This the multi-page printable view of this section. Click here to print.
Java I/0
- 1: CH01-IO分类
- 2: CH02-装饰模式
- 3: CH03-InputStream
- 4: CH04-OutputStream
- 5: CH05-常用操作.md
- 6: CH06-IO实现
- 7: CH07-IO模型
- 8: CH08-BIO原理
- 9: CH09-NIO基础
- 10: CH10-NIO原理
- 11: CH11-AIO原理
- 12: CH12-零拷贝
- 13: CH13-内存映射
1 - CH01-IO分类
基于传输方式
从数据传输方式或者说是运输方式角度看,可以将 IO 类分为:
- 字节流
- 字符流
字节是个计算机看的,字符才是给人看的。
字节流

字符流

二者区别
字节流读取单个字节,字符流读取单个字符(一个字符根据编码的不同,对应的字节也不同,如 UTF-8 编码是 3 个字节,中文编码是 2 个字节。)
字节流用来处理二进制文件(图片、MP3、视频文件),字符流用来处理文本文件(可以看做是特殊的二进制文件,使用了某种编码,人可以阅读)。
字节 -> 字符:Input/OutputStreamReader/Writer
编码就是把字符转换为字节,而解码是把字节重新组合成字符。
如果编码和解码过程使用不同的编码方式那么就出现了乱码。
- GBK 编码中,中文字符占 2 个字节,英文字符占 1 个字节;
- UTF-8 编码中,中文字符占 3 个字节,英文字符占 1 个字节;
- UTF-16be 编码中,中文字符和英文字符都占 2 个字节。
UTF-16be 中的 be 指的是 Big Endian,也就是大端。相应地也有 UTF-16le,le 指的是 Little Endian,也就是小端。
Java 使用双字节编码 UTF-16be,这不是指 Java 只支持这一种编码方式,而是说 char 这种类型使用 UTF-16be 进行编码。char 类型占 16 位,也就是两个字节,Java 使用这种双字节编码是为了让一个中文或者一个英文都能使用一个 char 来存储。
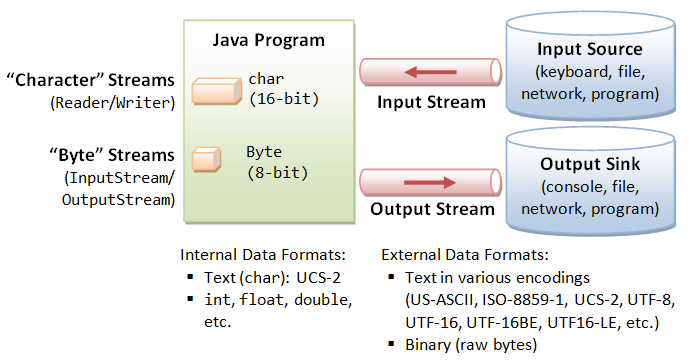
基于数据操作
从数据来源或操作对象角度看,IO 又可以按如下方式分类:
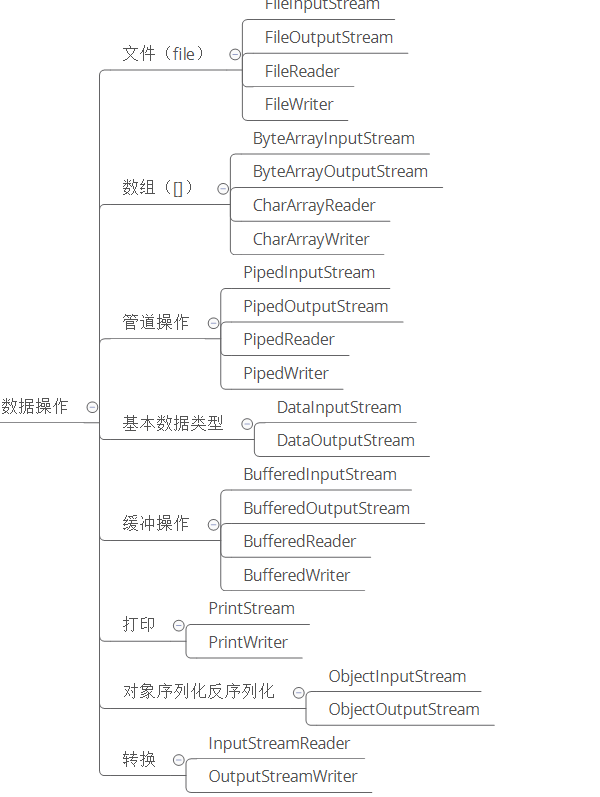
2 - CH02-装饰模式
装饰模式
装饰者(Decorator)和具体组件(ConcreteComponent)都继承自组件(Component),具体组件的方法实现不需要依赖于其它对象,而装饰者组合了一个组件,这样它可以装饰其它装饰者或者具体组件。
所谓装饰,就是把这个装饰者套在被装饰者之上,从而动态扩展被装饰者的功能。装饰者的方法有一部分是自己的,这属于它的功能,然后调用被装饰者的方法实现,从而也保留了被装饰者的功能。可以看到,具体组件应当是装饰层次的最低层,因为只有具体组件的方法实现不需要依赖于其它对象。
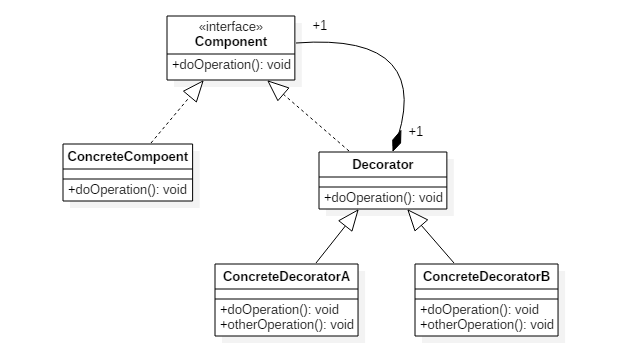
IO 装饰模式
以 InputStream 为例,
- InputStream 是抽象组件;
- FileInputStream 是 InputStream 的子类,属于具体组件,提供了字节流的输入操作;
- FilterInputStream 属于抽象装饰者,装饰者用于装饰组件,为组件提供额外的功能。例如 BufferedInputStream 为 FileInputStream 提供缓存的功能。
实例化一个具有缓存功能的字节流对象时,只需要在 FileInputStream 对象上再套一层 BufferedInputStream 对象即可。
FileInputStream fileInputStream = new FileInputStream(filePath);
BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);
DataInputStream 装饰者提供了对更多数据类型进行输入的操作,比如 int、double 等基本类型。
3 - CH03-InputStream
层级结构
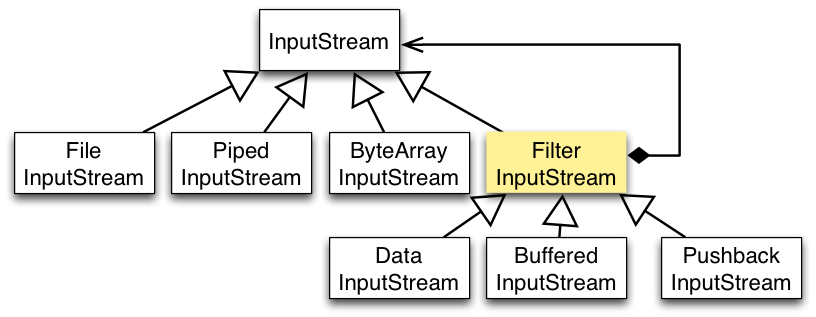
InputStream 抽象类
public abstract int read()
// 读取数据
public int read(byte b[])
// 将读取到的数据放在 byte 数组中,该方法实际上是根据下面的方法实现的,off 为 0,len 为数组的长度
public int read(byte b[], int off, int len)
// 从第 off 位置读取 len 长度字节的数据放到 byte 数组中,流是以 -1 来判断是否读取结束的
public long skip(long n)
// 跳过指定个数的字节不读取,想想看电影跳过片头片尾
public int available()
// 返回可读的字节数量
public void close()
// 读取完,关闭流,释放资源
public synchronized void mark(int readlimit)
// 标记读取位置,下次还可以从这里开始读取,使用前要看当前流是否支持,可以使用 markSupport() 方法判断
public synchronized void reset()
// 重置读取位置为上次 mark 标记的位置
public boolean markSupported()
// 判断当前流是否支持标记流,和上面两个方法配套使用
源码实现
InputStream
public abstract class InputStream implements Closeable {
private static final int SKIP_BUFFER_SIZE = 2048; //用于skip方法,和skipBuffer相关
private static byte[] skipBuffer; // skipBuffer is initialized in skip(long), if needed.
//从输入流中读取下一个字节,
//正常返回0-255,到达文件的末尾返回-1
//在流中还有数据,但是没有读到时该方法会阻塞(block)
//Java IO和New IO的区别就是阻塞流和非阻塞流
//抽象方法!不同的子类不同的实现!
public abstract int read() throws IOException;
//将流中的数据读入放在byte数组的第off个位置先后的len个位置中
//返回值为放入字节的个数。
//这个方法在利用抽象方法read,某种意义上简单的Templete模式。
public int read(byte b[], int off, int len) throws IOException {
//检查输入是否正常。一般情况下,检查输入是方法设计的第一步
if (b == null) {
throw new NullPointerException();
} else if (off < 0 || len < 0 || len > b.length - off) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
//读取下一个字节
int c = read();
//到达文件的末端返回-1
if (c == -1) { return -1; }
//返回的字节downcast
b[off] = (byte)c;
//已经读取了一个字节
int i = 1;
try {
//最多读取len个字节,所以要循环len次
for (; i < len ; i++) {
//每次循环从流中读取一个字节
//由于read方法阻塞,
//所以read(byte[],int,int)也会阻塞
c = read();
//到达末尾,理所当然返回-1
if (c == -1) { break; }
//读到就放入byte数组中
b[off + i] = (byte)c;
}
} catch (IOException ee) { }
return i;
}
//利用上面的方法read(byte[] b)
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
//方法内部使用的、表示要跳过的字节数目,
public long skip(long n) throws IOException {
long remaining = n;
int nr;
if (skipBuffer == null)
//初始化一个跳转的缓存
skipBuffer = new byte[SKIP_BUFFER_SIZE];
//本地化的跳转缓存
byte[] localSkipBuffer = skipBuffer;
//检查输入参数,应该放在方法的开始
if (n <= 0) { return 0; }
//一共要跳过n个,每次跳过部分,循环
while (remaining > 0) {
nr = read(localSkipBuffer, 0, (int) Math.min(SKIP_BUFFER_SIZE, remaining));
//利用上面的read(byte[],int,int)方法尽量读取n个字节
//读到流的末端,则返回
if (nr < 0) { break; }
//没有完全读到需要的,则继续循环
remaining -= nr;
}
return n - remaining;//返回时要么全部读完,要么因为到达文件末端,读取了部分
}
//查询流中还有多少可以读取的字节
//该方法不会block。在java中抽象类方法的实现一般有以下几种方式:
//1.抛出异常(java.util);2.“弱”实现。像上面这种。子类在必要的时候覆盖它。
//3.“空”实现。
public int available() throws IOException {
return 0;
}
//关闭当前流、同时释放与此流相关的资源
//关闭当前流、同时释放与此流相关的资源
public void close() throws IOException {}
//markSupport可以查询当前流是否支持mark
public synchronized void mark(int readlimit) {}
//对mark过的流进行复位。只有当流支持mark时才可以使用此方法。
public synchronized void reset() throws IOException {
throw new IOException("mark/reset not supported");
}
//查询是否支持mark
//绝大部分不支持,因此提供默认实现,返回false。子类有需要可以覆盖。
public boolean markSupported() {
return false;
}
}
FilterInputStream
public class FilterInputStream extends InputStream {
//装饰器的代码特征: 被装饰的对象一般是装饰器的成员变量
protected volatile InputStream in; //将要被装饰的字节输入流
protected FilterInputStream(InputStream in) { //通过构造方法传入此被装饰的流
this.in = in;
}
//下面这些方法,完成最小的装饰――0装饰,只是调用被装饰流的方法而已
public int read() throws IOException {
return in.read();
}
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
public int read(byte b[], int off, int len) throws IOException {
return in.read(b, off, len);
}
public long skip(long n) throws IOException {
return in.skip(n);
}
public int available() throws IOException {
return in.available();
}
public void close() throws IOException {
in.close();
}
public synchronized void mark(int readlimit) {
in.mark(readlimit);
}
public synchronized void reset() throws IOException {
in.reset();
}
public boolean markSupported() {
return in.markSupported();
}
}
ByteArrayInputStream
public class ByteArrayInputStream extends InputStream {
protected byte buf[]; //内部的buffer,一般通过构造器输入
protected int pos; //当前位置的cursor。从0至byte数组的长度。
//byte[pos]就是read方法读取的字节
protected int mark = 0; //mark的位置。
protected int count; //流中字节的数目。
//构造器,从一个byte[]创建一个ByteArrayInputStream
public ByteArrayInputStream(byte buf[]) {
//初始化流中的各个成员变量
this.buf = buf;
this.pos = 0;
this.count = buf.length;
}
//构造器
public ByteArrayInputStream(byte buf[], int offset, int length) {
this.buf = buf;
this.pos = offset; //与上面不同
this.count = Math.min(offset + length, buf.length);
this.mark = offset; //与上面不同
}
//从流中读取下一个字节
public synchronized int read() {
//返回下一个位置的字节//流中没有数据则返回-1
return (pos < count) ? (buf[pos++] & 0xff) : -1;
}
// ByteArrayInputStream要覆盖InputStream中可以看出其提供了该方法的实现
//某些时候,父类不能完全实现子类的功能,父类的实现一般比较通用。
//当子类有更有效的方法时,我们会覆盖这些方法。
public synchronized int read(byte b[], int off, int len) {
//首先检查输入参数的状态是否正确
if(b==null){
throw new NullPointerException();
} else if (off < 0 || len < 0 || len > b.length - off) {
throw new IndexOutOfBoundsException();
}
if (pos >= count) { return -1; }
if (pos + len > count) { len = count - pos; }
if (len <= 0) { return 0; }
//java中提供数据复制的方法
//出于速度的原因!他们都用到System.arraycopy方法
System.arraycopy(buf, pos, b, off, len);
pos += len;
return len;
}
//下面这个方法,在InputStream中也已经实现了。
//但是当时是通过将字节读入一个buffer中实现的,好像效率低了一点。
//比InputStream中的方法简单、高效
public synchronized long skip(long n) {
//当前位置,可以跳跃的字节数目
if (pos + n > count) { n = count - pos; }
//小于0,则不可以跳跃
if (n < 0) { return 0; }
//跳跃后,当前位置变化
pos += n;
return n;
}
//查询流中还有多少字节没有读取。
public synchronized int available() {
return count - pos;
}
//ByteArrayInputStream支持mark所以返回true
public boolean markSupported() {
return true;
}
//在流中当前位置mark。
public void mark(int readAheadLimit) {
mark = pos;
}
//重置流。即回到mark的位置。
public synchronized void reset() {
pos = mark;
}
//关闭ByteArrayInputStream不会产生任何动作。
public void close() throws IOException { }
}
BufferedInputStream
public class BufferedInputStream extends FilterInputStream {
private static int defaultBufferSize = 8192; //默认缓存的大小
protected volatile byte buf[]; //内部的缓存
protected int count; //buffer的大小
protected int pos; //buffer中cursor的位置
protected int markpos = -1; //mark的位置
protected int marklimit; //mark的范围
//原子性更新。和一致性编程相关
private static final
AtomicReferenceFieldUpdater<BufferedInputStream, byte[]> bufUpdater =
AtomicReferenceFieldUpdater.newUpdater (BufferedInputStream.class, byte[].class,"buf");
//检查输入流是否关闭,同时返回被包装流
private InputStream getInIfOpen() throws IOException {
InputStream input = in;
if (input == null) throw new IOException("Stream closed");
return input;
}
//检查buffer的状态,同时返回缓存
private byte[] getBufIfOpen() throws IOException {
byte[] buffer = buf;
//不太可能发生的状态
if (buffer == null) throw new IOException("Stream closed");
return buffer;
}
//构造器
public BufferedInputStream(InputStream in) {
//指定默认长度的buffer
this(in, defaultBufferSize);
}
//构造器
public BufferedInputStream(InputStream in, int size) {
super(in);
//检查输入参数
if(size<=0){
throw new IllegalArgumentException("Buffer size <= 0");
}
//创建指定长度的buffer
buf = new byte[size];
}
//从流中读取数据,填充如缓存中。
private void fill() throws IOException {
//得到buffer
byte[] buffer = getBufIfOpen();
if (markpos < 0)
//mark位置小于0,此时pos为0
pos = 0;
//pos大于buffer的长度
else if (pos >= buffer.length)
if (markpos > 0) {
int sz = pos - markpos;
System.arraycopy(buffer, markpos, buffer, 0, sz);
pos = sz;
markpos = 0;
} else if (buffer.length >= marklimit) {
//buffer的长度大于marklimit时,mark失效
markpos = -1;
//丢弃buffer中的内容
pos = 0;
}else{
//buffer的长度小于marklimit时对buffer扩容
int nsz = pos * 2;
if (nsz > marklimit)
nsz = marklimit;//扩容为原来的2倍,太大则为marklimit大小
byte nbuf[] = new byte[nsz];
//将buffer中的字节拷贝如扩容后的buf中
System.arraycopy(buffer, 0, nbuf, 0, pos);
if (!bufUpdater.compareAndSet(this, buffer, nbuf)) {
//在buffer在被操作时,不能取代此buffer
throw new IOException("Stream closed");
}
//将新buf赋值给buffer
buffer = nbuf;
}
count = pos;
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0) count = n + pos;
}
//读取下一个字节
public synchronized int read() throws IOException {
//到达buffer的末端
if (pos >= count) {
//就从流中读取数据,填充buffer
fill();
//读过一次,没有数据则返回-1
if (pos >= count) return -1;
}
//返回buffer中下一个位置的字节
return getBufIfOpen()[pos++] & 0xff;
}
//将数据从流中读入buffer中
private int read1(byte[] b, int off, int len) throws IOException {
int avail = count - pos; //buffer中还剩的可读字符
//buffer中没有可以读取的数据时
if(avail<=0){
//将输入流中的字节读入b中
if (len >= getBufIfOpen().length && markpos < 0) {
return getInIfOpen().read(b, off, len);
}
fill();//填充
avail = count - pos;
if (avail <= 0) return -1;
}
//从流中读取后,检查可以读取的数目
int cnt = (avail < len) ? avail : len;
//将当前buffer中的字节放入b的末端
System.arraycopy(getBufIfOpen(), pos, b, off, cnt);
pos += cnt;
return cnt;
}
public synchronized int read(byte b[], int off, int len)throws IOException {
getBufIfOpen();
// 检查buffer是否open
//检查输入参数是否正确
if ((off | len | (off + len) | (b.length - (off + len))) < 0) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
int n = 0;
for (;;) {
int nread = read1(b, off + n, len - n);
if (nread <= 0) return (n == 0) ? nread : n;
n += nread;
if (n >= len) return n;
InputStream input = in;
if (input != null && input.available() <= 0) return n;
}
}
public synchronized long skip(long n) throws IOException {
// 检查buffer是否关闭
getBufIfOpen();
//检查输入参数是否正确
if (n <= 0) { return 0; }
//buffered中可以读取字节的数目
long avail = count - pos;
//可以读取的小于0,则从流中读取
if (avail <= 0) {
//mark小于0,则mark在流中
if (markpos <0) return getInIfOpen().skip(n);
// 从流中读取数据,填充缓冲区。
fill();
//可以读的取字节为buffer的容量减当前位置
avail = count - pos;
if (avail <= 0) return 0;
}
long skipped = (avail < n) ? avail : n;
pos += skipped;
//当前位置改变
return skipped;
}
//该方法不会block!返回流中可以读取的字节的数目。
//该方法的返回值为缓存中的可读字节数目加流中可读字节数目的和
public synchronized int available() throws IOException {
return getInIfOpen().available() + (count - pos);
}
//当前位置处为mark位置
public synchronized void mark(int readlimit) {
marklimit = readlimit;
markpos = pos;
}
public synchronized void reset() throws IOException {
// 缓冲去关闭了,肯定就抛出异常!程序设计中经常的手段
getBufIfOpen();
if (markpos < 0) throw new IOException("Resetting to invalid mark");
pos = markpos;
}
//该流和ByteArrayInputStream一样都支持mark
public boolean markSupported() {
return true;
}
//关闭当前流同时释放相应的系统资源。
public void close() throws IOException {
byte[] buffer;
while ( (buffer = buf) != null) {
if (bufUpdater.compareAndSet(this, buffer, null)) {
InputStream input = in;
in = null;
if (input != null) input.close();
return;
}
// Else retry in case a new buf was CASed in fill()
}
}
}
PipedInputStream
public class PipedInputStream extends InputStream {
//标识有读取方或写入方关闭
boolean closedByWriter = false;
volatile boolean closedByReader = false;
//是否建立连接
boolean connected = false;
//标识哪个线程
Thread readSide;
Thread writeSide;
//缓冲区的默认大小
protected static final int PIPE_SIZE = 1024;
//缓冲区
protected byte buffer[] = new byte[PIPE_SIZE];
//下一个写入字节的位置。0代表空,in==out代表满
protected int in = -1;
//下一个读取字节的位置
protected int out = 0;
//给定源的输入流
public PipedInputStream(PipedOutputStream src) throws IOException {
connect(src);
}
//默认构造器,下部一定要connect源
public PipedInputStream() { }
//连接输入源
public void connect(PipedOutputStream src) throws IOException {
//调用源的connect方法连接当前对象
src.connect(this);
}
//只被PipedOuputStream调用
protected synchronized void receive(int b) throws IOException {
//检查状态,写入
checkStateForReceive();
//永远是PipedOuputStream
writeSide = Thread.currentThread();
//输入和输出相等,等待空间
if (in == out) awaitSpace();
if (in < 0) {
in = 0;
out = 0;
}
//放入buffer相应的位置
buffer[in++] = (byte)(b & 0xFF);
//in为0表示buffer已空
if (in >= buffer.length) { in = 0; }
}
synchronized void receive(byte b[], int off, int len) throws IOException {
checkStateForReceive();
//从PipedOutputStream可以看出
writeSide = Thread.currentThread();
int bytesToTransfer = len;
while (bytesToTransfer > 0) {
//满了,会通知读取的;空会通知写入
if (in == out) awaitSpace();
int nextTransferAmount = 0;
if (out < in) {
nextTransferAmount = buffer.length - in;
} else if (in < out) {
if (in == -1) {
in = out = 0;
nextTransferAmount = buffer.length - in;
} else {
nextTransferAmount = out - in;
}
}
if (nextTransferAmount > bytesToTransfer) nextTransferAmount = bytesToTransfer;
assert(nextTransferAmount > 0);
System.arraycopy(b, off, buffer, in, nextTransferAmount);
bytesToTransfer -= nextTransferAmount;
off += nextTransferAmount;
in += nextTransferAmount;
if (in >= buffer.length) { in = 0; }
}
}
//检查当前状态,等待输入
private void checkStateForReceive() throws IOException {
if (!connected) {
throw new IOException("Pipe not connected");
} else if (closedByWriter || closedByReader) {
throw new IOException("Pipe closed");
} else if (readSide != null && !readSide.isAlive()) {
throw new IOException("Read end dead");
}
}
//Buffer已满,等待一段时间
private void awaitSpace() throws IOException {
//in==out表示满了,没有空间
while (in == out) {
//检查接受端的状态
checkStateForReceive();
//通知读取端
notifyAll();
try {
wait(1000);
} catch (InterruptedException ex) {
throw new java.io.InterruptedIOException();
}
}
}
//通知所有等待的线程()已经接受到最后的字节
synchronized void receivedLast() {
closedByWriter = true; //
notifyAll();
}
public synchronized int read() throws IOException {
//检查一些内部状态
if (!connected) {
throw new IOException("Pipe not connected");
} else if (closedByReader) {
throw new IOException("Pipe closed");
} else if (writeSide != null && !writeSide.isAlive()&& !closedByWriter && (in < 0)) {
throw new IOException("Write end dead");
}
//当前线程读取
readSide = Thread.currentThread();
//重复两次? ? ?
int trials = 2;
while (in < 0) {
//输入断关闭返回-1
if (closedByWriter) { return -1; }
//状态错误
if ((writeSide != null) && (!writeSide.isAlive()) && (--trials < 0)) {
throw new IOException("Pipe broken");
}
notifyAll(); // 空了,通知写入端可以写入 try {
wait(1000);
} catch (InterruptedException ex) {
throw new java.io.InterruptedIOException();
}
}
int ret = buffer[out++] & 0xFF; if (out >= buffer.length) { out = 0; }
//没有任何字节
if (in == out) { in = -1; }
return ret;
}
public synchronized int read(byte b[], int off, int len) throws IOException {
//检查输入参数的正确性
if (b == null) {
throw new NullPointerException();
} else if (off < 0 || len < 0 || len > b.length - off) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
//读取下一个
int c = read();
//已经到达末尾了,返回-1
if (c < 0) { return -1; }
//放入外部buffer中
b[off] = (byte) c;
//return-len
int rlen = 1;
//下一个in存在,且没有到达len
while ((in >= 0) && (--len > 0)) {
//依次放入外部buffer
b[off + rlen] = buffer[out++];
rlen++;
//读到buffer的末尾,返回头部
if (out >= buffer.length) { out = 0; }
//读、写位置一致时,表示没有数据
if (in == out) { in = -1; }
}
//返回填充的长度
return rlen;
}
//返回还有多少字节可以读取
public synchronized int available() throws IOException {
//到达末端,没有字节
if(in < 0)
return 0;
else if(in == out)
//写入的和读出的一致,表示满
return buffer.length;
else if (in > out)
//写入的大于读出
return in - out;
else
//写入的小于读出的
return in + buffer.length - out;
}
//关闭当前流,同时释放与其相关的资源
public void close() throws IOException {
//表示由输入流关闭
closedByReader = true;
//同步化当前对象,in为-1
synchronized (this) { in = -1; }
}
}
4 - CH04-OutputStream
OutputStream 抽象类
public abstract void write(int b)
// 写入一个字节,可以看到这里的参数是一个 int 类型,对应上面的读方法,int 类型的 32 位,只有低 8 位才写入,高 24 位将舍弃。
public void write(byte b[])
// 将数组中的所有字节写入,和上面对应的 read() 方法类似,实际调用的也是下面的方法。
public void write(byte b[], int off, int len)
// 将 byte 数组从 off 位置开始,len 长度的字节写入
public void flush()
// 强制刷新,将缓冲中的数据写入
public void close()
// 关闭输出流,流被关闭后就不能再输出数据了
源码实现
FilterOutputStream
/**
* This class is the superclass of all classes that filter output
* streams. These streams sit on top of an already existing output
* stream (the <i>underlying</i> output stream) which it uses as its
* basic sink of data, but possibly transforming the data along the
* way or providing additional functionality.
* <p>
* The class <code>FilterOutputStream</code> itself simply overrides
* all methods of <code>OutputStream</code> with versions that pass
* all requests to the underlying output stream. Subclasses of
* <code>FilterOutputStream</code> may further override some of these
* methods as well as provide additional methods and fields.
*
* @author Jonathan Payne
* @since JDK1.0
*/
public
class FilterOutputStream extends OutputStream {
/**
* The underlying output stream to be filtered.
*/
protected OutputStream out;
/**
* Creates an output stream filter built on top of the specified
* underlying output stream.
*
* @param out the underlying output stream to be assigned to
* the field <tt>this.out</tt> for later use, or
* <code>null</code> if this instance is to be
* created without an underlying stream.
*/
public FilterOutputStream(OutputStream out) {
this.out = out;
}
/**
* Writes the specified <code>byte</code> to this output stream.
* <p>
* The <code>write</code> method of <code>FilterOutputStream</code>
* calls the <code>write</code> method of its underlying output stream,
* that is, it performs <tt>out.write(b)</tt>.
* <p>
* Implements the abstract <tt>write</tt> method of <tt>OutputStream</tt>.
*
* @param b the <code>byte</code>.
* @exception IOException if an I/O error occurs.
*/
public void write(int b) throws IOException {
out.write(b);
}
/**
* Writes <code>b.length</code> bytes to this output stream.
* <p>
* The <code>write</code> method of <code>FilterOutputStream</code>
* calls its <code>write</code> method of three arguments with the
* arguments <code>b</code>, <code>0</code>, and
* <code>b.length</code>.
* <p>
* Note that this method does not call the one-argument
* <code>write</code> method of its underlying stream with the single
* argument <code>b</code>.
*
* @param b the data to be written.
* @exception IOException if an I/O error occurs.
* @see java.io.FilterOutputStream#write(byte[], int, int)
*/
public void write(byte b[]) throws IOException {
write(b, 0, b.length);
}
/**
* Writes <code>len</code> bytes from the specified
* <code>byte</code> array starting at offset <code>off</code> to
* this output stream.
* <p>
* The <code>write</code> method of <code>FilterOutputStream</code>
* calls the <code>write</code> method of one argument on each
* <code>byte</code> to output.
* <p>
* Note that this method does not call the <code>write</code> method
* of its underlying input stream with the same arguments. Subclasses
* of <code>FilterOutputStream</code> should provide a more efficient
* implementation of this method.
*
* @param b the data.
* @param off the start offset in the data.
* @param len the number of bytes to write.
* @exception IOException if an I/O error occurs.
* @see java.io.FilterOutputStream#write(int)
*/
public void write(byte b[], int off, int len) throws IOException {
if ((off | len | (b.length - (len + off)) | (off + len)) < 0)
throw new IndexOutOfBoundsException();
for (int i = 0 ; i < len ; i++) {
write(b[off + i]);
}
}
/**
* Flushes this output stream and forces any buffered output bytes
* to be written out to the stream.
* <p>
* The <code>flush</code> method of <code>FilterOutputStream</code>
* calls the <code>flush</code> method of its underlying output stream.
*
* @exception IOException if an I/O error occurs.
* @see java.io.FilterOutputStream#out
*/
public void flush() throws IOException {
out.flush();
}
/**
* Closes this output stream and releases any system resources
* associated with the stream.
* <p>
* The <code>close</code> method of <code>FilterOutputStream</code>
* calls its <code>flush</code> method, and then calls the
* <code>close</code> method of its underlying output stream.
*
* @exception IOException if an I/O error occurs.
* @see java.io.FilterOutputStream#flush()
* @see java.io.FilterOutputStream#out
*/
@SuppressWarnings("try")
public void close() throws IOException {
try (OutputStream ostream = out) {
flush();
}
}
}
ByteArrayOutputStream
/**
* This class implements an output stream in which the data is
* written into a byte array. The buffer automatically grows as data
* is written to it.
* The data can be retrieved using <code>toByteArray()</code> and
* <code>toString()</code>.
* <p>
* Closing a <tt>ByteArrayOutputStream</tt> has no effect. The methods in
* this class can be called after the stream has been closed without
* generating an <tt>IOException</tt>.
*
* @author Arthur van Hoff
* @since JDK1.0
*/
public class ByteArrayOutputStream extends OutputStream {
/**
* The buffer where data is stored.
*/
protected byte buf[];
/**
* The number of valid bytes in the buffer.
*/
protected int count;
/**
* Creates a new byte array output stream. The buffer capacity is
* initially 32 bytes, though its size increases if necessary.
*/
public ByteArrayOutputStream() {
this(32);
}
/**
* Creates a new byte array output stream, with a buffer capacity of
* the specified size, in bytes.
*
* @param size the initial size.
* @exception IllegalArgumentException if size is negative.
*/
public ByteArrayOutputStream(int size) {
if (size < 0) {
throw new IllegalArgumentException("Negative initial size: "
+ size);
}
buf = new byte[size];
}
/**
* Increases the capacity if necessary to ensure that it can hold
* at least the number of elements specified by the minimum
* capacity argument.
*
* @param minCapacity the desired minimum capacity
* @throws OutOfMemoryError if {@code minCapacity < 0}. This is
* interpreted as a request for the unsatisfiably large capacity
* {@code (long) Integer.MAX_VALUE + (minCapacity - Integer.MAX_VALUE)}.
*/
private void ensureCapacity(int minCapacity) {
// overflow-conscious code
if (minCapacity - buf.length > 0)
grow(minCapacity);
}
/**
* The maximum size of array to allocate.
* Some VMs reserve some header words in an array.
* Attempts to allocate larger arrays may result in
* OutOfMemoryError: Requested array size exceeds VM limit
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = buf.length;
int newCapacity = oldCapacity << 1;
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
buf = Arrays.copyOf(buf, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
/**
* Writes the specified byte to this byte array output stream.
*
* @param b the byte to be written.
*/
public synchronized void write(int b) {
ensureCapacity(count + 1);
buf[count] = (byte) b;
count += 1;
}
/**
* Writes <code>len</code> bytes from the specified byte array
* starting at offset <code>off</code> to this byte array output stream.
*
* @param b the data.
* @param off the start offset in the data.
* @param len the number of bytes to write.
*/
public synchronized void write(byte b[], int off, int len) {
if ((off < 0) || (off > b.length) || (len < 0) ||
((off + len) - b.length > 0)) {
throw new IndexOutOfBoundsException();
}
ensureCapacity(count + len);
System.arraycopy(b, off, buf, count, len);
count += len;
}
/**
* Writes the complete contents of this byte array output stream to
* the specified output stream argument, as if by calling the output
* stream's write method using <code>out.write(buf, 0, count)</code>.
*
* @param out the output stream to which to write the data.
* @exception IOException if an I/O error occurs.
*/
public synchronized void writeTo(OutputStream out) throws IOException {
out.write(buf, 0, count);
}
/**
* Resets the <code>count</code> field of this byte array output
* stream to zero, so that all currently accumulated output in the
* output stream is discarded. The output stream can be used again,
* reusing the already allocated buffer space.
*
* @see java.io.ByteArrayInputStream#count
*/
public synchronized void reset() {
count = 0;
}
/**
* Creates a newly allocated byte array. Its size is the current
* size of this output stream and the valid contents of the buffer
* have been copied into it.
*
* @return the current contents of this output stream, as a byte array.
* @see java.io.ByteArrayOutputStream#size()
*/
public synchronized byte toByteArray()[] {
return Arrays.copyOf(buf, count);
}
/**
* Returns the current size of the buffer.
*
* @return the value of the <code>count</code> field, which is the number
* of valid bytes in this output stream.
* @see java.io.ByteArrayOutputStream#count
*/
public synchronized int size() {
return count;
}
/**
* Converts the buffer's contents into a string decoding bytes using the
* platform's default character set. The length of the new <tt>String</tt>
* is a function of the character set, and hence may not be equal to the
* size of the buffer.
