This the multi-page printable view of this section. Click here to print.
Java 并发
- 1: CH01-并发体系
- 2: CH02-理论基础
- 3: CH03-线程基础-1
- 4: CH04-线程基础-2
- 5: CH05-Synchronized
- 6: CH06-Volatile
- 7: CH07-Final
- 8: CH08-并发概览
- 9: CH09-底层支撑
- 10: CH10-LockSupport
- 11: CH11-AQS-1
- 12: CH12-AQS-2
- 13: CH13-AQS-3
- 14: CH14-AQS-4
- 15: CH15-ReentrantLock
- 16: CH16-ReentrantReadWriteLock
- 17: CH17-ConcurrentHashMap
- 18: CH18-ConcurrentLinkedQueue
- 19: CH19-BlockingQueue
- 20: CH20-FutureTask
- 21: CH21-ThreadPoolExecutor
- 22: CH22-ScheduledThreadPoolExecutor
- 23: CH23-ForkJoin.md
- 24: CH24-CountDownLatch
- 25: CH25-CyclicBarrier
- 26: CH26-Semaphore
- 27: CH27-Phaser
- 28: CH28-Exchanger
- 29: CH29-ThreadLocal
- 30: CH30-AllLocks
- 31: CH31-AllQueues
- 32: CH32-AllPools
1 - CH01-并发体系
理论基础
- 为什么需要多线程
- 什么是线程不安全
- 并发问题的根源
- 可见性
- 原子性
- 有序性
- Java 提供的方案
- 关键字
- volatile
- synchronized
- final
- 内存模型
- Happens Before 规则
- 锁优化
- 关键字
- 线程安全的范围
- 不可变
- 绝对线程安全
- 相对线程安全
- 线程兼容
- 线程对立
- 实现方法
- 互斥同步
- synchronized
- ReentrantLock
- 非阻塞同步
- CAS
- Atomic Class
- 无同步方案
- 栈封闭
- ThreadLocal
- 可重入代码 Reentrant Code
- 互斥同步
线程基础
- 线程状态转换
- 新建 New
- 可运行 Runnable
- 阻塞 Blocking
- 无限期等待 Waiting
- 限期等待 Timed Waiting
- 终止 Terminated
- 线程使用方式
- 实现 Runnable 接口
- 继承 Thread 类
- 实现 Callable 接口
- 线程基础机制
- Executor
- Daemon
- sleep
- yield
- 线程中断
- InterruptedException
- interrupted()
- Executor 的中断操作
- 线程互斥同步
- synchronized
- ReentrantLock
- 线程协作
- join()
- wait() notify() notifyAll()
- await() signal() signalAll()
并发工具
- Locks
- Lock 接口
- AQS
- Condition
- LockSupport
- 重入锁 ReentrantLock
- 读写锁 ReadWriteLock
- Collections
- ConcurrentHashMap
- ConcurrentLinkedQueue
- BlockingQueue
- CopyOnWriteArrayList
- Executors
- Executor
- ForkJoin
- ThreadPoolExecutor
- FutureTask
- Atomic
- 基本类型
- AtomicBoolean
- AtomicInteger
- AtomicLong
- Array
- AtomicBooleanArray
- AtomicIntegerArray
- AtomicLongArray
- Reference
- AtomicReference
- AtomicMarkedReference
- AtomicStampedReference
- FieldUpdater
- AtomicIntegerFiledUpdater
- AtomicLongFiledUpdater
- AtomicReferenceFiledUpdater
- 基本类型
- Tools
- CountDownLatch
- CyclicBarrier
- Semaphore
- Excahnger
并发本质
- 协作
- 管理
- Lock & Condition
- synchronized
- 信号量 Semaphone
- CountDownLatch
- CyclicBarrier
- Pharser
- Exchanger
- 管理
- 分工
- Executor 与 ThreadPool
- ForkJoin
- Future
- 模式
- Guarded Suspension
- ThreadPerMessage
- Balking
- Worker Thread
- 两阶段终止
- 生产消费
- 互斥
- 无锁
- CAS
- Atomic
- 模式
- Imutablity
- CopyOnWrite
- ThreadLocal
- 互斥锁
- synchronized
- Lock
- ReadWriteLock
- 无锁
并发模式
框架案例
- Guava RateLimitor
- Netty
- Disrutor
- HikariCP
2 - CH02-理论基础
多线程的优势
CPU、内存、IO 设备的速度存在巨大差异,为了合理利用 CPU 的高性能,平衡三者之间的速度差异,计算机体系结构、操作系统、编译程序实现了相关优化:
- CPU 增加了缓存,以平衡与内存的速度差异——导致了可见性问题
- 操作系统提供了进程、线程,以分时复用 CPU,进而均衡 CPU 与 IO 设备之间的速度差异——导致原子性问题
- 编译程序优化了指令执行顺序,使缓存能够得到更合理的利用——导致了有序性问题
线程不安全
如果多个线程对同一份数据执行读写而不采取同步措施的话,可能导致混乱(非预期)的操作结果。
class ThreadUnsafeCounter {
private int count =0;
public void add() {
count++;
}
public int get() {
return count;
}
}
class Bootstrap {
public static void main(String[] args) {
int threadSize=1000;
ThreadUnsafeCounter counter = new ThreadUnsafeCounter();
CountDownLatch latch = new CountDownLatch(threadSize);
ExecutorService executor = Executors.newCachedThreadPool();
for(int i=0;i<threadSize;i++){
executor.execute(() -> {
counter.add();
latch.countDown();
})
}
latch.await();
executor.shutdown();
System.out.println(counter.get()); // will always < 1000
}
}
并发三要素
可见性:CPU 缓存
可见性:一个线程对共享变量的修改,其他线程能够立即看到。
// thread 1
int i=0;
i=10;
// thread 2
j = i;
如果 CPU1 执行 Thread1、CPU2 执行 Thread2。当 Thread1 执行 i=10 时,会首先将 i 的初始值加载到 CPU1 的高速缓存中,然后赋值为 10,那么在 CPU1 的高速缓存中 i 的值变为了 10,却被没有被立即写回主存。
此时 Thread2 执行 j=i,首先去主存读取 i 的值加载到 CPU2 的高速缓存,(这时主存中 i 的值仍未 0),这就导致 j 的值为 0,而非 10。
原子性:分时复用
原子性:一个操作或多个操作那么全都执行,要么全不执行,不会被任何因素打断。
有序性:指令重排序
有序性:程序执行的顺序完全按照代码的先后顺序执行。
程序执行时为了提高性能,编译器和处理器通常会对执行进行重排序,分为三种类型:
编译器优化:编译器再不改变单线程程序语义的前提下,重新安排语句的执行顺序。
指令级并行:现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖,处理器可以改变语句对应机器指令的执行顺序。
内存系统重排序:由于处理器通过高速缓存读写缓冲区,是的加载和存储操作看上去实在乱序执行。
从 Java 代码到最终要执行的指令序列,会经历以上三种重排序。
- 第一种属于编译器重排序,2、3 属于处理器重排序。
- 这些重排序可能会导致多线程程序出现内存可见性问题。对于编译器,JMM 中的编译器重排序规则会禁止特定类型的重排序操作。
- 对于处理器重排序,JMM 的处理器重排序规则会要求 Java 编译器在生成指令序列时,插入特定类型的内存屏障指令,通过这些内存屏障指令来禁止特定类型的处理器重排序操作。
Java 如何解决并发问题:JMM
核心知识点
Java 内存模型规范了 JVM 如何提供按需禁用编译和缓存优化的方法。
- volatile、synchronized、final 关键字
- Happens Before 规则
可见性、有序性、原子性
- 原子性:Java 中通过 synchronized 和 Lock 实现原子性保证。
- 可见性:Java 中通过 volatie 提供可见性保证。
- synchronized 和 Lock 保证同一时刻只有一个线程获取锁然后执行代码,释放锁前或将数据刷新到主存。
- 有序性:Java 中通过 volatile 保证一定的有序性。
- synchronized 和 Lock 保证同一时刻只有一个线程执行,相当于多个线程顺序执行代码,即有序执行。
volatile、synchronized、final
Happens Before
除了 volatile、synchronized、Lock 能够保证有序性,JVM 还规定了先行发生规则,使一个操作无需显式控制即可保证先于另一个操作发生。
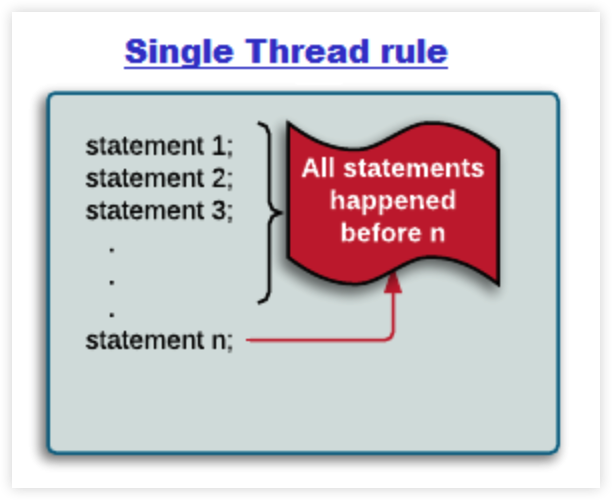
单一线程:Single Thread Rule
在一个线程内,程序中前面的操作先于后面的操作。
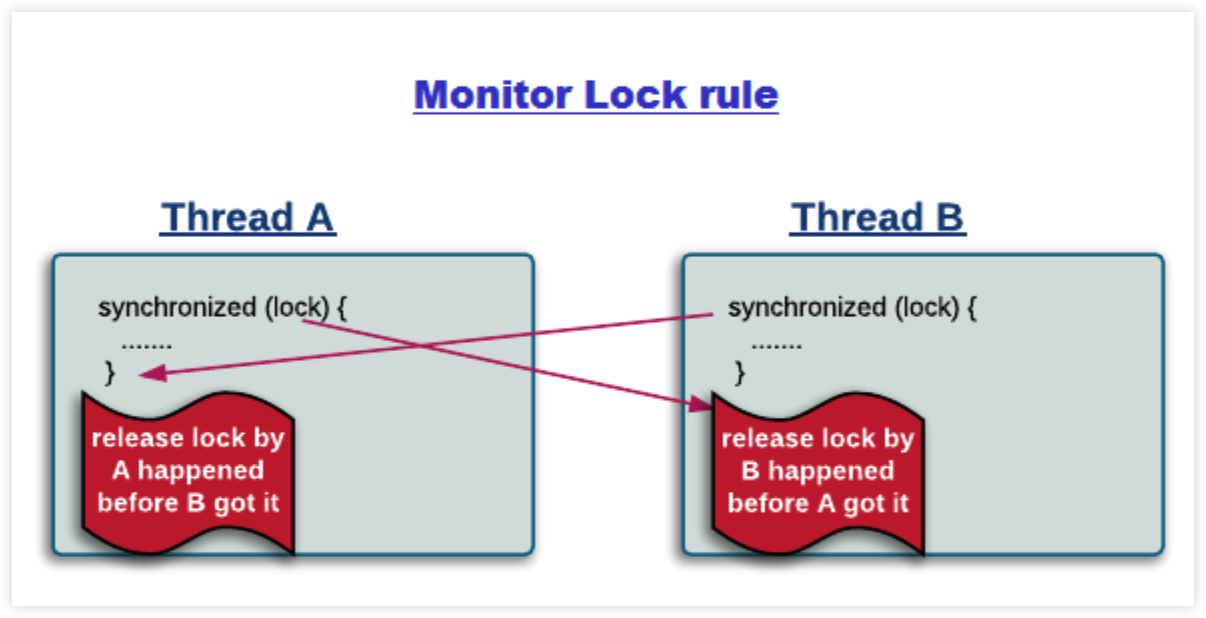
管程锁定:Monitor Lock Rule
- 一个 unlock 操作先于后面对一个锁的 lock 操作。
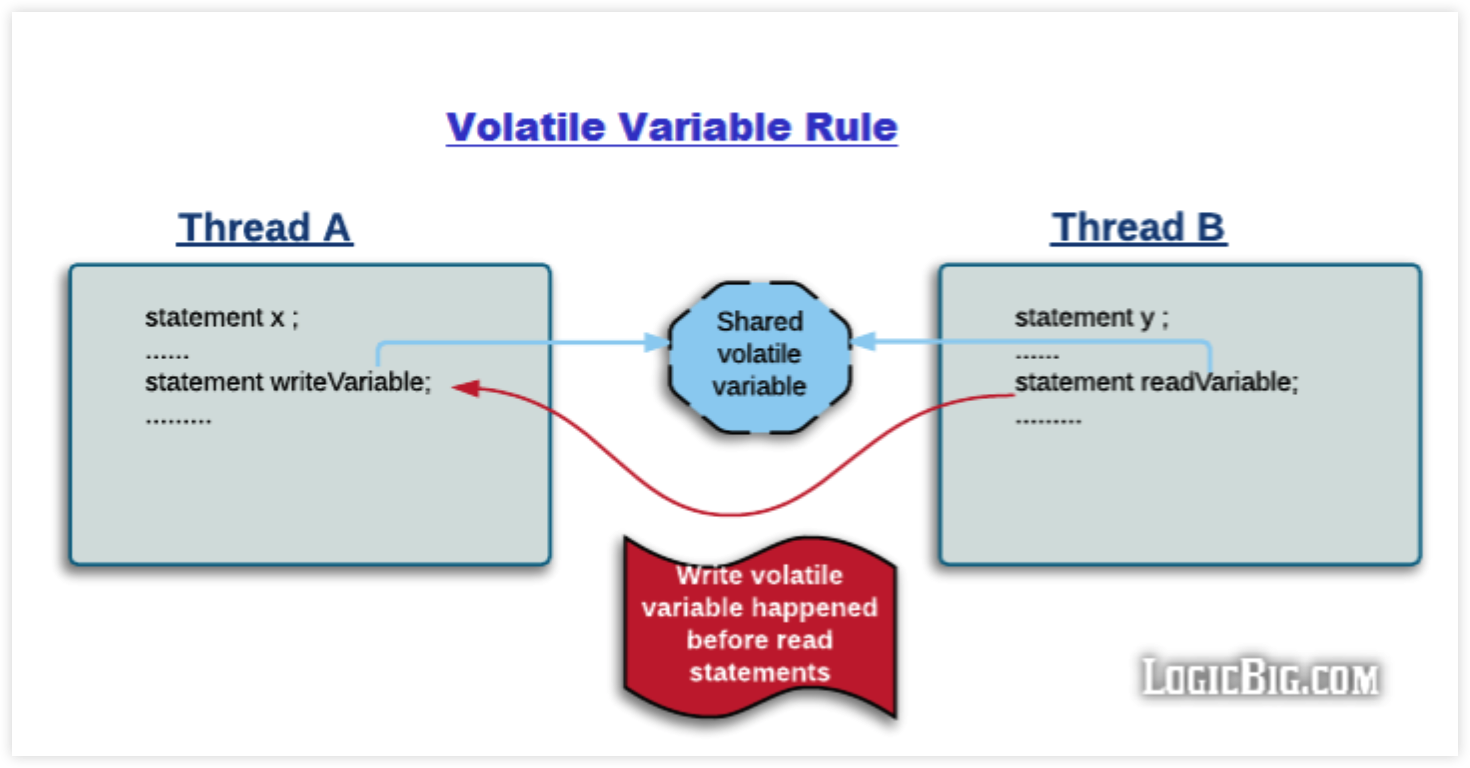
Volatile 变量:Volatile Variable Rule
对一个 volatile 变量的写操作先于对该变量的读操作。
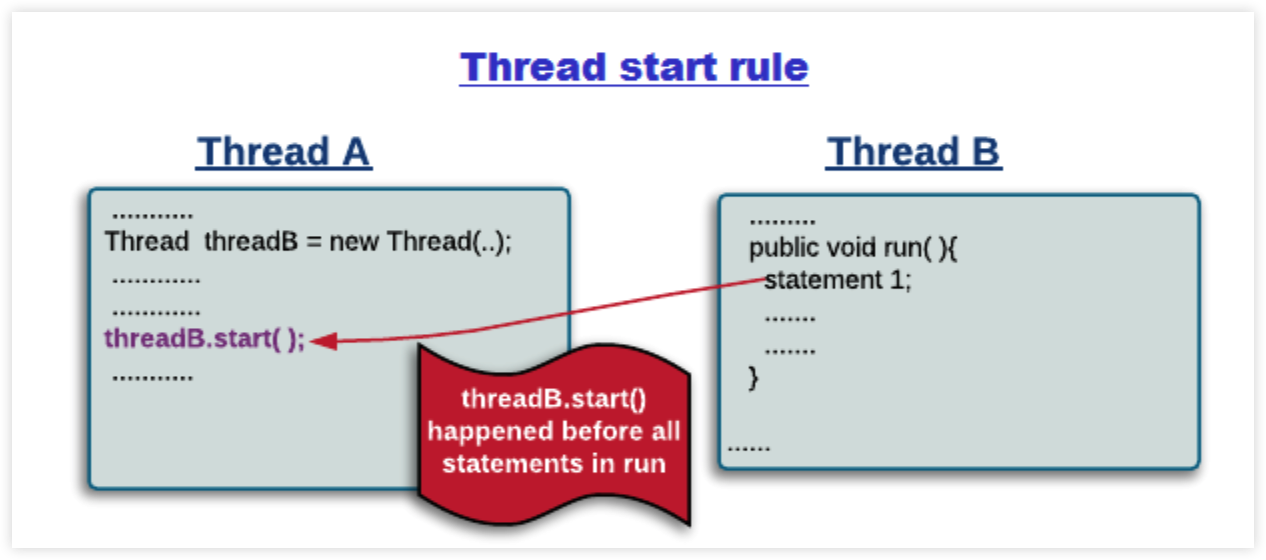
线程启动:Thread Start Rule
Thread 对象的 start 方法先于该线程的每一个动作。
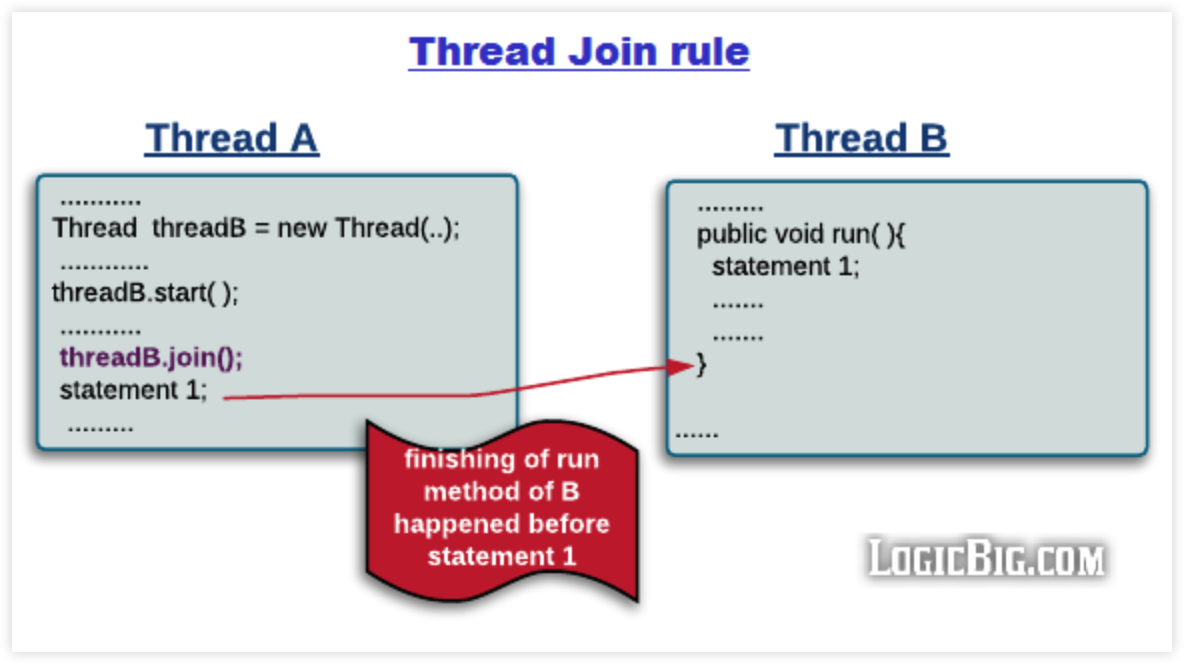
线程加入:Thread Join Rule
Thread 对象的结束先于 join 方法返回。
线程中断:Thread Interruption Rule
- 对线程 interrupt 方法的调用先于检测到中断的代码执行。
对象终结:Finalizer Rule
- 对象构造函数执行完成先于 finalize 方法开始。
传递性:Transitivity
- 如果操作 A 先于 B,B 先于 C,那么 A 先于 C。
线程安全:安全程度
一个类可以被多个线程安全调用时,该类就是线程安全的。
将共享数据按照安全程度的强弱来划分安全强度的等级:
- 不可变
- 绝对线程安全
- 相对线程安全
- 线程兼容
- 线程对立
不可变
不可变(Immutable)的对象一定是线程安全的,不需要再采取任何的线程安全保障措施。只要一个不可变的对象被正确地构建出来,永远也不会看到它在多个线程之中处于不一致的状态。
final 关键字修饰的基本数据类型
String
枚举类型
Number 部分子类,如 Long 和 Double 等数值包装类型,BigInteger 和 BigDecimal 等大数据类型。但同为 Number 的原子类 AtomicInteger 和 AtomicLong 则是可变的。
Collections.unmodifiableXXX() 先对原始的集合进行拷贝,需要对集合进行修改的方法都直接抛出异常。
绝对线程安全
不管运行时环境如何,调用者都不需要任何额外的同步措施。
相对线程安全
相对线程安全需要保证对这个对象单独的操作是线程安全的,在调用的时候不需要做额外的保障措施。但是对于一些特定顺序的连续调用,就可能需要在调用端使用额外的同步手段来保证调用的正确性。
在 Java 语言中,大部分的线程安全类都属于这种类型,例如 Vector、HashTable、Collections 的 synchronizedCollection() 方法包装的集合等。
线程兼容
线程兼容是指对象本身并不是线程安全的,但是可以通过在调用端正确地使用同步手段来保证对象在并发环境中可以安全地使用,我们平常说一个类不是线程安全的,绝大多数时候指的是这一种情况。Java API 中大部分的类都是属于线程兼容的,如与前面的 Vector 和 HashTable 相对应的集合类 ArrayList 和 HashMap 等。
线程对立
线程对立是指无论调用端是否采取了同步措施,都无法在多线程环境中并发使用的代码。由于 Java 语言天生就具备多线程特性,线程对立这种排斥多线程的代码是很少出现的,而且通常都是有害的,应当尽量避免。
线程安全:实现
互斥同步—阻塞同步
- synchronized
- ReentrantLock
非阻塞同步
互斥同步最主要的问题就是线程阻塞和唤醒所带来的性能问题,因此这种同步也称为阻塞同步。
互斥同步属于一种悲观的并发策略,总是认为只要不去做正确的同步措施,那就肯定会出现问题。无论共享数据是否真的会出现竞争,它都要进行加锁(这里讨论的是概念模型,实际上虚拟机会优化掉很大一部分不必要的加锁)、用户态核心态转换、维护锁计数器和检查是否有被阻塞的线程需要唤醒等操作。
- CAS
随着硬件指令集的发展,我们可以使用基于冲突检测的乐观并发策略: 先进行操作,如果没有其它线程争用共享数据,那操作就成功了,否则采取补偿措施(不断地重试,直到成功为止)。这种乐观的并发策略的许多实现都不需要将线程阻塞,因此这种同步操作称为非阻塞同步。
乐观锁需要操作和冲突检测这两个步骤具备原子性,这里就不能再使用互斥同步来保证了,只能靠硬件来完成。硬件支持的原子性操作最典型的是: 比较并交换(Compare-and-Swap,CAS)。CAS 指令需要有 3 个参数,分别是内存地址 V、旧的预期值 A 和新值 B。当执行操作时,只有当 V 的值等于 A,才将 V 的值更新为 B。
- AtomicInteger
J.U.C 包里面的整数原子类 AtomicInteger,其中的 compareAndSet() 和 getAndIncrement() 等方法都使用了 Unsafe 类的 CAS 操作。
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
var1 指示对象内存地址,var2 指示该字段相对对象内存地址的偏移,var4 指示操作需要加的数值,这里为 1。通过 getIntVolatile(var1, var2) 得到旧的预期值,通过调用 compareAndSwapInt() 来进行 CAS 比较,如果该字段内存地址中的值等于 var5,那么就更新内存地址为 var1+var2 的变量为 var5+var4。
可以看到 getAndAddInt() 在一个循环中进行,发生冲突的做法是不断的进行重试。
- ABA
如果一个变量初次读取的时候是 A 值,它的值被改成了 B,后来又被改回为 A,那 CAS 操作就会误认为它从来没有被改变过。
J.U.C 包提供了一个带有标记的原子引用类 AtomicStampedReference 来解决这个问题,它可以通过控制变量值的版本来保证 CAS 的正确性。大部分情况下 ABA 问题不会影响程序并发的正确性,如果需要解决 ABA 问题,改用传统的互斥同步可能会比原子类更高效。
无同步方案
要保证线程安全,并不是一定就要进行同步。如果一个方法本来就不涉及共享数据,那它自然就无须任何同步措施去保证正确性。
- 栈封闭
多个线程访问同一个方法的局部变量时,不会出现线程安全问题,因为局部变量存储在虚拟机栈中,属于线程私有的。
- ThreadLocal
如果一段代码中所需要的数据必须与其他代码共享,那就看看这些共享数据的代码是否能保证在同一个线程中执行。如果能保证,我们就可以把共享数据的可见范围限制在同一个线程之内,这样,无须同步也能保证线程之间不出现数据争用的问题。
符合这种特点的应用并不少见,大部分使用消费队列的架构模式(如“生产者-消费者”模式)都会将产品的消费过程尽量在一个线程中消费完。其中最重要的一个应用实例就是经典 Web 交互模型中的“一个请求对应一个服务器线程”(Thread-per-Request)的处理方式,这种处理方式的广泛应用使得很多 Web 服务端应用都可以使用线程本地存储来解决线程安全问题。
可以使用 java.lang.ThreadLocal 类来实现线程本地存储功能。每个 Thread 都有一个 ThreadLocal.ThreadLocalMap 对象,Thread 类中就定义了 ThreadLocal.ThreadLocalMap 成员。
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
ThreadLocal 从理论上讲并不是用来解决多线程并发问题的,因为根本不存在多线程竞争。
- 可重入代码
这种代码也叫做纯代码(Pure Code),可以在代码执行的任何时刻中断它,转而去执行另外一段代码(包括递归调用它本身),而在控制权返回后,原来的程序不会出现任何错误。
可重入代码有一些共同的特征,例如不依赖存储在堆上的数据和公用的系统资源、用到的状态量都由参数中传入、不调用非可重入的方法等。
3 - CH03-线程基础-1
线程状态
- New:新建,创建后尚未启动。
- Runnable:可运行,可能正在运行,也可能在等待 CPU 时间片。
- 包含操作系统线程状态的 Running 和 Ready。
- Blocking:等待获取一个排它锁,如果其他线程释放了锁就会结束该状态。
- Waiting:无限期等待,需要其他线程唤醒,否则不会分配 CPU 时间片。
- 未设置 Timeout 参数的 Object.wait 方法,需要 Object.notify 或 Object.notifyAll 唤醒
- 未设置 Timeout 参数的 Thread.join 方法,被调用的线程执行完毕
- LockSupport.park 调用
- Timed Waiting:限时等待,在一定时间后自动唤醒。
- 调用 Thread.sleep 方法,线程睡眠
- 设置了 Timeout 参数调用 Object.wait 进入限期等待,挂起线程
- 睡眠和挂起用于表述行为,阻塞和等待用于描述状态
- 阻塞和等待的区别在于,阻塞是被动的,等待的是一个排它锁,锁的释放由其他线程决定。
- 等待是祖东的,等待的是一个时间点,是线程自身通过 Thread.sleep 或 Object.wait 主动触发的等待。
- 设置了 Timeout 参数调用 Thread.join 方法
- LockSupport.parkNanos
- LockSupport.parkUntil
- Terminated:死亡,线程结束任务之后自然死亡,或异常导致任务终止而死亡
应用方式
- 实现 Runnable 接口:无返回值
- 实现 Callable 接口:有返回值
- 继承 Thread 类
实现 Runnable 后 Callable 接口的类只能被当做是一个可以在线程中执行的任务,并不是真正意义上的线程实例,因此最后还是需要通过 Thread 类来调用。即任务是通过线程来执行的。
线程机制
Executor
Executor 管理多个异步任务的执行,而无需开发者显式管理线程的生命周期。这里的异步是指多个任务的执行互不干扰,不需要执行同步操作。
- CachedThreadPool:每个任务创建一个线程
- FixedThreadPool:所有任务共用固定数量的线程
- SingleThreadExecutor:仅有一个线程的 FixedThreadPool
Daemon
守护线程是程序运行时在后台提供服务的线程,不属于程序中必要的部分,非必须。
- 当所有非守护线程结束时,程序即终止,同时会杀死所有守护线程。
- main 属于非守护线程。
- 通过 setDaemon 方法将一个线程设置为守护线程。
sleep
Thread.sleep(millisec) 方法会休眠当前正在执行的线程,millisec 单位为毫秒。
sleep() 可能会抛出 InterruptedException,因为异常不能跨线程传播回 main() 中,因此必须在本地进行处理。线程任务可能出现的其它异常也同样需要在本地进行处理。
yield
对静态方法 Thread.yield() 的调用表示当前线程已经完成了生命周期中最重要的部分,可以切换给其它线程来执行。该方法只是对线程调度器的一个建议,而且也只是建议具有相同优先级的其它线程可以运行。
线程中断
一个线程执行完毕之后会自动结束,如果在运行过程中发生异常也会提前结束。
InterruptedException
通过调用一个线程的 interrupt() 来中断该线程,如果该线程处于阻塞、限期等待或者无限期等待状态,那么就会抛出 InterruptedException,从而提前结束该线程。但是不能中断 I/O 阻塞和 synchronized 锁阻塞。
对于以下代码,在 main() 中启动一个线程之后再中断它,由于线程中调用了 Thread.sleep() 方法,因此会抛出一个 InterruptedException,从而提前结束线程,不执行之后的语句。
public class InterruptExample {
private static class MyThread1 extends Thread {
@Override
public void run() {
try {
Thread.sleep(2000);
System.out.println("Thread run");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new MyThread1();
thread1.start();
thread1.interrupt();
System.out.println("Main run");
}
// 在线程 sleep 期间中断,“Thread run” 将不会被打印
Main run
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at InterruptExample.lambda$main$0(InterruptExample.java:5)
at InterruptExample$$Lambda$1/713338599.run(Unknown Source)
at java.lang.Thread.run(Thread.java:745)
}
interrupted
如果一个线程的 run() 方法执行一个无限循环,并且没有执行 sleep() 等会抛出 InterruptedException 的操作,那么调用线程的 interrupt() 方法就无法使线程提前结束。
但是调用 interrupt() 方法会设置线程的中断标记,此时调用 interrupted() 方法会返回 true。因此可以在循环体中使用 interrupted() 方法来判断线程是否处于中断状态,从而提前结束线程。
public class InterruptExample {
private static class MyThread2 extends Thread {
@Override
public void run() {
while (!interrupted()) {
// ..
}
System.out.println("Thread end");
}
}
public static void main(String[] args) throws InterruptedException {
Thread thread2 = new MyThread2();
thread2.start();
thread2.interrupt();
}
// Thread end
}
Executor 中断操作
调用 Executor 的 shutdown() 方法会等待线程都执行完毕之后再关闭,但是如果调用的是 shutdownNow() 方法,则相当于调用每个线程的 interrupt() 方法。
以下使用 Lambda 创建线程,相当于创建了一个匿名内部线程。
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> {
try {
Thread.sleep(2000);
System.out.println("Thread run");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
executorService.shutdownNow();
System.out.println("Main run");
// 在线程 sleep 期间被中断,不会打印 "Thread run"
Main run
java.lang.InterruptedException: sleep interrupted
如果想要中断 Executor 中的一个线程,可以通过 submit 方法提交一个任务,然后返回一个 Future 对象,调用该 Future 对象的 cancel 方法即可中断对应线程:
Future<?> future = executorService.submit(() -> {
// ..
});
future.cancel(true);
线程同步:互斥
Java 提供了两种锁机制来控制多个线程对共享资源的互斥访问,第一个是 JVM 实现的 synchronized,而另一个是 JDK 实现的 ReentrantLock。
synchronized
- 同步代码块
- 只作用于同一个对象实例,比如 new Object(),如果调用两个对象上的同步代码块,就不会进行同步。
- 同步方法
- 它和同步代码块一样,作用于同一个对象。只是作用在了该方法所属的实例。
- 同步类
- 作用于整个类,也就是说两个线程调用同一个类的不同对象上的这种同步语句,也会进行同步。
- 同步静态方法
- 作用于整个类。
ReentrantLock
ReentrantLock 是 java.util.concurrent(J.U.C)包中的锁。
private Lock lock = new ReentrantLock();
public void func() {
lock.lock();
try {
for (int i = 0; i < 10; i++) {
System.out.print(i + " ");
}
} finally {
lock.unlock(); // 确保释放锁,从而避免发生死锁。
}
}
基本对比
- 实现层次:
- synchronized 是 JVM 实现的,而 ReentrantLock 是 JDK 实现的。
- 性能:
- 新版本 Java 对 synchronized 进行了很多优化,例如自旋锁等,synchronized 与 ReentrantLock 大致相同。
- 等待可中断:
- 当持有锁的线程长期不释放锁的时候,正在等待的线程可以选择放弃等待,改为处理其他事情。
- ReentrantLock 可中断,而 synchronized 不行。
- 公平锁
- 公平锁是指多个线程在等待同一个锁时,必须按照申请锁的时间顺序来依次获得锁。
- synchronized 中的锁是非公平的,ReentrantLock 默认情况下也是非公平的,但是也可以是公平的。
- 锁绑定多个条件
- 一个 ReentrantLock 可以同时绑定多个 Condition 对象。
应用选择
除非需要使用 ReentrantLock 的高级功能,否则优先使用 synchronized。这是因为 synchronized 是 JVM 实现的一种锁机制,JVM 原生地支持它,而 ReentrantLock 不是所有的 JDK 版本都支持。并且使用 synchronized 不用担心没有释放锁而导致死锁问题,因为 JVM 会确保锁的释放。
线程协作
当多个线程可以一起工作去解决某个问题时,如果某些部分必须在其它部分之前完成,那么就需要对线程进行协调。
join
在线程中调用另一个线程的 join() 方法,会将当前线程挂起,而不是忙等待,直到目标线程结束。
wait、notify、notifyAll
调用 wait() 使得线程等待某个条件满足,线程在等待时会被挂起,当其他线程的运行使得这个条件满足时,其它线程会调用 notify() 或者 notifyAll() 来唤醒挂起的线程。
它们都属于 Object 的一部分,而不属于 Thread。
只能用在同步方法或者同步控制块中使用,否则会在运行时抛出 IllegalMonitorStateExeception。
使用 wait() 挂起期间,线程会释放锁。这是因为,如果没有释放锁,那么其它线程就无法进入对象的同步方法或者同步控制块中,那么就无法执行 notify() 或者 notifyAll() 来唤醒挂起的线程,造成死锁。
public class WaitNotifyExample {
public synchronized void before() {
System.out.println("before");
notifyAll();
}
public synchronized void after() {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("after");
}
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
WaitNotifyExample example = new WaitNotifyExample();
executorService.execute(() -> example.after());
executorService.execute(() -> example.before());
}
// before
// after
}
wait() 和 sleep() 的区别
- wait() 是 Object 的方法,而 sleep() 是 Thread 的静态方法;
- wait() 会释放锁,sleep() 不会。
await() signal() signalAll()
JUC 类库中提供了 Condition 类来实现线程之间的协调,可以在 Condition 上调用 await() 方法使线程等待,其它线程调用 signal() 或 signalAll() 方法唤醒等待的线程。相比于 wait() 这种等待方式,await() 可以指定等待的条件,因此更加灵活。
使用 Lock 来获取一个 Condition 对象。
public class AwaitSignalExample {
private Lock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
public void before() {
lock.lock();
try {
System.out.println("before");
condition.signalAll();
} finally {
lock.unlock();
}
}
public void after() {
lock.lock();
try {
condition.await();
System.out.println("after");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
AwaitSignalExample example = new AwaitSignalExample();
executorService.execute(() -> example.after());
executorService.execute(() -> example.before());
}
// before
// after
}
4 - CH04-线程基础-2
Create Thread
- What happens when creating a Thread instance
Thread thread = new Thread(){
@Override
public void run() {
// code
}
};
// at this point the thread is in NEW state, all you have a simple java object,
// no actual thread is created
thread.start();
// when start() is invoked, at some unspecified point in the near future
// the thread will go into RUNNABLE state, this means an actual thread will be created.
// That can happen before start() returns.
- 通过
new创建线程时,你只是创建了一个 Thread 类的实例,该 Thread 实例的状态为 NEW。 - 通过
thread.start()调用线程时,该 Thread 实例的状态将会在未来某个时刻变为 RUNNABLE,这表示 OS 级别的线程将被创建,这部分工作由 JVM 完成。
用户空间 & 内核空间
在操作系统中,内存通常会被分成用户空间(User space)与内核空间(Kernel space)这两个部分。当进程/线程运行在用户空间时就处于用户态,运行在内核空间时就处于内核态:
- 运行在内核态的程序可以访问用户空间和内核空间,或者说它可以访问计算机的任何资源,不受限制,为所欲为,例如协调 CPU 资源,分配内存资源,提供稳定的环境供应用程序运行等
- 而应用程序基本都是运行在用户态的,或者说用户态就是提供应用程序运行的空间。运行在用户态的程序只能访问用户空间
那为什么要区分用户态和内核态呢?
早期操作系统是不区分用户态和内核态的,也就是说应用程序可以访问任意内存空间,如果程序不稳定常常会让系统崩溃,比如清除了操作系统的内存数据。为此大佬们设计出了一套规则:对于那些比较危险的操作需要切到内核态才能运行,比如 CPU、内存、设备等资源管理器程序就应该在内核态运行,否则安全性没有保证。
用户态的程序不能随意操作内核地址空间,这样有效地防止了操作系统程序受到应用程序的侵害。
那如果处于用户态的程序想要访问内核空间的话怎么办呢?就需要进行系统调用从用户态切换到内核态。
操作系统线程
在用户空间实现线程
在早期的操作系统中,所有的线程都是在用户空间下实现的,操作系统只能看到线程所属的进程,而不能看到线程。
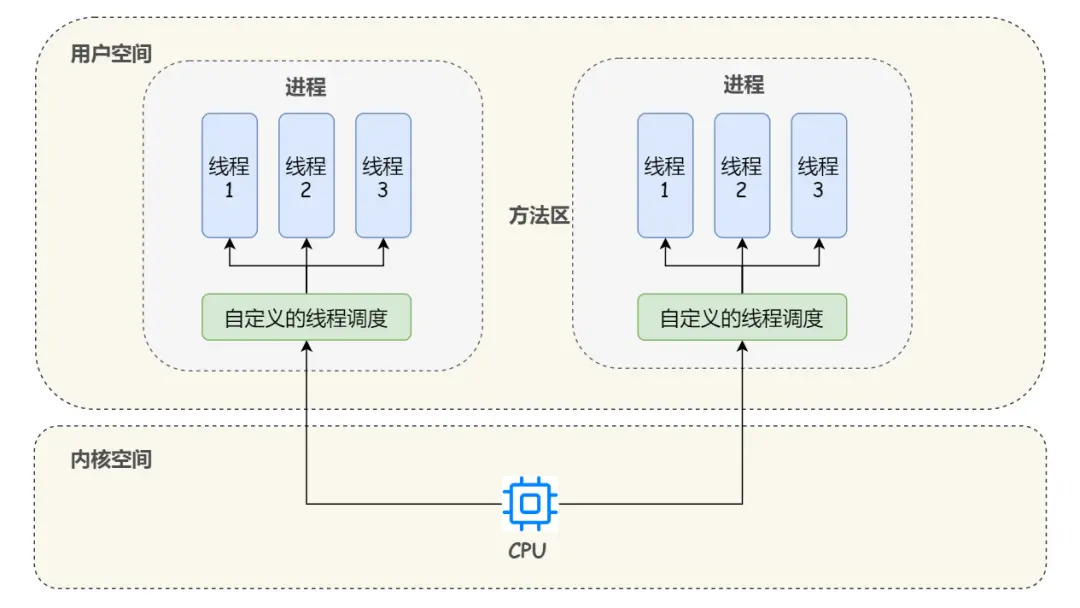
从我们开发者的角度来理解用户级线程就是说:在这种模型下,我们需要自己定义线程的数据结构、创建、销毁、调度和维护等,这些线程运行在操作系统的某个进程内,然后操作系统直接对进程进行调度。
这种方式的好处一目了然,首先第一点,就是即使操作系统原生不支持线程,我们也可以通过库函数来支持线程;第二点,线程的调度只发生在用户态,避免了操作系统从内核态到用户态的转换开销。
当然缺点也很明显:由于操作系统看不见线程,不知道线程的存在,而 CPU 的时间片切换是以进程为维度的,所以如果进程中某个线程进行了耗时比较长的操作,那么由于用户空间中没有时钟中断机制,就会导致此进程中的其它线程因为得不到 CPU 资源而长时间的持续等待;另外,如果某个线程进行系统调用时比如缺页中断而导致了线程阻塞,此时操作系统也会阻塞住整个进程,即使这个进程中其它线程还在工作。
在内核空间中实现线程
所谓内核级线程就是运行在内核空间的线程, 直接由内核负责,只能由内核来完成线程的调度。
每个内核线程可以视为内核的一个分身,这样操作系统就有能力同时处理多件事情,支持多线程的内核就叫做多线程内核(Multi-Threads Kernel)。
从我们开发者的角度来理解内核级线程就是说:我们可以直接使用操作系统中已经内置好的线程,线程的创建、销毁、调度和维护等,都是直接由操作系统的内核来实现,我们只需要使用系统调用就好了,不需要像用户级线程那样自己设计线程调度等。
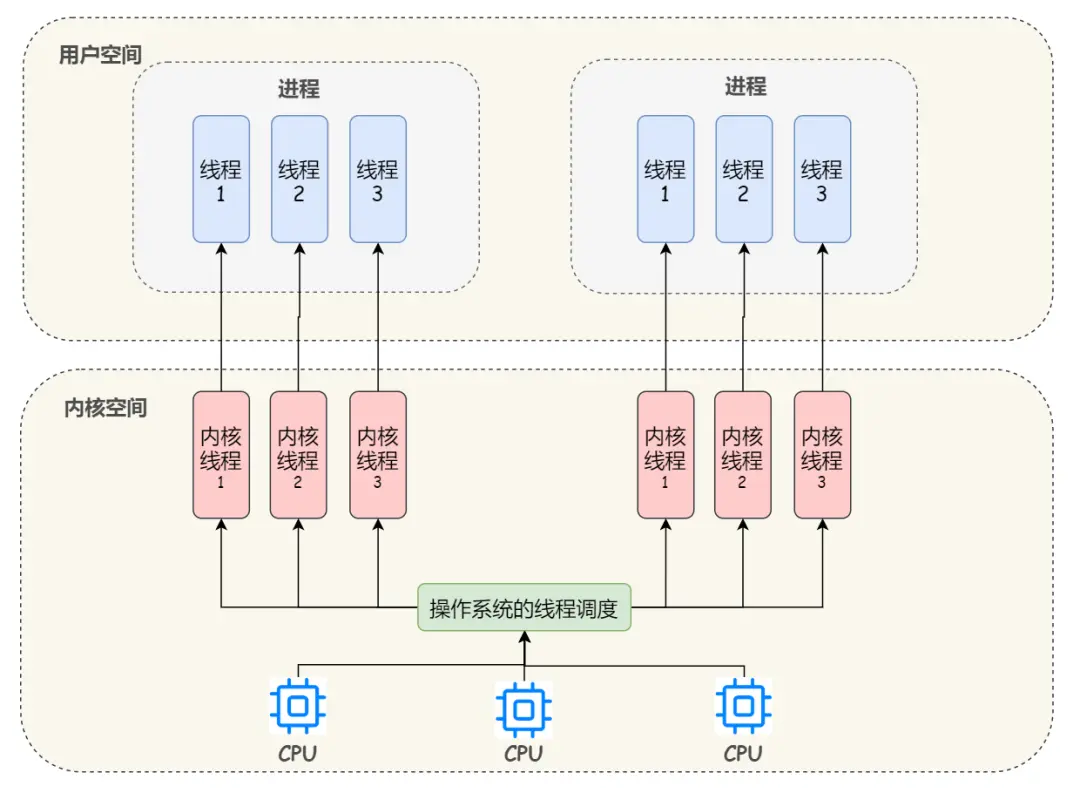
上图画的是 1:1 的线程模型,所谓线程模型,也就是用户线程和内核线程之间的关联方式,线程模型当然不止 1:1 这一种,下面我们来详细解释以下这三种多线程模型:
1. 多对一线程模型:
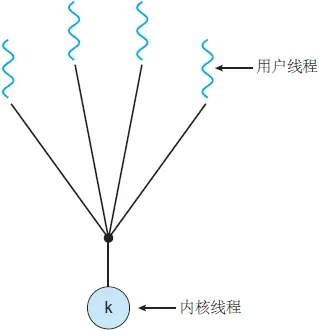
- 在多对一模型中,多个用户级线程映射到某一个内核线程上
- 线程管理由用户空间中的线程库处理,这非常有效
- 但是,如果进行了阻塞系统调用,那么即使其他用户线程能够继续,整个进程也会阻塞
- 由于单个内核线程只能在单个 CPU 上运行,因此多对一模型不允许在多个 CPU 之间拆分单个进程
从并发性角度来总结下,虽然多对一模型允许开发人员创建任意多的用户线程,但是由于内核只能一次调度一个线程,所以并未增加并发性。现在已经几乎没有操作系统来使用这个模型了,因为它无法利用多个处理核。
2. 一对一线程模型:
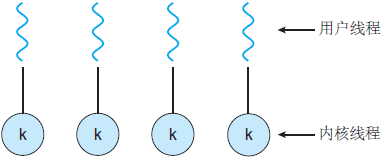
- 一对一模型克服了多对一模型的问题
- 一对一模型创建一个单独的内核线程来处理每个用户线程
- 但是,管理一对一模型的开销更大,涉及更多开销和减慢系统速度
- 此模型的大多数实现都限制了可以创建的线程数
从并发性角度来总结下,虽然一对一模型提供了更大的并发性,但是开发人员应注意不要在应用程序内创建太多线程(有时系统可能会限制创建线程的数量),因为管理一对一模型的开销更大。
3. 多对多线程模型:
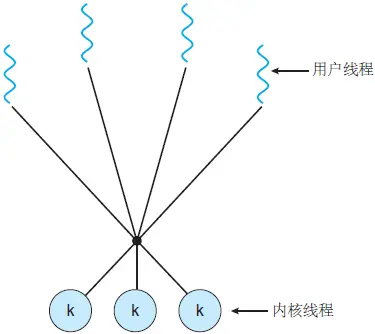
- 多对多模型将任意数量的用户线程复用到相同或更少数量的内核线程上,结合了一对一和多对一模型的最佳特性
- 用户对创建的线程数没有限制
- 阻止内核系统调用不会阻止整个进程
- 进程可以分布在多个处理器上
- 可以为各个进程分配可变数量的内核线程,具体取决于存在的 CPU 数量和其他因素
Java Thread
在上面的模型介绍中,我们提到了通过线程库来创建、管理线程,那么什么是线程库呢?
线程库就是为开发人员提供创建和管理线程的一套 API。
当然,线程库不仅可以在用户空间中实现,还可以在内核空间中实现。前者涉及仅在用户空间内实现的 API 函数,没有内核支持。后者涉及系统调用,也就是说调用库中的一个 API 函数将会导致对内核的系统调用,并且需要具有线程库支持的内核。
下面简单介绍下三个主要的线程库:
POSIX Pthreads:可以作为用户或内核库提供,作为 POSIX 标准的扩展
Win32 线程:用于 Window 操作系统的内核级线程库
Java 线程:Java 线程 API 通常采用宿主系统的线程库来实现,也就是说在 Win 系统上,Java 线程 API 通常采用 Win API 来实现,在 UNIX 类系统上,采用 Pthread 来实现。
事实上,在 JDK 1.2 之前,Java 线程是基于称为 “绿色线程”(Green Threads)的用户级线程实现的,也就是说程序员大佬们为 JVM 开发了自己的一套线程库或者说线程管理机制。
而在 JDK 1.2 及以后,JVM 选择了更加稳定且方便使用的操作系统原生的内核级线程,通过系统调用,将线程的调度交给了操作系统内核。而对于不同的操作系统来说,它们本身的设计思路基本上是完全不一样的,因此它们各自对于线程的设计也存在种种差异,所以 JVM 中明确声明了:虚拟机中的线程状态,不反应任何操作系统中的线程状态。
也就是说,在 JDK 1.2 及之后的版本中,Java 的线程很大程度上依赖于操作系统采用什么样的线程模型,这点在不同的平台上没有办法达成一致,JVM 规范中也并未限定 Java 线程需要使用哪种线程模型来实现,可能是一对一,也可能是多对多或多对一。
总结来说,现今 Java 中线程的本质,其实就是操作系统中的线程,其线程库和线程模型很大程度上依赖于操作系统(宿主系统)的具体实现,比如在 Windows 中 Java 就是基于 Wind32 线程库来管理线程,且 Windows 采用的是一对一的线程模型。
Java线程调度
线程调度是指系统为线程分配处理使用权的过程,调度主要方式有两种,分别是协同式(Cooperative Threads-Scheduling)线程调度和抢占式(Preemptive Threads-Scheduling)线程调度。
- 协同式线程调度:线程的执行时间由线程本身来控制,线程把自己的工作执行完了之后,要主动通知系统切换到另外一个线程上去。 优点:实现简单,切换操作对线程自己是可知的,所以一般没有什么线程同步问题。 缺点:线程执行时间不可控制,甚至如果一个线程的代码编写有问题,一直不告知系统进行线程切换,那么程序就会一直阻塞在那里。
- 抢占式线程调度:每个线程将由系统来分配执行时间,线程的切换不由线程本身来决定。
优点:可以主动让出执行时间(例如Java的
Thread::yield()方法),并且线程的执行时间是系统可控的,也不会有一个线程导致整个系统阻塞的问题。 缺点:无法主动获取执行时间。
Java使用的就是抢占式线程调度,虽然这种方式的线程调度是系统自己的完成的,但是我们可以给操作系统一些建议,就是通过设置线程优先级来实现。Java语言一共设置了10个级别的线程优先级。在两个线程同时处于Ready状态时,优先级越高的线程越容易被系统选择执行。
不过由于各个系统的提供的优先级数量不一致,所以导致Java提供的10个级别的线程优先级并不见得能与各系统的优先级都一一对应。
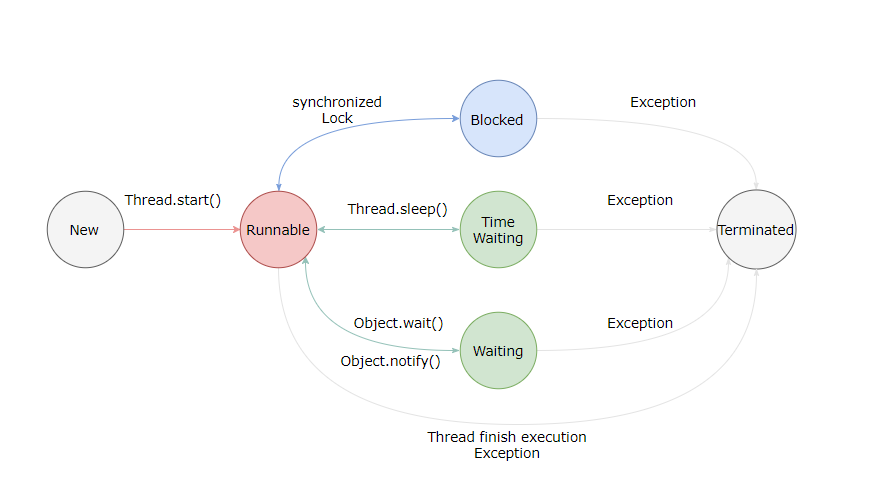
Java 线程状态转换
Java语言定义了6种线程状态,在任意一个时间点钟,一个线程只能有且只有其中的一种状态,并且可以通过特定的方法在不同状态之间切换。
- 新建(New):创建后尚未启动的线程处于这种状态。
- 运行(Runnable):包括操作系统线程状态中的Running和Ready,也就是处理此状态的线程有可能正在执行,也有可能正在等待着操作系统为它分配执行时间。
- 无限期等待(Waiting):处于这种状态的线程不会被分配处理器执行时间,它们要等待被其他线程显示唤醒。
以下方法会让线程陷入无限期等待状态:
1、没有设置Timeout参数的
Object::wait()方法; 2、没有设置Timeout参数的Thread::join()方法; 3、LockSupport::park()方法。 - 限期等待(Timed Waiting):处于这种状态的线程也不会被分配处理器执行时间,不过无须等待被其他线程显式唤醒,在一定时间之后它们会由系统自动唤醒。
以下方法会让线程进入限期等待状态:
1、
Thread::sleep()方法; 2、设置了Timeout参数的Object::wait()方法; 3、设置了Timeout参数的Thread::join()方法; 4、LockSupport::parkNanos()方法; 5、LockSupport::parkUntil()方法; - 阻塞(Blocked):线程被阻塞了,“阻塞状态”与“等待状态”的区别是“阻塞状态”在等待着获取到一个排他锁,这个事件将在另外一个线程放弃这个锁的时候发生;而“等待状态”则是在等待一段时间 ,或者唤醒动作发生。在程序进入同步区域的时候,线程将进入这种状态。
- 结束(Terminated):已终止线程的线程状态,线程已经结束执行。
Thread.sleep
如果执行了 Thread.sleep, 底层的执行流程:
- JVM 调用底层 OS 的线程 API
- 因为 JVM 采用关于内核线性一对一的线程模型, JVM 会要求操作系统在执行的时间内将线程的使用权归还给 CPU
- 一旦休眠时间到期, OS 调度器将会通过中断来唤醒线程, 并为线性分配 CPU 时间片以恢复该线程的执行
这里的关键点是, JVM 层面的这个线程在休眠期间是完全无法被复用的。
但是一个 JVM 内部能够创建的线程数量是有限的的,创建过多则会引起 OOM。
- java.lang.OutOfMemoryError : unable to create new native Thread
JVM 中的每个线程都会带来昂贵的内存开销,它会附带一个线程栈。
太多的 JVM 线程将产生开销,因为上下文切换非常昂贵,而且它们共享有限的硬件资源。
How to Thread.sleep without blocking on the JVM | by Daniel Sebban | Medium
5 - CH05-Synchronized
应用实践
- 一把锁同时只能被一个线程获取,没有获得锁的线程只能等待。
- 每个对象实例都有自己的锁(this),该锁不同实例之间互不影响。
- synchronized 修饰的方法,物理方法成功还是抛出异常,都会释放锁。
对象锁
包含实例方法锁(this)和同步代码块锁(自定义)。
代码块形式:手动设置锁定对象,也可以是 this,也可以是自定义的(对象实例)锁。
syhchronized(this)synchronized(object),比如new Object()作为一个实例锁。
方法锁形式:修饰实例的方法,锁对象是 this。
class Example { public synchronized void show() { System.out.println("example..."); } }
类锁
指 synchronized 修饰静态的方法或指定锁对象为 Class 对象。
静态方法:
class Example { public synchronized static void show() { System.out.println("example..."); } }Class 对象:
class Example { public void show() { synchronized(Example.class) { System.out.println("example..."); } } }
原理分析
加锁-解锁
创建如下代码:
public class SynchronizedDemo2 {
Object object = new Object();
public void method1() {
synchronized (object) {
}
}
}
使用 javac 命令编译生成 class 文件:
javac SynchronizedDemo2.java
使用 javap 命令反编译查看 class 文件的信息:
javap -verbose SynchronizedDemo2.class
得到如下信息:
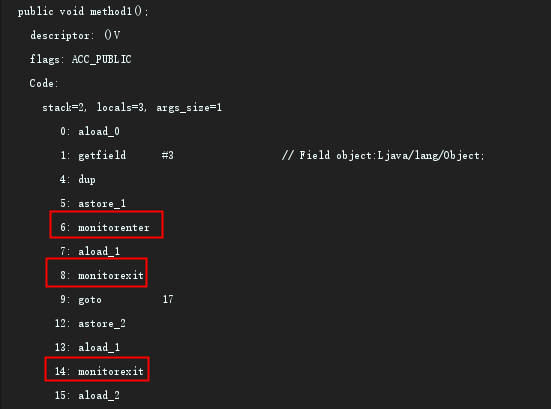
mointorenter 和 moniterexit 指令,会在程序执行时,使其锁计数器加一或减一。每个对象在同一时间只有一个 mointor(锁) 与其相关联,而一个 mointor 在同一时间只能被一个线程获得,一个对象在尝试获得与该对象关联的 monitor 锁的所有权时,monitorenter 指令会发生如下三种情况之一:
- mointor 计数器为 0,意味着目前尚未被某个线程获得,该线程会立即获得锁并将计数器加一,一旦执行加一,别的线程要想再获取就需要等待。
- 如果该线程已经拿到了该 mointor 锁的所有权,又重入了这把锁,锁计数器会继续累加一,值变为 2,随着重入次数的增加,计数值会一直累加。
- 如果该 monitor 锁已经被其他线程获得,当前线程等待锁被释放。
monitorexit 指令将释放对应 monitor 锁的所有权,释放过程很简单,即将 monitor 的计数器减一,如果结果不为 0,则表示当前是重入获得的锁,当前线程还继续持有该锁的所有权,如果计数器为 0,则表示当前线程不再拥有该 monitor 的所有权,即释放了锁。
下图描绘了真个过程:
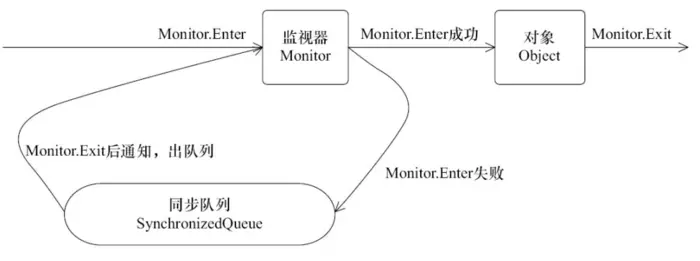
上图可以看出,任意线程对 Object 的访问,首先要获得 Object 的监视锁,如果获取失败,该线程就会进入同步状态,线程状态变为 Blocked,当 Object 的监视器占有者释放后,在同步队列中的线程就有就会获取到该监视器。
可冲入:加锁次数计数器
在同一个线程中,线程不需要再次获取通一把锁。synchronized 先天具有重入性。每个对象拥有一个计数器,当线程获取对象 monitor 锁后,计数器就会加一,释放锁后就会减一。
可见性保证:内存模型与 happens-before
synchronized 的 happens-before 规则,即监视器锁规则:(一个线程)对同一个监视器解锁,happens-before 于(另一个线程)对该监视器加锁。
public class MonitorDemo {
private int a = 0;
public synchronized void writer() { // 1
a++; // 2
} // 3
public synchronized void reader() { // 4
int i = a; // 5
} // 6
}
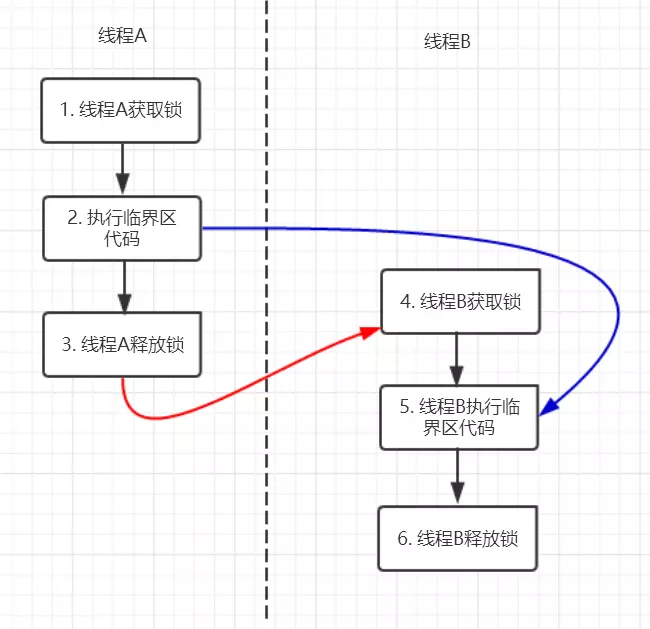
图中每个箭头的两个节点之间都是 happens-before 关系。黑色箭头由程序顺序规则推导得出,红色为监视器锁规则推导而出:线程 A 释放锁先于线程 B 获得锁。蓝色则是通过程序顺序规则和监视器锁规则推测出来的 happens-before 关系,通过传递性规则进一步推导出 happens-before 规则。
根据 happens-before 的定义:如果 A 先于 B,则 A 的执行顺序先于 B,并且 A 的执行结果对 B 可见。
线程 A 先对共享变量 +1,由 2 先于 5 得知线程 A 的执行结果对 B 可见,即 B 读取到 a 的值为 1。
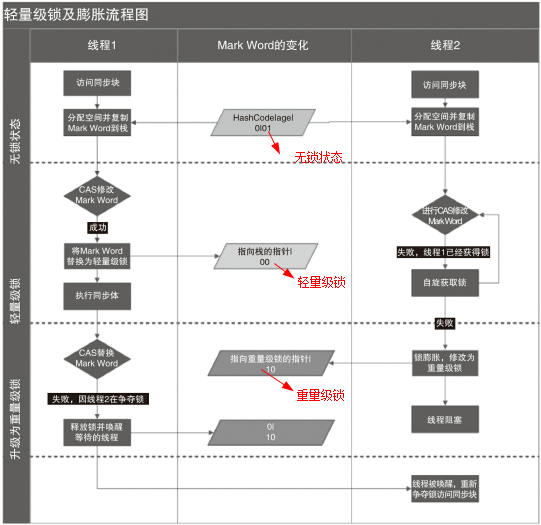
JVM 锁优化
JVM 在执行 monitorenter 和 monitorexit 这些指令时,依赖于底层操作系统的 Mutex Lock(互斥锁),但是由于 Mutex Lock 需要挂起当前线程,并从用户态切换到内核态来执行,这种切换的代价昂贵。然而在大部分的实际情况中,同步方法是运行在单线程环境(无锁竞争环境),如果每次都调用 Mutex Lock 则会严重影响性能。
JDK 1.6 引入了大量优化来提升性能:
- 锁粗化:减少不必要的紧连在一起的加锁、解锁操作,将多个连续的小锁扩展为一个更大的锁。
- 锁消除:通过运行时 JIT 编译器的逃逸分析来消除一些没有在当前同步块以外被其他线程共享的数据的锁保护,通过逃逸分析也可以在线程本地 Stack 上进行空间对象的分配(通知还可以减少 Heap 上垃圾收集的开销)。
- 轻量级锁:实现的原理是基于这样的假设,即在真是情况下程序中的大部分同步代码一般都属于无锁竞争状态(单线程执行环境),在无锁竞争的情况下完全可以避免调用操作系统层次的重量级互斥锁,取而代之的是在 monitorenter 和 monitorexit 之间依靠一条 CAS 原子指令就可以完成加锁解锁操作。但存在锁竞争时,执行 CAS 指令失败的线程将再去调用操作系统互斥锁进入阻塞状态,当锁被释放时再被唤醒。
- 偏向锁:为了在无锁竞争的情况下,避免在加锁过程中执行不必要的 CAS 原子指令,因为 CAS 指令虽然轻于OS 互斥锁,但还是存在(相对)可观的本地延迟。
- 适应性自旋:当线程在获取轻量级锁的过程中,如果 CAS 执行失败,在进入与 monitor 相关联的 OS 互斥锁之前,首先进入忙等待(自旋-Spinning),然后再次尝试 CAS,当尝试一定次数知乎仍然失败,再去调用与该 mointor 相关的 OS 互斥锁,进入阻塞状态。
锁的类型
Java 1.6 中 synchronized 同步锁,共有 4 种状态:无锁、偏向锁、轻量锁、重量锁。
会随着竞争状况逐渐升级。锁可以升级但不能降级,目的是为了提高获取锁和释放锁的效率。
自旋锁、自适应自旋
自旋锁
在多线程竞争锁时,当一个线程获取锁时,它会阻塞所有正在竞争的线程,这样对性能带来了极大的影响。在挂起线程和恢复线程的操作都需要转入内核态中完成,这些操作对系统的并发性能带来了很大的压力。同时HotSpot团队注意到在很多情况下,共享数据的锁定状态只会持续很短的一段时间,为了这段时间去挂起和回复阻塞线程并不值得。在如今多处理器环境下,完全可以让另一个没有获取到锁的线程在门外等待一会(自旋),但不放弃CPU的执行时间。等待持有锁的线程是否很快就会释放锁。为了让线程等待,我们只需要让线程执行一个忙循环(自旋),这便是自旋锁由来的原因。
自旋锁早在JDK1.4 中就引入了,只是当时默认时关闭的。在JDK 1.6后默认为开启状态。自旋锁本质上与阻塞并不相同,先不考虑其对多处理器的要求,如果锁占用的时间非常的短,那么自旋锁的新能会非常的好,相反,其会带来更多的性能开销(因为在线程自旋时,始终会占用CPU的时间片,如果锁占用的时间太长,那么自旋的线程会白白消耗掉CPU资源)。因此自旋等待的时间必须要有一定的限度,如果自选超过了限定的次数仍然没有成功获取到锁,就应该使用传统的方式去挂起线程了,在JDK定义中,自旋锁默认的自旋次数为10次,用户可以使用参数-XX:PreBlockSpin来更改。
可是现在又出现了一个问题:如果线程锁在线程自旋刚结束就释放掉了锁,那么是不是有点得不偿失。所以这时候我们需要更加聪明的锁来实现更加灵活的自旋。来提高并发的性能。
自适应自旋
在JDK 1.6中引入了自适应自旋锁。这就意味着自旋的时间不再固定了,而是由前一次在同一个锁上的自旋 时间及锁的拥有者的状态来决定的。如果在同一个锁对象上,自旋等待刚刚成功获取过锁,并且持有锁的线程正在运行中,那么JVM会认为该锁自旋获取到锁的可能性很大,会自动增加等待时间。比如增加到100次循环。相反,如果对于某个锁,自旋很少成功获取锁。那再以后要获取这个锁时将可能省略掉自旋过程,以避免浪费处理器资源。有了自适应自旋,JVM对程序的锁的状态预测会越来越准备,JVM也会越来越聪明。
锁消除
锁消除是指虚拟机即时编译器在运行过冲中,对一些在代码上要求同步、但是被检测到不可能存在共享数据竞争的锁进行消除。锁消除的主要判定依据来源于逃逸分析的数据支持。意思就是:JVM 会判断在一段程序中的同步数据明显不会逃逸出去从而被其他线程访问到,那 JVM 就把它们当作栈上数据对待,认为这些数据是线程独有的,不需要加同步。此时就会进行锁消除。
当然在实际开发中,我们很清楚的知道那些地方是线程独有的,不需要加同步锁,但是在 Java API 中有很多方法都是加了同步的,那么此时 JVM 会判断这段代码是否需要加锁。如果数据并不会逃逸,则会进行锁消除。比如如下操作:在操作 String 类型数据时,由于 String 是一个不可变类,对字符串的连接操作总是通过生成的新的 String 对象。因此 Javac 编译器会对 String 连接做自动优化。在 JDK 1.5 之前会使用 StringBuffer 对象的连续 append() 操作,在 JDK 1.5 及以后的版本中,会转化为 StringBuidler 对象的连续 append() 操作。
锁粗化
原则上,我们都知道在加同步锁时,尽可能的将同步块的作用范围限制到尽量小的范围(只在共享数据的实际作用域中才进行同步,这样是为了使得需要同步的操作数量尽可能变小。在存在锁同步竞争中,也可以使得等待锁的线程尽早的拿到锁。
大部分上述情况是正确的,但是如果存在连串的一系列操作都对同一个对象反复加锁和解锁,甚至加锁操作时出现在循环体中的,那即使没有线程竞争,频繁地进行互斥同步操作也会导致不必要地性能操作。
轻量锁
在 JDK 1.6 之后引入的轻量级锁,需要注意的是轻量级锁并不是替代重量级锁的,而是对在大多数情况下同步块并不会有竞争出现时提供的一种优化。它可以减少重量级锁对线程的阻塞带来地线程开销。从而提高并发性能。
如果要理解轻量级锁,那么必须先要了解 HotSpot 虚拟机中对象头地内存布局。在对象头中(Object Header)存在两部分。第一部分用于存储对象自身的运行时数据,HashCode、GC Age、锁标记位、是否为偏向锁等。一般为32位或者64位(视操作系统位数定)。官方称之为Mark Word,它是实现轻量级锁和偏向锁的关键。 另外一部分存储的是指向方法区对象类型数据的指针(Klass Point),如果对象是数组的话,还会有一个额外的部分用于存储数据的长度。

如上图所示,如果当前对象没有被锁定,那么锁标志位为 01 状态,JVM 在指向当前线程时,首先会在当前线程帧栈中创建锁记录 Lock Record 的空间,用于存储锁对象目前的 Mark Word 的拷贝。
然后,虚拟机使用 CAS 操作将标记字段 Mark Word 拷贝到锁记录中,并将 Mark Word 更新为指向 Lock Record 的指针。如果更新成功了,那么这个线程就有了使用该对象的锁,并且对象 Mark Word 的所标志位更新为(Mark Word 中最后为 2 bit) 00,即表示该对象处于轻量级锁定状态,如图:
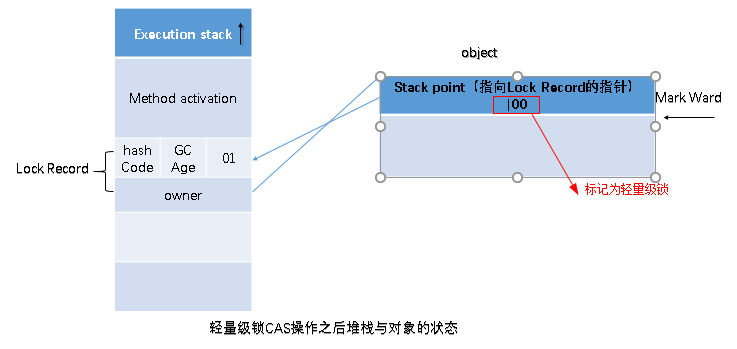
如果更新操作失败,JVM 会检查当前 Mark Word 中是否存在指向当前线程帧栈的指针,如果有,则表示锁已经被获取,可以直接使用。如果没有,则说明该锁已经被其他线程抢占,如果有两条以上的线程同时经常一个锁,那么轻量级锁就不再有效,直接升级为重量级锁,没有获得锁的线程会被阻塞。此时,锁的标志位为 10,Mark Word 中存储的是指向重量级锁的指针。
轻量级锁解锁时,会使用原子的 CAS 操作将 Displaced Mark Word 替换会对象头中,如果成功,则表示没有发生竞争,如果失败,则表示当前锁存在竞争关系。锁就会升级为重量级锁。
两个线程同时抢占锁,导致锁升级的流程如下:
偏向锁
在大多数实际环境中,锁不仅不存在多线程竞争,而且总是由同一个线程多次获取,那么在同一个线程反复加锁解锁的过程中,其中并没有对锁的竞争,这样一来,多次加锁解锁带来了不必要的性能开销。
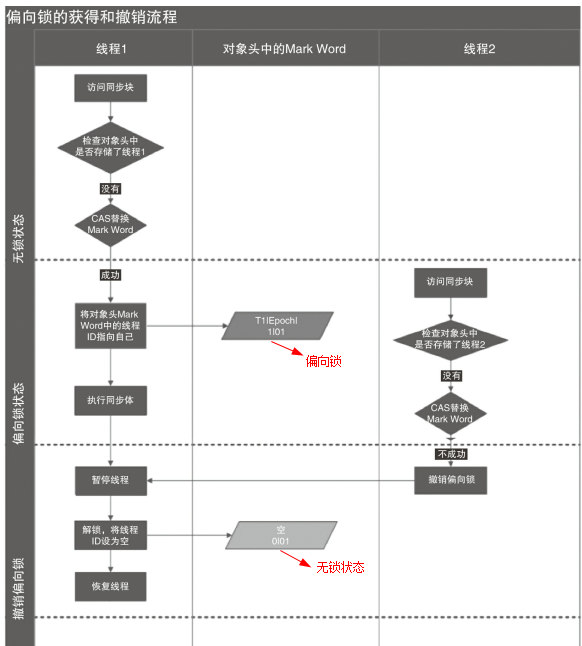
为了解决这一问题,HotSpot 的作者在 Java SE 1.6 中对 Synchronized 进行了优化,引入了偏向锁。
当一个线程访问同步块并获取锁时,会在对象头和帧栈中的锁记录里存储偏向锁偏向的线程 ID,以后该线程在进入和退出同步块时不需要进行 CAS 操作来加锁和解锁。只需要简单的测试一下对象头的 Mark Word 中是否保存了指向当前线程的偏向锁。如果成功,表示线程已经获得了锁。

