参考自 <MyBatis 技术内幕>。
This the multi-page printable view of this section. Click here to print.
Mybatis
- 1: CH01-整体架构
- 2: CH02-反射模块
- 3: CH03-基础支持模块
- 4: CH04-运行配置解析
- 5: CH05-通用配置解析
- 6: CH06-语句解析
- 7: CH07-接口层
- 8: CH08-执行器
- 9: CH09-集成 Spring
- 10: CH10-整体流程
- 11: CH11-插件机制
- 12: CH12-代码生成
- 13: CH13-多数据源
- 14: CH14-常用片段
- 15: CH15-事务管理原理
- 16: CH16-一级缓存原理
- 17: CH17-二级缓存原理
- 18: CH18-性能优化
1 - CH01-整体架构
MyBatis 是一款旨在帮助开发人员屏蔽底层重复性原生 JDBC 代码的持久化框架,其支持通过映射文件配置或注解将 ResultSet 映射为 Java 对象。相对于其它 ORM 框架,MyBatis 更为轻量级,支持定制化 SQL 和动态 SQL,方便优化查询性能,同时包含了良好的缓存机制。
整体架构
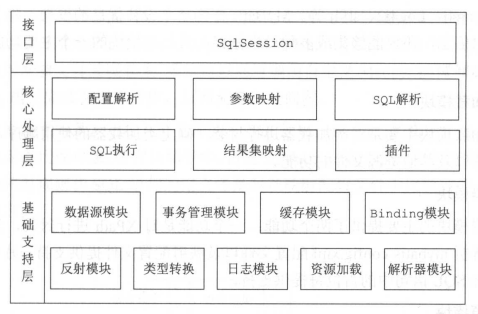
基础支持层
- 反射模块:提供封装的反射 API,方便上层调用。
- 类型转换:为简化配置文件提供了别名机制,并且实现了 Java 类型和 JDBC 类型的互转。
- 日志模块:能够集成多种第三方日志框架。
- 资源加载模块:对类加载器进行封装,提供加载类文件和其它资源文件的功能。
- 数据源模块:提供数据源实现并能够集成第三方数据源模块。
- 事务管理:可以和 Spring 集成开发,对事务进行管理。
- 缓存模块:提供一级缓存和二级缓存,将部分请求拦截在缓存层。
- Binding 模块:在调用 SqlSession 相应方法执行数据库操作时,需要指定映射文件中的 SQL 节点,MyBatis 通过 Binding 模块将自定义 Mapper 接口与映射文件关联,避免拼写等错误导致在运行时才发现相应异常。
核心处理层
- 配置解析:MyBatis 初始化时会加载配置文件、映射文件和 Mapper 接口的注解信息,解析后会以对象的形式保存到 Configuration 对象中。
- SQL 解析与 scripting 模块:MyBatis 支持通过配置实现动态 SQL,即根据不同入参生成 SQL。
- SQL 执行与结果解析:Executor 负责维护缓存和事务管理,并将数据库相关操作委托给 StatementHandler,ParmeterHadler 负责完成 SQL 语句的实参绑定并通过 Statement 对象执行 SQL,通过 ResultSet 返回结果,交由 ResultSetHandler 处理。
- 插件:支持开发者通过插件接口对 MyBatis 进行扩展。
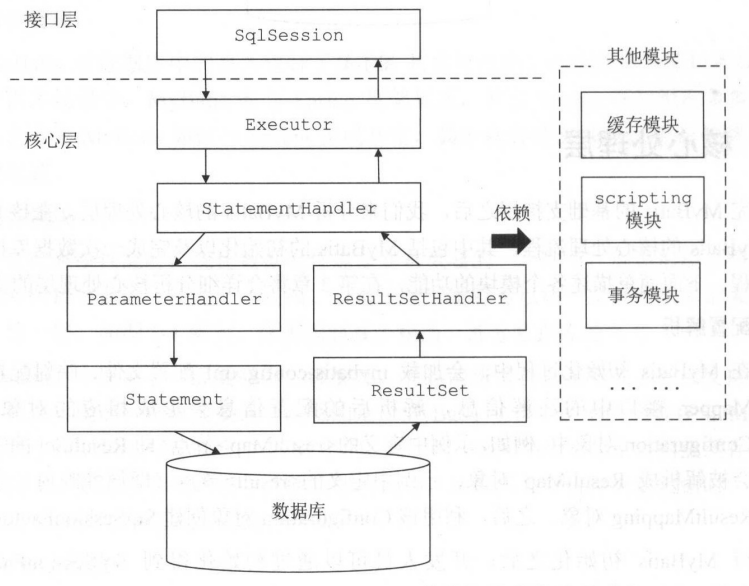
接口层
SqlSession 接口定义了暴露给应用程序调用的 API,接口层在收到请求时会调用核心处理层的相应模块完成具体的数据库操作。
2 - CH02-反射模块
MyBatis 在进行参数处理、结果映射时等操作时,会涉及大量的反射操作。为了简化这些反射相关操作,MyBatis 在 org.apache.ibatis.reflection 包下提供了专门的反射模块,对反射操作做了近一步封装,提供了更为简洁的 API。
缓存类的元信息
MyBatis 提供 Reflector 类来缓存类的字段名和 getter/setter 方法的元信息,使得反射时有更好的性能。使用方式是将原始类对象传入其构造方法,生成 Reflector 对象。
public Reflector(Class<?> clazz) {
type = clazz;
// 如果存在,记录无参构造方法
addDefaultConstructor(clazz);
// 记录字段名与get方法、get方法返回值的映射关系
addGetMethods(clazz);
// 记录字段名与set方法、set方法参数的映射关系
addSetMethods(clazz);
// 针对没有getter/setter方法的字段,通过Filed对象的反射来设置和读取字段值
addFields(clazz);
// 可读的字段名
readablePropertyNames = getMethods.keySet().toArray(new String[getMethods.keySet().size()]);
// 可写的字段名
writablePropertyNames = setMethods.keySet().toArray(new String[setMethods.keySet().size()]);
// 保存一份所有字段名大写与原始字段名的映射
for (String propName : readablePropertyNames) {
caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);
}
for (String propName : writablePropertyNames) {
caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);
}
}
addGetMethods 和 addSetMethods 分别获取类的所有方法,从符合 getter/setter 规范的方法中解析出字段名,并记录方法的参数类型、返回值类型等信息:
private void addGetMethods(Class<?> cls) {
// 字段名-get方法
Map<String, List<Method>> conflictingGetters = new HashMap<>();
// 获取类的所有方法,及其实现接口的方法,并根据方法签名去重
Method[] methods = getClassMethods(cls);
for (Method method : methods) {
if (method.getParameterTypes().length > 0) {
// 过滤有参方法
continue;
}
String name = method.getName();
if ((name.startsWith("get") && name.length() > 3)
|| (name.startsWith("is") && name.length() > 2)) {
// 由get属性获取对应的字段名(去除前缀,首字母转小写)
name = PropertyNamer.methodToProperty(name);
addMethodConflict(conflictingGetters, name, method);
}
}
// 保证每个字段只对应一个get方法
resolveGetterConflicts(conflictingGetters);
}
对 getter/setter 方法进行去重是通过类似 java.lang.String#getSignature:java.lang.reflect.Method 的方法签名来实现的,如果子类在实现过程中,参数、返回值使用了不同的类型(使用原类型的子类),则会导致方法签名不一致,同一字段就会对应不同的 getter/setter 方法,因此需要进行去重。
private void resolveGetterConflicts(Map<String, List<Method>> conflictingGetters) {
for (Entry<String, List<Method>> entry : conflictingGetters.entrySet()) {
Method winner = null;
// 属性名
String propName = entry.getKey();
for (Method candidate : entry.getValue()) {
if (winner == null) {
winner = candidate;
continue;
}
// 字段对应了多个get方法
Class<?> winnerType = winner.getReturnType();
Class<?> candidateType = candidate.getReturnType();
if (candidateType.equals(winnerType)) {
// 返回值类型相同
if (!boolean.class.equals(candidateType)) {
throw new ReflectionException(
"Illegal overloaded getter method with ambiguous type for property "
+ propName + " in class " + winner.getDeclaringClass()
+ ". This breaks the JavaBeans specification and can cause unpredictable results.");
} else if (candidate.getName().startsWith("is")) {
// 返回值为boolean的get方法可能有多个,如getIsSave和isSave,优先取is开头的
winner = candidate;
}
} else if (candidateType.isAssignableFrom(winnerType)) {
// OK getter type is descendant
// 可能会出现接口中的方法返回值是List,子类实现方法返回值是ArrayList,使用子类返回值方法
} else if (winnerType.isAssignableFrom(candidateType)) {
winner = candidate;
} else {
throw new ReflectionException(
"Illegal overloaded getter method with ambiguous type for property "
+ propName + " in class " + winner.getDeclaringClass()
+ ". This breaks the JavaBeans specification and can cause unpredictable results.");
}
}
// 记录字段名对应的get方法对象和返回值类型
addGetMethod(propName, winner);
}
}
去重的方式是使用更规范的方法以及使用子类的方法。在确认字段名对应的唯一 getter/setter 方法后,记录方法名对应的方法、参数、返回值等信息。MethodInvoker 可用于调用 Method 类的 invoke 方法来执行 getter/setter 方法(addSetMethods 记录映射关系的方式与 addGetMethods 大致相同)。
private void addGetMethod(String name, Method method) {
// 过滤$开头、serialVersionUID的get方法和getClass()方法
if (isValidPropertyName(name)) {
// 字段名-对应get方法的MethodInvoker对象
getMethods.put(name, new MethodInvoker(method));
Type returnType = TypeParameterResolver.resolveReturnType(method, type);
// 字段名-运行时方法的真正返回类型
getTypes.put(name, typeToClass(returnType));
}
}
接下来会执行 addFields 方法,此方法针对没有 getter/setter 方法的字段,通过包装为 SetFieldInvoker 在需要时通过 Field 对象的反射来设置和读取字段值。
private void addFields(Class<?> clazz) {
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) {
if (!setMethods.containsKey(field.getName())) {
// issue #379 - removed the check for final because JDK 1.5 allows
// modification of final fields through reflection (JSR-133). (JGB)
// pr #16 - final static can only be set by the classloader
int modifiers = field.getModifiers();
if (!(Modifier.isFinal(modifiers) && Modifier.isStatic(modifiers))) {
// 非final的static变量,没有set方法,可以通过File对象做赋值操作
addSetField(field);
}
}
if (!getMethods.containsKey(field.getName())) {
addGetField(field);
}
}
if (clazz.getSuperclass() != null) {
// 递归查找父类
addFields(clazz.getSuperclass());
}
}
抽象字段赋值与读取
Invoker 接口用于抽象设置和读取字段值的操作。对于有 getter/setter 方法的字段,通过 MethodInvoker 反射执行;对应其它字段,通过 GetFieldInvoker 和 SetFieldInvoker 操作 Field 对象的 getter/setter 方法反射执行。
/**
* 用于抽象设置和读取字段值的操作
*
* {@link MethodInvoker} 反射执行getter/setter方法
* {@link GetFieldInvoker} {@link SetFieldInvoker} 反射执行Field对象的get/set方法
*
* @author Clinton Begin
*/
public interface Invoker {
/**
* 通过反射设置或读取字段值
*
* @param target
* @param args
* @return
* @throws IllegalAccessException
* @throws InvocationTargetException
*/
Object invoke(Object target, Object[] args) throws IllegalAccessException, InvocationTargetException;
/**
* 字段类型
*
* @return
*/
Class<?> getType();
}
解析参数类型
针对 Java-Type 体系的多种实现,TypeParameterResolver 提供一系列方法来解析指定类中的字段、方法返回值或方法参数的类型。
Type 接口包含 4 个子接口和 1 个实现类:

- Class:原始类型
- ParameterizedType:泛型类型,如:List
- TypeVariable:泛型类型变量,如: List
中的 T - GenericArrayType:组成元素是 ParameterizedType 或 TypeVariable 的数组类型,如:List
[]、T[] - WildcardType:通配符泛型类型变量,如:List 中的 ?
TypeParameterResolver 分别提供 resolveFieldType、resolveReturnType、resolveParamTypes 方法用于解析字段类型、方法返回值类型和方法入参类型,这些方法均调用 resolveType 来获取类型信息:
/**
* 获取类型信息
*
* @param type 根据是否有泛型信息签名选择传入泛型类型或简单类型
* @param srcType 引用字段/方法的类(可能是子类,字段和方法在父类声明)
* @param declaringClass 字段/方法声明的类
* @return
*/
private static Type resolveType(Type type, Type srcType, Class<?> declaringClass) {
if (type instanceof TypeVariable) {
// 泛型类型变量,如:List<T> 中的 T
return resolveTypeVar((TypeVariable<?>) type, srcType, declaringClass);
} else if (type instanceof ParameterizedType) {
// 泛型类型,如:List<String>
return resolveParameterizedType((ParameterizedType) type, srcType, declaringClass);
} else if (type instanceof GenericArrayType) {
// TypeVariable/ParameterizedType 数组类型
return resolveGenericArrayType((GenericArrayType) type, srcType, declaringClass);
} else {
// 原始类型,直接返回
return type;
}
}
resolveTypeVar 用于解析泛型类型变量参数类型,如果字段或方法在当前类中声明,则返回泛型类型的上界或 Object 类型;如果在父类中声明,则递归解析父类;父类也无法解析,则递归解析实现的接口。
private static Type resolveTypeVar(TypeVariable<?> typeVar, Type srcType, Class<?> declaringClass) {
Type result;
Class<?> clazz;
if (srcType instanceof Class) {
// 原始类型
clazz = (Class<?>) srcType;
} else if (srcType instanceof ParameterizedType) {
// 泛型类型,如 TestObj<String>
ParameterizedType parameterizedType = (ParameterizedType) srcType;
// 取原始类型TestObj
clazz = (Class<?>) parameterizedType.getRawType();
} else {
throw new IllegalArgumentException("The 2nd arg must be Class or ParameterizedType, but was: " + srcType.getClass());
}
if (clazz == declaringClass) {
// 字段就是在当前引用类中声明的
Type[] bounds = typeVar.getBounds();
if (bounds.length > 0) {
// 返回泛型类型变量上界,如:T extends String,则返回String
return bounds[0];
}
// 没有上界返回Object
return Object.class;
}
// 字段/方法在父类中声明,递归查找父类泛型
Type superclass = clazz.getGenericSuperclass();
result = scanSuperTypes(typeVar, srcType, declaringClass, clazz, superclass);
if (result != null) {
return result;
}
// 递归泛型接口
Type[] superInterfaces = clazz.getGenericInterfaces();
for (Type superInterface : superInterfaces) {
result = scanSuperTypes(typeVar, srcType, declaringClass, clazz, superInterface);
if (result != null) {
return result;
}
}
return Object.class;
}
通过调用 scanSuperTypes 实现递归解析:
private static Type scanSuperTypes(TypeVariable<?> typeVar, Type srcType, Class<?> declaringClass, Class<?> clazz, Type superclass) {
if (superclass instanceof ParameterizedType) {
// 父类是泛型类型
ParameterizedType parentAsType = (ParameterizedType) superclass;
Class<?> parentAsClass = (Class<?>) parentAsType.getRawType();
// 父类中的泛型类型变量集合
TypeVariable<?>[] parentTypeVars = parentAsClass.getTypeParameters();
if (srcType instanceof ParameterizedType) {
// 子类可能对父类泛型变量做过替换,使用替换后的类型
parentAsType = translateParentTypeVars((ParameterizedType) srcType, clazz, parentAsType);
}
if (declaringClass == parentAsClass) {
// 字段/方法在当前父类中声明
for (int i = 0; i < parentTypeVars.length; i++) {
if (typeVar == parentTypeVars[i]) {
// 使用变量对应位置的真正类型(可能已经被替换),如父类 A<T>,子类 B extends A<String>,则返回String
return parentAsType.getActualTypeArguments()[i];
}
}
}
// 字段/方法声明的类是当前父类的父类,继续递归
if (declaringClass.isAssignableFrom(parentAsClass)) {
return resolveTypeVar(typeVar, parentAsType, declaringClass);
}
} else if (superclass instanceof Class && declaringClass.isAssignableFrom((Class<?>) superclass)) {
// 父类是原始类型,继续递归父类
return resolveTypeVar(typeVar, superclass, declaringClass);
}
return null;
}
解析方法返回值和方法参数的逻辑大致与解析字段类型相同,MyBatis 源码的TypeParameterResolverTest 类提供了相关的测试用例。
元信息工厂
MyBatis 还提供 ReflectorFactory 接口用于实现 Reflector 容器,其默认实现为 DefaultReflectorFactory,其中可以使用 classCacheEnabled 属性来配置是否使用缓存。
public class DefaultReflectorFactory implements ReflectorFactory {
/**
* 是否缓存Reflector类信息
*/
private boolean classCacheEnabled = true;
/**
* Reflector缓存容器
*/
private final ConcurrentMap<Class<?>, Reflector> reflectorMap = new ConcurrentHashMap<>();
public DefaultReflectorFactory() {
}
@Override
public boolean isClassCacheEnabled() {
return classCacheEnabled;
}
@Override
public void setClassCacheEnabled(boolean classCacheEnabled) {
this.classCacheEnabled = classCacheEnabled;
}
/**
* 获取类的Reflector信息
*
* @param type
* @return
*/
@Override
public Reflector findForClass(Class<?> type) {
if (classCacheEnabled) {
// synchronized (type) removed see issue #461
// 如果缓存Reflector信息,放入缓存容器
return reflectorMap.computeIfAbsent(type, Reflector::new);
} else {
return new Reflector(type);
}
}
}
对象创建工厂
ObjectFactory 接口是 MyBatis 对象创建工厂,其默认实现 DefaultObjectFactory 通过构造器反射创建对象,支持使用无参构造器和有参构造器。
属性工具集
MyBatis 在映射文件定义 resultMap 支持如下形式:
<resultMap id="map" type="Order">
<result property="orders[0].items[0].name" column="col1"/>
<result property="orders[0].items[1].name" column="col2"/>
...
</resultMap>
orders[0].items[0].name 这样的表达式是由 PropertyTokenizer 解析的,其构造方法能够对表达式进行解析;同时还实现了 Iterator 接口,能够迭代解析表达式。
public PropertyTokenizer(String fullname) {
// orders[0].items[0].name
int delim = fullname.indexOf('.');
if (delim > -1) {
// name = orders[0]
name = fullname.substring(0, delim);
// children = items[0].name
children = fullname.substring(delim + 1);
} else {
name = fullname;
children = null;
}
// orders[0]
indexedName = name;
delim = name.indexOf('[');
if (delim > -1) {
// 0
index = name.substring(delim + 1, name.length() - 1);
// order
name = name.substring(0, delim);
}
}
/**
* 是否有children表达式继续迭代
*
* @return
*/
@Override
public boolean hasNext() {
return children != null;
}
/**
* 分解出的 . 分隔符的 children 表达式可以继续迭代
* @return
*/
@Override
public PropertyTokenizer next() {
return new PropertyTokenizer(children);
}
PropertyNamer 可以根据 getter/setter 规范解析字段名称;PropertyCopier 则支持对有相同父类的对象,通过反射拷贝字段值。
封装类信息
MetaClass 类依赖 PropertyTokenizer 和 Reflector 查找表达式是否可以匹配 Java 对象中的字段,以及对应字段是否有 getter/setter 方法。
/**
* 验证传入的表达式,是否存在指定的字段
*
* @param name
* @param builder
* @return
*/
private StringBuilder buildProperty(String name, StringBuilder builder) {
// 映射文件表达式迭代器
PropertyTokenizer prop = new PropertyTokenizer(name);
if (prop.hasNext()) {
// 复杂表达式,如name = items[0].name,则prop.getName() = items
String propertyName = reflector.findPropertyName(prop.getName());
if (propertyName != null) {
builder.append(propertyName);
// items.
builder.append(".");
// 加载内嵌字段类型对应的MetaClass
MetaClass metaProp = metaClassForProperty(propertyName);
// 迭代子字段
metaProp.buildProperty(prop.getChildren(), builder);
}
} else {
// 非复杂表达式,获取字段名,如:userid->userId
String propertyName = reflector.findPropertyName(name);
if (propertyName != null) {
builder.append(propertyName);
}
}
return builder;
}
包装字段对象
相对于 MetaClass 关注类信息,MetalObject 关注的是对象的信息,除了保存传入的对象本身,还会为对象指定一个 ObjectWrapper 将对象包装起来。ObejctWrapper 体系如下:
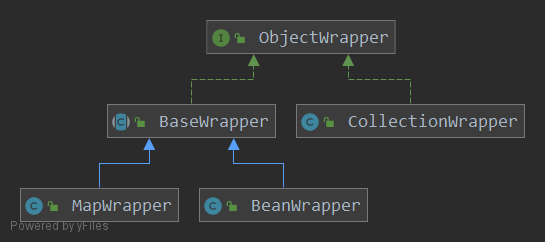
ObjectWrapper 的默认实现包括了对 Map、Collection 和普通 JavaBean 的包装。MyBatis 还支持通过 ObjectWrapperFactory 接口对 ObejctWrapper 进行扩展,生成自定义的包装类。MetaObject 对对象的具体操作,就委托给真正的 ObjectWrapper 处理。
private MetaObject(Object object, ObjectFactory objectFactory, ObjectWrapperFactory objectWrapperFactory, ReflectorFactory reflectorFactory) {
this.originalObject = object;
this.objectFactory = objectFactory;
this.objectWrapperFactory = objectWrapperFactory;
this.reflectorFactory = reflectorFactory;
// 根据传入object类型不同,指定不同的wrapper
if (object instanceof ObjectWrapper) {
this.objectWrapper = (ObjectWrapper) object;
} else if (objectWrapperFactory.hasWrapperFor(object)) {
this.objectWrapper = objectWrapperFactory.getWrapperFor(this, object);
} else if (object instanceof Map) {
this.objectWrapper = new MapWrapper(this, (Map) object);
} else if (object instanceof Collection) {
this.objectWrapper = new CollectionWrapper(this, (Collection) object);
} else {
this.objectWrapper = new BeanWrapper(this, object);
}
}
例如赋值操作,BeanWrapper 的实现如下:
@Override
public void set(PropertyTokenizer prop, Object value) {
if (prop.getIndex() != null) {
// 当前表达式是集合,如:items[0],就需要获取items集合对象
Object collection = resolveCollection(prop, object);
// 在集合的指定索引上赋值
setCollectionValue(prop, collection, value);
} else {
// 解析完成,通过Invoker接口做赋值操作
setBeanProperty(prop, object, value);
}
}
protected Object resolveCollection(PropertyTokenizer prop, Object object) {
if ("".equals(prop.getName())) {
return object;
} else {
// 在对象信息中查到此字段对应的集合对象
return metaObject.getValue(prop.getName());
}
}
根据 PropertyTokenizer 对象解析出的当前字段是否存在 index 索引来判断字段是否为集合。如果当前字段对应集合,则需要在对象信息中查到此字段对应的集合对象:
public Object getValue(String name) {
PropertyTokenizer prop = new PropertyTokenizer(name);
if (prop.hasNext()) {
// 如果表达式仍可迭代,递归寻找字段对应的对象
MetaObject metaValue = metaObjectForProperty(prop.getIndexedName());
if (metaValue == SystemMetaObject.NULL_META_OBJECT) {
return null;
} else {
return metaValue.getValue(prop.getChildren());
}
} else {
// 字段解析完成
return objectWrapper.get(prop);
}
}
如果字段是简单类型,BeanWrapper 获取字段对应的对象逻辑如下:
@Override
public Object get(PropertyTokenizer prop) {
if (prop.getIndex() != null) {
// 集合类型,递归获取
Object collection = resolveCollection(prop, object);
return getCollectionValue(prop, collection);
} else {
// 解析完成,反射读取
return getBeanProperty(prop, object);
}
}
可以看到,仍然是会判断表达式是否迭代完成,如果未解析完字段会不断递归,直至找到对应的类型。前面说到 Reflector 创建过程中将对字段的读取和赋值操作通过 Invoke 接口抽象出来,针对最终获取的字段,此时就会调用 Invoke 接口对字段反射读取对象值:
/**
* 通过Invoker接口反射执行读取操作
*
* @param prop
* @param object
*/
private Object getBeanProperty(PropertyTokenizer prop, Object object) {
try {
Invoker method = metaClass.getGetInvoker(prop.getName());
try {
return method.invoke(object, NO_ARGUMENTS);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
} catch (RuntimeException e) {
throw e;
} catch (Throwable t) {
throw new ReflectionException("Could not get property '" + prop.getName() + "' from " + object.getClass() + ". Cause: " + t.toString(), t);
}
}
对象读取完毕再通过 setCollectionValue 方法对集合指定索引进行赋值或通过 setBeanProperty 方法对简单类型反射赋值。MapWrapper 的操作与 BeanWrapper 大致相同,CollectionWrapper 相对更会简单,只支持对原始集合对象进行添加操作。
总结
MyBatis 根据自身需求,对反射 API 做了近一步封装。其目的是简化反射操作,为对象字段的读取和赋值提供更好的性能。
- org.apache.ibatis.reflection.Reflector:缓存类的字段名和 getter/setter 方法的元信息,使得反射时有更好的性能。
- org.apache.ibatis.reflection.invoker.Invoker:用于抽象设置和读取字段值的操作。
- org.apache.ibatis.reflection.TypeParameterResolver:针对 Java-Type 体系的多种实现,解析指定类中的字段、方法返回值或方法参数的类型。
- org.apache.ibatis.reflection.ReflectorFactory:反射信息创建工厂抽象接口。
- org.apache.ibatis.reflection.DefaultReflectorFactory:默认的反射信息创建工厂。
- org.apache.ibatis.reflection.factory.ObjectFactory:MyBatis 对象创建工厂,其默认实现 DefaultObjectFactory 通过构造器反射创建对象。
- org.apache.ibatis.reflection.property:property 工具包,针对映射文件表达式进行解析和 Java 对象的反射赋值。
- org.apache.ibatis.reflection.MetaClass:依赖 PropertyTokenizer 和 Reflector 查找表达式是否可以匹配 Java 对象中的字段,以及对应字段是否有 getter/setter 方法。
- org.apache.ibatis.reflection.MetaObject:对原始对象进行封装,将对象操作委托给 ObjectWrapper 处理。
- org.apache.ibatis.reflection.wrapper.ObjectWrapper:对象包装类,封装对象的读取和赋值等操作。
3 - CH03-基础支持模块
类型转换
JDBC 规范定义的数据类型与 Java 数据类型并不是完全对应的,所以在 PrepareStatement 为 SQL 语句绑定参数时,需要从 Java 类型转为 JDBC 类型;而从结果集中获取数据时,则需要将 JDBC 类型转为 Java 类型。
类型转换操作
MyBatis 中的所有类型转换器都继承自 BaseTypeHandler 抽象类,此类实现了 TypeHandler 接口。接口中定义了 1 个向 PreparedStatement 对象中设置参数的方法和 3 个从结果集中取值的方法:
public interface TypeHandler<T> {
/**
* 为PreparedStatement对象设置参数
*
* @param ps SQL 预编译对象
* @param i 参数索引
* @param parameter 参数值
* @param jdbcType 参数 JDBC类型
* @throws SQLException
*/
void setParameter(PreparedStatement ps, int i, T parameter, JdbcType jdbcType) throws SQLException;
/**
* 根据列名从结果集中取值
*
* @param rs 结果集
* @param columnName 列名
* @return
* @throws SQLException
*/
T getResult(ResultSet rs, String columnName) throws SQLException;
/**
* 根据索引从结果集中取值
* @param rs 结果集
* @param columnIndex 索引
* @return
* @throws SQLException
*/
T getResult(ResultSet rs, int columnIndex) throws SQLException;
/**
* 根据索引从存储过程函数中取值
*
* @param cs 存储过程对象
* @param columnIndex 索引
* @return
* @throws SQLException
*/
T getResult(CallableStatement cs, int columnIndex) throws SQLException;
}
BaseTypeHandler 及其实现
BaseTypeHandler 实现了 TypeHandler 接口,针对 null 和异常处理做了封装,但是具体逻辑封装成 4 个抽象方法仍交由相应的类型转换器子类实现,以 IntegerTypeHandler 为例,其实现如下:
public class IntegerTypeHandler extends BaseTypeHandler<Integer> {
@Override
public void setNonNullParameter(PreparedStatement ps, int i, Integer parameter, JdbcType jdbcType)
throws SQLException {
ps.setInt(i, parameter);
}
@Override
public Integer getNullableResult(ResultSet rs, String columnName)
throws SQLException {
int result = rs.getInt(columnName);
// 如果列值为空值返回控制否则返回原值
return result == 0 && rs.wasNull() ? null : result;
}
@Override
public Integer getNullableResult(ResultSet rs, int columnIndex)
throws SQLException {
int result = rs.getInt(columnIndex);
return result == 0 && rs.wasNull() ? null : result;
}
@Override
public Integer getNullableResult(CallableStatement cs, int columnIndex)
throws SQLException {
int result = cs.getInt(columnIndex);
return result == 0 && cs.wasNull() ? null : result;
}
}
其实现主要是调用 JDBC API 设置查询参数或取值,并对 null 等特定情况做特殊处理。
类型转换注册器
TypeHandlerRegistry 是 TypeHandler 的注册类,在其无参构造方法中维护了 JavaType、JdbcType 和 TypeHandler 的关系。其主要使用的容器如下:
/**
* JdbcType - TypeHandler对象
* 用于将Jdbc类型转为Java类型
*/
private final Map<JdbcType, TypeHandler<?>> jdbcTypeHandlerMap = new EnumMap<>(JdbcType.class);
/**
* JavaType - JdbcType - TypeHandler对象
* 用于将Java类型转为指定的Jdbc类型
*/
private final Map<Type, Map<JdbcType, TypeHandler<?>>> typeHandlerMap = new ConcurrentHashMap<>();
/**
* TypeHandler类型 - TypeHandler对象
* 注册所有的TypeHandler类型
*/
private final Map<Class<?>, TypeHandler<?>> allTypeHandlersMap = new HashMap<>();
别名注册
别名转换器注册
TypeAliasRegistry 提供了多种方式用于为 Java 类型注册别名。包括直接指定别名、注解指定别名、为指定包下类型注册别名:
/**
* 注册指定包下所有类型别名
*
* @param packageName
*/
public void registerAliases(String packageName) {
registerAliases(packageName, Object.class);
}
/**
* 注册指定包下指定类型的别名
*
* @param packageName
* @param superType
*/
public void registerAliases(String packageName, Class<?> superType) {
ResolverUtil<Class<?>> resolverUtil = new ResolverUtil<>();
// 找出该包下superType所有的子类
resolverUtil.find(new ResolverUtil.IsA(superType), packageName);
Set<Class<? extends Class<?>>> typeSet = resolverUtil.getClasses();
for (Class<?> type : typeSet) {
// Ignore inner classes and interfaces (including package-info.java)
// Skip also inner classes. See issue #6
if (!type.isAnonymousClass() && !type.isInterface() && !type.isMemberClass()) {
registerAlias(type);
}
}
}
/**
* 注册类型别名,默认为简单类名,优先从Alias注解获取
*
* @param type
*/
public void registerAlias(Class<?> type) {
String alias = type.getSimpleName();
// 从Alias注解读取别名
Alias aliasAnnotation = type.getAnnotation(Alias.class);
if (aliasAnnotation != null) {
alias = aliasAnnotation.value();
}
registerAlias(alias, type);
}
/**
* 注册类型别名
*
* @param alias 别名
* @param value 类型
*/
public void registerAlias(String alias, Class<?> value) {
if (alias == null) {
throw new TypeException("The parameter alias cannot be null");
}
// issue #748
String key = alias.toLowerCase(Locale.ENGLISH);
if (typeAliases.containsKey(key) && typeAliases.get(key) != null && !typeAliases.get(key).equals(value)) {
throw new TypeException("The alias '" + alias + "' is already mapped to the value '" + typeAliases.get(key).getName() + "'.");
}
typeAliases.put(key, value);
}
/**
* 注册类型别名
* @param alias 别名
* @param value 指定类型全名
*/
public void registerAlias(String alias, String value) {
try {
registerAlias(alias, Resources.classForName(value));
} catch (ClassNotFoundException e) {
throw new TypeException("Error registering type alias " + alias + " for " + value + ". Cause: " + e, e);
}
}
所有别名均注册到名为 typeAliases 的容器中。TypeAliasRegistry 的无参构造方法默认为一些常用类型注册了别名,如 Integer、String、byte[] 等。
日志配置
MyBatis 支持与多种日志工具集成,包括 Slf4j、log4j、log4j2、commons-logging 等。这些第三方工具类对应日志的实现各有不同,MyBatis 通过适配器模式抽象了这些第三方工具的集成过程,按照一定的优先级选择具体的日志工具,并将真正的日志实现委托给选择的日志工具。
日志适配接口
Log 接口是 MyBatis 的日志适配接口,支持 trace、debug、warn、error 四种级别。
日志工厂
LogFactory 负责对第三方日志工具进行适配,在类加载时会通过静态代码块按顺序选择合适的日志实现。
static {
// 按顺序加载日志实现,如果有某个第三方日志实现可以成功加载,则不继续加载其它实现
tryImplementation(LogFactory::useSlf4jLogging);
tryImplementation(LogFactory::useCommonsLogging);
tryImplementation(LogFactory::useLog4J2Logging);
tryImplementation(LogFactory::useLog4JLogging);
tryImplementation(LogFactory::useJdkLogging);
tryImplementation(LogFactory::useNoLogging);
}
/**
* 初始化 logConstructor
*
* @param runnable
*/
private static void tryImplementation(Runnable runnable) {
if (logConstructor == null) {
try {
// 同步执行
runnable.run();
} catch (Throwable t) {
// ignore
}
}
}
/**
* 配置第三方日志实现适配器
*
* @param implClass
*/
private static void setImplementation(Class<? extends Log> implClass) {
try {
Constructor<? extends Log> candidate = implClass.getConstructor(String.class);
Log log = candidate.newInstance(LogFactory.class.getName());
if (log.isDebugEnabled()) {
log.debug("Logging initialized using '" + implClass + "' adapter.");
}
logConstructor = candidate;
} catch (Throwable t) {
throw new LogException("Error setting Log implementation. Cause: " + t, t);
}
}
tryImplementation 按顺序加载第三方日志工具的适配实现,如 Slf4j 的适配器 Slf4jImpl:
public Slf4jImpl(String clazz) {
Logger logger = LoggerFactory.getLogger(clazz);
if (logger instanceof LocationAwareLogger) {
try {
// check for slf4j >= 1.6 method signature
logger.getClass().getMethod("log", Marker.class, String.class, int.class, String.class, Object[].class, Throwable.class);
log = new Slf4jLocationAwareLoggerImpl((LocationAwareLogger) logger);
return;
} catch (SecurityException | NoSuchMethodException e) {
// fail-back to Slf4jLoggerImpl
}
}
// Logger is not LocationAwareLogger or slf4j version < 1.6
log = new Slf4jLoggerImpl(logger);
}
如果 Slf4jImpl 能成功执行构造方法,则 LogFactory 的 logConstructor 被成功赋值,MyBatis 就找到了合适的日志实现,可以通过 getLog 方法获取 Log 对象。
JDBC 日志代理
org.apache.ibatis.logging.jdbc 包提供了 Connection、PrepareStatement、Statement、ResultSet 类中的相关方法执行的日志记录代理。BaseJdbcLogger 在创建时整理了 PreparedStatement 执行的相关方法名,并提供容器保存列值:
/**
* PreparedStatement 接口中的 set* 方法名称集合
*/
protected static final Set<String> SET_METHODS;
/**
* PreparedStatement 接口中的 部分执行方法
*/
protected static final Set<String> EXECUTE_METHODS = new HashSet<>();
/**
* 列名-列值
*/
private final Map<Object, Object> columnMap = new HashMap<>();
/**
* 列名集合
*/
private final List<Object> columnNames = new ArrayList<>();
/**
* 列值集合
*/
private final List<Object> columnValues = new ArrayList<>();
static {
SET_METHODS = Arrays.stream(PreparedStatement.class.getDeclaredMethods())
.filter(method -> method.getName().startsWith("set"))
.filter(method -> method.getParameterCount() > 1)
.map(Method::getName)
.collect(Collectors.toSet());
EXECUTE_METHODS.add("execute");
EXECUTE_METHODS.add("executeUpdate");
EXECUTE_METHODS.add("executeQuery");
EXECUTE_METHODS.add("addBatch");
}
protected void setColumn(Object key, Object value) {
columnMap.put(key, value);
columnNames.add(key);
columnValues.add(value);
}
ConnectionLogger、PreparedStatementLogger、StatementLogger、ResultSetLogger 都继承自 BaseJdbcLogger,并实现了 InvocationHandler 接口,在运行时通过 JDK 动态代理实现代理类,针对相关方法执行打印日志。如下是 ConnectionLogger 对 InvocationHandler 接口的实现:
@Override
public Object invoke(Object proxy, Method method, Object[] params)
throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, params);
}
if ("prepareStatement".equals(method.getName())) {
if (isDebugEnabled()) {
debug(" Preparing: " + removeBreakingWhitespace((String) params[0]), true);
}
PreparedStatement stmt = (PreparedStatement) method.invoke(connection, params);
// 执行创建PreparedStatement方法,使用PreparedStatementLogger代理
stmt = PreparedStatementLogger.newInstance(stmt, statementLog, queryStack);
return stmt;
} else if ("prepareCall".equals(method.getName())) {
if (isDebugEnabled()) {
debug(" Preparing: " + removeBreakingWhitespace((String) params[0]), true);
}
PreparedStatement stmt = (PreparedStatement) method.invoke(connection, params);
stmt = PreparedStatementLogger.newInstance(stmt, statementLog, queryStack);
return stmt;
} else if ("createStatement".equals(method.getName())) {
Statement stmt = (Statement) method.invoke(connection, params);
stmt = StatementLogger.newInstance(stmt, statementLog, queryStack);
return stmt;
} else {
return method.invoke(connection, params);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
如果执行 prepareStatement 方法创建 PrepareStatement 对象,则会使用动态代理创建 PreparedStatementLogger 对象增强原有对象。在 PreparedStatementLogger 的代理逻辑中,如果执行的是 executeQuery 或 getResultSet 方法,其返回值 ResultSet 也会包装为 ResultSetLogger 作为代理,其代理逻辑为如果执行 ResultSet 的 next 方法,会打印结果集的行。
资源加载
Resources 与 ClassLoaderWrapper
MyBatis 提供工具类 Resources 用于工具加载,其底层是通过 ClassLoaderWrapper 实现的。ClassLoaderWrapper 组合了一系列的 ClassLoader:
ClassLoader[] getClassLoaders(ClassLoader classLoader) {
return new ClassLoader[]{
// 指定 ClassLoader
classLoader,
// 默认 ClassLoader,默认为 null
defaultClassLoader,
// 当前线程对应的 ClassLoader
Thread.currentThread().getContextClassLoader(),
// 当前类对应的 ClassLoader
getClass().getClassLoader(),
// 默认为 SystemClassLoader
systemClassLoader};
}
当加载资源时会按组合的 ClassLoader 顺序依次尝试加载资源,例如 classForName 方法的实现:
Class<?> classForName(String name, ClassLoader[] classLoader) throws ClassNotFoundException {
// 按组合顺序依次加载
for (ClassLoader cl : classLoader) {
if (null != cl) {
try {
// 类加载
Class<?> c = Class.forName(name, true, cl);
if (null != c) {
return c;
}
} catch (ClassNotFoundException e) {
// we'll ignore this until all classloaders fail to locate the class
}
}
}
throw new ClassNotFoundException("Cannot find class: " + name);
}
加载指定包下的类
ResolverUtil 的 find 方法用于按条件加载指定包下的类。
public ResolverUtil<T> find(Test test, String packageName) {
// 包名.替换为/
String path = getPackagePath(packageName);
try {
// 虚拟文件系统加载文件路径
List<String> children = VFS.getInstance().list(path);
for (String child : children) {
if (child.endsWith(".class")) {
// 如果指定class文件符合条件,加入容器
addIfMatching(test, child);
}
}
} catch (IOException ioe) {
log.error("Could not read package: " + packageName, ioe);
}
return this;
}
ResolverUtil 还提供了一个内部接口 Test 用于判断指定类型是否满足条件,在 ResolverUtil 有两个默认实现:IsA 用于判断是否为指定类型的子类;AnnotatedWith 用于判断类上是否有指定注解。
/**
* A Test that checks to see if each class is assignable to the provided class. Note
* that this test will match the parent type itself if it is presented for matching.
