CH07-3-桥接模式
有些应用中对一个特定的功能拥有多种不同的实现。这些实现可能是一组算法或者在多个平台上执行的操作。这些实现经常会发生变化,同时贯穿整个应用的声明周期中会添加有新的实现。更进一步,这些实现可能会以不同的方式应用于不同的抽象。像在这些场景下,更好的方式是从我们的代码中解耦,否则我们将面临类爆炸的危险。
桥接模式的目的在于将抽象与其实现解耦,然后二者可以互相独立地进行变动。
当抽象或实现经常会独立的进行变动时,桥接设计模式会很有帮助。如果我们直接实现一个抽象,对于抽象或实现的变动将总是会影响继承层级中的其他类。这将使扩展、修改、对类的独立复用变得难以进行。
桥接模式消除了直接实现抽象带来的问题,因此能够使抽象和实现易于复用和修改。
桥接模式与适配器模式非常类似,而它们的不同在于,前者是我们在设计的时候应用,而后者是在使用一些遗留代码或外部库时应用。
类图
对于类图和代码实例,让我们假设我们正在编写一个散列密码的库。在实践中,以普通文本的方式保存密码是需要避免的。这也是我们的库能够帮助用户的地方。有很多不同的散列算法可用。比如 SHA-1,MD5 和 SHA-256。我们想最少能够支持这些必能够轻松地添加新的方式。有不同的散列策略——你可以散列多次,组合不同的散列,给密码加盐等等。这些策略会让我们的密码很难通过*彩虹表(rainbow-table, 一种破解工具)*猜到。作为例子,我们将会展示带盐的散列和没有任何算的简单散列。
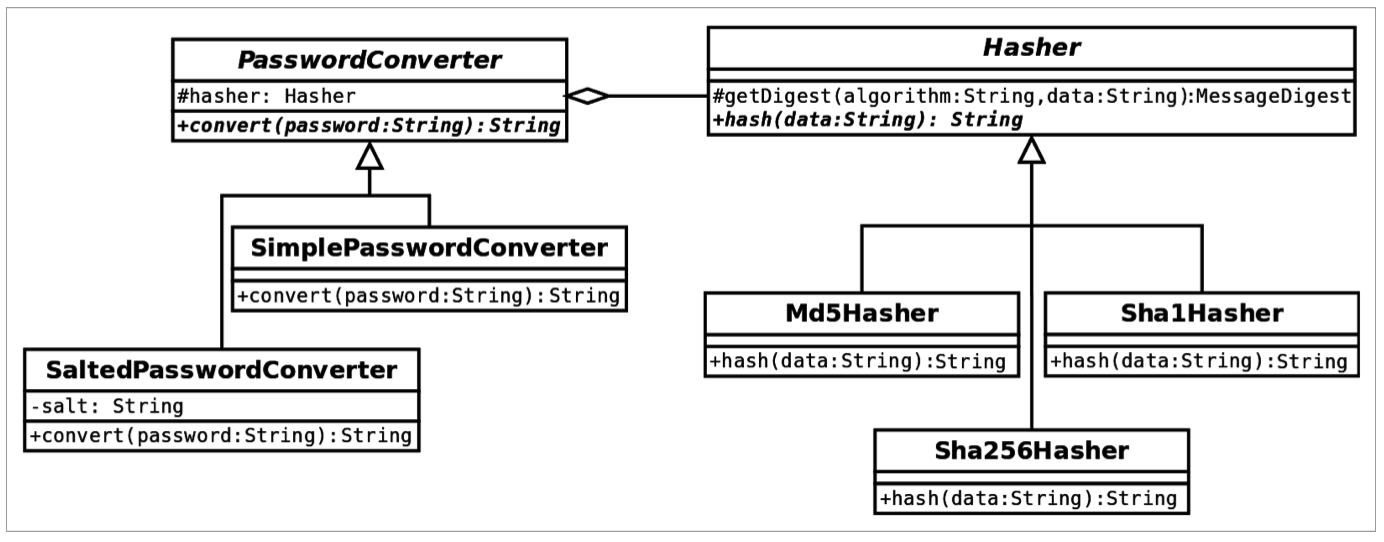
从上面的类图中你会发现,我们将实现(Hasher 及子类)和抽闲(PasswordConveter)进行了分离。这样就能支持我们添加新的散列实现,并在创建PasswordConveter的时候传入一个它的实例来立即使用它。如果我们没有之前的构建器模式,或许需要为每个散列算法分别创建一个密码转换器——这会使我们的代码规模膨胀或太过冗长而难以使用。
实例
现在让我们以 Scala 的视角看一下上面的类图。首先,我们会关注于实现这一边的Haser特质:
trait Hasher{
def hash(data:String):String
protected def getDigest(algorithm:String, data:String) = {
val crypt = MessageDigest.getInstance(algorithm)
crypt.reset()
crypt.update(data.getBytes("UTF-8"))
crypt
}
}
然后我们有三个类来实现它。代码看起来很简单也很类似,只是返回的结果不同:
class Sha1Hasher extends Hasher {
override def hash(data:String):String =
new String(Hex.encodeHex(getDigest("SHA-1", data).digest()))
}
class Sha256Hasher extends Hasher {
override def hash(data:String):String =
new String(Hex.encodeHex(getDigest("SHA-256", data).digest()))
}
class Md5Hasher extends Hasher{
override def hash(data:String):String =
new String(Hex.encodeHex(getDigest("MD5", data).digest()))
}
现在让我们看一下抽象这一边。这也就是客户端要使用的部分:
abstract class PasswordConverter(hasher:Hasher){
def convert(password:String):String
}
我们选择提供两种不同的实现,SimplePasswordConverter和SaltedPasswordConverter:
class SimplePasswrodConverter(hasher:Hasher) extends PasswordConveter(hasher){
override def convert(password:String):String = hasher.hash(password)
}
class SaltedPasswordConverter(hasher:Hasher) extends PasswordConverter(hasher){
override def convert(password:String):String = hasher.hash(passwrod)
}
现在,如果客户端想要使用这个库,可以编写类似下面这样的代码:
object BridgeExample extends App {
val p1 = new SimplePasswordConverter(new Sha256Hasher)
val p2 = new SimplePasswordConverter(new Md5Hasher)
val p3 = new SaltedPasswordConverter("8jsdf32T^$%", new Sha1Hasher)
val p4 = new SaltedPasswordConverter("8jsdf32T^$%", new Sha256Hasher)