偏向锁使用了一种等待竞争出现时才会释放锁的机制。当其他线程尝试获取偏向锁时,持有偏向锁的线程才会释放锁。但是偏向锁的撤销需要等到全局安全点(即当前线程没有正在执行的字节码)。
它首先会暂停拥有偏向锁的线程,然后检查持有偏向锁的线程是否还活着。如果线程不处于活动状态,直接将对象头设置为无锁状态。如果活着,JVM 会遍历帧栈中的锁记录,帧栈中的锁记录和对象头要么偏向于其他线程,要么恢复到无锁状态或者标记对象不适合作为偏向锁。
锁对比
| 锁 | 优点 | 缺点 | 场景 |
|---|---|---|---|
| 偏向锁 | 加锁解锁不需要 CAS,没有额外性能开销 | 如果线程间存在竞争,撤销锁会带来额外开销 | 仅一个线程访问同步块 |
| 轻量锁 | 竞争的线程不会阻塞,提供响应速度 | 如果线程始终得到到锁,自旋会消耗性能 | 同步块执行速度非常快 |
| 重量锁 | 线程竞争不适用自旋,不会消耗 CPU | 线程阻塞、响应慢、频繁加解锁开销大 | 追求吞吐量,同步块执行速度慢 |
Synchronized 与 Lock
Synchronized 的缺陷
- 效率低:锁的释放情况少,只有代码指向完或抛出异常时才会解锁;试图获取锁时不能设置超时,不能中断正在使用锁的线程,而 Lock 可以中断或设置超时。
- 不灵活:加锁和解锁的时机单一,每个锁仅有一个单一的条件(对象实例),Lock 更加灵活。
- 无法感知是否获得锁:Lock 可以显式获取状态,然后基于状态执行判断。
相比 Lock
Lock 的方法:
- lock:加锁
- unlock:解锁
- tryLock:尝试加锁,返回布尔值
- tryLock(long,TimeUnit):尝试加锁,设定超时
多线程竞争锁时,其余未获得锁的线程只能不停的尝试加锁,而不能中断,高并发情况下会导致性能下降。
ReentrantLock 的 lockInterruptibly() 方法可以优先考虑响应中断。 一个线程等待时间过长,它可以中断自己,然后 ReentrantLock 响应这个中断,不再让这个线程继续等待。有了这个机制,使用 ReentrantLock 时就不会像 synchronized 那样产生死锁了。
注意事项
Synchronized 由 JVM 实现,无需显式控制加解锁逻辑。
- 锁对象不能为空,因为锁的信息都保存在对象头里
- 作用域不宜过大,影响程序执行的速度,控制范围过大,编写代码也容易出错
- 避免死锁
- 在能选择的情况下,既不要用 Lock 也不要用 synchronized 关键字,用 JUC 包中的各种各样的类,如果不用该包下的类,在满足业务的情况下,可以使用 synchronized 关键,避免手动操作引起错误
- synchronized 是公平锁吗?
- 实际上是非公平的,新来的线程有可能立即获得监视器,而在等待区中等候已久的线程可能再次等待。
- 但这种抢占的方式可以预防饥饿。
6 - CH06-Volatile
基本作用
防止重排序
比如一个对象构造过程的场景,实例化一个对象可以分为 3 个步骤:
- 分配内存空间
- 初始化对象
- 将内存空间的地址赋值给对应的引用
但是由于操作系统可以“对指令进行重排序”,所以上面的过程可能会被转换为:
- 分配内存空间
- 将内存空间的地址赋值给对应的引用
- 初始化对象
这样一来,多线程环境下可能将一个尚未初始化的对象引用暴露到外部,从而导致非预期的行为。
因此为了防止该过程的重排序,我们可以将变量设置为 volatile 类型的变量。
实现可见性
可见性问题主要指一个线程修改了共享变量值,而另一个线程却看不到。引起可见性问题的主要原因是每个线程拥有自己的一个高速缓存区——线程工作内存。volatile 能有效的解决这个问题。
保证原子性:单次读/写
基于 volatile 保证单次的读/写操作具有原子性的理解,你将能够理解如下两个问题:
i++ 为什么不能保证原子性
对 volatile 变量的单次读/写操作可以保证原子性的,如 long 和 double 类型变量,但是并不能保证 i++ 这种操作的原子性,因为本质上 i++ 是读、写两次操作,包括三步骤:
- 读取 i 的值。
- 对 i 加 1。
- 将 i 的值写回内存。 volatile 是无法保证这三个操作是具有原子性的,我们可以通过 AtomicInteger 或者 Synchronized 来保证 +1 操作的原子性。 注:上面几段代码中多处执行了 Thread.sleep() 方法,目的是为了增加并发问题的产生几率,无其他作用。
共享的 long 和 double 变量的为什么要用 volatile?
因为 long 和 double 两种数据类型的操作可分为高 32 位和低 32 位两部分,因此普通的 long 或 double 类型读/写可能不是原子的。因此,鼓励大家将共享的 long 和 double 变量设置为 volatile 类型,这样能保证任何情况下对 long 和 double 的单次读/写操作都具有原子性。
目前各种平台下的商用虚拟机都选择把 64 位数据的读写操作作为原子操作来对待,因此我们在编写代码时一般不把 long 和 double 变量专门声明为 volatile 多数情况下也是不会错的。
实现原理
实现可见性
volatile 变量的内存可见性是基于内存屏障(Memory Barrier)实现。
- 内存屏障,又称内存栅栏,是一个 CPU 指令。
- 在程序运行时,为了提高执行性能,编译器和处理器会对指令进行重排序,JMM 为了保证在不同的编译器和 CPU 上有相同的结果,通过插入特定类型的内存屏障来禁止特定类型的编译器重排序和处理器重排序。
- 插入一条内存屏障会告诉编译器和 CPU:不管什么指令都不能和这条 Memory Barrier 指令执行重排序。
比如代码:
public class Test {
private volatile int a;
public void update() {
a = 1;
}
public static void main(String[] args) {
Test test = new Test();
test.update();
}
}
通过 hsdis 和 jitwatch 工具可以得到编译后的汇编代码:
......
0x0000000002951563: and $0xffffffffffffff87,%rdi
0x0000000002951567: je 0x00000000029515f8
0x000000000295156d: test $0x7,%rdi
0x0000000002951574: jne 0x00000000029515bd
0x0000000002951576: test $0x300,%rdi
0x000000000295157d: jne 0x000000000295159c
0x000000000295157f: and $0x37f,%rax
0x0000000002951586: mov %rax,%rdi
0x0000000002951589: or %r15,%rdi
0x000000000295158c: lock cmpxchg %rdi,(%rdx) //在 volatile 修饰的共享变量进行写操作的时候会多出 lock 前缀的指令
0x0000000002951591: jne 0x0000000002951a15
0x0000000002951597: jmpq 0x00000000029515f8
0x000000000295159c: mov 0x8(%rdx),%edi
0x000000000295159f: shl $0x3,%rdi
0x00000000029515a3: mov 0xa8(%rdi),%rdi
0x00000000029515aa: or %r15,%rdi
......
lock 前缀的指令在多核处理器下会引发两件事情:
- 将当前处理器缓存行的数据写回到系统内存。
- 写回内存的操作会使在其他 CPU 里缓存了该内存地址的额数据无效。
为了提高处理速度,处理器不直接和内存进行通信,而是先将系统内存的数据读到内部缓存(L1,L2 或其他)后再进行操作,但操作完不知道何时会写到内存。
如果对声明了 volatile 的变量进行写操作,JVM 就会向处理器发送一条 lock 前缀的指令,将这个变量所在缓存行的数据写回到系统内存。
为了保证各个处理器的缓存是一致的,实现了缓存一致性协议(MESI),每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存里。
所有多核处理器下还会完成:当处理器发现本地缓存失效后,就会从内存中重读该变量数据,即可以获取当前最新值。
volatile 变量通过这样的机制就使得每个线程都能获得该变量的最新值。
lock 指令
在 Pentium 和早期的 IA-32 处理器中,lock 前缀会使处理器执行当前指令时产生一个 LOCK# 信号,会对总线进行锁定,其它 CPU 对内存的读写请求都会被阻塞,直到锁释放。 后来的处理器,加锁操作是由高速缓存锁代替总线锁来处理。 因为锁总线的开销比较大,锁总线期间其他 CPU 没法访问内存。 这种场景多缓存的数据一致通过缓存一致性协议(MESI)来保证。
缓存一致性
缓存是分段(line)的,一个段对应一块存储空间,称之为缓存行,它是 CPU 缓存中可分配的最小存储单元,大小 32 字节、64 字节、128 字节不等,这与 CPU 架构有关,通常来说是 64 字节。 LOCK# 因为锁总线效率太低,因此使用了多组缓存。 为了使其行为看起来如同一组缓存那样。因而设计了 缓存一致性协议。
缓存一致性协议有多种,但是日常处理的大多数计算机设备都属于 " 嗅探(snooping)" 协议。 所有内存的传输都发生在一条共享的总线上,而所有的处理器都能看到这条总线。 缓存本身是独立的,但是内存是共享资源,所有的内存访问都要经过仲裁(同一个指令周期中,只有一个 CPU 缓存可以读写内存)。 CPU 缓存不仅仅在做内存传输的时候才与总线打交道,而是不停在嗅探总线上发生的数据交换,跟踪其他缓存在做什么。 当一个缓存代表它所属的处理器去读写内存时,其它处理器都会得到通知,它们以此来使自己的缓存保持同步。 只要某个处理器写内存,其它处理器马上知道这块内存在它们的缓存段中已经失效。
实现有序性
volatile 与 happens-before 的关系
happens-before 规则中有一条是 volatile 变量规则:对一个 volatile 域的写,先于任意后续对这个 volatile 域的读。
//假设线程A执行writer方法,线程B执行reader方法
class VolatileExample {
int a = 0;
volatile boolean flag = false;
public void writer() {
a = 1; // 1 线程A修改共享变量
flag = true; // 2 线程A写volatile变量
}
public void reader() {
if (flag) { // 3 线程B读同一个volatile变量
int i = a; // 4 线程B读共享变量
……
}
}
}
根据 happens-before 规则,上面过程会建立 3 类 happens-before 关系。
- 根据程序次序规则:1 先于 2,且 3 先于 4。
- 根据 volatile 规则:2 先于 3。
- 根据 happens-before 传递性:1 先于 4。
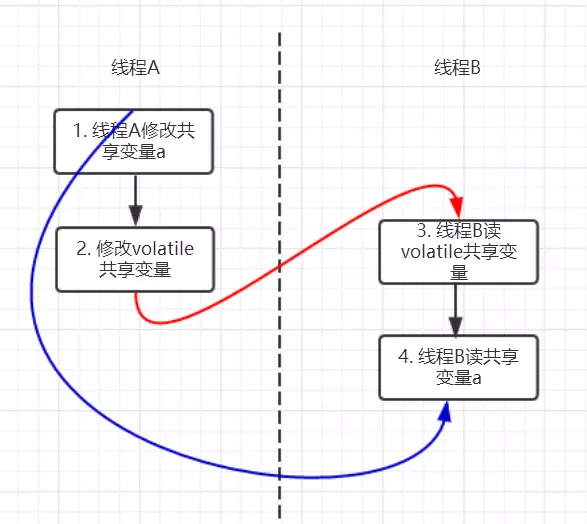
因为以上规则,当线程 A 将 volatile 变量 flag 更改为 true 后,线程 B 能够迅速感知。
volatile 禁止重排序
为了性能优化,JMM 在不改变正确语义的前提下,会允许编译器和处理器对指令序列进行重排序。JMM 提供了内存屏障阻止这种重排序。
Java 编译器会在生成指令系列时在适当的位置会插入内存屏障指令来禁止特定类型的处理器重排序。
JMM 会针对编译器制定 volatile 重排序规则表。

上图中 NO 表示禁止重排序。
为了实现 volatile 内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的重排序。
对于编译器来说,发现一个最优布置来最小化插入内存屏障的总数几乎是不可能的,为此,JVM 采取了保守策略:
- 在每个 volatile 写操作前插入 StoreStore 屏障。
- 在每个 volatile 写操作后插入 StoreLoad 屏障。
- 在每个 volatile 读操作后插入 LoadLoad 屏障。
- 在每个 volatile 读操作后插入 LoadStore 屏障。
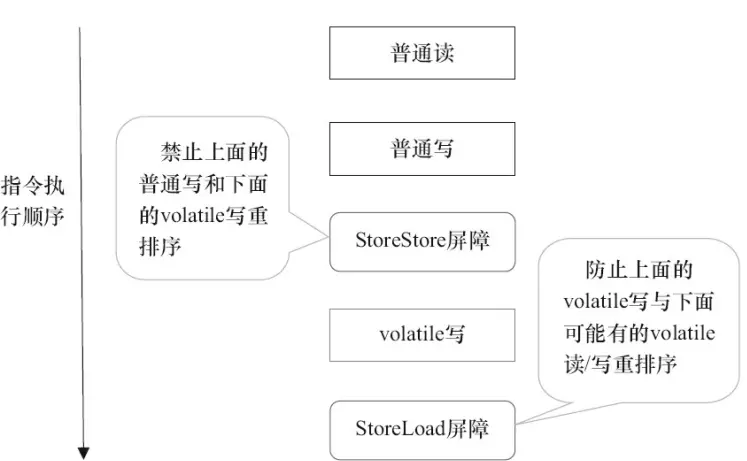
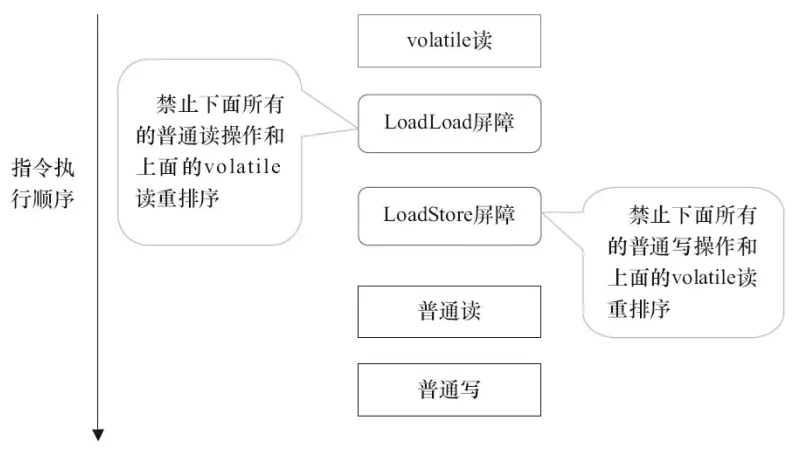
volatile 写是在前后分别插入屏障,而读是在后面插入两个内存屏障。
- StoreStore:禁止上面的普通写和下面的 volatile 写重排序。
- StoreLoad:防止上面的 volatile 写与下面可能出现的 volatile 读/写重排序。
- LoadLoad:禁止下面所有的普通读操作和上面的 volatile 读重排序。
- LoadStore:禁止下面所有的普通下和上面的 volatile 读重排序。
应用场景
使用 volatile 时必须具备的条件:
- 对变量的写操作不依赖于当前值。
- 该变量没有包含在其他变量的不变式中。
- 只有在状态真正独立于成语其他内容时才能使用 volatile。
模式-1:状态标志
或许实现 volatile 变量的规范应用仅仅是通过一个布尔状态标志,用于指示发生了一个重要的一次性事件,比如初始化完成或已经停机,即对变量的简单读写:
volatile boolean shutdownRequested;
...
public void shutdown(){}
public void execute() {
while(!shutdownRequested){
// execute something
}
}
模式-2:一次性安全发布
缺乏同步会导致无法实现可见性,这会使得确定何时写入对象引用而不是原始值变得更加困难。在缺乏同步的情况下,可能会遇到某个对象引用的更新值(由另一个线程写入)和该对象状态的旧值同时存在。
这就是著名的双检锁问题的根源,其中对象引用在没有同步的情况下进行读操作,产生的问题是可能看到一个更新的引用,但是也可能看到尚未构造完成的对象。
public class BackgroundFloobleLoader {
public volatile Flooble theFlooble;
public void initInBackground() {
// do lots of stuff
theFlooble = new Flooble(); // this is the only write to theFlooble
}
}
public class SomeOtherClass {
public void doWork() {
while (true) {
// do some stuff...
// use the Flooble, but only if it is ready
if (floobleLoader.theFlooble != null)
doSomething(floobleLoader.theFlooble);
}
}
}
模式-3:独立观察
安全使用 volatile 的另一种简单模式是定期 发布 观察结果供程序内部使用。例如,假设有一种环境传感器能够感觉环境温度。一个后台线程可能会每隔几秒读取一次该传感器,并更新包含当前文档的 volatile 变量。然后,其他线程可以读取这个变量,从而随时能够看到最新的温度值。
public class UserManager {
public volatile String lastUser;
public boolean authenticate(String user, String password) {
boolean valid = passwordIsValid(user, password);
if (valid) {
User u = new User();
activeUsers.add(u);
lastUser = user;
}
return valid;
}
}
模式-4:volatile bean
在 volatile bean 模式中,JavaBean 的所有数据成员都是 volatile 类型的,并且 getter 和 setter 方法必须非常普通 —— 除了获取或设置相应的属性外,不能包含任何逻辑。此外,对于对象引用的数据成员,引用的对象必须是有效不可变的。(这将禁止具有数组值的属性,因为当数组引用被声明为 volatile 时,只有引用而不是数组本身具有 volatile 语义)。对于任何 volatile 变量,不变式或约束都不能包含 JavaBean 属性。
@ThreadSafe
public class Person {
private volatile String firstName;
private volatile String lastName;
private volatile int age;
public String getFirstName() { return firstName; }
public String getLastName() { return lastName; }
public int getAge() { return age; }
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public void setAge(int age) {
this.age = age;
}
}
模式-5:开销较低的读写锁策略
volatile 的功能还不足以实现计数器。因为 ++x 实际上是三种操作(读、添加、存储)的简单组合,如果多个线程凑巧试图同时对 volatile 计数器执行增量操作,那么它的更新值有可能会丢失。 如果读操作远远超过写操作,可以结合使用内部锁和 volatile 变量来减少公共代码路径的开销。 安全的计数器使用 synchronized 确保增量操作是原子的,并使用 volatile 保证当前结果的可见性。如果更新不频繁的话,该方法可实现更好的性能,因为读路径的开销仅仅涉及 volatile 读操作,这通常要优于一个无竞争的锁获取的开销。
@ThreadSafe
public class CheesyCounter {
// Employs the cheap read-write lock trick
// All mutative operations MUST be done with the 'this' lock held
@GuardedBy("this") private volatile int value;
public int getValue() { return value; }
public synchronized int increment() {
return value++;
}
}
模式-6:双重检查
单例模式的一种实现方式,但很多人会忽略 volatile 关键字,因为没有该关键字,程序也可以很好的运行,只不过代码的稳定性总不是 100%,说不定在未来的某个时刻,隐藏的 bug 就出来了。
class Singleton {
private volatile static Singleton instance;
public static Singleton getInstance() {
if (instance == null) {
syschronized(Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
7 - CH07-Final
基本用法
修饰类
当某个类的整体定义为 final 时,就表明了你不能打算继承该类,而且也不允许别人这么做。即这个类是不能有子类的。
final 类中的所有方法都隐式为 final,因为无法覆写他们,所以在 final 类中给任何方法添加 final 关键字是没有任何意义的。
修饰方法
- private 方法是隐式的 final,即不能被子类重写
- final 方法是可以被重载的
private final
类中所有 private 方法都隐式地指定为 final 的,由于无法取用 private 方法,所以也就不能覆盖它。可以对 private 方法增添 final 关键字,但这样做并没有什么好处。
final 方法可以被重载
修饰参数
Java 允许在参数列表中以声明的方式将参数指明为 final,这意味这你无法在方法中更改参数引用所指向的对象。这个特性主要用来向匿名内部类传递数据。
修饰字段
并非所有的 fianl 字段都是编译期常量
比如:
class Example {
Random random = new Random();
final int value = random.nextInt();
}
这里的字段 value 并不能在编译期推导出实际的值,而是在运行时由 random 决定。
static final
static final 字段只是占用一段不能改变的存储空间,它必须在定义的时候进行赋值,否则编译期无法同步。
blank final
Java 允许生成空白 final,也就是说被声明为 final 但又没有给出定值的字段,但是必须在该字段被使用之前被赋值,这给予我们两种选择:
- 在定义处进行赋值(这不是空白 final)
- 在构造器中进行赋值,保证了该值在被使用之前赋值。
重排序规则
final 域为基本类型
public class FinalDemo {
private int a; //普通域
private final int b; //final域
private static FinalDemo finalDemo; //静态域
public FinalDemo() {
a = 1; // 1. 写普通域
b = 2; // 2. 写final域
}
public static void writer() {
finalDemo = new FinalDemo();
}
public static void reader() {
FinalDemo demo = finalDemo; // 3.读对象引用
int a = demo.a; //4.读普通域
int b = demo.b; //5.读final域
}
}
假设线程 A 执行 writer 方法,线程 B 执行 reader 方法。
写操作
写 final 域的重排序规则禁止对 final 域的写操作重排序到构造函数之外,该规则的实现主要包含两个方面:
- JMM 禁止编译器把 final 域的写重排序到构造函数之外。
- 编译器会在 final 域写之后,构造函数 return 之前,插入一个 storestore 屏障。
- 该屏障可以禁止处理器将 final 域的写重排序到构造函数之外。
writer 方法分析:
- 构造了一个 FinalDemo 对象。
- 把这个对象复制给成员变量 finalDemo。
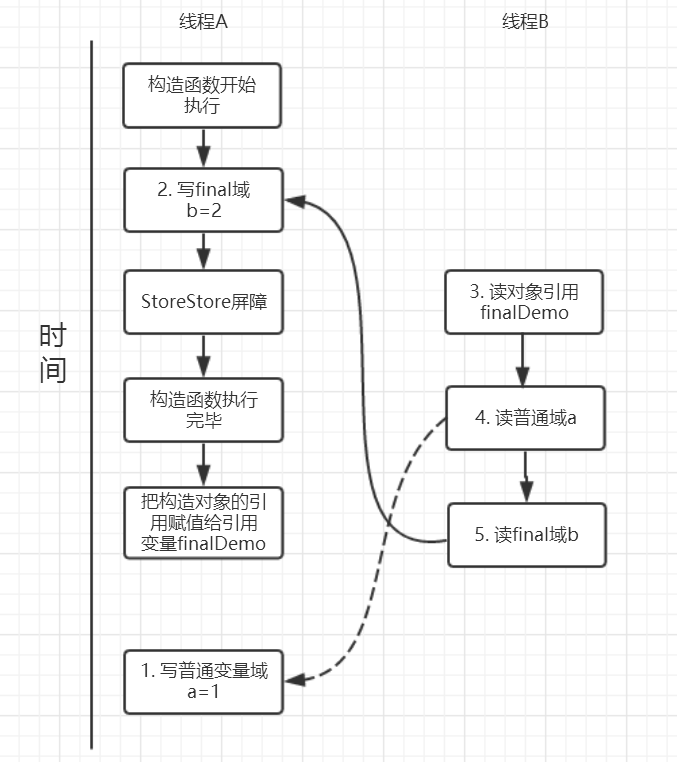
由于 a,b 之间没有依赖,普通域 a 可能会被重排序到构造函数之外,线程 B 肯呢个读到普通变量 a 初始化之前的值(零值),即引起错误。
而 final 域变量 b,根据重排序规则,会禁止 final 修饰的变量 b 被重排序到构造函数之外,因此 b 会在构造函数内完成赋值,线程 B 可以读到正确赋值后的 b 变量。
因此,写 final 域的重排序规则可以确保:在对象引用被任意线程可见之前,对象的 final 域已经被正确初始化过了,而普通域就不具有这个保障。
读操作
读 final 域的重排序规则为:在一个线程中,初次读对象引用和初次读该对象包含的 final 域,JMM 会禁止这两个操作的重排序。(仅针对处理器),处理器会在读 final 域操作之前插入一个 LoadLoad 屏障。
实际上,度对象的引用和读对象的 final 域存在间接依赖性,一般处理器不会对这两个操作执行重排序。但是不能排除有些处理器会执行重排序,因此,该规则就是针对这些处理器设定的。
reader 方法分析:
- 初次读引用变量 finalDemo;
- 初次读引用变量 finalDemo 的普通域;
- 初次读引用变量 finalDemo 的 fianl 域 b;
假设线程A写过程没有重排序,那么线程A和线程B有一种的可能执行时序为下图:
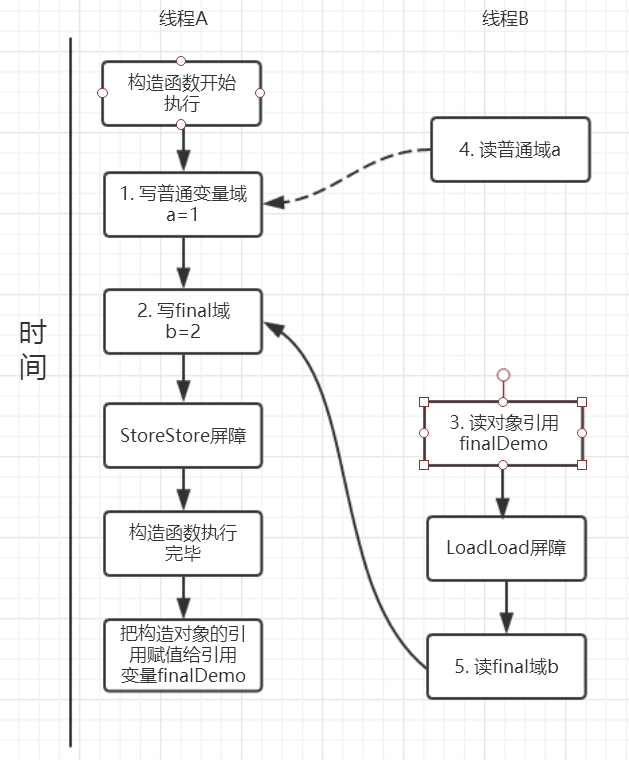
读对象的普通域被排序到读对象引用之前,就会出现线程 B 还未多读到对象引用就在读取该对象的普票域变量,这显然是错误操作。
而 final 域的读操作就限定了在读 final 域变量前就已经读到了该对象的引用,从而避免这种错误。
读 final 域的重排序规则可以保证:在读取一个对象的 fianl 域之前,一定会先读取该 final 域所属的对象引用。
final 域为引用类型
对 final 修饰对象的成员域执行写操作
针对引用数据类型,final域写针对编译器和处理器重排序增加了这样的约束:在构造函数内对一个final修饰的对象的成员域的写入,与随后在构造函数之外把这个被构造的对象的引用赋给一个引用变量,这两个操作是不能被重排序的。注意这里的是“增加”也就说前面对final基本数据类型的重排序规则在这里还是使用。这句话是比较拗口的,下面结合实例来看。
public class FinalReferenceDemo {
final int[] arrays;
private FinalReferenceDemo finalReferenceDemo;
public FinalReferenceDemo() {
arrays = new int[1]; //1
arrays[0] = 1; //2
}
public void writerOne() {
finalReferenceDemo = new FinalReferenceDemo(); //3
}
public void writerTwo() {
arrays[0] = 2; //4
}
public void reader() {
if (finalReferenceDemo != null) { //5
int temp = finalReferenceDemo.arrays[0]; //6
}
}
}
针对上面的实例程序,线程线程A执行wirterOne方法,执行完后线程B执行writerTwo方法,然后线程C执行reader方法。下图就以这种执行时序出现的一种情况来讨论(耐心看完才有收获)。
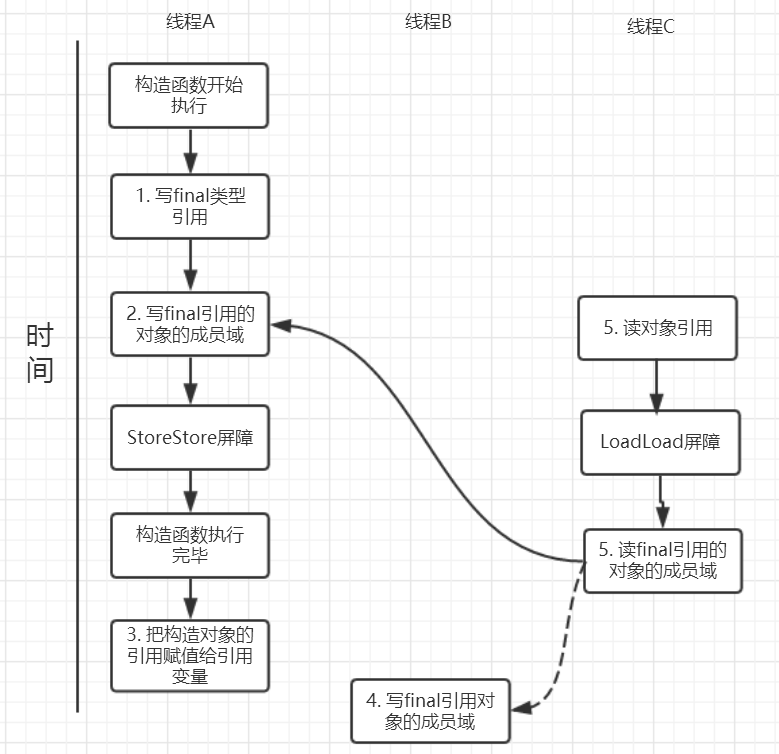
由于对final域的写禁止重排序到构造方法外,因此1和3不能被重排序。由于一个final域的引用对象的成员域写入不能与随后将这个被构造出来的对象赋给引用变量重排序,因此2和3不能重排序。
对final 修饰的对象的成员域执行读操作
JMM可以确保线程C至少能看到写线程A对final引用的对象的成员域的写入,即能看下 arrays[0] = 1,而写线程B对数组元素的写入可能看到可能看不到。JMM不保证线程B的写入对线程C可见,线程B和线程C之间存在数据竞争,此时的结果是不可预知的。如果可见的,可使用锁或者volatile。
final 重排序总结
- 基本数据类型
- 禁止 final 域写与构造函数重排序,即禁止 final 域重排序到构造方法之外,从而保证该对象对所有线程可见时,该对象的 final 域全部已经初始化过。
- 禁止初次读取该对象的引用与读取该对象 fianl 域的重排序。
- 引用数据类型
- 相比基本数据类型增加额外规则
- 禁止在构造函数对一个 final 修饰的对象的成员域的写入与随后将这个被构造的对象的引用复制给引用变量重排序。
- 即:现在构造函数中完成对 final 修饰的引用类型的字段赋值,再将该引用对象整体复制给 final 修饰的变量。
深入理解
实现原理
- 写 final 域会要求编译器在 final 域写之后,构造函数返回前插入一个 StoreStore 屏障。
- 读 final 域的重排序规则会要求编译器在读 final 域的操作前插入一个 LoadLoad 屏障。
为什么 final 引用不能从构造函数中逸出
上面对final域写重排序规则可以确保我们在使用一个对象引用的时候该对象的final域已经在构造函数被初始化过了。
但是这里其实是有一个前提条件的,也就是:在构造函数,不能让这个被构造的对象被其他线程可见,也就是说该对象引用不能在构造函数中“逸出”。
public class FinalReferenceEscapeDemo {
private final int a;
private FinalReferenceEscapeDemo referenceDemo;
public FinalReferenceEscapeDemo() {
a = 1; //1
referenceDemo = this; //2
}
public void writer() {
new FinalReferenceEscapeDemo();
}
public void reader() {
if (referenceDemo != null) { //3
int temp = referenceDemo.a; //4
}
}
}
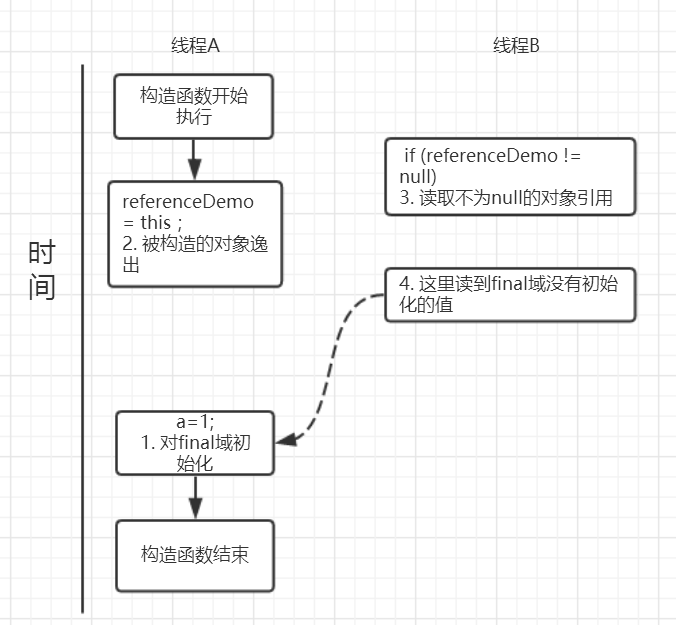
假设一个线程A执行writer方法另一个线程执行reader方法。因为构造函数中操作1和2之间没有数据依赖性,1和2可以重排序,先执行了2,这个时候引用对象referenceDemo是个没有完全初始化的对象,而当线程B去读取该对象时就会出错。尽管依然满足了final域写重排序规则:在引用对象对所有线程可见时,其final域已经完全初始化成功。但是,引用对象“this”逸出,该代码依然存在线程安全的问题。
使用 final 的限制条件和局限性
- 当声明一个 final 成员时,必须在构造函数退出前设置它的值。
- 或者,将指向对象的成员声明为 final 只能将该引用设为不可变的,而非所指的对象。
- 如果一个对象将会在多个线程中访问并且你并没有将其成员声明为 final,则必须提供其他方式保证线程安全。
- 比如声明成员为 volatile,使用 synchronized 或者显式 Lock 控制所有该成员的访问。
8 - CH08-并发概览
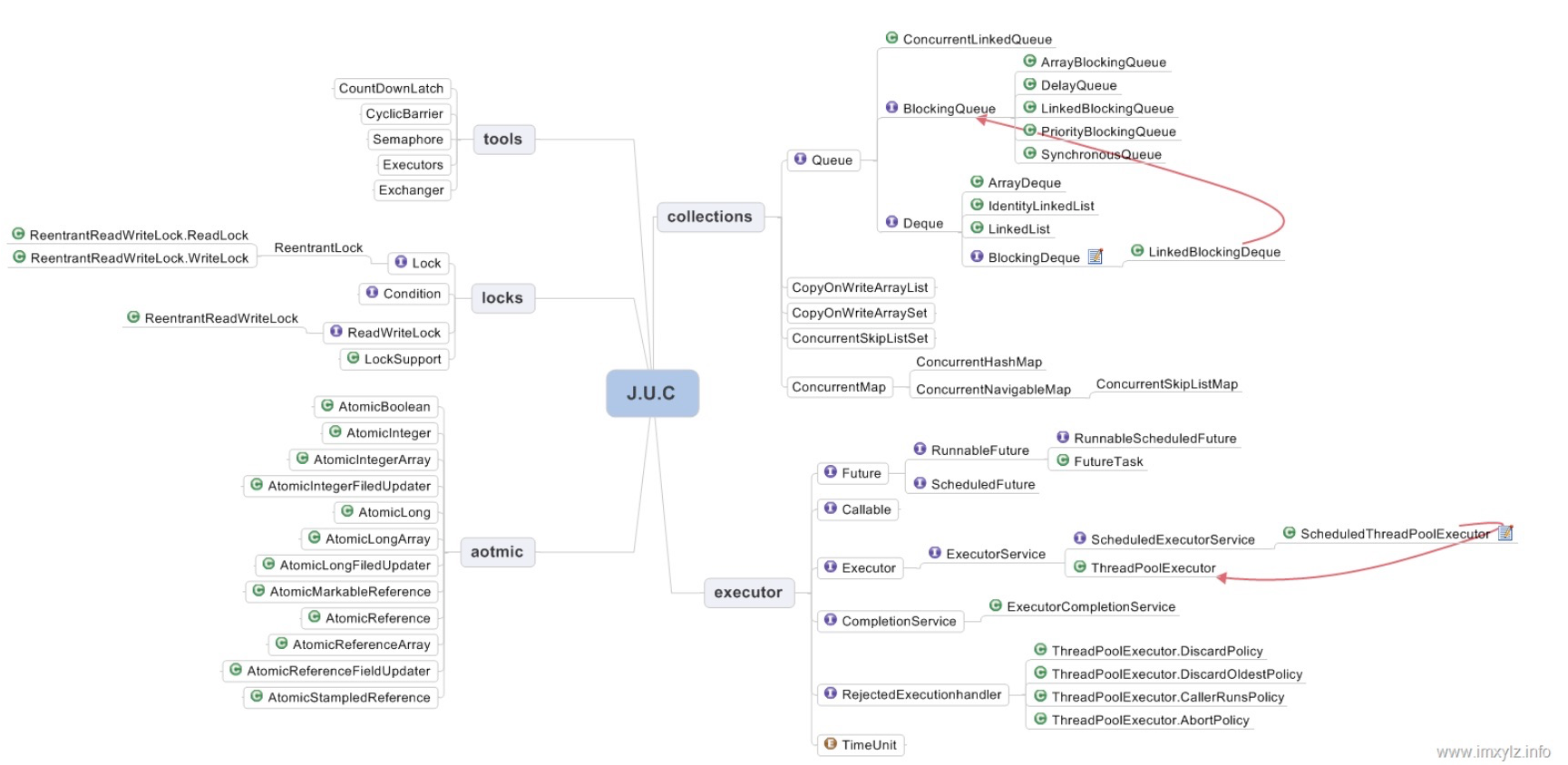
Locks & Tools
层级结构
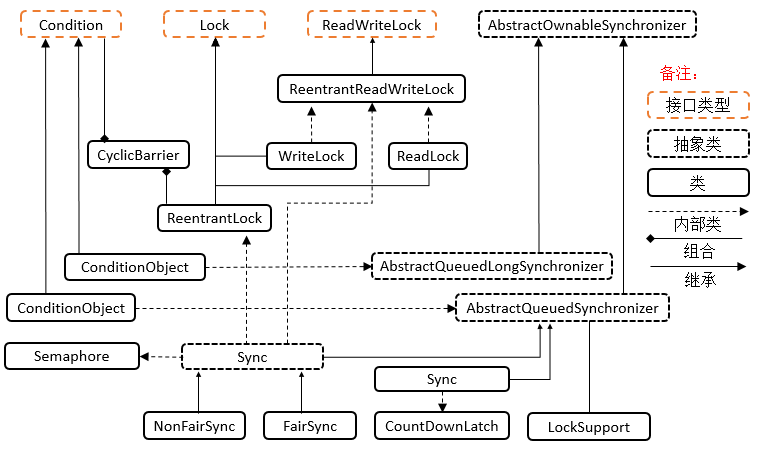
接口:Condition
Condition 为接口类型,它将 Object 监视器方法(wait、notify 和 notifyAll)分解成截然不同的对象,以便通过将这些对象与任意 Lock 实现组合使用,为每个对象提供多个等待集 (wait-set)。其中,Lock 替代了 synchronized 方法和语句的使用,Condition 替代了 Object 监视器方法的使用。可以通过 await(),signal() 来休眠/唤醒线程。
接口:Lock
Lock 为接口类型,Lock 提供了比使用 synchronized 方法和语句可获得的更广泛的锁定操作。允许更灵活的结构,可以具有差别很大的属性,可以支持多个相关的 Condition 对象。
接口:ReadWriteLock
维护了一对相关的锁,一个用于只读操作,另一个用于写入操作。只要没有 writer,读取锁可以由多个 reader 线程同时保持。写入锁是独占的。
抽象类:AbstractOwnableSynchonizer
可以由线程以独占方式拥有的同步器。此类为创建锁和相关同步器(伴随着所有权的概念)提供了基础。AbstractOwnableSynchronizer 类本身不管理或使用此信息。但是,子类和工具可以使用适当维护的值帮助控制和监视访问以及提供诊断。
抽象类(long):AbstractQueuedLongSynchronizer
以 long 形式维护同步状态的一个 AbstractQueuedSynchronizer 版本。此类具有的结构、属性和方法与 AbstractQueuedSynchronizer 完全相同,但所有与状态相关的参数和结果都定义为 long 而不是 int。当创建需要 64 位状态的多级别锁和屏障等同步器时,此类很有用。
抽象类(int):AbstractQueuedSynchonizer
其为实现依赖于先进先出 (FIFO) 等待队列的阻塞锁和相关同步器(信号量、事件,等等)提供一个框架。此类的设计目标是成为依靠单个原子 int 值来表示状态的大多数同步器的一个有用基础。
锁工具类:LockSupport
LockSupport为常用类,用来创建锁和其他同步类的基本线程阻塞原语。LockSupport的功能和"Thread中的 Thread.suspend()和Thread.resume()有点类似",LockSupport中的park() 和 unpark() 的作用分别是阻塞线程和解除阻塞线程。但是park()和unpark()不会遇到“Thread.suspend 和 Thread.resume所可能引发的死锁”问题。
锁常用类:ReentrantLock
它是一个可重入的互斥锁 Lock,它具有与使用 synchronized 方法和语句所访问的隐式监视器锁相同的一些基本行为和语义,但功能更强大。
锁常用类: ReentrantReadWriteLock
ReentrantReadWriteLock是读写锁接口ReadWriteLock的实现类,它包括Lock子类ReadLock和WriteLock。ReadLock是共享锁,WriteLock是独占锁。
锁常用类: StampedLock
它是 java8 在 java.util.concurrent.locks 新增的一个 API。StampedLock 控制锁有三种模式(写,读,乐观读),一个 StampedLock 状态是由版本和模式两个部分组成,锁获取方法返回一个数字作为票据 stamp,它用相应的锁状态表示并控制访问,数字 0 表示没有写锁被授权访问。在读锁上分为悲观锁和乐观锁。
工具常用类: CountDownLatch
它是一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待。
工具常用类: CyclicBarrier
CyclicBarrier 为常用类,其是一个同步辅助类,它允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point)。在涉及一组固定大小的线程的程序中,这些线程必须不时地互相等待,此时 CyclicBarrier 很有用。因为该 barrier 在释放等待线程后可以重用,所以称它为循环的 barrier。
工具常用类: Phaser
Phaser 是 JDK 7 新增的一个同步辅助类,它可以实现 CyclicBarrier 和 CountDownLatch 类似的功能,而且它支持对任务的动态调整,并支持分层结构来达到更高的吞吐量。
工具常用类: Semaphore
Semaphore 为常用类,其是一个计数信号量,从概念上讲,信号量维护了一个许可集。如有必要,在许可可用前会阻塞每一个 acquire(),然后再获取该许可。每个 release() 添加一个许可,从而可能释放一个正在阻塞的获取者。但是,不使用实际的许可对象,Semaphore 只对可用许可的号码进行计数,并采取相应的行动。通常用于限制可以访问某些资源(物理或逻辑的)的线程数目。
工具常用类: Exchanger
Exchanger 是用于线程协作的工具类, 主要用于两个线程之间的数据交换。它提供一个同步点,在这个同步点,两个线程可以交换彼此的数据。这两个线程通过 exchange() 方法交换数据,当一个线程先执行 exchange() 方法后,它会一直等待第二个线程也执行 exchange() 方法,当这两个线程到达同步点时,这两个线程就可以交换数据了。
Collections: 并发集合
层级结构
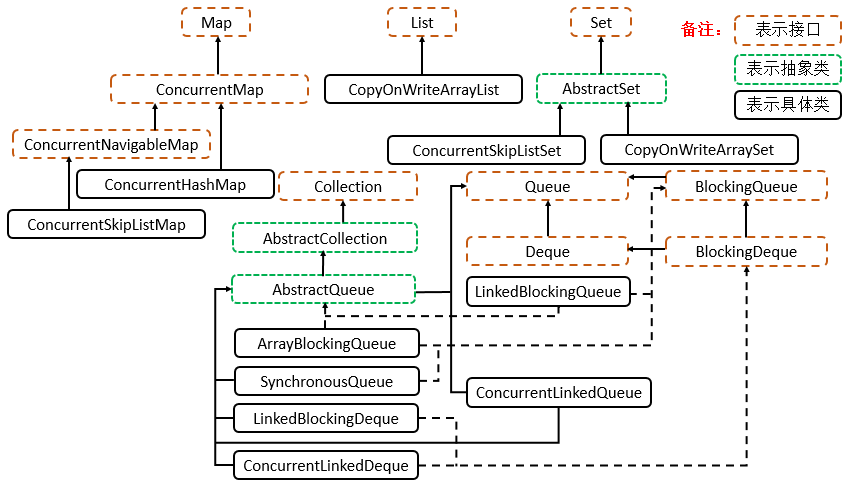
Queue: ArrayBlockingQueue
一个由数组支持的有界阻塞队列。此队列按 FIFO(先进先出)原则对元素进行排序。队列的头部是在队列中存在时间最长的元素。队列的尾部是在队列中存在时间最短的元素。新元素插入到队列的尾部,队列获取操作则是从队列头部开始获得元素。
Queue: LinkedBlockingQueue
一个基于已链接节点的、范围任意的 blocking queue。此队列按 FIFO(先进先出)排序元素。队列的头部 是在队列中时间最长的元素。队列的尾部 是在队列中时间最短的元素。新元素插入到队列的尾部,并且队列获取操作会获得位于队列头部的元素。链接队列的吞吐量通常要高于基于数组的队列,但是在大多数并发应用程序中,其可预知的性能要低。
Queue: LinkedBlockingDeque
一个基于已链接节点的、任选范围的阻塞双端队列。
Queue: ConcurrentLinkedQueue
一个基于链接节点的无界线程安全队列。此队列按照 FIFO(先进先出)原则对元素进行排序。队列的头部 是队列中时间最长的元素。队列的尾部 是队列中时间最短的元素。新的元素插入到队列的尾部,队列获取操作从队列头部获得元素。当多个线程共享访问一个公共 collection 时,ConcurrentLinkedQueue 是一个恰当的选择。此队列不允许使用 null 元素。
Queue: ConcurrentLinkedDeque
是双向链表实现的无界队列,该队列同时支持FIFO和FILO两种操作方式。
Queue: DelayQueue
延时无界阻塞队列,使用 Lock 机制实现并发访问。队列里只允许放可以“延期”的元素,队列中的 head 是最先“到期”的元素。如果队里中没有元素到“到期”,那么就算队列中有元素也不能获取到。
Queue: PriorityBlockingQueue
无界优先级阻塞队列,使用 Lock 机制实现并发访问。priorityQueue 的线程安全版,不允许存放 null 值,依赖于 comparable 的排序,不允许存放不可比较的对象类型。
Queue: SynchronousQueue
没有容量的同步队列,通过CAS实现并发访问,支持FIFO和FILO
Queue: LinkedTransferQueue
JDK 7新增,单向链表实现的无界阻塞队列,通过CAS实现并发访问,队列元素使用 FIFO(先进先出)方式。LinkedTransferQueue可以说是ConcurrentLinkedQueue、SynchronousQueue(公平模式)和LinkedBlockingQueue的超集, 它不仅仅综合了这几个类的功能,同时也提供了更高效的实现。
List: CopyOnWriteArrayList
ArrayList 的一个线程安全的变体,其中所有可变操作(add、set 等等)都是通过对底层数组进行一次新的复制来实现的。这一般需要很大的开销,但是当遍历操作的数量大大超过可变操作的数量时,这种方法可能比其他替代方法更 有效。在不能或不想进行同步遍历,但又需要从并发线程中排除冲突时,它也很有用。
Set: CopyOnWriteArraySet
对其所有操作使用内部CopyOnWriteArrayList的Set。即将所有操作转发至CopyOnWriteArayList来进行操作,能够保证线程安全。在add时,会调用addIfAbsent,由于每次add时都要进行数组遍历,因此性能会略低于CopyOnWriteArrayList。
Set: ConcurrentSkipListSet
一个基于ConcurrentSkipListMap 的可缩放并发 NavigableSet 实现。set 的元素可以根据它们的自然顺序进行排序,也可以根据创建 set 时所提供的 Comparator 进行排序,具体取决于使用的构造方法。
Map: ConcurrentHashMap
是线程安全HashMap的。ConcurrentHashMap在JDK 7之前是通过Lock和segment(分段锁)实现,JDK 8 之后改为CAS+synchronized来保证并发安全。
Map: ConcurrentSkipListMap
线程安全的有序的哈希表(相当于线程安全的TreeMap);映射可以根据键的自然顺序进行排序,也可以根据创建映射时所提供的 Comparator 进行排序,具体取决于使用的构造方法。
Atomic: 原子类
其基本的特性就是在多线程环境下,当有多个线程同时执行这些类的实例包含的方法时,具有排他性,即当某个线程进入方法,执行其中的指令时,不会被其他线程打断,而别的线程就像自旋锁一样,一直等到该方法执行完成,才由JVM从等待队列中选择一个另一个线程进入,这只是一种逻辑上的理解。实际上是借助硬件的相关指令来实现的,不会阻塞线程(或者说只是在硬件级别上阻塞了)。
基础类型:AtomicBoolean、AtomicInteger、AtomicLong
数组:AtomicIntegerArray,AtomicLongArray,BooleanArray
引用:AtomicReference,AtomicMarkedReference,AtomicStampedReference
FieldUpdater:AtomicLongFieldUpdater,AtomicIntegerFieldUpdater,AtomicReferenceFieldUpdater
Executors:线程池
层级结构
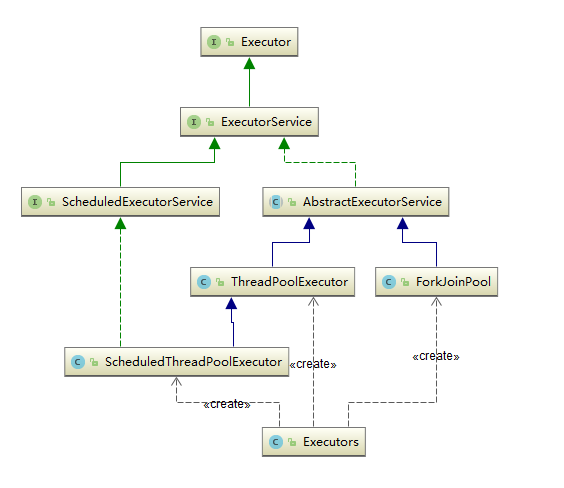
接口:Executor
Executor 接口提供一种将任务提交与每个任务将如何运行的机制(包括线程使用的细节、调度等)分离开来的方法。通常使用 Executor 而不是显式地创建线程。
ExecutorService
ExecutorService 继承自 Executor 接口,ExecutorService 提供了管理终止的方法,以及可为跟踪一个或多个异步任务执行状况而生成 Future 的方法。 可以关闭 ExecutorService,这将导致其停止接受新任务。关闭后,执行程序将最后终止,这时没有任务在执行,也没有任务在等待执行,并且无法提交新任务。
ScheduledExecutorService
ScheduledExecutorService继承自ExecutorService接口,可安排在给定的延迟后运行或定期执行的命令。
AbstractExecutorService
AbstractExecutorService 继承自 ExecutorService 接口,其提供 ExecutorService 执行方法的默认实现。此类使用 newTaskFor 返回的 RunnableFuture 实现 submit、invokeAny 和 invokeAll 方法,默认情况下,RunnableFuture 是此包中提供的 FutureTask 类。
FutureTask
FutureTask 为 Future 提供了基础实现,如获取任务执行结果(get)和取消任务(cancel)等。如果任务尚未完成,获取任务执行结果时将会阻塞。一旦执行结束,任务就不能被重启或取消(除非使用runAndReset执行计算)。FutureTask 常用来封装 Callable 和 Runnable,也可以作为一个任务提交到线程池中执行。除了作为一个独立的类之外,此类也提供了一些功能性函数供我们创建自定义 task 类使用。FutureTask 的线程安全由CAS来保证。
核心: ThreadPoolExecutor
ThreadPoolExecutor 实现了 AbstractExecutorService 接口,也是一个 ExecutorService,它使用可能的几个池线程之一执行每个提交的任务,通常使用 Executors 工厂方法配置。 线程池可以解决两个不同问题: 由于减少了每个任务调用的开销,它们通常可以在执行大量异步任务时提供增强的性能,并且还可以提供绑定和管理资源(包括执行任务集时使用的线程)的方法。每个 ThreadPoolExecutor 还维护着一些基本的统计数据,如完成的任务数。
核心: ScheduledThreadExecutor
ScheduledThreadPoolExecutor 实现 ScheduledExecutorService 接口,可安排在给定的延迟后运行命令,或者定期执行命令。需要多个辅助线程时,或者要求 ThreadPoolExecutor 具有额外的灵活性或功能时,此类要优于 Timer。
核心: Fork/Join框架
ForkJoinPool 是JDK 7 加入的一个线程池类。Fork/Join 技术是分治算法(Divide-and-Conquer)的并行实现,它是一项可以获得良好的并行性能的简单且高效的设计技术。目的是为了帮助我们更好地利用多处理器带来的好处,使用所有可用的运算能力来提升应用的性能。
工具类: Executors
Executors 是一个工具类,用其可以创建 ExecutorService、ScheduledExecutorService、ThreadFactory、Callable 等对象。它的使用融入到了 ThreadPoolExecutor, ScheduledThreadExecutor 和 ForkJoinPool 中。
9 - CH09-底层支撑
CAS
现在安全的实现方法:
- 互斥同步:synchronized、ReentrantLock
- 非阻塞同步:CAS、Atomic-
- 无同步方案:栈封闭、TreadLocal、可重入代码
什么是 CAS
CAS 的全称为 Compare-And-Swap,直译就是对比交换。是一条 CPU 的原子指令,其作用是让 CPU 先进行比较两个值是否相等,然后原子地更新某个位置的值,经过调查发现,其实现方式是基于硬件平台的汇编指令,就是说 CAS 是靠硬件实现的,JVM 只是封装了汇编调用,那些 AtomicInteger 类便是使用了这些封装后的接口。
简单解释:CAS操作需要输入两个数值,一个旧值(期望操作前的值)和一个新值,在操作期间先比较下在旧值有没有发生变化,如果没有发生变化,才交换成新值,发生了变化则不交换。
CAS 操作是原子性的,所以多线程并发使用 CAS 更新数据时,可以不使用锁。JDK 中大量使用了 CAS 来更新数据而防止加锁(synchronized 重量级锁)来保持原子更新。
应用示例
如果不使用CAS,在高并发下,多线程同时修改一个变量的值我们需要synchronized加锁(可能有人说可以用Lock加锁,Lock底层的AQS也是基于CAS进行获取锁的)。
public class Test {
private int i=0;
public synchronized int add(){
return i++;
}
}
java中为我们提供了AtomicInteger 原子类(底层基于CAS进行更新数据的),不需要加锁就在多线程并发场景下实现数据的一致性。
public class Test {
private AtomicInteger i = new AtomicInteger(0);
public int add(){
return i.addAndGet(1);
}
}
CAS 问题
CAS 方式为乐观锁,synchronized 为悲观锁。因此使用 CAS 解决并发问题通常情况下性能更优。
但使用 CAS 方式也会有几个问题:
ABA 问题
因为 CAS 需要在操作值的时候,检查值有没有发生变化,比如没有发生变化则更新,但是如果一个值原来是 A,变成了 B,又变成了 A,那么使用 CAS 进行检查时则会发现它的值没有发生变化,但是实际上却变化了。
ABA 问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加1,那么 A->B->A 就会变成 1A->2B->3A。
从 Java 1.5 开始,JDK 的 Atomic 包里提供了一个类 AtomicStampedReference 来解决 ABA 问题。这个类的 compareAndSet 方法的作用是首先检查当前引用是否等于预期引用,并且检查当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
循环时间长开销大
自旋 CAS 如果长时间不成功,会给 CPU 带来非常大的执行开销。如果 JVM 能支持处理器提供的 pause 指令,那么效率会有一定的提升。
pause 指令有两个作用:
- 第一,它可以延迟流水线执行命令(de-pipeline),使 CPU 不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零;
- 第二,它可以避免在退出循环的时候因内存顺序冲突(Memory Order Violation)而引起 CPU 流水线被清空(CPU Pipeline Flush),从而提高 CPU 的执行效率。
仅作用于单个变量
当对一个共享变量执行操作时,我们可以使用循环 CAS 的方式来保证原子操作,但是对多个共享变量操作时,循环 CAS 就无法保证操作的原子性,这个时候就可以用锁。
还有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如,有两个共享变量 i = 2,j = a,合并一下 ij = 2a,然后用 CAS 来操作 ij。
从 Java 1.5 开始,JDK 提供了 AtomicReference 类来保证引用对象之间的原子性,就可以把多个变量放在一个对象里来进行 CAS 操作。
UnSafe 类
Java 原子类是通过 UnSafe 类实现的。
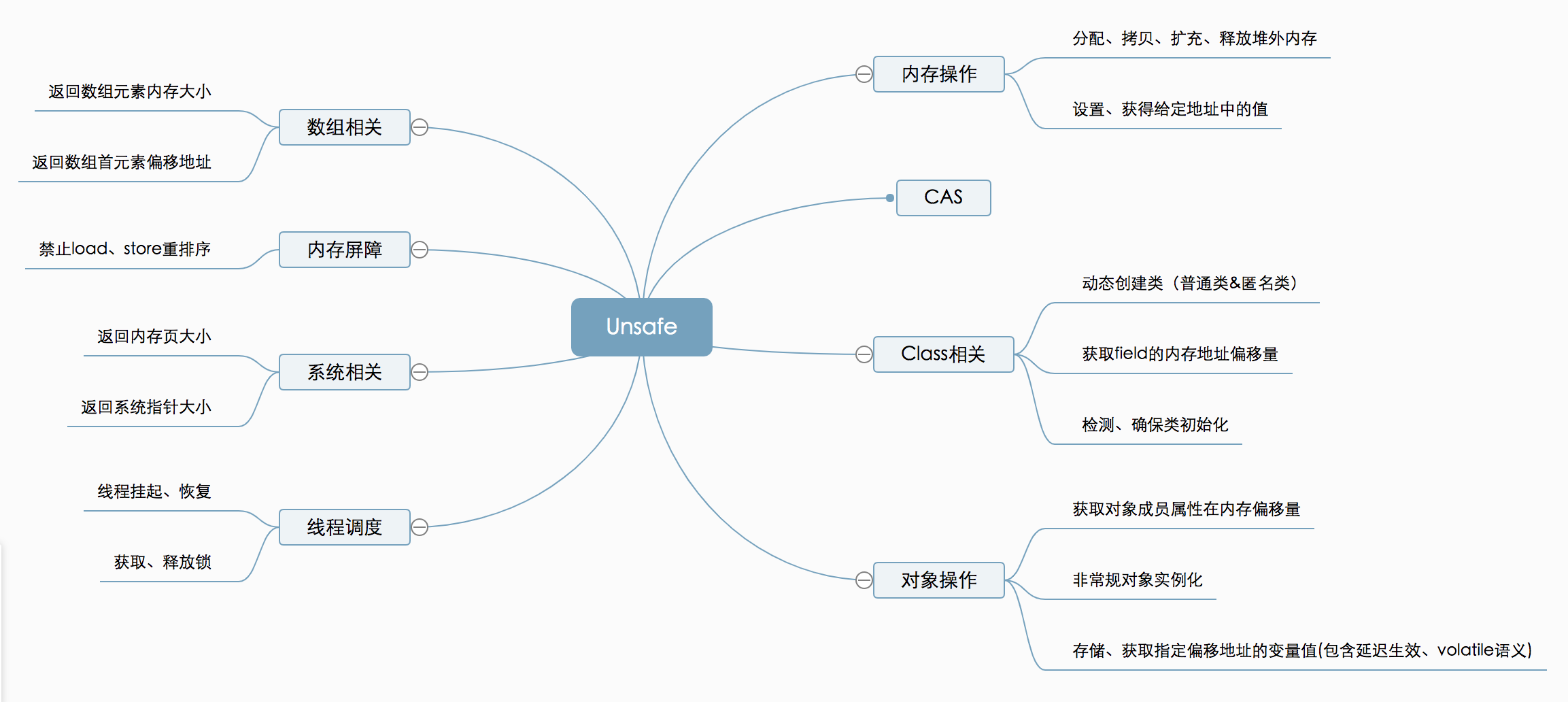
Unsafe 是位于 sun.misc 包下的一个类,主要提供一些用于执行低级别、不安全操作的方法,如直接访问系统内存资源、自主管理内存资源等,这些方法在提升 Java 运行效率、增强 Java 语言底层资源操作能力方面起到了很大的作用。
但由于 Unsafe 类使 Java 语言拥有了类似 C 语言指针一样操作内存空间的能力,这无疑也增加了程序发生相关指针问题的风险。在程序中过度、不正确使用 Unsafe 类会使得程序出错的概率变大,使得 Java 这种安全的语言变得不再“安全”,因此对 Unsafe 的使用一定要慎重。
这个类尽管里面的方法都是 public 的,但是并没有办法使用它们,JDK API 文档也没有提供任何关于这个类的方法的解释。总而言之,对于 Unsafe 类的使用都是受限制的,只有授信的代码才能获得该类的实例,当然 JDK 库里面的类是可以随意使用的。
功能概览:
UnSafe 与 CAS
内部使用自旋的方式进行CAS更新(while循环进行CAS更新,如果更新失败,则循环再次重试)。
public final int getAndAddInt(Object paramObject, long paramLong, int paramInt)
{
int i;
do
i = getIntVolatile(paramObject, paramLong);
while (!compareAndSwapInt(paramObject, paramLong, i, i + paramInt));
return i;
}
public final long getAndAddLong(Object paramObject, long paramLong1, long paramLong2)
{
long l;
do
l = getLongVolatile(paramObject, paramLong1);
while (!compareAndSwapLong(paramObject, paramLong1, l, l + paramLong2));
return l;
}
public final int getAndSetInt(Object paramObject, long paramLong, int paramInt)
{
int i;
do
i = getIntVolatile(paramObject, paramLong);
while (!compareAndSwapInt(paramObject, paramLong, i, paramInt));
return i;
}
public final long getAndSetLong(Object paramObject, long paramLong1, long paramLong2)
{
long l;
do
l = getLongVolatile(paramObject, paramLong1);
while (!compareAndSwapLong(paramObject, paramLong1, l, paramLong2));
return l;
}
public final Object getAndSetObject(Object paramObject1, long paramLong, Object paramObject2)
{
Object localObject;
do
localObject = getObjectVolatile(paramObject1, paramLong);
while (!compareAndSwapObject(paramObject1, paramLong, localObject, paramObject2));
return localObject;
}
从 UnSafe 类中发现,原子操作仅提供了三个方法:
public final native boolean compareAndSwapObject(Object paramObject1, long paramLong, Object paramObject2, Object paramObject3);
public final native boolean compareAndSwapInt(Object paramObject, long paramLong, int paramInt1, int paramInt2);
public final native boolean compareAndSwapLong(Object paramObject, long paramLong1, long paramLong2, long paramLong3);
UnSafe 底层
查看 Unsafe的compareAndSwap- 方法来实现 CAS 操作,它是一个本地方法,实现位于 unsafe.cpp 中。
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
UNSAFE_END
可以看到它通过 Atomic::cmpxchg 来实现比较和替换操作。其中参数x是即将更新的值,参数e是原内存的值。
如果是Linux的x86,Atomic::cmpxchg方法的实现如下:
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
int mp = os::is_MP();
__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}
而 windows 的 x86 的实现如下:
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
int mp = os::isMP(); //判断是否是多处理器
_asm {
mov edx, dest
mov ecx, exchange_value
mov eax, compare_value
LOCK_IF_MP(mp)
cmpxchg dword ptr [edx], ecx
}
}
// Adding a lock prefix to an instruction on MP machine
// VC++ doesn't like the lock prefix to be on a single line
// so we can't insert a label after the lock prefix.
// By emitting a lock prefix, we can define a label after it.
#define LOCK_IF_MP(mp) __asm cmp mp, 0 \
__asm je L0 \
__asm _emit 0xF0 \
__asm L0:
如果是多处理器,为 cmpxchg 指令添加 lock 前缀。反之,就省略 lock 前缀(单处理器会不需要 lock 前缀提供的内存屏障效果)。这里的 lock 前缀就是使用了处理器的总线锁(最新的处理器都使用缓存锁代替总线锁来提高性能)。
cmpxchg(void* ptr, int old, int new),如果 ptr 和 old 的值一样,则把 new 写到 ptr 内存,否则返回 ptr 的值,整个操作是原子的。在 Intel 平台下,会用 lock cmpxchg 来实现,使用 lock 触发缓存锁,这样另一个线程想访问 ptr 的内存,就会被 block 住。
UnSafe 其他功能
Unsafe 提供了硬件级别的操作,比如说获取某个属性在内存中的位置,比如说修改对象的字段值,即使它是私有的。不过 Java 本身就是为了屏蔽底层的差异,对于一般的开发而言也很少会有这样的需求。
举两个例子,比方说:
public native long staticFieldOffset(Field paramField);
这个方法可以用来获取给定的 paramField 的内存地址偏移量,这个值对于给定的 field 是唯一的且是固定不变的。
public native int arrayBaseOffset(Class paramClass);
public native int arrayIndexScale(Class paramClass);
前一个方法是用来获取数组第一个元素的偏移地址,后一个方法是用来获取数组的转换因子即数组中元素的增量地址的。
public native long allocateMemory(long paramLong);
public native long reallocateMemory(long paramLong1, long paramLong2);
public native void freeMemory(long paramLong);
分别用来分配内存,扩充内存和释放内存的。
AtomicInteger
public final int get():获取当前的值
public final int getAndSet(int newValue):获取当前的值,并设置新的值
public final int getAndIncrement():获取当前的值,并自增
public final int getAndDecrement():获取当前的值,并自减
public final int getAndAdd(int delta):获取当前的值,并加上预期的值
void lazySet(int newValue): 最终会设置成newValue,使用lazySet设置值后,可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
源码解析
public class AtomicInteger extends Number implements java.io.Serializable {
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
//用于获取value字段相对当前对象的“起始地址”的偏移量
valueOffset = unsafe.objectFieldOffset(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value;
//返回当前值
public final int get() {
return value;
}
//递增加detla
public final int getAndAdd(int delta) {
//三个参数,1、当前的实例 2、value实例变量的偏移量 3、当前value要加上的数(value+delta)。
return unsafe.getAndAddInt(this, valueOffset, delta);
}
//递增加1
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
...
}
AtomicInteger 底层用的是volatile的变量和CAS来进行更改数据的:
- volatile 保证线程的可见性,多线程并发时,一个线程修改数据,可以保证其它线程立马看到修改后的值
- CAS 保证数据更新的原子性
所有原子类
原子基本类型
使用原子的方式更新基本类型,Atomic 包共有 3 个类:
- AtomicBoolean
- AtomicInteger
- AtomicLong
原子数组
通过原子的方式更新数组里的某个元素,Atomic 包提供了以下的 4 个类:
- AtomicIntegerArray
- AtomicLongArray
- AtomicReferenceArray
常用方法:
get(int index)compareAndSet(int i, E expect, E update)
原子引用
- AtomicReference: 原子更新引用类型。
- AtomicStampedReference: 原子更新引用类型, 内部使用Pair来存储元素值及其版本号。
- AtomicMarkableReferce: 原子更新带有标记位的引用类型。
都是基于 UnSafe 实现,但 AtomicReferenceFieldUpdater 所更新的字段必须使用 volatile 修饰。
原子字段更新
AtomicIntegerFieldUpdater: 原子更新整型的字段的更新器。
AtomicLongFieldUpdater: 原子更新长整型字段的更新器。
AtomicStampedFieldUpdater: 原子更新带有版本号的引用类型。
AtomicReferenceFieldUpdater: 上面已经说过此处不在赘述。
以上均为基于反射的原子更新字段的值,要想原子地更新字段类需要两步:
- 第一步,因为原子更新字段类都是抽象类,每次使用的时候必须使用静态方法newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。
- 第二步,更新类的字段必须使用public volatile修饰。
public class TestAtomicIntegerFieldUpdater {
public static void main(String[] args){
TestAtomicIntegerFieldUpdater tIA = new TestAtomicIntegerFieldUpdater();
tIA.doIt();
}
public AtomicIntegerFieldUpdater<DataDemo> updater(String name){
return AtomicIntegerFieldUpdater.newUpdater(DataDemo.class,name);
}
public void doIt(){
DataDemo data = new DataDemo();
System.out.println("publicVar = "+updater("publicVar").getAndAdd(data, 2));
}
}
class DataDemo{
public volatile int publicVar=3;
protected volatile int protectedVar=4;
private volatile int privateVar=5;
public volatile static int staticVar = 10;
//public final int finalVar = 11;
public volatile Integer integerVar = 19;
public volatile Long longVar = 18L;
}
AtomicIntegerFieldUpdater 应用约束:
- 字段必须是 volatile 类型的,在线程之间共享变量时保证立即可见。
- 字段的描述类型(修饰符public/protected/default/private)是与调用者与操作对象字段的关系一致。
- 也就是说调用者能够直接操作对象字段,那么就可以反射进行原子操作。但是对于父类的字段,子类是不能直接操作的,尽管子类可以访问父类的字段。
- 只能是实例变量,不能是类变量,也就是说不能加 static 关键字。
- 只能是可修改变量,不能使 final 变量,因为 final 的语义就是不可修改。
- 实际上 final 的语义和 volatile 是有冲突的,这两个关键字不能同时存在。
- 对于 AtomicIntegerFieldUpdater 和 AtomicLongFieldUpdater 只能修改 int/long 类型的字段,不能修改其包装类型(Integer/Long)。
- 如果要修改包装类型就需要使用 AtomicReferenceFieldUpdater。
AtomicStampedReference 与 ABA
AtomicStampedReference 主要维护包含一个对象引用以及一个可以自动更新的整数 “stamp” 的 pair 对象来解决 ABA 问题。
public class AtomicStampedReference<V> {
private static class Pair<T> {
final T reference; //维护对象引用
final int stamp; //用于标志版本
private Pair(T reference, int stamp) {
this.reference = reference;
this.stamp = stamp;
}
static <T> Pair<T> of(T reference, int stamp) {
return new Pair<T>(reference, stamp);
}
}
private volatile Pair<V> pair;
....
/**
* expectedReference :更新之前的原始值
* newReference : 将要更新的新值
* expectedStamp : 期待更新的标志版本
* newStamp : 将要更新的标志版本
*/
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
// 获取当前的(元素值,版本号)对
Pair<V> current = pair;
return
// 引用没变
expectedReference == current.reference &&
// 版本号没变
expectedStamp == current.stamp &&
// 新引用等于旧引用
((newReference == current.reference &&
// 新版本号等于旧版本号
newStamp == current.stamp) ||
// 构造新的Pair对象并CAS更新
casPair(current, Pair.of(newReference, newStamp)));
}
private boolean casPair(Pair<V> cmp, Pair<V> val) {
// 调用Unsafe的compareAndSwapObject()方法CAS更新pair的引用为新引用
return UNSAFE.compareAndSwapObject(this, pairOffset, cmp, val);
}
- 如果元素值和版本号都没有变化,并且和新的也相同,返回true;
- 如果元素值和版本号都没有变化,并且和新的不完全相同,就构造一个新的Pair对象并执行CAS更新pair。
可以看到,java中的实现跟我们上面讲的ABA的解决方法是一致的。
- 首先,使用版本号控制;
- 其次,不重复使用节点(Pair)的引用,每次都新建一个新的Pair来作为CAS比较的对象,而不是复用旧的;
- 最后,外部传入元素值及版本号,而不是节点(Pair)的引用。
AtomicMarkableReference
AtomicMarkableReference,它不是维护一个版本号,而是维护一个boolean类型的标记,标记值有修改。
10 - CH10-LockSupport
功能介绍
LockSupport 是用来创建锁和其他同步类的基本线程阻塞原语。
- 当调用 LockSupport.park 时,当前线程会等待直至获取许可;
- 当调用 LockSupport.unpack 时,必须把扥带获取许可的线程作为参数传递,以使其恢复运行。
源码分析
基本属性
public class LockSupport {
// Hotspot implementation via intrinsics API
private static final sun.misc.Unsafe UNSAFE;
// 表示内存偏移地址
private static final long parkBlockerOffset;
// 表示内存偏移地址
private static final long SEED;
// 表示内存偏移地址
private static final long PROBE;
// 表示内存偏移地址
private static final long SECONDARY;
static {
try {
// 获取Unsafe实例
UNSAFE = sun.misc.Unsafe.getUnsafe();
// 线程类类型
Class<?> tk = Thread.class;
// 获取Thread的parkBlocker字段的内存偏移地址
parkBlockerOffset = UNSAFE.objectFieldOffset
(tk.getDeclaredField("parkBlocker"));
// 获取Thread的threadLocalRandomSeed字段的内存偏移地址
SEED = UNSAFE.objectFieldOffset
(tk.getDeclaredField("threadLocalRandomSeed"));
// 获取Thread的threadLocalRandomProbe字段的内存偏移地址
PROBE = UNSAFE.objectFieldOffset
(tk.getDeclaredField("threadLocalRandomProbe"));
// 获取Thread的threadLocalRandomSecondarySeed字段的内存偏移地址
SECONDARY = UNSAFE.objectFieldOffset
(tk.getDeclaredField("threadLocalRandomSecondarySeed"));
} catch (Exception ex) { throw new Error(ex); }
}
}
构造函数
仅有一个私有构造函数,无法被实例化。
核心函数
LockSupport的核心函数都是基于Unsafe类中定义的park和unpark函数,下面给出两个函数的定义:
public native void park(boolean isAbsolute, long time);
public native void unpark(Thread thread);
- park 函数:阻塞线程,该线程在下列情况发生之前都会被阻塞:
- 调用 unpark 函数,释放该线程的许可。
- 该线程被中断。
- 设置的时间到期,如果 time 为 0 则表示无限等待。
- unpark 函数:释放线程的许可,使调用 park 的线程恢复执行。调用时要确保线性仍然活着。
park
public static void park();
public static void park(Object blocker);
// 第二个函数的实现
public static void park(Object blocker) {
// 获取当前线程
Thread t = Thread.currentThread();
// 设置Blocker
setBlocker(t, blocker);
// 获取许可
UNSAFE.park(false, 0L);
// 重新可运行后再此设置Blocker
setBlocker(t, null);
}
调用 park 函数时,首先获取当前线程,然后设置当前线程的 parkBlocker 字段,即调用 setBlocker 方法,之后调用 UnSafe.park,之后再调用 setBlocker 方法。
调用 park 函数式,当前线程首先设置好 parkBlocker 字段,然后调用 UnSafe.park,此后,当前线程就阻塞了,开始等待该线程的 unpark 函数被调用,所以后面的一个 setBlocker 函数无法执行;unpack 函数被调用后,该线程获得许可,就可以接着执行第二个 setBlocker,把该线程的 parkBlocker 设为 null,即完成了整个 park 函数的逻辑。
如果没有第二个 setBlocker,那么之后没有调用 park(blocker),而直接调用 getBlocker 函数时,会得到原来设置的 blocker,显然不符合逻辑。总之,必须要保证 park 执行完成之后,blocker 被设为 null。
说明: 调用了park函数后,会禁用当前线程,除非许可可用。在以下三种情况之一发生之前,当前线程都将处于休眠状态,即下列情况发生时,当前线程会获取许可,可以继续运行。
- 其他某个线程将当前线程作为目标调用 unpark。
- 其他某个线程中断当前线程。
- 该调用不合逻辑地(即毫无理由地)返回。
parkNanos
此函数表示在许可可用前禁用当前线程,并最多等待指定的等待时间。
public static void parkNanos(Object blocker, long nanos) {
if (nanos > 0) { // 时间大于0
// 获取当前线程
Thread t = Thread.currentThread();
// 设置Blocker
setBlocker(t, blocker);
// 获取许可,并设置了时间
UNSAFE.park(false, nanos);
// 设置许可
setBlocker(t, null);
}
}
parkUntil
此函数表示在指定的时限前禁用当前线程,除非许可可用, 具体函数如下:
public static void parkUntil(Object blocker, long deadline) {
// 获取当前线程
Thread t = Thread.currentThread();
// 设置Blocker
setBlocker(t, blocker);
UNSAFE.park(true, deadline);
// 设置Blocker为null
setBlocker(t, null);
}
unpark
此函数表示如果给定线程的许可尚不可用,则使其可用。如果线程在 park 上受阻塞,则它将解除其阻塞状态。否则,保证下一次调用 park 不会受阻塞。如果给定线程尚未启动,则无法保证此操作有任何效果。
public static void unpark(Thread thread) {
if (thread != null) // 线程为不空
UNSAFE.unpark(thread); // 释放该线程许可
}
应用示例
使用wait/notify实现线程同步
class MyThread extends Thread {
public void run() {
synchronized (this) {
System.out.println("before notify");
notify();
System.out.println("after notify");
}
}
}
public class WaitAndNotifyDemo {
public static void main(String[] args) throws InterruptedException {
MyThread myThread = new MyThread();
synchronized (myThread) {
try {
myThread.start();
// 主线程睡眠3s
Thread.sleep(3000);
System.out.println("before wait");
// 阻塞主线程
myThread.wait();
System.out.println("after wait");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
before wait
before notify
after notify
after wait
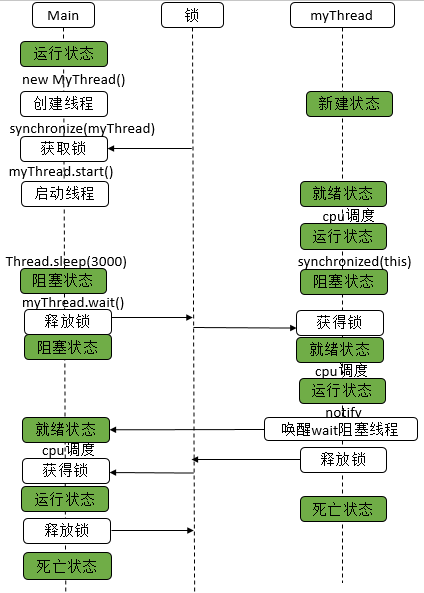
使用wait/notify实现同步时,必须先调用wait,后调用notify,如果先调用notify,再调用wait,将起不了作用。
使用park/unpark实现线程同步
import java.util.concurrent.locks.LockSupport;
class MyThread extends Thread {
private Object object;
public MyThread(Object object) {
this.object = object;
}
public void run() {
System.out.println("before unpark");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 获取blocker
System.out.println("Blocker info " + LockSupport.getBlocker((Thread) object));
// 释放许可
LockSupport.unpark((Thread) object);
// 休眠500ms,保证先执行park中的setBlocker(t, null);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 再次获取blocker
System.out.println("Blocker info " + LockSupport.getBlocker((Thread) object));
System.out.println("after unpark");
}
}
public class test {
public static void main(String[] args) {
MyThread myThread = new MyThread(Thread.currentThread());
myThread.start();
System.out.println("before park");
// 获取许可
LockSupport.park("ParkAndUnparkDemo");
System.out.println("after park");
}
}
before park
before unpark
Blocker info ParkAndUnparkDemo
after park
Blocker info null
after unpark
本程序先执行park,然后在执行unpark,进行同步,并且在unpark的前后都调用了getBlocker,可以看到两次的结果不一样,并且第二次调用的结果为null,这是因为在调用unpark之后,执行了Lock.park(Object blocker)函数中的setBlocker(t, null)函数,所以第二次调用getBlocker时为null。
中断响应
import java.util.concurrent.locks.LockSupport;
class MyThread extends Thread {
private Object object;
public MyThread(Object object) {
this.object = object;
}
public void run() {
System.out.println("before interrupt");
try {
// 休眠3s
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
Thread thread = (Thread) object;
// 中断线程
thread.interrupt();
System.out.println("after interrupt");
}
}
public class InterruptDemo {
public static void main(String[] args) {
MyThread myThread = new MyThread(Thread.currentThread());
myThread.start();
System.out.println("before park");
// 获取许可
LockSupport.park("ParkAndUnparkDemo");
System.out.println("after park");
}
}
before park
before interrupt
after interrupt
after park
可以看到,在主线程调用park阻塞后,在myThread线程中发出了中断信号,此时主线程会继续运行,也就是说明此时interrupt起到的作用与unpark一样。
深入理解
Thread.sleep() 和 Object.wait() 的区别
- Thread.sleep()不会释放占有的锁,Object.wait()会释放占有的锁;
- Thread.sleep()必须传入时间,Object.wait()可传可不传,不传表示一直阻塞下去;
- Thread.sleep()到时间了会自动唤醒,然后继续执行;
- Object.wait()不带时间的,需要另一个线程使用Object.notify()唤醒;
- Object.wait()带时间的,假如没有被notify,到时间了会自动唤醒,这时又分好两种情况:
- 一是立即获取到了锁,线程自然会继续执行;
- 二是没有立即获取锁,线程进入同步队列等待获取锁;
他们俩最大的区别就是Thread.sleep()不会释放锁资源,Object.wait()会释放锁资源。
Object.wait() 和 Condition.await() 的区别
Object.wait()和Condition.await()的原理是基本一致的,不同的是Condition.await()底层是调用LockSupport.park()来实现阻塞当前线程的。
实际上,它在阻塞当前线程之前还干了两件事,一是把当前线程添加到条件队列中,二是“完全”释放锁,也就是让state状态变量变为0,然后才是调用LockSupport.park()阻塞当前线程。
Thread.sleep()和LockSupport.park()的区别
LockSupport.park()还有几个兄弟方法——parkNanos()、parkUtil()等,我们这里说的park()方法统称这一类方法。
- 从功能上来说,Thread.sleep()和LockSupport.park()方法类似,都是阻塞当前线程的执行,且都不会释放当前线程占有的锁资源;
- Thread.sleep()没法从外部唤醒,只能自己醒过来;
- LockSupport.park()方法可以被另一个线程调用LockSupport.unpark()方法唤醒;
- Thread.sleep()方法声明上抛出了InterruptedException中断异常,所以调用者需要捕获这个异常或者再抛出;
- LockSupport.park()方法不需要捕获中断异常;
- Thread.sleep()本身就是一个native方法;
- LockSupport.park()底层是调用的Unsafe的native方法;
Object.wait()和LockSupport.park()的区别
二者都会阻塞当前线程的运行:
- Object.wait()方法需要在synchronized块中执行;
- LockSupport.park()可以在任意地方执行;
- Object.wait()方法声明抛出了中断异常,调用者需要捕获或者再抛出;
- LockSupport.park()不需要捕获中断异常;
- Object.wait()不带超时的,需要另一个线程执行notify()来唤醒,但不一定继续执行后续内容;
- LockSupport.park()不带超时的,需要另一个线程执行unpark()来唤醒,一定会继续执行后续内容;
- 如果在wait()之前执行了notify()会怎样? 抛出IllegalMonitorStateException异常;
- 如果在park()之前执行了unpark()会怎样? 线程不会被阻塞,直接跳过park(),继续执行后续内容;
park()/unpark()底层的原理是“二元信号量”,你可以把它相像成只有一个许可证的Semaphore,只不过这个信号量在重复执行unpark()的时候也不会再增加许可证,最多只有一个许可证。
LockSupport.park()会释放锁资源吗?
不会,它只负责阻塞当前线程,释放锁资源实际上是在Condition的await()方法中实现的。
11 - CH11-AQS-1
AbstractQueuedSynchronizer
AQS 是一个用来构建锁和同步器的框架,使用 AQS 能够简单高效的构造出应用广泛的同步器,比如 ReentrantLock、Semaphore,其他诸如 ReentrantReadWriteLock、SynchronousQueue、FutureTask 等也是基于 AQS 实现的。我们自己也可以基于 AQS 构造满足自己需要的同步器。
核心思想
- 如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。
- 如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制。
- AQS 使用 CLH 队列锁实现了该机制,将暂时获取不到锁的线程加入到队列中。
- AQS 使用一个 int 成员变量表示同步状态,通过内置的 FIFO 队列来完成获取资源线程的排队工作。
- AQS 使用 CAS 对该同步状态执行原子操作以实现值的修改,并使用 volatile 保证该状态的可见性。
CLH(Craig,Landin,and Hagersten) 队列是一个虚拟的双向队列(即不存在队列实例、仅存在结点之间的关联关系)。AQS是将每条请求共享资源的线程封装成一个 CLH 锁队列的一个结点(Node)来实现锁的分配。
状态信息通过 protected 范围的方法执行操作:
private volatile int state;
//返回同步状态的当前值
protected final int getState() {
return state;
}
// 设置同步状态的值
protected final void setState(int newState) {
state = newState;
}
//原子地(CAS操作)将同步状态值设置为给定值update如果当前同步状态的值等于expect(期望值)
protected final boolean compareAndSetState(int expect, int update) {
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
资源共享方式
- 独占(Exclusive):只有一个线程能够执行,如 ReentrantLock。又可以分为公平锁和非公平锁:
- 公平锁:按照线程在队列中的排队顺序,先到者先获得锁。
- 非公平锁:当线程要获得锁时,无视队列顺序直接抢锁,谁抢到随获取。
- 共享(Share):多个线程可以同时执行,如 Semaphore、CountDownLatch。
而 ReentrantReadWriteLock 可以看做是对以上两种方式的组合,因为它允许多个线程同时对一个资源执行读,但仅能有一个线程执行写。
不同的自定义同步器争用共享资源的方式不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败后入队/唤醒出队等),AQS 已经在上层实现了。
AQS 底层使用的模板方法模式
同步器的设计基于模板方法模式,自定义同步器时继承 AQS 并重写指定的方法即可:
- isHeldExclusively:判断线程是否正在独占资源,只有用到 condition 才需要实现。
- tryAcquire(int):独占获取资源,成功失败返回 ture、false。
- tryRelease(int):独占释放资源,成功失败返回 true、false。
- tryAcquireShared(int):共享获取资源,失败为负,为 0 表示成功但没有剩余可用资源,为正表示成且有可用资源。
- tryReleaseShared(int):共享释放资源,成功失败返回 true、false。
相关细节:
- 默认情况下,每个方法都能抛出 UnsupportedException。
- 所有方法的实现必须是内部线程安全的,并且应该简短且不阻塞。
- 其他方法均为 final,所以仅有以上方法可以被其他类使用。
以 ReentrantLock 为例:
- 初始状态 state 为 0,表示未锁定状态。
- A 线程 lock 时,会调用 tryAcquire 独占锁定并将 state+1。
- 此后其他线程再 tryAcquire 时会失败,直到 A 线程 unlock 并将 state=0(释放锁)为止。
- 在 A 线程释放锁之前,A 线程可以重复获取此锁(state 累加),即可重入。
- 获取多次就要释放多次,直至 state 为 0 才表示释放锁。
数据结构
- AQS 底层使用 CLH,将每条请求共享资源的线程封装为 CLH 队列的一个节点。
- 其中同步队列 Sync Queue 为双向链表,包括 head 和 tail 节点,head 节点主要用作后续的调度。
- 其中 Condition Queue 不是必须,是一个单向链表,只有使用 Condition 时,才会使用该队列。
- 并且可能会有多个 Condition Queue。
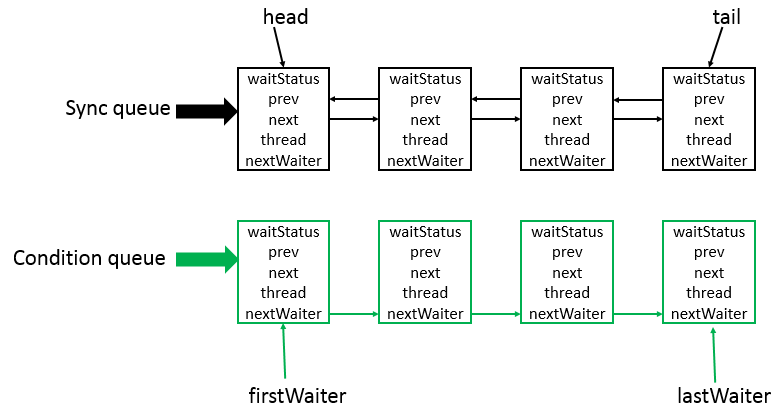
源码分析
层级结构
AQS 继承抽象类 AbstractOwnableSynchronizer,实现了 Serializable 接口,支持序列化。
public abstract class AbstractOwnableSynchronizer implements java.io.Serializable {
// 版本序列号
private static final long serialVersionUID = 3737899427754241961L;
// 构造方法
protected AbstractOwnableSynchronizer() { }
// 独占模式下的线程
private transient Thread exclusiveOwnerThread;
// 设置独占线程
protected final void setExclusiveOwnerThread(Thread thread) {
exclusiveOwnerThread = thread;
}
// 获取独占线程
protected final Thread getExclusiveOwnerThread() {
return exclusiveOwnerThread;
}
}
- 其中可以“设置独占资源线程”和“获取独占资源线程”,分别为 setExclusiveOwnerThread 与 getExclusiveOwnerThread 方法,这两个方法会被子类调用。
- 其中有两个内部类,Node、ConditionObject。
内部类:Node
static final class Node {
// 模式,分为共享与独占
// 共享模式
static final Node SHARED = new Node();
// 独占模式
static final Node EXCLUSIVE = null;
// 结点状态
// CANCELLED,值为1,表示当前的线程被取消
// SIGNAL,值为-1,表示当前节点的后继节点包含的线程需要运行,也就是unpark
// CONDITION,值为-2,表示当前节点在等待condition,也就是在condition队列中
// PROPAGATE,值为-3,表示当前场景下后续的acquireShared能够得以执行
// 值为0,表示当前节点在sync队列中,等待着获取锁
static final int CANCELLED = 1;
static final int SIGNAL = -1;
static final int CONDITION = -2;
static final int PROPAGATE = -3;
// 结点状态
volatile int waitStatus;
// 前驱结点
volatile Node prev;
// 后继结点
volatile Node next;
// 结点所对应的线程
volatile Thread thread;
// 下一个等待者
Node nextWaiter;
// 结点是否在共享模式下等待
final boolean isShared() {
return nextWaiter == SHARED;
}
// 获取前驱结点,若前驱结点为空,抛出异常
final Node predecessor() throws NullPointerException {
// 保存前驱结点
Node p = prev;
if (p == null) // 前驱结点为空,抛出异常
throw new NullPointerException();
else // 前驱结点不为空,返回
return p;
}
// 无参构造方法
Node() { // Used to establish initial head or SHARED marker
}
// 构造方法
Node(Thread thread, Node mode) { // Used by addWaiter
this.nextWaiter = mode;
this.thread = thread;
}
// 构造方法
Node(Thread thread, int waitStatus) { // Used by Condition
this.waitStatus = waitStatus;
this.thread = thread;
}
}
- 每个被阻塞的线程都会被封装为一个 Node 节点并放入队列。
- 每个节点包含了一个 Thread 类型的引用,并且每个节点都有一个状态,状态如下:
- CANCELLED:1,当前线程被取消。
- SIGNAL:-1,当前节点的后继节点中的线程需要运行,需要进行 unpark 操作。
- CONDITION:-2,当前节点在等待 condition,即 condition queue 中。
- PROPAGATE:-3,当前场景下后续的 acquireSHared 能够得以执行。
- 0:当前节点在 sync queue 中,等待获取锁。
内部类:ConditionObject
// 内部类
public class ConditionObject implements Condition, java.io.Serializable {
// 版本号
private static final long serialVersionUID = 1173984872572414699L;
/** First node of condition queue. */
// condition队列的头结点
private transient Node firstWaiter;
/** Last node of condition queue. */
// condition队列的尾结点
private transient Node lastWaiter;
/**
* Creates a new {@code ConditionObject} instance.
*/
// 构造方法
public ConditionObject() { }
// Internal methods
/**
* Adds a new waiter to wait queue.
* @return its new wait node
*/
// 添加新的waiter到wait队列
private Node addConditionWaiter() {
// 保存尾结点
Node t = lastWaiter;
// If lastWaiter is cancelled, clean out.
if (t != null && t.waitStatus != Node.CONDITION) { // 尾结点不为空,并且尾结点的状态不为CONDITION
// 清除状态为CONDITION的结点
unlinkCancelledWaiters();
// 将最后一个结点重新赋值给t
t = lastWaiter;
}
// 新建一个结点
Node node = new Node(Thread.currentThread(), Node.CONDITION);
if (t == null) // 尾结点为空
// 设置condition队列的头结点
firstWaiter = node;
else // 尾结点不为空
// 设置为节点的nextWaiter域为node结点
t.nextWaiter = node;
// 更新condition队列的尾结点
lastWaiter = node;
return node;
}
/**
* Removes and transfers nodes until hit non-cancelled one or
* null. Split out from signal in part to encourage compilers
* to inline the case of no waiters.
* @param first (non-null) the first node on condition queue
*/
private void doSignal(Node first) {
// 循环
do {
if ( (firstWaiter = first.nextWaiter) == null) // 该节点的nextWaiter为空
// 设置尾结点为空
lastWaiter = null;
// 设置first结点的nextWaiter域
first.nextWaiter = null;
} while (!transferForSignal(first) &&
(first = firstWaiter) != null); // 将结点从condition队列转移到sync队列失败并且condition队列中的头结点不为空,一直循环
}
/**
* Removes and transfers all nodes.
* @param first (non-null) the first node on condition queue
*/
private void doSignalAll(Node first) {
// condition队列的头结点尾结点都设置为空
lastWaiter = firstWaiter = null;
// 循环
do {
// 获取first结点的nextWaiter域结点
Node next = first.nextWaiter;
// 设置first结点的nextWaiter域为空
first.nextWaiter = null;
// 将first结点从condition队列转移到sync队列
transferForSignal(first);
// 重新设置first
first = next;
} while (first != null);
}
/**
* Unlinks cancelled waiter nodes from condition queue.
* Called only while holding lock. This is called when
* cancellation occurred during condition wait, and upon
* insertion of a new waiter when lastWaiter is seen to have
* been cancelled. This method is needed to avoid garbage
* retention in the absence of signals. So even though it may
* require a full traversal, it comes into play only when
* timeouts or cancellations occur in the absence of
* signals. It traverses all nodes rather than stopping at a
* particular target to unlink all pointers to garbage nodes
* without requiring many re-traversals during cancellation
* storms.
*/
// 从condition队列中清除状态为CANCEL的结点
private void unlinkCancelledWaiters() {
// 保存condition队列头结点
Node t = firstWaiter;
Node trail = null;
while (t != null) { // t不为空
// 下一个结点
Node next = t.nextWaiter;
if (t.waitStatus != Node.CONDITION) { // t结点的状态不为CONDTION状态
// 设置t节点的额nextWaiter域为空
t.nextWaiter = null;
if (trail == null) // trail为空
// 重新设置condition队列的头结点
firstWaiter = next;
else // trail不为空
// 设置trail结点的nextWaiter域为next结点
trail.nextWaiter = next;
if (next == null) // next结点为空
// 设置condition队列的尾结点
lastWaiter = trail;
}
else // t结点的状态为CONDTION状态
// 设置trail结点
trail = t;
// 设置t结点
t = next;
}
}
// public methods
/**
* Moves the longest-waiting thread, if one exists, from the
* wait queue for this condition to the wait queue for the
* owning lock.
*
* @throws IllegalMonitorStateException if {@link #isHeldExclusively}
* returns {@code false}
*/
// 唤醒一个等待线程。如果所有的线程都在等待此条件,则选择其中的一个唤醒。在从 await 返回之前,该线程必须重新获取锁。
public final void signal() {
if (!isHeldExclusively()) // 不被当前线程独占,抛出异常
throw new IllegalMonitorStateException();
// 保存condition队列头结点
Node first = firstWaiter;
if (first != null) // 头结点不为空
// 唤醒一个等待线程
doSignal(first);
}
/**
* Moves all threads from the wait queue for this condition to
* the wait queue for the owning lock.
*
* @throws IllegalMonitorStateException if {@link #isHeldExclusively}
* returns {@code false}
*/
// 唤醒所有等待线程。如果所有的线程都在等待此条件,则唤醒所有线程。在从 await 返回之前,每个线程都必须重新获取锁。
public final void signalAll() {
if (!isHeldExclusively()) // 不被当前线程独占,抛出异常
throw new IllegalMonitorStateException();
// 保存condition队列头结点
Node first = firstWaiter;
if (first != null) // 头结点不为空
// 唤醒所有等待线程
doSignalAll(first);
}
/**
* Implements uninterruptible condition wait.
* <ol>
* <li> Save lock state returned by {@link #getState}.
* <li> Invoke {@link #release} with saved state as argument,
* throwing IllegalMonitorStateException if it fails.
* <li> Block until signalled.
* <li> Reacquire by invoking specialized version of
* {@link #acquire} with saved state as argument.
* </ol>
*/
// 等待,当前线程在接到信号之前一直处于等待状态,不响应中断
public final void awaitUninterruptibly() {
// 添加一个结点到等待队列
Node node = addConditionWaiter();
// 获取释放的状态
int savedState = fullyRelease(node);
boolean interrupted = false;
while (!isOnSyncQueue(node)) { //
// 阻塞当前线程
LockSupport.park(this);
if (Thread.interrupted()) // 当前线程被中断
// 设置interrupted状态
interrupted = true;
}
if (acquireQueued(node, savedState) || interrupted) //
selfInterrupt();
}
/*
* For interruptible waits, we need to track whether to throw
* InterruptedException, if interrupted while blocked on
* condition, versus reinterrupt current thread, if
* interrupted while blocked waiting to re-acquire.
*/
/** Mode meaning to reinterrupt on exit from wait */
private static final int REINTERRUPT = 1;
/** Mode meaning to throw InterruptedException on exit from wait */
private static final int THROW_IE = -1;
/**
* Checks for interrupt, returning THROW_IE if interrupted
* before signalled, REINTERRUPT if after signalled, or
* 0 if not interrupted.
*/
private int checkInterruptWhileWaiting(Node node) {
return Thread.interrupted() ?
(transferAfterCancelledWait(node) ? THROW_IE : REINTERRUPT) :
0;
}
/**
* Throws InterruptedException, reinterrupts current thread, or
* does nothing, depending on mode.
*/
private void reportInterruptAfterWait(int interruptMode)
throws InterruptedException {
if (interruptMode == THROW_IE)
throw new InterruptedException();
else if (interruptMode == REINTERRUPT)
selfInterrupt();
}
/**
* Implements interruptible condition wait.
* <ol>
* <li> If current thread is interrupted, throw InterruptedException.
* <li> Save lock state returned by {@link #getState}.
* <li> Invoke {@link #release} with saved state as argument,
* throwing IllegalMonitorStateException if it fails.
* <li> Block until signalled or interrupted.
* <li> Reacquire by invoking specialized version of
* {@link #acquire} with saved state as argument.
* <li> If interrupted while blocked in step 4, throw InterruptedException.
* </ol>
*/
// // 等待,当前线程在接到信号或被中断之前一直处于等待状态
public final void await() throws InterruptedException {
if (Thread.interrupted()) // 当前线程被中断,抛出异常
throw new InterruptedException();
// 在wait队列上添加一个结点
Node node = addConditionWaiter();
//
int savedState = fullyRelease(node);
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
// 阻塞当前线程
LockSupport.park(this);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0) // 检查结点等待时的中断类型
break;
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null) // clean up if cancelled
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
/**
* Implements timed condition wait.
* <ol>
* <li> If current thread is interrupted, throw InterruptedException.
* <li> Save lock state returned by {@link #getState}.
* <li> Invoke {@link #release} with saved state as argument,
* throwing IllegalMonitorStateException if it fails.
* <li> Block until signalled, interrupted, or timed out.
* <li> Reacquire by invoking specialized version of
* {@link #acquire} with saved state as argument.
* <li> If interrupted while blocked in step 4, throw InterruptedException.
* </ol>
*/
// 等待,当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态
public final long awaitNanos(long nanosTimeout)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
final long deadline = System.nanoTime() + nanosTimeout;
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
if (nanosTimeout <= 0L) {
transferAfterCancelledWait(node);
break;
}
if (nanosTimeout >= spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
nanosTimeout = deadline - System.nanoTime();
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null)
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
return deadline - System.nanoTime();
}
/**
* Implements absolute timed condition wait.
* <ol>
* <li> If current thread is interrupted, throw InterruptedException.
* <li> Save lock state returned by {@link #getState}.
* <li> Invoke {@link #release} with saved state as argument,
* throwing IllegalMonitorStateException if it fails.
* <li> Block until signalled, interrupted, or timed out.
* <li> Reacquire by invoking specialized version of
* {@link #acquire} with saved state as argument.
* <li> If interrupted while blocked in step 4, throw InterruptedException.
* <li> If timed out while blocked in step 4, return false, else true.
* </ol>
*/
// 等待,当前线程在接到信号、被中断或到达指定最后期限之前一直处于等待状态
public final boolean awaitUntil(Date deadline)
throws InterruptedException {
long abstime = deadline.getTime();
if (Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
boolean timedout = false;
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
if (System.currentTimeMillis() > abstime) {
timedout = transferAfterCancelledWait(node);
break;
}
LockSupport.parkUntil(this, abstime);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null)
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
return !timedout;
}
/**
* Implements timed condition wait.
* <ol>
* <li> If current thread is interrupted, throw InterruptedException.
* <li> Save lock state returned by {@link #getState}.
* <li> Invoke {@link #release} with saved state as argument,
* throwing IllegalMonitorStateException if it fails.
* <li> Block until signalled, interrupted, or timed out.
* <li> Reacquire by invoking specialized version of
* {@link #acquire} with saved state as argument.
* <li> If interrupted while blocked in step 4, throw InterruptedException.
* <li> If timed out while blocked in step 4, return false, else true.
* </ol>
*/
// 等待,当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态。此方法在行为上等效于: awaitNanos(unit.toNanos(time)) > 0
public final boolean await(long time, TimeUnit unit)
throws InterruptedException {
long nanosTimeout = unit.toNanos(time);
if (Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
final long deadline = System.nanoTime() + nanosTimeout;
boolean timedout = false;
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
if (nanosTimeout <= 0L) {
timedout = transferAfterCancelledWait(node);
break;
}
if (nanosTimeout >= spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
nanosTimeout = deadline - System.nanoTime();
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null)
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
return !timedout;
}
// support for instrumentation
/**
* Returns true if this condition was created by the given
* synchronization object.
*
* @return {@code true} if owned
*/
final boolean isOwnedBy(AbstractQueuedSynchronizer sync) {
return sync == AbstractQueuedSynchronizer.this;
}
/**
* Queries whether any threads are waiting on this condition.
* Implements {@link AbstractQueuedSynchronizer#hasWaiters(ConditionObject)}.
*
* @return {@code true} if there are any waiting threads
* @throws IllegalMonitorStateException if {@link #isHeldExclusively}
* returns {@code false}
*/
// 查询是否有正在等待此条件的任何线程
protected final boolean hasWaiters() {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
for (Node w = firstWaiter; w != null; w = w.nextWaiter) {
if (w.waitStatus == Node.CONDITION)
return true;
}
return false;
}
/**
* Returns an estimate of the number of threads waiting on
* this condition.
* Implements {@link AbstractQueuedSynchronizer#getWaitQueueLength(ConditionObject)}.
*
* @return the estimated number of waiting threads
* @throws IllegalMonitorStateException if {@link #isHeldExclusively}
* returns {@code false}
*/
// 返回正在等待此条件的线程数估计值
protected final int getWaitQueueLength() {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
int n = 0;
for (Node w = firstWaiter; w != null; w = w.nextWaiter) {
if (w.waitStatus == Node.CONDITION)
++n;
}
return n;
}
/**
* Returns a collection containing those threads that may be
* waiting on this Condition.
* Implements {@link AbstractQueuedSynchronizer#getWaitingThreads(ConditionObject)}.
*
* @return the collection of threads
* @throws IllegalMonitorStateException if {@link #isHeldExclusively}
* returns {@code false}
*/
// 返回包含那些可能正在等待此条件的线程集合
protected final Collection<Thread> getWaitingThreads() {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
ArrayList<Thread> list = new ArrayList<Thread>();
for (Node w = firstWaiter; w != null; w = w.nextWaiter) {
if (w.waitStatus == Node.CONDITION) {
Thread t = w.thread;
if (t != null)
list.add(t);
}
}
return list;
}
}
该类实现了 Condition 接口,Condition 接口定义了条件操作的规范:
public interface Condition {
// 等待,当前线程在接到信号或被中断之前一直处于等待状态
void await() throws InterruptedException;
// 等待,当前线程在接到信号之前一直处于等待状态,不响应中断
void awaitUninterruptibly();
//等待,当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态
long awaitNanos(long nanosTimeout) throws InterruptedException;
// 等待,当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态。此方法在行为上等效于: awaitNanos(unit.toNanos(time)) > 0
boolean await(long time, TimeUnit unit) throws InterruptedException;
// 等待,当前线程在接到信号、被中断或到达指定最后期限之前一直处于等待状态
boolean awaitUntil(Date deadline) throws InterruptedException;
// 唤醒一个等待线程。如果所有的线程都在等待此条件,则选择其中的一个唤醒。在从 await 返回之前,该线程必须重新获取锁。
void signal();
// 唤醒所有等待线程。如果所有的线程都在等待此条件,则唤醒所有线程。在从 await 返回之前,每个线程都必须重新获取锁。
void signalAll();
}
类的属性
属性中包含了头结点 head,为节点 tail,状态 state,自旋时间 spinForTimeoutThreshold,以及 AQS 抽象的属性在内存中的便宜地址,通过该便宜地址,可以获取和设置属性的值,同时该包括一个静态初始化块,用于加载内存偏移地址:
public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer
implements java.io.Serializable {
// 版本号
private static final long serialVersionUID = 7373984972572414691L;
// 头结点
private transient volatile Node head;
// 尾结点
private transient volatile Node tail;
// 状态
private volatile int state;
// 自旋时间
static final long spinForTimeoutThreshold = 1000L;
// Unsafe类实例
private static final Unsafe unsafe = Unsafe.getUnsafe();
// state内存偏移地址
private static final long stateOffset;
// head内存偏移地址
private static final long headOffset;
// state内存偏移地址
private static final long tailOffset;
// tail内存偏移地址
private static final long waitStatusOffset;
// next内存偏移地址
private static final long nextOffset;
// 静态初始化块
static {
try {
stateOffset = unsafe.objectFieldOffset
(AbstractQueuedSynchronizer.class.getDeclaredField("state"));
headOffset = unsafe.objectFieldOffset
(AbstractQueuedSynchronizer.class.getDeclaredField("head"));
tailOffset = unsafe.objectFieldOffset
(AbstractQueuedSynchronizer.class.getDeclaredField("tail"));
waitStatusOffset = unsafe.objectFieldOffset
(Node.class.getDeclaredField("waitStatus"));
nextOffset = unsafe.objectFieldOffset
(Node.class.getDeclaredField("next"));
} catch (Exception ex) { throw new Error(ex); }
}
}
类的构造方法
该类构造方法为抽象构造方法,仅供子类调用。
类的核心方法:acquire
该方法以独占模式获取(资源),忽略中断,即线程在aquire过程中,中断此线程是无效的。源码如下:
public final void acquire(int arg) {
if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
线程在调用 tryAcquire 时的流程如下:

- 首先调用 tryAcquire 方法,线程会尝试在独占模式下获取对象状态。
- 此方法会查询是否允许它在独占模式下获取对象状态,如果允许则获取。
- 在 AQS 源码中会默认抛出一个异常,即需要子类重写该方法以实现需要的逻辑。
- 若 tryAcquire 失败,则调用 addWaiter 方法,addWaiter 方法完成的功能是将调用此方法的线程封装成为一个节点并放入 Sync Queue。
- 调用 acquireQueued 方法,此方法完成的功能是 Sync Queue 中的节点不断尝试获取资源,成功失败返回 true、false。
- 调用 tryAcquire 默认实现是抛出异常,因此需要继承者实现。
首先是 addWaiter 方法:
// 添加等待者
private Node addWaiter(Node mode) {
// 新生成一个结点,默认为独占模式
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
// 保存尾结点
Node pred = tail;
if (pred != null) { // 尾结点不为空,即已经被初始化
// 将node结点的prev域连接到尾结点
node.prev = pred;
if (compareAndSetTail(pred, node)) { // 比较pred是否为尾结点,是则将尾结点设置为node
// 设置尾结点的next域为node
pred.next = node;
return node; // 返回新生成的结点
}
}
enq(node); // 尾结点为空(即还没有被初始化过),或者是compareAndSetTail操作失败,则入队列
return node;
}
addWaiter 方法使用快速添加的方式往 sync queue 尾部添加结点,如果 sync queue 队列还没有初始化,则会使用 enq 插入队列中,enq 方法源码如下:
private Node enq(final Node node) {
for (;;) { // 无限循环,确保结点能够成功入队列
// 保存尾结点
Node t = tail;
if (t == null) { // 尾结点为空,即还没被初始化
if (compareAndSetHead(new Node())) // 头结点为空,并设置头结点为新生成的结点
tail = head; // 头结点与尾结点都指向同一个新生结点
} else { // 尾结点不为空,即已经被初始化过
// 将node结点的prev域连接到尾结点
node.prev = t;
if (compareAndSetTail(t, node)) { // 比较结点t是否为尾结点,若是则将尾结点设置为node
// 设置尾结点的next域为node
t.next = node;
return t; // 返回尾结点
}
}
}
}
enq 方法会使用无限循环来确保节点的成功插入。
acquireQueue方法:
// sync队列中的结点在独占且忽略中断的模式下获取(资源)
final boolean acquireQueued(final Node node, int arg) {
// 标志
boolean failed = true;
try {
// 中断标志
boolean interrupted = false;
for (;;) { // 无限循环
// 获取node节点的前驱结点
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) { // 前驱为头结点并且成功获得锁
setHead(node); // 设置头结点
p.next = null; // help GC
failed = false; // 设置标志
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
首先获取当前节点的前驱节点,如果前驱节点是头结点并且能够获取(资源),代表该当前节点能够占有锁,设置头结点为当前节点,返回。否则,调用shouldParkAfterFailedAcquire和parkAndCheckInterrupt方法,首先,我们看shouldParkAfterFailedAcquire方法,代码如下:
// 当获取(资源)失败后,检查并且更新结点状态
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
// 获取前驱结点的状态
int ws = pred.waitStatus;
if (ws == Node.SIGNAL) // 状态为SIGNAL,为-1
/*
* This node has already set status asking a release
* to signal it, so it can safely park.
*/
// 可以进行park操作
return true;
if (ws > 0) { // 表示状态为CANCELLED,为1
/*
* Predecessor was cancelled. Skip over predecessors and
* indicate retry.
*/
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0); // 找到pred结点前面最近的一个状态不为CANCELLED的结点
// 赋值pred结点的next域
pred.next = node;
} else { // 为PROPAGATE -3 或者是0 表示无状态,(为CONDITION -2时,表示此节点在condition queue中)
/*
* waitStatus must be 0 or PROPAGATE. Indicate that we
* need a signal, but don't park yet. Caller will need to
* retry to make sure it cannot acquire before parking.
*/
// 比较并设置前驱结点的状态为SIGNAL
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
// 不能进行park操作
return false;
}
只有当该节点的前驱结点的状态为SIGNAL时,才可以对该结点所封装的线程进行park操作。否则,将不能进行park操作。再看parkAndCheckInterrupt方法,源码如下:
// 进行park操作并且返回该线程是否被中断
private final boolean parkAndCheckInterrupt() {
// 在许可可用之前禁用当前线程,并且设置了blocker
LockSupport.park(this);
return Thread.interrupted(); // 当前线程是否已被中断,并清除中断标记位
}
parkAndCheckInterrupt方法里的逻辑是首先执行park操作,即禁用当前线程,然后返回该线程是否已经被中断。再看final块中的cancelAcquire方法,其源码如下:
// 取消继续获取(资源)
private void cancelAcquire(Node node) {
// Ignore if node doesn't exist
// node为空,返回
if (node == null)
return;
// 设置node结点的thread为空
node.thread = null;
// Skip cancelled predecessors
// 保存node的前驱结点
Node pred = node.prev;
while (pred.waitStatus > 0) // 找到node前驱结点中第一个状态小于0的结点,即不为CANCELLED状态的结点
node.prev = pred = pred.prev;
// predNext is the apparent node to unsplice. CASes below will
// fail if not, in which case, we lost race vs another cancel
// or signal, so no further action is necessary.
// 获取pred结点的下一个结点
Node predNext = pred.next;
// Can use unconditional write instead of CAS here.
// After this atomic step, other Nodes can skip past us.
// Before, we are free of interference from other threads.
// 设置node结点的状态为CANCELLED
node.waitStatus = Node.CANCELLED;
// If we are the tail, remove ourselves.
if (node == tail && compareAndSetTail(node, pred)) { // node结点为尾结点,则设置尾结点为pred结点
// 比较并设置pred结点的next节点为null
compareAndSetNext(pred, predNext, null);
} else { // node结点不为尾结点,或者比较设置不成功
// If successor needs signal, try to set pred's next-link
// so it will get one. Otherwise wake it up to propagate.
int ws;
if (pred != head &&
((ws = pred.waitStatus) == Node.SIGNAL ||
(ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) &&
pred.thread != null) { // (pred结点不为头结点,并且pred结点的状态为SIGNAL)或者
// pred结点状态小于等于0,并且比较并设置等待状态为SIGNAL成功,并且pred结点所封装的线程不为空
// 保存结点的后继
Node next = node.next;
if (next != null && next.waitStatus <= 0) // 后继不为空并且后继的状态小于等于0
compareAndSetNext(pred, predNext, next); // 比较并设置pred.next = next;
} else {
unparkSuccessor(node); // 释放node的前一个结点
}
node.next = node; // help GC
}
}
该方法完成的功能就是取消当前线程对资源的获取,即设置该结点的状态为CANCELLED,接着我们再看unparkSuccessor方法,源码如下:
// 释放后继结点
private void unparkSuccessor(Node node) {
/*
* If status is negative (i.e., possibly needing signal) try
* to clear in anticipation of signalling. It is OK if this
* fails or if status is changed by waiting thread.
*/
// 获取node结点的等待状态
int ws = node.waitStatus;
if (ws < 0) // 状态值小于0,为SIGNAL -1 或 CONDITION -2 或 PROPAGATE -3
// 比较并且设置结点等待状态,设置为0
compareAndSetWaitStatus(node, ws, 0);
/*
* Thread to unpark is held in successor, which is normally
* just the next node. But if cancelled or apparently null,
* traverse backwards from tail to find the actual
* non-cancelled successor.
*/
// 获取node节点的下一个结点
Node s = node.next;
if (s == null || s.waitStatus > 0) { // 下一个结点为空或者下一个节点的等待状态大于0,即为CANCELLED
// s赋值为空
s = null;
// 从尾结点开始从后往前开始遍历
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0) // 找到等待状态小于等于0的结点,找到最前的状态小于等于0的结点
// 保存结点
s = t;
}
if (s != null) // 该结点不为为空,释放许可
LockSupport.unpark(s.thread);
}
该方法的作用就是为了释放node节点的后继结点。
对于cancelAcquire与unparkSuccessor方法,如下示意图可以清晰的表示:
其中node为参数,在执行完cancelAcquire方法后的效果就是unpark了s结点所包含的t4线程。
现在,再来看acquireQueued方法的整个的逻辑。逻辑如下:
判断结点的前驱是否为head并且是否成功获取(资源)。
若步骤1均满足,则设置结点为head,之后会判断是否finally模块,然后返回。
若步骤2不满足,则判断是否需要park当前线程,是否需要park当前线程的逻辑是判断结点的前驱结点的状态是否为SIGNAL,若是,则park当前结点,否则,不进行park操作。
若park了当前线程,之后某个线程对本线程unpark后,并且本线程也获得机会运行。那么,将会继续进行步骤 1 的判断。
类的核心方法:release
以独占模式释放资源:
public final boolean release(int arg) {
if (tryRelease(arg)) { // 释放成功
// 保存头结点
Node h = head;
if (h != null && h.waitStatus != 0) // 头结点不为空并且头结点状态不为0
unparkSuccessor(h); //释放头结点的后继结点
return true;
}
return false;
}
其中,tryRelease的默认实现是抛出异常,需要具体的子类实现,如果tryRelease成功,那么如果头结点不为空并且头结点的状态不为0,则释放头结点的后继结点,unparkSuccessor方法已经分析过,不再累赘。
对于其他方法我们也可以分析,与前面分析的方法大同小异,所以,不再累赘。
参考资料
12 - CH12-AQS-2
应用示例
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
class MyThread extends Thread {
private Lock lock;
public MyThread(String name, Lock lock) {
super(name);
this.lock = lock;
}
public void run () {
lock.lock();
try {
System.out.println(Thread.currentThread() + " running");
} finally {
lock.unlock();
}
}
}
public class AbstractQueuedSynchonizerDemo {
public static void main(String[] args) {
Lock lock = new ReentrantLock();
MyThread t1 = new MyThread("t1", lock);
MyThread t2 = new MyThread("t2", lock);
t1.start();
t2.start();
}
}
// 前后随机
Thread[t1,5,main] running
Thread[t2,5,main] running
从示例可知,线程t1与t2共用了一把锁,即同一个lock。可能会存在如下一种时序:
首先 t1 线程调用 lock.lock 操作,然后 t2 再执行 lock.lock 操作,然后 t1 执行 lock.unlock,最后 t2 执行 lock.unlock。基于这样的时序尝试分析 AQS 内部的机制。
- t1 线程调用 lock.lock 操作:
- t2 再执行 lock.lock 操作:
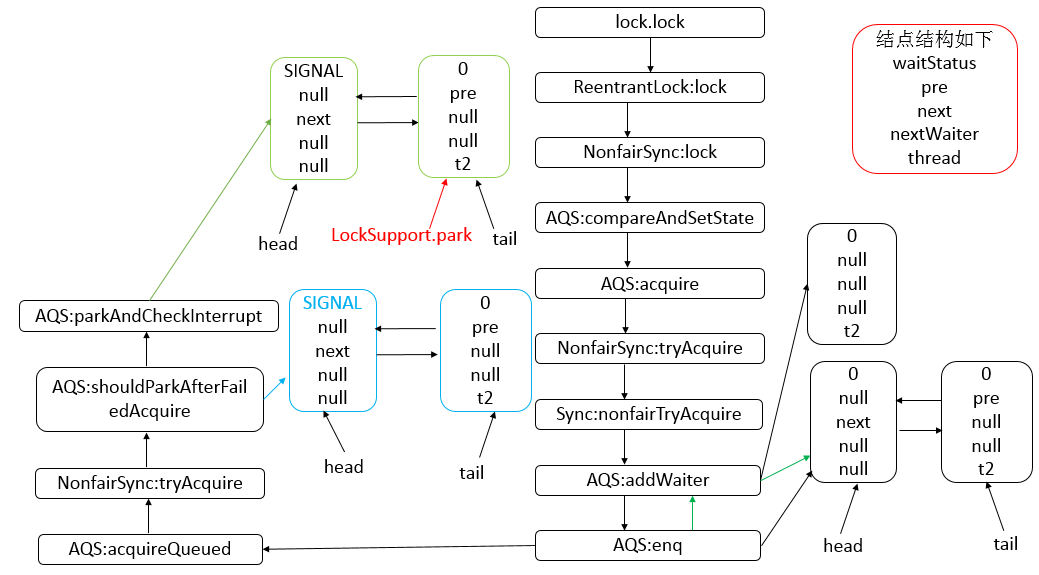
进过一系列方法调用,最后达到的状态是 t2 被禁用,因此调用了 LockSupport.lock。
- t1线程调用lock.unlock:
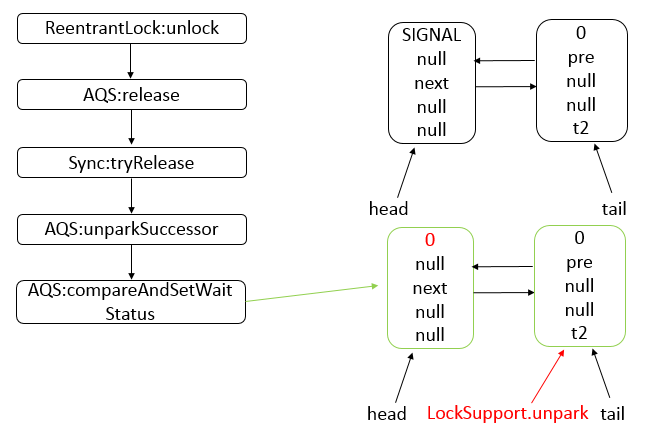
t1线程中调用lock.unlock后,经过一系列的调用,最终的状态是释放了许可,因为调用了LockSupport.unpark。这时,t2线程就可以继续运行了。此时,会继续恢复t2线程运行环境,继续执行LockSupport.park后面的语句,即进一步调用如下。
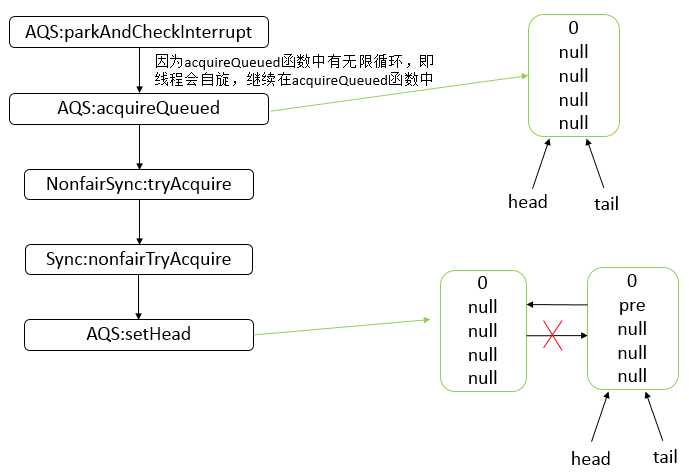
在上一步调用了LockSupport.unpark后,t2线程恢复运行,则运行parkAndCheckInterrupt,之后,继续运行acquireQueued方法,最后达到的状态是头结点head与尾结点tail均指向了t2线程所在的结点,并且之前的头结点已经从sync队列中断开了。
- t2线程调用lock.unlock,其方法调用顺序如下,只给出了主要的方法调用。
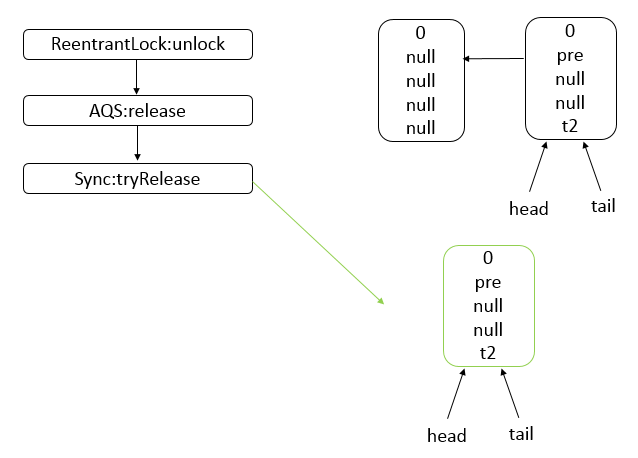
t2线程执行lock.unlock后,最终达到的状态还是与之前的状态一样。
13 - CH13-AQS-3
应用实例
下面我们结合Condition实现生产者与消费者,来进一步分析AbstractQueuedSynchronizer的内部工作机制。
Depot(仓库)类:
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class Depot {
private int size;
private int capacity;
private Lock lock;
private Condition fullCondition;
private Condition emptyCondition;
public Depot(int capacity) {
this.capacity = capacity;
lock = new ReentrantLock();
fullCondition = lock.newCondition();
emptyCondition = lock.newCondition();
}
public void produce(int no) {
lock.lock();
int left = no;
try {
while (left > 0) {
while (size >= capacity) {
System.out.println(Thread.currentThread() + " before await");
fullCondition.await();
System.out.println(Thread.currentThread() + " after await");
}
int inc = (left + size) > capacity ? (capacity - size) : left;
left -= inc;
size += inc;
System.out.println("produce = " + inc + ", size = " + size);
emptyCondition.signal();
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void consume(int no) {
lock.lock();
int left = no;
try {
while (left > 0) {
while (size <= 0) {
System.out.println(Thread.currentThread() + " before await");
emptyCondition.await();
System.out.println(Thread.currentThread() + " after await");
}
int dec = (size - left) > 0 ? left : size;
left -= dec;
size -= dec;
System.out.println("consume = " + dec + ", size = " + size);
fullCondition.signal();
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
测试类:
class Consumer {
private Depot depot;
public Consumer(Depot depot) {
this.depot = depot;
}
public void consume(int no) {
new Thread(new Runnable() {
@Override
public void run() {
depot.consume(no);
}
}, no + " consume thread").start();
}
}
class Producer {
private Depot depot;
public Producer(Depot depot) {
this.depot = depot;
}
public void produce(int no) {
new Thread(new Runnable() {
@Override
public void run() {
depot.produce(no);
}
}, no + " produce thread").start();
}
}
public class ReentrantLockDemo {
public static void main(String[] args) throws InterruptedException {
Depot depot = new Depot(500);
new Producer(depot).produce(500);
new Producer(depot).produce(200);
new Consumer(depot).consume(500);
new Consumer(depot).consume(200);
}
}
运行结果(随机):
produce = 500, size = 500
Thread[200 produce thread,5,main] before await
consume = 500, size = 0
Thread[200 consume thread,5,main] before await
Thread[200 produce thread,5,main] after await
produce = 200, size = 200
Thread[200 consume thread,5,main] after await
consume = 200, size = 0
根据结果,我们猜测一种可能的时序如下:
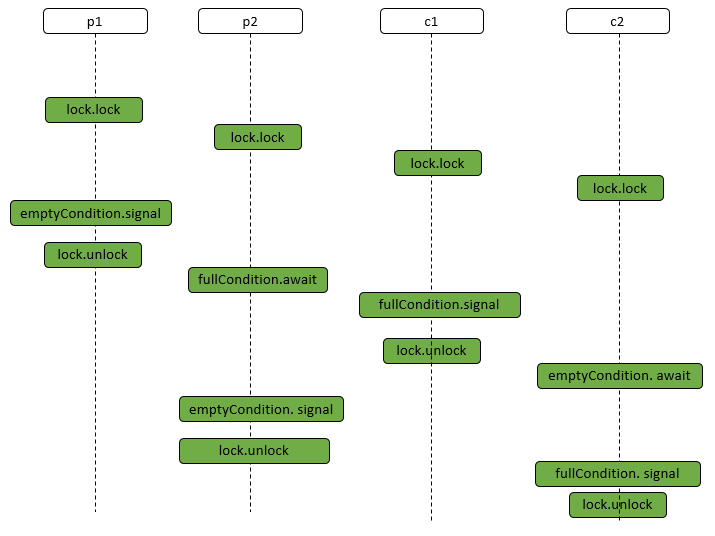
p1代表produce 500的那个线程,p2代表produce 200的那个线程,c1代表consume 500的那个线程,c2代表consume 200的那个线程。
- p1线程调用lock.lock,获得锁,继续运行,方法调用顺序在前面已经给出。
- p2线程调用lock.lock,由前面的分析可得到如下的最终状态。
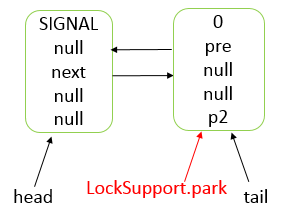
p2线程调用lock.lock后,会禁止p2线程的继续运行,因为执行了LockSupport.park操作。
- c1线程调用lock.lock,由前面的分析得到如下的最终状态。
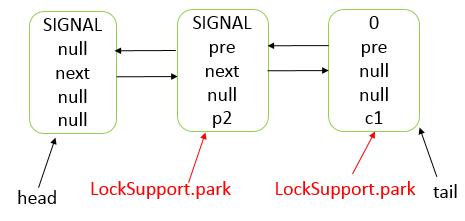
最终c1线程会在sync queue队列的尾部,并且其结点的前驱结点(包含p2的结点)的waitStatus变为了SIGNAL。
- c2线程调用lock.lock,由前面的分析得到如下的最终状态。

最终c1线程会在sync queue队列的尾部,并且其结点的前驱结点(包含c1的结点)的waitStatus变为了SIGNAL。
- p1线程执行emptyCondition.signal,其方法调用顺序如下,只给出了主要的方法调用。
AQS.CO表示AbstractQueuedSynchronizer.ConditionObject类。此时调用signal方法不会产生任何其他效果。
- p1线程执行lock.unlock,根据前面的分析可知,最终的状态如下。
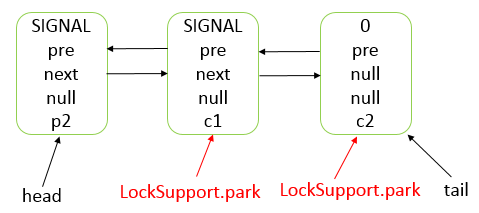
此时,p2线程所在的结点为头结点,并且其他两个线程(c1、c2)依旧被禁止,所以,此时p2线程继续运行,执行用户逻辑。
- p2线程执行fullCondition.await,其方法调用顺序如下,只给出了主要的方法调用。
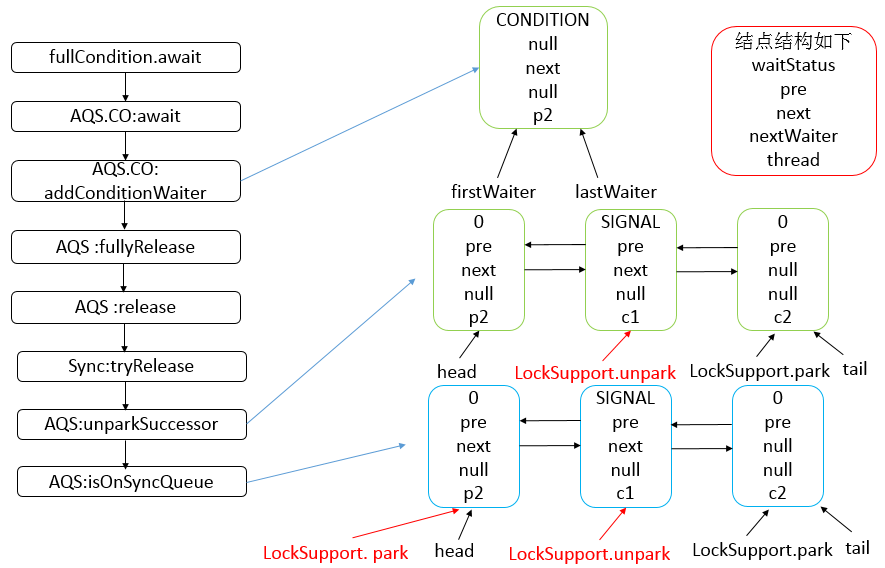
最终到达的状态是新生成了一个结点,包含了p2线程,此结点在condition queue中;并且sync queue中p2线程被禁止了,因为在执行了LockSupport.park操作。从方法一些调用可知,在await操作中线程会释放锁资源,供其他线程获取。同时,head结点后继结点的包含的线程的许可被释放了,故其可以继续运行。由于此时,只有c1线程可以运行,故运行c1。
- 继续运行c1线程,c1线程由于之前被park了,所以此时恢复,继续之前的步骤,即还是执行前面提到的acquireQueued方法,之后,c1判断自己的前驱结点为head,并且可以获取锁资源,最终到达的状态如下。
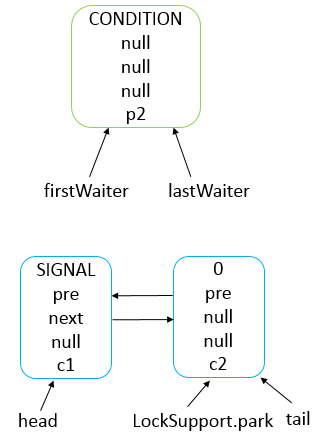
其中,head设置为包含c1线程的结点,c1继续运行。
- c1线程执行fullCondtion.signal,其方法调用顺序如下,只给出了主要的方法调用。

signal方法达到的最终结果是将包含p2线程的结点从condition queue中转移到sync queue中,之后condition queue为null,之前的尾结点的状态变为SIGNAL。
- c1线程执行lock.unlock操作,根据之前的分析,经历的状态变化如下。
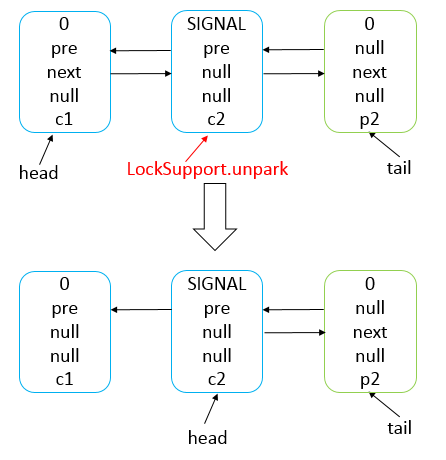
最终c2线程会获取锁资源,继续运行用户逻辑。
- c2线程执行emptyCondition.await,由前面的第七步分析,可知最终的状态如下。

await操作将会生成一个结点放入condition queue中与之前的一个condition queue是不相同的,并且unpark头结点后面的结点,即包含线程p2的结点。
- p2线程被unpark,故可以继续运行,经过CPU调度后,p2继续运行,之后p2线程在AQS:await方法中被park,继续AQS.CO:await方法的运行,其方法调用顺序如下,只给出了主要的方法调用。
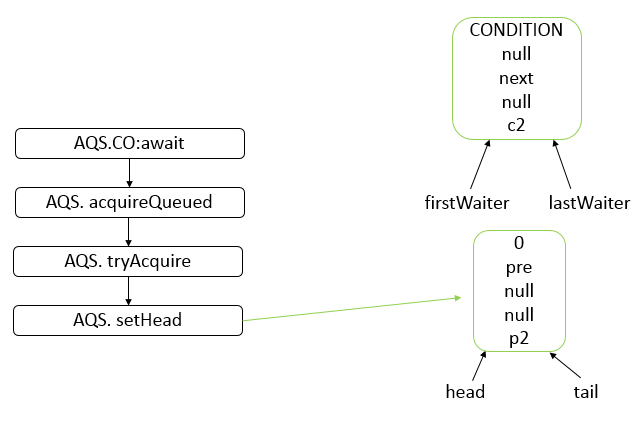
- p2继续运行,执行emptyCondition.signal,根据第九步分析可知,最终到达的状态如下。
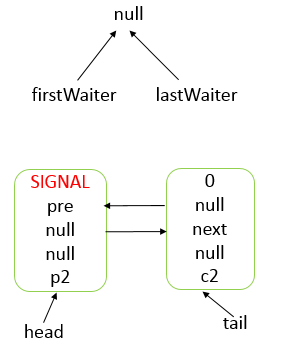
最终,将condition queue中的结点转移到sync queue中,并添加至尾部,condition queue会为空,并且将head的状态设置为SIGNAL。
- p2线程执行lock.unlock操作,根据前面的分析可知,最后的到达的状态如下。
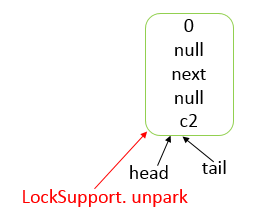
unlock操作会释放c2线程的许可,并且将头结点设置为c2线程所在的结点。
- c2线程继续运行,执行fullCondition. signal,由于此时fullCondition的condition queue已经不存在任何结点了,故其不会产生作用。
- c2执行lock.unlock,由于c2是sync队列中最后一个结点,故其不会再调用unparkSuccessor了,直接返回true。即整个流程就完成了。
14 - CH14-AQS-4
AQS 总结
最核心的就是sync queue的分析。
- 每个节点都是由前驱节点唤醒。
- 如果节点发现前驱节点是 head 并且尝试获取成功,则会轮到该线程执行。
- condition queue 中的节点想 sync queue 中转移是通过 signal 操作完成的。
- 当节点状态为 SIGNAL 时,表示后面的节点需要运行。
15 - CH15-ReentrantLock
源码分析
层级结构
ReentrantLock实现了Lock接口,Lock接口中定义了lock与unlock相关操作,并且还存在newCondition方法,表示生成一个条件。
内部类
ReentrantLock总共有三个内部类,并且三个内部类是紧密相关的,下面先看三个类的关系。
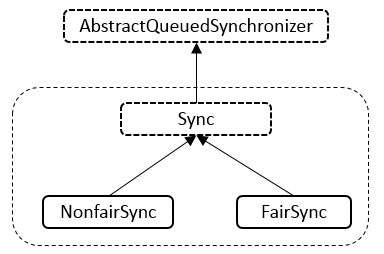
ReentrantLock类内部总共存在Sync、NonfairSync、FairSync三个类,NonfairSync与FairSync类继承自Sync类,Sync类继承自AbstractQueuedSynchronizer抽象类。下面逐个进行分析。
内部类:Sync
abstract static class Sync extends AbstractQueuedSynchronizer {
// 序列号
private static final long serialVersionUID = -5179523762034025860L;
// 获取锁
abstract void lock();
// 非公平方式获取
final boolean nonfairTryAcquire(int acquires) {
// 当前线程
final Thread current = Thread.currentThread();
// 获取状态
int c = getState();
if (c == 0) { // 表示没有线程正在竞争该锁
if (compareAndSetState(0, acquires)) { // 比较并设置状态成功,状态0表示锁没有被占用
// 设置当前线程独占
setExclusiveOwnerThread(current);
return true; // 成功
}
}
else if (current == getExclusiveOwnerThread()) { // 当前线程拥有该锁
int nextc = c + acquires; // 增加重入次数
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
// 设置状态
setState(nextc);
// 成功
return true;
}
// 失败
return false;
}
// 试图在共享模式下获取对象状态,此方法应该查询是否允许它在共享模式下获取对象状态,如果允许,则获取它
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread()) // 当前线程不为独占线程
throw new IllegalMonitorStateException(); // 抛出异常
// 释放标识
boolean free = false;
if (c == 0) {
free = true;
// 已经释放,清空独占
setExclusiveOwnerThread(null);
}
// 设置标识
setState(c);
return free;
}
// 判断资源是否被当前线程占有
protected final boolean isHeldExclusively() {
// While we must in general read state before owner,
// we don't need to do so to check if current thread is owner
return getExclusiveOwnerThread() == Thread.currentThread();
}
// 新生一个条件
final ConditionObject newCondition() {
return new ConditionObject();
}
// Methods relayed from outer class
// 返回资源的占用线程
final Thread getOwner() {
return getState() == 0 ? null : getExclusiveOwnerThread();
}
// 返回状态
final int getHoldCount() {
return isHeldExclusively() ? getState() : 0;
}
// 资源是否被占用
final boolean isLocked() {
return getState() != 0;
}
/**
* Reconstitutes the instance from a stream (that is, deserializes it).
*/
// 自定义反序列化逻辑
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
s.defaultReadObject();
setState(0); // reset to unlocked state
}
}
其中的方法及作用如下:

内部类:NonfairSync
NonfairSync类继承了Sync类,表示采用非公平策略获取锁,其实现了Sync类中抽象的lock方法,源码如下:
// 非公平锁
static final class NonfairSync extends Sync {
// 版本号
private static final long serialVersionUID = 7316153563782823691L;
// 获得锁
final void lock() {
if (compareAndSetState(0, 1)) // 比较并设置状态成功,状态0表示锁没有被占用
// 把当前线程设置独占了锁
setExclusiveOwnerThread(Thread.currentThread());
else // 锁已经被占用,或者set失败
// 以独占模式获取对象,忽略中断
acquire(1);
}
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
}
从lock方法的源码可知,每一次都尝试获取锁,而并不会按照公平等待的原则进行等待,让等待时间最久的线程获得锁。
内部类:FairSync
FairSync类也继承了Sync类,表示采用公平策略获取锁,其实现了Sync类中的抽象lock方法,源码如下:
// 公平锁
static final class FairSync extends Sync {
// 版本序列化
private static final long serialVersionUID = -3000897897090466540L;
final void lock() {
// 以独占模式获取对象,忽略中断
acquire(1);
}
/**
* Fair version of tryAcquire. Don't grant access unless
* recursive call or no waiters or is first.
*/
// 尝试公平获取锁
protected final boolean tryAcquire(int acquires) {
// 获取当前线程
final Thread current = Thread.currentThread();
// 获取状态
int c = getState();
if (c == 0) { // 状态为0
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) { // 不存在已经等待更久的线程并且比较并且设置状态成功
// 设置当前线程独占
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) { // 状态不为0,即资源已经被线程占据
// 下一个状态
int nextc = c + acquires;
if (nextc < 0) // 超过了int的表示范围
throw new Error("Maximum lock count exceeded");
// 设置状态
setState(nextc);
return true;
}
return false;
}
}
当资源空闲时,它总是会先判断sync队列(AbstractQueuedSynchronizer中的数据结构)是否有等待时间更长的线程,如果存在,则将该线程加入到等待队列的尾部,实现了公平获取原则。
其中,FairSync类的lock的方法调用如下,只给出了主要的方法。

可以看出只要资源被其他线程占用,该线程就会添加到sync queue中的尾部,而不会先尝试获取资源。这也是和Nonfair最大的区别,Nonfair每一次都会尝试去获取资源,如果此时该资源恰好被释放,则会被当前线程获取,这就造成了不公平的现象,当获取不成功,再加入队列尾部。
类的属性
ReentrantLock类的sync非常重要,对ReentrantLock类的操作大部分都直接转化为对Sync和AQS类的操作。
public class ReentrantLock implements Lock, java.io.Serializable {
// 序列号
private static final long serialVersionUID = 7373984872572414699L;
// 同步队列
private final Sync sync;
}
构造函数
- ReentrantLock()型构造函数:默认采用非公平策略获取锁
- ReentrantLock(boolean)型构造函数:true 表示采用公平策略获取锁,否则采用非公平策略
核心函数
通过分析ReentrantLock的源码,可知对其操作都转化为对Sync对象的操作,由于Sync继承了AQS,所以基本上都可以转化为对AQS的操作。如将ReentrantLock的lock函数转化为对Sync的lock函数的调用,而具体会根据采用的策略(如公平策略或者非公平策略)的不同而调用到Sync的不同子类。
应用示例
公平锁
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
class MyThread extends Thread {
private Lock lock;
public MyThread(String name, Lock lock) {
super(name);
this.lock = lock;
}
public void run () {
lock.lock();
try {
System.out.println(Thread.currentThread() + " running");
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
} finally {
lock.unlock();
}
}
}
public class AbstractQueuedSynchonizerDemo {
public static void main(String[] args) throws InterruptedException {
Lock lock = new ReentrantLock(true);
MyThread t1 = new MyThread("t1", lock);
MyThread t2 = new MyThread("t2", lock);
MyThread t3 = new MyThread("t3", lock);
t1.start();
t2.start();
t3.start();
}
}
// 随机结果
Thread[t1,5,main] running
Thread[t2,5,main] running
Thread[t3,5,main] running
该示例使用的是公平策略,由结果可知,可能会存在如下一种时序。
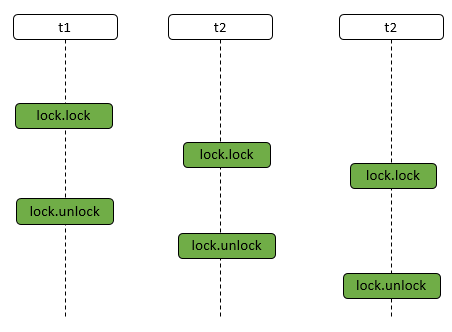
首先,t1线程的lock操作 -> t2线程的lock操作 -> t3线程的lock操作 -> t1线程的unlock操作 -> t2线程的unlock操作 -> t3线程的unlock操作。根据这个时序图来进一步分析源码的工作流程。
- t1线程执行lock.lock,下图给出了方法调用中的主要方法。

由调用流程可知,t1线程成功获取了资源,可以继续执行。
- t2线程执行lock.lock,下图给出了方法调用中的主要方法。
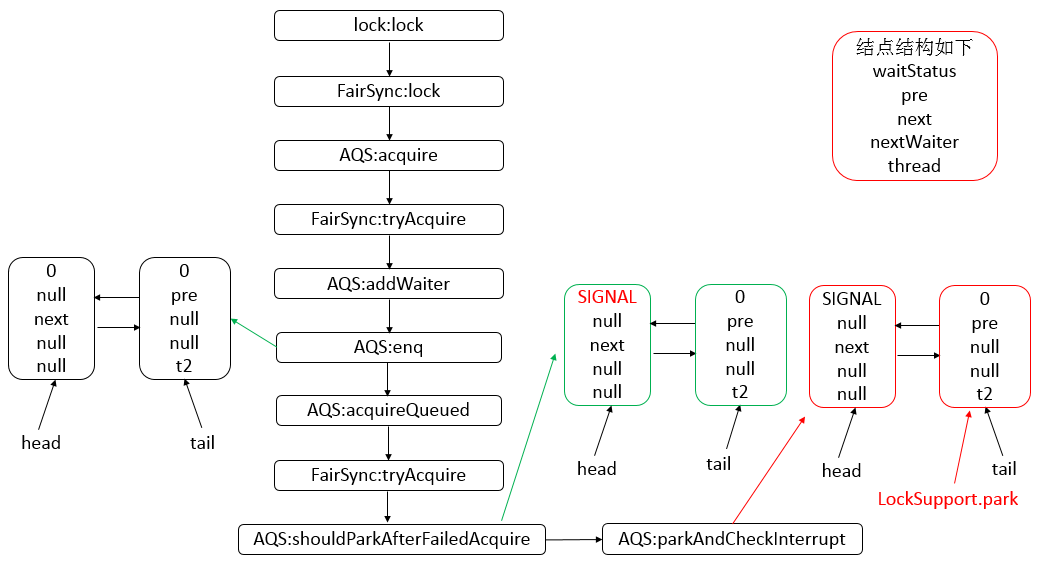
由上图可知,最后的结果是t2线程会被禁止,因为调用了LockSupport.park。
- t3线程执行lock.lock,下图给出了方法调用中的主要方法。