*
* <p> This method always replaces malformed-input and unmappable-character
* sequences with the default replacement string for the platform's
* default character set. The {@linkplain java.nio.charset.CharsetDecoder}
* class should be used when more control over the decoding process is
* required.
*
* @return String decoded from the buffer's contents.
* @since JDK1.1
*/
public synchronized String toString() {
return new String(buf, 0, count);
}
/**
* Converts the buffer's contents into a string by decoding the bytes using
* the named {@link java.nio.charset.Charset charset}. The length of the new
* <tt>String</tt> is a function of the charset, and hence may not be equal
* to the length of the byte array.
*
* <p> This method always replaces malformed-input and unmappable-character
* sequences with this charset's default replacement string. The {@link
* java.nio.charset.CharsetDecoder} class should be used when more control
* over the decoding process is required.
*
* @param charsetName the name of a supported
* {@link java.nio.charset.Charset charset}
* @return String decoded from the buffer's contents.
* @exception UnsupportedEncodingException
* If the named charset is not supported
* @since JDK1.1
*/
public synchronized String toString(String charsetName)
throws UnsupportedEncodingException
{
return new String(buf, 0, count, charsetName);
}
/**
* Creates a newly allocated string. Its size is the current size of
* the output stream and the valid contents of the buffer have been
* copied into it. Each character <i>c</i> in the resulting string is
* constructed from the corresponding element <i>b</i> in the byte
* array such that:
* <blockquote><pre>
* c == (char)(((hibyte & 0xff) << 8) | (b & 0xff))
* </pre></blockquote>
*
* @deprecated This method does not properly convert bytes into characters.
* As of JDK 1.1, the preferred way to do this is via the
* <code>toString(String enc)</code> method, which takes an encoding-name
* argument, or the <code>toString()</code> method, which uses the
* platform's default character encoding.
*
* @param hibyte the high byte of each resulting Unicode character.
* @return the current contents of the output stream, as a string.
* @see java.io.ByteArrayOutputStream#size()
* @see java.io.ByteArrayOutputStream#toString(String)
* @see java.io.ByteArrayOutputStream#toString()
*/
@Deprecated
public synchronized String toString(int hibyte) {
return new String(buf, hibyte, 0, count);
}
/**
* Closing a <tt>ByteArrayOutputStream</tt> has no effect. The methods in
* this class can be called after the stream has been closed without
* generating an <tt>IOException</tt>.
*/
public void close() throws IOException {
}
}
BufferedOutputStream
/**
* The class implements a buffered output stream. By setting up such
* an output stream, an application can write bytes to the underlying
* output stream without necessarily causing a call to the underlying
* system for each byte written.
*
* @author Arthur van Hoff
* @since JDK1.0
*/
public
class BufferedOutputStream extends FilterOutputStream {
/**
* The internal buffer where data is stored.
*/
protected byte buf[];
/**
* The number of valid bytes in the buffer. This value is always
* in the range <tt>0</tt> through <tt>buf.length</tt>; elements
* <tt>buf[0]</tt> through <tt>buf[count-1]</tt> contain valid
* byte data.
*/
protected int count;
/**
* Creates a new buffered output stream to write data to the
* specified underlying output stream.
*
* @param out the underlying output stream.
*/
public BufferedOutputStream(OutputStream out) {
this(out, 8192);
}
/**
* Creates a new buffered output stream to write data to the
* specified underlying output stream with the specified buffer
* size.
*
* @param out the underlying output stream.
* @param size the buffer size.
* @exception IllegalArgumentException if size <= 0.
*/
public BufferedOutputStream(OutputStream out, int size) {
super(out);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
/** Flush the internal buffer */
private void flushBuffer() throws IOException {
if (count > 0) {
out.write(buf, 0, count);
count = 0;
}
}
/**
* Writes the specified byte to this buffered output stream.
*
* @param b the byte to be written.
* @exception IOException if an I/O error occurs.
*/
public synchronized void write(int b) throws IOException {
if (count >= buf.length) {
flushBuffer();
}
buf[count++] = (byte)b;
}
/**
* Writes <code>len</code> bytes from the specified byte array
* starting at offset <code>off</code> to this buffered output stream.
*
* <p> Ordinarily this method stores bytes from the given array into this
* stream's buffer, flushing the buffer to the underlying output stream as
* needed. If the requested length is at least as large as this stream's
* buffer, however, then this method will flush the buffer and write the
* bytes directly to the underlying output stream. Thus redundant
* <code>BufferedOutputStream</code>s will not copy data unnecessarily.
*
* @param b the data.
* @param off the start offset in the data.
* @param len the number of bytes to write.
* @exception IOException if an I/O error occurs.
*/
public synchronized void write(byte b[], int off, int len) throws IOException {
if (len >= buf.length) {
/* If the request length exceeds the size of the output buffer,
flush the output buffer and then write the data directly.
In this way buffered streams will cascade harmlessly. */
flushBuffer();
out.write(b, off, len);
return;
}
if (len > buf.length - count) {
flushBuffer();
}
System.arraycopy(b, off, buf, count, len);
count += len;
}
/**
* Flushes this buffered output stream. This forces any buffered
* output bytes to be written out to the underlying output stream.
*
* @exception IOException if an I/O error occurs.
* @see java.io.FilterOutputStream#out
*/
public synchronized void flush() throws IOException {
flushBuffer();
out.flush();
}
}
PipedOutputStream
/**
* A piped output stream can be connected to a piped input stream
* to create a communications pipe. The piped output stream is the
* sending end of the pipe. Typically, data is written to a
* <code>PipedOutputStream</code> object by one thread and data is
* read from the connected <code>PipedInputStream</code> by some
* other thread. Attempting to use both objects from a single thread
* is not recommended as it may deadlock the thread.
* The pipe is said to be <a name=BROKEN> <i>broken</i> </a> if a
* thread that was reading data bytes from the connected piped input
* stream is no longer alive.
*
* @author James Gosling
* @see java.io.PipedInputStream
* @since JDK1.0
*/
public
class PipedOutputStream extends OutputStream {
/* REMIND: identification of the read and write sides needs to be
more sophisticated. Either using thread groups (but what about
pipes within a thread?) or using finalization (but it may be a
long time until the next GC). */
private PipedInputStream sink;
/**
* Creates a piped output stream connected to the specified piped
* input stream. Data bytes written to this stream will then be
* available as input from <code>snk</code>.
*
* @param snk The piped input stream to connect to.
* @exception IOException if an I/O error occurs.
*/
public PipedOutputStream(PipedInputStream snk) throws IOException {
connect(snk);
}
/**
* Creates a piped output stream that is not yet connected to a
* piped input stream. It must be connected to a piped input stream,
* either by the receiver or the sender, before being used.
*
* @see java.io.PipedInputStream#connect(java.io.PipedOutputStream)
* @see java.io.PipedOutputStream#connect(java.io.PipedInputStream)
*/
public PipedOutputStream() {
}
/**
* Connects this piped output stream to a receiver. If this object
* is already connected to some other piped input stream, an
* <code>IOException</code> is thrown.
* <p>
* If <code>snk</code> is an unconnected piped input stream and
* <code>src</code> is an unconnected piped output stream, they may
* be connected by either the call:
* <blockquote><pre>
* src.connect(snk)</pre></blockquote>
* or the call:
* <blockquote><pre>
* snk.connect(src)</pre></blockquote>
* The two calls have the same effect.
*
* @param snk the piped input stream to connect to.
* @exception IOException if an I/O error occurs.
*/
public synchronized void connect(PipedInputStream snk) throws IOException {
if (snk == null) {
throw new NullPointerException();
} else if (sink != null || snk.connected) {
throw new IOException("Already connected");
}
sink = snk;
snk.in = -1;
snk.out = 0;
snk.connected = true;
}
/**
* Writes the specified <code>byte</code> to the piped output stream.
* <p>
* Implements the <code>write</code> method of <code>OutputStream</code>.
*
* @param b the <code>byte</code> to be written.
* @exception IOException if the pipe is <a href=#BROKEN> broken</a>,
* {@link #connect(java.io.PipedInputStream) unconnected},
* closed, or if an I/O error occurs.
*/
public void write(int b) throws IOException {
if (sink == null) {
throw new IOException("Pipe not connected");
}
sink.receive(b);
}
/**
* Writes <code>len</code> bytes from the specified byte array
* starting at offset <code>off</code> to this piped output stream.
* This method blocks until all the bytes are written to the output
* stream.
*
* @param b the data.
* @param off the start offset in the data.
* @param len the number of bytes to write.
* @exception IOException if the pipe is <a href=#BROKEN> broken</a>,
* {@link #connect(java.io.PipedInputStream) unconnected},
* closed, or if an I/O error occurs.
*/
public void write(byte b[], int off, int len) throws IOException {
if (sink == null) {
throw new IOException("Pipe not connected");
} else if (b == null) {
throw new NullPointerException();
} else if ((off < 0) || (off > b.length) || (len < 0) ||
((off + len) > b.length) || ((off + len) < 0)) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return;
}
sink.receive(b, off, len);
}
/**
* Flushes this output stream and forces any buffered output bytes
* to be written out.
* This will notify any readers that bytes are waiting in the pipe.
*
* @exception IOException if an I/O error occurs.
*/
public synchronized void flush() throws IOException {
if (sink != null) {
synchronized (sink) {
sink.notifyAll();
}
}
}
/**
* Closes this piped output stream and releases any system resources
* associated with this stream. This stream may no longer be used for
* writing bytes.
*
* @exception IOException if an I/O error occurs.
*/
public void close() throws IOException {
if (sink != null) {
sink.receivedLast();
}
}
}
5 - CH05-常用操作.md
File
递归地列出一个目录下所有文件:
public static void listAllFiles(File dir) {
if (dir == null || !dir.exists()) {
return;
}
if (dir.isFile()) {
System.out.println(dir.getName());
return;
}
for (File file : dir.listFiles()) {
listAllFiles(file);
}
}
字节流
public static void copyFile(String src, String dist) throws IOException {
FileInputStream in = new FileInputStream(src);
FileOutputStream out = new FileOutputStream(dist);
byte[] buffer = new byte[20 * 1024];
// read() 最多读取 buffer.length 个字节
// 返回的是实际读取的个数
// 返回 -1 的时候表示读到 eof,即文件尾
while (in.read(buffer, 0, buffer.length) != -1) {
out.write(buffer);
}
in.close();
out.close();
}
逐行打印
public static void readFileContent(String filePath) throws IOException {
FileReader fileReader = new FileReader(filePath);
BufferedReader bufferedReader = new BufferedReader(fileReader);
String line;
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
// 装饰者模式使得 BufferedReader 组合了一个 Reader 对象
// 在调用 BufferedReader 的 close() 方法时会去调用 Reader 的 close() 方法
// 因此只要一个 close() 调用即可
bufferedReader.close();
}
序列化
序列化 & Serializable & transient
序列化就是将一个对象转换成字节序列,方便存储和传输。
- 序列化: ObjectOutputStream.writeObject()
- 反序列化: ObjectInputStream.readObject()
不会对静态变量进行序列化,因为序列化只是保存对象的状态,静态变量属于类的状态。
Serializable
序列化的类需要实现 Serializable 接口,它只是一个标准,没有任何方法需要实现,但是如果不去实现它的话而进行序列化,会抛出异常。
public static void main(String[] args) throws IOException, ClassNotFoundException {
A a1 = new A(123, "abc");
String objectFile = "file/a1";
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(objectFile));
objectOutputStream.writeObject(a1);
objectOutputStream.close();
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream(objectFile));
A a2 = (A) objectInputStream.readObject();
objectInputStream.close();
System.out.println(a2);
}
private static class A implements Serializable {
private int x;
private String y;
A(int x, String y) {
this.x = x;
this.y = y;
}
@Override
public String toString() {
return "x = " + x + " " + "y = " + y;
}
}
transient
transient 关键字可以使一些属性不会被序列化。
ArrayList 中存储数据的数组 elementData 是用 transient 修饰的,因为这个数组是动态扩展的,并不是所有的空间都被使用,因此就不需要所有的内容都被序列化。通过重写序列化和反序列化方法,使得可以只序列化数组中有内容的那部分数据。
private transient Object[] elementData;
网络
InetAddress
没有公有的构造函数,只能通过静态方法来创建实例。
InetAddress.getByName(String host);
InetAddress.getByAddress(byte[] address);
URL
可以直接从 URL 中读取字节流数据。
public static void main(String[] args) throws IOException {
URL url = new URL("http://www.baidu.com");
/* 字节流 */
InputStream is = url.openStream();
/* 字符流 */
InputStreamReader isr = new InputStreamReader(is, "utf-8");
/* 提供缓存功能 */
BufferedReader br = new BufferedReader(isr);
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
br.close();
}
Sockets
- ServerSocket: 服务器端类
- Socket: 客户端类
- 服务器和客户端通过 InputStream 和 OutputStream 进行输入输出。
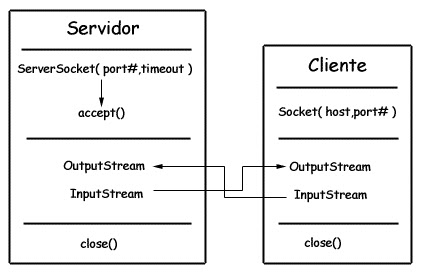
Datagram
- DatagramSocket: 通信类
- DatagramPacket: 数据包类
6 - CH06-IO实现
概览
说到 I/O,想必大家都不会陌生, I/O 英语全称:Input/Output,即输入/输出,通常指数据在内部存储器和外部存储器或其他周边设备之间的输入和输出。
比如我们常用的 SD卡、U盘、移动硬盘等等存储文件的硬件设备,当我们将其插入电脑的 usb 硬件接口时,我们就可以从电脑中读取设备中的信息或者写入信息,这个过程就涉及到 I/O 的操作。
当然,涉及 I/O 的操作,不仅仅局限于硬件设备的读写,还要网络数据的传输,比如,我们在电脑上用浏览器搜索互联网上的信息,这个过程也涉及到 I/O 的操作。
无论是从磁盘中读写文件,还是在网络中传输数据,可以说 I/O 主要为处理人机交互、机与机交互中获取和交换信息提供的一套解决方案。
在 Java 的 IO 体系中,类将近有 80 个,位于java.io包下,感觉很复杂,但是这些类大致可以分成四组:
- 基于字节操作的 I/O 接口:InputStream 和 OutputStream
- 基于字符操作的 I/O 接口:Writer 和 Reader
- 基于磁盘操作的 I/O 接口:File
- 基于网络操作的 I/O 接口:Socket
前两组主要从传输数据的数据格式不同,进行分组;后两组主要从传输数据的方式不同,进行分组。
虽然 Socket 类并不在 java.io包下,但是我们仍然把它们划分在一起,因为 I/O 的核心问题,要么是数据格式影响 I/O 操作,要么是传输方式影响 I/O 操作,也就是将什么样的数据写到什么地方的问题,I/O 只是人与机器或者机器与机器交互的手段,除了在它们能够完成这个交互功能外,我们关注的就是如何提高它的运行效率了,而数据格式和传输方式是影响效率最关键的因素。
字节格式
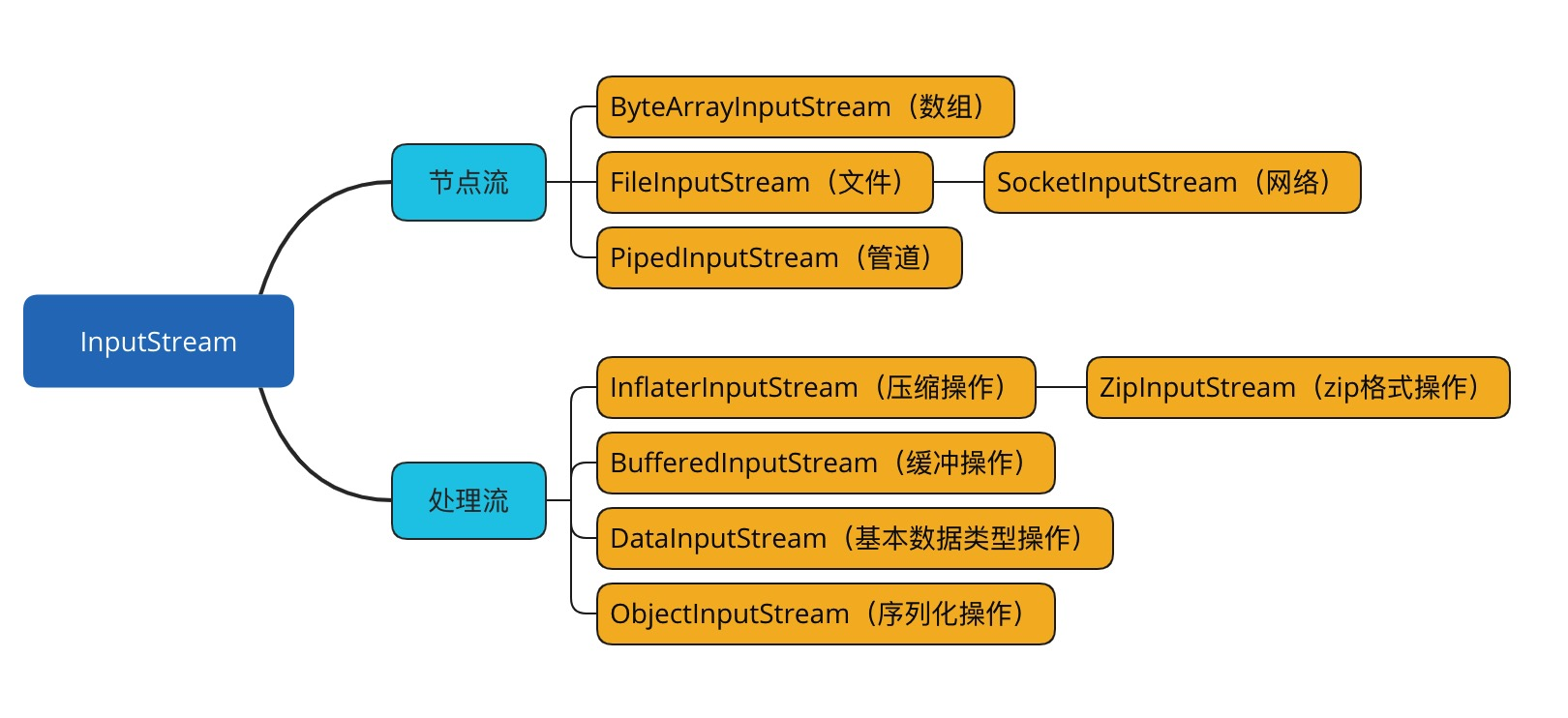
基于字节的输入和输出操作接口分别是:InputStream 和 OutputStream 。
字节输入流
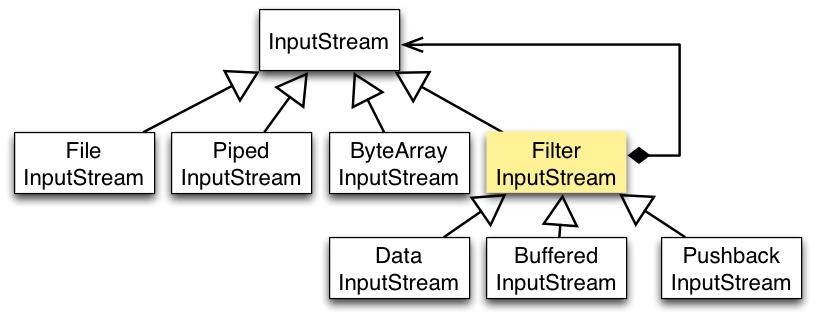
InputStream 输入流的类继承层次如下图所示:
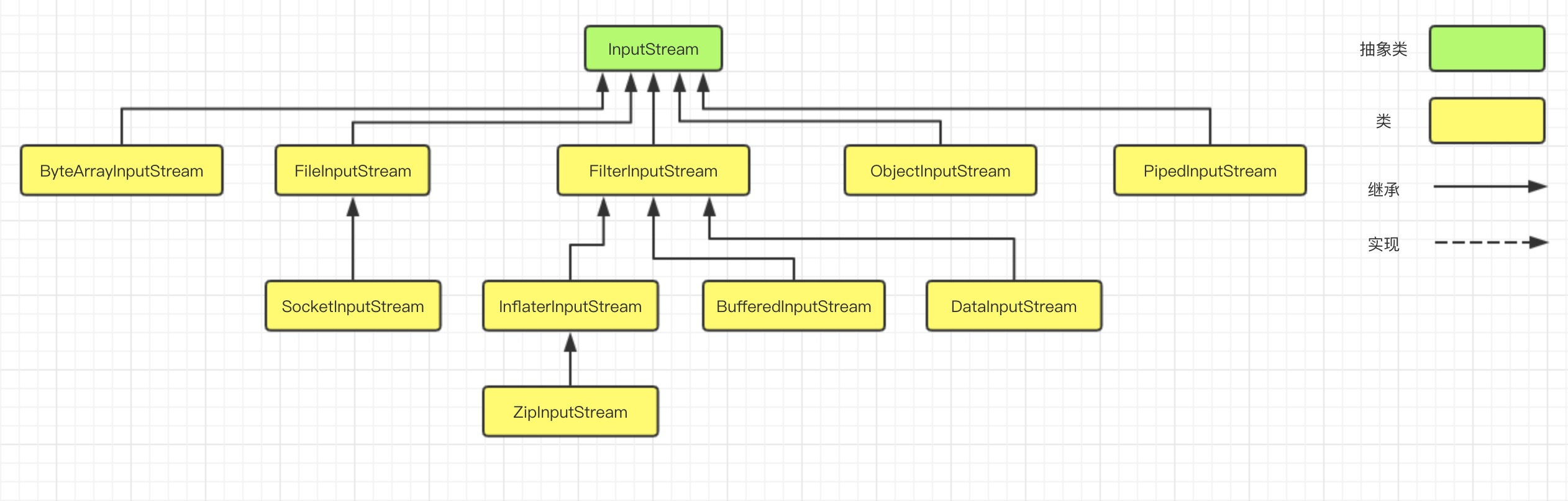
输入流根据数据节点类型和处理方式,分别可以划分出了若干个子类,如下图:
字节输出流
OutputStream 输出流的类继承层次如下图所示:
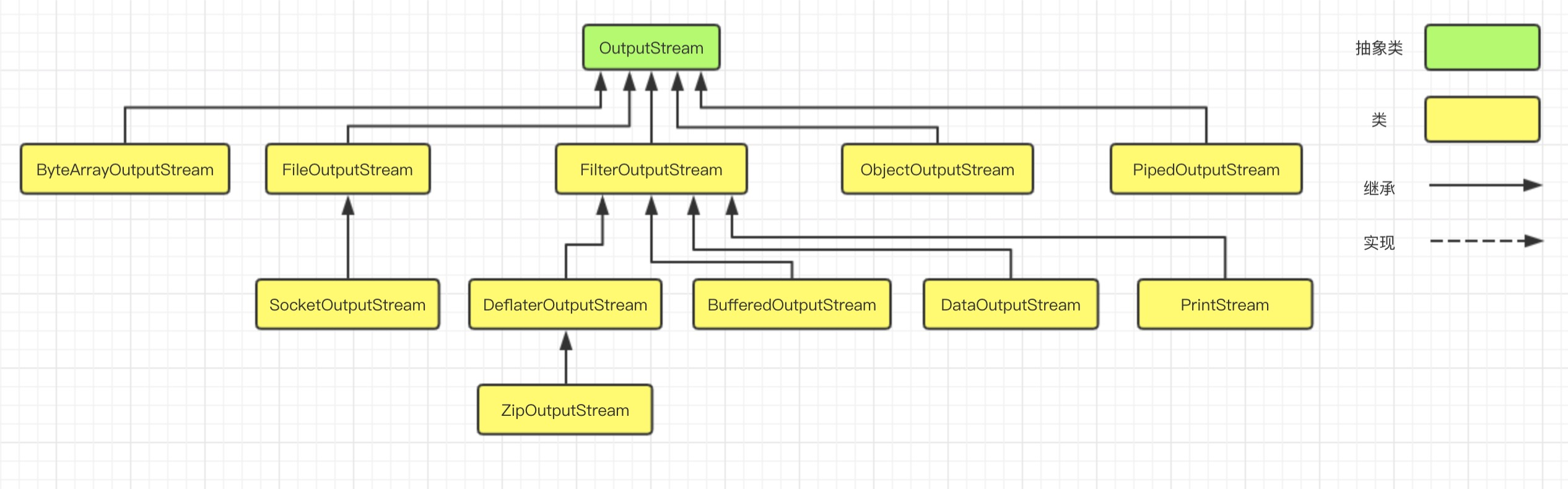
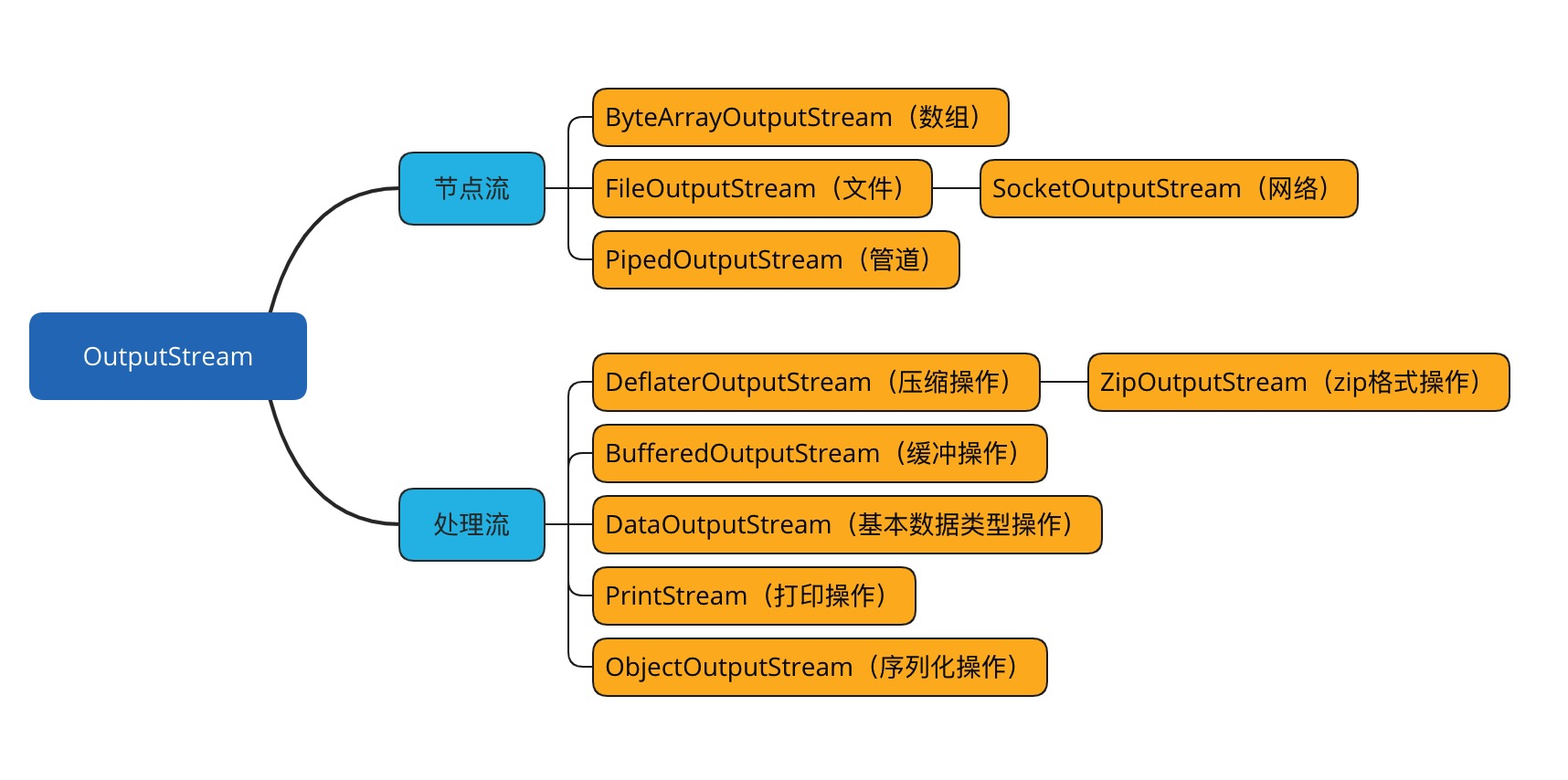
输出流根据数据节点类型和处理方式,也分别可以划分出了若干个子类,如下图:
在这里就不详细的介绍各个子类的使用方法,有兴趣的朋友可以查看 JDK 的 API 说明文档,笔者也会在后期的文章会进行详细的介绍,这里只是重点想说一下,无论是输入还是输出,操作数据的方式可以组合使用,各个处理流的类并不是只操作固定的节点流,比如如下输出方式:
//将文件输出流包装到序列化输出流中,再将序列化输出流包装到缓冲中 OutputStream out = new BufferedOutputStream(new ObjectOutputStream(new FileOutputStream(new File("fileName")));
另外,输出流最终写到什么地方必须要指定,要么是写到硬盘中,要么是写到网络中,从图中可以发现,写网络实际上也是写文件,只不过写到网络中,需要经过底层操作系统将数据发送到其他的计算机中,而不是写入到本地硬盘中。
字符格式
不管是磁盘还是网络传输,最小的存储单元都是字节,而不是字符,所以 I/O 操作的都是字节而不是字符,但是为什么要有操作字符的 I/O 接口呢?
