Parboiled 是一个轻量、易用、强大且优雅的解析库,用于解析任意任意输入文本,基于 “解析表达式文法(PEGs)”,同时支持 Java 和 Scala。PEGs 是一种针对形式特定语法的上下文无关文法,是对正则表达式的很好替代,通过 CFGs 来构建解析器通常也会比传统的方式要有很多优势。
This the multi-page printable view of this section. Click here to print.
Parboiled
- 1: CH01-Motivation
- 2: CH02-Features
- 3: CH03-Java Example
- 4: CH04-Scala Example
- 5: CH05-Comparison
- 6: CH06-Concepts
- 7: CH07-Java APIs
- 8: CH08-Scala APIs
- 9: CH09-Advanced Topics
1 - CH01-Motivation
Parboiled 的诞生源自对 JVM 上现有解析器构建工具的挫败感。
近年来流行动态语言(如 Ruby、Groovy)的巨大增长,很大一部分原因是它们将自身作为 DSL 的模型。虽然这些语言(甚至是一些静态类型的语言,如 Scala)具有简洁灵活的语法,通常直接可以用作内部 DSL 的基础,但相当笨拙的 Java 语法使得内部 DSL 非常缺乏吸引力。
对于很多项目来说,一个很小的 DSL 久能够构建出一个优雅的“用户接口”,以在没有 GUI 的情况下提供丰富的表现力以及灵活性。在 Java 中,内部 DSL 并不在规划之内,你不得不为外部 DSL 构建一个解析器以获得便利。尽管外部 DSL 并非解析器的唯一用例,像 Java 中这样对语言的传统解析支持工具并不出众。很多时候支持 DSL 并非项目的核心目标(如下编译器实现中),而是解决各种问题之一的优雅方案。因此,你可能并不希望将太多时间用于上下文无关的文法、词法理论以及错综复杂的外部解析器生成器。您只想以某种方式指定解析语法的外观并使其快速轻松地工作。这也就是 Parboiled 存在的原因。
下面是一些传统解析器生成器的缺点:
- 专有性,以非 Java 语法的形式保存在单独的项目文件(如外部 DSL)。
- 对文法文件没有 IDE 内置支持(语法高亮、内联检查、重构、代码导航等)。
- 运行外部解析器生成器需要特殊的构建步骤。
- “谜不可触”,在你项目中生成的 Java 源文件需要与文法规范保持同步。
- 通过词法分析(令牌生成)和令牌解析阶段中的分离解析过程进行更复杂的设计和维护。
- 综合占用(ANTLR 分发的生成器加上运行时占用多余 1.8 MB)。
2 - CH02-Features
- 以 Java、Scala 源码的形式定义文法。
- 没有外部的、非 Java/Scala 源码格式的文件。
- 无需学习额外的特有语法。
- 无需破坏 IDE 支持。
- 真实世界可读。
- 来自PEG的完整表现力。
- 支持强大且灵活的解析器动作。
- 游戏的解析错误包括与恢复。
- 高性能。
- 非常易于集成。
- 无需管理外部的解析器生成器。
- 没有特殊的步骤使你的构建过程复杂化。
- 你的项目结构中不再有“谜不可触”的、生成的源文件。
- 开放、轻量的结构使得非常易于集成到现有项目结构。
- 轻量、易用。
- 仅有一个解析阶段(词法分析代码不是必须的)。
- 少量且简单的 API。
- 整个库仅占用 300/450 KB,依赖较少。
虽然 Parboiled 最初设计的速度低于易用性和可维护性,但其解析性能自早期版本以来已显着改善,现在对于大多数应用程序来说已经足够了。它可以以近似的速率解析其自身的 Java 5 源码。以每秒 55,000 行或每秒 200 万个字符的速度运行(2.4 GHz Intel Core i5 单核,OS/X Java 6)。
3 - CH03-Java Example
首先是一个计算器的文法定义:
Expression <- Term (('+' / '-') Term)*
Term <- Factor (('*' / '/') Factor)*
Factor <- Number / '(' Expression ')'
Number <- [0-9]+
然后是基于 Java 代码的解析器定义:
@BuildParseTree
class CalculatorParser extends BaseParser<Object> {
Rule Expression() {
return Sequence(
Term(),
ZeroOrMore(AnyOf("+-"), Term())
);
}
Rule Term() {
return Sequence(
Factor(),
ZeroOrMore(AnyOf("*/"), Factor())
);
}
Rule Factor() {
return FirstOf(
Number(),
Sequence('(', Expression(), ')')
);
}
Rule Number() {
return OneOrMore(CharRange('0', '9'));
}
}
最后是对该解析器的应用:
String input = "1+2";
CalculatorParser parser = Parboiled.createParser(CalculatorParser.class);
ParsingResult<?> result = new ReportingParseRunner(parser.Expression()).run(input);
String parseTreePrintOut = ParseTreeUtils.printNodeTree(result);
System.out.println(parseTreePrintOut);
第 2 行创建了一个解释器实例,其方法可以被用于各种不同的 ParserRunner 来执行实际的解析过程并创建 ParsingResult。ParsingResult 对象除了包含输入是否匹配的信息之外,还包含表达式的解析树的根(如果启用了解析书构建)、结果值、解析错误列表。理解解析器是如何处理输入的方式是使用 ParseTreeUtils.printNodeTree,如上面示例中第 4~5 行那样。
通常来说,Parboiled 会在 Java 语法的约束下使你的规则规范尽可能的可读。
4 - CH04-Scala Example
首先是一个计算器的文法定义:
Expression <- Term (('+' / '-') Term)*
Term <- Factor (('*' / '/') Factor)*
Factor <- Number / '(' Expression ')'