*
* 判断是否为子类
*/
public static class IsA implements Test {
private Class<?> parent;
/** Constructs an IsA test using the supplied Class as the parent class/interface. */
public IsA(Class<?> parentType) {
this.parent = parentType;
}
/** Returns true if type is assignable to the parent type supplied in the constructor. */
@Override
public boolean matches(Class<?> type) {
return type != null && parent.isAssignableFrom(type);
}
}
/**
* A Test that checks to see if each class is annotated with a specific annotation. If it
* is, then the test returns true, otherwise false.
*
* 判断类上是否有指定注解
*/
public static class AnnotatedWith implements Test {
private Class<? extends Annotation> annotation;
/** Constructs an AnnotatedWith test for the specified annotation type. */
public AnnotatedWith(Class<? extends Annotation> annotation) {
this.annotation = annotation;
}
/** Returns true if the type is annotated with the class provided to the constructor. */
@Override
public boolean matches(Class<?> type) {
return type != null && type.isAnnotationPresent(annotation);
}
}
如果要加载的类复合条件,则将加载的类对象加入容器。
protected void addIfMatching(Test test, String fqn) {
try {
String externalName = fqn.substring(0, fqn.indexOf('.')).replace('/', '.');
ClassLoader loader = getClassLoader();
if (log.isDebugEnabled()) {
log.debug("Checking to see if class " + externalName + " matches criteria [" + test + "]");
}
// 加载类
Class<?> type = loader.loadClass(externalName);
if (test.matches(type)) {
// 符合条件,加入容器
matches.add((Class<T>) type);
}
} catch (Throwable t) {
log.warn("Could not examine class '" + fqn + "'" + " due to a " +
t.getClass().getName() + " with message: " + t.getMessage());
}
}
数据源实现
MyBatis 提供了自己的数据源实现,分别为非池化数据源 UnpooledDataSource 和池化数据源 PooledDataSource。两个数据源都实现了 javax.sql.DataSource 接口并分别由 UnpooledDataSourceFactory 和 PooledDataSourceFactory 工厂类创建。两个工厂类又都实现了 DataSourceFactory 接口。
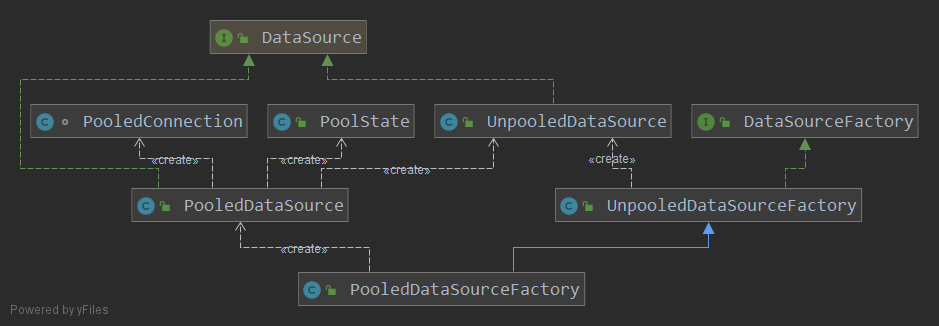
DataSourceFactory 实现
UnpooledDataSourceFactory 实现了 DataSourceFactory 接口的 setProperties 和 getDataSource 方法,分别用于在创建数据源工厂后配置数据源属性和获取数据源,PooledDataSourceFactory 继承了其实现:
public UnpooledDataSourceFactory() {
this.dataSource = new UnpooledDataSource();
}
/**
* 创建数据源工厂后配置数据源属性
*
* @param props
*/
@Override
public void setProperties(Properties properties) {
Properties driverProperties = new Properties();
// 数据源对象信息
MetaObject metaDataSource = SystemMetaObject.forObject(dataSource);
for (Object key : properties.keySet()) {
String propertyName = (String) key;
if (propertyName.startsWith(DRIVER_PROPERTY_PREFIX)) {
// 数据源驱动相关属性
String value = properties.getProperty(propertyName);
driverProperties.setProperty(propertyName.substring(DRIVER_PROPERTY_PREFIX_LENGTH), value);
} else if (metaDataSource.hasSetter(propertyName)) {
// 属性在数据源类中有相应的set方法
String value = (String) properties.get(propertyName);
// 转换类型
Object convertedValue = convertValue(metaDataSource, propertyName, value);
// 反射赋值
metaDataSource.setValue(propertyName, convertedValue);
} else {
throw new DataSourceException("Unknown DataSource property: " + propertyName);
}
}
if (driverProperties.size() > 0) {
metaDataSource.setValue("driverProperties", driverProperties);
}
}
/**
* 获取数据源
*
* @return
*/
@Override
public DataSource getDataSource() {
return dataSource;
}
非池化数据源
UnpooledDataSource 在静态语句块中从数据源驱动管理器 DriverManager 获取所有已注册驱动并放入本地容器:
static {
// 从数据库驱动类中获取所有驱动
Enumeration<Driver> drivers = DriverManager.getDrivers();
while (drivers.hasMoreElements()) {
Driver driver = drivers.nextElement();
registeredDrivers.put(driver.getClass().getName(), driver);
}
}
此数据源获取连接的实现为调用 doGetConnection 方法,每次获取连接时先校验当前驱动是否注册,如果已注册则直接创建新连接,并配置自动提交属性和默认事务隔离级别:
/**
* 获取连接
*
* @param properties
* @return
* @throws SQLException
*/
private Connection doGetConnection(Properties properties) throws SQLException {
// 校验当前驱动是否注册,如果未注册,加载驱动并注册
initializeDriver();
// 获取数据库连接
Connection connection = DriverManager.getConnection(url, properties);
// 配置自动提交和默认事务隔离级别属性
configureConnection(connection);
return connection;
}
/**
* 校验当前驱动是否注册
*
* @throws SQLException
*/
private synchronized void initializeDriver() throws SQLException {
if (!registeredDrivers.containsKey(driver)) {
// 当前驱动还未注册
Class<?> driverType;
try {
// 加载驱动类
if (driverClassLoader != null) {
driverType = Class.forName(driver, true, driverClassLoader);
} else {
driverType = Resources.classForName(driver);
}
// DriverManager requires the driver to be loaded via the system ClassLoader.
// http://www.kfu.com/~nsayer/Java/dyn-jdbc.html
Driver driverInstance = (Driver)driverType.newInstance();
// 注册驱动
DriverManager.registerDriver(new DriverProxy(driverInstance));
registeredDrivers.put(driver, driverInstance);
} catch (Exception e) {
throw new SQLException("Error setting driver on UnpooledDataSource. Cause: " + e);
}
}
}
/**
* 配置自动提交和默认事务隔离级别属性
*
* @param conn
* @throws SQLException
*/
private void configureConnection(Connection conn) throws SQLException {
if (autoCommit != null && autoCommit != conn.getAutoCommit()) {
conn.setAutoCommit(autoCommit);
}
if (defaultTransactionIsolationLevel != null) {
conn.setTransactionIsolation(defaultTransactionIsolationLevel);
}
}
池化数据源
数据库连接的创建是十分耗时的,在高并发环境下,频繁地创建和关闭连接会为系统带来很大的开销。而使用连接池实现对数据库连接的重用可以显著提高性能,避免反复创建连接。MyBatis 实现的连接池包含了维护连接队列、创建和保存连接、归还连接等功能。
池化连接
PooledConnection 是 MyBatis 的池化连接实现。其构造方法中传入了驱动管理器创建的真正连接,并通过 JDK 动态代理创建了连接的代理对象:
public PooledConnection(Connection connection, PooledDataSource dataSource) {
this.hashCode = connection.hashCode();
// 真正的数据库连接
this.realConnection = connection;
// 数据源对象
this.dataSource = dataSource;
// 连接创建时间
this.createdTimestamp = System.currentTimeMillis();
// 连接上次使用时间
this.lastUsedTimestamp = System.currentTimeMillis();
// 数据源有效标志
this.valid = true;
// 创建连接代理
this.proxyConnection = (Connection) Proxy.newProxyInstance(Connection.class.getClassLoader(), IFACES, this);
}
连接代理的逻辑如下,如果执行 close 方法,并不会真正的关闭连接,而是当作空闲连接交给数据源处理,根据连接池的状态选择将连接放入空闲队列或关闭连接;如果执行其它方法,则会判断当前连接是否有效,如果是无效连接会抛出异常:
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
if (CLOSE.hashCode() == methodName.hashCode() && CLOSE.equals(methodName)) {
// 调用连接关闭方法代理逻辑:处理空闲连接,放入空闲队列或关闭
dataSource.pushConnection(this);
return null;
}
try {
if (!Object.class.equals(method.getDeclaringClass())) {
// issue #579 toString() should never fail
// throw an SQLException instead of a Runtime
// 执行其它方法,验证连接是否有效,如果是无效连接,抛出异常
checkConnection();
}
return method.invoke(realConnection, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
连接池状态
PoolState 维护了数据库连接池状态。其内部维护了两个容器,分别为空闲连接集合和活跃连接集合。
/**
* 空闲连接集合
*/
protected final List<PooledConnection> idleConnections = new ArrayList<>();
/**
* 活跃连接集合
*/
protected final List<PooledConnection> activeConnections = new ArrayList<>();
获取连接
池化数据源 PooledDataSource 是依赖 UnpooledDataSource 实现的。其获取连接的方式是调用 popConnection 方法。在获取连接池同步锁后按照以下顺序尝试获取可用连接:
- 从空闲队列获取连接
- 活跃连接池未满,创建新连接
- 检查最早的活跃连接是否超时
- 等待释放连接
private PooledConnection popConnection(String username, String password) throws SQLException {
// 等待连接标志
boolean countedWait = false;
// 待获取的池化连接
PooledConnection conn = null;
long t = System.currentTimeMillis();
int localBadConnectionCount = 0;
while (conn == null) {
// 循环获取连接
synchronized (state) {
// 获取连接池的同步锁
if (!state.idleConnections.isEmpty()) {
// Pool has available connection 连接池中有空闲连接
conn = state.idleConnections.remove(0);
if (log.isDebugEnabled()) {
log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
}
} else {
// Pool does not have available connection 连接池无可用连接
if (state.activeConnections.size() < poolMaximumActiveConnections) {
// Can create new connection 活跃连接数小于设定的最大连接数,创建新的连接(从驱动管理器创建新的连接)
conn = new PooledConnection(dataSource.getConnection(), this);
if (log.isDebugEnabled()) {
log.debug("Created connection " + conn.getRealHashCode() + ".");
}
} else {
// Cannot create new connection 活跃连接数到达最大连接数
PooledConnection oldestActiveConnection = state.activeConnections.get(0);
// 查询最早入队的活跃连接使用时间(即使用时间最长的活跃连接使用时间)
long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
if (longestCheckoutTime > poolMaximumCheckoutTime) {
// Can claim overdue connection 超出活跃连接最大使用时间
state.claimedOverdueConnectionCount++;
// 超时连接累计使用时长
state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
state.accumulatedCheckoutTime += longestCheckoutTime;
// 活跃连接队列移除当前连接
state.activeConnections.remove(oldestActiveConnection);
if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
try {
// 创建的连接未自动提交,执行回滚
oldestActiveConnection.getRealConnection().rollback();
} catch (SQLException e) {
/*
Just log a message for debug and continue to execute the following
statement like nothing happened.
Wrap the bad connection with a new PooledConnection, this will help
to not interrupt current executing thread and give current thread a
chance to join the next competition for another valid/good database
connection. At the end of this loop, bad {@link @conn} will be set as null.
*/
log.debug("Bad connection. Could not roll back");
}
}
// 包装新的池化连接
conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
// 设置原连接无效
oldestActiveConnection.invalidate();
if (log.isDebugEnabled()) {
log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
}
} else {
// Must wait
try {
// 存活连接有效
if (!countedWait) {
state.hadToWaitCount++;
countedWait = true;
}
if (log.isDebugEnabled()) {
log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
}
long wt = System.currentTimeMillis();
// 释放锁等待连接,{@link PooledDataSource#pushConnection} 如果有连接空闲,会唤醒等待
state.wait(poolTimeToWait);
// 记录等待时长
state.accumulatedWaitTime += System.currentTimeMillis() - wt;
} catch (InterruptedException e) {
break;
}
}
}
}
if (conn != null) {
// ping to server and check the connection is valid or not
if (conn.isValid()) {
// 连接有效
if (!conn.getRealConnection().getAutoCommit()) {
// 非自动提交的连接,回滚上次任务
conn.getRealConnection().rollback();
}
conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
// 设置连接新的使用时间
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
// 添加到活跃连接集合队尾
state.activeConnections.add(conn);
// 连接请求次数+1
state.requestCount++;
// 请求连接花费的时间
state.accumulatedRequestTime += System.currentTimeMillis() - t;
} else {
// 未获取到连接
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
}
// 因为没有空闲连接导致获取连接失败次数+1
state.badConnectionCount++;
// 本次请求获取连接失败数+1
localBadConnectionCount++;
conn = null;
if (localBadConnectionCount > (poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)) {
// 超出获取连接失败的可容忍次数,抛出异常
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Could not get a good connection to the database.");
}
throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
}
}
}
}
}
if (conn == null) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
return conn;
}
如果暂时获取不到可用连接,则当前线程进入等待,等待新的空闲连接产生唤醒等待或等待超时后重新尝试获取连接。当尝试次数到达指定上限,会抛出异常跳出等待。
判断连接有效性
如果可以从连接池中获取连接,会调用 PooledConnection#isValid 方法判断连接是否有效,其逻辑为 PooledConnection 对象自身维护的标志有效且连接存活。判断连接存活的实现如下:
protected boolean pingConnection(PooledConnection conn) {
boolean result = true;
try {
// 连接是否关闭
result = !conn.getRealConnection().isClosed();
} catch (SQLException e) {
if (log.isDebugEnabled()) {
log.debug("Connection " + conn.getRealHashCode() + " is BAD: " + e.getMessage());
}
result = false;
}
if (result) {
if (poolPingEnabled) {
// 使用语句检测连接是否可用开关开启
if (poolPingConnectionsNotUsedFor >= 0 && conn.getTimeElapsedSinceLastUse() > poolPingConnectionsNotUsedFor) {
// 距上次连接使用经历时长超过设置的阈值
try {
if (log.isDebugEnabled()) {
log.debug("Testing connection " + conn.getRealHashCode() + " ...");
}
// 验证连接是否可用
Connection realConn = conn.getRealConnection();
try (Statement statement = realConn.createStatement()) {
statement.executeQuery(poolPingQuery).close();
}
if (!realConn.getAutoCommit()) {
// 未自动提交执行回滚
realConn.rollback();
}
result = true;
if (log.isDebugEnabled()) {
log.debug("Connection " + conn.getRealHashCode() + " is GOOD!");
}
} catch (Exception e) {
log.warn("Execution of ping query '" + poolPingQuery + "' failed: " + e.getMessage());
try {
// 抛出异常,连接不可用,关闭连接
conn.getRealConnection().close();
} catch (Exception e2) {
//ignore
}
result = false;
if (log.isDebugEnabled()) {
log.debug("Connection " + conn.getRealHashCode() + " is BAD: " + e.getMessage());
}
}
}
}
}
return result;
}
默认调用 Connection#isClosed 方法判断连接是否存活,如果连接存活,则可以选择执行 SQL 语句来进一步判断连接的有效性。是否进一步验证、验证使用的 SQL 语句、验证的时间条件,都是可配置的。
处理空闲连接
在池化连接的代理连接执行关闭操作时,会转为对空闲连接的处理,其实现逻辑如下:
protected void pushConnection(PooledConnection conn) throws SQLException {
synchronized (state) {
// 获取连接池状态同步锁,活跃连接队列移除当前连接
state.activeConnections.remove(conn);
if (conn.isValid()) {
// 连接有效
if (state.idleConnections.size() < poolMaximumIdleConnections && conn.getConnectionTypeCode() == expectedConnectionTypeCode) {
// 空闲连接数小于最大空闲连接数,累计连接使用时长
state.accumulatedCheckoutTime += conn.getCheckoutTime();
if (!conn.getRealConnection().getAutoCommit()) {
// 未自动提交连接回滚上次事务
conn.getRealConnection().rollback();
}
// 包装成新的代理连接
PooledConnection newConn = new PooledConnection(conn.getRealConnection(), this);
// 将新连接放入空闲队列
state.idleConnections.add(newConn);
// 设置相关统计时间戳
newConn.setCreatedTimestamp(conn.getCreatedTimestamp());
newConn.setLastUsedTimestamp(conn.getLastUsedTimestamp());
// 老连接设置失效
conn.invalidate();
if (log.isDebugEnabled()) {
log.debug("Returned connection " + newConn.getRealHashCode() + " to pool.");
}
// 唤醒等待连接的线程,通知有新连接可以使用
state.notifyAll();
} else {
// 空闲连接数达到最大空闲连接数
state.accumulatedCheckoutTime += conn.getCheckoutTime();
if (!conn.getRealConnection().getAutoCommit()) {
// 未自动提交连接回滚上次事务
conn.getRealConnection().rollback();
}
// 关闭多余的连接
conn.getRealConnection().close();
if (log.isDebugEnabled()) {
log.debug("Closed connection " + conn.getRealHashCode() + ".");
}
// 连接设置失效
conn.invalidate();
}
} else {
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") attempted to return to the pool, discarding connection.");
}
// 连接无效次数+1
state.badConnectionCount++;
}
}
}
如果当前空闲连接数小于最大空闲连接数,则将空闲连接放入空闲队列,否则关闭连接。
处理配置变更
在相关配置变更后,MyBatis 会调用 forceCloseAll 关闭连接池中所有存活的连接:
public void forceCloseAll() {
synchronized (state) {
// 获取连接池状态同步锁
expectedConnectionTypeCode = assembleConnectionTypeCode(dataSource.getUrl(), dataSource.getUsername(), dataSource.getPassword());
for (int i = state.activeConnections.size(); i > 0; i--) {
try {
// 移除活跃连接
PooledConnection conn = state.activeConnections.remove(i - 1);
// 原连接置为无效
conn.invalidate();
Connection realConn = conn.getRealConnection();
if (!realConn.getAutoCommit()) {
// 未提交连接回滚当前事务
realConn.rollback();
}
// 关闭连接
realConn.close();
} catch (Exception e) {
// ignore
}
}
for (int i = state.idleConnections.size(); i > 0; i--) {
try {
// 移除空闲连接
PooledConnection conn = state.idleConnections.remove(i - 1);
// 原连接置为无效
conn.invalidate();
Connection realConn = conn.getRealConnection();
if (!realConn.getAutoCommit()) {
// 未提交连接回滚当前事务
realConn.rollback();
}
// 关闭连接
realConn.close();
} catch (Exception e) {
// ignore
}
}
}
if (log.isDebugEnabled()) {
log.debug("PooledDataSource forcefully closed/removed all connections.");
}
}
缓存实现
Cache 是 MyBatis 的缓存抽象接口,其要求实现如下方法:
public interface Cache {
/**
* 缓存对象 id
*
* @return The identifier of this cache
*/
String getId();
/**
* 设置缓存
*
* @param key Can be any object but usually it is a {@link CacheKey}
* @param value The result of a select.
*/
void putObject(Object key, Object value);
/**
* 获取缓存
*
* @param key The key
* @return The object stored in the cache.
*/
Object getObject(Object key);
/**
* 移除缓存
*
* @param key The key
* @return Not used
*/
Object removeObject(Object key);
/**
* 清空缓存
*
* Clears this cache instance.
*/
void clear();
/**
* Optional. This method is not called by the core.
* 获取缓存项数量
*
* @return The number of elements stored in the cache (not its capacity).
*/
int getSize();
/**
* 获取读写锁
*
* @return A ReadWriteLock
*/
ReadWriteLock getReadWriteLock();
}
基础实现
PerpetualCache 类是基础实现类,核心是基于 HashMap 作为缓存维护容器。在此基础上,MyBatis 实现了多种缓存装饰器,用于满足不同的需求。
缓存装饰器
同步操作
SynchronizedCache 针对缓存操作方法加上了 synchronized 关键字用于进行同步操作。
阻塞操作
BlockingCache 在执行获取缓存操作时对 key 加锁,直到写缓存后释放锁,保证了相同 key 同一时刻只有一个线程执行数据库操作,其它线程在缓存层阻塞。
/**
* 写缓存完成后释放锁
*/
@Override
public void putObject(Object key, Object value) {
try {
delegate.putObject(key, value);
} finally {
releaseLock(key);
}
}
@Override
public Object getObject(Object key) {
// 获取锁
acquireLock(key);
Object value = delegate.getObject(key);
if (value != null) {
// 缓存不为空则释放锁,否则继续持有锁,在进行数据库操作后写缓存释放锁
releaseLock(key);
}
return value;
}
/**
* 删除指定 key 对应的缓存,并释放锁
*
* @param key The key
* @return
*/
@Override
public Object removeObject(Object key) {
// despite of its name, this method is called only to release locks
releaseLock(key);
return null;
}
/**
* 获取已有的锁或创建新锁
*
* @param key
* @return
*/
private ReentrantLock getLockForKey(Object key) {
return locks.computeIfAbsent(key, k -> new ReentrantLock());
}
/**
* 根据 key 获取锁
*
* @param key
*/
private void acquireLock(Object key) {
Lock lock = getLockForKey(key);
if (timeout > 0) {
try {
boolean acquired = lock.tryLock(timeout, TimeUnit.MILLISECONDS);
if (!acquired) {
throw new CacheException("Couldn't get a lock in " + timeout + " for the key " + key + " at the cache " + delegate.getId());
}
} catch (InterruptedException e) {
throw new CacheException("Got interrupted while trying to acquire lock for key " + key, e);
}
} else {
lock.lock();
}
}
/**
* 释放锁
*
* @param key
*/
private void releaseLock(Object key) {
ReentrantLock lock = locks.get(key);
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
日志记录
LoggingCache 是缓存日志装饰器。查询缓存时会记录查询日志并统计命中率。
/**
* 查询缓存时记录查询日志并统计命中率
*
* @param key The key
* @return
*/
@Override
public Object getObject(Object key) {
// 查询数+1
requests++;
final Object value = delegate.getObject(key);
if (value != null) {
// 命中数+1
hits++;
}
if (log.isDebugEnabled()) {
log.debug("Cache Hit Ratio [" + getId() + "]: " + getHitRatio());
}
return value;
}
定时清理
ScheduledCache 是缓存定时清理装饰器。在执行缓存相关操作时会根据设置的时间间隔判断是否需要清除全部的缓存。
/**
* 操作缓存时判断是否需要清除所有缓存。
*
* @return
*/
private boolean clearWhenStale() {
if (System.currentTimeMillis() - lastClear > clearInterval) {
clear();
return true;
}
return false;
}
序列化与反序列化
SerializedCache 是缓存序列化装饰器,其在写入时会将值序列化成对象流,并在读取时进行反序列化。
事务操作
TransactionalCache 是事务缓存装饰器。在事务提交后再将缓存写入,如果发生回滚则不写入。
先进先出
FifoCache 是先进先出缓存装饰器。其按写缓存顺序维护了一个缓存 key 队列,如果缓存项超出指定大小,则删除最先入队的缓存。
/**
* 按写缓存顺序维护缓存 key 队列,缓存项超出指定大小,删除最先入队的缓存
*
* @param key
*/
private void cycleKeyList(Object key) {
keyList.addLast(key);
if (keyList.size() > size) {
Object oldestKey = keyList.removeFirst();
delegate.removeObject(oldestKey);
}
}
最近最久未使用
LruCache 是缓存最近最久未使用装饰器。其基于 LinkedHashMap 维护了 key 的 LRU 顺序。
public void setSize(final int size) {
// LinkedHashMap 在执行 get 方法后会将对应的 entry 移到队尾来维护使用顺序
keyMap = new LinkedHashMap<Object, Object>(size, .75F, true) {
private static final long serialVersionUID = 4267176411845948333L;
@Override
protected boolean removeEldestEntry(Map.Entry<Object, Object> eldest) {
boolean tooBig = size() > size;
if (tooBig) {
// 超出缓存项数量限制,获取最近最久未使用的key
eldestKey = eldest.getKey();
}
return tooBig;
}
};
}
/**
* 更新缓存后检查是否需要删除最近最久未使用的缓存项
*/
@Override
public void putObject(Object key, Object value) {
delegate.putObject(key, value);
cycleKeyList(key);
}
private void cycleKeyList(Object key) {
keyMap.put(key, key);
if (eldestKey != null) {
delegate.removeObject(eldestKey);
eldestKey = null;
}
}
软引用缓存
SoftCache 是缓存软引用装饰器,其使用了软引用 + 强引用队列的方式维护缓存。在写缓存操作中,写入的数据其实时缓存项的软引用包装对象,在 Full GC 时,如果没有一个强引用指向被包装的缓存项或缓存值,并且系统内存不足,缓存项就会被 GC,被回收对象进入指定的引用队列。
/**
* 引用队列,用于记录已经被 GC 的 SoftEntry 对象
*/
private final ReferenceQueue<Object> queueOfGarbageCollectedEntries;
/**
* 写入缓存。
* 不直接写缓存的值,而是写入缓存项对应的软引用
*/
@Override
public void putObject(Object key, Object value) {
removeGarbageCollectedItems();
// 在 Full GC 时,如果没有一个强引用指向被包装的缓存项或缓存值,并且系统内存不足,缓存项就会被回收,被回收对象进入指定的引用队列
delegate.putObject(key, new SoftEntry(key, value, queueOfGarbageCollectedEntries));
}
/**
* 查询已被 GC 的软引用,删除对应的缓存项
*/
private void removeGarbageCollectedItems() {
SoftEntry sv;
while ((sv = (SoftEntry) queueOfGarbageCollectedEntries.poll()) != null) {
delegate.removeObject(sv.key);
}
}
/**
* 封装软引用对象
*/
private static class SoftEntry extends SoftReference<Object> {
private final Object key;
SoftEntry(Object key, Object value, ReferenceQueue<Object> garbageCollectionQueue) {
// 声明 value 为软引用对象
super(value, garbageCollectionQueue);
// key 为强引用
this.key = key;
}
}
在读取缓存时,如果软引用被回收,则删除对应的缓存项;否则将缓存项放入一个强引用队列中,该队列会将最新读取的缓存项放入队首,使得真正的缓存项有了强引用指向,其软引用包装就不会被垃圾回收。队列有数量限制,当超出限制时会删除队尾的缓存项。
/**
* 获取缓存。
* 如果软引用被回收则删除对应的缓存项,如果未回收则加入到有数量限制的 LRU 队列中
*
* @param key The key
* @return
*/
@Override
public Object getObject(Object key) {
Object result = null;
@SuppressWarnings("unchecked") // assumed delegate cache is totally managed by this cache
SoftReference<Object> softReference = (SoftReference<Object>) delegate.getObject(key);
if (softReference != null) {
result = softReference.get();
if (result == null) {
// 软引用已经被回收,删除对应的缓存项
delegate.removeObject(key);
} else {
// 如果未被回收,增将软引用加入到 LRU 队列
// See #586 (and #335) modifications need more than a read lock
synchronized (hardLinksToAvoidGarbageCollection) {
// 将对应的软引用
hardLinksToAvoidGarbageCollection.addFirst(result);
if (hardLinksToAvoidGarbageCollection.size() > numberOfHardLinks) {
// 超出数量限制,删除最近最久未使用的软引用对象
hardLinksToAvoidGarbageCollection.removeLast();
}
}
}
}
return result;
}
弱引用缓存
WeakCache 是缓存弱引用装饰器,使用弱引用 + 强引用队列的方式维护缓存,其实现方式与 SoftCache 是一致的。
Binding 模块
为了避免因拼写等错误导致在运行期才发现执行方法找不到对应的 SQL 语句,MyBatis 使用 Binding 模块在启动时对执行方法校验,如果找不到对应的语句,则会抛出 BindingException。
MyBatis 一般将执行数据库操作的方法所在的接口称为 Mapper,MapperRegistry 用来注册 Mapper 接口类型与其代理创建工厂的映射,其提供 addMapper 和 addMappers 接口用于注册。Mapper 接口代理工厂是通过 MapperProxyFactory 创建,创建过程依赖 MapperProxy 提供的 JDK 动态代理:
protected T newInstance(MapperProxy<T> mapperProxy) {
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
/**
* 使用 Mapper 代理封装 SqlSession 相关操作
*
* @param sqlSession
* @return
*/
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
MapperProxy 的代理逻辑如下,在 Mapper 接口中的方法真正执行时,会为指定的非 default 方法创建方法信息和 SQL 执行信息缓存:
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) {
// Object中的方法,直接执行
return method.invoke(this, args);
} else if (isDefaultMethod(method)) {
// 当前方法是接口中的非abstract、非static的public方法,即高版本JDK中的default方法
return invokeDefaultMethod(proxy, method, args);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
// 缓存 Mapper接口 对应的方法和 SQL 执行信息
final MapperMethod mapperMethod = cachedMapperMethod(method);
// 执行 SQL
return mapperMethod.execute(sqlSession, args);
}
/**
* 缓存 Mapper接口 对应的方法和 SQL 执行信息
*
* @param method
* @return
*/
private MapperMethod cachedMapperMethod(Method method) {
return methodCache.computeIfAbsent(method, k -> new MapperMethod(mapperInterface, method, sqlSession.getConfiguration()));
}
缓存通过 MapperMethod 类来保存,其构造方法创建了 SqlCommand 和 MethodSignature 对象。
public MapperMethod(Class<?> mapperInterface, Method method, Configuration config) {
// SQL 执行信息
this.command = new SqlCommand(config, mapperInterface, method);
// 获取方法参数和返回值相关信息
this.method = new MethodSignature(config, mapperInterface, method);
}
SqlCommand 会根据接口和方法名找到对应的 SQL statement 对象:
private MappedStatement resolveMappedStatement(Class<?> mapperInterface, String methodName,
Class<?> declaringClass, Configuration configuration) {
// statementId 为接口名与方法名组合
String statementId = mapperInterface.getName() + "." + methodName;
if (configuration.hasStatement(statementId)) {
// 配置中存在此 statementId,返回对应的 statement
return configuration.getMappedStatement(statementId);
} else if (mapperInterface.equals(declaringClass)) {
// 此方法就是在对应接口中声明的
return null;
}
// 递归查找父类
for (Class<?> superInterface : mapperInterface.getInterfaces()) {
if (declaringClass.isAssignableFrom(superInterface)) {
MappedStatement ms = resolveMappedStatement(superInterface, methodName,
declaringClass, configuration);
if (ms != null) {
return ms;
}
}
}
return null;
}
而 MethodSignature 会获取方法相关信息,如返回值类型、是否返回 void、是否返回多值等。对于 Param 注解的解析也会保存下来(MyBatis 使用 Param 注解重置参数名)。
总结
MyBatis 提供了一系列工具和实现,用于为整个框架提供基础支持。
- 类型转换
- org.apache.ibatis.type.TypeHandler:类型转换器接口,抽象 JDBC 类型和 Java 类型互转逻辑。
- org.apache.ibatis.type.BaseTypeHandler:TypeHandler 的抽象实现,针对 null 和异常处理做了封装,具体逻辑仍由相应的类型转换器实现。
- org.apache.ibatis.type.TypeHandlerRegistry:TypeHandler 注册类,维护 JavaType、JdbcType 和 TypeHandler 关系。
- 别名注册
- org.apache.ibatis.type.TypeAliasRegistry:别名注册类。注册常用类型的别名,并提供多种注册别名的方式。
- 日志配置
- org.apache.ibatis.logging.Log:MyBatis 日志适配接口,支持 trace、debug、warn、error 四种级别。
- org.apache.ibatis.logging.LogFactory:MyBatis 日志工厂,负责适配第三方日志实现。
- org.apache.ibatis.logging.jdbc:SQL 执行日志工具包,针对执行 Connection、PrepareStatement、Statement、ResultSet 类中的相关方法,提供日志记录工具。
- 资源加载
- org.apache.ibatis.io.Resources:MyBatis 封装的资源加载工具类。
- org.apache.ibatis.io.ClassLoaderWrapper:资源加载底层实现。组合多种 ClassLoader 按顺序尝试加载资源。
- org.apache.ibatis.io.ResolverUtil:按条件加载指定包下的类。
- 数据源实现
- org.apache.ibatis.datasource.DataSourceFactory:数据源创建工厂接口。
- org.apache.ibatis.datasource.unpooled.UnpooledDataSourceFactory:非池化数据源工厂。
- org.apache.ibatis.datasource.pooled.PooledDataSourceFactory:池化数据源工厂。
- org.apache.ibatis.datasource.unpooled.UnpooledDataSource:非池化数据源。
- org.apache.ibatis.datasource.pooled.PooledDataSource:池化数据源。
- org.apache.ibatis.datasource.pooled.PooledConnection:池化连接。
- org.apache.ibatis.datasource.pooled.PoolState:连接池状态。
- 事务实现
- org.apache.ibatis.transaction.Transaction:事务抽象接口
- org.apache.ibatis.session.TransactionIsolationLevel:事务隔离级别。
- org.apache.ibatis.transaction.TransactionFactory:事务创建工厂抽象接口。
- org.apache.ibatis.transaction.jdbc.JdbcTransaction:封装 JDBC 数据库事务操作。
- org.apache.ibatis.transaction.managed.ManagedTransaction:数据库事务操作依赖外部管理。
- 缓存实现
- org.apache.ibatis.cache.Cache:缓存抽象接口。
- org.apache.ibatis.cache.impl.PerpetualCache:使用 HashMap 作为缓存实现容器的 Cache 基本实现。
- org.apache.ibatis.cache.decorators.BlockingCache:缓存阻塞装饰器。保证相同 key 同一时刻只有一个线程执行数据库操作,其它线程在缓存层阻塞。
- org.apache.ibatis.cache.decorators.FifoCache:缓存先进先出装饰器。按写缓存顺序维护缓存 key 队列,缓存项超出指定大小,删除最先入队的缓存。
- org.apache.ibatis.cache.decorators.LruCache:缓存最近最久未使用装饰器。基于 LinkedHashMap 维护了 key 的 LRU 顺序。
- org.apache.ibatis.cache.decorators.LoggingCache:缓存日志装饰器。查询缓存时记录查询日志并统计命中率。
- org.apache.ibatis.cache.decorators.ScheduledCache:缓存定时清理装饰器。
- org.apache.ibatis.cache.decorators.SerializedCache:缓存序列化装饰器。
- org.apache.ibatis.cache.decorators.SynchronizedCache:缓存同步装饰器。在缓存操作方法上使用 synchronized 关键字同步。
- org.apache.ibatis.cache.decorators.TransactionalCache:事务缓存装饰器。在事务提交后再将缓存写入,如果发生回滚则不写入。
- org.apache.ibatis.cache.decorators.SoftCache:缓存软引用装饰器。使用软引用 + 强引用队列的方式维护缓存。
- org.apache.ibatis.cache.decorators.WeakCache:缓存弱引用装饰器。使用弱引用 + 强引用队列的方式维护缓存。
- Binding
- org.apache.ibatis.binding.MapperRegistry: Mapper 接口注册类,管理 Mapper 接口类型和其代理创建工厂的映射。
- org.apache.ibatis.binding.MapperProxyFactory:Mapper 接口代理创建工厂。
- org.apache.ibatis.binding.MapperProxy:Mapper 接口方法代理逻辑,封装 SqlSession 相关操作。
- org.apache.ibatis.binding.MapperMethod:封装 Mapper 接口对应的方法和 SQL 执行信息。
4 - CH04-运行配置解析
在 Spring 与 MyBatis 的集成中,通常需要声明一个 sqlSessionFactory 用于初始化 MyBatis:
<!-- 注册 sqlSessionFactory -->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="configLocation" value="classpath:config/mybatis-config.xml"/>
<property name="typeAliasesPackage" value="com.wch.base.domain"/>
<property name="mapperLocations" value="classpath:mapper/*.xml"/>
</bean>
在 bean 初始化的时候会调用 SqlSessionFactoryBean 的 afterPropertiesSet 方法,在此方法中 MyBatis 使用 XMLConfigBuilder 对配置进行解析。
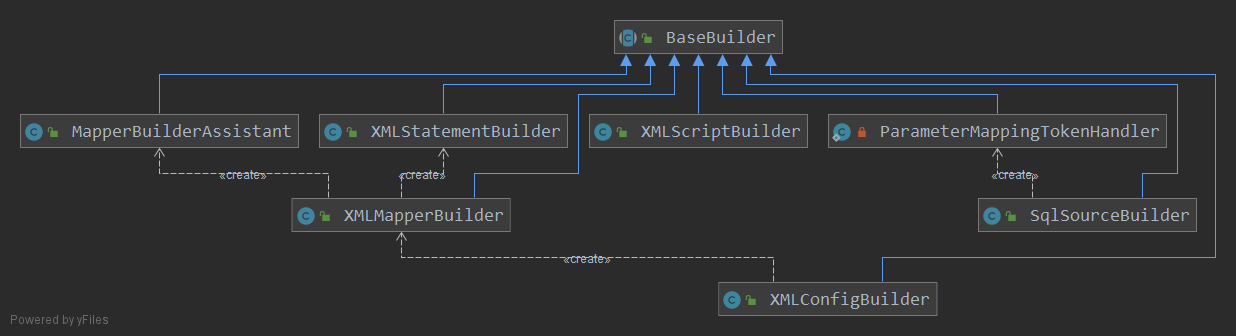
BaseBuilder 体系
XMLConfigBuilder 是 XML 配置解析的入口,继承自 BaseBuilder,其为 MyBatis 初始化提供了一系列工具方法,如别名转换、类型转换、类加载等。
全局配置对象
XMLConfigBuilder 在构造方法中创建了 Configuration 对象,这个对象中用于保存 MyBatis 相关的全部配置,包括运行行为、类型容器、别名容器、注册 Mapper、注册 statement 等。通过 XMLConfigBuilder 的 parse 方法可以看出,配置解析的目的就是为了获取 Configuration 对象。
private XMLConfigBuilder(XPathParser parser, String environment, Properties props) {
// 创建全局配置
super(new Configuration());
ErrorContext.instance().resource("SQL Mapper Configuration");
// 设置自定义配置
this.configuration.setVariables(props);
// 解析标志
this.parsed = false;
// 指定环境
this.environment = environment;
// 包装配置 InputStream 的 XPathParser
this.parser = parser;
}
public Configuration parse() {
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
parsed = true;
// 读取 configuration 元素并解析
parseConfiguration(parser.evalNode("/configuration"));
return configuration;
}
解析配置文件
配置解析分为多步,详情可参考 XML 配置。MyBatis 源码内置 mybatis-config.xsd 文件用于定义配置文件书写规则。
private void parseConfiguration(XNode root) {
try {
//issue #117 read properties first
// 解析 properties 元素
propertiesElement(root.evalNode("properties"));
// 加载 settings 配置并验证是否有效
Properties settings = settingsAsProperties(root.evalNode("settings"));
// 配置自定义虚拟文件系统实现
loadCustomVfs(settings);
// 配置自定义日志实现
loadCustomLogImpl(settings);
// 解析 typeAliases 元素
typeAliasesElement(root.evalNode("typeAliases"));
// 解析 plugins 元素
pluginElement(root.evalNode("plugins"));
// 解析 objectFactory 元素
objectFactoryElement(root.evalNode("objectFactory"));
// 解析 objectWrapperFactory 元素
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
// 解析 reflectorFactory 元素
reflectorFactoryElement(root.evalNode("reflectorFactory"));
// 将 settings 配置设置到全局配置中
settingsElement(settings);
// read it after objectFactory and objectWrapperFactory issue #631
// 解析 environments 元素
environmentsElement(root.evalNode("environments"));
// 解析 databaseIdProvider 元素
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
// 解析 typeHandlers 元素
typeHandlerElement(root.evalNode("typeHandlers"));
// 解析 mappers 元素
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
解析 properties 元素
properties 元素用于将自定义配置传递给 MyBatis,例如:
<properties resource="com/wch/mybatis/config.properties">
<property name="username" value="wch"/>
<property name="password" value="Noop"/>
</properties>
其加载逻辑为将不同配置转为 Properties 对象,并设置到全局配置中:
private void propertiesElement(XNode context) throws Exception {
if (context != null) {
// 获取子元素属性
Properties defaults = context.getChildrenAsProperties();
// 读取 resource 属性
String resource = context.getStringAttribute("resource");
// 读取 url 属性
String url = context.getStringAttribute("url");
if (resource != null && url != null) {
// 不可均为空
throw new BuilderException("The properties element cannot specify both a URL and a resource based property file reference. Please specify one or the other.");
}
// 加载指定路径文件,转为 properties
if (resource != null) {
defaults.putAll(Resources.getResourceAsProperties(resource));
} else if (url != null) {
defaults.putAll(Resources.getUrlAsProperties(url));
}
// 添加创建配置的附加属性
Properties vars = configuration.getVariables();
if (vars != null) {
defaults.putAll(vars);
}
parser.setVariables(defaults);
// 设置到全局配置中
configuration.setVariables(defaults);
}
}
解析 settings 元素
setteings 元素中的各子元素定义了 MyBatis 的运行时行为,例如:
<settings>
<!-- 缓存开关 -->
<setting name="cacheEnabled" value="true"/>
<!-- 懒加载开关 -->
<setting name="lazyLoadingEnabled" value="false"/>
<!-- 允许自动生成主键 -->
<setting name="useGeneratedKeys" value="false"/>
<!-- 驼峰命名开关 -->
<setting name="mapUnderscoreToCamelCase" value="true"/>
...