这是因为我们的程序中通常操作的数据都是以字符形式,为了程序操作更方便而提供一个直接写字符的 I/O 接口,仅此而已。
基于字符的输入和输出操作接口分别是:Reader 和 Writer ,下图是字符的 I/O 操作接口涉及到的类结构图。
字符输入流
Reader 输入流的类继承层次如下图所示:
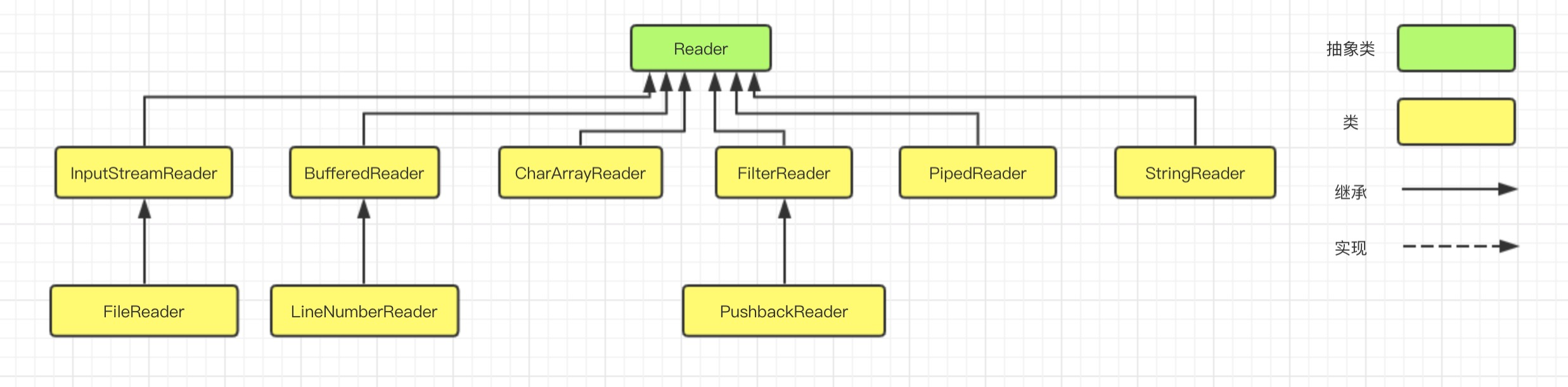
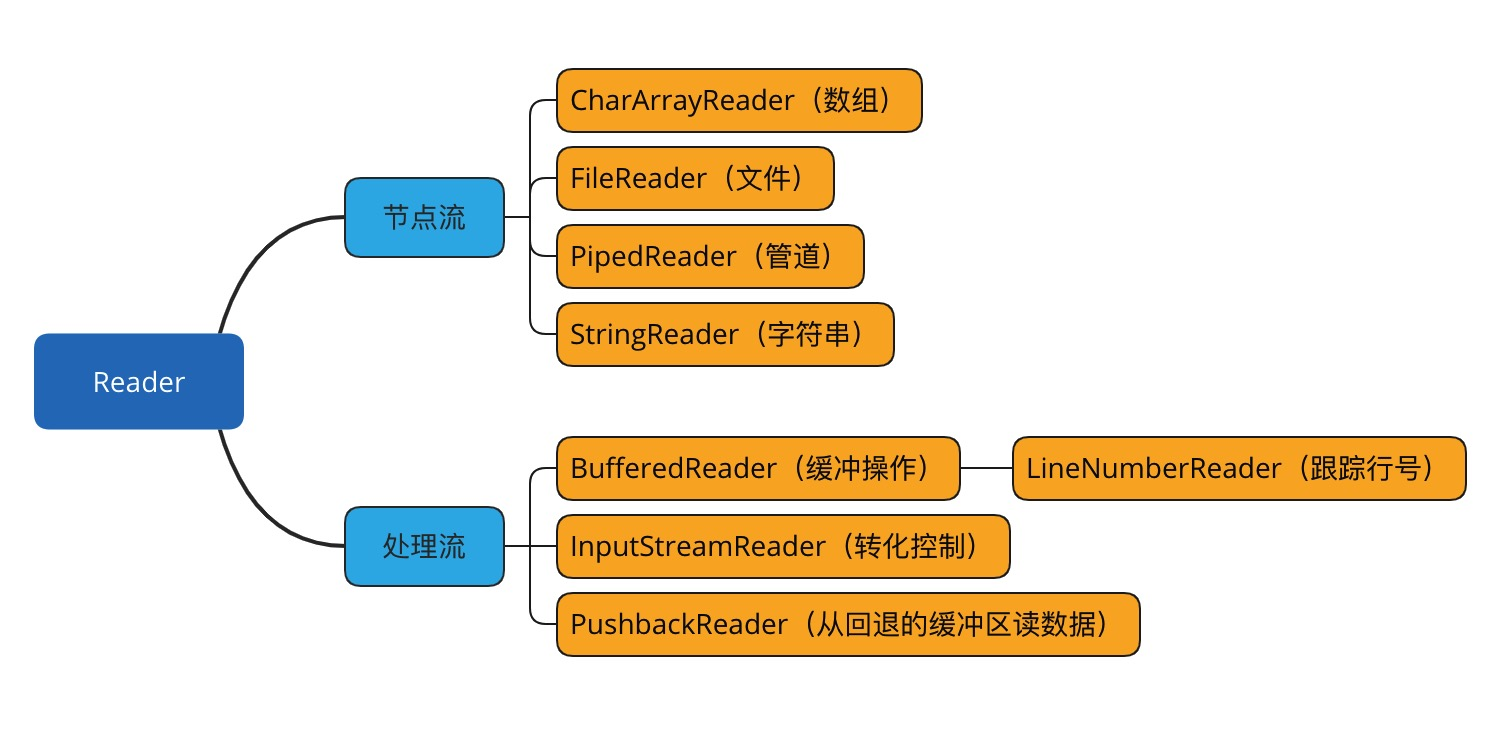
同样的,输入流根据数据节点类型和处理方式,分别可以划分出了若干个子类,如下图:
字符输出流
Writer 输出流的类继承层次如下图所示:
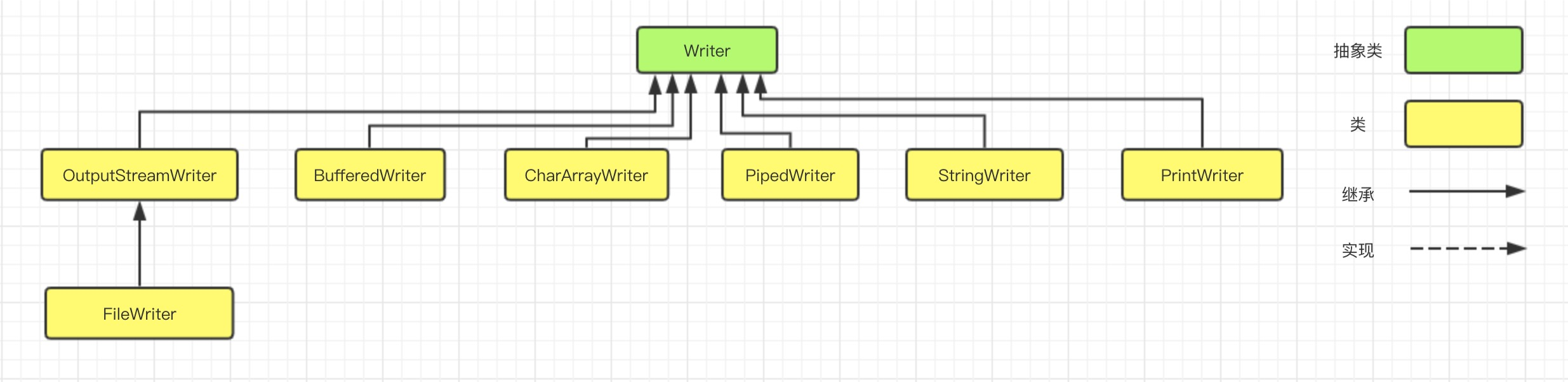
同样的,输出流根据数据节点类型和处理方式分类,分别可以划分出了若干个子类,如下图:
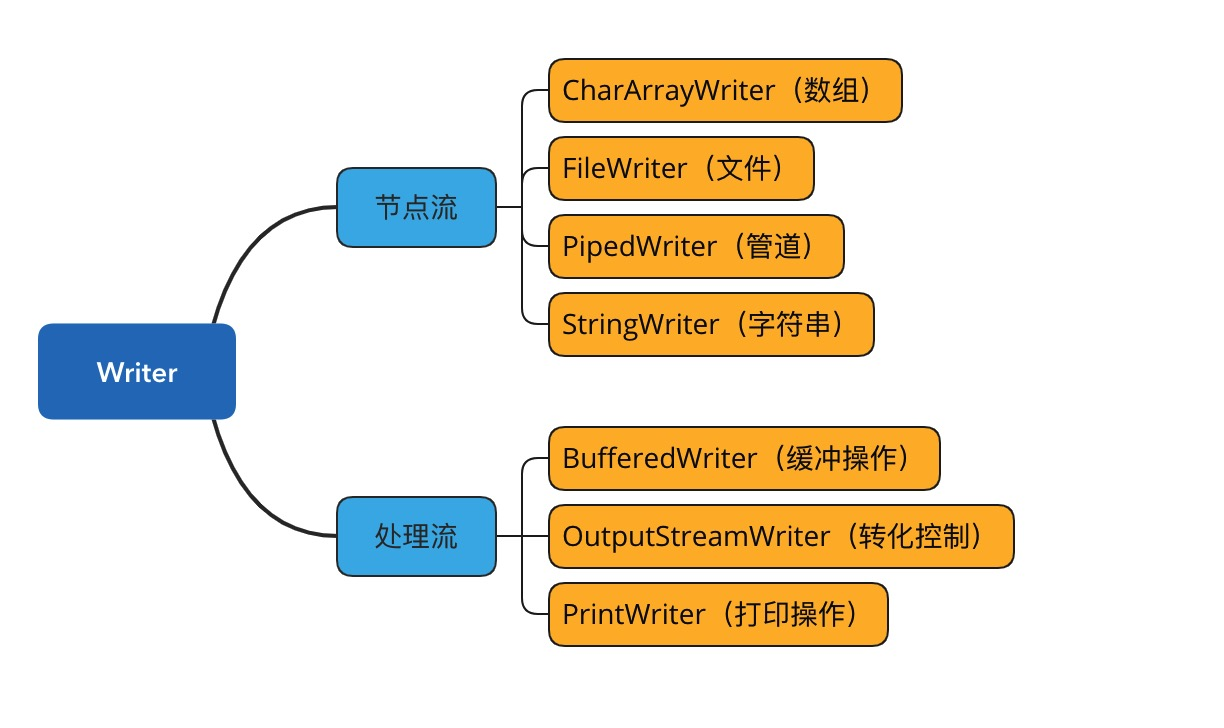
不管是 Reader 还是 Writer 类,它们都只定义了读取或写入数据字符的方式,也就是说要么是读要么是写,但是并没有规定数据要写到哪去,写到哪去就是我们后面要讨论的基于磁盘或网络的工作机制。
字节与字符的转化
刚刚我们说到,不管是磁盘还是网络传输,最小的存储单元都是字节,而不是字符,设计字符的原因是为了程序操作更方便,那么怎么将字符转化成字节或者将字节转化成字符呢?
InputStreamReader 和 OutputStreamWriter 就是转化桥梁。
输入流转化过程
输入流字符解码相关类结构的转化过程如下图所示:
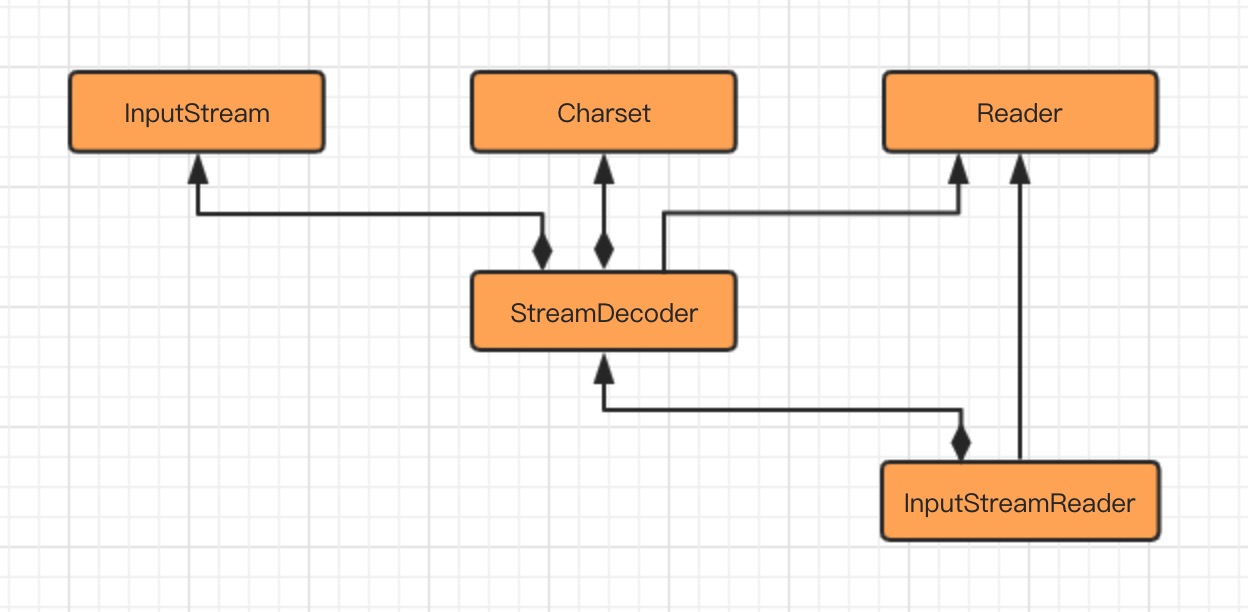
从图上可以看到,InputStreamReader 类是字节到字符的转化桥梁, 其中StreamDecoder指的是一个解码操作类,Charset指的是字符集。
InputStream 到 Reader 的过程需要指定编码字符集,否则将采用操作系统默认字符集,很可能会出现乱码问题,StreamDecoder 则是完成字节到字符的解码的实现类。
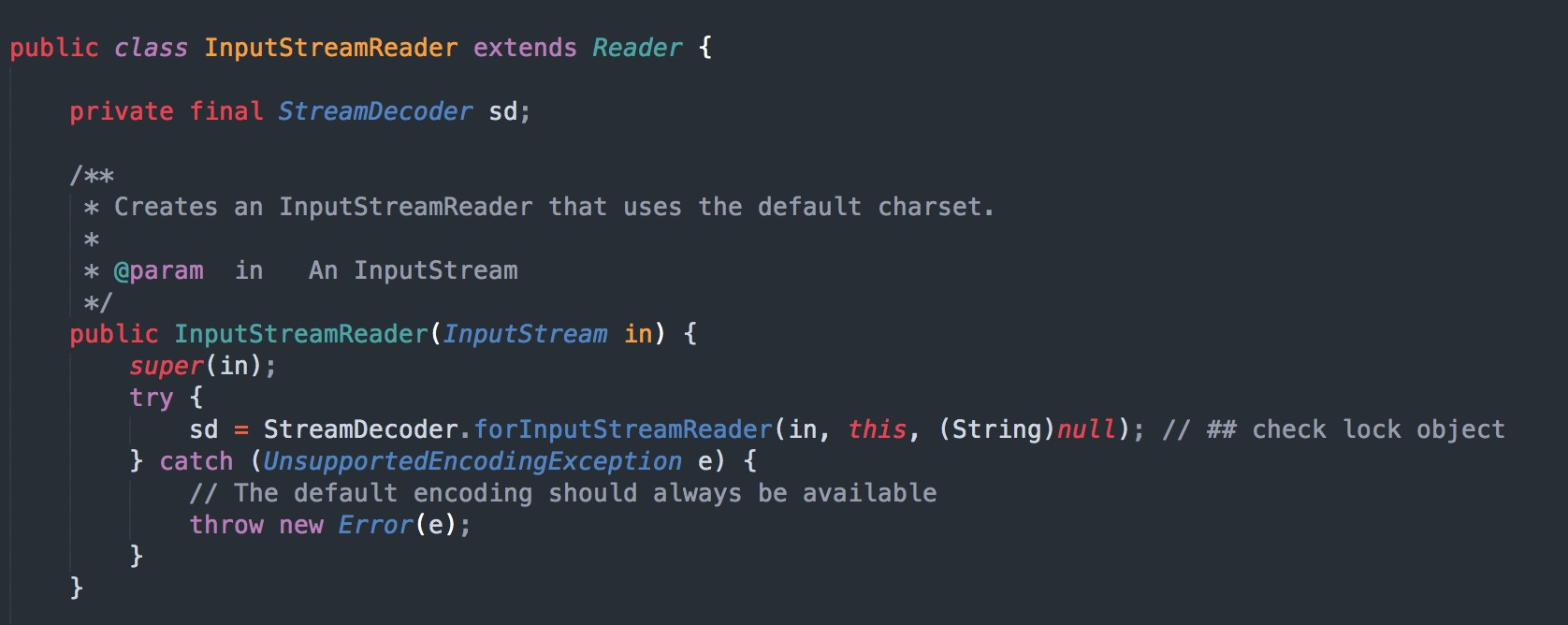
打开源码部分,InputStream 到 Reader 转化过程,如下图:
输出流转化过程
输出流转化过程也是类似,如下图所示:
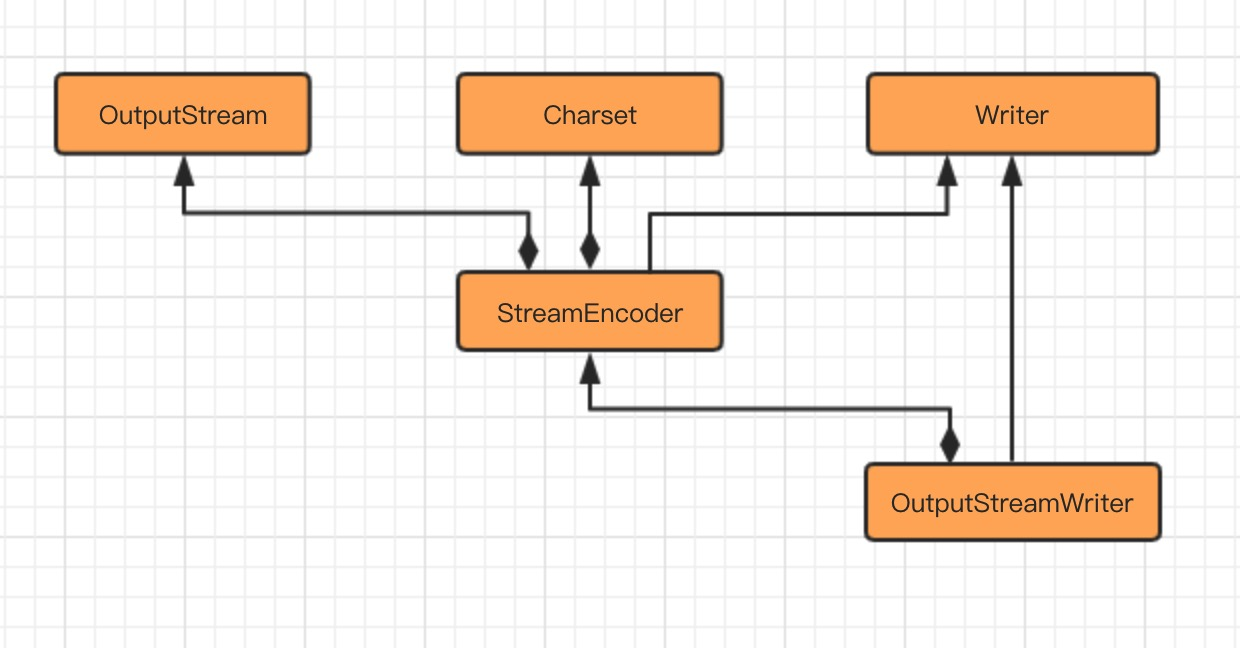
通过 OutputStreamWriter 类完成字符到字节的编码过程,由 StreamEncoder 完成编码过程。
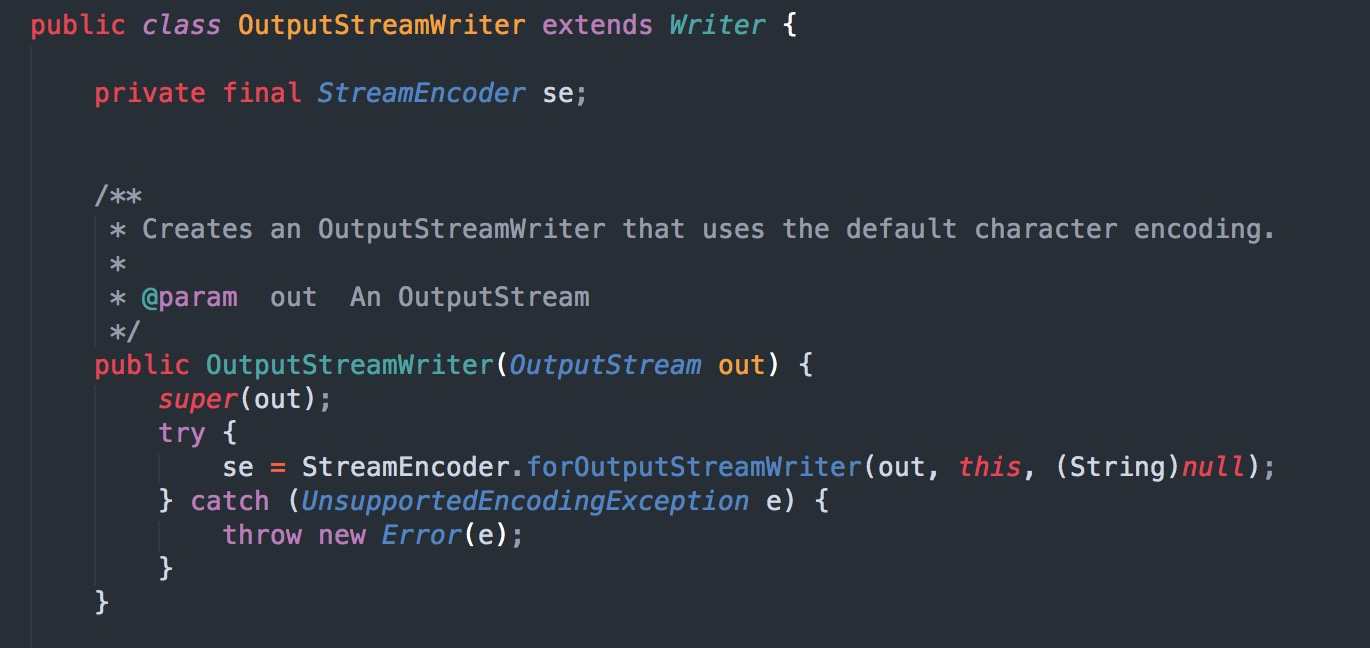
源码部分,Writer 到 OutputStream 转化过程,如下图:
磁盘传输
前面介绍了Java I/O 的操作接口,这些接口主要定义了如何操作数据,以及介绍了操作数据格式的方式:字节流和字符流。
还有一个关键问题就是数据写到何处,其中一个主要的处理方式就是将数据持久化到物理磁盘。
我们知道数据在磁盘的唯一最小描述就是文件,也就是说上层应用程序只能通过文件来操作磁盘上的数据,文件也是操作系统和磁盘驱动器交互的一个最小单元。
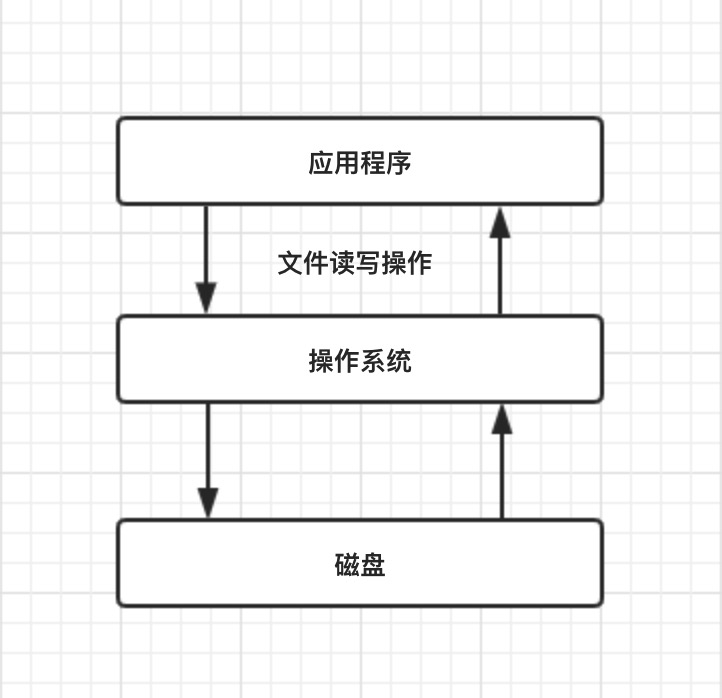
- 在 Java I/O 体系中,File 类是唯一代表磁盘文件本身的对象。
- File 类定义了一些与平台无关的方法来操作文件,包括检查一个文件是否存在、创建、删除文件、重命名文件、判断文件的读写权限是否存在、设置和查询文件的最近修改时间等等操作。
值得注意的是 Java 中通常的 File 并不代表一个真实存在的文件对象,当你通过指定一个路径描述符时,它就会返回一个代表这个路径相关联的一个虚拟对象,这个可能是一个真实存在的文件或者是一个包含多个文件的目录。
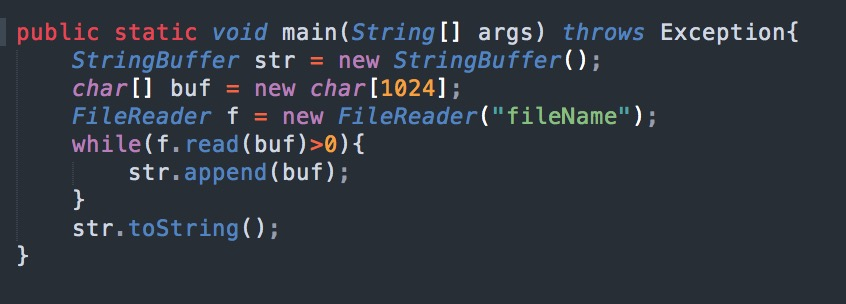
例如,读取一个文件内容,程序如下:
以上面的程序为例,从硬盘中读取一段文本字符,操作流程如下图:
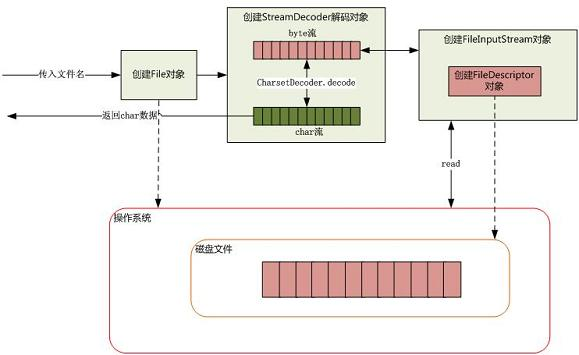
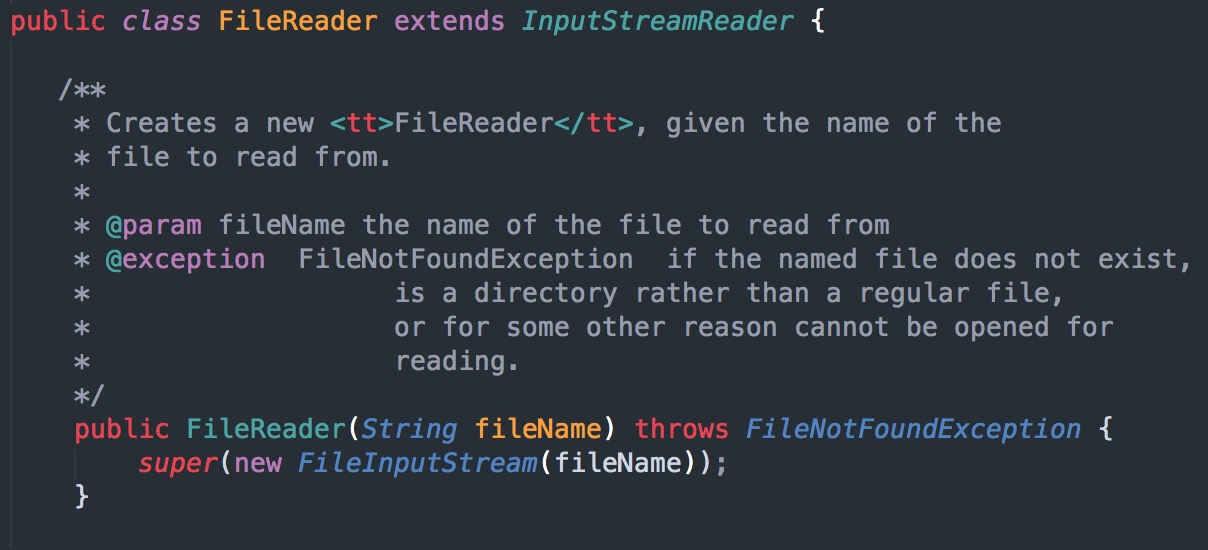
当我们传入一个指定的文件名来创建 File 对象,通过 FileReader 来读取文件内容时,会自动创建一个FileInputStream对象来读取文件内容,也就是我们上文中所说的字节流来读取文件。
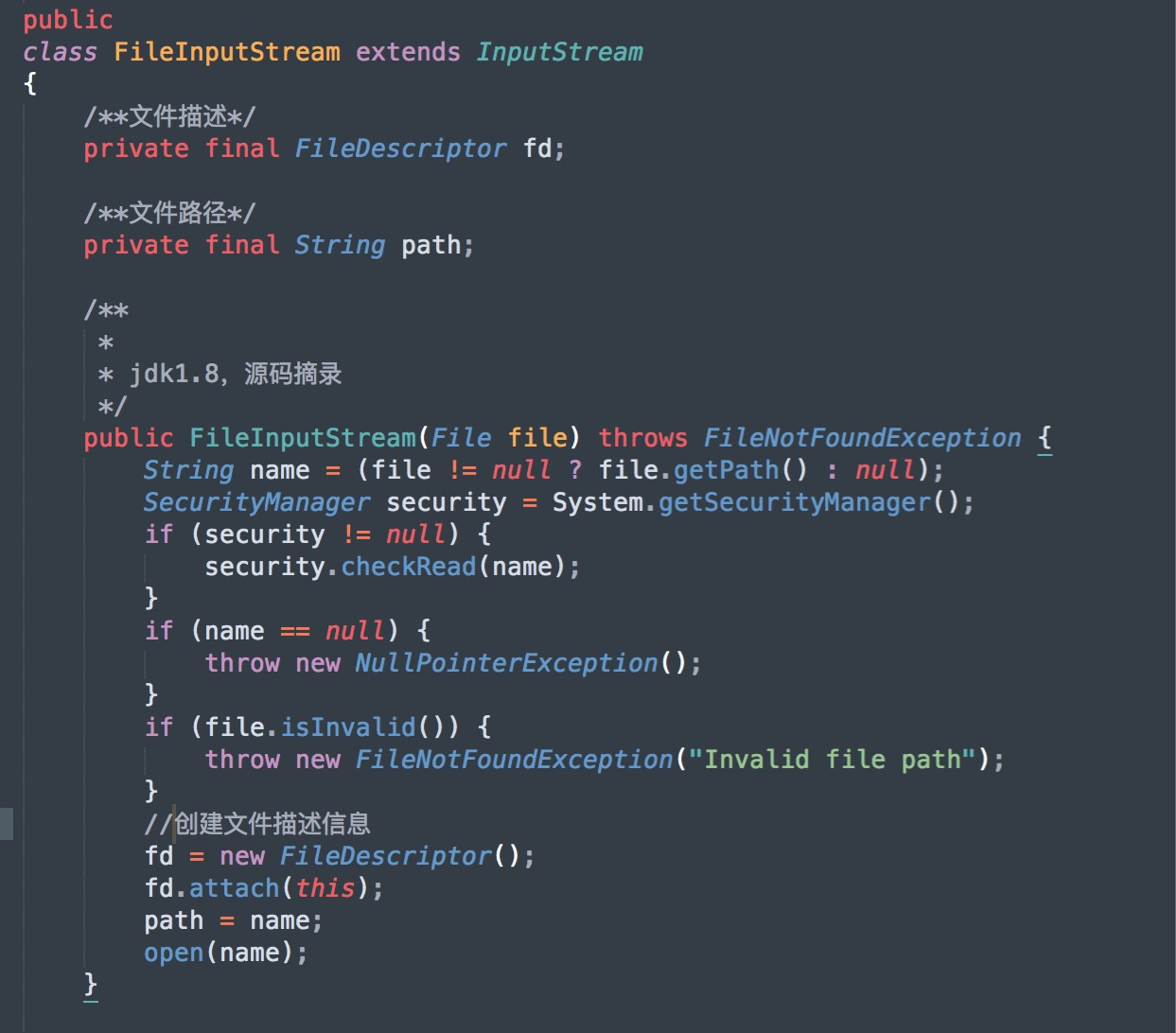
紧接着,会创建一个FileDescriptor的对象,其实这个对象就是真正代表一个存在的文件对象的描述。可以通过FileInputStream对象调用getFD() 方法获取真正与底层操作系统关联的文件描述。
由于我们需要读取的是字符格式,所以需要 StreamDecoder 类将byte解码为char格式,至于如何从磁盘驱动器上读取一段数据,由操作系统帮我们完成。
网络传输
继续来说说数据写到何处的另一种处理方式:将数据写入互联网中以供其他电脑能访问。
Socket简介
在现实中,Socket 这个概念没有一个具体的实体,它是描述计算机之间完成相互通信一种抽象定义。
打个比方,可以把 Socket 比作为两个城市之间的交通工具,有了它,就可以在城市之间来回穿梭了。并且,交通工具有多种,每种交通工具也有相应的交通规则。Socket 也一样,也有多种。大部分情况下我们使用的都是基于 TCP/IP 的流套接字,它是一种稳定的通信协议。
典型的基于 Socket 通信的应用程序场景,如下图:
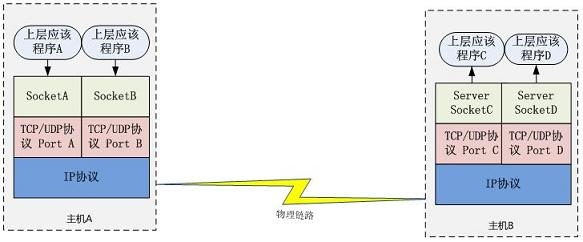
主机 A 的应用程序要想和主机 B 的应用程序通信,必须通过 Socket 建立连接,而建立 Socket 连接必须需要底层 TCP/IP 协议来建立 TCP 连接。
建立通信链路
我们知道网络层使用的 IP 协议可以帮助我们根据 IP 地址来找到目标主机,但是一台主机上可能运行着多个应用程序,如何才能与指定的应用程序通信就要通过 TCP 或 UPD 的地址也就是端口号来指定。这样就可以通过一个 Socket 实例代表唯一一个主机上的一个应用程序的通信链路了。
为了准确无误地把数据送达目标处,TCP 协议采用了三次握手策略,如下图:
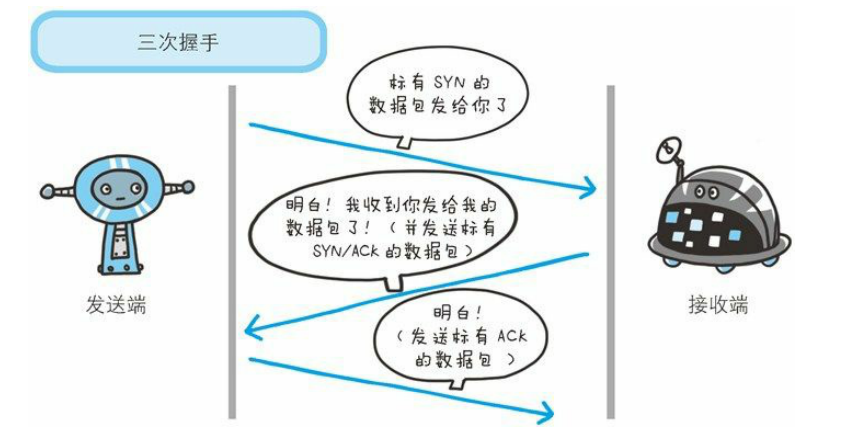
SYN 全称为 Synchronize Sequence Numbers,表示同步序列编号,是 TCP/IP 建立连接时使用的握手信号。
ACK 全称为 Acknowledge character,即确认字符,表示发来的数据已确认接收无误。
在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN + ACK 应答表示接收到了这个消息,最后客户机再以 ACK 消息响应。
这样在客户机和服务器之间才能建立起可靠的 TCP 连接,数据才可以在客户机和服务器之间传递。
- 发送端 –(发送带有 SYN 标志的数据包 )–> 接受端(第一次握手);
- 接受端 –(发送带有 SYN + ACK 标志的数据包)–> 发送端(第二次握手);
- 发送端 –(发送带有 ACK 标志的数据包) –> 接受端(第三次握手);
完成三次握手之后,客户端应用程序与服务器应用程序就可以开始传送数据了。
传输数据
当客户端要与服务端通信时,客户端首先要创建一个 Socket 实例,默认操作系统将为这个 Socket 实例分配一个没有被使用的本地端口号,并创建一个包含本地、远程地址和端口号的套接字数据结构,这个数据结构将一直保存在系统中直到这个连接关闭。
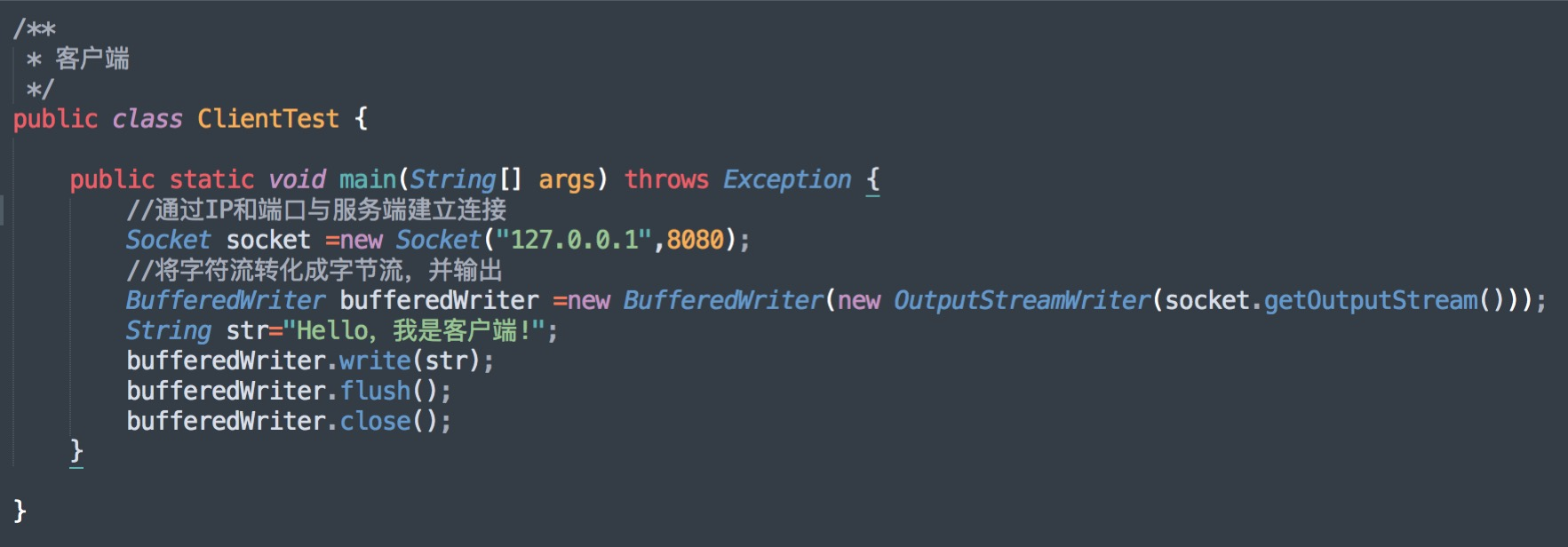
与之对应的服务端,也将创建一个 ServerSocket 实例,ServerSocket 创建比较简单,只要指定的端口号没有被占用,一般实例创建都会成功,同时操作系统也会为 ServerSocket 实例创建一个底层数据结构,这个数据结构中包含指定监听的端口号和包含监听地址的通配符,通常情况下都是*即监听所有地址。
之后当调用 accept() 方法时,将进入阻塞(等待)状态,等待客户端的请求。
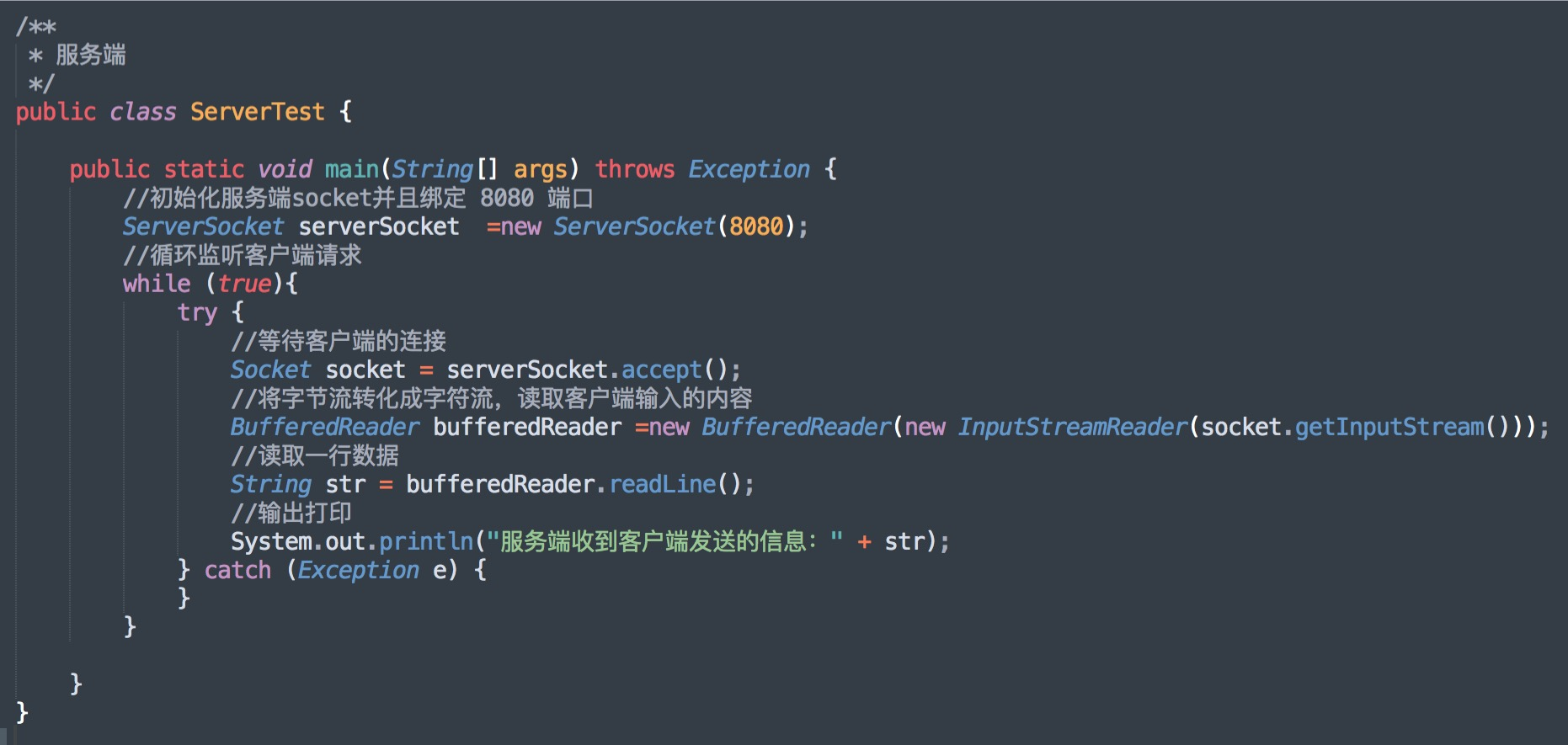
我们先启动服务端程序,再运行客户端,服务端收到客户端发送的信息,服务端打印结果如下:
服务端收到客户端发送的消息:Hello,我是客户端!