Number <- [0-9]+
然后是基于 Scala 代码的解析器定义:
import org.parboiled.scala._
class SimpleCalculator extends Parser {
def Expression:Rule0 = rule { Term ~ zeroOrMore(anyOf("+-") ~ Term) }
def Term = rule { Factor ~ zeroOrMore(anyOf("*/") ~ Factor) }
def Factor = rule { Number | "(" ~ Expression ~ ")" }
def Number = rule { oneOrMore("0" - "9") }
}
最后是对该解析器的应用:
val input = "1+2"
val parser = new SimpleCalculator { override val buildParseTree = true }
val result = ReportingParseRunner(parser.Expression).run(input)
val parseTreePrintOut = org.parboiled.support.ParseTreeUtils.printNodeTree(result)
println(parseTreePrintOut)
5 - CH05-Comparison
如果你将解析需求想象为一个光谱,一边是“脏且快”的正则表达式,一边是像 ANTLR 一样完整的解析器生成器,Parboiled 则旨在填补两端之间的巨大空间。对于非常简单的用例,正则表达式可能是一个具有最小开销的适当解决方案。然而,正则表达式可以很快变成丑陋的混乱、难以阅读理解并最终难以维护。在许多情况下,它们也缺乏表达能力来解析像嵌套构造这样需要递归规则定义的东西。它们也不会生成正确的错误消息或从输入的错误中恢复,而这可以在开发过程中节省大量时间。
在光谱的另一端,像 ANTLR 和 Rats! 这样强大的工具当然也有其适用场景。当必须解析那些用复杂语言编写的大量源码时,解析器生成器可能是合适的工具。比如,你可能想要使用现有的语法,或者需要一些发展多年的企业工具的完整特性集。
然而,当你需要定义自己的语法,并且对解析器生成器没有丰富的经验,Parboiled 则可以快速简便的帮你达到目的。Parboiled 可以用于小的任务,如解析日期与时间;也可以用于复杂的任务,如解析 Java 源码或像 Markdown 这样的标记语言。占用小、轻量的架构使其很容易与其他应用集成,同时又能为多种定制需求提供良好的基础。
6 - CH06-Concepts
纵观全局
Parboiled 提供了一个递归下降的 PEG 解析器实现来操作你指定的 PEG 规则。
你的语法规范可以包含解析器动作,这些动作可以在解析过程中的任意一点执行额外的逻辑,比如使用自定义条件来增强输入识别,或者构造抽象语法树(AST)。
两个阶段
你的代码会在两个阶段与 Parboiled 交互。在第一个阶段——“规则构造”阶段,Parboiled 会基于你定义的 Java/Scala 代码为解析器规则构建一个树(一个有向图)。该阶段与实际的输入阶段没有依赖,仅需要在整个 JVM 的生命周期中执行一次,即构建过的规则树是可复用的。第二个阶段是实际的解析阶段,使用第一阶段中的规则来处理特定的输入文本。最终的执行结构将包含以下信息:
- 一个布尔值来表示输入是否与根规则匹配。
- 可能遇到的所有解析错误。
- 由你的解析器动作构造的一个或多个值对象。
规则构造
在执行由 Java/Scala 定义的规则代码时将触发规则构造。Parboiled 分别为 Java 和 Scala 提供了单独的 DSL 来使得规则的定义过程与语言本身结合的更加舒适。
在 Java 中你需要实现一个自定义类来继承 BaseParser 类,并定义一些方法来返回 Rule 实例。这些方法可以通过调用其他自定义方法、终止符、预定义原语、动作表达式来构造规则实例。由于 Java 语法的限制,Parboiled 则使用了一个名为“解析器扩展(Parser Extension)”的过程来支持比其他方式更加简洁的规则构造代码。
因为 Scala 本身就富有较强的表现力,因此 Parboiled 并不需要为 Scala 再提供一个单独的解析器扩展步骤。在 Scala 中,你可以直接通过 Scala 语言元素来构造解析器规则树。
解析动作
为了避免你的解析器仅仅是一个“识别器”(一段仅能检测输入是否与定义的语法匹配的代码),在你的解析器中需要包含一些动作。解析器动作是一段自定义的代码,在规则执行期间的一些特定点被执行。除了检查解析器状态(如查看匹配的输入文本片段),解析器动作通常用于构造“值”(如 AST 节点),并可以作为语义谓词主动影响解析过程。
值栈
在规则执行阶段,你的解析器动作可以利用“值栈”来组织自定义对象的构造,如 AST 节点。值栈是一个简单的栈结构,作为一个临时存储为自定义对象提供服务。使用值栈的方式取决于你使用的是 Parboiled Java 还是 Parboiled Scala。
解析树
在规则执行阶段 Parboiled 能够以可选的方式构造一个解析树,其节点对应于已识别的规则。每个解析树 Node 包含一个对应规则的 Matcher,同时,被匹配的输入文本(位置)也会作为当前值栈的栈顶元素。该解析树可以被看做是输入对已匹配规则的记录,在调试过程中尤其有用。
解析执行器
ParseRunner 的职责是“监管”解析的执行过程,并能以可选的方式提供额外的逻辑,尤其重要的是对非法输入字符的处理(基于语法)。当你使用 Parboiled 执行解析时可以选择一下 5 种预定义的 ParseRunner:
- BasicParseRunner,最快最基本的 ParseRunner,不执行错误处理。
- ReportingParseRunner,为输入的第一个错误创建衣蛾 InvalidInputError。
- RecoveringParseRunner,最复杂的 ParseRunner,报告输入中的所有错误,并尝试从错误中恢复。
- TracingParseRunner,为每条匹配的或未匹配的规则有选择的打印追踪信息。
- ProfilingParseRunner,在你的解析器处理一个或多个输入时生成详细的统计信息。
Rule Tree
像大多数解析相关的程序一样,Parboiled 严重依赖于图和树结构。第一个这样的结构会在解析过程中创建,即规则“树”。该规则树这时尚未与实际的输入产生依赖。解析输入会在解析执行的过程中被解析器消费并被应用到规则树上,该过程可以以可选的方式生成一个解析树。
假设以下示例语法:
a ← b ‘a’ c
b ← ‘b’ d
c ← ‘c’ d
d ← ‘d’ c?
