Flink Type System
为什么以及如何构建一个类型系统。
Flink 在内部构建了一套自己的类型系统,因为 Flink 需要推导那些在分布式计算过程中被传输和存储的数据的相关类型信息。就像数据库对表结构的引用一样。在大多数情况下,Flink 均使用自己的这套类型系统来无缝的推导类型信息。基于丰富的类型类型信息,Flink 可以完成更多功能的实现,如:
- 使用 POJO 类型,并通过对其字段名的引用来执行 grouping、joining、aggregating。类型信息能够帮助 Flink 在早期完成检查(拼写错误或类型兼容性),而非在运行时导致失败。
- Flink 对类型信息了解越多,序列化和数据布局结构则会更好。这对于 Flink 中内存的应用范式是非常重要的(尽可能在堆内外处理序列化数据,以使得序列化过程变得廉价)。
- 避免用户在大多数情况下对序列化框架的担心,同时避免对类型的手动注册过程。
类型层级
- Basic
- Java Primitive Types
- void/String/Date/BigDecimal/BigInteger
- Array
- Array of Primitive
- Array of Object
- Composite
- Java Tuple, max 25 fields
- Scala case class/tuple, max 22 fields
- Row, tuples with any number fields
- POJO, bean-like class
- Auxiliary
- Option/Either/List/Map…
- Generic
- Using Kryo
抽象结构
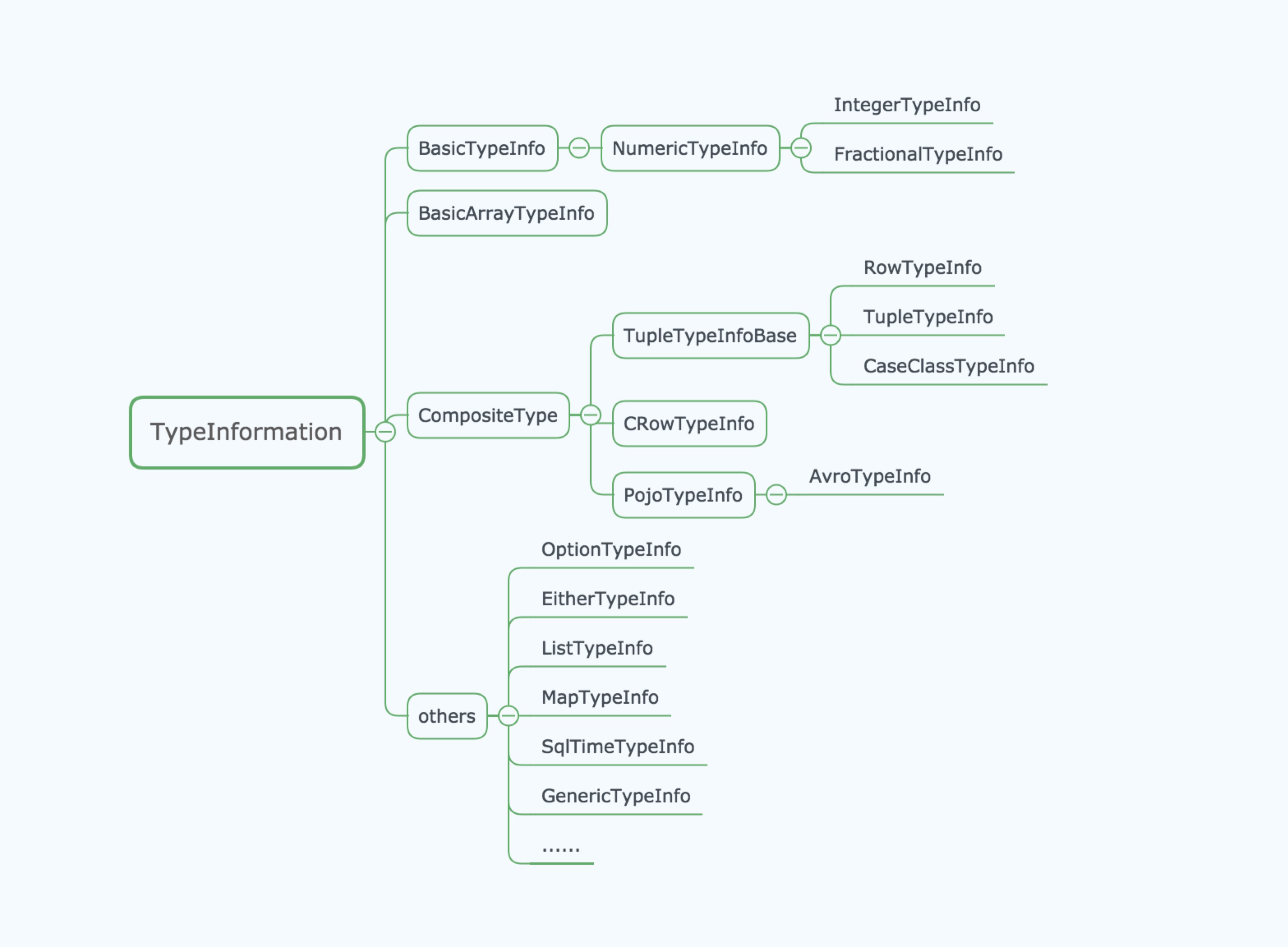
可以看到,抽象结构与类型层级定义基本对应。TypeInformation 是所有类型的基类。
module: flink-core
package: org.apache.flink.api.common.typeinfo
Comments on TypeInformation class:
- 这是 Flink 类型系统的核心类。对于一个用户函数来说(UDF),Flink 需要一个类型信息来作为该函数的输入输出类型。该类型信息类作为一个工具来生成对应类型的序列化器和比较器,并用于执行语义检查,比如当一些字段在作为 joing 或 grouping 的键时,检查这些字段是否在该类型中存在。
- 该类型信息同时连接了编程语言对象模型和逻辑扁平模式(ligical flat schema)。它将类型的字段映射到扁平模式的列(字段)。
类型提取
TypeExtractor 类可以根据方法签名、子类信息等蛛丝马迹自动提取或恢复类型信息。
module: flink-core
package: org.apache.flink.api.java.typeutils s Comments on TypeExtractor class:
一个对类进行反射分析的工具类,用于检测转换函数的返回类型。 该类可以从 function、operator、Class、实例等对象中提取类型信息。
由于 Java 中的类型擦除机制,自动提起并不是很有效,因此有些情况下(比如由 URLClassLoader 动态加载的类)仍然需要手动处理。比如下面的示例中使用 returns 方法来声明返回类型:
inputDS
.groupBy(gourpKeys:_*)
.reduce(new DistinctReduce)
.setCombineHint(CombineHint.HASH)
.name(newName="distinct")
.returns(inputDS.getType)
returns 方法接收 3 种类型的参数:
- 字符串描述的类名,如 “String”。
- 用于泛型类型参数的 TypeHint。
- Java 原生 Class 对象。
类型注册
ExecutionEnvironment 提供的 registerType 方法可以用来向 Flink 注册子类信息(Flink 认识父类,但不一定认识子类的一些独特特性,因此需要注册)。以 Flink-ML 为例:
def registerFlinkMLTypes(env:ExecutionEnvironment):Unit = {
