CH08-执行器
执行器 Executor 是 MyBatis 的核心接口之一,接口层提供的相关数据库操作,都是基于 Executor 的子类实现的。
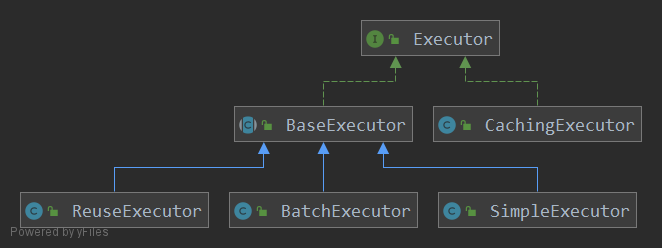
创建执行器
在创建 sql 会话时,MyBatis 会调用 Configuration#newExecutor 方法创建执行器。枚举类 ExecutorType 定义了三种执行器类型,即 SIMPLE、REUSE 和 Batch,这些执行器的主要区别在于:
SIMPLE在每次执行完成后都会关闭statement对象;REUSE会在本地维护一个容器,当前statement创建完成后放入容器中,当下次执行相同的sql时会复用statement对象,执行完毕后也不会关闭;BATCH会将修改操作记录在本地,等待程序触发或有下一次查询时才批量执行修改操作。
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
// 默认类型为 simple
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
if (cacheEnabled) {
// 如果全局缓存打开,使用 CachingExecutor 代理执行器
executor = new CachingExecutor(executor);
}
// 应用插件
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
执行器创建后,如果全局缓存配置是有效的,则会将执行器装饰为 CachingExecutor。
基础执行器
SimpleExecutor、ReuseExecutor、BatchExecutor 均继承自 BaseExecutor。BaseExecutor 实现了 Executor 的全部方法,对缓存、事务、连接处理等提供了一些模板方法,但是针对具体的数据库操作留下了四个抽象方法交由子类实现。
/**
* 更新
*/
protected abstract int doUpdate(MappedStatement ms, Object parameter)
throws SQLException;
/**
* 刷新 statement
*/
protected abstract List<BatchResult> doFlushStatements(boolean isRollback)
throws SQLException;
/**
* 查询
*/
protected abstract <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql)
throws SQLException;
/**
* 查询获取游标对象
*/
protected abstract <E> Cursor<E> doQueryCursor(MappedStatement ms, Object parameter, RowBounds rowBounds, BoundSql boundSql)
throws SQLException;
基础执行器的查询逻辑如下:
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
// 非嵌套查询且设置强制刷新时清除缓存
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
// 缓存不为空,组装存储过程出参
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 无本地缓存,执行数据库查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
// 全局配置语句不共享缓存
clearLocalCache();
}
}
return list;
}
/**
* 查询本地缓存,组装存储过程结果集
*/
private void handleLocallyCachedOutputParameters(MappedStatement ms, CacheKey key, Object parameter, BoundSql boundSql) {
if (ms.getStatementType() == StatementType.CALLABLE) {
// 存储过程类型,查询缓存
final Object cachedParameter = localOutputParameterCache.getObject(key);
if (cachedParameter != null && parameter != null) {
final MetaObject metaCachedParameter = configuration.newMetaObject(cachedParameter);
final MetaObject metaParameter = configuration.newMetaObject(parameter);
for (ParameterMapping parameterMapping : boundSql.getParameterMappings()) {
if (parameterMapping.getMode() != ParameterMode.IN) {
// 参数类型为 OUT 或 INOUT 的,组装结果集
final String parameterName = parameterMapping.getProperty();
final Object cachedValue = metaCachedParameter.getValue(parameterName);
metaParameter.setValue(parameterName, cachedValue);
}
}
}
}
}
/**
* 查询数据库获取结果集
*/
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 放一个 placeHolder 标志
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 执行查询
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
// 查询结果集放入本地缓存
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
// 如果是存储过程查询,将存储过程结果集放入本地缓存
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
执行查询时 MyBatis 首先会根据 CacheKey 查询本地缓存,CacheKey 由本次查询的参数生成,本地缓存由 PerpetualCache 实现,这就是 MyBatis 的一级缓存。一级缓存维护对象 localCache 是基础执行器的本地变量,因此只有相同 sql 会话的查询才能共享一级缓存。当一级缓存中没有对应的数据,基础执行器最终会调用 doQuery 方法交由子类去获取数据。
而执行 update 等其它操作时,则会首先清除本地的一级缓存再交由子类执行具体的操作:
