This the multi-page printable view of this section. Click here to print.
Udf Modeling
1 - Transport UDF at Linkedin
如何使用户能够仅编写一次 UDF,并在任何引擎中复用,同时又不牺牲性能。
Transport UDF at Linkedin
在统一数据视图一文中,我们介绍了 Dali 的新型架构,它使得数据和逻辑在 Linkedin 的各种环境中能够被无缝访问和共享。Dali 通过采用物理与逻辑独立的原则来实现这一目标。物理独立性指的是用户能够透明的访问数据,无论其物理位置、存储格式、分区策略,甚至是跨机房的分片策略。逻辑独立性指的是 Dali 的用户自定义逻辑能够用于任何引擎或数据处理框架,而无论其语言接口或数据处理能力如何。作为一个数据和逻辑的共享层,Dali 致力于实现这些目标,同时致力于为其服务的关键任务系统提供几乎相同的性能保证。
这里将介绍逻辑独立性的实现原理:可翻译和可移植的 UDF,或者称为可传输的 UDF。
Dali 中的逻辑以 SQL 视图的形式表示。一个 SQL 视图由一系列应用在输入数据集(基本数据集或其他视图)的逻辑转换构成。在 Linkedin,Dali 视图广泛用于汇总和聚合数据、清除数据噪音、提取感兴趣的或相关信息、应用隐私过滤器,或用于组合来自不同源头的数据以从这些数据中创建洞察力和业务价值。UDF 被广泛的应用于当单纯的 SQL 无法表达应用需要的转换逻辑时,并且通常涉及诸如 Java 这种命令式语言中所表达的相当复杂的操作。只有在视图逻辑和 UDF 定义都能够跨引擎移植时,才能实现真正的逻辑独立性。虽然用于表达视图转换的关系代数表达式可以映射到不同数据处理引擎的不同声明性语言结构,但 UDF 定义却不同,它是命令式且不透明的,因此这也是挑战所在。
UDF 的 API 在数据处理引擎之间存在很大的差异,因为这些 API 必须考虑每个引擎所选择的 内部数据表示,并且必须提供 将数据表示连接到关系模式的能力。这种差异则给应用程序开发人员带来了负担,一旦需要进行引擎迁移或者跨引擎共享相同的逻辑,他们必须学习 UDF 的 API 和每个引擎的数据模型,然后在不同的引擎上以不同的 API 来重新实现相同的逻辑。这引入了我们称之为“UDF 非规范化”的概念,即有害的冗余,这会对生产力和工艺产生负面的影响。
基于这些挑战,问题则变成了:我们如何使用户能够仅编写一次 UDF,并在任何引擎中复用,同时又不牺牲性能。为了解决这个问题,我们将可翻译、可移植的 UDF 构建为一个框架,名为 Transport。虽然在一开始这似乎是一个疯狂而模糊的想法,但到目前为止,我们已经有很多用户在生产中使用了这些功能,我们目前覆盖了 3 个引擎(Hive/Presto/Spark)和一种数据格式(Avro),并且仍在扩展其他处理引擎。
Transport 是一套 API 和框架。用户使用可翻译的 UDF API 来实现 UDF,然后框架再将这些 UDF 转换为各种目标引擎特定的原生 UDF。比如,用于可以基于 Transport UDF API 实现自己的 UDF,框架可以透明的将这些 UDF 转换为原生的 Hive UDF,就像用户直接编写的就是 Hive UDF。现在,如果用户想要在其他引擎中使用这些 UDF 也同样没有问题。比如,如果用户想要在 Presto 查询中使用相同的 UDF,框架同样可以透明的将这些 UDF 转换为 Presto 原生的 UDF,就像用户直接编写的就是 Presto UDF 一样。
在解释 Transport 的工作原理之前,我们先来浏览一下该想法背后的动机,主要有两点:UDF API 的差异性和复杂性。
