page printable view of this section. Click here to print.
深入理解并行
- 1: CH01-关于本书
- 2: CH02-简介
- 3: CH03-硬件特性
- 4: CH04-并行工具
- 5: CH05-计数
- 6: CH06-分割同步设计
- 7: CH07-锁
- 8: CH08-数据所有权
- 9: CH09-延后处理
- 10: CH10-数据结构
- 11: CH11-验证
- 12: CH12-形式验证
- 13: CH13-综合应用
- 14: CH14-高级同步
- 15: CH15-高级同步-内存序
- 16: ENDIX-C-内存屏障
1 - CH01-关于本书
- Is Parallel Programming Hard, And If So, What Can You Do About It?
- 中文版:深入理解并行编程
- 作者:Paul E. McKenney
- 译者:谢宝友、鲁阳
- 中文版基于 2015.x,对照英文版本 2017.11.22a。
- 本书的英文版以长期维护的开源形式免费供读者阅读,且每个版本都存在变更,大到整书的组织结构、小到示例代码。
- 因此建议想要基于本书开展实践的同学直接阅读英文版。
本书专注于基于 基于共享内存的并行编程 ,重点放在软件栈底层的软件,比如操作系统内核、并行的数据库管理系统、底层系统库等。
本书包含一些广泛应用且使用频繁的设计技巧,而非一些适用范围有限的最佳算法。
内容简介:
- CH01:关于本书。
- CH02:并行编程概览。
- CH03:介绍共享内存并行硬件。因为,在不了解底层硬件的情况下很难编写出正确的并行代码。
- CH04:为常用的、基于共享内存的并行编程原语提供了一个简要的概览。
- CH05:深入介绍了并行领域中可能最简单的一个问题——计数。
- CH06:介绍了一些设计层的方法,用于解决 CH05 中遇到的问题。
- CH07:锁。
- CH08:数据所有权。
- CH09:延期处理机制——引用计数、危险指针、顺序锁、RCU。
- CH10:将前面介绍的技术应用到哈希表。
- CH11:各种形式的并行代码校验手段。
- CH12:形式验证。
- CH13:通过示例的形式介绍了一系列中等规模的并行编程问题。
- CH14:高级同步方法,如无锁同步、并行实时计算。
- CH15:关于内存序的高级主题。
- CH16:一些实践建议。
- CH17:并行编程的未来方向,包括共享内存并行系统设计、软件和硬件事务内存、函数式并行编程。
- 附录-C:着重介绍了内存屏障的原理与实践。
本文作者 Paul 是 Linux 内核大神,40 年开发经验。 全书干货居多,作者的介绍非常细致,很多高级主题让我这个新手感到震撼,值得反复阅读。 这里为了学习理解、加深记忆,标注、摘抄、整理了中文版、英文版中的内容,仅供个人学习、交流、查阅。 写书、译书不易,感谢作者、译者的辛勤汗水,请支持正版。
2 - CH02-简介
导致并行编程困难的历史原因
困难的分类:
- 并行系统在历史上的高价格与稀缺性。
- 研究者和从业人员对并行系统的经验欠缺。
- 缺少公开的并行代码。
- 并行编程缺少被广泛了解的工程准则。
- 相对于处理本身,通信的代价高昂,即使在紧凑的 共享内存系统 中也是如此。
目前这些问题的现状:
- 基于摩尔定律,并行系统的价格降低。
- 研究者和从业人员开始广泛接触并行系统。
- 大量开源的并行软件项目出现。
- 开发者社区形成,这些开发者知道产品级的并行代码需要什么样的准则。
- 通信、处理代价高昂的问题依然存在,而光的有限速度及原子特性会限制该领域的进展,但方法总是有的。
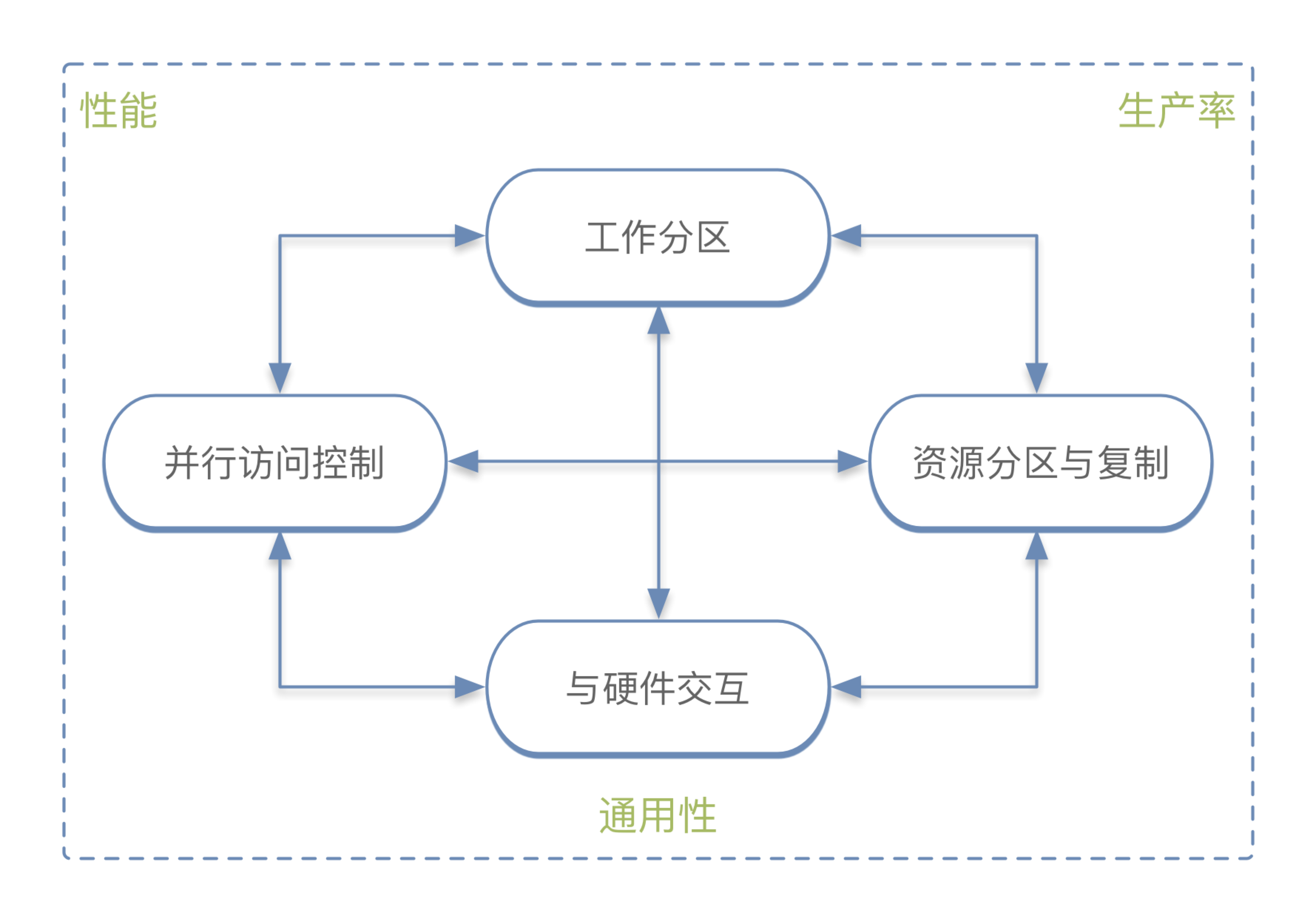
并行编程的目标
性能
大多并行编程的尝试都是为了提升性能。摩尔定律仍然在晶体管密度方面有效,但在单线程性能方面已经不再有效,因此 对性能的关注点从硬件转移到了并行软件。这意味着先编写单线程代码,再通过升级 CPU 来提升性能已不再可行。因此首先要考虑的是性能而不是扩展性。
即使拥有多个 CPU,也不必全部都用起来。并行编程主要是为了性能优化,但这只是众多优化措施中的一种。 如果程序够快则无需优化或并行化,亦或是基于单线程方式的优化。如果需要基于并行的方式进行优化,则需要与最好的串行算法进行比较,已确定并行化的必要性。
生产率
硬件的价格已远低于软件的开发与维护成本。仅仅高效的使用硬件已经不再足够,高效的利用开发者已经变得同等重要。
通用性
要想减少开发并行程序的高昂成本,一种方式是 让程序尽量通用。如果其他影响因素一样,通用的软件能获得更多用户从而摊薄成本。但通用性会带来更大的性能损失和生产率损失。如下是一些典型的并行开发环境。
- C/C++ 锁与线程:包含 POSIX 线程(pthreads)、Windows 线程以及众多系统内核环境。性能优秀、通用性良好,但生产率低。
- Java:生产率比 C/C++ 要高,虽然性能不断进步但仍低于 C/C++。
- MPI:该消息传递接口向大量的科学和技术计算提供能力,提供了无与伦比的性能和扩展性。虽然通用但主要面向科学计算。生产率低于 C/C++。
- OpenMP:该编译指令集用于并行循环,因此用于特定任务从而限制了其性能。比 MPI、C/C++ 要简单。
- SQL:结构化编程语言 SQL 仅用于数据库查询,性能出色、生产率优秀。
同时满足性能、生产率、通用性要求的并行编程环境仍不存在,因此必须在三者之间进行权衡。 越往上层,生成率越重要;越往下层,性能和通用性越重要。大量的开发工作消耗在上层,必须提高通用性以降低成本;下层的性能损失很难在上层得到恢复。越往上层,采用额外的硬件比采用额外的开发者更划算。
本书面向底层开发,因此主要关心 性能和通用性。
并行编程的替代方案
并行编程只是提升性能的方案之一,以下是一些其他流行的方案:
- 运行多个串行应用实例:
- 会增加内存消耗、CPU 指令周期浪费在重复计算中间结果上,也会增加数据复制操作。
- 利用现有的并行软件构建应用:
- 通常会牺牲性能,至少会逊色于精心构造的并行程序,但可以显著降低开发难度。
- 对串行应用进行逻辑优化:
- 来自并行计算的速度提升与 CPU 个数大约成正比,而对软件逻辑进行的优化可能会带来指数级的性能提升。
- 不同程序的性能瓶颈不同。
复杂的原因
并行编程需要双向交互:人告诉计算机要做什么;人还需要通过结果的性能和扩展性来评价程序。
我们所要考虑的并行程序开发者的任务,对于串行程序开发者来说是完全不需要的。我们将这些任务分为 4 类:
分割任务
合理的对任务进行分割以提升并行度,可以极大提升性能和扩展性,但是也会增加复杂性。 比如,分割任务可能会让全局错误处理和事件处理更复杂,并行程序可能需要一些相当复杂的同步措施来安全的处理这些全局事件。总的来说,每个任务分割都需要一些交互,如果某个线程不存在任何交互,那它的执行对任务本身也就不产生任何影响。但是交互也就意味着额外的、可能降低性能的开销。
如果同时执行太多线程,CPU 缓存将会溢出,引起过高的缓存未命中,降低性能。
运行程序并发执行会大量增加程序的状态集,导致程序难以理解和调试,降低生产率。
并行访问控制
单线程的线性程序对程序的所有资源都有访问权,主要是内存数据结构,但也可能是 CPU、内存、高速缓存、IO 设备、计算加速器、文件等。并行访问控制的问题有:
- 访问特定的资源是否受限于资源的位置。 比如本地或远程、显式或隐式、赋值或消息传递等。
- 线程如何协调对资源的访问。 这种协调由不同的并行语言或环境通过大量同步机制实现,如:消息传递、加锁、事务、引用计数、显式计时、共享原子变量、数据所有权等。因此要面对死锁、活锁、事务回滚等问题。
资源分割与复制
最有效的并行算法和系统都善于对资源进行并行化,所以并行编程的编写最好从分割写密集型资源和复制经常访问的读密集型资源开始。 这里所说的访问频繁的数据,可能是计算机系统、海量存储设备、NUMA节点、CPU、页面、Cache Line、同步原语实例、代码临界区等等多个层次。
与硬件交互
开发者需要根据目标硬件的高速缓存分布、系统的拓扑结果或者内部互联协议来对应用进行量体裁衣。
组合使用
最好的实践会将上述 4 种类型的基础性任务组合应用。比如,数据并行方案首先把数据分割以减少组件内的交互需求,然后分割相应的代码,最后对数据分区并与线程映射,以便提升吞吐、减少线程内交互。
3 - CH03-硬件特性
本章主要关注 共享内存系统中的同步和通信开销,仅涉及一些共享内存并行硬件设计的初级知识。
概述
人们容易认为 CPU 的性能就像在一条干净的赛道上赛跑,但事实上更像是一个障碍赛训练场。
流水线 CPU
在 20 世纪 80 年代,典型的微处理器在处理一条指令之前,至少需要取值、解码和执行这三个时钟周期来完成当前指令。到 90 年代之后,CPU 可以同时处理多条指令,通过一条很长的流水线来控制 CPU 内部的指令流。
带有长流水线的 CPU 要想达到最佳性能,需要程序给出高度可预测的控制流。如果程序代码执行的是紧凑循环,那么这种程序就能提供 可预测的控制流,此时 CPU 可以正确预测出在大多数情况下代码循环结束后的分支走向。在这种程序中,流水线可以一直保持在满状态,CPU 高速运行。
如果程序中带有很多循环,且循环计数都比较小,或者面向对象的程序中带有很多虚方法,每个虚方法都可以引用不同的对象实例,而这些对象实例都实现了一些频繁被调用的成员函数,此时 CPU 很难或者完全不可能预测某个分支的走向。这样一来,CPU 要么等待控制流进行到足以知道分支走向的方向,要么干脆猜测,但常常出错。这时流水线会被排空,CPU 需要等待流水线被新指令填充,这将大幅降低 CPU 的性能。
- 分支预测的原理?
内存引用
在 20 世纪 80 年代,微处理器从内存中读取一个值的时间一般比执行一条指令的时间短,即指令执行慢于内存 IO。在 2006 年,同样是读取内存中的一个值的时间,微处理器可以执行上百条甚至千条指令。这源于摩尔定律对 CPU 性能的提升,以及内存容量的增长。
虽然现代微型计算机上的大型缓存极大减少了内存访问延迟,但是只有高度可预测的数据访问模式才能发挥缓存的最大效用。因此对内存的引用也就造成了对 CPU 性能的严重影响。
原子操作
原子操作本身的概念在某种意义上与 CPU 流水线上一次执行多条指令的操作产生了冲突。而现代 CPU 使用了很多手段让这些操作看起来是原子的,即使这些指令实际上并非原子。比如标出所有包含原子操作所需数据的流水线,确保 CPU 在执行原子操作时,所有这些流水线都属于正在执行原子操作的 CPU,并且只有在这些流水线仍归该 CPU 所有时才推进原子操作的执行。这样一来,因为所有数据都只属于该 CPU,即使 CPU 流水线可以同时执行多条指令,其他 CPU 也无法干扰此 CPU 的原子操作执行。但这种方式要求流水线必须能够被延迟或冲刷,这样才能执行让原子操作过程正确完成的一系列操作。
非原子操作则与之相反,CPU 可以从流水线中按照数据出现的顺序读取并把结果放入缓冲区,无需等待流水线的归属切换。
虽然 CPU 设计者已经开始优化原子操作的开销,但原子指令仍频繁对 CPU 性能造成影响。
内存屏障
原子操作通常只用于数据的单个元素,由于许多并行算法都需要在更新多个元素时保证正确的执行顺序,因此大多数 CPU 都提供了内存屏障。
spin_lock(&mylock);
a = a +1;
spin_unlock(&mylock);
像这样一个基于锁的临界区中,锁操作必须包含隐式或显式的内存屏障。内存屏障可以防止 CPU 为了提升性能而进行乱序执行,因此内存屏障也一定会影响性能。
高速缓存未命中
现代 CPU 使用大容量的高速缓存来降低由于低速的内存访问带来的性能惩罚。但是,CPU 高速缓存事实上对多 CPU 间频繁访问的变量起到了反面效果。因为当某个 CPU 想去改变变量的值时,极有可能该变量的值刚被其他 CPU 修改过。这时,变量存在于其他 CPU 的高速缓存中,这将导致代价高昂的高速缓存为命中。
IO 操作
缓存未命中可被视为 CPU 之间的 IO 操作,也是代价最小的 IO 操作之一。IO 操作涉及网络、大容量存储,或者人类本身(人机交互 IO)。IO 操作对性能的影响也远远大于前面所有提到的所有影响因素。
这也是共享内存并行计算和分布式系统式的并行编程的其中一个不同点:共享内存式并行编程的程序一般不会处理比缓存未命中更糟的情况,而分布式并行编程的程序则会遭遇网络通信延迟。因此,通信的开销占实际执行任务的比率是一项关键的设计参数。
开销
硬件体系结构
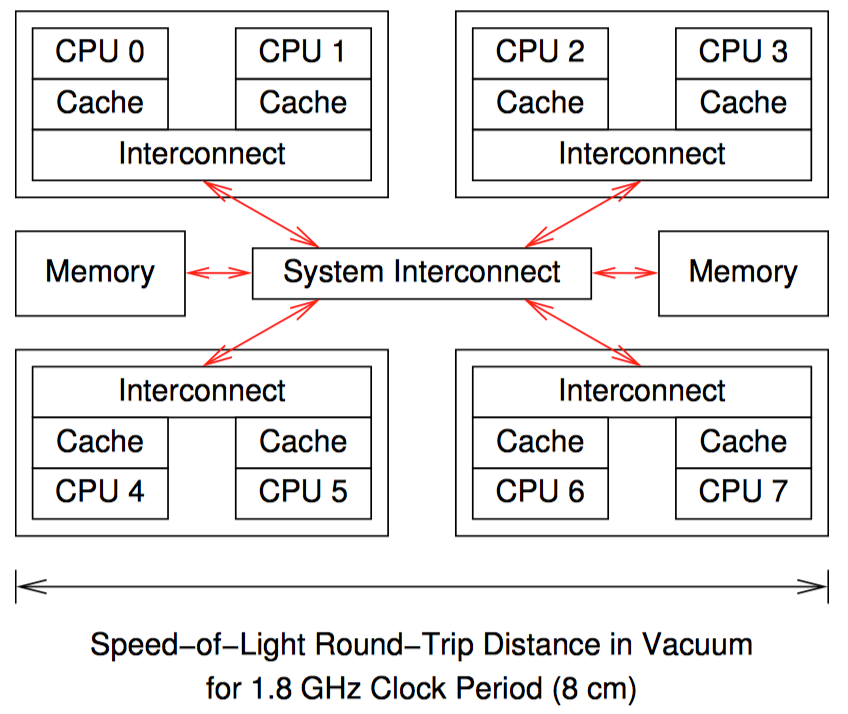
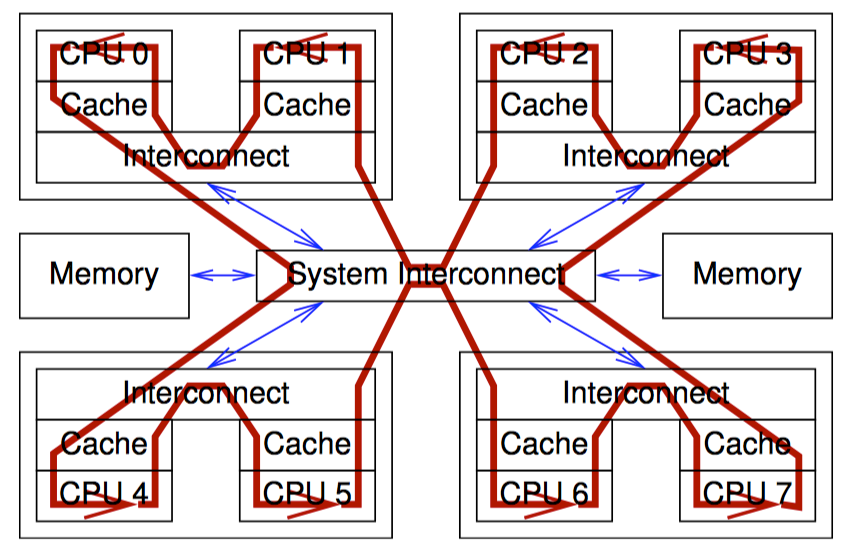
这是一个 8 核计算机概要图:每个芯片上有 2 个核,每个核带有自己的高速缓存,每个芯片内还带有一个互联模块,使芯片内的两个核可以互相通信,图中央的系统互联模块可以让 4 个芯片之间互相通信,并且与主存进行连接。
数据以缓存行(cache line)为单位在系统中传输,缓存行对应内存中一个 2 的乘方大小的字节,大小通常为 32 到 256 之间。当 CPU 从内存中读取一个变量到它的寄存器中时,必须首先将该变量的缓存行读取到 CPU 高速缓存;CPU 寄存器中的一个值存储到内存时,不仅需要将包含了该值的缓存行写入 CPU 高速缓存,还必须确保其他 CPU 没有该缓存行的复制。
比如,如果 CPU0 在对一个变量执行"比较并交换(CAS)“操作,而该变量所在的缓存行存储在 CPU7 的高速缓存中。下面是将要发送的事件序列:
- CPU0 检查本地高速缓存,没有找到缓存行。
- 请求被转发到 CPU0 和 CPU1 的互联模块,检查 CPU1 的高速缓存,没有找到缓存行。
- 请求被转发到系统互联模块,检查其他三个芯片,得知缓存行被 CPU6 和 CPU7 所在的芯片持有。
- 请求被转发到 CPU6 和 CPU7 的互联模块,检查这两个 CPU 的高速缓存,在 CPU7 的高速缓存中找到缓存行。
- CPU7 将缓存行发送到自己所属的互联模块,并且刷新掉自己高速缓存中的缓存行。
- CPU6 和 CPU7 所在芯片的互联模块将缓存行发送给系统互联模块。
- 系统互联模块将缓存行发送给 CPU0 和 CPU1 所在芯片的互联模块。
- CPU0 和 CPU1 所在芯片的互联模块将缓存行发送给 CPU0 的高速缓存。
- CPU0 现在可以对高速缓存中的变量执行 CAS 操作。
操作开销
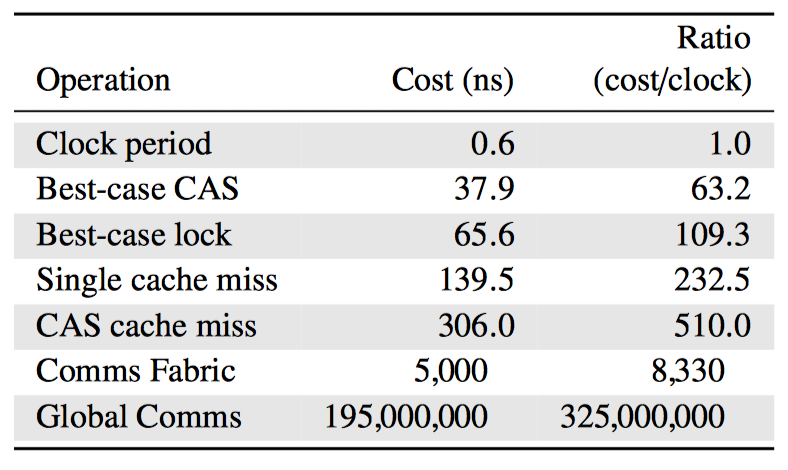
上图是各种同步机制相与 CPU 周期时间的比率。(4-CPU 1.8 GHz AMD Opteron 844 System)
软件设计的启示
并行算法必须将每个线程设计成尽可能独立运行的线程。越少使用线程间的同步通信手段,比如原子操作、锁或其他消息传递方法,应用程序的性能和扩展性就会越好。想要达到优秀的并行性和扩展性,就需要在并行算法和实现中挣扎,小心的选择数据结构和算法,尽量使用现有的并行软件和环境,或者将并行问题转换为已经拥有并行解决方案的问题。
- 好消息是多核系统变得廉价且可靠。
- 另一个好消息是,现在很多同步操作的开销正变得越来越小。
- 坏消息是 高速缓存未命中的开销仍然很高,特别是在大型系统上。 本书剩余部分则会讨论如何解决该问题。
4 - CH04-并行工具
本章主要介绍一些并行编程领域的基本工具,主要是类 Linux 系统上可以供应用程序使用的工具。
脚本语言
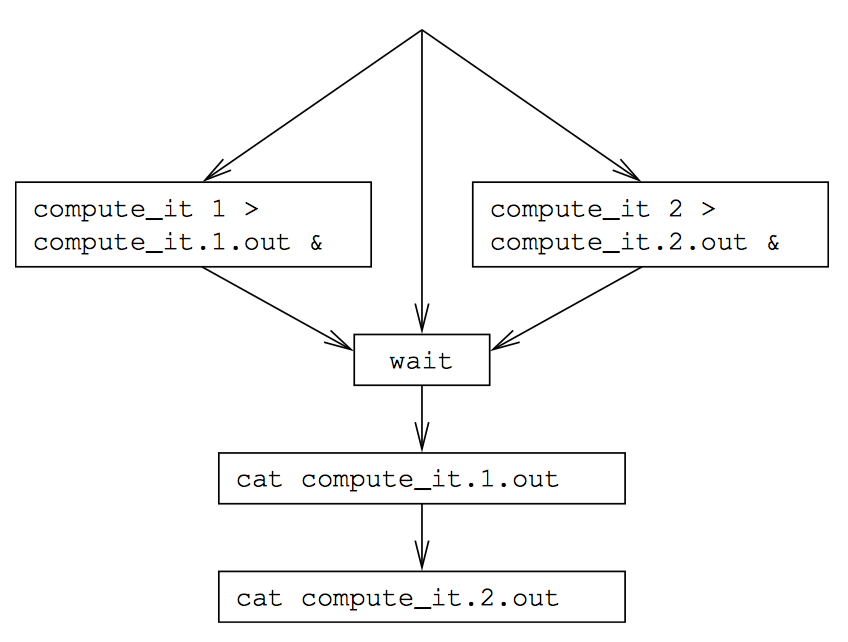
Shell 脚本提供了一种简单有效的并行化:
1 compute_it 1 > compute_it.1.out &
2 compute_it 2 > compute_it.2.out &
3 wait
4 cat compute_it.1.out
5 cat compute_it.2.out
第 1、2 行分别启动了两个实例,通过 & 符号使这两个程序在后台运行,并分别将程序的输出重定向到一个文件。第 3 行等待两个实例执行完毕,第 4、5 行显示程序的输出。
另外,例如 make 脚本语言提供了一个 -j 选项来指定编译过程中同时执行多少个并行任务,make -j4 则表示同时执行 4 个并行编译过程。
既然基于脚本的并行编程这么简单,为什么还需要其他工具呢?
POSIX 多进程
POSIX 进程的创建与销毁
进程通过 fork() 原语创建,通过 kill() 原语销毁,也可以通过 exit() 原语实现自我销毁。执行 fork() 原语的进程被称为新创建进程的父进程,父进程可以功能通过 wait() 原语等待子进程执行完毕。
1 pid = fork();
2 if (pid == 0) {
3 / * child * /
4 } else if (pid < 0) {
5 / * parent, upon error * /
6 perror("fork");
7 exit(-1);
8 } else {
9 / * parent, pid == child ID * /
10 }
fork() 的返回值表示了其执行状态,即上面片段中的 pid。
1 void waitall(void)
2 {
3 int pid;
4 int status;
5
6 for (;;) {
7 pid = wait(&status);
8 if (pid == -1) {
9 if (errno == ECHILD)
10 break;
11 perror("wait");
12 exit(-1);
13 }
14 }
15 }
父进程使用 wait() 原语来等待子进程时,wait() 只能等待一个子进程。我们将 wait() 原语封装成一个 waitall() 函数,该函数与 shell 中的 wait 意义一样:for(;;) 将会一直循环,每次循环等待一个子进程,阻塞直到该子进程退出,并返回子进程的进程 ID 号,如果该进程号为 -1,则表示 wait() 无法等待子进程执行完毕。如果检查错误码为 ECHILD 则表示没有其他子进程了,这时退出循环。
wait() 原语的复杂性在于,父进程与子进程之间不共享内存,而最细粒度的并行化需要共享内存,这时则要比不共享内存式的并行化复杂很多。
这种 fork-waitall 的形式被称为 fork-join。
POSIX 线程创建与销毁
在一个已有的进程中创建线程,需要调用 pthread_create() 原语,它的第一个参数指向 pthread_t 类型的指针,第二个 NULL 参数是一个可选的指向 pthread_attr_t 结构的指针,第三个参数是新线程要调用的函数(下面的例子中是 mythread()),最后一个 NULL 参数是传递给 mythread() 的参数。
1 int x = 0;
2
3 void * mythread(void * arg)
4 {
5 x = 1;
6 printf("Child process set x=1\n");
7 return NULL;
8 }
9
10 int main(int argc, char * argv[])
11 {
12 pthread_t tid;
13 void * vp;
14
15 if (pthread_create(&tid, NULL,
16 mythread, NULL) != 0) {
17 perror("pthread_create");
18 exit(-1);
19 }
20 if (pthread_join(tid, &vp) != 0) {
21 perror("pthread_join");
22 exit(-1);
23 }
24 printf("Parent process sees x=%d\n", x);
25 return 0;
26 }
- 第 7 行中,
mythread直接选择了返回,也可以使用pthread_exist()结束。 - 第 20 行的
pthread_join()原语是对 fork-join 中wait()的模仿,它一直阻塞到 tid 变量指向的线程返回。线程的返回值要么是传给pthread_exit()的返回值,要么是线程调用函数的返回值,这取决于线程退出的方式。
上面代码的执行结果为:
Child process set x=1
Parent process sees x=1
上面的代码中小心构造了一次只有一个线程为变量赋值的场景。任何一个线程为某变量赋值而另一线程读取变量值的场景,都会产生数据竞争(data-race)。因此我们需要一些手段来安全的并发读取数据,即下面的加锁原语。
POSIX 锁
POSIX 规范支持开发者使用 POSIX 锁来避免数据竞争。POSIX 锁包括几个原语,其中最基础的是 pthread_mutex_lock() 和 pthread_mutex_unlock()。这些原语将会操作 pthread_mutex_t 类型的锁。该锁的静态声明和初始化由 PTHREAD_MUTEX_INITIALIZER 完成,或者由 pthread_mutex_init() 来动态分配并初始化。
因为这些加锁、解锁原语是互相排斥的,所以一次只能有一个线程在一个特定的时刻持有一把特定的锁。比如,如果两个线程尝试同时获取一把锁,那么其中一个线程会首先获准持有该锁,另一线程只能等待第一个线程释放该锁。
POSIX 读写锁
POSIX API 提供了一种读写锁,用 pthread_rwlock_t 类型来表示,与 pthread_mutex_t 的初始化方式类似。pthread_rwlock_wrlock() 获取写锁,pthread_rwlock_rdlock() 获取读锁,pthread_rwlock_unlock() 用于释放锁。
读写锁是专门为大多数读的情况设计的。该锁能够提供比互斥锁更多的扩展性,因为互斥锁从定义上已经限制了任意时刻只能有一个线程持有锁,而读写锁运行任意多的线程同时持有读锁。
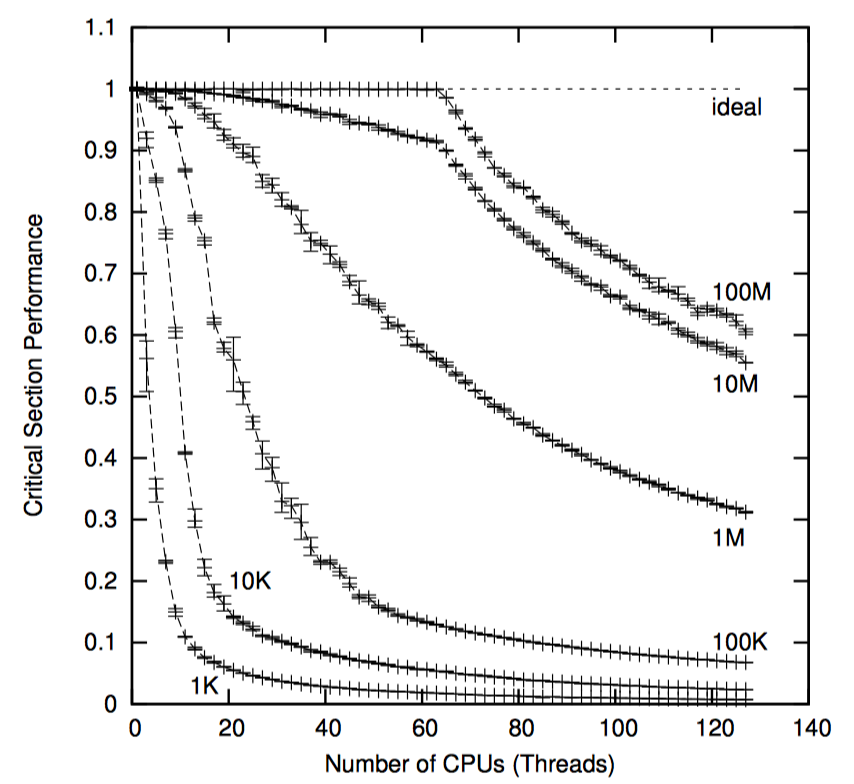
读写锁的可扩展性不甚理想,尤其是临界区较小时。为什么读锁的获取这么慢呢?应该是由于所有想获取读锁的线程都要更新 pthread_rwlock_t 的数据结构,因此一旦 128 个线程同时尝试获取读写锁的读锁时,那么这些线程必须逐个更新读锁中的 pthread_rwlock_t 结构。最幸运的线程几乎立即就获得了读锁,而最倒霉的线程则必须在前 127 的线程完成对该结构的更新后再能获得读锁。而增加 CPU 则会让性能变得更糟。
但是在临界区较大,比如开发者进行高延迟的文件或网络 IO 操纵时,读写锁仍然值得使用。
原子操作(GCC)
读写锁在临界区最小时开销最大,因此需要其他手段来保护极其短小的临界区。GCC 编译器提供了许多附加的原子操作:
- 返回参数原值
__sync_fetch_and_sub()__sync_fetch_and_or()__sync_fetch_and_and()__sync_fetch_and_xor()__sync_fetch_and_nand()
- 返回变量新值
__sync_add_and_fetch()__sync_sub_and_fetch()__sync_or_ and_fetch()__sync_and_and_fetch()__sync_xor_and_fetch()__sync_nand_ and_fetch()
经典的比较并交换(CAS)是由一对原语 __sync_bool_compare_and_swap() 和 __sync_val_compare_and_swap() 提供的,当变量的原值与指定的参数值相等时,这两个原语会自动将新值写到指定变量。第一个原语在操作成功时返回 1,或在变量原值不等于指定值时返回 0;第二个原语在变量值等于指定的参数值时返回变量的原值,表示操作成功。任何对单一变量进行的原子操作都可以用 CAS 方式实现,上述两个原语是通用的,虽然第一个原语在适用的场景中效率更高。CAS 操作通常作为其他原子操作的基础。
__sync_synchronize() 原语是一个内存屏障,它限制编译器和 CPU 对指令乱序执行的优化。有些时候只限制编译器对指令的优化就够了,CPU 的优化可以保留,这时则需要 barrier() 原语。有时只需要让编译器不优化某个内存访问就够了,这时可以使用 ACCESS_ONCE() 原语。后两个原语并非由 GCC 直接提供,可以按如下方式实现:
#define ACCESS_ONCE(x) (*(volatile typeof(x) *)&(x))
#define barrier() __asm____volatile__("": : :"memory")
POSIX 的操作的替代选择
线程操作、加解锁原语、原子操作的出现早于各种标准委员会,因此这些操作存在多种变体。直接使用汇编实现这些操作也十分常见,不仅因为历史原因,还可以在某些特定场景下获得更好的性能。
如何选择
基于经验法则,应该在能够胜任工作的工具中选择最简单的一个。
- 尽量保持串行。
- Shell 脚本。
- C 中的 fork-join。
- POSIX 线程库原语。
- 第几章将要介绍的原语。
除此之外,不要忘记除了共享内存多线程执行之外,还可以选择进程间通信和消息传递。
5 - CH05-计数
计数概念的简单性让我们在探索并发中的基本问题时,无需被繁复的数据结构或复杂的同步原语干扰,因此可以作为并行编程的极佳切入对象。
并发计数并不简单
1 long counter = 0;
2
3 void inc_count(void)
4 {
5 counter++;
6 }
7
8 long read_count(void)
9 {
10 return counter;
11 }
- 1,声明一个计数器
- 5,将计数器加 1
- 10,读取计数器的值
当计数器不停读取计数但又几乎不增加计数时,计算性能非常好。但存在计数丢失。精确计数的最简单方式是使用原子操作:
1 atomic_t counter = ATOMIC_INIT(0);
2
3 void inc_count(void)
4 {
5 atomic_inc(&counter);
6 }
7
8 long read_count(void)
9 {
10 return atomic_read(&counter);
11 }
- 1,声明一个原子计数器
- 5,将计数器原子加 1
- 10,原子读取计数器的值
以上都是原子操作,因此非常精确,单线程时速度是非原子方式的 1/6,两个线程时速度是非原子方式的 1/10,即原子计数的性能随着 CPU 和线程数的增加而下降。
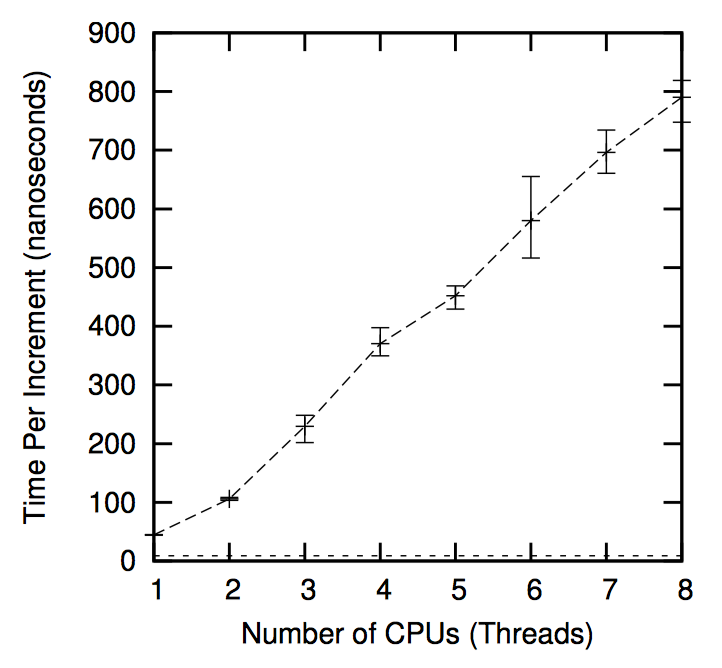
下图以 CPU 视角展示了原子操作带来的性能损耗,为了让每个 CPU 得到机会来增加一个全局变量,包含变量的缓存行需要在所有 CPU 间传播,沿下图中箭头所示的方向。这种传播相当耗时,从而导致了上图中糟糕的性能。
统计计数器
常见的统计计数器场景中,计数器更新频繁但很少被读,或者甚至完全不读。
设计
统计计数器一般以每个线程一个计数器的方式实现(或者在内核运行时以每个 CPU 一个),所以每个线程仅更更新自己的计数。而总的计数值就是所有线程计数值的和。
基于数组的实现
分配一个数组,数组每个元素对应一个线程(假设数组已经按缓存行对其并且被填充,以防止出现假共享)。
该数组可以用一个“每线程”原语来表示:
1 DEFINE_PER_THREAD(long, counter);
2
3 void inc_count(void)
4 {
5 __get_thread_var(counter)++;
6 }
7
8 long read_count(void)
9 {
10 int t;
11 long sum = 0;
12
13 for_each_thread(t)
14 sum += per_thread(counter, t);
15 return sum;
16 }
- 1,定义了一个数组,包含一套类型为 long 的每线程计数器 counter。
- 3~6,增加计数的函数,使用
__get_thread_var()原语来定位当前运行线程对应 counter 数组的元素。因为该元素仅能由对应的线程修改,因此使用非原子自增即可。 - 8~16,读取总计数的函数,使用
for_each_thread()原语遍历当前运行的所有线程,使用per_thread()原语获取指定线程的计数。因为硬件可以原子地存取正确对齐的 long 型数据,并且 GCC 充分利用了这一点,所以使用非原子读取操作即可。
该方法随着 inc_count() 函数的更新者线程增加而线性扩展,原因是每个 CPU 可以快速的增加自己线程的变量值,不再需要代价高昂的、跨越整个计算机系统的通信,如下图所示:
但这种在“更新端”扩展极佳的方式在存在大量线程时会给“读取端”带来极大代价。接下来将介绍另一种方式,能在保留更新端扩展性的同时,减少读取端产生的代价。
最终结果一致的实现
一种保留更新端扩展性的同时又能提升读取端性能的方式是:削弱一致性要求。
前面介绍的计数算法要求保证返回的值在 read_count() 执行前一刻的理想计数值和 read_count() 执行完毕时的理想计数值之间。最终一致性方式提供了弱一些的保证:当不调用 inc_count() 时,调用 read_count() 最终会返回正确的值。
我们维护一个全局计数来利用”最终结果一致性“。但是因为写者只操作自己线程的每线程计数,我们需要一个单独的线程负责将每线程计数的计数值传递给全局计数,而读者仅需访问全局计数值。如果写者正在更新计数,读者读取的全局计数值将不是最新的,不过一旦写者更新完毕,全局计数最终会回归正确的值。
1 DEFINE_PER_THREAD(unsigned long, counter);
2 unsigned long global_count;
3 int stopflag;
4
5 void inc_count(void)
6 {
7 ACCESS_ONCE(__get_thread_var(counter))++;
8 }
9
10 unsigned long read_count(void)
11 {
12 return ACCESS_ONCE(global_count);
13 }
14
15 void * eventual(void * arg)
16 {
17 int t;
18 int sum;
19
20 while (stopflag < 3) {
21 sum = 0;
22 for_each_thread(t)
23 sum += ACCESS_ONCE(per_thread(counter, t));
24 ACCESS_ONCE(global_count) = sum;
25 poll(NULL, 0, 1);
26 if (stopflag) {
27 smp_mb();
28 stopflag++;
29 }
30 }
31 return NULL;
32 }
33
34 void count_init(void)
35 {
36 thread_id_t tid;
37
38 if (pthread_create(&tid, NULL, eventual, NULL)) {
39 perror("count_init:pthread_create");
40 exit(-1);
41 }
42 }
43
44 void count_cleanup(void)
45 {
46 stopflag = 1;
47 while (stopflag < 3)
48 poll(NULL, 0, 1);
49 smp_mb();
50 }
- 1~2,定义了跟踪计数值的没线程变量和全局变量。
- 3,定义了 stopflag,用于控制程序结束。
- 5~8,增加计数函数
- 10~13,读取计数函数
- 34~42,
count_init()函数创建了位于 15~32 行的eventual()线程,该线程将遍历所有线程,对每个线程的本地计算 counter 进行累加,将结果放入 global_count。eventual线程在每次循环之间等待 1ms(随便选择的值)。 - 44~50,
count_cleanup()函数用来控制程序结束。
本方法在提供极快的读取端计数性能的同时,仍然保持线性的更新端计数性能曲线。但也带来额额外的开销,即 eventual 线程。
基于每线程变量的实现
GCC 提供了一个用于每线程存储的 _thread 存储类。下面使用该类来实现统计计数器,该实现不仅能扩展,而且相对于简单的非原子自增来说几乎没有性能损失。
1 long __thread counter = 0;
2 long * counterp[NR_THREADS] = { NULL };
3 long finalcount = 0;
4 DEFINE_SPINLOCK(final_mutex);
5
6 void inc_count(void)
7 {
8 counter++;
9 }
10
11 long read_count(void)
12 {
13 int t;
14 long sum;
15
16 spin_lock(&final_mutex);
17 sum = finalcount;
18 for_each_thread(t)
19 if (counterp[t] != NULL)
20 sum += * counterp[t];
21 spin_unlock(&final_mutex);
22 return sum;
23 }
24
25 void count_register_thread(void)
26 {
27 int idx = smp_thread_id();
28
29 spin_lock(&final_mutex);
30 counterp[idx] = &counter;
31 spin_unlock(&final_mutex);
32 }
33
34 void count_unregister_thread(int nthreadsexpected)
35 {
36 int idx = smp_thread_id();
37
38 spin_lock(&final_mutex);
39 finalcount += counter;
40 counterp[idx] = NULL;
41 spin_unlock(&final_mutex);
42 }
- 1~4,定义所需变量,
counter是每线程计数变量,counterp[]数组允许线程访问彼此的计数,finalcount在各个线程退出时将计数值累加到综合,final_mutex协调累加计数总和值的线程和退出的线程。 - 更新者调用
inc_count()函数,见 6~9 行。 - 写者调用
read_count()函数,首先在 16 行获取与正在退出线程互斥的锁,21 行释放锁。17 行初始化已退出线程的每线程计数总和,18~20 将还在运行的线程的每线程计数累加进总和,最后,22 行返回总和。 - 25~32,
count_register_thread()函数,每个线程在访问自己的计数前都要调用它,将本线程对应countp[]数组中的元素指向线程的每线程变量 counter。 - 34~42,
count_unregister_thread()函数,每个之前调用过count_register_thread()函数的线程在退出时都要调用该函数。38 行获取锁,41 行释放锁,因此排除了有线程正在调用read_count()同时又有线程调用count_unregister_thread()函数的情况。39 行将本线程的每线程计数添加到全局 finalcount 中,然后将countp[]数组的对应元素设置为 NULL。随后read_count()调用可以在全局变量 finalcount 里找到已退出线程的计数值,并且顺序访问countp[]数组时可以跳过已退出线程,从而获得正确的总计数结果。
该方式让更新者的性能几乎和非原子计数一样,并且也能线性扩展。另外,并发的读者竞争一个全局锁,因此性能不佳,扩展性差。但是这不是统计计数器要面对的问题,因为统计计数器总是在增加计数,很少读取计数。
近似上限计数器
另一种计数的场景是上限检查,比如需要维护一个已分配数据结构数目的计数器,来防止分配超过一个上限。我们假设这些结构的生命周期很短,数目也极少能超出上限。对近似值上限来说,偶尔超出少许是可以接受的。
设计
一种可能的实现是将近似总数值(10000)平均分配给每个线程,然后每个线程一个固定个数的资源池。假如有 100 个线程,每个线程管理一个有 100 个结构的资源池。这种方式简单,在有些情况下有效,但是无法处理一种常见情况:某个结构由一个结构创建,但由另一个线程释放。一方面,如果线程释放一个结构就得一分的话,那么一直在分配结构的线程很快就会分配光资源池,而一直在释放结构的线程积攒了大量分数却无法使用。另一方面,如果每个被释放的结构都能让分配它的 CPU 加一分,CPU 就需要操纵其他 CPU 的计数,这会带来昂贵的原子操作或其他跨线程通信手段。
因此,在很多重要的情况下我们不能讲计数问题完全分割。对于上限计数,我们可以采用一种分割计数方法的变体,部分地分割计数。比如在四个线程中,每个线程拥有一份每线程变量 counter,但同时每个线程也持有一份每线程的最大值 countermax。
如果某个线程需要增加其 counter,可是此时 counter 等于 countermax,这时该如何处理呢?此时可以把此线程 counter 值的一半转移给 globalcount,然后在增加 counter。举个例子,加入某线程的 counter 和 countermax 都为 10,我们可以执行如下操作:
- 获取全局锁
- 给 globalcount 增加 5
- 当前线程的 couter 减少 5,以抵消全局的增加
- 释放全局锁
- 递增当前线程的 counter,编程 6
虽然该操作中需要全局锁,但是该锁只有在每 5 次增加操作后才获取一次,从而降低了竞争程度,如果我们增大了 countermax 的值,竞争程度还会进一步降低。但是增大 countermax 值的副作用是 globalcount 精确度的降低。假设一台 4 CPU 系统,此时 countermax 值为 10,global 和真实计数值的误差最高可达 40,如果把 countermax 增加到 100,那么 globalcount 和真实计数值的误差可达 400。
因此问题成了我们到底有多在意 globalcount 和真实计数值的偏差。真实计数值由 globalcount 和所有每线程 counter 相加得出。误差取决于真实计数值和计数上限的差值有多大,差值越大,countermax 就越不容易超过 globalcountmax 的上限。这就代表着任何一个线程的 countermax 变量可以根据当前的差值计算取值。当离上限还比较远时,可以给每线程变量 countermax 赋值一个较大的数,这样对性能和扩展性都有好处。当靠近上限时,可以给这些 countermax 赋值一个比较小的数,这样可以降低超过统计上限 globalcountmax 的风险,从而减少误差。
这种设计就是一个并行快速路径的例子,这是一种重要的设计模式,适用于下面的情况:在多数情况下没有线程间的通信和交互开销,对偶尔进行的跨线程通信又使用了静心设计的(但是开销仍然很大的)全局算法。
精确上限计数器
一种实现精确计数的方式是允许线程放弃自己的计数,另一种是采用原子操作。当然,原子操作会减慢快速路径。
原子上限计数
如果想要一个线程减少另一个线程上的计数,需要自动的操作两个线程的 counter 和 countermax 变量。通常的做法是将这两个变量合并成一个变量,比如一个 32 位的变量,高 16 位代表 counter,低 16 位代表 countermax。
这种方式运行计数一直增长直到上限,但是也带来了快速路径上原子操作的开销,让快速路径明显变慢了。虽然在某些场合这种变慢是允许的,但是仍然值得我们去探索让读取端性能更好的算法。而使用信号处理函数从其他线程窃取计数就是一种算法。因为信号处理函数可以运行在收到信号线程的上下文,所以就不需要原子操作了。
Signal-Theft 上限计数
虽然每线程状态只由对应线程修改,但是信号处理函数仍然有必要进行同步。
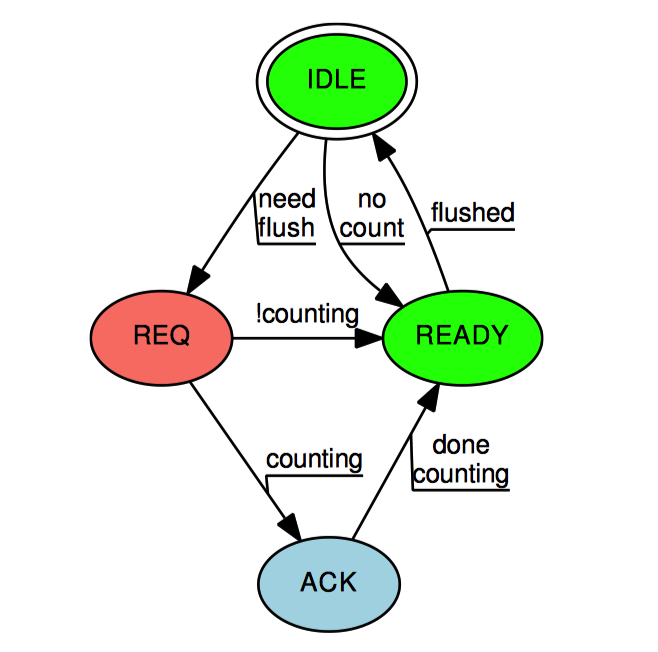
上图中的状态机展示了这种同步机制。Signal-Threft 状态机从”空闲“状态开始,当 add_count() 和 sub_count() 发现线程的本地计数和全局计数之和已经不足以容纳请求的大小时,对应的慢速路径将每线程的 threft 状态设置为”请求”(除非线程没有计数值,这样它就直接转换为“准备完毕”)。只有在慢速路径获得 gblcnt_mutex_lock 之后,才允许从“空闲”状态转换为其他状态。然后慢速路径向每个线程发送一个信号,对应的信号处理函数检查本地线程的 threft 和 counting 状态。如果 threft 状态不为“请求”,则信号处理函数就不能改变其状态,只能直接返回。而 threft 状态为“请求”时,如果设置了 counting 变量,表名当前线程正处于快速路径,信号处理函数将 threft 状态设置为“确认”,而不是“准备完毕”。
如果 threft 状态为“确认”,那么只有快速路径才有权改变 threft 的状态。当快速路径完成时,会将 threft 状态设置为“准备完毕”。
一旦慢速路径发现某个线程的 threft 状态为“准备完毕”,这时慢速路径有权窃取此线程的计数。然后慢速路径将线程的 threft 状态设置为“空闲”。
在一般笔记本电脑上,使用 signal-threft 的实现比原子操作的实现快两倍。由于原子操作的相对缓慢,signal-threft 实现在 Pentium-4 处理器上比原子操作好的多,但是后来,老式的 8086 对称处理器系统在原子操作实现的路径深度更短,原子操作的性能也随之提升。可是,更新端的性能提升是以读取端的高昂开销为代价的,POSIX 信号不是没有开销的。如果考虑最终的性能,则需要在实际部署应用的系统上测试这两种方式。
特殊场合的并行计数
即便如此,如果计数的值总是在 0 附近变动,精确计数就没什么用了,正如统计对 IO 设备的访问计数一样。如果我们并不关心当前有多少计数,这种统计值总是在 0 附近变动的计数开销很大。比如在可移除 IO 设备的访问计数问题,除非有人想移除设备,否则访问次数完全不重要,而移除设备这种情况本身又很少见。
一种简单的解决办法是,为计数增加一个很大的“偏差值”(比如 10 亿),确保计数的值远离 0,让计数可以有效工作。当有人想拔出设备时,计数又减去偏差值。计数最后几次的增长将是非常低效的,但是对之前的所有计数去可以全速运行。
虽然带偏差的计数有用且有效,但这只是可插拔 IO 设备访问计数问题的部分解决办法。当尝试移除设备时,我们不仅需要当前精确的 IO 访问计数,还需要从现在开始阻止未来的访问请求。一种方式是在更新计数时使用读写锁的读锁,在读取计数时使用同一把读写锁的写锁。
并行计数讨论
本章展示了传统计数原语会遇见的问题:可靠性、性能、扩展性。C 语言的 ++ 操作符不能在多线程代码中保证函数的可靠性,对单个变量的原子操作性能不好,可扩展性也差。
并行计数性能
统计计数算法性能:
| 算法 | 写延迟 | 延迟(1核) | 读延迟(32核) |
|---|---|---|---|
| 数组快速通道 | 11.5ns | 308ns | 409ns |
| 最终一致 | 11.6ns | 1ns | 1ns |
| 每线程变量 | 6.3ns | 389ns | 51,200ns |
| RCU | 5.7ns | 354ns | 501ns |
上限计数算法性能:
| 算法 | 是否精确 | 写延迟 | 读延迟(1核) | 读延迟(32核) |
|---|---|---|---|---|
| 每线程变量-1 | 否 | 3.6ns | 375ns | 50,700ns |
| 每线程变量-2 | 否 | 11.7ns | 369ns | 51,000ns |
| 原子方式 | 是 | 51.4ns | 427ns | 49,400ns |
| 信号方式 | 是 | 10.2ns | 370ns | 54,000ns |
并行计算的专门化
上述算法仅在各自的问题领域性能出色,这可以说是并行计算的一个主要问题。毕竟 C 语言的 ++ 操作符在所有单线程程序中性能都不错,不仅仅是个别领域。
我们提到的问题不仅是并行性,更是扩展性。我们提到的问题也不专属于算术问题,假设你还要存储和查询数据库,是不是还会用 ASCII 文件、XML、关系型数据库、链表、紧凑数组、B 树、基树或其他什么数据结构和环境来存取数据,这取决于你需要做什么、做多快、数据集有多大。
同样,如果需要计数,合适的方案取决于统计的数有多大、有多少个 CPU 并发操纵计数、如何使用计数,以及需要的性能和可扩展性程度。
总结
本章的例子显示,分割是提升可扩展性和性能的重要工具。计数有时可以被完全分割,或者被部分分割。
- 分割能够提升性能和可扩展性。
- 部分分割,也就是仅分割主要情况的代码路径,性能也很出色。
- 部分分割可以应用在代码上,但是也可以应用在时间空间上。
- 读取端的代码路径应该保持只读,对共享内存的“伪同步写”严重降低性能和扩展性。
- 经过审慎思考的延迟处理能够提升性能和扩展性。
- 并行性能和扩展性通常是跷跷板的两端,达到某种程度后,对代码的优化反而会降低另一方的表现。
- 对性能和可扩展性的不同需求及其他很多因素,会影响算法、数据结构的设计。
6 - CH06-分割同步设计
本章将描述如何设计能够更好利用多核优势的软件。编写并行软件时最重要的考虑是如何进行分割。正确的分割问题能够让解决方案简单、扩展性好且高性能,而不恰当的分割问题则会产生缓慢且复杂的解决方案。“设计”这个词非常重要:对你来说,应该是分割问题第一、编码第二。顺序颠倒会让你产生极大的挫败感,同时导致软件低劣的性能和扩展性。
分割练习
哲学家就餐
该问题指的是,桌子周围坐着 5 位哲学家,而桌子上每两个哲学家之间有一根叉子,因此是 5 个哲学家 5 根叉子。每个哲学家只能用他左手和右手旁的叉子用餐,一旦开始用餐则不吃到心满意足是不会停下的。
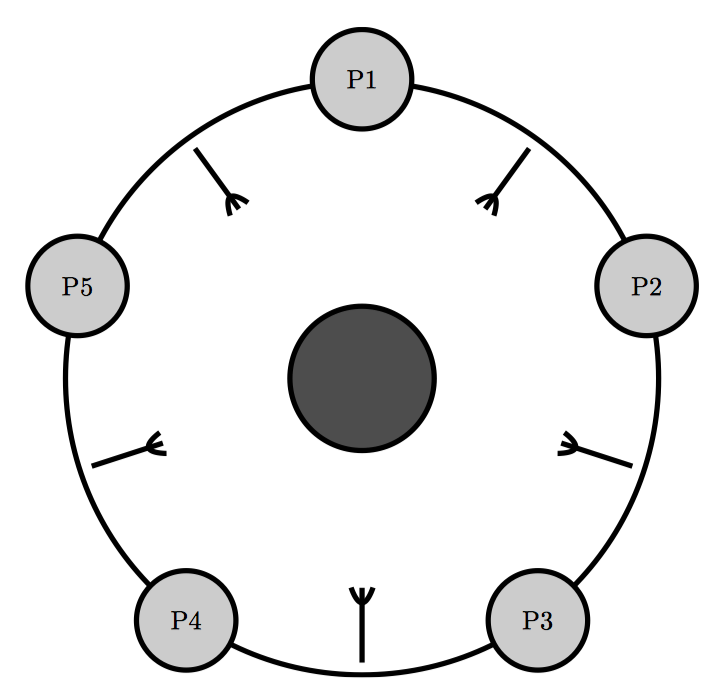
我们的目标就是构建一种算法来阻止饥饿。一种饥饿的场景是所有哲学家都去拿左手边的叉子。因为他们在吃饱前不会放下叉子,并且他们还需要第二把叉子才能开始用餐,所以所有哲学家都会挨饿。注意,让至少一位哲学家就餐并不是我们的目标,即使让个别哲学家挨饿也是要避免的。
Dijkstra 的解决方法是使用一个全局信号量。假设通信延迟忽略不计,这种方法十分完美。因此,近来的解决办法是像下图一样为叉子编号。每个哲学家都先拿他盘子周围编号最小的叉子,然后再拿编号最高的叉子。这样坐在图中最上方的哲学家会先拿起他左手边的叉子,然后是右手边的叉子,而其他哲学家则先拿起右手边的叉子。因为有两个哲学家试着会去拿叉子 1,而只有一位会成功,所以只有 4 位哲学家抢 5 把叉子。至少 4 位中的一位肯定能够拿到两把叉子,这样就能开始就餐了。
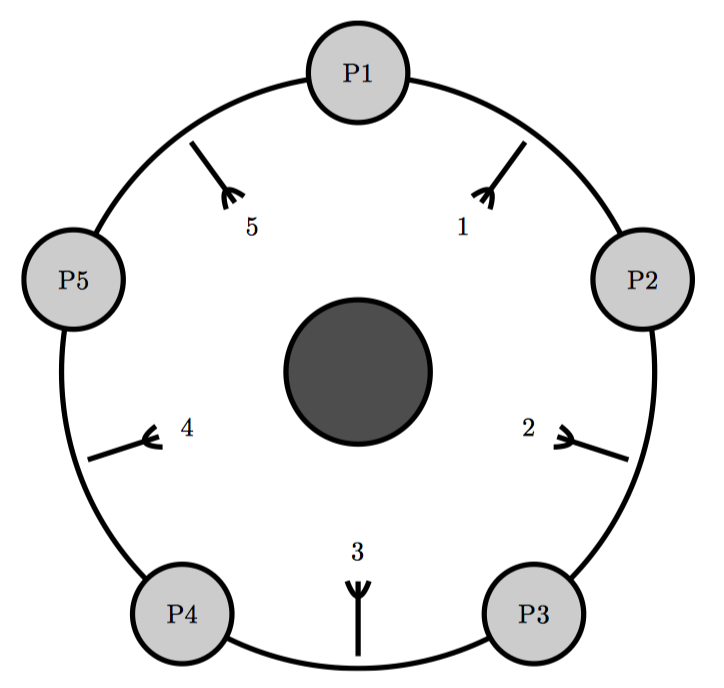
这种为资源编号并按照编号顺序获取资源的通用技术经常在被用在防止死锁上。 但是很容易就能想象出来一个事件序列来产生这种效果:虽然大家都在挨饿,但是一次只有一个哲学家就餐。
- P2 拿起叉子 1,阻止 P1 拿起叉子 1。
- P3 拿起叉子 2。
- P4 拿起叉子 3。
- P5 拿起叉子 4。
- P5 拿起叉子 5,开始就餐。
- P5 放下叉子 4 和 5。
- P4 拿起叉子 4,开始就餐。
简单来说,该算法会导致每次仅有一个哲学家能够就餐,即使 5 个哲学家都在挨饿,但事实上此时有足够的叉子供两名哲学家同时就餐。
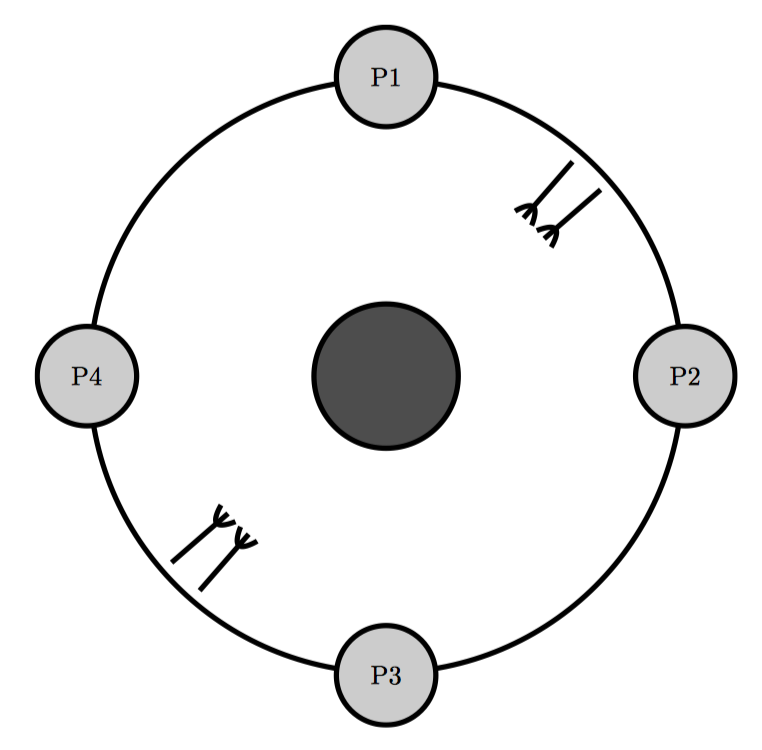
上图是另一种解决方式,里面只有 4 位哲学家,而不是 5 位,这样可以更好的说明分割技术。最上方和最右边的哲学家合用一个叉子,而最下面和最左面的哲学家合用一个叉子。如果所有哲学家同时感觉饿了,至少有两位能够同时就餐。另外如图所示,现在叉子可以捆绑成一对,这样同时拿起或放下,就简化了获取和释放锁的算法。
这是水平化分割的一个例子,或者叫数据并行化,这么叫是因为哲学家之间没有依赖关系。在数处理型的系统中,“数据并行化”是指一种类型的数据只会被多个同类型软件组件中的一个处理。
双端队列
双端队列是一种元素可以从两端插入和删除的数据结构。这里将展示一种分割设计策略,能实现合理且简单的解决方案。
右手锁与左手锁
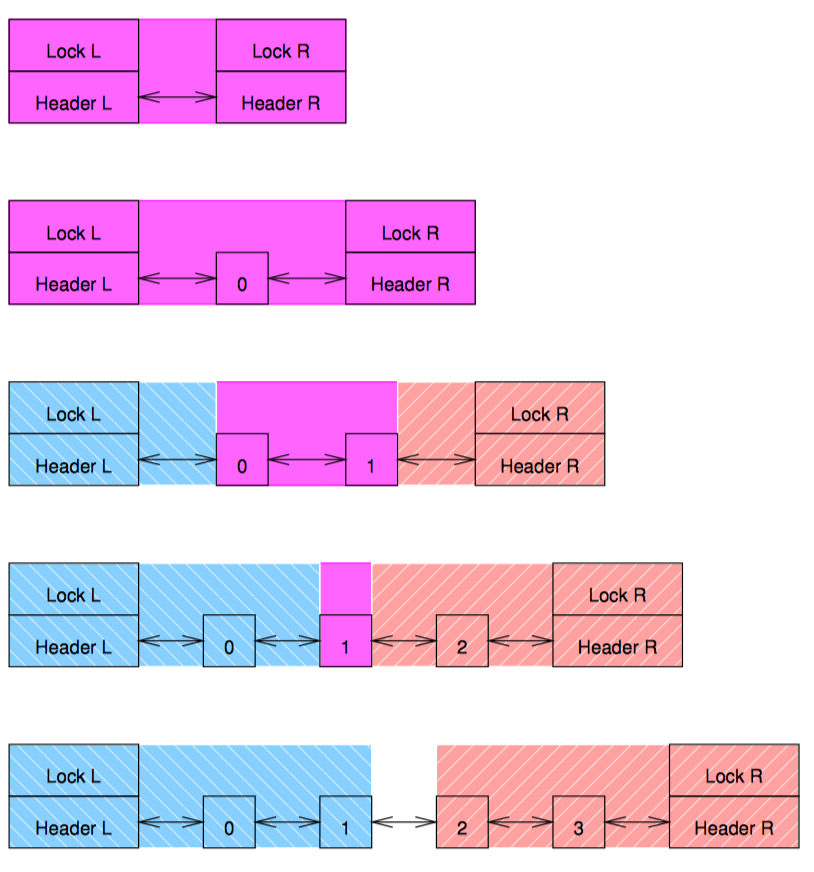
右手锁与左手锁是一种看起来很直接的办法,为左手端的入列操作添加一个左手锁,为右手端的出列操作添加一个右手锁。但是这种办法的问题是当队列中的元素不足 4 个时,两个锁的返回会发生重叠。这种重叠是由于移动任何一个元素不仅只影响元素本身,还要影响它左边和右边相邻的元素。这种范围在图中被涂上了淹死,蓝色表示左手锁的范围,红色表示右手锁的范围,紫色表示重叠的范围。虽然创建这样一种算法是可能的,但是至少要小心着五种特殊情况,尤其是在队列另一端的并发活动会让队列随时可能从一种特殊情况转变为另外一种特殊情况的场景。所以最好考虑其他解决方案。
复合双端队列
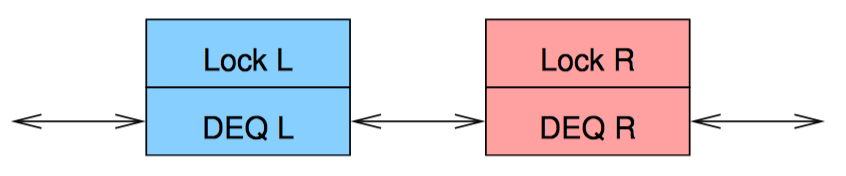
上图是一种强制确保锁的范围不会发生冲突的方法。两个单独的双端队列串联在一起,每个队列用自己的锁保护。这意味着数据偶尔会从双端队列的一列跑到另一列。此时必须同时持有两把锁。为避免死锁,可以使用一种简单的锁层级关系,比如,在获取右手锁前先获取左手锁。这比在同一列上同时使用两把锁要简单的多,因为我们可以无条件的让左边的入列元素进入左手队列,右边的入列元素进入右手队列。主要的复杂度来源于从空队列中出列,这种情况下必须做到如下几点:
- 如果持有右手锁,释放并获取左手锁,重新检查队列释放仍然为空。
- 获取右手锁。
- 重新平衡跨越两个队列的元素。
- 移除指定的元素。
- 释放两把锁。
代码实现也并不复杂,再平衡操作可能会将某个元素在两个队列之间来回移动,这不仅浪费时间,而且想要获得最佳性能,还需针对工作负荷不断微调。
哈希双端队列
哈希永远是分割一个数据结构的最简单有效的方法。可以根据元素在队列中的位置为每个元素分配一个序号,然后以此对双端队列进行哈希,这样第一个从左边进入空队列的元素编号为 0,第一个从右边进入空队列的元素编号为 1。其他从左边进入只有一个元素的队列的元素编号依次递减(-1,-2,-3…),而其他从右边进入只有一个元素的队列的元素编号依次递增(2,3,4…)。关键是,实际上并不用真正为元素编号,元素的序号暗含它们在队列中的位置中。
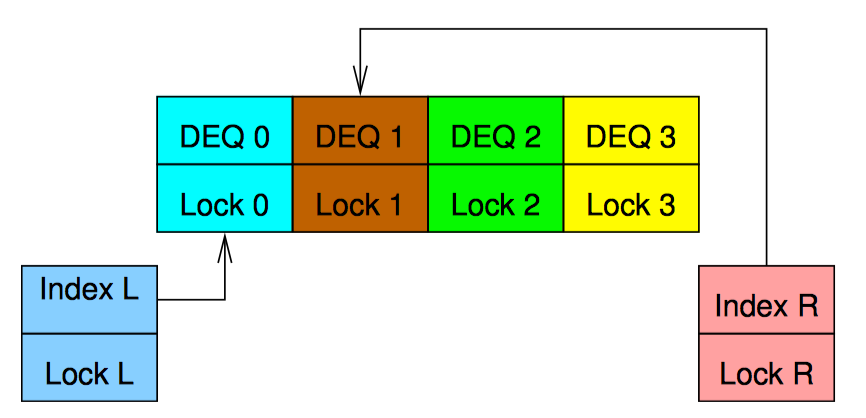
然后,我们用一个锁保护左手下标,用另外一个锁保护右手下标,再各用一个锁保护对应的哈希链表。上图展示了 4 个哈希链表的数据结构。注意锁的范围没有重叠,为了避免死锁,只在获取链表锁之前获取下标锁,每种类型的锁(下标或链表),一次获取从不超过一个。
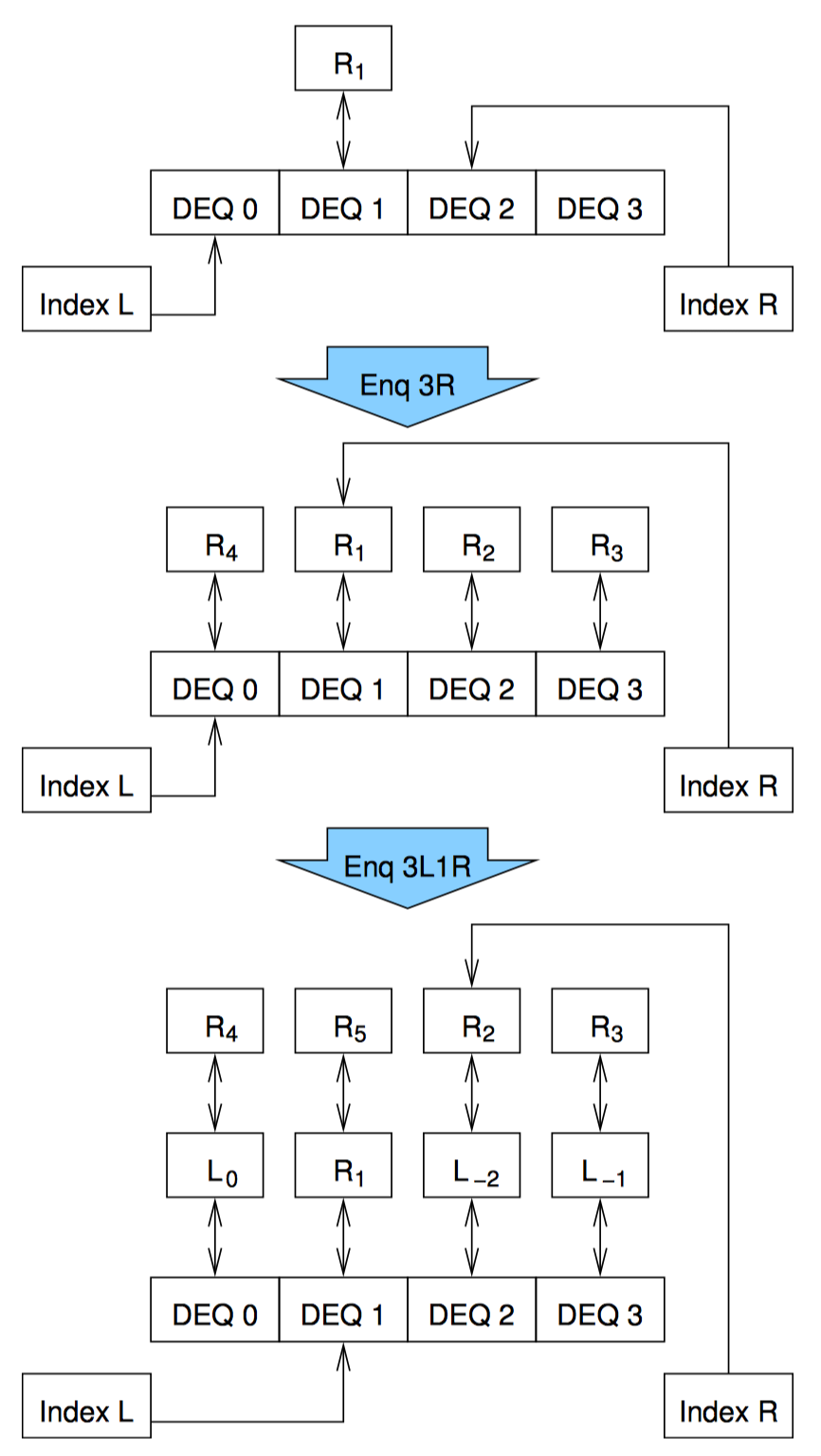
每个哈希链表都是一个双端队列,在这个例子中,每个链表拥有四分之一的队列元素。上图最上面部分是 R1 元素从右边入队后的状态,右手的下标增加,用来引用哈希链表 2。上图第二部分是又有 3 个元素从右手入队。正如你所见,下标回到了它们初始的状态,但是每个哈希队列现在都是非空的。上图第三部分是另外三个元素从左边入队,而另外一个元素从右边入队后的状态。
从上图第三部分的状态可以看出,左出队操作将会返回元素 L-2,并让左手下边指向哈希链 2,此时该链表只剩下 R2。这种状态下,并发的左入队和右入队操作可能会导致锁竞争,但这种锁竞争发生的可能性可以通过使用更大的哈希表来降低。
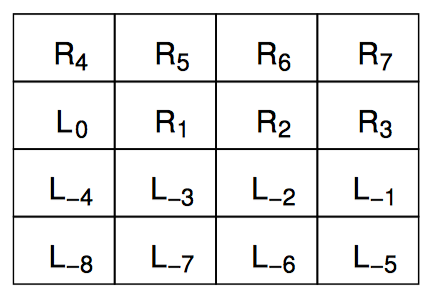
上图展示了 12 个元素如何组成一个有 4 个并行哈希桶的双端队列。每个持有单锁的双端队列拥有整个并行双端队列的四分之一。
双端队列讨论
复合式实现在某种程度上要比哈希式实现复杂,但是仍然属于比较简单的。当然,更加智能的再平衡机制可以非常复杂,但是和软件实现相比,这里使用的软件再平衡机制已经很不错了,这个方法甚至不比使用硬件辅助算法的实现差多少。不过,从这种机制中我们最好也只能获得 2 倍的扩展能力,因为最多只有两个线程并发的持有出列的锁。这个局限同样适用于使用非足额同步方法的算法,比如 Michael 的使用 CAS 的出队算法。
事实上,正如 Dice 等人所说,非同步的单线程双端队列实现性能非常好,比任何他们研究过的并行实现都搞很多。因此,不管哪种实现,由于队列的严格先入先出特性,关键点都在于共享队列中出队或出队的巨大开销。
更近一步,对于严格先入先出的队列,只有在线性化点不对调用者可见时,队列才是严格先入先出。事实上,在事前的例子中“线性化点”都隐藏在带锁的临界区内。而这些队列在单独的指令开始时,并不保证先入先出。这表明对于并发程序来说,严格先入先出的特性并没有那么有价值。实际上 Kirsch 等人已经证明不提供先入先出保证的队列在性能和扩展性上更好。这些例子说明,如果你打算让并发数据出入一个单队列时,真的该重新考虑一下整体设计。
分割讨论
哲学家就餐问题的最后解法是该问题的最优解法,是“水平并行化”或“数据并行化”的极佳例子。在这个例子中,同步的开销接近于 0 或等于 0。相反,双端队列的实现是“垂直并行化”或者“管道”极佳示例,因为数据从一个线程转移到另一个线程。“管道”需要密切合作,因此为获得某种程度上的效率,需要做的工作更多。
设计准则
想要获取最佳的性能和扩展性,简单的办法就是不断尝试,直到你的程序和最优实现水平相当。但是如果你的代码不是短短数行,如何能在浩如烟海的代码中找到最优实现呢?另外,什么才是最优实现呢?前面给出了三个并行编程的目标:性能、生产率和通用性,最优的性能常常要付出生产率和通用性的代价。如果不在设计时就将这些选择考虑进去,就很难在限定的时间内开发出性能良好的并行程序。
但是除此之外,还需要更详细的设计准则来指导实际的设计,这就是本节的主题。在真实的世界中,这些准则将在某种程度上冲突,这需要设计者小心权衡得失。这些准则可以被认为是设计中的阻力,对这些阻力进行恰当权衡,就被称为“设计模式”。
基于三个并行编程目标的设计准则是加速、竞争、开销、读写比率和复杂性。
加速倍速:之所以花费如此多时间和精力进行并行化,加速性能是主要原因。加速倍速的定义是运行程序的顺序执行版本所需要的时间,除以执行并行版本所需时间的比例。
竞争:如果对一个并行程序来说,增加更多的 CPU 并不能让程序忙起来,那么多出来的 CPU 是因为竞争的关系而无法工作。可能是锁竞争、内存竞争或者其他什么性能杀手的原因。
工作-同步比率:单处理器、单线程、不可抢占、不可中断版本的并行程序完全不需要任何同步原语。因此,任何消耗在这些原语上(通信中的高速缓存为命中、消息延迟、加解锁原语、原子指令和内存屏障)的时间都是对程序意图完成的工作没有直接帮助的开销。同步开销与临界区中代码的开销之间的关系是重要的衡量准则,更大的临界区能容忍更大的同步开销。工作-同步开销比率与同步效率的概念有关。
读-写比率:对于极少更新的数据结构,更多是采用“复制”而不是“分割”,并且用非对称的同步原语来保护,以提高写者同步开销的代价来降低读者的同步开销。对频繁更新的数据结构的优化也是可以的。
复杂性:并行程序比相同的顺序执行的程序复杂,这是因为并行程序要比顺序执行程序维护更多的状态,虽然这些状态在某些情况下理解起来很容易。并行程序员必须要考虑同步原语、消息传递、锁的设计、临界区识别以及死锁等诸多问题。
更大的复杂性通常转换为了更高的开发代价和维护代价。因此,对现有程序修改的范围和类型非常受代码预算的限制,因为对原有程序的新年能加速需要消耗相当的时间和精力。在更糟糕的情况,增加复杂性甚至会降低性能和扩展性。
进一步说,在某种范围内,还可以对顺序执行程序进行一定程度的优化,这笔并行化更廉价、高效。并行化只是众多优化手段中的其中一种,并且只是 一种主要解决 CPU 为性能瓶颈的优化。
这些准则结合在一起,会让程序达到最大程度的加速倍数。前三个准则相互交织在一起,所以本节将着重分写这三个准则的交互关系。
请注意,这些准则也是需求说明的一部分。比如,加速倍速既是愿望、又是工作符合的绝对需求,或者说是运行环境。
理解这些设计准则之间的关系,对于权衡并行程序的各个设计目标十分有用。
- 程序在临界区上所花费的时间越少,潜在的加速倍速就越大。这是 Amdahl 定律的结果,这也是因为在一个时刻只能有一个 CPU 进入临界区的原因。更确切的说,程序在某个互斥的临界区上所耗费的时间必须大大小于 CPU 数的倒数,因为这样增加 CPU 数量才能达到事实上的加速。比如在 10 核系统上运行的程序只能在关键的临界区上花费少于 1/10 的时间,这样才能有效的扩展。
- 因为竞争所浪费的大量 CPU 或者时间,这些时间本来可以用于提高加速倍速,应该少于可用 CPU 的数目。CPU 数量和实际的加速倍速之间的差距越大,CPU 的使用率越低。同样,需要的效率越高,可以继续提升的加速倍速就越小。
- 如果使用的同步原语相较它们保护的临界区来说开销太大,那么加速程序运行的最佳办法是减少调用这些原语的次数(比如分批进入临界区、数据所有权、非对称同步、代码锁)。
- 如果临界区相较保护这块临界区的原语来说开销太大,那么加速程序运行的最佳办法是增加程序的并行化程度,比如使用读写锁、数据锁、非对称同步或数据所有权。
- 如果临界区相较保护这块临界区的原语来说开销太大,并且对受保护的数据结构读多于写,那么加速程序运行的最佳办法是增加程序的并行化程度,比如读写锁或非对称同步。
- 各种增加 SMP 性能的改动,比如减少锁竞争程度,能改善响应时间。
同步粒度
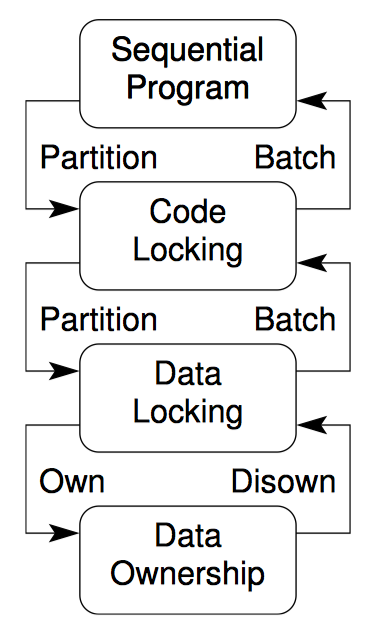
上图是对同步粒度不同层次的图形表示。每一种同步粒度都用一节内容来描述。
串行程序
如果程序在单处理器上运行足够快,并且不与其他进程、线程或者中断处理程序发生交互,那么你可以将代码中所有的同步原语删除,远离他们带来的开销和复杂性。好多年前曾有人争论摩尔定律最终会让所有程序变得如此,但是随着 2003 年以来 Intel CPU 的 CPU MIPS 和时钟频率增长速度的停止,此后要增加性能,就必须提高程序的并行化程度。是否这种趋势会导致一块芯片上继承几千个 CPU,这方面的争论不会很快停息,但是考虑本文作者 Paul 是在一台双核笔记本上敲下这句话的,SMP 的寿命极有可能比你我都长。另一个需要注意的地方是以太网的带宽持续增长。这种增长会进一步促进对多线程服务器的优化,这样才能有效处理通信载荷。