由上图可知,最后的结果是t3线程会被禁止,因为调用了LockSupport.park。
- t1线程调用了lock.unlock,下图给出了方法调用中的主要方法。

如上图所示,最后,head的状态会变为0,t2线程会被unpark,即t2线程可以继续运行。此时t3线程还是被禁止。
- t2获得cpu资源,继续运行,由于t2之前被park了,现在需要恢复之前的状态,下图给出了方法调用中的主要方法。
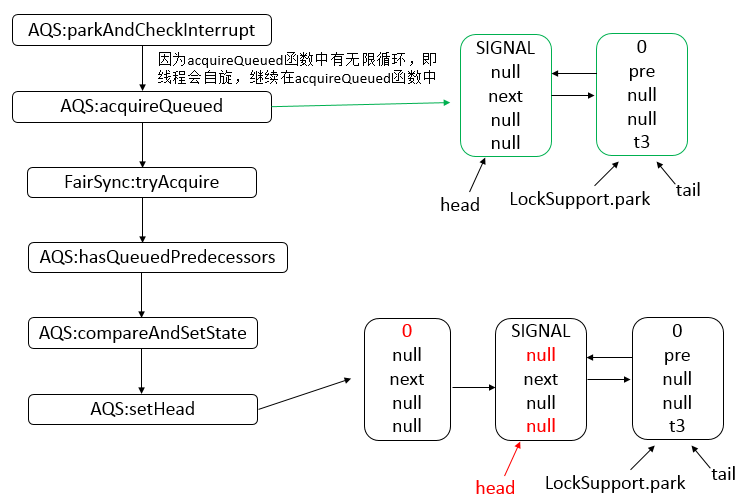
在setHead函数中会将head设置为之前head的下一个结点,并且将pre域与thread域都设置为null,在acquireQueued返回之前,sync queue就只有两个结点了。
- t2执行lock.unlock,下图给出了方法调用中的主要方法。
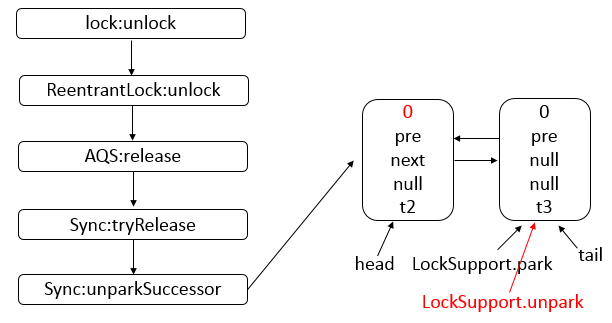
由上图可知,最终unpark t3线程,让t3线程可以继续运行。
- t3线程获取cpu资源,恢复之前的状态,继续运行。
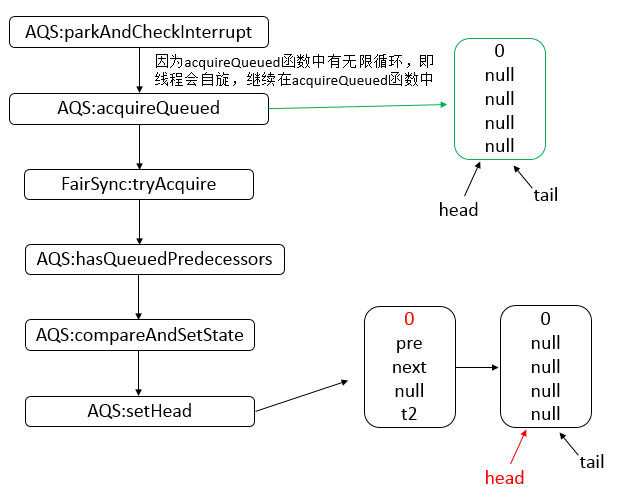
最终达到的状态是sync queue中只剩下了一个结点,并且该节点除了状态为0外,其余均为null。
- t3执行lock.unlock,下图给出了方法调用中的主要方法。
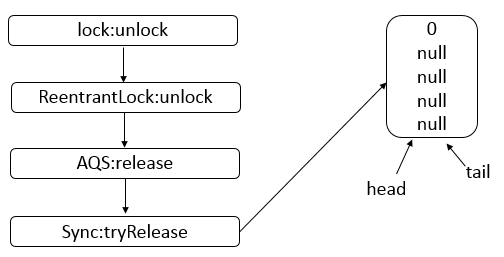
最后的状态和之前的状态是一样的,队列中有一个空节点,头结点为尾节点均指向它。
使用公平策略和Condition的情况可以参考上一篇关于AQS的源码示例分析部分,不再累赘。
16 - CH16-ReentrantReadWriteLock
数据结构
其实现是基于 ReentrantLock 和 AQS,因此底层基于 AQS 的数据结构。
源码分析
层级结构
- ReentrantReadWriteLock 实现了 ReadWriteLock 接口,ReadWriteLock 接口定义了获取读锁和写锁的规范,需要实现类来提供具体实现;
- 同时实现了 Serializable 接口,表示可以进行序列化。
内部类
内部有 5 个类,5 个内部类之间互相关联,关系如下:
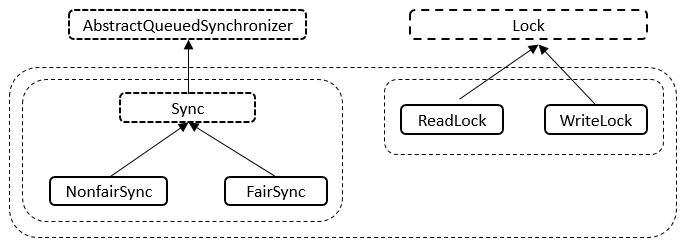
内部类:Sync
Sync 直接继承了 AQS,它的内部又有两个内部类,分别为 HoldCounter 和 ThreadLocalHoldCounter,其中 HoldCounter 主要与读锁配套使用。
HoldCounter 源码如下:
// 计数器
static final class HoldCounter {
// 计数
int count = 0;
// Use id, not reference, to avoid garbage retention
// 获取当前线程的TID属性的值
final long tid = getThreadId(Thread.currentThread());
}
- count 表示某个读线程重入的次数
- tid 表示该线程的 tid 字段值,线程的唯一标识
ThreadLocalHoldCounter 源码如下:
// 本地线程计数器
static final class ThreadLocalHoldCounter
extends ThreadLocal<HoldCounter> {
// 重写初始化方法,在没有进行set的情况下,获取的都是该HoldCounter值
public HoldCounter initialValue() {
return new HoldCounter();
}
}
ThreadLocalHoldCounter 重写了 ThreadLocal 的 initialValue 方法,ThreadLocal 类可以将线程与对象进行关联。在没有执行 set 的情况下,get 到的均为 initialValue 方法中生成的 HolderCounter 对象。
Sync 类的属性:
abstract static class Sync extends AbstractQueuedSynchronizer {
// 版本序列号
private static final long serialVersionUID = 6317671515068378041L;
// 高16位为读锁,低16位为写锁
static final int SHARED_SHIFT = 16;
// 读锁单位
static final int SHARED_UNIT = (1 << SHARED_SHIFT);
// 读锁最大数量
static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1;
// 写锁最大数量
static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1;
// 本地线程计数器
private transient ThreadLocalHoldCounter readHolds;
// 缓存的计数器
private transient HoldCounter cachedHoldCounter;
// 第一个读线程
private transient Thread firstReader = null;
// 第一个读线程的计数
private transient int firstReaderHoldCount;
}
- 属性中包括了读锁和写锁线程的最大数量、本地线程计数器等。
Sync 类的构造函数:
// 构造函数
Sync() {
// 本地线程计数器
readHolds = new ThreadLocalHoldCounter();
// 设置AQS的状态
setState(getState()); // ensures visibility of readHolds
}
- 在 Sync 类的构造函数中设置了本地线程计数器和 AQS 的状态 state。
内部类:Sync 核心函数
ReentrantReadWriteLock 的大部分操作都会交由 Sync 对象执行。以下是 Sync 的主要函数:
sharedCount:
- 表示占有读锁的线程数量
static int sharedCount(int c) { return c >>> SHARED_SHIFT; }- 直接将 state 右移 16 位,就可以得到读锁的线程数量,因为 state 的高 16 位表示读锁,低 16 位表示写锁的线程数量。
exclusiveCount:
- 表示占有写锁的线程数量
static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK; }- 直接将 state 和
(2^16 - 1)做与运算,等效于将 state 模上 2^16,写锁线程数量由低 16 位表示。
tryRelease:
/*
* Note that tryRelease and tryAcquire can be called by
* Conditions. So it is possible that their arguments contain
* both read and write holds that are all released during a
* condition wait and re-established in tryAcquire.
*/
protected final boolean tryRelease(int releases) {
// 判断是否伪独占线程
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
// 计算释放资源后的写锁的数量
int nextc = getState() - releases;
boolean free = exclusiveCount(nextc) == 0; // 是否释放成功
if (free)
setExclusiveOwnerThread(null); // 设置独占线程为空
setState(nextc); // 设置状态
return free;
}
- 用于释放写锁资源,首先会判断该线程是否为独占线程,如果不是独占线程,则抛出异常;否则,计算释放资源后的写锁数量,如果为 0 则表示释放成功,资源不再被占用,否则表示资源仍被占用。
tryAcquire:
protected final boolean tryAcquire(int acquires) {
/*
* Walkthrough:
* 1. If read count nonzero or write count nonzero
* and owner is a different thread, fail.
* 2. If count would saturate, fail. (This can only
* happen if count is already nonzero.)
* 3. Otherwise, this thread is eligible for lock if
* it is either a reentrant acquire or
* queue policy allows it. If so, update state
* and set owner.
*/
// 获取当前线程
Thread current = Thread.currentThread();
// 获取状态
int c = getState();
// 写线程数量
int w = exclusiveCount(c);
if (c != 0) { // 状态不为0
// (Note: if c != 0 and w == 0 then shared count != 0)
if (w == 0 || current != getExclusiveOwnerThread()) // 写线程数量为0或者当前线程没有占有独占资源
return false;
if (w + exclusiveCount(acquires) > MAX_COUNT) // 判断是否超过最高写线程数量
throw new Error("Maximum lock count exceeded");
// Reentrant acquire
// 设置AQS状态
setState(c + acquires);
return true;
}
if (writerShouldBlock() ||
!compareAndSetState(c, c + acquires)) // 写线程是否应该被阻塞
return false;
// 设置独占线程
setExclusiveOwnerThread(current);
return true;
}
用于获取写锁。首先获取 state,判断如果为 0 表示此时没有读锁线程,再判断写线程是否应该被阻塞,而在非公平策略下总是不会被阻塞,在公平策略下会进行判断(判断同步队列中是否已有等待时间更长的线程,存在则被阻塞,否则无需组织),之后设置状态 state 并返回 true。
如果 state 不为 0,表示此时存在读锁或写锁线程,弱写锁线程数量为 0 或当前线程为独占锁线程则返回 false,表示不成功。否则,判断写线程的重入次数是否大于了最大值,若是则抛出异常,否则设置状态 state 并返回 true,表示成功。
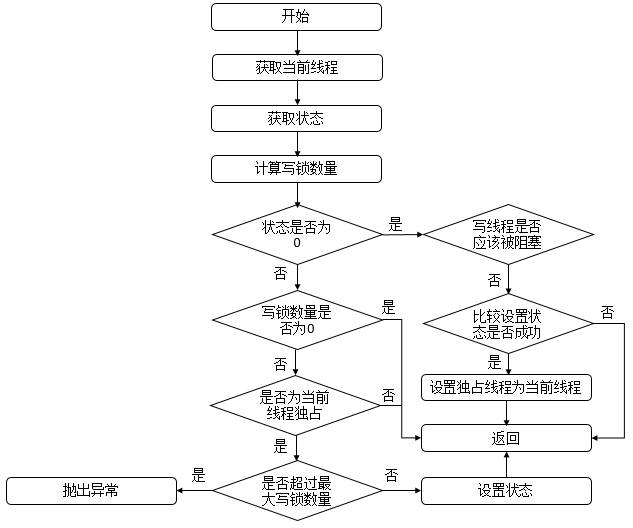
tryReleaseShared:
protected final boolean tryReleaseShared(int unused) {
// 获取当前线程
Thread current = Thread.currentThread();
if (firstReader == current) { // 当前线程为第一个读线程
// assert firstReaderHoldCount > 0;
if (firstReaderHoldCount == 1) // 读线程占用的资源数为1
firstReader = null;
else // 减少占用的资源
firstReaderHoldCount--;
} else { // 当前线程不为第一个读线程
// 获取缓存的计数器
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current)) // 计数器为空或者计数器的tid不为当前正在运行的线程的tid
// 获取当前线程对应的计数器
rh = readHolds.get();
// 获取计数
int count = rh.count;
if (count <= 1) { // 计数小于等于1
// 移除
readHolds.remove();
if (count <= 0) // 计数小于等于0,抛出异常
throw unmatchedUnlockException();
}
// 减少计数
--rh.count;
}
for (;;) { // 无限循环
// 获取状态
int c = getState();
// 获取状态
int nextc = c - SHARED_UNIT;
if (compareAndSetState(c, nextc)) // 比较并进行设置
// Releasing the read lock has no effect on readers,
// but it may allow waiting writers to proceed if
// both read and write locks are now free.
return nextc == 0;
}
}
此函数表示读锁线程释放锁。首先判断当前线程是否为第一个读线程 firstReader,若是,则判断第一个读线程占有的资源数 firstReaderHoldCount 是否为 1,若是,则设置第一个读线程 firstReader 为空,否则,将第一个读线程占有的资源数 firstReaderHoldCount 减1;若当前线程不是第一个读线程,那么首先会获取缓存计数器(上一个读锁线程对应的计数器 ),若计数器为空或者 tid 不等于当前线程的 tid 值,则获取当前线程的计数器,如果计数器的计数 count 小于等于1,则移除当前线程对应的计数器,如果计数器的计数 count 小于等于 0,则抛出异常,之后再减少计数即可。无论何种情况,都会进入无限循环,该循环可以确保成功设置状态 state。
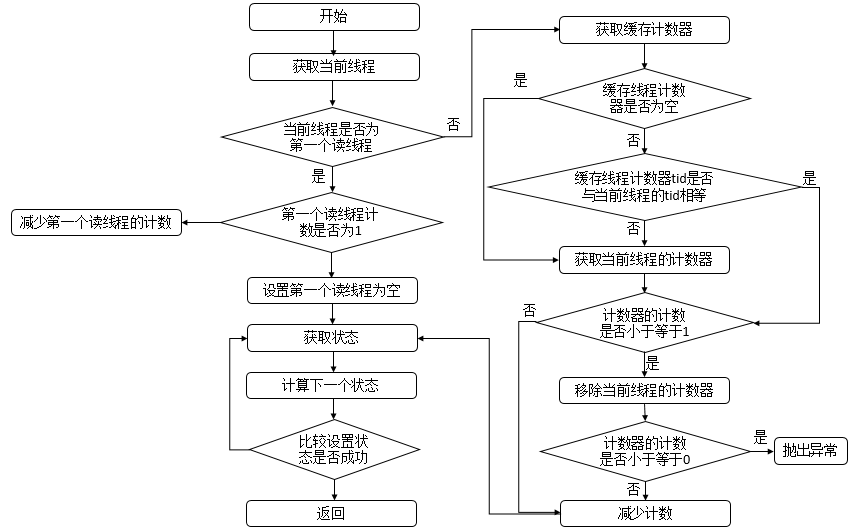
tryAcquireShared
private IllegalMonitorStateException unmatchedUnlockException() {
return new IllegalMonitorStateException(
"attempt to unlock read lock, not locked by current thread");
}
// 共享模式下获取资源
protected final int tryAcquireShared(int unused) {
/*
* Walkthrough:
* 1. If write lock held by another thread, fail.
* 2. Otherwise, this thread is eligible for
* lock wrt state, so ask if it should block
* because of queue policy. If not, try
* to grant by CASing state and updating count.
* Note that step does not check for reentrant
* acquires, which is postponed to full version
* to avoid having to check hold count in
* the more typical non-reentrant case.
* 3. If step 2 fails either because thread
* apparently not eligible or CAS fails or count
* saturated, chain to version with full retry loop.
*/
// 获取当前线程
Thread current = Thread.currentThread();
// 获取状态
int c = getState();
if (exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current) // 写线程数不为0并且占有资源的不是当前线程
return -1;
// 读锁数量
int r = sharedCount(c);
if (!readerShouldBlock() &&
r < MAX_COUNT &&
compareAndSetState(c, c + SHARED_UNIT)) { // 读线程是否应该被阻塞、并且小于最大值、并且比较设置成功
if (r == 0) { // 读锁数量为0
// 设置第一个读线程
firstReader = current;
// 读线程占用的资源数为1
firstReaderHoldCount = 1;
} else if (firstReader == current) { // 当前线程为第一个读线程
// 占用资源数加1
firstReaderHoldCount++;
} else { // 读锁数量不为0并且不为当前线程
// 获取计数器
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current)) // 计数器为空或者计数器的tid不为当前正在运行的线程的tid
// 获取当前线程对应的计数器
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0) // 计数为0
// 设置
readHolds.set(rh);
rh.count++;
}
return 1;
}
return fullTryAcquireShared(current);
}
此函数表示读锁线程获取读锁。首先判断写锁是否为 0 并且当前线程不占有独占锁,直接返回;否则,判断读线程是否需要被阻塞并且读锁数量是否小于最大值并且比较设置状态成功,若当前没有读锁,则设置第一个读线程 firstReade r和 firstReaderHoldCount;若当前线程线程为第一个读线程,则增加 firstReaderHoldCount;否则,将设置当前线程对应的 HoldCounter 对象的值。
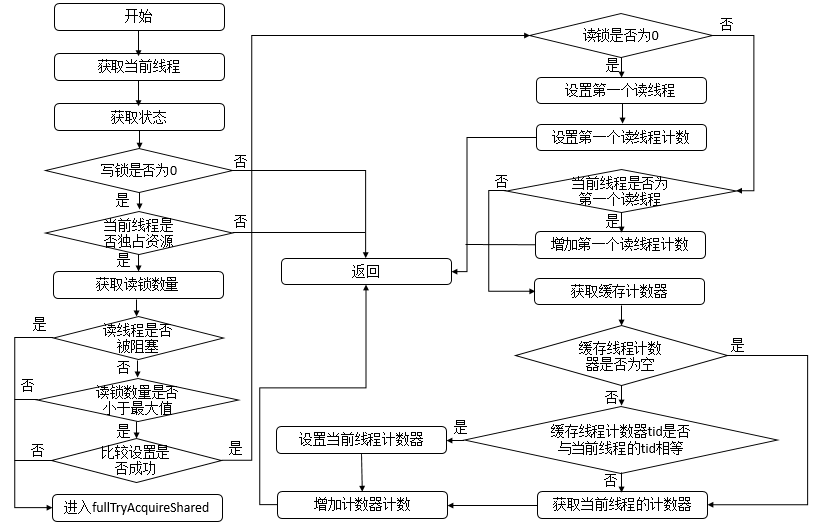
fullTryAcquireShared
final int fullTryAcquireShared(Thread current) {
/*
* This code is in part redundant with that in
* tryAcquireShared but is simpler overall by not
* complicating tryAcquireShared with interactions between
* retries and lazily reading hold counts.
*/
HoldCounter rh = null;
for (;;) { // 无限循环
// 获取状态
int c = getState();
if (exclusiveCount(c) != 0) { // 写线程数量不为0
if (getExclusiveOwnerThread() != current) // 不为当前线程
return -1;
// else we hold the exclusive lock; blocking here
// would cause deadlock.
} else if (readerShouldBlock()) { // 写线程数量为0并且读线程被阻塞
// Make sure we're not acquiring read lock reentrantly
if (firstReader == current) { // 当前线程为第一个读线程
// assert firstReaderHoldCount > 0;
} else { // 当前线程不为第一个读线程
if (rh == null) { // 计数器不为空
//
rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current)) { // 计数器为空或者计数器的tid不为当前正在运行的线程的tid
rh = readHolds.get();
if (rh.count == 0)
readHolds.remove();
}
}
if (rh.count == 0)
return -1;
}
}
if (sharedCount(c) == MAX_COUNT) // 读锁数量为最大值,抛出异常
throw new Error("Maximum lock count exceeded");
if (compareAndSetState(c, c + SHARED_UNIT)) { // 比较并且设置成功
if (sharedCount(c) == 0) { // 读线程数量为0
// 设置第一个读线程
firstReader = current;
//
firstReaderHoldCount = 1;
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
if (rh == null)
rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
cachedHoldCounter = rh; // cache for release
}
return 1;
}
}
}
在 tryAcquireShared 函数中,如果下列三个条件不满足(读线程是否应该被阻塞、小于最大值、比较设置成功)则会进行 fullTryAcquireShared 函数中,它用来保证相关操作可以成功。其逻辑与 tryAcquireShared 逻辑类似,不再累赘。
而其他内部类的操作基本上都是转化到了对Sync对象的操作,在此不再累赘。
类属性
public class ReentrantReadWriteLock
implements ReadWriteLock, java.io.Serializable {
// 版本序列号
private static final long serialVersionUID = -6992448646407690164L;
// 读锁
private final ReentrantReadWriteLock.ReadLock readerLock;
// 写锁
private final ReentrantReadWriteLock.WriteLock writerLock;
// 同步队列
final Sync sync;
private static final sun.misc.Unsafe UNSAFE;
// 线程ID的偏移地址
private static final long TID_OFFSET;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> tk = Thread.class;
// 获取线程的tid字段的内存地址
TID_OFFSET = UNSAFE.objectFieldOffset
(tk.getDeclaredField("tid"));
} catch (Exception e) {
throw new Error(e);
}
}
}
包括了一个 ReentrantReadWriteLock.ReadLock 对象,表示读锁;
一个ReentrantReadWriteLock.WriteLock对象,表示写锁;
一个Sync对象,表示同步队列。
类的构造函数
- ReentrantReadWriteLock()
- 默认非公平策略
- ReentrantReadWriteLock(boolean)
- true:公平策略
- false:非公平策略
类的核心函数
对ReentrantReadWriteLock的操作基本上都转化为了对Sync对象的操作。
应用示例
import java.util.concurrent.locks.ReentrantReadWriteLock;
class ReadThread extends Thread {
private ReentrantReadWriteLock rrwLock;
public ReadThread(String name, ReentrantReadWriteLock rrwLock) {
super(name);
this.rrwLock = rrwLock;
}
public void run() {
System.out.println(Thread.currentThread().getName() + " trying to lock");
try {
rrwLock.readLock().lock();
System.out.println(Thread.currentThread().getName() + " lock successfully");
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
rrwLock.readLock().unlock();
System.out.println(Thread.currentThread().getName() + " unlock successfully");
}
}
}
class WriteThread extends Thread {
private ReentrantReadWriteLock rrwLock;
public WriteThread(String name, ReentrantReadWriteLock rrwLock) {
super(name);
this.rrwLock = rrwLock;
}
public void run() {
System.out.println(Thread.currentThread().getName() + " trying to lock");
try {
rrwLock.writeLock().lock();
System.out.println(Thread.currentThread().getName() + " lock successfully");
} finally {
rrwLock.writeLock().unlock();
System.out.println(Thread.currentThread().getName() + " unlock successfully");
}
}
}
public class ReentrantReadWriteLockDemo {
public static void main(String[] args) {
ReentrantReadWriteLock rrwLock = new ReentrantReadWriteLock();
ReadThread rt1 = new ReadThread("rt1", rrwLock);
ReadThread rt2 = new ReadThread("rt2", rrwLock);
WriteThread wt1 = new WriteThread("wt1", rrwLock);
rt1.start();
rt2.start();
wt1.start();
}
}
rt1 trying to lock
rt2 trying to lock
wt1 trying to lock
rt1 lock successfully
rt2 lock successfully
rt1 unlock successfully
rt2 unlock successfully
wt1 lock successfully
wt1 unlock successfully
程序中生成了一个ReentrantReadWriteLock对象,并且设置了两个读线程,一个写线程。根据结果,可能存在如下的时序图。
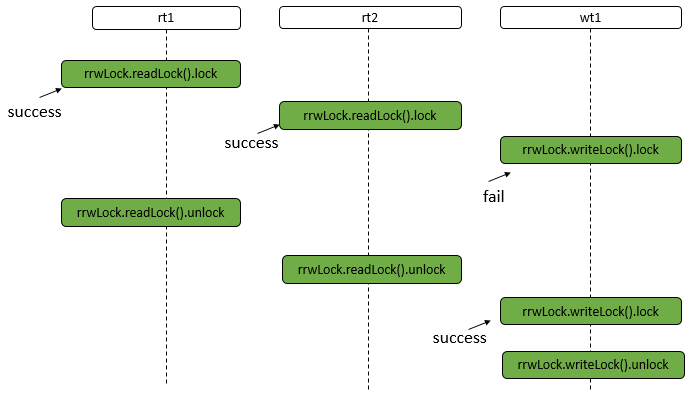
rt1 线程执行 rrwLock.readLock().lock 操作的调用链路:

此时 AQS 的状态 state 为 2^16,表示当前读线程数量为 1。
rt2 线程执行 rrwLock.readLock().lock 操作,主要的函数调用如下:

此时,在同步队列 Sync queue 中存在两个结点,并且 wt1 线程会被禁止运行。
rt1 线程执行 rrwLock.readLock().unlock 操作,主要的函数调用如下:
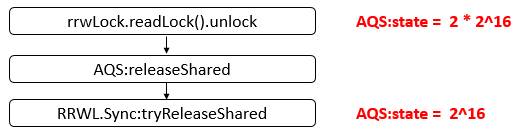
此时,AQS的state为2^16次方,表示还有一个读线程。
rt2 线程执行 rrwLock.readLock().unlock 操作,主要的函数调用如下:
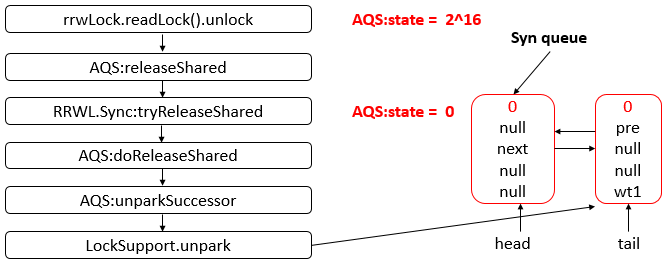
当 rt2 线程执行 unlock 操作后,AQS 的 state 为 0,并且 wt1 线程将会被 unpark,其获得 CPU 资源就可以运行。
wt1线程获得CPU资源,继续运行,需要恢复。由于之前acquireQueued函数中的parkAndCheckInterrupt函数中被禁止的,所以,恢复到parkAndCheckInterrupt函数中,主要的函数调用如下:
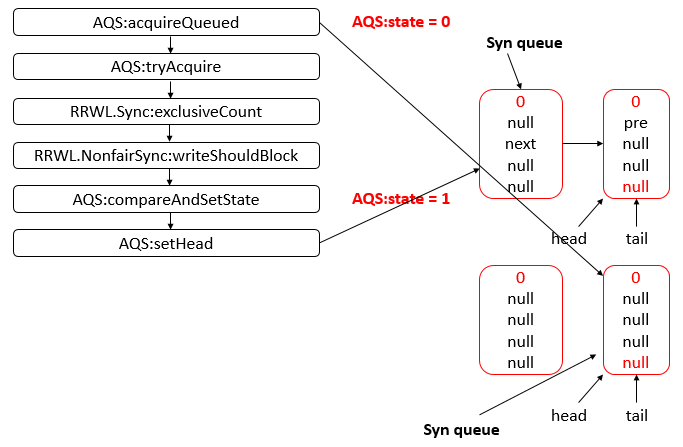
最后,sync queue 队列中只有一个结点,并且头结点尾节点均指向它,AQS 的 state 值为 1,表示此时有一个写线程。
wt1 执行 rrwLock.writeLock().unlock 操作,主要的函数调用如下:
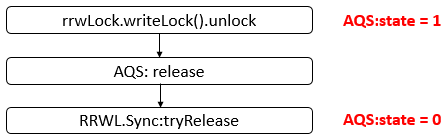
此时,AQS 的 state 为 0,表示没有任何读线程或者写线程了。并且 Sync queue 结构与上一个状态的结构相同,没有变化。
深入理解
什么是锁升级、降级
锁降级指的是写锁降级成为读锁。如果当前线程拥有写锁,然后将其释放,最后再获取读锁,这种分段完成的过程不能称之为锁降级。
锁降级是指把持住(当前拥有的)写锁,再获取到读锁,随后释放(先前拥有的)写锁的过程。
因为数据不常变化,所以多个线程可以并发地进行数据处理,当数据变更后,如果当前线程感知到数据变化,则进行数据的准备工作,同时其他处理线程被阻塞,直到当前线程完成数据的准备工作,如代码如下所示:
public void processData() {
readLock.lock();
if (!update) {
// 必须先释放读锁
readLock.unlock();
// 锁降级从写锁获取到开始
writeLock.lock();
try {
if (!update) {
// 准备数据的流程(略)
update = true;
}
readLock.lock();
} finally {
writeLock.unlock();
}
// 锁降级完成,写锁降级为读锁
}
try {
// 使用数据的流程(略)
} finally {
readLock.unlock();
}
}
上述示例中,当数据发生变更后,update 变量(布尔类型且volatile修饰)被设置为 false,此时所有访问 processData() 方法的线程都能够感知到变化,但只有一个线程能够获取到写锁,其他线程会被阻塞在读锁和写锁的 lock() 方法上。当前线程获取写锁完成数据准备之后,再获取读锁,随后释放写锁,完成锁降级。
锁降级中读锁的获取是否必要呢? 答案是必要的。主要是为了保证数据的可见性,如果当前线程不获取读锁而是直接释放写锁,假设此刻另一个线程(记作线程T)获取了写锁并修改了数据,那么当前线程无法感知线程T的数据更新。如果当前线程获取读锁,即遵循锁降级的步骤,则线程T将会被阻塞,直到当前线程使用数据并释放读锁之后,线程T才能获取写锁进行数据更新。
RentrantReadWriteLock不支持锁升级(把持读锁、获取写锁,最后释放读锁的过程)。目的也是保证数据可见性,如果读锁已被多个线程获取,其中任意线程成功获取了写锁并更新了数据,则其更新对其他获取到读锁的线程是不可见的。
17 - CH17-ConcurrentHashMap
HashTable 为什么慢
Hashtable 之所以效率低下主要是因为其实现使用了 synchronized 关键字对 put 等操作进行加锁,而 synchronized 关键字加锁是对整个对象示例进行加锁,也就是说在进行 put 等修改 Hash 表的操作时,锁住了整个 Hash 表,从而使得其表现的效率低下。
JDK 1.7-ConcurrentHashMap
在 JDK 1.5~1.7 版本,Java 使用了分段锁机制实现 ConcurrentHashMap。
简而言之,ConcurrentHashMap 在对象中保存了一个 Segment 数组,即将整个 Hash 表划分为多个分段;
而每个 Segment 元素,即每个分段则类似于一个 Hashtable;
这样,在执行 put 操作时首先根据 hash 算法定位到元素属于哪个 Segment,然后对该 Segment 加锁即可。
因此,ConcurrentHashMap 在多线程并发编程中可是实现多线程 put 操作。
数据结构
整个 ConcurrentHashMap 由一个个 Segment 组成,Segment 代表”部分“或”一段“的意思,所以很多地方都会将其描述为分段锁。注意,行文中,我很多地方用了“槽”来代表一个 segment。
简单理解就是,ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
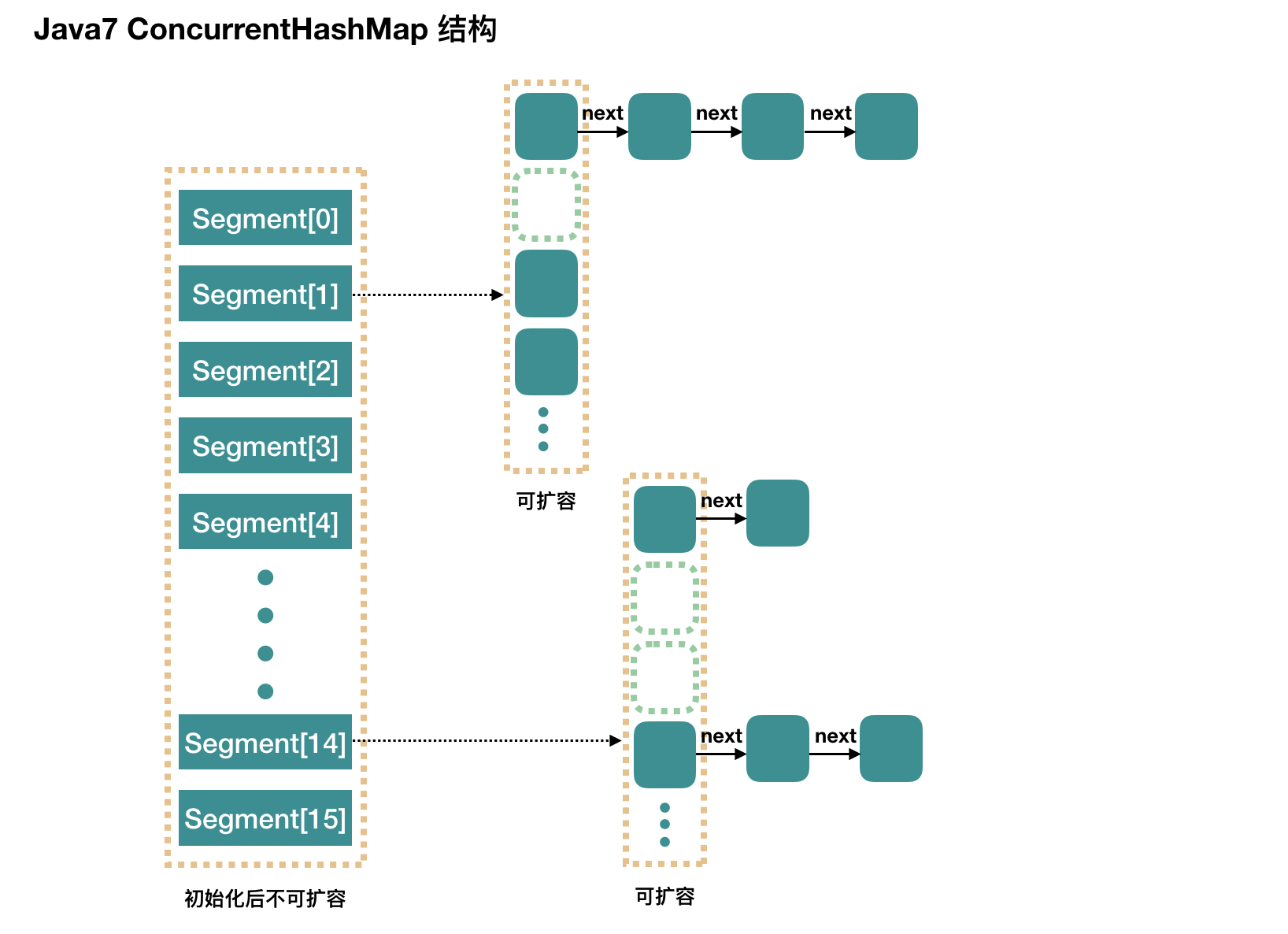
- concurrencyLevel:并行级别、Segment 数量。
- 默认为 16,即拥有 16 个 segments,理论上同时支持 16 个线程并发写,只要它们的操作分布在不同的 Segment 上。
- 该值可以在初始化时设定为其他值,但是一点设置不可修改。
- 每个 Segment 内部类似于 HashMap,但通过继承 ReentrantLock 来保证线程安全。
初始化
- initialCapacity: 初始容量,这个值指的是整个 ConcurrentHashMap 的初始容量,实际操作的时候需要平均分给每个 Segment。
- loadFactor: 负载因子,之前我们说了,Segment 数量不可变,所以这个负载因子是给每个 Segment 内部使用的。
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
// 计算并行级别 ssize,因为要保持并行级别是 2 的 n 次方
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// 我们这里先不要那么烧脑,用默认值,concurrencyLevel 为 16,sshift 为 4
// 那么计算出 segmentShift 为 28,segmentMask 为 15,后面会用到这两个值
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// initialCapacity 是设置整个 map 初始的大小,
// 这里根据 initialCapacity 计算 Segment 数组中每个位置可以分到的大小
// 如 initialCapacity 为 64,那么每个 Segment 或称之为"槽"可以分到 4 个
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
// 默认 MIN_SEGMENT_TABLE_CAPACITY 是 2,这个值也是有讲究的,因为这样的话,对于具体的槽上,
// 插入一个元素不至于扩容,插入第二个的时候才会扩容
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// 创建 Segment 数组,
// 并创建数组的第一个元素 segment[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
// 往数组写入 segment[0]
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
当使用无参构造器创建 ConcurrentHashMap 实例时,初始化完成后的状态如下:
- Segment 数组长度为 16,不可以扩容
Segment[i]的默认大小为 2,负载因子是 0.75,得出初始阈值为 1.5,也就是以后插入第一个元素不会触发扩容,插入第二个会进行第一次扩容- 这里初始化了
segment[0],其他位置还是 null,至于为什么要初始化segment[0],后面的代码会介绍 - 当前 segmentShift 的值为 32 - 4 = 28,segmentMask 为 16 - 1 = 15,姑且把它们简单翻译为移位数和掩码,这两个值马上就会用到
put 过程分析
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
// 1. 计算 key 的 hash 值
int hash = hash(key);
// 2. 根据 hash 值找到 Segment 数组中的位置 j
// hash 是 32 位,无符号右移 segmentShift(28) 位,剩下高 4 位,
// 然后和 segmentMask(15) 做一次与操作,也就是说 j 是 hash 值的高 4 位,也就是槽的数组下标
int j = (hash >>> segmentShift) & segmentMask;
// 刚刚说了,初始化的时候初始化了 segment[0],但是其他位置还是 null,
// ensureSegment(j) 对 segment[j] 进行初始化
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
// 3. 插入新值到 槽 s 中
return s.put(key, hash, value, false);
}
第一层操作较简单,基于 hash 值找到对应的 segment,之后执行 segment 内部的 put 操作。
Segment 内部由 数组+链表 构成:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 在往该 segment 写入前,需要先获取该 segment 的独占锁
// 先看主流程,后面还会具体介绍这部分内容
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
// 这个是 segment 内部的数组
HashEntry<K,V>[] tab = table;
// 再利用 hash 值,求应该放置的数组下标
int index = (tab.length - 1) & hash;
// first 是数组该位置处的链表的表头
HashEntry<K,V> first = entryAt(tab, index);
// 下面这串 for 循环虽然很长,不过也很好理解,想想该位置没有任何元素和已经存在一个链表这两种情况
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
// 覆盖旧值
e.value = value;
++modCount;
}
break;
}
// 继续顺着链表走
e = e.next;
}
else {
// node 到底是不是 null,这个要看获取锁的过程,不过和这里都没有关系。
// 如果不为 null,那就直接将它设置为链表表头;如果是null,初始化并设置为链表表头。
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// 如果超过了该 segment 的阈值,这个 segment 需要扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node); // 扩容后面也会具体分析
else
// 没有达到阈值,将 node 放到数组 tab 的 index 位置,
// 其实就是将新的节点设置成原链表的表头
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
// 解锁
unlock();
}
return oldValue;
}
由于有独占锁的保护,所以 segment 内部的操作并不复杂。
下面为其中的关键函数:
初始化槽:ensureSegment
ConcurrentHashMap 初始化的时候会初始化第一个槽 segment[0],对于其他槽来说,在插入第一个值的时候才进行初始化。
这里需要考虑并发,因为很可能会有多个线程同时进来初始化同一个槽 segment[k],不过只要有一个成功了就可以。
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
// 这里看到为什么之前要初始化 segment[0] 了,
// 使用当前 segment[0] 处的数组长度和负载因子来初始化 segment[k]
// 为什么要用“当前”,因为 segment[0] 可能早就扩容过了
Segment<K,V> proto = ss[0];
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
// 初始化 segment[k] 内部的数组
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) { // 再次检查一遍该槽是否被其他线程初始化了。
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
// 使用 while 循环,内部用 CAS,当前线程成功设值或其他线程成功设值后,退出
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
对于并发操作使用 CAS 进行控制。
获取写入锁: scanAndLockForPut
在往某个 segment 中 put 的时候,首先会调用 node = tryLock() ? null : scanAndLockForPut(key, hash, value),也就是说先进行一次 tryLock() 快速获取该 segment 的独占锁,如果失败,那么进入到 scanAndLockForPut 这个方法来获取锁。
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
// 循环获取锁
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
// 进到这里说明数组该位置的链表是空的,没有任何元素
// 当然,进到这里的另一个原因是 tryLock() 失败,所以该槽存在并发,不一定是该位置
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
// 顺着链表往下走
e = e.next;
}
// 重试次数如果超过 MAX_SCAN_RETRIES(单核1多核64),那么不抢了,进入到阻塞队列等待锁
// lock() 是阻塞方法,直到获取锁后返回
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
// 这个时候是有大问题了,那就是有新的元素进到了链表,成为了新的表头
// 所以这边的策略是,相当于重新走一遍这个 scanAndLockForPut 方法
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
这个方法有两个出口,一个是 tryLock() 成功了,循环终止,另一个就是重试次数超过了 MAX_SCAN_RETRIES,进到 lock() 方法,此方法会阻塞等待,直到成功拿到独占锁。
这个方法就是看似复杂,但是其实就是做了一件事,那就是获取该 segment 的独占锁,如果需要的话顺便实例化了一下 node。
扩容:rehash
segment 数组不能扩容,扩容是 segment 数组某个位置内部的数组
HashEntry<K,V>[]进行扩容,扩容后,容量为原来的 2 倍。执行 put 时,如果判断该值的插入会导致 segment 的元素个数超过阈值,需要先扩容再插入。
因为这时已经持有了 segment 的独占锁,因此无需再考虑并发:
// 方法参数上的 node 是这次扩容后,需要添加到新的数组中的数据。
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
// 2 倍
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
// 创建新数组
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
// 新的掩码,如从 16 扩容到 32,那么 sizeMask 为 31,对应二进制 ‘000...00011111’
int sizeMask = newCapacity - 1;
// 遍历原数组,老套路,将原数组位置 i 处的链表拆分到 新数组位置 i 和 i+oldCap 两个位置
for (int i = 0; i < oldCapacity ; i++) {
// e 是链表的第一个元素
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
// 计算应该放置在新数组中的位置,
// 假设原数组长度为 16,e 在 oldTable[3] 处,那么 idx 只可能是 3 或者是 3 + 16 = 19
int idx = e.hash & sizeMask;
if (next == null) // 该位置处只有一个元素,那比较好办
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
// e 是链表表头
HashEntry<K,V> lastRun = e;
// idx 是当前链表的头结点 e 的新位置
int lastIdx = idx;
// 下面这个 for 循环会找到一个 lastRun 节点,这个节点之后的所有元素是将要放到一起的
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
// 将 lastRun 及其之后的所有节点组成的这个链表放到 lastIdx 这个位置
newTable[lastIdx] = lastRun;
// 下面的操作是处理 lastRun 之前的节点,
// 这些节点可能分配在另一个链表中,也可能分配到上面的那个链表中
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
// 将新来的 node 放到新数组中刚刚的 两个链表之一 的 头部
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
扩容过程中有两个 for 循环。如果没有第一个 for 循环也是可以工作的,但是在首个 for 循环中,如果 lastRun 的后面还有比较多的节点,那么首次循环就值得。因为我们要克隆 lastRun 前面的节点,后面的一串节点跟着 lastRun 走就可以了,无需其他操作。
比较坏的情况是每次 lastRun 都是链表的最后一个元素或者很靠后的元素,那么就会比较浪费。基于 Doug Lea 的说法,如果使用默认的阈值,大约只有 1/6 的节点需要克隆。
get 过程分析
- 计算 hash 值,找到 segment 的数组下标,得到 segment
- segment 中也是一个数组,根据 hash 找到数据中的位置
- 得到链表,顺着链表查找即可
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
// 1. hash 值
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// 2. 根据 hash 找到对应的 segment
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
// 3. 找到segment 内部数组相应位置的链表,遍历
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
并发问题分析
注意 get 操作并未加锁。
添加节点的操作 put 和删除节点的操作 remove 都是要加 segment 上的独占锁的,所以它们之间自然不会有问题。
我们需要考虑的问题就是 get 的时候在同一个 segment 中发生了 put 或 remove 操作。
put 操作的安全性:
- 初始化槽,这个我们之前就说过了,使用了 CAS 来初始化 Segment 中的数组。
- 添加节点到链表的操作是插入到表头的,所以,如果这个时候 get 操作在链表遍历的过程已经到了中间,是不会影响的。当然,另一个并发问题就是 get 操作在 put 之后,需要保证刚刚插入表头的节点被读取,这个依赖于 setEntryAt 方法中使用的 UNSAFE.putOrderedObject。
- 扩容。扩容是新创建了数组,然后进行迁移数据,最后面将 newTable 设置给属性 table。所以,如果 get 操作此时也在进行,那么也没关系,如果 get 先行,那么就是在旧的 table 上做查询操作;而 put 先行,那么 put 操作的可见性保证就是 table 使用了 volatile 关键字。
remove 操作的线程安全性:
- get 操作需要遍历链表,但是 remove 操作会"破坏"链表。
- 如果 remove 破坏的节点 get 操作已经过去了,那么这里不存在任何问题。
- 如果 remove 先破坏了一个节点,分两种情况考虑。
- 1、如果此节点是头结点,那么需要将头结点的 next 设置为数组该位置的元素,table 虽然使用了 volatile 修饰,但是 volatile 并不能提供数组内部操作的可见性保证,所以源码中使用了 UNSAFE 来操作数组,请看方法 setEntryAt。
- 2、如果要删除的节点不是头结点,它会将要删除节点的后继节点接到前驱节点中,这里的并发保证就是 next 属性是 volatile 的。
JDK 1.8-ConcurrentHashMap
在 JDK 1.7 之前,ConcurrentHashMap 是通过分段锁机制来实现的,所以其最大并发度受 Segment 的个数限制。因此,在 JDK1.8 中,ConcurrentHashMap 的实现原理摒弃了这种设计,而是选择了与 HashMap 类似的数组+链表+红黑树的方式实现,而加锁则采用 CAS 和 synchronized 实现。
数据结构
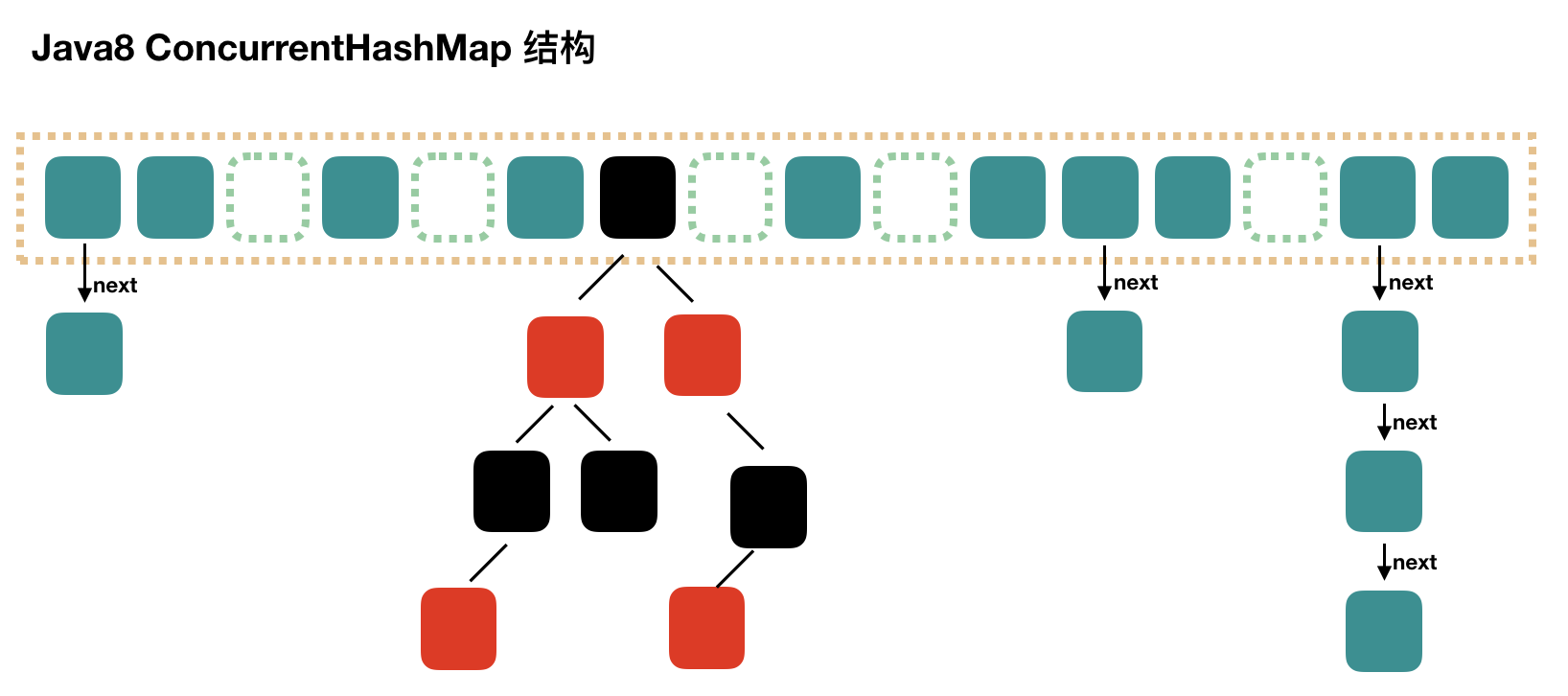
初始化
// 这构造函数里,什么都不干
public ConcurrentHashMap() {
}
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
通过提供的初始容量,计算了 sizeCtl,sizeCtl = 【 (1.5 * initialCapacity + 1),然后向上取最近的 2 的 n 次方】,如果 initialCapacity 为 10,那么得到 sizeCtl 为 16,如果 initialCapacity 为 11,sizeCtl 为 32。
put 过程分析
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 得到 hash 值
int hash = spread(key.hashCode());
// 用于记录相应链表的长度
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果数组"空",进行数组初始化
if (tab == null || (n = tab.length) == 0)
// 初始化数组,后面会详细介绍
tab = initTable();
// 找该 hash 值对应的数组下标,得到第一个节点 f
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 如果数组该位置为空,
// 用一次 CAS 操作将这个新值放入其中即可,这个 put 操作差不多就结束了,可以拉到最后面了
// 如果 CAS 失败,那就是有并发操作,进到下一个循环就好了
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// hash 居然可以等于 MOVED,这个需要到后面才能看明白,不过从名字上也能猜到,肯定是因为在扩容
else if ((fh = f.hash) == MOVED)
// 帮助数据迁移,这个等到看完数据迁移部分的介绍后,再理解这个就很简单了
tab = helpTransfer(tab, f);
else { // 到这里就是说,f 是该位置的头结点,而且不为空
V oldVal = null;
// 获取数组该位置的头结点的监视器锁
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) { // 头结点的 hash 值大于 0,说明是链表
// 用于累加,记录链表的长度
binCount = 1;
// 遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果发现了"相等"的 key,判断是否要进行值覆盖,然后也就可以 break 了
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 到了链表的最末端,将这个新值放到链表的最后面
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) { // 红黑树
Node<K,V> p;
binCount = 2;
// 调用红黑树的插值方法插入新节点
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 判断是否要将链表转换为红黑树,临界值和 HashMap 一样,也是 8
if (binCount >= TREEIFY_THRESHOLD)
// 这个方法和 HashMap 中稍微有一点点不同,那就是它不是一定会进行红黑树转换,
// 如果当前数组的长度小于 64,那么会选择进行数组扩容,而不是转换为红黑树
// 具体源码我们就不看了,扩容部分后面说
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//
addCount(1L, binCount);
return null;
}
初始化数组:initTable
初始化一个合适大小的数组,然后会设置 sizeCtl。初始化方法中的并发问题通过对 sizeCtl 执行一个 CAS 操作来控制的。
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// 初始化的"功劳"被其他线程"抢去"了
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// CAS 一下,将 sizeCtl 设置为 -1,代表抢到了锁
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
// DEFAULT_CAPACITY 默认初始容量是 16
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
// 初始化数组,长度为 16 或初始化时提供的长度
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
// 将这个数组赋值给 table,table 是 volatile 的
table = tab = nt;
// 如果 n 为 16 的话,那么这里 sc = 12
// 其实就是 0.75 * n
sc = n - (n >>> 2);
}
} finally {
// 设置 sizeCtl 为 sc,我们就当是 12 吧
sizeCtl = sc;
}
break;
}
}
return tab;
}
链表转红黑树:treeifyBin
treeifyBin 不一定就会进行红黑树转换,也可能是仅仅做数组扩容。
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
// MIN_TREEIFY_CAPACITY 为 64
// 所以,如果数组长度小于 64 的时候,其实也就是 32 或者 16 或者更小的时候,会进行数组扩容
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
// 后面我们再详细分析这个方法
tryPresize(n << 1);
// b 是头结点
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
// 加锁
synchronized (b) {
if (tabAt(tab, index) == b) {
// 下面就是遍历链表,建立一颗红黑树
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
// 将红黑树设置到数组相应位置中
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
扩容:tryPresize
扩容也是做翻倍扩容的,扩容后数组容量为原来的 2 倍。
// 首先要说明的是,方法参数 size 传进来的时候就已经翻了倍了
private final void tryPresize(int size) {
// c: size 的 1.5 倍,再加 1,再往上取最近的 2 的 n 次方。
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);
int sc;
while ((sc = sizeCtl) >= 0) {
Node<K,V>[] tab = table; int n;
// 这个 if 分支和之前说的初始化数组的代码基本上是一样的,在这里,我们可以不用管这块代码
if (tab == null || (n = tab.length) == 0) {
n = (sc > c) ? sc : c;
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = nt;
sc = n - (n >>> 2); // 0.75 * n
}
} finally {
sizeCtl = sc;
}
}
}
else if (c <= sc || n >= MAXIMUM_CAPACITY)
break;
else if (tab == table) {
// 我没看懂 rs 的真正含义是什么,不过也关系不大
int rs = resizeStamp(n);
if (sc < 0) {
Node<K,V>[] nt;
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
// 2. 用 CAS 将 sizeCtl 加 1,然后执行 transfer 方法
// 此时 nextTab 不为 null
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
// 1. 将 sizeCtl 设置为 (rs << RESIZE_STAMP_SHIFT) + 2)
// 我是没看懂这个值真正的意义是什么? 不过可以计算出来的是,结果是一个比较大的负数
// 调用 transfer 方法,此时 nextTab 参数为 null
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
}
}
}
这个方法的核心在于 sizeCtl 值的操作,首先将其设置为一个负数,然后执行 transfer(tab, null),再下一个循环将 sizeCtl 加 1,并执行 transfer(tab, nt),之后可能是继续 sizeCtl 加 1,并执行 transfer(tab, nt)。
所以,可能的操作就是执行 1 次 transfer(tab, null) + 多次 transfer(tab, nt),这里怎么结束循环的需要看完 transfer 源码才清楚。
数据迁移:transfer
将原来的 tab 数组的元素迁移到新的 nextTab 数组中。
虽然我们之前说的 tryPresize 方法中多次调用 transfer 不涉及多线程,但是这个 transfer 方法可以在其他地方被调用,典型地,我们之前在说 put 方法的时候就说过了,请往上看 put 方法,是不是有个地方调用了 helpTransfer 方法,helpTransfer 方法会调用 transfer 方法的。
此方法支持多线程执行,外围调用此方法的时候,会保证第一个发起数据迁移的线程,nextTab 参数为 null,之后再调用此方法的时候,nextTab 不会为 null。
阅读源码之前,先要理解并发操作的机制。原数组长度为 n,所以我们有 n 个迁移任务,让每个线程每次负责一个小任务是最简单的,每做完一个任务再检测是否有其他没做完的任务,帮助迁移就可以了,而 Doug Lea 使用了一个 stride,简单理解就是步长,每个线程每次负责迁移其中的一部分,如每次迁移 16 个小任务。所以,我们就需要一个全局的调度者来安排哪个线程执行哪几个任务,这个就是属性 transferIndex 的作用。
第一个发起数据迁移的线程会将 transferIndex 指向原数组最后的位置,然后从后往前的 stride 个任务属于第一个线程,然后将 transferIndex 指向新的位置,再往前的 stride 个任务属于第二个线程,依此类推。当然,这里说的第二个线程不是真的一定指代了第二个线程,也可以是同一个线程,这个读者应该能理解吧。其实就是将一个大的迁移任务分为了一个个任务包。
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
// stride 在单核下直接等于 n,多核模式下为 (n>>>3)/NCPU,最小值是 16
// stride 可以理解为”步长“,有 n 个位置是需要进行迁移的,
// 将这 n 个任务分为多个任务包,每个任务包有 stride 个任务
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
// 如果 nextTab 为 null,先进行一次初始化
// 前面我们说了,外围会保证第一个发起迁移的线程调用此方法时,参数 nextTab 为 null
// 之后参与迁移的线程调用此方法时,nextTab 不会为 null
if (nextTab == null) {
try {
// 容量翻倍
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
// nextTable 是 ConcurrentHashMap 中的属性
nextTable = nextTab;
// transferIndex 也是 ConcurrentHashMap 的属性,用于控制迁移的位置
transferIndex = n;
}
int nextn = nextTab.length;
// ForwardingNode 翻译过来就是正在被迁移的 Node
// 这个构造方法会生成一个Node,key、value 和 next 都为 null,关键是 hash 为 MOVED
// 后面我们会看到,原数组中位置 i 处的节点完成迁移工作后,
// 就会将位置 i 处设置为这个 ForwardingNode,用来告诉其他线程该位置已经处理过了
// 所以它其实相当于是一个标志。
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// advance 指的是做完了一个位置的迁移工作,可以准备做下一个位置的了
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
/*
* 下面这个 for 循环,最难理解的在前面,而要看懂它们,应该先看懂后面的,然后再倒回来看
*
*/
// i 是位置索引,bound 是边界,注意是从后往前
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
// 下面这个 while 真的是不好理解
// advance 为 true 表示可以进行下一个位置的迁移了
// 简单理解结局: i 指向了 transferIndex,bound 指向了 transferIndex-stride
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
// 将 transferIndex 值赋给 nextIndex
// 这里 transferIndex 一旦小于等于 0,说明原数组的所有位置都有相应的线程去处理了
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
// 看括号中的代码,nextBound 是这次迁移任务的边界,注意,是从后往前
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
// 所有的迁移操作已经完成
nextTable = null;
// 将新的 nextTab 赋值给 table 属性,完成迁移
table = nextTab;
// 重新计算 sizeCtl: n 是原数组长度,所以 sizeCtl 得出的值将是新数组长度的 0.75 倍
sizeCtl = (n << 1) - (n >>> 1);
return;
}
// 之前我们说过,sizeCtl 在迁移前会设置为 (rs << RESIZE_STAMP_SHIFT) + 2
// 然后,每有一个线程参与迁移就会将 sizeCtl 加 1,
// 这里使用 CAS 操作对 sizeCtl 进行减 1,代表做完了属于自己的任务
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
// 任务结束,方法退出
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
// 到这里,说明 (sc - 2) == resizeStamp(n) << RESIZE_STAMP_SHIFT,
// 也就是说,所有的迁移任务都做完了,也就会进入到上面的 if(finishing){} 分支了
finishing = advance = true;
i = n; // recheck before commit
}
}
// 如果位置 i 处是空的,没有任何节点,那么放入刚刚初始化的 ForwardingNode ”空节点“
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
// 该位置处是一个 ForwardingNode,代表该位置已经迁移过了
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
// 对数组该位置处的结点加锁,开始处理数组该位置处的迁移工作
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
// 头结点的 hash 大于 0,说明是链表的 Node 节点
if (fh >= 0) {
// 下面这一块和 Java7 中的 ConcurrentHashMap 迁移是差不多的,
// 需要将链表一分为二,
// 找到原链表中的 lastRun,然后 lastRun 及其之后的节点是一起进行迁移的
// lastRun 之前的节点需要进行克隆,然后分到两个链表中
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
// 其中的一个链表放在新数组的位置 i
setTabAt(nextTab, i, ln);
// 另一个链表放在新数组的位置 i+n
setTabAt(nextTab, i + n, hn);
// 将原数组该位置处设置为 fwd,代表该位置已经处理完毕,
// 其他线程一旦看到该位置的 hash 值为 MOVED,就不会进行迁移了
setTabAt(tab, i, fwd);
// advance 设置为 true,代表该位置已经迁移完毕
advance = true;
}
else if (f instanceof TreeBin) {
// 红黑树的迁移
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
// 如果一分为二后,节点数少于 8,那么将红黑树转换回链表
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
// 将 ln 放置在新数组的位置 i
setTabAt(nextTab, i, ln);
// 将 hn 放置在新数组的位置 i+n
setTabAt(nextTab, i + n, hn);
// 将原数组该位置处设置为 fwd,代表该位置已经处理完毕,
// 其他线程一旦看到该位置的 hash 值为 MOVED,就不会进行迁移了
setTabAt(tab, i, fwd);
// advance 设置为 true,代表该位置已经迁移完毕
advance = true;
}
}
}
}
}
}
transfer 这个方法并没有实现所有的迁移任务,每次调用这个方法只实现了 transferIndex 往前 stride 个位置的迁移工作,其他的需要由外围来控制。
get 过程分析
- 计算 hash 值
- 根据 hash 值找到数组对应位置:
(n - 1) & h - 根据该位置处结点性质进行相应查找
- 如果该位置为 null,那么直接返回 null 就可以了
- 如果该位置处的节点刚好就是我们需要的,返回该节点的值即可
- 如果该位置节点的 hash 值小于 0,说明正在扩容,或者是红黑树,后面我们再介绍 find 方法
- 如果以上 3 条都不满足,那就是链表,进行遍历比对即可
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// 判断头结点是否就是我们需要的节点
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// 如果头结点的 hash 小于 0,说明 正在扩容,或者该位置是红黑树
else if (eh < 0)
// 参考 ForwardingNode.find(int h, Object k) 和 TreeBin.find(int h, Object k)
return (p = e.find(h, key)) != null ? p.val : null;
// 遍历链表
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
当遇到扩容时的情况最为复杂,ForwardingNode.find(int h, Object k)。
对比总结
HashTable: 使用了synchronized关键字对put等操作进行加锁;ConcurrentHashMap JDK1.7: 使用分段锁机制实现;ConcurrentHashMap JDK1.8: 则使用数组+链表+红黑树数据结构和 CAS 原子操作实现;
18 - CH18-ConcurrentLinkedQueue
- 基于链接节点的无界线程安全队列。
- 此队列按照 FIFO(先进先出)原则对元素进行排序。
- 队列的头部是队列中时间最长的元素。
- 队列的尾部是队列中时间最短的元素。
- 新的元素插入到队列的尾部,队列获取操作从队列头部获得元素。
- 当多个线程共享访问一个公共 collection 时,ConcurrentLinkedQueue 是一个恰当的选择。
- 此队列不允许使用 null 元素。
数据结构
与 LinkedBlockingQueue 的数据结构相同,都是使用的链表结构。ConcurrentLinkedQueue 的数据结构如下:

ConcurrentLinkedQueue 采用的链表结构,并且包含有一个头结点和一个尾结点。
源码分析
层级结构
继承了抽象类 AbstractQueue,AbstractQueue 定义了对队列的基本操作;
同时实现了 Queue 接口,Queue 定义了对队列的基本操作,
同时,还实现了 Serializable 接口,表示可以被序列化。
内部类
Node 类表示链表结点,用于存放元素,包含 item 域和 next 域,item 域表示元素,next 域表示下一个结点,其利用反射机制和 CAS 机制来更新 item 域和 next 域,保证原子性。
private static class Node<E> {
// 元素
volatile E item;
// next域
volatile Node<E> next;
/**
* Constructs a new node. Uses relaxed write because item can
* only be seen after publication via casNext.
*/
// 构造函数
Node(E item) {
// 设置item的值
UNSAFE.putObject(this, itemOffset, item);
}
// 比较并替换item值
boolean casItem(E cmp, E val) {
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
void lazySetNext(Node<E> val) {
// 设置next域的值,并不会保证修改对其他线程立即可见
UNSAFE.putOrderedObject(this, nextOffset, val);
}
// 比较并替换next域的值
boolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
// Unsafe mechanics
// 反射机制
private static final sun.misc.Unsafe UNSAFE;
// item域的偏移量
private static final long itemOffset;
// next域的偏移量
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Node.class;
itemOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("item"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
类的属性
属性中包含了 head 域和 tail 域,表示链表的头结点和尾结点,同时,ConcurrentLinkedQueue 也使用了反射机制和 CAS 机制来更新头结点和尾结点,保证原子性。
public class ConcurrentLinkedQueue<E> extends AbstractQueue<E>
implements Queue<E>, java.io.Serializable {
// 版本序列号
private static final long serialVersionUID = 196745693267521676L;
// 反射机制
private static final sun.misc.Unsafe UNSAFE;
// head域的偏移量
private static final long headOffset;
// tail域的偏移量
private static final long tailOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = ConcurrentLinkedQueue.class;
headOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("head"));
tailOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("tail"));
} catch (Exception e) {
throw new Error(e);
}
}
// 头结点
private transient volatile Node<E> head;
// 尾结点
private transient volatile Node<E> tail;
}
类的构造函数
ConcurrentLinkedQueue()型构造函数- 该构造函数用于创建一个最初为空的 ConcurrentLinkedQueue,头结点与尾结点指向同一个结点,该结点的item域为null,next域也为null。
ConcurrentLinkedQueue(Collection<? extends E>)型构造函数- 该构造函数用于创建一个最初包含给定 collection 元素的 ConcurrentLinkedQueue,按照此 collection 迭代器的遍历顺序来添加元素。
核心函数
offer
public boolean offer(E e) {
// 元素不为null
checkNotNull(e);
// 新生一个结点
final Node<E> newNode = new Node<E>(e);
for (Node<E> t = tail, p = t;;) { // 无限循环
// q为p结点的下一个结点
Node<E> q = p.next;
if (q == null) { // q结点为null
// p is last node
if (p.casNext(null, newNode)) { // 比较并进行替换p结点的next域
// Successful CAS is the linearization point
// for e to become an element of this queue,
// and for newNode to become "live".
if (p != t) // p不等于t结点,不一致 // hop two nodes at a time
// 比较并替换尾结点
casTail(t, newNode); // Failure is OK.
// 返回
return true;
}
// Lost CAS race to another thread; re-read next
}
else if (p == q) // p结点等于q结点
// We have fallen off list. If tail is unchanged, it
// will also be off-list, in which case we need to
// jump to head, from which all live nodes are always
// reachable. Else the new tail is a better bet.
// 原来的尾结点与现在的尾结点是否相等,若相等,则p赋值为head,否则,赋值为现在的尾结点
p = (t != (t = tail)) ? t : head;
else
// Check for tail updates after two hops.
// 重新赋值p结点
p = (p != t && t != (t = tail)) ? t : q;
}
}
offer 函数用于将指定元素插入此队列的尾部。下面模拟 offer 函数的操作,队列状态的变化(假设单线程添加元素,连续添加10、20两个元素)。

- 若ConcurrentLinkedQueue的初始状态如上图所示,即队列为空。单线程添加元素,此时,添加元素10,则状态如下所示
- 如上图所示,添加元素10后,tail没有变化,还是指向之前的结点,继续添加元素20,则状态如下所示
- 如上图所示,添加元素20后,tail指向了最新添加的结点。
poll
public E poll() {
restartFromHead:
for (;;) { // 无限循环
for (Node<E> h = head, p = h, q;;) { // 保存头结点
// item项
E item = p.item;
if (item != null && p.casItem(item, null)) { // item不为null并且比较并替换item成功
// Successful CAS is the linearization point
// for item to be removed from this queue.
if (p != h) // p不等于h // hop two nodes at a time
// 更新头结点
updateHead(h, ((q = p.next) != null) ? q : p);
// 返回item
return item;
}
else if ((q = p.next) == null) { // q结点为null
// 更新头结点
updateHead(h, p);
return null;
}
else if (p == q) // p等于q
// 继续循环
continue restartFromHead;
else
// p赋值为q
p = q;
}
}
}
此函数用于获取并移除此队列的头,如果此队列为空,则返回 null。
下面模拟 poll 函数的操作,队列状态的变化(假设单线程操作,状态为之前 offer10、20 后的状态,poll 两次)。
- 队列初始状态如上图所示,在poll操作后,队列的状态如下图所示
- 如上图可知,poll操作后,head改变了,并且head所指向的结点的item变为了null。再进行一次poll操作,队列的状态如下图所示。
- 如上图可知,poll操作后,head结点没有变化,只是指示的结点的item域变成了null。
remove
public boolean remove(Object o) {
// 元素为null,返回
if (o == null) return false;
Node<E> pred = null;
for (Node<E> p = first(); p != null; p = succ(p)) { // 获取第一个存活的结点
// 第一个存活结点的item值
E item = p.item;
if (item != null &&
o.equals(item) &&
p.casItem(item, null)) { // 找到item相等的结点,并且将该结点的item设置为null
// p的后继结点
Node<E> next = succ(p);
if (pred != null && next != null) // pred不为null并且next不为null
// 比较并替换next域
pred.casNext(p, next);
return true;
}
// pred赋值为p
pred = p;
}
return false;
}
此函数用于从队列中移除指定元素的单个实例(如果存在)。其中,会调用到first函数和succ函数,first函数的源码如下:
Node<E> first() {
restartFromHead:
for (;;) { // 无限循环,确保成功
for (Node<E> h = head, p = h, q;;) {
// p结点的item域是否为null
boolean hasItem = (p.item != null);
if (hasItem || (q = p.next) == null) { // item不为null或者next域为null
// 更新头结点
updateHead(h, p);
// 返回结点
return hasItem ? p : null;
}
else if (p == q) // p等于q
// 继续从头结点开始
continue restartFromHead;
else
// p赋值为q
p = q;
}
}
}
first函数用于找到链表中第一个存活的结点。
succ函数源码如下:
final Node<E> succ(Node<E> p) {
// p结点的next域
Node<E> next = p.next;
// 如果next域为自身,则返回头结点,否则,返回next
return (p == next) ? head : next;
}
succ用于获取结点的下一个结点。如果结点的next域指向自身,则返回head头结点,否则,返回next结点。
下面模拟remove函数的操作,队列状态的变化(假设单线程操作,状态为之前offer10、20后的状态,执行remove(10)、remove(20)操作)。
- 如上图所示,为ConcurrentLinkedQueue的初始状态,remove(10)后的状态如下图所示
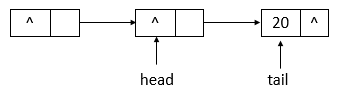
- 如上图所示,当执行remove(10)后,head指向了head结点之前指向的结点的下一个结点,并且head结点的item域置为null。继续执行remove(20),状态如下图所示