</settings>
这些配置在 Configuration 类中都有对应的 setter 方法。settings 元素的解析方法对配置进行了验证:
private Properties settingsAsProperties(XNode context) {
if (context == null) {
return new Properties();
}
// 获取子元素配置
Properties props = context.getChildrenAsProperties();
// Check that all settings are known to the configuration class
// 获取 Configuration 类的相关信息
MetaClass metaConfig = MetaClass.forClass(Configuration.class, localReflectorFactory);
for (Object key : props.keySet()) {
if (!metaConfig.hasSetter(String.valueOf(key))) {
// 验证对应的 setter 方法存在,保证配置是有效的
throw new BuilderException("The setting " + key + " is not known. Make sure you spelled it correctly (case sensitive).");
}
}
return props;
}
如果不存在对应的配置,会抛出 BuilderException 异常,如果自定义配置都是生效的,随后会调用 settingsElement 方法将这些运行时行为设置到全局配置中。
解析 typeAliases 元素
typeAliases 元素用于定义类别名:
<typeAliases>
<package name="com.wch.mybatis.User"/>
<typeAlias alias="User" type="com.wch.mybatis.User"/>
<typeAlias type="com.wch.mybatis.Item"/>
</typeAliases>
如果使用 package 元素注册别名,则对应包下的所有类都会注册到 TypeAliasRegistry 别名注册容器中;如果使用 typeAlias 元素,则会注册指定类到别名容器中。注册逻辑如下,如果没有指定别名,则优先从类的 Alias 注解获取别名,如果未在类上定义,则默认使用简单类名:
/**
* 注册指定包下所有类型别名
*
* @param packageName
*/
public void registerAliases(String packageName) {
registerAliases(packageName, Object.class);
}
/**
* 注册指定包下指定类型的别名
*
* @param packageName
* @param superType
*/
public void registerAliases(String packageName, Class<?> superType) {
ResolverUtil<Class<?>> resolverUtil = new ResolverUtil<>();
// 找出该包下superType所有的子类
resolverUtil.find(new ResolverUtil.IsA(superType), packageName);
Set<Class<? extends Class<?>>> typeSet = resolverUtil.getClasses();
for (Class<?> type : typeSet) {
// Ignore inner classes and interfaces (including package-info.java)
// Skip also inner classes. See issue #6
if (!type.isAnonymousClass() && !type.isInterface() && !type.isMemberClass()) {
registerAlias(type);
}
}
}
/**
* 注册类型别名,默认为简单类名,优先从 Alias 注解获取
*
* @param type
*/
public void registerAlias(Class<?> type) {
String alias = type.getSimpleName();
// 从Alias注解读取别名
Alias aliasAnnotation = type.getAnnotation(Alias.class);
if (aliasAnnotation != null) {
alias = aliasAnnotation.value();
}
registerAlias(alias, type);
}
/**
* 注册类型别名
*
* @param alias 别名
* @param value 类型
*/
public void registerAlias(String alias, Class<?> value) {
if (alias == null) {
throw new TypeException("The parameter alias cannot be null");
}
// issue #748
String key = alias.toLowerCase(Locale.ENGLISH);
if (typeAliases.containsKey(key) && typeAliases.get(key) != null && !typeAliases.get(key).equals(value)) {
throw new TypeException("The alias '" + alias + "' is already mapped to the value '" + typeAliases.get(key).getName() + "'.");
}
typeAliases.put(key, value);
}
解析 plugins 元素
插件是 MyBatis 提供的扩展机制之一,通过添加自定义插件可以实现在 SQL 执行过程中的某个时机进行拦截。 plugins 元素用于定义调用拦截器:
<plugins>
<plugin interceptor="com.wch.mybatis.ExamplePlugin">
<property name="name" value="ExamplePlugin"/>
</plugin>
</plugins>
指定的 interceptor 需要实现 org.apache.ibatis.plugin.Interceptor 接口,在创建对象后被加到全局配置过滤器链中:
private void pluginElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
// 获取 interceptor 属性
String interceptor = child.getStringAttribute("interceptor");
// 从子元素中读取属性配置
Properties properties = child.getChildrenAsProperties();
// 加载指定拦截器并创建实例
Interceptor interceptorInstance = (Interceptor) resolveClass(interceptor).newInstance();
interceptorInstance.setProperties(properties);
// 加入全局配置拦截器链
configuration.addInterceptor(interceptorInstance);
}
}
}
objectFactory、 objectWrapperFactory、reflectorFactory 元素的解析方式与 plugins 元素类似 ,指定的子类对象创建后被设置到全局对象中。
解析 environments 元素
在实际生产中,一个项目可能会分为多个不同的环境,通过配置enviroments 元素可以定义不同的数据环境,并在运行时使用指定的环境:
<environments default="development">
<environment id="development">
<transactionManager type="JDBC">
<property name="" value=""/>
</transactionManager>
<dataSource type="UNPOOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
<environment id="prd">
...
</environment>
</environments>
在解析过程中,只有被 default 属性指定的数据环境才会被加载:
private void environmentsElement(XNode context) throws Exception {
if (context != null) {
if (environment == null) {
// 获取指定的数据源名
environment = context.getStringAttribute("default");
}
for (XNode child : context.getChildren()) {
// 环境配置 id
String id = child.getStringAttribute("id");
if (isSpecifiedEnvironment(id)) {
// 加载指定环境配置
// 解析 transactionManager 元素并创建事务工厂实例
TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));
// 解析 dataSource 元素并创建数据源工厂实例
DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));
// 创建数据源
DataSource dataSource = dsFactory.getDataSource();
// 创建环境
Environment.Builder environmentBuilder = new Environment.Builder(id)
.transactionFactory(txFactory)
.dataSource(dataSource);
// 将环境配置信息设置到全局配置中
configuration.setEnvironment(environmentBuilder.build());
}
}
}
}
/**
* 解析 transactionManager 元素并创建事务工厂实例
*
* @param context
* @return
* @throws Exception
*/
private TransactionFactory transactionManagerElement(XNode context) throws Exception {
if (context != null) {
// 指定事务工厂类型
String type = context.getStringAttribute("type");
// 从子元素读取属性配置
Properties props = context.getChildrenAsProperties();
// 加载事务工厂并创建实例
TransactionFactory factory = (TransactionFactory) resolveClass(type).newInstance();
factory.setProperties(props);
return factory;
}
throw new BuilderException("Environment declaration requires a TransactionFactory.");
}
/**
* 解析 dataSource 元素并创建数据源工厂实例
*
* @param context
* @return
* @throws Exception
*/
private DataSourceFactory dataSourceElement(XNode context) throws Exception {
if (context != null) {
// 指定数据源工厂类型
String type = context.getStringAttribute("type");
// 从子元素读取属性配置
Properties props = context.getChildrenAsProperties();
// 加载数据源工厂并创建实例
DataSourceFactory factory = (DataSourceFactory) resolveClass(type).newInstance();
factory.setProperties(props);
return factory;
}
throw new BuilderException("Environment declaration requires a DataSourceFactory.");
}
解析 databaseIdProvider 元素
MyBatis 支持通过 databaseIdProvider 元素来指定支持的数据库的 databaseId,这样在映射配置文件中指定 databaseId 就能够与对应的数据源进行匹配:
<databaseIdProvider type="DB_VENDOR">
<property name="SQL Server" value="sqlserver"/>
<property name="DB2" value="db2"/>
<property name="Oracle" value="oracle" />
</databaseIdProvider>
在根据指定类型解析出对应的 DatabaseIdProvider 后,MyBatis 会根据数据源获取对应的厂商信息:
private void databaseIdProviderElement(XNode context) throws Exception {
DatabaseIdProvider databaseIdProvider = null;
if (context != null) {
String type = context.getStringAttribute("type");
// awful patch to keep backward compatibility
if ("VENDOR".equals(type)) {
type = "DB_VENDOR";
}
// 从子元素读取属性配置
Properties properties = context.getChildrenAsProperties();
// 加载数据库厂商信息配置类并创建实例
databaseIdProvider = (DatabaseIdProvider) resolveClass(type).newInstance();
databaseIdProvider.setProperties(properties);
}
Environment environment = configuration.getEnvironment();
if (environment != null && databaseIdProvider != null) {
// 获取数据库厂商标识
String databaseId = databaseIdProvider.getDatabaseId(environment.getDataSource());
configuration.setDatabaseId(databaseId);
}
}
因为 DB_VENDOR 被指定为 VendorDatabaseIdProvider 的别名,所以默认的获取厂商信息的逻辑如下,当通过 property 属性指定了数据库产品名则使用指定的名称,否则使用数据库元信息对应的产品名。
/**
* 根据数据源获取对应的厂商信息
*
* @param dataSource
* @return
*/
@Override
public String getDatabaseId(DataSource dataSource) {
if (dataSource == null) {
throw new NullPointerException("dataSource cannot be null");
}
try {
return getDatabaseName(dataSource);
} catch (Exception e) {
LogHolder.log.error("Could not get a databaseId from dataSource", e);
}
return null;
}
@Override
public void setProperties(Properties p) {
this.properties = p;
}
/**
* 如果传入的属性配置包含当前数据库产品名,返回指定的值,否则返回数据库产品名
*
* @param dataSource
* @return
* @throws SQLException
*/
private String getDatabaseName(DataSource dataSource) throws SQLException {
String productName = getDatabaseProductName(dataSource);
if (this.properties != null) {
for (Map.Entry<Object, Object> property : properties.entrySet()) {
if (productName.contains((String) property.getKey())) {
return (String) property.getValue();
}
}
// no match, return null
return null;
}
return productName;
}
/**
* 获取数据库产品名
*
* @param dataSource
* @return
* @throws SQLException
*/
private String getDatabaseProductName(DataSource dataSource) throws SQLException {
Connection con = null;
try {
con = dataSource.getConnection();
DatabaseMetaData metaData = con.getMetaData();
return metaData.getDatabaseProductName();
} finally {
if (con != null) {
try {
con.close();
} catch (SQLException e) {
// ignored
}
}
}
}
解析 typeHandlers 元素
typeHandlers 元素用于配置自定义类型转换器:
<typeHandlers>
<typeHandler handler="com.wch.mybatis.ExampleTypeHandler"/>
</typeHandlers>
如果配置的是 package 元素,则会将包下的所有类注册为类型转换器;如果配置的是 typeHandler 元素,则会根据 javaType、jdbcType、handler 属性注册类型转换器。
private void typeHandlerElement(XNode parent) {
if (parent != null) {
for (XNode child : parent.getChildren()) {
if ("package".equals(child.getName())) {
// 注册指定包下的类作为类型转换器,如果声明了 MappedTypes 注解则注册为指定 java 类型的转换器
String typeHandlerPackage = child.getStringAttribute("name");
typeHandlerRegistry.register(typeHandlerPackage);
} else {
// 获取相关属性
String javaTypeName = child.getStringAttribute("javaType");
String jdbcTypeName = child.getStringAttribute("jdbcType");
String handlerTypeName = child.getStringAttribute("handler");
// 加载指定 java 类型类对象
Class<?> javaTypeClass = resolveClass(javaTypeName);
// 加载指定 JDBC 类型并创建实例
JdbcType jdbcType = resolveJdbcType(jdbcTypeName);
// 加载指定类型转换器类对象
Class<?> typeHandlerClass = resolveClass(handlerTypeName);
if (javaTypeClass != null) {
// 注册类型转换器
if (jdbcType == null) {
typeHandlerRegistry.register(javaTypeClass, typeHandlerClass);
} else {
typeHandlerRegistry.register(javaTypeClass, jdbcType, typeHandlerClass);
}
} else {
typeHandlerRegistry.register(typeHandlerClass);
}
}
}
}
}
解析 mappers 元素
mappers 元素用于定义 Mapper 映射文件和 Mapper 调用接口:
<mappers>
<mapper resource="com/wch/mybatis/UserMapper.xml"/>
<mapper url="file://mappers/ItemMapper.xml"/>
<mapper class="com.wch.mybatis.UserMapper"/>
<package name="com.wch.mybatis.mappers"/>
</mappers>
如果定义的是 mapper 元素并指定了 class 属性,或定义了 package 元素,则会将指定类型在 MapperRegistry 中注册为 Mapper 接口,并使用 MapperAnnotationBuilder 对接口方法进行解析;如果定义的是 mapper 元素并指定了 resource、或 url 属性,则会使用 XMLMapperBuilder 解析。对于 Mapper 接口和映射文件将在下一章进行分析。
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
if ("package".equals(child.getName())) {
// 注册指定包名下的类为 Mapper 接口
String mapperPackage = child.getStringAttribute("name");
configuration.addMappers(mapperPackage);
} else {
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
if (resource != null && url == null && mapperClass == null) {
// 加载指定资源
ErrorContext.instance().resource(resource);
InputStream inputStream = Resources.getResourceAsStream(resource);
// 加载指定 Mapper 文件并解析
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url != null && mapperClass == null) {
// 加载指定 URL
ErrorContext.instance().resource(url);
InputStream inputStream = Resources.getUrlAsStream(url);
// 加载指定 Mapper 文件并解析
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url == null && mapperClass != null) {
// 注册指定类为 Mapper 接口
Class<?> mapperInterface = Resources.classForName(mapperClass);
configuration.addMapper(mapperInterface);
} else {
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
}
总结
XMLConfigBuilder 是 XML 配置解析的入口,通常 MyBatis 启动时会使用此类解析配置文件获取运行时行为。
- org.apache.ibatis.builder.BaseBuilder:为 MyBatis 初始化过程提供一系列工具方法。如别名转换、类型转换、类加载等。
- org.apache.ibatis.builder.xml.XMLConfigBuilder:XML 配置解析入口。
- org.apache.ibatis.session.Configuration:MyBatis 全局配置,包括运行行为、类型容器、别名容器、注册 Mapper、注册 statement 等。
- org.apache.ibatis.mapping.VendorDatabaseIdProvider:根据数据源获取对应的厂商信息。
5 - CH05-通用配置解析
在上章的配置解析中可以看到 MyBatis 在解析完运行时行为相关配置后会继续解析 Mapper 映射文件和接口,其中参数映射的解析入口为 XMLMapperBuilder 。
映射文件解析
XMLMapperBuilder 调用 parse 方法解析 Mapper 映射文件。
public void parse() {
if (!configuration.isResourceLoaded(resource)) {
// 解析 mapper 元素
configurationElement(parser.evalNode("/mapper"));
// 加入已解析队列
configuration.addLoadedResource(resource);
// Mapper 映射文件与对应 namespace 的接口进行绑定
bindMapperForNamespace();
}
// 重新引用配置
parsePendingResultMaps();
parsePendingCacheRefs();
parsePendingStatements();
}
解析 mapper 元素
mapper 元素通常需要指定 namespace 用于唯一区别映射文件,不同映射文件支持通过其它映射文件的 namespace 来引用其配置。mapper 元素下可以配置二级缓存(cache、cache-ref)、返回值映射(resultMap)、sql fragments(sql)、statement(select、insert、update、delete)等,MyBatis 源码提供 mybatis-mapper.xsd 文件用于规范映射文件书写规则。
private void configurationElement(XNode context) {
try {
// 获取元素对应的 namespace 名称
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
// 设置 Mapper 文件对应的 namespace 名称
builderAssistant.setCurrentNamespace(namespace);
// 解析 cache-ref 元素
cacheRefElement(context.evalNode("cache-ref"));
// 解析 cache 元素,会覆盖 cache-ref 配置
cacheElement(context.evalNode("cache"));
// 解析 parameterMap 元素(废弃)
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
// 解析 resultMap 元素
resultMapElements(context.evalNodes("/mapper/resultMap"));
// 解析 sql 元素
sqlElement(context.evalNodes("/mapper/sql"));
// 解析 select|insert|update|delete 元素
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
}
}
解析 cache 元素
如果要为某命名空间开启二级缓存功能,可以通过配置 cache 元素,示例配置如下:
<cache type=“PERPETUAL” eviction="LRU" flushInterval="60000" size="512" readOnly="true" blocking="true">
<property name="name" value="cache"/>
</cache>
cache 元素的解析逻辑如下:
private void cacheElement(XNode context) {
if (context != null) {
// 获取缓存类型,默认为 PERPETUAL
String type = context.getStringAttribute("type", "PERPETUAL");
// Configuration 构造方法中已为默认的缓存实现注册别名,从别名转换器中获取类对象
Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type);
// 获取失效类型,默认为 LRU
String eviction = context.getStringAttribute("eviction", "LRU");
Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction);
// 缓存刷新时间间隔
Long flushInterval = context.getLongAttribute("flushInterval");
// 缓存项大小
Integer size = context.getIntAttribute("size");
// 是否将序列化成二级制数据
boolean readWrite = !context.getBooleanAttribute("readOnly", false);
// 缓存不命中进入数据库查询时是否加锁(保证同一时刻相同缓存key只有一个线程执行数据库查询任务)
boolean blocking = context.getBooleanAttribute("blocking", false);
// 从子元素中加载属性
Properties props = context.getChildrenAsProperties();
// 创建缓存配置
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
}
}
在第三章基础支持模块中已经详细介绍了 MyBatis 实现的各种缓存。从 cache 元素中获取缓存参数配置后会交由 MapperBuilderAssistant#useNewCache 方法处理。MapperBuilderAssistant 方法是一个映射文件解析工具,它负责将映射文件各个元素解析的参数生成配置对象,最终设置到全局配置类 Configuration 中。
public Cache useNewCache(Class<? extends Cache> typeClass,
Class<? extends Cache> evictionClass,
Long flushInterval,
Integer size,
boolean readWrite,
boolean blocking,
Properties props) {
Cache cache = new CacheBuilder(currentNamespace)
// 基础缓存配置
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
// 失效类型,默认 LRU
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
// 定时清理缓存时间间隔
.clearInterval(flushInterval)
// 缓存项大小
.size(size)
// 是否将缓存系列化成二级制数据
.readWrite(readWrite)
// 缓存不命中进入数据库查询时是否加锁(保证同一时刻相同缓存key只有一个线程执行数据库查询任务)
.blocking(blocking)
.properties(props)
.build();
// 设置到全局配置中
configuration.addCache(cache);
currentCache = cache;
return cache;
}
解析 cache-ref 元素
如果希望引用其它 namespace 的缓存配置,可以通过 cache-ref 元素配置:
<cache-ref namespace="com.wch.mybatis.OtherMapper" />
其解析逻辑是将当前 namespace 与引用缓存配置的 namespace 在全局配置中进行绑定。
private void cacheRefElement(XNode context) {
if (context != null) {
// 当前 namespace - 引用缓存配置的 namespace,在全局配置中进行绑定
configuration.addCacheRef(builderAssistant.getCurrentNamespace(), context.getStringAttribute("namespace"));
// 获取缓存配置解析器
CacheRefResolver cacheRefResolver = new CacheRefResolver(builderAssistant, context.getStringAttribute("namespace"));
try {
// 解析获得引用的缓存配置
cacheRefResolver.resolveCacheRef();
} catch (IncompleteElementException e) {
// 指定引用的 namespace 缓存还未加载,暂时放入集合,等待全部 namespace 都加载完成后重新引用
configuration.addIncompleteCacheRef(cacheRefResolver);
}
}
}
由于存在被引用配置还未被加载,因而无法从全局配置中获取的情况,MyBatis 定义了 IncompleteElementException 在此时抛出,未解析完成的缓存解析对象会被加入到全局配置中的 incompleteCacheRefs 集合中,用于后续处理。
public Cache useCacheRef(String namespace) {
if (namespace == null) {
throw new BuilderException("cache-ref element requires a namespace attribute.");
}
try {
unresolvedCacheRef = true;
// 从全局配置中获取缓存配置
Cache cache = configuration.getCache(namespace);
if (cache == null) {
throw new IncompleteElementException("No cache for namespace '" + namespace + "' could be found.");
}
currentCache = cache;
unresolvedCacheRef = false;
return cache;
} catch (IllegalArgumentException e) {
// 可能指定引用的 namespace 缓存还未加载,抛出异常
throw new IncompleteElementException("No cache for namespace '" + namespace + "' could be found.", e);
}
}
MyBatis 允许 resultMap、cache-ref、statement 元素延迟加载,以 cache-ref 重新引用的方法 parsePendingCacheRefs 为例,其重新引用逻辑如下:
private void parsePendingCacheRefs() {
// 从全局配置中获取未解析的缓存引用配置
Collection<CacheRefResolver> incompleteCacheRefs = configuration.getIncompleteCacheRefs();
synchronized (incompleteCacheRefs) {
Iterator<CacheRefResolver> iter = incompleteCacheRefs.iterator();
while (iter.hasNext()) {
try {
// 逐个重新引用缓存配置
iter.next().resolveCacheRef();
// 引用成功,删除集合元素
iter.remove();
} catch (IncompleteElementException e) {
// 引用的缓存配置不存在
// Cache ref is still missing a resource...
}
}
}
}
解析 resultMap 元素
resultMap 元素用于定义结果集与结果对象(JavaBean 对象)之间的映射规则。resultMap 下除了 discriminator 的其它元素,都会被解析成 ResultMapping 对象,其解析过程如下:
private ResultMap resultMapElement(XNode resultMapNode, List<ResultMapping> additionalResultMappings, Class<?> enclosingType) throws Exception {
ErrorContext.instance().activity("processing " + resultMapNode.getValueBasedIdentifier());
// 获取返回值类型
String type = resultMapNode.getStringAttribute("type",
resultMapNode.getStringAttribute("ofType",
resultMapNode.getStringAttribute("resultType",
resultMapNode.getStringAttribute("javaType"))));
// 加载返回值类对象
Class<?> typeClass = resolveClass(type);
if (typeClass == null) {
// association 和 case 元素没有显式地指定返回值类型
typeClass = inheritEnclosingType(resultMapNode, enclosingType);
}
Discriminator discriminator = null;
List<ResultMapping> resultMappings = new ArrayList<>();
resultMappings.addAll(additionalResultMappings);
// 加载子元素
List<XNode> resultChildren = resultMapNode.getChildren();
for (XNode resultChild : resultChildren) {
if ("constructor".equals(resultChild.getName())) {
// 解析 constructor 元素
processConstructorElement(resultChild, typeClass, resultMappings);
} else if ("discriminator".equals(resultChild.getName())) {
// 解析 discriminator 元素
discriminator = processDiscriminatorElement(resultChild, typeClass, resultMappings);
} else {
// 解析 resultMap 元素下的其它元素
List<ResultFlag> flags = new ArrayList<>();
if ("id".equals(resultChild.getName())) {
// id 元素增加标志
flags.add(ResultFlag.ID);
}
// 解析元素映射关系
resultMappings.add(buildResultMappingFromContext(resultChild, typeClass, flags));
}
}
String id = resultMapNode.getStringAttribute("id",
resultMapNode.getValueBasedIdentifier());
// extend resultMap id
String extend = resultMapNode.getStringAttribute("extends");
// 是否设置自动映射
Boolean autoMapping = resultMapNode.getBooleanAttribute("autoMapping");
// resultMap 解析器
ResultMapResolver resultMapResolver = new ResultMapResolver(builderAssistant, id, typeClass, extend, discriminator, resultMappings, autoMapping);
try {
// 解析生成 ResultMap 对象并设置到全局配置中
return resultMapResolver.resolve();
} catch (IncompleteElementException e) {
// 异常稍后处理
configuration.addIncompleteResultMap(resultMapResolver);
throw e;
}
}
以下从不同元素配置的角度分别分析 MyBatis 解析规则。
id & result
id 和 result 元素都会将一个列的值映射到一个简单数据类型字段,不同的是 id 元素对应对象的标识属性,在比较对象时会用到。此外还可以设置 typeHandler 属性用于自定义类型转换逻辑。
buildResultMappingFromContext 方法负责将 resultMap 子元素解析为 ResultMapping 对象:
/**
* 解析 resultMap 子元素映射关系
*/
private ResultMapping buildResultMappingFromContext(XNode context, Class<?> resultType, List<ResultFlag> flags) throws Exception {
String property;
if (flags.contains(ResultFlag.CONSTRUCTOR)) {
// constructor 子元素,通过 name 获取参数名
property = context.getStringAttribute("name");
} else {
property = context.getStringAttribute("property");
}
// 列名
String column = context.getStringAttribute("column");
// java 类型
String javaType = context.getStringAttribute("javaType");
// jdbc 类型
String jdbcType = context.getStringAttribute("jdbcType");
// 嵌套的 select id
String nestedSelect = context.getStringAttribute("select");
// 获取嵌套的 resultMap id
String nestedResultMap = context.getStringAttribute("resultMap",
processNestedResultMappings(context, Collections.emptyList(), resultType));
// 获取指定的不为空才创建实例的列
String notNullColumn = context.getStringAttribute("notNullColumn");
// 列前缀
String columnPrefix = context.getStringAttribute("columnPrefix");
// 类型转换器
String typeHandler = context.getStringAttribute("typeHandler");
// 集合的多结果集
String resultSet = context.getStringAttribute("resultSet");
// 指定外键对应的列名
String foreignColumn = context.getStringAttribute("foreignColumn");
// 是否懒加载
boolean lazy = "lazy".equals(context.getStringAttribute("fetchType", configuration.isLazyLoadingEnabled() ? "lazy" : "eager"));
// 加载返回值类型
Class<?> javaTypeClass = resolveClass(javaType);
// 加载类型转换器类型
Class<? extends TypeHandler<?>> typeHandlerClass = resolveClass(typeHandler);
// 加载 jdbc 类型对象
JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);
return builderAssistant.buildResultMapping(resultType, property, column, javaTypeClass, jdbcTypeEnum, nestedSelect, nestedResultMap, notNullColumn, columnPrefix, typeHandlerClass, flags, resultSet, foreignColumn, lazy);
}
ResultMapping 对象保存了列名与 JavaBean 中字段名的对应关系,并明确了 Java 类型和 JDBC 类型,如果指定了类型转换器则使用指定的转化器将结果集字段映射为 Java 对象字段;否则根据 Java 类型和 JDBC 类型到类型转换器注册类中寻找适合的类型转换器。最终影响映射的一系列因素都被保存到 ResultMapping 对象中并加入到全局配置。
constructor
使用 constructor 元素允许返回值对象使用指定的构造方法创建而不是默认的构造方法。
<constructor>
<idArg name="id" column="id"/>
<arg name="productId" column="product_id"/>
</constructor>
在解析 constructor 元素时,MyBatis 特别指定了将 constructor 子元素解析为 ResultMapping 对象。
...
// 加载子元素
List<XNode> resultChildren = resultMapNode.getChildren();
for (XNode resultChild : resultChildren) {
if ("constructor".equals(resultChild.getName())) {
// 解析 constructor 元素
processConstructorElement(resultChild, typeClass, resultMappings);
}
...
}
...
/**
* 解析 constructor 元素下的子元素
*/
private void processConstructorElement(XNode resultChild, Class<?> resultType, List<ResultMapping> resultMappings) throws Exception {
// 获取子元素
List<XNode> argChildren = resultChild.getChildren();
for (XNode argChild : argChildren) {
List<ResultFlag> flags = new ArrayList<>();
// 标明此元素在 constructor 元素中
flags.add(ResultFlag.CONSTRUCTOR);
if ("idArg".equals(argChild.getName())) {
// 此元素映射 id
flags.add(ResultFlag.ID);
}
// 解析子元素映射关系
resultMappings.add(buildResultMappingFromContext(argChild, resultType, flags));
}
}
解析 constructor 子元素的逻辑与解析 id、result 元素的逻辑是一致的。
association
association 用于配置非简单类型的映射关系。其不仅支持在当前查询中做嵌套映射:
<resultMap id="userResult" type="User">
<id property="id" column="user_id" />
<association property="product" column="product_id" resultMap="productResult"/>
</resultMap>
也支持通过 select 属性嵌套其它查询:
<resultMap id="userResult" type="User">
<id property="id" column="user_id" />
<association property="product" column="product_id" select="queryProduct"/>
</resultMap>
在解析 resultMap 子元素方法 buildResultMappingFromContext 的逻辑中,MyBatis 会尝试获取每个子元素的 resultMap 属性,如果未指定,则会调用 processNestedResultMappings 方法,在此方法中对于 asociation 元素来说,如果指定了 select 属性,则映射时只需要获取对应 select 语句的 resultMap;如果未指定,则需要重新调用 resultMapElement 解析结果集映射关系。
private ResultMapping buildResultMappingFromContext(XNode context, Class<?> resultType, List<ResultFlag> flags) throws Exception {
...
// 尝试获取嵌套的 resultMap id
String nestedResultMap = context.getStringAttribute("resultMap", processNestedResultMappings(context, Collections.emptyList(), resultType));
...
}
/**
* 处理嵌套的 resultMap,获取 id
*
* @param context
* @param resultMappings
* @param enclosingType
* @return
* @throws Exception
*/
private String processNestedResultMappings(XNode context, List<ResultMapping> resultMappings, Class<?> enclosingType) throws Exception {
if ("association".equals(context.getName())
|| "collection".equals(context.getName())
|| "case".equals(context.getName())) {
if (context.getStringAttribute("select") == null) {
// 如果是 association、collection 或 case 元素并且没有 select 属性
// collection 元素没有指定 resultMap 或 javaType 属性,需要验证 resultMap 父元素对应的返回值类型是否有对当前集合的赋值入口
validateCollection(context, enclosingType);
ResultMap resultMap = resultMapElement(context, resultMappings, enclosingType);
return resultMap.getId();
}
}
return null;
}
在 resultMapElement 方法中调用了 inheritEnclosingType 针对未定义返回类型的元素的返回值类型解析:
private ResultMap resultMapElement(XNode resultMapNode, List<ResultMapping> additionalResultMappings, Class<?> enclosingType) throws Exception {
...
// 获取返回值类型
String type = resultMapNode.getStringAttribute("type",
resultMapNode.getStringAttribute("ofType",
resultMapNode.getStringAttribute("resultType",
resultMapNode.getStringAttribute("javaType"))));
// 加载返回值类对象
Class<?> typeClass = resolveClass(type);
if (typeClass == null) {
// association 等元素没有显式地指定返回值类型
typeClass = inheritEnclosingType(resultMapNode, enclosingType);
}
}
protected Class<?> inheritEnclosingType(XNode resultMapNode, Class<?> enclosingType) {
if ("association".equals(resultMapNode.getName()) && resultMapNode.getStringAttribute("resultMap") == null) {
// association 元素没有指定 resultMap 属性
String property = resultMapNode.getStringAttribute("property");
if (property != null && enclosingType != null) {
// 根据反射信息确定字段的类型
MetaClass metaResultType = MetaClass.forClass(enclosingType, configuration.getReflectorFactory());
return metaResultType.getSetterType(property);
}
} else if ("case".equals(resultMapNode.getName()) && resultMapNode.getStringAttribute("resultMap") == null) {
// case 元素返回值属性与 resultMap 父元素相同
return enclosingType;
}
return null;
}
在 inheritEnclosingType 方法中,如果未定义 resultMap 属性,则会通过反射工具 MetaClass 获取父元素 resultMap 返回类型的类信息,association 元素对应的字段名称的 setter 方法的参数就是其返回值类型。由此 association 元素必定可以关联到其结果集映射。
collection
collection 元素用于配置集合属性的映射关系,其解析过程与 association 元素大致相同,重要的区别是 collection 元素使用 ofType 属性指定集合元素类型,例如需要映射的 Java 集合为 List
<collection property="users" column="
user_id" ofType="com.wch.mybatis.User" javaType="ArrayList" select="queryUsers"/>
javaType熟悉指定的是字段类型,而 ofType 属性指定的才是需要映射的集合存储的类型。
discriminator
discriminator 支持对一个查询可能出现的不同结果集做鉴别,根据具体的条件为 resultMap 动态选择返回值类型。
<discriminator javaType="int" column="type">
<case value="1" resultType="Apple"/>
<case value="2" resultType="Banana"/>
</discriminator>
discriminator 元素的解析是通过 processDiscriminatorElement 方法完成的:
private Discriminator processDiscriminatorElement(XNode context, Class<?> resultType, List<ResultMapping> resultMappings) throws Exception {
// 获取需要鉴别的字段的相关信息
String column = context.getStringAttribute("column");
String javaType = context.getStringAttribute("javaType");
String jdbcType = context.getStringAttribute("jdbcType");
String typeHandler = context.getStringAttribute("typeHandler");
Class<?> javaTypeClass = resolveClass(javaType);
Class<? extends TypeHandler<?>> typeHandlerClass = resolveClass(typeHandler);
JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);
Map<String, String> discriminatorMap = new HashMap<>();
// 解析 discriminator 的 case 子元素
for (XNode caseChild : context.getChildren()) {
// 解析不同列值对应的不同 resultMap
String value = caseChild.getStringAttribute("value");
String resultMap = caseChild.getStringAttribute("resultMap", processNestedResultMappings(caseChild, resultMappings, resultType));
discriminatorMap.put(value, resultMap);
}
return builderAssistant.buildDiscriminator(resultType, column, javaTypeClass, jdbcTypeEnum, typeHandlerClass, discriminatorMap);
}
创建 ResultMap
在 resultMap 各子元素解析完成,ResultMapResolver 负责将生成的 ResultMapping 集合解析为 ResultMap 对象:
public ResultMap addResultMap(String id, Class<?> type, String extend, Discriminator discriminator, List<ResultMapping> resultMappings, Boolean autoMapping) {
id = applyCurrentNamespace(id, false);
extend = applyCurrentNamespace(extend, true);
if (extend != null) {
if (!configuration.hasResultMap(extend)) {
throw new IncompleteElementException("Could not find a parent resultmap with id '" + extend + "'");
}
// 获取继承的 ResultMap 对象
ResultMap resultMap = configuration.getResultMap(extend);
List<ResultMapping> extendedResultMappings = new ArrayList<>(resultMap.getResultMappings());
extendedResultMappings.removeAll(resultMappings);
// Remove parent constructor if this resultMap declares a constructor.
boolean declaresConstructor = false;
for (ResultMapping resultMapping : resultMappings) {
if (resultMapping.getFlags().contains(ResultFlag.CONSTRUCTOR)) {
// 当前 resultMap 指定了构造方法
declaresConstructor = true;
break;
}
}
if (declaresConstructor) {
// 移除继承的 ResultMap 的构造器映射对象
extendedResultMappings.removeIf(resultMapping -> resultMapping.getFlags().contains(ResultFlag.CONSTRUCTOR));
}
resultMappings.addAll(extendedResultMappings);
}
ResultMap resultMap = new ResultMap.Builder(configuration, id, type, resultMappings, autoMapping).discriminator(discriminator).build();
configuration.addResultMap(resultMap);
return resultMap;
}
如果当前 ResultMap 指定了 extend 属性,MyBatis 会从全局配置中获取被继承的 ResultMap 的相关映射关系,加入到当前映射关系中。但是如果被继承的 ResultMap 指定了构造器映射关系,当前 ResultMap 会选择移除。
解析 sql 元素
sql 元素用于定义可重用的 SQL 代码段,这些代码段可以通过 include 元素进行引用。
<sql id="baseColumns">
id, name, value
</sql>
<sql id="other">
${alias}
</sql>
<select id="query" resultType="Product">
SELECT
<include refid="baseColumns">,
<include refid="other">
<property name="alias" value="other"/>
</include>
FROM
t_something
</select>
对 sql 元素的解析逻辑如下,符合 databaseId 要求的 sql 元素才会被加载到全局配置中。
private void sqlElement(List<XNode> list) {
if (configuration.getDatabaseId() != null) {
sqlElement(list, configuration.getDatabaseId());
}
sqlElement(list, null);
}
/**
* 解析 sql 元素,将对应的 sql 片段设置到全局配置中
*/
private void sqlElement(List<XNode> list, String requiredDatabaseId) {
for (XNode context : list) {
String databaseId = context.getStringAttribute("databaseId");
String id = context.getStringAttribute("id");
id = builderAssistant.applyCurrentNamespace(id, false);
if (databaseIdMatchesCurrent(id, databaseId, requiredDatabaseId)) {
// 符合当前 databaseId 的 sql fragment,加入到全局配置中
sqlFragments.put(id, context);
}
}
}
/**
* 判断 sql 元素是否满足加载条件
*
* @param id
* @param databaseId
* @param requiredDatabaseId
* @return
*/
private boolean databaseIdMatchesCurrent(String id, String databaseId, String requiredDatabaseId) {
if (requiredDatabaseId != null) {
// 如果指定了当前数据源的 databaseId
if (!requiredDatabaseId.equals(databaseId)) {
// 被解析 sql 元素的 databaseId 需要符合
return false;
}
} else {
if (databaseId != null) {
// 全局未指定 databaseId,不会加载指定了 databaseId 的 sql 元素
return false;
}
// skip this fragment if there is a previous one with a not null databaseId
if (this.sqlFragments.containsKey(id)) {
XNode context = this.sqlFragments.get(id);
if (context.getStringAttribute("databaseId") != null) {
return false;
}
}
}
return true;
}
总结
MyBatis 能够轻松实现列值转换为 Java 对象依靠的是其强大的参数映射功能,能够支持集合、关联类型、嵌套等复杂场景的映射。同时缓存配置、sql 片段配置,也为开发者方便的提供了配置入口。
- org.apache.ibatis.builder.annotation.MapperAnnotationBuilder:解析 Mapper 接口。
- org.apache.ibatis.builder.xml.XMLMapperBuilder:解析 Mapper 文件。
- org.apache.ibatis.builder.MapperBuilderAssistant:Mapper 文件解析工具。生成元素对象并设置到全局配置中。
- org.apache.ibatis.builder.CacheRefResolver:缓存引用配置解析器,应用其它命名空间缓存配置到当前命名空间下。
- org.apache.ibatis.builder.IncompleteElementException:当前映射文件引用了其它命名空间下的配置,而该配置还未加载到全局配置中时会抛出此异常。
- org.apache.ibatis.mapping.ResultMapping:返回值字段映射关系对象。
- org.apache.ibatis.builder.ResultMapResolver:ResultMap 解析器。
- org.apache.ibatis.mapping.ResultMap:返回值映射对象。
6 - CH06-语句解析
Mapper 映射文件解析的最后一步是解析所有 statement 元素,即 select、insert、update、delete 元素,这些元素中可能会包含动态 SQL,即使用 ${} 占位符或 if、choose、where 等元素动态组成的 SQL。动态 SQL 功能正是 MyBatis 强大的所在,其解析过程也是十分复杂的。
解析工具
为了方便 statement 的解析,MyBatis 提供了一些解析工具。
Token 解析
MyBatis 支持使用 ${} 或 #{} 类型的 token 作为动态参数,不仅文本中可以使用 token,xml 元素中的属性等也可以使用。
GenericTokenParser
GenericTokenParser 是 MyBatis 提供的通用 token 解析器,其解析逻辑是根据指定的 token 前缀和后缀搜索 token,并使用传入的 TokenHandler 对文本进行处理。
public String parse(String text) {
if (text == null || text.isEmpty()) {
return "";
}
// search open token 搜索 token 前缀
int start = text.indexOf(openToken);
if (start == -1) {
// 没有 token 前缀,返回原文本
return text;
}
char[] src = text.toCharArray();
// 当前解析偏移量
int offset = 0;
// 已解析文本
final StringBuilder builder = new StringBuilder();
// 当前占位符内的表达式
StringBuilder expression = null;
while (start > -1) {
if (start > 0 && src[start - 1] == '\\') {
// 如果待解析属性前缀被转义,则去掉转义字符,加入已解析文本
// this open token is escaped. remove the backslash and continue.
