CH06-Concepts
纵观全局
Parboiled 提供了一个递归下降的 PEG 解析器实现来操作你指定的 PEG 规则。
你的语法规范可以包含解析器动作,这些动作可以在解析过程中的任意一点执行额外的逻辑,比如使用自定义条件来增强输入识别,或者构造抽象语法树(AST)。
两个阶段
你的代码会在两个阶段与 Parboiled 交互。在第一个阶段——“规则构造”阶段,Parboiled 会基于你定义的 Java/Scala 代码为解析器规则构建一个树(一个有向图)。该阶段与实际的输入阶段没有依赖,仅需要在整个 JVM 的生命周期中执行一次,即构建过的规则树是可复用的。第二个阶段是实际的解析阶段,使用第一阶段中的规则来处理特定的输入文本。最终的执行结构将包含以下信息:
- 一个布尔值来表示输入是否与根规则匹配。
- 可能遇到的所有解析错误。
- 由你的解析器动作构造的一个或多个值对象。
规则构造
在执行由 Java/Scala 定义的规则代码时将触发规则构造。Parboiled 分别为 Java 和 Scala 提供了单独的 DSL 来使得规则的定义过程与语言本身结合的更加舒适。
在 Java 中你需要实现一个自定义类来继承 BaseParser 类,并定义一些方法来返回 Rule 实例。这些方法可以通过调用其他自定义方法、终止符、预定义原语、动作表达式来构造规则实例。由于 Java 语法的限制,Parboiled 则使用了一个名为“解析器扩展(Parser Extension)”的过程来支持比其他方式更加简洁的规则构造代码。
因为 Scala 本身就富有较强的表现力,因此 Parboiled 并不需要为 Scala 再提供一个单独的解析器扩展步骤。在 Scala 中,你可以直接通过 Scala 语言元素来构造解析器规则树。
解析动作
为了避免你的解析器仅仅是一个“识别器”(一段仅能检测输入是否与定义的语法匹配的代码),在你的解析器中需要包含一些动作。解析器动作是一段自定义的代码,在规则执行期间的一些特定点被执行。除了检查解析器状态(如查看匹配的输入文本片段),解析器动作通常用于构造“值”(如 AST 节点),并可以作为语义谓词主动影响解析过程。
值栈
在规则执行阶段,你的解析器动作可以利用“值栈”来组织自定义对象的构造,如 AST 节点。值栈是一个简单的栈结构,作为一个临时存储为自定义对象提供服务。使用值栈的方式取决于你使用的是 Parboiled Java 还是 Parboiled Scala。
解析树
在规则执行阶段 Parboiled 能够以可选的方式构造一个解析树,其节点对应于已识别的规则。每个解析树 Node 包含一个对应规则的 Matcher,同时,被匹配的输入文本(位置)也会作为当前值栈的栈顶元素。该解析树可以被看做是输入对已匹配规则的记录,在调试过程中尤其有用。
解析执行器
ParseRunner 的职责是“监管”解析的执行过程,并能以可选的方式提供额外的逻辑,尤其重要的是对非法输入字符的处理(基于语法)。当你使用 Parboiled 执行解析时可以选择一下 5 种预定义的 ParseRunner:
- BasicParseRunner,最快最基本的 ParseRunner,不执行错误处理。
- ReportingParseRunner,为输入的第一个错误创建衣蛾 InvalidInputError。
- RecoveringParseRunner,最复杂的 ParseRunner,报告输入中的所有错误,并尝试从错误中恢复。
- TracingParseRunner,为每条匹配的或未匹配的规则有选择的打印追踪信息。
- ProfilingParseRunner,在你的解析器处理一个或多个输入时生成详细的统计信息。
Rule Tree
像大多数解析相关的程序一样,Parboiled 严重依赖于图和树结构。第一个这样的结构会在解析过程中创建,即规则“树”。该规则树这时尚未与实际的输入产生依赖。解析输入会在解析执行的过程中被解析器消费并被应用到规则树上,该过程可以以可选的方式生成一个解析树。
假设以下示例语法:
a ← b ‘a’ c
b ← ‘b’ d
c ← ‘c’ d
d ← ‘d’ c?