- 如上图所示,执行remove(20)后,head与tail指向同一个结点,item域为null。
size
public int size() {
// 计数
int count = 0;
for (Node<E> p = first(); p != null; p = succ(p)) // 从第一个存活的结点开始往后遍历
if (p.item != null) // 结点的item域不为null
// Collection.size() spec says to max out
if (++count == Integer.MAX_VALUE) // 增加计数,若达到最大值,则跳出循环
break;
// 返回大小
return count;
}
此函数用于返回ConcurrenLinkedQueue的大小,从第一个存活的结点(first)开始,往后遍历链表,当结点的item域不为null时,增加计数,之后返回大小。
应用示例
import java.util.concurrent.ConcurrentLinkedQueue;
class PutThread extends Thread {
private ConcurrentLinkedQueue<Integer> clq;
public PutThread(ConcurrentLinkedQueue<Integer> clq) {
this.clq = clq;
}
public void run() {
for (int i = 0; i < 10; i++) {
try {
System.out.println("add " + i);
clq.add(i);
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class GetThread extends Thread {
private ConcurrentLinkedQueue<Integer> clq;
public GetThread(ConcurrentLinkedQueue<Integer> clq) {
this.clq = clq;
}
public void run() {
for (int i = 0; i < 10; i++) {
try {
System.out.println("poll " + clq.poll());
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class ConcurrentLinkedQueueDemo {
public static void main(String[] args) {
ConcurrentLinkedQueue<Integer> clq = new ConcurrentLinkedQueue<Integer>();
PutThread p1 = new PutThread(clq);
GetThread g1 = new GetThread(clq);
p1.start();
g1.start();
}
}
GetThread 线程不会因为 ConcurrentLinkedQueue 队列为空而等待,而是直接返回 null,所以当实现队列不空时,等待时,则需要用户自己实现等待逻辑。
深入理解
HOPS:延迟更新策略
通过上面对offer和poll方法的分析,我们发现tail和head是延迟更新的,两者更新触发时机为:
tail更新触发时机:当tail指向的节点的下一个节点不为null的时候,会执行定位队列真正的队尾节点的操作,找到队尾节点后完成插入之后才会通过casTail进行tail更新;当tail指向的节点的下一个节点为null的时候,只插入节点不更新tail。head更新触发时机:当head指向的节点的item域为null的时候,会执行定位队列真正的队头节点的操作,找到队头节点后完成删除之后才会通过updateHead进行head更新;当head指向的节点的item域不为null的时候,只删除节点不更新head。
并且在更新操作时,源码中会有注释为:hop two nodes at a time。所以这种延迟更新的策略就被叫做HOPS的大概原因是这个,从上面更新时的状态图可以看出,head和tail的更新是“跳着的”即中间总是间隔了一个。那么这样设计的意图是什么呢?
如果让tail永远作为队列的队尾节点,实现的代码量会更少,而且逻辑更易懂。但是,这样做有一个缺点,如果大量的入队操作,每次都要执行CAS进行tail的更新,汇总起来对性能也会是大大的损耗。如果能减少CAS更新的操作,无疑可以大大提升入队的操作效率,所以doug lea大师每间隔1次(tail和队尾节点的距离为1)进行才利用CAS更新tail。对head的更新也是同样的道理,虽然,这样设计会多出在循环中定位队尾节点,但总体来说读的操作效率要远远高于写的性能,因此,多出来的在循环中定位尾节点的操作的性能损耗相对而言是很小的。
适用场景
通过无锁来做到了更高的并发量,是个高性能的队列,但是使用场景相对不如阻塞队列常见,毕竟取数据也要不停的去循环,不如阻塞的逻辑好设计,但是在并发量特别大的情况下,是个不错的选择,性能上好很多,而且这个队列的设计也是特别费力,尤其的使用的改良算法和对哨兵的处理。整体的思路都是比较严谨的,这个也是使用了无锁造成的,我们自己使用无锁的条件的话,这个队列是个不错的参考。
19 - CH19-BlockingQueue
BlockingQueue
通常用于一个线程生产对象,而另外一个线程消费这些对象的场景。下图是对这个原理的阐述:
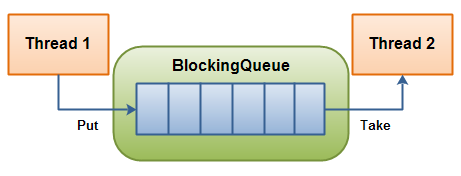
一个线程将会持续生产新对象并将其插入到队列之中,直到队列达到它所能容纳的临界点。也就是说,它是有限的。如果该阻塞队列到达了其临界点,负责生产的线程将会在往里边插入新对象时发生阻塞。它会一直处于阻塞之中,直到负责消费的线程从队列中拿走一个对象。 负责消费的线程将会一直从该阻塞队列中拿出对象。如果消费线程尝试去从一个空的队列中提取对象的话,这个消费线程将会处于阻塞之中,直到一个生产线程把一个对象丢进队列。
操作方法
具有 4 组不同的方法用于插入、移除以及对队列中的元素进行检查。如果请求的操作不能得到立即执行的话,每个方法的表现也不同。这些方法如下:
| 抛异常 | 布尔值 | 阻塞 | 超时 | |
|---|---|---|---|---|
| 插入 | add(o) | offer(o) | put(o) | offer(o,timeout,timeunit) |
| 移除 | remove(o) | poll(o) | take(o) | poll(timeout,timeunit) |
| 检查 | element(o) | peek(o) |
- 抛异常:如果试图的操作无法立即执行,抛一个异常。
- 特定值:如果试图的操作无法立即执行,返回一个特定的值(常常是 true / false)。
- 阻塞:如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行。
- 超时:如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行,但等待时间不会超过给定值。返回一个特定值以告知该操作是否成功(典型的是 true / false)。
无法向一个 BlockingQueue 中插入 null。如果你试图插入 null,BlockingQueue 将会抛出一个 NullPointerException。
可以访问到 BlockingQueue 中的所有元素,而不仅仅是开始和结束的元素。比如说,你将一个对象放入队列之中以等待处理,但你的应用想要将其取消掉。那么你可以调用诸如 remove(o) 方法来将队列之中的特定对象进行移除。但是这么干效率并不高(译者注: 基于队列的数据结构,获取除开始或结束位置的其他对象的效率不会太高),因此你尽量不要用这一类的方法,除非你确实不得不那么做。
BlockingDeque
BlockingDeque 接口表示一个线程安放入和提取实例的双端队列。
BlockingDeque 类是一个双端队列,在不能够插入元素时,它将阻塞住试图插入元素的线程;在不能够抽取元素时,它将阻塞住试图抽取的线程。 deque(双端队列) 是 “Double Ended Queue” 的缩写。因此,双端队列是一个你可以从任意一端插入或者抽取元素的队列。
在线程既是一个队列的生产者又是这个队列的消费者的时候可以使用到 BlockingDeque。如果生产者线程需要在队列的两端都可以插入数据,消费者线程需要在队列的两端都可以移除数据,这个时候也可以使用 BlockingDeque。BlockingDeque 图解:
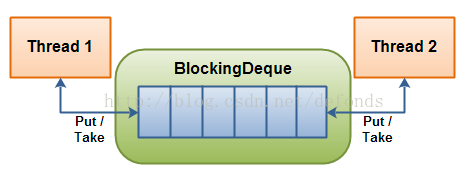
操作方法
一个 BlockingDeque - 线程在双端队列的两端都可以插入和提取元素。 一个线程生产元素,并把它们插入到队列的任意一端。如果双端队列已满,插入线程将被阻塞,直到一个移除线程从该队列中移出了一个元素。如果双端队列为空,移除线程将被阻塞,直到一个插入线程向该队列插入了一个新元素。
BlockingDeque 具有 4 组不同的方法用于插入、移除以及对双端队列中的元素进行检查。如果请求的操作不能得到立即执行的话,每个方法的表现也不同。这些方法如下:
| 抛异常 | 布尔值 | 阻塞 | 超时 | |
|---|---|---|---|---|
| 队首-插入 | addFirst(o) | offerFirst(o) | putFirst(o) | offerFirst(o, timeout, timeunit) |
| 队首-移除 | removeFirst(o) | pollFirst(o) | takeFirst(o) | pollFirst(timeout, timeunit) |
| 队首-检查 | getFirst(o) | peekFirst(o) | ||
| 队尾-插入 | addLast(o) | offerLast(o) | putLast(o) | offerLast(o, timeout, timeunit) |
| 队尾-移除 | removeLast(o) | pollLast(o) | takeLast(o) | pollLast(timeout, timeunit) |
| 队尾-检查 | getLast(o) | peekLast(o) |
- 抛异常:如果试图的操作无法立即执行,抛一个异常。
- 特定值:如果试图的操作无法立即执行,返回一个特定的值(常常是 true / false)。
- 阻塞:如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行。
- 超时:如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行,但等待时间不会超过给定值。返回一个特定值以告知该操作是否成功(典型的是 true / false)。
BlockingQueue & BlockingDeque
BlockingDeque 接口继承自 BlockingQueue 接口。这就意味着你可以像使用一个 BlockingQueue 那样使用 BlockingDeque。如果你这么干的话,各种插入方法将会把新元素添加到双端队列的尾端,而移除方法将会把双端队列的首端的元素移除。正如 BlockingQueue 接口的插入和移除方法一样。
应用实例
这里是一个 Java 中使用 BlockingQueue 的示例。本示例使用的是 BlockingQueue 接口的 ArrayBlockingQueue 实现。 首先,BlockingQueueExample 类分别在两个独立的线程中启动了一个 Producer 和 一个 Consumer。Producer 向一个共享的 BlockingQueue 中注入字符串,而 Consumer 则会从中把它们拿出来。
public class BlockingQueueExample {
public static void main(String[] args) throws Exception {
BlockingQueue queue = new ArrayBlockingQueue(1024);
Producer producer = new Producer(queue);
Consumer consumer = new Consumer(queue);
new Thread(producer).start();
new Thread(consumer).start();
Thread.sleep(4000);
}
}
以下是 Producer 类。注意它在每次 put() 调用时是如何休眠一秒钟的。这将导致 Consumer 在等待队列中对象的时候发生阻塞。
public class Producer implements Runnable{
protected BlockingQueue queue = null;
public Producer(BlockingQueue queue) {
this.queue = queue;
}
public void run() {
try {
queue.put("1");
Thread.sleep(1000);
queue.put("2");
Thread.sleep(1000);
queue.put("3");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
以下是 Consumer 类。它只是把对象从队列中抽取出来,然后将它们打印到 System.out。
public class Consumer implements Runnable{
protected BlockingQueue queue = null;
public Consumer(BlockingQueue queue) {
this.queue = queue;
}
public void run() {
try {
System.out.println(queue.take());
System.out.println(queue.take());
System.out.println(queue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
ArrayBlockingQueue
ArrayBlockingQueue 类实现了 BlockingQueue 接口。
ArrayBlockingQueue 是一个有界的阻塞队列,其内部实现是将对象放到一个数组里。有界也就意味着,它不能够存储无限多数量的元素。它有一个同一时间能够存储元素数量的上限。你可以在对其初始化的时候设定这个上限,但之后就无法对这个上限进行修改了。
ArrayBlockingQueue 内部以 FIFO(先进先出)的顺序对元素进行存储。队列中的头元素在所有元素之中是放入时间最久的那个,而尾元素则是最短的那个。
DelayQueue
DelayQueue 实现了 BlockingQueue 接口。
DelayQueue是一个无界的 BlockingQueue,用于放置实现了 Delayed 接口的对象,其中的对象只能在其到期时才能从队列中取走。这种队列是有序的,即队头对象的延迟到期时间最长。
元素进入队列后,先进行排序,然后,只有 getDelay 也就是剩余时间为0的时候,该元素才有资格被消费者从队列中取出来,所以构造函数一般都有一个时间传入。
public interface Delayed extends Comparable<Delayed< {
public long getDelay(TimeUnit timeUnit);
}
传递给 getDelay 方法的 getDelay 实例是一个枚举类型,它表明了将要延迟的时间段。
Delayed 接口也继承了 java.lang.Comparable 接口,这也就意味着 Delayed 对象之间可以进行对比。这个可能在对 DelayQueue 队列中的元素进行排序时有用,因此它们可以根据过期时间进行有序释放。 以下是使用 DelayQueue 的例子:
public class DelayQueueExample {
public static void main(String[] args) {
DelayQueue queue = new DelayQueue();
Delayed element1 = new DelayedElement();
queue.put(element1);
Delayed element2 = queue.take();
}
}
LinkedBlocingQueue
LinkedBlockingQueue 类实现了 BlockingQueue 接口。
LinkedBlockingQueue 内部以一个链式结构(链接节点)对其元素进行存储。如果需要的话,这一链式结构可以选择一个上限。如果没有定义上限,将使用 Integer.MAX_VALUE 作为上限。
LinkedBlockingQueue 内部以 FIFO(先进先出)的顺序对元素进行存储。队列中的头元素在所有元素之中是放入时间最久的那个,而尾元素则是最短的那个。
PriorityBlockingQueue
PriorityBlockingQueue 类实现了 BlockingQueue 接口。
PriorityBlockingQueue 是一个无界的并发队列。它使用了和类 java.util.PriorityQueue 一样的排序规则。你无法向这个队列中插入 null 值。 所有插入到 PriorityBlockingQueue 的元素必须实现 java.lang.Comparable 接口。因此该队列中元素的排序就取决于你自己的 Comparable 实现。 注意 PriorityBlockingQueue 对于具有相等优先级(compare() == 0)的元素并不强制任何特定行为。
同时注意,如果你从一个 PriorityBlockingQueue 获得一个 Iterator 的话,该 Iterator 并不能保证它对元素的遍历是以优先级为序的。
SynchronousQueue
SynchronousQueue 类实现了 BlockingQueue 接口。
SynchronousQueue 是一个特殊的队列,它的内部同时只能够容纳单个元素。如果该队列已有一元素的话,试图向队列中插入一个新元素的线程将会阻塞,直到另一个线程将该元素从队列中抽走。同样,如果该队列为空,试图向队列中抽取一个元素的线程将会阻塞,直到另一个线程向队列中插入了一条新的元素。 据此,把这个类称作一个队列显然是夸大其词了。它更多像是一个汇合点。
20 - CH20-FutureTask
概览
- FutureTask 为 Future 提供了基础实现,如获取任务执行结果(get)和取消任务等。
- 如果任务尚未完成,获取任务执行结果时将会阻塞。
- 一旦执行结束,任务就不能被重启或取消(除非使用runAndReset执行计算)。
- FutureTask 常用来封装 Callable 和 Runnable,也可以作为一个任务提交到线程池中执行。
- 除了作为一个独立的类之外,此类也提供了一些功能性函数供我们创建自定义 task 类使用。
- FutureTask 的线程安全由 CAS 来保证。
层级结构
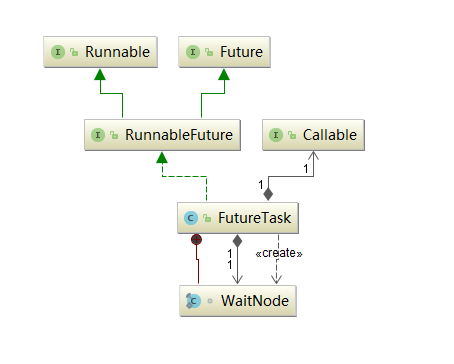
FutureTask 实现了 RunnableFuture 接口,则 RunnableFuture 接口继承了 Runnable 接口和 Future 接口,所以 FutureTask 既能当做一个 Runnable 直接被 Thread 执行,也能作为 Future 用来得到 Callable 的计算结果。
源码分析
Callable 接口
Callable 是个泛型接口,泛型V就是要 call() 方法返回的类型。对比 Runnable 接口,Runnable 不会返回数据也不能抛出异常。
public interface Callable<V> {
/**
* Computes a result, or throws an exception if unable to do so.
*
* @return computed result
* @throws Exception if unable to compute a result
*/
V call() throws Exception;
}
Future 接口
Future 接口代表异步计算的结果,通过 Future 接口提供的方法可以查看异步计算是否执行完成,或者等待执行结果并获取执行结果,同时还可以取消执行。Future 接口的定义如下:
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
- cancel:取消异步任务的执行。
- 如果异步任务已经完成或者已经被取消,或者由于某些原因不能取消,则会返回 false。
- 如果任务还没有被执行,则会返回 true 并且异步任务不会被执行。
- 如果任务已经开始执行了但是还没有执行完成:
- 若 mayInterruptIfRunning 为 true,则会立即中断执行任务的线程并返回 true;
- 若 mayInterruptIfRunning 为 false,则会返回 true 且不会中断任务执行线程。
- isCanceled:判断任务是否被取消。
- 如果任务在结束(正常执行结束或者执行异常结束)前被取消则返回 true,
- 否则返回 false。
- isDone:判断任务是否已经完成。
- 如果完成则返回 true,否则返回 false。
- 任务执行过程中发生异常、任务被取消也属于任务已完成,也会返回true。
- get:获取任务执行结果。
- 如果任务还没完成则会阻塞等待直到任务执行完成。
- 如果任务被取消则会抛出 CancellationException 异常。
- 如果任务执行过程发生异常则会抛出 ExecutionException 异常。
- 如果阻塞等待过程中被中断则会抛出 InterruptedException 异常。
- get(timeout,timeunit):带超时时间的 get() 版本。
- 如果阻塞等待过程中超时则会抛出 TimeoutException 异常。
核心属性
//内部持有的callable任务,运行完毕后置空
private Callable<V> callable;
//从get()中返回的结果或抛出的异常
private Object outcome; // non-volatile, protected by state reads/writes
//运行callable的线程
private volatile Thread runner;
//使用Treiber栈保存等待线程
private volatile WaitNode waiters;
//任务状态
private volatile int state;
private static final int NEW = 0;
private static final int COMPLETING = 1;
private static final int NORMAL = 2;
private static final int EXCEPTIONAL = 3;
private static final int CANCELLED = 4;
private static final int INTERRUPTING = 5;
private static final int INTERRUPTED = 6;
其中的状态值 state 使用 volatile 修饰,以确保任何一个线程对状态的修改立即会对其他线程可见。
7 种具体状态表示:
- NEW:初始状态,表示这个是新任务或者尚未被执行完的任务。
- COMPLETING:任务已经执行完成或者执行任务的时候发生异常。
- 但是任务执行结果或者异常原因还没有保存到 outcome 字段时,状态由 NEW 变为 COMPLETING。
- outcome字段用来保存任务执行结果,如果发生异常,则用来保存异常原因。
- 该状态持续时间较短,属于中间状态。
- NORMAL:任务已经执行完成并且任务执行结果已经保存到 outcome 字段,状态会从 COMPLETING 转换到 NORMAL。
- 这是一个最终态。
- EXCEPTIONAL:任务执行发生异常并且异常原因已经保存到 outcome 字段中后,状态会从 COMPLETING 转换到 EXCEPTIONAL。
- 这是一个最终态。
- CANCELED:任务还没开始执行或者已经开始执行但是还没有执行完成的时候,用户调用了
cancel(false)方法取消任务且不中断任务执行线程,这个时候状态会从 NEW 转化为 CANCELLED 状态。- 这是一个最终态。
- INTERRUPTING:任务还没开始执行或者已经执行但是还没有执行完成的时候,用户调用了
cancel(true)方法取消任务并且要中断任务执行线程但是还没有中断任务执行线程之前,状态会从 NEW 转化为 INTERRUPTING。- 这是一个中间状态。
- INTERRUPTED:调用 interrupt() 中断任务执行线程之后状态会从 INTERRUPTING 转换到 INTERRUPTED。
- 这是一个最终态。
- 所有值大于 COMPLETING 的状态都表示任务已经执行完成(任务正常执行完成,任务执行异常或者任务被取消)。
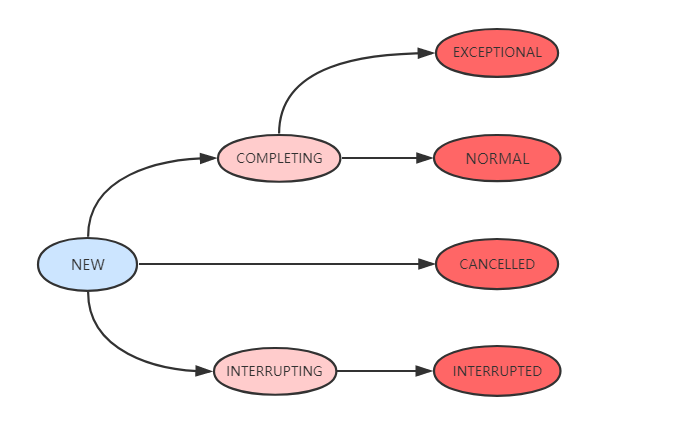
构造函数
FutureTask(Callable<V> callable)
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}
- 该构造函数会把传入的 Callable 变量保存在t his.callable 字段中。
- 该字段定义为
private Callable<V> callable; 用来保存底层的调用,在被执行完成以后会指向 null。 - 接着会初始化 state 字段为 NEW。
FutureTask(Runnable runnable, V result)
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW; // ensure visibility of callable
}
- 这个构造函数会把传入的 Runnable 封装成一个 Callable 对象保存在 callable 字段中。
- 同时如果任务执行成功的话就会返回传入的 result。
- 如果不需要返回值的话可以传入一个 null 作为 result。
- Executors.callable() 的功能是把 Runnable 转换成 Callable。
public static <T> Callable<T> callable(Runnable task, T result) {
if (task == null)
throw new NullPointerException();
return new RunnableAdapter<T>(task, result); // 适配器
}
这里采用了适配器模式:
static final class RunnableAdapter<T> implements Callable<T> {
final Runnable task;
final T result;
RunnableAdapter(Runnable task, T result) {
this.task = task;
this.result = result;
}
public T call() {
task.run();
return result;
}
}
这里的适配器只是简单实现了 Callable 接口,在 call 中调用 Runnable.run 方法,然后把传入的 result 作为返回值返回调用。
在 new 了一个 FutureTask 之后,接下来就是在另一个线程中执行该 Task,无论是通过直接 new 一个 Thread 还是通过线程池,执行的都是 run 方法。
核心方法:run
public void run() {
//新建任务,CAS替换runner为当前线程
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
set(result);//设置执行结果
}
} finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);//处理中断逻辑
}
}
- 运行任务:如果任务状态为NEW状态,则利用CAS修改为当前线程。执行完毕调用set(result)方法设置执行结果。set(result)源码如下:
protected void set(V v) {
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {
outcome = v;
UNSAFE.putOrderedInt(this, stateOffset, NORMAL); // final state
finishCompletion();//执行完毕,唤醒等待线程
}
}
- 首先利用cas修改state状态为COMPLETING,设置返回结果,然后使用 lazySet(UNSAFE.putOrderedInt)的方式设置state状态为NORMAL。结果设置完毕后,调用finishCompletion()方法唤醒等待线程,源码如下:
private void finishCompletion() {
// assert state > COMPLETING;
for (WaitNode q; (q = waiters) != null;) {
if (UNSAFE.compareAndSwapObject(this, waitersOffset, q, null)) {//移除等待线程
for (;;) {//自旋遍历等待线程
Thread t = q.thread;
if (t != null) {
q.thread = null;
LockSupport.unpark(t);//唤醒等待线程
}
WaitNode next = q.next;
if (next == null)
break;
q.next = null; // unlink to help gc
q = next;
}
break;
}
}
//任务完成后调用函数,自定义扩展
done();
callable = null; // to reduce footprint
}
- 回到run方法,如果在 run 期间被中断,此时需要调用handlePossibleCancellationInterrupt方法来处理中断逻辑,确保任何中断(例如cancel(true))只停留在当前run或runAndReset的任务中,源码如下:
private void handlePossibleCancellationInterrupt(int s) {
//在中断者中断线程之前可能会延迟,所以我们只需要让出CPU时间片自旋等待
if (s == INTERRUPTING)
while (state == INTERRUPTING)
Thread.yield(); // wait out pending interrupt
}
核心方法:get
//获取执行结果
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING)
s = awaitDone(false, 0L);
return report(s);
}
FutureTask 通过get()方法获取任务执行结果。如果任务处于未完成的状态(state <= COMPLETING),就调用awaitDone方法(后面单独讲解)等待任务完成。任务完成后,通过report方法获取执行结果或抛出执行期间的异常。report源码如下:
//返回执行结果或抛出异常
private V report(int s) throws ExecutionException {
Object x = outcome;
if (s == NORMAL)
return (V)x;
if (s >= CANCELLED)
throw new CancellationException();
throw new ExecutionException((Throwable)x);
}
核心方法:awaitDone(boolean timed, long nanos)
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
WaitNode q = null;
boolean queued = false;
for (;;) {//自旋
if (Thread.interrupted()) {//获取并清除中断状态
removeWaiter(q);//移除等待WaitNode
throw new InterruptedException();
}
int s = state;
if (s > COMPLETING) {
if (q != null)
q.thread = null;//置空等待节点的线程
return s;
}
else if (s == COMPLETING) // cannot time out yet
Thread.yield();
else if (q == null)
q = new WaitNode();
else if (!queued)
//CAS修改waiter
queued = UNSAFE.compareAndSwapObject(this, waitersOffset,
q.next = waiters, q);
else if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
removeWaiter(q);//超时,移除等待节点
return state;
}
LockSupport.parkNanos(this, nanos);//阻塞当前线程
}
else
LockSupport.park(this);//阻塞当前线程
}
}
awaitDone 用于等待任务完成,或任务因为中断或超时而终止。返回任务的完成状态。函数执行逻辑如下:
private void removeWaiter(WaitNode node) {
if (node != null) {
node.thread = null;//首先置空线程
retry:
for (;;) { // restart on removeWaiter race
//依次遍历查找
for (WaitNode pred = null, q = waiters, s; q != null; q = s) {
s = q.next;
if (q.thread != null)
pred = q;
else if (pred != null) {
pred.next = s;
if (pred.thread == null) // check for race
continue retry;
}
else if (!UNSAFE.compareAndSwapObject(this, waitersOffset,q, s)) //cas替换
continue retry;
}
break;
}
}
}
- 加入当前线程状态为结束(state>COMPLETING),则根据需要置空等待节点的线程,并返回 Future 状态;
- 如果当前状态为正在完成(COMPLETING),说明此时 Future 还不能做出超时动作,为任务让出CPU执行时间片;
- 如果state为NEW,先新建一个WaitNode,然后CAS修改当前waiters;
- 如果等待超时,则调用removeWaiter移除等待节点,返回任务状态;如果设置了超时时间但是尚未超时,则park阻塞当前线程;
- 其他情况直接阻塞当前线程。
核心方法:cancel(boolean mayInterruptIfRunning)
public boolean cancel(boolean mayInterruptIfRunning) {
//如果当前Future状态为NEW,根据参数修改Future状态为INTERRUPTING或CANCELLED
if (!(state == NEW &&
UNSAFE.compareAndSwapInt(this, stateOffset, NEW,
mayInterruptIfRunning ? INTERRUPTING : CANCELLED)))
return false;
try { // in case call to interrupt throws exception
if (mayInterruptIfRunning) {//可以在运行时中断
try {
Thread t = runner;
if (t != null)
t.interrupt();
} finally { // final state
UNSAFE.putOrderedInt(this, stateOffset, INTERRUPTED);
}
}
} finally {
finishCompletion();//移除并唤醒所有等待线程
}
return true;
}
尝试取消任务。如果任务已经完成或已经被取消,此操作会失败。
- 如果当前Future状态为NEW,根据参数修改Future状态为INTERRUPTING或CANCELLED。
- 如果当前状态不为NEW,则根据参数mayInterruptIfRunning决定是否在任务运行中也可以中断。中断操作完成后,调用finishCompletion移除并唤醒所有等待线程。
应用实例
Future & ExecutorService
public class FutureDemo {
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
Future future = executorService.submit(new Callable<Object>() {
@Override
public Object call() throws Exception {
Long start = System.currentTimeMillis();
while (true) {
Long current = System.currentTimeMillis();
if ((current - start) > 1000) {
return 1;
}
}
}
});
try {
Integer result = (Integer)future.get();
System.out.println(result);
}catch (Exception e){
e.printStackTrace();
}
}
}
FutureTask & ExecutorService
ExecutorService executor = Executors.newCachedThreadPool();
Task task = new Task();
FutureTask<Integer> futureTask = new FutureTask<Integer>(task);
executor.submit(futureTask);
executor.shutdown();
Future & Thread
import java.util.concurrent.*;
public class CallDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 2. 新建FutureTask,需要一个实现了Callable接口的类的实例作为构造函数参数
FutureTask<Integer> futureTask = new FutureTask<Integer>(new Task());
// 3. 新建Thread对象并启动
Thread thread = new Thread(futureTask);
thread.setName("Task thread");
thread.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Thread [" + Thread.currentThread().getName() + "] is running");
// 4. 调用isDone()判断任务是否结束
if(!futureTask.isDone()) {
System.out.println("Task is not done");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
int result = 0;
try {
// 5. 调用get()方法获取任务结果,如果任务没有执行完成则阻塞等待
result = futureTask.get();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("result is " + result);
}
// 1. 继承Callable接口,实现call()方法,泛型参数为要返回的类型
static class Task implements Callable<Integer> {
@Override
public Integer call() throws Exception {
System.out.println("Thread [" + Thread.currentThread().getName() + "] is running");
int result = 0;
for(int i = 0; i < 100;++i) {
result += i;
}
Thread.sleep(3000);
return result;
}
}
}
21 - CH21-ThreadPoolExecutor
线程池的作用
- 降低资源消耗:线程无限制的创建,使用完毕后消耗
- 提高响应速度:无需频繁新建线程
- 提高线程的可管理性
应用详解
线程池即一个线程集合 workerSet 和一个阻塞队列 workQueue。
当用户向线程池提交一个任务时,线程池会先将任务放入 workQueue 中。
workerSet 中的线程会不断的从 workQueue 中获取任务并执行。
当 workQueue 中没有任务时,worker 则会阻塞,直到队列中有任务了再开始执行。
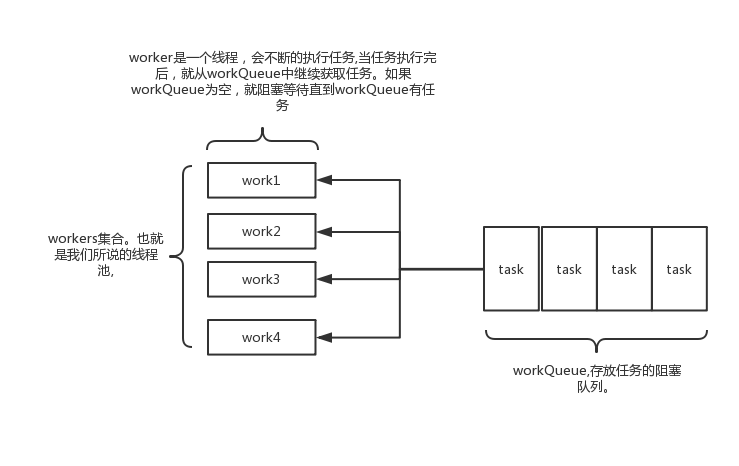
Executor 原理
当一个线程提交至线程池后:
- 线程池首先判断当前运行的线程数量是否少于与 corePoolSize。如果是则新建工作线程来执行任务,否则进入 2。
- 判断 BlockingQueue 是否已满,如果没满,则将任务放入 BlockingQueue,否则进入 3。
- 如果新建线程会使当前线程珊瑚粮超过 maximumPoolSize,则交给 RejectedExecutionHandler 来处理。
当 ThreadPoolExecutor 新建线程时,通过 CAS 来更新线程池的状态 ctl。
参数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler)
- corePoolSize:核心线程数。
- 当提交一个任务时,线程池新建线程来执行任务,直到线程数量等于 corePoolSize,即使存在空闲线程。
- 如果当前线程数量等于 corePoolSize,提交的任务将会被保存到阻塞队列,等待执行。
- 如果执行了线程池的 prestartAllCoreThreads 方法,线程池会提前创建并开启所有核心线程。
- workQueue:用于保存需要被执行的任务,可选的队列类型有:
- ArrayBlockingQueue:基于数组结构,按 FIFO 排序任务。
- LinkedBlockingQueue:基于链表结构,按 FIFO 排序任务,吞吐量高于 ArrayBlockingQueue。
- 比 ArrayBlockingQueue 在插入、删除元素时性能更优,但 put、take 时均需加锁。
- SynchronousQueue:不存储元素的阻塞队列,每个插入操作必须等待另一个线程调用移除操作,否则插入操作将一直阻塞,吞吐量高于 LinkedBlockingQueue。
- 使用无锁算法,基于节点状态执行判断,无需使用锁,核心是 Transfer.transfer。
- PriorityBlockingQueue:具有优先级的无界阻塞队列。
- maximumPoolSize:允许的最大线程数量。
- 如果阻塞队列已满后继续提交任务,则需创建新的线程来执行任务,前提是线程数小于最大允许数量。
- 当阻塞队列是无界队列时,则最大允许数量不起作用。
- keepAliveTime:线程空闲存活时间。
- 即当线程没有执行任务时,该线程继续存活的时间。
- 默认情况下,该参数只有在线程数量大于 corePoolSize 时才起效。
- 超过空闲存活时间的现场将被终止。
- unit:线程空闲存活时间的时间单位。
- threadFactory:创建线程的工厂,通过自定义工厂可以设置线程的属性,如名称、demaon。
- handler:线程池饱和策略。如果队列已满且没有空闲线程,如果继续提交任务,必须采取一种策略来处理该任务,共有四种策略:
- AbortPolicy:直接抛出异常,默认策略。
- CallerRunPolicy:用调用者线程来执行任务。
- DiscardOldestPolicy:丢弃队列中较靠前的任务,以执行当前任务。
- DiscardPolicy:直接丢弃任务。
- 支持自定义饱和策略,比如记录日志会持久化存储任务信息。
类型
newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
- 固定线程数量(corePoolSize)。
- 即使线程池没有可执行的任务,也不会终止线程。
- 采用无界队列 LinkedBlockingQueue(Integer.MAX_VALUE),潜在问题:
- 线程数量不会超过 corePoolSize,导致 maximumPoolSize 和 keepAliveTIme 参数失效。
- 采用无界队列导致永远不会拒绝提交的任务,导致饱和策略失效。
newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
- 初始化的线程池中仅一个线程,如果该线程异常结束,会新建线程以继续执行任务。
- 该唯一线程可以保证顺序处理队列中的任务。
- 基于无界队列,因此饱和策略失效。
newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
- 线程数最多可达 Integer.MAX_VALUE。
- 内部使用 SynchronousQueue 作为阻塞队列。
- 线程空间时间超过最大空闲时长会终止线程。
- 如果提交任务没有可用线程,则新建线程。
- 执行过程与前两个线程池不同:
- 主线程调用 SynchronousQueue.offer 添加 task,如果此时线程池中有空闲线程尝试读取队列中的任务,即调用 SynchronousQueue.poll,则主线程将该 task 交给空闲线程。否则进入下一步。
- 当线程池为空或没有空闲线程,则新建线程。
- 执行完任务的线程如果在 60 秒内空间,则被终止,因此长时间空闲的线程池不会持有任何线程资源。
关闭线程池
遍历线程池中的所有线程,然后逐个调用线程的 interrupt 方法来中断线程。
关闭方式:shutdown
将线程池里的线程状态设置成SHUTDOWN状态, 然后中断所有没有正在执行任务的线程。
关闭方式:shutdownNow
将线程池里的线程状态设置成STOP状态, 然后停止所有正在执行或暂停任务的线程。
只要调用这两个关闭方法中的任意一个, isShutDown() 返回true. 当所有任务都成功关闭了, isTerminated()返回true。
ThreadPoolExecutor
关键属性
//这个属性是用来存放 当前运行的worker数量以及线程池状态的
//int是32位的,这里把int的高3位拿来充当线程池状态的标志位,后29位拿来充当当前运行worker的数量
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
//存放任务的阻塞队列
private final BlockingQueue<Runnable> workQueue;
//worker的集合,用set来存放
private final HashSet<Worker> workers = new HashSet<Worker>();
//历史达到的worker数最大值
private int largestPoolSize;
//当队列满了并且worker的数量达到maxSize的时候,执行具体的拒绝策略
private volatile RejectedExecutionHandler handler;
//超出coreSize的worker的生存时间
private volatile long keepAliveTime;
//常驻worker的数量
private volatile int corePoolSize;
//最大worker的数量,一般当workQueue满了才会用到这个参数
private volatile int maximumPoolSize;
内部状态
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
其中AtomicInteger变量ctl的功能非常强大: 利用低29位表示线程池中线程数,通过高3位表示线程池的运行状态:
- RUNNING: -1 « COUNT_BITS,即高3位为111,该状态的线程池会接收新任务,并处理阻塞队列中的任务;
- SHUTDOWN: 0 « COUNT_BITS,即高3位为000,该状态的线程池不会接收新任务,但会处理阻塞队列中的任务;
- STOP : 1 « COUNT_BITS,即高3位为001,该状态的线程不会接收新任务,也不会处理阻塞队列中的任务,而且会中断正在运行的任务;
- TIDYING : 2 « COUNT_BITS,即高3位为010, 所有的任务都已经终止;
- TERMINATED: 3 « COUNT_BITS,即高3位为011, terminated()方法已经执行完成
执行过程
execute –> addWorker –> runworker(getTask)
- 线程池的工作线程通过Woker类实现,在ReentrantLock锁的保证下,把Woker实例插入到HashSet后,并启动Woker中的线程。
- 从Woker类的构造方法实现可以发现: 线程工厂在创建线程thread时,将Woker实例本身this作为参数传入,当执行start方法启动线程thread时,本质是执行了Worker的runWorker方法。
- firstTask执行完成之后,通过getTask方法从阻塞队列中获取等待的任务,如果队列中没有任务,getTask方法会被阻塞并挂起,不会占用cpu资源;
execute 方法
ThreadPoolExecutor.execute(task)实现了Executor.execute(task)
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
//workerCountOf获取线程池的当前线程数;小于corePoolSize,执行addWorker创建新线程执行command任务
if (addWorker(command, true))
return;
c = ctl.get();
}
// double check: c, recheck
// 线程池处于RUNNING状态,把提交的任务成功放入阻塞队列中
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// recheck and if necessary 回滚到入队操作前,即倘若线程池shutdown状态,就remove(command)
//如果线程池没有RUNNING,成功从阻塞队列中删除任务,执行reject方法处理任务
if (! isRunning(recheck) && remove(command))
reject(command);
//线程池处于running状态,但是没有线程,则创建线程
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 往线程池中创建新的线程失败,则reject任务
else if (!addWorker(command, false))
reject(command);
}
- 为什么需要double check线程池的状态?
在多线程环境下,线程池的状态时刻在变化,而ctl.get()是非原子操作,很有可能刚获取了线程池状态后线程池状态就改变了。判断是否将command加入workque是线程池之前的状态。倘若没有double check,万一线程池处于非running状态(在多线程环境下很有可能发生),那么command永远不会执行。
addWorker 方法
从方法execute的实现可以看出: addWorker主要负责创建新的线程并执行任务。
线程池创建新线程执行任务时,需要获取全局锁:
private final ReentrantLock mainLock = new ReentrantLock();
private boolean addWorker(Runnable firstTask, boolean core) {
// CAS更新线程池数量
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
// 线程池重入锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start(); // 线程启动,执行任务(Worker.thread(firstTask).start());
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
Worker.runWorker 方法
private final class Worker extends AbstractQueuedSynchronizer implements Runnable{
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this); // 创建线程
}
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}
// ...
}
- 继承了AQS类,可以方便的实现工作线程的中止操作;
- 实现了Runnable接口,可以将自身作为一个任务在工作线程中执行;
- 当前提交的任务firstTask作为参数传入Worker的构造方法;
一些属性还有构造方法:
//运行的线程,前面addWorker方法中就是直接通过启动这个线程来启动这个worker
final Thread thread;
//当一个worker刚创建的时候,就先尝试执行这个任务
Runnable firstTask;
//记录完成任务的数量
volatile long completedTasks;
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
//创建一个Thread,将自己设置给他,后面这个thread启动的时候,也就是执行worker的run方法
this.thread = getThreadFactory().newThread(this);
}
runWorker方法是线程池的核心:
- 线程启动之后,通过unlock方法释放锁,设置AQS的state为0,表示运行可中断;
- Worker执行firstTask或从workQueue中获取任务
- 进行加锁操作,保证thread不被其他线程中断(除非线程池被中断)
- 检查线程池状态,倘若线程池处于中断状态,当前线程将中断。
- 执行beforeExecute
- 执行任务的run方法
- 执行afterExecute方法
- 解锁操作
通过getTask方法从阻塞队列中获取等待的任务,如果队列中没有任务,getTask方法会被阻塞并挂起,不会占用cpu资源;
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
// 先执行firstTask,再从workerQueue中取task(getTask())
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
getTask 方法
下面来看一下getTask()方法,这里面涉及到keepAliveTime的使用,从这个方法我们可以看出先吃池是怎么让超过corePoolSize的那部分worker销毁的。
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
注意这里一段代码是keepAliveTime起作用的关键:
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
- allowCoreThreadTimeOut为false,线程即使空闲也不会被销毁;
- 倘若为ture,在keepAliveTime内仍空闲则会被销毁。
如果线程允许空闲等待而不被销毁timed == false,workQueue.take任务:
如果阻塞队列为空,当前线程会被挂起等待;
当队列中有任务加入时,线程被唤醒,take方法返回任务,并执行;
如果线程不允许无休止空闲timed == true, workQueue.poll任务: 如果在keepAliveTime时间内,阻塞队列还是没有任务,则返回null;
提交过程
- submit任务,等待线程池execute
- 执行FutureTask类的get方法时,会把主线程封装成WaitNode节点并保存在waiters链表中, 并阻塞等待运行结果;
- FutureTask任务执行完成后,通过UNSAFE设置waiters相应的waitNode为null,并通过LockSupport类unpark方法唤醒主线程;
在实际业务场景中,Future和Callable基本是成对出现的,Callable负责产生结果,Future负责获取结果。
- Callable接口类似于Runnable,只是Runnable没有返回值。
- Callable任务除了返回正常结果之外,如果发生异常,该异常也会被返回,即Future可以拿到异步执行任务各种结果;
- Future.get方法会导致主线程阻塞,直到Callable任务执行完成;
submit 方法
AbstractExecutorService.submit()实现了ExecutorService.submit() 可以获取执行完的返回值, 而ThreadPoolExecutor 是AbstractExecutorService.submit()的子类,所以submit方法也是ThreadPoolExecutor的方法。
// submit()在ExecutorService中的定义
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
// submit方法在AbstractExecutorService中的实现
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
// 通过submit方法提交的Callable任务会被封装成了一个FutureTask对象。
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
通过submit方法提交的Callable任务会被封装成了一个FutureTask对象。通过Executor.execute方法提交FutureTask到线程池中等待被执行,最终执行的是FutureTask的run方法;
关闭过程
shutdown方法会将线程池的状态设置为SHUTDOWN,线程池进入这个状态后,就拒绝再接受任务,然后会将剩余的任务全部执行完:
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//检查是否可以关闭线程
checkShutdownAccess();
//设置线程池状态
advanceRunState(SHUTDOWN);
//尝试中断worker
interruptIdleWorkers();
//预留方法,留给子类实现
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
tryTerminate();
}
private void interruptIdleWorkers() {
interruptIdleWorkers(false);
}
private void interruptIdleWorkers(boolean onlyOne) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//遍历所有的worker
for (Worker w : workers) {
Thread t = w.thread;
//先尝试调用w.tryLock(),如果获取到锁,就说明worker是空闲的,就可以直接中断它
//注意的是,worker自己本身实现了AQS同步框架,然后实现的类似锁的功能
//它实现的锁是不可重入的,所以如果worker在执行任务的时候,会先进行加锁,这里tryLock()就会返回false
if (!t.isInterrupted() && w.tryLock()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
} finally {
w.unlock();
}
}
if (onlyOne)
break;
}
} finally {
mainLock.unlock();
}
}
shutdownNow做的比较绝,它先将线程池状态设置为STOP,然后拒绝所有提交的任务。最后中断左右正在运行中的worker,然后清空任务队列。
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
//检测权限
advanceRunState(STOP);
//中断所有的worker
interruptWorkers();
//清空任务队列
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
private void interruptWorkers() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//遍历所有worker,然后调用中断方法
for (Worker w : workers)
w.interruptIfStarted();
} finally {
mainLock.unlock();
}
}
配置线程池需要考虑因素
从任务的优先级,任务的执行时间长短,任务的性质(CPU密集/ IO密集),任务的依赖关系这四个角度来分析。并且近可能地使用有界的工作队列。
性质不同的任务可用使用不同规模的线程池分开处理:
- CPU密集型: 尽可能少的线程,Ncpu+1
- IO密集型: 尽可能多的线程, Ncpu*2,比如数据库连接池
- 混合型: CPU密集型的任务与IO密集型任务的执行时间差别较小,拆分为两个线程池;否则没有必要拆分。
监控线程池的状态
可以使用ThreadPoolExecutor以下方法:
- getTaskCount
- getCompletedTaskCount
- getLargestPoolSize
- getPoolSize
- getActiveCount
参考
22 - CH22-ScheduledThreadPoolExecutor
概览
继承自 ThreadPoolExecutor,为任务提供延迟或周期执行,属于线程池的一种。相比 ThreadPoolExecutor 具有以下特性:
- 使用专门的任务类型—ScheduledFutureTask 来执行周期任务,也可以接收无需时间调度的任务(这些任务通过 ExecutorService 直接执行)。
- 使用专门的存储队列—DelayedWorkQueue 来存储任务,DelayedWorkQueue 是无界延迟队列 DelayedQueue 的一种。相比 ThreadPoolExecutor 简化了执行机制。
- 支持可选的 run-after-shutdown 参数,在池被关闭(shutdown)之后支持可选的逻辑来决定是否继续运行周期或延迟任务。并且当任务的(重新)提交操作与 shutdown 操作重叠时,复查逻辑也不相同。
层级结构
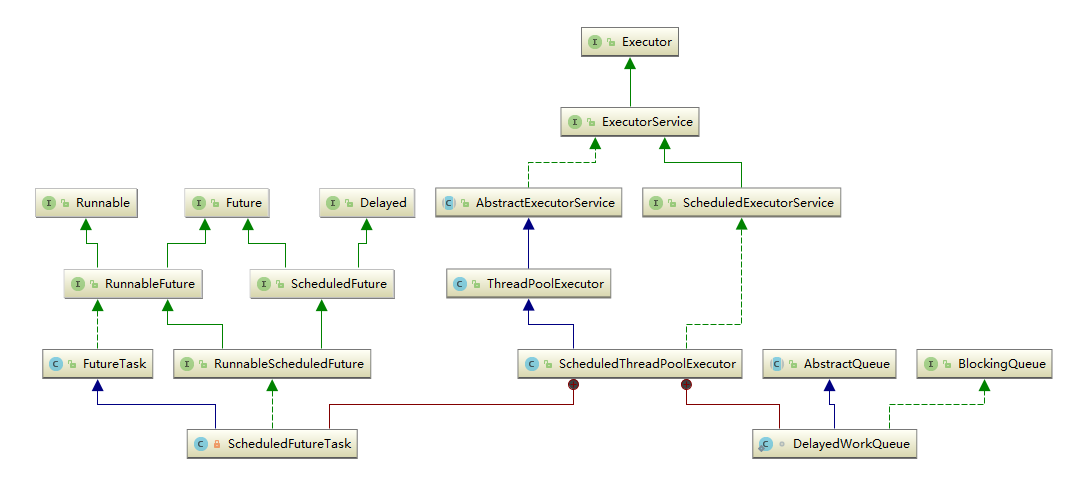
ScheduledThreadPoolExecutor 内部构造了两个类:
- ScheduledFutureTask:
- 继承 FutureTask,说明是一个异步运算任务。
- 实现 Rnnable、Future、Delayed 接口,说明是一个可以延迟执行的异步运算任务。
- DelayedWorkQueue:
- 专用于存储周期或延迟任务而定义的延迟队列,继承了 AbstractQueue,为了契合 ThreadPoolExecutor 也实现了 BlockingQueue 接口。
- 内部只允许存储 RunnableScheduledFuture 类型的任务。
- 与 DelayQueue 的不同之处在于它只允许存放 RunnableScheduledFuture 对象,并且自己实现了二叉堆(DelayQueue 利用了 PriorityQueue 的二叉堆结构)。
源码分析
内部类:ScheduledFutureTask
属性:
//为相同延时任务提供的顺序编号
private final long sequenceNumber;
//任务可以执行的时间,纳秒级
private long time;
//重复任务的执行周期时间,纳秒级。
private final long period;
//重新入队的任务
RunnableScheduledFuture<V> outerTask = this;
//延迟队列的索引,以支持更快的取消操作
int heapIndex;
- sequenceNumber:当两个任务具有相同的延迟时间时,按照 FIFO 的顺序入队,用于给这些任务编号。
- time:任务可以执行的时间点,纳秒单位,通过 triggerTime 方法计算得出。
- period:任务执行的周期间隔,那秒单位。
- 正数表示固定速率执行(为 scheduleAtFixedRate 提供服务)
- 负数表示固定延迟执行(为 scheduleWithFixedDelay 提供服务)
- 0 表示不重复执行。
- outerTask:重新入队的任务,通过 reExecutePeriodic 方法入队重新排序。
核心方法:run
public void run() {
boolean periodic = isPeriodic();//是否为周期任务
if (!canRunInCurrentRunState(periodic))//当前状态是否可以执行
cancel(false);
else if (!periodic)
//不是周期任务,直接执行
ScheduledFutureTask.super.run();
else if (ScheduledFutureTask.super.runAndReset()) {
setNextRunTime();//设置下一次运行时间
reExecutePeriodic(outerTask);//重排序一个周期任务
}
}
ScheduledFutureTask 的 run 方法重写了 FutureTask 的版本,以便执行周期任务时重置、重排任务。任务的执行通过父类 FutureTask.run 实现。
内部有两个针对周期任务的方法:
setNextRunTime:用于设置下一次运行的时间:
//设置下一次执行任务的时间 private void setNextRunTime() { long p = period; if (p > 0) //固定速率执行,scheduleAtFixedRate time += p; else time = triggerTime(-p); //固定延迟执行,scheduleWithFixedDelay } //计算固定延迟任务的执行时间 long triggerTime(long delay) { return now() + ((delay < (Long.MAX_VALUE >> 1)) ? delay : overflowFree(delay)); }reExecutePeriodic:周期任务重新入队等待下一次执行:
//重排序一个周期任务 void reExecutePeriodic(RunnableScheduledFuture<?> task) { if (canRunInCurrentRunState(true)) {//池关闭后可继续执行 super.getQueue().add(task);//任务入列 //重新检查run-after-shutdown参数,如果不能继续运行就移除队列任务,并取消任务的执行 if (!canRunInCurrentRunState(true) && remove(task)) task.cancel(false); else ensurePrestart();//启动一个新的线程等待任务 } }
reExecutePeriodic 与 delayedExecute 的执行策略一致,只不过 reExecutePeriodic 不会执行拒绝策略而是直接丢弃任务。
cancel
public boolean cancel(boolean mayInterruptIfRunning) {
boolean cancelled = super.cancel(mayInterruptIfRunning);
if (cancelled && removeOnCancel && heapIndex >= 0)
remove(this);
return cancelled;
}
ScheduledFutureTask.cancel 本质上由其父类 FutureTask.cancel 实现。取消任务成功后会根据 removeOnCancel 参数来决定是否从队列中移除该任务。
核心属性
//关闭后继续执行已经存在的周期任务
private volatile boolean continueExistingPeriodicTasksAfterShutdown;
//关闭后继续执行已经存在的延时任务
private volatile boolean executeExistingDelayedTasksAfterShutdown = true;
//取消任务后移除
private volatile boolean removeOnCancel = false;
//为相同延时的任务提供的顺序编号,保证任务之间的FIFO顺序
private static final AtomicLong sequencer = new AtomicLong();
- 前两个参数是由 ScheduledThreadPoolExecutor 定义的 run-after-shutdown 参数,用于控制池关闭后任务的执行逻辑。
- removeOnCancel:用于控制取消任务后是否从队列中移除。
- 当一个已经提交的周期或延迟任务在运行之前被取消,那么它之后将不会再被执行。
- 默认配置下,这种已经取消的任务在届期之前不会被移除。
- 通过这种机制,可以方便检查和监控线程池状态,但也可能导致已经取消的任务无线滞留。
- 为了避免无线滞留,可以通过 setRemoveOnCancelPolicy 来设置移除策略,将参数 removeOnCancel 设为 true 可以在任务取消后立即从队列中移除。
- sequencer 是为具有相同延时时间的任务提供顺序编号,保证任务之间的 FIFO 顺序。与 ScheduledFutureTask 内部的 sequenceNumber 参数作用一致。
构造函数
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory, handler);
}
- 核心线程数
- 线程工厂
- 拒绝策略
核心方法:schedule
public <V> ScheduledFuture<V> schedule(Callable<V> callable,
long delay,
TimeUnit unit) {
if (callable == null || unit == null)
throw new NullPointerException();
RunnableScheduledFuture<V> t = decorateTask(callable,
new ScheduledFutureTask<V>(callable, triggerTime(delay, unit)));//构造ScheduledFutureTask任务
delayedExecute(t);//任务执行主方法
return t;
}
主要用于执行一次性延迟任务,执行逻辑分为两步:
封装 Callable/Runnable:通过 triggerTime 计算出任务的延迟执行时加点,然后通过 ScheduledFutureTask 的构造函数将 Runnable/Callable 任务构造为 ScheduledThreadPoolExecutor 可以执行的任务类型,最后调用 decorateTask 方法执行用户自定义的任务逻辑。
- decorateTask 是一个用户可以自定义扩展的方法,默认实现下直接返回封装的 RunnableScheduledFuture:
protected <V> RunnableScheduledFuture<V> decorateTask( Runnable runnable, RunnableScheduledFuture<V> task) { return task; }执行任务:通过 delayedExecute 实现:
private void delayedExecute(RunnableScheduledFuture<?> task) { if (isShutdown()) reject(task);//池已关闭,执行拒绝策略 else { super.getQueue().add(task);//任务入队 if (isShutdown() && !canRunInCurrentRunState(task.isPeriodic()) &&//判断run-after-shutdown参数 remove(task))//移除任务 task.cancel(false); else ensurePrestart();//启动一个新的线程等待任务 } }- 如果池已经关闭(ctr <= SHUTDOWN),执行任务拒绝策略。
- 池正在运行,首先将任务入队排序,然后重新检查池的关闭状态,执行如下逻辑:
- 如果池正在运行,或者 run-after-shutdown 参数为 true,则调用父类方法 ensurePrestart 启动新线程等待执行任务。
- 如果池已经关闭,并且 run-after-shutdown 参数为 false,则执行父类(ThreadPoolExecutor)方法 remove 移除队列中的指定任务,成功移除后调用 ScheduledFutureTask.cancel 取消任务。
ensurePrestart 源码如下:
void ensurePrestart() {
int wc = workerCountOf(ctl.get());
if (wc < corePoolSize)
addWorker(null, true);
else if (wc == 0)
addWorker(null, false);
}
ensurePrestart是父类 ThreadPoolExecutor 的方法,用于启动一个新的工作线程等待执行任务,即使corePoolSize为0也会安排一个新线程。
核心方法:scheduleAtFixedRate、scheduleWithFixedDelay
/**
* 创建一个周期执行的任务,第一次执行延期时间为initialDelay,
* 之后每隔period执行一次,不等待第一次执行完成就开始计时
*/
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (period <= 0)
throw new IllegalArgumentException();
//构建RunnableScheduledFuture任务类型
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),//计算任务的延迟时间
unit.toNanos(period));//计算任务的执行周期
RunnableScheduledFuture<Void> t = decorateTask(command, sft);//执行用户自定义逻辑
sft.outerTask = t;//赋值给outerTask,准备重新入队等待下一次执行
delayedExecute(t);//执行任务
return t;
}
/**
* 创建一个周期执行的任务,第一次执行延期时间为initialDelay,
* 在第一次执行完之后延迟delay后开始下一次执行
*/
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (delay <= 0)
throw new IllegalArgumentException();
//构建RunnableScheduledFuture任务类型
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),//计算任务的延迟时间
unit.toNanos(-delay));//计算任务的执行周期
RunnableScheduledFuture<Void> t = decorateTask(command, sft);//执行用户自定义逻辑
sft.outerTask = t;//赋值给outerTask,准备重新入队等待下一次执行
delayedExecute(t);//执行任务
return t;
}
二者的区别在于 unit.toNanos,scheduleAtFixedRate 传的是正值,而 scheduleWithFixedDelay 传的则是负值,这个值就是 ScheduledFutureTask 的 period 属性。
核心方法:shutdown
public void shutdown() {
super.shutdown();
}
//取消并清除由于关闭策略不应该运行的所有任务
@Override void onShutdown() {
BlockingQueue<Runnable> q = super.getQueue();
//获取run-after-shutdown参数
boolean keepDelayed =
getExecuteExistingDelayedTasksAfterShutdownPolicy();
boolean keepPeriodic =
getContinueExistingPeriodicTasksAfterShutdownPolicy();
if (!keepDelayed && !keepPeriodic) {//池关闭后不保留任务
//依次取消任务
for (Object e : q.toArray())
if (e instanceof RunnableScheduledFuture<?>)
((RunnableScheduledFuture<?>) e).cancel(false);
q.clear();//清除等待队列
}
else {//池关闭后保留任务
// Traverse snapshot to avoid iterator exceptions
//遍历快照以避免迭代器异常
for (Object e : q.toArray()) {
if (e instanceof RunnableScheduledFuture) {
RunnableScheduledFuture<?> t =
(RunnableScheduledFuture<?>)e;
if ((t.isPeriodic() ? !keepPeriodic : !keepDelayed) ||
t.isCancelled()) { // also remove if already cancelled
//如果任务已经取消,移除队列中的任务
if (q.remove(t))
t.cancel(false);
}
}
}
}
tryTerminate(); //终止线程池
}
池关闭方法调用了父类ThreadPoolExecutor的shutdown。
在shutdown方法中调用了关闭钩子onShutdown方法,它的主要作用是在关闭线程池后取消并清除由于关闭策略不应该运行的所有任务,这里主要是根据 run-after-shutdown 参数(continueExistingPeriodicTasksAfterShutdown和executeExistingDelayedTasksAfterShutdown)来决定线程池关闭后是否关闭已经存在的任务。
深入理解
为什么ThreadPoolExecutor 的调整策略却不适用于 ScheduledThreadPoolExecutor?
例如: 由于 ScheduledThreadPoolExecutor 是一个固定核心线程数大小的线程池,并且使用了一个无界队列,所以调整maximumPoolSize对其没有任何影响(所以 ScheduledThreadPoolExecutor 没有提供可以调整最大线程数的构造函数,默认最大线程数固定为Integer.MAX_VALUE)。此外,设置corePoolSize为0或者设置核心线程空闲后清除(allowCoreThreadTimeOut)同样也不是一个好的策略,因为一旦周期任务到达某一次运行周期时,可能导致线程池内没有线程去处理这些任务。
Executors 提供了哪几种方法来构造 ScheduledThreadPoolExecutor?
- newScheduledThreadPool: 可指定核心线程数的线程池。
- newSingleThreadScheduledExecutor: 只有一个工作线程的线程池。如果内部工作线程由于执行周期任务异常而被终止,则会新建一个线程替代它的位置。
注意: newScheduledThreadPool(1, threadFactory) 不等价于newSingleThreadScheduledExecutor。newSingleThreadScheduledExecutor创建的线程池保证内部只有一个线程执行任务,并且线程数不可扩展;而通过newScheduledThreadPool(1, threadFactory)创建的线程池可以通过setCorePoolSize方法来修改核心线程数。
23 - CH23-ForkJoin.md
概览
ForkJoin 框架是 JUC 中一种可以将大任务拆分为多个小任务并异步执行的工具,由 JDK 1.7 引入。
层级结构
主要包含 3 个模块:
- 任务对象:ForkJoinTask
- RecursiveTask
- RecursiveAction
- CountedCompleter
- 执行线程:ForkJoinWorkerThread
- 线程池:ForkJoinPool
ForkJoinPool 可以通过池中的 ForkJoinThread 来处理 ForkJoinTask。
// from 《A Java Fork/Join Framework》Dong Lea
Result solve(Problem problem) {
if (problem is small)
directly solve problem
else {
split problem into independent parts
fork new subtasks to solve each part
join all subtasks
compose result from subresults
}
}
- ForkJoinPool 只接收 ForkJoinTask 任务(在实际使用中,也可以接收 Runnable/Callable 任务,但在真正运行时,也会把这些任务封装成 ForkJoinTask 类型的任务)。
- RecursiveTask 是 ForkJoinTask 的子类,是一个可以递归执行的 ForkJoinTask。
- RecursiveAction 是一个无返回值的 RecursiveTask。
- CountedCompleter 在任务完成执行后会触发执行一个自定义的钩子函数。
在实际运用中,我们一般都会继承 RecursiveTask 、RecursiveAction 或 CountedCompleter 来实现我们的业务需求,而不会直接继承 ForkJoinTask 类。
核心思想:分治算法
分治算法(Divide-and-Conquer)把任务递归的拆分为各个子任务,这样可以更好的利用系统资源,尽可能的使用所有可用的计算能力来提升应用性能。首先看一下 Fork/Join 框架的任务运行机制:
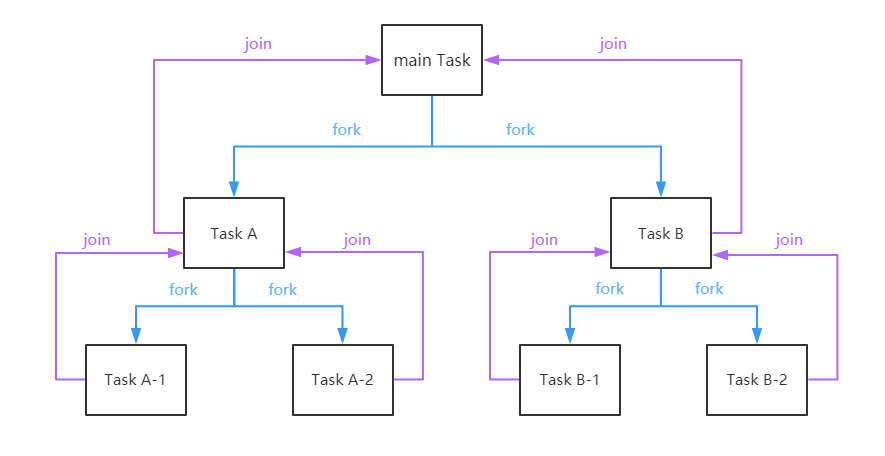
核心思想:work-stealing
work-stealing(工作窃取)算法: 线程池内的所有工作线程都尝试找到并执行已经提交的任务,或者是被其他活动任务创建的子任务(如果不存在就阻塞等待)。
这种特性使得 ForkJoinPool 在运行多个可以产生子任务的任务,或者是提交的许多小任务时效率更高。尤其是构建异步模型的 ForkJoinPool 时,对不需要合并(join)的事件类型任务也非常适用。
在 ForkJoinPool 中,线程池中每个工作线程(ForkJoinWorkerThread)都对应一个任务队列(WorkQueue),工作线程优先处理来自自身队列的任务(LIFO或FIFO顺序,参数 mode 决定),然后以FIFO的顺序随机窃取其他队列中的任务。
具体思路如下:
- 每个线程都有自己的 WorkQueue,这是一个双端队列。
- 队列支持三个功能:push、pop、poll。
- push、pop 只能被队列的拥有线程调用,而 poll 可以被其他线程调用。
- 划分的子任务调用 fork 时,都会被 push 到自己的队列中。
- 默认情况下,工作线程从自己的双端队列中获取任务并执行。
- 当工作线程自己的队列已空,会随机从另一个线程的队列的尾部调用 poll 方法窃取任务。
执行流程
上图可以看出任务有两类:
- 直接通过 ForkJoinPool 提交的外部任务,存放在 workQueues 的偶数槽位。
- 通过内部 fork 分割的子任务,存放在 workQueues 的奇数槽位。
类层级
继承关系
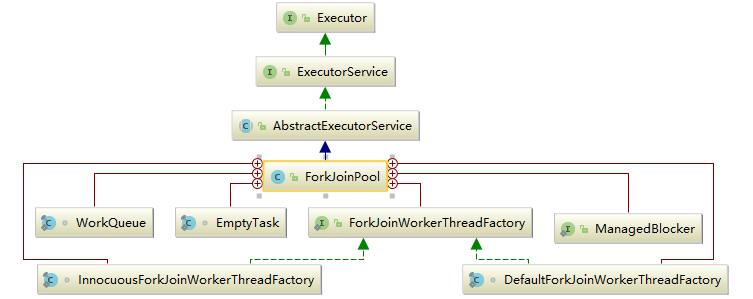
内部类
- ForkJoinWorkerThreadFactory:内部线程工厂接口,用于创建工作线程 ForkJoinWorkerThread。
- DefautFaorkJoinWorkerThreadFactory:默认线程工厂。
- InnocuousForkJoinWorkerThreadFactory:无许可线程工厂,当系统变量中存在系统安全相关的属性时,使用该线程工厂。
- EmptyTask:内部占位类,用户替换队列中 join 的任务。
- ManagedBlocker:为 ForkJoinPool 中的任务提供扩展管理并行数的接口,一般用于可能会阻塞的任务。
- WorkQueue:ForkJoinPool 的核心数据结构,本质上是 work-stealing 模式的双端任务队列,内部存放 ForkJoinTask 任务对象,使用 @Contented 注解修饰防止伪共享。
- 工作线程在运行中产生新的任务(通常是应为调用了 fork)时,可以把 WorkQueue 的数据结构视为一个栈,新的任务放入栈顶;工作线程在处理自己队列中的任务时,按照 LIFO 的顺序。
- 工作线程在处理自己的工作队列的同时,会尝试窃取一个任务(可能来自刚刚提交到池的任务,或是来之其他工作线程的队列任务),此时可以把 WorkQueue 的数据结构视为一个 FIFO 队列,窃取任务唯一其他线程的工作队列的队首。
- 伪共享状态:缓存系统中是以缓存行(cache line)为单位存储的。缓存行是 2 的整数幂个连续字节,一般为 32-256 个字节。最常见的缓存行大小是 64 字节。但多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,即伪共享。
ForkJoinTask 继承关系
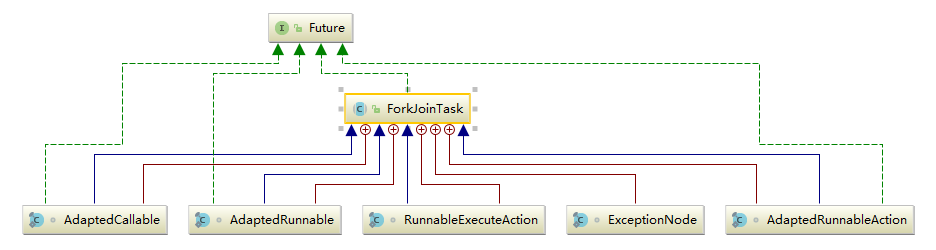
- ForkJoinTask 实现了 Future 接口,说明它也是一个可取消的异步运算任务。
- 实际上ForkJoinTask 是 Future 的轻量级实现,主要用在纯粹是计算的函数式任务或者操作完全独立的对象计算任务。
- fork 是主运行方法,用于异步执行;而 join 方法在任务结果计算完毕之后才会运行,用来合并或返回计算结果。
- 其内部类都比较简单:
- ExceptionNode 是用于存储任务执行期间的异常信息的单向链表;
- 其余四个类是为 Runnable/Callable 任务提供的适配器类,用于把 Runnable/Callable 转化为 ForkJoinTask 类型的任务(因为 ForkJoinPool 只可以运行 ForkJoinTask 类型的任务)。
源码解析
- 提交流程:外部任务提交
- 提交流程:子任务提交
- 执行过程:ForkJoinWorkerThread.run -> ForkJoinTask.doExec
- 结果获取:ForkJoinTask.join -> ForkJoinTask.invoke
ForkJoinPool
核心参数
在后面的源码解析中,我们会看到大量的位运算,这些位运算都是通过我们接下来介绍的一些常量参数来计算的。
例如,如果要更新活跃线程数,使用公式(UC_MASK & (c + AC_UNIT)) | (SP_MASK & c);c 代表当前 ctl,UC_MASK 和 SP_MASK 分别是高位和低位掩码,AC_UNIT 为活跃线程的增量数,使用(UC_MASK & (c + AC_UNIT))就可以计算出高32位,然后再加上低32位(SP_MASK & c),就拼接成了一个新的ctl。
ForkJoinPool 与 内部类 WorkQueue 共享的一些常量:
// Constants shared across ForkJoinPool and WorkQueue
// 限定参数
static final int SMASK = 0xffff; // 低位掩码,也是最大索引位
static final int MAX_CAP = 0x7fff; // 工作线程最大容量
static final int EVENMASK = 0xfffe; // 偶数低位掩码
static final int SQMASK = 0x007e; // workQueues 数组最多64个槽位
// ctl 子域和 WorkQueue.scanState 的掩码和标志位
static final int SCANNING = 1; // 标记是否正在运行任务
static final int INACTIVE = 1 << 31; // 失活状态 负数
static final int SS_SEQ = 1 << 16; // 版本戳,防止ABA问题
// ForkJoinPool.config 和 WorkQueue.config 的配置信息标记
static final int MODE_MASK = 0xffff << 16; // 模式掩码
static final int LIFO_QUEUE = 0; //LIFO队列
static final int FIFO_QUEUE = 1 << 16;//FIFO队列
static final int SHARED_QUEUE = 1 << 31; // 共享模式队列,负数
ForkJoinPool 中的相关常量和实例字段:
// 低位和高位掩码
private static final long SP_MASK = 0xffffffffL;
private static final long UC_MASK = ~SP_MASK;
// 活跃线程数
private static final int AC_SHIFT = 48;
private static final long AC_UNIT = 0x0001L << AC_SHIFT; //活跃线程数增量
private static final long AC_MASK = 0xffffL << AC_SHIFT; //活跃线程数掩码
// 工作线程数
private static final int TC_SHIFT = 32;
private static final long TC_UNIT = 0x0001L << TC_SHIFT; //工作线程数增量
private static final long TC_MASK = 0xffffL << TC_SHIFT; //掩码
private static final long ADD_WORKER = 0x0001L << (TC_SHIFT + 15); // 创建工作线程标志
// 池状态
private static final int RSLOCK = 1;
private static final int RSIGNAL = 1 << 1;
private static final int STARTED = 1 << 2;
private static final int STOP = 1 << 29;
private static final int TERMINATED = 1 << 30;
private static final int SHUTDOWN = 1 << 31;
// 实例字段
volatile long ctl; // 主控制参数
volatile int runState; // 运行状态锁
final int config; // 并行度|模式
int indexSeed; // 用于生成工作线程索引
volatile WorkQueue[] workQueues; // 主对象注册信息,workQueue
final ForkJoinWorkerThreadFactory factory;// 线程工厂
final UncaughtExceptionHandler ueh; // 每个工作线程的异常信息
final String workerNamePrefix; // 用于创建工作线程的名称
volatile AtomicLong stealCounter; // 偷取任务总数,也可作为同步监视器
/** 静态初始化字段 */
//线程工厂
public static final ForkJoinWorkerThreadFactory defaultForkJoinWorkerThreadFactory;
//启动或杀死线程的方法调用者的权限
private static final RuntimePermission modifyThreadPermission;
// 公共静态pool
static final ForkJoinPool common;
//并行度,对应内部common池
static final int commonParallelism;
//备用线程数,在tryCompensate中使用
private static int commonMaxSpares;
//创建workerNamePrefix(工作线程名称前缀)时的序号
private static int poolNumberSequence;
//线程阻塞等待新的任务的超时值(以纳秒为单位),默认2秒
private static final long IDLE_TIMEOUT = 2000L * 1000L * 1000L; // 2sec
//空闲超时时间,防止timer未命中
private static final long TIMEOUT_SLOP = 20L * 1000L * 1000L; // 20ms
//默认备用线程数
private static final int DEFAULT_COMMON_MAX_SPARES = 256;
//阻塞前自旋的次数,用在在awaitRunStateLock和awaitWork中
private static final int SPINS = 0;
//indexSeed的增量
private static final int SEED_INCREMENT = 0x9e3779b9;
ForkJoinPool 的内部状态都是通过一个64位的 long 型 变量ctl来存储,它由四个16位的子域组成:
- AC: 正在运行工作线程数减去目标并行度,高16位
- TC: 总工作线程数减去目标并行度,中高16位
- SS: 栈顶等待线程的版本计数和状态,中低16位
- ID: 栈顶 WorkQueue 在池中的索引(poolIndex),低16位
某些地方也提取了ctl的低32位(sp=(int)ctl)来检查工作线程状态,例如,当sp不为0时说明当前还有空闲工作线程。
ForkJoinPool.WorkQueue 中的相关属性:
//初始队列容量,2的幂
static final int INITIAL_QUEUE_CAPACITY = 1 << 13;
//最大队列容量
static final int MAXIMUM_QUEUE_CAPACITY = 1 << 26; // 64M
// 实例字段
volatile int scanState; // Woker状态, <0: inactive; odd:scanning
int stackPred; // 记录前一个栈顶的ctl
int nsteals; // 偷取任务数
int hint; // 记录偷取者索引,初始为随机索引
int config; // 池索引和模式
volatile int qlock; // 1: locked, < 0: terminate; else 0
volatile int base; //下一个poll操作的索引(栈底/队列头)
int top; // 下一个push操作的索引(栈顶/队列尾)
ForkJoinTask<?>[] array; // 任务数组
final ForkJoinPool pool; // the containing pool (may be null)
final ForkJoinWorkerThread owner; // 当前工作队列的工作线程,共享模式下为null
volatile Thread parker; // 调用park阻塞期间为owner,其他情况为null
volatile ForkJoinTask<?> currentJoin; // 记录被join过来的任务
volatile ForkJoinTask<?> currentSteal; // 记录从其他工作队列偷取过来的任务
ForkJoinTask
核心参数
/** 任务运行状态 */
volatile int status; // 任务运行状态
static final int DONE_MASK = 0xf0000000; // 任务完成状态标志位
static final int NORMAL = 0xf0000000; // must be negative
static final int CANCELLED = 0xc0000000; // must be < NORMAL
static final int EXCEPTIONAL = 0x80000000; // must be < CANCELLED
static final int SIGNAL = 0x00010000; // must be >= 1 << 16 等待信号
static final int SMASK = 0x0000ffff; // 低位掩码
ForkJoinPool:构造函数
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode) {
this(checkParallelism(parallelism),
checkFactory(factory),
handler,
asyncMode ? FIFO_QUEUE : LIFO_QUEUE,
"ForkJoinPool-" + nextPoolId() + "-worker-");
checkPermission();
}
- parallelism: 并行度,默认为CPU数,最小为1
- factory: 工作线程工厂
- handler: 处理工作线程运行任务时的异常情况类,默认为null
- asyncMode: 是否为异步模式,默认为 false。
- 如果为true,表示子任务的执行遵循 FIFO 顺序并且任务不能被合并(join),这种模式适用于工作线程只运行事件类型的异步任务。
在多数场景使用时,如果没有太强的业务需求,我们一般直接使用 ForkJoinPool 中的common池,在JDK1.8之后提供了ForkJoinPool.commonPool()方法可以直接使用common池,来看一下它的构造:
private static ForkJoinPool makeCommonPool() {
int parallelism = -1;
ForkJoinWorkerThreadFactory factory = null;
UncaughtExceptionHandler handler = null;
try { // ignore exceptions in accessing/parsing
String pp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.parallelism");//并行度
String fp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.threadFactory");//线程工厂
String hp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.exceptionHandler");//异常处理类
if (pp != null)
parallelism = Integer.parseInt(pp);
if (fp != null)
factory = ((ForkJoinWorkerThreadFactory) ClassLoader.
getSystemClassLoader().loadClass(fp).newInstance());
if (hp != null)
handler = ((UncaughtExceptionHandler) ClassLoader.
getSystemClassLoader().loadClass(hp).newInstance());
} catch (Exception ignore) {
}
if (factory == null) {
if (System.getSecurityManager() == null)
factory = defaultForkJoinWorkerThreadFactory;
else // use security-managed default
factory = new InnocuousForkJoinWorkerThreadFactory();
}
if (parallelism < 0 && // default 1 less than #cores
(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0)
parallelism = 1;//默认并行度为1
if (parallelism > MAX_CAP)
parallelism = MAX_CAP;
return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE,
"ForkJoinPool.commonPool-worker-");
}
使用common pool的优点就是我们可以通过指定系统参数的方式定义“并行度、线程工厂和异常处理类”;并且它使用的是同步模式,也就是说可以支持任务合并(join)。
ForkJoinPool:外部任务提交
向 ForkJoinPool 提交任务有三种方式:
- invoke()会等待任务计算完毕并返回计算结果;
- execute()是直接向池提交一个任务来异步执行,无返回结果;
- submit()也是异步执行,但是会返回提交的任务,在适当的时候可通过 task.get() 获取执行结果。
这三种提交方式都都是调用externalPush()方法来完成,所以接下来我们将从externalPush()方法开始逐步分析外部任务的执行过程。
externalPush
//添加给定任务到submission队列中
final void externalPush(ForkJoinTask<?> task) {
WorkQueue[] ws;
WorkQueue q;
int m;
int r = ThreadLocalRandom.getProbe();//探针值,用于计算WorkQueue槽位索引
int rs = runState;
if ((ws = workQueues) != null && (m = (ws.length - 1)) >= 0 &&
(q = ws[m & r & SQMASK]) != null && r != 0 && rs > 0 && //获取随机偶数槽位的workQueue
U.compareAndSwapInt(q, QLOCK, 0, 1)) {//锁定workQueue
ForkJoinTask<?>[] a;
int am, n, s;
if ((a = q.array) != null &&
(am = a.length - 1) > (n = (s = q.top) - q.base)) {
int j = ((am & s) << ASHIFT) + ABASE;//计算任务索引位置
U.putOrderedObject(a, j, task);//任务入列
U.putOrderedInt(q, QTOP, s + 1);//更新push slot
U.putIntVolatile(q, QLOCK, 0);//解除锁定
if (n <= 1)
signalWork(ws, q);//任务数小于1时尝试创建或激活一个工作线程
return;
}
U.compareAndSwapInt(q, QLOCK, 1, 0);//解除锁定
}
externalSubmit(task);//初始化workQueues及相关属性
}
externalPush和externalSubmit两个方法的联系:
- 它们的作用都是把任务放到队列中等待执行。
- 不同的是,externalSubmit可以说是完整版的externalPush,在任务首次提交时,需要初始化workQueues及其他相关属性,这个初始化操作就是externalSubmit来完成的;
- 而后再向池中提交的任务都是通过简化版的externalSubmit-externalPush来完成。
externalPush的执行流程很简单: 首先找到一个随机偶数槽位的 workQueue,然后把任务放入这个 workQueue 的任务数组中,并更新top位。如果队列的剩余任务数小于1,则尝试创建或激活一个工作线程来运行任务(防止在externalSubmit初始化时发生异常导致工作线程创建失败)。
externalSubmit
//任务提交
private void externalSubmit(ForkJoinTask<?> task) {
//初始化调用线程的探针值,用于计算WorkQueue索引
int r; // initialize caller's probe
if ((r = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit();
r = ThreadLocalRandom.getProbe();
}
for (; ; ) {
WorkQueue[] ws;
WorkQueue q;
int rs, m, k;
boolean move = false;
if ((rs = runState) < 0) {// 池已关闭
tryTerminate(false, false); // help terminate
throw new RejectedExecutionException();
}
//初始化workQueues
else if ((rs & STARTED) == 0 || // initialize
((ws = workQueues) == null || (m = ws.length - 1) < 0)) {
int ns = 0;
rs = lockRunState();//锁定runState
try {
//初始化
if ((rs & STARTED) == 0) {
//初始化stealCounter
U.compareAndSwapObject(this, STEALCOUNTER, null,
new AtomicLong());
//创建workQueues,容量为2的幂次方
// create workQueues array with size a power of two
int p = config & SMASK; // ensure at least 2 slots
int n = (p > 1) ? p - 1 : 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
n = (n + 1) << 1;
workQueues = new WorkQueue[n];
ns = STARTED;
}
} finally {
unlockRunState(rs, (rs & ~RSLOCK) | ns);//解锁并更新runState
}
} else if ((q = ws[k = r & m & SQMASK]) != null) {//获取随机偶数槽位的workQueue
if (q.qlock == 0 && U.compareAndSwapInt(q, QLOCK, 0, 1)) {//锁定 workQueue
ForkJoinTask<?>[] a = q.array;//当前workQueue的全部任务
int s = q.top;
boolean submitted = false; // initial submission or resizing
try { // locked version of push
if ((a != null && a.length > s + 1 - q.base) ||
(a = q.growArray()) != null) {//扩容
int j = (((a.length - 1) & s) << ASHIFT) + ABASE;
U.putOrderedObject(a, j, task);//放入给定任务
U.putOrderedInt(q, QTOP, s + 1);//修改push slot
submitted = true;
}
} finally {
U.compareAndSwapInt(q, QLOCK, 1, 0);//解除锁定
}
if (submitted) {//任务提交成功,创建或激活工作线程
signalWork(ws, q);//创建或激活一个工作线程来运行任务
return;
}
}
move = true; // move on failure 操作失败,重新获取探针值
} else if (((rs = runState) & RSLOCK) == 0) { // create new queue
q = new WorkQueue(this, null);
q.hint = r;
q.config = k | SHARED_QUEUE;
q.scanState = INACTIVE;
rs = lockRunState(); // publish index
if (rs > 0 && (ws = workQueues) != null &&
k < ws.length && ws[k] == null)
ws[k] = q; // 更新索引k位值的workQueue
//else terminated
unlockRunState(rs, rs & ~RSLOCK);
} else
move = true; // move if busy
if (move)
r = ThreadLocalRandom.advanceProbe(r);//重新获取线程探针值
}
}
externalSubmit是externalPush的完整版本,主要用于第一次提交任务时初始化workQueues及相关属性,并且提交给定任务到队列中。具体执行步骤如下:
如果池为终止状态(runState<0),调用tryTerminate来终止线程池,并抛出任务拒绝异常;
如果尚未初始化,就为 FJP 执行初始化操作: 初始化stealCounter、创建workerQueues,然后继续自旋;
初始化完成后,执行在externalPush中相同的操作: 获取 workQueue,放入指定任务。任务提交成功后调用signalWork方法创建或激活线程;
如果在步骤3中获取到的 workQueue 为null,会在这一步中创建一个 workQueue,创建成功继续自旋执行第三步操作;
如果非上述情况,或者有线程争用资源导致获取锁失败,就重新获取线程探针值继续自旋。
signalWork
final void signalWork(WorkQueue[] ws, WorkQueue q) {
long c;
int sp, i;
WorkQueue v;
Thread p;
while ((c = ctl) < 0L) { // too few active
if ((sp = (int) c) == 0) { // no idle workers
if ((c & ADD_WORKER) != 0L) // too few workers
tryAddWorker(c);//工作线程太少,添加新的工作线程
break;
}
if (ws == null) // unstarted/terminated
break;
if (ws.length <= (i = sp & SMASK)) // terminated
break;
if ((v = ws[i]) == null) // terminating
break;
//计算ctl,加上版本戳SS_SEQ避免ABA问题
int vs = (sp + SS_SEQ) & ~INACTIVE; // next scanState
int d = sp - v.scanState; // screen CAS
//计算活跃线程数(高32位)并更新为下一个栈顶的scanState(低32位)
long nc = (UC_MASK & (c + AC_UNIT)) | (SP_MASK & v.stackPred);
if (d == 0 && U.compareAndSwapLong(this, CTL, c, nc)) {
v.scanState = vs; // activate v
if ((p = v.parker) != null)
U.unpark(p);//唤醒阻塞线程
break;
}
if (q != null && q.base == q.top) // no more work
break;
}
}