如果你将该语法转换为一个图,仅将规则作为图的节点,规则引用作为有向边,这时该语法可以用以下结构来表示:
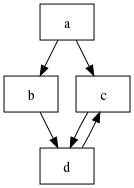
你会发现该图存在一个环,同时节点 d 拥有两个父亲,这也就是为什么该图不是一个树而仅仅是一个有向图。很多真实世界的语法的大多部分都像是一个树,带有非常清晰的规则到子规则层级引用。虽然回环(递归)并不十分罕见,但与“常规”分层引用相比,它们的数量确实很少。
因此这样的原因(以及对许多人而言,“树”是一种更常见的心理图景),你可能会选择将这样的规则图看做是带有两个特殊异常的规则树:多父亲、回环。
顺便提一下,PEG 语法的这种有向图特性几乎与方法调用在 JVM 中的工作方式一致:方法调用其他方法,可能包括调用堆栈祖先。这也是为什么 Parboiled 会或多或少的将规则声明映射到 Java/Scala 的方法调用。你的每个解析器规则方法都会构造一个规则对象,并在构造过程中潜在的调用其他规则构造方法。
然而这里还有两个问题:
- Java/Scala 方法递归到方法自身或其祖先时需要一种方式来终止递归。通常这是通过一些逻辑实现的,可以在逻辑中通过一些条件来退出递归。然而规则声明无法做到这一点,只有解析的输入文本(是有限的)将会终止任何规则递归。因此为了防止用于构造规则的 Java/Scala 方法出现无限递归,需要采取一些技巧。
- 当一个规则构造方法被调用多次时(可能被多起其他规则构造方法调用),通常会为每次调用创建结构相同的全新的规则实例。虽然这不是什么问题,但在规模较大的语法中则会比较低效,这时一个大型的规则树中会包含很多重复的规则实例。
Parboiled 在 Java 中通过重写解析类的规则方法来、并注入开发者不可见的代码来解决这两个问题。这些代码会确保每个方法仅会被调用一次,即背个规则仅被创建一次,后续的调用则会返回已创建的相同规则实例。如果规则的创建过程递归会自身,则插入代理规则以防止无限递归。所有这些事情都在幕后透明地发生,开发者无需关心。
Parboiled 在 Scala 中则不需要重写实际的字节码,而是将实际的规则创建代码封装到一个函数块,并作为主规则构建方法的参数。
最后,当你调用你的顶级规则方法并传给所选的 ParseRunner 时,则会得到一个规则树,没有重复节点,正确的链接关系,甚至还有递归。
Mathcers
你可能已经在 Javadoc API 文档中看到 Rule 接口仅仅是一个外观接口,带有很少的方法以指定特殊的规则属性。所有实现该接口的类被定义在 org.parboiled.matchers 中。有一个用于所有规则原语的 Matcher 实现,它实现了实际规则类型的逻辑。因此规则树实际上是一个 Matcher 树。然而,大多时候你不必了解这些内部细节,仅需关注于解析器规则和值栈。
Value Stack
在规则执行阶段,你的解析器动作可以利用“值栈”来组织自定义对象(如 AST 节点)的构造。值栈是一个简单的栈结构,作为临时存储服务于自定义对象。
通常,规则可以以任何方式修改值栈。可以创建新的值并推到栈上,或者消费已有的值,或者转换已有的值并重新推到栈上,等等。Parboiled 解析引擎并不关心你的规则和解析器动作与值栈之间的交互。
有两个特殊异常:
规则未匹配
如果规则因任何原因未匹配成功,则将值栈重置为执行该失败规则之前的状态。这意味着失败的规则无法修改值栈(这包括失败的语义判定动作)。
此行为的原因是使您不仅可以将动作放在一系列规则的最后位置。考虑如下规则:
Rule ← ‘a’ ‘b’ action ‘c’
假设匹配规则 “b” 之后将一个新值推到栈上。如果因为最终的元素 “c” 不能匹配到规则而导致规则序列失败,该值栈仍然会包含刚才被动作推入的新值。即使您的规则逻辑可能能够处理这些情况,这也会使动作设计复杂化并使解析器逻辑更加脆弱。
事实上,当规则不匹配时 Parboiled 重置堆栈的行为使得你可以自由的放置解析器动作,并将值栈用于规则内临时存储,这在很多情况下都非常方便。
语义判定
Test 和 TestNot 规则永远不会影响值栈。Parboiled 会使用一个以保存的快照将值栈重置回 Test/TestNot 规则匹配之前的状态。因此,您可以确定语法判定永远不会“混乱”您的值栈设置,即使它们包含解析器动作或引用其他规则。
Parse Tree
Parboiled 在规则执行阶段以可选的方式支持构建一个解析树。查看解析树可以更好的理解你的解析器对输入的消费过程,因此有助于解析器的开发和调试。
由 Parboiled 创建的解析树由一系列实现 Node 接口的不可变对象组成。除了基本的树节点功能(父亲、儿子)之外,该接口定义了节点名、所匹配输入文本的起始终止位置,以及一个自定义值对象。一些工具类为解析树提供了额外的处理方法,有 ParseTreeUtils、TreeUtils、GraphUtils。
需要注意的是解析树的节点是不可变的,即一旦被创建则不再能被修改。这实际上意味着它们的子节点结构和它们的值对象“引用”不能被修改。(尽管它们的值对象可以是可变的,或者仍然能够被修改。)整个解析树会从底向上被构建,先从叶子节点开始。通常来说,如果开启了解析树构建选项,匹配成功的每个规则都会创建一个解析树节点,该节点将匹配成功的子规则所创建的节点作为子节点。匹配失败的规则不会创建节点。解析树可以被认为是“已匹配规则的记录”。Parboiled 将解析树节点的 value 字段值设置为节点构造时值栈的栈顶元素。因此产看解析树值对象可以为你提供解析器如何使用值栈的线索。
或许对解析树最有用的使用方式是使用 ParseTreeUtils 的 printNodeTree 来将其打印出来。