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 清空本地缓存
clearLocalCache();
// 调用子类执行器逻辑
return doUpdate(ms, parameter);
}
简单执行器
简单执行器是 MyBatis 的默认执行器。其封装了对 JDBC 的操作,对于查询方法 doQuery 的实现如下,其主要包括创建 statement 处理器、创建 statement、执行查询、关闭 statement。
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 创建 statement 处理器
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 创建 statement
stmt = prepareStatement(handler, ms.getStatementLog());
// 执行查询
return handler.query(stmt, resultHandler);
} finally {
// 关闭 statement
closeStatement(stmt);
}
}
创建 statement 处理器
全局配置类 Configuration 提供了方法 newStatementHandler 用于创建 statement 处理器:
/**
* 创建 statement 处理器
*/
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// StatementHandler 包装对象,根据 statement 类型创建代理处理器,并将实际操作委托给代理处理器处理
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
// 应用插件
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
实际每次创建的 statement 处理器对象都是由 RoutingStatementHandler 创建的,RoutingStatementHandler 根据当前 MappedStatement 的类型创建具体的 statement 类型处理器。StatementType 定义了 3 个 statement 类型枚举,分别对应 JDBC 的普通语句、预编译语句和存储过程语句。
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// 根据 statement 类型选择对应的 statementHandler
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}
创建 statement
简单执行器中的 Statement 对象是根据上述步骤中生成的 statement 处理器获取的。
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
// 获取代理连接对象
Connection connection = getConnection(statementLog);
// 创建 statement 对象
stmt = handler.prepare(connection, transaction.getTimeout());
// 设置 statement 参数
handler.parameterize(stmt);
return stmt;
}
@Override
public Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException {
ErrorContext.instance().sql(boundSql.getSql());
Statement statement = null;
try {
// 从连接中创建 statement 对象
statement = instantiateStatement(connection);
// 设置超时时间
setStatementTimeout(statement, transactionTimeout);
// 设置分批获取数据数量
setFetchSize(statement);
return statement;
} catch (SQLException e) {
closeStatement(statement);
throw e;
} catch (Exception e) {
closeStatement(statement);
throw new ExecutorException("Error preparing statement. Cause: " + e, e);
}
}
执行查询
创建 statement 对象完成即可通过 JDBC 的 API 执行数据库查询,并从 statement 对象中获取查询结果,根据配置进行转换。
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
// 执行查询
ps.execute();
// 处理结果集
return resultSetHandler.handleResultSets(ps);
}
/**
* 处理结果集
*/
@Override
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
// 多结果集
final List<Object> multipleResults = new ArrayList<>();
int resultSetCount = 0;
ResultSetWrapper rsw = getFirstResultSet(stmt);
// statement 对应的所有 ResultMap 对象
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
// 验证结果集不为空时,ResultMap 数量不能为 0
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
// 逐个获取 ResultMap
ResultMap resultMap = resultMaps.get(resultSetCount);
// 转换结果集,放到 multipleResults 容器中
handleResultSet(rsw, resultMap, multipleResults, null);
// 获取下一个待处理的结果集
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
// statement 配置的多结果集类型
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
return collapseSingleResultList(multipleResults);
}
关闭连接
查询完成后 statement 对象会被关闭。
/**
* 关闭 statement
*
* @param statement
*/
protected void closeStatement(Statement statement) {