新建或唤醒一个工作线程,在externalPush、externalSubmit、workQueue.push、scan中调用。如果还有空闲线程,则尝试唤醒索引到的 WorkQueue 的parker线程;如果工作线程过少((ctl & ADD_WORKER) != 0L),则调用tryAddWorker添加一个新的工作线程。
tryAddWorker
private void tryAddWorker(long c) {
boolean add = false;
do {
long nc = ((AC_MASK & (c + AC_UNIT)) |
(TC_MASK & (c + TC_UNIT)));
if (ctl == c) {
int rs, stop; // check if terminating
if ((stop = (rs = lockRunState()) & STOP) == 0)
add = U.compareAndSwapLong(this, CTL, c, nc);
unlockRunState(rs, rs & ~RSLOCK);//释放锁
if (stop != 0)
break;
if (add) {
createWorker();//创建工作线程
break;
}
}
} while (((c = ctl) & ADD_WORKER) != 0L && (int)c == 0);
}
尝试添加一个新的工作线程,首先更新ctl中的工作线程数,然后调用createWorker()创建工作线程。
createWorker
private boolean createWorker() {
ForkJoinWorkerThreadFactory fac = factory;
Throwable ex = null;
ForkJoinWorkerThread wt = null;
try {
if (fac != null && (wt = fac.newThread(this)) != null) {
wt.start();
return true;
}
} catch (Throwable rex) {
ex = rex;
}
deregisterWorker(wt, ex);//线程创建失败处理
return false;
}
createWorker首先通过线程工厂创一个新的ForkJoinWorkerThread,然后启动这个工作线程(wt.start())。如果期间发生异常,调用deregisterWorker处理线程创建失败的逻辑(deregisterWorker在后面再详细说明)。
ForkJoinWorkerThread 的构造函数如下:
protected ForkJoinWorkerThread(ForkJoinPool pool) {
// Use a placeholder until a useful name can be set in registerWorker
super("aForkJoinWorkerThread");
this.pool = pool;
this.workQueue = pool.registerWorker(this);
}
可以看到 ForkJoinWorkerThread 在构造时首先调用父类 Thread 的方法,然后为工作线程注册pool和workQueue,而workQueue的注册任务由ForkJoinPool.registerWorker来完成。
registerWorker
final WorkQueue registerWorker(ForkJoinWorkerThread wt) {
UncaughtExceptionHandler handler;
//设置为守护线程
wt.setDaemon(true); // configure thread
if ((handler = ueh) != null)
wt.setUncaughtExceptionHandler(handler);
WorkQueue w = new WorkQueue(this, wt);//构造新的WorkQueue
int i = 0; // assign a pool index
int mode = config & MODE_MASK;
int rs = lockRunState();
try {
WorkQueue[] ws;
int n; // skip if no array
if ((ws = workQueues) != null && (n = ws.length) > 0) {
//生成新建WorkQueue的索引
int s = indexSeed += SEED_INCREMENT; // unlikely to collide
int m = n - 1;
i = ((s << 1) | 1) & m; // Worker任务放在奇数索引位 odd-numbered indices
if (ws[i] != null) { // collision 已存在,重新计算索引位
int probes = 0; // step by approx half n
int step = (n <= 4) ? 2 : ((n >>> 1) & EVENMASK) + 2;
//查找可用的索引位
while (ws[i = (i + step) & m] != null) {
if (++probes >= n) {//所有索引位都被占用,对workQueues进行扩容
workQueues = ws = Arrays.copyOf(ws, n <<= 1);//workQueues 扩容
m = n - 1;
probes = 0;
}
}
}
w.hint = s; // use as random seed
w.config = i | mode;
w.scanState = i; // publication fence
ws[i] = w;
}
} finally {
unlockRunState(rs, rs & ~RSLOCK);
}
wt.setName(workerNamePrefix.concat(Integer.toString(i >>> 1)));
return w;
}
registerWorker是 ForkJoinWorkerThread 构造器的回调函数,用于创建和记录工作线程的 WorkQueue。比较简单,就不多赘述了。注意在此为工作线程创建的 WorkQueue 是放在奇数索引的(代码行: i = ((s « 1) | 1) & m;)
总结
在createWorker()中启动工作线程后(wt.start()),当为线程分配到CPU执行时间片之后会运行 ForkJoinWorkerThread 的run方法开启线程来执行任务。工作线程执行任务的流程我们在讲完内部任务提交之后会统一讲解。
ForkJoinPool:子任务提交
子任务的提交相对比较简单,由任务的fork()方法完成。通过上面的流程图可以看到任务被分割(fork)之后调用了ForkJoinPool.WorkQueue.push()方法直接把任务放到队列中等待被执行。
ForkJoinTask.fork()
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
- 如果当前线程是 Worker 线程,说明当前任务是fork分割的子任务,通过ForkJoinPool.workQueue.push()方法直接把任务放到自己的等待队列中;
- 否则调用ForkJoinPool.externalPush()提交到一个随机的等待队列中(外部任务)。
ForkJoinPool.WorkQueue.push()
final void push(ForkJoinTask<?> task) {
ForkJoinTask<?>[] a;
ForkJoinPool p;
int b = base, s = top, n;
if ((a = array) != null) { // ignore if queue removed
int m = a.length - 1; // fenced write for task visibility
U.putOrderedObject(a, ((m & s) << ASHIFT) + ABASE, task);
U.putOrderedInt(this, QTOP, s + 1);
if ((n = s - b) <= 1) {//首次提交,创建或唤醒一个工作线程
if ((p = pool) != null)
p.signalWork(p.workQueues, this);
} else if (n >= m)
growArray();
}
}
首先把任务放入等待队列并更新top位;如果当前 WorkQueue 为新建的等待队列(top-base<=1),则调用signalWork方法为当前 WorkQueue 新建或唤醒一个工作线程;如果 WorkQueue 中的任务数组容量过小,则调用growArray()方法对其进行两倍扩容,growArray()方法源码如下:
final ForkJoinTask<?>[] growArray() {
ForkJoinTask<?>[] oldA = array;//获取内部任务列表
int size = oldA != null ? oldA.length << 1 : INITIAL_QUEUE_CAPACITY;
if (size > MAXIMUM_QUEUE_CAPACITY)
throw new RejectedExecutionException("Queue capacity exceeded");
int oldMask, t, b;
//新建一个两倍容量的任务数组
ForkJoinTask<?>[] a = array = new ForkJoinTask<?>[size];
if (oldA != null && (oldMask = oldA.length - 1) >= 0 &&
(t = top) - (b = base) > 0) {
int mask = size - 1;
//从老数组中拿出数据,放到新的数组中
do { // emulate poll from old array, push to new array
ForkJoinTask<?> x;
int oldj = ((b & oldMask) << ASHIFT) + ABASE;
int j = ((b & mask) << ASHIFT) + ABASE;
x = (ForkJoinTask<?>) U.getObjectVolatile(oldA, oldj);
if (x != null &&
U.compareAndSwapObject(oldA, oldj, x, null))
U.putObjectVolatile(a, j, x);
} while (++b != t);
}
return a;
}
总结
到此,两种任务的提交流程都已经解析完毕,下一节我们来一起看看任务提交之后是如何被运行的。
ForkJoinPool:任务执行
回到我们开始时的流程图,在ForkJoinPool .createWorker()方法中创建工作线程后,会启动工作线程,系统为工作线程分配到CPU执行时间片之后会执行 ForkJoinWorkerThread 的run()方法正式开始执行任务。
ForkJoinWorkerThread.run()
public void run() {
if (workQueue.array == null) { // only run once
Throwable exception = null;
try {
onStart();//钩子方法,可自定义扩展
pool.runWorker(workQueue);
} catch (Throwable ex) {
exception = ex;
} finally {
try {
onTermination(exception);//钩子方法,可自定义扩展
} catch (Throwable ex) {
if (exception == null)
exception = ex;
} finally {
pool.deregisterWorker(this, exception);//处理异常
}
}
}
}
在工作线程运行前后会调用自定义钩子函数(onStart和onTermination),任务的运行则是调用了ForkJoinPool.runWorker()。如果全部任务执行完毕或者期间遭遇异常,则通过ForkJoinPool.deregisterWorker关闭工作线程并处理异常信息(deregisterWorker方法我们后面会详细讲解)。
ForkJoinPool.runWorker(WorkQueue w)
final void runWorker(WorkQueue w) {
w.growArray(); // allocate queue
int seed = w.hint; // initially holds randomization hint
int r = (seed == 0) ? 1 : seed; // avoid 0 for xorShift
for (ForkJoinTask<?> t; ; ) {
if ((t = scan(w, r)) != null)//扫描任务执行
w.runTask(t);
else if (!awaitWork(w, r))
break;
r ^= r << 13;
r ^= r >>> 17;
r ^= r << 5; // xorshift
}
}
runWorker是 ForkJoinWorkerThread 的主运行方法,用来依次执行当前工作线程中的任务。函数流程很简单: 调用scan方法依次获取任务,然后调用WorkQueue .runTask运行任务;如果未扫描到任务,则调用awaitWork等待,直到工作线程/线程池终止或等待超时。
ForkJoinPool.scan(WorkQueue w, int r)
private ForkJoinTask<?> scan(WorkQueue w, int r) {
WorkQueue[] ws;
int m;
if ((ws = workQueues) != null && (m = ws.length - 1) > 0 && w != null) {
int ss = w.scanState; // initially non-negative
//初始扫描起点,自旋扫描
for (int origin = r & m, k = origin, oldSum = 0, checkSum = 0; ; ) {
WorkQueue q;
ForkJoinTask<?>[] a;
ForkJoinTask<?> t;
int b, n;
long c;
if ((q = ws[k]) != null) {//获取workQueue
if ((n = (b = q.base) - q.top) < 0 &&
(a = q.array) != null) { // non-empty
//计算偏移量
long i = (((a.length - 1) & b) << ASHIFT) + ABASE;
if ((t = ((ForkJoinTask<?>)
U.getObjectVolatile(a, i))) != null && //取base位置任务
q.base == b) {//stable
if (ss >= 0) { //scanning
if (U.compareAndSwapObject(a, i, t, null)) {//
q.base = b + 1;//更新base位
if (n < -1) // signal others
signalWork(ws, q);//创建或唤醒工作线程来运行任务
return t;
}
} else if (oldSum == 0 && // try to activate 尝试激活工作线程
w.scanState < 0)
tryRelease(c = ctl, ws[m & (int) c], AC_UNIT);//唤醒栈顶工作线程
}
//base位置任务为空或base位置偏移,随机移位重新扫描
if (ss < 0) // refresh
ss = w.scanState;
r ^= r << 1;
r ^= r >>> 3;
r ^= r << 10;
origin = k = r & m; // move and rescan
oldSum = checkSum = 0;
continue;
}
checkSum += b;//队列任务为空,记录base位
}
//更新索引k 继续向后查找
if ((k = (k + 1) & m) == origin) { // continue until stable
//运行到这里说明已经扫描了全部的 workQueues,但并未扫描到任务
if ((ss >= 0 || (ss == (ss = w.scanState))) &&
oldSum == (oldSum = checkSum)) {
if (ss < 0 || w.qlock < 0) // already inactive
break;// 已经被灭活或终止,跳出循环
//对当前WorkQueue进行灭活操作
int ns = ss | INACTIVE; // try to inactivate
long nc = ((SP_MASK & ns) |
(UC_MASK & ((c = ctl) - AC_UNIT)));//计算ctl为INACTIVE状态并减少活跃线程数
w.stackPred = (int) c; // hold prev stack top
U.putInt(w, QSCANSTATE, ns);//修改scanState为inactive状态
if (U.compareAndSwapLong(this, CTL, c, nc))//更新scanState为灭活状态
ss = ns;
else
w.scanState = ss; // back out
}
checkSum = 0;//重置checkSum,继续循环
}
}
}
return null;
}
扫描并尝试偷取一个任务。使用w.hint进行随机索引 WorkQueue,也就是说并不一定会执行当前 WorkQueue 中的任务,而是偷取别的Worker的任务来执行。
函数的大致流程如下:
- 取随机位置的一个 WorkQueue;
- 获取base位的 ForkJoinTask,成功取到后更新base位并返回任务;如果取到的 WorkQueue 中任务数大于1,则调用signalWork创建或唤醒其他工作线程;
- 如果当前工作线程处于不活跃状态(INACTIVE),则调用tryRelease尝试唤醒栈顶工作线程来执行。
tryRelease源码如下:
private boolean tryRelease(long c, WorkQueue v, long inc) {
int sp = (int) c, vs = (sp + SS_SEQ) & ~INACTIVE;
Thread p;
//ctl低32位等于scanState,说明可以唤醒parker线程
if (v != null && v.scanState == sp) { // v is at top of stack
//计算活跃线程数(高32位)并更新为下一个栈顶的scanState(低32位)
long nc = (UC_MASK & (c + inc)) | (SP_MASK & v.stackPred);
if (U.compareAndSwapLong(this, CTL, c, nc)) {
v.scanState = vs;
if ((p = v.parker) != null)
U.unpark(p);//唤醒线程
return true;
}
}
return false;
}
- 如果base位任务为空或发生偏移,则对索引位进行随机移位,然后重新扫描;
- 如果扫描整个workQueues之后没有获取到任务,则设置当前工作线程为INACTIVE状态;然后重置checkSum,再次扫描一圈之后如果还没有任务则跳出循环返回null。
ForkJoinPool.awaitWork(WorkQueue w, int r)
private boolean awaitWork(WorkQueue w, int r) {
if (w == null || w.qlock < 0) // w is terminating
return false;
for (int pred = w.stackPred, spins = SPINS, ss; ; ) {
if ((ss = w.scanState) >= 0)//正在扫描,跳出循环
break;
else if (spins > 0) {
r ^= r << 6;
r ^= r >>> 21;
r ^= r << 7;
if (r >= 0 && --spins == 0) { // randomize spins
WorkQueue v;
WorkQueue[] ws;
int s, j;
AtomicLong sc;
if (pred != 0 && (ws = workQueues) != null &&
(j = pred & SMASK) < ws.length &&
(v = ws[j]) != null && // see if pred parking
(v.parker == null || v.scanState >= 0))
spins = SPINS; // continue spinning
}
} else if (w.qlock < 0) // 当前workQueue已经终止,返回false recheck after spins
return false;
else if (!Thread.interrupted()) {//判断线程是否被中断,并清除中断状态
long c, prevctl, parkTime, deadline;
int ac = (int) ((c = ctl) >> AC_SHIFT) + (config & SMASK);//活跃线程数
if ((ac <= 0 && tryTerminate(false, false)) || //无active线程,尝试终止
(runState & STOP) != 0) // pool terminating
return false;
if (ac <= 0 && ss == (int) c) { // is last waiter
//计算活跃线程数(高32位)并更新为下一个栈顶的scanState(低32位)
prevctl = (UC_MASK & (c + AC_UNIT)) | (SP_MASK & pred);
int t = (short) (c >>> TC_SHIFT); // shrink excess spares
if (t > 2 && U.compareAndSwapLong(this, CTL, c, prevctl))//总线程过量
return false; // else use timed wait
//计算空闲超时时间
parkTime = IDLE_TIMEOUT * ((t >= 0) ? 1 : 1 - t);
deadline = System.nanoTime() + parkTime - TIMEOUT_SLOP;
} else
prevctl = parkTime = deadline = 0L;
Thread wt = Thread.currentThread();
U.putObject(wt, PARKBLOCKER, this); // emulate LockSupport
w.parker = wt;//设置parker,准备阻塞
if (w.scanState < 0 && ctl == c) // recheck before park
U.park(false, parkTime);//阻塞指定的时间
U.putOrderedObject(w, QPARKER, null);
U.putObject(wt, PARKBLOCKER, null);
if (w.scanState >= 0)//正在扫描,说明等到任务,跳出循环
break;
if (parkTime != 0L && ctl == c &&
deadline - System.nanoTime() <= 0L &&
U.compareAndSwapLong(this, CTL, c, prevctl))//未等到任务,更新ctl,返回false
return false; // shrink pool
}
}
return true;
}
回到runWorker方法,如果scan方法未扫描到任务,会调用awaitWork等待获取任务。函数的具体执行流程大家看源码,这里简单说一下:
- 在等待获取任务期间,如果工作线程或线程池已经终止则直接返回false。
- 如果当前无 active 线程,尝试终止线程池并返回false,如果终止失败并且当前是最后一个等待的 Worker,就阻塞指定的时间(IDLE_TIMEOUT);等到届期或被唤醒后如果发现自己是scanning(scanState >= 0)状态,说明已经等到任务,跳出等待返回true继续 scan,否则的更新ctl并返回false。
WorkQueue.runTask()
final void runTask(ForkJoinTask<?> task) {
if (task != null) {
scanState &= ~SCANNING; // mark as busy
(currentSteal = task).doExec();//更新currentSteal并执行任务
U.putOrderedObject(this, QCURRENTSTEAL, null); // release for GC
execLocalTasks();//依次执行本地任务
ForkJoinWorkerThread thread = owner;
if (++nsteals < 0) // collect on overflow
transferStealCount(pool);//增加偷取任务数
scanState |= SCANNING;
if (thread != null)
thread.afterTopLevelExec();//执行钩子函数
}
}
在scan方法扫描到任务之后,调用WorkQueue.runTask()来执行获取到的任务,大概流程如下:
- 标记scanState为正在执行状态;
- 更新currentSteal为当前获取到的任务并执行它,任务的执行调用了ForkJoinTask.doExec()方法,源码如下:
//ForkJoinTask.doExec()
final int doExec() {
int s; boolean completed;
if ((s = status) >= 0) {
try {
completed = exec();//执行我们定义的任务
} catch (Throwable rex) {
return setExceptionalCompletion(rex);
}
if (completed)
s = setCompletion(NORMAL);
}
return s;
}
- 调用execLocalTasks依次执行当前WorkerQueue中的任务,源码如下:
//执行并移除所有本地任务
final void execLocalTasks() {
int b = base, m, s;
ForkJoinTask<?>[] a = array;
if (b - (s = top - 1) <= 0 && a != null &&
(m = a.length - 1) >= 0) {
if ((config & FIFO_QUEUE) == 0) {//FIFO模式
for (ForkJoinTask<?> t; ; ) {
if ((t = (ForkJoinTask<?>) U.getAndSetObject
(a, ((m & s) << ASHIFT) + ABASE, null)) == null)//FIFO执行,取top任务
break;
U.putOrderedInt(this, QTOP, s);
t.doExec();//执行
if (base - (s = top - 1) > 0)
break;
}
} else
pollAndExecAll();//LIFO模式执行,取base任务
}
}
- 更新窃取次数。
- 还原scanState并执行钩子函数。
ForkJoinPool.deregisterWorker(ForkJoinWorkerThread wt, Throwable ex)
final void deregisterWorker(ForkJoinWorkerThread wt, Throwable ex) {
WorkQueue w = null;
//1.移除workQueue
if (wt != null && (w = wt.workQueue) != null) {//获取ForkJoinWorkerThread的等待队列
WorkQueue[] ws; // remove index from array
int idx = w.config & SMASK;//计算workQueue索引
int rs = lockRunState();//获取runState锁和当前池运行状态
if ((ws = workQueues) != null && ws.length > idx && ws[idx] == w)
ws[idx] = null;//移除workQueue
unlockRunState(rs, rs & ~RSLOCK);//解除runState锁
}
//2.减少CTL数
long c; // decrement counts
do {} while (!U.compareAndSwapLong
(this, CTL, c = ctl, ((AC_MASK & (c - AC_UNIT)) |
(TC_MASK & (c - TC_UNIT)) |
(SP_MASK & c))));
//3.处理被移除workQueue内部相关参数
if (w != null) {
w.qlock = -1; // ensure set
w.transferStealCount(this);
w.cancelAll(); // cancel remaining tasks
}
//4.如果线程未终止,替换被移除的workQueue并唤醒内部线程
for (;;) { // possibly replace
WorkQueue[] ws; int m, sp;
//尝试终止线程池
if (tryTerminate(false, false) || w == null || w.array == null ||
(runState & STOP) != 0 || (ws = workQueues) == null ||
(m = ws.length - 1) < 0) // already terminating
break;
//唤醒被替换的线程,依赖于下一步
if ((sp = (int)(c = ctl)) != 0) { // wake up replacement
if (tryRelease(c, ws[sp & m], AC_UNIT))
break;
}
//创建工作线程替换
else if (ex != null && (c & ADD_WORKER) != 0L) {
tryAddWorker(c); // create replacement
break;
}
else // don't need replacement
break;
}
//5.处理异常
if (ex == null) // help clean on way out
ForkJoinTask.helpExpungeStaleExceptions();
else // rethrow
ForkJoinTask.rethrow(ex);
}
deregisterWorker方法用于工作线程运行完毕之后终止线程或处理工作线程异常,主要就是清除已关闭的工作线程或回滚创建线程之前的操作,并把传入的异常抛给 ForkJoinTask 来处理。具体步骤见源码注释。
ForkJoinPool:获取结果
- join
//合并任务结果
public final V join() {
int s;
if ((s = doJoin() & DONE_MASK) != NORMAL)
reportException(s);
return getRawResult();
}
//join, get, quietlyJoin的主实现方法
private int doJoin() {
int s; Thread t; ForkJoinWorkerThread wt; ForkJoinPool.WorkQueue w;
return (s = status) < 0 ? s :
((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ?
(w = (wt = (ForkJoinWorkerThread)t).workQueue).
tryUnpush(this) && (s = doExec()) < 0 ? s :
wt.pool.awaitJoin(w, this, 0L) :
externalAwaitDone();
}
- invoke
//执行任务,并等待任务完成并返回结果
public final V invoke() {
int s;
if ((s = doInvoke() & DONE_MASK) != NORMAL)
reportException(s);
return getRawResult();
}
//invoke, quietlyInvoke的主实现方法
private int doInvoke() {
int s; Thread t; ForkJoinWorkerThread wt;
return (s = doExec()) < 0 ? s :
((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ?
(wt = (ForkJoinWorkerThread)t).pool.
awaitJoin(wt.workQueue, this, 0L) :
externalAwaitDone();
}
join()方法一把是在任务fork()之后调用,用来获取(或者叫“合并”)任务的执行结果。
ForkJoinTask的join()和invoke()方法都可以用来获取任务的执行结果(另外还有get方法也是调用了doJoin来获取任务结果,但是会响应运行时异常),它们对外部提交任务的执行方式一致,都是通过externalAwaitDone方法等待执行结果。
不同的是invoke()方法会直接执行当前任务;而join()方法则是在当前任务在队列 top 位时(通过tryUnpush方法判断)才能执行,如果当前任务不在 top 位或者任务执行失败调用ForkJoinPool.awaitJoin方法帮助执行或阻塞当前 join 任务。(所以在官方文档中建议了我们对ForkJoinTask任务的调用顺序,一对 fork-join操作一般按照如下顺序调用: a.fork(); b.fork(); b.join(); a.join();。因为任务 b 是后面进入队列,也就是说它是在栈顶的(top 位),在它fork()之后直接调用join()就可以直接执行而不会调用ForkJoinPool.awaitJoin方法去等待。)
在这些方法中,join()相对比较全面,所以之后的讲解我们将从join()开始逐步向下分析,首先看一下join()的执行流程:
后面的源码分析中,我们首先讲解比较简单的外部 join 任务(externalAwaitDone),然后再讲解内部 join 任务(从ForkJoinPool.awaitJoin()开始)。
ForkJoinTask.externalAwaitDone()
private int externalAwaitDone() {
//执行任务
int s = ((this instanceof CountedCompleter) ? // try helping
ForkJoinPool.common.externalHelpComplete( // CountedCompleter任务
(CountedCompleter<?>)this, 0) :
ForkJoinPool.common.tryExternalUnpush(this) ? doExec() : 0); // ForkJoinTask任务
if (s >= 0 && (s = status) >= 0) {//执行失败,进入等待
boolean interrupted = false;
do {
if (U.compareAndSwapInt(this, STATUS, s, s | SIGNAL)) { //更新state
synchronized (this) {
if (status >= 0) {//SIGNAL 等待信号
try {
wait(0L);
} catch (InterruptedException ie) {
interrupted = true;
}
}
else
notifyAll();
}
}
} while ((s = status) >= 0);
if (interrupted)
Thread.currentThread().interrupt();
}
return s;
}
如果当前join为外部调用,则调用此方法执行任务,如果任务执行失败就进入等待。方法本身是很简单的,需要注意的是对不同的任务类型分两种情况:
- 如果我们的任务为 CountedCompleter 类型的任务,则调用externalHelpComplete方法来执行任务。
- 其他类型的 ForkJoinTask 任务调用tryExternalUnpush来执行,源码如下:
//为外部提交者提供 tryUnpush 功能(给定任务在top位时弹出任务)
final boolean tryExternalUnpush(ForkJoinTask<?> task) {
WorkQueue[] ws;
WorkQueue w;
ForkJoinTask<?>[] a;
int m, s;
int r = ThreadLocalRandom.getProbe();
if ((ws = workQueues) != null && (m = ws.length - 1) >= 0 &&
(w = ws[m & r & SQMASK]) != null &&
(a = w.array) != null && (s = w.top) != w.base) {
long j = (((a.length - 1) & (s - 1)) << ASHIFT) + ABASE; //取top位任务
if (U.compareAndSwapInt(w, QLOCK, 0, 1)) { //加锁
if (w.top == s && w.array == a &&
U.getObject(a, j) == task &&
U.compareAndSwapObject(a, j, task, null)) { //符合条件,弹出
U.putOrderedInt(w, QTOP, s - 1); //更新top
U.putOrderedInt(w, QLOCK, 0); //解锁,返回true
return true;
}
U.compareAndSwapInt(w, QLOCK, 1, 0); //当前任务不在top位,解锁返回false
}
}
return false;
}
tryExternalUnpush的作用就是判断当前任务是否在top位,如果是则弹出任务,然后在externalAwaitDone中调用doExec()执行任务。
ForkJoinPool.awaitJoin()
final int awaitJoin(WorkQueue w, ForkJoinTask<?> task, long deadline) {
int s = 0;
if (task != null && w != null) {
ForkJoinTask<?> prevJoin = w.currentJoin; //获取给定Worker的join任务
U.putOrderedObject(w, QCURRENTJOIN, task); //把currentJoin替换为给定任务
//判断是否为CountedCompleter类型的任务
CountedCompleter<?> cc = (task instanceof CountedCompleter) ?
(CountedCompleter<?>) task : null;
for (; ; ) {
if ((s = task.status) < 0) //已经完成|取消|异常 跳出循环
break;
if (cc != null)//CountedCompleter任务由helpComplete来完成join
helpComplete(w, cc, 0);
else if (w.base == w.top || w.tryRemoveAndExec(task)) //尝试执行
helpStealer(w, task); //队列为空或执行失败,任务可能被偷,帮助偷取者执行该任务
if ((s = task.status) < 0) //已经完成|取消|异常,跳出循环
break;
//计算任务等待时间
long ms, ns;
if (deadline == 0L)
ms = 0L;
else if ((ns = deadline - System.nanoTime()) <= 0L)
break;
else if ((ms = TimeUnit.NANOSECONDS.toMillis(ns)) <= 0L)
ms = 1L;
if (tryCompensate(w)) {//执行补偿操作
task.internalWait(ms);//补偿执行成功,任务等待指定时间
U.getAndAddLong(this, CTL, AC_UNIT);//更新活跃线程数
}
}
U.putOrderedObject(w, QCURRENTJOIN, prevJoin);//循环结束,替换为原来的join任务
}
return s;
}
如果当前 join 任务不在Worker等待队列的top位,或者任务执行失败,调用此方法来帮助执行或阻塞当前 join 的任务。函数执行流程如下:
- 由于每次调用awaitJoin都会优先执行当前join的任务,所以首先会更新currentJoin为当前join任务;
- 进入自旋
- 首先检查任务是否已经完成(通过task.status < 0判断),如果给定任务执行完毕|取消|异常 则跳出循环返回执行状态s;
- 如果是 CountedCompleter 任务类型,调用helpComplete方法来完成join操作(后面笔者会开新篇来专门讲解CountedCompleter,本篇暂时不做详细解析);
- 非 CountedCompleter 任务类型调用WorkQueue.tryRemoveAndExec尝试执行任务;
- 如果给定 WorkQueue 的等待队列为空或任务执行失败,说明任务可能被偷,调用helpStealer帮助偷取者执行任务(也就是说,偷取者帮我执行任务,我去帮偷取者执行它的任务);
- 再次判断任务是否执行完毕(task.status < 0),如果任务执行失败,计算一个等待时间准备进行补偿操作;
- 调用tryCompensate方法为给定 WorkQueue 尝试执行补偿操作。在执行补偿期间,如果发现 资源争用|池处于unstable状态|当前Worker已终止,则调用ForkJoinTask.internalWait()方法等待指定的时间,任务唤醒之后继续自旋,ForkJoinTask.internalWait()源码如下:
final void internalWait(long timeout) {
int s;
if ((s = status) >= 0 && // force completer to issue notify
U.compareAndSwapInt(this, STATUS, s, s | SIGNAL)) {//更新任务状态为SIGNAL(等待唤醒)
synchronized (this) {
if (status >= 0)
try { wait(timeout); } catch (InterruptedException ie) { }
else
notifyAll();
}
}
}
在awaitJoin中,我们总共调用了三个比较复杂的方法: tryRemoveAndExec、helpStealer和tryCompensate,下面我们依次讲解。
WorkQueue.tryRemoveAndExec(ForkJoinTask task)
final boolean tryRemoveAndExec(ForkJoinTask<?> task) {
ForkJoinTask<?>[] a;
int m, s, b, n;
if ((a = array) != null && (m = a.length - 1) >= 0 &&
task != null) {
while ((n = (s = top) - (b = base)) > 0) {
//从top往下自旋查找
for (ForkJoinTask<?> t; ; ) { // traverse from s to b
long j = ((--s & m) << ASHIFT) + ABASE;//计算任务索引
if ((t = (ForkJoinTask<?>) U.getObject(a, j)) == null) //获取索引到的任务
return s + 1 == top; // shorter than expected
else if (t == task) { //给定任务为索引任务
boolean removed = false;
if (s + 1 == top) { // pop
if (U.compareAndSwapObject(a, j, task, null)) { //弹出任务
U.putOrderedInt(this, QTOP, s); //更新top
removed = true;
}
} else if (base == b) // replace with proxy
removed = U.compareAndSwapObject(
a, j, task, new EmptyTask()); //join任务已经被移除,替换为一个占位任务
if (removed)
task.doExec(); //执行
break;
} else if (t.status < 0 && s + 1 == top) { //给定任务不是top任务
if (U.compareAndSwapObject(a, j, t, null)) //弹出任务
U.putOrderedInt(this, QTOP, s);//更新top
break; // was cancelled
}
if (--n == 0) //遍历结束
return false;
}
if (task.status < 0) //任务执行完毕
return false;
}
}
return true;
}
从top位开始自旋向下找到给定任务,如果找到把它从当前 Worker 的任务队列中移除并执行它。注意返回的参数: 如果任务队列为空或者任务未执行完毕返回true;任务执行完毕返回false。
ForkJoinPool.helpStealer(WorkQueue w, ForkJoinTask task)
private void helpStealer(WorkQueue w, ForkJoinTask<?> task) {
WorkQueue[] ws = workQueues;
int oldSum = 0, checkSum, m;
if (ws != null && (m = ws.length - 1) >= 0 && w != null &&
task != null) {
do { // restart point
checkSum = 0; // for stability check
ForkJoinTask<?> subtask;
WorkQueue j = w, v; // v is subtask stealer
descent:
for (subtask = task; subtask.status >= 0; ) {
//1. 找到给定WorkQueue的偷取者v
for (int h = j.hint | 1, k = 0, i; ; k += 2) {//跳两个索引,因为Worker在奇数索引位
if (k > m) // can't find stealer
break descent;
if ((v = ws[i = (h + k) & m]) != null) {
if (v.currentSteal == subtask) {//定位到偷取者
j.hint = i;//更新stealer索引
break;
}
checkSum += v.base;
}
}
//2. 帮助偷取者v执行任务
for (; ; ) { // help v or descend
ForkJoinTask<?>[] a; //偷取者内部的任务
int b;
checkSum += (b = v.base);
ForkJoinTask<?> next = v.currentJoin;//获取偷取者的join任务
if (subtask.status < 0 || j.currentJoin != subtask ||
v.currentSteal != subtask) // stale
break descent; // stale,跳出descent循环重来
if (b - v.top >= 0 || (a = v.array) == null) {
if ((subtask = next) == null) //偷取者的join任务为null,跳出descent循环
break descent;
j = v;
break; //偷取者内部任务为空,可能任务也被偷走了;跳出本次循环,查找偷取者的偷取者
}
int i = (((a.length - 1) & b) << ASHIFT) + ABASE;//获取base偏移地址
ForkJoinTask<?> t = ((ForkJoinTask<?>)
U.getObjectVolatile(a, i));//获取偷取者的base任务
if (v.base == b) {
if (t == null) // stale
break descent; // stale,跳出descent循环重来
if (U.compareAndSwapObject(a, i, t, null)) {//弹出任务
v.base = b + 1; //更新偷取者的base位
ForkJoinTask<?> ps = w.currentSteal;//获取调用者偷来的任务
int top = w.top;
//首先更新给定workQueue的currentSteal为偷取者的base任务,然后执行该任务
//然后通过检查top来判断给定workQueue是否有自己的任务,如果有,
// 则依次弹出任务(LIFO)->更新currentSteal->执行该任务(注意这里是自己偷自己的任务执行)
do {
U.putOrderedObject(w, QCURRENTSTEAL, t);
t.doExec(); // clear local tasks too
} while (task.status >= 0 &&
w.top != top && //内部有自己的任务,依次弹出执行
(t = w.pop()) != null);
U.putOrderedObject(w, QCURRENTSTEAL, ps);//还原给定workQueue的currentSteal
if (w.base != w.top)//给定workQueue有自己的任务了,帮助结束,返回
return; // can't further help
}
}
}
}
} while (task.status >= 0 && oldSum != (oldSum = checkSum));
}
}
如果队列为空或任务执行失败,说明任务可能被偷,调用此方法来帮助偷取者执行任务。基本思想是: 偷取者帮助我执行任务,我去帮助偷取者执行它的任务。 函数执行流程如下:
循环定位偷取者,由于Worker是在奇数索引位,所以每次会跳两个索引位。定位到偷取者之后,更新调用者 WorkQueue 的hint为偷取者的索引,方便下次定位; 定位到偷取者后,开始帮助偷取者执行任务。从偷取者的base索引开始,每次偷取一个任务执行。在帮助偷取者执行任务后,如果调用者发现本身已经有任务(w.top != top),则依次弹出自己的任务(LIFO顺序)并执行(也就是说自己偷自己的任务执行)。
ForkJoinPool.tryCompensate(WorkQueue w)
//执行补偿操作: 尝试缩减活动线程量,可能释放或创建一个补偿线程来准备阻塞
private boolean tryCompensate(WorkQueue w) {
boolean canBlock;
WorkQueue[] ws;
long c;
int m, pc, sp;
if (w == null || w.qlock < 0 || // caller terminating
(ws = workQueues) == null || (m = ws.length - 1) <= 0 ||
(pc = config & SMASK) == 0) // parallelism disabled
canBlock = false; //调用者已终止
else if ((sp = (int) (c = ctl)) != 0) // release idle worker
canBlock = tryRelease(c, ws[sp & m], 0L);//唤醒等待的工作线程
else {//没有空闲线程
int ac = (int) (c >> AC_SHIFT) + pc; //活跃线程数
int tc = (short) (c >> TC_SHIFT) + pc;//总线程数
int nbusy = 0; // validate saturation
for (int i = 0; i <= m; ++i) { // two passes of odd indices
WorkQueue v;
if ((v = ws[((i << 1) | 1) & m]) != null) {//取奇数索引位
if ((v.scanState & SCANNING) != 0)//没有正在运行任务,跳出
break;
++nbusy;//正在运行任务,添加标记
}
}
if (nbusy != (tc << 1) || ctl != c)
canBlock = false; // unstable or stale
else if (tc >= pc && ac > 1 && w.isEmpty()) {//总线程数大于并行度 && 活动线程数大于1 && 调用者任务队列为空,不需要补偿
long nc = ((AC_MASK & (c - AC_UNIT)) |
(~AC_MASK & c)); // uncompensated
canBlock = U.compareAndSwapLong(this, CTL, c, nc);//更新活跃线程数
} else if (tc >= MAX_CAP ||
(this == common && tc >= pc + commonMaxSpares))//超出最大线程数
throw new RejectedExecutionException(
"Thread limit exceeded replacing blocked worker");
else { // similar to tryAddWorker
boolean add = false;
int rs; // CAS within lock
long nc = ((AC_MASK & c) |
(TC_MASK & (c + TC_UNIT)));//计算总线程数
if (((rs = lockRunState()) & STOP) == 0)
add = U.compareAndSwapLong(this, CTL, c, nc);//更新总线程数
unlockRunState(rs, rs & ~RSLOCK);
//运行到这里说明活跃工作线程数不足,需要创建一个新的工作线程来补偿
canBlock = add && createWorker(); // throws on exception
}
}
return canBlock;
}
具体的执行看源码及注释,这里我们简单总结一下需要和不需要补偿的几种情况:
- 需要补偿 :
- 调用者队列不为空,并且有空闲工作线程,这种情况会唤醒空闲线程(调用tryRelease方法)
- 池尚未停止,活跃线程数不足,这时会新建一个工作线程(调用createWorker方法)
- 不需要补偿 :
- 调用者已终止或池处于不稳定状态
- 总线程数大于并行度 && 活动线程数大于1 && 调用者任务队列为空
注意事项
避免不必要的fork()
划分成两个子任务后,不要同时调用两个子任务的fork()方法。
表面上看上去两个子任务都fork(),然后join()两次似乎更自然。但事实证明,直接调用compute()效率更高。因为直接调用子任务的compute()方法实际上就是在当前的工作线程进行了计算(线程重用),这比“将子任务提交到工作队列,线程又从工作队列中拿任务”快得多。
当一个大任务被划分成两个以上的子任务时,尽可能使用前面说到的三个衍生的invokeAll方法,因为使用它们能避免不必要的fork()。
注意fork()、compute()、join()的顺序
为了两个任务并行,三个方法的调用顺序需要万分注意。
right.fork(); // 计算右边的任务
long leftAns = left.compute(); // 计算左边的任务(同时右边任务也在计算)
long rightAns = right.join(); // 等待右边的结果
return leftAns + rightAns;
选择合适的子任务粒度
选择划分子任务的粒度(顺序执行的阈值)很重要,因为使用Fork/Join框架并不一定比顺序执行任务的效率高: 如果任务太大,则无法提高并行的吞吐量;如果任务太小,子任务的调度开销可能会大于并行计算的性能提升,我们还要考虑创建子任务、fork()子任务、线程调度以及合并子任务处理结果的耗时以及相应的内存消耗。
官方文档给出的粗略经验是: 任务应该执行100~10000个基本的计算步骤。决定子任务的粒度的最好办法是实践,通过实际测试结果来确定这个阈值才是“上上策”。
和其他Java代码一样,Fork/Join框架测试时需要“预热”或者说执行几遍才会被JIT(Just-in-time)编译器优化,所以测试性能之前跑几遍程序很重要。
避免重量级任务划分与结果合并
Fork/Join的很多使用场景都用到数组或者List等数据结构,子任务在某个分区中运行,最典型的例子如并行排序和并行查找。拆分子任务以及合并处理结果的时候,应该尽量避免System.arraycopy这样耗时耗空间的操作,从而最小化任务的处理开销
有哪些JDK源码中使用了Fork/Join思想?
我们常用的数组工具类 Arrays 在JDK 8之后新增的并行排序方法(parallelSort)就运用了 ForkJoinPool 的特性,还有 ConcurrentHashMap 在JDK 8之后添加的函数式方法(如forEach等)也有运用。
使用Executors工具类创建ForkJoinPool
Java8在Executors工具类中新增了两个工厂方法:
// parallelism定义并行级别
public static ExecutorService newWorkStealingPool(int parallelism);
// 默认并行级别为JVM可用的处理器个数
// Runtime.getRuntime().availableProcessors()
public static ExecutorService newWorkStealingPool();
关于Fork/Join异常处理
Java的受检异常机制一直饱受诟病,所以在ForkJoinTask的invoke()、join()方法及其衍生方法中都没有像get()方法那样抛出个ExecutionException的受检异常。
所以你可以在ForkJoinTask中看到内部把受检异常转换成了运行时异常。
static void rethrow(Throwable ex) {
if (ex != null)
ForkJoinTask.<RuntimeException>uncheckedThrow(ex);
}
@SuppressWarnings("unchecked")
static <T extends Throwable> void uncheckedThrow(Throwable t) throws T {
throw (T)t; // rely on vacuous cast
}
应用实例
计算1+2+3+…+10000的结果
public class Test {
static final class SumTask extends RecursiveTask<Integer> {
private static final long serialVersionUID = 1L;
final int start; //开始计算的数
final int end; //最后计算的数
SumTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
//如果计算量小于1000,那么分配一个线程执行if中的代码块,并返回执行结果
if(end - start < 1000) {
System.out.println(Thread.currentThread().getName() + " 开始执行: " + start + "-" + end);
int sum = 0;
for(int i = start; i <= end; i++)
sum += i;
return sum;
}
//如果计算量大于1000,那么拆分为两个任务
SumTask task1 = new SumTask(start, (start + end) / 2);
SumTask task2 = new SumTask((start + end) / 2 + 1, end);
//执行任务
task1.fork();
task2.fork();
//获取任务执行的结果
return task1.join() + task2.join();
}
}
public static void main(String[] args) throws InterruptedException, ExecutionException {
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Integer> task = new SumTask(1, 10000);
pool.submit(task);
System.out.println(task.get());
}
}
斐波那契数列
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool(4); // 最大并发数4
Fibonacci fibonacci = new Fibonacci(20);
long startTime = System.currentTimeMillis();
Integer result = forkJoinPool.invoke(fibonacci);
long endTime = System.currentTimeMillis();
System.out.println("Fork/join sum: " + result + " in " + (endTime - startTime) + " ms.");
}
//以下为官方API文档示例
static class Fibonacci extends RecursiveTask<Integer> {
final int n;
Fibonacci(int n) {
this.n = n;
}
@Override
protected Integer compute() {
if (n <= 1) {
return n;
}
Fibonacci f1 = new Fibonacci(n - 1);
f1.fork();
Fibonacci f2 = new Fibonacci(n - 2);
return f2.compute() + f1.join();
}
}
参考资料
24 - CH24-CountDownLatch
概览
其底层是由AQS提供支持,所以其数据结构可以参考AQS的数据结构,而AQS的数据结构核心就是两个虚拟队列: 同步队列sync queue 和条件队列condition queue,不同的条件会有不同的条件队列。
CountDownLatch典型的用法是将一个程序分为n个互相独立的可解决任务,并创建值为n的CountDownLatch。当每一个任务完成时,都会在这个锁存器上调用countDown,等待问题被解决的任务调用这个锁存器的await,将他们自己拦住,直至锁存器计数结束。
源码分析
层级结构
CountDownLatch没有显示继承哪个父类或者实现哪个父接口, 它底层是AQS是通过内部类Sync来实现的。
内部类
CountDownLatch类存在一个内部类Sync,继承自AbstractQueuedSynchronizer,其源代码如下。
private static final class Sync extends AbstractQueuedSynchronizer {
// 版本号
private static final long serialVersionUID = 4982264981922014374L;
// 构造器
Sync(int count) {
setState(count);
}
// 返回当前计数
int getCount() {
return getState();
}
// 试图在共享模式下获取对象状态
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
// 试图设置状态来反映共享模式下的一个释放
protected boolean tryReleaseShared(int releases) {
// Decrement count; signal when transition to zero
// 无限循环
for (;;) {
// 获取状态
int c = getState();
if (c == 0) // 没有被线程占有
return false;
// 下一个状态
int nextc = c-1;
if (compareAndSetState(c, nextc)) // 比较并且设置成功
return nextc == 0;
}
}
}
对CountDownLatch方法的调用会转发到对Sync或AQS的方法的调用,所以,AQS对CountDownLatch提供支持。
类属性
可以看到CountDownLatch类的内部只有一个Sync类型的属性:
public class CountDownLatch {
// 同步队列
private final Sync sync;
}
构造函数
public CountDownLatch(int count) {
if (count < 0) throw new IllegalArgumentException("count < 0");
// 初始化状态数
this.sync = new Sync(count);
}
该构造函数可以构造一个用给定计数初始化的CountDownLatch,并且构造函数内完成了sync的初始化,并设置了状态数。
核心函数:await
此函数将会使当前线程在锁存器倒计数至零之前一直等待,除非线程被中断。其源码如下
public void await() throws InterruptedException {
// 转发到sync对象上
sync.acquireSharedInterruptibly(1);
}
对CountDownLatch对象的await的调用会转发为对Sync的acquireSharedInterruptibly(从AQS继承的方法)方法的调用。
- acquireSharedInterruptibly源码如下:
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
acquireSharedInterruptibly又调用了CountDownLatch的内部类Sync的tryAcquireShared和AQS的doAcquireSharedInterruptibly函数。
- tryAcquireShared函数的源码如下:
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
该函数只是简单的判断AQS的state是否为0,为0则返回1,不为0则返回-1。
- doAcquireSharedInterruptibly函数的源码如下:
private void doAcquireSharedInterruptibly(int arg) throws InterruptedException {
// 添加节点至等待队列
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
for (;;) { // 无限循环
// 获取node的前驱节点
final Node p = node.predecessor();
if (p == head) { // 前驱节点为头结点
// 试图在共享模式下获取对象状态
int r = tryAcquireShared(arg);
if (r >= 0) { // 获取成功
// 设置头结点并进行繁殖
setHeadAndPropagate(node, r);
// 设置节点next域
p.next = null; // help GC
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt()) // 在获取失败后是否需要禁止线程并且进行中断检查
// 抛出异常
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
在AQS的doAcquireSharedInterruptibly中可能会再次调用CountDownLatch的内部类Sync的tryAcquireShared方法和AQS的setHeadAndPropagate方法。
- setHeadAndPropagate方法源码如下
private void setHeadAndPropagate(Node node, int propagate) {
// 获取头结点
Node h = head; // Record old head for check below
// 设置头结点
setHead(node);
/*
* Try to signal next queued node if:
* Propagation was indicated by caller,
* or was recorded (as h.waitStatus either before
* or after setHead) by a previous operation
* (note: this uses sign-check of waitStatus because
* PROPAGATE status may transition to SIGNAL.)
* and
* The next node is waiting in shared mode,
* or we don't know, because it appears null
*
* The conservatism in both of these checks may cause
* unnecessary wake-ups, but only when there are multiple
* racing acquires/releases, so most need signals now or soon
* anyway.
*/
// 进行判断
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
// 获取节点的后继
Node s = node.next;
if (s == null || s.isShared()) // 后继为空或者为共享模式
// 以共享模式进行释放
doReleaseShared();
}
}
该方法设置头结点并且释放头结点后面的满足条件的结点,该方法中可能会调用到AQS的doReleaseShared方法,其源码如下。
private void doReleaseShared() {
/*
* Ensure that a release propagates, even if there are other
* in-progress acquires/releases. This proceeds in the usual
* way of trying to unparkSuccessor of head if it needs
* signal. But if it does not, status is set to PROPAGATE to
* ensure that upon release, propagation continues.
* Additionally, we must loop in case a new node is added
* while we are doing this. Also, unlike other uses of
* unparkSuccessor, we need to know if CAS to reset status
* fails, if so rechecking.
*/
// 无限循环
for (;;) {
// 保存头结点
Node h = head;
if (h != null && h != tail) { // 头结点不为空并且头结点不为尾结点
// 获取头结点的等待状态
int ws = h.waitStatus;
if (ws == Node.SIGNAL) { // 状态为SIGNAL
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0)) // 不成功就继续
continue; // loop to recheck cases
// 释放后继结点
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE)) // 状态为0并且不成功,继续
continue; // loop on failed CAS
}
if (h == head) // 若头结点改变,继续循环
break;
}
}
该方法在共享模式下释放,具体的流程再之后会通过一个示例给出。
所以,对CountDownLatch的await调用大致会有如下的调用链。
上图给出了可能会调用到的主要方法,并非一定会调用到,之后,会通过一个示例给出详细的分析。
核心函数:countDown
此函数将递减锁存器的计数,如果计数到达零,则释放所有等待的线程
public void countDown() {
sync.releaseShared(1);
}
对countDown的调用转换为对Sync对象的releaseShared(从AQS继承而来)方法的调用。
- releaseShared源码如下
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
此函数会以共享模式释放对象,并且在函数中会调用到CountDownLatch的tryReleaseShared函数,并且可能会调用AQS的doReleaseShared函数。
- tryReleaseShared源码如下
protected boolean tryReleaseShared(int releases) {
// Decrement count; signal when transition to zero
// 无限循环
for (;;) {
// 获取状态
int c = getState();
if (c == 0) // 没有被线程占有
return false;
// 下一个状态
int nextc = c-1;
if (compareAndSetState(c, nextc)) // 比较并且设置成功
return nextc == 0;
}
}
此函数会试图设置状态来反映共享模式下的一个释放。具体的流程在下面的示例中会进行分析。
- AQS的doReleaseShared的源码如下
private void doReleaseShared() {
/*
* Ensure that a release propagates, even if there are other
* in-progress acquires/releases. This proceeds in the usual
* way of trying to unparkSuccessor of head if it needs
* signal. But if it does not, status is set to PROPAGATE to
* ensure that upon release, propagation continues.
* Additionally, we must loop in case a new node is added
* while we are doing this. Also, unlike other uses of
* unparkSuccessor, we need to know if CAS to reset status
* fails, if so rechecking.
*/
// 无限循环
for (;;) {
// 保存头结点
Node h = head;
if (h != null && h != tail) { // 头结点不为空并且头结点不为尾结点
// 获取头结点的等待状态
int ws = h.waitStatus;
if (ws == Node.SIGNAL) { // 状态为SIGNAL
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0)) // 不成功就继续
continue; // loop to recheck cases
// 释放后继结点
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE)) // 状态为0并且不成功,继续
continue; // loop on failed CAS
}
if (h == head) // 若头结点改变,继续循环
break;
}
}
此函数在共享模式下释放资源。
所以,对CountDownLatch的countDown调用大致会有如下的调用链。
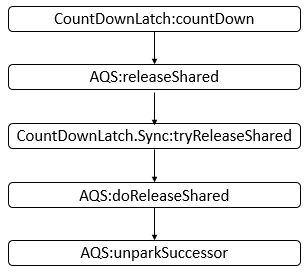
上图给出了可能会调用到的主要方法,并非一定会调用到,之后,会通过一个示例给出详细的分析。
应用示例
import java.util.concurrent.CountDownLatch;
class MyThread extends Thread {
private CountDownLatch countDownLatch;
public MyThread(String name, CountDownLatch countDownLatch) {
super(name);
this.countDownLatch = countDownLatch;
}
public void run() {
System.out.println(Thread.currentThread().getName() + " doing something");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " finish");
countDownLatch.countDown();
}
}
public class CountDownLatchDemo {
public static void main(String[] args) {
CountDownLatch countDownLatch = new CountDownLatch(2);
MyThread t1 = new MyThread("t1", countDownLatch);
MyThread t2 = new MyThread("t2", countDownLatch);
t1.start();
t2.start();
System.out.println("Waiting for t1 thread and t2 thread to finish");
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " continue");
}
}
Waiting for t1 thread and t2 thread to finish
t1 doing something
t2 doing something
t1 finish
t2 finish
main continue
本程序首先计数器初始化为2。根据结果,可能会存在如下的一种时序图。
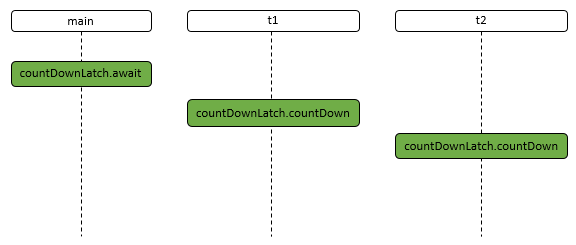
首先main线程会调用await操作,此时main线程会被阻塞,等待被唤醒,之后t1线程执行了countDown操作,最后,t2线程执行了countDown操作,此时main线程就被唤醒了,可以继续运行。下面,进行详细分析。
- main线程执行countDownLatch.await操作,主要调用的函数如下。
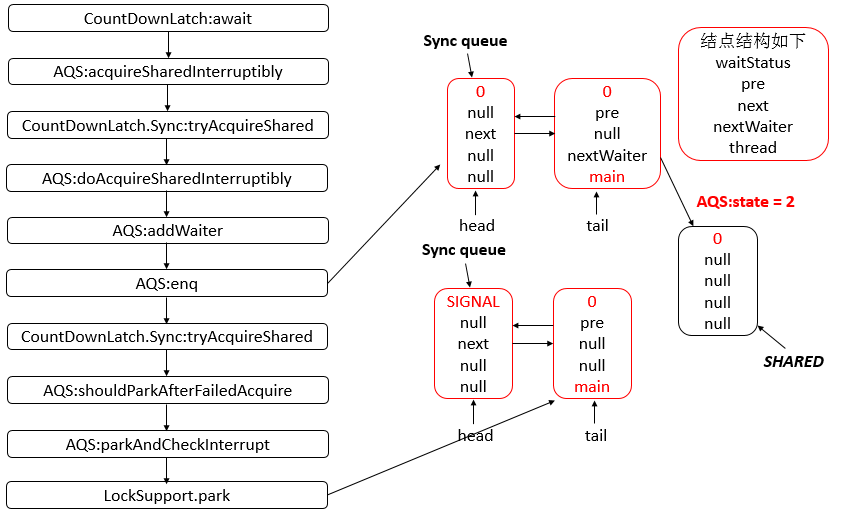
在最后,main线程就被park了,即禁止运行了。此时Sync queue(同步队列)中有两个节点,AQS的state为2,包含main线程的结点的nextWaiter指向SHARED结点。
- t1线程执行countDownLatch.countDown操作,主要调用的函数如下。
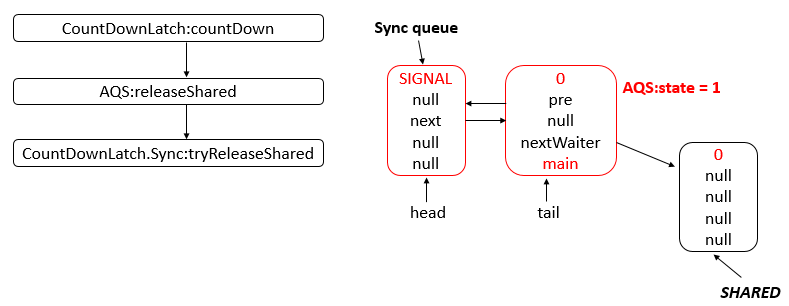
此时,Sync queue队列里的结点个数未发生变化,但是此时,AQS的state已经变为1了。
- t2线程执行countDownLatch.countDown操作,主要调用的函数如下。
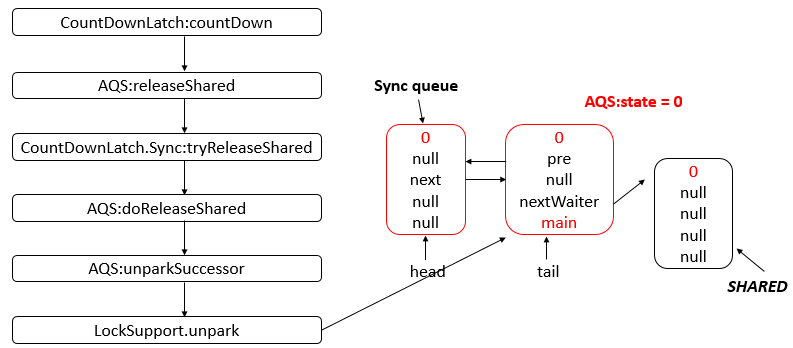
经过调用后,AQS的state为0,并且此时,main线程会被unpark,可以继续运行。当main线程获取cpu资源后,继续运行。
- main线程获取cpu资源,继续运行,由于main线程是在parkAndCheckInterrupt函数中被禁止的,所以此时,继续在parkAndCheckInterrupt函数运行.
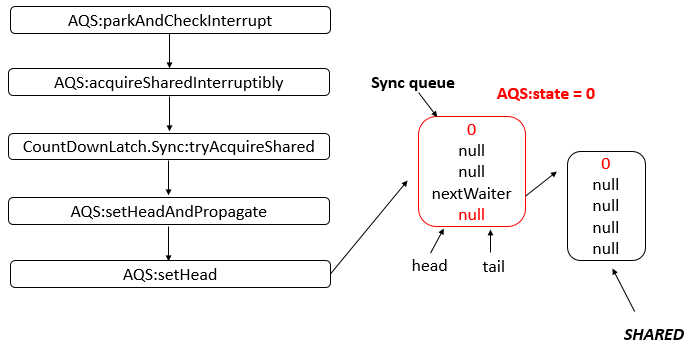
main线程恢复,继续在parkAndCheckInterrupt函数中运行,之后又会回到最终达到的状态为AQS的state为0,并且head与tail指向同一个结点,该节点的额nextWaiter域还是指向SHARED结点。
25 - CH25-CyclicBarrier
源码解析
层级结构
CyclicBarrier没有显示继承哪个父类或者实现哪个父接口, 所有AQS和重入锁不是通过继承实现的,而是通过组合实现的。
public class CyclicBarrier {}
```
### 类的内部类
CyclicBarrier类存在一个内部类Generation,每一次使用的CycBarrier可以当成Generation的实例,其源代码如下
```java
private static class Generation {
boolean broken = false;
}
Generation类有一个属性broken,用来表示当前屏障是否被损坏。
类属性
public class CyclicBarrier {
/** The lock for guarding barrier entry */
// 可重入锁
private final ReentrantLock lock = new ReentrantLock();
/** Condition to wait on until tripped */
// 条件队列
private final Condition trip = lock.newCondition();
/** The number of parties */
// 参与的线程数量
private final int parties;
/* The command to run when tripped */
// 由最后一个进入 barrier 的线程执行的操作
private final Runnable barrierCommand;
/** The current generation */
// 当前代
private Generation generation = new Generation();
// 正在等待进入屏障的线程数量
private int count;
}
该属性有一个为ReentrantLock对象,有一个为Condition对象,而Condition对象又是基于AQS的,所以,归根到底,底层还是由AQS提供支持。
构造函数
- CyclicBarrier(int, Runnable)型构造函数
public CyclicBarrier(int parties, Runnable barrierAction) {
// 参与的线程数量小于等于0,抛出异常
if (parties <= 0) throw new IllegalArgumentException();
// 设置parties
this.parties = parties;
// 设置count
this.count = parties;
// 设置barrierCommand
this.barrierCommand = barrierAction;
}
该构造函数可以指定关联该CyclicBarrier的线程数量,并且可以指定在所有线程都进入屏障后的执行动作,该执行动作由最后一个进行屏障的线程执行。
- CyclicBarrier(int)型构造函数
public CyclicBarrier(int parties) {
// 调用含有两个参数的构造函数
this(parties, null);
}
该构造函数仅仅执行了关联该CyclicBarrier的线程数量,没有设置执行动作。
核心函数:dowait
此函数为CyclicBarrier类的核心函数,CyclicBarrier类对外提供的await函数在底层都是调用该了doawait函数,其源代码如下。
private int dowait(boolean timed, long nanos)
throws InterruptedException, BrokenBarrierException,
TimeoutException {
// 保存当前锁
final ReentrantLock lock = this.lock;
// 锁定
lock.lock();
try {
// 保存当前代
final Generation g = generation;
if (g.broken) // 屏障被破坏,抛出异常
throw new BrokenBarrierException();
if (Thread.interrupted()) { // 线程被中断
// 损坏当前屏障,并且唤醒所有的线程,只有拥有锁的时候才会调用
breakBarrier();
// 抛出异常
throw new InterruptedException();
}
// 减少正在等待进入屏障的线程数量
int index = --count;
if (index == 0) { // 正在等待进入屏障的线程数量为0,所有线程都已经进入
// 运行的动作标识
boolean ranAction = false;
try {
// 保存运行动作
final Runnable command = barrierCommand;
if (command != null) // 动作不为空
// 运行
command.run();
// 设置ranAction状态
ranAction = true;
// 进入下一代
nextGeneration();
return 0;
} finally {
if (!ranAction) // 没有运行的动作
// 损坏当前屏障
breakBarrier();
}
}
// loop until tripped, broken, interrupted, or timed out
// 无限循环
for (;;) {
try {
if (!timed) // 没有设置等待时间
// 等待
trip.await();
else if (nanos > 0L) // 设置了等待时间,并且等待时间大于0
// 等待指定时长
nanos = trip.awaitNanos(nanos);
} catch (InterruptedException ie) {
if (g == generation && ! g.broken) { // 等于当前代并且屏障没有被损坏
// 损坏当前屏障
breakBarrier();
// 抛出异常
throw ie;
} else { // 不等于当前带后者是屏障被损坏
// We're about to finish waiting even if we had not
// been interrupted, so this interrupt is deemed to
// "belong" to subsequent execution.
// 中断当前线程
Thread.currentThread().interrupt();
}
}
if (g.broken) // 屏障被损坏,抛出异常
throw new BrokenBarrierException();
if (g != generation) // 不等于当前代
// 返回索引
return index;
if (timed && nanos <= 0L) { // 设置了等待时间,并且等待时间小于0
// 损坏屏障
breakBarrier();
// 抛出异常
throw new TimeoutException();
}
}
} finally {
// 释放锁
lock.unlock();
}
}
该方法的逻辑会进行一系列的判断,大致流程如下:
核心函数:nextGeneration
此函数在所有线程进入屏障后会被调用,即生成下一个版本,所有线程又可以重新进入到屏障中,其源代码如下:
private void nextGeneration() {
// signal completion of last generation
// 唤醒所有线程
trip.signalAll();
// set up next generation
// 恢复正在等待进入屏障的线程数量
count = parties;
// 新生一代
generation = new Generation();
}
在此函数中会调用AQS的signalAll方法,即唤醒所有等待线程。如果所有的线程都在等待此条件,则唤醒所有线程。其源代码如下:
public final void signalAll() {
if (!isHeldExclusively()) // 不被当前线程独占,抛出异常
throw new IllegalMonitorStateException();
// 保存condition队列头结点
Node first = firstWaiter;
if (first != null) // 头结点不为空
// 唤醒所有等待线程
doSignalAll(first);
}
此函数判断头结点是否为空,即条件队列是否为空,然后会调用doSignalAll函数,doSignalAll函数源码如下:
private void doSignalAll(Node first) {
// condition队列的头结点尾结点都设置为空
lastWaiter = firstWaiter = null;
// 循环
do {
// 获取first结点的nextWaiter域结点
Node next = first.nextWaiter;
// 设置first结点的nextWaiter域为空
first.nextWaiter = null;
// 将first结点从condition队列转移到sync队列
transferForSignal(first);
// 重新设置first
first = next;
} while (first != null);
}
此函数会依次将条件队列中的节点转移到同步队列中,会调用到transferForSignal函数,其源码如下:
final boolean transferForSignal(Node node) {
/*
* If cannot change waitStatus, the node has been cancelled.
*/
if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))
return false;
/*
* Splice onto queue and try to set waitStatus of predecessor to
* indicate that thread is (probably) waiting. If cancelled or
* attempt to set waitStatus fails, wake up to resync (in which
* case the waitStatus can be transiently and harmlessly wrong).
*/
Node p = enq(node);
int ws = p.waitStatus;
if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL))
LockSupport.unpark(node.thread);
return true;
}
此函数的作用就是将处于条件队列中的节点转移到同步队列中,并设置结点的状态信息,其中会调用到enq函数,其源代码如下。
private Node enq(final Node node) {
for (;;) { // 无限循环,确保结点能够成功入队列
// 保存尾结点
Node t = tail;
if (t == null) { // 尾结点为空,即还没被初始化
if (compareAndSetHead(new Node())) // 头结点为空,并设置头结点为新生成的结点
tail = head; // 头结点与尾结点都指向同一个新生结点
} else { // 尾结点不为空,即已经被初始化过
// 将node结点的prev域连接到尾结点
node.prev = t;
if (compareAndSetTail(t, node)) { // 比较结点t是否为尾结点,若是则将尾结点设置为node
// 设置尾结点的next域为node
t.next = node;
return t; // 返回尾结点
}
}
}
}
此函数完成了结点插入同步队列的过程,也很好理解。
综合上面的分析可知,newGeneration函数的主要方法的调用如下,之后会通过一个例子详细讲解:
核心函数:breakBarrier
此函数的作用是损坏当前屏障,会唤醒所有在屏障中的线程。源代码如下:
private void breakBarrier() {
// 设置状态
generation.broken = true;
// 恢复正在等待进入屏障的线程数量
count = parties;
// 唤醒所有线程
trip.signalAll();
}
可以看到,此函数也调用了AQS的signalAll函数,由signal函数提供支持。
应用示例
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
class MyThread extends Thread {
private CyclicBarrier cb;
public MyThread(String name, CyclicBarrier cb) {
super(name);
this.cb = cb;
}
public void run() {
System.out.println(Thread.currentThread().getName() + " going to await");
try {
cb.await();
System.out.println(Thread.currentThread().getName() + " continue");
} catch (Exception e) {
e.printStackTrace();
}
}
}
public class CyclicBarrierDemo {
public static void main(String[] args) throws InterruptedException, BrokenBarrierException {
CyclicBarrier cb = new CyclicBarrier(3, new Thread("barrierAction") {
public void run() {
System.out.println(Thread.currentThread().getName() + " barrier action");
}
});
MyThread t1 = new MyThread("t1", cb);
MyThread t2 = new MyThread("t2", cb);
t1.start();
t2.start();
System.out.println(Thread.currentThread().getName() + " going to await");
cb.await();
System.out.println(Thread.currentThread().getName() + " continue");
}
}
t1 going to await
main going to await
t2 going to await
t2 barrier action
t2 continue
t1 continue
main continue
根据结果可知,可能会存在如下的调用时序。
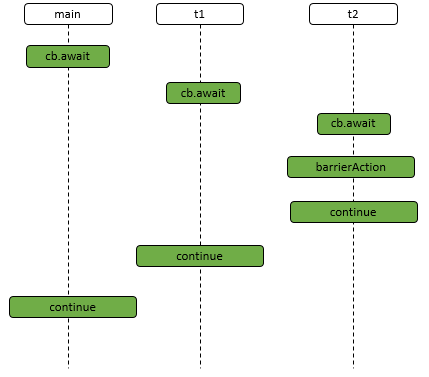
由上图可知,假设t1线程的cb.await是在main线程的cb.barrierAction动作是由最后一个进入屏障的线程执行的。根据时序图,进一步分析出其内部工作流程。
- main(主)线程执行cb.await操作,主要调用的函数如下。
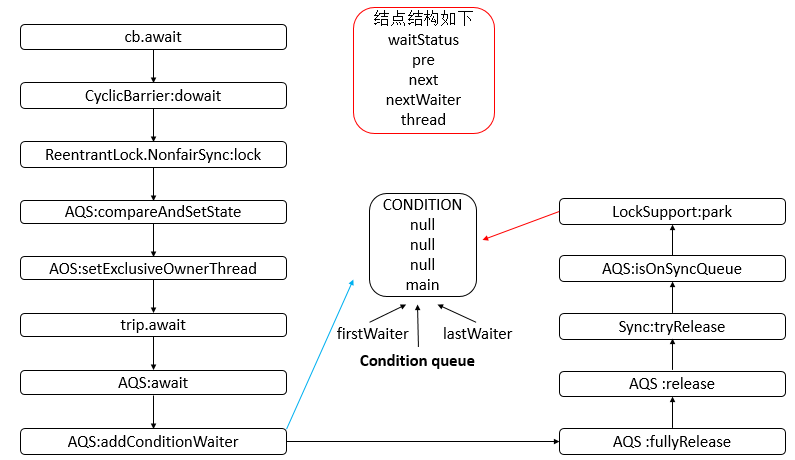
由于ReentrantLock的默认采用非公平策略,所以在dowait函数中调用的是ReentrantLock.NonfairSync的lock函数,由于此时AQS的状态是0,表示还没有被任何线程占用,故main线程可以占用,之后在dowait中会调用trip.await函数,最终的结果是条件队列中存放了一个包含main线程的结点,并且被禁止运行了,同时,main线程所拥有的资源也被释放了,可以供其他线程获取。
- t1线程执行cb.await操作,其中假设t1线程的lock.lock操作在main线程释放了资源之后,则其主要调用的函数如下。
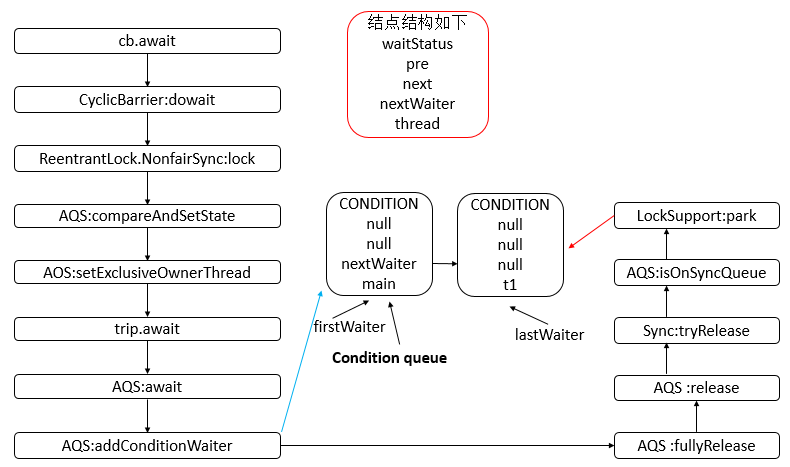
可以看到,之后condition queue(条件队列)里面有两个节点,包含t1线程的结点插入在队列的尾部,并且t1线程也被禁止了,因为执行了park操作,此时两个线程都被禁止了。
- t2线程执行cb.await操作,其中假设t2线程的lock.lock操作在t1线程释放了资源之后,则其主要调用的函数如下。
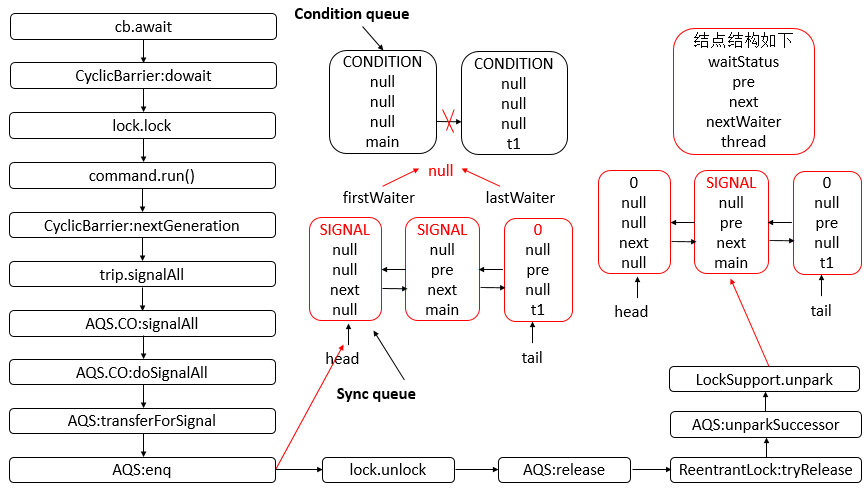
由上图可知,在t2线程执行await操作后,会直接执行command.run方法,不是重新开启一个线程,而是最后进入屏障的线程执行。同时,会将Condition queue中的所有节点都转移到Sync queue中,并且最后main线程会被unpark,可以继续运行。main线程获取cpu资源,继续运行。
- main线程获取cpu资源,继续运行,下图给出了主要的方法调用:
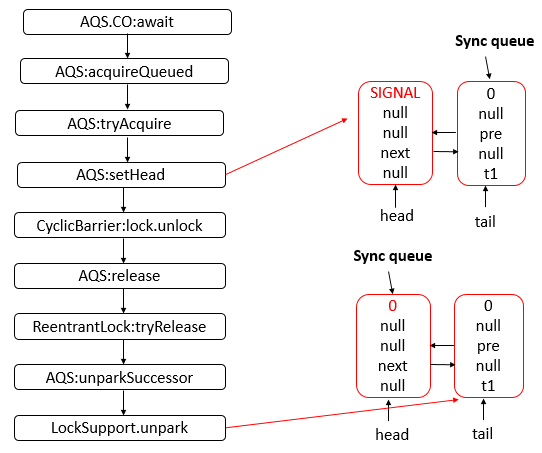
其中,由于main线程是在AQS.CO的wait中被park的,所以恢复时,会继续在该方法中运行。运行过后,t1线程被unpark,它获得cpu资源可以继续运行。
- t1线程获取cpu资源,继续运行,下图给出了主要的方法调用。
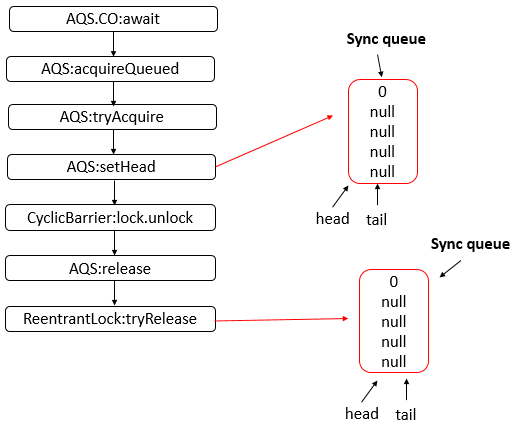
其中,由于t1线程是在AQS.CO的wait方法中被park,所以恢复时,会继续在该方法中运行。运行过后,Sync queue中保持着一个空节点。头结点与尾节点均指向它。
注意: 在线程await过程中中断线程会抛出异常,所有进入屏障的线程都将被释放。至于CyclicBarrier的其他用法,读者可以自行查阅API,不再累赘。
对比 CountDownLatch
CountDownLatch减计数,CyclicBarrier加计数。
CountDownLatch是一次性的,CyclicBarrier可以重用。
CountDownLatch和CyclicBarrier都有让多个线程等待同步然后再开始下一步动作的意思,但是CountDownLatch的下一步的动作实施者是主线程,具有不可重复性;
而CyclicBarrier的下一步动作实施者还是“其他线程”本身,具有往复多次实施动作的特点。
26 - CH26-Semaphore
概览
Semaphore底层基于 AQS。Semaphore称为计数信号量,它允许n个任务同时访问某个资源,可以将信号量看做是在向外分发使用资源的许可证,只有成功获取许可证,才能使用资源。
源码分析
层级结构
public class Semaphore implements java.io.Serializable {}
内部类
Semaphore总共有三个内部类,并且三个内部类是紧密相关的,下面先看三个类的关系。
Semaphore与ReentrantLock的内部类的结构相同,类内部总共存在Sync、NonfairSync、FairSync三个类,NonfairSync与FairSync类继承自Sync类,Sync类继承自AbstractQueuedSynchronizer抽象类。
内部类:Sync
// 内部类,继承自AQS
abstract static class Sync extends AbstractQueuedSynchronizer {
// 版本号
private static final long serialVersionUID = 1192457210091910933L;
// 构造函数
Sync(int permits) {
// 设置状态数
setState(permits);
}
// 获取许可
final int getPermits() {
return getState();
}
// 共享模式下非公平策略获取
final int nonfairTryAcquireShared(int acquires) {
for (;;) { // 无限循环
// 获取许可数
int available = getState();
// 剩余的许可
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining)) // 许可小于0或者比较并且设置状态成功
return remaining;
}
}
// 共享模式下进行释放
protected final boolean tryReleaseShared(int releases) {
for (;;) { // 无限循环
// 获取许可
int current = getState();
// 可用的许可
int next = current + releases;
if (next < current) // overflow
throw new Error("Maximum permit count exceeded");
if (compareAndSetState(current, next)) // 比较并进行设置成功
return true;
}
}
// 根据指定的缩减量减小可用许可的数目
final void reducePermits(int reductions) {
for (;;) { // 无限循环
// 获取许可
int current = getState();
// 可用的许可
int next = current - reductions;
if (next > current) // underflow
throw new Error("Permit count underflow");
if (compareAndSetState(current, next)) // 比较并进行设置成功
return;
}
}
// 获取并返回立即可用的所有许可
final int drainPermits() {
for (;;) { // 无限循环
// 获取许可
int current = getState();
if (current == 0 || compareAndSetState(current, 0)) // 许可为0或者比较并设置成功
return current;
}
}
}
Sync类的属性相对简单,只有一个版本号,Sync类存在如下方法和作用如下。
内部类:NonfairSync
NonfairSync类继承了Sync类,表示采用非公平策略获取资源,其只有一个tryAcquireShared方法,重写了AQS的该方法,其源码如下:
static final class NonfairSync extends Sync {
// 版本号
private static final long serialVersionUID = -2694183684443567898L;
// 构造函数
NonfairSync(int permits) {
super(permits);
}
// 共享模式下获取
protected int tryAcquireShared(int acquires) {
return nonfairTryAcquireShared(acquires);
}
}
从tryAcquireShared方法的源码可知,其会调用父类Sync的nonfairTryAcquireShared方法,表示按照非公平策略进行资源的获取。
内部类:FairSync
FairSync类继承了Sync类,表示采用公平策略获取资源,其只有一个tryAcquireShared方法,重写了AQS的该方法,其源码如下。
protected int tryAcquireShared(int acquires) {
for (;;) { // 无限循环
if (hasQueuedPredecessors()) // 同步队列中存在其他节点
return -1;
// 获取许可
int available = getState();
// 剩余的许可
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining)) // 剩余的许可小于0或者比较设置成功
return remaining;
}
}
从tryAcquireShared方法的源码可知,它使用公平策略来获取资源,它会判断同步队列中是否存在其他的等待节点。
类属性
public class Semaphore implements java.io.Serializable {
// 版本号
private static final long serialVersionUID = -3222578661600680210L;
// 属性
private final Sync sync;
}
Semaphore自身只有两个属性,最重要的是sync属性,基于Semaphore对象的操作绝大多数都转移到了对sync的操作。
构造函数
- Semaphore(int)型构造函数
public Semaphore(int permits) {
sync = new NonfairSync(permits);
}
该构造函数会创建具有给定的许可数和非公平的公平设置的Semaphore。
- Semaphore(int, boolean)型构造函数
public Semaphore(int permits, boolean fair) {
sync = fair ? new FairSync(permits) : new NonfairSync(permits);
}
该构造函数会创建具有给定的许可数和给定的公平设置的Semaphore。
核心函数:acquire
此方法从信号量获取一个(多个)许可,在提供一个许可前一直将线程阻塞,或者线程被中断,其源码如下
public void acquire() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
该方法中将会调用Sync对象的acquireSharedInterruptibly(从AQS继承而来的方法)方法,而acquireSharedInterruptibly方法在上一篇CountDownLatch中已经进行了分析,在此不再累赘。
最终可以获取大致的方法调用序列(假设使用非公平策略)。如下图所示。
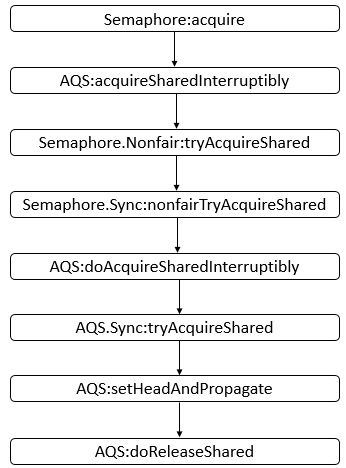
上图只是给出了大体会调用到的方法,和具体的示例可能会有些差别,之后会根据具体的示例进行分析。
核心函数:release
此方法释放一个(多个)许可,将其返回给信号量,源码如下。
public void release() {
sync.releaseShared(1);
}
该方法中将会调用Sync对象的releaseShared(从AQS继承而来的方法)方法,而releaseShared方法在上一篇CountDownLatch中已经进行了分析,在此不再累赘。
最终可以获取大致的方法调用序列(假设使用非公平策略)。如下图所示:
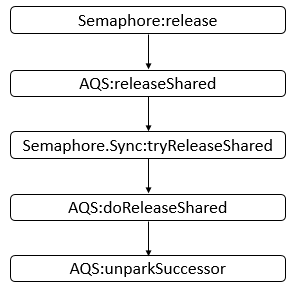
应用实例
import java.util.concurrent.Semaphore;
class MyThread extends Thread {
private Semaphore semaphore;
public MyThread(String name, Semaphore semaphore) {
super(name);
this.semaphore = semaphore;
}
public void run() {
int count = 3;
System.out.println(Thread.currentThread().getName() + " trying to acquire");
try {
semaphore.acquire(count);
System.out.println(Thread.currentThread().getName() + " acquire successfully");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release(count);
System.out.println(Thread.currentThread().getName() + " release successfully");
}
}
}
public class SemaphoreDemo {
public final static int SEM_SIZE = 10;
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(SEM_SIZE);
MyThread t1 = new MyThread("t1", semaphore);
MyThread t2 = new MyThread("t2", semaphore);
t1.start();
t2.start();
int permits = 5;
System.out.println(Thread.currentThread().getName() + " trying to acquire");
try {
semaphore.acquire(permits);
System.out.println(Thread.currentThread().getName() + " acquire successfully");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release();
System.out.println(Thread.currentThread().getName() + " release successfully");
}
}
}
main trying to acquire
main acquire successfully
t1 trying to acquire
t1 acquire successfully
t2 trying to acquire
t1 release successfully
main release successfully
t2 acquire successfully
t2 release successfully
首先,生成一个信号量,信号量有10个许可,然后,main,t1,t2三个线程获取许可运行,根据结果,可能存在如下的一种时序。
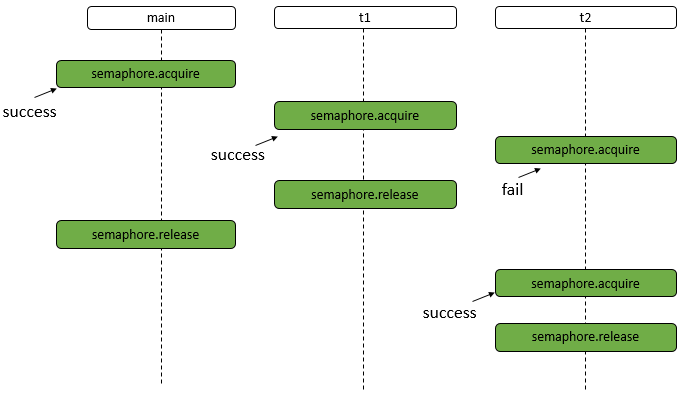
如上图所示,首先,main线程执行acquire操作,并且成功获得许可,之后t1线程执行acquire操作,成功获得许可,之后t2执行acquire操作,由于此时许可数量不够,t2线程将会阻塞,直到许可可用。之后t1线程释放许可,main线程释放许可,此时的许可数量可以满足t2线程的要求,所以,此时t2线程会成功获得许可运行,t2运行完成后释放许可。下面进行详细分析。
- main线程执行semaphore.acquire操作。主要的函数调用如下图所示。
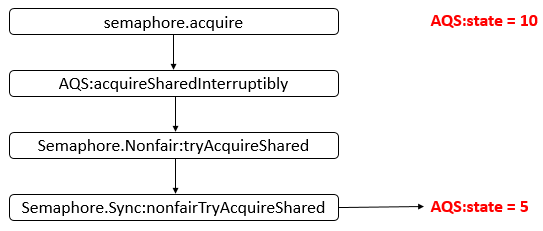
说明: 此时,可以看到只是AQS的state变为了5,main线程并没有被阻塞,可以继续运行。
- t1线程执行semaphore.acquire操作。主要的函数调用如下图所示。
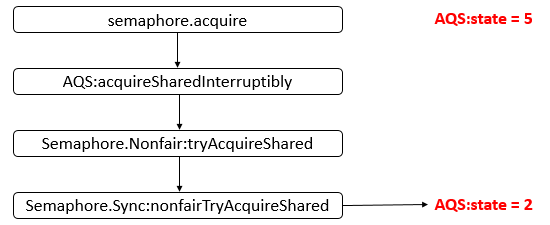
说明: 此时,可以看到只是AQS的state变为了2,t1线程并没有被阻塞,可以继续运行。
- t2线程执行semaphore.acquire操作。主要的函数调用如下图所示。
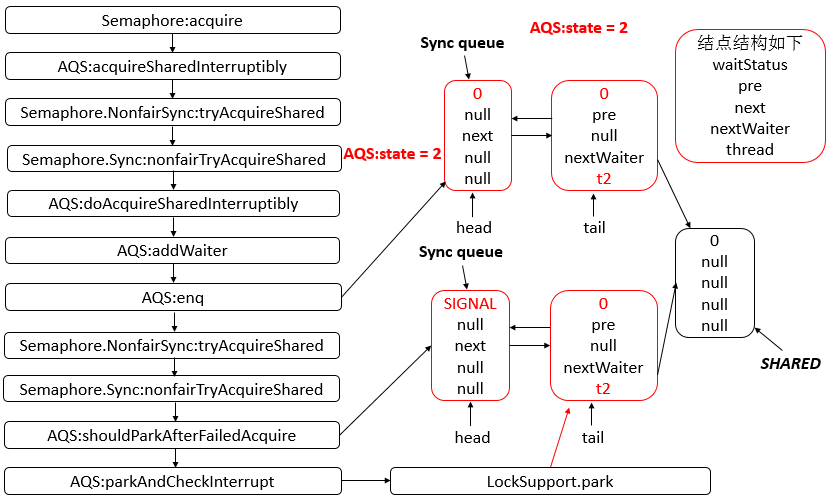
说明: 此时,t2线程获取许可不会成功,之后会导致其被禁止运行,值得注意的是,AQS的state还是为2。
- t1执行semaphore.release操作。主要的函数调用如下图所示。

