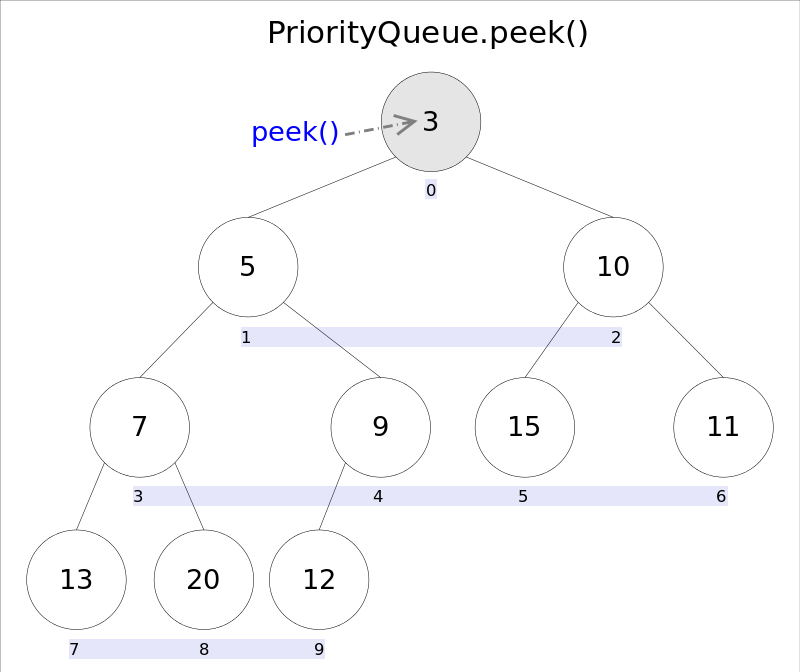
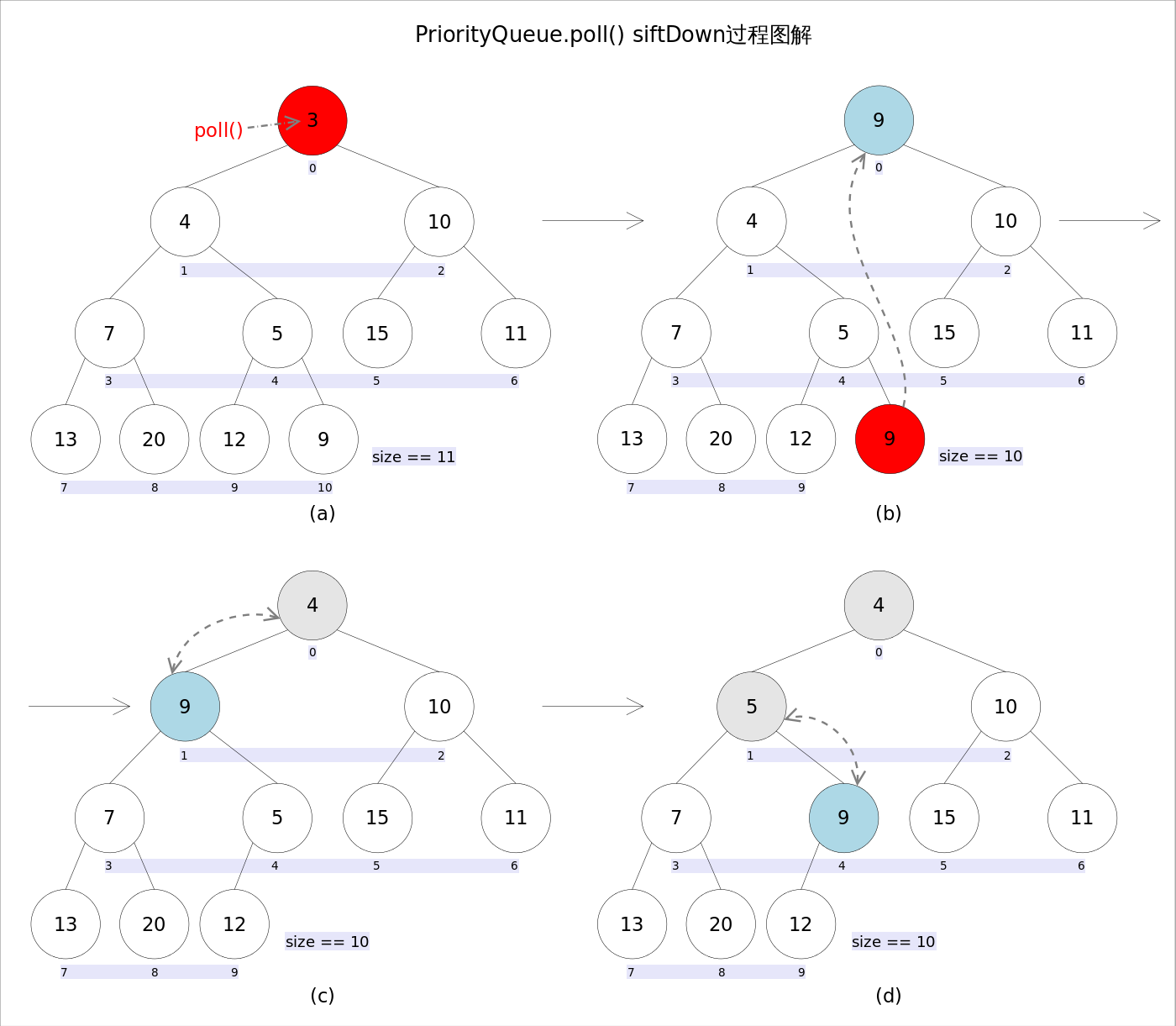
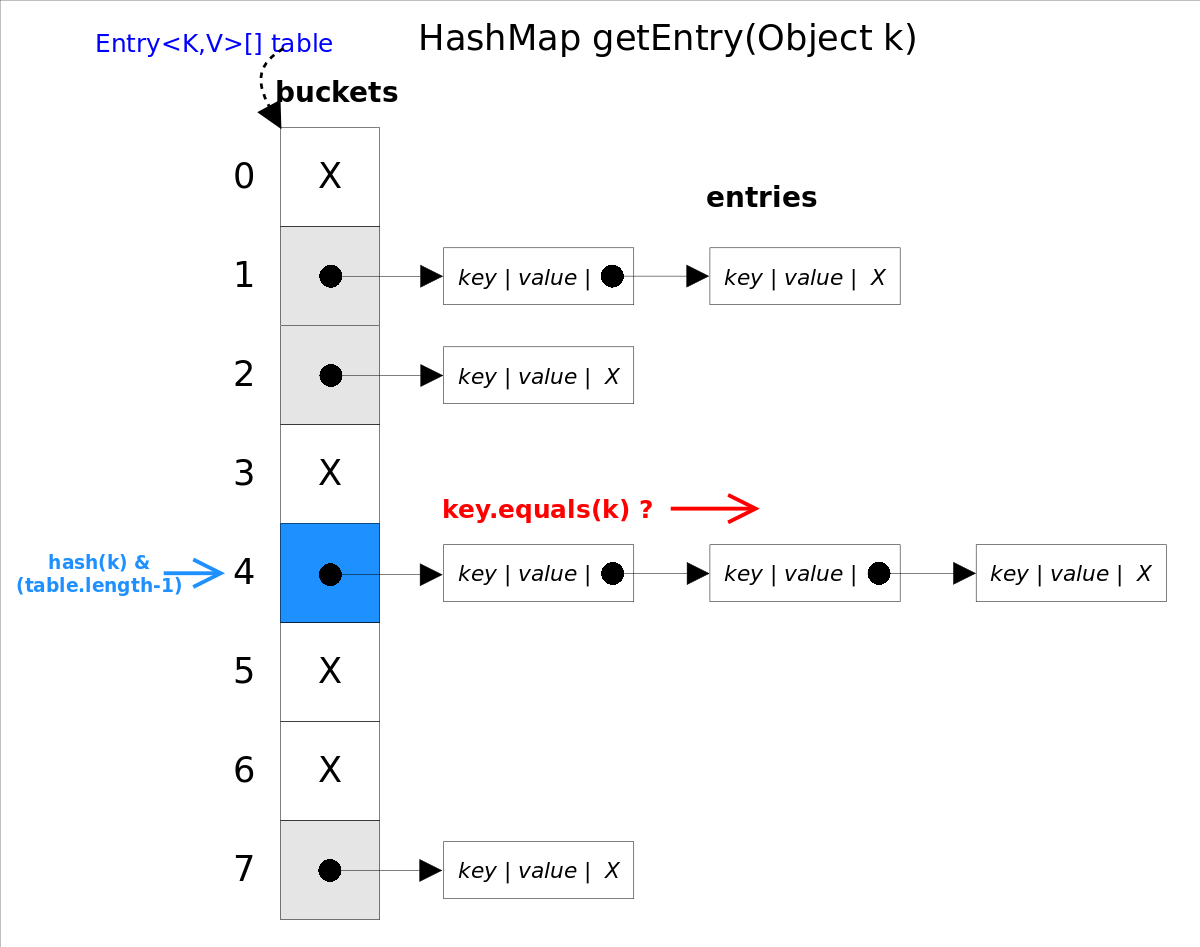
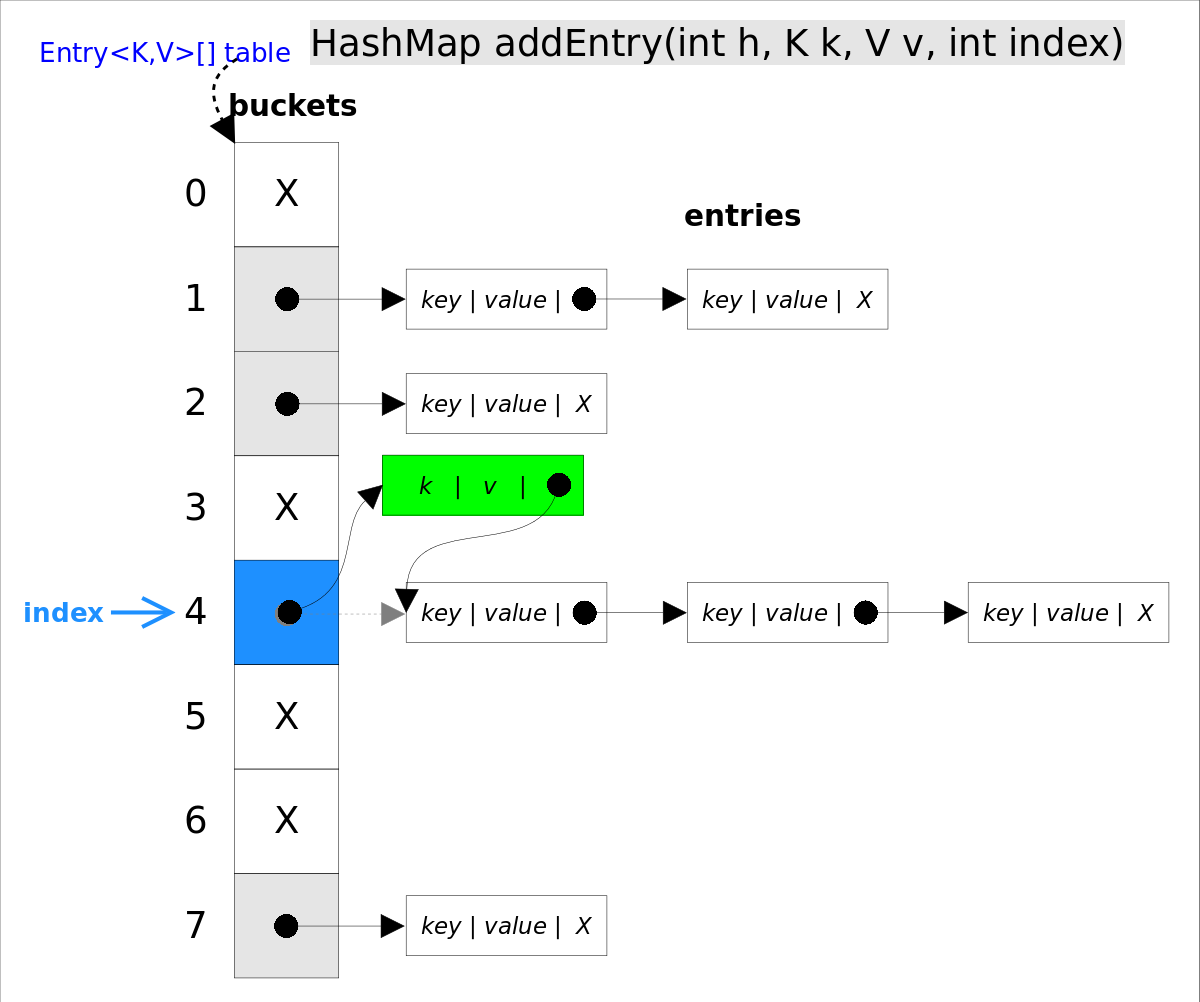
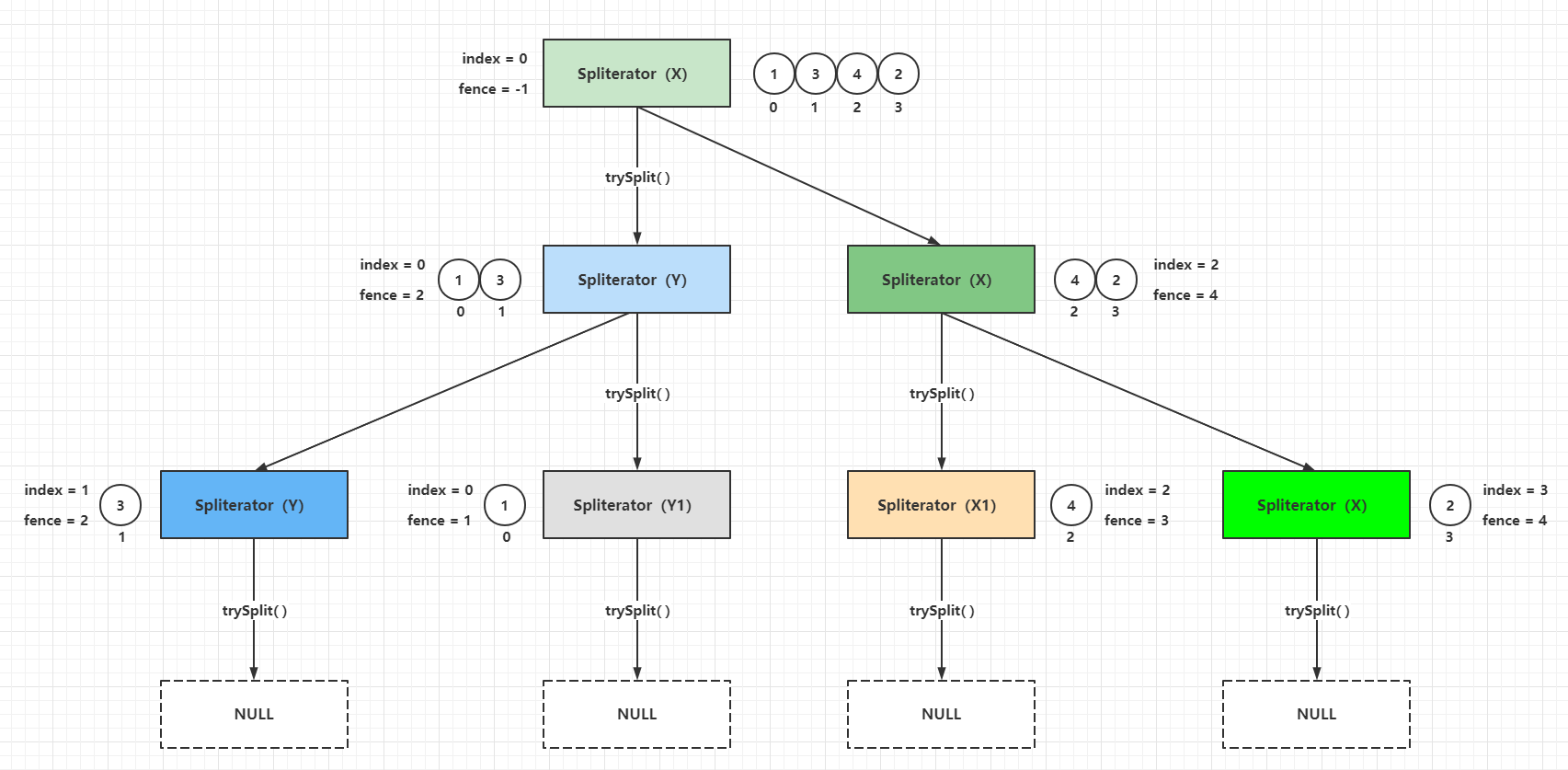
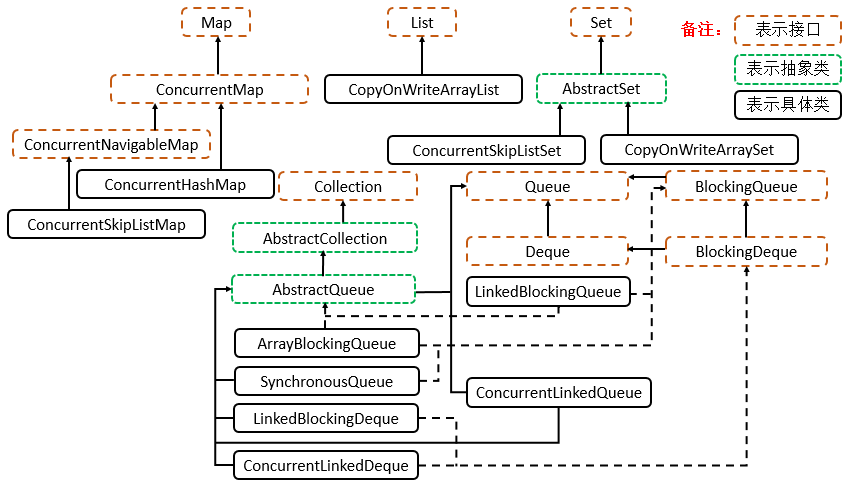
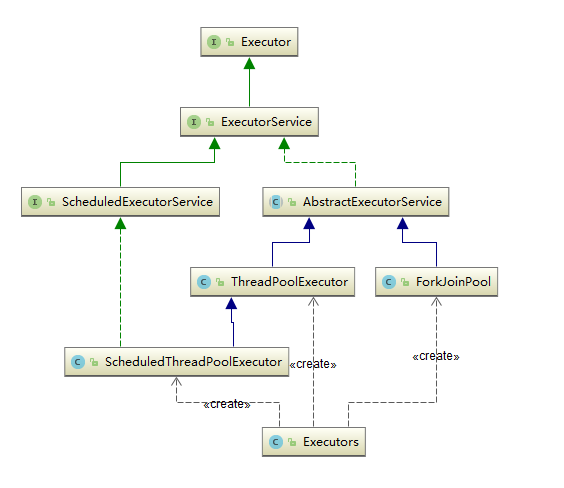
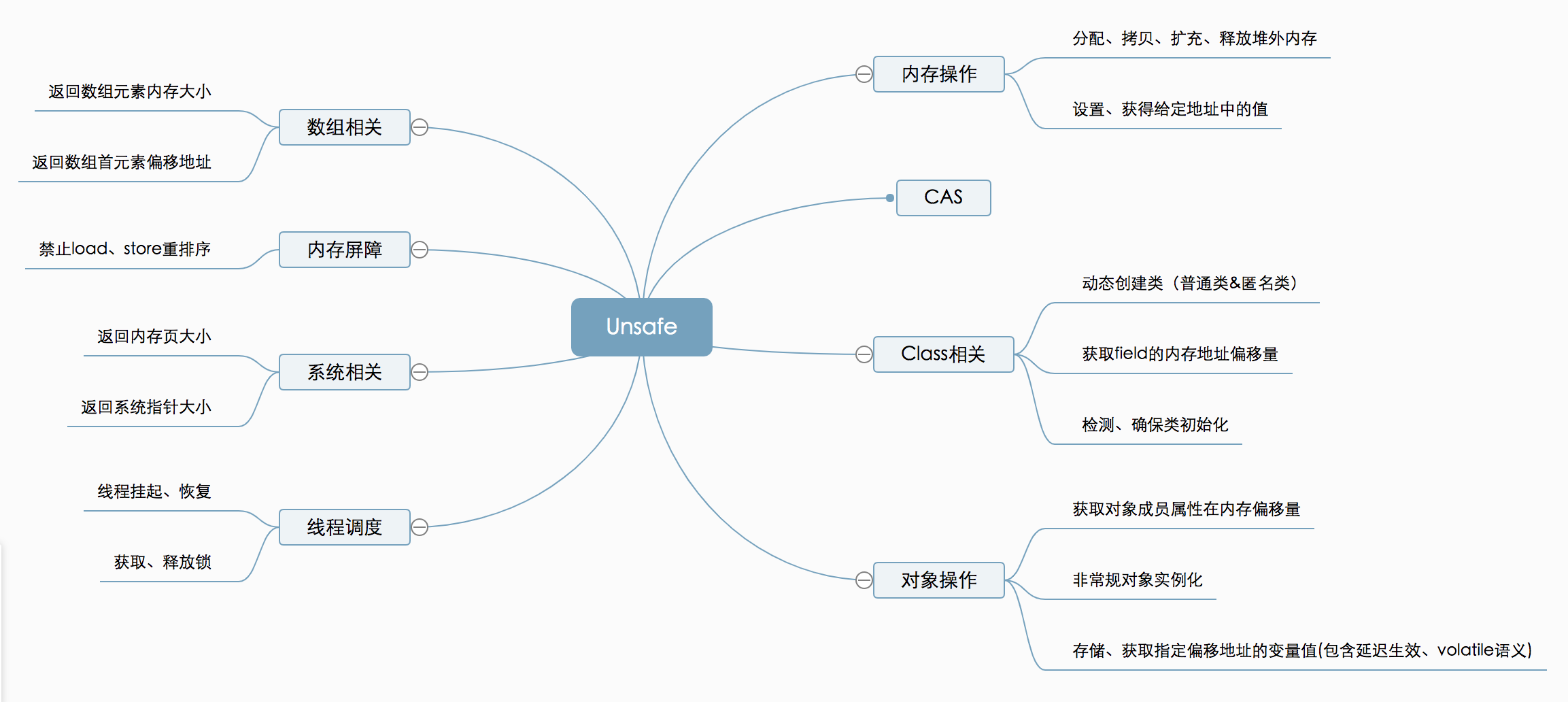
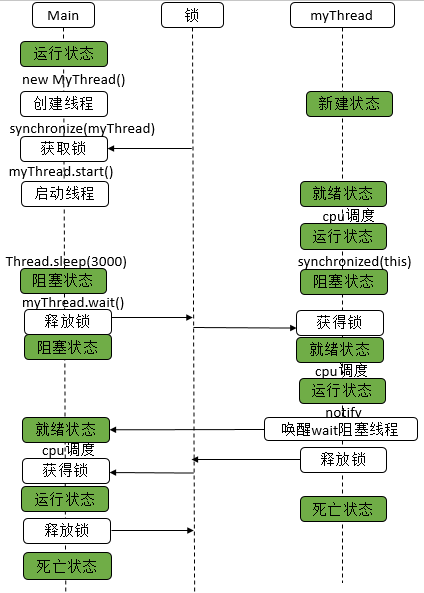
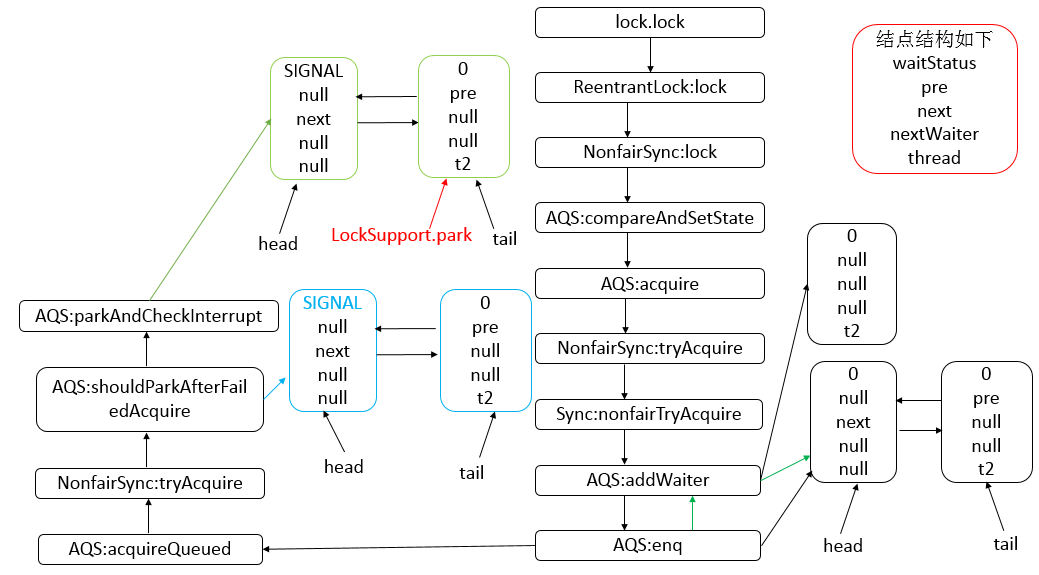
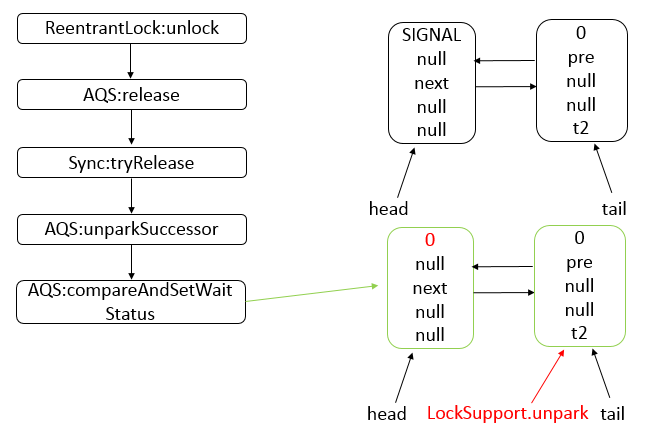
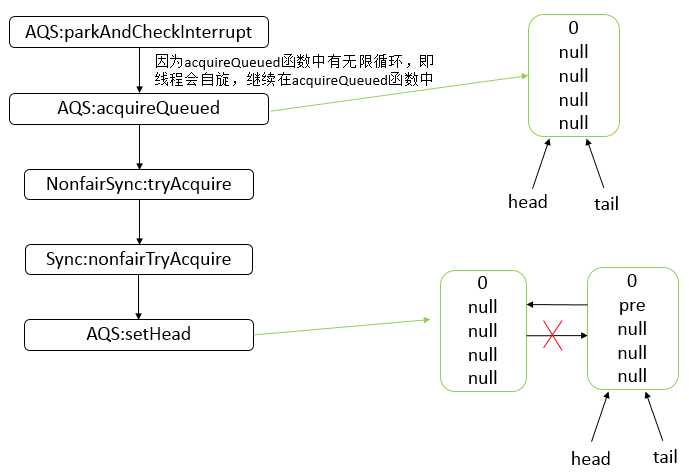
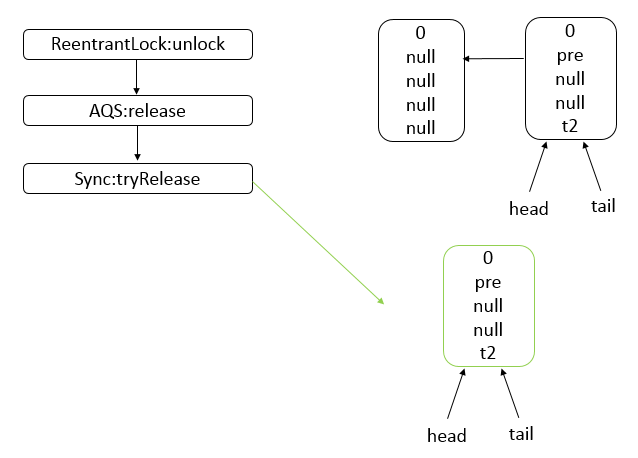
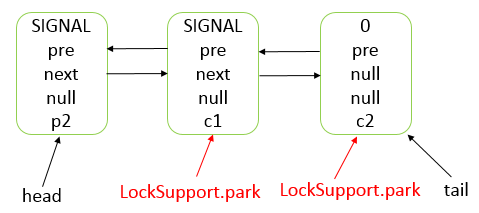
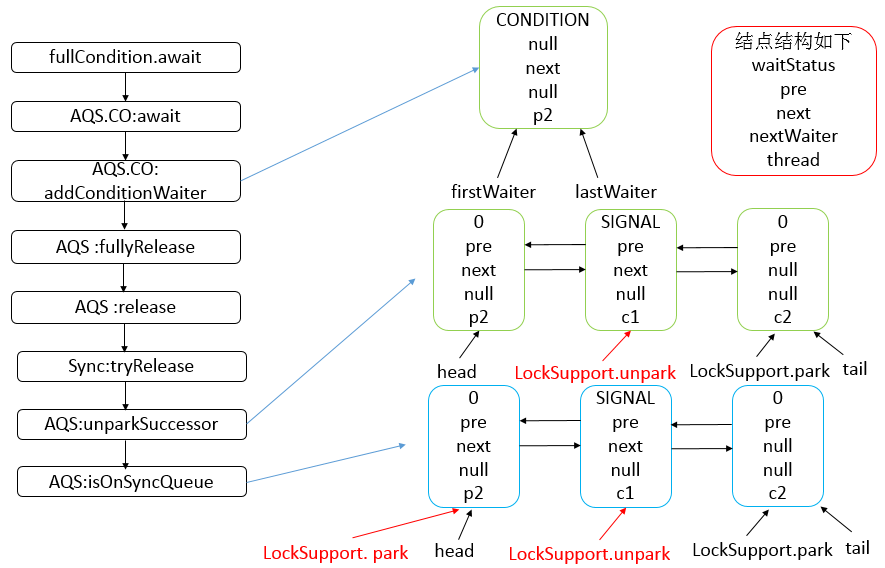
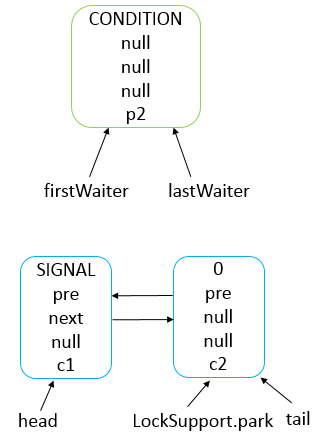
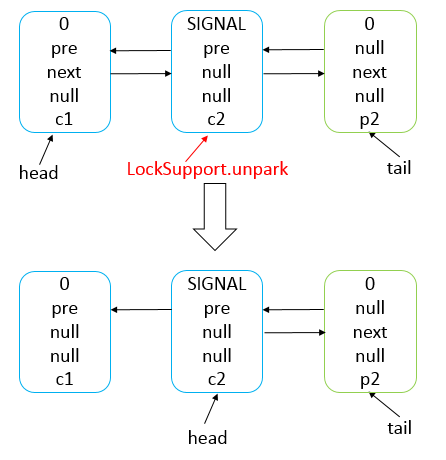
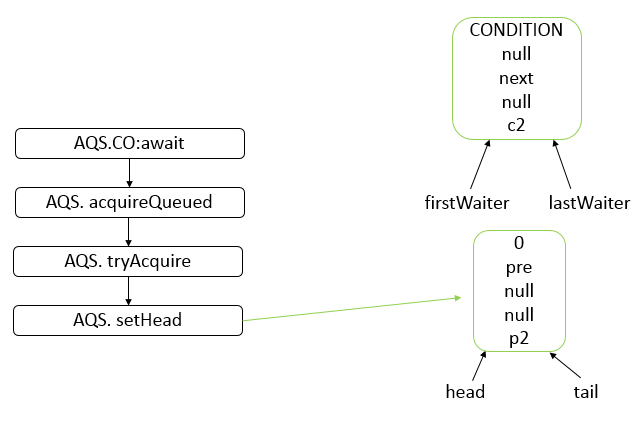
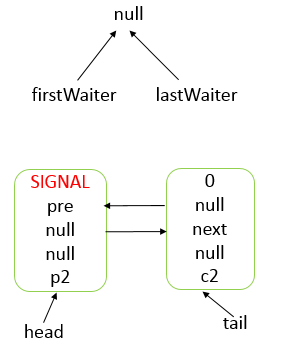
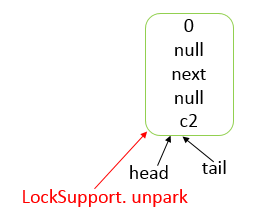
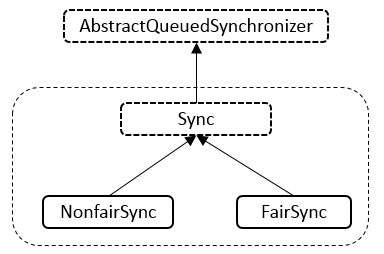
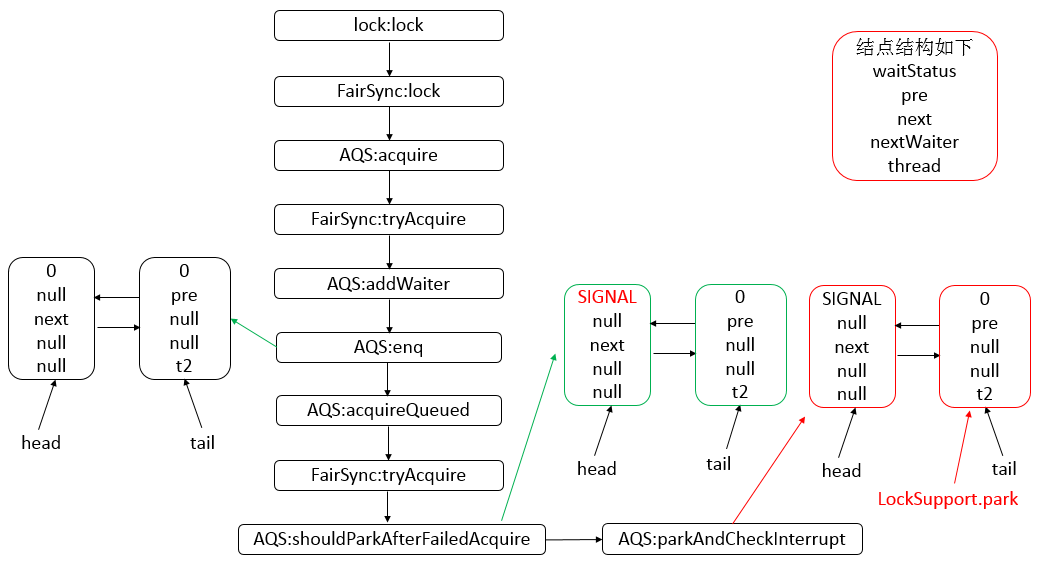
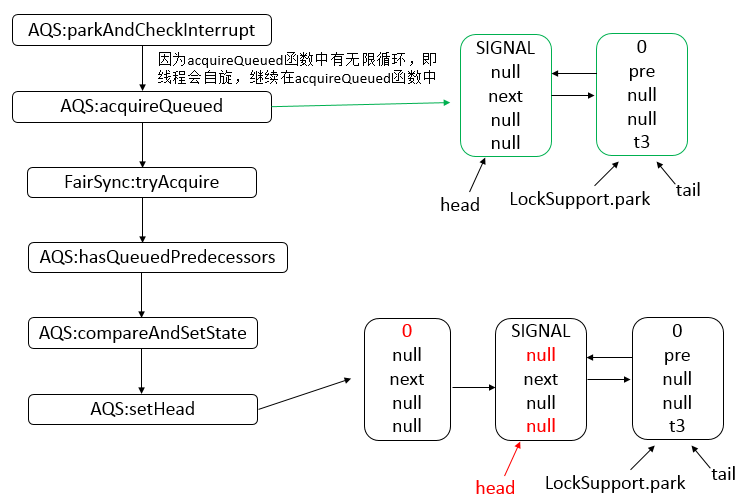
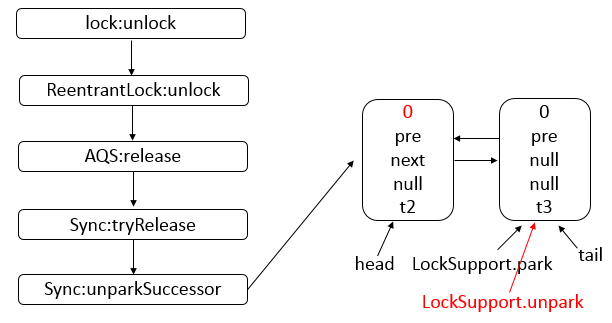
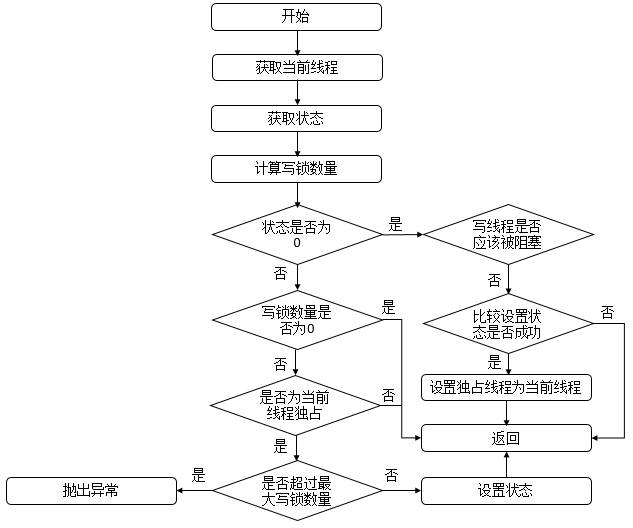
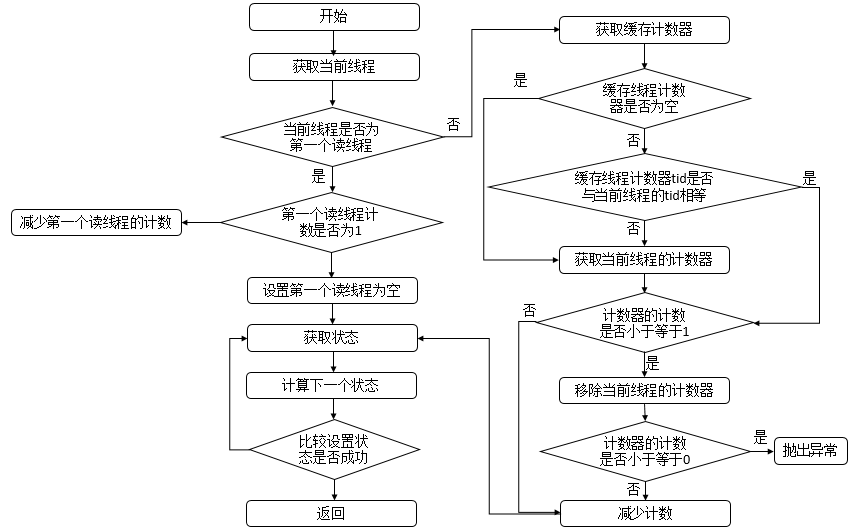
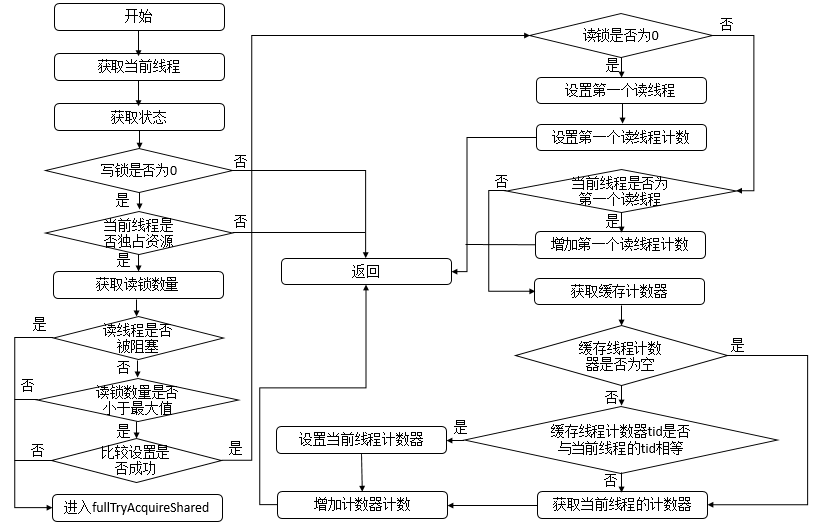
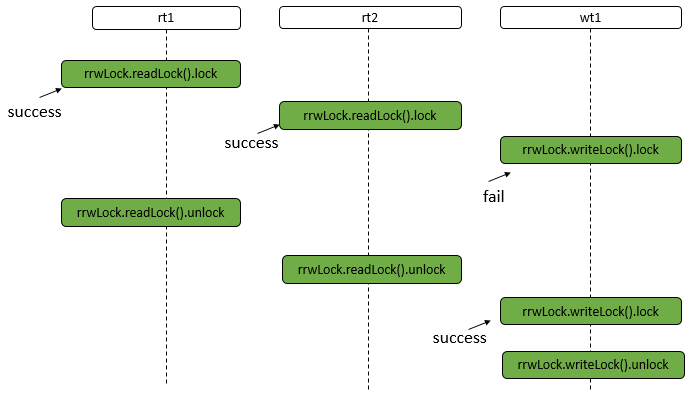
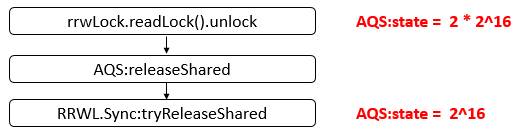
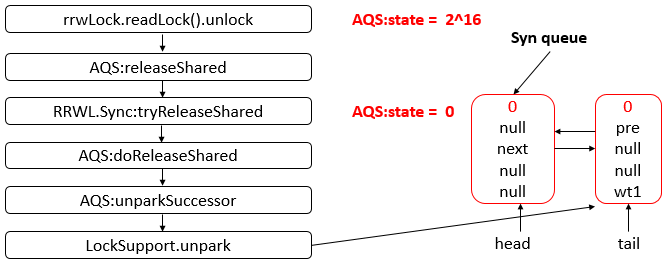
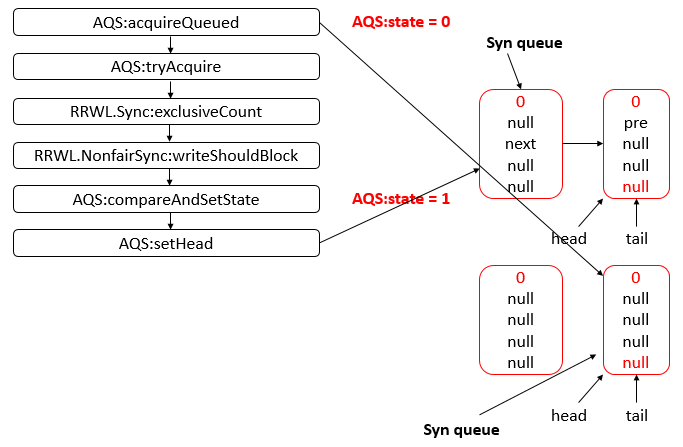
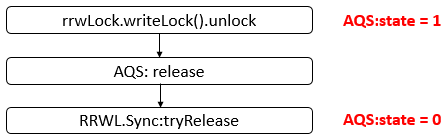
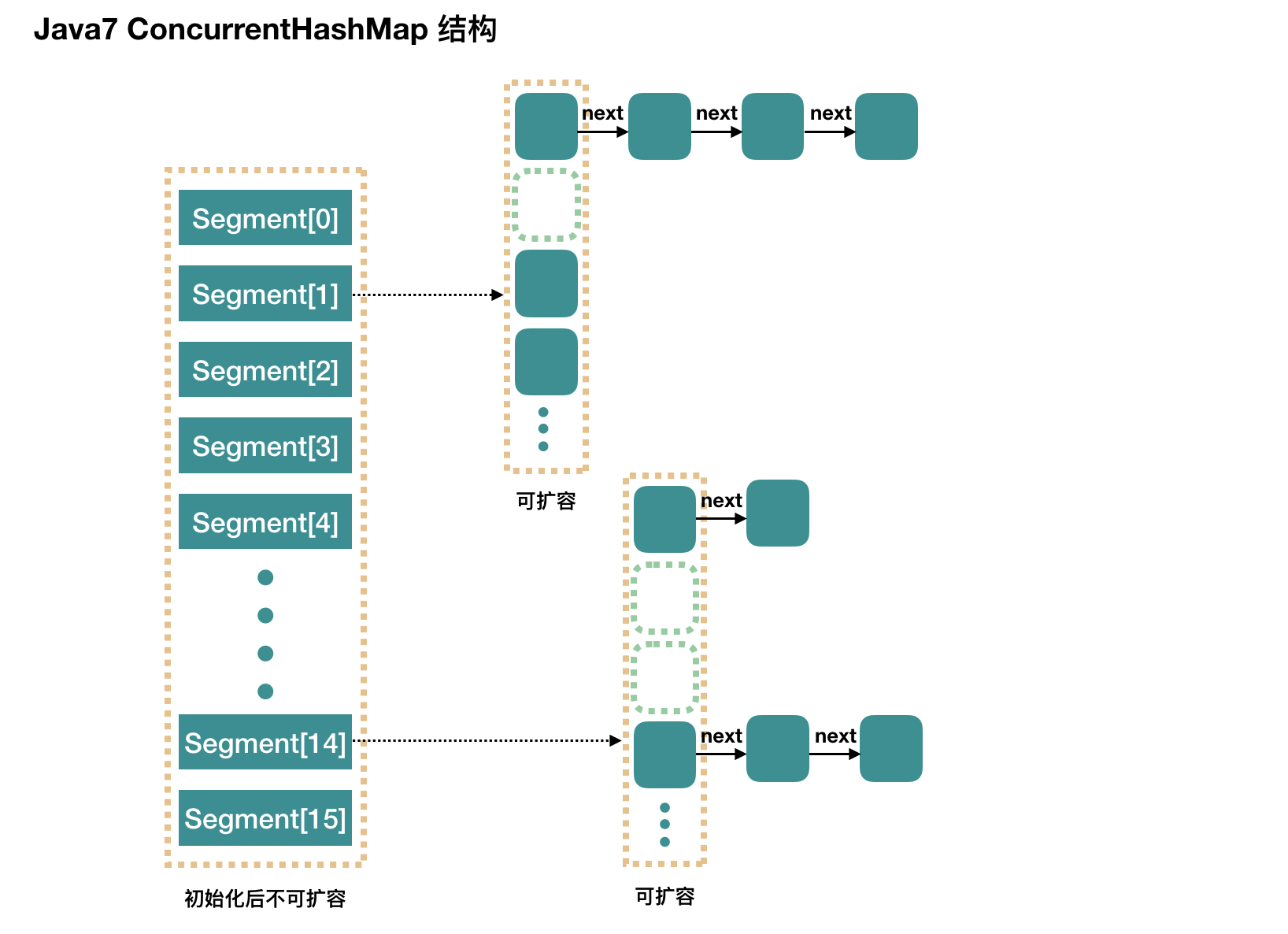
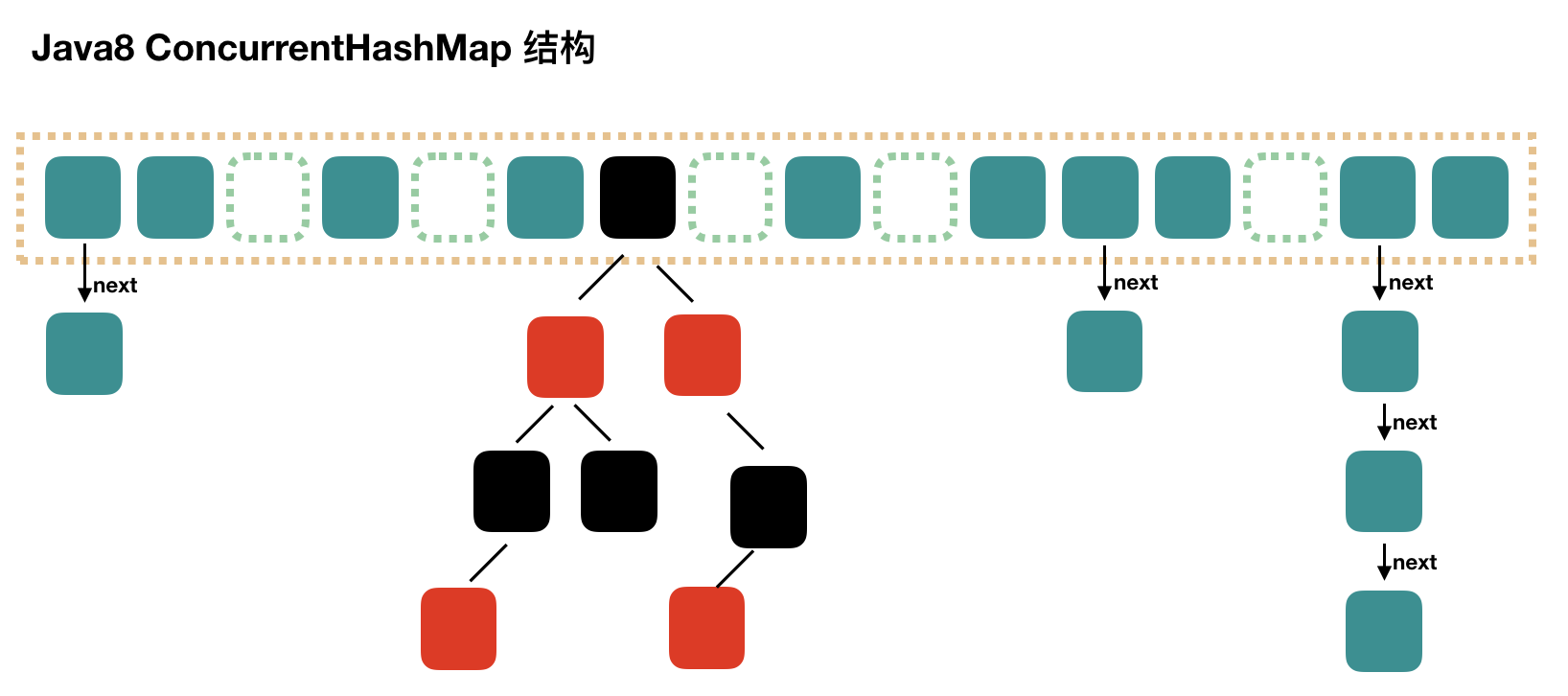
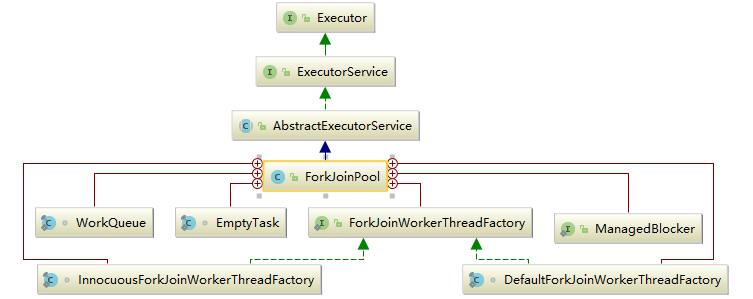
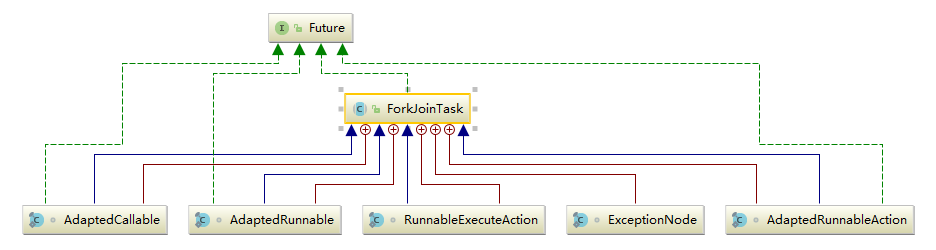
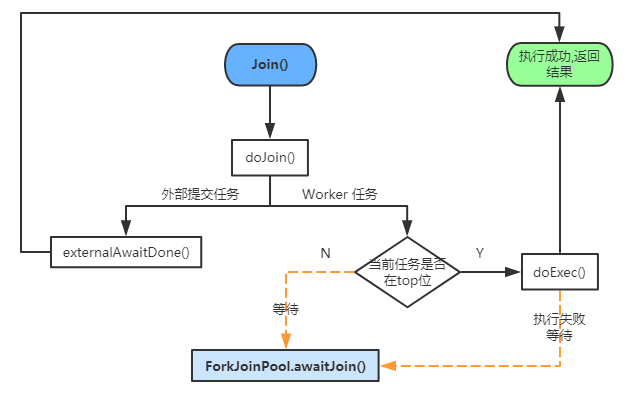
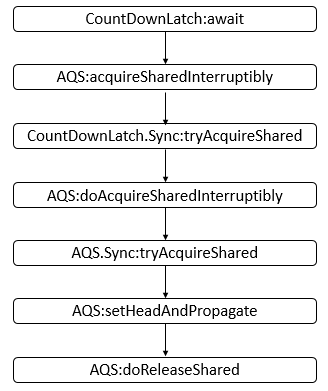
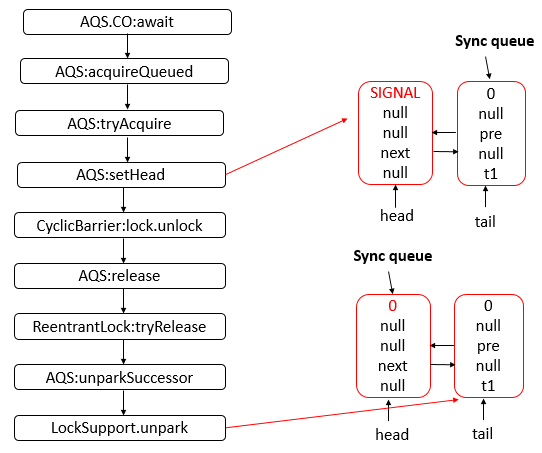
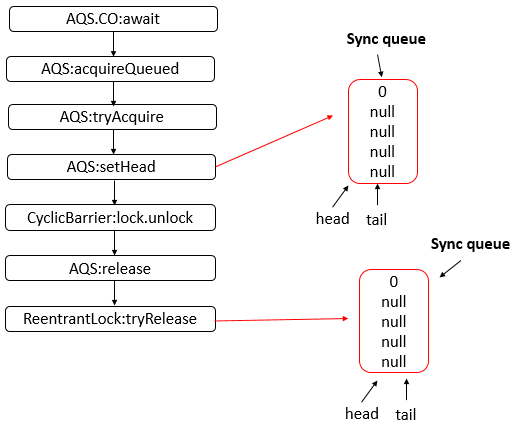
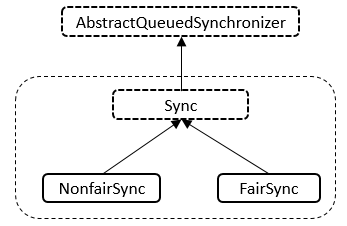
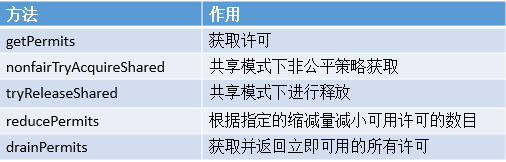
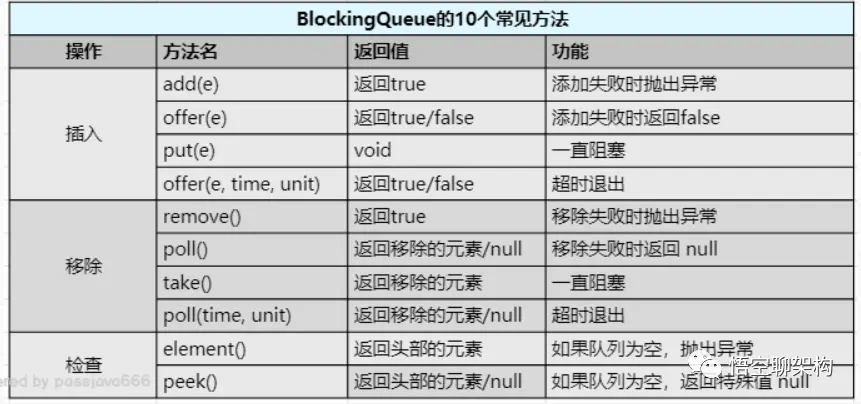
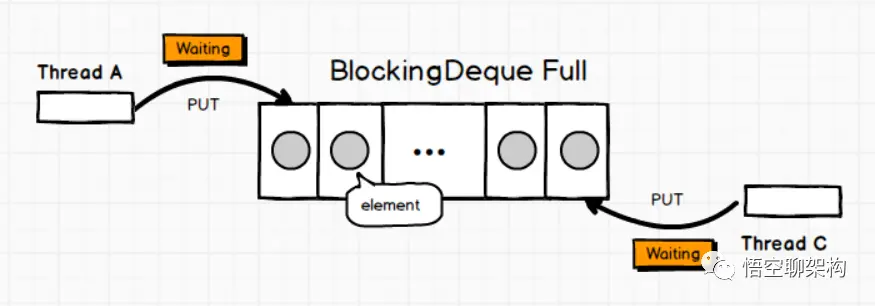
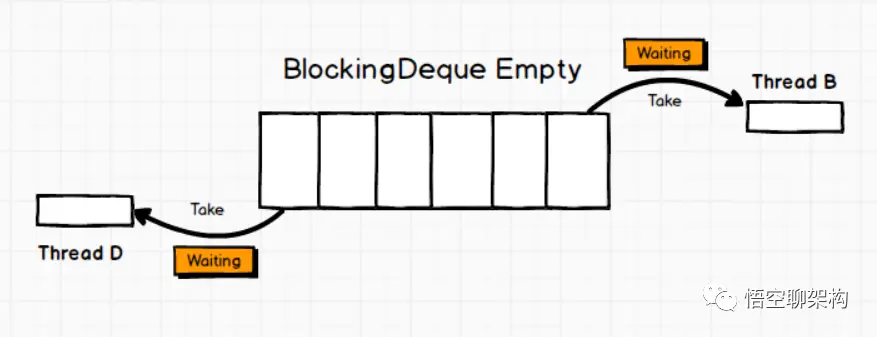
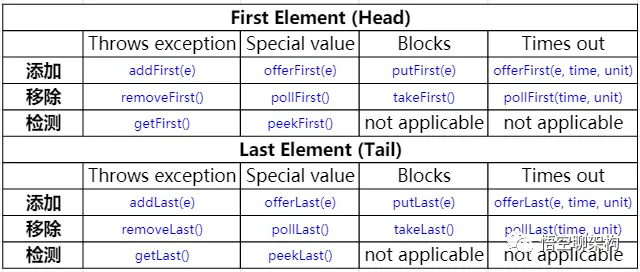
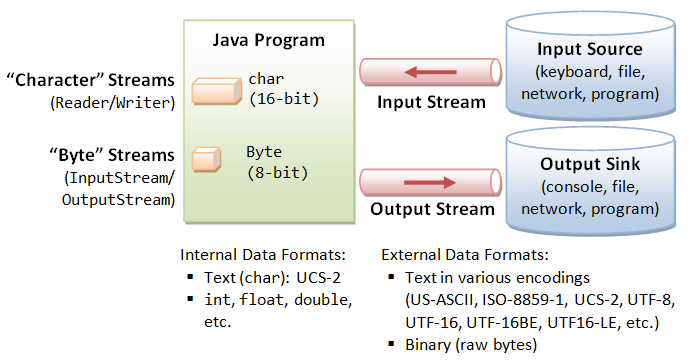
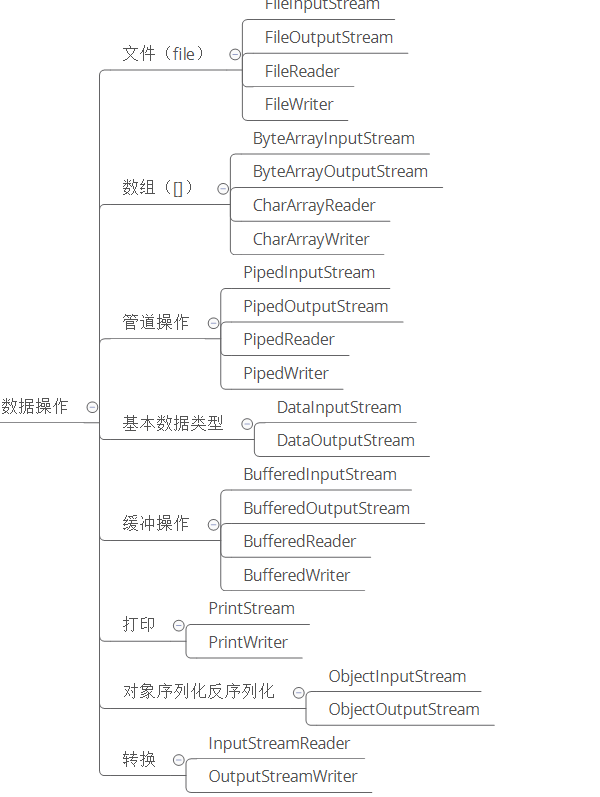
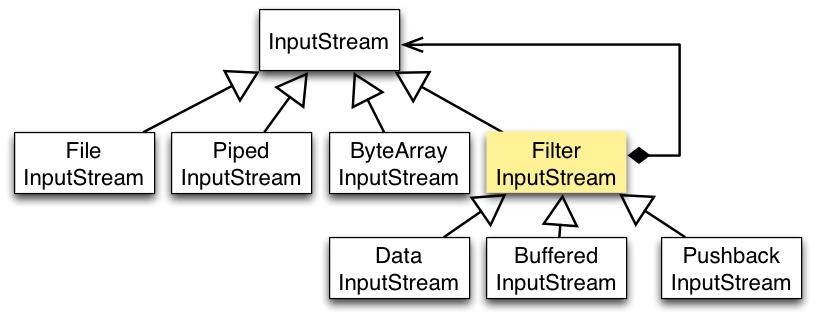
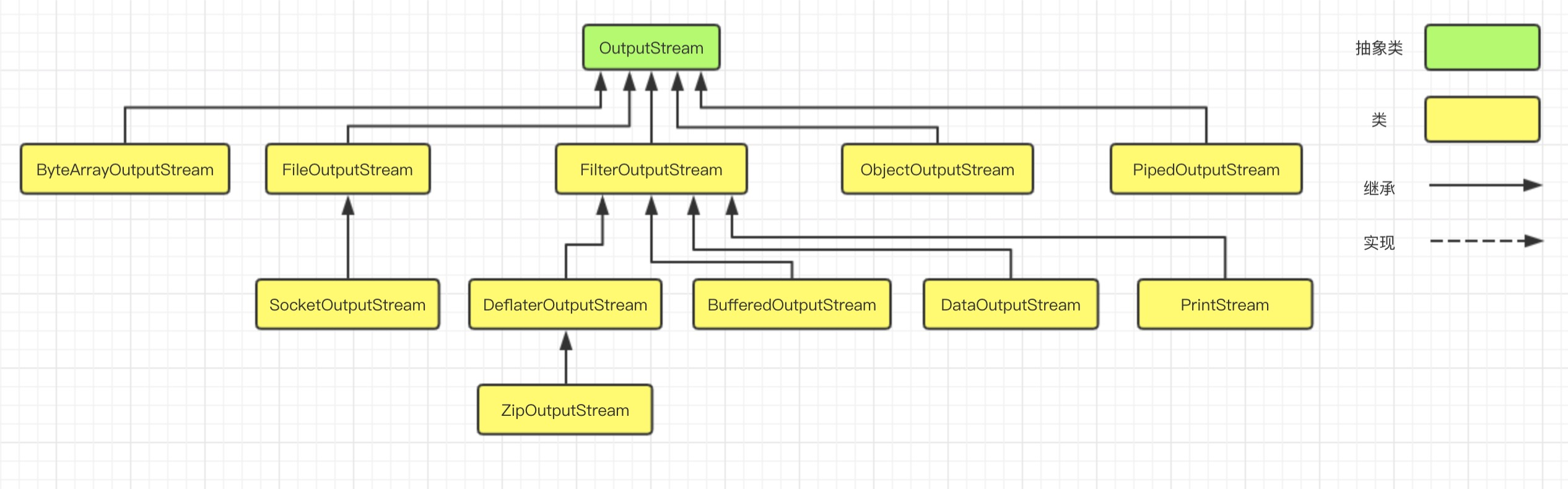
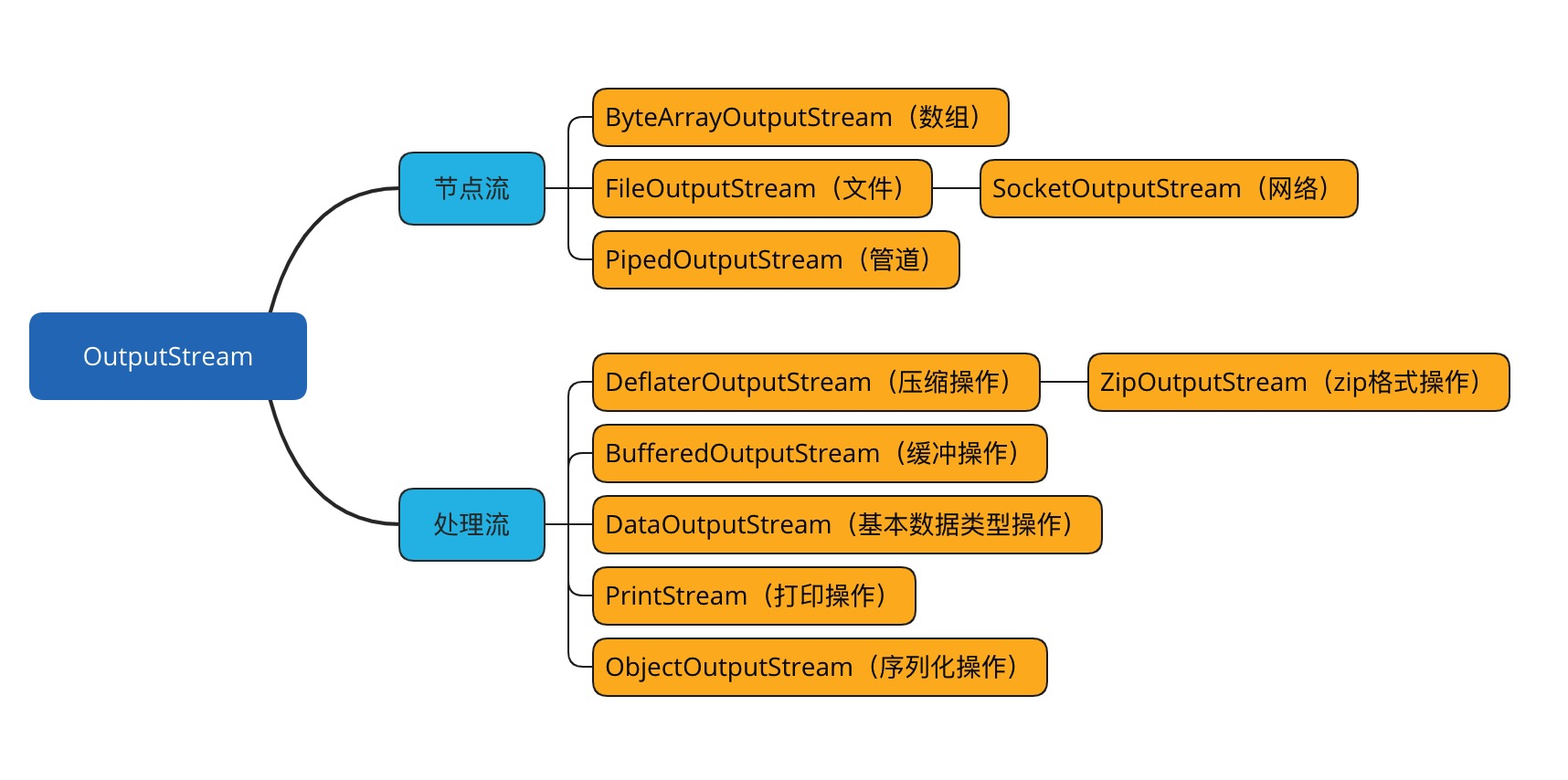
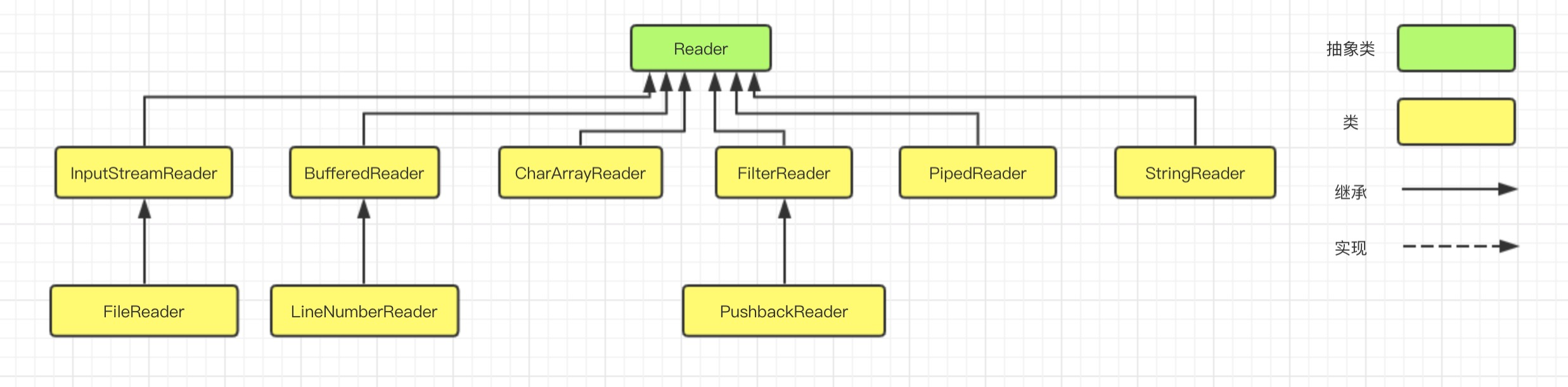
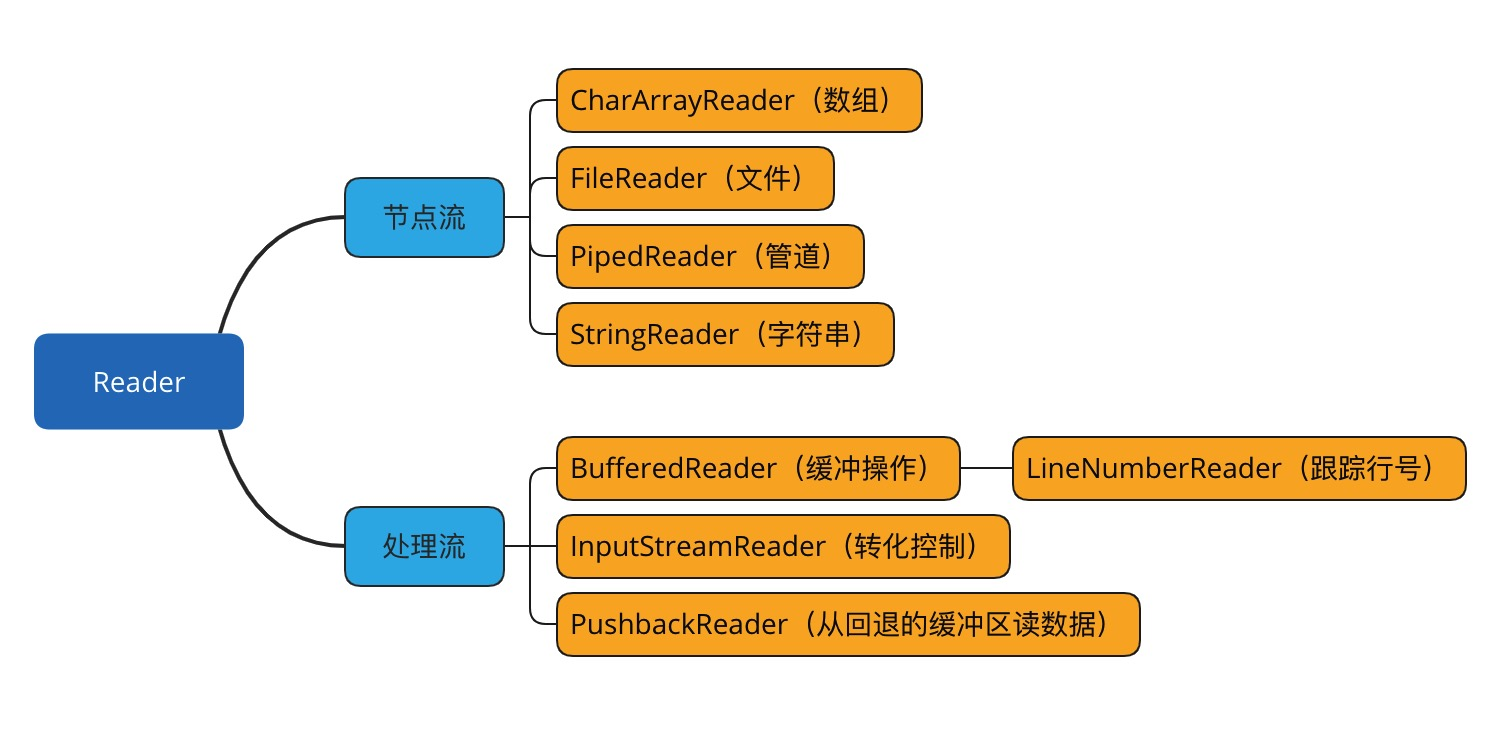
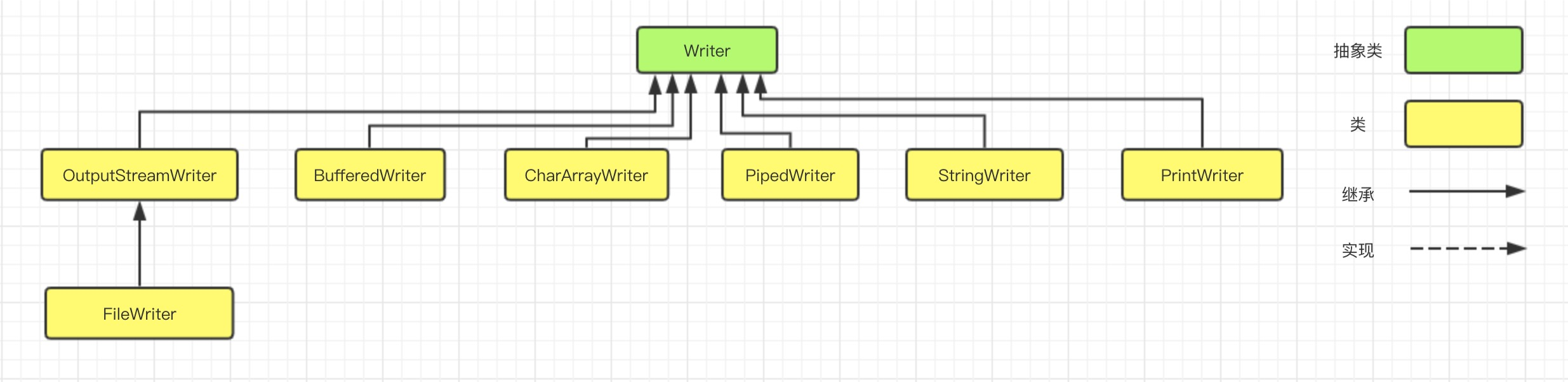
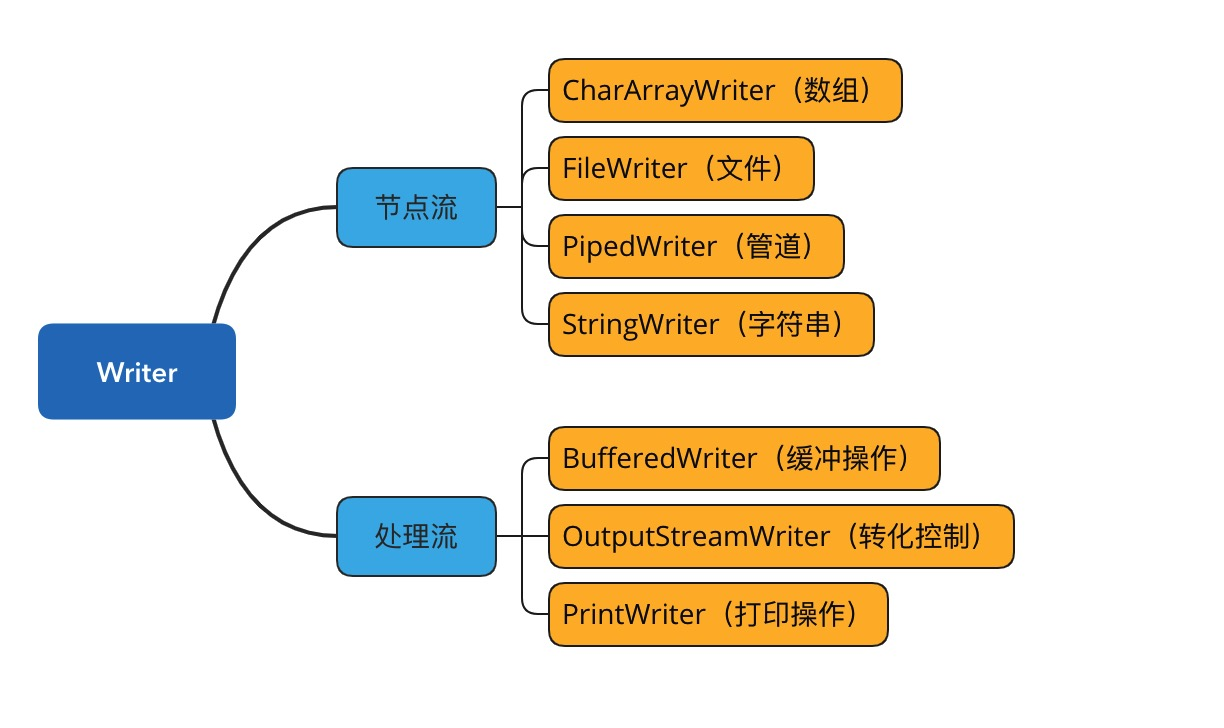
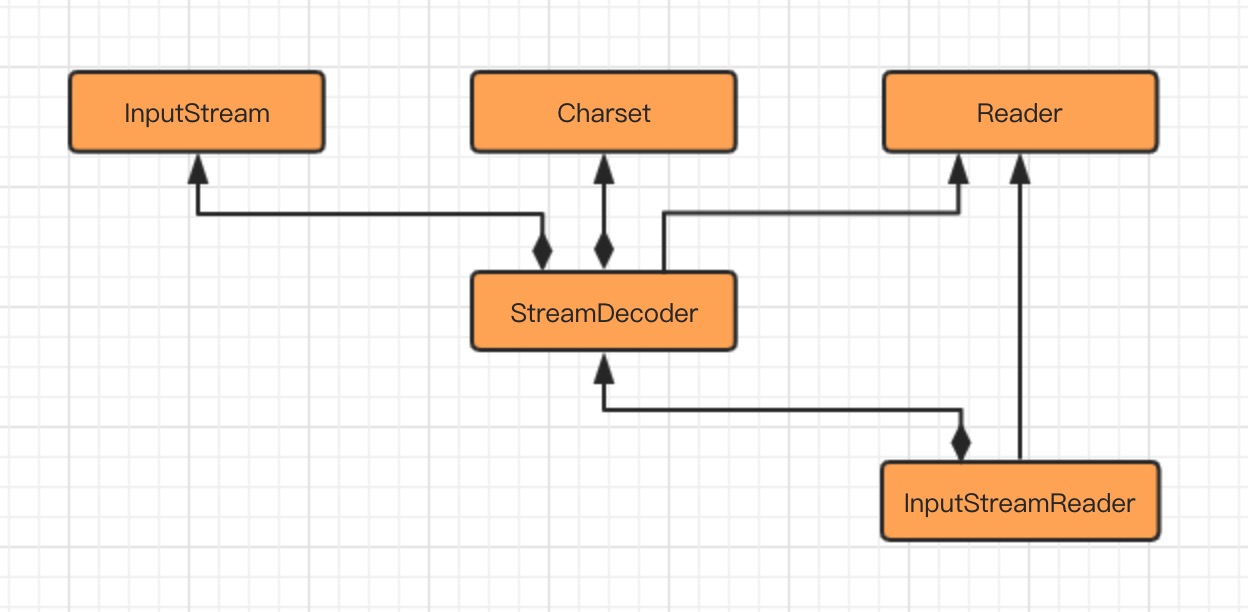
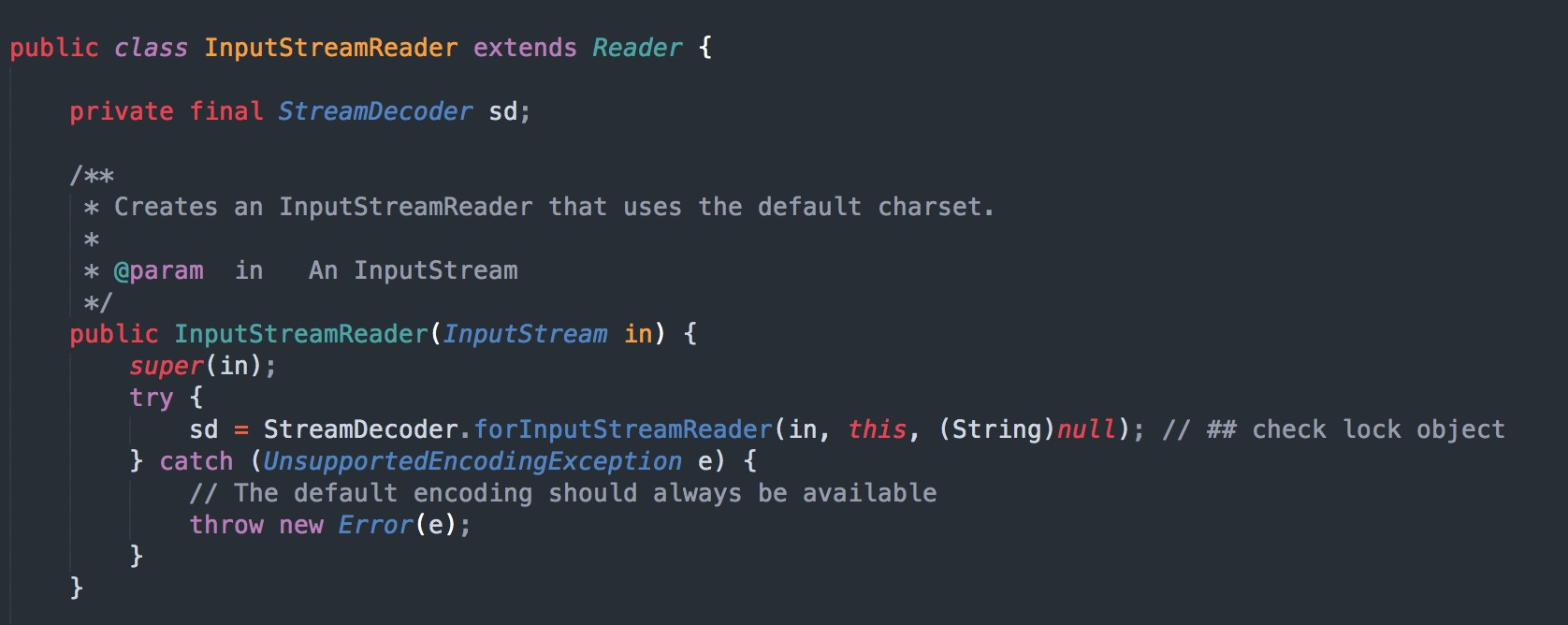
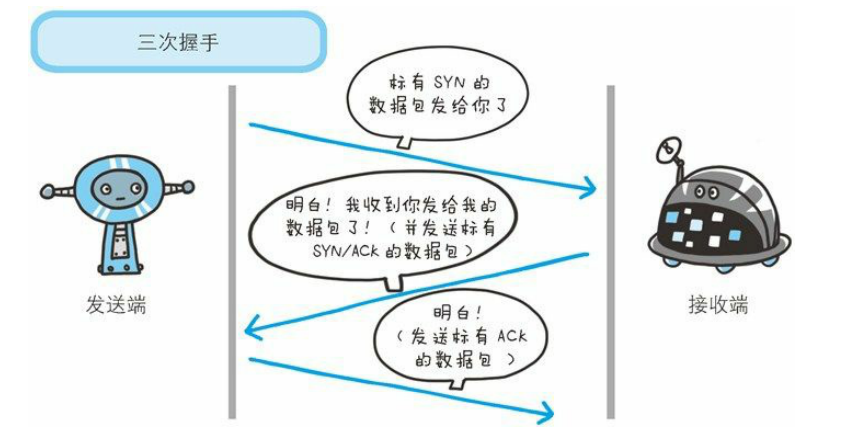
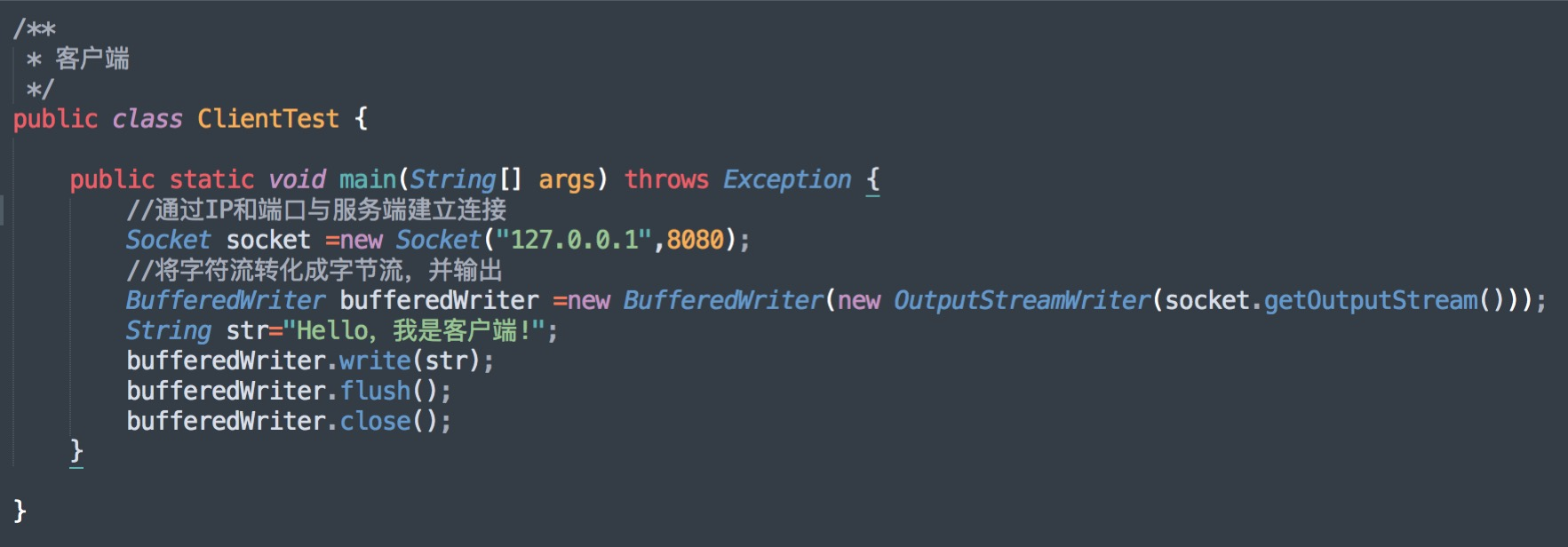
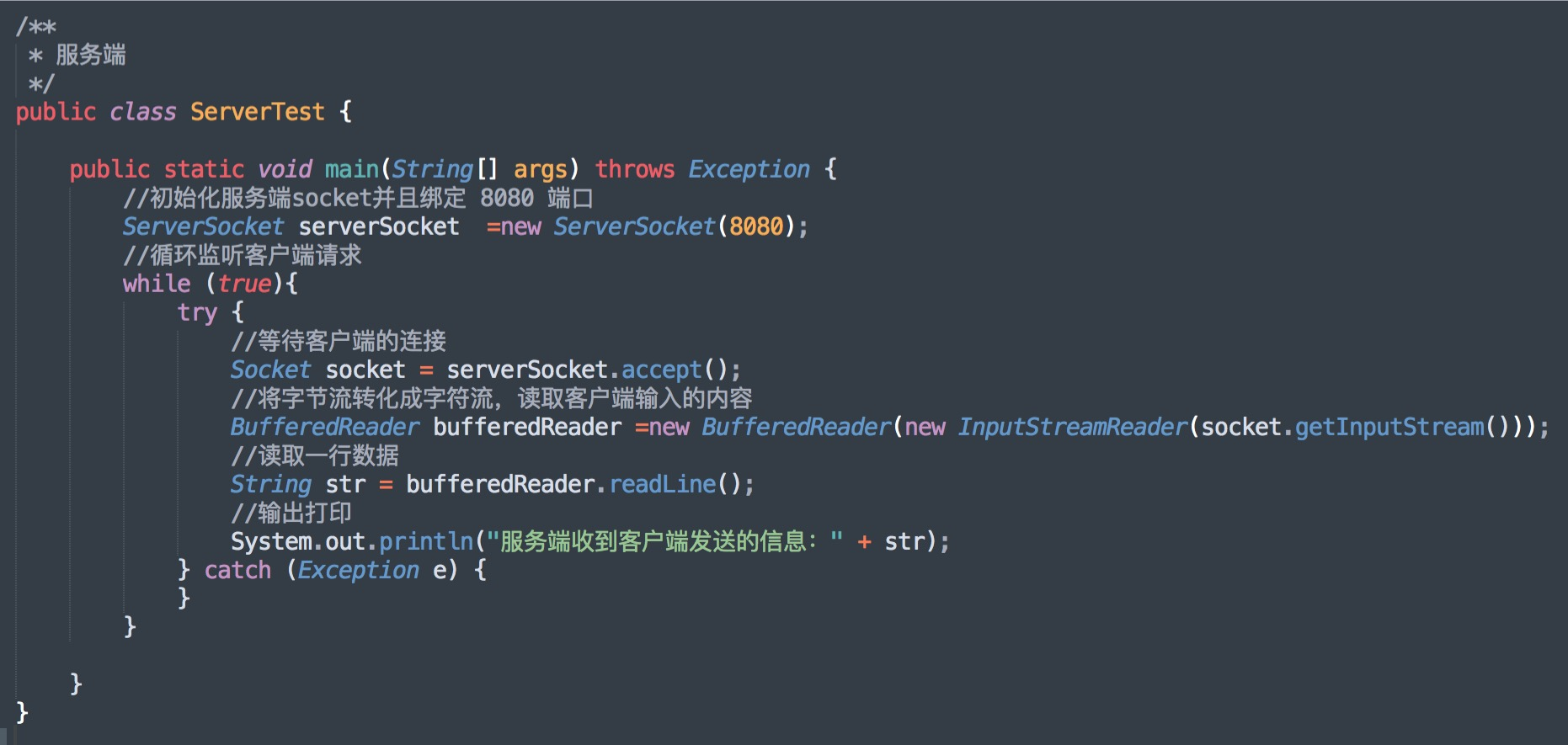
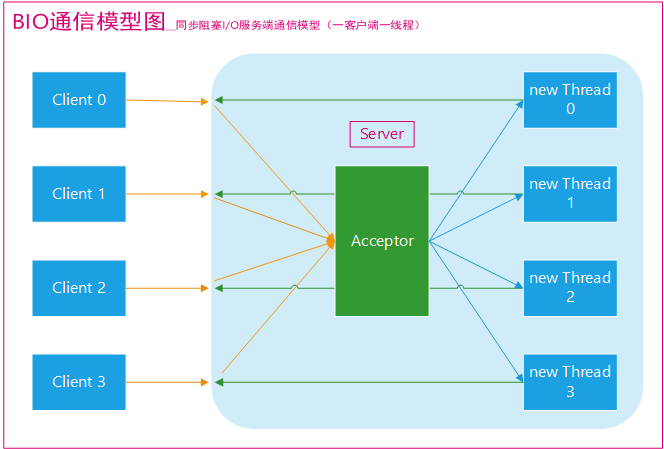
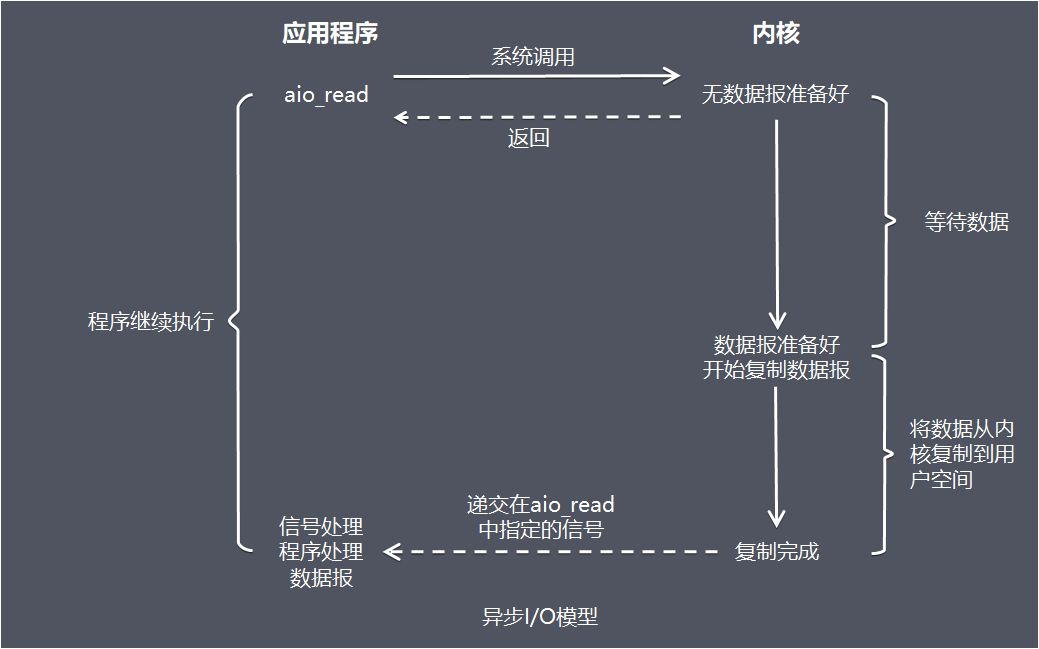
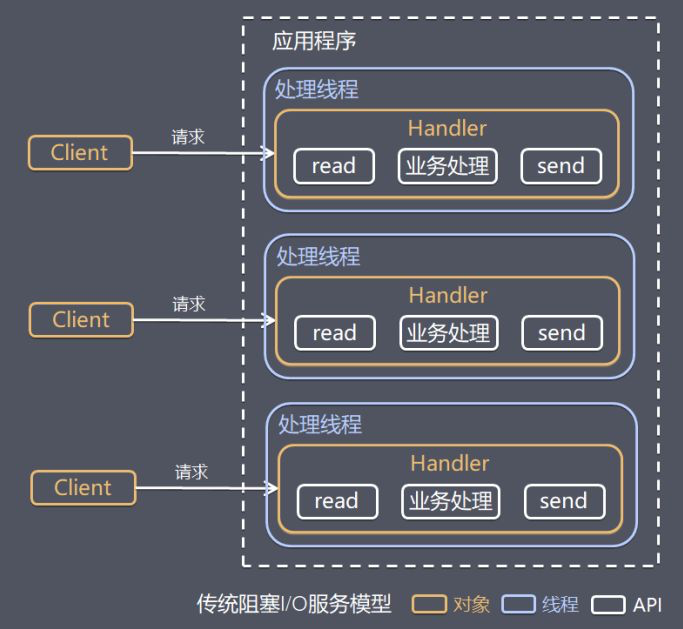
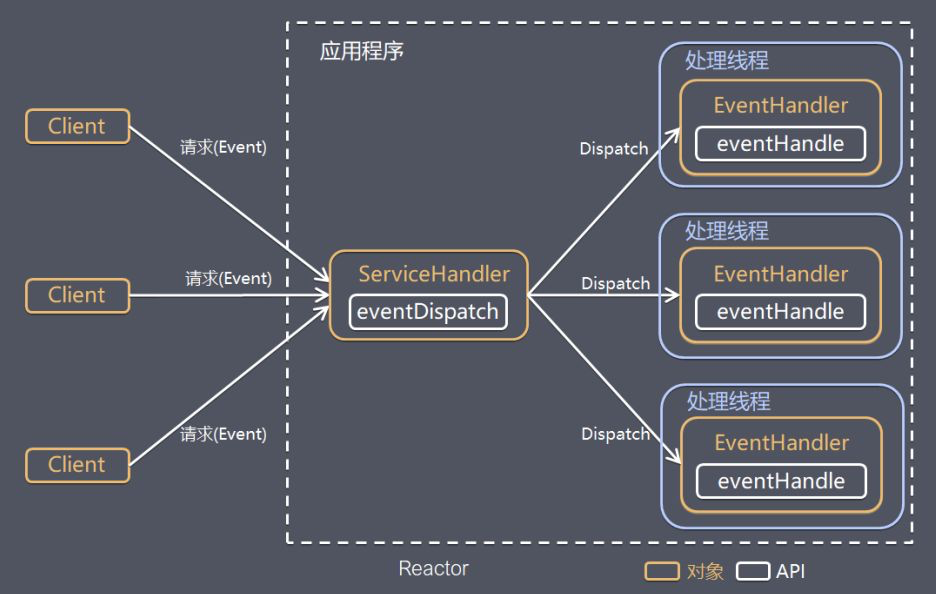
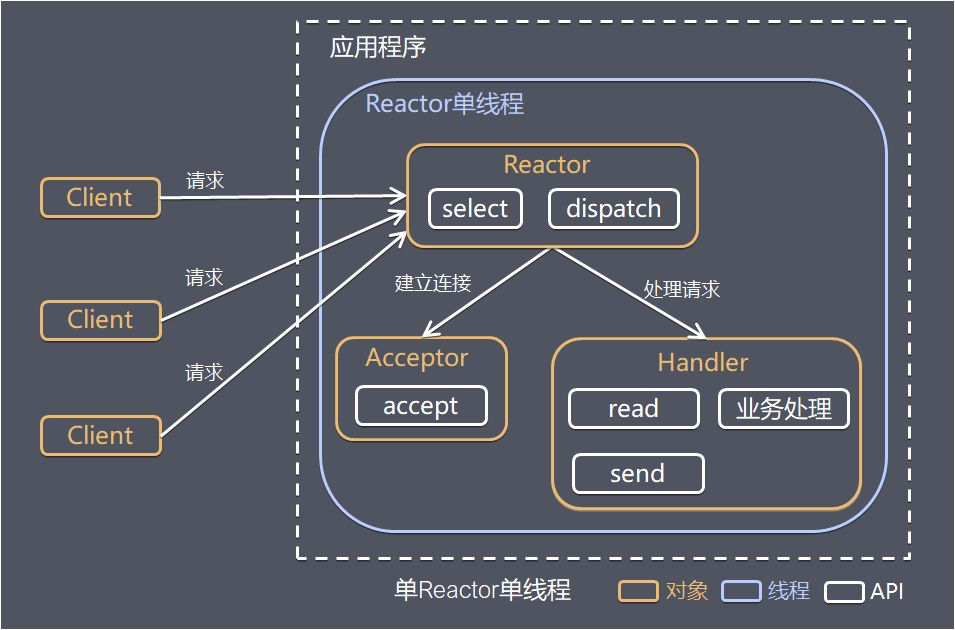
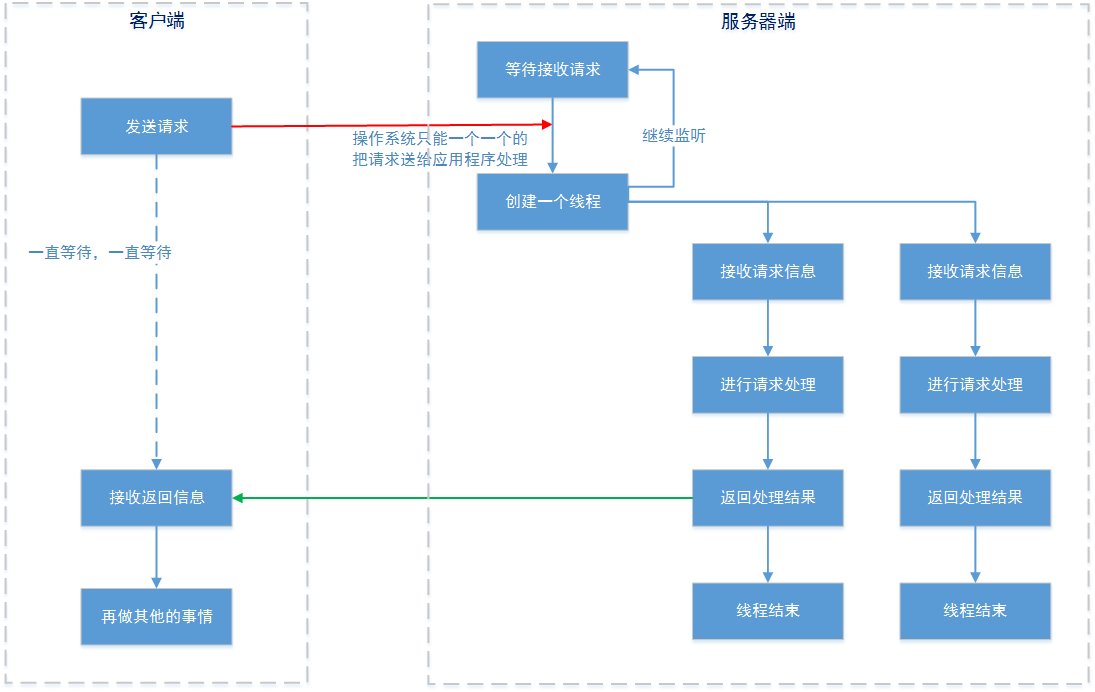
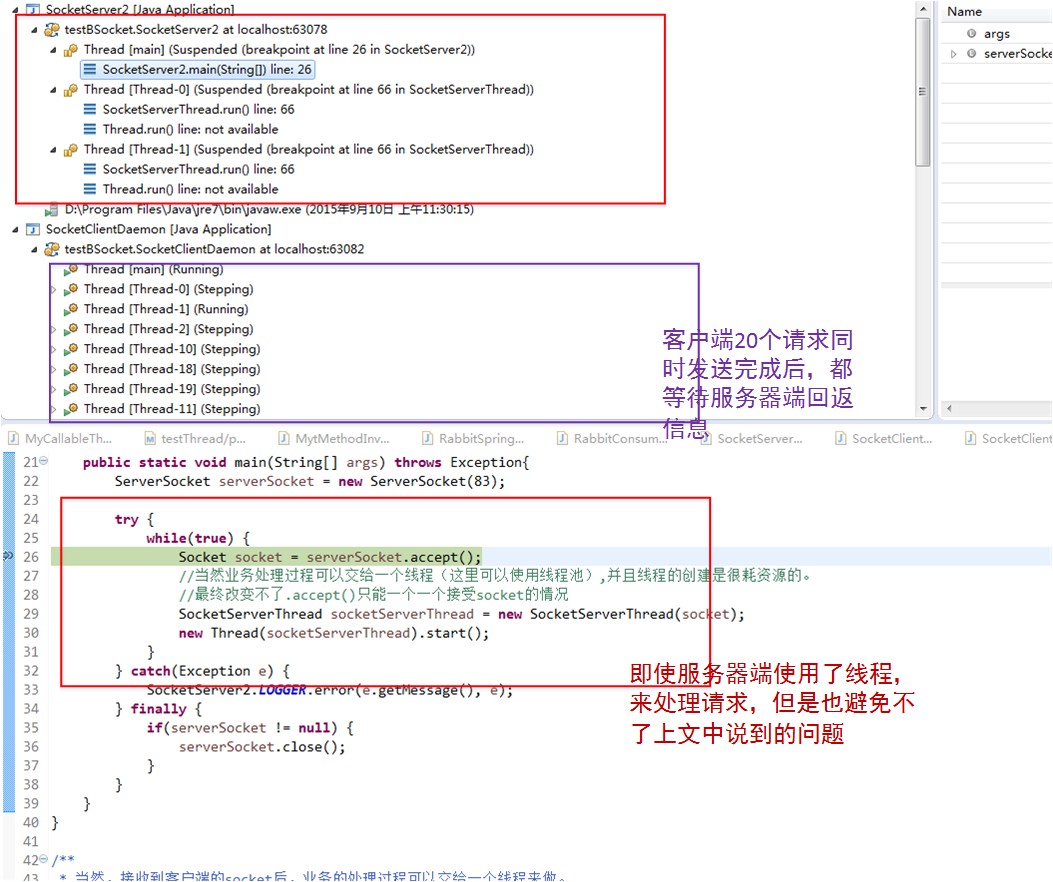
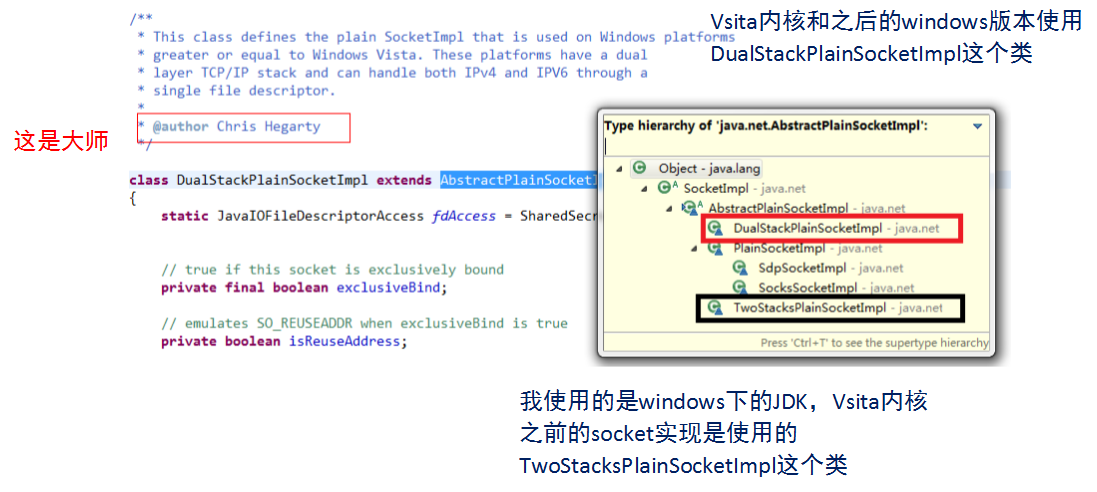
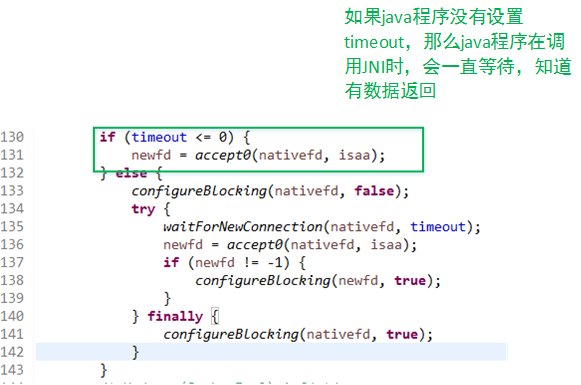
Java 编程
Java 9
接口私有方法
支持在接口内声明私有默认方法。
匿名内部类类型推断
List<Integer> numbers = new ArrayList<>() {
// ..
}
try-with-resources 新语法
BufferedReader br1 = new BufferedReader(...);
BufferedReader br2 = new BufferedReader(...);
try (br1; br2) {
System.out.println(br1.readLine() + br2.readLine());
}
弃用下划线标识符
int _ = 10; // Compile error
警告提升
私有方法支持 @SafeVarargs。
引入废弃类型时不再警告。
Java 11
本地变量类型推断
省略类型声明并不表示动态类型,而是更加智能的类型推断:
var greetingMessage = "Hello!";
var date = LocalDate.parse("2019-08-13");
var dayOfWeek = date.getDayOfWeek();
var dayOfMonth = date.getDayOfMonth();
Map<String, String> myMap = new HashMap<String, String>(); // Pre Java 7
Map<String, String> myMap = new HashMap<>(); // Using Diamond operator
Java 14
Switch 表达式
新的 switch 语句:
int numLetters = switch (day) {
case MONDAY, FRIDAY, SUNDAY -> 6;
case TUESDAY -> 7;
default -> {
String s = day.toString();
int result = s.length();
yield result;
}
};
可以只用作为表达式使用:
int k = 3;
System.out.println(
switch (k) {
case 1 -> "one";
case 2 -> "two";
default -> "many";
}
);
每个 case 都拥有自己的域:
String s = switch (k) {
case 1 -> {
String temp = "one";
yield temp;
}
case 2 -> {
String temp = "two";
yield temp;
}
default -> "many";
}
switch 的 case 必须详尽,这意味着 String、原始类型及其包装类型的 default 必须提供:
int k = 3;
String s = switch (k) {
case 1 -> "one";
case 2 -> "two";
default -> "many";
}
对于枚举来说,要么匹配所有子类,要么提供 default case:
enum Day {
MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY
}
Day day = Day.TUESDAY;
switch (day) {
case MONDAY -> ":(";
case TUESDAY, WEDNESDAY, THURSDAY -> ":|";
case FRIDAY -> ":)";
case SATURDAY, SUNDAY -> ":D";
}
Java 15
文本块
String html = """
<html>
<body>
<p>Hello, world</p>
</body>
</html>
""";
System.out.println(html);
每个换行尾部都会自动追加 \n 标识,如果在尾部显式添加一个 \ 字符,则表示不换行,但又增加了可读性:
String singleLine = """
Hello \
World
""";
额外缩进会被自动移除:
String indentedByToSpaces = """
First line
Second line
""";
String indentedByToSpaces = """
First line
Second line
""";
目前还不支持插值语法,但可以使用 formatted 方法:
var greeting = """
hello
%s
""".formatted("world");
NPE 更有意义
原有异常栈:
node.getElementsByTagName("name").item(0).getChildNodes().item(0).getNodeValue();
Exception in thread "main" java.lang.NullPointerException
at Unlucky.method(Unlucky.java:83)
新的异常栈:
Exception in thread "main" java.lang.NullPointerException:
Cannot invoke "org.w3c.dom.Node.getChildNodes()" because
the return value of "org.w3c.dom.NodeList.item(int)" is null
at Unlucky.method(Unlucky.java:83)
Java 16
Record 类
与 Scala 中 case class 类似。
用于声明一个不可变的数据类。
public record Point(int x, int y) { }
var point = new Point(1, 2);
point.x(); // returns 1
point.y(); // returns 2
该声明的含义如下:
- two
private final fields, int x and int y - a constructor that takes
x and y as a parameter x() and y() methods that act as getters for the fieldshashCode, equals and toString, each taking x and y into account
其限制如下:
- 不能含有任何非 final 字段
- 默认构造器需要包含所有字段,可以声明额外构造器以提供默认字段值
- 不能继承其他类
- 不能声明 native 方法
- 隐式 final,不能声明为 abstract
提供隐私无参构造器,也可以显式声明无参构造器以实现参数校验:
public record Point(int x, int y) {
public Point {
if (x < 0) {
throw new IllegalArgumentException("x can't be negative");
}
if (y < 0) {
y = 0;
}
}
}
声明额外构造器必须委托给其他构造器:
public record Point(int x, int y) {
public Point(int x) {
this(x, 0);
}
}
访问器可以被覆写,其他隐私的方法如 hashCode、equals、toString 也可以被覆写:
public record Point(int x, int y) {
@Override
public int x() {
return x;
}
}
能够声明静态或实例方法:
public record Point(int x, int y) {
static Point zero() {
return new Point(0, 0);
}
boolean isZero() {
return x == 0 && y == 0;
}
}
可以实现 Serializable 接口,且不需要提供 serialVersionUID:
public record Point(int x, int y) implements Serializable { }
public static void recordSerializationExample() throws Exception {
Point point = new Point(1, 2);
// Serialize
var oos = new ObjectOutputStream(new FileOutputStream("tmp"));
oos.writeObject(point);
// Deserialize
var ois = new ObjectInputStream(new FileInputStream("tmp"));
Point deserialized = (Point) ois.readObject();
}
可以直接在方法体内声明 Record 类:
public List<Product> findProductsWithMostSaving(List<Product> products) {
record ProductWithSaving(Product product, double savingInEur) {}
products.stream()
.map(p -> new ProductWithSaving(p, p.basePriceInEur * p.discountPercentage))
.sorted((p1, p2) -> Double.compare(p2.savingInEur, p1.savingInEur))
.map(ProductWithSaving::product)
.limit(5)
.collect(Collectors.toList());
}
模式匹配:instanceof
instanceof 语法支持自动 cast:
if (obj instanceof String s) {
// use s
}
新的 instanceof 检查与原来的逻辑类似,但如果检查总是通过,将会直接抛出错误:
// "old" instanceof, without pattern variable:
// compiles with a condition that is always true
Integer i = 1;
if (i instanceof Object) { ... } // works
// "new" instanceof, with the pattern variable:
// yields a compile error in this case
if (i instanceof Object o) { ... } // error
模式检查通过则提取出一个模式变量,该变量为常规的 non-final 变量类似:
- 可以被修改
- 覆盖字段声明
- 如果有相同名称的本地变量,则编译失败
模式变量可以直接用于后置的检查逻辑:
if (obj instanceof String s && s.length() > 5) {
// use s
}
模式变量的作用域也不仅限于检查内部:
private static int getLength(Object obj) {
if (!(obj instanceof String s)) {
throw new IllegalArgumentException();
}
// s is in scope - if the instanceof does not match
// the execution will not reach this statement
return s.length();
}
Java 17
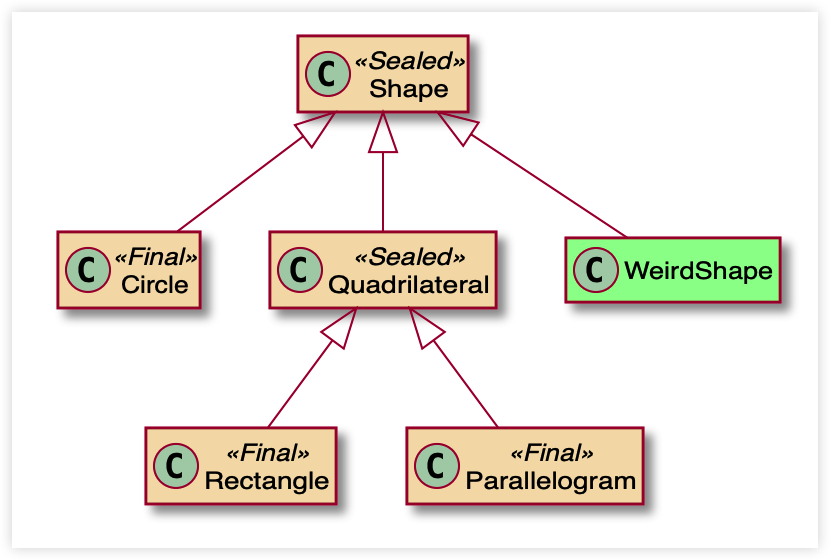
Sealed 类
与 Scala 中 sealed trait 类似。
用于声明一个边界清晰的抽象层级。Sealed 类的子类可以选择 3 种修饰符,以约束抽象边界:
- final:子类无法再被继承
- sealed:子类仅能被允许的类继承
- non-sealed:子类可以被自由继承
public sealed class Shape {
public final class Circle extends Shape {}
public sealed class Quadrilateral extends Shape {
public final class Rectangle extends Quadrilateral {}
public final class Parallelogram extends Quadrilateral {}
}
public non-sealed class WeirdShape extends Shape {}
}
替代 Enum
在支持 Sealed 类之前,只能在单个类文件内通过 Enum 建模固定类型,Sealed 则更加灵活,而且能够用于模式匹配。
Enum 类可以通过 values 方法遍历子类,而 Seaed 类的子类也可以通过 getPermittedSubclasses 来遍历。
模式匹配:switch
之前的 switch 表达式是有限的,仅能用于判定完全相等性,且仅支持有限的类型:数字、枚举、字符串。
该预览特性支持 switch 表达式走用于任意类型,以及更加复杂的匹配模式。
原来的模式:
var symbol = switch (expression) {
case ADDITION -> "+";
case SUBTRACTION -> "-";
case MULTIPLICATION -> "*";
case DIVISION -> "/";
};
增强后支持类型模式语法:
return switch (expression) {
case Addition expr -> "+";
case Subtraction expr -> "-";
case Multiplication expr -> "*";
case Division expr -> "/";
};
比如:
String formatted = switch (o) {
case Integer i && i > 10 -> String.format("a large Integer %d", i); // 引用了 i
case Integer i -> String.format("a small Integer %d", i);
default -> "something else";
};
同时支持 null 值,不再是抛出 NPE:
switch (s) {
case null -> System.out.println("Null");
case "Foo" -> System.out.println("Foo");
default -> System.out.println("Something else");
}
如果匹配语句没有包含所有可能的输入,编译器则会直接报错:
Object o = 1234;
// OK
String formatted = switch (o) {
case Integer i && i > 10 -> String.format("a large Integer %d", i);
case Integer i -> String.format("a small Integer %d", i);
default -> "something else";
};
// Compile error - 'switch' expression does not cover all possible input values
String formatted = switch (o) {
case Integer i && i > 10 -> String.format("a large Integer %d", i);
case Integer i -> String.format("a small Integer %d", i);
};
// Compile error - the second case is dominated by a preceding case label
String formatted = switch (o) {
case Integer i -> String.format("a small Integer %d", i);
case Integer i && i > 10 -> String.format("a large Integer %d", i);
default -> "something else";
};
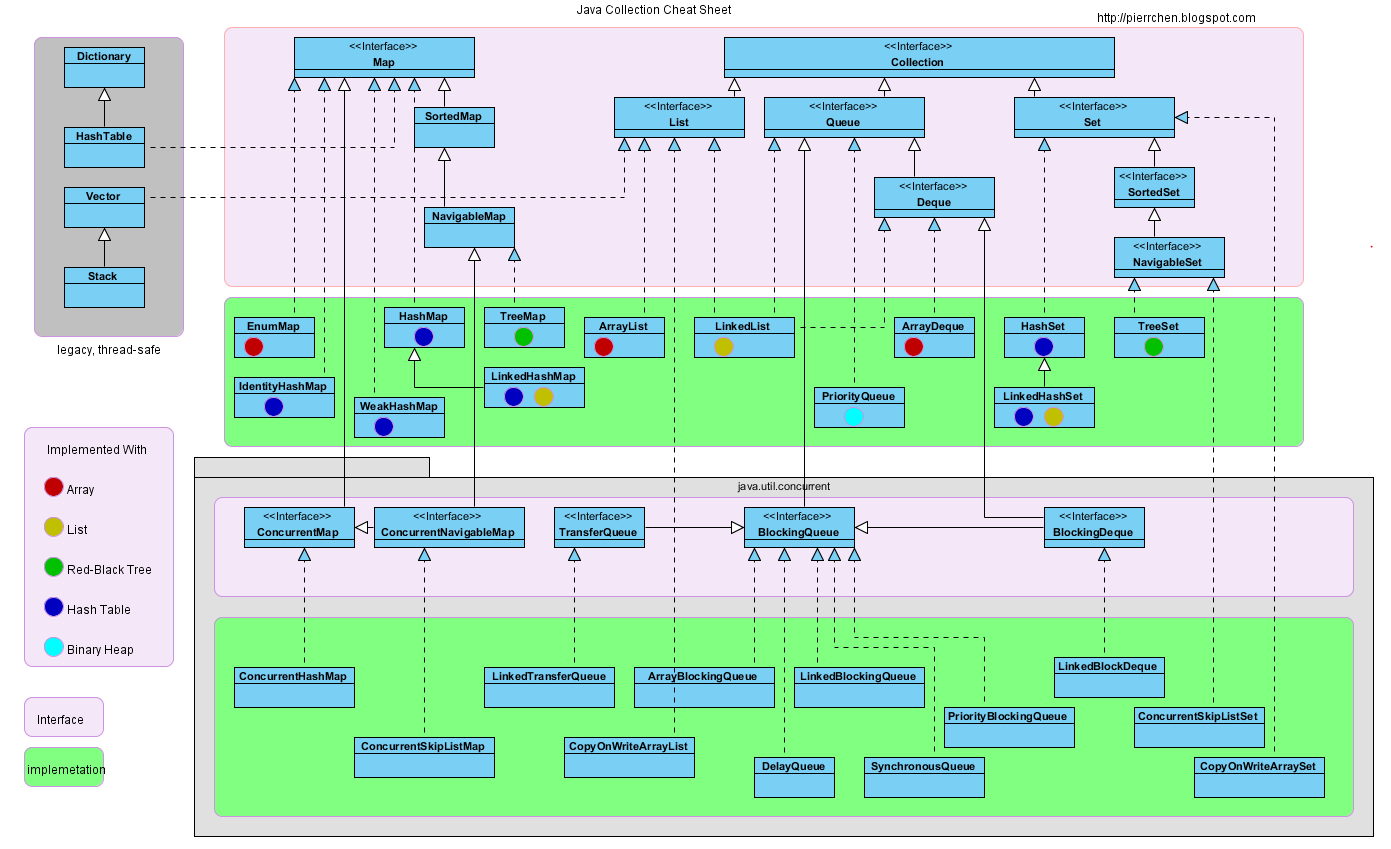
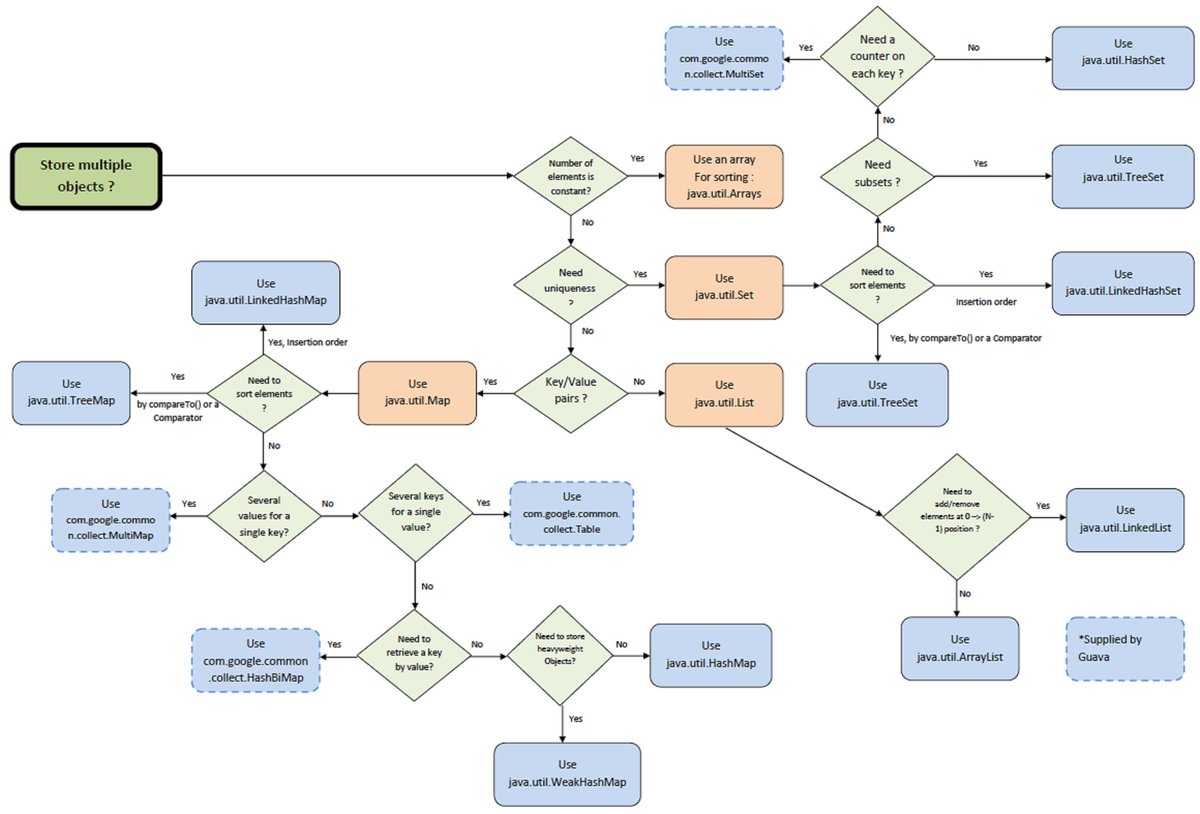
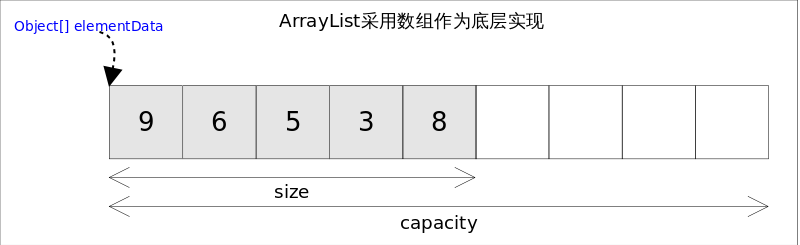
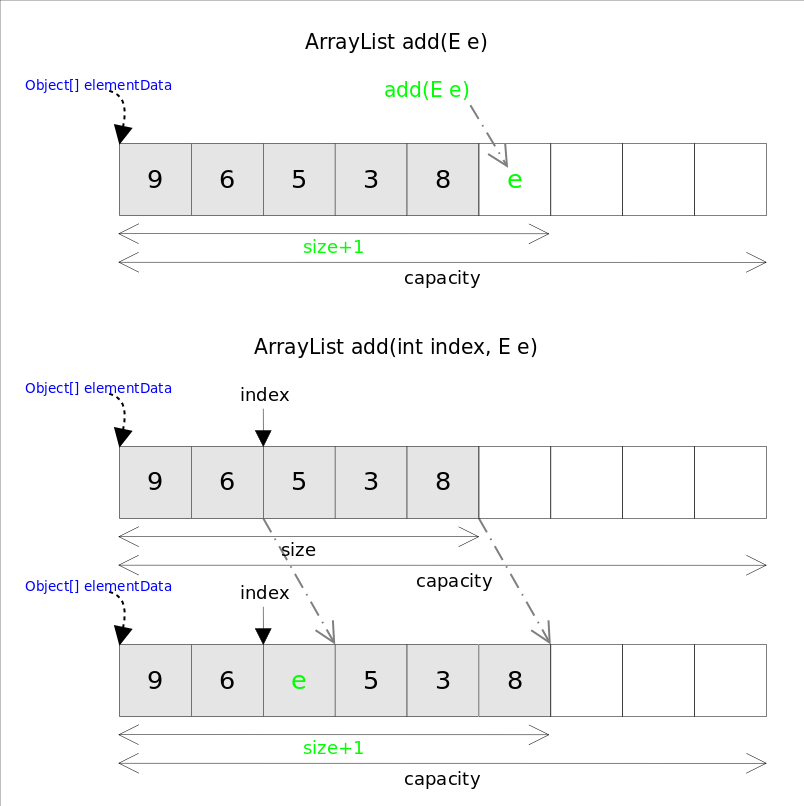
1 - Java 基础
1.1 - CH01-面向对象
三大特性
封装
利用抽象数据类型将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体。数据被保护在抽象数据类型的内部,尽可能的隐藏内部的细节,只保留一些对外接口使其与外部发生关系。用户无需知道对象内部的细节,但可以通过对象所提供的接口来访问对象。
优点:
- 减少耦合:可以独立的开发、测试、优化、使用、理解、修改
- 减少维护负担:可以更容易的被其他开发者理解,并且在调试的时候可以不影响其他模块
- 有效的调节性能:可以通过剖析确定哪些模块影响了系统的性能
- 提高软件的可重用性
- 降低了构建大型系统的风险:即使整个系统不可用,但是这些独立的模块却有可能是可用的
继承
继承实现了 IS-A 关系,比如 Cat 和 Animal 就是一种 IS-A 关系,因此 Cat 可以继承自 Animal,从而获得属于 Animal 的非私有的属性和方法。
继承应该遵循里氏替换原则,子类对象必须能够替换掉父类对象(可以直接将子类对象看做是父类对象)。
Cat 可以当做 Animal 来使用,也就是说可以使用 Animal 引用 Cat 对象。父类引用指向子类对象称为 向上转型。
多态
多态分为编译时多态和运行时多态:
- 编译时多态主要指方法的重载
- 运行时多态指程序中定义的对象引用所指向的具体类型在运行期才确定
运行时多态有三个条件:
类图
泛化关系
Java extend。
实现关系
Java implement。
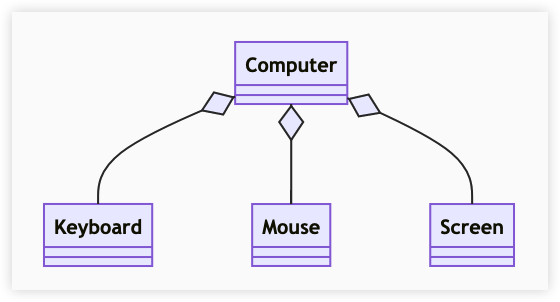
聚合关系
表示整体由部分组成,但是整体和部分不是强依赖,整体不存在了部分还会存在。
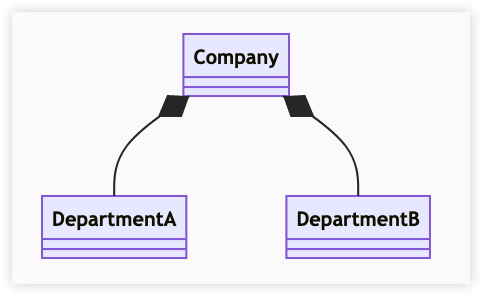
组合关系
和聚合不同,组合中整体和部分是强依赖的,整体不存在了部分也不存在了。比如公司和部门,公司没了部门就不存在了。
关联关系
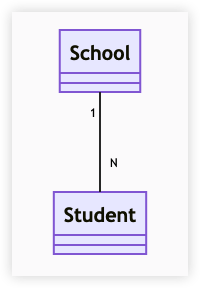
表示不同类对象之间有关联,这是一种静态关系,与运行过程的状态无关,在最开始就是可以确定的。因此也可以用一对一、一对多、多对一、多对多这种表述来表示。
比如学生和学校就是一种关联关系,一个学校可以有多个学生,但是一个学生只属于一个学校,因此这是一种多对一关系,在运行开始就能确定。
依赖关系
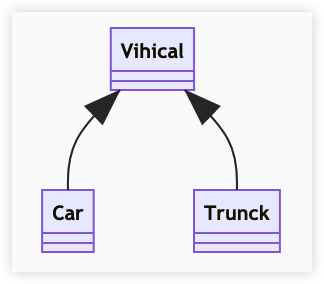
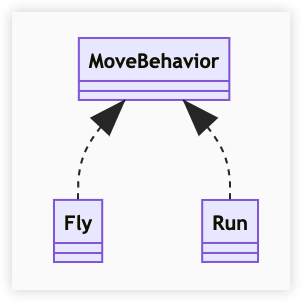
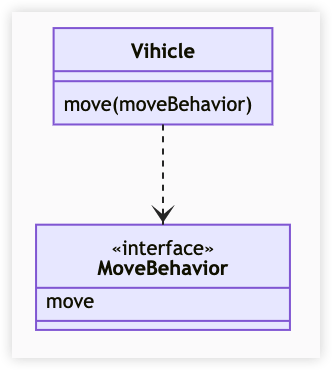
依赖关系是在运行中起作用的。A 类对 B 类的依赖关系主要有三种形式:
- A 类是 B 类中的局部变量
- A 类是 B 类方法中的参数
- A 类向 B 类发送消息,从而影响 B 类
Vihicle 的 move 方法接收一个 MoveBehavior 对象作为参数来实现移动逻辑,而 MoveBehavior 可能的实现是向上或向下移动。
参考资料
1.2 - CH02-基本知识
数据类型
包装类型
八个基本类型:
- boolean:1
- byte:8
- char:16
- short:16
- int:32
- float:32
- long:64
- double:64
基本类型都拥有对应的包装类型,它们之间的赋值使用自动装箱与拆箱完成:
Integer x=2; // 装箱
int y=x; // 拆箱
缓存池
new Integer(21) 与 Integer.valueOf(21) 的区别在于:
- 前者每次都会创建一个新的对象
- 后者会使用缓存池中的对象,多次调用会获得同一个对象的引用
Integer x = new Integer(21);
Integer y = new Integer(21);
System.out.println(x == y); // false
Integer m = Integer.valueOf(21);
Integer n = Integer.valueOf(21);
System.out.println(m == n); // true
valueOf() 方法的实现比较简单,它会先判断值是否在缓存池中,有则返回否则新建并返回。
public static Integer valueOf(int i) {
if(i >= IngegerCache.low && i <= Integer.high){
return IntegerCache[i + (-IngegerCache.low)];
}
return new Integer(i);
}
在 Java 8 中,Integer 缓存池的大小默认为 -128 至 127。
编译器会在缓冲池范围内的基本类型自动装箱过程中调用 valueOf 方法,因此多个取值相同的 Integer 实例在使用自动装箱来创建时,会引用相同的对象。
Integer m = 123;
Integer n = 123;
System.out.println(m == n); // true
基本类型对应的缓冲池如下:
boolean: true, false
all byte values
short values between -128 to 127
int values between -128 to 127
char in range \u0000 to \u007F
String
概览
String 被声明为 final,因此不可被继承。
其内部使用 char 数组存储数据,该数据也被声明为 final,表示该 value 数组初始化之后便不能再被修改。并且没有提供修改该数组的方法,因此可以保证 String 不可变。
不可变的好处
- 可以缓存哈希值
因为 String 的 hash 值经常被使用,比如 String 作为 HashMap 的 key。不可变使得其 hash 值也不会变,因此仅需计算一次。
- String Pool 的需要
如果一个 String 对象已经被创建过了,那么就会从 String Pool 中取得引用。只有 String 是不可变的,才可能使用 String Pool。
- 安全性
String 经常被作为参数类型,String 不可变性可以保证参数不可变。
- 线程安全
不可变特性天生具备线程安全性,可以在多个线程中并发使用。
Program Creek: Why String is immutable in Java?
