CH05-AOP 与组件
AOP 与组件
有些时候在编程中,我们会发现一些代码片段重复出现在不同的方法中。有些情况下,我们会重构我们的代码将它们移到单独的模块中。有时这又是行不通的。有一些经典的日志和验证的例子。面向切面编程在这种情况下会很有帮助,我们将在本章的末尾来理解它。
组件是可复用的代码片段,它会提供多种服务并具有一定的要求。它们对避免代码重复极其有用,当然也能促进代码的复用。这里我们将会看到如何构建组件,以及 Scala 是如何让组件的编写和使用相比其他语言更加简单。
在熟悉面向切面编程和组件的过程中,我们将会贯穿以下主题:
- 面向切面编程
- Scala 中的组件
面向切面编程
面向切面编程,即 AOP(Aspect-oriented programming),解决了一个通用的功能,贯穿于整个应用,但是又无法使用传统的面向对象技术抽象成一个单独的模块。这种重复的功能通常被引用为“横切关注点(cross-cutting concerns)”。一个通用的例子是日志——通常日志记录器会在一个类中创建,然后在类的方法中调用这个记录器的方法。这有助于调试和追踪应用中的事件,但由于应用实际的功能没什么相关性。
AOP 推荐将横切关注点抽象并封装在它们自己的模块中。在下面的几个章节中我们将会深入了解 AOP 如何来改善代码并能够使横切关注点更易扩展。
实例
效率是每个程序中很重要的部分。很多情况下,我们可以对方法计时以查找应用中的瓶颈。让我们看一个示例程序。
我们将会看一下解析。在很多真实的应用中,我们需要以特定的格式读取数据并将其解析为我们代码中的对象。比如,我们拥有一个记录人员的小数据库并以 JSON 格式表示:
[
{
"firstName": "Ivan",
"lastName": "Nikolov",
"age": 26
},
{
"firstName": "John",
"lastName": "Smith",
"age": 55 },
{
"firstName": "Maria",
"lastName": "Cooper",
"age": 19
}
]
为了在 Scala 中表示这段 Json,我们需要定义模型。这会很简单而且只有一个类:Person。下面是代码:
case class Person(firstName:String, lastName:String, age:Int)
由于我们要读取 Json 输入,因此要对其进行解析。有很多解析器,每种或许会有各自不同的特性。在当前这个例子中我们将会使用 Json4s。这需要在pom.xml中配置额外的依赖:
<dependency>
<groupId>org.json4s</groupId>
<artifactId>json4s-jackson_2.11</artifactId>
<version>3.2.11</version>
</dependency>
上面这个依赖可以轻易转换为 SBT,如果读者更愿意使用 SBT 作为构建系统的话。
我们要编写一个拥有两个方法的类,用于解析前面所指定的格式的输入文件并返回一个Person对象列表。这两个方法实际上在做同一件事,但是其中一个会比另一个效率更高:
trait DataReader{
def readData():List[Person]
def readDataInefficiently():List[Person]
}
class DataReaderImpl extends DataReader{
implicit val formats = DefaultFormats
private def readUnitimed():List[Person] =
parse(StreamInput(getClass.getResourceAsStream("/users/json"))).
extract[List[Person]]
override def readData():List[Person] = readUntimed()
override def readDataInefficiently():List[Person] = {
(1 to 10000).foreach{
case num => readUntimed()
}
readUntimed()
}
}
特质DataReader扮演一个借口,对实现的使用也十分直接:
object DataReaderExample extends App{
val dataReader = new DataReadImpl
System.out.println(s"I just read the following data efficiently: ${dataReader.readData()}")
System.out.println(s"I just read the following data inefficiently: ${dataReader.readDataInefficiently()}")
}
运行这段代码将会得到和预期一样的结果。
上面的这个例子是很清晰的。然后,如果你想优化你的代码并查看运行缓慢的原因呢?上面的代码并没有提供这种能力,因此我们要做一些额外的工作来对应用计时并查看它是如何执行的。下一个小节我们将会同时展示不适用 AOP 和使用 AOP 的实现。
不使用 AOP
有一种基本的方法来进行计时。我们可以把println语句包裹起来,或者让计时称为DataReaderImpl类方法的一部分。通常,将计时作为方法的一部分会是一个更好的选择,因为这个方法可能会在不同的地方被调用,同时它们的性能也取决于传入的参数和一些其他因素。基于我们所说,这也就是DataReaderImpl类将会如何被重构以支持计时的方式:
class DataReaderImpl extends DataReader {
implicit val formats = DefaultFormats
private def readUnitimed():List[Person] = parse(StreamInput(getClass.getResourceAsStream("users.json"))).extract[List[Person]]
override def readData(): List[Person] = {
val startMillis = System.currentTimeMillis()
val result = readUnitimed()
val time = System.currentTimeMillis() - startMillis
System.err.println(s"readData took $time milliseconds")
result
}
override def readDataInefficiently():List[Person] = {
val startMillis = System.currentTimeMillis()
(1 to 1000) foreach {
case num => readUntimed()
}
val result = readUntimed()
val time = System.currentTimeMillis() - startMillis
System.err.println(s"readDataInefficiently took ${time} milliseconds.")