UDF API 的差异性
数据处理世界中有很多引擎,每个都有各自的特性以满足某个特定的应用场景。同样,每个引擎也都拥有与其他引擎完全不同的 UDF API,这里具体列举其中一些主要的不同点,包括 3 个比较流行的引擎:Hive、Presto、Spark。
UDF 类型验证与推断
UDF API 通常会为用户提供一些手段来指定 UDF 预期的数据类型(如类型验证)、UDF 的输出类型与输入类型的关联关系(类型推断)。比如 Presto 的 UDF API 使用类型签名来描述 UDF 对类型的预期要求,而 Hive 和 Spark 则要求用户通过遍历给定的类型对象树来编写命令式的代码来表示类型验证和推断。
引擎内部数据模型
不同的平台使用不同的数据模型来表示执行引擎中处理的数据,同样也会将这些数据模型直接暴露给 UDF API。比如,Presto 的 UDF 使用 Presto 的 Type Object、Block、Slice、Long、boolean、double 等数据类型来描述数据,而 Hive 的 UDF 使用 ObjectInspectors 和 Objects。其他引擎也类似。
UDF 的定义 API
此外,用户定义 UDF 的方式也随着引擎的不同的不同。比如,Presto 使用特殊的类型注解来声明一个表示 UDF 的类。Hive UDF 类则需要继承 GenericUDF 抽象类,而 Spark UDF 实现则使用 SQL API 或 Expression API。
UDF 的 API 特性
最后,UDF API 提供的特性集也不尽相同。比如,Hive UDF 提供了将文件添加到 MapReduce 分布式缓存的钩子,允许在不同工作程序上执行的 UDF 处理这些文件。Presto 或 Spark 的 UDF 则不提供这种功能。即使多个引擎中都存在某个功能,其在 API 中的表达方式也会有所不同。Presto UDF 允许用户声明哪些参数可以为空,而 Hive 和 Spark UDF 将 null 直接委托给用户。Presto 通过在使用相同名称的情况下多次实现 UDF 来实现 UDF 重载。在 Hive 和 Spark 中,用户使用相同的类,但需要手动检查输入类型是否是符合预期的类型。
UDF API 的复杂性
当前引擎的 API 具有不同程度的复杂性和对 UDF 开发者技能集的期望。比如,Hive UDF 要求开发者理解 Object 和 ObjectInspector 模型。期望用户在 UDF 初始化时捕获输入的 ObjectInspectors,并以树遍历的方式逐级检查来验证它是否符合预期类型。此外,还期望用户通过捕获输入的 ObjectInspectors 子树并从中创建新的 ObjectInspectors 树来显式绑定参数,以作为输出 ObjectInspectors 返回。比如 UDF 期望类型为 Map[String, Array[K]] => Map[K, K],在查询执行时,会使用 Map[String, Array[K]] 来调用 UDF,下面的对象检查器树会被传给 UDF 的初始化方法:
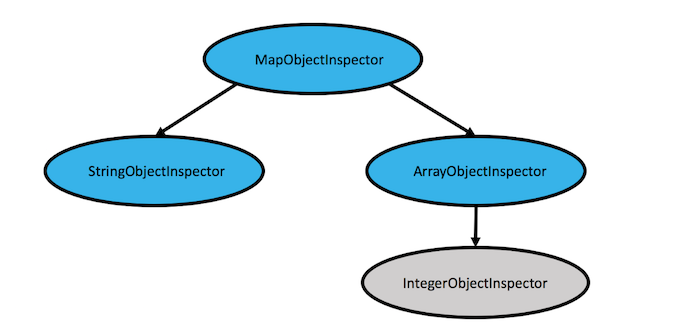
需要由开发者来完成树遍历的工作,验证上面的蓝色节点是否符合用户预期,然后再捕获灰色节点的值(或子树),这里是 K,然后通过将绿色节点添加到从 K 子树捕获的内容来构建下面的树,从而构造返回类型,如下图所示:
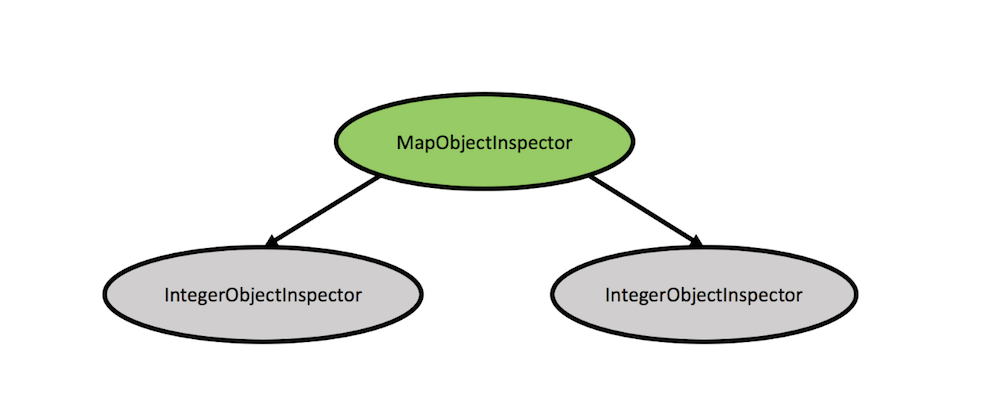