// Vector types
env.registerType(classOf[org.apache.flink.ml.math.DenseVector])
env.registerType(classOf[org.apache.flink.ml.math.SparseVector])
// Matrix types
env.registerType(classOf[org.apache.flink.ml.math.DenseVector])
env.registerType(classOf[org.apache.flink.ml.math.SparseVector])
// Breeze Vector types
env.registerType(classOf[breeze.linalg.DenseVector[_]])
env.registerType(classOf[breeze.linalg.SparseVector[_]])
}
在 registerType 方法内部,会使用 TypeExtractor 来提取类型信息。上面注册过程中调用的方法是:
public void registerType(Class<?> type) {
if(type == null) {
throw new NullPointException(...);
}
TypeInformation<?> typeInfo = TypeExtractor.createTypeInfo(type);
if(typeInfo instanceof PojoTypeInfo) {
config.registerPojoType(type);
} else {
config.registerKryoType(type);
}
}
可以发现,获取到的类型信息属于 PojoTypeInfo 及其子类,那么将其注册到一起;否则统一交给 Kryo 去处理,Flink 并不过问(这种情况下性能会变差)。
类型声明
通过 TypeInformation.of() 方法可以非常方便的创建类型信息对象。
- 对于非泛型类,直接传入 Class 对象即可:
Outer o = new Outer(a:10, new Inner(x:4L), (short) 12); PojoTypeInfo<Outer> typeInfo = (PojoTypeInfo<Outer>) TypeInformation.of(Outer.class); - 对于泛型类,需要借助 TypeHint 来保存泛型类型信息。
final TypeInfomation<Tuple2<Integer,Integer>> resultType =
TypeInformation.of(new TypeHint<Tuple2<Integer,Integer>>(){});
- TypeHint 的原理是创建一个匿名子类,运行时 TypeExtractor 可以通过
getGenericSuperclass().getActuralTypeArguments()方法来回去保存的实际类型。
- 预定义常量。如 BasicTypeInfo 中定义了一系列常用原生类型的类型信息实例。或者直接使用更简单的 Types 类。
- 自定义 TypeInfo 和 TypeInfoFactory。
- 通过自定义 TypeInfo 为任意类提供 Flink 原生内存管理(而非 Kryo),可令存储更紧凑,运行时也更高效。
- 开发者在自定义类上使用 @TypeInfo 注解,随后创建相应的 TypeInfoFactory 并覆盖 createTypeInfo 方法。
- 注意需要继承 TypeInformation 类,为每个字段定义类型,并覆盖元数据方法,例如 isBasicType、isTupleType、元数(对于一维的 Row 类型,等于字段的个数)等等,从而为 TypeExtractor 提供决策依据。
类型序列化
Flink 自带了很多 TypeSerializer 子类,大多数情况下各种自定义类型都是常用类型的排列组合,因而可以直接复用。
如果不能满足,可以继承 TypeSerializer 及其子类来实现自己的特定类型的序列化器。
Kryo 序列化
陷阱与缺陷
- Lambda 函数的类型提取?