String, StringBuffer, String Builder
- 可变性
- String 不可变
- StringBuffer、StringBuilder 可变
- 线程安全
- String 不可变,即线程安全
- StringBuilder 非线程安全
- StringBuffer 保证线程安全,内部使用 synchronized 实现同步
StackOverflow : String, StringBuffer, and StringBuilder
Stirng.intern()
使用 Stirng.intern() 可以保证相同内容的字符串变量引用同一个内存对象。
String s1 = new String("aaa");
String s2 = new String("aaa");
System.out.println(s1 == s2); // false
String s3 = s1.intern();
System.out.println(s1.intern() == s3); // true
如果直接使用 "bbb" 这种形式而非 new 来创建字符串实例,会自动将其放入 String Pool 中。
String s4 = "bbb";
String s5 = "bbb";
System.out.println(s4 == s5); // true
在 Java 7 之前,字符串常量池被放在运行时常量池中,属于永久代。在 Java 7 中,字符串常量池被移到 Native Method 中。这是因为永久代的空间有限,在大量使用字符串的场景下会导致 OOM。
运算
参数传递
Java 中的参数是以值传递的形式传入方法中,而不是引用传递。(这里的值值得是引用的地址值)
以下代码中,Dog dog 是一个指针,存储的是对象的地址值。在将一个参数传入一个方法时,本质上是将对象的地址以值的形式传递到形参中。因此在方法中改变指针引用的对象,那么这两个指针将指向不同的对象,一方改变自身指向的对象不会对另一方产生影响。
public class Dog {
String name;
Dog(String name) {
this.name = name;
}
String getName() {
return this.name;
}
void setName(String name) {
this.name = name;
}
String getObjectAddress() {
return super.toString();
}
}
public class PassByValueExample {
public static void main(String[] args) {
Dog dog = new Dog("A");
System.out.println(dog.getObjectAddress()); // Dog@4554617c
func(dog);
System.out.println(dog.getObjectAddress()); // Dog@4554617c
System.out.println(dog.getName()); // A
}
private static void func(Dog dog) {
System.out.println(dog.getObjectAddress()); // Dog@4554617c
dog = new Dog("B");
System.out.println(dog.getObjectAddress()); // Dog@74a14482
System.out.println(dog.getName()); // B
}
}
但是如果在方法中改变对象的字段值,则会改变原对象的字段值,因为改变的是同一个地址指向的内容。
class PassByValueExample {
public static void main(String[] args) {
Dog dog = new Dog("A");
func(dog);
System.out.println(dog.getName()); // B
}
private static void func(Dog dog) {
dog.setName("B");
}
}
StackOverflow: Is Java “pass-by-reference” or “pass-by-value”?
float 与 double
1.1 这样的字面量属于 double 类型,不能直接将其赋值给 float 变量,因为是向下转型。Java 不能隐式执行向下转型,因为会使得精度降低。
float f = 1.1; // error
float m = 1.1f; // right
隐式类型转换
因为字面量 1 是 int 类型,它比 short 类型精度要高,因此不能隐式的将 int 类型向下转型为 short 类型。
但是使用 += 运算可以执行隐式类型转换:
short s1 = 1;
// s1 = s1 + 1;
s1 += 1;
这其实相当于将 s1 + 1 的计算结果执行了向下转型:
StackOverflow : Why don’t Java’s +=, -=, *=, /= compound assignment operators require casting?
switch
从 Java 7 开始,可以在 switch 条件判断语句中使用 String 对象。
Switch 不支持 long,是因为 switch 的设计初衷是对那些只有极少数的几个值进行等值判断,如果值的范围过大,那么还是使用 if 比较合适。
Why can’t your switch statement data type be long, Java? - Stack Overflow
继承
访问权限
Java 中有三个访问权限修饰符:private、protected、public,如果不加访问修饰符,则表示 package 范围内可见。
可以对类或类中的成员(字段/方法)添加修饰符。
- 类可见表示其他类可以用这类来创建实例对象。(即通过类来引用成员)
- 成员可见表示其他类可以用这个类的实例对象访问到该成员。(即通过类实例来引用成员)
protected 用于修饰成员,表示在继承体系中成员对于子类可见,但是该修饰符对于类没有作用。
设计良好的模块会隐藏所有实现细节,将其 API 和实现细节清晰的隔离开来。模块之间仅通过他们的 API 进行通信,一个模块不需要知道其他模块内部的具体细节,这个概念被称为信息隐藏或封装。因此访问权限应当尽可能的使每个类或成员不被外界访问。
如果子类的方法重写了父类的方法,那么子类中该方法的访问级别不允许低于父类的访问级别。这是为了确保可以在使用父类实例的地方都能使用子类实例,即子类实例提供了父类应该具体的能力,即里氏替换原则。
字段决不能是 public,因为这么做就是去了对这个字段修改行为的控制,外部可以对其执行任意修改。
如果是 package 范围或私有的嵌套类,那么直接暴露成员不会有太大的影响。
抽象类与接口
- 抽象类
抽象类和抽象方法使用 abstract 关键字声明。抽象类一般会包含抽象方法,抽象方法一定位于抽象类中。
抽象类和普通类之间最大的区别是,抽象类不能被实例化,需要继承抽象类并实例化子类。
- 接口
接口是抽象类型的延伸,在 Java 8 之前,可以看做是一个完全抽象的类,即不能拥有任何实现方法。
从 Java 8 开始,接口也可以拥有默认的实现方法,这是因为不支持默认方法的接口的维护成本太高了。在此之前,如果一个接口想要添加新方法,那么要修改所有实现了该接口的类。
接口的成员都是 public 可见,并且不允许定义为 private 或 protected。
接口的字段默认都是 static final 的,即静态的。
- 比较
- 从设计层面看,抽象类提供了 IS-A 关系,那么就必须满足里氏替换原则,即子类对象必须能够替换所有父类对象。
- 接口更像是 LIKE-A 关系,它只是提供一种方法实现契约,并不要求接口和实现接口的类具有 IS-A 关系。
- 从使用上来看,一个类可以实现多个接口,但不能同时继承多个抽象类。
- 接口的字段只能是 static final,抽象类没有该限制。
- 即可的成员只能是 public 可见,而抽象类的成员可以有多种范围可见。
- 选择
使用接口:
- 需要让不相关的类都都实现一个方法,比如无关的类都可以实现 Comparable 接口中的 compareTo 方法。
- 需要使用多重继承。
使用抽象类:
- 需要在几个相关的类中共享代码。
- 需要能够控制继承的成员的访问权限,而非均为 public。
- 需要集成非静态和非常量字段。
在很多情况下,接口优先于抽象类,因为接口没有抽象类严格的类层次结构要求,可以灵活的为一个类添加行为。并且从 Java 8 开始,接口也可以有默认的实现方法,使得修改接口的成本降低。
super
- 访问父类的构造函数:从而委托父类完成一些初始化工作。
- 方位父类的成员:如果子类重写了父类的某个方法实现,则可以通过 super 来引用父类原有的方法实现。
Using the Keyword super (opens new window) (oracle.com)
重写与重载
- 重写(overwrite)
存在与继承体系中,子类实现了与父类在方法声明上完全相同的一个方法。
为了满足里氏替换原则,重写必须有以下两个限制:
- 子类方法的访问权限不能低于父类方法
- 子类方法的返回类型必须是父类方法返回类型的原类型或其子类型。
使用 @Overwrite 注解可以通过编译器来检查这两个限制是否满足。
- 重载(overload)
存在与同一个类中,指多个方法的名称相同,但是参数类型、个数、顺序至少有一个不同。
如果仅返回值不同,其他都相同,不能认为是重载。
Object 通用方法
public final native Class<?> getClass()
public native int hashCode()
public boolean equals(Object obj)
protected native Object clone() throws CloneNotSupportedException
public String toString()
public final native void notify()
public final native void notifyAll()
public final native void wait(long timeout) throws InterruptedException
public final void wait(long timeout, int nanos) throws InterruptedException
public final void wait() throws InterruptedException
protected void finalize() throws Throwable {}
equals
等价关系
- 自反性:
x.equals(x) 为 true - 对称性:
x.equals(y) == y.equals(x) 为 true - 传递性:
x.equals(y) && y.equals(z) 则 x.equals(z) 为 true - 一致性:多次调用 equals 方法的结果不会变化
- 与 null 比较:任何不为 null 的对象 x 调用
x.equals(null) 均为 false
equals 与 ==
- 对于基本类型,== 判断值是否相等,基本类型没有 equals 方法
- 对于引用类型,== 判断两变量的引用是否相等,而 equals 则判断引用的对象是否等价
实现
- 检查是否为同一个对象的引用,如果是则直接返回 true
- 检查是否为同一个类型,不同直接返回 false
- 将 Object 转型
- 判断每个关键域是否相等
public class EqualExample {
private int x;
private int y;
private int z;
public EqualExample(int x, int y, int z) {
this.x = x;
this.y = y;
this.z = z;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
EqualExample that = (EqualExample) o;
if (x != that.x) return false;
if (y != that.y) return false;
return z == that.z;
}
}
hashCode
hashCode 返回哈希值,而 equals 用于判断两个对象是否等价。等价的两个对象的哈希值也一定相等,但是哈希值相等的两个对象不一定等价。
在重写 equals 方法时应当总是重写 hashCode 以确保等价对象的哈希值也一定相等。
理想的哈希函数应该具有均匀性,不相等的对象应该均匀分布到所有可能的哈希值上。这就要求哈希函数能把所有域的值都考虑进来,可以将每个域都当做 R 进制的某一位,然后组成一个 R 进制的整数。R 一般取 31,因为它是一个奇素数,如果是偶数的话,当出现乘法溢出,信息就会丢失,因为与 2 相乘相当于左移一位。
一个数与 31 相乘可以转换成移位和减法操作:31*X == (X<<5)-X,编译器会自动执行该优化。
@Override
public int hashCode() {
int result = 17;
result = 31 * result + x;
result = 31 * result + y;
result = 31 * result + z;
return result;
}
toString
默认返回的是对象的内存地址,如 ToStringExample@4554617c,其中 @ 符号后面的值为散列码的无符号十六进制表示。
Clone
- cloneable
clone() 是 Object 对象的 protected 方法,并非 public,如果一个类不显式的重新 clone 方法,其他类就无法直接去调用该类实例的 clone 方法。
public class CloneExample {
private int a;
private int b;
@Override
protected CloneExample clone() throws CloneNotSupportedException {
return (CloneExample)super.clone();
}
}
CloneExample e1 = new CloneExample();
CloneExample e2 = e1.clone(); // will throw: CloneNotSupportedException
直接调用重写后的 clone 方法会抛出以上异常,这是因为 CloneExample 并未实现 Cloneable 接口。
注意,clone 并非 Cloneable 接口的方法,而是 Object 的一个 protected 方法。Cloneable 只是规定了:如果一个类没有实现 Cloneable 接口,直接调用 clone 方法时就会抛出该异常。
- 浅拷贝
拷贝对象和原始对象的引用类型引用同一个对象。
// 像上面一样实现 Cloneable 接口并重写 clone 方法
ShallowCloneExample e1 = new ShallowCloneExample();
ShallowCloneExample e2 = e1.clone();
e2.setValue(11);
assert e1.getValue() == 11; // true
- 深拷贝
拷贝对象和原始对象的引用类型引用不同对象。
public class DeepCloneExample implements Cloneable {
private int[] arr;
@Override
protected DeepCloneExample clone() throws CloneNotSupportException {
DeepCloneExample cloned = (DeepCloneExample) super.clone();
result.arr = new int[arr.length];
for(int i=0;i<arr.length;i++){
cloned.arr[i]=arr[i];
}
return cloned;
}
}
- clone 的替代方案
使用 clone 方法来拷贝对象既复杂又有风险,可能会抛出异常,并且还需要类型转换。可以基于 Effective Java 中的建议,通过拷贝构造函数或拷贝工厂来拷贝一个对象。
public class CloneConstructorExample {
private int[] arr;
public CloneConstructorExample() {
arr = new int[10];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
}
public CloneConstructorExample(CloneConstructorExample original) {
arr = new int[original.arr.length];
for (int i = 0; i < original.arr.length; i++) {
arr[i] = original.arr[i];
}
}
public void set(int index, int value) {
arr[index] = value;
}
public int get(int index) {
return arr[index];
}
}
关键字
final
- 变量
声明数据为常量,可以为编译时常量,也可以是在运行时被初始化后不能修改的常量。
- 对于基本类型,fianl 使数值不变
- 对于引用类型,final 使引用不变,即不能被重新赋值为别的对象,但是所引用对象的值可以被修改
- 方法
声明的方法不能被子类重写。
被 private 修饰的方法隐式的被指定为 fianl,如果在子类中定义的方法和基类中某个 private 方法签名一样,此时子类的方法并被重写基类方法,而是在子类中重新定义了一个新的方法。
- 类
声明类不能被继承。
static
- 静态变量
静态变量:又称为类变量,该变量属于类,而非该类的实例,类的所有实例都共享该变量,并通过类名来引用该变量,在内存中仅有一份。
实例变量:每创建一个实例就会产生一个实例变量,它与该实例同生共死。
- 静态方法
静态方法在类加载的时候就存在了,它不依赖于任何实例。所以静态方法必须要实现,也就是说他不能抽象方法。
只能访问所属类的静态字段(变量)和静态方法,方法中不能有 this 和 super 关键字。
- 静态语句块
静态语句块将在类初始化时执行一次。
- 静态内部类
非静态内部类属于外部类的实例,而静态内部类属于外部类本身,通过外部类来引用该静态内部类。
- 静态导包
通过静态导包,可以在使用静态变量和方法时不用再逐个指明 ClassName,可一件简化代码:
import static com.xxx.ClassName.*;
- 初始化顺序
静态变量和语句块优先于实例变量和普通语句块,它们的顺序由代码中的编写顺序决定。然后才是构造函数。
存在集成的情况下,初始化顺序为:
- 父类(静态变量、静态语句块)
- 子类(静态变量、静态语句块)
- 父类(实例变量、普通语句块)
- 父类(构造函数)
- 子类(实例变量、普通语句块)
- 子类(构造函数)
反射
每个类都有一个 Class 对象,包含了与类有关的信息。当编译一个新类时,会产生一个同名的 class 文件,该文件内存保存着 Class 对象。
类加载相当于 Class 对象的加载。类在第一次使用时才会动态加载到 JVM 中,或者使用 Class.forName(...) 主动加载一个类,该方法会返回一个 Class 对象。
反射可以在运行时提供类的信息,并且该类可以在运行时才被加载进来,甚至在编译期该类的 class 尚不存在。
Class 和 java.lang.reflect 一起为反射提供了支持,java.lang.reflect 类库主要包括以下三个类:
- Field:可以使用 get 和 set 方法读取或修改 Field 对象关联的字段。
- Method:可以使用 invoke 方法滴啊用与 Method 对象关联的方法。
- Constructor:可以使用 Constructor 创建新的对象。
高级用法:
Extensibility Features : An application may make use of external, user-defined classes by creating instances of extensibility objects using their fully-qualified names.
Class Browsers and Visual Development Environments : A class browser needs to be able to enumerate the members of classes. Visual development environments can benefit from making use of type information available in reflection to aid the developer in writing correct code.
Debuggers and Test Tools : Debuggers need to be able to examine private members on classes. Test harnesses can make use of reflection to systematically call a discoverable set APIs defined on a class, to insure a high level of code coverage in a test suite.
反射的缺点:
反射虽然强大但不应被直接使用。如果能够在不使用反射的情况下完成操作,则应避免使用反射。使用反射时应注意以下几点:
- Performance Overhead : Because reflection involves types that are dynamically resolved, certain Java virtual machine optimizations can not be performed. Consequently, reflective operations have slower performance than their non-reflective counterparts, and should be avoided in sections of code which are called frequently in performance-sensitive applications.
- Security Restrictions : Reflection requires a runtime permission which may not be present when running under a security manager. This is in an important consideration for code which has to run in a restricted security context, such as in an Applet.
- Exposure of Internals :Since reflection allows code to perform operations that would be illegal in non-reflective code, such as accessing private fields and methods, the use of reflection can result in unexpected side-effects, which may render code dysfunctional and may destroy portability. Reflective code breaks abstractions and therefore may change behavior with upgrades of the platform.
异常
Throwable 可以用来表示任何可以作为异常抛出的类,分为两种:Error 和 Exception。其中 Error 用来表示 JVM 无法处理的错误,Exception 分为两种:
- 受检异常:需要 try…catch 语句捕获并进行处理,并且可以从异常中恢复。
- 非受检异常:程序运行时错误,比如除零操作会引起 ArithmeticException,这时程序崩溃且无法恢复。
泛型
注解
Java 注解是附加在代码中的一些元信息,用于一些工具在编译期、运行时执行解析并使用,起到说明、配置的功能。注解不会也不应该影响代码的实际逻辑,仅仅起到辅助性的作用。
特性
版本特性
Java 8
- Lambda Expressions
- Pipelines and Streams
- Date and Time API
- Default Methods
- Type Annotations
- Nashhorn JavaScript Engine
- Concurrent Accumulators
- Parallel operations
- PermGen Error Removed
Java 7
Strings in Switch Statement
Type Inference for Generic Instance Creation
Multiple Exception Handling
Support for Dynamic Languages
Try with Resources
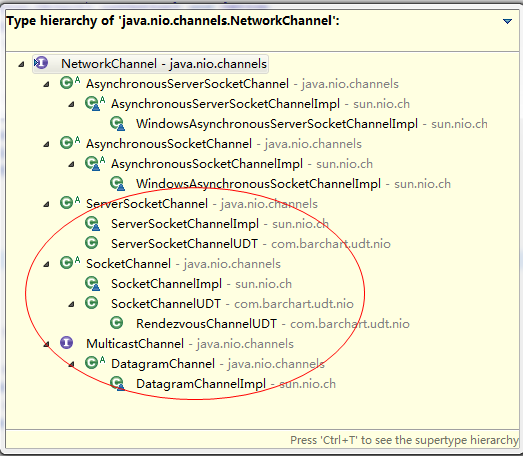
Java nio Package
Binary Literals, Underscore in literals
Diamond Syntax
与 C++
- Java 是纯粹的面向对象语言,所有的对象都继承自 Object,C++ 为了兼容 C 同时支持面向对象和面向过程。
- Java 通过虚拟机实现跨平台特性,但是 C++ 依赖于特定的平台。
- Java 没有指针,其引用可以理解为安全指针,而 C++ 具有与 C 一样的指针。
- Java 支持自动垃圾回收,而 C++ 需要手动回收。
- Java 不支持多重继承,只能通过实现多个接口到达相同的目的,而 C++ 支持多重继承。
- Java 不支持操作符重载,虽然可以对两个 String 对象执行加法运算,但是是语言内置的操作,不属于操作符重载,而 C++ 可以。
- Java 的 goto 是保留字,不可以使用,C++ 可以使用。
- Java 不支持条件编译,C++ 通过
#ifdef #ifndef 等预处理制冷可以实现条件编译。
JRE 与 JDK
- JRE 是 JVM 程序,Java 应用需要运行在 JRE 之上。
- JDK 是 JRE 的超集,带有 JRE 和用于编写 Java 程序的工具,比如 javac。
参考资料
1.3 - CH03-基本图谱
概述
- 术语
- JDK:Java 开发者工具,Java Developer’s Kit
- JRE:Java 运行时环境,Java Runtime Environment
- JVM:Java 虚拟机,Java Vitual Machine
- API:应用程序编程接口,Application Programming Interface
- IDE
- 程序构造块
- package
- import
- class
- main
- 大括号
- 语句
- 注释
- 工作方式
- 先编译后执行
- Java 扩平台的根本
- 编译生成中间代码
- JVM 加载执行中间代码
语言核心
语言元素
- 关键字:有特殊含义的单词
- 标识符
- 字符、数字、下划线、
$ - 不能以数字开头
- 不能有
!等特殊字符 - 不能是关键字
- 大小写敏感
- 驼峰风格
- 运算符
- 赋值:
= - 算术:
+,-,*,/,% - 关系:
>,<,>=,<=,!=,== - 短路:
&&,|| - 三目:
..?..:.. - 逻辑:
&,|,! - 自增/减运:
++,-- - 下标运:
[] - 类型运:
(ClassName) - 其他:
- 字面量:
- 整形:122
- 实数:3.14,2.1E-3
- 字符:
'a' - 字符串:
"b" - 布尔:true
- 引用:null
- 类型:
int.class, String.class
- 分隔符
变量/常量
数据类型
- 基本类型:
- byte-1
- short-2
- int-4
- long-8
- float-4
- double-8
- boolean
- char-2
- 枚举类型:符号常量
- 引用类型:对象
字符串
- 创建
String str = new String("abc")String str = "abc";
- 操作
数组
- 一维数组:
int[] a = [1,2,3] - 二维数组:
int[][] a = [[1,2,3],[4,5,6]]
循环
分支
FAQ
使用哪种数据类型表示价格
如果不是特别关心内存和性能的话,使用BigDecimal,否则使用预定义精度的 double 类型。
怎么将 byte 转换为 String
可以使用 String 接收 byte[] 参数的构造器来进行转换,需要注意的点是要使用的正确的编码,否则会使用平台默认编码,这个编码可能跟原来的编码相同,也可能不同。
Java 中怎样将 bytes 转换为 long 类型
String接收bytes的构造器转成String,再 Long.parseLong。
我们能将 int 强制转换为 byte 类型的变量吗
是的,我们可以做强制转换,但是 Java 中 int 是 32 位的,而 byte 是 8 位的,所以,如果强制转化是,int 类型的高 24 位将会被丢弃,byte 类型的范围是从 -128 到 127。
存在两个类,B 继承 A,C 继承 B,我们能将 B 转换为 C 么? 如 C = (C) B
可以,向下转型。但是不建议使用,容易出现类型转型异常.
哪个类包含 clone 方法? 是 Cloneable 还是 Object?
java.lang.Cloneable 是一个标示性接口,不包含任何方法,clone 方法在 object 类中定义。并且需要知道 clone() 方法是一个本地方法,这意味着它是由 c 或 c++ 或 其他本地语言实现的。
Java 中 ++ 操作符是线程安全的吗?
不是线程安全的操作。它涉及到多个指令,如读取变量值,增加,然后存储回内存,这个过程可能会出现多个线程交差。还会存在竞态条件(读取-修改-写入)。
a = a + b 与 a += b 的区别
+= 隐式的将加操作的结果类型强制转换为持有结果的类型。如果两这个整型相加,如 byte、short 或者 int,首先会将它们提升到 int 类型,然后在执行加法操作。
我能在不进行强制转换的情况下将一个 double 值赋值给 long 类型的变量吗?
不行,你不能在没有强制类型转换的前提下将一个 double 值赋值给 long 类型的变量,因为 double 类型的范围比 long 类型更广,所以必须要进行强制转换。
3*0.1 == 0.3 将会返回什么? true 还是 false?
false,因为有些浮点数不能完全精确的表示出来。
int 和 Integer 哪个会占用更多的内存?
Integer 对象会占用更多的内存。Integer 是一个对象,需要存储对象的元数据。但是 int 是一个原始类型的数据,所以占用的空间更少。
为什么 Java 中的 String 是不可变的(Immutable)?
Java 中的 String 不可变是因为 Java 的设计者认为字符串使用非常频繁,将字符串设置为不可变可以允许多个客户端之间共享相同的字符串。更详细的内容参见答案。
我们能在 Switch 中使用 String 吗?
从 Java 7 开始,我们可以在 switch case 中使用字符串,但这仅仅是一个语法糖。内部实现在 switch 中使用字符串的 hash code。
Java 中的构造器链是什么?
当你从一个构造器中调用另一个构造器,就是Java 中的构造器链。这种情况只在重载了类的构造器的时候才会出现。
枚举类
JDK1.5出现 每个枚举值都需要调用一次构造函数
什么是不可变对象(immutable object)? Java 中怎么创建一个不可变对象?
不可变对象指对象一旦被创建,状态就不能再改变。任何修改都会创建一个新的对象,如 String、Integer及其它包装类。
- 对象的状态在创建之后就不能发生改变,任何对它的改变都应该产生一个新的对象。
- 类的所有的属性都应该是final的。
- 对象必须被正确的创建,比如: 对象引用在对象创建过程中不能泄露(leak)。
- 对象应该是final的,以此来限制子类继承父类,以避免子类改变了父类的immutable特性。
- 如果类中包含mutable类对象,那么返回给客户端的时候,返回该对象的一个拷贝,而不是该对象本身(该条可以归为第一条中的一个特例)
我们能创建一个包含可变对象的不可变对象吗?
是的,我们是可以创建一个包含可变对象的不可变对象的,你只需要谨慎一点,不要共享可变对象的引用就可以了,如果需要变化时,就返回原对象的一个拷贝。最常见的例子就是对象中包含一个日期对象的引用。
有没有可能两个不相等的对象有有相同的 hashcode?
有可能,两个不相等的对象可能会有相同的 hashcode 值,这就是为什么在 hashmap 中会有冲突。相等 hashcode 值的规定只是说如果两个对象相等,必须有相同的hashcode 值,但是没有关于不相等对象的任何规定。
两个相同的对象会有不同的的 hash code 吗?
不能,根据 hash code 的规定,这是不可能的。
我们可以在 hashcode() 中使用随机数字吗?
不行,因为对象的 hashcode 值必须是相同的。
Java 中,Comparator 与 Comparable 有什么不同?
Comparable 接口用于定义对象的自然顺序,而 comparator 通常用于定义用户定制的顺序。Comparable 总是只有一个,但是可以有多个 comparator 来定义对象的顺序。
为什么在重写 equals 方法的时候需要重写 hashCode 方法?
因为有强制的规范指定需要同时重写 hashcode 与 equal 是方法,许多容器类,如 HashMap、HashSet 都依赖于 hashcode 与 equals 的规定。
“a==b”和”a.equals(b)”有什么区别?
如果 a 和 b 都是对象,则 a==b 是比较两个对象的引用,只有当 a 和 b 指向的是堆中的同一个对象才会返回 true,而 a.equals(b) 是进行逻辑比较,所以通常需要重写该方法来提供逻辑一致性的比较。例如,String 类重写 equals() 方法,所以可以用于两个不同对象,但是包含的字母相同的比较。
a.hashCode() 有什么用? 与 a.equals(b) 有什么关系?
hashCode() 方法是相应对象整型的 hash 值。它常用于基于 hash 的集合类,如 Hashtable、HashMap、LinkedHashMap等等。
它与 equals() 方法关系特别紧密。根据 Java 规范,两个使用 equal() 方法来判断相等的对象,必须具有相同的 hash code。
final、finalize 和 finally 的不同之处?
- final 是一个修饰符,可以修饰变量、方法和类。如果 final 修饰变量,意味着该变量的值在初始化后不能被改变。
- Java 技术允许使用 finalize() 方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。这个方法是由垃圾收集器在确定这个对象没有被引用时对这个对象调用的,但是什么时候调用 finalize 没有保证。
- finally 是一个关键字,与 try 和 catch 一起用于异常的处理。finally 块一定会被执行,无论在 try 块中是否有发生异常。
Java 中的编译期常量是什么? 使用它又什么风险?
变量也就是我们所说的编译期常量,这里的 public 可选的。实际上这些变量在编译时会被替换掉,因为编译器知道这些变量的值,并且知道这些变量在运行时不能改变。这种方式存在的一个问题是你使用了一个内部的或第三方库中的公有编译时常量,但是这个值后面被其他人改变了,但是你的客户端仍然在使用老的值,甚至你已经部署了一个新的jar。为了避免这种情况,当你在更新依赖 JAR 文件时,确保重新编译你的程序。
静态内部类与顶级类有什么区别?
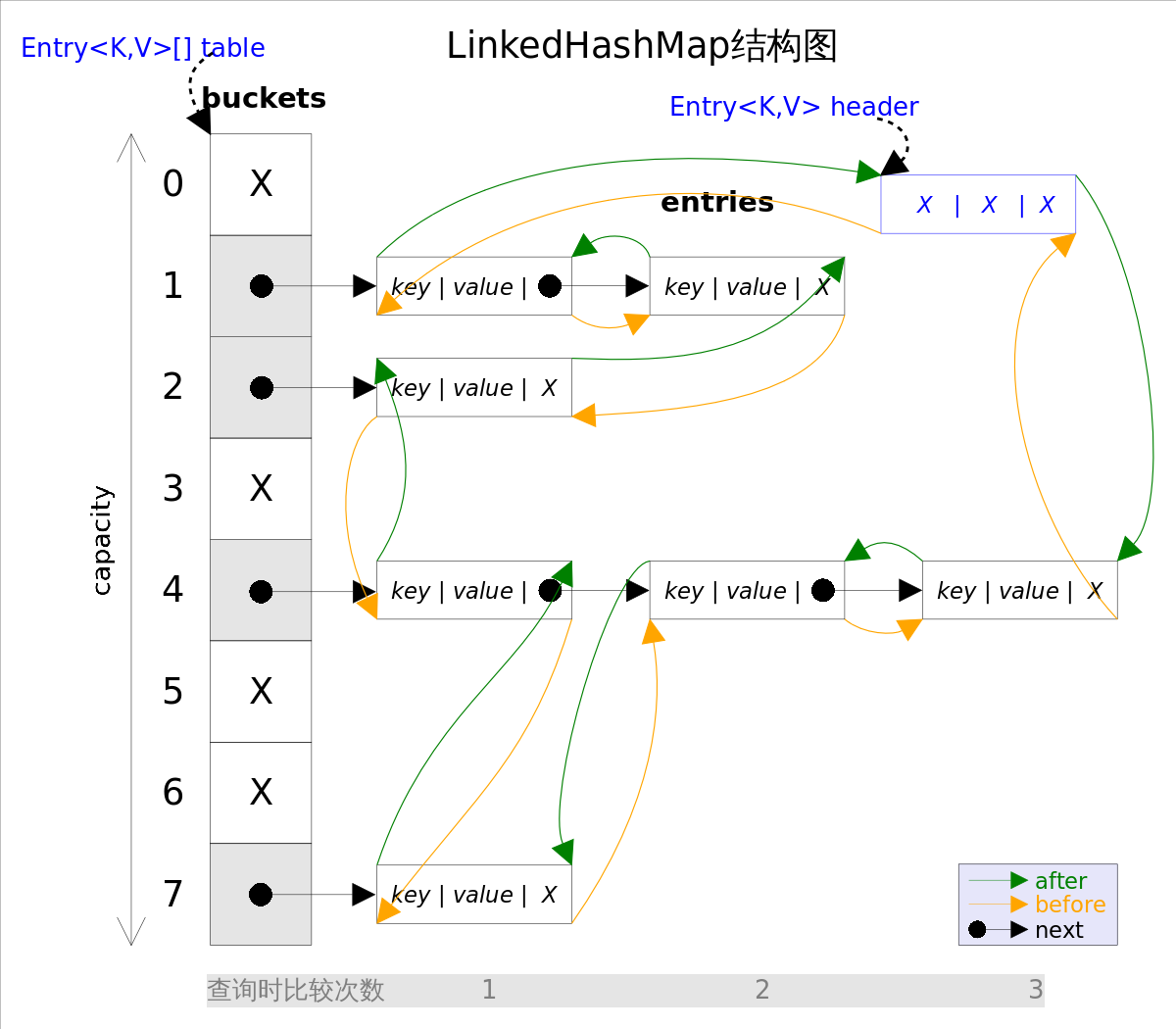
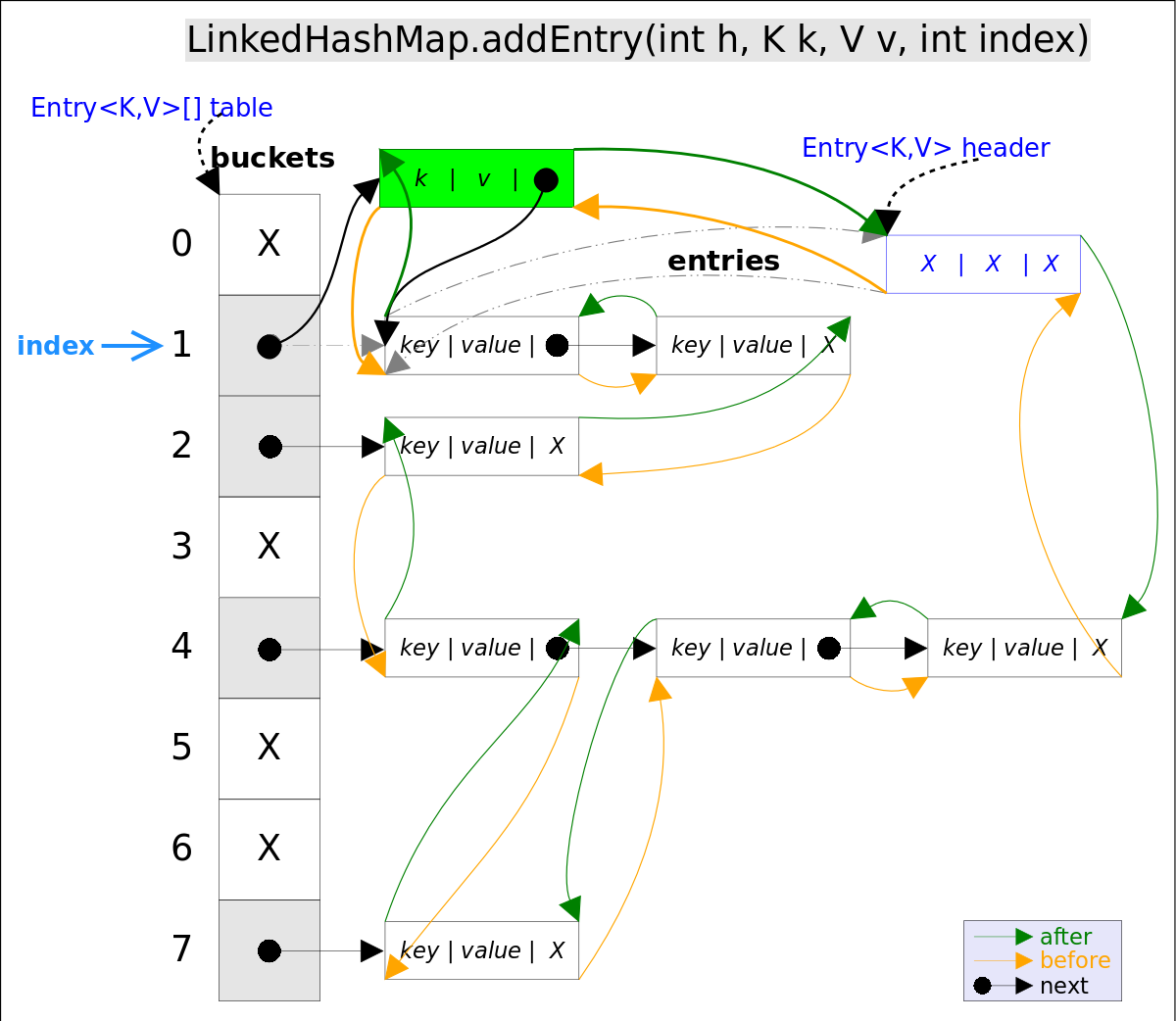
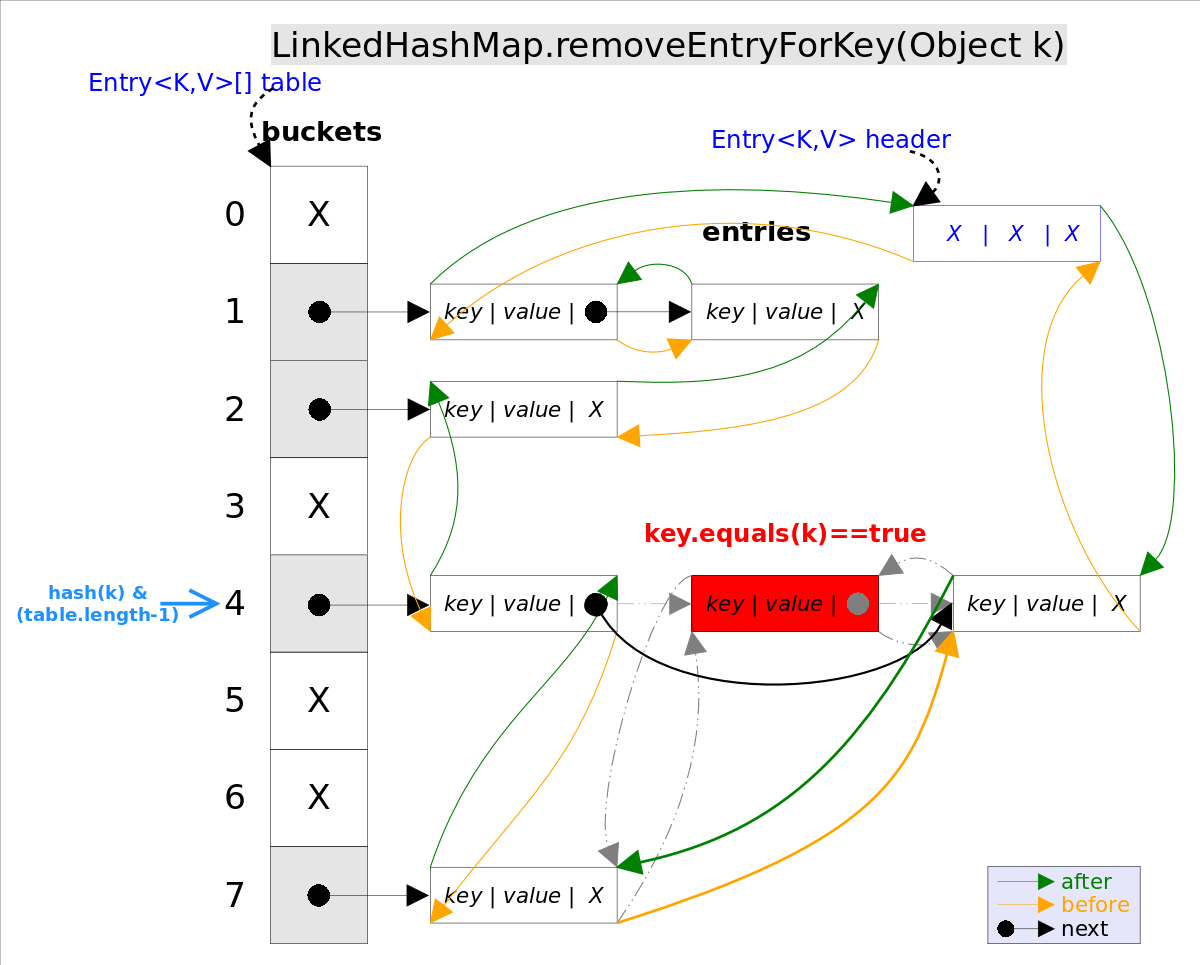
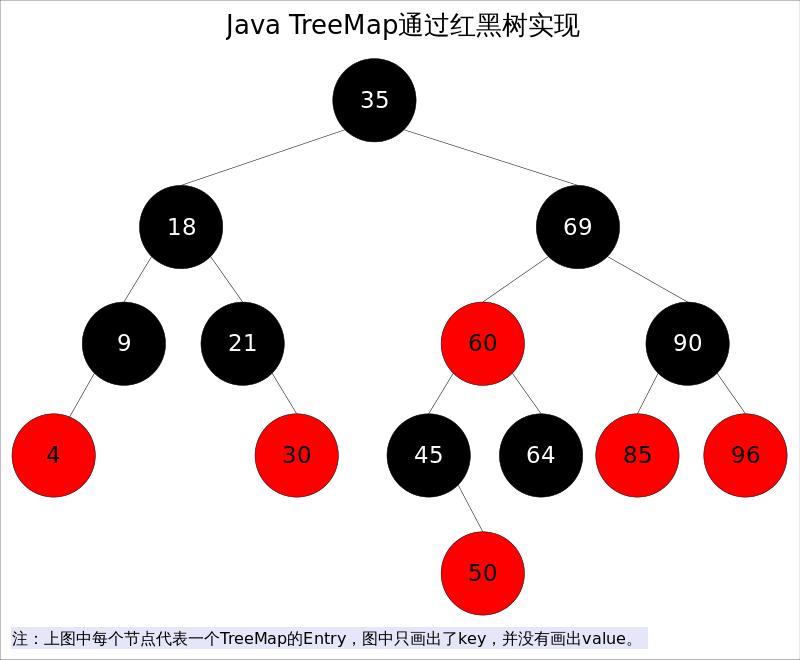
一个公共的顶级类的源文件名称与类名相同,而嵌套静态类没有这个要求。一个嵌套类位于顶级类内部,需要使用顶级类的名称来引用嵌套静态类,如 HashMap.Entry 是一个嵌套静态类,HashMap 是一个顶级类,Entry是一个嵌套静态类。
Java 中,Serializable 与 Externalizable 的区别?
Serializable 接口是一个序列化 Java 类的接口,以便于它们可以在网络上传输或者可以将它们的状态保存在磁盘上,是 JVM 内嵌的默认序列化方式,成本高、脆弱而且不安全。Externalizable 允许你控制整个序列化过程,指定特定的二进制格式,增加安全机制。
说出 JDK 1.7 中的三个新特性?
虽然 JDK 1.7 不像 JDK 5 和 8 一样的大版本,但是,还是有很多新的特性,如 try-with-resource 语句,这样你在使用流或者资源的时候,就不需要手动关闭,Java 会自动关闭。Fork-Join 池某种程度上实现 Java 版的 Map-reduce。允许 Switch 中有 String 变量和文本。菱形操作符(<>)用于泛型推断,不再需要在变量声明的右边申明泛型,因此可以写出可读写更强、更简洁的代码。另一个值得一提的特性是改善异常处理,如允许在同一个 catch 块中捕获多个异常。
说出 5 个 JDK 1.8 引入的新特性?
Java 8 在 Java 历史上是一个开创新的版本,下面 JDK 8 中 5 个主要的特性: Lambda 表达式,允许像对象一样传递匿名函数 Stream API,充分利用现代多核 CPU,可以写出很简洁的代码 Date 与 Time API,最终,有一个稳定、简单的日期和时间库可供你使用 扩展方法,现在,接口中可以有静态、默认方法。 重复注解,现在你可以将相同的注解在同一类型上使用多次。
下述包含 Java 面试过程中关于 SOLID 的设计原则,OOP 基础,如类,对象,接口,继承,多态,封装,抽象以及更高级的一些概念,如组合、聚合及关联。也包含了 GOF 设计模式的问题。
接口是什么? 为什么要使用接口而不是直接使用具体类?
接口用于定义 API。它定义了类必须得遵循的规则。同时,它提供了一种抽象,因为客户端只使用接口,这样可以有多重实现,如 List 接口,你可以使用可随机访问的 ArrayList,也可以使用方便插入和删除的 LinkedList。接口中不允许普通方法,以此来保证抽象,但是 Java 8 中你可以在接口声明静态方法和默认普通方法。
Java 中,抽象类与接口之间有什么不同?
Java 中,抽象类和接口有很多不同之处,但是最重要的一个是 Java 中限制一个类只能继承一个类,但是可以实现多个接口。抽象类可以很好的定义一个家族类的默认行为,而接口能更好的定义类型,有助于后面实现多态机制 参见第六条。
Object有哪些公用方法?
clone equals hashcode wait notify notifyall finalize toString getClass 除了clone和finalize其他均为公共方法。
11个方法,wait被重载了两次
equals与==的区别
- == 是一个运算符 equals是Object类的方法
- 比较时的区别
- 用于基本类型的变量比较时: ==用于比较值是否相等,equals不能直接用于基本数据类型的比较,需要转换为其对应的包装类型。
- 用于引用类型的比较时。==和equals都是比较栈内存中的地址是否相等 。相等为true 否则为false。但是通常会重写equals方法去实现对象内容的比较。
String、StringBuffer与StringBuilder的区别
第一点: 可变和适用范围。String对象是不可变的,而StringBuffer和StringBuilder是可变字符序列。每次对String的操作相当于生成一个新的String对象,而对StringBuffer和StringBuilder的操作是对对象本身的操作,而不会生成新的对象,所以对于频繁改变内容的字符串避免使用String,因为频繁的生成对象将会对系统性能产生影响。
第二点: 线程安全。String由于有final修饰,是immutable的,安全性是简单而纯粹的。StringBuilder和StringBuffer的区别在于StringBuilder不保证同步,也就是说如果需要线程安全需要使用StringBuffer,不需要同步的StringBuilder效率更高。
接口与抽象类
- 一个子类只能继承一个抽象类,但能实现多个接口
- 抽象类可以有构造方法,接口没有构造方法
- 抽象类可以有普通成员变量,接口没有普通成员变量
- 抽象类和接口都可有静态成员变量,抽象类中静态成员变量访问类型任意,接口只能public static final(默认)
- 抽象类可以没有抽象方法,抽象类可以有普通方法,接口中都是抽象方法
- 抽象类可以有静态方法,接口不能有静态方法
- 抽象类中的方法可以是public、protected;接口方法只有public abstract
抽象类和最终类
抽象类可以没有抽象方法, 最终类可以没有最终方法
最终类不能被继承, 最终方法不能被重写(可以重载)
异常
相关的关键字 throw、throws、try…catch、finally
- throws 用在方法签名上, 以便抛出的异常可以被调用者处理
- throw 方法内部通过throw抛出异常
- try 用于检测包住的语句块, 若有异常, catch子句捕获并执行catch块
关于finally
- finally不管有没有异常都要处理
- 当try和catch中有return时,finally仍然会执行,finally比return先执行
- 不管有木有异常抛出, finally在return返回前执行
- finally是在return后面的表达式运算后执行的(此时并没有返回运算后的值,而是先把要返回的值保存起来,管finally中的代码怎么样,返回的值都不会改变,仍然是之前保存的值),所以函数返回值是在finally执行前确定的
注意: finally中最好不要包含return,否则程序会提前退出,返回值不是try或catch中保存的返回值
finally不执行的几种情况: 程序提前终止如调用了 System.exit、断电
受检查异常和运行时异常
- 受检查的异常(checked exceptions),其必须被try…catch语句块所捕获, 或者在方法签名里通过throws子句声明。受检查的异常必须在编译时被捕捉处理,命名为Checked Exception是因为Java编译器要进行检查, Java虚拟机也要进行检查, 以确保这个规则得到遵守。
- 运行时异常(runtime exceptions), 需要程序员自己分析代码决定是否捕获和处理,比如空指针,被0除…
- Error的,则属于严重错误,如系统崩溃、虚拟机错误、动态链接失败等,这些错误无法恢复或者不可能捕捉,将导致应用程序中断,Error不需要捕获。
super出现在父类的子类中。有三种存在方式
- super.xxx(xxx为变量名或对象名)意思是获取父类中xxx的变量或引用
- super.xxx(); (xxx为方法名)意思是直接访问并调用父类中的方法
- super() 调用父类构造
this() & super()在构造方法中的区别
- 调用super()必须写在子类构造方法的第一行, 否则编译不通过
- super从子类调用父类构造, this在同一类中调用其他构造均需要放在第一行
- 尽管可以用this调用一个构造器, 却不能调用2个
- this和super不能出现在同一个构造器中, 否则编译不通过
- this()、super()都指的对象,不可以在static环境中使用
- 本质this指向本对象的指针。super是一个关键字
序列化
声明为static和transient类型的数据不能被序列化, 反序列化需要一个无参构造函数
Java移位运算符
<< :左移运算符,x << 1,相当于x乘以2(不溢出的情况下),低位补0>> :带符号右移,x >> 1,相当于x除以2,正数高位补0,负数高位补1>>> :无符号右移,忽略符号位,空位都以0补齐
形参&实参
形式参数可被视为local variable.形参和局部变量一样都不能离开方法。只有在方法中使用,不会在方法外可见。 形式参数只能用final修饰符,其它任何修饰符都会引起编译器错误。但是用这个修饰符也有一定的限制,就是在方法中不能对参数做任何修改。不过一般情况下,一个方法的形参不用final修饰。只有在特殊情况下,那就是: 方法内部类。一个方法内的内部类如果使用了这个方法的参数或者局部变量的话,这个参数或局部变量应该是final。 形参的值在调用时根据调用者更改,实参则用自身的值更改形参的值(指针、引用皆在此列),也就是说真正被传递的是实参。
局部变量为什么要初始化
局部变量是指类方法中的变量,必须初始化。局部变量运行时被分配在栈中,量大,生命周期短,如果虚拟机给每个局部变量都初始化一下,是一笔很大的开销,但变量不初始化为默认值就使用是不安全的。出于速度和安全性两个方面的综合考虑,解决方案就是虚拟机不初始化,但要求编写者一定要在使用前给变量赋值。
Java语言的鲁棒性
Java在编译和运行程序时,都要对可能出现的问题进行检查,以消除错误的产生。它提供自动垃圾收集来进行内存管理,防止程序员在管理内存时容易产生的错误。通过集成的面向对象的例外处理机制,在编译时,Java揭示出可能出现但未被处理的异常,帮助程序员正确地进行选择以防止系统的崩溃。另外,Java在编译时还可捕获类型声明中的许多常见错误,防止动态运行时不匹配问题的出现。
1.4 - CH04-泛型机制
概览
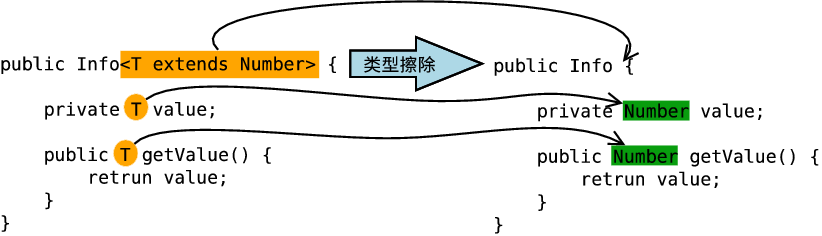
Java 的泛型特性由 JDK 1.5 引入,因此为了兼容之前的版本,Java 泛型的实现采用了“伪泛型”策略。即 Java 在语法上支持泛型,但是在编译阶段会执行“类型擦除(Type Erasure)”,将所有的泛型表示都替换为实际的类型,就像完全没有泛型一样。
泛型的本质是为了参数化类型,在不创建新类型的情况下,通过泛型指定的不同类型来控制形式化参数所限制的具体类型。也就是说在泛型的使用过程中,操作的数据类型被指定为一个参数,该类型参数可以用在类、接口、方法中,分别被称为泛型类、泛型接口、泛型方法。
引入泛型的最直接意义在于:
- 适用于多种数据类型执行相同的代码逻辑(代码复用)。
- 泛型中的类型在使用时指定,不需要强制类型转换(类型安全,由编译器执行检查)。
基本使用
泛型类
class Point<T> {
private T var;
public T getVar() {
return var;
}
public void setVar(T var){
this.var = var;
}
}
Point<String> point = new Point<>();
pioint.setVar("value");
泛型接口
interface Info<T> {
T getVar();
}
class InfoImpl<T> implements Info<T> {
private T var;
}
泛型方法
class Caster {
public static <T> T castAs(Class<T> clazz, Object value) {
return clazz.cast(value);
}
}
泛型边界
泛型擦除
擦除原则:
- 消除类型参数声明,即删除
<> 及其包围的部分。 - 根据类型参数的上下界推断并替换所有的类型参数为具体类型:
- 如果类型参数是无限制通配符或没有上下界限定则替换为 Object。
- 如果存在上下界限定则根据子类替换原则取类型参数的最左侧限定类型,即父类。
- 为了保证类型安全,必要时插入强制类型转换代码。
- 自动产生“桥接方法”以保证类型擦除后的代码仍然具有泛型的“多态性”。
如何执行类型擦除:
参数类定义中的类型参数:无限制类型擦除
当类定义中类型参数没有任何限制时,直接将其替换为 Object,如 <T> 或 <?> 会被直接替换为 Object。
擦除类定义中的类型参数:有限制类型擦除
如果类定义中的类型参数有上下界限定,在擦除时将其替换为类型参数的上界或下界,如 <T extends Number> 和 <? extends Number> 会被替换为 Number,<? super Number> 会被替换为 Object。
擦除方法定义中的类型参数
原则和擦除类定义中的类型参数一致,这里仅擦除方法定义中的有限制类型参数为例。
如何证明类型擦除
原始类型相等
ArrayList<String> list1 = new ArrayList<>();
list1.add("abc");
ArrayList<Integer> list2 = new ArrayList<>();
list2.add(123);
assert list1.getClass() == list2.getClass();
通过反射添加其他类型的元素
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.getClass().getMethod("add", Object.class).invoke(list, "abc");
类型擦除后的原生类型(Raw Type)
原生类型为擦除掉泛型信息后,保留在字节码中的类型变量的真正类型,无论何时定义一个泛型类型,对应的原始类型都会自动提供,类型变量擦除,并使用其限定类型或 Object 替换。
如何理解编译期检查
Java 编译器首先检查代码中泛型的类型,然后再执行类型擦除,然后再执行编译。
基于代码的类型检查是如何进行的呢?
比如以下代码:
ArrayList<String> list1 = new ArrayList(); //第一种 情况
ArrayList list2 = new ArrayList<String>(); //第二种 情况
以上代码可以编译通过,且不会出现变异警告。但是仅第一种可以实现与完全使用泛型参数一样的效果,第二种不行。
因为类型检查就是编译时完成的,new ArrayList() 只是在内存中开辟一个存储空间,可以存储任何类型的对象,而真正涉及类型检查的是它的引用,因为我们是通过引用 list1 来调用它的方法,比如调用其 add 方法,所以 list1 引用能能完成泛型类型的检查。而引用 list2 没有使用泛型,所以不行。
ArrayList<String> list1 = new ArrayList();
list1.add("1"); //编译通过
list1.add(1); //编译错误
String str1 = list1.get(0); //返回类型就是String
ArrayList list2 = new ArrayList<String>();
list2.add("1"); //编译通过
ist2.add(1); //编译通过
Object object = list2.get(0); //返回类型就是Object
new ArrayList<String>().add("11"); //编译通过
new ArrayList<String>().add(22); //编译错误
String str2 = new ArrayList<String>().get(0); //返回类型就是String
因此可以得出,类型检查就是针对引用执行的检查,谁是一个引用,通过该引用调用泛型方法,就会对这个引用调用的方法进行类型检测,而无关它真正引用的对象。
泛型多态/桥接方法
类型擦除会造成多态冲突,而 JVM 通过桥接方法类解决。
class Pair<T> {
private T value;
public T getValue() {
return value;
}
public void setValue(T value) {
this.value = value;
}
}
然后实现一个子类:
class DateInter extends Pair<Date> {
@Override
public void setValue(Date value) {
super.setValue(value);
}
@Override
public Date getValue() {
return super.getValue();
}
}
在这个子类中,我们设定父类的泛型类型为Pair<Date>,在子类中,我们覆盖了父类的两个方法,我们的原意是这样的:将父类的泛型类型限定为 Date,那么父类里面的两个方法的参数都为 Date 类型。
实际上类型擦除后,父类的泛型类型全部变成了 Object,所以父类编译之后会成为如下形式:
class Pair {
private Object value;
public Object getValue() {
return value;
}
public void setValue(Object value) {
this.value = value;
}
}
这时子类中的两个重写方法:
@Override
public void setValue(Date value) {
super.setValue(value);
}
@Override
public Date getValue() {
return super.getValue();
}
首先是 setValue 方法,父类的类型是 Object,而子类的类型是 Date,参数类型不一样,如果是在普通的继承体系中,根本就不会是重写,而是重载。但是如果通过基于重载的形式以子类来调用父类的方法:
DateInter dateInter = new DateInter();
dateInter.setValue(new Date());
dateInter.setValue(new Object()); //编译错误
如果是重载,那么子类中会有两个 setValue 方法,一个参数为 Object,一个参数为 Date,但编译错误可以得出这里实际上是重写。
原因是,当我们集成父类并设定其类型参数为 Date,期望将泛型类变成如下形式:
class Pair {
private Date value;
public Date getValue() {
return value;
}
public void setValue(Date value) {
this.value = value;
}
}
然后在子类中重写参数类型为 Date 的两个方法,实现继承中的多态。
但是由于种种原因,JVM 并不能将泛型类型转换为 Date,只能将其擦除,称为原生类型 Object。这样我们本意是重写来实现多态,但类型擦除后只能变为了重载。从而导致类型擦除与多态的冲突。因此 JVM 决定通过桥接来解决该问题。
首先通过命令 javap -c className 的方式反编译 DateInter 子类的字节码,结果如下:
class com.tao.test.DateInter extends com.tao.test.Pair<java.util.Date> {
com.tao.test.DateInter();
Code:
0: aload_0
1: invokespecial #8 // Method com/tao/test/Pair."<init>":()V
4: return
public void setValue(java.util.Date); //我们重写的setValue方法
Code:
0: aload_0
1: aload_1
2: invokespecial #16 // Method com/tao/test/Pair.setValue:(Ljava/lang/Object;)V
5: return
public java.util.Date getValue(); //我们重写的getValue方法
Code:
0: aload_0
1: invokespecial #23 // Method com/tao/test/Pair.getValue:()Ljava/lang/Object;
4: checkcast #26 // class java/util/Date
7: areturn
public java.lang.Object getValue(); //编译时由编译器生成的巧方法
Code:
0: aload_0
1: invokevirtual #28 // Method getValue:()Ljava/util/Date 去调用我们重写的getValue方法;
4: areturn
public void setValue(java.lang.Object); //编译时由编译器生成的巧方法
Code:
0: aload_0
1: aload_1
2: checkcast #26 // class java/util/Date
5: invokevirtual #30 // Method setValue:(Ljava/util/Date; 去调用我们重写的setValue方法)V
8: return
}
从编译结果来看,我们原本要重写方法实际上成了 4 个方法,最后两个方法即为编译器自动生成的桥接方法。可以发现桥接方法的参数类型都是 Object,也就是说,子类中真正覆盖父类方法的就是这两个桥接方法。桥接方法的内部会执行类型转换并调用我们重写的那两个方法。
基本类型不能作为泛型参数
比如只能使用 List<Integer> 而不能使用 List<int>。因为当类型擦除后,List 的原生类型变为 Object,但是 Object 不能存储 int 值,只能是引用类型 Integer 的值。
然后实际操作中使用的 list.add(1),则是基本类型的自动装箱机制。
泛型类型不能实例化
以上代码会直接报错。因为 Java 编译期没法确定泛型参数的实际类型,也就找不到对应的类的字节码文件,所以自然就不能完成编译。此外由于 T 被擦除为 Object,如果可以执行 new T(),则就变成了 new Object(),失去了代码的本意。
泛型数组:通过具体类型参数初始化
List<String>[] lsa = new List<String>[10]; // Not really allowed.
Object o = lsa;
Object[] oa = (Object[]) o;
List<Integer> li = new ArrayList<Integer>();
li.add(new Integer(3));
oa[1] = li; // Unsound, but passes run time store check
String s = lsa[1].get(0); // Run-time error ClassCastException.
由于擦除机制,上面代码可以给 oa[1] 赋值为 ArrayList 类型的变量也不会出现异常。但是在取出数据时要做一次类型转换,所以就会出现 ClassCastException。
如果可以执行泛型数组的声明则上面这种情况就不会出现任何警告和错误,只有在运行时才会报错,但是泛型的出现就是为了避免转型错误,所有 Java 支持泛型数组初始化则与初衷违背。
下面的代码是成立的:
List<?>[] lsa = new List<?>[10]; // OK, array of unbounded wildcard type.
Object o = lsa;
Object[] oa = (Object[]) o;
List<Integer> li = new ArrayList<Integer>();
li.add(new Integer(3));
oa[1] = li; // Correct.
Integer i = (Integer) lsa[1].get(0); // OK
所以说采用通配符的方式初始化泛型数组是允许的,因为对于通配符的方式是最后取出数据时才执行转型,符合预期逻辑。
Java 的泛型数组初始化时数组类型不能是具体的泛型类型,只能是通配符的形式,因为具体类型会导致可存入任意类型对象,在取出时会发生类型转换异常,会与泛型的设计思想冲突,而通配符形式本来就需要自己强转,符合预期。
泛型数组:正确的初始化数组实例
无论是 new ArrayList[10] 的形式还是通过泛型通配符的形式来初始化都存在转型异常风险。
在需要使用泛型数组时应尽量使用列表集合替代,此外也可以通过反射来创建一个具有指定类型的数组:
public class ArrayWithTypeToken<T> {
private T[] array;
public ArrayWithTypeToken(Class<T> type, int size) {
array = (T[]) Array.newInstance(type, size);
}
public void put(int index, T item) {
array[index] = item;
}
public T get(int index) {
return array[index];
}
public T[] create() {
return array;
}
}
//...
ArrayWithTypeToken<Integer> arrayToken = new ArrayWithTypeToken<Integer>(Integer.class, 100);
Integer[] array = arrayToken.create();
泛型类中的静态方法与静态变量
public class Test<T> {
public static T one; //编译错误
public static T show(T one){ //编译错误
return null;
}
}
因为泛型类中的类型参数是在定义对象时才指定的,而静态变量或静态方法不需要使用对象实例来调用。对象未被创建,如何确定该泛型参数的具体类型,所以错误。
public class Test<T> {
public static <T> T show(T one){ //这是正确的
return null;
}
}
注意这里 show 方法的类型参数 T 并非 Test 类的类型参数 T。
异常中使用泛型
- 不能抛出也不能捕获泛型对象。继承 Throwable 时使用泛型也是非法的。
- 因为异常仅在运行时抛出,编译期擦除参数类型后无法区分不同具体类型的泛型异常。
- 不能在 catch 子句中使用泛型变量
- 因为泛型信息会被擦除为原生类型,
catch(T e) 会变成 catch(Throwable e) - 根据异常捕获原则,如果下面还有别的 catch 语句来处理其他异常类型,导致冲突。
- 可以在声明中抛出参数啊类型的异常,
<T extends Throwable> void do(T t) throws T
如何获取类型参数
java.lang.reflect.Type 是 Java 中所有类型的公共高级接口,代表了所有 Java 中的类型。Type 体系中的类型包括:
- 数组类型:GenericArrayType
- 参数化类型:ParameterizedType
- 类型变量:TypeVariable
- 通配符类型:WildcardType
- 原始类型:Class
- 基本类型:Class
1.5 - CH05-注解机制
概览
注解是 JDK 1.5 版本开始引入的一个特性,用于对代码进行说明,可以对包、类、接口、字段、方法参数、局部变量等进行注解。它主要的作用有以下四方面:
生成文档,通过代码里标识的元数据生成javadoc文档。
编译检查,通过代码里标识的元数据让编译器在编译期间进行检查验证。
编译时动态处理,编译时通过代码里标识的元数据动态处理,例如动态生成代码。
运行时动态处理,运行时通过代码里标识的元数据动态处理,例如使用反射注入实例。
比如:
- Java自带的标准注解,包括
@Override、@Deprecated和@SuppressWarnings,分别用于标明重写某个方法、标明某个类或方法过时、标明要忽略的警告,用这些注解标明后编译器就会进行检查。 - 元注解,元注解是用于定义注解的注解,包括
@Retention、@Target、@Inherited、@Documented,@Retention用于标明注解被保留的阶段,@Target用于标明注解使用的范围,@Inherited用于标明注解可继承,@Documented用于标明是否生成javadoc文档。 - 自定义注解,可以根据自己的需求定义注解,并可用元注解对自定义注解进行注解。
内置注解
- @Override
- @Deprecated
- @SuppressWarnings
元注解
- @Target
- @Retention,@RetentionTarget
- @Documented
- @Inherited
- @Repeatable
- @Native
注解与反射接口
通过反射工具包 java.lang.reflect 中的 AnnotatedElement 可以访问注解信息。注意仅在注解被声明为 RUNTIME 时,才能在运行时获取注解信息,当 class 文件被加载时保存在 class 文件中的注解信息才会被 JVM 读取。
AnnotatedElement 接口是所有成语元素的父接口,所有程序通过反射获得了某个类的 AnnotatedElement 对象之后,就可以调用该对象的方法来访问具体的注解信息:
boolean isAnnotationPresent(Class<?extends Annotation> annotationClass)<T extends Annotation> T getAnnotation(Class<T> annotationClass)Annotation[] getAnnotations()<T extends Annotation> T[] getAnnotationsByType(Class<T> annotationClass)<T extends Annotation> T[] getDeclaredAnnotationsByType(Class<T> annotationClass)Annotation[] getDeclaredAnnotations()
自定义注解
定义注解:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface MyMethodAnnotation {
public String title() default "";
public String description() default "";
}
使用注解:
public class TestMethodAnnotation {
@Override
@MyMethodAnnotation(title = "toStringMethod", description = "override toString method")
public String toString() {
return "Override toString method";
}
@Deprecated
@MyMethodAnnotation(title = "old static method", description = "deprecated old static method")
public static void oldMethod() {
System.out.println("old method, don't use it.");
}
@SuppressWarnings({"unchecked", "deprecation"})
@MyMethodAnnotation(title = "test method", description = "suppress warning static method")
public static void genericsTest() throws FileNotFoundException {
List l = new ArrayList();
l.add("abc");
oldMethod();
}
}
读取注解:
Method[] methods = TestMethodAnnotation.class.getClassLoader()
.loadClass(("com.pdai.java.annotation.TestMethodAnnotation"))
.getMethods();
for (Method method : methods) {
// 方法上是否有MyMethodAnnotation注解
if (method.isAnnotationPresent(MyMethodAnnotation.class)) {
try {
// 获取并遍历方法上的所有注解
for (Annotation anno : method.getDeclaredAnnotations()) {
System.out.println("Annotation in Method '"
+ method + "' : " + anno);
}
// 获取MyMethodAnnotation对象信息
MyMethodAnnotation methodAnno = method
.getAnnotation(MyMethodAnnotation.class);
System.out.println(methodAnno.title());
} catch (Throwable ex) {
ex.printStackTrace();
}
}
}
注解特性
Java 8 新特性
- @Repeatable
- @ElementType.TYPE_USE
- @ElementType.TYPE_PARAMETER
TYPE_USE 包括类型声明和类型参数声明,是为了方便设计者进行类型检查。
// 自定义ElementType.TYPE_PARAMETER注解
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE_PARAMETER)
public @interface MyNotEmpty {
}
// 自定义ElementType.TYPE_USE注解
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE_USE)
public @interface MyNotNull {
}
// 测试类
public class TypeParameterAndTypeUseAnnotation<@MyNotEmpty T>{
//使用TYPE_PARAMETER类型,会编译不通过
// public @MyNotEmpty T test(@MyNotEmpty T a){
// new ArrayList<@MyNotEmpty String>();
// return a;
// }
//使用TYPE_USE类型,编译通过
public @MyNotNull T test2(@MyNotNull T a){
new ArrayList<@MyNotNull String>();
return a;
}
}
1.6 - CH06-异常机制
概览
Java 异常是 Java 提供的一种识别及响应错误的机制,Java 异常机制可以使程序中异常处理的代码和正常业务代码分离,保证程序代码更加优雅,并提高程序的健壮性。
层次结构
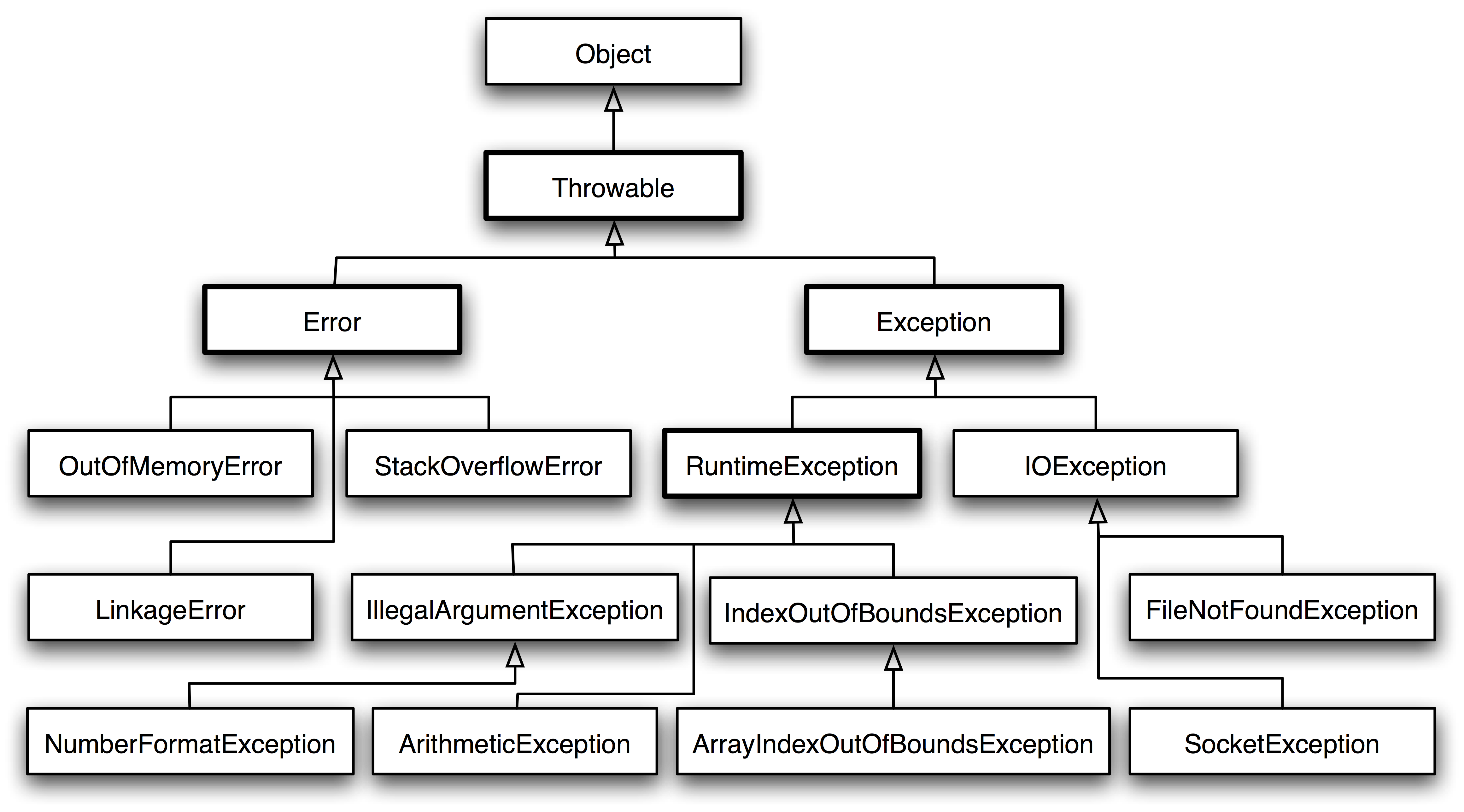
异常是指非预期的各种状况,如:文件找不到、网络连接失败、非法参数等。异常是一个事件,它发生在程序运行期间,干扰了正常的指令流程。Java 通过 API 中 Throwable 类的众多子类描述各种不同的异常。因此,Java 异常都是对象,是 Throwable 子类的实例,描述了出现在一段编码中的错误条件。当条件生成时,错误将引发异常。
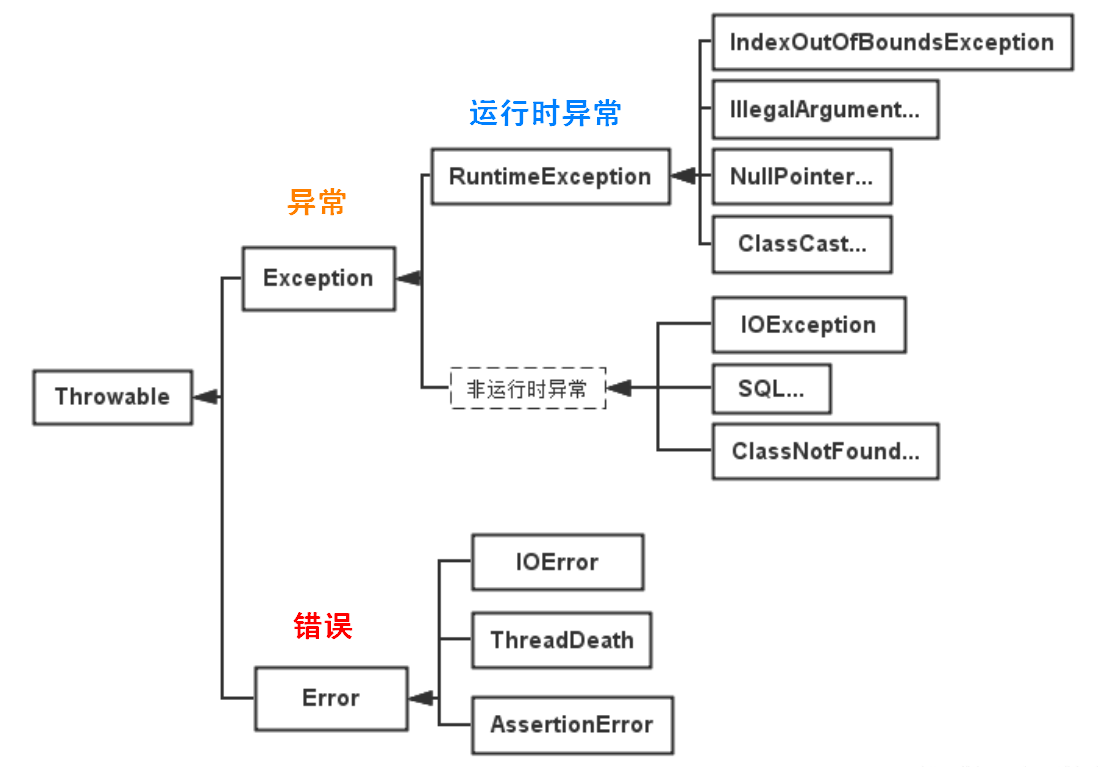
Throwable
Throwable 是 Java 语言中所有错误与异常的超类。
Throwable 包含两个子类:Error(错误)和 Exception(异常),它们通常用于指示发生了异常情况。
Throwable 包含了其线程创建时线程执行堆栈的快照,它提供了 printStackTrace() 等接口用于获取堆栈跟踪数据等信息。
Error
Error 类及其子类:程序中无法处理的错误,表示运行应用程序中出现了严重的错误。
此类错误一般表示代码运行时 JVM 出现问题。通常有 Virtual MachineError(虚拟机运行错误)、NoClassDefFoundError(类定义错误)等。比如 OutOfMemoryError:内存不足错误;StackOverflowError:栈溢出错误。此类错误发生时,JVM 将终止线程。
这些错误是不受检异常,非代码性错误。因此,当此类错误发生时,应用程序不应该去处理此类错误。按照 Java 惯例,我们是不应该实现任何新的 Error 子类的!
Exception
程序本身可以捕获并且可以处理的异常。Exception 这种异常又分为两类:运行时异常和编译时异常。
- 运行时异常
- 都是 RuntimeException 类及其子类异常,如 NullPointerException(空指针异常)、IndexOutOfBoundsException(下标越界异常)等,这些异常是不检查异常,程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生。
- 运行时异常的特点是 Java 编译器不会检查它,也就是说,当程序中可能出现这类异常,即使没有用 try-catch 语句捕获它,也没有用 throws 子句声明抛出它,也会编译通过。
- 编译期异常
- 是 RuntimeException 以外的异常,类型上都属于 Exception 类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如 IOException、SQLException 等以及用户自定义的 Exception 异常,一般情况下不自定义检查异常。
受检异常/非受检异常
- 受检异常:编译器妖气必须处理的异常
- 正确的程序在运行中,很容易出现的、情理可容的异常状况。可查异常虽然是异常状况,但在一定程度上它的发生是可以预计的,而且一旦发生这种异常状况,就必须采取某种方式进行处理。
- 除了 RuntimeException 及其子类以外,其他的 Exception 类及其子类都属于受检异常。这种异常的特点是 Java 编译器会检查它,也就是说,当程序中可能出现这类异常,要么用 try-catch 语句捕获它,要么用 throws 子句声明抛出它,否则编译不会通过。
- 非受检异常:编译器不强制要求检查的异常
- 包括运行时异常(RuntimeException与其子类)和错误(Error)。
异常基础
关键字
- try:监听异常
- catch:捕获异常
- finally:总是执行
- throw:抛出异常
- throws:声明异常
异常捕获
- try-catch
- try-catch-finally
- try-finally
- try-with-resource: AutoCloseable
常见异常
- RuntimeException
- ArrayIndexOutOfBoundsException:数组索引越界
- ArithmeticException:除零异常
- NullPointerException:空指针
- ClassNotFoundException:类加载
- NegativeArraySizeException:数组长度为负
- ArrayStoreException:数组元素类型不兼容
- SecurityException:安全性异常
- IllegalArgumentException:非法参数
- IOException
- IOException:输出输出流异常
- EOFException:文件结束
- FileNotFoundException:文件未找到
- Others
- ClassCastException
- SQLException
- NoSuchFieldException
- NoSuchMethodException
- NumberFormatException
- StringIndexOutOfBoundsException
- IllegalAccessException
- InstantiationException
应用实践
- 在恰当的级别处理异常,即知道该如何处理的地方及时处理异常。
- 解决问题并且重新调用产生异常的方法。
- 进行少许修补,然后绕过异常发生的地方继续执行。
- 用别的数据进行计算,以代替方法预计会返回的值。
- 把当前运行环境下能做的事尽量做完,然后把相同的异常重抛到更高层。
- 终止程序。
- 进行简化。
- 让类库和程序更安全。
- 不要通过异常来实现业务流程。
底层机制
try-catch
public static void simpleTryCatch() {
try {
testNPE();
} catch (Exception e) {
e.printStackTrace();
}
}
通过 javap 的带编译后的代码:
//javap -c Main
public static void simpleTryCatch();
Code:
0: invokestatic #3 // Method testNPE:()V
3: goto 11
6: astore_0
7: aload_0
8: invokevirtual #5 // Method java/lang/Exception.printStackTrace:()V
11: return
Exception table:
from to target type
0 3 6 Class java/lang/Exception
异常表中包含了一个或多个异常处理器的信息,内容如下:
- from:可能发生异常的起始点
- to:可能发生异常的结束点
- target:从 from 到 to 之间发生异常后异常处理器的位置
- type:异常处理器所处理的异常类型
当发生一个异常时:
- JVM 会在当前出现异常的方法中查找异常表,检查是否有合适的处理器
- 如果当前方法的异常表不为空,且异常符合表中 from to 的范围,同时 type 匹配,则 JVM 将调用位于 target 的处理器来处理异常
- 如果上一步没有找到处理器,则继续检查异常表中的下一项
- 如果当前异常表无法处理,则向上查找(弹栈)调用方法的调用点,并重复 1-3 步的操作。
- 如果所有栈帧都被弹出,仍然没有处理,则抛出异常给当前 Thread,Thread 会终止。
- 如果当前 Thread 为最后一个非守护线程,且异常未处理,则导致 JVM 终止运行。
try-catch-finally
public static void simpleTryCatchFinally() {
try {
testNPE();
} catch (Exception e) {
e.printStackTrace();
} finally {
System.out.println("Finally");
}
}
通过 javap 得到异常表部分:
public static void simpleTryCatchFinally();
Code:
0: invokestatic #3 // Method testNPE:()V
3: getstatic #6 // Field java/lang/System.out:Ljava/io/PrintStream;
6: ldc #7 // String Finally
8: invokevirtual #8 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
11: goto 41
14: astore_0
15: aload_0
16: invokevirtual #5 // Method java/lang/Exception.printStackTrace:()V
19: getstatic #6 // Field java/lang/System.out:Ljava/io/PrintStream;
22: ldc #7 // String Finally
24: invokevirtual #8 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
27: goto 41
30: astore_1
31: getstatic #6 // Field java/lang/System.out:Ljava/io/PrintStream;
34: ldc #7 // String Finally
36: invokevirtual #8 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
39: aload_1
40: athrow
41: return
Exception table:
from to target type
0 3 14 Class java/lang/Exception
0 3 30 any
14 19 30 any
- 如果 0-3 之间发生了 Exception 异常,调用 14 位置的处理器。
- 如果 0-3 之间无论发生哪种异常,都调用 30 位置的处理器。
- 如果 14-19(catch) 之间无论发生什么异常,都调用 30 位置的处理器。
注意异常表会代码中 finally 的部分同时在异常表的 catch 和 finally 部分注册,以实现无论是否发生异常都执行的逻辑。
catch 先后顺序
先 catch 类层级较高的异常类型会导致编译错误。
return 与 finally
public static String tryCatchReturn() {
try {
testNPE();
return "OK";
} catch (Exception e) {
return "ERROR";
} finally {
System.out.println("tryCatchReturn");
}
}
这里无论是否抛出一查,finally 部分都会执行。
性能损耗
创建一个异常对象是创建一个普通对象所需耗时的几十倍,抛出、捕获异常则是创建异常对象所需耗时的数倍。
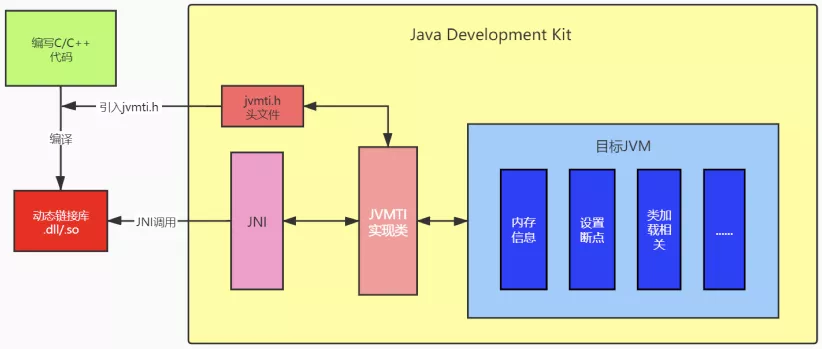
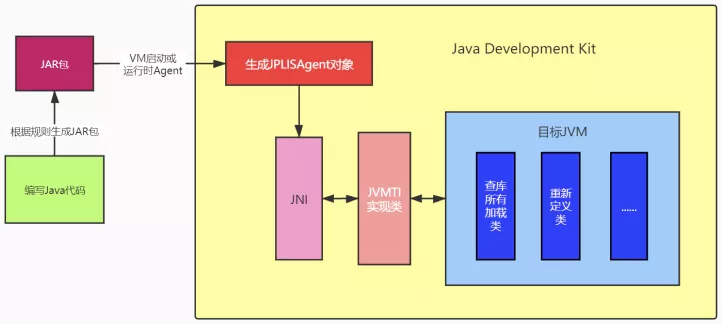
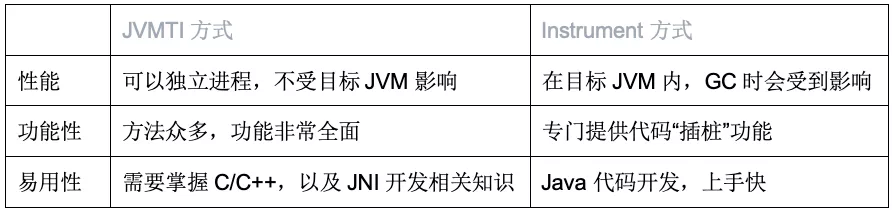
1.7 - CH07-反射机制
反射基础
Runtime Type Identification(RTTI) 运行时类型识别,作用是在运行时识别一个对象的类型和类信息。主要有两种方式:
- 传统的的 RTTI,它假设我们在编译期就知道了所有的类型。
- 反射机制,它允许我们在运行时发现和使用类的信息。
Class 类
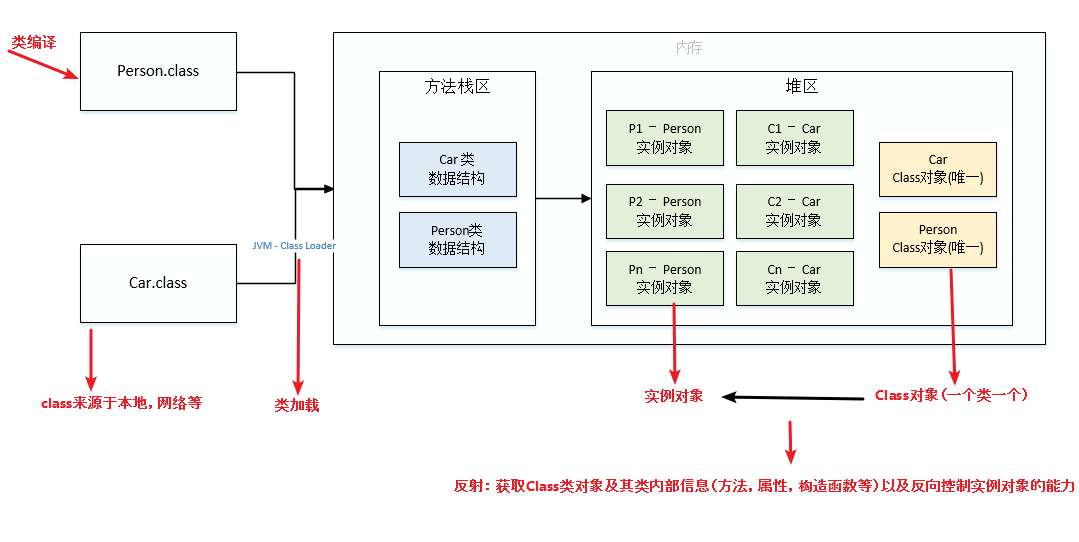
Class 类就像 String 类、Object 类一样,是一个实实在在的类,存在与 java.lang 包中。Class 类的实例表示 java 应用运行时的类(class ans enum)或接口(interface and annotation),可以通过 类名.class、类型.class、Class.forName(类名)等方法获取 Class 类的对象实例。
数组同样也被映射为为 class 对象的一个类,所有具有相同元素类型和维数的数组都共享该 Class 对象。基本类型boolean,byte,char,short,int,long,float,double 和关键字 void 同样表现为 class 对象。
- Class 类也是类的一种,与 class 关键字是不一样的。
- 手动编写的类被编译后会产生一个 Class 对象,其表示的是创建的类的类型信息,而且这个 Class 对象保存在 同名.class 的文件中(字节码文件)
- 每个通过关键字 class 标识的类,在内存中有且只有一个与之对应的 Class 对象来描述其类型信息,无论创建多少个实例对象,其依据的都是用一个Class对象。
- Class 类只有私有构造函数,因此对应 Class 对象只能由 JVM 创建和加载。
- Class 类的对象作用是运行时提供或获得某个对象的类型信息。
类加载
类加载流程:
反射应用
在Java中,Class类与java.lang.reflect类库一起对反射技术进行了全力的支持。在反射包中,我们常用的类主要有Constructor类表示的是Class 对象所表示的类的构造方法,利用它可以在运行时动态创建对象、Field表示Class对象所表示的类的成员变量,通过它可以在运行时动态修改成员变量的属性值(包含private)、Method表示Class对象所表示的类的成员方法,通过它可以动态调用对象的方法(包含private),下面将对这几个重要类进行分别说明。
Class 对象
- 类名.class
- 对象.getClass()
- 完全限定名:Class.forName(全限定类名)
Class 方法
- forName()
- Object.getClass()
- getName():类的全限定名,可用于 Class.forName
- getSimpleName():仅类名
- getCanonicalName():更易理解的完全限定名,数组时表示不同
- isInterface()
- getInterfaces()
- getSupercalss()
- newInstance()
- getFields()
- getDeclaredFields()
- getConstructors()
- …
Constructor
Field
Method
反射流程
public class HelloReflect {
public static void main(String[] args) {
try {
// 1. 使用外部配置的实现,进行动态加载类
TempFunctionTest test = (TempFunctionTest)Class.forName("com.tester.HelloReflect").newInstance();
test.sayHello("call directly");
// 2. 根据配置的函数名,进行方法调用(不需要通用的接口抽象)
Object t2 = new TempFunctionTest();
Method method = t2.getClass().getDeclaredMethod("sayHello", String.class);
method.invoke(test, "method invoke");
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (NoSuchMethodException e ) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
public void sayHello(String word) {
System.out.println("hello," + word);
}
}
反射获取类实例
通过 Class 的静态方法,获取类信息:
@CallerSensitive
public static Class<?> forName(String className) throws ClassNotFoundException {
// 先通过反射,获取调用进来的类信息,从而获取当前的 classLoader
Class<?> caller = Reflection.getCallerClass();
// 调用native方法进行获取class信息
return forName0(className, true, ClassLoader.getClassLoader(caller), caller);
}
最后,JVM 会回调 ClassLoader 执行类加载:
public Class<?> loadClass(String name) throws ClassNotFoundException {
return loadClass(name, false);
}
// sun.misc.Launcher
public Class<?> loadClass(String var1, boolean var2) throws ClassNotFoundException {
int var3 = var1.lastIndexOf(46);
if(var3 != -1) {
SecurityManager var4 = System.getSecurityManager();
if(var4 != null) {
var4.checkPackageAccess(var1.substring(0, var3));
}
}
if(this.ucp.knownToNotExist(var1)) {
Class var5 = this.findLoadedClass(var1);
if(var5 != null) {
if(var2) {
this.resolveClass(var5);
}
return var5;
} else {
throw new ClassNotFoundException(var1);
}
} else {
return super.loadClass(var1, var2);
}
}
// java.lang.ClassLoader
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
// 先获取锁
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
// 如果已经加载了的话,就不用再加载了
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
// 双亲委托加载
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
// 父类没有加载到时,再自己加载
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
protected Object getClassLoadingLock(String className) {
Object lock = this;
if (parallelLockMap != null) {
// 使用 ConcurrentHashMap来保存锁
Object newLock = new Object();
lock = parallelLockMap.putIfAbsent(className, newLock);
if (lock == null) {
lock = newLock;
}
}
return lock;
}
protected final Class<?> findLoadedClass(String name) {
if (!checkName(name))
return null;
return findLoadedClass0(name);
}
以下是 newInstance 的实现:
// 首先肯定是 Class.newInstance
@CallerSensitive
public T newInstance()
throws InstantiationException, IllegalAccessException
{
if (System.getSecurityManager() != null) {
checkMemberAccess(Member.PUBLIC, Reflection.getCallerClass(), false);
}
// NOTE: the following code may not be strictly correct under
// the current Java memory model.
// Constructor lookup
// newInstance() 其实相当于调用类的无参构造函数,所以,首先要找到其无参构造器
if (cachedConstructor == null) {
if (this == Class.class) {
// 不允许调用 Class 的 newInstance() 方法
throw new IllegalAccessException(
"Can not call newInstance() on the Class for java.lang.Class"
);
}
try {
// 获取无参构造器
Class<?>[] empty = {};
final Constructor<T> c = getConstructor0(empty, Member.DECLARED);
// Disable accessibility checks on the constructor
// since we have to do the security check here anyway
// (the stack depth is wrong for the Constructor's
// security check to work)
java.security.AccessController.doPrivileged(
new java.security.PrivilegedAction<Void>() {
public Void run() {
c.setAccessible(true);
return null;
}
});
cachedConstructor = c;
} catch (NoSuchMethodException e) {
throw (InstantiationException)
new InstantiationException(getName()).initCause(e);
}
}
Constructor<T> tmpConstructor = cachedConstructor;
// Security check (same as in java.lang.reflect.Constructor)
int modifiers = tmpConstructor.getModifiers();
if (!Reflection.quickCheckMemberAccess(this, modifiers)) {
Class<?> caller = Reflection.getCallerClass();
if (newInstanceCallerCache != caller) {
Reflection.ensureMemberAccess(caller, this, null, modifiers);
newInstanceCallerCache = caller;
}
}
// Run constructor
try {
// 调用无参构造器
return tmpConstructor.newInstance((Object[])null);
} catch (InvocationTargetException e) {
Unsafe.getUnsafe().throwException(e.getTargetException());
// Not reached
return null;
}
}
newInstance 的主要逻辑:
- 权限检测,如果不通过则直接报错
- 查找无参构造器,并将其缓存
- 调用具体方法的无参构造方法,生成实例并返回
以下是获取构造器过程:
private Constructor<T> getConstructor0(Class<?>[] parameterTypes,
int which) throws NoSuchMethodException
{
// 获取所有构造器
Constructor<T>[] constructors = privateGetDeclaredConstructors((which == Member.PUBLIC));
for (Constructor<T> constructor : constructors) {
if (arrayContentsEq(parameterTypes,
constructor.getParameterTypes())) {
return getReflectionFactory().copyConstructor(constructor);
}
}
throw new NoSuchMethodException(getName() + ".<init>" + argumentTypesToString(parameterTypes));
}
获取构造器分为三步:
- 先获取所有的 constructors, 然后执行参数类型比较;
- 如果存在匹配,通过 ReflectionFactory copy 一份 constructor 返回;
- 否则抛出 NoSuchMethodException;
下面是获取所有构造器的过程:
// 获取当前类所有的构造方法,通过jvm或者缓存
// Returns an array of "root" constructors. These Constructor
// objects must NOT be propagated to the outside world, but must
// instead be copied via ReflectionFactory.copyConstructor.
private Constructor<T>[] privateGetDeclaredConstructors(boolean publicOnly) {
checkInitted();
Constructor<T>[] res;
// 调用 reflectionData(), 获取保存的信息,使用软引用保存,从而使内存不够可以回收
ReflectionData<T> rd = reflectionData();
if (rd != null) {
res = publicOnly ? rd.publicConstructors : rd.declaredConstructors;
// 存在缓存,则直接返回
if (res != null) return res;
}
// No cached value available; request value from VM
if (isInterface()) {
@SuppressWarnings("unchecked")
Constructor<T>[] temporaryRes = (Constructor<T>[]) new Constructor<?>[0];
res = temporaryRes;
} else {
// 使用native方法从jvm获取构造器
res = getDeclaredConstructors0(publicOnly);
}
if (rd != null) {
// 最后,将从jvm中读取的内容,存入缓存
if (publicOnly) {
rd.publicConstructors = res;
} else {
rd.declaredConstructors = res;
}
}
return res;
}
// Lazily create and cache ReflectionData
private ReflectionData<T> reflectionData() {
SoftReference<ReflectionData<T>> reflectionData = this.reflectionData;
int classRedefinedCount = this.classRedefinedCount;
ReflectionData<T> rd;
if (useCaches &&
reflectionData != null &&
(rd = reflectionData.get()) != null &&
rd.redefinedCount == classRedefinedCount) {
return rd;
}
// else no SoftReference or cleared SoftReference or stale ReflectionData
// -> create and replace new instance
return newReflectionData(reflectionData, classRedefinedCount);
}
// 新创建缓存,保存反射信息
private ReflectionData<T> newReflectionData(SoftReference<ReflectionData<T>> oldReflectionData,
int classRedefinedCount) {
if (!useCaches) return null;
// 使用cas保证更新的线程安全性,所以反射是保证线程安全的
while (true) {
ReflectionData<T> rd = new ReflectionData<>(classRedefinedCount);
// try to CAS it...
if (Atomic.casReflectionData(this, oldReflectionData, new SoftReference<>(rd))) {
return rd;
}
// 先使用CAS更新,如果更新成功,则立即返回,否则测查当前已被其他线程更新的情况,如果和自己想要更新的状态一致,则也算是成功了
oldReflectionData = this.reflectionData;
classRedefinedCount = this.classRedefinedCount;
if (oldReflectionData != null &&
(rd = oldReflectionData.get()) != null &&
rd.redefinedCount == classRedefinedCount) {
return rd;
}
}
}
- 首先阐释缓存中获取
- 如果没有缓存,则从 JVM 中重新加载,并存入缓存,缓存使用软引用保存,保证内存可用。
另外,使用 relactionData() 进行缓存保存;ReflectionData 的数据结构如下:
// reflection data that might get invalidated when JVM TI RedefineClasses() is called
private static class ReflectionData<T> {
volatile Field[] declaredFields;
volatile Field[] publicFields;
volatile Method[] declaredMethods;
volatile Method[] publicMethods;
volatile Constructor<T>[] declaredConstructors;
volatile Constructor<T>[] publicConstructors;
// Intermediate results for getFields and getMethods
volatile Field[] declaredPublicFields;
volatile Method[] declaredPublicMethods;
volatile Class<?>[] interfaces;
// Value of classRedefinedCount when we created this ReflectionData instance
final int redefinedCount;
ReflectionData(int redefinedCount) {
this.redefinedCount = redefinedCount;
}
}
比较构造是否是要查找构造器,其实就是比较类型完全相等性,有一个不相等则返回 false。
最终通过以下逻辑获得构造器:
private static boolean arrayContentsEq(Object[] a1, Object[] a2) {
if (a1 == null) {
return a2 == null || a2.length == 0;
}
if (a2 == null) {
return a1.length == 0;
}
if (a1.length != a2.length) {
return false;
}
for (int i = 0; i < a1.length; i++) {
if (a1[i] != a2[i]) {
return false;
}
}
return true;
}
// sun.reflect.ReflectionFactory
/** Makes a copy of the passed constructor. The returned
constructor is a "child" of the passed one; see the comments
in Constructor.java for details. */
public <T> Constructor<T> copyConstructor(Constructor<T> arg) {
return langReflectAccess().copyConstructor(arg);
}
// java.lang.reflect.Constructor, copy 其实就是新new一个 Constructor 出来
Constructor<T> copy() {
// This routine enables sharing of ConstructorAccessor objects
// among Constructor objects which refer to the same underlying
// method in the VM. (All of this contortion is only necessary
// because of the "accessibility" bit in AccessibleObject,
// which implicitly requires that new java.lang.reflect
// objects be fabricated for each reflective call on Class
// objects.)
if (this.root != null)
throw new IllegalArgumentException("Can not copy a non-root Constructor");
Constructor<T> res = new Constructor<>(clazz,
parameterTypes,
exceptionTypes, modifiers, slot,
signature,
annotations,
parameterAnnotations);
// root 指向当前 constructor
res.root = this;
// Might as well eagerly propagate this if already present
res.constructorAccessor = constructorAccessor;
return res;
}
然后只需调用对应构造器的 newInstance 方法即可返回实例:
// return tmpConstructor.newInstance((Object[])null);
// java.lang.reflect.Constructor
@CallerSensitive
public T newInstance(Object ... initargs)
throws InstantiationException, IllegalAccessException,
IllegalArgumentException, InvocationTargetException
{
if (!override) {
if (!Reflection.quickCheckMemberAccess(clazz, modifiers)) {
Class<?> caller = Reflection.getCallerClass();
checkAccess(caller, clazz, null, modifiers);
}
}
if ((clazz.getModifiers() & Modifier.ENUM) != 0)
throw new IllegalArgumentException("Cannot reflectively create enum objects");
ConstructorAccessor ca = constructorAccessor; // read volatile
if (ca == null) {
ca = acquireConstructorAccessor();
}
@SuppressWarnings("unchecked")
T inst = (T) ca.newInstance(initargs);
return inst;
}
// sun.reflect.DelegatingConstructorAccessorImpl
public Object newInstance(Object[] args)
throws InstantiationException,
IllegalArgumentException,
InvocationTargetException
{
return delegate.newInstance(args);
}
// sun.reflect.NativeConstructorAccessorImpl
public Object newInstance(Object[] args)
throws InstantiationException,
IllegalArgumentException,
InvocationTargetException
{
// We can't inflate a constructor belonging to a vm-anonymous class
// because that kind of class can't be referred to by name, hence can't
// be found from the generated bytecode.
if (++numInvocations > ReflectionFactory.inflationThreshold()
&& !ReflectUtil.isVMAnonymousClass(c.getDeclaringClass())) {
ConstructorAccessorImpl acc = (ConstructorAccessorImpl)
new MethodAccessorGenerator().
generateConstructor(c.getDeclaringClass(),
c.getParameterTypes(),
c.getExceptionTypes(),
c.getModifiers());
parent.setDelegate(acc);
}
// 调用native方法,进行调用 constructor
return newInstance0(c, args);
}
返回实例之后,可以根据实际需要执行类型转化,以调用具体类型的方法。
反射获取方法
首先获取 Method:
// java.lang.Class
@CallerSensitive
public Method getDeclaredMethod(String name, Class<?>... parameterTypes)
throws NoSuchMethodException, SecurityException {
checkMemberAccess(Member.DECLARED, Reflection.getCallerClass(), true);
Method method = searchMethods(privateGetDeclaredMethods(false), name, parameterTypes);
if (method == null) {
throw new NoSuchMethodException(getName() + "." + name + argumentTypesToString(parameterTypes));
}
return method;
}
- 获取所有方法列表
- 更具方法名和方法列表,找到符合要求的方法
- 如果没有则抛出异常,有则返回方法
首先获取类的所有方法:
// Returns an array of "root" methods. These Method objects must NOT
// be propagated to the outside world, but must instead be copied
// via ReflectionFactory.copyMethod.
private Method[] privateGetDeclaredMethods(boolean publicOnly) {
checkInitted();
Method[] res;
ReflectionData<T> rd = reflectionData();
if (rd != null) {
res = publicOnly ? rd.declaredPublicMethods : rd.declaredMethods;
if (res != null) return res;
}
// No cached value available; request value from VM
res = Reflection.filterMethods(this, getDeclaredMethods0(publicOnly));
if (rd != null) {
if (publicOnly) {
rd.declaredPublicMethods = res;
} else {
rd.declaredMethods = res;
}
}
return res;
}
与构造器类似,首先读取缓存,没有缓存则从 JVM 中获取。
不同的是,方法列表执行过滤 Reflection.filterMethods。
// sun.misc.Reflection
public static Method[] filterMethods(Class<?> containingClass, Method[] methods) {
if (methodFilterMap == null) {
// Bootstrapping
return methods;
}
return (Method[])filter(methods, methodFilterMap.get(containingClass));
}
// 可以过滤指定的方法,一般为空,如果要指定过滤,可以调用 registerMethodsToFilter(), 或者...
private static Member[] filter(Member[] members, String[] filteredNames) {
if ((filteredNames == null) || (members.length == 0)) {
return members;
}
int numNewMembers = 0;
for (Member member : members) {
boolean shouldSkip = false;
for (String filteredName : filteredNames) {
if (member.getName() == filteredName) {
shouldSkip = true;
break;
}
}
if (!shouldSkip) {
++numNewMembers;
}
}
Member[] newMembers =
(Member[])Array.newInstance(members[0].getClass(), numNewMembers);
int destIdx = 0;
for (Member member : members) {
boolean shouldSkip = false;
for (String filteredName : filteredNames) {
if (member.getName() == filteredName) {
shouldSkip = true;
break;
}
}
if (!shouldSkip) {
newMembers[destIdx++] = member;
}
}
return newMembers;
}
然后根据方法名和参数类型过滤指定方法返回:
private static Method searchMethods(Method[] methods,
String name,
Class<?>[] parameterTypes)
{
Method res = null;
// 使用常量池,避免重复创建String
String internedName = name.intern();
for (int i = 0; i < methods.length; i++) {
Method m = methods[i];
if (m.getName() == internedName
&& arrayContentsEq(parameterTypes, m.getParameterTypes())
&& (res == null
|| res.getReturnType().isAssignableFrom(m.getReturnType())))
res = m;
}
return (res == null ? res : getReflectionFactory().copyMethod(res));
}
在执行匹配的过程将会尝试最精确的匹配,最后会通过 ReflectionFactory.copy 返回方法。
调用 method.invoke
@CallerSensitive
public Object invoke(Object obj, Object... args)
throws IllegalAccessException, IllegalArgumentException,
InvocationTargetException
{
if (!override) {
if (!Reflection.quickCheckMemberAccess(clazz, modifiers)) {
Class<?> caller = Reflection.getCallerClass();
checkAccess(caller, clazz, obj, modifiers);
}
}
MethodAccessor ma = methodAccessor; // read volatile
if (ma == null) {
ma = acquireMethodAccessor();
}
return ma.invoke(obj, args);
}
通过 MethodAccessor 执行调用,而 MethodAccessor 为接口,在第一次使用时或调用 acquireMethodAccessor 新建实例。
// probably make the implementation more scalable.
private MethodAccessor acquireMethodAccessor() {
// First check to see if one has been created yet, and take it
// if so
MethodAccessor tmp = null;
if (root != null) tmp = root.getMethodAccessor();
if (tmp != null) {
// 存在缓存时,存入 methodAccessor,否则调用 ReflectionFactory 创建新的 MethodAccessor
methodAccessor = tmp;
} else {
// Otherwise fabricate one and propagate it up to the root
tmp = reflectionFactory.newMethodAccessor(this);
setMethodAccessor(tmp);
}
return tmp;
}
// sun.reflect.ReflectionFactory
public MethodAccessor newMethodAccessor(Method method) {
checkInitted();
if (noInflation && !ReflectUtil.isVMAnonymousClass(method.getDeclaringClass())) {
return new MethodAccessorGenerator().
generateMethod(method.getDeclaringClass(),
method.getName(),
method.getParameterTypes(),
method.getReturnType(),
method.getExceptionTypes(),
method.getModifiers());
} else {
NativeMethodAccessorImpl acc =
new NativeMethodAccessorImpl(method);
DelegatingMethodAccessorImpl res =
new DelegatingMethodAccessorImpl(acc);
acc.setParent(res);
return res;
}
}
两种 Accessor 的细节:
// NativeMethodAccessorImpl / DelegatingMethodAccessorImpl
class NativeMethodAccessorImpl extends MethodAccessorImpl {
private final Method method;
private DelegatingMethodAccessorImpl parent;
private int numInvocations;
NativeMethodAccessorImpl(Method method) {
this.method = method;
}
public Object invoke(Object obj, Object[] args)
throws IllegalArgumentException, InvocationTargetException
{
// We can't inflate methods belonging to vm-anonymous classes because
// that kind of class can't be referred to by name, hence can't be
// found from the generated bytecode.
if (++numInvocations > ReflectionFactory.inflationThreshold()
&& !ReflectUtil.isVMAnonymousClass(method.getDeclaringClass())) {
MethodAccessorImpl acc = (MethodAccessorImpl)
new MethodAccessorGenerator().
generateMethod(method.getDeclaringClass(),
method.getName(),
method.getParameterTypes(),
method.getReturnType(),
method.getExceptionTypes(),
method.getModifiers());
parent.setDelegate(acc);
}
return invoke0(method, obj, args);
}
void setParent(DelegatingMethodAccessorImpl parent) {
this.parent = parent;
}
private static native Object invoke0(Method m, Object obj, Object[] args);
}
class DelegatingMethodAccessorImpl extends MethodAccessorImpl {
private MethodAccessorImpl delegate;
DelegatingMethodAccessorImpl(MethodAccessorImpl delegate) {
setDelegate(delegate);
}
public Object invoke(Object obj, Object[] args)
throws IllegalArgumentException, InvocationTargetException
{
return delegate.invoke(obj, args);
}
void setDelegate(MethodAccessorImpl delegate) {
this.delegate = delegate;
}
}
执行 method.invoke(obj, args) 时,滴啊用 DelegatingMethodAccessorImpl.invoke(),最后被委托到 NativeMethodAccessorImpl.invoke():
public Object invoke(Object obj, Object[] args)
throws IllegalArgumentException, InvocationTargetException
{
// We can't inflate methods belonging to vm-anonymous classes because
// that kind of class can't be referred to by name, hence can't be
// found from the generated bytecode.
if (++numInvocations > ReflectionFactory.inflationThreshold()
&& !ReflectUtil.isVMAnonymousClass(method.getDeclaringClass())) {
MethodAccessorImpl acc = (MethodAccessorImpl)
new MethodAccessorGenerator().
generateMethod(method.getDeclaringClass(),
method.getName(),
method.getParameterTypes(),
method.getReturnType(),
method.getExceptionTypes(),
method.getModifiers());
parent.setDelegate(acc);
}
// invoke0 是个 native 方法,由jvm进行调用业务方法。从而完成反射调用功能。
return invoke0(method, obj, args);
}
其中,generateMethod 是生成具体类的方法:
/** This routine is not thread-safe */
public MethodAccessor generateMethod(Class<?> declaringClass,
String name,
Class<?>[] parameterTypes,
Class<?> returnType,
Class<?>[] checkedExceptions,
int modifiers)
{
return (MethodAccessor) generate(declaringClass,
name,
parameterTypes,
returnType,
checkedExceptions,
modifiers,
false,
false,
null);
}
generate 的实现中会出现:ClassDefiner.defineClass(xx, declaringClass.getClassLoader()).newInstance()。
在ClassDefiner.defineClass方法实现中,每被调用一次都会生成一个DelegatingClassLoader类加载器对象 ,这里每次都生成新的类加载器,是为了性能考虑,在某些情况下可以卸载这些生成的类,因为类的卸载是只有在类加载器可以被回收的情况下才会被回收的,如果用了原来的类加载器,那可能导致这些新创建的类一直无法被卸载。
而反射生成的类,有时候可能用了就可以卸载了,所以使用其独立的类加载器,从而使得更容易控制反射类的生命周期。
反射汇总
- 反射类及反射方法的获取,都是通过从列表中搜寻查找匹配的方法,所以查找性能会随类的大小方法多少而变化;
- 每个类都会有一个与之对应的Class实例,从而每个类都可以获取method反射方法,并作用到其他实例身上;
- 反射也是考虑了线程安全;
- 反射使用软引用relectionData缓存class信息,避免每次重新从jvm获取带来的开销;
- 反射调用多次生成新代理Accessor, 而通过字节码生成的则考虑了卸载功能,所以会使用独立的类加载器;
- 当找到需要的方法,都会copy一份出来,而不是使用原来的实例,从而保证数据隔离;
- 调用反射方法,最终是由jvm执行invoke0()执行;
1.8 - CH08-SPI 机制
概览
Service Provider Interface(SPI) 是 JDK 内置的服务发现机制,可以用来启用框架扩展或替换组件,主要用于框架。比如 java.sql.Driver 接口,不同的数据库厂商可以针对同一接口提供不同的实现,MySQL 和 PostgreSQL 分别为用户提供了不同的实现。
Java SPI 机制的主要思想是将装配的控制权移交到程序之外,目的在于解耦。
当服务的提供者提供了一种接口的实现后,需要在 classpath 下的 META-INF/services/ 目录中创建一个以服务接口命名的文件,并在该文件中添加实现类的完全限定名。其他程序可以通过 ServiceLoader 查找这个 jar 包的配置文件,根据其中的实现类名加载并实例化,然后使用实现类提供的功能。
示例
定义接口
public interface Serach {
List<String> serach(String keyword);
}
实现接口
public class FileSearch implements Search {
@Override
public List<String> search(String keyword){
return ...;
}
}
public class DatabaseSearch implements Search {
@Override
public List<String> search(String keyword){
return ...;
}
}
在 /resource/META-INF/services/ 目录下创建 com.example.Search 文件,在其中添加我们要使用的某个实现类的完全限定名,如com.example.FileSearch。
加载接口实现类
ServiceLoader<Search> impls = SeraiceLoader.load(Serach.class);
Iterator<Serach> itor = impls.iterator();
while(itor.hasNext()){
Search search = itor.next();
search.search("keyword");
}
实际应用
JDBC DriverManager
- JDBC 接口定义:首先 Java 中定义了接口
java.sql.Driver。 - MySQL 实现类:在 mysql-connector-java-version.jar 中,可以找打
META-INF/services 目录查看其中的 java.sql.Driver 文件,其中定义了实现类名 com.mysql.cj.jdbc.Driver。 - 加载实现类:
DriverManager.getConnection(uil,username,password)。
DriverManager 的具体加载过程:
private static void loadInitialDrivers() {
String drivers;
try {
drivers = AccessController.doPrivileged(new PrivilegedAction<String>() {
public String run() {
return System.getProperty("jdbc.drivers");
}
});
} catch (Exception ex) {
drivers = null;
}
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
//使用SPI的ServiceLoader来加载接口的实现
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
try{
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
// Do nothing
}
return null;
}
});
println("DriverManager.initialize: jdbc.drivers = " + drivers);
if (drivers == null || drivers.equals("")) {
return;
}
String[] driversList = drivers.split(":");
println("number of Drivers:" + driversList.length);
for (String aDriver : driversList) {
try {
println("DriverManager.Initialize: loading " + aDriver);
Class.forName(aDriver, true,
ClassLoader.getSystemClassLoader());
} catch (Exception ex) {
println("DriverManager.Initialize: load failed: " + ex);
}
}
}
- 从系统变量中获取有关驱动的定义。
- 使用 SPI 获取驱动实现。
- 遍历 SPI 获取到的具体实现类,实例化各个实现类。
- 根据第一步得到的驱动列表实例化具体实现类。
Common Logging
通过 LogFactory.getLog 获取日志实例:
public static getLog(Class clazz) throws LogConfigurationException {
return getFactory().getInstance(clazz);
}
LogFactory 是一个抽象类,它负责加载具体的日志实现,具体过程为:
- 从 JVM 系统属性获取相关配置
- 使用 SPI 查找得到
org.apache.commons.logging.LogFactory 实现 - 查找 classpath 根目录
commons-logging.properties 的属性是否设置特定的实现 - 使用默认实现类
Eclipse OSGI 插件体系
Eclipse使用OSGi作为插件系统的基础,动态添加新插件和停止现有插件,以动态的方式管理组件生命周期。
一般来说,插件的文件结构必须在指定目录下包含以下三个文件:
META-INF/MANIFEST.MF: 项目基本配置信息,版本、名称、启动器等build.properties: 项目的编译配置信息,包括,源代码路径、输出路径plugin.xml:插件的操作配置信息,包含弹出菜单及点击菜单后对应的操作执行类等
当eclipse启动时,会遍历plugins文件夹中的目录,扫描每个插件的清单文件MANIFEST.MF,并建立一个内部模型来记录它所找到的每个插件的信息,就实现了动态添加新的插件。
这也意味着是 eclipse 制定了一系列的规则,像是文件结构、类型、参数等。插件开发者遵循这些规则去开发自己的插件,eclipse并不需要知道插件具体是怎样开发的,只需要在启动的时候根据配置文件解析、加载到系统里就好了,是spi思想的一种体现。
Spring Factory
在 springboot 的自动装配过程中,最终会加载META-INF/spring.factories文件,而加载的过程是由SpringFactoriesLoader加载的。从 CLASSPATH 下的每个 Jar 包中搜寻所有META-INF/spring.factories配置文件,然后将解析 properties 文件,找到指定名称的配置后返回。需要注意的是,其实这里不仅仅是会去 ClassPath 路径下查找,会扫描所有路径下的 Jar 包,只不过这个文件只会在 Classpath 下的 jar 包中。
实现原理
ServiceLoader 的具体实现:
//ServiceLoader实现了Iterable接口,可以遍历所有的服务实现者
public final class ServiceLoader<S>
implements Iterable<S>
{
//查找配置文件的目录
private static final String PREFIX = "META-INF/services/";
//表示要被加载的服务的类或接口
private final Class<S> service;
//这个ClassLoader用来定位,加载,实例化服务提供者
private final ClassLoader loader;
// 访问控制上下文
private final AccessControlContext acc;
// 缓存已经被实例化的服务提供者,按照实例化的顺序存储
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
// 迭代器
private LazyIterator lookupIterator;
//重新加载,就相当于重新创建ServiceLoader了,用于新的服务提供者安装到正在运行的Java虚拟机中的情况。
public void reload() {
//清空缓存中所有已实例化的服务提供者
providers.clear();
//新建一个迭代器,该迭代器会从头查找和实例化服务提供者
lookupIterator = new LazyIterator(service, loader);
}
//私有构造器
//使用指定的类加载器和服务创建服务加载器
//如果没有指定类加载器,使用系统类加载器,就是应用类加载器。
private ServiceLoader(Class<S> svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
reload();
}
//解析失败处理的方法
private static void fail(Class<?> service, String msg, Throwable cause)
throws ServiceConfigurationError
{
throw new ServiceConfigurationError(service.getName() + ": " + msg,
cause);
}
private static void fail(Class<?> service, String msg)
throws ServiceConfigurationError
{
throw new ServiceConfigurationError(service.getName() + ": " + msg);
}
private static void fail(Class<?> service, URL u, int line, String msg)
throws ServiceConfigurationError
{
fail(service, u + ":" + line + ": " + msg);
}
//解析服务提供者配置文件中的一行
//首先去掉注释校验,然后保存
//返回下一行行号
//重复的配置项和已经被实例化的配置项不会被保存
private int parseLine(Class<?> service, URL u, BufferedReader r, int lc,
List<String> names)
throws IOException, ServiceConfigurationError
{
//读取一行
String ln = r.readLine();
if (ln == null) {
return -1;
}
//#号代表注释行
int ci = ln.indexOf('#');
if (ci >= 0) ln = ln.substring(0, ci);
ln = ln.trim();
int n = ln.length();
if (n != 0) {
if ((ln.indexOf(' ') >= 0) || (ln.indexOf('\t') >= 0))
fail(service, u, lc, "Illegal configuration-file syntax");
int cp = ln.codePointAt(0);
if (!Character.isJavaIdentifierStart(cp))
fail(service, u, lc, "Illegal provider-class name: " + ln);
for (int i = Character.charCount(cp); i < n; i += Character.charCount(cp)) {
cp = ln.codePointAt(i);
if (!Character.isJavaIdentifierPart(cp) && (cp != '.'))
fail(service, u, lc, "Illegal provider-class name: " + ln);
}
if (!providers.containsKey(ln) && !names.contains(ln))
names.add(ln);
}
return lc + 1;
}
//解析配置文件,解析指定的url配置文件
//使用parseLine方法进行解析,未被实例化的服务提供者会被保存到缓存中去
private Iterator<String> parse(Class<?> service, URL u)
throws ServiceConfigurationError
{
InputStream in = null;
BufferedReader r = null;
ArrayList<String> names = new ArrayList<>();
try {
in = u.openStream();
r = new BufferedReader(new InputStreamReader(in, "utf-8"));
int lc = 1;
while ((lc = parseLine(service, u, r, lc, names)) >= 0);
}
return names.iterator();
}
//服务提供者查找的迭代器
private class LazyIterator
implements Iterator<S>
{
Class<S> service;//服务提供者接口
ClassLoader loader;//类加载器
Enumeration<URL> configs = null;//保存实现类的url
Iterator<String> pending = null;//保存实现类的全名
String nextName = null;//迭代器中下一个实现类的全名
private LazyIterator(Class<S> service, ClassLoader loader) {
this.service = service;
this.loader = loader;
}
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
c = Class.forName(cn, false, loader);
}
if (!service.isAssignableFrom(c)) {
fail(service, "Provider " + cn + " not a subtype");
}
try {
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
}
}
public boolean hasNext() {
if (acc == null) {
return hasNextService();
} else {
PrivilegedAction<Boolean> action = new PrivilegedAction<Boolean>() {
public Boolean run() { return hasNextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
public S next() {
if (acc == null) {
return nextService();
} else {
PrivilegedAction<S> action = new PrivilegedAction<S>() {
public S run() { return nextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
public void remove() {
throw new UnsupportedOperationException();
}
}
//获取迭代器
//返回遍历服务提供者的迭代器
//以懒加载的方式加载可用的服务提供者
//懒加载的实现是:解析配置文件和实例化服务提供者的工作由迭代器本身完成
public Iterator<S> iterator() {
return new Iterator<S>() {
//按照实例化顺序返回已经缓存的服务提供者实例
Iterator<Map.Entry<String,S>> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}
//为指定的服务使用指定的类加载器来创建一个ServiceLoader
public static <S> ServiceLoader<S> load(Class<S> service,
ClassLoader loader)
{
return new ServiceLoader<>(service, loader);
}
//使用线程上下文的类加载器来创建ServiceLoader
public static <S> ServiceLoader<S> load(Class<S> service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
//使用扩展类加载器为指定的服务创建ServiceLoader
//只能找到并加载已经安装到当前Java虚拟机中的服务提供者,应用程序类路径中的服务提供者将被忽略
public static <S> ServiceLoader<S> loadInstalled(Class<S> service) {
ClassLoader cl = ClassLoader.getSystemClassLoader();
ClassLoader prev = null;
while (cl != null) {
prev = cl;
cl = cl.getParent();
}
return ServiceLoader.load(service, prev);
}
public String toString() {
return "java.util.ServiceLoader[" + service.getName() + "]";
}
}
- SeriviceLoader 实现了 Iterable 接口,所有具有迭代器属性,即 hasNext 和 next。其中主要是调用 lookupIterator 的对应 hasNext 和 next 方法,lookupIterator 为懒加载迭代器。
- LazyIterator 中的 hasNext 方法,静态变量 PREFIX 为
META-INF/services 目录。 - 通过反射
Class.forName 加载类对象,并通过 newInstance 方法创建实现类的实例,并将实例缓存,然后返回实例对象。
2 - Java 集合
2.2 - CH02-ArrayList
概述
- ArrayList 实现了 List 接口,是顺序型容器,允许 NULL 元素,底层结构为数组。
- 除了没有实现线程安全,其余实现与 Vector 类似。
- 拥有容量(capacity)属性,表示底层数组大小,实际元素个数不能大于容量。
- 容量不足以承载更多元素时,会执行扩容。
- size、isEmpty、get、set 均可在常数时间内完成。
- add 的时间开销与插入位置有关。
- addAll 的时间开销与所要添加元素的个数成正比。
- 其余方法大多为线性时间。
内部实现
数据结构
transient Object[] elementData;
private int size;
构造函数
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; // 10
}
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
自动扩容
每当向数组中添加元素时,都要去检查添加后元素的个数是否会超出当前数组的长度,如果超出,数组将会进行扩容,以满足添加数据的需求。数组扩容通过一个公开的方法ensureCapacity(int minCapacity)来实现。在实际添加大量元素前,我也可以使用ensureCapacity来手动增加ArrayList实例的容量,以减少递增式再分配的数量。
数组进行扩容时,会将老数组中的元素重新拷贝一份到新的数组中,每次数组容量的增长大约是其原容量的 1.5 倍。这种操作的代价是很高的,因此在实际使用时,我们应该尽量避免数组容量的扩张。当我们可预知要保存的元素的多少时,要在构造ArrayList实例时,就指定其容量,以避免数组扩容的发生。或者根据实际需求,通过调用ensureCapacity方法来手动增加ArrayList实例的容量。
/**
* Increases the capacity of this <tt>ArrayList</tt> instance, if
* necessary, to ensure that it can hold at least the number of elements
* specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
public void ensureCapacity(int minCapacity) {
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
/**
* The maximum size of array to allocate.
* Some VMs reserve some header words in an array.
* Attempts to allocate larger arrays may result in
* OutOfMemoryError: Requested array size exceeds VM limit
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
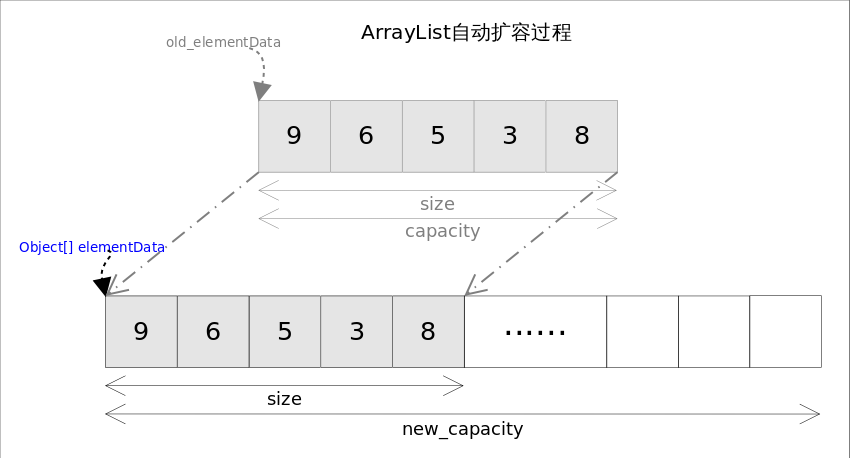
add/addAll
添加单个元素的方法 add(E e) 和 add(int index, E e),在执行之前都需要检查剩余容量,如果需要则自动扩容,即执行 grow 方法。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
add(int index, E e) 首先需要移动元素,然后完成插入操作,因此具有线性时间的复杂度。
addAll() 能够一次添加多个元素,根据添加的位置拥有两种版本的实现:
- 向末尾添加:
addAll(Collection<? extends E> c) - 向指定位置添加:
addAll(int index, Collection<? extends E> c)
在插入之前也需要扩容检查,如果需要就执行扩容。如果插入指定位置,也需要移动元素。因此同时与插入元素的数据和插入的位置相关。
set
首先执行越界检查,然后对数组指定位置的元素赋值。
get
首先执行越界检查,然后数组指定位置的元素值,最后转换类型。
remove
remove(int index) 删除指定位置的元素remove(Object o) 删除第一满足 equals 条件的元素
remove 是 add 的逆操作,需要将删除位置之后的元素向前移动。
为了让 GC 起作用,必须显式的为最后一个位置赋值为 null,即解除引用。如果不设为 null,那么该位置将会继续引用原有的对象,除非被一个新的对象覆盖。
trimToSize
该方法可以将数组的容量调整为当前实际元素的个数。
/**
* Trims the capacity of this <tt>ArrayList</tt> instance to be the
* list's current size. An application can use this operation to minimize
* the storage of an <tt>ArrayList</tt> instance.
*/
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
indexOf, lastIndexOf
分别获取第一次和最后一次出现的元素位置:
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
fail-fast 机制
通过记录 modCount 的值,在面对并发修改时,迭代器很快就会完全失败,避免在将来某个不确定时间发生任意不确定行为。
2.3 - CH03-LinkedList
概述
- LinkedList 同时实现了 List 接口和 Deque 接口,也就是说它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(Stack)。
- 栈或队列,现在的首选是 ArrayDeque,它有着比 LinkedList (当作栈或队列使用时)有着更好的性能。
- 所有跟下标相关的操作都是线性时间。
- 在首段或者末尾删除元素只需要常数时间。
- 为追求效率 LinkedList 没有实现同步(synchronized)。
内部实现
数据结构
- 底层通过双向链表实现。
- 双向链表的每个节点用内部类 Node 表示。
- LinkedList 通过
first和last引用分别指向链表的第一个和最后一个元素。 - 当链表为空的时候
first和last都指向null。
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
构造函数
/**
* Constructs an empty list.
*/
public LinkedList() {
}
/**
* Constructs a list containing the elements of the specified
* collection, in the order they are returned by the collection's
* iterator.
*
* @param c the collection whose elements are to be placed into this list
* @throws NullPointerException if the specified collection is null
*/
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
getFirst, getLast
/**
* Returns the first element in this list.
*
* @return the first element in this list
* @throws NoSuchElementException if this list is empty
*/
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
/**
* Returns the last element in this list.
*
* @return the last element in this list
* @throws NoSuchElementException if this list is empty
*/
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
removeFirest(), removeLast(), remove(e), remove(index)
remove 可以删除首个 equals 指定对象的元素,或者删除指定位置的元素。
add
add(E e) 将在末尾添加元素,因为 last 指向链表的末尾元素,因此操作为常数时间,仅需修改几个相关的引用即可。
add(int index, E element) 是在指定位置插入元素,首选需要线性查找到具体位置,然后修改相关引用,完成操作。
addAll
addAll(index, c) 实现方式并不是直接调用add(index,e)来实现,主要是因为效率的问题,另一个是fail-fast中modCount只会增加1次;
/**
* Appends all of the elements in the specified collection to the end of
* this list, in the order that they are returned by the specified
* collection's iterator. The behavior of this operation is undefined if
* the specified collection is modified while the operation is in
* progress. (Note that this will occur if the specified collection is
* this list, and it's nonempty.)
*
* @param c collection containing elements to be added to this list
* @return {@code true} if this list changed as a result of the call
* @throws NullPointerException if the specified collection is null
*/
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
/**
* Inserts all of the elements in the specified collection into this
* list, starting at the specified position. Shifts the element
* currently at that position (if any) and any subsequent elements to
* the right (increases their indices). The new elements will appear
* in the list in the order that they are returned by the
* specified collection's iterator.
*
* @param index index at which to insert the first element
* from the specified collection
* @param c collection containing elements to be added to this list
* @return {@code true} if this list changed as a result of the call
* @throws IndexOutOfBoundsException {@inheritDoc}
* @throws NullPointerException if the specified collection is null
*/
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index);
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
Node<E> pred, succ;
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
clear
为了让GC更快可以回收放置的元素,需要将node之间的引用关系赋值为 null。
/**
* Removes all of the elements from this list.
* The list will be empty after this call returns.
*/
public void clear() {
// Clearing all of the links between nodes is "unnecessary", but:
// - helps a generational GC if the discarded nodes inhabit
// more than one generation
// - is sure to free memory even if there is a reachable Iterator
for (Node<E> x = first; x != null; ) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
first = last = null;
size = 0;
modCount++;
}
Positional Access 方法
通过 index 获取元素:
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
通过 index 赋值元素:
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
通过 index 插入元素:
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
通过 index 删除元素:
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
查找
即查找元素的下标,查找第一次出现元素值相等的 index,否则返回 -1:
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
查找最后一次出现的元素则类似,区别是从 last 开始向前查找。
Queue 方法
- peek
- element
- poll
- remove
- offer
Deque 方法
- offerFirst
- offerLast
- peekFirst
- peekLast
- pollFirst
- pollLast
- push
- pop
2.4 - CH04-Stack-Queue
概述
- Java 中存在 Stack 实现类,但没有提供 Queue 实现类,仅有一个 Queue 接口。
- 但是在需要使用栈时,Java 推荐的结果是更加高效的 ArrayQueue。
- 在需要使用队列时,首选是 ArrayQueue,其次是 LinkedList。
Queue
Queue 接口继承自 Collection 接口,除了最基本的 Collection 方法之外,还额外支持 insertion、extraction、inspection 操作。这里有两组格式共 6 个方法,一组是抛出异常的实现,一组是返回值的实现(或 null)。
| Throws Exception | Returns special Value |
|---|
| Insert | add(e) | offer(e) |
| Remove | remove() | poll() |
| Examine | element() | peek() |
Deque
Deque 是 “double ended queue”,表示双向队列,英文读作 deck。Deque 继承自 Queue 接口,除了支持 Queue 的方法外,还支持 insert、remove、examine 操作。
由于 Deque 是双向的,所以可以支持队列的头尾操作,同时支持两种格式共 12 个方法:
| First Element-Head | | Last Element-Tail | |
|---|
| Throws Exception | Special Value | Throws Exception | Speicial Value |
| Insert | addFirst(e) | offerFirst(e) | addLast(e) | offerLast(e) |
| Remove | removeFirst() | pollFirst() | removeLast() | pollLast() |
| Examine | getFirst() | peekFirst() | getLast() | peekLast() |
当把 Deque 当做 FIFO 来使用时,元素是从 deque 的尾部添加,从头部进行删除。所谓 Deque 的部分方法和 Queue 是等同的。
| Queue Method | Equivalent Deque Method | 说明 |
|---|
| add(e) | addLast(e) | 向队尾添加元素,失败时抛异常 |
| offer(e) | offerLast(e) | 向队尾添加元素,失败时返回 false |
| remove() | removeFirst() | 获取并删除队首元素,失败时抛异常 |
| poll() | pollFirst() | 获取并删除队首元素,失败时返回 null |
| element() | getFirst() | 获取但不删除队首元素,失败时抛异常 |
| peek() | peekFirst() | 获取但不删除队首元素,失败时返回 null |
Deque 与 Stack 的对应方法:
| Stack Method | Equivalent Deque Method | 说明 |
|---|
| push(e) | addFirst(e) | 向栈顶插入元素,失败则抛出异常 |
| 无 | offerFirst(e) | 向栈顶插入元素,失败则返回false |
| pop() | removeFirst() | 获取并删除栈顶元素,失败则抛出异常 |
| 无 | pollFirst() | 获取并删除栈顶元素,失败则返回null |
| peek() | peekFirst() | 获取但不删除栈顶元素,失败则抛出异常 |
| 无 | peekFirst() | 获取但不删除栈顶元素,失败则返回null |
以上操作中,除非对容量有限制,否则添加操作是不会失败的。
ArrayDeque
ArrayDeque 底层为数组结构,为了满足可以同时在数组两端添加或删除元素,该数组必须是循环数组,即数组的任何一点都可能被看做起点或终点。
ArrayDeque 非线程安全,不能添加 null 元素。
head 指向首端第一个有效元素,tail 指向尾端第一个可以插入元素的空位。
因为是循环数组,所谓 head 的位置不一定是 0,tail 的位置也不一定总是比 head 的位置大。
addFirst
在 Deque 首端添加元素,也就是在 head 前面添加元素,在空间足够且下标没有越界的情况下,只需要将 elements[--head]=e 即可。即将 head 的索引递减 1 的位置赋值为新加的元素。
//addFirst(E e)
public void addFirst(E e) {
if (e == null)//不允许放入null
throw new NullPointerException();
elements[head = (head - 1) & (elements.length - 1)] = e;//2.下标是否越界
if (head == tail)//1.空间是否够用
doubleCapacity();//扩容
}
上述代码中可以发现,空间问题是在插入之后开始解决的,因为 tail 总是指向下一个可插入的空位,也就意味着 elements 数组至少会存在一个空位,所以插入元素时不用先考虑空间问题。
下标越界的解决方法很简单,head = (head -1) & (elements.length -1)即可,这段代码相当于取余,同时解决了 head 值为负的情况。因为 elements.length 必须是 2 的指数倍,elements -1 就是二进制低位全为 1,跟 head-1 相与之后就起到了取模的作用,如果 head-1为负(-1),则相当于对其取 elements.length 的补码。
对于扩容函数 doubleCapacity,其逻辑就是申请一个更大的数组(原数据的两倍空间),然后复制原来的元素。
复制分为两次,第一次复制 head 右边的元素,第二次复制 head 左边的数据。
addLast
作用是在 Deque 的尾端插入元素,也就是在tail的位置插入元素,由于tail总是指向下一个可以插入的空位,因此只需要elements[tail] = e;即可。插入完成后再检查空间,如果空间已经用光,则调用doubleCapacity()进行扩容。
poolFirst
作用是删除并返回 Deque 首端元素,也即是head位置处的元素。如果容器不空,只需要直接返回elements[head]即可,当然还需要处理下标的问题。由于ArrayDeque中不允许放入null,当elements[head] == null时,意味着容器为空。
pollLast
作用是删除并返回Deque尾端元素,也即是tail位置前面的那个元素。
peekFirst
作用是返回但不删除Deque首端元素,也即是head位置处的元素,直接返回elements[head]即可。
peekLast
作用是返回但不删除Deque尾端元素,也即是tail位置前面的那个元素。
2.5 - CH05-PriorityQueue
概览
- 优先队列的作用是能保证每次取出的元素都是队列中权值最小的。
- 元素大小的评判可以通过元素本身的自然顺序(natural ordering),也可以通过构造时传入的比较器。
- Java 中 PriorityQueue 实现了 Queue 接口,不允许放入
null元素。 - 底层结构为堆,通过完全二叉树实现的小顶堆,表示可以通过数组作为实现结构。
- PriorityQueue 的
peek()和element()操作是常数时间,add(), offer(), 无参数的remove()以及poll()方法的时间复杂度都是log(N)。
观察上图中每个元素的索引编号,会发现父节点与子节点的编号存在联系:
- leftNo = parentNo*2+1
- rightNo = parentNo*2+2
- parentNo = (nodeNo-1)/2
通过这三个公式,可以轻易计算出某个节点的父节点以及子节点的索引编号。即可以通过数组来实现存储堆。
方法实现
add & offer
两者语义相同,都是相对列中添加元素,只是 Queue 接口规定二者对插入失败是的处理方式不同,前者抛出异常,后者返回 false。
新加入的元素可能会破坏小顶堆的性质,因此需要进行必要的调整。
//offer(E e)
public boolean offer(E e) {
if (e == null)//不允许放入null元素
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);//自动扩容
size = i + 1;
if (i == 0)//队列原来为空,这是插入的第一个元素
queue[0] = e;
else
siftUp(i, e);//调整
return true;
}
扩容函数 grow 类似于 ArrayList 中的 grow 函数,申请更大空间的数组并复制数据。
siftUp(int k, E x) 方法用于插入元素 x 同时维持堆的特性:
//siftUp()
private void siftUp(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;//parentNo = (nodeNo-1)/2
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)//调用比较器的比较方法
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}
调整过程为:从 k 指定的位置开始,将 x 逐层与当前点的 parent 进行比较并交换,直到满足 x >= queue[parent] 为止。
element & peek
语义完全相同,都是获取但不删除队首元素,也就是队列中权值最小的那个元素,二者唯一的区别是当方法失败时前者抛出异常,后者返回null。
根据小顶堆的性质,堆顶那个元素就是全局最小的那个;由于堆用数组表示,根据下标关系,0下标处的那个元素既是堆顶元素。所以直接返回数组0下标处的那个元素即可。
remove & poll
语义也完全相同,都是获取并删除队首元素,区别是当方法失败时前者抛出异常,后者返回null。
由于删除操作会改变队列的结构,为维护小顶堆的性质,需要进行必要的调整。
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
E result = (E) queue[0];//0下标处的那个元素就是最小的那个
E x = (E) queue[s];
queue[s] = null;
if (s != 0)
siftDown(0, x);//调整
return result;
}
上述代码首先记录0下标处的元素,并用最后一个元素替换0下标位置的元素,之后调用siftDown()方法对堆进行调整,最后返回原来0下标处的那个元素(也就是最小的那个元素)。
重点是siftDown(int k, E x)方法,该方法的作用是从k指定的位置开始,将x逐层向下与当前点的左右孩子中较小的那个交换,直到x小于或等于左右孩子中的任何一个为止。
//siftDown()
private void siftDown(int k, E x) {
int half = size >>> 1;
while (k < half) {
//首先找到左右孩子中较小的那个,记录到c里,并用child记录其下标
int child = (k << 1) + 1;//leftNo = parentNo*2+1
Object c = queue[child];
int right = child + 1;
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0)
c = queue[child = right];
if (comparator.compare(x, (E) c) <= 0)
break;
queue[k] = c;//然后用c取代原来的值
k = child;
}
queue[k] = x;
}
remove
用于删除队列中跟o相等的某一个元素(如果有多个相等,只删除一个),该方法不是Queue接口内的方法,而是Collection接口的方法。由于删除操作会改变队列结构,所以要进行调整;又由于删除元素的位置可能是任意的,所以调整过程比其它函数稍加繁琐。具体来说,remove(Object o)可以分为2种情况: 1. 删除的是最后一个元素。直接删除即可,不需要调整。2. 删除的不是最后一个元素,从删除点开始以最后一个元素为参照调用一次siftDown()即可。此处不再赘述。
//remove(Object o)
public boolean remove(Object o) {
//通过遍历数组的方式找到第一个满足o.equals(queue[i])元素的下标
int i = indexOf(o);
if (i == -1)
return false;
int s = --size;
if (s == i) //情况1
queue[i] = null;
else {
E moved = (E) queue[s];
queue[s] = null;
siftDown(i, moved);//情况2
......
}
return true;
}
2.6 - CH06-HashSet-Map
概述
- HashSet 与 HashMap 在 Java 内部的实现类似,前者仅仅是对后者进行了封装。
- HashMap 实现了 Map 接口,允许放入 null key 和 null value。
- 与 HashTable 的区别在于没有实现同步。
- 与 TreeMap 的区别在于不保证元素顺序。
- 采用冲突链表(Sepratate chaining with linked lists)解决哈希冲突。
- 另一种实现是开放地址方式(Open Addressing)。
如果选择合适的哈希函数,put 与 get 方法可以在常数内完成。但是在对 HashMap 执行迭代时,需要遍历整个 table 以及后边跟的冲突链表。因此对于迭代频繁的场景,不宜将 HashMap 的初始大小设置的过大。
有两个参数可以影响 HashMap 的性能:初始容量(inital capacity)和负载系数(load factor)。
初始容量指定了初始 table 的大小,负载系数用来指定自动扩容的临界值。当 entry 的数量超过 capacity * load-factor 时,容器将自动扩容并重新哈希。对于插入元素较多的场景,将初始容量设置较大可以减少重新哈希的次数。
将对象放入到 HashSet 和 HashMap 时,有两个方法要格外留意:hashCode 和 equals。
hashCode 方法决定了对象会被放到哪个 bucket 中,当多个对象的哈希值冲突,equals 方法决定了这些对象是否是同一个对象。因此,如果要将自定义的对象放入到 HashMap 或 HashSet,需要重写 hashCode 和 equals 方法。
HashMap
get
get(Object key)方法根据指定的key值返回对应的value,该方法调用了getEntry(Object key)得到相应的entry,然后返回entry.getValue()。因此getEntry()是算法的核心。 算法思想是首先通过hash()函数得到对应bucket的下标,然后依次遍历冲突链表,通过key.equals(k)方法来判断是否是要找的那个entry。
上图中 hash(k) & (table.length-1) 等价于 hash(k) % table.length,原因是 HashMap 要求 table.length 均为 2 的指数,因此 table.length -1 就是二进制低位全是 1,跟 hash(k) 相与会将哈希值的高位全部抹掉,剩下的就是余数了。
//getEntry()方法
final Entry<K,V> getEntry(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[hash&(table.length-1)];//得到冲突链表
e != null; e = e.next) {//依次遍历冲突链表中的每个entry
Object k;
//依据equals()方法判断是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
put
put(K key, V value)方法是将指定的key, value对添加到map里。该方法首先会对map做一次查找,看是否包含该元组,如果已经包含则直接返回,查找过程类似于getEntry()方法;如果没有找到,则会通过addEntry(int hash, K key, V value, int bucketIndex)方法插入新的entry,插入方式为头插法。
//addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);//自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);//hash%table.length
}
//在冲突链表头部插入新的entry
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
remove
remove(Object key)的作用是删除key值对应的entry,该方法的具体逻辑是在removeEntryForKey(Object key)里实现的。removeEntryForKey()方法会首先找到key值对应的entry,然后删除该entry(修改链表的相应引用)。查找过程跟getEntry()过程类似。
//removeEntryForKey()
final Entry<K,V> removeEntryForKey(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);//hash&(table.length-1)
Entry<K,V> prev = table[i];//得到冲突链表
Entry<K,V> e = prev;
while (e != null) {//遍历冲突链表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {//找到要删除的entry
modCount++; size--;
if (prev == e) table[i] = next;//删除的是冲突链表的第一个entry
else prev.next = next;
return e;
}
prev = e; e = next;
}
return e;
}
HashSet
HashSet是对HashMap的简单包装,对HashSet的函数调用都会转换成合适的HashMap方法。
//HashSet是对HashMap的简单包装
public class HashSet<E>
{
......
//HashSet里面有一个HashMap
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
......
public boolean add(E e) {//简单的方法转换
return map.put(e, PRESENT)==null;
}
......