此外在 Hive 中,甚至是单个类的 ObjectInspectors(如 StringObjectInspector)也具有该类相同顶级 ObjectInspector 类的变体和不同实现。编写 Hive UDF 的用户必须了解这些差异,并且不同的实现不可互换。处理这些可互换性检查和保证时会带来大量的代码复杂性。
在 Presto UDF 中可以发现另一种形式的 API 复杂性。Presto UDF 允许用户通过 Block API 处理容器数据类型,如 Array、Map、Struct,Block API 是用于操作字节数组的 API。因此,用户会接触到字节数组内复杂数据类型的物理布局,并且必须编写多个步骤的低级操作来表示在这些容器类型上的简单高级操作。另一个例子是使用依赖项注入来解析与泛型类型数组相对应的具体运行时类型,以及解析 UDF 依赖项。此外,当 UDF 期望顶级泛型类型(即它可以采用任何类型)时,必须为每个匹配的顶级具体类型的每个实例重新实现,实现数量的增加使得泛型参数的数量呈指数级增长。虽然通过编写代码生成的 UDF 可以缓解这个问题,但也仍然是一种复杂的方法。
可传输的 UDF
在物理和逻辑独立性的驱动下,以及 API 差异和复杂性问题的推动下,我们设计的 Transport UDF API,它支持用户专注于 UDF 逻辑,而不是实现和遵守特定于平台的接口。用户编写一次逻辑就可以在任何平台上运行。
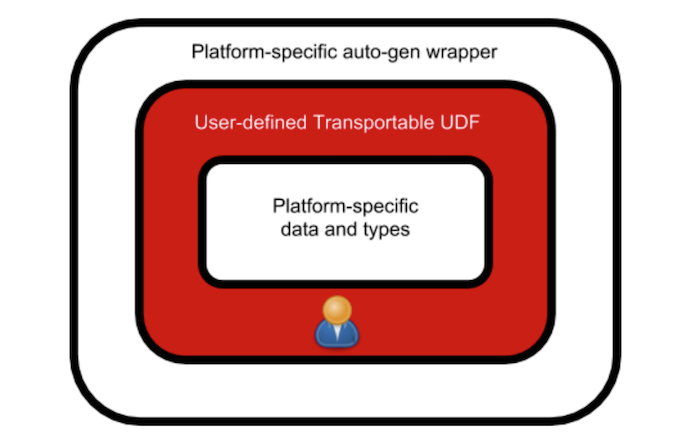
高阶想法是为用户提供一个用于实现 UDF 的标准数据 API。该标准数据 API 可以由任何平台、使用其在原生 UDF 中使用的原生数据类型来实现。比如,Map 对象将在 Presto 中显示为 PrestoMapType 以及 Block 数据类型。在 Hive 中则是 MapObjectInspector 和一个 Object。这些标准数据 API 被操作仅可传输 UDF API,来表达标准数据上的实际逻辑。
可传输 UDF API 可以通过类型签名来操作泛型容器类型,如 Array[T] 或 Map[K,V]。可传输 UDF 被构造为抽象类,并被表达实际逻辑的具体 UDF 继承。最后,可以从自动生成的特定于平台的包装器来调用这些 UDF API。这意味着,可传输 UDF API 实现是一个独立于平台的中间表示逻辑。它也有两个特定于平台的外观,可以很容易的提供给用户。一个外观向下,这是特定于平台的标准数据 API 实现,另一个外观向上,这是特定于平台的自动生成的包装器。该家头如图所示:
示例
如上所述,用户所要做的就是定义可传输 UDF。在下面的例子中,接收两个数组作为输入来构造一个 Map——第一个数组作为 Map 的键,第二个数组作为 Map 的值。
public class MapFromTwoArraysFunction
extends StdUDF2<StdArray, StdArray, StdMap>
implements TopLevelStdUDF {
private StdType _mapType;
@Override
public List<String> getInputParameterSignatures() {
return ImmutableList.of("array(K)", "array(V)");
}
@Override
public String getOutputParameterSignature() {
return "map(K,V)";
}
@Override
public void init(StdFactory stdFactory) {
super.init(stdFactory);
_mapType = getStdFactory().createStdType(getOutputParameterSignature());