builder.append(src, offset, start - offset - 1).append(openToken);
// 更新解析偏移量
offset = start + openToken.length();
} else {
// found open token. let's search close token.
if (expression == null) {
expression = new StringBuilder();
} else {
expression.setLength(0);
}
// 前缀前面的部分加入已解析文本
builder.append(src, offset, start - offset);
// 更新解析偏移量
offset = start + openToken.length();
// 获取对应的后缀索引
int end = text.indexOf(closeToken, offset);
while (end > -1) {
if (end > offset && src[end - 1] == '\\') {
// 后缀被转义,加入已解析文本
// this close token is escaped. remove the backslash and continue.
expression.append(src, offset, end - offset - 1).append(closeToken);
offset = end + closeToken.length();
// 寻找下一个后缀
end = text.indexOf(closeToken, offset);
} else {
// 找到后缀,获取占位符内的表达式
expression.append(src, offset, end - offset);
offset = end + closeToken.length();
break;
}
}
if (end == -1) {
// 找不到后缀,前缀之后的部分全部加入已解析文本
// close token was not found.
builder.append(src, start, src.length - start);
offset = src.length;
} else {
// 能够找到后缀,追加 token 处理器处理后的文本
builder.append(handler.handleToken(expression.toString()));
// 更新解析偏移量
offset = end + closeToken.length();
}
}
// 寻找下一个前缀,重复解析表达式
start = text.indexOf(openToken, offset);
}
if (offset < src.length) {
// 将最后的部分加入已解析文本
builder.append(src, offset, src.length - offset);
}
// 返回解析后的文本
return builder.toString();
}
由于 GenericTokenParser 的 token 前后缀和具体解析逻辑都是可指定的,因此基于 GenericTokenParser 可以实现对不同 token 的定制化解析。
TokenHandler
TokenHandler 是 token 处理器抽象接口。实现此接口可以定义 token 以何种方式被解析。
public interface TokenHandler {
/**
* 对 token 进行解析
*
* @param content 待解析 token
* @return
*/
String handleToken(String content);
}
PropertyParser
PropertyParser 是 token 解析的一种具体实现,其指定对 ${} 类型 token 进行解析,具体解析逻辑由其内部类 VariableTokenHandler 实现:
/**
* 对 ${} 类型 token 进行解析
*
* @param string
* @param variables
* @return
*/
public static String parse(String string, Properties variables) {
VariableTokenHandler handler = new VariableTokenHandler(variables);
GenericTokenParser parser = new GenericTokenParser("${", "}", handler);
return parser.parse(string);
}
/**
* 根据配置属性对 ${} token 进行解析
*/
private static class VariableTokenHandler implements TokenHandler {
/**
* 预先设置的属性
*/
private final Properties variables;
/**
* 是否运行使用默认值,默认为 false
*/
private final boolean enableDefaultValue;
/**
* 默认值分隔符号,即如待解析属性 ${key:default},key 的默认值为 default
*/
private final String defaultValueSeparator;
private VariableTokenHandler(Properties variables) {
this.variables = variables;
this.enableDefaultValue = Boolean.parseBoolean(getPropertyValue(KEY_ENABLE_DEFAULT_VALUE, ENABLE_DEFAULT_VALUE));
this.defaultValueSeparator = getPropertyValue(KEY_DEFAULT_VALUE_SEPARATOR, DEFAULT_VALUE_SEPARATOR);
}
private String getPropertyValue(String key, String defaultValue) {
return (variables == null) ? defaultValue : variables.getProperty(key, defaultValue);
}
@Override
public String handleToken(String content) {
if (variables != null) {
String key = content;
if (enableDefaultValue) {
// 如待解析属性 ${key:default},key 的默认值为 default
final int separatorIndex = content.indexOf(defaultValueSeparator);
String defaultValue = null;
if (separatorIndex >= 0) {
key = content.substring(0, separatorIndex);
defaultValue = content.substring(separatorIndex + defaultValueSeparator.length());
}
if (defaultValue != null) {
// 使用默认值
return variables.getProperty(key, defaultValue);
}
}
if (variables.containsKey(key)) {
// 不使用默认值
return variables.getProperty(key);
}
}
// 返回原文本
return "${" + content + "}";
}
}
VariableTokenHandler 实现了 TokenHandler 接口,其构造方法允许传入一组 Properties 用于获取 token 表达式的值。如果开启了使用默认值,则表达式 ${key:default} 会在 key 没有映射值的时候使用 default 作为默认值。
特殊容器
StrictMap
Configuration 中的 StrictMap 继承了 HashMap,相对于 HashMap,其存取键值的要求更为严格。put 方法不允许添加相同的 key,并获取最后一个 . 后的部分作为 shortKey,如果 shortKey 也重复了,其会向容器中添加一个 Ambiguity 对象,当使用 get 方法获取这个 shortKey 对应的值时,就会抛出异常。get 方法对于不存在的 key 也会抛出异常。
public V put(String key, V value) {
if (containsKey(key)) {
// 重复 key 异常
throw new IllegalArgumentException(name + " already contains value for " + key
+ (conflictMessageProducer == null ? "" : conflictMessageProducer.apply(super.get(key), value)));
}
if (key.contains(".")) {
// 获取最后一个 . 后的部分作为 shortKey
final String shortKey = getShortName(key);
// shortKey 不允许重复,否则在获取时异常
if (super.get(shortKey) == null) {
super.put(shortKey, value);
} else {
super.put(shortKey, (V) new Ambiguity(shortKey));
}
}
return super.put(key, value);
}
public V get(Object key) {
V value = super.get(key);
if (value == null) {
// key 不存在抛异常
throw new IllegalArgumentException(name + " does not contain value for " + key);
}
// 重复的 key 抛异常
if (value instanceof Ambiguity) {
throw new IllegalArgumentException(((Ambiguity) value).getSubject() + " is ambiguous in " + name
+ " (try using the full name including the namespace, or rename one of the entries)");
}
return value;
}
ContextMap
ContextMap 是 DynamicContext 的静态内部类,用于保存 sql 上下文中的绑定参数。
static class ContextMap extends HashMap<String, Object> {
private static final long serialVersionUID = 2977601501966151582L;
/**
* 参数对象
*/
private MetaObject parameterMetaObject;
public ContextMap(MetaObject parameterMetaObject) {
this.parameterMetaObject = parameterMetaObject;
}
@Override
public Object get(Object key) {
// 先根据 key 查找原始容器
String strKey = (String) key;
if (super.containsKey(strKey)) {
return super.get(strKey);
}
// 再进入参数对象查找
if (parameterMetaObject != null) {
// issue #61 do not modify the context when reading
return parameterMetaObject.getValue(strKey);
}
return null;
}
}
OGNL 参数
OgnlCache
OGNL 工具支持通过字符串表达式调用 Java 方法,但是其实现需要对 OGNL 表达式进行编译,为了提高性能,MyBatis 提供 OgnlCache 工具类用于对 OGNL 表达式编译结果进行缓存。
/**
* 根据 ognl 表达式和参数计算值
*
* @param expression
* @param root
* @return
*/
public static Object getValue(String expression, Object root) {
try {
Map context = Ognl.createDefaultContext(root, MEMBER_ACCESS, CLASS_RESOLVER, null);
return Ognl.getValue(parseExpression(expression), context, root);
} catch (OgnlException e) {
throw new BuilderException("Error evaluating expression '" + expression + "'. Cause: " + e, e);
}
}
/**
* 编译 ognl 表达式并放入缓存
*
* @param expression
* @return
* @throws OgnlException
*/
private static Object parseExpression(String expression) throws OgnlException {
Object node = expressionCache.get(expression);
if (node == null) {
// 编译 ognl 表达式
node = Ognl.parseExpression(expression);
// 放入缓存
expressionCache.put(expression, node);
}
return node;
}
ExpressionEvaluator
ExpressionEvaluator 是 OGNL 表达式计算工具,evaluateBoolean 和 evaluateIterable 方法分别根据传入的表达式和参数计算出一个 boolean 值或一个可迭代对象。
/**
* 计算 ognl 表达式 true / false
*
* @param expression
* @param parameterObject
* @return
*/
public boolean evaluateBoolean(String expression, Object parameterObject) {
// 根据 ognl 表达式和参数计算值
Object value = OgnlCache.getValue(expression, parameterObject);
// true / false
if (value instanceof Boolean) {
return (Boolean) value;
}
// 不为 0
if (value instanceof Number) {
return new BigDecimal(String.valueOf(value)).compareTo(BigDecimal.ZERO) != 0;
}
// 不为 null
return value != null;
}
/**
* 计算获得一个可迭代的对象
*
* @param expression
* @param parameterObject
* @return
*/
public Iterable<?> evaluateIterable(String expression, Object parameterObject) {
Object value = OgnlCache.getValue(expression, parameterObject);
if (value == null) {
throw new BuilderException("The expression '" + expression + "' evaluated to a null value.");
}
if (value instanceof Iterable) {
// 已实现 Iterable 接口
return (Iterable<?>) value;
}
if (value.getClass().isArray()) {
// 数组转集合
// the array may be primitive, so Arrays.asList() may throw
// a ClassCastException (issue 209). Do the work manually
// Curse primitives! :) (JGB)
int size = Array.getLength(value);
List<Object> answer = new ArrayList<>();
for (int i = 0; i < size; i++) {
Object o = Array.get(value, i);
answer.add(o);
}
return answer;
}
if (value instanceof Map) {
// Map 获取 entry
return ((Map) value).entrySet();
}
throw new BuilderException("Error evaluating expression '" + expression + "'. Return value (" + value + ") was not iterable.");
}
解析逻辑
MyBastis 中调用 XMLStatementBuilder#parseStatementNode 方法解析单个 statement 元素。此方法中除了逐个获取元素属性,还对 include 元素、selectKey 元素进行解析,创建了 sql 生成对象 SqlSource,并将 statement 的全部信息聚合到 MappedStatement 对象中。
public void parseStatementNode() {
// 获取 id
String id = context.getStringAttribute("id");
// 自定义数据库厂商信息
String databaseId = context.getStringAttribute("databaseId");
if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) {
// 不符合当前数据源对应的数据厂商信息的语句不加载
return;
}
// 获取元素名
String nodeName = context.getNode().getNodeName();
// 元素名转为对应的 SqlCommandType 枚举
SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
// 是否为查询
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
// 获取 flushCache 属性,查询默认为 false,其它默认为 true
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
// 获取 useCache 属性,查询默认为 true,其它默认为 false
boolean useCache = context.getBooleanAttribute("useCache", isSelect);
// 获取 resultOrdered 属性,默认为 false
boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false);
// Include Fragments before parsing
XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant);
// 解析 include 属性
includeParser.applyIncludes(context.getNode());
// 参数类型
String parameterType = context.getStringAttribute("parameterType");
Class<?> parameterTypeClass = resolveClass(parameterType);
// 获取 Mapper 语法类型
String lang = context.getStringAttribute("lang");
// 默认使用 XMLLanguageDriver
LanguageDriver langDriver = getLanguageDriver(lang);
// Parse selectKey after includes and remove them.
// 解析 selectKey 元素
processSelectKeyNodes(id, parameterTypeClass, langDriver);
// 获取 KeyGenerator
// Parse the SQL (pre: <selectKey> and <include> were parsed and removed)
KeyGenerator keyGenerator;
String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX;
keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true);
if (configuration.hasKeyGenerator(keyStatementId)) {
// 获取解析完成的 KeyGenerator 对象
keyGenerator = configuration.getKeyGenerator(keyStatementId);
} else {
// 如果开启了 useGeneratedKeys 属性,并且为插入类型的 sql 语句、配置了 keyProperty 属性,则可以批量自动设置属性
keyGenerator = context.getBooleanAttribute("useGeneratedKeys",
configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType))
? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
}
// 生成有效 sql 语句和参数绑定对象
SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
// sql 类型
StatementType statementType = StatementType.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString()));
// 分批获取数据的数量
Integer fetchSize = context.getIntAttribute("fetchSize");
// 执行超时时间
Integer timeout = context.getIntAttribute("timeout");
// 参数映射
String parameterMap = context.getStringAttribute("parameterMap");
// 返回值类型
String resultType = context.getStringAttribute("resultType");
Class<?> resultTypeClass = resolveClass(resultType);
// 返回值映射 map
String resultMap = context.getStringAttribute("resultMap");
// 结果集类型
String resultSetType = context.getStringAttribute("resultSetType");
ResultSetType resultSetTypeEnum = resolveResultSetType(resultSetType);
// 插入、更新生成键值的字段
String keyProperty = context.getStringAttribute("keyProperty");
// 插入、更新生成键值的列
String keyColumn = context.getStringAttribute("keyColumn");
// 指定多结果集名称
String resultSets = context.getStringAttribute("resultSets");
// 新增 MappedStatement
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
}
语法驱动
LanguageDriver 是 statement 创建语法驱动,默认实现为 XMLLanguageDriver,其提供 createSqlSource 方法用于使用 XMLScriptBuilder 创建 sql 生成对象。
递归解析 include
include 元素是 statement 元素的子元素,通过 refid 属性可以指向在别处定义的 sql fragments。
public void applyIncludes(Node source) {
Properties variablesContext = new Properties();
Properties configurationVariables = configuration.getVariables();
// 拷贝全局配置中设置的额外配置属性
Optional.ofNullable(configurationVariables).ifPresent(variablesContext::putAll);
applyIncludes(source, variablesContext, false);
}
/**
* 递归解析 statement 元素中的 include 元素
*
* Recursively apply includes through all SQL fragments.
* @param source Include node in DOM tree
* @param variablesContext Current context for static variables with values
*/
private void applyIncludes(Node source, final Properties variablesContext, boolean included) {
if (source.getNodeName().equals("include")) {
// include 元素,从全局配置中找对应的 sql 节点并 clone
Node toInclude = findSqlFragment(getStringAttribute(source, "refid"), variablesContext);
// 读取 include 子元素中的 property 元素,获取全部属性
Properties toIncludeContext = getVariablesContext(source, variablesContext);
applyIncludes(toInclude, toIncludeContext, true);
if (toInclude.getOwnerDocument() != source.getOwnerDocument()) {
toInclude = source.getOwnerDocument().importNode(toInclude, true);
}
source.getParentNode().replaceChild(toInclude, source);
while (toInclude.hasChildNodes()) {
toInclude.getParentNode().insertBefore(toInclude.getFirstChild(), toInclude);
}
toInclude.getParentNode().removeChild(toInclude);
} else if (source.getNodeType() == Node.ELEMENT_NODE) {
if (included && !variablesContext.isEmpty()) {
// replace variables in attribute values
// include 指向的 sql clone 节点,逐个对属性进行解析
NamedNodeMap attributes = source.getAttributes();
for (int i = 0; i < attributes.getLength(); i++) {
Node attr = attributes.item(i);
attr.setNodeValue(PropertyParser.parse(attr.getNodeValue(), variablesContext));
}
}
// statement 元素中可能包含 include 子元素
NodeList children = source.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
applyIncludes(children.item(i), variablesContext, included);
}
} else if (included && source.getNodeType() == Node.TEXT_NODE
&& !variablesContext.isEmpty()) {
// replace variables in text node
// 替换元素值,如果使用了 ${} 占位符,会对 token 进行解析
source.setNodeValue(PropertyParser.parse(source.getNodeValue(), variablesContext));
}
}
/**
* 从全局配置中找对应的 sql fragment
*
* @param refid
* @param variables
* @return
*/
private Node findSqlFragment(String refid, Properties variables) {
// 解析 refid
refid = PropertyParser.parse(refid, variables);
// namespace.refid
refid = builderAssistant.applyCurrentNamespace(refid, true);
try {
// 从全局配置中找对应的 sql fragment
XNode nodeToInclude = configuration.getSqlFragments().get(refid);
return nodeToInclude.getNode().cloneNode(true);
} catch (IllegalArgumentException e) {
// sql fragments 定义在全局配置中的 StrictMap 中,获取不到会抛出异常
throw new IncompleteElementException("Could not find SQL statement to include with refid '" + refid + "'", e);
}
}
private String getStringAttribute(Node node, String name) {
return node.getAttributes().getNamedItem(name).getNodeValue();
}
/**
* Read placeholders and their values from include node definition.
*
* 读取 include 子元素中的 property 元素
* @param node Include node instance
* @param inheritedVariablesContext Current context used for replace variables in new variables values
* @return variables context from include instance (no inherited values)
*/
private Properties getVariablesContext(Node node, Properties inheritedVariablesContext) {
Map<String, String> declaredProperties = null;
// 解析 include 元素中的 property 子元素
NodeList children = node.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node n = children.item(i);
if (n.getNodeType() == Node.ELEMENT_NODE) {
// include 运行包含 property 元素
String name = getStringAttribute(n, "name");
// Replace variables inside
String value = PropertyParser.parse(getStringAttribute(n, "value"), inheritedVariablesContext);
if (declaredProperties == null) {
declaredProperties = new HashMap<>();
}
if (declaredProperties.put(name, value) != null) {
// 不允许添加同名属性
throw new BuilderException("Variable " + name + " defined twice in the same include definition");
}
}
}
if (declaredProperties == null) {
return inheritedVariablesContext;
} else {
// 聚合属性配置
Properties newProperties = new Properties();
newProperties.putAll(inheritedVariablesContext);
newProperties.putAll(declaredProperties);
return newProperties;
}
}
在开始解析前,从全局配置中获取全部的属性配置,如果 include 元素中有 property 元素,解析并获取键值,放入 variablesContext 中,在后续处理中针对可能出现的 ${} 类型 token 使用 PropertyParser 进行解析。
因为解析 statement 元素前已经加载过 sql 元素,因此会根据 include 元素的 refid 属性查找对应的 sql fragments,如果全局配置中无法找到就会抛出异常;如果能够找到则克隆 sql 元素并插入到当前 xml 文档中。
解析 selectKey
selectKey 用于指定 sql 在 insert 或 update 语句执行前或执行后生成或获取列值,在 MyBatis 中 selectKey 也被当做 statement 语句进行解析并设置到全局配置中。单个 selectKey 元素会以SelectKeyGenerator 对象的形式进行保存用于后续调用。
private void parseSelectKeyNode(String id, XNode nodeToHandle, Class<?> parameterTypeClass, LanguageDriver langDriver, String databaseId) {
// 返回值类型
String resultType = nodeToHandle.getStringAttribute("resultType");
Class<?> resultTypeClass = resolveClass(resultType);
StatementType statementType = StatementType.valueOf(nodeToHandle.getStringAttribute("statementType", StatementType.PREPARED.toString()));
// 对应字段名
String keyProperty = nodeToHandle.getStringAttribute("keyProperty");
// 对应列名
String keyColumn = nodeToHandle.getStringAttribute("keyColumn");
// 是否在父sql执行前执行
boolean executeBefore = "BEFORE".equals(nodeToHandle.getStringAttribute("order", "AFTER"));
//defaults
boolean useCache = false;
boolean resultOrdered = false;
KeyGenerator keyGenerator = NoKeyGenerator.INSTANCE;
Integer fetchSize = null;
Integer timeout = null;
boolean flushCache = false;
String parameterMap = null;
String resultMap = null;
ResultSetType resultSetTypeEnum = null;
// 创建 sql 生成对象
SqlSource sqlSource = langDriver.createSqlSource(configuration, nodeToHandle, parameterTypeClass);
SqlCommandType sqlCommandType = SqlCommandType.SELECT;
// 将 KeyGenerator 生成 sql 作为 MappedStatement 加入全局对象
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, null);
id = builderAssistant.applyCurrentNamespace(id, false);
MappedStatement keyStatement = configuration.getMappedStatement(id, false);
// 包装为 SelectKeyGenerator 对象
configuration.addKeyGenerator(id, new SelectKeyGenerator(keyStatement, executeBefore));
}
在 selectKey 解析完成后,按指定的 namespace 规则从全局配置中获取 SelectKeyGenerator 对象,等待创建 MappedStatement 对象。如果未指定 selectKey 元素,但是全局配置中开启了 useGeneratedKeys,并且指定 insert 元素的 useGeneratedKeys 属性为 true,则 MyBatis 会指定 Jdbc3KeyGenerator 作为 useGeneratedKeys 的默认实现。
创建 sql 生成对象
SqlSource
SqlSource 是 sql 生成抽象接口,其提供 getBoundSql 方法用于根据参数生成有效 sql 语句和参数绑定对象 BoundSql。在生成 statement 元素的解析结果 MappedStatement 对象前,需要先创建 sql 生成对象,即 SqlSource 对象。
public interface SqlSource {
/**
* 根据参数生成有效 sql 语句和参数绑定对象
*
* @param parameterObject
* @return
*/
BoundSql getBoundSql(Object parameterObject);
}
SqlNode
SqlNode 是 sql 节点抽象接口。sql 节点指的是 statement 中的组成部分,如果简单文本、if 元素、where 元素等。SqlNode 提供 apply 方法用于判断当前 sql 节点是否可以加入到生效的 sql 语句中。
public interface SqlNode {
/**
* 根据条件判断当前 sql 节点是否可以加入到生效的 sql 语句中
*
* @param context
* @return
*/
boolean apply(DynamicContext context);
}

DynamicContext
DynamicContext 是动态 sql 上下文,用于保存绑定参数和生效 sql 节点。DynamicContext 使用 ContextMap 作为参数绑定容器。由于动态 sql 是根据参数条件组合生成 sql,DynamicContext 还提供了对 sqlBuilder 修改和访问方法,用于添加有效 sql 节点和生成 sql 文本。
/**
* 生效的 sql 部分,以空格相连
*/
private final StringJoiner sqlBuilder = new StringJoiner(" ");
public void appendSql(String sql) {
sqlBuilder.add(sql);
}
public String getSql() {
return sqlBuilder.toString().trim();
}
节点解析
将 statement 元素转为 sql 生成对象依赖于 LanguageDriver 的 createSqlSource 方法,此方法中创建 XMLScriptBuilder 对象,并调用 parseScriptNode 方法对 sql 组成节点逐个解析并进行组合。
public SqlSource parseScriptNode() {
// 递归解析各 sql 节点
MixedSqlNode rootSqlNode = parseDynamicTags(context);
SqlSource sqlSource;
if (isDynamic) {
// 动态 sql
sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
} else {
// 原始文本 sql
sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
}
return sqlSource;
}
/**
* 处理 statement 各 SQL 组成部分,并进行组合
*/
protected MixedSqlNode parseDynamicTags(XNode node) {
// SQL 各组成部分
List<SqlNode> contents = new ArrayList<>();
// 遍历子元素
NodeList children = node.getNode().getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
XNode child = node.newXNode(children.item(i));
if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
// 解析 sql 文本
String data = child.getStringBody("");
TextSqlNode textSqlNode = new TextSqlNode(data);
if (textSqlNode.isDynamic()) {
// 判断是否为动态 sql,包含 ${} 占位符即为动态 sql
contents.add(textSqlNode);
isDynamic = true;
} else {
// 静态 sql 元素
contents.add(new StaticTextSqlNode(data));
}
} else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628
// 如果是子元素
String nodeName = child.getNode().getNodeName();
// 获取支持的子元素语法处理器
NodeHandler handler = nodeHandlerMap.get(nodeName);
if (handler == null) {
throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
}
// 根据子元素标签类型使用对应的处理器处理子元素
handler.handleNode(child, contents);
// 包含标签元素,认定为动态 SQL
isDynamic = true;
}
}
return new MixedSqlNode(contents);
}
parseDynamicTags 方法会对 sql 各组成部分进行分解,如果 statement 元素包含 ${} 类型 token 或含有标签子元素,则认为当前 statement 是动态 sql,随后 isDynamic 属性会被设置为 true。对于文本节点,如 sql 纯文本和仅含 ${} 类型 token 的文本,会被包装为 StaticTextSqlNode 或 TextSqlNode 加入到 sql 节点容器中,而其它元素类型的 sql 节点会经过 NodeHandler 的 handleNode 方法处理过之后才能加入到节点容器中。nodeHandlerMap 定义了不同动态 sql 元素节点与 NodeHandler 的关系:
private void initNodeHandlerMap() {
nodeHandlerMap.put("trim", new TrimHandler());
nodeHandlerMap.put("where", new WhereHandler());
nodeHandlerMap.put("set", new SetHandler());
nodeHandlerMap.put("foreach", new ForEachHandler());
nodeHandlerMap.put("if", new IfHandler());
nodeHandlerMap.put("choose", new ChooseHandler());
nodeHandlerMap.put("when", new IfHandler());
nodeHandlerMap.put("otherwise", new OtherwiseHandler());
nodeHandlerMap.put("bind", new BindHandler());
}
MixedSqlNode
MixedSqlNode 中定义了一个 SqlNode 集合,用于保存 statement 中包含的全部 sql 节点。其生成有效 sql 的逻辑为逐个判断节点是否有效。
/**
* 组合 SQL 各组成部分
*
* @author Clinton Begin
*/
public class MixedSqlNode implements SqlNode {
/**
* SQL 各组装成部分
*/
private final List<SqlNode> contents;
public MixedSqlNode(List<SqlNode> contents) {
this.contents = contents;
}
@Override
public boolean apply(DynamicContext context) {
// 逐个判断各个 sql 节点是否能生效
contents.forEach(node -> node.apply(context));
return true;
}
}
StaticTextSqlNode
StaticTextSqlNode 中仅包含静态 sql 文本,在组装时会直接追加到 sql 上下文的有效 sql 中:
@Override
public boolean apply(DynamicContext context) {
context.appendSql(text);
return true;
}
TextSqlNode
TextSqlNode 中的 sql 文本包含 ${} 类型 token,使用 GenericTokenParser 搜索到 token 后会使用 BindingTokenParser 对 token 进行解析,解析后的文本会被追加到生效 sql 中。
@Override
public boolean apply(DynamicContext context) {
// 搜索 ${} 类型 token 节点
GenericTokenParser parser = createParser(new BindingTokenParser(context, injectionFilter));
// 解析 token 并追加解析后的文本到生效 sql 中
context.appendSql(parser.parse(text));
return true;
}
private GenericTokenParser createParser(TokenHandler handler) {
return new GenericTokenParser("${", "}", handler);
}
private static class BindingTokenParser implements TokenHandler {
private DynamicContext context;
private Pattern injectionFilter;
public BindingTokenParser(DynamicContext context, Pattern injectionFilter) {
this.context = context;
this.injectionFilter = injectionFilter;
}
@Override
public String handleToken(String content) {
// 获取绑定参数
Object parameter = context.getBindings().get("_parameter");
if (parameter == null) {
context.getBindings().put("value", null);
} else if (SimpleTypeRegistry.isSimpleType(parameter.getClass())) {
context.getBindings().put("value", parameter);
}
// 计算 ognl 表达式的值
Object value = OgnlCache.getValue(content, context.getBindings());
String srtValue = value == null ? "" : String.valueOf(value); // issue #274 return "" instead of "null"
checkInjection(srtValue);
return srtValue;
}
}
IfSqlNode
if 标签用于在 test 条件生效时才追加标签内的文本。
<if test="userId > 0">
AND user_id = #{userId}
</if>
IfSqlNode 保存了 if 元素下的节点内容和 test 表达式,在生成有效 sql 时会根据 OGNL 工具计算 test 表达式是否生效。
@Override
public boolean apply(DynamicContext context) {
// 根据 test 表达式判断当前节点是否生效
if (evaluator.evaluateBoolean(test, context.getBindings())) {
contents.apply(context);
return true;
}
return false;
}
TrimSqlNode
trim 标签用于解决动态 sql 中由于条件不同不能拼接正确语法的问题。
SELECT * FROM test
<trim prefix="WHERE" prefixOverrides="AND|OR">
<if test="a > 0">
a = #{a}
</if>
<if test="b > 0">
OR b = #{b}
</if>
<if test="c > 0">
AND c = #{c}
</if>
</trim>
如果没有 trim 标签,这个 statement 的有效 sql 最终可能会是这样的:
SELECT * FROM test OR b = #{b}
但是加上 trim 标签,生成的 sql 语法是正确的:
SELECT * FROM test WHERE b = #{b}
prefix 属性用于指定 trim 节点生成的 sql 语句的前缀,prefixOverrides 则会指定生成的 sql 语句的前缀需要去除的部分,多个需要去除的前缀可以使用 | 隔开。suffix 与 suffixOverrides 的功能类似,但是作用于后缀。
TrimSqlNode 首先调用 parseOverrides 对 prefixOverrides 和 suffixOverrides 进行解析,通过 | 分隔,分别加入字符串集合。
private static List<String> parseOverrides(String overrides) {
if (overrides != null) {
// 解析 token,按 | 分隔
final StringTokenizer parser = new StringTokenizer(overrides, "|", false);
final List<String> list = new ArrayList<>(parser.countTokens());
while (parser.hasMoreTokens()) {
// 保存为字符串集合
list.add(parser.nextToken().toUpperCase(Locale.ENGLISH));
}
return list;
}
return Collections.emptyList();
}
在调用包含的 SqlNode 的 apply 方法后还会调用 FilteredDynamicContext 的 applyAll 方法处理前缀和后缀。
@Override
public boolean apply(DynamicContext context) {
FilteredDynamicContext filteredDynamicContext = new FilteredDynamicContext(context);
boolean result = contents.apply(filteredDynamicContext);
// 加上前缀和和后缀,并去除多余字段
filteredDynamicContext.applyAll();
return result;
}
对于已经生成的 sql 文本,分别根据规则加上和去除指定前缀和后缀。
public void applyAll() {
sqlBuffer = new StringBuilder(sqlBuffer.toString().trim());
String trimmedUppercaseSql = sqlBuffer.toString().toUpperCase(Locale.ENGLISH);
if (trimmedUppercaseSql.length() > 0) {
// 加上前缀和和后缀,并去除多余字段
applyPrefix(sqlBuffer, trimmedUppercaseSql);
applySuffix(sqlBuffer, trimmedUppercaseSql);
}
delegate.appendSql(sqlBuffer.toString());
}
private void applyPrefix(StringBuilder sql, String trimmedUppercaseSql) {
if (!prefixApplied) {
prefixApplied = true;
if (prefixesToOverride != null) {
// 文本最前去除多余字段
for (String toRemove : prefixesToOverride) {
if (trimmedUppercaseSql.startsWith(toRemove)) {
sql.delete(0, toRemove.trim().length());
break;
}
}
}
// 在文本最前插入前缀和空格
if (prefix != null) {
sql.insert(0, " ");
sql.insert(0, prefix);
}
}
}
private void applySuffix(StringBuilder sql, String trimmedUppercaseSql) {
if (!suffixApplied) {
suffixApplied = true;
if (suffixesToOverride != null) {
// 文本最后去除多余字段
for (String toRemove : suffixesToOverride) {
if (trimmedUppercaseSql.endsWith(toRemove) || trimmedUppercaseSql.endsWith(toRemove.trim())) {
int start = sql.length() - toRemove.trim().length();
int end = sql.length();
sql.delete(start, end);
break;
}
}
}
// 文本最后插入空格和后缀
if (suffix != null) {
sql.append(" ");
sql.append(suffix);
}
}
}
WhereSqlNode
where 元素与 trim 元素的功能类似,区别在于 where 元素不提供属性配置可以处理的前缀和后缀。
<where>
...
</where>
WhereSqlNode 继承了 TrimSqlNode,并指定了需要添加和删除的前缀。
public class WhereSqlNode extends TrimSqlNode {
private static List<String> prefixList = Arrays.asList("AND ","OR ","AND\n", "OR\n", "AND\r", "OR\r", "AND\t", "OR\t");
public WhereSqlNode(Configuration configuration, SqlNode contents) {
// 默认添加 WHERE 前缀,去除 AND、OR 等前缀
super(configuration, contents, "WHERE", prefixList, null, null);
}
}
因此,生成的 sql 语句会自动在最前加上 WHERE,并去除前缀中包含的 AND、OR 等字符串。
SetSqlNode
set 标签用于 update 语句中。
UPDATE test
<set>
<if test="a > 0">
a = #{a},
</if>
<if test="b > 0">
b = #{b}
</if>
</set>
SetSqlNode 同样继承自 TrimSqlNode,并指定默认添加 SET 前缀,去除 , 前缀和后缀。
public class SetSqlNode extends TrimSqlNode {
private static final List<String> COMMA = Collections.singletonList(",");
public SetSqlNode(Configuration configuration,SqlNode contents) {
// 默认添加 SET 前缀,去除 , 前缀和后缀
super(configuration, contents, "SET", COMMA, null, COMMA);
}
}
ForEachSqlNode
foreach 元素用于指定对集合循环添加 sql 语句。
<foreach collection="list" item="item" index="index" open="(" close=")" separator=",">
AND itm = #{item} AND idx #{index}
</foreach>
ForEachSqlNode 解析生成有效 sql 的逻辑如下,除了计算 collection 表达式的值、添加前缀、后缀外,还将参数与索引进行了绑定。
@Override
public boolean apply(DynamicContext context) {
// 获取绑定参数
Map<String, Object> bindings = context.getBindings();
// 计算 ognl 表达式获取可迭代对象
final Iterable<?> iterable = evaluator.evaluateIterable(collectionExpression, bindings);
if (!iterable.iterator().hasNext()) {
return true;
}
boolean first = true;
// 添加动态语句前缀
applyOpen(context);
// 迭代索引
int i = 0;
for (Object o : iterable) {
DynamicContext oldContext = context;
// 首个元素
if (first || separator == null) {
context = new PrefixedContext(context, "");
} else {
context = new PrefixedContext(context, separator);
}
int uniqueNumber = context.getUniqueNumber();
// Issue #709
if (o instanceof Map.Entry) {
// entry 集合项索引为 key,集合项为 value
@SuppressWarnings("unchecked")
Map.Entry<Object, Object> mapEntry = (Map.Entry<Object, Object>) o;
applyIndex(context, mapEntry.getKey(), uniqueNumber);
applyItem(context, mapEntry.getValue(), uniqueNumber);
} else {
// 绑定集合项索引关系
applyIndex(context, i, uniqueNumber);
// 绑定集合项关系
applyItem(context, o, uniqueNumber);
}
// 对解析的表达式进行替换,如 idx = #{index} AND itm = #{item} 替换为 idx = #{__frch_index_1} AND itm = #{__frch_item_1}
contents.apply(new FilteredDynamicContext(configuration, context, index, item, uniqueNumber));
if (first) {
first = !((PrefixedContext) context).isPrefixApplied();
}
context = oldContext;
i++;
}
// 添加动态语句后缀
applyClose(context);
// 移除原始的表达式
context.getBindings().remove(item);
context.getBindings().remove(index);
return true;
}
/**
* 绑定集合项索引关系
*
* @param context
* @param o
* @param i
*/
private void applyIndex(DynamicContext context, Object o, int i) {
if (index != null) {
context.bind(index, o);
context.bind(itemizeItem(index, i), o);
}
}
/**
* 绑定集合项关系
*
* @param context
* @param o
* @param i
*/
private void applyItem(DynamicContext context, Object o, int i) {
if (item != null) {
context.bind(item, o);
context.bind(itemizeItem(item, i), o);
}
}
对于循环中的 #{} 类型 token,ForEachSqlNode 在内部类 FilteredDynamicContext 中定义了解析规则:
@Override
public void appendSql(String sql) {
GenericTokenParser parser = new GenericTokenParser("#{", "}", content -> {
// 对解析的表达式进行替换,如 idx = #{index} AND itm = #{item} 替换为 idx = #{__frch_index_1} AND itm = #{__frch_item_1}
String newContent = content.replaceFirst("^\\s*" + item + "(?![^.,:\\s])", itemizeItem(item, index));
if (itemIndex != null && newContent.equals(content)) {
newContent = content.replaceFirst("^\\s*" + itemIndex + "(?![^.,:\\s])", itemizeItem(itemIndex, index));
}
return "#{" + newContent + "}";
});
delegate.appendSql(parser.parse(sql));
}
类似 idx = #{index} AND itm = #{item} 会被替换为 idx = #{__frch_index_1} AND itm = #{__frch_item_1},而 ForEachSqlNode 也做了参数与索引的绑定,因此在替换时可以快速绑定参数。
ChooseSqlNode
choose 元素用于生成带默认 sql 文本的语句,当 when 元素中的条件都不生效,就可以使用 otherwise 元素的默认文本。
<choose>
<when test="a > 0">
AND a = #{a}
</when>
<otherwise>
AND b = #{b}
</otherwise>
</choose>
ChooseSqlNode 是由 choose 节点和 otherwise 节点组合而成的,在生成有效 sql 于语句时会逐个计算 when 节点的 test 表达式,如果返回 true 则生效当前 when 语句中的 sql。如果均不生效则使用 otherwise 语句对应的默认 sql 文本。
@Override
public boolean apply(DynamicContext context) {
// when 节点根据 test 表达式判断是否生效
for (SqlNode sqlNode : ifSqlNodes) {
if (sqlNode.apply(context)) {
return true;
}
}
// when 节点如果都未生效,且存在 otherwise 节点,则使用 otherwise 节点
if (defaultSqlNode != null) {
defaultSqlNode.apply(context);
return true;
}
return false;
}
VarDeclSqlNode
bind 元素用于绑定一个 OGNL 表达式到一个动态 sql 变量中。
<bind name="pattern" value="'%' + _parameter.getTitle() + '%'" />
VarDeclSqlNode 会计算表达式的值并将参数名和值绑定到参数容器中。
@Override
public boolean apply(DynamicContext context) {
// 解析 ognl 表达式
final Object value = OgnlCache.getValue(expression, context.getBindings());
// 绑定参数
context.bind(name, value);
return true;
}
创建解析对象与生成可执行 sql
statemen 解析完毕后会创建 MappedStatement 对象,statement 的相关属性以及生成的 sql 创建对象都会被保存到该对象中。MappedStatement 还提供了 getBoundSql 方法用于获取可执行 sql 和参数绑定对象,即 BoundSql 对象。
public BoundSql getBoundSql(Object parameterObject) {
// 生成可执行 sql 和参数绑定对象
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
// 获取参数映射
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings == null || parameterMappings.isEmpty()) {
boundSql = new BoundSql(configuration, boundSql.getSql(), parameterMap.getParameterMappings(), parameterObject);
}
// check for nested result maps in parameter mappings (issue #30)
// 检查是否有嵌套的 resultMap
for (ParameterMapping pm : boundSql.getParameterMappings()) {
String rmId = pm.getResultMapId();
if (rmId != null) {
ResultMap rm = configuration.getResultMap(rmId);
if (rm != null) {
hasNestedResultMaps |= rm.hasNestedResultMaps();
}
}
}
return boundSql;
}
BoundSql 对象由 DynamicSqlSource 的 getBoundSql 方法生成,在验证各个 sql 节点,生成了有效 sql 后会继续调用 SqlSourceBuilder 将 sql 解析为 StaticSqlSource,即可执行 sql。
@Override
public BoundSql getBoundSql(Object parameterObject) {
DynamicContext context = new DynamicContext(configuration, parameterObject);
// 验证各 sql 节点,生成有效 sql
rootSqlNode.apply(context);
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
// 将生成的 sql 文本解析为 StaticSqlSource
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
context.getBindings().forEach(boundSql::setAdditionalParameter);
return boundSql;
}
此时的 sql 文本中仍包含 #{} 类型 token,需要通过 ParameterMappingTokenHandler 进行解析。
public SqlSource parse(String originalSql, Class<?> parameterType, Map<String, Object> additionalParameters) {
ParameterMappingTokenHandler handler = new ParameterMappingTokenHandler(configuration, parameterType, additionalParameters);
// 创建 #{} 类型 token 搜索对象
GenericTokenParser parser = new GenericTokenParser("#{", "}", handler);
// 解析 token
String sql = parser.parse(originalSql);
// 创建静态 sql 生成对象,并绑定参数
return new StaticSqlSource(configuration, sql, handler.getParameterMappings());
}
token 的具体解析逻辑为根据表达式的参数名生成对应的参数映射对象,并将表达式转为预编译 sql 的占位符 ?。
@Override
public String handleToken(String content) {
// 创建参数映射对象
parameterMappings.add(buildParameterMapping(content));
// 将表达式转为预编译 sql 占位符
return "?";
}
最终解析完成的 sql 与参数映射关系集合包装为 StaticSqlSource 对象,该对象在随后的逻辑中通过构造方法创建了 BoundSql 对象。
接口解析
除了使用 xml 方式配置 statement,MyBatis 同样支持使用 Java 注解配置。但是相对于 xml 的映射方式,将动态 sql 写在 Java 代码中是不合适的。如果在配置文件中指定了需要注册 Mapper 接口的类或包,MyBatis 会扫描相关类进行注册;在 Mapper 文件解析完成后也会尝试加载 namespace 的同名类,如果存在,则注册为 Mapper 接口。
无论是绑定还是直接注册 Mapper 接口,都是调用 MapperAnnotationBuilder#parse 方法来解析的。此方法中的解析方式与上述 xml 解析方式大致相同,区别只在于相关配置参数是从注解中获取而不是从 xml 元素属性中获取。
public <T> void addMapper(Class<T> type) {
if (type.isInterface()) {
if (hasMapper(type)) {
// 不允许相同接口重复注册
throw new BindingException("Type " + type + " is already known to the MapperRegistry.");
}
boolean loadCompleted = false;
try {
knownMappers.put(type, new MapperProxyFactory<>(type));
// It's important that the type is added before the parser is run
// otherwise the binding may automatically be attempted by the
// mapper parser. If the type is already known, it won't try.