}
2.7 - CH07-LinkedHashSet-Map
概述
- LinkedHashSet 和 LinkedHashMap 在 Java 中也是类似的实现,前者只是对后者的简单封装。
- LinkedHashMap 实现了 Map 接口,允许放入 null key 和 null value。
- 同时满足 HashMap 和 linked list 的一些特性。
- 可以将 LinkedHashMap 看做是通过 linked list 增强的 HashMap。
- LinkedHashMap 是 HashMap 的直接子类,二者唯一的区别是 LinkedHashMap 在 HashMap 的基础上,采用双向链表的形式将所有 entry 连接起来,以保证元素的迭代顺序和插入顺序相同。
如上图,相比 HashMap,在 entry 部分多了个属性用于连接所有 entry。而 header 用于指向双向链表的头部。
这种结构体还有一个好处,迭代时不需要像 HashMap 那样遍历整个 table,只需要遍历 header 指向的双向链表即可。也就是说,LinkedHashMap 的迭代时间只和 entry 的数量相关,与 table 的大小无关。
有两个参数可以影响 LinkedHashMap 的性能:初始容量(inital capacity)和负载系数(load factor)。初始容量指定了 table 的大小,负载系数用来指定自动扩容的临界值。当entry的数量超过capacity*load_factor时,容器将自动扩容并重新哈希。对于插入元素较多的场景,将初始容量设大可以减少重新哈希的次数。
将对象放入到LinkedHashMap或LinkedHashSet中时,有两个方法需要特别关心: hashCode()和equals()。hashCode()方法决定了对象会被放到哪个bucket里,当多个对象的哈希值冲突时,equals()方法决定了这些对象是否是“同一个对象”。所以,如果要将自定义的对象放入到LinkedHashMap或LinkedHashSet中,需要重写 hashCode()和equals()方法。
内部实现
get
get(Object key)方法根据指定的key值返回对应的value。该方法跟HashMap.get()方法的流程几乎完全一样。
put
put(K key, V value)方法是将指定的key, value对添加到map里。该方法首先会对map做一次查找,看是否包含该元组,如果已经包含则直接返回,查找过程类似于get()方法;如果没有找到,则会通过addEntry(int hash, K key, V value, int bucketIndex)方法插入新的entry。
注意这里的插入有两重含义:
- 从 table 的角度看,新的 entry 需要插入到对应的 bucket 中,当有哈希冲突时,采用头插法将新的 entry 插入到冲突链表的头部。
- 从 header 的角度看,新的 entry 需要插入到双向链表大尾部。
addEntry 的实现逻辑:
// LinkedHashMap.addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);// 自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);// hash%table.length
}
// 1.在冲突链表头部插入新的entry
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
// 2.在双向链表的尾部插入新的entry
e.addBefore(header);
size++;
}
上述代码中用到了 addBefore 方法将新的 entry 插入到双向链表头引用的 header 的前面,这样 e 就称为双向链表中的最后一个元素。addBefore 的实现逻辑如下:
// LinkedHashMap.Entry.addBefor(),将this插入到existingEntry的前面
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
上述到吗只是简单的修改 entry 的引用就实现了整个逻辑。
remove
remove(Object key)的作用是删除key值对应的entry,该方法的具体逻辑是在removeEntryForKey(Object key)里实现的。removeEntryForKey()方法会首先找到key值对应的entry,然后删除该entry(修改链表的相应引用)。查找过程跟get()方法类似。
注意这里的删除也有两重含义:
- 从 table 的角度看,需要将 entry 从对应的 bucket 中删除,如果对应的冲突链表不为空,需要修改冲突链表的引用。
- 从 header 的角度看,需要将该 entry 从双向链表中删除,同时修改链表中前置和后置元素的引用。
removeEntryForKey 的实现逻辑如下:
// LinkedHashMap.removeEntryForKey(),删除key值对应的entry
final Entry<K,V> removeEntryForKey(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);// hash&(table.length-1)
Entry<K,V> prev = table[i];// 得到冲突链表
Entry<K,V> e = prev;
while (e != null) {// 遍历冲突链表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {// 找到要删除的entry
modCount++; size--;
// 1. 将e从对应bucket的冲突链表中删除
if (prev == e) table[i] = next;
else prev.next = next;
// 2. 将e从双向链表中删除
e.before.after = e.after;
e.after.before = e.before;
return e;
}
prev = e; e = next;
}
return e;
}
LinkedHashSet
LinkedHashSet是对LinkedHashMap的简单包装,对LinkedHashSet的函数调用都会转换成合适的LinkedHashMap方法。
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
......
// LinkedHashSet里面有一个LinkedHashMap
public LinkedHashSet(int initialCapacity, float loadFactor) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
......
public boolean add(E e) {//简单的方法转换
return map.put(e, PRESENT)==null;
}
......
}
常用场景
LinkedHashMap除了可以保证迭代顺序外,还有一个非常有用的用法: 可以轻松实现一个采用了FIFO替换策略的缓存。具体说来,LinkedHashMap有一个子类方法protected boolean removeEldestEntry(Map.Entry<K,V> eldest),该方法的作用是告诉Map是否要删除“最老”的Entry,所谓最老就是当前Map中最早插入的Entry,如果该方法返回true,最老的那个元素就会被删除。在每次插入新元素的之后LinkedHashMap会自动询问removeEldestEntry()是否要删除最老的元素。这样只需要在子类中重载该方法,当元素个数超过一定数量时让removeEldestEntry()返回true,就能够实现一个固定大小的FIFO策略的缓存。示例代码如下:
class FifoCache<K,V> extends LinkedHashMap<K,v> {
private final int size;
public FifoCache(int size){
this.size = size;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K,V> eldest){
return size() > size;
}
}
2.8 - CH08-TreeSet-Map
概述
- TreeSet 和 TreeMap 在 Java 中具有类似的实现,前者仅仅是对后者的简单封装。
- TreeMap实现了SortedMap接口,也就是说会按照
key的大小顺序对Map中的元素进行排序,key大小的评判可以通过其本身的自然顺序(natural ordering),也可以通过构造时传入的比较器(Comparator)。 - *TreeMap*底层通过红黑树(Red-Black tree)实现,也就意味着
containsKey(), get(), put(), remove()都有着log(n)的时间复杂度。 - 出于性能原因,TreeMap是非同步的(not synchronized)。
红黑树是一种近似平衡的二叉查找树,它能保证任何一个节点的左右子树的高度差不会超过二者中较低那个的一倍。
具体来说,红黑树是满足如下条件的二叉查找树:
- 每个节点要么是红色,要么是黑色。
- 根节点必须是黑色。
- 红色节点不能有连续(父子节点均不能为红色)。
- 对于每个节点,从该节点至 null(树尾)的任何路径,都含有相同个数的黑色节点。
在树的结构发生改变时(插入或删除),往往会破坏上面的 3 和 4,需要执行调整以使得重新满足所有条件。
树操作
调整可以分为两类,颜色调整和结构调整。
结构调整:左旋
左旋的过程就是想 X 的右子树绕 X 向左方向(逆时针)旋转,使 X 的右子树称为 X 的父亲,同时修改相关节点的引用。旋转之后,二叉查找树的条件仍然满足。
结构调整:右旋
右旋的过程是将 X 的左子树绕 X 向右方向(顺时针)旋转,使 X 的左子树称为 X 的父亲,同时修改相关的引用。旋转之后,二叉查找树的条件仍然满足。
寻找节点后继
对二叉查找树,给定节点 T,其后继(树中大于 T 的最小元素)可以通过如下方式找到:
- T 的右子树不空,则 T 的后继是其右子树中最小的按个元素。
- T 的右子树为空,则 T 的后继是其第一个向左走的父亲。
该操作用于删除红黑树中的删除操作。
// 寻找节点后继函数successor()
static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) {
if (t == null)
return null;
else if (t.right != null) {// 1. t的右子树不空,则t的后继是其右子树中最小的那个元素
Entry<K,V> p = t.right;
while (p.left != null)
p = p.left;
return p;
} else {// 2. t的右孩子为空,则t的后继是其第一个向左走的祖先
Entry<K,V> p = t.parent;
Entry<K,V> ch = t;
while (p != null && ch == p.right) {
ch = p;
p = p.parent;
}
return p;
}
}
内部实现
get
get(Object key)方法根据指定的key值返回对应的value,该方法调用了getEntry(Object key)得到相应的entry,然后返回entry.value。因此getEntry()是算法的核心。算法思想是根据key的自然顺序(或者比较器顺序)对二叉查找树进行查找,直到找到满足k.compareTo(p.key) == 0的entry。
//getEntry()方法
final Entry<K,V> getEntry(Object key) {
......
if (key == null)//不允许key值为null
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;//使用元素的自然顺序
Entry<K,V> p = root;
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)//向左找
p = p.left;
else if (cmp > 0)//向右找
p = p.right;
else
return p;
}
return null;
}
put
put(K key, V value)方法是将指定的key, value对添加到map里。该方法首先会对map做一次查找,看是否包含该元组,如果已经包含则直接返回,查找过程类似于getEntry()方法;如果没有找到则会在红黑树中插入新的entry,如果插入之后破坏了红黑树的约束条件,还需要进行调整(旋转,改变某些节点的颜色)。
public V put(K key, V value) {
......
int cmp;
Entry<K,V> parent;
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;//使用元素的自然顺序
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0) t = t.left;//向左找
else if (cmp > 0) t = t.right;//向右找
else return t.setValue(value);
} while (t != null);
Entry<K,V> e = new Entry<>(key, value, parent);//创建并插入新的entry
if (cmp < 0) parent.left = e;
else parent.right = e;
fixAfterInsertion(e);//调整
size++;
return null;
}
上述代码首先在红黑树上找到合适的位置,然后创建新的 entry 并插入(插入的节点一定是叶子)。难点是调整函数 fixAfterInsertion,需要执行颜色调整和结构调整。
调整函数的具体实现如下,其中用到了前面提到的 rotateLeft 和 rotateRight 函数。通过代码我们可以看到,情况 2 其实是落在情况 3 内。情况 4~6 跟前三种情况是对称的,因此图解中没有展示后 3 种情况。
//红黑树调整函数fixAfterInsertion()
private void fixAfterInsertion(Entry<K,V> x) {
x.color = RED;
while (x != null && x != root && x.parent.color == RED) {
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
Entry<K,V> y = rightOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK); // 情况1
setColor(y, BLACK); // 情况1
setColor(parentOf(parentOf(x)), RED); // 情况1
x = parentOf(parentOf(x)); // 情况1
} else {
if (x == rightOf(parentOf(x))) {
x = parentOf(x); // 情况2
rotateLeft(x); // 情况2
}
setColor(parentOf(x), BLACK); // 情况3
setColor(parentOf(parentOf(x)), RED); // 情况3
rotateRight(parentOf(parentOf(x))); // 情况3
}
} else {
Entry<K,V> y = leftOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK); // 情况4
setColor(y, BLACK); // 情况4
setColor(parentOf(parentOf(x)), RED); // 情况4
x = parentOf(parentOf(x)); // 情况4
} else {
if (x == leftOf(parentOf(x))) {
x = parentOf(x); // 情况5
rotateRight(x); // 情况5
}
setColor(parentOf(x), BLACK); // 情况6
setColor(parentOf(parentOf(x)), RED); // 情况6
rotateLeft(parentOf(parentOf(x))); // 情况6
}
}
}
root.color = BLACK;
}
remove
remove(Object key)的作用是删除key值对应的entry,该方法首先通过上文中提到的getEntry(Object key)方法找到key值对应的entry,然后调用deleteEntry(Entry<K,V> entry)删除对应的entry。由于删除操作会改变红黑树的结构,有可能破坏红黑树的约束条件,因此有可能要进行调整。
getEntry()函数前面已经讲解过,这里重点放deleteEntry()上,该函数删除指定的entry并在红黑树的约束被破坏时进行调用fixAfterDeletion(Entry<K,V> x)进行调整。
由于红黑树是一棵增强版的二叉查找树,红黑树的删除操作跟普通二叉查找树的删除操作也就非常相似,唯一的区别是红黑树在节点删除之后可能需要进行调整。现在考虑一棵普通二叉查找树的删除过程,可以简单分为两种情况:
删除节点 P 的左右子树都为空,或者只有一个子树为空。
删除节点 P 的左右子树都非空。
对于上述情况1,处理起来比较简单,直接将p删除(左右子树都为空时),或者用非空子树替代p(只有一棵子树非空时);对于情况2,可以用p的后继s(树中大于x的最小的那个元素)代替p,然后使用情况1删除s(此时s一定满足情况1.可以画画看)。
基于以上逻辑,红黑树的节点删除函数deleteEntry()代码如下:
// 红黑树entry删除函数deleteEntry()
private void deleteEntry(Entry<K,V> p) {
modCount++;
size--;
if (p.left != null && p.right != null) {// 2. 删除点p的左右子树都非空。
Entry<K,V> s = successor(p);// 后继
p.key = s.key;
p.value = s.value;
p = s;
}
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
if (replacement != null) {// 1. 删除点p只有一棵子树非空。
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
p.left = p.right = p.parent = null;
if (p.color == BLACK)
fixAfterDeletion(replacement);// 调整
} else if (p.parent == null) {
root = null;
} else { // 1. 删除点p的左右子树都为空
if (p.color == BLACK)
fixAfterDeletion(p);// 调整
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}
上述代码中占据大量代码行的,是用来修改父子节点间引用关系的代码,其逻辑并不难理解。下面着重讲解删除后调整函数fixAfterDeletion()。首先请思考一下,删除了哪些点才会导致调整?只有删除点是BLACK的时候,才会触发调整函数,因为删除RED节点不会破坏红黑树的任何约束,而删除BLACK节点会破坏规则4。
跟上文中讲过的fixAfterInsertion()函数一样,这里也要分成若干种情况。记住,无论有多少情况,具体的调整操作只有两种: 1.改变某些节点的颜色,2.对某些节点进行旋转。
上图的整体思路为:将情况 1 首先转换为情况 2,或者转换成 3 或 4。当然,该图解并不意味着调整情况一定是从情况 1 开始的。通过后续的代码我们会发现一些规则:
- 如果是由情况 1 之后紧接着进入情况 2,那么情况 2 之后一定会退出循环(因为 X 为红色)。
- 一旦进入情况 3 和 4,一定会退出循环(因为 X 为 root)。
删除后跳转函数 fixAfterDeletion 的具体实现如下,其中用到了上文中提到的rotateLeft()和rotateRight()函数。通过代码我们能够看到,情况3其实是落在情况4内的。情况5~情况8跟前四种情况是对称的,因此图解中并没有画出后四种情况,读者可以参考代码自行理解。
private void fixAfterDeletion(Entry<K,V> x) {
while (x != root && colorOf(x) == BLACK) {
if (x == leftOf(parentOf(x))) {
Entry<K,V> sib = rightOf(parentOf(x));
if (colorOf(sib) == RED) {
setColor(sib, BLACK); // 情况1
setColor(parentOf(x), RED); // 情况1
rotateLeft(parentOf(x)); // 情况1
sib = rightOf(parentOf(x)); // 情况1
}
if (colorOf(leftOf(sib)) == BLACK &&
colorOf(rightOf(sib)) == BLACK) {
setColor(sib, RED); // 情况2
x = parentOf(x); // 情况2
} else {
if (colorOf(rightOf(sib)) == BLACK) {
setColor(leftOf(sib), BLACK); // 情况3
setColor(sib, RED); // 情况3
rotateRight(sib); // 情况3
sib = rightOf(parentOf(x)); // 情况3
}
setColor(sib, colorOf(parentOf(x))); // 情况4
setColor(parentOf(x), BLACK); // 情况4
setColor(rightOf(sib), BLACK); // 情况4
rotateLeft(parentOf(x)); // 情况4
x = root; // 情况4
}
} else { // 跟前四种情况对称
Entry<K,V> sib = leftOf(parentOf(x));
if (colorOf(sib) == RED) {
setColor(sib, BLACK); // 情况5
setColor(parentOf(x), RED); // 情况5
rotateRight(parentOf(x)); // 情况5
sib = leftOf(parentOf(x)); // 情况5
}
if (colorOf(rightOf(sib)) == BLACK &&
colorOf(leftOf(sib)) == BLACK) {
setColor(sib, RED); // 情况6
x = parentOf(x); // 情况6
} else {
if (colorOf(leftOf(sib)) == BLACK) {
setColor(rightOf(sib), BLACK); // 情况7
setColor(sib, RED); // 情况7
rotateLeft(sib); // 情况7
sib = leftOf(parentOf(x)); // 情况7
}
setColor(sib, colorOf(parentOf(x))); // 情况8
setColor(parentOf(x), BLACK); // 情况8
setColor(leftOf(sib), BLACK); // 情况8
rotateRight(parentOf(x)); // 情况8
x = root; // 情况8
}
}
}
setColor(x, BLACK);
}
TreeSet
前面已经说过TreeSet是对TreeMap的简单包装,对TreeSet的函数调用都会转换成合适的TreeMap方法。
// TreeSet是对TreeMap的简单包装
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
......
private transient NavigableMap<E,Object> m;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public TreeSet() {
this.m = new TreeMap<E,Object>();// TreeSet里面有一个TreeMap
}
......
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
......
}
2.9 - CH09-WeakHashMap
概述
它的特殊之处在于 WeakHashMap 里的entry可能会被GC自动删除,即使程序员没有调用remove()或者clear()方法。
当使用 WeakHashMap 时,即使没有显式的添加或删除任何元素,也可能发生如下情况:
- 调用两次 size 方法所返回的结果不同。
- 调用两次 isEmpty 方法,第一次返回 false,第二次返回 true。
- 调用两次 containskey 方法,首次返回 true,第二次返回 false,尽管两次使用相同的 key。
- 调用两次 get 方法,首次返回 value,第二次返回 null,尽管两次使用相同的对象。
这些特性尤其适用于需要缓存的场景。在缓存场景中,由于内存的局限,不能缓存所有对象,对象缓存命中可以提供系统效率,但缓存 MISS 也不会引起错误,因为可以通过计算重新得到。
Java 内存是通过 GC 自动管理的,GC 会在程序运行过程中自动判断哪些对象是可以被回收的,并在合适的时机执行内存释放。GC 判断某个对象释放可以被回收的依据是,释放有有效的引用指向该对象。如果没有有效引用指向该对象(即基本意味着不存在访问该对象的方式),那么该对象就是可以被回收的。这里的有效应用并不包括弱引用。也就是说,虽然弱引用可以用来访问对象,但进行垃圾回收时弱引用并不会被考虑在内,仅有弱引用指向的对象仍然会被 GC 回收。
WeakHashMap 内部是通过弱引用来管理 entry 的,弱引用的特性应用到 WeakHashMap 上意味着什么呢?将一对 key value 放入到 WeakHashMap 中并不能避免该 key 被 GC 回收,除非在 WeakHashMap 在外还有对该 key 的强引用。
具体实现
类似于 HashMap 和 HashSet。
WeakHashSet
Set<Object> weakHashSet = Collections
.newSetFromMap(new WeakHashMap<Object, Boolean>());
该工具方法可以直接将 Map 包装为 Set,只是对 Map 的简单封装。
// Collections.newSetFromMap()用于将任何Map包装成一个Set
public static <E> Set<E> newSetFromMap(Map<E, Boolean> map) {
return new SetFromMap<>(map);
}
private static class SetFromMap<E> extends AbstractSet<E>
implements Set<E>, Serializable
{
private final Map<E, Boolean> m; // The backing map
private transient Set<E> s; // Its keySet
SetFromMap(Map<E, Boolean> map) {
if (!map.isEmpty())
throw new IllegalArgumentException("Map is non-empty");
m = map;
s = map.keySet();
}
public void clear() { m.clear(); }
public int size() { return m.size(); }
public boolean isEmpty() { return m.isEmpty(); }
public boolean contains(Object o) { return m.containsKey(o); }
public boolean remove(Object o) { return m.remove(o) != null; }
public boolean add(E e) { return m.put(e, Boolean.TRUE) == null; }
public Iterator<E> iterator() { return s.iterator(); }
public Object[] toArray() { return s.toArray(); }
public <T> T[] toArray(T[] a) { return s.toArray(a); }
public String toString() { return s.toString(); }
public int hashCode() { return s.hashCode(); }
public boolean equals(Object o) { return o == this || s.equals(o); }
public boolean containsAll(Collection<?> c) {return s.containsAll(c);}
public boolean removeAll(Collection<?> c) {return s.removeAll(c);}
public boolean retainAll(Collection<?> c) {return s.retainAll(c);}
// addAll is the only inherited implementation
......
}
2.10 - CH10-Stream
Stream 是 JDK1.8 中首次引入的,距今已经过去了接近8年时间(JDK1.8正式版是2013年底发布的)。Stream 的引入一方面极大地简化了某些开发场景,另一方面也可能降低了编码的可读性(确实有不少人说到Stream会降低代码的可读性,但是在笔者看来,熟练使用之后反而觉得代码的可读性提高了)。这篇文章会花巨量篇幅,详细分析 Stream 的底层实现原理,参考的源码是 JDK11 的源码,其他版本 JDK 可能不适用于本文中的源码展示和相关例子。
向前兼容
Stream是JDK1.8引入的,如要需要JDK1.7或者以前的代码也能在JDK1.8或以上运行,那么Stream的引入必定不能在原来已经发布的接口方法进行修改,否则必定会因为兼容性问题导致老版本的接口实现无法在新版本中运行(方法签名出现异常),猜测是基于这个问题引入了接口默认方法,也就是default关键字。查看源码可以发现,ArrayList的超类Collection和Iterable分别添加了数个default方法:
// java.util.Collection部分源码
public interface Collection<E> extends Iterable<E> {
// 省略其他代码
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
}
// java.lang.Iterable部分源码
public interface Iterable<T> {
// 省略其他代码
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
}
从直觉来看,这些新增的方法应该就是Stream实现的关键方法(后面会印证这不是直觉,而是查看源码的结果)。接口默认方法在使用上和实例方法一致,在实现上可以直接在接口方法中编写方法体,有点静态方法的意味,但是子类可以覆盖其实现(也就是接口默认方法在本接口中的实现有点像静态方法,可以被子类覆盖,使用上和实例方法一致)。这种实现方式,有可能是一种突破,也有可能是一种妥协,但是无论是妥协还是突破,都实现了向前兼容:
// JDK1.7中的java.lang.Iterable
public interface Iterable<T> {
Iterator<T> iterator();
}
// JDK1.7中的Iterable实现
public MyIterable<Long> implements Iterable<Long>{
public Iterator<Long> iterator(){
....
}
}
如上,MyIterable在JDK1.7中定义,如果该类在JDK1.8中运行,那么调用其实例中的forEach()和spliterator()方法,相当于直接调用JDK1.8中的Iterable中的接口默认方法forEach()和spliterator()。当然受限于JDK版本,这里只能确保编译通过,旧功能正常使用,而无法在JDK1.7中使用Stream相关功能或者使用default方法关键字。总结这么多,就是想说明为什么使用JDK7开发和编译的代码可以在JDK8环境下运行。
可拆分迭代器 Spliterator
Stream实现的基石是Spliterator,Spliterator是splitable iterator的缩写,意为"可拆分迭代器",用于遍历指定数据源(例如数组、集合或者IO Channel等)中的元素,在设计上充分考虑了串行和并行的场景。上一节提到了Collection存在接口默认方法spliterator(),此方法会生成一个Spliterator<E>实例,意为着所有的集合子类都具备创建Spliterator实例的能力。Stream的实现在设计上和Netty中的ChannelHandlerContext十分相似,本质是一个链表,而Spliterator就是这个链表的Head节点(Spliterator实例就是一个流实例的头节点,后面分析具体的源码时候再具体展开)。
Spliterator 接口方法
接着看Spliterator接口定义的方法:
public interface Spliterator<T> {
// 暂时省略其他代码
boolean tryAdvance(Consumer<? super T> action);
default void forEachRemaining(Consumer<? super T> action) {
do { } while (tryAdvance(action));
}
Spliterator<T> trySplit();
long estimateSize();
default long getExactSizeIfKnown() {
return (characteristics() & SIZED) == 0 ? -1L : estimateSize();
}
int characteristics();
default boolean hasCharacteristics(int characteristics) {
return (characteristics() & characteristics) == characteristics;
}
default Comparator<? super T> getComparator() {
throw new IllegalStateException();
}
// 暂时省略其他代码
}
tryAdvance
- 方法签名:
boolean tryAdvance(Consumer<? super T> action) - 功能:如果
Spliterator中存在剩余元素,则对其中的某个元素执行传入的action回调,并且返回true,否则返回false。如果Spliterator启用了ORDERED特性,会按照顺序(这里的顺序值可以类比为ArrayList中容器数组元素的下标,ArrayList中添加新元素是天然有序的,下标由零开始递增)处理下一个元素 - 例子:
public static void main(String[] args) throws Exception {
List<Integer> list = new ArrayList<>();
list.add(2);
list.add(1);
list.add(3);
Spliterator<Integer> spliterator = list.stream().spliterator();
final AtomicInteger round = new AtomicInteger(1);
final AtomicInteger loop = new AtomicInteger(1);
while (spliterator.tryAdvance(num -> System.out.printf("第%d轮回调Action,值:%d\n", round.getAndIncrement(), num))) {
System.out.printf("第%d轮循环\n", loop.getAndIncrement());
}
}
// 控制台输出
第1轮回调Action,值:2
第1轮循环
第2轮回调Action,值:1
第2轮循环
第3轮回调Action,值:3
第3轮循环
forEachRemaining
- 方法签名:
default void forEachRemaining(Consumer<? super T> action) - 功能:如果
Spliterator中存在剩余元素,则对其中的所有剩余元素在当前线程中执行传入的action回调。如果Spliterator启用了ORDERED特性,会按照顺序处理剩余所有元素。这是一个接口默认方法,方法体比较粗暴,直接是一个死循环包裹着tryAdvance()方法,直到false退出循环 - 例子:
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(2);
list.add(1);
list.add(3);
Spliterator<Integer> spliterator = list.stream().spliterator();
final AtomicInteger round = new AtomicInteger(1);
spliterator.forEachRemaining(num -> System.out.printf("第%d轮回调Action,值:%d\n", round.getAndIncrement(), num));
}
// 控制台输出
第1轮回调Action,值:2
第2轮回调Action,值:1
第3轮回调Action,值:3
trySplit
- 方法签名:
Spliterator<T> trySplit() - 功能:如果当前的
Spliterator是可分区(可分割)的,那么此方法将会返回一个全新的Spliterator实例,这个全新的Spliterator实例里面的元素不会被当前Spliterator实例中的元素覆盖(这里是直译了API注释,实际要表达的意思是:当前的Spliterator实例X是可分割的,trySplit()方法会分割X产生一个全新的Spliterator实例Y,原来的X所包含的元素(范围)也会收缩,类似于X = [a,b,c,d] => X = [a,b], Y = [c,d];如果当前的Spliterator实例X是不可分割的,此方法会返回NULL),具体的分割算法由实现类决定 - 例子:
public static void main(String[] args) throws Exception {
List<Integer> list = new ArrayList<>();
list.add(2);
list.add(3);
list.add(4);
list.add(1);
Spliterator<Integer> first = list.stream().spliterator();
Spliterator<Integer> second = first.trySplit();
first.forEachRemaining(num -> {
System.out.printf("first spliterator item: %d\n", num);
});
second.forEachRemaining(num -> {
System.out.printf("second spliterator item: %d\n", num);
});
}
// 控制台输出
first spliterator item: 4
first spliterator item: 1
second spliterator item: 2
second spliterator item: 3
estimateSize
- 方法签名:
long estimateSize() - 功能:返回
forEachRemaining()方法需要遍历的元素总量的估计值,如果样本个数是无限、计算成本过高或者未知,会直接返回Long.MAX_VALUE - 例子:
public static void main(String[] args) throws Exception {
List<Integer> list = new ArrayList<>();
list.add(2);
list.add(3);
list.add(4);
list.add(1);
Spliterator<Integer> spliterator = list.stream().spliterator();
System.out.println(spliterator.estimateSize());
}
// 控制台输出
4
getExactSizeIfKnown
- 方法签名:
default long getExactSizeIfKnown() - 功能:如果当前的
Spliterator具备SIZED特性(关于特性,下文再展开分析),那么直接调用estimateSize()方法,否则返回-1 - 例子:
public static void main(String[] args) throws Exception {
List<Integer> list = new ArrayList<>();
list.add(2);
list.add(3);
list.add(4);
list.add(1);
Spliterator<Integer> spliterator = list.stream().spliterator();
System.out.println(spliterator.getExactSizeIfKnown());
}
// 控制台输出
4
int characteristics()
- 方法签名:
long estimateSize() - 功能:当前的
Spliterator具备的特性(集合),采用位运算,存储在32位整数中(关于特性,下文再展开分析)
hasCharacteristics
- 方法签名:
default boolean hasCharacteristics(int characteristics) - 功能:判断当前的
Spliterator是否具备传入的特性
getComparator
- 方法签名:
default Comparator<? super T> getComparator() - 功能:如果当前的
Spliterator具备SORTED特性,则需要返回一个Comparator实例;如果Spliterator中的元素是天然有序(例如元素实现了Comparable接口),则返回NULL;其他情况直接抛出IllegalStateException异常
Spliterator自分割
Spliterator#trySplit()可以把一个既有的Spliterator实例分割为两个Spliterator实例,笔者这里把这种方式称为Spliterator自分割,示意图如下:
这里的分割在实现上可以采用两种方式:
- 物理分割:对于
ArrayList而言,把底层数组拷贝并且进行分割,用上面的例子来说相当于X = [1,3,4,2] => X = [4,2], Y = [1,3],这样实现加上对于ArrayList中本身的元素容器数组,相当于多存了一份数据,显然不是十分合理 - 逻辑分割:对于
ArrayList而言,由于元素容器数组天然有序,可以采用数组的索引(下标)进行分割,用上面的例子来说相当于X = 索引表[0,1,2,3] => X = 索引表[2,3], Y = 索引表[0,1],这种方式是共享底层容器数组,只对元素索引进行分割,实现上比较简单而且相对合理
参看ArrayListSpliterator的源码,可以分析其分割算法实现:
// ArrayList#spliterator()
public Spliterator<E> spliterator() {
return new ArrayListSpliterator(0, -1, 0);
}
// ArrayList中内部类ArrayListSpliterator
final class ArrayListSpliterator implements Spliterator<E> {
// 当前的处理的元素索引值,其实是剩余元素的下边界值(包含),在tryAdvance()或者trySplit()方法中被修改,一般初始值为0
private int index;
// 栅栏,其实是元素索引值的上边界值(不包含),一般初始化的时候为-1,使用时具体值为元素索引值上边界加1
private int fence;
// 预期的修改次数,一般初始化值等于modCount
private int expectedModCount;
ArrayListSpliterator(int origin, int fence, int expectedModCount) {
this.index = origin;
this.fence = fence;
this.expectedModCount = expectedModCount;
}
// 获取元素索引值的上边界值,如果小于0,则把hi和fence都赋值为(ArrayList中的)size,expectedModCount赋值为(ArrayList中的)modCount,返回上边界值
// 这里注意if条件中有赋值语句hi = fence,也就是此方法调用过程中临时变量hi总是重新赋值为fence,fence是ArrayListSpliterator实例中的成员属性
private int getFence() {
int hi;
if ((hi = fence) < 0) {
expectedModCount = modCount;
hi = fence = size;
}
return hi;
}
// Spliterator自分割,这里采用了二分法
public ArrayListSpliterator trySplit() {
// hi等于当前ArrayListSpliterator实例中的fence变量,相当于获取剩余元素的上边界值
// lo等于当前ArrayListSpliterator实例中的index变量,相当于获取剩余元素的下边界值
// mid = (lo + hi) >>> 1,这里的无符号右移动1位运算相当于(lo + hi)/2
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
// 当lo >= mid的时候为不可分割,返回NULL,否则,以index = lo,fence = mid和expectedModCount = expectedModCount创建一个新的ArrayListSpliterator
// 这里有个细节之处,在新的ArrayListSpliterator构造参数中,当前的index被重新赋值为index = mid,这一点容易看漏,老程序员都喜欢做这样的赋值简化
// lo >= mid返回NULL的时候,不会创建新的ArrayListSpliterator,也不会修改当前ArrayListSpliterator中的参数
return (lo >= mid) ? null : new ArrayListSpliterator(lo, index = mid, expectedModCount);
}
// tryAdvance实现
public boolean tryAdvance(Consumer<? super E> action) {
if (action == null)
throw new NullPointerException();
// 获取迭代的上下边界
int hi = getFence(), i = index;
// 由于前面分析下边界是包含关系,上边界是非包含关系,所以这里要i < hi而不是i <= hi
if (i < hi) {
index = i + 1;
// 这里的elementData来自ArrayList中,也就是前文经常提到的元素数组容器,这里是直接通过元素索引访问容器中的数据
@SuppressWarnings("unchecked") E e = (E)elementData[i];
// 对传入的Action进行回调
action.accept(e);
// 并发修改异常判断
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
return false;
}
// forEachRemaining实现,这里没有采用默认实现,而是完全覆盖实现一个新方法
public void forEachRemaining(Consumer<? super E> action) {
// 这里会新建所需的中间变量,i为index的中间变量,hi为fence的中间变量,mc为expectedModCount的中间变量
int i, hi, mc;
Object[] a;
if (action == null)
throw new NullPointerException();
// 判断容器数组存在性
if ((a = elementData) != null) {
// hi、fence和mc初始化
if ((hi = fence) < 0) {
mc = modCount;
hi = size;
}
else
mc = expectedModCount;
// 这里就是先做参数合法性校验,再遍历临时数组容器a中中[i,hi)的剩余元素对传入的Action进行回调
// 这里注意有一处隐蔽的赋值(index = hi),下界被赋值为上界,意味着每个ArrayListSpliterator实例只能调用一次forEachRemaining()方法
if ((i = index) >= 0 && (index = hi) <= a.length) {
for (; i < hi; ++i) {
@SuppressWarnings("unchecked") E e = (E) a[i];
action.accept(e);
}
// 这里校验ArrayList的modCount和mc是否一致,理论上在forEachRemaining()遍历期间,不能对数组容器进行元素的新增或者移除,一旦发生modCount更变会抛出异常
if (modCount == mc)
return;
}
}
throw new ConcurrentModificationException();
}
// 获取剩余元素估计值,就是用剩余元素索引上边界直接减去下边界
public long estimateSize() {
return getFence() - index;
}
// 具备ORDERED、SIZED和SUBSIZED特性
public int characteristics() {
return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SUBSIZED;
}
}
在阅读源码的时候务必注意,老一辈的程序员有时候会采用比较隐蔽的赋值方式,笔者认为需要展开一下:
第一处红圈位置在构建新的ArrayListSpliterator的时候,当前ArrayListSpliterator的index属性也被修改了,过程如下图:
第二处红圈位置,在forEachRemaining()方法调用时候做参数校验,并且if分支里面把index(下边界值)赋值为hi(上边界值),那么一个ArrayListSpliterator实例中的forEachRemaining()方法的遍历操作必定只会执行一次。可以这样验证一下:
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(2);
list.add(1);
list.add(3);
Spliterator<Integer> spliterator = list.stream().spliterator();
final AtomicInteger round = new AtomicInteger(1);
spliterator.forEachRemaining(num -> System.out.printf("[第一次遍历forEachRemaining]第%d轮回调Action,值:%d\n", round.getAndIncrement(), num));
round.set(1);
spliterator.forEachRemaining(num -> System.out.printf("[第二次遍历forEachRemaining]第%d轮回调Action,值:%d\n", round.getAndIncrement(), num));
}
// 控制台输出
[第一次遍历forEachRemaining]第1轮回调Action,值:2
[第一次遍历forEachRemaining]第2轮回调Action,值:1
[第一次遍历forEachRemaining]第3轮回调Action,值:3
对于ArrayListSpliterator的实现可以确认下面几点:
- 一个新的
ArrayListSpliterator实例中的forEachRemaining()方法只能调用一次 ArrayListSpliterator实例中的forEachRemaining()方法遍历元素的边界是[index, fence)ArrayListSpliterator自分割的时候,分割出来的新ArrayListSpliterator负责处理元素下标小的分段(类比fork的左分支),而原ArrayListSpliterator负责处理元素下标大的分段(类比fork的右分支)ArrayListSpliterator提供的estimateSize()方法得到的分段元素剩余数量是一个准确值
如果把上面的例子继续分割,可以得到下面的过程:
Spliterator自分割是并行流实现的基础,并行流计算过程其实就是fork-join的处理过程,trySplit()方法的实现决定了fork任务的粒度,每个fork任务进行计算的时候是并发安全的,这一点由线程封闭(线程栈封闭)保证,每一个fork任务计算完成最后的结果再由单个线程进行join操作,才能得到正确的结果。下面的例子是求整数1 ~ 100的和:
public class ConcurrentSplitCalculateSum {
private static class ForkTask extends Thread {
private int result = 0;
private final Spliterator<Integer> spliterator;
private final CountDownLatch latch;
public ForkTask(Spliterator<Integer> spliterator,
CountDownLatch latch) {
this.spliterator = spliterator;
this.latch = latch;
}
@Override
public void run() {
long start = System.currentTimeMillis();
spliterator.forEachRemaining(num -> result = result + num);
long end = System.currentTimeMillis();
System.out.printf("线程[%s]完成计算任务,当前段计算结果:%d,耗时:%d ms\n",
Thread.currentThread().getName(), result, end - start);
latch.countDown();
}
public int result() {
return result;
}
}
private static int join(List<ForkTask> tasks) {
int result = 0;
for (ForkTask task : tasks) {
result = result + task.result();
}
return result;
}
private static final int THREAD_NUM = 4;
public static void main(String[] args) throws Exception {
List<Integer> source = new ArrayList<>();
for (int i = 1; i < 101; i++) {
source.add(i);
}
Spliterator<Integer> root = source.stream().spliterator();
List<Spliterator<Integer>> spliteratorList = new ArrayList<>();
Spliterator<Integer> x = root.trySplit();
Spliterator<Integer> y = x.trySplit();
Spliterator<Integer> z = root.trySplit();
spliteratorList.add(root);
spliteratorList.add(x);
spliteratorList.add(y);
spliteratorList.add(z);
List<ForkTask> tasks = new ArrayList<>();
CountDownLatch latch = new CountDownLatch(THREAD_NUM);
for (int i = 0; i < THREAD_NUM; i++) {
ForkTask task = new ForkTask(spliteratorList.get(i), latch);
task.setName("fork-task-" + (i + 1));
tasks.add(task);
}
tasks.forEach(Thread::start);
latch.await();
int result = join(tasks);
System.out.println("最终计算结果为:" + result);
}
}
// 控制台输出结果
线程[fork-task-4]完成计算任务,当前段计算结果:1575,耗时:0 ms
线程[fork-task-2]完成计算任务,当前段计算结果:950,耗时:1 ms
线程[fork-task-3]完成计算任务,当前段计算结果:325,耗时:1 ms
线程[fork-task-1]完成计算任务,当前段计算结果:2200,耗时:1 ms
最终计算结果为:5050
当然,最终并行流的计算用到了ForkJoinPool,并不像这个例子中这么粗暴地进行异步执行。关于并行流的实现下文会详细分析。
Spliterator 支持特性
某一个Spliterator实例支持的特性由方法characteristics()决定,这个方法返回的是一个32位数值,实际使用中会展开为bit数组,所有的特性分配在不同的位上,而hasCharacteristics(int characteristics)就是通过输入的具体特性值通过位运算判断该特性是否存在于characteristics()中。下面简化characteristics为byte分析一下这个技巧:
假设:byte characteristics() => 也就是最多8个位用于表示特性集合,如果每个位只表示一种特性,那么可以总共表示8种特性
特性X:0000 0001
特性Y:0000 0010
以此类推
假设:characteristics = X | Y = 0000 0001 | 0000 0010 = 0000 0011
那么:characteristics & X = 0000 0011 & 0000 0001 = 0000 0001
判断characteristics是否包含X:(characteristics & X) == X
上面推断的过程就是Spliterator中特性判断方法的处理逻辑:
// 返回特性集合
int characteristics();
// 基于位运算判断特性集合中是否存在输入的特性
default boolean hasCharacteristics(int characteristics) {
return (characteristics() & characteristics) == characteristics;
}
这里可以验证一下:
public class CharacteristicsCheck {
public static void main(String[] args) {
System.out.printf("是否存在ORDERED特性:%s\n", hasCharacteristics(Spliterator.ORDERED));
System.out.printf("是否存在SIZED特性:%s\n", hasCharacteristics(Spliterator.SIZED));
System.out.printf("是否存在DISTINCT特性:%s\n", hasCharacteristics(Spliterator.DISTINCT));
}
private static int characteristics() {
return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SORTED;
}
private static boolean hasCharacteristics(int characteristics) {
return (characteristics() & characteristics) == characteristics;
}
}
// 控制台输出
是否存在ORDERED特性:true
是否存在SIZED特性:true
是否存在DISTINCT特性:false
目前Spliterator支持的特性一共有8个,如下:
| 特性 | 十六进制值 | 二进制值 | 功能 |
|---|
DISTINCT | 0x00000001 | 0000 0000 0000 0001 | 去重,例如对于每对要处理的元素(x,y),使用!x.equals(y)比较,Spliterator中去重实际上基于Set处理 |
ORDERED | 0x00000010 | 0000 0000 0001 0000 | (元素)顺序处理,可以理解为trySplit()、tryAdvance()和forEachRemaining()方法对所有元素处理都保证一个严格的前缀顺序 |
SORTED | 0x00000004 | 0000 0000 0000 0100 | 排序,元素使用getComparator()方法提供的Comparator进行排序,如果定义了SORTED特性,则必须定义ORDERED特性 |
SIZED | 0x00000040 | 0000 0000 0100 0000 | (元素)预估数量,启用此特性,那么Spliterator拆分或者迭代之前,estimateSize()返回的是元素的准确数量 |
NONNULL | 0x00000040 | 0000 0001 0000 0000 | (元素)非NULL,数据源保证Spliterator需要处理的元素不能为NULL,最常用于并发容器中的集合、队列和Map |
IMMUTABLE | 0x00000400 | 0000 0100 0000 0000 | (元素)不可变,数据源不可被修改,也就是处理过程中元素不能被添加、替换和移除(更新属性是允许的) |
CONCURRENT | 0x00001000 | 0001 0000 0000 0000 | (元素源)的修改是并发安全的,意味着多线程在数据源中添加、替换或者移除元素在不需要额外的同步条件下是并发安全的 |
SUBSIZED | 0x00004000 | 0100 0000 0000 0000 | (子Spliterator元素)预估数量,启用此特性,意味着通过trySplit()方法分割出来的所有子Spliterator(当前Spliterator分割后也属于子Spliterator)都启用SIZED特性 |
细心点观察可以发现:所有特性采用32位的整数存储,使用了隔1位存储的策略,位下标和特性的映射是:(0 => DISTINCT)、(3 => SORTED)、(5 => ORDERED)、(7=> SIZED)、(9 => NONNULL)、(11 => IMMUTABLE)、(13 => CONCURRENT)、(15 => SUBSIZED)
所有特性的功能这里只概括了核心的定义,还有一些小字或者特例描述限于篇幅没有完全加上,这一点可以参考具体的源码中的API注释。这些特性最终会转化为StreamOpFlag再提供给Stream中的操作判断使用,由于StreamOpFlag会更加复杂,下文再进行详细分析。
流的实现原理以及源码分析
由于流的实现是高度抽象的工程代码,所以在源码阅读上会有点困难。整个体系涉及到大量的接口、类和枚举,如下图:
图中的顶层类结构图描述的就是流的流水线相关类继承关系,其中IntStream、LongStream和DoubleStream都是特化类型,分别针对于Integer、Long和Double三种类型,其他引用类型构建的Pipeline都是ReferencePipeline实例,因此笔者认为,ReferencePipeline(引用类型流水线)是流的核心数据结构,下面会基于ReferencePipeline的实现做深入分析。
StreamOpFlag源码分析
StreamOpFlag是一个枚举,功能是存储Stream和操作的标志(Flags corresponding to characteristics of streams and operations,下称Stream标志),这些标志提供给Stream框架用于控制、定制化和优化计算。Stream标志可以用于描述与流相关联的若干不同实体的特征,这些实体包括:Stream的源、Stream的中间操作(Op)和Stream的终端操作(Terminal Op)。但是并非所有的Stream标志对所有的Stream实体都具备意义,目前这些实体和标志映射关系如下:
| Type(Stream Entity Type) | DISTINCT | SORTED | ORDERED | SIZED | SHORT_CIRCUIT |
|---|
SPLITERATOR | 01 | 01 | 01 | 01 | 00 |
STREAM | 01 | 01 | 01 | 01 | 00 |
OP | 11 | 11 | 11 | 10 | 01 |
TERMINAL_OP | 00 | 00 | 10 | 00 | 01 |
UPSTREAM_TERMINAL_OP | 00 | 00 | 10 | 00 | 00 |
其中:
- 01:表示设置/注入
- 10:表示清除
- 11:表示保留
- 00:表示初始化值(默认填充值),这是一个关键点,
0值表示绝对不会是某个类型的标志
StreamOpFlag的顶部注释中还有一个表格如下:
| - | DISTINCT | SORTED | ORDERED | SIZED | SHORT_CIRCUIT |
|---|
Stream source(Stream的源) | Y | Y | Y | Y | N |
| Intermediate operation(中间操作) | PCI | PCI | PCI | PC | PI |
| Terminal operation(终结操作) | N | N | PC | N | PI |
标记 -> 含义:
Y:允许N:非法P:保留C:清除I:注入- 组合
PCI:可以保留、清除或者注入 - 组合
PC:可以保留或者清除 - 组合
PI:可以保留或者注入
两个表格其实是在描述同一个结论,可以相互对照和理解,但是最终实现参照于第一个表的定义。注意一点:这里的preserved(P)表示保留的意思,如果Stream实体某个标志被赋值为preserved,意味着该实体可以使用此标志代表的特性。例如此小节第一个表格中的OP的DISTINCT、SORTED和ORDERED都赋值为11(preserved),意味着OP类型的实体允许使用去重、自然排序和顺序处理特性。回到源码部分,先看StreamOpFlag的核心属性和构造器:
enum StreamOpFlag {
// 暂时忽略其他代码
// 类型枚举,Stream相关实体类型
enum Type {
// SPLITERATOR类型,关联所有和Spliterator相关的特性
SPLITERATOR,
// STREAM类型,关联所有和Stream相关的标志
STREAM,
// STREAM类型,关联所有和Stream中间操作相关的标志
OP,
// TERMINAL_OP类型,关联所有和Stream终结操作相关的标志
TERMINAL_OP,
// UPSTREAM_TERMINAL_OP类型,关联所有在最后一个有状态操作边界上游传播的终止操作标志
// 这个类型的意义直译有点拗口,不过实际上在JDK11源码中,这个类型没有被流相关功能引用,暂时可以忽略
UPSTREAM_TERMINAL_OP
}
// 设置/注入标志的bit模式,二进制数0001,十进制数1
private static final int SET_BITS = 0b01;
// 清除标志的bit模式,二进制数0010,十进制数2
private static final int CLEAR_BITS = 0b10;
// 保留标志的bit模式,二进制数0011,十进制数3
private static final int PRESERVE_BITS = 0b11;
// 掩码建造器工厂方法,注意这个方法用于实例化MaskBuilder
private static MaskBuilder set(Type t) {
return new MaskBuilder(new EnumMap<>(Type.class)).set(t);
}
// 私有静态内部类,掩码建造器,里面的map由上面的set(Type t)方法得知是EnumMap实例
private static class MaskBuilder {
// Type -> SET_BITS|CLEAR_BITS|PRESERVE_BITS|0
final Map<Type, Integer> map;
MaskBuilder(Map<Type, Integer> map) {
this.map = map;
}
// 设置类型和对应的掩码
MaskBuilder mask(Type t, Integer i) {
map.put(t, i);
return this;
}
// 对类型添加/inject
MaskBuilder set(Type t) {
return mask(t, SET_BITS);
}
MaskBuilder clear(Type t) {
return mask(t, CLEAR_BITS);
}
MaskBuilder setAndClear(Type t) {
return mask(t, PRESERVE_BITS);
}
// 这里的build方法对于类型中的NULL掩码填充为0,然后把map返回
Map<Type, Integer> build() {
for (Type t : Type.values()) {
map.putIfAbsent(t, 0b00);
}
return map;
}
}
// 类型->掩码映射
private final Map<Type, Integer> maskTable;
// bit的起始偏移量,控制下面set、clear和preserve的起始偏移量
private final int bitPosition;
// set/inject的bit set(map),其实准确来说应该是一个表示set/inject的bit map
private final int set;
// clear的bit set(map),其实准确来说应该是一个表示clear的bit map
private final int clear;
// preserve的bit set(map),其实准确来说应该是一个表示preserve的bit map
private final int preserve;
private StreamOpFlag(int position, MaskBuilder maskBuilder) {
// 这里会基于MaskBuilder初始化内部的EnumMap
this.maskTable = maskBuilder.build();
// Two bits per flag <= 这里会把入参position放大一倍
position *= 2;
this.bitPosition = position;
this.set = SET_BITS << position; // 设置/注入标志的bit模式左移2倍position
this.clear = CLEAR_BITS << position; // 清除标志的bit模式左移2倍position
this.preserve = PRESERVE_BITS << position; // 保留标志的bit模式左移2倍position
}
// 省略中间一些方法
// 下面这些静态变量就是直接返回标志对应的set/injec、清除和保留的bit map
/**
* The bit value to set or inject {@link #DISTINCT}.
*/
static final int IS_DISTINCT = DISTINCT.set;
/**
* The bit value to clear {@link #DISTINCT}.
*/
static final int NOT_DISTINCT = DISTINCT.clear;
/**
* The bit value to set or inject {@link #SORTED}.
*/
static final int IS_SORTED = SORTED.set;
/**
* The bit value to clear {@link #SORTED}.
*/
static final int NOT_SORTED = SORTED.clear;
/**
* The bit value to set or inject {@link #ORDERED}.
*/
static final int IS_ORDERED = ORDERED.set;
/**
* The bit value to clear {@link #ORDERED}.
*/
static final int NOT_ORDERED = ORDERED.clear;
/**
* The bit value to set {@link #SIZED}.
*/
static final int IS_SIZED = SIZED.set;
/**
* The bit value to clear {@link #SIZED}.
*/
static final int NOT_SIZED = SIZED.clear;
/**
* The bit value to inject {@link #SHORT_CIRCUIT}.
*/
static final int IS_SHORT_CIRCUIT = SHORT_CIRCUIT.set;
}
又因为StreamOpFlag是一个枚举,一个枚举成员是一个独立的标志,而一个标志会对多个Stream实体类型产生作用,所以它的一个成员描述的是上面实体和标志映射关系的一个列(竖着看):
// 纵向看
DISTINCT Flag:
maskTable: {
SPLITERATOR: 0000 0001,
STREAM: 0000 0001,
OP: 0000 0011,
TERMINAL_OP: 0000 0000,
UPSTREAM_TERMINAL_OP: 0000 0000
}
position(input): 0
bitPosition: 0
set: 1 => 0000 0000 0000 0000 0000 0000 0000 0001
clear: 2 => 0000 0000 0000 0000 0000 0000 0000 0010
preserve: 3 => 0000 0000 0000 0000 0000 0000 0000 0011
SORTED Flag:
maskTable: {
SPLITERATOR: 0000 0001,
STREAM: 0000 0001,
OP: 0000 0011,
TERMINAL_OP: 0000 0000,
UPSTREAM_TERMINAL_OP: 0000 0000
}
position(input): 1
bitPosition: 2
set: 4 => 0000 0000 0000 0000 0000 0000 0000 0100
clear: 8 => 0000 0000 0000 0000 0000 0000 0000 1000
preserve: 12 => 0000 0000 0000 0000 0000 0000 0000 1100
ORDERED Flag:
maskTable: {
SPLITERATOR: 0000 0001,
STREAM: 0000 0001,
OP: 0000 0011,
TERMINAL_OP: 0000 0010,
UPSTREAM_TERMINAL_OP: 0000 0010
}
position(input): 2
bitPosition: 4
set: 16 => 0000 0000 0000 0000 0000 0000 0001 0000
clear: 32 => 0000 0000 0000 0000 0000 0000 0010 0000
preserve: 48 => 0000 0000 0000 0000 0000 0000 0011 0000
SIZED Flag:
maskTable: {
SPLITERATOR: 0000 0001,
STREAM: 0000 0001,
OP: 0000 0010,
TERMINAL_OP: 0000 0000,
UPSTREAM_TERMINAL_OP: 0000 0000
}
position(input): 3
bitPosition: 6
set: 64 => 0000 0000 0000 0000 0000 0000 0100 0000
clear: 128 => 0000 0000 0000 0000 0000 0000 1000 0000
preserve: 192 => 0000 0000 0000 0000 0000 0000 1100 0000
SHORT_CIRCUIT Flag:
maskTable: {
SPLITERATOR: 0000 0000,
STREAM: 0000 0000,
OP: 0000 0001,
TERMINAL_OP: 0000 0001,
UPSTREAM_TERMINAL_OP: 0000 0000
}
position(input): 12
bitPosition: 24
set: 16777216 => 0000 0001 0000 0000 0000 0000 0000 0000
clear: 33554432 => 0000 0010 0000 0000 0000 0000 0000 0000
preserve: 50331648 => 0000 0011 0000 0000 0000 0000 0000 0000
接着就用到按位与(&)和按位或(|)的操作,假设A = 0001、B = 0010、C = 1000,那么:
A|B = A | B = 0001 | 0010 = 0011(按位或,1|0=1, 0|1=1,0|0 =0,1|1=1)A&B = A & B = 0001 | 0010 = 0000(按位与,1|0=0, 0|1=0,0|0 =0,1|1=1)MASK = A | B | C = 0001 | 0010 | 1000 = 1011- 那么判断
A|B是否包含A的条件为:A == (A|B & A) - 那么判断
MASK是否包含A的条件为:A == MASK & A
这里把StreamOpFlag中的枚举套用进去分析:
static int DISTINCT_SET = 0b0001;
static int SORTED_CLEAR = 0b1000;
public static void main(String[] args) throws Exception {
// 支持DISTINCT标志和不支持SORTED标志
int flags = DISTINCT_SET | SORTED_CLEAR;
System.out.println(Integer.toBinaryString(flags));
System.out.printf("支持DISTINCT标志:%s\n", DISTINCT_SET == (DISTINCT_SET & flags));
System.out.printf("不支持SORTED标志:%s\n", SORTED_CLEAR == (SORTED_CLEAR & flags));
}
// 控制台输出
1001
支持DISTINCT标志:true
不支持SORTED标志:true
由于StreamOpFlag的修饰符是默认,不能直接使用,可以把它的代码拷贝出来修改包名验证里面的功能:
public static void main(String[] args) {
int flags = StreamOpFlag.DISTINCT.set | StreamOpFlag.SORTED.clear;
System.out.println(StreamOpFlag.DISTINCT.set == (StreamOpFlag.DISTINCT.set & flags));
System.out.println(StreamOpFlag.SORTED.clear == (StreamOpFlag.SORTED.clear & flags));
}
// 输出
true
true
下面这些方法就是基于这些运算特性而定义的:
enum StreamOpFlag {
// 暂时忽略其他代码
// 返回当前StreamOpFlag的set/inject的bit map
int set() {
return set;
}
// 返回当前StreamOpFlag的清除的bit map
int clear() {
return clear;
}
// 这里判断当前StreamOpFlag类型->标记映射中Stream类型的标记,如果大于0说明不是初始化状态,那么当前StreamOpFlag就是Stream相关的标志
boolean isStreamFlag() {
return maskTable.get(Type.STREAM) > 0;
}
// 这里就用到按位与判断输入的flags中是否设置当前StreamOpFlag(StreamOpFlag.set)
boolean isKnown(int flags) {
return (flags & preserve) == set;
}
// 这里就用到按位与判断输入的flags中是否清除当前StreamOpFlag(StreamOpFlag.clear)
boolean isCleared(int flags) {
return (flags & preserve) == clear;
}
// 这里就用到按位与判断输入的flags中是否保留当前StreamOpFlag(StreamOpFlag.clear)
boolean isPreserved(int flags) {
return (flags & preserve) == preserve;
}
// 判断当前的Stream实体类型是否可以设置本标志,要求Stream实体类型的标志位为set或者preserve,按位与要大于0
boolean canSet(Type t) {
return (maskTable.get(t) & SET_BITS) > 0;
}
// 暂时忽略其他代码
}
这里有个特殊操作,位运算的时候采用了(flags & preserve),理由是:同一个标志中的同一个Stream实体类型只可能存在set/inject、clear和preserve的其中一种,也就是同一个flags中不可能同时存在StreamOpFlag.SORTED.set和StreamOpFlag.SORTED.clear,从语义上已经矛盾,而set/inject、clear和preserve在bit map中的大小(为2位)和位置已经是固定的,preserve在设计的时候为0b11刚好2位取反,因此可以特化为(这个特化也让判断更加严谨):
(flags & set) == set => (flags & preserve) == set
(flags & clear) == clear => (flags & preserve) == clear
(flags & preserve) == preserve => (flags & preserve) == preserve
分析这么多,总的来说,就是想通过一个32位整数,每2位分别表示3种状态,那么一个完整的Flags(标志集合)一共可以表示16种标志(position=[0,15],可以查看API注释,[4,11]和[13,15]的位置是未需实现或者预留的,属于gap)。接着分析掩码Mask的计算过程例子:
// 横向看(位移动运算符优先级高于与或,例如<<的优先级比|高)
SPLITERATOR_CHARACTERISTICS_MASK:
mask(init) = 0
mask(DISTINCT,SPLITERATOR[DISTINCT]=01,bitPosition=0) = 0000 0000 | 0000 0001 << 0 = 0000 0000 | 0000 0001 = 0000 0001
mask(SORTED,SPLITERATOR[SORTED]=01,bitPosition=2) = 0000 0001 | 0000 0001 << 2 = 0000 0001 | 0000 0100 = 0000 0101
mask(ORDERED,SPLITERATOR[ORDERED]=01,bitPosition=4) = 0000 0101 | 0000 0001 << 4 = 0000 0101 | 0001 0000 = 0001 0101
mask(SIZED,SPLITERATOR[SIZED]=01,bitPosition=6) = 0001 0101 | 0000 0001 << 6 = 0001 0101 | 0100 0000 = 0101 0101
mask(SHORT_CIRCUIT,SPLITERATOR[SHORT_CIRCUIT]=00,bitPosition=24) = 0101 0101 | 0000 0000 << 24 = 0101 0101 | 0000 0000 = 0101 0101
mask(final) = 0000 0000 0000 0000 0000 0000 0101 0101(二进制)、85(十进制)
STREAM_MASK:
mask(init) = 0
mask(DISTINCT,SPLITERATOR[DISTINCT]=01,bitPosition=0) = 0000 0000 | 0000 0001 << 0 = 0000 0000 | 0000 0001 = 0000 0001
mask(SORTED,SPLITERATOR[SORTED]=01,bitPosition=2) = 0000 0001 | 0000 0001 << 2 = 0000 0001 | 0000 0100 = 0000 0101
mask(ORDERED,SPLITERATOR[ORDERED]=01,bitPosition=4) = 0000 0101 | 0000 0001 << 4 = 0000 0101 | 0001 0000 = 0001 0101
mask(SIZED,SPLITERATOR[SIZED]=01,bitPosition=6) = 0001 0101 | 0000 0001 << 6 = 0001 0101 | 0100 0000 = 0101 0101
mask(SHORT_CIRCUIT,SPLITERATOR[SHORT_CIRCUIT]=00,bitPosition=24) = 0101 0101 | 0000 0000 << 24 = 0101 0101 | 0000 0000 = 0101 0101
mask(final) = 0000 0000 0000 0000 0000 0000 0101 0101(二进制)、85(十进制)
OP_MASK:
mask(init) = 0
mask(DISTINCT,SPLITERATOR[DISTINCT]=11,bitPosition=0) = 0000 0000 | 0000 0011 << 0 = 0000 0000 | 0000 0011 = 0000 0011
mask(SORTED,SPLITERATOR[SORTED]=11,bitPosition=2) = 0000 0011 | 0000 0011 << 2 = 0000 0011 | 0000 1100 = 0000 1111
mask(ORDERED,SPLITERATOR[ORDERED]=11,bitPosition=4) = 0000 1111 | 0000 0011 << 4 = 0000 1111 | 0011 0000 = 0011 1111
mask(SIZED,SPLITERATOR[SIZED]=10,bitPosition=6) = 0011 1111 | 0000 0010 << 6 = 0011 1111 | 1000 0000 = 1011 1111
mask(SHORT_CIRCUIT,SPLITERATOR[SHORT_CIRCUIT]=01,bitPosition=24) = 1011 1111 | 0000 0001 << 24 = 1011 1111 | 0100 0000 0000 0000 0000 0000 0000 = 0100 0000 0000 0000 0000 1011 1111
mask(final) = 0000 0000 1000 0000 0000 0000 1011 1111(二进制)、16777407(十进制)
TERMINAL_OP_MASK:
mask(init) = 0
mask(DISTINCT,SPLITERATOR[DISTINCT]=00,bitPosition=0) = 0000 0000 | 0000 0000 << 0 = 0000 0000 | 0000 0000 = 0000 0000
mask(SORTED,SPLITERATOR[SORTED]=00,bitPosition=2) = 0000 0000 | 0000 0000 << 2 = 0000 0000 | 0000 0000 = 0000 0000
mask(ORDERED,SPLITERATOR[ORDERED]=10,bitPosition=4) = 0000 0000 | 0000 0010 << 4 = 0000 0000 | 0010 0000 = 0010 0000
mask(SIZED,SPLITERATOR[SIZED]=00,bitPosition=6) = 0010 0000 | 0000 0000 << 6 = 0010 0000 | 0000 0000 = 0010 0000
mask(SHORT_CIRCUIT,SPLITERATOR[SHORT_CIRCUIT]=01,bitPosition=24) = 0010 0000 | 0000 0001 << 24 = 0010 0000 | 0001 0000 0000 0000 0000 0000 0000 = 0001 0000 0000 0000 0000 0010 0000
mask(final) = 0000 0001 0000 0000 0000 0000 0010 0000(二进制)、16777248(十进制)
UPSTREAM_TERMINAL_OP_MASK:
mask(init) = 0
mask(DISTINCT,SPLITERATOR[DISTINCT]=00,bitPosition=0) = 0000 0000 | 0000 0000 << 0 = 0000 0000 | 0000 0000 = 0000 0000
mask(SORTED,SPLITERATOR[SORTED]=00,bitPosition=2) = 0000 0000 | 0000 0000 << 2 = 0000 0000 | 0000 0000 = 0000 0000
mask(ORDERED,SPLITERATOR[ORDERED]=10,bitPosition=4) = 0000 0000 | 0000 0010 << 4 = 0000 0000 | 0010 0000 = 0010 0000
mask(SIZED,SPLITERATOR[SIZED]=00,bitPosition=6) = 0010 0000 | 0000 0000 << 6 = 0010 0000 | 0000 0000 = 0010 0000
mask(SHORT_CIRCUIT,SPLITERATOR[SHORT_CIRCUIT]=00,bitPosition=24) = 0010 0000 | 0000 0000 << 24 = 0010 0000 | 0000 0000 = 0010 0000
mask(final) = 0000 0000 0000 0000 0000 0000 0010 0000(二进制)、32(十进制)
相关的方法和属性如下:
enum StreamOpFlag {
// SPLITERATOR类型的标志bit map
static final int SPLITERATOR_CHARACTERISTICS_MASK = createMask(Type.SPLITERATOR);
// STREAM类型的标志bit map
static final int STREAM_MASK = createMask(Type.STREAM);
// OP类型的标志bit map
static final int OP_MASK = createMask(Type.OP);
// TERMINAL_OP类型的标志bit map
static final int TERMINAL_OP_MASK = createMask(Type.TERMINAL_OP);
// UPSTREAM_TERMINAL_OP类型的标志bit map
static final int UPSTREAM_TERMINAL_OP_MASK = createMask(Type.UPSTREAM_TERMINAL_OP);
// 基于Stream类型,创建对应类型填充所有标志的bit map
private static int createMask(Type t) {
int mask = 0;
for (StreamOpFlag flag : StreamOpFlag.values()) {
mask |= flag.maskTable.get(t) << flag.bitPosition;
}
return mask;
}
// 构造一个标志本身的掩码,就是所有标志都采用保留位表示,目前作为flags == 0时候的初始值
private static final int FLAG_MASK = createFlagMask();
// 构造一个包含全部标志中的preserve位的bit map,按照目前来看是暂时是一个固定值,二进制表示为0011 0000 0000 0000 0000 1111 1111
private static int createFlagMask() {
int mask = 0;
for (StreamOpFlag flag : StreamOpFlag.values()) {
mask |= flag.preserve;
}
return mask;
}
// 构造一个Stream类型包含全部标志中的set位的bit map,这里直接使用了STREAM_MASK,按照目前来看是暂时是一个固定值,二进制表示为0000 0000 0000 0000 0000 0000 0101 0101
private static final int FLAG_MASK_IS = STREAM_MASK;
// 构造一个Stream类型包含全部标志中的clear位的bit map,按照目前来看是暂时是一个固定值,二进制表示为0000 0000 0000 0000 0000 0000 1010 1010
private static final int FLAG_MASK_NOT = STREAM_MASK << 1;
// 初始化操作的标志bit map,目前来看就是Stream的头节点初始化时候需要合并在flags里面的初始化值,照目前来看是暂时是一个固定值,二进制表示为0000 0000 0000 0000 0000 0000 1111 1111
static final int INITIAL_OPS_VALUE = FLAG_MASK_IS | FLAG_MASK_NOT;
}
SPLITERATOR_CHARACTERISTICS_MASK等5个成员(见上面的Mask计算例子)其实就是预先计算好对应的Stream实体类型的所有StreamOpFlag标志的bit map,也就是之前那个展示Stream的类型和标志的映射图的"横向"展示:
前面的分析已经相对详细,过程非常复杂,但是更复杂的Mask应用还在后面的方法。Mask的初始化就是提供给标志的合并(combine)和转化(从Spliterator中的characteristics转化为flags)操作的,见下面的方法:
enum StreamOpFlag {
// 这个方法完全没有注释,只使用在下面的combineOpFlags()方法中
// 从源码来看
// 入参flags == 0的时候,那么直接返回0011 0000 0000 0000 0000 1111 1111
// 入参flags != 0的时候,那么会把当前flags的所有set/inject、clear和preserve所在位在bit map中全部置为0,然后其他位全部置为1
private static int getMask(int flags) {
return (flags == 0)
? FLAG_MASK
: ~(flags | ((FLAG_MASK_IS & flags) << 1) | ((FLAG_MASK_NOT & flags) >> 1));
}
// 合并新的flags和前一个flags,这里还是用到老套路先和Mask按位与,再进行一次按位或
// 作为Stream的头节点的时候,prevCombOpFlags必须为INITIAL_OPS_VALUE
static int combineOpFlags(int newStreamOrOpFlags, int prevCombOpFlags) {
// 0x01 or 0x10 nibbles are transformed to 0x11
// 0x00 nibbles remain unchanged
// Then all the bits are flipped
// Then the result is logically or'ed with the operation flags.
return (prevCombOpFlags & StreamOpFlag.getMask(newStreamOrOpFlags)) | newStreamOrOpFlags;
}
// 通过合并后的flags,转换出Stream类型的flags
static int toStreamFlags(int combOpFlags) {
// By flipping the nibbles 0x11 become 0x00 and 0x01 become 0x10
// Shift left 1 to restore set flags and mask off anything other than the set flags
return ((~combOpFlags) >> 1) & FLAG_MASK_IS & combOpFlags;
}
// Stream的标志转换为Spliterator的characteristics
static int toCharacteristics(int streamFlags) {
return streamFlags & SPLITERATOR_CHARACTERISTICS_MASK;
}
// Spliterator的characteristics转换为Stream的标志,入参是Spliterator实例
static int fromCharacteristics(Spliterator<?> spliterator) {
int characteristics = spliterator.characteristics();
if ((characteristics & Spliterator.SORTED) != 0 && spliterator.getComparator() != null) {
// Do not propagate the SORTED characteristic if it does not correspond
// to a natural sort order
return characteristics & SPLITERATOR_CHARACTERISTICS_MASK & ~Spliterator.SORTED;
}
else {
return characteristics & SPLITERATOR_CHARACTERISTICS_MASK;
}
}
// Spliterator的characteristics转换为Stream的标志,入参是Spliterator的characteristics
static int fromCharacteristics(int characteristics) {
return characteristics & SPLITERATOR_CHARACTERISTICS_MASK;
}
}
这里的位运算很复杂,只展示简单的计算结果和相关功能:
combineOpFlags():用于合并新的flags和上一个flags,因为Stream的数据结构是一个Pipeline,后继节点需要合并前驱节点的flags,例如前驱节点flags是ORDERED.set,当前新加入Pipeline的节点(后继节点)的新flags为SIZED.set,那么在后继节点中应该合并前驱节点的标志,简单想象为SIZED.set | ORDERED.set,如果是头节点,那么初始化头节点时候的flags要合并INITIAL_OPS_VALUE,这里举个例子:
int left = ORDERED.set | DISTINCT.set;
int right = SIZED.clear | SORTED.clear;
System.out.println("left:" + Integer.toBinaryString(left));
System.out.println("right:" + Integer.toBinaryString(right));
System.out.println("right mask:" + Integer.toBinaryString(getMask(right)));
System.out.println("combine:" + Integer.toBinaryString(combineOpFlags(right, left)));
// 输出结果
left:1010001
right:10001000
right mask:11111111111111111111111100110011
combine:10011001
characteristics的转化问题:Spliterator中的characteristics可以通过简单的按位与转换为flags的原因是Spliterator中的characteristics在设计时候本身就是和StreamOpFlag匹配的,准确来说就是bit map的位分布是匹配的,所以直接与SPLITERATOR_CHARACTERISTICS_MASK做按位与即可,见下面的例子:
// 这里简单点只展示8 bit
SPLITERATOR_CHARACTERISTICS_MASK: 0101 0101
Spliterator.ORDERED: 0001 0000
StreamOpFlag.ORDERED.set: 0001 0000
至此,已经分析完StreamOpFlag的完整实现,Mask相关的方法限于篇幅就不打算详细展开,下面会开始分析Stream中的"流水线"结构实现,因为习惯问题,下文的"标志"和"特性"两个词语会混用。
ReferencePipeline源码分析
既然Stream具备流的特性,那么就需要一个链式数据结构,让元素能够从Source一直往下"流动"和传递到每一个链节点,实现这种场景的常用数据结构就是双向链表(考虑需要回溯,单向链表不太合适),目前比较著名的实现有AQS和Netty中的ChannelHandlerContext。例如Netty中的流水线ChannelPipeline设计如下:
对于这个双向链表的数据结构,Stream中对应的类就是AbstractPipeline,核心实现类在ReferencePipeline和ReferencePipeline的内部类。
主要接口
先简单展示AbstractPipeline的核心父类方法定义,主要接父类是Stream、BaseStream和PipelineHelper:
Stream代表一个支持串行和并行聚合操作集合的元素序列,此顶层接口提供了流中间操作、终结操作和一些静态工厂方法的定义(由于方法太多,这里不全部列举),这个接口本质是一个建造器类型接口(对接中间操作来说),可以构成一个多中间操作,单终结操作的链,例如:
public interface Stream<T> extends BaseStream<T, Stream<T>> {
// 忽略其他代码
// 过滤Op
Stream<T> filter(Predicate<? super T> predicate);
// 映射Op
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
// 终结操作 - 遍历
void forEach(Consumer<? super T> action);
// 忽略其他代码
}
// init
Stream x = buildStream();
// chain: head -> filter(Op) -> map(Op) -> forEach(Terminal Op)
x.filter().map().forEach()
BaseStream:Stream的基础接口,定义流的迭代器、流的等效变体(并发处理变体、同步处理变体和不支持顺序处理元素变体)、并发和同步判断以及关闭相关方法
// T是元素类型,S是BaseStream<T, S>类型
// 流的基础接口,这里的流指定的支持同步执行和异步执行的聚合操作的元素序列
public interface BaseStream<T, S extends BaseStream<T, S>> extends AutoCloseable {
// 返回一个当前Stream实例中所有元素的迭代器
// 这是一个终结操作
Iterator<T> iterator();
// 返回一个当前Stream实例中所有元素的可拆分迭代器
Spliterator<T> spliterator();
// 当前的Stream实例是否支持并发
boolean isParallel();
// 返回一个等效的同步处理的Stream实例
S sequential();
// 返回一个等效的并发处理的Stream实例
S parallel();
// 返回一个等效的不支持StreamOpFlag.ORDERED特性的Stream实例
// 或者说支持StreamOpFlag.NOT_ORDERED的特性,也就返回的变体Stream在处理元素的时候不需要顺序处理
S unordered();
// 返回一个添加了close处理器的Stream实例,close处理器会在下面的close方法中回调
S onClose(Runnable closeHandler);
// 关闭当前Stream实例,回调关联本Stream的所有close处理器
@Override
void close();
}
abstract class PipelineHelper<P_OUT> {
// 获取流的流水线的数据源的"形状",其实就是数据源元素的类型
// 主要有四种类型:REFERENCE(除了int、long和double之外的引用类型)、INT_VALUE、LONG_VALUE和DOUBLE_VALUE
abstract StreamShape getSourceShape();
// 获取合并流和流操作的标志,合并的标志包括流的数据源标志、中间操作标志和终结操作标志
// 从实现上看是当前流管道节点合并前面所有节点和自身节点标志的所有标志
abstract int getStreamAndOpFlags();
// 如果当前的流管道节点的合并标志集合支持SIZED,则调用Spliterator.getExactSizeIfKnown()返回数据源中的准确元素数量,否则返回-1
abstract<P_IN> long exactOutputSizeIfKnown(Spliterator<P_IN> spliterator);
// 相当于调用下面的方法组合:copyInto(wrapSink(sink), spliterator)
abstract<P_IN, S extends Sink<P_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator);
// 发送所有来自Spliterator中的元素到Sink中,如果支持SHORT_CIRCUIT标志,则会调用copyIntoWithCancel
abstract<P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator);
// 发送所有来自Spliterator中的元素到Sink中,Sink处理完每个元素后会检查Sink#cancellationRequested()方法的状态去判断是否中断推送元素的操作
abstract <P_IN> boolean copyIntoWithCancel(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator);
// 创建接收元素类型为P_IN的Sink实例,实现PipelineHelper中描述的所有中间操作,用这个Sink去包装传入的Sink实例(传入的Sink实例的元素类型为PipelineHelper的输出类型P_OUT)
abstract<P_IN> Sink<P_IN> wrapSink(Sink<P_OUT> sink);
// 包装传入的spliterator,从源码来看,在Stream链的头节点调用会直接返回传入的实例,如果在非头节点调用会委托到StreamSpliterators.WrappingSpliterator()方法进行包装
// 这个方法在源码中没有API注释
abstract<P_IN> Spliterator<P_OUT> wrapSpliterator(Spliterator<P_IN> spliterator);
// 构造一个兼容当前Stream元素"形状"的Node.Builder实例
// 从源码来看直接委托到Nodes.builder()方法
abstract Node.Builder<P_OUT> makeNodeBuilder(long exactSizeIfKnown,
IntFunction<P_OUT[]> generator);
// Stream流水线所有阶段(节点)应用于数据源Spliterator,输出的元素作为结果收集起来转化为Node实例
// 此方法应用于toArray()方法的计算,本质上是一个终结操作
abstract<P_IN> Node<P_OUT> evaluate(Spliterator<P_IN> spliterator,
boolean flatten,
IntFunction<P_OUT[]> generator);
}
注意一点(重复3次):
- 这里把同步流称为同步处理|执行的流,“并行流"称为并发处理|执行的流,因为并行流有歧义,实际上只是并发执行,不是并行执行
- 这里把同步流称为同步处理|执行的流,“并行流"称为并发处理|执行的流,因为并行流有歧义,实际上只是并发执行,不是并行执行
- 这里把同步流称为同步处理|执行的流,“并行流"称为并发处理|执行的流,因为并行流有歧义,实际上只是并发执行,不是并行执行
Sink 和引用类型链
PipelineHelper的几个方法中存在Sink这个接口,上一节没有分析,这一小节会详细展开。Stream在构建的时候虽然是一个双向链表的结构,但是在最终应用终结操作的时候,会把所有操作转化为引用类型链(ChainedReference),记得之前也提到过这种类似于多层包装器的编程模式,简化一下模型如下:
public class WrapperApp {
interface Wrapper {
void doAction();
}
public static void main(String[] args) {
AtomicInteger counter = new AtomicInteger(0);
Wrapper first = () -> System.out.printf("wrapper [depth => %d] invoke\n", counter.incrementAndGet());
Wrapper second = () -> {
first.doAction();
System.out.printf("wrapper [depth => %d] invoke\n", counter.incrementAndGet());
};
second.doAction();
}
}
// 控制台输出
wrapper [depth => 1] invoke
wrapper [depth => 2] invoke
上面的例子有点突兀,两个不同Sink的实现可以做到无感知融合,举另一个例子如下:
public interface Sink<T> extends Consumer<T> {
default void begin(long size) {
}
default void end() {
}
abstract class ChainedReference<T, OUT> implements Sink<T> {
protected final Sink<OUT> downstream;
public ChainedReference(Sink<OUT> downstream) {
this.downstream = downstream;
}
}
}
@SuppressWarnings({"unchecked", "rawtypes"})
public class ReferenceChain<OUT, R> {
/**
* sink chain
*/
private final List<Supplier<Sink<?>>> sinkBuilders = new ArrayList<>();
/**
* current sink
*/
private final AtomicReference<Sink> sinkReference = new AtomicReference<>();
public ReferenceChain<OUT, R> filter(Predicate<OUT> predicate) {
//filter
sinkBuilders.add(() -> {
Sink<OUT> prevSink = (Sink<OUT>) sinkReference.get();
Sink.ChainedReference<OUT, OUT> currentSink = new Sink.ChainedReference<>(prevSink) {
@Override
public void accept(OUT out) {
if (predicate.test(out)) {
downstream.accept(out);
}
}
};
sinkReference.set(currentSink);
return currentSink;
});
return this;
}
public ReferenceChain<OUT, R> map(Function<OUT, R> function) {
// map
sinkBuilders.add(() -> {
Sink<R> prevSink = (Sink<R>) sinkReference.get();
Sink.ChainedReference<OUT, R> currentSink = new Sink.ChainedReference<>(prevSink) {
@Override
public void accept(OUT in) {
downstream.accept(function.apply(in));
}
};
sinkReference.set(currentSink);
return currentSink;
});
return this;
}
public void forEachPrint(Collection<OUT> collection) {
forEachPrint(collection, false);
}
public void forEachPrint(Collection<OUT> collection, boolean reverse) {
Spliterator<OUT> spliterator = collection.spliterator();
// 这个是类似于terminal op
Sink<OUT> sink = System.out::println;
sinkReference.set(sink);
Sink<OUT> stage = sink;
// 反向包装 -> 正向遍历
if (reverse) {
for (int i = 0; i <= sinkBuilders.size() - 1; i++) {
Supplier<Sink<?>> supplier = sinkBuilders.get(i);
stage = (Sink<OUT>) supplier.get();
}
} else {
// 正向包装 -> 反向遍历
for (int i = sinkBuilders.size() - 1; i >= 0; i--) {
Supplier<Sink<?>> supplier = sinkBuilders.get(i);
stage = (Sink<OUT>) supplier.get();
}
}
Sink<OUT> finalStage = stage;
spliterator.forEachRemaining(finalStage);
}
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(12);
ReferenceChain<Integer, Integer> chain = new ReferenceChain<>();
// filter -> map -> for each
chain.filter(item -> item > 10)
.map(item -> item * 2)
.forEachPrint(list);
}
}
// 输出结果
24
执行的流程如下:
多层包装器的编程模式的核心要领就是:
- 绝大部分操作可以转换为
java.util.function.Consumer的实现,也就是实现accept(T t)方法完成对传入的元素进行处理 - 先处理的
Sink总是以后处理的Sink为入参,在自身处理方法中判断和回调传入的Sink的处理方法回调,也就是构建引用链的时候,需要从后往前构建,这种方式的实现逻辑可以参考AbstractPipeline#wrapSink(),例如:
// 目标顺序:filter -> map
Sink mapSink = new Sink(inputSink){
private Function mapper;
public void accept(E ele) {
inputSink.accept(mapper.apply(ele))
}
}
Sink filterSink = new Sink(mapSink){
private Predicate predicate;
public void accept(E ele) {
if(predicate.test(ele)){
mapSink.accept(ele);
}
}
}
- 由上一点得知,一般来说,最后的终结操作会应用在引用链的第一个
Sink上
上面的代码并非笔者虚构出来,可见java.util.stream.Sink的源码:
// 继承自Consumer,主要是继承函数式接口方法void accept(T t)
interface Sink<T> extends Consumer<T> {
// 重置当前Sink的状态(为了接收一个新的数据集),传入的size是推送到downstream的准确数据量,无法评估数据量则传入-1
default void begin(long size) {}
//
default void end() {}
// 返回true的时候表示当前的Sink不会接收数据
default boolean cancellationRequested() {
return false;
}
// 特化方法,接受一个int类型的值
default void accept(int value) {
throw new IllegalStateException("called wrong accept method");
}
// 特化方法,接受一个long类型的值
default void accept(long value) {
throw new IllegalStateException("called wrong accept method");
}
// 特化方法,接受一个double类型的值
default void accept(double value) {
throw new IllegalStateException("called wrong accept method");
}
// 引用类型链,准确来说是Sink链
abstract static class ChainedReference<T, E_OUT> implements Sink<T> {
// 下一个Sink
protected final Sink<? super E_OUT> downstream;
public ChainedReference(Sink<? super E_OUT> downstream) {
this.downstream = Objects.requireNonNull(downstream);
}
@Override
public void begin(long size) {
downstream.begin(size);
}
@Override
public void end() {
downstream.end();
}
@Override
public boolean cancellationRequested() {
return downstream.cancellationRequested();
}
}
// 暂时忽略Int、Long、Double的特化类型场景
}
如果用过RxJava或者Project-Reactor,Sink更像是Subscriber,多个Subscriber组成了ChainedReference(Sink Chain,可以理解为一个复合的Subscriber),而Terminal Op则类似于Publisher,只有在Subscriber订阅Publisher的时候才会进行数据的处理,这里是应用了Reactive编程模式。
AbstractPipeline和ReferencePipeline的实现
AbstractPipeline和ReferencePipeline都是抽象类,AbstractPipeline用于构建Pipeline的数据结构,提供一些Shape相关的抽象方法给ReferencePipeline实现,而ReferencePipeline就是Stream中Pipeline的基础类型,从源码上看,Stream链式(管道式)结构的头节点和操作节点都是ReferencePipeline的子类。先看AbstractPipeline的成员变量和构造函数:
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
// 流管道链式结构的头节点(只有当前的AbstractPipeline引用是头节点,此变量才会被赋值,非头节点为NULL)
@SuppressWarnings("rawtypes")
private final AbstractPipeline sourceStage;
// 流管道链式结构的upstream,也就是上一个节点,如果是头节点此引用为NULL
@SuppressWarnings("rawtypes")
private final AbstractPipeline previousStage;
// 合并数据源的标志和操作标志的掩码
protected final int sourceOrOpFlags;
// 流管道链式结构的下一个节点,如果是头节点此引用为NULL
@SuppressWarnings("rawtypes")
private AbstractPipeline nextStage;
// 流的深度
// 串行执行的流中,表示当前流管道实例中中间操作节点的个数(除去头节点和终结操作)
// 并发执行的流中,表示当前流管道实例中中间操作节点和前一个有状态操作节点之间的节点个数
private int depth;
// 合并了所有数据源的标志、操作标志和当前的节点(AbstractPipeline)实例的标志,也就是当前的节点可以基于此属性得知所有支持的标志
private int combinedFlags;
// 数据源的Spliterator实例
private Spliterator<?> sourceSpliterator;
// 数据源的Spliterator实例封装的Supplier实例
private Supplier<? extends Spliterator<?>> sourceSupplier;
// 标记当前的流节点是否被连接或者消费掉,不能重复连接或者重复消费
private boolean linkedOrConsumed;
// 标记当前的流管道链式结构中是否存在有状态的操作节点,这个属性只会在头节点中有效
private boolean sourceAnyStateful;
// 数据源关闭动作,这个属性只会在头节点中有效,由sourceStage持有
private Runnable sourceCloseAction;
// 标记当前流是否并发执行
private boolean parallel;
// 流管道结构头节点的父构造方法,使用数据源的Spliterator实例封装的Supplier实例
AbstractPipeline(Supplier<? extends Spliterator<?>> source,
int sourceFlags, boolean parallel) {
// 头节点的前驱节点置为NULL
this.previousStage = null;
this.sourceSupplier = source;
this.sourceStage = this;
// 合并传入的源标志和流标志的掩码
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
// The following is an optimization of:
// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);
// 初始化合并标志集合为sourceOrOpFlags和所有流操作标志的初始化值
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
// 深度设置为0
this.depth = 0;
this.parallel = parallel;
}
// 流管道结构头节点的父构造方法,使用数据源的Spliterator实例
AbstractPipeline(Spliterator<?> source,
int sourceFlags, boolean parallel) {
// 头节点的前驱节点置为NULL
this.previousStage = null;
this.sourceSpliterator = source;
this.sourceStage = this;
// 合并传入的源标志和流标志的掩码
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
// The following is an optimization of:
// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);
// 初始化合并标志集合为sourceOrOpFlags和所有流操作标志的初始化值
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
this.depth = 0;
this.parallel = parallel;
}
// 流管道结构中间操作节点的父构造方法
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
// 设置前驱节点的后继节点引用为当前的AbstractPipeline实例
previousStage.nextStage = this;
// 设置前驱节点引用为传入的前驱节点实例
this.previousStage = previousStage;
// 合并传入的中间操作标志和流操作标志的掩码
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
// 合并标志集合为传入的标志和前驱节点的标志集合
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
// 赋值sourceStage为前驱节点的sourceStage
this.sourceStage = previousStage.sourceStage;
if (opIsStateful())
// 标记当前的流存在有状态操作
sourceStage.sourceAnyStateful = true;
// 深度设置为前驱节点深度加1
this.depth = previousStage.depth + 1;
}
// 省略其他方法
}
至此,可以看出流管道的数据结构:
Terminal Op不参与管道链式结构的构建。接着看AbstractPipeline中的终结求值方法(Terminal evaluation methods):
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
// 省略其他方法
// 基于终结操作进行求值,这个是Stream执行的常用核心方法,常用于collect()这类终结操作
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
// 判断linkedOrConsumed,以防多次终结求值,也就是每个终结操作只能执行一次
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
// 如果当前流支持并发执行,则委托到TerminalOp.evaluateParallel(),如果当前流只支持同步执行,则委托到TerminalOp.evaluateSequential()
// 这里注意传入到TerminalOp中的方法参数分别是this(PipelineHelper类型)和数据源Spliterator
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
// 基于当前的流实例转换为最终的Node实例,传入的IntFunction用于创建数组实例
// 此终结方法一般用于toArray()这类终结操作
@SuppressWarnings("unchecked")
final Node<E_OUT> evaluateToArrayNode(IntFunction<E_OUT[]> generator) {
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
// If the last intermediate operation is stateful then
// evaluate directly to avoid an extra collection step
// 当前流支持并发执行,并且最后一个中间操作是有状态,则委托到opEvaluateParallel(),否则委托到evaluate(),这两个都是AbstractPipeline中的方法
if (isParallel() && previousStage != null && opIsStateful()) {
// Set the depth of this, last, pipeline stage to zero to slice the
// pipeline such that this operation will not be included in the
// upstream slice and upstream operations will not be included
// in this slice
depth = 0;
return opEvaluateParallel(previousStage, previousStage.sourceSpliterator(0), generator);
}
else {
return evaluate(sourceSpliterator(0), true, generator);
}
}
// 这个方法比较简单,就是获取当前流的数据源所在的Spliterator,并且确保流已经消费,一般用于forEach()这类终结操作
final Spliterator<E_OUT> sourceStageSpliterator() {
if (this != sourceStage)
throw new IllegalStateException();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
if (sourceStage.sourceSpliterator != null) {
@SuppressWarnings("unchecked")
Spliterator<E_OUT> s = sourceStage.sourceSpliterator;
sourceStage.sourceSpliterator = null;
return s;
}
else if (sourceStage.sourceSupplier != null) {
@SuppressWarnings("unchecked")
Spliterator<E_OUT> s = (Spliterator<E_OUT>) sourceStage.sourceSupplier.get();
sourceStage.sourceSupplier = null;
return s;
}
else {
throw new IllegalStateException(MSG_CONSUMED);
}
}
// 省略其他方法
}
AbstractPipeline中实现了BaseStream的方法:
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
// 省略其他方法
// 设置头节点的parallel属性为false,返回自身实例,表示当前的流是同步执行的
@Override
@SuppressWarnings("unchecked")
public final S sequential() {
sourceStage.parallel = false;
return (S) this;
}
// 设置头节点的parallel属性为true,返回自身实例,表示当前的流是并发执行的
@Override
@SuppressWarnings("unchecked")
public final S parallel() {
sourceStage.parallel = true;
return (S) this;
}
// 流关闭操作,设置linkedOrConsumed为true,数据源的Spliterator相关引用置为NULL,置空并且回调sourceCloseAction钩子实例
@Override
public void close() {
linkedOrConsumed = true;
sourceSupplier = null;
sourceSpliterator = null;
if (sourceStage.sourceCloseAction != null) {
Runnable closeAction = sourceStage.sourceCloseAction;
sourceStage.sourceCloseAction = null;
closeAction.run();
}
}
// 返回一个添加了close处理器的Stream实例,close处理器会在下面的close方法中回调
// 如果本来持有的引用sourceStage.sourceCloseAction非空,会使用传入的closeHandler与sourceStage.sourceCloseAction进行合并
@Override
@SuppressWarnings("unchecked")
public S onClose(Runnable closeHandler) {
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
Objects.requireNonNull(closeHandler);
Runnable existingHandler = sourceStage.sourceCloseAction;
sourceStage.sourceCloseAction =
(existingHandler == null)
? closeHandler
: Streams.composeWithExceptions(existingHandler, closeHandler);
return (S) this;
}
// Primitive specialization use co-variant overrides, hence is not final
// 返回当前流实例中所有元素的Spliterator实例
@Override
@SuppressWarnings("unchecked")
public Spliterator<E_OUT> spliterator() {
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
// 标记当前节点被链接或者消费
linkedOrConsumed = true;
// 如果当前节点为头节点,那么返回sourceStage.sourceSpliterator或者延时加载的sourceStage.sourceSupplier(延时加载封装由lazySpliterator实现)
if (this == sourceStage) {
if (sourceStage.sourceSpliterator != null) {
@SuppressWarnings("unchecked")
Spliterator<E_OUT> s = (Spliterator<E_OUT>) sourceStage.sourceSpliterator;
sourceStage.sourceSpliterator = null;
return s;
}
else if (sourceStage.sourceSupplier != null) {
@SuppressWarnings("unchecked")
Supplier<Spliterator<E_OUT>> s = (Supplier<Spliterator<E_OUT>>) sourceStage.sourceSupplier;
sourceStage.sourceSupplier = null;
return lazySpliterator(s);
}
else {
throw new IllegalStateException(MSG_CONSUMED);
}
}
else {
// 如果当前节点不是头节点,重新对sourceSpliterator进行包装,包装后的实例为WrappingSpliterator
return wrap(this, () -> sourceSpliterator(0), isParallel());
}
}
// 当前流实例是否并发执行,从头节点的parallel属性进行判断
@Override
public final boolean isParallel() {
return sourceStage.parallel;
}
// 从当前combinedFlags中获取数据源标志和所有流中间操作标志的集合
final int getStreamFlags() {
return StreamOpFlag.toStreamFlags(combinedFlags);
}
/**
* Get the source spliterator for this pipeline stage. For a sequential or
* stateless parallel pipeline, this is the source spliterator. For a
* stateful parallel pipeline, this is a spliterator describing the results
* of all computations up to and including the most recent stateful
* operation.
*/
@SuppressWarnings("unchecked")
private Spliterator<?> sourceSpliterator(int terminalFlags) {
// 从sourceStage.sourceSpliterator或者sourceStage.sourceSupplier中获取当前流实例中的Spliterator实例,确保必定存在,否则抛出IllegalStateException
Spliterator<?> spliterator = null;
if (sourceStage.sourceSpliterator != null) {
spliterator = sourceStage.sourceSpliterator;
sourceStage.sourceSpliterator = null;
}
else if (sourceStage.sourceSupplier != null) {
spliterator = (Spliterator<?>) sourceStage.sourceSupplier.get();
sourceStage.sourceSupplier = null;
}
else {
throw new IllegalStateException(MSG_CONSUMED);
}
// 下面这段逻辑是对于并发执行并且存在有状态操作的节点,那么需要重新计算节点的深度和节点的合并标志集合
// 这里只提一下计算过程,从头节点的后继节点开始遍历到当前节点,如果被遍历的节点时有状态的,那么对depth、combinedFlags和spliterator会进行重新计算
// depth一旦出现有状态节点就会重置为0,然后从1重新开始增加
// combinedFlags会重新合并sourceOrOpFlags、SHORT_CIRCUIT(如果sourceOrOpFlags支持)和Spliterator.SIZED
// spliterator简单来看就是从并发执行的toArray()=>Array数组=>Spliterator实例
if (isParallel() && sourceStage.sourceAnyStateful) {
// Adapt the source spliterator, evaluating each stateful op
// in the pipeline up to and including this pipeline stage.
// The depth and flags of each pipeline stage are adjusted accordingly.
int depth = 1;
for (@SuppressWarnings("rawtypes") AbstractPipeline u = sourceStage, p = sourceStage.nextStage, e = this;
u != e;
u = p, p = p.nextStage) {
int thisOpFlags = p.sourceOrOpFlags;
if (p.opIsStateful()) {
depth = 0;
if (StreamOpFlag.SHORT_CIRCUIT.isKnown(thisOpFlags)) {
// Clear the short circuit flag for next pipeline stage
// This stage encapsulates short-circuiting, the next
// stage may not have any short-circuit operations, and
// if so spliterator.forEachRemaining should be used
// for traversal
thisOpFlags = thisOpFlags & ~StreamOpFlag.IS_SHORT_CIRCUIT;
}
spliterator = p.opEvaluateParallelLazy(u, spliterator);
// Inject or clear SIZED on the source pipeline stage
// based on the stage's spliterator
thisOpFlags = spliterator.hasCharacteristics(Spliterator.SIZED)
? (thisOpFlags & ~StreamOpFlag.NOT_SIZED) | StreamOpFlag.IS_SIZED
: (thisOpFlags & ~StreamOpFlag.IS_SIZED) | StreamOpFlag.NOT_SIZED;
}
p.depth = depth++;
p.combinedFlags = StreamOpFlag.combineOpFlags(thisOpFlags, u.combinedFlags);
}
}
// 如果传入的terminalFlags标志不为0,则当前节点的combinedFlags会合并terminalFlags
if (terminalFlags != 0) {
// Apply flags from the terminal operation to last pipeline stage
combinedFlags = StreamOpFlag.combineOpFlags(terminalFlags, combinedFlags);
}
return spliterator;
}
// 省略其他方法
}
AbstractPipeline中实现了PipelineHelper的方法:
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
// 省略其他方法
// 获取数据源元素的类型,这里的类型包括引用、int、double和float
// 其实实现上就是获取depth<=0的第一个节点的输出类型
@Override
final StreamShape getSourceShape() {
@SuppressWarnings("rawtypes")
AbstractPipeline p = AbstractPipeline.this;
while (p.depth > 0) {
p = p.previousStage;
}
return p.getOutputShape();
}
// 基于当前节点的标志集合判断和返回流中待处理的元素数量,无法获取则返回-1
@Override
final <P_IN> long exactOutputSizeIfKnown(Spliterator<P_IN> spliterator) {
return StreamOpFlag.SIZED.isKnown(getStreamAndOpFlags()) ? spliterator.getExactSizeIfKnown() : -1;
}
// 通过流管道链式结构构建元素引用链,再遍历元素引用链
@Override
final <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator) {
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
return sink;
}
// 遍历元素引用链
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
// 当前节点不支持SHORT_CIRCUIT(短路)特性,则直接遍历元素引用链,不支持短路跳出
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
// 支持短路(中途取消)遍历元素引用链
copyIntoWithCancel(wrappedSink, spliterator);
}
}
// 支持短路(中途取消)遍历元素引用链
@Override
@SuppressWarnings("unchecked")
final <P_IN> boolean copyIntoWithCancel(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
@SuppressWarnings({"rawtypes","unchecked"})
AbstractPipeline p = AbstractPipeline.this;
// 基于当前节点,获取流管道链式结构中第最后一个depth=0的前驱节点
while (p.depth > 0) {
p = p.previousStage;
}
wrappedSink.begin(spliterator.getExactSizeIfKnown());
// 委托到forEachWithCancel()进行遍历
boolean cancelled = p.forEachWithCancel(spliterator, wrappedSink);
wrappedSink.end();
return cancelled;
}
// 返回当前节点的标志集合
@Override
final int getStreamAndOpFlags() {
return combinedFlags;
}
// 当前节点标志集合中是否支持ORDERED
final boolean isOrdered() {
return StreamOpFlag.ORDERED.isKnown(combinedFlags);
}
// 构建元素引用链,生成一个多重包装的Sink(WrapSink),这里的逻辑可以看前面的分析章节
@Override
@SuppressWarnings("unchecked")
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
// 这里遍历的时候,总是从当前节点向前驱节点遍历,也就是传入的sink实例总是包裹在最里面一层执行
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
// 包装数据源的Spliterator,如果depth=0,则直接返回sourceSpliterator,否则返回的是延迟加载的WrappingSpliterator
@Override
@SuppressWarnings("unchecked")
final <P_IN> Spliterator<E_OUT> wrapSpliterator(Spliterator<P_IN> sourceSpliterator) {
if (depth == 0) {
return (Spliterator<E_OUT>) sourceSpliterator;
}
else {
return wrap(this, () -> sourceSpliterator, isParallel());
}
}
// 计算Node实例,这个方法用于toArray()方法系列,是一个终结操作,下面会另开章节详细分析
@Override
@SuppressWarnings("unchecked")
final <P_IN> Node<E_OUT> evaluate(Spliterator<P_IN> spliterator,
boolean flatten,
IntFunction<E_OUT[]> generator) {
if (isParallel()) {
// @@@ Optimize if op of this pipeline stage is a stateful op
return evaluateToNode(this, spliterator, flatten, generator);
}
else {
Node.Builder<E_OUT> nb = makeNodeBuilder(
exactOutputSizeIfKnown(spliterator), generator);
return wrapAndCopyInto(nb, spliterator).build();
}
}
// 省略其他方法
}
AbstractPipeline中剩余的待如XXYYZZPipeline等子类实现的抽象方法:
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
// 省略其他方法
// 获取当前流的输出"形状",REFERENCE、INT_VALUE、LONG_VALUE或者DOUBLE_VALUE
abstract StreamShape getOutputShape();
// 收集当前流的所有输出元素,转化为一个适配当前流输出"形状"的Node实例
abstract <P_IN> Node<E_OUT> evaluateToNode(PipelineHelper<E_OUT> helper,
Spliterator<P_IN> spliterator,
boolean flattenTree,
IntFunction<E_OUT[]> generator);
// 包装Spliterator为WrappingSpliterator实例
abstract <P_IN> Spliterator<E_OUT> wrap(PipelineHelper<E_OUT> ph,
Supplier<Spliterator<P_IN>> supplier,
boolean isParallel);
// 包装Spliterator为DelegatingSpliterator实例
abstract <P_IN> Spliterator<E_OUT> wrap(PipelineHelper<E_OUT> ph,
Supplier<Spliterator<P_IN>> supplier,
boolean isParallel);
// 基于Sink遍历Spliterator中的元素,支持取消操作,简单理解就是支持cancel的tryAdvance方法
abstract boolean forEachWithCancel(Spliterator<E_OUT> spliterator, Sink<E_OUT> sink);
// 返回Node的建造器实例,用于toArray方法系列
abstract Node.Builder<E_OUT> makeNodeBuilder(long exactSizeIfKnown,
IntFunction<E_OUT[]> generator);
// 判断当前的操作(节点)是否有状态,如果是有状态的操作,必须覆盖opEvaluateParallel方法
abstract boolean opIsStateful();
// 当前操作生成的结果会作为传入的Sink实例的入参,这是一个包装Sink的过程,通俗理解就是之前提到的元素引用链添加一个新的链节点,这个方法算是流执行的一个核心方法
abstract Sink<E_IN> opWrapSink(int flags, Sink<E_OUT> sink);
// 并发执行的操作节点求值
<P_IN> Node<E_OUT> opEvaluateParallel(PipelineHelper<E_OUT> helper,
Spliterator<P_IN> spliterator,
IntFunction<E_OUT[]> generator) {
throw new UnsupportedOperationException("Parallel evaluation is not supported");
}
// 并发执行的操作节点惰性求值
@SuppressWarnings("unchecked")
<P_IN> Spliterator<E_OUT> opEvaluateParallelLazy(PipelineHelper<E_OUT> helper,
Spliterator<P_IN> spliterator) {
return opEvaluateParallel(helper, spliterator, i -> (E_OUT[]) new Object[i]).spliterator();
}
// 省略其他方法
}
这里提到的抽象方法opWrapSink()其实就是元素引用链的添加链节点的方法,它的实现逻辑见子类,这里只考虑非特化子类ReferencePipeline的部分源码:
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 构造函数,用于头节点,传入基于Supplier封装的Spliterator实例作为数据源,数据源的标志集合和是否支持并发执行的判断标记
ReferencePipeline(Supplier<? extends Spliterator<?>> source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
// 构造函数,用于头节点,传入Spliterator实例作为数据源,数据源的标志集合和是否支持并发执行的判断标记
ReferencePipeline(Spliterator<?> source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
// 构造函数,用于中间节点,传入上一个流管道节点的实例(前驱节点)和当前操作节点支持的标志集合
ReferencePipeline(AbstractPipeline<?, P_IN, ?> upstream, int opFlags) {
super(upstream, opFlags);
}
// 这里流的输出"形状"固定为REFERENCE
@Override
final StreamShape getOutputShape() {
return StreamShape.REFERENCE;
}
// 转换当前流实例为Node实例,应用于toArray方法,后面详细分析终结操作的时候再展开
@Override
final <P_IN> Node<P_OUT> evaluateToNode(PipelineHelper<P_OUT> helper,
Spliterator<P_IN> spliterator,
boolean flattenTree,
IntFunction<P_OUT[]> generator) {
return Nodes.collect(helper, spliterator, flattenTree, generator);
}
// 包装Spliterator=>WrappingSpliterator
@Override
final <P_IN> Spliterator<P_OUT> wrap(PipelineHelper<P_OUT> ph,
Supplier<Spliterator<P_IN>> supplier,
boolean isParallel) {
return new StreamSpliterators.WrappingSpliterator<>(ph, supplier, isParallel);
}
// 包装Spliterator=>DelegatingSpliterator,实现惰性加载
@Override
final Spliterator<P_OUT> lazySpliterator(Supplier<? extends Spliterator<P_OUT>> supplier) {
return new StreamSpliterators.DelegatingSpliterator<>(supplier);
}
// 遍历Spliterator中的元素,基于传入的Sink实例进行处理,支持Cancel操作
@Override
final boolean forEachWithCancel(Spliterator<P_OUT> spliterator, Sink<P_OUT> sink) {
boolean cancelled;
do { } while (!(cancelled = sink.cancellationRequested()) && spliterator.tryAdvance(sink));
return cancelled;
}
// 构造Node建造器实例
@Override
final Node.Builder<P_OUT> makeNodeBuilder(long exactSizeIfKnown, IntFunction<P_OUT[]> generator) {
return Nodes.builder(exactSizeIfKnown, generator);
}
// 基于当前流的Spliterator生成迭代器实例
@Override
public final Iterator<P_OUT> iterator() {
return Spliterators.iterator(spliterator());
}
// 省略其他OP的代码
// 流管道结构的头节点
static class Head<E_IN, E_OUT> extends ReferencePipeline<E_IN, E_OUT> {
// 构造函数,用于头节点,传入基于Supplier封装的Spliterator实例作为数据源,数据源的标志集合和是否支持并发执行的判断标记
Head(Supplier<? extends Spliterator<?>> source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
// 构造函数,用于头节点,传入Spliterator实例作为数据源,数据源的标志集合和是否支持并发执行的判断标记
Head(Spliterator<?> source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
// 不支持判断是否状态操作
@Override
final boolean opIsStateful() {
throw new UnsupportedOperationException();
}
// 不支持包装Sink实例
@Override
final Sink<E_IN> opWrapSink(int flags, Sink<E_OUT> sink) {
throw new UnsupportedOperationException();
}
// 区分同步异步执行forEach,同步则简单理解为调用Spliterator.forEachRemaining,异步则调用终结操作forEach
@Override
public void forEach(Consumer<? super E_OUT> action) {
if (!isParallel()) {
sourceStageSpliterator().forEachRemaining(action);
}
else {
super.forEach(action);
}
}
// 区分同步异步执行forEachOrdered,同步则简单理解为调用Spliterator.forEachRemaining,异步则调用终结操作forEachOrdered
@Override
public void forEachOrdered(Consumer<? super E_OUT> action) {
if (!isParallel()) {
sourceStageSpliterator().forEachRemaining(action);
}
else {
super.forEachOrdered(action);
}
}
}
// 无状态操作节点的父类
abstract static class StatelessOp<E_IN, E_OUT>
extends ReferencePipeline<E_IN, E_OUT> {
// 基于上一个节点引用、输入元素"形状"和当前节点支持的标志集合创建StatelessOp实例
StatelessOp(AbstractPipeline<?, E_IN, ?> upstream,
StreamShape inputShape,
int opFlags) {
super(upstream, opFlags);
assert upstream.getOutputShape() == inputShape;
}
// 操作状态标记设置为无状态
@Override
final boolean opIsStateful() {
return false;
}
}
// 有状态操作节点的父类
abstract static class StatefulOp<E_IN, E_OUT>
extends ReferencePipeline<E_IN, E_OUT> {
// 基于上一个节点引用、输入元素"形状"和当前节点支持的标志集合创建StatefulOp实例
StatefulOp(AbstractPipeline<?, E_IN, ?> upstream,
StreamShape inputShape,
int opFlags) {
super(upstream, opFlags);
assert upstream.getOutputShape() == inputShape;
}
// 操作状态标记设置为有状态
@Override
final boolean opIsStateful() {
return true;
}
// 前面也提到,节点操作异步求值的方法在无状态节点下必须覆盖,这里重新把这个方法抽象,子类必须实现
@Override
abstract <P_IN> Node<E_OUT> opEvaluateParallel(PipelineHelper<E_OUT> helper,
Spliterator<P_IN> spliterator,
IntFunction<E_OUT[]> generator);
}
}
这里重重重点分析一下ReferencePipeline中的wrapSink方法实现:
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
入参是一个Sink实例,返回值也是一个Sink实例,里面的for循环是基于当前的AbstractPipeline节点向前遍历,直到depth为0的节点跳出循环,而depth为0意味着该节点必定为头节点,也就是该循环是遍历当前节点到头节点的后继节点,Sink是"向前包装的”,也就是处于链后面的节点Sink总是会作为其前驱节点的opWrapSink()方法的入参,在同步执行流求值计算的时候,前驱节点的Sink处理完元素后就会通过downstream引用(其实就是后驱节点的Sink)调用其accept()把元素或者处理完的元素结果传递进去,激活下一个Sink,以此类推。另外,ReferencePipeline的三个内部类Head、StatelessOp和StatefulOp就是流的节点类,其中只有Head是非抽象类,代表流管道结构(或者说双向链表结构)的头节点,StatelessOp(无状态操作)和StatefulOp(有状态操作)的子类构成了流管道结构的操作节点或者是终结操作。在忽略是否有状态操作的前提下看ReferencePipeline,它只是流数据结构的承载体,表面上看到的双向链表结构在流的求值计算过程中并不会进行直接遍历每个节点进行求值,而是先转化成一个多层包装的Sink,也就是前文笔者提到的元素引用链后者前一句分析的Sink元素处理以及传递,正确来说应该是一个Sink栈或者Sink包装器,它的实现可以类比为现实生活中的洋葱,或者编程模式中的AOP编程模式。形象一点的描述如下:
Head(Spliterator) -> Op(filter) -> Op(map) -> Op(sorted) -> Terminal Op(forEach)
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
forEach ele in Spliterator:
Sink[filter](ele){
if filter process == true:
Sink[map](ele){
ele = mapper(ele)
Sink[sorted](ele){
var array
begin:
accept(ele):
add ele to array
end:
sort ele in array
}
}
}
终结操作forEach是目前分析源码中最简单的实现,下面会详细分析每种终结操作的实现细节。
流中间操作的源码实现
限于篇幅,这里只能挑选一部分的中间Op进行分析。流的中间操作基本都是由BaseStream接口定义,在ReferencePipeline中进行实现,这里挑选比较常用的filter、map和sorted进行分析。先看filter:
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 暂时省略其他代码
// filter操作,泛型参数Predicate类型接受一个任意类型(这里考虑到泛型擦除)的元素,输出布尔值,它是一个无状态操作
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
// 这里注意到,StatelessOp的第一个参数是指upstream,也就是理解为上一个节点,这里使用了this,意味着upstream为当前的ReferencePipeline实例,元素"形状"为引用类型,操作标志位不支持SIZED
// 在AbstractPipeline,previousStage指向了this,当前的节点就是StatelessOp[filter]实例,那么前驱节点this的后继节点引用nextStage就指向了StatelessOp[filter]实例
// 也就是StatelessOp[filter].previousStage = this; this.nextStage = StatelessOp[filter]; ===> 也就是这个看起来简单的new StatelessOp()其实已经把自身加入到管道中
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
// 这里通知下一个节点的Sink.begin(),由于filter方法不感知元素数量,所以传值-1
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
// 基于输入的Predicate实例判断当前处理元素是否符合判断,只有判断结果为true才会把元素原封不动直接传递到下一个Sink
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
// 暂时省略其他代码
}
接着是map:
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 暂时省略其他代码
// map操作,基于传入的Function实例做映射转换(P_OUT->R),它是一个无状态操作
@Override
@SuppressWarnings("unchecked")
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
// upstream为当前的ReferencePipeline实例,元素"形状"为引用类型,操作标志位不支持SORTED和DISTINCT
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
// 基于传入的Function实例转换元素后把转换结果传递到下一个Sink
downstream.accept(mapper.apply(u));
}
};
}
};
}
// 暂时省略其他代码
}
然后是sorted,sorted操作会相对复杂一点:
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 暂时省略其他代码
// sorted操作,基于传入的Comparator实例对处理的元素进行排序,从源码中看,它是一个有状态操作
@Override
public final Stream<P_OUT> sorted(Comparator<? super P_OUT> comparator) {
return SortedOps.makeRef(this, comparator);
}
// 暂时省略其他代码
}
// SortedOps工具类
final class SortedOps {
// 暂时省略其他代码
// 构建排序操作的链节点
static <T> Stream<T> makeRef(AbstractPipeline<?, T, ?> upstream,
Comparator<? super T> comparator) {
return new OfRef<>(upstream, comparator);
}
// 有状态的排序操作节点
private static final class OfRef<T> extends ReferencePipeline.StatefulOp<T, T> {
// 是否自然排序,不定义Comparator实例的时候为true,否则为false
private final boolean isNaturalSort;
// 用于排序的Comparator实例
private final Comparator<? super T> comparator;
// 自然排序情况下的构造方法,元素"形状"为引用类型,操作标志位不支持ORDERED和SORTED
OfRef(AbstractPipeline<?, T, ?> upstream) {
super(upstream, StreamShape.REFERENCE,
StreamOpFlag.IS_ORDERED | StreamOpFlag.IS_SORTED);
this.isNaturalSort = true;
// Comparator实例赋值为Comparator.naturalOrder(),本质是基于Object中的equals或者子类覆盖Object中的equals方法进行元素排序
@SuppressWarnings("unchecked")
Comparator<? super T> comp = (Comparator<? super T>) Comparator.naturalOrder();
this.comparator = comp;
}
// 非自然排序情况下的构造方法,需要传入Comparator实例,元素"形状"为引用类型,操作标志位不支持ORDERED和SORTED
OfRef(AbstractPipeline<?, T, ?> upstream, Comparator<? super T> comparator) {
super(upstream, StreamShape.REFERENCE,
StreamOpFlag.IS_ORDERED | StreamOpFlag.NOT_SORTED);
this.isNaturalSort = false;
this.comparator = Objects.requireNonNull(comparator);
}
@Override
public Sink<T> opWrapSink(int flags, Sink<T> sink) {
Objects.requireNonNull(sink);
// If the input is already naturally sorted and this operation
// also naturally sorted then this is a no-op
// 流中的所有元素本身已经按照自然顺序排序,并且没有定义Comparator实例,则不需要进行排序,所以no op就行
if (StreamOpFlag.SORTED.isKnown(flags) && isNaturalSort)
return sink;
else if (StreamOpFlag.SIZED.isKnown(flags))
// 知道要处理的元素的确切数量,使用数组进行排序
return new SizedRefSortingSink<>(sink, comparator);
else
// 不知道要处理的元素的确切数量,使用ArrayList进行排序
return new RefSortingSink<>(sink, comparator);
}
// 这里是并行执行流中toArray方法的实现,暂不分析
@Override
public <P_IN> Node<T> opEvaluateParallel(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator,
IntFunction<T[]> generator) {
// If the input is already naturally sorted and this operation
// naturally sorts then collect the output
if (StreamOpFlag.SORTED.isKnown(helper.getStreamAndOpFlags()) && isNaturalSort) {
return helper.evaluate(spliterator, false, generator);
}
else {
// @@@ Weak two-pass parallel implementation; parallel collect, parallel sort
T[] flattenedData = helper.evaluate(spliterator, true, generator).asArray(generator);
Arrays.parallelSort(flattenedData, comparator);
return Nodes.node(flattenedData);
}
}
}
// 这里考虑到篇幅太长,SizedRefSortingSink和RefSortingSink的源码不复杂,只展开RefSortingSink进行分析
// 无法确认待处理元素确切数量时候用于元素排序的Sink实现
private static final class RefSortingSink<T> extends AbstractRefSortingSink<T> {
// 临时ArrayList实例
private ArrayList<T> list;
// 构造函数,需要的参数为下一个Sink引用和Comparator实例
RefSortingSink(Sink<? super T> sink, Comparator<? super T> comparator) {
super(sink, comparator);
}
@Override
public void begin(long size) {
if (size >= Nodes.MAX_ARRAY_SIZE)
throw new IllegalArgumentException(Nodes.BAD_SIZE);
// 基于传入的size是否大于0,大于等于0用于作为initialCapacity构建ArrayList,小于0则构建默认initialCapacity的ArrayList,赋值到临时变量list
list = (size >= 0) ? new ArrayList<>((int) size) : new ArrayList<>();
}
@Override
public void end() {
// 临时的ArrayList实例基于Comparator实例进行潘旭
list.sort(comparator);
// 下一个Sink节点的激活,区分是否支持取消操作
downstream.begin(list.size());
if (!cancellationRequestedCalled) {
list.forEach(downstream::accept);
}
else {
for (T t : list) {
if (downstream.cancellationRequested()) break;
downstream.accept(t);
}
}
downstream.end();
// 激活下一个Sink完成后,临时的ArrayList实例置为NULL,便于GC回收
list = null;
}
@Override
public void accept(T t) {
// 当前Sink处理元素直接添加到临时的ArrayList实例
list.add(t);
}
}
// 暂时省略其他代码
}
sorted操作有个比较显著的特点,一般的Sink处理完自身的逻辑,会在accept()方法激活下一个Sink引用,但是它在accept()方法中只做元素的累积(元素富集),在end()方法进行最终的排序操作和模仿Spliterator的两个元素遍历方法向downstream推送待处理的元素。示意图如下:
其他中间操作的实现逻辑是大致相同的。
同步执行流终结操作的源码实现
限于篇幅,这里只能挑选一部分的Terminal Op进行分析,简单起见只分析同步执行的场景,这里挑选最典型和最复杂的froEach()和collect(),还有比较独特的toArray()方法。先看froEach()方法的实现过程:
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 暂时省略其他代码
// 遍历元素
@Override
public void forEach(Consumer<? super P_OUT> action) {
evaluate(ForEachOps.makeRef(action, false));
}
// 暂时省略其他代码
// 基于终结操作的求值方法
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
// 确保只会执行一次,linkedOrConsumed是流管道结构最后一个节点的属性
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
// 这里暂且只分析同步执行的流的终结操作,终结操作节点的标志会合并到流最后一个节点的combinedFlags中,执行的关键就是evaluateSequential方法
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
// 暂时省略其他代码
}
// ForEachOps类,TerminalOp接口的定义比较简单,这里不展开
final class ForEachOps {
// 暂时省略其他代码
// 构造变量元素的终结操作实例,传入的元素是T类型,结果是Void类型(返回NULL,或者说是没有返回值,毕竟是一个元素遍历过程)
// 参数为一个Consumer接口实例和一个标记是否顺序处理元素的布尔值
public static <T> TerminalOp<T, Void> makeRef(Consumer<? super T> action,
boolean ordered) {
Objects.requireNonNull(action);
return new ForEachOp.OfRef<>(action, ordered);
}
// 遍历元素操作的终结操作实现,同时它是一个适配器,适配TerminalSink(Sink)接口
abstract static class ForEachOp<T>
implements TerminalOp<T, Void>, TerminalSink<T, Void> {
// 标记是否顺序处理元素
private final boolean ordered;
protected ForEachOp(boolean ordered) {
this.ordered = ordered;
}
// TerminalOp
// 终结操作节点的标志集合,如果ordered为true则返回0,否则返回StreamOpFlag.NOT_ORDERED,表示不支持顺序处理元素
@Override
public int getOpFlags() {
return ordered ? 0 : StreamOpFlag.NOT_ORDERED;
}
// 同步遍历和处理元素
@Override
public <S> Void evaluateSequential(PipelineHelper<T> helper,
Spliterator<S> spliterator) {
// 以当前的ForEachOp实例作为最后一个Sink添加到Sink链(也就是前面经常说的元素引用链),然后对Sink链进行遍历
return helper.wrapAndCopyInto(this, spliterator).get();
}
// 并发遍历和处理元素,这里暂不分析
@Override
public <S> Void evaluateParallel(PipelineHelper<T> helper,
Spliterator<S> spliterator) {
if (ordered)
new ForEachOrderedTask<>(helper, spliterator, this).invoke();
else
new ForEachTask<>(helper, spliterator, helper.wrapSink(this)).invoke();
return null;
}
// TerminalSink
// 实现TerminalSink的方法,实际上TerminalSink继承接口Supplier,这里是实现了Supplier接口的get()方法,由于PipelineHelper.wrapAndCopyInto()方法会返回最后一个Sink的引用,这里其实就是evaluateSequential()中的返回值
@Override
public Void get() {
return null;
}
// ForEachOp的静态内部类,引用类型的ForEachOp的最终实现,依赖入参遍历元素处理的最后一步回调Consumer实例
static final class OfRef<T> extends ForEachOp<T> {
// 最后的遍历回调的Consumer句柄
final Consumer<? super T> consumer;
OfRef(Consumer<? super T> consumer, boolean ordered) {
super(ordered);
this.consumer = consumer;
}
@Override
public void accept(T t) {
// 遍历元素回调操作
consumer.accept(t);
}
}
}
}
forEach终结操作实现上,自身这个操作并不会构成流的链式结构的一部分,也就是它不是一个AbstractPipeline的子类实例,而是构建一个回调Consumer实例操作的一个Sink实例(准确来说是TerminalSink)实例,这里暂且叫forEach terminal sink,通过流最后一个操作节点的wrapSink()方法,把forEach terminal sink添加到Sink链的尾部,通过流最后一个操作节点的copyInto()方法进行元素遍历,按照copyInto()方法的套路,只要多层包装的Sink方法在回调其实现方法的时候总是激活downstream的前提下,执行的顺序就是流链式结构定义的操作节点顺序,而forEach最后添加的Consumer实例一定就是最后回调的。
接着分析collect()方法的实现,先看Collector接口的定义:
// T:需要进行reduce操作的输入元素类型
// A:reduce操作中可变累加对象的类型,可以简单理解为累加操作中,累加到Container<A>中的可变对象类型
// R:reduce操作结果类型
public interface Collector<T, A, R> {
// 注释中称为Container,用于承载最终结果的可变容器,而此方法的Supplier实例持有的是创建Container实例的get()方法实现,后面称为Supplier
// 也就是一般使用如:Supplier<Container> supplier = () -> new Container();
Supplier<A> supplier();
// Accumulator,翻译为累加器,用于处理值并且把处理结果传递(累加)到Container中,后面称为Accumulator
BiConsumer<A, T> accumulator();
// Combiner,翻译为合并器,真实泛型类型为BinaryOperator<A,A,A>,BiFunction的子类,接收两个部分的结果并且合并为一个结果,后面称为Combiner
// 这个方法可以把一个参数的状态转移到另一个参数,然后返回更新状态后的参数,例如:(arg1, arg2) -> {arg2.state = arg1.state; return arg2;}
// 可以把一个参数的状态转移到另一个参数,然后返回一个新的容器,例如:(arg1, arg2) -> {arg2.state = arg1.state; return new Container(arg2);}
BinaryOperator<A> combiner();
// Finisher,直接翻译感觉意义不合理,实际上就是做最后一步转换工作的处理器,后面称为Finisher
Function<A, R> finisher();
// Collector支持的特性集合,见枚举Characteristics
Set<Characteristics> characteristics();
// 这里忽略两个Collector的静态工厂方法,因为并不常用
enum Characteristics {
// 标记Collector支持并发执行,一般和并发容器相关
CONCURRENT,
// 标记Collector处理元素时候无序
UNORDERED,
// 标记Collector的输入和输出元素是同类型,也就是Finisher在实现上R -> A可以等效于A -> R,unchecked cast会成功(也就是类型强转可以成功)
// 在这种场景下,对于Container来说其实类型强制转换也是等效的,也就是Supplier<A>和Supplier<R>得出的Container是同一种类型的Container
IDENTITY_FINISH
}
}
// Collector的实现Collectors.CollectorImpl
public final class Collectors {
// 这一大堆常量就是预设的多种特性组合,CH_NOID比较特殊,是空集合,也就是Collector三种特性都不支持
static final Set<Collector.Characteristics> CH_CONCURRENT_ID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.CONCURRENT,
Collector.Characteristics.UNORDERED,
Collector.Characteristics.IDENTITY_FINISH));
static final Set<Collector.Characteristics> CH_CONCURRENT_NOID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.CONCURRENT,
Collector.Characteristics.UNORDERED));
static final Set<Collector.Characteristics> CH_ID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.IDENTITY_FINISH));
static final Set<Collector.Characteristics> CH_UNORDERED_ID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.UNORDERED,
Collector.Characteristics.IDENTITY_FINISH));
static final Set<Collector.Characteristics> CH_NOID = Collections.emptySet();
static final Set<Collector.Characteristics> CH_UNORDERED_NOID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.UNORDERED));
private Collectors() { }
// 省略大量代码
// 静态类,Collector的实现,实现其实就是Supplier、Accumulator、Combiner、Finisher和Characteristics集合的成员属性承载
static class CollectorImpl<T, A, R> implements Collector<T, A, R> {
private final Supplier<A> supplier;
private final BiConsumer<A, T> accumulator;
private final BinaryOperator<A> combiner;
private final Function<A, R> finisher;
private final Set<Characteristics> characteristics;
CollectorImpl(Supplier<A> supplier,
BiConsumer<A, T> accumulator,
BinaryOperator<A> combiner,
Function<A,R> finisher,
Set<Characteristics> characteristics) {
this.supplier = supplier;
this.accumulator = accumulator;
this.combiner = combiner;
this.finisher = finisher;
this.characteristics = characteristics;
}
CollectorImpl(Supplier<A> supplier,
BiConsumer<A, T> accumulator,
BinaryOperator<A> combiner,
Set<Characteristics> characteristics) {
this(supplier, accumulator, combiner, castingIdentity(), characteristics);
}
@Override
public BiConsumer<A, T> accumulator() {
return accumulator;
}
@Override
public Supplier<A> supplier() {
return supplier;
}
@Override
public BinaryOperator<A> combiner() {
return combiner;
}
@Override
public Function<A, R> finisher() {
return finisher;
}
@Override
public Set<Characteristics> characteristics() {
return characteristics;
}
}
// 省略大量代码
// IDENTITY_FINISH特性下,Finisher的实现,也就是之前提到的A->R和R->A等效,可以强转
private static <I, R> Function<I, R> castingIdentity() {
return i -> (R) i;
}
// 省略大量代码
}
collect()方法的求值执行入口在ReferencePipeline中:
// ReferencePipeline
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 暂时省略其他代码
// 基于Collector实例进行求值
public final <R, A> R collect(Collector<? super P_OUT, A, R> collector) {
A container;
// 并发求值场景暂不考虑
if (isParallel()
&& (collector.characteristics().contains(Collector.Characteristics.CONCURRENT))
&& (!isOrdered() || collector.characteristics().contains(Collector.Characteristics.UNORDERED))) {
container = collector.supplier().get();
BiConsumer<A, ? super P_OUT> accumulator = collector.accumulator();
forEach(u -> accumulator.accept(container, u));
}
else {
// 这里就是同步执行场景下的求值过程,这里可以看出其实所有Collector的求值都是Reduce操作
container = evaluate(ReduceOps.makeRef(collector));
}
// 如果Collector的Finisher输入类型和输出类型相同,所以Supplier<A>和Supplier<R>得出的Container是同一种类型的Container,可以直接类型转换,否则就要调用Collector中的Finisher进行最后一步处理
return collector.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)
? (R) container
: collector.finisher().apply(container);
}
// 暂时省略其他代码
}
// ReduceOps
final class ReduceOps {
private ReduceOps() { }
// 暂时省略其他代码
// 引用类型Reduce操作创建TerminalOp实例
public static <T, I> TerminalOp<T, I>
makeRef(Collector<? super T, I, ?> collector) {
// Supplier
Supplier<I> supplier = Objects.requireNonNull(collector).supplier();
// Accumulator
BiConsumer<I, ? super T> accumulator = collector.accumulator();
// Combiner
BinaryOperator<I> combiner = collector.combiner();
// 这里注意一点,ReducingSink是方法makeRef中的内部类,作用域只在方法内,它是封装为TerminalOp最终转化为Sink链中最后一个Sink实例的类型
class ReducingSink extends Box<I>
implements AccumulatingSink<T, I, ReducingSink> {
@Override
public void begin(long size) {
// 这里把从Supplier创建的新Container实例存放在父类Box的状态属性中
state = supplier.get();
}
@Override
public void accept(T t) {
// 处理元素,Accumulator处理状态(容器实例)和元素,这里可以想象,如果state为一个ArrayList实例,这里的accept()实现可能为add(ele)操作
accumulator.accept(state, t);
}
@Override
public void combine(ReducingSink other) {
// Combiner合并两个状态(容器实例)
state = combiner.apply(state, other.state);
}
}
return new ReduceOp<T, I, ReducingSink>(StreamShape.REFERENCE) {
@Override
public ReducingSink makeSink() {
return new ReducingSink();
}
@Override
public int getOpFlags() {
return collector.characteristics().contains(Collector.Characteristics.UNORDERED)
? StreamOpFlag.NOT_ORDERED
: 0;
}
};
}
// 暂时省略其他代码
// 继承自接口TerminalSink,主要添加了combine()抽象方法,用于合并元素
private interface AccumulatingSink<T, R, K extends AccumulatingSink<T, R, K>>
extends TerminalSink<T, R> {
void combine(K other);
}
// 状态盒,用于持有和获取状态,状态属性的修饰符为default,包内的类实例都能修改
private abstract static class Box<U> {
U state;
Box() {} // Avoid creation of special accessor
public U get() {
return state;
}
}
// ReduceOp的最终实现,这个就是Reduce操作终结操作的实现
private abstract static class ReduceOp<T, R, S extends AccumulatingSink<T, R, S>>
implements TerminalOp<T, R> {
// 流输入元素"形状"
private final StreamShape inputShape;
ReduceOp(StreamShape shape) {
inputShape = shape;
}
// 抽象方法,让子类生成终结操作的Sink
public abstract S makeSink();
// 获取流输入元素"形状"
@Override
public StreamShape inputShape() {
return inputShape;
}
// 同步执行求值,还是相似的思路,使用wrapAndCopyInto()进行Sink链构建和元素遍历
@Override
public <P_IN> R evaluateSequential(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator) {
// 以当前的ReduceOp实例的makeSink()返回的Sink实例作为最后一个Sink添加到Sink链(也就是前面经常说的元素引用链),然后对Sink链进行遍历
// 这里向上一步一步推演思考,最终get()方法执行完毕拿到的结果就是ReducingSink父类Box中的state变量,也就是容器实例
return helper.wrapAndCopyInto(makeSink(), spliterator).get();
}
// 异步执行求值,暂时忽略
@Override
public <P_IN> R evaluateParallel(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator) {
return new ReduceTask<>(this, helper, spliterator).invoke().get();
}
}
// 暂时省略其他代码
}
接着就看Collector的静态工厂方法,看一些常用的Collector实例是如何构建的,例如看Collectors.toList():
// Supplier => () -> new ArrayList<T>(); // 初始化ArrayList
// Accumulator => (list,number) -> list.add(number); // 往ArrayList中添加元素
// Combiner => (left, right) -> { left.addAll(right); return left;} // 合并ArrayList
// Finisher => X -> X; // 输入什么就返回什么,这里实际返回的是ArrayList
public static <T>
Collector<T, ?, List<T>> toList() {
return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new, List::add,
(left, right) -> { left.addAll(right); return left; },
CH_ID);
}
把过程画成流程图如下:
甚至可以更通俗地用伪代码表示Collector这类Terminal Op的执行过程(还是以Collectors.toList()为例):
[begin]
Supplier supplier = () -> new ArrayList<T>();
Container container = supplier.get();
Box.state = container;
[accept]
Box.state.add(element);
[end]
return supplier.get(); (=> return Box.state);
↓↓↓↓↓↓↓↓↓甚至更加通俗的过程如下↓↓↓↓↓↓↓↓↓↓↓↓↓↓
ArrayList<T> container = new ArrayList<T>();
loop:
container.add(element)
return container;
也就是虽然工程化的代码看起来很复杂,最终的实现就是简单的:初始化ArrayList实例由state属性持有,遍历处理元素的时候把元素添加到state中,最终返回state。最后看toArray()的方法实现(下面的方法代码没有按照实际的位置贴出,笔者把零散的代码块放在一起方便分析):
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
// 暂时省略其他代码
// 流的所有元素转换为数组,这里的IntFunction有一种比较特殊的用法,就是用于创建数组实例
// 例如IntFunction<String[]> f = String::new; String[] arry = f.apply(2); 相当于String[] arry = new String[2];
@Override
@SuppressWarnings("unchecked")
public final <A> A[] toArray(IntFunction<A[]> generator) {
// 这里主动擦除了IntFunction的类型,只要保证求值的过程是正确,最终可以做类型强转
@SuppressWarnings("rawtypes")
IntFunction rawGenerator = (IntFunction) generator;
// 委托到evaluateToArrayNode()方法进行计算
return (A[]) Nodes.flatten(evaluateToArrayNode(rawGenerator), rawGenerator)
.asArray(rawGenerator);
}
// 流的所有元素转换为Object数组
@Override
public final Object[] toArray() {
return toArray(Object[]::new);
}
// 流元素求值转换为ArrayNode
final Node<E_OUT> evaluateToArrayNode(IntFunction<E_OUT[]> generator) {
// 确保不会处理多次
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
// 并发执行暂时跳过
if (isParallel() && previousStage != null && opIsStateful()) {
depth = 0;
return opEvaluateParallel(previousStage, previousStage.sourceSpliterator(0), generator);
}
else {
return evaluate(sourceSpliterator(0), true, generator);
}
}
// 最终的转换Node的方法
final <P_IN> Node<E_OUT> evaluate(Spliterator<P_IN> spliterator,
boolean flatten,
IntFunction<E_OUT[]> generator) {
// 并发执行暂时跳过
if (isParallel()) {
// @@@ Optimize if op of this pipeline stage is a stateful op
return evaluateToNode(this, spliterator, flatten, generator);
}
else {
// 兜兜转换还是回到了wrapAndCopyInto()方法,遍历Sink链,所以基本可以得知Node.Builder是Sink的一个实现
Node.Builder<E_OUT> nb = makeNodeBuilder(
exactOutputSizeIfKnown(spliterator), generator);
return wrapAndCopyInto(nb, spliterator).build();
}
}
// 获取Node的建造器实例
final Node.Builder<P_OUT> makeNodeBuilder(long exactSizeIfKnown, IntFunction<P_OUT[]> generator) {
return Nodes.builder(exactSizeIfKnown, generator);
}
// 暂时省略其他代码
}
// Node接口定义
interface Node<T> {
// 获取待处理的元素封装成的Spliterator实例
Spliterator<T> spliterator();
// 遍历当前Node实例中所有待处理的元素,回调到Consumer实例中
void forEach(Consumer<? super T> consumer);
// 获取当前Node实例的所有子Node的个数
default int getChildCount() {
return 0;
}
// 获取当前Node实例的子Node实例,入参i是子Node的索引
default Node<T> getChild(int i) {
throw new IndexOutOfBoundsException();
}
// 分割当前Node实例的一个部分,生成一个新的sub Node,类似于ArrayList中的subList方法
default Node<T> truncate(long from, long to, IntFunction<T[]> generator) {
if (from == 0 && to == count())
return this;
Spliterator<T> spliterator = spliterator();
long size = to - from;
Node.Builder<T> nodeBuilder = Nodes.builder(size, generator);
nodeBuilder.begin(size);
for (int i = 0; i < from && spliterator.tryAdvance(e -> { }); i++) { }
if (to == count()) {
spliterator.forEachRemaining(nodeBuilder);
} else {
for (int i = 0; i < size && spliterator.tryAdvance(nodeBuilder); i++) { }
}
nodeBuilder.end();
return nodeBuilder.build();
}
// 创建一个包含当前Node实例所有元素的元素数组视图
T[] asArray(IntFunction<T[]> generator);
//
void copyInto(T[] array, int offset);
// 返回Node实例基于Stream的元素"形状"
default StreamShape getShape() {
return StreamShape.REFERENCE;
}
// 获取当前Node实例包含的元素个数
long count();
// Node建造器,注意这个Node.Builder接口是继承自Sink,那么其子类实现都可以添加到Sink链中作为一个节点(终结节点)
interface Builder<T> extends Sink<T> {
// 创建Node实例
Node<T> build();
// 基于Integer元素类型的特化类型Node.Builder
interface OfInt extends Node.Builder<Integer>, Sink.OfInt {
@Override
Node.OfInt build();
}
// 基于Long元素类型的特化类型Node.Builder
interface OfLong extends Node.Builder<Long>, Sink.OfLong {
@Override
Node.OfLong build();
}
// 基于Double元素类型的特化类型Node.Builder
interface OfDouble extends Node.Builder<Double>, Sink.OfDouble {
@Override
Node.OfDouble build();
}
}
// 暂时省略其他代码
}
// 这里下面的方法来源于Nodes类
final class Nodes {
// 暂时省略其他代码
// Node扁平化处理,如果传入的Node实例存在子Node实例,则使用fork-join对Node进行分割和并发计算,结果添加到IntFunction生成的数组中,如果不存在子Node,直接返回传入的Node实例
// 关于并发计算部分暂时不分析
public static <T> Node<T> flatten(Node<T> node, IntFunction<T[]> generator) {
if (node.getChildCount() > 0) {
long size = node.count();
if (size >= MAX_ARRAY_SIZE)
throw new IllegalArgumentException(BAD_SIZE);
T[] array = generator.apply((int) size);
new ToArrayTask.OfRef<>(node, array, 0).invoke();
return node(array);
} else {
return node;
}
}
// 创建Node的建造器实例
static <T> Node.Builder<T> builder(long exactSizeIfKnown, IntFunction<T[]> generator) {
// 当知道待处理元素的准确数量并且小于允许创建的数组的最大长度MAX_ARRAY_SIZE(Integer.MAX_VALUE - 8),使用FixedNodeBuilder(固定长度数组Node建造器),否则使用SpinedNodeBuilder实例
return (exactSizeIfKnown >= 0 && exactSizeIfKnown < MAX_ARRAY_SIZE)
? new FixedNodeBuilder<>(exactSizeIfKnown, generator)
: builder();
}
// 创建Node的建造器实例,使用SpinedNodeBuilder的实例,此SpinedNode支持元素添加,但是不支持元素移除
static <T> Node.Builder<T> builder() {
return new SpinedNodeBuilder<>();
}
// 固定长度固定长度数组Node实现(也就是最终的Node实现是一个ArrayNode,最终的容器为一个T类型元素的数组T[])
private static final class FixedNodeBuilder<T>
extends ArrayNode<T>
implements Node.Builder<T> {
// 基于size(元素个数,或者说创建数组的长度)和数组创建方法IntFunction构建FixedNodeBuilder实例
FixedNodeBuilder(long size, IntFunction<T[]> generator) {
super(size, generator);
assert size < MAX_ARRAY_SIZE;
}
// 返回当前FixedNodeBuilder实例,判断数组元素计数值curSize必须大于等于实际数组容器中元素的个数
@Override
public Node<T> build() {
if (curSize < array.length)
throw new IllegalStateException(String.format("Current size %d is less than fixed size %d",
curSize, array.length));
return this;
}
// Sink的begin方法回调,传入的size必须和数组长度相等,因为后面的accept()方法会执行size此
@Override
public void begin(long size) {
if (size != array.length)
throw new IllegalStateException(String.format("Begin size %d is not equal to fixed size %d",
size, array.length));
// 重置数组元素计数值为0
curSize = 0;
}
// Sink的accept方法回调,当数组元素计数值小于数组长度,直接向数组下标curSize++添加传入的元素
@Override
public void accept(T t) {
if (curSize < array.length) {
array[curSize++] = t;
} else {
throw new IllegalStateException(String.format("Accept exceeded fixed size of %d",
array.length));
}
}
// Sink的end方法回调,再次判断数组元素计数值curSize必须大于等于实际数组容器中元素的个数
@Override
public void end() {
if (curSize < array.length)
throw new IllegalStateException(String.format("End size %d is less than fixed size %d",
curSize, array.length));
}
// 返回FixedNodeBuilder当前信息,当前处理的下标和当前数组中所有的元素
@Override
public String toString() {
return String.format("FixedNodeBuilder[%d][%s]",
array.length - curSize, Arrays.toString(array));
}
}
// Node实现,容器为一个固定长度的数组
private static class ArrayNode<T> implements Node<T> {
// 数组容器
final T[] array;
// 数组容器中当前元素的个数,这个值是一个固定值,或者在FixedNodeBuilder的accept()方法回调中递增
int curSize;
// 基于size和数组创建的工厂IntFunction构建ArrayNode实例
@SuppressWarnings("unchecked")
ArrayNode(long size, IntFunction<T[]> generator) {
if (size >= MAX_ARRAY_SIZE)
throw new IllegalArgumentException(BAD_SIZE);
// 创建szie长度的数组容器
this.array = generator.apply((int) size);
this.curSize = 0;
}
// 这个方法是基于一个现成的数组创建ArrayNode实例,直接改变数组的引用为array,元素个数curSize置为输入参数长度
ArrayNode(T[] array) {
this.array = array;
this.curSize = array.length;
}
// Node - 接下来是Node接口的实现
// 基于数组实例,起始索引0和结束索引curSize构造一个全新的Spliterator实例
@Override
public Spliterator<T> spliterator() {
return Arrays.spliterator(array, 0, curSize);
}
// 拷贝array中的元素到外部传入的dest数组中
@Override
public void copyInto(T[] dest, int destOffset) {
System.arraycopy(array, 0, dest, destOffset, curSize);
}
// 返回元素数组视图,这里直接返回array引用
@Override
public T[] asArray(IntFunction<T[]> generator) {
if (array.length == curSize) {
return array;
} else {
throw new IllegalStateException();
}
}
// 获取array中的元素个数
@Override
public long count() {
return curSize;
}
// 遍历array,每个元素回调Consumer实例
@Override
public void forEach(Consumer<? super T> consumer) {
for (int i = 0; i < curSize; i++) {
consumer.accept(array[i]);
}
}
// 返回ArrayNode当前信息,当前处理的下标和当前数组中所有的元素
@Override
public String toString() {
return String.format("ArrayNode[%d][%s]",
array.length - curSize, Arrays.toString(array));
}
}
// 暂时省略其他代码
}
很多集合容器的Spliterator其实并不支持SIZED特性,其实Node的最终实现很多情况下都是Nodes.SpinedNodeBuilder,因为SpinedNodeBuilder重实现实现了数组扩容和Spliterator基于数组进行分割的方法,源码相对复杂(特别是spliterator()方法),这里挑部分进行分析,由于SpinedNodeBuilder绝大部分方法都是使用父类SpinedBuffer中的实现,这里可以直接分析SpinedBuffer:
// SpinedBuffer的当前数组在超过了元素数量阈值之后,会拆分为多个数组块,存储到spine中,而curChunk引用指向的是当前处理的数组块
class SpinedBuffer<E>
extends AbstractSpinedBuffer
implements Consumer<E>, Iterable<E> {
// 暂时省略其他代码
// 当前的数组块
protected E[] curChunk;
// 所有数组块
protected E[][] spine;
// 构造函数,指定初始化容量
SpinedBuffer(int initialCapacity) {
super(initialCapacity);
curChunk = (E[]) new Object[1 << initialChunkPower];
}
// 构造函数,指定默认初始化容量
@SuppressWarnings("unchecked")
SpinedBuffer() {
super();
curChunk = (E[]) new Object[1 << initialChunkPower];
}
// 拷贝当前SpinedBuffer中的数组元素到传入的数组实例
public void copyInto(E[] array, int offset) {
// 计算最终的offset,区分单个chunk和多个chunk的情况
long finalOffset = offset + count();
if (finalOffset > array.length || finalOffset < offset) {
throw new IndexOutOfBoundsException("does not fit");
}
// 单个chunk的情况,由curChunk最接拷贝
if (spineIndex == 0)
System.arraycopy(curChunk, 0, array, offset, elementIndex);
else {
// 多个chunk的情况,由遍历spine并且对每个chunk进行拷贝
// full chunks
for (int i=0; i < spineIndex; i++) {
System.arraycopy(spine[i], 0, array, offset, spine[i].length);
offset += spine[i].length;
}
if (elementIndex > 0)
System.arraycopy(curChunk, 0, array, offset, elementIndex);
}
}
// 返回数组元素视图,基于IntFunction构建数组实例,使用copyInto()方法进行元素拷贝
public E[] asArray(IntFunction<E[]> arrayFactory) {
long size = count();
if (size >= Nodes.MAX_ARRAY_SIZE)
throw new IllegalArgumentException(Nodes.BAD_SIZE);
E[] result = arrayFactory.apply((int) size);
copyInto(result, 0);
return result;
}
// 清空SpinedBuffer,清空分块元素和所有引用
@Override
public void clear() {
if (spine != null) {
curChunk = spine[0];
for (int i=0; i<curChunk.length; i++)
curChunk[i] = null;
spine = null;
priorElementCount = null;
}
else {
for (int i=0; i<elementIndex; i++)
curChunk[i] = null;
}
elementIndex = 0;
spineIndex = 0;
}
// 遍历元素回调Consumer,分别遍历spine和curChunk
@Override
public void forEach(Consumer<? super E> consumer) {
// completed chunks, if any
for (int j = 0; j < spineIndex; j++)
for (E t : spine[j])
consumer.accept(t);
// current chunk
for (int i=0; i<elementIndex; i++)
consumer.accept(curChunk[i]);
}
// Consumer的accept实现,最终会作为Sink接口的accept方法调用
@Override
public void accept(E e) {
// 如果当前分块(第一个)的元素已经满了,就初始化spine,然后元素添加到spine[0]中
if (elementIndex == curChunk.length) {
inflateSpine();
// 然后元素添加到spine[0]中的元素已经满了,就新增spine[n],把元素放进spine[n]中
if (spineIndex+1 >= spine.length || spine[spineIndex+1] == null)
increaseCapacity();
elementIndex = 0;
++spineIndex;
// 当前的chunk更新为最新的chunk,就是spine中的最新一个chunk
curChunk = spine[spineIndex];
}
// 当前的curChunk添加元素
curChunk[elementIndex++] = e;
}
// 暂时省略其他代码
}
源码已经基本分析完毕,下面还是用一个例子转化为流程图:
流并发执行的源码实现
如果流实例调用了parallel(),注释中提到会返回一个异步执行流的变体,实际上并没有构造变体,只是把sourceStage.parallel标记为true,异步求值的基本过程是:构建流管道结构的时候和同步求值的过程一致,构建完Sink链之后,Spliterator会使用特定算法基于trySplit()进行自分割,自分割算法由具体的子类决定,例如ArrayList采用的就是二分法,分割完成后每个Spliterator持有所有元素中的一小部分,然后把每个Spliterator作为sourceSpliterator在fork-join线程池中执行Sink链,得到多个部分的结果在当前调用线程中聚合,得到最终结果。这里用到的技巧就是:线程封闭和fork-join。因为不同Terminal Op的并发求值过程大同小异,这里只分析forEach并发执行的实现。首先展示一个使用fork-join线程池的简单例子:
public class MapReduceApp {
public static void main(String[] args) {
// 数组中每个元素*2,再求和
Integer result = new MapReducer<>(new Integer[]{1, 2, 3, 4}, x -> x * 2, Integer::sum).invoke();
System.out.println(result);
}
interface Mapper<S, T> {
T apply(S source);
}
interface Reducer<S, T> {
T apply(S first, S second);
}
public static class MapReducer<T> extends CountedCompleter<T> {
final T[] array;
final Mapper<T, T> mapper;
final Reducer<T, T> reducer;
final int lo, hi;
MapReducer<T> sibling;
T result;
public MapReducer(T[] array,
Mapper<T, T> mapper,
Reducer<T, T> reducer) {
this.array = array;
this.mapper = mapper;
this.reducer = reducer;
this.lo = 0;
this.hi = array.length;
}
public MapReducer(CountedCompleter<?> p,
T[] array,
Mapper<T, T> mapper,
Reducer<T, T> reducer,
int lo,
int hi) {
super(p);
this.array = array;
this.mapper = mapper;
this.reducer = reducer;
this.lo = lo;
this.hi = hi;
}
@Override
public void compute() {
if (hi - lo >= 2) {
int mid = (lo + hi) >> 1;
MapReducer<T> left = new MapReducer<>(this, array, mapper, reducer, lo, mid);
MapReducer<T> right = new MapReducer<>(this, array, mapper, reducer, mid, hi);
left.sibling = right;
right.sibling = left;
// 创建子任务父任务的pending计数器加1
setPendingCount(1);
// 提交右子任务
right.fork();
// 在当前线程计算左子任务
left.compute();
} else {
if (hi > lo) {
result = mapper.apply(array[lo]);
}
// 叶子节点完成,尝试合并其他兄弟节点的结果,会调用onCompletion方法
tryComplete();
}
}
@Override
public T getRawResult() {
return result;
}
@SuppressWarnings("unchecked")
@Override
public void onCompletion(CountedCompleter<?> caller) {
if (caller != this) {
MapReducer<T> child = (MapReducer<T>) caller;
MapReducer<T> sib = child.sibling;
// 合并子任务结果,只有两个子任务
if (Objects.isNull(sib) || Objects.isNull(sib.result)) {
result = child.result;
} else {
result = reducer.apply(child.result, sib.result);
}
}
}
}
}
这里简单使用了fork-join编写了一个简易的MapReduce应用,main方法中运行的是数组[1,2,3,4]中的所有元素先映射为i -> i * 2,再进行reduce(求和)的过程,代码中也是简单使用二分法对原始的array进行分割,当最终的任务只包含一个元素,也就是lo < hi且hi - lo == 1的时候,会基于单个元素调用Mapper的方法进行完成通知tryComplete(),任务完成会最终通知onCompletion()方法,Reducer就是在此方法中进行结果的聚合操作。对于流的并发求值来说,过程是类似的,ForEachOp中最终调用ForEachOrderedTask或者ForEachTask,这里挑选ForEachTask进行分析:
abstract static class ForEachOp<T>
implements TerminalOp<T, Void>, TerminalSink<T, Void> {
// 暂时省略其他代码
@Override
public <S> Void evaluateParallel(PipelineHelper<T> helper,
Spliterator<S> spliterator) {
if (ordered)
new ForEachOrderedTask<>(helper, spliterator, this).invoke();
else
// 最终是调用ForEachTask的invoke方法,invoke会阻塞到所有fork任务执行完,获取最终的结果
new ForEachTask<>(helper, spliterator, helper.wrapSink(this)).invoke();
return null;
}
// 暂时省略其他代码
}
// ForEachOps类
final class ForEachOps {
private ForEachOps() { }
// forEach的fork-join任务实现,没有覆盖getRawResult()方法,最终只会返回NULL
static final class ForEachTask<S, T> extends CountedCompleter<Void> {
// Spliterator实例,如果是父任务则代表所有待处理的元素,如果是子任务则是一个分割后的新Spliterator实例
private Spliterator<S> spliterator;
// Sink链实例
private final Sink<S> sink;
// 流管道引用
private final PipelineHelper<T> helper;
// 目标数量,其实是每个任务处理元素数量的建议值
private long targetSize;
// 这个构造器是提供给父(根)任务
ForEachTask(PipelineHelper<T> helper,
Spliterator<S> spliterator,
Sink<S> sink) {
super(null);
this.sink = sink;
this.helper = helper;
this.spliterator = spliterator;
this.targetSize = 0L;
}
// 这个构造器是提供给子任务,所以需要父任务的引用和一个分割后的新Spliterator实例作为参数
ForEachTask(ForEachTask<S, T> parent, Spliterator<S> spliterator) {
super(parent);
this.spliterator = spliterator;
this.sink = parent.sink;
this.targetSize = parent.targetSize;
this.helper = parent.helper;
}
// Similar to AbstractTask but doesn't need to track child tasks
// 实现compute方法,用于分割Spliterator成多个子任务,这里不需要跟踪所有子任务
public void compute() {
// 神奇的赋值,相当于Spliterator<S> rightSplit = spliterator; Spliterator<S> leftSplit;
// rightSplit总是指向当前的spliterator实例
Spliterator<S> rightSplit = spliterator, leftSplit;
// 这里也是神奇的赋值,相当于long sizeEstimate = rightSplit.estimateSize(); long sizeThreshold;
long sizeEstimate = rightSplit.estimateSize(), sizeThreshold;
// sizeThreshold赋值为targetSize
if ((sizeThreshold = targetSize) == 0L)
// 基于Spliterator分割后的右分支实例的元素数量重新赋值sizeThreshold和targetSize
// 计算方式是待处理元素数量/(fork-join线程池并行度<<2)或者1(当前一个计算方式结果为0的时候)
targetSize = sizeThreshold = AbstractTask.suggestTargetSize(sizeEstimate);
// 当前的流是否支持SHORT_CIRCUIT,也就是短路特性
boolean isShortCircuit = StreamOpFlag.SHORT_CIRCUIT.isKnown(helper.getStreamAndOpFlags());
// 当前的任务是否fork右分支
boolean forkRight = false;
// taskSink作为Sink的临时变量
Sink<S> taskSink = sink;
// 当前任务的临时变量
ForEachTask<S, T> task = this;
// Spliterator分割和创建新的fork任务ForEachTask,前提是不支持短路或者Sink不支持取消
while (!isShortCircuit || !taskSink.cancellationRequested()) {
// 当前的任务中的Spliterator(rightSplit)中的待处理元素小于等于每个任务应该处理的元素阈值或者再分割后得到NULL,则不需要再分割,直接基于rightSplit和Sink链执行循环处理元素
if (sizeEstimate <= sizeThreshold || (leftSplit = rightSplit.trySplit()) == null) {
// 这里就是遍历rightSplit元素回调Sink链的操作
task.helper.copyInto(taskSink, rightSplit);
break;
}
// rightSplit还能分割,则基于分割后的leftSplit和以当前任务作为父任务创建一个新的fork任务
ForEachTask<S, T> leftTask = new ForEachTask<>(task, leftSplit);
// 待处理子任务加1
task.addToPendingCount(1);
// 需要fork的任务实例临时变量
ForEachTask<S, T> taskToFork;
// 因为rightSplit总是分割Spliterator后对应原来的Spliterator引用,而leftSplit总是trySplit()后生成的新的Spliterator
// 所以这里leftSplit也需要作为rightSplit进行分割,通俗来说就是周星驰007那把梅花间足发射的枪
if (forkRight) {
// 这里交换leftSplit为rightSplit,所以forkRight设置为false,下一轮循环相当于fork left
forkRight = false;
rightSplit = leftSplit;
taskToFork = task;
// 赋值下一轮的父Task为当前的fork task
task = leftTask;
}
else {
forkRight = true;
taskToFork = leftTask;
}
// 添加fork任务到任务队列中
taskToFork.fork();
// 其实这里是更新剩余待分割的Spliterator中的所有元素数量到sizeEstimate
sizeEstimate = rightSplit.estimateSize();
}
// 置空spliterator实例并且传播任务完成状态,等待所有任务执行完成
task.spliterator = null;
task.propagateCompletion();
}
}
}
上面的源码分析看起来可能比较难理解,这里举个简单的例子:
public static void main(String[] args) throws Exception {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.stream().parallel().forEach(System.out::println);
}
这段代码中最终转换成ForEachTask中评估后得到的targetSize = sizeThreshold == 1,当前调用线程会参与计算,会执行3次fork,也就是一共有4个处理流程实例(也就是原始的Spliterator实例最终会分割出3个全新的Spliterator实例,加上自身一个4个Spliterator实例),每个处理流程实例只处理1个元素,对应的流程图如下:
最终的计算结果是调用CountedCompleter.invoke()方法获取的,此方法会阻塞直到所有子任务处理完成,当然forEach终结操作不需要返回值,所以没有实现getRawResult()方法,这里只是为了阻塞到所有任务执行完毕才解除调用线程的阻塞状态。
状态操作与短路操作
Stream中按照中间操作是否有状态可以把这些操作分为无状态操作和有状态操作。Stream中按照终结操作是否支持短路特性可以把这些操作分为非短路操作和短路操作。理解如下:
- 无状态操作:当前操作节点处理元素完成后,在满足前提条件下直接把结果传递到下一个操作节点,也就是操作内部不存在状态也不需要保存状态,例如
filter、map等操作 - 有状态操作:处理元素的时候,依赖于节点的内部状态对元素进行累积,当处理一个新的元素的时候,其实可以感知到所有处理过的元素的历史状态,这个"状态"其实更像是缓冲区的概念,例如
sort、limit等操作,以sort操作为例,一般是把所有待处理的元素全部添加到一个容器如ArrayList,再进行所有元素的排序,然后再重新模拟Spliterator把元素推送到后一个节点 - 非短路(终结)操作:终结操作在处理元素时候不能基于短路条件提前中断处理并且返回,也就是必须处理所有的元素,如
forEach - 短路(终结)操作:终结操作在处理元素时候允许基于短路条件提前中断处理并且返回,但是最终实现中是有可能遍历完所有的元素中,只是在处理方法中基于前置的短路条件跳过了实际的处理过程,如
anyMatch(实际上anyMatch会遍历完所有的元素,不过在命中了短路条件下,元素回调Sink.accept()方法时候会基于stop短路标记跳过具体的处理流程)
这里不展开源码进行分析,仅仅展示一个经常见到的Stream操作汇总表如下:
这里还有两点要注意:
- 从源码上看部分中间操作也是支持短路的,例如
slice和while相关操作 - 从源码上看
find相关终结操作中findFirst、findAny均支持和判断StreamOpFlag.SHORT_CIRCUIT,而match相关终结操作是通过内部的临时状态stop和value进行短路控制
总结
前前后后写了十多万字,其实也仅仅相对浅层次介绍了Stream的基本实现,笔者认为很多没分析到的中间操作实现和终结操作实现,特别是并发执行的终结操作实现是十分复杂的,多线程环境下需要进行一些想象和多处DEBUG定位执行位置和推演执行的过程。简单总结一下:
JDK中Stream的实现是精炼的高度工程化代码Stream的载体虽然是AbstractPipeline,管道结构,但是只用其形,实际求值操作之前会转化为一个多层包裹的Sink结构,也就是前文一直说的Sink链,从编程模式来看,应用的是Reactor编程模式Stream目前支持的固有求值执行结构一定是Head(Source Spliterator) -> Op -> Op ... -> Terminal Op的形式,这算是一个局限性,没有办法做到像LINQ那样可以灵活实现类似内存视图的功能Stream目前支持并发求值方案是针对Source Spliterator进行分割,封装Terminal Op和固定Sink链构造的ForkJoinTask进行并发计算,调用线程和fork-join线程池中的工作线程都可以参与求值过程,笔者认为这部分是Stream中除了那些标志集合位运算外最复杂的实现Stream实现的功能是一个突破,也有人说过此功能是一个"早产儿”,在此希望JDK能够在矛盾螺旋中前进和发展
Reference
3 - Java 并发
3.2 - CH02-理论基础
多线程的优势
CPU、内存、IO 设备的速度存在巨大差异,为了合理利用 CPU 的高性能,平衡三者之间的速度差异,计算机体系结构、操作系统、编译程序实现了相关优化:
- CPU 增加了缓存,以平衡与内存的速度差异——导致了可见性问题
- 操作系统提供了进程、线程,以分时复用 CPU,进而均衡 CPU 与 IO 设备之间的速度差异——导致原子性问题
- 编译程序优化了指令执行顺序,使缓存能够得到更合理的利用——导致了有序性问题
线程不安全
如果多个线程对同一份数据执行读写而不采取同步措施的话,可能导致混乱(非预期)的操作结果。
class ThreadUnsafeCounter {
private int count =0;
public void add() {
count++;
}
public int get() {
return count;
}
}
class Bootstrap {
public static void main(String[] args) {
int threadSize=1000;
ThreadUnsafeCounter counter = new ThreadUnsafeCounter();
CountDownLatch latch = new CountDownLatch(threadSize);
ExecutorService executor = Executors.newCachedThreadPool();
for(int i=0;i<threadSize;i++){
executor.execute(() -> {
counter.add();
latch.countDown();
})
}
latch.await();
executor.shutdown();
System.out.println(counter.get()); // will always < 1000
}
}
并发三要素
可见性:CPU 缓存
可见性:一个线程对共享变量的修改,其他线程能够立即看到。
// thread 1
int i=0;
i=10;
// thread 2
j = i;
如果 CPU1 执行 Thread1、CPU2 执行 Thread2。当 Thread1 执行 i=10 时,会首先将 i 的初始值加载到 CPU1 的高速缓存中,然后赋值为 10,那么在 CPU1 的高速缓存中 i 的值变为了 10,却被没有被立即写回主存。
此时 Thread2 执行 j=i,首先去主存读取 i 的值加载到 CPU2 的高速缓存,(这时主存中 i 的值仍未 0),这就导致 j 的值为 0,而非 10。
原子性:分时复用
原子性:一个操作或多个操作那么全都执行,要么全不执行,不会被任何因素打断。
有序性:指令重排序
有序性:程序执行的顺序完全按照代码的先后顺序执行。
程序执行时为了提高性能,编译器和处理器通常会对执行进行重排序,分为三种类型:
编译器优化:编译器再不改变单线程程序语义的前提下,重新安排语句的执行顺序。
指令级并行:现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖,处理器可以改变语句对应机器指令的执行顺序。
内存系统重排序:由于处理器通过高速缓存读写缓冲区,是的加载和存储操作看上去实在乱序执行。
从 Java 代码到最终要执行的指令序列,会经历以上三种重排序。
- 第一种属于编译器重排序,2、3 属于处理器重排序。
- 这些重排序可能会导致多线程程序出现内存可见性问题。对于编译器,JMM 中的编译器重排序规则会禁止特定类型的重排序操作。
- 对于处理器重排序,JMM 的处理器重排序规则会要求 Java 编译器在生成指令序列时,插入特定类型的内存屏障指令,通过这些内存屏障指令来禁止特定类型的处理器重排序操作。
Java 如何解决并发问题:JMM
核心知识点
Java 内存模型规范了 JVM 如何提供按需禁用编译和缓存优化的方法。
- volatile、synchronized、final 关键字
- Happens Before 规则
可见性、有序性、原子性
- 原子性:Java 中通过 synchronized 和 Lock 实现原子性保证。
- 可见性:Java 中通过 volatie 提供可见性保证。
- synchronized 和 Lock 保证同一时刻只有一个线程获取锁然后执行代码,释放锁前或将数据刷新到主存。
- 有序性:Java 中通过 volatile 保证一定的有序性。
- synchronized 和 Lock 保证同一时刻只有一个线程执行,相当于多个线程顺序执行代码,即有序执行。
volatile、synchronized、final
Happens Before
除了 volatile、synchronized、Lock 能够保证有序性,JVM 还规定了先行发生规则,使一个操作无需显式控制即可保证先于另一个操作发生。
单一线程:Single Thread Rule
管程锁定:Monitor Lock Rule
- 一个 unlock 操作先于后面对一个锁的 lock 操作。
Volatile 变量:Volatile Variable Rule
线程启动:Thread Start Rule
线程加入:Thread Join Rule
线程中断:Thread Interruption Rule
- 对线程 interrupt 方法的调用先于检测到中断的代码执行。
对象终结:Finalizer Rule
- 对象构造函数执行完成先于 finalize 方法开始。
传递性:Transitivity
- 如果操作 A 先于 B,B 先于 C,那么 A 先于 C。
线程安全:安全程度
一个类可以被多个线程安全调用时,该类就是线程安全的。
将共享数据按照安全程度的强弱来划分安全强度的等级:
不可变
不可变(Immutable)的对象一定是线程安全的,不需要再采取任何的线程安全保障措施。只要一个不可变的对象被正确地构建出来,永远也不会看到它在多个线程之中处于不一致的状态。
绝对线程安全
不管运行时环境如何,调用者都不需要任何额外的同步措施。
相对线程安全
相对线程安全需要保证对这个对象单独的操作是线程安全的,在调用的时候不需要做额外的保障措施。但是对于一些特定顺序的连续调用,就可能需要在调用端使用额外的同步手段来保证调用的正确性。
在 Java 语言中,大部分的线程安全类都属于这种类型,例如 Vector、HashTable、Collections 的 synchronizedCollection() 方法包装的集合等。
线程兼容
线程兼容是指对象本身并不是线程安全的,但是可以通过在调用端正确地使用同步手段来保证对象在并发环境中可以安全地使用,我们平常说一个类不是线程安全的,绝大多数时候指的是这一种情况。Java API 中大部分的类都是属于线程兼容的,如与前面的 Vector 和 HashTable 相对应的集合类 ArrayList 和 HashMap 等。
线程对立
线程对立是指无论调用端是否采取了同步措施,都无法在多线程环境中并发使用的代码。由于 Java 语言天生就具备多线程特性,线程对立这种排斥多线程的代码是很少出现的,而且通常都是有害的,应当尽量避免。
线程安全:实现
互斥同步—阻塞同步
- synchronized
- ReentrantLock
非阻塞同步
互斥同步最主要的问题就是线程阻塞和唤醒所带来的性能问题,因此这种同步也称为阻塞同步。
互斥同步属于一种悲观的并发策略,总是认为只要不去做正确的同步措施,那就肯定会出现问题。无论共享数据是否真的会出现竞争,它都要进行加锁(这里讨论的是概念模型,实际上虚拟机会优化掉很大一部分不必要的加锁)、用户态核心态转换、维护锁计数器和检查是否有被阻塞的线程需要唤醒等操作。
随着硬件指令集的发展,我们可以使用基于冲突检测的乐观并发策略: 先进行操作,如果没有其它线程争用共享数据,那操作就成功了,否则采取补偿措施(不断地重试,直到成功为止)。这种乐观的并发策略的许多实现都不需要将线程阻塞,因此这种同步操作称为非阻塞同步。
乐观锁需要操作和冲突检测这两个步骤具备原子性,这里就不能再使用互斥同步来保证了,只能靠硬件来完成。硬件支持的原子性操作最典型的是: 比较并交换(Compare-and-Swap,CAS)。CAS 指令需要有 3 个参数,分别是内存地址 V、旧的预期值 A 和新值 B。当执行操作时,只有当 V 的值等于 A,才将 V 的值更新为 B。
J.U.C 包里面的整数原子类 AtomicInteger,其中的 compareAndSet() 和 getAndIncrement() 等方法都使用了 Unsafe 类的 CAS 操作。
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
var1 指示对象内存地址,var2 指示该字段相对对象内存地址的偏移,var4 指示操作需要加的数值,这里为 1。通过 getIntVolatile(var1, var2) 得到旧的预期值,通过调用 compareAndSwapInt() 来进行 CAS 比较,如果该字段内存地址中的值等于 var5,那么就更新内存地址为 var1+var2 的变量为 var5+var4。
可以看到 getAndAddInt() 在一个循环中进行,发生冲突的做法是不断的进行重试。
如果一个变量初次读取的时候是 A 值,它的值被改成了 B,后来又被改回为 A,那 CAS 操作就会误认为它从来没有被改变过。
J.U.C 包提供了一个带有标记的原子引用类 AtomicStampedReference 来解决这个问题,它可以通过控制变量值的版本来保证 CAS 的正确性。大部分情况下 ABA 问题不会影响程序并发的正确性,如果需要解决 ABA 问题,改用传统的互斥同步可能会比原子类更高效。
无同步方案
要保证线程安全,并不是一定就要进行同步。如果一个方法本来就不涉及共享数据,那它自然就无须任何同步措施去保证正确性。
多个线程访问同一个方法的局部变量时,不会出现线程安全问题,因为局部变量存储在虚拟机栈中,属于线程私有的。
如果一段代码中所需要的数据必须与其他代码共享,那就看看这些共享数据的代码是否能保证在同一个线程中执行。如果能保证,我们就可以把共享数据的可见范围限制在同一个线程之内,这样,无须同步也能保证线程之间不出现数据争用的问题。
符合这种特点的应用并不少见,大部分使用消费队列的架构模式(如“生产者-消费者”模式)都会将产品的消费过程尽量在一个线程中消费完。其中最重要的一个应用实例就是经典 Web 交互模型中的“一个请求对应一个服务器线程”(Thread-per-Request)的处理方式,这种处理方式的广泛应用使得很多 Web 服务端应用都可以使用线程本地存储来解决线程安全问题。
可以使用 java.lang.ThreadLocal 类来实现线程本地存储功能。每个 Thread 都有一个 ThreadLocal.ThreadLocalMap 对象,Thread 类中就定义了 ThreadLocal.ThreadLocalMap 成员。
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
ThreadLocal 从理论上讲并不是用来解决多线程并发问题的,因为根本不存在多线程竞争。
这种代码也叫做纯代码(Pure Code),可以在代码执行的任何时刻中断它,转而去执行另外一段代码(包括递归调用它本身),而在控制权返回后,原来的程序不会出现任何错误。
可重入代码有一些共同的特征,例如不依赖存储在堆上的数据和公用的系统资源、用到的状态量都由参数中传入、不调用非可重入的方法等。
3.3 - CH03-线程基础-1
线程状态
- New:新建,创建后尚未启动。
- Runnable:可运行,可能正在运行,也可能在等待 CPU 时间片。
- 包含操作系统线程状态的 Running 和 Ready。
- Blocking:等待获取一个排它锁,如果其他线程释放了锁就会结束该状态。
- Waiting:无限期等待,需要其他线程唤醒,否则不会分配 CPU 时间片。
- 未设置 Timeout 参数的 Object.wait 方法,需要 Object.notify 或 Object.notifyAll 唤醒
- 未设置 Timeout 参数的 Thread.join 方法,被调用的线程执行完毕
- LockSupport.park 调用
- Timed Waiting:限时等待,在一定时间后自动唤醒。
- 调用 Thread.sleep 方法,线程睡眠
- 设置了 Timeout 参数调用 Object.wait 进入限期等待,挂起线程
- 睡眠和挂起用于表述行为,阻塞和等待用于描述状态
- 阻塞和等待的区别在于,阻塞是被动的,等待的是一个排它锁,锁的释放由其他线程决定。
- 等待是祖东的,等待的是一个时间点,是线程自身通过 Thread.sleep 或 Object.wait 主动触发的等待。
- 设置了 Timeout 参数调用 Thread.join 方法
- LockSupport.parkNanos
- LockSupport.parkUntil
- Terminated:死亡,线程结束任务之后自然死亡,或异常导致任务终止而死亡
应用方式
- 实现 Runnable 接口:无返回值
- 实现 Callable 接口:有返回值
- 继承 Thread 类
实现 Runnable 后 Callable 接口的类只能被当做是一个可以在线程中执行的任务,并不是真正意义上的线程实例,因此最后还是需要通过 Thread 类来调用。即任务是通过线程来执行的。
线程机制
Executor
Executor 管理多个异步任务的执行,而无需开发者显式管理线程的生命周期。这里的异步是指多个任务的执行互不干扰,不需要执行同步操作。
- CachedThreadPool:每个任务创建一个线程
- FixedThreadPool:所有任务共用固定数量的线程
- SingleThreadExecutor:仅有一个线程的 FixedThreadPool
Daemon
守护线程是程序运行时在后台提供服务的线程,不属于程序中必要的部分,非必须。
- 当所有非守护线程结束时,程序即终止,同时会杀死所有守护线程。
- main 属于非守护线程。
- 通过 setDaemon 方法将一个线程设置为守护线程。
sleep
Thread.sleep(millisec) 方法会休眠当前正在执行的线程,millisec 单位为毫秒。
sleep() 可能会抛出 InterruptedException,因为异常不能跨线程传播回 main() 中,因此必须在本地进行处理。线程任务可能出现的其它异常也同样需要在本地进行处理。
yield
对静态方法 Thread.yield() 的调用表示当前线程已经完成了生命周期中最重要的部分,可以切换给其它线程来执行。该方法只是对线程调度器的一个建议,而且也只是建议具有相同优先级的其它线程可以运行。
线程中断
一个线程执行完毕之后会自动结束,如果在运行过程中发生异常也会提前结束。
InterruptedException
通过调用一个线程的 interrupt() 来中断该线程,如果该线程处于阻塞、限期等待或者无限期等待状态,那么就会抛出 InterruptedException,从而提前结束该线程。但是不能中断 I/O 阻塞和 synchronized 锁阻塞。
对于以下代码,在 main() 中启动一个线程之后再中断它,由于线程中调用了 Thread.sleep() 方法,因此会抛出一个 InterruptedException,从而提前结束线程,不执行之后的语句。
public class InterruptExample {
private static class MyThread1 extends Thread {
@Override
public void run() {
try {
Thread.sleep(2000);
System.out.println("Thread run");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new MyThread1();
thread1.start();
thread1.interrupt();
System.out.println("Main run");
}
// 在线程 sleep 期间中断,“Thread run” 将不会被打印
Main run
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at InterruptExample.lambda$main$0(InterruptExample.java:5)
at InterruptExample$$Lambda$1/713338599.run(Unknown Source)
at java.lang.Thread.run(Thread.java:745)
}
interrupted
如果一个线程的 run() 方法执行一个无限循环,并且没有执行 sleep() 等会抛出 InterruptedException 的操作,那么调用线程的 interrupt() 方法就无法使线程提前结束。
但是调用 interrupt() 方法会设置线程的中断标记,此时调用 interrupted() 方法会返回 true。因此可以在循环体中使用 interrupted() 方法来判断线程是否处于中断状态,从而提前结束线程。
public class InterruptExample {
private static class MyThread2 extends Thread {
@Override
public void run() {
while (!interrupted()) {
// ..