注意,客户端只有与服务端建立三次握手成功之后,才会发送数据,而 TCP/IP 握手过程,底层操作系统已经帮我们实现了!
- 当连接已经建立成功,服务端和客户端都会拥有一个 Socket 实例,每个 Socket 实例都有一个 InputStream 和 OutputStream,正如我们前面所说的,网络 I/O 都是以字节流传输的,Socket 正是通过这两个对象来交换数据。
- 当 Socket 对象创建时,操作系统将会为 InputStream 和 OutputStream 分别分配一定大小的缓冲区,数据的写入和读取都是通过这个缓存区完成的。
- 写入端将数据写到 OutputStream 对应的 SendQ 队列中,当队列填满时,数据将被发送到另一端 InputStream 的 RecvQ 队列中,如果这时 RecvQ 已经满了,那么 OutputStream 的 write 方法将会阻塞直到 RecvQ 队列有足够的空间容纳 SendQ 发送的数据。
值得特别注意的是,缓存区的大小以及写入端的速度和读取端的速度非常影响这个连接的数据传输效率,由于可能会发生阻塞,所以网络 I/O 与磁盘 I/O 在数据的写入和读取还要有一个协调的过程,如果两边同时传送数据时可能会产生死锁的问题。
如何提高网络 IO 传输效率、保证数据传输的可靠,已经成了工程师们急需解决的问题。
IO 工作方式
在计算机中,IO 传输数据有三种工作方式,分别是 BIO、NIO、AIO。
在讲解 BIO、NIO、AIO 之前,我们先来回顾一下这几个概念:同步与异步,阻塞与非阻塞。
同步与异步的区别
- 同步就是发起一个请求后,接受者未处理完请求之前,不返回结果。
- 异步就是发起一个请求后,立刻得到接受者的回应表示已接收到请求,但是接受者并没有处理完,接受者通常依靠事件回调等机制来通知请求者其处理结果。
阻塞和非阻塞的区别
- 阻塞就是请求者发起一个请求,一直等待其请求结果返回,也就是当前线程会被挂起,无法从事其他任务,只有当条件就绪才能继续。
- 非阻塞就是请求者发起一个请求,不用一直等着结果返回,可以先去干其他事情,当条件就绪的时候,就自动回来。
而我们要讲的 BIO、NIO、AIO 就是同步与异步、阻塞与非阻塞的组合。
- BIO:同步阻塞 IO;
- NIO:同步非阻塞 IO;
- AIO:异步非阻塞 IO;
BIO
BIO 俗称同步阻塞 IO,一种非常传统的 IO 模型,比如我们上面所举的那个程序例子,就是一个典型的**同步阻塞 IO **的工作方式。
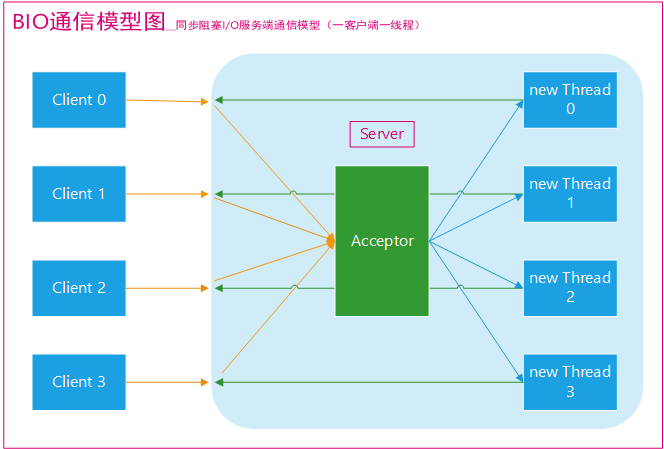
采用 BIO 通信模型的服务端,通常由一个独立的 Acceptor 线程负责监听客户端的连接。
我们一般在服务端通过while(true)循环中会调用accept() 方法等待监听客户端的连接,一旦接收到一个连接请求,就可以建立通信套接字进行读写操作,此时不能再接收其他客户端连接请求,只能等待同当前连接的客户端的操作执行完成, 不过可以通过多线程来支持多个客户端的连接。
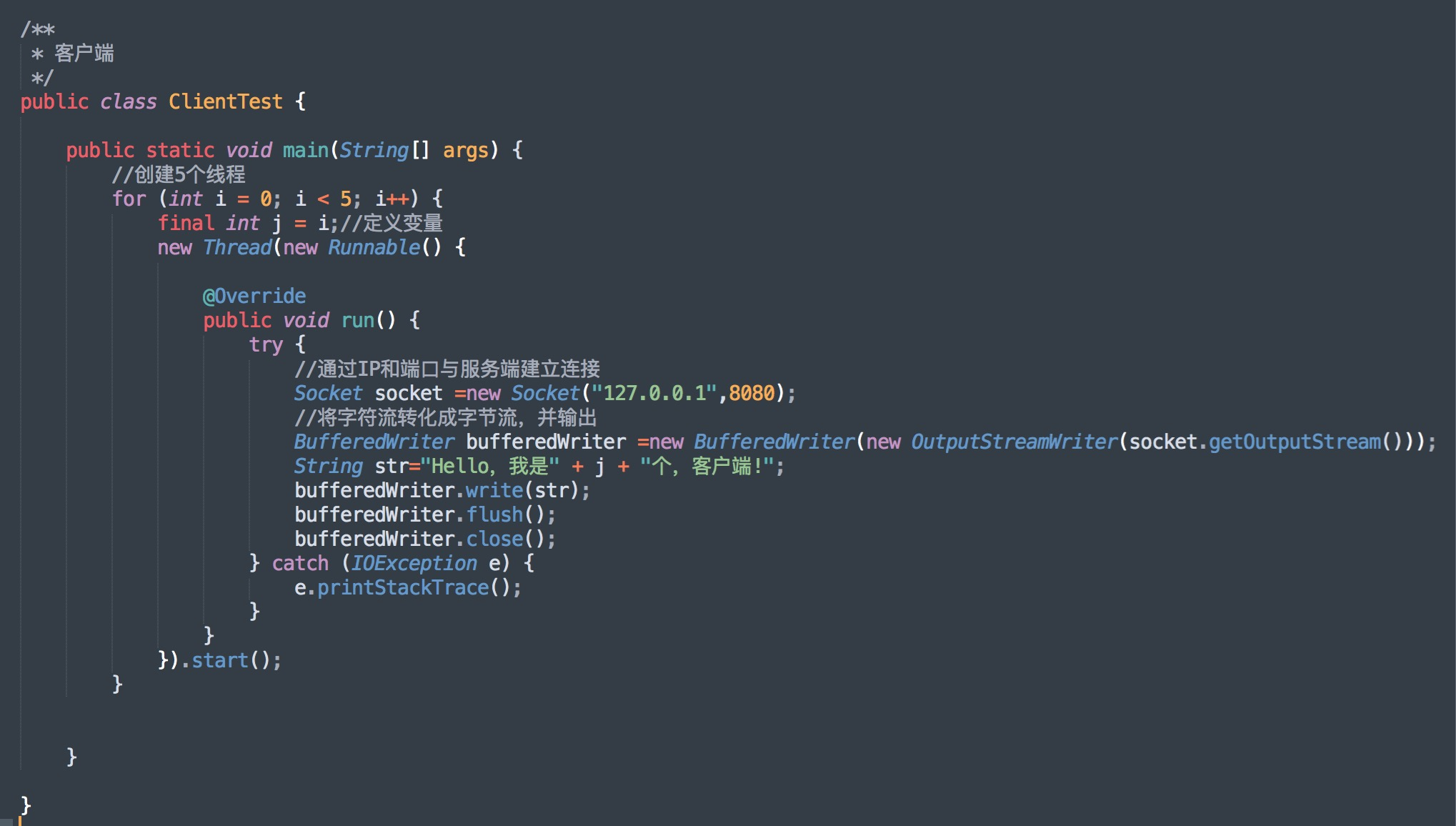
客户端多线程操作,程序如下:
服务端多线程操作,程序如下:
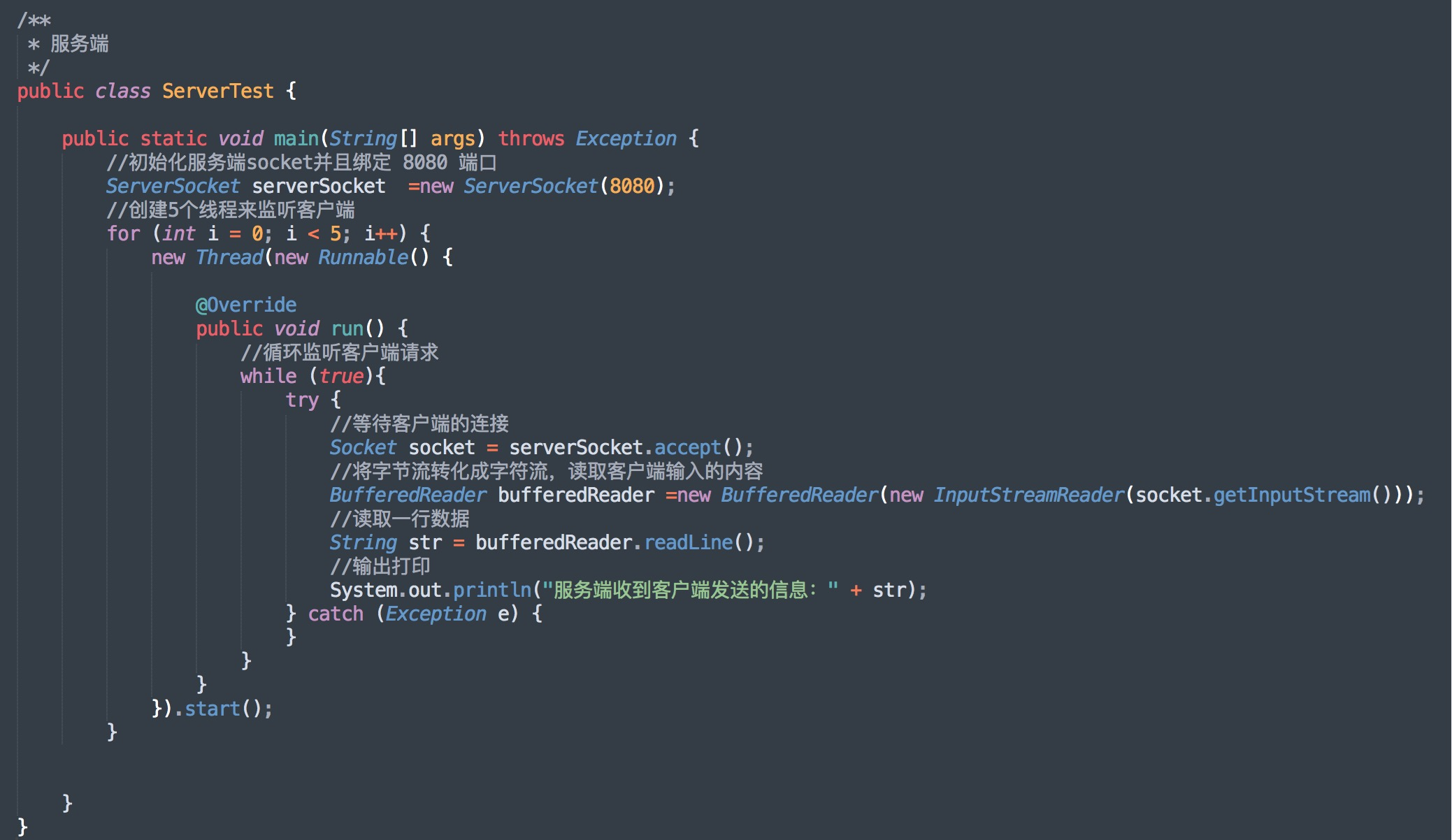
服务端运行结果,如下:
服务端收到客户端发送的消息:Hello,我是第 2 个,客户端!
服务端收到客户端发送的消息:Hello,我是第 4 个,客户端!
服务端收到客户端发送的消息:Hello,我是第 3 个,客户端!
服务端收到客户端发送的消息:Hello,我是第 0 个,客户端!
服务端收到客户端发送的消息:Hello,我是第 1 个,客户端!
如果要让 BIO 通信模型能够同时处理多个客户端请求,就必须使用多线程,也就是说它在接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理,处理完成之后,通过输出流返回应答给客户端,线程销毁。
这就是典型的一请求一应答通信模型 。
如果出现100、1000、甚至10000个用户同时访问服务器,这个时候,如果使用这种模型,那么服务端也会创建与之相同的线程数量,线程数急剧膨胀可能会导致线程堆栈溢出、创建新线程失败等问题,最终导致进程宕机或者僵死,不能对外提供服务。
当然,我们可以通过使用 Java 中 ThreadPoolExecutor 线程池机制来改善,让线程的创建和回收成本相对较低,保证了系统有限的资源的控制,实现了 N (客户端请求数量)大于 M (处理客户端请求的线程数量)的伪异步 I/O 模型。
伪异步 BIO
为了解决同步阻塞 I/O 面临的一个链路需要一个线程处理的问题,后来有人对它的线程模型进行了优化,后端通过一个线程池来处理多个客户端的请求接入,形成客户端个数 M:线程池最大线程数 N 的比例关系,其中 M 可以远远大于 N,通过线程池可以灵活地调配线程资源,设置线程的最大值,防止由于海量并发接入导致资源耗尽。
伪异步IO模型图,如下图:
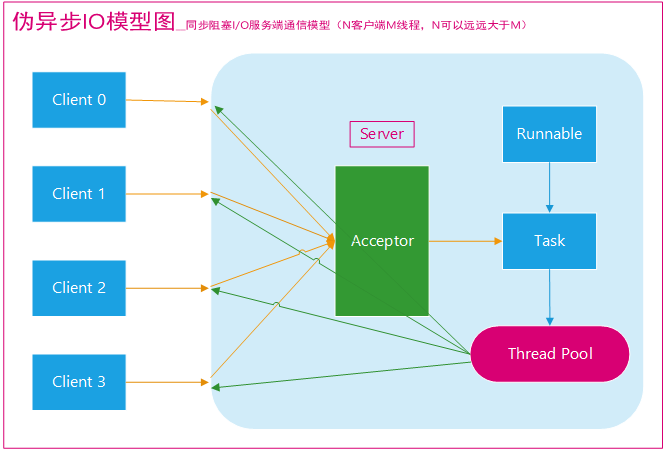
采用线程池和任务队列可以实现一种叫做伪异步的 I/O 通信框架,当有新的客户端接入时,将客户端的 Socket 封装成一个 Task 投递到后端的线程池中进行处理。
Java 的线程池维护一个消息队列和 N 个活跃线程,对消息队列中的任务进行处理。
客户端,程序如下:
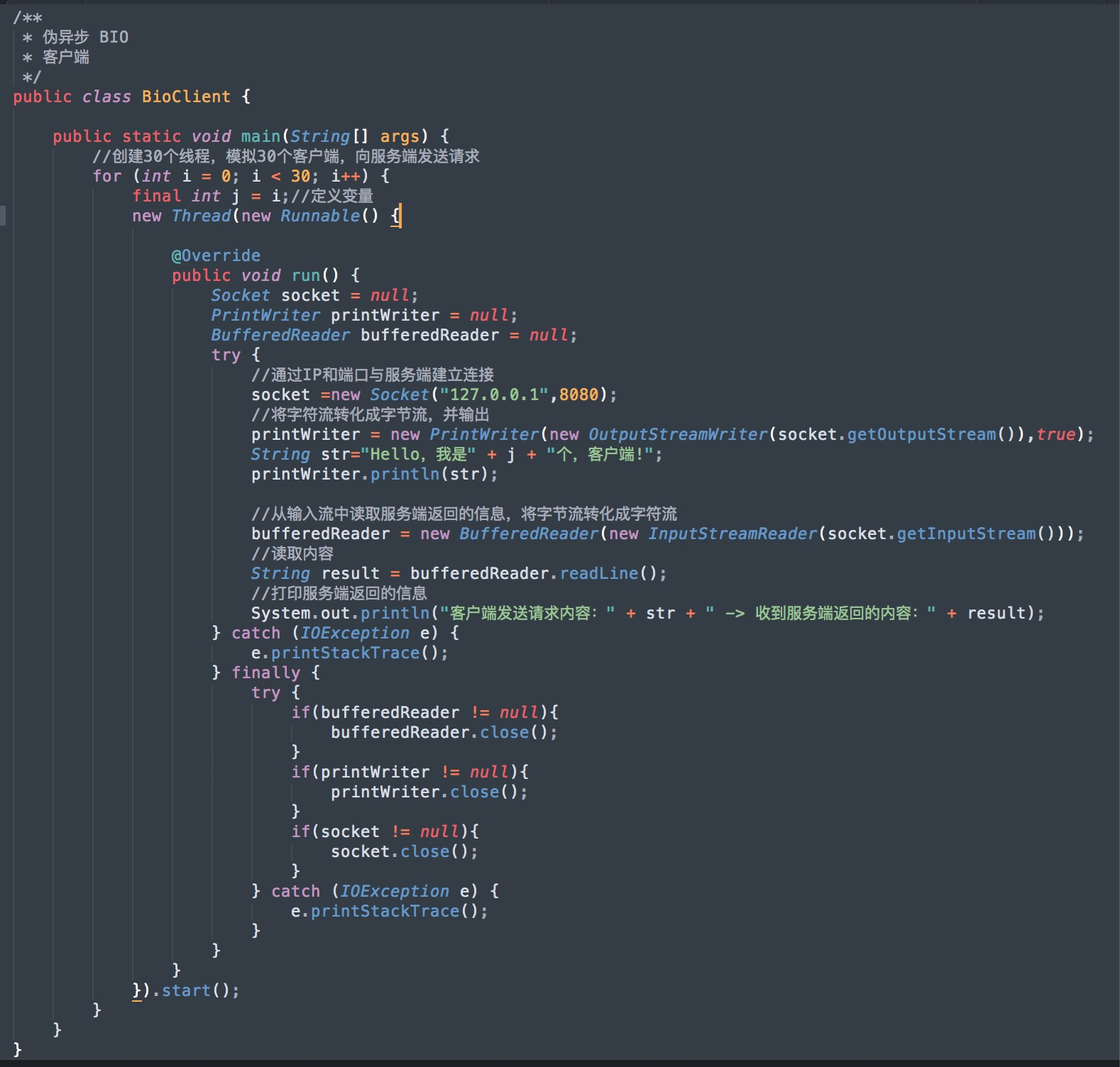
服务端,程序如下:
先启动服务端程序,再启动客户端程序,看看运行结果!
服务端,运行结果如下:
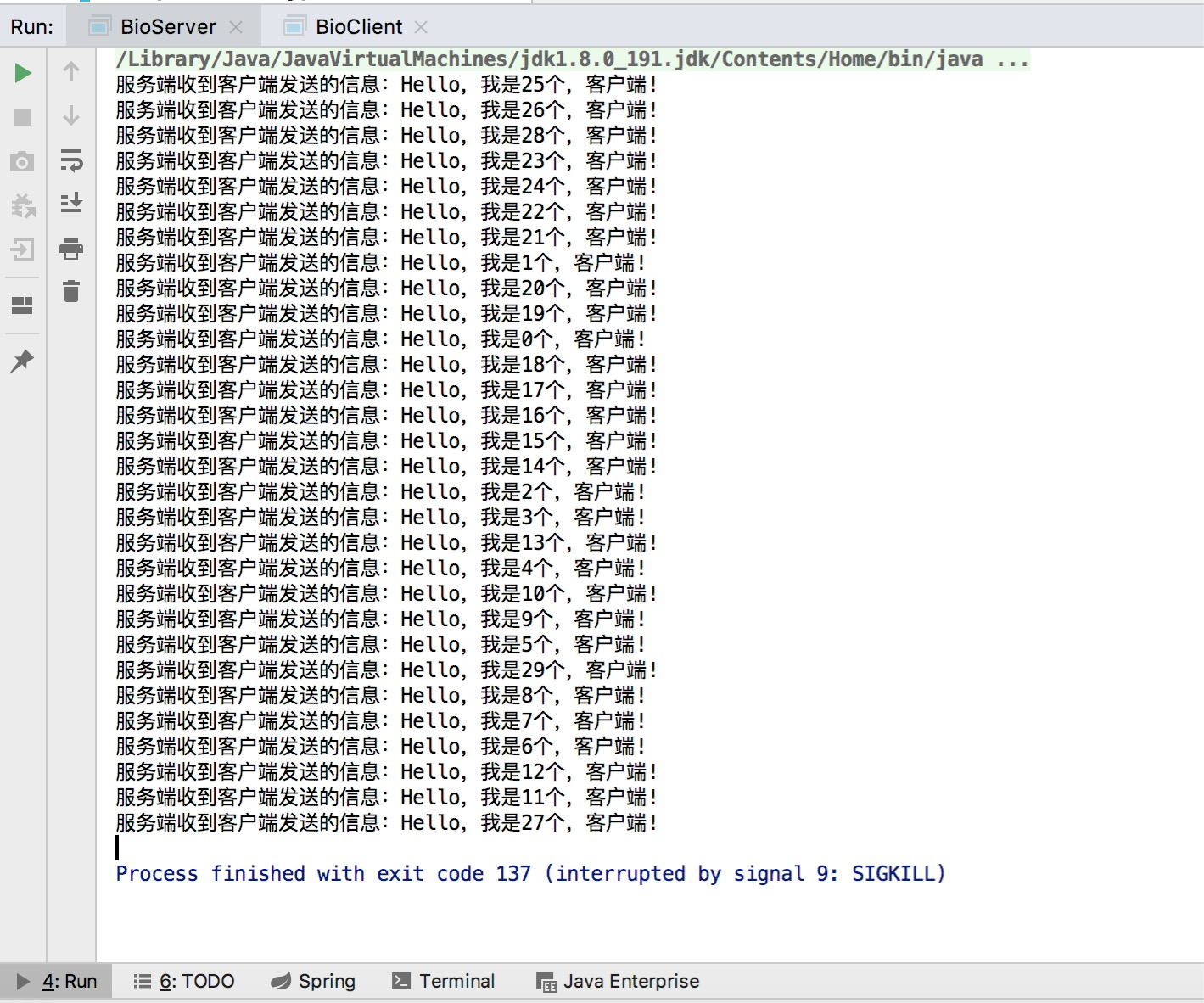
客户端,运行结果如下:
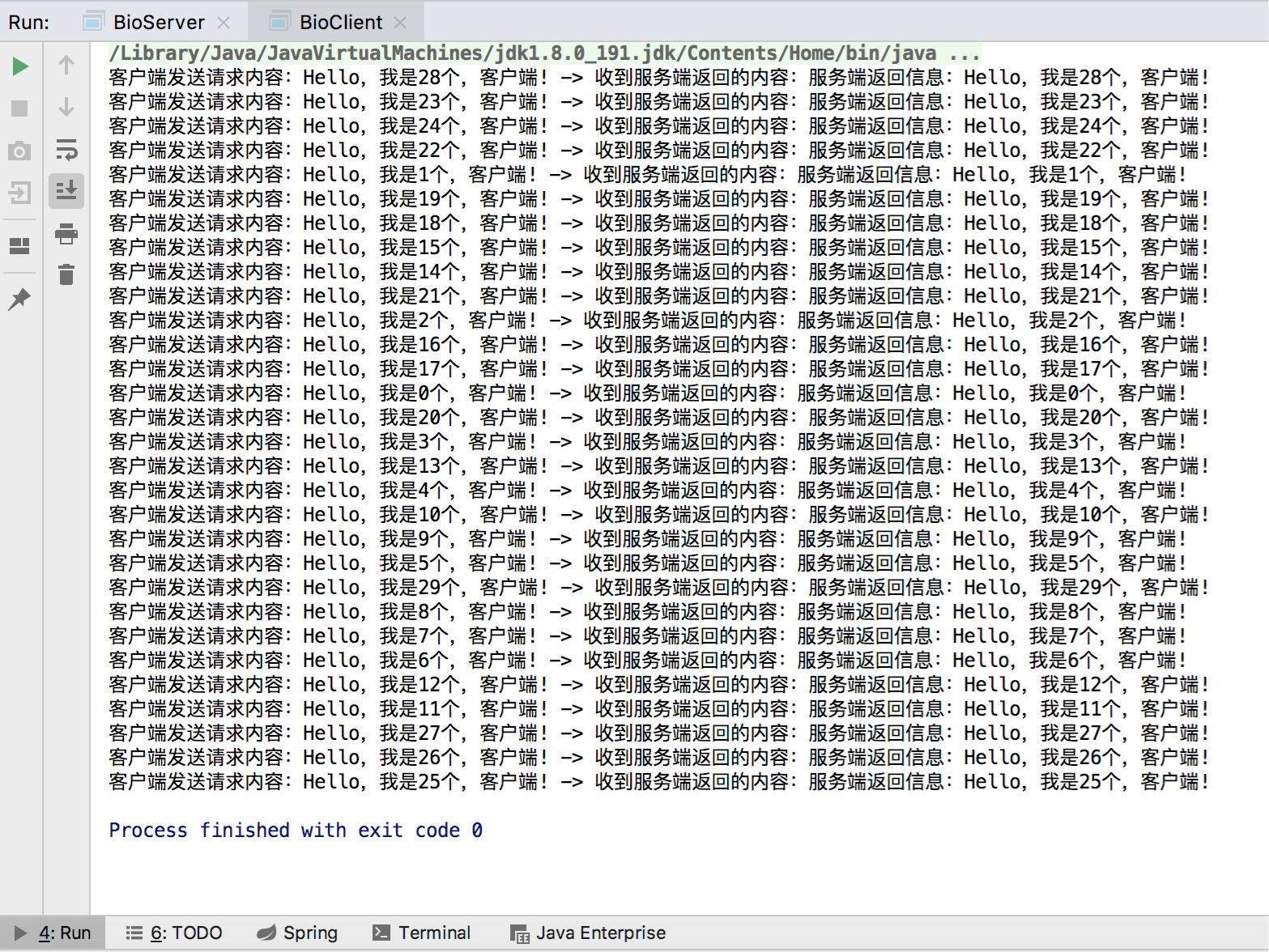
本例中测试的客户端数量是 30,服务端使用 java 线程池来处理任务,线程数量为 5 个,服务端不用为每个客户端都创建一个线程,由于线程池可以设置消息队列的大小和最大线程数,因此,它的资源占用是可控的,无论多少个客户端并发访问,都不会导致资源的耗尽和宕机。
在活动连接数不是特别高的情况下,这种模型是还不错,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。
但是,它的底层仍然是同步阻塞的 BIO 模型,当面对十万甚至百万级连接的时候,传统的 BIO 模型真的是无能为力的,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
NIO
NIO 中的 N 可以理解为 Non-blocking,一种同步非阻塞的 I/O 模型,在 Java 1.4 中引入,对应的在
java.nio包下。NIO 新增了 Channel、Selector、Buffer 等抽象概念,支持面向缓冲、基于通道的 I/O 操作方法。
NIO 提供了与传统 BIO 模型中的
Socket和ServerSocket相对应的SocketChannel和ServerSocketChannel两种不同的套接字通道实现。NIO 这两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。
对于低负载、低并发的应用程序,可以使用同步阻塞 I/O 来提升开发效率和更好的维护性;
对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发。
我们先看一下 NIO 涉及到的核心关联类图,如下:
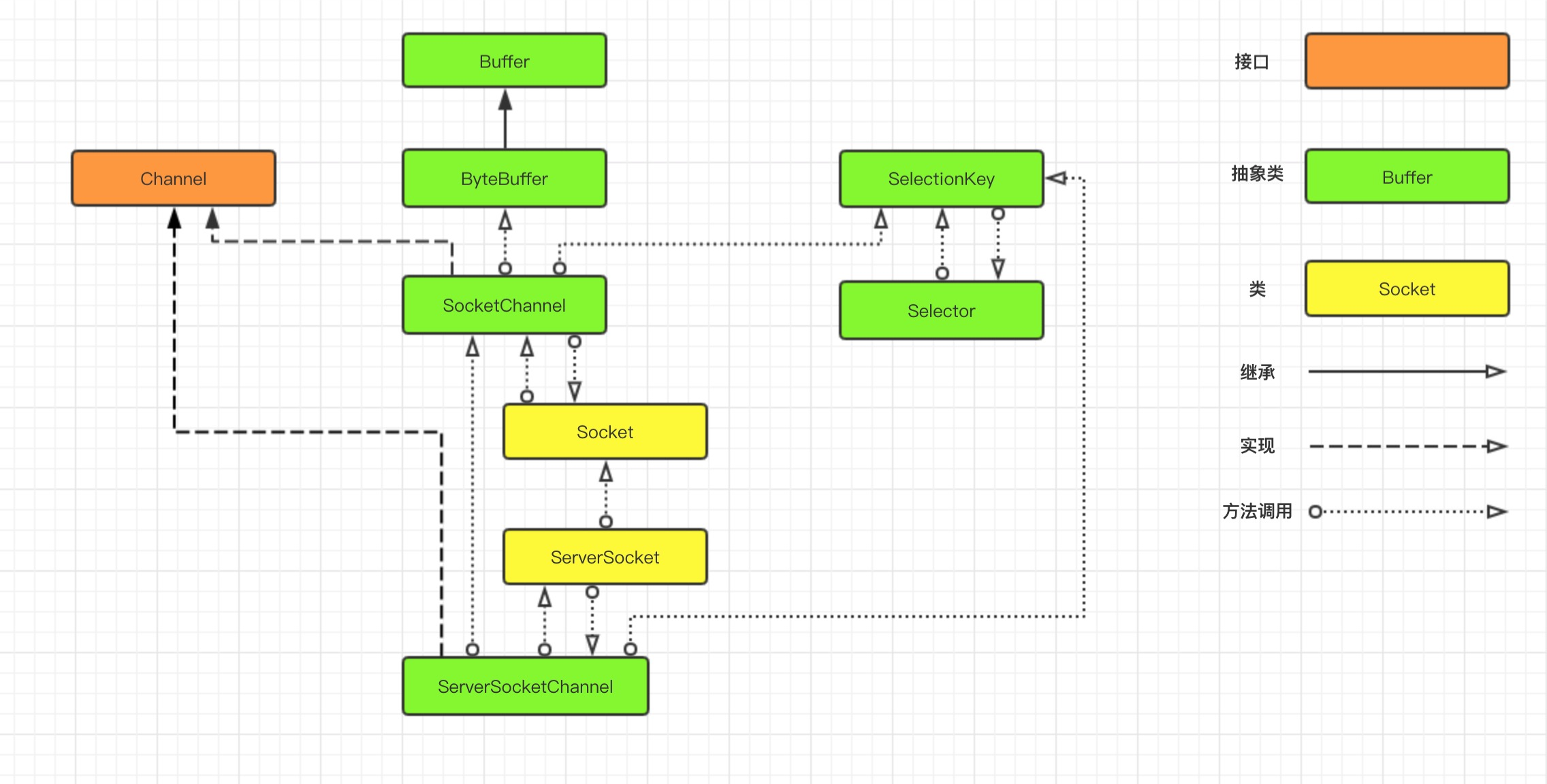
上图中有三个关键类:Channel 、Selector 和 Buffer,它们是 NIO 中的核心概念。
- Channel:可以理解为通道;
- Selector:可以理解为选择器;
- Buffer:可以理解为数据缓冲流;
我们还是用前面的城市交通工具来继续形容 NIO 的工作方式,这里的 Channel 要比 Socket 更加具体,它可以比作为某种具体的交通工具,如汽车或是高铁、飞机等,而 Selector 可以比作为一个车站的车辆运行调度系统,它将负责监控每辆车的当前运行状态:是已经出站还是在路上等等,也就是说它可以轮询每个 Channel 的状态。
还有一个 Buffer 类,你可以将它看作为 IO 中 Stream,但是它比 IO 中的 Stream 更加具体化,我们可以将它比作为车上的座位,Channel 如果是汽车的话,那么 Buffer 就是汽车上的座位,Channel 如果是高铁,那么 Buffer 就是高铁上的座位,它始终是一个具体的概念,这一点与 Stream 不同。
Socket 中的 Stream 只能代表是一个座位,至于是什么座位由你自己去想象,也就是说你在上车之前并不知道这个车上是否还有没有座位,也不知道上的是什么车,因为你并不能选择,这些信息都已经被封装在了运输工具(Socket)里面了。
NIO 引入了 Channel、Buffer 和 Selector 就是想把 IO 传输过程中涉及到的信息具体化,让程序员有机会去控制它们。
当我们进行传统的网络 IO 操作时,比如调用 write() 往 Socket 中的 SendQ 队列写数据时,当一次写的数据超过 SendQ 长度时,操作系统会按照 SendQ 的长度进行分割的,这个过程中需要将用户空间数据和内核地址空间进行切换,而这个切换不是程序员可以控制的,由底层操作系统来帮我们处理。
而在 Buffer 中,我们可以控制 Buffer 的 capacity(容量),并且是否扩容以及如何扩容都可以控制。
还是以上面的操作为例子,为了方便观看结果,本次的客户端线程请求数改成15个。
客户端,程序如下:
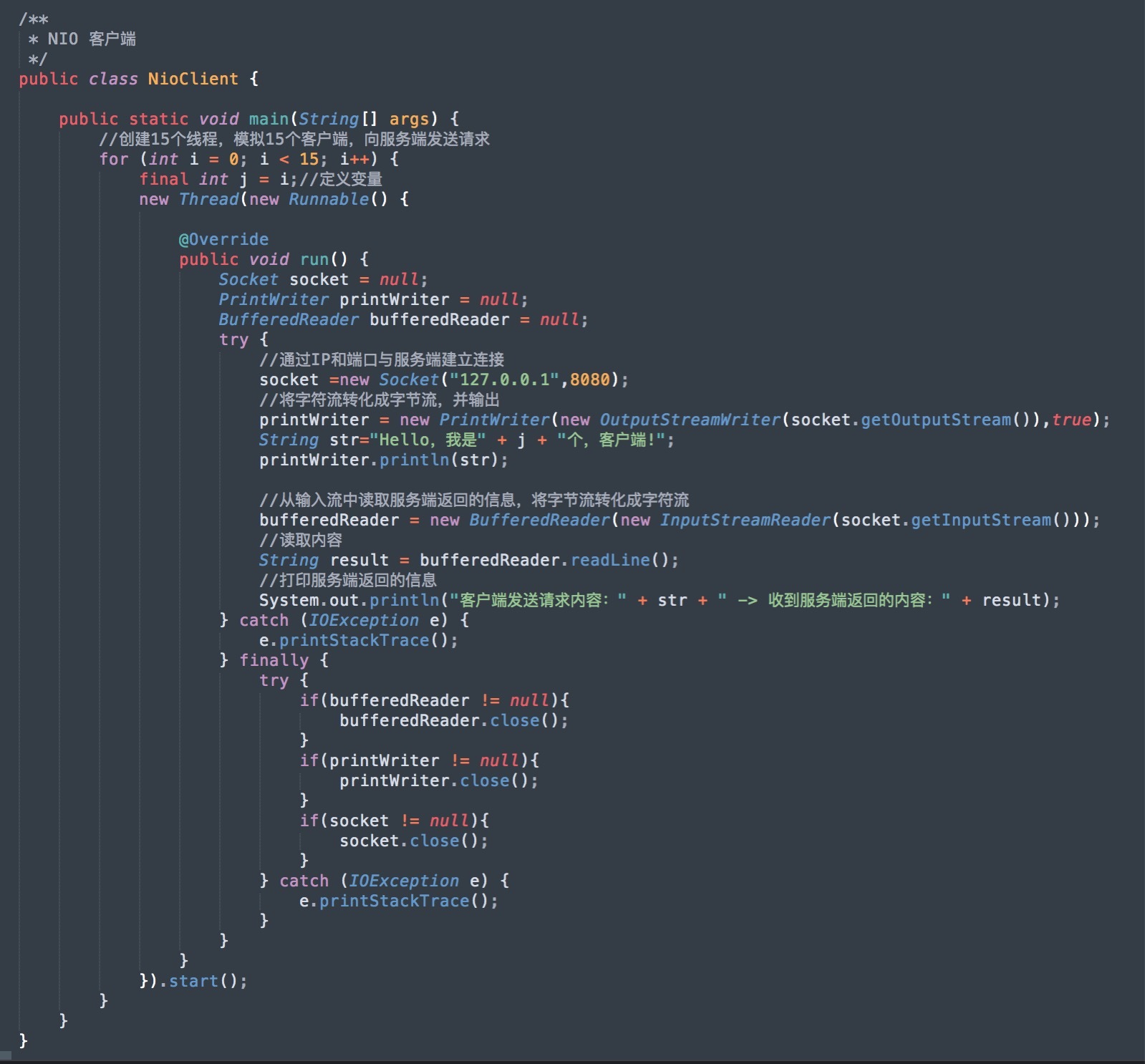
服务端,程序如下:
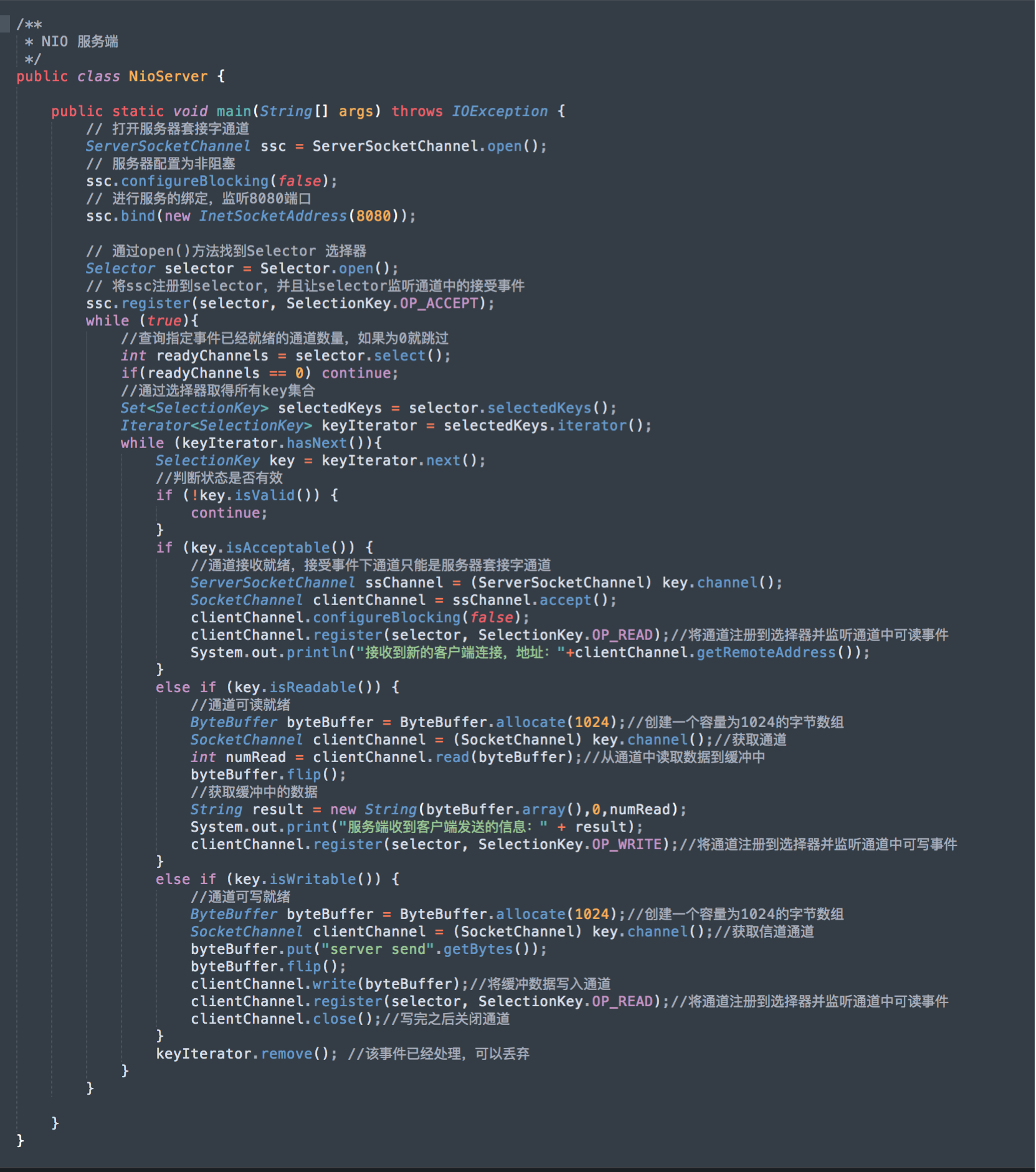
先启动服务端程序,再启动客户端程序,看看运行结果!
服务端,运行结果如下:
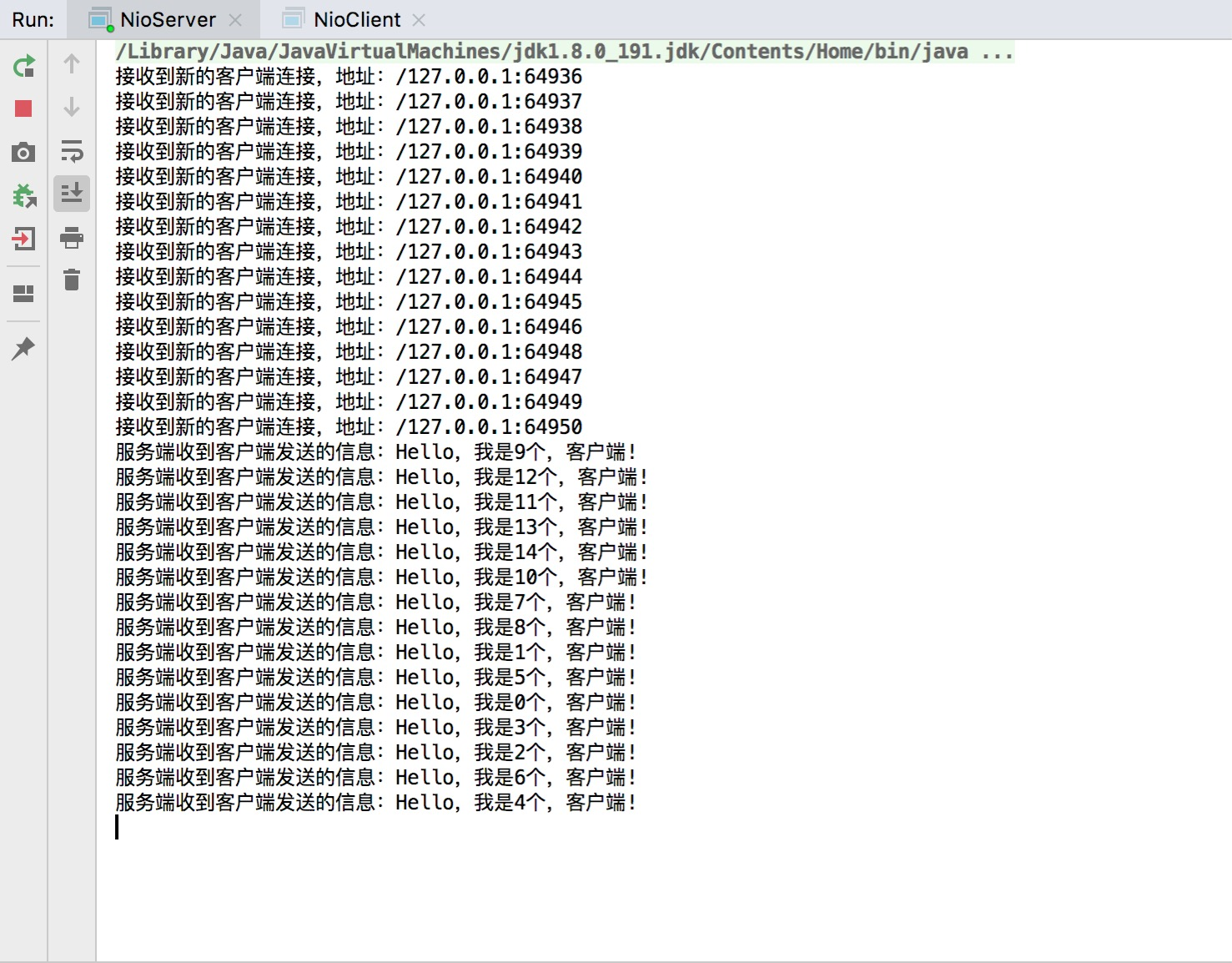
客户端,运行结果如下:

当然,客户端也不仅仅只限制于 IO 的写法,还可以使用SocketChannel 来操作客户端,程序如下:
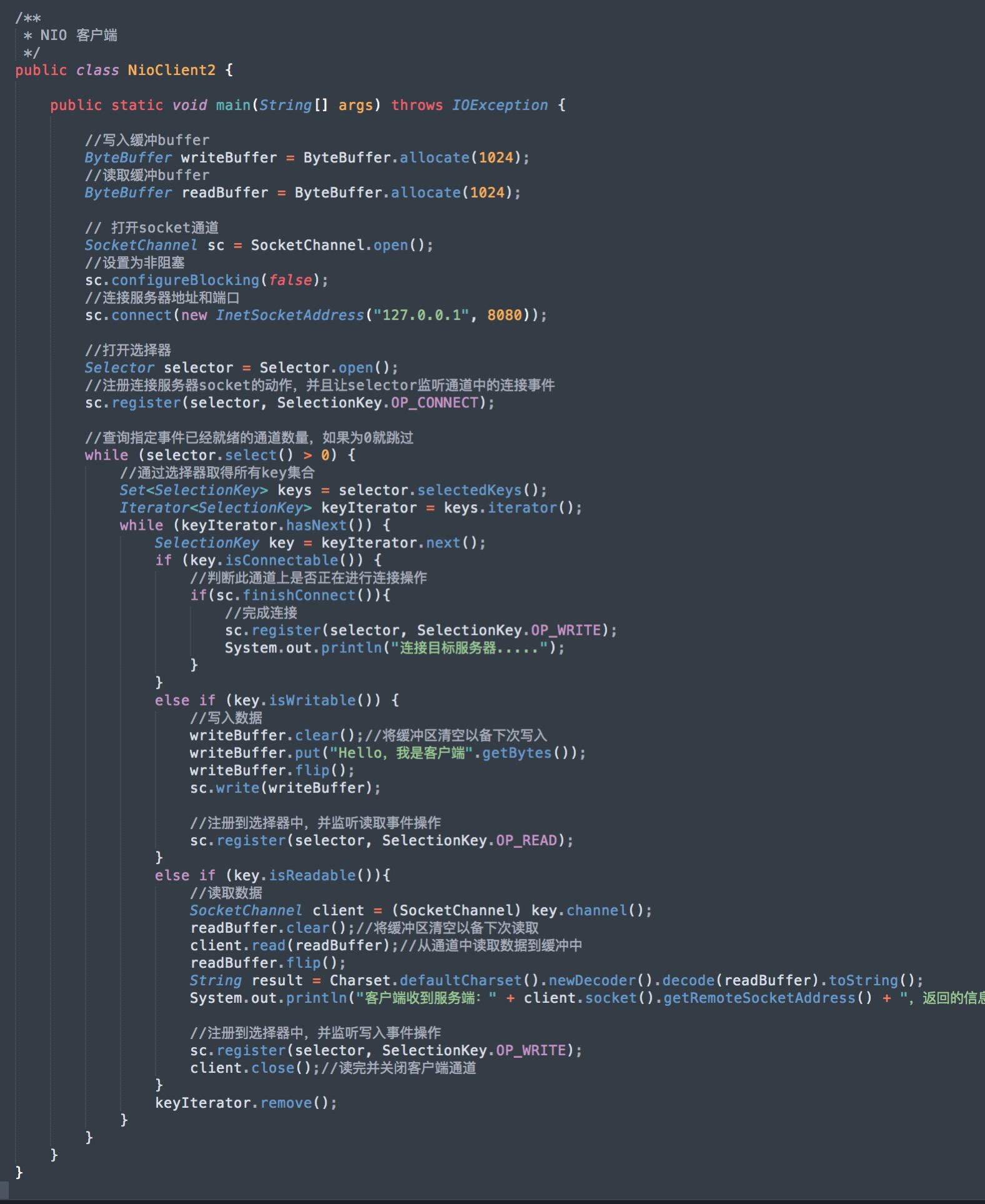
从操作上可以看到,NIO 的操作比传统的 IO 操作要复杂的多!
Selector 被称为选择器 ,当然你也可以翻译为多路复用器 。它是Java NIO 核心组件中的一个,用于检查一个或多个 Channel(通道)的状态是否处于连接就绪、接受就绪、可读就绪、可写就绪。
如此可以实现单线程管理多个 channels,也就是可以管理多个网络连接。
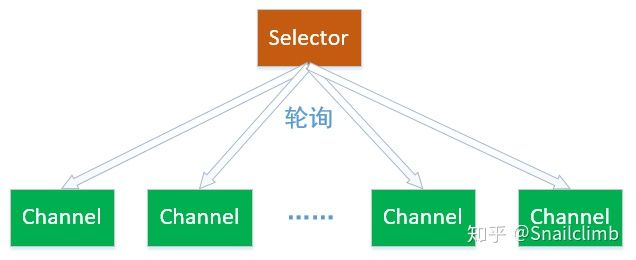
使用 Selector 的好处在于: 相比传统方式使用多个线程来管理 IO,Selector 使用了更少的线程就可以处理通道了,并且实现网络高效传输!
虽然 java 中的 nio 传输比较快,为什么大家都不愿意用 JDK 原生 NIO 进行开发呢?
从上面的代码中大家都可以看出来,除了编程复杂、编程模型难之外,还有几个让人诟病的问题:
- JDK 的 NIO 底层由 epoll 实现,该实现饱受诟病的空轮询 bug 会导致 cpu 飙升 100%!
- 项目庞大之后,自行实现的 NIO 很容易出现各类 bug,维护成本较高!
但是,Google 的 Netty 框架的出现,很大程度上改善了 JDK 原生 NIO 所存在的一些让人难以忍受的问题。
AIO
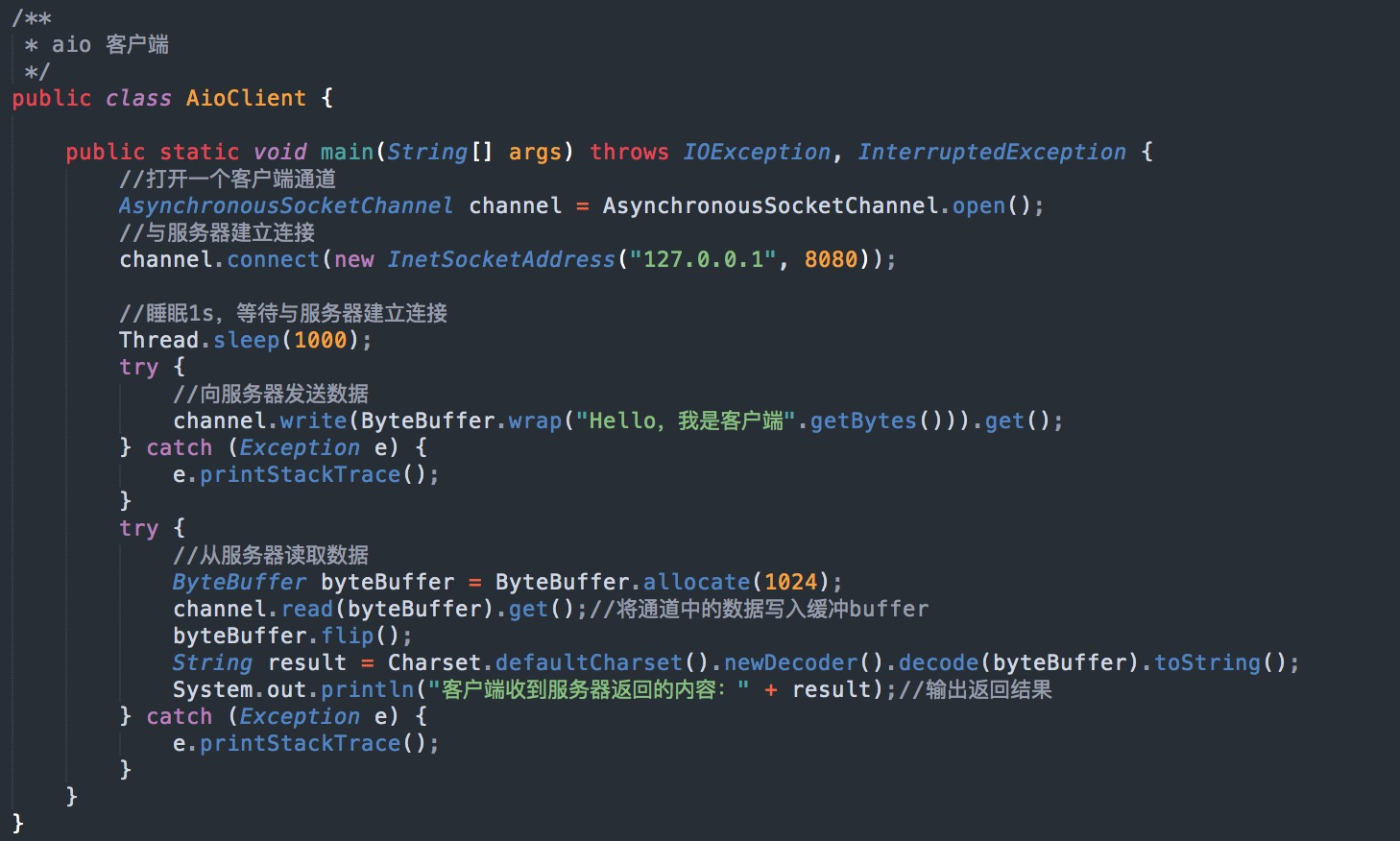
最后就是 AIO 了,全称 Asynchronous I/O,可以理解为异步 IO,也被称为 NIO 2,在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的 IO 模型,也就是我们现在所说的 AIO。
异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
客户端,程序示例:
服务端,程序示例:
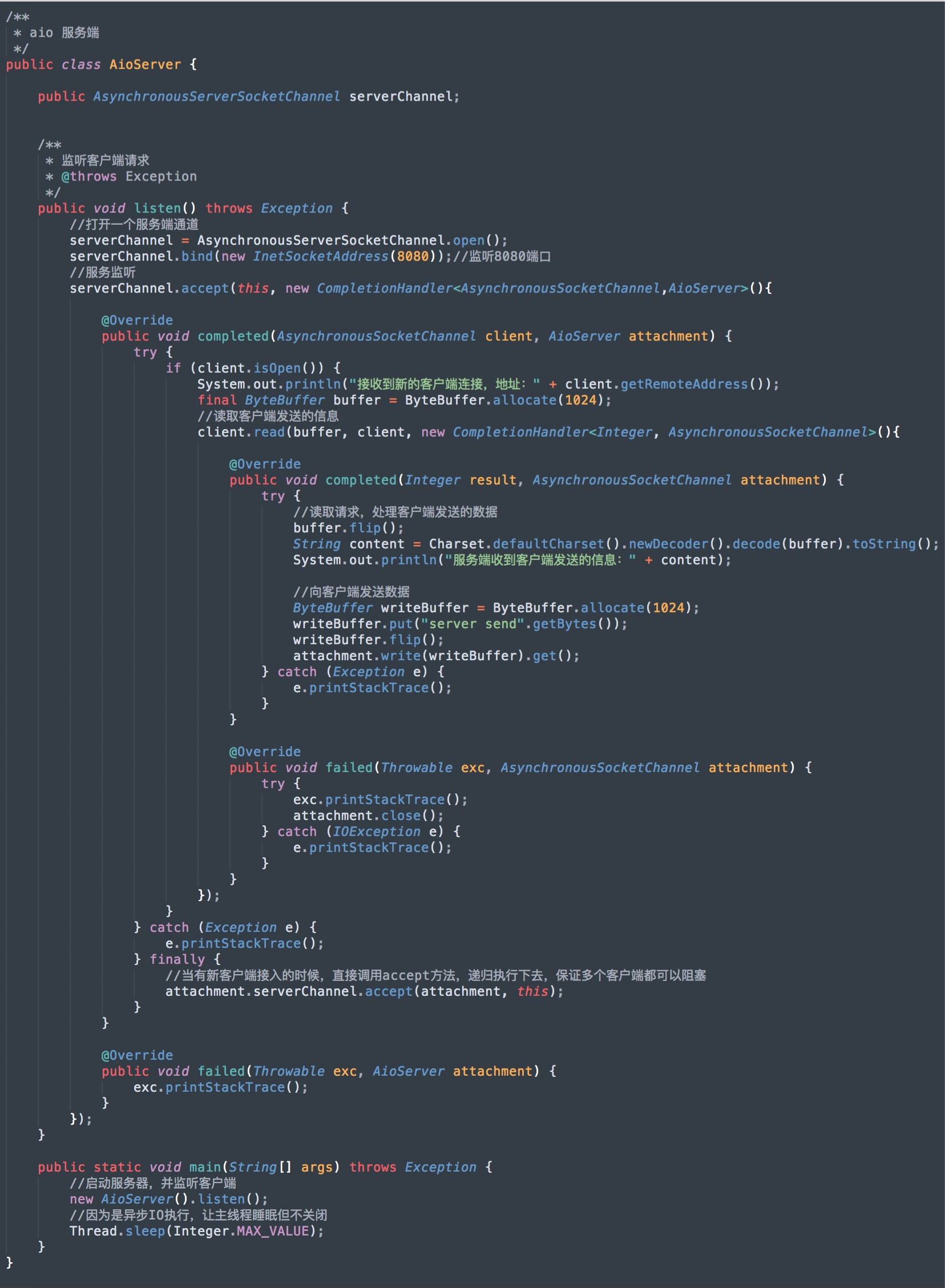
这种组合方式用起来比较复杂,只有在一些非常复杂的分布式情况下使用,像集群之间的消息同步机制一般用这种 I/O 组合方式。如 Cassandra 的 Gossip 通信机制就是采用异步非阻塞的方式。
参考资料
7 - CH07-IO模型
用户空间与内核空间
我们知道现在的操作系统都是采用虚拟存储器,那么对 32 位操作系统来说,它的寻址空间即虚拟存储空间为 4G,2 的 32 次方。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核,保证内核的的安全,操作系统将虚拟内存空间划分为两部分,一部分是内核空间,一部分是用户空间。
针对 Linux 操作系统而言,将最高的 1G 字节,即从虚拟地址 0xC0000000 到 0xFFFFFFFF 供内核使用,称为内核空间。而较低的 3G 字节,即从虚拟地址 0x00000000 到 0xBFFFFFFF,供进程使用,称为用户空间。每个进程都可以通过系统调用进入内核,因此 Linux 内核由系统内的所有进程共享。于是,从具体进程的角度看,每个进程可以拥有 4G 字节的虚拟空间。
有了用户空间和内核空间,整个 Linux 内部结构可以分为三个部分,从最底层到最上层依次是:硬件、内核空间、用户空间。
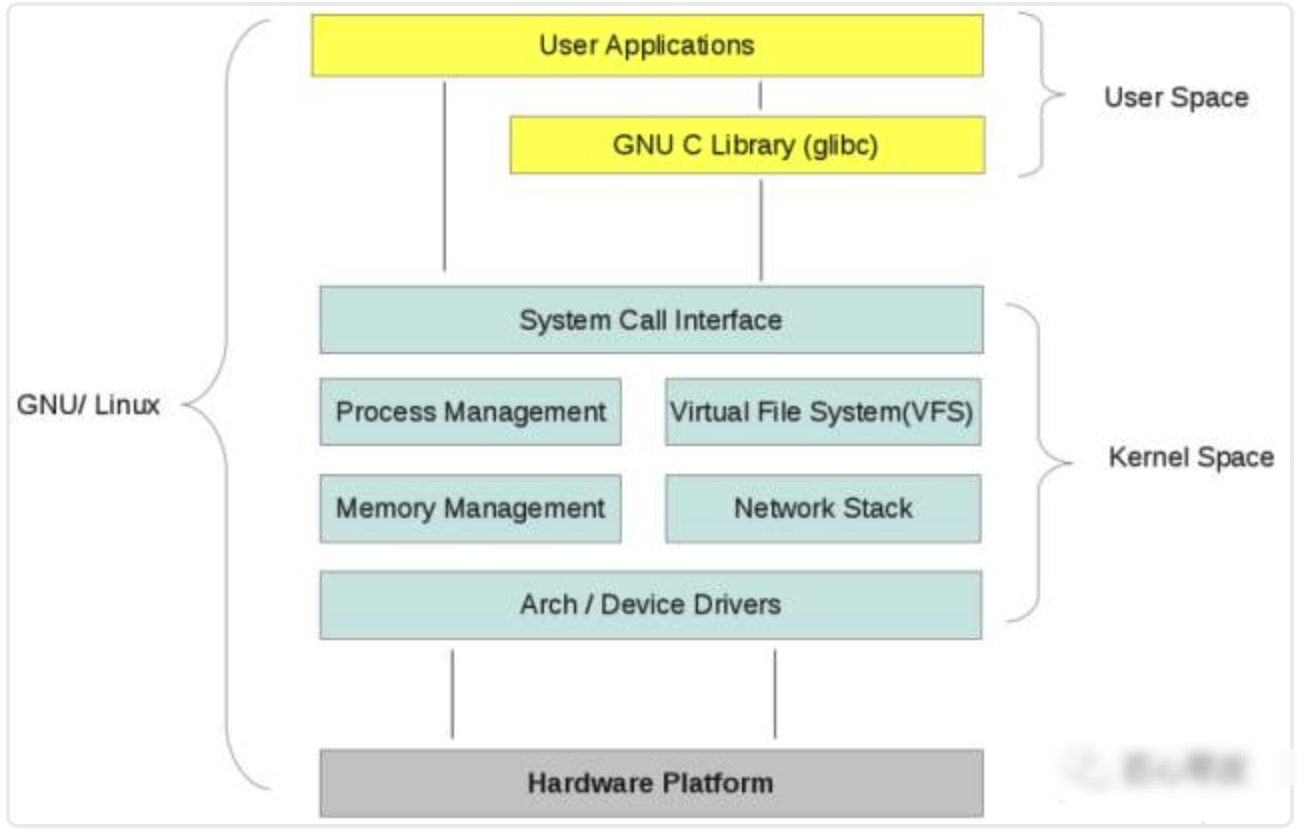
需要注意的细节是,从上图可以看出内核的组成:
- 内核空间中存放的是内核代码和数据,而进程的用户空间存放的是用户程序的代码和数据。不管是内核空间还是用户空间,都处于虚拟空间之中。
- Linux 使用两级保护机制:0 级供内核使用,3 级供用户程序使用。
服务端处理网络请求的流程
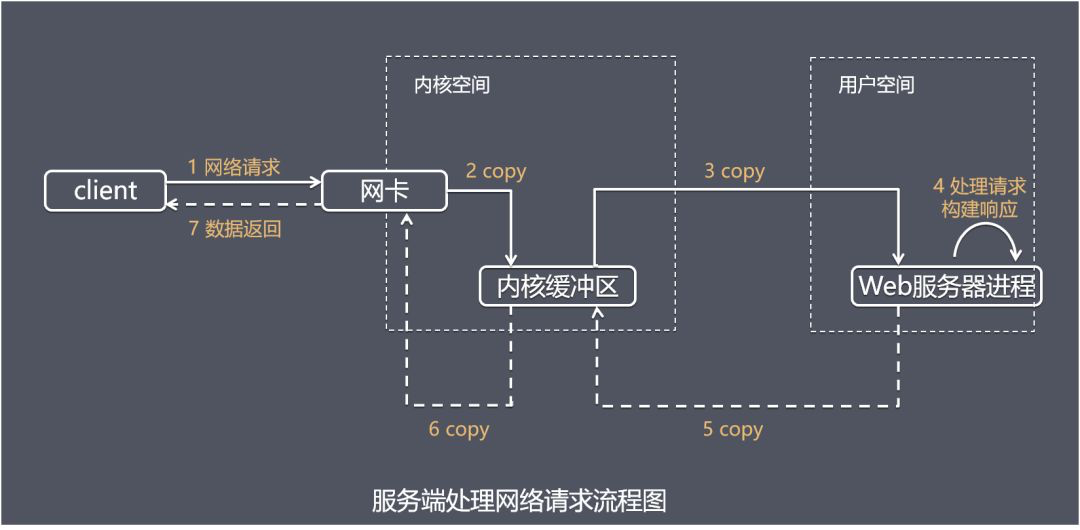
为了 OS 的安全性等考虑,进程是无法直接操作 IO 设备的,其必须通过系统调用来请求内核以协助完成 IO 动作,而内核会为每个 IO 设备维护一个 buffer。
整个请求过程为:
- 用户进程发起请求;
- 内核接收到请求后;
- 从 IO 设备中获取数据到 buffer 中;
- 再将 buffer 中的数据 copy 到用户进程的地址空间;
- 该用户进程获取到数据后再响应客户端。
服务端处理网络请求的典型流程图如下:
在请求过程中,数据从 IO 设备输入至 buffer 需要时间,从 buffer 复制将数据复制到用户进程也需要时间。因此根据在这两段时间内等待方式的不同,IO 动作可以分为以下五种:
- 阻塞 IO,Blocking IO
- 非阻塞 IO,Non-Blocking IO
- IO 复用,IO Multiplexing
- 信号驱动的 IO,Signal Driven IO
- 异步 IO,Asynchrnous IO
更多细节参考 <Unix 网络编程>,6.2 节 “IO Models”。
设计服务端并发模型时,主要有如下两个关键点:
- 服务器如何管理连接,获取请求数据。
- 服务器如何处理请求。
以上两个关键点最终都与操作系统的 I/O 模型以及线程(进程)模型相关,下面详细介绍这两个模型。
阻塞/非阻塞、同步/异步
阻塞/非阻塞:
- 阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
- 非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
区别:
- 两者的最大区别在于被调用方在收到请求到返回结果之前的这段时间内,调用方是否一直在等待。
- 阻塞是指调用方一直在等待而且别的事情什么都不做;非阻塞是指调用方先去忙别的事情。
同步/异步:
- 同步处理是指被调用方得到最终结果之后才返回给调用方;
- 异步处理是指被调用方先返回应答,然后再计算调用结果,计算完最终结果后再通知并返回给调用方。
区别与联系
阻塞、非阻塞和同步、异步其实针对的对象是不一样的:
- 阻塞、非阻塞的讨论对象是调用者。
- 同步、异步的讨论对象是被调用者。
Linux 网络 I/O 模型
recvfrom 函数