说明: 此时,t2线程将会被unpark,并且AQS的state为5,t2获取cpu资源后可以继续运行。
- main线程执行semaphore.release操作。主要的函数调用如下图所示。
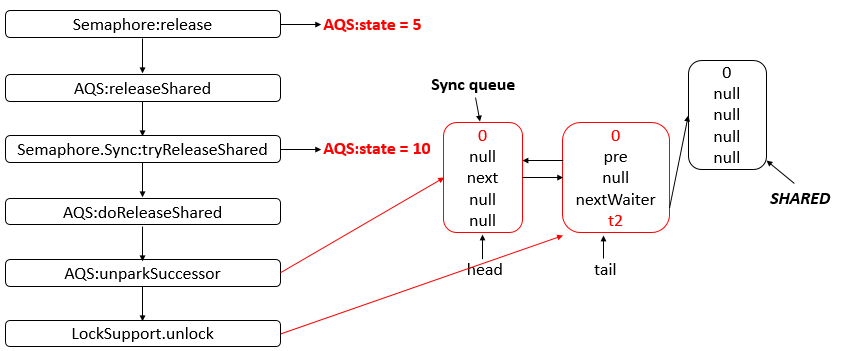
说明: 此时,t2线程还会被unpark,但是不会产生影响,此时,只要t2线程获得CPU资源就可以运行了。此时,AQS的state为10。
- t2获取CPU资源,继续运行,此时t2需要恢复现场,回到parkAndCheckInterrupt函数中,也是在should继续运行。主要的函数调用如下图所示。
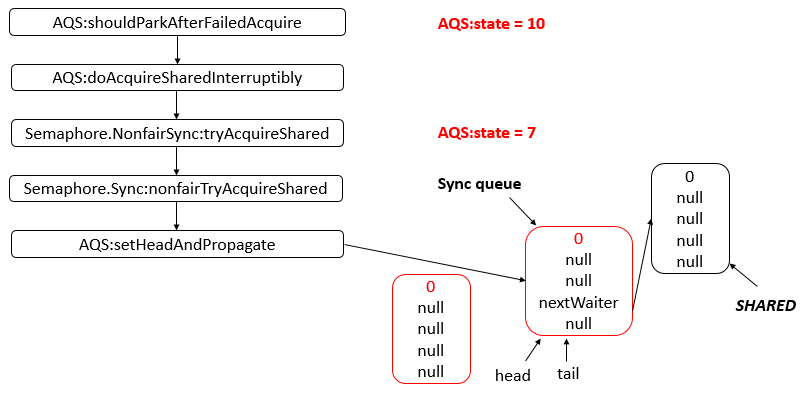
说明: 此时,可以看到,Sync queue中只有一个结点,头结点与尾节点都指向该结点,在setHeadAndPropagate的函数中会设置头结点并且会unpark队列中的其他结点。
- t2线程执行semaphore.release操作。主要的函数调用如下图所示。
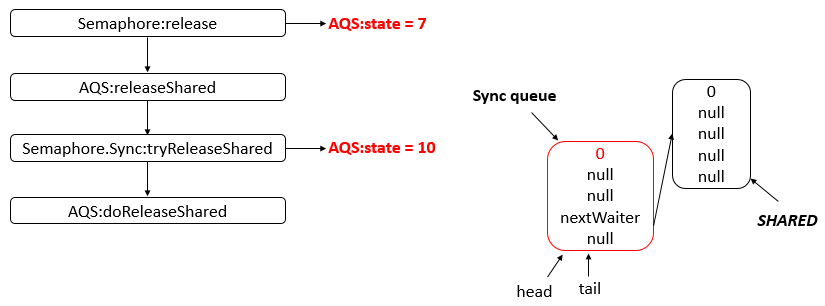
说明: t2线程经过release后,此时信号量的许可又变为10个了,此时Sync queue中的结点还是没有变化。
深入理解
单独使用Semaphore是不会使用到AQS的条件队列的
不同于CyclicBarrier和ReentrantLock,单独使用Semaphore是不会使用到AQS的条件队列的,其实,只有进行await操作才会进入条件队列,其他的都是在同步队列中,只是当前线程会被park。
场景问题
semaphore初始化有10个令牌,11个线程同时各调用1次acquire方法,会发生什么?
答案:拿不到令牌的线程阻塞,不会继续往下运行。
semaphore初始化有10个令牌,一个线程重复调用11次acquire方法,会发生什么?
答案:线程阻塞,不会继续往下运行。可能你会考虑类似于锁的重入的问题,很好,但是,令牌没有重入的概念。你只要调用一次acquire方法,就需要有一个令牌才能继续运行。
semaphore初始化有1个令牌,1个线程调用一次acquire方法,然后调用两次release方法,之后另外一个线程调用acquire(2)方法,此线程能够获取到足够的令牌并继续运行吗?
答案:能,原因是release方法会添加令牌,并不会以初始化的大小为准。
semaphore初始化有2个令牌,一个线程调用1次release方法,然后一次性获取3个令牌,会获取到吗?
答案:能,原因是release会添加令牌,并不会以初始化的大小为准。Semaphore中release方法的调用并没有限制要在acquire后调用。
27 - CH27-Phaser
概览
Phaser是JDK 7新增的一个同步辅助类,它可以实现CyclicBarrier和CountDownLatch类似的功能,而且它支持对任务的动态调整,并支持分层结构来达到更高的吞吐量。
运行机制