result
}
}
因此你会发现,代码会变得不可读,计时功能干扰了实际的功能。运行这段代码将会发现其中一个方法花费的更多的时间来执行。
在下节中将会展示如何使用 AOP 来提升我们的代码。
使用 AOP
向前面看到的一样,向我们的方法中添加计时代码将会引入重复代码同时也使代码难以追踪,尽管是一个很小的例子。现在,假如我们同样需要打印一些日志或进行一些其他活动。AOP 将会帮助分离这些关注点。
我们可以把DataReadImpl重置到一开始的状态,这时它不再打印任何日志。现在创建另一个名为LoggingDataReader的特质,它扩展自DataReader并拥有以下内容:
trait LoggingDataReader extends DataReader {
abstract override def readData(): List[Person] = {
val startMillis = System.currentTimeMillis()
val result = super.readData()
val time = System.currentTimeMillis() - startMillis
System.err.pringln(s"readData took $time milliseconds.")
result
}
abstract override def readDataInefficiently():List[Person] = {
val startMillis = System.currentTimeMillis()
val result = super.readDataInefficiently()
val time = System.currentTimeMillis() - startMillis
System.err.println(s"readDataIneffieciently took $time milliseconds.")
result
}
}
这里有趣的地方在于abstract override修饰符。它提醒编译器我们会进行**叠加性(stackable)**的修改。如果我们不使用该修饰符,编译将会失败:
Error:(9, 24) method readData in trait DataReader is accessed from super. It may not be abstract unless it is overridden by a member declared `abstract' and `override'
val result = super.readData()
^
Error:(17, 24) method readDataInefficiently in trait DataReader is accessed from super. It may not be abstract unless it is overridden by a member declared `abstract' and `override'
val result = super.readDataInefficiently()
^
现在让我们的新特质使用之前提到过的混入组合,在下面的程序中:
object DataReaderAOPExample extends App{
val dataReader = new DataReaderImpl with LoggingDataReader
System.out.println(s"I just read the following data efficiently: ${dataReader.readData()}")
System.out.println(s"I just read the following data inefficiently: ${dataReader.readDataInefficiently()}")
}
运行这段代码将会得到带有计时信息的输出。
使用 AOP 的优势是很明显的——实现不会被其他代码污染。再者,我们可以以同样的方式添加更多修改——更多的日志、重试逻辑、回滚等等。所有这些都可以通过创建一个新特质并扩展DataReader接口,然后在创建具体实现的实例中混入即可。当然,我们可以同时应用多个修改,它们将会按顺序执行,而顺序将会遵循线性化原则。
组件
组件作为应用的一部分意味着会与应用的其他部分进行结合。它们应该是可复用的,以便减少代码的重复。组件通常拥有接口,用于描述它们提供的服务或者它们依赖的一些服务或是其他组件。
在大型的应用中,我们通常会看到多个组件会被集成在一起工作。要描述一个组件提供的服务通常会很直接,这会使用接口的帮助来完成。与其他组件进行集成则可能需要开发者完成更多的工作。这通常会通过将需要的组件的接口作为参数来传递。然而,加入有一个大型的应用需要很多的组件;完成这些链接需要花费时间和精力。进一步,每次需要一个新的需求,我们也需要进行大量的重构。多重继承可以作为参数传递的替代方案;然而,首先需要语言支持这种方式。
像 Java 语言中用来链接组件的流行做法是使用依赖注入。Java 中拥有这样的库用于在运行时将组件注入。
丰富的 Scala
本书中我们已经提到多次,Scala 比简单的面向对象语言拥有更强的表现力。我们已经讨论了一些概念,比如:抽象类型、自类型、统一化、混入组合。这支持我们创建通用的代码,特定的类,并能以相同的方式来处理对象、类、变量或函数,并实现多重继承。使用不同的组合用法可以让我们编写期望的模块化代码。
实现组件
作为一个例子,假如我们尝试构建一个做饭机器人。我们的机器人能够查找食谱并制作我们需要的菜肴。我们可以通过创建新的组件来给机器人添加新的功能。
我们期望代码是模块化的,因此有必要对功能进行拆分。下面的图示展示了机器人的雏形以及各组件间的关系:
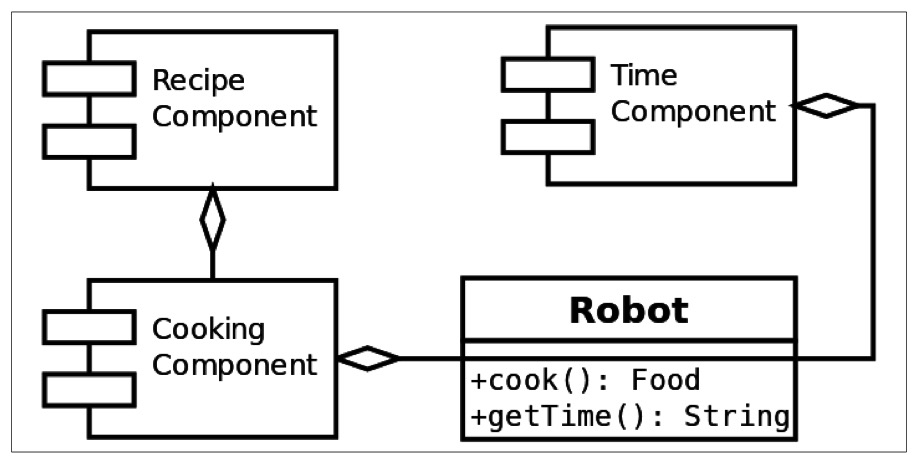
首先让我们给不同的组件定义接口:
trait Time{
def getTime():String
}
trait RecipeFinder{
def findRecipe(dish:String):String
}
trait Cooker{
def cook(what:String): Food
}
这个例子中需要一个简单的Food类:
case class Food(name:String)
一旦这些完成后,我们就可以开始创建组件了。首先是TimeConponent,而Time的实现是一个嵌套类:
trait TimeConponent{
val time:Time
class TimeImpl extends Time{
val formatter = DateTimeFormatter.ofPattern("HH:mm:ss")
override def getTime():String =
s"The time is: ${LocalDateTime.now.format(formatter)}"
}
}
现在以类似的方式实现RecipeComponent,下面是组件和实现的代码:
trait RecipeComponent{
val recipe:RecipeFinder
class RecipeFinderImpl extends RecipeFinder{
override def findRecipe(dish:String):String = dish match {
case "chips" => "Fry the potatoes for 10 minutes."
case "fish" => "Clean the fish and put in the oven for 30 minutes."
case "sandwich" => "Put butter, ham and cheese on the bread, toast and add tomatoes."
case _ => throw new RuntimeException(s"${dish} is unknown recipe.")
}
}
}
最终,我们需要实现CookingComponent。它实际上会使用RecipeComponent,下面是它的实现:
trait CookingComponent{
this: RecipeComponent =>
val cooker:Cooker
class CookerImpl extends Cooker {
override def cook(what:String):Food = {
val recipeText = recipe.findRecipe(what)
Food(s"We just cooked $what using the following recipe: '$recipeText'.")
}
}
}
现在所有的组件都各自实现了,我们可以将它们组合来创建我们的机器人。首先创建一个机器人要使用的组件注册表:
class RobotRegisty extends TimeComponent with ReipeComponent with CookingComponent {
override val time:Time = new TimeImpl
override val recipe:RecipeFinder = new RecipeFinderImpl
override val cooker:Cooker = new CookerImpl
}
现在创建机器人:
class Robot extends RobotRegisty{
def cook(what:String) = cooker.cook(what)
def getTime() = time.getTime()
}
最后使用我们的机器人:
object RobotExample extends App {
val robot = new Robot
System.out.println(robot.getTime())
System.out.println(robot.cook("chips"))
System.out.println(robot.cook("sandwich"))
}
上面的例子中,我们看到了 Scala 不使用外部库来实现依赖注入的方式。这种方式真的很有用,它会避免我们的构造器过大,也不需要扩展过多的类。更进一步,各个组件可以很好的分离,可测试,并能清晰定义各自的依赖。我们同样看到了可以使用一些依赖其他组件的组件来递归的添加需求。
上面这个例子实际上展示了蛋糕模式。一个好的特性是,依赖的存在会在编译期间进行求值,而不像 Java 那些流行的库一样在运行时进行求值。
蛋糕模式同样也存在缺点,我们会在稍后关注所有特性——无论好坏。那里我们将会展示组件如何可以被测试。
这个蛋糕模式例子实质上很简单。在真是的应用中,我们可能需要一些组件依赖于其他组件,而那些组件有拥有各自的依赖。在这些情况下,事情会变得很复杂。我们将会本书的后续部分更好更详细的展示这一点。
总结
本章我们探讨了 Scala 中的 AOP,现在我们知道如何将那些本不需要出现在模块中的代码进行拆分。这将有效减少代码重复并使我们的程序拥有不同的专用模块。
我们同样展示了如何使用本书前面部分讨论的技术来创建可复用的组件。组件提供接口并拥有指定的需求,这可以很方便的使用 Scala 的丰富特性。这与设计模式很相关,应为它们拥有相同的目标——使代码更好,避免重复,易于测试。
本书的后续章节我们将会讨论一些具体的设计模式,及其有用特性和用法。我们将会以创建型模式开始,它们由四人帮(Gof)创建,当然,这里会以 Scala 的视角。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.