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {
// ignore
}
}
}
简单执行器中的其它数据库执行方法与 doQuery 方法实现类似。
复用执行器
ReuseExecutor 相对于 SimpleExecutor 实现了对 statment 对象的复用,其在本地维护了 statementMap 用于保存 sql 语句和 statement 对象的关系。当调用 prepareStatement 方法获取 statement 对象时首先会查找本地是否有对应的 statement 对象,如果有则进行复用,负责重新创建并将 statement 对象放入本地缓存。
/**
* 创建 statement 对象
*
* @param handler
* @param statementLog
* @return
* @throws SQLException
*/
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
BoundSql boundSql = handler.getBoundSql();
String sql = boundSql.getSql();
if (hasStatementFor(sql)) {
// 如果本地容器中包含当前 sql 对应的 statement 对象,进行复用
stmt = getStatement(sql);
applyTransactionTimeout(stmt);
} else {
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
putStatement(sql, stmt);
}
handler.parameterize(stmt);
return stmt;
}
private boolean hasStatementFor(String sql) {
try {
return statementMap.keySet().contains(sql) && !statementMap.get(sql).getConnection().isClosed();
} catch (SQLException e) {
return false;
}
}
private Statement getStatement(String s) {
return statementMap.get(s);
}
private void putStatement(String sql, Statement stmt) {
statementMap.put(sql, stmt);
}
提交或回滚会导致执行器调用 doFlushStatements 方法,复用执行器会因此批量关闭本地的 statement 对象。
/**
* 批量关闭 statement 对象
*
* @param isRollback
* @return
*/
@Override
public List<BatchResult> doFlushStatements(boolean isRollback) {
for (Statement stmt : statementMap.values()) {
closeStatement(stmt);
}
statementMap.clear();
return Collections.emptyList();
}
批量执行器
BatchExecutor 相对于 SimpleExecutor ,其 update 操作是批量执行的。
@Override
public int doUpdate(MappedStatement ms, Object parameterObject) throws SQLException {
final Configuration configuration = ms.getConfiguration();
final StatementHandler handler = configuration.newStatementHandler(this, ms, parameterObject, RowBounds.DEFAULT, null, null);
final BoundSql boundSql = handler.getBoundSql();
final String sql = boundSql.getSql();
final Statement stmt;
if (sql.equals(currentSql) && ms.equals(currentStatement)) {
// 如果当前 sql 与上次传入 sql 相同且为相同的 MappedStatement,复用 statement 对象
int last = statementList.size() - 1;
// 获取最后一个 statement 对象
stmt = statementList.get(last);
// 设置超时时间
applyTransactionTimeout(stmt);
// 设置参数
handler.parameterize(stmt);//fix Issues 322
// 获取批量执行结果对象
BatchResult batchResult = batchResultList.get(last);
batchResult.addParameterObject(parameterObject);
} else {
// 创建新的 statement 对象
Connection connection = getConnection(ms.getStatementLog());
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt); //fix Issues 322
currentSql = sql;
currentStatement = ms;
statementList.add(stmt);
batchResultList.add(new BatchResult(ms, sql, parameterObject));
}
// 执行 JDBC 批量添加 sql 语句操作
handler.batch(stmt);
return BATCH_UPDATE_RETURN_VALUE;
}
/**
* 批量执行 sql
*
* @param isRollback
* @return
* @throws SQLException
*/
@Override
public List<BatchResult> doFlushStatements(boolean isRollback) throws SQLException {
try {
// 批量执行结果
List<BatchResult> results = new ArrayList<>();
if (isRollback) {
return Collections.emptyList();
}
for (int i = 0, n = statementList.size(); i < n; i++) {
Statement stmt = statementList.get(i);
applyTransactionTimeout(stmt);