请注意,这并不意味着你应该在每个程序中都使用多线程方式编程。我再次说明,如果一个程序在单处理器上运行的很好,那么你就从 SMP 同步原语的开销和复杂性中解脱出来吧。
代码锁
代码锁是最简单的设计,仅使用全局锁。在已有的程序中使用代码锁,可以很容易让程序在多个处理器上运行。如果程序只有一个共享资源,那么代码锁的性能是最优的。但是,许多较大且复杂的程序会在临界区上执行多次,这就让代码锁的扩展性大大受限。
因此,最好在这样的程序中使用代码锁:只有一小段执行时间在临界区程序,或者对扩展性要求不高。在这种情况下,代码锁可以让程序相对简单,和单线程版本类似。
并且,代码锁尤其容易引起“锁竞争”,一种多个 CPU 并发访问同一把锁的情况。
数据锁
许多数据结构都可以分割,数据结构的每个部分带有一把自己的锁。这样虽然每个部分一次只能执行一个临界区,但是数据结构的各个部分形成的临界区就可以并行执行了。如果此时同步带来的开销不是主要瓶颈,那么可以使用数据来降低锁竞争程度。数据锁通过将一块过大的临界区分散到各个小的临界区来减少锁竞争,比如,维护哈希表中的 per-hash-bucket 临界区。不过这种扩展性的增强带来的是复杂性的少量提升,增加了额外的数据结构 struct bucket。
但是数据锁带来了和谐,在并行程序中,这总是意味着性能和扩展性的提升。因为这个原因,Sequent 在它的 DYNIX 和 DYNIX/ptx 操作系统中使用了数据锁。
不过,那些照顾过小孩的人可以证明,再细心的照料也不能保证一切风平浪静(多个小孩争抢一个玩具)。同样的情况也适用于 SMP 程序。比如,Linux 内核维护了一种文件和目录的缓存(dcache)。该缓存中的每个条目都有一把自己的锁。但是相较于其他条目,对应根目录的条目和它的直接后代更容易被遍历到。这将导致许多 CPU 竞争这些热门条目的锁。这就像虽然玩具有多个,但所有的孩子都要去挣同一个玩具。
在动态分配结构中,在许多情况下,可以设计算法来减少数据冲突的次数,某些情况下甚至可以完全消灭冲突(如 dcache)。数据锁通常用于分割像哈希表一样的数据结构,也适用于每个条目用某个数据结构的实例表示这种情况。
数据锁的关键挑战是对动态分配数据结构加锁,如何保证在获取锁时结构本身还存在。通过将锁放入静态分配且永不释放的哈希桶可以解决该挑战。但是这种手法不适用于哈希表大小可变的情况,所以锁也需要动态分配。在这种情况,还需要一些手段来阻止哈希桶在锁被获取之后的这段时间内释放。
数据所有权
数据所有权方法按照线程或者 CPU 的个数分割数据结构,在不需要任何同步开销的情况下,每个线程或者 CPU 都可以访问属于它的子集。但是如果线程 A 希望访问另一个线程 B 的数据,那么线程 A 是无法直接做到这一点。取而代之的是,线程 A 需要先与线程 B 通信,这样线程 B 以线程 A 的名义执行操作,或者另一种方法,将数据迁移到线程 A 上来。
数据所有权看起来很神秘,但是却应用得十分频繁:
- 任何只能被一个 CPU 或者一个线程访问的变量都属于这个 CPU 或者这个线程。
- 用户接口的实例拥有对应的用户上下文。这在与并行数据库引擎交互的应用程序中十分常见,让并行引擎看起来就像顺序执行的程序一样。这样应用程序拥有用户接口和当前操作。显式的并行化只在数据库引擎内部可见。
- 参数模拟,通常授予每个线程一段特定的参数区间,以此达到某种程度的并行化。有一些计算平台专门用来解决这类问题。
如果共享比较多,线程或者 CPU 间的通信会带来较大的复杂性和通信开销。不仅如此,如果最热的数据正好被一个 CPU 拥有,那么这个 CPU 就成了热点。不过,在不需要共享的情况下,数据所有权可以达到理想性能,代码也可以像顺序程序一样简单。最坏情况通常被称为尴尬的并行化。
另一个数据所有权的重要用法是当数据是只读时,这种情况下,所有线程可以通过复制来拥有数据。
并行快速路径
细粒度(通常能够带来更高的性能)的设计要比粗粒度的设计复杂。在许多情况下,一小部分代码带来了绝大部分开销。所以为什么不把精力放在这一小块代码上呢?
这就是并行快速路径设计模式背后的思想,尽可能并行化常见情况下的代码路径,同时不产生并行化整个算法所带来的复杂性。必须要理解这一点,不只是算法需要并行化,算法所属的工作负载也要并行化。构建这种并行快速路径,需要极大的创造性和设计上的努力。
并行快速路径结合了两种以上的设计模式,因此成为了一种模板设计模式。下列是并行快速路径结合其他设计模式的例子:
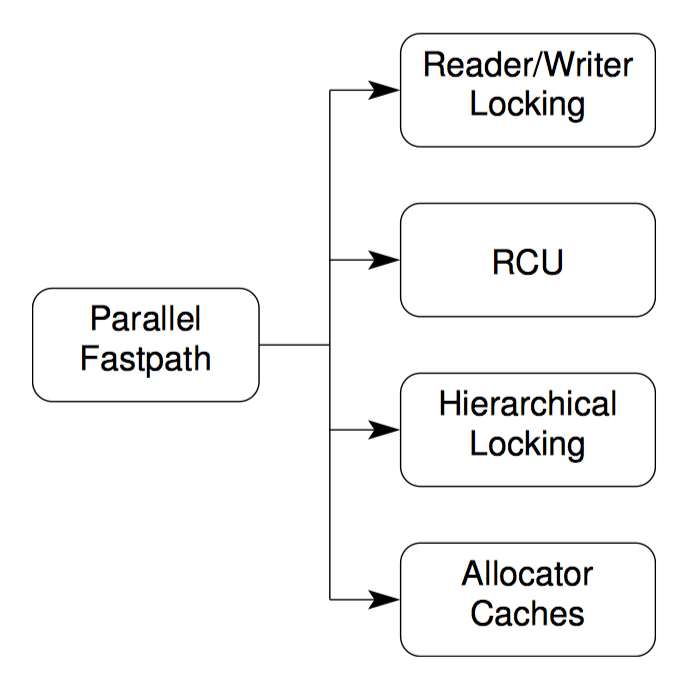
- 读写锁。
- Read-Copy-Update,大多作为读写锁的替代使用。
- 层次锁。
- 资源分配器缓存。
读写锁
如果同步开销可以忽略不计(比如程序使用了粗粒度的并行化),并且只有一小段临界区修改数据,那么让多个读者并行处理可以显著提升扩展性。写者与读者互斥,写者与另一写者也互斥。
读写锁是非对称锁的一种简单实例。Snaman 描述了一种在许多集群系统上使用的非对称锁,该锁有 6 种模式,其设计令人叹为观止。
层次锁
层次锁背后的思想是,在持有一把粗粒度锁时,同时再持有一把细粒度锁。这样一来,我们付出了获取第二把锁的开销,但是我们只持有它一小段时间。在这种情况下,简单的数据锁方法则更简单,而且性能更好。
资源分配器缓存
本节展示一种简明扼要的并行内存分配器,用于分配固定大小的内存。
并行资源分配问题
并行内存分配器锁面临的基本问题,是在大多数情况下快速地分配和释放内存,和在特殊情况下高效地分配和释放内存之间的矛盾。
假设有一个使用了数据所有权的程序——该程序简单地将内存按照 CPU 个数划分,这样每个 CPU 都有属于自己的一份内存。例如,该系统有 2 个 CPU 和 2G 内存。我们可以为每个 CPU 分配 1G 内存,这样每个 CPU 都可以访问属于自己的那一份内存,无需加锁,也不必关心由锁带来的复杂性和开销。可是这种简单的模型存在问题,如果有一种算法,需要让 CPU0 分配所有内存,让 CPU1 释放内存,就像生产者——消费者算法中的行为一样,这样该模型就失效了。
另一个极端,代码锁,则受到大量竞争和通信开销的影响。
资源分配的并行快速路径
常见的解决方案让每个 CPU 拥有一块规模适中的内存块缓存,以此作为快速路径,同时提供一块较大的共享内存池分配额外的内存块,该内存池使用代码锁加以保护。为了防止任何 CPU 独占内存块,我们给每个 CPU 的缓存可以容纳的内存块大小加以限制。在双核系统中,内存块的数据流如下图所示,当某个 CPU 的缓存池满时,该 CPU 释放的内存块被传送到全局缓存池中,类似的,当 CPU 缓存池为空时,该 CPU 所要分配的内存块也是从全局缓存池中取出来。