recvfrom 函数(经 Socket 接收数据),这里把它视为系统调用。一个输入操作通常包括两个不同的阶段:
- 等待数据准就绪。
- 从内核向应用进程复制数据。
对于一个套接字上的输入操作,第一步通常涉及等待数据从网络中到达。当所等待分组到达时,它被复制到内核中的某个缓冲区。第二步就是把数据从内核缓冲区复制到应用进程缓冲区。
实际应用程序在通过系统调用完成上面的 2 步操作时,调用方式的阻塞、非阻塞,操作系统在处理应用程序请求时处理方式的同步、异步,可以分为 5 种 I/O 模型。
阻塞式 IO
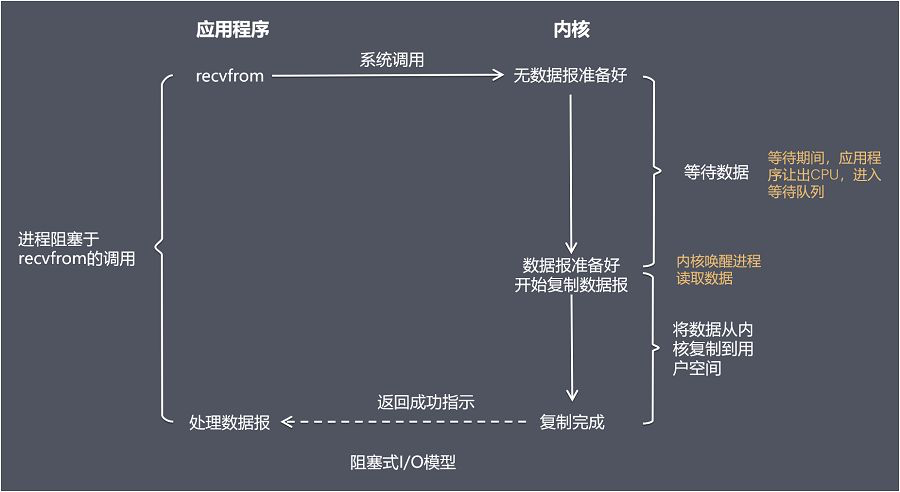
在阻塞式 IO 模型中,应用程序从调用 recvfrom 开始到它返回有数据报准备好这段时间是阻塞的,recvfrom 返回成功后,应用程序开始处理数据报。
- 优点:程序实现简单,在阻塞等待数据期间,进程、线程挂起,基本不会占用 CPU 资源。
- 每个连接需要独立的进程、线程单独处理,当并发请求量大时为了维护程序,内存、线程切换开销很大,这种模型在实际生产中很少使用。
非阻塞 IO
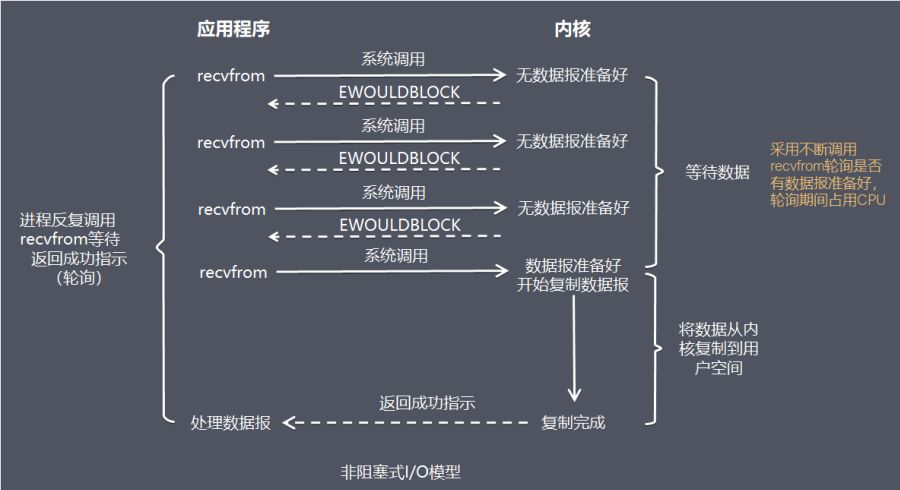
在非阻塞 IO 模型中,应用程序把一个套接口设置为非阻塞,就是告诉内核,当所有请求的 IO 操作无法完成时,不要将进程睡眠。
而是返回一个错误,应用程序基于 IO 操作函数,将会不断的轮询数据是否已经准备就绪,直到数据准备就绪。
- 优点:不会阻塞在内核的等待数据过程,每次发起的 IO 请求可以立即返回,不会阻塞等待,实时性比较好。
- 缺点:轮询将会不断的询问内核,这将占用大量的 CPU 时间,系统资源利用率较低,所以一般 Web 服务器不会使用这种 IO 模型。
IO 多路复用

在 IO 复用模型中,会用到 Select、Poll、Epoll 函数,这些函数会使进程阻塞,但是和阻塞 IO 有所不同。
这些函数可以同时阻塞多个 IO 操作,而且可以同时对多个读、写操作的 IO 函数进行检测,直到有数据可读或可写时,才会真正调用 IO 操作函数。
- 优点:可以基于一个阻塞对象,同时在多个描述符上等待就绪,而不是使用多个线程(每个文件描述符一个线程),这样可以大大节省系统资源。
- 当连接数较少时效率比“多线程+阻塞IO”的模式效率低,可能延迟更大,因为单个连接处理需要 2 次系统调用,占用时间会增加。
信号驱动 IO
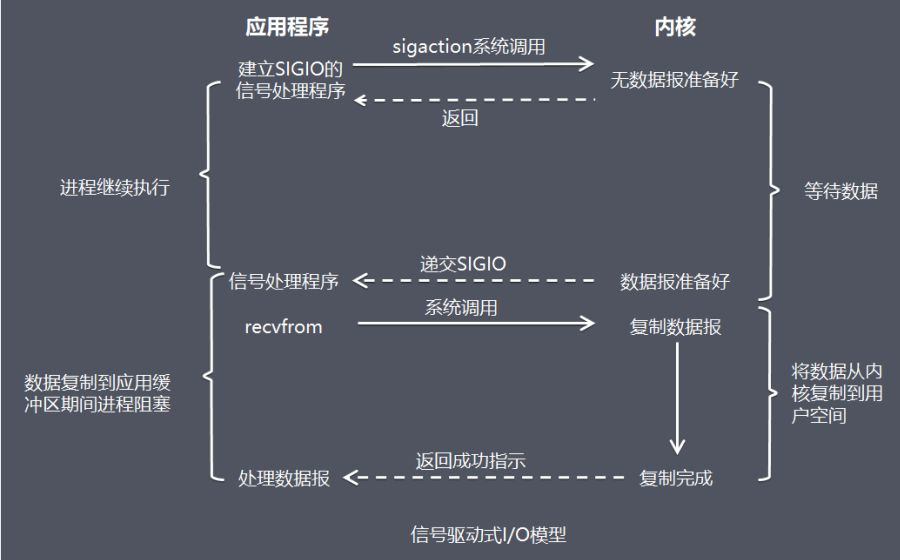
在信号驱动 IO 模型中,应用程序使用套接口进行信号驱动 IO,并安装一个信号处理函数,进程继续运行并不阻塞。
当数据准备好时,进程会收到一个 SIGIO 信号,可以在信号处理函数中调用 IO 操作函数处理数据。
- 优点:线程没有在等待数据时被阻塞,可以提高资源利用率。
- 缺点:信号 IO 模式在大量 IO 操作时可能会因为信号队列溢出而导致无法通知。
信号驱动 IO 尽管对于处理 UDP 套接字来说有用,即这种信号通知意味着到达了一个数据报,或者返回一个异步错误。
但是,对于 TCP 而言,信号驱动 IO 方式近乎无用。因为导致这种通知的条件为数众多,逐个进行判断会消耗很大的资源,与前几种方式相比优势尽失。
异步 IO
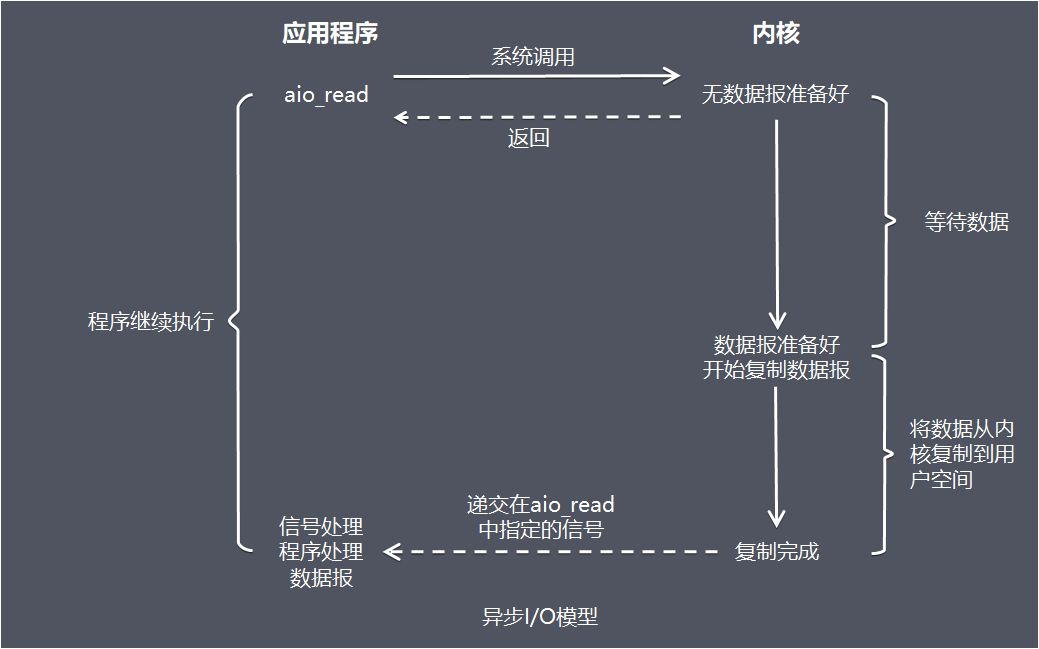
由 POSIX 规范定义,应用程序告知内核启动某个操作,并让内核在整个操作完成后(包括将数据从内核拷贝到应用程序的缓冲区)通知应用程序。
这种模型与信号驱动模型的主要区别在于:信号驱动 IO 是由内核通知应用程序合适启动一个 IO 操作,而异步 IO 模型是由内核通知应用程序 IO 操作合适完成。
- 优点:异步 IO 能够充分利用 DMA 特性,让 IO 操作与计算重叠。
- 缺点:需要实现真正的异步 IO,操作系统需要做大量的工作。当前 Windows 下通过 IOCP 实现了真正的异步 IO。
而在 Linux 系统下直到 2.6 版本才引入,目前 AIO 并不完善,因此在 Linux 下实现并发网络编程时都是以 IO 复用模型为主。
IO 模型对比

从上图可以看出,越往后,阻塞越少,理论上效率也最优。
这五种模型中,前四种属于同步 IO,因为其中真正的 IO 操作(recvfrom 函数调用)将阻塞进程/线程,只有异步 IO 模型才与 POSIX 定义的异步 IO 相匹配。
进程/线程模型
介绍完服务器如何基于 IO 模型管理连接、获取输入数据,下面介绍服务器如何基于进程、线程模型来处理请求。
传统阻塞 IO 服务模型
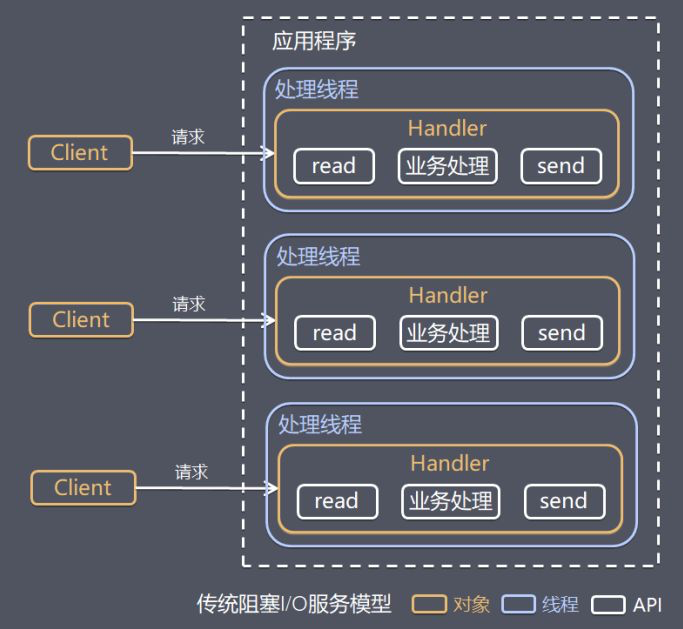
特点:
- 采用阻塞式 IO 模型获取输入数据。
- 每个连接都需要独立的线程完成数据输入的读取、业务处理、数据返回操作。
存在问题:
- 当请求的并发数较大时,需要创建大量线程来处理连接,系统资源占用较大。
- 当连接建立后,如果当前线程暂时没有数据可读,则线程就阻塞在 Read 操作上,造成线程资源浪费。
Reactor 模式
针对传统阻塞 IO 服务模型的 2 个缺点,比较常见的有如下解决方案:
- 基于 IO 复用模型,多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象上等待,无需阻塞等待所有连接。
- 当某条连接有新的数据可处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务处理。
- 基于线程池复用线程资源,不必再为每个连接创建线程,将连接完成后的业务处理任务分配给线程进行处理,一个线程可以多个连接的业务。
IO 复用模式结合线程池,就是 Reactor 模式的基本设计思想,如下图:
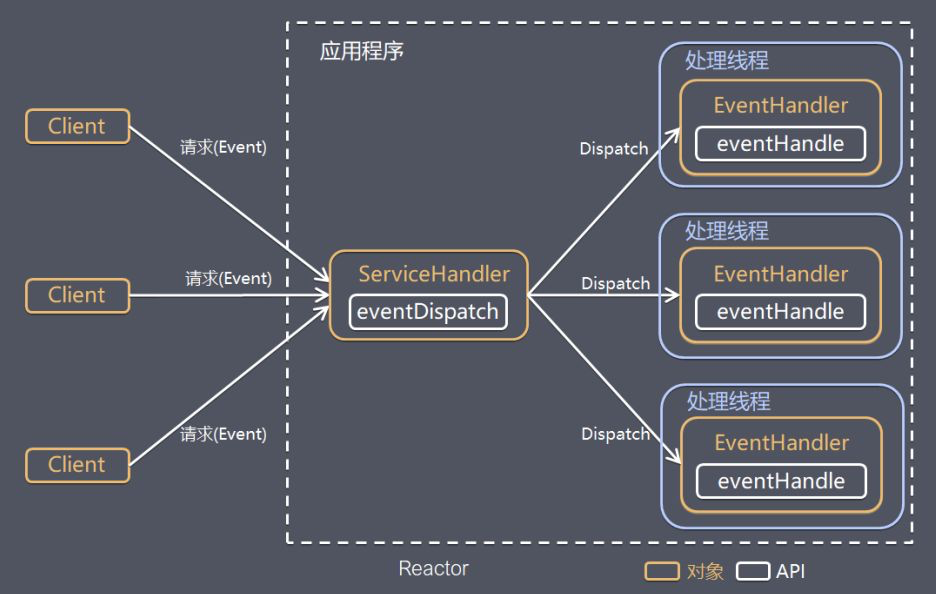
Reactor 模式,是指通过一个或多个输入同时传递给服务器来处理服务请求的事件驱动处理模式。
服务端程序处理传入的多路请求,并将它们同步分派给请求对应的处理线程,Reactor 模式也叫 Dispatcher 模式。
即 IO 多路复用以统一的方式监听事件,收到事件后分发(Dispatch 给某线程),是编写高性能服务器的必备技术之一。
Reactor 模式有两个关键组件构成:
- Reactor:在一个单独的线程中运行,负责监听和分发事件,分发给适当的处理程序对 IO 事件做出反应。它就像公司的电话接线员,接听来自客户的电话并将线路转移给适当的联系人。
- Handlers:处理程序执行 IO 事件需要完成的实际组件,类似于客户想要与之交谈的客服坐席。Reactor 通过调度适当的处理程序来响应 IO 事件,处理程序执行非阻塞操作。
根据 Reactor 的数量和处理资源池线程的数量不同,有 3 种典型的实现:
- 单 Reactor 单线程
- 单 Reactor 多线程
- 主从 Reactor 多线程
单 Reactor 单线程
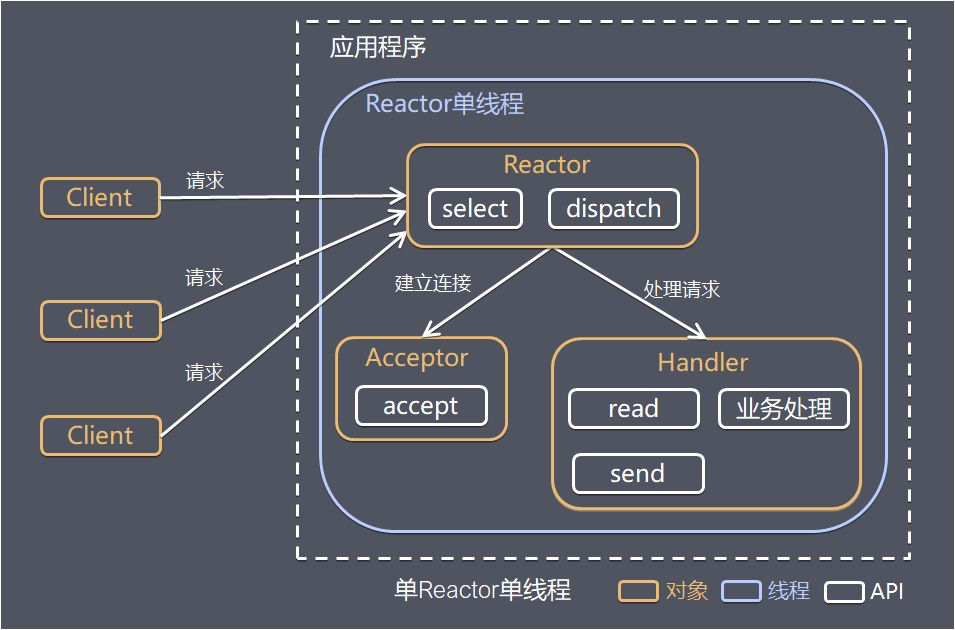
其中,Select 是前面 IO 复用模型介绍的标准网络编程 API,可以实现应用程序通过一个阻塞多向监听多路连接请求,其他方案的示意图也类似。
方案说明:
Reactor 对象通过 Select 监听客户端请求事件,收到事件后通过 Dispatch 进行分发。
如果是“建立连接”请求事件,则由 Acceptor 通过 Accept 处理连接请求,同时创建一个 Handler 对象来处理连接完成后的后续业务处理。
如果不是“建立连接”事件,则 Reactor 会分发调用“连接”对应的 Handler 来响应。
Handler 会完成 “Read->业务处理->Send” 的完整业务流程。
优点:模型简单,没有多线程、进程通信、竞争的问题,全部都在一个线程中完成。
缺点:性能问题,只有一个线程,无法完全发挥多个 CPU 的性能。Handler 在处理某个连接上的业务时,整个进程无法处理其他连接事件,很容易导致性能瓶颈。
可靠性问题、线程意外跑飞、进入死循环,或导致整个系统的通信模块不可用,不能接收或处理外部消息,造成节点故障。
应用场景:客户端的数量有限,业务处理非常快,比如 Redis,业务处理的时间复杂度为 O(1)。
单 Reactor 多线程
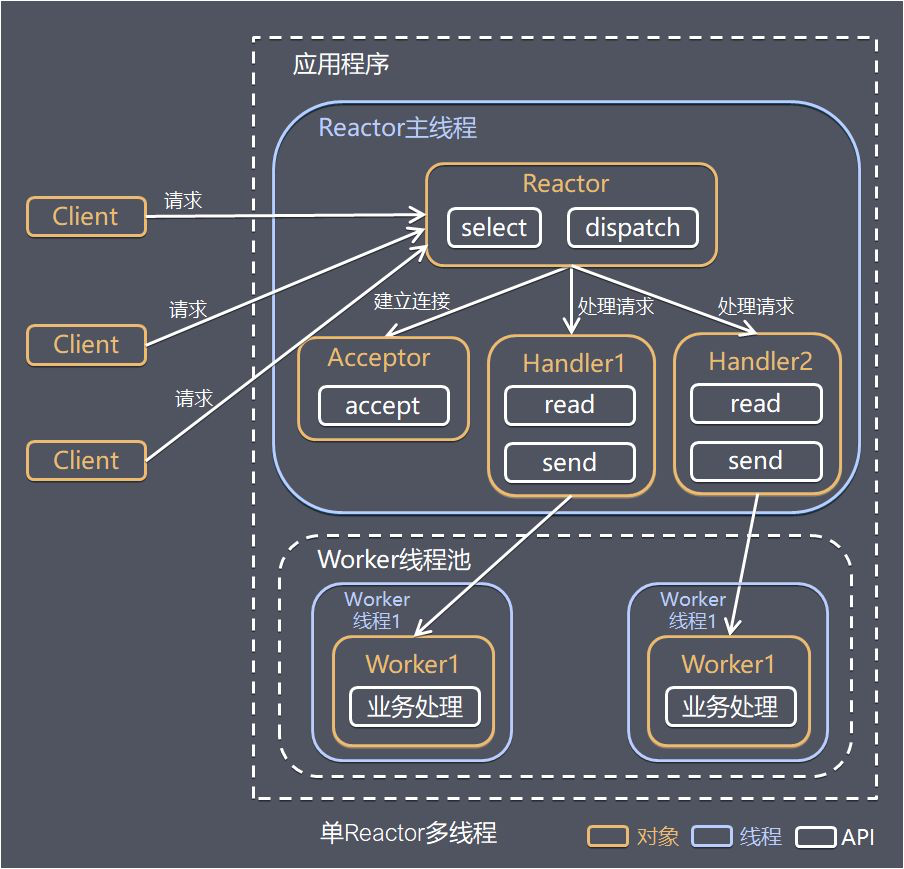
Reactor 对象通过 Select 监控客户端请求事件,收到事件后通过 Dispatch 进行分发。
如果是建立连接请求事件,则由 Acceptor 通过 Accept 处理连接请求,同时创建一个 Handler 对象处理连接完成后续的各种事件。
如果不是建立连接事件,则 Reactor 会分发调用连接对应的 Handler 来响应。
Handler 只负责响应事件,不做具体业务处理,通过 Read 读取数据后,会分发给后面的 Worker 线程池进行业务处理。
Worker 线程池会分配独立的线程完成真正的业务处理,如何将响应结果发给 Handler 进行处理。
Handler 收到响应结果后通过 Send 将响应结果返回给 Client。
优点:可以充分利用多核 CPU 的处理能力。
缺点:
- 多线程数据共享和访问比较复杂;
- Reactor 承担所有事件的监听和响应,在单线程中运行,高并发场景下容易成为性能瓶颈。
主从 Reactor 多线程
针对单 Reactor 多线程模型中,Reactor 在单线程中运行,高并发场景下容易成为性能瓶颈,可以让 Reactor 在多线程中运行。
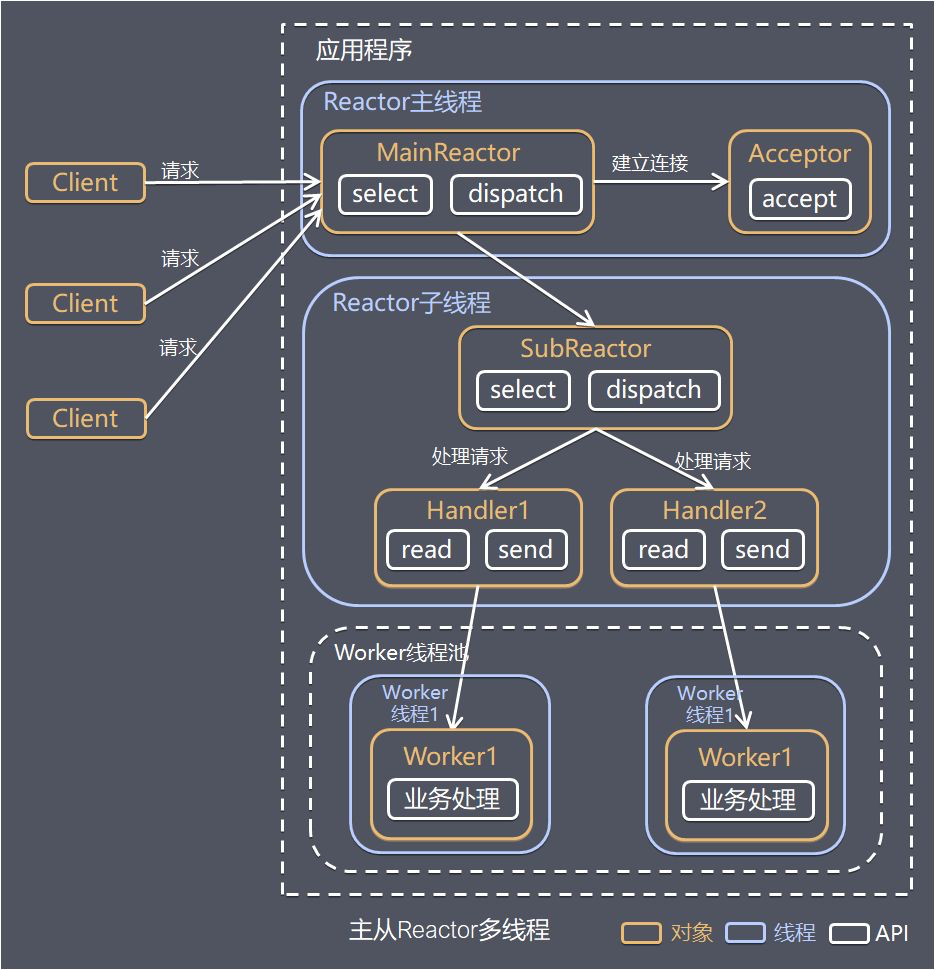
Reactor 主线程 MainReactor 对象通过 Select 监控建立连接事件,收到事件后通过 Acceptor 接收,处理建立连接事件。
Acceptor 处理建立连接事件后,MainReactor 将连接分配 Reactor 子线程给 SubReactor 进行处理。
SubReactor 将连接加入连接队列进行监听,并创建一个 Handler 用于处理各种连接事件。
当有新的事件发生时,SubReactor 会调用连接对应的 Handler 进行响应。
Handler 通过 Read 读取数据后,会分发给后面的 Worker 线程池进行业务处理。
Worker 线程池会分配独立的线程完成真正的业务处理,如何将响应结果发给 Handler 进行处理。
Handler 收到响应结果后通过 Send 将响应结果返回给 Client。
优点:父线程与子线程的数据交互简单、职责明确,父线程只需要接收新连接,子线程完成后续的业务处理。
父线程与子线程的数据交互简单,Reactor 主线程只需要把新连接传递给子线程即可,子线程无需返回数据。
这种模型在很多项目中广泛使用,包括 Nginx 主从 Reactor 多线程模型,Memcached 主从多线程。
Reactor 模式总结
三种模式可以用一个比喻来理解:餐厅常常雇佣接待员负责迎接顾客,当顾客入座后,侍应生专门为这张桌子服务。
- 单 Reactor 单线程:接待员和侍应生是同一个人,全程为顾客服务。
- 单 Reactor 多线程:一个接待员、多个侍应生,接待员只负责接待。
- 主从 Reactor:多个接待员,多个侍应生。
Reactor 模式具有如下的优点:
- 响应快:不必为单个同步时间所阻塞,虽然 Reactor 本身依然是同步的。
- 编程相对简单:可以最大程度的避免复杂的多线程及同步问题,并且避免了多线程的切换开销。
- 可扩展性:可以方便的通过增加 Reactor 实例个数来充分利用 CPU 资源。
- 可复用性:Reactor 模型本身与具体事件处理逻辑无关,具有很高的复用性。
Proactor 模型
在 Reactor 模式中,Reactor 等待某个事件、可应用或操作的状态发生(比如文件描述符可读、Socket 可读写)。
然后把该事件传递给事先注册的 Handler(事件处理函数或回调函数),由后者来做实际的读写操作。
其中的读写操作都需要应用程序同步操作,所以 Reactor 是非阻塞同步网络模型。
如果把 IO 操作改为异步,即交给操作系统来完成 IO 操作,就能进一步提升性能,这就是异步网络模型 Proactor。
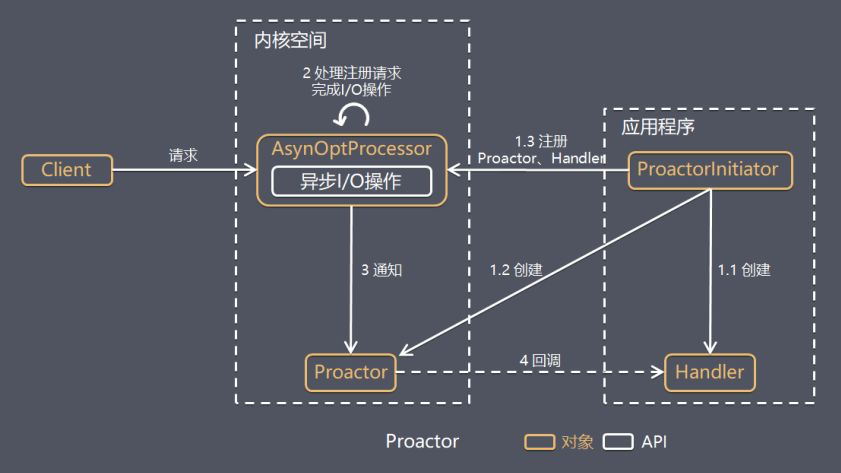
Proactor 是和异步 I/O 相关的,详细方案如下:
- ProactorInitiator 创建 Proactor 和 Handler 对象,并将 Proactor 和 Handler 都通过 AsyOptProcessor(Asynchronous Operation Processor) 注册到内核。
- AsyOptProcessor 处理注册请求,并处理 I/O 操作。
- AsyOptProcessor 完成 I/O 操作后通知 Proactor。
- Proactor 根据不同的事件类型回调不同的 Handler 进行业务处理。
- Handler 完成业务处理。
可以看出 Proactor 和 Reactor 的区别:
- Reactor 是在事件发生时就通知事先注册的事件(读写在应用程序线程中处理完成)。
- Proactor 是在事件发生时基于异步 I/O 完成读写操作(由内核完成),待 I/O 操作完成后才回调应用程序的处理器来进行业务处理。
理论上 Proactor 比 Reactor 效率更高,异步 I/O 更加充分发挥 DMA(Direct Memory Access,直接内存存取)的优势,但是有如下缺点:
- 编程复杂性:由于异步操作流程的事件的初始化和事件完成在时间和空间上都是相互分离的,因此开发异步应用程序更加复杂。应用程序还可能因为反向的流控而变得更加难以 Debug。
- 内存使用:缓冲区在读或写操作的时间段内必须保持住,可能造成持续的不确定性,并且每个并发操作都要求有独立的缓存,相比 Reactor 模式,在 Socket 已经准备好读或写前,是不要求开辟缓存的。
- 操作系统支持,Windows 下通过 IOCP 实现了真正的异步 I/O,而在 Linux 系统下,Linux 2.6 才引入,目前异步 I/O 还不完善。
因此在 Linux 下实现高并发网络编程都是以 Reactor 模型为主。
8 - CH08-BIO原理
概览
BIO就是: blocking IO。最容易理解、最容易实现的IO工作方式,应用程序向操作系统请求网络IO操作,这时应用程序会一直等待;另一方面,操作系统收到请求后,也会等待,直到网络上有数据传到监听端口;操作系统在收集数据后,会把数据发送给应用程序;最后应用程序受到数据,并解除等待状态。
概念
阻塞IO和非阻塞IO这两个概念是
程序级别的。主要描述的是程序请求操作系统IO操作后,如果IO资源没有准备好,那么程序该如何处理的问题: 前者等待;后者继续执行(并且使用线程一直轮询,直到有IO资源准备好了)同步IO和非同步IO这两个概念是
操作系统级别的。主要描述的是操作系统在收到程序请求IO操作后,如果IO资源没有准备好,该如何相应程序的问题: 前者不响应,直到IO资源准备好以后;后者返回一个标记(好让程序和自己知道以后的数据往哪里通知),当IO资源准备好以后,再用事件机制返回给程序。
BIO通信方式
以前大多数网络通信方式都是阻塞模式的,即:
- 客户端向服务器端发出请求后,客户端会一直等待(不会再做其他事情),直到服务器端返回结果或者网络出现问题。
- 服务器端同样的,当在处理某个客户端A发来的请求时,另一个客户端B发来的请求会等待,直到服务器端的这个处理线程完成上一个处理。
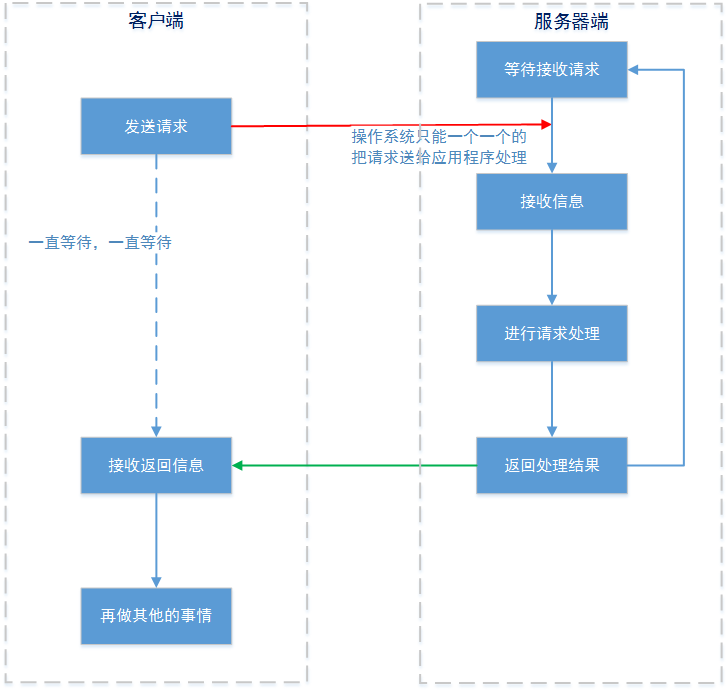
传统的BIO的问题
- 同一时间,服务器只能接受来自于客户端A的请求信息;虽然客户端A和客户端B的请求是同时进行的,但客户端B发送的请求信息只能等到服务器接受完A的请求数据后,才能被接受。
- 由于服务器一次只能处理一个客户端请求,当处理完成并返回后(或者异常时),才能进行第二次请求的处理。很显然,这样的处理方式在高并发的情况下,是不能采用的。
多线程方式 - 伪异步方式
上面说的情况是服务器只有一个线程的情况,那么读者会直接提出我们可以使用多线程技术来解决这个问题:
- 当服务器收到客户端X的请求后,(读取到所有请求数据后)将这个请求送入一个独立线程进行处理,然后主线程继续接受客户端Y的请求。
- 客户端一侧,也可以使用一个子线程和服务器端进行通信。这样客户端主线程的其他工作就不受影响了,当服务器端有响应信息的时候再由这个子线程通过 监听模式/观察模式(等其他设计模式)通知主线程。