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
parser.parse();
loadCompleted = true;
} finally {
if (!loadCompleted) {
knownMappers.remove(type);
}
}
}
}
总结
statement 解析的最终目的是为每个 statement 创建一个 MappedStatement 对象保存相关定义,在 sql 执行时根据传入参数动态获取可执行 sql 和参数绑定对象。
org.apache.ibatis.builder.xml.XMLStatementBuilder:解析Mapper文件中的select|insert|update|delete元素。org.apache.ibatis.parsing.GenericTokenParser.GenericTokenParser:搜索指定格式token并进行解析。org.apache.ibatis.parsing.TokenHandler:token处理器抽象接口。定义token以何种方式被解析。org.apache.ibatis.parsing.PropertyParser:${}类型token解析器。org.apache.ibatis.session.Configuration.StrictMap:封装HashMap,对键值存取有严格要求。org.apache.ibatis.builder.xml.XMLIncludeTransformer:include元素解析器。org.apache.ibatis.mapping.SqlSource:sql生成抽象接口。根据传入参数生成有效sql语句和参数绑定对象。org.apache.ibatis.scripting.xmltags.XMLScriptBuilder:解析statement各个sql节点并进行组合。org.apache.ibatis.scripting.xmltags.SqlNode:sql节点抽象接口。用于判断当前sql节点是否可以加入到生效的 sql 语句中。org.apache.ibatis.scripting.xmltags.DynamicContext:动态sql上下文。用于保存绑定参数和生效sql节点。org.apache.ibatis.scripting.xmltags.OgnlCache:ognl缓存工具,缓存表达式编译结果。org.apache.ibatis.scripting.xmltags.ExpressionEvaluator:ognl表达式计算工具。org.apache.ibatis.scripting.xmltags.MixedSqlNode:sql节点组合对象。org.apache.ibatis.scripting.xmltags.StaticTextSqlNode:静态sql节点对象。org.apache.ibatis.scripting.xmltags.TextSqlNode:${}类型sql节点对象。org.apache.ibatis.scripting.xmltags.IfSqlNode:if元素sql节点对象。org.apache.ibatis.scripting.xmltags.TrimSqlNode:trim元素sql节点对象。org.apache.ibatis.scripting.xmltags.WhereSqlNode:where元素sql节点对象。org.apache.ibatis.scripting.xmltags.SetSqlNode:set元素sql节点对象。org.apache.ibatis.scripting.xmltags.ForEachSqlNode:foreach元素sql节点对象。org.apache.ibatis.scripting.xmltags.ChooseSqlNode:choose元素sql节点对象。org.apache.ibatis.scripting.xmltags.VarDeclSqlNode:bind元素sql节点对象。org.apache.ibatis.mapping.MappedStatement:statement解析对象。org.apache.ibatis.mapping.BoundSql:可执行sql和参数绑定对象。org.apache.ibatis.scripting.xmltags.DynamicSqlSource:根据参数动态生成有效sql和绑定参数。org.apache.ibatis.builder.SqlSourceBuilder:解析#{}类型token并绑定参数对象。
7 - CH07-接口层
sql 会话创建工厂
SqlSessionFactoryBuilder 经过复杂的解析逻辑之后,会根据全局配置创建 DefaultSqlSessionFactory,该类是 sql 会话创建工厂抽象接口 SqlSessionFactory 的默认实现,其提供了若干 openSession 方法用于打开一个会话,在会话中进行相关数据库操作。这些 openSession 方法最终都会调用 openSessionFromDataSource 或 openSessionFromConnection 创建会话,即基于数据源配置创建还是基于已有连接对象创建。
基于数据源配置创建会话
要使用数据源打开一个会话需要先从全局配置中获取当前生效的数据源环境配置,如果没有生效配置或没用设置可用的事务工厂,就会创建一个 ManagedTransactionFactory 实例作为默认事务工厂实现,其与 MyBatis 提供的另一个事务工厂实现 JdbcTransactionFactory 的区别在于其生成的事务实现 ManagedTransaction 的提交和回滚方法是空实现,即希望将事务管理交由外部容器管理。
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
final Environment environment = configuration.getEnvironment();
// 获取事务工厂
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
// 创建事务配置
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
// 创建执行器
final Executor executor = configuration.newExecutor(tx, execType);
// 创建 sql 会话
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
/**
* 获取生效数据源环境配置的事务工厂
*/
private TransactionFactory getTransactionFactoryFromEnvironment(Environment environment) {
if (environment == null || environment.getTransactionFactory() == null) {
// 未配置数据源环境或事务工厂,默认使用 ManagedTransactionFactory
return new ManagedTransactionFactory();
}
return environment.getTransactionFactory();
}
随后会根据入参传入的 execType 选择对应的执行器 Executor,execType 的取值来源于 ExecutorType,这是一个枚举类。在下一章将会详细分析各类 Executor 的作用及其实现。
获取到事务工厂配置和执行器对象后会结合传入的数据源自动提交属性创建 DefaultSqlSession,即 sql 会话对象。
基于数据连接创建会话
基于连接创建会话的流程大致与基于数据源配置创建相同,区别在于自动提交属性 autoCommit 是从连接对象本身获取的。
private SqlSession openSessionFromConnection(ExecutorType execType, Connection connection) {
try {
// 获取自动提交配置
boolean autoCommit;
try {
autoCommit = connection.getAutoCommit();
} catch (SQLException e) {
// Failover to true, as most poor drivers
// or databases won't support transactions
autoCommit = true;
}
final Environment environment = configuration.getEnvironment();
// 获取事务工厂
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
// 创建事务配置
final Transaction tx = transactionFactory.newTransaction(connection);
// 创建执行器
final Executor executor = configuration.newExecutor(tx, execType);
// 创建 sql 会话
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
sql 会话
SqlSession 是 MyBatis 面向用户编程的接口,其提供了一系列方法用于执行相关数据库操作,默认实现为 DefaultSqlSession,在该类中,增删查改对应的操作最终会调用 selectList、select 和 update 方法,其分别用于普通查询、执行存储过程和修改数据库记录。
/**
* 查询结果集
*/
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
/**
* 调用存储过程
*/
@Override
public void select(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
executor.query(ms, wrapCollection(parameter), rowBounds, handler);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
/**
* 修改
*/
@Override
public int update(String statement, Object parameter) {
try {
dirty = true;
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.update(ms, wrapCollection(parameter));
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error updating database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
以上操作均是根据传入的 statement 名称到全局配置中查找对应的 MappedStatement 对象,并将操作委托给执行器对象 executor 完成。select、selectMap 等方法则是对 selectList 方法返回的结果集做处理来实现的。
此外,提交和回滚方法也是基于 executor 实现的。
/**
* 提交事务
*/
@Override
public void commit(boolean force) {
try {
executor.commit(isCommitOrRollbackRequired(force));
dirty = false;
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error committing transaction. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
/**
* 回滚事务
*/
@Override
public void rollback(boolean force) {
try {
executor.rollback(isCommitOrRollbackRequired(force));
dirty = false;
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error rolling back transaction. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
/**
* 非自动提交且事务未提交 || 强制提交或回滚 时返回 true
*/
private boolean isCommitOrRollbackRequired(boolean force) {
return (!autoCommit && dirty) || force;
}
在执行 update 方法时,会设置 dirty 属性为 true ,意为事务还未提交,当事务提交或回滚后才会将 dirty 属性修改为 false。如果当前会话不是自动提交且 dirty 熟悉为 true,或者设置了强制提交或回滚的标志,则会将强制标志提交给 executor 处理。
sql 会话管理器
SqlSessionManager 同时实现了 SqlSessionFactory 和 SqlSession 接口,使得其既能够创建 sql 会话,又能够执行 sql 会话的相关数据库操作。
/**
* sql 会话创建工厂
*/
private final SqlSessionFactory sqlSessionFactory;
/**
* sql 会话代理对象
*/
private final SqlSession sqlSessionProxy;
/**
* 保存线程对应 sql 会话
*/
private final ThreadLocal<SqlSession> localSqlSession = new ThreadLocal<>();
private SqlSessionManager(SqlSessionFactory sqlSessionFactory) {
this.sqlSessionFactory = sqlSessionFactory;
this.sqlSessionProxy = (SqlSession) Proxy.newProxyInstance(
SqlSessionFactory.class.getClassLoader(),
new Class[]{SqlSession.class},
new SqlSessionInterceptor());
}
@Override
public SqlSession openSession() {
return sqlSessionFactory.openSession();
}
/**
* 设置当前线程对应的 sql 会话
*/
public void startManagedSession() {
this.localSqlSession.set(openSession());
}
/**
* sql 会话代理逻辑
*/
private class SqlSessionInterceptor implements InvocationHandler {
public SqlSessionInterceptor() {
// Prevent Synthetic Access
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 获取当前线程对应的 sql 会话对象并执行对应方法
final SqlSession sqlSession = SqlSessionManager.this.localSqlSession.get();
if (sqlSession != null) {
try {
return method.invoke(sqlSession, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
} else {
// 如果当前线程没有对应的 sql 会话,默认创建不自动提交的 sql 会话
try (SqlSession autoSqlSession = openSession()) {
try {
final Object result = method.invoke(autoSqlSession, args);
autoSqlSession.commit();
return result;
} catch (Throwable t) {
autoSqlSession.rollback();
throw ExceptionUtil.unwrapThrowable(t);
}
}
}
}
}
SqlSessionManager 的构造方法要求 SqlSessionFactory 对象作为入参传入,其各个创建会话的方法实际是由该传入对象完成的。执行 sql 会话的操作由 sqlSessionProxy 对象完成,这是一个由 JDK 动态代理创建的对象,当执行方法时会去 ThreadLocal 对象中查找当前线程有没有对应的 sql 会话对象,如果有则使用已有的会话对象执行,否则创建新的会话对象执行,而线程对应的会话对象需要使用 startManagedSession 方法来维护。
之所以 SqlSessionManager 需要为每个线程维护会话对象,是因为 DefaultSqlSession 是非线程安全的,多线程操作会导致执行错误。如上文中提到的 dirty 属性,其修改是没有经过任何同步操作的。
总结
SqlSession 是 MyBatis 提供的面向开发者编程的接口,其提供了一系列数据库相关操作,并屏蔽了底层细节。使用 MyBatis 的正确方式应该是像 SqlSessionManager 那样为每个线程创建 sql 会话对象,避免造成线程安全问题。
org.apache.ibatis.session.SqlSessionFactory:sql会话创建工厂。org.apache.ibatis.session.defaults.DefaultSqlSessionFactory:sql会话创建工厂默认实现。org.apache.ibatis.session.SqlSession:sql会话。org.apache.ibatis.session.defaults.DefaultSqlSession:sql会话默认实现。org.apache.ibatis.session.SqlSessionManager:sql会话管理器。
8 - CH08-执行器
执行器 Executor 是 MyBatis 的核心接口之一,接口层提供的相关数据库操作,都是基于 Executor 的子类实现的。
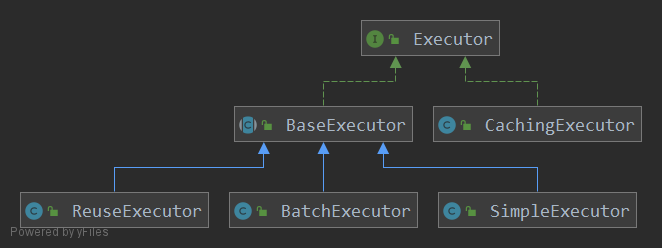
创建执行器
在创建 sql 会话时,MyBatis 会调用 Configuration#newExecutor 方法创建执行器。枚举类 ExecutorType 定义了三种执行器类型,即 SIMPLE、REUSE 和 Batch,这些执行器的主要区别在于:
SIMPLE在每次执行完成后都会关闭statement对象;REUSE会在本地维护一个容器,当前statement创建完成后放入容器中,当下次执行相同的sql时会复用statement对象,执行完毕后也不会关闭;BATCH会将修改操作记录在本地,等待程序触发或有下一次查询时才批量执行修改操作。
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
// 默认类型为 simple
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
if (cacheEnabled) {
// 如果全局缓存打开,使用 CachingExecutor 代理执行器
executor = new CachingExecutor(executor);
}
// 应用插件
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
执行器创建后,如果全局缓存配置是有效的,则会将执行器装饰为 CachingExecutor。
基础执行器
SimpleExecutor、ReuseExecutor、BatchExecutor 均继承自 BaseExecutor。BaseExecutor 实现了 Executor 的全部方法,对缓存、事务、连接处理等提供了一些模板方法,但是针对具体的数据库操作留下了四个抽象方法交由子类实现。
/**
* 更新
*/
protected abstract int doUpdate(MappedStatement ms, Object parameter)
throws SQLException;
/**
* 刷新 statement
*/
protected abstract List<BatchResult> doFlushStatements(boolean isRollback)
throws SQLException;
/**
* 查询
*/
protected abstract <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql)
throws SQLException;
/**
* 查询获取游标对象
*/
protected abstract <E> Cursor<E> doQueryCursor(MappedStatement ms, Object parameter, RowBounds rowBounds, BoundSql boundSql)
throws SQLException;
基础执行器的查询逻辑如下:
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
// 非嵌套查询且设置强制刷新时清除缓存
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
// 缓存不为空,组装存储过程出参
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 无本地缓存,执行数据库查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
// 全局配置语句不共享缓存
clearLocalCache();
}
}
return list;
}
/**
* 查询本地缓存,组装存储过程结果集
*/
private void handleLocallyCachedOutputParameters(MappedStatement ms, CacheKey key, Object parameter, BoundSql boundSql) {
if (ms.getStatementType() == StatementType.CALLABLE) {
// 存储过程类型,查询缓存
final Object cachedParameter = localOutputParameterCache.getObject(key);
if (cachedParameter != null && parameter != null) {
final MetaObject metaCachedParameter = configuration.newMetaObject(cachedParameter);
final MetaObject metaParameter = configuration.newMetaObject(parameter);
for (ParameterMapping parameterMapping : boundSql.getParameterMappings()) {
if (parameterMapping.getMode() != ParameterMode.IN) {
// 参数类型为 OUT 或 INOUT 的,组装结果集
final String parameterName = parameterMapping.getProperty();
final Object cachedValue = metaCachedParameter.getValue(parameterName);
metaParameter.setValue(parameterName, cachedValue);
}
}
}
}
}
/**
* 查询数据库获取结果集
*/
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 放一个 placeHolder 标志
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 执行查询
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
// 查询结果集放入本地缓存
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
// 如果是存储过程查询,将存储过程结果集放入本地缓存
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
执行查询时 MyBatis 首先会根据 CacheKey 查询本地缓存,CacheKey 由本次查询的参数生成,本地缓存由 PerpetualCache 实现,这就是 MyBatis 的一级缓存。一级缓存维护对象 localCache 是基础执行器的本地变量,因此只有相同 sql 会话的查询才能共享一级缓存。当一级缓存中没有对应的数据,基础执行器最终会调用 doQuery 方法交由子类去获取数据。
而执行 update 等其它操作时,则会首先清除本地的一级缓存再交由子类执行具体的操作:
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 清空本地缓存
clearLocalCache();
// 调用子类执行器逻辑
return doUpdate(ms, parameter);
}
简单执行器
简单执行器是 MyBatis 的默认执行器。其封装了对 JDBC 的操作,对于查询方法 doQuery 的实现如下,其主要包括创建 statement 处理器、创建 statement、执行查询、关闭 statement。
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 创建 statement 处理器
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 创建 statement
stmt = prepareStatement(handler, ms.getStatementLog());
// 执行查询
return handler.query(stmt, resultHandler);
} finally {
// 关闭 statement
closeStatement(stmt);
}
}
创建 statement 处理器
全局配置类 Configuration 提供了方法 newStatementHandler 用于创建 statement 处理器:
/**
* 创建 statement 处理器
*/
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// StatementHandler 包装对象,根据 statement 类型创建代理处理器,并将实际操作委托给代理处理器处理
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
// 应用插件
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
实际每次创建的 statement 处理器对象都是由 RoutingStatementHandler 创建的,RoutingStatementHandler 根据当前 MappedStatement 的类型创建具体的 statement 类型处理器。StatementType 定义了 3 个 statement 类型枚举,分别对应 JDBC 的普通语句、预编译语句和存储过程语句。
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// 根据 statement 类型选择对应的 statementHandler
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}
创建 statement
简单执行器中的 Statement 对象是根据上述步骤中生成的 statement 处理器获取的。
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
// 获取代理连接对象
Connection connection = getConnection(statementLog);
// 创建 statement 对象
stmt = handler.prepare(connection, transaction.getTimeout());
// 设置 statement 参数
handler.parameterize(stmt);
return stmt;
}
@Override
public Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException {
ErrorContext.instance().sql(boundSql.getSql());
Statement statement = null;
try {
// 从连接中创建 statement 对象
statement = instantiateStatement(connection);
// 设置超时时间
setStatementTimeout(statement, transactionTimeout);
// 设置分批获取数据数量
setFetchSize(statement);
return statement;
} catch (SQLException e) {
closeStatement(statement);
throw e;
} catch (Exception e) {
closeStatement(statement);
throw new ExecutorException("Error preparing statement. Cause: " + e, e);
}
}
执行查询
创建 statement 对象完成即可通过 JDBC 的 API 执行数据库查询,并从 statement 对象中获取查询结果,根据配置进行转换。
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
// 执行查询
ps.execute();
// 处理结果集
return resultSetHandler.handleResultSets(ps);
}
/**
* 处理结果集
*/
@Override
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
// 多结果集
final List<Object> multipleResults = new ArrayList<>();
int resultSetCount = 0;
ResultSetWrapper rsw = getFirstResultSet(stmt);
// statement 对应的所有 ResultMap 对象
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
// 验证结果集不为空时,ResultMap 数量不能为 0
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
// 逐个获取 ResultMap
ResultMap resultMap = resultMaps.get(resultSetCount);
// 转换结果集,放到 multipleResults 容器中
handleResultSet(rsw, resultMap, multipleResults, null);
// 获取下一个待处理的结果集
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
// statement 配置的多结果集类型
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
return collapseSingleResultList(multipleResults);
}
关闭连接
查询完成后 statement 对象会被关闭。
/**
* 关闭 statement
*
* @param statement
*/
protected void closeStatement(Statement statement) {
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {
// ignore
}
}
}
简单执行器中的其它数据库执行方法与 doQuery 方法实现类似。
复用执行器
ReuseExecutor 相对于 SimpleExecutor 实现了对 statment 对象的复用,其在本地维护了 statementMap 用于保存 sql 语句和 statement 对象的关系。当调用 prepareStatement 方法获取 statement 对象时首先会查找本地是否有对应的 statement 对象,如果有则进行复用,负责重新创建并将 statement 对象放入本地缓存。
/**
* 创建 statement 对象
*
* @param handler
* @param statementLog
* @return
* @throws SQLException
*/
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
BoundSql boundSql = handler.getBoundSql();
String sql = boundSql.getSql();
if (hasStatementFor(sql)) {
// 如果本地容器中包含当前 sql 对应的 statement 对象,进行复用
stmt = getStatement(sql);
applyTransactionTimeout(stmt);
} else {
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
putStatement(sql, stmt);
}
handler.parameterize(stmt);
return stmt;
}
private boolean hasStatementFor(String sql) {
try {
return statementMap.keySet().contains(sql) && !statementMap.get(sql).getConnection().isClosed();
} catch (SQLException e) {
return false;
}
}
private Statement getStatement(String s) {
return statementMap.get(s);
}
private void putStatement(String sql, Statement stmt) {
statementMap.put(sql, stmt);
}
提交或回滚会导致执行器调用 doFlushStatements 方法,复用执行器会因此批量关闭本地的 statement 对象。
/**
* 批量关闭 statement 对象
*
* @param isRollback
* @return
*/
@Override
public List<BatchResult> doFlushStatements(boolean isRollback) {
for (Statement stmt : statementMap.values()) {
closeStatement(stmt);
}
statementMap.clear();
return Collections.emptyList();
}
批量执行器
BatchExecutor 相对于 SimpleExecutor ,其 update 操作是批量执行的。
@Override
public int doUpdate(MappedStatement ms, Object parameterObject) throws SQLException {
final Configuration configuration = ms.getConfiguration();
final StatementHandler handler = configuration.newStatementHandler(this, ms, parameterObject, RowBounds.DEFAULT, null, null);
final BoundSql boundSql = handler.getBoundSql();
final String sql = boundSql.getSql();
final Statement stmt;
if (sql.equals(currentSql) && ms.equals(currentStatement)) {
// 如果当前 sql 与上次传入 sql 相同且为相同的 MappedStatement,复用 statement 对象
int last = statementList.size() - 1;
// 获取最后一个 statement 对象
stmt = statementList.get(last);
// 设置超时时间
applyTransactionTimeout(stmt);
// 设置参数
handler.parameterize(stmt);//fix Issues 322
// 获取批量执行结果对象
BatchResult batchResult = batchResultList.get(last);
batchResult.addParameterObject(parameterObject);
} else {
// 创建新的 statement 对象
Connection connection = getConnection(ms.getStatementLog());
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt); //fix Issues 322
currentSql = sql;
currentStatement = ms;
statementList.add(stmt);
batchResultList.add(new BatchResult(ms, sql, parameterObject));
}
// 执行 JDBC 批量添加 sql 语句操作
handler.batch(stmt);
return BATCH_UPDATE_RETURN_VALUE;
}
/**
* 批量执行 sql
*
* @param isRollback
* @return
* @throws SQLException
*/
@Override
public List<BatchResult> doFlushStatements(boolean isRollback) throws SQLException {
try {
// 批量执行结果
List<BatchResult> results = new ArrayList<>();
if (isRollback) {
return Collections.emptyList();
}
for (int i = 0, n = statementList.size(); i < n; i++) {
Statement stmt = statementList.get(i);
applyTransactionTimeout(stmt);
BatchResult batchResult = batchResultList.get(i);
try {
// 设置执行影响行数
batchResult.setUpdateCounts(stmt.executeBatch());
MappedStatement ms = batchResult.getMappedStatement();
List<Object> parameterObjects = batchResult.getParameterObjects();
KeyGenerator keyGenerator = ms.getKeyGenerator();
if (Jdbc3KeyGenerator.class.equals(keyGenerator.getClass())) {
Jdbc3KeyGenerator jdbc3KeyGenerator = (Jdbc3KeyGenerator) keyGenerator;
// 设置数据库生成的主键
jdbc3KeyGenerator.processBatch(ms, stmt, parameterObjects);
} else if (!NoKeyGenerator.class.equals(keyGenerator.getClass())) { //issue #141
for (Object parameter : parameterObjects) {
keyGenerator.processAfter(this, ms, stmt, parameter);
}
}
// Close statement to close cursor #1109
closeStatement(stmt);
} catch (BatchUpdateException e) {
StringBuilder message = new StringBuilder();
message.append(batchResult.getMappedStatement().getId())
.append(" (batch index #")
.append(i + 1)
.append(")")
.append(" failed.");
if (i > 0) {
message.append(" ")
.append(i)
.append(" prior sub executor(s) completed successfully, but will be rolled back.");
}
throw new BatchExecutorException(message.toString(), e, results, batchResult);
}
results.add(batchResult);
}
return results;
} finally {
for (Statement stmt : statementList) {
closeStatement(stmt);
}
currentSql = null;
statementList.clear();
batchResultList.clear();
}
}
执行器提交或回滚事务时会调用 doFlushStatements,从而批量执行提交的 sql 语句并最终批量关闭 statement 对象。
缓存执行器与二级缓存
CachingExecutor 对基础执行器进行了装饰,其作用就是为查询提供二级缓存。所谓的二级缓存是由 CachingExecutor 维护的,相对默认内置的一级缓存而言的缓存。二者区别如下:
- 一级缓存由基础执行器维护,且不可关闭。二级缓存的配置是开发者可干预的,在
xml文件或注解中针对namespace的缓存配置就是二级缓存配置。 - 一级缓存在执行器中维护,即不同
sql会话不能共享一级缓存。二级缓存则是根据namespace维护,不同sql会话是可以共享二级缓存的。
CachingExecutor 中的方法大多是通过直接调用其代理的执行器来实现的,而查询操作则会先查询二级缓存。
/**
* 缓存事务管理器
*/
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 查询二级缓存配置
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
// 当前 statement 配置使用二级缓存
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// 二级缓存中没用数据,调用代理执行器
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 将查询结果放入二级缓存
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
// 无二级缓存配置,调用代理执行器获取结果
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
private void flushCacheIfRequired(MappedStatement ms) {
Cache cache = ms.getCache();
if (cache != null && ms.isFlushCacheRequired()) {
// 存在 namespace 对应的缓存配置,且当前 statement 配置了刷新缓存,执行清空缓存操作
// 非 select 语句配置了默认刷新
tcm.clear(cache);
}
}
如果对应的 statement 的二级缓存配置有效,则会先通过缓存事务管理器 TransactionalCacheManager 查询二级缓存,如果没有命中则查询一级缓存,仍没有命中才会执行数据库查询。
缓存事务管理器
缓存执行器对二级缓存的维护是基于缓存事务管理器 TransactionalCacheManager 的,其内部维护了一个 Map 容器,用于保存 namespace 缓存配置与事务缓存对象的映射关系。
public class TransactionalCacheManager {
/**
* 缓存配置 - 缓存事务对象
*/
private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<>();
/**
* 清除缓存
*
* @param cache
*/
public void clear(Cache cache) {
getTransactionalCache(cache).clear();
}
/**
* 获取缓存
*/
public Object getObject(Cache cache, CacheKey key) {
return getTransactionalCache(cache).getObject(key);
}
/**
* 写缓存
*/
public void putObject(Cache cache, CacheKey key, Object value) {
getTransactionalCache(cache).putObject(key, value);
}
/**
* 缓存提交
*/
public void commit() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.commit();
}
}
/**
* 缓存回滚
*/
public void rollback() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.rollback();
}
}
/**
* 获取或新建事务缓存对象
*/
private TransactionalCache getTransactionalCache(Cache cache) {
return transactionalCaches.computeIfAbsent(cache, TransactionalCache::new);
}
}
缓存配置映射的事务缓存对象就是前文中提到过的事务缓存装饰器 TransactionalCache。getTransactionalCache 会从维护容器中查找对应的事务缓存对象,如果找不到就创建一个事务缓存对象,即通过事务缓存对象装饰当前缓存配置。
查询缓存时,如果缓存未命中,则将对应的 key 放入未命中队列,执行数据库查询完毕后写缓存时并不是立刻写到缓存配置的本地容器中,而是暂时放入待提交队列中,当触发事务提交时才将提交队列中的缓存数据写到缓存配置中。如果发生回滚,则提交队列中的数据会被清空,从而保证了数据的一致性。
@Override
public Object getObject(Object key) {
// issue #116
Object object = delegate.getObject(key);
if (object == null) {
// 放入未命中缓存的 key 的队列
entriesMissedInCache.add(key);
}
// issue #146
if (clearOnCommit) {
return null;
} else {
return object;
}
}
@Override
public void putObject(Object key, Object object) {
// 缓存先写入待提交容器
entriesToAddOnCommit.put(key, object);
}
/**
* 事务提交
*/
public void commit() {
if (clearOnCommit) {
delegate.clear();
}
// 提交缓存
flushPendingEntries();
reset();
}
/**
* 事务回滚
*/
public void rollback() {
unlockMissedEntries();
reset();
}
/**
* 事务提交,提交待提交的缓存。
*/
private void flushPendingEntries() {
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}
/**
* 事务回滚,清理未命中缓存。
*/
private void unlockMissedEntries() {
for (Object entry : entriesMissedInCache) {
try {
delegate.removeObject(entry);
} catch (Exception e) {
log.warn("Unexpected exception while notifiying a rollback to the cache adapter."
+ "Consider upgrading your cache adapter to the latest version. Cause: " + e);
}
}
}
二级缓存与一级缓存的互斥性
使用二级缓存要求无论是否配置了事务自动提交,在执行完成后, sql 会话必须手动提交事务才能触发事务缓存管理器维护缓存到缓存配置中,否则二级缓存无法生效。而缓存执行器在触发事务提交时,不仅会调用事务缓存管理器提交,还会调用代理执行器提交事务:
@Override
public void commit(boolean required) throws SQLException {
// 代理执行器提交
delegate.commit(required);
// 事务缓存管理器提交
tcm.commit();
}
代理执行器的事务提交方法继承自 BaseExecutor,其 commit 方法中调用了 clearLocalCache 方法清除本地一级缓存。因此二级缓存和一级缓存的使用是互斥的。
@Override
public void commit(boolean required) throws SQLException {
if (closed) {
throw new ExecutorException("Cannot commit, transaction is already closed");
}
// 清除本地一级缓存
clearLocalCache();
flushStatements();
if (required) {
transaction.commit();
}
}
总结
MyBatis 提供若干执行器封装底层 JDBC 操作和结果集转换,并嵌入 sql 会话维度的一级缓存和 namespace 维度的二级缓存。接口层可以通过调用不同类型的执行器来完成 sql 相关操作。
org.apache.ibatis.executor.Executor:数据库操作执行器抽象接口。org.apache.ibatis.executor.BaseExecutor:执行器基础抽象实现。org.apache.ibatis.executor.SimpleExecutor:简单类型执行器。org.apache.ibatis.executor.ReuseExecutor:statement复用执行器。org.apache.ibatis.executor.BatchExecutor:批量执行器。org.apache.ibatis.executor.CachingExecutor:二级缓存执行器。org.apache.ibatis.executor.statement.StatementHandler:statement处理器抽象接口。org.apache.ibatis.executor.statement.BaseStatementHandler:statement处理器基础抽象实现。org.apache.ibatis.executor.statement.RoutingStatementHandler:statement处理器路由对象。org.apache.ibatis.executor.statement.SimpleStatementHandler:简单statement处理器。org.apache.ibatis.executor.statement.PreparedStatementHandler:预编译statement处理器。org.apache.ibatis.executor.statement.CallableStatementHandler:存储过程statement处理器。org.apache.ibatis.cache.TransactionalCacheManager:缓存事务管理器。
9 - CH09-集成 Spring
mybatis-spring 是 MyBatis 的一个子项目,用于帮助开发者将 MyBatis 无缝集成到 Spring 中。它允许 MyBatis 参与到 Spring 的事务管理中,创建映射器 mapper 和 SqlSession 并注入到 Spring bean 中。
SqlSessionFactoryBean
在 MyBatis 的基础用法中,是通过 SqlSessionFactoryBuilder 来创建 SqlSessionFactory,最终获得执行接口 SqlSession 的,而在 mybatis-spring 中,则使用 SqlSessionFactoryBean 来创建。其使用方式如下:
@Bean
public SqlSessionFactory sqlSessionFactory(DataSource dataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
// 设置配置文件路径
bean.setConfigLocation(new ClassPathResource("config/mybatis-config.xml"));
// 别名转化类所在的包
bean.setTypeAliasesPackage("com.wch.domain");
// 设置数据源
bean.setDataSource(dataSource);
// 设置 mapper 文件路径
bean.setMapperLocations(new ClassPathResource("mapper/*.xml"));
// 获取 SqlSessionFactory 对象
return bean.getObject();
}
SqlSessionFactoryBean 实现了 FactoryBean 接口,因此可以通过其 getObject 方法获取 SqlSessionFactory 对象。
@Override
public SqlSessionFactory getObject() throws Exception {
if (this.sqlSessionFactory == null) {
afterPropertiesSet();
}
return this.sqlSessionFactory;
}
@Override
public void afterPropertiesSet() throws Exception {
notNull(dataSource, "Property 'dataSource' is required");
notNull(sqlSessionFactoryBuilder, "Property 'sqlSessionFactoryBuilder' is required");
state((configuration == null && configLocation == null) || !(configuration != null && configLocation != null),
"Property 'configuration' and 'configLocation' can not specified with together");
this.sqlSessionFactory = buildSqlSessionFactory();
}
protected SqlSessionFactory buildSqlSessionFactory() throws Exception {
final Configuration targetConfiguration;
XMLConfigBuilder xmlConfigBuilder = null;
if (this.configuration != null) {
// 使用已配置的全局配置对象和附加属性
targetConfiguration = this.configuration;
if (targetConfiguration.getVariables() == null) {
targetConfiguration.setVariables(this.configurationProperties);
} else if (this.configurationProperties != null) {
targetConfiguration.getVariables().putAll(this.configurationProperties);
}
} else if (this.configLocation != null) {
// 使用配置文件路径加载全局配置
xmlConfigBuilder = new XMLConfigBuilder(this.configLocation.getInputStream(), null, this.configurationProperties);
targetConfiguration = xmlConfigBuilder.getConfiguration();
} else {
// 新建全局配置对象
LOGGER.debug(
() -> "Property 'configuration' or 'configLocation' not specified, using default MyBatis Configuration");
targetConfiguration = new Configuration();
Optional.ofNullable(this.configurationProperties).ifPresent(targetConfiguration::setVariables);
}
// 设置对象创建工厂、对象包装工厂、虚拟文件系统实现
Optional.ofNullable(this.objectFactory).ifPresent(targetConfiguration::setObjectFactory);
Optional.ofNullable(this.objectWrapperFactory).ifPresent(targetConfiguration::setObjectWrapperFactory);
Optional.ofNullable(this.vfs).ifPresent(targetConfiguration::setVfsImpl);
// 以包的维度注册别名转换器
if (hasLength(this.typeAliasesPackage)) {
// 扫描之类包下的符合条件的类对象
scanClasses(this.typeAliasesPackage, this.typeAliasesSuperType).stream()
// 过滤匿名类
.filter(clazz -> !clazz.isAnonymousClass())
// 过滤接口
.filter(clazz -> !clazz.isInterface())
// 过滤成员类
.filter(clazz -> !clazz.isMemberClass()).
// 注册别名转换器
forEach(targetConfiguration.getTypeAliasRegistry()::registerAlias);
}
// 以类的维度注册别名转换器
if (!isEmpty(this.typeAliases)) {
Stream.of(this.typeAliases).forEach(typeAlias -> {
// 注册类对象到别名转换器
targetConfiguration.getTypeAliasRegistry().registerAlias(typeAlias);
LOGGER.debug(() -> "Registered type alias: '" + typeAlias + "'");
});
}
// 设置插件
if (!isEmpty(this.plugins)) {
Stream.of(this.plugins).forEach(plugin -> {
targetConfiguration.addInterceptor(plugin);
LOGGER.debug(() -> "Registered plugin: '" + plugin + "'");
});
}
// 以包的维度注册类型转换器
if (hasLength(this.typeHandlersPackage)) {
// 扫描指定包下 TypeHandler 的子类
scanClasses(this.typeHandlersPackage, TypeHandler.class).stream().