}
@Override
public StdMap eval(StdArray a1, StdArray a2) {
if (a1.size() != a2.size()) {
return null;
}
StdMap map = getStdFactory().createMap(_mapType);
for (int i = 0; i < a1.size(); i++) {
map.put(a1.get(i), a2.get(i));
}
return map;
}
@Override
public String getFunctionName() {
return "map_from_two_arrays";
}
@Override
public String getFunctionDescription() {
return "A function to create a map out of two arrays";
}
}
在上面的例子中,StdMap 和 StdArray 作为接口为 Map 和 Array 对象提供了高阶操作方法。基于 UDF 所要执行的引擎,这些接口会以不同的方式来处理特定引擎的原生数据类型。getStdFactory() 方法会以给定的数据类型来创建对象,比如上面的例子中,Map 的键类型以第一个数组的元素类型为准,Map 的值类型以第二个数组的元素类型为准。StdUDF2 是一个抽象类,表示一个接收两个参数的 UDF,被具体 UDF 的输入输出类型来参数化。
总结
Transport 作为定义 UDF 的 API 和框架,在不牺牲任何性能的同时能够在不同平台上像使用原生 UDF 一样来复用 UDF。这是实现物理与逻辑独立性目标的第一步。被当前 UDF 的差异性和复杂性所驱动。在 LinkedIn,事实证明,可传输 UDF 是提供开发人员工作效率的强大工具,使他们能够共享 UDF 逻辑并确保跨引擎的数据处理一致性。
UDF 的其他应用场景与问题
统一数据处理 API:Apache Beam
在 Apache Beam 的技术愿景中,希望可以使用任意语言 Beam SDK 编写 Beam Pipeline,然后可以运行在任何 Runner 中(每个 Runner 对应一个底层的大数据引擎,例如 Flink Runner、Spark Runner)的能力。设计中通过两个可移植的层来实现这个目标:
- Runner API 层提供了 SDK 和 Runner 无关的 Pipeline 定义。
- Fn API 层,允许 Runner 调用使用特定语言 SDK 编写的 UDF(用户自定义函数)。
通用数据处理框架:Apache Nifi
Nifi 中预定义了大量的 Processor,并支持自定义。Processor 本身仍然可以被看做是扩展了 Nifi 执行上下文的 Function。
Nifi 提供了表达式来操作 FlowFile 的属性,用于配置处理器。表达式有 Antlr 解析,其中的执行函数由 Evaluator 类建模,Evaluator 的建模过程也与 Function 抽象类似,值得借鉴。
流式计算引擎:Apache Flink
Flink 中将函数分为 3 类:
- Scalar Functions,将零个、一个或多个标量值转换到一个标量值。
- Table Functions,将零个、一个或多个标量值转换到多个数据行。
- Aggregation Functions,将一个表转换为一个标量值。
用户自定义并注册函数之后,可以直接在 Table、SQL API 中使用。
流式计算引擎:Aliyun(Antfin) MaxCompute