在 Java 中开启解析树构建
可以在解析器实现类上添加 @BuildParseTree 注解来开启解析树构建。还可以在解析器方法上使用 @SuppressNode/@SuppresssSubnodes/@SkipNode 来对解析树进行微调。
在 Scala 中开启解析树构建
在 Scala 中,Parser 特质拥有一个 buildParseTree 标记方法,将其设置为 true 则可以开启解析树构建。最简单的方式是在解析器类的构造方法上调用 .withParseTreeBuilding() 方法。类似 Java API,可以使用 Parser$RuleOption 中的选项来对解析树的构建过程进行微调。
AST Construction
和解析树与语法之间的紧密关联关系相反,你想要构造的抽象语法树(AST)则完全取决于你的项目需要。这就是为什么 Parboiled 采用非常开放和灵活的方法来支持它。
事实上对 AST 节点的类型没有任何约束。Parboiled 没有提供任何不变或可变的对象来使用,因此也不会强制你使用什么。可以查看 org.parboiled.trees 包来开始。
通常你可以使用解析器值栈来作为构造 AST 的“工作台”。对于 Java API 可以参考 Calculators 示例,Scala API 可以参考 JSON Parser 示例。
Error Handling
对非法输入的适当处理是任何要被应用到真实项目的解析器的关键特性,这也是正则比倒是的最大缺陷之一。比如,如果用户在自定义 DSL 中提供了输入,你可以清楚的知道其中的语法或语义错误。语义错误可以被更高级的应用程序捕获并报告,但是语法错误必须在解析器中直接被捕获并报告。Parboiled 通过提供 4 种不同的 ParseRunner 实现来支持你选择处理解析错误的方式。
BasicParseRunner
这是最简单的实现。它不会执行任何错误处理,如果输入与指定的语法规则无效,则会简单的导致解析过程不匹配。这时,它的行为就像正则表达式引擎一样。它只执行一次解析,是确定指定输入是否符合解析器语法定义的最快方式。
RecordingParseRunner
比 BasicParseRunner 多一点特性:跟踪输入字符流中成功匹配的最远输入位置。如果给定的语法根规则不匹配,则紧随其后的位置必须是错误位置。和 BasicParseRunner 一样,仅执行一次解析运行。
ReportingParseRunner
不提供任何错误恢复功能,但是会在发现输入中的第一个匹配错误时报告错误。它在无错误输入上执行一次解析运行,但如果输入包含解析错误,则内部触发另外两次运行。在第二次运行期间,它会记录第一个解析错误的位置,并且在第三次运行期间,它会“监视”解析器尝试匹配错误字符时的行为,以便为用户创建有意义的错误消息。然后实例化一个 InvalidInputError 并将其添加到 ParsingResult 中返回的错误解析列表中。
RecoveringParseRunner
这是 4 种 ParseRunner 实现中最复杂的一个,它提供了自动的、只能的错误恢复,并且即便是存在解析错误也能完整的解析整个输入文本。Parboiled 提供的这种策略与 ANTLR 类似。如果可能的话,Parboiled 会在识别到非法输入时尝试进行单字符删除、插入或替换。如果仍然失败,Parboiled 会在当前规则堆栈中找到合适的重新同步规则,并是由所有非法字符,知道解析器可以重新同步以继续解析为止。
解析错误恢复细节
类似于 ReportingParseRunner,RecoveringParseRunner 首先会尝试一次快速的基本运行以发现输入是否存在错误。如果整个输入没有任何错误则直接结束执行。
如果首次运行出现错误,RecoveringParseRunner 则会执行以下算法来尝试克服错误:
- 首先执行一次“记录运行”以检测当前错误的位置。
- 然后执行一次“报告运行”,并将有意义的 InvalidInputError 添加到解析错误列表。
- 然后当前错误位置的字符会被临时性的删除,随后再次执行“记录运行”来发现下个错误的位置,以此类推。如果没有发现更多错误,则表示所有错误已被解决,然后直接结束解析。
- 在“报告运行”期间,运行器会收集所有在预期字符发生错误的规则并失败。对于所有这些规则,运行期会尝试插入临时性的“虚拟”字符到输入字符流,然后执行一次“记录运行”来检测下个错误的位置。如果这些插入的字符能够使得完整运行整个输入文本,则直接结束解析。
- 运行器尝试使用一个配件“虚拟”字符来替换错误字符(像上一步一些样)。如果这样能够使得错误得到解决则直接结束解析。
- 在这一步中,运行器知道没有单个字符恢复能够完全修复错误输入。但是它现在知道是否有一个动作(单个字符删除、插入、替换)允许解析器能够继续解析直到超出错误的位置。如果是这种情况,则可以通过单个字符恢复来克服错误,并且运行器应用允许解析器继续解析最远输入流的修复。因此,如果有可用的话,运行器总是选择最好的单字符修复。
- 如果没有单字符修复能够使得将下一个错误位置推送到当前错误位置之外,则会强制运行程序重新同步并重新执行“记录运行”以确定下一个错误的位置。为了做到这一点,运行器首先识别重新同步规则,该规则是作为序列并且已经匹配至少一个字符的第一个父规则。运行器确定运行哪些字符在合法解析中遵循此重新同步规则,并跳过所有不符合条件的字符。
- 既然最佳单字符修复或重新同步已经克服了当前的解析错误,则运行器继续解析到下一个错误并从步骤 1 开始从该错误中恢复。
动作设计的后果
由于上述概述的解析错误恢复策略允许解析即使已存在错误,如果你决定使用 RecoveringParseRunner,解析器动作应该能够处理一些意外情况。