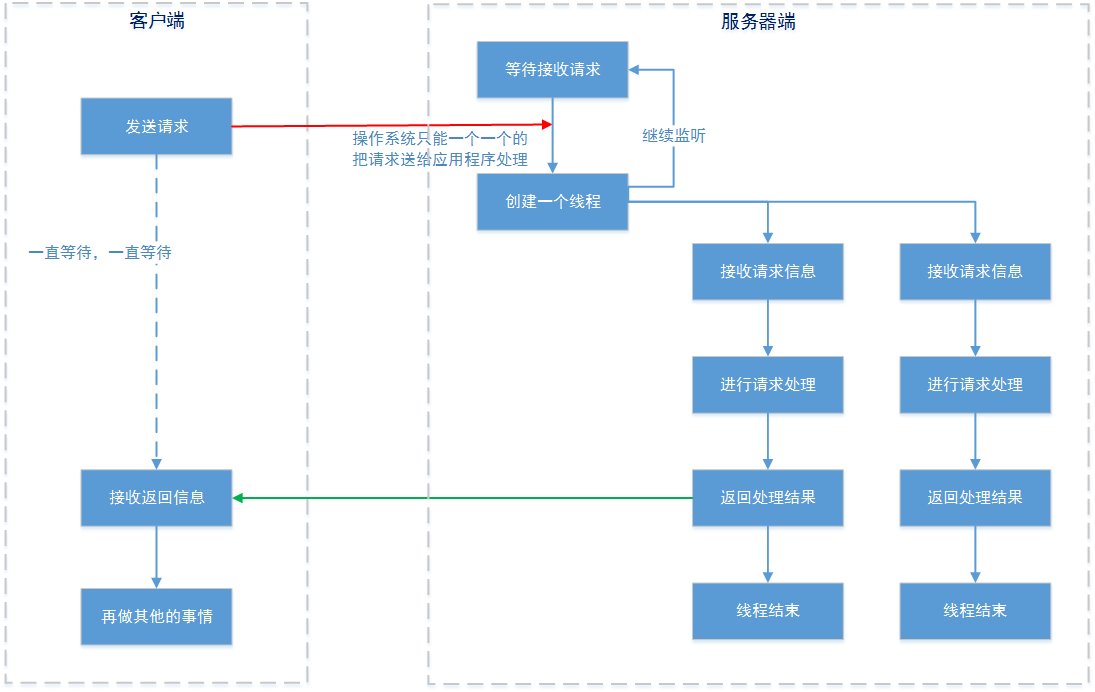
但是使用线程来解决这个问题实际上是有局限性的:
- 虽然在服务器端,请求的处理交给了一个独立线程进行,但是操作系统通知accept()的方式还是单个的。也就是,实际上是服务器接收到数据报文后的“业务处理过程”可以多线程,但是数据报文的接受还是需要一个一个的来(下文的示例代码和debug过程我们可以明确看到这一点)
- 在linux系统中,可以创建的线程是有限的。我们可以通过cat /proc/sys/kernel/threads-max 命令查看可以创建的最大线程数。当然这个值是可以更改的,但是线程越多,CPU切换所需的时间也就越长,用来处理真正业务的需求也就越少。
- 创建一个线程是有较大的资源消耗的。JVM创建一个线程的时候,即使这个线程不做任何的工作,JVM都会分配一个堆栈空间。这个空间的大小默认为128K,您可以通过-Xss参数进行调整。当然您还可以使用ThreadPoolExecutor线程池来缓解线程的创建问题,但是又会造成BlockingQueue积压任务的持续增加,同样消耗了大量资源。
- 另外,如果您的应用程序大量使用长连接的话,线程是不会关闭的。这样系统资源的消耗更容易失控。 那么,如果你真想单纯使用线程解决阻塞的问题,那么您自己都可以算出来您一个服务器节点可以一次接受多大的并发了。看来,单纯使用线程解决这个问题不是最好的办法。
深入分析
BIO的问题关键不在于是否使用了多线程(包括线程池)处理这次请求,而在于accept()、read()的操作点都是被阻塞。要测试这个问题,也很简单。我们模拟了20个客户端(用20根线程模拟),利用JAVA的同步计数器CountDownLatch,保证这20个客户都初始化完成后然后同时向服务器发送请求,然后我们来观察一下Server这边接受信息的情况。
模拟20个客户端并发请求,服务器端使用单线程:
客户端代码(SocketClientDaemon)
package testBSocket;
import java.util.concurrent.CountDownLatch;
public class SocketClientDaemon {
public static void main(String[] args) throws Exception {
Integer clientNumber = 20;
CountDownLatch countDownLatch = new CountDownLatch(clientNumber);
//分别开始启动这20个客户端
for(int index = 0 ; index < clientNumber ; index++ , countDownLatch.countDown()) {
SocketClientRequestThread client = new SocketClientRequestThread(countDownLatch, index);
new Thread(client).start();
}
//这个wait不涉及到具体的实验逻辑,只是为了保证守护线程在启动所有线程后,进入等待状态
synchronized (SocketClientDaemon.class) {
SocketClientDaemon.class.wait();
}
}
}
客户端代码(SocketClientRequestThread模拟请求)
package testBSocket;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
import java.util.concurrent.CountDownLatch;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.log4j.BasicConfigurator;
/**
* 一个SocketClientRequestThread线程模拟一个客户端请求。
* @author yinwenjie
*/
public class SocketClientRequestThread implements Runnable {
static {
BasicConfigurator.configure();
}
/**
* 日志
*/
private static final Log LOGGER = LogFactory.getLog(SocketClientRequestThread.class);
private CountDownLatch countDownLatch;
/**
* 这个线层的编号
* @param countDownLatch
*/
private Integer clientIndex;
/**
* countDownLatch是java提供的同步计数器。
* 当计数器数值减为0时,所有受其影响而等待的线程将会被激活。这样保证模拟并发请求的真实性
* @param countDownLatch
*/
public SocketClientRequestThread(CountDownLatch countDownLatch , Integer clientIndex) {
this.countDownLatch = countDownLatch;
this.clientIndex = clientIndex;
}
@Override
public void run() {
Socket socket = null;
OutputStream clientRequest = null;
InputStream clientResponse = null;
try {
socket = new Socket("localhost",83);
clientRequest = socket.getOutputStream();
clientResponse = socket.getInputStream();
//等待,直到SocketClientDaemon完成所有线程的启动,然后所有线程一起发送请求
this.countDownLatch.await();
//发送请求信息
clientRequest.write(("这是第" + this.clientIndex + " 个客户端的请求。").getBytes());
clientRequest.flush();
//在这里等待,直到服务器返回信息
SocketClientRequestThread.LOGGER.info("第" + this.clientIndex + "个客户端的请求发送完成,等待服务器返回信息");
int maxLen = 1024;
byte[] contextBytes = new byte[maxLen];
int realLen;
String message = "";
//程序执行到这里,会一直等待服务器返回信息(注意,前提是in和out都不能close,如果close了就收不到服务器的反馈了)
while((realLen = clientResponse.read(contextBytes, 0, maxLen)) != -1) {
message += new String(contextBytes , 0 , realLen);
}
SocketClientRequestThread.LOGGER.info("接收到来自服务器的信息:" + message);
} catch (Exception e) {
SocketClientRequestThread.LOGGER.error(e.getMessage(), e);
} finally {
try {
if(clientRequest != null) {
clientRequest.close();
}
if(clientResponse != null) {
clientResponse.close();
}
} catch (IOException e) {
SocketClientRequestThread.LOGGER.error(e.getMessage(), e);
}
}
}
}
服务器端(SocketServer1)单个线程
package testBSocket;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.ServerSocket;
import java.net.Socket;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.log4j.BasicConfigurator;
public class SocketServer1 {
static {
BasicConfigurator.configure();
}
/**
* 日志
*/
private static final Log LOGGER = LogFactory.getLog(SocketServer1.class);
public static void main(String[] args) throws Exception{
ServerSocket serverSocket = new ServerSocket(83);
try {
while(true) {
Socket socket = serverSocket.accept();
//下面我们收取信息
InputStream in = socket.getInputStream();
OutputStream out = socket.getOutputStream();
Integer sourcePort = socket.getPort();
int maxLen = 2048;
byte[] contextBytes = new byte[maxLen];
//这里也会被阻塞,直到有数据准备好
int realLen = in.read(contextBytes, 0, maxLen);
//读取信息
String message = new String(contextBytes , 0 , realLen);
//下面打印信息
SocketServer1.LOGGER.info("服务器收到来自于端口: " + sourcePort + "的信息: " + message);
//下面开始发送信息
out.write("回发响应信息!".getBytes());
//关闭
out.close();
in.close();
socket.close();
}
} catch(Exception e) {
SocketServer1.LOGGER.error(e.getMessage(), e);
} finally {
if(serverSocket != null) {
serverSocket.close();
}
}
}
}
多线程来优化服务器端
客户端代码和上文一样,最主要是更改服务器端的代码:
package testBSocket;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.ServerSocket;
import java.net.Socket;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.log4j.BasicConfigurator;
public class SocketServer2 {
static {
BasicConfigurator.configure();
}
private static final Log LOGGER = LogFactory.getLog(SocketServer2.class);
public static void main(String[] args) throws Exception{
ServerSocket serverSocket = new ServerSocket(83);
try {
while(true) {
Socket socket = serverSocket.accept();
//当然业务处理过程可以交给一个线程(这里可以使用线程池),并且线程的创建是很耗资源的。
//最终改变不了.accept()只能一个一个接受socket的情况,并且被阻塞的情况
SocketServerThread socketServerThread = new SocketServerThread(socket);
new Thread(socketServerThread).start();
}
} catch(Exception e) {
SocketServer2.LOGGER.error(e.getMessage(), e);
} finally {
if(serverSocket != null) {
serverSocket.close();
}
}
}
}
/**
* 当然,接收到客户端的socket后,业务的处理过程可以交给一个线程来做。
* 但还是改变不了socket被一个一个的做accept()的情况。
* @author yinwenjie
*/
class SocketServerThread implements Runnable {
/**
* 日志
*/
private static final Log LOGGER = LogFactory.getLog(SocketServerThread.class);
private Socket socket;
public SocketServerThread (Socket socket) {
this.socket = socket;
}
@Override
public void run() {
InputStream in = null;
OutputStream out = null;
try {
//下面我们收取信息
in = socket.getInputStream();
out = socket.getOutputStream();
Integer sourcePort = socket.getPort();
int maxLen = 1024;
byte[] contextBytes = new byte[maxLen];
//使用线程,同样无法解决read方法的阻塞问题,
//也就是说read方法处同样会被阻塞,直到操作系统有数据准备好
int realLen = in.read(contextBytes, 0, maxLen);
//读取信息
String message = new String(contextBytes , 0 , realLen);
//下面打印信息
SocketServerThread.LOGGER.info("服务器收到来自于端口: " + sourcePort + "的信息: " + message);
//下面开始发送信息
out.write("回发响应信息!".getBytes());
} catch(Exception e) {
SocketServerThread.LOGGER.error(e.getMessage(), e);
} finally {
//试图关闭
try {
if(in != null) {
in.close();
}
if(out != null) {
out.close();
}
if(this.socket != null) {
this.socket.close();
}
} catch (IOException e) {
SocketServerThread.LOGGER.error(e.getMessage(), e);
}
}
}
}
优化效果
我们主要看一看服务器使用多线程处理时的情况:
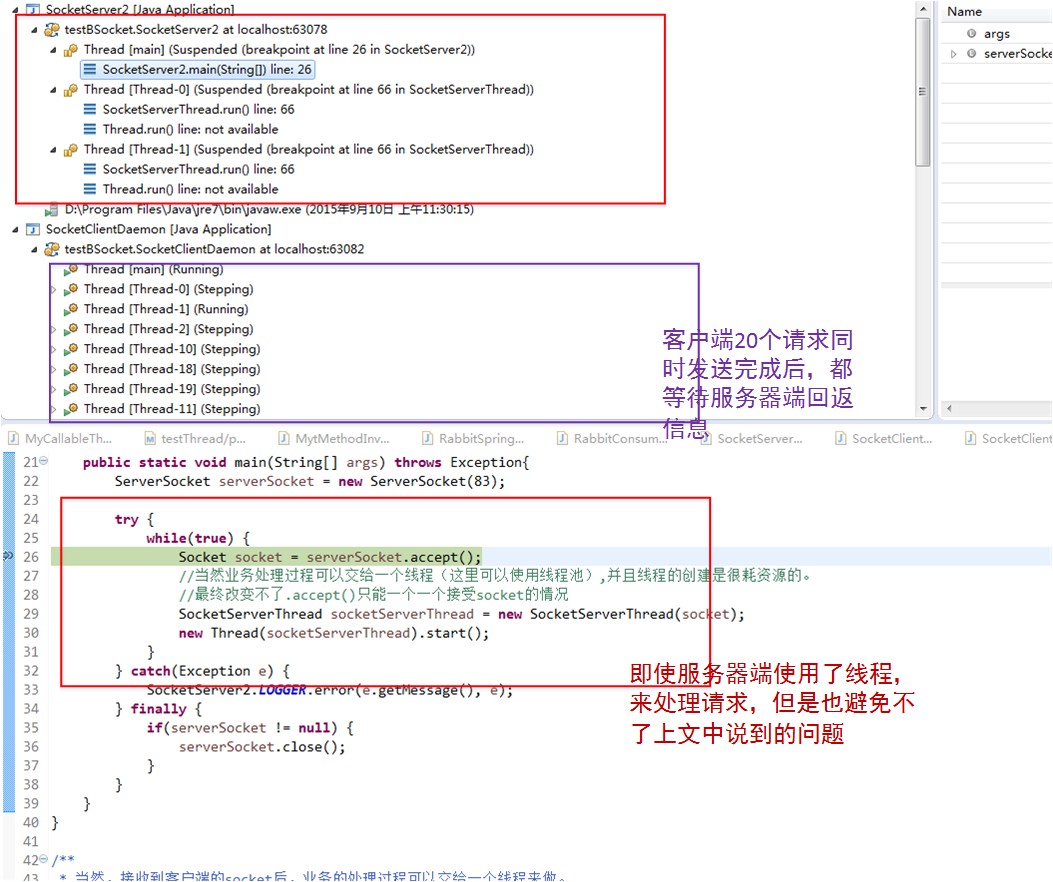
问题根源
那么重点的问题并不是“是否使用了多线程”,而是为什么accept()、read()方法会被阻塞。即: 异步IO模式 就是为了解决这样的并发性存在的。但是为了说清楚异步IO模式,在介绍IO模式的时候,我们就要首先了解清楚,什么是 阻塞式同步、非阻塞式同步、多路复用同步模式。
API文档中对于 serverSocket.accept() 方法的使用描述:
Listens for a connection to be made to this socket and accepts it. The method blocks until a connection is made.