如果你将该语法转换为一个图,仅将规则作为图的节点,规则引用作为有向边,这时该语法可以用以下结构来表示:
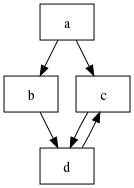
你会发现该图存在一个环,同时节点 d 拥有两个父亲,这也就是为什么该图不是一个树而仅仅是一个有向图。很多真实世界的语法的大多部分都像是一个树,带有非常清晰的规则到子规则层级引用。虽然回环(递归)并不十分罕见,但与“常规”分层引用相比,它们的数量确实很少。
因此这样的原因(以及对许多人而言,“树”是一种更常见的心理图景),你可能会选择将这样的规则图看做是带有两个特殊异常的规则树:多父亲、回环。
顺便提一下,PEG 语法的这种有向图特性几乎与方法调用在 JVM 中的工作方式一致:方法调用其他方法,可能包括调用堆栈祖先。这也是为什么 Parboiled 会或多或少的将规则声明映射到 Java/Scala 的方法调用。你的每个解析器规则方法都会构造一个规则对象,并在构造过程中潜在的调用其他规则构造方法。
然而这里还有两个问题:
- Java/Scala 方法递归到方法自身或其祖先时需要一种方式来终止递归。通常这是通过一些逻辑实现的,可以在逻辑中通过一些条件来退出递归。然而规则声明无法做到这一点,只有解析的输入文本(是有限的)将会终止任何规则递归。因此为了防止用于构造规则的 Java/Scala 方法出现无限递归,需要采取一些技巧。
- 当一个规则构造方法被调用多次时(可能被多起其他规则构造方法调用),通常会为每次调用创建结构相同的全新的规则实例。虽然这不是什么问题,但在规模较大的语法中则会比较低效,这时一个大型的规则树中会包含很多重复的规则实例。
Parboiled 在 Java 中通过重写解析类的规则方法来、并注入开发者不可见的代码来解决这两个问题。这些代码会确保每个方法仅会被调用一次,即背个规则仅被创建一次,后续的调用则会返回已创建的相同规则实例。如果规则的创建过程递归会自身,则插入代理规则以防止无限递归。所有这些事情都在幕后透明地发生,开发者无需关心。
Parboiled 在 Scala 中则不需要重写实际的字节码,而是将实际的规则创建代码封装到一个函数块,并作为主规则构建方法的参数。
最后,当你调用你的顶级规则方法并传给所选的 ParseRunner 时,则会得到一个规则树,没有重复节点,正确的链接关系,甚至还有递归。
Mathcers
你可能已经在 Javadoc API 文档中看到 Rule 接口仅仅是一个外观接口,带有很少的方法以指定特殊的规则属性。所有实现该接口的类被定义在 org.parboiled.matchers 中。有一个用于所有规则原语的 Matcher 实现,它实现了实际规则类型的逻辑。因此规则树实际上是一个 Matcher 树。然而,大多时候你不必了解这些内部细节,仅需关注于解析器规则和值栈。
Value Stack
在规则执行阶段,你的解析器动作可以利用“值栈”来组织自定义对象(如 AST 节点)的构造。值栈是一个简单的栈结构,作为临时存储服务于自定义对象。
通常,规则可以以任何方式修改值栈。可以创建新的值并推到栈上,或者消费已有的值,或者转换已有的值并重新推到栈上,等等。Parboiled 解析引擎并不关心你的规则和解析器动作与值栈之间的交互。
有两个特殊异常:
规则未匹配
如果规则因任何原因未匹配成功,则将值栈重置为执行该失败规则之前的状态。这意味着失败的规则无法修改值栈(这包括失败的语义判定动作)。
此行为的原因是使您不仅可以将动作放在一系列规则的最后位置。考虑如下规则:
Rule ← ‘a’ ‘b’ action ‘c’
假设匹配规则 “b” 之后将一个新值推到栈上。如果因为最终的元素 “c” 不能匹配到规则而导致规则序列失败,该值栈仍然会包含刚才被动作推入的新值。即使您的规则逻辑可能能够处理这些情况,这也会使动作设计复杂化并使解析器逻辑更加脆弱。
事实上,当规则不匹配时 Parboiled 重置堆栈的行为使得你可以自由的放置解析器动作,并将值栈用于规则内临时存储,这在很多情况下都非常方便。