// 过滤匿名类
filter(clazz -> !clazz.isAnonymousClass())
// 过滤接口
.filter(clazz -> !clazz.isInterface())
// 过滤抽象类
.filter(clazz -> !Modifier.isAbstract(clazz.getModifiers()))
// 注册类对象到类型转换器
.forEach(targetConfiguration.getTypeHandlerRegistry()::register);
}
// 以类的维度注册类型转换器
if (!isEmpty(this.typeHandlers)) {
Stream.of(this.typeHandlers).forEach(typeHandler -> {
// 注册类对象到类型转换器
targetConfiguration.getTypeHandlerRegistry().register(typeHandler);
LOGGER.debug(() -> "Registered type handler: '" + typeHandler + "'");
});
}
// 注册脚本语言驱动
if (!isEmpty(this.scriptingLanguageDrivers)) {
Stream.of(this.scriptingLanguageDrivers).forEach(languageDriver -> {
targetConfiguration.getLanguageRegistry().register(languageDriver);
LOGGER.debug(() -> "Registered scripting language driver: '" + languageDriver + "'");
});
}
Optional.ofNullable(this.defaultScriptingLanguageDriver)
.ifPresent(targetConfiguration::setDefaultScriptingLanguage);
// 配置数据库产品识别转换器
if (this.databaseIdProvider != null) {// fix #64 set databaseId before parse mapper xmls
try {
targetConfiguration.setDatabaseId(this.databaseIdProvider.getDatabaseId(this.dataSource));
} catch (SQLException e) {
throw new NestedIOException("Failed getting a databaseId", e);
}
}
// 设置缓存配置
Optional.ofNullable(this.cache).ifPresent(targetConfiguration::addCache);
// 如果设置了配置文件路径,则解析并加载到全局配置中
if (xmlConfigBuilder != null) {
try {
xmlConfigBuilder.parse();
LOGGER.debug(() -> "Parsed configuration file: '" + this.configLocation + "'");
} catch (Exception ex) {
throw new NestedIOException("Failed to parse config resource: " + this.configLocation, ex);
} finally {
ErrorContext.instance().reset();
}
}
// 设置数据源环境
targetConfiguration.setEnvironment(new Environment(this.environment,
this.transactionFactory == null ? new SpringManagedTransactionFactory() : this.transactionFactory,
this.dataSource));
// 解析 xml statement 文件
if (this.mapperLocations != null) {
if (this.mapperLocations.length == 0) {
LOGGER.warn(() -> "Property 'mapperLocations' was specified but matching resources are not found.");
} else {
for (Resource mapperLocation : this.mapperLocations) {
if (mapperLocation == null) {
continue;
}
try {
XMLMapperBuilder xmlMapperBuilder = new XMLMapperBuilder(mapperLocation.getInputStream(),
targetConfiguration, mapperLocation.toString(), targetConfiguration.getSqlFragments());
xmlMapperBuilder.parse();
} catch (Exception e) {
throw new NestedIOException("Failed to parse mapping resource: '" + mapperLocation + "'", e);
} finally {
ErrorContext.instance().reset();
}
LOGGER.debug(() -> "Parsed mapper file: '" + mapperLocation + "'");
}
}
} else {
LOGGER.debug(() -> "Property 'mapperLocations' was not specified.");
}
// 创建 sql 会话工厂
return this.sqlSessionFactoryBuilder.build(targetConfiguration);
}
buildSqlSessionFactory 方法会分别对配置文件、别名转换类、mapper 文件等进行解析,逐步配置全局配置对象,并最终调用 SqlSessionFactoryBuilder 创建 SqlSessionFactory 对象。
SqlSessionTemplatge
在前章分析 MyBatis 接口层时说到 SqlSessionManager 通过 JDK 动态代理为每个线程创建不同的 SqlSession 来解决 DefaultSqlSession 的线程不安全问题。mybatis-spring 的实现与 SqlSessionManager 大致相同,但是其提供了更好的方式与 Spring 事务集成。
SqlSessionTemplate 实现了 SqlSession 接口,但是都是委托给成员对象 sqlSessionProxy 来实现的。sqlSessionProxy 在构造方法中使用 JDK 动态代理初始化为代理类。
public SqlSessionTemplate(SqlSessionFactory sqlSessionFactory, ExecutorType executorType,
PersistenceExceptionTranslator exceptionTranslator) {
notNull(sqlSessionFactory, "Property 'sqlSessionFactory' is required");
notNull(executorType, "Property 'executorType' is required");
this.sqlSessionFactory = sqlSessionFactory;
this.executorType = executorType;
this.exceptionTranslator = exceptionTranslator;
this.sqlSessionProxy = (SqlSession) newProxyInstance(SqlSessionFactory.class.getClassLoader(),
new Class[] { SqlSession.class }, new SqlSessionInterceptor());
}
sqlSessionProxy 的代理逻辑如下。
private class SqlSessionInterceptor implements InvocationHandler {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 获取 sqlSession
SqlSession sqlSession = getSqlSession(SqlSessionTemplate.this.sqlSessionFactory,
SqlSessionTemplate.this.executorType, SqlSessionTemplate.this.exceptionTranslator);
try {
// 执行原始调用
Object result = method.invoke(sqlSession, args);
if (!isSqlSessionTransactional(sqlSession, SqlSessionTemplate.this.sqlSessionFactory)) {
// 如果事务没有交给外部事务管理器管理,进行提交
sqlSession.commit(true);
}
return result;
} catch (Throwable t) {
Throwable unwrapped = unwrapThrowable(t);
if (SqlSessionTemplate.this.exceptionTranslator != null && unwrapped instanceof PersistenceException) {
// 异常为 PersistenceException,使用配置的 exceptionTranslator 来包装异常
closeSqlSession(sqlSession, SqlSessionTemplate.this.sqlSessionFactory);
sqlSession = null;
Throwable translated = SqlSessionTemplate.this.exceptionTranslator
.translateExceptionIfPossible((PersistenceException) unwrapped);
if (translated != null) {
unwrapped = translated;
}
}
throw unwrapped;
} finally {
if (sqlSession != null) {
// 关闭 sql session
closeSqlSession(sqlSession, SqlSessionTemplate.this.sqlSessionFactory);
}
}
}
}
获取 SqlSession
在执行原始调用前会先根据 SqlSessionUtils#getSqlSession 方法获取 SqlSession,如果通过事务同步管理器 TransactionSynchronizationManager 获取不到 SqlSession,就会使用 SqlSessionFactory 新建一个 SqlSession,并尝试将获取的 SqlSession 注册到 TransactionSynchronizationManager 中。
public static SqlSession getSqlSession(SqlSessionFactory sessionFactory, ExecutorType executorType,
PersistenceExceptionTranslator exceptionTranslator) {
// SqlSessionFactory 和 ExecutorType 参数不可为 null
notNull(sessionFactory, NO_SQL_SESSION_FACTORY_SPECIFIED);
notNull(executorType, NO_EXECUTOR_TYPE_SPECIFIED);
// 尝试从事务同步管理器中获取 SqlSessionHolder
SqlSessionHolder holder = (SqlSessionHolder) TransactionSynchronizationManager.getResource(sessionFactory);
// 获取 SqlSession
SqlSession session = sessionHolder(executorType, holder);
if (session != null) {
return session;
}
// 新建 SqlSession
LOGGER.debug(() -> "Creating a new SqlSession");
session = sessionFactory.openSession(executorType);
// 将新建的 SqlSession 注册到事务同步管理器中
registerSessionHolder(sessionFactory, executorType, exceptionTranslator, session);
return session;
}
事务同步管理器
每次获取 SqlSession 时是新建还是从事务同步管理器中获取决于事务同步管理器是否开启。事务同步管理器用于维护当前线程的同步资源,如判断当前线程是否已经开启了一个事务就需要查询事务同步管理器,以便后续根据事务传播方式决定是新开启一个事务或加入当前事务。Spring 支持使用注解开启事务或编程式事务。
注解开启事务
在 Spring 工程中可以通过添加 EnableTransactionManagement 注解来开启 Spring 事务管理。EnableTransactionManagement 注解的参数 mode = AdviceMode.PROXY 默认指定了加载代理事务管理器配置 ProxyTransactionManagementConfiguration,在此配置中其默认地对使用 Transactional 注解的方法进行 AOP 代理。在代理逻辑中,会调用 AbstractPlatformTransactionManager#getTransaction 方法获取当前线程对应的事务,根据当前线程是否有活跃事务、事务传播属性等来配置事务。如果是新创建事务,就会调用 TransactionSynchronizationManager#initSynchronization 方法来初始化当前线程在事务同步管理器中的资源。
编程式事务
编程开启事务的方式与注解式其实是一样的,区别在于编程式需要手动开启事务,其最终也会为当前线程在事务同步管理器中初始化资源。
// 手动开启事务
TransactionStatus txStatus = transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
// invoke...
} catch (Exception e) {
transactionManager.rollback(txStatus);
throw e;
}
transactionManager.commit(txStatus);
SqlSession 注册
如果当前方法开启了事务,那么创建的 SqlSession 就会被注册到事务同步管理器中。SqlSession 会首先被包装为 SqlSessionHolder,其还包含了 SqlSession 对应的执行器类型、异常处理器。
// ...
holder = new SqlSessionHolder(session, executorType, exceptionTranslator);
TransactionSynchronizationManager.bindResource(sessionFactory, holder);
// ...
随后 SqlSessionHolder 对象通过 TransactionSynchronizationManager#bindResource 方法绑定到事务同步管理器中,其实现为将 SqlSessionFactory 和 SqlSessionHolder 绑定到 ThreadLocal 中,从而完成了线程到 SqlSessionFactory 到 SqlSession 的映射。
事务提交与回滚
如果事务是交给 Spring 事务管理器管理的,那么Spring 会自动在执行成功或异常后对当前事务进行提交或回滚。如果没有配置 Spring 事务管理,那么将会调用 SqlSession 的 commit 方法对事务进行提交。
if (!isSqlSessionTransactional(sqlSession, SqlSessionTemplate.this.sqlSessionFactory)) {
// 未被事务管理器管理,设置提交
sqlSession.commit(true);
}
而 SqlSessionTemplate 是不允许用来显式地提交或回滚的,其提交或回滚的方法实现为直接抛出 UnsupportedOperationException 异常。
关闭 SqlSession
在当前调用结束后 SqlSessionTemplate 会调动 closeSqlSession 方法来关闭 SqlSession,如果事务同步管理器中存在当前线程绑定的 SqlSessionHolder,即当前调用被事务管理器管理,则将 SqlSession 的持有释放掉。如果没被事务管理器管理,则会真实地关闭 SqlSession。
public static void closeSqlSession(SqlSession session, SqlSessionFactory sessionFactory) {
notNull(session, NO_SQL_SESSION_SPECIFIED);
notNull(sessionFactory, NO_SQL_SESSION_FACTORY_SPECIFIED);
SqlSessionHolder holder = (SqlSessionHolder) TransactionSynchronizationManager.getResource(sessionFactory);
if ((holder != null) && (holder.getSqlSession() == session)) {
// 被事务管理器管理,释放 SqlSession
LOGGER.debug(() -> "Releasing transactional SqlSession [" + session + "]");
holder.released();
} else {
// 真实地关闭 SqlSesion
LOGGER.debug(() -> "Closing non transactional SqlSession [" + session + "]");
session.close();
}
}
映射器
单个映射器
在 MyBatis 的基础用法中,MyBatis 配置文件支持使用 mappers 标签的子元素 mapper 或 package 来指定需要扫描的 mapper 接口。被扫描到的接口类将被注册到 MapperRegistry 中,通过 MapperRegistry#getMapper 方法可以获得 Mapper 接口的代理类。
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
// 生成 mapper 接口的代理类
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
通过代理类的方式可以使得 statement 的 id 直接与接口方法的全限定名关联,消除了 mapper 接口实现类的样板代码。但是此种方式在每次获取 mapper 代理类的时候都需要指定 sqlSession 对象,而 mybatis-spring 中的 sqlSession 对象是 SqlSessionTemplate 代理创建的,为了适配代理逻辑,mybatis-spring 提供了 MapperFactoryBean 来创建代理类。
@Bean
public UserMapper userMapper(SqlSessionFactory sqlSessionFactory) throws Exception {
MapperFactoryBean<UserMapper> factoryBean = new MapperFactoryBean<>(UserMapper.class);
factoryBean.setSqlSessionFactory(sqlSessionFactory);
return factoryBean.getObject();
}
MapperFactoryBean 继承了 SqlSessionDaoSupport,其会根据传入的 SqlSessionFactory 来创建 SqlSessionTemplate,并使用 SqlSessionTemplate 来生成代理类。
@Override
public T getObject() throws Exception {
// 使用 SqlSessionTemplate 来创建代理类
return getSqlSession().getMapper(this.mapperInterface);
}
public SqlSession getSqlSession() {
return this.sqlSessionTemplate;
}
批量映射器
每次手动获取单个映射器的效率是低下的,MyBatis 还提供了 MapperScan 注解用于批量扫描 mapper 接口并通过 MapperFactoryBean 创建代理类,注册为 Spring bean。
@Configuration
@MapperScan("org.mybatis.spring.sample.mapper")
public class AppConfig {
// ...
}
MapperScan 注解解析后注册 Spring bean 的逻辑是由 MapperScannerConfigure 实现的,其实现 了 BeanDefinitionRegistryPostProcessor 接口的 postProcessBeanDefinitionRegistry 方法。
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) {
// ...
ClassPathMapperScanner scanner = new ClassPathMapperScanner(registry);
// ...
scanner.scan(
StringUtils.tokenizeToStringArray(this.basePackage, ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS));
}
扫描逻辑由 ClassPathMapperScanner 提供,其继承了 ClassPathBeanDefinitionScanner 扫描指定包下的类并注册为 BeanDefinitionHolder 的能力。
public int scan(String... basePackages) {
int beanCountAtScanStart = this.registry.getBeanDefinitionCount();
// 扫描指定包并注册 bean definion
doScan(basePackages);
// Register annotation config processors, if necessary.
if (this.includeAnnotationConfig) {
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
return (this.registry.getBeanDefinitionCount() - beanCountAtScanStart);
}
@Override
public Set<BeanDefinitionHolder> doScan(String... basePackages) {
// 扫描指定包已经获取的 bean 定义
Set<BeanDefinitionHolder> beanDefinitions = super.doScan(basePackages);
if (beanDefinitions.isEmpty()) {
LOGGER.warn(() -> "No MyBatis mapper was found in '" + Arrays.toString(basePackages)
+ "' package. Please check your configuration.");
} else {
// 增强 bean 配置
processBeanDefinitions(beanDefinitions);
}
return beanDefinitions;
}
private void processBeanDefinitions(Set<BeanDefinitionHolder> beanDefinitions) {
GenericBeanDefinition definition;
for (BeanDefinitionHolder holder : beanDefinitions) {
definition = (GenericBeanDefinition) holder.getBeanDefinition();
// ...
// 设置 bean class 类型为 MapperFactoryBean
definition.setBeanClass(this.mapperFactoryBeanClass);
// ...
}
}
获取到指定 bean 的定义后,重新设置 beanClass 为 MapperFactoryBean,因此在随后的 bean 初始化中,这些被扫描的 mapper 接口可以创建代理类并被注册到 Spring 容器中。
映射器注册完成后,就可以使用引用 Spring bean 的配置来使用 mapper 接口。
总结
mybatis-spring 提供了与 Spring 集成的更高层次的封装。
SqlSessionFactoryBean遵循Spring FactoryBean的定义,使得SqlSessionFactory注册在Spring容器中。SqlSessionTemplate是SqlSession另一种线程安全版本的实现,并且能够更好地与Spring事务管理集成。MapperFactoryBean是生成mapper接口代理类的SqlSessionTemplate版本实现。MapperScannerConfigurer简化了生成mapper接口代理的逻辑,指定扫描的包即可将生成mapper接口代理类并注册为Spring bean。
10 - CH10-整体流程
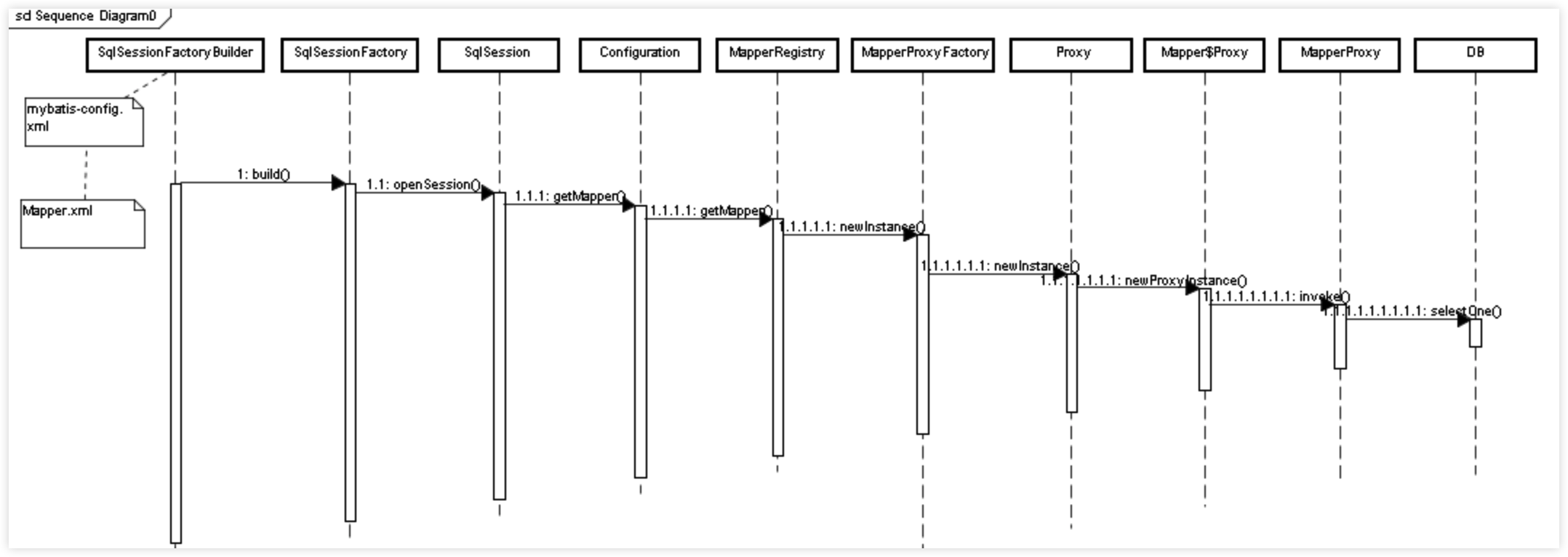
1. 通过 Resource 加载配置
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.IOException;
import java.io.InputStream;
public class MyBatisUtils {
private static SqlSessionFactory sqlSessionFactory;
static {
try {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
public static SqlSession getSqlSession() {
return sqlSessionFactory.openSession();
}
}
2. 实例化 sqlSessionFactoryBuilder 构造器
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
3. 通过 build 中 XmlConfigBuilder 类解析文件流以及环境和属性
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
var5 = this.build(parser.parse());
4. 将配置信息存放到 Configuration 中
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
5. 实例化 SqlSessionFactory 实现类 DefaultSqlSessionFactory
6. 由 TransactionFactory 创建一个 Transaction 事务对象
7. 创建执行器 Excutor,执行 mapper

8. 创建 SqlSession 接口实现类 DefaultSqlSession
SqlSession sqlSession = MybatisUtils.getSqlSession()
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
9. 执行 CRUD
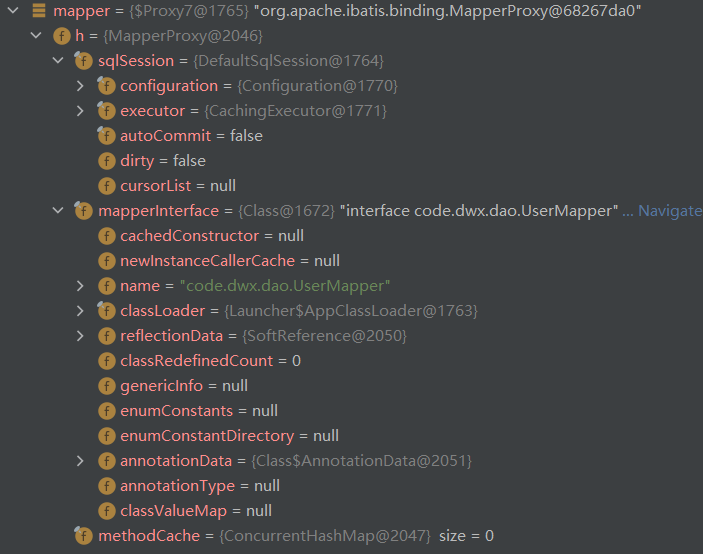
10. 判断是否成功,失败则回滚到事务提交器
11. 提交事务
sqlSession.commit();
12. 关闭
sqlSession.close();
11 - CH11-插件机制
MyBatis支持用插件对四大核心组件进行拦截,对MyBatis来说插件就是拦截器,用来增强核心组件的功能,增强功能本质上是借助于底层的动态代理实现的,换句话说,MyBatis中的四大对象都是代理对象。
Executor:用于执行增删改查操作的执行器类StatementHandler:处理数据库SQL语句的类ParameterHandler:处理SQL的参数的类ResultSetHandler:处理SQL的返回结果集的类
以下是这四种处理各自能够拦截的方法:
| 对象 | 描述 | 可拦截方法 | 方法作用 |
|---|---|---|---|
| Executor | 上层对象,包含 SQL 执行全过程 | update | 执行 update/insert/delete |
| query | 执行 query | ||
| flushStatements | 在 commit 时自动调用,SimpleExecutor/ReuseExecutor/BatchExecutor 处理不同 | ||
| commit | 提交事务 | ||
| rollback | 回滚事务 | ||
| getTransaction | 获取事务 | ||
| close | 结束事务 | ||
| isClosed | 判断事务是否关闭 | ||
| StatementHandler | 执行 SQL 的过程,常用拦截对象 | prepare | SQL 预编译 |
| parameterize | 设置 SQL 参数 | ||
| batch | 批处理 | ||
| update | 增删改操作 | ||
| query | 查询操作 | ||
| ParameterHandler | SQL 参数组装过程 | getParameterObject | 获取参数 |
| setParameters | 设置参数 | ||
| ResultSetHandler | 执行 SQL 结果的组装 | handleResultSets | 处理结果集 |
| handleOutputParameters | 处理存储过程出参 |
插件原理
MyBatis的插件借助于责任链的模式进行对拦截的处理- 使用
动态代理对目标对象进行包装,达到拦截的目的
拦截
插件具体是如何拦截并附加额外的功能的呢?以ParameterHandler来说:
public ParameterHandlernewParameterHandler(
MappedStatement mappedStatement,
Object object,
BoundSql sql,
InterceptorChain interceptorChain){
ParameterHandler parameterHandler =
mappedStatement.getLang().createParameterHandler(mappedStatement,object,sql);
parameterHandler = (ParameterHandler) interceptorChain.pluginAll(parameterHandler);
return parameterHandler;
}
public Object pluginAll(Objecttarget){
for(Interceptorinterceptor:interceptors){
target = interceptor.plugin(target);
}
return target;
}
interceptorChain保存了所有的拦截器(interceptors),是MyBatis初始化的时候创建的。
调用拦截器链中的拦截器依次的对目标进行拦截或增强。
interceptor.plugin(target) 中的 target 就可以理解为MyBatis中的四大组件,返回的target是被重重代理后的对象。
插件接口Interceptor
intercept()方法,插件的核心方法plugin()方法,生成target的代理对象setProperties()方法,传递插件所需参数
插件实例
插件开发需要以下步骤
- 自定义插件需要实现上述接口
- 增加@Intercepts注解(声明是哪个核心组件的插件,以及对哪些方法进行扩展)
- 在xml文件中配置插件
**
*插件签名,告诉MyBatis插件用来拦截那个对象的哪个方法
**/
@Intercepts({
@Signature(type=StatementHandler.class,method="parameterize",args=Statement.class)
})
public class MyInterceptsimplementsInterceptor {
/**
*拦截目标对象的目标方法
*
*@paraminvocation
*@return
*@throwsThrowable
*/
@Override
public Object intercept(Invocation invocation) throws Throwable{
System.out.println("进入自定义的拦截器,拦截目标对象"+invocation+invocation.getMethod()+invocation.getTarget());
return invocation.proceed();
}
/**
*包装目标对象为目标对象创建代理对象
*
*@Paramtarget为要拦截的对象
*@Return代理对象
*/
@Override
public Object plugin(Object target){
System.out.println("自定义plugin方法,将要包装的目标对象"+target.toString()+target.getClass());
returnPlugin.wrap(target,this);
}
/**
*获取配置文件的属性
*
*@paramproperties
*/
@Override
public void setProperties(Properties properties){
System.out.println("自定义插件的初始化参数"+properties);
}
}
在mybatis-config.xml中配置插件
<!--自定义插件-->
<plugins>
<plugininterceptor="com.boxuegu.javaee.mybatissourcelearn.MyIntercepts">
<propertyname="test"value="testvalue"/>
</plugin>
</plugins>
调用查询方法,查询方法会返回ResultSet
public class Test{
public static void main(String[]args){
//1.加载配置文件
String resource="mybatis-config.xml";
InputStream inputStream=null;
try{
inputStream=Resources.getResourceAsStream(resource);
}catch(IOExceptione){
e.printStackTrace();
}
//2.获取sqlSessionFactory
SqlSessionFactory sqlSessionFactory=
new SqlSessionFactoryBuilder().build(inputStream);
//3.获取sqlSession
SqlSession sqlSession=sqlSessionFactory.openSession();
try{
//通过xml文件直接执行sql语句
//Employeeemployee=sqlSession.selectOne("com.boxuegu.javaee.mybatissourcelearn.dao.EmployeeMapper.getEmployeeById",1);
//alt+shift+Lintroducelocalvariables;
Thread thread=newThread(()->System.out.println("test"));
//4.获取mapper接口实现
EmployeeMapper mapper=sqlSession.getMapper(EmployeeMapper.class);
System.out.println("mapper::::"+mapper.getClass());
//5.执行sql语句
Employee employee=mapper.getEmployeeById(1);
System.out.println(employee);
}finally{
sqlSession.close();
}
}
}
分页插件
MyBatis 自带的 RowBounds 是一次查询所有结果,然后再内存中计算并提取分页,最终返回指定页数的数据。
这种分页方式对于数据量小的还好,如果数据量大就有很大性能影响了。因为这种方式是将数据全部查询出来放到内存里,再进行分页长度的截取,是一种伪分页,是一种逻辑分页。
因此通常会使用 PageHelper 插件:
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.3.0</version>
</dependency>
在 mybatis-config.xml 中配置插件:
<plugins>
<plugininterceptor="com.github.pagehelper.PageInterceptor" />
</plugins>
执行分页查询:
PageHelper.startPage(/*pageNum*/ 2, /*pageSize*/ 4);
List<User> users = userMapper.findAll();
PageInfo<User> pageInfo = new PageInfo(list);
// return pageInfo to controller
实现原理
PageHelper是利用Mybatis的插件原理,对Executor接口的query方法进行了拦截。
@Intercepts({
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class}),
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class, CacheKey.class, BoundSql.class}),
})
public class PageInterceptor implements Interceptor {
//...
}
在创建Executor时,如果有插件对Executor进行拦截,则会对Executor对象生成代理,在执行相对应的方法时进行增强处理。
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
// 根据数据库操作类型创建市级执行器
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
// 根据配置文件中的 settings 节点cacheEnabled配置项确定是否启用缓存
if (cacheEnabled) { // 如果配置启用该缓存
// 使用CachingExecutor装饰实际的执行器
executor = new CachingExecutor(executor);
}
// 为执行器增加拦截器(插件),以启用各个拦截器的功能
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
当程序走到DefaultSqlSession中时,会调用Executor的query方法,此时就会触发PageHelper的代理,进入PageHelper的逻辑:
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
/**
* 获取查询语句
* 设置MappedStatement映射,见{@link XMLStatementBuilder#parseStatementNode()}
*/
MappedStatement ms = configuration.getMappedStatement(statement);
/**
* 交由执行器进行查询,由于全局配置cacheEnabled默认是打开的,因此此处的executor通常都是CachingExecutor
* 获取executor,见{@link Configuration#newExecutor(org.apache.ibatis.transaction.Transaction, org.apache.ibatis.session.ExecutorType)}
*/
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
PageHelper拦截器PageInterceptor执行流程:
@Override
public Object intercept(Invocation invocation) throws Throwable {
try {
...
//调用方法判断是否需要进行分页,如果不需要,直接返回结果
if (!dialect.skip(ms, parameter, rowBounds)) {
//判断是否需要进行count查询
if (dialect.beforeCount(ms, parameter, rowBounds)) {
//查询总数
Long count = count(executor, ms, parameter, rowBounds, null, boundSql);
//处理查询总数,返回true时继续分页查询,false时直接返回
if (!dialect.afterCount(count, parameter, rowBounds)) {
//当查询总数为0时,直接返回空的结果
return dialect.afterPage(new ArrayList(), parameter, rowBounds);
}
}
// 生成不同方言对应的分页 SQL 并执行
resultList = ExecutorUtil.pageQuery(dialect, executor,
ms, parameter, rowBounds, resultHandler, boundSql, cacheKey);
} else {
//rowBounds有参数值,不使用分页插件处理时,仍然支持默认的内存分页
resultList = executor.query(ms, parameter, rowBounds, resultHandler, cacheKey, boundSql);
}
// 将查询结果设置到Page对象中
return dialect.afterPage(resultList, parameter, rowBounds);
} finally {
if(dialect != null){
dialect.afterAll();
}
}
}
ExecutorUtil.pageQuery主要是基于不同的数据库方言生成分页查询 SQL,比如最简单的是在原 SQL 后追加 LIMIT ? OFFSET ?。
多插件开发
- 创建代理对象时,按照插件配置的顺序进行包装
- 执行目标方法后,是按照代理的逆向进行执行
总结
1.遵循插件尽量不使用的原则,因为会修改底层设计
2.插件是生成的层层代理对象的责任链模式,使用反射机制实现
3.插件的编写要考虑全面,特别是多个插件层层代理的时候
12 - CH12-代码生成
运行方式
Mybatis-Generator的运行方式有很多种:
- 基于
mybatis-generator-core-x.x.x.jar和其XML配置文件,通过命令行运行。 - 通过
Ant的Task结合其XML配置文件运行。 - 通过
Maven插件运行。 - 通过
Java代码和其XML配置文件运行。 - 通过
Java代码和编程式配置运行。 - 通过
Eclipse Feature运行。
这里只介绍通过Maven插件运行和通过Java代码和其XML配置文件运行这两种方式,两种方式有个特点:都要提前编写好XML配置文件。个人感觉XML配置文件相对直观,后文会花大量篇幅去说明XML配置文件中的配置项及其作用。这里先注意一点:默认的配置文件为ClassPath:generatorConfig.xml。
通过编码和配置文件运行
通过编码方式去运行插件先需要引入mybatis-generator-core依赖,编写本文的时候最新的版本为:
<dependency>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-core</artifactId>
<version>1.4.0</version>
</dependency>
假设编写好的XML配置文件是ClassPath下的generator-configuration.xml,那么使用代码生成器的编码方式大致如下:
List<String> warnings = new ArrayList<>();
// 如果已经存在生成过的文件是否进行覆盖
boolean overwrite = true;
File configFile = new File("ClassPath路径/generator-configuration.xml");
ConfigurationParser cp = new ConfigurationParser(warnings);
Configuration config = cp.parseConfiguration(configFile);
DefaultShellCallback callback = new DefaultShellCallback(overwrite);
MyBatisGenerator generator = new MyBatisGenerator(config, callback, warnings);
generator.generate(null);
通过 Maven 插件运行
如果使用Maven插件,那么不需要引入mybatis-generator-core依赖,只需要引入一个Maven的插件mybatis-generator-maven-plugin:
<plugins>
<plugin>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-maven-plugin</artifactId>
<version>1.4.0</version>
<executions>
<execution>
<id>Generate MyBatis Artifacts</id>
<goals>
<goal>generate</goal>
</goals>
</execution>
</executions>
<configuration>
<!-- 输出详细信息 -->
<verbose>true</verbose>
<!-- 覆盖生成文件 -->
<overwrite>true</overwrite>
<!-- 定义配置文件 -->
<configurationFile>${basedir}/src/main/resources/generator-configuration.xml</configurationFile>
</configuration>
</plugin>
</plugins>
XML 配置详解
XML配置文件才是Mybatis-Generator的核心,它用于控制代码生成的所有行为。所有非标签独有的公共配置的Key可以在mybatis-generator-core的PropertyRegistry类中找到。下面是一个相对完整的配置文件的模板:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<properties resource="db.properties"/>
<classPathEntry location="/Program Files/IBM/SQLLIB/java/db2java.zip" />
<context id="DB2Tables" targetRuntime="MyBatis3">
<jdbcConnection driverClass="COM.ibm.db2.jdbc.app.DB2Driver"
connectionURL="jdbc:db2:TEST"
userId="db2admin"
password="db2admin">
</jdbcConnection>
<plugin type="org.mybatis.generator.plugins.SerializablePlugin"/>
<commentGenerator>
<property name="suppressDate" value="true"/>
<property name="suppressAllComments" value="true"/>
</commentGenerator>
<javaTypeResolver>
<property name="forceBigDecimals" value="false" />
</javaTypeResolver>
<javaModelGenerator targetPackage="test.model" targetProject="\MBGTestProject\src">
<property name="enableSubPackages" value="true" />
<property name="trimStrings" value="true" />
</javaModelGenerator>
<sqlMapGenerator targetPackage="test.xml" targetProject="\MBGTestProject\src">
<property name="enableSubPackages" value="true" />
</sqlMapGenerator>
<javaClientGenerator type="XMLMAPPER" targetPackage="test.dao" targetProject="\MBGTestProject\src">
<property name="enableSubPackages" value="true" />
</javaClientGenerator>
<table schema="DB2ADMIN" tableName="ALLTYPES" domainObjectName="Customer" >
<property name="useActualColumnNames" value="true"/>
<generatedKey column="ID" sqlStatement="DB2" identity="true" />
<columnOverride column="DATE_FIELD" property="startDate" />
<ignoreColumn column="FRED" />
<columnOverride column="LONG_VARCHAR_FIELD" jdbcType="VARCHAR" />
</table>
</context>
</generatorConfiguration>
配置文件中,最外层的标签为<generatorConfiguration>,它的子标签包括:
- 0或者1个
<properties>标签,用于指定全局配置文件,下面可以通过占位符的形式读取<properties>指定文件中的值。 - 0或者N个
<classPathEntry>标签,<classPathEntry>只有一个location属性,用于指定数据源驱动包(jar或者zip)的绝对路径,具体选择什么驱动包取决于连接什么类型的数据源。 - 1或者N个
<context>标签,用于运行时的解析模式和具体的代码生成行为,所以这个标签里面的配置是最重要的。
下面分别列举和分析一下<context>标签和它的主要子标签的一些属性配置和功能。
context 标签
<context>标签在mybatis-generator-core中对应的实现类为org.mybatis.generator.config.Context,它除了大量的子标签配置之外,比较主要的属性是:
id:Context示例的唯一ID,用于输出错误信息时候作为唯一标记。targetRuntime:用于执行代码生成模式。defaultModelType:控制 Domain 类的生成行为。执行引擎为 MyBatis3DynamicSql 或者 MyBatis3Kotlin 时忽略此配置,可选值:conditional:默认值,类似hierarchical,但是只有一个主键的时候会合并所有属性生成在同一个类。flat:所有内容全部生成在一个对象中。hierarchical:键生成一个XXKey对象,Blob等单独生成一个对象,其他简单属性在一个对象中。
targetRuntime属性的可选值比较多,这里做个简单的小结:
属性:
- MyBatis3DynamicSql:默认值,兼容 JDK8+ 和 MyBatis 3.4.2+,不会生成 XML 映射文件,忽略
<sqlMapGenerator>的配置项,也就是 Mapper 全部注解化,依赖于 MyBatis Dynamic SQL 类库。 - MyBatis3Kotlin:行为类似于 MyBatis3DynamicSql,不过兼容 Kotlin 的代码生成。
- MyBatis3:提供基本的基于动态 SQL 的 CRUD 方法和 XXXByExample 方法,会生成 XML 映射文件。
- MyBatis3Simple:提供基本的基于动态 SQL 的 CRUD 方法,会生成 XML 映射文件。
- MyBatis3DynamicSqlV1:已经过时,不推荐使用。
笔者偏向于把SQL文件和代码分离,所以一般选用MyBatis3或者MyBatis3Simple。例如:
<context id="default" targetRuntime="MyBatis3">
<context>标签支持0或N个<property>标签,<property>的可选属性有:
| property属性 | 功能描述 | 默认值 | 备注 |
|---|---|---|---|
autoDelimitKeywords | 是否使用分隔符号括住数据库关键字 | false | 例如MySQL中会使用反引号括住关键字 |
beginningDelimiter | 分隔符号的开始符号 | " | |
endingDelimiter | 分隔符号的结束号 | " | |
javaFileEncoding | 文件的编码 | 系统默认值 | 来源于java.nio.charset.Charset |
javaFormatter | 类名和文件格式化器 | DefaultJavaFormatter | 见JavaFormatter和DefaultJavaFormatter |
targetJava8 | 是否JDK8和启动其特性 | true | |
kotlinFileEncoding | Kotlin文件编码 | 系统默认值 | 来源于java.nio.charset.Charset |
kotlinFormatter | Kotlin类名和文件格式化器 | DefaultKotlinFormatter | 见KotlinFormatter和DefaultKotlinFormatter |
xmlFormatter | XML文件格式化器 | DefaultXmlFormatter | 见XmlFormatter和DefaultXmlFormatter |
jdbcConnection 标签
<jdbcConnection>标签用于指定数据源的连接信息,它在mybatis-generator-core中对应的实现类为org.mybatis.generator.config.JDBCConnectionConfiguration,主要属性包括:
| 属性 | 功能描述 | 是否必须 |
|---|---|---|
driverClass | 数据源驱动的全类名 | Y |
connectionURL | JDBC的连接URL | Y |
userId | 连接到数据源的用户名 | N |
password | 连接到数据源的密码 | N |
commentGenerator 标签
<commentGenerator>标签是可选的,用于控制生成的实体的注释内容。它在mybatis-generator-core中对应的实现类为org.mybatis.generator.internal.DefaultCommentGenerator,可以通过可选的type属性指定一个自定义的CommentGenerator实现。<commentGenerator>标签支持0或N个<property>标签,<property>的可选属性有:
| property属性 | 功能描述 | 默认值 |
|---|---|---|
suppressAllComments | 是否生成注释 | false |
suppressDate | 是否在注释中添加生成的时间戳 | false |
dateFormat | 配合suppressDate使用,指定输出时间戳的格式 | java.util.Date#toString() |
addRemarkComments | 是否输出表和列的Comment信息 | false |
笔者建议保持默认值,也就是什么注释都不输出,生成代码干净的实体。
javaTypeResolver 标签
<javaTypeResolver>标签是<context>的子标签,用于解析和计算数据库列类型和Java类型的映射关系,该标签只包含一个type属性,用于指定org.mybatis.generator.api.JavaTypeResolver接口的实现类。<javaTypeResolver>标签支持0或N个<property>标签,<property>的可选属性有:
| property属性 | 功能描述 | 默认值 |
|---|---|---|
forceBigDecimals | 是否强制把所有的数字类型强制使用java.math.BigDecimal类型表示 | false |
useJSR310Types | 是否支持JSR310,主要是JSR310的新日期类型 | false |
如果useJSR310Types属性设置为true,那么生成代码的时候类型映射关系如下(主要针对日期时间类型):
| 数据库(JDBC)类型 | Java类型 |
|---|---|
DATE | java.time.LocalDate |
TIME | java.time.LocalTime |
TIMESTAMP | java.time.LocalDateTime |
TIME_WITH_TIMEZONE | java.time.OffsetTime |
TIMESTAMP_WITH_TIMEZONE | java.time.OffsetDateTime |
引入mybatis-generator-core后,可以查看JavaTypeResolver的默认实现为JavaTypeResolverDefaultImpl,从它的源码可以得知一些映射关系:
BIGINT --> Long
BIT --> Boolean
INTEGER --> Integer
SMALLINT --> Short
TINYINT --> Byte
......