真实世界设计
虽然并行的玩具资源分配器非常简单,但是真实世界中的设计在几个方面上继续扩展了这个方案。
首先,真实的资源分配器需要处理各种不同的资源大小,在示例中只能分配固定的大小。一种比较流行的做法是提供一些列固定大小的资源,恰当地放置以平衡内碎片和外碎片,比如 20 世纪 80 年代后期的 BSD 内存分配器。这样做就意味着每种资源大小都要有一个“globalmem”变量,同样对应的锁也要每种一个,因此真实的实现将采用数据锁,而非玩具程序中的代码锁。
其次,产品级的系统必须可以改变内存的用途,这意味着这些系统必须能将内存块组合成更大的数据结构,比如页(page)。这种组合也需要锁的保护,这种锁必须是专属于每种资源大小的。
第三,组合后的内存必须回到内存管理系统,内存页也必须是从内存管理系统分配的。这一层面所需要的锁将依赖于内存管理系统,但也可以是代码锁。在这一层面中使用代码锁通常是可以容忍的,因为在设计良好的系统中很少触及这一级别。
尽管真实世界中的设计需要复杂许多,但背后的思想也是一样的——对并行快速路径这一原则的反复利用。以下是真实世界中的并行分配器类型:
| 等级 | 锁类型 | 目的 |
|---|---|---|
| 每线程资源池 | 数据所有权 | 高速分配 |
| 全局内存资源池 | 数据锁 | 将内存块放在各个线程中 |
| 组合 | 数据锁 | 将内存块放在页中 |
| 系统内存 | 代码锁 | 获取、释放系统内存 |
分割之外
本章讨论了如何运用数据分割这一思想,来设计既简单又能线性扩展的并行程序。运用分割和复制的主要目标是达到线性的加速倍数,换句话说,确保需要做的工作不会随着 CPU 或线程的增长而显著增长。通过分割或复制可以解决尴尬的并行问题,使其可以线性加速,但是我们还能做得更好吗?
为了回答这个问题,让我们来看一看迷宫问题。前年依赖,迷宫问题一直是一个令人着迷的研究对象,所以请读者不要感到意外,计算机可以生产并且解决迷宫问题,其中包括生物计算机、甚至是一些可插拔硬件。大学有时会将迷宫的并行解法布置成课程作业,作为展示并行计算框架优点的工具。
常见的解法是使用一个并行工作队列的算法(PWQ)。本节比较 PWQ 方法、串行解法(SEQ)、和使用了另一种并行算法的解法,这些方法都能解决任何随机生成的矩形迷宫问题。
略。
7 - CH07-锁
近来对并行编程的研究中,锁总是扮演着坏人的角色。在许多论文和演讲中,锁背负着诸多质控,包括引起死锁、锁争抢、饥饿、不公平的锁、并发数据访问以及其他许多并发带来的罪恶。有趣的是,真正在产品级共享内存并行软件中承担重担的角色是——你猜对了——锁。那锁到底是英雄还是坏蛋呢?
这种认识源于以下几个原因:
- 很多因锁产生的问题都在设计层面就可以解决,而且在大多数场合工作良好,比如:
- 使用锁层级以避免死锁。
- 使用死锁检测工具,比如 Linux 内核 lockdep 模块。
- 使用对锁友好的数据结构,比如数组、哈希表、基树。
- 有些锁的问题只在竞争程度很高时才会出现,一般只有不良的设计才会出现竞争如此激烈的锁。
- 有些锁的问题可以通过其他同步机制配合锁来避免。包括统计计数、引用计数、危险指针、顺序锁、RCU,以及简单的非阻塞数据结构。
- 直到不久之前,几乎所有的共享内存并行程序都是闭源的,所以多数研究者很难了解业界的实践解决方案。
- 锁在某些软件上运行的很好,在某些软件上运行的很差。那些在锁运行良好的软件上做开发的程序员,对锁的态度往往比另一些没那么幸运的程序员更加正面。
- 所有美好的故事都需要一个坏人,锁在研究文献中扮演坏小子的角色已经有着悠久而光荣的历史了。
努力活着
死锁
当一组线程中的每个线程都持有至少一把锁,此时又等待该组线程中的某个成员释放它持有的一把锁时,死锁就会发生。
如果缺乏外界干预,死锁会一直持续。除非持有锁的线程释放,没有线程可以获取到该锁,但是持有锁的线程在等待获取该锁的线程释放其他锁之前,又无法释放该锁。
我们可以用有向图来表示死锁,节点代表锁和线程。
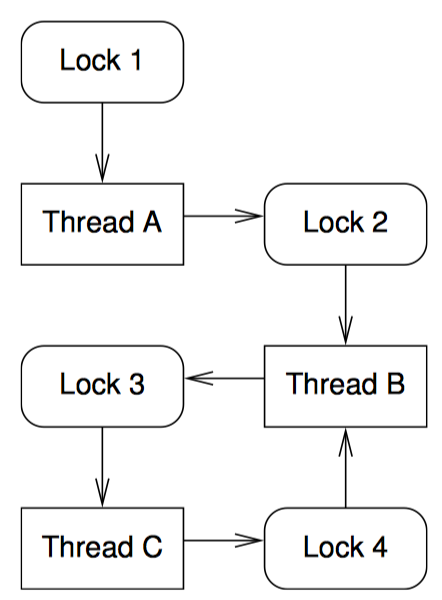
如上图。从锁指向线程的箭头表示该线程持有了该锁。比如线程 B 持有锁 2 和 4。从线程到锁的箭头表示线程在等待这把锁,比如线程 B 等待锁 3 释放。死锁场景至少包含至少一个以上的死锁循环。在上图中,死锁循环是线程 B、锁 3 、线程 C、锁 4,然后又回到线程 B。
虽然有一些软件环境,比如数据库系统,可以修复已有的死锁,但是这种方式要么杀掉其中一个线程,要么强制从某个线程中偷走一把锁。杀掉线程和强制偷锁对于事务交易是可以的,但是对内核和应用程序这种层次的锁来说问题多多,处理部分更新的数据库极端复杂,非常危险,而且很容易出错。
因此,内核和应用程序要么避免死锁,而非从死锁中恢复。避免死锁的策略有很多,包括锁的层次、锁的本地层次、锁的分级层次、包含指向锁的指针的 API 的使用策略、条件锁、先获取必须的锁、一次只用一把锁的设计,以及信号/中断处理函数的使用策略。虽然没有任何一个避免死锁策略可以适用于所有情况,但是市面上有很多避免死锁的工具可供选择。
锁的层次
锁的层次是指为锁逐级编号,禁止不按顺序获取锁。在上图中我们可以用数字为锁编号,这样如果线程已经获得了编号相同的锁或者更高编号的锁,就不允许获得编号相同或者编号更低的锁。线程 B 违反这个层次,因此它在持有锁 4 时又视图获取锁 3,因此导致死锁发生。
再次强调,按层次使用锁时要为锁编号,严禁不按顺序获取锁。在大型程序中,最好用工具来检查锁的层次。
锁的本地层次
但是所的层次本质要求全局性,因此很难应用在库函数上。如果调用了某个库函数的应用程序开没开始实现,那么倒霉的库函数程序员又怎么才能遵循这个还不存在的应用程序中的锁层次呢?
一种特殊的情况是,幸运的也是普遍的情况,是库函数并不涉及任何调用者代码。这时,如果库函数持有任何库函数的锁,它绝对不会再去获取调用者的锁,这样就避免出现库函数和调用者之间互相持有锁的死循环。
但假设某个库函数确实调用了某个调用者的代码。比如,qsort() 函数调用了调用者提供的比较函数。并发版本的 qsort() 通常会使用锁,虽然可能性不大,但是如果比较函数复杂且使用了锁,那么久有可能发生死锁。这时库函数该如何避免死锁?
出现这种情况时的黄金定律是:在调用未知代码前释放所有的锁。为了遵循该定律,qsort() 函数必须在调用比较函数前释放它所持有的全部锁。
为了理解本地层次锁的好处,让我们比较一下下面的两个图:
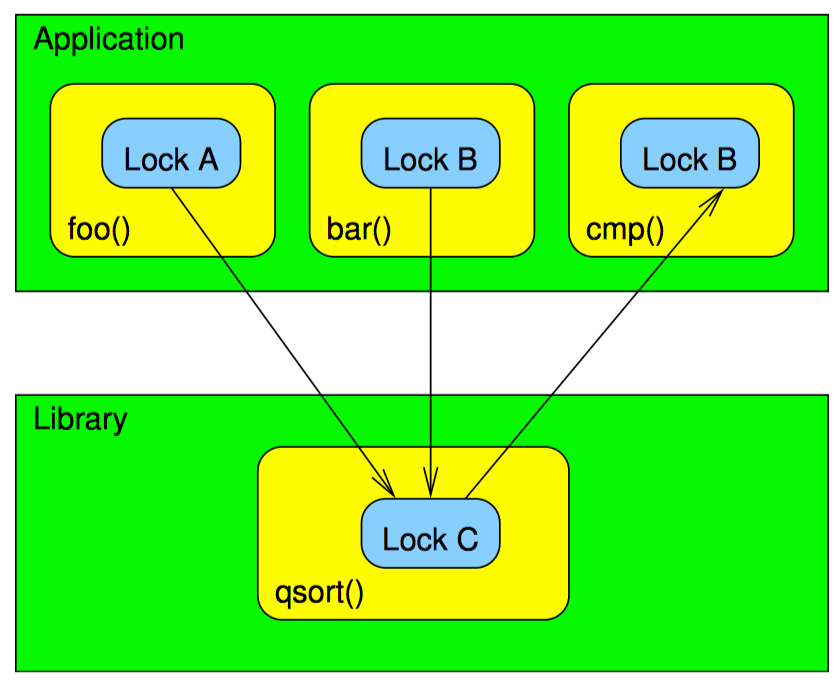
不带本地层次锁的 qsort:
基于所的本地层次实现的 qsort():
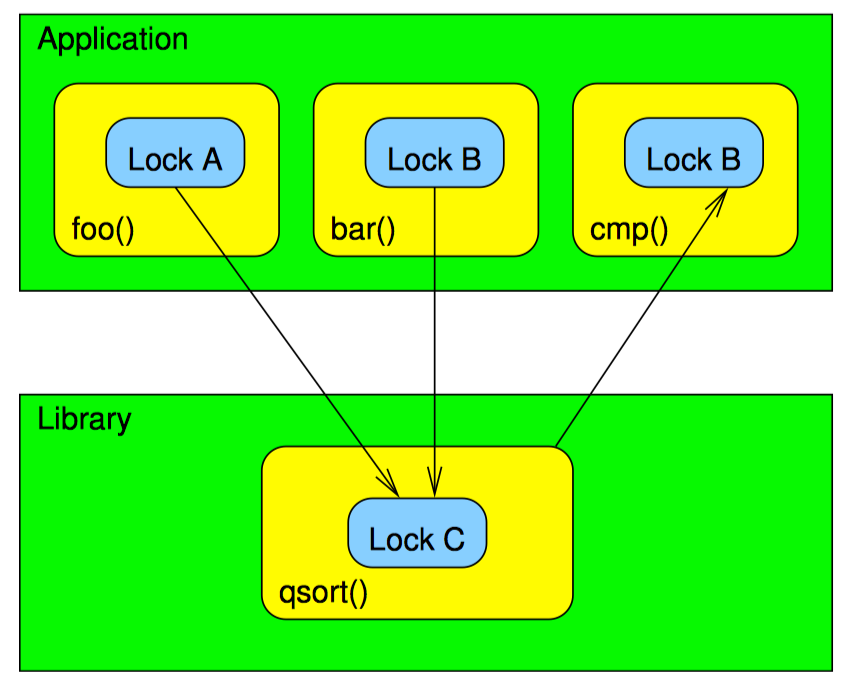
在两幅图中,应用程序 foo() 和 bar() 在分别持有锁 A 和锁 B 时调用了 qsort()。因为这是并行版本,所以 qsort() 内还要获取锁 C。函数 foo() 将函数 cmp() 传给 qsort(),而 cmp() 中要获取锁 B。函数 bar() 将一个简单的整数比较函数传给 qsort(),而这个简单的函数不支持任何锁。
现在假设 qsort() 在持有锁 C 时调用 cmp(),这违背了之前提过的黄金定律“释放所有锁”,那么死锁会发生。为了让读者理解,假设一个线程调用 foo(),另一个线程调用 bar()。第一个线程会获取锁 A,第二个线程会获取锁 B。如果第一个线程调用 qsort() 时获取锁 C,那么这时它在调用 cmp() 时将无法获得锁 B。但第一个线程获得了锁 C,所以第二个线程调用 qsort() 时无法获取锁 C,因此也无法释放锁 B,导致死锁。
相反,如果 qsort() 在调用比较函数之前释放锁 C,就可以避免死锁。
如果每个模块在调用未知代码前释放全部锁,那么每个模块自身都避免了死锁,这样整个系统也就避免发生死锁了。这个定律极大的简化了死锁分析,增强了代码的模块化。
锁的分级层次
不幸的是,有时 qsort() 无法在调用比较函数前释放全部锁。这时,我们无法通过以调用未知代码之前释放全部锁的方式来构建锁的本地层次。可是我们可以构建一种分级层次,如下图:
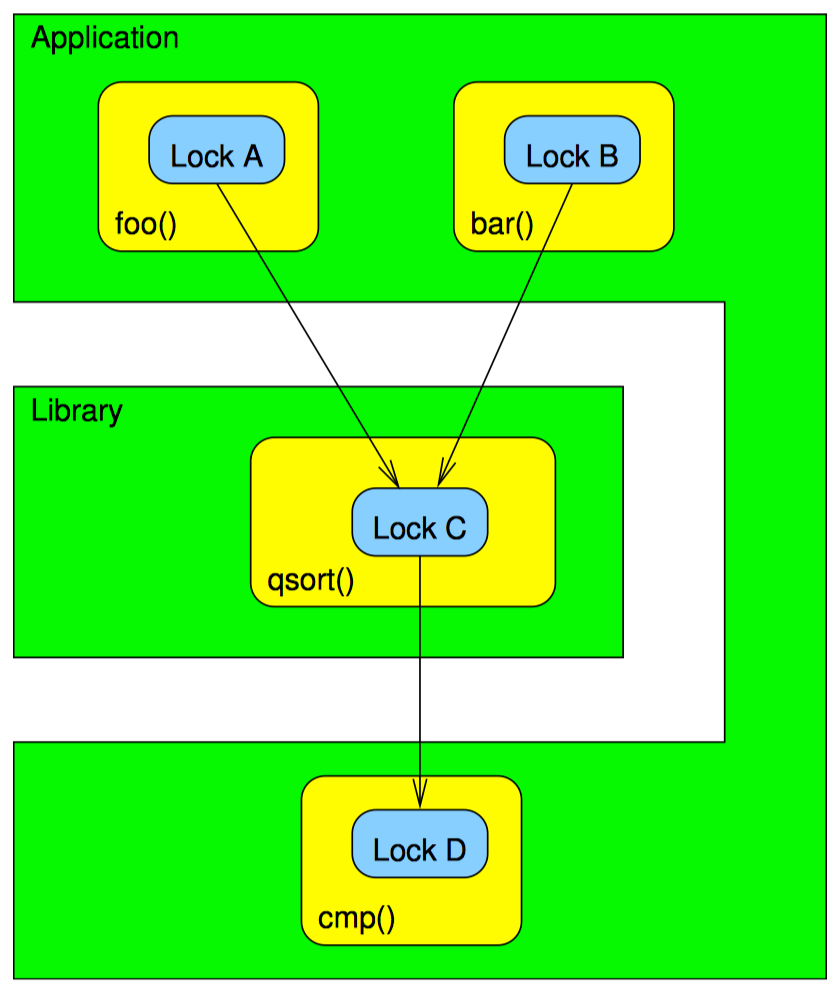
在这张图上,cmp() 函数在获取了锁 A、B、C 后再获取新的锁 D,这就避免了死锁。这样我们把全局层次锁分成了三级,第一级是锁 A 和锁 B,第二级是锁 C,第三级是锁 D。
请注意,让 cmp() 使用分级的层次锁 D 并不容易。恰恰相反,这种改动需要在设计层面进行大量更改。然而,这种变动往往是避免死锁时需要付出的点小小代价。
锁的层次和指向锁的指针
虽然有些例外情况,一般来说设计一个包含着指向锁的指针的 API 意味着这个设计本身就存在问题。将内部的锁传递给其他软件组件违反了信息隐藏原则,而信息隐藏恰恰是一个关键的设计准则。
比如两个函数要返回某个对象,而在对象成功返回之前必须持有调用者提供的锁。再比如 POSIX 的 pthread_cond_wait() 函数,要传递一个指向 pthread_mutex_t 的指针来放置错过唤醒而导致的挂起。
长话短说,如果你发现 API 需要将一个指向锁的指针作为参数或者返回值,请慎重考虑一下是否需要修改这个设计。有可能这是正确的做法,但是经验告诉我们这种可能性很低。
条件锁
假如某个场景设计不出合理的层次锁。这在现实生活中是可能发生的,比如,在分层网络协议栈里,报文流是双向的。当报文从一个层传向另一个层时,有可能需要在两层中同时获取锁。因为报文可以从协议栈上层往下层传,也可能相反,这简直是死锁的天然温床。
在这个例子中,当报文在协议栈中从上往下发送时,必须逆序获取下一层锁。反之则需要顺序获得锁。解决办法是强加一套锁的层次,但在必要时又可以有条件地乱序获取锁。
先获取必要的锁
条件锁有一个重要的特例,在执行真正的处理工作之前,已经拿到了所有必须的锁。在这种情况下,处理不需要是幂等的:如果这时不能在不释放锁的情况下拿到某把锁,那么释放所有持有的锁,重新获取。只有在持有所有必要的锁以后才开始处理工作。但是这样又可能导致活锁,后续将会讨论这一点。
两阶段加锁在事务数据库系统中已经存在很长时间了,它就应用了这个策略。两阶段加锁事务的第一个阶段,只获取锁但不释放锁。一旦所有必须的锁全部获得,事务进入第二阶段,只释放锁但不获取锁。这种加锁方法使得数据库可以对执行的事务提供串行化保护,换句话说,保证事务看到和产生的数据在全局范围内顺序一致。很多数据库系统都依靠这种能力来终止事务,不过两阶段加锁也可以简化这种方法,在持有所有必要的锁之前,避免修改共享数据。虽然使用两阶段锁仍然会出现活锁或死锁,但是在现有的大量数据库类教科书中已经有很多实用的解决办法。
一次只用一把锁
在某些情况下,可以避免嵌套加锁,从而避免死锁。比如,如果有一个可以完美分割的问题,每个分片拥有一把锁。然后处理任何特定分片的线程只需获取对应该分片的锁。因为没有任何线程在同一时刻持有一把以上的锁,死锁就不可能发生。但是必须有一些机制来保证在没有持锁的情况下所需数据结构依然存在。
信号/中断处理函数
涉及信号处理函数的死锁通常可以很快解决:在信号处理函数中调用 pthread_mutex_lock() 是非法的。可是,精心构造一种可以在信号处理函数中使用的锁是有可能的。除此之外,基本所有的操作系统内核都允许在中断处理函数里获取锁,中断处理函数可以说是内核对信号处理函数的模拟。
其中的诀窍是在任何可能中断的处理函数里获取锁的时候阻塞信号(或者屏蔽中断)。不仅如此,如果已经获取了锁,那么在不阻塞信号的情况下,尝试去获取任何可能中断处理函数之外被持有的锁,都是非法操作。
假如处理函数获取锁是为了处理多个信号,那么无论是否获得了锁,甚至无论锁是否是在信号处理函数之内获取的,每个信号也都必须被阻塞。
不幸的是,在一些操作系统里阻塞和解除阻塞信号都属于代价昂贵的操作,这里包括 Linux,所以出于性能上的考虑,能在信号处理函数内持有的锁仅能在信号处理函数内获取,应用程序和信号处理函数之间的通信通常使用无锁同步机制。
或者除非处理致命异常,否则完全禁用信号处理函数。
本节讨论
对于基于内存共享的并行程序员来说,有大量避免死锁的策略可用,但是如果遇到这些策略都不适用的场景,总还是可以用串行代码来实现的。这也是为什么专家级程序员的工具箱里总是有好几样工具的原因之一,但是别忘了总有些活适合用其他工具处理。不过,本节描述的这些策略在很多场合都被证明非常有用。
活锁与饥饿
虽然条件锁是一种有效避免死锁的机制,但是有可能被滥用。考虑下面的例子:
1 void thread1(void)
2 {
3 retry:
4 spin_lock(&lock1);
5 do_one_thing();
6 if (!spin_trylock(&lock2)) {
7 spin_unlock(&lock1);
8 goto retry;
9 }
10 do_another_thing();
11 spin_unlock(&lock2);
12 spin_unlock(&lock1);
13 }
14
15 void thread2(void)
16 {
17 retry:
18 spin_lock(&lock2);
19 do_a_third_thing();
20 if (!spin_trylock(&lock1)) {
21 spin_unlock(&lock2);
22 goto retry;
23 }
24 do_a_fourth_thing();
25 spin_unlock(&lock1);
26 spin_unlock(&lock2);
27 }
考虑以下事件顺序:
- 4:线程 1 获取 lock1,然后调用 do_one_thing()
- 18:线程 2 获取 lock2,然后调用 do_a_third_thing()
- 6:线程 1 试图获取 lock2,由于线程 2 已经持有而失败
- 20:线程 2 试图后去 lock1,由于线程 1 已经持有而失败
- 7:线程 1 释放 lock1,然后跳转到第 3 行的 retry
- 21:线程 2 释放 lock2,然后跳转到 17 行的 retry
- 以上过程不断重复,活锁将华丽登场
活锁可以被看做是饥饿的一种极端形式,此时不再是一个线程,而是所有线程都饥饿了。活锁和饥饿都属于事务内存软件实现中的严重问题,所以现在引入了竞争管理器这样的概念来封装这些问题。以锁为例,通常简单的指数级退避就能解决活锁和饥饿。指数级退避是指在每次重试之前增加按指数级增长的延迟。不过,为了获取更好的性能,退避应该有个上限,如果使用排队锁甚至可以在高竞争时获取更好的性能。当然,更好的办法还是通过良好的并行设计使锁的竞争程度变低。
不公平的锁
不公平的锁被看成是饥饿的一种不太严重的表现形式,当某些线程争抢同一把锁时,其中一部分线程在绝大多数时间都可以获取到锁,另一部分线程则遭遇不公平对待。这在带有道速共享缓存或者 NUMA 内存的机器上可能出现。
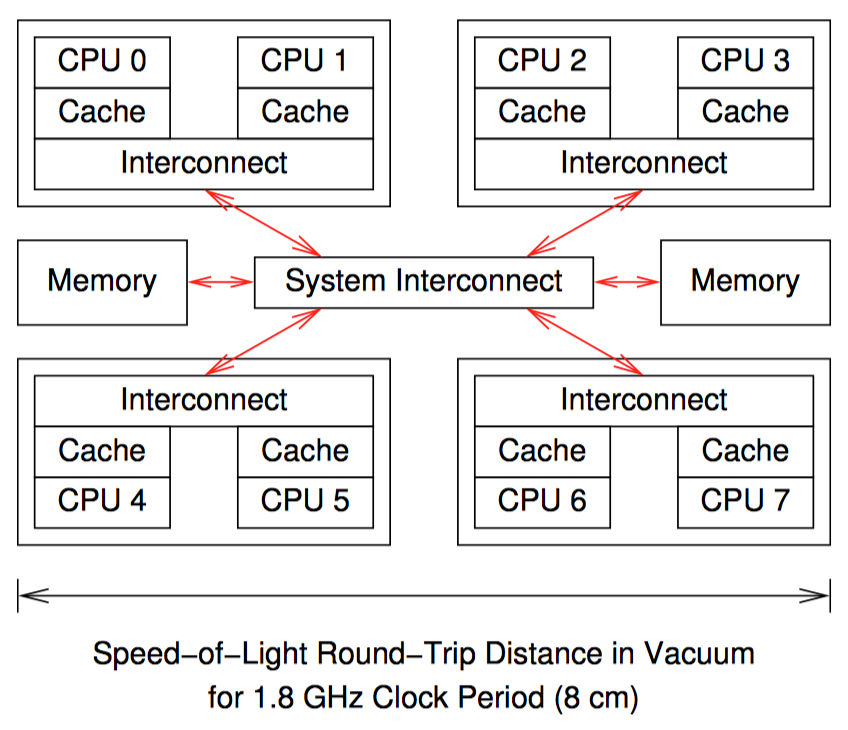
如上图。如果 CPU0 释放了一把其他 CPU 都想获得的锁,因为 CPU0 与 CPU1 共享内部链接,所以 CPU1 相较于 CPU2~7 则更易抢到锁。反之亦然,如果一段时间后 CPU0 又开始争抢该锁,那么 CPU1 释放时 CPU0 则更易获得锁,导致锁绕过 CPU2~7,只在 CPU0 和 CPU1 之间换手。
低效率的锁
锁是由原子操作和内存屏障实现的,并且常常带有高速缓存未命中。正如我们第三章所见,这些指令代价都是十分昂贵的,粗略地说开销比简单指令要高出两个数量级。这可能是锁的一个严重问题,如果用锁来保护一条指令,你很可能在以百倍的速度带来开销。对于相同的代码,即使假设扩展性非常完美,也需要 100 个 CPU 才能跟上一个执行不加锁版本的 CPU。
这种情况强调了“同步粒度”一节中的权衡,粒度太粗会限制扩展性,粒度太小会导致巨大的同步开销。
不过一旦持有了锁,持有者可以不受干扰的访问被锁保护的代码。获取锁可能代价高昂,但是一旦持有,特别是对较大的临界区来说,CPU 高速缓存反而是高效的性能加速器。
锁的类型
互斥锁
互斥锁正如其名,一次只能被一个线程持有。持锁者对受锁保护的代码享有排他性的访问权。当然,这是在假设该锁保护了所有应当受保护的数据的前提下。虽然有些工具可以帮你检查,但最终的责任还是落在开发者身上,一定要保证所有需要的路径都受互斥锁的保护。
读写锁
读写锁一方面允许任意数量的读者同时持有锁,另一方面允许最多一个写者持有锁。理论上,读写锁对读侧重的数据来说拥有极佳的扩展性。在实践中的扩展性则取决于具体的实现方式。
经典的读写锁实现使用一组只能以原子操作方式修改的计数和标志。这种实现和互斥锁一样,对于很小的临界区来说开销太大,获取和释放锁的开销比一条简单指令的开销要高出两个数量级。当然,如果临界区足够长,获取和释放锁的开销与之相比就可以忽略不计了。可是因为一次只有一个线程能操作锁,随着 CPU 数目的增加,临界区的代价也需要增加才能平衡掉开销。
另一个设计读写锁的方式是使用每线程互斥锁,这种读写锁对读者非常有利。线程在读的时候只需要获取本线程的锁即可,而在写的时候需要获取所有线程的锁。在没有写者的情况下,每个读锁的开销相当于一条原子操作和一个内存屏障的开销之和,而且不会有高速缓存未命中,这点对于锁来说非常不错。不过,写锁的开销包括高速缓存未命中,再加上原子操作和内存屏障的开销之和——再乘以线程的个数。
简单的说,读写锁在有些场景非常有用,但各种实现方式都有各自的缺点。读写锁的正统用法是用于非常长的只读临界区,临界区耗时几百微秒或者毫秒甚至更多则最好。
读写锁之外
读写锁和互斥锁允许的规则大不相同:互斥锁只允许一个持有者,读写锁允许任意多个持有者持有读锁(但只能有一个持有写锁)。锁可能的允许规则有很多,VAX/VMS 分布式锁管理器就是其中一个例子。下图是各种状态之间的兼容性:
| 规则类型 | 空(未持锁) | 并发读 | 并发写 | 受保护读 | 受保护写 | 互斥访问 |
|---|---|---|---|---|---|---|
| 空(未持锁) | ||||||
| 并发读 | N | |||||
| 并发写 | N | N | N | |||
| 受保护读 | N | N | N | |||
| 受保护写 | N | N | N | N | ||
| 互斥访问 | N | N | N | N | N |
N 表示不兼容,空值表示兼容。
VAX/VMS 分布式锁管理器有 6 个状态。为了更好的比较,互斥锁有 2 个状态(持锁和未持锁),而读写锁有 3 个状态(未持锁、持读锁、持写锁)。
这里第一个状态是空状态,也就是未持锁。这个状态与其他任何状态兼容,这也是我们期待的,如果没有线程持有锁,那么也不会阻止其他获取了锁的线程执行。
第二个状态是并发读,该状态与除了排他状态之外的所有状态兼容。并发读状态可用于对数据结构进行粗略的累加统计,同时允许并发写的操作。
第三个状态是并发写,与空状态、并发读、并发写兼容。并发写状态可以用于近似统计计数的更新,同时允许并发的读操作和写操作。
第四个状态是受保护读,与空状态、并发读、受保护兼容。受保护状态可用于读取数据结构的准确结果,同时允许并发的读操作,但是不允许并发的写操作。
第五个状态是受保护写,与空状态、并发读兼容。受保护写状态可用于在可能会受到受保护读干扰的情况下写数据结构,允许并发的读操作。
第六个状态是互斥访问,仅与空状态兼容。互斥访问状态可用于需要排他访问的场合。
有趣的是,互斥锁和读写锁可以用 VAX/VMS 分布式锁管理器来模拟。互斥锁仅使用空状态和互斥访问状态,读写锁仅使用空状态、受保护的读/写状态。
虽然 VAX/VMS 分布式锁管理器广泛用于分布式数据库领域,但是在共享内存的应用程序中却很少见。其中一个可能的原因是分布式数据库中的通信开销在一定程度上可以抵消 VAX/VMS 分布式锁管理器带来的复杂性。
然而,VAX/VMS 分布式锁管理器只是一个例子,用来说明锁背后的概念和灵活性。同时这个例子也是对现代数据库管理系统所使用的锁机制的简单介绍,相对于 VAX/VMS 分布式锁管理器的 6 个状态,有些数据库中使用的锁甚至可以有 30 多个状态。
范围锁
到目前为止我们讨论的加锁原语都需要明确的获取和释放函数,比如 spin_lock() 和 spin_unlock()。另一种方式是使用面向对象的“资源分配即初始化”(RAII)模式。该设计模式常见于支持自动变量的语言,如 C++,当进入对象的范围时调用构造函数,当退出对象的范围时调用析构函数。同理,加锁可以让构造函数去获取锁、析构函数来释放锁。
这种方法十分有用,事实上 1991 年本书作者曾认为这是唯一有用的加锁方法。RAII 式加锁有一个非常好的特性,你不需要精心思考在每个会退出对象范围的代码路径上释放锁,该特性避免了一系列 BUG 的出现。
但是,RAII 式加锁也有其黑暗面。RAII 使得对获取和释放锁的封装极其困难,比如在迭代器内。在很多迭代器的实现中,你需要在迭代器的开始函数内获取锁,在结束函数内释放锁。相反 RAII 式加锁要求获取和释放锁都发生在相同的对象范围,这使得对它们的封装变得困难,甚至无法实现。
因为范围只能嵌套,所以 RAII 式加锁不允许重叠的临界区。这让锁的很多有用的用法变得不可能,比如,对于协调对并发访问某事件的树状锁。对于任意规模的并发访问,只允许其中一个成功,其余请求最好是让他们越早失败越好。否则在大型系统上(几百个 CPU)对锁的竞争会称为大的问题。
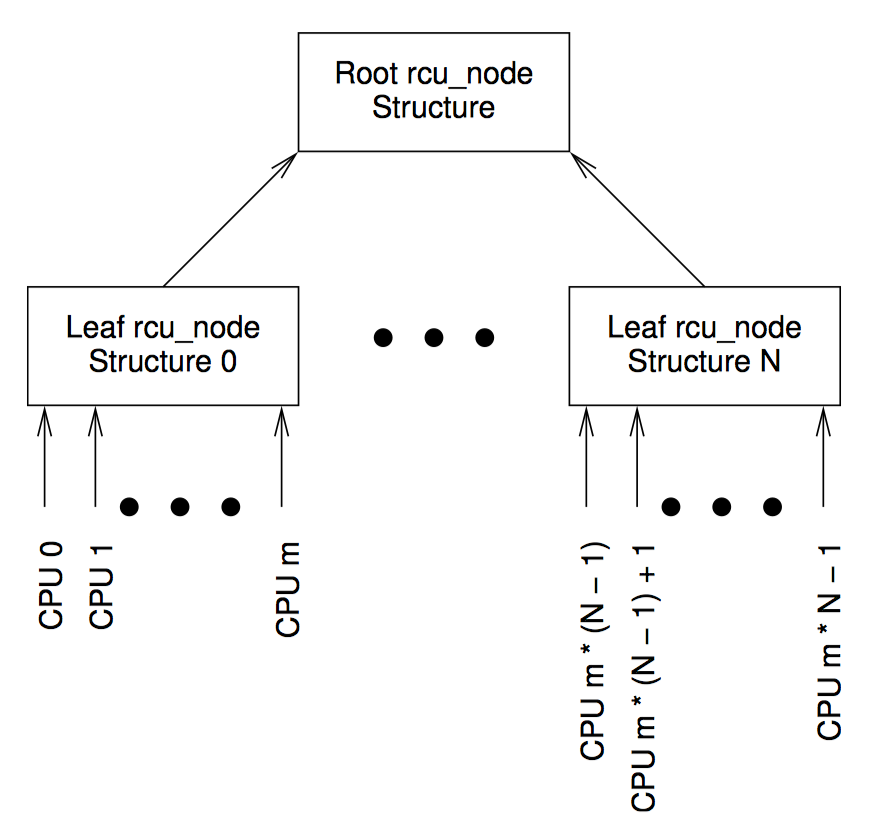
上图是一个示例数据结构(来自 Linux 内核的 RCU 实现)。在这里,每个 CPU 都分配一个 rcu_node 的叶子节点,每个 rcu_node 节点都拥有一个指向父节点的指针 ->parent,直到根节点的 rcu_node 节点,它的 ->parent 指针为 NULL。每个父节点可以拥有的子节点数目可以不同,但是一般是 32 或 64。每个 rcu_node 节点都有一把名为 ->fqslock 的锁。
这里使用的是一种通用策略——锦标赛,任意指定 CPU 有条件地获取它对应的 rcu_node 叶子节点的锁 ->fqslock,如果成功,尝试获取其父节点的锁,如成功再释放子节点的锁。除此之外,CPU 在每一层检查全局变量 gp_flags,如果每个变量表明其他 CPU 已经访问过这个事件,该 CPU 被淘汰出锦标赛。这种先获取——再释放顺序一直持续到要么 gp_flags 变量表明已经有人赢得锦标赛,某一层获取 ->fqslock 锁失败,要么拿到了根节点 rcu_node 结构的锁 ->fqslock。
锁在实现中的问题
系统总是给开发者提供最好的加、解锁原语,例如 POSIX pthread 互斥锁。然而,学习范例实现总是有点用的,因为这样读者可以考虑极端工作负载和环境带来的挑战。
基于原子交换的互斥锁实现示例
1 typedefintxchglock_t;
2 #define DEFINE_XCHG_LOCK(n) xchglock_t n = 0
3
4 void xchg_lock(xchglock_t *xp)
5 {
6 while (xchg(xp, 1) ==1) {
7 while(*xp == 1)
8 continue;
9 }
10 }
11
12 void xchg_unlock(xchglock_t *xp)
13 {
14 (void)xchg(xp, 0);
15 }
这个锁的结构只是一个 int,如第 1 行所示,这里可以是任何整数类型。这个锁的初始值为 0,代表锁已释放,即第二行代码。
通过 4~10 行上的 xchg_lock() 函数执行锁的获取。此函数使用嵌套循环,外部循环重复地将锁的值与 1 做原子交换(即加锁)。如果旧值已经是 1(即该锁已经被别人持有),那么内部循环(7~8)持续自旋直到锁可用,那么到时候外部循环再一次尝试获取锁。
锁的释放由 12~15 行的 xchg_unlock() 函数执行。第 14 行将值 0(即解锁)原子地交换到锁中,从而标记锁已经释放。
虽然这是一个测试并设置(test-and-set)的例子,但是在生产环境中广泛采用一种非常类似的机制来实现纯自旋锁。
互斥锁的其他实现
基于原子指令的锁有很多可能的实现,Mellor-Crummey 和 Scott 综述了其中很多种。这些实现代表着设计权衡多个维度中的不同顶点。例如,上一节提到的基于原子交换的测试并设置锁,在低度锁竞争时性能良好,并且具有内存占用小的有点。它避免了给不能使用它的线程提供锁,但作为结果可能会导致不公平或甚至在高度锁竞争时出现饥饿。
相比之下,在 Linux 内核中使用的门票锁(ticket-lock)避免了在高度锁竞争时的不公平,但后果是其先入先出的准则可以将锁授予给当前无法使用它的线程,例如,线程由于被抢占、中断或其他方式而失去 CPU。然而,避免太过担心抢占和中断的可能性同样重要,因为抢占和中断也有可能在线程刚获取锁后发生。
只要是等待者在某个内存地址自旋以等待锁的各种实现,包括测试并设置锁和门票锁,都在高度锁竞争时存在性能问题。原因是释放锁的线程必须更新对应的内存地址。在低度竞争时,这不是问题:相对的缓存行很可能仍然属于本地 CPU 并且仍然可以由持有锁的线程来更改。相反,在高度竞争时,每个尝试获取锁的线程将拥有高速缓存行的只读副本,因此锁的持有者将需要使所有此类副本无效,然后才能更新内存地址来释放锁。通常,CPU 和线程越多,在高度竞争条件下释放锁时所产生的开销就约大。
这种负可扩展性已经引发了许多种不同的排队锁(queued-lock)实现。排队锁通过为每个线程分配一个队列元素,避免了高昂的缓存无效化开销。这些队列元素链接在一起构成了一个队列,控制着等待线程获取锁的顺序。这里的关键点在于每个线程只在自己的队列元素上自旋,使得锁持有者只需要使下一个线程的 CPU 缓存中的第一个元素无效即可。这种安排大大减少了在高度锁竞争时交换锁的开销。
最近的排队锁实现也将系统的架构纳入到考虑之中,优先在本地予锁,同时采取措施避免饥饿。这些实现可以看成是传统上用在调度磁盘 IO 时使用的电梯算法的模拟。
不幸的是,相同的调度逻辑虽然提高了排队锁在高度竞争时的时效率,也增加了其在低度竞争时的开销。因此,Beng-hong Lim 和 AnantAgarwal 将简单的测试并设置锁与排队锁结合,在低度竞争时使用测试并设置锁,在高度竞争时切换到排队锁,因此得以在低度竞争时获得低开销,并在高度竞争时获得公平的高吞吐量。Browning 等人采取了类似的方法,但避免了单独标志的使用,这样测试并设置锁的快速路径可以使用简单测试和设置锁实现所用的代码。这种方法已经用于生产环境。
在高度锁竞争中出现的另一个问题是当锁的持有者受到延迟,特别是当延迟的原因是抢占时,这可能导致优先级翻转,其中低优先级的线程持有锁,但是被中等优先级且绑定在某 CPU 上的线程抢占,这导致高优先级线程在尝试获取锁时阻塞。结果是绑定在某 CPU 的中优先级进程阻止高优先级进程运行。一种解决方案是优先级继承,这已被广泛用于实时计算,尽管这种做法仍有一些持续的争议。
避免优先级翻转的另一种做法是在持有锁时防止抢占。由于在持有锁的同时防止抢占也提高了吞吐量,因此大多数私有的 UNIX 内核都提供某种形式的调度器同步机制,当然这主要是由于某家大型数据库供应商的努力。这些机制通常采取提示的形式,即此时不应当抢占。这些提示通过在特定寄存器中设置某个比特位的形式实现,这使得提示机制拥有极低的锁获取开销。作为对比,Linux 没有使用提示机制,而是用一种称为 futexes 的机制来获得类似的效果。
有趣的是,在锁的实现中原子指令并不是不可或缺的部分。在 Herlihy 和 Shavit 的教科书中可以找到一种锁的漂亮实现,只使用简单的加载和存储,提到这点的目的是,虽然这个实现没有什么实际应用,但是详细的研究这个实现将非常具有娱乐性和启发性。不过,除了下面描述的一个例外,这样的研究将留下作为读者的练习。
Gamsa 等人描述了一种基于令牌的机制,其中令牌在 CPU 之间循环,当令牌到达给定的 CPU 时,它可以排他性的访问由该令牌保护的任何内容。很多方案可以实现这种基于令牌的机制,例如:
- 维护一个每 CPU 标志,对于除一个 CPU 之外的所有 CPU,其标志始终为 0。当某个 CPU 的标志非 0 时,它持有令牌。当它不需要令牌时,将令牌置 0,并将下一个 CPU 的标志设置为 1 或其他任何非 0 标志值。
- 维护每 CPU 计数器,其初始值设置为对应 CPU 的编号,我们假定其范围值为 0 到 N-1,其中 N 是 CPU 的数目。当某个 CPU 的计数大于下一个 CPU 的计数时(要考虑计数的溢出),这个 CPU 持有令牌。当它不需要令牌时,它将下一个 CPU 的计数器设置为一个比自己的计数更大的值。
这种锁不太常见,因为即使没有其他 CPU 正在持有令牌,给定的 CPU 也不一定能立即获得令牌。相反,CPU 必须等待直到令牌到来。当 CPU 需要定期访问临界区的情况下这种方法很有用,但是必须要容忍不确定的令牌传递速率。Gamas 等人使用它来实现一种 RCU 的变体,但是这种方法也可以用于保护周期性的每 CPU 操作,例如冲刷内存分配器使用的每 CPU 缓存,或者垃圾收集的每 CPU 数据结构,又或者是将每 CPU 数据写入共享内存(或大容量存储)。
随着越来越多的人熟悉并行硬件及并且越来越多的并行化代码,我们可以期望出现更多的专用加解锁原语。不过,你应该仔细考虑这个重要的安全提示,只要可能,尽量使用标准同步原语。标准同步原语与自己开发的原语相比,最大的优点就是标准原语通常更不容易出现 BUG。
基于所的存在保证
并行编程一个关键挑战是提供存在保证,使得在整个访问尝试过程中,可以在保证该对象存在的前提下访问给定对象。在某些情况下,存在保证是隐式的。
- 基本模块中的全局变量和静态局部变量在应用程序正在运行时存在。
- 加载模块中的全局和静态局部变量在该模块保持加载时存在。
- 只要存在至少一个函数还在被使用,包括将保持加载状态。
- 给定的函数实例的堆栈变量,在该实例返回前一直存在。
- 如果你正在某个函数中执行,或者正在被这个函数调用(直接或间接),那么这个函数一定有一个获得实例。
虽然这些隐式存在保证非常直白,但是设计隐式存在保证的故障真的发生过。
但更有趣也更麻烦的涉及堆内存的存在保证,动态分配的数据结构将存在到它被释放为止。这里要解决的问题是如何将结构的释放和对其的并发访问同步起来。一种方法是使用显式保证,例如加锁。如果给定结构只能在持有一个给定的锁时被释放,那么持有锁就保证那个结构的存在。
但这种保证取决于锁本身的存在。一种保证锁存在的简单方式是把锁放在一个全局变量内,但全局锁具有可扩展性受限的特点。有种可以让可扩展性随着数据结构的大小增加而改进的方法,是在每个元素中放置锁的结构。不幸的是,把锁放在一个数据元素中以保护这个数据元素本身的做法会导致微秒的竟态条件。
解决该问题的方式是使用一个全局锁的哈希集合,使得每个哈希桶都有自己的锁。该方法允许在获取指向数据元素的指针之前获取合适的锁。虽然这种方式对于只存放单个数据结构中的元素非常有效,比如哈希表,但是如果有某个数据元素可以是多个哈希表成员,或者更复杂的数据结构,比如树或图时,就会有问题了。不过这些问题还是可以解决的,事实上,这些解决办法形成了基于锁的软件事务性内存实现。后续将介绍如何简单快速地提供存在保证。
锁:英雄还是恶棍
如现实生活中的情况一样,锁可以是英雄也可以是恶棍,既取决于如何使用它,也取决于要解决的问题。以作者的经验,那些写应用程序的家伙很喜欢锁,那些写并行库的同行不那么开心,那些需啊哟并行化现有顺序库的人则非常不爽。
应用程序中的锁:英雄
当编写整个应用程序时(或整个内核)时,开发人员可以完全控制设计,包括同步设计,假设设计中能够良好地使用分割,锁可以是非常有效的同步机制,锁在生产环境级别的高质量并行软件中大量使用已经说明了一切。
然而,尽管通常其大部分同步设计是基于锁,这些软件也几乎总还是利用了其他一些同步机制,包括特殊计数算法、数据所有权、引用计数、顺序锁和 RCU。此外,业界也使用死锁检测工具。获取/释放锁平衡工具、高速缓存未命中分析和基于计数器的性能剖析等等。
通过仔细设计、使用良好的同步机制和良好的工具,锁在应用程序和内核领域工作的相当出色。
并行库中的锁:只是一个工具
与应用程序和内核不同,库的设计者不知道与库函数交互的代码中锁是如何设计的。事实上,那段代码可能在几年后才会出现。因此,库函数设计者对锁的控制力较弱,必须在思考同步设计时更加小心。
死锁当然是需要特别关注的,这里需要运用前面介绍死锁时提到的技术。一个流行的死锁避免策略是确保库函数中的锁是整个程序的锁层次中的独立子树。然而,这个策略实现起来可能比他看起来更难。
前面死锁一节中讨论了一种复杂情况,即库函数调用应用程序代码,qsort() 的比较函数的参数是切入点。另一个复杂情况是与信号处理程序的交互。如果库函数接收的信号调用了应用程序的信号处理函数,几乎可以肯定这会导致死锁,就像库函数直接调用了应用程序的信号处理程序一样。最后一种复杂情况发生在那些可以在 fork() 和 exec() 之间使用的库函数,例如,由于使用了 system() 函数。在这种情况下,如果你的库函数在 fork() 的时候持有锁,那么子进程就在持有该锁的情况下出生。因为会释放锁的线程在父进程运行,而不是子进程,如果子进程调用你的库函数,死锁会随之而来。
在这些情况下,可以使用一下策略来避免死锁问题:
- 不要使用回调或信号。
- 不要从回调或信号处理函数中获取锁。
- 让调用者控制同步。
- 将库 API 参数化,以便让调用者处理锁。
- 显式地避免回调死锁。
- 显式地避免信号处理程序死锁。
既不使用回调,也不使用信号
如果库函数避免使用回调,并且应用程序作为一个整体也避免使用信号,那么由该库函数获得的任何锁将是锁层次中的叶子节点。这种安排避免了死锁。虽然这个策略在其适用时工作的非常好,但是有一些应用程序必须使用信号处理程序,并且有一些库函数必须使用回调。这时可以使用下一个策略。
避免在回调和信号处理函数中用锁
如果回调和处理函数都不获取锁,他们就不会出现在死锁循环中,这使得库函数只能成为锁层次树上的叶子节点。这个策略对于 qsort 的大多数使用情况非常有效,它的回调通常只是比较两个传递给回调的值。这个策略也奇妙地适合许多信号处理函数,通常来说在信号处理函数内获取锁是不明智的行为,但如果应用程序需要处理来自信号处理函数的复杂数据结构,这种策略可能会行不通。
这里有一些方法,即便必须操作复杂的数据结构也可以避免在信号处理函数中获取锁。
- 使用基于非阻塞同步的简单数据结构。
- 如果数据结构太复杂,无法合理使用非阻塞同步,那么创建一个允许非阻塞入队操作的队列。在信号处理函数中,而不是在复杂的数据结构中,添加一个元素到队列,描述所需的更改。然后一个单独的线程在队列中将元素删除,并执行需要使用锁的更改。关于并发队列已经有很多现成的实现。
这种策略应当在偶尔的人工或(最好是)自动的检查回调和信号处理函数时强制使用。当进行这些检查时要小心警惕,防止那些聪明的开发者(不明智地)自制一些使用原子操作的加锁原语。
调用者控制的同步
让调用者控制同步。当调用者可控数据结构的不同实例调用库函数时,这招非常管用,这时每个实例都可以单独同步。例如,如果库函数要操作一个搜索树,并且如果应用程序需要大量的独立搜索树,那么应用程序可以将锁与每个树关联。然后应用程序获取并根据需要来释放锁,使得库函数完全不需要知道并行性。
但是,如果库函数实现的数据结构需要内部并发执行,则此策略将失败。例如,哈希表或并行排序。在这种情况下,库绝对必须控制自己的同步。
参数化的库函数同步
这里的想法是向库的 API 添加参数以指定要获取的锁、如何获取和释放锁。该策略允许应用程序通过指定要获取的锁(通过传入指向所的指针等)以及如何获取它们(通过传递指针来加锁和解锁),来全局避免死锁。而且还允许线程给定的库函数通过决定加锁和解锁的位置,来控制自己的并发性。
特别的,该策略允许加锁和解锁函数根据需要来阻塞信号,而不需要库函数代码关心那些信号需要被哪些锁阻塞。这种策略使用的分离关注点的方式十分有效,不过在某些情况下,后续介绍的策略将会表现的更好。
也就是说,如果需要明确的将指向所的指针传递给外部 API,必须非常小心考虑。虽然这种做法有时在所难免,但你总应该试着寻找一种替代设计。
明确地避免回调死锁
前面已经讨论了此策略的基本规则:在调用未知代码之前释放所有锁。这通常是最好的办法,因为它允许应用程序忽略库函数的锁层次结构,库函数仍然是应用程序锁层次结构中的一个叶子节点或孤立子树。
若在调用未知代码之前不能释放所有的锁,死锁一节介绍的分层锁层级就适合这种情况。例如,如果未知代码是一个信号处理函数,这意味着库函数要在所有持有锁的情况屏蔽信号,这种做法复杂且缓慢。因此,在信号处理函数(可能不明智地)获取锁的情况,可以使用下一种策略。
明确地避免信号处理函数死锁
信号处理函数的死锁可以按如下方式明确避免:
- 如果应用程序从信号处理函数中调用库函数,那么每次在除信号处理函数以外的地方调用库函数时,必须阻塞该信号。
- 如果应用程序在持有从某个信号处理函数中获取的锁时调用库函数,那么每次在除信号处理函数之外的地方调用库函数时,必须阻塞该信号。
这些规则可以通过使用类似 Linux 内核的 lockdep 锁依赖关系检测工具来检查。lockdep 的一大优点就是它从不受人类直觉的影响。
在 fork() 和 exec() 之间使用的库函数
如前所述,如果执行库函数的线程在其他线程调用 fork 时持有锁,父进程的内存会被复制到子进程,这个事实意味着子进程从被创建的那一刻就持有该锁。负责释放锁的线程运行在父进程的上下文,而不是在子进程,这意味着子进程中这个锁的副本永远不会被释放。因此,任何在子进程中调用相同库函数的尝试都将会导致死锁。
这个问题的解决方法是让库函数检查是否锁的持有者仍在运行,若不是,则通过重新初始化来“撬开”锁并再次获取它。然而,这种方法有几个漏洞:
- 受该锁保护的数据结构可能在某些中间状态,所以简单的“撬开”锁可能会导致任意内存被更改。
- 如果子进程创建了额外的线程,则两个线程可能会同时“撬开”锁,结果是两个线程都相信自己拥有锁。从而再次导致任意内存被更改。
atfork() 函数就是专门用来帮助处理这些情况的。这里的想法是注册一个三元组函数,一个由父进程在 fork 之前调用,一个由父进程在 fork 之后调用,一个由子进程在 fork 之后调用。然后可以在这三个点进行适当的清理工作。
但是要注意,atfork 处理函数的代码通常十分微秒。atfork 最适合的情况是锁保护的数据结构可以简单的由子进程重新初始化。
讨论
无论使用何种策略,对库 API 的描述都必须包含该策略和调用者如何使用该策略的清晰描述。简而言之,设计并行库时使用锁是完全可能的,但没有像设计并行应用程序那样简单。
并行化串行库时的锁:恶棍
随着到处可见的低成本多核系统的出现,常见的任务往往是并行化已有的库,这些库的设计仅考虑了单线程使用的情况。从并行编程的角度看,这种对于并行性的全面忽视可能导致库函数 API 的严重缺陷。比如:
- 隐式的禁止分割。
- 需要锁的回调函数。
- 面向对象的意大利面条式代码。
禁止分割
假设你正在编写一个单线程哈希表实现。可以很容易并且快速地得到哈希表中元素总数的精确计数,同时也可以很容易并且快速地在每次添加和删除操作后返回此计数。所以为什么在实际中不这么做呢?
一个原因是精确计数器在多核系统上要么执行错误,要么扩展性不佳。因此,并行化这个哈希表的实现将会出现错误或者扩展性不佳的情况。
那么我们能做什么呢?一种方式是返回近似计数,另一种方式是完全不用元素计数。无论哪种方式,都有必要检查哈希表的使用,看看为什么添加和删除操作需要元素的精确计数。这里有几种可能性:
- 确定何时调整哈希表的大小。这时,近似计数应该工作得很好。调整大小的操作也可以由哈希桶中最长链的长度触发,如果合理分割每个哈希桶的话,那么很容易得出每个链的长度。
- 得到遍历整个哈希表所需的大概时间。这时,使用近似计数也不错。
- 处于诊断的目的。例如,检查传入哈希表和从哈希表传出时丢失的元素。然而,鉴于这种用法是诊断性目的,分别维护每个哈希链的长度也可以满足要求,然后偶尔再锁住添加删除操作时将各个长度求和输出。
现在有一些理论基础研究,阐述了并行库 API 在性能和扩展性上受到的约束。任何设计并行库的人都需要密切注意这些约束。
虽然对于一个对并发不友好的 API 来说,人们很容易去职责锁是罪魁祸首,但这并没有用。另一方面,人们除了同情当年写下这段代码的倒霉程序员之外,也没有什么更好的办法。如果程序员能在 1985 年就能遇见未来对并行性的需求,那简直是稀罕和高瞻远瞩,如果那时就能设计出一个对并行友好的 API,那真是运气和荣耀的罕见巧合了。
随着时间的变化,代码必须随之改变。也就是说,如果某个受欢迎的库拥有大量用户,在这种情况下对 API 进行不兼容的更改将是相当愚蠢的。添加一个对并行友好的 API 来补充现有的串行 API,可能是这种情况下的最佳行动方案。
然而,出于人类的本性,不行的开发者们更可能抱怨的是锁带来的问题,而不是他们自身对糟糕(虽然可以理解) API 的设计选择。
容易死锁的回调
前面已经描述了对回调的无规律使用将提高加锁的难度,同时还描述了如何设计库函数来避免这些问题,但是期望一个 20 世纪 90 年代的程序员在没有并行编程经验时就能遵循这些设计,是不是有点不切实际?因此,尝试并行化拥有大量回调的已有单线程程序库的程序员,很可能会相当憎恨锁。
如果有一个库使用了大量回调,可能明智的举动是向库函数中添加一个并行友好的 API,以允许现有用户逐步进行代码的切换。或者,一些人主张在这种情况下使用事务内存。有一点需要注意,硬件事务内存无助于解决上述情景,除非硬件事务内存实现提供了前进保证(forward-progress guarantee),不过很少有事务内存做到这一点。
面向对象的意大利面条式代码
从 20 世纪 80 年代末或 90 年代初的某个时候,面向对象编程变得流行起来,因此在生产环境中出现了大量面向对象式的代码,大部分是单线程的。虽然 OO 是一种很有价值的软件技术,但是毫无节制的使用对象可以很容易写出面向对象式的意大利面条代码。在面向对象式的意大利面条代码中,执行流基本上是以随机的方式从一个对象走到另一个对象,使得代码难以理解,甚至无法加入锁层次结构。
虽然很多人可能会认为,不管在任何情况下这样的代码都应该清理,说着容易做着难。如果你的任务是并行化这样的野兽,通过对前面描述的技巧的运用,以及后续将继续讨论的技术,你对人生(还有锁)感到绝望的机会会大大减少。这种场景似乎是事务性内存出现的原因,所以事务内存也值得一试。也就是说,应该根据前面讨论的硬件习惯来选择同步机制,如果同步机制的开销大于那些被保护的操作一个数量级,结果必然不会漂亮。
这些情况下有一个问题值得提出,代码是否应该继续保持串行执行?例如,或许在进程级别而不是线程级别引入并行性。一般来说,如果任务证明是非常困难,确实值得花一些时间思考并通过其他方法来完成任务,或者通过其他任务来解决手头的问题。
总结
锁也许是最广泛也最常用的同步工具。然而,最好是在一开始设计应用程序或库时就把锁考虑进去。考虑可能要花一整天的时间,才能让很多已有的单线程代码并行运行,因此锁不应该是并行编程工具箱里的唯一工具。
8 - CH08-数据所有权
避免锁带来的同步开销的最简单方式之一,就是在线程之间(或者对于内核来说,CPU 之间)包装数据,以便让数据仅被一个线程访问或修改。这种方式非常重要,事实上,它是一种应用模式,甚至新手凭借本能也会如此使用。
多进程
在前面基于 Shell 的并行编程示例中,两个进程之间不共享内存。这种方法几乎完全消除了同步开销。这种极度简单和最佳性能的组合显然是相当有吸引力的。
部分数据所有权和 pthread 线程库
在第五章“计数”中大量使用了数据所有权技术,但是做了一些改变。不允许线程修改其他线程拥有的数据,但是允许线程读取这些数据。总之,使用共享内存允许更细粒度的所有权和访问权限概念。
纯数据所有权也是常见且有用的。比如前面讨论的每线程内存分配器缓存,在该算法中,每个线程的缓存完全归该线程所有。
函数输送
上面讨论的是一种弱形式的数据所有权,线程需要更改其他线程的数据。这可以被认为是将数据带给他需要的函数。另一种方式是将函数发送给数据。
指派线程
前面的小节描述了允许每个线程保留自己的数据副本或部分数据副本的方式。相比之下,本节将描述一种分解功能的方式,其中特定的指定线程拥有完成其他工作所需的数据的权限。之前讨论的最终一致性计数器实现就提供了一个例子。eventual() 函数中运行了一个指定线程,该线程周期性地将每线程计数拉入全局计数器,最终将全局计数器收敛于实际值。
私有化
对于共享内存的并行程序,一种提升性能的和可扩展性的方式是将共享数据转换成由特定线程拥有的私有数据。
比如使用私有化方式来解决哲学家就餐问题,这种方式具有比标准教科书解法更好的性能和扩展性。原来的问题是 5 个哲学家坐在桌子旁边,每个相邻的哲学家之间有一把叉子,最多允许两个哲学家同时就餐。我们可以通过提供 5 把额外的叉子来简单地私有化这个问题,所有每个哲学家都有自己的私人叉子。这允许所有 5 个哲学家同时就餐,也大大减少了一些传播疾病的机会。
在其他情况下,私有化会带来开销。总之,在并行程序员的工具箱中,私有化是一个强大的工具,但必须小心使用。就像其他同步原语一样,他可能会带来复杂性,同时降低性能和扩展性。
数据所有权的其他用途
当数据可以被分割时,数据所有权最为有效,此时很少或没有需要跨线程访问或更新的地方。幸运的是,这种情况很常见,并且在各种并行编程环境中广泛存在。
- 所有消息传递环境,例如 MPI。
- MapReduce。
- 客户端——服务器系统,包括 RPC、Web 服务好几乎任何带有后端数据库服务的系统。
- 无共享式数据库系统。
- 具有单独的每进程地址空间的 fork-join 系统。
- 基于进程的并行性,比如 Erlang 语言。
- 私有变量,例如 C 语言在线程环境中的堆栈自动变量。
数据所有权可能是最不起眼的同步机制。当使用得当时,它能提供无与伦比的简单性、性能、扩展性。也许他的简单性使他没有得到应有的尊重。
9 - CH09-延后处理
延后工作的策略可能在人类有记录历史出现之前就存在了,它偶尔被嘲笑为拖延甚至纯粹的懒惰。但直到最近几十年,人们才认识到该策略在简化并行化算法的价值。通用的并行编程延后处理方式包括引用计数、顺序锁、RCU。
引用计数
引用计数指的是跟踪一个对象被引用的次数,防止对象被过早释放。虽然这是一种概念上很简单的技术,但是细节中隐藏着很多魔鬼。毕竟,如果对象不会太提前释放,那么就不需要引用计数了。但是如果容易被提前释放,那么如何阻止对象在获取引用计数过程中被提前释放呢?
该问题有以下几种可能的答案:
- 在操作引用计数时必须持有一把处于对象之外的锁。
- 使用不为 0 的引用计数创建对象,只有在当前引用计数不为 0 时才能获取新的引用计数。如果线程没有对某指定对象的引用,则它可以在已经具有引用的另一线程的帮助下获得引用。
- 为对象提供存在担保,这样在任何有实体尝试获取引用的时刻都无法释放对象。存在担保通常是由自动垃圾收集器来提供,并且在后续章节介绍的 RCU 中也会能提供存在担保。
- 为对象提供类型安全的存在担保,当获取到引用时将会执行附加的类型检查。类型安全的存在担保可以由专用内存分配器提供,也可以由 Linux 内核中的 SLAB_DESTORY_BY_RCU 特性提供。
当然,任何提供存在担保的机制,根据其定义也能提供类型安全的保证。所以本节将后两种答案合并成放在 RCU 一类,这样我们就有 3 种保护引用获取的类型,即锁、引用计数和 RCU。
考虑到引用计数问题的关键是对引用获取和释放对象之间的同步,我们共有 9 种可能的机制组合。
| 获取同步 | 释放同步—锁 | 释放同步—引用计数 | 释放同步—RCU |
|---|---|---|---|
| 锁 | — | CAM | CA |
| 引用计数 | A | AM | A |
| RCU | CA | MCA | CA |
下图将引用计数机制归为以下几个大类:
- (—):简单计数,不适用原子操作、内存屏障、对齐限制。
- (A):不使用内存屏障的原子计数。
- (AM):原子计数,仅在释放时使用内存屏障。
- (CAM):原子计数,在获取时使用原子操作检查,在释放时使用内存屏障。
- (CA):原子计数,在获取时使用原子操作检查。
- (MCA):原子计数,在获取时使用原子操作检查,同时还使用内存屏障。
但是,由于 Linux 内核中所有“返回值的原子”都包含内存屏障,所有释放操作也包含内存屏障。因此类型 CA 和 MCA 与 CAM 相等,这样就剩下四种类型:—、A、AM、CAM。后续章节将会列出支持引用计数的 Linux 原语。稍后的章节也将给出一种优化,可以改进引用获取和释放十分频繁、而很少需要检查引用是否为 0 这一情况下的性能。
各种引用计数的实现
简单计数
简单计数,既不使用原子操作、也不使用内存屏障,可以用于在获取和释放引用计数时都用同一把锁保护的情况。在这种情况下,引用计数可以以非原子操作方式读写,因为锁提供了必要的互斥保护、内存屏障、原子指令和禁用编译器优化。这种方式适用于锁在保护引用计数之外还保护其他操作的情况,这样也使得引用一个对象必须得等到锁(被其他地方)释放后再持有。
原子计数
原子计数适用于这种情况:任何 CPU 必须先持有一个引用才能获取引用。这是用在当单个 CPU 创建一个对象以供自己使用时,同时也允许其他 CPU、任务、定时器处理函数或者 CPU 后来产生的 IO 完成回调处理函数来访问该对象。CPU 在将对象传递给其他实体之前,必须先以该实体的名义获取一个新的引用。在 Linux 内核中,kref 原语就是用于这种引用计数的。
因为锁无法保护所有引用计数操作,所以需要原子计数,这意味着可能会有两个不同的 CPU 并发地操纵引用计数。如果使用普通的增减函数,一对 CPU 可以同时获取引用计数,假设他们都获取到了计数值 3。如果他们各自都增加各自的值,就得到计数值 4,然后将值写回引用计数中。但是引用计数的新值本该是 5,这样就丢失了其中一次增加。因此,计数的增减操作必须使用原子操作。
如果释放引用计数由锁或 RCU 保护,那么就不需要再使用内存屏障了(以及禁用编译器优化),并且锁也可以防止一对释放操作同时执行。如果是 RCU,清理必须延后直到所有当前 RCU 读端的临界区执行完毕,RCU 框架会提供所有需要的内存屏障和进制编译器优化。因此,如果 2 个 CPU 同时释放了最后 2 个引用,实际的清理工作将延后到所有 CPU 退出它们读端的连接区才会开始。
带释放内存屏障的原子计数
Linux 内核的网络层采用了这种风格的引用,在报文路由中用于跟踪目的地缓存。实际的实现要更复杂一点,本节将关注 struct_dst_entry 引用计数是如何满足这种实例的。
如果调用者已经持有一个 dst_entry 的引用,那么可以使用 dist_clone() 原语,该原语会获取另一个引用,然后传递给内核中的其他实体。因为调用者已经持有了一个引用,dis_clone() 不需要再执行任何内存屏障。将 dst_entry 传递给其他实体的行为是否需要内存屏障,要视情况而定,不过如果需要内存屏障,那么内存屏障已经嵌入在传递给 dst_entry 的过程中了。
dist_release() 原语可以在任何情况下调用,调用者可能在调用 dst_release() 的上一条语句获取 dst_entry 结构的元素的引用。因此在第 14 行上,dst_release() 原语包含了一个内存屏障,阻止编译器和 CPU 的乱序执行。
请注意,开发者在调用 dst_clone() 和 dst_release() 时不需要关心内存屏障,只需要了解使用这两个原语的规则就够了。
带检查和释放内存屏障的原子计数
引用计数的获取和释放可以并发执行这一事实增加了引用计数的复杂性。假设某次引用计数的释放操作发现引用计数的新值为 0,这表明他现在可以安全清除被引用的对象。此时我们肯定不希望在清理工作进行时又发生一次引用计数的获取操作,所以获取操作必须包含一个检查当前引用值是否为 0 的检查。该检查必须是原子自增的一部分。
Linux 黑盒的 fget() 和 fput() 原语都属于这种风格的引用计数,下面是简化后的实现:
第 4 行的 fget 取出一个指向当前进程的文件描述符表的指针,该表可能在多个进程间共享。第 6 行调用 rcu_read_lock,进入 RCU 读端临界区。后续任何 call_rcu 原语调用的回调函数将延后到对应的 rcu_read_unlock 完成后执行。第 7 行根据参数 fd 指定的文件描述符,查找对应的 struct file 结构,文件描述符的内容稍后再讲。如果指定的文件描述符存在一个对应的已打开文件,那么第 9 行尝试原子地获取一个引用计数。如果第 9 行的操作失败,那么第 10、11 行退出 RCU 读写端临界区,返回失败。如果第 9 行的操作成功,那么第 14、15 行退出读写端临界区,返回一个指向 struct file 的指针。
fcheck_files 原语是 fget 的辅助函数。该函数使用 rcu_dereference 原语来安全地获取受 RCU 保护的指针,用于之后的解引用(这会在如 DEC Alpha 之类的 CPU 上产生一个内存屏障,在这种机器上数据依赖并不保证内存顺序执行)。第 22 行使用 rcu_dereference 来获取指向任务当前的文件描述符表的指针,第 25 行获取该 struct file 的指针,然后调用 rcu_dereference 原语。第 26 行返回 struct file 的指针,如果第 24 行检查失败,那么这里返回 NULL。
fput 原语释放一个 struct file 的引用。第 31 行原子地减少引用计数,如果自减后值为 0,那么第 32 行调用 call_rcu 原语来释放 struct file(通过 call_rcu() 的第二个参数指定的 file_free_rcu 函数),不过这只在当前所有执行 RCU 读端临界区的代码执行完毕后才会发生。等待当前所有执行 RCU 读端临界区的时间被称为“宽限期”。请注意,atomic_dec_and_test 原语中包含一个内存屏障。在本例中该屏障并非必要,因为 struct file 只有在所有 RCU 读端临界区完成后才能销毁,但是在 Linux 中,根据定义所有会返回值的原子操作都需要包含内存屏障。
一旦宽限期完毕,第 39 行 file_free_rcu 函数获取 struct file 的指针,第 40 行释放该指针。
本方法也用于 Linux 虚拟内存系统中,请见针对 page 结构的 get_page_unless_zero 和 put_page_test_zero 函数,以及针对内存映射的 try_to_unuse 和 mmput 函数。
危险指针
前面小节讨论的所有引用计数机制都需要一些其他预防机制,以防止在正在获取引用计数的引用时删除数据元素。该机制可以是一个预先存在的对数据元素的引用、锁、RCU 或原子操作,但所有这些操作都会降低性能和扩展性,或者限制应用场景。
有一种避免这些问题的方法是反过来实现引用计数,也就是说,不是增加存储在数据元素内的某个整数,而是在每 CPU(或每线程)链表中存储指向该数据元素的指针。这个链表里的元素被称为危险指针。每个元素都有一个“虚引用计数”,其值可以通过计算有多少个危险指针指向该元素而得到。因此,如果该元素已经被标记为不可访问,并且不再有任何引用它的危险指针,该元素就可以安全地释放。
当然,这意味着危险指针的获取必须要谨慎,以避免并发删除导致的破坏性后果。
因为使用危险指针的算法可能在他们的任何步骤中重新启动对数据结构的遍历,这些算法通常在获得所有危险指针之前,必须注意避免对数据结构进行任何更改。
以这些限制为交换,危险指针可以为读端提供优秀的性能和扩展性。在第十章将会比较危险指针及其他引用计数机制的性能。
支持引用计数的 Linux 原语
atomic_t,可提供原子操作的 32 位类型定义。void atomic_dec(atomic_t *var),不需要内存屏障或阻止编译器优化的原子自减引用计数操作。int atomic_dec_and_test(atomic_t *var),原子减少引用计数,如果结果为 0 则返回 true。需要内存屏障并且阻止编译器优化,否则可能让引用计数在原语外改变。void atomic_inc(atomic_t *var),原子增加引用计数,不需要内存屏障或禁用编译器优化。int atomic_inc_not_zero(atomic_t *var),原子增加引用计数,如果结果不为 0,那么在增加后返回 true。会产生内存屏障并禁止编译器优化,否则引用会在原语外改变。int atomic_read(atomic_t *var),返回引用计数的整数值。非原子操作、不需要内存屏障、不需要禁止编译器优化。void atomic_set(atomic_t *var, int val),将引用计数的值设置为 val。非原子操作、不需要内存屏障、不需要禁止编译器优化。void call_rcu(struct rcu_head *head, void (*func)(struct rcu_head *head)),在当前所有执行 RCU 读端临界区完成后调用 func,不过call_rcu原语是立即返回的。请注意,head 通常是受 RCU 保护的数据结构的一个字段,func 通常是释放该数据结构的函数。从调用call_rcu到调用 func 之间的时间间隔被称为宽限期。任何包含一个宽限期的时间间隔本身就是一个宽限期。type *container_of(p, type, f),给出指针 p,指向类型为 type 的数据结构中的字段 f,返回指向数据结构的指针。void rcu_read_lock(void),标记一个 RCU 读端临界区的开始。void rcu_read_unlock(void),标记一个 RCU 读端临界区的结束。RCU 读临界区可以嵌套。void smp_mb__before_atomic_dec(vod),只有在该平台的atomic_dec原语没有产生内存屏障,禁止编译器的乱序优化时才有用,执行上面的操作。struct rcu_head用于 RCU 基础框架的数据结构,用来跟踪等待宽限期的对象。通常作为受 RCU 保护的数据结构中的一个字段。
计数优化
在经常更改计数但很少检查计数是否为 0 的场合里,像第 5 章讨论的那样,维护一个每 CPU 或者每任务计数很有用。关于此计数在 RCU 上的实例,参见关于可睡眠 RCU 的论文。该方法可避免在增减计数函数中使用原子操作或内存屏障,但还是要禁用编译器的乱序优化。另外,像 synchronize_srcu 这样的原语,检查总的引用计数是否为 0 的速度十分缓慢。这使得该方法不适合用于频繁获取和释放引用计数的场合,不过对于极少检查引用计数是否为 0 的场合还是合适的。
顺序锁
Linux 内核中使用的顺序锁主要用于保护以读取为主的数据,多个读者观察到的状态必须一致。不像读写锁,顺序锁的读者不能阻塞写者。它反而更像是危险指针,如果检测到有并发的写者,顺序锁会强迫读者重试。在代码中使用顺序锁的时候,设计很重要,尽量不要让读者有重试的机会。
顺序锁的关键组成部分是序列号,没有写着的情况下其序列号为偶数值,如果有一个更新正在进行中,其序列号为奇数值。读者在每次访问之前和之后可以对值进行快照。如果快照是奇数值,又或者如果两个快照的值不同,则存在并发更新,此时读者必须丢弃访问的结果,然后重试。读者使用 read_seqbegin 和 read_seqretry 函数访问由顺序锁保护的数据。写者必须在每次更新前后增加该值,并且在任意时间内只允许一个写者。写者使用 write_seqlock 和 write_sequnlock 函数更新由顺序锁保护的数据。
顺序锁保护的数据可以拥有任意数量的并发读者,但一次只有有一个写者。在 Linux 内核中顺序锁用于保护计时的校准值。它也用在遍历路径名时检测并发的重命名操作。
可以将顺序锁的读端和写端临界区视为事务,因此顺序锁定可以被认为是一种有限形式的事务内存,后续将会讨论。顺序锁的限制是:顺序锁限制更新和;顺序锁不允许遍历指向可能被写者释放的指针。事务内存当然不存在这些限制,但是通过配合使用其他同步原语,顺序锁也可以克服这些限制。
顺序锁允许写者延迟读者,但反之不可。在存在大量写操作的环境中,这可能引起对读者的不公平甚至饥饿。另一方面,在没有写者时,顺序锁的运行相当快且可以线性扩展。人们总是要鱼和熊掌兼得:快速的读者和不需要重试的读者,并且不会发生饥饿。此外,如果能够不受顺序锁对指针的限制就更好了。下面将介绍同时拥有这些特性的同步机制。
读-复制-修改(RCU)
RCU 介绍
假设你正在编写一个需要访问随时变化的数据的并行实时程序,数据可能是随着温度、湿度的变化而逐渐变化的大气压。该程序的实时响应要求是如此严格,不允许存在任何自旋或阻塞,因此锁就被排除了。同样也不允许使用重试循环,这就排除了顺序锁。幸运的是,温度和压力的范围通常是可控的,这样使用默认的编码数据集也可行。
但是,温度、湿度和压力偶尔会偏离默认值太远,在这种情况下,有必要提供替换默认值的数据。因为温度、湿度和压力是逐渐变化的,尽管数值必须在几分钟内更新,但提供更新值并不是非常紧急的事情。该程序使用一个全局指针,即 gptr,通常为 NULL,表示要使用默认值。否则,gptr 指向假设命名为 a/b/c 的变量,它们的值用于实时计算。
我们如何在不妨碍实时性的情况下安全地为读者提供更新后的数据呢?
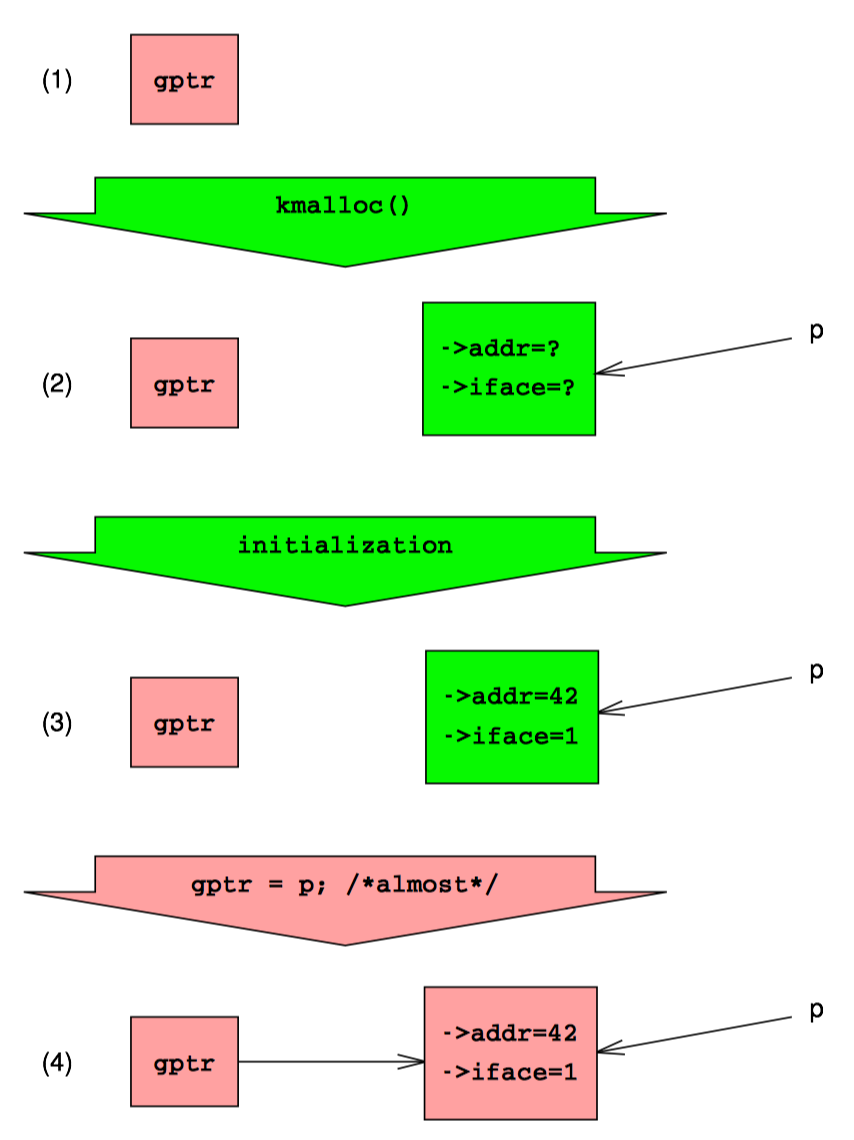
上图是一种经典的方式。第一排显示默认状态,其中 gptr 等于 NULL。在第二排中,我们已经分配了一个默认的结构,如问号所示。在第三排,我们已经初始化了该结构。接下来,我们让 gptr 来引用这个新元素。在现代计算机系统中,并发的读者要么看到一个 NULL 指针、要么看到指向新结构 p 的指针,不会看到中间结果,从这种意义上说,这种赋值是原子的。因此,每个读者都可以读到默认值 NULL,或者获取新赋值的非默认值。但无论哪种方式,每个读者都会看到一致的结果。更好的是,读者不需要使用任何昂贵的同步原语,因此这种方式非常适合用于实时场景。
但是我们迟早需要从并发的读者手中删除指向指针的数据。让我们转到一个更加复杂的例子,我们正在删除一个来自链表的元素,如下图:
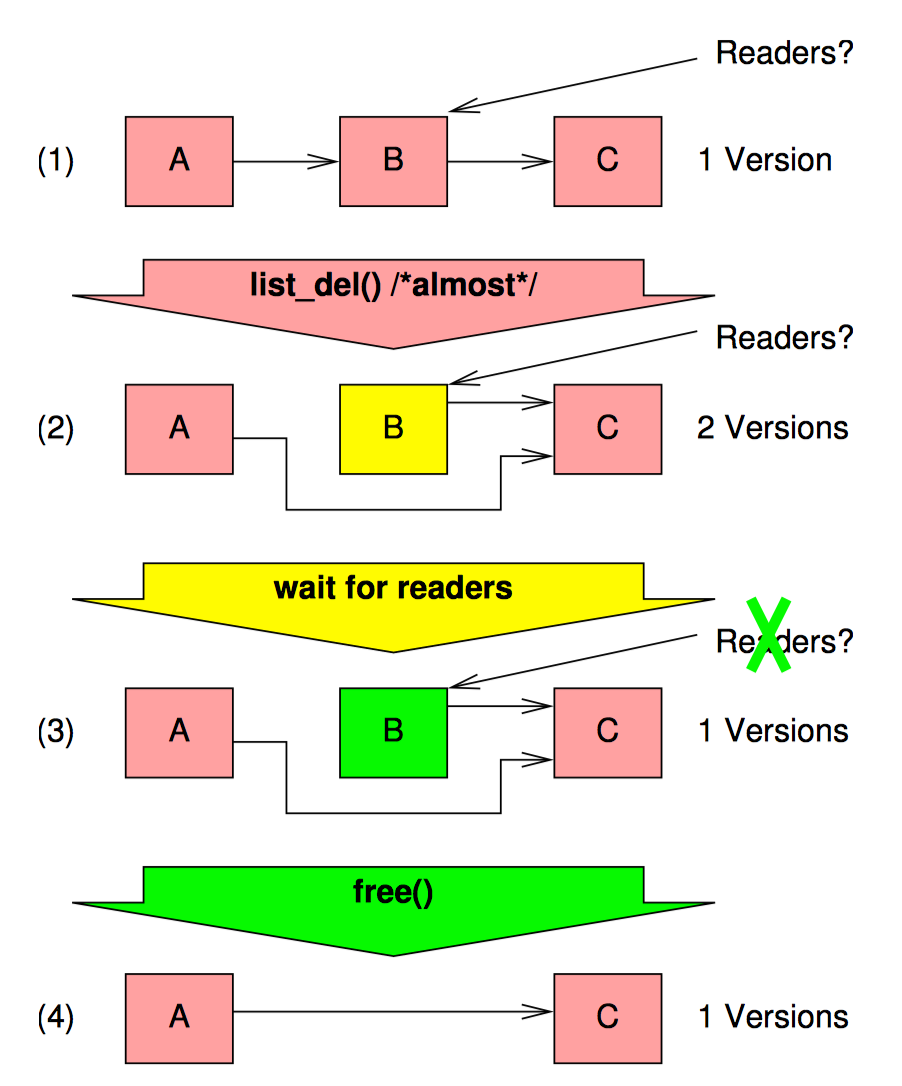
此链表最初包含元素 A/B/C,首先我们需要删除元素 B,我们使用 list_del() 执行删除操作,此时所有新加入的读者都将看到元素 B 已经从链表删除了。然而,可能仍然有老读者在引用这个元素。一旦所有这些旧的读者读取完成,我们可以安全地释放元素 B,如图中最后一部分所示。
但是我们怎么知道读者何时完成读取呢?
引用计数的方案很有诱惑力,但是这也可能导致长延迟,正如锁和顺序锁,我们已经拒绝这种选择。
让我们考虑极端情况下的逻辑,读者完全不将他们的存在告诉任何人。这种方式显然让读者的性能更佳(毕竟免费是一个非常好的价格),但留给写者的问题是如何才能确定所有的老读者都已经完成。如果要给这个问题提供一个合理的答案,我们显然需要一些额外的约束条件。
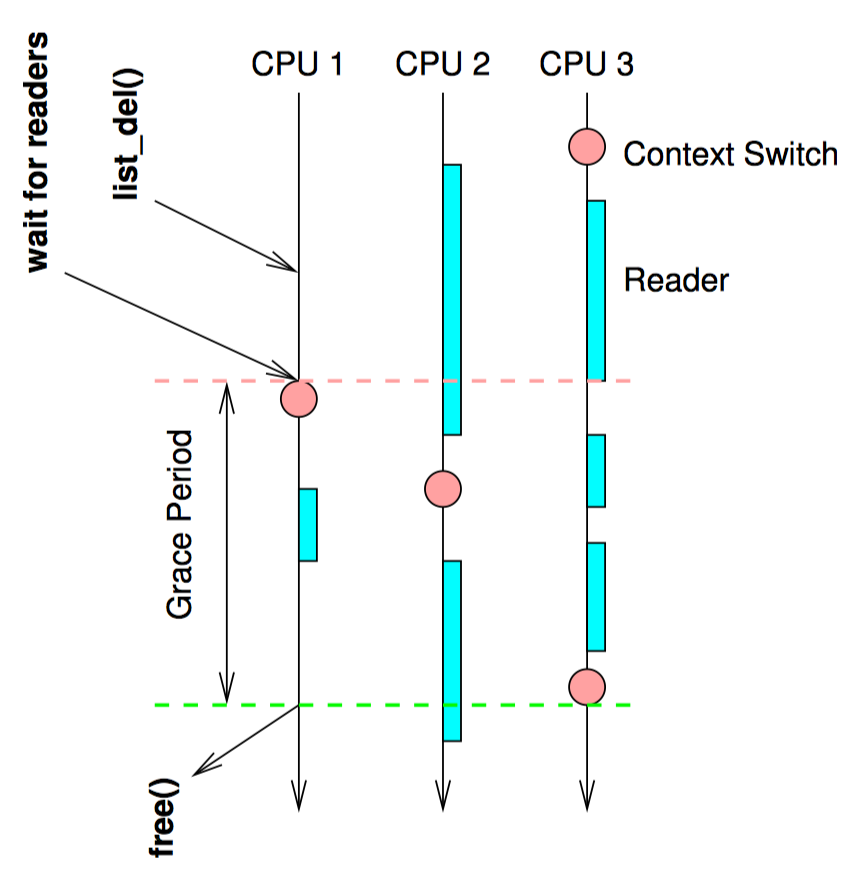
有一种约束适合某种类型的实时操作系统(以及某些操作系统内核),让线程不会被抢占。在这种不可抢占的环境中,每个线程将一直运行,直到它明确地并自愿地阻塞自己。这意味着一个不能阻塞的无限循环将使该 CPU 在循环开始后无法用于任何其他目的。不可抢占性还要求线程在持有自旋锁时禁止阻塞。如果没有这个禁止,当持有自旋锁的线程被阻塞后,所有 CPU 都可能陷入某个要求获取自旋锁的线程中无法自拔。要求获取自旋锁的线程在获得锁之前不会放弃他们的 CPU,但是持有锁的线程因为拿不到 CPU,又不能释放自旋锁。这是一种经典的死锁。
然后我们对遍历链表的读线程施加相同的约束:这样的线程在完成遍历之前不允许阻塞。返回到上图的第二排,其中写者刚刚执行完 list_del(),想象 CPU0 这时做了一个上下文切换。因为读者不允许在遍历链表时阻塞,所以我们可以保证所有先前运行在 CPU0 上的读者已经完成。将这个推理扩展到其他 CPU,一旦每个 CPU 被观察到执行了上下文切换,我们就能保证所有之前的读者都已经完成,该 CPU 不会再有任何引用元素 B 的读线程。此时写者可以安全地释放元素 B 了,也就是上图最后一排所示的状态。
这种方法的示意图如下所示,图中的时间从顶部推移到底部:
虽然这种方法在生产环境上的实现可能相当复杂,但是玩具实现却非常简单:
for_each_online_cpu(cpu);
run_on(cpu);
for_each_online_cpu() 原语遍历所有 CUP,run_on() 函数导致当前线程在指定的 CPU 上运行,这会强制目标 CPU 切换上下文。因此,一旦 for_each_online_cpu 完成,每个 CPU 都执行了一次上下文切换,这又保证了所有之前存在的读线程已经完成。
请注意,该方法不能用于生产环境。正确处理各种边界条件和对性能优化的强烈要求意味着用于生产环境的代码实现将十分复杂。此外,可抢占环境的 RCU 实现需要读者实际去做点什么事情。不过,这种简单的不可抢占方法在概念上是完整的,并为下一节理解 RCU 的基本原理形成了良好的初步基础。
RCU 基础
RCU 是一种同步机制,2002 年 10 月引入 Linux 内核。RCU 允许读操作可以与更新操作并发执行,这一点提升了程序的可扩展性。常规的互斥锁让并发线程互斥执行,并不关心该线程是读者还是写者,而读写锁在没有写者时允许并发的读者,相比于这些常规操作,RCU 在维护对象的每个版本时确保读线程保持一致,同时保证只在所有当前读端临界区都执行完毕后才释放对象。RCU 定义并使用了高效且易于扩展的机制,用来发布和读取对象的新版本,还用于延后旧版本对象的垃圾收集工作。这些机制恰当地在读端和更新端分布工作,让读端非常快速。在某些场合下(比如非抢占式内核里),RCU 读端的函数完全是零开销。
看到这里,读者通常会疑惑“究竟 RCU 是什么”,或者“RCU 怎么工作”。本节将致力于从一种基本的视角回答上述问题,稍后的章节将从用户使用和 API 的视角从新看待这些问题。最后一节会给出一个图表。
RCU 由三种基础机制构成,第一个机制用于插入,第二个机制用于删除,第三个用于让读者可以不受并发插入和删除的干扰。
订阅机制
RCU 的一个关键特性是可以安全的扫描数据,即使数据此时正被修改。RCU 通过一种发布——订阅机制达到了并发的数据插入。举个例子,假设初始值为 NULL 的全局指针 gp 现在被赋值指向一个刚分配并初始化的数据结构。如下代码所示:
1 struct foo {
2 int a;
3 int b;
4 int c;
5 };
6 struct foo *gp = NULL;
7
8 /* . . . */
9
10 p = kmalloc(sizeof(*p), GFP_KERNEL);
11 p->a = 1;
12 p->b = 2;
13 p->c = 3;
14 gp = p;
不幸的是,这块代码无法保证编译器和 CPU 会按照顺序执行最后 4 条赋值语句。如果对 gp 的复制发生在初始化 p 的各种字段之前,那么并发的读者会读到未初始化的值。这里需要内存屏障来保证事情按顺序发生,可是内存屏障又向来以难用著称。所以我们这里用一句 rcu_assign_pointer() 原语将内存屏障封装起来,让其拥有发布的语义。最后 4 行代码如下:
1 p->a = 1;
2 p->b = 2;
3 p->c = 3;
4 rcu_assign_pointer(gp, p);
rcu_assign_pointer “发布”一个新结构,强制让编译器和 CPU 在为 p 的个字段复制之后再去为 gp 赋值。
不过,只保证更新者的执行顺序并不够,因为读者也需要保证读取顺序。请看下面的代码:
1 p = gp;
2 if (p != NULL) {
3 do_something_with(p->a, p->b, p->c);
4 }
这块代码看起来好像不会受乱序执行的影响,可惜事与愿违,在 DEC Alpha CPU 机器上,还有启用编译器值推测优化时,会让 p->a, p->b, p->c 的值在 p 赋值之前被读取,此时编译器会先猜测 p->a, p->b, p->c 的值,然后再去读取 p 的实际值来检查编译器的猜测是否正确。这种类型的优化十分激进,甚至有点疯狂,但是这确实发生在档案驱动(profile-driven)优化的上下文中。
显然,我们必须在编译器和 CPU 层面阻止这种危险的优化。rcu_dereference 原语用了各种内存屏障和编译器指令来达到这一目的。
1 rcu_read_lock();
2 p = rcu_dereference(gp);
3 if (p != NULL) {
4 do_something_with(p->a, p->b, p->c);
5 }
6 rcu_read_unlock();
rcu_dereference() 原语用一种订阅的方式来获取指定指针的值。然后后续的解引用操作可以看见在对应的发布操作(rcu_read_pointer)前进行的初始化。rcu_read_lock 和 rcu_read_unlock 是肯定需要的:这对原语定义了 RCU 读端的临界区。后续将会介绍它们的意图,不过请注意,这对原语既不会自旋或阻塞,也不会组织 list_add_rcu 的并发执行。事实上,在没有配置 CONFIG_PREEMPT 的内核里,这对原语就是空函数。
虽然理论上 rcu_assign_pointer 的 rcu_dereference 可以用于构造任何能想象到的受 RCU 保护的数据结构,但是实践中常常只用于上层的构造。因此这两个原语是嵌入在特殊的 RCU 变体——即 Linux 操纵链表的 API 中。Linux 有两种双链表的变体,循环链表和哈希表 struct hlist_head/struct hlist_node。前一种如第一个图所示,深色代表链表元头,浅色代表链表元素。而第二张图给出了一种简化方法:
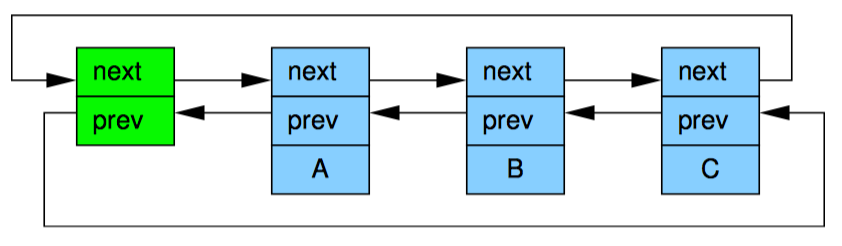