语义判定
Test 和 TestNot 规则永远不会影响值栈。Parboiled 会使用一个以保存的快照将值栈重置回 Test/TestNot 规则匹配之前的状态。因此,您可以确定语法判定永远不会“混乱”您的值栈设置,即使它们包含解析器动作或引用其他规则。
Parse Tree
Parboiled 在规则执行阶段以可选的方式支持构建一个解析树。查看解析树可以更好的理解你的解析器对输入的消费过程,因此有助于解析器的开发和调试。
由 Parboiled 创建的解析树由一系列实现 Node 接口的不可变对象组成。除了基本的树节点功能(父亲、儿子)之外,该接口定义了节点名、所匹配输入文本的起始终止位置,以及一个自定义值对象。一些工具类为解析树提供了额外的处理方法,有 ParseTreeUtils、TreeUtils、GraphUtils。
需要注意的是解析树的节点是不可变的,即一旦被创建则不再能被修改。这实际上意味着它们的子节点结构和它们的值对象“引用”不能被修改。(尽管它们的值对象可以是可变的,或者仍然能够被修改。)整个解析树会从底向上被构建,先从叶子节点开始。通常来说,如果开启了解析树构建选项,匹配成功的每个规则都会创建一个解析树节点,该节点将匹配成功的子规则所创建的节点作为子节点。匹配失败的规则不会创建节点。解析树可以被认为是“已匹配规则的记录”。Parboiled 将解析树节点的 value 字段值设置为节点构造时值栈的栈顶元素。因此产看解析树值对象可以为你提供解析器如何使用值栈的线索。
或许对解析树最有用的使用方式是使用 ParseTreeUtils 的 printNodeTree 来将其打印出来。
在 Java 中开启解析树构建
可以在解析器实现类上添加 @BuildParseTree 注解来开启解析树构建。还可以在解析器方法上使用 @SuppressNode/@SuppresssSubnodes/@SkipNode 来对解析树进行微调。
在 Scala 中开启解析树构建
在 Scala 中,Parser 特质拥有一个 buildParseTree 标记方法,将其设置为 true 则可以开启解析树构建。最简单的方式是在解析器类的构造方法上调用 .withParseTreeBuilding() 方法。类似 Java API,可以使用 Parser$RuleOption 中的选项来对解析树的构建过程进行微调。
AST Construction
和解析树与语法之间的紧密关联关系相反,你想要构造的抽象语法树(AST)则完全取决于你的项目需要。这就是为什么 Parboiled 采用非常开放和灵活的方法来支持它。
事实上对 AST 节点的类型没有任何约束。Parboiled 没有提供任何不变或可变的对象来使用,因此也不会强制你使用什么。可以查看 org.parboiled.trees 包来开始。
通常你可以使用解析器值栈来作为构造 AST 的“工作台”。对于 Java API 可以参考 Calculators 示例,Scala API 可以参考 JSON Parser 示例。
Error Handling
对非法输入的适当处理是任何要被应用到真实项目的解析器的关键特性,这也是正则比倒是的最大缺陷之一。比如,如果用户在自定义 DSL 中提供了输入,你可以清楚的知道其中的语法或语义错误。语义错误可以被更高级的应用程序捕获并报告,但是语法错误必须在解析器中直接被捕获并报告。Parboiled 通过提供 4 种不同的 ParseRunner 实现来支持你选择处理解析错误的方式。
BasicParseRunner
这是最简单的实现。它不会执行任何错误处理,如果输入与指定的语法规则无效,则会简单的导致解析过程不匹配。这时,它的行为就像正则表达式引擎一样。它只执行一次解析,是确定指定输入是否符合解析器语法定义的最快方式。
RecordingParseRunner
比 BasicParseRunner 多一点特性:跟踪输入字符流中成功匹配的最远输入位置。如果给定的语法根规则不匹配,则紧随其后的位置必须是错误位置。和 BasicParseRunner 一样,仅执行一次解析运行。