}
System.out.println("Thread end");
}
}
public static void main(String[] args) throws InterruptedException {
Thread thread2 = new MyThread2();
thread2.start();
thread2.interrupt();
}
// Thread end
}
Executor 中断操作
调用 Executor 的 shutdown() 方法会等待线程都执行完毕之后再关闭,但是如果调用的是 shutdownNow() 方法,则相当于调用每个线程的 interrupt() 方法。
以下使用 Lambda 创建线程,相当于创建了一个匿名内部线程。
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(() -> {
try {
Thread.sleep(2000);
System.out.println("Thread run");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
executorService.shutdownNow();
System.out.println("Main run");
// 在线程 sleep 期间被中断,不会打印 "Thread run"
Main run
java.lang.InterruptedException: sleep interrupted
如果想要中断 Executor 中的一个线程,可以通过 submit 方法提交一个任务,然后返回一个 Future 对象,调用该 Future 对象的 cancel 方法即可中断对应线程:
Future<?> future = executorService.submit(() -> {
// ..
});
future.cancel(true);
线程同步:互斥
Java 提供了两种锁机制来控制多个线程对共享资源的互斥访问,第一个是 JVM 实现的 synchronized,而另一个是 JDK 实现的 ReentrantLock。
synchronized
- 同步代码块
- 只作用于同一个对象实例,比如 new Object(),如果调用两个对象上的同步代码块,就不会进行同步。
- 同步方法
- 它和同步代码块一样,作用于同一个对象。只是作用在了该方法所属的实例。
- 同步类
- 作用于整个类,也就是说两个线程调用同一个类的不同对象上的这种同步语句,也会进行同步。
- 同步静态方法
ReentrantLock
ReentrantLock 是 java.util.concurrent(J.U.C)包中的锁。
private Lock lock = new ReentrantLock();
public void func() {
lock.lock();
try {
for (int i = 0; i < 10; i++) {
System.out.print(i + " ");
}
} finally {
lock.unlock(); // 确保释放锁,从而避免发生死锁。
}
}
基本对比
- 实现层次:
- synchronized 是 JVM 实现的,而 ReentrantLock 是 JDK 实现的。
- 性能:
- 新版本 Java 对 synchronized 进行了很多优化,例如自旋锁等,synchronized 与 ReentrantLock 大致相同。
- 等待可中断:
- 当持有锁的线程长期不释放锁的时候,正在等待的线程可以选择放弃等待,改为处理其他事情。
- ReentrantLock 可中断,而 synchronized 不行。
- 公平锁
- 公平锁是指多个线程在等待同一个锁时,必须按照申请锁的时间顺序来依次获得锁。
- synchronized 中的锁是非公平的,ReentrantLock 默认情况下也是非公平的,但是也可以是公平的。
- 锁绑定多个条件
- 一个 ReentrantLock 可以同时绑定多个 Condition 对象。
应用选择
除非需要使用 ReentrantLock 的高级功能,否则优先使用 synchronized。这是因为 synchronized 是 JVM 实现的一种锁机制,JVM 原生地支持它,而 ReentrantLock 不是所有的 JDK 版本都支持。并且使用 synchronized 不用担心没有释放锁而导致死锁问题,因为 JVM 会确保锁的释放。
线程协作
当多个线程可以一起工作去解决某个问题时,如果某些部分必须在其它部分之前完成,那么就需要对线程进行协调。
join
在线程中调用另一个线程的 join() 方法,会将当前线程挂起,而不是忙等待,直到目标线程结束。
wait、notify、notifyAll
调用 wait() 使得线程等待某个条件满足,线程在等待时会被挂起,当其他线程的运行使得这个条件满足时,其它线程会调用 notify() 或者 notifyAll() 来唤醒挂起的线程。
它们都属于 Object 的一部分,而不属于 Thread。
只能用在同步方法或者同步控制块中使用,否则会在运行时抛出 IllegalMonitorStateExeception。
使用 wait() 挂起期间,线程会释放锁。这是因为,如果没有释放锁,那么其它线程就无法进入对象的同步方法或者同步控制块中,那么就无法执行 notify() 或者 notifyAll() 来唤醒挂起的线程,造成死锁。
public class WaitNotifyExample {
public synchronized void before() {
System.out.println("before");
notifyAll();
}
public synchronized void after() {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("after");
}
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
WaitNotifyExample example = new WaitNotifyExample();
executorService.execute(() -> example.after());
executorService.execute(() -> example.before());
}
// before
// after
}
wait() 和 sleep() 的区别
- wait() 是 Object 的方法,而 sleep() 是 Thread 的静态方法;
- wait() 会释放锁,sleep() 不会。
await() signal() signalAll()
JUC 类库中提供了 Condition 类来实现线程之间的协调,可以在 Condition 上调用 await() 方法使线程等待,其它线程调用 signal() 或 signalAll() 方法唤醒等待的线程。相比于 wait() 这种等待方式,await() 可以指定等待的条件,因此更加灵活。
使用 Lock 来获取一个 Condition 对象。
public class AwaitSignalExample {
private Lock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
public void before() {
lock.lock();
try {
System.out.println("before");
condition.signalAll();
} finally {
lock.unlock();
}
}
public void after() {
lock.lock();
try {
condition.await();
System.out.println("after");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
AwaitSignalExample example = new AwaitSignalExample();
executorService.execute(() -> example.after());
executorService.execute(() -> example.before());
}
// before
// after
}
3.4 - CH04-线程基础-2
Create Thread
- What happens when creating a Thread instance
Thread thread = new Thread(){
@Override
public void run() {
// code
}
};
// at this point the thread is in NEW state, all you have a simple java object,
// no actual thread is created
thread.start();
// when start() is invoked, at some unspecified point in the near future
// the thread will go into RUNNABLE state, this means an actual thread will be created.
// That can happen before start() returns.
- 通过
new 创建线程时,你只是创建了一个 Thread 类的实例,该 Thread 实例的状态为 NEW。 - 通过
thread.start() 调用线程时,该 Thread 实例的状态将会在未来某个时刻变为 RUNNABLE,这表示 OS 级别的线程将被创建,这部分工作由 JVM 完成。
用户空间 & 内核空间
在操作系统中,内存通常会被分成用户空间(User space)与内核空间(Kernel space)这两个部分。当进程/线程运行在用户空间时就处于用户态,运行在内核空间时就处于内核态:
- 运行在内核态的程序可以访问用户空间和内核空间,或者说它可以访问计算机的任何资源,不受限制,为所欲为,例如协调 CPU 资源,分配内存资源,提供稳定的环境供应用程序运行等
- 而应用程序基本都是运行在用户态的,或者说用户态就是提供应用程序运行的空间。运行在用户态的程序只能访问用户空间
那为什么要区分用户态和内核态呢?
早期操作系统是不区分用户态和内核态的,也就是说应用程序可以访问任意内存空间,如果程序不稳定常常会让系统崩溃,比如清除了操作系统的内存数据。为此大佬们设计出了一套规则:对于那些比较危险的操作需要切到内核态才能运行,比如 CPU、内存、设备等资源管理器程序就应该在内核态运行,否则安全性没有保证。
用户态的程序不能随意操作内核地址空间,这样有效地防止了操作系统程序受到应用程序的侵害。
那如果处于用户态的程序想要访问内核空间的话怎么办呢?就需要进行系统调用从用户态切换到内核态。
操作系统线程
在用户空间实现线程
在早期的操作系统中,所有的线程都是在用户空间下实现的,操作系统只能看到线程所属的进程,而不能看到线程。
从我们开发者的角度来理解用户级线程就是说:在这种模型下,我们需要自己定义线程的数据结构、创建、销毁、调度和维护等,这些线程运行在操作系统的某个进程内,然后操作系统直接对进程进行调度。
这种方式的好处一目了然,首先第一点,就是即使操作系统原生不支持线程,我们也可以通过库函数来支持线程;第二点,线程的调度只发生在用户态,避免了操作系统从内核态到用户态的转换开销。
当然缺点也很明显:由于操作系统看不见线程,不知道线程的存在,而 CPU 的时间片切换是以进程为维度的,所以如果进程中某个线程进行了耗时比较长的操作,那么由于用户空间中没有时钟中断机制,就会导致此进程中的其它线程因为得不到 CPU 资源而长时间的持续等待;另外,如果某个线程进行系统调用时比如缺页中断而导致了线程阻塞,此时操作系统也会阻塞住整个进程,即使这个进程中其它线程还在工作。
在内核空间中实现线程
所谓内核级线程就是运行在内核空间的线程, 直接由内核负责,只能由内核来完成线程的调度。
每个内核线程可以视为内核的一个分身,这样操作系统就有能力同时处理多件事情,支持多线程的内核就叫做多线程内核(Multi-Threads Kernel)。
从我们开发者的角度来理解内核级线程就是说:我们可以直接使用操作系统中已经内置好的线程,线程的创建、销毁、调度和维护等,都是直接由操作系统的内核来实现,我们只需要使用系统调用就好了,不需要像用户级线程那样自己设计线程调度等。
上图画的是 1:1 的线程模型,所谓线程模型,也就是用户线程和内核线程之间的关联方式,线程模型当然不止 1:1 这一种,下面我们来详细解释以下这三种多线程模型:
1. 多对一线程模型:
- 在多对一模型中,多个用户级线程映射到某一个内核线程上
- 线程管理由用户空间中的线程库处理,这非常有效
- 但是,如果进行了阻塞系统调用,那么即使其他用户线程能够继续,整个进程也会阻塞
- 由于单个内核线程只能在单个 CPU 上运行,因此多对一模型不允许在多个 CPU 之间拆分单个进程
从并发性角度来总结下,虽然多对一模型允许开发人员创建任意多的用户线程,但是由于内核只能一次调度一个线程,所以并未增加并发性。现在已经几乎没有操作系统来使用这个模型了,因为它无法利用多个处理核。
2. 一对一线程模型:
- 一对一模型克服了多对一模型的问题
- 一对一模型创建一个单独的内核线程来处理每个用户线程
- 但是,管理一对一模型的开销更大,涉及更多开销和减慢系统速度
- 此模型的大多数实现都限制了可以创建的线程数
从并发性角度来总结下,虽然一对一模型提供了更大的并发性,但是开发人员应注意不要在应用程序内创建太多线程(有时系统可能会限制创建线程的数量),因为管理一对一模型的开销更大。
3. 多对多线程模型:
- 多对多模型将任意数量的用户线程复用到相同或更少数量的内核线程上,结合了一对一和多对一模型的最佳特性
- 用户对创建的线程数没有限制
- 阻止内核系统调用不会阻止整个进程
- 进程可以分布在多个处理器上
- 可以为各个进程分配可变数量的内核线程,具体取决于存在的 CPU 数量和其他因素
Java Thread
在上面的模型介绍中,我们提到了通过线程库来创建、管理线程,那么什么是线程库呢?
线程库就是为开发人员提供创建和管理线程的一套 API。
当然,线程库不仅可以在用户空间中实现,还可以在内核空间中实现。前者涉及仅在用户空间内实现的 API 函数,没有内核支持。后者涉及系统调用,也就是说调用库中的一个 API 函数将会导致对内核的系统调用,并且需要具有线程库支持的内核。
下面简单介绍下三个主要的线程库:
POSIX Pthreads:可以作为用户或内核库提供,作为 POSIX 标准的扩展
Win32 线程:用于 Window 操作系统的内核级线程库
Java 线程:Java 线程 API 通常采用宿主系统的线程库来实现,也就是说在 Win 系统上,Java 线程 API 通常采用 Win API 来实现,在 UNIX 类系统上,采用 Pthread 来实现。
事实上,在 JDK 1.2 之前,Java 线程是基于称为 “绿色线程”(Green Threads)的用户级线程实现的,也就是说程序员大佬们为 JVM 开发了自己的一套线程库或者说线程管理机制。
而在 JDK 1.2 及以后,JVM 选择了更加稳定且方便使用的操作系统原生的内核级线程,通过系统调用,将线程的调度交给了操作系统内核。而对于不同的操作系统来说,它们本身的设计思路基本上是完全不一样的,因此它们各自对于线程的设计也存在种种差异,所以 JVM 中明确声明了:虚拟机中的线程状态,不反应任何操作系统中的线程状态。
也就是说,在 JDK 1.2 及之后的版本中,Java 的线程很大程度上依赖于操作系统采用什么样的线程模型,这点在不同的平台上没有办法达成一致,JVM 规范中也并未限定 Java 线程需要使用哪种线程模型来实现,可能是一对一,也可能是多对多或多对一。
总结来说,现今 Java 中线程的本质,其实就是操作系统中的线程,其线程库和线程模型很大程度上依赖于操作系统(宿主系统)的具体实现,比如在 Windows 中 Java 就是基于 Wind32 线程库来管理线程,且 Windows 采用的是一对一的线程模型。
Java线程调度
线程调度是指系统为线程分配处理使用权的过程,调度主要方式有两种,分别是协同式(Cooperative Threads-Scheduling)线程调度和抢占式(Preemptive Threads-Scheduling)线程调度。
- 协同式线程调度:线程的执行时间由线程本身来控制,线程把自己的工作执行完了之后,要主动通知系统切换到另外一个线程上去。
优点:实现简单,切换操作对线程自己是可知的,所以一般没有什么线程同步问题。
缺点:线程执行时间不可控制,甚至如果一个线程的代码编写有问题,一直不告知系统进行线程切换,那么程序就会一直阻塞在那里。
- 抢占式线程调度:每个线程将由系统来分配执行时间,线程的切换不由线程本身来决定。
优点:可以主动让出执行时间(例如Java的
Thread::yield()方法),并且线程的执行时间是系统可控的,也不会有一个线程导致整个系统阻塞的问题。
缺点:无法主动获取执行时间。
Java使用的就是抢占式线程调度,虽然这种方式的线程调度是系统自己的完成的,但是我们可以给操作系统一些建议,就是通过设置线程优先级来实现。Java语言一共设置了10个级别的线程优先级。在两个线程同时处于Ready状态时,优先级越高的线程越容易被系统选择执行。
不过由于各个系统的提供的优先级数量不一致,所以导致Java提供的10个级别的线程优先级并不见得能与各系统的优先级都一一对应。
Java 线程状态转换
Java语言定义了6种线程状态,在任意一个时间点钟,一个线程只能有且只有其中的一种状态,并且可以通过特定的方法在不同状态之间切换。
- 新建(New):创建后尚未启动的线程处于这种状态。
- 运行(Runnable):包括操作系统线程状态中的Running和Ready,也就是处理此状态的线程有可能正在执行,也有可能正在等待着操作系统为它分配执行时间。
- 无限期等待(Waiting):处于这种状态的线程不会被分配处理器执行时间,它们要等待被其他线程显示唤醒。
以下方法会让线程陷入无限期等待状态:
1、没有设置Timeout参数的
Object::wait()方法;
2、没有设置Timeout参数的Thread::join()方法;
3、LockSupport::park()方法。 - 限期等待(Timed Waiting):处于这种状态的线程也不会被分配处理器执行时间,不过无须等待被其他线程显式唤醒,在一定时间之后它们会由系统自动唤醒。
以下方法会让线程进入限期等待状态:
1、
Thread::sleep()方法;
2、设置了Timeout参数的Object::wait()方法;
3、设置了Timeout参数的Thread::join()方法;
4、LockSupport::parkNanos()方法;
5、LockSupport::parkUntil()方法; - 阻塞(Blocked):线程被阻塞了,“阻塞状态”与“等待状态”的区别是“阻塞状态”在等待着获取到一个排他锁,这个事件将在另外一个线程放弃这个锁的时候发生;而“等待状态”则是在等待一段时间 ,或者唤醒动作发生。在程序进入同步区域的时候,线程将进入这种状态。
- 结束(Terminated):已终止线程的线程状态,线程已经结束执行。
Thread.sleep
如果执行了 Thread.sleep, 底层的执行流程:
- JVM 调用底层 OS 的线程 API
- 因为 JVM 采用关于内核线性一对一的线程模型, JVM 会要求操作系统在执行的时间内将线程的使用权归还给 CPU
- 一旦休眠时间到期, OS 调度器将会通过中断来唤醒线程, 并为线性分配 CPU 时间片以恢复该线程的执行
这里的关键点是, JVM 层面的这个线程在休眠期间是完全无法被复用的。
3.5 - CH05-Synchronized
应用实践
- 一把锁同时只能被一个线程获取,没有获得锁的线程只能等待。
- 每个对象实例都有自己的锁(this),该锁不同实例之间互不影响。
- synchronized 修饰的方法,物理方法成功还是抛出异常,都会释放锁。
对象锁
包含实例方法锁(this)和同步代码块锁(自定义)。
类锁
指 synchronized 修饰静态的方法或指定锁对象为 Class 对象。
静态方法:
class Example {
public synchronized static void show() {
System.out.println("example...");
}
}
Class 对象:
class Example {
public void show() {
synchronized(Example.class) {
System.out.println("example...");
}
}
}
原理分析
加锁-解锁
创建如下代码:
public class SynchronizedDemo2 {
Object object = new Object();
public void method1() {
synchronized (object) {
}
}
}
使用 javac 命令编译生成 class 文件:
javac SynchronizedDemo2.java
使用 javap 命令反编译查看 class 文件的信息:
javap -verbose SynchronizedDemo2.class
得到如下信息:
mointorenter 和 moniterexit 指令,会在程序执行时,使其锁计数器加一或减一。每个对象在同一时间只有一个 mointor(锁) 与其相关联,而一个 mointor 在同一时间只能被一个线程获得,一个对象在尝试获得与该对象关联的 monitor 锁的所有权时,monitorenter 指令会发生如下三种情况之一:
- mointor 计数器为 0,意味着目前尚未被某个线程获得,该线程会立即获得锁并将计数器加一,一旦执行加一,别的线程要想再获取就需要等待。
- 如果该线程已经拿到了该 mointor 锁的所有权,又重入了这把锁,锁计数器会继续累加一,值变为 2,随着重入次数的增加,计数值会一直累加。
- 如果该 monitor 锁已经被其他线程获得,当前线程等待锁被释放。
monitorexit 指令将释放对应 monitor 锁的所有权,释放过程很简单,即将 monitor 的计数器减一,如果结果不为 0,则表示当前是重入获得的锁,当前线程还继续持有该锁的所有权,如果计数器为 0,则表示当前线程不再拥有该 monitor 的所有权,即释放了锁。
下图描绘了真个过程:
上图可以看出,任意线程对 Object 的访问,首先要获得 Object 的监视锁,如果获取失败,该线程就会进入同步状态,线程状态变为 Blocked,当 Object 的监视器占有者释放后,在同步队列中的线程就有就会获取到该监视器。
可冲入:加锁次数计数器
在同一个线程中,线程不需要再次获取通一把锁。synchronized 先天具有重入性。每个对象拥有一个计数器,当线程获取对象 monitor 锁后,计数器就会加一,释放锁后就会减一。
可见性保证:内存模型与 happens-before
synchronized 的 happens-before 规则,即监视器锁规则:(一个线程)对同一个监视器解锁,happens-before 于(另一个线程)对该监视器加锁。
public class MonitorDemo {
private int a = 0;
public synchronized void writer() { // 1
a++; // 2
} // 3
public synchronized void reader() { // 4
int i = a; // 5
} // 6
}
图中每个箭头的两个节点之间都是 happens-before 关系。黑色箭头由程序顺序规则推导得出,红色为监视器锁规则推导而出:线程 A 释放锁先于线程 B 获得锁。蓝色则是通过程序顺序规则和监视器锁规则推测出来的 happens-before 关系,通过传递性规则进一步推导出 happens-before 规则。
根据 happens-before 的定义:如果 A 先于 B,则 A 的执行顺序先于 B,并且 A 的执行结果对 B 可见。
线程 A 先对共享变量 +1,由 2 先于 5 得知线程 A 的执行结果对 B 可见,即 B 读取到 a 的值为 1。
JVM 锁优化
JVM 在执行 monitorenter 和 monitorexit 这些指令时,依赖于底层操作系统的 Mutex Lock(互斥锁),但是由于 Mutex Lock 需要挂起当前线程,并从用户态切换到内核态来执行,这种切换的代价昂贵。然而在大部分的实际情况中,同步方法是运行在单线程环境(无锁竞争环境),如果每次都调用 Mutex Lock 则会严重影响性能。
JDK 1.6 引入了大量优化来提升性能:
- 锁粗化:减少不必要的紧连在一起的加锁、解锁操作,将多个连续的小锁扩展为一个更大的锁。
- 锁消除:通过运行时 JIT 编译器的逃逸分析来消除一些没有在当前同步块以外被其他线程共享的数据的锁保护,通过逃逸分析也可以在线程本地 Stack 上进行空间对象的分配(通知还可以减少 Heap 上垃圾收集的开销)。
- 轻量级锁:实现的原理是基于这样的假设,即在真是情况下程序中的大部分同步代码一般都属于无锁竞争状态(单线程执行环境),在无锁竞争的情况下完全可以避免调用操作系统层次的重量级互斥锁,取而代之的是在 monitorenter 和 monitorexit 之间依靠一条 CAS 原子指令就可以完成加锁解锁操作。但存在锁竞争时,执行 CAS 指令失败的线程将再去调用操作系统互斥锁进入阻塞状态,当锁被释放时再被唤醒。
- 偏向锁:为了在无锁竞争的情况下,避免在加锁过程中执行不必要的 CAS 原子指令,因为 CAS 指令虽然轻于OS 互斥锁,但还是存在(相对)可观的本地延迟。
- 适应性自旋:当线程在获取轻量级锁的过程中,如果 CAS 执行失败,在进入与 monitor 相关联的 OS 互斥锁之前,首先进入忙等待(自旋-Spinning),然后再次尝试 CAS,当尝试一定次数知乎仍然失败,再去调用与该 mointor 相关的 OS 互斥锁,进入阻塞状态。
锁的类型
Java 1.6 中 synchronized 同步锁,共有 4 种状态:无锁、偏向锁、轻量锁、重量锁。
会随着竞争状况逐渐升级。锁可以升级但不能降级,目的是为了提高获取锁和释放锁的效率。
自旋锁、自适应自旋
自旋锁
在多线程竞争锁时,当一个线程获取锁时,它会阻塞所有正在竞争的线程,这样对性能带来了极大的影响。在挂起线程和恢复线程的操作都需要转入内核态中完成,这些操作对系统的并发性能带来了很大的压力。同时HotSpot团队注意到在很多情况下,共享数据的锁定状态只会持续很短的一段时间,为了这段时间去挂起和回复阻塞线程并不值得。在如今多处理器环境下,完全可以让另一个没有获取到锁的线程在门外等待一会(自旋),但不放弃CPU的执行时间。等待持有锁的线程是否很快就会释放锁。为了让线程等待,我们只需要让线程执行一个忙循环(自旋),这便是自旋锁由来的原因。
自旋锁早在JDK1.4 中就引入了,只是当时默认时关闭的。在JDK 1.6后默认为开启状态。自旋锁本质上与阻塞并不相同,先不考虑其对多处理器的要求,如果锁占用的时间非常的短,那么自旋锁的新能会非常的好,相反,其会带来更多的性能开销(因为在线程自旋时,始终会占用CPU的时间片,如果锁占用的时间太长,那么自旋的线程会白白消耗掉CPU资源)。因此自旋等待的时间必须要有一定的限度,如果自选超过了限定的次数仍然没有成功获取到锁,就应该使用传统的方式去挂起线程了,在JDK定义中,自旋锁默认的自旋次数为10次,用户可以使用参数-XX:PreBlockSpin来更改。
可是现在又出现了一个问题:如果线程锁在线程自旋刚结束就释放掉了锁,那么是不是有点得不偿失。所以这时候我们需要更加聪明的锁来实现更加灵活的自旋。来提高并发的性能。
自适应自旋
在JDK 1.6中引入了自适应自旋锁。这就意味着自旋的时间不再固定了,而是由前一次在同一个锁上的自旋 时间及锁的拥有者的状态来决定的。如果在同一个锁对象上,自旋等待刚刚成功获取过锁,并且持有锁的线程正在运行中,那么JVM会认为该锁自旋获取到锁的可能性很大,会自动增加等待时间。比如增加到100次循环。相反,如果对于某个锁,自旋很少成功获取锁。那再以后要获取这个锁时将可能省略掉自旋过程,以避免浪费处理器资源。有了自适应自旋,JVM对程序的锁的状态预测会越来越准备,JVM也会越来越聪明。
锁消除
锁消除是指虚拟机即时编译器在运行过冲中,对一些在代码上要求同步、但是被检测到不可能存在共享数据竞争的锁进行消除。锁消除的主要判定依据来源于逃逸分析的数据支持。意思就是:JVM 会判断在一段程序中的同步数据明显不会逃逸出去从而被其他线程访问到,那 JVM 就把它们当作栈上数据对待,认为这些数据是线程独有的,不需要加同步。此时就会进行锁消除。
当然在实际开发中,我们很清楚的知道那些地方是线程独有的,不需要加同步锁,但是在 Java API 中有很多方法都是加了同步的,那么此时 JVM 会判断这段代码是否需要加锁。如果数据并不会逃逸,则会进行锁消除。比如如下操作:在操作 String 类型数据时,由于 String 是一个不可变类,对字符串的连接操作总是通过生成的新的 String 对象。因此 Javac 编译器会对 String 连接做自动优化。在 JDK 1.5 之前会使用 StringBuffer 对象的连续 append() 操作,在 JDK 1.5 及以后的版本中,会转化为 StringBuidler 对象的连续 append() 操作。
锁粗化
原则上,我们都知道在加同步锁时,尽可能的将同步块的作用范围限制到尽量小的范围(只在共享数据的实际作用域中才进行同步,这样是为了使得需要同步的操作数量尽可能变小。在存在锁同步竞争中,也可以使得等待锁的线程尽早的拿到锁。
大部分上述情况是正确的,但是如果存在连串的一系列操作都对同一个对象反复加锁和解锁,甚至加锁操作时出现在循环体中的,那即使没有线程竞争,频繁地进行互斥同步操作也会导致不必要地性能操作。
轻量锁
在 JDK 1.6 之后引入的轻量级锁,需要注意的是轻量级锁并不是替代重量级锁的,而是对在大多数情况下同步块并不会有竞争出现时提供的一种优化。它可以减少重量级锁对线程的阻塞带来地线程开销。从而提高并发性能。
如果要理解轻量级锁,那么必须先要了解 HotSpot 虚拟机中对象头地内存布局。在对象头中(Object Header)存在两部分。第一部分用于存储对象自身的运行时数据,HashCode、GC Age、锁标记位、是否为偏向锁等。一般为32位或者64位(视操作系统位数定)。官方称之为Mark Word,它是实现轻量级锁和偏向锁的关键。 另外一部分存储的是指向方法区对象类型数据的指针(Klass Point),如果对象是数组的话,还会有一个额外的部分用于存储数据的长度。
如上图所示,如果当前对象没有被锁定,那么锁标志位为 01 状态,JVM 在指向当前线程时,首先会在当前线程帧栈中创建锁记录 Lock Record 的空间,用于存储锁对象目前的 Mark Word 的拷贝。
然后,虚拟机使用 CAS 操作将标记字段 Mark Word 拷贝到锁记录中,并将 Mark Word 更新为指向 Lock Record 的指针。如果更新成功了,那么这个线程就有了使用该对象的锁,并且对象 Mark Word 的所标志位更新为(Mark Word 中最后为 2 bit) 00,即表示该对象处于轻量级锁定状态,如图:
如果更新操作失败,JVM 会检查当前 Mark Word 中是否存在指向当前线程帧栈的指针,如果有,则表示锁已经被获取,可以直接使用。如果没有,则说明该锁已经被其他线程抢占,如果有两条以上的线程同时经常一个锁,那么轻量级锁就不再有效,直接升级为重量级锁,没有获得锁的线程会被阻塞。此时,锁的标志位为 10,Mark Word 中存储的是指向重量级锁的指针。
轻量级锁解锁时,会使用原子的 CAS 操作将 Displaced Mark Word 替换会对象头中,如果成功,则表示没有发生竞争,如果失败,则表示当前锁存在竞争关系。锁就会升级为重量级锁。
两个线程同时抢占锁,导致锁升级的流程如下:
偏向锁
在大多数实际环境中,锁不仅不存在多线程竞争,而且总是由同一个线程多次获取,那么在同一个线程反复加锁解锁的过程中,其中并没有对锁的竞争,这样一来,多次加锁解锁带来了不必要的性能开销。
为了解决这一问题,HotSpot 的作者在 Java SE 1.6 中对 Synchronized 进行了优化,引入了偏向锁。
当一个线程访问同步块并获取锁时,会在对象头和帧栈中的锁记录里存储偏向锁偏向的线程 ID,以后该线程在进入和退出同步块时不需要进行 CAS 操作来加锁和解锁。只需要简单的测试一下对象头的 Mark Word 中是否保存了指向当前线程的偏向锁。如果成功,表示线程已经获得了锁。
偏向锁使用了一种等待竞争出现时才会释放锁的机制。当其他线程尝试获取偏向锁时,持有偏向锁的线程才会释放锁。但是偏向锁的撤销需要等到全局安全点(即当前线程没有正在执行的字节码)。
它首先会暂停拥有偏向锁的线程,然后检查持有偏向锁的线程是否还活着。如果线程不处于活动状态,直接将对象头设置为无锁状态。如果活着,JVM 会遍历帧栈中的锁记录,帧栈中的锁记录和对象头要么偏向于其他线程,要么恢复到无锁状态或者标记对象不适合作为偏向锁。
锁对比
| 锁 | 优点 | 缺点 | 场景 |
|---|
| 偏向锁 | 加锁解锁不需要 CAS,没有额外性能开销 | 如果线程间存在竞争,撤销锁会带来额外开销 | 仅一个线程访问同步块 |
| 轻量锁 | 竞争的线程不会阻塞,提供响应速度 | 如果线程始终得到到锁,自旋会消耗性能 | 同步块执行速度非常快 |
| 重量锁 | 线程竞争不适用自旋,不会消耗 CPU | 线程阻塞、响应慢、频繁加解锁开销大 | 追求吞吐量,同步块执行速度慢 |
Synchronized 与 Lock
Synchronized 的缺陷
- 效率低:锁的释放情况少,只有代码指向完或抛出异常时才会解锁;试图获取锁时不能设置超时,不能中断正在使用锁的线程,而 Lock 可以中断或设置超时。
- 不灵活:加锁和解锁的时机单一,每个锁仅有一个单一的条件(对象实例),Lock 更加灵活。
- 无法感知是否获得锁:Lock 可以显式获取状态,然后基于状态执行判断。
相比 Lock
Lock 的方法:
- lock:加锁
- unlock:解锁
- tryLock:尝试加锁,返回布尔值
- tryLock(long,TimeUnit):尝试加锁,设定超时
多线程竞争锁时,其余未获得锁的线程只能不停的尝试加锁,而不能中断,高并发情况下会导致性能下降。
ReentrantLock 的 lockInterruptibly() 方法可以优先考虑响应中断。 一个线程等待时间过长,它可以中断自己,然后 ReentrantLock 响应这个中断,不再让这个线程继续等待。有了这个机制,使用 ReentrantLock 时就不会像 synchronized 那样产生死锁了。
注意事项
Synchronized 由 JVM 实现,无需显式控制加解锁逻辑。
- 锁对象不能为空,因为锁的信息都保存在对象头里
- 作用域不宜过大,影响程序执行的速度,控制范围过大,编写代码也容易出错
- 避免死锁
- 在能选择的情况下,既不要用 Lock 也不要用 synchronized 关键字,用 JUC 包中的各种各样的类,如果不用该包下的类,在满足业务的情况下,可以使用 synchronized 关键,避免手动操作引起错误
- synchronized 是公平锁吗?
- 实际上是非公平的,新来的线程有可能立即获得监视器,而在等待区中等候已久的线程可能再次等待。
- 但这种抢占的方式可以预防饥饿。
3.6 - CH06-Volatile
基本作用
防止重排序
比如一个对象构造过程的场景,实例化一个对象可以分为 3 个步骤:
- 分配内存空间
- 初始化对象
- 将内存空间的地址赋值给对应的引用
但是由于操作系统可以“对指令进行重排序”,所以上面的过程可能会被转换为:
- 分配内存空间
- 将内存空间的地址赋值给对应的引用
- 初始化对象
这样一来,多线程环境下可能将一个尚未初始化的对象引用暴露到外部,从而导致非预期的行为。
因此为了防止该过程的重排序,我们可以将变量设置为 volatile 类型的变量。
实现可见性
可见性问题主要指一个线程修改了共享变量值,而另一个线程却看不到。引起可见性问题的主要原因是每个线程拥有自己的一个高速缓存区——线程工作内存。volatile 能有效的解决这个问题。
保证原子性:单次读/写
基于 volatile 保证单次的读/写操作具有原子性的理解,你将能够理解如下两个问题:
i++ 为什么不能保证原子性
对 volatile 变量的单次读/写操作可以保证原子性的,如 long 和 double 类型变量,但是并不能保证 i++ 这种操作的原子性,因为本质上 i++ 是读、写两次操作,包括三步骤:
- 读取 i 的值。
- 对 i 加 1。
- 将 i 的值写回内存。 volatile 是无法保证这三个操作是具有原子性的,我们可以通过 AtomicInteger 或者 Synchronized 来保证 +1 操作的原子性。 注:上面几段代码中多处执行了 Thread.sleep() 方法,目的是为了增加并发问题的产生几率,无其他作用。
共享的 long 和 double 变量的为什么要用 volatile?
因为 long 和 double 两种数据类型的操作可分为高 32 位和低 32 位两部分,因此普通的 long 或 double 类型读/写可能不是原子的。因此,鼓励大家将共享的 long 和 double 变量设置为 volatile 类型,这样能保证任何情况下对 long 和 double 的单次读/写操作都具有原子性。
目前各种平台下的商用虚拟机都选择把 64 位数据的读写操作作为原子操作来对待,因此我们在编写代码时一般不把 long 和 double 变量专门声明为 volatile 多数情况下也是不会错的。
实现原理
实现可见性
volatile 变量的内存可见性是基于内存屏障(Memory Barrier)实现。
- 内存屏障,又称内存栅栏,是一个 CPU 指令。
- 在程序运行时,为了提高执行性能,编译器和处理器会对指令进行重排序,JMM 为了保证在不同的编译器和 CPU 上有相同的结果,通过插入特定类型的内存屏障来禁止特定类型的编译器重排序和处理器重排序。
- 插入一条内存屏障会告诉编译器和 CPU:不管什么指令都不能和这条 Memory Barrier 指令执行重排序。
比如代码:
public class Test {
private volatile int a;
public void update() {
a = 1;
}
public static void main(String[] args) {
Test test = new Test();
test.update();
}
}
通过 hsdis 和 jitwatch 工具可以得到编译后的汇编代码:
......
0x0000000002951563: and $0xffffffffffffff87,%rdi
0x0000000002951567: je 0x00000000029515f8
0x000000000295156d: test $0x7,%rdi
0x0000000002951574: jne 0x00000000029515bd
0x0000000002951576: test $0x300,%rdi
0x000000000295157d: jne 0x000000000295159c
0x000000000295157f: and $0x37f,%rax
0x0000000002951586: mov %rax,%rdi
0x0000000002951589: or %r15,%rdi
0x000000000295158c: lock cmpxchg %rdi,(%rdx) //在 volatile 修饰的共享变量进行写操作的时候会多出 lock 前缀的指令
0x0000000002951591: jne 0x0000000002951a15
0x0000000002951597: jmpq 0x00000000029515f8
0x000000000295159c: mov 0x8(%rdx),%edi
0x000000000295159f: shl $0x3,%rdi
0x00000000029515a3: mov 0xa8(%rdi),%rdi
0x00000000029515aa: or %r15,%rdi
......
lock 前缀的指令在多核处理器下会引发两件事情:
- 将当前处理器缓存行的数据写回到系统内存。
- 写回内存的操作会使在其他 CPU 里缓存了该内存地址的额数据无效。
为了提高处理速度,处理器不直接和内存进行通信,而是先将系统内存的数据读到内部缓存(L1,L2 或其他)后再进行操作,但操作完不知道何时会写到内存。
如果对声明了 volatile 的变量进行写操作,JVM 就会向处理器发送一条 lock 前缀的指令,将这个变量所在缓存行的数据写回到系统内存。
为了保证各个处理器的缓存是一致的,实现了缓存一致性协议(MESI),每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存里。
所有多核处理器下还会完成:当处理器发现本地缓存失效后,就会从内存中重读该变量数据,即可以获取当前最新值。
volatile 变量通过这样的机制就使得每个线程都能获得该变量的最新值。
lock 指令
在 Pentium 和早期的 IA-32 处理器中,lock 前缀会使处理器执行当前指令时产生一个 LOCK# 信号,会对总线进行锁定,其它 CPU 对内存的读写请求都会被阻塞,直到锁释放。 后来的处理器,加锁操作是由高速缓存锁代替总线锁来处理。 因为锁总线的开销比较大,锁总线期间其他 CPU 没法访问内存。 这种场景多缓存的数据一致通过缓存一致性协议(MESI)来保证。
缓存一致性
缓存是分段(line)的,一个段对应一块存储空间,称之为缓存行,它是 CPU 缓存中可分配的最小存储单元,大小 32 字节、64 字节、128 字节不等,这与 CPU 架构有关,通常来说是 64 字节。 LOCK# 因为锁总线效率太低,因此使用了多组缓存。 为了使其行为看起来如同一组缓存那样。因而设计了 缓存一致性协议。
缓存一致性协议有多种,但是日常处理的大多数计算机设备都属于 " 嗅探(snooping)" 协议。 所有内存的传输都发生在一条共享的总线上,而所有的处理器都能看到这条总线。 缓存本身是独立的,但是内存是共享资源,所有的内存访问都要经过仲裁(同一个指令周期中,只有一个 CPU 缓存可以读写内存)。 CPU 缓存不仅仅在做内存传输的时候才与总线打交道,而是不停在嗅探总线上发生的数据交换,跟踪其他缓存在做什么。 当一个缓存代表它所属的处理器去读写内存时,其它处理器都会得到通知,它们以此来使自己的缓存保持同步。 只要某个处理器写内存,其它处理器马上知道这块内存在它们的缓存段中已经失效。
实现有序性
volatile 与 happens-before 的关系
happens-before 规则中有一条是 volatile 变量规则:对一个 volatile 域的写,先于任意后续对这个 volatile 域的读。
//假设线程A执行writer方法,线程B执行reader方法
class VolatileExample {
int a = 0;
volatile boolean flag = false;
public void writer() {
a = 1; // 1 线程A修改共享变量
flag = true; // 2 线程A写volatile变量
}
public void reader() {
if (flag) { // 3 线程B读同一个volatile变量
int i = a; // 4 线程B读共享变量
……
}
}
}
根据 happens-before 规则,上面过程会建立 3 类 happens-before 关系。
- 根据程序次序规则:1 先于 2,且 3 先于 4。
- 根据 volatile 规则:2 先于 3。
- 根据 happens-before 传递性:1 先于 4。
因为以上规则,当线程 A 将 volatile 变量 flag 更改为 true 后,线程 B 能够迅速感知。
volatile 禁止重排序
为了性能优化,JMM 在不改变正确语义的前提下,会允许编译器和处理器对指令序列进行重排序。JMM 提供了内存屏障阻止这种重排序。
Java 编译器会在生成指令系列时在适当的位置会插入内存屏障指令来禁止特定类型的处理器重排序。
JMM 会针对编译器制定 volatile 重排序规则表。
上图中 NO 表示禁止重排序。
为了实现 volatile 内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的重排序。
对于编译器来说,发现一个最优布置来最小化插入内存屏障的总数几乎是不可能的,为此,JVM 采取了保守策略:
- 在每个 volatile 写操作前插入 StoreStore 屏障。
- 在每个 volatile 写操作后插入 StoreLoad 屏障。
- 在每个 volatile 读操作后插入 LoadLoad 屏障。
- 在每个 volatile 读操作后插入 LoadStore 屏障。
volatile 写是在前后分别插入屏障,而读是在后面插入两个内存屏障。
- StoreStore:禁止上面的普通写和下面的 volatile 写重排序。
- StoreLoad:防止上面的 volatile 写与下面可能出现的 volatile 读/写重排序。
- LoadLoad:禁止下面所有的普通读操作和上面的 volatile 读重排序。
- LoadStore:禁止下面所有的普通下和上面的 volatile 读重排序。
应用场景
使用 volatile 时必须具备的条件:
- 对变量的写操作不依赖于当前值。
- 该变量没有包含在其他变量的不变式中。
- 只有在状态真正独立于成语其他内容时才能使用 volatile。
模式-1:状态标志
或许实现 volatile 变量的规范应用仅仅是通过一个布尔状态标志,用于指示发生了一个重要的一次性事件,比如初始化完成或已经停机,即对变量的简单读写:
volatile boolean shutdownRequested;
...
public void shutdown(){}
public void execute() {
while(!shutdownRequested){
// execute something
}
}
模式-2:一次性安全发布
缺乏同步会导致无法实现可见性,这会使得确定何时写入对象引用而不是原始值变得更加困难。在缺乏同步的情况下,可能会遇到某个对象引用的更新值(由另一个线程写入)和该对象状态的旧值同时存在。
这就是著名的双检锁问题的根源,其中对象引用在没有同步的情况下进行读操作,产生的问题是可能看到一个更新的引用,但是也可能看到尚未构造完成的对象。
public class BackgroundFloobleLoader {
public volatile Flooble theFlooble;
public void initInBackground() {
// do lots of stuff
theFlooble = new Flooble(); // this is the only write to theFlooble
}
}
public class SomeOtherClass {
public void doWork() {
while (true) {
// do some stuff...
// use the Flooble, but only if it is ready
if (floobleLoader.theFlooble != null)
doSomething(floobleLoader.theFlooble);
}
}
}
模式-3:独立观察
安全使用 volatile 的另一种简单模式是定期 发布 观察结果供程序内部使用。例如,假设有一种环境传感器能够感觉环境温度。一个后台线程可能会每隔几秒读取一次该传感器,并更新包含当前文档的 volatile 变量。然后,其他线程可以读取这个变量,从而随时能够看到最新的温度值。
public class UserManager {
public volatile String lastUser;
public boolean authenticate(String user, String password) {
boolean valid = passwordIsValid(user, password);
if (valid) {
User u = new User();
activeUsers.add(u);
lastUser = user;
}
return valid;
}
}
模式-4:volatile bean
在 volatile bean 模式中,JavaBean 的所有数据成员都是 volatile 类型的,并且 getter 和 setter 方法必须非常普通 —— 除了获取或设置相应的属性外,不能包含任何逻辑。此外,对于对象引用的数据成员,引用的对象必须是有效不可变的。(这将禁止具有数组值的属性,因为当数组引用被声明为 volatile 时,只有引用而不是数组本身具有 volatile 语义)。对于任何 volatile 变量,不变式或约束都不能包含 JavaBean 属性。
@ThreadSafe
public class Person {
private volatile String firstName;
private volatile String lastName;
private volatile int age;
public String getFirstName() { return firstName; }
public String getLastName() { return lastName; }
public int getAge() { return age; }
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public void setAge(int age) {
this.age = age;
}
}
模式-5:开销较低的读写锁策略
volatile 的功能还不足以实现计数器。因为 ++x 实际上是三种操作(读、添加、存储)的简单组合,如果多个线程凑巧试图同时对 volatile 计数器执行增量操作,那么它的更新值有可能会丢失。 如果读操作远远超过写操作,可以结合使用内部锁和 volatile 变量来减少公共代码路径的开销。 安全的计数器使用 synchronized 确保增量操作是原子的,并使用 volatile 保证当前结果的可见性。如果更新不频繁的话,该方法可实现更好的性能,因为读路径的开销仅仅涉及 volatile 读操作,这通常要优于一个无竞争的锁获取的开销。
@ThreadSafe
public class CheesyCounter {
// Employs the cheap read-write lock trick
// All mutative operations MUST be done with the 'this' lock held
@GuardedBy("this") private volatile int value;
public int getValue() { return value; }
public synchronized int increment() {
return value++;
}
}
模式-6:双重检查
单例模式的一种实现方式,但很多人会忽略 volatile 关键字,因为没有该关键字,程序也可以很好的运行,只不过代码的稳定性总不是 100%,说不定在未来的某个时刻,隐藏的 bug 就出来了。
class Singleton {
private volatile static Singleton instance;
public static Singleton getInstance() {
if (instance == null) {
syschronized(Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
3.7 - CH07-Final
基本用法
修饰类
当某个类的整体定义为 final 时,就表明了你不能打算继承该类,而且也不允许别人这么做。即这个类是不能有子类的。
final 类中的所有方法都隐式为 final,因为无法覆写他们,所以在 final 类中给任何方法添加 final 关键字是没有任何意义的。
修饰方法
- private 方法是隐式的 final,即不能被子类重写
- final 方法是可以被重载的
private final
类中所有 private 方法都隐式地指定为 final 的,由于无法取用 private 方法,所以也就不能覆盖它。可以对 private 方法增添 final 关键字,但这样做并没有什么好处。
final 方法可以被重载
修饰参数
Java 允许在参数列表中以声明的方式将参数指明为 final,这意味这你无法在方法中更改参数引用所指向的对象。这个特性主要用来向匿名内部类传递数据。
修饰字段
并非所有的 fianl 字段都是编译期常量
比如:
class Example {
Random random = new Random();
final int value = random.nextInt();
}
这里的字段 value 并不能在编译期推导出实际的值,而是在运行时由 random 决定。
static final
static final 字段只是占用一段不能改变的存储空间,它必须在定义的时候进行赋值,否则编译期无法同步。
blank final
Java 允许生成空白 final,也就是说被声明为 final 但又没有给出定值的字段,但是必须在该字段被使用之前被赋值,这给予我们两种选择:
- 在定义处进行赋值(这不是空白 final)
- 在构造器中进行赋值,保证了该值在被使用之前赋值。
重排序规则
final 域为基本类型
public class FinalDemo {
private int a; //普通域
private final int b; //final域
private static FinalDemo finalDemo; //静态域
public FinalDemo() {
a = 1; // 1. 写普通域
b = 2; // 2. 写final域
}
public static void writer() {
finalDemo = new FinalDemo();
}
public static void reader() {
FinalDemo demo = finalDemo; // 3.读对象引用
int a = demo.a; //4.读普通域
int b = demo.b; //5.读final域
}
}
假设线程 A 执行 writer 方法,线程 B 执行 reader 方法。
写操作
写 final 域的重排序规则禁止对 final 域的写操作重排序到构造函数之外,该规则的实现主要包含两个方面:
- JMM 禁止编译器把 final 域的写重排序到构造函数之外。
- 编译器会在 final 域写之后,构造函数 return 之前,插入一个 storestore 屏障。
- 该屏障可以禁止处理器将 final 域的写重排序到构造函数之外。
writer 方法分析:
- 构造了一个 FinalDemo 对象。
- 把这个对象复制给成员变量 finalDemo。
由于 a,b 之间没有依赖,普通域 a 可能会被重排序到构造函数之外,线程 B 肯呢个读到普通变量 a 初始化之前的值(零值),即引起错误。
而 final 域变量 b,根据重排序规则,会禁止 final 修饰的变量 b 被重排序到构造函数之外,因此 b 会在构造函数内完成赋值,线程 B 可以读到正确赋值后的 b 变量。
因此,写 final 域的重排序规则可以确保:在对象引用被任意线程可见之前,对象的 final 域已经被正确初始化过了,而普通域就不具有这个保障。
读操作
读 final 域的重排序规则为:在一个线程中,初次读对象引用和初次读该对象包含的 final 域,JMM 会禁止这两个操作的重排序。(仅针对处理器),处理器会在读 final 域操作之前插入一个 LoadLoad 屏障。
实际上,度对象的引用和读对象的 final 域存在间接依赖性,一般处理器不会对这两个操作执行重排序。但是不能排除有些处理器会执行重排序,因此,该规则就是针对这些处理器设定的。
reader 方法分析:
- 初次读引用变量 finalDemo;
- 初次读引用变量 finalDemo 的普通域;
- 初次读引用变量 finalDemo 的 fianl 域 b;
假设线程A写过程没有重排序,那么线程A和线程B有一种的可能执行时序为下图:
读对象的普通域被排序到读对象引用之前,就会出现线程 B 还未多读到对象引用就在读取该对象的普票域变量,这显然是错误操作。
而 final 域的读操作就限定了在读 final 域变量前就已经读到了该对象的引用,从而避免这种错误。
读 final 域的重排序规则可以保证:在读取一个对象的 fianl 域之前,一定会先读取该 final 域所属的对象引用。
final 域为引用类型
对 final 修饰对象的成员域执行写操作
针对引用数据类型,final域写针对编译器和处理器重排序增加了这样的约束:在构造函数内对一个final修饰的对象的成员域的写入,与随后在构造函数之外把这个被构造的对象的引用赋给一个引用变量,这两个操作是不能被重排序的。注意这里的是“增加”也就说前面对final基本数据类型的重排序规则在这里还是使用。这句话是比较拗口的,下面结合实例来看。
public class FinalReferenceDemo {
final int[] arrays;
private FinalReferenceDemo finalReferenceDemo;
public FinalReferenceDemo() {
arrays = new int[1]; //1
arrays[0] = 1; //2
}
public void writerOne() {
finalReferenceDemo = new FinalReferenceDemo(); //3
}
public void writerTwo() {
arrays[0] = 2; //4
}
public void reader() {
if (finalReferenceDemo != null) { //5
int temp = finalReferenceDemo.arrays[0]; //6
}
}
}
针对上面的实例程序,线程线程A执行wirterOne方法,执行完后线程B执行writerTwo方法,然后线程C执行reader方法。下图就以这种执行时序出现的一种情况来讨论(耐心看完才有收获)。
由于对final域的写禁止重排序到构造方法外,因此1和3不能被重排序。由于一个final域的引用对象的成员域写入不能与随后将这个被构造出来的对象赋给引用变量重排序,因此2和3不能重排序。
对final 修饰的对象的成员域执行读操作
JMM可以确保线程C至少能看到写线程A对final引用的对象的成员域的写入,即能看下 arrays[0] = 1,而写线程B对数组元素的写入可能看到可能看不到。JMM不保证线程B的写入对线程C可见,线程B和线程C之间存在数据竞争,此时的结果是不可预知的。如果可见的,可使用锁或者volatile。
final 重排序总结
- 基本数据类型
- 禁止 final 域写与构造函数重排序,即禁止 final 域重排序到构造方法之外,从而保证该对象对所有线程可见时,该对象的 final 域全部已经初始化过。
- 禁止初次读取该对象的引用与读取该对象 fianl 域的重排序。
- 引用数据类型
- 相比基本数据类型增加额外规则
- 禁止在构造函数对一个 final 修饰的对象的成员域的写入与随后将这个被构造的对象的引用复制给引用变量重排序。
- 即:现在构造函数中完成对 final 修饰的引用类型的字段赋值,再将该引用对象整体复制给 final 修饰的变量。
深入理解
实现原理
- 写 final 域会要求编译器在 final 域写之后,构造函数返回前插入一个 StoreStore 屏障。
- 读 final 域的重排序规则会要求编译器在读 final 域的操作前插入一个 LoadLoad 屏障。
为什么 final 引用不能从构造函数中逸出
上面对final域写重排序规则可以确保我们在使用一个对象引用的时候该对象的final域已经在构造函数被初始化过了。
但是这里其实是有一个前提条件的,也就是:在构造函数,不能让这个被构造的对象被其他线程可见,也就是说该对象引用不能在构造函数中“逸出”。
public class FinalReferenceEscapeDemo {
private final int a;
private FinalReferenceEscapeDemo referenceDemo;
public FinalReferenceEscapeDemo() {
a = 1; //1
referenceDemo = this; //2
}
public void writer() {
new FinalReferenceEscapeDemo();
}
public void reader() {
if (referenceDemo != null) { //3
int temp = referenceDemo.a; //4
}
}
}
假设一个线程A执行writer方法另一个线程执行reader方法。因为构造函数中操作1和2之间没有数据依赖性,1和2可以重排序,先执行了2,这个时候引用对象referenceDemo是个没有完全初始化的对象,而当线程B去读取该对象时就会出错。尽管依然满足了final域写重排序规则:在引用对象对所有线程可见时,其final域已经完全初始化成功。但是,引用对象“this”逸出,该代码依然存在线程安全的问题。
使用 final 的限制条件和局限性
- 当声明一个 final 成员时,必须在构造函数退出前设置它的值。
- 或者,将指向对象的成员声明为 final 只能将该引用设为不可变的,而非所指的对象。
- 如果一个对象将会在多个线程中访问并且你并没有将其成员声明为 final,则必须提供其他方式保证线程安全。
- 比如声明成员为 volatile,使用 synchronized 或者显式 Lock 控制所有该成员的访问。
3.8 - CH08-并发概览
层级结构
接口:Condition
Condition 为接口类型,它将 Object 监视器方法(wait、notify 和 notifyAll)分解成截然不同的对象,以便通过将这些对象与任意 Lock 实现组合使用,为每个对象提供多个等待集 (wait-set)。其中,Lock 替代了 synchronized 方法和语句的使用,Condition 替代了 Object 监视器方法的使用。可以通过 await(),signal() 来休眠/唤醒线程。
接口:Lock
Lock 为接口类型,Lock 提供了比使用 synchronized 方法和语句可获得的更广泛的锁定操作。允许更灵活的结构,可以具有差别很大的属性,可以支持多个相关的 Condition 对象。
接口:ReadWriteLock
维护了一对相关的锁,一个用于只读操作,另一个用于写入操作。只要没有 writer,读取锁可以由多个 reader 线程同时保持。写入锁是独占的。
抽象类:AbstractOwnableSynchonizer
可以由线程以独占方式拥有的同步器。此类为创建锁和相关同步器(伴随着所有权的概念)提供了基础。AbstractOwnableSynchronizer 类本身不管理或使用此信息。但是,子类和工具可以使用适当维护的值帮助控制和监视访问以及提供诊断。
抽象类(long):AbstractQueuedLongSynchronizer
以 long 形式维护同步状态的一个 AbstractQueuedSynchronizer 版本。此类具有的结构、属性和方法与 AbstractQueuedSynchronizer 完全相同,但所有与状态相关的参数和结果都定义为 long 而不是 int。当创建需要 64 位状态的多级别锁和屏障等同步器时,此类很有用。
抽象类(int):AbstractQueuedSynchonizer
其为实现依赖于先进先出 (FIFO) 等待队列的阻塞锁和相关同步器(信号量、事件,等等)提供一个框架。此类的设计目标是成为依靠单个原子 int 值来表示状态的大多数同步器的一个有用基础。
锁工具类:LockSupport
LockSupport为常用类,用来创建锁和其他同步类的基本线程阻塞原语。LockSupport的功能和"Thread中的 Thread.suspend()和Thread.resume()有点类似",LockSupport中的park() 和 unpark() 的作用分别是阻塞线程和解除阻塞线程。但是park()和unpark()不会遇到“Thread.suspend 和 Thread.resume所可能引发的死锁”问题。
锁常用类:ReentrantLock
它是一个可重入的互斥锁 Lock,它具有与使用 synchronized 方法和语句所访问的隐式监视器锁相同的一些基本行为和语义,但功能更强大。
锁常用类: ReentrantReadWriteLock
ReentrantReadWriteLock是读写锁接口ReadWriteLock的实现类,它包括Lock子类ReadLock和WriteLock。ReadLock是共享锁,WriteLock是独占锁。
锁常用类: StampedLock
它是 java8 在 java.util.concurrent.locks 新增的一个 API。StampedLock 控制锁有三种模式(写,读,乐观读),一个 StampedLock 状态是由版本和模式两个部分组成,锁获取方法返回一个数字作为票据 stamp,它用相应的锁状态表示并控制访问,数字 0 表示没有写锁被授权访问。在读锁上分为悲观锁和乐观锁。
工具常用类: CountDownLatch
它是一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待。
工具常用类: CyclicBarrier
CyclicBarrier 为常用类,其是一个同步辅助类,它允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point)。在涉及一组固定大小的线程的程序中,这些线程必须不时地互相等待,此时 CyclicBarrier 很有用。因为该 barrier 在释放等待线程后可以重用,所以称它为循环的 barrier。
工具常用类: Phaser
Phaser 是 JDK 7 新增的一个同步辅助类,它可以实现 CyclicBarrier 和 CountDownLatch 类似的功能,而且它支持对任务的动态调整,并支持分层结构来达到更高的吞吐量。
工具常用类: Semaphore
Semaphore 为常用类,其是一个计数信号量,从概念上讲,信号量维护了一个许可集。如有必要,在许可可用前会阻塞每一个 acquire(),然后再获取该许可。每个 release() 添加一个许可,从而可能释放一个正在阻塞的获取者。但是,不使用实际的许可对象,Semaphore 只对可用许可的号码进行计数,并采取相应的行动。通常用于限制可以访问某些资源(物理或逻辑的)的线程数目。
工具常用类: Exchanger
Exchanger 是用于线程协作的工具类, 主要用于两个线程之间的数据交换。它提供一个同步点,在这个同步点,两个线程可以交换彼此的数据。这两个线程通过 exchange() 方法交换数据,当一个线程先执行 exchange() 方法后,它会一直等待第二个线程也执行 exchange() 方法,当这两个线程到达同步点时,这两个线程就可以交换数据了。
Collections: 并发集合
层级结构
Queue: ArrayBlockingQueue
一个由数组支持的有界阻塞队列。此队列按 FIFO(先进先出)原则对元素进行排序。队列的头部是在队列中存在时间最长的元素。队列的尾部是在队列中存在时间最短的元素。新元素插入到队列的尾部,队列获取操作则是从队列头部开始获得元素。
Queue: LinkedBlockingQueue
一个基于已链接节点的、范围任意的 blocking queue。此队列按 FIFO(先进先出)排序元素。队列的头部 是在队列中时间最长的元素。队列的尾部 是在队列中时间最短的元素。新元素插入到队列的尾部,并且队列获取操作会获得位于队列头部的元素。链接队列的吞吐量通常要高于基于数组的队列,但是在大多数并发应用程序中,其可预知的性能要低。
Queue: LinkedBlockingDeque
一个基于已链接节点的、任选范围的阻塞双端队列。
Queue: ConcurrentLinkedQueue
一个基于链接节点的无界线程安全队列。此队列按照 FIFO(先进先出)原则对元素进行排序。队列的头部 是队列中时间最长的元素。队列的尾部 是队列中时间最短的元素。新的元素插入到队列的尾部,队列获取操作从队列头部获得元素。当多个线程共享访问一个公共 collection 时,ConcurrentLinkedQueue 是一个恰当的选择。此队列不允许使用 null 元素。
Queue: ConcurrentLinkedDeque
是双向链表实现的无界队列,该队列同时支持FIFO和FILO两种操作方式。
Queue: DelayQueue
延时无界阻塞队列,使用 Lock 机制实现并发访问。队列里只允许放可以“延期”的元素,队列中的 head 是最先“到期”的元素。如果队里中没有元素到“到期”,那么就算队列中有元素也不能获取到。
Queue: PriorityBlockingQueue
无界优先级阻塞队列,使用 Lock 机制实现并发访问。priorityQueue 的线程安全版,不允许存放 null 值,依赖于 comparable 的排序,不允许存放不可比较的对象类型。
Queue: SynchronousQueue
没有容量的同步队列,通过CAS实现并发访问,支持FIFO和FILO
Queue: LinkedTransferQueue
JDK 7新增,单向链表实现的无界阻塞队列,通过CAS实现并发访问,队列元素使用 FIFO(先进先出)方式。LinkedTransferQueue可以说是ConcurrentLinkedQueue、SynchronousQueue(公平模式)和LinkedBlockingQueue的超集, 它不仅仅综合了这几个类的功能,同时也提供了更高效的实现。
List: CopyOnWriteArrayList
ArrayList 的一个线程安全的变体,其中所有可变操作(add、set 等等)都是通过对底层数组进行一次新的复制来实现的。这一般需要很大的开销,但是当遍历操作的数量大大超过可变操作的数量时,这种方法可能比其他替代方法更 有效。在不能或不想进行同步遍历,但又需要从并发线程中排除冲突时,它也很有用。
Set: CopyOnWriteArraySet
对其所有操作使用内部CopyOnWriteArrayList的Set。即将所有操作转发至CopyOnWriteArayList来进行操作,能够保证线程安全。在add时,会调用addIfAbsent,由于每次add时都要进行数组遍历,因此性能会略低于CopyOnWriteArrayList。
Set: ConcurrentSkipListSet
一个基于ConcurrentSkipListMap 的可缩放并发 NavigableSet 实现。set 的元素可以根据它们的自然顺序进行排序,也可以根据创建 set 时所提供的 Comparator 进行排序,具体取决于使用的构造方法。
Map: ConcurrentHashMap
是线程安全HashMap的。ConcurrentHashMap在JDK 7之前是通过Lock和segment(分段锁)实现,JDK 8 之后改为CAS+synchronized来保证并发安全。
Map: ConcurrentSkipListMap
线程安全的有序的哈希表(相当于线程安全的TreeMap);映射可以根据键的自然顺序进行排序,也可以根据创建映射时所提供的 Comparator 进行排序,具体取决于使用的构造方法。
Atomic: 原子类
其基本的特性就是在多线程环境下,当有多个线程同时执行这些类的实例包含的方法时,具有排他性,即当某个线程进入方法,执行其中的指令时,不会被其他线程打断,而别的线程就像自旋锁一样,一直等到该方法执行完成,才由JVM从等待队列中选择一个另一个线程进入,这只是一种逻辑上的理解。实际上是借助硬件的相关指令来实现的,不会阻塞线程(或者说只是在硬件级别上阻塞了)。
基础类型:AtomicBoolean、AtomicInteger、AtomicLong
数组:AtomicIntegerArray,AtomicLongArray,BooleanArray
引用:AtomicReference,AtomicMarkedReference,AtomicStampedReference
FieldUpdater:AtomicLongFieldUpdater,AtomicIntegerFieldUpdater,AtomicReferenceFieldUpdater
Executors:线程池
层级结构
接口:Executor
Executor 接口提供一种将任务提交与每个任务将如何运行的机制(包括线程使用的细节、调度等)分离开来的方法。通常使用 Executor 而不是显式地创建线程。
ExecutorService
ExecutorService 继承自 Executor 接口,ExecutorService 提供了管理终止的方法,以及可为跟踪一个或多个异步任务执行状况而生成 Future 的方法。 可以关闭 ExecutorService,这将导致其停止接受新任务。关闭后,执行程序将最后终止,这时没有任务在执行,也没有任务在等待执行,并且无法提交新任务。
ScheduledExecutorService
ScheduledExecutorService继承自ExecutorService接口,可安排在给定的延迟后运行或定期执行的命令。
AbstractExecutorService
AbstractExecutorService 继承自 ExecutorService 接口,其提供 ExecutorService 执行方法的默认实现。此类使用 newTaskFor 返回的 RunnableFuture 实现 submit、invokeAny 和 invokeAll 方法,默认情况下,RunnableFuture 是此包中提供的 FutureTask 类。
FutureTask
FutureTask 为 Future 提供了基础实现,如获取任务执行结果(get)和取消任务(cancel)等。如果任务尚未完成,获取任务执行结果时将会阻塞。一旦执行结束,任务就不能被重启或取消(除非使用runAndReset执行计算)。FutureTask 常用来封装 Callable 和 Runnable,也可以作为一个任务提交到线程池中执行。除了作为一个独立的类之外,此类也提供了一些功能性函数供我们创建自定义 task 类使用。FutureTask 的线程安全由CAS来保证。
核心: ThreadPoolExecutor
ThreadPoolExecutor 实现了 AbstractExecutorService 接口,也是一个 ExecutorService,它使用可能的几个池线程之一执行每个提交的任务,通常使用 Executors 工厂方法配置。 线程池可以解决两个不同问题: 由于减少了每个任务调用的开销,它们通常可以在执行大量异步任务时提供增强的性能,并且还可以提供绑定和管理资源(包括执行任务集时使用的线程)的方法。每个 ThreadPoolExecutor 还维护着一些基本的统计数据,如完成的任务数。
核心: ScheduledThreadExecutor
ScheduledThreadPoolExecutor 实现 ScheduledExecutorService 接口,可安排在给定的延迟后运行命令,或者定期执行命令。需要多个辅助线程时,或者要求 ThreadPoolExecutor 具有额外的灵活性或功能时,此类要优于 Timer。
核心: Fork/Join框架
ForkJoinPool 是JDK 7 加入的一个线程池类。Fork/Join 技术是分治算法(Divide-and-Conquer)的并行实现,它是一项可以获得良好的并行性能的简单且高效的设计技术。目的是为了帮助我们更好地利用多处理器带来的好处,使用所有可用的运算能力来提升应用的性能。
工具类: Executors
Executors 是一个工具类,用其可以创建 ExecutorService、ScheduledExecutorService、ThreadFactory、Callable 等对象。它的使用融入到了 ThreadPoolExecutor, ScheduledThreadExecutor 和 ForkJoinPool 中。
3.9 - CH09-底层支撑
CAS
现在安全的实现方法:
- 互斥同步:synchronized、ReentrantLock
- 非阻塞同步:CAS、Atomic-
- 无同步方案:栈封闭、TreadLocal、可重入代码
什么是 CAS
CAS 的全称为 Compare-And-Swap,直译就是对比交换。是一条 CPU 的原子指令,其作用是让 CPU 先进行比较两个值是否相等,然后原子地更新某个位置的值,经过调查发现,其实现方式是基于硬件平台的汇编指令,就是说 CAS 是靠硬件实现的,JVM 只是封装了汇编调用,那些 AtomicInteger 类便是使用了这些封装后的接口。
简单解释:CAS操作需要输入两个数值,一个旧值(期望操作前的值)和一个新值,在操作期间先比较下在旧值有没有发生变化,如果没有发生变化,才交换成新值,发生了变化则不交换。
CAS 操作是原子性的,所以多线程并发使用 CAS 更新数据时,可以不使用锁。JDK 中大量使用了 CAS 来更新数据而防止加锁(synchronized 重量级锁)来保持原子更新。
应用示例
如果不使用CAS,在高并发下,多线程同时修改一个变量的值我们需要synchronized加锁(可能有人说可以用Lock加锁,Lock底层的AQS也是基于CAS进行获取锁的)。
public class Test {
private int i=0;
public synchronized int add(){
return i++;
}
}
java中为我们提供了AtomicInteger 原子类(底层基于CAS进行更新数据的),不需要加锁就在多线程并发场景下实现数据的一致性。
public class Test {
private AtomicInteger i = new AtomicInteger(0);
public int add(){
return i.addAndGet(1);
}
}
CAS 问题
CAS 方式为乐观锁,synchronized 为悲观锁。因此使用 CAS 解决并发问题通常情况下性能更优。
但使用 CAS 方式也会有几个问题:
ABA 问题
因为 CAS 需要在操作值的时候,检查值有没有发生变化,比如没有发生变化则更新,但是如果一个值原来是 A,变成了 B,又变成了 A,那么使用 CAS 进行检查时则会发现它的值没有发生变化,但是实际上却变化了。
ABA 问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加1,那么 A->B->A 就会变成 1A->2B->3A。
从 Java 1.5 开始,JDK 的 Atomic 包里提供了一个类 AtomicStampedReference 来解决 ABA 问题。这个类的 compareAndSet 方法的作用是首先检查当前引用是否等于预期引用,并且检查当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
循环时间长开销大
自旋 CAS 如果长时间不成功,会给 CPU 带来非常大的执行开销。如果 JVM 能支持处理器提供的 pause 指令,那么效率会有一定的提升。
pause 指令有两个作用:
- 第一,它可以延迟流水线执行命令(de-pipeline),使 CPU 不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零;
- 第二,它可以避免在退出循环的时候因内存顺序冲突(Memory Order Violation)而引起 CPU 流水线被清空(CPU Pipeline Flush),从而提高 CPU 的执行效率。
仅作用于单个变量
当对一个共享变量执行操作时,我们可以使用循环 CAS 的方式来保证原子操作,但是对多个共享变量操作时,循环 CAS 就无法保证操作的原子性,这个时候就可以用锁。
还有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如,有两个共享变量 i = 2,j = a,合并一下 ij = 2a,然后用 CAS 来操作 ij。
从 Java 1.5 开始,JDK 提供了 AtomicReference 类来保证引用对象之间的原子性,就可以把多个变量放在一个对象里来进行 CAS 操作。
UnSafe 类
Java 原子类是通过 UnSafe 类实现的。
Unsafe 是位于 sun.misc 包下的一个类,主要提供一些用于执行低级别、不安全操作的方法,如直接访问系统内存资源、自主管理内存资源等,这些方法在提升 Java 运行效率、增强 Java 语言底层资源操作能力方面起到了很大的作用。
但由于 Unsafe 类使 Java 语言拥有了类似 C 语言指针一样操作内存空间的能力,这无疑也增加了程序发生相关指针问题的风险。在程序中过度、不正确使用 Unsafe 类会使得程序出错的概率变大,使得 Java 这种安全的语言变得不再“安全”,因此对 Unsafe 的使用一定要慎重。
这个类尽管里面的方法都是 public 的,但是并没有办法使用它们,JDK API 文档也没有提供任何关于这个类的方法的解释。总而言之,对于 Unsafe 类的使用都是受限制的,只有授信的代码才能获得该类的实例,当然 JDK 库里面的类是可以随意使用的。
功能概览:
UnSafe 与 CAS
内部使用自旋的方式进行CAS更新(while循环进行CAS更新,如果更新失败,则循环再次重试)。
public final int getAndAddInt(Object paramObject, long paramLong, int paramInt)
{
int i;
do
i = getIntVolatile(paramObject, paramLong);
while (!compareAndSwapInt(paramObject, paramLong, i, i + paramInt));
return i;
}
public final long getAndAddLong(Object paramObject, long paramLong1, long paramLong2)
{
long l;
do
l = getLongVolatile(paramObject, paramLong1);
while (!compareAndSwapLong(paramObject, paramLong1, l, l + paramLong2));
return l;
}
public final int getAndSetInt(Object paramObject, long paramLong, int paramInt)
{
int i;
do
i = getIntVolatile(paramObject, paramLong);
while (!compareAndSwapInt(paramObject, paramLong, i, paramInt));
return i;
}
public final long getAndSetLong(Object paramObject, long paramLong1, long paramLong2)
{
long l;
do
l = getLongVolatile(paramObject, paramLong1);
while (!compareAndSwapLong(paramObject, paramLong1, l, paramLong2));
return l;
}
public final Object getAndSetObject(Object paramObject1, long paramLong, Object paramObject2)
{
Object localObject;
do
localObject = getObjectVolatile(paramObject1, paramLong);
while (!compareAndSwapObject(paramObject1, paramLong, localObject, paramObject2));
return localObject;
}
从 UnSafe 类中发现,原子操作仅提供了三个方法:
public final native boolean compareAndSwapObject(Object paramObject1, long paramLong, Object paramObject2, Object paramObject3);
public final native boolean compareAndSwapInt(Object paramObject, long paramLong, int paramInt1, int paramInt2);
public final native boolean compareAndSwapLong(Object paramObject, long paramLong1, long paramLong2, long paramLong3);
UnSafe 底层
查看 Unsafe的compareAndSwap- 方法来实现 CAS 操作,它是一个本地方法,实现位于 unsafe.cpp 中。
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
UNSAFE_END
可以看到它通过 Atomic::cmpxchg 来实现比较和替换操作。其中参数x是即将更新的值,参数e是原内存的值。
如果是Linux的x86,Atomic::cmpxchg方法的实现如下:
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
int mp = os::is_MP();
__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}
而 windows 的 x86 的实现如下:
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
int mp = os::isMP(); //判断是否是多处理器
_asm {
mov edx, dest
mov ecx, exchange_value
mov eax, compare_value
LOCK_IF_MP(mp)
cmpxchg dword ptr [edx], ecx
}
}
// Adding a lock prefix to an instruction on MP machine
// VC++ doesn't like the lock prefix to be on a single line
// so we can't insert a label after the lock prefix.
// By emitting a lock prefix, we can define a label after it.
#define LOCK_IF_MP(mp) __asm cmp mp, 0 \
__asm je L0 \
__asm _emit 0xF0 \
__asm L0:
如果是多处理器,为 cmpxchg 指令添加 lock 前缀。反之,就省略 lock 前缀(单处理器会不需要 lock 前缀提供的内存屏障效果)。这里的 lock 前缀就是使用了处理器的总线锁(最新的处理器都使用缓存锁代替总线锁来提高性能)。
cmpxchg(void* ptr, int old, int new),如果 ptr 和 old 的值一样,则把 new 写到 ptr 内存,否则返回 ptr 的值,整个操作是原子的。在 Intel 平台下,会用 lock cmpxchg 来实现,使用 lock 触发缓存锁,这样另一个线程想访问 ptr 的内存,就会被 block 住。
UnSafe 其他功能
Unsafe 提供了硬件级别的操作,比如说获取某个属性在内存中的位置,比如说修改对象的字段值,即使它是私有的。不过 Java 本身就是为了屏蔽底层的差异,对于一般的开发而言也很少会有这样的需求。
举两个例子,比方说:
public native long staticFieldOffset(Field paramField);
这个方法可以用来获取给定的 paramField 的内存地址偏移量,这个值对于给定的 field 是唯一的且是固定不变的。
public native int arrayBaseOffset(Class paramClass);
public native int arrayIndexScale(Class paramClass);
前一个方法是用来获取数组第一个元素的偏移地址,后一个方法是用来获取数组的转换因子即数组中元素的增量地址的。
public native long allocateMemory(long paramLong);
public native long reallocateMemory(long paramLong1, long paramLong2);
public native void freeMemory(long paramLong);
分别用来分配内存,扩充内存和释放内存的。
AtomicInteger
public final int get():获取当前的值
public final int getAndSet(int newValue):获取当前的值,并设置新的值
public final int getAndIncrement():获取当前的值,并自增
public final int getAndDecrement():获取当前的值,并自减
public final int getAndAdd(int delta):获取当前的值,并加上预期的值
void lazySet(int newValue): 最终会设置成newValue,使用lazySet设置值后,可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
源码解析
public class AtomicInteger extends Number implements java.io.Serializable {
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
//用于获取value字段相对当前对象的“起始地址”的偏移量
valueOffset = unsafe.objectFieldOffset(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value;
//返回当前值
public final int get() {
return value;
}
//递增加detla
public final int getAndAdd(int delta) {
//三个参数,1、当前的实例 2、value实例变量的偏移量 3、当前value要加上的数(value+delta)。
return unsafe.getAndAddInt(this, valueOffset, delta);
}
//递增加1
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
...
}
AtomicInteger 底层用的是volatile的变量和CAS来进行更改数据的:
- volatile 保证线程的可见性,多线程并发时,一个线程修改数据,可以保证其它线程立马看到修改后的值
- CAS 保证数据更新的原子性
所有原子类
原子基本类型
使用原子的方式更新基本类型,Atomic 包共有 3 个类:
- AtomicBoolean
- AtomicInteger
- AtomicLong
原子数组
通过原子的方式更新数组里的某个元素,Atomic 包提供了以下的 4 个类:
- AtomicIntegerArray
- AtomicLongArray
- AtomicReferenceArray
常用方法:
get(int index)compareAndSet(int i, E expect, E update)
原子引用
- AtomicReference: 原子更新引用类型。
- AtomicStampedReference: 原子更新引用类型, 内部使用Pair来存储元素值及其版本号。
- AtomicMarkableReferce: 原子更新带有标记位的引用类型。
都是基于 UnSafe 实现,但 AtomicReferenceFieldUpdater 所更新的字段必须使用 volatile 修饰。
原子字段更新
AtomicIntegerFieldUpdater: 原子更新整型的字段的更新器。
AtomicLongFieldUpdater: 原子更新长整型字段的更新器。
AtomicStampedFieldUpdater: 原子更新带有版本号的引用类型。
AtomicReferenceFieldUpdater: 上面已经说过此处不在赘述。
以上均为基于反射的原子更新字段的值,要想原子地更新字段类需要两步:
- 第一步,因为原子更新字段类都是抽象类,每次使用的时候必须使用静态方法newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。
- 第二步,更新类的字段必须使用public volatile修饰。
public class TestAtomicIntegerFieldUpdater {
public static void main(String[] args){
TestAtomicIntegerFieldUpdater tIA = new TestAtomicIntegerFieldUpdater();
tIA.doIt();
}
public AtomicIntegerFieldUpdater<DataDemo> updater(String name){
return AtomicIntegerFieldUpdater.newUpdater(DataDemo.class,name);
}
public void doIt(){
DataDemo data = new DataDemo();
System.out.println("publicVar = "+updater("publicVar").getAndAdd(data, 2));
}
}
class DataDemo{
public volatile int publicVar=3;
protected volatile int protectedVar=4;
private volatile int privateVar=5;
public volatile static int staticVar = 10;
//public final int finalVar = 11;
public volatile Integer integerVar = 19;
public volatile Long longVar = 18L;
}
AtomicIntegerFieldUpdater 应用约束:
- 字段必须是 volatile 类型的,在线程之间共享变量时保证立即可见。
- 字段的描述类型(修饰符public/protected/default/private)是与调用者与操作对象字段的关系一致。
- 也就是说调用者能够直接操作对象字段,那么就可以反射进行原子操作。但是对于父类的字段,子类是不能直接操作的,尽管子类可以访问父类的字段。
- 只能是实例变量,不能是类变量,也就是说不能加 static 关键字。
- 只能是可修改变量,不能使 final 变量,因为 final 的语义就是不可修改。
- 实际上 final 的语义和 volatile 是有冲突的,这两个关键字不能同时存在。
- 对于 AtomicIntegerFieldUpdater 和 AtomicLongFieldUpdater 只能修改 int/long 类型的字段,不能修改其包装类型(Integer/Long)。
- 如果要修改包装类型就需要使用 AtomicReferenceFieldUpdater。
AtomicStampedReference 与 ABA
AtomicStampedReference 主要维护包含一个对象引用以及一个可以自动更新的整数 “stamp” 的 pair 对象来解决 ABA 问题。
public class AtomicStampedReference<V> {
private static class Pair<T> {
final T reference; //维护对象引用
final int stamp; //用于标志版本
private Pair(T reference, int stamp) {
this.reference = reference;
this.stamp = stamp;
}
static <T> Pair<T> of(T reference, int stamp) {
return new Pair<T>(reference, stamp);
}
}
private volatile Pair<V> pair;
....
/**
* expectedReference :更新之前的原始值
* newReference : 将要更新的新值
* expectedStamp : 期待更新的标志版本
* newStamp : 将要更新的标志版本
*/
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
// 获取当前的(元素值,版本号)对
Pair<V> current = pair;
return
// 引用没变
expectedReference == current.reference &&
// 版本号没变
expectedStamp == current.stamp &&
// 新引用等于旧引用
((newReference == current.reference &&
// 新版本号等于旧版本号
newStamp == current.stamp) ||
// 构造新的Pair对象并CAS更新
casPair(current, Pair.of(newReference, newStamp)));
}
private boolean casPair(Pair<V> cmp, Pair<V> val) {
// 调用Unsafe的compareAndSwapObject()方法CAS更新pair的引用为新引用
return UNSAFE.compareAndSwapObject(this, pairOffset, cmp, val);
}
- 如果元素值和版本号都没有变化,并且和新的也相同,返回true;
- 如果元素值和版本号都没有变化,并且和新的不完全相同,就构造一个新的Pair对象并执行CAS更新pair。
可以看到,java中的实现跟我们上面讲的ABA的解决方法是一致的。
- 首先,使用版本号控制;
- 其次,不重复使用节点(Pair)的引用,每次都新建一个新的Pair来作为CAS比较的对象,而不是复用旧的;
- 最后,外部传入元素值及版本号,而不是节点(Pair)的引用。
AtomicMarkableReference
AtomicMarkableReference,它不是维护一个版本号,而是维护一个boolean类型的标记,标记值有修改。
3.10 - CH10-LockSupport
功能介绍
LockSupport 是用来创建锁和其他同步类的基本线程阻塞原语。
- 当调用 LockSupport.park 时,当前线程会等待直至获取许可;
- 当调用 LockSupport.unpack 时,必须把扥带获取许可的线程作为参数传递,以使其恢复运行。
源码分析
基本属性
public class LockSupport {
// Hotspot implementation via intrinsics API
private static final sun.misc.Unsafe UNSAFE;
// 表示内存偏移地址
private static final long parkBlockerOffset;
// 表示内存偏移地址
private static final long SEED;
// 表示内存偏移地址
private static final long PROBE;
// 表示内存偏移地址
private static final long SECONDARY;
static {
try {
// 获取Unsafe实例
UNSAFE = sun.misc.Unsafe.getUnsafe();
// 线程类类型
Class<?> tk = Thread.class;
// 获取Thread的parkBlocker字段的内存偏移地址
parkBlockerOffset = UNSAFE.objectFieldOffset
(tk.getDeclaredField("parkBlocker"));
// 获取Thread的threadLocalRandomSeed字段的内存偏移地址
SEED = UNSAFE.objectFieldOffset
(tk.getDeclaredField("threadLocalRandomSeed"));
// 获取Thread的threadLocalRandomProbe字段的内存偏移地址
PROBE = UNSAFE.objectFieldOffset
(tk.getDeclaredField("threadLocalRandomProbe"));
// 获取Thread的threadLocalRandomSecondarySeed字段的内存偏移地址
SECONDARY = UNSAFE.objectFieldOffset
(tk.getDeclaredField("threadLocalRandomSecondarySeed"));
} catch (Exception ex) { throw new Error(ex); }
}
}
构造函数
仅有一个私有构造函数,无法被实例化。
核心函数
LockSupport的核心函数都是基于Unsafe类中定义的park和unpark函数,下面给出两个函数的定义:
public native void park(boolean isAbsolute, long time);
public native void unpark(Thread thread);
- park 函数:阻塞线程,该线程在下列情况发生之前都会被阻塞:
- 调用 unpark 函数,释放该线程的许可。
- 该线程被中断。
- 设置的时间到期,如果 time 为 0 则表示无限等待。
- unpark 函数:释放线程的许可,使调用 park 的线程恢复执行。调用时要确保线性仍然活着。
park
public static void park();
public static void park(Object blocker);
// 第二个函数的实现
public static void park(Object blocker) {
// 获取当前线程
Thread t = Thread.currentThread();
// 设置Blocker
setBlocker(t, blocker);
// 获取许可
UNSAFE.park(false, 0L);
// 重新可运行后再此设置Blocker
setBlocker(t, null);
}
调用 park 函数时,首先获取当前线程,然后设置当前线程的 parkBlocker 字段,即调用 setBlocker 方法,之后调用 UnSafe.park,之后再调用 setBlocker 方法。
调用 park 函数式,当前线程首先设置好 parkBlocker 字段,然后调用 UnSafe.park,此后,当前线程就阻塞了,开始等待该线程的 unpark 函数被调用,所以后面的一个 setBlocker 函数无法执行;unpack 函数被调用后,该线程获得许可,就可以接着执行第二个 setBlocker,把该线程的 parkBlocker 设为 null,即完成了整个 park 函数的逻辑。
如果没有第二个 setBlocker,那么之后没有调用 park(blocker),而直接调用 getBlocker 函数时,会得到原来设置的 blocker,显然不符合逻辑。总之,必须要保证 park 执行完成之后,blocker 被设为 null。
说明: 调用了park函数后,会禁用当前线程,除非许可可用。在以下三种情况之一发生之前,当前线程都将处于休眠状态,即下列情况发生时,当前线程会获取许可,可以继续运行。
- 其他某个线程将当前线程作为目标调用 unpark。
- 其他某个线程中断当前线程。
- 该调用不合逻辑地(即毫无理由地)返回。
parkNanos
此函数表示在许可可用前禁用当前线程,并最多等待指定的等待时间。
public static void parkNanos(Object blocker, long nanos) {
if (nanos > 0) { // 时间大于0
// 获取当前线程
Thread t = Thread.currentThread();
// 设置Blocker
setBlocker(t, blocker);
// 获取许可,并设置了时间
UNSAFE.park(false, nanos);
// 设置许可
setBlocker(t, null);
}
}
parkUntil
此函数表示在指定的时限前禁用当前线程,除非许可可用, 具体函数如下:
public static void parkUntil(Object blocker, long deadline) {
// 获取当前线程
Thread t = Thread.currentThread();
// 设置Blocker
setBlocker(t, blocker);
UNSAFE.park(true, deadline);
// 设置Blocker为null
setBlocker(t, null);
}
unpark
此函数表示如果给定线程的许可尚不可用,则使其可用。如果线程在 park 上受阻塞,则它将解除其阻塞状态。否则,保证下一次调用 park 不会受阻塞。如果给定线程尚未启动,则无法保证此操作有任何效果。
public static void unpark(Thread thread) {
if (thread != null) // 线程为不空
UNSAFE.unpark(thread); // 释放该线程许可
}
应用示例
使用wait/notify实现线程同步
class MyThread extends Thread {
public void run() {
synchronized (this) {
System.out.println("before notify");
notify();
System.out.println("after notify");
}
}
}
public class WaitAndNotifyDemo {
public static void main(String[] args) throws InterruptedException {
MyThread myThread = new MyThread();
synchronized (myThread) {
try {
myThread.start();
// 主线程睡眠3s
Thread.sleep(3000);
System.out.println("before wait");
// 阻塞主线程
myThread.wait();
System.out.println("after wait");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
before wait
before notify
after notify
after wait
使用wait/notify实现同步时,必须先调用wait,后调用notify,如果先调用notify,再调用wait,将起不了作用。
使用park/unpark实现线程同步
import java.util.concurrent.locks.LockSupport;
class MyThread extends Thread {
private Object object;
public MyThread(Object object) {
this.object = object;
}
public void run() {
System.out.println("before unpark");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 获取blocker
System.out.println("Blocker info " + LockSupport.getBlocker((Thread) object));
// 释放许可
LockSupport.unpark((Thread) object);
// 休眠500ms,保证先执行park中的setBlocker(t, null);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 再次获取blocker
System.out.println("Blocker info " + LockSupport.getBlocker((Thread) object));
System.out.println("after unpark");
}
}
public class test {
public static void main(String[] args) {
MyThread myThread = new MyThread(Thread.currentThread());
myThread.start();
System.out.println("before park");
// 获取许可
LockSupport.park("ParkAndUnparkDemo");
System.out.println("after park");
}
}
before park
before unpark
Blocker info ParkAndUnparkDemo
after park
Blocker info null
after unpark
本程序先执行park,然后在执行unpark,进行同步,并且在unpark的前后都调用了getBlocker,可以看到两次的结果不一样,并且第二次调用的结果为null,这是因为在调用unpark之后,执行了Lock.park(Object blocker)函数中的setBlocker(t, null)函数,所以第二次调用getBlocker时为null。
中断响应
import java.util.concurrent.locks.LockSupport;
class MyThread extends Thread {
private Object object;
public MyThread(Object object) {
this.object = object;
}
public void run() {
System.out.println("before interrupt");
try {
// 休眠3s
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
Thread thread = (Thread) object;
// 中断线程
thread.interrupt();
System.out.println("after interrupt");
}
}
public class InterruptDemo {
public static void main(String[] args) {
MyThread myThread = new MyThread(Thread.currentThread());
myThread.start();
System.out.println("before park");
// 获取许可
LockSupport.park("ParkAndUnparkDemo");
System.out.println("after park");
}
}
before park
before interrupt
after interrupt
after park
可以看到,在主线程调用park阻塞后,在myThread线程中发出了中断信号,此时主线程会继续运行,也就是说明此时interrupt起到的作用与unpark一样。
深入理解
Thread.sleep() 和 Object.wait() 的区别
- Thread.sleep()不会释放占有的锁,Object.wait()会释放占有的锁;
- Thread.sleep()必须传入时间,Object.wait()可传可不传,不传表示一直阻塞下去;
- Thread.sleep()到时间了会自动唤醒,然后继续执行;
- Object.wait()不带时间的,需要另一个线程使用Object.notify()唤醒;
- Object.wait()带时间的,假如没有被notify,到时间了会自动唤醒,这时又分好两种情况:
- 一是立即获取到了锁,线程自然会继续执行;
- 二是没有立即获取锁,线程进入同步队列等待获取锁;
他们俩最大的区别就是Thread.sleep()不会释放锁资源,Object.wait()会释放锁资源。
Object.wait() 和 Condition.await() 的区别
Object.wait()和Condition.await()的原理是基本一致的,不同的是Condition.await()底层是调用LockSupport.park()来实现阻塞当前线程的。
实际上,它在阻塞当前线程之前还干了两件事,一是把当前线程添加到条件队列中,二是“完全”释放锁,也就是让state状态变量变为0,然后才是调用LockSupport.park()阻塞当前线程。
Thread.sleep()和LockSupport.park()的区别
LockSupport.park()还有几个兄弟方法——parkNanos()、parkUtil()等,我们这里说的park()方法统称这一类方法。
- 从功能上来说,Thread.sleep()和LockSupport.park()方法类似,都是阻塞当前线程的执行,且都不会释放当前线程占有的锁资源;
- Thread.sleep()没法从外部唤醒,只能自己醒过来;
- LockSupport.park()方法可以被另一个线程调用LockSupport.unpark()方法唤醒;
- Thread.sleep()方法声明上抛出了InterruptedException中断异常,所以调用者需要捕获这个异常或者再抛出;
- LockSupport.park()方法不需要捕获中断异常;
- Thread.sleep()本身就是一个native方法;
- LockSupport.park()底层是调用的Unsafe的native方法;
Object.wait()和LockSupport.park()的区别
二者都会阻塞当前线程的运行:
- Object.wait()方法需要在synchronized块中执行;
- LockSupport.park()可以在任意地方执行;
- Object.wait()方法声明抛出了中断异常,调用者需要捕获或者再抛出;
- LockSupport.park()不需要捕获中断异常;
- Object.wait()不带超时的,需要另一个线程执行notify()来唤醒,但不一定继续执行后续内容;
- LockSupport.park()不带超时的,需要另一个线程执行unpark()来唤醒,一定会继续执行后续内容;
- 如果在wait()之前执行了notify()会怎样? 抛出IllegalMonitorStateException异常;
- 如果在park()之前执行了unpark()会怎样? 线程不会被阻塞,直接跳过park(),继续执行后续内容;
park()/unpark()底层的原理是“二元信号量”,你可以把它相像成只有一个许可证的Semaphore,只不过这个信号量在重复执行unpark()的时候也不会再增加许可证,最多只有一个许可证。
LockSupport.park()会释放锁资源吗?
不会,它只负责阻塞当前线程,释放锁资源实际上是在Condition的await()方法中实现的。
3.11 - CH11-AQS-1
AbstractQueuedSynchronizer
AQS 是一个用来构建锁和同步器的框架,使用 AQS 能够简单高效的构造出应用广泛的同步器,比如 ReentrantLock、Semaphore,其他诸如 ReentrantReadWriteLock、SynchronousQueue、FutureTask 等也是基于 AQS 实现的。我们自己也可以基于 AQS 构造满足自己需要的同步器。
核心思想
- 如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。
- 如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制。
- AQS 使用 CLH 队列锁实现了该机制,将暂时获取不到锁的线程加入到队列中。
- AQS 使用一个 int 成员变量表示同步状态,通过内置的 FIFO 队列来完成获取资源线程的排队工作。
- AQS 使用 CAS 对该同步状态执行原子操作以实现值的修改,并使用 volatile 保证该状态的可见性。
CLH(Craig,Landin,and Hagersten) 队列是一个虚拟的双向队列(即不存在队列实例、仅存在结点之间的关联关系)。AQS是将每条请求共享资源的线程封装成一个 CLH 锁队列的一个结点(Node)来实现锁的分配。
状态信息通过 protected 范围的方法执行操作:
private volatile int state;
//返回同步状态的当前值
protected final int getState() {
return state;
}
// 设置同步状态的值
protected final void setState(int newState) {
state = newState;
}
//原子地(CAS操作)将同步状态值设置为给定值update如果当前同步状态的值等于expect(期望值)
protected final boolean compareAndSetState(int expect, int update) {
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
资源共享方式
- 独占(Exclusive):只有一个线程能够执行,如 ReentrantLock。又可以分为公平锁和非公平锁:
- 公平锁:按照线程在队列中的排队顺序,先到者先获得锁。
- 非公平锁:当线程要获得锁时,无视队列顺序直接抢锁,谁抢到随获取。
- 共享(Share):多个线程可以同时执行,如 Semaphore、CountDownLatch。
而 ReentrantReadWriteLock 可以看做是对以上两种方式的组合,因为它允许多个线程同时对一个资源执行读,但仅能有一个线程执行写。
不同的自定义同步器争用共享资源的方式不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败后入队/唤醒出队等),AQS 已经在上层实现了。
AQS 底层使用的模板方法模式
同步器的设计基于模板方法模式,自定义同步器时继承 AQS 并重写指定的方法即可:
- isHeldExclusively:判断线程是否正在独占资源,只有用到 condition 才需要实现。
- tryAcquire(int):独占获取资源,成功失败返回 ture、false。
- tryRelease(int):独占释放资源,成功失败返回 true、false。
- tryAcquireShared(int):共享获取资源,失败为负,为 0 表示成功但没有剩余可用资源,为正表示成且有可用资源。
- tryReleaseShared(int):共享释放资源,成功失败返回 true、false。
相关细节:
- 默认情况下,每个方法都能抛出 UnsupportedException。
- 所有方法的实现必须是内部线程安全的,并且应该简短且不阻塞。
- 其他方法均为 final,所以仅有以上方法可以被其他类使用。
以 ReentrantLock 为例:
- 初始状态 state 为 0,表示未锁定状态。
- A 线程 lock 时,会调用 tryAcquire 独占锁定并将 state+1。
- 此后其他线程再 tryAcquire 时会失败,直到 A 线程 unlock 并将 state=0(释放锁)为止。
- 在 A 线程释放锁之前,A 线程可以重复获取此锁(state 累加),即可重入。
- 获取多次就要释放多次,直至 state 为 0 才表示释放锁。
数据结构
- AQS 底层使用 CLH,将每条请求共享资源的线程封装为 CLH 队列的一个节点。
- 其中同步队列 Sync Queue 为双向链表,包括 head 和 tail 节点,head 节点主要用作后续的调度。
- 其中 Condition Queue 不是必须,是一个单向链表,只有使用 Condition 时,才会使用该队列。
- 并且可能会有多个 Condition Queue。
源码分析
层级结构
AQS 继承抽象类 AbstractOwnableSynchronizer,实现了 Serializable 接口,支持序列化。
public abstract class AbstractOwnableSynchronizer implements java.io.Serializable {
// 版本序列号
private static final long serialVersionUID = 3737899427754241961L;
// 构造方法
protected AbstractOwnableSynchronizer() { }
// 独占模式下的线程
private transient Thread exclusiveOwnerThread;
// 设置独占线程
protected final void setExclusiveOwnerThread(Thread thread) {
exclusiveOwnerThread = thread;
}
// 获取独占线程
protected final Thread getExclusiveOwnerThread() {
return exclusiveOwnerThread;
}
}
- 其中可以“设置独占资源线程”和“获取独占资源线程”,分别为 setExclusiveOwnerThread 与 getExclusiveOwnerThread 方法,这两个方法会被子类调用。
- 其中有两个内部类,Node、ConditionObject。
内部类:Node
static final class Node {
// 模式,分为共享与独占
// 共享模式
static final Node SHARED = new Node();
// 独占模式
static final Node EXCLUSIVE = null;
// 结点状态
// CANCELLED,值为1,表示当前的线程被取消
// SIGNAL,值为-1,表示当前节点的后继节点包含的线程需要运行,也就是unpark
// CONDITION,值为-2,表示当前节点在等待condition,也就是在condition队列中
// PROPAGATE,值为-3,表示当前场景下后续的acquireShared能够得以执行
// 值为0,表示当前节点在sync队列中,等待着获取锁
static final int CANCELLED = 1;
static final int SIGNAL = -1;
static final int CONDITION = -2;
static final int PROPAGATE = -3;
// 结点状态
volatile int waitStatus;
// 前驱结点
volatile Node prev;
// 后继结点
volatile Node next;
// 结点所对应的线程
volatile Thread thread;
// 下一个等待者
Node nextWaiter;
// 结点是否在共享模式下等待
final boolean isShared() {
return nextWaiter == SHARED;
}
// 获取前驱结点,若前驱结点为空,抛出异常
final Node predecessor() throws NullPointerException {
// 保存前驱结点
Node p = prev;
if (p == null) // 前驱结点为空,抛出异常
throw new NullPointerException();
else // 前驱结点不为空,返回
return p;
}
// 无参构造方法
Node() { // Used to establish initial head or SHARED marker
}
// 构造方法
Node(Thread thread, Node mode) { // Used by addWaiter
this.nextWaiter = mode;
this.thread = thread;
}
// 构造方法
Node(Thread thread, int waitStatus) { // Used by Condition
this.waitStatus = waitStatus;
this.thread = thread;
}
}
- 每个被阻塞的线程都会被封装为一个 Node 节点并放入队列。
- 每个节点包含了一个 Thread 类型的引用,并且每个节点都有一个状态,状态如下:
- CANCELLED:1,当前线程被取消。
- SIGNAL:-1,当前节点的后继节点中的线程需要运行,需要进行 unpark 操作。
- CONDITION:-2,当前节点在等待 condition,即 condition queue 中。
- PROPAGATE:-3,当前场景下后续的 acquireSHared 能够得以执行。
- 0:当前节点在 sync queue 中,等待获取锁。
内部类:ConditionObject
// 内部类
public class ConditionObject implements Condition, java.io.Serializable {
// 版本号
private static final long serialVersionUID = 1173984872572414699L;
/** First node of condition queue. */
// condition队列的头结点
private transient Node firstWaiter;
/** Last node of condition queue. */
// condition队列的尾结点
private transient Node lastWaiter;
/**
* Creates a new {@code ConditionObject} instance.
*/
// 构造方法
public ConditionObject() { }
// Internal methods
/**
* Adds a new waiter to wait queue.
* @return its new wait node
*/
// 添加新的waiter到wait队列
private Node addConditionWaiter() {
// 保存尾结点
Node t = lastWaiter;
// If lastWaiter is cancelled, clean out.
if (t != null && t.waitStatus != Node.CONDITION) { // 尾结点不为空,并且尾结点的状态不为CONDITION
// 清除状态为CONDITION的结点
unlinkCancelledWaiters();
// 将最后一个结点重新赋值给t
t = lastWaiter;
}
// 新建一个结点
Node node = new Node(Thread.currentThread(), Node.CONDITION);
if (t == null) // 尾结点为空
// 设置condition队列的头结点
firstWaiter = node;
else // 尾结点不为空
// 设置为节点的nextWaiter域为node结点
t.nextWaiter = node;
// 更新condition队列的尾结点
lastWaiter = node;
return node;
}
/**
* Removes and transfers nodes until hit non-cancelled one or
* null. Split out from signal in part to encourage compilers
* to inline the case of no waiters.
* @param first (non-null) the first node on condition queue
*/
private void doSignal(Node first) {
// 循环
do {
if ( (firstWaiter = first.nextWaiter) == null) // 该节点的nextWaiter为空
// 设置尾结点为空
lastWaiter = null;
// 设置first结点的nextWaiter域
first.nextWaiter = null;
} while (!transferForSignal(first) &&
(first = firstWaiter) != null); // 将结点从condition队列转移到sync队列失败并且condition队列中的头结点不为空,一直循环
}
/**
* Removes and transfers all nodes.
* @param first (non-null) the first node on condition queue
*/
private void doSignalAll(Node first) {
// condition队列的头结点尾结点都设置为空
lastWaiter = firstWaiter = null;
// 循环
do {
// 获取first结点的nextWaiter域结点
Node next = first.nextWaiter;
// 设置first结点的nextWaiter域为空
first.nextWaiter = null;
// 将first结点从condition队列转移到sync队列
transferForSignal(first);
// 重新设置first
first = next;
} while (first != null);
}
/**
* Unlinks cancelled waiter nodes from condition queue.
* Called only while holding lock. This is called when
* cancellation occurred during condition wait, and upon
* insertion of a new waiter when lastWaiter is seen to have
* been cancelled. This method is needed to avoid garbage
* retention in the absence of signals. So even though it may
* require a full traversal, it comes into play only when
* timeouts or cancellations occur in the absence of
* signals. It traverses all nodes rather than stopping at a
* particular target to unlink all pointers to garbage nodes
* without requiring many re-traversals during cancellation
* storms.
*/
// 从condition队列中清除状态为CANCEL的结点
private void unlinkCancelledWaiters() {
// 保存condition队列头结点
Node t = firstWaiter;
Node trail = null;
while (t != null) { // t不为空
// 下一个结点
Node next = t.nextWaiter;
if (t.waitStatus != Node.CONDITION) { // t结点的状态不为CONDTION状态
// 设置t节点的额nextWaiter域为空
t.nextWaiter = null;
if (trail == null) // trail为空
// 重新设置condition队列的头结点
firstWaiter = next;
else // trail不为空
// 设置trail结点的nextWaiter域为next结点
trail.nextWaiter = next;
if (next == null) // next结点为空
// 设置condition队列的尾结点
lastWaiter = trail;
}
else // t结点的状态为CONDTION状态
// 设置trail结点
trail = t;
// 设置t结点
t = next;
}
}
// public methods
/**
* Moves the longest-waiting thread, if one exists, from the
* wait queue for this condition to the wait queue for the
* owning lock.
*
* @throws IllegalMonitorStateException if {@link #isHeldExclusively}
* returns {@code false}
*/
// 唤醒一个等待线程。如果所有的线程都在等待此条件,则选择其中的一个唤醒。在从 await 返回之前,该线程必须重新获取锁。
public final void signal() {
if (!isHeldExclusively()) // 不被当前线程独占,抛出异常
throw new IllegalMonitorStateException();
// 保存condition队列头结点
Node first = firstWaiter;
if (first != null) // 头结点不为空
// 唤醒一个等待线程
doSignal(first);
}
/**
* Moves all threads from the wait queue for this condition to
* the wait queue for the owning lock.
*
* @throws IllegalMonitorStateException if {@link #isHeldExclusively}
* returns {@code false}
*/
// 唤醒所有等待线程。如果所有的线程都在等待此条件,则唤醒所有线程。在从 await 返回之前,每个线程都必须重新获取锁。
public final void signalAll() {
if (!isHeldExclusively()) // 不被当前线程独占,抛出异常
throw new IllegalMonitorStateException();
// 保存condition队列头结点
Node first = firstWaiter;
if (first != null) // 头结点不为空
// 唤醒所有等待线程
doSignalAll(first);
}
/**
* Implements uninterruptible condition wait.
* <ol>
* <li> Save lock state returned by {@link #getState}.
* <li> Invoke {@link #release} with saved state as argument,
* throwing IllegalMonitorStateException if it fails.
* <li> Block until signalled.
* <li> Reacquire by invoking specialized version of
* {@link #acquire} with saved state as argument.
* </ol>
*/
// 等待,当前线程在接到信号之前一直处于等待状态,不响应中断
public final void awaitUninterruptibly() {
// 添加一个结点到等待队列
Node node = addConditionWaiter();
// 获取释放的状态
int savedState = fullyRelease(node);
boolean interrupted = false;
while (!isOnSyncQueue(node)) { //
// 阻塞当前线程
LockSupport.park(this);
if (Thread.interrupted()) // 当前线程被中断
// 设置interrupted状态
interrupted = true;
}
if (acquireQueued(node, savedState) || interrupted) //
selfInterrupt();
}
/*
* For interruptible waits, we need to track whether to throw
* InterruptedException, if interrupted while blocked on
* condition, versus reinterrupt current thread, if
* interrupted while blocked waiting to re-acquire.
*/
/** Mode meaning to reinterrupt on exit from wait */
private static final int REINTERRUPT = 1;
/** Mode meaning to throw InterruptedException on exit from wait */
private static final int THROW_IE = -1;
/**
* Checks for interrupt, returning THROW_IE if interrupted
* before signalled, REINTERRUPT if after signalled, or
* 0 if not interrupted.
*/
private int checkInterruptWhileWaiting(Node node) {
return Thread.interrupted() ?
(transferAfterCancelledWait(node) ? THROW_IE : REINTERRUPT) :
0;
}
/**
* Throws InterruptedException, reinterrupts current thread, or
* does nothing, depending on mode.
*/
private void reportInterruptAfterWait(int interruptMode)
throws InterruptedException {
if (interruptMode == THROW_IE)
throw new InterruptedException();
else if (interruptMode == REINTERRUPT)
selfInterrupt();
}
/**
* Implements interruptible condition wait.
* <ol>
* <li> If current thread is interrupted, throw InterruptedException.
* <li> Save lock state returned by {@link #getState}.
* <li> Invoke {@link #release} with saved state as argument,
* throwing IllegalMonitorStateException if it fails.
* <li> Block until signalled or interrupted.
* <li> Reacquire by invoking specialized version of
* {@link #acquire} with saved state as argument.
* <li> If interrupted while blocked in step 4, throw InterruptedException.
* </ol>
*/
// // 等待,当前线程在接到信号或被中断之前一直处于等待状态
public final void await() throws InterruptedException {
if (Thread.interrupted()) // 当前线程被中断,抛出异常
throw new InterruptedException();
// 在wait队列上添加一个结点
Node node = addConditionWaiter();
//
int savedState = fullyRelease(node);
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
// 阻塞当前线程
LockSupport.park(this);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0) // 检查结点等待时的中断类型
break;
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null) // clean up if cancelled
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
/**
* Implements timed condition wait.
* <ol>
* <li> If current thread is interrupted, throw InterruptedException.
* <li> Save lock state returned by {@link #getState}.
* <li> Invoke {@link #release} with saved state as argument,
* throwing IllegalMonitorStateException if it fails.
* <li> Block until signalled, interrupted, or timed out.
* <li> Reacquire by invoking specialized version of
* {@link #acquire} with saved state as argument.
* <li> If interrupted while blocked in step 4, throw InterruptedException.
* </ol>
*/
// 等待,当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态
public final long awaitNanos(long nanosTimeout)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
final long deadline = System.nanoTime() + nanosTimeout;
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
if (nanosTimeout <= 0L) {
transferAfterCancelledWait(node);
break;
}
if (nanosTimeout >= spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
nanosTimeout = deadline - System.nanoTime();
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null)
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
return deadline - System.nanoTime();
}
/**
* Implements absolute timed condition wait.
* <ol>
* <li> If current thread is interrupted, throw InterruptedException.
* <li> Save lock state returned by {@link #getState}.
* <li> Invoke {@link #release} with saved state as argument,
* throwing IllegalMonitorStateException if it fails.
* <li> Block until signalled, interrupted, or timed out.
* <li> Reacquire by invoking specialized version of
* {@link #acquire} with saved state as argument.
* <li> If interrupted while blocked in step 4, throw InterruptedException.
* <li> If timed out while blocked in step 4, return false, else true.
* </ol>
*/
// 等待,当前线程在接到信号、被中断或到达指定最后期限之前一直处于等待状态
public final boolean awaitUntil(Date deadline)
throws InterruptedException {
long abstime = deadline.getTime();
if (Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
boolean timedout = false;
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
if (System.currentTimeMillis() > abstime) {
timedout = transferAfterCancelledWait(node);
break;
}
LockSupport.parkUntil(this, abstime);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null)
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
return !timedout;
}
/**
* Implements timed condition wait.
* <ol>
* <li> If current thread is interrupted, throw InterruptedException.
* <li> Save lock state returned by {@link #getState}.
* <li> Invoke {@link #release} with saved state as argument,
* throwing IllegalMonitorStateException if it fails.
* <li> Block until signalled, interrupted, or timed out.
* <li> Reacquire by invoking specialized version of
* {@link #acquire} with saved state as argument.
* <li> If interrupted while blocked in step 4, throw InterruptedException.
* <li> If timed out while blocked in step 4, return false, else true.