第 15 行必须采用某种同步机制(最常见的是各种锁)来保护,放置多核 list_add 实例并发执行。不过,同步并不能阻止 list_add 的实例与 RCU 的读者并发执行。
订阅一个受 RCU 保护的链表则非常直接:
1 struct foo {
2 struct list_head *list;
3 int a;
4 int b;
5 int c;
6 };
7 LIST_HEAD(head);
8
9 /* . . . */
10
11 p = kmalloc(sizeof(*p), GFP_KERNEL);
12 p->a = 1;
13 p->b = 2;
14 p->c = 3;
15 list_add_rcu(&p->list, &head);
list_add_rcu 原语向指定的链表发布了一条项目,保证对应的 list_for_each_entry_rcu 可以订阅到同一条目。
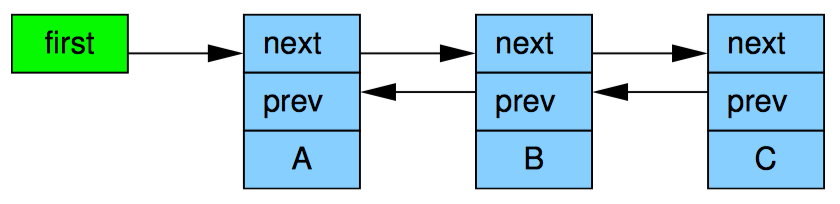
Linux 的其他双链表、哈希链表都是线性链表,这意味着它的头部节点只需要一个指针,而不是向循环链表那样需要两个,如上图所示。因此哈希表的使用可以减少哈希表的 hash bucket 数组一半的内存消耗。和前面一样,这种表示法太麻烦了,哈希表也可以用和链表一样的简化表达方式。
向受 RCU 保护的哈希表发布新元素和向循环链表的操作十分类似,如下面的示例:
1 struct foo {
2 struct hlist_node *list;
3 int a;
4 int b;
5 int c;
6 };
7 HLIST_HEAD(head);
8
9 /* . . . */
10
11 p = kmalloc(sizeof(*p), GFP_KERNEL);
12 p->a = 1;
13 p->b = 2;
14 p->c = 3;
15 hlist_add_head_rcu(&p->list, &head);
和之前一样,第 15 行必须要使用某种同步机制来保护,比如锁。
订阅受 RCU 保护的哈希表和订阅循环链表没什么区别:
1 rcu_read_lock();
2 hlist_for_each_entry_rcu(p, head, list) {
3 do_something_with(p->a, p->b, p->c);
4 }
5 rcu_read_unlock();
下表是 RCU 的订阅和发布原语,及一个取消发布原语:
| 类别 | 发布 | 取消发布 | 订阅 |
|---|---|---|---|
| 指针 | rcu_asign_pointer | rcu_assign_pointer(…, NULL) | rcu_dereference |
| 链表 | list_add_rcu list_add_tail_rcu list_replace_rcu | list_del_rcu | list_for_each_entry_rcu |
| 哈希链表 | hlist_add_after_rcu hlist_add_before_rcu hlist_add_head_rcu hlist_replace_rcu | hlist_del_rcu | hlist_for_each_entry_rcu |
请注意,list_replace_rcu/list_del_rcu/hlist_replace_rcu/hlist_del_rcu 这些 API 引入了一点复杂性。何时才能安全地释放刚被替换或删除的数据元素?我们怎么知道何时所有读者释放了他们对数据元素的引用?
这些问题将在随后的小节中得到回到。
等待已有的 RCU 读者执行完毕
从最基本的角度来说,RCU 就是一种等待事物结束的方式。当然,有很多其他的方式可以用来等待事物结束,比如引用计数、读写锁、事件等等。RCU 最伟大之处在于它可以等待 20000 种不同的事物,而无需显式的跟追他们中的每一个,也无需去单行对性能的影响、对扩展性的限制、复杂的死锁场景、还有内存泄露带来的危害等等那些使用显式跟踪手段会出现的问题。
在 RCU 的例子中,被等待的事物称为 RCU 读端临界区。RCU 读端临界区从 rcu_read_lock 原语开始,到对应的 rcu_read_unlock 原语结束。RCU 读端临界区可以嵌套,也可以包含一大段代码,只要这其中的代码不会阻塞会睡眠。如果遵守这些约定,就可以使用 RCU 去等待任何代码的完成。
RCU 通过间接地确定这些事物合适完成,才实现了这样的壮举。
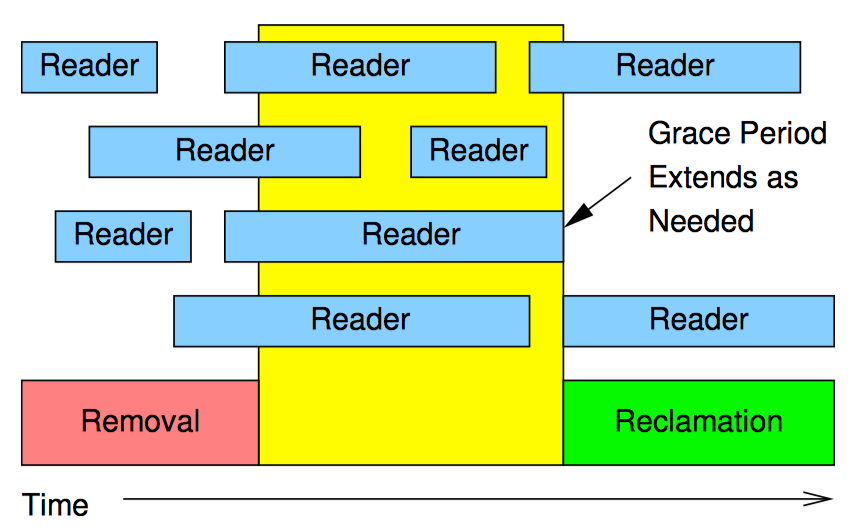
如上图所示,RCU 是一种等待已有的 RCU 读端临界区执行完毕的方法,这里的执行完毕也包括在临界区内执行的内存操作。不过请注意,某个宽限期开始后才启动的 RCU 读端临界区会扩展到该宽限期的结尾处。
下列伪代码展示了使用 RCU 等待读者的基本算法:
- 做出改变,比如替换链表中的一个元素。
- 等待所有已有的 RCU 读端临界区执行完毕,这里需要注意的是后续的 RCU 读端临界区无法获取刚刚删除元素的引用。
- 清理,比如释放刚才被替换的元素。
如下面的代码片段所示,其中演示了这个过程,其中字段 a 是搜索关键字:
1 struct foo {
2 struct list_head *list;
3 int a;
4 int b;
5 int c;
6 };
7 LIST_HEAD(head);
8
9 /* . . . */
10
11 p = search(head, key);
12 if (p == NULL) {
13 /* Take appropriate action, unlock, & return. */
14 }
15 q = kmalloc(sizeof(*p), GFP_KERNEL);
16 *q = *p;
17 q->b = 2;
18 q->c = 3;
19 list_replace_rcu(&p->list, &q->list);
20 synchronize_rcu();
21 kfree(p);
第 9、20、21 行实现了刚才提到的 3 个步骤。16~19 行正如 RCU 其名(读-复制-更新),在允许并发度的同时,第 16 行复制,17~19 更新。
正如前面讨论的 synchronize_rcu 原语可以相当简单。然而,想要达到生产质量,代码实现必须处理一些困难的边界情况,并且需要大量优化,这两者都将导致显著的复杂性。虽然知道 synchronize_rcu 有一个简单的实现很好,但是其他问题仍然存在。例如,当 RCU 读者遍历正在更新的链表时会看到什么?该问题将在下节讨论。
维护最近被更新对象的多个版本
本节将展示 RCU 如何维护链表的多个版本,供并发的读者访问。本节通过两个例子来说明在读者还处于 RCU 读端临界区时,被读者引用的数据元素如何保持完整性。第一个例子展示了链表元素的删除,第二个例子展示了链表元素的替换。
例子1:在删除过程中维护多个版本
在开始这个例子前,我们先将上面的代码中 11~20 行改为如下形式:
1 p = search(head, key);
2 if (p != NULL) {
3 list_del_rcu(&p->list);
4 synchronize_rcu();
5 kfree(p);
6 }
这段代码用下图展示的方式跟新链表。每个元素中的三个数字分别代表子弹 a/b/c 的值。红色的元素表示 RCU 读者此时正持有该元素的引用。请注意,我们为了让图更清楚,忽略了后向指针和从尾指向头的指针。
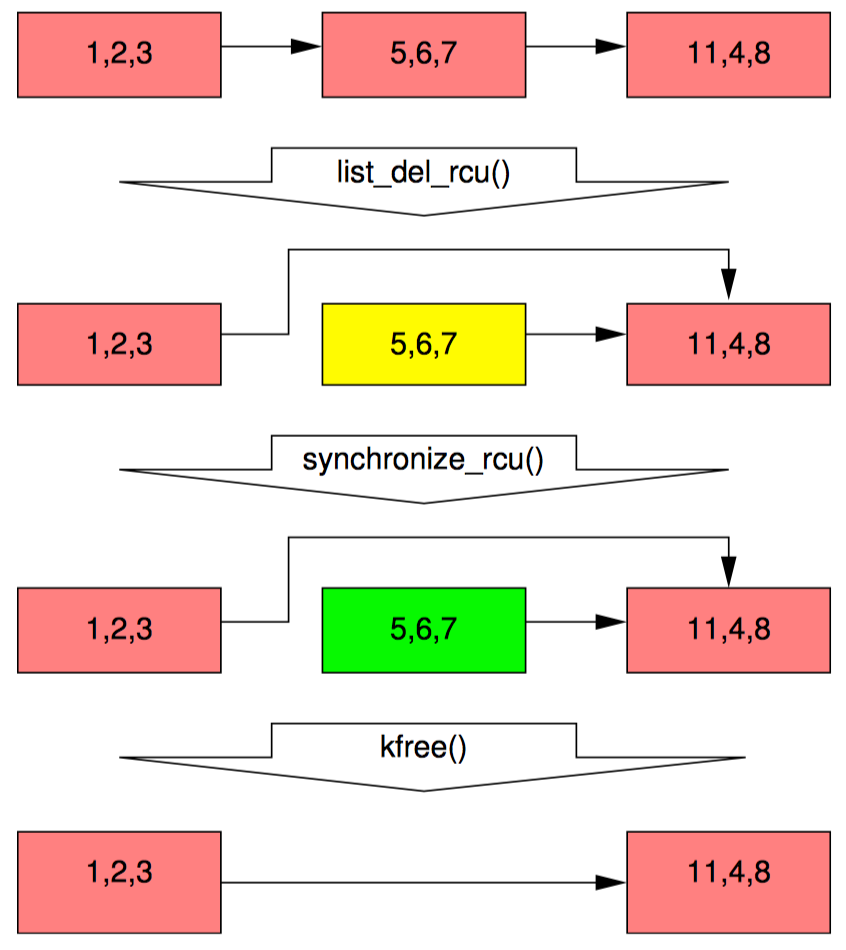
等第 3 行的 list_del_rcu 执行完毕后,5、6、7 元素从链表中被删除,如第 2 行代码所示。如果读者不直接与更新者同步,所以读者可能还在并发地扫描链表。这些并发的读者都有可能看见,也有可能看不见刚刚被删除的元素,这取决于扫描的时机。不过,刚好在取出指向被删除元素指针后被延迟的读者(比如由于终端、ECC 内存错误、配置了 CONFIG_PREEMPT_RT 内核中的抢占),有就可能在删除后还看见链表元素的值。因此,我们此时有两个版本的链表,一个拥有元素 5、6、7,而另一个没有。元素 5、6、7 用黄色标注,表名老读者可能还在引用它,但是新读者已经无法得到它的引用。
请注意,读者不允许在退出 RCU 读临界区后还维护元素 5、6、7的引用。因此,一旦第 4 行的 synchronize_rcu 执行完毕,所有已有的读者都要保证执行完成,不能再有读者引用该元素,图图中第三排的绿色部分。这样我们就又回到了唯一版本的链表。
此时,元素 5、6、7 可以被安全释放了。如图中最后一排所示。这样我们就完成了元素的删除。本节后面部分将描述元素的替换。
例子2:在替换过程中维护多个版本
在开始替换之前,我们先看看前面例子中最后几行代码:
1 q = kmalloc(sizeof(*p), GFP_KERNEL);
2 *q = *p;
3 q->b = 2;
4 q->c = 3;
5 list_replace_rcu(&p->list, &q->list);
6 synchronize_rcu();
7 kfree(p);
链表的初始状态包括指针 p 都和删除例子中一样,如下图中的第一排所示:
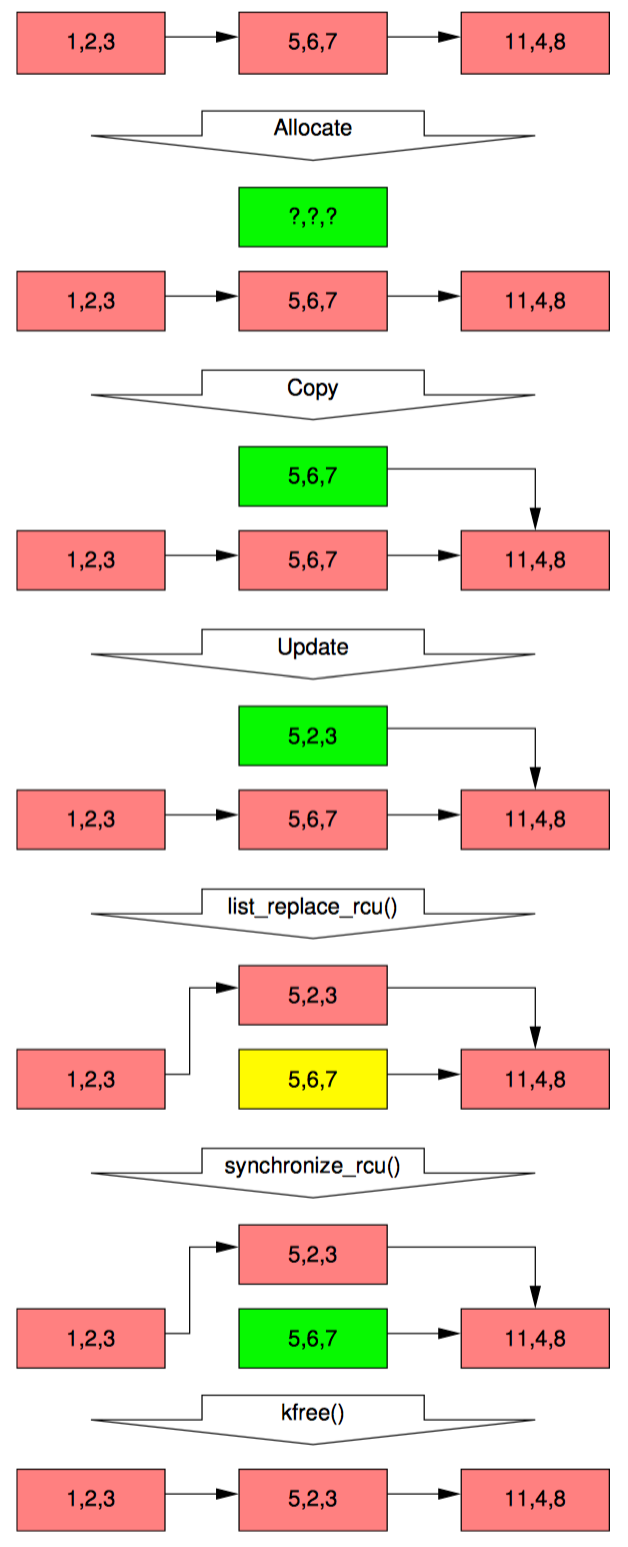
和前面一样,每个元素的三个数字分别代表字段 a/b/c。红色的元素表示读者可能正在引用,并且因为读者不直接与更新者同步,所以读者有可能与整个替换过程并发执行。请注意我们为了图表的清晰,再一次忽略了后向指针和指向头的指针。
下面描述了元素 2、5、3 如何替换元素 5、6、7 的过程,任何特定的读者都有可能看见这两个值的其中一个。
第 1 行用 kmalloc 分配了要替换的元素,如图第二排所示。此时没有读者持有刚分配的元素的引用(绿色),并且该元素是未初始化的(问号)。
第 2 行将旧元素复制给新元素,如图第三排所示。新元素此时还不能被读者访问,但是已经初始化了。
第 3 行将 q->b 的值更新为 2,这样新元素终于对读者可见了,因此颜色也变成了红色,如图第五排所示。此时,链表就有两个版本了。已经存在的老读者也可能看到元素 5、6、7(黄色),而新读者可能会看到 5、2、3。不过这里可以保证任何读者都能看到一个完好的链表。
随着第 6 行 synchronize_rcu 的返回,宽限期结束,所有在 list_replace_rcu 之前开始的读者都已经完成。特别是任何可能持有元素 5、6、7 引用的读者保证已经退出了它们的 RCU 读端临界区,不能继续持有引用。因此,不再有任何读者持有旧数据的引用,如图第六排绿色部分所示。这样我们又回到了单一版本的链表,只是用新元素替换了旧元素。
等第 7 行的 kfree 完成后,链表就成了图中最后一排的样子。
不过尽管 RCU 是因替换的例子而得名的,但是 RCU 在内核中的用途还是和简单的删除例子一样。
讨论上述这些例子假设整个更新操作都持有一把互斥锁,这意味着任意时刻最多会有两个版本的链表。
这个事件序列显示了 RCU 更新如何使用多个版本,在有读者并发的情况下安全地执行改变。当然,有些算法无法优雅地处理多个版本。有些技术在 RCU 中采用了这些算法,但是超过了本节的范围。
RCU 基础总结
本节描述了 RCU 算法的三个基本组件。
- 添加新数据的发布——订阅机制。
- 等待已有 RCU 读者结束的方法。
- 维护多个版本数据的准则,允许在不影响或延迟其他并发 RCU 读者的前提下改变数据。
这三个 RCU 组件使得数据可以在有并发读者时被改写,通过不同方式的组合,这三种组件可以实现各种基于 RCU 算法的变体,后续将会讨论。
RCU 的用法
本节将从使用 RCU 的视角,以及使用哪种 RCU 的角度来回答“什么是 RCU”。因为 RCU 最常用的目的是替换已有的机制,所以我们首先观察 RCU 与这些机制之间的关系。
RCU 是读写锁的替代者
也许在 Linux 内核中 RCU 最常见的用途就是在读占大多数时间的情况下替换读写锁了。可是在一开始我并没有想到 RCU 的这个用途,事实上在 20 世纪 90 年代初期,我在实现通用 RCU 实现之前选择实现了一种轻量的读写锁。我为这个轻量级读写锁原型想象的每个用途最后都是用 RCU 来实现了。事实上,在请练级读写锁第一次实际使用时 RCU 已经出现了不止三年了。兄弟们,我是不是看起来很傻!
RCU 和读写锁最关键的相似之处在于两者都有可以并行执行的读端临界区。事实上,在某些情况下,完全可以从机制上用对应的读写锁 API 来替换 RCU 的 API。不过,这样做有什么必要呢?
RCU 的有点在于性能、没有死锁,并能提供实时的延迟。当然 RCU 也有一些缺点,比如读者与写者并发执行,比如低优先级 RCU 读者可以阻塞正等待宽限期完毕的高优先级线程,还比如宽限期的延迟可以有好几毫秒。这些优点和缺点在后续会继续介绍。
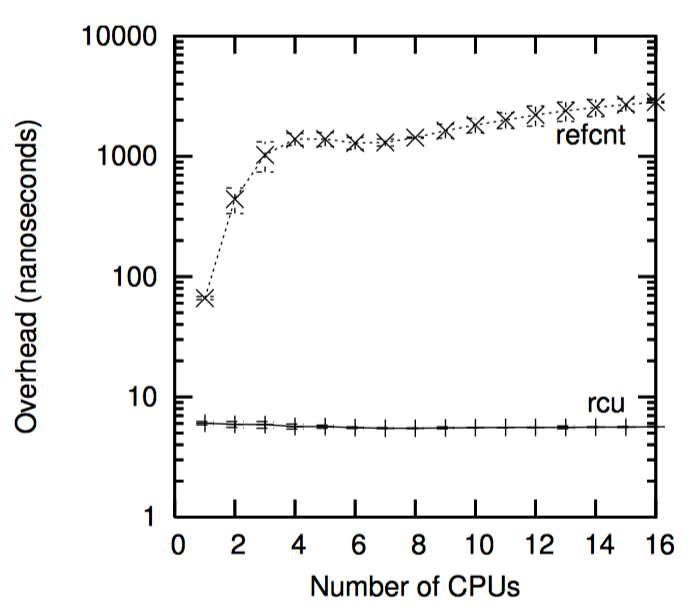
如下图,“性能 RCU”相较于读写锁在读端的性能优势。
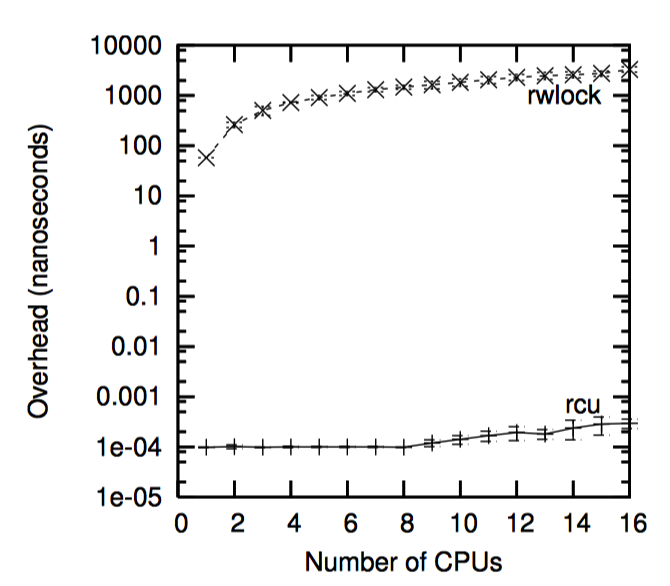
请注意,在单个 CPU 上读写锁比 RCU 慢一个数量级,在 16 个 CPU 要慢两个数量级,RCU 的扩展性要好很多。在上面两个例子中,错误曲线几乎是水平的。
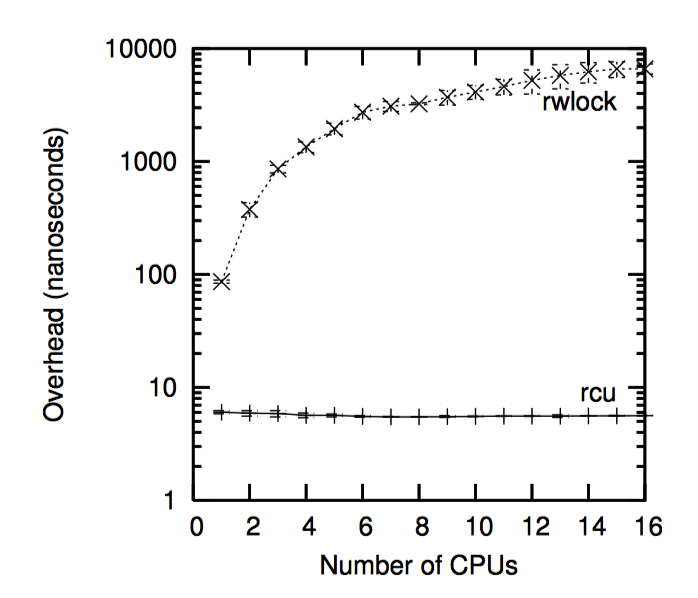
更温和的视角来自 CONFIG_PREEMPT 内核,虽然 RCU 仍然超过了读写锁 1 到 3 个数量级,如下图。请注意,读写锁在 CPU 数目很多时的陡峭曲线。在任一方向上误差都超过了一个标准差。
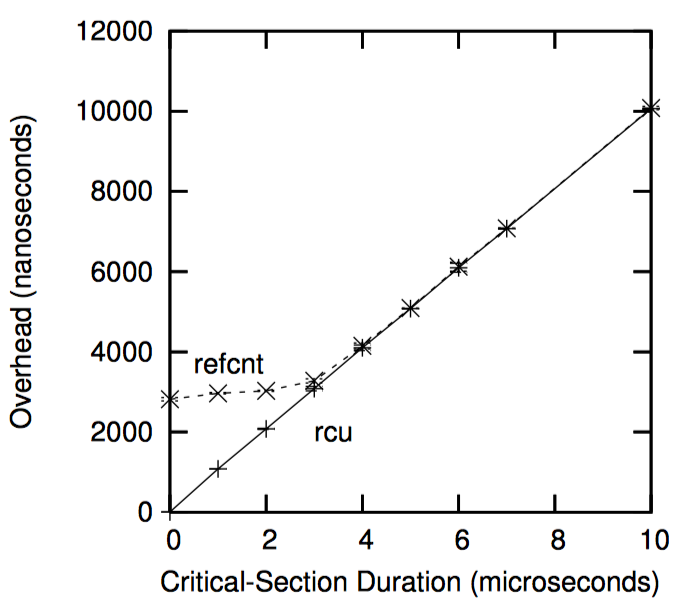
当然,如下图中所示,由于不现实的零临界区长度,读写锁的低性能被夸大了。随着临界区的增长,RCU 的性能优势也不再显著,在上图的 16 个 CPU 系统中,Y 轴代表读端原语的总开销,X 轴代表临界区长度。
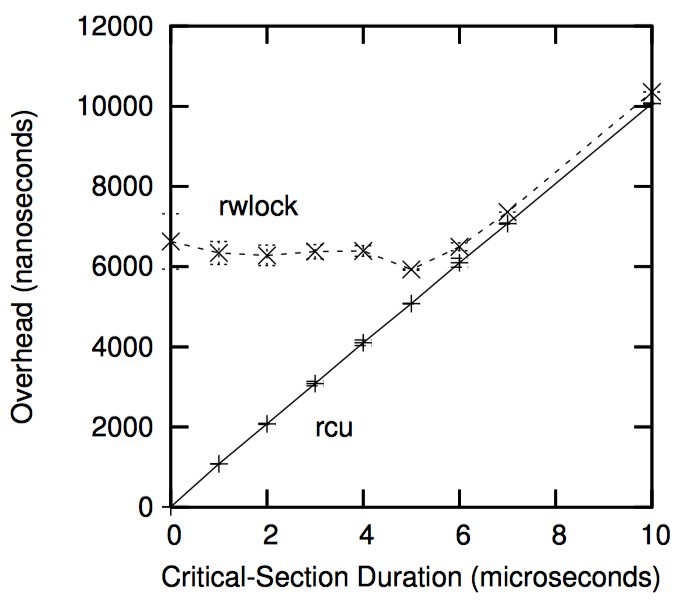
但是考虑到很多系统调用(以及他们所包含的 RCU 读端临界区)都能在几毫秒内完成,所以这个结果对 RCU 是有利的。另外,下面将会讨论,RCU 读端原语基本上是不会死锁的。
免于死锁虽然 RCU 在多数为读的工作符合下提供了显著的性能优势,但是使用 RCU 的主要目标却不是它可以免于死锁的特性。这种免于死锁的能力来源于 RCU 的读端原语不阻塞、不自旋,甚至不会向后跳转,所以 RCU 读端原语的执行实现是确定的。这使得 RCU 读端原语不可能组成死锁循环。
RCU 读端免于死锁的能力带来了一个有趣的结果,RCU 读者可以无条件地升级为 RCU 更新者。在读写锁中尝试这种升级则会造成死锁。进行 RCU 读者到更新者提升的代码如下所示:
1 rcu_read_lock();
2 list_for_each_entry_rcu(p, &head, list_field) {
3 do_something_with(p);
4 if (need_update(p)) {
5 spin_lock(my_lock);
6 do_update(p);
7 spin_unlock(&my_lock);
8 }
9 }
10 rcu_read_unlock();
请注意,do_update 是在所的保护下执行的,也是在 RCU 读端的保护下执行。
RCU 免于死锁的特性带来的另一个有趣后果是 RCU 不会受很多优先级反转问题的影响。比如,低优先级的 RCU 读者无法阻止高优先级的 RCU 更新者获取更新端锁。类似的,低优先级的更新者也无法阻止高优先级的 RCU 读者进入 RCU 读端临界区。
实时延迟因为 RCU 读端原语既不自旋也不阻塞,所以这些原语有着极佳的实时延迟。另外,如之前所说,这也就意味着这些原语不会受与 RCU 读端原语和锁有关的优先级反转影响。
但是,RCU 还是会受到更隐晦的优先级反转问题影响,比如,在等待 RCU 宽限期结束时阻塞的高优先级进程,会被 -rt 内核的低优先级 RCU 读者阻塞。这也可以用 RCU 优先级提升来解决。
RCU 读者与更新着并发执行因为 RCU 读者既不自旋也不阻塞,还因为 RCU 更新者没有任何类似回滚或中止的语义,所以 RCU 读者和更新者必然可以并发执行。这意味着 RCU 读者有可能访问旧数据,还有可能发现数据不一致,无论这两个问题中的哪一个都有可能让读写锁卷土重来。
不过,令人吃惊的是在大量场景中,数据不一致的旧数据都不是问题。网络路由表是一个经典例子。因为路由的更新可能要花相当长的一段时间才能到达指定系统,所以系统可能会在更新到来后的一段时间内仍然将报文发到错误的地址去。通常在几毫秒内将报文发送到错误的地址并不算什么问题。并且,因为 RCU 的更新者可以在无需等待 RCU 读者执行完毕的情况下发生,所以 RCU 读者可能会比读写锁的读者更早看到更新后的路由表。如下图所示:
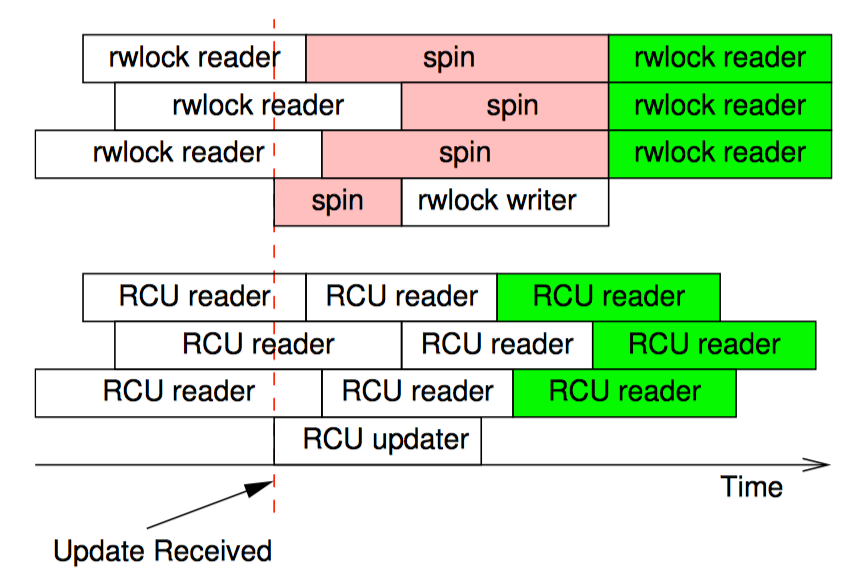
一旦收到更新,rwlock 的写者在最后一个读者完成之前不能继续执行,后续的读者在写者更新完成之前不能去读。不过,这一点也保证了后续的读者可以看见最新的值,如果图中绿色部分。相反,RCU 读者和更新者互相不会阻塞,这就允许 RCU 读者可以更快看见更新后的值。当然,因为读者和更新者的执行重叠了一部分,所以所有 RCU 读者都“可能”看见更新后的值,包括图中三个在更新者之前就已开始的 RCU 读者。然而,再一次强调,只有绿色的 RCU 读者才能保证看到更新后的值。
简而言之,读写锁和 RCU 提供了不同的保证。在读写锁中,任何在写者开始之后开始的读者都保证能看到新值,而在写者正在自旋时候开始的读者有可能看到新值,也有可能看到旧值,这取决于读写锁实现中的读写这哪一个优先级更高。与之相反,在 RCU 中,在更新者完成后才开始的读者都保证能看见新值,在更新者开始后才完成的读者有可能看见新值或旧值,这取决于具体的时机。
这里面的关键点是,虽然限定在计算机系统这一范围内读写锁保证了一致性,但是这种一致性是以增加外部世界的不一致性作为代价的。换句话说,读写锁以外部世界的旧数据作为代价,获取了内部的一致性。
然而,总有一种场合让系统无法容忍数据不一致和旧数据。幸运的是,有很多种办法可以避免这种问题,有一些办法是基于前面提到的引用计数。
低优先级 RCU 读者可以阻塞高优先级的回收者。在实时 RCU 中,被抢占的读者将阻止正在进行中的宽限期完成,即使高优先级的任务因为等待宽限期完成而阻塞也是如此。实时 RCU 可以通过用 call_rcu 替换 synchronize_rcu 来避免该问题,或者采用 RCU 优先级提升来避免,不过该方法在 2008 年初还处于实验状态。虽然有必要讨论 SRCU 和 QRCU 的优先级提升,但是现在实时领域还没有实际的需求。
延续好几毫秒的 RCU 宽限期。除了 QRCU 和前面提到的几个玩具 RCU 实现,RCU 宽限期会延续好几个毫秒。虽然有些手段可以消除这样长的延迟带来的损害,比如使用在可能时使用异步接口,但是根据拇指定律,这也是 RCU 使用在读数据占多数的场景的主要原因。
读写锁与 RCU 代码对比。在最好的情况下,将读写锁转换成 RCU 非常简单,如下图所示,这些都来自 Wikipedia。



详细阐述如何使用 RCU 替换读写锁已经超出了本书的范围。
RCU 是一种受限的引用计数机制
因为宽限期不能在 RCU 读端临界区进行时完毕,所以 RCU 读端原语可以像受限的引用计数机制一样使用。比如下面的代码片段:
1 rcu_read_lock(); /* acquire reference. */
2 p = rcu_dereference(head);
3 /* do something with p. */
4 rcu_read_unlock(); /* release reference. */
rcu_read_lock 原语可以看做是获取对 p 的引用,因为在 rcu_dereference 为 p 赋值之后才开始宽限期无法在配对的 rcu_read_unlock 之前完成。这种引用计数机制是受限的,因为我们不允许在 RCU 读端临界区中阻塞,也不允许将一个任务的 RCU 读端临界区传递给另一个任务。
不管上述的限制,下列代码可以安全的删除 p:
1 spin_lock(&mylock);
2 p = head;
3 rcu_assign_pointer(head, NULL);
4 spin_unlock(&mylock);
5 /* Wait for all references to be released. */
6 synchronize_rcu();
7 kfree(p);
将 p 赋值给 head 阻止了任何获取将来对 p 的引用的操作,synchronize_rcu 等待所有值钱获取的引用释放。
当然,RCU 也可以与传统的引用计数结合,LKML 中对此有过讨论,前面也做过了总结。
但是何必这么麻烦呢?我再回到一次,部分原因是性能,如果下图所示,图中再次显示了在 16 个 3GHZ CPU 的 Intel x86 系统中采集的数据。
并且,和读写锁一样,RCU 的性能优势主要来源于较短的临界区,如下图中所示。另外,和读写锁一样,许多系统调用(以及他们包含的任何 RCU 读端临界区)都在几毫秒内完成。
但是,伴随着 RCU 的限制有可能相当麻烦,比如,在许多情况下,在 RCU 读端临界区中禁止睡眠可能与我们的整个目标不符。下节将从解决该问题的方式触发,同时涉及在某些情况下如何降低传统引用计数的复杂性。
RCU 是一种可大规模使用的引用计数机制
前面曾经说过,传统的引用计数通常与某种或者一组数据结构有联系。然而,维护大量不同种类的数据结构的单一全局引用计数,通常会导致包含引用计数的缓存来回“乒乓”。这种缓存行“乒乓”会严重影响系统性能。
相反,RCU 的较轻量级读端原语允许读端极其频繁的调用,却只带来微不足道的性能影响,这使得 RCU 可以作为一种几乎没有任何惩罚的“批量引用计数机制”。当某个任务需要在一系列代码中持有引用时,可以送可休眠 RCU(SRCU)。但是这里没有包含特殊情景,一个任务将引用传递给另一个引用,在开始一次 IO 时获取引用,然后当对应的 IO 完成时在中断处理函数里释放该引用。(原则上 SRCU 的实现可以处理这一点,但是在实践中还不清楚这是否是一个好的权衡)
当然,SRCU 带来了它自己的限制条件,即要传递给对应 srcu_read_lock 和 srcu_read_unlock 返回值,以及硬件终端处理函数或者 NMI/SMI 处理函数不能调用 SRCU 原语。SRCU 的限制会带来多少问题,如何更好的处理这些问题,这一切还尚未有定论。
RCU 是穷人版的垃圾回收器
当人们开始学习 RCU 时,有种比较少见的感叹是“RCU 有点像垃圾回收器”。这种感叹有一部分是对的,不过还是会给学习造成误导。
也许思考 RCU 与垃圾回收器(GC)之间关系的最好办法是,RCU 类似自动的决定垃圾回收的时机。但是 RCU 与 GC 有两个不同点:
- 程序员必须手动指示何时可以回收数据结构。
- 程序员必须手动标出可以合法持有引用的 RCU 读端临界区。
尽管存在这些差异,两者的相似度仍然很高,就我所知至少有一篇理论分析 RCU 的文献曾经分析过两者的相似度。不仅如此,我所知道的第一种类 RCU 的机制就是运用垃圾回收器来处理宽限期。下节提供了一种更好思考 RCU 的方法。
RCU 是一种提供存在担保的方法
Gamsa 等人讨论了存在担保,并且描述了如何用一种类似 RCU 的机制提供这种担保。前面讨论过如何通过锁来提供存在担保及其弊端。如果任何受 RCU 保护的数据元素在 RCU 读端临界区中被访问,那么数据元素在 RCU 读端临界区持续期间保证存在。
1 int delete(int key)
2 {
3 struct element *p;
4 int b;
5
6 b = hashfunction(key);
7 rcu_read_lock();
8 p = rcu_dereference(hashtable[b]);
9 if (p == NULL || p->key != key) {
10 rcu_read_unlock();
11 return 0;
12 }
13 spin_lock(&p->lock);
14 if (hashtable[b] == p && p->key == key) {
15 rcu_read_unlock();
16 rcu_assign_pointer(hashtable[b], NULL);
17 spin_unlock(&p->lock);
18 synchronize_rcu();
19 kfree(p);
20 return 1;
21 }
22 spin_unlock(&p->lock);
23 rcu_read_unlock();
24 return 0;
25 }
上面的代码展示了基于 RCU 的存在担保如何通过从哈希表删除元素的函数来实现每数据元素锁。第 6 行计算哈希函数,第 7 行进入 RCU 读端临界区。如果第 9 行发现哈希表对应的哈希项(bucket)为空,或者数据元素不是我们想要删除的那个,那么第 10 行退出 RCU 读端临界区,第 11 行返回错误。
如果第 9 行判断为 false,第 13 行获取更新端的自旋锁,然后第 14 行检查元素是否还是我们想要的。如果是,第 15 行退出 RCU 读端临界区,第 16 行从哈希表中删除找到的元素,第 17 行释放锁,第 18 行等待所有值钱已经存在的 RCU 读端临界区退出,第 19 行释放刚被删除的元素,最后 20 行返回成功。如果 14 行的判断发现元素不再是我们想要的,那么 22 行释放锁,第 23 行退出 RCU 读端临界区,第 24 行返回错误以删除该关键字。
细心的读者可能会发现,该例子中只不过是前面“RCU 是一种等待事物结束的方式”中那个例子的变体。细心的读者还会发现免于死锁要比 前面讨论的基于锁的存在担保更好。
RCU 是一种提供类型安全内存的方法
很多无锁算法并不需要数据元素在被 RCU 读端临界区引用时保持完全一致,只要数据元素的类型不变就可以了。换句话说,只要结构类型不变,无锁算法可以允许某个数据元素在被其他对象引用时可以释放并重新分配,但是决不允许类型上的改变。这种“保证”,在学术文献中被称为“类型安全的内存”,比前一节提到的存在担保要弱一些,因此处理起来也要困难一些。类型安全的内存算法在 Linux 内核中的应用是 slab 缓存,被 SLAB_DESTROY_BY_RCU 专门标记出来的缓存通过 RCU 将释放的 slab 返回给系统内存。在任何已有的 RCU 读端临界区持续读期间,使用 RCU 可以保证所有带有 SLAB_DESTROY_BY_RCU 标记且正在使用的 slab 元素仍然在 slab 中,且类型保持一致。
这些算法一般使用了一个验证步骤,用于确定刚刚被引用的数据结构确实是被请求的数据。这种验证要求数据结构的一部分不能被释放——重新分配过程触碰。通常这种有效性检查很难保证不存在隐晦且难以解决的故障。
因此,虽然基于类型安全的无锁算法在一种很难达到的情景下非常有效,但是你最好还是尽量使用存在担保。毕竟简单总是好的。
RCU 是一种等待事物结束的方式
在前面我们提到 RCU 的一个重要组件是等待 RCU 读者结束的方法。RCU 的强大之处,其中之一就是允许你在等待上千个不同事物结束的同时,又不用显式去跟踪其中每一个,因此也就无需担心性能下降、扩展限制、复杂的死锁场景、内存泄露等显式跟踪机制自身的问题。
在本节中,我们将展示 synchronize_sched 的读端版本(包括禁止抢占、禁止中断原语)如何让你实现与不可屏蔽中断(NMI)处理函数的交互,如果用锁来实现,这将极其困难。这种方法被称为“纯 RCU”,Linux 的多处使用了该方法。
“纯 RCU” 设计的基本形式如下:
- 做出改变,比如,OS 对一个 NMI 做出反应。
- 等待所有已有读端临界区完全退出(比如使用 synchronize_sched 原语)。这里的关键是后续的 RCU 读端临界区保证可以看见变化发生后的样子。
- 扫尾工作,比如,返回表明改变成功完成的状态。
本节剩下的部分将使用 Linux 内核中的例子做展示。在下面的例子中 timer_stop 函数使用 synchronize_sched 确保在释放相关资源之前,所有正在处理的 NMI 处理函数都已完成。下面是对该例简化后的代码实现:
1 struct profile_buffer {
2 long size;
3 atomic_t entry[0];
4 };
5 static struct profile_buffer *buf = NULL;
6
7 void nmi_profile(unsigned long pcvalue)
8 {
9 struct profile_buffer *p = rcu_dereference(buf);
10
11 if (p == NULL)
12 return;
13 if (pcvalue >= p->size)
14 return;
15 atomic_inc(&p->entry[pcvalue]);
16 }
17
18 void nmi_stop(void)
19 {
20 struct profile_buffer *p = buf;
21
22 if (p == NULL)
23 return;
24 rcu_assign_pointer(buf, NULL);
25 synchronize_sched();
26 kfree(p);
27 }
第 1~4 行定义了 profile_buffer 结构,包含一个大小和一个变长数据的入口。第 5 行定义了指向 profile_buffer 的指针,这里假设别处对该指针进行了初始化,指向内存的动态分配区。
第 7~16 行定义了 nmi_profile 函数,供 NMI 中断处理函数使用。该函数不会被抢占,也不会被普通的中断处理函数中断,但是,该函数还是会受高速缓存未命中、ECC 错误以及被一个核的其他硬件线程抢占时钟周期等因素影响。第 9 行使用 rcu_dereference 原语来获取指向 profile_buffer 的本地指针,这样做是为了确保在 DEC Alpha 上的内存顺序执行,如果当前没有分配 profile_buffer,第 11 和 12 行退出,如果参数 pcvalue 超出范围,第 13 和 14 行退出。否则,第 15 行增加以参数 pcvalue 为下标的 profile_buffer 项的值。请注意,profile_buffer 结构中的 size 保证了 pcvalue 不会超出缓冲区的范围,即使突然将较大的缓冲区替换成了较小的缓冲区也是如此。
第 18~27 行定义了 nmi_stop 函数,由调用者负责互斥访问(比如持有正确的锁)。第 20 行获取 profile_buffer 的指针,如果缓冲区为空,第 22 和 23 行退出。否则,第 24 行将 profile_buffer 的指针置 NULL(使用 rcu_assign_pointer 原语在弱顺序的机器中保证内存顺序访问)。第 25 行等待 RCU Sched 的宽限期结束,尤其是等待所有不可抢占的代码——包括 NMI 中断处理函数一一结束。一旦执行到第 26 行,我们就可以保证所有获取到指向旧缓冲区指针的 nmi_profile 实例都已经返回了。现在可以安全释放缓冲区,这时使用 kfree 原语。
简而言之,RCU 让 profile_buffer 动态切换变得简单(你可以试试原子操作,或者还可以用锁来折磨下自己)。但是,RCU 通常还是运用在较高层次的抽象上,正如前面几个小节所述。
RCU 用法总结
RCU 的核心只是提供一下功能的 API。
- 用于添加新数据的发布——订阅机制。
- 等待已有 RCU 读者结束的方法。
- 维护多版本的准则,使得在有 RCU 读者并发时不会影响或延迟数据更新。
也就是说,在 RCU 之上建造更高抽象级别的架构是可能的,比如前面几节列出的读写锁、引用计数和存在担保。更进一步,我对 Linux 社区会继续为 RCU 寻找新用法丝毫不感到怀疑,当然其他的同步原语肯定也是这样。
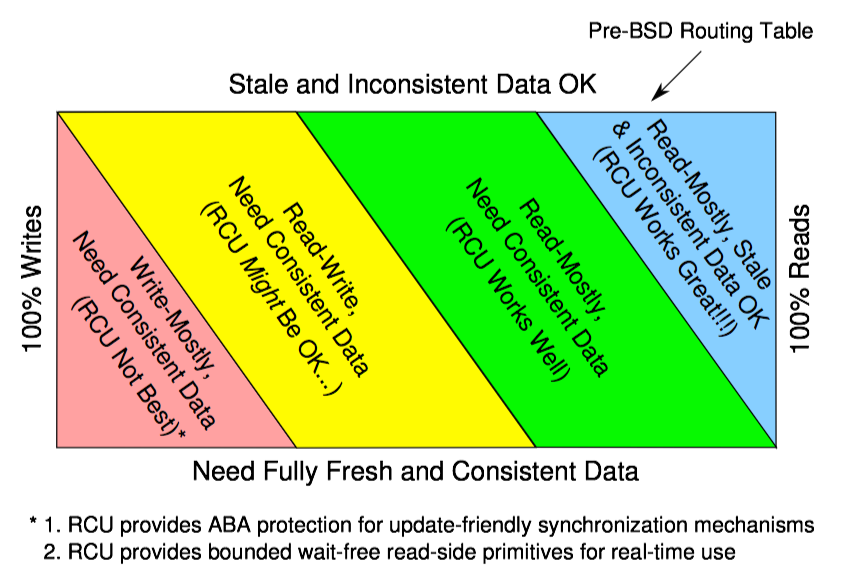
上图展示了 RCU 的适用范围,这是关于 RCU 最有用的经验法则。
如图中顶部的蓝色框所示,如果你的读侧重数据允许获取旧值和不一致的结果,RCU 是最好的(但有关旧值和不一致数据的更多信息见下面的部分)。Linux 内核在这种情况的例子是路由表。因为可能需要很多秒甚至几分钟,才能更新路由表并通过互联网传播出去,这时系统已经以错误的方式发送相当一段时间的数据包了。再以小概率发送几毫秒错误的数据就简直算不上什么事了。
如果你有一个以读为主工作的负载,需要一致的数据,RCU 可以工作的不错,如绿色“读侧重,需要一致数据”框所示。Linux 内核在这种情况下的例子是从系统 V 的用户态信号 ID 映射到相应的内核数据结构。读信号量往往大大超过它们被创建和销毁的速度,所以这个映射是读侧重的。然而,在已被删除的信号量上执行信号量操作是错误的。这种对一致性的要求是通过内核信号量数据结构中的锁、以及在删除信号量时设置“已删除”标志达到的。如果用户 ID 映射到了一个具有“已删除”标志的内核数据结构,这个内核数据结构将被忽略,同时用户 ID 被设为无效。
虽然这要求读者获得内核信号量的锁,但这允许内核不用对要映射的数据结构加锁。因此,读者可以无锁地遍历从 ID 映射来的树状数据结构,这反过来大大提升了性能、可扩展性和实时响应性。
如黄色“读写”框所示,当数据需要一致性时,RCU 也可用于读写平衡的工作负载,虽然通常要与其他同步原语结合使用。例如,在最近的 Linux 内核中,目录项缓存使用了 RCU、顺序锁、每 CPU 锁和每数据结构锁,这才用于在常见情况下无锁地遍历路径名。虽然 RCU 在这种读写平衡的情况下可以非常有益,但是这种用法通常要比读侧重情况复杂的多。
最后,如底部的红色框所示,当以更新为主并且需要数据一致性的工作负载时,很少有适用 RCU 的地方,虽然也存在一些例外。此外,如前所述,在 Linux 内核里,SLAB_DESTROY_BY_RCU slab 分配器为 RCU 读者提供类型安全的内存,这可以大大简化非阻塞同步和其他无锁算法的实现。
简而言之,RCU 是一个包括用于添加新数据的发布——订阅机制的 API,等待已存在的 RCU 读者完成的一种方式,以及一门维护多个版本以使更新不会上海或延迟并发的 RCU 读者的学科。这个 RCU API 最适合以读者为主的情况,特别是如果应用程序可以容仍陈旧不一致的数据。
Linux 内核中的 RCU API
等待完成的 API 族
发布-订阅、版本维护 API
这些 API 的用处
RCU 究竟是什么
RCU 的核心不过是一种支持对插入操作的发布和订阅、等待所有 RCU 读者完成、维护多个版本的 API。也就是说,完全可以在 RCU 之上构建抽象级别更高的模型,比如读写锁、引用计数、存在担保等在前面列出的模型。更进一步,我相信 Linux 社区也会继续不断的寻找新的用法,当然其他的同步原语肯定也是一样。
当然,对 RCU 更复杂的看法还包括所有拿这些 API 能做的事情。
但是,对很多人来说,想要完整观察 RCU,就需要一个 RCU 的例子实现。
RCU 的玩具实现
基于锁的 RCU
基于每线程锁的 RCU
基于计数的简单 RCU
避免更新者饥饿的引用计数 RCU
可扩展的基于计数的 RCU
基于自由增长计数的 RCU
基于自由增长计数的可嵌套 RCU
基于静止状态的 RCU
总结
之前的章节列出了各种 RCU 原语的理想特性。这里我们整理一个列表,供有意实现自己的 RCU 的读者作为参考:
- 必须有读者端原语和宽限期原语,如:rcu_read_lock/rcu_read_unlock, synchronize_rcu。任何在宽限期开始前就存在的 RCU 读端临界区必须在宽限期结束前完毕。
- RCU 读端原语应该有最小的开销。特别是应该避免如高速缓存未命中、原子操作、内存平展和分支之类的操作。
- RCU 读端原语应该有 O(1) 的时间复杂度,可以用于实时用途。(这意味着读者可以与更新着并发执行)
- RCU 读端原语应该在所有上下文中都可以使用(在 Linux 内核中,只有空循环时不能使用 RCU 读端原语)。一个重要的特例是 RCU 读端原语必须可以在 RCU 读端临界区中使用,换句话说,必须允许 RCU 读端临界区嵌套。
- RCU 读端临界区不应该有条件判断,不会返回失败。该特性十分重要,因为错误检查会增加复杂度,让测试和验证变得更加复杂。
- 除了静止状态意外的任何操作都能在 RCU 读端原语中执行。比如像 IO 这样不幂等的操作也应用允许。
- 应该允许在 RCU 读端临界区中执行的同时更新一个受 RCU 保护的数据结构。
- RCU 读端和更新端的原语应该在内存分配器的设计和实现上独立,换句话说,同样的 RCU 实现应该能在不管数据原语是分配还是释放的同时,保护数据元素。
- RCU 宽限期不应该被在 RCU 读端临界区之外阻塞的线程而阻塞(但是请注意,大多数基于静止状态的实现破坏了这一愿望)。
RCU 练习
如何选择
下图提供了一些粗略的经验法则,可以帮助你选择延迟处理技术。
| 存在保证 | 写读者并行 | 读取端开销 | 批量引用 | 低内存占用 | 无条件获取 | 非阻塞更新 | |
|---|---|---|---|---|---|---|---|
| 引用计数 | Y | Y | ++->atomic(*) | Y | ? | ||
| 危险指针 | Y | Y | MB(**) | Y | Y | ||
| 顺序锁 | 2MB(***) | N/A | N/A | ||||
| RCU | Y | Y | 0->2MB | Y | Y | ? |
*:在每次重试中遍历的每个元素上产生**:在每次重试时产生***:原子操作MB:内存屏障
如“存在保证”一列中所示,如果你需要链接的数据元素的存在保证,那么必须使用引用计数、危险指针或 RCU。顺序锁不提供存在保证,而是提供更新检测,遭遇更新时重试读取端临界区。
当然,如“写读者并行”一列中所示,更新检测意味着顺序锁定不允许更新者和读者同步进行。毕竟,防止这种同步前进是使用顺序锁的全部意义所在。这时可以让顺序锁与引用计数、危险指针或 RCU 结合,以便同时提供存在保证和更新检测。事实上,Linux 内核就是以结合 RCU 和顺序锁的方式进行路径名查找的。
“读取端开销”一列给出了这些技术在读取端的大致开销。引用技术的开销变化范围很大。在低端,简单的非原子自增就够了,至少在有锁的保护下获取引用时如此。在高端,则需要完全有序的原子操作。引用计数会在遍历每个数据元素时产生此开销。危险指针在遍历每个元素时都产生一个内存屏障的开销,顺序锁在每次尝试执行临界区会产生两个内存屏障的开销。RCU 实现的开销从零到每次执行读取端临界区时的两个内存屏障开销不等,后者为 RCU 带来最佳性能,特别是对于读取端临界区需要遍历很多数据元素时。
“批量引用”一列表示只有 RCU 能够以恒定开销获取多个引用。属性怒锁的条件“N/A”,这是因为顺序锁采用更新检测额不是获取引用。
“低内存占用”一列表示那些技术的内存占用较低。此列和“批量引用”一列互补:因为获取大量元素的引用的能力意味着所有这些数据元素必须持续存在,这反过来意味着交道的内存占用。例如,一个线程可能会删除大量的数据元素,而此时另一个线程则并发执行长时间的 RCU 读端临界区。因为读端临界区可能潜在保留对任何新近删除元素的引用,所以在整个临界区持续时间内都必须保留所有这些元素。相反,引用计数和危险指针保留只有那些实际上并发读者引用的特定数据元素。
然而,这种低内存占用的优势是有代价的,如表中“无条件获取”一列。想要看到这一点,请想象哟一个大型的链式数据结构,引用技术或危险指针的读者(线程 A)持有该结构中某个鼓励数据元素的引用。考虑如下事件顺序:
- 线程 B 删除 A 引用的数据元素。由于这个引用,数据元素还不能被释放。
- B 删除 与 A 引用的所有数据元素相邻的所有数据元素。因为没有指向这些数据元素的引用,所有他们都被立即释放。因为 A 的数据元素已被删除,它指向的外部指针不更新。
- 所有 A 的数据元素的外部指针现在指向的是被释放的地址,因此已经不能安全的遍历。
- 因此,引用计数或危险指针的实现无法让 A 通过任何指向数据元素外部的指针来获取引用。
简而言之。任何提供精确引用追踪的延后处理计数都要做好无法获取引用的准备。因此,RCU 高内存占用的缺点反而意味着易于使用的优势,即 RCU 读者不需要处理获取失败的情况。
Linux 内核有时通过结合使用 RCU 和引用技术,来解决内存占用、精确跟踪和获取失败之间的这种竞争关系。RCU 用于短期引用,这意味着 RCU 读端临界区可以很短。这就意味着响应的 RCU 宽限期也很短,从而限制了内存占用。对于一些需要长期引用的数据元素,可以使用引用计数。这意味着只有少数数据元素需要处理应用获取失败的复杂性,因为 RCU,大部分引用的获取都是无条件的。
最后,“非阻塞更新”一列表示危险指针可以提供这种特性。引用计数则要取决于实现。然而,因为在更新端的锁,顺序锁定不能提供非阻塞更新。RCU 的写者必须等待读者,这也排除了完全非阻塞更新。不过有时唯一的阻塞操作是等待释放内存,这在很多情况下都可视为是非阻塞的。
更新端的问题
对于读侧重的情况,本章中提到的延迟处理技术一般都非常适用,但这提出了一个问题:“更新端怎么办?”。毕竟,增加读者的性能和扩展性是很好的,但是自然而然我们也希望为写者提供出色的性能和扩展性。
对于写者,我们已经看到了一种具有高性能和扩展性的情况,即前面提到的计数算法。这些计数算法通过部分分割数据结构,使得可以在本地进行更新,而较昂贵的读取则必须在整个数据结构上求和。Silas BoydWickhizer 把这种概念推广到 OpLog 上,Linux 内核路径名查找、VM 反向映射和 stat 系统调用都使用了这个工具。
另一种方法,称为 Disruptor,是为处理大量流数据输入的引用程序设计的。该方法是依靠单个生产者和单个消费者的 FIFO 队列,最小化对同步的需要。对于 Java 应用程序,Disruptor 还具有减少对垃圾处理器的使用这个优点。
当然,只要是可行的情况,完全分割或“分片”系统总是能提供优秀的性能和扩展性。
10 - CH10-数据结构
访问数据的效率如此重要,因此对算法的讨论也包括相关数据结构的时间复杂度。然而,对于并行程序,时间复杂度的度量还必须包括并发效应。如前所述,这些效应可能是压倒性的因素,这意味着对并发数据结构的设计,必须要像关注串行数据结构中时间复杂度一样关注并发复杂度。
例子
我们将使用薛定谔的动物园这个应用来评估性能。薛定谔拥有一个动物园,里面有大量的动物,他想使用内存数据库来记录他们。动物园中的每个动物在数据库中都有一个条目,每个动物都有一个唯一的名称作为主键,同时还有与每个动物有关的各种数据。
出生、捕获、购买将导致数据插入,而死亡、释放和销售将导致数据删除。因为薛定谔的动物园包括了大量短命动物,包括老鼠可昆虫,所以数据库必须能够支持高频更新请求。
对薛定谔的动物感兴趣的人可以查阅它们,但是,薛定谔已经注意到他的猫拥有非常高的查询率,多到以至于他怀疑是他的老鼠们在使用数据库来查询它们的天敌。这意味着薛定谔的应用必须支持对单个数据条目的高频查询请求。
记住这个应用程序,这里面包含了大量的数据结构。
可分割的数据结构
如今的计算机世界使用了各种各样的数据结构,市面上讲数据结构的教科书多如牛毛。本节专注于单个数据结构,即哈希表。这种方法允许我们更深入地研究如何与并发数据结构交互,同时也能让我们更加熟悉这个在实践中大量应用的数据结构。
哈希表的设计
第六章中强调了通过分割来获得可观性能和扩展性的必要,因此可分割性必须是选择数据结构的首要标准。并行性的主力军——哈希表——很好的满足了这个标准。哈希表在概念上非常简单,包含一个哈希桶的数组。哈希函数将指定数据的键映射到哈希桶元素,也就是存储数据的地方。因此,每个哈希桶有一个数据元素的链表,称为哈希链。如果配置得当,这些哈希链会相当短,允许哈希表可以非常有效地访问任意指定的元素。
另外,每个桶可以有自己的锁,所以哈希表中不同的桶可以完全独立的插入、删除和查找。因此,包含大量元素的哈希表提供了极好的可扩展性。
哈希表的实现
1 struct ht_elem {
2 struct cds_list_head hte_next;
3 unsigned long hte_hash;
4 };
5
6 struct ht_bucket {
7 struct cds_list_head htb_head;
8 spinlock_t htb_lock;
9 };
10
11 struct hashtab {
12 unsigned long ht_nbuckets;
13 struct ht_bucket ht_bkt[0];
14 };
上面的片段展示了简单的固定大小的哈希表使用的一组数据结构,使用链表和每哈希桶的锁。下面的片段展示了如何将它们组合在一起。hashtab 结构包含了 4 个 ht_bucket 结构,->bt_nbuckets 字段代表桶的数量。每个桶都包含链表头 ->htb_head 和锁 ->htb_lock。链表元素 htb_elem 结构通过它们的 ->hte_next 字段找到下一个元素,每个 ht_elem 结构在 ->hte_hash 字段中缓存相应元素的哈希值。ht_elem 结构嵌入在哈希表中的另一个较大结构里,并且这个较大结构可能包含了复杂的键。
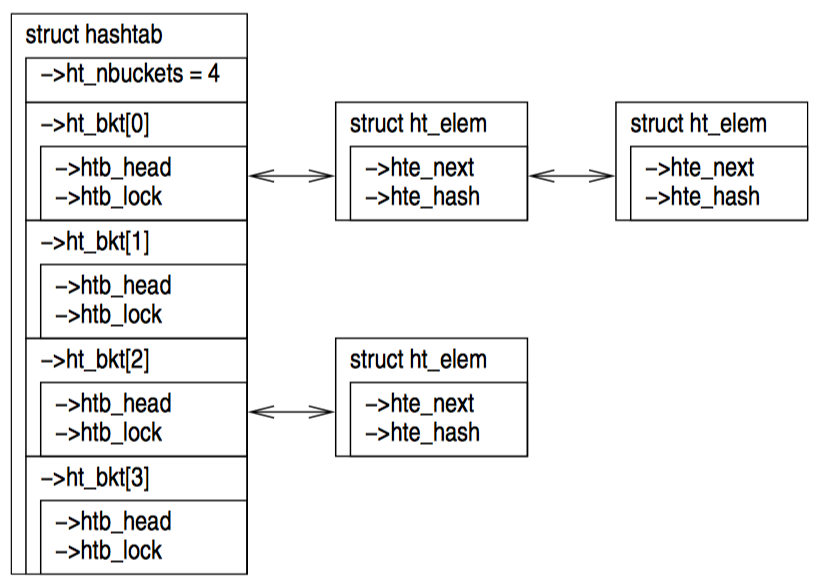
下面的片段展示了映射和加解锁函数。第 1~2 行定义了宏 HASH2BKT,它将哈希值映射到相应的 ht_bucket 结构体。这个宏使用了一个简单的模数,如果需要更好的哈希函数,调用者需要自行实现从数据键到哈希值的映射函数。剩下的两个函数分别获取和释放与指定的哈希桶对应的 ->htb_lock 锁。
1 #define HASH2BKT(htp, h) \
2 (&(htp)->ht_bkt[h % (htp)->ht_nbuckets])
3
4 static void hashtab_lock(struct hashtab *htp,
5 unsigned long hash)
6 {
7 spin_lock(&HASH2BKT(htp, hash)->htb_lock);
8 }
9
10 static void hashtab_unlock(struct hashtab *htp,
11 unsigned long hash)
12 {
13 spin_unlock(&HASH2BKT(htp, hash)->htb_lock);
14 }
下面的片段展示了 hashtab_lookup,如果指定的键或哈希值存在,它返回一个指向元素的指针,否则返回 NULL。此函数同时接受哈希值和指向键的指针,因为这允许此函数的调用者使用任意的键和哈希函数,cmp 函数指针用于传递比较键的函数,类似于 qsort 的方式。第 11 行将哈希值映射成指向相应哈希桶的指针。第 12~19 行的循环每次执行检查哈希桶中链表的一个元素。第 15 行检查是否与哈希值匹配,如果否,则第 16 行前进到下一个元素。第 17 行检查是否与实际的键匹配,如果是,则第 18 行返回指向匹配元素的指针。如果没有与之匹配的元素,则第 20 行返回 NULL。
1 struct ht_elem *
2 hashtab_lookup(struct hashtab *htp,
3 unsigned long hash,
4 void *key,
5 int (*cmp)(struct ht_elem *htep,
6 void *key))
7 {
8 struct ht_bucket *htb;
9 struct ht_elem *htep;
10
11 htb = HASH2BKT(htp, hash);
12 cds_list_for_each_entry(htep,
13 &htb->htb_head, 14 hte_next) {
15 if (htep->hte_hash != hash)
16 continue;
17 if (cmp(htep, key))
18 return htep;
19 }
20 return NULL;
21 }
下面的片段是 hashtab_add 和 hashtab_del 函数,分别从哈希表中添加和删除元素。
1 void
2 hashtab_add(struct hashtab *htp,
3 unsigned long hash,
4 struct ht_elem *htep)
5 {
6 htep->hte_hash = hash;
7 cds_list_add(&htep->hte_next,
8 &HASH2BKT(htp, hash)->htb_head);
9 }
10
11 void hashtab_del(struct ht_elem *htep)
12 {
13 cds_list_del_init(&htep->hte_next);
14 }
hashtab_add 函数只是简单的在第 6 行设置元素的哈希值,然后将其添加到第 7~8 行的相应桶中。hashtab_del 函数简单地从哈希桶的链表中移除指定的元素,因为是双向链表所以这很容易。在调用这个函数中任何一个之前,调用者需要确保此时没有其他线程正在访问或修改相同的哈希桶,例如,可以通过事先调用 hashtab_lock 来加以保护。
下面的片段展示了 hashtab_alloc 和 hashtab_free 函数,分别负责表的分配和释放。分配从第 7~9 行开始,分配使用的是系统内存。如果第 10 行检测到内存已耗尽,则第 11 行返回 NULL 给调用者。否则,第 12 行将初始化桶的数量,第 13~16 行的循环初始化桶本身,第 14 行初始化链表头,第 15 行初始化锁。最后,第 17 行返回一个指向新分配哈希表的指针。第 20~23 行的 hashtab_free 函数则直接了当地释放内存。
1 void
2 hashtab_add(struct hashtab *htp,
3 unsigned long hash,
4 struct ht_elem *htep)
5 {
6 htep->hte_hash = hash;
7 cds_list_add(&htep->hte_next,
8 &HASH2BKT(htp, hash)->htb_head);
9 }
10
11 void hashtab_del(struct ht_elem *htep)
12 {
13 cds_list_del_init(&htep->hte_next);
14 }
哈希表的性能
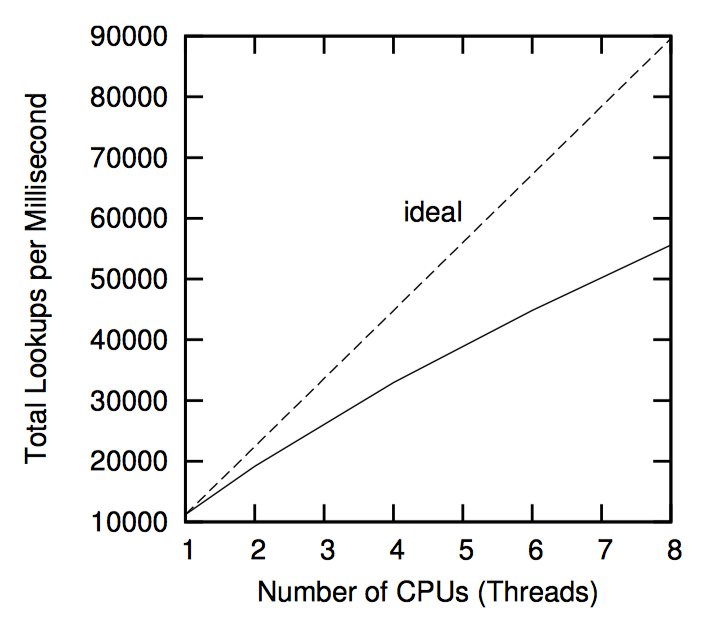
上图展示的是在 8 核 2GHZ Intel Xeon 系统上的性能测试结果,使用的哈希表具有 1024 个桶,每个桶带有一个锁。性能的扩展性几乎接近线性,但是即使只有 8 个 CPU,性能已经不到理想性能水平的一半。产生这个缺口的一部分原因是由于虽然在单 CPU 上获取和释放锁不会产生高速缓存未命中,但是在两个或更多 CPU 上则不然。
随着 CPU 数目的增加,情况只有变得更糟,如下图所示。
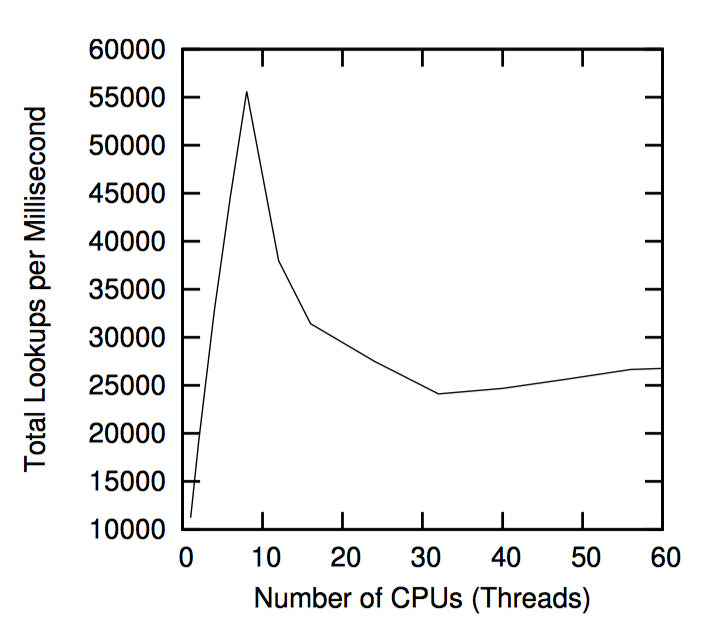
我们甚至不需要额外的线来表示理想性能, 9 个或 9 个以上的 CPU 时性能非常糟糕。这显然警示了我们按照中等数量的 CPU 外推性能的危险。
当然,性能大幅下降的一个原因可能是哈系桶数目的不足。毕竟,我们没有将哈系桶填充到占据一条完整的缓存行,因此每条缓存行有多个哈系桶。这可能是在 9 个 CPU 上导致高速缓存颠簸的原因。当然这一点很容易通过增加哈希桶的数量来验证。
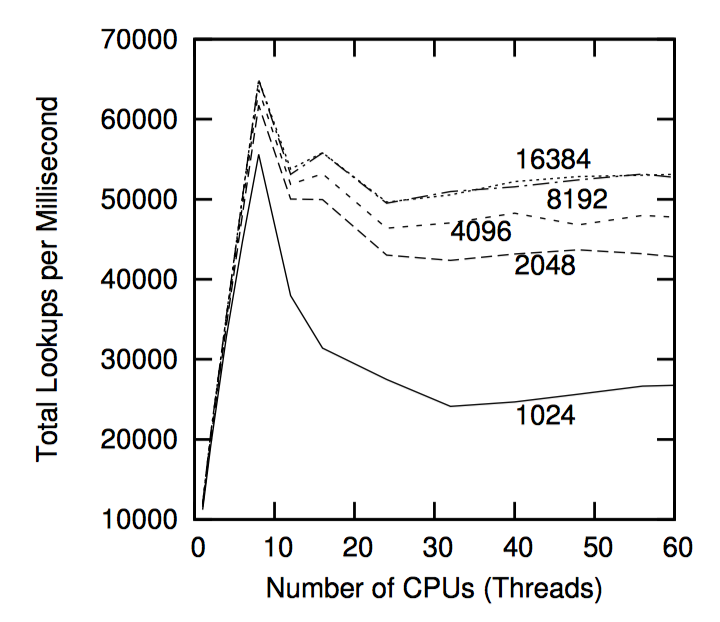
如上图所示,虽然增加了哈系统的数量后性能确实有点提高,可扩展性仍然惨不忍睹。特别是,我们还是看到 9 个 CPU 之后性能会急剧下降。此外,从 8192 个桶增加到 16384 个桶,性能几乎没有提升。显然还有别的东西再捣鬼。
其实这是多 CPU 插槽系统惹的祸,CPU 0~7 和 32~39 会映射到第一个槽位,如下图所示。因此测试程序只用前 8 个 CPU 时性能相当好,但是测试涉及到插槽 0 的 CPU 0~7 和插槽 1 的 CPU 8 时,会产生跨插槽边界数据传递的开销。如果前所述,这可能会验证降低性能。总之,对于多插槽系统来说,除了数据结构完全分割之外,还需要良好的局部性访问能力。
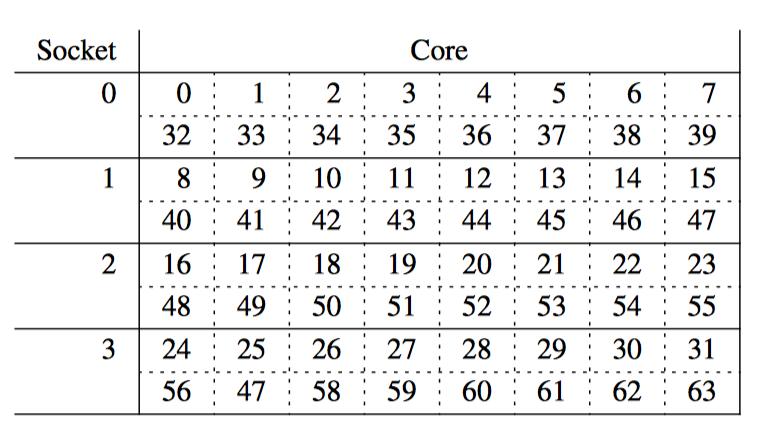
读侧重的数据结构
虽然通过分割数据结构可以帮助我们带来出色的可扩展性,但是 NUMA 效应也会导致性能和扩展性的严重恶化。另外,要求读者互斥写者也可能会导致在读侧重的场景下的性能。然而,我们可以通过使用前面介绍的 RCU 来实现性能和可扩展性的双丰收。使用危险指针也可以达到类似的效果。
受 RCU 保护的哈希表实现
对于受 RCU 保护的每桶一锁的哈希表,写者按照上节描述的方式使用锁,但读者使用 RCU。数据结构、HASH2BKT、hashtab_lock、hashtab_unlock 函数与上一节保持一致。但是读者使用拥有更轻量级并发控制的 hashtab_lock_lookup。如下片段所示:
下面的片段则展示了 hashtab_lookup 函数的实现。这与前面的实现类似,除了将 cds_list_for_each_entry 替换为 cds_list_for_each_entry_rcu。这两个原语都按照顺序遍历 htb->htb_head 指向的哈希链表,但是 cds_list_for_each_entry_rcu 还要强制执行内存屏障以应对并发插入的情况。这是两种哈希表实现的重大区别,与纯粹的每桶一锁实现不同,受 RCU 保护的实现允许查找、插入、删除操作同时运行,支持 RCU 的 cds_list_for_each_entry_rcu 可以正确处理这种增加的并发性。还要主要 hashtab_lookup 的调用者必须在 RCU 读端临界区内,例如,调用者必须在调用 hashtab_lookup 之前调用 hashtab_lock_lookup(当前在之后还要调用 hashtab_unlock_lookup)。