注册:Registration
跟其他barrier不同,在phaser上注册的parties会随着时间的变化而变化。任务可以随时注册(使用方法register,bulkRegister注册,或者由构造器确定初始parties),并且在任何抵达点可以随意地撤销注册(方法arriveAndDeregister)。就像大多数基本的同步结构一样,注册和撤销只影响内部count;不会创建更深的内部记录,所以任务不能查询他们是否已经注册。(不过,可以通过继承来实现类似的记录)
同步:Synchronization
和CyclicBarrier一样,Phaser也可以重复await。方法arriveAndAwaitAdvance的效果类似CyclicBarrier.await。phaser的每一代都有一个相关的phase number,初始值为0,当所有注册的任务都到达phaser时phase+1,到达最大值(Integer.MAX_VALUE)之后清零。使用phase number可以独立控制 到达phaser 和 等待其他线程 的动作,通过下面两种类型的方法:
到达机制:Arrival
arrive和arriveAndDeregister方法记录到达状态。这些方法不会阻塞,但是会返回一个相关的arrival phase number;也就是说,phase number用来确定到达状态。当所有任务都到达给定phase时,可以执行一个可选的函数,这个函数通过重写onAdvance方法实现,通常可以用来控制终止状态。重写此方法类似于为CyclicBarrier提供一个barrierAction,但比它更灵活。
等待机制:Waiting
awaitAdvance方法需要一个表示arrival phase number的参数,并且在phaser前进到与给定phase不同的phase时返回。和CyclicBarrier不同,即使等待线程已经被中断,awaitAdvance方法也会一直等待。中断状态和超时时间同样可用,但是当任务等待中断或超时后未改变phaser的状态时会遭遇异常。如果有必要,在方法forceTermination之后可以执行这些异常的相关的handler进行恢复操作,Phaser也可能被ForkJoinPool中的任务使用,这样在其他任务阻塞等待一个phase时可以保证足够的并行度来执行任务。
终止:Termination
可以用isTerminated方法检查phaser的终止状态。在终止时,所有同步方法立刻返回一个负值。在终止时尝试注册也没有效果。当调用onAdvance返回true时Termination被触发。当deregistration操作使已注册的parties变为0时,onAdvance的默认实现就会返回true。也可以重写onAdvance方法来定义终止动作。forceTermination方法也可以释放等待线程并且允许它们终止。
分层:Tiering
Phaser支持分层结构(树状构造)来减少竞争。注册了大量parties的Phaser可能会因为同步竞争消耗很高的成本, 因此可以设置一些子Phaser来共享一个通用的parent。这样的话即使每个操作消耗了更多的开销,但是会提高整体吞吐量。 在一个分层结构的phaser里,子节点phaser的注册和取消注册都通过父节点管理。子节点phaser通过构造或方法register、bulkRegister进行首次注册时,在其父节点上注册。子节点phaser通过调用arriveAndDeregister进行最后一次取消注册时,也在其父节点上取消注册。
监控:Monitoring
由于同步方法可能只被已注册的parties调用,所以phaser的当前状态也可能被任何调用者监控。在任何时候,可以通过getRegisteredParties获取parties数,其中getArrivedParties方法返回已经到达当前phase的parties数。当剩余的parties(通过方法getUnarrivedParties获取)到达时,phase进入下一代。这些方法返回的值可能只表示短暂的状态,所以一般来说在同步结构里并没有啥卵用。
源码分析
核心属性
private volatile long state;
/**
* The parent of this phaser, or null if none
*/
private final Phaser parent;
/**
* The root of phaser tree. Equals this if not in a tree.
*/
private final Phaser root;
//等待线程的栈顶元素,根据phase取模定义为一个奇数header和一个偶数header
private final AtomicReference<QNode> evenQ;
private final AtomicReference<QNode> oddQ;
Phaser使用一个long型state值来标识内部状态:
- 低0-15位表示未到达parties数;
- 中16-31位表示等待的parties数;
- 中32-62位表示phase当前代;
- 高63位表示当前phaser的终止状态。
子Phaser的phase在没有被真正使用之前,允许滞后于它的root节点。这里在后面源码分析的reconcileState方法里会讲解。 Qnode是Phaser定义的内部等待队列,用于在阻塞时记录等待线程及相关信息。实现了ForkJoinPool的一个内部接口ManagedBlocker,上面已经说过,Phaser也可能被ForkJoinPool中的任务使用,这样在其他任务阻塞等待一个phase时可以保证足够的并行度来执行任务(通过内部实现方法isReleasable和block)。
函数列表
//构造方法
public Phaser() {
this(null, 0);
}
public Phaser(int parties) {
this(null, parties);
}
public Phaser(Phaser parent) {
this(parent, 0);
}
public Phaser(Phaser parent, int parties)
//注册一个新的party
public int register()
//批量注册
public int bulkRegister(int parties)
//使当前线程到达phaser,不等待其他任务到达。返回arrival phase number
public int arrive()
//使当前线程到达phaser并撤销注册,返回arrival phase number
public int arriveAndDeregister()
/*
* 使当前线程到达phaser并等待其他任务到达,等价于awaitAdvance(arrive())。
* 如果需要等待中断或超时,可以使用awaitAdvance方法完成一个类似的构造。
* 如果需要在到达后取消注册,可以使用awaitAdvance(arriveAndDeregister())。
*/
public int arriveAndAwaitAdvance()
//等待给定phase数,返回下一个 arrival phase number
public int awaitAdvance(int phase)
//阻塞等待,直到phase前进到下一代,返回下一代的phase number
public int awaitAdvance(int phase)
//响应中断版awaitAdvance
public int awaitAdvanceInterruptibly(int phase) throws InterruptedException
public int awaitAdvanceInterruptibly(int phase, long timeout, TimeUnit unit)
throws InterruptedException, TimeoutException
//使当前phaser进入终止状态,已注册的parties不受影响,如果是分层结构,则终止所有phaser
public void forceTermination()
方法:register
//注册一个新的party
public int register() {
return doRegister(1);
}
private int doRegister(int registrations) {
// adjustment to state
long adjust = ((long)registrations << PARTIES_SHIFT) | registrations;
final Phaser parent = this.parent;
int phase;
for (;;) {
long s = (parent == null) ? state : reconcileState();
int counts = (int)s;
int parties = counts >>> PARTIES_SHIFT;//获取已注册parties数
int unarrived = counts & UNARRIVED_MASK;//未到达数
if (registrations > MAX_PARTIES - parties)
throw new IllegalStateException(badRegister(s));
phase = (int)(s >>> PHASE_SHIFT);//获取当前代
if (phase < 0)
break;
if (counts != EMPTY) { // not 1st registration
if (parent == null || reconcileState() == s) {
if (unarrived == 0) // wait out advance
root.internalAwaitAdvance(phase, null);//等待其他任务到达
else if (UNSAFE.compareAndSwapLong(this, stateOffset,
s, s + adjust))//更新注册的parties数
break;
}
}
else if (parent == null) { // 1st root registration
long next = ((long)phase << PHASE_SHIFT) | adjust;
if (UNSAFE.compareAndSwapLong(this, stateOffset, s, next))//更新phase
break;
}
else {
//分层结构,子phaser首次注册用父节点管理
synchronized (this) { // 1st sub registration
if (state == s) { // recheck under lock
phase = parent.doRegister(1);//分层结构,使用父节点注册
if (phase < 0)
break;
// finish registration whenever parent registration
// succeeded, even when racing with termination,
// since these are part of the same "transaction".
//由于在同一个事务里,即使phaser已终止,也会完成注册
while (!UNSAFE.compareAndSwapLong
(this, stateOffset, s,
((long)phase << PHASE_SHIFT) | adjust)) {//更新phase
s = state;
phase = (int)(root.state >>> PHASE_SHIFT);
// assert (int)s == EMPTY;
}
break;
}
}
}
}
return phase;
}
register方法为phaser添加一个新的party,如果onAdvance正在运行,那么这个方法会等待它运行结束再返回结果。如果当前phaser有父节点,并且当前phaser上没有已注册的party,那么就会交给父节点注册。
register和bulkRegister都由doRegister实现,大概流程如下:
- 如果当前操作不是首次注册,那么直接在当前phaser上更新注册parties数
- 如果是首次注册,并且当前phaser没有父节点,说明是root节点注册,直接更新phase
- 如果当前操作是首次注册,并且当前phaser由父节点,则注册操作交由父节点,并更新当前phaser的phase
- 上面说过,子Phaser的phase在没有被真正使用之前,允许滞后于它的root节点。非首次注册时,如果Phaser有父节点,则调用reconcileState()方法解决root节点的phase延迟传递问题, 源码如下:
private long reconcileState() {
final Phaser root = this.root;
long s = state;
if (root != this) {
int phase, p;
// CAS to root phase with current parties, tripping unarrived
while ((phase = (int)(root.state >>> PHASE_SHIFT)) !=
(int)(s >>> PHASE_SHIFT) &&
!UNSAFE.compareAndSwapLong
(this, stateOffset, s,
s = (((long)phase << PHASE_SHIFT) |
((phase < 0) ? (s & COUNTS_MASK) :
(((p = (int)s >>> PARTIES_SHIFT) == 0) ? EMPTY :
((s & PARTIES_MASK) | p))))))
s = state;
}
return s;
}
当root节点的phase已经advance到下一代,但是子节点phaser还没有,这种情况下它们必须通过更新未到达parties数 完成它们自己的advance操作(如果parties为0,重置为EMPTY状态)。
回到register方法的第一步,如果当前未到达数为0,说明上一代phase正在进行到达操作,此时调用internalAwaitAdvance()方法等待其他任务完成到达操作,源码如下:
//阻塞等待phase到下一代
private int internalAwaitAdvance(int phase, QNode node) {
// assert root == this;
releaseWaiters(phase-1); // ensure old queue clean
boolean queued = false; // true when node is enqueued
int lastUnarrived = 0; // to increase spins upon change
int spins = SPINS_PER_ARRIVAL;
long s;
int p;
while ((p = (int)((s = state) >>> PHASE_SHIFT)) == phase) {
if (node == null) { // spinning in noninterruptible mode
int unarrived = (int)s & UNARRIVED_MASK;//未到达数
if (unarrived != lastUnarrived &&
(lastUnarrived = unarrived) < NCPU)
spins += SPINS_PER_ARRIVAL;
boolean interrupted = Thread.interrupted();
if (interrupted || --spins < 0) { // need node to record intr
//使用node记录中断状态
node = new QNode(this, phase, false, false, 0L);
node.wasInterrupted = interrupted;
}
}
else if (node.isReleasable()) // done or aborted
break;
else if (!queued) { // push onto queue
AtomicReference<QNode> head = (phase & 1) == 0 ? evenQ : oddQ;
QNode q = node.next = head.get();
if ((q == null || q.phase == phase) &&
(int)(state >>> PHASE_SHIFT) == phase) // avoid stale enq
queued = head.compareAndSet(q, node);
}
else {
try {
ForkJoinPool.managedBlock(node);//阻塞给定node
} catch (InterruptedException ie) {
node.wasInterrupted = true;
}
}
}
if (node != null) {
if (node.thread != null)
node.thread = null; // avoid need for unpark()
if (node.wasInterrupted && !node.interruptible)
Thread.currentThread().interrupt();
if (p == phase && (p = (int)(state >>> PHASE_SHIFT)) == phase)
return abortWait(phase); // possibly clean up on abort
}
releaseWaiters(phase);
return p;
}
简单介绍下第二个参数node,如果不为空,则说明等待线程需要追踪中断状态或超时状态。以doRegister中的调用为例,不考虑线程争用,internalAwaitAdvance大概流程如下:
- 首先调用releaseWaiters唤醒上一代所有等待线程,确保旧队列中没有遗留的等待线程。
- 循环SPINS_PER_ARRIVAL指定的次数或者当前线程被中断,创建node记录等待线程及相关信息。
- 继续循环调用ForkJoinPool.managedBlock运行被阻塞的任务
- 继续循环,阻塞任务运行成功被释放,跳出循环
- 最后唤醒当前phase的线程
方法:arrive
//使当前线程到达phaser,不等待其他任务到达。返回arrival phase number
public int arrive() {
return doArrive(ONE_ARRIVAL);
}
private int doArrive(int adjust) {
final Phaser root = this.root;
for (;;) {
long s = (root == this) ? state : reconcileState();
int phase = (int)(s >>> PHASE_SHIFT);
if (phase < 0)
return phase;
int counts = (int)s;
//获取未到达数
int unarrived = (counts == EMPTY) ? 0 : (counts & UNARRIVED_MASK);
if (unarrived <= 0)
throw new IllegalStateException(badArrive(s));
if (UNSAFE.compareAndSwapLong(this, stateOffset, s, s-=adjust)) {//更新state
if (unarrived == 1) {//当前为最后一个未到达的任务
long n = s & PARTIES_MASK; // base of next state
int nextUnarrived = (int)n >>> PARTIES_SHIFT;
if (root == this) {
if (onAdvance(phase, nextUnarrived))//检查是否需要终止phaser
n |= TERMINATION_BIT;
else if (nextUnarrived == 0)
n |= EMPTY;
else
n |= nextUnarrived;
int nextPhase = (phase + 1) & MAX_PHASE;
n |= (long)nextPhase << PHASE_SHIFT;
UNSAFE.compareAndSwapLong(this, stateOffset, s, n);
releaseWaiters(phase);//释放等待phase的线程
}
//分层结构,使用父节点管理arrive
else if (nextUnarrived == 0) { //propagate deregistration
phase = parent.doArrive(ONE_DEREGISTER);
UNSAFE.compareAndSwapLong(this, stateOffset,
s, s | EMPTY);
}
else
phase = parent.doArrive(ONE_ARRIVAL);
}
return phase;
}
}
}
arrive方法手动调整到达数,使当前线程到达phaser。arrive和arriveAndDeregister都调用了doArrive实现,大概流程如下:
- 首先更新state(state - adjust);
- 如果当前不是最后一个未到达的任务,直接返回phase
- 如果当前是最后一个未到达的任务:
- 如果当前是root节点,判断是否需要终止phaser,CAS更新phase,最后释放等待的线程;
- 如果是分层结构,并且已经没有下一代未到达的parties,则交由父节点处理doArrive逻辑,然后更新state为EMPTY。
方法:arriveAndAwaitAdvance
public int arriveAndAwaitAdvance() {
// Specialization of doArrive+awaitAdvance eliminating some reads/paths
final Phaser root = this.root;
for (;;) {
long s = (root == this) ? state : reconcileState();
int phase = (int)(s >>> PHASE_SHIFT);
if (phase < 0)
return phase;
int counts = (int)s;
int unarrived = (counts == EMPTY) ? 0 : (counts & UNARRIVED_MASK);//获取未到达数
if (unarrived <= 0)
throw new IllegalStateException(badArrive(s));
if (UNSAFE.compareAndSwapLong(this, stateOffset, s,
s -= ONE_ARRIVAL)) {//更新state
if (unarrived > 1)
return root.internalAwaitAdvance(phase, null);//阻塞等待其他任务
if (root != this)
return parent.arriveAndAwaitAdvance();//子Phaser交给父节点处理
long n = s & PARTIES_MASK; // base of next state
int nextUnarrived = (int)n >>> PARTIES_SHIFT;
if (onAdvance(phase, nextUnarrived))//全部到达,检查是否可销毁
n |= TERMINATION_BIT;
else if (nextUnarrived == 0)
n |= EMPTY;
else
n |= nextUnarrived;
int nextPhase = (phase + 1) & MAX_PHASE;//计算下一代phase
n |= (long)nextPhase << PHASE_SHIFT;
if (!UNSAFE.compareAndSwapLong(this, stateOffset, s, n))//更新state
return (int)(state >>> PHASE_SHIFT); // terminated
releaseWaiters(phase);//释放等待phase的线程
return nextPhase;
}
}
}
说明: 使当前线程到达phaser并等待其他任务到达,等价于awaitAdvance(arrive())。如果需要等待中断或超时,可以使用awaitAdvance方法完成一个类似的构造。如果需要在到达后取消注册,可以使用awaitAdvance(arriveAndDeregister())。效果类似于CyclicBarrier.await。大概流程如下:
- 更新state(state - 1);
- 如果未到达数大于1,调用internalAwaitAdvance阻塞等待其他任务到达,返回当前phase
- 如果为分层结构,则交由父节点处理arriveAndAwaitAdvance逻辑
- 如果未到达数<=1,判断phaser终止状态,CAS更新phase到下一代,最后释放等待当前phase的线程,并返回下一代phase。
方法:awaitAdvance(int phase)
public int awaitAdvance(int phase) {
final Phaser root = this.root;
long s = (root == this) ? state : reconcileState();
int p = (int)(s >>> PHASE_SHIFT);
if (phase < 0)
return phase;
if (p == phase)
return root.internalAwaitAdvance(phase, null);
return p;
}
//响应中断版awaitAdvance
public int awaitAdvanceInterruptibly(int phase)
throws InterruptedException {
final Phaser root = this.root;
long s = (root == this) ? state : reconcileState();
int p = (int)(s >>> PHASE_SHIFT);
if (phase < 0)
return phase;
if (p == phase) {
QNode node = new QNode(this, phase, true, false, 0L);
p = root.internalAwaitAdvance(phase, node);
if (node.wasInterrupted)
throw new InterruptedException();
}
return p;
}
awaitAdvance用于阻塞等待线程到达,直到phase前进到下一代,返回下一代的phase number。方法很简单,不多赘述。awaitAdvanceInterruptibly方法是响应中断版的awaitAdvance,不同之处在于,调用阻塞时会记录线程的中断状态。
28 - CH28-Exchanger
概览
Exchanger是用于线程协作的工具类, 主要用于两个线程之间的数据交换。
它提供一个同步点,在这个同步点,两个线程可以交换彼此的数据。这两个线程通过exchange()方法交换数据,当一个线程先执行exchange()方法后,它会一直等待第二个线程也执行exchange()方法,当这两个线程到达同步点时,这两个线程就可以交换数据了。
实现机制
for (;;) {
if (slot is empty) { // offer
// slot为空时,将item 设置到Node 中
place item in a Node;
if (can CAS slot from empty to node) {
// 当将node通过CAS交换到slot中时,挂起线程等待被唤醒
wait for release;
// 被唤醒后返回node中匹配到的item
return matching item in node;
}
} else if (can CAS slot from node to empty) { // release
// 将slot设置为空
// 获取node中的item,将需要交换的数据设置到匹配的item
get the item in node;
set matching item in node;
// 唤醒等待的线程
release waiting thread;
}
// else retry on CAS failure
}
比如有2条线程A和B,A线程交换数据时,发现slot为空,则将需要交换的数据放在slot中等待其它线程进来交换数据,等线程B进来,读取A设置的数据,然后设置线程B需要交换的数据,然后唤醒A线程,原理就是这么简单。但是当多个线程之间进行交换数据时就会出现问题,所以Exchanger加入了slot数组。
源码解析
内部类:Node
@sun.misc.Contended static final class Node {
// arena的下标,多个槽位的时候利用
int index;
// 上一次记录的Exchanger.bound
int bound;
// 在当前bound下CAS失败的次数;
int collides;
// 用于自旋;
int hash;
// 这个线程的当前项,也就是需要交换的数据;
Object item;
//做releasing操作的线程传递的项;
volatile Object match;
//挂起时设置线程值,其他情况下为null;
volatile Thread parked;
}
在Node定义中有两个变量值得思考:bound以及collides。前面提到了数组area是为了避免竞争而产生的,如果系统不存在竞争问题,那么完全没有必要开辟一个高效的arena来徒增系统的复杂性。
首先通过单个slot的exchanger来交换数据,当探测到竞争时将安排不同的位置的slot来保存线程Node,并且可以确保没有slot会在同一个缓存行上。
如何来判断会有竞争呢? CAS替换slot失败,如果失败,则通过记录冲突次数来扩展arena的尺寸,我们在记录冲突的过程中会跟踪“bound”的值,以及会重新计算冲突次数在bound的值被改变时。
核心属性
private final Participant participant;
private volatile Node[] arena;
private volatile Node slot;
- 为什么会有
arena数组槽?
slot为单个槽,arena为数组槽, 他们都是Node类型。在这里可能会感觉到疑惑,slot作为Exchanger交换数据的场景,应该只需要一个就可以了啊? 为何还多了一个Participant 和数组类型的arena呢?
一个slot交换场所原则上来说应该是可以的,但实际情况却不是如此,多个参与者使用同一个交换场所时,会存在严重伸缩性问题。既然单个交换场所存在问题,那么我们就安排多个,也就是数组arena。通过数组arena来安排不同的线程使用不同的slot来降低竞争问题,并且可以保证最终一定会成对交换数据。但是Exchanger不是一来就会生成arena数组来降低竞争,只有当产生竞争是才会生成arena数组。
- 那么怎么将Node与当前线程绑定呢?
Participant,Participant 的作用就是为每个线程保留唯一的一个Node节点,它继承ThreadLocal,同时在Node节点中记录在arena中的下标index。
构造函数
/**
* Creates a new Exchanger.
*/
public Exchanger() {
participant = new Participant();
}
核心方法:exchange(V x)
等待另一个线程到达此交换点(除非当前线程被中断),然后将给定的对象传送给该线程,并接收该线程的对象。
public V exchange(V x) throws InterruptedException {
Object v;
// 当参数为null时需要将item设置为空的对象
Object item = (x == null) ? NULL_ITEM : x; // translate null args
// 注意到这里的这个表达式是整个方法的核心
if ((arena != null ||
(v = slotExchange(item, false, 0 L)) == null) &&
((Thread.interrupted() || // disambiguates null return
(v = arenaExchange(item, false, 0 L)) == null)))
throw new InterruptedException();
return (v == NULL_ITEM) ? null : (V) v;
}
这个方法比较好理解:arena为数组槽,如果为null,则执行slotExchange()方法,否则判断线程是否中断,如果中断值抛出InterruptedException异常,没有中断则执行arenaExchange()方法。整套逻辑就是:如果slotExchange(Object item, boolean timed, long ns)方法执行失败了就执行arenaExchange(Object item, boolean timed, long ns)方法,最后返回结果V。
NULL_ITEM 为一个空节点,其实就是一个Object对象而已,slotExchange()为单个slot交换。
slotExchange(Object item, boolean timed, long ns)
private final Object slotExchange(Object item, boolean timed, long ns) {
// 获取当前线程node对象
Node p = participant.get();
// 当前线程
Thread t = Thread.currentThread();
// 若果线程被中断,就直接返回null
if (t.isInterrupted()) // preserve interrupt status so caller can recheck
return null;
// 自旋
for (Node q;;) {
// 将slot值赋给q
if ((q = slot) != null) {
// slot 不为null,即表示已有线程已经把需要交换的数据设置在slot中了
// 通过CAS将slot设置成null
if (U.compareAndSwapObject(this, SLOT, q, null)) {
// CAS操作成功后,将slot中的item赋值给对象v,以便返回。
// 这里也是就读取之前线程要交换的数据
Object v = q.item;
// 将当前线程需要交给的数据设置在q中的match
q.match = item;
// 获取被挂起的线程
Thread w = q.parked;
if (w != null)
// 如果线程不为null,唤醒它
U.unpark(w);
// 返回其他线程给的V
return v;
}
// create arena on contention, but continue until slot null
// CAS 操作失败,表示有其它线程竞争,在此线程之前将数据已取走
// NCPU:CPU的核数
// bound == 0 表示arena数组未初始化过,CAS操作bound将其增加SEQ
if (NCPU > 1 && bound == 0 &&
U.compareAndSwapInt(this, BOUND, 0, SEQ))
// 初始化arena数组
arena = new Node[(FULL + 2) << ASHIFT];
}
// 上面分析过,只有当arena不为空才会执行slotExchange方法的
// 所以表示刚好已有其它线程加入进来将arena初始化
else if (arena != null)
// 这里就需要去执行arenaExchange
return null; // caller must reroute to arenaExchange
else {
// 这里表示当前线程是以第一个线程进来交换数据
// 或者表示之前的数据交换已进行完毕,这里可以看作是第一个线程
// 将需要交换的数据先存放在当前线程变量p中
p.item = item;
// 将需要交换的数据通过CAS设置到交换区slot
if (U.compareAndSwapObject(this, SLOT, null, p))
// 交换成功后跳出自旋
break;
// CAS操作失败,表示有其它线程刚好先于当前线程将数据设置到交换区slot
// 将当前线程变量中的item设置为null,然后自旋获取其它线程存放在交换区slot的数据
p.item = null;
}
}
// await release
// 执行到这里表示当前线程已将需要的交换的数据放置于交换区slot中了,
// 等待其它线程交换数据然后唤醒当前线程
int h = p.hash;
long end = timed ? System.nanoTime() + ns : 0 L;
// 自旋次数
int spins = (NCPU > 1) ? SPINS : 1;
Object v;
// 自旋等待直到p.match不为null,也就是说等待其它线程将需要交换的数据放置于交换区slot
while ((v = p.match) == null) {
// 下面的逻辑主要是自旋等待,直到spins递减到0为止
if (spins > 0) {
h ^= h << 1;
h ^= h >>> 3;
h ^= h << 10;
if (h == 0)
h = SPINS | (int) t.getId();
else if (h < 0 && (--spins & ((SPINS >>> 1) - 1)) == 0)
Thread.yield();
} else if (slot != p)
spins = SPINS;
// 此处表示未设置超时或者时间未超时
else if (!t.isInterrupted() && arena == null &&
(!timed || (ns = end - System.nanoTime()) > 0 L)) {
// 设置线程t被当前对象阻塞
U.putObject(t, BLOCKER, this);
// 给p挂机线程的值赋值
p.parked = t;
if (slot == p)
// 如果slot还没有被置为null,也就表示暂未有线程过来交换数据,需要将当前线程挂起
U.park(false, ns);
// 线程被唤醒,将被挂起的线程设置为null
p.parked = null;
// 设置线程t未被任何对象阻塞
U.putObject(t, BLOCKER, null);
// 不是以上条件时(可能是arena已不为null或者超时)
} else if (U.compareAndSwapObject(this, SLOT, p, null)) {
// arena不为null则v为null,其它为超时则v为超市对象TIMED_OUT,并且跳出循环
v = timed && ns <= 0 L && !t.isInterrupted() ? TIMED_OUT : null;
break;
}
}
// 取走match值,并将p中的match置为null
U.putOrderedObject(p, MATCH, null);
// 设置item为null
p.item = null;
p.hash = h;
// 返回交换值
return v;
}
程序首先通过participant获取当前线程节点Node。检测是否中断,如果中断return null,等待后续抛出InterruptedException异常。
- 如果slot不为null,则进行slot消除,成功直接返回数据V,否则失败,则创建arena消除数组。
- 如果slot为null,但arena不为null,则返回null,进入arenaExchange逻辑。
- 如果slot为null,且arena也为null,则尝试占领该slot,失败重试,成功则跳出循环进入spin+block(自旋+阻塞)模式。
在自旋+阻塞模式中,首先取得结束时间和自旋次数。如果match(做releasing操作的线程传递的项)为null,其首先尝试spins+随机次自旋(改自旋使用当前节点中的hash,并改变之)和退让。当自旋数为0后,假如slot发生了改变(slot != p)则重置自旋数并重试。否则假如:当前未中断&arena为null&(当前不是限时版本或者限时版本+当前时间未结束):阻塞或者限时阻塞。假如:当前中断或者arena不为null或者当前为限时版本+时间已经结束:不限时版本:置v为null;限时版本:如果时间结束以及未中断则TIMED_OUT;否则给出null(原因是探测到arena非空或者当前线程中断)。
match不为空时跳出循环。
arenaExchange(Object item, boolean timed, long ns)
此方法被执行时表示多个线程进入交换区交换数据,arena数组已被初始化,此方法中的一些处理方式和slotExchange比较类似,它是通过遍历arena数组找到需要交换的数据。
// timed 为true表示设置了超时时间,ns为>0的值,反之没有设置超时时间
private final Object arenaExchange(Object item, boolean timed, long ns) {
Node[] a = arena;
// 获取当前线程中的存放的node
Node p = participant.get();
//index初始值0
for (int i = p.index;;) { // access slot at i
// 遍历,如果在数组中找到数据则直接交换并唤醒线程,如未找到则将需要交换给其它线程的数据放置于数组中
int b, m, c;
long j; // j is raw array offset
// 其实这里就是向右遍历数组,只是用到了元素在内存偏移的偏移量
// q实际为arena数组偏移(i + 1) * 128个地址位上的node
Node q = (Node) U.getObjectVolatile(a, j = (i << ASHIFT) + ABASE);
// 如果q不为null,并且CAS操作成功,将下标j的元素置为null
if (q != null && U.compareAndSwapObject(a, j, q, null)) {
// 表示当前线程已发现有交换的数据,然后获取数据,唤醒等待的线程
Object v = q.item; // release
q.match = item;
Thread w = q.parked;
if (w != null)
U.unpark(w);
return v;
// q 为null 并且 i 未超过数组边界
} else if (i <= (m = (b = bound) & MMASK) && q == null) {
// 将需要给其它线程的item赋予给p中的item
p.item = item; // offer
if (U.compareAndSwapObject(a, j, null, p)) {
// 交换成功
long end = (timed && m == 0) ? System.nanoTime() + ns : 0 L;
Thread t = Thread.currentThread(); // wait
// 自旋直到有其它线程进入,遍历到该元素并与其交换,同时当前线程被唤醒
for (int h = p.hash, spins = SPINS;;) {
Object v = p.match;
if (v != null) {
// 其它线程设置的需要交换的数据match不为null
// 将match设置null,item设置为null
U.putOrderedObject(p, MATCH, null);
p.item = null; // clear for next use
p.hash = h;
return v;
} else if (spins > 0) {
h ^= h << 1;
h ^= h >>> 3;
h ^= h << 10; // xorshift
if (h == 0) // initialize hash
h = SPINS | (int) t.getId();
else if (h < 0 && // approx 50% true
(--spins & ((SPINS >>> 1) - 1)) == 0)
Thread.yield(); // two yields per wait
} else if (U.getObjectVolatile(a, j) != p)
// 和slotExchange方法中的类似,arena数组中的数据已被CAS设置
// match值还未设置,让其再自旋等待match被设置
spins = SPINS; // releaser hasn't set match yet
else if (!t.isInterrupted() && m == 0 &&
(!timed ||
(ns = end - System.nanoTime()) > 0 L)) {
// 设置线程t被当前对象阻塞
U.putObject(t, BLOCKER, this); // emulate LockSupport
// 线程t赋值
p.parked = t; // minimize window
if (U.getObjectVolatile(a, j) == p)
// 数组中对象还相等,表示线程还未被唤醒,唤醒线程
U.park(false, ns);
p.parked = null;
// 设置线程t未被任何对象阻塞
U.putObject(t, BLOCKER, null);
} else if (U.getObjectVolatile(a, j) == p &&
U.compareAndSwapObject(a, j, p, null)) {
// 这里给bound增加加一个SEQ
if (m != 0) // try to shrink
U.compareAndSwapInt(this, BOUND, b, b + SEQ - 1);
p.item = null;
p.hash = h;
i = p.index >>>= 1; // descend
if (Thread.interrupted())
return null;
if (timed && m == 0 && ns <= 0 L)
return TIMED_OUT;
break; // expired; restart
}
}
} else
// 交换失败,表示有其它线程更改了arena数组中下标i的元素
p.item = null; // clear offer
} else {
// 此时表示下标不在bound & MMASK或q不为null但CAS操作失败
// 需要更新bound变化后的值
if (p.bound != b) { // stale; reset
p.bound = b;
p.collides = 0;
// 反向遍历
i = (i != m || m == 0) ? m : m - 1;
} else if ((c = p.collides) < m || m == FULL ||
!U.compareAndSwapInt(this, BOUND, b, b + SEQ + 1)) {
// 记录CAS失败的次数
p.collides = c + 1;
// 循环遍历
i = (i == 0) ? m : i - 1; // cyclically traverse
} else
// 此时表示bound值增加了SEQ+1
i = m + 1; // grow
// 设置下标
p.index = i;
}
}
}
首先通过participant取得当前节点Node,然后根据当前节点Node的index去取arena中相对应的节点node。
- 前面提到过arena可以确保不同的slot在arena中是不会相冲突的,那么是怎么保证的呢?
arena = new Node[(FULL + 2) << ASHIFT];
// 这个arena到底有多大呢? 我们先看FULL 和ASHIFT的定义:
static final int FULL = (NCPU >= (MMASK << 1)) ? MMASK : NCPU >>> 1;
private static final int ASHIFT = 7;
private static final int NCPU = Runtime.getRuntime().availableProcessors();
private static final int MMASK = 0xff; // 255
// 假如我的机器NCPU = 8 ,则得到的是768大小的arena数组。然后通过以下代码取得在arena中的节点:
Node q = (Node)U.getObjectVolatile(a, j = (i << ASHIFT) + ABASE);
// 它仍然是通过右移ASHIFT位来取得Node的,ABASE定义如下:
Class<?> ak = Node[].class;
ABASE = U.arrayBaseOffset(ak) + (1 << ASHIFT);
// U.arrayBaseOffset获取对象头长度,数组元素的大小可以通过unsafe.arrayIndexScale(T[].class) 方法获取到。这也就是说要访问类型为T的第N个元素的话,你的偏移量offset应该是arrayOffset+N*arrayScale。也就是说BASE = arrayOffset+ 128 。
- 用@sun.misc.Contended来规避伪共享?
伪共享说明:假设一个类的两个相互独立的属性a和b在内存地址上是连续的(比如FIFO队列的头尾指针),那么它们通常会被加载到相同的cpu cache line里面。并发情况下,如果一个线程修改了a,会导致整个cache line失效(包括b),这时另一个线程来读b,就需要从内存里再次加载了,这种多线程频繁修改ab的情况下,虽然a和b看似独立,但它们会互相干扰,非常影响性能。
我们再看Node节点的定义, 在Java 8 中我们是可以利用sun.misc.Contended来规避伪共享的。所以说通过 « ASHIFT方式加上sun.misc.Contended,所以使得任意两个可用Node不会再同一个缓存行中。
@sun.misc.Contended static final class Node{
....
}
我们再次回到arenaExchange()。取得arena中的node节点后,如果定位的节点q 不为空,且CAS操作成功,则交换数据,返回交换的数据,唤醒等待的线程。
- 如果q等于null且下标在bound & MMASK范围之内,则尝试占领该位置,如果成功,则采用自旋 + 阻塞的方式进行等待交换数据。
- 如果下标不在bound & MMASK范围之内获取由于q不为null但是竞争失败的时候:消除p。加入bound 不等于当前节点的bond(b != p.bound),则更新p.bound = b,collides = 0 ,i = m或者m - 1。如果冲突的次数不到m 获取m 已经为最大值或者修改当前bound的值失败,则通过增加一次collides以及循环递减下标i的值;否则更新当前bound的值成功:我们令i为m+1即为此时最大的下标。最后更新当前index的值。
深入理解
- SynchronousQueue对比?
Exchanger是一种线程间安全交换数据的机制。可以和之前分析过的SynchronousQueue对比一下:线程A通过SynchronousQueue将数据a交给线程B;线程A通过Exchanger和线程B交换数据,线程A把数据a交给线程B,同时线程B把数据b交给线程A。可见,SynchronousQueue是交给一个数据,Exchanger是交换两个数据。
- 不同JDK实现有何差别?
- 在JDK5中Exchanger被设计成一个容量为1的容器,存放一个等待线程,直到有另外线程到来就会发生数据交换,然后清空容器,等到下一个到来的线程。
- 从JDK6开始,Exchanger用了类似ConcurrentMap的分段思想,提供了多个slot,增加了并发执行时的吞吐量。
应用示例
来一个非常经典的并发问题:你有相同的数据buffer,一个或多个数据生产者,和一个或多个数据消费者。只是Exchange类只能同步2个线程,所以你只能在你的生产者和消费者问题中只有一个生产者和一个消费者时使用这个类。
public class Test {
static class Producer extends Thread {
private Exchanger<Integer> exchanger;
private static int data = 0;
Producer(String name, Exchanger<Integer> exchanger) {
super("Producer-" + name);
this.exchanger = exchanger;
}
@Override
public void run() {
for (int i=1; i<5; i++) {
try {
TimeUnit.SECONDS.sleep(1);
data = i;
System.out.println(getName()+" 交换前:" + data);
data = exchanger.exchange(data);
System.out.println(getName()+" 交换后:" + data);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
static class Consumer extends Thread {
private Exchanger<Integer> exchanger;
private static int data = 0;
Consumer(String name, Exchanger<Integer> exchanger) {
super("Consumer-" + name);
this.exchanger = exchanger;
}
@Override
public void run() {
while (true) {
data = 0;
System.out.println(getName()+" 交换前:" + data);
try {
TimeUnit.SECONDS.sleep(1);
data = exchanger.exchange(data);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(getName()+" 交换后:" + data);
}
}
}
public static void main(String[] args) throws InterruptedException {
Exchanger<Integer> exchanger = new Exchanger<Integer>();
new Producer("", exchanger).start();
new Consumer("", exchanger).start();
TimeUnit.SECONDS.sleep(7);
System.exit(-1);
}
}
29 - CH29-ThreadLocal
概览
ThreadLocal是通过线程隔离的方式防止任务在共享资源上产生冲突, 线程本地存储是一种自动化机制,可以为使用相同变量的每个不同线程都创建不同的存储。
线程安全的解决思路:
- 互斥同步: synchronized 和 ReentrantLock
- 非阻塞同步: CAS, AtomicXXXX
- 无同步方案: 栈封闭,本地存储(Thread Local),可重入代码
线程安全:是指广义上的共享资源访问安全性,因为线程隔离是通过副本保证本线程访问资源安全性,它不保证线程之间还存在共享关系的狭义上的安全性。
ThreadLocal 的官方解释:
This class provides thread-local variables. These variables differ from their normal counterparts in that each thread that accesses one (via its {@code get} or {@code set} method) has its own, independently initialized copy of the variable. {@code ThreadLocal} instances are typically private static fields in classes that wish to associate state with a thread (e.g., a user ID or Transaction ID)
该类提供了线程局部 (thread-local) 变量。这些变量不同于它们的普通对应物,因为访问某个变量(通过其 get 或 set 方法)的每个线程都有自己的局部变量,它独立于变量的初始化副本。ThreadLocal 实例通常是类中的 private static 字段,它们希望将状态与某一个线程(例如,用户 ID 或事务 ID)相关联。
ThreadLocal是一个将在多线程中为每一个线程创建单独的变量副本的类; 当使用ThreadLocal来维护变量时, ThreadLocal会为每个线程创建单独的变量副本, 避免因多线程操作共享变量而导致的数据不一致的情况。
理解
- 如下数据库管理类在单线程使用是没有任何问题的
class ConnectionManager {
private static Connection connect = null;
public static Connection openConnection() {
if (connect == null) {
connect = DriverManager.getConnection();
}
return connect;
}
public static void closeConnection() {
if (connect != null)
connect.close();
}
}
很显然,在多线程中使用会存在线程安全问题:第一,这里面的2个方法都没有进行同步,很可能在openConnection方法中会多次创建connect;第二,由于connect是共享变量,那么必然在调用connect的地方需要使用到同步来保障线程安全,因为很可能一个线程在使用connect进行数据库操作,而另外一个线程调用closeConnection关闭链接。
- 为了解决上述线程安全的问题,第一考虑:互斥同步
你可能会说,将这段代码的两个方法进行同步处理,并且在调用connect的地方需要进行同步处理,比如用Synchronized或者ReentrantLock互斥锁。
- 这里再抛出一个问题:这地方到底需不需要将connect变量进行共享?
事实上,是不需要的。假如每个线程中都有一个connect变量,各个线程之间对connect变量的访问实际上是没有依赖关系的,即一个线程不需要关心其他线程是否对这个connect进行了修改的。即改后的代码可以这样:
class ConnectionManager {
private Connection connect = null;
public Connection openConnection() {
if (connect == null) {
connect = DriverManager.getConnection();
}
return connect;
}
public void closeConnection() {
if (connect != null)
connect.close();
}
}
class Dao {
public void insert() {
ConnectionManager connectionManager = new ConnectionManager();
Connection connection = connectionManager.openConnection();
// 使用connection进行操作
connectionManager.closeConnection();
}
}
这样处理确实也没有任何问题,由于每次都是在方法内部创建的连接,那么线程之间自然不存在线程安全问题。但是这样会有一个致命的影响:导致服务器压力非常大,并且严重影响程序执行性能。由于在方法中需要频繁地开启和关闭数据库连接,这样不仅严重影响程序执行效率,还可能导致服务器压力巨大。
- 这时候ThreadLocal登场了
那么这种情况下使用ThreadLocal是再适合不过的了,因为ThreadLocal在每个线程中对该变量会创建一个副本,即每个线程内部都会有一个该变量,且在线程内部任何地方都可以使用,线程之间互不影响,这样一来就不存在线程安全问题,也不会严重影响程序执行性能。下面就是网上出现最多的例子:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class ConnectionManager {
private static final ThreadLocal<Connection> dbConnectionLocal = new ThreadLocal<Connection>() {
@Override
protected Connection initialValue() {
try {
return DriverManager.getConnection("", "", "");
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}
};
public Connection getConnection() {
return dbConnectionLocal.get();
}
}
- 再注意下ThreadLocal的修饰符
ThreaLocal的JDK文档中说明:ThreadLocal instances are typically private static fields in classes that wish to associate state with a thread。如果我们希望通过某个类将状态(例如用户ID、事务ID)与线程关联起来,那么通常在这个类中定义private static类型的ThreadLocal 实例。
但是要注意,虽然ThreadLocal能够解决上面说的问题,但是由于在每个线程中都创建了副本,所以要考虑它对资源的消耗,比如内存的占用会比不使用ThreadLocal要大。
原理
如何实现线程隔离
主要是用到了 Thread 对象中的一个 ThreadLocalMap 类型的变量 threadLocals,负责存储当前线程的关于 Connection 的对象,dbConnectionLocal 变量为 key,以新建的 Connection 对象为 value;这样的话,线程第一次读取的时候如果不存在就会调用 ThreadLocal 的 initialValue 方法创建一个 Connection 对象并返回。
具体关于为线程分配变量副本的代码如下:
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
- 首先获取当前线程对象 t,然后从线程 t 中获取到 ThreadLocalMap 的成员属性 threadLocals
- 如果当前线程的 threadLocals 已经初始化并且存在以当前 ThreadLocal 对象为 Key 的值,则直接返回当前线程要获取的对象,比如上例中的 Connection。
- 如果当前线程的 threadLocals 已经初始化但不存在以当前 ThreadLocal 对象为 key 的对象,那么新建一个 Connection 对象,并且添加到当前线程的 threadLocals map 中,并返回。
- 如果当前线程的 threadLocals 属性尚未初始化,则重新创建一个 ThreadLocalMap 对象,并且创建一个 Connection 对象并添加到 ThreadLocalMap 中并返回。
初始化逻辑:
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
- 首先调用我们提供的 initialValue 方法,创建一个 Conneciton 对象
- 继续查看当前线程的 threadLocals 是否为空,如果 ThreadLocalMap 已经初始化,直接将产生的connection 对象添加到 ThreadLocalMap 中,如果没有初始化,则创建并添加到其中。
同时,ThreadLocal 还提供了直接操作 Thread 对象中 threadLocals 的方法
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
这样我们也可以不实现initialValue, 将初始化工作放到DBConnectionFactory的getConnection方法中:
public Connection getConnection() {
Connection connection = dbConnectionLocal.get();
if (connection == null) {
try {
connection = DriverManager.getConnection("", "", "");
dbConnectionLocal.set(connection);
} catch (SQLException e) {
e.printStackTrace();
}
}
return connection;
}
那么我们看过代码之后就很清晰的知道了为什么ThreadLocal能够实现变量的多线程隔离了; 其实就是用了Map的数据结构给当前线程缓存了, 要使用的时候就从本线程的threadLocals对象中获取就可以了, key就是当前线程;
当然了在当前线程下获取当前线程里面的Map里面的对象并操作肯定没有线程并发问题了, 当然能做到变量的线程间隔离了;
现在我们知道了ThreadLocal到底是什么了, 又知道了如何使用ThreadLocal以及其基本实现原理了是不是就可以结束了呢? 其实还有一个问题就是ThreadLocalMap是个什么对象, 为什么要用这个对象呢?
ThreadLocalMap
本质上来讲, 它就是一个Map, 但是这个ThreadLocalMap与我们平时见到的Map有点不一样:
- 它没有实现Map接口;
- 它没有public的方法, 最多有一个default的构造方法, 因为这个ThreadLocalMap的方法仅仅在ThreadLocal类中调用, 属于静态内部类
- ThreadLocalMap的Entry实现继承了WeakReference<ThreadLocal>
- 该方法仅仅用了一个Entry数组来存储Key, Value; Entry并不是链表形式, 而是每个bucket里面仅仅放一个Entry;
要了解ThreadLocalMap的实现, 我们先从入口开始, 就是往该Map中添加一个值:
private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
先进行简单的分析, 对该代码表层意思进行解读:
- 看下当前threadLocal的在数组中的索引位置 比如:
i = 2, 看i = 2位置上面的元素(Entry)的Key是否等于threadLocal 这个 Key, 如果等于就很好说了, 直接将该位置上面的Entry的Value替换成最新的就可以了; - 如果当前位置上面的 Entry 的 Key为空, 说明ThreadLocal对象已经被回收了, 那么就调用replaceStaleEntry
- 如果清理完无用条目(ThreadLocal被回收的条目)、并且数组中的数据大小 > 阈值的时候对当前的Table进行重新哈希 所以, 该HashMap是处理冲突检测的机制是向后移位, 清除过期条目 最终找到合适的位置;
后面就是Get方法了:
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
先找到ThreadLocal的索引位置, 如果索引位置处的entry不为空并且键与threadLocal是同一个对象, 则直接返回; 否则去后面的索引位置继续查找。
内存泄露
如果用线程池来操作ThreadLocal 对象确实会造成内存泄露, 因为对于线程池里面不会销毁的线程, 里面总会存在着<ThreadLocal, LocalVariable>的强引用, 因为final static 修饰的 ThreadLocal 并不会释放, 而ThreadLocalMap 对于 Key 虽然是弱引用, 但是强引用不会释放, 弱引用当然也会一直有值, 同时创建的LocalVariable对象也不会释放, 就造成了内存泄露; 如果LocalVariable对象不是一个大对象的话, 其实泄露的并不严重, 泄露的内存 = 核心线程数 * LocalVariable对象的大小;
所以, 为了避免出现内存泄露的情况, ThreadLocal提供了一个清除线程中对象的方法, 即 remove, 其实内部实现就是调用 ThreadLocalMap 的remove方法:
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
expungeStaleEntry(i);
return;
}
}
}
参考资料
30 - CH30-AllLocks
概览
| 序号 | 术语 | 应用 |
|---|---|---|
| 1 | 乐观锁 | CAS |
| 2 | 悲观锁 | synchronized、vector、hashtable |
| 3 | 自旋锁 | CAS |
| 4 | 可重入锁 | synchronized、ReentrantLock、Lock |
| 5 | 读写锁 | ReentrantReadWriteLock、CopyOnWriteLock、CopyOnWriteArraySet |
| 6 | 公平锁 | ReentrantLock(true) |
| 7 | 非公平锁 | synchronized、ReentrantLock(false) |
| 8 | 共享锁 | ReentranReadWriteLock-ReadLock |
| 9 | 独占锁 | synchronized、vector、hashtable、ReentranReadWriteLock-WriteLock |
| 10 | 重量级锁 | synchronized |
| 11 | 轻量级锁 | 锁优化技术 |
| 12 | 偏向锁 | 锁优化技术 |
| 13 | 分段锁 | ConcurrentHashMap |
| 14 | 互斥锁 | synchronized |
| 15 | 同步锁 | synchronized |
| 16 | 死锁 | 相互请求对方资源 |
| 17 | 锁粗化 | 锁优化技术 |
| 18 | 锁消除 | 锁优化技术 |
1. 乐观锁
即乐观思想,假定当前场景是读多写少、遇到并发写的概览较低,读数据时认为别的线程不会正在修改数据(因此不加锁);写数据时,判断当前与期望值是否相同,如果相同则更新(更新期间加锁,保证原子性)。
Java 中乐观锁的实现是 CAS——比较并交换。比较(主内存中的)当前值,与(当前线程中的)预期值是否一样,一样则更新,否则继续进行 CAS 操作。
可以同时进行读操作,读的时候其他线程不能执行写操作。
2. 悲观锁
即悲观思想,认为写多读少,遇到并发写的可能性高。每次读数据都认为其他线程会在同一时间修改数据,所以每次写数据都会认为其他线程会修改,因此每次都加锁。其他线程想要读写这个数据时都会被该锁阻塞,直到当前写数据的线程是否锁。
Java 中的悲观锁实现有 synchronized 关键字、ReentrantLock。
只有一个线程能够进行读操作或写操作。
3. 自旋锁
自旋指的是一种行为:为了让线程等待,我们只需让该线程循环。
现在绝大多数的个人电脑和服务器都是多路(核)处理器系统,如果物理机器有一个以上的处理器或者处理器核心,能让两个或以上的线程同时并行执行,就可以让后面请求锁的那个线程“稍等一会”,但不放弃处理器的执行时间,看看持有锁的线程是否很快就会释放锁。
优点:避免了线程切换的开销。挂起线程和恢复线程的操作都需要转入内核态中完成,这些操作给Java虚拟机的并发性能带来了很大的压力。
缺点:占用处理器的时间,如果占用的时间很长,会白白消耗处理器资源,而不会做任何有价值的工作,带来性能的浪费。因此自旋等待的时间必须有一定的限度,如果自旋超过了限定的次数仍然没有成功获得锁,就应当使用传统的方式去挂起线程。
Java 中默认的自旋次数为 10,可以通过参数 -XX:PreBlockSpin 来修改。
自适应自旋:自适应意味着自旋的时间不再是固定的,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定的。有了自适应自旋,随着程序运行时间的增长及性能监控信息的不断完善,虚拟机对程序锁的状态预测就会越来越精准。
Java 中对自旋的应用:CAS 操作中比较操作失败后会执行自旋等待。
4. 可重入锁(递归锁)
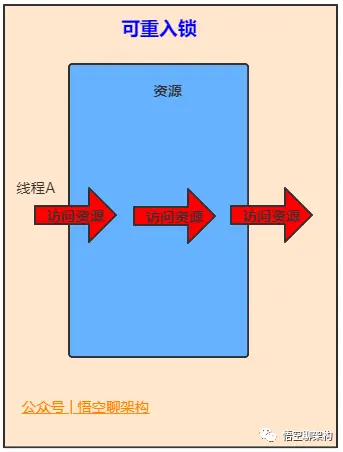
可重入指的是:某个线程在获取到锁之后能够再次获取该锁,而不会阻塞。
原理:通过组合自定义同步器来实现锁的获取与释放。
- 再次获取锁:识别获取锁的线程是否为当前持有锁的线程,如果是则再次获取成功,并将技术 +1。
- 释放锁:释放锁并将计数 -1。
作用:避免死锁。
Java 中的实现有:ReentrantLock、synchronized 关键字。
5. 读写锁
读写锁指定是指:为了提高性能,在读的时候使用读锁,写的时候使用写锁,灵活控制。在没有写的时候,读是无阻塞的,在一定程度上提高了程序的执行效率。
读写锁分为读锁和写锁,多个读锁不互斥,读锁与写锁互斥。
读锁:允许多个线程同时访问资源。
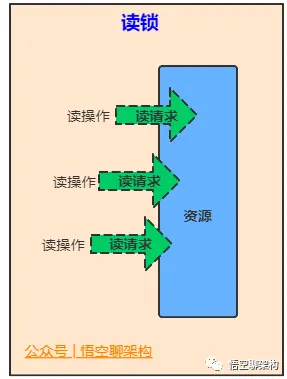
写锁:同时只允许一个线程访问资源。
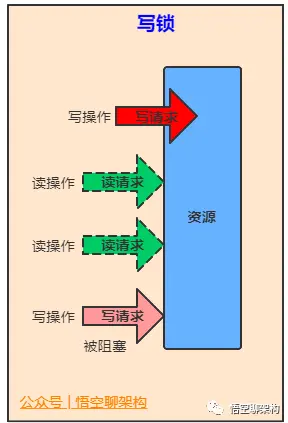
Java 中的实现为 ReentrantReadWriteLock。
6. 公平锁
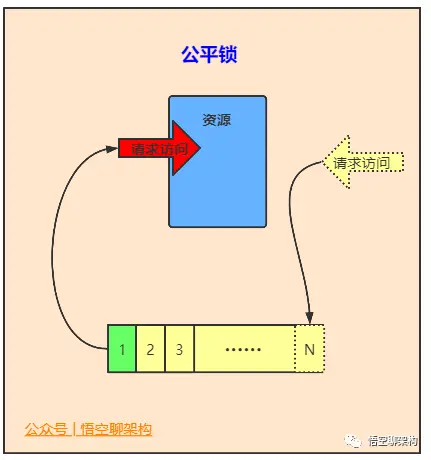
公平锁的思想是:多个线程按照请求所的顺序来依次获取锁。
在并发环境中,每个线程会先查看此锁维护的等待队列,如果当前等待队列为空,则占有锁,如果等待队列不为空,则加入到等待队列的末尾,按照FIFO的原则从队列中拿到线程,然后占有锁。
7. 非公平锁
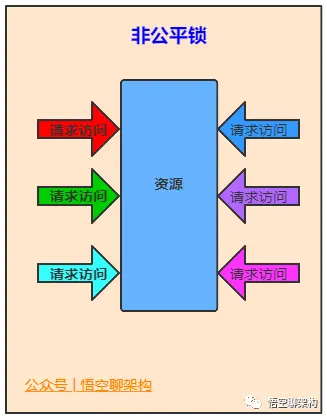
非公平锁的思想是:线程尝试获取锁,如果获取不到,则再采用公平锁的方式。多个线程获取锁的顺序,不是按照先到先得的顺序,有可能后申请锁的线程比先申请的线程优先获取锁。
非公平锁的性能高于公平锁,但可能导致某个线程总是获取不到锁,即饥饿。
Java 中的实现:synchronized 是非公平锁,ReentrantLock 通过构造函数指定该锁是公平的还是非公平的,默认是非公平的。
8. 共享锁
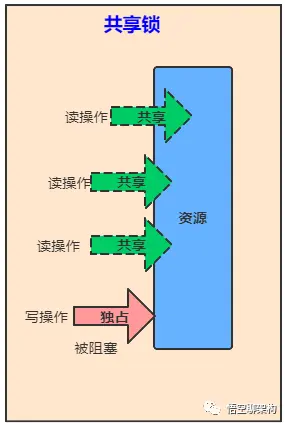
共享锁的思想是:可以有多个线程获取读锁,以共享的方式持有锁。和乐观锁、读写锁同义。
Java中用到的共享锁: ReentrantReadWriteLock。
9. 独占锁
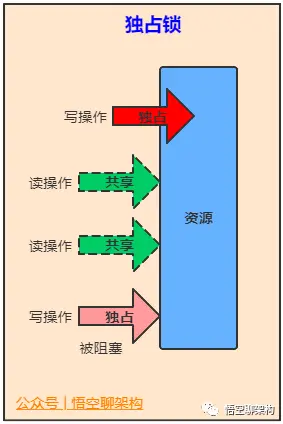
独占锁的思想是:只能有一个线程获取锁,以独占的方式持有锁。和悲观锁、互斥锁同义。
Java中用到的独占锁: synchronized,ReentrantLock
10. 重量级锁
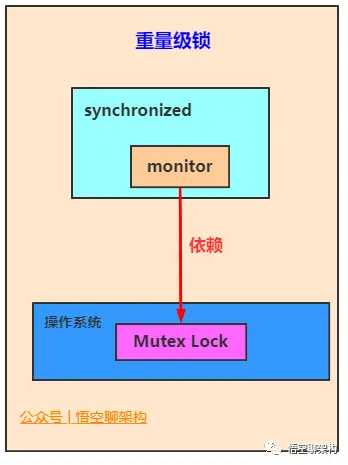
重量级锁是一种称谓: synchronized是通过对象内部的一个叫做监视器锁(monitor)来实现的,监视器锁本身依赖底层的操作系统的 Mutex Lock来实现。操作系统实现线程的切换需要从用户态切换到核心态,成本非常高。这种依赖于操作系统 Mutex Lock来实现的锁称为重量级锁。为了优化synchonized,引入了轻量级锁,偏向锁。
Java中的重量级锁: synchronized
11. 轻量级锁
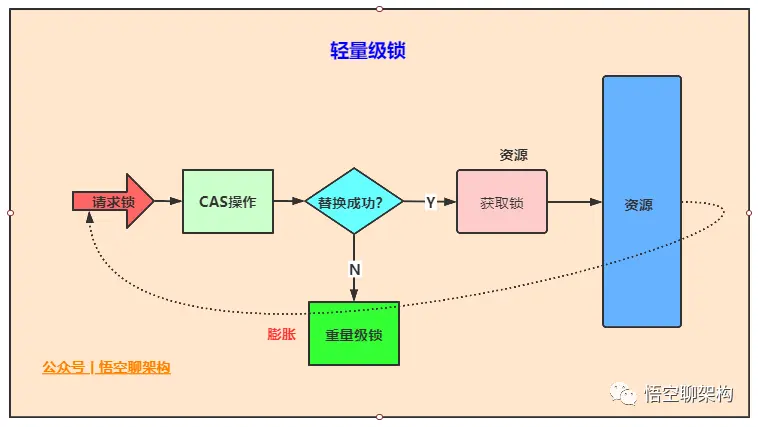
是JDK6时加入的一种锁优化机制: 轻量级锁是在无竞争的情况下使用CAS操作去消除同步使用的互斥量。轻量级是相对于使用操作系统互斥量来实现的重量级锁而言的。轻量级锁在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。如果出现两条以上的线程争用同一个锁的情况,那轻量级锁将不会有效,必须膨胀为重量级锁。
优点: 如果没有竞争,通过CAS操作成功避免了使用互斥量的开销。
缺点: 如果存在竞争,除了互斥量本身的开销外,还额外产生了CAS操作的开销,因此在有竞争的情况下,轻量级锁比传统的重量级锁更慢。
12. 偏向锁
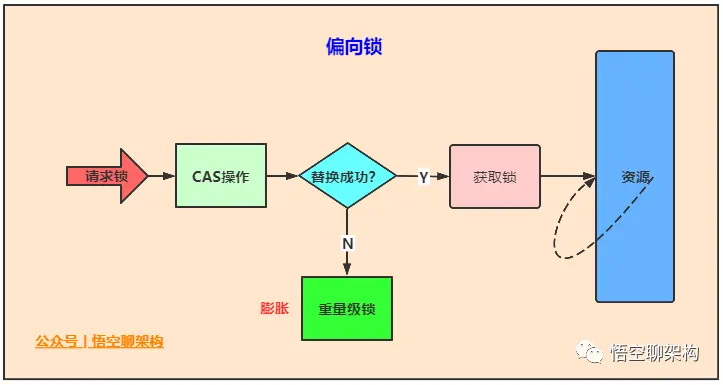
是JDK6时加入的一种锁优化机制: 在无竞争的情况下把整个同步都消除掉,连CAS操作都不去做了。偏是指偏心,它的意思是这个锁会偏向于第一个获得它的线程,如果在接下来的执行过程中,该锁一直没有被其他的线程获取,则持有偏向锁的线程将永远不需要再进行同步。持有偏向锁的线程以后每次进入这个锁相关的同步块时,虚拟机都可以不再进行任何同步操作(例如加锁、解锁及对Mark Word的更新操作等)。
优点: 把整个同步都消除掉,连CAS操作都不去做了,优于轻量级锁。
缺点: 如果程序中大多数的锁都总是被多个不同的线程访问,那偏向锁就是多余的。
13. 分段锁
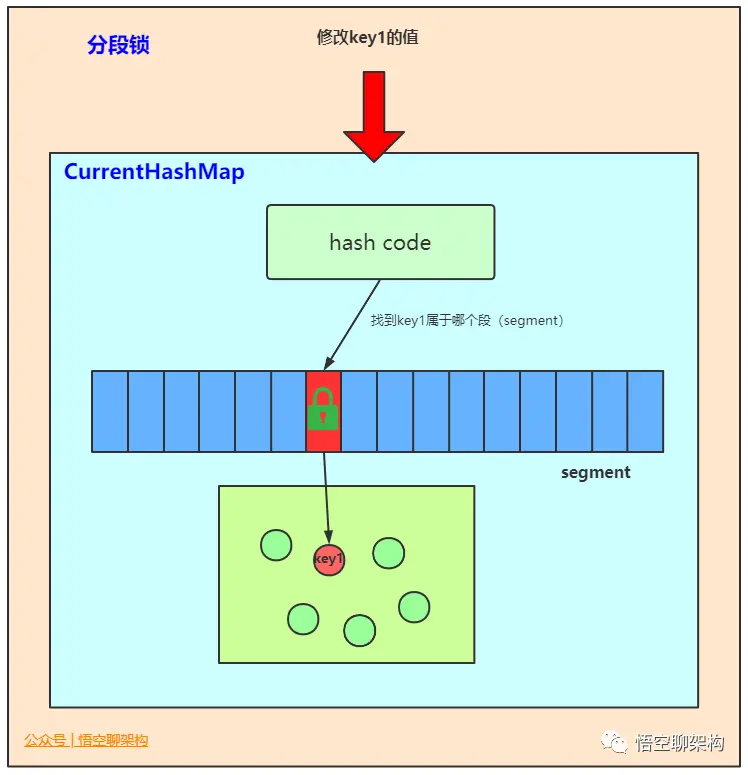
一种机制: 最好的例子来说明分段锁是ConcurrentHashMap。**ConcurrentHashMap原理:**它内部细分了若干个小的 HashMap,称之为段(Segment)。默认情况下一个 ConcurrentHashMap 被进一步细分为 16 个段,既就是锁的并发度。如果需要在 ConcurrentHashMap 添加一项key-value,并不是将整个 HashMap 加锁,而是首先根据 hashcode 得到该key-value应该存放在哪个段中,然后对该段加锁,并完成 put 操作。在多线程环境中,如果多个线程同时进行put操作,只要被加入的key-value不存放在同一个段中,则线程间可以做到真正的并行。
**线程安全:**ConcurrentHashMap 是一个 Segment 数组, Segment 通过继承ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全
14. 互斥锁
互斥锁与悲观锁、独占锁同义,表示某个资源只能被一个线程访问,其他线程不能访问。
- 读-读互斥
- 读-写互斥
- 写-读互斥
- 写-写互斥
Java中的同步锁: synchronized
15. 同步锁
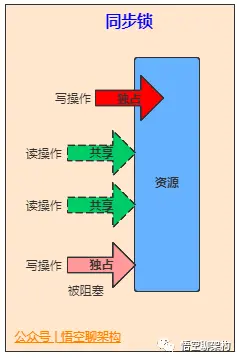
同步锁与互斥锁同义,表示并发执行的多个线程,在同一时间内只允许一个线程访问共享数据。
Java中的同步锁: synchronized
16. 死锁
**死锁是一种现象:**如线程A持有资源x,线程B持有资源y,线程A等待线程B释放资源y,线程B等待线程A释放资源x,两个线程都不释放自己持有的资源,则两个线程都获取不到对方的资源,就会造成死锁。
Java中的死锁不能自行打破,所以线程死锁后,线程不能进行响应。所以一定要注意程序的并发场景,避免造成死锁。
17. 锁粗化
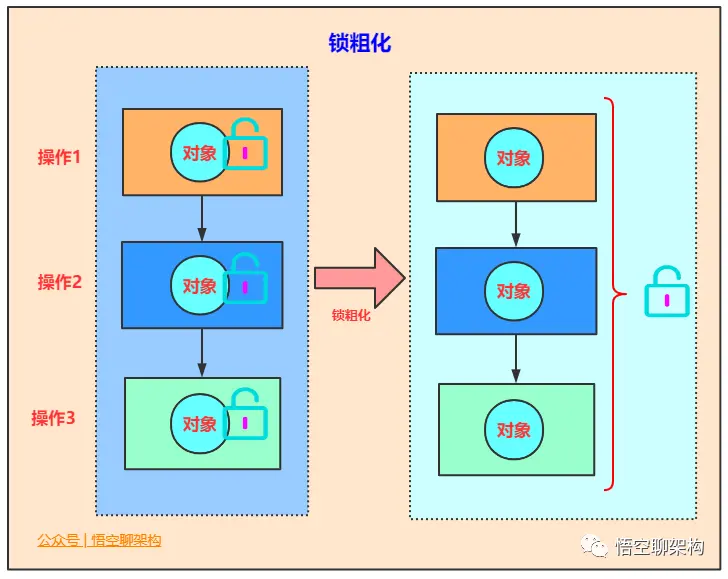
一种优化技术: 如果一系列的连续操作都对同一个对象反复加锁和解锁,甚至加锁操作都是出现在循环体体之中,就算真的没有线程竞争,频繁地进行互斥同步操作将会导致不必要的性能损耗,所以就采取了一种方案:把加锁的范围扩展(粗化)到整个操作序列的外部,这样加锁解锁的频率就会大大降低,从而减少了性能损耗。
18. 锁消除
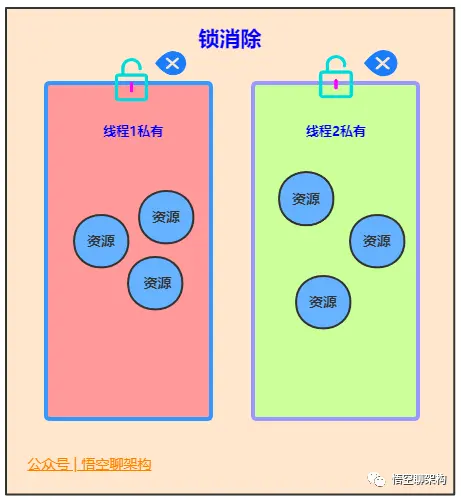
一种优化技术: 就是把锁干掉。当Java虚拟机运行时发现有些共享数据不会被线程竞争时就可以进行锁消除。
那如何判断共享数据不会被线程竞争?
利用逃逸分析技术:分析对象的作用域,如果对象在A方法中定义后,被作为参数传递到B方法中,则称为方法逃逸;如果被其他线程访问,则称为线程逃逸。
在堆上的某个数据不会逃逸出去被其他线程访问到,就可以把它当作栈上数据对待,认为它是线程私有的,同步加锁就不需要了。
TODO
31 - CH31-AllQueues
| 名称 | 类型 | 有界 | 线程安全 | 说明 |
|---|---|---|---|---|
| Queue | 接口 | — | — | 顶层队列接口 |
| BlockingQueue | 接口 | — | — | 阻塞队列接口 |
| BlockingDeuque | 接口 | — | — | 双向阻塞队列接口 |
| Dequeu | 接口 | — | — | 双向队列接口 |
| TransferQueue | 接口 | — | — | 传输队列接口 |
| AbstractQueue | 抽象类 | — | — | 队列抽象类 |
| PriorityQueue | 实现类 | N | N | 优先级队列 |
| ArrayDeque | 实现类 | N | N | 数组双向队列 |
| LinkedList | 实现类 | N | N | 链表对象类 |
| ConcurrentLinkedQueue | 实现类 | N | Y | 链表结构并发队列 |
| ConcurrentLinkedDeque | 实现类 | N | Y | 链表结构双向并发队列 |
| ArrayBlockingQueue | 实现类 | Y | Y | 数组结构有界阻塞队列 |
| LinkedBlockingQueue | 实现类 | Y | Y | 链表结构有界阻塞队列 |
| LinkedBlockingDeque | 实现类 | Y | Y | 链表结构双向有界阻塞队列 |
| LinkedTransferQueue | 实现类 | N | Y | 连接结构无界阻塞传输队列 |
| SynchronousQueue | 实现类 | Y | Y | 不存储元素的有界阻塞队列 |
| PriorityBlockingQueue | 实现类 | N | Y | 支持优先级排序的无界阻塞队列 |
| DelayQueue | 实现类 | N | Y | 延时无界阻塞队列 |
层级结构
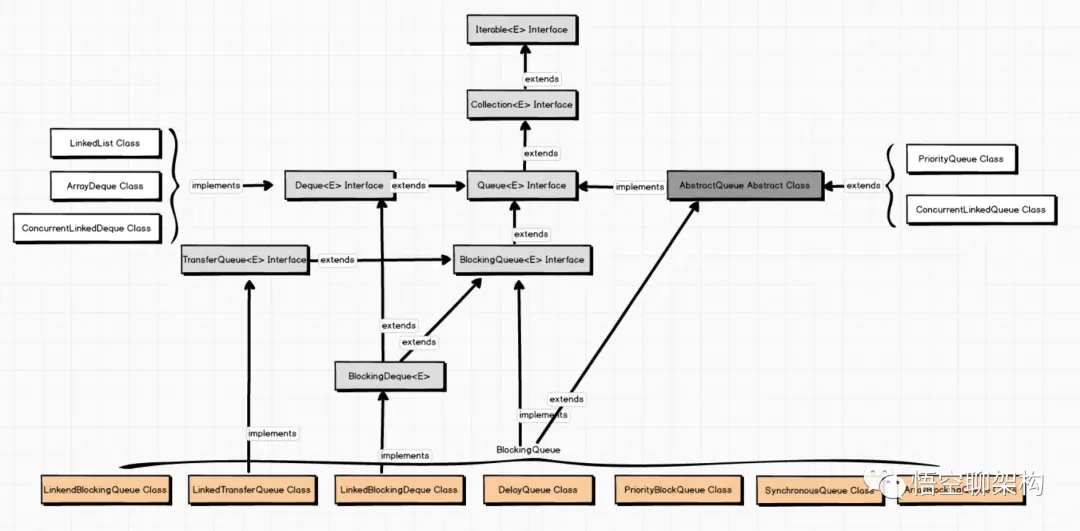
1. Queue
- Queue接口是一种Collection,被设计用于处理之前临时保存在某处的元素。
- 除了基本的Collection操作之外,队列还提供了额外的插入、提取和检查操作。每一种操作都有两种形式:如果操作失败,则抛出一个异常;如果操作失败,则返回一个特殊值(null或false,取决于是什么操作)。
- 队列通常是以FIFO(先进先出)的方式排序元素,但是这不是必须的。
- 只有优先级队列可以根据提供的比较器对元素进行排序或者是采用正常的排序。无论怎么排序,队列的头将通过调用remove()或poll()方法进行移除。在FIFO队列种,所有新的元素被插入到队尾。其他种类的队列可能使用不同的布局来存放元素。
- 每个Queue必须指定排序属性。
2. Deque
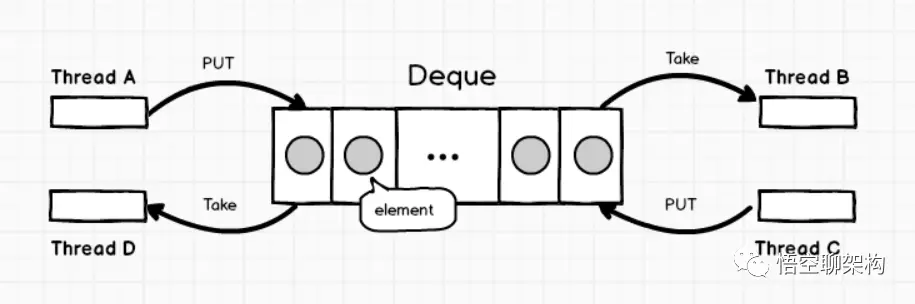
支持两端元素插入和移除的线性集合。名称deque是双端队列的缩写(Double-Ended queue),通常发音为deck。大多数实现Deque的类,对它们包含的元素的数量没有固定的限制的,支持有界和无界。
- 该列表包含包含访问deque两端元素的方法,提供了插入,移除和检查元素的方法。
- 这些方法种的每一种都存在两种形式:如果操作失败,则会抛出异常,另一种方法返回一个特殊值(null或false,取决于具体操作)。
- 插入操作的后一种形式专门设计用于容量限制的Deque实现,大多数实现中,插入操作不能失败,所以可以用插入操作的后一种形式。
- Deque接口扩展了Queue接口,当使用deque作为队列时,作为FIFO。元素将添加到deque的末尾,并从头开始删除。
- Deque也可以用作LIFO(后进先出)栈,这个接口优于传统的Stack类。当作为栈使用时,元素被push到deque队列的头,而pop也是从队列的头pop出来。
3. AbstractQueue
AbstractQueue是一个抽象类,继承了Queue接口,提供了一些Queue操作的骨架实现。
方法add、remove、element方法基于offer、poll和peek。也就是说如果不能正常操作,则抛出异常。我们来看下AbstactQueue是怎么做到的。
- AbstractQueue的add方法
public boolean add(E e) {
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}
- AbstractQueue的remove方法
public E remove() {
E x = poll();
if (x != null)
return x;
else
throw new NoSuchElementException();
}
- AbstractQueue的element方法
public E element() {
E x = peek();
if (x != null)
return x;
else
throw new NoSuchElementException();
}
如果继承AbstractQueue抽象类则必须保证offer方法不允许null值插入。
4. BlockingQueue
- BlockQueue满了,PUT操作被阻塞
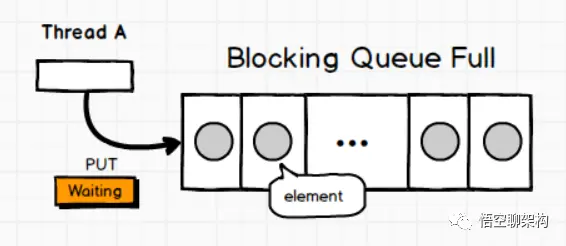
- BlockQueue为空,Take操作被阻塞
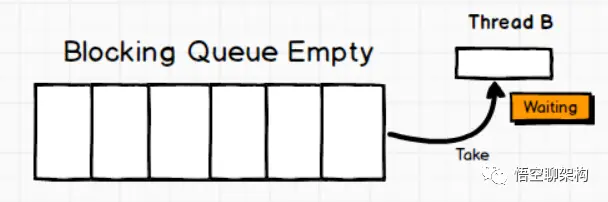
说明:
- BlockingQueue(阻塞队列)也是一种队列,支持阻塞的插入和移除方法。
- 阻塞的插入:当队列满时,队列会阻塞插入元素的线程,直到队列不满。
- 阻塞的移除:当队列为空,获取元素的线程会等待队列变为非空。
- 应用场景:生产者和消费者,生产者线程向队列里添加元素,消费者线程从队列里移除元素,阻塞队列时获取和存放元素的容器。
- 为什么要用阻塞队列:生产者生产和消费者消费的速率不一样,需要用队列来解决速率差问题,当队列满了或空的时候,则需要阻塞生产或消费动作来解决队列满或空的问题。
方法总结:
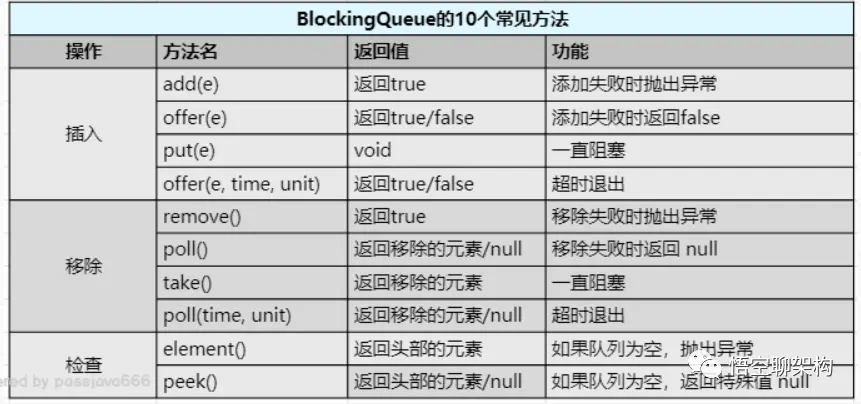
如何实现的阻塞
- 当往队列里插入一个元素时,如果队列不可用,那么阻塞生产者主要通过LockSupport. park(this)来实现。
- park这个方法会阻塞当前线程,只有以下4种情况中的一种发生时,该方法才会返回。
- 与park对应的unpark执行或已经执行时。“已经执行”是指unpark先执行,然后再执行park的情况。
- 线程被中断时。
- 等待完time参数指定的毫秒数时。
- 异常现象发生时,这个异常现象没有任何原因。
5. BlockingDeque
- BlockingDeque 满了,两端的 put 操作被阻塞
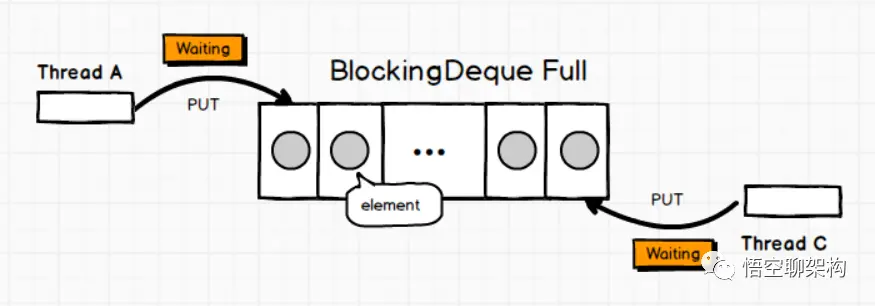
- BlockingDeque 为空,两端的Take操作被阻塞
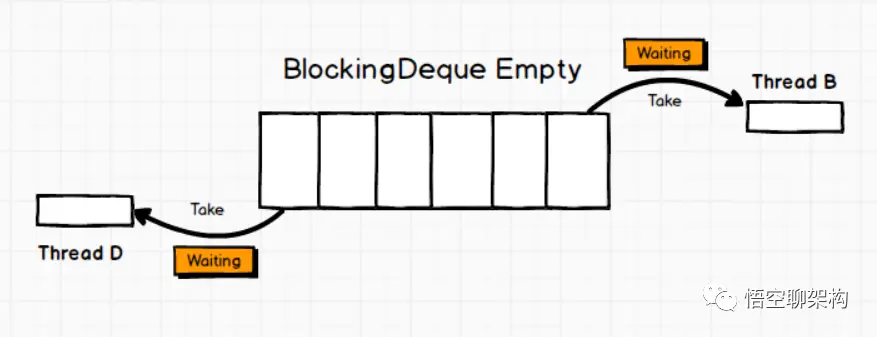
它是阻塞队列BlockingQueue和双向队列Deque接口的结合。有如下方法:
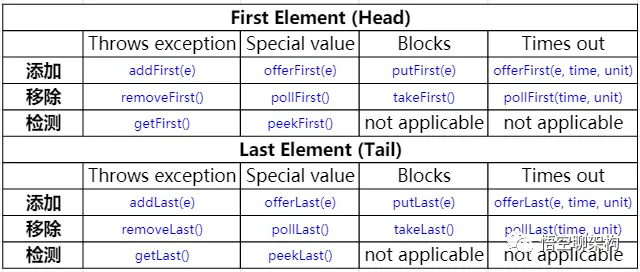
BlockDeque和BlockQueue的对等方法:
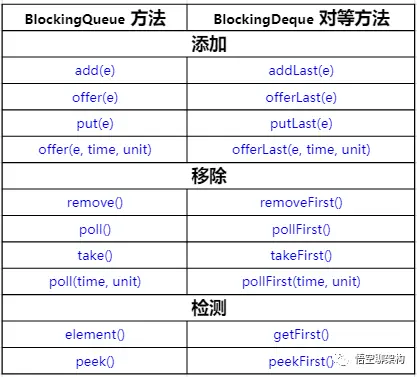
6. TransferQueue
如果有消费者正在获取元素,则将队列中的元素传递给消费者。如果没有消费者,则等待消费者消费。必须将任务完成才能返回。
transfer(E e)
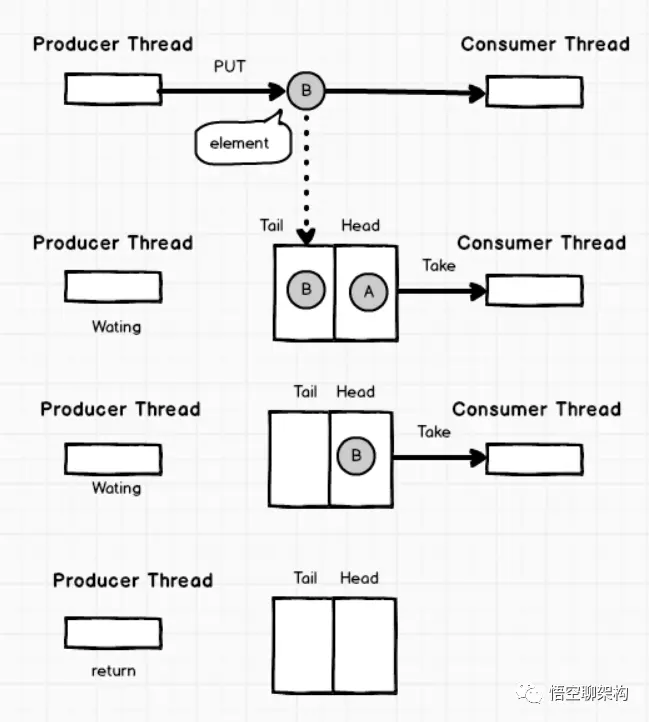
- 生产者线程Producer Thread尝试将元素B传给消费者线程,如果没有消费者线程,则将元素B放到尾节点。并且生产者线程等待元素B被消费。当元素B被消费后,生产者线程返回。
- 如果当前有消费者正在等待接收元素(消费者通过take方法或超时限制的poll方法时),transfer方法可以把生产者传入的元素立刻transfer(传输)给消费者。
- 如果没有消费者等待接收元素,transfer方法会将元素放在队列的tail(尾)节点,并等到该元素被消费者消费了才返回。
tryTransfer(E e)
- 试探生产者传入的元素是否能直接传给消费者。
- 如果没有消费者等待接收元素,则返回false。
- 和transfer方法的区别是,无论消费者是否接收,方法立即返回。
tryTransfer(E e, long timeout, TimeUnit unit)
- 带有时间限制的tryTransfer方法。
- 试图把生产者传入的元素直接传给消费者。
- 如果没有消费者消费该元素则等待指定的时间再返回。
- 如果超时了还没有消费元素,则返回false。
- 如果在超时时间内消费了元素,则返回true。
getWaitingConsumerCount()
- 获取通过BlockingQueue.take()方法或超时限制poll方法等待接受元素的消费者数量。近似值。
- 返回等待接收元素的消费者数量。
hasWaitingConsumer()
- 获取是否有通过BlockingQueue.tabke()方法或超时限制poll方法等待接受元素的消费者。
- 返回true则表示至少有一个等待消费者。
7. PriorityQueue
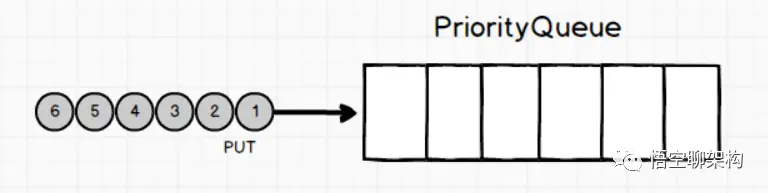
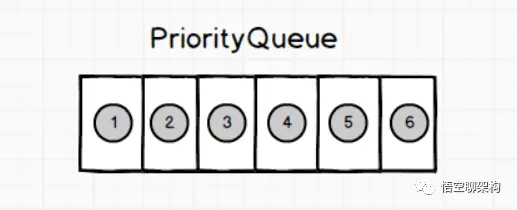
- PriorityQueue是一个支持优先级的无界阻塞队列。
- 默认自然顺序升序排序。
- 可以通过构造参数Comparator来对元素进行排序。
- 自定义实现comapreTo()方法来指定元素排序规则。
- 不允许插入null元素。
- 实现PriorityQueue接口的类,不保证线程安全,除非是PriorityBlockingQueue。
- PriorityQueue的迭代器不能保证以任何特定顺序遍历元素,如果需要有序遍历,请考虑使用
Arrays.sort(pq.toArray)。 - 进列(
offer、add)和出列(poll、remove())的时间复杂度O(log(n))。 - remove(Object) 和 contains(Object)的算法时间复杂度O(n)。
- peek、element、size的算法时间复杂度为O(1)。
8. LinkedList
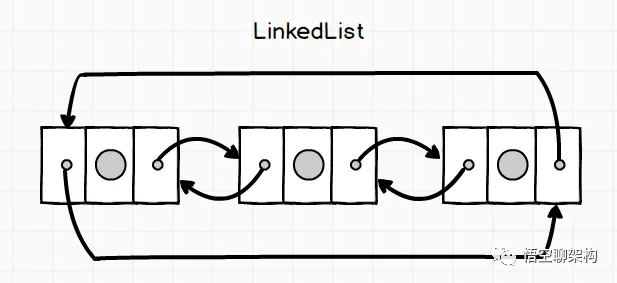
- LinkedList实现了List和Deque接口,所以是一种双链表结构,可以当作堆栈、队列、双向队列使用。
- 一个双向列表的每一个元素都有三个整数值:元素、向后的节点链接、向前的节点链接
private static class Node<E> {
E item; //元素
Node<E> next; //向后的节点链接
Node<E> prev; //向前的节点链接
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
9. ConcurrentLinkedQueue
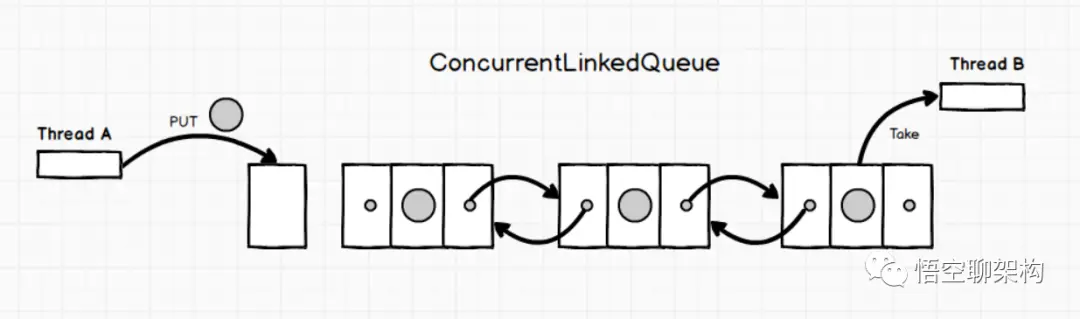
- ConcurrentLinked是由链表结构组成的线程安全的先进先出无界队列。
- 当多线程要共享访问集合时,ConcurrentLinkedQueue是一个比较好的选择。
- 不允许插入null元素
- 支持非阻塞地访问并发安全的队列,不会抛出ConcurrentModifiationException异常。
- size方法不是准确的,因为在统计集合的时候,队列可能正在添加元素,导致统计不准。
- 批量操作addAll、removeAll、retainAll、containsAll、equals和toArray不保证原子性(操作不可分割)
- 添加元素happen-before其他线程移除元素。
10. ArrayDeque
- 由数组组成的双端队列。
- 没有容量限制,根据需要扩容。
- 不是线程安全的。
- 禁止插入null元素。
- 当用作栈时,比栈速度快,当用作队列时,速度比LinkList快。
- 大部分方法的算法时间复杂度为O(1)。
- remove、removeFirstOccurrence、removeLastOccurrence、contains、remove 和批量操作的算法时间复杂度O(n)
11. ConcurrentLinkedDeque
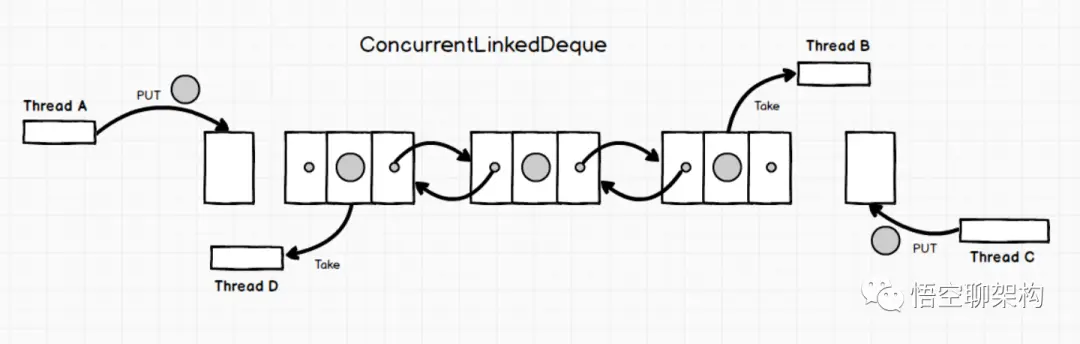
- 由链表结构组成的双向无界阻塞队列
- 插入、删除和访问操作可以并发进行,线程安全的类
- 不允许插入null元素
- 在并发场景下,计算队列的大小是不准确的,因为计算时,可能有元素加入队列。
- 批量操作addAll、removeAll、retainAll、containsAll、equals和toArray不保证原子性(操作不可分割)
12. ArrayBlockingQueue
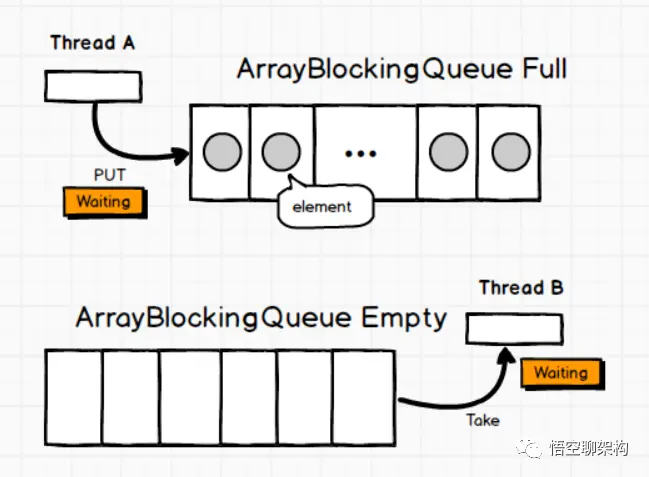
- ArrayBlockingQueue是一个用数组实现的有界阻塞队列。
- 队列满时插入操作被阻塞,队列空时,移除操作被阻塞。
- 按照先进先出(FIFO)原则对元素进行排序。
- 默认不保证线程公平的访问队列。
- 公平访问队列:按照阻塞的先后顺序访问队列,即先阻塞的线程先访问队列。
- 非公平性是对先等待的线程是非公平的,当队列可用时,阻塞的线程都可以争夺访问队列的资格。有可能先阻塞的线程最后才访问访问队列。
- 公平性会降低吞吐量。
13. LinkedBlockinQueue
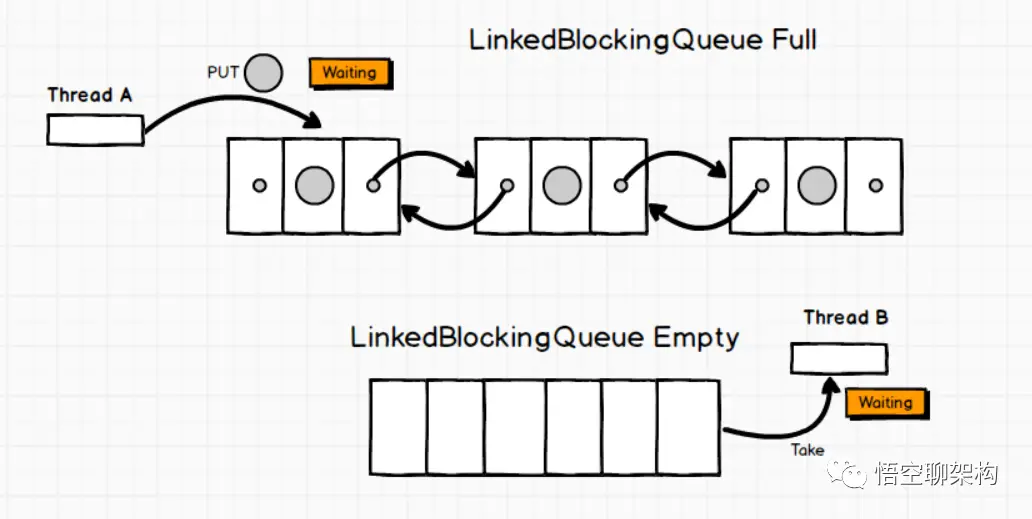
- LinkedBlockingQueue具有单链表和有界阻塞队列的功能。
- 队列满时插入操作被阻塞,队列空时,移除操作被阻塞。
- 默认和最大长度为Integer.MAX_VALUE,相当于无界(值非常大:2^31-1)。
- 吞吐量通常要高于ArrayBlockingQueue。
- 创建线程池时,参数runnableTaskQueue(任务队列),用于保存等待执行的任务的阻塞队列可以选择LinkedBlockingQueue。
- 静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
14. LinkedBlockingDeque
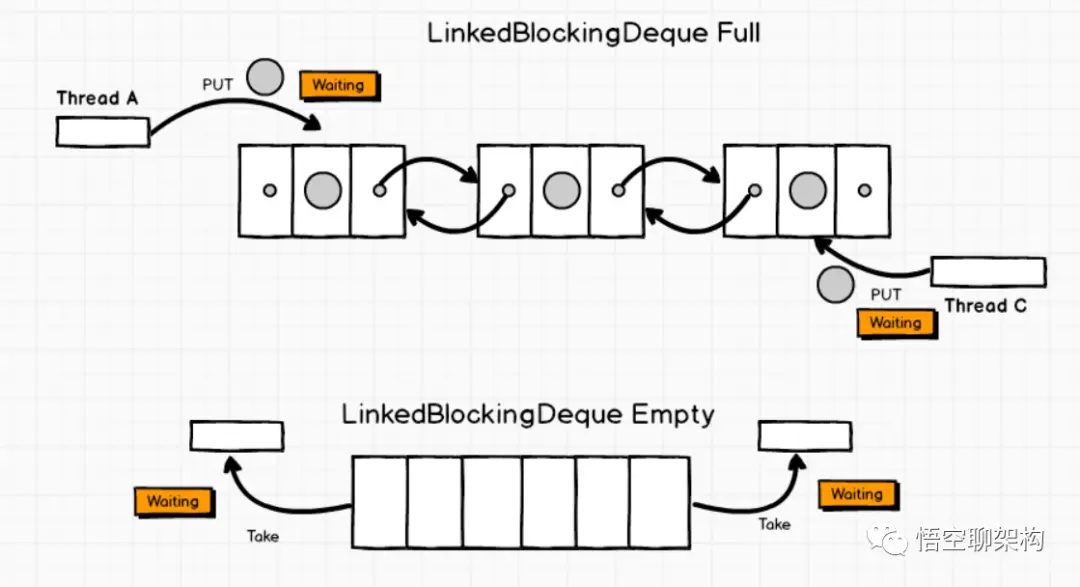
- 由链LinkedBlockingDeque = 阻塞队列+链表+双端访问
- 线程安全。
- 多线程同时入队时,因多了一端访问入口,所以减少了一半的竞争。
- 默认容量大小为Integer.MAX_VALUE。可指定容量大小。
- 可以用在“工作窃取“模式中。
15. LinkedTransferQueue
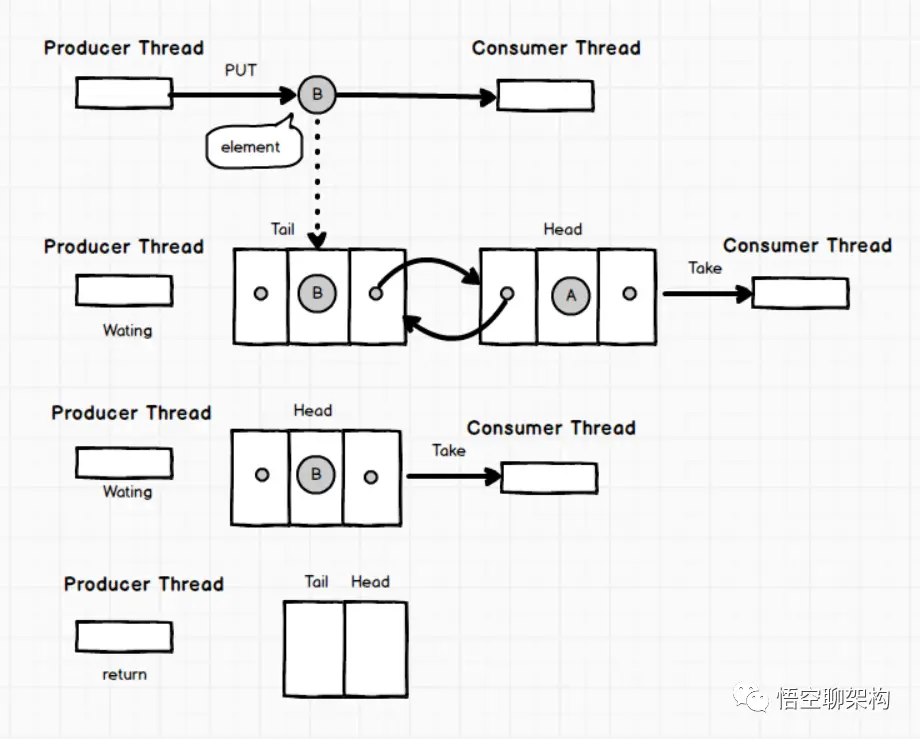
LinkedTransferQueue = 阻塞队列+链表结构+TransferQueue
之前我们讲TransferQueue接口时已经介绍过了TransferQueue接口 ,所以LinkedTransferQueue接口跟它相似,只是加入了阻塞插入和移除的功能,以及结构是链表结构。
16. SynchronousQueue
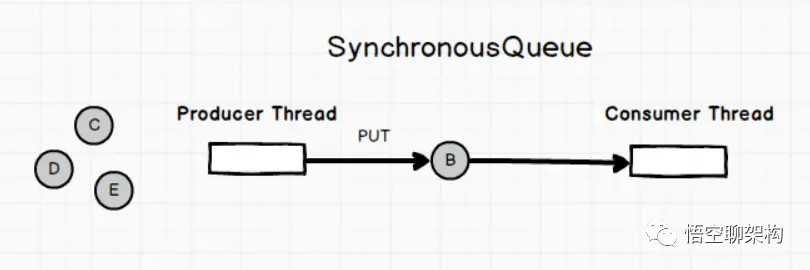
- 我称SynchronousQueue为”传球好手“。想象一下这个场景:小明抱着一个篮球想传给小花,如果小花没有将球拿走,则小明是不能再拿其他球的。
- SynchronousQueue负责把生产者产生的数据传递给消费者线程。
- SynchronousQueue本身不存储数据,调用了put方法后,队列里面也是空的。
- 每一个put操作必须等待一个take操作完成,否则不能添加元素。
- 适合传递性场景。
- 性能高于ArrayBlockingQueue和LinkedBlockingQueue。
- 吞吐量通常要高于LinkedBlockingQueue。
- 创建线程池时,参数runnableTaskQueue(任务队列),用于保存等待执行的任务的阻塞队列可以选择SynchronousQueue。
- 静态工厂方法Executors.newCachedThreadPool()使用了这个队列
17. PriorityBlockQueue
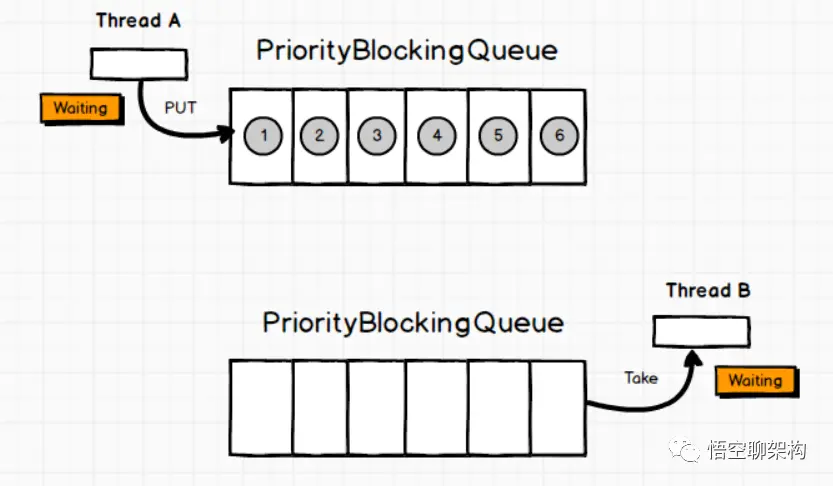
- PriorityBlockQueue = PriorityQueue + BlockingQueue
- 之前我们也讲到了PriorityQueue的原理,支持对元素排序。
- 元素默认自然升序排序。
- 可以自定义CompareTo()方法来指定元素排序规则。
- 可以通过构造函数构造参数Comparator来对元素进行排序。
18. DelayQueue
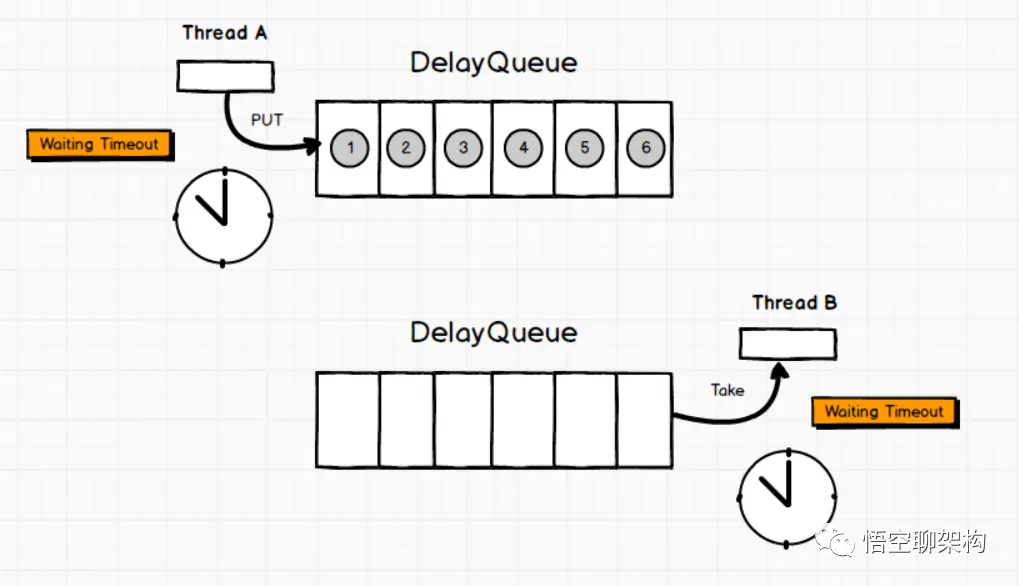
- DelayQueue = Delayed + BlockingQueue。队列中的元素必须实现Delayed接口。
- 在创建元素时,可以指定多久可以从队列中获取到当前元素。只有在延时期满才能从队列中获取到当前元素。
场景:
- 缓存系统的设计:可以用DelayQueue保存缓存元素的有效期。然后用一个线程循环的查询DelayQueue队列,一旦能从DelayQueue中获取元素时,表示缓存有效期到了。
- 定时任务调度:使用DelayQueue队列保存当天将会执行的任务和执行时间,一旦从DelayQueue中获取到任务就开始执行。比如Java中的TimerQueue就是使用DelayQueue实现的。
32 - CH32-AllPools
七大属性
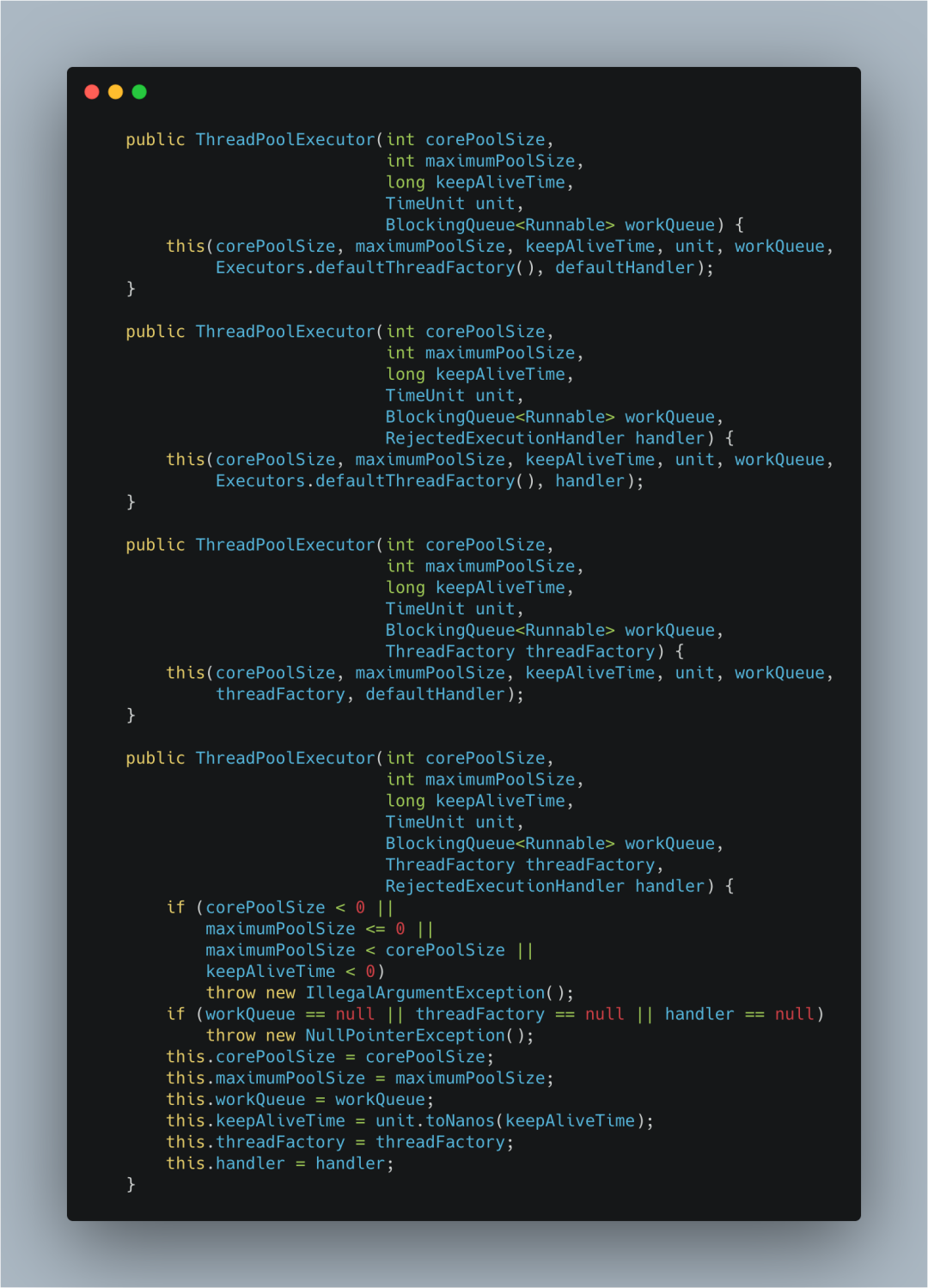
- corePoolSize(int):核心线程数量。默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到任务队列当中。线程池将长期保证这些线程处于存活状态,即使线程已经处于闲置状态。除非配置了allowCoreThreadTimeOut=true,核心线程数的线程也将不再保证长期存活于线程池内,在空闲时间超过keepAliveTime后被销毁。
- workQueue:阻塞队列,存放等待执行的任务,线程从workQueue中取任务,若无任务将阻塞等待。当线程池中线程数量达到corePoolSize后,就会把新任务放到该队列当中。JDK提供了四个可直接使用的队列实现,分别是:基于数组的有界队列ArrayBlockingQueue、基于链表的无界队列LinkedBlockingQueue、只有一个元素的同步队列SynchronousQueue、优先级队列PriorityBlockingQueue。在实际使用时一定要设置队列长度。
- maximumPoolSize(int):线程池内的最大线程数量,线程池内维护的线程不得超过该数量,大于核心线程数量小于最大线程数量的线程将在空闲时间超过keepAliveTime后被销毁。当阻塞队列存满后,将会创建新线程执行任务,线程的数量不会大于maximumPoolSize。
- keepAliveTime(long):线程存活时间,若线程数超过了corePoolSize,线程闲置时间超过了存活时间,该线程将被销毁。除非配置了allowCoreThreadTimeOut=true,核心线程数的线程也将不再保证长期存活于线程池内,在空闲时间超过keepAliveTime后被销毁。
- TimeUnit unit:线程存活时间的单位,例如TimeUnit.SECONDS表示秒。
- RejectedExecutionHandler:拒绝策略,当任务队列存满并且线程池个数达到maximunPoolSize后采取的策略。ThreadPoolExecutor中提供了四种拒绝策略,分别是:抛RejectedExecutionException异常的AbortPolicy(如果不指定的默认策略)、使用调用者所在线程来运行任务CallerRunsPolicy、丢弃一个等待执行的任务,然后尝试执行当前任务DiscardOldestPolicy、不动声色的丢弃并且不抛异常DiscardPolicy。项目中如果为了更多的用户体验,可以自定义拒绝策略。
- threadFactory:创建线程的工厂,虽说JDK提供了线程工厂的默认实现DefaultThreadFactory,但还是建议自定义实现最好,这样可以自定义线程创建的过程,例如线程分组、自定义线程名称等。
工作原理
- 通过execute方法提交任务时,当线程池中的线程数小于corePoolSize时,新提交的任务将通过创建一个新线程来执行,即使此时线程池中存在空闲线程。
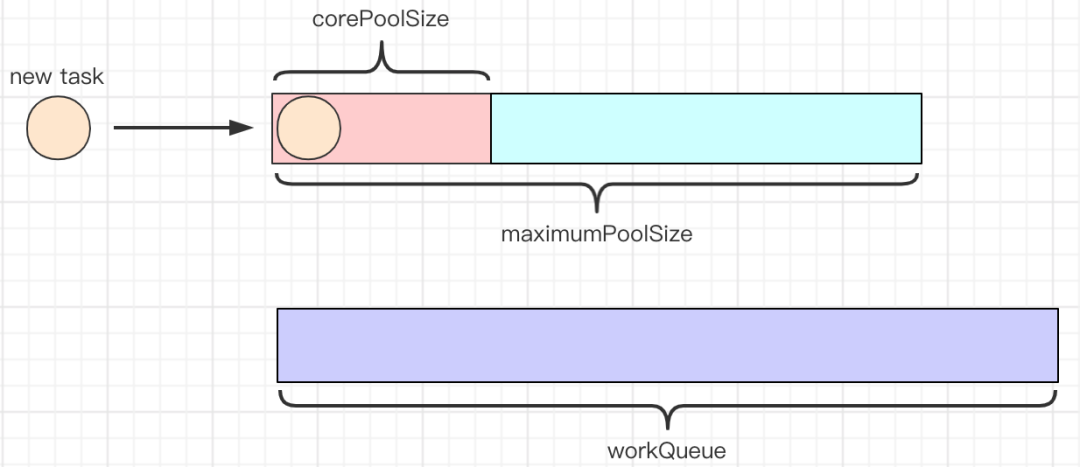
- 通过execute方法提交任务时,当线程池中线程数量达到corePoolSize时,新提交的任务将被放入workQueue中,等待线程池中线程调度执行。
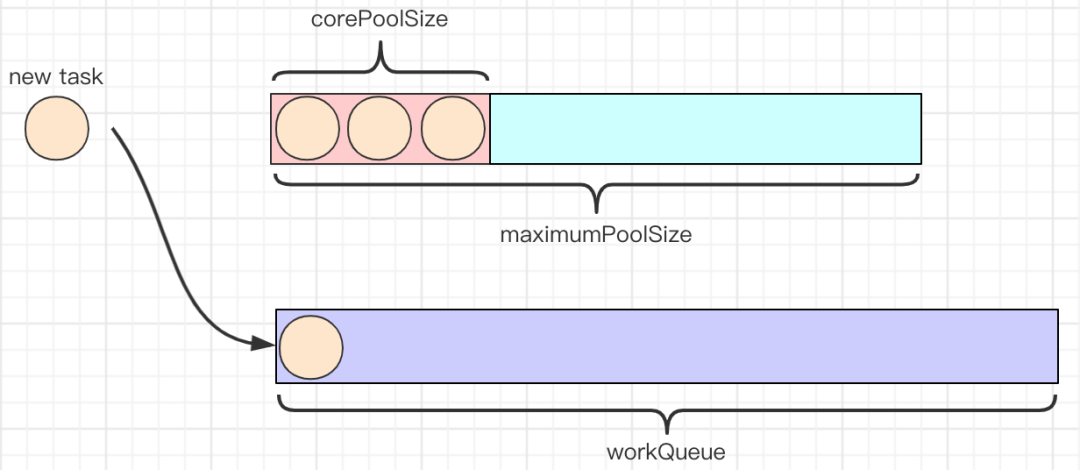
- 通过execute方法提交任务时,当workQueue已存满,且maximumPoolSize大于corePoolSize时,新提交的任务将通过创建新线程执行。
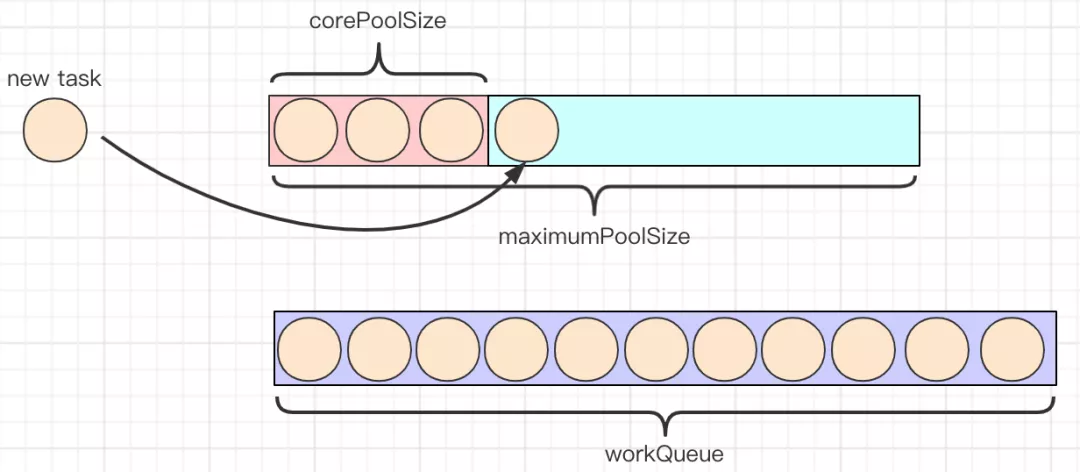
- 当线程池中的线程执行完任务空闲时,会尝试从workQueue中取头结点任务执行。
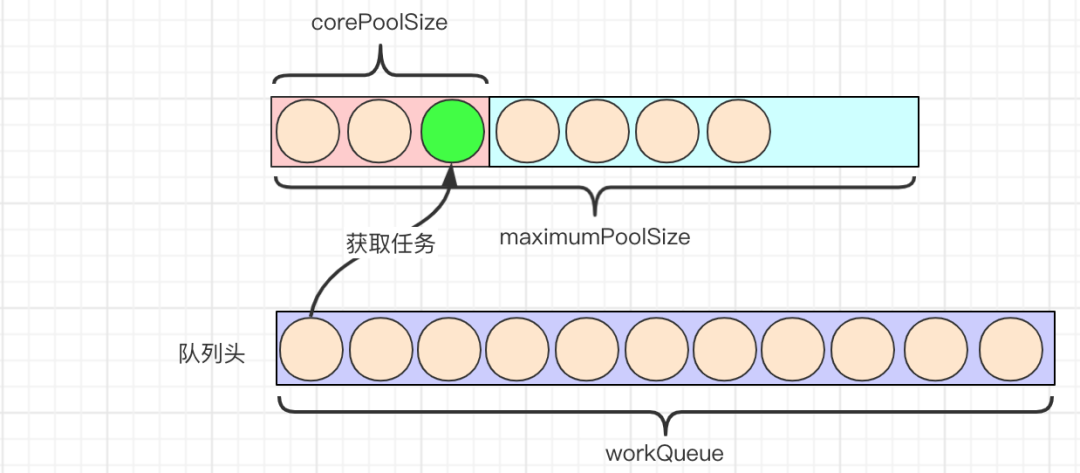
- 通过execute方法提交任务,当线程池中线程数达到maxmumPoolSize,并且workQueue也存满时,新提交的任务由RejectedExecutionHandler执行拒绝操作。
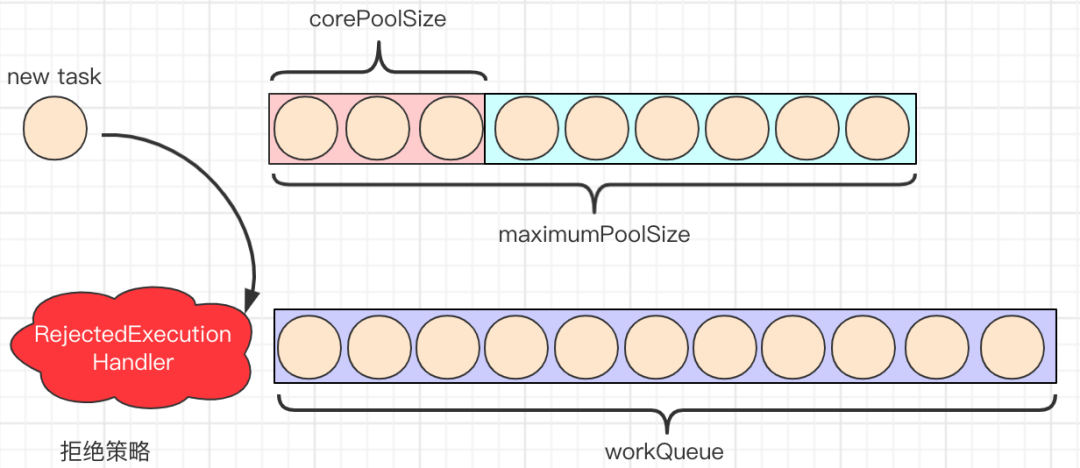
- 当线程池中线程数超过corePoolSize,并且未配置allowCoreThreadTimeOut=true,空闲时间超过keepAliveTime的线程会被销毁,保持线程池中线程数为corePoolSize。
- 当设置allowCoreThreadTimeOut=true时,任何空闲时间超过keepAliveTime的线程都会被销毁。
状态切换