System.out.println(s"'password' in SHA-256 is: ${p1.convert("password")}")
System.out.println(s"'1234567890' in MD5 is: ${p2.convert("1234567890")}")
System.out.println(s"'password' in salted SHA-1 is: ${p3.convert("password")}")
System.out.println(s"'password' in salted SHA-256 is: ${p4.convert("password")}")
}
Scala 方式的桥接模式
桥接模式是另一种能够通过使用 Scala 的强大语言特性来实现的模式。这里我们将使用自类型。最初的Hasher特质将会保持不变。而实现将会转为为特质而不再是类:
trait Sha1Hasher extends Hasher{
override def hash(data: String): String =
new String(Hex.encodeHex(getDigest("SHA-1", data).digest()))
}
trait Sha256Hasher extends Hasher {
override def hash(data: String): String =
new String(Hex.encodeHex(getDigest("SHA-256", data).digest()))
}
trait Md5Hasher extends Hasher {
override def hash(data: String): String =
new String(Hex.encodeHex(getDigest("MD5", data).digest()))
}
使用特质将支持我们在后面需要的时候混入。
我们改变了例子中一些类的名字以避免冲突。PasswordConverter抽象现在看起来会像这样:
abstract class PasswordConverterBase {
self: Hasher =>
def convert(password:String):String
}
自类型会告诉编译器当我们使用PasswordConverterBase的时候同时需要混入一个Hasher。
class SimplePasswordConverterScala extends PasswordConverterBase {
self:Hasher =>
override def convert(password:String):String = convert(password)
}
class SaltedPasswrodConverterScala(salt:String) extends PasswordConverterBase{
self: Hasher =>
override def convert(password:String):String = hash(s"${salt}:${password}")
}
最终,我们可以像下面这样使用新的实现:
object ScalaBridgeExample extends App{
val p1 = new SimplePasswordConverterScala with Sha256Hasher
val p2 = new SimplePasswordConverterScala with Md5Hasher
val p3 = new SaltedPasswordConverterScala("8jsdf32T^$%") with Sha1Hasher
val p4 = new SaltedPasswordConverterScala("8jsdf32T^$%") with Sha256Hasher
System.out.println(s"'password' in SHA-256 is: ${p1.convert("password")}")
System.out.println(s"'1234567890' in MD5 is: ${p2.convert("1234567890")}")
System.out.println(s"'password' in salted SHA-1 is: ${p3.convert("password")}")
System.out.println(s"'password' in salted SHA-256 is: ${p4.convert("password")}")
}
运行这段代码将会与第一种实现得到的输出一样。然而,当我们使用我们的抽象时,可以混入我们需要使用的散列算法。但我们拥有更多的实现需要与散列结合时,这种优势会变得更加明显。使用混入看起来也会更加自然和易懂。
优点
像我们已经提到的,桥接模式类似于适配器模式,不过我们会在设计应用的时候应用该模式。使用它的一个明显优势是最终我们的应用中不会拥有爆炸数量的类,从而导致库的使用变得相当复杂。分离的层级结构也支持我们能够独立的扩展它们而不会影响其他的类。
缺点
桥接模式需要我们编写一些模板代码。当需要选择哪种的具体的实现时,会增加使用库的复杂性,或许使用桥接模式和一些创建型模式相结合或是一个不错的主意。总而言之,它没有主要的缺点,开发者需要根据当前的情况明智的选择是否使用这种模式。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.