单字符修复通常不会对你的动作产生任何影响,因为解析器动作所能看到的匹配输入文本已经包含错误更正,即排除掉了非法字符,并且在错误恢复期间插入的虚拟字符也包含在其结果中。但是,通过重新同步进行错误恢复会导致不匹配的规则序列“神奇的”匹配,即使并非是所有序列子规则都匹配或甚至运行。由于这会抛弃预期的值栈设置,因此在重新同步期间,Parboiled 会在重新同步序列中执行所有低限度要求的解析器动作。所有这些动作都会看到空匹配,因此可以提供有意义的默认值。
7 - CH07-Java APIs
Parboiled Java 的应用步骤:
- 安装依赖。
- 确定要解析器值栈中要参数化的类型,继承 BaseParser 实现自定义解析类。
- 在该解析类中添加返回类型为 Rule 的规则方法。
- 通过
Parboiled.createParser创建解析器实例。 - 调用解析器的根规则方法来创建规则树。
- 选择 ParseRunner 的特定实现,调用其 run 方法并传入根规则和输入文本。
- 查看 ParsingResult 对象的属性。
Rule Construction
一个 PEG 由任意数量的规则组成,规则又可以由其他规则、终止符、或下表中的原语规则组成:
| Name | Common Notation | Primitive |
|---|---|---|
| Sequence | a b | Sequence(a, b) |
| Ordered Choice | a | b | FisrtOf(a, b) |
| Zero-Or-More | a * | ZeroOrMore(a) |
| One-Or-More | a + | OneOrMore(a) |
| Optional | a ? | Optional(a) |
| And-Predicate | & a | Test(a) |
| Non-Predicate | ! a | TestNot(a) |
这些原语实际是 BaseParser 类的实例方法,即所有自定义解析器的必要父类。这些原语规则创建方法可以接收一个或多个 Object 参数,这些参数的类型可以是:
- 一个 Rule 实例
- 一个字符字面量
- 一个字符串字面量
- 一个字符数组
- 一个动作表达式
- 实现了 Action 接口的类的实例
除了以上原语方法,还有以下原语可供使用:
| Method/Field | Description |
|---|---|
| ANY | 匹配任何除了 EOI 的单个字符 |
| NOTHING | 不匹配任何,总是失败 |
| EMPTY | 不匹配任何,总是成功 |
| EOI | 匹配特殊的 EOI 字符 |
| Ch(char) | 创建一个匹配单个字符的规则 |
| CharRange(char, char) | 匹配给定的字符范围 |
| AnyOf(string) | 匹配给定字符串中的任意字符 |
| NoneOf(string) | 不匹配给定字符串中的任意字符和 EOI |
| IgnoreCase(char) | 匹配单个字符且忽略大小写 |
| IgnoreCase(String) | 匹配整个字符串且胡烈大小写 |
| String(string) | 创建一个匹配整个字符串的 |
Parser Action Expressions
Parboiled Java 的解析器可以在规则定义的任意位置包含解析器动作。这些动作可以分为 4 类。
“Regular” objects implementing the Action interface
如果你的动作代码较多,则可以将其封装到一个实现了 Action 接口的自定义类中,然后再在规则定义方法中使用该自定义类的实例。
class MyParser extends BaseParser<Object> {
Action myAction = new MyActionClass();
Rule MyRule() {
return Sequence(
...,
myAction,
...
);
}
}
如果使用这种方式,你的自定义动作类也可以实现 SkippableAction 接口以告诉解析器引擎在执行内部的语法判定时是否跳过这些动作。
Anonymous inner classes implementing the Action interface
更多时候动作仅会包含少量的代码,这时可以直接使用匿名类:
class MyParser extends BaseParser<Object> {
Rule MyRule() {
return Sequence(
...,
new Action() {
public boolean run(Context context) {
...; // arbitrary action code
return true; // could also return false to stop matching the Sequence and continue looking for other matching alternatives
}
},
...
);
}
}
Explicit action expressions
虽然匿名类要比独立的动作类定义简单一点,但仍然显得冗余。可以继续简化为一个布尔表达式:
class MyParser extends BaseParser<Object> {
Rule MyRule() {
return Sequence(
...,
ACTION(...), // the argument being the boolean expression to wrap
...