下面的片段展示了 hashtab_add 和 hashtab_del,两者都是非常类似于其在非 RCU 哈希表实现中的对应函数。hashtab_add 函数使用 cds_list_add_rcu 而不是 cds_list_add,以便在有人正在查询哈希表时,将元素安装正确的排序添加到哈希表。hashtab_del 函数使用 cds_list_del_rcu 而不是 cds_list_del_init,它允许在查找到某数据元素后该元素马上被删除的情况。和 cds_list_del_init 不同,cds_list_del_rcu 仍然保留该元素的前向指针,这样 hashtab_lookup 可以遍历新删除元素的后继元素。
当让,在调用 hashtab_del 之后,调用者必须等待一个 RCU 宽限期(例如在释放或以其他方式重用新删除元素的内存之前调用 syncronize_rcu)。
受 RCU 保护的哈希表的性能
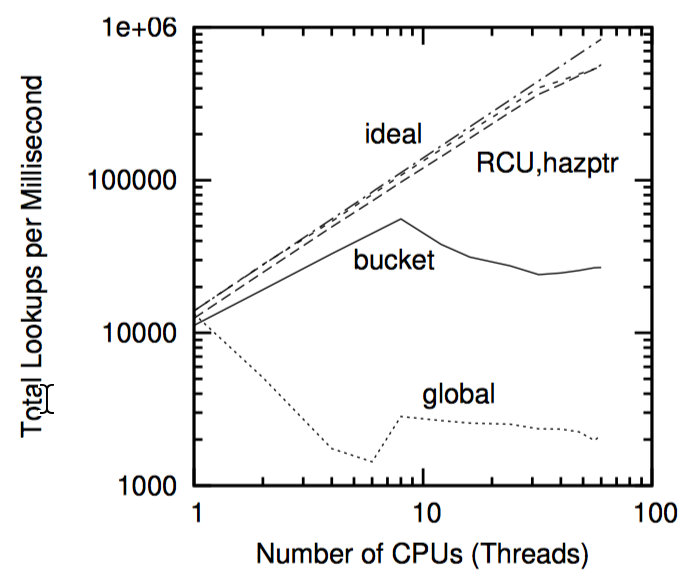
上图展示了受 RCU 保护的和受危险指针保护的只读哈希表的性能,同时与上一节的每桶一锁实现做比较。如你所见,尽管 CPU 数和 NUMA 效应更大,RCU 和危险指针实现都能接近理想的性能和可扩展性。使用全局锁的实现的性能也在图中给出了标示,正如预期一样,其结果针织比每桶一锁的实现更加糟糕。RCU 做得比危险指针稍微好一些,但在这个以对数刻度表示的图中很难看出差异来。
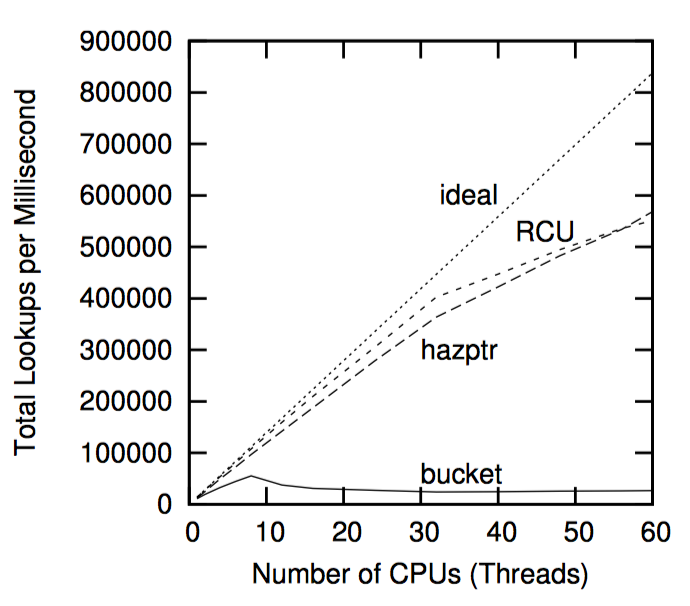
上图显示了线性刻度上的相同数据。这使得全局锁实现基本和 X 轴平行,但也更容易辨别 RCU 和危险指针的相对性能。两者都显示在 32 CPU 处的斜率变化,这是由于硬件多线程的缘故。当使用 32 个或更少的 CPU 时,每个线程都有自己的 CPU 时,每个线程都有自己的 CPU 核。在这种情况下,RCU 比危险指针做的更好,因为危险指针的读取端内存屏障会导致 CPU 时间的浪费。总之,RCU 比危险指针能更好地利用每个硬件线程上的 CPU 核。
如前所述,薛定谔对他的猫的受欢迎程度感到惊讶,但是随后他认识到需要在他的设计中考虑这种受欢迎程度。下图显示了程序在 60 个 CPU 上运行的结果,应用程序除了查询猫咪以外什么也不做。对这个挑战,RCU 和危险指针实现的表现很好,但是每桶一锁实现的负载为负,最终性能比全局锁实现还差。我们不应该对此感到吃惊,因为如果所有的 CPU 都在查询猫咪,对应于猫的那个桶的锁实际上就是全局锁。
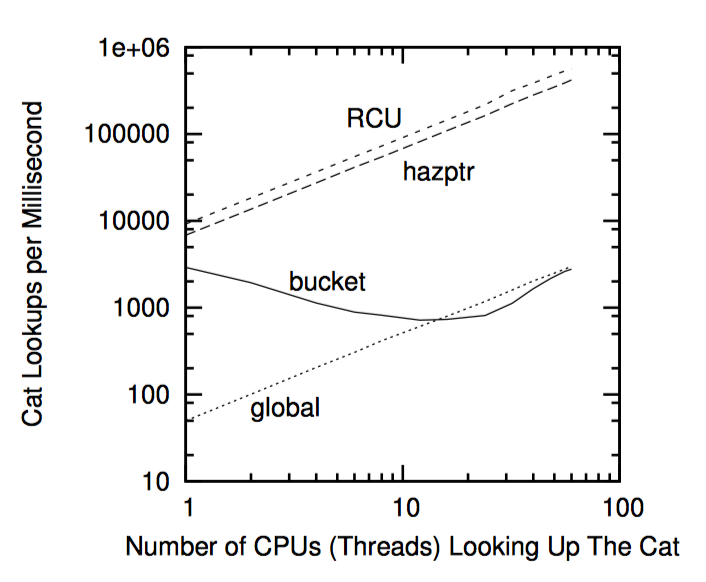
这个只有猫的基准测试显示了数据分片方法的一个潜在问题。只有与猫的分区关联的 CPU 才能访问有关猫的数据,这限制了只查询猫时系统的吞吞量。当然,有很多应用程序可以将数据均匀地分散,对于这些应用,数据分片非常适用。然而,数据分片不能很好地处理“热点”,由薛定谔的猫触发的热点只是其中一个例子。
当然,如果我们只是去读数据,那么一开始我们并不需要任何并发控制。因此,下图显示修正后的结果。在该图的最左侧,所有 60 个 CPU 都在进行查找,在图的最右侧,所有 60 个 CPU 都在做更新。对于哈希表的 4 种实现来说,每毫秒查找数随着做更新的 CPU 数量的增加而减少,当所有 60 个 CPU 都在更新时,每毫秒查找数达到 0。相对于危险指针 RCU 做的更好一些,因为危险指针的读取端内存屏障在有更新存在时产生了更大的开销。这似乎也说明,现代硬件大大优化了内存屏障的执行,从而大幅减少了在只读情况下的内存屏障开销。
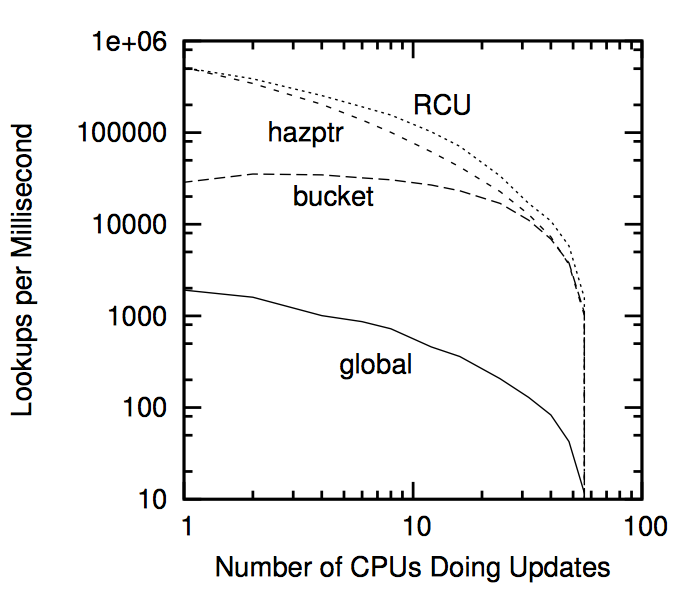
上图展示了更新频率增加对查找的影响,而下图则显示了更新频率的增加对更新本身的影响。危险指针和 RCU 从一开始就占据领先,因为,与每桶一锁不同,危险指针和 RCU 的读者并不排斥写者。然而,随着做更新操作的 CPU 数量的增加,开始显示出更新端开销的存在,首先是 RCU,然后是危险指针。当然,所有这三种实现都要比全局锁实现更好。
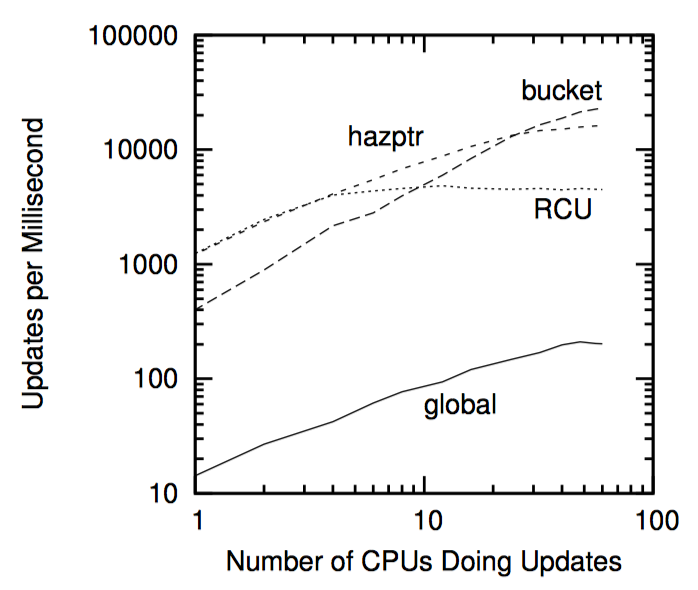
当然,很可能查找性能的差异也受到更新速率差异的影响。为了检查这一点,一种方法是人为地限制每桶一锁和危险指针实现的更新速率,以匹配 RCU 的更新速率。这样做显然不会显著提高每桶一锁实现的查找性能,也不会拉近危险指针与 RCU 之间的差距。但是,去掉危险指针的读取端内存屏障(从而导致危险指针的实现不安全)确实弥合了危险指针和 RCU 之间的差距。虽然这种不安全的危险指针实现通常足够可靠,足以用于基准测试用途,但是绝对不推荐用于生产用途。
对受 RCU 保护的哈希表的讨论
RCU 实现和危险指针会导致一种后果,一对并发读者可能会不同意猫此时的状态。比如,其中在某只猫被删除之前,一个读者可能已经提取了指向猫的数据结构的指针,而另一个读者可能在之后获得了相同的指针。第一个读者会相信那只猫还活着,而第二个读者会相信猫已经死了。
当然,薛定谔的猫不就是这么一回事吗,但事实证明这对于正常的非量子猫也是相当合理的。
合理的原因是,我们我发准确得知动物出生或死亡的时间。
为了搞明白这一点,让我们假设我们可以通过心跳检查来测得猫的死亡。这又带来一个问题,我们应该在最后一次心跳之后等待多久才宣布死亡。只等待 1ms?这无疑是荒谬的,因为这样一只健康活猫也会被宣布死亡——然后复活,而且每秒钟还发生不止一次。等待一整个月也是可笑的,因为到那时我们通过嗅觉手段也能非常清楚地知道,这只可怜的猫已经死亡。
因为动物的心脏可以停止几秒钟,然后再次跳动,因此及时发现死亡和假警概率之间存在一种权衡。在最后一次心跳和死亡宣言之间要等待多久,两个兽医很有可能不同意彼此的意见。例如,一个兽医可能声明死亡发生在最后一次心跳后 30s,而另一个可能要坚持等待完整的一分钟。在猫咪最后一次心跳后第二个 30s 周期内,两个兽医会对猫的状态有不同的看法。
当然,海森堡教导我们生活充满了这种不确定性,这也是一件好事,因为计算机硬件和软件的行为在某种程度上类似。例如,你怎么知道计算机有个硬件出问题了呢?通常是因为它没有及时回应。就像猫的心跳,折让硬件是否有故障出现了一个不确定性窗口。
此外,大多数的计算机系统旨在与外部世界交互。因此,对外的一致性是至关重要的。然而,正如我们在前面看到的,增加内部的一致性常常以外部一致性作为代价。像 RCU 和危险指针这样的技术放弃了某种程度上的内部一致性,以获得改善后的外部一致性。
总之,内部一致性不一定是所有问题域关心的部分,而且经常在性能、可扩展性、外部一致性或者所有上述方面产生巨大的开销。
不可分割的数据结构
固定大小的哈希表可以完美分割,但是当可扩展的哈希表在增长或收缩时,就不那么容易分割了。不过事实证明,对于受 RCU 保护的哈希表,完全可以写出高性能并且可扩展的实现。
可扩展哈希表的设计
与 21 世纪初的情况形成鲜明对比的是,现在有不少于三个不同类型的可扩展的受 RCU 保护的哈希表实现。第一个也是最简单的一个是 Herbert Xu 为 Linux 内核开发的实现,我们首先来介绍它。
这个哈希表实现背后的关键之处,是每个数据元素可以有两组链表指针,RCU 读者(以及非 RCU 的写者)使用其中一组,而另一组则用于构造新的可扩展的哈希表。此方法允许在哈希表调整大小时,可以并发地执行查找、插入和删除操作。
调整大小操作的过程下图 1~4 所示,图 1 展示了两个哈希桶的初始状态,时间从图 2 推进到 图 3。初始状态使用 0 号链表来将元素与哈希桶链接起来。然后分配一个包含 4 个桶的数组,并且用 1 号链表将进入 4 个新的哈希桶的元素链接起来。者产生了如图 2 所示的状态(b),此时 RCU 读者仍让使用原来的两桶数组。
随着新的四桶数组暴露给读者,紧接着是等待所有老读者完成读取的宽限期操作,产生如图 3 所示的状态(c)。这时,所有 RCU 读者都开始使用新的四桶数组,这意味着现在可以释放旧的两桶数组,产生图 4 所示的状态(d)。
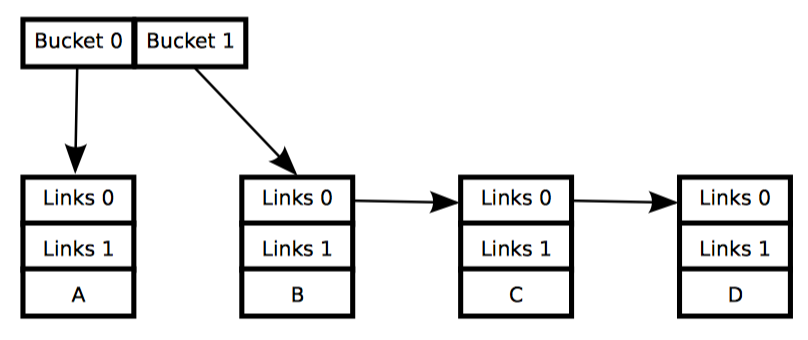
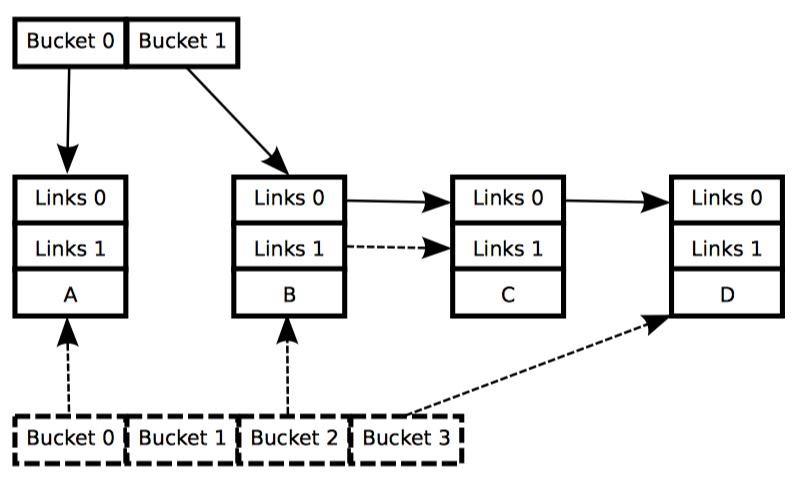
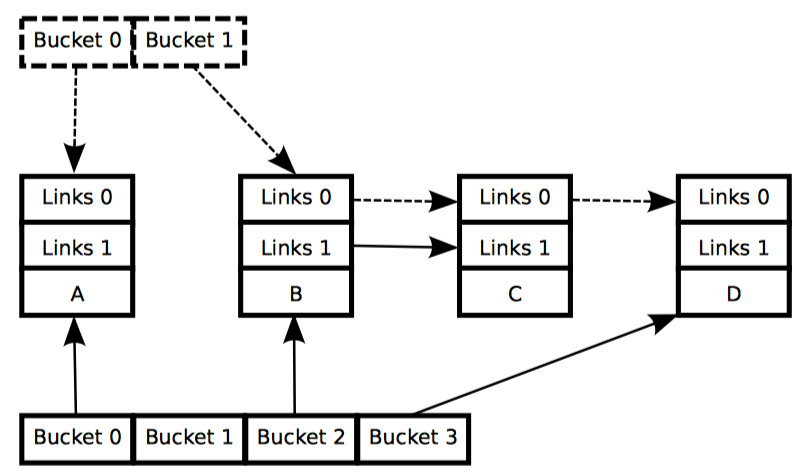
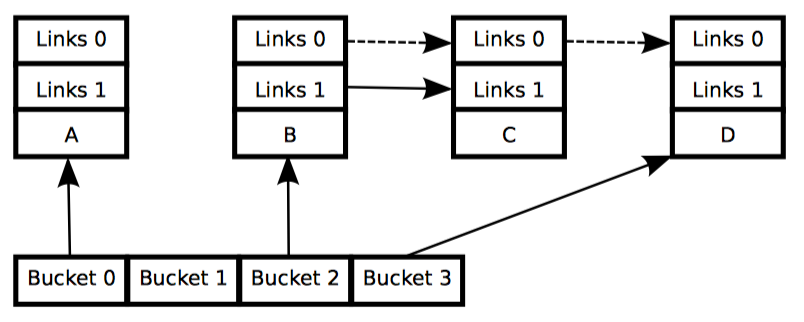
可扩展哈希表的实现
调整大小操作是通过插入一个中间层次的经典方法完成的,这个中间层次如下面的片段中 12~25 行的结构体 ht 所示。第 27~30 行所示的是结构体 hashtab 仅包含指向当前 ht 结构的指针以及用于控制并发地请求调整哈希大小的自旋锁。如果我们使用传统的基于锁或原子操作的实现,这个 hashtab 结构可能会称为性能和可扩展性的严重瓶颈。但是,因为调整大小操作应该相对少见,所以这里 RCU 应该能帮我们大忙。

结构体 ht 表示哈希表的尺寸信息,其大小第 13 行的 ->ht_nbuckets 字段指定。为了避免出现不匹配的情况,哈希表的大小和哈系统的数组(第 24 行 ->ht_btk[])存储于相同的结构中。第 14 行上的 ->ht_resize_cur 字段通常等于 -1,当正在进行调整大小操作时,该字段的值表示其对应数据已经添入新哈希表的哈希桶索引,如果当前没有进行调整大小的操作,则 ->ht_new 为 NULL。因此,进行调整大小操作本质上就是通过分配新的 ht 结构体并让 ->ht_new 指针指向它,然后没遍历一个旧表的桶就前进一次 ->ht_resize_cur。当所有元素都移入新表时,hashtab 结构的 ->ht_cur 字段开始指向新表。一旦所有的旧 RCU 读者完成读取,就可以释放旧哈希表的 ht 结构了。
第 16 行的 ->ht_idx 字段指示哈希表实例此时应该使用哪一组链表指针,ht_elem 结构体里的 ->hte_next[] 数组用该字段作为此时的数组下标,见第 3 行。
第 17~23 行定义了 ->ht_hash_private、->ht_cmp、->ht_gethash、->ht_getkey 等字段,分别代表着每个元素的键和哈希函数。->ht_hash_private 用于扰乱哈希函数,其目的是防止通过对哈希函数所使用的参数进行统计分析来发起拒绝服务攻击。->ht_cmp 函数用于比较两个键,->ht_gethash 计算指定键的哈希值,->ht_getkey 从数据中提取键。
ht_bucket 结构与之前相同,而 ht_elem 结构与先前实现的不同仅在于用两组链表指针代替了代替了先前的单个链表指针。
在固定大小的哈希表中,对桶的选择非常简单,将哈希值转换成相应的桶索引。相比之下,当哈希表调整大小时,还有必要确定此时应该从旧表还是新表的哈希桶中进行选择。如果旧表中要选择的桶已经被移入新表中,那么应该从新表中选择存储桶。相反,如果旧表中要选择的桶还没有被移入新表,则应从旧表中选择。

桶的选择如相面的代码所示,包括第 1~8 行的 ht_get_bucket_single 和第 10~24 行的 ht_get_bucket。ht_get_bucket_single 函数返回一个指向包含指定键的桶,调用时不允许发生调整大小的操作。第 5~6 行,他还将与键相对应的哈希值存储到参数 b 指向的内存。第 7 行返回对应的桶。
ht_get_bucket 函数处理哈希表的选择,在第 16 行调用 ht_get_bucket_single 选择当前哈希表的哈希值对应的桶,用参数 b 存储哈希值。如果第 17 行确定哈希表正在调整大小,并且第 16 行的桶已经被移入新表,则第 18 行选择新的哈希表,并且第 19 行选择新表中的哈希值对应的桶,并再次用参数 b 存储哈希值。
如果第 21 行确定参数 i 为空,则第 22 行记录当前使用的是哪一组链表指针。最后,第 23 行返回指向所选哈希桶的指针。
这个实现的 ht_get_bucket_single 和 ht_get_bucket 允许查找、修改和调整大小操作同时执行。
读取端的并发控制由 RCU 提供。但是更新端的并发控制函数 hashtab_lock_mod 和 hashtab_unlock_mod 现在需要处理并发调整带下操作的可能性,如下片段所示:

第 1~19 行是 hashtab_lock_mod,第 9 行进入 RCU 读端临界区,以放置数据结构在遍历期间被释放,第 10 行获取对当前哈希表的引用,然后第 11 行获得哈希桶所对应的键的指针。第 12 行获得了哈希桶的锁,这将防止任何并发的调整大小操作移动这个桶,当然如果调整大小操作已经移动了该桶,则这一步没有任何效果。然后第 13 行检查并发的调整大小操作是否已经将这个桶移入新表。然后第 13 行检查并发的调整大小操作是否已经将这个桶移入新表,如果没有,则第 14 行在持有所选桶的锁时返回(此时仍处于 RCU 读端临界区内)。
否则,并发的调整大小操作将此桶移入新表,因此第 15 行获取新的哈希表,第 16 行选择键对应的桶。最后,第 17 行获取桶的锁,第 18 行释放旧表的桶的锁。最后,hashtab_lock_mod 退出 RCU 读端临界区。
hashtab_unlock_mod 函数负责释放由 hashtab_lock_mod 获取的锁。第 28 行能拿到当前哈希表,然后第 29 行调用 ht_get_bucket,以获得键锁对应的桶的指针,当让该桶可能已经位于新表。第 30 行释放桶的锁,以及最后第 31 行退出 RCU 读端临界区。
现在已经有了桶选择和并发控制逻辑,我们已经准备好开始搜索和更新哈希表了。如下所示的 hashtab_lookup、hashtab_add、hashtab_del 函数:

上面第 1~21 行的 hashtab_lookup 函数执行哈希查找。第 11 行获取当前哈希表,第 12 行获取指定键对应的桶的指针。当调整大小操作已经越过该桶在旧表中的位置时,则该桶位于新表中。注意,第 12 行业传入了表明使用哪一组链表指针的索引。第 13~19 行的循环搜索指定的桶,如果第 16 行检测到匹配的桶,第 18 行则返回指向包含数据元素的指针。否则如果没有找到匹配的桶,第 20 行返回 NULL 表示失败。
第 23~37 行的 hashtab_add 函数向哈希表添加了新的数据元素。第 32~34 行获取指定键对应的桶的指针(同时提供链表指针组下标)。第 35 行如前所述,为哈希表添加新元素。在这里条用者需要处理并发性,例如在调用 hashtab_add 前后分别调用 hashtab_lock_mod 和 hashtab_unlock_mod。这两个并发控制函数能正确地与并发调整大小操作互相同步:如果调整大小操作已经超越了该数据元素被添加到的桶,那么元素将添加到新表中。
第 39~52 行的 hashtab_del 函数从哈希表中删除一个已经存在的元素。与之前一样,第 48~50 行获取桶并传入索引,第 51 行删除指定元素。与 hashtab_add 一样,调用者负责并发控制,并且需要确保并发控制可以处理并发调整大小的操作。

实际调整大小由 hashtab_resize 执行,如上所示。第 17 行有条件地获取最顶层的 ht_lock,如果获取失败,则第 18 行返回 EBUSY 以表明正在进行调整大小操作。否则,第 19 行获取当前哈希表的指针,第 21~24 行分配所需大小的新哈希表。如果指定了新的哈希函数,将其应用于表,否则继续使用旧哈希表的哈希函数。如果第 25 行检测到内存分配失败,则第 26 行释放 htlock 锁并且在第 27 行返回出错的原因。
第 29 行开始桶的移动过程,将新表的指针放入酒标的 ht_new 字段,第 30 行确保所有不知道新表存在的读者在调整大小操作继续之前完成释放。第 31 行获取当前表的链表指针索引,并将其存储到新表中,以防止两个哈希表重写彼此的链表。
第 33~44 行的循环每次将旧表的一个桶移动到新的哈希表中。第 34 行将获取旧表的当前桶的指针,第 35 行获取该桶的自旋锁,并且第 36 行更新 ht_resize_cur 以表明此桶正在移动中。
第 37~42 行的循环每次从旧表的桶中移动一个元素到对应新表的桶中,在整个操作期间持有新表桶中的锁。最后,第 43 行释放旧表中的桶锁。
一旦执行到 45 行,所有旧表的桶都已经被移动到新表。第 45 行将新创建的表视为当前表,第 46 行等待所有的旧读者(可能还在引用旧表)完成。然后第 47 行释放调整大小操作的锁,第 48 行释放旧的哈希表,最后第 49 行返回成功。
可扩展哈希表的讨论
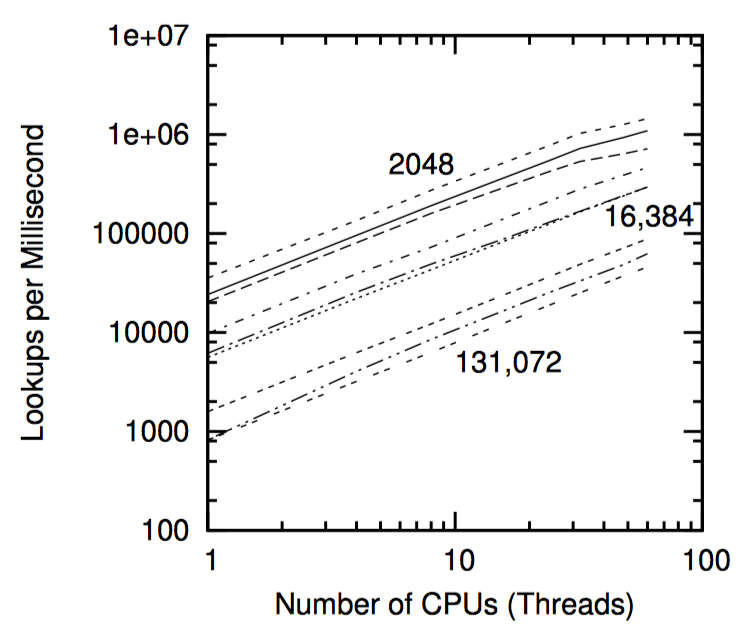
上图比较了可扩展哈希表和固定哈希表在拥有不同元素数量下的性能。图中为每种元素个数绘制了三条曲线。
最上面的三条线是有 2048 个元素的哈希表,这三条线分别是:2048 个桶的固定哈希表、1024 个桶的固定哈希表、可扩展哈希表。这种情况下,因为哈希链很短因此正常的查找开销很低,因此调整大小的开销反而占据主导地位。不过,因为桶的个数越多,固定大小哈希表性能优势越大,至少在给予足够操作暂停时间的情况下,调整大小操作还是有用的,一次 1ms 的暂停时间显然太短。
中间三条线是 16348 个元素的哈希表。这三条线分别是:2048 个桶的固定哈希表、可扩展哈希表、1024 个桶的固定哈希表。这种情况下,较长的哈希链将导致较高的查找开销,因此查找开销大大超过了调整哈希表大小的操作开销。但是,所有这三种方法的性能在 131072 个元素时比在 2048 个元素时差一个数量级以上,这表明每次将哈希表大小增加 64 倍才是最佳策略。
该图的一个关键点是,对受 RCU 保护的可扩展哈希表来说,无论是执行效率还是可扩展性都是与其固定大小的对应者相当。当然在实际调整大小过程中的性能还是受到一定程度的影响,这是由于更新每个元素的指针时产生了高速缓存未命中,当桶的链表很短时这种效果最显著。这表明每次调整哈希表的大小时应该一步到位,并且应该防止由于频繁的调整操作而导致的性能下降,在内存宽裕的环境中,哈希表大小的增长幅度应该比缩小时的幅度更大。
该图的另一个关键点是,虽然 hashtab 结构体是不可分割的,但是它特使读侧重的数据结构,这说明可以使用 RCU。鉴于无论是在性能还是在扩展性上,可扩展哈希表都非常接近于受 RCU 保护的固定大小哈希表,我们必须承认这种方法是相当成功的。
最后,请注意插入、删除和查找操作可以与调整大小操作同时进行。当调整元素个数极多的哈希表大小时,需要重视这种并发性,特别是对于那些必须有严格响应是时间限制的应用程序来说。
当然,ht_elem 结构的两个指针集合确实会带来一定的内存开销,我们将在下一节展开讨论。
其他可扩展哈希表
上一节讨论的可扩展哈希表,其缺点之一就是消耗的内存大。每个数据元素拥有两对链表指针。是否可以设计一种受 RCU 保护的可扩展哈希表,但链表只有一对?
答案是“是”。Josh Triplett 等人创造了一种相对(relativistic)哈希表,可以递增地分割和组合相应的哈希链,以便读者在调整大小操作期间始终可以看到有效的哈希链。这种增量分割和组合取决于一点事实,读者可以看到在其他哈希链中的数据元素。这一点是无害的,当发生这种情况时,读者可以简单地忽略这些由于键不匹配而看见的无关数据元素。

上图展示了如何将相对哈希表缩小两倍的过程。此时,两个桶的哈希表收缩成一个桶的哈希表,又称为线性链表。这个过程将较大的旧表中的桶合并为较小的新标中的桶。为了让这个过程正常进行,我们显然需要限制两个表的哈希函数。一种约束是在底层两个表中使用相同的哈希函数,但是当从大到小收缩时去除哈希值的最低位。例如,旧的两桶哈希表使用哈希值的高两位,而新的单桶哈希表使用哈希值的最高位。这样,在较大的旧表中相邻的偶数和奇数桶可以合并成较小的新表中的单个桶里,同时哈希值仍然可以覆盖单桶中的所有元素。
初始状态显示在图的顶部,从初始状态(a)开始,时间从顶部到底部前进,收缩过程从分配新的较小数组开始,并且使新数组的每个桶都指向旧表中相应桶的第一个元素,到达状态(b)。
然后,两个哈希链连接在一起,到达状态(c)。在这种状态下,读了偶数编号元素的读者看不出有什么变化,查找元素 1 和 3 的读者同样也看不到变化。然而,查找其他奇数编号元素的读者会遍历元素 0 和 2。这样做是无害的,因为任何奇数键都不等于这两个元素。这里会有一些性能损失,但是另一方面,这与新表完全就位以后将经历的性能损失完全一样。
接下来,读者可以开始访问新表,产生状态(d)。请注意,较旧的读者可能仍然在遍历大哈希表,所以在这种状态下两个哈希表都在使用。
下一步是等待所有旧的读者完成,产生状态(e)。
在这种状态下,所有读者都使用新表,以便旧表中桶可以被释放,最终到达状态(f)。
扩展相对哈希表的过程与收缩相反,但需要更多的宽限期步骤,如下图。

在该图的顶部是初始状态(a),时间从顶部前进到底部。
一开始我们分配较大的哈希表,带有两个桶,到达状态(b)。请注意,这些新桶指向旧桶对应部分的第一个元素。当这些新桶被发布给读者后,到达状态(c)。过了宽限期后,所有读者都将使用新的大哈希表,到达状态(d)。在这个状态下,只有那些遍历偶数值哈希桶的读者才会遍历到元素 0,因此现在的元素 0 是白色的。
此时,旧表的哈希桶可以被释放,但是在很多实现中仍然使用这些旧桶来跟踪将链表元素“解压缩”到对应新桶中的进度。在对这些元素的第一遍执行中,最后一个偶数编号的元素其“next”指针将指向后面的偶数编号元素。在随后的宽限期操作之后,到达状态(e)。垂直箭头表示要解压缩的下一个元素,元素 1 的颜色现在为黑色,表示只有那些遍历奇数哈希桶的读者才可以接触到它。
接下来,在对这些元素的第一遍执行中,最后一个奇数编号的元素其“next”指针将指向后面的奇数编号元素。在随后的宽限期操作之后,到达状态(f)。最后的解压缩操作(包括宽限期操作)到达最终状态(g)。
简而言之,相对哈希表减少了每个元素的链表指针的数量,但是在调整大小期间产生额外的宽限期。一般来说这些额外的宽限期不是问题,因为插入、删除和查找可能与调整大小同时进行。
结果证明,完全可以将每元素的内存开销从一对指针降到一个指针,同时保留 O(1) 复杂度的删除操作。这是通过使用受 RCU 保护的增广拆序链表(split-order list)做到的。哈希表中的数据元素被排列成排序后的单向链表,每个哈希桶指向该桶中的第一个元素。通过设置元素的 next 指针的低阶位来标记为删除,并且在随后的遍历中再次访问这些元素时将它们从链表中移除。
受 RCU 保护的拆序链表非常复杂,但是为所有插入、删除、查找操作提供无锁的进度保证。在实时应用中这种保证及其重要。最新版本的用户态 RCU 库提供了一个实现。
其他数据结构
前面的小节主要关注因为可分割性而带来的高并发性数据结构,高效的处理读侧重的访问模式,或者应用读侧重性来避免不可分割性。本节会简要介绍其他数据结构。
哈希表在并行应用上的最大优点之一就是它是可以完全分割的,至少是在不调整大小时。一种保持可分割性的尺寸独立性的方法是使用基树(radix tree)。也称 trie。Trie 将需要搜索的键进行分割,通过各个连续的键分区来遍历下一级 trie。因此,trie 可以被认为是一组嵌套的哈希表,从而提供所需的可分割性。Trie 的一个缺点是稀疏的键空间导致无法充分利用内存。有许多压缩技术可以解决这个缺点,包括在遍历前将键映射到较小的键空间中。基树在实践中被大量使用,包括在 Linux 内核中。
哈希表和 trie 的一种重要特例,同时也可能是最古老的数据结构,是数组及其多维对应物——矩阵。因为矩阵的可完全分割性质,在并发数值计算算法中大量应用了矩阵。
自平衡树在串行代码中被大量使用,AVL 树和红黑树可能是最著名的例子。早期尝试并行化 AVL 树的实现很复杂,效率也很可疑。但是最近关于红黑树的研究是使用 RCU 读者来保护读,哈希后的锁数组来保护写,这种实现提供了更好的性能和可扩展性。事实证明,红黑树的积极再平衡虽然适用于串行程序,但不一定适用于并行场景。因此,最近有文章创造出受 RCU 保护的较少再平衡的“盆景树”,通过付出最佳树深度的代价以获得跟有效的并发更新。
并发跳跃链表(skip list)非常适合 RCU 读者,事实上这代表着早期在学术上对类似 RCU 技术的使用。
前面讨论过的并行双端队列,虽然同是在性能和扩展性上不太令人印象深刻,并行堆栈和并行队列也有着悠久的历史。但是它们往往是并行库具有的共同特征。研究人员最近提出放松堆栈和队列对排序的约束,有一些工作表名放松排序的队列实际上比严格 FIFO 的队列具有更好的排序属性。
乐观来说,未来对并行数据结构的持续研究似乎会产生具有惊人性能的新颖算法。
微优化
以上展示的数据结构都比较直白,没有利用底层系统的缓存层次结构。此外,对于键到哈希值的转换和其他一些频繁的操作,很多实现使用了指向函数的指针。虽然这种方式提供了简单性和可移植性,但在很多情况下会损失一些性能。
以下部分涉及实例化(specializtion)、节省内存、基于硬件角度的考虑。请不要错误的将这些小节看成是本书讨论的主题。市面上已经有大部头讲述如何在特定 CPU 上做优化,更不用说如今常用的 CPU 了。
实例化
前面提到的可扩展哈希表使用不透明类型的键。这给我们带来了极大地灵活性,允许使用任何类型的键,但是由于使用了函数指针,也导致了显著的开销。现在,现代化的硬件使用复杂的分支预测技术来最小化这种开销,但在另一方面,真实世界的软件往往比今天的大型硬件分支越策表可容纳的范围更大。对于调用指针来说尤其如此,在这种情况下,分支预测硬件必须是在分支信息之外另外记录指针信息。
这种开销可以通过实例化哈希表实现来确定键的类型和哈希函数。这样做出列图 10.24 和图 10.25 的 ht 结构体中的 ht_cmp、ht_gethash、ht_getkey 函数指针,也消除了这些指针的相应调用。这使得编译器可以内联生成固定函数,这消除的不仅是调用指令的开销,而且消除了参数打包的开销。
此外,可扩展哈希表的设计考虑了将桶选择与并发控制分离的 API。虽然这样可以用单个极限测试来执行本章中的所有哈希表实现,但是这也意味着许多操作必须将计算哈希值和与可能的大小调整操作交互这些事情来回做两次。在要求性能的环境中,hashtab_lock_mod 函数也可以返回对所选桶的指针,从而避免后续调用 ht_get_bucket。
除此之外,和我在 20 世纪 70 年代带一次开始学习编程相比,现代硬件的一大好处是不太需要实例化。这可比回到 4K 地址空间的时代效率高多了。
比特与字节
本章讨论的哈希表几乎没有尝试节省内存。例如在 10.24 中,ht 结构体的 ht_idx 字段的取值只能是 0 或 1,但是却占用完整的 32 位内存。完全可以删除它,例如,从 ht_resize_key 字段窃取一个比特。因为 ht_resize_key 字段足够大寻址任何内存地址,而且 ht_bucket 结构体总是要比一个字节长,所以 ht_resize_key 字段肯定有多个空闲比特。
这种比特打包技巧经常用在高度复制的数据结构中,就像 Linux 内核中的 page 结构体一样。但是,可扩展哈希表的 ht 结构复制程度并不太高。相反我们应该关注 ht_bucket 结构体。有两个地方可以减小 ht_bucket 结构:将 htb_lock 字段放在 htb_head 指针的低位比特中;减少所需的指针数量。
第一点可以利用 Linux 内核中的位自旋锁,由 include/linux/bit_spinlock.h 头文件提供。他们用在 Linux 内核的内存敏感数据结构中,但也不是没有缺点:
- 比传统的自旋锁语义慢。
- 不能参与 Linux 内核中的 lockdep 死锁检测工具。
- 不记录锁的所有权,想要进一步调试会变得复杂。
- 不参与 -rt 内核中的优先级提升,这意味着保持位自旋锁时必须禁用抢占,这可能会降级实时延迟。
尽管有这些缺点,位自旋锁在内存十分珍贵时非常有用。
10.4.4 节讨论了第二点的一个方面,可扩展哈希表只需要一组桶链表指针来代替 10.4 节实现中所需的两组指针。另一个办法是使用单链表来替代在此使用的双向链表。这种方式的一个缺点是,删除需要额外的开销:要么标记传出指针以便以后删除、要么通过搜索要删除的元素的桶链表。
简而言之,人们需要在最小内存开销和性能、简单性之间权衡。幸运的是,在现代系统上连接内存允许我们优先考虑性能和简单性,而不是内存开销。然而,即使拥有今天的大内存系统,有时仍然需要采取极端措施以减少内存开销。
硬件层面的考虑
现代计算机通常在 CPU 和主存储器之间移动固定大小的数据块,从 32 字节到 256 字节不等。这些块名为缓存行(cacheline),如 3.2 节所述,这对于高性能和可扩展性是非常重要的。将不兼容的变量放入同一缓存行会严重降低性能和扩展性。例如,假设一个可扩展哈希表的数据元素具有一个 ht_elem 结构,它与某个频繁增加的计数器处于相同的高速缓存行中。频繁增加的计数器将导致高速缓存行出现在执行增量的 CPU 中。如果其他 CPU 尝试遍历包含数据元素的哈希桶链表,则会导致昂贵的告诉缓存未命中,降低性能和扩展性。

如上图所示,这是一种在 64 位字节高速缓存行的系统上解决问题的方法。这里的 gcc aligned 属性用于强制将 counter 字段和 ht_elem 结构体分成独立的缓存行。这将允许 CPU 全速遍历哈希桶链表,尽管此时计数器也在频繁增加。
当然,这引出了一个问题,“我们怎么知道缓存行是 64 位大小?”。在 Linux 系统中,此信息可以从 /sys/devices/system/cpu/cpu */cache/ 目录得到,甚至有时可以在安装过程重新编译应用程序以适应系统的硬件结构。然而,如果你想要体验困难,也可以让应用程序在非 Linux 系统上运行。此外,即使你满足于运行只有在 Linux 上,这种自修改安装又带来了验证的挑战。
幸运的是,有一些经验法则在实践中工作的相当好,这是作者从一份 1995 年的文件中收到的。第一组规则设计重新排列结构以适应告诉缓存的拓扑结构。
- 将经常更新的数据与以读为主的数据分开。例如,将读侧重高的数据放在结构的开头,而将频繁更新的数据放于末尾。如果可能,将很少访问的数据放在中间。
- 如果结构有几组字段,并且每组字段都会在独立的代码路径中被更新,将这些组彼此分开。再次,尽量在不同的组之间放置很少访问的数据。在某些情况下,将每个这样的组放置在被原始结构单独引用的数据结构中也是可行的。
- 在可能的情况下,将经常更新的数据与 CPU、线程或任务相关联。
- 在有可能的情况下,应该尽量将数据分割在每 CPU、每线程、每任务。
最近已经有一些朝向基于痕迹的自动重排的结构域的研究。这项工作可能会让优化的工作变得不那么痛苦,从而从多线程软件中获得出色性能和可扩展性。
以下是一组处理锁的额外的经验法则:
- 当使用高竞争度的锁来保护被频繁更新的数据时,采取以下方式之一:
- 将锁与其保护的数据处于不同的缓存行中。
- 使用适用于高度竞争的锁,例如排队锁。
- 重新设计以减少竞争。
- 将低度竞争的锁置于与它们保护的数据相同的高速缓存行中。这种方法意味着因锁导致的当前 CPU 的高速缓存未命中同时也带来了它的数据。
- 使用 RCU 保护读侧重的数据,或者,如果 RCU 不能使用并且临界区非常长时,使用读写锁。
当然这些只是经验法则,而非绝对规则。最好是先做一些实验以找到最适合你的特殊情况的方法。
总结
本章主要关注哈希表,包括不可完全分割的可扩展哈希表。本章关于哈希表的阐述是围绕高性能可扩展数据访问的许多问题的绝佳展示,包括:
- 可完全分割的数据结构在小型系统上工作良好,比如单 CPU 插槽系统。
- 对于较大型的系统,需要将局部数据访问性和完全分割同等看待。
- 读侧重技术,如危险指针和 RCU,在以读为主的工作负载时提供了良好的局部访问性,因此即使在大型系统中也能提供出色的新能和可扩展性。
- 读侧重技术在某些不可分割的数据结构上也工作得不错,例如可扩展的哈希表。
- 在特定工作负载时实例化数据可以获得额外的性能和可扩展性,例如,将通用的键替换成 32 位整数。
- 尽管可移植性和极端性能的要求通常是互相干扰的,但是还是有一些数据结构布局技术可以在这两套要求之间达到良好的平衡。
但是如果没有可靠性,性能和可扩展性也算不上什么。因此下一章将介绍“验证”。
11 - CH11-验证
我也写过一些并行软件,他们一来就能够运行。但这仅仅是因为在过去的 20 年中我写了大量的并行软件。而更多的并行程序是在捉弄我,但却让我认为它们第一次就能正确工作。
因此,我强烈需要对我的并行程序进行验证。与其他软件验证相比,并行软件验证的基本点是:意识到计算机知道什么是错误的。因此,你的任务就是逼迫计算机告诉你哪里是错误的。所以说,本章可以认为是一个审问计算机的简单教程。
更多的教程可以在最近的验证书籍中找到,至少有一本比较老但相当有价值的书籍。验证是及其重要的主题,它涵盖了所有形式的软件,因此也值得深入研究。但是,本书主要关注并行方面,因此本章只会粗略对这一重要主题进行阐述。
简介
BUG 来自何处
BUG 来自于开发者。基本问题是:人类大脑并没有伴随着计算机一起进化。相反,人类大脑是伴随着其他人类以及动物大脑而进化的。由于这个历史原因,下面三个计算机的特征往往会让人类觉得惊奇。
- 计算机缺乏常识性的东西。几十年来,人工智能总是无功而返。
- 计算机通常无法理解人类的意图,或者更正式的说,计算机缺少心理理论。
- 计算机通常不能做局部性的计划,与之相反,它需要你将所有细节和每一个可能的场景都一一列出。
前两点是毋庸置疑的,这已经被大量失败的产品证明。这些产品中,最著名的可能要算 Clippy 和 Microsoft Bob 了。通过视图与人类用户相关联,这两款产品所表现出的常识和心理理论预期不尽如人意。也许,最近在智能手机上出现的软件助手将有良好的表现。也就是说,开发者仍然在走老路,软件助手可能对终端用户有益,但对开发者来说并没有什么助益。
对于人类喜欢的局部性计划来说,需要跟过的解释。特别是它是一个典型的双刃剑。很显然,人类对局部性计划的偏爱是由于我们假设这些计划将拥有常识和对计划意图的良好理解。后一个假设通常类似于这样一种常见情况,执行计划的人和制定计划的人是同一个人。在这种情况下,当阻碍计划执行的情况出现时,计划总是会在随后被修正。因此,局部性计划对于人类来说表现的很不错。举个特别的例子,在无法订立计划时,与其等待死亡还不如采取一些随机动作,这有更高的可能性找到食物。不过,以往在日常生活中行之有效的局部性计划,在计算机中并不见得凑效。
而且,对遵循局部性计划的需求,对于人类心灵有重要的影响。这来自于贯穿人类历史的事实,生命通常是艰难而危险的。这一点通常好不令人奇怪,当遭遇到锋利的牙齿好爪子时,执行一个局部性的计划需要一种几乎癫狂的乐观精神——这种精神实际上存在于绝大多数人类身上。这也延伸到对编程能力的自我评估上来了。这已经被包括实验性编程这样的面试技术的效果锁证实。实际上,比疯狂更低一级的乐观水平,在临床上被称为“临床型郁闷”。在他们的日常生活中,这类人通常面临严重的困扰。这里强调一下,近乎疯狂的乐观对于一个正常、健康的生命反直觉的重要性。如果你没有近乎癫狂的乐观精神,就不太可能会启动一个困难但有价值的项目。
一个重要的特殊情况是,虽然项目有价值,但是其价值尚不值得花费它所需要的时间。这种特殊情况是十分常见的,早期遇到的情况是,投资者没有足够的意愿投入项目实际需要的投资。对于开发者来说,自然的反应就是产生不切实际的乐观估计,认为项目已经被允许启动。如果组织足够强大,幸运的结果是进度受到影响或者预算超支,而项目终归还有见到天日的哪一天。但是,如果组织还不够强大,并且决策者在项目变得明朗之前预估它不值得投资,因而快速、错误的终止项目,这样的项目将可能毁掉组织。这可能导致其他组织重拾该项目,并且要么完美它、要么终止它,或者被它所毁掉。这样的项目可能会在毁掉多个组织后取得成功。人们只能期望,组织最终能够成功的管理一系列杀手项目,使其保持一个适当的水平,使得自身不会被下一个项目毁掉。
虽然疯狂乐观可能是重要的,但是它是 BUG 的重要来源(也许还包括组织失败)。因此问题是,如何保持一个大型项目所需要的乐观情绪,同时保持足够清醒的认识,使 BUG 保持在足够低的水平?
心态
当你进行任何验证工作时,应当记住以下规则:
- 没有 BUG 的程序,仅仅是那种微不足道的程序。
- 一个可靠的程序,不存在已知的 BUG。
从这些规则来看,可以得出结论,任何可靠的、有用的程序至少都包含一个未知的 BUG。因此,对一个有用的程序进行验证工作,如果没有找到任何 BUG,这本身就是一件失败的事情。因此,一个好的验证工作,就是一项破坏性的实践工作。这意味着,如果你是那种乐于破坏事务的人,验证工作就是一项好差事。
要求脚本检查错误的输入,如果找到 time 输出错误,还要给出相应的诊断结果。你应当向这个程序提供什么样的测试输入?这些输入与单线程程序生成的 time 输出一致。
但是,也许你是超级程序员,你的代码每次都在初次完成时就完美无缺。如果真是这样,那么祝贺你!可以放心跳过本章了。但是请原谅,我对此表示怀疑。我遇到那些声称能在第一次就能写出完美程序的人,比真正能够实现这一壮举的人还要多的多。根据前面堆乐观和过于自信的讨论,这并不令人奇怪。并且,即使你真是一个超级程序员,也将会发现,你的调试工作也仅仅是比一般人少一些而已。
对我们其他人来说,另一种情况是,在正常的乐观状态和严重的悲观情绪之间摇摆。如果你乐于毁坏事物,这将是有帮助的。如果你不喜欢毁坏事物,或者仅仅乐于毁坏其他人的事物,那就找那些喜欢毁坏代码并且让他们帮助你测试这些代码吧。
另一种有用的心态是,当其他人找到代码中的 BUG 时,你就仇恨代码吧。这种仇恨有助于你越过理智的界限,折磨你的代码,以便增加自己发现代码中 BUG 的可能性,而不是由其他人来发现。
最后一种心态是,考虑其他人的生命依赖于你的代码的正确性的几率。这将激励你去折磨代码,以找到 BUG 的下落。
不同种类的心态,导致了这样一种可能性,不同的人带着不同的心态参与到项目中。如果组织得当,就能很好的工作。
有些人可能会提醒自己,他们只不过是在折磨一个没有生命的物品。而且,他们也会做这样的假设,谁不折磨自己的代码,代码将会反过来折磨自己。
不过,这也留下一个问题,在项目生命周期中,何时开始验证工作。
何时开始验证
验证工作应该与项目的启动同时进行。
需要明白这一点,需要考虑到,与小型软件相比,在大型软件中找到一个 BUG 困难的多。因此,要将查找 BUG 的时间和精力减少到最小,应当对较小的代码单元进行测试。即使这种方式不会找到所有 BUG,至少能找到相当大一部分 BUG,并且更易于找到并修复这些 BUG。这种层次的测试也可以提醒在设计中的不足之处,将设计不足造成的浪费在代码编写上的时间减少的最小。
但是为什么在验证设计之前,要等待代码就绪呢?希望你阅读一下第 3、4 章,这两章展示了避免一些常见设计缺陷的信息。与同事讨论你的设计,甚至将其简单写出来,这将有助于消除额外的缺陷。
有一种很常见的情形,当你拥有一份设计,并等待开始验证时,其等待时间过长。在你完整理解需求之前,过于乐观的心态难道不会导致你开始设计?对此问题的回到总是会是“是的”。避免缺陷需求的一个好办法是,了解你的用户。要真正为用户服务好,你不得不与他们一起共度一段时间。
某类项目的首个项目,需要不同的方法进行验证,例如,快速原型。第一个原型的主要目的,是学习应当如何实现项目,而不是在第一次尝试时就创建一个正确的实现。但是,请注意,你不应该忽略验证工作,这是很重要的。不过,对于一个原型的验证工作可以采取不同的、快速的方法。
现在,我们已经为你树立了这样的观念,你应当在开始项目时就启动验证工作。后面的章节包含了一定数量的验证技术和方法,这些技术和方法已经证明了其价值。
开元之路
开源编程技术已经证明其有效,它包含严格的代码审查和测试。
我本人可以证明开源社区代码审查的有效性。我早期为 Linux 内核所提供的某个补丁,涉及一个分布式文件系统。在这个分布式文件系统中,某个节点上的用户向一个特定文件写入数据,而另一个节点的用户已经将该文件映射到内存中。在这种情况下,有必要使收到影响的页面映射失效,以允许在写入操作期间,文件系统所维护数据的一致性。我在补丁中进行了初次尝试,并且恪守开源格言“尽早发布、经常发布”,我提交了补丁。然后考虑如何测试它。
但是就在我确定整体测试策略之前,我收到一个回复,指出了补丁中的一些 BUG。我修复了这些 BUG,重新提交补丁,然后回过头来考虑测试策略。但是,在我有机会编写测试代码之前,我收到了针对重新提交补丁的回复,指出了更多的 BUG。这样的过程重复了很多次,以至于我不确定自己是否有机会测试补丁了。
这个经历将开源界所说的真理在我的脑海中打上了深深的烙印:只要有足够多的眼球,所有 BUG 都是浅显的。
当你提交代码或补丁时,想想以下问题:
- 到底有多少这样的眼球真正看了你的代码?
- 到底有多少这样的眼球,他们经验丰富、足够聪明,能够真正找到你的 BUG?
- 他们究竟什么时候看你的代码?
我是幸运的,有一些人,他们期望我的补丁中提供的功能,他们在分布式文件系统方面有着长期的经验,并且几乎立即就查看了我的补丁。如果没有人查看我的补丁,就不会有代码走查,因此也就不会找到 BUG。如果查看我补丁的人缺少分布式文件系统方面的经验,那么就不大可能找到所有的 BUG。如果它们等几个月或几年之后才查看我的补丁,我可能会忘记补丁是如何工作的,修复它们将更困难。
我们也千万不能忘记开源开发的第二个原则,即密集测试。例如,大量的人测试 Linux 内核。它们某些人会提交一些测试补丁,甚至你也提交过这样的补丁。另外一些人测试 next 树,这是有益的。但是,很有可能在你编写补丁,到补丁出现在 next 树之间,存在几周甚至几个月的延迟。这样的延迟可能使你对补丁没了新鲜感。对于其他测试维护树来说,仍然有类似的延迟。
相当一部分人直接将补丁提交到主线,或者提交到主源码树时,才测试它们的代码。如果你的维护者只有在你已经提交测试之后才会接受代码,这将形成死锁情形,你的代码需要测试后才能被接受,而只有被接受后才能开始测试。但是,测试主线代码的人们还是很积极的,因为很多人及组织要等到代码被拉入 Linux 分发版才测试其代码。
即使有人测试了你的补丁,也不能保证他们在适当的硬件和软件配置,以及适当的工作负载下测试了这些补丁,而这些配置和负载是找到 BUG 所必须的。
因此,即使你是为开源项目写代码,也有必要为开发和运行自己的测试套件而做好准备。测试开发是一项被低估,但是非常有价值的技能,因此请务必获取可用套件的全部优势。鉴于测试开发的重要性,我们将对这个主题进行更多的讨论。因此,随后的章节中,将讨论当你已经有一个好的测试套件时,怎么找到代码中的 BUG。
跟踪
如果你正在基于用户态 C 语言程序进行工作,当所有其他手段失效时,添加 printk 或 printf。
原理很简单,如果你不清楚如何运行到代码中某一点,在代码中多加点打印语句,以展示出到底发生了什么。你可以通过使用类似 gdb 或 kgdb 这样的调试器,来达到类似的效果,并且这些调试器拥有更多的方便性和灵活性。还有其他更多先进的工具,一些最新发行的工具提供在错误点回放的能力。
这些强大的测试工具都是有价值的。尤其是目前的典型系统都拥有超过 64K 内存,并且 CPU 都允许在超过 4MHZ 的频率。关于这些工具已经存在不少文章了,本章将再补充一点。
但是,当手上的工作是为了在高性能并行算法的快速路径上指出错误所在,那么这些工具都有严重的缺陷,即这些工具本身机会带来过高的负载。为了这个目的,存在一些特定的跟踪技术,典型的是使用数据所有权技术,以便将运行时数据收集负载最小化。在 Linux 内核中的一个例子是“teace event”。另一个处理用户态程序的例子是 LTTng。这些技术都无一例外使用了每 CPU 缓冲区,这允许以极低的负载来收集数据。即使如此,使用跟踪有时也会改变时序,并足以隐藏 BUG,导致海森堡 BUG。
即使你避免了海森堡 BUG,也还有其他陷阱。例如,即使机器知道所有的东西,它几乎知道所有的东西,以至于超过了大脑的处理能力,该怎么办呢?为此,高质量的测试套件通常配有精巧的脚本来分析大量的输出数据。但是请注意:脚本并不必然揭示那些奇怪的事件。有的 RCU 压力脚本就是一个很好的例子,在 RCU 周期被无限延迟的情况下,这个脚本的早期版本运行的很好。这当然会导致脚本被修改,以检查 RCU 优雅周期延迟的情况,但是这并不能改变如下事实,该脚本仅仅检查那些为认为能够检查的问题。这个脚本是有用的,但是有时候,它仍然不能代替对 RCU 压力输出结果的手动扫描。
对应产品来说,使用追踪,特别是使用 printk 调用进行追踪,存在另外一个问题,他们的负载太高了。在这样的情况下,断言是有用的。
断言
通常假设以下面的方式实现断言:
1 if (something_bad_is_happening())
2 complain();
这种模式通常被封装成 C-预处理宏或者语言内联函数,例如,在 Linux 内核中,它可能被表示为 WARN_ON(something_bad_is_happening())。当然,如果 something_bad_is_happening 被调用得过于频繁,其输出结果将掩盖其错误报告,在这种情况下 WARN_ON_ONCE(something_bad_is_happening) 可能更合适。
在并行代码中,可能发生的一个特别糟糕的情况是,某个函数期望在一个特定的锁保护下运行,但是实际上并没有获得锁。有时候,这样的函数会有这样的注释,调用者在调用本函数时,必须持有 foo_lock。但是,这样的注释并没有真正的作用,除非有人真的读了它。像 lock_is_held(&foo_lock) 这样的语句则会更有效。
Linux 内核的 lockdep 机制更进一步,它即报告潜在的死锁,也允许函数验证适当的锁持有者。当然,这些额外的函数引入了大量负载。因此,lockdep 并不一定适用于生产环境。
那么,当检查是必须的,但是运行时负载不能被容忍时,能够做些什么呢?一种方式是静态分析。
静态分析
静态分析是一种验证技术,其中一个程序将第二个程序作为输入,它报告第二个程序的错误和漏洞。非常有趣的是,几乎所有的程序都通过它们的编译器和解释器来执行静态分析。这些工具远远算不上完美,但在过去的几十年中,它们定位错误的能力得到了几大的改善。部分原因是它们现在拥有超过 64K 内存进行它们的分析工作。
早期的 UNIX lint 工具是非常有用的,虽然它的很多功能都被并入 C 编译器了。目前仍然有类似 lint 的工具在开发和使用中。
Sparse 静态分析查找 Linux 内核中的高级错误,包括:
- 对指向用户态数据结构的指针进行误用。
- 对过长的常量接收赋值。
- 空的 switch 语句。
- 不匹配的锁申请、释放原语。
- 对每 CPU 原语的误用。
- 在非 RCU 指针上使用 RCU 原语,反之亦然。
虽然编译器极有可能会继续提升其静态分析能力,但是 sparse 静态分析展示了编译器外静态分析的优势,尤其是查找应用特定 BUG 的优势。
代码走查
各种代码走查活动是特殊的静态分析活动,只不过是由人来完成分析而已。
审查
传统意义上来说,正式的代码审查采取面对面会谈的形式,会谈者有正式定义的角色:主持人、开发者以及一个或两个其他参与者。开发者通读整个代码,解释做什么,以及它为什么这样运行。一个或者两个参与者提出疑问并抛出问题。而主持人的任务,则是解决冲突并做记录。这个过程对于定于 BUG 是非常有效的,尤其是当所有参与者都熟悉手头代码时,更加有效。
但是,对于全球 Linux 内核开发社区来说,这种面对面的过程并不一定运行得很好,虽然通过 IRC 会话它也许能够很好运行。与之相反,全球 Linux 内核社区有个人进行单独的代码审查,并通过邮件或者 IRC 提供意见。则记录由邮件文档或者 IRC 日志提供。主持人志愿提供相应的服务。偶尔来一点口水战,这样的过程也允许的相当不错,尤其是参与者对手头的代码都很熟悉的时候。
是时候进行 Linux 内核社区的代码审查过程改进了,这是很有可能的。
- 有时,人们缺少进行有效的代码审查所需要的时间和专业知识。
- 即使所有的审查讨论都被存档,人们也经常没有记录对问题的见解,人们通常无法找到这些讨论过程。这会导致相同的错误被再次引入。
- 当参与者吵得不可开交时,有时难于解决口水纷争。尤其是交战双方的目的、经验及词汇都没有共同之处时。
因此,在审查时,查阅相关的提交记录、错误报告及 LWN 文档等相关文档是有价值的。
走查
传统的代码走查类似于正式的代码审查,只不过小组成员以特定的测试用例集来驱动,对着代码摆弄电脑。典型的走查小组包含一个主持人,一个秘书,一个测试专家,以及一个或者两个其他的人。这也是非常有效的,但是也非常耗时。
自从我参加到正式的走查依赖,已经有好几十年了。而且我也怀疑如今的走查将使用单步调试。我想到的一个特别恐怖的过程是这样的:
- 测试者提供测试用例。
- 主持人使用特定的用例作为输入,在调试器中启动代码。
- 在每一行语句执行前,开发者需要预先指出语句的输出,并解释为什么这样的输出是正确的。
- 如果输出与开发者预先指出的不一致,这将被作为一个潜在 BUG 的迹象。
- 在并发代码走查中,一个并发老手将提出问题,什么样的代码会与当前代码并发运行,为什么这样的并行没有问题?
恐怖吧,当然。但是有效吗?也许。如果参与者对需求、软件工具、数据结构及算法都有良好的理解,相应的走查可能非常有效。如果不是如此,走查通常是在浪费时间。
自查
虽然开发者审查自己的代码并不总是有效,但是有一些情形下,无法找到合适的替代方案。例如,开发者可能是被授权查看代码的唯一人员,其他合格的开发人员可能太忙,或者有问题的代码太离奇,以至于只有在开发者展示一个原型后,他才能说服他人认证对待它。在这行情况下,下面的过程是十分有用的,特别是对于复杂的并行代码而言。
- 写出包含需求的设计文档、数据结构图表,以及设计选择的原因。
- 咨询专家,如果有必要就修正设计文档。
- 用笔在纸上写下代码,一边写代码一边修正错误。抵制住对已经存在的、几乎相同的代码序列的引用,相反,你应该复制他们。
- 如果有错误,用笔在干净的纸上面复制代码,以便做这些事情一边修正错误。一直重复,直到最后两份副本完全相同。
- 为那些不是那么显而易见的代码,给出正确性证明。
- 在可能的情况下,自底向上的测试代码片段。
- 当所有代码都集成后,进行全功能测试和压力测试。
- 一旦代码通过了所有测试,写下代码级的文档,也许还会对前面讨论的设计文档进行扩充。
当我在新的 RCU 代码中,忠实的遵循这个流程时,最终只有少量 BUG 存在。在面对一些著名的异常时,我通常能够在其他人之前定位 BUG。也就是说,随着时间的推移,以及 Linux 内核用户数量和种类的增加,这变得更难以解决。
对于新代码来说,上面的过程运转的很好,但是如果你需要对已经编写完成的代码进行审查时,又会怎样呢?如果你编写哪种将废弃的代码,在这种情况下,当然可以实施上面的过程,但是下面的方法也是有帮助的,这是不是会令你感到不适那么绝望。
- 使用你喜欢的文档工具,描述问题中所述代码的高层设计。使用大量的图来表示数据结构,以及这些是如何被修改的。
- 复制一份代码,删掉所有的注释。
- 用文档逐行记录代码是在干什么。
- 修复你所找到的 BUG。
这种方法能够工作,是因为对代码进行详细描述,是一种极为有效的发现 BUG 的方法。虽然后面的过程也是一种真正理解别人代码的好方法,但是在很多情况下,只需要第一步就够了。
虽然由别人来进行复查及审查可能更有效,但是由于某种原因无法让别人参与进来时,上述过程就十分有用了。
在这一点上,你可能想知道如何在不做上述那些无聊的纸面工作的情况下,编写并行代码。下面是一些能够达到目的的且经过时间检验的方法。
- 通过扩展使用已有并行库函数,写出一个顺序程序。
- 为并行框架写出顺序执行的插件。如果地图渲染、BIONC 或者 WEB 应用服务器。
- 做如下优秀的并行设计,问题被完整的分割,然后仅仅实现顺序程序,这些顺序程序并发运行而不必相互通信。
- 坚守在某个领域(如线性代数),在这些领域中,工具可以自定对问题进行分解及并行化。
- 对并行原语进行及其严格的使用,这样最终代码容易被看出其正确性。但是请注意,它总是诱使你打破“小步前进”这个规则,以获得更好的性能可扩展性。破坏规则常常导致意外。也就是说,除非你小心进行本节描述的纸面工作,否则就会有意外发生。
一个不幸的事情是,即使你做了纸面工作,或者使用前述某个方法,以安全地避免纸面工作,仍然会有 BUG。如果不出意外,更多用户或者更多类型的用户将更快暴露出更多的 BUG。特别是,这些用户做了最初那些开发者所没有考虑到的事情时,更容易暴露 BUG。下一步将描述如何处理概率性 BUG,这些 BUG 在验证并行软件时都非常常见。
几率和海森堡 BUG
某些时候你的并行程序失败了。
但是你使用前面章节的技术定位问题,现在,有了适当的修复办法!
现在的问题是,需要多少测试以确定你真的修复了 BUG,而不仅仅是降低了故障发生的几率,或者说仅仅修复了几个相关 BUG 中的某几个,或者是干了一些无效的、不相关的修改。简而言之,是通过了还是侥幸?
不幸的是,摸着良心来回答这个问题,其答案是:要获得绝对的确定性,其所需要的测试量是无限的。
假如我们愿意放弃绝对的确定性,取而代之的是获得某种高几率的东西。那么我们可以用强大的统计工具来应对这个问题。但是,本节专注于简单的统计工具。这些工具是及其有用的,但是请注意,阅读本节并不能代替你采用那些优秀的统计工具。
从简单的统计工具开始,我们需要确定,我们是在做离散测试,还是在做连续测试。离散测试以良好定义的、独立的测试用例为特征。例如,Linux 内核补丁的启动测试就是一个离散测试的例子。启动内核,它要么启动、要么不能启动。虽然你可能花费一小时来进行内核启动测试,试图启动内核的次数、启动成功的次数,通常比花在测试上面的时间更人关注。功能测试往往是离散的。
另一方面,如果我的补丁与 RCU 相关,我很可能会运行 rcutortue,这是一个十分奇妙的内核模块,用于测试 RCU。它不同于启动测试。在启动测试中,一旦出现相应的登录提示符,就表名离散测试已经成功结束。Rcutortue 则会一直持续运行,知道内存崩溃或要求它停止为止。因此,rcutortue 测试的持续时间,将比启动、停止它的次数更令人关注。所以说,rcutortue 是一个持续测试的例子,这类测试包含很多压力测试。
离散测试和持续测试的统计方式有所不同。离散测试的统计更简单,并且,离散测试的统计通常可以被计入持续测试中。因此,我们先从离散测试开始。
离散测试统计
假设在一个特定的测试中,BUG 有 10% 的机会发生,并且我们做了 5 次测试。我们怎么算一次运行失败的几率?方法如下:
- 计算一次测试过程成功的几率,应该是 90%。
- 计算所有 5 次测试成功的几率,应该是 0.9 的 5 次方,大约是 59%。
- 存在两种可能性,要么 5 次全都成功,要么至少又一次失败。因此,至少又一次失败的可能是 100% 减去 59%,即 41%。
假设一个特定测试有 10% 的几率失败。那需要允许多少次测试用例,才能导致失败的几率超过 99%?毕竟,如果我们将测试用例运行的次数足够多,使得至少有一次失败的几率达到 99%,如果此时并没有失败,那么斤斤有 1% 的几率表名这是由于好运气所导致。
公式太多….省略…
持续测试统计
定位海森堡 BUG
这个思路也有助于说明海森堡 BUG,增加追踪和断言可以轻易减少 BUG 出现的几率。这也是为什么轻量级追踪和断言机制是如此重要的原因。
“海森堡 BUG” 这个名字来源于量子力学的海森堡不确定性原理,该原理指出,在任何特定时间点,不可能同时精确计量某个粒子的位置和速度。任何视图更精确计量某个粒子位置的手段,都会增加速度的不确定性。类似的效果出现在海森堡 BUG 上,视图对海森堡 BUG 进行追踪,将会根本上改变其症状,甚至导致 BUG 不再出现。
既然物理领域启发出这个问题的名字,那么我们着眼于物理领域的解决方案是合乎逻辑的。幸运的是,粒子物理学能够用于这个任务,为什么不构造“反——海森堡 BUG”的东西来消灭海森堡 BUG 呢?
本节描述一些手段来实现这一点。
- 为竞争区增加延迟。
- 增加负载强度。
- 独立的测试可疑子系统。
- 模拟不常见的事件。
- 对有惊无险的事件进行计数。
针对海森堡 BUG 来构造“反——海森堡 BUG”,这更像是一种艺术,而不是科学。
增加延迟
增加负载强度
隔离可疑的子系统
模拟不常见的事件
对有惊无险的事件进行计数
性能评估
12 - CH12-形式验证
本章通过形式证明的方式来弥补测试的不足。略。
13 - CH13-综合应用
本章会给出一些处理某些并发编程难题的提示。
计数难题
对更新进行计数
假设薛定谔想要对每一只动物的更新数量进行计数,并且这些更新使用一个没数据元素锁进行同步。这样的计数怎样才能做得最好?
当然,可以考虑第 5 章中任何一种计数算法,但是在这种情况下,最优的方法简单的多。仅仅需要在每一个数据元素中放置一个计数器,并且在元素锁的保护下递增元素就行了。
对查找进行计数
如果薛定谔还想对每只动物的查找进行计数,而这些查找由 RCU 保护。怎样的计数才能做到最好?
一种方法是像 13.1.1 节所述,由一个每元素锁来对查找计数进行保护。不幸的是,这将要求所有查找过程都获得这个锁,在大型系统中,这将形成一个严重的瓶颈。
另一种方法是对计数说“不”,就像 noatime 挂载选项的例子。如果这种方法可行,那显然是最好的办法。毕竟,什么都没有比什么都不做还快。如果查找计数不能被省略,就继续读下去。
第 5 章中的任何计数都可以做成服务,5.2 节中描述的统计计数可能是最常见的选择。但是,这导致大量的内存访问,所需要的计数器数量是数据元素的数量乘以线程数量。
如果内存开销太大,另一个方法是保持每 socket 计数,而不是每 CPU 计数,请注意图 10.8 所示的哈希表性能结果。这需要计数递增作为原子操作,尤其对于用户态来说更是这样。在用户态中,一个特定的线程可能随时迁移到另一个 CPU 上运行。
如果某些元素被频繁的查找,那么存在一些其他方法。这些方法通过维护一个每线程日志来进行批量更新,其对特定元素的多次日志操作可以被合并。当对一个特定日志操作达到一定的递增次数,或者一定的时间过去以后,日志记录将被反映到相应的数据元素中去。Silas Boyd-Wickizer 已经做了一些工作。
使用 RCU 拯救并行软件性能
本节展示如何对本书较早讨论的某些例子应用 RCU 技术。某些情况下,RCU 提供更加简单的代码,另外一些情况下则能提供更好的性能和可扩展性,还有一些情况下,同时提供两者的优势。
RCU 和基于每 CPU 变量的统计计数
5.2.4 节描述了一个统计计数的实现,该实现提供了良好的性能,大致的说是简单的递增,并且能够线性扩展——但仅仅通过 inc_count 递增。不幸的是,需要通过 read_count 读取其值的线程需要获得一个全局锁,因此招致高的高效,并且扩展性不佳。
设计
设计的目的是使用 RCU 而不是 final_mutex 来保护线程在 read_count 中的遍历,已获得良好的性能和扩展性,而不仅仅是保护 inc_count。但是,我们并不希望放弃求和计算的精确性。特别是,当一个特定线程退出时,我们绝对不能丢失退出线程的计数,也不能重复对它进行计数。这样的错误将导致将不精确的结果作为精确结果,换句话说,这样的错误使得结果完全没有意义。并且事实上,final_mutex 的一个目的是,确保线程不会在 read_count 运行过程中,进入并退出。
因此,如果我们不用 final_mutex,就必须拿出其他确保一致性的方法。其中一种方法是将所有已退出线程的计数和,以及指向每线程计数的指针放到一个单一的数据结构。这样的数据结构,一旦没 read_count 使用就保持不变,以确保 read_count 看到一致的数据。
实现
片段 13.5 第 1~4 行展示了 countarray 结构,它包含一个 total 字段,用于对之前已经退出线程的计数、counterp[] 数组,指向当前正在运行的每线程 counter。这个及饿哦股允许特定的 read_count 执行过程看到一致的计数总和,以及运行线程的集合。