* </ol>
*/
// 等待,当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态。此方法在行为上等效于: awaitNanos(unit.toNanos(time)) > 0
public final boolean await(long time, TimeUnit unit)
throws InterruptedException {
long nanosTimeout = unit.toNanos(time);
if (Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
final long deadline = System.nanoTime() + nanosTimeout;
boolean timedout = false;
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
if (nanosTimeout <= 0L) {
timedout = transferAfterCancelledWait(node);
break;
}
if (nanosTimeout >= spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanosTimeout);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
nanosTimeout = deadline - System.nanoTime();
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null)
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
return !timedout;
}
// support for instrumentation
/**
* Returns true if this condition was created by the given
* synchronization object.
*
* @return {@code true} if owned
*/
final boolean isOwnedBy(AbstractQueuedSynchronizer sync) {
return sync == AbstractQueuedSynchronizer.this;
}
/**
* Queries whether any threads are waiting on this condition.
* Implements {@link AbstractQueuedSynchronizer#hasWaiters(ConditionObject)}.
*
* @return {@code true} if there are any waiting threads
* @throws IllegalMonitorStateException if {@link #isHeldExclusively}
* returns {@code false}
*/
// 查询是否有正在等待此条件的任何线程
protected final boolean hasWaiters() {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
for (Node w = firstWaiter; w != null; w = w.nextWaiter) {
if (w.waitStatus == Node.CONDITION)
return true;
}
return false;
}
/**
* Returns an estimate of the number of threads waiting on
* this condition.
* Implements {@link AbstractQueuedSynchronizer#getWaitQueueLength(ConditionObject)}.
*
* @return the estimated number of waiting threads
* @throws IllegalMonitorStateException if {@link #isHeldExclusively}
* returns {@code false}
*/
// 返回正在等待此条件的线程数估计值
protected final int getWaitQueueLength() {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
int n = 0;
for (Node w = firstWaiter; w != null; w = w.nextWaiter) {
if (w.waitStatus == Node.CONDITION)
++n;
}
return n;
}
/**
* Returns a collection containing those threads that may be
* waiting on this Condition.
* Implements {@link AbstractQueuedSynchronizer#getWaitingThreads(ConditionObject)}.
*
* @return the collection of threads
* @throws IllegalMonitorStateException if {@link #isHeldExclusively}
* returns {@code false}
*/
// 返回包含那些可能正在等待此条件的线程集合
protected final Collection<Thread> getWaitingThreads() {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
ArrayList<Thread> list = new ArrayList<Thread>();
for (Node w = firstWaiter; w != null; w = w.nextWaiter) {
if (w.waitStatus == Node.CONDITION) {
Thread t = w.thread;
if (t != null)
list.add(t);
}
}
return list;
}
}
该类实现了 Condition 接口,Condition 接口定义了条件操作的规范:
public interface Condition {
// 等待,当前线程在接到信号或被中断之前一直处于等待状态
void await() throws InterruptedException;
// 等待,当前线程在接到信号之前一直处于等待状态,不响应中断
void awaitUninterruptibly();
//等待,当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态
long awaitNanos(long nanosTimeout) throws InterruptedException;
// 等待,当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态。此方法在行为上等效于: awaitNanos(unit.toNanos(time)) > 0
boolean await(long time, TimeUnit unit) throws InterruptedException;
// 等待,当前线程在接到信号、被中断或到达指定最后期限之前一直处于等待状态
boolean awaitUntil(Date deadline) throws InterruptedException;
// 唤醒一个等待线程。如果所有的线程都在等待此条件,则选择其中的一个唤醒。在从 await 返回之前,该线程必须重新获取锁。
void signal();
// 唤醒所有等待线程。如果所有的线程都在等待此条件,则唤醒所有线程。在从 await 返回之前,每个线程都必须重新获取锁。
void signalAll();
}
类的属性
属性中包含了头结点 head,为节点 tail,状态 state,自旋时间 spinForTimeoutThreshold,以及 AQS 抽象的属性在内存中的便宜地址,通过该便宜地址,可以获取和设置属性的值,同时该包括一个静态初始化块,用于加载内存偏移地址:
public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer
implements java.io.Serializable {
// 版本号
private static final long serialVersionUID = 7373984972572414691L;
// 头结点
private transient volatile Node head;
// 尾结点
private transient volatile Node tail;
// 状态
private volatile int state;
// 自旋时间
static final long spinForTimeoutThreshold = 1000L;
// Unsafe类实例
private static final Unsafe unsafe = Unsafe.getUnsafe();
// state内存偏移地址
private static final long stateOffset;
// head内存偏移地址
private static final long headOffset;
// state内存偏移地址
private static final long tailOffset;
// tail内存偏移地址
private static final long waitStatusOffset;
// next内存偏移地址
private static final long nextOffset;
// 静态初始化块
static {
try {
stateOffset = unsafe.objectFieldOffset
(AbstractQueuedSynchronizer.class.getDeclaredField("state"));
headOffset = unsafe.objectFieldOffset
(AbstractQueuedSynchronizer.class.getDeclaredField("head"));
tailOffset = unsafe.objectFieldOffset
(AbstractQueuedSynchronizer.class.getDeclaredField("tail"));
waitStatusOffset = unsafe.objectFieldOffset
(Node.class.getDeclaredField("waitStatus"));
nextOffset = unsafe.objectFieldOffset
(Node.class.getDeclaredField("next"));
} catch (Exception ex) { throw new Error(ex); }
}
}
类的构造方法
该类构造方法为抽象构造方法,仅供子类调用。
类的核心方法:acquire
该方法以独占模式获取(资源),忽略中断,即线程在aquire过程中,中断此线程是无效的。源码如下:
public final void acquire(int arg) {
if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
线程在调用 tryAcquire 时的流程如下:
- 首先调用 tryAcquire 方法,线程会尝试在独占模式下获取对象状态。
- 此方法会查询是否允许它在独占模式下获取对象状态,如果允许则获取。
- 在 AQS 源码中会默认抛出一个异常,即需要子类重写该方法以实现需要的逻辑。
- 若 tryAcquire 失败,则调用 addWaiter 方法,addWaiter 方法完成的功能是将调用此方法的线程封装成为一个节点并放入 Sync Queue。
- 调用 acquireQueued 方法,此方法完成的功能是 Sync Queue 中的节点不断尝试获取资源,成功失败返回 true、false。
- 调用 tryAcquire 默认实现是抛出异常,因此需要继承者实现。
首先是 addWaiter 方法:
// 添加等待者
private Node addWaiter(Node mode) {
// 新生成一个结点,默认为独占模式
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
// 保存尾结点
Node pred = tail;
if (pred != null) { // 尾结点不为空,即已经被初始化
// 将node结点的prev域连接到尾结点
node.prev = pred;
if (compareAndSetTail(pred, node)) { // 比较pred是否为尾结点,是则将尾结点设置为node
// 设置尾结点的next域为node
pred.next = node;
return node; // 返回新生成的结点
}
}
enq(node); // 尾结点为空(即还没有被初始化过),或者是compareAndSetTail操作失败,则入队列
return node;
}
addWaiter 方法使用快速添加的方式往 sync queue 尾部添加结点,如果 sync queue 队列还没有初始化,则会使用 enq 插入队列中,enq 方法源码如下:
private Node enq(final Node node) {
for (;;) { // 无限循环,确保结点能够成功入队列
// 保存尾结点
Node t = tail;
if (t == null) { // 尾结点为空,即还没被初始化
if (compareAndSetHead(new Node())) // 头结点为空,并设置头结点为新生成的结点
tail = head; // 头结点与尾结点都指向同一个新生结点
} else { // 尾结点不为空,即已经被初始化过
// 将node结点的prev域连接到尾结点
node.prev = t;
if (compareAndSetTail(t, node)) { // 比较结点t是否为尾结点,若是则将尾结点设置为node
// 设置尾结点的next域为node
t.next = node;
return t; // 返回尾结点
}
}
}
}
enq 方法会使用无限循环来确保节点的成功插入。
acquireQueue方法:
// sync队列中的结点在独占且忽略中断的模式下获取(资源)
final boolean acquireQueued(final Node node, int arg) {
// 标志
boolean failed = true;
try {
// 中断标志
boolean interrupted = false;
for (;;) { // 无限循环
// 获取node节点的前驱结点
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) { // 前驱为头结点并且成功获得锁
setHead(node); // 设置头结点
p.next = null; // help GC
failed = false; // 设置标志
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
首先获取当前节点的前驱节点,如果前驱节点是头结点并且能够获取(资源),代表该当前节点能够占有锁,设置头结点为当前节点,返回。否则,调用shouldParkAfterFailedAcquire和parkAndCheckInterrupt方法,首先,我们看shouldParkAfterFailedAcquire方法,代码如下:
// 当获取(资源)失败后,检查并且更新结点状态
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
// 获取前驱结点的状态
int ws = pred.waitStatus;
if (ws == Node.SIGNAL) // 状态为SIGNAL,为-1
/*
* This node has already set status asking a release
* to signal it, so it can safely park.
*/
// 可以进行park操作
return true;
if (ws > 0) { // 表示状态为CANCELLED,为1
/*
* Predecessor was cancelled. Skip over predecessors and
* indicate retry.
*/
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0); // 找到pred结点前面最近的一个状态不为CANCELLED的结点
// 赋值pred结点的next域
pred.next = node;
} else { // 为PROPAGATE -3 或者是0 表示无状态,(为CONDITION -2时,表示此节点在condition queue中)
/*
* waitStatus must be 0 or PROPAGATE. Indicate that we
* need a signal, but don't park yet. Caller will need to
* retry to make sure it cannot acquire before parking.
*/
// 比较并设置前驱结点的状态为SIGNAL
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
// 不能进行park操作
return false;
}
只有当该节点的前驱结点的状态为SIGNAL时,才可以对该结点所封装的线程进行park操作。否则,将不能进行park操作。再看parkAndCheckInterrupt方法,源码如下:
// 进行park操作并且返回该线程是否被中断
private final boolean parkAndCheckInterrupt() {
// 在许可可用之前禁用当前线程,并且设置了blocker
LockSupport.park(this);
return Thread.interrupted(); // 当前线程是否已被中断,并清除中断标记位
}
parkAndCheckInterrupt方法里的逻辑是首先执行park操作,即禁用当前线程,然后返回该线程是否已经被中断。再看final块中的cancelAcquire方法,其源码如下:
// 取消继续获取(资源)
private void cancelAcquire(Node node) {
// Ignore if node doesn't exist
// node为空,返回
if (node == null)
return;
// 设置node结点的thread为空
node.thread = null;
// Skip cancelled predecessors
// 保存node的前驱结点
Node pred = node.prev;
while (pred.waitStatus > 0) // 找到node前驱结点中第一个状态小于0的结点,即不为CANCELLED状态的结点
node.prev = pred = pred.prev;
// predNext is the apparent node to unsplice. CASes below will
// fail if not, in which case, we lost race vs another cancel
// or signal, so no further action is necessary.
// 获取pred结点的下一个结点
Node predNext = pred.next;
// Can use unconditional write instead of CAS here.
// After this atomic step, other Nodes can skip past us.
// Before, we are free of interference from other threads.
// 设置node结点的状态为CANCELLED
node.waitStatus = Node.CANCELLED;
// If we are the tail, remove ourselves.
if (node == tail && compareAndSetTail(node, pred)) { // node结点为尾结点,则设置尾结点为pred结点
// 比较并设置pred结点的next节点为null
compareAndSetNext(pred, predNext, null);
} else { // node结点不为尾结点,或者比较设置不成功
// If successor needs signal, try to set pred's next-link
// so it will get one. Otherwise wake it up to propagate.
int ws;
if (pred != head &&
((ws = pred.waitStatus) == Node.SIGNAL ||
(ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) &&
pred.thread != null) { // (pred结点不为头结点,并且pred结点的状态为SIGNAL)或者
// pred结点状态小于等于0,并且比较并设置等待状态为SIGNAL成功,并且pred结点所封装的线程不为空
// 保存结点的后继
Node next = node.next;
if (next != null && next.waitStatus <= 0) // 后继不为空并且后继的状态小于等于0
compareAndSetNext(pred, predNext, next); // 比较并设置pred.next = next;
} else {
unparkSuccessor(node); // 释放node的前一个结点
}
node.next = node; // help GC
}
}
该方法完成的功能就是取消当前线程对资源的获取,即设置该结点的状态为CANCELLED,接着我们再看unparkSuccessor方法,源码如下:
// 释放后继结点
private void unparkSuccessor(Node node) {
/*
* If status is negative (i.e., possibly needing signal) try
* to clear in anticipation of signalling. It is OK if this
* fails or if status is changed by waiting thread.
*/
// 获取node结点的等待状态
int ws = node.waitStatus;
if (ws < 0) // 状态值小于0,为SIGNAL -1 或 CONDITION -2 或 PROPAGATE -3
// 比较并且设置结点等待状态,设置为0
compareAndSetWaitStatus(node, ws, 0);
/*
* Thread to unpark is held in successor, which is normally
* just the next node. But if cancelled or apparently null,
* traverse backwards from tail to find the actual
* non-cancelled successor.
*/
// 获取node节点的下一个结点
Node s = node.next;
if (s == null || s.waitStatus > 0) { // 下一个结点为空或者下一个节点的等待状态大于0,即为CANCELLED
// s赋值为空
s = null;
// 从尾结点开始从后往前开始遍历
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0) // 找到等待状态小于等于0的结点,找到最前的状态小于等于0的结点
// 保存结点
s = t;
}
if (s != null) // 该结点不为为空,释放许可
LockSupport.unpark(s.thread);
}
该方法的作用就是为了释放node节点的后继结点。
对于cancelAcquire与unparkSuccessor方法,如下示意图可以清晰的表示:
其中node为参数,在执行完cancelAcquire方法后的效果就是unpark了s结点所包含的t4线程。
现在,再来看acquireQueued方法的整个的逻辑。逻辑如下:
判断结点的前驱是否为head并且是否成功获取(资源)。
若步骤1均满足,则设置结点为head,之后会判断是否finally模块,然后返回。
若步骤2不满足,则判断是否需要park当前线程,是否需要park当前线程的逻辑是判断结点的前驱结点的状态是否为SIGNAL,若是,则park当前结点,否则,不进行park操作。
若park了当前线程,之后某个线程对本线程unpark后,并且本线程也获得机会运行。那么,将会继续进行步骤 1 的判断。
类的核心方法:release
以独占模式释放资源:
public final boolean release(int arg) {
if (tryRelease(arg)) { // 释放成功
// 保存头结点
Node h = head;
if (h != null && h.waitStatus != 0) // 头结点不为空并且头结点状态不为0
unparkSuccessor(h); //释放头结点的后继结点
return true;
}
return false;
}
其中,tryRelease的默认实现是抛出异常,需要具体的子类实现,如果tryRelease成功,那么如果头结点不为空并且头结点的状态不为0,则释放头结点的后继结点,unparkSuccessor方法已经分析过,不再累赘。
对于其他方法我们也可以分析,与前面分析的方法大同小异,所以,不再累赘。
参考资料
3.12 - CH12-AQS-2
应用示例
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
class MyThread extends Thread {
private Lock lock;
public MyThread(String name, Lock lock) {
super(name);
this.lock = lock;
}
public void run () {
lock.lock();
try {
System.out.println(Thread.currentThread() + " running");
} finally {
lock.unlock();
}
}
}
public class AbstractQueuedSynchonizerDemo {
public static void main(String[] args) {
Lock lock = new ReentrantLock();
MyThread t1 = new MyThread("t1", lock);
MyThread t2 = new MyThread("t2", lock);
t1.start();
t2.start();
}
}
// 前后随机
Thread[t1,5,main] running
Thread[t2,5,main] running
从示例可知,线程t1与t2共用了一把锁,即同一个lock。可能会存在如下一种时序:
首先 t1 线程调用 lock.lock 操作,然后 t2 再执行 lock.lock 操作,然后 t1 执行 lock.unlock,最后 t2 执行 lock.unlock。基于这样的时序尝试分析 AQS 内部的机制。
进过一系列方法调用,最后达到的状态是 t2 被禁用,因此调用了 LockSupport.lock。
t1线程中调用lock.unlock后,经过一系列的调用,最终的状态是释放了许可,因为调用了LockSupport.unpark。这时,t2线程就可以继续运行了。此时,会继续恢复t2线程运行环境,继续执行LockSupport.park后面的语句,即进一步调用如下。
在上一步调用了LockSupport.unpark后,t2线程恢复运行,则运行parkAndCheckInterrupt,之后,继续运行acquireQueued方法,最后达到的状态是头结点head与尾结点tail均指向了t2线程所在的结点,并且之前的头结点已经从sync队列中断开了。
- t2线程调用lock.unlock,其方法调用顺序如下,只给出了主要的方法调用。
t2线程执行lock.unlock后,最终达到的状态还是与之前的状态一样。
3.13 - CH13-AQS-3
应用实例
下面我们结合Condition实现生产者与消费者,来进一步分析AbstractQueuedSynchronizer的内部工作机制。
Depot(仓库)类:
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class Depot {
private int size;
private int capacity;
private Lock lock;
private Condition fullCondition;
private Condition emptyCondition;
public Depot(int capacity) {
this.capacity = capacity;
lock = new ReentrantLock();
fullCondition = lock.newCondition();
emptyCondition = lock.newCondition();
}
public void produce(int no) {
lock.lock();
int left = no;
try {
while (left > 0) {
while (size >= capacity) {
System.out.println(Thread.currentThread() + " before await");
fullCondition.await();
System.out.println(Thread.currentThread() + " after await");
}
int inc = (left + size) > capacity ? (capacity - size) : left;
left -= inc;
size += inc;
System.out.println("produce = " + inc + ", size = " + size);
emptyCondition.signal();
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void consume(int no) {
lock.lock();
int left = no;
try {
while (left > 0) {
while (size <= 0) {
System.out.println(Thread.currentThread() + " before await");
emptyCondition.await();
System.out.println(Thread.currentThread() + " after await");
}
int dec = (size - left) > 0 ? left : size;
left -= dec;
size -= dec;
System.out.println("consume = " + dec + ", size = " + size);
fullCondition.signal();
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
测试类:
class Consumer {
private Depot depot;
public Consumer(Depot depot) {
this.depot = depot;
}
public void consume(int no) {
new Thread(new Runnable() {
@Override
public void run() {
depot.consume(no);
}
}, no + " consume thread").start();
}
}
class Producer {
private Depot depot;
public Producer(Depot depot) {
this.depot = depot;
}
public void produce(int no) {
new Thread(new Runnable() {
@Override
public void run() {
depot.produce(no);
}
}, no + " produce thread").start();
}
}
public class ReentrantLockDemo {
public static void main(String[] args) throws InterruptedException {
Depot depot = new Depot(500);
new Producer(depot).produce(500);
new Producer(depot).produce(200);
new Consumer(depot).consume(500);
new Consumer(depot).consume(200);
}
}
运行结果(随机):
produce = 500, size = 500
Thread[200 produce thread,5,main] before await
consume = 500, size = 0
Thread[200 consume thread,5,main] before await
Thread[200 produce thread,5,main] after await
produce = 200, size = 200
Thread[200 consume thread,5,main] after await
consume = 200, size = 0
根据结果,我们猜测一种可能的时序如下:
p1代表produce 500的那个线程,p2代表produce 200的那个线程,c1代表consume 500的那个线程,c2代表consume 200的那个线程。
- p1线程调用lock.lock,获得锁,继续运行,方法调用顺序在前面已经给出。
- p2线程调用lock.lock,由前面的分析可得到如下的最终状态。
p2线程调用lock.lock后,会禁止p2线程的继续运行,因为执行了LockSupport.park操作。
- c1线程调用lock.lock,由前面的分析得到如下的最终状态。
最终c1线程会在sync queue队列的尾部,并且其结点的前驱结点(包含p2的结点)的waitStatus变为了SIGNAL。
- c2线程调用lock.lock,由前面的分析得到如下的最终状态。
最终c1线程会在sync queue队列的尾部,并且其结点的前驱结点(包含c1的结点)的waitStatus变为了SIGNAL。
- p1线程执行emptyCondition.signal,其方法调用顺序如下,只给出了主要的方法调用。
AQS.CO表示AbstractQueuedSynchronizer.ConditionObject类。此时调用signal方法不会产生任何其他效果。
- p1线程执行lock.unlock,根据前面的分析可知,最终的状态如下。
此时,p2线程所在的结点为头结点,并且其他两个线程(c1、c2)依旧被禁止,所以,此时p2线程继续运行,执行用户逻辑。
- p2线程执行fullCondition.await,其方法调用顺序如下,只给出了主要的方法调用。
最终到达的状态是新生成了一个结点,包含了p2线程,此结点在condition queue中;并且sync queue中p2线程被禁止了,因为在执行了LockSupport.park操作。从方法一些调用可知,在await操作中线程会释放锁资源,供其他线程获取。同时,head结点后继结点的包含的线程的许可被释放了,故其可以继续运行。由于此时,只有c1线程可以运行,故运行c1。
- 继续运行c1线程,c1线程由于之前被park了,所以此时恢复,继续之前的步骤,即还是执行前面提到的acquireQueued方法,之后,c1判断自己的前驱结点为head,并且可以获取锁资源,最终到达的状态如下。
其中,head设置为包含c1线程的结点,c1继续运行。
- c1线程执行fullCondtion.signal,其方法调用顺序如下,只给出了主要的方法调用。
signal方法达到的最终结果是将包含p2线程的结点从condition queue中转移到sync queue中,之后condition queue为null,之前的尾结点的状态变为SIGNAL。
- c1线程执行lock.unlock操作,根据之前的分析,经历的状态变化如下。
最终c2线程会获取锁资源,继续运行用户逻辑。
- c2线程执行emptyCondition.await,由前面的第七步分析,可知最终的状态如下。
await操作将会生成一个结点放入condition queue中与之前的一个condition queue是不相同的,并且unpark头结点后面的结点,即包含线程p2的结点。
- p2线程被unpark,故可以继续运行,经过CPU调度后,p2继续运行,之后p2线程在AQS:await方法中被park,继续AQS.CO:await方法的运行,其方法调用顺序如下,只给出了主要的方法调用。
- p2继续运行,执行emptyCondition.signal,根据第九步分析可知,最终到达的状态如下。
最终,将condition queue中的结点转移到sync queue中,并添加至尾部,condition queue会为空,并且将head的状态设置为SIGNAL。
- p2线程执行lock.unlock操作,根据前面的分析可知,最后的到达的状态如下。
unlock操作会释放c2线程的许可,并且将头结点设置为c2线程所在的结点。
- c2线程继续运行,执行fullCondition. signal,由于此时fullCondition的condition queue已经不存在任何结点了,故其不会产生作用。
- c2执行lock.unlock,由于c2是sync队列中最后一个结点,故其不会再调用unparkSuccessor了,直接返回true。即整个流程就完成了。
3.14 - CH14-AQS-4
AQS 总结
最核心的就是sync queue的分析。
- 每个节点都是由前驱节点唤醒。
- 如果节点发现前驱节点是 head 并且尝试获取成功,则会轮到该线程执行。
- condition queue 中的节点想 sync queue 中转移是通过 signal 操作完成的。
- 当节点状态为 SIGNAL 时,表示后面的节点需要运行。
3.15 - CH15-ReentrantLock
源码分析
层级结构
ReentrantLock实现了Lock接口,Lock接口中定义了lock与unlock相关操作,并且还存在newCondition方法,表示生成一个条件。
内部类
ReentrantLock总共有三个内部类,并且三个内部类是紧密相关的,下面先看三个类的关系。
ReentrantLock类内部总共存在Sync、NonfairSync、FairSync三个类,NonfairSync与FairSync类继承自Sync类,Sync类继承自AbstractQueuedSynchronizer抽象类。下面逐个进行分析。
内部类:Sync
abstract static class Sync extends AbstractQueuedSynchronizer {
// 序列号
private static final long serialVersionUID = -5179523762034025860L;
// 获取锁
abstract void lock();
// 非公平方式获取
final boolean nonfairTryAcquire(int acquires) {
// 当前线程
final Thread current = Thread.currentThread();
// 获取状态
int c = getState();
if (c == 0) { // 表示没有线程正在竞争该锁
if (compareAndSetState(0, acquires)) { // 比较并设置状态成功,状态0表示锁没有被占用
// 设置当前线程独占
setExclusiveOwnerThread(current);
return true; // 成功
}
}
else if (current == getExclusiveOwnerThread()) { // 当前线程拥有该锁
int nextc = c + acquires; // 增加重入次数
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
// 设置状态
setState(nextc);
// 成功
return true;
}
// 失败
return false;
}
// 试图在共享模式下获取对象状态,此方法应该查询是否允许它在共享模式下获取对象状态,如果允许,则获取它
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread()) // 当前线程不为独占线程
throw new IllegalMonitorStateException(); // 抛出异常
// 释放标识
boolean free = false;
if (c == 0) {
free = true;
// 已经释放,清空独占
setExclusiveOwnerThread(null);
}
// 设置标识
setState(c);
return free;
}
// 判断资源是否被当前线程占有
protected final boolean isHeldExclusively() {
// While we must in general read state before owner,
// we don't need to do so to check if current thread is owner
return getExclusiveOwnerThread() == Thread.currentThread();
}
// 新生一个条件
final ConditionObject newCondition() {
return new ConditionObject();
}
// Methods relayed from outer class
// 返回资源的占用线程
final Thread getOwner() {
return getState() == 0 ? null : getExclusiveOwnerThread();
}
// 返回状态
final int getHoldCount() {
return isHeldExclusively() ? getState() : 0;
}
// 资源是否被占用
final boolean isLocked() {
return getState() != 0;
}
/**
* Reconstitutes the instance from a stream (that is, deserializes it).
*/
// 自定义反序列化逻辑
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
s.defaultReadObject();
setState(0); // reset to unlocked state
}
}
其中的方法及作用如下:
内部类:NonfairSync
NonfairSync类继承了Sync类,表示采用非公平策略获取锁,其实现了Sync类中抽象的lock方法,源码如下:
// 非公平锁
static final class NonfairSync extends Sync {
// 版本号
private static final long serialVersionUID = 7316153563782823691L;
// 获得锁
final void lock() {
if (compareAndSetState(0, 1)) // 比较并设置状态成功,状态0表示锁没有被占用
// 把当前线程设置独占了锁
setExclusiveOwnerThread(Thread.currentThread());
else // 锁已经被占用,或者set失败
// 以独占模式获取对象,忽略中断
acquire(1);
}
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
}
从lock方法的源码可知,每一次都尝试获取锁,而并不会按照公平等待的原则进行等待,让等待时间最久的线程获得锁。
内部类:FairSync
FairSync类也继承了Sync类,表示采用公平策略获取锁,其实现了Sync类中的抽象lock方法,源码如下:
// 公平锁
static final class FairSync extends Sync {
// 版本序列化
private static final long serialVersionUID = -3000897897090466540L;
final void lock() {
// 以独占模式获取对象,忽略中断
acquire(1);
}
/**
* Fair version of tryAcquire. Don't grant access unless
* recursive call or no waiters or is first.
*/
// 尝试公平获取锁
protected final boolean tryAcquire(int acquires) {
// 获取当前线程
final Thread current = Thread.currentThread();
// 获取状态
int c = getState();
if (c == 0) { // 状态为0
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) { // 不存在已经等待更久的线程并且比较并且设置状态成功
// 设置当前线程独占
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) { // 状态不为0,即资源已经被线程占据
// 下一个状态
int nextc = c + acquires;
if (nextc < 0) // 超过了int的表示范围
throw new Error("Maximum lock count exceeded");
// 设置状态
setState(nextc);
return true;
}
return false;
}
}
当资源空闲时,它总是会先判断sync队列(AbstractQueuedSynchronizer中的数据结构)是否有等待时间更长的线程,如果存在,则将该线程加入到等待队列的尾部,实现了公平获取原则。
其中,FairSync类的lock的方法调用如下,只给出了主要的方法。
可以看出只要资源被其他线程占用,该线程就会添加到sync queue中的尾部,而不会先尝试获取资源。这也是和Nonfair最大的区别,Nonfair每一次都会尝试去获取资源,如果此时该资源恰好被释放,则会被当前线程获取,这就造成了不公平的现象,当获取不成功,再加入队列尾部。
类的属性
ReentrantLock类的sync非常重要,对ReentrantLock类的操作大部分都直接转化为对Sync和AQS类的操作。
public class ReentrantLock implements Lock, java.io.Serializable {
// 序列号
private static final long serialVersionUID = 7373984872572414699L;
// 同步队列
private final Sync sync;
}
构造函数
- ReentrantLock()型构造函数:默认采用非公平策略获取锁
- ReentrantLock(boolean)型构造函数:true 表示采用公平策略获取锁,否则采用非公平策略
核心函数
通过分析ReentrantLock的源码,可知对其操作都转化为对Sync对象的操作,由于Sync继承了AQS,所以基本上都可以转化为对AQS的操作。如将ReentrantLock的lock函数转化为对Sync的lock函数的调用,而具体会根据采用的策略(如公平策略或者非公平策略)的不同而调用到Sync的不同子类。
应用示例
公平锁
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
class MyThread extends Thread {
private Lock lock;
public MyThread(String name, Lock lock) {
super(name);
this.lock = lock;
}
public void run () {
lock.lock();
try {
System.out.println(Thread.currentThread() + " running");
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
} finally {
lock.unlock();
}
}
}
public class AbstractQueuedSynchonizerDemo {
public static void main(String[] args) throws InterruptedException {
Lock lock = new ReentrantLock(true);
MyThread t1 = new MyThread("t1", lock);
MyThread t2 = new MyThread("t2", lock);
MyThread t3 = new MyThread("t3", lock);
t1.start();
t2.start();
t3.start();
}
}
// 随机结果
Thread[t1,5,main] running
Thread[t2,5,main] running
Thread[t3,5,main] running
该示例使用的是公平策略,由结果可知,可能会存在如下一种时序。
首先,t1线程的lock操作 -> t2线程的lock操作 -> t3线程的lock操作 -> t1线程的unlock操作 -> t2线程的unlock操作 -> t3线程的unlock操作。根据这个时序图来进一步分析源码的工作流程。
- t1线程执行lock.lock,下图给出了方法调用中的主要方法。
由调用流程可知,t1线程成功获取了资源,可以继续执行。
- t2线程执行lock.lock,下图给出了方法调用中的主要方法。
由上图可知,最后的结果是t2线程会被禁止,因为调用了LockSupport.park。
- t3线程执行lock.lock,下图给出了方法调用中的主要方法。
由上图可知,最后的结果是t3线程会被禁止,因为调用了LockSupport.park。
- t1线程调用了lock.unlock,下图给出了方法调用中的主要方法。
如上图所示,最后,head的状态会变为0,t2线程会被unpark,即t2线程可以继续运行。此时t3线程还是被禁止。
- t2获得cpu资源,继续运行,由于t2之前被park了,现在需要恢复之前的状态,下图给出了方法调用中的主要方法。
在setHead函数中会将head设置为之前head的下一个结点,并且将pre域与thread域都设置为null,在acquireQueued返回之前,sync queue就只有两个结点了。
- t2执行lock.unlock,下图给出了方法调用中的主要方法。
由上图可知,最终unpark t3线程,让t3线程可以继续运行。
- t3线程获取cpu资源,恢复之前的状态,继续运行。
最终达到的状态是sync queue中只剩下了一个结点,并且该节点除了状态为0外,其余均为null。
- t3执行lock.unlock,下图给出了方法调用中的主要方法。
最后的状态和之前的状态是一样的,队列中有一个空节点,头结点为尾节点均指向它。
使用公平策略和Condition的情况可以参考上一篇关于AQS的源码示例分析部分,不再累赘。
3.16 - CH16-ReentrantReadWriteLock
数据结构
其实现是基于 ReentrantLock 和 AQS,因此底层基于 AQS 的数据结构。
源码分析
层级结构
- ReentrantReadWriteLock 实现了 ReadWriteLock 接口,ReadWriteLock 接口定义了获取读锁和写锁的规范,需要实现类来提供具体实现;
- 同时实现了 Serializable 接口,表示可以进行序列化。
内部类
内部有 5 个类,5 个内部类之间互相关联,关系如下:
内部类:Sync
Sync 直接继承了 AQS,它的内部又有两个内部类,分别为 HoldCounter 和 ThreadLocalHoldCounter,其中 HoldCounter 主要与读锁配套使用。
HoldCounter 源码如下:
// 计数器
static final class HoldCounter {
// 计数
int count = 0;
// Use id, not reference, to avoid garbage retention
// 获取当前线程的TID属性的值
final long tid = getThreadId(Thread.currentThread());
}
- count 表示某个读线程重入的次数
- tid 表示该线程的 tid 字段值,线程的唯一标识
ThreadLocalHoldCounter 源码如下:
// 本地线程计数器
static final class ThreadLocalHoldCounter
extends ThreadLocal<HoldCounter> {
// 重写初始化方法,在没有进行set的情况下,获取的都是该HoldCounter值
public HoldCounter initialValue() {
return new HoldCounter();
}
}
ThreadLocalHoldCounter 重写了 ThreadLocal 的 initialValue 方法,ThreadLocal 类可以将线程与对象进行关联。在没有执行 set 的情况下,get 到的均为 initialValue 方法中生成的 HolderCounter 对象。
Sync 类的属性:
abstract static class Sync extends AbstractQueuedSynchronizer {
// 版本序列号
private static final long serialVersionUID = 6317671515068378041L;
// 高16位为读锁,低16位为写锁
static final int SHARED_SHIFT = 16;
// 读锁单位
static final int SHARED_UNIT = (1 << SHARED_SHIFT);
// 读锁最大数量
static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1;
// 写锁最大数量
static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1;
// 本地线程计数器
private transient ThreadLocalHoldCounter readHolds;
// 缓存的计数器
private transient HoldCounter cachedHoldCounter;
// 第一个读线程
private transient Thread firstReader = null;
// 第一个读线程的计数
private transient int firstReaderHoldCount;
}
- 属性中包括了读锁和写锁线程的最大数量、本地线程计数器等。
Sync 类的构造函数:
// 构造函数
Sync() {
// 本地线程计数器
readHolds = new ThreadLocalHoldCounter();
// 设置AQS的状态
setState(getState()); // ensures visibility of readHolds
}
- 在 Sync 类的构造函数中设置了本地线程计数器和 AQS 的状态 state。
内部类:Sync 核心函数
ReentrantReadWriteLock 的大部分操作都会交由 Sync 对象执行。以下是 Sync 的主要函数:
sharedCount:
- 表示占有读锁的线程数量
static int sharedCount(int c) { return c >>> SHARED_SHIFT; }- 直接将 state 右移 16 位,就可以得到读锁的线程数量,因为 state 的高 16 位表示读锁,低 16 位表示写锁的线程数量。
exclusiveCount:
- 表示占有写锁的线程数量
static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK; }- 直接将 state 和
(2^16 - 1) 做与运算,等效于将 state 模上 2^16,写锁线程数量由低 16 位表示。
tryRelease:
/*
* Note that tryRelease and tryAcquire can be called by
* Conditions. So it is possible that their arguments contain
* both read and write holds that are all released during a
* condition wait and re-established in tryAcquire.
*/
protected final boolean tryRelease(int releases) {
// 判断是否伪独占线程
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
// 计算释放资源后的写锁的数量
int nextc = getState() - releases;
boolean free = exclusiveCount(nextc) == 0; // 是否释放成功
if (free)
setExclusiveOwnerThread(null); // 设置独占线程为空
setState(nextc); // 设置状态
return free;
}
- 用于释放写锁资源,首先会判断该线程是否为独占线程,如果不是独占线程,则抛出异常;否则,计算释放资源后的写锁数量,如果为 0 则表示释放成功,资源不再被占用,否则表示资源仍被占用。
tryAcquire:
protected final boolean tryAcquire(int acquires) {
/*
* Walkthrough:
* 1. If read count nonzero or write count nonzero
* and owner is a different thread, fail.
* 2. If count would saturate, fail. (This can only
* happen if count is already nonzero.)
* 3. Otherwise, this thread is eligible for lock if
* it is either a reentrant acquire or
* queue policy allows it. If so, update state
* and set owner.
*/
// 获取当前线程
Thread current = Thread.currentThread();
// 获取状态
int c = getState();
// 写线程数量
int w = exclusiveCount(c);
if (c != 0) { // 状态不为0
// (Note: if c != 0 and w == 0 then shared count != 0)
if (w == 0 || current != getExclusiveOwnerThread()) // 写线程数量为0或者当前线程没有占有独占资源
return false;
if (w + exclusiveCount(acquires) > MAX_COUNT) // 判断是否超过最高写线程数量
throw new Error("Maximum lock count exceeded");
// Reentrant acquire
// 设置AQS状态
setState(c + acquires);
return true;
}
if (writerShouldBlock() ||
!compareAndSetState(c, c + acquires)) // 写线程是否应该被阻塞
return false;
// 设置独占线程
setExclusiveOwnerThread(current);
return true;
}
用于获取写锁。首先获取 state,判断如果为 0 表示此时没有读锁线程,再判断写线程是否应该被阻塞,而在非公平策略下总是不会被阻塞,在公平策略下会进行判断(判断同步队列中是否已有等待时间更长的线程,存在则被阻塞,否则无需组织),之后设置状态 state 并返回 true。
如果 state 不为 0,表示此时存在读锁或写锁线程,弱写锁线程数量为 0 或当前线程为独占锁线程则返回 false,表示不成功。否则,判断写线程的重入次数是否大于了最大值,若是则抛出异常,否则设置状态 state 并返回 true,表示成功。
tryReleaseShared:
protected final boolean tryReleaseShared(int unused) {
// 获取当前线程
Thread current = Thread.currentThread();
if (firstReader == current) { // 当前线程为第一个读线程
// assert firstReaderHoldCount > 0;
if (firstReaderHoldCount == 1) // 读线程占用的资源数为1
firstReader = null;
else // 减少占用的资源
firstReaderHoldCount--;
} else { // 当前线程不为第一个读线程
// 获取缓存的计数器
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current)) // 计数器为空或者计数器的tid不为当前正在运行的线程的tid
// 获取当前线程对应的计数器
rh = readHolds.get();
// 获取计数
int count = rh.count;
if (count <= 1) { // 计数小于等于1
// 移除
readHolds.remove();
if (count <= 0) // 计数小于等于0,抛出异常
throw unmatchedUnlockException();
}
// 减少计数
--rh.count;
}
for (;;) { // 无限循环
// 获取状态
int c = getState();
// 获取状态
int nextc = c - SHARED_UNIT;
if (compareAndSetState(c, nextc)) // 比较并进行设置
// Releasing the read lock has no effect on readers,
// but it may allow waiting writers to proceed if
// both read and write locks are now free.
return nextc == 0;
}
}
此函数表示读锁线程释放锁。首先判断当前线程是否为第一个读线程 firstReader,若是,则判断第一个读线程占有的资源数 firstReaderHoldCount 是否为 1,若是,则设置第一个读线程 firstReader 为空,否则,将第一个读线程占有的资源数 firstReaderHoldCount 减1;若当前线程不是第一个读线程,那么首先会获取缓存计数器(上一个读锁线程对应的计数器 ),若计数器为空或者 tid 不等于当前线程的 tid 值,则获取当前线程的计数器,如果计数器的计数 count 小于等于1,则移除当前线程对应的计数器,如果计数器的计数 count 小于等于 0,则抛出异常,之后再减少计数即可。无论何种情况,都会进入无限循环,该循环可以确保成功设置状态 state。
tryAcquireShared
private IllegalMonitorStateException unmatchedUnlockException() {
return new IllegalMonitorStateException(
"attempt to unlock read lock, not locked by current thread");
}
// 共享模式下获取资源
protected final int tryAcquireShared(int unused) {
/*
* Walkthrough:
* 1. If write lock held by another thread, fail.
* 2. Otherwise, this thread is eligible for
* lock wrt state, so ask if it should block
* because of queue policy. If not, try
* to grant by CASing state and updating count.
* Note that step does not check for reentrant
* acquires, which is postponed to full version
* to avoid having to check hold count in
* the more typical non-reentrant case.
* 3. If step 2 fails either because thread
* apparently not eligible or CAS fails or count
* saturated, chain to version with full retry loop.
*/
// 获取当前线程
Thread current = Thread.currentThread();
// 获取状态
int c = getState();
if (exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current) // 写线程数不为0并且占有资源的不是当前线程
return -1;
// 读锁数量
int r = sharedCount(c);
if (!readerShouldBlock() &&
r < MAX_COUNT &&
compareAndSetState(c, c + SHARED_UNIT)) { // 读线程是否应该被阻塞、并且小于最大值、并且比较设置成功
if (r == 0) { // 读锁数量为0
// 设置第一个读线程
firstReader = current;
// 读线程占用的资源数为1
firstReaderHoldCount = 1;
} else if (firstReader == current) { // 当前线程为第一个读线程
// 占用资源数加1
firstReaderHoldCount++;
} else { // 读锁数量不为0并且不为当前线程
// 获取计数器
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current)) // 计数器为空或者计数器的tid不为当前正在运行的线程的tid
// 获取当前线程对应的计数器
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0) // 计数为0
// 设置
readHolds.set(rh);
rh.count++;
}
return 1;
}
return fullTryAcquireShared(current);
}
此函数表示读锁线程获取读锁。首先判断写锁是否为 0 并且当前线程不占有独占锁,直接返回;否则,判断读线程是否需要被阻塞并且读锁数量是否小于最大值并且比较设置状态成功,若当前没有读锁,则设置第一个读线程 firstReade r和 firstReaderHoldCount;若当前线程线程为第一个读线程,则增加 firstReaderHoldCount;否则,将设置当前线程对应的 HoldCounter 对象的值。
fullTryAcquireShared
final int fullTryAcquireShared(Thread current) {
/*
* This code is in part redundant with that in
* tryAcquireShared but is simpler overall by not
* complicating tryAcquireShared with interactions between
* retries and lazily reading hold counts.
*/
HoldCounter rh = null;
for (;;) { // 无限循环
// 获取状态
int c = getState();
if (exclusiveCount(c) != 0) { // 写线程数量不为0
if (getExclusiveOwnerThread() != current) // 不为当前线程
return -1;
// else we hold the exclusive lock; blocking here
// would cause deadlock.
} else if (readerShouldBlock()) { // 写线程数量为0并且读线程被阻塞
// Make sure we're not acquiring read lock reentrantly
if (firstReader == current) { // 当前线程为第一个读线程
// assert firstReaderHoldCount > 0;
} else { // 当前线程不为第一个读线程
if (rh == null) { // 计数器不为空
//
rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current)) { // 计数器为空或者计数器的tid不为当前正在运行的线程的tid
rh = readHolds.get();
if (rh.count == 0)
readHolds.remove();
}
}
if (rh.count == 0)
return -1;
}
}
if (sharedCount(c) == MAX_COUNT) // 读锁数量为最大值,抛出异常
throw new Error("Maximum lock count exceeded");
if (compareAndSetState(c, c + SHARED_UNIT)) { // 比较并且设置成功
if (sharedCount(c) == 0) { // 读线程数量为0
// 设置第一个读线程
firstReader = current;
//
firstReaderHoldCount = 1;
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
if (rh == null)
rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
cachedHoldCounter = rh; // cache for release
}
return 1;
}
}
}
在 tryAcquireShared 函数中,如果下列三个条件不满足(读线程是否应该被阻塞、小于最大值、比较设置成功)则会进行 fullTryAcquireShared 函数中,它用来保证相关操作可以成功。其逻辑与 tryAcquireShared 逻辑类似,不再累赘。
而其他内部类的操作基本上都是转化到了对Sync对象的操作,在此不再累赘。
类属性
public class ReentrantReadWriteLock
implements ReadWriteLock, java.io.Serializable {
// 版本序列号
private static final long serialVersionUID = -6992448646407690164L;
// 读锁
private final ReentrantReadWriteLock.ReadLock readerLock;
// 写锁
private final ReentrantReadWriteLock.WriteLock writerLock;
// 同步队列
final Sync sync;
private static final sun.misc.Unsafe UNSAFE;
// 线程ID的偏移地址
private static final long TID_OFFSET;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> tk = Thread.class;
// 获取线程的tid字段的内存地址
TID_OFFSET = UNSAFE.objectFieldOffset
(tk.getDeclaredField("tid"));
} catch (Exception e) {
throw new Error(e);
}
}
}
类的构造函数
- ReentrantReadWriteLock()
- ReentrantReadWriteLock(boolean)
类的核心函数
对ReentrantReadWriteLock的操作基本上都转化为了对Sync对象的操作。
应用示例
import java.util.concurrent.locks.ReentrantReadWriteLock;
class ReadThread extends Thread {
private ReentrantReadWriteLock rrwLock;
public ReadThread(String name, ReentrantReadWriteLock rrwLock) {
super(name);
this.rrwLock = rrwLock;
}
public void run() {
System.out.println(Thread.currentThread().getName() + " trying to lock");
try {
rrwLock.readLock().lock();
System.out.println(Thread.currentThread().getName() + " lock successfully");
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
rrwLock.readLock().unlock();
System.out.println(Thread.currentThread().getName() + " unlock successfully");
}
}
}
class WriteThread extends Thread {
private ReentrantReadWriteLock rrwLock;
public WriteThread(String name, ReentrantReadWriteLock rrwLock) {
super(name);
this.rrwLock = rrwLock;
}
public void run() {
System.out.println(Thread.currentThread().getName() + " trying to lock");
try {
rrwLock.writeLock().lock();
System.out.println(Thread.currentThread().getName() + " lock successfully");
} finally {
rrwLock.writeLock().unlock();
System.out.println(Thread.currentThread().getName() + " unlock successfully");
}
}
}
public class ReentrantReadWriteLockDemo {
public static void main(String[] args) {
ReentrantReadWriteLock rrwLock = new ReentrantReadWriteLock();
ReadThread rt1 = new ReadThread("rt1", rrwLock);
ReadThread rt2 = new ReadThread("rt2", rrwLock);
WriteThread wt1 = new WriteThread("wt1", rrwLock);
rt1.start();
rt2.start();
wt1.start();
}
}
rt1 trying to lock
rt2 trying to lock
wt1 trying to lock
rt1 lock successfully
rt2 lock successfully
rt1 unlock successfully
rt2 unlock successfully
wt1 lock successfully
wt1 unlock successfully
程序中生成了一个ReentrantReadWriteLock对象,并且设置了两个读线程,一个写线程。根据结果,可能存在如下的时序图。
rt1 线程执行 rrwLock.readLock().lock 操作的调用链路:
此时 AQS 的状态 state 为 2^16,表示当前读线程数量为 1。
rt2 线程执行 rrwLock.readLock().lock 操作,主要的函数调用如下:
此时,在同步队列 Sync queue 中存在两个结点,并且 wt1 线程会被禁止运行。
rt1 线程执行 rrwLock.readLock().unlock 操作,主要的函数调用如下:
此时,AQS的state为2^16次方,表示还有一个读线程。
rt2 线程执行 rrwLock.readLock().unlock 操作,主要的函数调用如下:
当 rt2 线程执行 unlock 操作后,AQS 的 state 为 0,并且 wt1 线程将会被 unpark,其获得 CPU 资源就可以运行。
wt1线程获得CPU资源,继续运行,需要恢复。由于之前acquireQueued函数中的parkAndCheckInterrupt函数中被禁止的,所以,恢复到parkAndCheckInterrupt函数中,主要的函数调用如下:
最后,sync queue 队列中只有一个结点,并且头结点尾节点均指向它,AQS 的 state 值为 1,表示此时有一个写线程。
wt1 执行 rrwLock.writeLock().unlock 操作,主要的函数调用如下:
此时,AQS 的 state 为 0,表示没有任何读线程或者写线程了。并且 Sync queue 结构与上一个状态的结构相同,没有变化。
深入理解
什么是锁升级、降级
锁降级指的是写锁降级成为读锁。如果当前线程拥有写锁,然后将其释放,最后再获取读锁,这种分段完成的过程不能称之为锁降级。
锁降级是指把持住(当前拥有的)写锁,再获取到读锁,随后释放(先前拥有的)写锁的过程。
因为数据不常变化,所以多个线程可以并发地进行数据处理,当数据变更后,如果当前线程感知到数据变化,则进行数据的准备工作,同时其他处理线程被阻塞,直到当前线程完成数据的准备工作,如代码如下所示:
public void processData() {
readLock.lock();
if (!update) {
// 必须先释放读锁
readLock.unlock();
// 锁降级从写锁获取到开始
writeLock.lock();
try {
if (!update) {
// 准备数据的流程(略)
update = true;
}
readLock.lock();
} finally {
writeLock.unlock();
}
// 锁降级完成,写锁降级为读锁
}
try {
// 使用数据的流程(略)
} finally {
readLock.unlock();
}
}
上述示例中,当数据发生变更后,update 变量(布尔类型且volatile修饰)被设置为 false,此时所有访问 processData() 方法的线程都能够感知到变化,但只有一个线程能够获取到写锁,其他线程会被阻塞在读锁和写锁的 lock() 方法上。当前线程获取写锁完成数据准备之后,再获取读锁,随后释放写锁,完成锁降级。
锁降级中读锁的获取是否必要呢? 答案是必要的。主要是为了保证数据的可见性,如果当前线程不获取读锁而是直接释放写锁,假设此刻另一个线程(记作线程T)获取了写锁并修改了数据,那么当前线程无法感知线程T的数据更新。如果当前线程获取读锁,即遵循锁降级的步骤,则线程T将会被阻塞,直到当前线程使用数据并释放读锁之后,线程T才能获取写锁进行数据更新。
RentrantReadWriteLock不支持锁升级(把持读锁、获取写锁,最后释放读锁的过程)。目的也是保证数据可见性,如果读锁已被多个线程获取,其中任意线程成功获取了写锁并更新了数据,则其更新对其他获取到读锁的线程是不可见的。
3.17 - CH17-ConcurrentHashMap
HashTable 为什么慢
Hashtable 之所以效率低下主要是因为其实现使用了 synchronized 关键字对 put 等操作进行加锁,而 synchronized 关键字加锁是对整个对象示例进行加锁,也就是说在进行 put 等修改 Hash 表的操作时,锁住了整个 Hash 表,从而使得其表现的效率低下。
JDK 1.7-ConcurrentHashMap
在 JDK 1.5~1.7 版本,Java 使用了分段锁机制实现 ConcurrentHashMap。
简而言之,ConcurrentHashMap 在对象中保存了一个 Segment 数组,即将整个 Hash 表划分为多个分段;
而每个 Segment 元素,即每个分段则类似于一个 Hashtable;
这样,在执行 put 操作时首先根据 hash 算法定位到元素属于哪个 Segment,然后对该 Segment 加锁即可。
因此,ConcurrentHashMap 在多线程并发编程中可是实现多线程 put 操作。
数据结构
整个 ConcurrentHashMap 由一个个 Segment 组成,Segment 代表”部分“或”一段“的意思,所以很多地方都会将其描述为分段锁。注意,行文中,我很多地方用了“槽”来代表一个 segment。
简单理解就是,ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
- concurrencyLevel:并行级别、Segment 数量。
- 默认为 16,即拥有 16 个 segments,理论上同时支持 16 个线程并发写,只要它们的操作分布在不同的 Segment 上。
- 该值可以在初始化时设定为其他值,但是一点设置不可修改。
- 每个 Segment 内部类似于 HashMap,但通过继承 ReentrantLock 来保证线程安全。
初始化
- initialCapacity: 初始容量,这个值指的是整个 ConcurrentHashMap 的初始容量,实际操作的时候需要平均分给每个 Segment。
- loadFactor: 负载因子,之前我们说了,Segment 数量不可变,所以这个负载因子是给每个 Segment 内部使用的。
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
// 计算并行级别 ssize,因为要保持并行级别是 2 的 n 次方
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// 我们这里先不要那么烧脑,用默认值,concurrencyLevel 为 16,sshift 为 4
// 那么计算出 segmentShift 为 28,segmentMask 为 15,后面会用到这两个值
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// initialCapacity 是设置整个 map 初始的大小,
// 这里根据 initialCapacity 计算 Segment 数组中每个位置可以分到的大小
// 如 initialCapacity 为 64,那么每个 Segment 或称之为"槽"可以分到 4 个
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
// 默认 MIN_SEGMENT_TABLE_CAPACITY 是 2,这个值也是有讲究的,因为这样的话,对于具体的槽上,
// 插入一个元素不至于扩容,插入第二个的时候才会扩容
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// 创建 Segment 数组,
// 并创建数组的第一个元素 segment[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
// 往数组写入 segment[0]
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
当使用无参构造器创建 ConcurrentHashMap 实例时,初始化完成后的状态如下:
- Segment 数组长度为 16,不可以扩容
Segment[i] 的默认大小为 2,负载因子是 0.75,得出初始阈值为 1.5,也就是以后插入第一个元素不会触发扩容,插入第二个会进行第一次扩容- 这里初始化了
segment[0],其他位置还是 null,至于为什么要初始化 segment[0],后面的代码会介绍 - 当前 segmentShift 的值为 32 - 4 = 28,segmentMask 为 16 - 1 = 15,姑且把它们简单翻译为移位数和掩码,这两个值马上就会用到
put 过程分析
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
// 1. 计算 key 的 hash 值
int hash = hash(key);
// 2. 根据 hash 值找到 Segment 数组中的位置 j
// hash 是 32 位,无符号右移 segmentShift(28) 位,剩下高 4 位,
// 然后和 segmentMask(15) 做一次与操作,也就是说 j 是 hash 值的高 4 位,也就是槽的数组下标
int j = (hash >>> segmentShift) & segmentMask;
// 刚刚说了,初始化的时候初始化了 segment[0],但是其他位置还是 null,
// ensureSegment(j) 对 segment[j] 进行初始化
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
// 3. 插入新值到 槽 s 中
return s.put(key, hash, value, false);
}
第一层操作较简单,基于 hash 值找到对应的 segment,之后执行 segment 内部的 put 操作。
Segment 内部由 数组+链表 构成:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 在往该 segment 写入前,需要先获取该 segment 的独占锁
// 先看主流程,后面还会具体介绍这部分内容
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
// 这个是 segment 内部的数组
HashEntry<K,V>[] tab = table;
// 再利用 hash 值,求应该放置的数组下标
int index = (tab.length - 1) & hash;
// first 是数组该位置处的链表的表头
HashEntry<K,V> first = entryAt(tab, index);
// 下面这串 for 循环虽然很长,不过也很好理解,想想该位置没有任何元素和已经存在一个链表这两种情况
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
// 覆盖旧值
e.value = value;
++modCount;
}
break;
}
// 继续顺着链表走
e = e.next;
}
else {
// node 到底是不是 null,这个要看获取锁的过程,不过和这里都没有关系。
// 如果不为 null,那就直接将它设置为链表表头;如果是null,初始化并设置为链表表头。
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// 如果超过了该 segment 的阈值,这个 segment 需要扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node); // 扩容后面也会具体分析
else
// 没有达到阈值,将 node 放到数组 tab 的 index 位置,
// 其实就是将新的节点设置成原链表的表头
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
// 解锁
unlock();
}
return oldValue;
}
由于有独占锁的保护,所以 segment 内部的操作并不复杂。
下面为其中的关键函数:
初始化槽:ensureSegment
ConcurrentHashMap 初始化的时候会初始化第一个槽 segment[0],对于其他槽来说,在插入第一个值的时候才进行初始化。
这里需要考虑并发,因为很可能会有多个线程同时进来初始化同一个槽 segment[k],不过只要有一个成功了就可以。
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
// 这里看到为什么之前要初始化 segment[0] 了,
// 使用当前 segment[0] 处的数组长度和负载因子来初始化 segment[k]
// 为什么要用“当前”,因为 segment[0] 可能早就扩容过了
Segment<K,V> proto = ss[0];
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
// 初始化 segment[k] 内部的数组
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) { // 再次检查一遍该槽是否被其他线程初始化了。
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
// 使用 while 循环,内部用 CAS,当前线程成功设值或其他线程成功设值后,退出
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
对于并发操作使用 CAS 进行控制。
获取写入锁: scanAndLockForPut
在往某个 segment 中 put 的时候,首先会调用 node = tryLock() ? null : scanAndLockForPut(key, hash, value),也就是说先进行一次 tryLock() 快速获取该 segment 的独占锁,如果失败,那么进入到 scanAndLockForPut 这个方法来获取锁。
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
// 循环获取锁
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
// 进到这里说明数组该位置的链表是空的,没有任何元素
// 当然,进到这里的另一个原因是 tryLock() 失败,所以该槽存在并发,不一定是该位置
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
// 顺着链表往下走
e = e.next;
}
// 重试次数如果超过 MAX_SCAN_RETRIES(单核1多核64),那么不抢了,进入到阻塞队列等待锁
// lock() 是阻塞方法,直到获取锁后返回
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
// 这个时候是有大问题了,那就是有新的元素进到了链表,成为了新的表头
// 所以这边的策略是,相当于重新走一遍这个 scanAndLockForPut 方法
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
这个方法有两个出口,一个是 tryLock() 成功了,循环终止,另一个就是重试次数超过了 MAX_SCAN_RETRIES,进到 lock() 方法,此方法会阻塞等待,直到成功拿到独占锁。
这个方法就是看似复杂,但是其实就是做了一件事,那就是获取该 segment 的独占锁,如果需要的话顺便实例化了一下 node。
扩容:rehash
segment 数组不能扩容,扩容是 segment 数组某个位置内部的数组 HashEntry<K,V>[] 进行扩容,扩容后,容量为原来的 2 倍。
执行 put 时,如果判断该值的插入会导致 segment 的元素个数超过阈值,需要先扩容再插入。
因为这时已经持有了 segment 的独占锁,因此无需再考虑并发:
// 方法参数上的 node 是这次扩容后,需要添加到新的数组中的数据。
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
// 2 倍
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
// 创建新数组
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
// 新的掩码,如从 16 扩容到 32,那么 sizeMask 为 31,对应二进制 ‘000...00011111’
int sizeMask = newCapacity - 1;
// 遍历原数组,老套路,将原数组位置 i 处的链表拆分到 新数组位置 i 和 i+oldCap 两个位置
for (int i = 0; i < oldCapacity ; i++) {
// e 是链表的第一个元素
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
// 计算应该放置在新数组中的位置,
// 假设原数组长度为 16,e 在 oldTable[3] 处,那么 idx 只可能是 3 或者是 3 + 16 = 19
int idx = e.hash & sizeMask;
if (next == null) // 该位置处只有一个元素,那比较好办
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
// e 是链表表头
HashEntry<K,V> lastRun = e;
// idx 是当前链表的头结点 e 的新位置
int lastIdx = idx;
// 下面这个 for 循环会找到一个 lastRun 节点,这个节点之后的所有元素是将要放到一起的
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
// 将 lastRun 及其之后的所有节点组成的这个链表放到 lastIdx 这个位置
newTable[lastIdx] = lastRun;
// 下面的操作是处理 lastRun 之前的节点,
// 这些节点可能分配在另一个链表中,也可能分配到上面的那个链表中
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
// 将新来的 node 放到新数组中刚刚的 两个链表之一 的 头部
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
扩容过程中有两个 for 循环。如果没有第一个 for 循环也是可以工作的,但是在首个 for 循环中,如果 lastRun 的后面还有比较多的节点,那么首次循环就值得。因为我们要克隆 lastRun 前面的节点,后面的一串节点跟着 lastRun 走就可以了,无需其他操作。
比较坏的情况是每次 lastRun 都是链表的最后一个元素或者很靠后的元素,那么就会比较浪费。基于 Doug Lea 的说法,如果使用默认的阈值,大约只有 1/6 的节点需要克隆。
get 过程分析
- 计算 hash 值,找到 segment 的数组下标,得到 segment
- segment 中也是一个数组,根据 hash 找到数据中的位置
- 得到链表,顺着链表查找即可
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
// 1. hash 值
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// 2. 根据 hash 找到对应的 segment
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
// 3. 找到segment 内部数组相应位置的链表,遍历
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
并发问题分析
JDK 1.8-ConcurrentHashMap
在 JDK 1.7 之前,ConcurrentHashMap 是通过分段锁机制来实现的,所以其最大并发度受 Segment 的个数限制。因此,在 JDK1.8 中,ConcurrentHashMap 的实现原理摒弃了这种设计,而是选择了与 HashMap 类似的数组+链表+红黑树的方式实现,而加锁则采用 CAS 和 synchronized 实现。
数据结构
初始化
// 这构造函数里,什么都不干
public ConcurrentHashMap() {
}
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
通过提供的初始容量,计算了 sizeCtl,sizeCtl = 【 (1.5 * initialCapacity + 1),然后向上取最近的 2 的 n 次方】,如果 initialCapacity 为 10,那么得到 sizeCtl 为 16,如果 initialCapacity 为 11,sizeCtl 为 32。
put 过程分析
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 得到 hash 值
int hash = spread(key.hashCode());
// 用于记录相应链表的长度
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果数组"空",进行数组初始化
if (tab == null || (n = tab.length) == 0)
// 初始化数组,后面会详细介绍
tab = initTable();
// 找该 hash 值对应的数组下标,得到第一个节点 f
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 如果数组该位置为空,
// 用一次 CAS 操作将这个新值放入其中即可,这个 put 操作差不多就结束了,可以拉到最后面了
// 如果 CAS 失败,那就是有并发操作,进到下一个循环就好了
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// hash 居然可以等于 MOVED,这个需要到后面才能看明白,不过从名字上也能猜到,肯定是因为在扩容
else if ((fh = f.hash) == MOVED)
// 帮助数据迁移,这个等到看完数据迁移部分的介绍后,再理解这个就很简单了
tab = helpTransfer(tab, f);
else { // 到这里就是说,f 是该位置的头结点,而且不为空
V oldVal = null;
// 获取数组该位置的头结点的监视器锁
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) { // 头结点的 hash 值大于 0,说明是链表
// 用于累加,记录链表的长度
binCount = 1;
// 遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果发现了"相等"的 key,判断是否要进行值覆盖,然后也就可以 break 了
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 到了链表的最末端,将这个新值放到链表的最后面
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) { // 红黑树
Node<K,V> p;
binCount = 2;
// 调用红黑树的插值方法插入新节点
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 判断是否要将链表转换为红黑树,临界值和 HashMap 一样,也是 8
if (binCount >= TREEIFY_THRESHOLD)
// 这个方法和 HashMap 中稍微有一点点不同,那就是它不是一定会进行红黑树转换,
// 如果当前数组的长度小于 64,那么会选择进行数组扩容,而不是转换为红黑树
// 具体源码我们就不看了,扩容部分后面说
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//
addCount(1L, binCount);
return null;
}
初始化数组:initTable
初始化一个合适大小的数组,然后会设置 sizeCtl。初始化方法中的并发问题通过对 sizeCtl 执行一个 CAS 操作来控制的。
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// 初始化的"功劳"被其他线程"抢去"了
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// CAS 一下,将 sizeCtl 设置为 -1,代表抢到了锁
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
// DEFAULT_CAPACITY 默认初始容量是 16
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
// 初始化数组,长度为 16 或初始化时提供的长度
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
// 将这个数组赋值给 table,table 是 volatile 的
table = tab = nt;
// 如果 n 为 16 的话,那么这里 sc = 12
// 其实就是 0.75 * n
sc = n - (n >>> 2);
}
} finally {
// 设置 sizeCtl 为 sc,我们就当是 12 吧
sizeCtl = sc;
}
break;
}
}
return tab;
}
链表转红黑树:treeifyBin
treeifyBin 不一定就会进行红黑树转换,也可能是仅仅做数组扩容。
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
// MIN_TREEIFY_CAPACITY 为 64
// 所以,如果数组长度小于 64 的时候,其实也就是 32 或者 16 或者更小的时候,会进行数组扩容
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
// 后面我们再详细分析这个方法
tryPresize(n << 1);
// b 是头结点
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
// 加锁
synchronized (b) {
if (tabAt(tab, index) == b) {
// 下面就是遍历链表,建立一颗红黑树
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
// 将红黑树设置到数组相应位置中
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
扩容:tryPresize
扩容也是做翻倍扩容的,扩容后数组容量为原来的 2 倍。
// 首先要说明的是,方法参数 size 传进来的时候就已经翻了倍了
private final void tryPresize(int size) {
// c: size 的 1.5 倍,再加 1,再往上取最近的 2 的 n 次方。
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);
int sc;
while ((sc = sizeCtl) >= 0) {
Node<K,V>[] tab = table; int n;
// 这个 if 分支和之前说的初始化数组的代码基本上是一样的,在这里,我们可以不用管这块代码
if (tab == null || (n = tab.length) == 0) {
n = (sc > c) ? sc : c;
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = nt;
sc = n - (n >>> 2); // 0.75 * n
}
} finally {
sizeCtl = sc;
}
}
}
else if (c <= sc || n >= MAXIMUM_CAPACITY)
break;
else if (tab == table) {
// 我没看懂 rs 的真正含义是什么,不过也关系不大
int rs = resizeStamp(n);
if (sc < 0) {
Node<K,V>[] nt;
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
// 2. 用 CAS 将 sizeCtl 加 1,然后执行 transfer 方法
// 此时 nextTab 不为 null
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
// 1. 将 sizeCtl 设置为 (rs << RESIZE_STAMP_SHIFT) + 2)
// 我是没看懂这个值真正的意义是什么? 不过可以计算出来的是,结果是一个比较大的负数
// 调用 transfer 方法,此时 nextTab 参数为 null
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
}
}
}
这个方法的核心在于 sizeCtl 值的操作,首先将其设置为一个负数,然后执行 transfer(tab, null),再下一个循环将 sizeCtl 加 1,并执行 transfer(tab, nt),之后可能是继续 sizeCtl 加 1,并执行 transfer(tab, nt)。
所以,可能的操作就是执行 1 次 transfer(tab, null) + 多次 transfer(tab, nt),这里怎么结束循环的需要看完 transfer 源码才清楚。
数据迁移:transfer
将原来的 tab 数组的元素迁移到新的 nextTab 数组中。
虽然我们之前说的 tryPresize 方法中多次调用 transfer 不涉及多线程,但是这个 transfer 方法可以在其他地方被调用,典型地,我们之前在说 put 方法的时候就说过了,请往上看 put 方法,是不是有个地方调用了 helpTransfer 方法,helpTransfer 方法会调用 transfer 方法的。
此方法支持多线程执行,外围调用此方法的时候,会保证第一个发起数据迁移的线程,nextTab 参数为 null,之后再调用此方法的时候,nextTab 不会为 null。
阅读源码之前,先要理解并发操作的机制。原数组长度为 n,所以我们有 n 个迁移任务,让每个线程每次负责一个小任务是最简单的,每做完一个任务再检测是否有其他没做完的任务,帮助迁移就可以了,而 Doug Lea 使用了一个 stride,简单理解就是步长,每个线程每次负责迁移其中的一部分,如每次迁移 16 个小任务。所以,我们就需要一个全局的调度者来安排哪个线程执行哪几个任务,这个就是属性 transferIndex 的作用。
第一个发起数据迁移的线程会将 transferIndex 指向原数组最后的位置,然后从后往前的 stride 个任务属于第一个线程,然后将 transferIndex 指向新的位置,再往前的 stride 个任务属于第二个线程,依此类推。当然,这里说的第二个线程不是真的一定指代了第二个线程,也可以是同一个线程,这个读者应该能理解吧。其实就是将一个大的迁移任务分为了一个个任务包。
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
// stride 在单核下直接等于 n,多核模式下为 (n>>>3)/NCPU,最小值是 16
// stride 可以理解为”步长“,有 n 个位置是需要进行迁移的,
// 将这 n 个任务分为多个任务包,每个任务包有 stride 个任务
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
// 如果 nextTab 为 null,先进行一次初始化
// 前面我们说了,外围会保证第一个发起迁移的线程调用此方法时,参数 nextTab 为 null
// 之后参与迁移的线程调用此方法时,nextTab 不会为 null
if (nextTab == null) {
try {
// 容量翻倍
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
// nextTable 是 ConcurrentHashMap 中的属性
nextTable = nextTab;
// transferIndex 也是 ConcurrentHashMap 的属性,用于控制迁移的位置
transferIndex = n;
}
int nextn = nextTab.length;
// ForwardingNode 翻译过来就是正在被迁移的 Node
// 这个构造方法会生成一个Node,key、value 和 next 都为 null,关键是 hash 为 MOVED
// 后面我们会看到,原数组中位置 i 处的节点完成迁移工作后,
// 就会将位置 i 处设置为这个 ForwardingNode,用来告诉其他线程该位置已经处理过了
// 所以它其实相当于是一个标志。
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// advance 指的是做完了一个位置的迁移工作,可以准备做下一个位置的了
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
/*
* 下面这个 for 循环,最难理解的在前面,而要看懂它们,应该先看懂后面的,然后再倒回来看
*
*/
// i 是位置索引,bound 是边界,注意是从后往前
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
// 下面这个 while 真的是不好理解
// advance 为 true 表示可以进行下一个位置的迁移了
// 简单理解结局: i 指向了 transferIndex,bound 指向了 transferIndex-stride
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
// 将 transferIndex 值赋给 nextIndex
// 这里 transferIndex 一旦小于等于 0,说明原数组的所有位置都有相应的线程去处理了
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
// 看括号中的代码,nextBound 是这次迁移任务的边界,注意,是从后往前
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
// 所有的迁移操作已经完成
nextTable = null;
// 将新的 nextTab 赋值给 table 属性,完成迁移
table = nextTab;
// 重新计算 sizeCtl: n 是原数组长度,所以 sizeCtl 得出的值将是新数组长度的 0.75 倍
sizeCtl = (n << 1) - (n >>> 1);
return;
}
// 之前我们说过,sizeCtl 在迁移前会设置为 (rs << RESIZE_STAMP_SHIFT) + 2
// 然后,每有一个线程参与迁移就会将 sizeCtl 加 1,
// 这里使用 CAS 操作对 sizeCtl 进行减 1,代表做完了属于自己的任务
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
// 任务结束,方法退出
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
// 到这里,说明 (sc - 2) == resizeStamp(n) << RESIZE_STAMP_SHIFT,
// 也就是说,所有的迁移任务都做完了,也就会进入到上面的 if(finishing){} 分支了
finishing = advance = true;
i = n; // recheck before commit
}
}
// 如果位置 i 处是空的,没有任何节点,那么放入刚刚初始化的 ForwardingNode ”空节点“
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
// 该位置处是一个 ForwardingNode,代表该位置已经迁移过了
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
// 对数组该位置处的结点加锁,开始处理数组该位置处的迁移工作
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
// 头结点的 hash 大于 0,说明是链表的 Node 节点
if (fh >= 0) {
// 下面这一块和 Java7 中的 ConcurrentHashMap 迁移是差不多的,
// 需要将链表一分为二,
// 找到原链表中的 lastRun,然后 lastRun 及其之后的节点是一起进行迁移的
// lastRun 之前的节点需要进行克隆,然后分到两个链表中
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
// 其中的一个链表放在新数组的位置 i
setTabAt(nextTab, i, ln);
// 另一个链表放在新数组的位置 i+n
setTabAt(nextTab, i + n, hn);
// 将原数组该位置处设置为 fwd,代表该位置已经处理完毕,
// 其他线程一旦看到该位置的 hash 值为 MOVED,就不会进行迁移了
setTabAt(tab, i, fwd);
// advance 设置为 true,代表该位置已经迁移完毕
advance = true;
}
else if (f instanceof TreeBin) {
// 红黑树的迁移
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
// 如果一分为二后,节点数少于 8,那么将红黑树转换回链表
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
// 将 ln 放置在新数组的位置 i
setTabAt(nextTab, i, ln);
// 将 hn 放置在新数组的位置 i+n
setTabAt(nextTab, i + n, hn);
// 将原数组该位置处设置为 fwd,代表该位置已经处理完毕,
// 其他线程一旦看到该位置的 hash 值为 MOVED,就不会进行迁移了
setTabAt(tab, i, fwd);
// advance 设置为 true,代表该位置已经迁移完毕
advance = true;
}
}
}
}
}
}
transfer 这个方法并没有实现所有的迁移任务,每次调用这个方法只实现了 transferIndex 往前 stride 个位置的迁移工作,其他的需要由外围来控制。
get 过程分析
- 计算 hash 值
- 根据 hash 值找到数组对应位置:
(n - 1) & h - 根据该位置处结点性质进行相应查找
- 如果该位置为 null,那么直接返回 null 就可以了
- 如果该位置处的节点刚好就是我们需要的,返回该节点的值即可
- 如果该位置节点的 hash 值小于 0,说明正在扩容,或者是红黑树,后面我们再介绍 find 方法
- 如果以上 3 条都不满足,那就是链表,进行遍历比对即可
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// 判断头结点是否就是我们需要的节点
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// 如果头结点的 hash 小于 0,说明 正在扩容,或者该位置是红黑树
else if (eh < 0)
// 参考 ForwardingNode.find(int h, Object k) 和 TreeBin.find(int h, Object k)
return (p = e.find(h, key)) != null ? p.val : null;
// 遍历链表
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
当遇到扩容时的情况最为复杂,ForwardingNode.find(int h, Object k)。
对比总结
HashTable: 使用了synchronized关键字对put等操作进行加锁;ConcurrentHashMap JDK1.7: 使用分段锁机制实现;ConcurrentHashMap JDK1.8: 则使用数组+链表+红黑树数据结构和 CAS 原子操作实现;
3.18 - CH18-ConcurrentLinkedQueue
- 基于链接节点的无界线程安全队列。
- 此队列按照 FIFO(先进先出)原则对元素进行排序。
- 队列的头部是队列中时间最长的元素。
- 队列的尾部是队列中时间最短的元素。
- 新的元素插入到队列的尾部,队列获取操作从队列头部获得元素。
- 当多个线程共享访问一个公共 collection 时,ConcurrentLinkedQueue 是一个恰当的选择。
- 此队列不允许使用 null 元素。
数据结构
与 LinkedBlockingQueue 的数据结构相同,都是使用的链表结构。ConcurrentLinkedQueue 的数据结构如下:
ConcurrentLinkedQueue 采用的链表结构,并且包含有一个头结点和一个尾结点。
源码分析
层级结构
继承了抽象类 AbstractQueue,AbstractQueue 定义了对队列的基本操作;
同时实现了 Queue 接口,Queue 定义了对队列的基本操作,
同时,还实现了 Serializable 接口,表示可以被序列化。
内部类
Node 类表示链表结点,用于存放元素,包含 item 域和 next 域,item 域表示元素,next 域表示下一个结点,其利用反射机制和 CAS 机制来更新 item 域和 next 域,保证原子性。
private static class Node<E> {
// 元素
volatile E item;
// next域
volatile Node<E> next;
/**
* Constructs a new node. Uses relaxed write because item can
* only be seen after publication via casNext.
*/
// 构造函数
Node(E item) {
// 设置item的值
UNSAFE.putObject(this, itemOffset, item);
}
// 比较并替换item值
boolean casItem(E cmp, E val) {
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
void lazySetNext(Node<E> val) {
// 设置next域的值,并不会保证修改对其他线程立即可见
UNSAFE.putOrderedObject(this, nextOffset, val);
}
// 比较并替换next域的值
boolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
// Unsafe mechanics
// 反射机制
private static final sun.misc.Unsafe UNSAFE;
// item域的偏移量
private static final long itemOffset;
// next域的偏移量
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Node.class;
itemOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("item"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
类的属性
属性中包含了 head 域和 tail 域,表示链表的头结点和尾结点,同时,ConcurrentLinkedQueue 也使用了反射机制和 CAS 机制来更新头结点和尾结点,保证原子性。
public class ConcurrentLinkedQueue<E> extends AbstractQueue<E>
implements Queue<E>, java.io.Serializable {
// 版本序列号
private static final long serialVersionUID = 196745693267521676L;
// 反射机制
private static final sun.misc.Unsafe UNSAFE;
// head域的偏移量
private static final long headOffset;
// tail域的偏移量
private static final long tailOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = ConcurrentLinkedQueue.class;
headOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("head"));
tailOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("tail"));
} catch (Exception e) {
throw new Error(e);
}
}
// 头结点
private transient volatile Node<E> head;
// 尾结点
private transient volatile Node<E> tail;
}
类的构造函数
ConcurrentLinkedQueue()型构造函数- 该构造函数用于创建一个最初为空的 ConcurrentLinkedQueue,头结点与尾结点指向同一个结点,该结点的item域为null,next域也为null。
ConcurrentLinkedQueue(Collection<? extends E>)型构造函数- 该构造函数用于创建一个最初包含给定 collection 元素的 ConcurrentLinkedQueue,按照此 collection 迭代器的遍历顺序来添加元素。
核心函数
offer
public boolean offer(E e) {
// 元素不为null
checkNotNull(e);
// 新生一个结点
final Node<E> newNode = new Node<E>(e);
for (Node<E> t = tail, p = t;;) { // 无限循环
// q为p结点的下一个结点
Node<E> q = p.next;
if (q == null) { // q结点为null
// p is last node
if (p.casNext(null, newNode)) { // 比较并进行替换p结点的next域
// Successful CAS is the linearization point
// for e to become an element of this queue,
// and for newNode to become "live".
if (p != t) // p不等于t结点,不一致 // hop two nodes at a time
// 比较并替换尾结点
casTail(t, newNode); // Failure is OK.
// 返回
return true;
}
// Lost CAS race to another thread; re-read next
}
else if (p == q) // p结点等于q结点
// We have fallen off list. If tail is unchanged, it
// will also be off-list, in which case we need to
// jump to head, from which all live nodes are always
// reachable. Else the new tail is a better bet.
// 原来的尾结点与现在的尾结点是否相等,若相等,则p赋值为head,否则,赋值为现在的尾结点
p = (t != (t = tail)) ? t : head;
else
// Check for tail updates after two hops.
// 重新赋值p结点
p = (p != t && t != (t = tail)) ? t : q;
}
}
offer 函数用于将指定元素插入此队列的尾部。下面模拟 offer 函数的操作,队列状态的变化(假设单线程添加元素,连续添加10、20两个元素)。
- 若ConcurrentLinkedQueue的初始状态如上图所示,即队列为空。单线程添加元素,此时,添加元素10,则状态如下所示
- 如上图所示,添加元素10后,tail没有变化,还是指向之前的结点,继续添加元素20,则状态如下所示
- 如上图所示,添加元素20后,tail指向了最新添加的结点。
poll
public E poll() {
restartFromHead:
for (;;) { // 无限循环
for (Node<E> h = head, p = h, q;;) { // 保存头结点
// item项
E item = p.item;
if (item != null && p.casItem(item, null)) { // item不为null并且比较并替换item成功
// Successful CAS is the linearization point
// for item to be removed from this queue.
if (p != h) // p不等于h // hop two nodes at a time
// 更新头结点
updateHead(h, ((q = p.next) != null) ? q : p);
// 返回item
return item;
}
else if ((q = p.next) == null) { // q结点为null
// 更新头结点
updateHead(h, p);
return null;
}
else if (p == q) // p等于q
// 继续循环
continue restartFromHead;
else
// p赋值为q
p = q;
}
}
}
此函数用于获取并移除此队列的头,如果此队列为空,则返回 null。
下面模拟 poll 函数的操作,队列状态的变化(假设单线程操作,状态为之前 offer10、20 后的状态,poll 两次)。
- 队列初始状态如上图所示,在poll操作后,队列的状态如下图所示
- 如上图可知,poll操作后,head改变了,并且head所指向的结点的item变为了null。再进行一次poll操作,队列的状态如下图所示。
- 如上图可知,poll操作后,head结点没有变化,只是指示的结点的item域变成了null。
remove
public boolean remove(Object o) {
// 元素为null,返回
if (o == null) return false;
Node<E> pred = null;
for (Node<E> p = first(); p != null; p = succ(p)) { // 获取第一个存活的结点
// 第一个存活结点的item值
E item = p.item;
if (item != null &&
o.equals(item) &&
p.casItem(item, null)) { // 找到item相等的结点,并且将该结点的item设置为null
// p的后继结点
Node<E> next = succ(p);
if (pred != null && next != null) // pred不为null并且next不为null
// 比较并替换next域
pred.casNext(p, next);
return true;
}
// pred赋值为p
pred = p;
}
return false;
}
此函数用于从队列中移除指定元素的单个实例(如果存在)。其中,会调用到first函数和succ函数,first函数的源码如下:
Node<E> first() {
restartFromHead:
for (;;) { // 无限循环,确保成功
for (Node<E> h = head, p = h, q;;) {
// p结点的item域是否为null
boolean hasItem = (p.item != null);
if (hasItem || (q = p.next) == null) { // item不为null或者next域为null
// 更新头结点
updateHead(h, p);
// 返回结点
return hasItem ? p : null;
}
else if (p == q) // p等于q
// 继续从头结点开始
continue restartFromHead;
else
// p赋值为q
p = q;
}
}
}
first函数用于找到链表中第一个存活的结点。
succ函数源码如下:
final Node<E> succ(Node<E> p) {
// p结点的next域
Node<E> next = p.next;
// 如果next域为自身,则返回头结点,否则,返回next
return (p == next) ? head : next;
}
succ用于获取结点的下一个结点。如果结点的next域指向自身,则返回head头结点,否则,返回next结点。
下面模拟remove函数的操作,队列状态的变化(假设单线程操作,状态为之前offer10、20后的状态,执行remove(10)、remove(20)操作)。
- 如上图所示,为ConcurrentLinkedQueue的初始状态,remove(10)后的状态如下图所示
- 如上图所示,当执行remove(10)后,head指向了head结点之前指向的结点的下一个结点,并且head结点的item域置为null。继续执行remove(20),状态如下图所示
- 如上图所示,执行remove(20)后,head与tail指向同一个结点,item域为null。
size
public int size() {
// 计数
int count = 0;
for (Node<E> p = first(); p != null; p = succ(p)) // 从第一个存活的结点开始往后遍历
if (p.item != null) // 结点的item域不为null
// Collection.size() spec says to max out
if (++count == Integer.MAX_VALUE) // 增加计数,若达到最大值,则跳出循环
break;
// 返回大小
return count;
}
此函数用于返回ConcurrenLinkedQueue的大小,从第一个存活的结点(first)开始,往后遍历链表,当结点的item域不为null时,增加计数,之后返回大小。
应用示例
import java.util.concurrent.ConcurrentLinkedQueue;
class PutThread extends Thread {
private ConcurrentLinkedQueue<Integer> clq;
public PutThread(ConcurrentLinkedQueue<Integer> clq) {
this.clq = clq;
}
public void run() {
for (int i = 0; i < 10; i++) {
try {
System.out.println("add " + i);
clq.add(i);
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class GetThread extends Thread {
private ConcurrentLinkedQueue<Integer> clq;
public GetThread(ConcurrentLinkedQueue<Integer> clq) {
this.clq = clq;
}
public void run() {
for (int i = 0; i < 10; i++) {
try {
System.out.println("poll " + clq.poll());
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class ConcurrentLinkedQueueDemo {
public static void main(String[] args) {
ConcurrentLinkedQueue<Integer> clq = new ConcurrentLinkedQueue<Integer>();
PutThread p1 = new PutThread(clq);
GetThread g1 = new GetThread(clq);
p1.start();
g1.start();
}
}
GetThread 线程不会因为 ConcurrentLinkedQueue 队列为空而等待,而是直接返回 null,所以当实现队列不空时,等待时,则需要用户自己实现等待逻辑。
深入理解
HOPS:延迟更新策略
通过上面对offer和poll方法的分析,我们发现tail和head是延迟更新的,两者更新触发时机为:
tail更新触发时机:当tail指向的节点的下一个节点不为null的时候,会执行定位队列真正的队尾节点的操作,找到队尾节点后完成插入之后才会通过casTail进行tail更新;当tail指向的节点的下一个节点为null的时候,只插入节点不更新tail。head更新触发时机:当head指向的节点的item域为null的时候,会执行定位队列真正的队头节点的操作,找到队头节点后完成删除之后才会通过updateHead进行head更新;当head指向的节点的item域不为null的时候,只删除节点不更新head。
并且在更新操作时,源码中会有注释为:hop two nodes at a time。所以这种延迟更新的策略就被叫做HOPS的大概原因是这个,从上面更新时的状态图可以看出,head和tail的更新是“跳着的”即中间总是间隔了一个。那么这样设计的意图是什么呢?
如果让tail永远作为队列的队尾节点,实现的代码量会更少,而且逻辑更易懂。但是,这样做有一个缺点,如果大量的入队操作,每次都要执行CAS进行tail的更新,汇总起来对性能也会是大大的损耗。如果能减少CAS更新的操作,无疑可以大大提升入队的操作效率,所以doug lea大师每间隔1次(tail和队尾节点的距离为1)进行才利用CAS更新tail。对head的更新也是同样的道理,虽然,这样设计会多出在循环中定位队尾节点,但总体来说读的操作效率要远远高于写的性能,因此,多出来的在循环中定位尾节点的操作的性能损耗相对而言是很小的。
适用场景
通过无锁来做到了更高的并发量,是个高性能的队列,但是使用场景相对不如阻塞队列常见,毕竟取数据也要不停的去循环,不如阻塞的逻辑好设计,但是在并发量特别大的情况下,是个不错的选择,性能上好很多,而且这个队列的设计也是特别费力,尤其的使用的改良算法和对哨兵的处理。整体的思路都是比较严谨的,这个也是使用了无锁造成的,我们自己使用无锁的条件的话,这个队列是个不错的参考。
3.19 - CH19-BlockingQueue
BlockingQueue
通常用于一个线程生产对象,而另外一个线程消费这些对象的场景。下图是对这个原理的阐述:
一个线程将会持续生产新对象并将其插入到队列之中,直到队列达到它所能容纳的临界点。也就是说,它是有限的。如果该阻塞队列到达了其临界点,负责生产的线程将会在往里边插入新对象时发生阻塞。它会一直处于阻塞之中,直到负责消费的线程从队列中拿走一个对象。 负责消费的线程将会一直从该阻塞队列中拿出对象。如果消费线程尝试去从一个空的队列中提取对象的话,这个消费线程将会处于阻塞之中,直到一个生产线程把一个对象丢进队列。
操作方法
具有 4 组不同的方法用于插入、移除以及对队列中的元素进行检查。如果请求的操作不能得到立即执行的话,每个方法的表现也不同。这些方法如下:
| 抛异常 | 布尔值 | 阻塞 | 超时 |
|---|
| 插入 | add(o) | offer(o) | put(o) | offer(o,timeout,timeunit) |
| 移除 | remove(o) | poll(o) | take(o) | poll(timeout,timeunit) |
| 检查 | element(o) | peek(o) | | |
- 抛异常:如果试图的操作无法立即执行,抛一个异常。
- 特定值:如果试图的操作无法立即执行,返回一个特定的值(常常是 true / false)。
- 阻塞:如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行。
- 超时:如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行,但等待时间不会超过给定值。返回一个特定值以告知该操作是否成功(典型的是 true / false)。
无法向一个 BlockingQueue 中插入 null。如果你试图插入 null,BlockingQueue 将会抛出一个 NullPointerException。
可以访问到 BlockingQueue 中的所有元素,而不仅仅是开始和结束的元素。比如说,你将一个对象放入队列之中以等待处理,但你的应用想要将其取消掉。那么你可以调用诸如 remove(o) 方法来将队列之中的特定对象进行移除。但是这么干效率并不高(译者注: 基于队列的数据结构,获取除开始或结束位置的其他对象的效率不会太高),因此你尽量不要用这一类的方法,除非你确实不得不那么做。
BlockingDeque
BlockingDeque 接口表示一个线程安放入和提取实例的双端队列。
BlockingDeque 类是一个双端队列,在不能够插入元素时,它将阻塞住试图插入元素的线程;在不能够抽取元素时,它将阻塞住试图抽取的线程。 deque(双端队列) 是 “Double Ended Queue” 的缩写。因此,双端队列是一个你可以从任意一端插入或者抽取元素的队列。
在线程既是一个队列的生产者又是这个队列的消费者的时候可以使用到 BlockingDeque。如果生产者线程需要在队列的两端都可以插入数据,消费者线程需要在队列的两端都可以移除数据,这个时候也可以使用 BlockingDeque。BlockingDeque 图解:
操作方法
一个 BlockingDeque - 线程在双端队列的两端都可以插入和提取元素。 一个线程生产元素,并把它们插入到队列的任意一端。如果双端队列已满,插入线程将被阻塞,直到一个移除线程从该队列中移出了一个元素。如果双端队列为空,移除线程将被阻塞,直到一个插入线程向该队列插入了一个新元素。
BlockingDeque 具有 4 组不同的方法用于插入、移除以及对双端队列中的元素进行检查。如果请求的操作不能得到立即执行的话,每个方法的表现也不同。这些方法如下:
| 抛异常 | 布尔值 | 阻塞 | 超时 |
|---|
| 队首-插入 | addFirst(o) | offerFirst(o) | putFirst(o) | offerFirst(o, timeout, timeunit) |
| 队首-移除 | removeFirst(o) | pollFirst(o) | takeFirst(o) | pollFirst(timeout, timeunit) |
| 队首-检查 | getFirst(o) | peekFirst(o) | | |
| 队尾-插入 | addLast(o) | offerLast(o) | putLast(o) | offerLast(o, timeout, timeunit) |
| 队尾-移除 | removeLast(o) | pollLast(o) | takeLast(o) | pollLast(timeout, timeunit) |
| 队尾-检查 | getLast(o) | peekLast(o) | | |
- 抛异常:如果试图的操作无法立即执行,抛一个异常。
- 特定值:如果试图的操作无法立即执行,返回一个特定的值(常常是 true / false)。
- 阻塞:如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行。
- 超时:如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行,但等待时间不会超过给定值。返回一个特定值以告知该操作是否成功(典型的是 true / false)。
BlockingQueue & BlockingDeque
BlockingDeque 接口继承自 BlockingQueue 接口。这就意味着你可以像使用一个 BlockingQueue 那样使用 BlockingDeque。如果你这么干的话,各种插入方法将会把新元素添加到双端队列的尾端,而移除方法将会把双端队列的首端的元素移除。正如 BlockingQueue 接口的插入和移除方法一样。
应用实例
这里是一个 Java 中使用 BlockingQueue 的示例。本示例使用的是 BlockingQueue 接口的 ArrayBlockingQueue 实现。 首先,BlockingQueueExample 类分别在两个独立的线程中启动了一个 Producer 和 一个 Consumer。Producer 向一个共享的 BlockingQueue 中注入字符串,而 Consumer 则会从中把它们拿出来。
public class BlockingQueueExample {
public static void main(String[] args) throws Exception {
BlockingQueue queue = new ArrayBlockingQueue(1024);
Producer producer = new Producer(queue);
Consumer consumer = new Consumer(queue);
new Thread(producer).start();
new Thread(consumer).start();
Thread.sleep(4000);
}
}
以下是 Producer 类。注意它在每次 put() 调用时是如何休眠一秒钟的。这将导致 Consumer 在等待队列中对象的时候发生阻塞。
public class Producer implements Runnable{
protected BlockingQueue queue = null;
public Producer(BlockingQueue queue) {
this.queue = queue;
}
public void run() {
try {
queue.put("1");
Thread.sleep(1000);
queue.put("2");
Thread.sleep(1000);
queue.put("3");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
以下是 Consumer 类。它只是把对象从队列中抽取出来,然后将它们打印到 System.out。
public class Consumer implements Runnable{
protected BlockingQueue queue = null;
public Consumer(BlockingQueue queue) {
this.queue = queue;
}
public void run() {
try {
System.out.println(queue.take());
System.out.println(queue.take());
System.out.println(queue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
ArrayBlockingQueue
ArrayBlockingQueue 类实现了 BlockingQueue 接口。
ArrayBlockingQueue 是一个有界的阻塞队列,其内部实现是将对象放到一个数组里。有界也就意味着,它不能够存储无限多数量的元素。它有一个同一时间能够存储元素数量的上限。你可以在对其初始化的时候设定这个上限,但之后就无法对这个上限进行修改了。
ArrayBlockingQueue 内部以 FIFO(先进先出)的顺序对元素进行存储。队列中的头元素在所有元素之中是放入时间最久的那个,而尾元素则是最短的那个。
DelayQueue
DelayQueue 实现了 BlockingQueue 接口。
DelayQueue是一个无界的 BlockingQueue,用于放置实现了 Delayed 接口的对象,其中的对象只能在其到期时才能从队列中取走。这种队列是有序的,即队头对象的延迟到期时间最长。
元素进入队列后,先进行排序,然后,只有 getDelay 也就是剩余时间为0的时候,该元素才有资格被消费者从队列中取出来,所以构造函数一般都有一个时间传入。
public interface Delayed extends Comparable<Delayed< {
public long getDelay(TimeUnit timeUnit);
}
传递给 getDelay 方法的 getDelay 实例是一个枚举类型,它表明了将要延迟的时间段。
Delayed 接口也继承了 java.lang.Comparable 接口,这也就意味着 Delayed 对象之间可以进行对比。这个可能在对 DelayQueue 队列中的元素进行排序时有用,因此它们可以根据过期时间进行有序释放。 以下是使用 DelayQueue 的例子:
public class DelayQueueExample {
public static void main(String[] args) {
DelayQueue queue = new DelayQueue();
Delayed element1 = new DelayedElement();
queue.put(element1);
Delayed element2 = queue.take();
}
}
LinkedBlocingQueue
LinkedBlockingQueue 类实现了 BlockingQueue 接口。
LinkedBlockingQueue 内部以一个链式结构(链接节点)对其元素进行存储。如果需要的话,这一链式结构可以选择一个上限。如果没有定义上限,将使用 Integer.MAX_VALUE 作为上限。
LinkedBlockingQueue 内部以 FIFO(先进先出)的顺序对元素进行存储。队列中的头元素在所有元素之中是放入时间最久的那个,而尾元素则是最短的那个。
PriorityBlockingQueue
PriorityBlockingQueue 类实现了 BlockingQueue 接口。
PriorityBlockingQueue 是一个无界的并发队列。它使用了和类 java.util.PriorityQueue 一样的排序规则。你无法向这个队列中插入 null 值。 所有插入到 PriorityBlockingQueue 的元素必须实现 java.lang.Comparable 接口。因此该队列中元素的排序就取决于你自己的 Comparable 实现。 注意 PriorityBlockingQueue 对于具有相等优先级(compare() == 0)的元素并不强制任何特定行为。
同时注意,如果你从一个 PriorityBlockingQueue 获得一个 Iterator 的话,该 Iterator 并不能保证它对元素的遍历是以优先级为序的。
SynchronousQueue
SynchronousQueue 类实现了 BlockingQueue 接口。
SynchronousQueue 是一个特殊的队列,它的内部同时只能够容纳单个元素。如果该队列已有一元素的话,试图向队列中插入一个新元素的线程将会阻塞,直到另一个线程将该元素从队列中抽走。同样,如果该队列为空,试图向队列中抽取一个元素的线程将会阻塞,直到另一个线程向队列中插入了一条新的元素。 据此,把这个类称作一个队列显然是夸大其词了。它更多像是一个汇合点。
3.20 - CH20-FutureTask
概览
- FutureTask 为 Future 提供了基础实现,如获取任务执行结果(get)和取消任务等。
- 如果任务尚未完成,获取任务执行结果时将会阻塞。
- 一旦执行结束,任务就不能被重启或取消(除非使用runAndReset执行计算)。
- FutureTask 常用来封装 Callable 和 Runnable,也可以作为一个任务提交到线程池中执行。
- 除了作为一个独立的类之外,此类也提供了一些功能性函数供我们创建自定义 task 类使用。
- FutureTask 的线程安全由 CAS 来保证。
层级结构
FutureTask 实现了 RunnableFuture 接口,则 RunnableFuture 接口继承了 Runnable 接口和 Future 接口,所以 FutureTask 既能当做一个 Runnable 直接被 Thread 执行,也能作为 Future 用来得到 Callable 的计算结果。
源码分析
Callable 接口
Callable 是个泛型接口,泛型V就是要 call() 方法返回的类型。对比 Runnable 接口,Runnable 不会返回数据也不能抛出异常。
public interface Callable<V> {
/**
* Computes a result, or throws an exception if unable to do so.
*
* @return computed result
* @throws Exception if unable to compute a result
*/
V call() throws Exception;
}
Future 接口
Future 接口代表异步计算的结果,通过 Future 接口提供的方法可以查看异步计算是否执行完成,或者等待执行结果并获取执行结果,同时还可以取消执行。Future 接口的定义如下:
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
- cancel:取消异步任务的执行。
- 如果异步任务已经完成或者已经被取消,或者由于某些原因不能取消,则会返回 false。
- 如果任务还没有被执行,则会返回 true 并且异步任务不会被执行。
- 如果任务已经开始执行了但是还没有执行完成:
- 若 mayInterruptIfRunning 为 true,则会立即中断执行任务的线程并返回 true;
- 若 mayInterruptIfRunning 为 false,则会返回 true 且不会中断任务执行线程。
- isCanceled:判断任务是否被取消。
- 如果任务在结束(正常执行结束或者执行异常结束)前被取消则返回 true,
- 否则返回 false。
- isDone:判断任务是否已经完成。
- 如果完成则返回 true,否则返回 false。
- 任务执行过程中发生异常、任务被取消也属于任务已完成,也会返回true。
- get:获取任务执行结果。
- 如果任务还没完成则会阻塞等待直到任务执行完成。
- 如果任务被取消则会抛出 CancellationException 异常。
- 如果任务执行过程发生异常则会抛出 ExecutionException 异常。
- 如果阻塞等待过程中被中断则会抛出 InterruptedException 异常。
- get(timeout,timeunit):带超时时间的 get() 版本。
- 如果阻塞等待过程中超时则会抛出 TimeoutException 异常。
核心属性
//内部持有的callable任务,运行完毕后置空
private Callable<V> callable;
//从get()中返回的结果或抛出的异常
private Object outcome; // non-volatile, protected by state reads/writes
//运行callable的线程
private volatile Thread runner;
//使用Treiber栈保存等待线程
private volatile WaitNode waiters;
//任务状态
private volatile int state;
private static final int NEW = 0;
private static final int COMPLETING = 1;
private static final int NORMAL = 2;
private static final int EXCEPTIONAL = 3;
private static final int CANCELLED = 4;
private static final int INTERRUPTING = 5;
private static final int INTERRUPTED = 6;
其中的状态值 state 使用 volatile 修饰,以确保任何一个线程对状态的修改立即会对其他线程可见。
7 种具体状态表示:
- NEW:初始状态,表示这个是新任务或者尚未被执行完的任务。
- COMPLETING:任务已经执行完成或者执行任务的时候发生异常。
- 但是任务执行结果或者异常原因还没有保存到 outcome 字段时,状态由 NEW 变为 COMPLETING。
- outcome字段用来保存任务执行结果,如果发生异常,则用来保存异常原因。
- 该状态持续时间较短,属于中间状态。
- NORMAL:任务已经执行完成并且任务执行结果已经保存到 outcome 字段,状态会从 COMPLETING 转换到 NORMAL。
- EXCEPTIONAL:任务执行发生异常并且异常原因已经保存到 outcome 字段中后,状态会从 COMPLETING 转换到 EXCEPTIONAL。
- CANCELED:任务还没开始执行或者已经开始执行但是还没有执行完成的时候,用户调用了
cancel(false) 方法取消任务且不中断任务执行线程,这个时候状态会从 NEW 转化为 CANCELLED 状态。 - INTERRUPTING:任务还没开始执行或者已经执行但是还没有执行完成的时候,用户调用了
cancel(true) 方法取消任务并且要中断任务执行线程但是还没有中断任务执行线程之前,状态会从 NEW 转化为 INTERRUPTING。 - INTERRUPTED:调用 interrupt() 中断任务执行线程之后状态会从 INTERRUPTING 转换到 INTERRUPTED。
- 这是一个最终态。
- 所有值大于 COMPLETING 的状态都表示任务已经执行完成(任务正常执行完成,任务执行异常或者任务被取消)。
构造函数
FutureTask(Callable<V> callable)
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}
- 该构造函数会把传入的 Callable 变量保存在t his.callable 字段中。
- 该字段定义为
private Callable<V> callable; 用来保存底层的调用,在被执行完成以后会指向 null。 - 接着会初始化 state 字段为 NEW。
FutureTask(Runnable runnable, V result)
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW; // ensure visibility of callable
}
- 这个构造函数会把传入的 Runnable 封装成一个 Callable 对象保存在 callable 字段中。
- 同时如果任务执行成功的话就会返回传入的 result。
- 如果不需要返回值的话可以传入一个 null 作为 result。
- Executors.callable() 的功能是把 Runnable 转换成 Callable。
public static <T> Callable<T> callable(Runnable task, T result) {
if (task == null)
throw new NullPointerException();
return new RunnableAdapter<T>(task, result); // 适配器
}
这里采用了适配器模式:
static final class RunnableAdapter<T> implements Callable<T> {
final Runnable task;
final T result;
RunnableAdapter(Runnable task, T result) {
this.task = task;
this.result = result;
}
public T call() {
task.run();
return result;
}
}
这里的适配器只是简单实现了 Callable 接口,在 call 中调用 Runnable.run 方法,然后把传入的 result 作为返回值返回调用。
在 new 了一个 FutureTask 之后,接下来就是在另一个线程中执行该 Task,无论是通过直接 new 一个 Thread 还是通过线程池,执行的都是 run 方法。
核心方法:run
public void run() {
//新建任务,CAS替换runner为当前线程
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
set(result);//设置执行结果
}
} finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);//处理中断逻辑
}
}
- 运行任务:如果任务状态为NEW状态,则利用CAS修改为当前线程。执行完毕调用set(result)方法设置执行结果。set(result)源码如下:
protected void set(V v) {
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {
outcome = v;
UNSAFE.putOrderedInt(this, stateOffset, NORMAL); // final state
finishCompletion();//执行完毕,唤醒等待线程
}
}
- 首先利用cas修改state状态为COMPLETING,设置返回结果,然后使用 lazySet(UNSAFE.putOrderedInt)的方式设置state状态为NORMAL。结果设置完毕后,调用finishCompletion()方法唤醒等待线程,源码如下:
private void finishCompletion() {
// assert state > COMPLETING;
for (WaitNode q; (q = waiters) != null;) {
if (UNSAFE.compareAndSwapObject(this, waitersOffset, q, null)) {//移除等待线程
for (;;) {//自旋遍历等待线程
Thread t = q.thread;
if (t != null) {
q.thread = null;
LockSupport.unpark(t);//唤醒等待线程
}
WaitNode next = q.next;
if (next == null)
break;
q.next = null; // unlink to help gc
q = next;
}
break;
}
}
//任务完成后调用函数,自定义扩展
done();
callable = null; // to reduce footprint
}
- 回到run方法,如果在 run 期间被中断,此时需要调用handlePossibleCancellationInterrupt方法来处理中断逻辑,确保任何中断(例如cancel(true))只停留在当前run或runAndReset的任务中,源码如下:
private void handlePossibleCancellationInterrupt(int s) {
//在中断者中断线程之前可能会延迟,所以我们只需要让出CPU时间片自旋等待
if (s == INTERRUPTING)
while (state == INTERRUPTING)
Thread.yield(); // wait out pending interrupt
}
核心方法:get
//获取执行结果
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING)
s = awaitDone(false, 0L);
return report(s);
}
FutureTask 通过get()方法获取任务执行结果。如果任务处于未完成的状态(state <= COMPLETING),就调用awaitDone方法(后面单独讲解)等待任务完成。任务完成后,通过report方法获取执行结果或抛出执行期间的异常。report源码如下:
//返回执行结果或抛出异常
private V report(int s) throws ExecutionException {
Object x = outcome;
if (s == NORMAL)
return (V)x;
if (s >= CANCELLED)
throw new CancellationException();
throw new ExecutionException((Throwable)x);
}
核心方法:awaitDone(boolean timed, long nanos)
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
WaitNode q = null;
boolean queued = false;
for (;;) {//自旋
if (Thread.interrupted()) {//获取并清除中断状态
removeWaiter(q);//移除等待WaitNode
throw new InterruptedException();
}
int s = state;
if (s > COMPLETING) {
if (q != null)
q.thread = null;//置空等待节点的线程
return s;
}
else if (s == COMPLETING) // cannot time out yet
Thread.yield();
else if (q == null)
q = new WaitNode();
else if (!queued)
//CAS修改waiter
queued = UNSAFE.compareAndSwapObject(this, waitersOffset,
q.next = waiters, q);
else if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
removeWaiter(q);//超时,移除等待节点
return state;
}
LockSupport.parkNanos(this, nanos);//阻塞当前线程
}
else
LockSupport.park(this);//阻塞当前线程
}
}
awaitDone 用于等待任务完成,或任务因为中断或超时而终止。返回任务的完成状态。函数执行逻辑如下:
private void removeWaiter(WaitNode node) {
if (node != null) {
node.thread = null;//首先置空线程
retry:
for (;;) { // restart on removeWaiter race
//依次遍历查找
for (WaitNode pred = null, q = waiters, s; q != null; q = s) {
s = q.next;
if (q.thread != null)
pred = q;
else if (pred != null) {
pred.next = s;
if (pred.thread == null) // check for race
continue retry;
}
else if (!UNSAFE.compareAndSwapObject(this, waitersOffset,q, s)) //cas替换
continue retry;
}
break;
}
}
}
- 加入当前线程状态为结束(state>COMPLETING),则根据需要置空等待节点的线程,并返回 Future 状态;
- 如果当前状态为正在完成(COMPLETING),说明此时 Future 还不能做出超时动作,为任务让出CPU执行时间片;
- 如果state为NEW,先新建一个WaitNode,然后CAS修改当前waiters;
- 如果等待超时,则调用removeWaiter移除等待节点,返回任务状态;如果设置了超时时间但是尚未超时,则park阻塞当前线程;
- 其他情况直接阻塞当前线程。
核心方法:cancel(boolean mayInterruptIfRunning)
public boolean cancel(boolean mayInterruptIfRunning) {
//如果当前Future状态为NEW,根据参数修改Future状态为INTERRUPTING或CANCELLED
if (!(state == NEW &&
UNSAFE.compareAndSwapInt(this, stateOffset, NEW,
mayInterruptIfRunning ? INTERRUPTING : CANCELLED)))
return false;
try { // in case call to interrupt throws exception
if (mayInterruptIfRunning) {//可以在运行时中断
try {
Thread t = runner;
if (t != null)
t.interrupt();
} finally { // final state
UNSAFE.putOrderedInt(this, stateOffset, INTERRUPTED);
}
}
} finally {
finishCompletion();//移除并唤醒所有等待线程
}
return true;
}
尝试取消任务。如果任务已经完成或已经被取消,此操作会失败。
- 如果当前Future状态为NEW,根据参数修改Future状态为INTERRUPTING或CANCELLED。
- 如果当前状态不为NEW,则根据参数mayInterruptIfRunning决定是否在任务运行中也可以中断。中断操作完成后,调用finishCompletion移除并唤醒所有等待线程。
应用实例
Future & ExecutorService
public class FutureDemo {
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
Future future = executorService.submit(new Callable<Object>() {
@Override
public Object call() throws Exception {
Long start = System.currentTimeMillis();
while (true) {
Long current = System.currentTimeMillis();
if ((current - start) > 1000) {
return 1;
}
}
}
});
try {
Integer result = (Integer)future.get();
System.out.println(result);
}catch (Exception e){
e.printStackTrace();
}
}
}
FutureTask & ExecutorService
ExecutorService executor = Executors.newCachedThreadPool();
Task task = new Task();
FutureTask<Integer> futureTask = new FutureTask<Integer>(task);
executor.submit(futureTask);
executor.shutdown();
Future & Thread
import java.util.concurrent.*;
public class CallDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 2. 新建FutureTask,需要一个实现了Callable接口的类的实例作为构造函数参数
FutureTask<Integer> futureTask = new FutureTask<Integer>(new Task());
// 3. 新建Thread对象并启动
Thread thread = new Thread(futureTask);
thread.setName("Task thread");
thread.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Thread [" + Thread.currentThread().getName() + "] is running");
// 4. 调用isDone()判断任务是否结束
if(!futureTask.isDone()) {
System.out.println("Task is not done");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
int result = 0;
try {
// 5. 调用get()方法获取任务结果,如果任务没有执行完成则阻塞等待
result = futureTask.get();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("result is " + result);
}
// 1. 继承Callable接口,实现call()方法,泛型参数为要返回的类型
static class Task implements Callable<Integer> {
@Override
public Integer call() throws Exception {
System.out.println("Thread [" + Thread.currentThread().getName() + "] is running");
int result = 0;
for(int i = 0; i < 100;++i) {
result += i;
}
Thread.sleep(3000);
return result;
}
}
}
3.21 - CH21-ThreadPoolExecutor
线程池的作用
- 降低资源消耗:线程无限制的创建,使用完毕后消耗
- 提高响应速度:无需频繁新建线程
- 提高线程的可管理性
应用详解
线程池即一个线程集合 workerSet 和一个阻塞队列 workQueue。
当用户向线程池提交一个任务时,线程池会先将任务放入 workQueue 中。
workerSet 中的线程会不断的从 workQueue 中获取任务并执行。
当 workQueue 中没有任务时,worker 则会阻塞,直到队列中有任务了再开始执行。
Executor 原理
当一个线程提交至线程池后:
- 线程池首先判断当前运行的线程数量是否少于与 corePoolSize。如果是则新建工作线程来执行任务,否则进入 2。
- 判断 BlockingQueue 是否已满,如果没满,则将任务放入 BlockingQueue,否则进入 3。
- 如果新建线程会使当前线程珊瑚粮超过 maximumPoolSize,则交给 RejectedExecutionHandler 来处理。
当 ThreadPoolExecutor 新建线程时,通过 CAS 来更新线程池的状态 ctl。
参数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler)
- corePoolSize:核心线程数。
- 当提交一个任务时,线程池新建线程来执行任务,直到线程数量等于 corePoolSize,即使存在空闲线程。
- 如果当前线程数量等于 corePoolSize,提交的任务将会被保存到阻塞队列,等待执行。
- 如果执行了线程池的 prestartAllCoreThreads 方法,线程池会提前创建并开启所有核心线程。
- workQueue:用于保存需要被执行的任务,可选的队列类型有:
- ArrayBlockingQueue:基于数组结构,按 FIFO 排序任务。
- LinkedBlockingQueue:基于链表结构,按 FIFO 排序任务,吞吐量高于 ArrayBlockingQueue。
- 比 ArrayBlockingQueue 在插入、删除元素时性能更优,但 put、take 时均需加锁。
- SynchronousQueue:不存储元素的阻塞队列,每个插入操作必须等待另一个线程调用移除操作,否则插入操作将一直阻塞,吞吐量高于 LinkedBlockingQueue。
- 使用无锁算法,基于节点状态执行判断,无需使用锁,核心是 Transfer.transfer。
- PriorityBlockingQueue:具有优先级的无界阻塞队列。
- maximumPoolSize:允许的最大线程数量。
- 如果阻塞队列已满后继续提交任务,则需创建新的线程来执行任务,前提是线程数小于最大允许数量。
- 当阻塞队列是无界队列时,则最大允许数量不起作用。
- keepAliveTime:线程空闲存活时间。
- 即当线程没有执行任务时,该线程继续存活的时间。
- 默认情况下,该参数只有在线程数量大于 corePoolSize 时才起效。
- 超过空闲存活时间的现场将被终止。
- unit:线程空闲存活时间的时间单位。
- threadFactory:创建线程的工厂,通过自定义工厂可以设置线程的属性,如名称、demaon。
- handler:线程池饱和策略。如果队列已满且没有空闲线程,如果继续提交任务,必须采取一种策略来处理该任务,共有四种策略:
- AbortPolicy:直接抛出异常,默认策略。
- CallerRunPolicy:用调用者线程来执行任务。
- DiscardOldestPolicy:丢弃队列中较靠前的任务,以执行当前任务。
- DiscardPolicy:直接丢弃任务。
- 支持自定义饱和策略,比如记录日志会持久化存储任务信息。
类型
newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
- 固定线程数量(corePoolSize)。
- 即使线程池没有可执行的任务,也不会终止线程。
- 采用无界队列 LinkedBlockingQueue(Integer.MAX_VALUE),潜在问题:
- 线程数量不会超过 corePoolSize,导致 maximumPoolSize 和 keepAliveTIme 参数失效。
- 采用无界队列导致永远不会拒绝提交的任务,导致饱和策略失效。
newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
- 初始化的线程池中仅一个线程,如果该线程异常结束,会新建线程以继续执行任务。
- 该唯一线程可以保证顺序处理队列中的任务。
- 基于无界队列,因此饱和策略失效。
newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
- 线程数最多可达 Integer.MAX_VALUE。
- 内部使用 SynchronousQueue 作为阻塞队列。
- 线程空间时间超过最大空闲时长会终止线程。
- 如果提交任务没有可用线程,则新建线程。
- 执行过程与前两个线程池不同:
- 主线程调用 SynchronousQueue.offer 添加 task,如果此时线程池中有空闲线程尝试读取队列中的任务,即调用 SynchronousQueue.poll,则主线程将该 task 交给空闲线程。否则进入下一步。
- 当线程池为空或没有空闲线程,则新建线程。
- 执行完任务的线程如果在 60 秒内空间,则被终止,因此长时间空闲的线程池不会持有任何线程资源。
关闭线程池
遍历线程池中的所有线程,然后逐个调用线程的 interrupt 方法来中断线程。
关闭方式:shutdown
将线程池里的线程状态设置成SHUTDOWN状态, 然后中断所有没有正在执行任务的线程。
关闭方式:shutdownNow
将线程池里的线程状态设置成STOP状态, 然后停止所有正在执行或暂停任务的线程。
只要调用这两个关闭方法中的任意一个, isShutDown() 返回true. 当所有任务都成功关闭了, isTerminated()返回true。
ThreadPoolExecutor
关键属性
//这个属性是用来存放 当前运行的worker数量以及线程池状态的
//int是32位的,这里把int的高3位拿来充当线程池状态的标志位,后29位拿来充当当前运行worker的数量
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
//存放任务的阻塞队列
private final BlockingQueue<Runnable> workQueue;
//worker的集合,用set来存放
private final HashSet<Worker> workers = new HashSet<Worker>();
//历史达到的worker数最大值
private int largestPoolSize;
//当队列满了并且worker的数量达到maxSize的时候,执行具体的拒绝策略
private volatile RejectedExecutionHandler handler;
//超出coreSize的worker的生存时间
private volatile long keepAliveTime;
//常驻worker的数量
private volatile int corePoolSize;
//最大worker的数量,一般当workQueue满了才会用到这个参数
private volatile int maximumPoolSize;
内部状态
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
其中AtomicInteger变量ctl的功能非常强大: 利用低29位表示线程池中线程数,通过高3位表示线程池的运行状态:
- RUNNING: -1 « COUNT_BITS,即高3位为111,该状态的线程池会接收新任务,并处理阻塞队列中的任务;
- SHUTDOWN: 0 « COUNT_BITS,即高3位为000,该状态的线程池不会接收新任务,但会处理阻塞队列中的任务;
- STOP : 1 « COUNT_BITS,即高3位为001,该状态的线程不会接收新任务,也不会处理阻塞队列中的任务,而且会中断正在运行的任务;
- TIDYING : 2 « COUNT_BITS,即高3位为010, 所有的任务都已经终止;
- TERMINATED: 3 « COUNT_BITS,即高3位为011, terminated()方法已经执行完成
执行过程
execute –> addWorker –> runworker(getTask)
- 线程池的工作线程通过Woker类实现,在ReentrantLock锁的保证下,把Woker实例插入到HashSet后,并启动Woker中的线程。
- 从Woker类的构造方法实现可以发现: 线程工厂在创建线程thread时,将Woker实例本身this作为参数传入,当执行start方法启动线程thread时,本质是执行了Worker的runWorker方法。
- firstTask执行完成之后,通过getTask方法从阻塞队列中获取等待的任务,如果队列中没有任务,getTask方法会被阻塞并挂起,不会占用cpu资源;
execute 方法
ThreadPoolExecutor.execute(task)实现了Executor.execute(task)
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
//workerCountOf获取线程池的当前线程数;小于corePoolSize,执行addWorker创建新线程执行command任务
if (addWorker(command, true))
return;
c = ctl.get();
}
// double check: c, recheck
// 线程池处于RUNNING状态,把提交的任务成功放入阻塞队列中
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// recheck and if necessary 回滚到入队操作前,即倘若线程池shutdown状态,就remove(command)
//如果线程池没有RUNNING,成功从阻塞队列中删除任务,执行reject方法处理任务
if (! isRunning(recheck) && remove(command))
reject(command);
//线程池处于running状态,但是没有线程,则创建线程
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 往线程池中创建新的线程失败,则reject任务
else if (!addWorker(command, false))
reject(command);
}
在多线程环境下,线程池的状态时刻在变化,而ctl.get()是非原子操作,很有可能刚获取了线程池状态后线程池状态就改变了。判断是否将command加入workque是线程池之前的状态。倘若没有double check,万一线程池处于非running状态(在多线程环境下很有可能发生),那么command永远不会执行。
addWorker 方法
从方法execute的实现可以看出: addWorker主要负责创建新的线程并执行任务。
线程池创建新线程执行任务时,需要获取全局锁:
private final ReentrantLock mainLock = new ReentrantLock();
private boolean addWorker(Runnable firstTask, boolean core) {
// CAS更新线程池数量
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
// 线程池重入锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start(); // 线程启动,执行任务(Worker.thread(firstTask).start());
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
Worker.runWorker 方法
private final class Worker extends AbstractQueuedSynchronizer implements Runnable{
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this); // 创建线程
}
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}
// ...
}
- 继承了AQS类,可以方便的实现工作线程的中止操作;
- 实现了Runnable接口,可以将自身作为一个任务在工作线程中执行;
- 当前提交的任务firstTask作为参数传入Worker的构造方法;
一些属性还有构造方法:
//运行的线程,前面addWorker方法中就是直接通过启动这个线程来启动这个worker
final Thread thread;
//当一个worker刚创建的时候,就先尝试执行这个任务
Runnable firstTask;
//记录完成任务的数量
volatile long completedTasks;
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
//创建一个Thread,将自己设置给他,后面这个thread启动的时候,也就是执行worker的run方法
this.thread = getThreadFactory().newThread(this);
}
runWorker方法是线程池的核心:
- 线程启动之后,通过unlock方法释放锁,设置AQS的state为0,表示运行可中断;
- Worker执行firstTask或从workQueue中获取任务
- 进行加锁操作,保证thread不被其他线程中断(除非线程池被中断)
- 检查线程池状态,倘若线程池处于中断状态,当前线程将中断。
- 执行beforeExecute
- 执行任务的run方法
- 执行afterExecute方法
- 解锁操作
通过getTask方法从阻塞队列中获取等待的任务,如果队列中没有任务,getTask方法会被阻塞并挂起,不会占用cpu资源;
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
// 先执行firstTask,再从workerQueue中取task(getTask())
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
getTask 方法
下面来看一下getTask()方法,这里面涉及到keepAliveTime的使用,从这个方法我们可以看出先吃池是怎么让超过corePoolSize的那部分worker销毁的。
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
注意这里一段代码是keepAliveTime起作用的关键:
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
- allowCoreThreadTimeOut为false,线程即使空闲也不会被销毁;
- 倘若为ture,在keepAliveTime内仍空闲则会被销毁。
如果线程允许空闲等待而不被销毁timed == false,workQueue.take任务:
如果阻塞队列为空,当前线程会被挂起等待;
当队列中有任务加入时,线程被唤醒,take方法返回任务,并执行;
如果线程不允许无休止空闲timed == true, workQueue.poll任务: 如果在keepAliveTime时间内,阻塞队列还是没有任务,则返回null;
提交过程
- submit任务,等待线程池execute
- 执行FutureTask类的get方法时,会把主线程封装成WaitNode节点并保存在waiters链表中, 并阻塞等待运行结果;
- FutureTask任务执行完成后,通过UNSAFE设置waiters相应的waitNode为null,并通过LockSupport类unpark方法唤醒主线程;
在实际业务场景中,Future和Callable基本是成对出现的,Callable负责产生结果,Future负责获取结果。
- Callable接口类似于Runnable,只是Runnable没有返回值。
- Callable任务除了返回正常结果之外,如果发生异常,该异常也会被返回,即Future可以拿到异步执行任务各种结果;
- Future.get方法会导致主线程阻塞,直到Callable任务执行完成;
submit 方法
AbstractExecutorService.submit()实现了ExecutorService.submit() 可以获取执行完的返回值, 而ThreadPoolExecutor 是AbstractExecutorService.submit()的子类,所以submit方法也是ThreadPoolExecutor的方法。
// submit()在ExecutorService中的定义
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
// submit方法在AbstractExecutorService中的实现
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
// 通过submit方法提交的Callable任务会被封装成了一个FutureTask对象。
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
通过submit方法提交的Callable任务会被封装成了一个FutureTask对象。通过Executor.execute方法提交FutureTask到线程池中等待被执行,最终执行的是FutureTask的run方法;
关闭过程
shutdown方法会将线程池的状态设置为SHUTDOWN,线程池进入这个状态后,就拒绝再接受任务,然后会将剩余的任务全部执行完:
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//检查是否可以关闭线程
checkShutdownAccess();
//设置线程池状态
advanceRunState(SHUTDOWN);
//尝试中断worker
interruptIdleWorkers();
//预留方法,留给子类实现
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
tryTerminate();
}
private void interruptIdleWorkers() {
interruptIdleWorkers(false);
}
private void interruptIdleWorkers(boolean onlyOne) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//遍历所有的worker
for (Worker w : workers) {
Thread t = w.thread;
//先尝试调用w.tryLock(),如果获取到锁,就说明worker是空闲的,就可以直接中断它
//注意的是,worker自己本身实现了AQS同步框架,然后实现的类似锁的功能
//它实现的锁是不可重入的,所以如果worker在执行任务的时候,会先进行加锁,这里tryLock()就会返回false
if (!t.isInterrupted() && w.tryLock()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
} finally {
w.unlock();
}
}
if (onlyOne)
break;
}
} finally {
mainLock.unlock();
}
}
shutdownNow做的比较绝,它先将线程池状态设置为STOP,然后拒绝所有提交的任务。最后中断左右正在运行中的worker,然后清空任务队列。
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
//检测权限
advanceRunState(STOP);
//中断所有的worker
interruptWorkers();
//清空任务队列
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
private void interruptWorkers() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//遍历所有worker,然后调用中断方法
for (Worker w : workers)
w.interruptIfStarted();
} finally {
mainLock.unlock();
}
}
配置线程池需要考虑因素
从任务的优先级,任务的执行时间长短,任务的性质(CPU密集/ IO密集),任务的依赖关系这四个角度来分析。并且近可能地使用有界的工作队列。
性质不同的任务可用使用不同规模的线程池分开处理:
- CPU密集型: 尽可能少的线程,Ncpu+1
- IO密集型: 尽可能多的线程, Ncpu*2,比如数据库连接池
- 混合型: CPU密集型的任务与IO密集型任务的执行时间差别较小,拆分为两个线程池;否则没有必要拆分。
监控线程池的状态
可以使用ThreadPoolExecutor以下方法:
- getTaskCount
- getCompletedTaskCount
- getLargestPoolSize
- getPoolSize
- getActiveCount
参考
3.22 - CH22-ScheduledThreadPoolExecutor
概览
继承自 ThreadPoolExecutor,为任务提供延迟或周期执行,属于线程池的一种。相比 ThreadPoolExecutor 具有以下特性:
- 使用专门的任务类型—ScheduledFutureTask 来执行周期任务,也可以接收无需时间调度的任务(这些任务通过 ExecutorService 直接执行)。
- 使用专门的存储队列—DelayedWorkQueue 来存储任务,DelayedWorkQueue 是无界延迟队列 DelayedQueue 的一种。相比 ThreadPoolExecutor 简化了执行机制。
- 支持可选的 run-after-shutdown 参数,在池被关闭(shutdown)之后支持可选的逻辑来决定是否继续运行周期或延迟任务。并且当任务的(重新)提交操作与 shutdown 操作重叠时,复查逻辑也不相同。
层级结构
ScheduledThreadPoolExecutor 内部构造了两个类:
- ScheduledFutureTask:
- 继承 FutureTask,说明是一个异步运算任务。
- 实现 Rnnable、Future、Delayed 接口,说明是一个可以延迟执行的异步运算任务。
- DelayedWorkQueue:
- 专用于存储周期或延迟任务而定义的延迟队列,继承了 AbstractQueue,为了契合 ThreadPoolExecutor 也实现了 BlockingQueue 接口。
- 内部只允许存储 RunnableScheduledFuture 类型的任务。
- 与 DelayQueue 的不同之处在于它只允许存放 RunnableScheduledFuture 对象,并且自己实现了二叉堆(DelayQueue 利用了 PriorityQueue 的二叉堆结构)。
源码分析
内部类:ScheduledFutureTask
属性:
//为相同延时任务提供的顺序编号
private final long sequenceNumber;
//任务可以执行的时间,纳秒级
private long time;
//重复任务的执行周期时间,纳秒级。
private final long period;
//重新入队的任务
RunnableScheduledFuture<V> outerTask = this;
//延迟队列的索引,以支持更快的取消操作
int heapIndex;
- sequenceNumber:当两个任务具有相同的延迟时间时,按照 FIFO 的顺序入队,用于给这些任务编号。
- time:任务可以执行的时间点,纳秒单位,通过 triggerTime 方法计算得出。
- period:任务执行的周期间隔,那秒单位。
- 正数表示固定速率执行(为 scheduleAtFixedRate 提供服务)
- 负数表示固定延迟执行(为 scheduleWithFixedDelay 提供服务)
- 0 表示不重复执行。
- outerTask:重新入队的任务,通过 reExecutePeriodic 方法入队重新排序。
核心方法:run
public void run() {
boolean periodic = isPeriodic();//是否为周期任务
if (!canRunInCurrentRunState(periodic))//当前状态是否可以执行
cancel(false);
else if (!periodic)
//不是周期任务,直接执行
ScheduledFutureTask.super.run();
else if (ScheduledFutureTask.super.runAndReset()) {
setNextRunTime();//设置下一次运行时间
reExecutePeriodic(outerTask);//重排序一个周期任务
}
}
ScheduledFutureTask 的 run 方法重写了 FutureTask 的版本,以便执行周期任务时重置、重排任务。任务的执行通过父类 FutureTask.run 实现。
内部有两个针对周期任务的方法:
reExecutePeriodic 与 delayedExecute 的执行策略一致,只不过 reExecutePeriodic 不会执行拒绝策略而是直接丢弃任务。
cancel
public boolean cancel(boolean mayInterruptIfRunning) {
boolean cancelled = super.cancel(mayInterruptIfRunning);
if (cancelled && removeOnCancel && heapIndex >= 0)
remove(this);
return cancelled;
}
ScheduledFutureTask.cancel 本质上由其父类 FutureTask.cancel 实现。取消任务成功后会根据 removeOnCancel 参数来决定是否从队列中移除该任务。
核心属性
//关闭后继续执行已经存在的周期任务
private volatile boolean continueExistingPeriodicTasksAfterShutdown;
//关闭后继续执行已经存在的延时任务
private volatile boolean executeExistingDelayedTasksAfterShutdown = true;
//取消任务后移除
private volatile boolean removeOnCancel = false;
//为相同延时的任务提供的顺序编号,保证任务之间的FIFO顺序
private static final AtomicLong sequencer = new AtomicLong();
- 前两个参数是由 ScheduledThreadPoolExecutor 定义的 run-after-shutdown 参数,用于控制池关闭后任务的执行逻辑。
- removeOnCancel:用于控制取消任务后是否从队列中移除。
- 当一个已经提交的周期或延迟任务在运行之前被取消,那么它之后将不会再被执行。
- 默认配置下,这种已经取消的任务在届期之前不会被移除。
- 通过这种机制,可以方便检查和监控线程池状态,但也可能导致已经取消的任务无线滞留。
- 为了避免无线滞留,可以通过 setRemoveOnCancelPolicy 来设置移除策略,将参数 removeOnCancel 设为 true 可以在任务取消后立即从队列中移除。
- sequencer 是为具有相同延时时间的任务提供顺序编号,保证任务之间的 FIFO 顺序。与 ScheduledFutureTask 内部的 sequenceNumber 参数作用一致。
构造函数
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory, handler);
}
核心方法:schedule
public <V> ScheduledFuture<V> schedule(Callable<V> callable,
long delay,
TimeUnit unit) {
if (callable == null || unit == null)
throw new NullPointerException();
RunnableScheduledFuture<V> t = decorateTask(callable,
new ScheduledFutureTask<V>(callable, triggerTime(delay, unit)));//构造ScheduledFutureTask任务
delayedExecute(t);//任务执行主方法
return t;
}
主要用于执行一次性延迟任务,执行逻辑分为两步:
封装 Callable/Runnable:通过 triggerTime 计算出任务的延迟执行时加点,然后通过 ScheduledFutureTask 的构造函数将 Runnable/Callable 任务构造为 ScheduledThreadPoolExecutor 可以执行的任务类型,最后调用 decorateTask 方法执行用户自定义的任务逻辑。
- decorateTask 是一个用户可以自定义扩展的方法,默认实现下直接返回封装的 RunnableScheduledFuture:
protected <V> RunnableScheduledFuture<V> decorateTask(
Runnable runnable, RunnableScheduledFuture<V> task) {
return task;
}
执行任务:通过 delayedExecute 实现:
private void delayedExecute(RunnableScheduledFuture<?> task) {
if (isShutdown())
reject(task);//池已关闭,执行拒绝策略
else {
super.getQueue().add(task);//任务入队
if (isShutdown() &&
!canRunInCurrentRunState(task.isPeriodic()) &&//判断run-after-shutdown参数
remove(task))//移除任务
task.cancel(false);
else
ensurePrestart();//启动一个新的线程等待任务
}
}
- 如果池已经关闭(ctr <= SHUTDOWN),执行任务拒绝策略。
- 池正在运行,首先将任务入队排序,然后重新检查池的关闭状态,执行如下逻辑:
- 如果池正在运行,或者 run-after-shutdown 参数为 true,则调用父类方法 ensurePrestart 启动新线程等待执行任务。
- 如果池已经关闭,并且 run-after-shutdown 参数为 false,则执行父类(ThreadPoolExecutor)方法 remove 移除队列中的指定任务,成功移除后调用 ScheduledFutureTask.cancel 取消任务。
ensurePrestart 源码如下:
void ensurePrestart() {
int wc = workerCountOf(ctl.get());
if (wc < corePoolSize)
addWorker(null, true);
else if (wc == 0)
addWorker(null, false);
}
ensurePrestart是父类 ThreadPoolExecutor 的方法,用于启动一个新的工作线程等待执行任务,即使corePoolSize为0也会安排一个新线程。
核心方法:scheduleAtFixedRate、scheduleWithFixedDelay
/**
* 创建一个周期执行的任务,第一次执行延期时间为initialDelay,
* 之后每隔period执行一次,不等待第一次执行完成就开始计时
*/
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (period <= 0)
throw new IllegalArgumentException();
//构建RunnableScheduledFuture任务类型
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),//计算任务的延迟时间
unit.toNanos(period));//计算任务的执行周期
RunnableScheduledFuture<Void> t = decorateTask(command, sft);//执行用户自定义逻辑
sft.outerTask = t;//赋值给outerTask,准备重新入队等待下一次执行
delayedExecute(t);//执行任务
return t;
}
/**
* 创建一个周期执行的任务,第一次执行延期时间为initialDelay,
* 在第一次执行完之后延迟delay后开始下一次执行
*/
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
if (delay <= 0)
throw new IllegalArgumentException();
//构建RunnableScheduledFuture任务类型
ScheduledFutureTask<Void> sft =
new ScheduledFutureTask<Void>(command,
null,
triggerTime(initialDelay, unit),//计算任务的延迟时间
unit.toNanos(-delay));//计算任务的执行周期
RunnableScheduledFuture<Void> t = decorateTask(command, sft);//执行用户自定义逻辑
sft.outerTask = t;//赋值给outerTask,准备重新入队等待下一次执行
delayedExecute(t);//执行任务
return t;
}
二者的区别在于 unit.toNanos,scheduleAtFixedRate 传的是正值,而 scheduleWithFixedDelay 传的则是负值,这个值就是 ScheduledFutureTask 的 period 属性。
核心方法:shutdown
public void shutdown() {
super.shutdown();
}
//取消并清除由于关闭策略不应该运行的所有任务
@Override void onShutdown() {
BlockingQueue<Runnable> q = super.getQueue();
//获取run-after-shutdown参数
boolean keepDelayed =
getExecuteExistingDelayedTasksAfterShutdownPolicy();
boolean keepPeriodic =
getContinueExistingPeriodicTasksAfterShutdownPolicy();
if (!keepDelayed && !keepPeriodic) {//池关闭后不保留任务
//依次取消任务
for (Object e : q.toArray())
if (e instanceof RunnableScheduledFuture<?>)
((RunnableScheduledFuture<?>) e).cancel(false);
q.clear();//清除等待队列
}
else {//池关闭后保留任务
// Traverse snapshot to avoid iterator exceptions
//遍历快照以避免迭代器异常
for (Object e : q.toArray()) {
if (e instanceof RunnableScheduledFuture) {
RunnableScheduledFuture<?> t =
(RunnableScheduledFuture<?>)e;
if ((t.isPeriodic() ? !keepPeriodic : !keepDelayed) ||
t.isCancelled()) { // also remove if already cancelled
//如果任务已经取消,移除队列中的任务
if (q.remove(t))
t.cancel(false);
}
}
}
}
tryTerminate(); //终止线程池
}
池关闭方法调用了父类ThreadPoolExecutor的shutdown。
在shutdown方法中调用了关闭钩子onShutdown方法,它的主要作用是在关闭线程池后取消并清除由于关闭策略不应该运行的所有任务,这里主要是根据 run-after-shutdown 参数(continueExistingPeriodicTasksAfterShutdown和executeExistingDelayedTasksAfterShutdown)来决定线程池关闭后是否关闭已经存在的任务。
深入理解
为什么ThreadPoolExecutor 的调整策略却不适用于 ScheduledThreadPoolExecutor?
例如: 由于 ScheduledThreadPoolExecutor 是一个固定核心线程数大小的线程池,并且使用了一个无界队列,所以调整maximumPoolSize对其没有任何影响(所以 ScheduledThreadPoolExecutor 没有提供可以调整最大线程数的构造函数,默认最大线程数固定为Integer.MAX_VALUE)。此外,设置corePoolSize为0或者设置核心线程空闲后清除(allowCoreThreadTimeOut)同样也不是一个好的策略,因为一旦周期任务到达某一次运行周期时,可能导致线程池内没有线程去处理这些任务。
Executors 提供了哪几种方法来构造 ScheduledThreadPoolExecutor?