);
}
}
BaseParser.ACTION 是一个特殊的标记方法,其告诉 Parboiled 将参数表达式封装到一个单独的、自动创建的动作类中,类似上面匿名类的例子。这样的动作表达式中可以包含对本地变量的访问代码或方法参数、读写非私有的解析器字段、调用非私有的解析器方法。
此外,如果动作表达式中调用实现了 ContextAware 接口的类对象方法,将自动在调用方法之前插入 setContext 方法。比如你想将所有的动作代码移出到解析器类之外以简化实现:
class MyParser extends BaseParser<Object> {
MyActions actions = new MyActions();
Rule MyRule() {
return Sequence(
...,
ACTION(actions.someAction()),
...
);
}
}
如果 MyActions 实现了 ContextAware 接口,Parboiled 将会自动在内部转换为类似下列清单的代码:
class MyParser extends BaseParser<Object> {
MyActions actions = new MyActions();
Rule MyRule() {
return Sequence(
...,
new Action() {
public boolean run(Context context) {
actions.setContext(context);
return actions.someAction();
}
},
...
);
}
}
注意 BaseParser 已经继承了 BaseActions,其实现了 ContextAware 接口,所以解析器类中的所有动作方法可以通过 getContext 方法获得当前的上下文。
Implicit action expressions
大多数情况下,Parboiled 可以自动识别你的规则定义中哪些是动作表达式。比如下面的规则定义中包含了一个隐式的动作表达式:
Rule Number() {
return Sequence(
OneOrMore(CharRange('0', '9')),
Math.random() < 0.5 ? extractIntegerValue(match()) : someObj.doSomething()
);
}
Parboiled 的检测逻辑如下:
BaseParser 中所有的默认规则创建器方法都拥有通用的 Java Object 参数,Java 编译器会自动将原始布尔表达式的结果作为一个 Boolean 对象传递。这是通过在布尔动作表达式的代码之后隐式地插入对 Boolean.valueOf 的调用来实现的。Parboiled 会在你的规则方法字节码中查找这些调用然后将其当做隐式动作表达式来处理,如果其结果直接被用作规则创建方法的参数的话。也可以通过 @ExplicitActionsOnly 注解(定义在解析类或规则方法上)来关闭该功能。
Return Values
动作表达式均为布尔表达式。其返回值将影响对当前值的解析进度。如果动作表达式的结果为 false,解析将继续,就像替换动作表达式的假设解析规则失败一样。因此,你可以将动作表达式视作可以(匹配)成功或(匹配)失败的“规则”,具体则取决于其返回值。
Value Stack
在任何特定的解析项目中,解析器动作都希望能够以某种方式来创建对应输入文本结构的自定义对象。Parboiled Java 提供了两种工具来在解析器规则中管理创建的自定义对象:
- 值栈
- 动作变量
值栈是一个简单的栈结构,作为一个临时存储为你的自定义对象提供服务。你的解析器动作可以将对象推到栈上、推出栈、推出再推入栈交换对象,等等。值栈的实现隐藏在 ValueStack 接口下面,其定义了操作值栈的一系列方法。
所有的解析器动作可以通过当前 context 的 getValueStack 来获得当前值栈。为了简化值栈操作的冗余,BaseActions 类(BaseParser)的父类提供了一些值栈操作的快捷方法,可以直接在解析器动作表达式中内联使用。
在解析器规则中使用值栈的方式通常有以下几种:
- 匹配分隔符、空格或其他辅助结构的规则通常不会影响值栈。
- 较底层的规则会从匹配到的输入中创建基本对象并推到栈上。
- 调用一个或多个底层规则的高级别规则,会从栈上推出值对象,然后创建高级别的对象并重新推到栈上。
- 根规则作为最高级别的规则会创建自定义结构的根对象。
大多时候,但一个规则被完整处理过后,最多会推一个对象到栈上(尽管在处理过程中会推多个对象到栈上)。那么你可以认为:如果规则匹配,一个规则会在栈上创建一个特定类型的对象,否则则不会影响栈。
规则定义须知
一条重要的原则是一个规则总是应该确保其对值栈的操作是“稳定的行为”,而无论输入是什么。因此,如果一个规则将一个特定类型的值对象推到栈上,则其应该为所有可能的输入都推一个值到栈上。如果不然,那么引用该规则之外的规则时将无法在规则匹配之后会值栈的状态进行假设,这将使动作设计复杂化。以下讨论着眼于各种 PEG 原语以及在使用影响值栈的解析器操作时需要注意的事项。
Sequence 规则
由于它们不提供任何可选组件,因此关于值栈操作,序列规则相当直接。它们的最终结果本质上是稳定的,仅包括所有子操作的串联。
FirstOf 规则
FirstOf 规则提供了几种替代子规则匹配。为了向外部提供稳定的“输出”,重要的是所有替代方案都表现出兼容的值堆栈行为。考虑以下例子:
Rule R() {
return FirstOf(A(), B(), C());
}
如果子规则 A 将推一个对象到栈,则 B 和 C 也需要这样做。
Optional 规则
Optional 规则的子规则通常不应该在值栈中添加或删除对象。由于 Optional 规则始终会匹配成功,即使其子规则不匹配,对值栈上的对象数量的任何影响都将违反“稳定行为”的原则。但是,Optional 规则可以很好的转换值栈上的内容,而避免不稳定的行为。
Rule R() {
return Sequence(
Number(), // number adds an Integer object to the stack
Optional(
'+',