MaxCompute 与 Flink 类似将函数分为三类,但通过注解或反射来获得函数的类型签名。
规则引擎:Drools
如果业务逻辑复杂,通常会使用规则引擎来代替大量的 if-else 语句。在 Drools 规则定义中,when 部分的断言函数和字段引用、then 部分的数据操作函数都需要应用到函数建模来实现业务特定的计算逻辑。
when
$s : Order(amout > 500 && amout <= 1000)
then
$s.setScore(500);
update($s);
消息路由规则:Apache Camel
Camel 中提供了各种 DSL 或 XML 配置来完成路由规则的定义,如:
from("file:src/data?noop=true")
.choice()
.when(xpath("/person/city = 'London'"))
.to("file:target/messages/uk")
.otherwise()
.to("file:target/messages/others");
对函数的应用主要集中在 when 部分的数据引用与值判定,这里使用的是 xpath 表达式。
有限状态机
在有限状态机中,需要定义状态的迁移条件,迁移条件中包含对领域模型的数据引用、求值与判定,同样需要使用函数建模。
业务应用集成
总的来说,需要在各个层次和维度上,面向业务场景或业务层框架提供一组通用的函数建模 API,以提升业务开发和框架开发的效率。比如:
- 定义较为宽泛的类型系统,以支持对各种引擎、框架中 UDF 的集成。
- 为原生类型提供预定义的函数(或称为算子),以便直接引用来(动态)构建更加复杂的函数。
- 支持基于原生类型构建复杂类型,并为这些复杂类型定义函数。
- 支持直接以代码形式,定义、注册、调用类型安全的函数。
- 支持以字符串表达式形式来定义函数,以满足动态(定义、更新、执行)场景。
- 支持以类似 IDE GUI Plugin 插件的形式定义、引用、执行函数。
- 支持函数式的、类型安全的链式调用、组合、柯里化。
- 提供良好的扩展机制,以优雅的、类型安全的方式扩展、引用函数。
- 提供良好的集成机制,以简便的方式将函数适配到其他框架、引擎以实现复用。
- 提供良好的测试机制,使得函数可测试、且能简化测试过程。
References
2 - Flink Type System
为什么以及如何构建一个类型系统。
Flink 在内部构建了一套自己的类型系统,因为 Flink 需要推导那些在分布式计算过程中被传输和存储的数据的相关类型信息。就像数据库对表结构的引用一样。在大多数情况下,Flink 均使用自己的这套类型系统来无缝的推导类型信息。基于丰富的类型类型信息,Flink 可以完成更多功能的实现,如:
- 使用 POJO 类型,并通过对其字段名的引用来执行 grouping、joining、aggregating。类型信息能够帮助 Flink 在早期完成检查(拼写错误或类型兼容性),而非在运行时导致失败。
- Flink 对类型信息了解越多,序列化和数据布局结构则会更好。这对于 Flink 中内存的应用范式是非常重要的(尽可能在堆内外处理序列化数据,以使得序列化过程变得廉价)。
- 避免用户在大多数情况下对序列化框架的担心,同时避免对类型的手动注册过程。
类型层级
- Basic
- Java Primitive Types
- void/String/Date/BigDecimal/BigInteger
- Array
- Array of Primitive
- Array of Object
- Composite
- Java Tuple, max 25 fields