BatchResult batchResult = batchResultList.get(i);
try {
// 设置执行影响行数
batchResult.setUpdateCounts(stmt.executeBatch());
MappedStatement ms = batchResult.getMappedStatement();
List<Object> parameterObjects = batchResult.getParameterObjects();
KeyGenerator keyGenerator = ms.getKeyGenerator();
if (Jdbc3KeyGenerator.class.equals(keyGenerator.getClass())) {
Jdbc3KeyGenerator jdbc3KeyGenerator = (Jdbc3KeyGenerator) keyGenerator;
// 设置数据库生成的主键
jdbc3KeyGenerator.processBatch(ms, stmt, parameterObjects);
} else if (!NoKeyGenerator.class.equals(keyGenerator.getClass())) { //issue #141
for (Object parameter : parameterObjects) {
keyGenerator.processAfter(this, ms, stmt, parameter);
}
}
// Close statement to close cursor #1109
closeStatement(stmt);
} catch (BatchUpdateException e) {
StringBuilder message = new StringBuilder();
message.append(batchResult.getMappedStatement().getId())
.append(" (batch index #")
.append(i + 1)
.append(")")
.append(" failed.");
if (i > 0) {
message.append(" ")
.append(i)
.append(" prior sub executor(s) completed successfully, but will be rolled back.");
}
throw new BatchExecutorException(message.toString(), e, results, batchResult);
}
results.add(batchResult);
}
return results;
} finally {
for (Statement stmt : statementList) {
closeStatement(stmt);
}
currentSql = null;
statementList.clear();
batchResultList.clear();
}
}
执行器提交或回滚事务时会调用 doFlushStatements,从而批量执行提交的 sql 语句并最终批量关闭 statement 对象。
缓存执行器与二级缓存
CachingExecutor 对基础执行器进行了装饰,其作用就是为查询提供二级缓存。所谓的二级缓存是由 CachingExecutor 维护的,相对默认内置的一级缓存而言的缓存。二者区别如下:
- 一级缓存由基础执行器维护,且不可关闭。二级缓存的配置是开发者可干预的,在
xml文件或注解中针对namespace的缓存配置就是二级缓存配置。 - 一级缓存在执行器中维护,即不同
sql会话不能共享一级缓存。二级缓存则是根据namespace维护,不同sql会话是可以共享二级缓存的。
CachingExecutor 中的方法大多是通过直接调用其代理的执行器来实现的,而查询操作则会先查询二级缓存。
/**
* 缓存事务管理器
*/
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 查询二级缓存配置
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
// 当前 statement 配置使用二级缓存
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// 二级缓存中没用数据,调用代理执行器
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 将查询结果放入二级缓存
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
// 无二级缓存配置,调用代理执行器获取结果
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
private void flushCacheIfRequired(MappedStatement ms) {
Cache cache = ms.getCache();
if (cache != null && ms.isFlushCacheRequired()) {
// 存在 namespace 对应的缓存配置,且当前 statement 配置了刷新缓存,执行清空缓存操作
// 非 select 语句配置了默认刷新
tcm.clear(cache);
}
}
如果对应的 statement 的二级缓存配置有效,则会先通过缓存事务管理器 TransactionalCacheManager 查询二级缓存,如果没有命中则查询一级缓存,仍没有命中才会执行数据库查询。
缓存事务管理器
缓存执行器对二级缓存的维护是基于缓存事务管理器 TransactionalCacheManager 的,其内部维护了一个 Map 容器,用于保存 namespace 缓存配置与事务缓存对象的映射关系。
public class TransactionalCacheManager {
/**
* 缓存配置 - 缓存事务对象
*/
private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<>();
/**
* 清除缓存
*
* @param cache
*/
public void clear(Cache cache) {
getTransactionalCache(cache).clear();
}
/**
* 获取缓存
*/
public Object getObject(Cache cache, CacheKey key) {
return getTransactionalCache(cache).getObject(key);
}
/**
* 写缓存
*/
public void putObject(Cache cache, CacheKey key, Object value) {
getTransactionalCache(cache).putObject(key, value);
}
/**
* 缓存提交
*/
public void commit() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.commit();