Number(), // another Integer object on the stack
push(pop() + pop()) // pop two and repush one Integer
)
);
}
该规则的行为始终是稳定的,因为它总是会将一个值推送到栈上。
ZeroOrMore/OneOrMore 规则
与 Optional 规则类似,不能添加或删除值栈的元素,而可以修改值栈的元素内容。
Action Variables
对值栈的操作需要一些设计素养,同时为了类型安全,值栈中仅能使用一个较为宽泛的通用类型,然后再在解析器动作使用使用强制类型转换,这会带来维护成本。为了提供更多的灵活性,提供了动作变量功能。
通常,一个规则方法会在规则的子结构中包含多个动作表达式,以协同的方式来构造出最终规则。在很多情况下如果能够通过一个通用的临时辅助变量来访问规则中所有的动作,则会大有帮助。考虑如下例子:
Rule Verbatim() {
StringVar text = new StringVar("");
StringVar temp = new StringVar("");
return Sequence(
OneOrMore(
ZeroOrMore(BlankLine(), temp.append("\n")),
NonblankIndentedLine(), text.append(temp.getAndSet(""), pop().getText())
),
push(new VerbatimNode(text.get()))
);
}
该规则用于解析 Markdown 的逐行结构,其中包含一行或多行的缩进文本。这些缩进行可以通过完全的空行来拆分,如果其跟随的有最少一个缩进行则也可以被匹配。该规则的工作是创建一个 AST 节点并初始化为匹配到的文本(不带有行缩进)。
为了能够构建该 AST 节点的文本参数,如果能够访问一个字符串变量——作为构建字符串的临时容器,则会非常有帮助。在通常的 Java 方法中可以使用一个本地变量,然而,因为规则方法仅包含规则的构造代码而非规则实际运行的代码,因此本地变量起不了作用。因为本地变量仅能在规则的构造期间而非运行期间可见。
这就是为什么 Parboiled Java 提供了一个名为 Var 的类,它可以用作规则执行阶段的本地变量。Var 对象包装一个任意类型的值,可以拥有初始值,支持对值的读写,可以在嵌套规则方法之间传递。每轮规则调用(如规则匹配重试)都会接受到自己的 Var 域,因此递归规则中的动作也会像预期一样运行。此外,Var 类还定义了一系列简便的辅助方法来简化其在动作表达式中的应用过程。
如下所示:
Rule A() {
Var<Integer> i = new Var<Integer>();
return Sequence(
...,
i.set(42),
B(i),
action(i.get())
);
}
Rule B(Var<Integer> i) {
return Sequence(
...,
i.set(26)
);
}
规则方法 A 传递一个其域内定义的 Var 作为参数到规则方法 B,规则方法 B 内的动作向该 Var 写入一个新值,规则方法 A 中所有运行在 B 之后的动作都能看到该新写入的 Var 的值。上面的例子中,A 中的 action 读取 Var 值时会得到 26。
Parser Extension
当你首次调用 Parboiled.createParser 来构造你的解析器实例时,Parboiled Java 会在内部运行解析器扩展逻辑来为你的解析器类增加所有可能的特殊功能。因为你定义的解析器类一定不是 private 和 final 的,因此可以被子类化。新创建的类与你原有的解析器类处于同一个包下,使用原有的类名并加上 $$parboiled 后缀。
自动穿件的解析器子类会覆写所有返回 Rule 实例的方法。这些覆写会在某个点将调用为派给父方法(即原始解析器类中的方法),或者甚至完全重写而不会父类方法做任何调用。
以下规则方法扩展需要完全重写而不会对父方法执行委派调用:
- 解析器动作表达式
- 动作变量
以下规则方法扩展可以无需方法重写而应用,如果方法中没有上面列出的转换时也可以调用父方法:
- @Label
- @Cache
- @SuppressNode
- @SuppressSubnodes
- @SkipNode
- @MemoMismatches
通常你不必担心是否需要进行方法覆写的问题。然而在调试环节,当你需要在规则方法中添加断点以追踪执行过程时,如果你的规则方法被重写,则端点就无法没命中。因此,比如你需要调试一个带有隐式或显式动作表达式的规则方法时,需要临时将动作表达式改写为显式匿名内部 Action 类,来避免对该规则方法的完全重写。
解析器扩展逻辑不会触碰那些不返回 Rule 实例的方法则,而是直接保留。
Examples
8 - CH08-Scala APIs
与 Java 的区别在于规则的构造过程,在 Scala 中使用了特殊的 Scala DSL 构造。相比 Java API,Scala API 更具优势:
- 更加简明的规则构建 DSL(Scala 语言的丰富表现力)。
- 通过对值栈的进一步抽象隐藏了值栈,增加了类型安全性(Scala Type Inference)。
- 高阶规则构造。
- 更快的初次规则构建(不再有昂贵的解析器扩展步骤)。
Rule Construction
一个 PEG 由任意数量的规则组成,规则又可以由其他规则、终止符、或下表中的原语规则组成:
| Name | Common Notation | Primitive |
|---|---|---|
| Sequence | a b | a ~ b |
| Ordered Choice | a | b | a | b |
| Zero-Or-More | a * | zeroOrMore(a) |
| One-Or-More | a + | oneOrMore(a) |
| Optional | a ? | optional(a) |
| And-Predicate | & a | &(a) |
| Non-Predicate | ! a | !a |
除了以上原语方法,还有以下原语可供使用:
| Method/Field | Description |
|---|---|