- Scala case class/tuple, max 22 fields
- Row, tuples with any number fields
- POJO, bean-like class
- Auxiliary
- Option/Either/List/Map…
- Generic
- Using Kryo
抽象结构
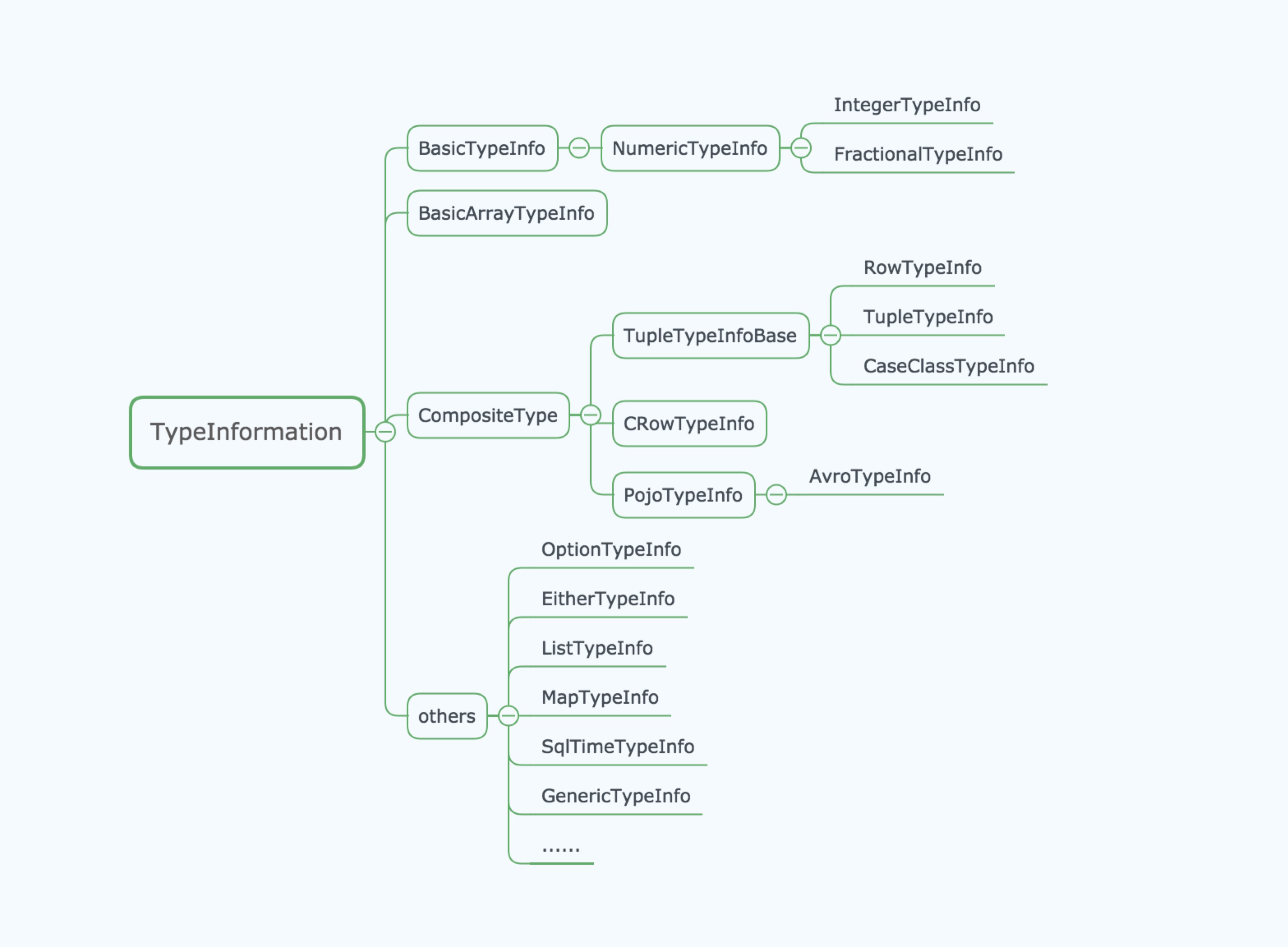
可以看到,抽象结构与类型层级定义基本对应。TypeInformation 是所有类型的基类。
module: flink-core
package: org.apache.flink.api.common.typeinfo
Comments on TypeInformation class:
- 这是 Flink 类型系统的核心类。对于一个用户函数来说(UDF),Flink 需要一个类型信息来作为该函数的输入输出类型。该类型信息类作为一个工具来生成对应类型的序列化器和比较器,并用于执行语义检查,比如当一些字段在作为 joing 或 grouping 的键时,检查这些字段是否在该类型中存在。
- 该类型信息同时连接了编程语言对象模型和逻辑扁平模式(ligical flat schema)。它将类型的字段映射到扁平模式的列(字段)。
类型提取
TypeExtractor 类可以根据方法签名、子类信息等蛛丝马迹自动提取或恢复类型信息。
module: flink-core
package: org.apache.flink.api.java.typeutils s Comments on TypeExtractor class:
一个对类进行反射分析的工具类,用于检测转换函数的返回类型。 该类可以从 function、operator、Class、实例等对象中提取类型信息。
由于 Java 中的类型擦除机制,自动提起并不是很有效,因此有些情况下(比如由 URLClassLoader 动态加载的类)仍然需要手动处理。比如下面的示例中使用 returns 方法来声明返回类型:
inputDS
.groupBy(gourpKeys:_*)
.reduce(new DistinctReduce)
.setCombineHint(CombineHint.HASH)
.name(newName="distinct")
.returns(inputDS.getType)
returns 方法接收 3 种类型的参数:
- 字符串描述的类名,如 “String”。
- 用于泛型类型参数的 TypeHint。
- Java 原生 Class 对象。
类型注册
ExecutionEnvironment 提供的 registerType 方法可以用来向 Flink 注册子类信息(Flink 认识父类,但不一定认识子类的一些独特特性,因此需要注册)。以 Flink-ML 为例:
def registerFlinkMLTypes(env:ExecutionEnvironment):Unit = {
// Vector types
env.registerType(classOf[org.apache.flink.ml.math.DenseVector])
env.registerType(classOf[org.apache.flink.ml.math.SparseVector])
// Matrix types
env.registerType(classOf[org.apache.flink.ml.math.DenseVector])
env.registerType(classOf[org.apache.flink.ml.math.SparseVector])