}
}
/**
* 缓存回滚
*/
public void rollback() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.rollback();
}
}
/**
* 获取或新建事务缓存对象
*/
private TransactionalCache getTransactionalCache(Cache cache) {
return transactionalCaches.computeIfAbsent(cache, TransactionalCache::new);
}
}
缓存配置映射的事务缓存对象就是前文中提到过的事务缓存装饰器 TransactionalCache。getTransactionalCache 会从维护容器中查找对应的事务缓存对象,如果找不到就创建一个事务缓存对象,即通过事务缓存对象装饰当前缓存配置。
查询缓存时,如果缓存未命中,则将对应的 key 放入未命中队列,执行数据库查询完毕后写缓存时并不是立刻写到缓存配置的本地容器中,而是暂时放入待提交队列中,当触发事务提交时才将提交队列中的缓存数据写到缓存配置中。如果发生回滚,则提交队列中的数据会被清空,从而保证了数据的一致性。
@Override
public Object getObject(Object key) {
// issue #116
Object object = delegate.getObject(key);
if (object == null) {
// 放入未命中缓存的 key 的队列
entriesMissedInCache.add(key);
}
// issue #146
if (clearOnCommit) {
return null;
} else {
return object;
}
}
@Override
public void putObject(Object key, Object object) {
// 缓存先写入待提交容器
entriesToAddOnCommit.put(key, object);
}
/**
* 事务提交
*/
public void commit() {
if (clearOnCommit) {
delegate.clear();
}
// 提交缓存
flushPendingEntries();
reset();
}
/**
* 事务回滚
*/
public void rollback() {
unlockMissedEntries();
reset();
}
/**
* 事务提交,提交待提交的缓存。
*/
private void flushPendingEntries() {
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}
/**
* 事务回滚,清理未命中缓存。
*/
private void unlockMissedEntries() {
for (Object entry : entriesMissedInCache) {
try {
delegate.removeObject(entry);
} catch (Exception e) {
log.warn("Unexpected exception while notifiying a rollback to the cache adapter."
+ "Consider upgrading your cache adapter to the latest version. Cause: " + e);
}
}
}
二级缓存与一级缓存的互斥性
使用二级缓存要求无论是否配置了事务自动提交,在执行完成后, sql 会话必须手动提交事务才能触发事务缓存管理器维护缓存到缓存配置中,否则二级缓存无法生效。而缓存执行器在触发事务提交时,不仅会调用事务缓存管理器提交,还会调用代理执行器提交事务:
@Override
public void commit(boolean required) throws SQLException {
// 代理执行器提交
delegate.commit(required);
// 事务缓存管理器提交
tcm.commit();
}
代理执行器的事务提交方法继承自 BaseExecutor,其 commit 方法中调用了 clearLocalCache 方法清除本地一级缓存。因此二级缓存和一级缓存的使用是互斥的。
@Override
public void commit(boolean required) throws SQLException {
if (closed) {
throw new ExecutorException("Cannot commit, transaction is already closed");
}
// 清除本地一级缓存
clearLocalCache();
flushStatements();
if (required) {
transaction.commit();
}
}
总结
MyBatis 提供若干执行器封装底层 JDBC 操作和结果集转换,并嵌入 sql 会话维度的一级缓存和 namespace 维度的二级缓存。接口层可以通过调用不同类型的执行器来完成 sql 相关操作。
org.apache.ibatis.executor.Executor:数据库操作执行器抽象接口。org.apache.ibatis.executor.BaseExecutor:执行器基础抽象实现。org.apache.ibatis.executor.SimpleExecutor:简单类型执行器。org.apache.ibatis.executor.ReuseExecutor:statement复用执行器。org.apache.ibatis.executor.BatchExecutor:批量执行器。org.apache.ibatis.executor.CachingExecutor:二级缓存执行器。org.apache.ibatis.executor.statement.StatementHandler:statement处理器抽象接口。org.apache.ibatis.executor.statement.BaseStatementHandler:statement处理器基础抽象实现。org.apache.ibatis.executor.statement.RoutingStatementHandler:statement处理器路由对象。org.apache.ibatis.executor.statement.SimpleStatementHandler:简单statement处理器。org.apache.ibatis.executor.statement.PreparedStatementHandler:预编译statement处理器。org.apache.ibatis.executor.statement.CallableStatementHandler:存储过程statement处理器。org.apache.ibatis.cache.TransactionalCacheManager:缓存事务管理器。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.