有些时候,我们希望INTEGER、SMALLINT和TINYINT都映射为Integer,那么我们需要覆盖JavaTypeResolverDefaultImpl的构造方法:
public class DefaultJavaTypeResolver extends JavaTypeResolverDefaultImpl {
public DefaultJavaTypeResolver() {
super();
typeMap.put(Types.SMALLINT, new JdbcTypeInformation("SMALLINT",
new FullyQualifiedJavaType(Integer.class.getName())));
typeMap.put(Types.TINYINT, new JdbcTypeInformation("TINYINT",
new FullyQualifiedJavaType(Integer.class.getName())));
}
}
注意一点的是这种自定义实现JavaTypeResolver接口的方式使用编程式运行MBG会相对方便,如果需要使用Maven插件运行,那么需要把上面的DefaultJavaTypeResolver类打包到插件中。
javaModelGenerator 标签
<javaModelGenerator标签>标签是<context>的子标签,主要用于控制实体(Model)类的代码生成行为。它支持的属性如下:
| 属性 | 功能描述 | 是否必须 | 备注 |
|---|---|---|---|
targetPackage | 生成的实体类的包名 | Y | 例如club.throwable.model |
targetProject | 生成的实体类文件相对于项目(根目录)的位置 | Y | 例如src/main/java |
<javaModelGenerator标签>标签支持0或N个<property>标签,<property>的可选属性有:
| property属性 | 功能描述 | 默认值 | 备注 |
|---|---|---|---|
constructorBased | 是否生成一个带有所有字段属性的构造函数 | false | MyBatis3Kotlin模式下忽略此属性配置 |
enableSubPackages | 是否允许通过Schema生成子包 | false | 如果为true,例如包名为club.throwable,如果Schema为xyz,那么实体类文件最终会生成在club.throwable.xyz目录 |
exampleTargetPackage | 生成的伴随实体类的Example类的包名 | - | - |
exampleTargetProject | 生成的伴随实体类的Example类文件相对于项目(根目录)的位置 | - | - |
immutable | 是否不可变 | false | 如果为true,则不会生成Setter方法,所有字段都使用final修饰,提供一个带有所有字段属性的构造函数 |
rootClass | 为生成的实体类添加父类 | - | 通过value指定父类的全类名即可 |
trimStrings | Setter方法是否对字符串类型进行一次trim操作 | false | - |
javaClientGenerator 标签
<javaClientGenerator>标签是<context>的子标签,主要用于控制Mapper接口的代码生成行为。它支持的属性如下:
| 属性 | 功能描述 | 是否必须 | 备注 |
|---|---|---|---|
type | Mapper接口生成策略 | Y | <context>标签的targetRuntime属性为MyBatis3DynamicSql或者MyBatis3Kotlin时此属性配置忽略 |
targetPackage | 生成的Mapper接口的包名 | Y | 例如club.throwable.mapper |
targetProject | 生成的Mapper接口文件相对于项目(根目录)的位置 | Y | 例如src/main/java |
type属性的可选值如下:
ANNOTATEDMAPPER:Mapper接口生成的时候依赖于注解和SqlProviders(也就是纯注解实现),不会生成XML映射文件。XMLMAPPER:Mapper接口生成接口方法,对应的实现代码生成在XML映射文件中(也就是纯映射文件实现)。MIXEDMAPPER:Mapper接口生成的时候复杂的方法实现生成在XML映射文件中,而简单的实现通过注解和SqlProviders实现(也就是注解和映射文件混合实现)。
注意两点:
<context>标签的targetRuntime属性指定为MyBatis3Simple的时候,type只能选用ANNOTATEDMAPPER或者XMLMAPPER。<context>标签的targetRuntime属性指定为MyBatis3的时候,type可以选用ANNOTATEDMAPPER、XMLMAPPER或者MIXEDMAPPER。
<javaClientGenerator>标签支持0或N个<property>标签,<property>的可选属性有:
| property属性 | 功能描述 | 默认值 | 备注 |
|---|---|---|---|
enableSubPackages | 是否允许通过Schema生成子包 | false | 如果为true,例如包名为club.throwable,如果Schema为xyz,那么Mapper接口文件最终会生成在club.throwable.xyz目录 |
useLegacyBuilder | 是否通过SQL Builder生成动态SQL | false | |
rootInterface | 为生成的Mapper接口添加父接口 | - | 通过value指定父接口的全类名即可 |
sqlMapGenerator 标签
<sqlMapGenerator>标签是<context>的子标签,主要用于控制XML映射文件的代码生成行为。它支持的属性如下:
| 属性 | 功能描述 | 是否必须 | 备注 |
|---|---|---|---|
targetPackage | 生成的XML映射文件的包名 | Y | 例如mappings |
targetProject | 生成的XML映射文件相对于项目(根目录)的位置 | Y | 例如src/main/resources |
<sqlMapGenerator>标签支持0或N个<property>标签,<property>的可选属性有:
| property属性 | 功能描述 | 默认值 | 备注 |
|---|---|---|---|
enableSubPackages | 是否允许通过Schema生成子包 | false | - |
plugin 标签
<plugin>标签是<context>的子标签,用于引入一些插件对代码生成的一些特性进行扩展,该标签只包含一个type属性,用于指定org.mybatis.generator.api.Plugin接口的实现类。内置的插件实现见Supplied Plugins。例如:引入org.mybatis.generator.plugins.SerializablePlugin插件会让生成的实体类自动实现java.io.Serializable接口并且添加serialVersionUID属性。
table 标签
<table> 标签是 <context> 的子标签,主要用于配置要生成代码的数据库表格,定制一些代码生成行为等等。它支持的属性众多,列举如下:
| 属性 | 功能描述 | 是否必须 | 备注 |
|---|---|---|---|
tableName | 数据库表名称 | Y | 例如t_order |
schema | 数据库Schema | N | - |
catalog | 数据库Catalog | N | - |
alias | 表名称标签 | N | 如果指定了此值,则查询列的时候结果格式为alias_column |
domainObjectName | 表对应的实体类名称,可以通过.指定包路径 | N | 如果指定了bar.User,则包名为bar,实体类名称为User |
mapperName | 表对应的Mapper接口类名称,可以通过.指定包路径 | N | 如果指定了bar.UserMapper,则包名为bar,Mapper接口类名称为UserMapper |
sqlProviderName | 动态SQL提供类SqlProvider的类名称 | N | - |
enableInsert | 是否允许生成insert方法 | N | 默认值为true,执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
enableSelectByPrimaryKey | 是否允许生成selectByPrimaryKey方法 | N | 默认值为true,执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
enableSelectByExample | 是否允许生成selectByExample方法 | N | 默认值为true,执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
enableUpdateByPrimaryKey | 是否允许生成updateByPrimaryKey方法 | N | 默认值为true,执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
enableDeleteByPrimaryKey | 是否允许生成deleteByPrimaryKey方法 | N | 默认值为true,执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
enableDeleteByExample | 是否允许生成deleteByExample方法 | N | 默认值为true,执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
enableCountByExample | 是否允许生成countByExample方法 | N | 默认值为true,执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
enableUpdateByExample | 是否允许生成updateByExample方法 | N | 默认值为true,执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
selectByPrimaryKeyQueryId | value指定对应的主键列提供列表查询功能 | N | 执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
selectByExampleQueryId | value指定对应的查询ID提供列表查询功能 | N | 执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
modelType | 覆盖<context>的defaultModelType属性 | N | 见<context>的defaultModelType属性 |
escapeWildcards | 是否对通配符进行转义 | N | - |
delimitIdentifiers | 标记匹配表名称的时候是否需要使用分隔符去标记生成的SQL | N | - |
delimitAllColumns | 是否所有的列都添加分隔符 | N | 默认值为false,如果设置为true,所有列名会添加起始和结束分隔符 |
<table> 标签支持0或N个 <property> 标签,<property> 的可选属性有:
| property属性 | 功能描述 | 默认值 | 备注 |
|---|---|---|---|
constructorBased | 是否为实体类生成一个带有所有字段的构造函数 | false | 执行引擎为MyBatis3Kotlin的时候此属性忽略 |
ignoreQualifiersAtRuntime | 是否在运行时忽略别名 | false | 如果为true,则不会在生成表的时候把schema和catalog作为表的前缀 |
immutable | 实体类是否不可变 | false | 执行引擎为MyBatis3Kotlin的时候此属性忽略 |
modelOnly | 是否仅仅生成实体类 | false | - |
rootClass | 如果配置此属性,则实体类会继承此指定的超类 | - | 如果有主键属性会把主键属性在超类生成 |
rootInterface | 如果配置此属性,则实体类会实现此指定的接口 | - | 执行引擎为MyBatis3Kotlin或者MyBatis3DynamicSql的时候此属性忽略 |
runtimeCatalog | 指定运行时的Catalog | - | 当生成表和运行时的表的Catalog不一样的时候可以使用该属性进行配置 |
runtimeSchema | 指定运行时的Schema | - | 当生成表和运行时的表的Schema不一样的时候可以使用该属性进行配置 |
runtimeTableName | 指定运行时的表名称 | - | 当生成表和运行时的表的表名称不一样的时候可以使用该属性进行配置 |
selectAllOrderByClause | 指定字句内容添加到selectAll()方法的order by子句之中 | - | 执行引擎为MyBatis3Simple的时候此属性才适用 |
trimStrings | 实体类的字符串类型属性会做trim处理 | - | 执行引擎为MyBatis3Kotlin的时候此属性忽略 |
useActualColumnNames | 是否使用列名作为实体类的属性名 | false | - |
useColumnIndexes | XML映射文件中生成的ResultMap使用列索引定义而不是列名称 | false | 执行引擎为MyBatis3Kotlin或者MyBatis3DynamicSql的时候此属性忽略 |
useCompoundPropertyNames | 是否把列名和列备注拼接起来生成实体类属性名 | false | - |
<table> 标签还支持众多的非 property 的子标签:
- 0或1个
<generatedKey>用于指定主键生成的规则,指定此标签后会生成一个<selectKey>标签:
<!-- column:指定主键列 -->
<!-- sqlStatement:查询主键的SQL语句,例如填写了MySql,则使用SELECT LAST_INSERT_ID() -->
<!-- type:可选值为pre或者post,pre指定selectKey标签的order为BEFORE,post指定selectKey标签的order为AFTER -->
<!-- identity:true的时候,指定selectKey标签的order为AFTER -->
<generatedKey column="id" sqlStatement="MySql" type="post" identity="true" />
- 0或1个
<domainObjectRenamingRule>用于指定实体类重命名规则:
<!-- searchString中正则命中的实体类名部分会替换为replaceString -->
<domainObjectRenamingRule searchString="^Sys" replaceString=""/>
<!-- 例如 SysUser会变成User -->
<!-- 例如 SysUserMapper会变成UserMapper -->
- 0或1个
<columnRenamingRule>用于指定列重命名规则:
<!-- searchString中正则命中的列名部分会替换为replaceString -->
<columnRenamingRule searchString="^CUST_" replaceString=""/>
<!-- 例如 CUST_BUSINESS_NAME会变成BUSINESS_NAME(useActualColumnNames=true) -->
<!-- 例如 CUST_BUSINESS_NAME会变成businessName(useActualColumnNames=false) -->
- 0或N个
<columnOverride>用于指定具体列的覆盖映射规则:
<!-- column:指定要覆盖配置的列 -->
<!-- property:指定要覆盖配置的属性 -->
<!-- delimitedColumnName:是否为列名添加定界符,例如`{column}` -->
<!-- isGeneratedAlways:是否一定生成此列 -->
<columnOverride column="customer_name" property="customerName" javaType="" jdbcType="" typeHandler="" delimitedColumnName="" isGeneratedAlways="">
<!-- 覆盖table或者javaModelGenerator级别的trimStrings属性配置 -->
<property name="trimStrings" value="true"/>
<columnOverride/>
- 0或N个
<ignoreColumn>用于指定忽略生成的列:
<ignoreColumn column="version" delimitedColumnName="false"/>
应用实例
如果需要深度定制一些代码生成行为,建议引入mybatis-generator-core并且通过编程式执行代码生成方法,否则可以选用Maven插件。假设我们在本地数据local有一张t_order表如下:
CREATE TABLE `t_order`
(
id BIGINT UNSIGNED PRIMARY KEY COMMENT '主键',
order_id VARCHAR(64) NOT NULL COMMENT '订单ID',
create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
amount DECIMAL(10, 2) NOT NULL DEFAULT 0 COMMENT '金额',
order_status TINYINT NOT NULL DEFAULT 0 COMMENT '订单状态',
UNIQUE uniq_order_id (`order_id`)
) COMMENT '订单表';
假设项目的结构如下:
mbg-sample
- main
- java
- club
- throwable
- resources
下面会基于此前提举三个例子。编写基础的XML配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<!-- 驱动包绝对路径 -->
<classPathEntry
location="I:\Develop\Maven-Repository\mysql\mysql-connector-java\5.1.48\mysql-connector-java-5.1.48.jar"/>
<context id="default" targetRuntime="这里选择合适的引擎">
<property name="javaFileEncoding" value="UTF-8"/>
<!-- 不输出注释 -->
<commentGenerator>
<property name="suppressDate" value="true"/>
<property name="suppressAllComments" value="true"/>
</commentGenerator>
<jdbcConnection driverClass="com.mysql.jdbc.Driver"
connectionURL="jdbc:mysql://localhost:3306/local"
userId="root"
password="root">
</jdbcConnection>
<!-- 不强制把所有的数字类型转化为BigDecimal -->
<javaTypeResolver>
<property name="forceBigDecimals" value="false"/>
</javaTypeResolver>
<javaModelGenerator targetPackage="club.throwable.entity" targetProject="src/main/java">
<property name="enableSubPackages" value="true"/>
</javaModelGenerator>
<sqlMapGenerator targetPackage="mappings" targetProject="src/main/resources">
<property name="enableSubPackages" value="true"/>
</sqlMapGenerator>
<javaClientGenerator type="这里选择合适的Mapper类型" targetPackage="club.throwable.dao" targetProject="src/main/java">
<property name="enableSubPackages" value="true"/>
</javaClientGenerator>
<table tableName="t_order"
enableCountByExample="false"
enableDeleteByExample="false"
enableSelectByExample="false"
enableUpdateByExample="false"
domainObjectName="Order"
mapperName="OrderMapper">
<generatedKey column="id" sqlStatement="MySql"/>
</table>
</context>
</generatorConfiguration>
纯注解
使用纯注解需要引入mybatis-dynamic-sql:
<dependency>
<groupId>org.mybatis.dynamic-sql</groupId>
<artifactId>mybatis-dynamic-sql</artifactId>
<version>1.1.4</version>
</dependency>
需要修改两个位置:
<context id="default" targetRuntime="MyBatis3DynamicSql">
...
<javaClientGenerator type="ANNOTATEDMAPPER"
...
运行结果会生成三个类:
// club.throwable.entity
public class Order {
@Generated("org.mybatis.generator.api.MyBatisGenerator")
private Long id;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
private String orderId;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
private Date createTime;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
private BigDecimal amount;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
private Byte orderStatus;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public Long getId() {
return id;
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public void setId(Long id) {
this.id = id;
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public String getOrderId() {
return orderId;
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public void setOrderId(String orderId) {
this.orderId = orderId;
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public Date getCreateTime() {
return createTime;
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public void setCreateTime(Date createTime) {
this.createTime = createTime;
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public BigDecimal getAmount() {
return amount;
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public void setAmount(BigDecimal amount) {
this.amount = amount;
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public Byte getOrderStatus() {
return orderStatus;
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public void setOrderStatus(Byte orderStatus) {
this.orderStatus = orderStatus;
}
}
// club.throwable.dao
public final class OrderDynamicSqlSupport {
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public static final Order order = new Order();
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public static final SqlColumn<Long> id = order.id;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public static final SqlColumn<String> orderId = order.orderId;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public static final SqlColumn<Date> createTime = order.createTime;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public static final SqlColumn<BigDecimal> amount = order.amount;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public static final SqlColumn<Byte> orderStatus = order.orderStatus;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public static final class Order extends SqlTable {
public final SqlColumn<Long> id = column("id", JDBCType.BIGINT);
public final SqlColumn<String> orderId = column("order_id", JDBCType.VARCHAR);
public final SqlColumn<Date> createTime = column("create_time", JDBCType.TIMESTAMP);
public final SqlColumn<BigDecimal> amount = column("amount", JDBCType.DECIMAL);
public final SqlColumn<Byte> orderStatus = column("order_status", JDBCType.TINYINT);
public Order() {
super("t_order");
}
}
}
@Mapper
public interface OrderMapper {
@Generated("org.mybatis.generator.api.MyBatisGenerator")
BasicColumn[] selectList = BasicColumn.columnList(id, orderId, createTime, amount, orderStatus);
@Generated("org.mybatis.generator.api.MyBatisGenerator")
@SelectProvider(type=SqlProviderAdapter.class, method="select")
long count(SelectStatementProvider selectStatement);
@Generated("org.mybatis.generator.api.MyBatisGenerator")
@DeleteProvider(type=SqlProviderAdapter.class, method="delete")
int delete(DeleteStatementProvider deleteStatement);
@Generated("org.mybatis.generator.api.MyBatisGenerator")
@InsertProvider(type=SqlProviderAdapter.class, method="insert")
@SelectKey(statement="SELECT LAST_INSERT_ID()", keyProperty="record.id", before=true, resultType=Long.class)
int insert(InsertStatementProvider<Order> insertStatement);
@Generated("org.mybatis.generator.api.MyBatisGenerator")
@SelectProvider(type=SqlProviderAdapter.class, method="select")
@Results(id="OrderResult", value = {
@Result(column="id", property="id", jdbcType=JdbcType.BIGINT, id=true),
@Result(column="order_id", property="orderId", jdbcType=JdbcType.VARCHAR),
@Result(column="create_time", property="createTime", jdbcType=JdbcType.TIMESTAMP),
@Result(column="amount", property="amount", jdbcType=JdbcType.DECIMAL),
@Result(column="order_status", property="orderStatus", jdbcType=JdbcType.TINYINT)
})
Optional<Order> selectOne(SelectStatementProvider selectStatement);
@Generated("org.mybatis.generator.api.MyBatisGenerator")
@SelectProvider(type=SqlProviderAdapter.class, method="select")
@Results(id="OrderResult", value = {
@Result(column="id", property="id", jdbcType=JdbcType.BIGINT, id=true),
@Result(column="order_id", property="orderId", jdbcType=JdbcType.VARCHAR),
@Result(column="create_time", property="createTime", jdbcType=JdbcType.TIMESTAMP),
@Result(column="amount", property="amount", jdbcType=JdbcType.DECIMAL),
@Result(column="order_status", property="orderStatus", jdbcType=JdbcType.TINYINT)
})
List<Order> selectMany(SelectStatementProvider selectStatement);
@Generated("org.mybatis.generator.api.MyBatisGenerator")
@UpdateProvider(type=SqlProviderAdapter.class, method="update")
int update(UpdateStatementProvider updateStatement);
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default long count(CountDSLCompleter completer) {
return MyBatis3Utils.countFrom(this::count, order, completer);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default int delete(DeleteDSLCompleter completer) {
return MyBatis3Utils.deleteFrom(this::delete, order, completer);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default int deleteByPrimaryKey(Long id_) {
return delete(c ->
c.where(id, isEqualTo(id_))
);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default int insert(Order record) {
return MyBatis3Utils.insert(this::insert, record, order, c ->
c.map(id).toProperty("id")
.map(orderId).toProperty("orderId")
.map(createTime).toProperty("createTime")
.map(amount).toProperty("amount")
.map(orderStatus).toProperty("orderStatus")
);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default int insertSelective(Order record) {
return MyBatis3Utils.insert(this::insert, record, order, c ->
c.map(id).toProperty("id")
.map(orderId).toPropertyWhenPresent("orderId", record::getOrderId)
.map(createTime).toPropertyWhenPresent("createTime", record::getCreateTime)
.map(amount).toPropertyWhenPresent("amount", record::getAmount)
.map(orderStatus).toPropertyWhenPresent("orderStatus", record::getOrderStatus)
);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default Optional<Order> selectOne(SelectDSLCompleter completer) {
return MyBatis3Utils.selectOne(this::selectOne, selectList, order, completer);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default List<Order> select(SelectDSLCompleter completer) {
return MyBatis3Utils.selectList(this::selectMany, selectList, order, completer);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default List<Order> selectDistinct(SelectDSLCompleter completer) {
return MyBatis3Utils.selectDistinct(this::selectMany, selectList, order, completer);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default Optional<Order> selectByPrimaryKey(Long id_) {
return selectOne(c ->
c.where(id, isEqualTo(id_))
);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default int update(UpdateDSLCompleter completer) {
return MyBatis3Utils.update(this::update, order, completer);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
static UpdateDSL<UpdateModel> updateAllColumns(Order record, UpdateDSL<UpdateModel> dsl) {
return dsl.set(id).equalTo(record::getId)
.set(orderId).equalTo(record::getOrderId)
.set(createTime).equalTo(record::getCreateTime)
.set(amount).equalTo(record::getAmount)
.set(orderStatus).equalTo(record::getOrderStatus);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
static UpdateDSL<UpdateModel> updateSelectiveColumns(Order record, UpdateDSL<UpdateModel> dsl) {
return dsl.set(id).equalToWhenPresent(record::getId)
.set(orderId).equalToWhenPresent(record::getOrderId)
.set(createTime).equalToWhenPresent(record::getCreateTime)
.set(amount).equalToWhenPresent(record::getAmount)
.set(orderStatus).equalToWhenPresent(record::getOrderStatus);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default int updateByPrimaryKey(Order record) {
return update(c ->
c.set(orderId).equalTo(record::getOrderId)
.set(createTime).equalTo(record::getCreateTime)
.set(amount).equalTo(record::getAmount)
.set(orderStatus).equalTo(record::getOrderStatus)
.where(id, isEqualTo(record::getId))
);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default int updateByPrimaryKeySelective(Order record) {
return update(c ->
c.set(orderId).equalToWhenPresent(record::getOrderId)
.set(createTime).equalToWhenPresent(record::getCreateTime)
.set(amount).equalToWhenPresent(record::getAmount)
.set(orderStatus).equalToWhenPresent(record::getOrderStatus)
.where(id, isEqualTo(record::getId))
);
}
}
极简 XML 映射文件
极简XML映射文件生成只需要简单修改配置文件:
<context id="default" targetRuntime="MyBatis3Simple">
...
<javaClientGenerator type="XMLMAPPER"
...
生成三个文件:
// club.throwable.entity
public class Order {
private Long id;
private String orderId;
private Date createTime;
private BigDecimal amount;
private Byte orderStatus;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public Date getCreateTime() {
return createTime;
}
public void setCreateTime(Date createTime) {
this.createTime = createTime;
}
public BigDecimal getAmount() {
return amount;
}
public void setAmount(BigDecimal amount) {
this.amount = amount;
}
public Byte getOrderStatus() {
return orderStatus;
}
public void setOrderStatus(Byte orderStatus) {
this.orderStatus = orderStatus;
}
}
// club.throwable.dao
public interface OrderMapper {
int deleteByPrimaryKey(Long id);
int insert(Order record);
Order selectByPrimaryKey(Long id);
List<Order> selectAll();
int updateByPrimaryKey(Order record);
}
// mappings
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="club.throwable.dao.OrderMapper">
<resultMap id="BaseResultMap" type="club.throwable.entity.Order">
<id column="id" jdbcType="BIGINT" property="id"/>
<result column="order_id" jdbcType="VARCHAR" property="orderId"/>
<result column="create_time" jdbcType="TIMESTAMP" property="createTime"/>
<result column="amount" jdbcType="DECIMAL" property="amount"/>
<result column="order_status" jdbcType="TINYINT" property="orderStatus"/>
</resultMap>
<delete id="deleteByPrimaryKey" parameterType="java.lang.Long">
delete
from t_order
where id = #{id,jdbcType=BIGINT}
</delete>
<insert id="insert" parameterType="club.throwable.entity.Order">
<selectKey keyProperty="id" order="AFTER" resultType="java.lang.Long">
SELECT LAST_INSERT_ID()
</selectKey>
insert into t_order (order_id, create_time, amount,
order_status)
values (#{orderId,jdbcType=VARCHAR}, #{createTime,jdbcType=TIMESTAMP}, #{amount,jdbcType=DECIMAL},
#{orderStatus,jdbcType=TINYINT})
</insert>
<update id="updateByPrimaryKey" parameterType="club.throwable.entity.Order">
update t_order
set order_id = #{orderId,jdbcType=VARCHAR},
create_time = #{createTime,jdbcType=TIMESTAMP},
amount = #{amount,jdbcType=DECIMAL},
order_status = #{orderStatus,jdbcType=TINYINT}
where id = #{id,jdbcType=BIGINT}
</update>
<select id="selectByPrimaryKey" parameterType="java.lang.Long" resultMap="BaseResultMap">
select id, order_id, create_time, amount, order_status
from t_order
where id = #{id,jdbcType=BIGINT}
</select>
<select id="selectAll" resultMap="BaseResultMap">
select id, order_id, create_time, amount, order_status
from t_order
</select>
<resultMap id="BaseResultMap" type="club.throwable.entity.Order">
<id column="id" jdbcType="BIGINT" property="id"/>
<result column="order_id" jdbcType="VARCHAR" property="orderId"/>
<result column="create_time" jdbcType="TIMESTAMP" property="createTime"/>
<result column="amount" jdbcType="DECIMAL" property="amount"/>
<result column="order_status" jdbcType="TINYINT" property="orderStatus"/>
</resultMap>
<delete id="deleteByPrimaryKey" parameterType="java.lang.Long">
delete
from t_order
where id = #{id,jdbcType=BIGINT}
</delete>
<insert id="insert" parameterType="club.throwable.entity.Order">
<selectKey keyProperty="id" order="BEFORE" resultType="java.lang.Long">
SELECT LAST_INSERT_ID()
</selectKey>
insert into t_order (id, order_id, create_time,
amount, order_status)
values (#{id,jdbcType=BIGINT}, #{orderId,jdbcType=VARCHAR}, #{createTime,jdbcType=TIMESTAMP},
#{amount,jdbcType=DECIMAL}, #{orderStatus,jdbcType=TINYINT})
</insert>
<update id="updateByPrimaryKey" parameterType="club.throwable.entity.Order">
update t_order
set order_id = #{orderId,jdbcType=VARCHAR},
create_time = #{createTime,jdbcType=TIMESTAMP},
amount = #{amount,jdbcType=DECIMAL},
order_status = #{orderStatus,jdbcType=TINYINT}
where id = #{id,jdbcType=BIGINT}
</update>
<select id="selectByPrimaryKey" parameterType="java.lang.Long" resultMap="BaseResultMap">
select id, order_id, create_time, amount, order_status
from t_order
where id = #{id,jdbcType=BIGINT}
</select>
<select id="selectAll" resultMap="BaseResultMap">
select id, order_id, create_time, amount, order_status
from t_order
</select>
</mapper>
编程式自定义类型映射
笔者喜欢把所有的非长整型的数字,统一使用Integer接收,因此需要自定义类型映射。编写映射器如下:
public class DefaultJavaTypeResolver extends JavaTypeResolverDefaultImpl {
public DefaultJavaTypeResolver() {
super();
typeMap.put(Types.SMALLINT, new JdbcTypeInformation("SMALLINT",
new FullyQualifiedJavaType(Integer.class.getName())));
typeMap.put(Types.TINYINT, new JdbcTypeInformation("TINYINT",
new FullyQualifiedJavaType(Integer.class.getName())));
}
}
此时最好使用编程式运行代码生成器,修改XML配置文件:
<javaTypeResolver type="club.throwable.mbg.DefaultJavaTypeResolver">
<property name="forceBigDecimals" value="false"/>
</javaTypeResolver>
...
运行方法代码如下:
public class Main {
public static void main(String[] args) throws Exception {
List<String> warnings = new ArrayList<>();
// 如果已经存在生成过的文件是否进行覆盖
boolean overwrite = true;
ConfigurationParser cp = new ConfigurationParser(warnings);
Configuration config = cp.parseConfiguration(Main.class.getResourceAsStream("/generator-configuration.xml"));
DefaultShellCallback callback = new DefaultShellCallback(overwrite);
MyBatisGenerator generator = new MyBatisGenerator(config, callback, warnings);
generator.generate(null);
}
}
数据库的order_status是TINYINT类型,生成出来的文件中的orderStatus字段全部替换使用Integer类型定义。
总结
本文相对详尽地介绍了Mybatis Generator的使用方式,具体分析了XML配置文件中主要标签以及标签属性的功能。因为Mybatis在Java的ORM框架体系中还会有一段很长的时间处于主流地位,了解Mybatis Generator可以简化CRUD方法模板代码、实体以及Mapper接口代码生成,从而解放大量生产力。Mybatis Generator有不少第三方的扩展,例如tk.mapper或者mybatis-plus自身的扩展,可能附加的功能不一样,但是基本的使用是一致的。
引用
13 - CH13-多数据源
如果要在查询端实现数据库的主从访问,或者业务较复杂,需要访问不同的数据库,则需要实现多数据源的集成与切换。
配置文件
mybatis.config-location=classpath:mybatis/mybatis-config.xml
spring.datasource.test1.jdbc-url=jdbc:mysql://localhost:3306/test1?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true
spring.datasource.test1.username=root
spring.datasource.test1.password=root
spring.datasource.test1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.test2.jdbc-url=jdbc:mysql://localhost:3306/test2?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true
spring.datasource.test2.username=root
spring.datasource.test2.password=root
spring.datasource.test2.driver-class-name=com.mysql.cj.jdbc.Driver
一个 test1 库和一个 test2 库,其中 test1 位主库,在使用的过程中必须指定主库,不然会报错。
数据源配置
@Configuration
@MapperScan(basePackages = "com.neo.mapper.test1", sqlSessionTemplateRef = "test1SqlSessionTemplate")
public class DataSource1Config {
@Bean(name = "test1DataSource")
@ConfigurationProperties(prefix = "spring.datasource.test1")
@Primary
public DataSource testDataSource() {
return DataSourceBuilder.create().build();
}
@Bean(name = "test1SqlSessionFactory")
@Primary
public SqlSessionFactory testSqlSessionFactory(@Qualifier("test1DataSource") DataSource dataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mybatis/mapper/test1/*.xml"));
return bean.getObject();
}
@Bean(name = "test1TransactionManager")
@Primary
public DataSourceTransactionManager testTransactionManager(@Qualifier("test1DataSource") DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
@Bean(name = "test1SqlSessionTemplate")
@Primary
public SqlSessionTemplate testSqlSessionTemplate(@Qualifier("test1SqlSessionFactory") SqlSessionFactory sqlSessionFactory) throws Exception {
return new SqlSessionTemplate(sqlSessionFactory);
}
}
最关键的地方就是这块了,一层一层注入,首先创建 DataSource,然后创建 SqlSessionFactory 再创建事务,最后包装到 SqlSessionTemplate 中。其中需要指定分库的 mapper 文件地址,以及分库dao层代码:
@MapperScan(basePackages = "com.neo.mapper.test1", sqlSessionTemplateRef = "test1SqlSessionTemplate")
这块的注解就是指明了扫描 dao 层,并且给 dao 层注入指定的 SqlSessionTemplate。所有@Bean都需要按照命名指定正确。
dao & mapper
dao 层和 xml 需要按照库来分在不同的目录,比如:test1 库 dao 层在 com.neo.mapper.test1 包下,test2 库在com.neo.mapper.test2:
public interface User1Mapper {
List<UserEntity> getAll();
UserEntity getOne(Long id);
void insert(UserEntity user);
void update(UserEntity user);
void delete(Long id);
}
mapper:
<mapper namespace="com.neo.mapper.test1.User1Mapper" >
<resultMap id="BaseResultMap" type="com.neo.model.User" >
<id column="id" property="id" jdbcType="BIGINT" />
<result column="userName" property="userName" jdbcType="VARCHAR" />
<result column="passWord" property="passWord" jdbcType="VARCHAR" />
<result column="user_sex" property="userSex" javaType="com.neo.enums.UserSexEnum"/>
<result column="nick_name" property="nickName" jdbcType="VARCHAR" />
</resultMap>
<sql id="Base_Column_List" >
id, userName, passWord, user_sex, nick_name
</sql>
<select id="getAll" resultMap="BaseResultMap" >
SELECT
<include refid="Base_Column_List" />
FROM users
</select>
<select id="getOne" parameterType="java.lang.Long" resultMap="BaseResultMap" >
SELECT
<include refid="Base_Column_List" />
FROM users
WHERE id = #{id}
</select>
<insert id="insert" parameterType="com.neo.model.User" >
INSERT INTO
users
(userName,passWord,user_sex)
VALUES
(#{userName}, #{passWord}, #{userSex})
</insert>
<update id="update" parameterType="com.neo.model.User" >
UPDATE
users
SET
<if test="userName != null">userName = #{userName},</if>
<if test="passWord != null">passWord = #{passWord},</if>
nick_name = #{nickName}
WHERE
id = #{id}
</update>
<delete id="delete" parameterType="java.lang.Long" >
DELETE FROM
users
WHERE
id =#{id}
</delete>
</mapper>
测试验证
测试可以使用 SpringBootTest,也可以放到 Controller中,这里只贴 Controller 层的使用:
@RestController
public class UserController {
@Autowired
private User1Mapper user1Mapper;
@Autowired
private User2Mapper user2Mapper;
@RequestMapping("/getUsers")
public List<UserEntity> getUsers() {
List<UserEntity> users=user1Mapper.getAll();
return users;
}
@RequestMapping("/getUser")
public UserEntity getUser(Long id) {
UserEntity user=user2Mapper.getOne(id);
return user;
}
@RequestMapping("/add")
public void save(UserEntity user) {
user2Mapper.insert(user);
}
@RequestMapping(value="update")
public void update(UserEntity user) {
user2Mapper.update(user);
}
@RequestMapping(value="/delete/{id}")
public void delete(@PathVariable("id") Long id) {
user1Mapper.delete(id);
}
}
14 - CH14-常用片段
容器循环 foreach
foreach 元素的属性主要有:
- item:集合中元素迭代时的别名
- index:集合中元素迭代时的索引
- open:常用语where语句中,表示以什么开始,比如以’(‘开始
- separator:表示在每次进行迭代时的分隔符
- close 常用语where语句中,表示以什么结束
在使用 foreach 的时候最关键的也是最容易出错的就是 collection 属性,该属性是必须指定的,但是在不同情况下,该属性的值是不一样的,主要有一下 3 种情况:
- 如果传入的是单参数且参数类型是一个 List 的时候,collection 属性值为 list。
- 如果传入的是单参数且参数类型是一个 array 数组的时候,collection 的属性值为 array。
- 如果传入的参数是多个的时候,我们就需要把它们封装成一个 Map 了,当然单参数也可以封装成 map,实际上如果你在传入参数的时候,在 MyBatis 里面也是会把它封装成一个 Map 的,map 的 key 就是参数名,所以这个时候 collection 属性值就是传入的 List 或 array 对象在自己封装的 map 里面的 key.