// Breeze Vector types
env.registerType(classOf[breeze.linalg.DenseVector[_]])
env.registerType(classOf[breeze.linalg.SparseVector[_]])
}
在 registerType 方法内部,会使用 TypeExtractor 来提取类型信息。上面注册过程中调用的方法是:
public void registerType(Class<?> type) {
if(type == null) {
throw new NullPointException(...);
}
TypeInformation<?> typeInfo = TypeExtractor.createTypeInfo(type);
if(typeInfo instanceof PojoTypeInfo) {
config.registerPojoType(type);
} else {
config.registerKryoType(type);
}
}
可以发现,获取到的类型信息属于 PojoTypeInfo 及其子类,那么将其注册到一起;否则统一交给 Kryo 去处理,Flink 并不过问(这种情况下性能会变差)。
类型声明
通过 TypeInformation.of() 方法可以非常方便的创建类型信息对象。
- 对于非泛型类,直接传入 Class 对象即可:
Outer o = new Outer(a:10, new Inner(x:4L), (short) 12); PojoTypeInfo<Outer> typeInfo = (PojoTypeInfo<Outer>) TypeInformation.of(Outer.class); - 对于泛型类,需要借助 TypeHint 来保存泛型类型信息。
final TypeInfomation<Tuple2<Integer,Integer>> resultType =
TypeInformation.of(new TypeHint<Tuple2<Integer,Integer>>(){});
- TypeHint 的原理是创建一个匿名子类,运行时 TypeExtractor 可以通过
getGenericSuperclass().getActuralTypeArguments()方法来回去保存的实际类型。
- 预定义常量。如 BasicTypeInfo 中定义了一系列常用原生类型的类型信息实例。或者直接使用更简单的 Types 类。
- 自定义 TypeInfo 和 TypeInfoFactory。
- 通过自定义 TypeInfo 为任意类提供 Flink 原生内存管理(而非 Kryo),可令存储更紧凑,运行时也更高效。
- 开发者在自定义类上使用 @TypeInfo 注解,随后创建相应的 TypeInfoFactory 并覆盖 createTypeInfo 方法。
- 注意需要继承 TypeInformation 类,为每个字段定义类型,并覆盖元数据方法,例如 isBasicType、isTupleType、元数(对于一维的 Row 类型,等于字段的个数)等等,从而为 TypeExtractor 提供决策依据。
类型序列化
Flink 自带了很多 TypeSerializer 子类,大多数情况下各种自定义类型都是常用类型的排列组合,因而可以直接复用。
如果不能满足,可以继承 TypeSerializer 及其子类来实现自己的特定类型的序列化器。
Kryo 序列化
陷阱与缺陷
- Lambda 函数的类型提取?
- Kryo 的 JavaSerializer 在 Flink 下存在 Bug?