第 6~8 行包含每线程 counter 变量的定义,全局指针 countarray 引用单签 countarray 结构,以及 final_mutex 自旋锁。
第 10~13 行展示 inc_count,与之前没有变化。
第 15~29 行展示 read_count,它被大量修改了。第 21~27 行以 rcu_read_lock 和 rcu_read_unlock 代替获得、释放 final_mutex 锁。第 22 行使用 rcu_dereference 将当前 countarray 数据结构的快照获取到临时变量 cap 中。正确的使用 RCU 将确保:在第 27 行的 RCU 读端临界区结束前,该 countarray 数据结构不会被释放掉。第 23 行初始化 sum 作为 cap->total,它表示之前已经退出的线程计数值之和。第 23~26 行将正在运行的线程对应的每线程计数值添加到 sum 中。最后第 28 行返回 sum。
countarray 的初始值由第 31~39 行的 count_init 提供。这个函数在第一个线程创建之前运行,其任务是分配初始数据结构,并将其置为 0,然后将它赋值给 countarray。
第 41~48 行展示了 count_register_thread 函数,他被每一个新创建线程所调用。第 43 行获取当前线程的索引,第 45 行获取 final_mutex,的 46 行将指针指向线程的 counter,第 47 行释放 final_mutex 锁。
第 50~70 行展示了 count_unregister_thread 函数,没一个线程在退出前,条用此函数。第 56~60 行分配一个新的 countarray 数据结构,第 61 行获得 final_mutex 锁,第 67 行释放锁。第 62 行将当前 countarray 的值复制到新分配的副本,第 63 行将现存线程的 counterp 添加到新结构的总和值中,第 64 行将真正退出线程的 counterp[] 数组元素置空,第 66 行保留当前值(很快就会变成旧的)countarray 结构的指针引用,第 66 行使用 rcu_assign_pointer 设置 countarray 结构的新版本。第 68 行等待一个优雅周期的流逝。这样,任何可能并发执行 read_count,并且可能拥有对旧的 countarray 结构引用的线程,都能退出它们的 RCU 读端临界区,并放弃对这些结构的引用。因此,第 69 行能够安全释放旧的 countarray 结构。
讨论
对 RCU 的使用,使得正在退出的线程进行等待,直到其他线程保证,其已经结束对退出线程的 thread 变量的使用。这允许 read_count 函数免于使用锁,因而对 inc_count 和 read_count 函数来说,都为其提供了优良的性能和可扩展性。但是这些性能和扩展性来自于代码复杂性的增加。希望编译器和库函数的编写者能够提供用户层的 RCU,以实现跨越线程安全访问 thread 变量,大大减少 thread 变量使用者所能见到的复杂性。
RCU 及可插拔 IO 设备的计数器
5.5 节展示了一对奇怪的代码段,以处理对可插拔设备的 IO 访问计数。由于需要获取读写锁,因此这些代码段会在快速路径上(开始一个 IO)招致过高的负载。
执行 IO 的代码与原来的代码非常类似,它使用 RCU 读端临界区代替原代码中的读写锁的读端临界区。
1 rcu_read_lock();
2 if (removing) {
3 rcu_read_unlock();
4 cancel_io();
5 } else {
6 add_count(1);
7 rcu_read_unlock();
8 do_io();
9 sub_count(1);
10 }
RCU 读端原语拥有极小的负载,因此提升了快速路径的速度。
移除设备的新代码片段如下:
1 spin_lock(&mylock);
2 removing = 1;
3 sub_count(mybias);
4 spin_unlock(&mylock);
5 synchronize_rcu();
6 while (read_count() != 0) {
7 poll(NULL, 0, 1);
8 }
9 remove_device();
在此,我们将读写锁替换为排他自旋锁,并增加 synchronize_rcu 以等待所有 RCU 读端临界区完成。由于 synchronize_rcu 的缘故,一旦我们允许到第 6 行,就能够知道,所有剩余 IO 已经被识别到了。
当然 synchronize_rcu 的开销可能比较大。不过,既然移除设备这种情况比较少见,那么这种方法通常是一个不错的权衡。
数组及长度
如果我们有一个受 RCU 保护的可变长度数组,如下面的代码片段:
1 struct foo {
2 int length;
3 char *a;
4 };
数组 ->a[] 的长度可能会动态变化。在任意时刻,其长度由字段 ->length 表示。当然,这带来了如下竞争条件。
- 数组被初始化为 16 个字节,因此 length 等于 16。
- CPU0 紧挨着 length 的值,得到 16。
- CPU1 压缩数组长度到 8,并将 ->a[] 赋值为指向新 8 字节长的内存块的指针。
- CPU0 从 ->a[] 获取到新的指针,并且将新值存储到元素 12 中。由于数组仅仅有 8 个字符,这导致 SEGV 或内存破坏。
我们可以使用内存屏障来放置这种情况。该方法确实可行,但是带来了读端的开销,更糟的是需要显式使用内存屏障。
一个更好的办法是将值及数组放进同一个数据结构,如下所示:
1 struct foo_a {
2 int length;
3 char a[0];
4 };
5
6 struct foo {
7 struct foo_a *fa;
8 };
分配一个新的数组(foo_a 数据结构),然后为新的数组长度提供一个新的存储空间。这意味着,如果某个 CPU 获得 fa 引用,也就能能确保 length 能够与 a 的长度相匹配。
- 数组最初为 16 字节,因此 length 等于 16.
- CPU0 加载 fa 的值,获得指向数据结构的指针,该数据结构包含值 16,以及 16 字节的数组。
- CPU0 加载 fa->length 的值,获得其值 16.
- CPU 压缩数组,使其长度为 8,并且将指针赋值为新分配的 foo_a 数据结构,该结构包含一个 8 字节的内存块 a。
- CPU 0 从 a 获得新指针,并且将新值存储到第 12 个元素。由于 CPU0 仍然引用旧的 foo_a 数据结构,该结构包含 16 字节的数组,一切都正常。
当然,在所有情况下,CPU1 必须在释放旧数组前等待下一个优雅周期。
相关联的字段
假设每一只薛定谔动物由下面所示的数据元素表示:
1 struct animal {
2 char name[40];
3 double age;
4 double meas_1;
5 double meas_2;
6 double meas_3;
7 char photo[0]; /* large bitmap. */
8 };
meas_1、meas_2、meas_3 字段是一组相关联的计量字段,它们被频繁更新。读端从单词完整更新的角度看到这三个值,这是特别重要的,如果读端看到 meas_1 的旧值,而看到 meas_2 和 meas_3 的新值,读端将会变得非常迷惑。我们怎样才能确保读端看到协调一致的三个值呢?
一种方法是分配一个新的 animal 数据结构,将旧结构复制到新结构中,更新新结构的三个字段,然后,通过更新指针的方式,将旧的结构替换为新的结构。这确保所有读 端看到测量值的一致集合。但是由于 photo 字段的原因,这需要复制一个大的数据结构。这样的复制操作可能带来不能接受的大开销。
另一种方式是如下所示中的那样插入一个中间层:
1 struct measurement {
2 double meas_1;
3 double meas_2;
4 double meas_3;
5 };
6
7 struct animal {
8 char name[40];
9 double age;
10 struct measurement *mp;
11 char photo[0]; /* large bitmap. */
12 };
当进行一次新的测量时,一个新的 measurement 数据结构被分配,将测量值填充到该结构,并且 animal 的及饿哦股 mp 字段被更新为指向先 measurement 结构,这是使用 rcu_asign_pointer 完成的更新。当一个优雅周期流逝以后,旧的 measurement 数据可以被释放。
这种方式运行读端以最小的开销,看到所选字段的关联值。
散列问题
本节着眼于在处理哈希表时,可能会碰上的一些问题。请注意,这些问题也适用于许多其他与搜索相关的数据结构。
相关联的数据元素
这种情形类似于 13.2.4 节中的问题:存在一个哈希表,我们需要两个或更多元素的关联视图。这些数据元素被同时更新,并且我们不希望看到不同元素之间的不同版本。
一种方式是使用顺序锁,这样更新将在 write_seqlock 的保护下进行。而要求一致性的读请求将在 read_seqbegin/read_seqretry 循环体中进行。请注意,顺序锁并不是 RCU 保护机制的替代品:顺序锁是保护并发修改操作,而 RCU 仍然是需要的,它保护并发的删除。
当相关数据元素少,读这些元素的时间很短,更新速度也低的时候,这种方式可以运行的很好。否则,更新可能会频繁发生,以至于读者总是不能完成。要逃避读者饥饿问题,一种方式是在读端重试太多次之后让其使用写端原语,但是这会同时降低性能和扩展性。
另外,如果写端原语使用得太频繁,那么,由于锁竞争的原因,将带来性能和扩展性的问题。要避免这个问题,其中一种方法是维护一个每数据元素的顺序锁,并且,在更新时应该持有所有涉及元素的锁。但是复杂性在于:在单词扫描数据库期间,需要获得所有数据的文档视图。
如果元素分组被良好定义且有持久性,那么一种方式是将指针添加到数据元素中,将特定组的元素链接在一起。读者就能遍历所有这些指针,以访问同一组内的所有元素。
对更新友好的哈希表遍历
如果需要对哈希表中的所有元素进行统计扫描。例如,薛定谔可能希望计算所有动物的平均长度——重量比率。更进一步假设,薛定谔愿意忽略在统计扫描进行时,那些正在从哈希表中添加或移除的动物引起的轻微错误。那么如何来控制并发性?
一种方法是:将统计扫描置于 RCU 读端临界区之内。这允许更新并发的进行,而不影响扫描进程。特别是,扫描过程并不阻塞更新操作,反之亦然。这允许对包含大量数据元素的哈希表进行扫描,这样的扫描将被优雅的支持,即使面对高频率的更新时也是如此。
14 - CH14-高级同步
本章将介绍高级同步的两个分类:无锁同步、实时同步。
当面临极端要求时,无锁同步会非常有帮助,但不幸的是无锁同步并非灵丹妙药。如在第五章的末尾所述,你应该在考虑采用无锁同步之前首先考虑分区、并行,以及在第八、九章所述的充分测试的脆弱 API。
避免锁
尽管锁在并行生产环境中吃苦耐劳,但在很多场景下可以通过无锁技术来大幅提高性能、扩展性和实时响应性。这种无锁技术的一个实际例子是第 5.2 节中所述的统计计数,它不但避免了锁,同时还避免了原子操作、内存屏障,甚至是计数器自增时的缓存未命中。我们已经介绍过的与无锁技术相关的例子有:
- 第 5 章中一些计数算法的快速路径。
- 第 6.4.3 中资源分配器缓存的快速路径。
- 第 6.5 中的迷宫求解器。
- 第 8 章中的数据所有权技术。
- 第 9 章中介绍的引用计数与 RCU 技术。
- 第 10 章中查找逻辑的代码路径。
- 第 13 章中介绍的大多数技术。
总的来说,无锁技术十分有用且已被大量应用。
然后,无锁技术最好是能够因此在设计良好的 API 之后,比如 inc_count、memblock_allock、rcu_read_lock 等等。因为对无锁的技术的混乱使用可能会引入一些难以解决的 BUG。
很多无锁技术的关键组件是内存屏障,下面的章节将会详细介绍。
无阻塞同步
术语“非阻塞同步(NBS)”描述 6 类线性化算法,这些算法具有前向执行保证。这些前向执行保证与构成实时程序的基础相混淆。
- 实时前向执行保证通常有些与之相关的确定时间。例如,“调度延迟必须小于 100ms”。相反,NBS 仅仅要求执行过程限定在有限时间内,没有确定的边界。
- 有时,实时前向执行具有概率性。比如,在软实时保证中“至少在 99.9% 的时间内,调度延迟必须小于 100ms”。相反,NBS 的前向执行保证传统上是无条件的。
- 实时前向执行保证通常以环境约束为条件。例如,仅仅当每个 CPU 至少有一定比例处于空闲时间,或者 IO 速度低于某些特定的最大值时,对最高优先级任务才能得到保证。相反,NBS 的前向执行保证通常是无条件的。
- 实时前向执行保证通常适用于没有软件 BUG 的情况下。相反,绝大多数 NBS 保证即使在面对错误终止 BUG 时也适用。
- NBS 前向执行保证隐含线性化的意思。相反,实时前向执行保证通常独立于像线性化这样的约束。
不考虑这样的差异,很多 NBS 算法对实时程序极其有用。
在 NBS 层级中,目前有 6 种级别,大致如下:
- 无等待同步:每个线程在有限时间内运行。
- 无锁同步:至少某一个线程将在有限时间内运行。
- 无障碍同步:在没有争用的情况下,每个线程将在有限时间内运行。
- 无冲突同步:在没有争用的情况下,至少某一线程将在有限时间内运行。
- 无饥饿同步:在没有错误的情况下,每个线程将在有限时间内运行。
- 无死锁同步:在么有错误的情况下,至少某一个线程将在有限时间内运行。
第 1、2 类 NBS 于 1990 年代初期制定。第 3 类首次在 2000 年代初期制定。第 4 类首次在 2013 年制定。最后两类已经非正式使用了数十年,但是在 2013 年重新制定。
从原理上讲,任何并行算法都能够被转换为无等待形式,但是存在一个相对小的常用 NBS 算法子集,将在后续章节列出。
简单 NBS
最简单的 NBS 算法可能是使用获取——增加(atomic_add_return)原语对下整型计数器进行原子更新。
另一个简单的 NBS 算法用数组实现整数集合。在此,数组索引标识一个值,该值可能是集合的成员,并且数组元素标识该值是否真的是集合成员。NBS 算法的线性化准则要求对数组的读写,要么使用原子指令、要么与内存屏障一起使用,但是在某些不太罕见的情况下,线性化并不重要,简单使用易失性加载和存储就足够了。例如,使用 ACCESS_ONCE。
NBS 集合也可以使用位图来实现,其中每一个值可能是集合中的某一位。通常,读写操作可以通过原子位维护指令来实现。虽然 CAS 指令也可以使用。
5.2 一节中讨论的统计计数算法可被认为是无等待算法,但仅仅是用了一个狡猾的定义技巧,在该定义中,综合被考虑为近似值而不是精确值。由于足够大的误差区间是计算计数器综合的 read_count 函数的时间长度函数,因此不可能证明发生了任何非线性化行为。这绝对将统计计算算法划分为无等待算法。该算法可能是 Linux 内核中最常见的 NBS 算法。
另一个常见的 NBS 算法是原子队列,其中元素入队操作通过一个原子交换指令实现,随后是对新元素前驱元素的 next 指针的存储,如图 14.19 所示。该图展示了用户态 RCU 库的实现。当返回前向元素的引用时,第 9 行更新引用新元素的尾指针,该指针存储在局部变量 old_tail 中。然后第 10 行更新前向 next 指针,以引用最新添加的元素。最后第 11 行返回队列最初是否为空的标志。
虽然将单个元素出队需要互斥(因此出队是阻塞的),但是将所有队列元素非阻塞的移除是可能的。不可能的是以非阻塞的方式将特定元素出队。入队可能是在第 9 行和第10 行之间失败,因此问题中的元素仅仅部分入队。这将导致半 NBS 算法,其中入队是 NBS 但是出队是阻塞式的。因此在实践中使用此算法的部分原因是,大多数产品软件不需要容忍随意的故障终止错误。

NBS 讨论
创建完全的非阻塞队列是可能的。但是,这样的队列要比上面列出的半 NBS 算法负责的多。这里的经验是,认真考虑你真的需要什么?放宽不相关的需求通常可以极大增加简单性和性能。
最近的研究指出另一种放宽需求的重要方式。结果是,不管是从理论上还是从实践上来说,提供公平调度的系统可以得到大部分无等待同步的优势,即使当算法仅仅提供 NBS 时也是这样。事实上,由于大量产品中使用的调度器都提供公平性,因此,与简单也更快的 NBS 相比,提供无等待同步的更复杂算法通常并没有实际的优势。
有趣的是,公平调度仅仅是一个有益的约束,在实践中常常得到满足。其他的约束集合可以允许阻塞算法实现确定性的实时响应。例如,如果以特定有限级的 FIFO 顺序来授予请求的公平锁,那么避免优先级翻转(如优先级继承或优先级上限)、有限数量的线程、有限长度的临界区、有限的加载,以及避免故障终止 BUG,可以让基于锁的应用获得确定性的响应时间。这个方法当然模糊了锁及无等待同步之间的区别,一切无疑都是好的。期望理论框架持续进步,进一步提高其描述如何在实践中构建软件的能力。
并行实时计算
什么是实时计算
将实时计算进行分类的一种传统方式,是将其分为硬实时和软实时。其中充满阳刚之气的硬实时应用绝不会错过其最后期限,而仅有阴柔之美的软实时应用,则可能被频繁(并且经常)错误其最后期限。
软实时
很容易发现软实时定义的问题。一方面,通过这个定义,任何软件都可以被说成是软实时应用:我的应用在 0.5ps 内计算 100 万点傅里叶变换;没门,系统时钟周期超过 300ps!如果术语软实时被滥用,那就明显需要某些限定条件。
因此,我们应当这么说:一个特定软实时应用必须至少在一定比例的时间范围内,满足实时响应的要求。例如,我们可能这么说,它必须在 99.9% 的时间范围内,在 20ms 内执行完毕。
这当然带来的问题,当应用程序不能满足响应时间要求,应当做什么?答案根据应用程序而不同,不过有一个可能是,被控制的系统有足够的灵活性和惯性,对于偶尔出现的延迟控制行文,也不会出现问题。另一种可能的做法是,应用有两种方式计算结果,一种方式是快速且具有确定性,但是不太精确的方法,还有一种方式是非常精确,但是具有不确定的计算时间。合理的方法是并行启动这两种方法,如果精确的方法不能按时完成,就中止并使用快速但不精确方法所产生的结果。对于快速但不精确的方法,一种实现是在当前时间周期内不采取任何控制行为,另一种实现是采取上一个时间周期同样的控制行为。
简而言之,不对软实时进行精确的度量,谈论软实时就没有任何意义。
硬实时
相对的,硬实时的定义相当明确。毕竟,一个特定的系统,它要么是满足其执行期限,要么不满足。不幸的是,这种严格的定义意味着不可能存在任何硬实时的系统。事实上,你能够构建更强大的系统,也许还有额外的冗余性。但是另一个事实是,我们可以找到一把更大的锤子。
不过话说回来,由于这明显不仅仅是一个硬件问题,而实在是一个大的硬件问题,因此指责软件是不公平的。这表明我们定义硬实时软件为哪种总是能够满足其最后期限的软件,其前提是没有硬件故障。不幸的是,故障不仅仅是一个可选项。硬实时响应是整个系统的属性,而不仅仅是软件属性。
但是我们不能求全责备,也许我们可以像前面所述的软实时方法那样,通过发出通知消息的方法来解决问题。
如果一个系统在不能满足符合法律条文的最后期限是,总是立即发出告警通知。但是这样的系统是无用的。很明显,很明显,必须要求系统在一定比例的时间内,满足其最后期限,或者,必须禁止其连续突破其最后期限这样的操作达到一定次数。
显然,我们没办法来对硬实时或软实时给出一种明确无误的说法。
现实世界的实时
虽然像“硬实时系统总是满足最后期限的要求”这样的句子读起来很上口,无疑也易于记忆,但是,其他一些东西也是现实世界的实时系统所需要的。虽然最终规格难于记忆,但是可以对环境、负载及实时应用本省施加一些约束,以简化构建实时系统。
环境约束
环境约束处理“硬实时”所隐含的响应时间上的无限制承诺。这些约束指定允许的操作温度、空气质量、电磁辐射的水平及类型。
当然,某些约束比其他一些约束更容易满足。人们都知道市面上的计算机组件通常不能在低于冰点的温度下运行,这表明了对气候控制的要求。
一位大学老朋友曾经遇到过这样的挑战,在具有相当活跃的氯化合物条件下的太空中,操作实时系统。他明智的将这个跳转转交给硬件设计同事了。实际上,同事在计算机上环绕施加大气成分的约束,这样的约束是由硬件设计者通过物理密封来实现的。
另一个大学朋友在计算机控制系统上工作,该系统在真空中使用工业强度的电弧来喷镀钛锭。有时,有时,将不会基于钛锭的路径来确定电弧的路径,而是选择更短更优的路径。正如我们在物理课程中学习到的一样,电流的突然变化会形成电磁波,电流越大、变化越大,形成超高功率的电磁波。这种情况下,形成的电磁脉冲足以导致 400 米外的 rubber ducky 天线引线产生 1/4 伏的变化。这意味着附近的导体能看到更大的电压。这包含那些组成控制喷镀过程的计算机导体。尤其是,包括计算机复位线的电压,也足以将计算机复位。这使得每一位涉及的人感到惊奇。这种情况下,面临的挑战是使用适当的硬件,包括屏蔽电缆、低速光钎网络。也就是说,不太引人注目的电子环境通常可能通过使用错误检测及纠正这样的软件代码来处理。也就是说,重要的是需要记住,虽然错误检测及纠正代码可以减少错误几率,但是通常不能将错误几率降低到零,这可能形成另一种实时响应的障碍。
也存在一些其他情形,需要最低水平的能源。例如,通过系统电源线和通过设备的能源。系统与这些设备通信,这些设备是被监控或者控制的外部系统的一部分。
一些欲在高强度的震动、冲击环境下运行的系统,例如发动机控制系统。当我们从连续震动转向间歇性冲击,将会发现更多令人头疼的需求。例如,在我大学本科学习期间,遇到一台老旧的雅典娜弹道计算机,它被设计用于即使手榴弹在其附近引爆也能持续正常工作。最后一个例子,是飞机上的黑匣子,它必须在飞机发生意外之前、之中、之后都持续运行。
当然,在面对环境冲击和碰撞时,使硬件更健壮是有可能的。巧妙的机械减震装置可以减少震动和冲击的影响,多层屏蔽可以减少低能量的电磁辐射的影响,错误纠正代码可以减少高能量辐射的影响,不同的灌封、密封技术可以减少空气质量的影响,加热、制冷系统可以应付温度的影响。极端情况下,三模冗余可以减少系统部分失效导致的整体不正确几率。但是,所有这些方法都有一个共同点:虽然它们能减少系统失败的几率,但是不能将其减低为零。
尽管这些重要的环境约束通常是通过使用更健壮的硬件来处理,但是在接下来的两节中的工作负载及应用约束通常由软件来处理。
负载约束
和人一样的道理,通过使其过载,通常可以阻止实时系统满足其最后期限的要求。例如,如果系统被过于频繁的中断,他就没有足够的 CPU 带宽来处理它的实时应用。对于这种问题,一种使用硬件的解决方案是限制中断提交给系统的速率。可能的软件解决方案包括:当中断被频繁提交给系统时,在一段时间内禁止中断,将频繁产生中断的设备进行复位,甚至完全禁止中断,转而采用轮询。
由于排队的影响,过载也可能降低响应时间,因此对于实时系统来说,过度供应 CPU 贷款并非不正常,一个运行的系统应该有 80% 的空闲时间。这种方法也适用于存储和网络设备。某些情况下,应该讲独立的存储和网络硬件保留给高优先级实时应用所使用。当然,这些硬件大部分时间都处于空闲状态,这并非不正常。因为对于实时系统来说,响应时间比吞吐量更重要。
单谈,要想保持足够低的利用率,在整个设计和实现过程汇总都需要强大的专业知识。没有什么事情与之相似,一个小小的功能就不经意间将最后期限破坏掉。
应用约束
对于某些操作来说,比其他操作更易于提供其最后响应时间。例如,对于中断和唤醒操作来说,得到其响应时间规格是很常见的,而对于文件系统卸载操作来说,则很难得到其响应时间规格。其中一个原因是,非常难于阶段文件系统卸载操作锁需要完成的工作量,因为卸载操作需要将所有内存中的数据刷新到存储设备中。
这意味着,实时应用程序必须限定其操作,这些操作必须合理提供受限的延迟。不能提供合理延迟的操作,要么将其放到非实时部分中去,要么将其完全放弃。
也可能对应用的非实时部分进行约束。例如,非实时应用是否可以合法使用实时应用的 CPU?在应用个实时部分预期非常繁忙期间,是否允许非实时部分全速运行?最后,应用实时部分允许将非实时应用的吞吐量降低到多少?
现实世界的实时规格
正如前面章节所见,现实世界的实时规格需要包装环境约束,负载及应用本身的约束。此外,应用的实时部分允许使用的操作,必然受限于硬件及软件实现方面的约束。
对于每一个这样的操作,这些约束包括最大响应时间(也可能包含一个最小响应时间),以及满足响应时间的几率。100% 的几率表示相应的操作必须提供硬实时服务。
某些情况下,响应时间以及满足响应时间的几率,都十分依赖于操作参数。例如,在本地局域网中的网络操作很有可能在 100ms 内完成,这好于穿越大陆的广域网上的网络操作。更进一步来说,在铜制电缆和光纤网络上的网络操作,更有可能不需要耗时的重传操作就能完成,而相同的操作,在有损 WIFI 网络之上,则更有可能错误严格的最后期限。类似的可以预期,从固态硬盘 SSD 读取数据,将比从老式 USB 连接的旋转硬盘读取更快完成。
某些实时应用贯穿操作的不同阶段。例如,一个控制胶合板的实时系统,它从旋转的原木上剥离木材薄片。这样的系统必须:将原木装载到车床;将原木固定在车床上,以便将原木中最大的柱面暴露给刀片;开始旋转原木;持续的改变刀具位置,以将原木切割为木板;将残留下来的、太小而不能切割的原木移除;同时,等待下一根原木。5 个阶段的每一步,都有自身的最后期限和环境约束,例如,第 4 步的最后期限远比第 6 步严格,其最后期限是毫秒级而不是秒级。因此,希望低优先级任务在第 6 阶段运行,而不要在第 4 阶段运行。也就是说,应当小心选择硬件、驱动和软件装置,这些选择将被要求支持第 4 步更严格的要求。
每种阶段区别对待的方法,其关键优势是,延迟额度可以被细分,这样应用的不同部分可以被独立的开发,每一部分都有其自己的延迟额度。当然,与其他种类的额度相比,偶尔会存在一些冲突,即哪些组件应当获得多大比例的额度。并且,从另一个角度来说,与其他种类的额度相比,严格的验证工作是需要的,以确保正确聚焦与延迟,并且对于延迟方面的问题给出早期预警。成功的验证工作几乎总是包含一个好的测试集,这样的测试集对于学究来说并不总是感到满意,但是好在有助于完成相应的任务。事实上,截止 2015 年初,大多数现实世界的实时系统使用验收测试,而不是形式化证明。
也就是说,广泛使用测试条件来验证实时系统有一个确实存在的缺点,即实时软件仅仅在特定硬件上,使用特定的硬件和软件配置来进行验证。额外的硬件及配置需要额外的开销,也需要耗时的测试。也许形式验证领域将大大改进,足以改变这种状况,但是直到 2015 年初,形式验证还需要继续进行大的改进。
除了应用程序实时部分的延迟需求,也存在应用程序非实时部分的性能及扩展性需求。这些额外的需求反映出一个事实,最终的实时延迟通常都是通过降低扩展性和平均性能来实现的。
软件工程需求也是很重要的,尤其是对于大型应用程序来说,更是如此。这些大型应用程序必须被大型项目组锁开发和维护。这些工程需求往往偏重于增加模块化和故障的隔离性。
以上所述,仅仅是产品化实时系统中,最后期限及环境约束所需工作的一个大概说明。我们期望,它们能够清晰展示那些实时计算方面教科书式方法的不足。
谁需要实时计算
如果说,所有计算实际上都是实时计算,这可能会引起争议。举一个极端的例子,当在线购买生日礼物的时候,你可能在接受者生日之前礼物能够到达。甚至是前年之交的 Web 服务,也存在亚秒级的响应约束,这样的需求并没有随着时间的推移而缓解。虽然如此,专注于那些实时应用更好一点,这些实时应用的实时需求并不能由非实时系统及其应用所实现。当然,由于硬件成本的降低,以及带宽和内存的增加,实时和非实时之间的界限在持续变化,不过这样的变化并不是坏事。
实时计算用于工业控制应用,范围涵盖制造业到航空电子;科学应用,也许最引人注目的是用于大型天文望远镜上的自适应光学;军事应用,包含前面提到的航空电子;金融服务应用,其第一台挖掘出机会的计算机最有可能获得大多数最终利润。这 4 个领域以“产品探索”、“声明探索”、“死亡探索”、“金钱探索”为特征。
金融服务应用于其他三种应用之间的微秒差异在于其他的非物质特征,这意味着非计算机方面的延迟非常小。与之相对的是,其他三类应用的固有延迟使得实时响应的优势很小,甚至没有什么优势。所以金融服务应用,相对于其他实时信息处理应用来说,更面临着装备竞争,有最低延迟的应用通常能够获胜。虽然最终的延迟需求仍然可以由第 15.1.3.4 节中描述的内容来指定,但是这些需求的特殊性质,已经将金融和信息处理应用的需求变为“低延迟”,而不是实时。
不管我们到底如何称呼它,实时计算总是有实实在在的需求。
谁需要并行实时计算
还不太清楚谁真正需要并行实时计算,但是低成本多核系统的出现已经将并行实时计算推向了前沿。不幸的是,传统实时计算的数学基础均假设运行在单 CPU 系统中,很少有例外。例如,有一些现代平方计算硬件,其方式适合于实时计算周期,一些 Linux 内核黑客已经鼓励学术界进行转型,以利用其优势。
一种方法是,意识到如下事实,许多实时系统表现为生物神经系统,其相应范围包含实时反映和非实时策略与计划,如图 15.4 所示。硬实时反应运行在单 CPU 上,它从传感器读数据并控制动作。而应用的非实时策略与计划部分,则运行在余下的 CPU 上面。策略与计划活动可能包括静态分析、定期校准、用户接口、支撑链活动及其他准备活动。高计算负载准备活动的例子,请回想 15.1.3.4 节讨论的应用。当某个 CPU 正在进行剥离原木的高速实时计算时,其他 CPU 可以分析下一原木的长度及形状,以确定如何放置原木,以最大可能的获得更多数量的高品质模板。事实证明,很多应用都包含非实时及实时组件。因此这种方法通常能用于将传统实时分析与现代多核硬件相结合。
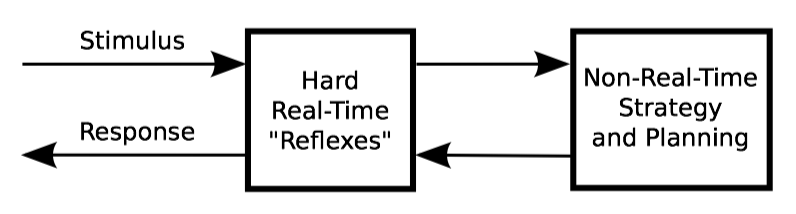
另一个不太有用的方法,是将所有其他硬件线程关闭,只保留其中一个硬件线程,这就回到了单处理器实时数学计算。不过,这种方法失去了潜在的成本和能源优势。也就是说,获得这些优势需要克服第 3 章所述的并行计算困难。而且,不但要处理一般情况,更要处理最坏的情况。
因此,实现并行实时系统可能是一个巨大的挑战。处理这些挑战的方法将在随后的章节给出。
实现并行实时系统
我们将着眼于两种类型的实时系统:事件驱动及轮询。事件驱动的实时系统有更多事件处理空闲状态,对实时事件的响应,是通过操作系统向上传递给应用的。可选的系统可以在后台运行非实时的工作负载,而不是使其处于空闲状态。轮询实时系统有一个特点,存在一个绑在 CPU 上运行的实时线程,该线程运行在一个紧凑循环中,在每一轮轮询中,线程轮询输入事件并更新输出。该循环通常完全运行在用户态,它读取并写入硬件寄存器,这些寄存器被映射到用户态应用程序的地址空间。可选的,某些应用将轮询循环放到内核中,例如,通过使用可加载内核磨矿将其放到内核中。
不管选择何种类型,用来实现实时系统的方法都依赖于最后期限。如图 15.5 所示。从图的顶部开始,如果你可以接受超过 1s 的响应时间,就可以使用脚本语言来实现实时应用。实际上,脚本语言通常是奇怪的用户,并不是我推荐一定要用这种方法。如果要求延迟大于几十毫秒,旧的 Linux 内核也可以使用,同样的,这也不是我推荐一定要用这种方法。特定的实时 Java 实现可以通过几毫秒的实时响应延迟,即使在垃圾回收器被使用时也是这样。如果仔细配置、调整并运行在实时友好的硬件中,Linux 2.6 及 3.x 内核能够提供几百微秒的实时延迟。如果小心避免垃圾回收,特定的 Java 实现可以提供低于 100ms 的实时延迟。(但是请注意,避免垃圾回收就意味着避免使用 Java 大型标准库,也就失去了 Java 的生成效率优势)。打上了 -rt 实时补丁的 Linux 内核可以提供低于 20ms 的延迟。没有内存转换的特定实时系统(RTOSes)可以提供低于 10ms 的延迟。典型的,要实现低于微秒的延迟,需要手写汇编代码,甚至需要特殊硬件。
当然,小心的配置及调节工作,需要针对所有调用路径。特别是需要考虑硬件或固件不能提供实时延迟的情况,这种情况下,想要弥补其消耗的时间,软件是无能为力的。并且,那些高性能的硬件有时会牺牲最坏情况下的表现,以获得吞吐量。实际上,在禁止中断的情况允许紧致循环,可以提供高质量随机数生成器的基础。而且,某些固件窃取时钟周期,以进行各种内置任务,在某些情况下,它们还会视图通过重新对受影响 CPU 的硬件时钟进行编程,来掩盖其踪迹。当然,在虚拟化环境中,窃取时钟周期是其期望的行为,不过人们仍然努力在虚拟化环境中实现实时响应。因此,对你的硬件和固件的实时能力进行评估,是至关重要的。存在一些组织,它们进行这种评估,包括开源自动开发实验室(OSADL)。
假设有合适的实时硬件和挂进,栈中更上一层就是操作系统,这将在下一节讨论。
实现并行实时操作系统
存在一些可用于实现实时系统的策略。其中一种方法是,将长剑非实时系统置于特定目的的实时操作系统之上,如图 15.6 所示。其中绿色的 “Linux 进程” 框表示非实时任务,这些进程运行在 Linux 内核中,而黄色的“RTOS 进程”框表示运行在 RTOS 之中的实时任务。
在 Linux 内核拥有实时能力之前,这是一种非常常见的方法,并且至今仍然在用。但是,这种方法要求应用被分割为不同的部分,其中一部分运行在 RTOS 之中,而另外的部分运行在 Linux 之中。虽然有可能使两种运行环境看起来类似,例如,通过将 RTOS 侧的 POSIX 系统调用转发给 Linux 侧的线程。这种方法还是存在一些粗糙的边界。
另外,RTOS 必须同时与硬件和内核进行交互,因此,当硬件和内核更改时,需要大量的维护工作。而且,每一个这样的 RTOS 通常都有其独有的系统调用接口和系统库集合,其生态系统和开发者都相互对立。事实上,正是这些问题,驱使将 Linux 和 RTOS 进行结合,因为这种方法允许访问 RTOS 的全实时能力,同时允许应用的非实时代码完全访问 Linux 丰富而充满活力的开源生态系统。
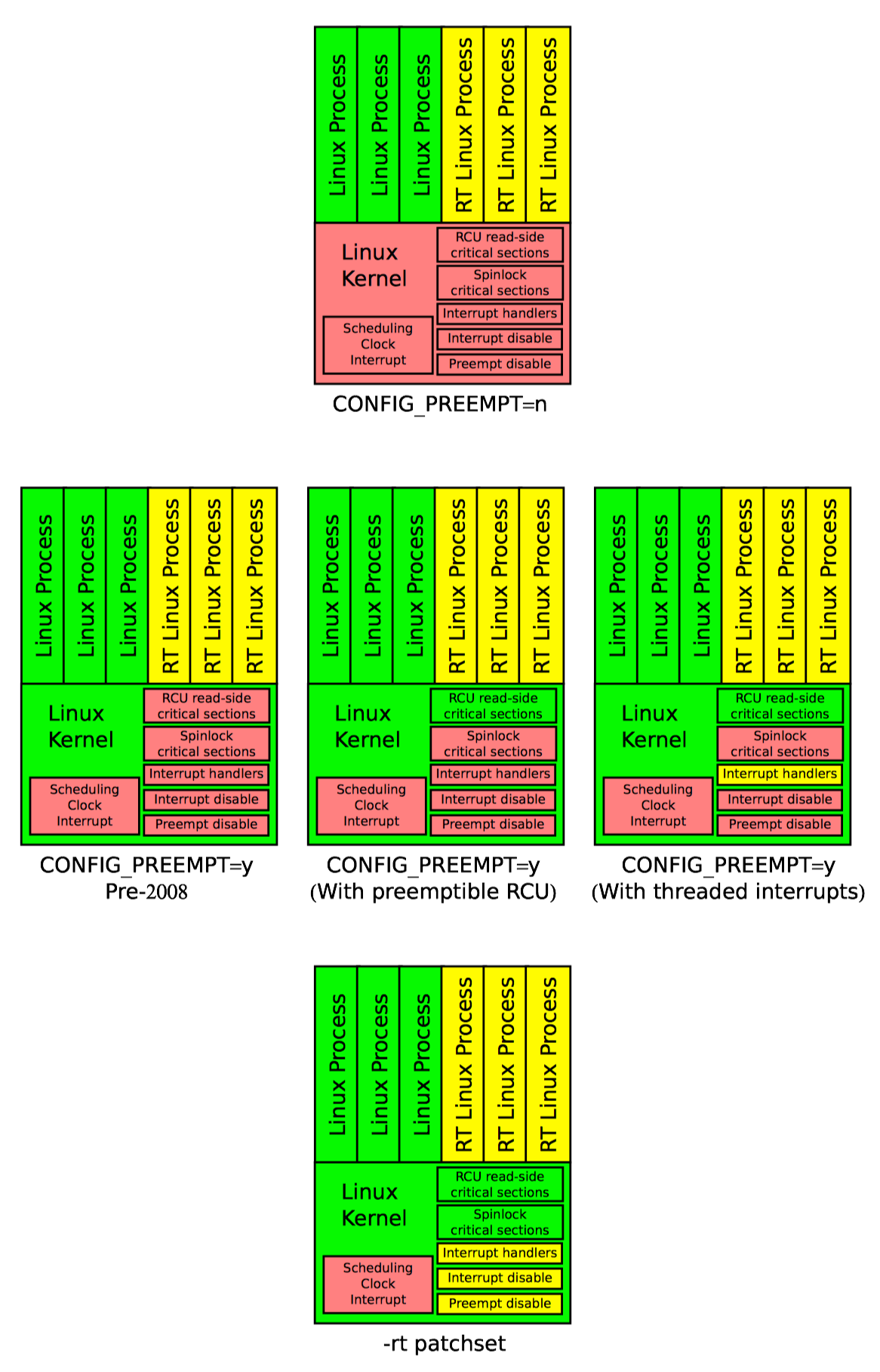
虽然,在 Linux 仅仅拥有最小实时能力的时候,将 Linux 内核与 RTOS 绑在一起,不失为明智而且有用的临时应对措施,这也将激励将实时能力添加到 Linux 内核中。实现这一目标的进展情况如图 15.7 所示。上面的进展展示了抢占禁止的 Linux 内核图。由于抢占被禁止的原因,它基本没有实时能力。中间的展示的一组图其中包含了抢占 Linux 主线内核,其实时能力的增加过程。最后,最下面的行展示了打上 -rt 补丁包的 Linux 内核,它拥有最大化的实时能力。来自于 -rt 补丁包的功能,已经被添加到主线分支,因此随着时间的推移,主线 Linux 内核的能力在不断增加。但是,最苛刻的实时应用仍然使用 -rt 补丁包。
如图 15.7 顶部所示的不可抢占内核以 CONFIG_PREEMPT=n 的配置进行构建,因此在 Linux 内核中的执行是不能被抢占的。这就意味着,内核的实时响应延迟由 Linux 内核中最长的代码路径所决定,这是在是有点长。不过,用户态的执行是可抢占的,因此在右上角所示的实时 Linux 进程,可以在任意时刻抢占左上角的,运行在用户态的非实时进程。
图 15.7 中部所示的可抢占内核,以 CONFIG_PREEMPT=n 的配置进行构建,这样大多数运行在 Linux 内核中的、进程级的代码可以被抢占。这当然极大改善了实时响应延迟,但是在 RCU 读端临界区、自旋锁临界区、中断处理、中断关闭代码段,以及抢占禁止代码段中,抢占仍然是禁止的。禁止抢占的部分,由图中间行中,最左边的红色框所示。可抢占 RCU 的出现,允许 RCU 读端临界区被抢占,如图中间部分所示。线程化中断处理函数的实现,允许设备中断处理被抢占,如图最右边所示。当然,在此期间,大量其他实时功能被添加,不过,在这种图中不容易将其表示出来。这将在 15.4.1.1 节讨论。
最后一个方法是简单将所有与实时任务无关的东西,都从实时任务中移除,将所有其他事务都从实时任务所需的 CPU 上面清除。在 3.10 Linux 内核中,这是通过 CONFIG_NO_HZ_FULL 配置参数来实现的。请注意,这种方法需要至少一个守护 CPU 执行后台处理,例如运行内核守护任务,这是非常重要的。当然,当在特定的、非守护 CPU 上面,如果仅仅只有一个可运行任务,那么该 CPU 上面的调度时钟中断被关闭,这移除了一个重要的干扰源和 OS 颠簸。除了少数例外情况,内核不会强制将其他非守护 CPU 下线,当在特定 CPU 上只有一个可运行任务时,这会简单的提供更好的性能。如果配置适当,可以郑重向你保证,CONFIG_NO_HZ_FULL 将提供近乎裸机系统的实时线程级性能。
当然,这有一些争议,这些方法到底是不是实时系统最好的方式。而且这些争议已经持续了相当长一段时间。一般来说,正如后面章节所讨论的那样,答案要视情况而定。15.4.1.1 节考虑事件驱动的实时系统,15.4.1.2 节考虑使用 CPU 绑定的轮序循环的实时系统。
事件驱动的实时支持
操作系统为事件确定的实时应用所提供的支持是相当广泛的。不过,本节只关注一部分内容,即时钟、线程化中断、优先级继承、可抢占 CPU、可抢占自旋锁。
很明显,定时器对于实时操作系统来说是极其重要的。毕竟,如果你不能指定某些事件在特定事件完成,又怎能在某个事件点得到其响应?即使在非实时系统中,也会产生大量定时器,因此必须高效处理它们。作为示例的用法,包括 TCP 连接重传定时器(它们几乎总是会在触发之前被中止),定时延迟(在 sleep(1) 中,它几乎不被中断),超时 poll 系统调用(它通常会在触发之前就被中止)。对于这些定时器,一个好的数据结构是优先级队列,对于这样的队列,其添加删除原语非常快速,并且与已经入队的定时器数量相比,其时间复杂度是 O(1)。
用于此目的的经典数据结构是日历队列,在 Linux 内核中被称为时钟轮。这个古老的数据结构也被大量用于离散时间模拟。其思想是时间时能度量的,例如,在 Linux 内核中,时间度量周期是调度时钟中断的周期。一个特定时间可以被表示为整型数,任何视图在一个非整型数时刻提交一个定时器,都将被取整到一个最接近的整数时间值。
一种简单的实现是分配一个一维数组,以时间的地界位进行索引。从原理上来说,这可以运转,但是在那些创建大量长周期超时定时器的实际系统中(例如为 TCP 会话而创建的 45 分钟保活超时定时器),这些定时器几乎总是被中止。长周期的超过定时器对于小数组来说会导致问题,这是因为有太多时间浪费在跳过那些还没有到期的定时器上。从另一个方面来说,一个大道足以优雅的容纳大量长周期定时器的数组,会浪费很多内存,尤其是处于性能和可扩展性考虑,每个 CPU 都需要这样的数组。
解决该冲突的一个常规办法是,以多级分层的方式提供多个数组。在最底层,每一个数组元素表示一个单位时间。在第二层,每个数组元素表示 N 个单位时间,这里的 N 是每个数组的元素个数。在第三层,每一个数组元素表示 N2 个单位时间,一次类推。这种方法允许不同的数组以不同的位进行索引,如图 15.9 所示,它表示一个不太实际的、小的 8 位时钟。在此图中,每一个数组有 16 个元素,因此时钟低 4 位(0xf)对低阶(最右边)数组进行索引,接下来 4 位(0x1)对上一级进行索引。这样,我们有两个数组,每一个数组有 16 个元素,共计 32 个元素。远小于单一数组所需要的 256 的元素。
这个方法对于基于流量的系统来说运行的非常好。每一个特定时间操作的时间复杂度是小于常数的 O(1),每个元素最多访问 m+1 次,其中 m 是层数。
不过,时钟轮对于实时系统来说并不好,有两个原因。第一个原因是:需要在定时器精度和定时器开销之间进行权衡:定时器处理仅仅每毫秒才发生一次,这在很多(但非全部)工作环境是可以接受的。但是这也意味着不能保证定时器低于 1ms 的精度;从另一个角度来说,每 10us 进行一次定时器处理,对于绝大部分(但非全部)环境来说,这提供了可以接受的定时精度,但是这种情况下,处理定时器是如此频繁,以至于不能有时间去做任何其他事情。
第二个原因是需要将定时器从上级级联移动到下级。再次参照 15.9,我们将看到,在上层数组(最左边)的元素 1x 必须向下移动到更低(最右边)数组中,这样才能在它们到期后被调用。不幸的是,可能有大量的超时定时器等待移动,尤其是有较多层数时。这种移动操作的效率,对于面向吞吐量的系统来说是没有问题的,但是在实时系统中,可能导致有问题的延迟。
当然,实时系统可以简单宣策一个不同的数据结构,例如某种形式的堆或者树,对于插入或删除这样的数据维护操作来说,这样会失去 O(1) 时间复杂度,而变成 O(log n)。对于特定目的的 RTOS 来说,这可能是一个不错的选择。对于像 Linux 这样的通用操作系统来说,其效率不高。Linux 这样的通用操作系统通常支持非常大量的定时器。
Linux 内核的 -rt 补丁所做的选择,是将两种定时器进行区分处理,一种是调度延后活动的定时器,一种是对类似于 TCP 报文丢失这样的低可能性粗无偶进行调度的定时器。其中一个关键点是:错误处理通常并不是对时间特别敏感,因此时钟轮的毫秒级精度就足够了。另一个关键点是:错误处理超定时器通常会在早期就被中止,这通常是发生在它们被级联移动之前。最后一点是:与执行事件的定时器相比,系统通常拥有更多的执行错误处理的超时定时器。对于定时事件来说,O(log n) 的数据结构能够提供可接受的性能。
简而言之,Linux 内核的 -rt 补丁将时钟轮用于超时错误处理,将树这样的数据结构用于定时器事件,为所需要的服务类型提供不同的定时器类型。
线程化中断用于处理那些显著降低实时延迟的事件源,即长时间运行的中断处理程序,如图 15.12 所示。这些延迟对那些在单次中断后,发送大量事件的设备来说尤其验证,这意味着中断处理程序将运行一个超长的时间周期以处理这些事情。更糟糕的是,在中断处理程序正在运行时,设备可能产生新的事件,这样的总段处理程序可能会无限期运行,因为无限期的降低实时响应。
处理这个问题的方法是,使用如图 15.13 所示的线程化中断。中断处理程序运行在可抢占 IRQ 线程上下文,它运行在可配置的优先级。设备中断处理程序仅仅运行一小段时间,其运行时间仅仅可以使 IRQ 线程知道新事件的产生。如图所示,线程化中断可以极大的提升实时延迟,部分原因是运行在 IRQ 线程上下文的中断处理程序可以被高优先级实时线程抢占。
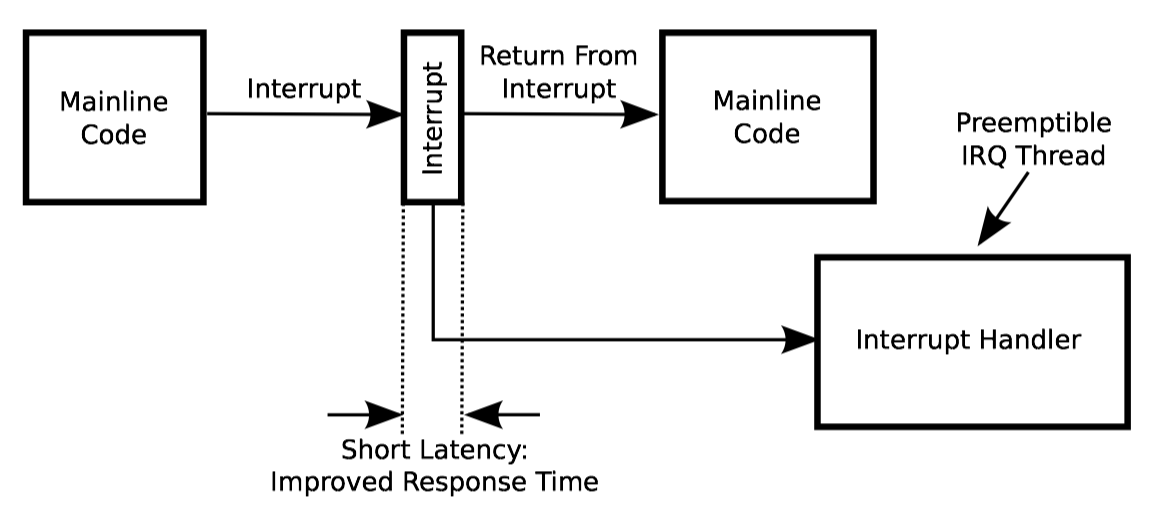
但是天下没有免费的午餐,线程化中断有一些缺点。其中一个缺点是增加了中断延迟。中断处理程序并不会立即运行,其执行被延后到 IRQ 线程中。当然,除非设备在实时应用关键路径执行时产生中断,否则也不会存在问题。
另一个缺点是写得不好的高优先级实时代码可能会中断处理程序饿死,例如,会阻止网络代码运行,导致调试问题非常困难。因此,开发者在编写高优先级实时代码时必须非常小心。这被称为蜘蛛侠原则:能力越大、责任越大。
优先级继承用于处理优先级反转。优先级反转可能是这样产生的,在处理其他事情时,锁被可抢占中断处理程序获得。假定一个低优先级线程获得某个锁,但是他被一组中优先级线程所抢占,每个 CPU 都至少有一个这样的中优先级线程。如果一个中断产生,那么一个高优先级 IRQ 线程将抢占一个中优先级线程,但是直到它决定火红的被低优先级所获得的锁,才会发生优先级反转。不幸的是,低优先级线程直到它开始运行才能释放锁,而中优先级线程会阻止它这样做。这样一来,直到某个中优先级线程释放它的 CPU 之后,高优先级 IRQ 线程才能获得锁。简而言之,中优先级线程间接阻塞了高优先级 IRQ 线程,这是一种典型的优先级反转。
注意,这样的优先级饭庄在非线程化中断中不会发生,这是因为低优先级线程必须在持有锁的时候,禁止中断,这也阻止了中优先级线程抢占它。
在优先级继承方案中,视图获得锁的高优先级线程将其优先级传递给获得锁的低优先级线程,直到锁被释放。这组织了长时间的优先级反转。
当然,优先级继承有其限制。比如,如果能够设计你的应用,已完全避免优先级反转,将很有肯能获得稍微好一些的延迟。这不足为怪,因为优先级继承在最坏的情况下,增加了两次上下文切换。也就是说,优先级继承可以将无限期的延迟转换为有限增加的延迟,并且在许多应用中,优先级继承的软件工程优势可能超过其他延迟成本。
另一个限制是,它仅仅处理特定操作系统环境中,基于所的优先级反转。它所能处理的一种优先级反转情况是,一个高优先级线程等待网络 Socket 消息,而该消息被低优先级进程所写入,但是低优先级线程被一组绑定在 CPU 上的中优先级进程所抢占。
最后一个限制包含读写锁。假设我们有非常多的低优先级线程吗,也许有数千个,每个读线程持有一个特定的读写锁。如果所有这些线程都被中优先级线程抢占,而每 CPU 都有至少一个这样的中优先级线程。最终,假设一个高优先级线层被唤醒并试图获得相同读写锁的锁。我们要如何去大量提升持有这些读写锁的线程优先级,这本身更没有什么问题,但是在高优先级线程获得写锁之前,他可能要等待很长一段时间。
有不少针对这种读写锁优先级反转难题的解决方案。
- 在同一时刻,仅仅允许一个读写锁有一个读请求(这是被 Linux 内核的 -rt 补丁所采用的传统方法)。
- 在同一时刻,对于某个特定读写锁,仅仅允许 N 个读请求。其中 N 是 CPU 个数。
- 在同一时刻,对于某个特定读写锁,仅仅允许 N 个读请求。其中 N 是由开发者指定的某个数值。Linux 内核的 -rt 补丁将在某个事件采取这种方法的几率还是比较大的。
- 当读写锁被正在运行的低优先级线程获得读锁时,防止高优先级线层获得其写锁(这是优先级上限协议的一个变种)。
某些情况下,可以通过将读写锁转换为 RCU,来避免读写锁优先级反转。
有时,可抢占 RCU 可被用作读写锁的替代品。在它可以被使用的地方,它允许读者和写者并发运行,这防止了低优先级的读者对高优先级的写者加以任何类型的优先级反转。但是,要使其有用,能够抢占长时间允许的 RCU 读端临界区是有必要的。否则,长时间运行的 RCU 读端临界区将导致过长的实时延迟。
因此,可抢占 RCU 实现被添加到 Linux 内核中。通过在当前读端临界区中,跟踪所有可抢占任务的链表这种方式,该实现就不必分别跟踪每一个任务的状态。以下情况下,允许终止一个优雅周期:所有 CPU 都已经完成所有读端临界区,这些临界区在当前优雅周期之前已经有效;在这些已经存在的临界区运行期间,被抢占的所有任务都已经从链表移除。这种实现的简单版本如 15.15 所示。__rcu_read_lock 函数位于第 1~5 行,而 __rcu_read_unlock 函数位于第 7~22 行。
__rcu_read_lock 函数第 3 行递增一个每任务计数,该计数是嵌套调用 __rcu_read_lock 的计数,第 4 行放置编译器将 RCU 读端临界区后面的代码与 __rcu_read_lock 之前的代码之间进行乱序。
__rcu_read_unlock 函数第 11 行检查嵌套计数是否为 1,换句话说,检查当前是否为 __rcu_read_unlock 嵌套调用的最外一层。如果不是,第 12 行递减该计数,并将控制流程返回到调用者。否则,这是 __rcu_read_unlock 的最外层,这需要通过第 14~20 行对终止临界区进行处理。
第 14 行防止编译器将临界区中的代码与构成 rcu_read_unlock 函数的代码进行乱序。第 15 行设置嵌套计数为一个大的负数,以防止与包含在中断处理程序中的读端临界区产生破坏性竞争。第 16 行防止编译器将这一行的赋值与第 17 行对特殊处理的检查进行乱序。如果第 17 行确定需要进行特殊处理,就在第 18 行调用 rcu_read_unlock_special 进行特殊处理。
有几种情况需要进行特殊处理,但是我们将关注其中一种情况,即当 RCU 读端临界区被抢占时的处理。这种情况下,任务必须将自己从链表中移除,当它第一次在 RCU 读端临界区中被抢占时,它被添加到这个链表中。不过,请注意这些链表被锁保护很重要。这意味着 rcu_read_unlock 不再是有锁的。不过,最高优先级的线程不会被抢占,因此,对那些最高优先级线程来说,rcu_read_unlock 将不会视图去获取任何锁。另外,如果小心实现,锁可以被用来同步实时软件。
无论是否需要特殊处理,第 19 行防止编译器将第 17 行的检查与第 20 行进行乱序,第 20 行将嵌套计数置 0。