- newScheduledThreadPool: 可指定核心线程数的线程池。
- newSingleThreadScheduledExecutor: 只有一个工作线程的线程池。如果内部工作线程由于执行周期任务异常而被终止,则会新建一个线程替代它的位置。
注意: newScheduledThreadPool(1, threadFactory) 不等价于newSingleThreadScheduledExecutor。newSingleThreadScheduledExecutor创建的线程池保证内部只有一个线程执行任务,并且线程数不可扩展;而通过newScheduledThreadPool(1, threadFactory)创建的线程池可以通过setCorePoolSize方法来修改核心线程数。
3.23 - CH23-ForkJoin.md
概览
ForkJoin 框架是 JUC 中一种可以将大任务拆分为多个小任务并异步执行的工具,由 JDK 1.7 引入。
层级结构
主要包含 3 个模块:
- 任务对象:ForkJoinTask
- RecursiveTask
- RecursiveAction
- CountedCompleter
- 执行线程:ForkJoinWorkerThread
- 线程池:ForkJoinPool
ForkJoinPool 可以通过池中的 ForkJoinThread 来处理 ForkJoinTask。
// from 《A Java Fork/Join Framework》Dong Lea
Result solve(Problem problem) {
if (problem is small)
directly solve problem
else {
split problem into independent parts
fork new subtasks to solve each part
join all subtasks
compose result from subresults
}
}
- ForkJoinPool 只接收 ForkJoinTask 任务(在实际使用中,也可以接收 Runnable/Callable 任务,但在真正运行时,也会把这些任务封装成 ForkJoinTask 类型的任务)。
- RecursiveTask 是 ForkJoinTask 的子类,是一个可以递归执行的 ForkJoinTask。
- RecursiveAction 是一个无返回值的 RecursiveTask。
- CountedCompleter 在任务完成执行后会触发执行一个自定义的钩子函数。
在实际运用中,我们一般都会继承 RecursiveTask 、RecursiveAction 或 CountedCompleter 来实现我们的业务需求,而不会直接继承 ForkJoinTask 类。
核心思想:分治算法
分治算法(Divide-and-Conquer)把任务递归的拆分为各个子任务,这样可以更好的利用系统资源,尽可能的使用所有可用的计算能力来提升应用性能。首先看一下 Fork/Join 框架的任务运行机制:
核心思想:work-stealing
work-stealing(工作窃取)算法: 线程池内的所有工作线程都尝试找到并执行已经提交的任务,或者是被其他活动任务创建的子任务(如果不存在就阻塞等待)。
这种特性使得 ForkJoinPool 在运行多个可以产生子任务的任务,或者是提交的许多小任务时效率更高。尤其是构建异步模型的 ForkJoinPool 时,对不需要合并(join)的事件类型任务也非常适用。
在 ForkJoinPool 中,线程池中每个工作线程(ForkJoinWorkerThread)都对应一个任务队列(WorkQueue),工作线程优先处理来自自身队列的任务(LIFO或FIFO顺序,参数 mode 决定),然后以FIFO的顺序随机窃取其他队列中的任务。
具体思路如下:
- 每个线程都有自己的 WorkQueue,这是一个双端队列。
- 队列支持三个功能:push、pop、poll。
- push、pop 只能被队列的拥有线程调用,而 poll 可以被其他线程调用。
- 划分的子任务调用 fork 时,都会被 push 到自己的队列中。
- 默认情况下,工作线程从自己的双端队列中获取任务并执行。
- 当工作线程自己的队列已空,会随机从另一个线程的队列的尾部调用 poll 方法窃取任务。
执行流程
上图可以看出任务有两类:
- 直接通过 ForkJoinPool 提交的外部任务,存放在 workQueues 的偶数槽位。
- 通过内部 fork 分割的子任务,存放在 workQueues 的奇数槽位。
类层级
继承关系
内部类
- ForkJoinWorkerThreadFactory:内部线程工厂接口,用于创建工作线程 ForkJoinWorkerThread。
- DefautFaorkJoinWorkerThreadFactory:默认线程工厂。
- InnocuousForkJoinWorkerThreadFactory:无许可线程工厂,当系统变量中存在系统安全相关的属性时,使用该线程工厂。
- EmptyTask:内部占位类,用户替换队列中 join 的任务。
- ManagedBlocker:为 ForkJoinPool 中的任务提供扩展管理并行数的接口,一般用于可能会阻塞的任务。
- WorkQueue:ForkJoinPool 的核心数据结构,本质上是 work-stealing 模式的双端任务队列,内部存放 ForkJoinTask 任务对象,使用 @Contented 注解修饰防止伪共享。
- 工作线程在运行中产生新的任务(通常是应为调用了 fork)时,可以把 WorkQueue 的数据结构视为一个栈,新的任务放入栈顶;工作线程在处理自己队列中的任务时,按照 LIFO 的顺序。
- 工作线程在处理自己的工作队列的同时,会尝试窃取一个任务(可能来自刚刚提交到池的任务,或是来之其他工作线程的队列任务),此时可以把 WorkQueue 的数据结构视为一个 FIFO 队列,窃取任务唯一其他线程的工作队列的队首。
- 伪共享状态:缓存系统中是以缓存行(cache line)为单位存储的。缓存行是 2 的整数幂个连续字节,一般为 32-256 个字节。最常见的缓存行大小是 64 字节。但多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,即伪共享。
ForkJoinTask 继承关系
- ForkJoinTask 实现了 Future 接口,说明它也是一个可取消的异步运算任务。
- 实际上ForkJoinTask 是 Future 的轻量级实现,主要用在纯粹是计算的函数式任务或者操作完全独立的对象计算任务。
- fork 是主运行方法,用于异步执行;而 join 方法在任务结果计算完毕之后才会运行,用来合并或返回计算结果。
- 其内部类都比较简单:
- ExceptionNode 是用于存储任务执行期间的异常信息的单向链表;
- 其余四个类是为 Runnable/Callable 任务提供的适配器类,用于把 Runnable/Callable 转化为 ForkJoinTask 类型的任务(因为 ForkJoinPool 只可以运行 ForkJoinTask 类型的任务)。
源码解析
- 提交流程:外部任务提交
- 提交流程:子任务提交
- 执行过程:ForkJoinWorkerThread.run -> ForkJoinTask.doExec
- 结果获取:ForkJoinTask.join -> ForkJoinTask.invoke
ForkJoinPool
核心参数
在后面的源码解析中,我们会看到大量的位运算,这些位运算都是通过我们接下来介绍的一些常量参数来计算的。
例如,如果要更新活跃线程数,使用公式(UC_MASK & (c + AC_UNIT)) | (SP_MASK & c);c 代表当前 ctl,UC_MASK 和 SP_MASK 分别是高位和低位掩码,AC_UNIT 为活跃线程的增量数,使用(UC_MASK & (c + AC_UNIT))就可以计算出高32位,然后再加上低32位(SP_MASK & c),就拼接成了一个新的ctl。
ForkJoinPool 与 内部类 WorkQueue 共享的一些常量:
// Constants shared across ForkJoinPool and WorkQueue
// 限定参数
static final int SMASK = 0xffff; // 低位掩码,也是最大索引位
static final int MAX_CAP = 0x7fff; // 工作线程最大容量
static final int EVENMASK = 0xfffe; // 偶数低位掩码
static final int SQMASK = 0x007e; // workQueues 数组最多64个槽位
// ctl 子域和 WorkQueue.scanState 的掩码和标志位
static final int SCANNING = 1; // 标记是否正在运行任务
static final int INACTIVE = 1 << 31; // 失活状态 负数
static final int SS_SEQ = 1 << 16; // 版本戳,防止ABA问题
// ForkJoinPool.config 和 WorkQueue.config 的配置信息标记
static final int MODE_MASK = 0xffff << 16; // 模式掩码
static final int LIFO_QUEUE = 0; //LIFO队列
static final int FIFO_QUEUE = 1 << 16;//FIFO队列
static final int SHARED_QUEUE = 1 << 31; // 共享模式队列,负数
ForkJoinPool 中的相关常量和实例字段:
// 低位和高位掩码
private static final long SP_MASK = 0xffffffffL;
private static final long UC_MASK = ~SP_MASK;
// 活跃线程数
private static final int AC_SHIFT = 48;
private static final long AC_UNIT = 0x0001L << AC_SHIFT; //活跃线程数增量
private static final long AC_MASK = 0xffffL << AC_SHIFT; //活跃线程数掩码
// 工作线程数
private static final int TC_SHIFT = 32;
private static final long TC_UNIT = 0x0001L << TC_SHIFT; //工作线程数增量
private static final long TC_MASK = 0xffffL << TC_SHIFT; //掩码
private static final long ADD_WORKER = 0x0001L << (TC_SHIFT + 15); // 创建工作线程标志
// 池状态
private static final int RSLOCK = 1;
private static final int RSIGNAL = 1 << 1;
private static final int STARTED = 1 << 2;
private static final int STOP = 1 << 29;
private static final int TERMINATED = 1 << 30;
private static final int SHUTDOWN = 1 << 31;
// 实例字段
volatile long ctl; // 主控制参数
volatile int runState; // 运行状态锁
final int config; // 并行度|模式
int indexSeed; // 用于生成工作线程索引
volatile WorkQueue[] workQueues; // 主对象注册信息,workQueue
final ForkJoinWorkerThreadFactory factory;// 线程工厂
final UncaughtExceptionHandler ueh; // 每个工作线程的异常信息
final String workerNamePrefix; // 用于创建工作线程的名称
volatile AtomicLong stealCounter; // 偷取任务总数,也可作为同步监视器
/** 静态初始化字段 */
//线程工厂
public static final ForkJoinWorkerThreadFactory defaultForkJoinWorkerThreadFactory;
//启动或杀死线程的方法调用者的权限
private static final RuntimePermission modifyThreadPermission;
// 公共静态pool
static final ForkJoinPool common;
//并行度,对应内部common池
static final int commonParallelism;
//备用线程数,在tryCompensate中使用
private static int commonMaxSpares;
//创建workerNamePrefix(工作线程名称前缀)时的序号
private static int poolNumberSequence;
//线程阻塞等待新的任务的超时值(以纳秒为单位),默认2秒
private static final long IDLE_TIMEOUT = 2000L * 1000L * 1000L; // 2sec
//空闲超时时间,防止timer未命中
private static final long TIMEOUT_SLOP = 20L * 1000L * 1000L; // 20ms
//默认备用线程数
private static final int DEFAULT_COMMON_MAX_SPARES = 256;
//阻塞前自旋的次数,用在在awaitRunStateLock和awaitWork中
private static final int SPINS = 0;
//indexSeed的增量
private static final int SEED_INCREMENT = 0x9e3779b9;
ForkJoinPool 的内部状态都是通过一个64位的 long 型 变量ctl来存储,它由四个16位的子域组成:
- AC: 正在运行工作线程数减去目标并行度,高16位
- TC: 总工作线程数减去目标并行度,中高16位
- SS: 栈顶等待线程的版本计数和状态,中低16位
- ID: 栈顶 WorkQueue 在池中的索引(poolIndex),低16位
某些地方也提取了ctl的低32位(sp=(int)ctl)来检查工作线程状态,例如,当sp不为0时说明当前还有空闲工作线程。
ForkJoinPool.WorkQueue 中的相关属性:
//初始队列容量,2的幂
static final int INITIAL_QUEUE_CAPACITY = 1 << 13;
//最大队列容量
static final int MAXIMUM_QUEUE_CAPACITY = 1 << 26; // 64M
// 实例字段
volatile int scanState; // Woker状态, <0: inactive; odd:scanning
int stackPred; // 记录前一个栈顶的ctl
int nsteals; // 偷取任务数
int hint; // 记录偷取者索引,初始为随机索引
int config; // 池索引和模式
volatile int qlock; // 1: locked, < 0: terminate; else 0
volatile int base; //下一个poll操作的索引(栈底/队列头)
int top; // 下一个push操作的索引(栈顶/队列尾)
ForkJoinTask<?>[] array; // 任务数组
final ForkJoinPool pool; // the containing pool (may be null)
final ForkJoinWorkerThread owner; // 当前工作队列的工作线程,共享模式下为null
volatile Thread parker; // 调用park阻塞期间为owner,其他情况为null
volatile ForkJoinTask<?> currentJoin; // 记录被join过来的任务
volatile ForkJoinTask<?> currentSteal; // 记录从其他工作队列偷取过来的任务
ForkJoinTask
核心参数
/** 任务运行状态 */
volatile int status; // 任务运行状态
static final int DONE_MASK = 0xf0000000; // 任务完成状态标志位
static final int NORMAL = 0xf0000000; // must be negative
static final int CANCELLED = 0xc0000000; // must be < NORMAL
static final int EXCEPTIONAL = 0x80000000; // must be < CANCELLED
static final int SIGNAL = 0x00010000; // must be >= 1 << 16 等待信号
static final int SMASK = 0x0000ffff; // 低位掩码
ForkJoinPool:构造函数
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode) {
this(checkParallelism(parallelism),
checkFactory(factory),
handler,
asyncMode ? FIFO_QUEUE : LIFO_QUEUE,
"ForkJoinPool-" + nextPoolId() + "-worker-");
checkPermission();
}
- parallelism: 并行度,默认为CPU数,最小为1
- factory: 工作线程工厂
- handler: 处理工作线程运行任务时的异常情况类,默认为null
- asyncMode: 是否为异步模式,默认为 false。
- 如果为true,表示子任务的执行遵循 FIFO 顺序并且任务不能被合并(join),这种模式适用于工作线程只运行事件类型的异步任务。
在多数场景使用时,如果没有太强的业务需求,我们一般直接使用 ForkJoinPool 中的common池,在JDK1.8之后提供了ForkJoinPool.commonPool()方法可以直接使用common池,来看一下它的构造:
private static ForkJoinPool makeCommonPool() {
int parallelism = -1;
ForkJoinWorkerThreadFactory factory = null;
UncaughtExceptionHandler handler = null;
try { // ignore exceptions in accessing/parsing
String pp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.parallelism");//并行度
String fp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.threadFactory");//线程工厂
String hp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.exceptionHandler");//异常处理类
if (pp != null)
parallelism = Integer.parseInt(pp);
if (fp != null)
factory = ((ForkJoinWorkerThreadFactory) ClassLoader.
getSystemClassLoader().loadClass(fp).newInstance());
if (hp != null)
handler = ((UncaughtExceptionHandler) ClassLoader.
getSystemClassLoader().loadClass(hp).newInstance());
} catch (Exception ignore) {
}
if (factory == null) {
if (System.getSecurityManager() == null)
factory = defaultForkJoinWorkerThreadFactory;
else // use security-managed default
factory = new InnocuousForkJoinWorkerThreadFactory();
}
if (parallelism < 0 && // default 1 less than #cores
(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0)
parallelism = 1;//默认并行度为1
if (parallelism > MAX_CAP)
parallelism = MAX_CAP;
return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE,
"ForkJoinPool.commonPool-worker-");
}
使用common pool的优点就是我们可以通过指定系统参数的方式定义“并行度、线程工厂和异常处理类”;并且它使用的是同步模式,也就是说可以支持任务合并(join)。
ForkJoinPool:外部任务提交
向 ForkJoinPool 提交任务有三种方式:
- invoke()会等待任务计算完毕并返回计算结果;
- execute()是直接向池提交一个任务来异步执行,无返回结果;
- submit()也是异步执行,但是会返回提交的任务,在适当的时候可通过 task.get() 获取执行结果。
这三种提交方式都都是调用externalPush()方法来完成,所以接下来我们将从externalPush()方法开始逐步分析外部任务的执行过程。
externalPush
//添加给定任务到submission队列中
final void externalPush(ForkJoinTask<?> task) {
WorkQueue[] ws;
WorkQueue q;
int m;
int r = ThreadLocalRandom.getProbe();//探针值,用于计算WorkQueue槽位索引
int rs = runState;
if ((ws = workQueues) != null && (m = (ws.length - 1)) >= 0 &&
(q = ws[m & r & SQMASK]) != null && r != 0 && rs > 0 && //获取随机偶数槽位的workQueue
U.compareAndSwapInt(q, QLOCK, 0, 1)) {//锁定workQueue
ForkJoinTask<?>[] a;
int am, n, s;
if ((a = q.array) != null &&
(am = a.length - 1) > (n = (s = q.top) - q.base)) {
int j = ((am & s) << ASHIFT) + ABASE;//计算任务索引位置
U.putOrderedObject(a, j, task);//任务入列
U.putOrderedInt(q, QTOP, s + 1);//更新push slot
U.putIntVolatile(q, QLOCK, 0);//解除锁定
if (n <= 1)
signalWork(ws, q);//任务数小于1时尝试创建或激活一个工作线程
return;
}
U.compareAndSwapInt(q, QLOCK, 1, 0);//解除锁定
}
externalSubmit(task);//初始化workQueues及相关属性
}
externalPush和externalSubmit两个方法的联系:
- 它们的作用都是把任务放到队列中等待执行。
- 不同的是,externalSubmit可以说是完整版的externalPush,在任务首次提交时,需要初始化workQueues及其他相关属性,这个初始化操作就是externalSubmit来完成的;
- 而后再向池中提交的任务都是通过简化版的externalSubmit-externalPush来完成。
externalPush的执行流程很简单: 首先找到一个随机偶数槽位的 workQueue,然后把任务放入这个 workQueue 的任务数组中,并更新top位。如果队列的剩余任务数小于1,则尝试创建或激活一个工作线程来运行任务(防止在externalSubmit初始化时发生异常导致工作线程创建失败)。
externalSubmit
//任务提交
private void externalSubmit(ForkJoinTask<?> task) {
//初始化调用线程的探针值,用于计算WorkQueue索引
int r; // initialize caller's probe
if ((r = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit();
r = ThreadLocalRandom.getProbe();
}
for (; ; ) {
WorkQueue[] ws;
WorkQueue q;
int rs, m, k;
boolean move = false;
if ((rs = runState) < 0) {// 池已关闭
tryTerminate(false, false); // help terminate
throw new RejectedExecutionException();
}
//初始化workQueues
else if ((rs & STARTED) == 0 || // initialize
((ws = workQueues) == null || (m = ws.length - 1) < 0)) {
int ns = 0;
rs = lockRunState();//锁定runState
try {
//初始化
if ((rs & STARTED) == 0) {
//初始化stealCounter
U.compareAndSwapObject(this, STEALCOUNTER, null,
new AtomicLong());
//创建workQueues,容量为2的幂次方
// create workQueues array with size a power of two
int p = config & SMASK; // ensure at least 2 slots
int n = (p > 1) ? p - 1 : 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
n = (n + 1) << 1;
workQueues = new WorkQueue[n];
ns = STARTED;
}
} finally {
unlockRunState(rs, (rs & ~RSLOCK) | ns);//解锁并更新runState
}
} else if ((q = ws[k = r & m & SQMASK]) != null) {//获取随机偶数槽位的workQueue
if (q.qlock == 0 && U.compareAndSwapInt(q, QLOCK, 0, 1)) {//锁定 workQueue
ForkJoinTask<?>[] a = q.array;//当前workQueue的全部任务
int s = q.top;
boolean submitted = false; // initial submission or resizing
try { // locked version of push
if ((a != null && a.length > s + 1 - q.base) ||
(a = q.growArray()) != null) {//扩容
int j = (((a.length - 1) & s) << ASHIFT) + ABASE;
U.putOrderedObject(a, j, task);//放入给定任务
U.putOrderedInt(q, QTOP, s + 1);//修改push slot
submitted = true;
}
} finally {
U.compareAndSwapInt(q, QLOCK, 1, 0);//解除锁定
}
if (submitted) {//任务提交成功,创建或激活工作线程
signalWork(ws, q);//创建或激活一个工作线程来运行任务
return;
}
}
move = true; // move on failure 操作失败,重新获取探针值
} else if (((rs = runState) & RSLOCK) == 0) { // create new queue
q = new WorkQueue(this, null);
q.hint = r;
q.config = k | SHARED_QUEUE;
q.scanState = INACTIVE;
rs = lockRunState(); // publish index
if (rs > 0 && (ws = workQueues) != null &&
k < ws.length && ws[k] == null)
ws[k] = q; // 更新索引k位值的workQueue
//else terminated
unlockRunState(rs, rs & ~RSLOCK);
} else
move = true; // move if busy
if (move)
r = ThreadLocalRandom.advanceProbe(r);//重新获取线程探针值
}
}
externalSubmit是externalPush的完整版本,主要用于第一次提交任务时初始化workQueues及相关属性,并且提交给定任务到队列中。具体执行步骤如下:
如果池为终止状态(runState<0),调用tryTerminate来终止线程池,并抛出任务拒绝异常;
如果尚未初始化,就为 FJP 执行初始化操作: 初始化stealCounter、创建workerQueues,然后继续自旋;
初始化完成后,执行在externalPush中相同的操作: 获取 workQueue,放入指定任务。任务提交成功后调用signalWork方法创建或激活线程;
如果在步骤3中获取到的 workQueue 为null,会在这一步中创建一个 workQueue,创建成功继续自旋执行第三步操作;
如果非上述情况,或者有线程争用资源导致获取锁失败,就重新获取线程探针值继续自旋。
signalWork
final void signalWork(WorkQueue[] ws, WorkQueue q) {
long c;
int sp, i;
WorkQueue v;
Thread p;
while ((c = ctl) < 0L) { // too few active
if ((sp = (int) c) == 0) { // no idle workers
if ((c & ADD_WORKER) != 0L) // too few workers
tryAddWorker(c);//工作线程太少,添加新的工作线程
break;
}
if (ws == null) // unstarted/terminated
break;
if (ws.length <= (i = sp & SMASK)) // terminated
break;
if ((v = ws[i]) == null) // terminating
break;
//计算ctl,加上版本戳SS_SEQ避免ABA问题
int vs = (sp + SS_SEQ) & ~INACTIVE; // next scanState
int d = sp - v.scanState; // screen CAS
//计算活跃线程数(高32位)并更新为下一个栈顶的scanState(低32位)
long nc = (UC_MASK & (c + AC_UNIT)) | (SP_MASK & v.stackPred);
if (d == 0 && U.compareAndSwapLong(this, CTL, c, nc)) {
v.scanState = vs; // activate v
if ((p = v.parker) != null)
U.unpark(p);//唤醒阻塞线程
break;
}
if (q != null && q.base == q.top) // no more work
break;
}
}
新建或唤醒一个工作线程,在externalPush、externalSubmit、workQueue.push、scan中调用。如果还有空闲线程,则尝试唤醒索引到的 WorkQueue 的parker线程;如果工作线程过少((ctl & ADD_WORKER) != 0L),则调用tryAddWorker添加一个新的工作线程。
tryAddWorker
private void tryAddWorker(long c) {
boolean add = false;
do {
long nc = ((AC_MASK & (c + AC_UNIT)) |
(TC_MASK & (c + TC_UNIT)));
if (ctl == c) {
int rs, stop; // check if terminating
if ((stop = (rs = lockRunState()) & STOP) == 0)
add = U.compareAndSwapLong(this, CTL, c, nc);
unlockRunState(rs, rs & ~RSLOCK);//释放锁
if (stop != 0)
break;
if (add) {
createWorker();//创建工作线程
break;
}
}
} while (((c = ctl) & ADD_WORKER) != 0L && (int)c == 0);
}
尝试添加一个新的工作线程,首先更新ctl中的工作线程数,然后调用createWorker()创建工作线程。
createWorker
private boolean createWorker() {
ForkJoinWorkerThreadFactory fac = factory;
Throwable ex = null;
ForkJoinWorkerThread wt = null;
try {
if (fac != null && (wt = fac.newThread(this)) != null) {
wt.start();
return true;
}
} catch (Throwable rex) {
ex = rex;
}
deregisterWorker(wt, ex);//线程创建失败处理
return false;
}
createWorker首先通过线程工厂创一个新的ForkJoinWorkerThread,然后启动这个工作线程(wt.start())。如果期间发生异常,调用deregisterWorker处理线程创建失败的逻辑(deregisterWorker在后面再详细说明)。
ForkJoinWorkerThread 的构造函数如下:
protected ForkJoinWorkerThread(ForkJoinPool pool) {
// Use a placeholder until a useful name can be set in registerWorker
super("aForkJoinWorkerThread");
this.pool = pool;
this.workQueue = pool.registerWorker(this);
}
可以看到 ForkJoinWorkerThread 在构造时首先调用父类 Thread 的方法,然后为工作线程注册pool和workQueue,而workQueue的注册任务由ForkJoinPool.registerWorker来完成。
registerWorker
final WorkQueue registerWorker(ForkJoinWorkerThread wt) {
UncaughtExceptionHandler handler;
//设置为守护线程
wt.setDaemon(true); // configure thread
if ((handler = ueh) != null)
wt.setUncaughtExceptionHandler(handler);
WorkQueue w = new WorkQueue(this, wt);//构造新的WorkQueue
int i = 0; // assign a pool index
int mode = config & MODE_MASK;
int rs = lockRunState();
try {
WorkQueue[] ws;
int n; // skip if no array
if ((ws = workQueues) != null && (n = ws.length) > 0) {
//生成新建WorkQueue的索引
int s = indexSeed += SEED_INCREMENT; // unlikely to collide
int m = n - 1;
i = ((s << 1) | 1) & m; // Worker任务放在奇数索引位 odd-numbered indices
if (ws[i] != null) { // collision 已存在,重新计算索引位
int probes = 0; // step by approx half n
int step = (n <= 4) ? 2 : ((n >>> 1) & EVENMASK) + 2;
//查找可用的索引位
while (ws[i = (i + step) & m] != null) {
if (++probes >= n) {//所有索引位都被占用,对workQueues进行扩容
workQueues = ws = Arrays.copyOf(ws, n <<= 1);//workQueues 扩容
m = n - 1;
probes = 0;
}
}
}
w.hint = s; // use as random seed
w.config = i | mode;
w.scanState = i; // publication fence
ws[i] = w;
}
} finally {
unlockRunState(rs, rs & ~RSLOCK);
}
wt.setName(workerNamePrefix.concat(Integer.toString(i >>> 1)));
return w;
}
registerWorker是 ForkJoinWorkerThread 构造器的回调函数,用于创建和记录工作线程的 WorkQueue。比较简单,就不多赘述了。注意在此为工作线程创建的 WorkQueue 是放在奇数索引的(代码行: i = ((s « 1) | 1) & m;)
总结
在createWorker()中启动工作线程后(wt.start()),当为线程分配到CPU执行时间片之后会运行 ForkJoinWorkerThread 的run方法开启线程来执行任务。工作线程执行任务的流程我们在讲完内部任务提交之后会统一讲解。
ForkJoinPool:子任务提交
子任务的提交相对比较简单,由任务的fork()方法完成。通过上面的流程图可以看到任务被分割(fork)之后调用了ForkJoinPool.WorkQueue.push()方法直接把任务放到队列中等待被执行。
ForkJoinTask.fork()
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
- 如果当前线程是 Worker 线程,说明当前任务是fork分割的子任务,通过ForkJoinPool.workQueue.push()方法直接把任务放到自己的等待队列中;
- 否则调用ForkJoinPool.externalPush()提交到一个随机的等待队列中(外部任务)。
ForkJoinPool.WorkQueue.push()
final void push(ForkJoinTask<?> task) {
ForkJoinTask<?>[] a;
ForkJoinPool p;
int b = base, s = top, n;
if ((a = array) != null) { // ignore if queue removed
int m = a.length - 1; // fenced write for task visibility
U.putOrderedObject(a, ((m & s) << ASHIFT) + ABASE, task);
U.putOrderedInt(this, QTOP, s + 1);
if ((n = s - b) <= 1) {//首次提交,创建或唤醒一个工作线程
if ((p = pool) != null)
p.signalWork(p.workQueues, this);
} else if (n >= m)
growArray();
}
}
首先把任务放入等待队列并更新top位;如果当前 WorkQueue 为新建的等待队列(top-base<=1),则调用signalWork方法为当前 WorkQueue 新建或唤醒一个工作线程;如果 WorkQueue 中的任务数组容量过小,则调用growArray()方法对其进行两倍扩容,growArray()方法源码如下:
final ForkJoinTask<?>[] growArray() {
ForkJoinTask<?>[] oldA = array;//获取内部任务列表
int size = oldA != null ? oldA.length << 1 : INITIAL_QUEUE_CAPACITY;
if (size > MAXIMUM_QUEUE_CAPACITY)
throw new RejectedExecutionException("Queue capacity exceeded");
int oldMask, t, b;
//新建一个两倍容量的任务数组
ForkJoinTask<?>[] a = array = new ForkJoinTask<?>[size];
if (oldA != null && (oldMask = oldA.length - 1) >= 0 &&
(t = top) - (b = base) > 0) {
int mask = size - 1;
//从老数组中拿出数据,放到新的数组中
do { // emulate poll from old array, push to new array
ForkJoinTask<?> x;
int oldj = ((b & oldMask) << ASHIFT) + ABASE;
int j = ((b & mask) << ASHIFT) + ABASE;
x = (ForkJoinTask<?>) U.getObjectVolatile(oldA, oldj);
if (x != null &&
U.compareAndSwapObject(oldA, oldj, x, null))
U.putObjectVolatile(a, j, x);
} while (++b != t);
}
return a;
}
总结
到此,两种任务的提交流程都已经解析完毕,下一节我们来一起看看任务提交之后是如何被运行的。
ForkJoinPool:任务执行
回到我们开始时的流程图,在ForkJoinPool .createWorker()方法中创建工作线程后,会启动工作线程,系统为工作线程分配到CPU执行时间片之后会执行 ForkJoinWorkerThread 的run()方法正式开始执行任务。
ForkJoinWorkerThread.run()
public void run() {
if (workQueue.array == null) { // only run once
Throwable exception = null;
try {
onStart();//钩子方法,可自定义扩展
pool.runWorker(workQueue);
} catch (Throwable ex) {
exception = ex;
} finally {
try {
onTermination(exception);//钩子方法,可自定义扩展
} catch (Throwable ex) {
if (exception == null)
exception = ex;
} finally {
pool.deregisterWorker(this, exception);//处理异常
}
}
}
}
在工作线程运行前后会调用自定义钩子函数(onStart和onTermination),任务的运行则是调用了ForkJoinPool.runWorker()。如果全部任务执行完毕或者期间遭遇异常,则通过ForkJoinPool.deregisterWorker关闭工作线程并处理异常信息(deregisterWorker方法我们后面会详细讲解)。
ForkJoinPool.runWorker(WorkQueue w)
final void runWorker(WorkQueue w) {
w.growArray(); // allocate queue
int seed = w.hint; // initially holds randomization hint
int r = (seed == 0) ? 1 : seed; // avoid 0 for xorShift
for (ForkJoinTask<?> t; ; ) {
if ((t = scan(w, r)) != null)//扫描任务执行
w.runTask(t);
else if (!awaitWork(w, r))
break;
r ^= r << 13;
r ^= r >>> 17;
r ^= r << 5; // xorshift
}
}
runWorker是 ForkJoinWorkerThread 的主运行方法,用来依次执行当前工作线程中的任务。函数流程很简单: 调用scan方法依次获取任务,然后调用WorkQueue .runTask运行任务;如果未扫描到任务,则调用awaitWork等待,直到工作线程/线程池终止或等待超时。
ForkJoinPool.scan(WorkQueue w, int r)
private ForkJoinTask<?> scan(WorkQueue w, int r) {
WorkQueue[] ws;
int m;
if ((ws = workQueues) != null && (m = ws.length - 1) > 0 && w != null) {
int ss = w.scanState; // initially non-negative
//初始扫描起点,自旋扫描
for (int origin = r & m, k = origin, oldSum = 0, checkSum = 0; ; ) {
WorkQueue q;
ForkJoinTask<?>[] a;
ForkJoinTask<?> t;
int b, n;
long c;
if ((q = ws[k]) != null) {//获取workQueue
if ((n = (b = q.base) - q.top) < 0 &&
(a = q.array) != null) { // non-empty
//计算偏移量
long i = (((a.length - 1) & b) << ASHIFT) + ABASE;
if ((t = ((ForkJoinTask<?>)
U.getObjectVolatile(a, i))) != null && //取base位置任务
q.base == b) {//stable
if (ss >= 0) { //scanning
if (U.compareAndSwapObject(a, i, t, null)) {//
q.base = b + 1;//更新base位
if (n < -1) // signal others
signalWork(ws, q);//创建或唤醒工作线程来运行任务
return t;
}
} else if (oldSum == 0 && // try to activate 尝试激活工作线程
w.scanState < 0)
tryRelease(c = ctl, ws[m & (int) c], AC_UNIT);//唤醒栈顶工作线程
}
//base位置任务为空或base位置偏移,随机移位重新扫描
if (ss < 0) // refresh
ss = w.scanState;
r ^= r << 1;
r ^= r >>> 3;
r ^= r << 10;
origin = k = r & m; // move and rescan
oldSum = checkSum = 0;
continue;
}
checkSum += b;//队列任务为空,记录base位
}
//更新索引k 继续向后查找
if ((k = (k + 1) & m) == origin) { // continue until stable
//运行到这里说明已经扫描了全部的 workQueues,但并未扫描到任务
if ((ss >= 0 || (ss == (ss = w.scanState))) &&
oldSum == (oldSum = checkSum)) {
if (ss < 0 || w.qlock < 0) // already inactive
break;// 已经被灭活或终止,跳出循环
//对当前WorkQueue进行灭活操作
int ns = ss | INACTIVE; // try to inactivate
long nc = ((SP_MASK & ns) |
(UC_MASK & ((c = ctl) - AC_UNIT)));//计算ctl为INACTIVE状态并减少活跃线程数
w.stackPred = (int) c; // hold prev stack top
U.putInt(w, QSCANSTATE, ns);//修改scanState为inactive状态
if (U.compareAndSwapLong(this, CTL, c, nc))//更新scanState为灭活状态
ss = ns;
else
w.scanState = ss; // back out
}
checkSum = 0;//重置checkSum,继续循环
}
}
}
return null;
}
扫描并尝试偷取一个任务。使用w.hint进行随机索引 WorkQueue,也就是说并不一定会执行当前 WorkQueue 中的任务,而是偷取别的Worker的任务来执行。
函数的大致流程如下:
- 取随机位置的一个 WorkQueue;
- 获取base位的 ForkJoinTask,成功取到后更新base位并返回任务;如果取到的 WorkQueue 中任务数大于1,则调用signalWork创建或唤醒其他工作线程;
- 如果当前工作线程处于不活跃状态(INACTIVE),则调用tryRelease尝试唤醒栈顶工作线程来执行。
tryRelease源码如下:
private boolean tryRelease(long c, WorkQueue v, long inc) {
int sp = (int) c, vs = (sp + SS_SEQ) & ~INACTIVE;
Thread p;
//ctl低32位等于scanState,说明可以唤醒parker线程
if (v != null && v.scanState == sp) { // v is at top of stack
//计算活跃线程数(高32位)并更新为下一个栈顶的scanState(低32位)
long nc = (UC_MASK & (c + inc)) | (SP_MASK & v.stackPred);
if (U.compareAndSwapLong(this, CTL, c, nc)) {
v.scanState = vs;
if ((p = v.parker) != null)
U.unpark(p);//唤醒线程
return true;
}
}
return false;
}
- 如果base位任务为空或发生偏移,则对索引位进行随机移位,然后重新扫描;
- 如果扫描整个workQueues之后没有获取到任务,则设置当前工作线程为INACTIVE状态;然后重置checkSum,再次扫描一圈之后如果还没有任务则跳出循环返回null。
ForkJoinPool.awaitWork(WorkQueue w, int r)
private boolean awaitWork(WorkQueue w, int r) {
if (w == null || w.qlock < 0) // w is terminating
return false;
for (int pred = w.stackPred, spins = SPINS, ss; ; ) {
if ((ss = w.scanState) >= 0)//正在扫描,跳出循环
break;
else if (spins > 0) {
r ^= r << 6;
r ^= r >>> 21;
r ^= r << 7;
if (r >= 0 && --spins == 0) { // randomize spins
WorkQueue v;
WorkQueue[] ws;
int s, j;
AtomicLong sc;
if (pred != 0 && (ws = workQueues) != null &&
(j = pred & SMASK) < ws.length &&
(v = ws[j]) != null && // see if pred parking
(v.parker == null || v.scanState >= 0))
spins = SPINS; // continue spinning
}
} else if (w.qlock < 0) // 当前workQueue已经终止,返回false recheck after spins
return false;
else if (!Thread.interrupted()) {//判断线程是否被中断,并清除中断状态
long c, prevctl, parkTime, deadline;
int ac = (int) ((c = ctl) >> AC_SHIFT) + (config & SMASK);//活跃线程数
if ((ac <= 0 && tryTerminate(false, false)) || //无active线程,尝试终止
(runState & STOP) != 0) // pool terminating
return false;
if (ac <= 0 && ss == (int) c) { // is last waiter
//计算活跃线程数(高32位)并更新为下一个栈顶的scanState(低32位)
prevctl = (UC_MASK & (c + AC_UNIT)) | (SP_MASK & pred);
int t = (short) (c >>> TC_SHIFT); // shrink excess spares
if (t > 2 && U.compareAndSwapLong(this, CTL, c, prevctl))//总线程过量
return false; // else use timed wait
//计算空闲超时时间
parkTime = IDLE_TIMEOUT * ((t >= 0) ? 1 : 1 - t);
deadline = System.nanoTime() + parkTime - TIMEOUT_SLOP;
} else
prevctl = parkTime = deadline = 0L;
Thread wt = Thread.currentThread();
U.putObject(wt, PARKBLOCKER, this); // emulate LockSupport
w.parker = wt;//设置parker,准备阻塞
if (w.scanState < 0 && ctl == c) // recheck before park
U.park(false, parkTime);//阻塞指定的时间
U.putOrderedObject(w, QPARKER, null);
U.putObject(wt, PARKBLOCKER, null);
if (w.scanState >= 0)//正在扫描,说明等到任务,跳出循环
break;
if (parkTime != 0L && ctl == c &&
deadline - System.nanoTime() <= 0L &&
U.compareAndSwapLong(this, CTL, c, prevctl))//未等到任务,更新ctl,返回false
return false; // shrink pool
}
}
return true;
}
回到runWorker方法,如果scan方法未扫描到任务,会调用awaitWork等待获取任务。函数的具体执行流程大家看源码,这里简单说一下:
- 在等待获取任务期间,如果工作线程或线程池已经终止则直接返回false。
- 如果当前无 active 线程,尝试终止线程池并返回false,如果终止失败并且当前是最后一个等待的 Worker,就阻塞指定的时间(IDLE_TIMEOUT);等到届期或被唤醒后如果发现自己是scanning(scanState >= 0)状态,说明已经等到任务,跳出等待返回true继续 scan,否则的更新ctl并返回false。
WorkQueue.runTask()
final void runTask(ForkJoinTask<?> task) {
if (task != null) {
scanState &= ~SCANNING; // mark as busy
(currentSteal = task).doExec();//更新currentSteal并执行任务
U.putOrderedObject(this, QCURRENTSTEAL, null); // release for GC
execLocalTasks();//依次执行本地任务
ForkJoinWorkerThread thread = owner;
if (++nsteals < 0) // collect on overflow
transferStealCount(pool);//增加偷取任务数
scanState |= SCANNING;
if (thread != null)
thread.afterTopLevelExec();//执行钩子函数
}
}
在scan方法扫描到任务之后,调用WorkQueue.runTask()来执行获取到的任务,大概流程如下:
- 标记scanState为正在执行状态;
- 更新currentSteal为当前获取到的任务并执行它,任务的执行调用了ForkJoinTask.doExec()方法,源码如下:
//ForkJoinTask.doExec()
final int doExec() {
int s; boolean completed;
if ((s = status) >= 0) {
try {
completed = exec();//执行我们定义的任务
} catch (Throwable rex) {
return setExceptionalCompletion(rex);
}
if (completed)
s = setCompletion(NORMAL);
}
return s;
}
- 调用execLocalTasks依次执行当前WorkerQueue中的任务,源码如下:
//执行并移除所有本地任务
final void execLocalTasks() {
int b = base, m, s;
ForkJoinTask<?>[] a = array;
if (b - (s = top - 1) <= 0 && a != null &&
(m = a.length - 1) >= 0) {
if ((config & FIFO_QUEUE) == 0) {//FIFO模式
for (ForkJoinTask<?> t; ; ) {
if ((t = (ForkJoinTask<?>) U.getAndSetObject
(a, ((m & s) << ASHIFT) + ABASE, null)) == null)//FIFO执行,取top任务
break;
U.putOrderedInt(this, QTOP, s);
t.doExec();//执行
if (base - (s = top - 1) > 0)
break;
}
} else
pollAndExecAll();//LIFO模式执行,取base任务
}
}
- 更新窃取次数。
- 还原scanState并执行钩子函数。
ForkJoinPool.deregisterWorker(ForkJoinWorkerThread wt, Throwable ex)
final void deregisterWorker(ForkJoinWorkerThread wt, Throwable ex) {
WorkQueue w = null;
//1.移除workQueue
if (wt != null && (w = wt.workQueue) != null) {//获取ForkJoinWorkerThread的等待队列
WorkQueue[] ws; // remove index from array
int idx = w.config & SMASK;//计算workQueue索引
int rs = lockRunState();//获取runState锁和当前池运行状态
if ((ws = workQueues) != null && ws.length > idx && ws[idx] == w)
ws[idx] = null;//移除workQueue
unlockRunState(rs, rs & ~RSLOCK);//解除runState锁
}
//2.减少CTL数
long c; // decrement counts
do {} while (!U.compareAndSwapLong
(this, CTL, c = ctl, ((AC_MASK & (c - AC_UNIT)) |
(TC_MASK & (c - TC_UNIT)) |
(SP_MASK & c))));
//3.处理被移除workQueue内部相关参数
if (w != null) {
w.qlock = -1; // ensure set
w.transferStealCount(this);
w.cancelAll(); // cancel remaining tasks
}
//4.如果线程未终止,替换被移除的workQueue并唤醒内部线程
for (;;) { // possibly replace
WorkQueue[] ws; int m, sp;
//尝试终止线程池
if (tryTerminate(false, false) || w == null || w.array == null ||
(runState & STOP) != 0 || (ws = workQueues) == null ||
(m = ws.length - 1) < 0) // already terminating
break;
//唤醒被替换的线程,依赖于下一步
if ((sp = (int)(c = ctl)) != 0) { // wake up replacement
if (tryRelease(c, ws[sp & m], AC_UNIT))
break;
}
//创建工作线程替换
else if (ex != null && (c & ADD_WORKER) != 0L) {
tryAddWorker(c); // create replacement
break;
}
else // don't need replacement
break;
}
//5.处理异常
if (ex == null) // help clean on way out
ForkJoinTask.helpExpungeStaleExceptions();
else // rethrow
ForkJoinTask.rethrow(ex);
}
deregisterWorker方法用于工作线程运行完毕之后终止线程或处理工作线程异常,主要就是清除已关闭的工作线程或回滚创建线程之前的操作,并把传入的异常抛给 ForkJoinTask 来处理。具体步骤见源码注释。
ForkJoinPool:获取结果
//合并任务结果
public final V join() {
int s;
if ((s = doJoin() & DONE_MASK) != NORMAL)
reportException(s);
return getRawResult();
}
//join, get, quietlyJoin的主实现方法
private int doJoin() {
int s; Thread t; ForkJoinWorkerThread wt; ForkJoinPool.WorkQueue w;
return (s = status) < 0 ? s :
((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ?
(w = (wt = (ForkJoinWorkerThread)t).workQueue).
tryUnpush(this) && (s = doExec()) < 0 ? s :
wt.pool.awaitJoin(w, this, 0L) :
externalAwaitDone();
}
//执行任务,并等待任务完成并返回结果
public final V invoke() {
int s;
if ((s = doInvoke() & DONE_MASK) != NORMAL)
reportException(s);
return getRawResult();
}
//invoke, quietlyInvoke的主实现方法
private int doInvoke() {
int s; Thread t; ForkJoinWorkerThread wt;
return (s = doExec()) < 0 ? s :
((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ?
(wt = (ForkJoinWorkerThread)t).pool.
awaitJoin(wt.workQueue, this, 0L) :
externalAwaitDone();
}
join()方法一把是在任务fork()之后调用,用来获取(或者叫“合并”)任务的执行结果。
ForkJoinTask的join()和invoke()方法都可以用来获取任务的执行结果(另外还有get方法也是调用了doJoin来获取任务结果,但是会响应运行时异常),它们对外部提交任务的执行方式一致,都是通过externalAwaitDone方法等待执行结果。
不同的是invoke()方法会直接执行当前任务;而join()方法则是在当前任务在队列 top 位时(通过tryUnpush方法判断)才能执行,如果当前任务不在 top 位或者任务执行失败调用ForkJoinPool.awaitJoin方法帮助执行或阻塞当前 join 任务。(所以在官方文档中建议了我们对ForkJoinTask任务的调用顺序,一对 fork-join操作一般按照如下顺序调用: a.fork(); b.fork(); b.join(); a.join();。因为任务 b 是后面进入队列,也就是说它是在栈顶的(top 位),在它fork()之后直接调用join()就可以直接执行而不会调用ForkJoinPool.awaitJoin方法去等待。)
在这些方法中,join()相对比较全面,所以之后的讲解我们将从join()开始逐步向下分析,首先看一下join()的执行流程:
后面的源码分析中,我们首先讲解比较简单的外部 join 任务(externalAwaitDone),然后再讲解内部 join 任务(从ForkJoinPool.awaitJoin()开始)。
ForkJoinTask.externalAwaitDone()
private int externalAwaitDone() {
//执行任务
int s = ((this instanceof CountedCompleter) ? // try helping
ForkJoinPool.common.externalHelpComplete( // CountedCompleter任务
(CountedCompleter<?>)this, 0) :
ForkJoinPool.common.tryExternalUnpush(this) ? doExec() : 0); // ForkJoinTask任务
if (s >= 0 && (s = status) >= 0) {//执行失败,进入等待
boolean interrupted = false;
do {
if (U.compareAndSwapInt(this, STATUS, s, s | SIGNAL)) { //更新state
synchronized (this) {
if (status >= 0) {//SIGNAL 等待信号
try {
wait(0L);
} catch (InterruptedException ie) {
interrupted = true;
}
}
else
notifyAll();
}
}
} while ((s = status) >= 0);
if (interrupted)
Thread.currentThread().interrupt();
}
return s;
}
如果当前join为外部调用,则调用此方法执行任务,如果任务执行失败就进入等待。方法本身是很简单的,需要注意的是对不同的任务类型分两种情况:
- 如果我们的任务为 CountedCompleter 类型的任务,则调用externalHelpComplete方法来执行任务。
- 其他类型的 ForkJoinTask 任务调用tryExternalUnpush来执行,源码如下:
//为外部提交者提供 tryUnpush 功能(给定任务在top位时弹出任务)
final boolean tryExternalUnpush(ForkJoinTask<?> task) {
WorkQueue[] ws;
WorkQueue w;
ForkJoinTask<?>[] a;
int m, s;
int r = ThreadLocalRandom.getProbe();
if ((ws = workQueues) != null && (m = ws.length - 1) >= 0 &&
(w = ws[m & r & SQMASK]) != null &&
(a = w.array) != null && (s = w.top) != w.base) {
long j = (((a.length - 1) & (s - 1)) << ASHIFT) + ABASE; //取top位任务
if (U.compareAndSwapInt(w, QLOCK, 0, 1)) { //加锁
if (w.top == s && w.array == a &&
U.getObject(a, j) == task &&
U.compareAndSwapObject(a, j, task, null)) { //符合条件,弹出
U.putOrderedInt(w, QTOP, s - 1); //更新top
U.putOrderedInt(w, QLOCK, 0); //解锁,返回true
return true;
}
U.compareAndSwapInt(w, QLOCK, 1, 0); //当前任务不在top位,解锁返回false
}
}
return false;
}
tryExternalUnpush的作用就是判断当前任务是否在top位,如果是则弹出任务,然后在externalAwaitDone中调用doExec()执行任务。
ForkJoinPool.awaitJoin()
final int awaitJoin(WorkQueue w, ForkJoinTask<?> task, long deadline) {
int s = 0;
if (task != null && w != null) {
ForkJoinTask<?> prevJoin = w.currentJoin; //获取给定Worker的join任务
U.putOrderedObject(w, QCURRENTJOIN, task); //把currentJoin替换为给定任务
//判断是否为CountedCompleter类型的任务
CountedCompleter<?> cc = (task instanceof CountedCompleter) ?
(CountedCompleter<?>) task : null;
for (; ; ) {
if ((s = task.status) < 0) //已经完成|取消|异常 跳出循环
break;
if (cc != null)//CountedCompleter任务由helpComplete来完成join
helpComplete(w, cc, 0);
else if (w.base == w.top || w.tryRemoveAndExec(task)) //尝试执行
helpStealer(w, task); //队列为空或执行失败,任务可能被偷,帮助偷取者执行该任务
if ((s = task.status) < 0) //已经完成|取消|异常,跳出循环
break;
//计算任务等待时间
long ms, ns;
if (deadline == 0L)
ms = 0L;
else if ((ns = deadline - System.nanoTime()) <= 0L)
break;
else if ((ms = TimeUnit.NANOSECONDS.toMillis(ns)) <= 0L)
ms = 1L;
if (tryCompensate(w)) {//执行补偿操作
task.internalWait(ms);//补偿执行成功,任务等待指定时间
U.getAndAddLong(this, CTL, AC_UNIT);//更新活跃线程数
}
}
U.putOrderedObject(w, QCURRENTJOIN, prevJoin);//循环结束,替换为原来的join任务
}
return s;
}
如果当前 join 任务不在Worker等待队列的top位,或者任务执行失败,调用此方法来帮助执行或阻塞当前 join 的任务。函数执行流程如下:
- 由于每次调用awaitJoin都会优先执行当前join的任务,所以首先会更新currentJoin为当前join任务;
- 进入自旋
- 首先检查任务是否已经完成(通过task.status < 0判断),如果给定任务执行完毕|取消|异常 则跳出循环返回执行状态s;
- 如果是 CountedCompleter 任务类型,调用helpComplete方法来完成join操作(后面笔者会开新篇来专门讲解CountedCompleter,本篇暂时不做详细解析);
- 非 CountedCompleter 任务类型调用WorkQueue.tryRemoveAndExec尝试执行任务;
- 如果给定 WorkQueue 的等待队列为空或任务执行失败,说明任务可能被偷,调用helpStealer帮助偷取者执行任务(也就是说,偷取者帮我执行任务,我去帮偷取者执行它的任务);
- 再次判断任务是否执行完毕(task.status < 0),如果任务执行失败,计算一个等待时间准备进行补偿操作;
- 调用tryCompensate方法为给定 WorkQueue 尝试执行补偿操作。在执行补偿期间,如果发现 资源争用|池处于unstable状态|当前Worker已终止,则调用ForkJoinTask.internalWait()方法等待指定的时间,任务唤醒之后继续自旋,ForkJoinTask.internalWait()源码如下:
final void internalWait(long timeout) {
int s;
if ((s = status) >= 0 && // force completer to issue notify
U.compareAndSwapInt(this, STATUS, s, s | SIGNAL)) {//更新任务状态为SIGNAL(等待唤醒)
synchronized (this) {
if (status >= 0)
try { wait(timeout); } catch (InterruptedException ie) { }
else
notifyAll();
}
}
}
在awaitJoin中,我们总共调用了三个比较复杂的方法: tryRemoveAndExec、helpStealer和tryCompensate,下面我们依次讲解。
WorkQueue.tryRemoveAndExec(ForkJoinTask task)
final boolean tryRemoveAndExec(ForkJoinTask<?> task) {
ForkJoinTask<?>[] a;
int m, s, b, n;
if ((a = array) != null && (m = a.length - 1) >= 0 &&
task != null) {
while ((n = (s = top) - (b = base)) > 0) {
//从top往下自旋查找
for (ForkJoinTask<?> t; ; ) { // traverse from s to b
long j = ((--s & m) << ASHIFT) + ABASE;//计算任务索引
if ((t = (ForkJoinTask<?>) U.getObject(a, j)) == null) //获取索引到的任务
return s + 1 == top; // shorter than expected
else if (t == task) { //给定任务为索引任务
boolean removed = false;
if (s + 1 == top) { // pop
if (U.compareAndSwapObject(a, j, task, null)) { //弹出任务
U.putOrderedInt(this, QTOP, s); //更新top
removed = true;
}
} else if (base == b) // replace with proxy
removed = U.compareAndSwapObject(
a, j, task, new EmptyTask()); //join任务已经被移除,替换为一个占位任务
if (removed)
task.doExec(); //执行
break;
} else if (t.status < 0 && s + 1 == top) { //给定任务不是top任务
if (U.compareAndSwapObject(a, j, t, null)) //弹出任务
U.putOrderedInt(this, QTOP, s);//更新top
break; // was cancelled
}
if (--n == 0) //遍历结束
return false;
}
if (task.status < 0) //任务执行完毕
return false;
}
}
return true;
}
从top位开始自旋向下找到给定任务,如果找到把它从当前 Worker 的任务队列中移除并执行它。注意返回的参数: 如果任务队列为空或者任务未执行完毕返回true;任务执行完毕返回false。
ForkJoinPool.helpStealer(WorkQueue w, ForkJoinTask task)
private void helpStealer(WorkQueue w, ForkJoinTask<?> task) {
WorkQueue[] ws = workQueues;
int oldSum = 0, checkSum, m;
if (ws != null && (m = ws.length - 1) >= 0 && w != null &&
task != null) {
do { // restart point
checkSum = 0; // for stability check
ForkJoinTask<?> subtask;
WorkQueue j = w, v; // v is subtask stealer
descent:
for (subtask = task; subtask.status >= 0; ) {
//1. 找到给定WorkQueue的偷取者v
for (int h = j.hint | 1, k = 0, i; ; k += 2) {//跳两个索引,因为Worker在奇数索引位
if (k > m) // can't find stealer
break descent;
if ((v = ws[i = (h + k) & m]) != null) {
if (v.currentSteal == subtask) {//定位到偷取者
j.hint = i;//更新stealer索引
break;
}
checkSum += v.base;
}
}
//2. 帮助偷取者v执行任务
for (; ; ) { // help v or descend
ForkJoinTask<?>[] a; //偷取者内部的任务
int b;
checkSum += (b = v.base);
ForkJoinTask<?> next = v.currentJoin;//获取偷取者的join任务
if (subtask.status < 0 || j.currentJoin != subtask ||
v.currentSteal != subtask) // stale
break descent; // stale,跳出descent循环重来
if (b - v.top >= 0 || (a = v.array) == null) {
if ((subtask = next) == null) //偷取者的join任务为null,跳出descent循环
break descent;
j = v;
break; //偷取者内部任务为空,可能任务也被偷走了;跳出本次循环,查找偷取者的偷取者
}
int i = (((a.length - 1) & b) << ASHIFT) + ABASE;//获取base偏移地址
ForkJoinTask<?> t = ((ForkJoinTask<?>)
U.getObjectVolatile(a, i));//获取偷取者的base任务
if (v.base == b) {
if (t == null) // stale
break descent; // stale,跳出descent循环重来
if (U.compareAndSwapObject(a, i, t, null)) {//弹出任务
v.base = b + 1; //更新偷取者的base位
ForkJoinTask<?> ps = w.currentSteal;//获取调用者偷来的任务
int top = w.top;
//首先更新给定workQueue的currentSteal为偷取者的base任务,然后执行该任务
//然后通过检查top来判断给定workQueue是否有自己的任务,如果有,
// 则依次弹出任务(LIFO)->更新currentSteal->执行该任务(注意这里是自己偷自己的任务执行)
do {
U.putOrderedObject(w, QCURRENTSTEAL, t);
t.doExec(); // clear local tasks too
} while (task.status >= 0 &&
w.top != top && //内部有自己的任务,依次弹出执行
(t = w.pop()) != null);
U.putOrderedObject(w, QCURRENTSTEAL, ps);//还原给定workQueue的currentSteal
if (w.base != w.top)//给定workQueue有自己的任务了,帮助结束,返回
return; // can't further help
}
}
}
}
} while (task.status >= 0 && oldSum != (oldSum = checkSum));
}
}
如果队列为空或任务执行失败,说明任务可能被偷,调用此方法来帮助偷取者执行任务。基本思想是: 偷取者帮助我执行任务,我去帮助偷取者执行它的任务。 函数执行流程如下:
循环定位偷取者,由于Worker是在奇数索引位,所以每次会跳两个索引位。定位到偷取者之后,更新调用者 WorkQueue 的hint为偷取者的索引,方便下次定位; 定位到偷取者后,开始帮助偷取者执行任务。从偷取者的base索引开始,每次偷取一个任务执行。在帮助偷取者执行任务后,如果调用者发现本身已经有任务(w.top != top),则依次弹出自己的任务(LIFO顺序)并执行(也就是说自己偷自己的任务执行)。
ForkJoinPool.tryCompensate(WorkQueue w)
//执行补偿操作: 尝试缩减活动线程量,可能释放或创建一个补偿线程来准备阻塞
private boolean tryCompensate(WorkQueue w) {
boolean canBlock;
WorkQueue[] ws;
long c;
int m, pc, sp;
if (w == null || w.qlock < 0 || // caller terminating
(ws = workQueues) == null || (m = ws.length - 1) <= 0 ||
(pc = config & SMASK) == 0) // parallelism disabled
canBlock = false; //调用者已终止
else if ((sp = (int) (c = ctl)) != 0) // release idle worker
canBlock = tryRelease(c, ws[sp & m], 0L);//唤醒等待的工作线程
else {//没有空闲线程
int ac = (int) (c >> AC_SHIFT) + pc; //活跃线程数
int tc = (short) (c >> TC_SHIFT) + pc;//总线程数
int nbusy = 0; // validate saturation
for (int i = 0; i <= m; ++i) { // two passes of odd indices
WorkQueue v;
if ((v = ws[((i << 1) | 1) & m]) != null) {//取奇数索引位
if ((v.scanState & SCANNING) != 0)//没有正在运行任务,跳出
break;
++nbusy;//正在运行任务,添加标记
}
}
if (nbusy != (tc << 1) || ctl != c)
canBlock = false; // unstable or stale
else if (tc >= pc && ac > 1 && w.isEmpty()) {//总线程数大于并行度 && 活动线程数大于1 && 调用者任务队列为空,不需要补偿
long nc = ((AC_MASK & (c - AC_UNIT)) |
(~AC_MASK & c)); // uncompensated
canBlock = U.compareAndSwapLong(this, CTL, c, nc);//更新活跃线程数
} else if (tc >= MAX_CAP ||
(this == common && tc >= pc + commonMaxSpares))//超出最大线程数
throw new RejectedExecutionException(
"Thread limit exceeded replacing blocked worker");
else { // similar to tryAddWorker
boolean add = false;
int rs; // CAS within lock
long nc = ((AC_MASK & c) |
(TC_MASK & (c + TC_UNIT)));//计算总线程数
if (((rs = lockRunState()) & STOP) == 0)
add = U.compareAndSwapLong(this, CTL, c, nc);//更新总线程数
unlockRunState(rs, rs & ~RSLOCK);
//运行到这里说明活跃工作线程数不足,需要创建一个新的工作线程来补偿
canBlock = add && createWorker(); // throws on exception
}
}
return canBlock;
}
具体的执行看源码及注释,这里我们简单总结一下需要和不需要补偿的几种情况:
- 需要补偿 :
- 调用者队列不为空,并且有空闲工作线程,这种情况会唤醒空闲线程(调用tryRelease方法)
- 池尚未停止,活跃线程数不足,这时会新建一个工作线程(调用createWorker方法)
- 不需要补偿 :
- 调用者已终止或池处于不稳定状态
- 总线程数大于并行度 && 活动线程数大于1 && 调用者任务队列为空
注意事项
避免不必要的fork()
划分成两个子任务后,不要同时调用两个子任务的fork()方法。
表面上看上去两个子任务都fork(),然后join()两次似乎更自然。但事实证明,直接调用compute()效率更高。因为直接调用子任务的compute()方法实际上就是在当前的工作线程进行了计算(线程重用),这比“将子任务提交到工作队列,线程又从工作队列中拿任务”快得多。
当一个大任务被划分成两个以上的子任务时,尽可能使用前面说到的三个衍生的invokeAll方法,因为使用它们能避免不必要的fork()。
注意fork()、compute()、join()的顺序
为了两个任务并行,三个方法的调用顺序需要万分注意。
right.fork(); // 计算右边的任务
long leftAns = left.compute(); // 计算左边的任务(同时右边任务也在计算)
long rightAns = right.join(); // 等待右边的结果
return leftAns + rightAns;
选择合适的子任务粒度
选择划分子任务的粒度(顺序执行的阈值)很重要,因为使用Fork/Join框架并不一定比顺序执行任务的效率高: 如果任务太大,则无法提高并行的吞吐量;如果任务太小,子任务的调度开销可能会大于并行计算的性能提升,我们还要考虑创建子任务、fork()子任务、线程调度以及合并子任务处理结果的耗时以及相应的内存消耗。
官方文档给出的粗略经验是: 任务应该执行100~10000个基本的计算步骤。决定子任务的粒度的最好办法是实践,通过实际测试结果来确定这个阈值才是“上上策”。
和其他Java代码一样,Fork/Join框架测试时需要“预热”或者说执行几遍才会被JIT(Just-in-time)编译器优化,所以测试性能之前跑几遍程序很重要。
避免重量级任务划分与结果合并
Fork/Join的很多使用场景都用到数组或者List等数据结构,子任务在某个分区中运行,最典型的例子如并行排序和并行查找。拆分子任务以及合并处理结果的时候,应该尽量避免System.arraycopy这样耗时耗空间的操作,从而最小化任务的处理开销
有哪些JDK源码中使用了Fork/Join思想?
我们常用的数组工具类 Arrays 在JDK 8之后新增的并行排序方法(parallelSort)就运用了 ForkJoinPool 的特性,还有 ConcurrentHashMap 在JDK 8之后添加的函数式方法(如forEach等)也有运用。
使用Executors工具类创建ForkJoinPool
Java8在Executors工具类中新增了两个工厂方法:
// parallelism定义并行级别
public static ExecutorService newWorkStealingPool(int parallelism);
// 默认并行级别为JVM可用的处理器个数
// Runtime.getRuntime().availableProcessors()
public static ExecutorService newWorkStealingPool();
关于Fork/Join异常处理
Java的受检异常机制一直饱受诟病,所以在ForkJoinTask的invoke()、join()方法及其衍生方法中都没有像get()方法那样抛出个ExecutionException的受检异常。
所以你可以在ForkJoinTask中看到内部把受检异常转换成了运行时异常。
static void rethrow(Throwable ex) {
if (ex != null)
ForkJoinTask.<RuntimeException>uncheckedThrow(ex);
}
@SuppressWarnings("unchecked")
static <T extends Throwable> void uncheckedThrow(Throwable t) throws T {
throw (T)t; // rely on vacuous cast
}
应用实例
计算1+2+3+…+10000的结果
public class Test {
static final class SumTask extends RecursiveTask<Integer> {
private static final long serialVersionUID = 1L;
final int start; //开始计算的数
final int end; //最后计算的数
SumTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
//如果计算量小于1000,那么分配一个线程执行if中的代码块,并返回执行结果
if(end - start < 1000) {
System.out.println(Thread.currentThread().getName() + " 开始执行: " + start + "-" + end);
int sum = 0;
for(int i = start; i <= end; i++)
sum += i;
return sum;
}
//如果计算量大于1000,那么拆分为两个任务
SumTask task1 = new SumTask(start, (start + end) / 2);
SumTask task2 = new SumTask((start + end) / 2 + 1, end);
//执行任务
task1.fork();
task2.fork();
//获取任务执行的结果
return task1.join() + task2.join();
}
}
public static void main(String[] args) throws InterruptedException, ExecutionException {
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Integer> task = new SumTask(1, 10000);
pool.submit(task);
System.out.println(task.get());
}
}
斐波那契数列
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool(4); // 最大并发数4
Fibonacci fibonacci = new Fibonacci(20);
long startTime = System.currentTimeMillis();
Integer result = forkJoinPool.invoke(fibonacci);
long endTime = System.currentTimeMillis();
System.out.println("Fork/join sum: " + result + " in " + (endTime - startTime) + " ms.");
}
//以下为官方API文档示例
static class Fibonacci extends RecursiveTask<Integer> {
final int n;
Fibonacci(int n) {
this.n = n;
}
@Override
protected Integer compute() {
if (n <= 1) {
return n;
}
Fibonacci f1 = new Fibonacci(n - 1);
f1.fork();
Fibonacci f2 = new Fibonacci(n - 2);
return f2.compute() + f1.join();
}
}
参考资料
3.24 - CH24-CountDownLatch
概览
其底层是由AQS提供支持,所以其数据结构可以参考AQS的数据结构,而AQS的数据结构核心就是两个虚拟队列: 同步队列sync queue 和条件队列condition queue,不同的条件会有不同的条件队列。
CountDownLatch典型的用法是将一个程序分为n个互相独立的可解决任务,并创建值为n的CountDownLatch。当每一个任务完成时,都会在这个锁存器上调用countDown,等待问题被解决的任务调用这个锁存器的await,将他们自己拦住,直至锁存器计数结束。
源码分析
层级结构
CountDownLatch没有显示继承哪个父类或者实现哪个父接口, 它底层是AQS是通过内部类Sync来实现的。
内部类
CountDownLatch类存在一个内部类Sync,继承自AbstractQueuedSynchronizer,其源代码如下。
private static final class Sync extends AbstractQueuedSynchronizer {
// 版本号
private static final long serialVersionUID = 4982264981922014374L;
// 构造器
Sync(int count) {
setState(count);
}
// 返回当前计数
int getCount() {
return getState();
}
// 试图在共享模式下获取对象状态
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
// 试图设置状态来反映共享模式下的一个释放
protected boolean tryReleaseShared(int releases) {
// Decrement count; signal when transition to zero
// 无限循环
for (;;) {
// 获取状态
int c = getState();
if (c == 0) // 没有被线程占有
return false;
// 下一个状态
int nextc = c-1;
if (compareAndSetState(c, nextc)) // 比较并且设置成功
return nextc == 0;
}
}
}
对CountDownLatch方法的调用会转发到对Sync或AQS的方法的调用,所以,AQS对CountDownLatch提供支持。
类属性
可以看到CountDownLatch类的内部只有一个Sync类型的属性:
public class CountDownLatch {
// 同步队列
private final Sync sync;
}
构造函数
public CountDownLatch(int count) {
if (count < 0) throw new IllegalArgumentException("count < 0");
// 初始化状态数
this.sync = new Sync(count);
}
该构造函数可以构造一个用给定计数初始化的CountDownLatch,并且构造函数内完成了sync的初始化,并设置了状态数。
核心函数:await
此函数将会使当前线程在锁存器倒计数至零之前一直等待,除非线程被中断。其源码如下
public void await() throws InterruptedException {
// 转发到sync对象上
sync.acquireSharedInterruptibly(1);
}
对CountDownLatch对象的await的调用会转发为对Sync的acquireSharedInterruptibly(从AQS继承的方法)方法的调用。
- acquireSharedInterruptibly源码如下:
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
acquireSharedInterruptibly又调用了CountDownLatch的内部类Sync的tryAcquireShared和AQS的doAcquireSharedInterruptibly函数。
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
该函数只是简单的判断AQS的state是否为0,为0则返回1,不为0则返回-1。
- doAcquireSharedInterruptibly函数的源码如下:
private void doAcquireSharedInterruptibly(int arg) throws InterruptedException {
// 添加节点至等待队列
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
for (;;) { // 无限循环
// 获取node的前驱节点
final Node p = node.predecessor();
if (p == head) { // 前驱节点为头结点
// 试图在共享模式下获取对象状态
int r = tryAcquireShared(arg);
if (r >= 0) { // 获取成功
// 设置头结点并进行繁殖
setHeadAndPropagate(node, r);
// 设置节点next域
p.next = null; // help GC
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt()) // 在获取失败后是否需要禁止线程并且进行中断检查
// 抛出异常
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
在AQS的doAcquireSharedInterruptibly中可能会再次调用CountDownLatch的内部类Sync的tryAcquireShared方法和AQS的setHeadAndPropagate方法。
- setHeadAndPropagate方法源码如下
private void setHeadAndPropagate(Node node, int propagate) {
// 获取头结点
Node h = head; // Record old head for check below
// 设置头结点
setHead(node);
/*
* Try to signal next queued node if:
* Propagation was indicated by caller,
* or was recorded (as h.waitStatus either before
* or after setHead) by a previous operation
* (note: this uses sign-check of waitStatus because
* PROPAGATE status may transition to SIGNAL.)
* and
* The next node is waiting in shared mode,
* or we don't know, because it appears null
*
* The conservatism in both of these checks may cause
* unnecessary wake-ups, but only when there are multiple
* racing acquires/releases, so most need signals now or soon
* anyway.
*/
// 进行判断
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
// 获取节点的后继
Node s = node.next;
if (s == null || s.isShared()) // 后继为空或者为共享模式
// 以共享模式进行释放
doReleaseShared();
}
}
该方法设置头结点并且释放头结点后面的满足条件的结点,该方法中可能会调用到AQS的doReleaseShared方法,其源码如下。
private void doReleaseShared() {
/*
* Ensure that a release propagates, even if there are other
* in-progress acquires/releases. This proceeds in the usual
* way of trying to unparkSuccessor of head if it needs
* signal. But if it does not, status is set to PROPAGATE to
* ensure that upon release, propagation continues.
* Additionally, we must loop in case a new node is added
* while we are doing this. Also, unlike other uses of
* unparkSuccessor, we need to know if CAS to reset status
* fails, if so rechecking.
*/
// 无限循环
for (;;) {
// 保存头结点
Node h = head;
if (h != null && h != tail) { // 头结点不为空并且头结点不为尾结点
// 获取头结点的等待状态
int ws = h.waitStatus;
if (ws == Node.SIGNAL) { // 状态为SIGNAL
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0)) // 不成功就继续
continue; // loop to recheck cases
// 释放后继结点
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE)) // 状态为0并且不成功,继续
continue; // loop on failed CAS
}
if (h == head) // 若头结点改变,继续循环
break;
}
}
该方法在共享模式下释放,具体的流程再之后会通过一个示例给出。
所以,对CountDownLatch的await调用大致会有如下的调用链。
上图给出了可能会调用到的主要方法,并非一定会调用到,之后,会通过一个示例给出详细的分析。
核心函数:countDown
此函数将递减锁存器的计数,如果计数到达零,则释放所有等待的线程
public void countDown() {
sync.releaseShared(1);
}
对countDown的调用转换为对Sync对象的releaseShared(从AQS继承而来)方法的调用。
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
此函数会以共享模式释放对象,并且在函数中会调用到CountDownLatch的tryReleaseShared函数,并且可能会调用AQS的doReleaseShared函数。
protected boolean tryReleaseShared(int releases) {
// Decrement count; signal when transition to zero
// 无限循环
for (;;) {
// 获取状态
int c = getState();
if (c == 0) // 没有被线程占有
return false;
// 下一个状态
int nextc = c-1;
if (compareAndSetState(c, nextc)) // 比较并且设置成功
return nextc == 0;
}
}
此函数会试图设置状态来反映共享模式下的一个释放。具体的流程在下面的示例中会进行分析。
private void doReleaseShared() {
/*
* Ensure that a release propagates, even if there are other
* in-progress acquires/releases. This proceeds in the usual
* way of trying to unparkSuccessor of head if it needs
* signal. But if it does not, status is set to PROPAGATE to
* ensure that upon release, propagation continues.
* Additionally, we must loop in case a new node is added
* while we are doing this. Also, unlike other uses of
* unparkSuccessor, we need to know if CAS to reset status
* fails, if so rechecking.
*/
// 无限循环
for (;;) {
// 保存头结点
Node h = head;
if (h != null && h != tail) { // 头结点不为空并且头结点不为尾结点
// 获取头结点的等待状态
int ws = h.waitStatus;
if (ws == Node.SIGNAL) { // 状态为SIGNAL
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0)) // 不成功就继续
continue; // loop to recheck cases
// 释放后继结点
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE)) // 状态为0并且不成功,继续
continue; // loop on failed CAS
}
if (h == head) // 若头结点改变,继续循环
break;
}
}
此函数在共享模式下释放资源。
所以,对CountDownLatch的countDown调用大致会有如下的调用链。
上图给出了可能会调用到的主要方法,并非一定会调用到,之后,会通过一个示例给出详细的分析。
应用示例
import java.util.concurrent.CountDownLatch;
class MyThread extends Thread {
private CountDownLatch countDownLatch;
public MyThread(String name, CountDownLatch countDownLatch) {
super(name);
this.countDownLatch = countDownLatch;
}
public void run() {
System.out.println(Thread.currentThread().getName() + " doing something");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " finish");
countDownLatch.countDown();
}
}
public class CountDownLatchDemo {
public static void main(String[] args) {
CountDownLatch countDownLatch = new CountDownLatch(2);
MyThread t1 = new MyThread("t1", countDownLatch);
MyThread t2 = new MyThread("t2", countDownLatch);
t1.start();
t2.start();
System.out.println("Waiting for t1 thread and t2 thread to finish");
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " continue");
}
}
Waiting for t1 thread and t2 thread to finish
t1 doing something
t2 doing something
t1 finish
t2 finish
main continue
本程序首先计数器初始化为2。根据结果,可能会存在如下的一种时序图。
首先main线程会调用await操作,此时main线程会被阻塞,等待被唤醒,之后t1线程执行了countDown操作,最后,t2线程执行了countDown操作,此时main线程就被唤醒了,可以继续运行。下面,进行详细分析。
- main线程执行countDownLatch.await操作,主要调用的函数如下。
在最后,main线程就被park了,即禁止运行了。此时Sync queue(同步队列)中有两个节点,AQS的state为2,包含main线程的结点的nextWaiter指向SHARED结点。
- t1线程执行countDownLatch.countDown操作,主要调用的函数如下。
此时,Sync queue队列里的结点个数未发生变化,但是此时,AQS的state已经变为1了。
- t2线程执行countDownLatch.countDown操作,主要调用的函数如下。
经过调用后,AQS的state为0,并且此时,main线程会被unpark,可以继续运行。当main线程获取cpu资源后,继续运行。
- main线程获取cpu资源,继续运行,由于main线程是在parkAndCheckInterrupt函数中被禁止的,所以此时,继续在parkAndCheckInterrupt函数运行.
main线程恢复,继续在parkAndCheckInterrupt函数中运行,之后又会回到最终达到的状态为AQS的state为0,并且head与tail指向同一个结点,该节点的额nextWaiter域还是指向SHARED结点。
3.25 - CH25-CyclicBarrier
源码解析
层级结构
CyclicBarrier没有显示继承哪个父类或者实现哪个父接口, 所有AQS和重入锁不是通过继承实现的,而是通过组合实现的。
public class CyclicBarrier {}
```
### 类的内部类
CyclicBarrier类存在一个内部类Generation,每一次使用的CycBarrier可以当成Generation的实例,其源代码如下
```java
private static class Generation {
boolean broken = false;
}
Generation类有一个属性broken,用来表示当前屏障是否被损坏。
类属性
public class CyclicBarrier {
/** The lock for guarding barrier entry */
// 可重入锁
private final ReentrantLock lock = new ReentrantLock();
/** Condition to wait on until tripped */
// 条件队列
private final Condition trip = lock.newCondition();
/** The number of parties */
// 参与的线程数量
private final int parties;
/* The command to run when tripped */
// 由最后一个进入 barrier 的线程执行的操作
private final Runnable barrierCommand;
/** The current generation */
// 当前代
private Generation generation = new Generation();
// 正在等待进入屏障的线程数量
private int count;
}
该属性有一个为ReentrantLock对象,有一个为Condition对象,而Condition对象又是基于AQS的,所以,归根到底,底层还是由AQS提供支持。
构造函数
- CyclicBarrier(int, Runnable)型构造函数
public CyclicBarrier(int parties, Runnable barrierAction) {
// 参与的线程数量小于等于0,抛出异常
if (parties <= 0) throw new IllegalArgumentException();
// 设置parties
this.parties = parties;
// 设置count
this.count = parties;
// 设置barrierCommand
this.barrierCommand = barrierAction;
}
该构造函数可以指定关联该CyclicBarrier的线程数量,并且可以指定在所有线程都进入屏障后的执行动作,该执行动作由最后一个进行屏障的线程执行。
public CyclicBarrier(int parties) {
// 调用含有两个参数的构造函数
this(parties, null);
}
该构造函数仅仅执行了关联该CyclicBarrier的线程数量,没有设置执行动作。
核心函数:dowait
此函数为CyclicBarrier类的核心函数,CyclicBarrier类对外提供的await函数在底层都是调用该了doawait函数,其源代码如下。
private int dowait(boolean timed, long nanos)
throws InterruptedException, BrokenBarrierException,
TimeoutException {
// 保存当前锁
final ReentrantLock lock = this.lock;
// 锁定
lock.lock();
try {
// 保存当前代
final Generation g = generation;
if (g.broken) // 屏障被破坏,抛出异常
throw new BrokenBarrierException();
if (Thread.interrupted()) { // 线程被中断
// 损坏当前屏障,并且唤醒所有的线程,只有拥有锁的时候才会调用
breakBarrier();
// 抛出异常
throw new InterruptedException();
}
// 减少正在等待进入屏障的线程数量
int index = --count;
if (index == 0) { // 正在等待进入屏障的线程数量为0,所有线程都已经进入
// 运行的动作标识
boolean ranAction = false;
try {
// 保存运行动作
final Runnable command = barrierCommand;
if (command != null) // 动作不为空
// 运行
command.run();
// 设置ranAction状态
ranAction = true;
// 进入下一代
nextGeneration();
return 0;
} finally {
if (!ranAction) // 没有运行的动作
// 损坏当前屏障
breakBarrier();
}
}
// loop until tripped, broken, interrupted, or timed out
// 无限循环
for (;;) {
try {
if (!timed) // 没有设置等待时间
// 等待
trip.await();
else if (nanos > 0L) // 设置了等待时间,并且等待时间大于0
// 等待指定时长
nanos = trip.awaitNanos(nanos);
} catch (InterruptedException ie) {
if (g == generation && ! g.broken) { // 等于当前代并且屏障没有被损坏
// 损坏当前屏障
breakBarrier();
// 抛出异常
throw ie;
} else { // 不等于当前带后者是屏障被损坏
// We're about to finish waiting even if we had not
// been interrupted, so this interrupt is deemed to
// "belong" to subsequent execution.
// 中断当前线程
Thread.currentThread().interrupt();
}
}
if (g.broken) // 屏障被损坏,抛出异常
throw new BrokenBarrierException();
if (g != generation) // 不等于当前代
// 返回索引
return index;
if (timed && nanos <= 0L) { // 设置了等待时间,并且等待时间小于0
// 损坏屏障
breakBarrier();
// 抛出异常
throw new TimeoutException();
}
}
} finally {
// 释放锁
lock.unlock();
}
}
该方法的逻辑会进行一系列的判断,大致流程如下:
核心函数:nextGeneration
此函数在所有线程进入屏障后会被调用,即生成下一个版本,所有线程又可以重新进入到屏障中,其源代码如下:
private void nextGeneration() {
// signal completion of last generation
// 唤醒所有线程
trip.signalAll();
// set up next generation
// 恢复正在等待进入屏障的线程数量
count = parties;
// 新生一代
generation = new Generation();
}
在此函数中会调用AQS的signalAll方法,即唤醒所有等待线程。如果所有的线程都在等待此条件,则唤醒所有线程。其源代码如下:
public final void signalAll() {
if (!isHeldExclusively()) // 不被当前线程独占,抛出异常
throw new IllegalMonitorStateException();
// 保存condition队列头结点
Node first = firstWaiter;
if (first != null) // 头结点不为空
// 唤醒所有等待线程
doSignalAll(first);
}
此函数判断头结点是否为空,即条件队列是否为空,然后会调用doSignalAll函数,doSignalAll函数源码如下:
private void doSignalAll(Node first) {
// condition队列的头结点尾结点都设置为空
lastWaiter = firstWaiter = null;
// 循环
do {
// 获取first结点的nextWaiter域结点
Node next = first.nextWaiter;
// 设置first结点的nextWaiter域为空
first.nextWaiter = null;
// 将first结点从condition队列转移到sync队列
transferForSignal(first);
// 重新设置first
first = next;
} while (first != null);
}
此函数会依次将条件队列中的节点转移到同步队列中,会调用到transferForSignal函数,其源码如下:
final boolean transferForSignal(Node node) {
/*
* If cannot change waitStatus, the node has been cancelled.
*/
if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))
return false;
/*
* Splice onto queue and try to set waitStatus of predecessor to
* indicate that thread is (probably) waiting. If cancelled or
* attempt to set waitStatus fails, wake up to resync (in which
* case the waitStatus can be transiently and harmlessly wrong).
*/
Node p = enq(node);
int ws = p.waitStatus;
if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL))
LockSupport.unpark(node.thread);
return true;
}
此函数的作用就是将处于条件队列中的节点转移到同步队列中,并设置结点的状态信息,其中会调用到enq函数,其源代码如下。
private Node enq(final Node node) {
for (;;) { // 无限循环,确保结点能够成功入队列
// 保存尾结点
Node t = tail;
if (t == null) { // 尾结点为空,即还没被初始化
if (compareAndSetHead(new Node())) // 头结点为空,并设置头结点为新生成的结点
tail = head; // 头结点与尾结点都指向同一个新生结点
} else { // 尾结点不为空,即已经被初始化过
// 将node结点的prev域连接到尾结点
node.prev = t;
if (compareAndSetTail(t, node)) { // 比较结点t是否为尾结点,若是则将尾结点设置为node
// 设置尾结点的next域为node
t.next = node;
return t; // 返回尾结点
}
}
}
}
此函数完成了结点插入同步队列的过程,也很好理解。
综合上面的分析可知,newGeneration函数的主要方法的调用如下,之后会通过一个例子详细讲解:
核心函数:breakBarrier
此函数的作用是损坏当前屏障,会唤醒所有在屏障中的线程。源代码如下:
private void breakBarrier() {
// 设置状态
generation.broken = true;
// 恢复正在等待进入屏障的线程数量
count = parties;
// 唤醒所有线程
trip.signalAll();
}
可以看到,此函数也调用了AQS的signalAll函数,由signal函数提供支持。
应用示例
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
class MyThread extends Thread {
private CyclicBarrier cb;
public MyThread(String name, CyclicBarrier cb) {
super(name);
this.cb = cb;
}
public void run() {
System.out.println(Thread.currentThread().getName() + " going to await");
try {
cb.await();
System.out.println(Thread.currentThread().getName() + " continue");
} catch (Exception e) {
e.printStackTrace();
}
}
}
public class CyclicBarrierDemo {
public static void main(String[] args) throws InterruptedException, BrokenBarrierException {
CyclicBarrier cb = new CyclicBarrier(3, new Thread("barrierAction") {
public void run() {
System.out.println(Thread.currentThread().getName() + " barrier action");
}
});
MyThread t1 = new MyThread("t1", cb);
MyThread t2 = new MyThread("t2", cb);
t1.start();
t2.start();
System.out.println(Thread.currentThread().getName() + " going to await");
cb.await();
System.out.println(Thread.currentThread().getName() + " continue");
}
}
t1 going to await
main going to await
t2 going to await
t2 barrier action
t2 continue
t1 continue
main continue
根据结果可知,可能会存在如下的调用时序。
由上图可知,假设t1线程的cb.await是在main线程的cb.barrierAction动作是由最后一个进入屏障的线程执行的。根据时序图,进一步分析出其内部工作流程。
- main(主)线程执行cb.await操作,主要调用的函数如下。
由于ReentrantLock的默认采用非公平策略,所以在dowait函数中调用的是ReentrantLock.NonfairSync的lock函数,由于此时AQS的状态是0,表示还没有被任何线程占用,故main线程可以占用,之后在dowait中会调用trip.await函数,最终的结果是条件队列中存放了一个包含main线程的结点,并且被禁止运行了,同时,main线程所拥有的资源也被释放了,可以供其他线程获取。
- t1线程执行cb.await操作,其中假设t1线程的lock.lock操作在main线程释放了资源之后,则其主要调用的函数如下。
可以看到,之后condition queue(条件队列)里面有两个节点,包含t1线程的结点插入在队列的尾部,并且t1线程也被禁止了,因为执行了park操作,此时两个线程都被禁止了。
- t2线程执行cb.await操作,其中假设t2线程的lock.lock操作在t1线程释放了资源之后,则其主要调用的函数如下。
由上图可知,在t2线程执行await操作后,会直接执行command.run方法,不是重新开启一个线程,而是最后进入屏障的线程执行。同时,会将Condition queue中的所有节点都转移到Sync queue中,并且最后main线程会被unpark,可以继续运行。main线程获取cpu资源,继续运行。
- main线程获取cpu资源,继续运行,下图给出了主要的方法调用:
其中,由于main线程是在AQS.CO的wait中被park的,所以恢复时,会继续在该方法中运行。运行过后,t1线程被unpark,它获得cpu资源可以继续运行。
- t1线程获取cpu资源,继续运行,下图给出了主要的方法调用。
其中,由于t1线程是在AQS.CO的wait方法中被park,所以恢复时,会继续在该方法中运行。运行过后,Sync queue中保持着一个空节点。头结点与尾节点均指向它。
注意: 在线程await过程中中断线程会抛出异常,所有进入屏障的线程都将被释放。至于CyclicBarrier的其他用法,读者可以自行查阅API,不再累赘。
对比 CountDownLatch
CountDownLatch减计数,CyclicBarrier加计数。
CountDownLatch是一次性的,CyclicBarrier可以重用。
CountDownLatch和CyclicBarrier都有让多个线程等待同步然后再开始下一步动作的意思,但是CountDownLatch的下一步的动作实施者是主线程,具有不可重复性;
而CyclicBarrier的下一步动作实施者还是“其他线程”本身,具有往复多次实施动作的特点。
3.26 - CH26-Semaphore
概览
Semaphore底层基于 AQS。Semaphore称为计数信号量,它允许n个任务同时访问某个资源,可以将信号量看做是在向外分发使用资源的许可证,只有成功获取许可证,才能使用资源。
源码分析
层级结构
public class Semaphore implements java.io.Serializable {}
内部类
Semaphore总共有三个内部类,并且三个内部类是紧密相关的,下面先看三个类的关系。
Semaphore与ReentrantLock的内部类的结构相同,类内部总共存在Sync、NonfairSync、FairSync三个类,NonfairSync与FairSync类继承自Sync类,Sync类继承自AbstractQueuedSynchronizer抽象类。
内部类:Sync
// 内部类,继承自AQS
abstract static class Sync extends AbstractQueuedSynchronizer {
// 版本号
private static final long serialVersionUID = 1192457210091910933L;
// 构造函数
Sync(int permits) {
// 设置状态数
setState(permits);
}
// 获取许可
final int getPermits() {
return getState();
}
// 共享模式下非公平策略获取
final int nonfairTryAcquireShared(int acquires) {
for (;;) { // 无限循环
// 获取许可数
int available = getState();
// 剩余的许可
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining)) // 许可小于0或者比较并且设置状态成功
return remaining;
}
}
// 共享模式下进行释放
protected final boolean tryReleaseShared(int releases) {
for (;;) { // 无限循环
// 获取许可
int current = getState();
// 可用的许可
int next = current + releases;
if (next < current) // overflow
throw new Error("Maximum permit count exceeded");
if (compareAndSetState(current, next)) // 比较并进行设置成功
return true;
}
}
// 根据指定的缩减量减小可用许可的数目
final void reducePermits(int reductions) {
for (;;) { // 无限循环
// 获取许可
int current = getState();
// 可用的许可
int next = current - reductions;
if (next > current) // underflow
throw new Error("Permit count underflow");
if (compareAndSetState(current, next)) // 比较并进行设置成功
return;
}
}
// 获取并返回立即可用的所有许可
final int drainPermits() {
for (;;) { // 无限循环
// 获取许可
int current = getState();
if (current == 0 || compareAndSetState(current, 0)) // 许可为0或者比较并设置成功
return current;
}
}
}
Sync类的属性相对简单,只有一个版本号,Sync类存在如下方法和作用如下。
内部类:NonfairSync
NonfairSync类继承了Sync类,表示采用非公平策略获取资源,其只有一个tryAcquireShared方法,重写了AQS的该方法,其源码如下:
static final class NonfairSync extends Sync {
// 版本号
private static final long serialVersionUID = -2694183684443567898L;
// 构造函数
NonfairSync(int permits) {
super(permits);
}
// 共享模式下获取
protected int tryAcquireShared(int acquires) {
return nonfairTryAcquireShared(acquires);
}
}
从tryAcquireShared方法的源码可知,其会调用父类Sync的nonfairTryAcquireShared方法,表示按照非公平策略进行资源的获取。
内部类:FairSync
FairSync类继承了Sync类,表示采用公平策略获取资源,其只有一个tryAcquireShared方法,重写了AQS的该方法,其源码如下。
protected int tryAcquireShared(int acquires) {
for (;;) { // 无限循环
if (hasQueuedPredecessors()) // 同步队列中存在其他节点
return -1;
// 获取许可
int available = getState();
// 剩余的许可
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining)) // 剩余的许可小于0或者比较设置成功
return remaining;
}
}
从tryAcquireShared方法的源码可知,它使用公平策略来获取资源,它会判断同步队列中是否存在其他的等待节点。
类属性
public class Semaphore implements java.io.Serializable {
// 版本号
private static final long serialVersionUID = -3222578661600680210L;
// 属性
private final Sync sync;
}
Semaphore自身只有两个属性,最重要的是sync属性,基于Semaphore对象的操作绝大多数都转移到了对sync的操作。
构造函数
public Semaphore(int permits) {
sync = new NonfairSync(permits);
}
该构造函数会创建具有给定的许可数和非公平的公平设置的Semaphore。
- Semaphore(int, boolean)型构造函数
public Semaphore(int permits, boolean fair) {
sync = fair ? new FairSync(permits) : new NonfairSync(permits);
}
该构造函数会创建具有给定的许可数和给定的公平设置的Semaphore。
核心函数:acquire
此方法从信号量获取一个(多个)许可,在提供一个许可前一直将线程阻塞,或者线程被中断,其源码如下
public void acquire() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
该方法中将会调用Sync对象的acquireSharedInterruptibly(从AQS继承而来的方法)方法,而acquireSharedInterruptibly方法在上一篇CountDownLatch中已经进行了分析,在此不再累赘。
最终可以获取大致的方法调用序列(假设使用非公平策略)。如下图所示。
上图只是给出了大体会调用到的方法,和具体的示例可能会有些差别,之后会根据具体的示例进行分析。
核心函数:release
此方法释放一个(多个)许可,将其返回给信号量,源码如下。
public void release() {
sync.releaseShared(1);
}
该方法中将会调用Sync对象的releaseShared(从AQS继承而来的方法)方法,而releaseShared方法在上一篇CountDownLatch中已经进行了分析,在此不再累赘。
最终可以获取大致的方法调用序列(假设使用非公平策略)。如下图所示:
应用实例
import java.util.concurrent.Semaphore;
class MyThread extends Thread {
private Semaphore semaphore;
public MyThread(String name, Semaphore semaphore) {
super(name);
this.semaphore = semaphore;
}
public void run() {
int count = 3;
System.out.println(Thread.currentThread().getName() + " trying to acquire");
try {
semaphore.acquire(count);
System.out.println(Thread.currentThread().getName() + " acquire successfully");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release(count);
System.out.println(Thread.currentThread().getName() + " release successfully");
}
}
}
public class SemaphoreDemo {
public final static int SEM_SIZE = 10;
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(SEM_SIZE);
MyThread t1 = new MyThread("t1", semaphore);
MyThread t2 = new MyThread("t2", semaphore);
t1.start();
t2.start();
int permits = 5;
System.out.println(Thread.currentThread().getName() + " trying to acquire");
try {
semaphore.acquire(permits);
System.out.println(Thread.currentThread().getName() + " acquire successfully");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release();
System.out.println(Thread.currentThread().getName() + " release successfully");
}
}
}
main trying to acquire
main acquire successfully
t1 trying to acquire
t1 acquire successfully
t2 trying to acquire
t1 release successfully
main release successfully
t2 acquire successfully
t2 release successfully
首先,生成一个信号量,信号量有10个许可,然后,main,t1,t2三个线程获取许可运行,根据结果,可能存在如下的一种时序。
如上图所示,首先,main线程执行acquire操作,并且成功获得许可,之后t1线程执行acquire操作,成功获得许可,之后t2执行acquire操作,由于此时许可数量不够,t2线程将会阻塞,直到许可可用。之后t1线程释放许可,main线程释放许可,此时的许可数量可以满足t2线程的要求,所以,此时t2线程会成功获得许可运行,t2运行完成后释放许可。下面进行详细分析。
- main线程执行semaphore.acquire操作。主要的函数调用如下图所示。
说明: 此时,可以看到只是AQS的state变为了5,main线程并没有被阻塞,可以继续运行。
- t1线程执行semaphore.acquire操作。主要的函数调用如下图所示。
说明: 此时,可以看到只是AQS的state变为了2,t1线程并没有被阻塞,可以继续运行。
- t2线程执行semaphore.acquire操作。主要的函数调用如下图所示。
说明: 此时,t2线程获取许可不会成功,之后会导致其被禁止运行,值得注意的是,AQS的state还是为2。
- t1执行semaphore.release操作。主要的函数调用如下图所示。
说明: 此时,t2线程将会被unpark,并且AQS的state为5,t2获取cpu资源后可以继续运行。
- main线程执行semaphore.release操作。主要的函数调用如下图所示。
说明: 此时,t2线程还会被unpark,但是不会产生影响,此时,只要t2线程获得CPU资源就可以运行了。此时,AQS的state为10。
- t2获取CPU资源,继续运行,此时t2需要恢复现场,回到parkAndCheckInterrupt函数中,也是在should继续运行。主要的函数调用如下图所示。
说明: 此时,可以看到,Sync queue中只有一个结点,头结点与尾节点都指向该结点,在setHeadAndPropagate的函数中会设置头结点并且会unpark队列中的其他结点。
- t2线程执行semaphore.release操作。主要的函数调用如下图所示。
说明: t2线程经过release后,此时信号量的许可又变为10个了,此时Sync queue中的结点还是没有变化。
深入理解
单独使用Semaphore是不会使用到AQS的条件队列的
不同于CyclicBarrier和ReentrantLock,单独使用Semaphore是不会使用到AQS的条件队列的,其实,只有进行await操作才会进入条件队列,其他的都是在同步队列中,只是当前线程会被park。
场景问题
semaphore初始化有10个令牌,11个线程同时各调用1次acquire方法,会发生什么?
答案:拿不到令牌的线程阻塞,不会继续往下运行。
semaphore初始化有10个令牌,一个线程重复调用11次acquire方法,会发生什么?
答案:线程阻塞,不会继续往下运行。可能你会考虑类似于锁的重入的问题,很好,但是,令牌没有重入的概念。你只要调用一次acquire方法,就需要有一个令牌才能继续运行。
semaphore初始化有1个令牌,1个线程调用一次acquire方法,然后调用两次release方法,之后另外一个线程调用acquire(2)方法,此线程能够获取到足够的令牌并继续运行吗?
答案:能,原因是release方法会添加令牌,并不会以初始化的大小为准。
semaphore初始化有2个令牌,一个线程调用1次release方法,然后一次性获取3个令牌,会获取到吗?
答案:能,原因是release会添加令牌,并不会以初始化的大小为准。Semaphore中release方法的调用并没有限制要在acquire后调用。
3.27 - CH27-Phaser
概览
Phaser是JDK 7新增的一个同步辅助类,它可以实现CyclicBarrier和CountDownLatch类似的功能,而且它支持对任务的动态调整,并支持分层结构来达到更高的吞吐量。
运行机制
注册:Registration
跟其他barrier不同,在phaser上注册的parties会随着时间的变化而变化。任务可以随时注册(使用方法register,bulkRegister注册,或者由构造器确定初始parties),并且在任何抵达点可以随意地撤销注册(方法arriveAndDeregister)。就像大多数基本的同步结构一样,注册和撤销只影响内部count;不会创建更深的内部记录,所以任务不能查询他们是否已经注册。(不过,可以通过继承来实现类似的记录)
同步:Synchronization
和CyclicBarrier一样,Phaser也可以重复await。方法arriveAndAwaitAdvance的效果类似CyclicBarrier.await。phaser的每一代都有一个相关的phase number,初始值为0,当所有注册的任务都到达phaser时phase+1,到达最大值(Integer.MAX_VALUE)之后清零。使用phase number可以独立控制 到达phaser 和 等待其他线程 的动作,通过下面两种类型的方法:
到达机制:Arrival
arrive和arriveAndDeregister方法记录到达状态。这些方法不会阻塞,但是会返回一个相关的arrival phase number;也就是说,phase number用来确定到达状态。当所有任务都到达给定phase时,可以执行一个可选的函数,这个函数通过重写onAdvance方法实现,通常可以用来控制终止状态。重写此方法类似于为CyclicBarrier提供一个barrierAction,但比它更灵活。
等待机制:Waiting
awaitAdvance方法需要一个表示arrival phase number的参数,并且在phaser前进到与给定phase不同的phase时返回。和CyclicBarrier不同,即使等待线程已经被中断,awaitAdvance方法也会一直等待。中断状态和超时时间同样可用,但是当任务等待中断或超时后未改变phaser的状态时会遭遇异常。如果有必要,在方法forceTermination之后可以执行这些异常的相关的handler进行恢复操作,Phaser也可能被ForkJoinPool中的任务使用,这样在其他任务阻塞等待一个phase时可以保证足够的并行度来执行任务。
终止:Termination
可以用isTerminated方法检查phaser的终止状态。在终止时,所有同步方法立刻返回一个负值。在终止时尝试注册也没有效果。当调用onAdvance返回true时Termination被触发。当deregistration操作使已注册的parties变为0时,onAdvance的默认实现就会返回true。也可以重写onAdvance方法来定义终止动作。forceTermination方法也可以释放等待线程并且允许它们终止。
分层:Tiering
Phaser支持分层结构(树状构造)来减少竞争。注册了大量parties的Phaser可能会因为同步竞争消耗很高的成本, 因此可以设置一些子Phaser来共享一个通用的parent。这样的话即使每个操作消耗了更多的开销,但是会提高整体吞吐量。 在一个分层结构的phaser里,子节点phaser的注册和取消注册都通过父节点管理。子节点phaser通过构造或方法register、bulkRegister进行首次注册时,在其父节点上注册。子节点phaser通过调用arriveAndDeregister进行最后一次取消注册时,也在其父节点上取消注册。
监控:Monitoring
由于同步方法可能只被已注册的parties调用,所以phaser的当前状态也可能被任何调用者监控。在任何时候,可以通过getRegisteredParties获取parties数,其中getArrivedParties方法返回已经到达当前phase的parties数。当剩余的parties(通过方法getUnarrivedParties获取)到达时,phase进入下一代。这些方法返回的值可能只表示短暂的状态,所以一般来说在同步结构里并没有啥卵用。
源码分析
核心属性
private volatile long state;
/**
* The parent of this phaser, or null if none
*/
private final Phaser parent;
/**
* The root of phaser tree. Equals this if not in a tree.
*/
private final Phaser root;
//等待线程的栈顶元素,根据phase取模定义为一个奇数header和一个偶数header
private final AtomicReference<QNode> evenQ;
private final AtomicReference<QNode> oddQ;
Phaser使用一个long型state值来标识内部状态:
- 低0-15位表示未到达parties数;
- 中16-31位表示等待的parties数;
- 中32-62位表示phase当前代;
- 高63位表示当前phaser的终止状态。
子Phaser的phase在没有被真正使用之前,允许滞后于它的root节点。这里在后面源码分析的reconcileState方法里会讲解。 Qnode是Phaser定义的内部等待队列,用于在阻塞时记录等待线程及相关信息。实现了ForkJoinPool的一个内部接口ManagedBlocker,上面已经说过,Phaser也可能被ForkJoinPool中的任务使用,这样在其他任务阻塞等待一个phase时可以保证足够的并行度来执行任务(通过内部实现方法isReleasable和block)。
函数列表
//构造方法
public Phaser() {
this(null, 0);
}
public Phaser(int parties) {
this(null, parties);
}
public Phaser(Phaser parent) {
this(parent, 0);
}
public Phaser(Phaser parent, int parties)
//注册一个新的party
public int register()
//批量注册
public int bulkRegister(int parties)
//使当前线程到达phaser,不等待其他任务到达。返回arrival phase number
public int arrive()
//使当前线程到达phaser并撤销注册,返回arrival phase number
public int arriveAndDeregister()
/*
* 使当前线程到达phaser并等待其他任务到达,等价于awaitAdvance(arrive())。
* 如果需要等待中断或超时,可以使用awaitAdvance方法完成一个类似的构造。
* 如果需要在到达后取消注册,可以使用awaitAdvance(arriveAndDeregister())。
*/
public int arriveAndAwaitAdvance()
//等待给定phase数,返回下一个 arrival phase number
public int awaitAdvance(int phase)
//阻塞等待,直到phase前进到下一代,返回下一代的phase number
public int awaitAdvance(int phase)
//响应中断版awaitAdvance
public int awaitAdvanceInterruptibly(int phase) throws InterruptedException
public int awaitAdvanceInterruptibly(int phase, long timeout, TimeUnit unit)
throws InterruptedException, TimeoutException
//使当前phaser进入终止状态,已注册的parties不受影响,如果是分层结构,则终止所有phaser
public void forceTermination()
方法:register
//注册一个新的party
public int register() {
return doRegister(1);
}
private int doRegister(int registrations) {
// adjustment to state
long adjust = ((long)registrations << PARTIES_SHIFT) | registrations;
final Phaser parent = this.parent;
int phase;
for (;;) {
long s = (parent == null) ? state : reconcileState();
int counts = (int)s;
int parties = counts >>> PARTIES_SHIFT;//获取已注册parties数
int unarrived = counts & UNARRIVED_MASK;//未到达数
if (registrations > MAX_PARTIES - parties)
throw new IllegalStateException(badRegister(s));
phase = (int)(s >>> PHASE_SHIFT);//获取当前代
if (phase < 0)
break;
if (counts != EMPTY) { // not 1st registration
if (parent == null || reconcileState() == s) {
if (unarrived == 0) // wait out advance
root.internalAwaitAdvance(phase, null);//等待其他任务到达
else if (UNSAFE.compareAndSwapLong(this, stateOffset,
s, s + adjust))//更新注册的parties数
break;
}
}
else if (parent == null) { // 1st root registration
long next = ((long)phase << PHASE_SHIFT) | adjust;
if (UNSAFE.compareAndSwapLong(this, stateOffset, s, next))//更新phase
break;
}
else {
//分层结构,子phaser首次注册用父节点管理
synchronized (this) { // 1st sub registration
if (state == s) { // recheck under lock
phase = parent.doRegister(1);//分层结构,使用父节点注册
if (phase < 0)
break;
// finish registration whenever parent registration
// succeeded, even when racing with termination,
// since these are part of the same "transaction".
//由于在同一个事务里,即使phaser已终止,也会完成注册
while (!UNSAFE.compareAndSwapLong
(this, stateOffset, s,
((long)phase << PHASE_SHIFT) | adjust)) {//更新phase
s = state;
phase = (int)(root.state >>> PHASE_SHIFT);
// assert (int)s == EMPTY;
}
break;
}
}
}
}
return phase;
}
register方法为phaser添加一个新的party,如果onAdvance正在运行,那么这个方法会等待它运行结束再返回结果。如果当前phaser有父节点,并且当前phaser上没有已注册的party,那么就会交给父节点注册。
register和bulkRegister都由doRegister实现,大概流程如下:
- 如果当前操作不是首次注册,那么直接在当前phaser上更新注册parties数
- 如果是首次注册,并且当前phaser没有父节点,说明是root节点注册,直接更新phase
- 如果当前操作是首次注册,并且当前phaser由父节点,则注册操作交由父节点,并更新当前phaser的phase
- 上面说过,子Phaser的phase在没有被真正使用之前,允许滞后于它的root节点。非首次注册时,如果Phaser有父节点,则调用reconcileState()方法解决root节点的phase延迟传递问题, 源码如下:
private long reconcileState() {
final Phaser root = this.root;
long s = state;
if (root != this) {
int phase, p;
// CAS to root phase with current parties, tripping unarrived
while ((phase = (int)(root.state >>> PHASE_SHIFT)) !=
(int)(s >>> PHASE_SHIFT) &&
!UNSAFE.compareAndSwapLong
(this, stateOffset, s,
s = (((long)phase << PHASE_SHIFT) |
((phase < 0) ? (s & COUNTS_MASK) :
(((p = (int)s >>> PARTIES_SHIFT) == 0) ? EMPTY :
((s & PARTIES_MASK) | p))))))
s = state;
}
return s;
}
当root节点的phase已经advance到下一代,但是子节点phaser还没有,这种情况下它们必须通过更新未到达parties数 完成它们自己的advance操作(如果parties为0,重置为EMPTY状态)。
回到register方法的第一步,如果当前未到达数为0,说明上一代phase正在进行到达操作,此时调用internalAwaitAdvance()方法等待其他任务完成到达操作,源码如下:
//阻塞等待phase到下一代
private int internalAwaitAdvance(int phase, QNode node) {
// assert root == this;
releaseWaiters(phase-1); // ensure old queue clean
boolean queued = false; // true when node is enqueued
int lastUnarrived = 0; // to increase spins upon change
int spins = SPINS_PER_ARRIVAL;
long s;
int p;
while ((p = (int)((s = state) >>> PHASE_SHIFT)) == phase) {
if (node == null) { // spinning in noninterruptible mode
int unarrived = (int)s & UNARRIVED_MASK;//未到达数
if (unarrived != lastUnarrived &&
(lastUnarrived = unarrived) < NCPU)
spins += SPINS_PER_ARRIVAL;
boolean interrupted = Thread.interrupted();
if (interrupted || --spins < 0) { // need node to record intr
//使用node记录中断状态
node = new QNode(this, phase, false, false, 0L);
node.wasInterrupted = interrupted;
}
}
else if (node.isReleasable()) // done or aborted
break;
else if (!queued) { // push onto queue
AtomicReference<QNode> head = (phase & 1) == 0 ? evenQ : oddQ;
QNode q = node.next = head.get();
if ((q == null || q.phase == phase) &&
(int)(state >>> PHASE_SHIFT) == phase) // avoid stale enq
queued = head.compareAndSet(q, node);
}
else {
try {
ForkJoinPool.managedBlock(node);//阻塞给定node
} catch (InterruptedException ie) {
node.wasInterrupted = true;
}
}
}
if (node != null) {
if (node.thread != null)
node.thread = null; // avoid need for unpark()
if (node.wasInterrupted && !node.interruptible)
Thread.currentThread().interrupt();
if (p == phase && (p = (int)(state >>> PHASE_SHIFT)) == phase)
return abortWait(phase); // possibly clean up on abort
}
releaseWaiters(phase);
return p;
}
简单介绍下第二个参数node,如果不为空,则说明等待线程需要追踪中断状态或超时状态。以doRegister中的调用为例,不考虑线程争用,internalAwaitAdvance大概流程如下:
- 首先调用releaseWaiters唤醒上一代所有等待线程,确保旧队列中没有遗留的等待线程。
- 循环SPINS_PER_ARRIVAL指定的次数或者当前线程被中断,创建node记录等待线程及相关信息。
- 继续循环调用ForkJoinPool.managedBlock运行被阻塞的任务
- 继续循环,阻塞任务运行成功被释放,跳出循环
- 最后唤醒当前phase的线程
方法:arrive
//使当前线程到达phaser,不等待其他任务到达。返回arrival phase number
public int arrive() {
return doArrive(ONE_ARRIVAL);
}
private int doArrive(int adjust) {
final Phaser root = this.root;
for (;;) {
long s = (root == this) ? state : reconcileState();
int phase = (int)(s >>> PHASE_SHIFT);
if (phase < 0)
return phase;
int counts = (int)s;
//获取未到达数
int unarrived = (counts == EMPTY) ? 0 : (counts & UNARRIVED_MASK);
if (unarrived <= 0)
throw new IllegalStateException(badArrive(s));
if (UNSAFE.compareAndSwapLong(this, stateOffset, s, s-=adjust)) {//更新state
if (unarrived == 1) {//当前为最后一个未到达的任务
long n = s & PARTIES_MASK; // base of next state
int nextUnarrived = (int)n >>> PARTIES_SHIFT;
if (root == this) {
if (onAdvance(phase, nextUnarrived))//检查是否需要终止phaser
n |= TERMINATION_BIT;
else if (nextUnarrived == 0)
n |= EMPTY;
else
n |= nextUnarrived;
int nextPhase = (phase + 1) & MAX_PHASE;
n |= (long)nextPhase << PHASE_SHIFT;
UNSAFE.compareAndSwapLong(this, stateOffset, s, n);
releaseWaiters(phase);//释放等待phase的线程
}
//分层结构,使用父节点管理arrive
else if (nextUnarrived == 0) { //propagate deregistration
phase = parent.doArrive(ONE_DEREGISTER);
UNSAFE.compareAndSwapLong(this, stateOffset,
s, s | EMPTY);
}
else
phase = parent.doArrive(ONE_ARRIVAL);
}
return phase;
}
}
}
arrive方法手动调整到达数,使当前线程到达phaser。arrive和arriveAndDeregister都调用了doArrive实现,大概流程如下:
- 首先更新state(state - adjust);
- 如果当前不是最后一个未到达的任务,直接返回phase
- 如果当前是最后一个未到达的任务:
- 如果当前是root节点,判断是否需要终止phaser,CAS更新phase,最后释放等待的线程;
- 如果是分层结构,并且已经没有下一代未到达的parties,则交由父节点处理doArrive逻辑,然后更新state为EMPTY。
方法:arriveAndAwaitAdvance
public int arriveAndAwaitAdvance() {
// Specialization of doArrive+awaitAdvance eliminating some reads/paths
final Phaser root = this.root;
for (;;) {
long s = (root == this) ? state : reconcileState();
int phase = (int)(s >>> PHASE_SHIFT);
if (phase < 0)
return phase;
int counts = (int)s;
int unarrived = (counts == EMPTY) ? 0 : (counts & UNARRIVED_MASK);//获取未到达数
if (unarrived <= 0)
throw new IllegalStateException(badArrive(s));
if (UNSAFE.compareAndSwapLong(this, stateOffset, s,
s -= ONE_ARRIVAL)) {//更新state
if (unarrived > 1)
return root.internalAwaitAdvance(phase, null);//阻塞等待其他任务
if (root != this)
return parent.arriveAndAwaitAdvance();//子Phaser交给父节点处理
long n = s & PARTIES_MASK; // base of next state
int nextUnarrived = (int)n >>> PARTIES_SHIFT;
if (onAdvance(phase, nextUnarrived))//全部到达,检查是否可销毁
n |= TERMINATION_BIT;
else if (nextUnarrived == 0)
n |= EMPTY;
else
n |= nextUnarrived;
int nextPhase = (phase + 1) & MAX_PHASE;//计算下一代phase
n |= (long)nextPhase << PHASE_SHIFT;
if (!UNSAFE.compareAndSwapLong(this, stateOffset, s, n))//更新state
return (int)(state >>> PHASE_SHIFT); // terminated
releaseWaiters(phase);//释放等待phase的线程
return nextPhase;
}
}
}
说明: 使当前线程到达phaser并等待其他任务到达,等价于awaitAdvance(arrive())。如果需要等待中断或超时,可以使用awaitAdvance方法完成一个类似的构造。如果需要在到达后取消注册,可以使用awaitAdvance(arriveAndDeregister())。效果类似于CyclicBarrier.await。大概流程如下:
- 更新state(state - 1);
- 如果未到达数大于1,调用internalAwaitAdvance阻塞等待其他任务到达,返回当前phase
- 如果为分层结构,则交由父节点处理arriveAndAwaitAdvance逻辑
- 如果未到达数<=1,判断phaser终止状态,CAS更新phase到下一代,最后释放等待当前phase的线程,并返回下一代phase。
方法:awaitAdvance(int phase)
public int awaitAdvance(int phase) {
final Phaser root = this.root;
long s = (root == this) ? state : reconcileState();
int p = (int)(s >>> PHASE_SHIFT);
if (phase < 0)
return phase;
if (p == phase)
return root.internalAwaitAdvance(phase, null);
return p;
}
//响应中断版awaitAdvance
public int awaitAdvanceInterruptibly(int phase)
throws InterruptedException {
final Phaser root = this.root;
long s = (root == this) ? state : reconcileState();
int p = (int)(s >>> PHASE_SHIFT);
if (phase < 0)
return phase;
if (p == phase) {
QNode node = new QNode(this, phase, true, false, 0L);
p = root.internalAwaitAdvance(phase, node);
if (node.wasInterrupted)
throw new InterruptedException();
}
return p;
}
awaitAdvance用于阻塞等待线程到达,直到phase前进到下一代,返回下一代的phase number。方法很简单,不多赘述。awaitAdvanceInterruptibly方法是响应中断版的awaitAdvance,不同之处在于,调用阻塞时会记录线程的中断状态。
3.28 - CH28-Exchanger
概览
Exchanger是用于线程协作的工具类, 主要用于两个线程之间的数据交换。
它提供一个同步点,在这个同步点,两个线程可以交换彼此的数据。这两个线程通过exchange()方法交换数据,当一个线程先执行exchange()方法后,它会一直等待第二个线程也执行exchange()方法,当这两个线程到达同步点时,这两个线程就可以交换数据了。
实现机制
for (;;) {
if (slot is empty) { // offer
// slot为空时,将item 设置到Node 中
place item in a Node;
if (can CAS slot from empty to node) {
// 当将node通过CAS交换到slot中时,挂起线程等待被唤醒
wait for release;
// 被唤醒后返回node中匹配到的item
return matching item in node;
}
} else if (can CAS slot from node to empty) { // release
// 将slot设置为空
// 获取node中的item,将需要交换的数据设置到匹配的item
get the item in node;
set matching item in node;
// 唤醒等待的线程
release waiting thread;
}
// else retry on CAS failure
}
比如有2条线程A和B,A线程交换数据时,发现slot为空,则将需要交换的数据放在slot中等待其它线程进来交换数据,等线程B进来,读取A设置的数据,然后设置线程B需要交换的数据,然后唤醒A线程,原理就是这么简单。但是当多个线程之间进行交换数据时就会出现问题,所以Exchanger加入了slot数组。
源码解析
内部类:Node
@sun.misc.Contended static final class Node {
// arena的下标,多个槽位的时候利用
int index;
// 上一次记录的Exchanger.bound
int bound;
// 在当前bound下CAS失败的次数;
int collides;
// 用于自旋;
int hash;
// 这个线程的当前项,也就是需要交换的数据;
Object item;
//做releasing操作的线程传递的项;
volatile Object match;
//挂起时设置线程值,其他情况下为null;
volatile Thread parked;
}
在Node定义中有两个变量值得思考:bound以及collides。前面提到了数组area是为了避免竞争而产生的,如果系统不存在竞争问题,那么完全没有必要开辟一个高效的arena来徒增系统的复杂性。
首先通过单个slot的exchanger来交换数据,当探测到竞争时将安排不同的位置的slot来保存线程Node,并且可以确保没有slot会在同一个缓存行上。
如何来判断会有竞争呢? CAS替换slot失败,如果失败,则通过记录冲突次数来扩展arena的尺寸,我们在记录冲突的过程中会跟踪“bound”的值,以及会重新计算冲突次数在bound的值被改变时。
核心属性
private final Participant participant;
private volatile Node[] arena;
private volatile Node slot;
slot为单个槽,arena为数组槽, 他们都是Node类型。在这里可能会感觉到疑惑,slot作为Exchanger交换数据的场景,应该只需要一个就可以了啊? 为何还多了一个Participant 和数组类型的arena呢?
一个slot交换场所原则上来说应该是可以的,但实际情况却不是如此,多个参与者使用同一个交换场所时,会存在严重伸缩性问题。既然单个交换场所存在问题,那么我们就安排多个,也就是数组arena。通过数组arena来安排不同的线程使用不同的slot来降低竞争问题,并且可以保证最终一定会成对交换数据。但是Exchanger不是一来就会生成arena数组来降低竞争,只有当产生竞争是才会生成arena数组。
Participant,Participant 的作用就是为每个线程保留唯一的一个Node节点,它继承ThreadLocal,同时在Node节点中记录在arena中的下标index。
构造函数
/**
* Creates a new Exchanger.
*/
public Exchanger() {
participant = new Participant();
}
核心方法:exchange(V x)
等待另一个线程到达此交换点(除非当前线程被中断),然后将给定的对象传送给该线程,并接收该线程的对象。
public V exchange(V x) throws InterruptedException {
Object v;
// 当参数为null时需要将item设置为空的对象
Object item = (x == null) ? NULL_ITEM : x; // translate null args
// 注意到这里的这个表达式是整个方法的核心
if ((arena != null ||
(v = slotExchange(item, false, 0 L)) == null) &&
((Thread.interrupted() || // disambiguates null return
(v = arenaExchange(item, false, 0 L)) == null)))
throw new InterruptedException();
return (v == NULL_ITEM) ? null : (V) v;
}
这个方法比较好理解:arena为数组槽,如果为null,则执行slotExchange()方法,否则判断线程是否中断,如果中断值抛出InterruptedException异常,没有中断则执行arenaExchange()方法。整套逻辑就是:如果slotExchange(Object item, boolean timed, long ns)方法执行失败了就执行arenaExchange(Object item, boolean timed, long ns)方法,最后返回结果V。
NULL_ITEM 为一个空节点,其实就是一个Object对象而已,slotExchange()为单个slot交换。
slotExchange(Object item, boolean timed, long ns)
private final Object slotExchange(Object item, boolean timed, long ns) {
// 获取当前线程node对象
Node p = participant.get();
// 当前线程
Thread t = Thread.currentThread();
// 若果线程被中断,就直接返回null
if (t.isInterrupted()) // preserve interrupt status so caller can recheck
return null;
// 自旋
for (Node q;;) {
// 将slot值赋给q
if ((q = slot) != null) {
// slot 不为null,即表示已有线程已经把需要交换的数据设置在slot中了
// 通过CAS将slot设置成null
if (U.compareAndSwapObject(this, SLOT, q, null)) {
// CAS操作成功后,将slot中的item赋值给对象v,以便返回。
// 这里也是就读取之前线程要交换的数据
Object v = q.item;
// 将当前线程需要交给的数据设置在q中的match
q.match = item;
// 获取被挂起的线程
Thread w = q.parked;
if (w != null)
// 如果线程不为null,唤醒它
U.unpark(w);
// 返回其他线程给的V
return v;
}
// create arena on contention, but continue until slot null
// CAS 操作失败,表示有其它线程竞争,在此线程之前将数据已取走
// NCPU:CPU的核数
// bound == 0 表示arena数组未初始化过,CAS操作bound将其增加SEQ
if (NCPU > 1 && bound == 0 &&
U.compareAndSwapInt(this, BOUND, 0, SEQ))
// 初始化arena数组
arena = new Node[(FULL + 2) << ASHIFT];
}
// 上面分析过,只有当arena不为空才会执行slotExchange方法的
// 所以表示刚好已有其它线程加入进来将arena初始化
else if (arena != null)
// 这里就需要去执行arenaExchange
return null; // caller must reroute to arenaExchange
else {
// 这里表示当前线程是以第一个线程进来交换数据
// 或者表示之前的数据交换已进行完毕,这里可以看作是第一个线程
// 将需要交换的数据先存放在当前线程变量p中
p.item = item;
// 将需要交换的数据通过CAS设置到交换区slot
if (U.compareAndSwapObject(this, SLOT, null, p))
// 交换成功后跳出自旋
break;
// CAS操作失败,表示有其它线程刚好先于当前线程将数据设置到交换区slot
// 将当前线程变量中的item设置为null,然后自旋获取其它线程存放在交换区slot的数据
p.item = null;
}
}
// await release
// 执行到这里表示当前线程已将需要的交换的数据放置于交换区slot中了,
// 等待其它线程交换数据然后唤醒当前线程
int h = p.hash;
long end = timed ? System.nanoTime() + ns : 0 L;
// 自旋次数
int spins = (NCPU > 1) ? SPINS : 1;
Object v;
// 自旋等待直到p.match不为null,也就是说等待其它线程将需要交换的数据放置于交换区slot
while ((v = p.match) == null) {
// 下面的逻辑主要是自旋等待,直到spins递减到0为止
if (spins > 0) {
h ^= h << 1;
h ^= h >>> 3;
h ^= h << 10;
if (h == 0)
h = SPINS | (int) t.getId();
else if (h < 0 && (--spins & ((SPINS >>> 1) - 1)) == 0)
Thread.yield();
} else if (slot != p)
spins = SPINS;
// 此处表示未设置超时或者时间未超时
else if (!t.isInterrupted() && arena == null &&
(!timed || (ns = end - System.nanoTime()) > 0 L)) {
// 设置线程t被当前对象阻塞
U.putObject(t, BLOCKER, this);
// 给p挂机线程的值赋值
p.parked = t;
if (slot == p)
// 如果slot还没有被置为null,也就表示暂未有线程过来交换数据,需要将当前线程挂起
U.park(false, ns);
// 线程被唤醒,将被挂起的线程设置为null
p.parked = null;
// 设置线程t未被任何对象阻塞
U.putObject(t, BLOCKER, null);
// 不是以上条件时(可能是arena已不为null或者超时)
} else if (U.compareAndSwapObject(this, SLOT, p, null)) {
// arena不为null则v为null,其它为超时则v为超市对象TIMED_OUT,并且跳出循环
v = timed && ns <= 0 L && !t.isInterrupted() ? TIMED_OUT : null;
break;
}
}
// 取走match值,并将p中的match置为null
U.putOrderedObject(p, MATCH, null);
// 设置item为null
p.item = null;
p.hash = h;
// 返回交换值
return v;
}
程序首先通过participant获取当前线程节点Node。检测是否中断,如果中断return null,等待后续抛出InterruptedException异常。
- 如果slot不为null,则进行slot消除,成功直接返回数据V,否则失败,则创建arena消除数组。
- 如果slot为null,但arena不为null,则返回null,进入arenaExchange逻辑。
- 如果slot为null,且arena也为null,则尝试占领该slot,失败重试,成功则跳出循环进入spin+block(自旋+阻塞)模式。
在自旋+阻塞模式中,首先取得结束时间和自旋次数。如果match(做releasing操作的线程传递的项)为null,其首先尝试spins+随机次自旋(改自旋使用当前节点中的hash,并改变之)和退让。当自旋数为0后,假如slot发生了改变(slot != p)则重置自旋数并重试。否则假如:当前未中断&arena为null&(当前不是限时版本或者限时版本+当前时间未结束):阻塞或者限时阻塞。假如:当前中断或者arena不为null或者当前为限时版本+时间已经结束:不限时版本:置v为null;限时版本:如果时间结束以及未中断则TIMED_OUT;否则给出null(原因是探测到arena非空或者当前线程中断)。
match不为空时跳出循环。
arenaExchange(Object item, boolean timed, long ns)
此方法被执行时表示多个线程进入交换区交换数据,arena数组已被初始化,此方法中的一些处理方式和slotExchange比较类似,它是通过遍历arena数组找到需要交换的数据。
// timed 为true表示设置了超时时间,ns为>0的值,反之没有设置超时时间
private final Object arenaExchange(Object item, boolean timed, long ns) {
Node[] a = arena;
// 获取当前线程中的存放的node
Node p = participant.get();
//index初始值0
for (int i = p.index;;) { // access slot at i
// 遍历,如果在数组中找到数据则直接交换并唤醒线程,如未找到则将需要交换给其它线程的数据放置于数组中
int b, m, c;
long j; // j is raw array offset
// 其实这里就是向右遍历数组,只是用到了元素在内存偏移的偏移量
// q实际为arena数组偏移(i + 1) * 128个地址位上的node
Node q = (Node) U.getObjectVolatile(a, j = (i << ASHIFT) + ABASE);
// 如果q不为null,并且CAS操作成功,将下标j的元素置为null
if (q != null && U.compareAndSwapObject(a, j, q, null)) {
// 表示当前线程已发现有交换的数据,然后获取数据,唤醒等待的线程
Object v = q.item; // release
q.match = item;
Thread w = q.parked;
if (w != null)
U.unpark(w);
return v;
// q 为null 并且 i 未超过数组边界
} else if (i <= (m = (b = bound) & MMASK) && q == null) {
// 将需要给其它线程的item赋予给p中的item
p.item = item; // offer
if (U.compareAndSwapObject(a, j, null, p)) {
// 交换成功
long end = (timed && m == 0) ? System.nanoTime() + ns : 0 L;
Thread t = Thread.currentThread(); // wait
// 自旋直到有其它线程进入,遍历到该元素并与其交换,同时当前线程被唤醒
for (int h = p.hash, spins = SPINS;;) {
Object v = p.match;
if (v != null) {
// 其它线程设置的需要交换的数据match不为null
// 将match设置null,item设置为null
U.putOrderedObject(p, MATCH, null);
p.item = null; // clear for next use
p.hash = h;
return v;
} else if (spins > 0) {
h ^= h << 1;
h ^= h >>> 3;
h ^= h << 10; // xorshift
if (h == 0) // initialize hash
h = SPINS | (int) t.getId();
else if (h < 0 && // approx 50% true
(--spins & ((SPINS >>> 1) - 1)) == 0)
Thread.yield(); // two yields per wait
} else if (U.getObjectVolatile(a, j) != p)
// 和slotExchange方法中的类似,arena数组中的数据已被CAS设置
// match值还未设置,让其再自旋等待match被设置
spins = SPINS; // releaser hasn't set match yet
else if (!t.isInterrupted() && m == 0 &&
(!timed ||
(ns = end - System.nanoTime()) > 0 L)) {
// 设置线程t被当前对象阻塞
U.putObject(t, BLOCKER, this); // emulate LockSupport
// 线程t赋值
p.parked = t; // minimize window
if (U.getObjectVolatile(a, j) == p)
// 数组中对象还相等,表示线程还未被唤醒,唤醒线程
U.park(false, ns);
p.parked = null;
// 设置线程t未被任何对象阻塞
U.putObject(t, BLOCKER, null);
} else if (U.getObjectVolatile(a, j) == p &&
U.compareAndSwapObject(a, j, p, null)) {
// 这里给bound增加加一个SEQ
if (m != 0) // try to shrink
U.compareAndSwapInt(this, BOUND, b, b + SEQ - 1);
p.item = null;
p.hash = h;
i = p.index >>>= 1; // descend
if (Thread.interrupted())
return null;
if (timed && m == 0 && ns <= 0 L)
return TIMED_OUT;
break; // expired; restart
}
}
} else
// 交换失败,表示有其它线程更改了arena数组中下标i的元素
p.item = null; // clear offer
} else {
// 此时表示下标不在bound & MMASK或q不为null但CAS操作失败
// 需要更新bound变化后的值
if (p.bound != b) { // stale; reset
p.bound = b;
p.collides = 0;
// 反向遍历
i = (i != m || m == 0) ? m : m - 1;
} else if ((c = p.collides) < m || m == FULL ||
!U.compareAndSwapInt(this, BOUND, b, b + SEQ + 1)) {
// 记录CAS失败的次数
p.collides = c + 1;
// 循环遍历
i = (i == 0) ? m : i - 1; // cyclically traverse
} else
// 此时表示bound值增加了SEQ+1
i = m + 1; // grow
// 设置下标
p.index = i;
}
}
}
首先通过participant取得当前节点Node,然后根据当前节点Node的index去取arena中相对应的节点node。
- 前面提到过arena可以确保不同的slot在arena中是不会相冲突的,那么是怎么保证的呢?
arena = new Node[(FULL + 2) << ASHIFT];
// 这个arena到底有多大呢? 我们先看FULL 和ASHIFT的定义:
static final int FULL = (NCPU >= (MMASK << 1)) ? MMASK : NCPU >>> 1;
private static final int ASHIFT = 7;
private static final int NCPU = Runtime.getRuntime().availableProcessors();
private static final int MMASK = 0xff; // 255
// 假如我的机器NCPU = 8 ,则得到的是768大小的arena数组。然后通过以下代码取得在arena中的节点:
Node q = (Node)U.getObjectVolatile(a, j = (i << ASHIFT) + ABASE);
// 它仍然是通过右移ASHIFT位来取得Node的,ABASE定义如下:
Class<?> ak = Node[].class;
ABASE = U.arrayBaseOffset(ak) + (1 << ASHIFT);
// U.arrayBaseOffset获取对象头长度,数组元素的大小可以通过unsafe.arrayIndexScale(T[].class) 方法获取到。这也就是说要访问类型为T的第N个元素的话,你的偏移量offset应该是arrayOffset+N*arrayScale。也就是说BASE = arrayOffset+ 128 。
- 用@sun.misc.Contended来规避伪共享?
伪共享说明:假设一个类的两个相互独立的属性a和b在内存地址上是连续的(比如FIFO队列的头尾指针),那么它们通常会被加载到相同的cpu cache line里面。并发情况下,如果一个线程修改了a,会导致整个cache line失效(包括b),这时另一个线程来读b,就需要从内存里再次加载了,这种多线程频繁修改ab的情况下,虽然a和b看似独立,但它们会互相干扰,非常影响性能。
我们再看Node节点的定义, 在Java 8 中我们是可以利用sun.misc.Contended来规避伪共享的。所以说通过 « ASHIFT方式加上sun.misc.Contended,所以使得任意两个可用Node不会再同一个缓存行中。
@sun.misc.Contended static final class Node{
....
}
我们再次回到arenaExchange()。取得arena中的node节点后,如果定位的节点q 不为空,且CAS操作成功,则交换数据,返回交换的数据,唤醒等待的线程。
- 如果q等于null且下标在bound & MMASK范围之内,则尝试占领该位置,如果成功,则采用自旋 + 阻塞的方式进行等待交换数据。
- 如果下标不在bound & MMASK范围之内获取由于q不为null但是竞争失败的时候:消除p。加入bound 不等于当前节点的bond(b != p.bound),则更新p.bound = b,collides = 0 ,i = m或者m - 1。如果冲突的次数不到m 获取m 已经为最大值或者修改当前bound的值失败,则通过增加一次collides以及循环递减下标i的值;否则更新当前bound的值成功:我们令i为m+1即为此时最大的下标。最后更新当前index的值。
深入理解
Exchanger是一种线程间安全交换数据的机制。可以和之前分析过的SynchronousQueue对比一下:线程A通过SynchronousQueue将数据a交给线程B;线程A通过Exchanger和线程B交换数据,线程A把数据a交给线程B,同时线程B把数据b交给线程A。可见,SynchronousQueue是交给一个数据,Exchanger是交换两个数据。
- 不同JDK实现有何差别?
- 在JDK5中Exchanger被设计成一个容量为1的容器,存放一个等待线程,直到有另外线程到来就会发生数据交换,然后清空容器,等到下一个到来的线程。
- 从JDK6开始,Exchanger用了类似ConcurrentMap的分段思想,提供了多个slot,增加了并发执行时的吞吐量。
应用示例
来一个非常经典的并发问题:你有相同的数据buffer,一个或多个数据生产者,和一个或多个数据消费者。只是Exchange类只能同步2个线程,所以你只能在你的生产者和消费者问题中只有一个生产者和一个消费者时使用这个类。
public class Test {
static class Producer extends Thread {
private Exchanger<Integer> exchanger;
private static int data = 0;
Producer(String name, Exchanger<Integer> exchanger) {
super("Producer-" + name);
this.exchanger = exchanger;
}
@Override
public void run() {
for (int i=1; i<5; i++) {
try {
TimeUnit.SECONDS.sleep(1);
data = i;
System.out.println(getName()+" 交换前:" + data);
data = exchanger.exchange(data);
System.out.println(getName()+" 交换后:" + data);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
static class Consumer extends Thread {
private Exchanger<Integer> exchanger;
private static int data = 0;
Consumer(String name, Exchanger<Integer> exchanger) {
super("Consumer-" + name);
this.exchanger = exchanger;
}
@Override
public void run() {
while (true) {
data = 0;
System.out.println(getName()+" 交换前:" + data);
try {
TimeUnit.SECONDS.sleep(1);
data = exchanger.exchange(data);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(getName()+" 交换后:" + data);
}
}
}
public static void main(String[] args) throws InterruptedException {
Exchanger<Integer> exchanger = new Exchanger<Integer>();
new Producer("", exchanger).start();
new Consumer("", exchanger).start();
TimeUnit.SECONDS.sleep(7);
System.exit(-1);
}
}
3.29 - CH29-ThreadLocal
概览
ThreadLocal是通过线程隔离的方式防止任务在共享资源上产生冲突, 线程本地存储是一种自动化机制,可以为使用相同变量的每个不同线程都创建不同的存储。
线程安全的解决思路:
- 互斥同步: synchronized 和 ReentrantLock
- 非阻塞同步: CAS, AtomicXXXX
- 无同步方案: 栈封闭,本地存储(Thread Local),可重入代码
线程安全:是指广义上的共享资源访问安全性,因为线程隔离是通过副本保证本线程访问资源安全性,它不保证线程之间还存在共享关系的狭义上的安全性。
ThreadLocal 的官方解释:
This class provides thread-local variables. These variables differ from their normal counterparts in that each thread that accesses one (via its {@code get} or {@code set} method) has its own, independently initialized copy of the variable. {@code ThreadLocal} instances are typically private static fields in classes that wish to associate state with a thread (e.g., a user ID or Transaction ID)
该类提供了线程局部 (thread-local) 变量。这些变量不同于它们的普通对应物,因为访问某个变量(通过其 get 或 set 方法)的每个线程都有自己的局部变量,它独立于变量的初始化副本。ThreadLocal 实例通常是类中的 private static 字段,它们希望将状态与某一个线程(例如,用户 ID 或事务 ID)相关联。
ThreadLocal是一个将在多线程中为每一个线程创建单独的变量副本的类; 当使用ThreadLocal来维护变量时, ThreadLocal会为每个线程创建单独的变量副本, 避免因多线程操作共享变量而导致的数据不一致的情况。
理解
class ConnectionManager {
private static Connection connect = null;
public static Connection openConnection() {
if (connect == null) {
connect = DriverManager.getConnection();
}
return connect;
}
public static void closeConnection() {
if (connect != null)
connect.close();
}
}
很显然,在多线程中使用会存在线程安全问题:第一,这里面的2个方法都没有进行同步,很可能在openConnection方法中会多次创建connect;第二,由于connect是共享变量,那么必然在调用connect的地方需要使用到同步来保障线程安全,因为很可能一个线程在使用connect进行数据库操作,而另外一个线程调用closeConnection关闭链接。
你可能会说,将这段代码的两个方法进行同步处理,并且在调用connect的地方需要进行同步处理,比如用Synchronized或者ReentrantLock互斥锁。
- 这里再抛出一个问题:这地方到底需不需要将connect变量进行共享?
事实上,是不需要的。假如每个线程中都有一个connect变量,各个线程之间对connect变量的访问实际上是没有依赖关系的,即一个线程不需要关心其他线程是否对这个connect进行了修改的。即改后的代码可以这样:
class ConnectionManager {
private Connection connect = null;
public Connection openConnection() {
if (connect == null) {
connect = DriverManager.getConnection();
}
return connect;
}
public void closeConnection() {
if (connect != null)
connect.close();
}
}
class Dao {
public void insert() {
ConnectionManager connectionManager = new ConnectionManager();
Connection connection = connectionManager.openConnection();
// 使用connection进行操作
connectionManager.closeConnection();
}
}
这样处理确实也没有任何问题,由于每次都是在方法内部创建的连接,那么线程之间自然不存在线程安全问题。但是这样会有一个致命的影响:导致服务器压力非常大,并且严重影响程序执行性能。由于在方法中需要频繁地开启和关闭数据库连接,这样不仅严重影响程序执行效率,还可能导致服务器压力巨大。
那么这种情况下使用ThreadLocal是再适合不过的了,因为ThreadLocal在每个线程中对该变量会创建一个副本,即每个线程内部都会有一个该变量,且在线程内部任何地方都可以使用,线程之间互不影响,这样一来就不存在线程安全问题,也不会严重影响程序执行性能。下面就是网上出现最多的例子:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class ConnectionManager {
private static final ThreadLocal<Connection> dbConnectionLocal = new ThreadLocal<Connection>() {
@Override
protected Connection initialValue() {
try {
return DriverManager.getConnection("", "", "");
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}
};
public Connection getConnection() {
return dbConnectionLocal.get();
}
}
ThreaLocal的JDK文档中说明:ThreadLocal instances are typically private static fields in classes that wish to associate state with a thread。如果我们希望通过某个类将状态(例如用户ID、事务ID)与线程关联起来,那么通常在这个类中定义private static类型的ThreadLocal 实例。
但是要注意,虽然ThreadLocal能够解决上面说的问题,但是由于在每个线程中都创建了副本,所以要考虑它对资源的消耗,比如内存的占用会比不使用ThreadLocal要大。
原理
如何实现线程隔离
主要是用到了 Thread 对象中的一个 ThreadLocalMap 类型的变量 threadLocals,负责存储当前线程的关于 Connection 的对象,dbConnectionLocal 变量为 key,以新建的 Connection 对象为 value;这样的话,线程第一次读取的时候如果不存在就会调用 ThreadLocal 的 initialValue 方法创建一个 Connection 对象并返回。
具体关于为线程分配变量副本的代码如下:
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
- 首先获取当前线程对象 t,然后从线程 t 中获取到 ThreadLocalMap 的成员属性 threadLocals
- 如果当前线程的 threadLocals 已经初始化并且存在以当前 ThreadLocal 对象为 Key 的值,则直接返回当前线程要获取的对象,比如上例中的 Connection。
- 如果当前线程的 threadLocals 已经初始化但不存在以当前 ThreadLocal 对象为 key 的对象,那么新建一个 Connection 对象,并且添加到当前线程的 threadLocals map 中,并返回。
- 如果当前线程的 threadLocals 属性尚未初始化,则重新创建一个 ThreadLocalMap 对象,并且创建一个 Connection 对象并添加到 ThreadLocalMap 中并返回。
初始化逻辑:
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
- 首先调用我们提供的 initialValue 方法,创建一个 Conneciton 对象
- 继续查看当前线程的 threadLocals 是否为空,如果 ThreadLocalMap 已经初始化,直接将产生的connection 对象添加到 ThreadLocalMap 中,如果没有初始化,则创建并添加到其中。
同时,ThreadLocal 还提供了直接操作 Thread 对象中 threadLocals 的方法
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
这样我们也可以不实现initialValue, 将初始化工作放到DBConnectionFactory的getConnection方法中:
public Connection getConnection() {
Connection connection = dbConnectionLocal.get();
if (connection == null) {
try {
connection = DriverManager.getConnection("", "", "");
dbConnectionLocal.set(connection);
} catch (SQLException e) {
e.printStackTrace();
}
}
return connection;
}
那么我们看过代码之后就很清晰的知道了为什么ThreadLocal能够实现变量的多线程隔离了; 其实就是用了Map的数据结构给当前线程缓存了, 要使用的时候就从本线程的threadLocals对象中获取就可以了, key就是当前线程;
当然了在当前线程下获取当前线程里面的Map里面的对象并操作肯定没有线程并发问题了, 当然能做到变量的线程间隔离了;
现在我们知道了ThreadLocal到底是什么了, 又知道了如何使用ThreadLocal以及其基本实现原理了是不是就可以结束了呢? 其实还有一个问题就是ThreadLocalMap是个什么对象, 为什么要用这个对象呢?