类型机制与内存管理
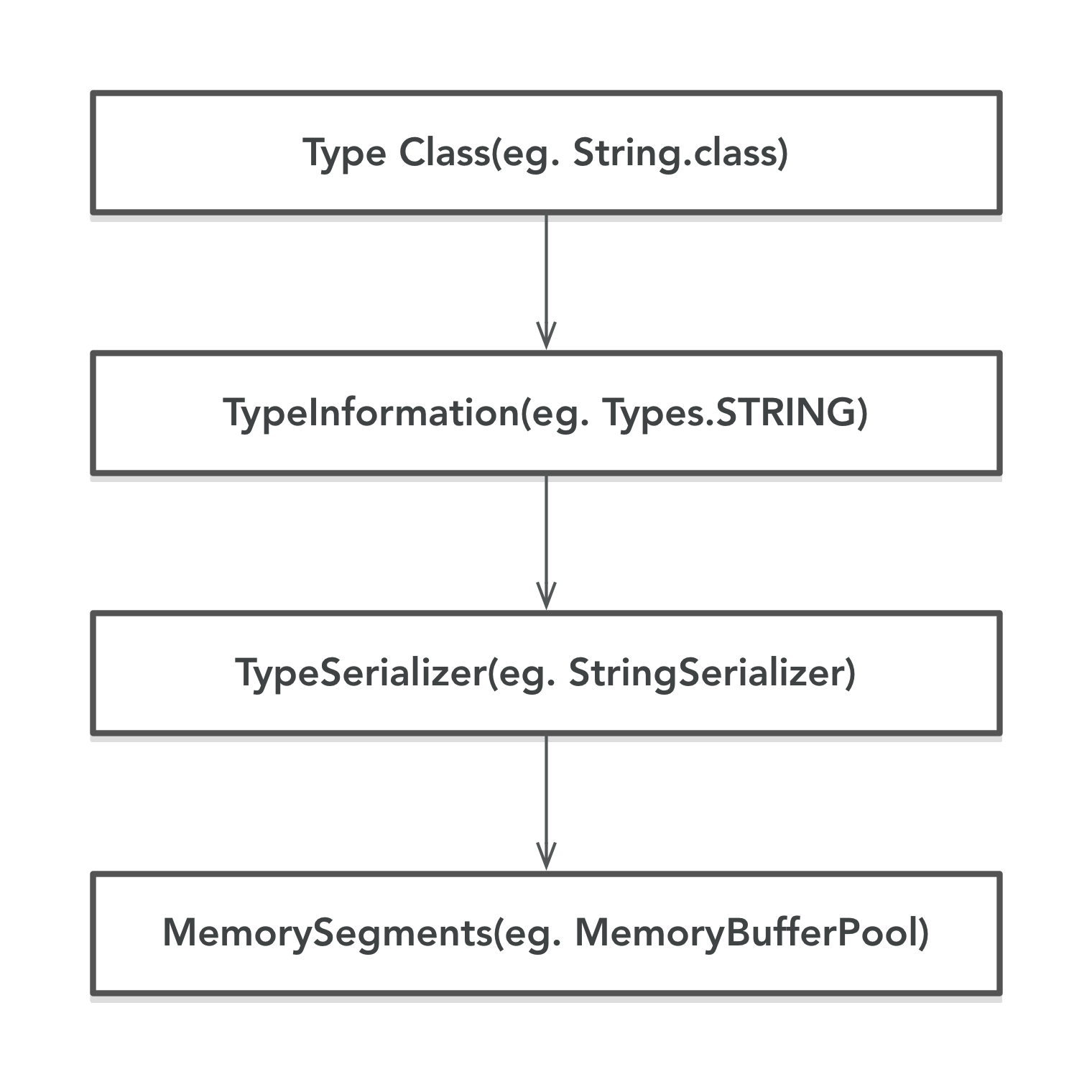
下面以 StringSerializer 为例,来看下 Flink 是如何紧凑管理内存的。下面是 StringSerializer 的序列化方法:
@Override
public void serialize(String record, DataOutputView target) throws IOException {
StringValue.writeString(record, target);
}
然后是具体的序列化过程:
public static final void writeString(CharSequence cs, DataOutput out) thorws IOException {
if(cs != null) {
// the length we write is offset by one, because a length of zero indicates a null value
int lenToWrite = cs.length() + 1;
if(lenToWrite < 0) {
throw new IllegalArgumentException();
}
// write the length, variable-length ecdoded
while(lenToWrite >= HIGH_BIT) {
out.write(b:lenToWrite | HIGH_BIT);
lenToWrite >>>= 7;
}
out.write(lenToWrite);
for(int i=0; i<cs.length(); i++) {
int c = cs.charAt(i);
while(c >= HIGH_BIT) {
out.write(b:c | HIGH_BIT);
c >>>= 7;
}
out.write(c);
}
} else {
out.write(b:0);
}
}
可以看到,Flink 对于内存管理是非常细致的,层次分明,代码也容易理解。