CH07-2-装饰器模式
有些情况下我们需要给应用中的类添加一些功能。这可以通过继承来完成;然而,我们并不像这么做以避免影响应用中的其他所有类。这也就是装饰器的用途。
装饰器的目的在于在不扩展原有类、并不影响其他扩展自该类的对象的行为的基础上为原有类添加额外的功能。
装饰器模式通过包装被装饰的类来工作,并可以在运行时应用。装饰器尤其适用于一个类拥有多个扩展,并且这些扩展会以不同的方式组合的场景。替代编写所有可能的组合,装饰器可以被创建并在每个之上叠加它们的修改。后面的几个小节我们将展示何时在真实的场景中使用装饰器。
类图
像我们之前看到的适配器设计模式,它的目标是将接口改变成不同的一个。在装饰器中,另一方面来说,帮助我们给方法提供额外的功能来增强一个接口。对于类图,我们将使用一个数据流的例子。假如我们拥有一个基本的流(stream),我们想要对其加密、压缩、替换字符等等。下面是类图:
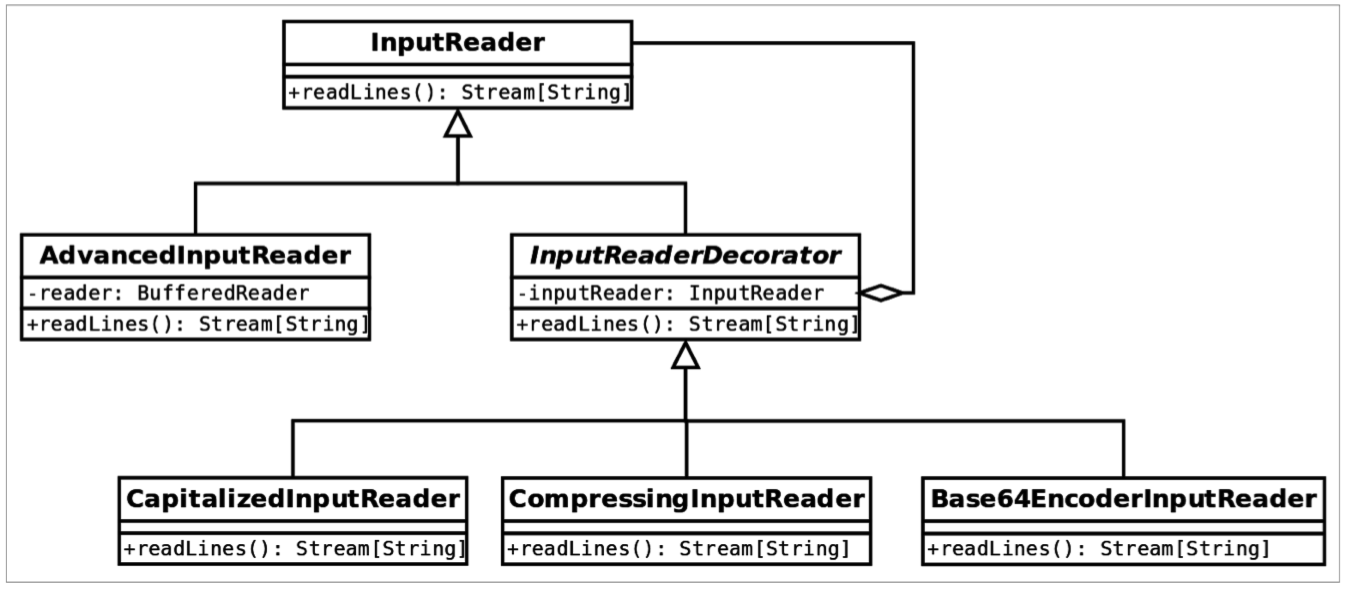
在上面的类图中,AdvancedInputReader为InputReader提供了基本的实现。它包装了一个BufferedReader。然后我们拥有一个抽象的InputReaderDecorator类扩展自InputReader并拥有它的一个实例。通过扩展基本的装饰器,我们为流提供了加密、压缩或 Base64 编码它得到的输入的能力。我们可能在应用中想要不同的流,并且想要在上面的操作中以不同的顺序执行一个或多个。如果我们想要提供所有的可能性,代码将很快变得凌乱从而难以维护,尤其是当可能的操作数量很多。而使用装饰器,会在后面小节中看到的一样清晰整洁。
实例
让我们看一下描述上面类图的具体代码实例。首先,我们使用一个特质来定义InputReader接口:
trait InputReader {
def readLines():Stream[String]
}
然后在AdvancedInputReader类中为接口提供一个基本的实现:
class AdvancedInputReader(reader:BufferedReader) extends InputReader {
override def readLines():Stream[String] =
reader.readLines().iterator.asScala.toStream
}
为了能够应用装饰器模式,我们需要创建一些不同的装饰器。现在定义一个基本的装饰器:
abstract class InputReaderDecorator(inputReader:InputReader) extends InputReader{
override def readLines():Stream[String] = inputReader.readLines()
}
然后拥有不同的装饰器实现。首先定义一个将所有文本转换为大写的装饰器:
class CapitalizedInputReader(inputReader:InputReader) extends InputReaderDecorator(inputReader) {
override def readLines():Stream[String] =
super.readLines().map(_.toUpperCase)
}
再实现一个装饰器使用 gzip 分别将每一行输入进行压缩:
class CompressingInputReader(inputReader:InputReader) extends InputReaderDecorator(inputReader) {
override def readLines():Stream[String] = super.readLines().map {
case line =>
val text = line.getBytes(Charset.forName("UTF-8"))
logger.info("Length before compression: {}",text.length.toString)
val output = new ByteArrayOutputStream()
val compressor = new GZIPOutputStream(output)
try {
compressor.write(text, 0, text.length)
val outputByteArray = output.toByteArray
logger.info("Length after compression: {}",outputByteArray.length.toString)
new String(outputByteArray, Charset.forName("UTF-8"))
} finally {
compressor.close()
output.close()
}
}
}
最终,一个将所有行编码为 Base64 的装饰器:
class Base64EncoderInputReader(inputReader:InputReader) extends InputReaderDecorator(inputReader){
override readLines():Stream[String] = super.readLines().map {
case line =>
Base64.getEncoder.encodeToString(line.getBytes (Charset.forName("UTF-8")))
}
}
我们使用了一个中间的抽象类来演示装饰器模式,所有具体的装饰器都扩展自该抽象类。也可以不使用该中间抽象类而是直接扩展 InputReader 并包装其实例来实现这种模式。
现在则可以在应用中根据需要来使用这些装饰器给输入流增加功能。用法和直接,像下面这样:
object DecoratorExample extends App{
val stream = new BufferedReader(
new InputStreamReader(
new BufferedInputStream(this.getClass.getResourceAsStream ("data.txt"))
)
)
try{
val reader = new CapitalizedInputReader(
new AdvancedInputReader(stream)
)
reader.readLines().foreach(println)
} finally {
stream.close()
}
}
上面的例子中我们使用了类路径中的文本文件,它有如下内如:
this is a data file
which contains lines
and those lines will be
manipulated by our stream reader.