ThreadLocalMap
本质上来讲, 它就是一个Map, 但是这个ThreadLocalMap与我们平时见到的Map有点不一样:
- 它没有实现Map接口;
- 它没有public的方法, 最多有一个default的构造方法, 因为这个ThreadLocalMap的方法仅仅在ThreadLocal类中调用, 属于静态内部类
- ThreadLocalMap的Entry实现继承了WeakReference<ThreadLocal>
- 该方法仅仅用了一个Entry数组来存储Key, Value; Entry并不是链表形式, 而是每个bucket里面仅仅放一个Entry;
要了解ThreadLocalMap的实现, 我们先从入口开始, 就是往该Map中添加一个值:
private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
if (k == key) {
e.value = value;
return;
}
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
先进行简单的分析, 对该代码表层意思进行解读:
- 看下当前threadLocal的在数组中的索引位置 比如:
i = 2, 看 i = 2 位置上面的元素(Entry)的Key是否等于threadLocal 这个 Key, 如果等于就很好说了, 直接将该位置上面的Entry的Value替换成最新的就可以了; - 如果当前位置上面的 Entry 的 Key为空, 说明ThreadLocal对象已经被回收了, 那么就调用replaceStaleEntry
- 如果清理完无用条目(ThreadLocal被回收的条目)、并且数组中的数据大小 > 阈值的时候对当前的Table进行重新哈希 所以, 该HashMap是处理冲突检测的机制是向后移位, 清除过期条目 最终找到合适的位置;
后面就是Get方法了:
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
先找到ThreadLocal的索引位置, 如果索引位置处的entry不为空并且键与threadLocal是同一个对象, 则直接返回; 否则去后面的索引位置继续查找。
内存泄露
如果用线程池来操作ThreadLocal 对象确实会造成内存泄露, 因为对于线程池里面不会销毁的线程, 里面总会存在着<ThreadLocal, LocalVariable>的强引用, 因为final static 修饰的 ThreadLocal 并不会释放, 而ThreadLocalMap 对于 Key 虽然是弱引用, 但是强引用不会释放, 弱引用当然也会一直有值, 同时创建的LocalVariable对象也不会释放, 就造成了内存泄露; 如果LocalVariable对象不是一个大对象的话, 其实泄露的并不严重, 泄露的内存 = 核心线程数 * LocalVariable对象的大小;
所以, 为了避免出现内存泄露的情况, ThreadLocal提供了一个清除线程中对象的方法, 即 remove, 其实内部实现就是调用 ThreadLocalMap 的remove方法:
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
expungeStaleEntry(i);
return;
}
}
}
参考资料
3.30 - CH30-AllLocks
概览
| 序号 | 术语 | 应用 |
|---|
| 1 | 乐观锁 | CAS |
| 2 | 悲观锁 | synchronized、vector、hashtable |
| 3 | 自旋锁 | CAS |
| 4 | 可重入锁 | synchronized、ReentrantLock、Lock |
| 5 | 读写锁 | ReentrantReadWriteLock、CopyOnWriteLock、CopyOnWriteArraySet |
| 6 | 公平锁 | ReentrantLock(true) |
| 7 | 非公平锁 | synchronized、ReentrantLock(false) |
| 8 | 共享锁 | ReentranReadWriteLock-ReadLock |
| 9 | 独占锁 | synchronized、vector、hashtable、ReentranReadWriteLock-WriteLock |
| 10 | 重量级锁 | synchronized |
| 11 | 轻量级锁 | 锁优化技术 |
| 12 | 偏向锁 | 锁优化技术 |
| 13 | 分段锁 | ConcurrentHashMap |
| 14 | 互斥锁 | synchronized |
| 15 | 同步锁 | synchronized |
| 16 | 死锁 | 相互请求对方资源 |
| 17 | 锁粗化 | 锁优化技术 |
| 18 | 锁消除 | 锁优化技术 |
1. 乐观锁
即乐观思想,假定当前场景是读多写少、遇到并发写的概览较低,读数据时认为别的线程不会正在修改数据(因此不加锁);写数据时,判断当前与期望值是否相同,如果相同则更新(更新期间加锁,保证原子性)。
Java 中乐观锁的实现是 CAS——比较并交换。比较(主内存中的)当前值,与(当前线程中的)预期值是否一样,一样则更新,否则继续进行 CAS 操作。
可以同时进行读操作,读的时候其他线程不能执行写操作。
2. 悲观锁
即悲观思想,认为写多读少,遇到并发写的可能性高。每次读数据都认为其他线程会在同一时间修改数据,所以每次写数据都会认为其他线程会修改,因此每次都加锁。其他线程想要读写这个数据时都会被该锁阻塞,直到当前写数据的线程是否锁。
Java 中的悲观锁实现有 synchronized 关键字、ReentrantLock。
只有一个线程能够进行读操作或写操作。
3. 自旋锁
自旋指的是一种行为:为了让线程等待,我们只需让该线程循环。
现在绝大多数的个人电脑和服务器都是多路(核)处理器系统,如果物理机器有一个以上的处理器或者处理器核心,能让两个或以上的线程同时并行执行,就可以让后面请求锁的那个线程“稍等一会”,但不放弃处理器的执行时间,看看持有锁的线程是否很快就会释放锁。
优点:避免了线程切换的开销。挂起线程和恢复线程的操作都需要转入内核态中完成,这些操作给Java虚拟机的并发性能带来了很大的压力。
缺点:占用处理器的时间,如果占用的时间很长,会白白消耗处理器资源,而不会做任何有价值的工作,带来性能的浪费。因此自旋等待的时间必须有一定的限度,如果自旋超过了限定的次数仍然没有成功获得锁,就应当使用传统的方式去挂起线程。
Java 中默认的自旋次数为 10,可以通过参数 -XX:PreBlockSpin 来修改。
自适应自旋:自适应意味着自旋的时间不再是固定的,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定的。有了自适应自旋,随着程序运行时间的增长及性能监控信息的不断完善,虚拟机对程序锁的状态预测就会越来越精准。
Java 中对自旋的应用:CAS 操作中比较操作失败后会执行自旋等待。
4. 可重入锁(递归锁)
可重入指的是:某个线程在获取到锁之后能够再次获取该锁,而不会阻塞。
原理:通过组合自定义同步器来实现锁的获取与释放。
- 再次获取锁:识别获取锁的线程是否为当前持有锁的线程,如果是则再次获取成功,并将技术 +1。
- 释放锁:释放锁并将计数 -1。
作用:避免死锁。
Java 中的实现有:ReentrantLock、synchronized 关键字。
5. 读写锁
读写锁指定是指:为了提高性能,在读的时候使用读锁,写的时候使用写锁,灵活控制。在没有写的时候,读是无阻塞的,在一定程度上提高了程序的执行效率。
读写锁分为读锁和写锁,多个读锁不互斥,读锁与写锁互斥。
读锁:允许多个线程同时访问资源。
写锁:同时只允许一个线程访问资源。
Java 中的实现为 ReentrantReadWriteLock。
6. 公平锁
公平锁的思想是:多个线程按照请求所的顺序来依次获取锁。
在并发环境中,每个线程会先查看此锁维护的等待队列,如果当前等待队列为空,则占有锁,如果等待队列不为空,则加入到等待队列的末尾,按照FIFO的原则从队列中拿到线程,然后占有锁。
7. 非公平锁
非公平锁的思想是:线程尝试获取锁,如果获取不到,则再采用公平锁的方式。多个线程获取锁的顺序,不是按照先到先得的顺序,有可能后申请锁的线程比先申请的线程优先获取锁。
非公平锁的性能高于公平锁,但可能导致某个线程总是获取不到锁,即饥饿。
Java 中的实现:synchronized 是非公平锁,ReentrantLock 通过构造函数指定该锁是公平的还是非公平的,默认是非公平的。
8. 共享锁
共享锁的思想是:可以有多个线程获取读锁,以共享的方式持有锁。和乐观锁、读写锁同义。
Java中用到的共享锁: ReentrantReadWriteLock。
9. 独占锁
独占锁的思想是:只能有一个线程获取锁,以独占的方式持有锁。和悲观锁、互斥锁同义。
Java中用到的独占锁: synchronized,ReentrantLock
10. 重量级锁
重量级锁是一种称谓: synchronized是通过对象内部的一个叫做监视器锁(monitor)来实现的,监视器锁本身依赖底层的操作系统的 Mutex Lock来实现。操作系统实现线程的切换需要从用户态切换到核心态,成本非常高。这种依赖于操作系统 Mutex Lock来实现的锁称为重量级锁。为了优化synchonized,引入了轻量级锁,偏向锁。
Java中的重量级锁: synchronized
11. 轻量级锁
是JDK6时加入的一种锁优化机制: 轻量级锁是在无竞争的情况下使用CAS操作去消除同步使用的互斥量。轻量级是相对于使用操作系统互斥量来实现的重量级锁而言的。轻量级锁在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。如果出现两条以上的线程争用同一个锁的情况,那轻量级锁将不会有效,必须膨胀为重量级锁。
优点: 如果没有竞争,通过CAS操作成功避免了使用互斥量的开销。
缺点: 如果存在竞争,除了互斥量本身的开销外,还额外产生了CAS操作的开销,因此在有竞争的情况下,轻量级锁比传统的重量级锁更慢。
12. 偏向锁
是JDK6时加入的一种锁优化机制: 在无竞争的情况下把整个同步都消除掉,连CAS操作都不去做了。偏是指偏心,它的意思是这个锁会偏向于第一个获得它的线程,如果在接下来的执行过程中,该锁一直没有被其他的线程获取,则持有偏向锁的线程将永远不需要再进行同步。持有偏向锁的线程以后每次进入这个锁相关的同步块时,虚拟机都可以不再进行任何同步操作(例如加锁、解锁及对Mark Word的更新操作等)。
优点: 把整个同步都消除掉,连CAS操作都不去做了,优于轻量级锁。
缺点: 如果程序中大多数的锁都总是被多个不同的线程访问,那偏向锁就是多余的。
13. 分段锁
一种机制: 最好的例子来说明分段锁是ConcurrentHashMap。**ConcurrentHashMap原理:**它内部细分了若干个小的 HashMap,称之为段(Segment)。默认情况下一个 ConcurrentHashMap 被进一步细分为 16 个段,既就是锁的并发度。如果需要在 ConcurrentHashMap 添加一项key-value,并不是将整个 HashMap 加锁,而是首先根据 hashcode 得到该key-value应该存放在哪个段中,然后对该段加锁,并完成 put 操作。在多线程环境中,如果多个线程同时进行put操作,只要被加入的key-value不存放在同一个段中,则线程间可以做到真正的并行。
**线程安全:**ConcurrentHashMap 是一个 Segment 数组, Segment 通过继承ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全
14. 互斥锁
互斥锁与悲观锁、独占锁同义,表示某个资源只能被一个线程访问,其他线程不能访问。
Java中的同步锁: synchronized
15. 同步锁
同步锁与互斥锁同义,表示并发执行的多个线程,在同一时间内只允许一个线程访问共享数据。
Java中的同步锁: synchronized
16. 死锁
**死锁是一种现象:**如线程A持有资源x,线程B持有资源y,线程A等待线程B释放资源y,线程B等待线程A释放资源x,两个线程都不释放自己持有的资源,则两个线程都获取不到对方的资源,就会造成死锁。
Java中的死锁不能自行打破,所以线程死锁后,线程不能进行响应。所以一定要注意程序的并发场景,避免造成死锁。
17. 锁粗化
一种优化技术: 如果一系列的连续操作都对同一个对象反复加锁和解锁,甚至加锁操作都是出现在循环体体之中,就算真的没有线程竞争,频繁地进行互斥同步操作将会导致不必要的性能损耗,所以就采取了一种方案:把加锁的范围扩展(粗化)到整个操作序列的外部,这样加锁解锁的频率就会大大降低,从而减少了性能损耗。
18. 锁消除
一种优化技术: 就是把锁干掉。当Java虚拟机运行时发现有些共享数据不会被线程竞争时就可以进行锁消除。
那如何判断共享数据不会被线程竞争?
利用逃逸分析技术:分析对象的作用域,如果对象在A方法中定义后,被作为参数传递到B方法中,则称为方法逃逸;如果被其他线程访问,则称为线程逃逸。
在堆上的某个数据不会逃逸出去被其他线程访问到,就可以把它当作栈上数据对待,认为它是线程私有的,同步加锁就不需要了。
TODO
3.31 - CH31-AllQueues
| 名称 | 类型 | 有界 | 线程安全 | 说明 |
|---|
| Queue | 接口 | — | — | 顶层队列接口 |
| BlockingQueue | 接口 | — | — | 阻塞队列接口 |
| BlockingDeuque | 接口 | — | — | 双向阻塞队列接口 |
| Dequeu | 接口 | — | — | 双向队列接口 |
| TransferQueue | 接口 | — | — | 传输队列接口 |
| AbstractQueue | 抽象类 | — | — | 队列抽象类 |
| PriorityQueue | 实现类 | N | N | 优先级队列 |
| ArrayDeque | 实现类 | N | N | 数组双向队列 |
| LinkedList | 实现类 | N | N | 链表对象类 |
| ConcurrentLinkedQueue | 实现类 | N | Y | 链表结构并发队列 |
| ConcurrentLinkedDeque | 实现类 | N | Y | 链表结构双向并发队列 |
| ArrayBlockingQueue | 实现类 | Y | Y | 数组结构有界阻塞队列 |
| LinkedBlockingQueue | 实现类 | Y | Y | 链表结构有界阻塞队列 |
| LinkedBlockingDeque | 实现类 | Y | Y | 链表结构双向有界阻塞队列 |
| LinkedTransferQueue | 实现类 | N | Y | 连接结构无界阻塞传输队列 |
| SynchronousQueue | 实现类 | Y | Y | 不存储元素的有界阻塞队列 |
| PriorityBlockingQueue | 实现类 | N | Y | 支持优先级排序的无界阻塞队列 |
| DelayQueue | 实现类 | N | Y | 延时无界阻塞队列 |
层级结构
1. Queue
- Queue接口是一种Collection,被设计用于处理之前临时保存在某处的元素。
- 除了基本的Collection操作之外,队列还提供了额外的插入、提取和检查操作。每一种操作都有两种形式:如果操作失败,则抛出一个异常;如果操作失败,则返回一个特殊值(null或false,取决于是什么操作)。
- 队列通常是以FIFO(先进先出)的方式排序元素,但是这不是必须的。
- 只有优先级队列可以根据提供的比较器对元素进行排序或者是采用正常的排序。无论怎么排序,队列的头将通过调用remove()或poll()方法进行移除。在FIFO队列种,所有新的元素被插入到队尾。其他种类的队列可能使用不同的布局来存放元素。
- 每个Queue必须指定排序属性。
2. Deque
支持两端元素插入和移除的线性集合。名称deque是双端队列的缩写(Double-Ended queue),通常发音为deck。大多数实现Deque的类,对它们包含的元素的数量没有固定的限制的,支持有界和无界。
- 该列表包含包含访问deque两端元素的方法,提供了插入,移除和检查元素的方法。
- 这些方法种的每一种都存在两种形式:如果操作失败,则会抛出异常,另一种方法返回一个特殊值(null或false,取决于具体操作)。
- 插入操作的后一种形式专门设计用于容量限制的Deque实现,大多数实现中,插入操作不能失败,所以可以用插入操作的后一种形式。
- Deque接口扩展了Queue接口,当使用deque作为队列时,作为FIFO。元素将添加到deque的末尾,并从头开始删除。
- Deque也可以用作LIFO(后进先出)栈,这个接口优于传统的Stack类。当作为栈使用时,元素被push到deque队列的头,而pop也是从队列的头pop出来。
3. AbstractQueue
AbstractQueue是一个抽象类,继承了Queue接口,提供了一些Queue操作的骨架实现。
方法add、remove、element方法基于offer、poll和peek。也就是说如果不能正常操作,则抛出异常。我们来看下AbstactQueue是怎么做到的。
public boolean add(E e) {
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}
public E remove() {
E x = poll();
if (x != null)
return x;
else
throw new NoSuchElementException();
}
public E element() {
E x = peek();
if (x != null)
return x;
else
throw new NoSuchElementException();
}
如果继承AbstractQueue抽象类则必须保证offer方法不允许null值插入。
4. BlockingQueue
说明:
- BlockingQueue(阻塞队列)也是一种队列,支持阻塞的插入和移除方法。
- 阻塞的插入:当队列满时,队列会阻塞插入元素的线程,直到队列不满。
- 阻塞的移除:当队列为空,获取元素的线程会等待队列变为非空。
- 应用场景:生产者和消费者,生产者线程向队列里添加元素,消费者线程从队列里移除元素,阻塞队列时获取和存放元素的容器。
- 为什么要用阻塞队列:生产者生产和消费者消费的速率不一样,需要用队列来解决速率差问题,当队列满了或空的时候,则需要阻塞生产或消费动作来解决队列满或空的问题。
方法总结:
如何实现的阻塞
- 当往队列里插入一个元素时,如果队列不可用,那么阻塞生产者主要通过LockSupport. park(this)来实现。
- park这个方法会阻塞当前线程,只有以下4种情况中的一种发生时,该方法才会返回。
- 与park对应的unpark执行或已经执行时。“已经执行”是指unpark先执行,然后再执行park的情况。
- 线程被中断时。
- 等待完time参数指定的毫秒数时。
- 异常现象发生时,这个异常现象没有任何原因。
5. BlockingDeque
- BlockingDeque 满了,两端的 put 操作被阻塞
- BlockingDeque 为空,两端的Take操作被阻塞
它是阻塞队列BlockingQueue和双向队列Deque接口的结合。有如下方法:
BlockDeque和BlockQueue的对等方法:
6. TransferQueue
如果有消费者正在获取元素,则将队列中的元素传递给消费者。如果没有消费者,则等待消费者消费。必须将任务完成才能返回。
transfer(E e)
- 生产者线程Producer Thread尝试将元素B传给消费者线程,如果没有消费者线程,则将元素B放到尾节点。并且生产者线程等待元素B被消费。当元素B被消费后,生产者线程返回。
- 如果当前有消费者正在等待接收元素(消费者通过take方法或超时限制的poll方法时),transfer方法可以把生产者传入的元素立刻transfer(传输)给消费者。
- 如果没有消费者等待接收元素,transfer方法会将元素放在队列的tail(尾)节点,并等到该元素被消费者消费了才返回。
tryTransfer(E e)
- 试探生产者传入的元素是否能直接传给消费者。
- 如果没有消费者等待接收元素,则返回false。
- 和transfer方法的区别是,无论消费者是否接收,方法立即返回。
tryTransfer(E e, long timeout, TimeUnit unit)
- 带有时间限制的tryTransfer方法。
- 试图把生产者传入的元素直接传给消费者。
- 如果没有消费者消费该元素则等待指定的时间再返回。
- 如果超时了还没有消费元素,则返回false。
- 如果在超时时间内消费了元素,则返回true。
getWaitingConsumerCount()
- 获取通过BlockingQueue.take()方法或超时限制poll方法等待接受元素的消费者数量。近似值。
- 返回等待接收元素的消费者数量。
hasWaitingConsumer()
- 获取是否有通过BlockingQueue.tabke()方法或超时限制poll方法等待接受元素的消费者。
- 返回true则表示至少有一个等待消费者。
7. PriorityQueue
- PriorityQueue是一个支持优先级的无界阻塞队列。
- 默认自然顺序升序排序。
- 可以通过构造参数Comparator来对元素进行排序。
- 自定义实现comapreTo()方法来指定元素排序规则。
- 不允许插入null元素。
- 实现PriorityQueue接口的类,不保证线程安全,除非是PriorityBlockingQueue。
- PriorityQueue的迭代器不能保证以任何特定顺序遍历元素,如果需要有序遍历,请考虑使用
Arrays.sort(pq.toArray)。 - 进列(
offer、 add)和出列( poll、 remove())的时间复杂度O(log(n))。 - remove(Object) 和 contains(Object)的算法时间复杂度O(n)。
- peek、element、size的算法时间复杂度为O(1)。
8. LinkedList
- LinkedList实现了List和Deque接口,所以是一种双链表结构,可以当作堆栈、队列、双向队列使用。
- 一个双向列表的每一个元素都有三个整数值:元素、向后的节点链接、向前的节点链接
private static class Node<E> {
E item; //元素
Node<E> next; //向后的节点链接
Node<E> prev; //向前的节点链接
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
9. ConcurrentLinkedQueue
- ConcurrentLinked是由链表结构组成的线程安全的先进先出无界队列。
- 当多线程要共享访问集合时,ConcurrentLinkedQueue是一个比较好的选择。
- 不允许插入null元素
- 支持非阻塞地访问并发安全的队列,不会抛出ConcurrentModifiationException异常。
- size方法不是准确的,因为在统计集合的时候,队列可能正在添加元素,导致统计不准。
- 批量操作addAll、removeAll、retainAll、containsAll、equals和toArray不保证原子性(操作不可分割)
- 添加元素happen-before其他线程移除元素。
10. ArrayDeque
- 由数组组成的双端队列。
- 没有容量限制,根据需要扩容。
- 不是线程安全的。
- 禁止插入null元素。
- 当用作栈时,比栈速度快,当用作队列时,速度比LinkList快。
- 大部分方法的算法时间复杂度为O(1)。
- remove、removeFirstOccurrence、removeLastOccurrence、contains、remove 和批量操作的算法时间复杂度O(n)
11. ConcurrentLinkedDeque
- 由链表结构组成的双向无界阻塞队列
- 插入、删除和访问操作可以并发进行,线程安全的类
- 不允许插入null元素
- 在并发场景下,计算队列的大小是不准确的,因为计算时,可能有元素加入队列。
- 批量操作addAll、removeAll、retainAll、containsAll、equals和toArray不保证原子性(操作不可分割)
12. ArrayBlockingQueue
- ArrayBlockingQueue是一个用数组实现的有界阻塞队列。
- 队列满时插入操作被阻塞,队列空时,移除操作被阻塞。
- 按照先进先出(FIFO)原则对元素进行排序。
- 默认不保证线程公平的访问队列。
- 公平访问队列:按照阻塞的先后顺序访问队列,即先阻塞的线程先访问队列。
- 非公平性是对先等待的线程是非公平的,当队列可用时,阻塞的线程都可以争夺访问队列的资格。有可能先阻塞的线程最后才访问访问队列。
- 公平性会降低吞吐量。
13. LinkedBlockinQueue
- LinkedBlockingQueue具有单链表和有界阻塞队列的功能。
- 队列满时插入操作被阻塞,队列空时,移除操作被阻塞。
- 默认和最大长度为Integer.MAX_VALUE,相当于无界(值非常大:2^31-1)。
- 吞吐量通常要高于ArrayBlockingQueue。
- 创建线程池时,参数runnableTaskQueue(任务队列),用于保存等待执行的任务的阻塞队列可以选择LinkedBlockingQueue。
- 静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
14. LinkedBlockingDeque
- 由链LinkedBlockingDeque = 阻塞队列+链表+双端访问
- 线程安全。
- 多线程同时入队时,因多了一端访问入口,所以减少了一半的竞争。
- 默认容量大小为Integer.MAX_VALUE。可指定容量大小。
- 可以用在“工作窃取“模式中。
15. LinkedTransferQueue
LinkedTransferQueue = 阻塞队列+链表结构+TransferQueue
之前我们讲TransferQueue接口时已经介绍过了TransferQueue接口 ,所以LinkedTransferQueue接口跟它相似,只是加入了阻塞插入和移除的功能,以及结构是链表结构。
16. SynchronousQueue
- 我称SynchronousQueue为”传球好手“。想象一下这个场景:小明抱着一个篮球想传给小花,如果小花没有将球拿走,则小明是不能再拿其他球的。
- SynchronousQueue负责把生产者产生的数据传递给消费者线程。
- SynchronousQueue本身不存储数据,调用了put方法后,队列里面也是空的。
- 每一个put操作必须等待一个take操作完成,否则不能添加元素。
- 适合传递性场景。
- 性能高于ArrayBlockingQueue和LinkedBlockingQueue。
- 吞吐量通常要高于LinkedBlockingQueue。
- 创建线程池时,参数runnableTaskQueue(任务队列),用于保存等待执行的任务的阻塞队列可以选择SynchronousQueue。
- 静态工厂方法Executors.newCachedThreadPool()使用了这个队列
17. PriorityBlockQueue
- PriorityBlockQueue = PriorityQueue + BlockingQueue
- 之前我们也讲到了PriorityQueue的原理,支持对元素排序。
- 元素默认自然升序排序。
- 可以自定义CompareTo()方法来指定元素排序规则。
- 可以通过构造函数构造参数Comparator来对元素进行排序。
18. DelayQueue
- DelayQueue = Delayed + BlockingQueue。队列中的元素必须实现Delayed接口。
- 在创建元素时,可以指定多久可以从队列中获取到当前元素。只有在延时期满才能从队列中获取到当前元素。
场景:
- 缓存系统的设计:可以用DelayQueue保存缓存元素的有效期。然后用一个线程循环的查询DelayQueue队列,一旦能从DelayQueue中获取元素时,表示缓存有效期到了。
- 定时任务调度:使用DelayQueue队列保存当天将会执行的任务和执行时间,一旦从DelayQueue中获取到任务就开始执行。比如Java中的TimerQueue就是使用DelayQueue实现的。
3.32 - CH32-AllPools
七大属性
- corePoolSize(int):核心线程数量。默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到任务队列当中。线程池将长期保证这些线程处于存活状态,即使线程已经处于闲置状态。除非配置了allowCoreThreadTimeOut=true,核心线程数的线程也将不再保证长期存活于线程池内,在空闲时间超过keepAliveTime后被销毁。
- workQueue:阻塞队列,存放等待执行的任务,线程从workQueue中取任务,若无任务将阻塞等待。当线程池中线程数量达到corePoolSize后,就会把新任务放到该队列当中。JDK提供了四个可直接使用的队列实现,分别是:基于数组的有界队列ArrayBlockingQueue、基于链表的无界队列LinkedBlockingQueue、只有一个元素的同步队列SynchronousQueue、优先级队列PriorityBlockingQueue。在实际使用时一定要设置队列长度。
- maximumPoolSize(int):线程池内的最大线程数量,线程池内维护的线程不得超过该数量,大于核心线程数量小于最大线程数量的线程将在空闲时间超过keepAliveTime后被销毁。当阻塞队列存满后,将会创建新线程执行任务,线程的数量不会大于maximumPoolSize。
- keepAliveTime(long):线程存活时间,若线程数超过了corePoolSize,线程闲置时间超过了存活时间,该线程将被销毁。除非配置了allowCoreThreadTimeOut=true,核心线程数的线程也将不再保证长期存活于线程池内,在空闲时间超过keepAliveTime后被销毁。
- TimeUnit unit:线程存活时间的单位,例如TimeUnit.SECONDS表示秒。
- RejectedExecutionHandler:拒绝策略,当任务队列存满并且线程池个数达到maximunPoolSize后采取的策略。ThreadPoolExecutor中提供了四种拒绝策略,分别是:抛RejectedExecutionException异常的AbortPolicy(如果不指定的默认策略)、使用调用者所在线程来运行任务CallerRunsPolicy、丢弃一个等待执行的任务,然后尝试执行当前任务DiscardOldestPolicy、不动声色的丢弃并且不抛异常DiscardPolicy。项目中如果为了更多的用户体验,可以自定义拒绝策略。
- threadFactory:创建线程的工厂,虽说JDK提供了线程工厂的默认实现DefaultThreadFactory,但还是建议自定义实现最好,这样可以自定义线程创建的过程,例如线程分组、自定义线程名称等。
工作原理
- 通过execute方法提交任务时,当线程池中的线程数小于corePoolSize时,新提交的任务将通过创建一个新线程来执行,即使此时线程池中存在空闲线程。
- 通过execute方法提交任务时,当线程池中线程数量达到corePoolSize时,新提交的任务将被放入workQueue中,等待线程池中线程调度执行。
- 通过execute方法提交任务时,当workQueue已存满,且maximumPoolSize大于corePoolSize时,新提交的任务将通过创建新线程执行。
- 当线程池中的线程执行完任务空闲时,会尝试从workQueue中取头结点任务执行。
- 通过execute方法提交任务,当线程池中线程数达到maxmumPoolSize,并且workQueue也存满时,新提交的任务由RejectedExecutionHandler执行拒绝操作。
- 当线程池中线程数超过corePoolSize,并且未配置allowCoreThreadTimeOut=true,空闲时间超过keepAliveTime的线程会被销毁,保持线程池中线程数为corePoolSize。
- 当设置allowCoreThreadTimeOut=true时,任何空闲时间超过keepAliveTime的线程都会被销毁。
状态切换
4 - Java I/0
4.1 - CH01-IO分类
基于传输方式
从数据传输方式或者说是运输方式角度看,可以将 IO 类分为:
字节是个计算机看的,字符才是给人看的。
字节流
字符流
二者区别
编码就是把字符转换为字节,而解码是把字节重新组合成字符。
如果编码和解码过程使用不同的编码方式那么就出现了乱码。
- GBK 编码中,中文字符占 2 个字节,英文字符占 1 个字节;
- UTF-8 编码中,中文字符占 3 个字节,英文字符占 1 个字节;
- UTF-16be 编码中,中文字符和英文字符都占 2 个字节。
UTF-16be 中的 be 指的是 Big Endian,也就是大端。相应地也有 UTF-16le,le 指的是 Little Endian,也就是小端。
Java 使用双字节编码 UTF-16be,这不是指 Java 只支持这一种编码方式,而是说 char 这种类型使用 UTF-16be 进行编码。char 类型占 16 位,也就是两个字节,Java 使用这种双字节编码是为了让一个中文或者一个英文都能使用一个 char 来存储。
基于数据操作
从数据来源或操作对象角度看,IO 又可以按如下方式分类:
4.2 - CH02-装饰模式
装饰模式
装饰者(Decorator)和具体组件(ConcreteComponent)都继承自组件(Component),具体组件的方法实现不需要依赖于其它对象,而装饰者组合了一个组件,这样它可以装饰其它装饰者或者具体组件。
所谓装饰,就是把这个装饰者套在被装饰者之上,从而动态扩展被装饰者的功能。装饰者的方法有一部分是自己的,这属于它的功能,然后调用被装饰者的方法实现,从而也保留了被装饰者的功能。可以看到,具体组件应当是装饰层次的最低层,因为只有具体组件的方法实现不需要依赖于其它对象。
IO 装饰模式
以 InputStream 为例,
- InputStream 是抽象组件;
- FileInputStream 是 InputStream 的子类,属于具体组件,提供了字节流的输入操作;
- FilterInputStream 属于抽象装饰者,装饰者用于装饰组件,为组件提供额外的功能。例如 BufferedInputStream 为 FileInputStream 提供缓存的功能。
实例化一个具有缓存功能的字节流对象时,只需要在 FileInputStream 对象上再套一层 BufferedInputStream 对象即可。
FileInputStream fileInputStream = new FileInputStream(filePath);
BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);
DataInputStream 装饰者提供了对更多数据类型进行输入的操作,比如 int、double 等基本类型。
4.3 - CH03-InputStream
层级结构
public abstract int read()
// 读取数据
public int read(byte b[])
// 将读取到的数据放在 byte 数组中,该方法实际上是根据下面的方法实现的,off 为 0,len 为数组的长度
public int read(byte b[], int off, int len)
// 从第 off 位置读取 len 长度字节的数据放到 byte 数组中,流是以 -1 来判断是否读取结束的
public long skip(long n)
// 跳过指定个数的字节不读取,想想看电影跳过片头片尾
public int available()
// 返回可读的字节数量
public void close()
// 读取完,关闭流,释放资源
public synchronized void mark(int readlimit)
// 标记读取位置,下次还可以从这里开始读取,使用前要看当前流是否支持,可以使用 markSupport() 方法判断
public synchronized void reset()
// 重置读取位置为上次 mark 标记的位置
public boolean markSupported()
// 判断当前流是否支持标记流,和上面两个方法配套使用
源码实现
public abstract class InputStream implements Closeable {
private static final int SKIP_BUFFER_SIZE = 2048; //用于skip方法,和skipBuffer相关
private static byte[] skipBuffer; // skipBuffer is initialized in skip(long), if needed.
//从输入流中读取下一个字节,
//正常返回0-255,到达文件的末尾返回-1
//在流中还有数据,但是没有读到时该方法会阻塞(block)
//Java IO和New IO的区别就是阻塞流和非阻塞流
//抽象方法!不同的子类不同的实现!
public abstract int read() throws IOException;
//将流中的数据读入放在byte数组的第off个位置先后的len个位置中
//返回值为放入字节的个数。
//这个方法在利用抽象方法read,某种意义上简单的Templete模式。
public int read(byte b[], int off, int len) throws IOException {
//检查输入是否正常。一般情况下,检查输入是方法设计的第一步
if (b == null) {
throw new NullPointerException();
} else if (off < 0 || len < 0 || len > b.length - off) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
//读取下一个字节
int c = read();
//到达文件的末端返回-1
if (c == -1) { return -1; }
//返回的字节downcast
b[off] = (byte)c;
//已经读取了一个字节
int i = 1;
try {
//最多读取len个字节,所以要循环len次
for (; i < len ; i++) {
//每次循环从流中读取一个字节
//由于read方法阻塞,
//所以read(byte[],int,int)也会阻塞
c = read();
//到达末尾,理所当然返回-1
if (c == -1) { break; }
//读到就放入byte数组中
b[off + i] = (byte)c;
}
} catch (IOException ee) { }
return i;
}
//利用上面的方法read(byte[] b)
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
//方法内部使用的、表示要跳过的字节数目,
public long skip(long n) throws IOException {
long remaining = n;
int nr;
if (skipBuffer == null)
//初始化一个跳转的缓存
skipBuffer = new byte[SKIP_BUFFER_SIZE];
//本地化的跳转缓存
byte[] localSkipBuffer = skipBuffer;
//检查输入参数,应该放在方法的开始
if (n <= 0) { return 0; }
//一共要跳过n个,每次跳过部分,循环
while (remaining > 0) {
nr = read(localSkipBuffer, 0, (int) Math.min(SKIP_BUFFER_SIZE, remaining));
//利用上面的read(byte[],int,int)方法尽量读取n个字节
//读到流的末端,则返回
if (nr < 0) { break; }
//没有完全读到需要的,则继续循环
remaining -= nr;
}
return n - remaining;//返回时要么全部读完,要么因为到达文件末端,读取了部分
}
//查询流中还有多少可以读取的字节
//该方法不会block。在java中抽象类方法的实现一般有以下几种方式:
//1.抛出异常(java.util);2.“弱”实现。像上面这种。子类在必要的时候覆盖它。
//3.“空”实现。
public int available() throws IOException {
return 0;
}
//关闭当前流、同时释放与此流相关的资源
//关闭当前流、同时释放与此流相关的资源
public void close() throws IOException {}
//markSupport可以查询当前流是否支持mark
public synchronized void mark(int readlimit) {}
//对mark过的流进行复位。只有当流支持mark时才可以使用此方法。
public synchronized void reset() throws IOException {
throw new IOException("mark/reset not supported");
}
//查询是否支持mark
//绝大部分不支持,因此提供默认实现,返回false。子类有需要可以覆盖。
public boolean markSupported() {
return false;
}
}
public class FilterInputStream extends InputStream {
//装饰器的代码特征: 被装饰的对象一般是装饰器的成员变量
protected volatile InputStream in; //将要被装饰的字节输入流
protected FilterInputStream(InputStream in) { //通过构造方法传入此被装饰的流
this.in = in;
}
//下面这些方法,完成最小的装饰――0装饰,只是调用被装饰流的方法而已
public int read() throws IOException {
return in.read();
}
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
public int read(byte b[], int off, int len) throws IOException {
return in.read(b, off, len);
}
public long skip(long n) throws IOException {
return in.skip(n);
}
public int available() throws IOException {
return in.available();
}
public void close() throws IOException {
in.close();
}
public synchronized void mark(int readlimit) {
in.mark(readlimit);
}
public synchronized void reset() throws IOException {
in.reset();
}
public boolean markSupported() {
return in.markSupported();
}
}
public class ByteArrayInputStream extends InputStream {
protected byte buf[]; //内部的buffer,一般通过构造器输入
protected int pos; //当前位置的cursor。从0至byte数组的长度。
//byte[pos]就是read方法读取的字节
protected int mark = 0; //mark的位置。
protected int count; //流中字节的数目。
//构造器,从一个byte[]创建一个ByteArrayInputStream
public ByteArrayInputStream(byte buf[]) {
//初始化流中的各个成员变量
this.buf = buf;
this.pos = 0;
this.count = buf.length;
}
//构造器
public ByteArrayInputStream(byte buf[], int offset, int length) {
this.buf = buf;
this.pos = offset; //与上面不同
this.count = Math.min(offset + length, buf.length);
this.mark = offset; //与上面不同
}
//从流中读取下一个字节
public synchronized int read() {
//返回下一个位置的字节//流中没有数据则返回-1
return (pos < count) ? (buf[pos++] & 0xff) : -1;
}
// ByteArrayInputStream要覆盖InputStream中可以看出其提供了该方法的实现
//某些时候,父类不能完全实现子类的功能,父类的实现一般比较通用。
//当子类有更有效的方法时,我们会覆盖这些方法。
public synchronized int read(byte b[], int off, int len) {
//首先检查输入参数的状态是否正确
if(b==null){
throw new NullPointerException();
} else if (off < 0 || len < 0 || len > b.length - off) {
throw new IndexOutOfBoundsException();
}
if (pos >= count) { return -1; }
if (pos + len > count) { len = count - pos; }
if (len <= 0) { return 0; }
//java中提供数据复制的方法
//出于速度的原因!他们都用到System.arraycopy方法
System.arraycopy(buf, pos, b, off, len);
pos += len;
return len;
}
//下面这个方法,在InputStream中也已经实现了。
//但是当时是通过将字节读入一个buffer中实现的,好像效率低了一点。
//比InputStream中的方法简单、高效
public synchronized long skip(long n) {
//当前位置,可以跳跃的字节数目
if (pos + n > count) { n = count - pos; }
//小于0,则不可以跳跃
if (n < 0) { return 0; }
//跳跃后,当前位置变化
pos += n;
return n;
}
//查询流中还有多少字节没有读取。
public synchronized int available() {
return count - pos;
}
//ByteArrayInputStream支持mark所以返回true
public boolean markSupported() {
return true;
}
//在流中当前位置mark。
public void mark(int readAheadLimit) {
mark = pos;
}
//重置流。即回到mark的位置。
public synchronized void reset() {
pos = mark;
}
//关闭ByteArrayInputStream不会产生任何动作。
public void close() throws IOException { }
}
public class BufferedInputStream extends FilterInputStream {
private static int defaultBufferSize = 8192; //默认缓存的大小
protected volatile byte buf[]; //内部的缓存
protected int count; //buffer的大小
protected int pos; //buffer中cursor的位置
protected int markpos = -1; //mark的位置
protected int marklimit; //mark的范围
//原子性更新。和一致性编程相关
private static final
AtomicReferenceFieldUpdater<BufferedInputStream, byte[]> bufUpdater =
AtomicReferenceFieldUpdater.newUpdater (BufferedInputStream.class, byte[].class,"buf");
//检查输入流是否关闭,同时返回被包装流
private InputStream getInIfOpen() throws IOException {
InputStream input = in;
if (input == null) throw new IOException("Stream closed");
return input;
}
//检查buffer的状态,同时返回缓存
private byte[] getBufIfOpen() throws IOException {
byte[] buffer = buf;
//不太可能发生的状态
if (buffer == null) throw new IOException("Stream closed");
return buffer;
}
//构造器
public BufferedInputStream(InputStream in) {
//指定默认长度的buffer
this(in, defaultBufferSize);
}
//构造器
public BufferedInputStream(InputStream in, int size) {
super(in);
//检查输入参数
if(size<=0){
throw new IllegalArgumentException("Buffer size <= 0");
}
//创建指定长度的buffer
buf = new byte[size];
}
//从流中读取数据,填充如缓存中。
private void fill() throws IOException {
//得到buffer
byte[] buffer = getBufIfOpen();
if (markpos < 0)
//mark位置小于0,此时pos为0
pos = 0;
//pos大于buffer的长度
else if (pos >= buffer.length)
if (markpos > 0) {
int sz = pos - markpos;
System.arraycopy(buffer, markpos, buffer, 0, sz);
pos = sz;
markpos = 0;
} else if (buffer.length >= marklimit) {
//buffer的长度大于marklimit时,mark失效
markpos = -1;
//丢弃buffer中的内容
pos = 0;
}else{
//buffer的长度小于marklimit时对buffer扩容
int nsz = pos * 2;
if (nsz > marklimit)
nsz = marklimit;//扩容为原来的2倍,太大则为marklimit大小
byte nbuf[] = new byte[nsz];
//将buffer中的字节拷贝如扩容后的buf中
System.arraycopy(buffer, 0, nbuf, 0, pos);
if (!bufUpdater.compareAndSet(this, buffer, nbuf)) {
//在buffer在被操作时,不能取代此buffer
throw new IOException("Stream closed");
}
//将新buf赋值给buffer
buffer = nbuf;
}
count = pos;
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0) count = n + pos;
}
//读取下一个字节
public synchronized int read() throws IOException {
//到达buffer的末端
if (pos >= count) {
//就从流中读取数据,填充buffer
fill();
//读过一次,没有数据则返回-1
if (pos >= count) return -1;
}
//返回buffer中下一个位置的字节
return getBufIfOpen()[pos++] & 0xff;
}
//将数据从流中读入buffer中
private int read1(byte[] b, int off, int len) throws IOException {
int avail = count - pos; //buffer中还剩的可读字符
//buffer中没有可以读取的数据时
if(avail<=0){
//将输入流中的字节读入b中
if (len >= getBufIfOpen().length && markpos < 0) {
return getInIfOpen().read(b, off, len);
}
fill();//填充
avail = count - pos;
if (avail <= 0) return -1;
}
//从流中读取后,检查可以读取的数目
int cnt = (avail < len) ? avail : len;
//将当前buffer中的字节放入b的末端
System.arraycopy(getBufIfOpen(), pos, b, off, cnt);
pos += cnt;
return cnt;
}
public synchronized int read(byte b[], int off, int len)throws IOException {
getBufIfOpen();
// 检查buffer是否open
//检查输入参数是否正确
if ((off | len | (off + len) | (b.length - (off + len))) < 0) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
int n = 0;
for (;;) {
int nread = read1(b, off + n, len - n);
if (nread <= 0) return (n == 0) ? nread : n;
n += nread;
if (n >= len) return n;
InputStream input = in;
if (input != null && input.available() <= 0) return n;
}
}
public synchronized long skip(long n) throws IOException {
// 检查buffer是否关闭
getBufIfOpen();
//检查输入参数是否正确
if (n <= 0) { return 0; }
//buffered中可以读取字节的数目
long avail = count - pos;
//可以读取的小于0,则从流中读取
if (avail <= 0) {
//mark小于0,则mark在流中
if (markpos <0) return getInIfOpen().skip(n);
// 从流中读取数据,填充缓冲区。
fill();
//可以读的取字节为buffer的容量减当前位置
avail = count - pos;
if (avail <= 0) return 0;
}
long skipped = (avail < n) ? avail : n;
pos += skipped;
//当前位置改变
return skipped;
}
//该方法不会block!返回流中可以读取的字节的数目。
//该方法的返回值为缓存中的可读字节数目加流中可读字节数目的和
public synchronized int available() throws IOException {
return getInIfOpen().available() + (count - pos);
}
//当前位置处为mark位置
public synchronized void mark(int readlimit) {
marklimit = readlimit;
markpos = pos;
}
public synchronized void reset() throws IOException {
// 缓冲去关闭了,肯定就抛出异常!程序设计中经常的手段
getBufIfOpen();
if (markpos < 0) throw new IOException("Resetting to invalid mark");
pos = markpos;
}
//该流和ByteArrayInputStream一样都支持mark
public boolean markSupported() {
return true;
}
//关闭当前流同时释放相应的系统资源。
public void close() throws IOException {
byte[] buffer;
while ( (buffer = buf) != null) {
if (bufUpdater.compareAndSet(this, buffer, null)) {
InputStream input = in;
in = null;
if (input != null) input.close();
return;
}
// Else retry in case a new buf was CASed in fill()
}
}
}
public class PipedInputStream extends InputStream {
//标识有读取方或写入方关闭
boolean closedByWriter = false;
volatile boolean closedByReader = false;
//是否建立连接
boolean connected = false;
//标识哪个线程
Thread readSide;
Thread writeSide;
//缓冲区的默认大小
protected static final int PIPE_SIZE = 1024;
//缓冲区
protected byte buffer[] = new byte[PIPE_SIZE];
//下一个写入字节的位置。0代表空,in==out代表满
protected int in = -1;
//下一个读取字节的位置
protected int out = 0;
//给定源的输入流
public PipedInputStream(PipedOutputStream src) throws IOException {
connect(src);
}
//默认构造器,下部一定要connect源
public PipedInputStream() { }
//连接输入源
public void connect(PipedOutputStream src) throws IOException {
//调用源的connect方法连接当前对象
src.connect(this);
}
//只被PipedOuputStream调用
protected synchronized void receive(int b) throws IOException {
//检查状态,写入
checkStateForReceive();
//永远是PipedOuputStream
writeSide = Thread.currentThread();
//输入和输出相等,等待空间
if (in == out) awaitSpace();
if (in < 0) {
in = 0;
out = 0;
}
//放入buffer相应的位置
buffer[in++] = (byte)(b & 0xFF);
//in为0表示buffer已空
if (in >= buffer.length) { in = 0; }
}
synchronized void receive(byte b[], int off, int len) throws IOException {
checkStateForReceive();
//从PipedOutputStream可以看出
writeSide = Thread.currentThread();
int bytesToTransfer = len;
while (bytesToTransfer > 0) {
//满了,会通知读取的;空会通知写入
if (in == out) awaitSpace();
int nextTransferAmount = 0;
if (out < in) {
nextTransferAmount = buffer.length - in;
} else if (in < out) {
if (in == -1) {
in = out = 0;
nextTransferAmount = buffer.length - in;
} else {
nextTransferAmount = out - in;
}
}
if (nextTransferAmount > bytesToTransfer) nextTransferAmount = bytesToTransfer;
assert(nextTransferAmount > 0);
System.arraycopy(b, off, buffer, in, nextTransferAmount);
bytesToTransfer -= nextTransferAmount;
off += nextTransferAmount;
in += nextTransferAmount;
if (in >= buffer.length) { in = 0; }
}
}
//检查当前状态,等待输入
private void checkStateForReceive() throws IOException {
if (!connected) {
throw new IOException("Pipe not connected");
} else if (closedByWriter || closedByReader) {
throw new IOException("Pipe closed");
} else if (readSide != null && !readSide.isAlive()) {
throw new IOException("Read end dead");
}
}
//Buffer已满,等待一段时间
private void awaitSpace() throws IOException {
//in==out表示满了,没有空间
while (in == out) {
//检查接受端的状态
checkStateForReceive();
//通知读取端
notifyAll();
try {
wait(1000);
} catch (InterruptedException ex) {
throw new java.io.InterruptedIOException();
}
}
}
//通知所有等待的线程()已经接受到最后的字节
synchronized void receivedLast() {
closedByWriter = true; //
notifyAll();
}
public synchronized int read() throws IOException {
//检查一些内部状态
if (!connected) {
throw new IOException("Pipe not connected");
} else if (closedByReader) {
throw new IOException("Pipe closed");
} else if (writeSide != null && !writeSide.isAlive()&& !closedByWriter && (in < 0)) {
throw new IOException("Write end dead");
}
//当前线程读取
readSide = Thread.currentThread();
//重复两次? ? ?
int trials = 2;
while (in < 0) {
//输入断关闭返回-1
if (closedByWriter) { return -1; }
//状态错误
if ((writeSide != null) && (!writeSide.isAlive()) && (--trials < 0)) {
throw new IOException("Pipe broken");
}
notifyAll(); // 空了,通知写入端可以写入 try {
wait(1000);
} catch (InterruptedException ex) {
throw new java.io.InterruptedIOException();
}
}
int ret = buffer[out++] & 0xFF; if (out >= buffer.length) { out = 0; }
//没有任何字节
if (in == out) { in = -1; }
return ret;
}
public synchronized int read(byte b[], int off, int len) throws IOException {
//检查输入参数的正确性
if (b == null) {
throw new NullPointerException();
} else if (off < 0 || len < 0 || len > b.length - off) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
//读取下一个
int c = read();
//已经到达末尾了,返回-1
if (c < 0) { return -1; }
//放入外部buffer中
b[off] = (byte) c;
//return-len
int rlen = 1;
//下一个in存在,且没有到达len
while ((in >= 0) && (--len > 0)) {
//依次放入外部buffer
b[off + rlen] = buffer[out++];
rlen++;
//读到buffer的末尾,返回头部
if (out >= buffer.length) { out = 0; }
//读、写位置一致时,表示没有数据
if (in == out) { in = -1; }
}
//返回填充的长度
return rlen;
}
//返回还有多少字节可以读取
public synchronized int available() throws IOException {
//到达末端,没有字节
if(in < 0)
return 0;
else if(in == out)
//写入的和读出的一致,表示满
return buffer.length;
else if (in > out)
//写入的大于读出
return in - out;
else
//写入的小于读出的
return in + buffer.length - out;
}
//关闭当前流,同时释放与其相关的资源
public void close() throws IOException {
//表示由输入流关闭
closedByReader = true;
//同步化当前对象,in为-1
synchronized (this) { in = -1; }
}
}
4.4 - CH04-OutputStream
OutputStream 抽象类
public abstract void write(int b)
// 写入一个字节,可以看到这里的参数是一个 int 类型,对应上面的读方法,int 类型的 32 位,只有低 8 位才写入,高 24 位将舍弃。
public void write(byte b[])
// 将数组中的所有字节写入,和上面对应的 read() 方法类似,实际调用的也是下面的方法。
public void write(byte b[], int off, int len)
// 将 byte 数组从 off 位置开始,len 长度的字节写入
public void flush()
// 强制刷新,将缓冲中的数据写入
public void close()
// 关闭输出流,流被关闭后就不能再输出数据了
源码实现
FilterOutputStream
/**
* This class is the superclass of all classes that filter output
* streams. These streams sit on top of an already existing output
* stream (the <i>underlying</i> output stream) which it uses as its
* basic sink of data, but possibly transforming the data along the
* way or providing additional functionality.
* <p>
* The class <code>FilterOutputStream</code> itself simply overrides
* all methods of <code>OutputStream</code> with versions that pass
* all requests to the underlying output stream. Subclasses of
* <code>FilterOutputStream</code> may further override some of these
* methods as well as provide additional methods and fields.
*
* @author Jonathan Payne
* @since JDK1.0
*/
public
class FilterOutputStream extends OutputStream {
/**
* The underlying output stream to be filtered.
*/
protected OutputStream out;
/**
* Creates an output stream filter built on top of the specified
* underlying output stream.
*
* @param out the underlying output stream to be assigned to
* the field <tt>this.out</tt> for later use, or
* <code>null</code> if this instance is to be
* created without an underlying stream.
*/
public FilterOutputStream(OutputStream out) {
this.out = out;
}
/**
* Writes the specified <code>byte</code> to this output stream.
* <p>
* The <code>write</code> method of <code>FilterOutputStream</code>
* calls the <code>write</code> method of its underlying output stream,
* that is, it performs <tt>out.write(b)</tt>.
* <p>
* Implements the abstract <tt>write</tt> method of <tt>OutputStream</tt>.
*
* @param b the <code>byte</code>.
* @exception IOException if an I/O error occurs.
*/
public void write(int b) throws IOException {
out.write(b);
}
/**
* Writes <code>b.length</code> bytes to this output stream.
* <p>
* The <code>write</code> method of <code>FilterOutputStream</code>
* calls its <code>write</code> method of three arguments with the
* arguments <code>b</code>, <code>0</code>, and
* <code>b.length</code>.
* <p>
* Note that this method does not call the one-argument
* <code>write</code> method of its underlying stream with the single
* argument <code>b</code>.
*
* @param b the data to be written.
* @exception IOException if an I/O error occurs.
* @see java.io.FilterOutputStream#write(byte[], int, int)
*/
public void write(byte b[]) throws IOException {
write(b, 0, b.length);
}
/**
* Writes <code>len</code> bytes from the specified
* <code>byte</code> array starting at offset <code>off</code> to
* this output stream.
* <p>
* The <code>write</code> method of <code>FilterOutputStream</code>
* calls the <code>write</code> method of one argument on each
* <code>byte</code> to output.
* <p>
* Note that this method does not call the <code>write</code> method
* of its underlying input stream with the same arguments. Subclasses
* of <code>FilterOutputStream</code> should provide a more efficient
* implementation of this method.
*
* @param b the data.
* @param off the start offset in the data.
* @param len the number of bytes to write.
* @exception IOException if an I/O error occurs.
* @see java.io.FilterOutputStream#write(int)
*/
public void write(byte b[], int off, int len) throws IOException {
if ((off | len | (b.length - (len + off)) | (off + len)) < 0)
throw new IndexOutOfBoundsException();
for (int i = 0 ; i < len ; i++) {
write(b[off + i]);
}
}
/**
* Flushes this output stream and forces any buffered output bytes
* to be written out to the stream.
* <p>
* The <code>flush</code> method of <code>FilterOutputStream</code>
* calls the <code>flush</code> method of its underlying output stream.
*
* @exception IOException if an I/O error occurs.
* @see java.io.FilterOutputStream#out
*/
public void flush() throws IOException {
out.flush();
}
/**
* Closes this output stream and releases any system resources
* associated with the stream.
* <p>
* The <code>close</code> method of <code>FilterOutputStream</code>
* calls its <code>flush</code> method, and then calls the
* <code>close</code> method of its underlying output stream.
*
* @exception IOException if an I/O error occurs.
* @see java.io.FilterOutputStream#flush()
* @see java.io.FilterOutputStream#out
*/
@SuppressWarnings("try")
public void close() throws IOException {
try (OutputStream ostream = out) {
flush();
}
}
}
ByteArrayOutputStream
/**
* This class implements an output stream in which the data is
* written into a byte array. The buffer automatically grows as data
* is written to it.
* The data can be retrieved using <code>toByteArray()</code> and
* <code>toString()</code>.
* <p>
* Closing a <tt>ByteArrayOutputStream</tt> has no effect. The methods in
* this class can be called after the stream has been closed without
* generating an <tt>IOException</tt>.
*
* @author Arthur van Hoff
* @since JDK1.0
*/
public class ByteArrayOutputStream extends OutputStream {
/**
* The buffer where data is stored.
*/
protected byte buf[];
/**
* The number of valid bytes in the buffer.
*/
protected int count;
/**
* Creates a new byte array output stream. The buffer capacity is
* initially 32 bytes, though its size increases if necessary.
*/
public ByteArrayOutputStream() {
this(32);
}
/**
* Creates a new byte array output stream, with a buffer capacity of
* the specified size, in bytes.
*
* @param size the initial size.
* @exception IllegalArgumentException if size is negative.
*/
public ByteArrayOutputStream(int size) {
if (size < 0) {
throw new IllegalArgumentException("Negative initial size: "
+ size);
}
buf = new byte[size];
}
/**
* Increases the capacity if necessary to ensure that it can hold
* at least the number of elements specified by the minimum
* capacity argument.
*
* @param minCapacity the desired minimum capacity
* @throws OutOfMemoryError if {@code minCapacity < 0}. This is
* interpreted as a request for the unsatisfiably large capacity
* {@code (long) Integer.MAX_VALUE + (minCapacity - Integer.MAX_VALUE)}.
*/
private void ensureCapacity(int minCapacity) {
// overflow-conscious code
if (minCapacity - buf.length > 0)
grow(minCapacity);
}
/**
* The maximum size of array to allocate.
* Some VMs reserve some header words in an array.
* Attempts to allocate larger arrays may result in
* OutOfMemoryError: Requested array size exceeds VM limit
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = buf.length;
int newCapacity = oldCapacity << 1;
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
buf = Arrays.copyOf(buf, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
/**
* Writes the specified byte to this byte array output stream.
*
* @param b the byte to be written.
*/
public synchronized void write(int b) {
ensureCapacity(count + 1);
buf[count] = (byte) b;
count += 1;
}
/**
* Writes <code>len</code> bytes from the specified byte array
* starting at offset <code>off</code> to this byte array output stream.
*
* @param b the data.
* @param off the start offset in the data.
* @param len the number of bytes to write.
*/
public synchronized void write(byte b[], int off, int len) {
if ((off < 0) || (off > b.length) || (len < 0) ||
((off + len) - b.length > 0)) {
throw new IndexOutOfBoundsException();
}
ensureCapacity(count + len);
System.arraycopy(b, off, buf, count, len);
count += len;
}
/**
* Writes the complete contents of this byte array output stream to
* the specified output stream argument, as if by calling the output
* stream's write method using <code>out.write(buf, 0, count)</code>.
*
* @param out the output stream to which to write the data.
* @exception IOException if an I/O error occurs.
*/
public synchronized void writeTo(OutputStream out) throws IOException {
out.write(buf, 0, count);
}
/**
* Resets the <code>count</code> field of this byte array output
* stream to zero, so that all currently accumulated output in the
* output stream is discarded. The output stream can be used again,
* reusing the already allocated buffer space.
*
* @see java.io.ByteArrayInputStream#count
*/
public synchronized void reset() {
count = 0;
}
/**
* Creates a newly allocated byte array. Its size is the current
* size of this output stream and the valid contents of the buffer
* have been copied into it.
*
* @return the current contents of this output stream, as a byte array.
* @see java.io.ByteArrayOutputStream#size()
*/
public synchronized byte toByteArray()[] {
return Arrays.copyOf(buf, count);
}
/**
* Returns the current size of the buffer.
*
* @return the value of the <code>count</code> field, which is the number
* of valid bytes in this output stream.
* @see java.io.ByteArrayOutputStream#count
*/
public synchronized int size() {
return count;
}
/**
* Converts the buffer's contents into a string decoding bytes using the
* platform's default character set. The length of the new <tt>String</tt>
* is a function of the character set, and hence may not be equal to the
* size of the buffer.
*
* <p> This method always replaces malformed-input and unmappable-character
* sequences with the default replacement string for the platform's
* default character set. The {@linkplain java.nio.charset.CharsetDecoder}
* class should be used when more control over the decoding process is
* required.
*
* @return String decoded from the buffer's contents.
* @since JDK1.1
*/
public synchronized String toString() {
return new String(buf, 0, count);
}
/**
* Converts the buffer's contents into a string by decoding the bytes using
* the named {@link java.nio.charset.Charset charset}. The length of the new
* <tt>String</tt> is a function of the charset, and hence may not be equal
* to the length of the byte array.
*
* <p> This method always replaces malformed-input and unmappable-character
* sequences with this charset's default replacement string. The {@link
* java.nio.charset.CharsetDecoder} class should be used when more control
* over the decoding process is required.
*
* @param charsetName the name of a supported
* {@link java.nio.charset.Charset charset}
* @return String decoded from the buffer's contents.
* @exception UnsupportedEncodingException
* If the named charset is not supported
* @since JDK1.1
*/
public synchronized String toString(String charsetName)
throws UnsupportedEncodingException
{
return new String(buf, 0, count, charsetName);
}
/**
* Creates a newly allocated string. Its size is the current size of
* the output stream and the valid contents of the buffer have been
* copied into it. Each character <i>c</i> in the resulting string is
* constructed from the corresponding element <i>b</i> in the byte
* array such that:
* <blockquote><pre>
* c == (char)(((hibyte & 0xff) << 8) | (b & 0xff))
* </pre></blockquote>
*
* @deprecated This method does not properly convert bytes into characters.
* As of JDK 1.1, the preferred way to do this is via the
* <code>toString(String enc)</code> method, which takes an encoding-name
* argument, or the <code>toString()</code> method, which uses the
* platform's default character encoding.
*
* @param hibyte the high byte of each resulting Unicode character.
* @return the current contents of the output stream, as a string.
* @see java.io.ByteArrayOutputStream#size()
* @see java.io.ByteArrayOutputStream#toString(String)
* @see java.io.ByteArrayOutputStream#toString()
*/
@Deprecated
public synchronized String toString(int hibyte) {
return new String(buf, hibyte, 0, count);
}
/**
* Closing a <tt>ByteArrayOutputStream</tt> has no effect. The methods in
* this class can be called after the stream has been closed without
* generating an <tt>IOException</tt>.
*/
public void close() throws IOException {
}
}
BufferedOutputStream
/**
* The class implements a buffered output stream. By setting up such
* an output stream, an application can write bytes to the underlying
* output stream without necessarily causing a call to the underlying
* system for each byte written.
*
* @author Arthur van Hoff
* @since JDK1.0
*/
public
class BufferedOutputStream extends FilterOutputStream {
/**
* The internal buffer where data is stored.
*/
protected byte buf[];
/**
* The number of valid bytes in the buffer. This value is always
* in the range <tt>0</tt> through <tt>buf.length</tt>; elements
* <tt>buf[0]</tt> through <tt>buf[count-1]</tt> contain valid
* byte data.
*/
protected int count;
/**
* Creates a new buffered output stream to write data to the
* specified underlying output stream.
*
* @param out the underlying output stream.
*/
public BufferedOutputStream(OutputStream out) {
this(out, 8192);
}
/**
* Creates a new buffered output stream to write data to the
* specified underlying output stream with the specified buffer
* size.
*
* @param out the underlying output stream.
* @param size the buffer size.
* @exception IllegalArgumentException if size <= 0.
*/
public BufferedOutputStream(OutputStream out, int size) {
super(out);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
/** Flush the internal buffer */
private void flushBuffer() throws IOException {
if (count > 0) {
out.write(buf, 0, count);
count = 0;
}
}
/**
* Writes the specified byte to this buffered output stream.
*
* @param b the byte to be written.
* @exception IOException if an I/O error occurs.
*/
public synchronized void write(int b) throws IOException {
if (count >= buf.length) {
flushBuffer();
}
buf[count++] = (byte)b;
}
/**
* Writes <code>len</code> bytes from the specified byte array
* starting at offset <code>off</code> to this buffered output stream.
*
* <p> Ordinarily this method stores bytes from the given array into this
* stream's buffer, flushing the buffer to the underlying output stream as
* needed. If the requested length is at least as large as this stream's
* buffer, however, then this method will flush the buffer and write the
* bytes directly to the underlying output stream. Thus redundant
* <code>BufferedOutputStream</code>s will not copy data unnecessarily.
*
* @param b the data.
* @param off the start offset in the data.
* @param len the number of bytes to write.
* @exception IOException if an I/O error occurs.
*/
public synchronized void write(byte b[], int off, int len) throws IOException {
if (len >= buf.length) {
/* If the request length exceeds the size of the output buffer,
flush the output buffer and then write the data directly.
In this way buffered streams will cascade harmlessly. */
flushBuffer();
out.write(b, off, len);
return;
}
if (len > buf.length - count) {
flushBuffer();
}
System.arraycopy(b, off, buf, count, len);
count += len;
}
/**
* Flushes this buffered output stream. This forces any buffered
* output bytes to be written out to the underlying output stream.
*
* @exception IOException if an I/O error occurs.
* @see java.io.FilterOutputStream#out
*/
public synchronized void flush() throws IOException {
flushBuffer();
out.flush();
}
}
PipedOutputStream
/**
* A piped output stream can be connected to a piped input stream
* to create a communications pipe. The piped output stream is the
* sending end of the pipe. Typically, data is written to a
* <code>PipedOutputStream</code> object by one thread and data is
* read from the connected <code>PipedInputStream</code> by some
* other thread. Attempting to use both objects from a single thread
* is not recommended as it may deadlock the thread.
* The pipe is said to be <a name=BROKEN> <i>broken</i> </a> if a
* thread that was reading data bytes from the connected piped input
* stream is no longer alive.
*
* @author James Gosling
* @see java.io.PipedInputStream
* @since JDK1.0
*/
public
class PipedOutputStream extends OutputStream {
/* REMIND: identification of the read and write sides needs to be
more sophisticated. Either using thread groups (but what about
pipes within a thread?) or using finalization (but it may be a
long time until the next GC). */
private PipedInputStream sink;
/**
* Creates a piped output stream connected to the specified piped
* input stream. Data bytes written to this stream will then be
* available as input from <code>snk</code>.
*
* @param snk The piped input stream to connect to.
* @exception IOException if an I/O error occurs.
*/
public PipedOutputStream(PipedInputStream snk) throws IOException {
connect(snk);
}
/**
* Creates a piped output stream that is not yet connected to a
* piped input stream. It must be connected to a piped input stream,
* either by the receiver or the sender, before being used.
*
* @see java.io.PipedInputStream#connect(java.io.PipedOutputStream)
* @see java.io.PipedOutputStream#connect(java.io.PipedInputStream)
*/
public PipedOutputStream() {
}
/**
* Connects this piped output stream to a receiver. If this object
* is already connected to some other piped input stream, an
* <code>IOException</code> is thrown.
* <p>
* If <code>snk</code> is an unconnected piped input stream and
* <code>src</code> is an unconnected piped output stream, they may
* be connected by either the call:
* <blockquote><pre>
* src.connect(snk)</pre></blockquote>
* or the call:
* <blockquote><pre>
* snk.connect(src)</pre></blockquote>
* The two calls have the same effect.
*
* @param snk the piped input stream to connect to.
* @exception IOException if an I/O error occurs.
*/
public synchronized void connect(PipedInputStream snk) throws IOException {
if (snk == null) {
throw new NullPointerException();
} else if (sink != null || snk.connected) {
throw new IOException("Already connected");
}
sink = snk;
snk.in = -1;
snk.out = 0;
snk.connected = true;
}
/**
* Writes the specified <code>byte</code> to the piped output stream.
* <p>
* Implements the <code>write</code> method of <code>OutputStream</code>.
*
* @param b the <code>byte</code> to be written.
* @exception IOException if the pipe is <a href=#BROKEN> broken</a>,
* {@link #connect(java.io.PipedInputStream) unconnected},
* closed, or if an I/O error occurs.
*/
public void write(int b) throws IOException {
if (sink == null) {
throw new IOException("Pipe not connected");
}
sink.receive(b);
}
/**
* Writes <code>len</code> bytes from the specified byte array
* starting at offset <code>off</code> to this piped output stream.
* This method blocks until all the bytes are written to the output
* stream.
*
* @param b the data.
* @param off the start offset in the data.
* @param len the number of bytes to write.
* @exception IOException if the pipe is <a href=#BROKEN> broken</a>,
* {@link #connect(java.io.PipedInputStream) unconnected},
* closed, or if an I/O error occurs.
*/
public void write(byte b[], int off, int len) throws IOException {
if (sink == null) {
throw new IOException("Pipe not connected");
} else if (b == null) {
throw new NullPointerException();
} else if ((off < 0) || (off > b.length) || (len < 0) ||
((off + len) > b.length) || ((off + len) < 0)) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return;
}
sink.receive(b, off, len);
}
/**
* Flushes this output stream and forces any buffered output bytes
* to be written out.
* This will notify any readers that bytes are waiting in the pipe.
*
* @exception IOException if an I/O error occurs.
*/
public synchronized void flush() throws IOException {
if (sink != null) {
synchronized (sink) {
sink.notifyAll();
}
}
}
/**
* Closes this piped output stream and releases any system resources
* associated with this stream. This stream may no longer be used for
* writing bytes.
*
* @exception IOException if an I/O error occurs.
*/
public void close() throws IOException {
if (sink != null) {
sink.receivedLast();
}
}
}
4.5 - CH05-常用操作.md
File
递归地列出一个目录下所有文件:
public static void listAllFiles(File dir) {
if (dir == null || !dir.exists()) {
return;
}
if (dir.isFile()) {
System.out.println(dir.getName());
return;
}
for (File file : dir.listFiles()) {
listAllFiles(file);
}
}
字节流
public static void copyFile(String src, String dist) throws IOException {
FileInputStream in = new FileInputStream(src);
FileOutputStream out = new FileOutputStream(dist);
byte[] buffer = new byte[20 * 1024];
// read() 最多读取 buffer.length 个字节
// 返回的是实际读取的个数
// 返回 -1 的时候表示读到 eof,即文件尾
while (in.read(buffer, 0, buffer.length) != -1) {
out.write(buffer);
}
in.close();
out.close();
}
逐行打印
public static void readFileContent(String filePath) throws IOException {
FileReader fileReader = new FileReader(filePath);
BufferedReader bufferedReader = new BufferedReader(fileReader);
String line;
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
// 装饰者模式使得 BufferedReader 组合了一个 Reader 对象
// 在调用 BufferedReader 的 close() 方法时会去调用 Reader 的 close() 方法
// 因此只要一个 close() 调用即可
bufferedReader.close();
}
序列化
序列化 & Serializable & transient
序列化就是将一个对象转换成字节序列,方便存储和传输。
- 序列化: ObjectOutputStream.writeObject()
- 反序列化: ObjectInputStream.readObject()
不会对静态变量进行序列化,因为序列化只是保存对象的状态,静态变量属于类的状态。
Serializable
序列化的类需要实现 Serializable 接口,它只是一个标准,没有任何方法需要实现,但是如果不去实现它的话而进行序列化,会抛出异常。
public static void main(String[] args) throws IOException, ClassNotFoundException {
A a1 = new A(123, "abc");
String objectFile = "file/a1";
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(objectFile));
objectOutputStream.writeObject(a1);
objectOutputStream.close();
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream(objectFile));
A a2 = (A) objectInputStream.readObject();
objectInputStream.close();
System.out.println(a2);
}
private static class A implements Serializable {
private int x;
private String y;
A(int x, String y) {
this.x = x;
this.y = y;
}
@Override
public String toString() {
return "x = " + x + " " + "y = " + y;
}
}
transient
transient 关键字可以使一些属性不会被序列化。
ArrayList 中存储数据的数组 elementData 是用 transient 修饰的,因为这个数组是动态扩展的,并不是所有的空间都被使用,因此就不需要所有的内容都被序列化。通过重写序列化和反序列化方法,使得可以只序列化数组中有内容的那部分数据。
private transient Object[] elementData;
网络
InetAddress
没有公有的构造函数,只能通过静态方法来创建实例。
InetAddress.getByName(String host);
InetAddress.getByAddress(byte[] address);
URL
可以直接从 URL 中读取字节流数据。
public static void main(String[] args) throws IOException {
URL url = new URL("http://www.baidu.com");
/* 字节流 */
InputStream is = url.openStream();
/* 字符流 */
InputStreamReader isr = new InputStreamReader(is, "utf-8");
/* 提供缓存功能 */
BufferedReader br = new BufferedReader(isr);
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
br.close();
}
Sockets
- ServerSocket: 服务器端类
- Socket: 客户端类
- 服务器和客户端通过 InputStream 和 OutputStream 进行输入输出。
Datagram
- DatagramSocket: 通信类
- DatagramPacket: 数据包类
4.6 - CH06-IO实现
概览
说到 I/O,想必大家都不会陌生, I/O 英语全称:Input/Output,即输入/输出,通常指数据在内部存储器和外部存储器或其他周边设备之间的输入和输出。
比如我们常用的 SD卡、U盘、移动硬盘等等存储文件的硬件设备,当我们将其插入电脑的 usb 硬件接口时,我们就可以从电脑中读取设备中的信息或者写入信息,这个过程就涉及到 I/O 的操作。
当然,涉及 I/O 的操作,不仅仅局限于硬件设备的读写,还要网络数据的传输,比如,我们在电脑上用浏览器搜索互联网上的信息,这个过程也涉及到 I/O 的操作。
无论是从磁盘中读写文件,还是在网络中传输数据,可以说 I/O 主要为处理人机交互、机与机交互中获取和交换信息提供的一套解决方案。
在 Java 的 IO 体系中,类将近有 80 个,位于java.io包下,感觉很复杂,但是这些类大致可以分成四组:
- 基于字节操作的 I/O 接口:InputStream 和 OutputStream
- 基于字符操作的 I/O 接口:Writer 和 Reader
- 基于磁盘操作的 I/O 接口:File
- 基于网络操作的 I/O 接口:Socket
前两组主要从传输数据的数据格式不同,进行分组;后两组主要从传输数据的方式不同,进行分组。
虽然 Socket 类并不在 java.io包下,但是我们仍然把它们划分在一起,因为 I/O 的核心问题,要么是数据格式影响 I/O 操作,要么是传输方式影响 I/O 操作,也就是将什么样的数据写到什么地方的问题,I/O 只是人与机器或者机器与机器交互的手段,除了在它们能够完成这个交互功能外,我们关注的就是如何提高它的运行效率了,而数据格式和传输方式是影响效率最关键的因素。
字节格式
基于字节的输入和输出操作接口分别是:InputStream 和 OutputStream 。
字节输入流
InputStream 输入流的类继承层次如下图所示:
输入流根据数据节点类型和处理方式,分别可以划分出了若干个子类,如下图:
字节输出流
OutputStream 输出流的类继承层次如下图所示:
输出流根据数据节点类型和处理方式,也分别可以划分出了若干个子类,如下图:
在这里就不详细的介绍各个子类的使用方法,有兴趣的朋友可以查看 JDK 的 API 说明文档,笔者也会在后期的文章会进行详细的介绍,这里只是重点想说一下,无论是输入还是输出,操作数据的方式可以组合使用,各个处理流的类并不是只操作固定的节点流,比如如下输出方式:
//将文件输出流包装到序列化输出流中,再将序列化输出流包装到缓冲中 OutputStream out = new BufferedOutputStream(new ObjectOutputStream(new FileOutputStream(new File("fileName")));
另外,输出流最终写到什么地方必须要指定,要么是写到硬盘中,要么是写到网络中,从图中可以发现,写网络实际上也是写文件,只不过写到网络中,需要经过底层操作系统将数据发送到其他的计算机中,而不是写入到本地硬盘中。
字符格式
不管是磁盘还是网络传输,最小的存储单元都是字节,而不是字符,所以 I/O 操作的都是字节而不是字符,但是为什么要有操作字符的 I/O 接口呢?
这是因为我们的程序中通常操作的数据都是以字符形式,为了程序操作更方便而提供一个直接写字符的 I/O 接口,仅此而已。
基于字符的输入和输出操作接口分别是:Reader 和 Writer ,下图是字符的 I/O 操作接口涉及到的类结构图。
字符输入流
Reader 输入流的类继承层次如下图所示:
同样的,输入流根据数据节点类型和处理方式,分别可以划分出了若干个子类,如下图:
字符输出流
Writer 输出流的类继承层次如下图所示:
同样的,输出流根据数据节点类型和处理方式分类,分别可以划分出了若干个子类,如下图:
不管是 Reader 还是 Writer 类,它们都只定义了读取或写入数据字符的方式,也就是说要么是读要么是写,但是并没有规定数据要写到哪去,写到哪去就是我们后面要讨论的基于磁盘或网络的工作机制。
字节与字符的转化
刚刚我们说到,不管是磁盘还是网络传输,最小的存储单元都是字节,而不是字符,设计字符的原因是为了程序操作更方便,那么怎么将字符转化成字节或者将字节转化成字符呢?
InputStreamReader 和 OutputStreamWriter 就是转化桥梁。
输入流转化过程
输入流字符解码相关类结构的转化过程如下图所示:
从图上可以看到,InputStreamReader 类是字节到字符的转化桥梁, 其中StreamDecoder指的是一个解码操作类,Charset指的是字符集。
InputStream 到 Reader 的过程需要指定编码字符集,否则将采用操作系统默认字符集,很可能会出现乱码问题,StreamDecoder 则是完成字节到字符的解码的实现类。
打开源码部分,InputStream 到 Reader 转化过程,如下图:
输出流转化过程
输出流转化过程也是类似,如下图所示:
通过 OutputStreamWriter 类完成字符到字节的编码过程,由 StreamEncoder 完成编码过程。
源码部分,Writer 到 OutputStream 转化过程,如下图:
磁盘传输
前面介绍了Java I/O 的操作接口,这些接口主要定义了如何操作数据,以及介绍了操作数据格式的方式:字节流和字符流。
还有一个关键问题就是数据写到何处,其中一个主要的处理方式就是将数据持久化到物理磁盘。
我们知道数据在磁盘的唯一最小描述就是文件,也就是说上层应用程序只能通过文件来操作磁盘上的数据,文件也是操作系统和磁盘驱动器交互的一个最小单元。
- 在 Java I/O 体系中,File 类是唯一代表磁盘文件本身的对象。
- File 类定义了一些与平台无关的方法来操作文件,包括检查一个文件是否存在、创建、删除文件、重命名文件、判断文件的读写权限是否存在、设置和查询文件的最近修改时间等等操作。
值得注意的是 Java 中通常的 File 并不代表一个真实存在的文件对象,当你通过指定一个路径描述符时,它就会返回一个代表这个路径相关联的一个虚拟对象,这个可能是一个真实存在的文件或者是一个包含多个文件的目录。
例如,读取一个文件内容,程序如下:
以上面的程序为例,从硬盘中读取一段文本字符,操作流程如下图:
当我们传入一个指定的文件名来创建 File 对象,通过 FileReader 来读取文件内容时,会自动创建一个FileInputStream对象来读取文件内容,也就是我们上文中所说的字节流来读取文件。
紧接着,会创建一个FileDescriptor的对象,其实这个对象就是真正代表一个存在的文件对象的描述。可以通过FileInputStream对象调用getFD() 方法获取真正与底层操作系统关联的文件描述。
由于我们需要读取的是字符格式,所以需要 StreamDecoder 类将byte解码为char格式,至于如何从磁盘驱动器上读取一段数据,由操作系统帮我们完成。
网络传输
继续来说说数据写到何处的另一种处理方式:将数据写入互联网中以供其他电脑能访问。
Socket简介
在现实中,Socket 这个概念没有一个具体的实体,它是描述计算机之间完成相互通信一种抽象定义。
打个比方,可以把 Socket 比作为两个城市之间的交通工具,有了它,就可以在城市之间来回穿梭了。并且,交通工具有多种,每种交通工具也有相应的交通规则。Socket 也一样,也有多种。大部分情况下我们使用的都是基于 TCP/IP 的流套接字,它是一种稳定的通信协议。
典型的基于 Socket 通信的应用程序场景,如下图:
主机 A 的应用程序要想和主机 B 的应用程序通信,必须通过 Socket 建立连接,而建立 Socket 连接必须需要底层 TCP/IP 协议来建立 TCP 连接。
建立通信链路
我们知道网络层使用的 IP 协议可以帮助我们根据 IP 地址来找到目标主机,但是一台主机上可能运行着多个应用程序,如何才能与指定的应用程序通信就要通过 TCP 或 UPD 的地址也就是端口号来指定。这样就可以通过一个 Socket 实例代表唯一一个主机上的一个应用程序的通信链路了。
为了准确无误地把数据送达目标处,TCP 协议采用了三次握手策略,如下图:
在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN + ACK 应答表示接收到了这个消息,最后客户机再以 ACK 消息响应。
这样在客户机和服务器之间才能建立起可靠的 TCP 连接,数据才可以在客户机和服务器之间传递。
- 发送端 –(发送带有 SYN 标志的数据包 )–> 接受端(第一次握手);
- 接受端 –(发送带有 SYN + ACK 标志的数据包)–> 发送端(第二次握手);
- 发送端 –(发送带有 ACK 标志的数据包) –> 接受端(第三次握手);
完成三次握手之后,客户端应用程序与服务器应用程序就可以开始传送数据了。
传输数据
当客户端要与服务端通信时,客户端首先要创建一个 Socket 实例,默认操作系统将为这个 Socket 实例分配一个没有被使用的本地端口号,并创建一个包含本地、远程地址和端口号的套接字数据结构,这个数据结构将一直保存在系统中直到这个连接关闭。
与之对应的服务端,也将创建一个 ServerSocket 实例,ServerSocket 创建比较简单,只要指定的端口号没有被占用,一般实例创建都会成功,同时操作系统也会为 ServerSocket 实例创建一个底层数据结构,这个数据结构中包含指定监听的端口号和包含监听地址的通配符,通常情况下都是*即监听所有地址。
之后当调用 accept() 方法时,将进入阻塞(等待)状态,等待客户端的请求。
我们先启动服务端程序,再运行客户端,服务端收到客户端发送的信息,服务端打印结果如下:
服务端收到客户端发送的消息:Hello,我是客户端!
注意,客户端只有与服务端建立三次握手成功之后,才会发送数据,而 TCP/IP 握手过程,底层操作系统已经帮我们实现了!
- 当连接已经建立成功,服务端和客户端都会拥有一个 Socket 实例,每个 Socket 实例都有一个 InputStream 和 OutputStream,正如我们前面所说的,网络 I/O 都是以字节流传输的,Socket 正是通过这两个对象来交换数据。
- 当 Socket 对象创建时,操作系统将会为 InputStream 和 OutputStream 分别分配一定大小的缓冲区,数据的写入和读取都是通过这个缓存区完成的。
- 写入端将数据写到 OutputStream 对应的 SendQ 队列中,当队列填满时,数据将被发送到另一端 InputStream 的 RecvQ 队列中,如果这时 RecvQ 已经满了,那么 OutputStream 的 write 方法将会阻塞直到 RecvQ 队列有足够的空间容纳 SendQ 发送的数据。
值得特别注意的是,缓存区的大小以及写入端的速度和读取端的速度非常影响这个连接的数据传输效率,由于可能会发生阻塞,所以网络 I/O 与磁盘 I/O 在数据的写入和读取还要有一个协调的过程,如果两边同时传送数据时可能会产生死锁的问题。
如何提高网络 IO 传输效率、保证数据传输的可靠,已经成了工程师们急需解决的问题。
IO 工作方式
在计算机中,IO 传输数据有三种工作方式,分别是 BIO、NIO、AIO。
在讲解 BIO、NIO、AIO 之前,我们先来回顾一下这几个概念:同步与异步,阻塞与非阻塞。
同步与异步的区别
- 同步就是发起一个请求后,接受者未处理完请求之前,不返回结果。
- 异步就是发起一个请求后,立刻得到接受者的回应表示已接收到请求,但是接受者并没有处理完,接受者通常依靠事件回调等机制来通知请求者其处理结果。
阻塞和非阻塞的区别
- 阻塞就是请求者发起一个请求,一直等待其请求结果返回,也就是当前线程会被挂起,无法从事其他任务,只有当条件就绪才能继续。
- 非阻塞就是请求者发起一个请求,不用一直等着结果返回,可以先去干其他事情,当条件就绪的时候,就自动回来。
而我们要讲的 BIO、NIO、AIO 就是同步与异步、阻塞与非阻塞的组合。
- BIO:同步阻塞 IO;
- NIO:同步非阻塞 IO;
- AIO:异步非阻塞 IO;
BIO
BIO 俗称同步阻塞 IO,一种非常传统的 IO 模型,比如我们上面所举的那个程序例子,就是一个典型的**同步阻塞 IO **的工作方式。
采用 BIO 通信模型的服务端,通常由一个独立的 Acceptor 线程负责监听客户端的连接。
我们一般在服务端通过while(true)循环中会调用accept() 方法等待监听客户端的连接,一旦接收到一个连接请求,就可以建立通信套接字进行读写操作,此时不能再接收其他客户端连接请求,只能等待同当前连接的客户端的操作执行完成, 不过可以通过多线程来支持多个客户端的连接。
客户端多线程操作,程序如下:
服务端多线程操作,程序如下:
服务端运行结果,如下:
服务端收到客户端发送的消息:Hello,我是第 2 个,客户端!
服务端收到客户端发送的消息:Hello,我是第 4 个,客户端!
服务端收到客户端发送的消息:Hello,我是第 3 个,客户端!
服务端收到客户端发送的消息:Hello,我是第 0 个,客户端!
服务端收到客户端发送的消息:Hello,我是第 1 个,客户端!
如果要让 BIO 通信模型能够同时处理多个客户端请求,就必须使用多线程,也就是说它在接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理,处理完成之后,通过输出流返回应答给客户端,线程销毁。
这就是典型的一请求一应答通信模型 。
如果出现100、1000、甚至10000个用户同时访问服务器,这个时候,如果使用这种模型,那么服务端也会创建与之相同的线程数量,线程数急剧膨胀可能会导致线程堆栈溢出、创建新线程失败等问题,最终导致进程宕机或者僵死,不能对外提供服务。
当然,我们可以通过使用 Java 中 ThreadPoolExecutor 线程池机制来改善,让线程的创建和回收成本相对较低,保证了系统有限的资源的控制,实现了 N (客户端请求数量)大于 M (处理客户端请求的线程数量)的伪异步 I/O 模型。
伪异步 BIO
为了解决同步阻塞 I/O 面临的一个链路需要一个线程处理的问题,后来有人对它的线程模型进行了优化,后端通过一个线程池来处理多个客户端的请求接入,形成客户端个数 M:线程池最大线程数 N 的比例关系,其中 M 可以远远大于 N,通过线程池可以灵活地调配线程资源,设置线程的最大值,防止由于海量并发接入导致资源耗尽。
伪异步IO模型图,如下图:
采用线程池和任务队列可以实现一种叫做伪异步的 I/O 通信框架,当有新的客户端接入时,将客户端的 Socket 封装成一个 Task 投递到后端的线程池中进行处理。
Java 的线程池维护一个消息队列和 N 个活跃线程,对消息队列中的任务进行处理。
客户端,程序如下:
服务端,程序如下:
先启动服务端程序,再启动客户端程序,看看运行结果!
服务端,运行结果如下:
客户端,运行结果如下:
本例中测试的客户端数量是 30,服务端使用 java 线程池来处理任务,线程数量为 5 个,服务端不用为每个客户端都创建一个线程,由于线程池可以设置消息队列的大小和最大线程数,因此,它的资源占用是可控的,无论多少个客户端并发访问,都不会导致资源的耗尽和宕机。
在活动连接数不是特别高的情况下,这种模型是还不错,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。
但是,它的底层仍然是同步阻塞的 BIO 模型,当面对十万甚至百万级连接的时候,传统的 BIO 模型真的是无能为力的,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
NIO
NIO 中的 N 可以理解为 Non-blocking,一种同步非阻塞的 I/O 模型,在 Java 1.4 中引入,对应的在java.nio包下。
NIO 新增了 Channel、Selector、Buffer 等抽象概念,支持面向缓冲、基于通道的 I/O 操作方法。
NIO 提供了与传统 BIO 模型中的 Socket 和 ServerSocket 相对应的 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现。
NIO 这两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。
对于低负载、低并发的应用程序,可以使用同步阻塞 I/O 来提升开发效率和更好的维护性;
对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发。
我们先看一下 NIO 涉及到的核心关联类图,如下:
上图中有三个关键类:Channel 、Selector 和 Buffer,它们是 NIO 中的核心概念。
- Channel:可以理解为通道;
- Selector:可以理解为选择器;
- Buffer:可以理解为数据缓冲流;
我们还是用前面的城市交通工具来继续形容 NIO 的工作方式,这里的 Channel 要比 Socket 更加具体,它可以比作为某种具体的交通工具,如汽车或是高铁、飞机等,而 Selector 可以比作为一个车站的车辆运行调度系统,它将负责监控每辆车的当前运行状态:是已经出站还是在路上等等,也就是说它可以轮询每个 Channel 的状态。
还有一个 Buffer 类,你可以将它看作为 IO 中 Stream,但是它比 IO 中的 Stream 更加具体化,我们可以将它比作为车上的座位,Channel 如果是汽车的话,那么 Buffer 就是汽车上的座位,Channel 如果是高铁,那么 Buffer 就是高铁上的座位,它始终是一个具体的概念,这一点与 Stream 不同。
Socket 中的 Stream 只能代表是一个座位,至于是什么座位由你自己去想象,也就是说你在上车之前并不知道这个车上是否还有没有座位,也不知道上的是什么车,因为你并不能选择,这些信息都已经被封装在了运输工具(Socket)里面了。
NIO 引入了 Channel、Buffer 和 Selector 就是想把 IO 传输过程中涉及到的信息具体化,让程序员有机会去控制它们。
当我们进行传统的网络 IO 操作时,比如调用 write() 往 Socket 中的 SendQ 队列写数据时,当一次写的数据超过 SendQ 长度时,操作系统会按照 SendQ 的长度进行分割的,这个过程中需要将用户空间数据和内核地址空间进行切换,而这个切换不是程序员可以控制的,由底层操作系统来帮我们处理。
而在 Buffer 中,我们可以控制 Buffer 的 capacity(容量),并且是否扩容以及如何扩容都可以控制。
还是以上面的操作为例子,为了方便观看结果,本次的客户端线程请求数改成15个。
客户端,程序如下:
服务端,程序如下:
先启动服务端程序,再启动客户端程序,看看运行结果!
服务端,运行结果如下:
客户端,运行结果如下:
当然,客户端也不仅仅只限制于 IO 的写法,还可以使用SocketChannel 来操作客户端,程序如下:
从操作上可以看到,NIO 的操作比传统的 IO 操作要复杂的多!
Selector 被称为选择器 ,当然你也可以翻译为多路复用器 。它是Java NIO 核心组件中的一个,用于检查一个或多个 Channel(通道)的状态是否处于连接就绪、接受就绪、可读就绪、可写就绪。
如此可以实现单线程管理多个 channels,也就是可以管理多个网络连接。
使用 Selector 的好处在于: 相比传统方式使用多个线程来管理 IO,Selector 使用了更少的线程就可以处理通道了,并且实现网络高效传输!
虽然 java 中的 nio 传输比较快,为什么大家都不愿意用 JDK 原生 NIO 进行开发呢?
从上面的代码中大家都可以看出来,除了编程复杂、编程模型难之外,还有几个让人诟病的问题:
- JDK 的 NIO 底层由 epoll 实现,该实现饱受诟病的空轮询 bug 会导致 cpu 飙升 100%!
- 项目庞大之后,自行实现的 NIO 很容易出现各类 bug,维护成本较高!
但是,Google 的 Netty 框架的出现,很大程度上改善了 JDK 原生 NIO 所存在的一些让人难以忍受的问题。
AIO
最后就是 AIO 了,全称 Asynchronous I/O,可以理解为异步 IO,也被称为 NIO 2,在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的 IO 模型,也就是我们现在所说的 AIO。
异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
客户端,程序示例:
服务端,程序示例:
这种组合方式用起来比较复杂,只有在一些非常复杂的分布式情况下使用,像集群之间的消息同步机制一般用这种 I/O 组合方式。如 Cassandra 的 Gossip 通信机制就是采用异步非阻塞的方式。
参考资料
4.7 - CH07-IO模型
用户空间与内核空间
我们知道现在的操作系统都是采用虚拟存储器,那么对 32 位操作系统来说,它的寻址空间即虚拟存储空间为 4G,2 的 32 次方。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核,保证内核的的安全,操作系统将虚拟内存空间划分为两部分,一部分是内核空间,一部分是用户空间。
针对 Linux 操作系统而言,将最高的 1G 字节,即从虚拟地址 0xC0000000 到 0xFFFFFFFF 供内核使用,称为内核空间。而较低的 3G 字节,即从虚拟地址 0x00000000 到 0xBFFFFFFF,供进程使用,称为用户空间。每个进程都可以通过系统调用进入内核,因此 Linux 内核由系统内的所有进程共享。于是,从具体进程的角度看,每个进程可以拥有 4G 字节的虚拟空间。
有了用户空间和内核空间,整个 Linux 内部结构可以分为三个部分,从最底层到最上层依次是:硬件、内核空间、用户空间。
需要注意的细节是,从上图可以看出内核的组成:
- 内核空间中存放的是内核代码和数据,而进程的用户空间存放的是用户程序的代码和数据。不管是内核空间还是用户空间,都处于虚拟空间之中。
- Linux 使用两级保护机制:0 级供内核使用,3 级供用户程序使用。
服务端处理网络请求的流程
为了 OS 的安全性等考虑,进程是无法直接操作 IO 设备的,其必须通过系统调用来请求内核以协助完成 IO 动作,而内核会为每个 IO 设备维护一个 buffer。
整个请求过程为:
- 用户进程发起请求;
- 内核接收到请求后;
- 从 IO 设备中获取数据到 buffer 中;
- 再将 buffer 中的数据 copy 到用户进程的地址空间;
- 该用户进程获取到数据后再响应客户端。
服务端处理网络请求的典型流程图如下:
在请求过程中,数据从 IO 设备输入至 buffer 需要时间,从 buffer 复制将数据复制到用户进程也需要时间。因此根据在这两段时间内等待方式的不同,IO 动作可以分为以下五种:
- 阻塞 IO,Blocking IO
- 非阻塞 IO,Non-Blocking IO
- IO 复用,IO Multiplexing
- 信号驱动的 IO,Signal Driven IO
- 异步 IO,Asynchrnous IO
更多细节参考 <Unix 网络编程>,6.2 节 “IO Models”。
设计服务端并发模型时,主要有如下两个关键点:
- 服务器如何管理连接,获取请求数据。
- 服务器如何处理请求。
以上两个关键点最终都与操作系统的 I/O 模型以及线程(进程)模型相关,下面详细介绍这两个模型。
阻塞/非阻塞、同步/异步
阻塞/非阻塞:
- 阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
- 非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
区别:
- 两者的最大区别在于被调用方在收到请求到返回结果之前的这段时间内,调用方是否一直在等待。
- 阻塞是指调用方一直在等待而且别的事情什么都不做;非阻塞是指调用方先去忙别的事情。
同步/异步:
- 同步处理是指被调用方得到最终结果之后才返回给调用方;
- 异步处理是指被调用方先返回应答,然后再计算调用结果,计算完最终结果后再通知并返回给调用方。
区别与联系
阻塞、非阻塞和同步、异步其实针对的对象是不一样的:
- 阻塞、非阻塞的讨论对象是调用者。
- 同步、异步的讨论对象是被调用者。
Linux 网络 I/O 模型
recvfrom 函数
recvfrom 函数(经 Socket 接收数据),这里把它视为系统调用。一个输入操作通常包括两个不同的阶段:
对于一个套接字上的输入操作,第一步通常涉及等待数据从网络中到达。当所等待分组到达时,它被复制到内核中的某个缓冲区。第二步就是把数据从内核缓冲区复制到应用进程缓冲区。
实际应用程序在通过系统调用完成上面的 2 步操作时,调用方式的阻塞、非阻塞,操作系统在处理应用程序请求时处理方式的同步、异步,可以分为 5 种 I/O 模型。
阻塞式 IO
在阻塞式 IO 模型中,应用程序从调用 recvfrom 开始到它返回有数据报准备好这段时间是阻塞的,recvfrom 返回成功后,应用程序开始处理数据报。
- 优点:程序实现简单,在阻塞等待数据期间,进程、线程挂起,基本不会占用 CPU 资源。
- 每个连接需要独立的进程、线程单独处理,当并发请求量大时为了维护程序,内存、线程切换开销很大,这种模型在实际生产中很少使用。
非阻塞 IO
在非阻塞 IO 模型中,应用程序把一个套接口设置为非阻塞,就是告诉内核,当所有请求的 IO 操作无法完成时,不要将进程睡眠。
而是返回一个错误,应用程序基于 IO 操作函数,将会不断的轮询数据是否已经准备就绪,直到数据准备就绪。
- 优点:不会阻塞在内核的等待数据过程,每次发起的 IO 请求可以立即返回,不会阻塞等待,实时性比较好。
- 缺点:轮询将会不断的询问内核,这将占用大量的 CPU 时间,系统资源利用率较低,所以一般 Web 服务器不会使用这种 IO 模型。
IO 多路复用
在 IO 复用模型中,会用到 Select、Poll、Epoll 函数,这些函数会使进程阻塞,但是和阻塞 IO 有所不同。
这些函数可以同时阻塞多个 IO 操作,而且可以同时对多个读、写操作的 IO 函数进行检测,直到有数据可读或可写时,才会真正调用 IO 操作函数。
- 优点:可以基于一个阻塞对象,同时在多个描述符上等待就绪,而不是使用多个线程(每个文件描述符一个线程),这样可以大大节省系统资源。
- 当连接数较少时效率比“多线程+阻塞IO”的模式效率低,可能延迟更大,因为单个连接处理需要 2 次系统调用,占用时间会增加。
信号驱动 IO
在信号驱动 IO 模型中,应用程序使用套接口进行信号驱动 IO,并安装一个信号处理函数,进程继续运行并不阻塞。
当数据准备好时,进程会收到一个 SIGIO 信号,可以在信号处理函数中调用 IO 操作函数处理数据。
- 优点:线程没有在等待数据时被阻塞,可以提高资源利用率。
- 缺点:信号 IO 模式在大量 IO 操作时可能会因为信号队列溢出而导致无法通知。
信号驱动 IO 尽管对于处理 UDP 套接字来说有用,即这种信号通知意味着到达了一个数据报,或者返回一个异步错误。
但是,对于 TCP 而言,信号驱动 IO 方式近乎无用。因为导致这种通知的条件为数众多,逐个进行判断会消耗很大的资源,与前几种方式相比优势尽失。
异步 IO
由 POSIX 规范定义,应用程序告知内核启动某个操作,并让内核在整个操作完成后(包括将数据从内核拷贝到应用程序的缓冲区)通知应用程序。
这种模型与信号驱动模型的主要区别在于:信号驱动 IO 是由内核通知应用程序合适启动一个 IO 操作,而异步 IO 模型是由内核通知应用程序 IO 操作合适完成。
- 优点:异步 IO 能够充分利用 DMA 特性,让 IO 操作与计算重叠。
- 缺点:需要实现真正的异步 IO,操作系统需要做大量的工作。当前 Windows 下通过 IOCP 实现了真正的异步 IO。
而在 Linux 系统下直到 2.6 版本才引入,目前 AIO 并不完善,因此在 Linux 下实现并发网络编程时都是以 IO 复用模型为主。
IO 模型对比
从上图可以看出,越往后,阻塞越少,理论上效率也最优。
这五种模型中,前四种属于同步 IO,因为其中真正的 IO 操作(recvfrom 函数调用)将阻塞进程/线程,只有异步 IO 模型才与 POSIX 定义的异步 IO 相匹配。
进程/线程模型
介绍完服务器如何基于 IO 模型管理连接、获取输入数据,下面介绍服务器如何基于进程、线程模型来处理请求。
传统阻塞 IO 服务模型
特点:
- 采用阻塞式 IO 模型获取输入数据。
- 每个连接都需要独立的线程完成数据输入的读取、业务处理、数据返回操作。
存在问题:
- 当请求的并发数较大时,需要创建大量线程来处理连接,系统资源占用较大。
- 当连接建立后,如果当前线程暂时没有数据可读,则线程就阻塞在 Read 操作上,造成线程资源浪费。
Reactor 模式
针对传统阻塞 IO 服务模型的 2 个缺点,比较常见的有如下解决方案:
- 基于 IO 复用模型,多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象上等待,无需阻塞等待所有连接。
- 当某条连接有新的数据可处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务处理。
- 基于线程池复用线程资源,不必再为每个连接创建线程,将连接完成后的业务处理任务分配给线程进行处理,一个线程可以多个连接的业务。
IO 复用模式结合线程池,就是 Reactor 模式的基本设计思想,如下图:
Reactor 模式,是指通过一个或多个输入同时传递给服务器来处理服务请求的事件驱动处理模式。
服务端程序处理传入的多路请求,并将它们同步分派给请求对应的处理线程,Reactor 模式也叫 Dispatcher 模式。
即 IO 多路复用以统一的方式监听事件,收到事件后分发(Dispatch 给某线程),是编写高性能服务器的必备技术之一。
Reactor 模式有两个关键组件构成:
- Reactor:在一个单独的线程中运行,负责监听和分发事件,分发给适当的处理程序对 IO 事件做出反应。它就像公司的电话接线员,接听来自客户的电话并将线路转移给适当的联系人。
- Handlers:处理程序执行 IO 事件需要完成的实际组件,类似于客户想要与之交谈的客服坐席。Reactor 通过调度适当的处理程序来响应 IO 事件,处理程序执行非阻塞操作。
根据 Reactor 的数量和处理资源池线程的数量不同,有 3 种典型的实现:
- 单 Reactor 单线程
- 单 Reactor 多线程
- 主从 Reactor 多线程
单 Reactor 单线程
其中,Select 是前面 IO 复用模型介绍的标准网络编程 API,可以实现应用程序通过一个阻塞多向监听多路连接请求,其他方案的示意图也类似。
方案说明:
Reactor 对象通过 Select 监听客户端请求事件,收到事件后通过 Dispatch 进行分发。
如果是“建立连接”请求事件,则由 Acceptor 通过 Accept 处理连接请求,同时创建一个 Handler 对象来处理连接完成后的后续业务处理。
如果不是“建立连接”事件,则 Reactor 会分发调用“连接”对应的 Handler 来响应。
Handler 会完成 “Read->业务处理->Send” 的完整业务流程。
优点:模型简单,没有多线程、进程通信、竞争的问题,全部都在一个线程中完成。
缺点:性能问题,只有一个线程,无法完全发挥多个 CPU 的性能。Handler 在处理某个连接上的业务时,整个进程无法处理其他连接事件,很容易导致性能瓶颈。
可靠性问题、线程意外跑飞、进入死循环,或导致整个系统的通信模块不可用,不能接收或处理外部消息,造成节点故障。
应用场景:客户端的数量有限,业务处理非常快,比如 Redis,业务处理的时间复杂度为 O(1)。
单 Reactor 多线程
Reactor 对象通过 Select 监控客户端请求事件,收到事件后通过 Dispatch 进行分发。
如果是建立连接请求事件,则由 Acceptor 通过 Accept 处理连接请求,同时创建一个 Handler 对象处理连接完成后续的各种事件。
如果不是建立连接事件,则 Reactor 会分发调用连接对应的 Handler 来响应。
Handler 只负责响应事件,不做具体业务处理,通过 Read 读取数据后,会分发给后面的 Worker 线程池进行业务处理。
Worker 线程池会分配独立的线程完成真正的业务处理,如何将响应结果发给 Handler 进行处理。
Handler 收到响应结果后通过 Send 将响应结果返回给 Client。
优点:可以充分利用多核 CPU 的处理能力。
缺点:
- 多线程数据共享和访问比较复杂;
- Reactor 承担所有事件的监听和响应,在单线程中运行,高并发场景下容易成为性能瓶颈。
主从 Reactor 多线程
针对单 Reactor 多线程模型中,Reactor 在单线程中运行,高并发场景下容易成为性能瓶颈,可以让 Reactor 在多线程中运行。
Reactor 主线程 MainReactor 对象通过 Select 监控建立连接事件,收到事件后通过 Acceptor 接收,处理建立连接事件。
Acceptor 处理建立连接事件后,MainReactor 将连接分配 Reactor 子线程给 SubReactor 进行处理。
SubReactor 将连接加入连接队列进行监听,并创建一个 Handler 用于处理各种连接事件。
当有新的事件发生时,SubReactor 会调用连接对应的 Handler 进行响应。
Handler 通过 Read 读取数据后,会分发给后面的 Worker 线程池进行业务处理。
Worker 线程池会分配独立的线程完成真正的业务处理,如何将响应结果发给 Handler 进行处理。
Handler 收到响应结果后通过 Send 将响应结果返回给 Client。
优点:父线程与子线程的数据交互简单、职责明确,父线程只需要接收新连接,子线程完成后续的业务处理。
父线程与子线程的数据交互简单,Reactor 主线程只需要把新连接传递给子线程即可,子线程无需返回数据。
这种模型在很多项目中广泛使用,包括 Nginx 主从 Reactor 多线程模型,Memcached 主从多线程。
Reactor 模式总结
三种模式可以用一个比喻来理解:餐厅常常雇佣接待员负责迎接顾客,当顾客入座后,侍应生专门为这张桌子服务。
- 单 Reactor 单线程:接待员和侍应生是同一个人,全程为顾客服务。
- 单 Reactor 多线程:一个接待员、多个侍应生,接待员只负责接待。
- 主从 Reactor:多个接待员,多个侍应生。
Reactor 模式具有如下的优点:
- 响应快:不必为单个同步时间所阻塞,虽然 Reactor 本身依然是同步的。
- 编程相对简单:可以最大程度的避免复杂的多线程及同步问题,并且避免了多线程的切换开销。
- 可扩展性:可以方便的通过增加 Reactor 实例个数来充分利用 CPU 资源。
- 可复用性:Reactor 模型本身与具体事件处理逻辑无关,具有很高的复用性。
Proactor 模型
在 Reactor 模式中,Reactor 等待某个事件、可应用或操作的状态发生(比如文件描述符可读、Socket 可读写)。
然后把该事件传递给事先注册的 Handler(事件处理函数或回调函数),由后者来做实际的读写操作。
其中的读写操作都需要应用程序同步操作,所以 Reactor 是非阻塞同步网络模型。
如果把 IO 操作改为异步,即交给操作系统来完成 IO 操作,就能进一步提升性能,这就是异步网络模型 Proactor。
Proactor 是和异步 I/O 相关的,详细方案如下:
- ProactorInitiator 创建 Proactor 和 Handler 对象,并将 Proactor 和 Handler 都通过 AsyOptProcessor(Asynchronous Operation Processor) 注册到内核。
- AsyOptProcessor 处理注册请求,并处理 I/O 操作。
- AsyOptProcessor 完成 I/O 操作后通知 Proactor。
- Proactor 根据不同的事件类型回调不同的 Handler 进行业务处理。
- Handler 完成业务处理。
可以看出 Proactor 和 Reactor 的区别:
- Reactor 是在事件发生时就通知事先注册的事件(读写在应用程序线程中处理完成)。
- Proactor 是在事件发生时基于异步 I/O 完成读写操作(由内核完成),待 I/O 操作完成后才回调应用程序的处理器来进行业务处理。
理论上 Proactor 比 Reactor 效率更高,异步 I/O 更加充分发挥 DMA(Direct Memory Access,直接内存存取)的优势,但是有如下缺点:
- 编程复杂性:由于异步操作流程的事件的初始化和事件完成在时间和空间上都是相互分离的,因此开发异步应用程序更加复杂。应用程序还可能因为反向的流控而变得更加难以 Debug。
- 内存使用:缓冲区在读或写操作的时间段内必须保持住,可能造成持续的不确定性,并且每个并发操作都要求有独立的缓存,相比 Reactor 模式,在 Socket 已经准备好读或写前,是不要求开辟缓存的。
- 操作系统支持,Windows 下通过 IOCP 实现了真正的异步 I/O,而在 Linux 系统下,Linux 2.6 才引入,目前异步 I/O 还不完善。
因此在 Linux 下实现高并发网络编程都是以 Reactor 模型为主。
4.8 - CH08-BIO原理
概览
BIO就是: blocking IO。最容易理解、最容易实现的IO工作方式,应用程序向操作系统请求网络IO操作,这时应用程序会一直等待;另一方面,操作系统收到请求后,也会等待,直到网络上有数据传到监听端口;操作系统在收集数据后,会把数据发送给应用程序;最后应用程序受到数据,并解除等待状态。
概念
阻塞IO 和 非阻塞IO
这两个概念是程序级别的。主要描述的是程序请求操作系统IO操作后,如果IO资源没有准备好,那么程序该如何处理的问题: 前者等待;后者继续执行(并且使用线程一直轮询,直到有IO资源准备好了)
同步IO 和 非同步IO
这两个概念是操作系统级别的。主要描述的是操作系统在收到程序请求IO操作后,如果IO资源没有准备好,该如何相应程序的问题: 前者不响应,直到IO资源准备好以后;后者返回一个标记(好让程序和自己知道以后的数据往哪里通知),当IO资源准备好以后,再用事件机制返回给程序。
BIO通信方式
以前大多数网络通信方式都是阻塞模式的,即:
- 客户端向服务器端发出请求后,客户端会一直等待(不会再做其他事情),直到服务器端返回结果或者网络出现问题。
- 服务器端同样的,当在处理某个客户端A发来的请求时,另一个客户端B发来的请求会等待,直到服务器端的这个处理线程完成上一个处理。
传统的BIO的问题
- 同一时间,服务器只能接受来自于客户端A的请求信息;虽然客户端A和客户端B的请求是同时进行的,但客户端B发送的请求信息只能等到服务器接受完A的请求数据后,才能被接受。
- 由于服务器一次只能处理一个客户端请求,当处理完成并返回后(或者异常时),才能进行第二次请求的处理。很显然,这样的处理方式在高并发的情况下,是不能采用的。
多线程方式 - 伪异步方式
上面说的情况是服务器只有一个线程的情况,那么读者会直接提出我们可以使用多线程技术来解决这个问题:
- 当服务器收到客户端X的请求后,(读取到所有请求数据后)将这个请求送入一个独立线程进行处理,然后主线程继续接受客户端Y的请求。
- 客户端一侧,也可以使用一个子线程和服务器端进行通信。这样客户端主线程的其他工作就不受影响了,当服务器端有响应信息的时候再由这个子线程通过 监听模式/观察模式(等其他设计模式)通知主线程。
但是使用线程来解决这个问题实际上是有局限性的:
- 虽然在服务器端,请求的处理交给了一个独立线程进行,但是操作系统通知accept()的方式还是单个的。也就是,实际上是服务器接收到数据报文后的“业务处理过程”可以多线程,但是数据报文的接受还是需要一个一个的来(下文的示例代码和debug过程我们可以明确看到这一点)
- 在linux系统中,可以创建的线程是有限的。我们可以通过cat /proc/sys/kernel/threads-max 命令查看可以创建的最大线程数。当然这个值是可以更改的,但是线程越多,CPU切换所需的时间也就越长,用来处理真正业务的需求也就越少。
- 创建一个线程是有较大的资源消耗的。JVM创建一个线程的时候,即使这个线程不做任何的工作,JVM都会分配一个堆栈空间。这个空间的大小默认为128K,您可以通过-Xss参数进行调整。当然您还可以使用ThreadPoolExecutor线程池来缓解线程的创建问题,但是又会造成BlockingQueue积压任务的持续增加,同样消耗了大量资源。
- 另外,如果您的应用程序大量使用长连接的话,线程是不会关闭的。这样系统资源的消耗更容易失控。 那么,如果你真想单纯使用线程解决阻塞的问题,那么您自己都可以算出来您一个服务器节点可以一次接受多大的并发了。看来,单纯使用线程解决这个问题不是最好的办法。
深入分析
BIO的问题关键不在于是否使用了多线程(包括线程池)处理这次请求,而在于accept()、read()的操作点都是被阻塞。要测试这个问题,也很简单。我们模拟了20个客户端(用20根线程模拟),利用JAVA的同步计数器CountDownLatch,保证这20个客户都初始化完成后然后同时向服务器发送请求,然后我们来观察一下Server这边接受信息的情况。
模拟20个客户端并发请求,服务器端使用单线程:
客户端代码(SocketClientDaemon)
package testBSocket;
import java.util.concurrent.CountDownLatch;
public class SocketClientDaemon {
public static void main(String[] args) throws Exception {
Integer clientNumber = 20;
CountDownLatch countDownLatch = new CountDownLatch(clientNumber);
//分别开始启动这20个客户端
for(int index = 0 ; index < clientNumber ; index++ , countDownLatch.countDown()) {
SocketClientRequestThread client = new SocketClientRequestThread(countDownLatch, index);
new Thread(client).start();
}
//这个wait不涉及到具体的实验逻辑,只是为了保证守护线程在启动所有线程后,进入等待状态
synchronized (SocketClientDaemon.class) {
SocketClientDaemon.class.wait();
}
}
}
客户端代码(SocketClientRequestThread模拟请求)
package testBSocket;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
import java.util.concurrent.CountDownLatch;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.log4j.BasicConfigurator;
/**
* 一个SocketClientRequestThread线程模拟一个客户端请求。
* @author yinwenjie
*/
public class SocketClientRequestThread implements Runnable {
static {
BasicConfigurator.configure();
}
/**
* 日志
*/
private static final Log LOGGER = LogFactory.getLog(SocketClientRequestThread.class);
private CountDownLatch countDownLatch;
/**
* 这个线层的编号
* @param countDownLatch
*/
private Integer clientIndex;
/**
* countDownLatch是java提供的同步计数器。
* 当计数器数值减为0时,所有受其影响而等待的线程将会被激活。这样保证模拟并发请求的真实性
* @param countDownLatch
*/
public SocketClientRequestThread(CountDownLatch countDownLatch , Integer clientIndex) {
this.countDownLatch = countDownLatch;
this.clientIndex = clientIndex;
}
@Override
public void run() {
Socket socket = null;
OutputStream clientRequest = null;
InputStream clientResponse = null;
try {
socket = new Socket("localhost",83);
clientRequest = socket.getOutputStream();
clientResponse = socket.getInputStream();
//等待,直到SocketClientDaemon完成所有线程的启动,然后所有线程一起发送请求
this.countDownLatch.await();
//发送请求信息
clientRequest.write(("这是第" + this.clientIndex + " 个客户端的请求。").getBytes());
clientRequest.flush();
//在这里等待,直到服务器返回信息
SocketClientRequestThread.LOGGER.info("第" + this.clientIndex + "个客户端的请求发送完成,等待服务器返回信息");
int maxLen = 1024;
byte[] contextBytes = new byte[maxLen];
int realLen;
String message = "";
//程序执行到这里,会一直等待服务器返回信息(注意,前提是in和out都不能close,如果close了就收不到服务器的反馈了)
while((realLen = clientResponse.read(contextBytes, 0, maxLen)) != -1) {
message += new String(contextBytes , 0 , realLen);
}
SocketClientRequestThread.LOGGER.info("接收到来自服务器的信息:" + message);
} catch (Exception e) {
SocketClientRequestThread.LOGGER.error(e.getMessage(), e);
} finally {
try {
if(clientRequest != null) {
clientRequest.close();
}
if(clientResponse != null) {
clientResponse.close();
}
} catch (IOException e) {
SocketClientRequestThread.LOGGER.error(e.getMessage(), e);
}
}
}
}
服务器端(SocketServer1)单个线程
package testBSocket;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.ServerSocket;
import java.net.Socket;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.log4j.BasicConfigurator;
public class SocketServer1 {
static {
BasicConfigurator.configure();
}
/**
* 日志
*/
private static final Log LOGGER = LogFactory.getLog(SocketServer1.class);
public static void main(String[] args) throws Exception{
ServerSocket serverSocket = new ServerSocket(83);
try {
while(true) {
Socket socket = serverSocket.accept();
//下面我们收取信息
InputStream in = socket.getInputStream();
OutputStream out = socket.getOutputStream();
Integer sourcePort = socket.getPort();
int maxLen = 2048;
byte[] contextBytes = new byte[maxLen];
//这里也会被阻塞,直到有数据准备好
int realLen = in.read(contextBytes, 0, maxLen);
//读取信息
String message = new String(contextBytes , 0 , realLen);
//下面打印信息
SocketServer1.LOGGER.info("服务器收到来自于端口: " + sourcePort + "的信息: " + message);
//下面开始发送信息
out.write("回发响应信息!".getBytes());
//关闭
out.close();
in.close();
socket.close();
}
} catch(Exception e) {
SocketServer1.LOGGER.error(e.getMessage(), e);
} finally {
if(serverSocket != null) {
serverSocket.close();
}
}
}
}
多线程来优化服务器端
客户端代码和上文一样,最主要是更改服务器端的代码:
package testBSocket;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.ServerSocket;
import java.net.Socket;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.log4j.BasicConfigurator;
public class SocketServer2 {
static {
BasicConfigurator.configure();
}
private static final Log LOGGER = LogFactory.getLog(SocketServer2.class);
public static void main(String[] args) throws Exception{
ServerSocket serverSocket = new ServerSocket(83);
try {
while(true) {
Socket socket = serverSocket.accept();
//当然业务处理过程可以交给一个线程(这里可以使用线程池),并且线程的创建是很耗资源的。
//最终改变不了.accept()只能一个一个接受socket的情况,并且被阻塞的情况
SocketServerThread socketServerThread = new SocketServerThread(socket);
new Thread(socketServerThread).start();
}
} catch(Exception e) {
SocketServer2.LOGGER.error(e.getMessage(), e);
} finally {
if(serverSocket != null) {
serverSocket.close();
}
}
}
}
/**
* 当然,接收到客户端的socket后,业务的处理过程可以交给一个线程来做。
* 但还是改变不了socket被一个一个的做accept()的情况。
* @author yinwenjie
*/
class SocketServerThread implements Runnable {
/**
* 日志
*/
private static final Log LOGGER = LogFactory.getLog(SocketServerThread.class);
private Socket socket;
public SocketServerThread (Socket socket) {
this.socket = socket;
}
@Override
public void run() {
InputStream in = null;
OutputStream out = null;
try {
//下面我们收取信息
in = socket.getInputStream();
out = socket.getOutputStream();
Integer sourcePort = socket.getPort();
int maxLen = 1024;
byte[] contextBytes = new byte[maxLen];
//使用线程,同样无法解决read方法的阻塞问题,
//也就是说read方法处同样会被阻塞,直到操作系统有数据准备好
int realLen = in.read(contextBytes, 0, maxLen);
//读取信息
String message = new String(contextBytes , 0 , realLen);
//下面打印信息
SocketServerThread.LOGGER.info("服务器收到来自于端口: " + sourcePort + "的信息: " + message);
//下面开始发送信息
out.write("回发响应信息!".getBytes());
} catch(Exception e) {
SocketServerThread.LOGGER.error(e.getMessage(), e);
} finally {
//试图关闭
try {
if(in != null) {
in.close();
}
if(out != null) {
out.close();
}
if(this.socket != null) {
this.socket.close();
}
} catch (IOException e) {
SocketServerThread.LOGGER.error(e.getMessage(), e);
}
}
}
}
优化效果
我们主要看一看服务器使用多线程处理时的情况:
问题根源
那么重点的问题并不是“是否使用了多线程”,而是为什么accept()、read()方法会被阻塞。即: 异步IO模式 就是为了解决这样的并发性存在的。但是为了说清楚异步IO模式,在介绍IO模式的时候,我们就要首先了解清楚,什么是 阻塞式同步、非阻塞式同步、多路复用同步模式。
API文档中对于 serverSocket.accept() 方法的使用描述:
Listens for a connection to be made to this socket and accepts it. The method blocks until a connection is made.
serverSocket.accept()会被阻塞? 这里涉及到阻塞式同步IO的工作原理:
- 服务器线程发起一个accept动作,询问操作系统 是否有新的socket套接字信息从端口X发送过来。
- 注意,是询问操作系统。也就是说socket套接字的IO模式支持是基于操作系统的,那么自然同步IO/异步IO的支持就是需要操作系统级别的了。如下图:
如果操作系统没有发现有套接字从指定的端口X来,那么操作系统就会等待。这样serverSocket.accept()方法就会一直等待。这就是为什么accept()方法为什么会阻塞: 它内部的实现是使用的操作系统级别的同步IO。
4.9 - CH09-NIO基础
Standard IO是对字节流的读写,在进行IO之前,首先创建一个流对象,流对象进行读写操作都是按字节 ,一个字节一个字节的来读或写。而NIO把IO抽象成块,类似磁盘的读写,每次IO操作的单位都是一个块,块被读入内存之后就是一个byte[],NIO一次可以读或写多个字节。
流与块
I/O 与 NIO 最重要的区别是数据打包和传输的方式,I/O 以流的方式处理数据,而 NIO 以块的方式处理数据。
面向流的 I/O 一次处理一个字节数据: 一个输入流产生一个字节数据,一个输出流消费一个字节数据。为流式数据创建过滤器非常容易,链接几个过滤器,以便每个过滤器只负责复杂处理机制的一部分。不利的一面是,面向流的 I/O 通常相当慢。
面向块的 I/O 一次处理一个数据块,按块处理数据比按流处理数据要快得多。但是面向块的 I/O 缺少一些面向流的 I/O 所具有的优雅性和简单性。
I/O 包和 NIO 已经很好地集成了,java.io.* 已经以 NIO 为基础重新实现了,所以现在它可以利用 NIO 的一些特性。例如,java.io.* 包中的一些类包含以块的形式读写数据的方法,这使得即使在面向流的系统中,处理速度也会更快。
通道与缓冲区
通道
通道 Channel 是对原 I/O 包中的流的模拟,可以通过它读取和写入数据。
通道与流的不同之处在于,流只能在一个方向上移动(一个流必须是 InputStream 或者 OutputStream 的子类),而通道是双向的,可以用于读、写或者同时用于读写。
通道包括以下类型:
- FileChannel: 从文件中读写数据;
- DatagramChannel: 通过 UDP 读写网络中数据;
- SocketChannel: 通过 TCP 读写网络中数据;
- ServerSocketChannel: 可以监听新进来的 TCP 连接,对每一个新进来的连接都会创建一个 SocketChannel。
缓冲区
发送给一个通道的所有数据都必须首先放到缓冲区中,同样地,从通道中读取的任何数据都要先读到缓冲区中。也就是说,不会直接对通道进行读写数据,而是要先经过缓冲区。
缓冲区实质上是一个数组,但它不仅仅是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。
缓冲区包括以下类型:
- ByteBuffer
- CharBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
缓冲区状态变量
- capacity: 最大容量;
- position: 当前已经读写的字节数;
- limit: 还可以读写的字节数。
状态变量的改变过程举例:
① 新建一个大小为 8 个字节的缓冲区,此时 position 为 0,而 limit = capacity = 8。capacity 变量不会改变,下面的讨论会忽略它。
② 从输入通道中读取 5 个字节数据写入缓冲区中,此时 position 移动设置为 5,limit 保持不变。
③ 在将缓冲区的数据写到输出通道之前,需要先调用 flip() 方法,这个方法将 limit 设置为当前 position,并将 position 设置为 0。
④ 从缓冲区中取 4 个字节到输出缓冲中,此时 position 设为 4。
⑤ 最后需要调用 clear() 方法来清空缓冲区,此时 position 和 limit 都被设置为最初位置。
文件 NIO 实例
以下展示了使用 NIO 快速复制文件的实例:
public static void fastCopy(String src, String dist) throws IOException {
/* 获得源文件的输入字节流 */
FileInputStream fin = new FileInputStream(src);
/* 获取输入字节流的文件通道 */
FileChannel fcin = fin.getChannel();
/* 获取目标文件的输出字节流 */
FileOutputStream fout = new FileOutputStream(dist);
/* 获取输出字节流的通道 */
FileChannel fcout = fout.getChannel();
/* 为缓冲区分配 1024 个字节 */
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
while (true) {
/* 从输入通道中读取数据到缓冲区中 */
int r = fcin.read(buffer);
/* read() 返回 -1 表示 EOF */
if (r == -1) {
break;
}
/* 切换读写 */
buffer.flip();
/* 把缓冲区的内容写入输出文件中 */
fcout.write(buffer);
/* 清空缓冲区 */
buffer.clear();
}
}
选择器
NIO 常常被叫做非阻塞 IO,主要是因为 NIO 在网络通信中的非阻塞特性被广泛使用。
NIO 实现了 IO 多路复用中的 Reactor 模型,一个线程 Thread 使用一个选择器 Selector 通过轮询的方式去监听多个通道 Channel 上的事件,从而让一个线程就可以处理多个事件。
通过配置监听的通道 Channel 为非阻塞,那么当 Channel 上的 IO 事件还未到达时,就不会进入阻塞状态一直等待,而是继续轮询其它 Channel,找到 IO 事件已经到达的 Channel 执行。
因为创建和切换线程的开销很大,因此使用一个线程来处理多个事件而不是一个线程处理一个事件具有更好的性能。
应该注意的是,只有套接字 Channel 才能配置为非阻塞,而 FileChannel 不能,为 FileChannel 配置非阻塞也没有意义。
1. 创建选择器
Selector selector = Selector.open();
2. 将通道注册到选择器上
ServerSocketChannel ssChannel = ServerSocketChannel.open();
ssChannel.configureBlocking(false);
ssChannel.register(selector, SelectionKey.OP_ACCEPT);
通道必须配置为非阻塞模式,否则使用选择器就没有任何意义了,因为如果通道在某个事件上被阻塞,那么服务器就不能响应其它事件,必须等待这个事件处理完毕才能去处理其它事件,显然这和选择器的作用背道而驰。
在将通道注册到选择器上时,还需要指定要注册的具体事件,主要有以下几类:
- SelectionKey.OP_CONNECT
- SelectionKey.OP_ACCEPT
- SelectionKey.OP_READ
- SelectionKey.OP_WRITE
它们在 SelectionKey 的定义如下:
public static final int OP_READ = 1 << 0;
public static final int OP_WRITE = 1 << 2;
public static final int OP_CONNECT = 1 << 3;
public static final int OP_ACCEPT = 1 << 4;
可以看出每个事件可以被当成一个位域,从而组成事件集整数。例如:
int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
监听事件
int num = selector.select();
使用 select() 来监听到达的事件,它会一直阻塞直到有至少一个事件到达。
4. 获取到达的事件
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// ...
} else if (key.isReadable()) {
// ...
}
keyIterator.remove();
}
5. 事件循环
因为一次 select() 调用不能处理完所有的事件,并且服务器端有可能需要一直监听事件,因此服务器端处理事件的代码一般会放在一个死循环内。
while (true) {
int num = selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// ...
} else if (key.isReadable()) {
// ...
}
keyIterator.remove();
}
}
套接字 NIO 实例
public class NIOServer {
public static void main(String[] args) throws IOException {
Selector selector = Selector.open();
ServerSocketChannel ssChannel = ServerSocketChannel.open();
ssChannel.configureBlocking(false);
ssChannel.register(selector, SelectionKey.OP_ACCEPT);
ServerSocket serverSocket = ssChannel.socket();
InetSocketAddress address = new InetSocketAddress("127.0.0.1", 8888);
serverSocket.bind(address);
while (true) {
selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
ServerSocketChannel ssChannel1 = (ServerSocketChannel) key.channel();
// 服务器会为每个新连接创建一个 SocketChannel
SocketChannel sChannel = ssChannel1.accept();
sChannel.configureBlocking(false);
// 这个新连接主要用于从客户端读取数据
sChannel.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
SocketChannel sChannel = (SocketChannel) key.channel();
System.out.println(readDataFromSocketChannel(sChannel));
sChannel.close();
}
keyIterator.remove();
}
}
}
private static String readDataFromSocketChannel(SocketChannel sChannel) throws IOException {
ByteBuffer buffer = ByteBuffer.allocate(1024);
StringBuilder data = new StringBuilder();
while (true) {
buffer.clear();
int n = sChannel.read(buffer);
if (n == -1) {
break;
}
buffer.flip();
int limit = buffer.limit();
char[] dst = new char[limit];
for (int i = 0; i < limit; i++) {
dst[i] = (char) buffer.get(i);
}
data.append(dst);
buffer.clear();
}
return data.toString();
}
}
public class NIOClient {
public static void main(String[] args) throws IOException {
Socket socket = new Socket("127.0.0.1", 8888);
OutputStream out = socket.getOutputStream();
String s = "hello world";
out.write(s.getBytes());
out.close();
}
}
内存映射文件
内存映射文件 I/O 是一种读和写文件数据的方法,它可以比常规的基于流或者基于通道的 I/O 快得多。
向内存映射文件写入可能是危险的,只是改变数组的单个元素这样的简单操作,就可能会直接修改磁盘上的文件。修改数据与将数据保存到磁盘是没有分开的。
下面代码行将文件的前 1024 个字节映射到内存中,map() 方法返回一个 MappedByteBuffer,它是 ByteBuffer 的子类。因此,可以像使用其他任何 ByteBuffer 一样使用新映射的缓冲区,操作系统会在需要时负责执行映射。
MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE, 0, 1024);
对比
NIO 与普通 I/O 的区别主要有以下两点:
4.10 - CH10-NIO原理
现实场景
我们试想一下这样的现实场景:
一个餐厅同时有100位客人到店,当然到店后第一件要做的事情就是点菜。但是问题来了,餐厅老板为了节约人力成本目前只有一位大堂服务员拿着唯一的一本菜单等待客人进行服务。
- 那么最笨(但是最简单)的方法是(方法A),无论有多少客人等待点餐,服务员都把仅有的一份菜单递给其中一位客人,然后站在客人身旁等待这个客人完成点菜过程。在记录客人点菜内容后,把点菜记录交给后堂厨师。然后是第二位客人。。。。然后是第三位客人。很明显,只有脑袋被门夹过的老板,才会这样设置服务流程。因为随后的80位客人,再等待超时后就会离店(还会给差评)。
- 于是还有一种办法(方法B),老板马上新雇佣99名服务员,同时印制99本新的菜单。每一名服务员手持一本菜单负责一位客人(关键不只在于服务员,还在于菜单。因为没有菜单客人也无法点菜)。在客人点完菜后,记录点菜内容交给后堂厨师(当然为了更高效,后堂厨师最好也有100名)。这样每一位客人享受的就是VIP服务咯,当然客人不会走,但是人力成本可是一个大头哦(亏死你)。
- 另外一种办法(方法C),就是改进点菜的方式,当客人到店后,自己申请一本菜单。想好自己要点的才后,就呼叫服务员。服务员站在自己身边后记录客人的菜单内容。将菜单递给厨师的过程也要进行改进,并不是每一份菜单记录好以后,都要交给后堂厨师。服务员可以记录号多份菜单后,同时交给厨师就行了。那么这种方式,对于老板来说人力成本是最低的;对于客人来说,虽然不再享受VIP服务并且要进行一定的等待,但是这些都是可接受的;对于服务员来说,基本上她的时间都没有浪费,基本上被老板压杆了最后一滴油水。
如果您是老板,您会采用哪种方式呢?
到店情况: 并发量。到店情况不理想时,一个服务员一本菜单,当然是足够了。所以不同的老板在不同的场合下,将会灵活选择服务员和菜单的配置。
- 客人: 客户端请求
- 点餐内容: 客户端发送的实际数据
- 老板: 操作系统
- 人力成本: 系统资源
- 菜单: 文件状态描述符。操作系统对于一个进程能够同时持有的文件状态描述符的个数是有限制的,在linux系统中$ulimit -n查看这个限制值,当然也是可以(并且应该)进行内核参数调整的。
- 服务员: 操作系统内核用于IO操作的线程(内核线程)
- 厨师: 应用程序线程(当然厨房就是应用程序进程咯)
- 餐单传递方式: 包括了阻塞式和非阻塞式两种。
- 方法A: 阻塞式/非阻塞式 同步IO
- 方法B: 使用线程进行处理的 阻塞式/非阻塞式 同步IO
- 方法C: 阻塞式/非阻塞式 多路复用IO
典型的多路复用IO实现
目前流程的多路复用IO实现主要包括四种: select、poll、epoll、kqueue。下表是他们的一些重要特性的比较:
| IO模型 | 相对性能 | 关键思路 | 操作系统 | JAVA支持情况 |
|---|
| select | 较高 | Reactor | windows/Linux | 支持,Reactor模式(反应器设计模式)。Linux操作系统的 kernels 2.4内核版本之前,默认使用select;而目前windows下对同步IO的支持,都是select模型 |
| poll | 较高 | Reactor | Linux | Linux下的JAVA NIO框架,Linux kernels 2.6内核版本之前使用poll进行支持。也是使用的Reactor模式 |
| epoll | 高 | Reactor/Proactor | Linux | Linux kernels 2.6内核版本及以后使用epoll进行支持;Linux kernels 2.6内核版本之前使用poll进行支持;另外一定注意,由于Linux下没有Windows下的IOCP技术提供真正的 异步IO 支持,所以Linux下使用epoll模拟异步IO |
| kqueue | 高 | Proactor | Linux | 目前JAVA的版本不支持 |
多路复用IO技术最适用的是“高并发”场景,所谓高并发是指1毫秒内至少同时有上千个连接请求准备好。其他情况下多路复用IO技术发挥不出来它的优势。另一方面,使用JAVA NIO进行功能实现,相对于传统的Socket套接字实现要复杂一些,所以实际应用中,需要根据自己的业务需求进行技术选择。
Reactor模型和Proactor模型
JAVA对多路复用IO的支持
重要概念: Channel
通道,被建立的一个应用程序和操作系统交互事件、传递内容的渠道(注意是连接到操作系统)。一个通道会有一个专属的文件状态描述符。那么既然是和操作系统进行内容的传递,那么说明应用程序可以通过通道读取数据,也可以通过通道向操作系统写数据。
JDK API中的Channel的描述是:
A channel represents an open connection to an entity such as a hardware device, a file, a network socket, or a program component that is capable of performing one or more distinct I/O operations, for example reading or writing.
A channel is either open or closed. A channel is open upon creation, and once closed it remains closed. Once a channel is closed, any attempt to invoke an I/O operation upon it will cause a ClosedChannelException to be thrown. Whether or not a channel is open may be tested by invoking its isOpen method.
JAVA NIO 框架中,自有的Channel通道包括:
所有被Selector(选择器)注册的通道,只能是继承了SelectableChannel类的子类。如上图所示
- ServerSocketChannel: 应用服务器程序的监听通道。只有通过这个通道,应用程序才能向操作系统注册支持“多路复用IO”的端口监听。同时支持UDP协议和TCP协议。
- ScoketChannel: TCP Socket套接字的监听通道,一个Socket套接字对应了一个客户端IP: 端口 到 服务器IP: 端口的通信连接。
- DatagramChannel: UDP 数据报文的监听通道。
重要概念: Buffer
数据缓存区: 在JAVA NIO 框架中,为了保证每个通道的数据读写速度JAVA NIO 框架为每一种需要支持数据读写的通道集成了Buffer的支持。
这句话怎么理解呢? 例如ServerSocketChannel通道它只支持对OP_ACCEPT事件的监听,所以它是不能直接进行网络数据内容的读写的。所以ServerSocketChannel是没有集成Buffer的。
Buffer有两种工作模式: 写模式和读模式。在读模式下,应用程序只能从Buffer中读取数据,不能进行写操作。但是在写模式下,应用程序是可以进行读操作的,这就表示可能会出现脏读的情况。所以一旦您决定要从Buffer中读取数据,一定要将Buffer的状态改为读模式。
如下图:
- position: 缓存区目前这在操作的数据块位置
- limit: 缓存区最大可以进行操作的位置。缓存区的读写状态正式由这个属性控制的。
- capacity: 缓存区的最大容量。这个容量是在缓存区创建时进行指定的。由于高并发时通道数量往往会很庞大,所以每一个缓存区的容量最好不要过大。
在下文JAVA NIO框架的代码实例中,我们将进行Buffer缓存区操作的演示。
重要概念: Selector
Selector的英文含义是“选择器”,不过根据我们详细介绍的Selector的岗位职责,您可以把它称之为“轮询代理器”、“事件订阅器”、“channel容器管理机”都行。
应用程序将向Selector对象注册需要它关注的Channel,以及具体的某一个Channel会对哪些IO事件感兴趣。Selector中也会维护一个“已经注册的Channel”的容器。以下代码来自WindowsSelectorImpl实现类中,对已经注册的Channel的管理容器:
// Initial capacity of the poll array
private final int INIT_CAP = 8;
// Maximum number of sockets for select().
// Should be INIT_CAP times a power of 2
private final static int MAX_SELECTABLE_FDS = 1024;
// The list of SelectableChannels serviced by this Selector. Every mod
// MAX_SELECTABLE_FDS entry is bogus, to align this array with the poll
// array, where the corresponding entry is occupied by the wakeupSocket
private SelectionKeyImpl[] channelArray = new SelectionKeyImpl[INIT_CAP];
应用层不再通过阻塞模式或者非阻塞模式直接询问操作系统“事件有没有发生”,而是由Selector代其询问。
之前已经提到过,多路复用IO技术 是需要操作系统进行支持的,其特点就是操作系统可以同时扫描同一个端口上不同网络连接的事件。所以作为上层的JVM,必须要为 不同操作系统的多路复用IO实现 编写不同的代码。同样我使用的测试环境是Windows,它对应的实现类是sun.nio.ch.WindowsSelectorImpl:
JAVA NIO 框架简要设计分析
通过上文的描述,我们知道了多路复用IO技术是操作系统的内核实现。在不同的操作系统,甚至同一系列操作系统的版本中所实现的多路复用IO技术都是不一样的。那么作为跨平台的JAVA JVM来说如何适应多种多样的多路复用IO技术实现呢? 面向对象的威力就显现出来了: 无论使用哪种实现方式,他们都会有“选择器”、“通道”、“缓存”这几个操作要素,那么可以为不同的多路复用IO技术创建一个统一的抽象组,并且为不同的操作系统进行具体的实现。JAVA NIO中对各种多路复用IO的支持,主要的基础是java.nio.channels.spi.SelectorProvider抽象类,其中的几个主要抽象方法包括:
- public abstract DatagramChannel openDatagramChannel(): 创建和这个操作系统匹配的UDP 通道实现。
- public abstract AbstractSelector openSelector(): 创建和这个操作系统匹配的NIO选择器,就像上文所述,不同的操作系统,不同的版本所默认支持的NIO模型是不一样的。
- public abstract ServerSocketChannel openServerSocketChannel(): 创建和这个NIO模型匹配的服务器端通道。
- public abstract SocketChannel openSocketChannel(): 创建和这个NIO模型匹配的TCP Socket套接字通道(用来反映客户端的TCP连接)
由于JAVA NIO框架的整个设计是很大的,所以我们只能还原一部分我们关心的问题。这里我们以JAVA NIO框架中对于不同多路复用IO技术的选择器 进行实例化创建的方式作为例子,以点窥豹观全局:
很明显,不同的SelectorProvider实现对应了不同的 选择器。由具体的SelectorProvider实现进行创建。另外说明一下,实际上netty底层也是通过这个设计获得具体使用的NIO模型,我们后文讲解Netty时,会讲到这个问题。以下代码是Netty 4.0中NioServerSocketChannel进行实例化时的核心代码片段:
private static ServerSocketChannel newSocket(SelectorProvider provider) {
try {
/**
* Use the {@link SelectorProvider} to open {@link SocketChannel} and so remove condition in
* {@link SelectorProvider#provider()} which is called by each ServerSocketChannel.open() otherwise.
*
* See <a href="See https://github.com/netty/netty/issues/2308">#2308</a>.
*/
return provider.openServerSocketChannel();
} catch (IOException e) {
throw new ChannelException(
"Failed to open a server socket.", e);
}
}
多路复用IO的优缺点
不用再使用多线程来进行IO处理了(包括操作系统内核IO管理模块和应用程序进程而言)。当然实际业务的处理中,应用程序进程还是可以引入线程池技术的
同一个端口可以处理多种协议,例如,使用ServerSocketChannel测测的服务器端口监听,既可以处理TCP协议又可以处理UDP协议。
操作系统级别的优化: 多路复用IO技术可以是操作系统级别在一个端口上能够同时接受多个客户端的IO事件。同时具有之前我们讲到的阻塞式同步IO和非阻塞式同步IO的所有特点。Selector的一部分作用更相当于“轮询代理器”。
都是同步IO: 目前我们介绍的 阻塞式IO、非阻塞式IO甚至包括多路复用IO,这些都是基于操作系统级别对“同步IO”的实现。我们一直在说“同步IO”,一直都没有详细说,什么叫做“同步IO”。实际上一句话就可以说清楚: 只有上层(包括上层的某种代理机制)系统询问我是否有某个事件发生了,否则我不会主动告诉上层系统事件发生了。
4.11 - CH11-AIO原理
异步IO
上面两篇文章中,我们分别讲解了阻塞式同步IO、非阻塞式同步IO、多路复用IO 这三种IO模型,以及JAVA对于这三种IO模型的支持。重点说明了IO模型是由操作系统提供支持,且这三种IO模型都是同步IO,都是采用的“应用程序不询问我,我绝不会主动通知”的方式。
异步IO则是采用“订阅-通知”模式: 即应用程序向操作系统注册IO监听,然后继续做自己的事情。当操作系统发生IO事件,并且准备好数据后,在主动通知应用程序,触发相应的函数:
和同步IO一样,异步IO也是由操作系统进行支持的。微软的windows系统提供了一种异步IO技术: IOCP(I/O Completion Port,I/O完成端口);
Linux下由于没有这种异步IO技术,所以使用的是epoll(上文介绍过的一种多路复用IO技术的实现)对异步IO进行模拟。
JAVA AIO框架简析
这里通过这个结构分析要告诉各位读者JAVA AIO中类设计和操作系统的相关性
在文中我们一再说明JAVA AIO框架在windows下使用windows IOCP技术,在Linux下使用epoll多路复用IO技术模拟异步IO,这个从JAVA AIO框架的部分类设计上就可以看出来。例如框架中,在Windows下负责实现套接字通道的具体类是“sun.nio.ch.WindowsAsynchronousSocketChannelImpl”,其引用的IOCP类型文档注释如是:
/**
* Windows implementation of AsynchronousChannelGroup encapsulating an I/O
* completion port.