ReportingParseRunner
不提供任何错误恢复功能,但是会在发现输入中的第一个匹配错误时报告错误。它在无错误输入上执行一次解析运行,但如果输入包含解析错误,则内部触发另外两次运行。在第二次运行期间,它会记录第一个解析错误的位置,并且在第三次运行期间,它会“监视”解析器尝试匹配错误字符时的行为,以便为用户创建有意义的错误消息。然后实例化一个 InvalidInputError 并将其添加到 ParsingResult 中返回的错误解析列表中。
RecoveringParseRunner
这是 4 种 ParseRunner 实现中最复杂的一个,它提供了自动的、只能的错误恢复,并且即便是存在解析错误也能完整的解析整个输入文本。Parboiled 提供的这种策略与 ANTLR 类似。如果可能的话,Parboiled 会在识别到非法输入时尝试进行单字符删除、插入或替换。如果仍然失败,Parboiled 会在当前规则堆栈中找到合适的重新同步规则,并是由所有非法字符,知道解析器可以重新同步以继续解析为止。
解析错误恢复细节
类似于 ReportingParseRunner,RecoveringParseRunner 首先会尝试一次快速的基本运行以发现输入是否存在错误。如果整个输入没有任何错误则直接结束执行。
如果首次运行出现错误,RecoveringParseRunner 则会执行以下算法来尝试克服错误:
- 首先执行一次“记录运行”以检测当前错误的位置。
- 然后执行一次“报告运行”,并将有意义的 InvalidInputError 添加到解析错误列表。
- 然后当前错误位置的字符会被临时性的删除,随后再次执行“记录运行”来发现下个错误的位置,以此类推。如果没有发现更多错误,则表示所有错误已被解决,然后直接结束解析。
- 在“报告运行”期间,运行器会收集所有在预期字符发生错误的规则并失败。对于所有这些规则,运行期会尝试插入临时性的“虚拟”字符到输入字符流,然后执行一次“记录运行”来检测下个错误的位置。如果这些插入的字符能够使得完整运行整个输入文本,则直接结束解析。
- 运行器尝试使用一个配件“虚拟”字符来替换错误字符(像上一步一些样)。如果这样能够使得错误得到解决则直接结束解析。
- 在这一步中,运行器知道没有单个字符恢复能够完全修复错误输入。但是它现在知道是否有一个动作(单个字符删除、插入、替换)允许解析器能够继续解析直到超出错误的位置。如果是这种情况,则可以通过单个字符恢复来克服错误,并且运行器应用允许解析器继续解析最远输入流的修复。因此,如果有可用的话,运行器总是选择最好的单字符修复。
- 如果没有单字符修复能够使得将下一个错误位置推送到当前错误位置之外,则会强制运行程序重新同步并重新执行“记录运行”以确定下一个错误的位置。为了做到这一点,运行器首先识别重新同步规则,该规则是作为序列并且已经匹配至少一个字符的第一个父规则。运行器确定运行哪些字符在合法解析中遵循此重新同步规则,并跳过所有不符合条件的字符。
- 既然最佳单字符修复或重新同步已经克服了当前的解析错误,则运行器继续解析到下一个错误并从步骤 1 开始从该错误中恢复。
动作设计的后果
由于上述概述的解析错误恢复策略允许解析即使已存在错误,如果你决定使用 RecoveringParseRunner,解析器动作应该能够处理一些意外情况。
单字符修复通常不会对你的动作产生任何影响,因为解析器动作所能看到的匹配输入文本已经包含错误更正,即排除掉了非法字符,并且在错误恢复期间插入的虚拟字符也包含在其结果中。但是,通过重新同步进行错误恢复会导致不匹配的规则序列“神奇的”匹配,即使并非是所有序列子规则都匹配或甚至运行。由于这会抛弃预期的值栈设置,因此在重新同步期间,Parboiled 会在重新同步序列中执行所有低限度要求的解析器动作。所有这些动作都会看到空匹配,因此可以提供有意义的默认值。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.