和预期一样,我们应用装饰器的顺序也定义了这个被增强的功能的顺序。
让我们看另一个例子,这次会应用所有的装饰器:
object DecoratorExampleBig extends App{
val stream = new BufferedReader(
new InputStreamReader(
new BufferedInputStream(this.getClass.getResourceAsStream ("data.txt"))
)
)
try{
val reader = new CompressingInputReader(
new Base64InputReader(
new CapitalizedInputReader(
new AdvancedInputReader(stream)
)
)
)
reader.readLines().foreach(println)
} finally {
stream.close()
}
}
这个例子会读取文本、转换为大写、Base64 编码,最终压缩为 GZIP。
Scala 方式的装饰器模式
向其他设计模式一样,该模式也有一种利用 Scala 丰富特性的实现,其中使用了一些本书开头介绍的几种概念。在 Scala 中装饰器模式被称为特质叠加(stackable traits)。让我们看一下它的形式以及如何使用它。InputReader和AdvancedInputReader会像前面小节的实现一样被完全保留。我们实际是在两个例子中对其进行了复用。
下一步,不再定义一个abstract decorator类,取而代之的是仅仅在新的特质中定义不同的读取器修改:
trait CapitalizedInputReaderTrait extends InputReader {
abstract override def readLines():Stream[String]
super.readLines().map(_.toUpperCase)
}
然后,定义压缩输入读取器:
trait CompressingInuptReadrTrait extends InputReader with LazyLogging{
abstract override def readLines():Stream[String]
super.readLines().map{
case line =>
val text = line.getBytes(Charset.forName("UTF-8"))
logger.info("Length before compression: {}", text.length.toString)
val output = new ByteArrayOutputStream()
val compressor = new GZIPOutputStream(output)
try {
compressor.write(text, 0, text.length)
val outputByteArray = output.toByteArray
logger.info("Length after compression: {}", outputByteArray.length.toString)
new String(outputByteArray, Charset.forName("UTF-8"))
} finally {
conpressor.close()
output.close()
}
}
}
最后是 Base64 编码读取器:
trait Base64EncoderInputReaderTrait extends InputReader{
abstract override def readLines(): Stream[String] = super.readlines.map{
case line =>
Base64.getEncoder.encodeToString(line.getBytes(Charset.forName("UTF-8")))
}
}
你会发现这些实现并没有很大区别,这里我们使用特质替代了类,扩展自基本的InputReader特质,并使用了abstract override。
抽象覆写(abstract override)支持我们在特质中对声明为 abstract 的方法调用 super。这允许在混入了一个已实现前一个方法的特质或类之后混入特质。abstract override 会告诉编译器我们是在故意这么做从而避免编译失败——它会在稍后进行检查,当我们使用特质并且其需要已经被满足的时候。
上面我们展示了两个例子,现在我们会展示使用堆叠特质又会是什么样子。首先是仅进行转换大写:
object StackableTraitsExample extends App{
val stream = new BufferedReader(
new InputStreamReader(
new BufferedInputStream(this.getClass.getResourceAsStream ("data.txt"))
)
)
try {
val reader = new AdvancedInputReader(stream) with CapitalizedInputReaderTrait
reader.readLines().foreach(println)
} finally {
stream.close()
}
}
第二个例子包括转换大写、Base64 编码和压缩:
object StackableTraitsBigExample extends App{
val stream = new BufferedReader(
new InputStreamReader(
new BufferedInputStream(this.getClass.getResourceAsStream ("data.txt"))
)
)
try {
val reader = new AdvancedInputReader(stream) with
CapitalizedInputReaderTrait with
Base64EncoderInputReaderTrait with
CompressingInputReaderTrait
reader.readLines().foreach(println)
} finally {
stream.close()
}
}
这两个例子的输出将会和原来的例子一样。然而这里我们使用了混入组合,看起来则会更加清晰。同时我们也少了一个类,因为我们不再需要abstract decorator类。要理解修改是如何被应用的也很简单——这里将会遵循叠加特质被混入的顺序。
叠加特质遵循线性化规则
事实上在我们当前的例子中,修改从左到右被应用会被误解。这会发生的原因是,我们会将调用推到栈上,直到我们抵达 readLines 的基本实现,然后再以反向的顺序应用修改。
在后续的章节中我们将会看到更加深入的例子。
优点
装饰器给我们的应用带了个更多灵活性。它们不会修改原有的类,因此不会向原有的代码引入错误,也会节省更多代码的编写和维护。同时,它们可以避免我们对所创建的类的应用场景有所遗忘或没有遇见到。
在上面的例子中,我们展示了一些静态行为修改。然而,同样能够在运行时对实例进行动态装饰。
缺点
我们已经覆盖了使用装饰器的正面影响;然而,同样要支持的是对装饰器的过度使用仍然会带来问题。最终我们会得到大量很小的类,这会使我们的库难以使用,对领域知识的要求也更高。它们也会使初始化过程变得复杂,会需要一些其他的(创建型)设计模式,比如工厂或构建器。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.