serverSocket.accept()会被阻塞? 这里涉及到阻塞式同步IO的工作原理:
- 服务器线程发起一个accept动作,询问操作系统 是否有新的socket套接字信息从端口X发送过来。
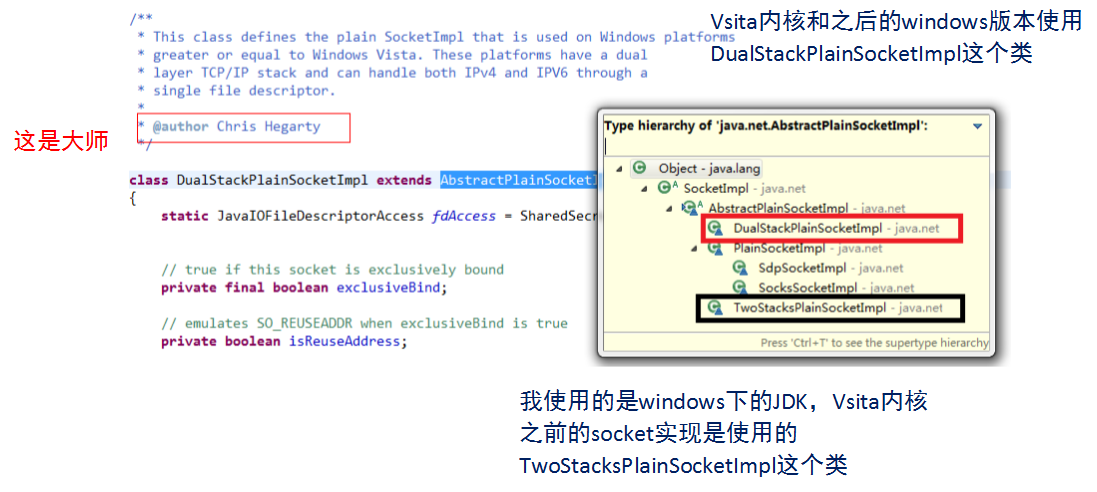
- 注意,是询问操作系统。也就是说socket套接字的IO模式支持是基于操作系统的,那么自然同步IO/异步IO的支持就是需要操作系统级别的了。如下图:
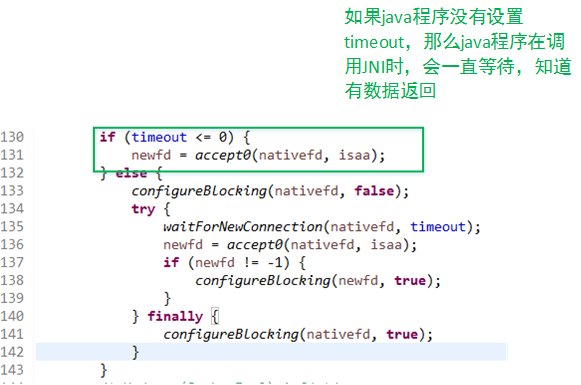

如果操作系统没有发现有套接字从指定的端口X来,那么操作系统就会等待。这样serverSocket.accept()方法就会一直等待。这就是为什么accept()方法为什么会阻塞: 它内部的实现是使用的操作系统级别的同步IO。
9 - CH09-NIO基础
Standard IO是对字节流的读写,在进行IO之前,首先创建一个流对象,流对象进行读写操作都是按字节 ,一个字节一个字节的来读或写。而NIO把IO抽象成块,类似磁盘的读写,每次IO操作的单位都是一个块,块被读入内存之后就是一个byte[],NIO一次可以读或写多个字节。
流与块
I/O 与 NIO 最重要的区别是数据打包和传输的方式,I/O 以流的方式处理数据,而 NIO 以块的方式处理数据。
面向流的 I/O 一次处理一个字节数据: 一个输入流产生一个字节数据,一个输出流消费一个字节数据。为流式数据创建过滤器非常容易,链接几个过滤器,以便每个过滤器只负责复杂处理机制的一部分。不利的一面是,面向流的 I/O 通常相当慢。
面向块的 I/O 一次处理一个数据块,按块处理数据比按流处理数据要快得多。但是面向块的 I/O 缺少一些面向流的 I/O 所具有的优雅性和简单性。
I/O 包和 NIO 已经很好地集成了,java.io.* 已经以 NIO 为基础重新实现了,所以现在它可以利用 NIO 的一些特性。例如,java.io.* 包中的一些类包含以块的形式读写数据的方法,这使得即使在面向流的系统中,处理速度也会更快。
通道与缓冲区
通道
通道 Channel 是对原 I/O 包中的流的模拟,可以通过它读取和写入数据。
通道与流的不同之处在于,流只能在一个方向上移动(一个流必须是 InputStream 或者 OutputStream 的子类),而通道是双向的,可以用于读、写或者同时用于读写。
通道包括以下类型:
- FileChannel: 从文件中读写数据;
- DatagramChannel: 通过 UDP 读写网络中数据;
- SocketChannel: 通过 TCP 读写网络中数据;
- ServerSocketChannel: 可以监听新进来的 TCP 连接,对每一个新进来的连接都会创建一个 SocketChannel。
缓冲区
发送给一个通道的所有数据都必须首先放到缓冲区中,同样地,从通道中读取的任何数据都要先读到缓冲区中。也就是说,不会直接对通道进行读写数据,而是要先经过缓冲区。
缓冲区实质上是一个数组,但它不仅仅是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。
缓冲区包括以下类型:
- ByteBuffer
- CharBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
缓冲区状态变量
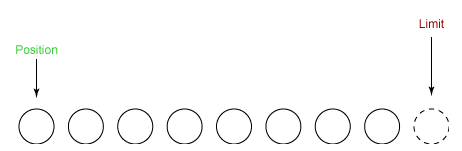
- capacity: 最大容量;
- position: 当前已经读写的字节数;
- limit: 还可以读写的字节数。
状态变量的改变过程举例:
① 新建一个大小为 8 个字节的缓冲区,此时 position 为 0,而 limit = capacity = 8。capacity 变量不会改变,下面的讨论会忽略它。
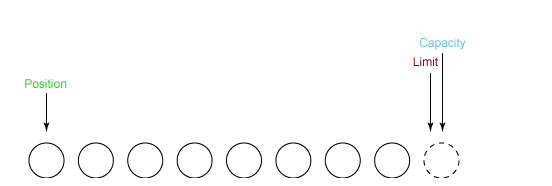
② 从输入通道中读取 5 个字节数据写入缓冲区中,此时 position 移动设置为 5,limit 保持不变。
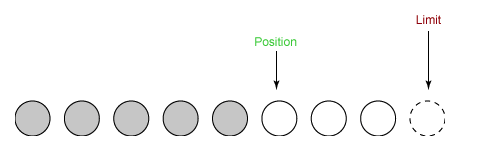
③ 在将缓冲区的数据写到输出通道之前,需要先调用 flip() 方法,这个方法将 limit 设置为当前 position,并将 position 设置为 0。
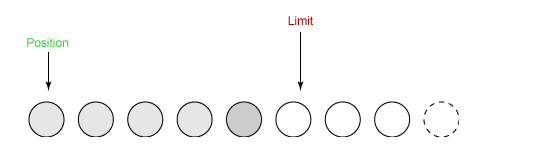
④ 从缓冲区中取 4 个字节到输出缓冲中,此时 position 设为 4。
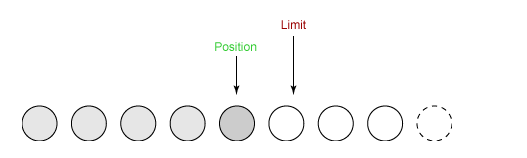
⑤ 最后需要调用 clear() 方法来清空缓冲区,此时 position 和 limit 都被设置为最初位置。
文件 NIO 实例
以下展示了使用 NIO 快速复制文件的实例:
public static void fastCopy(String src, String dist) throws IOException {
/* 获得源文件的输入字节流 */
FileInputStream fin = new FileInputStream(src);
/* 获取输入字节流的文件通道 */
FileChannel fcin = fin.getChannel();
/* 获取目标文件的输出字节流 */
FileOutputStream fout = new FileOutputStream(dist);
/* 获取输出字节流的通道 */
FileChannel fcout = fout.getChannel();
/* 为缓冲区分配 1024 个字节 */
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
while (true) {
/* 从输入通道中读取数据到缓冲区中 */
int r = fcin.read(buffer);
/* read() 返回 -1 表示 EOF */
if (r == -1) {
break;
}
/* 切换读写 */
buffer.flip();
/* 把缓冲区的内容写入输出文件中 */
fcout.write(buffer);
/* 清空缓冲区 */
buffer.clear();
}
}
选择器
NIO 常常被叫做非阻塞 IO,主要是因为 NIO 在网络通信中的非阻塞特性被广泛使用。
NIO 实现了 IO 多路复用中的 Reactor 模型,一个线程 Thread 使用一个选择器 Selector 通过轮询的方式去监听多个通道 Channel 上的事件,从而让一个线程就可以处理多个事件。
通过配置监听的通道 Channel 为非阻塞,那么当 Channel 上的 IO 事件还未到达时,就不会进入阻塞状态一直等待,而是继续轮询其它 Channel,找到 IO 事件已经到达的 Channel 执行。
因为创建和切换线程的开销很大,因此使用一个线程来处理多个事件而不是一个线程处理一个事件具有更好的性能。
应该注意的是,只有套接字 Channel 才能配置为非阻塞,而 FileChannel 不能,为 FileChannel 配置非阻塞也没有意义。
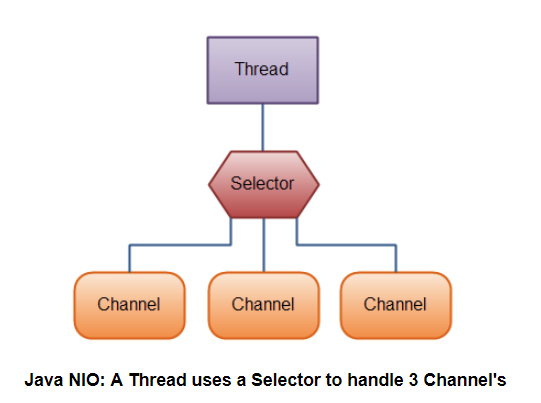
1. 创建选择器
Selector selector = Selector.open();
2. 将通道注册到选择器上
ServerSocketChannel ssChannel = ServerSocketChannel.open();
ssChannel.configureBlocking(false);
ssChannel.register(selector, SelectionKey.OP_ACCEPT);
通道必须配置为非阻塞模式,否则使用选择器就没有任何意义了,因为如果通道在某个事件上被阻塞,那么服务器就不能响应其它事件,必须等待这个事件处理完毕才能去处理其它事件,显然这和选择器的作用背道而驰。
在将通道注册到选择器上时,还需要指定要注册的具体事件,主要有以下几类:
- SelectionKey.OP_CONNECT
- SelectionKey.OP_ACCEPT
- SelectionKey.OP_READ
- SelectionKey.OP_WRITE
它们在 SelectionKey 的定义如下:
public static final int OP_READ = 1 << 0;
public static final int OP_WRITE = 1 << 2;
public static final int OP_CONNECT = 1 << 3;
public static final int OP_ACCEPT = 1 << 4;
可以看出每个事件可以被当成一个位域,从而组成事件集整数。例如:
int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
监听事件
int num = selector.select();
使用 select() 来监听到达的事件,它会一直阻塞直到有至少一个事件到达。
4. 获取到达的事件
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// ...
} else if (key.isReadable()) {
// ...
}
keyIterator.remove();
}
5. 事件循环
因为一次 select() 调用不能处理完所有的事件,并且服务器端有可能需要一直监听事件,因此服务器端处理事件的代码一般会放在一个死循环内。
while (true) {
int num = selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// ...
} else if (key.isReadable()) {
// ...
}
keyIterator.remove();
}
}
套接字 NIO 实例
public class NIOServer {
public static void main(String[] args) throws IOException {
Selector selector = Selector.open();
ServerSocketChannel ssChannel = ServerSocketChannel.open();
ssChannel.configureBlocking(false);
ssChannel.register(selector, SelectionKey.OP_ACCEPT);
ServerSocket serverSocket = ssChannel.socket();
InetSocketAddress address = new InetSocketAddress("127.0.0.1", 8888);
serverSocket.bind(address);
while (true) {
selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
ServerSocketChannel ssChannel1 = (ServerSocketChannel) key.channel();
// 服务器会为每个新连接创建一个 SocketChannel
SocketChannel sChannel = ssChannel1.accept();
sChannel.configureBlocking(false);
// 这个新连接主要用于从客户端读取数据
sChannel.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
SocketChannel sChannel = (SocketChannel) key.channel();
System.out.println(readDataFromSocketChannel(sChannel));
sChannel.close();
}
keyIterator.remove();
}
}
}
private static String readDataFromSocketChannel(SocketChannel sChannel) throws IOException {
ByteBuffer buffer = ByteBuffer.allocate(1024);
StringBuilder data = new StringBuilder();
while (true) {
buffer.clear();
int n = sChannel.read(buffer);
if (n == -1) {
break;
}
buffer.flip();
int limit = buffer.limit();
char[] dst = new char[limit];
for (int i = 0; i < limit; i++) {
dst[i] = (char) buffer.get(i);
}
data.append(dst);
buffer.clear();
}
return data.toString();
}
}
public class NIOClient {
public static void main(String[] args) throws IOException {
Socket socket = new Socket("127.0.0.1", 8888);
OutputStream out = socket.getOutputStream();
String s = "hello world";
out.write(s.getBytes());
out.close();
}
}
内存映射文件
内存映射文件 I/O 是一种读和写文件数据的方法,它可以比常规的基于流或者基于通道的 I/O 快得多。
向内存映射文件写入可能是危险的,只是改变数组的单个元素这样的简单操作,就可能会直接修改磁盘上的文件。修改数据与将数据保存到磁盘是没有分开的。
下面代码行将文件的前 1024 个字节映射到内存中,map() 方法返回一个 MappedByteBuffer,它是 ByteBuffer 的子类。因此,可以像使用其他任何 ByteBuffer 一样使用新映射的缓冲区,操作系统会在需要时负责执行映射。
MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE, 0, 1024);
对比
NIO 与普通 I/O 的区别主要有以下两点:
- NIO 是非阻塞的
- NIO 面向块,I/O 面向流
10 - CH10-NIO原理
现实场景
我们试想一下这样的现实场景:
一个餐厅同时有100位客人到店,当然到店后第一件要做的事情就是点菜。但是问题来了,餐厅老板为了节约人力成本目前只有一位大堂服务员拿着唯一的一本菜单等待客人进行服务。
- 那么最笨(但是最简单)的方法是(方法A),无论有多少客人等待点餐,服务员都把仅有的一份菜单递给其中一位客人,然后站在客人身旁等待这个客人完成点菜过程。在记录客人点菜内容后,把点菜记录交给后堂厨师。然后是第二位客人。。。。然后是第三位客人。很明显,只有脑袋被门夹过的老板,才会这样设置服务流程。因为随后的80位客人,再等待超时后就会离店(还会给差评)。
- 于是还有一种办法(方法B),老板马上新雇佣99名服务员,同时印制99本新的菜单。每一名服务员手持一本菜单负责一位客人(关键不只在于服务员,还在于菜单。因为没有菜单客人也无法点菜)。在客人点完菜后,记录点菜内容交给后堂厨师(当然为了更高效,后堂厨师最好也有100名)。这样每一位客人享受的就是VIP服务咯,当然客人不会走,但是人力成本可是一个大头哦(亏死你)。
- 另外一种办法(方法C),就是改进点菜的方式,当客人到店后,自己申请一本菜单。想好自己要点的才后,就呼叫服务员。服务员站在自己身边后记录客人的菜单内容。将菜单递给厨师的过程也要进行改进,并不是每一份菜单记录好以后,都要交给后堂厨师。服务员可以记录号多份菜单后,同时交给厨师就行了。那么这种方式,对于老板来说人力成本是最低的;对于客人来说,虽然不再享受VIP服务并且要进行一定的等待,但是这些都是可接受的;对于服务员来说,基本上她的时间都没有浪费,基本上被老板压杆了最后一滴油水。
如果您是老板,您会采用哪种方式呢?