*/
如果您感兴趣,当然可以去看看全部完整代码(建议从“java.nio.channels.spi.AsynchronousChannelProvider”这个类看起)。
特别说明一下,请注意图中的“java.nio.channels.NetworkChannel”接口,这个接口同样被JAVA NIO框架实现了,如下图所示:
要点讲解
注意在JAVA NIO框架中,我们说到了一个重要概念“selector”(选择器)。它负责代替应用查询中所有已注册的通道到操作系统中进行IO事件轮询、管理当前注册的通道集合,定位发生事件的通道等操操作;但是在JAVA AIO框架中,由于应用程序不是“轮询”方式,而是订阅-通知方式,所以不再需要“selector”(选择器)了,改由channel通道直接到操作系统注册监听。
JAVA AIO框架中,只实现了两种网络IO通道“AsynchronousServerSocketChannel”(服务器监听通道)、“AsynchronousSocketChannel”(socket套接字通道)。但是无论哪种通道他们都有独立的fileDescriptor(文件标识符)、attachment(附件,附件可以使任意对象,类似“通道上下文”),并被独立的SocketChannelReadHandle类实例引用。我们通过debug操作来看看它们的引用结构:
在测试过程中,我们启动了两个客户端(客户端用什么语言来写都行,用阻塞或者非阻塞方式也都行,只要是支持 TCP Socket套接字的就行,然后我们观察服务器端对这两个客户端通道的处理情况:
可以看到,在服务器端分别为客户端1和客户端2创建的两个WindowsAsynchronousSocketChannelImpl对象为:
客户端1: WindowsAsynchronousSocketChannelImpl: 760 | FileDescriptor: 762
客户端2: WindowsAsynchronousSocketChannelImpl: 792 | FileDescriptor: 797
接下来,我们让两个客户端发送信息到服务器端,并观察服务器端的处理情况。客户端1发来的消息和客户端2发来的消息,在服务器端的处理情况如下图所示:
客户端1: WindowsAsynchronousSocketChannelImpl: 760 | FileDescriptor: 762 | SocketChannelReadHandle: 803 | HeapByteBuffer: 808
客户端2: WindowsAsynchronousSocketChannelImpl: 792 | FileDescriptor: 797 | SocketChannelReadHandle: 828 | HeapByteBuffer: 833
可以明显看到,服务器端处理每一个客户端通道所使用的SocketChannelReadHandle(处理器)对象都是独立的,并且所引用的SocketChannel对象都是独立的。
JAVA NIO和JAVA AIO框架,除了因为操作系统的实现不一样而去掉了Selector外,其他的重要概念都是存在的,例如上文中提到的Channel的概念,还有演示代码中使用的Buffer缓存方式。实际上JAVA NIO和JAVA AIO框架您可以看成是一套完整的“高并发IO处理”的实现。
还有改进可能
当然,以上代码是示例代码,目标是为了让您了解JAVA AIO框架的基本使用。所以它还有很多改造的空间,例如:
在生产环境下,我们需要记录这个通道上“用户的登录信息”。那么这个需求可以使用JAVA AIO中的“附件”功能进行实现。
记住JAVA AIO 和 JAVA NIO 框架都是要使用线程池的(当然您也可以不用),线程池的使用原则,一定是只有业务处理部分才使用,使用后马上结束线程的执行(还回线程池或者消灭它)。JAVA AIO框架中还有一个线程池,是拿给“通知处理器”使用的,这是因为JAVA AIO框架是基于“订阅-通知”模型的,“订阅”操作可以由主线程完成,但是您总不能要求在应用程序中并发的“通知”操作也在主线程上完成吧^_^。
最好的改进方式,当然就是使用Netty或者Mina咯
为什么还有Netty
- 那么有的读者可能就会问,既然JAVA NIO / JAVA AIO已经实现了各主流操作系统的底层支持,那么为什么现在主流的JAVA NIO技术会是Netty和MINA呢? 答案很简单: 因为更好用,这里举几个方面的例子:
- 虽然JAVA NIO 和 JAVA AIO框架提供了 多路复用IO/异步IO的支持,但是并没有提供上层“信息格式”的良好封装。例如前两者并没有提供针对 Protocol Buffer、JSON这些信息格式的封装,但是Netty框架提供了这些数据格式封装(基于责任链模式的编码和解码功能)
- 要编写一个可靠的、易维护的、高性能的(注意它们的排序)NIO/AIO 服务器应用。除了框架本身要兼容实现各类操作系统的实现外。更重要的是它应该还要处理很多上层特有服务,例如: 客户端的权限、还有上面提到的信息格式封装、简单的数据读取。这些Netty框架都提供了响应的支持。
- JAVA NIO框架存在一个poll/epoll bug: Selector doesn’t block on Selector.select(timeout),不能block意味着CPU的使用率会变成100%(这是底层JNI的问题,上层要处理这个异常实际上也好办)。当然这个bug只有在Linux内核上才能重现。
- 这个问题在JDK 1.7版本中还没有被完全解决: http://bugs.java.com/bugdatabase/view_bug.do?bug_id=2147719。虽然Netty 4.0中也是基于JAVA NIO框架进行封装的(上文中已经给出了Netty中NioServerSocketChannel类的介绍),但是Netty已经将这个bug进行了处理。
4.12 - CH12-零拷贝
CPU 并不执行将数据从一个存储区域拷贝到另一个存储区域这样的任务。通常用于在网络传输文件时节省 CPU 周期和内存带宽。
缓存 IO
缓存 IO 又被称为标准 IO,大多数文件系统的默认 IO 操作都是缓存 IO。在 Linux 的缓存 IO 机制中,操作系统会将 IO 的数据缓存在文件系统的页缓存(page cache)中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
缓存 IO 的缺点:数据在传输过程中需要在应用程序地址空间和内核间进行多次数据复制操作,这些数据复制所带来的 CPU 及内存开销是非常大的。
零拷贝技术分类
零拷贝技术的发展很多样化,现有的零拷贝技术种类也非常多,而当前并没有一个适合于所有场景的零拷贝技术出现。对于 Linux 来说,现有的零拷贝技术也比较多,这些零拷贝技术大部分存在于不同的 Linux 内核版本,有些旧的技术在不同的 Linux 内核版本间得到了很大的发展或者已经渐渐被新的技术所代替。
本文针对这些零拷贝技术所适用的不同场景对它们进行了划分。概括起来,Linux 中的零拷贝技术主要有下面这几种:
- 直接 I/O:对于这种数据传输方式来说,应用程序可以直接访问硬件存储,操作系统内核只是辅助数据传输:这类零拷贝技术针对的是操作系统内核并不需要对数据进行直接处理的情况,数据可以在应用程序地址空间的缓冲区和磁盘之间直接进行传输,完全不需要 Linux 操作系统内核提供的页缓存的支持。
- 在数据传输的过程中,避免数据在操作系统内核地址空间的缓冲区和用户应用程序地址空间的缓冲区之间进行拷贝。有的时候,应用程序在数据进行传输的过程中不需要对数据进行访问,那么,将数据从 Linux 的页缓存拷贝到用户进程的缓冲区中就可以完全避免,传输的数据在页缓存中就可以得到处理。在某些特殊的情况下,这种零拷贝技术可以获得较好的性能。Linux 中提供类似的系统调用主要有 mmap(),sendfile() 以及 splice()。
- 对数据在 Linux 的页缓存和用户进程的缓冲区之间的传输过程进行优化。该零拷贝技术侧重于灵活地处理数据在用户进程的缓冲区和操作系统的页缓存之间的拷贝操作。这种方法延续了传统的通信方式,但是更加灵活。在Linux 中,该方法主要利用了写时复制技术。
前两类方法的目的主要是为了避免应用程序地址空间和操作系统内核地址空间这两者之间的缓冲区拷贝操作。这两类零拷贝技术通常适用在某些特殊的情况下,比如要传送的数据不需要经过操作系统内核的处理或者不需要经过应用程序的处理。第三类方法则继承了传统的应用程序地址空间和操作系统内核地址空间之间数据传输的概念,进而针对数据传输本身进行优化。我们知道,硬件和软件之间的数据传输可以通过使用 DMA 来进行,DMA 进行数据传输的过程中几乎不需要CPU参与,这样就可以把 CPU 解放出来去做更多其他的事情,但是当数据需要在用户地址空间的缓冲区和 Linux 操作系统内核的页缓存之间进行传输的时候,并没有类似DMA 这种工具可以使用,CPU 需要全程参与到这种数据拷贝操作中,所以这第三类方法的目的是可以有效地改善数据在用户地址空间和操作系统内核地址空间之间传递的效率。
当应用程序访问某块数据时,操作系统首先会检查,是不是最近访问过此文件,文件内容是否缓存在内核缓冲区,如果是,操作系统则直接根据read系统调用提供的buf地址,将内核缓冲区的内容拷贝到buf所指定的用户空间缓冲区中去。如果不是,操作系统则首先将磁盘上的数据拷贝的内核缓冲区,这一步目前主要依靠DMA来传输,然后再把内核缓冲区上的内容拷贝到用户缓冲区中。 接下来,write系统调用再把用户缓冲区的内容拷贝到网络堆栈相关的内核缓冲区中,最后socket再把内核缓冲区的内容发送到网卡上。
从上图中可以看出,共产生了四次数据拷贝,即使使用了DMA来处理了与硬件的通讯,CPU仍然需要处理两次数据拷贝,与此同时,在用户态与内核态也发生了多次上下文切换,无疑也加重了CPU负担。
在此过程中,我们没有对文件内容做任何修改,那么在内核空间和用户空间来回拷贝数据无疑就是一种浪费,而零拷贝主要就是为了解决这种低效性。
mmap:让数据传输不需要经过user space
我们减少拷贝次数的一种方法是调用mmap()来代替read调用:
buf = mmap(diskfd, len);
write(sockfd, buf, len);
应用程序调用 mmap(),磁盘上的数据会通过 DMA被拷贝的内核缓冲区,接着操作系统会把这段内核缓冲区与应用程序共享,这样就不需要把内核缓冲区的内容往用户空间拷贝。应用程序再调用 write(),操作系统直接将内核缓冲区的内容拷贝到 socket缓冲区中,这一切都发生在内核态,最后, socket缓冲区再把数据发到网卡去。
如下图:
使用mmap替代read很明显减少了一次拷贝,当拷贝数据量很大时,无疑提升了效率。但是使用 mmap是有代价的。当你使用 mmap时,你可能会遇到一些隐藏的陷阱。例如,当你的程序 map了一个文件,但是当这个文件被另一个进程截断(truncate)时, write系统调用会因为访问非法地址而被 SIGBUS信号终止。 SIGBUS信号默认会杀死你的进程并产生一个 coredump,如果你的服务器这样被中止了,那会产生一笔损失。
通常我们使用以下解决方案避免这种问题:
- 为SIGBUS信号建立信号处理程序:当遇到 SIGBUS信号时,信号处理程序简单地返回, write系统调用在被中断之前会返回已经写入的字节数,并且 errno会被设置成success,但是这是一种糟糕的处理办法,因为你并没有解决问题的实质核心。
- 使用文件租借锁:通常我们使用这种方法,在文件描述符上使用租借锁,我们为文件向内核申请一个租借锁,当其它进程想要截断这个文件时,内核会向我们发送一个实时的 RT_SIGNAL_LEASE信号,告诉我们内核正在破坏你加持在文件上的读写锁。这样在程序访问非法内存并且被 SIGBUS杀死之前,你的 write系统调用会被中断。 write会返回已经写入的字节数,并且置 errno为success。 我们应该在 mmap文件之前加锁,并且在操作完文件后解锁:
if(fcntl(diskfd, F_SETSIG, RT_SIGNAL_LEASE) == -1){
perror("kernel lease set signal");
return -1;
}
/* l_type can be F_RDLCK_F_WRLCK 加锁 */
/* l_type can be F_UNLCK 解锁 */
if(fcntl(diskfd, F_SETLEASE, l_type)){
perror("kernel lease set_type");
return -1;
}
参考资料
4.13 - CH13-内存映射
内存映射文件非常特别,它允许Java程序直接从内存中读取文件内容,通过将整个或部分文件映射到内存,由操作系统来处理加载请求和写入文件,应用只需要和内存打交道,这使得IO操作非常快。加载内存映射文件所使用的内存在Java堆区之外。Java编程语言支持内存映射文件,通过java.nio包和MappedByteBuffer 可以从内存直接读写文件。
内存映射文件
内存映射文件,是由一个文件到一块内存的映射。Win32提供了允许应用程序把文件映射到一个进程的函数 (CreateFileMapping)。内存映射文件与虚拟内存有些类似,通过内存映射文件可以保留一个地址空间的区域,同时将物理存储器提交给此区域,内存文件映射的物理存储器来自一个已经存在于磁盘上的文件,而且在对该文件进行操作之前必须首先对文件进行映射。使用内存映射文件处理存储于磁盘上的文件时,将不必再对文件执行I/O操作,使得内存映射文件在处理大数据量的文件时能起到相当重要的作用。
内存映射 IO
在传统的文件IO操作中,我们都是调用操作系统提供的底层标准IO系统调用函数 read()、write() ,此时调用此函数的进程(在JAVA中即java进程)由当前的用户态切换到内核态,然后OS的内核代码负责将相应的文件数据读取到内核的IO缓冲区,然 后再把数据从内核IO缓冲区拷贝到进程的私有地址空间中去,这样便完成了一次IO操作。这么做是为了减少磁盘的IO操作,为了提高性能而考虑的,因为我们的程序访问一般都带有局部性,也就是所谓的局部性原理,在这里主要是指的空间局部性,即我们访问了文件的某一段数据,那么接下去很可能还会访问接下去的一段数据,由于磁盘IO操作的速度比直接 访问内存慢了好几个数量级,所以OS根据局部性原理会在一次 read()系统调用过程中预读更多的文件数据缓存在内核IO缓冲区中,当继续访问的文件数据在缓冲区中时便直接拷贝数据到进程私有空间,避免了再次的低 效率磁盘IO操作。其过程如下
内存映射文件和之前说的 标准IO操作最大的不同之处就在于它虽然最终也是要从磁盘读取数据,但是它并不需要将数据读取到OS内核缓冲区,而是直接将进程的用户私有地址空间中的一 部分区域与文件对象建立起映射关系,就好像直接从内存中读、写文件一样,速度当然快了。
内存映射的优缺点
内存映射IO最大的优点可能在于性能,这对于建立高频电子交易系统尤其重要。内存映射文件通常比标准通过正常IO访问文件要快。另一个巨大的优势是内存映 射IO允许加载不能直接访问的潜在巨大文件 。经验表明,内存映射IO在大文件处理方面性能更加优异。尽管它也有不足——增加了页面错误的数目。由于操作系统只将一部分文件加载到内存,如果一个请求 页面没有在内存中,它将导致页面错误。同样它可以被用来在两个进程中共享数据。
操作系统支持
大多数主流操作系统比如Windows平台,UNIX,Solaris和其他类UNIX操作系统都支持内存映射IO和64位架构,你几乎可以将所有文件映射到内存并通过JAVA编程语言直接访问。
Java 内存映射 IO 的要点
- java通过java.nio包来支持内存映射IO。
- 内存映射文件主要用于性能敏感的应用,例如高频电子交易平台。
- 通过使用内存映射IO,你可以将大文件加载到内存。
- 内存映射文件可能导致页面请求错误,如果请求页面不在内存中的话。
- 映射文件区域的能力取决于于内存寻址的大小。在32位机器中,你不能访问超过4GB或2 ^ 32(以上的文件)。
- 内存映射IO比起Java中的IO流要快的多。
- 加载文件所使用的内存是Java堆区之外,并驻留共享内存,允许两个不同进程共享文件。
- 内存映射文件读写由操作系统完成,所以即使在将内容写入内存后java程序崩溃了,它将仍然会将它写入文件直到操作系统恢复。
- 出于性能考虑,推荐使用直接字节缓冲而不是非直接缓冲。
- 不要频繁调用MappedByteBuffer.force()方法,这个方法意味着强制操作系统将内存中的内容写入磁盘,所以如果你每次写入内存映射文件都调用force()方法,你将不会体会到使用映射字节缓冲的好处,相反,它(的性能)将类似于磁盘IO的性能。
- 万一发生了电源故障或主机故障,将会有很小的机率发生内存映射文件没有写入到磁盘,这意味着你可能会丢失关键数据。
public static void readFile3(String path) {
long start = System.currentTimeMillis();//开始时间
long fileLength = 0;
final int BUFFER_SIZE = 0x300000;// 3M的缓冲
File file = new File(path);
fileLength = file.length();
try {
MappedByteBuffer inputBuffer = new RandomAccessFile(file, "r").getChannel().map(FileChannel.MapMode.READ_ONLY, 0, fileLength);// 读取大文件
byte[] dst = new byte[BUFFER_SIZE];// 每次读出3M的内容
for (int offset = 0; offset < fileLength; offset += BUFFER_SIZE) {
if (fileLength - offset >= BUFFER_SIZE) {
for (int i = 0; i < BUFFER_SIZE; i++)
dst[i] = inputBuffer.get(offset + i);
} else {
for (int i = 0; i < fileLength - offset; i++)
dst[i] = inputBuffer.get(offset + i);
}
// 将得到的3M内容给Scanner,这里的XXX是指Scanner解析的分隔符
Scanner scan = new Scanner(new ByteArrayInputStream(dst)).useDelimiter(" ");
while (scan.hasNext()) {
// 这里为对读取文本解析的方法
System.out.print(scan.next() + " ");
}
scan.close();
}
System.out.println();
long end = System.currentTimeMillis();//结束时间
System.out.println("NIO 内存映射读大文件,总共耗时:"+(end - start)+"ms");
} catch (Exception e) {
e.printStackTrace();
}
}
5 - Java Effective
6 - Java Debug
6.1 - 内存溢出
Heap 堆内存溢出
在 Java 堆内存中要不断的创建对象,如果 GC-Roots 到对象之间存在引用链,JVM 就不会回收对象。
如果将 -Xms 和 -Xmx (最小堆和最大堆)设置为一样的值,就会禁止 JVM 自动扩展堆内存。
当使用一个 while(true) 循环来不断创建对象就会发生 OMM 异常,还可以使用 -XX:+HeapDumpOutofMemoryError 在发生 OOM 时自动将堆栈信息 dump 到文件中,以便排查分析。
public static void main(String[] args) {
List<String> list = new ArrayList<>(10) ;
while (true){
list.add("1") ;
}
}
当出现 OOM 时可以通过工具来分析 GC-Roots ,查看对象和 GC-Roots 是如何进行关联的,是否存在对象的生命周期过长,或者是这些对象确实改存在的,那就要考虑将堆内存调大了。
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3210)
at java.util.Arrays.copyOf(Arrays.java:3181)
at java.util.ArrayList.grow(ArrayList.java:261)
at java.util.ArrayList.ensureExplicitCapacity(ArrayList.java:235)
at java.util.ArrayList.ensureCapacityInternal(ArrayList.java:227)
at java.util.ArrayList.add(ArrayList.java:458)
at com.crossoverjie.oom.HeapOOM.main(HeapOOM.java:18)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:147)
Process finished with exit code 1
java.lang.OutOfMemoryError: Java heap space表示堆内存溢出。
JDK 8 中将永久代移除,使用 MetaSpace 来保存类加载之后的类信息,字符串常量池也被移动到了堆内存之中。
PermSize 和 MaxPermSize 已经不能使用了,在 JDK8 中配置这两个参数将会发出警告。
JDK 8 中将类信息移到到了本地堆内存(Native Heap)中,将原有的永久代移动到了本地堆中成为 MetaSpace ,如果不指定该区域的大小,JVM 将会动态的调整。
可以使用 -XX:MaxMetaspaceSize=10M 来限制最大元数据。这样当不停的·创建类时将会占满该区域并出现 OOM。
public static void main(String[] args) {
while (true){
Enhancer enhancer = new Enhancer() ;
enhancer.setSuperclass(HeapOOM.class);
enhancer.setUseCache(false) ;
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
return methodProxy.invoke(o,objects) ;
}
});
enhancer.create() ;
}
}
使用 cglib 不停的创建新类,最终会抛出:
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.GeneratedMethodAccessor1.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at net.sf.cglib.core.ReflectUtils.defineClass(ReflectUtils.java:459)
at net.sf.cglib.core.AbstractClassGenerator.generate(AbstractClassGenerator.java:336)
... 11 more
Caused by: java.lang.OutOfMemoryError: Metaspace
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:763)
... 16 more
注意: 这里的 OOM 伴随的是 java.lang.OutOfMemoryError: Metaspace 也就是元数据溢出。
6.2 - 溢出分析
Thread Dump
什么是 Thread Dump
Thread Dump 是非常有用的用于诊断 Java 应用问题的工具。每一个 Java 虚拟机都有及时生成所有线程在某一点状态的 thread-dump 的能力,虽然各个 Java虚拟机打印的thread dump略有不同,但是 大多都提供了当前活动线程的快照,及 JVM 中所有 Java 线程的堆栈跟踪信息,堆栈信息一般包含完整的类名及所执行的方法,如果可能的话还有源代码的行数。
Thread Dump 特点
- 能在各种操作系统下使用;
- 能在各种Java应用服务器下使用;
- 能在生产环境下使用而不影响系统的性能;
- 能将问题直接定位到应用程序的代码行上;
Thread Dump 抓取
一般当服务器挂起,崩溃或者性能低下时,就需要抓取服务器的线程堆栈(Thread Dump)用于后续的分析。在实际运行中,往往一次 dump的信息,还不足以确认问题。为了反映线程状态的动态变化,需要接连多次做thread dump,每次间隔10-20s,建议至少产生三次 dump信息,如果每次 dump都指向同一个问题,我们才确定问题的典型性。
系统命令获取 ThreadDump
ps –ef | grep java
kill -3 <pid>
注意:kill -9 命令会杀死进程。
JVM 自带工具获取 ThreadDump
jps 或 ps –ef | grep java (获取PID)
jstack [-l ] <pid> | tee -a jstack.log(获取ThreadDump)
Thread Dump 分析
头部信息:时间,JVM信息
2011-11-02 19:05:06
Full thread dump Java HotSpot(TM) Server VM (16.3-b01 mixed mode):
线程 INFO 信息
1. "Timer-0" daemon prio=10 tid=0xac190c00 nid=0xaef in Object.wait() [0xae77d000]
# 线程名称:Timer-0;线程类型:daemon;优先级: 10,默认是5;
# JVM线程id:tid=0xac190c00,JVM内部线程的唯一标识(通过java.lang.Thread.getId()获取,通常用自增方式实现)。
# 对应系统线程id(NativeThread ID):nid=0xaef,和top命令查看的线程pid对应,不过一个是10进制,一个是16进制。(通过命令:top -H -p pid,可以查看该进程的所有线程信息)
# 线程状态:in Object.wait();
# 起始栈地址:[0xae77d000],对象的内存地址,通过JVM内存查看工具,能够看出线程是在哪儿个对象上等待;
2. java.lang.Thread.State: TIMED_WAITING (on object monitor)
3. at java.lang.Object.wait(Native Method)
4. -waiting on <0xb3885f60> (a java.util.TaskQueue) # 继续wait
5. at java.util.TimerThread.mainLoop(Timer.java:509)
6. -locked <0xb3885f60> (a java.util.TaskQueue) # 已经locked
7. at java.util.TimerThread.run(Timer.java:462)
Java thread statck trace:是上面2-7行的信息。到目前为止这是最重要的数据,Java stack trace提供了大部分信息来精确定位问题根源。
Thread Stack Trace
堆栈信息应该逆向解读:程序先执行的是第7行,然后是第6行,依次类推。
- locked <0xb3885f60> (a java.util.ArrayList)
- waiting on <0xb3885f60> (a java.util.ArrayList)
也就是说对象先上锁,锁住对象0xb3885f60,然后释放该对象锁,进入waiting状态。为啥会出现这样的情况呢?看看下面的java代码示例,就会明白:
synchronized(obj) {
.........
obj.wait();
.........
}
如上,线程的执行过程,先用 synchronized 获得了这个对象的 Monitor(对应于 locked <0xb3885f60> )。当执行到 obj.wait(),线程即放弃了 Monitor的所有权,进入 “wait set”队列(对应于 waiting on <0xb3885f60> )。
在堆栈的第一行信息中,进一步标明了线程在代码级的状态,例如:
java.lang.Thread.State: TIMED_WAITING (parking)
解释如下:
|blocked|
> This thread tried to enter asynchronized block, but the lock was taken by another thread. This thread isblocked until the lock gets released.
|blocked (on thin lock)|
> This is the same state asblocked, but the lock in question is a thin lock.
|waiting|
> This thread calledObject.wait() on an object. The thread will remain there until some otherthread sends a notification to that object.
|sleeping|
> This thread calledjava.lang.Thread.sleep().
|parked|
> This thread calledjava.util.concurrent.locks.LockSupport.park().
|suspended|
> The thread's execution wassuspended by java.lang.Thread.suspend() or a JVMTI agent call.
Thread State
线程的状态是一个很重要的东西,因此thread dump中会显示这些状态,通过对这些状态的分析,能够得出线程的运行状况,进而发现可能存在的问题。线程的状态在Thread.State这个枚举类型中定义:
public enum State {
/**
* Thread state for a thread which has not yet started.
*/
NEW,
/**
* Thread state for a runnable thread. A thread in the runnable
* state is executing in the Java virtual machine but it may
* be waiting for other resources from the operating system
* such as processor.
*/
RUNNABLE,
/**
* Thread state for a thread blocked waiting for a monitor lock.
* A thread in the blocked state is waiting for a monitor lock
* to enter a synchronized block/method or
* reenter a synchronized block/method after calling
* {@link Object#wait() Object.wait}.
*/
BLOCKED,
/**
* Thread state for a waiting thread.
* A thread is in the waiting state due to calling one of the
* following methods:
* <ul>
* <li>{@link Object#wait() Object.wait} with no timeout</li>
* <li>{@link #join() Thread.join} with no timeout</li>
* <li>{@link LockSupport#park() LockSupport.park}</li>
* </ul>
*
* <p>A thread in the waiting state is waiting for another thread to
* perform a particular action.
*
* For example, a thread that has called <tt>Object.wait()</tt>
* on an object is waiting for another thread to call
* <tt>Object.notify()</tt> or <tt>Object.notifyAll()</tt> on
* that object. A thread that has called <tt>Thread.join()</tt>
* is waiting for a specified thread to terminate.
*/
WAITING,
/**
* Thread state for a waiting thread with a specified waiting time.
* A thread is in the timed waiting state due to calling one of
* the following methods with a specified positive waiting time:
* <ul>
* <li>{@link #sleep Thread.sleep}</li>
* <li>{@link Object#wait(long) Object.wait} with timeout</li>
* <li>{@link #join(long) Thread.join} with timeout</li>
* <li>{@link LockSupport#parkNanos LockSupport.parkNanos}</li>
* <li>{@link LockSupport#parkUntil LockSupport.parkUntil}</li>
* </ul>
*/
TIMED_WAITING,
/**
* Thread state for a terminated thread.
* The thread has completed execution.
*/
TERMINATED;
}
NEW:
- 每一个线程,在堆内存中都有一个对应的Thread对象。Thread t = new Thread();当刚刚在堆内存中创建Thread对象,还没有调用t.start()方法之前,线程就处在NEW状态。在这个状态上,线程与普通的java对象没有什么区别,就仅仅是一个堆内存中的对象。
RUNNABLE:
- 该状态表示线程具备所有运行条件,在运行队列中准备操作系统的调度,或者正在运行。 这个状态的线程比较正常,但如果线程长时间停留在在这个状态就不正常了,这说明线程运行的时间很长(存在性能问题),或者是线程一直得不得执行的机会(存在线程饥饿的问题)。
BLOCKED:
- 线程正在等待获取java对象的监视器(也叫内置锁),即线程正在等待进入由synchronized保护的方法或者代码块。synchronized用来保证原子性,任意时刻最多只能由一个线程进入该临界区域,其他线程只能排队等待。
WAITING:
- 处在该线程的状态,正在等待某个事件的发生,只有特定的条件满足,才能获得执行机会。而产生这个特定的事件,通常都是另一个线程。也就是说,如果不发生特定的事件,那么处在该状态的线程一直等待,不能获取执行的机会。比如:
- A线程调用了obj对象的obj.wait()方法,如果没有线程调用obj.notify或obj.notifyAll,那么A线程就没有办法恢复运行; 如果A线程调用了LockSupport.park(),没有别的线程调用LockSupport.unpark(A),那么A没有办法恢复运行。 TIMED_WAITING:
- J.U.C中很多与线程相关类,都提供了限时版本和不限时版本的API。TIMED_WAITING意味着线程调用了限时版本的API,正在等待时间流逝。当等待时间过去后,线程一样可以恢复运行。如果线程进入了WAITING状态,一定要特定的事件发生才能恢复运行;而处在TIMED_WAITING的线程,如果特定的事件发生或者是时间流逝完毕,都会恢复运行。
TERMINATED:
- 线程执行完毕,执行完run方法正常返回,或者抛出了运行时异常而结束,线程都会停留在这个状态。这个时候线程只剩下Thread对象了,没有什么用了。
关键状态分析
Wait on condition:
The thread is either sleeping or waiting to be notified by another thread.
该状态说明它在等待另一个条件的发生,来把自己唤醒,或者干脆它是调用了 sleep(n)。
此时线程状态大致为以下几种:
java.lang.Thread.State: WAITING (parking):一直等那个条件发生;
java.lang.Thread.State: TIMED_WAITING (parking或sleeping):定时的,那个条件不到来,也将定时唤醒自己。
Waiting for Monitor Entry 和 in Object.wait():
The thread is waiting to get the lock for an object (some other thread may be holding the lock). This happens if two or more threads try to execute synchronized code. Note that the lock is always for an object and not for individual methods.
在多线程的JAVA程序中,实现线程之间的同步,就要说说 Monitor。Monitor是Java中用以实现线程之间的互斥与协作的主要手段,它可以看成是对象或者Class的锁。每一个对象都有,也仅有一个 Monitor 。下面这个图,描述了线程和 Monitor之间关系,以及线程的状态转换图:
如上图,每个Monitor在某个时刻,只能被一个线程拥有,该线程就是 “ActiveThread”,而其它线程都是 “Waiting Thread”,分别在两个队列“Entry Set”和“Wait Set”里等候。在“Entry Set”中等待的线程状态是“Waiting for monitor entry”,而在“Wait Set”中等待的线程状态是“in Object.wait()”。
先看“Entry Set”里面的线程。我们称被 synchronized保护起来的代码段为临界区。当一个线程申请进入临界区时,它就进入了“Entry Set”队列。对应的 code就像:
synchronized(obj) {
.........
}
这时有两种可能性:
- 该 monitor不被其它线程拥有, Entry Set 里面也没有其它等待线程。本线程即成为相应类或者对象的 Monitor的 Owner,执行临界区的代码。
- 该 monitor被其它线程拥有,本线程在 Entry Set 队列中等待。
在第一种情况下,线程将处于 “Runnable”的状态,而第二种情况下,线程 DUMP 会显示处于 “waiting for monitor entry”。如下:
"Thread-0" prio=10 tid=0x08222eb0 nid=0x9 waiting for monitor entry [0xf927b000..0xf927bdb8]
at testthread.WaitThread.run(WaitThread.java:39)
- waiting to lock <0xef63bf08> (a java.lang.Object)
- locked <0xef63beb8> (a java.util.ArrayList)
at java.lang.Thread.run(Thread.java:595)
临界区的设置,是为了保证其内部的代码执行的原子性和完整性。但是因为临界区在任何时间只允许线程串行通过,这和我们多线程的程序的初衷是相反的。如果在多线程的程序中,大量使用 synchronized,或者不适当的使用了它,会造成大量线程在临界区的入口等待,造成系统的性能大幅下降。如果在线程 DUMP中发现了这个情况,应该审查源码,改进程序。
再看“Wait Set”里面的线程。当线程获得了 Monitor,进入了临界区之后,如果发现线程继续运行的条件没有满足,它则调用对象(一般就是被 synchronized 的对象)的 wait() 方法,放弃 Monitor,进入 “Wait Set”队列。只有当别的线程在该对象上调用了 notify() 或者 notifyAll(),“Wait Set”队列中线程才得到机会去竞争,但是只有一个线程获得对象的Monitor,恢复到运行态。在 “Wait Set”中的线程, DUMP中表现为: in Object.wait()。如下:
"Thread-1" prio=10 tid=0x08223250 nid=0xa in Object.wait() [0xef47a000..0xef47aa38]
at java.lang.Object.wait(Native Method)
- waiting on <0xef63beb8> (a java.util.ArrayList)
at java.lang.Object.wait(Object.java:474)
at testthread.MyWaitThread.run(MyWaitThread.java:40)
- locked <0xef63beb8> (a java.util.ArrayList)
at java.lang.Thread.run(Thread.java:595)
综上,一般CPU很忙时,则关注runnable的线程,CPU很闲时,则关注waiting for monitor entry的线程。
上面提到如果 synchronized和 monitor机制运用不当,可能会造成多线程程序的性能问题。在 JDK 5.0中,引入了 Lock 机制,从而使开发者能更灵活的开发高性能的并发多线程程序,可以替代以往 JDK中的 synchronized和 Monitor的 机制。但是,要注意的是,因为 Lock类只是一个普通类,JVM无从得知 Lock对象的占用情况,所以在线程 DUMP中,也不会包含关于 Lock的信息, 关于死锁等问题,就不如用 synchronized的编程方式容易识别。
关键状态示例
显示BLOCKED状态
public class BlockedState {
private static Object object = new Object();
public static void main(String[] args)
{
Runnable task = new Runnable() {
@Override
public void run()
{
synchronized (object)
{
long begin = System.currentTimeMillis();
long end = System.currentTimeMillis();
// 让线程运行5分钟,会一直持有object的监视器
while ((end - begin) <= 5 * 60 * 1000)
{
}
}
}
};
new Thread(task, "t1").start();
new Thread(task, "t2").start();
}
}
先获取object的线程会执行5分钟,这5分钟内会一直持有object的监视器,另一个线程无法执行处在BLOCKED状态:
Full thread dump Java HotSpot(TM) Server VM (20.12-b01 mixed mode):
"DestroyJavaVM" prio=6 tid=0x00856c00 nid=0x1314 waiting on condition [0x00000000]
java.lang.Thread.State: RUNNABLE
"t2" prio=6 tid=0x27d7a800 nid=0x1350 waiting for monitor entry [0x2833f000]
java.lang.Thread.State: BLOCKED (on object monitor)
at jstack.BlockedState$1.run(BlockedState.java:17)
- waiting to lock <0x1cfcdc00> (a java.lang.Object)
at java.lang.Thread.run(Thread.java:662)
"t1" prio=6 tid=0x27d79400 nid=0x1338 runnable [0x282ef000]
java.lang.Thread.State: RUNNABLE
at jstack.BlockedState$1.run(BlockedState.java:22)
- locked <0x1cfcdc00> (a java.lang.Object)
at java.lang.Thread.run(Thread.java:662)
通过thread dump可以看到:t2线程确实处在BLOCKED (on object monitor)。waiting for monitor entry 等待进入synchronized保护的区域。
显示WAITING状态
package jstack;
public class WaitingState
{
private static Object object = new Object();
public static void main(String[] args)
{
Runnable task = new Runnable() {
@Override
public void run()
{
synchronized (object)
{
long begin = System.currentTimeMillis();
long end = System.currentTimeMillis();
// 让线程运行5分钟,会一直持有object的监视器
while ((end - begin) <= 5 * 60 * 1000)
{
try
{
// 进入等待的同时,会进入释放监视器
object.wait();
} catch (InterruptedException e)
{
e.printStackTrace();
}
}
}
}
};
new Thread(task, "t1").start();
new Thread(task, "t2").start();
}
}
Full thread dump Java HotSpot(TM) Server VM (20.12-b01 mixed mode):
"DestroyJavaVM" prio=6 tid=0x00856c00 nid=0x1734 waiting on condition [0x00000000]
java.lang.Thread.State: RUNNABLE
"t2" prio=6 tid=0x27d7e000 nid=0x17f4 in Object.wait() [0x2833f000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
- waiting on <0x1cfcdc00> (a java.lang.Object)
at java.lang.Object.wait(Object.java:485)
at jstack.WaitingState$1.run(WaitingState.java:26)
- locked <0x1cfcdc00> (a java.lang.Object)
at java.lang.Thread.run(Thread.java:662)
"t1" prio=6 tid=0x27d7d400 nid=0x17f0 in Object.wait() [0x282ef000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
- waiting on <0x1cfcdc00> (a java.lang.Object)
at java.lang.Object.wait(Object.java:485)
at jstack.WaitingState$1.run(WaitingState.java:26)
- locked <0x1cfcdc00> (a java.lang.Object)
at java.lang.Thread.run(Thread.java:662)
可以发现t1和t2都处在WAITING (on object monitor),进入等待状态的原因是调用了in Object.wait()。通过J.U.C包下的锁和条件队列,也是这个效果,大家可以自己实践下。
显示TIMED_WAITING状态
package jstack;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class TimedWaitingState
{
// java的显示锁,类似java对象内置的监视器
private static Lock lock = new ReentrantLock();
// 锁关联的条件队列(类似于object.wait)
private static Condition condition = lock.newCondition();
public static void main(String[] args)
{
Runnable task = new Runnable() {
@Override
public void run()
{
// 加锁,进入临界区
lock.lock();
try
{
condition.await(5, TimeUnit.MINUTES);
} catch (InterruptedException e)
{
e.printStackTrace();
}
// 解锁,退出临界区
lock.unlock();
}
};
new Thread(task, "t1").start();
new Thread(task, "t2").start();
}
}
Full thread dump Java HotSpot(TM) Server VM (20.12-b01 mixed mode):
"DestroyJavaVM" prio=6 tid=0x00856c00 nid=0x169c waiting on condition [0x00000000]
java.lang.Thread.State: RUNNABLE
"t2" prio=6 tid=0x27d7d800 nid=0xc30 waiting on condition [0x2833f000]
java.lang.Thread.State: TIMED_WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x1cfce5b8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:196)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2116)
at jstack.TimedWaitingState$1.run(TimedWaitingState.java:28)
at java.lang.Thread.run(Thread.java:662)
"t1" prio=6 tid=0x280d0c00 nid=0x16e0 waiting on condition [0x282ef000]
java.lang.Thread.State: TIMED_WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x1cfce5b8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:196)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2116)
at jstack.TimedWaitingState$1.run(TimedWaitingState.java:28)
at java.lang.Thread.run(Thread.java:662)
可以看到t1和t2线程都处在java.lang.Thread.State: TIMED_WAITING (parking),这个parking代表是调用的JUC下的工具类,而不是java默认的监视器。
重要线程
Attach Listener Attach Listener
线程是负责接收到外部的命令,而对该命令进行执行的并把结果返回给发送者。通常我们会用一些命令去要求JVM给我们一些反馈信息,如:java -version、jmap、jstack等等。 如果该线程在JVM启动的时候没有初始化,那么,则会在用户第一次执行JVM命令时,得到启动。
Signal Dispatcher
前面提到Attach Listener线程的职责是接收外部JVM命令,当命令接收成功后,会交给signal dispather线程去进行分发到各个不同的模块处理命令,并且返回处理结果。signal dispather线程也是在第一次接收外部JVM命令时,进行初始化工作。
CompilerThread0
用来调用JITing,实时编译装卸class 。 通常,JVM会启动多个线程来处理这部分工作,线程名称后面的数字也会累加,例如:CompilerThread1。
Concurrent Mark-Sweep GC Thread
并发标记清除垃圾回收器(就是通常所说的CMS GC)线程, 该线程主要针对于老年代垃圾回收。ps:启用该垃圾回收器,需要在JVM启动参数中加上:-XX:+UseConcMarkSweepGC。
DestroyJavaVM
执行main()的线程,在main执行完后调用JNI中的 jni_DestroyJavaVM() 方法唤起DestroyJavaVM 线程,处于等待状态,等待其它线程(Java线程和Native线程)退出时通知它卸载JVM。每个线程退出时,都会判断自己当前是否是整个JVM中最后一个非deamon线程,如果是,则通知DestroyJavaVM 线程卸载JVM。
Finalizer Thread
这个线程也是在main线程之后创建的,其优先级为10,主要用于在垃圾收集前,调用对象的finalize()方法;关于Finalizer线程的几点:1) 只有当开始一轮垃圾收集时,才会开始调用finalize()方法;因此并不是所有对象的finalize()方法都会被执行;2) 该线程也是daemon线程,因此如果虚拟机中没有其他非daemon线程,不管该线程有没有执行完finalize()方法,JVM也会退出;3) JVM在垃圾收集时会将失去引用的对象包装成Finalizer对象(Reference的实现),并放入ReferenceQueue,由Finalizer线程来处理;最后将该Finalizer对象的引用置为null,由垃圾收集器来回收;4) JVM为什么要单独用一个线程来执行finalize()方法呢?如果JVM的垃圾收集线程自己来做,很有可能由于在finalize()方法中误操作导致GC线程停止或不可控,这对GC线程来说是一种灾难;
Low Memory Detector
这个线程是负责对可使用内存进行检测,如果发现可用内存低,分配新的内存空间。
Reference Handler
JVM在创建main线程后就创建Reference Handler线程,其优先级最高,为10,它主要用于处理引用对象本身(软引用、弱引用、虚引用)的垃圾回收问题 。
VM Thread
JVM里面的线程母体,根据hotspot源码(vmThread.hpp)里面的注释,它是一个单个的对象(最原始的线程)会产生或触发所有其他的线程,这个单个的VM线程是会被其他线程所使用来做一些VM操作(如:清扫垃圾等)。
6.3 - Linux 命令
文本操作
文本查找 - grep
grep常用命令:
# 基本使用
grep yoursearchkeyword f.txt #文件查找
grep 'KeyWord otherKeyWord' f.txt cpf.txt #多文件查找, 含空格加引号
grep 'KeyWord' /home/admin -r -n #目录下查找所有符合关键字的文件
grep 'keyword' /home/admin -r -n -i # -i 忽略大小写
grep 'KeyWord' /home/admin -r -n --include *.{vm,java} #指定文件后缀
grep 'KeyWord' /home/admin -r -n --exclude *.{vm,java} #反匹配
# cat + grep
cat f.txt | grep -i keyword # 查找所有keyword且不分大小写
cat f.txt | grep -c 'KeyWord' # 统计Keyword次数
# seq + grep
seq 10 | grep 5 -A 3 #上匹配
seq 10 | grep 5 -B 3 #下匹配
seq 10 | grep 5 -C 3 #上下匹配,平时用这个就妥了
文本分析 - awk
awk基本命令:
# 基本使用
awk '{print $4,$6}' f.txt
awk '{print NR,$0}' f.txt cpf.txt
awk '{print FNR,$0}' f.txt cpf.txt
awk '{print FNR,FILENAME,$0}' f.txt cpf.txt
awk '{print FILENAME,"NR="NR,"FNR="FNR,"$"NF"="$NF}' f.txt cpf.txt
echo 1:2:3:4 | awk -F: '{print $1,$2,$3,$4}'
# 匹配
awk '/ldb/ {print}' f.txt #匹配ldb
awk '!/ldb/ {print}' f.txt #不匹配ldb
awk '/ldb/ && /LISTEN/ {print}' f.txt #匹配ldb和LISTEN
awk '$5 ~ /ldb/ {print}' f.txt #第五列匹配ldb
内建变量:
`NR`: NR表示从awk开始执行后,按照记录分隔符读取的数据次数,默认的记录分隔符为换行符,因此默认的就是读取的数据行数,NR可以理解为Number of Record的缩写。
`FNR`: 在awk处理多个输入文件的时候,在处理完第一个文件后,NR并不会从1开始,而是继续累加,因此就出现了FNR,每当处理一个新文件的时候,FNR就从1开始计数,FNR可以理解为File Number of Record。
`NF`: NF表示目前的记录被分割的字段的数目,NF可以理解为Number of Field。
文本处理 - sed
sed常用:
# 文本打印
sed -n '3p' xxx.log #只打印第三行
sed -n '$p' xxx.log #只打印最后一行
sed -n '3,9p' xxx.log #只查看文件的第3行到第9行
sed -n -e '3,9p' -e '=' xxx.log #打印3-9行,并显示行号
sed -n '/root/p' xxx.log #显示包含root的行
sed -n '/hhh/,/omc/p' xxx.log # 显示包含"hhh"的行到包含"omc"的行之间的行
# 文本替换
sed -i 's/root/world/g' xxx.log # 用world 替换xxx.log文件中的root; s==search 查找并替换, g==global 全部替换, -i: implace
# 文本插入
sed '1,4i hahaha' xxx.log # 在文件第一行和第四行的每行下面添加hahaha
sed -e '1i happy' -e '$a new year' xxx.log #【界面显示】在文件第一行添加happy,文件结尾添加new year
sed -i -e '1i happy' -e '$a new year' xxx.log #【真实写入文件】在文件第一行添加happy,文件结尾添加new year
# 文本删除
sed '3,9d' xxx.log # 删除第3到第9行,只是不显示而已
sed '/hhh/,/omc/d' xxx.log # 删除包含"hhh"的行到包含"omc"的行之间的行
sed '/omc/,10d' xxx.log # 删除包含"omc"的行到第十行的内容
# 与find结合
find . -name "*.txt" |xargs sed -i 's/hhhh/\hHHh/g'
find . -name "*.txt" |xargs sed -i 's#hhhh#hHHh#g'
find . -name "*.txt" -exec sed -i 's/hhhh/\hHHh/g' {} \;
find . -name "*.txt" |xargs cat
文件操作
文件监听 - tail
最常用的tail -f filename
# 基本使用
tail -f xxx.log # 循环监听文件
tail -300f xxx.log #倒数300行并追踪文件
tail +20 xxx.log #从第 20 行至文件末尾显示文件内容
# tailf使用
tailf xxx.log #等同于tail -f -n 10 打印最后10行,然后追踪文件
tail -f 与tail F 与tailf三者区别
`tail -f ` 等于--follow=descriptor,根据文件描述进行追踪,当文件改名或删除后,停止追踪。
`tail -F` 等于 --follow=name ==retry,根据文件名字进行追踪,当文件改名或删除后,保持重试,当有新的文件和他同名时,继续追踪
`tailf` 等于tail -f -n 10(tail -f或-F默认也是打印最后10行,然后追踪文件),与tail -f不同的是,如果文件不增长,它不会去访问磁盘文件,所以tailf特别适合那些便携机上跟踪日志文件,因为它减少了磁盘访问,可以省电。
tail的参数
-f 循环读取
-q 不显示处理信息
-v 显示详细的处理信息
-c<数目> 显示的字节数
-n<行数> 显示文件的尾部 n 行内容
--pid=PID 与-f合用,表示在进程ID,PID死掉之后结束
-q, --quiet, --silent 从不输出给出文件名的首部
-s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
文件查找 - find
sudo -u admin find /home/admin /tmp /usr -name \*.log(多个目录去找)
find . -iname \*.txt(大小写都匹配)
find . -type d(当前目录下的所有子目录)
find /usr -type l(当前目录下所有的符号链接)
find /usr -type l -name "z*" -ls(符号链接的详细信息 eg:inode,目录)
find /home/admin -size +250000k(超过250000k的文件,当然+改成-就是小于了)
find /home/admin f -perm 777 -exec ls -l {} \; (按照权限查询文件)
find /home/admin -atime -1 1天内访问过的文件
find /home/admin -ctime -1 1天内状态改变过的文件
find /home/admin -mtime -1 1天内修改过的文件
find /home/admin -amin -1 1分钟内访问过的文件
find /home/admin -cmin -1 1分钟内状态改变过的文件
find /home/admin -mmin -1 1分钟内修改过的文件
pgm
批量查询vm-shopbase满足条件的日志
pgm -A -f vm-shopbase 'cat /home/admin/shopbase/logs/shopbase.log.2017-01-17|grep 2069861630'
查看网络和进程
查看所有网络接口的属性
# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.31.165.194 netmask 255.255.240.0 broadcast 172.31.175.255
ether 00:16:3e:08:c1:ea txqueuelen 1000 (Ethernet)
RX packets 21213152 bytes 2812084823 (2.6 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 25264438 bytes 46566724676 (43.3 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Local Loopback)
RX packets 502 bytes 86350 (84.3 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 502 bytes 86350 (84.3 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
查看防火墙设置
# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
查看路由表
# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.31.175.253 0.0.0.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0
172.31.160.0 0.0.0.0 255.255.240.0 U 0 0 0 eth0
netstat
查看所有监听端口
# netstat -lntp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:443 0.0.0.0:* LISTEN 970/nginx: master p
tcp 0 0 0.0.0.0:9999 0.0.0.0:* LISTEN 1249/java
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 970/nginx: master p
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1547/sshd
tcp6 0 0 :::3306 :::* LISTEN 1894/mysqld
查看所有已经建立的连接
# netstat -antp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:443 0.0.0.0:* LISTEN 970/nginx: master p
tcp 0 0 0.0.0.0:9999 0.0.0.0:* LISTEN 1249/java
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 970/nginx: master p
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1547/sshd
tcp 0 0 172.31.165.194:53874 100.100.30.25:80 ESTABLISHED 18041/AliYunDun
tcp 0 64 172.31.165.194:22 xxx.194.1.200:2649 ESTABLISHED 32516/sshd: root@pt
tcp6 0 0 :::3306 :::* LISTEN 1894/m
查看当前连接
[root@pdai.tech ~]# netstat -nat|awk '{print $6}'|sort|uniq -c|sort -rn
5 LISTEN
2 ESTABLISHED
1 Foreign
1 established)
查看网络统计信息进程
# netstat -s
Ip:
21017132 total packets received
0 forwarded
0 incoming packets discarded
21017131 incoming packets delivered
25114367 requests sent out
324 dropped because of missing route
Icmp:
18088 ICMP messages received
692 input ICMP message failed.
ICMP input histogram:
destination unreachable: 4241
timeout in transit: 19
echo requests: 13791
echo replies: 4
timestamp request: 33
13825 ICMP messages sent
0 ICMP messages failed
ICMP output histogram:
destination unreachable: 1
echo replies: 13791
timestamp replies: 33
IcmpMsg:
InType0: 4
InType3: 4241
InType8: 13791
InType11: 19
InType13: 33
OutType0: 13791
OutType3: 1
OutType14: 33
Tcp:
12210 active connections openings
208820 passive connection openings
54198 failed connection attempts
9805 connection resets received
...
查看所有进程
# ps -ef | grep java
root 1249 1 0 Nov04 ? 00:58:05 java -jar /opt/tech_doc/bin/tech_arch-0.0.1-RELEASE.jar --server.port=9999
root 32718 32518 0 08:36 pts/0 00:00:00 grep --color=auto java
top
top除了看一些基本信息之外,剩下的就是配合来查询vm的各种问题了
# top -H -p pid
top - 08:37:51 up 45 days, 18:45, 1 user, load average: 0.01, 0.03, 0.05
Threads: 28 total, 0 running, 28 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.7 us, 0.7 sy, 0.0 ni, 98.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1882088 total, 74608 free, 202228 used, 1605252 buff/cache
KiB Swap: 2097148 total, 1835392 free, 261756 used. 1502036 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1347 root 20 0 2553808 113752 1024 S 0.3 6.0 48:46.74 VM Periodic Tas
1249 root 20 0 2553808 113752 1024 S 0.0 6.0 0:00.00 java
1289 root 20 0 2553808 113752 1024 S 0.0 6.0 0:03.74 java
...
查看磁盘和内存相关
查看内存使用 - free -m
[root@pdai.tech ~]# free -m
total used free shared buff/cache available
Mem: 1837 196 824 0 816 1469
Swap: 2047 255 1792
查看各分区使用情况
[root@pdai.tech ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 909M 0 909M 0% /dev
tmpfs 919M 0 919M 0% /dev/shm
tmpfs 919M 452K 919M 1% /run
tmpfs 919M 0 919M 0% /sys/fs/cgroup
/dev/vda1 40G 15G 23G 40% /
tmpfs 184M 0 184M 0% /run/user/0
查看指定目录的大小
[root@pdai.tech ~]# du -sh
803M
查看内存总量
[root@pdai.tech ~]# grep MemTotal /proc/meminfo
MemTotal: 1882088 kB
查看空闲内存量
[root@pdai.tech ~]# grep MemFree /proc/meminfo
MemFree: 74120 kB
查看系统负载磁盘和分区
[root@pdai.tech ~]# grep MemFree /proc/meminfo
MemFree: 74120 kB
查看系统负载磁盘和分区
[root@pdai.tech ~]# cat /proc/loadavg
0.01 0.04 0.05 2/174 32751
查看挂接的分区状态
[root@pdai.tech ~]# mount | column -t
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
devtmpfs on /dev type devtmpfs (rw,nosuid,size=930732k,nr_inodes=232683,mode=755)
securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime)
...
查看所有分区
# fdisk -l
Disk /dev/vda: 42.9 GB, 42949672960 bytes, 83886080 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x0008d73a
Device Boot Start End Blocks Id System
/dev/vda1 * 2048 83884031 41940992 83 Linux
查看所有交换分区
[root@pdai.tech ~]# swapon -s
Filename Type Size Used Priority
/etc/swap file 2097148 261756 -2
查看硬盘大小
[root@pdai.tech ~]# fdisk -l |grep Disk
Disk /dev/vda: 42.9 GB, 42949672960 bytes, 83886080 sectors
Disk label type: dos
Disk identifier: 0x0008d73a
查看用户和组相关
查看活动用户
# w
08:47:20 up 45 days, 18:54, 1 user, load average: 0.01, 0.03, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 xxx.194.1.200 08:32 0.00s 0.32s 0.32s -bash
查看指定用户信息
# id
uid=0(root) gid=0(root) groups=0(root)
查看用户登录日志
# last
root pts/0 xxx.194.1.200 Fri Dec 20 08:32 still logged in
root pts/0 xxx.73.164.60 Thu Dec 19 21:47 - 00:28 (02:41)
root pts/0 xxx.106.236.255 Thu Dec 19 16:00 - 18:24 (02:23)
root pts/1 xxx.194.3.173 Tue Dec 17 13:35 - 17:37 (04:01)
root pts/0 xxx.194.3.173 Tue Dec 17 13:35 - 17:37 (04:02)
...
查看系统所有用户
[root@pdai.tech ~]# cut -d: -f1 /etc/passwd
root
bin
daemon
adm
...
查看系统所有组
查看服务,模块和包相关
# 查看当前用户的计划任务服务
crontab -l
# 列出所有系统服务
chkconfig –list
# 列出所有启动的系统服务程序
chkconfig –list | grep on
# 查看所有安装的软件包
rpm -qa
# 列出加载的内核模块
lsmod
查看系统,设备,环境信息
# 常用
env # 查看环境变量资源
uptime # 查看系统运行时间、用户数、负载
lsusb -tv # 列出所有USB设备的linux系统信息命令
lspci -tv # 列出所有PCI设备
head -n 1 /etc/issue # 查看操作系统版本,是数字1不是字母L
uname -a # 查看内核/操作系统/CPU信息的linux系统信息命令
# /proc/
cat /proc/cpuinfo :查看CPU相关参数的linux系统命令
cat /proc/partitions :查看linux硬盘和分区信息的系统信息命令
cat /proc/meminfo :查看linux系统内存信息的linux系统命令
cat /proc/version :查看版本,类似uname -r
cat /proc/ioports :查看设备io端口
cat /proc/interrupts :查看中断
cat /proc/pci :查看pci设备的信息
cat /proc/swaps :查看所有swap分区的信息
cat /proc/cpuinfo |grep "model name" && cat /proc/cpuinfo |grep "physical id"
tsar
tsar是淘宝开源的的采集工具。很好用, 将历史收集到的数据持久化在磁盘上,所以我们快速来查询历史的系统数据。当然实时的应用情况也是可以查询的啦。大部分机器上都有安装。
tsar ##可以查看最近一天的各项指标
tsar --live ##可以查看实时指标,默认五秒一刷
tsar -d 20161218 ##指定查看某天的数据,貌似最多只能看四个月的数据
tsar --mem
tsar --load
tsar --cpu ##当然这个也可以和-d参数配合来查询某天的单个指标的情况
6.4 - 调试工具集
自带工具
jps
jps是jdk提供的一个查看当前java进程的小工具, 可以看做是JavaVirtual Machine Process Status Tool的缩写。
jps常用命令
jps # 显示进程的ID 和 类的名称
jps –l # 输出输出完全的包名,应用主类名,jar的完全路径名
jps –v # 输出jvm参数
jps –q # 显示java进程号
jps -m # main 方法
jps -l xxx.xxx.xx.xx # 远程查看
jps参数
-q:仅输出VM标识符,不包括classname,jar name,arguments in main method
-m:输出main method的参数
-l:输出完全的包名,应用主类名,jar的完全路径名
-v:输出jvm参数
-V:输出通过flag文件传递到JVM中的参数(.hotspotrc文件或-XX:Flags=所指定的文件
-Joption:传递参数到vm,例如:-J-Xms512m
jps原理
java程序在启动以后,会在java.io.tmpdir指定的目录下,就是临时文件夹里,生成一个类似于hsperfdata_User的文件夹,这个文件夹里(在Linux中为/tmp/hsperfdata_{userName}/),有几个文件,名字就是java进程的pid,因此列出当前运行的java进程,只是把这个目录里的文件名列一下而已。 至于系统的参数什么,就可以解析这几个文件获得。
更多请参考 jps - Java Virtual Machine Process Status Tool (opens new window)
jstack
jstack是jdk自带的线程堆栈分析工具,使用该命令可以查看或导出 Java 应用程序中线程堆栈信息。
jstack常用命令:
# 基本
jstack 2815
# java和native c/c++框架的所有栈信息
jstack -m 2815
# 额外的锁信息列表,查看是否死锁
jstack -l 2815
jstack参数:
-l 长列表. 打印关于锁的附加信息,例如属于java.util.concurrent 的 ownable synchronizers列表.
-F 当’jstack [-l] pid’没有相应的时候强制打印栈信息
-m 打印java和native c/c++框架的所有栈信息.
-h | -help 打印帮助信息
jinfo
jinfo 是 JDK 自带的命令,可以用来查看正在运行的 java 应用程序的扩展参数,包括Java System属性和JVM命令行参数;也可以动态的修改正在运行的 JVM 一些参数。当系统崩溃时,jinfo可以从core文件里面知道崩溃的Java应用程序的配置信息
jinfo常用命令:
# 输出当前 jvm 进程的全部参数和系统属性
jinfo 2815
# 输出所有的参数
jinfo -flags 2815
# 查看指定的 jvm 参数的值
jinfo -flag PrintGC 2815
# 开启/关闭指定的JVM参数
jinfo -flag +PrintGC 2815
# 设置flag的参数
jinfo -flag name=value 2815
# 输出当前 jvm 进行的全部的系统属性
jinfo -sysprops 2815
jinfo参数:
no option 输出全部的参数和系统属性
-flag name 输出对应名称的参数
-flag [+|-]name 开启或者关闭对应名称的参数
-flag name=value 设定对应名称的参数
-flags 输出全部的参数
-sysprops 输出系统属性
jmap
命令jmap是一个多功能的命令。它可以生成 java 程序的 dump 文件, 也可以查看堆内对象示例的统计信息、查看 ClassLoader 的信息以及 finalizer 队列。
两个用途
# 查看堆的情况
jmap -heap 2815
# dump
jmap -dump:live,format=b,file=/tmp/heap2.bin 2815
jmap -dump:format=b,file=/tmp/heap3.bin 2815
# 查看堆的占用
jmap -histo 2815 | head -10
jmap 参数
no option: 查看进程的内存映像信息,类似 Solaris pmap 命令。
heap: 显示Java堆详细信息
histo[:live]: 显示堆中对象的统计信息
clstats:打印类加载器信息
finalizerinfo: 显示在F-Queue队列等待Finalizer线程执行finalizer方法的对象
dump:<dump-options>:生成堆转储快照
F: 当-dump没有响应时,使用-dump或者-histo参数. 在这个模式下,live子参数无效.
help:打印帮助信息
J<flag>:指定传递给运行jmap的JVM的参数
jstat
利用JVM内建的指令对Java应用程序的资源和性能进行实时的命令行的监控,包括了对Heap size和垃圾回收状况的监控。
jstat 是用于见识虚拟机各种运行状态信息的命令行工具。它可以显示本地或者远程虚拟机进程中的类装载、内存、垃圾收集、jit编译等运行数据,它是线上定位jvm性能的首选工具。
jdb
jdb可以用来预发debug,假设你预发的java_home是/opt/java/,远程调试端口是8000.那么
出现以上代表jdb启动成功。后续可以进行设置断点进行调试。
具体参数可见oracle官方说明jdb - The Java Debugger (opens new window)
CHLSDB
CHLSDB感觉很多情况下可以看到更好玩的东西,不详细叙述了。 查询资料听说jstack和jmap等工具就是基于它的。
java -classpath /opt/taobao/java/lib/sa-jdi.jar sun.jvm.hotspot.CLHSDB
进阶工具
btrace
首当其冲的要说的是btrace。
- 查看当前谁调用了ArrayList的add方法,同时只打印当前ArrayList的size大于500的线程调用栈
@OnMethod(clazz = "java.util.ArrayList", method="add", location = @Location(value = Kind.CALL, clazz = "/./", method = "/./"))
public static void m(@ProbeClassName String probeClass, @ProbeMethodName String probeMethod, @TargetInstance Object instance, @TargetMethodOrField String method) {
if(getInt(field("java.util.ArrayList", "size"), instance) > 479){
println("check who ArrayList.add method:" + probeClass + "#" + probeMethod + ", method:" + method + ", size:" + getInt(field("java.util.ArrayList", "size"), instance));
jstack();
println();
println("===========================");
println();
}
}
@OnMethod(clazz = "com.taobao.sellerhome.transfer.biz.impl.C2CApplyerServiceImpl", method="nav", location = @Location(value = Kind.RETURN))
public static void mt(long userId, int current, int relation, String check, String redirectUrl, @Return AnyType result) {
println("parameter# userId:" + userId + ", current:" + current + ", relation:" + relation + ", check:" + check + ", redirectUrl:" + redirectUrl + ", result:" + result);
}
btrace 具体可以参考这里:https://github.com/btraceio/btrace
注意:
- 经过观察,1.3.9的release输出不稳定,要多触发几次才能看到正确的结果
- 正则表达式匹配trace类时范围一定要控制,否则极有可能出现跑满CPU导致应用卡死的情况
- 由于是字节码注入的原理,想要应用恢复到正常情况,需要重启应用。
Greys
Greys是@杜琨的大作。说几个挺棒的功能(部分功能和btrace重合):
sc -df xxx: 输出当前类的详情,包括源码位置和classloader结构trace class method: 打印出当前方法调用的耗时情况,细分到每个方法, 对排查方法性能时很有帮助。
Arthas
Arthas是基于Greys。
javOSize
就说一个功能:
classes:通过修改了字节码,改变了类的内容,即时生效。 所以可以做到快速的在某个地方打个日志看看输出,缺点是对代码的侵入性太大。但是如果自己知道自己在干嘛,的确是不错的玩意儿。
其他功能 Greys 和 btrace 都能很轻易做的到,不说了。
JProfiler
之前判断许多问题要通过JProfiler,但是现在Greys和btrace基本都能搞定了。再加上出问题的基本上都是生产环境(网络隔离),所以基本不怎么使用了,但是还是要标记一下。
dmesg
如果发现自己的java进程悄无声息的消失了,几乎没有留下任何线索,那么dmesg一发,很有可能有你想要的。
sudo dmesg|grep -i kill|less 去找关键字oom_killer。找到的结果类似如下:
[6710782.021013] java invoked oom-killer: gfp_mask=0xd0, order=0, oom_adj=0, oom_scoe_adj=0
[6710782.070639] [<ffffffff81118898>] ? oom_kill_process+0x68/0x140
[6710782.257588] Task in /LXC011175068174 killed as a result of limit of /LXC011175068174
[6710784.698347] Memory cgroup out of memory: Kill process 215701 (java) score 854 or sacrifice child
[6710784.707978] Killed process 215701, UID 679, (java) total-vm:11017300kB, anon-rss:7152432kB, file-rss:1232kB
以上表明,对应的java进程被系统的OOM Killer给干掉了,得分为854. 解释一下OOM killer(Out-Of-Memory killer),该机制会监控机器的内存资源消耗。当机器内存耗尽前,该机制会扫描所有的进程(按照一定规则计算,内存占用,时间等),挑选出得分最高的进程,然后杀死,从而保护机器。
dmesg日志时间转换公式: log实际时间=格林威治1970-01-01+(当前时间秒数-系统启动至今的秒数+dmesg打印的log时间)秒数:
date -d “1970-01-01 UTC echo "$(date +%s)-$(cat /proc/uptime|cut -f 1 -d' ')+12288812.926194"|bc seconds” 剩下的,就是看看为什么内存这么大,触发了OOM-Killer了。
Flight Recorder
是Oracle官方推出的商业环境的性能调优利器;其本身对运行期系统的侵入性很小,同时又能提供相对准确和丰富的运行期信息。
JFR本身是基于周期性对JVM虚拟机的运行状况进行采样记录的,其采样的频率可以通过其参数传入;只是需要留意的是,采样间隔越小对系统的性能干扰就越大。 和传统的JProfiler/VisualVM这些基于JMX的工具所不同的是,JFR记录的信息是近似而非精确的;当然大部分情况下这些模糊性信息就足够说明问题了。 对于大部分场景下,这些近似信息反而可以更容易发现一些真正的问题。
JEP 328: Flight Recorder (java.net)
6.5 - Java Agent
在平时的开发中,我们不可避免的会使用到Debug工具,JVM作为一个单独的进程,我们使用的Debug工具可以获取JVM运行时的相关的信息,查看变量值,甚至加入断点控制,还有我们平时使用JDK自带的JMAP、JSTACK等工具,可以在JVM运行时动态的dump内存、查询线程信息,甚至一些第三方的工具,比如说京东内部使用的JEX、pfinder,阿里巴巴的Arthas,优秀的开源的框架skywalking等等,也可以做到这些,那么这些工具究竟是通过什么技术手段来实现对JVM的监控和动态修改呢?本文会进行介绍和简单的原理分析,同时附带一些样例代码来进行分析。
从 JVMTI 说起
JVM在设计之初,就考虑到了虚拟机状态的监控、debug、线程和内存分析等功能,在 JDK5.0 之前,JVM 规范就定义了 JVMPI(Java Virtual Machine Profiler Interface)也就是 JVM 分析接口以及 JVMDI(Java Virtual Machine Debug Interface)也就是 JVM 调试接口,JDK5 以及以后的版本,这两套接口合并成了一套,也就是 Java Virtual Machine Tool Interface,就是我们这里说的 JVMTI,这里需要注意的是:
- JVMTI 是一套 JVM 的接口规范,不同的 JVM 实现方式可以不同,有的 JVM 提供了拓展性的功能,比如 openJ9,当然也可能存在 JVM 不提供这个接口的实现。
- JVMTI 提供的是 Native 方式调用的 API,也就是常说的 JNI 方式,JVMTI 接口用 C/C++ 的语言提供,最终以动态链接库的形式由 JVM 加载并运行。
使用 JNI 方式调用 JVMTI 接口访问目标虚拟机的大体过程入下图:
jvmti.h 头文件中定义了 JVMTI 接口提供的方法,但是其方法的实现是由 JVM 提供商实现的,比如说 hotspot 虚拟机其实现大部分在 src\share\vm\prims\jvmtiEnv.cpp 这个文件中。
Instrument Agent
在 Jdk1.5 之后,Java 语言中开始提供 Instrumentation 接口(java.lang.instrument)让开发者可以使用 Java 语言编写 Agent,但是其根本实现还是依靠 JVMTI,只不过是 SUN 在工具包(sun.instrument.InstrumentationImpl)编写了一些 native 方法,并且然后在 JDK 里提供了这些 native 方法的实现类(jdk\src\share\instrument\JPLISAgent.c),最终需要调用 jvmti.h 头文件定义的方法,跟前文提到采用 JNI 方式访问 JVMTI 提供的方法并无差异,大体流程如下图:
但是 Instrument agent 仅使用到了 JVMTI 提供部分功能,对开发者来说,主要提供的是对 JVM 加载的类字节码进行插桩操作。
1. JVM启动时Agent
我们知道,JVM 启动时可以指定 -javaagent:xxx.jar 参数来实现启动时代理,这里 xxx.jar 就是需要被代理到目标 JVM 上的 JAR 包,实现一个可以代理到指定 JVM 的 JAR 包需要满足以下条件:
- JAR 包的 MANIFEST.MF 清单文件中定义 Premain-Class 属性,指定一个类,加入 Can-Redefine-Classes 和 Can-Retr ansform-Classes 选项。
- JAR 包中包含清单文件中定义的这个类,类中包含 premain 方法,方法逻辑可以自己实现。
了解到这两点,我们可以定义下列类:
import java.lang.instrument.Instrumentation;
public class AgentMain {
// JVM启动时agent
public static void premain(String args, Instrumentation inst) {
agent0(args, inst);
}
public static void agent0(String args, Instrumentation inst) {
System.out.println("agent is running!");
// 添加一个类转换器
inst.addTransformer(new ClassFileTransformer() {
@Override
public byte[] transform(ClassLoader loader,
String className,
Class<?> classBeingRedefined,
ProtectionDomain protectionDomain,
byte[] classfileBuffer) {
// JVM加载的所有类会流经这个类转换器
// 这里找到自定义的测试类
if (className.endsWith("WorkerMain")) {
System.out.println("transform class WorkerMain");
}
// 直接返回原本的字节码
return classfileBuffer;
}
});
}
}
JAR 包内对应的清单文件(MANIFEST.MF)需要有如下内容:
PreMain-Class: AgentMain
Can-Redefine-Classes: true
Can-Retransform-Classes: true
-javaagent 所指定 jar 包内 Premain-Class 类的 premain 方法,方法签名可以有两种:
public static void premain(String agentArgs, Instrumentation inst)
public static void premain(String agentArgs)
JVM 会优先加载 1 签名的方法,加载成功忽略 2,如果 1 没有,加载 2 方法。这个逻辑在 sun.instrument.InstrumentationImpl 类中实现。
需要说明的是,addTransformer 方法的作用是添加一个字节码转换器,这个方法的入参对象需要实现 ClassFileTransformer 接口,唯一需要实现的方法就是 transform 方法,这个方法可以用来修改加载类的字节码,目前我们并不对字节码进行修改。
最后定义测试类:package test;
import java.util.Random;
class WorkerMain {
public static void main(String[] args) throws InterruptedException {
for (; ; ) {
int x = new Random().nextInt();
new WorkerMain().test(x);
}
}
public void test(int x) throws InterruptedException {
Thread.sleep(2000);
System.out.println("i'm working " + x);
}
}
启动时添加 -javaagent:xxx.jar 参数,指定 agent 刚刚生成的JAR包,可以看到运行结果:
流程解析
下面尝试结合 JDK 源码对该流程进行浅析:
JVM 开始启动时会解析 -javaagent 参数,如果存在这个参数,就会执行 Agent_OnLoad 方法读取并解析指定 JAR 包后生成 JPLISAgent 对象,然后注册 jvmtiEventCallbacks.VMInit 这个事件,也就是虚拟机初始化事件,并设置该事件的回调函数 eventHandlerVMInit,这些代码逻辑在 jdk\src\share\instrument\InvocationAdapter.c 和 jdk\src\share\instrument\JPLISAgent.c 中实现。
在 JVM 初始化时会调用之前注册的 eventHandlerVMInit 事件的回调函数,进入 processJavaStart 这个函数,首先会在注册另一个 JVM 事件 ClassFileLoadHook,然后会真正的执行我们在 Java 代码层面编写的 premain 方法。当 JVM 开始装载类字节码文件时,会触发之前注册的 ClassFileLoadHook 事件的回调方法 eventHandlerClassFileLoadHook,这个回调函数调用 transformClassFile 方法,生成新的字节码,被 JVM 装载,完成了启动时代理的全部流程。
以上代码逻辑在 jdk\src\share\instrument\JPLISAgent.c 中实现。
2. JVM运行时Agent
在 JDK1.6 版本中,SUN 更进一步,提供了可以在 JVM 运行时代理的能力,和启动时代理类似,只需要满足:
- JAR 包的 MANIFEST.MF 清单文件中定义 Agent-Class 属性,指定一个类,加入 Can-Redefine-Classes 和 Can-Retransform-Classes 选项。
- JAR 包中包含清单文件中定义的这个类,类中包含 agentmain 方法,方法逻辑可以自己实现。
运行时 Agent 可以在 JVM 运行时动态的修改某个类的字节码,然后 JVM 会重定义这个类(不需要创建新的类加载器),但是为了保证 JVM 的正常运行,新定义的类相较于原来的类需要满足:
父类是同一个。
实现的接口数也要相同,并且是相同的接口。
类访问符必须一致。
字段数和字段名要一致。
新增或删除的方法必须是 private static/final 的。
可以修改方法内部代码。
运行时 Agent 需要借助 JVM 的 Attach 机制,简单来说就是 JVM 提供的一种通信机制,JVM 中会存在一个 Attach Listener 线程,监听其他 JVM 的 attach 请求,其通信方式基于 socket,JVM Attach 机制大体流程图如下:
JVM Attach
SUN 在 JDK 中提供了 Attach 机制的 Java 语言工具包(com.sun.tools.attach),方便开发者使用 Java 语言进行操作,这里我们使用其中提供的 loadAgent 方法实现运行中 agent 的能力。
public class AttachUtil {
public static void main(String[] args) throws IOException, AgentLoadException, AgentInitializationException, AttachNotSupportedException {
// 获取运行中的JVM列表
List<VirtualMachineDescriptor> vmList = VirtualMachine.list();
// 需要agent的jar包路径
String agentJar = "xxxx/agent-test.jar";
for (VirtualMachineDescriptor vmd : vmList) {
// 找到测试的JVM
if (vmd.displayName().endsWith("WorkerMain")) {
// attach到目标ID的JVM上
VirtualMachine virtualMachine = VirtualMachine.attach(vmd.id());
// agent指定jar包到已经attach的JVM上
virtualMachine.loadAgent(agentJar);
virtualMachine.detach();
}
}
}
同时对之前启动时 Agent 的代码进行改写:
public class AgentMain {
// JVM启动时agent
public static void premain(String args, Instrumentation inst) {
agent0(args, inst);
}
// JVM运行时agent
public static void agentmain(String args, Instrumentation inst) {
agent0(args, inst);
}
public static void agent0(String args, Instrumentation inst) {
System.out.println("agent is running!");
inst.addTransformer(new ClassFileTransformer() {
@Override
public byte[] transform(ClassLoader loader, String className, Class<?> classBeingRedefined, ProtectionDomain protectionDomain, byte[] classfileBuffer) {
// 打印transform的类名
System.out.println(className);
return classfileBuffer;
}
},true);
try {
// 找到WorkerMain类,对其进行重定义
Class<?> c = Class.forName("test.WorkerMain");
inst.retransformClasses(c);
} catch (Exception e) {
System.out.println("error!");
}
}
}
这里我们也没有对字节码进行修改,还是直接返回原本的字节码。运行AttachUtil类,在目标JVM运行时完成了对其中test.WorkerMain 类的重新定义(虽然并没有修改字节码)。
流程解析
下面从JDK源码层面对整个流程进行浅析:
当 AttachUtil 的 loadAgent 方法调用时,目标 JVM 会调用自身的 Agent_OnAttach 方法,这个方法和之前提到的 Agent_OnLoad 方法类似,会进行 Agent JAR 包的解析,不同的是 Agent_OnAttach 方法会直接注册 ClassFileLoadHook 事件回调函数,然后执行 agentmain 方法添加类转换器。
需要注意的是我们在 Java 代码里调用了 Instrumentation#retransformClasses(Class…) 方法,追踪代码可以发现最终调用了一个 native 方法,而这个 native 方法的实现则在 jdk 的 src\share\instrument\JPLISAgent.c 类中,最终 retransformClasses 会调用到 JVMTI 的 RetransformClasses 方法,这里由于JVM源码实现非常复杂,感兴趣的同学可以自行阅读(hotspot源码路径 src\share\vm\prims\jvmtiEnv.cpp),简单来说在这个方法里,JVM 会触发 ClassFileLoadHook 事件回调完成类字节码的转换,并完成虚拟机内已经加载的类字节码的热替换。
至此,在JVM运行时悄无声息的完成了类的重定义,不得不佩服JDK开发者的高超手段。
运行方法分析
了解到上述机制以后,我们可以通过在目标 JVM 运行时对其中的类进行重新定义,做到运行时插桩代码。
我们知道 ASM 是一个字节码修改框架,因此就可以在类转换器中,对原本类的字节码进行修改,然后再对这个类进行重定义(retransform)。
首先我们实现 ClassFileTransformer 接口,前文中在 transform 方法中并没有对于字节码进行修改,只是单纯的打印了一些信息,既然需要对字目标类的节码进行修改,我们需要了解下 ClassFileTransformer 接口中唯一需要实现的方法 transform,方法签名如下:
byte[] transform(ClassLoader loader,
String className,
Class<?> classBeingRedefined,
ProtectionDomain protectionDomain,
byte[] classfileBuffer) throws IllegalClassFormatException;
可以看到方法入参有该类的类加载器、类名、类 Class 对象、类的保护域、以及最重要的 classfileBuffer,也就是这个类的字节码,此时就可以借助 ASM 这个字节码大杀器来为所欲为了。现在我们实现一个字节的类转换器 MyClassTransformer,然后使用 ASM 来对字节码进行修改。
public class MyClassTransformer implements ClassFileTransformer {
@Override
public byte[] transform(ClassLoader loader, String className, Class<?> classBeingRedefined, ProtectionDomain protectionDomain, byte[] classfileBuffer) throws IllegalClassFormatException {
// 对类字节码进行操作
// 这里需要注意,不能对classfileBuffer这个数组进行修改操作
try {
// 创建ASM ClassReader对象,导入需要增强的对象字节码
ClassReader reader = new ClassReader(classfileBuffer);
ClassWriter classWriter = new ClassWriter(ClassWriter.COMPUTE_MAXS);
// 自己实现的代码增强器
MyEnhancer myEnhancer = new MyEnhancer(classWriter);
// 增强字节码
reader.accept(myEnhancer, ClassReader.SKIP_FRAMES);
// 返回MyEnhancer增强后的字节码
return classWriter.toByteArray();
} catch (Exception e) {
e.printStackTrace();
}
// return null 则不会对类进行转换
return null;
}
}
至此,我们拼上了 JVM 运行时插桩代码的最后一块拼图,这样就可以理解 Arthas 这类基于 Java Agent 的性能分析工具是如何在 JVM 运行时对你的代码进行了修改。
接着实现一个字节码增强器,借助 ASM 将对方法入参和方法耗时的监控代码织入,这里需要对字节码有一定了解,这里笔者使用到 ASM 提供的 AdviceAdapter 类简化开发。
public class MyEnhancer extends ClassVisitor implements Opcodes {
public MyEnhancer(ClassVisitor classVisitor) {
super(ASM7, classVisitor);
}
/**
* 对字节码中的方法定义进行修改
*/
@Override
public MethodVisitor visitMethod(int access, final String name, String descriptor, String signature, String[] exceptions) {
MethodVisitor mv = super.visitMethod(access, name, descriptor, signature, exceptions);
if (isIgnore(mv, access, name)) {
return mv;
}
return new AdviceAdapter(Opcodes.ASM7, new JSRInlinerAdapter(mv, access, name, descriptor, signature, exceptions), access, name, descriptor) {
private final Type METHOD_CONTAINER = Type.getType(MethodContainer.class);
private int timeIdentifier;
private int argsIdentifier;
/**
* 进入方法前
*/
@Override
protected void onMethodEnter() {
// 调用System.nanoTime()方法,将方法出参推入栈顶
invokeStatic(Type.getType(System.class), Method.getMethod("long nanoTime()"));
// 构造一个Long类型的局部变量,然后返回这个变量的标识符
timeIdentifier = newLocal(Type.LONG_TYPE);
// 存储栈顶元素也就是System.nanoTime()返回值,到指定位置本地变量区
storeLocal(timeIdentifier);
// 加载入参数组,将入参数组ref推入栈顶
loadArgArray();
// 构造一个Object[]类型的局部变量,返回这个变量的标识符
argsIdentifier = newLocal(Type.getType(Object[].class));
// 存储入参到指定位置本地变量区
storeLocal(argsIdentifier);
}
@Override
protected void onMethodExit(int opcode) {
// 加载指定位置的本地变量到栈顶
loadLocal(timeIdentifier);
loadLocal(argsIdentifier);
// 相当于调用MethodContainer.showMethod(long, Object[])方法
invokeStatic(METHOD_CONTAINER, Method.getMethod("void showMethod(long,Object[])"));
}
};
}
/**
* 方法是否需要被忽略(静态构造函数和构造函数)
*/
private boolean isIgnore(MethodVisitor mv, int access, String methodName) {
return null == mv
|| isAbstract(access)
|| isFinalMethod(access)
|| "<clinit>".equals(methodName)
|| "<init>".equals(methodName);
}
private boolean isAbstract(int access) {
return (ACC_ABSTRACT & access) == ACC_ABSTRACT;
}
private boolean isFinalMethod(int methodAccess) {
return (ACC_FINAL & methodAccess) == ACC_FINAL;
}
}
由于这里对于字节码的修改是在方法内部,那么实现一些复杂逻辑的最好方式,就是调用外部类的静态方法,虚拟机字节码指令中的 invokestatic 是调用指定类的静态方法的指令,这里我们将方法开始时间和方法入参作为参数调用 MethodContainer.showMethod 方法,方法实现如下:
public class MethodContainer {
// 实现静态方法
public static void showMethod(long startTime, Object[] Args) {
System.out.println("方法耗时:" + (System.nanoTime() - startTime) / 1000000 + "ms, 方法入参:" + Arrays.toString(Args));
}
}
// ASM操作字节码需要一定的学习才能理解,如果把上述字节码增强前后用Java代码表示大体入下:
// ASM代码增强前
public void test(int x) throws InterruptedException {
Thread.sleep(2000L);
System.out.println("i'm working " + x);
}
// ASM代码增强后
public void test(int x) throws InterruptedException {
long var2 = System.nanoTime();
Object[] var4 = new Object[]{new Integer(x)};
Thread.sleep(2000L);
System.out.println("i'm working " + x);
MethodContainer.showMethod(var2, var4);
}
最后运行 AttachUitl,可以看到正在运行中的 JVM 被成功的插入了我们实现的字节码,对于目标虚拟机来说是完全不需要任何实现的,而且被重定义的代码也可以被还原,感兴趣的同学可以自己了解下。
对于 Java 开发者来说,代码插桩是很熟悉的一个概念,而且目前也有很多成熟的方式可以完成,比如说 Spring AOP实现采用的动态代理方式,Lombok 采用的插入式注解处理器方式等。
所谓术业有专攻,Instrument Agent 虽然强大,但也不见得适用所有的场景,对于日志统计、方法监控,动态代理已经能很好的满足这方面的需求,但是对于 JVM 性能监控或方法实时运行分析,Instrument Agent 可以随时插入、随时卸载、随时修改的特性就体现出了极大的优点,同时其基于 Java 代码开发又会相应的降低一些开发难度,这也是业内很多性能分析软件选择这种方式实现的原因。
6.6 - 动态调试技术
目标问题
断点调试是我们最常使用的调试手段,它可以获取到方法执行过程中的变量信息,并可以观察到方法的执行路径。但断点调试会在断点位置停顿,使得整个应用停止响应。在线上停顿应用是致命的,动态调试技术给了我们创造新的调试模式的想象空间。本文将研究Java语言中的动态调试技术,首先概括Java动态调试所涉及的技术基础,接着介绍我们在Java动态调试领域的思考及实践,通过结合实际业务场景,设计并实现了一种具备动态性的断点调试工具Java-debug-tool,显著提高了故障排查效率。
Java Agent
JVMTI (JVM Tool Interface)是Java虚拟机对外提供的Native编程接口,通过JVMTI,外部进程可以获取到运行时JVM的诸多信息,比如线程、GC等。Agent是一个运行在目标JVM的特定程序,它的职责是负责从目标JVM中获取数据,然后将数据传递给外部进程。加载Agent的时机可以是目标JVM启动之时,也可以是在目标JVM运行时进行加载,而在目标JVM运行时进行Agent加载具备动态性,对于时机未知的Debug场景来说非常实用。下面将详细分析Java Agent技术的实现细节。
实现模式
JVMTI是一套Native接口,在Java SE 5之前,要实现一个Agent只能通过编写Native代码来实现。从Java SE 5开始,可以使用Java的Instrumentation接口(java.lang.instrument)来编写Agent。无论是通过Native的方式还是通过Java Instrumentation接口的方式来编写Agent,它们的工作都是借助JVMTI来进行完成,下面介绍通过Java Instrumentation接口编写Agent的方法。
通过Java Instrumentation API
- 实现 Agent 启动方法
Java Agent支持目标JVM启动时加载,也支持在目标JVM运行时加载,这两种不同的加载模式会使用不同的入口函数,如果需要在目标JVM启动的同时加载Agent,那么可以选择实现下面的方法:
[1] public static void premain(String agentArgs, Instrumentation inst);
[2] public static void premain(String agentArgs);
JVM将首先寻找[1],如果没有发现[1],再寻找[2]。如果希望在目标JVM运行时加载Agent,则需要实现下面的方法:
[1] public static void agentmain(String agentArgs, Instrumentation inst);
[2] public static void agentmain(String agentArgs);
这两组方法的第一个参数AgentArgs是随同 “– javaagent”一起传入的程序参数,如果这个字符串代表了多个参数,就需要自己解析这些参数。inst是Instrumentation类型的对象,是JVM自动传入的,我们可以拿这个参数进行类增强等操作。
- 指定 Main-Class
Agent需要打包成一个jar包,在ManiFest属性中指定“Premain-Class”或者“Agent-Class”:
Premain-Class: class
Agent-Class: class
- 挂载到目标 JVM
将编写的Agent打成jar包后,就可以挂载到目标JVM上去了。如果选择在目标JVM启动时加载Agent,则可以使用 “-javaagent:[=
com.sun.tools.attach.VirtualMachine 这个类代表一个JVM抽象,可以通过这个类找到目标JVM,并且将Agent挂载到目标JVM上。下面是使用com.sun.tools.attach.VirtualMachine进行动态挂载Agent的一般实现:
private void attachAgentToTargetJVM() throws Exception {
List<VirtualMachineDescriptor> virtualMachineDescriptors = VirtualMachine.list();
VirtualMachineDescriptor targetVM = null;
for (VirtualMachineDescriptor descriptor : virtualMachineDescriptors) {
if (descriptor.id().equals(configure.getPid())) {
targetVM = descriptor;
break;
}
}
if (targetVM == null) {
throw new IllegalArgumentException("could not find the target jvm by process id:" + configure.getPid());
}
VirtualMachine virtualMachine = null;
try {
virtualMachine = VirtualMachine.attach(targetVM);
virtualMachine.loadAgent("{agent}", "{params}");
} catch (Exception e) {
if (virtualMachine != null) {
virtualMachine.detach();
}
}
}
首先通过指定的进程ID找到目标JVM,然后通过Attach挂载到目标JVM上,执行加载Agent操作。VirtualMachine的Attach方法就是用来将Agent挂载到目标JVM上去的,而Detach则是将Agent从目标JVM卸载。关于Agent是如何挂载到目标JVM上的具体技术细节,将在下文中进行分析。
启动时加载 Agent
参数解析
创建JVM时,JVM会进行参数解析,即解析那些用来配置JVM启动的参数,比如堆大小、GC等;本文主要关注解析的参数为-agentlib、 -agentpath、 -javaagent,这几个参数用来指定Agent,JVM会根据这几个参数加载Agent。下面来分析一下JVM是如何解析这几个参数的。
// -agentlib and -agentpath
if (match_option(option, "-agentlib:", &tail) ||
(is_absolute_path = match_option(option, "-agentpath:", &tail))) {
if(tail != NULL) {
const char* pos = strchr(tail, '=');
size_t len = (pos == NULL) ? strlen(tail) : pos - tail;
char* name = strncpy(NEW_C_HEAP_ARRAY(char, len + 1, mtArguments), tail, len);
name[len] = '\0';
char *options = NULL;
if(pos != NULL) {
options = os::strdup_check_oom(pos + 1, mtArguments);
}
#if !INCLUDE_JVMTI
if (valid_jdwp_agent(name, is_absolute_path)) {
jio_fprintf(defaultStream::error_stream(),
"Debugging agents are not supported in this VM\n");
return JNI_ERR;
}
#endif // !INCLUDE_JVMTI
add_init_agent(name, options, is_absolute_path);
}
// -javaagent
} else if (match_option(option, "-javaagent:", &tail)) {
#if !INCLUDE_JVMTI
jio_fprintf(defaultStream::error_stream(),
"Instrumentation agents are not supported in this VM\n");
return JNI_ERR;
#else
if (tail != NULL) {
size_t length = strlen(tail) + 1;
char *options = NEW_C_HEAP_ARRAY(char, length, mtArguments);
jio_snprintf(options, length, "%s", tail);
add_init_agent("instrument", options, false);
// java agents need module java.instrument
if (!create_numbered_property("jdk.module.addmods", "java.instrument", addmods_count++)) {
return JNI_ENOMEM;
}
}
#endif // !INCLUDE_JVMTI
}
上面的代码片段截取自hotspot/src/share/vm/runtime/arguments.cpp中的 Arguments::parse_each_vm_init_arg(const JavaVMInitArgs* args, bool* patch_mod_javabase, Flag::Flags origin) 函数,该函数用来解析一个具体的JVM参数。这段代码的主要功能是解析出需要加载的Agent路径,然后调用add_init_agent函数进行解析结果的存储。下面先看一下add_init_agent函数的具体实现:
// -agentlib and -agentpath arguments
static AgentLibraryList _agentList;
static void add_init_agent(const char* name, char* options, bool absolute_path)
{ _agentList.add(new AgentLibrary(name, options, absolute_path, NULL)); }
AgentLibraryList是一个简单的链表结构,add_init_agent函数将解析好的、需要加载的Agent添加到这个链表中,等待后续的处理。
这里需要注意,解析-javaagent参数有一些特别之处,这个参数用来指定一个我们通过Java Instrumentation API来编写的Agent,Java Instrumentation API底层依赖的是JVMTI,对-JavaAgent的处理也说明了这一点,在调用add_init_agent函数时第一个参数是“instrument”,关于加载Agent这个问题在下一小节进行展开。到此,我们知道在启动JVM时指定的Agent已经被JVM解析完存放在了一个链表结构中。下面来分析一下JVM是如何加载这些Agent的。
执行加载操作
在创建JVM进程的函数中,解析完JVM参数之后,下面的这段代码和加载Agent相关:
// Launch -agentlib/-agentpath and converted -Xrun agents
if (Arguments::init_agents_at_startup()) {
create_vm_init_agents();
}
static bool init_agents_at_startup() {
return !_agentList.is_empty();
}
当JVM判断出上一小节中解析出来的Agent不为空的时候,就要去调用函数create_vm_init_agents来加载Agent,下面来分析一下create_vm_init_agents函数是如何加载Agent的。
void Threads::create_vm_init_agents() {
AgentLibrary* agent;
for (agent = Arguments::agents(); agent != NULL; agent = agent->next()) {
OnLoadEntry_t on_load_entry = lookup_agent_on_load(agent);
if (on_load_entry != NULL) {
// Invoke the Agent_OnLoad function
jint err = (*on_load_entry)(&main_vm, agent->options(), NULL);
}
}
}
create_vm_init_agents这个函数通过遍历Agent链表来逐个加载Agent。通过这段代码可以看出,首先通过lookup_agent_on_load来加载Agent并且找到Agent_OnLoad函数,这个函数是Agent的入口函数。如果没找到这个函数,则认为是加载了一个不合法的Agent,则什么也不做,否则调用这个函数,这样Agent的代码就开始执行起来了。对于使用Java Instrumentation API来编写Agent的方式来说,在解析阶段观察到在add_init_agent函数里面传递进去的是一个叫做”instrument”的字符串,其实这是一个动态链接库。在Linux里面,这个库叫做libinstrument.so,在BSD系统中叫做libinstrument.dylib,该动态链接库在{JAVA_HOME}/jre/lib/目录下。
instrument 动态链接库
libinstrument用来支持使用Java Instrumentation API来编写Agent,在libinstrument中有一个非常重要的类称为:JPLISAgent(Java Programming Language Instrumentation Services Agent),它的作用是初始化所有通过Java Instrumentation API编写的Agent,并且也承担着通过JVMTI实现Java Instrumentation中暴露API的责任。
我们已经知道,在JVM启动的时候,JVM会通过-javaagent参数加载Agent。最开始加载的是libinstrument动态链接库,然后在动态链接库里面找到JVMTI的入口方法:Agent_OnLoad。下面就来分析一下在libinstrument动态链接库中,Agent_OnLoad函数是怎么实现的。
JNIEXPORT jint JNICALL
DEF_Agent_OnLoad(JavaVM *vm, char *tail, void * reserved) {
initerror = createNewJPLISAgent(vm, &agent);
if ( initerror == JPLIS_INIT_ERROR_NONE ) {
if (parseArgumentTail(tail, &jarfile, &options) != 0) {
fprintf(stderr, "-javaagent: memory allocation failure.\n");
return JNI_ERR;
}
attributes = readAttributes(jarfile);
premainClass = getAttribute(attributes, "Premain-Class");
/* Save the jarfile name */
agent->mJarfile = jarfile;
/*
* Convert JAR attributes into agent capabilities
*/
convertCapabilityAttributes(attributes, agent);
/*
* Track (record) the agent class name and options data
*/
initerror = recordCommandLineData(agent, premainClass, options);
}
return result;
}
上述代码片段是经过精简的libinstrument中Agent_OnLoad实现的,大概的流程就是:先创建一个JPLISAgent,然后将ManiFest中设定的一些参数解析出来, 比如(Premain-Class)等。创建了JPLISAgent之后,调用initializeJPLISAgent对这个Agent进行初始化操作。跟进initializeJPLISAgent看一下是如何初始化的:
JPLISInitializationError initializeJPLISAgent(JPLISAgent *agent, JavaVM *vm, jvmtiEnv *jvmtienv) {
/* check what capabilities are available */
checkCapabilities(agent);
/* check phase - if live phase then we don't need the VMInit event */
jvmtierror = (*jvmtienv)->GetPhase(jvmtienv, &phase);
/* now turn on the VMInit event */
if ( jvmtierror == JVMTI_ERROR_NONE ) {
jvmtiEventCallbacks callbacks;
memset(&callbacks, 0, sizeof(callbacks));
callbacks.VMInit = &eventHandlerVMInit;
jvmtierror = (*jvmtienv)->SetEventCallbacks(jvmtienv,&callbacks,sizeof(callbacks));
}
if ( jvmtierror == JVMTI_ERROR_NONE ) {
jvmtierror = (*jvmtienv)->SetEventNotificationMode(jvmtienv,JVMTI_ENABLE,JVMTI_EVENT_VM_INIT,NULL);
}
return (jvmtierror == JVMTI_ERROR_NONE)? JPLIS_INIT_ERROR_NONE : JPLIS_INIT_ERROR_FAILURE;
}
这里,我们关注callbacks.VMInit = &eventHandlerVMInit;这行代码,这里设置了一个VMInit事件的回调函数,表示在JVM初始化的时候会回调eventHandlerVMInit函数。下面来看一下这个函数的实现细节,猜测就是在这里调用了Premain方法:
void JNICALL eventHandlerVMInit( jvmtiEnv *jvmtienv,JNIEnv *jnienv,jthread thread) {
// ...
success = processJavaStart( environment->mAgent, jnienv);
// ...
}
jboolean processJavaStart(JPLISAgent *agent,JNIEnv *jnienv) {
result = createInstrumentationImpl(jnienv, agent);
/*
* Load the Java agent, and call the premain.
*/
if ( result ) {
result = startJavaAgent(agent, jnienv, agent->mAgentClassName, agent->mOptionsString, agent->mPremainCaller);
}
return result;
}
jboolean startJavaAgent( JPLISAgent *agent,JNIEnv *jnienv,const char *classname,const char *optionsString,jmethodID agentMainMethod) {
// ...
invokeJavaAgentMainMethod(jnienv,agent->mInstrumentationImpl,agentMainMethod, classNameObject,optionsStringObject);
// ...
}
看到这里,Instrument已经实例化,invokeJavaAgentMainMethod这个方法将我们的premain方法执行起来了。接着,我们就可以根据Instrument实例来做我们想要做的事情了。
运行时加载 Agent
比起JVM启动时加载Agent,运行时加载Agent就比较有诱惑力了,因为运行时加载Agent的能力给我们提供了很强的动态性,我们可以在需要的时候加载Agent来进行一些工作。因为是动态的,我们可以按照需求来加载所需要的Agent,下面来分析一下动态加载Agent的相关技术细节。
AttachListener
Attach机制通过Attach Listener线程来进行相关事务的处理,下面来看一下Attach Listener线程是如何初始化的。
// Starts the Attach Listener thread
void AttachListener::init() {
// 创建线程相关部分代码被去掉了
const char thread_name[] = "Attach Listener";
Handle string = java_lang_String::create_from_str(thread_name, THREAD);
{ MutexLocker mu(Threads_lock);
JavaThread* listener_thread = new JavaThread(&attach_listener_thread_entry);
// ...
}
}
我们知道,一个线程启动之后都需要指定一个入口来执行代码,Attach Listener线程的入口是attach_listener_thread_entry,下面看一下这个函数的具体实现:
static void attach_listener_thread_entry(JavaThread* thread, TRAPS) {
AttachListener::set_initialized();
for (;;) {
AttachOperation* op = AttachListener::dequeue();
// find the function to dispatch too
AttachOperationFunctionInfo* info = NULL;
for (int i=0; funcs[i].name != NULL; i++) {
const char* name = funcs[i].name;
if (strcmp(op->name(), name) == 0) {
info = &(funcs[i]); break;
}}
// dispatch to the function that implements this operation
res = (info->func)(op, &st);
//...
}
}
整个函数执行逻辑,大概是这样的:
- 拉取一个需要执行的任务:AttachListener::dequeue。
- 查询匹配的命令处理函数。
- 执行匹配到的命令执行函数。
其中第二步里面存在一个命令函数表,整个表如下:
static AttachOperationFunctionInfo funcs[] = {
{ "agentProperties", get_agent_properties },
{ "datadump", data_dump },
{ "dumpheap", dump_heap },
{ "load", load_agent },
{ "properties", get_system_properties },
{ "threaddump", thread_dump },
{ "inspectheap", heap_inspection },
{ "setflag", set_flag },
{ "printflag", print_flag },
{ "jcmd", jcmd },
{ NULL, NULL }
};
对于加载Agent来说,命令就是“load”。现在,我们知道了Attach Listener大概的工作模式,但是还是不太清楚任务从哪来,这个秘密就藏在AttachListener::dequeue这行代码里面,接下来我们来分析一下dequeue这个函数:
LinuxAttachOperation* LinuxAttachListener::dequeue() {
for (;;) {
// wait for client to connect
struct sockaddr addr;
socklen_t len = sizeof(addr);
RESTARTABLE(::accept(listener(), &addr, &len), s);
// get the credentials of the peer and check the effective uid/guid
// - check with jeff on this.
struct ucred cred_info;
socklen_t optlen = sizeof(cred_info);
if (::getsockopt(s, SOL_SOCKET, SO_PEERCRED, (void*)&cred_info, &optlen) == -1) {
::close(s);
continue;
}
// peer credential look okay so we read the request
LinuxAttachOperation* op = read_request(s);
return op;
}
}
这是Linux上的实现,不同的操作系统实现方式不太一样。上面的代码表面,Attach Listener在某个端口监听着,通过accept来接收一个连接,然后从这个连接里面将请求读取出来,然后将请求包装成一个AttachOperation类型的对象,之后就会从表里查询对应的处理函数,然后进行处理。
Attach Listener使用一种被称为“懒加载”的策略进行初始化,也就是说,JVM启动的时候Attach Listener并不一定会启动起来。下面我们来分析一下这种“懒加载”策略的具体实现方案。
// Start Attach Listener if +StartAttachListener or it can't be started lazily
if (!DisableAttachMechanism) {
AttachListener::vm_start();
if (StartAttachListener || AttachListener::init_at_startup()) {
AttachListener::init();
}
}
// Attach Listener is started lazily except in the case when
// +ReduseSignalUsage is used
bool AttachListener::init_at_startup() {
if (ReduceSignalUsage) {
return true;
} else {
return false;
}
}
上面的代码截取自create_vm函数,DisableAttachMechanism、StartAttachListener和ReduceSignalUsage这三个变量默认都是false,所以AttachListener::init();这行代码不会在create_vm的时候执行,而vm_start会执行。下面来看一下这个函数的实现细节:
void AttachListener::vm_start() {
char fn[UNIX_PATH_MAX];
struct stat64 st;
int ret;
int n = snprintf(fn, UNIX_PATH_MAX, "%s/.java_pid%d",
os::get_temp_directory(), os::current_process_id());
assert(n < (int)UNIX_PATH_MAX, "java_pid file name buffer overflow");
RESTARTABLE(::stat64(fn, &st), ret);
if (ret == 0) {
ret = ::unlink(fn);
if (ret == -1) {
log_debug(attach)("Failed to remove stale attach pid file at %s", fn);
}
}
}
这是在Linux上的实现,是将/tmp/目录下的.java_pid{pid}文件删除,后面在创建Attach Listener线程的时候会创建出来这个文件。上面说到,AttachListener::init()这行代码不会在create_vm的时候执行,这行代码的实现已经在上文中分析了,就是创建Attach Listener线程,并监听其他JVM的命令请求。现在来分析一下这行代码是什么时候被调用的,也就是“懒加载”到底是怎么加载起来的。
// Signal Dispatcher needs to be started before VMInit event is posted
os::signal_init();
这是create_vm中的一段代码,看起来跟信号相关,其实Attach机制就是使用信号来实现“懒加载“的。下面我们来仔细地分析一下这个过程。
void os::signal_init() {
if (!ReduceSignalUsage) {
// Setup JavaThread for processing signals
EXCEPTION_MARK;
Klass* k = SystemDictionary::resolve_or_fail(vmSymbols::java_lang_Thread(), true, CHECK);
instanceKlassHandle klass (THREAD, k);
instanceHandle thread_oop = klass->allocate_instance_handle(CHECK);
const char thread_name[] = "Signal Dispatcher";
Handle string = java_lang_String::create_from_str(thread_name, CHECK);
// Initialize thread_oop to put it into the system threadGroup
Handle thread_group (THREAD, Universe::system_thread_group());
JavaValue result(T_VOID);
JavaCalls::call_special(&result, thread_oop,klass,vmSymbols::object_initializer_name(),vmSymbols::threadgroup_string_void_signature(),
thread_group,string,CHECK);
KlassHandle group(THREAD, SystemDictionary::ThreadGroup_klass());
JavaCalls::call_special(&result,thread_group,group,vmSymbols::add_method_name(),vmSymbols::thread_void_signature(),thread_oop,CHECK);
os::signal_init_pd();
{ MutexLocker mu(Threads_lock);
JavaThread* signal_thread = new JavaThread(&signal_thread_entry);
// ...
}
// Handle ^BREAK
os::signal(SIGBREAK, os::user_handler());
}
}
JVM创建了一个新的进程来实现信号处理,这个线程叫“Signal Dispatcher”,一个线程创建之后需要有一个入口,“Signal Dispatcher”的入口是signal_thread_entry:
这段代码截取自signal_thread_entry函数,截取中的内容是和Attach机制信号处理相关的代码。这段代码的意思是,当接收到“SIGBREAK”信号,就执行接下来的代码,这个信号是需要Attach到JVM上的信号发出来,这个后面会再分析。我们先来看一句关键的代码:AttachListener::is_init_trigger():
bool AttachListener::is_init_trigger() {
if (init_at_startup() || is_initialized()) {
return false; // initialized at startup or already initialized
}
char fn[PATH_MAX+1];
sprintf(fn, ".attach_pid%d", os::current_process_id());
int ret;
struct stat64 st;
RESTARTABLE(::stat64(fn, &st), ret);
if (ret == -1) {
log_trace(attach)("Failed to find attach file: %s, trying alternate", fn);
snprintf(fn, sizeof(fn), "%s/.attach_pid%d", os::get_temp_directory(), os::current_process_id());
RESTARTABLE(::stat64(fn, &st), ret);
}
if (ret == 0) {
// simple check to avoid starting the attach mechanism when
// a bogus user creates the file
if (st.st_uid == geteuid()) {
init();
return true;
}
}
return false;
}
首先检查了一下是否在JVM启动时启动了Attach Listener,或者是否已经启动过。如果没有,才继续执行,在/tmp目录下创建一个叫做.attach_pid%d的文件,然后执行AttachListener的init函数,这个函数就是用来创建Attach Listener线程的函数,上面已经提到多次并进行了分析。到此,我们知道Attach机制的奥秘所在,也就是Attach Listener线程的创建依靠Signal Dispatcher线程,Signal Dispatcher是用来处理信号的线程,当Signal Dispatcher线程接收到“SIGBREAK”信号之后,就会执行初始化Attach Listener的工作。
运行时加载 Agent 的实现
我们继续分析,到底是如何将一个Agent挂载到运行着的目标JVM上,在上文中提到了一段代码,用来进行运行时挂载Agent,可以参考上文中展示的关于“attachAgentToTargetJvm”方法的代码。这个方法里面的关键是调用VirtualMachine的attach方法进行Agent挂载的功能。下面我们就来分析一下VirtualMachine的attach方法具体是怎么实现的。
public static VirtualMachine attach(String var0) throws AttachNotSupportedException, IOException {
if (var0 == null) {
throw new NullPointerException("id cannot be null");
} else {
List var1 = AttachProvider.providers();
if (var1.size() == 0) {
throw new AttachNotSupportedException("no providers installed");
} else {
AttachNotSupportedException var2 = null;
Iterator var3 = var1.iterator();
while(var3.hasNext()) {
AttachProvider var4 = (AttachProvider)var3.next();
try {
return var4.attachVirtualMachine(var0);
} catch (AttachNotSupportedException var6) {
var2 = var6;
}
}
throw var2;
}
}
}
这个方法通过attachVirtualMachine方法进行attach操作,在MacOS系统中,AttachProvider的实现类是BsdAttachProvider。我们来看一下BsdAttachProvider的attachVirtualMachine方法是如何实现的:
public VirtualMachine attachVirtualMachine(String var1) throws AttachNotSupportedException, IOException {
this.checkAttachPermission();
this.testAttachable(var1);
return new BsdVirtualMachine(this, var1);
}
BsdVirtualMachine(AttachProvider var1, String var2) throws AttachNotSupportedException, IOException {
int var3 = Integer.parseInt(var2);
this.path = this.findSocketFile(var3);
if (this.path == null) {
File var4 = new File(tmpdir, ".attach_pid" + var3);
createAttachFile(var4.getPath());
try {
sendQuitTo(var3);
int var5 = 0;
long var6 = 200L;
int var8 = (int)(this.attachTimeout() / var6);
do {
try {
Thread.sleep(var6);
} catch (InterruptedException var21) {
;
}
this.path = this.findSocketFile(var3);
++var5;
} while(var5 <= var8 && this.path == null);
} finally {
var4.delete();
}
}
int var24 = socket();
connect(var24, this.path);
}
private String findSocketFile(int var1) {
String var2 = ".java_pid" + var1;
File var3 = new File(tmpdir, var2);
return var3.exists() ? var3.getPath() : null;
}
findSocketFile方法用来查询目标JVM上是否已经启动了Attach Listener,它通过检查”tmp/“目录下是否存在java_pid{pid}来进行实现。如果已经存在了,则说明Attach机制已经准备就绪,可以接受客户端的命令了,这个时候客户端就可以通过connect连接到目标JVM进行命令的发送,比如可以发送“load”命令来加载Agent。如果java_pid{pid}文件还不存在,则需要通过sendQuitTo方法向目标JVM发送一个“SIGBREAK”信号,让它初始化Attach Listener线程并准备接受客户端连接。可以看到,发送了信号之后客户端会循环等待java_pid{pid}这个文件,之后再通过connect连接到目标JVM上。
load 命令的实现
下面来分析一下,“load”命令在JVM层面的实现:
static jint load_agent(AttachOperation* op, outputStream* out) {
// get agent name and options
const char* agent = op->arg(0);
const char* absParam = op->arg(1);
const char* options = op->arg(2);
// If loading a java agent then need to ensure that the java.instrument module is loaded
if (strcmp(agent, "instrument") == 0) {
Thread* THREAD = Thread::current();
ResourceMark rm(THREAD);
HandleMark hm(THREAD);
JavaValue result(T_OBJECT);
Handle h_module_name = java_lang_String::create_from_str("java.instrument", THREAD);
JavaCalls::call_static(&result,SystemDictionary::module_Modules_klass(),vmSymbols::loadModule_name(),
vmSymbols::loadModule_signature(),h_module_name,THREAD);
}
return JvmtiExport::load_agent_library(agent, absParam, options, out);
}
这个函数先确保加载了java.instrument模块,之后真正执行Agent加载的函数是 load_agent_library ,这个函数的套路就是加载Agent动态链接库,如果是通过Java instrument API实现的Agent,则加载的是libinstrument动态链接库,然后通过libinstrument里面的代码实现运行agentmain方法的逻辑,这一部分内容和libinstrument实现premain方法运行的逻辑其实差不多,这里不再做分析。至此,我们对Java Agent技术已经有了一个全面而细致的了解。
动态替换类字节码技术
动态字节码修改的限制
上文中已经详细分析了Agent技术的实现,我们使用Java Instrumentation API来完成动态类修改的功能,在Instrumentation接口中,通过addTransformer方法来增加一个类转换器,类转换器由类ClassFileTransformer接口实现。ClassFileTransformer接口中唯一的方法transform用于实现类转换,当类被加载的时候,就会调用transform方法,进行类转换。在运行时,我们可以通过Instrumentation的redefineClasses方法进行类重定义,在方法上有一段注释需要特别注意:
* The redefinition may change method bodies, the constant pool and attributes.
* The redefinition must not add, remove or rename fields or methods, change the
* signatures of methods, or change inheritance. These restrictions maybe be
* lifted in future versions. The class file bytes are not checked, verified and installed
* until after the transformations have been applied, if the resultant bytes are in
* error this method will throw an exception.
这里面提到,我们不可以增加、删除或者重命名字段和方法,改变方法的签名或者类的继承关系。认识到这一点很重要,当我们通过ASM获取到增强的字节码之后,如果增强后的字节码没有遵守这些规则,那么调用redefineClasses方法来进行类的重定义就会失败。那redefineClasses方法具体是怎么实现类的重定义的呢?它对运行时的JVM会造成什么样的影响呢?下面来分析redefineClasses的实现细节。
重定义类字节码的实现细节
上文中我们提到,libinstrument动态链接库中,JPLISAgent不仅实现了Agent入口代码执行的路由,而且还是Java代码与JVMTI之间的一道桥梁。我们在Java代码中调用Java Instrumentation API的redefineClasses,其实会调用libinstrument中的相关代码,我们来分析一下这条路径。
public void redefineClasses(ClassDefinition... var1) throws ClassNotFoundException {
if (!this.isRedefineClassesSupported()) {
throw new UnsupportedOperationException("redefineClasses is not supported in this environment");
} else if (var1 == null) {
throw new NullPointerException("null passed as 'definitions' in redefineClasses");
} else {
for(int var2 = 0; var2 < var1.length; ++var2) {
if (var1[var2] == null) {
throw new NullPointerException("element of 'definitions' is null in redefineClasses");
}
}
if (var1.length != 0) {
this.redefineClasses0(this.mNativeAgent, var1);
}
}
}
private native void redefineClasses0(long var1, ClassDefinition[] var3) throws ClassNotFoundException;
这是InstrumentationImpl中的redefineClasses实现,该方法的具体实现依赖一个Native方法redefineClasses(),我们可以在libinstrument中找到这个Native方法的实现:
JNIEXPORT void JNICALL Java_sun_instrument_InstrumentationImpl_redefineClasses0
(JNIEnv * jnienv, jobject implThis, jlong agent, jobjectArray classDefinitions) {
redefineClasses(jnienv, (JPLISAgent*)(intptr_t)agent, classDefinitions);
}
redefineClasses这个函数的实现比较复杂,代码很长。下面是一段关键的代码片段:
可以看到,其实是调用了JVMTI的RetransformClasses函数来完成类的重定义细节。Java-debug-tool
// class_count - pre-checked to be greater than or equal to 0
// class_definitions - pre-checked for NULL
jvmtiError JvmtiEnv::RedefineClasses(jint class_count, const jvmtiClassDefinition* class_definitions) {
//TODO: add locking
VM_RedefineClasses op(class_count, class_definitions, jvmti_class_load_kind_redefine);
VMThread::execute(&op);
return (op.check_error());
} /* end RedefineClasses */
重定义类的请求会被JVM包装成一个VM_RedefineClasses类型的VM_Operation,VM_Operation是JVM内部的一些操作的基类,包括GC操作等。VM_Operation由VMThread来执行,新的VM_Operation操作会被添加到VMThread的运行队列中去,VMThread会不断从队列里面拉取VM_Operation并调用其doit等函数执行具体的操作。VM_RedefineClasses函数的流程较为复杂,下面是VM_RedefineClasses的大致流程:
- 加载新的字节码,合并常量池,并且对新的字节码进行校验工作
// Load the caller's new class definition(s) into _scratch_classes.
// Constant pool merging work is done here as needed. Also calls
// compare_and_normalize_class_versions() to verify the class
// definition(s).
jvmtiError load_new_class_versions(TRAPS);
// Remove all breakpoints in methods of this class
JvmtiBreakpoints& jvmti_breakpoints = JvmtiCurrentBreakpoints::get_jvmti_breakpoints();
jvmti_breakpoints.clearall_in_class_at_safepoint(the_class());
// Deoptimize all compiled code that depends on this class
flush_dependent_code(the_class, THREAD);
- 进行字节码替换工作,需要进行更新类itable/vtable等操作
- 进行类重定义通知
SystemDictionary::notice_modification();
VM_RedefineClasses实现比较复杂的,详细实现可以参考 RedefineClasses的实现。
Java-debug-tool是一个使用Java Instrument API来实现的动态调试工具,它通过在目标JVM上启动一个TcpServer来和调试客户端通信。调试客户端通过命令行来发送调试命令给TcpServer,TcpServer中有专门用来处理命令的handler,handler处理完命令之后会将结果发送回客户端,客户端通过处理将调试结果展示出来。下面将详细介绍Java-debug-tool的整体设计和实现。
整体架构
Java-debug-tool包括一个Java Agent和一个用于处理调试命令的核心API,核心API通过一个自定义的类加载器加载进来,以保证目标JVM的类不会被污染。整体上Java-debug-tool的设计是一个Client-Server的架构,命令客户端需要完整的完成一个命令之后才能继续执行下一个调试命令。Java-debug-tool支持多人同时进行调试,下面是整体架构图:
下面对每一层做简单介绍:
- 交互层:负责将程序员的输入转换成调试交互协议,并且将调试信息呈现出来。
- 连接管理层:负责管理客户端连接,从连接中读调试协议数据并解码,对调试结果编码并将其写到连接中去;同时将那些超时未活动的连接关闭。
- 业务逻辑层:实现调试命令处理,包括命令分发、数据收集、数据处理等过程。
- 基础实现层:Java-debug-tool实现的底层依赖,通过Java Instrumentation提供的API进行类查找、类重定义等能力,Java Instrumentation底层依赖JVMTI来完成具体的功能。
在Agent被挂载到目标JVM上之后,Java-debug-tool会安排一个Spy在目标JVM内活动,这个Spy负责将目标JVM内部的相关调试数据转移到命令处理模块,命令处理模块会处理这些数据,然后给客户端返回调试结果。命令处理模块会增强目标类的字节码来达到数据获取的目的,多个客户端可以共享一份增强过的字节码,无需重复增强。下面从Java-debug-tool的字节码增强方案、命令设计与实现等角度详细说明。
字节码增强方案
Java-debug-tool使用字节码增强来获取到方法运行时的信息,比如方法入参、出参等,可以在不同的字节码位置进行增强,这种行为可以称为“插桩”,每个“桩”用于获取数据并将他转储出去。Java-debug-tool具备强大的插桩能力,不同的桩负责获取不同类别的数据,下面是Java-debug-tool目前所支持的“桩”:
- 方法进入点:用于获取方法入参信息。
- Fields获取点1:在方法执行前获取到对象的字段信息。
- 变量存储点:获取局部变量信息。
- Fields获取点2:在方法退出前获取到对象的字段信息。
- 方法退出点:用于获取方法返回值。
- 抛出异常点:用于获取方法抛出的异常信息。
通过上面这些代码桩,Java-debug-tool可以收集到丰富的方法执行信息,经过处理可以返回更加可视化的调试结果。
字节码增强
Java-debug-tool在实现上使用了ASM工具来进行字节码增强,并且每个插桩点都可以进行配置,如果不想要什么信息,则没必要进行对应的插桩操作。这种可配置的设计是非常有必要的,因为有时候我们仅仅是想要知道方法的入参和出参,但Java-debug-tool却给我们返回了所有的调试信息,这样我们就得在众多的输出中找到我们所关注的内容。如果可以进行配置,则除了入参点和出参点外其他的桩都不插,那么就可以快速看到我们想要的调试数据,这种设计的本质是为了让调试者更加专注。下面是Java-debug-tool的字节码增强工作方式:
如图4-2-1所示,当调试者发出调试命令之后,Java-debug-tool会识别命令并判断是否需要进行字节码增强,如果命令需要增强字节码,则判断当前类+当前方法是否已经被增强过。上文已经提到,字节码替换是有一定损耗的,这种具有损耗的操作发生的次数越少越好,所以字节码替换操作会被记录起来,后续命令直接使用即可,不需要重复进行字节码增强,字节码增强还涉及多个调试客户端的协同工作问题,当一个客户端增强了一个类的字节码之后,这个客户端就锁定了该字节码,其他客户端变成只读,无法对该类进行字节码增强,只有当持有锁的客户端主动释放锁或者断开连接之后,其他客户端才能继续增强该类的字节码。
字节码增强模块收到字节码增强请求之后,会判断每个增强点是否需要插桩,这个判断的根据就是上文提到的插桩配置,之后字节码增强模块会生成新的字节码,Java-debug-tool将执行字节码替换操作,之后就可以进行调试数据收集了。
经过字节码增强之后,原来的方法中会插入收集运行时数据的代码,这些代码在方法被调用的时候执行,获取到诸如方法入参、局部变量等信息,这些信息将传递给数据收集装置进行处理。数据收集的工作通过Advice完成,每个客户端同一时间只能注册一个Advice到Java-debug-tool调试模块上,多个客户端可以同时注册自己的Advice到调试模块上。Advice负责收集数据并进行判断,如果当前数据符合调试命令的要求,Java-debug-tool就会卸载这个Advice,Advice的数据就会被转移到Java-debug-tool的命令结果处理模块进行处理,并将结果发送到客户端。
Advice 的工作方式
Advice是调试数据收集器,不同的调试策略会对应不同的Advice。Advice是工作在目标JVM的线程内部的,它需要轻量级和高效,意味着Advice不能做太过于复杂的事情,它的核心接口“match”用来判断本次收集到的调试数据是否满足调试需求。如果满足,那么Java-debug-tool就会将其卸载,否则会继续让他收集调试数据,这种“加载Advice” -> “卸载Advice”的工作模式具备很好的灵活性。
关于Advice,需要说明的另外一点就是线程安全,因为它加载之后会运行在目标JVM的线程中,目标JVM的方法极有可能是多线程访问的,这也就是说,Advice需要有能力处理多个线程同时访问方法的能力,如果Advice处理不当,则可能会收集到杂乱无章的调试数据。下面的图片展示了Advice和Java-debug-tool调试分析模块、目标方法执行以及调试客户端等模块的关系。
Advice的首次挂载由Java-debug-tool的命令处理器完成,当一次调试数据收集完成之后,调试数据处理模块会自动卸载Advice,然后进行判断,如果调试数据符合Advice的策略,则直接将数据交由数据处理模块进行处理,否则会清空调试数据,并再次将Advice挂载到目标方法上去,等待下一次调试数据。非首次挂载由调试数据处理模块进行,它借助Advice按需取数据,如果不符合需求,则继续挂载Advice来获取数据,否则对调试数据进行处理并返回给客户端。
命令设计与实现
命令执行
上文已经完整的描述了Java-debug-tool的设计以及核心技术方案,本小节将详细介绍Java-debug-tool的命令设计与实现。首先需要将一个调试命令的执行流程描述清楚,下面是一张用来表示命令请求处理流程的图片:
图4-3-1简单的描述了Java-debug-tool的命令处理方式,客户端连接到服务端之后,会进行一些协议解析、协议认证、协议填充等工作,之后将进行命令分发。服务端如果发现客户端的命令不合法,则会立即返回错误信息,否则再进行命令处理。命令处理属于典型的三段式处理,前置命令处理、命令处理以及后置命令处理,同时会对命令处理过程中的异常信息进行捕获处理,三段式处理的好处是命令处理被拆成了多个阶段,多个阶段负责不同的职责。前置命令处理用来做一些命令权限控制的工作,并填充一些类似命令处理开始时间戳等信息,命令处理就是通过字节码增强,挂载Advice进行数据收集,再经过数据处理来产生命令结果的过程,后置处理则用来处理一些连接关闭、字节码解锁等事项。
Java-debug-tool允许客户端设置一个命令执行超时时间,超过这个时间则认为命令没有结果,如果客户端没有设置自己的超时时间,就使用默认的超时时间进行超时控制。Java-debug-tool通过设计了两阶段的超时检测机制来实现命令执行超时功能:首先,第一阶段超时触发,则Java-debug-tool会友好的警告命令处理模块处理时间已经超时,需要立即停止命令执行,这允许命令自己做一些现场清理工作,当然需要命令执行线程自己感知到这种超时警告;当第二阶段超时触发,则Java-debug-tool认为命令必须结束执行,会强行打断命令执行线程。超时机制的目的是为了不让命令执行太长时间,命令如果长时间没有收集到调试数据,则应该停止执行,并思考是否调试了一个错误的方法。当然,超时机制还可以定期清理那些因为未知原因断开连接的客户端持有的调试资源,比如字节码锁。
获取方法执行视图
Java-debug-tool通过下面的信息来向调试者呈现出一次方法执行的视图:
- 正在调试的方法信息。
- 方法调用堆栈。
- 调试耗时,包括对目标JVM造成的STW时间。
- 方法入参,包括入参的类型及参数值。
- 方法的执行路径。
- 代码执行耗时。
- 局部变量信息。
- 方法返回结果。
- 方法抛出的异常。
- 对象字段值快照。
图4-3-2展示了Java-debug-tool获取到正在运行的方法的执行视图的信息。
与同类产品对比分析
Java-debug-tool的同类产品主要是greys,其他类似的工具大部分都是基于greys进行的二次开发,所以直接选择greys来和Java-debug-tool进行对比。
总结
本文详细剖析了Java动态调试关键技术的实现细节,并介绍了我们基于Java动态调试技术结合实际故障排查场景进行的一点探索实践;动态调试技术为研发人员进行线上问题排查提供了一种新的思路,我们基于动态调试技术解决了传统断点调试存在的问题,使得可以将断点调试这种技术应用在线上,以线下调试的思维来进行线上调试,提高问题排查效率。
参考文献
6.7 - Arthas
简介
Arthas 是Alibaba开源的Java诊断工具,深受开发者喜爱。
能解决什么问题
当你遇到以下类似问题而束手无策时,Arthas可以帮助你解决:
- 这个类从哪个 jar 包加载的? 为什么会报各种类相关的 Exception?
- 我改的代码为什么没有执行到? 难道是我没 commit? 分支搞错了?
- 遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
- 线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
- 是否有一个全局视角来查看系统的运行状况?
- 有什么办法可以监控到JVM的实时运行状态?
Arthas支持JDK 6+,支持Linux/Mac/Windows,采用命令行交互模式,同时提供丰富的 Tab 自动补全功能,进一步方便进行问题的定位和诊断。
Arthas资源推荐
技术基础
- greys-anatomy: Arthas代码基于Greys二次开发而来,非常感谢Greys之前所有的工作,以及Greys原作者对Arthas提出的意见和建议!
- termd: Arthas的命令行实现基于termd开发,是一款优秀的命令行程序开发框架,感谢termd提供了优秀的框架。
- crash: Arthas的文本渲染功能基于crash中的文本渲染功能开发,可以从这里看到源码,感谢crash在这方面所做的优秀工作。
- cli: Arthas的命令行界面基于vert.x提供的cli库进行开发,感谢vert.x在这方面做的优秀工作。
- compiler Arthas里的内存编绎器代码来源
- Apache Commons Net Arthas里的Telnet Client代码来源
JavaAgent:运行在 main方法之前的拦截器,它内定的方法名叫 premain ,也就是说先执行 premain 方法然后再执行 main 方法ASM:一个通用的Java字节码操作和分析框架。它可以用于修改现有的类或直接以二进制形式动态生成类。ASM提供了一些常见的字节码转换和分析算法,可以从它们构建定制的复杂转换和代码分析工具。ASM提供了与其他Java字节码框架类似的功能,但是主要关注性能。因为它被设计和实现得尽可能小和快,所以非常适合在动态系统中使用(当然也可以以静态方式使用,例如在编译器中)
同类工具
入门
安装
curl -O https://alibaba.github.io/arthas/arthas-boot.jar
java -jar arthas-boot.jar
示例
Dashboard
Thread
$ thread -n 3
"as-command-execute-daemon" Id=29 cpuUsage=75% RUNNABLE
at sun.management.ThreadImpl.dumpThreads0(Native Method)
at sun.management.ThreadImpl.getThreadInfo(ThreadImpl.java:440)
at com.taobao.arthas.core.command.monitor200.ThreadCommand$1.action(ThreadCommand.java:58)
at com.taobao.arthas.core.command.handler.AbstractCommandHandler.execute(AbstractCommandHandler.java:238)
at com.taobao.arthas.core.command.handler.DefaultCommandHandler.handleCommand(DefaultCommandHandler.java:67)
at com.taobao.arthas.core.server.ArthasServer$4.run(ArthasServer.java:276)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Number of locked synchronizers = 1
- java.util.concurrent.ThreadPoolExecutor$Worker@6cd0b6f8
"as-session-expire-daemon" Id=25 cpuUsage=24% TIMED_WAITING
at java.lang.Thread.sleep(Native Method)
at com.taobao.arthas.core.server.DefaultSessionManager$2.run(DefaultSessionManager.java:85)
"Reference Handler" Id=2 cpuUsage=0% WAITING on java.lang.ref.Reference$Lock@69ba0f27
at java.lang.Object.wait(Native Method)
- waiting on java.lang.ref.Reference$Lock@69ba0f27
at java.lang.Object.wait(Object.java:503)
at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:133)
jad 反编译
$ jad javax.servlet.Servlet
ClassLoader:
+-java.net.URLClassLoader@6108b2d7
+-sun.misc.Launcher$AppClassLoader@18b4aac2
+-sun.misc.Launcher$ExtClassLoader@1ddf84b8
Location:
/Users/xxx/work/test/lib/servlet-api.jar
/*
* Decompiled with CFR 0_122.
*/
package javax.servlet;
import java.io.IOException;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
public interface Servlet {
public void init(ServletConfig var1) throws ServletException;
public ServletConfig getServletConfig();
public void service(ServletRequest var1, ServletResponse var2) throws ServletException, IOException;
public String getServletInfo();
public void destroy();
}
mc 编译 .class
redefine 加载外部 .class 修改已加载类
redefine /tmp/Test.class
redefine -c 327a647b /tmp/Test.class /tmp/Test\$Inner.class
sc 查找已加载类
$ sc -d org.springframework.web.context.support.XmlWebApplicationContext
class-info org.springframework.web.context.support.XmlWebApplicationContext
code-source /Users/xxx/work/test/WEB-INF/lib/spring-web-3.2.11.RELEASE.jar
name org.springframework.web.context.support.XmlWebApplicationContext
isInterface false
isAnnotation false
isEnum false
isAnonymousClass false
isArray false
isLocalClass false
isMemberClass false
isPrimitive false
isSynthetic false
simple-name XmlWebApplicationContext
modifier public
annotation
interfaces
super-class +-org.springframework.web.context.support.AbstractRefreshableWebApplicationContext
+-org.springframework.context.support.AbstractRefreshableConfigApplicationContext
+-org.springframework.context.support.AbstractRefreshableApplicationContext
+-org.springframework.context.support.AbstractApplicationContext
+-org.springframework.core.io.DefaultResourceLoader
+-java.lang.Object
class-loader +-org.apache.catalina.loader.ParallelWebappClassLoader
+-java.net.URLClassLoader@6108b2d7
+-sun.misc.Launcher$AppClassLoader@18b4aac2
+-sun.misc.Launcher$ExtClassLoader@1ddf84b8
classLoaderHash 25131501
stack 查看调用栈
$ stack test.arthas.TestStack doGet
Press Ctrl+C to abort.
Affect(class-cnt:1 , method-cnt:1) cost in 286 ms.
ts=2018-09-18 10:11:45;thread_name=http-bio-8080-exec-10;id=d9;is_daemon=true;priority=5;TCCL=org.apache.catalina.loader.ParallelWebappClassLoader@25131501
@test.arthas.TestStack.doGet()
at javax.servlet.http.HttpServlet.service(HttpServlet.java:624)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:731)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:303)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:208)
at org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:52)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:241)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:208)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:241)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:208)
at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:220)
at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:110)
...
at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:169)
at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:103)
at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:116)
at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:451)
at org.apache.coyote.http11.AbstractHttp11Processor.process(AbstractHttp11Processor.java:1121)
at org.apache.coyote.AbstractProtocol$AbstractConnectionHandler.process(AbstractProtocol.java:637)
at org.apache.tomcat.util.net.JIoEndpoint$SocketProcessor.run(JIoEndpoint.java:316)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61)
at java.lang.Thread.run(Thread.java:745)
trace 追踪方法调用
watch 查看方法调用入参
$ watch test.arthas.TestWatch doGet {params[0], throwExp} -e
Press Ctrl+C to abort.
Affect(class-cnt:1 , method-cnt:1) cost in 65 ms.
ts=2018-09-18 10:26:28;result=@ArrayList[
@RequestFacade[org.apache.catalina.connector.RequestFacade@79f922b2],
@NullPointerException[java.lang.NullPointerException],
]
monitor 监控方法调用统计信息
$ monitor -c 5 org.apache.dubbo.demo.provider.DemoServiceImpl sayHello
Press Ctrl+C to abort.
Affect(class-cnt:1 , method-cnt:1) cost in 109 ms.
timestamp class method total success fail avg-rt(ms) fail-rate
----------------------------------------------------------------------------------------------------------------------------
2018-09-20 09:45:32 org.apache.dubbo.demo.provider.DemoServiceImpl sayHello 5 5 0 0.67 0.00%
timestamp class method total success fail avg-rt(ms) fail-rate
----------------------------------------------------------------------------------------------------------------------------
2018-09-20 09:45:37 org.apache.dubbo.demo.provider.DemoServiceImpl sayHello 5 5 0 1.00 0.00%
timestamp class method total success fail avg-rt(ms) fail-rate
----------------------------------------------------------------------------------------------------------------------------
2018-09-20 09:45:42 org.apache.dubbo.demo.provider.DemoServiceImpl sayHello 5 5 0 0.43 0.00%
time tunnel 记录调用现场以回放
$ tt -t org.apache.dubbo.demo.provider.DemoServiceImpl sayHello
Press Ctrl+C to abort.
Affect(class-cnt:1 , method-cnt:1) cost in 75 ms.
INDEX TIMESTAMP COST(ms) IS-RET IS-EXP OBJECT CLASS METHOD
-------------------------------------------------------------------------------------------------------------------------------------
1000 2018-09-20 09:54:10 1.971195 true false 0x55965cca DemoServiceImpl sayHello
1001 2018-09-20 09:54:11 0.215685 true false 0x55965cca DemoServiceImpl sayHello
1002 2018-09-20 09:54:12 0.236303 true false 0x55965cca DemoServiceImpl sayHello
1003 2018-09-20 09:54:13 0.159598 true false 0x55965cca DemoServiceImpl sayHello
1004 2018-09-20 09:54:14 0.201982 true false 0x55965cca DemoServiceImpl sayHello
1005 2018-09-20 09:54:15 0.214205 true false 0x55965cca DemoServiceImpl sayHello
1006 2018-09-20 09:54:16 0.241863 true false 0x55965cca DemoServiceImpl sayHello
1007 2018-09-20 09:54:17 0.305747 true false 0x55965cca DemoServiceImpl sayHello
1008 2018-09-20 09:54:18 0.18468 true false 0x55965cca DemoServiceImpl sayHello
classloader 查看类加载信息
$ classloader
name numberOfInstances loadedCountTotal
BootstrapClassLoader 1 3346
com.taobao.arthas.agent.ArthasClassloader 1 1262
java.net.URLClassLoader 2 1033
org.apache.catalina.loader.ParallelWebappClassLoader 1 628
sun.reflect.DelegatingClassLoader 166 166
sun.misc.Launcher$AppClassLoader 1 31
com.alibaba.fastjson.util.ASMClassLoader 6 15
sun.misc.Launcher$ExtClassLoader 1 7
org.jvnet.hk2.internal.DelegatingClassLoader 2 2
sun.reflect.misc.MethodUtil 1 1
web console 基于 web 的控制台
命令集
基础命令
JVM 命令
class/classloader
- sc——查看JVM已加载的类信息
- sm——查看已加载类的方法信息
- jad——反编译指定已加载类的源码
- mc——内存编绎器,内存编绎
.java文件为.class文件 - redefine——加载外部的
.class文件,redefine到JVM里 - dump——dump 已加载类的 byte code 到特定目录
- classloader——查看classloader的继承树,urls,类加载信息,使用classloader去getResource
monitor/watch/trace
这些命令,都通过字节码增强技术来实现的,会在指定类的方法中插入一些切面来实现数据统计和观测,因此在线上、预发使用时,请尽量明确需要观测的类、方法以及条件,诊断结束要执行 shutdown 或将增强过的类执行 reset 命令。
- monitor——方法执行监控
- watch——方法执行数据观测
- trace——方法内部调用路径,并输出方法路径上的每个节点上耗时
- stack——输出当前方法被调用的调用路径
- tt——方法执行数据的时空隧道,记录下指定方法每次调用的入参和返回信息,并能对这些不同的时间下调用进行观测
options
管道
Arthas支持使用管道对上述命令的结果进行进一步的处理,如sm java.lang.String * | grep 'index'
- grep——搜索满足条件的�结果
- plaintext——将�命令的结果去除ANSI颜色
- wc——按行统计输出结果
后台异步任务
当线上出现偶发的问题,比如需要watch某个条件,而这个条件一天可能才会出现一次时,异步后台任务就派上用场了,详情请参考这里
- 使用 > 将结果重写向到日志文件,使用 & 指定命令是后台运行,session断开不影响任务执行(生命周期默认为1天)
- jobs——列出所有job
- kill——强制终止任务
- fg——将暂停的任务拉到前台执行
- bg——将暂停的任务放到后台执行
用户数据回报
在3.1.4版本后,增加了用户数据回报功能,方便统一做安全或者历史数据统计。
在启动时,指定stat-url,就会回报执行的每一行命令,比如: ./as.sh --stat-url 'http://192.168.10.11:8080/api/stat'
在tunnel server里有一个示例的回报代码,用户可以自己在服务器上实现。
其他特性
应用实例
查看最繁忙的线程,以及是否有阻塞情况发生?
场景:我想看下查看最繁忙的线程,以及是否有阻塞情况发生? 常规查看线程,一般我们可以通过 top 等系统命令进行查看,但是那毕竟要很多个步骤,很麻烦。
thread -n 3 # 查看最繁忙的三个线程栈信息
thread # 以直观的方式展现所有的线程情况
thread -b #找出当前阻塞其他线程的线程
确认某个类是否已被系统加载?
场景:我新写了一个类或者一个方法,我想知道新写的代码是否被部署了?
# 即可以找到需要的类全路径,如果存在的话
sc *MyServlet
# 查看这个某个类所有的方法
sm pdai.tech.servlet.TestMyServlet *
# 查看某个方法的信息,如果存在的话
sm pdai.tech.servlet.TestMyServlet testMethod
如何查看一个class类的源码信息?
场景:我新修改的内容在方法内部,而上一个步骤只能看到方法,这时候可以反编译看下源码
# 直接反编译出java 源代码,包含一此额外信息的
jad pdai.tech.servlet.TestMyServlet
重要:如何跟踪某个方法的返回值、入参…. ?
# 同时监控入参,返回值,及异常
watch pdai.tech.servlet.TestMyServlet testMethod "{params, returnObj, throwExp}" -e -x 2
如何看方法调用栈的信息?
stack pdai.tech.servlet.TestMyServlet testMethod
重要:找到最耗时的方法调用?
# 执行的时候每个子调用的运行时长,可以找到最耗时的子调用。
stack pdai.tech.servlet.TestMyServlet testMethod
重要:如何临时更改代码运行?
# 先反编译出class源码
jad --source-only com.example.demo.arthas.user.UserController > /tmp/UserController.java
# 然后使用外部工具编辑内容
mc /tmp/UserController.java -d /tmp # 再编译成class
# 最后,重新载入定义的类,就可以实时验证你的猜测了
redefine /tmp/com/example/demo/arthas/user/UserController.class
如上,是直接更改线上代码的方式,但是一般好像是编译不成功的。所以,最好是本地ide编译成 class文件后,再上传替换为好!
总之,已经完全不用重启和发布了!这个功能真的很方便,比起重启带来的代价,真的是不可比的。比如,重启时可能导致负载重分配,选主等等问题,就不是你能控制的了。
场景:我如何测试某个方法的性能问题?
monitor -c 5 demo.MathGame primeFactors
场景:Spring Context
通过请求处理器获取 Context
如果已知服务接口被调用的较为频繁,可以通过请求处理器获取上下文。
首先通过 tt 记录某次请求的上下文:
tt -t org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter invokeHandlerMethod
当请求出现时,会出现记录:
$ watch com.example.demo.Test * 'params[0]@sss'
$ tt -t org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter invokeHandlerMethod
Press Ctrl+C to abort.
Affect(class-cnt:1 , method-cnt:1) cost in 101 ms.
INDEX TIMESTAMP COST(ms IS-RE IS-EX OBJECT CLASS METHOD
) T P
------------------------------------------------------------------------------------------------------------------
1000 2019-01-27 16:31 3.66744 true false 0x4465cf70 RequestMappingHandlerAda invokeHandlerMethod
:54 pter
然后可以用tt命令的-i参数来指定index,并且用-w参数来执行ognl表达式来获取spring context:
$ tt -i 1000 -w 'target.getApplicationContext()'
@AnnotationConfigEmbeddedWebApplicationContext[
reader=@AnnotatedBeanDefinitionReader[org.springframework.context.annotation.AnnotatedBeanDefinitionReader@35dc90ec],
scanner=@ClassPathBeanDefinitionScanner[org.springframework.context.annotation.ClassPathBeanDefinitionScanner@72078a14],
annotatedClasses=null,
basePackages=null,
]
Affect(row-cnt:1) cost in 7 ms.
然后从 context 中获取 bean:
$ tt -i 1000 -w 'target.getApplicationContext().getBean("helloWorldService").getHelloMessage()'
@String[Hello World]
Affect(row-cnt:1) cost in 5 ms.
通过静态方法获取 Context
在很多代码里都有static函数或者static holder类,可以获取很多其它的对象。比如在Dubbo里通过SpringExtensionFactory获取spring context:
$ ognl '#context=@com.alibaba.dubbo.config.spring.extension.SpringExtensionFactory@contexts.iterator.next,
#context.getBean("userServiceImpl").findUser(1)'
@User[
id=@Integer[1],
name=@String[Deanna Borer],
]
实现原理
相关文章
6.8 - 本地调试
Intellij IDEA Debug
如下是在IDEA中启动Debug模式,进入断点后的界面,我这里是Windows,可能和Mac的图标等会有些不一样。就简单说下图中标注的8个地方:
- ① 以Debug模式启动服务,左边的一个按钮则是以Run模式启动。在开发中,我一般会直接启动Debug模式,方便随时调试代码。
- ② 断点:在左边行号栏单击左键,或者快捷键Ctrl+F8 打上/取消断点,断点行的颜色可自己去设置。
- ③ Debug窗口:访问请求到达第一个断点后,会自动激活Debug窗口。如果没有自动激活,可以去设置里设置,如图1.2。
- ④ 调试按钮:一共有8个按钮,调试的主要功能就对应着这几个按钮,鼠标悬停在按钮上可以查看对应的快捷键。在菜单栏Run里可以找到同样的对应的功能,如图1.4。
- ⑤ 服务按钮:可以在这里关闭/启动服务,设置断点等。
- ⑥ 方法调用栈:这里显示了该线程调试所经过的所有方法,勾选右上角的[Show All Frames]按钮,就不会显示其它类库的方法了,否则这里会有一大堆的方法。
- ⑦ Variables:在变量区可以查看当前断点之前的当前方法内的变量。
- ⑧ Watches:查看变量,可以将Variables区中的变量拖到Watches中查看
在设置里勾选Show debug window on breakpoint,则请求进入到断点后自动激活Debug窗口
基本应用
Show Execution Point (Alt + F10):如果你的光标在其它行或其它页面,点击这个按钮可跳转到当前代码执行的行。
Step Over (F8):步过,一行一行地往下走,如果这一行上有方法不会进入方法。
Step Into (F7):步入,如果当前行有方法,可以进入方法内部,一般用于进入自定义方法内,不会进入官方类库的方法,如第25行的put方法。
Force Step Into (Alt + Shift + F7):强制步入,能进入任何方法,查看底层源码的时候可以用这个进入官方类库的方法。
Step Out (Shift + F8):步出,从步入的方法内退出到方法调用处,此时方法已执行完毕,只是还没有完成赋值。
Drop Frame (默认无):回退断点,后面章节详细说明。
Run to Cursor (Alt + F9):运行到光标处,你可以将光标定位到你需要查看的那一行,然后使用这个功能,代码会运行至光标行,而不需要打断点。
Evaluate Expression (Alt + F8):计算表达式,后面章节详细说明。