| ANY | 匹配任何除了 EOI 的单个字符 |
| NOTHING | 不匹配任何,总是失败 |
| EMPTY | 不匹配任何,总是成功 |
| EOI | 匹配特殊的 EOI 字符 |
| ch(Char) | 创建一个匹配单个字符的规则 |
| {String} ~ {String} | 匹配给定的字符范围 |
| anyOf(String) | 匹配给定字符串中的任意字符 |
| ignoreCase(Char) | 匹配单个字符且忽略大小写 |
| ignoreCase(String) | 匹配整个字符串且胡烈大小写 |
| str(String) | 创建一个匹配整个字符串的 |
| nTimes(Int, Rule) | 创建一个匹配子规则 N 次的规则 |
Parser Actions
在 Parboiled Java 中需要以布尔表达式的形式设置解析器动作,然后再被自动转换为解析器动作规则。没有进一步的动作类型来支持 Parboiled Java 对值栈操作元素数量进行区分。这意味着 Java 开发者不能依赖编译器来检测解析器动作对值栈操作的一致性(主要是元素数量)。因此在动作的设计期间需要更多对人的规范约束。
在 Parboiled Scala 中,Scala 的类型推断能力使得解析器动作支持比 Java 中更高级别的抽象。在 Scala 解析器动作中,无需对值栈进行操作,而是将其指定为函数。因此,它们不仅仅是简单的代码块,其本身就是类型。
根据规则中包含的解析器动作,规则的实际类型会发生变化。对值栈没有任何影响的规则类型为 Rule0。将类型为 A 的值对象推送到值栈的规则具有类型 Rule1[A]。导致类型分别为 A 和 B 的两个值对象被推送到值栈的规则类型为 Rule2[A,B]。导致类型为 Z 的一个值对象从堆栈中弹出的规则具有类型 PopRule1[Z]。目前共 15 种具体的规则类型。
这种稍微复杂的类结构允许 Scala 在规则类型中进行编码,以确定规则如何影响解析器值堆栈,并确保所有解析器操作正确地协同工作以生成解析器最终结果值。请注意,这不会对值对象的类型施加任何限制!
支持 3 种形式的解析器动作:
- 动作操作符
- push/test/run 方法
- 独立动作
Action Operators
共定义了 9 种动作操作符。每种都会链接一个动作函数到语法规则结构,但与它们的动作函数参数的类型和语义不同。下表是一个概览:
| Action Result | Action Argument(String) | Action Argument(Value Object Pop) | Action Argument(Value Object Peek) | Action Argument(Char) | Action Argument(IndexRange) |
|---|---|---|---|---|---|
| Value Object | ~> | ~~> | ~~~> | ~:> | ~» |
| Boolean | ~? | ~~? | ~~~? | ||
| Unit | ~% | ~~% | ~~~% |
以单个 ~ 字符起始的操作符通常是解析器动作接收已匹配输入文本的方式。其参数是一个类型为 String => ... 的函数。该操作符内部会创建一个新的动作规则,在运行时,将与紧邻的规则匹配的输入文本作为参数传递给该函数。
以 ~~ 和 ~~~ 字符起始的操作符接收一个或多个值对象作为参数。
以 > 字符结尾的操作符创建一个或多个新的值对象,在动作函数运行之后推送到值栈。这些动作结构值的类型会被编码到操作符的返回类型。
以 ? 字符结尾的操作符接收一个返回布尔值的函数作为语义判定。如果动作函数返回 false 则停止当前规则序列的求值,即为匹配,然后强制解析器回退并查找其他匹配可能。
以 % 字符结尾的操作符支持你运行任意逻辑而不会对处理过程产生影响。其动作函数返回 Unit,一旦解析器经过,它们就会被运行。
push/test/run 方法
上述讨论的动作操作符均为将你的动作链接到当前的解析处理过程,要么是接收已匹配的输入文本作为参数,要么是生成新的栈值元素。但有时你的动作并不需要任何输入,因为其在规则结构中的位置就是其需要的所有上下文。这时你可以使用 push/test/run 方法来实现与上述讨论的操作符相同的功能,这些方法由 Parser 特质提供。
由这些方法构造的动作规则可以通过被链接在一起。如下所示:
def JsonTrue = rule { "true" ~ push(True) }
独立动作
独立动作是以 Context 对象作为参数的独立函数。它们可以像普通规则一样被使用,因为 Parser 特质提供了以下两种隐式转换:
| Method | Semantics |
|---|---|
| toRunAction(f:(Context[Any]) => Unit):Rule0 | 通用非判断动作 |
| toTestAction(f:(Context[Any]) => Boolean):Rule0 | 通用语义判定动作 |
当前解析的 Context 为通用动作提供了对解析器的所有状态访问能力。它们可以通过 getValueStack 方法来修改解析器的值栈。但并不推荐这种用法,因为这将导致 Scala 编译器无法有效的验证值栈操作的一致性。
“withContext” 动作
Parser 特质提供的另一个便利的工具是 withContext 方法,通过该方法,你可以包装一个动作函数然后再将其传递给动作操作符。该方法支持你的动作函数除了其常规的参数之外还能接收当前解析器的 Context。
withContext 的签名类似如下定义:
def withContext[A, B, R](f: (A, B, Context[_]) => R): ((A, B) => R)
因此,被该方法包装的动作函数在外部会显示为一个函数,比如,弹出值栈的两个对象并生成一个新的值。但是,在内部你的动作同样也可以接受到当前上下文的实例,比如可以查看当前输入位置以及行号。
Parser Tesing
从 0.9.9.0 开始提供了一个 ParboiledTest 特质来简化测试的开发工作。Parboiled 使用它来完成内部测试,你可以参考 WithContextTest 来查看应用方式。