在大量读的数据结构中,对于大量读者的情况下,这个可抢占 RCU 实现能到达实时响应,而不会有优先级提升方法所固有的延迟。
由于在 Linux 内核中,持续周期长的基于自旋锁的临界区的原因,可抢占自旋锁是 -rt 补丁集的重要组成部分。这个功能仍然没有合入主线,虽然从概念上来说,用睡眠锁代替自旋锁是一个简单的方案,但是已经证实这是有争议的。不过,对于那些想要实现低于 10us 延迟的实时任务来说,它是非常有必要的。
当然了,有其他不少数量的 Linux 内核组件,他们对于实现显示世界的延迟非常重要,例如最近的最终期限调度策略。不过,本节中的列表,已经可以让你对 -rt 补丁集所增加的 Linux 内核功能,找到好的感觉。
轮询实时支持
乍看之下,使用轮询可能会避免所有可能的操作系统的干扰问题。毕竟,如果一个特定的 CPU 从不进入内核,内核就完全不在我们的视线之内。要将内核排除在外的传统方法,最简单的是不使用内核,许多实时应用确实是运行在裸机之上,特别是那些运行在 8 位微控制器上的应用程序。
人们可能希望,在现代操作系统上,简单通过在特定 CPU 上运行一个 CPU 绑定的用户态线程,避免所有干扰,以获得裸机应用的性能。虽然事实上更复杂一些,但是这已经能够实现了,这是通过 NO_HZ_FULL 实现的。该实现由 Frederic Weisbcher 引入,并已经被接收进 Linux 内核 3.10 版本。不过,需要小心对这种环境进行适当的设置,因为对一些 OS 抖动来源进行控制是必要的。随后的讨论包含对不同 OS 抖动源的控制,包括设备中断、内核线程和守护线程序、调度器实时限制、定时器、非实时设备驱动、内核中的全局同步、调度时钟中断、页面异常,最后,还包括非实时硬件及固件。
中断是大量 OS 抖动源中很突出的一种。不幸的是,大多数情况下,中断是绝对需要的,以实现系统与外部世界的通信。解决 OS 抖动与外部世界通信之间的冲突,其中一个方法是保留少量守护 CPU,并强制将所有中断移动到这些 CPU 中。Linux 源码树中的文件 Documentation/IRQ-affinity.txt 描述了如何将设备中断绑定到特定 CPU、直到 2015 年初,解决该问题的方法如下所示:
echo 0f > /proc/irq/44/smp_affinity
该命令将第 44 号中断限制到 CPU 0~3。请注意,需要对调度时钟中断进行特殊处理,这将在随后章节进行讨论。
第二个 OS 抖动源是来自于内核线程和守护线程。个别的内核线程,例如 RCU 优雅周期内核线程,可以通过使用 taskset 命令、sched_setaffinity 系统调用或者 cgroups,来将其强制绑定到任意目标 CPU。
每 CPU 线程通常更具有挑战性,有时它限制了硬件配置及负载均衡布局。要防止来自于这些内核线程的 OS 干扰,要么不将特定类型的硬件应用到实时系统中,其所有中断和 IO 初始化均运行在守护 CPU 中,这种情况下,特定内核 Kconfig 或者启动参数被选择,从而将其事务从工作 CPU 中移除;要么工作 CPU 干脆不受内核管理。针对内核线程的建议可以在 Linux 内核源码 Documentation 目录 kernek-per-CPU-kthreads.txt 中找到。
在 Linux 内核中,运行在实时优先级的 CPU 绑定线程受到的第三个 OS 抖动是调度器本身。这是一个故意为之的调试空能,设计用于确保重要的非实时任务每秒至少分配到 30ms 的 CPU 时间,甚至是在你的实时应用存在死循环 BUG 时也是如此。不过,当你正在运行一个轮询实时应用时,需要禁止这个调度功能。可以用如下命令完成此项工作。
echo -1 > /proc/sys/kernel/sched_rt_runtime_us
当然,你必须以 Root 身份运行以执行以上命令,并且需要小心考虑蜘蛛侠原理。一种将风险最小化的方法,是将中断和内核线程、守护线程从所有运行 CPU 绑定线程的 CPU 中卸载,正如前面几段中所述那样。另外,应当认真阅读 Documentation/scheduler 目录中的材料。sched-rt-group.txt 中的材料尤为重要,当你正在使用 cgroups 实时功能时更是如此,这个功能通过 CONFIG_RT_GROUP_SCHED Kconfig 参数打开,这种情况下,你也应当阅读 Documentation/cgroups 目录下的材料。
第四个 OS 抖动来自于定时器。绝大多数情况下,将某个 CPU 配置于内核之外,将防止定时器被调度到该 CPU 上。一个重要的例外是再生定时器,即一个特定定时器处理函数触发同样的定时器在随后某个事件内再次发生。如果由于某种原因,这样的定时器在某个 CPU 上已经启动,该定时器被在该 CPU 上持续周期性运行,反复造成 OS 抖动。一个粗暴但是有效的移除再生定时器的方法,是使用 CPU 热插拔将所有运行 CPU 绑定实时应用线程的 CPU 卸载,并重新将这些 CPU 上线,然后启动你的实时应用。
第五个 OS 抖动来自于驱动设备,这些驱动不是用于实时用途。举一个老的典型例子,在 2005 年,VGA 驱动会在禁止中断的情况下,通过将帧缓冲置 0,以清除屏幕,这将导致数十毫秒的 OS 抖动。一种避免设备驱动引入 OS 抖动的方法,是小心选择那些已经在实时系统中大量使用的设备,由于已被大量使用,其实时故障已经被修复。另一个方法是将设备中断和使用该设备的代码限制到特定守护 CPU 中。第三个方法是测试设备支持实时负载的能力,并修复其实时 BUG。
第六个 OS 抖动源来自于一些内核全系统同步算法,也许最引人注目的是全局 TLB 刷新算法。这可以通过避免内存 unmap 操作来避免,特别是要避免在内核中的 unmap 操作。直到 2015 年年初,避免内核 unmap 操作的方法是避免卸载内核模块。
第七个 OS 抖动源来自于调度时钟中断及 RCU 回调。这些可以通过打开 NO_HZ_FULL Kconfig 参数来构建内核,然后 nohz_full= 参数启动内核来加以避免,该参数指定运行实时线程的工作 CPU 列表。例如,nohz_full=2-7 将保留 CPU 2~7 作为工作 CPU,余下 CPU 0~1 作为守护 CPU。只要在每一个工作 CPU 上,没有超过一个可运行任务,那么工作 CPU 将不会产生调度时钟中断。并且每个工作 CPU 的 RCU 回调将在守护 CPU 上被调用。由于其上仅仅只有一个可运行任务,因此那些抑制了调度时钟的 CPU 被称为处于自适应节拍模式。
作为 nohz_full= 启动参数的另一种可选方法,你可以用 NO_HZ_FULL_ALL 来构建内核,它将保留 CPU0 作为守护 CPU,其他所有 CPU 作为工作 CPU。无论哪种方式,重要的是确保保留足够多的守护 CPU,以处理其他所负担的系统其他部分的守护负载,这需要小心的进行评估和调整。
当然,天下没有免费的午餐,NO_HZ_FULL 也不例外。正如前面所提示的那样,NO_HZ_FULL 使得内核/用户之间的切换消耗更大,这是由于需要增加进程统计,也需要将切换事件通知给内核子系统(如 RCU)。开启 POSIX CPU 定时器的进程,其上的 CPU 也被阻止进入“自适应节拍模式”。额外的限制、权衡、配置建议可以在 Documentation/timers/NO_HZ.txt 中找到。
第八个 OS 抖动源是页面异常。由于绝大部分 Linux 实现使用 MMU 进行内存保护,运行在这些系统中的实时应用需要遵从页面异常的影响。使用 mlock 和 mlockall 系统调用来将应用页面锁进内存,以避免主要的页面异常。当然,蜘蛛侠原理仍然适用,因为锁住太多内存可能会阻止其他工作顺利完成。
很不幸,第九个 OS 抖动源是硬件和固件。因此使用那些涉及用于实时用途的系统是重要的。OSADL 运行产期的系统测试,参考其网站(http://osadl.org)定会有所收获。
1 cd /sys/kernel/debug/tracing
2 echo 1 > max_graph_depth
3 echo function_graph > current_tracer
4 # run workload
5 cat per_cpu/cpuN/trace
不幸的是,OS 抖动源列表觉不完整,因为它会随着每个新版本的内核而变化。这使得能够跟踪额外的 OS 抖动源是有必要的。加入 CPU N 运行一个 CPU 绑定的用户态线程。上面的命令片段将给出所有该 CPU 进入内核的时间列表。当然,第 5 行的 N 必须被替换为所要求的 CPU 的编号,第 2 行中 1 可以增加,以显式内核中函数调用的级别。跟踪结果有助于跟踪 OS 抖动源。
正如你所见到那样,在像 Linux 这样的通用 OS 上,运行 CPU 绑定实时线程来获得裸机性能,需要对细节进行耐心细致的关注。自动化将是有用的,某些自动化也得到了应用,但是鉴于其用户相对较少,预期其出现将相对缓慢。不过,在通用操作系统上获得几乎裸机系统的能力,将有望简化某些类型的实时系统建设。
实现并行实时应用
开发实时应用是一个宽泛的话题,本节仅仅涉及某些方面。
实时组件
在所有工程领域,健壮的组件集对于生产率和可靠性来说是比不可少的。本节不是完整的实时软件组件分类——这样的分类需要一整本书,这是一个可用组件类型的简要概述。
查看实时软件组件的一个很自然的地方,是实现无等待同步的算法,实际上,无锁算法对于实时计算也非常重要。不过,无等待同步仅仅保证在有限时间内推进处理过程,并且实时计算需要算法更严格的保证在有限时间内将处理过程向前推进。毕竟,一个世纪也是有限的时间,但是在你的最终期限是以毫秒计算时,它将无意义。
不过,有一些重要的无等待算法,以提供限期响应时间。包含原子测试和设置、原子交换、原子读加、基于唤醒数组的单生成者/单消费者 FIFO 队列,以及不少每线程分区算法。另外,最近的研究已经证实,在随机公平调度及不考虑错误终止故障的情况下,无锁算法确保提供相同的延迟。这意味着,无锁栈及队列将适用于实时用途。
在实践中,锁通常用于实时应用,尽管理论上讲并不完全如此。不过,在严格的约束中,基于所的算法也存在有限延迟。这些约束包括以下几点:
- 公平调度器。在固定优先级调度器的通常情况下,有限延迟通常提供给最高有限级的线程。
- 充足的带宽以支持负载。支持这个约束的一个实现原则也许是“正常运行,在所有 CPU 上至少存在 50% 的空闲时间”,或者更正式的说“提供的负载足够低,以允许工作负载在所有时刻都能够被调度”。
- 没有错误终止故障。
- 获得、切换、释放延迟均有限期的 FIFO 锁原语。同样,通常情况下的锁原语是带有优先级的 FIFO,有限延迟仅仅是提供给最高优先级的线程。
- 某些防止无限优先级反转的方法。本章前面部分提到的优先级上限及优先级继承就足够了。
- 有限的嵌套锁获取。我们可以有无限数量的锁,但是在同一个时刻,只要一个特定线程绝不获得超过一定数量的锁就行了。
- 有限数量的线程。与前面的约束相结合,这个约束意味着等待特定锁的线程数量是有限的。
- 消耗在任何特定临界区上的有限时间。对于有限的等待特定锁的线程数量,以及有限的临界区长度,其等待时间也是有限度的。
这个结果打开用于实时软件的算法及数据结构的宝藏,它也验证尝试的实时实践。
当然,仔细的、简单的应用设计也是十分重要的。世上最好的实时组件,也不能弥补那些缺乏深思熟虑的设计。对于并行实时应用来说,同步开销明显是设计的关键组件。
轮询应用
许多实时应用由绑定 CPU 的单个循环构成,该循环读取传感器数据,计算控制规则,并输出控制。如果提供传感器数据及控制输出的硬件寄存器被映射到应用地址空间,那么该循环就完全不可以使用系统调用。但是请当心蜘蛛侠原则,更多的权利伴随着更多的责任,在这种情况下,其责任是指避免通过对硬件寄存器的不恰当引用而破坏硬件。
这种方式通常运行在裸机上面,这没有操作系统带来的优势(或者说也没有其带来的干扰)。不过,需要增加硬件能力及增加自动化水平来提升软件功能,如用户界面、日志及报告,所有这些都可以受益于操作系统。
在裸机上运行,同时仍然想要获得通用擦做系统的所有特征和功能,其中一个方法是使用 Linux 内核的 NO_HZ_FULL 功能,该功能在 15.4.1.2 节中描述。该支持首先在 Linux 内核 3.10 版本中可用。
流应用程序
一种流行的大数据实时应用获得多种输入源的输入,内部处理它,并输出警告和摘要。这些流应用通常是高度并发的,并发的处理不同信息源。
实现流应用程序的一种方法是使用循环数组缓冲 FIFO,来联结不同的处理步骤。每一个这样的 FIFO,仅仅有一个线程向其放入数据,并有一个(大概是不同的线程)线程从其中取出数据。扇入扇出点使用线程而不是数据结构,因此,如果需要合并几个 FIFO 的输出,一个独立的线程将从一个 FIFO 中输入数据,并将它输出到另外一个 FIFO,该线程是唯一的处理者。类似的,如果一个特定 FIFO 的输出需要被分拆,一个单独的线程将从这个 FIFO 进行获取输入,并且将其输出到多个 FIFO 中。
该规则看起来严格,但是它允许在线程间的通信有最小的同步开销,当试图满足严格的延迟约束时,最下的同步开销是重要的。当每一步中的处理量小,因而同步开销与数据处理相比,同步负载所占比例更大时,这显得尤其重要。
不同的线程可能是 CPU 绑定的,这时,15.4.2.2 节中的建议是适用的。另一方面,如果不同线程阻塞等待其输入 FIFO 的数据,那么 15.4.2.4 节中的建议是适用的。
事件驱动应用
对于事件驱动应用,我们将展示一个奇特的例子,将燃料注入中型工业发动机。在正常的操作条件下,该发动机要求一个特定的时间点,以一度的间隔将燃料注入到顶端正中。我们假设 1500-RPM 的旋转速度,这样就是每秒 25 转,或者大约每秒 9000 个旋转刻度,转换为没刻度即为 111ms。因此,我们需要在大约 100ms 内调度燃料注入。

假设事件等待被用于初始化燃料注入,但是如果你正在构造一个发动机,我希望你提供一个旋转传感器。我们需要测试时间等待功能,可能使用图 15.17 所示的测试程序。不幸的是,如果运行这个程序,我们将遇到不可接受的时钟抖动,即使在 -rt 内核中也是如此。
一个问题是,POSIX CLOCK_REALTIME 并不是为了实时应用,很奇怪吧。相反的,它所表示的“实时”是与进程或者线程所消耗的 CPU 总时间相对。对于实时用途,应当使用 CLOCK_MONOTOMIC。但是,即使做了这样的改变,结果仍然是不可接受的。
另一个问题是,线程必须通过使用 sched_setscheduler 系统调用来提供实时优先级。但是即使有了这个改变还是不够的,因为我们仍然能遇到缺页异常。我们也必须使用 mlockall 系统调用来锁住应用的内存,以防止缺页异常。应用的所有这些改变,结果可能最终是可接受的。
在其他情况下,可能需要进一步调整。可能需要将时间关键的线程绑定到他们自己的 CPU 中,并且可能需要将中断从这些 CPU 中移除。也需要谨慎选择硬件和驱动,并且可能需要谨慎选择内核配置。
从这个例子可以看出,实时计算真不是省油的灯。
RCU 的角色
假设你正在编写一个并行实时应用,该应用需要访问可能会随着温度、湿度和气压的变化而变化的数据。对该应用的实时响应约束相当严格,因此不允许自旋或阻塞,这样就排除掉了锁;也不允许使用重试循环,这样一来排除掉了顺序锁和危险指针。幸运的是,温度和压力通常是受控制的,因此默认的编码数据集通常是足够的。
但是,温度、湿度和压力偶尔会偏离默认值较远,这时有必要提供替换默认值的数据。由于温度、湿度和压力是逐渐变化的,虽然需要在几分钟内完成,但提供更新的值并非紧急事项。该应用将使用一个名为 cur_cal 的全局指针,该指针通常引用 default_cal,这是一个静态分配并初始化的结构,并包含命名为 a/b/c 的默认校准值。否则,cur_dal 将指向提供当前校准值的动态分配结构。

上面的代码清单展示了如何使用 RCU 来解决这个问题。查找逻辑是确定的,如第 9~15 行中的 calc_control,并能符合实时要求。更新逻辑则比较复杂,如第 17~35 行的 update_cal 所示。
该示例展示了 RCU 如何为实时应用提供确定的读端数据结构访问。
实时 vs. 快速
在实时与快速计算之间进行选择可能是一件困难的事情。因为实时系统通常造成非实时系统的吞吐量损失,在不需要使用的时候,使用实时计算会带来问题。另一方面,在需要实时计算时,使用错误也会带来问题。
基于经验法则,使用以下 4 个问题来助你选择:
- 平均的长期吞吐量是唯一目标吗?
- 是否允许重负载降低响应时间?
- 是否有高内存压力,排除使用 mlockall 系统调用?
- 应用的基本工作项是否需要超过 100ms 才能完成?
如果每一个问题的答案都是“是”,则应当选择“快速”而不是“实时”,否则,则可以选择“实时”。请明智选择,并且如果你选择了“实时”,请确保硬件、固件、操作系统都恩能够胜任。
15 - CH15-高级同步-内存序
因果关系与顺序是非常直观的,黑客往往能比一般人更好的掌握这些概念。在编写、分析和调试使用标准互斥机制(尤其是锁)的顺序、并行代码时,这些直觉可以成为非常强大的工具。不幸的是,当面对那些并未使用标准机制的代码时这种直觉将彻底失败。一个重要的例子当然是一些代码使用了这些标准机制,但是另外一些使用了更弱的同步机制。事实上,一些人认为更弱也算是一个有点。本章将帮助你了解有效实现同步原语和性能敏感代码的内存排序。
15.1 排序:Why & How?

内存排序的一个动机可以在代码清单 15.1 中的石蕊测试中看到,咋一看似乎 exists 子句可能永远不会触发。毕竟,如果 exists 子句中的 0:r2=0,我们可以期望“线程 P0 中由 x1 加载到 r2”发生在“线程 P1 对 x1 的保存”,进一步期望“P1 中由 x0 加载到 r2”必须发生在“P0 对 x0 的保存”,因此 1:r2=2,从而不会触发 exists 子句。这个例子是对称的,因此类似的原因会让我们认为 1:r2=0 保证 0:r2=2。不幸的是,内存屏障的缺失使得这些期望破灭。即使是在相对更强排序的系统(x86)上,CPU 也有权对 P0 和 P1 中的语句进行重排序。
QQ 15.1:编译器同样能够对代码清单 15.1 中 P0 和 P1 的内存访问进行重排序,对吗?
通常来说,编译器优化比 CPU 可以执行更加广泛和深刻的重排序。但是,在这种情况下,READ_ONCE 和 WRITE_ONCE 中的易失性访问会阻止编译器重排序。而且还要做许多其他事情,因此本节中的示例将大量使用 READ_ONCE 和 WRITE_ONCE。有关 READ_ONCE 和 WRITE_ONCE 的更多细节可以参考 15.3 节。
这种重排序趋向可以使用诸如 Litmus7 之类的工具进行验证,该工具发现在我的笔记本上进行的 1 亿次实验中有 314 次反直觉排序。奇怪的是,两个加载返回值为 2 的完全合法的结果发生的概率反而较低,只有 167 次。这里的教训很清楚:增加反干涉性并不一定意味着能够降低概率!
15.1.1 为什么硬件乱序?
但是为什么第一处会发生内存乱序呢?是 CPU 自身不能追踪顺序吗?
人们期望计算机能够对事物保持追踪,而且很多人还坚持要求它们能够快速的追踪事物。然而如第 3 章中看到的那样,主存没有办法跟上 CPU 的速度,因为在从内存中读取单个变量的时间内,CPU 可以执行数百个指令。因此 CPU 引入了越来越大的缓存,如图 3.9 所示,这意味着虽然一个 CPU 对指定变量的第一次加载会导致昂贵的缓存未命中,如第 3.1.5 一节所述,随后的重复加载会因为初始化未命中会将该变量记载到该 CPU 的缓存中,因此 CPU 后续会非常快速的执行与该变量相关的操作。
然而,还需要适应从多个 CPU 到一组共享变量的频繁并发存储。在缓存一致性系统中,如果缓存包含指定变量的多个副本,则该变量的所有副本必须拥有相同的值。这对于并发加载非常有效,但对于并发存储不太友好:每个存储必须对旧值的所有副本(这是另一个缓存未命中)执行一些操作,考虑到光的有限速度和物质的原子性质,这要比性急的软件黑客预期的速度慢。
因此,CPU 配备了存储缓冲区,如图 15.1 所示。当一个 CPU 需要保存的变量 不在缓存时,新值将会被放置到 CPU 的存储缓冲区。然后 CPU 可以立即继续后续的执行,而不必等待存储对滞留在其他 CPU 缓存中的所有旧值执行操作。
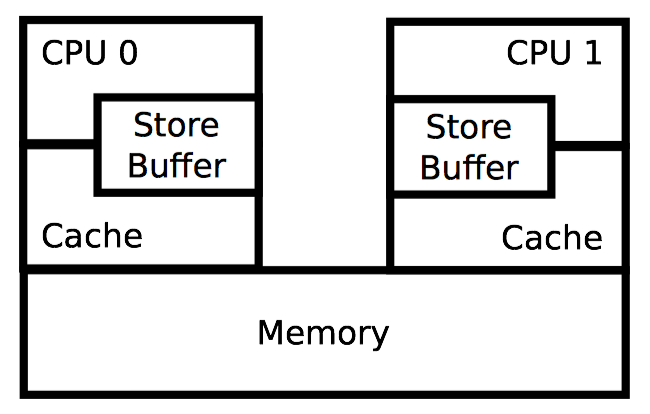
尽管存储缓冲区能够大大提升性能,但可能导致指令和内存引用无序执行,这反过来会导致严重的混淆。需要特别之处的是,这些存储缓冲区会导致内存错误排序,如清单 15.1 中 store-buffering 石蕊测试所示。
表 15.1 展示了内存乱序是如何发生的。第一行是初始状态,这时 CPU0 的缓存中持有 x1、CPU1 的缓存中持有 x0,两个变量的值均为 0。第二行展示了基于 CPU 存储的状态变化(即代码清单 15.1 中的第 9~18 行)。因为两个 CPU 在缓存中都没有要保存的变量,因此两个 CPU 都将他们的存储记录在自己的存储缓冲区中。
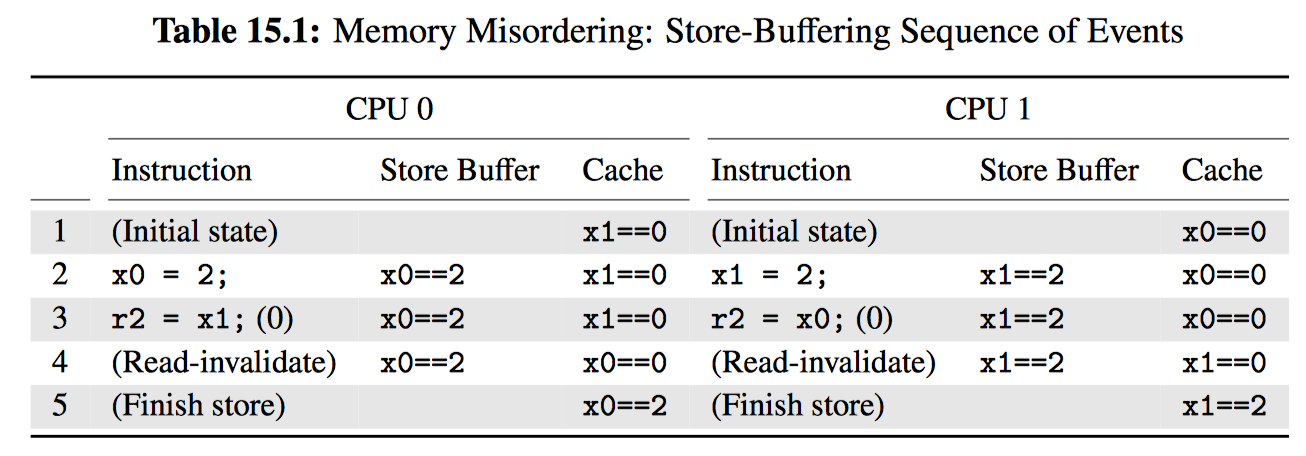
第 3 行展示了两个加载(即代码清单 15.1 中的第 1~19 行)。因为变量已被 CPU 的各自缓存加载,因此加载操作会立即返回已缓存的值,这里都是 0。
但是 CPU 还没有完成:稍后会清空自己的存储缓冲区。因为缓存在名为缓存行的较大的块中移动数据,并且因为每个缓存行可以保存多个变量,因此每个 CPU 必须将缓存行放入自己的缓存中,以便它可以更新与其存储器中的变量对应的缓存行部分,但不会影响缓存行的任何其他部分。每个 CPU 还必须确保缓存行不存在于任何其他 CPU 的缓存中,因此使用了“读无效”操作。如第 4 行所示,在两个“读无效”操作完成之后,两个 CPU 都交换了缓存行,因此 CPU0 的缓存现在包含 x0,而 CPU1 的缓存现在包含 x1。一旦两个变量出现在他们的新家中,每个 CPU 都可以将其存储缓冲区放入对应的缓存行中,使每个变量的最终值如第 5 行所示。
QQ 15.3: 但是这些值不需要由缓存被刷新到主存吗?
令人惊讶的是并不必要!在某些系统上,如果两个变量被大量使用,它们可能会在 CPU 之间来回反弹,而不会落到主存中。
总之,需要存储缓冲区来支持 CPU 高效的处理存储指令,但是可能会导致反直觉的存储器乱序。
但是如果你的算法真的需要有序的内存引用,又该怎么办呢?比如,你正在使用一对标志位来与驱动程序通信,其中一个标志表示驱动程序是否正在运行,另一个标志表示是否存在针对该驱动程序的待处理请求。请求者需要设置请求挂起的标志,然后检查驱动程序运行状态的标志,如果为 false 则唤醒驱动程序。一旦驱动程序开始为所有待处理的请求提供服务,就需要清除待处理请求的标志,然后检查请求挂起标志以查看是否需要重新启动。除非有某种办法可以确保硬件按顺序处理存储和加载,否则这种看起来非常合理的方式将无法工作。这也就是下一节的主题。
15.1.2 如何强制排序
事实上,存在编译器指令和标准同步原语(比如锁和 RCU),他们负责通过使用内存屏障(比如 Linux 内核中的 smp_mb)来维护排序错觉。这些内存屏障可以是显式指令,比如在 ARM、POWER、Itanium、Alpha 系统上;或者由其他指令暗含,通常在 X86 系统中既是如此。因为这些标准同步原语维护了排序错觉,从而让你能够以最小的阻力使用这些原语,这样你就可以不用阅读本章的内容了。
然而,如果你需要实现自己的同步原语,或者仅仅是想了解内存排序是如何工作的,那么请继续阅读!第一站是代码清单 15.2,这里将 Linux 内核的完整内存屏障 smp_mb 分别放置到 P0 和 P1 的存储和加载操作之间,其他部分则与代码清单 15.1 保持相同。这些屏障阻止了我的 X86 电脑上 1 亿次实现的反直觉结果的出现。有趣的是,由于这些屏障增加的开销导致结果合法,其中两个负载的返回值都超过 80 万次,而代码清单 15.1 中的无屏障代码仅有 167 次。

这些屏障对排序产生了深远的影响,如表 15.2 所示。虽然前两行与表 15.1 相同,同时第 3 行的 smp_mb 也不会改变状态,但是它们能够确保存储在加载之前完成,这会避免代码清单 15.1 中出现的反直觉结果。请注意,变量 x0 和 x1 在第二行仍然具有多个值,但是正如前面承诺的那样,smp_mb 最终会将一切理顺。
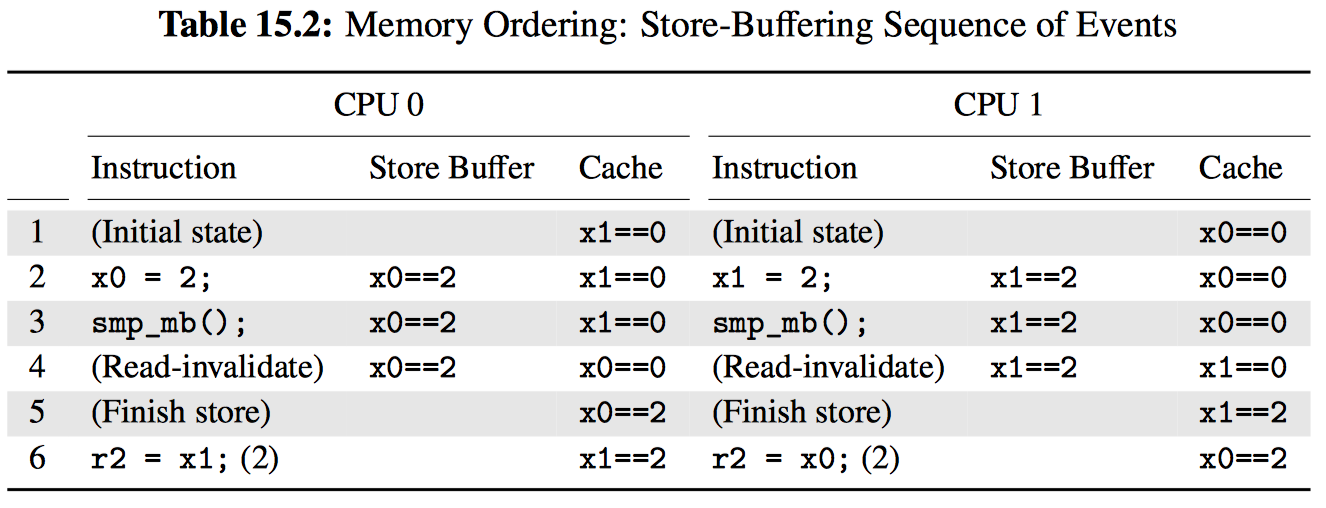
虽然像 smp_mb 这样的完整内存屏障拥有非常强的排序保证,其强度也伴随着极高的代价。很多情况下都可以使用更弱的排序保证来处理,这些保证使用更廉价的内存排序指令,或者在某些情况下根本不适用内存排序指令。表 15.3 提供了 Linux 内核的排序原语及对应保证的清单。每行对应一个原语或原语的类别,以及是否能够提供排序保证,同时又分为 “Prior Ordered Operation” 与 “Subsequent Ordered Operation” 两列。“Y” 表示无条件提供排序保证,否则表示排序保证是部分或有条件提供。“空”则表示不提供任何排序。
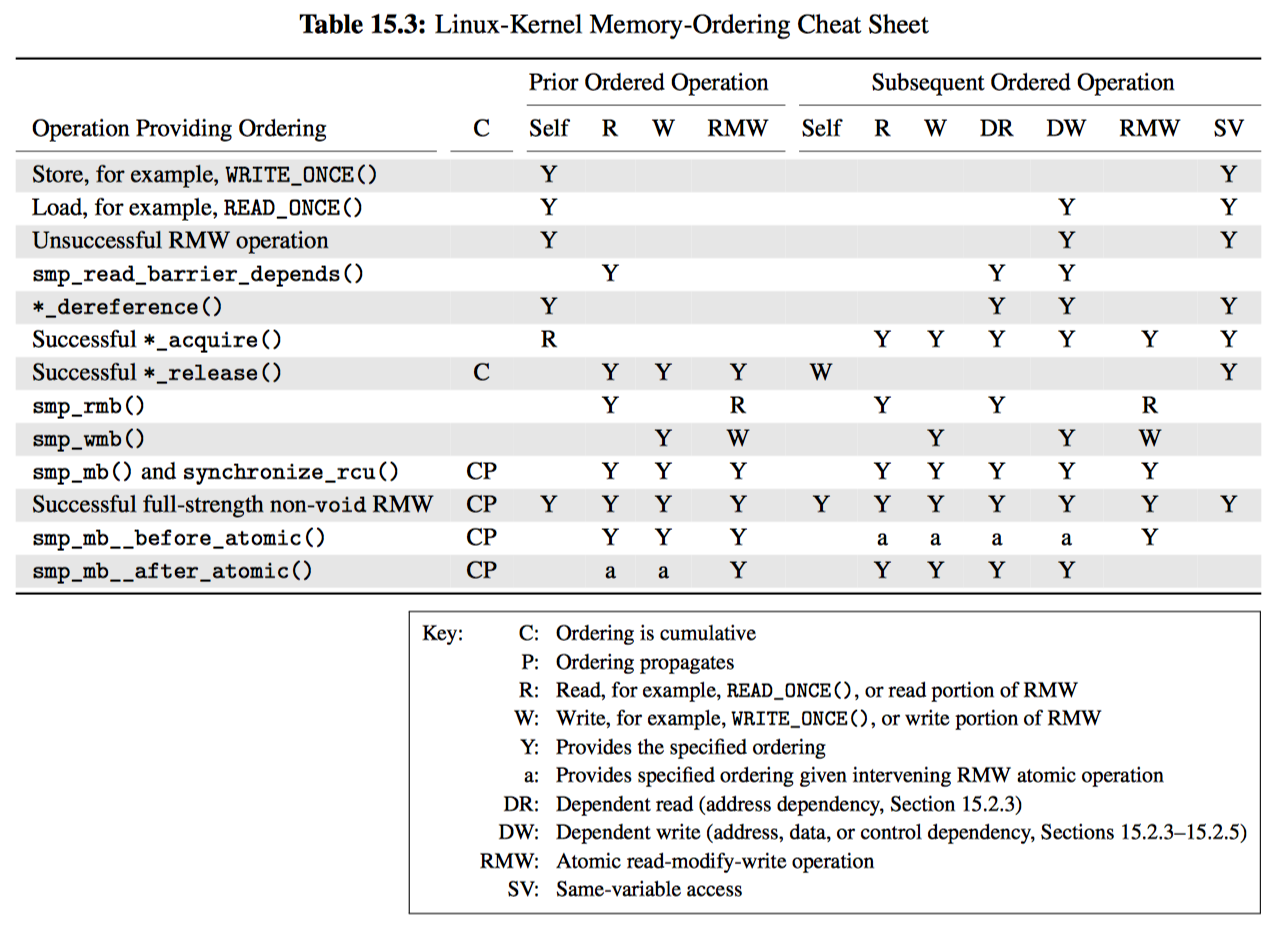
需要注意的是这只是一个速查表,因此并不能替代对内存排序的良好理解。
15.1.3 经验法则
QQ:但是我怎么知道一个给定的项目可以在这些经验法则的范围内进行设计和编码呢?
本节的内容将回答该问题。
- 一个给定线程将按顺序看到自身的访问。
- 排序具有条件性的 if-then 语义。
- 排序操作必须是成对的。
- 排序操作几乎不会提供加速效果。
- 排序操作并非魔法。
15.2 技巧与陷阱
现在你只知道硬件可以对内存访问进行重排序,而你也可以阻止这一切的发生,下一步则是让你承认自己的自觉有问题。
首先,让我们快速了解一个变量在一个时间点可能有多少值。
15.2.1 变量带有多个值
将一个变量视为在一个定义良好的全局顺序中采用一个定义良好的值序列是很自然的。不幸的是,接下来将对这个令人欣慰的事情说再见。
考虑代码清单 15.3 中的片段。该代码又多个 CPU 并行执行。第 1 行将共享变量设置为当前 CPU 的 ID,第 2 行从 gettb 函数初始化多个变量,该函数提供在所有 CPU 之间同步的细粒度硬件“基于时间的”计数器的值。第 3~8 行的循环记录了变量保留该 CPU 分配给他的值的时间长度。当然,其中一个 CPU 将赢,因此如果不是第 6~7 行的检查,将永远不会退出循环。

退出循环后,firsttb 将保留分配后不久的时间戳,lasttb 将保持在指定值的共享变量的最后一次采样之前所采用的时间戳,或者如果共享变量已更改则保持等于在进入循环之前的 firsttb 的值。这样我们可以子啊 532ns 的时间段内绘制每个 CPU 对 state.variable 值的视图,如图 15.4 所示。
每个横轴表示指定 CPU 随时间的观察结果,左侧的灰色区域表示对应 CPU 的第一次测量之前的时间。在前 5ns 期间,只有 CPU3 对变量的值有判断。在接下来的 10ns 期间,CPU2 和 CPU3 对变量的值不一致,但此后一致认为该值为 2,这实际是最终商定的值。但是 CPU1 认为该值为 1 的持续时间长达 300ns,而 CPU4 认为该值为 4 的持续时间长达 500ns。
15.2.2 内存引用重排序
上一节表明,即使是相对强有序的系统(x86)也可能在后续的加载中重排序之前的存储,至少在存储和加载不同的变量是会发生这样的状况。本节以此结果为基础,查看加载和存储的其他组合。
15.2.2.1 加载后跟加载
代码清单 15.4 展示了经典的消息传递石蕊测试,x0 表示消息,x1 作为一个标志来表示消息是否可用。在测试中,smp_mb 强制 P0 的存储排序,但是未对加载指定排序。相对强有序的体系结构(如 x86)会强制执行排序。但是弱有序的体系结构通常不会(如 AMP+11)。因此。列表第 25 行的 exists 子句可以被触发。

从不同位置排序加载的一个基本原理是,这样做允许在较早的加载错过缓存时继续执行,但是后续加载的值已经存在。
因此,依赖于有序加载的可移植代码必须添加显式排序,比如在清单 15.5 的第 20 行添加的 smp_mb,这会组织触发 exists 子句。

15.2.2.2 加载后跟存储
代码清单 15.6 展示了经典的“加载缓冲(load-buffering)”石蕊测试。尽管相对强排序的系统(如 x86 或 IBM Mainframe)不会使用后续的存储来重排序先前的加载,但是较弱排序的系统则允许这种排序(如 AMP+11)。因此第 22 行的 exist 子句确实可能被触发。

虽然实际硬件很少展示这种重排序,但可能需要这么做的一种原因是当加载错误缓存时,存储缓冲区几乎已满,且后续存储的缓存行已准备就绪。因此,可移植代码必须强制执行任何必要的排序。比如清单 15.7 所示。smp_store_release 和 smp_load_acquire 保证第 22 行的子句永远不会触发。

15.2.2.3 存储后跟存储
代码清单 15.8 再次展示了经典的消息传递石蕊测试,其中使用 smp_mb 为 P1 的加载提供排序,但是并未给 P0 的存储提供任何排序。再次,相对强的系统架构会执行强制排序,而相对弱的系统架构则并不一定会这么做,这意味着 exists 子句可能会触发。这种重排序可能有益的一种场景是:当存储缓冲区已满,另一个存储区已准备好执行,但最旧的缓存行尚不可用。在这种情况下,允许存储无需完成将允许继续执行。因此,可移植代码必须显式的对存储进行排序,如代码清单 15.5 所示,从而防止 exists 子句的触发。

15.2.3 地址依赖
当加载指令的返回值被用于计算稍后的内存引用所要使用的地址时,产生地址依赖。
代码清单 15.9 展示了消息传递模式的一种链式变型。头指针是 x1,它最初引用 int 变量 y(第 5 行),后者又被初始化为值 1(第 4 行)。P0 将头指针 x1 更新为引用 x0(第 12 行),但仅将其初始化为 2(第 10 行)并强制排序(第 11 行)。P1 获取头指针 x1(第 21 行),然后加载引用的值(第 22 行)。因此,从 21 行的加载到 22 行上的加载存在地址依赖性。在这种情况下,第 21 行返回的值恰好是第 22 行使用的地址,但是可能存在很多变化。

人们可能会期望在第 22 行的取消引用之前排序来自头指针的第 21 行的加载。但是,DEC Alpha 并不是这种做法,它可以使用相关加载的推测值,如第 15.4.1 节中更详细的描述。因此,代码清单 15.9 中的 exists 子句可以被触发。
代码清单 15.10 展示了如何使其正确的工作,即便是在 DEC Alpha 上,将第 21 行的 READ_ONCE 替换为 lockless_dereference,其作用类似于 DEC Alpha 意外所有平台上的 READ_ONCE 后跟 smp_mb,从而在所有平台上执行所需的排序,进而防止 exists 子句触发。

但是,如果依赖操作是存储而非加载又会发生什么呢,比如,在代码清单 15.11 中显示的石蕊测试。因为没有产生质量的平台推测存储,第 10 行的 WRITE_ONCE 不可能覆盖第 21 行的 WEITE_ONCE,这意味着第 25 行的 exists 子句及时在 DEC Alpha 上也无法触发,即使没有在依赖负载的情况下需要的 lockless_dereference。

然而,特别需要注意的是,地址依赖很脆弱,很容易就能被编译器优化打破。
15.2.4 数据依赖
当加载指令的返回值被用于计算稍后的存储指令要存储的数据时,则会发生数据依赖。请注意上面的“数据”:如果加载返回的值用于计算稍后的存储指令要使用的地址时,那么将是地址依赖性。
代码清单 15.12 与清单 15.7 类似,不同之处在于第 18~19 行之间的 P1 排序不是由获取加载强制执行,而是由数据依赖性完成:第 18 行加载的值是第 19 行要存储的值。这种数据依赖性提供的排序足以放置 exists 子句的触发。

和地址依赖性一样,数据依赖性也很脆弱,可以被编译器优化轻松破解。如第 15.3.2 节所述。实际上,数据依赖性可能比地址依赖性更加脆弱。原因是地址依赖性通常涉及指针值。相反,如清单 15.12 所示,通过整数值来传递数据依赖性是很诱人的,编译器可以更自由的优化不存在性。仅举一个例子,如果加载的整数乘以常数 0,编译器将知道结果为 0,因此可以用常数 0 替换加载的值,从而打破依赖性。
简而言之,你可以依赖于数据依赖性,但前提是你要注意防止编译器对他们的破坏。
15.2.5 控制依赖
当需要测试加载指令的返回值以确定是否执行稍后的存储指令时,发生控制依赖性,请注意“稍后的存储指令”:很多平台并不遵循加载到加载控制的依赖关系。
代码清单 15.13 展示了另一个加载——启动示例,这里使用的是控制依赖关系(第 19 行)来命令第 18 行的加载和第 20 行的存储。这种排序足以避免 exists 子句的触发。

但是,控制依赖性甚至比数据依赖性更易被优化掉。第 15.3.3 节描述了为了防止编译器破坏控制依赖性必须要遵循的一些规则。
值得重申的是,控制依赖性仅提供从加载到存储的排序。因此,代码清单 15.14 的第 17~19 行展示的加载到加载过程并不提供排序,因此不会阻止 exists 子句的触发。

总之,控制依赖关系可能很有用,但它们是高维护项。因此,只有在性能考虑不允许其他解决方案时才应使用。
15.2.6 缓存连贯性
在缓存一致性平台上,所有 CPU 都遵循加载到存储指定变量的顺序。幸运的是,当使用 READ_ONCE 和 WRITE_ONCE 时,几乎所有平台都是缓存一致的,如表 15.3 中所示的 SV 一列。
代码清单 15.15 展示了测试缓存连贯性的石蕊测试,其中 IRIW 代表独立写入的独立读取。因为该石蕊测试仅使用一个变量,所以 P2 和 P3 必须在 P0 和 P1 的存储顺序上达成一致。换句话说,如果 P2 认为 P0 的存储首先进行,则 P3 最好不要相信 P1 的存储首先出现。事实上,如果出现这样的情况,第 35 行的 exists 语句将被触发。

很容易推测,对于单个内存区域(比如使用 C 语言的 union 关键字设置),不同大小的重叠加载和存储将提供类似的排序保证。然而 Flur 等人发现了一些令人惊讶的简单石蕊测试,这名这些保证可以在真实硬件上被打破。因此,至少在考虑可移植性的情况下,有必要将代码限制为对指定变量的非重叠相同大小的对齐访问。
添加更多的变量和线程会增加重排序和违反其他反直觉行文的范围,如下一节所述。
15.2.7 多重原子性
Threads running on a multicopy atomic (SF95) platform are guaranteed to agree on the order of stores, even to different variables. A useful mental model of such a system is the single-bus architecture shown in Figure 15.7. If each store resulted in a message on the bus, and if the bus could accommodate only one store at a time, then any pair of CPUs would agree on the order of all stores that they observed. Unfortunately, building a computer system as shown in the figure, without store buffers or even caches, would result in glacial computation. CPU vendors interested in providing multicopy atomicity have therefore instead provided the slightly weaker other-multicopy atomicity (ARM17, Section B2.3), which excludes the CPU doing a given store from the requirement that all CPUs agree on the order of all stores. This means that if only a subset of CPUs are doing stores, the other CPUs will agree on the order of stores, hence the “other” in “other-multicopy atomicity”. Unlike multicopy-atomic platforms, within other-multicopy-atomic platforms, the CPU doing the store is permitted to observe its store early, which allows its later loads to obtain the newly stored value directly from the store buffer. This in turn avoids abysmal performance.
Perhaps there will come a day when all platforms provide some flavor of multicopy atomicity, but in the meantime, non-multicopy-atomic platforms do exist, and so software must deal with them.
Listing 15.16 (C-WRC+o+o-data-o+o-rmb-o.litmus) demonstrates multicopy atomicity, that is, on a multicopy-atomic platform, the exists clause on line 29 cannot trigger. In contrast, on a non-multicopy-atomic platform this exists clause can trigger, despite P1()’s accesses being ordered by a data dependency and P2()’s accesses being ordered by an smp_rmb(). Recall that the definition of multicopy atomicity requires that all threads agree on the order of stores, which can be thought of as all stores reaching all threads at the same time. Therefore, a non-multicopy-atomic platform can have a store reach different threads at different times. In particular, P0()’s store might reach P1() long before it reaches P2(), which raises the possibility that P1()’s store might reach P2() before P0()’s store does.

This leads to the question of why a real system constrained by the usual laws of physics would ever trigger the exists clause of Listing 15.16. The cartoonish diagram of a such a real system is shown in Figure 15.8. CPU 0 and CPU 1 share a store buffer, as do CPUs 2 and 3. This means that CPU 1 can load a value out of the store buffer, thus potentially immediately seeing a value stored by CPU 0. In contrast, CPUs 2 and 3 will have to wait for the corresponding cache line to carry this new value to them.
Table 15.4 shows one sequence of events that can result in the exists clause in Listing 15.16 triggering. This sequence of events will depend critically on P0() and P1() sharing both cache and a store buffer in the manner shown in Figure 15.8.
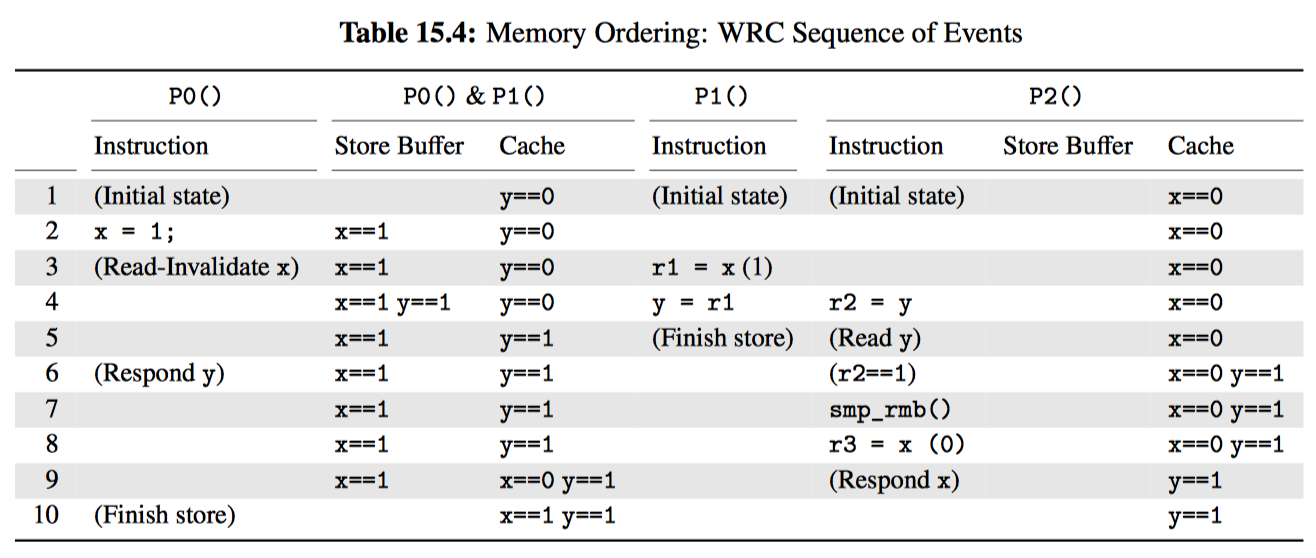
Row 1 shows the initial state, with the initial value of y in P0()’s and P1()’s shared cache, and the initial value of x in P2()’s cache.
Row 2 shows the immediate effect of P0() executing its store on line 8. Because the cacheline containing x is not in P0()’s and P1()’s shared cache, the new value (1) is stored in the shared store buffer.
Row 3 shows two transitions. First, P0() issues a read-invalidate operation to fetch the cacheline containing x so that it can flush the new value for x out of the shared store buffer. Second, P1() loads from x (line 15), an operation that completes immediately because the new value of x is immediately available from the shared store buffer.
Row 4 also shows two transitions. First, it shows the immediate effect of P1() executing its store to y (line 16), placing the new value into the shared store buffer. Second, it shows the start of P2()’s load from y (line 24).
Row 5 continues the tradition of showing two transitions. First, it shows P1() complete its store to y, flushing from the shared store buffer to the cache. Second, it shows P2() request the cacheline containing y.
Row 6 shows P2() receive the cacheline containing y, allowing it to finish its load into r2, which takes on the value 1.
Row 7 shows P2() execute its smp_rmb() (line 25), thus keeping its two loads ordered.
Row 8 shows P2() execute its load from x, which immediately returns with the value zero from P2()’s cache.
Row 9 shows P2() finally responding to P0()’s request for the cacheline containing x, which was made way back up on row 3.
Finally, row 10 shows P0() finish its store, flushing its value of x from the shared store buffer to the shared cache.
Note well that the exists clause on line 29 has triggered. The values of r1 and r2 are both the value one, and the final value of r3 the value zero. This strange result occurred because P0()’s new value of x was communicated to P1() long before it was communicated to P2().
This counter-intuitive result happens because although dependencies do provide ordering, they provide it only within the confines of their own thread. This threethread example requires stronger ordering, which is the subject of Sections 15.2.7.1 through 15.2.7.4.
15.2.7.1 Cumulativity
The three-thread example shown in Listing 15.16 requires cumulative ordering, or cumulativity. A cumulative memory-ordering operation orders not just any given access preceding it, but also earlier accesses by any thread to that same variable.
Dependencies do not provide cumulativity, which is why the “C” column is blank for both the READ_ONCE() and the smp_read_barrier_depends() rows of Table 15.3. However, as indicated by the “C” in their “C” column, release operations do provide cumulativity. Therefore, Listing 15.17 (C-WRC+o+o-r+a-o.litmus) substitutes a release operation for Listing 15.16’s data dependency. Because the release operation is cumulative, its ordering applies not only to Listing 15.17’s load from x by P1() on line 15, but also to the store to x by P0() on line 8—but only if that load returns the value stored, which matches the 1:r1=1 in the exists clause on line 28. This means that P2()’s load-acquire suffices to force the load from x on line 25 to happen after the store on line 8, so the value returned is one, which does not match 2:r3=0, which in turn prevents the exists clause from triggering.
These ordering constraints are depicted graphically in Figure 15.9. Note also that cumulativity is not limited to a single step back in time. If there was another load from x or store to x from any thread that came before the store on line 13, that prior load or store would also be ordered before the store on line 32, though only if both r1 and r2 both end up containing the address of x.
In short, use of cumulative ordering operations can suppress non-multicopy-atomic behaviors in some situations. Cumulativity nevertheless has limits, which are examined in the next section.
15.2.7.2 Propagation
Listing 15.18 (C-W+RWC+o-r+a-o+o-mb-o.litmus) shows the limitations of cumulativity and store-release, even with a full memory barrier. The problem is that although the smp_store_release() on line 12 has cumulativity, and although that cumulativity does order P2()’s load on line 30, the smp_store_release()’s ordering cannot propagate through the combination of P1()’s load (line 21) and P2()’s store (line 28). This means that the exists clause on line 33 really can trigger.

This situation might seem completely counter-intuitive, but keep in mind that the speed of light is finite and computers are of non-zero size. It therefore takes time for the effect of the P2()’s store to z to propagate to P1(), which in turn means that it is possible that P1()’s read from z happens much later in time, but nevertheless still sees the old value of zero. This situation is depicted in Figure 15.10: Just because a load sees the old value does not mean that this load executed at an earlier time than did the store of the new value.
Note that Listing 15.18 also shows the limitations of memory-barrier pairing, given that there are not two but three processes. These more complex litmus tests can instead be said to have cycles, where memory-barrier pairing is the special case of a twothread cycle. The cycle in Listing 15.18 goes through P0() (lines 11 and 12), P1() (lines 20 and 21), P2() (lines 28, 29, and 30), and back to P0() (line 11). The exists clause delineates this cycle: the 1:r1=1 indicates that the smp_load_acquire() on line 20 returned the value stored by the smp_store_release() on line 12, the 1:r2=0 indicates that the WRITE_ONCE() on line 28 came too late to affect the value returned by the READ_ONCE() on line 21, and finally the 2:r3=0 indicates that the WRITE_ONCE() on line 11 came too late to affect the value returned by the READ_ONCE() on line 30. In this case, the fact that the exists clause can trigger means that the cycle is said to be allowed. In contrast, in cases where the exists clause cannot trigger, the cycle is said to be prohibited.
But what if we need to keep the exists clause on line 33 of Listing 15.18? One solution is to replace P0()’s smp_store_release() with an smp_mb(), which Table 15.3 shows to have not only cumulativity, but also propagation. The result is shown in Listing 15.19 (C-W+RWC+o-mb-o+a-o+o-mb-o.litmus).

For completeness, Figure 15.11 shows that the “winning” store among a group of stores to the same variable is not necessarily the store that started last. This should not come as a surprise to anyone who carefully examined Figure 15.5.
But sometimes time really is on our side. Read on!
Happens-Before
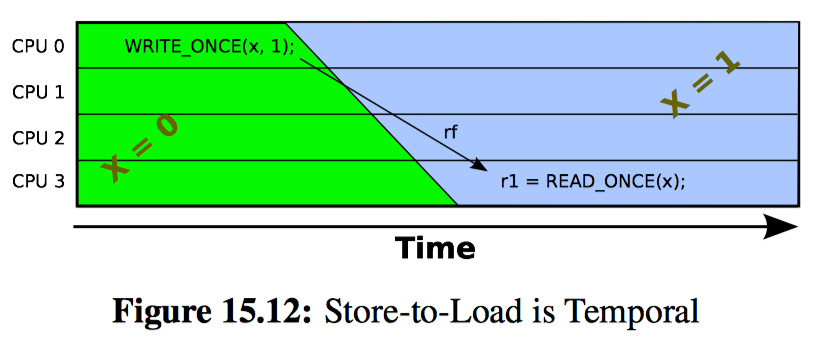
As shown in Figure 15.12, on platforms without user-visible speculation, if a load returns the value from a particular store, then, courtesy of the finite speed of light and the non-zero size of modern computing systems, the store absolutely has to have executed at an earlier time than did the load. This means that carefully constructed programs can rely on the passage of time itself as an memory-ordering operation.
Of course, just the passage of time by itself is not enough, as was seen in Listing 15.6, which has nothing but store-to-load links and, because it provides absolutely no ordering, still can trigger its exists clause. However, as long as each thread provides even the weakest possible ordering, exists clause would not be able to trigger. For example, Listing 15.21 (C-LB+a-o+o-data-o+o-data-o.litmus) shows P0() ordered with an smp_load_acquire() and both P1() and P2() ordered with data dependencies. These orderings, which are close to the top of Table 15.3, suffice to prevent the exists clause from triggering.

An important, to say nothing of more useful, use of time for ordering memory accesses is covered in the next section.
Release-Acquire Chains
A minimal release-acquire chain was shown in Listing 15.7 (C-LB+a-r+a-r+a-r+ar.litmus), but these chains can be much longer, as shown in Listing 15.22. The longer the release-acquire chain, the more ordering is gained from the passage of time, so that no matter how many threads are involved, the corresponding exists clause cannot trigger.


Although release-acquire chains are inherently store-to-load creatures, it turns out that they can tolerate one load-to-store step, despite such steps being counter-temporal, as shown in Figure 15.10. For example, Listing 15.23 (C-ISA2+o-r+a-r+a-r+ao.litmus) shows a three-step release-acquire chain, but where P3()’s final access is a READ_ONCE() from x0, which is accessed via WRITE_ONCE() by P0(), forming a non-temporal load-to-store link between these two processes. However, because P0()’s smp_store_release() (line 12) is cumulative, if P3()’s READ_ONCE() returns zero, this cumulativity will force the READ_ONCE() to be ordered before P0()’s smp_store_release(). In addition, the release-acquire chain (lines 12, 20, 21, 28, 29, and 37) forces P3()’s READ_ONCE() to be ordered after P0()’s smp_store_ release(). Because P3()’s READ_ONCE() cannot be both before and after P0()’s smp_store_release(), either or both of two things must be true:
P3()’s READ_ONCE() came after P0()’s WRITE_ONCE(), so that the READ_ ONCE() returned the value two, so that the exists clause’s 3:r2=0 is false.
The release-acquire chain did not form, that is, one or more of the exists clause’s 1:r2=2, 2:r2=2, or 3:r1=2 is false.
Either way, the exists clause cannot trigger, despite this litmus test containing a notorious load-to-store link between P3() and P0(). But never forget that releaseacquire chains can tolerate only one load-to-store link, as was seen in Listing 15.18.
Release-acquire chains can also tolerate a single store-to-store step, as shown in Listing 15.24 (C-Z6.2+o-r+a-r+a-r+a-o.litmus). As with the previous example, smp_store_release()’s cumulativity combined with the temporal nature of the release-acquire chain prevents the exists clause on line 36 from triggering. But beware: Adding a second store-to-store step would allow the correspondingly updated exists clause to trigger.