到店情况: 并发量。到店情况不理想时,一个服务员一本菜单,当然是足够了。所以不同的老板在不同的场合下,将会灵活选择服务员和菜单的配置。
- 客人: 客户端请求
- 点餐内容: 客户端发送的实际数据
- 老板: 操作系统
- 人力成本: 系统资源
- 菜单: 文件状态描述符。操作系统对于一个进程能够同时持有的文件状态描述符的个数是有限制的,在linux系统中$ulimit -n查看这个限制值,当然也是可以(并且应该)进行内核参数调整的。
- 服务员: 操作系统内核用于IO操作的线程(内核线程)
- 厨师: 应用程序线程(当然厨房就是应用程序进程咯)
- 餐单传递方式: 包括了阻塞式和非阻塞式两种。
- 方法A: 阻塞式/非阻塞式 同步IO
- 方法B: 使用线程进行处理的 阻塞式/非阻塞式 同步IO
- 方法C: 阻塞式/非阻塞式 多路复用IO
典型的多路复用IO实现
目前流程的多路复用IO实现主要包括四种: select、poll、epoll、kqueue。下表是他们的一些重要特性的比较:
| IO模型 | 相对性能 | 关键思路 | 操作系统 | JAVA支持情况 |
|---|---|---|---|---|
| select | 较高 | Reactor | windows/Linux | 支持,Reactor模式(反应器设计模式)。Linux操作系统的 kernels 2.4内核版本之前,默认使用select;而目前windows下对同步IO的支持,都是select模型 |
| poll | 较高 | Reactor | Linux | Linux下的JAVA NIO框架,Linux kernels 2.6内核版本之前使用poll进行支持。也是使用的Reactor模式 |
| epoll | 高 | Reactor/Proactor | Linux | Linux kernels 2.6内核版本及以后使用epoll进行支持;Linux kernels 2.6内核版本之前使用poll进行支持;另外一定注意,由于Linux下没有Windows下的IOCP技术提供真正的 异步IO 支持,所以Linux下使用epoll模拟异步IO |
| kqueue | 高 | Proactor | Linux | 目前JAVA的版本不支持 |
多路复用IO技术最适用的是“高并发”场景,所谓高并发是指1毫秒内至少同时有上千个连接请求准备好。其他情况下多路复用IO技术发挥不出来它的优势。另一方面,使用JAVA NIO进行功能实现,相对于传统的Socket套接字实现要复杂一些,所以实际应用中,需要根据自己的业务需求进行技术选择。
Reactor模型和Proactor模型
JAVA对多路复用IO的支持
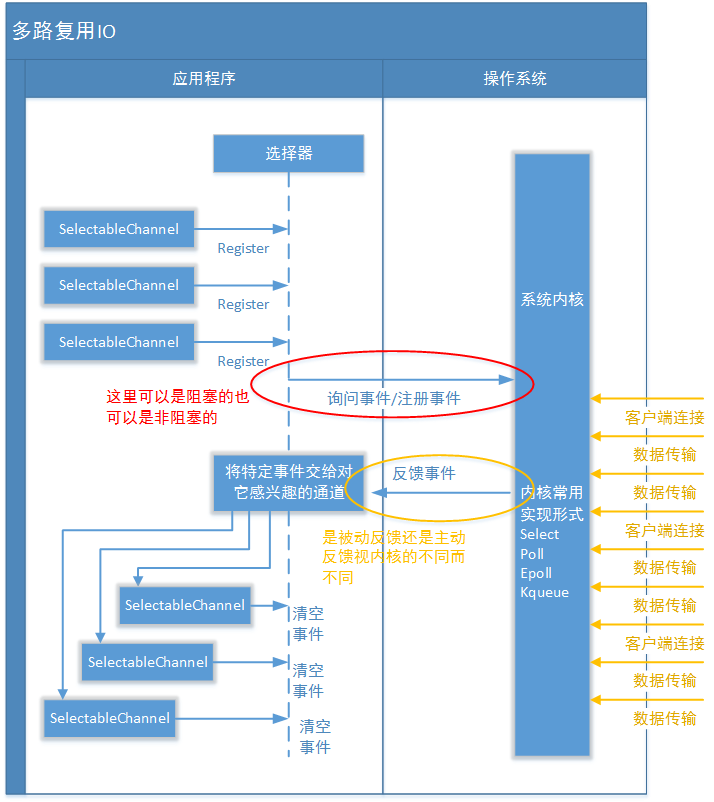
重要概念: Channel
通道,被建立的一个应用程序和操作系统交互事件、传递内容的渠道(注意是连接到操作系统)。一个通道会有一个专属的文件状态描述符。那么既然是和操作系统进行内容的传递,那么说明应用程序可以通过通道读取数据,也可以通过通道向操作系统写数据。
JDK API中的Channel的描述是:
A channel represents an open connection to an entity such as a hardware device, a file, a network socket, or a program component that is capable of performing one or more distinct I/O operations, for example reading or writing.
A channel is either open or closed. A channel is open upon creation, and once closed it remains closed. Once a channel is closed, any attempt to invoke an I/O operation upon it will cause a ClosedChannelException to be thrown. Whether or not a channel is open may be tested by invoking its isOpen method.
JAVA NIO 框架中,自有的Channel通道包括:

所有被Selector(选择器)注册的通道,只能是继承了SelectableChannel类的子类。如上图所示
- ServerSocketChannel: 应用服务器程序的监听通道。只有通过这个通道,应用程序才能向操作系统注册支持“多路复用IO”的端口监听。同时支持UDP协议和TCP协议。
- ScoketChannel: TCP Socket套接字的监听通道,一个Socket套接字对应了一个客户端IP: 端口 到 服务器IP: 端口的通信连接。
- DatagramChannel: UDP 数据报文的监听通道。
重要概念: Buffer
数据缓存区: 在JAVA NIO 框架中,为了保证每个通道的数据读写速度JAVA NIO 框架为每一种需要支持数据读写的通道集成了Buffer的支持。
这句话怎么理解呢? 例如ServerSocketChannel通道它只支持对OP_ACCEPT事件的监听,所以它是不能直接进行网络数据内容的读写的。所以ServerSocketChannel是没有集成Buffer的。
Buffer有两种工作模式: 写模式和读模式。在读模式下,应用程序只能从Buffer中读取数据,不能进行写操作。但是在写模式下,应用程序是可以进行读操作的,这就表示可能会出现脏读的情况。所以一旦您决定要从Buffer中读取数据,一定要将Buffer的状态改为读模式。
如下图:
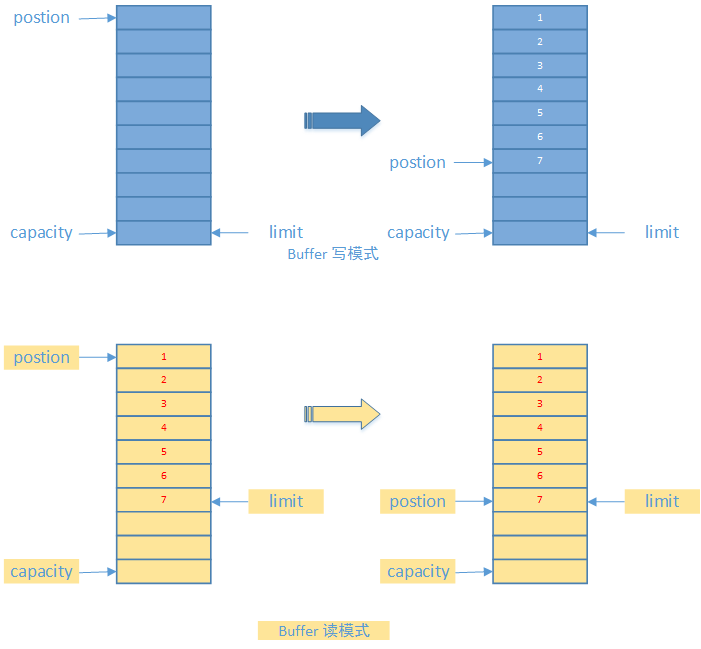
- position: 缓存区目前这在操作的数据块位置
- limit: 缓存区最大可以进行操作的位置。缓存区的读写状态正式由这个属性控制的。
- capacity: 缓存区的最大容量。这个容量是在缓存区创建时进行指定的。由于高并发时通道数量往往会很庞大,所以每一个缓存区的容量最好不要过大。
在下文JAVA NIO框架的代码实例中,我们将进行Buffer缓存区操作的演示。
重要概念: Selector
Selector的英文含义是“选择器”,不过根据我们详细介绍的Selector的岗位职责,您可以把它称之为“轮询代理器”、“事件订阅器”、“channel容器管理机”都行。
- 事件订阅和Channel管理
应用程序将向Selector对象注册需要它关注的Channel,以及具体的某一个Channel会对哪些IO事件感兴趣。Selector中也会维护一个“已经注册的Channel”的容器。以下代码来自WindowsSelectorImpl实现类中,对已经注册的Channel的管理容器:
// Initial capacity of the poll array
private final int INIT_CAP = 8;
// Maximum number of sockets for select().
// Should be INIT_CAP times a power of 2
private final static int MAX_SELECTABLE_FDS = 1024;
// The list of SelectableChannels serviced by this Selector. Every mod
// MAX_SELECTABLE_FDS entry is bogus, to align this array with the poll
// array, where the corresponding entry is occupied by the wakeupSocket
private SelectionKeyImpl[] channelArray = new SelectionKeyImpl[INIT_CAP];
- 轮询代理
应用层不再通过阻塞模式或者非阻塞模式直接询问操作系统“事件有没有发生”,而是由Selector代其询问。
- 实现不同操作系统的支持
之前已经提到过,多路复用IO技术 是需要操作系统进行支持的,其特点就是操作系统可以同时扫描同一个端口上不同网络连接的事件。所以作为上层的JVM,必须要为 不同操作系统的多路复用IO实现 编写不同的代码。同样我使用的测试环境是Windows,它对应的实现类是sun.nio.ch.WindowsSelectorImpl:
JAVA NIO 框架简要设计分析
通过上文的描述,我们知道了多路复用IO技术是操作系统的内核实现。在不同的操作系统,甚至同一系列操作系统的版本中所实现的多路复用IO技术都是不一样的。那么作为跨平台的JAVA JVM来说如何适应多种多样的多路复用IO技术实现呢? 面向对象的威力就显现出来了: 无论使用哪种实现方式,他们都会有“选择器”、“通道”、“缓存”这几个操作要素,那么可以为不同的多路复用IO技术创建一个统一的抽象组,并且为不同的操作系统进行具体的实现。JAVA NIO中对各种多路复用IO的支持,主要的基础是java.nio.channels.spi.SelectorProvider抽象类,其中的几个主要抽象方法包括:
- public abstract DatagramChannel openDatagramChannel(): 创建和这个操作系统匹配的UDP 通道实现。
- public abstract AbstractSelector openSelector(): 创建和这个操作系统匹配的NIO选择器,就像上文所述,不同的操作系统,不同的版本所默认支持的NIO模型是不一样的。
- public abstract ServerSocketChannel openServerSocketChannel(): 创建和这个NIO模型匹配的服务器端通道。
- public abstract SocketChannel openSocketChannel(): 创建和这个NIO模型匹配的TCP Socket套接字通道(用来反映客户端的TCP连接)
由于JAVA NIO框架的整个设计是很大的,所以我们只能还原一部分我们关心的问题。这里我们以JAVA NIO框架中对于不同多路复用IO技术的选择器 进行实例化创建的方式作为例子,以点窥豹观全局:
很明显,不同的SelectorProvider实现对应了不同的 选择器。由具体的SelectorProvider实现进行创建。另外说明一下,实际上netty底层也是通过这个设计获得具体使用的NIO模型,我们后文讲解Netty时,会讲到这个问题。以下代码是Netty 4.0中NioServerSocketChannel进行实例化时的核心代码片段:
private static ServerSocketChannel newSocket(SelectorProvider provider) {
try {
/**
* Use the {@link SelectorProvider} to open {@link SocketChannel} and so remove condition in
* {@link SelectorProvider#provider()} which is called by each ServerSocketChannel.open() otherwise.
*
* See <a href="See https://github.com/netty/netty/issues/2308">#2308</a>.
*/
return provider.openServerSocketChannel();
} catch (IOException e) {
throw new ChannelException(
"Failed to open a server socket.", e);
}
}
多路复用IO的优缺点
不用再使用多线程来进行IO处理了(包括操作系统内核IO管理模块和应用程序进程而言)。当然实际业务的处理中,应用程序进程还是可以引入线程池技术的
同一个端口可以处理多种协议,例如,使用ServerSocketChannel测测的服务器端口监听,既可以处理TCP协议又可以处理UDP协议。
操作系统级别的优化: 多路复用IO技术可以是操作系统级别在一个端口上能够同时接受多个客户端的IO事件。同时具有之前我们讲到的阻塞式同步IO和非阻塞式同步IO的所有特点。Selector的一部分作用更相当于“轮询代理器”。
都是同步IO: 目前我们介绍的 阻塞式IO、非阻塞式IO甚至包括多路复用IO,这些都是基于操作系统级别对“同步IO”的实现。我们一直在说“同步IO”,一直都没有详细说,什么叫做“同步IO”。实际上一句话就可以说清楚: 只有上层(包括上层的某种代理机制)系统询问我是否有某个事件发生了,否则我不会主动告诉上层系统事件发生了。
11 - CH11-AIO原理
异步IO
上面两篇文章中,我们分别讲解了阻塞式同步IO、非阻塞式同步IO、多路复用IO 这三种IO模型,以及JAVA对于这三种IO模型的支持。重点说明了IO模型是由操作系统提供支持,且这三种IO模型都是同步IO,都是采用的“应用程序不询问我,我绝不会主动通知”的方式。
异步IO则是采用“订阅-通知”模式: 即应用程序向操作系统注册IO监听,然后继续做自己的事情。当操作系统发生IO事件,并且准备好数据后,在主动通知应用程序,触发相应的函数:
和同步IO一样,异步IO也是由操作系统进行支持的。微软的windows系统提供了一种异步IO技术: IOCP(I/O Completion Port,I/O完成端口);
Linux下由于没有这种异步IO技术,所以使用的是epoll(上文介绍过的一种多路复用IO技术的实现)对异步IO进行模拟。
JAVA AIO框架简析
这里通过这个结构分析要告诉各位读者JAVA AIO中类设计和操作系统的相关性
在文中我们一再说明JAVA AIO框架在windows下使用windows IOCP技术,在Linux下使用epoll多路复用IO技术模拟异步IO,这个从JAVA AIO框架的部分类设计上就可以看出来。例如框架中,在Windows下负责实现套接字通道的具体类是“sun.nio.ch.WindowsAsynchronousSocketChannelImpl”,其引用的IOCP类型文档注释如是:
/**
* Windows implementation of AsynchronousChannelGroup encapsulating an I/O
* completion port.
*/
如果您感兴趣,当然可以去看看全部完整代码(建议从“java.nio.channels.spi.AsynchronousChannelProvider”这个类看起)。
特别说明一下,请注意图中的“java.nio.channels.NetworkChannel”接口,这个接口同样被JAVA NIO框架实现了,如下图所示:
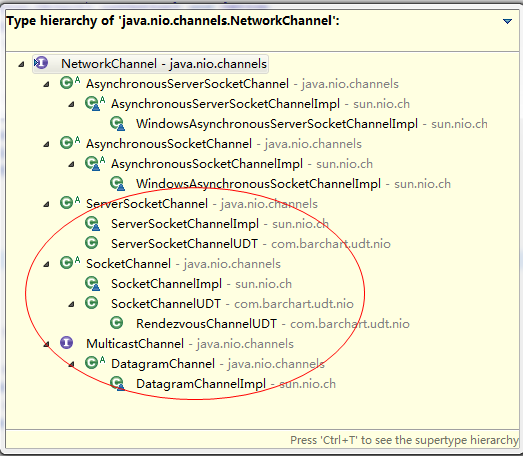
要点讲解
注意在JAVA NIO框架中,我们说到了一个重要概念“selector”(选择器)。它负责代替应用查询中所有已注册的通道到操作系统中进行IO事件轮询、管理当前注册的通道集合,定位发生事件的通道等操操作;但是在JAVA AIO框架中,由于应用程序不是“轮询”方式,而是订阅-通知方式,所以不再需要“selector”(选择器)了,改由channel通道直接到操作系统注册监听。
JAVA AIO框架中,只实现了两种网络IO通道“AsynchronousServerSocketChannel”(服务器监听通道)、“AsynchronousSocketChannel”(socket套接字通道)。但是无论哪种通道他们都有独立的fileDescriptor(文件标识符)、attachment(附件,附件可以使任意对象,类似“通道上下文”),并被独立的SocketChannelReadHandle类实例引用。我们通过debug操作来看看它们的引用结构:
在测试过程中,我们启动了两个客户端(客户端用什么语言来写都行,用阻塞或者非阻塞方式也都行,只要是支持 TCP Socket套接字的就行,然后我们观察服务器端对这两个客户端通道的处理情况:

可以看到,在服务器端分别为客户端1和客户端2创建的两个WindowsAsynchronousSocketChannelImpl对象为:
客户端1: WindowsAsynchronousSocketChannelImpl: 760 | FileDescriptor: 762
客户端2: WindowsAsynchronousSocketChannelImpl: 792 | FileDescriptor: 797
接下来,我们让两个客户端发送信息到服务器端,并观察服务器端的处理情况。客户端1发来的消息和客户端2发来的消息,在服务器端的处理情况如下图所示:
客户端1: WindowsAsynchronousSocketChannelImpl: 760 | FileDescriptor: 762 | SocketChannelReadHandle: 803 | HeapByteBuffer: 808
客户端2: WindowsAsynchronousSocketChannelImpl: 792 | FileDescriptor: 797 | SocketChannelReadHandle: 828 | HeapByteBuffer: 833
可以明显看到,服务器端处理每一个客户端通道所使用的SocketChannelReadHandle(处理器)对象都是独立的,并且所引用的SocketChannel对象都是独立的。
JAVA NIO和JAVA AIO框架,除了因为操作系统的实现不一样而去掉了Selector外,其他的重要概念都是存在的,例如上文中提到的Channel的概念,还有演示代码中使用的Buffer缓存方式。实际上JAVA NIO和JAVA AIO框架您可以看成是一套完整的“高并发IO处理”的实现。
还有改进可能
当然,以上代码是示例代码,目标是为了让您了解JAVA AIO框架的基本使用。所以它还有很多改造的空间,例如:
在生产环境下,我们需要记录这个通道上“用户的登录信息”。那么这个需求可以使用JAVA AIO中的“附件”功能进行实现。
记住JAVA AIO 和 JAVA NIO 框架都是要使用线程池的(当然您也可以不用),线程池的使用原则,一定是只有业务处理部分才使用,使用后马上结束线程的执行(还回线程池或者消灭它)。JAVA AIO框架中还有一个线程池,是拿给“通知处理器”使用的,这是因为JAVA AIO框架是基于“订阅-通知”模型的,“订阅”操作可以由主线程完成,但是您总不能要求在应用程序中并发的“通知”操作也在主线程上完成吧^_^。
最好的改进方式,当然就是使用Netty或者Mina咯
为什么还有Netty
- 那么有的读者可能就会问,既然JAVA NIO / JAVA AIO已经实现了各主流操作系统的底层支持,那么为什么现在主流的JAVA NIO技术会是Netty和MINA呢? 答案很简单: 因为更好用,这里举几个方面的例子:
- 虽然JAVA NIO 和 JAVA AIO框架提供了 多路复用IO/异步IO的支持,但是并没有提供上层“信息格式”的良好封装。例如前两者并没有提供针对 Protocol Buffer、JSON这些信息格式的封装,但是Netty框架提供了这些数据格式封装(基于责任链模式的编码和解码功能)
- 要编写一个可靠的、易维护的、高性能的(注意它们的排序)NIO/AIO 服务器应用。除了框架本身要兼容实现各类操作系统的实现外。更重要的是它应该还要处理很多上层特有服务,例如: 客户端的权限、还有上面提到的信息格式封装、简单的数据读取。这些Netty框架都提供了响应的支持。
- JAVA NIO框架存在一个poll/epoll bug: Selector doesn’t block on Selector.select(timeout),不能block意味着CPU的使用率会变成100%(这是底层JNI的问题,上层要处理这个异常实际上也好办)。当然这个bug只有在Linux内核上才能重现。
- 这个问题在JDK 1.7版本中还没有被完全解决: http://bugs.java.com/bugdatabase/view_bug.do?bug_id=2147719。虽然Netty 4.0中也是基于JAVA NIO框架进行封装的(上文中已经给出了Netty中NioServerSocketChannel类的介绍),但是Netty已经将这个bug进行了处理。
12 - CH12-零拷贝
CPU 并不执行将数据从一个存储区域拷贝到另一个存储区域这样的任务。通常用于在网络传输文件时节省 CPU 周期和内存带宽。
缓存 IO
缓存 IO 又被称为标准 IO,大多数文件系统的默认 IO 操作都是缓存 IO。在 Linux 的缓存 IO 机制中,操作系统会将 IO 的数据缓存在文件系统的页缓存(page cache)中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
缓存 IO 的缺点:数据在传输过程中需要在应用程序地址空间和内核间进行多次数据复制操作,这些数据复制所带来的 CPU 及内存开销是非常大的。
零拷贝技术分类
零拷贝技术的发展很多样化,现有的零拷贝技术种类也非常多,而当前并没有一个适合于所有场景的零拷贝技术出现。对于 Linux 来说,现有的零拷贝技术也比较多,这些零拷贝技术大部分存在于不同的 Linux 内核版本,有些旧的技术在不同的 Linux 内核版本间得到了很大的发展或者已经渐渐被新的技术所代替。
本文针对这些零拷贝技术所适用的不同场景对它们进行了划分。概括起来,Linux 中的零拷贝技术主要有下面这几种:
- 直接 I/O:对于这种数据传输方式来说,应用程序可以直接访问硬件存储,操作系统内核只是辅助数据传输:这类零拷贝技术针对的是操作系统内核并不需要对数据进行直接处理的情况,数据可以在应用程序地址空间的缓冲区和磁盘之间直接进行传输,完全不需要 Linux 操作系统内核提供的页缓存的支持。
- 在数据传输的过程中,避免数据在操作系统内核地址空间的缓冲区和用户应用程序地址空间的缓冲区之间进行拷贝。有的时候,应用程序在数据进行传输的过程中不需要对数据进行访问,那么,将数据从 Linux 的页缓存拷贝到用户进程的缓冲区中就可以完全避免,传输的数据在页缓存中就可以得到处理。在某些特殊的情况下,这种零拷贝技术可以获得较好的性能。Linux 中提供类似的系统调用主要有 mmap(),sendfile() 以及 splice()。
- 对数据在 Linux 的页缓存和用户进程的缓冲区之间的传输过程进行优化。该零拷贝技术侧重于灵活地处理数据在用户进程的缓冲区和操作系统的页缓存之间的拷贝操作。这种方法延续了传统的通信方式,但是更加灵活。在Linux 中,该方法主要利用了写时复制技术。
前两类方法的目的主要是为了避免应用程序地址空间和操作系统内核地址空间这两者之间的缓冲区拷贝操作。这两类零拷贝技术通常适用在某些特殊的情况下,比如要传送的数据不需要经过操作系统内核的处理或者不需要经过应用程序的处理。第三类方法则继承了传统的应用程序地址空间和操作系统内核地址空间之间数据传输的概念,进而针对数据传输本身进行优化。我们知道,硬件和软件之间的数据传输可以通过使用 DMA 来进行,DMA 进行数据传输的过程中几乎不需要CPU参与,这样就可以把 CPU 解放出来去做更多其他的事情,但是当数据需要在用户地址空间的缓冲区和 Linux 操作系统内核的页缓存之间进行传输的时候,并没有类似DMA 这种工具可以使用,CPU 需要全程参与到这种数据拷贝操作中,所以这第三类方法的目的是可以有效地改善数据在用户地址空间和操作系统内核地址空间之间传递的效率。
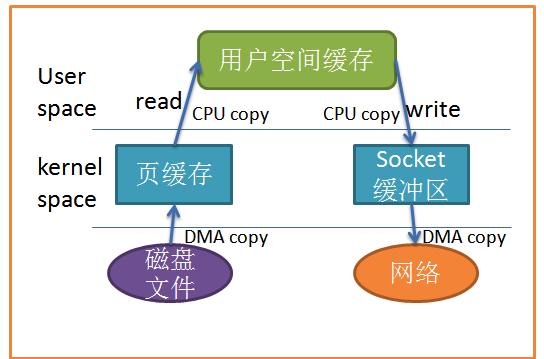
当应用程序访问某块数据时,操作系统首先会检查,是不是最近访问过此文件,文件内容是否缓存在内核缓冲区,如果是,操作系统则直接根据read系统调用提供的buf地址,将内核缓冲区的内容拷贝到buf所指定的用户空间缓冲区中去。如果不是,操作系统则首先将磁盘上的数据拷贝的内核缓冲区,这一步目前主要依靠DMA来传输,然后再把内核缓冲区上的内容拷贝到用户缓冲区中。 接下来,write系统调用再把用户缓冲区的内容拷贝到网络堆栈相关的内核缓冲区中,最后socket再把内核缓冲区的内容发送到网卡上。
从上图中可以看出,共产生了四次数据拷贝,即使使用了DMA来处理了与硬件的通讯,CPU仍然需要处理两次数据拷贝,与此同时,在用户态与内核态也发生了多次上下文切换,无疑也加重了CPU负担。
在此过程中,我们没有对文件内容做任何修改,那么在内核空间和用户空间来回拷贝数据无疑就是一种浪费,而零拷贝主要就是为了解决这种低效性。
mmap:让数据传输不需要经过user space
我们减少拷贝次数的一种方法是调用mmap()来代替read调用:
buf = mmap(diskfd, len);
write(sockfd, buf, len);
应用程序调用 mmap(),磁盘上的数据会通过 DMA被拷贝的内核缓冲区,接着操作系统会把这段内核缓冲区与应用程序共享,这样就不需要把内核缓冲区的内容往用户空间拷贝。应用程序再调用 write(),操作系统直接将内核缓冲区的内容拷贝到 socket缓冲区中,这一切都发生在内核态,最后, socket缓冲区再把数据发到网卡去。
如下图:
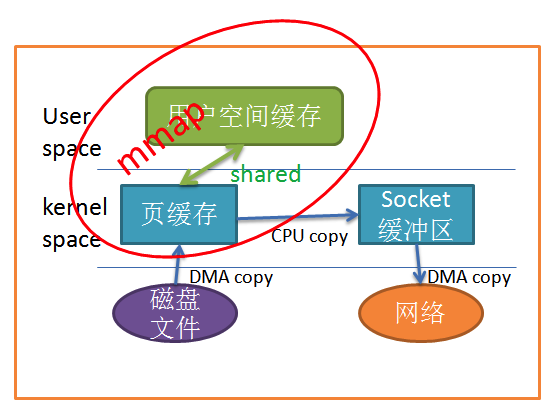
使用mmap替代read很明显减少了一次拷贝,当拷贝数据量很大时,无疑提升了效率。但是使用 mmap是有代价的。当你使用 mmap时,你可能会遇到一些隐藏的陷阱。例如,当你的程序 map了一个文件,但是当这个文件被另一个进程截断(truncate)时, write系统调用会因为访问非法地址而被 SIGBUS信号终止。 SIGBUS信号默认会杀死你的进程并产生一个 coredump,如果你的服务器这样被中止了,那会产生一笔损失。
通常我们使用以下解决方案避免这种问题:
- 为SIGBUS信号建立信号处理程序:当遇到 SIGBUS信号时,信号处理程序简单地返回, write系统调用在被中断之前会返回已经写入的字节数,并且 errno会被设置成success,但是这是一种糟糕的处理办法,因为你并没有解决问题的实质核心。
- 使用文件租借锁:通常我们使用这种方法,在文件描述符上使用租借锁,我们为文件向内核申请一个租借锁,当其它进程想要截断这个文件时,内核会向我们发送一个实时的 RT_SIGNAL_LEASE信号,告诉我们内核正在破坏你加持在文件上的读写锁。这样在程序访问非法内存并且被 SIGBUS杀死之前,你的 write系统调用会被中断。 write会返回已经写入的字节数,并且置 errno为success。 我们应该在 mmap文件之前加锁,并且在操作完文件后解锁:
if(fcntl(diskfd, F_SETSIG, RT_SIGNAL_LEASE) == -1){
perror("kernel lease set signal");
return -1;
}
/* l_type can be F_RDLCK_F_WRLCK 加锁 */
/* l_type can be F_UNLCK 解锁 */
if(fcntl(diskfd, F_SETLEASE, l_type)){
perror("kernel lease set_type");
return -1;
}
参考资料
13 - CH13-内存映射
内存映射文件非常特别,它允许Java程序直接从内存中读取文件内容,通过将整个或部分文件映射到内存,由操作系统来处理加载请求和写入文件,应用只需要和内存打交道,这使得IO操作非常快。加载内存映射文件所使用的内存在Java堆区之外。Java编程语言支持内存映射文件,通过java.nio包和MappedByteBuffer 可以从内存直接读写文件。
内存映射文件
内存映射文件,是由一个文件到一块内存的映射。Win32提供了允许应用程序把文件映射到一个进程的函数 (CreateFileMapping)。内存映射文件与虚拟内存有些类似,通过内存映射文件可以保留一个地址空间的区域,同时将物理存储器提交给此区域,内存文件映射的物理存储器来自一个已经存在于磁盘上的文件,而且在对该文件进行操作之前必须首先对文件进行映射。使用内存映射文件处理存储于磁盘上的文件时,将不必再对文件执行I/O操作,使得内存映射文件在处理大数据量的文件时能起到相当重要的作用。
内存映射 IO
在传统的文件IO操作中,我们都是调用操作系统提供的底层标准IO系统调用函数 read()、write() ,此时调用此函数的进程(在JAVA中即java进程)由当前的用户态切换到内核态,然后OS的内核代码负责将相应的文件数据读取到内核的IO缓冲区,然 后再把数据从内核IO缓冲区拷贝到进程的私有地址空间中去,这样便完成了一次IO操作。这么做是为了减少磁盘的IO操作,为了提高性能而考虑的,因为我们的程序访问一般都带有局部性,也就是所谓的局部性原理,在这里主要是指的空间局部性,即我们访问了文件的某一段数据,那么接下去很可能还会访问接下去的一段数据,由于磁盘IO操作的速度比直接 访问内存慢了好几个数量级,所以OS根据局部性原理会在一次 read()系统调用过程中预读更多的文件数据缓存在内核IO缓冲区中,当继续访问的文件数据在缓冲区中时便直接拷贝数据到进程私有空间,避免了再次的低 效率磁盘IO操作。其过程如下
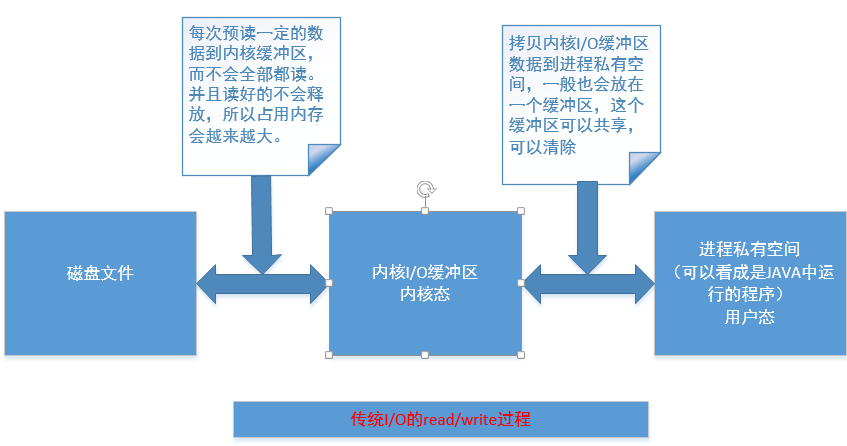
内存映射文件和之前说的 标准IO操作最大的不同之处就在于它虽然最终也是要从磁盘读取数据,但是它并不需要将数据读取到OS内核缓冲区,而是直接将进程的用户私有地址空间中的一 部分区域与文件对象建立起映射关系,就好像直接从内存中读、写文件一样,速度当然快了。
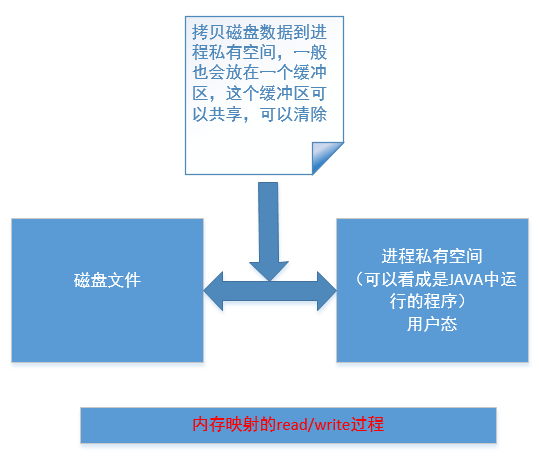
内存映射的优缺点
内存映射IO最大的优点可能在于性能,这对于建立高频电子交易系统尤其重要。内存映射文件通常比标准通过正常IO访问文件要快。另一个巨大的优势是内存映 射IO允许加载不能直接访问的潜在巨大文件 。经验表明,内存映射IO在大文件处理方面性能更加优异。尽管它也有不足——增加了页面错误的数目。由于操作系统只将一部分文件加载到内存,如果一个请求 页面没有在内存中,它将导致页面错误。同样它可以被用来在两个进程中共享数据。
操作系统支持
大多数主流操作系统比如Windows平台,UNIX,Solaris和其他类UNIX操作系统都支持内存映射IO和64位架构,你几乎可以将所有文件映射到内存并通过JAVA编程语言直接访问。
Java 内存映射 IO 的要点
- java通过java.nio包来支持内存映射IO。
- 内存映射文件主要用于性能敏感的应用,例如高频电子交易平台。
- 通过使用内存映射IO,你可以将大文件加载到内存。
- 内存映射文件可能导致页面请求错误,如果请求页面不在内存中的话。
- 映射文件区域的能力取决于于内存寻址的大小。在32位机器中,你不能访问超过4GB或2 ^ 32(以上的文件)。
- 内存映射IO比起Java中的IO流要快的多。
- 加载文件所使用的内存是Java堆区之外,并驻留共享内存,允许两个不同进程共享文件。
- 内存映射文件读写由操作系统完成,所以即使在将内容写入内存后java程序崩溃了,它将仍然会将它写入文件直到操作系统恢复。
- 出于性能考虑,推荐使用直接字节缓冲而不是非直接缓冲。
- 不要频繁调用MappedByteBuffer.force()方法,这个方法意味着强制操作系统将内存中的内容写入磁盘,所以如果你每次写入内存映射文件都调用force()方法,你将不会体会到使用映射字节缓冲的好处,相反,它(的性能)将类似于磁盘IO的性能。
- 万一发生了电源故障或主机故障,将会有很小的机率发生内存映射文件没有写入到磁盘,这意味着你可能会丢失关键数据。
public static void readFile3(String path) {
long start = System.currentTimeMillis();//开始时间
long fileLength = 0;
final int BUFFER_SIZE = 0x300000;// 3M的缓冲
File file = new File(path);
fileLength = file.length();
try {
MappedByteBuffer inputBuffer = new RandomAccessFile(file, "r").getChannel().map(FileChannel.MapMode.READ_ONLY, 0, fileLength);// 读取大文件
byte[] dst = new byte[BUFFER_SIZE];// 每次读出3M的内容
for (int offset = 0; offset < fileLength; offset += BUFFER_SIZE) {
if (fileLength - offset >= BUFFER_SIZE) {
for (int i = 0; i < BUFFER_SIZE; i++)
dst[i] = inputBuffer.get(offset + i);
} else {
for (int i = 0; i < fileLength - offset; i++)
dst[i] = inputBuffer.get(offset + i);
}
// 将得到的3M内容给Scanner,这里的XXX是指Scanner解析的分隔符
Scanner scan = new Scanner(new ByteArrayInputStream(dst)).useDelimiter(" ");
while (scan.hasNext()) {
// 这里为对读取文本解析的方法
System.out.print(scan.next() + " ");
}
scan.close();
}
System.out.println();
long end = System.currentTimeMillis();//结束时间
System.out.println("NIO 内存映射读大文件,总共耗时:"+(end - start)+"ms");
} catch (Exception e) {
e.printStackTrace();
}
}