- Kryo 的 JavaSerializer 在 Flink 下存在 Bug?
类型机制与内存管理
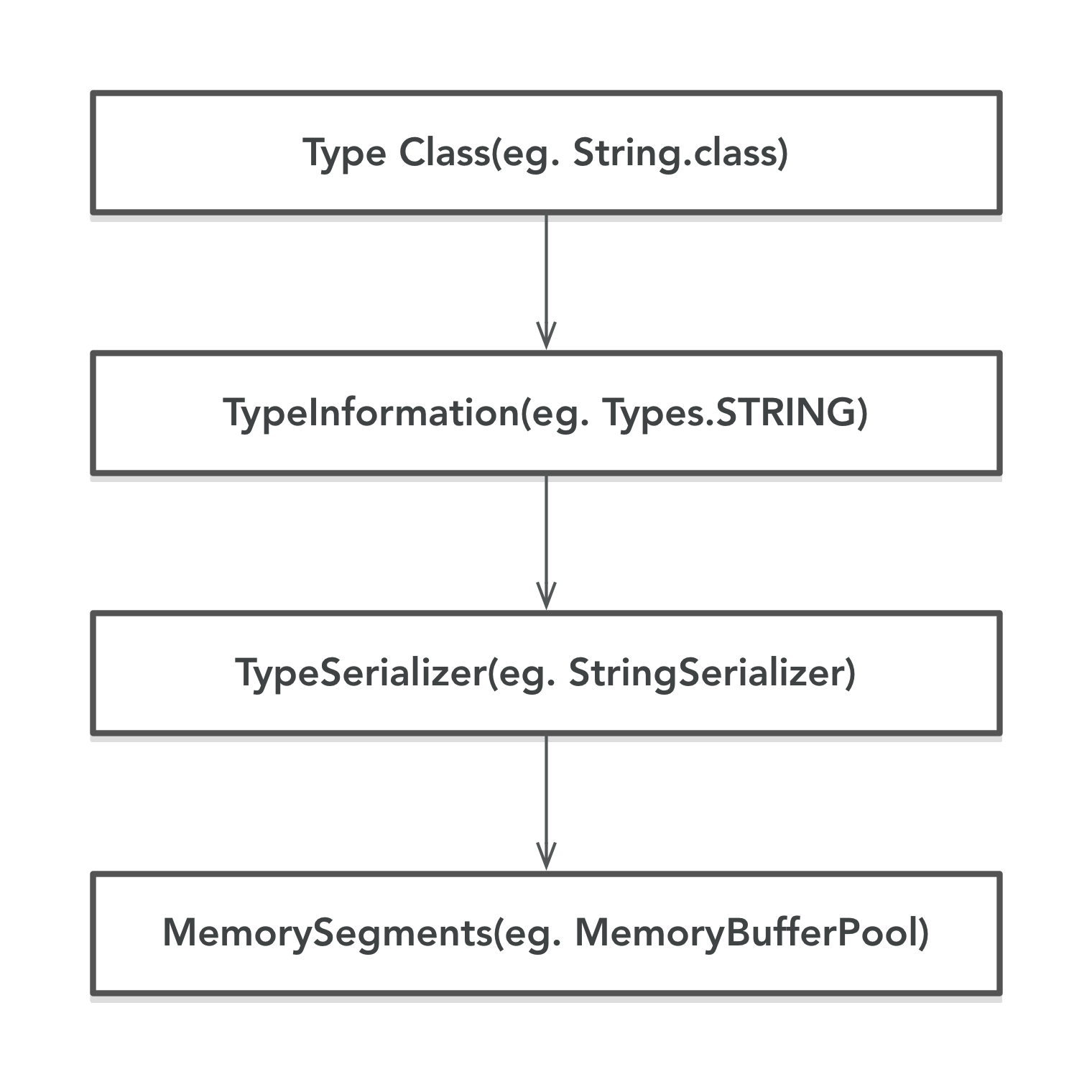
下面以 StringSerializer 为例,来看下 Flink 是如何紧凑管理内存的。下面是 StringSerializer 的序列化方法:
@Override
public void serialize(String record, DataOutputView target) throws IOException {
StringValue.writeString(record, target);
}
然后是具体的序列化过程:
public static final void writeString(CharSequence cs, DataOutput out) thorws IOException {
if(cs != null) {
// the length we write is offset by one, because a length of zero indicates a null value
int lenToWrite = cs.length() + 1;
if(lenToWrite < 0) {
throw new IllegalArgumentException();
}
// write the length, variable-length ecdoded
while(lenToWrite >= HIGH_BIT) {
out.write(b:lenToWrite | HIGH_BIT);
lenToWrite >>>= 7;
}
out.write(lenToWrite);
for(int i=0; i<cs.length(); i++) {
int c = cs.charAt(i);
while(c >= HIGH_BIT) {
out.write(b:c | HIGH_BIT);
c >>>= 7;
}
out.write(c);
}
} else {
out.write(b:0);
}
}
可以看到,Flink 对于内存管理是非常细致的,层次分明,代码也容易理解。
Reference
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.