In short, properly constructed release-acquire chains form a peaceful island of intuitive bliss surrounded by a strongly counter-intuitive sea of more complex memoryordering constraints.
15.3 Compile-Time Consternation
Most languages, including C, were developed on uniprocessor systems by people with little or no parallel-programming experience. As a results, unless explicitly told otherwise, these languages assume that the current CPU is the only thing that is reading or writing memory. This in turn means that these languages’ compilers’ optimizers are ready, willing, and oh so able to make dramatic changes to the order, number, and sizes of memory references that your program executes. In fact, the reordering carried out by hardware can seem quite tame by comparison.
15.3.1 Memory-Reference Restrictions
Again, unless told otherwise, compilers assume that nothing else is affecting the variables being accessed by the generated code. This assumption is not simply some design error, but is instead enshrined in various standards. 9 This assumption means that compilers are within their rights (as defined by the standards) to optimize the following code so as to hoist the load from a out of the loop, at least in cases where the compiler can prove that do_something() does not modify a:
1 while (a)
2 do_something();
The optimized code might look something like this, essentially fusing an arbitrarily large number of intended loads into a single actual load:
1 if (a)
2 for (;;)
3 do_something();
This optimization might come as a fatal surprise to code elsewhere that expected to terminate this loop by storing a zero to a. Fortunately, there are several ways of avoiding this sort of problem:
- Volatile accesses.
- Atomic variables.
- Prohibitions against introducing data races.
The volatile restrictions are necessary to write reliable device drivers, and the atomic variables and prohibitions against introducing data races are necessary to write reliable concurrent code.
Starting with volatile accesses, the following code relies on the volatile casts in READ_ONCE() to prevent the unfortunate infinite-loop optimization:
1 while (READ_ONCE(a))
2 do_something();
READ_ONCE() marks the load with a volatile cast. Now volatile was originally designed for accessing memory-mapped I/O (MMIO) registers, which are accessed using the same load and store instructions that are used when accessing normal memory. However, MMIO registers need not act at all like normal memory. Storing a value to an MMIO register does not necessarily mean that a subsequent load from that register will return the value stored. Loading from an MMIO register might well have side effects, for example, changing the device state or affecting the response to subsequent loads and stores involving other MMIO registers. Loads and stores of different sizes to the same MMIO address might well have different effects.
This means that, even on a uniprocessor system, changing the order, number, or size of MMIO accesses is strictly forbidden. And this is exactly the purpose of the C-language volatile keyword, to constrain the compiler so as to allow implementation of reliable device drivers.
This is why READ_ONCE() prevents the destructive hoisting of the load from a out of the loop: Doing so changes the number of volatile loads from a, so this optimization is disallowed. However, note well that volatile does absolutely nothing to constrain the hardware. Therefore, if the code following the loop needs to see the result of any memory references preceding the store of zero that terminated the loop, you will instead need to use something like smp_store_release() to store the zero and smp_load_ acquire() in the loop condition. But if all you need is to reliably control the loop without any other ordering, READ_ONCE() can do the job.
Compilers can also replicate loads. For example, consider this all-too-real code fragment:
1 tmp = p;
2 if (tmp != NULL && tmp <= q)
3 do_something(tmp);
Here the intent is that the do_something() function is never passed a NULL pointer or a pointer that is greater than q. However, the compiler is within its rights to transform this into the following:
1 if (p != NULL && p <= q)
2 do_something(p);
In this transformed code, the value of p is loaded three separate times. This transformation might seem silly at first glance, but it is quite useful when the surrounding code has consumed all of the machine registers. It is possible that the current value of p passes the test on line 1, but that some other thread stores NULL to p before line 2 executes, and the resulting NULL pointer could be a fatal surprise to do_something(). 10 To prevent the compiler from replicating the load, use READ_ONCE(), for example as follows:
1 tmp = READ_ONCE(p);
2 if (tmp != NULL && tmp <= q)
3 do_something(tmp);
Alternatively, the variable p could be declared volatile.
Compilers can also fuse stores. The most infamous example is probably the progressbar example shown below:
1 while (!am_done()) {
2 do_something(p);
3 progress++;
4 }
If the compiler used a feedback-driven optimizer, it might well notice that the store to the shared variable progress was quite expensive, resulting in the following well-intentioned optimization:
1 while (!am_done()) {
2 do_something(p);
3 tmp++;
4 }
5 progress = tmp;
This might well slightly increase performance, but the poor user watching the progress bar might be forgiven for harboring significant ill will towards this particular optimization. The progress bar will after all be stuck at zero for a long time, then jump at the very end. The following code will usually prevent this problem:
1 while (!am_done()) {
2 do_something(p);
3 WRITE_ONCE(progress, progress + 1);
4 }
Exceptions can occur if the compiler is able to analyze do_something() and learn that it has no accesses to atomic or volatile variables. In these cases the compiler could produce two loops, one invoking do_something() and the other incrementing progress. It may be necessary to replace the WRITE_ONCE() with something like smp_store_release() in the unlikely event that this occurs. It is important to note that although the compiler is forbidden from changing the number, size, or order of volatile accesses, it is perfectly within its rights to reorder normal accesses with unrelated volatile accesses.
Oddly enough, the compiler is within its rights to use a variable as temporary storage just before a normal store to that variable, thus inventing stores to that variable. Fortunately, most compilers avoid this sort of thing, at least outside of stack variables. In any case, using WRITE_ONCE(), declaring the variable volatile, or declaring the variable atomic (in recent C and C++ compilers supporting atomics) will prevent this sort of thing.
The previous examples involved compiler optimizations that changed the number of accesses. Now, it might seem that preventing the compiler from changing the order of accesses is an act of futility, given that the underlying hardware is free to reorder them. However, modern machines have exact exceptions and exact interrupts, meaning that any interrupt or exception will appear to have happened at a specific place in the instruction stream, so that the handler will see the effect of all prior instructions, but won’t see the effect of any subsequent instructions. READ_ONCE() and WRITE_ONCE() can therefore be used to control communication between interrupted code and interrupt handlers. 11
This leaves changes to the size of accesses, which is known as load tearing and store tearing when the actual size is smaller than desired. For example, storing the constant 0x00010002 into a 32-bit variable might seem quite safe. However, there are CPUs that can store small immediate values directly into memory, and on such CPUs, the compiler can be expected to split this into two 16-bit stores in order to avoid the overhead of explicitly forming the 32-bit constant. This could come as a fatal surprise to another thread concurrently loading from this variable, which might not expect to see the result of a half-completed store. Use of READ_ONCE() and WRITE_ONCE() prevent the compiler from engaging in load tearing and store tearing, respectively.
In short, use of READ_ONCE(), WRITE_ONCE(), and volatile are valuable tools in preventing the compiler from optimizing your parallel algorithm out of existence. Compilers are starting to provide other mechanisms for avoiding load and store tearing, for example, memory_order_relaxed atomic loads and stores, however, volatile is still needed to avoid fusing and splitting of accesses.
Please note that, it is possible to overdo use of READ_ONCE() and WRITE_ONCE(). For example, if you have prevented a given variable from changing (perhaps by holding the lock guarding all updates to that variable), there is no point in using READ_ONCE(). Similarly, if you have prevented any other CPUs or threads from reading a given variable (perhaps because you are initializing that variable before any other CPU or thread has access to it), there is no point in using WRITE_ONCE(). However, in my experience, developers need to use things like READ_ONCE() and WRITE_ONCE() more often than they think that they do, the overhead of unnecessary uses is quite low. Furthermore, the penalty for failing to use them when needed is quite high.
15.3.2 Address- and Data-Dependency Difficulties
Compilers do not understand either address or data dependencies, although there are efforts underway to teach them, or at the very least, standardize the process of teaching them (MWB + 17, MRP + 17). In the meantime, it is necessary to be very careful in order to prevent your compiler from breaking your dependencies.
15.3.2.1 Give your dependency chain a good start
The load that heads your dependency chain must use proper ordering, for example, lockless_dereference(), rcu_dereference(), or a READ_ONCE() followed by smp_read_barrier_depends(). Failure to follow this rule can have serious side effects:
On DEC Alpha, a dependent load might not be ordered with the load heading the dependency chain, as described in Section 15.4.1.
If the load heading the dependency chain is a C11 non-volatile memory_order_ relaxed load, the compiler could omit the load, for example, by using a value that it loaded in the past.
If the load heading the dependency chain is a plain load, the compiler can omit the load, again by using a value that it loaded in the past. Worse yet, it could load twice instead of once, so that different parts of your code use different values—and compilers really do this, especially when under register pressure.
The value loaded by the head of the dependency chain must be a pointer. In theory, yes, you could load an integer, perhaps to use it as an array index. In practice, the compiler knows too much about integers, and thus has way too many opportunities to break your dependency chain (MWB + 17).
15.3.2.2 Avoid arithmetic dependency breakage
Although it is just fine to do some arithmetic operations on a pointer in your dependency chain, you need to be careful to avoid giving the compiler too much information. After all, if the compiler learns enough to determine the exact value of the pointer, it can use that exact value instead of the pointer itself. As soon as the compiler does that, the dependency is broken and all ordering is lost.
- Although it is permissible to compute offsets from a pointer, these offsets must not result in total cancellation. For example, given a char pointer cp, cp-(uintptr_ t)cp) will cancel and can allow the compiler to break your dependency chain.
On the other hand, canceling offset values with each other is perfectly safe and legal. For example, if a and b are equal, cp+a-b is an identity function, including preserving the dependency.
- Comparisons can break dependencies. Listing 15.26 shows how this can happen. Here global pointer gp points to a dynamically allocated integer, but if memory is low, it might instead point to the reserve_int variable. This reserve_ int case might need special handling, as shown on lines 6 and 7 of the listing. But the compiler could reasonably transform this code into the form shown in Listing 15.27, especially on systems where instructions with absolute addresses run faster than instructions using addresses supplied in registers. However, there is clearly no ordering between the pointer load on line 5 and the dereference on line 8. Please note that this is simply an example: There are a great many other ways to break dependency chains with comparisons.

Note that a series of inequality comparisons might, when taken together, give the compiler enough information to determine the exact value of the pointer, at which point the dependency is broken. Furthermore, the compiler might be able to combine information from even a single inequality comparison with other information to learn the exact value, again breaking the dependency. Pointers to elements in arrays are especially susceptible to this latter form of dependency breakage.
15.3.2.3 Safe comparison of dependent pointers
It turns out that there are several safe ways to compare dependent pointers:
Comparisons against the NULL pointer. In this case, all the compiler can learn is that the pointer is NULL, in which case you are not allowed to dereference it anyway.
The dependent pointer is never dereferenced, whether before or after the comparison.
The dependent pointer is compared to a pointer that references objects that were last modified a very long time ago, where the only unconditionally safe value of “a very long time ago” is “at compile time”. The key point is that there absolutely must be something other than the address or data dependency that guarantees ordering.
Comparisons between two pointers, each of which is carrying a good-enough dependency. For example, you have a pair of pointers, each carrying a dependency, and you want to avoid deadlock by acquiring locks of the pointed-to data elements in address order.
The comparison is not-equal, and the compiler does not have enough other information to deduce the value of the pointer carrying the dependency.
Pointer comparisons can be quite tricky, and so it is well worth working through the example shown in Listing 15.28. This example uses a simple struct foo shown on lines 1-5 and two global pointers, gp1 and gp2, shown on lines 6 and 7, respectively. This example uses two threads, namely updater() on lines 9-22 and reader() on lines 24-39.

The updater() thread allocates memory on line 13, and complains bitterly on line 14 if none is available. Lines 15-17 initialize the newly allocated structure, and then line 18 assigns the pointer to gp1. Lines 19 and 20 then update two of the structure’s fields, and does so after line 18 has made those fields visible to readers. Please note that unsynchronized update of reader-visible fields often constitutes a bug. Although there are legitimate use cases doing just this, such use cases require more care than is exercised in this example.
Finally, line 21 assigns the pointer to gp2.
The reader() thread first fetches gp2 on line 30, with lines 31 and 32 checking for NULL and returning if so. Line 33 then fetches field ->b. Now line 34 fetches gp1, and if line 35 sees that the pointers fetched on lines 30 and 34 are equal, line 36 fetches p->c. Note that line 36 uses pointer p fetched on line 30, not pointer q fetched on line 34.
But this difference might not matter. An equals comparison on line 35 might lead the compiler to (incorrectly) conclude that both pointers are equivalent, when in fact they carry different dependencies. This means that the compiler might well transform line 36 to instead be r2 = q->c, which might well cause the value 44 to be loaded instead of the expected value 144.
In short, some care is required in order to ensure that dependency chains in your source code are still dependency chains once the compiler has gotten done with them.
15.3.3 Control-Dependency Calamities
Control dependencies are especially tricky because current compilers do not understand them and can easily break them. The rules and examples in this section are intended to help you prevent your compiler’s ignorance from breaking your code.
A load-load control dependency requires a full read memory barrier, not simply a data dependency barrier. Consider the following bit of code:
1 q = READ_ONCE(x);
2 if (q) {
3 <data dependency barrier>
4 q = READ_ONCE(y);
5 }
This will not have the desired effect because there is no actual data dependency, but rather a control dependency that the CPU may short-circuit by attempting to predict the outcome in advance, so that other CPUs see the load from y as having happened before the load from x. In such a case what’s actually required is:
1 q = READ_ONCE(x);
2 if (q) {
3 <read barrier>
4 q = READ_ONCE(y);
5 }
However, stores are not speculated. This means that ordering is provided for loadstore control dependencies, as in the following example:
1 q = READ_ONCE(x);
2 if (q)
3 WRITE_ONCE(y, 1);
Control dependencies pair normally with other types of ordering operations. That said, please note that neither READ_ONCE() nor WRITE_ONCE() are optional! Without the READ_ONCE(), the compiler might combine the load from x with other loads from x. Without the WRITE_ONCE(), the compiler might combine the store to y with other stores to y. Either can result in highly counterintuitive effects on ordering.
Worse yet, if the compiler is able to prove (say) that the value of variable x is always non-zero, it would be well within its rights to optimize the original example by eliminating the “if” statement as follows:
1 q = READ_ONCE(x);
2 WRITE_ONCE(y, 1); /* BUG: CPU can reorder!!! */
It is tempting to try to enforce ordering on identical stores on both branches of the “if” statement as follows:
1 q = READ_ONCE(x);
2 if (q) {
3 barrier();
4 WRITE_ONCE(y, 1);
5 do_something();
6 } else {
7 barrier();
8 WRITE_ONCE(y, 1);
9 do_something_else();
10 }
Unfortunately, current compilers will transform this as follows at high optimization levels:
1 q = READ_ONCE(x);
2 barrier();
3 WRITE_ONCE(y, 1); /* BUG: No ordering!!! */
4 if (q) {
5 do_something();
6 } else {
7 do_something_else();
8 }
Now there is no conditional between the load from x and the store to y, which means that the CPU is within its rights to reorder them: The conditional is absolutely required, and must be present in the assembly code even after all compiler optimizations have been applied. Therefore, if you need ordering in this example, you need explicit memory-ordering operations, for example, a release store:
1 q = READ_ONCE(x);
2 if (q) {
3 smp_store_release(&y, 1);
4 do_something();
5 } else {
6 smp_store_release(&y, 1);
7 do_something_else();
8 }
The initial READ_ONCE() is still required to prevent the compiler from proving the value of x.
In addition, you need to be careful what you do with the local variable q, otherwise the compiler might be able to guess the value and again remove the needed conditional. For example:
1 q = READ_ONCE(x);
2 if (q % MAX) {
3 WRITE_ONCE(y, 1);
4 do_something();
5 } else {
6 WRITE_ONCE(y, 2);
7 do_something_else();
8 }
If MAX is defined to be 1, then the compiler knows that (q%MAX) is equal to zero, in which case the compiler is within its rights to transform the above code into the following:
1 q = READ_ONCE(x);
2 WRITE_ONCE(y, 2);
3 do_something_else();
Given this transformation, the CPU is not required to respect the ordering between the load from variable x and the store to variable y. It is tempting to add a barrier() to constrain the compiler, but this does not help. The conditional is gone, and the barrier() won’t bring it back. Therefore, if you are relying on this ordering, you should make sure that MAX is greater than one, perhaps as follows:
1 q = READ_ONCE(x);
2 BUILD_BUG_ON(MAX <= 1);
3 if (q % MAX) {
4 WRITE_ONCE(y, 1);
5 do_something();
6 } else {
7 WRITE_ONCE(y, 2);
8 do_something_else();
9 }
Please note once again that the stores to y differ. If they were identical, as noted earlier, the compiler could pull this store outside of the “if” statement.
You must also avoid excessive reliance on boolean short-circuit evaluation. Consider this example:
1 q = READ_ONCE(x);
2 if (q || 1 > 0)
3 WRITE_ONCE(y, 1);
Because the first condition cannot fault and the second condition is always true, the compiler can transform this example as following, defeating control dependency:
1 q = READ_ONCE(x);
2 WRITE_ONCE(y, 1);
This example underscores the need to ensure that the compiler cannot out-guess your code. More generally, although READ_ONCE() does force the compiler to actually emit code for a given load, it does not force the compiler to use the results.
In addition, control dependencies apply only to the then-clause and else-clause of the if-statement in question. In particular, it does not necessarily apply to code following the if-statement:
1 q = READ_ONCE(x);
2 if (q) {
3 WRITE_ONCE(y, 1);
4 } else {
5 WRITE_ONCE(y, 2);
6 }
7 WRITE_ONCE(z, 1); /* BUG: No ordering. */
It is tempting to argue that there in fact is ordering because the compiler cannot reorder volatile accesses and also cannot reorder the writes to y with the condition. Unfortunately for this line of reasoning, the compiler might compile the two writes to y as conditional-move instructions, as in this fanciful pseudo-assembly language:
1 ld r1,x
2 cmp r1,$0
3 cmov,ne r4,$1
4 cmov,eq r4,$2
5 st r4,y
6 st $1,z
A weakly ordered CPU would have no dependency of any sort between the load from x and the store to z. The control dependencies would extend only to the pair of cmov instructions and the store depending on them. In short, control dependencies apply only to the stores in the “then” and “else” of the “if” in question (including functions invoked by those two clauses), not to code following that “if”.
Finally, control dependencies do not provide cumulativity. 12 This is demonstrated by two related litmus tests, namely Listings 15.29 and 15.30 with the initial values of x and y both being zero.
The exists clause in the two-thread example of Listing 15.29 (C-LB+o-cgt-o+ocgt-o.litmus) will never trigger. If control dependencies guaranteed cumulativity (which they do not), then adding a thread to the example as in Listing 15.30 (CWWC+o-cgt-o+o-cgt-o+o.litmus) would guarantee the related exists clause never to trigger.


But because control dependencies do not provide cumulativity, the exists clause in the three-thread litmus test can trigger. If you need the three-thread example to provide ordering, you will need smp_mb() between the load and store in P0(), that is, just before or just after the “if” statements. Furthermore, the original two-thread example is very fragile and should be avoided.
The following list of rules summarizes the lessons of this section:
Compilers do not understand control dependencies, so it is your job to make sure that the compiler cannot break your code.
Control dependencies can order prior loads against later stores. However, they do not guarantee any other sort of ordering: Not prior loads against later loads, nor prior stores against later anything. If you need these other forms of ordering, use smp_rmb(), smp_wmb(), or, in the case of prior stores and later loads, smp_mb().
If both legs of the “if” statement begin with identical stores to the same variable, then those stores must be ordered, either by preceding both of them with smp_ mb() or by using smp_store_release() to carry out the stores. Please note that it is not sufficient to use barrier() at beginning of each leg of the “if” statement because, as shown by the example above, optimizing compilers can destroy the control dependency while respecting the letter of the barrier() law.
Control dependencies require at least one run-time conditional between the prior load and the subsequent store, and this conditional must involve the prior load. If the compiler is able to optimize the conditional away, it will have also optimized away the ordering. Careful use of READ_ONCE() and WRITE_ONCE() can help to preserve the needed conditional.
Control dependencies require that the compiler avoid reordering the dependency into nonexistence. Careful use of READ_ONCE(), atomic_read(), or atomic64_read() can help to preserve your control dependency.
Control dependencies apply only to the “then” and “else” of the “if” containing the control dependency, including any functions that these two clauses call. Control dependencies do not apply to code following the end of the “if” statement containing the control dependency.
Control dependencies pair normally with other types of memory-ordering operations.
Control dependencies do not provide cumulativity. If you need cumulativity, use smp_mb().
In short, many popular languages were designed primarily with single-threaded use in mind. Successfully using these languages to construct multi-threaded software requires that you pay special attention to your memory references and dependencies.
15.4 Hardware Specifics
略。
15.5. WHERE IS MEMORY ORDERING NEEDED?
Memory-ordering operations are only required where there is a possibility of interaction involving at least two variables between at least two threads. As always, if a single-threaded program will provide sufficient performance, why bother with parallelism? 15 After all, avoiding parallelism also avoids the added cost of memory-ordering operations.
If all thread-to-thread communication in a given cycle use store-to-load links (that is, the next thread’s load returning the value that the previous thread stored), minimal ordering suffices, as illustrated by Listings 15.12 and 15.13. Minimal ordering includes dependencies, acquires, and all stronger ordering operations.
If all but one of the links in a given cycle is a store-to-load link, it is sufficient to use release-acquire pairs for each of those store-to-load links, as illustrated by Listings 15.23 and 15.24. You can replace a given acquire with a a dependency in environments permitting this, keeping in mind that the C11 standard’s memory model does not permit this. Note also that a dependency leading to a load must be headed by a lockless_ dereference() or an rcu_dereference(): READ_ONCE() is not sufficient. Never forget to carefully review Sections 15.3.2 and 15.3.3, because a dependency broken by your compiler is no help at all! The two threads sharing the sole non-store-to-load link can usually substitute WRITE_ONCE() plus smp_wmb() for smp_store_release() on the one hand, and READ_ONCE() plus smp_rmb() for smp_load_acquire() on the other.
If a given cycle contains two or more non-store-to-load links (that is, a total of two or more load-to-store and store-to-store links), you will need at least one full barrier between each pair of non-store-to-load links in that cycle, as illustrated by Listing 15.19 as well as in the answer to Quick Quiz 15.23. Full barriers include smp_mb(), successful full-strength non-void atomic RMW operations, and other atomic RMW operations in conjunction with either smp_mb__before_atomic() or smp_mb__after_atomic(). Any of RCU’s grace-period-wait primitives (synchronize_rcu() and friends) also act as full barriers, but at even greater expense than smp_mb(). With strength comes expense, though the overhead of full barriers usually hurts performance more than it hurts scalability.
Note that these are the minimum guarantees. Different architectures may give more substantial guarantees, as discussed in Section 15.4, but they may not be relied upon outside of code specifically designed to run only on the corresponding architecture.
One final word of advice: Again, use of raw memory-ordering primitives is a last resort. It is almost always better to use existing primitives, such as locking or RCU, that take care of memory ordering for you.
16 - ENDIX-C-内存屏障
是什么原因,让疯狂的 CPU 设计者将内存屏障强加给可怜的 SMP 软件设计者?
简而言之,这是由于重排内存引用可以达到更好的性能。因此,在某些情况下,如在同步原语中,正确的操作结果依赖于按序的内存引用,这就需要内存屏障以强制保证内存顺序。
对于这个问题,要得到更详细的回答,需要很好理解 CPU 缓存是如何工作的,特别是要使缓存工作的更好,我们需要什么东西。
缓存结构
现代 CPU 的速度比现代内存系统的速度快的多。2006 年的 CPU 可以在的每纳秒内执行 10 条指令。但是需要多个 10ns 才能从物理内存中读取一条数据。它们的速度差异(超过两个数量级)已经导致在现代 CPU 中出现了数兆级别的缓存。这些缓存与 CPU 相关联,如果 C.1 中所示,典型的,可以在几个时钟周期内被访问。
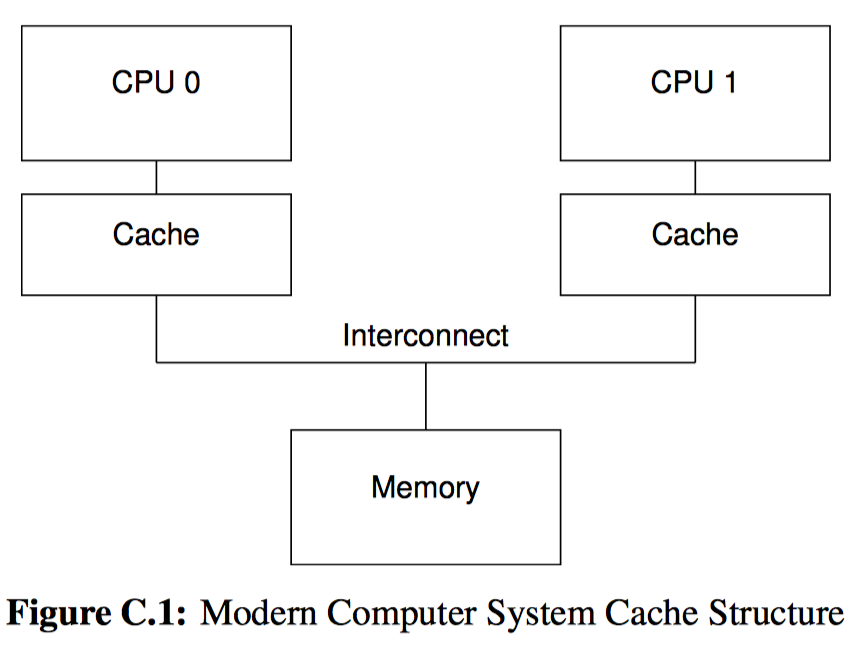
CPU 缓存和内存之间的数据流是固定长度的块,称为“缓存行”,其大小通常是 2 的 N 次方。范围从 16 到 256 字节不等。当一个特定的数据项初次被 CPU 访问时,它在缓存中还不存在,这被称为“缓存缺失”(或者更精确的称为“首次缓存缺失”或者“运行时缓存缺失”)。“缓存缺失”意味着从物理内存中读取数据时,CPU 必须等待(或处于“停顿”状态)数百个 CPU 周期。但是,数据项被装载入 CPU 缓存,因此后续的访问将在缓存中找到,于是 CPU 可以全速运行。
经过一段时间后,CPU 的缓存被填满,后续的缓存缺失很可能需要换出缓存中现有的数据,以便为最近的访问项腾出统建。这种“缓存缺失”被称为“容量缺失”,因为它是由于缓存容量限制而造成的。但是,即便此时缓存还没有被填满,大量缓存也可能由于一个新数据被换出。这是由于大容量缓存是通过硬件哈希表来实现的,这样哈希表有固定长度的哈希桶(或者叫 “sets”,CPU 设计者是这样称呼的),如图 C.2。
该缓存有 16 个 sets 和两条“路”,共 32 个缓存行,每个节点包含一个 256 字节的“缓存行”,它是一个 256 字节对齐的内存块。对于大容量缓存来说,这个缓存行的长度稍小了点,但是这使得 16 禁止的运行更加简单。从硬件角度来说,这是一个两路组相连缓存,类似于带 16 个桶的软件哈希表,每个桶的哈西链被限制为最多两个元素。大小(本例中是32个缓存行)和相连性(本例中是2)都被称为缓存行的 germetry。由于缓存是硬件实现的,哈希函数非常简单,从地址中取出 4 位作为哈希键值。
在 C.2 中,每个方框对应一个缓存项,每个缓存项包含一个 256 字节的缓存行。不过,一个缓存项可能为空,在图中表现为空框。其他的块用它所包含的内存行的内存地址标记。由于缓存行必须是 256 字节对齐,因此每一个地址的低 8 位为 0。并且,硬件哈希函数的选择。意味着接下来的高 4 位匹配缓存行中的位置。
如果陈旭代码位于地址 0x43210E00 到 0x43210EFF,并且程序一次访问地址 0x1234500 到 0x12345EFF,图中的情况就可能发生。假设程序正在准备访问地址 0x12345F00,这个地址会哈希到 0xF 行,该行的两路都是空的,因此可以容纳对应的 256 字节缓存行。如果程序访问地址 0x1233000,将会被哈希到第 0 行,相应的 256 字节缓存行可以放到第一路。但是,如果程序访问地址 0x123E00,将会哈希到 0xE 行,其中一个已经存在于缓存中缓存行必须被替换出去,以腾出空间给新的缓存行。如果随后访问刚被替换出去的行,会产生一次“缓存缺失”,这样的缓存缺失被称为“关联性缺失”。
更进一步说,我们仅仅考虑了某个 CPU 读数据的情况。当写的时候会发生什么呢?由于让所有 CPU 都对特定数据项达成一致,这一点非常重要。因此,在一个特定的 CPU 写数据前,它必须首先从其他 CPU 缓存中移除,或者叫做“使无效”。一旦“使无效”操作完成,CPU 可以安全的修改数据项。如果数据存在于该 CPU 缓存中,但是是只读的,这个过程被称为“写缺失”、一旦某个特定的 CPU 完成了对某个数据项的“使无效”操作,该 CPU 可以反复的重新写(或读)该数据项。
随后,如果另外某个 CPU 视图访问数据项,将会引起一次缓存缺失,此时,由于第一个 CPU 为了写而使得缓存项无效,这种类型的缓存缺失被称为“通信缺失”、因为通常是由于几个 CPU 使用数据项进行通信造成的。比如,锁就是一个用于在 CPU 之间使用互斥算法进行通信的数据项。
很明显,必须小心确保,所有 CPU 报纸一致性数据视图。可以很容易想到,通过所有取数据、使无效、写操作。它操作的数据可能已经丢失,或者(也许更糟糕)在不同 CPU 缓存之间拥有冲突的值。这些问题由“缓存一致性”来防止,将在下一节介绍。
缓存一致性协议
缓存一致性协议管理缓存行的状态,以防止数据不一致或者丢失数据。这些协议可能十分复杂,可能有数十种状态。但是为了我们的目的,我们仅仅需要关心仅有 4 种状态的 MESI 协议。
MESI 状态
MESI 代表 modified、exclusive、shared、inbalid,特定缓存行可以使用该协议采用的四种状态。因此,使用该协议的缓存,在每一个缓存行中,维护一个两位的状态标记,这个标记附着在缓存行的物理地址和数据后面。
处于 modified 状态的缓存行,已经收到了来自于响应 CPU 最近进行的内存存储。并且相应的内存却白没有在其他 CPU 的缓存中出现。因此,除以 modified 状态的缓存行可以被认为为被 CPU 所“拥有”。由于该缓存行持有最新的数据复制,因此缓存最终有责任:要么将数据写回到内存,要么将数据转移给其他缓存,并且必须在重新使用该缓存行以持有其他数据之前完成这些事情。
exclusive 状态非常类似于 modified 状态,唯一的差别是,该缓存行还没有被相应的 CPU 修改,这也表示缓存行中对内存数据的复制是最新的。但是,由于 CPU 能够在任意时刻将数据存储到该行,而不考虑其他 CPU,因此,处于 exclusive 状态也可以认为被相应的 CPU 所“拥有”。也就是说,由于物理内存中相应的值是最新的,该缓存行可以直接丢弃而不用会写到内存,也不用将该缓存转移给其他 CPU 的缓存。
处于 shared 状态的缓存行可能被复制到至少一个其他 CPU 的缓存行中,这样在没有得到其他 CPU 的许可时,不能向缓存行存储数据。与 exclusive 状态相同,由于内存中的值是最新的,因此可以不用向内存回写值而直接丢弃缓存中的值,也不用将该缓存转移给其他 CPU。
处于 invalid 状态的行是空的,换句话说,他没有持有任何有效数据。当新数据进入缓存时,如果有可能,它就会被放置到一个处于 invalid 状态的缓存行。这个方法是首选的,因为替换其他状态的缓存行将引起开销昂贵的缓存缺失,这些被替换的行在将来会被引用。
由于所有 CPU 必须维护那些已经搬运进缓存行中的数据一致性视图,因此缓存一致性协议提供消息以协调系统中缓存行的动作。
MESI 协议消息
前面章节中描述的许多事务都需要在 CPU 之间通信。如果 CPU 位于单一共享总线上,只需要如下消息就足够了。
- 读消息:包含要读取的缓存行的物理地址。
- 读响应消息:包含之前的“读消息”所请求的数据。这个读响应消息要么由物理内存提供,要么由一个其他缓存提供。例如,如果某一缓存拥有处于 modified 状态的目标数据,那么该缓存必须提供读响应消息。
- 使无效消息:包含要使无效的缓存行的物理地址。所有其他缓存行必须从它们的缓存中移除相应的数据并且响应此消息。
- 使无效应答消息:一个接收到使无效消息的 CPU 必须在移除指定数据后响应一个使无效应答消息。
- 读使无效消息:包含要被读取的缓存行的物理地址。同时指示其他缓存移除其数据。因此,正如名字所示,它将读和使无效消息进行合并。读使无效消息同时需要一个读响应消息及一组使无效应答消息进行应答。
- 写回消息:包含要写回到物理内存的地址和数据(并且也会“嗅探”进其他 CPU 的缓存)。该消息允许缓存在必要时换出处于 modified 状态的数据以便为其他数据腾出空间。
有趣的是,共享内存的多核系统实际上是一个消息传递的计算机。这意味着:使用分布式共享内存的 SMP 机器集群,正在以两种不同级别的系统架构,使用消息传递来共享内存。
MESI 状态图
由于接受或发送协议消息,特定的缓存行状态会变换,如图 C.3 所示:
图中的转换弧如下:
- 转 a:缓存行被写回到物理内存,但是 CPU 仍然将它保留在缓存中,并进一步的保留修改它的权限。这个转换需要一个“写回”消息。
- 转换 b:CPU 将数据写到缓存行,该缓存目前处于排他访问。该转换不需要发送或者接收任何消息。
- 转换 c:CPU 收到一个针对某个缓存行的“使无效”消息,对应的缓存行已经被修改。CPU 必须使无效本地副本,然后同时响应“读响应”和“使无效应答”消息,同时发送数据给请求的 CPU,并且标示它的本地副本不再有效。
- 转换 d:CPU 对一个数据项进行一个原子读——修改——写操作,对应的数据没有在他的缓存中。它发送一个“使无效”消息,通过“读响应”消息接收数据。一旦他接收到一个完整的“使无效应答”响应集合,CPU 就完成此转换。
- 转换 e:CPU 对一个数据项进行一个原子读——修改——写操作,对应的数据在缓存中是只读的。它必须发送一个“使无效”消息,并在完成此转换前,它必须等待一个完整的“使无效应答”响应集合。
- 转换 f:其他某些 CPU 读取缓存行,其数据由本 CPU 提供,本 CPU 包含一个只读副本,也可能已经将其写回内存。这个转换开始于接收到一个读消息,并且本 CPU 响应一个包含了所请求数据的“读响应”消息。
- 转换 g:其他 CPU 读取位于本缓存行的数据,并且数据要么是从本 CPU 的缓存提供,要么是从物理内存提供。无论哪种情况,本 CPU 都会保留一个只读副本。该转换开始于接收到一个“读”消息,并且本 CPU 响应一个包含所请求数据的“读响应”消息。
- 转换 h:当前 CPU 意识到,它很快将要写入一些位于本 CPU 缓存行的数据项,于是发送一个“使无效”消息。直到它接收到完整的“使无效”应答消息集合,CPU 才完成转换。可选的,所有其他 CPU 通过写回消息,从其缓存行将数据取出(可能是为其他缓存行腾出空间)。这样,当前 CPU 就是最后一个缓存该数据的 CPU。
- 转换 i:其他某些 CPU 对某个数据项进行了一个原子读——修改——写操作,相应的缓存行仅仅被本地的 CPU 缓存所持有。因此本 CPU 将缓存行状态编程无效状态。这个转换开始于接收到“读使无效”消息,并且本 CPU 返回一个“读响应”消息及一个“使无效应答”消息。
- 转换 j:本 CPU 保存一个数据项到缓存行,但是数据还没有在其他缓存行中。因此发送一个“使读无效”消息。直到它接收到“读响应”消息及完整的“使无效应答”消息集合后,才完成转换。缓存行可能会很快转到“修改”状态,这是在存储完成后由交换 b 完成的。
- 转换 k:本 CPU 装在一个数据项到缓存中,但是数据项还没有在缓存行中。CPU 发送一个“读”消息,当它接收到相应的“读响应”消息后完成转换。
- 转换 l:其他 CPU 存储一个位于本 CPU 缓存行的数据项,但是由于其他 CPU 也持有该缓存行的原因,本 CPU 仅仅以只读方式持有该缓存行。这个转换开始于接收到一个“使无效”消息,并且本 CPU 返回一个“使无效应答”消息。
MESI 协议实例
现在,让我们从数据缓存行价值的角度来看这一点。最初,数据驻留在地址为 0 的物理内存中。在一个 4-CPU 的系统中,它在几个直接映射的单缓存行中移动,表 C.1 展示了数据流向。第一列是操作序号,第二列表示执行操作的 CPU,第三列表示执行的操作,接下来的四列表示每一个缓存行的状态(内存地址后紧跟 MESI 状态)。最后两列表示对应的内存内容是否是最新的。V 表示最新,I 表示非最新。
最初,将要驻留数据的的 CPU 缓存行处于 invalid 状态,对应的数据在物理内存中是无效的。当 CPU0 从地址0装载数据时,它在 CPU0 的缓存中进入 shared 状态,并且物理内存中的数据仍是有效的。CPU3 也是从地址0装载数据,这样两个 CPU 中的缓存都处于 shared 状态,并且内存中的数据仍然有效。接下来 CPU0 转载其他缓存行(地址8),这个操作通过使无效操作强制将地址0的数据换出缓存,将缓存中的数据被换成地址8的数据。现在,CPU2 装载地址0的数据,但是该 CPU 发现它很快就会存储该数据,因此它使用一个“使读无效”消息以获得一个独享副本,这样,将使 CPU3 缓存中的数据变为无效(但是内存中的数据依然是有效的)。接下来 CPU2 开始预期的存储操作,并将状态改为 modified。内存中的数据副本不再是最新的。CPU1 开始一个原子递增操作,使用一个“读使无效”消息从 CPU2 的缓存中窥探数据并使之无效,这样 CPU1 的缓存编程 modified 状态,(内存中的数据仍然不是最新的)。最后,CPU1 从地址 8 读取数据,它使用一个写回消息将地址0的数据会写到内存。
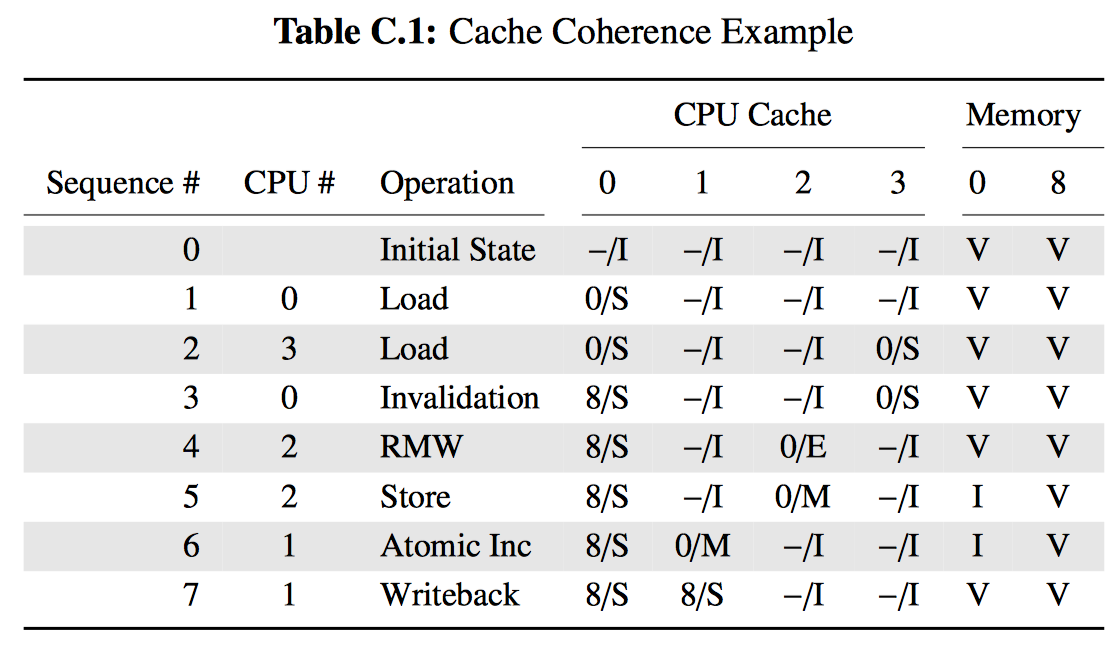
请注意,我们最终使数据位于某缓存行中。
存储导致不必要的停顿
对于特定的 CPU 反复读写特定的数据来说,图 C.1 显示的缓存结构提供了好的性能。但是对于特定缓存行的第一次写来说,其性能是不好的。要理解这一点,参考图 C.4,它显示了 CPU0 写数据到一个缓存行的时间线,而这个缓存行被 CPU1 缓存。在 CPU0 能够写数据前,它必须首先等到缓存行的数据到来。CPU0 不得不停顿额外的时间周期。
其他没有理由强制让 CPU0 延迟这么久,毕竟,不管 CPU1 发送给他的缓存数据是什么,CPU0 都会无条件的覆盖它。
存储缓冲
避免这种不必要的写停顿的方法之一,是在每个 CPU 和它的缓存之间,增加“存储缓冲”,如图 C.5。通过增加这些存储缓冲区,CPU0 可以简单的将要保存的数据放到存储缓冲区中,并且继续运行。当缓存行最终从 CPU1 转到 CPU0 时,数据将从存储缓冲区转到缓存行中。

这些存储缓冲对于特定 CPU 来说,是属于本地的。或者在硬件多线程系统中,对于特定核来说,是属于本地的。无论哪一种情况,一个特定 CPU 仅允许访问分配给它的存储缓冲。例如,在图 C.5 中,CPU0 不能访问 CPU0 的存储缓冲,反之亦然。通过将两者关注的点分开,该限制简化了硬件,存储缓冲区提升了连续写的性能,而在 CPU(核或其他可能的东西)之间的通信责任完全由缓存一致性协议承担。然而,及时有了这个限制,仍然有一些复杂的事情需要处理,将在下面两节中描述。
存储转发
第一个复杂的地方,违反了自身一致性。考虑变量 a 和 b 都初始化为 0,包含变量 a 的缓存行,最初被 CPU1 拥有,而包含变量 b 的缓存行最初被 CPU0 拥有。
1 a = 1;
2 b = a + 1;
3 assert(b == 2);
人们并不期望断言失败。可是,难道有谁足够愚蠢,以至于使用如果 C.5 所示的简单体系结构,这种体系结构是令人惊奇的。这样的系统可能看起来会按以下的事件顺序。
- CPU0 开始执行 a=1。
- CPU0 在缓存中查找 a,并且发现缓存缺失。
- 因此 CPU0 发送一个“读使无效”消息,以获得包含“a”的独享缓存行。
- CPU0 将 a 记录到存储缓冲区。
- CPU1 接收到“读使无效”消息,它通过发送缓存行数据,并从他的缓存行中移除数据来响应这个消息。
- CPU0 开始执行 b=a+1。
- CPU0 从 CPU1 接收到缓存行,它仍然拥有一个为 0 的 a 值。
- CPU0 从它的缓存中读取到 a 的值,发现其值为 0。
- CPU0 将存储队列中的条目应用到最近到达的缓存行,设置缓存行中的 a 的值为 1。
- CPU0 将前面加载的 a 值 0 加 1,并存储该值到包含 b 的缓存行中(假设已经被 CPU0 拥有)。
- CPU0 执行 assert(b==2),并引起错误。
问题在于我们拥有两个 a 的副本,一个在缓存中,另一个在存储缓冲区中。
这个例子破坏了一个重要的前提:即每个 CPU 将总是按照编程顺序看到他的操作。没有这个前提,结果将于直觉相反。因此,硬件设计者同情并实现了“存储转发”。在此,每个 CPU 在执行加载操作时,将考虑(或者嗅探)它的存储缓冲,如图 C.6。换句话说,一个特定的 CPU 存储操作直接转发给后续的读操作,而并不必然经过其缓存。
通过就地存储转发,在前面执行顺序的第 8 步,将在存储缓冲区中为 a 找到正确的值 1,因此最终 b 的值将是 2,这也正是我们期望的。
存储缓冲区及内存屏障
要明白第二个复杂性违反了全局内存序。开率如下的代码顺序,其中变量 a、b 的初始值为 0。
1 void foo(void)
2 {
3 a = 1;
4 b = 1;
5 }
6
7 void bar(void)
8 {
9 while (b == 0) continue;
10 assert(a == 1);
11 }
假设 CPU0 执行 foo 函数,CPU1 执行 bar 函数,再进一步假设包含 a 的缓存行仅仅位于 CPU1 的缓存中,包含 b 的缓存行被 CPU0 所拥有。那么操作属顺序可能如下:
- CPU0 执行 a=1、缓存行不在 CPU0 的缓存中,因此 CPU0 将 a 的新值放到存储缓冲区,并发送一个“读使无效”消息。
- CPU1 执行 while(b==0) continue,但是包含 b 的缓存行不再它的缓存内,因此发送一个“读”消息。
- CPU0 执行 b=1,它已经拥有了该缓存行(换句话说,缓存行要么处于 modified 要么处于 exclusive),因此它存储新的 b 值到它的缓存中。
- CPU0 接收到“读”消息,并且发送缓存行中的最近更新的 b 的值到 CPU1,同时将缓存行设置为 shared 状态。
- CPU1 接收到包含 b 值的缓存行,并将其值写到它的缓存行中。
- CPU1 现在结束执行 while(b==0) continue,引文它发现 b 的值为 1,它开始处理下一条语句。
- CPU1 执行 assert(a==1),并且,由于 CPU1 工作在旧的 a 的值,因此断言失败。
- CPU1 接收到 “读使无效”消息,并且发送包含 a 的缓存行到 CPU0,同时在它的缓存中,将该缓存行变成无效。但是已经太迟了。
- CPU0 接收到包含 a 的缓存行,并且及时将存储缓冲区的数据保存到缓存行中,CPU1 的断言失败受害于该缓存行。
在此,硬件设计者不能直接帮助我们,因为 CPU 没有方法识别那些相关联的变量,更不用说他们之间关联的方式。因此,硬件设计值提供了内存屏障指令,以允许软件告诉 CPU 这些关系的存在。程序必须修改以包含内存屏障。
1 void foo(void)
2 {
3 a = 1;
4 smp_mb();
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 assert(a == 1);
12 }
内存屏障 smp_mb 将导致 CPU 在刷新后续的存储到变量的缓存行之前,前面的存储缓冲被刷新。在继续处理之前,CPU 可能简单的停顿下来,直到存储缓冲区变为空;也可能是使用存储缓冲区来持有后续的存储操作,直到前面所有的存储缓冲区已经被保存到缓存行中。
后一种情况下,操作序列可能如下所示。
- CPU0 执行 a=1。缓存行不在 CPU0 的缓存内,因此 CPU0 将 a 的新值放到存储缓冲中,并发送一个“读使无效”消息。
- CPU1 执行 while(b==0) continue,但是包含 b 的缓存行不在它的缓存中,因此它发送一个“读”消息。
- CPU0 执行 smp_mb,并标记当前所有存储缓冲区的条目。即 a=1 这个条目。
- CPU0 执行 b=1。它已经拥有这个缓存行了。(即缓存行已经处于 modified 或 exclusive),但是在存储缓冲区中存在一个标记条目。因此,它不讲 b 的新值存放到缓存行,而是存放到存储缓冲区,这里 b 不是一个标记条目。
- CPU0 接收到“读”消息,随后发送包含原始 b 值的缓存行给 CPU1.它也标记该缓存行的复制为 shared 状态。
- CPU1 读取到包含 b 的缓存行,并将它复制到本地缓存中。
- CPU1 现在可以装在 b 的值了。但是,由于它发现其值仍然我 0,因此它重复执行 while 语句。b 的心智被安全的隐藏在 CPU0 的存储缓冲区中。
- CPU1 接收到“读使无效”消息,发送包含 a 的缓存行给 CPU0,并且是他的缓存无效。
- CPU0 接收到包含 a 的缓存行,使用存储缓冲区的值替换缓存行,将这一行设置为 modified 状态。
- 由于被存储的 a 是存储缓冲区中唯一被 smp_mb 标记的条目,因此 CPU0 能够存储 b 的新值到缓存行中,除非包含 b 的缓存行当前处于 shared 状态。
- CPU0 发送一个“使无效”消息给 CPU1。
- CPU1 接收到“使无效”消息,使包含 b 的缓存行无效,并且发送一个“使无效应答”消息给 CPU0.
- CPU1 执行 while(b==0) continue,但是包含 b 的缓存行不再它的缓存中,因此它发送一个“读”消息给 CPU0.
- CPU0 接收到“使无效应答”消息,将包含 b 的缓存行设置成 exclusive 状态。CPU0 现在存储新的 b 值到缓存行。
- CPU0 接收到“读”消息,同时发送包含新的 b 值的缓存行给 CPU1。他也标记该缓存行的复制为“shared”状态。
- CPU1 接收到包含 b 的缓存行,并将它复制到本地缓存中。
- CPU1 现在能够装载 b 的值了,由于它发现 b 的值为 1,它对出 while 循环并执行下一条语句。
- CPU1 执行 assert(a==1),但是包含 a 的缓存行不再它的缓存中。一旦它从 CPU0 获得这个缓存行,它将使用最新的 a 的值,因此断言语句将通过。
正如你看到的那样,这个过程涉及不少工作。即使某些事情从直觉上看是简单的操作,就像“加载 a 的值”这样的操作,都会包含大量复杂的步骤。
存储序列导致不必要的停顿
不幸的是,每一个存储缓冲区相对而言都比较小,这意味着执行一段较小的存储操作序列的 CPU,就可能填满它的存储缓冲区(比如当所有的这些结果发生了缓存缺失时)。从这一点来看,CPU 在能够继续执行前,必须再次等待刷新操作完成,其目的是为了清空它的存储缓冲。相同的情况可能在内存屏障之后发生,内存屏障之后的所有存储操作指令,都必须等待刷新操作完成,而不管这些后续存储是否存在缓存缺失。
这可以通过使用“使无效应答”消息更快到达 CPU 来得到改善。实现这一点的方法之一是使用每 CPU 的使无效消息队列,或者成为“使无效队列”。
使无效队列
“使无效应答”消息需要如此长的时间,其原因之一是它们必须确保相应的缓存行确实已经变成无效了。如果缓存比较忙的话,这个使无效操作可能被延迟。例如,如果 CPU 密集的装载或者存储数据,并且这些数据都在缓存中。另外,如果在一个较短的时间内,大量的“使无效”消息到达,一个特定的 CPU 会忙于处理它们。这会使得其他 CPU 陷入停顿。
但是,在发送应答前,CPU 不必真正使无效缓存行。它可以将使无效消息排队,在发送各国的关于该缓存行的消息前,需要处理这个消息。
使无效队列及使无效应答
图 C.7 显示了一个包含使无效队列的系统。只要将使无效消息放入队列,一个带有使无效队列的 CPU 就可以迅速应答使无效消息,而不必等待相应的缓存行真的变成无效状态。当然,CPU 必须在准备发送使无效消息前引用它的使无效队列。如果一个缓存行对应的条目在使无效队列中,则 CPU 不能立即发送使无效消息,它必须等待使无效队列中的条目被处理。
将一个条目放进使无效队列,实际上是由 CPU 承诺,在发送任何与该缓存行相关的 MESI 协议消息前处理该条目。只要相应的数据结构不存在大的竞争,CPU 会很出色的完成此事。
但是,消息能够被缓冲在使无效队列中,该事实带来了额外的内存乱序机会,浙江在下一节讨论。
使无效队列及内存屏障
我们假设 CPU 将使用使无效请求队列,并立即响应它们。这个方法使得执行存储操作的 CPU 看到的缓存使无效消息的延迟降到最小,但是这会将内存屏障失效,看看如下示例。
假设 a 和 b 都被初始化为 0,a 是只读的(MESI 状态为 shared),b 被 CPU0 拥有(MESI 状态为 exclusive 或 modified)。然后假设 CPU0 执行 foo 而 CPU1 执行 bar,代码片段如下。
1 void foo(void)
2 {
3 a = 1;
4 smp_mb();
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 assert(a == 1);
12 }
操作顺序可能如下:
- CPU0 执行 a=1。在 CPU0 中,对应的缓存行是只读的,因此 CPU0 将 a 的新值放入存储缓冲区,并发送一个“使无效”消息,这是为了使 CPU1 的缓存中的对应缓存行失效。
- CPU1 执行 while(b==0) continue,但是包含 b 的缓存行不在它的缓存中,因此发送一个“读”消息。
- CPU1 接收到 CPU0 的“使无效”消息,将其排队并立即响应该消息。
- CPU0 接收到来自于 CPU1 的使无效消息,因此它放心的通过第 4 行的 smp_mb,从存储缓冲区移动 a 的值到缓存行。
- CPU0 执行 b=1。它已经拥有这个缓存行(也即是说,缓存行已经处于 modified 或者 exclusive 状态),因此它将 b 的新值存储到缓存行中。
- CPU0 接收到“读”消息,并且发送包含 b 的新值的缓存行到 CPU1,同时在自己的缓存中标记缓存行为“shared”状态。
- CPU1 接收到包含 b 的缓存行并且将其应用到本地缓存。
- CPU1 现在可以完成 while(b==0) continue,因为它发现 b 的值为 1,因此开始处理下一条语句。
- CPU1 执行 assert(a==1),并且,由于旧的 a 值还在 CPU1 的缓存中,因此陷入错误。
- 虽然陷入错误,CPU1 处理已经排队的使无效消息,并且(迟到)在自己的缓存中刷新包含 a 值的缓存行。
如果加速使无效响应会导致内存屏障被忽略,那么就没有什么意义了。但是,内存屏障指令能够与使无效队列交互,这样,当一个特定的 CPU 执行一个内存屏障时,它标记无效队列中的所有条目,并强制所有后续的装载操作进行等待,直到所有标记的条目都保存到 CPU 的缓存中。因此,我们可以在 bar 函数中添加一个内存屏障,具体如下:
1 void foo(void)
2 {
3 a = 1;
4 smp_mb();
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 smp_mb();
12 assert(a == 1);
13 }
有了这个变化之后,操作顺序可能如下:
- CPU0 执行 a=1。对应的缓存行在 CPU0 的缓存中是只读的,因此 CPU0 将 a 的新值放入它的存储缓冲区,并且发送一个使无效消息以刷新 CPU1 对应的缓存行。
- CPU1 执行 while(b==0) continue,但是包含 b 的缓存行不再它的缓存中,因此它发送一个 读 消息。
- CPU1 接收到 CPU0 的使无效消息,将其排队并立即响应它。
- CPU0 接收到 CPU1 的响应,因此它放心的通过第 4 行 smp_mb 语句将 a 从他的存储缓冲区移到缓存行。
- CPU0 执行 b=1。它已经拥有该缓存行(MESI 状态为 modified 或 exclusive),因此它存储 b 的新值到缓存行。
- CPU0 接收到读消息,并且发送包含新的 b 值的缓存行给 CPU1,同时在自己的缓存行中,标记缓存行为 shared 状态。
- CPU1 接收到包含 b 的缓存行并更新到它的缓存中。
- CPU1 现在结束执行 while 循环,引文它发现 b 的值为 1,因此开始处理小一条语句,这是一条内存屏障指令。
- CPU1 必须停顿,知道它处理完使无效队列中的所有消息。
- CPU1 处理已经入队的 使无效 消息,从它的缓存中使无效包含 a 的缓存行。
- CPU1 执行 assert(a==1),由于包含 a 的缓存行已经不在它的缓存中,它发送一个 读 消息。
- CPU0 使用包含新的 a 值的缓存行来响应该读消息。
- CPU1 接收到该缓存行,它包含新的 a 的值 1,因此断言不会被触发。
即使有很多 MESI 消息传递,CPU 最终都会正确的应答。下一节阐述了 CPU 设计者为什么必须格外小心的处理它的缓存一致性优化操作。
读和写内存屏障
在前一节,内存屏障用来标记存储缓冲区和使无效队列中的条目。但是在我们的代码片段中 foo 没有必要进行使无效队列相关的任何操作,类似的,bar 也没有必要进行与存储缓冲区相关的任何操作。
因此,很多 CPU 体系结构提供更弱的内存屏障指令,这些指令仅仅做其中一项或者几项工作。不准确的说,一个“读内存屏障”仅仅标记它的使无效队列,一个“写内存屏障”仅仅标记它的存储缓冲区,而完整的内存屏障同时标记使无效队列和存储缓冲区。
这样的效果是,读内存屏障仅仅保证执行该指令的 CPU 上面的装载顺序,因此所有在读内存平展之前的装载,将在所有随后的装载前完成。类似的,写内存屏障仅仅保证写之间的属性怒,也是针对执行该指令的 CPU 来说。同样的,所有在内存屏障之前的存储操作,将在其后的存储操作完成之前完成。完整的内存屏障同时保证写和读之间的顺序,这也仅仅针对执行该内存屏障的 CPU 来说的。
我们修改 foo 好 bar,以使用读和写内存屏障,如下所示:
1 void foo(void)
2 {
3 a = 1;
4 smp_wmb();
5 b = 1;
6 }
7
8 void bar(void)
9 {
10 while (b == 0) continue;
11 smp_rmb();
12 assert(a == 1);
13 }
某些计算机甚至拥有更多的内存屏障,理解这三个屏障通常能让我们更好的理解内存屏障。
内存屏障示例
本节提供了一些有趣的、但是稍显不同的内存屏障用法。虽然他们能在大多数时候正常工作,但是其中一些仅能在特定 CPU 上运行。如果目的是为了产生哪些能在所有 CPU 上都能运行的代码,那么这些用法是必须要避免的。为了能够更好理解他们之间的细微差别,我们首先要关注乱序体系结构。
乱序体系结构
一定数量的乱序计算机系统已经被生产了数十年。不过乱序问题的实质十分微秒,真正理解它需要非常丰富的特定硬件方面的知识。与其针对一个特定的硬件厂商说事,这会把读者带到详细的技术规范中去,不如让我们设计一个虚构的、最大限度的乱序体系结构。
这个硬件必须遵循以下顺序约束:
- 单个 CPU 总是按照编程顺序来感知它自己的内存访问。
- 仅仅在操作不同地址时,CPU 才对给定的存储操作进行重排序。
- 一个特定的 CPU,在内存屏障之前的所有装载操作(smp_rmb)将在所有读内存屏障后面的操作之前被其他 CPU 所感知。
- 一个特定的 CPU,所有在写内存屏障之前的写操作(smp_wmb)都将在所有内存屏障之后的写操作之前被其他 CPU 所感知。
- 一个特定的 CPU,所有在内存屏障之前的内存访问(装载和存储)(smp_mb)都将在所有内存屏障之后的内存访问之前,被所有其他 CPU 感知。
假设一个大的非一致性缓存体系(NUCA)系统,为了给特定节点内部的 CPU 提供一个公平的内部访问带宽,在每一个节点的内连接口提供了一个每 CPU 队列,如图 C.8。虽然一个特定 CPU 的访问是由内存屏障排序的,但是,一堆相关 CPU 的相关访问顺序被严重的重排,正如我们将要看到的。

示例 1
表 C.2 展示了三个代码片段,被 CPU 0/1/2 并发执行,a、b、c 都被初始化为 0。

假设 CPU0 刚经过很多缓存缺失,因此它的消息队列是满的,但是 CPU1 在它的缓存中独占性运行,因此它的消息队列是空的。那么 CPU0 在向 a/b 赋值时,看起来节点 0 的缓存是立即生效的(因此对 CPU1 来说也是可见的),但是将阻塞于 CPU0 之前的流量。与之相对的是,CPU1 向 c 赋值时,由于 CPU1 的消息队列为空,因此可以很快执行。因此,CPU2 将在看到 CPU0 对 a 的赋值前,先看到 CPU1 对 c 的赋值,这将导致验证失败,即使有内存屏障也会如此。
可移植代码不能认为断言不会触发。由于编译器和 CPU 都能够重排代码,因此可能触发断言。
示例 2
表 C.3 展示了代码片段,在 CPU 0/1/2 上并行执行,a/b 均被赋值为 0。

我们再一次假设 CPU0 刚遇到很多缓存缺失,因此它的消息队列满了,但是 CPU1 在它的缓存中独占性运行,因此它的消息是空的。那么,CPU0 给 a 赋值将立即反映在及诶单 0 上,(因此对于 CPU1 来说也是立即可见的),但是将阻塞于 CPU0 之前的流量。相对的,CPU1 对 b 的赋值将于 CPU1 的空队列进行工作。因此,CPU2 在看到 CPU2 对 a 赋值前,可以看到 CPU1 对 b 的赋值。这将导致断言失败,尽管存在内存屏障。
从原理上来说,编写可移植代码不能用上面的例子,但是,正如前面一样,实际上这段代码可以在大多数主流的计算机上正常运行。
示例 3
表 C.4 展示了三个代码片段,在 CPU 0/1/2 上并行执行。所有变量均被初始化为 0。

请注意,不管是 CPU1 还是 CPU2 都要看到 CPU0 在第三行对 b 的赋值后,才能处理第 5 行,一旦 CPU 1 和 2 已经执行了第 4 行的内存屏障,他们就能看到 CPU0 在第 2 行的内存屏障前的所有赋值。类似的,CPU0 在第 8 行的内存屏障与 CPU1 和 CPU2 在第 4 行的内存屏障是一对内存屏障,因此 CPU0 将不会执行第 9 行的内存赋值,直到它对 a 的赋值被其他 CPU 可见。因此,CPU2 在第 9 行的 assert 将不会触发。
Linux 内核中的 synchronize_rcu 原语使用了类似于本地中的算法。
内存屏障是永恒的吗
已经有不少最近的系统,他们对于通常的乱序执行,特别是对乱序内存引用不大积极。这个趋势将会持续下去以至于将内存屏障变为历史吗?
赞成这个观点的人会拿大规模多线程硬件体系说事,这样一来每个线程都必须等待内存就绪,在此期间,可能有数十个、数百个甚至数千个线程在继续运行。在这样的体系结构中,没有必要使用内存屏障了。因为一个特定的线程在处理下一条指令前,将简单的等待所有外部操作全部完成。由于可能有数千个其他线程,CPU 将被完全利用,没有 CPU 周期会被浪费。
反对者则会说,极少量的应用有能力扩展到上千个线程。除此以外,还有越来越严重的实时响应需求,对某些应用来说,其响应需求是数十毫秒。在这种系统中,实时响应需求是难以实现的。而且,对于大规模多线程场景来说,机器低的单线程吞吐量更难以实现。
另一种支持的观点认为,更多的减少延迟的硬件实现技术会给 CPU 一种假象,使得 CPU 觉得按全频率、一致性的运行,这几乎提供了与乱序执行一样的性能优势。反对的观点则会认为,对于电池供电的设备及环境责任来说,这将带来严重的能耗需求。
没法下结论谁是对的,因此咱们还是准备同时接受两者吧。
对硬件设计者的建议
硬件设计者可以做很多事情,这些事情给软件开发者带来了困难。以下是我们在过去遇到的一些事情,在此列出来,希望能够帮助你防止在将来出现下列问题。
IO 设备忽略了缓存一致性
这个糟糕的特性将导致从内存中机械能 DMA 会丢失刚从输出缓冲区中对他进行的修改。同样不好的是,也导致输入缓冲区在 DMA 完成后被 CPU 缓存中的内容覆盖。要使你的系统在这样的情况下正常工作,必须在为 IO 设备准备 DMA 缓冲区时,小心刷新 CPU 缓存。类似的,在 DMA 操作完成后,你需要刷新所有位于 DMA 缓冲区的缓存。而且,你需要非常小心的避免指针方面的 BUG,因为错误的读取输入缓冲区可能会导致对输入数据的破坏。
外部总线错误的发送缓存一致性数据
该问题是上一问题的一个更难缠的变种,导致设备组甚至是在内存自身不能遵从缓存一致性。我痛苦的责任是通知你:随着嵌入式系统转移到多核体系,不用怀疑,这样的问题会越来越多。希望这些问题能在 2015 年得到处理。
设备中忽略了缓存一致性
这听起来真的无辜,毕竟中断不是内存引用,对吧?但是假设一个 CPU 有一个分区的缓存,其中一个缓存带非常忙,因此一直持有输入缓冲的最后一个缓存行。如果对应的 IO 完成中断到达这个 CPU,在 CPU 中引用这个缓存行的内存引用将返回旧值,再导致数据被破坏,在随后以异常转储的形式被发现。但是,当系统对引起错误的输入缓冲区进行转储时,DMA 很可能已经完成了。
核间中断(IPI)忽略了缓存一致性
当位于对应的消息缓冲区的所有缓存行,他们被提交到内存之前,IPI 就已经到达该目标 CPU,这可能会有问题。
上下文切换领先于缓存一致性
如果内存访问可以完全乱序,那么上下文切换就很麻烦。如果任务从一个 CPU 切迁移到另一个 CPU,而原 CPU 上的内存访问在目标 CPU 上还不完全可见,那么任务就会发现,它看到的变量还是以前的值,这会扰乱大多数算法。
过度宽松的模拟器和仿真器
编写模拟器或者仿真器来模拟内存乱序是很困难的。因此在这些环境上面运行得很好的软件,在实际硬件上运行时,将得到令人惊讶的结果。不幸的是,规则仍然是,硬件比模拟器和仿真器更复杂,但是我们这种状况能够改变。
我们再次鼓励硬件设计者避免这些做法。