针对最后一条,我们看一下官方的说法:
注意:你可以将一个 List 实例或者数组作为参数对象传给 MyBatis,当你这么做的时候,MyBatis 会自动将它包装在一个 Map 中并以名称为键。List 实例将会以 “list” 作为键,而数组实例的键将是 “array”。
所以,不管是多参数还是单参数的 list,array 类型,都可以封装为 map 进行传递。如果传递的是一个 List,则 mybatis 会封装为一个 list 为 key,list 值为 object 的 map,如果是 array,则封装成一个 array 为 key,array 的值为 object 的 map,如果自己封装呢,则 colloection里 放的是自己封装的 map 里的 key 值。
//mapper中我们要为这个方法传递的是一个容器,将容器中的元素一个一个的
//拼接到xml的方法中就要使用这个forEach这个标签了
public List<Entity> queryById(List<String> userids);
//对应的xml中如下
<select id="queryById" resultMap="BaseReslutMap" >
select * FROM entity
where id in
<foreach collection="userids" item="userid" index="index" open="(" separator="," close=")">
#{userid}
</foreach>
</select>
foreach array
public List<StudentEntity> getStudentListByClassIds_foreach_array(String[] classIds);
<!-- 7.1 foreach(循环array参数) - 作为where中in的条件 -->
<select id="getStudentListByClassIds_foreach_array" resultMap="resultMap_studentEntity">
SELECT ST.STUDENT_ID,
ST.STUDENT_NAME,
ST.STUDENT_SEX,
ST.STUDENT_BIRTHDAY,
ST.STUDENT_PHOTO,
ST.CLASS_ID,
ST.PLACE_ID
FROM STUDENT_TBL ST
WHERE ST.CLASS_ID IN
<foreach collection="array" item="classIds" open="(" separator="," close=")">
#{classIds}
</foreach>
</select>
foreach list
public List<StudentEntity> getStudentListByClassIds_foreach_list(List<String> classIdList);
<!-- 7.2 foreach(循环List<String>参数) - 作为where中in的条件 -->
<select id="getStudentListByClassIds_foreach_list" resultMap="resultMap_studentEntity">
SELECT ST.STUDENT_ID,
ST.STUDENT_NAME,
ST.STUDENT_SEX,
ST.STUDENT_BIRTHDAY,
ST.STUDENT_PHOTO,
ST.CLASS_ID,
ST.PLACE_ID
FROM STUDENT_TBL ST
WHERE ST.CLASS_ID IN
<foreach collection="list" item="classIdList" open="(" separator="," close=")">
#{classIdList}
</foreach>
</select>
模糊查询 concat
//比如说我们想要进行条件查询,但是几个条件不是每次都要使用,那么我们就可以
//通过判断是否拼接到sql中
<select id="queryById" resultMap="BascResultMap" parameterType="entity">
SELECT * from entity
<where>
<if test="name!=null">
name like concat('%',concat(#{name},'%'))
</if>
</where>
</select>
choose、when、otherwise
choose 标签是按顺序判断其内部 when 标签中的 test 条件出否成立,如果有一个成立,则 choose 结束。当 choose 中所有 when 的条件都不满则时,则执行 otherwise 中的 sql。类似于 Java 的 switch 语句,choose 为 switch,when 为 case,otherwise 则为 default。
例如下面例子,同样把所有可以限制的条件都写上,方面使用。choose 会从上到下选择一个 when 标签的 test 为 true 的 sql 执行。安全考虑,我们使用 where 将 choose 包起来,放置关键字多于错误。
<!-- choose(判断参数) - 按顺序将实体类 User 第一个不为空的属性作为:where条件 -->
<select id="getUserList_choose" resultMap="resultMap_user" parameterType="com.yiibai.pojo.User">
SELECT *
FROM User u
<where>
<choose>
<when test="username !=null ">
u.username LIKE CONCAT(CONCAT('%', #{username, jdbcType=VARCHAR}),'%')
</when >
<when test="sex != null and sex != '' ">
AND u.sex = #{sex, jdbcType=INTEGER}
</when >
<when test="birthday != null ">
AND u.birthday = #{birthday, jdbcType=DATE}
</when >
<otherwise>
</otherwise>
</choose>
</where>
</select>
selectKey
在insert语句中,在Oracle经常使用序列、在MySQL中使用函数来自动生成插入表的主键,而且需要方法能返回这个生成主键。使用myBatis的selectKey标签可以实现这个效果。
下面例子,使用 mysql 数据库自定义函数 nextval(‘student’),用来生成一个 key,并把他设置到传入的实体类中的 studentId 属性上。所以在执行完此方法后,边可以通过这个实体类获取生成的 key。
<!-- 插入学生 自动主键-->
<insert id="createStudentAutoKey" parameterType="com.demo.model.StudentEntity" keyProperty="studentId">
<selectKey keyProperty="studentId" resultType="String" order="BEFORE">
select nextval('student')
</selectKey>
INSERT INTO STUDENT_TBL(STUDENT_ID,
STUDENT_NAME,
STUDENT_SEX,
STUDENT_BIRTHDAY,
STUDENT_PHOTO,
CLASS_ID,
PLACE_ID)
VALUES (#{studentId},
#{studentName},
#{studentSex},
#{studentBirthday},
#{studentPhoto, javaType=byte[], jdbcType=BLOB, typeHandler=org.apache.ibatis.type.BlobTypeHandler},
#{classId},
#{placeId})
</insert>
调用接口方法,和获取自动生成 key:
StudentEntity entity = new StudentEntity();
entity.setStudentName("黎明你好");
entity.setStudentSex(1);
entity.setStudentBirthday(DateUtil.parse("1985-05-28"));
entity.setClassId("20000001");
entity.setPlaceId("70000001");
this.dynamicSqlMapper.createStudentAutoKey(entity);
System.out.println("新增学生ID: " + entity.getStudentId());
if
if 标签可用在许多类型的 sql 语句中,我们以查询为例。首先看一个很普通的查询:
<!-- 查询学生list,like姓名 -->
<select id="getStudentListLikeName" parameterType="StudentEntity" resultMap="studentResultMap">
SELECT * from STUDENT_TBL ST
WHERE ST.STUDENT_NAME LIKE CONCAT(CONCAT('%', #{studentName}),'%')
</select>
但是此时如果 studentName 为 null,此语句很可能报错或查询结果为空。此时我们使用 if 动态 sql 语句先进行判断,如果值为 null 或等于空字符串,我们就不进行此条件的判断,增加灵活性。
参数为实体类 StudentEntity。将实体类中所有的属性均进行判断,如果不为空则执行判断条件。
<!-- 2 if(判断参数) - 将实体类不为空的属性作为where条件 -->
<select id="getStudentList_if" resultMap="resultMap_studentEntity" parameterType="liming.student.manager.data.model.StudentEntity">
SELECT ST.STUDENT_ID,
ST.STUDENT_NAME,
ST.STUDENT_SEX,
ST.STUDENT_BIRTHDAY,
ST.STUDENT_PHOTO,
ST.CLASS_ID,
ST.PLACE_ID
FROM STUDENT_TBL ST
WHERE
<if test="studentName !=null ">
ST.STUDENT_NAME LIKE CONCAT(CONCAT('%', #{studentName, jdbcType=VARCHAR}),'%')
</if>
<if test="studentSex != null and studentSex != '' ">
AND ST.STUDENT_SEX = #{studentSex, jdbcType=INTEGER}
</if>
<if test="studentBirthday != null ">
AND ST.STUDENT_BIRTHDAY = #{studentBirthday, jdbcType=DATE}
</if>
<if test="classId != null and classId!= '' ">
AND ST.CLASS_ID = #{classId, jdbcType=VARCHAR}
</if>
<if test="classEntity != null and classEntity.classId !=null and classEntity.classId !=' ' ">
AND ST.CLASS_ID = #{classEntity.classId, jdbcType=VARCHAR}
</if>
<if test="placeId != null and placeId != '' ">
AND ST.PLACE_ID = #{placeId, jdbcType=VARCHAR}
</if>
<if test="placeEntity != null and placeEntity.placeId != null and placeEntity.placeId != '' ">
AND ST.PLACE_ID = #{placeEntity.placeId, jdbcType=VARCHAR}
</if>
<if test="studentId != null and studentId != '' ">
AND ST.STUDENT_ID = #{studentId, jdbcType=VARCHAR}
</if>
</select>
使用时比较灵活,new 一个这样的实体类,我们需要限制那个条件,只需要附上相应的值就会 where 这个条件,相反不去赋值就可以不在 where 中判断。
public void select_test_2_1() {
StudentEntity entity = new StudentEntity();
entity.setStudentName("");
entity.setStudentSex(1);
entity.setStudentBirthday(DateUtil.parse("1985-05-28"));
entity.setClassId("20000001");
//entity.setPlaceId("70000001");
List<StudentEntity> list = this.dynamicSqlMapper.getStudentList_if(entity);
for (StudentEntity e : list) {
System.out.println(e.toString());
}
}
if + where
当 where 中的条件使用的 if 标签较多时,这样的组合可能会导致错误。我们以在 3.1 中的查询语句为例子,当 java 代码按如下方法调用时:
@Test
public void select_test_2_1() {
StudentEntity entity = new StudentEntity();
entity.setStudentName(null);
entity.setStudentSex(1);
List<StudentEntity> list = this.dynamicSqlMapper.getStudentList_if(entity);
for (StudentEntity e : list) {
System.out.println(e.toString());
}
}
如果上面例子,参数studentName为null,将不会进行STUDENT_NAME列的判断,则会直接导“WHERE AND”关键字多余的错误SQL。
这时我们可以使用where动态语句来解决。这个“where”标签会知道如果它包含的标签中有返回值的话,它就插入一个‘where’。此外,如果标签返回的内容是以AND 或OR 开头的,则它会剔除掉。
上面例子修改为:
<!-- 3 select - where/if(判断参数) - 将实体类不为空的属性作为where条件 -->
<select id="getStudentList_whereIf" resultMap="resultMap_studentEntity" parameterType="liming.student.manager.data.model.StudentEntity">
SELECT ST.STUDENT_ID,
ST.STUDENT_NAME,
ST.STUDENT_SEX,
ST.STUDENT_BIRTHDAY,
ST.STUDENT_PHOTO,
ST.CLASS_ID,
ST.PLACE_ID
FROM STUDENT_TBL ST
<where>
<if test="studentName !=null ">
ST.STUDENT_NAME LIKE CONCAT(CONCAT('%', #{studentName, jdbcType=VARCHAR}),'%')
</if>
<if test="studentSex != null and studentSex != '' ">
AND ST.STUDENT_SEX = #{studentSex, jdbcType=INTEGER}
</if>
<if test="studentBirthday != null ">
AND ST.STUDENT_BIRTHDAY = #{studentBirthday, jdbcType=DATE}
</if>
<if test="classId != null and classId!= '' ">
AND ST.CLASS_ID = #{classId, jdbcType=VARCHAR}
</if>
<if test="classEntity != null and classEntity.classId !=null and classEntity.classId !=' ' ">
AND ST.CLASS_ID = #{classEntity.classId, jdbcType=VARCHAR}
</if>
<if test="placeId != null and placeId != '' ">
AND ST.PLACE_ID = #{placeId, jdbcType=VARCHAR}
</if>
<if test="placeEntity != null and placeEntity.placeId != null and placeEntity.placeId != '' ">
AND ST.PLACE_ID = #{placeEntity.placeId, jdbcType=VARCHAR}
</if>
<if test="studentId != null and studentId != '' ">
AND ST.STUDENT_ID = #{studentId, jdbcType=VARCHAR}
</if>
</where>
</select>
if + set
当update语句中没有使用if标签时,如果有一个参数为null,都会导致错误。
当在update语句中使用if标签时,如果前面的if没有执行,则或导致逗号多余错误。使用set标签可以将动态的配置SET 关键字,和剔除追加到条件末尾的任何不相关的逗号。使用if+set标签修改后,如果某项为null则不进行更新,而是保持数据库原值。
如下示例:
<!-- 4 if/set(判断参数) - 将实体类不为空的属性更新 -->
<update id="updateStudent_if_set" parameterType="liming.student.manager.data.model.StudentEntity">
UPDATE STUDENT_TBL
<set>
<if test="studentName != null and studentName != '' ">
STUDENT_TBL.STUDENT_NAME = #{studentName},
</if>
<if test="studentSex != null and studentSex != '' ">
STUDENT_TBL.STUDENT_SEX = #{studentSex},
</if>
<if test="studentBirthday != null ">
STUDENT_TBL.STUDENT_BIRTHDAY = #{studentBirthday},
</if>
<if test="studentPhoto != null ">
STUDENT_TBL.STUDENT_PHOTO = #{studentPhoto, javaType=byte[], jdbcType=BLOB, typeHandler=org.apache.ibatis.type.BlobTypeHandler},
</if>
<if test="classId != '' ">
STUDENT_TBL.CLASS_ID = #{classId}
</if>
<if test="placeId != '' ">
STUDENT_TBL.PLACE_ID = #{placeId}
</if>
</set>
WHERE STUDENT_TBL.STUDENT_ID = #{studentId};
</update>
if + trim 代替 where/set
trim是更灵活的去处多余关键字的标签,他可以实践where和set的效果。
trim 代替 where
<!-- 5.1if/trim代替where(判断参数) -将实体类不为空的属性作为where条件-->
<select id="getStudentList_if_trim" resultMap="resultMap_studentEntity">
SELECT ST.STUDENT_ID,
ST.STUDENT_NAME,
ST.STUDENT_SEX,
ST.STUDENT_BIRTHDAY,
ST.STUDENT_PHOTO,
ST.CLASS_ID,
ST.PLACE_ID
FROM STUDENT_TBL ST
<trim prefix="WHERE" prefixOverrides="AND|OR">
<if test="studentName !=null ">
ST.STUDENT_NAME LIKE CONCAT(CONCAT('%', #{studentName, jdbcType=VARCHAR}),'%')
</if>
<if test="studentSex != null and studentSex != '' ">
AND ST.STUDENT_SEX = #{studentSex, jdbcType=INTEGER}
</if>
<if test="studentBirthday != null ">
AND ST.STUDENT_BIRTHDAY = #{studentBirthday, jdbcType=DATE}
</if>
<if test="classId != null and classId!= '' ">
AND ST.CLASS_ID = #{classId, jdbcType=VARCHAR}
</if>
<if test="classEntity != null and classEntity.classId !=null and classEntity.classId !=' ' ">
AND ST.CLASS_ID = #{classEntity.classId, jdbcType=VARCHAR}
</if>
<if test="placeId != null and placeId != '' ">
AND ST.PLACE_ID = #{placeId, jdbcType=VARCHAR}
</if>
<if test="placeEntity != null and placeEntity.placeId != null and placeEntity.placeId != '' ">
AND ST.PLACE_ID = #{placeEntity.placeId, jdbcType=VARCHAR}
</if>
<if test="studentId != null and studentId != '' ">
AND ST.STUDENT_ID = #{studentId, jdbcType=VARCHAR}
</if>
</trim>
</select>
trim 代替 set
<!-- 5.2 if/trim代替set(判断参数) - 将实体类不为空的属性更新 -->
<update id="updateStudent_if_trim" parameterType="liming.student.manager.data.model.StudentEntity">
UPDATE STUDENT_TBL
<trim prefix="SET" suffixOverrides=",">
<if test="studentName != null and studentName != '' ">
STUDENT_TBL.STUDENT_NAME = #{studentName},
</if>
<if test="studentSex != null and studentSex != '' ">
STUDENT_TBL.STUDENT_SEX = #{studentSex},
</if>
<if test="studentBirthday != null ">
STUDENT_TBL.STUDENT_BIRTHDAY = #{studentBirthday},
</if>
<if test="studentPhoto != null ">
STUDENT_TBL.STUDENT_PHOTO = #{studentPhoto, javaType=byte[], jdbcType=BLOB, typeHandler=org.apache.ibatis.type.BlobTypeHandler},
</if>
<if test="classId != '' ">
STUDENT_TBL.CLASS_ID = #{classId},
</if>
<if test="placeId != '' ">
STUDENT_TBL.PLACE_ID = #{placeId}
</if>
</trim>
WHERE STUDENT_TBL.STUDENT_ID = #{studentId}
</update>
sql 复用
sql片段标签
需要配置的属性:id="" »>表示需要改sql语句片段的唯一标识
引用:通过
<!--定义sql片段-->
<sql id="orderAndItem">
o.order_id,o.cid,o.address,o.create_date,o.orderitem_id,i.orderitem_id,i.product_id,i.count
</sql>
<select id="findOrderAndItemsByOid" parameterType="java.lang.String" resultMap="BaseResultMap">
select
<!--引用sql片段-->
<include refid="orderAndItem" />
from ordertable o
join orderitem i on o.orderitem_id = i.orderitem_id
where o.order_id = #{orderId}
</select>
upsert
基于唯一键冲突
<select id="createRecord" parameterType="map" resultType="long" flushCache="true">
INSERT INTO MYTABLE (id, name, creator, description)
VALUES (nextval('my_seq'), #{name}, #{creator}, #{description})
ON CONFLICT ON CONSTRAINT (name, creator)
DO UPDATE SET
name = #{name},
creator = #{creator},
description = #{description}
RETURNING id
</insert>
基于主键
<insert id="AddTeacher" parameterType="com.mycompany.entity.Teacher">
<selectKey keyProperty="count" resultType="int" order="BEFORE">
select count(*) from Teacher where teacher_id = #{teacherId}
</selectKey>
<if test="count > 0">
update event
<set>
<if test="teacherName!= null" >
teacher_name= #{teacherName},
</if>
</set>
<where>
teacher_id = #{teacherId}
</where>
</if>
<if test="count==0">
insert into teacher(teacher_id,teacher_name) values (#{teacherId},#{teacherName})
</if>
</insert>
基于唯一键冲突批量执行
public interface ExcelDataMapper {
/**
* 根据excel解析的实体,插入到数据库。
*
* @param dbColumnToValueMap <code>Map<String, String></code> 表示excel解析的实体。
*/
int insert(@Param("dbColumnToValueMap") Map<String, Object> dbColumnToValueMap);
}
<insert id="upsert" parameterType="map">
insert into excel_data_info
<foreach collection="dbColumnToValueMap.keys" item="key" open="(" close=")" separator=",">
${key}
</foreach>
values
<foreach collection="dbColumnToValueMap.keys" item="key" open="(" close=")" separator=",">
#{dbColumnToValueMap[${key}]}
</foreach>
on duplicate key update
<foreach collection="dbColumnToValueMap.keys" item="key" separator="," >
<if test=" key != 'id' ">
${key} = #{dbColumnToValueMap[${key}]}
</if>
</foreach>
</insert>
15 - CH15-事务管理原理
概述
对数据库的事务而言,应该具有以下几点:创建(create)、提交(commit)、回滚(rollback)、关闭(close)。对应地,MyBatis将事务抽象成了Transaction接口:
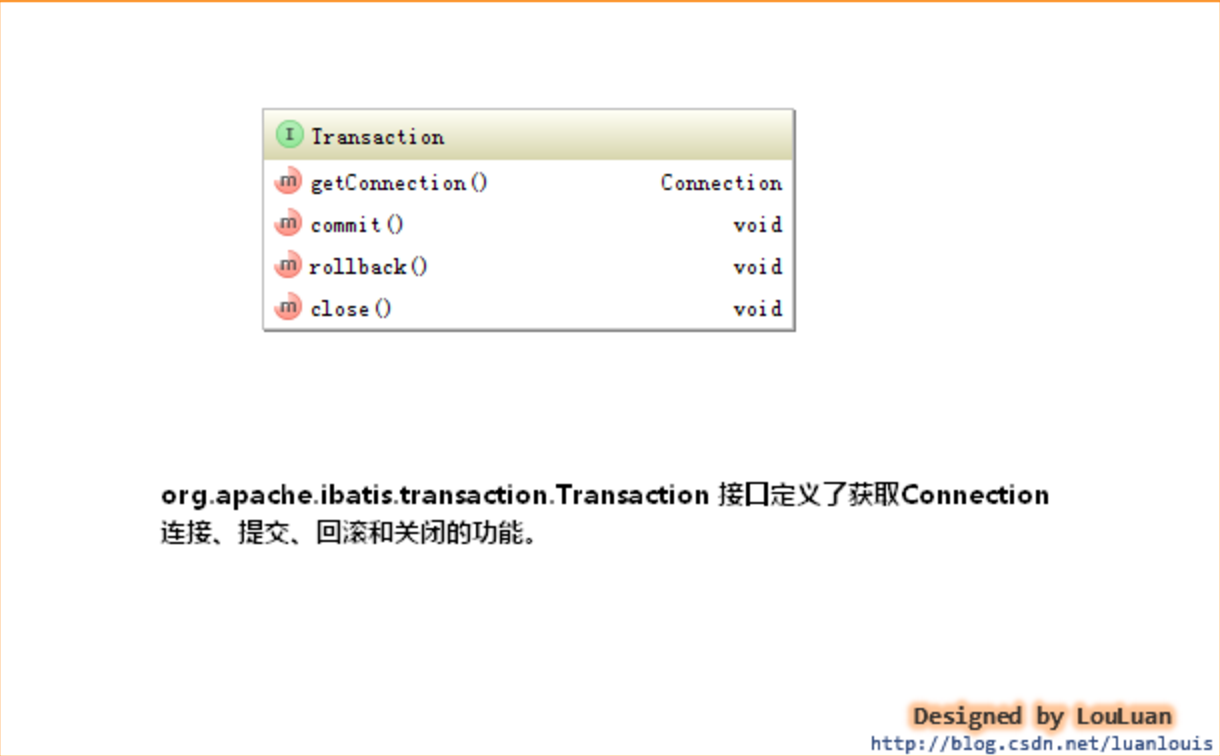
MyBatis的事务管理分为两种形式:
- 使用JDBC的事务管理机制:即利用java.sql.Connection对象完成对事务的提交(commit())、回滚(rollback())、关闭(close())等。
- 使用MANAGED的事务管理机制:这种机制MyBatis自身不会去实现事务管理,而是让程序的容器如(JBOSS,Weblogic)来实现对事务的管理。
这两者的类图如下所示:
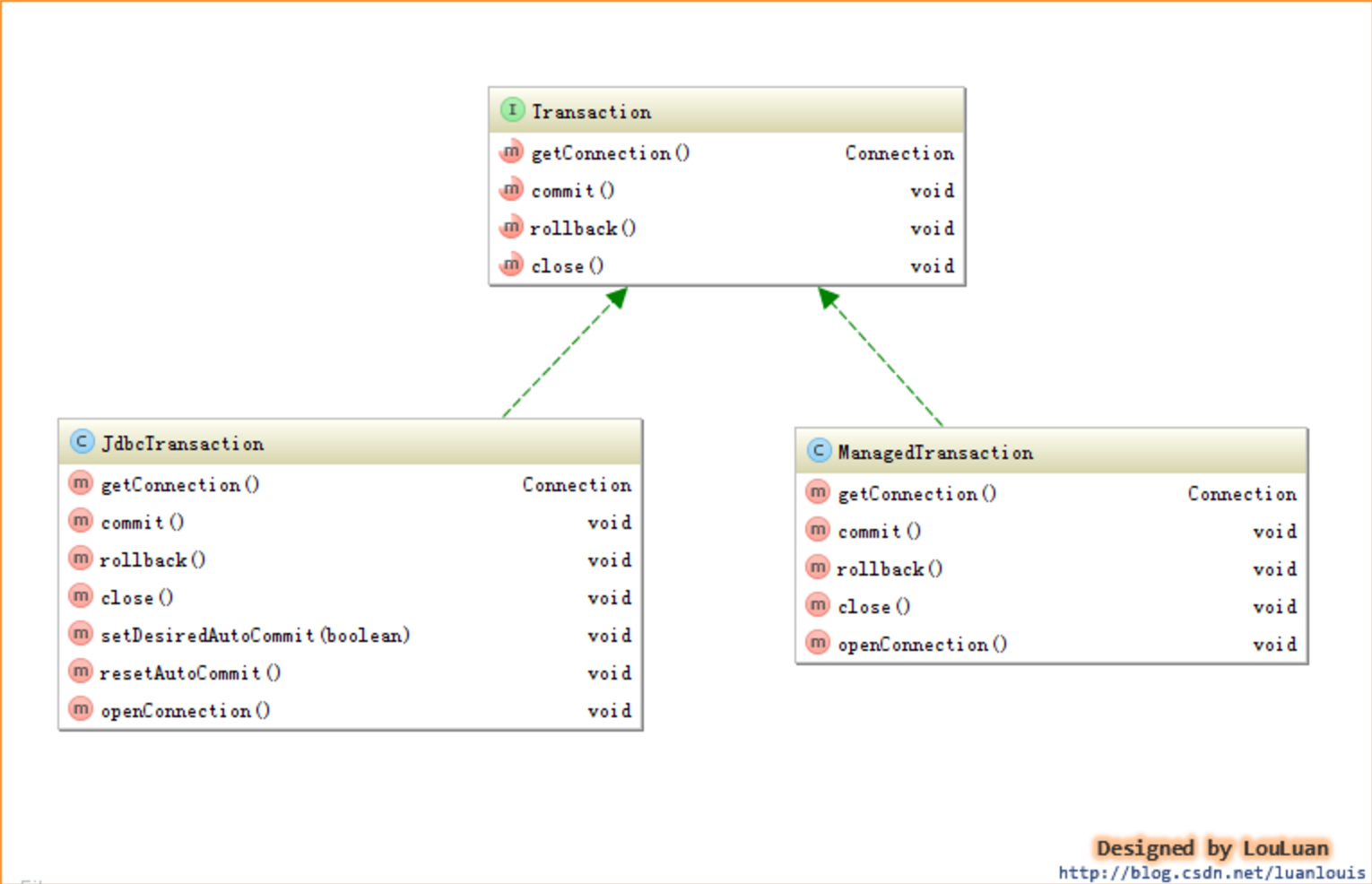
事务配置
在 MyBatis 中有两种类型的事务管理器(也就是 type="[JDBC|MANAGED]"):
- JDBC – 这个配置直接使用了 JDBC 的提交和回滚设施,它依赖从数据源获得的连接来管理事务作用域。
- MANAGED – 这个配置几乎没做什么。它从不提交或回滚一个连接,而是让容器来管理事务的整个生命周期(比如 JEE 应用服务器的上下文)。 默认情况下它会关闭连接。然而一些容器并不希望连接被关闭,因此需要将 closeConnection 属性设置为 false 来阻止默认的关闭行为。例如:
<transactionManager type="MANAGED">
<property name="closeConnection" value="false"/>
</transactionManager>
如果你正在使用 Spring + MyBatis,则没有必要配置事务管理器,因为 Spring 模块会使用自带的管理器来覆盖前面的配置。
这两种事务管理器类型都不需要设置任何属性。它们其实是类型别名,换句话说,你可以用 TransactionFactory 接口实现类的全限定名或类型别名代替它们。
public interface TransactionFactory {
default void setProperties(Properties props) { // 从 3.5.2 开始,该方法为默认方法
// 空实现
}
Transaction newTransaction(Connection conn);
Transaction newTransaction(DataSource dataSource, TransactionIsolationLevel level, boolean autoCommit);
}
在事务管理器实例化后,所有在 XML 中配置的属性将会被传递给 setProperties() 方法。你的实现还需要创建一个 Transaction 接口的实现类,这个接口也很简单:
public interface Transaction {
Connection getConnection() throws SQLException;
void commit() throws SQLException;
void rollback() throws SQLException;
void close() throws SQLException;
Integer getTimeout() throws SQLException;
}
使用这两个接口,你可以完全自定义 MyBatis 对事务的处理。
事务的配置、创建和使用
事务的配置
我们在使用MyBatis时,一般会在MyBatisXML配置文件中定义类似如下的信息:
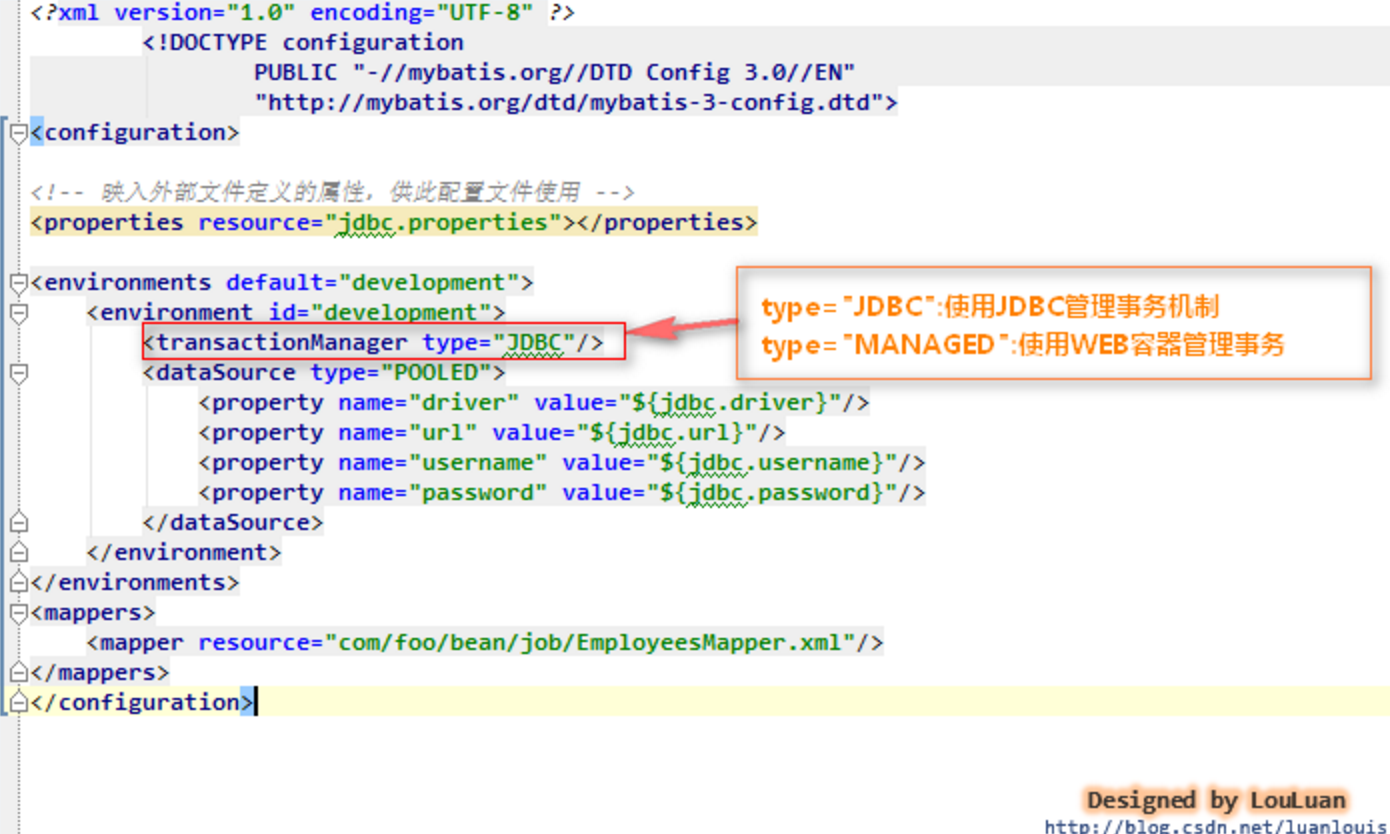
<environment>节点定义了连接某个数据库的信息,其子节点<transactionManager> 的type 会决定我们用什么类型的事务管理机制。
事务工厂的创建
MyBatis事务的创建是交给TransactionFactory 事务工厂来创建的,如果我们将<transactionManager>的type 配置为"JDBC",那么,在MyBatis初始化解析 <environment>节点时,会根据type=“JDBC"创建一个JdbcTransactionFactory工厂,其源码如下:
/**
* 解析<transactionManager>节点,创建对应的TransactionFactory
* @param context
* @return
* @throws Exception
*/
private TransactionFactory transactionManagerElement(XNode context) throws Exception {
if (context != null) {
String type = context.getStringAttribute("type");
Properties props = context.getChildrenAsProperties();
/*
* 在Configuration初始化的时候,会通过以下语句,给JDBC和MANAGED对应的工厂类
* typeAliasRegistry.registerAlias("JDBC", JdbcTransactionFactory.class);
* typeAliasRegistry.registerAlias("MANAGED", ManagedTransactionFactory.class);
* 下述的resolveClass(type).newInstance()会创建对应的工厂实例
*/
TransactionFactory factory = (TransactionFactory) resolveClass(type).newInstance();
factory.setProperties(props);
return factory;
}
throw new BuilderException("Environment declaration requires a TransactionFactory.");
}
@pdai: 代码已经复制到剪贴板
如上述代码所示,如果type = “JDBC”,则MyBatis会创建一个JdbcTransactionFactory.class 实例;如果type=“MANAGED”,则MyBatis会创建一个MangedTransactionFactory.class实例。
MyBatis对<transactionManager>节点的解析会生成TransactionFactory实例;而对<dataSource>解析会生成datasouce实例,作为<environment>节点,会根据TransactionFactory和DataSource实例创建一个Environment对象,代码如下所示:
private void environmentsElement(XNode context) throws Exception {
if (context != null) {
if (environment == null) {
environment = context.getStringAttribute("default");
}
for (XNode child : context.getChildren()) {
String id = child.getStringAttribute("id");
//是和默认的环境相同时,解析之
if (isSpecifiedEnvironment(id)) {
//1.解析<transactionManager>节点,决定创建什么类型的TransactionFactory
TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));
//2. 创建dataSource
DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));
DataSource dataSource = dsFactory.getDataSource();
//3. 使用了Environment内置的构造器Builder,传递id 事务工厂TransactionFactory和数据源DataSource
Environment.Builder environmentBuilder = new Environment.Builder(id)
.transactionFactory(txFactory)
.dataSource(dataSource);
configuration.setEnvironment(environmentBuilder.build());
}
}
}
}
Environment表示着一个数据库的连接,生成后的Environment对象会被设置到Configuration实例中,以供后续的使用。
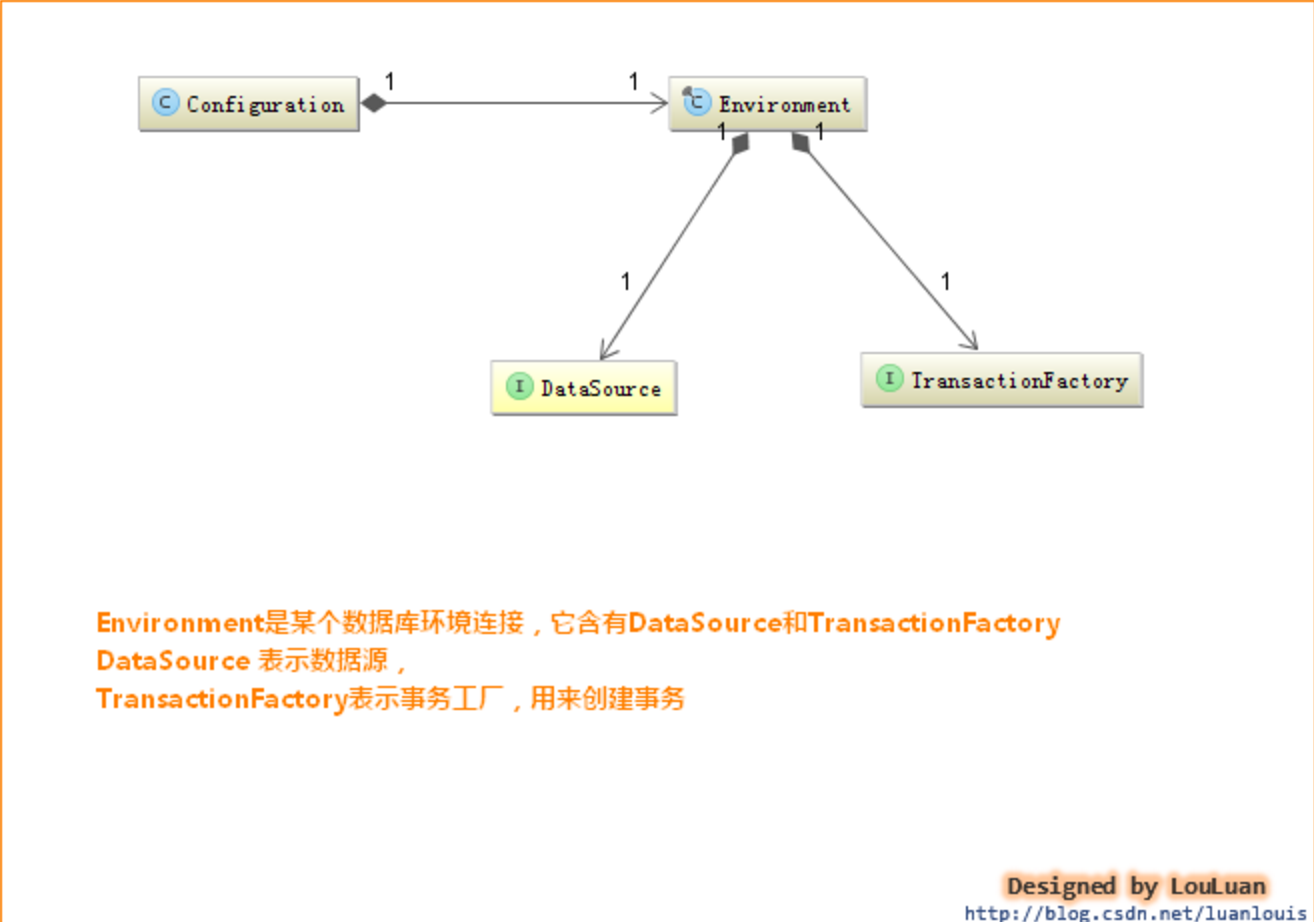
上述一直在讲事务工厂TransactionFactory来创建的Transaction,现在让我们看一下MyBatis中的TransactionFactory的定义吧。
事务工厂 TransactionFactory
事务工厂Transaction定义了创建Transaction的两个方法:一个是通过指定的Connection对象创建Transaction,另外是通过数据源DataSource来创建Transaction。与JDBC 和MANAGED两种Transaction相对应,TransactionFactory有两个对应的实现的子类:
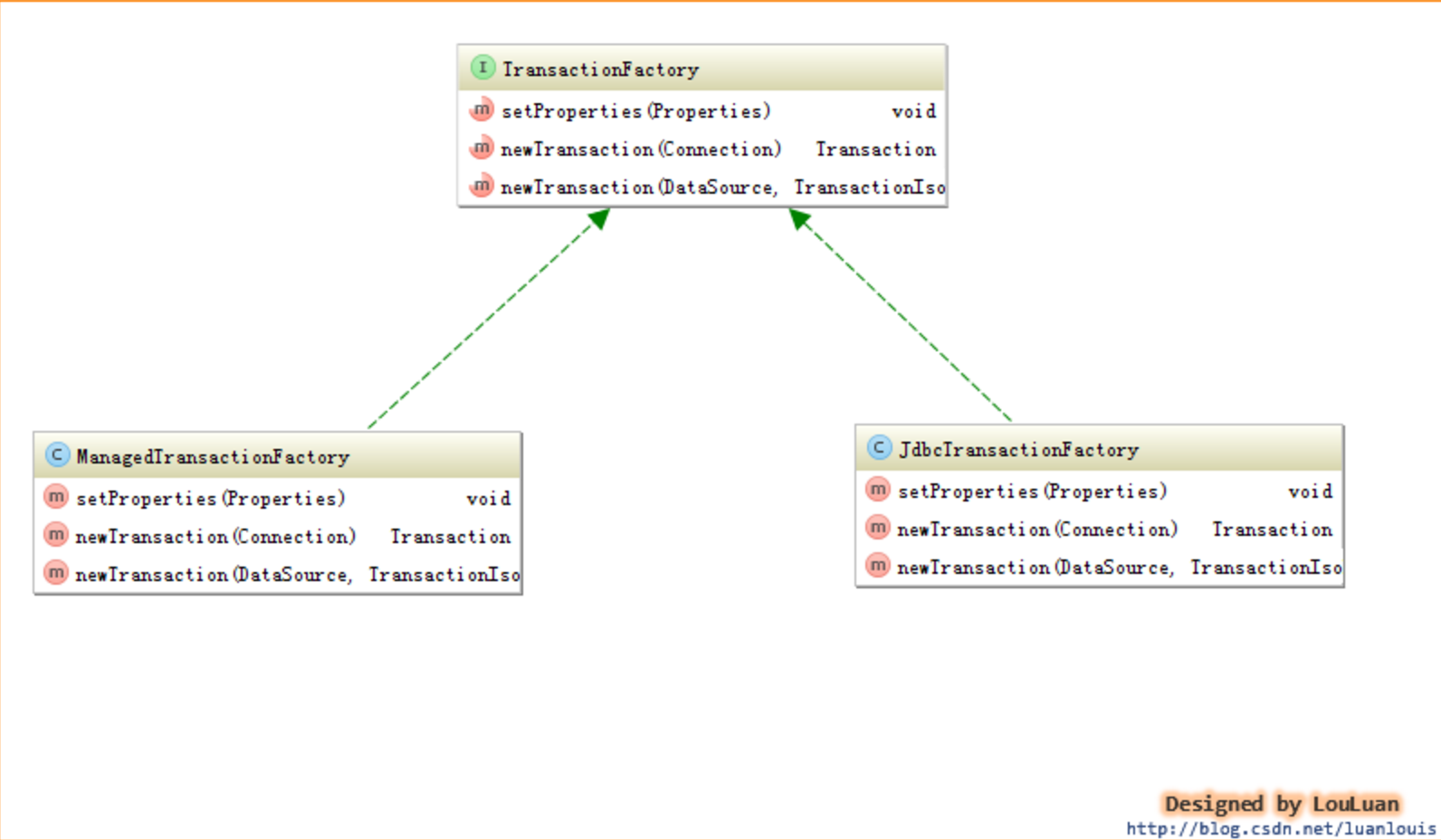
事务Transaction的创建
通过事务工厂TransactionFactory很容易获取到Transaction对象实例。我们以JdbcTransaction为例,看一下JdbcTransactionFactory是怎样生成JdbcTransaction的,代码如下:
public class JdbcTransactionFactory implements TransactionFactory {
public void setProperties(Properties props) {
}
/**
* 根据给定的数据库连接Connection创建Transaction
* @param conn Existing database connection
* @return
*/
public Transaction newTransaction(Connection conn) {
return new JdbcTransaction(conn);
}
/**
* 根据DataSource、隔离级别和是否自动提交创建Transacion
*
* @param ds
* @param level Desired isolation level
* @param autoCommit Desired autocommit
* @return
*/
public Transaction newTransaction(DataSource ds, TransactionIsolationLevel level, boolean autoCommit) {
return new JdbcTransaction(ds, level, autoCommit);
}
}
如上说是,JdbcTransactionFactory会创建JDBC类型的Transaction,即JdbcTransaction。类似地,ManagedTransactionFactory也会创建ManagedTransaction。下面我们会分别深入JdbcTranaction 和ManagedTransaction,看它们到底是怎样实现事务管理的。
JdbcTranscation
JdbcTransaction直接使用JDBC的提交和回滚事务管理机制。它依赖与从dataSource中取得的连接connection 来管理transaction 的作用域,connection对象的获取被延迟到调用getConnection()方法。如果autocommit设置为on,开启状态的话,它会忽略commit和rollback。
直观地讲,就是JdbcTransaction是使用的java.sql.Connection 上的commit和rollback功能,JdbcTransaction只是相当于对java.sql.Connection事务处理进行了一次包装(wrapper),Transaction的事务管理都是通过java.sql.Connection实现的。JdbcTransaction的代码实现如下:
public class JdbcTransaction implements Transaction {
private static final Log log = LogFactory.getLog(JdbcTransaction.class);
//数据库连接
protected Connection connection;
//数据源
protected DataSource dataSource;
//隔离级别
protected TransactionIsolationLevel level;
//是否为自动提交
protected boolean autoCommmit;
public JdbcTransaction(DataSource ds, TransactionIsolationLevel desiredLevel, boolean desiredAutoCommit) {
dataSource = ds;
level = desiredLevel;
autoCommmit = desiredAutoCommit;
}
public JdbcTransaction(Connection connection) {
this.connection = connection;
}
public Connection getConnection() throws SQLException {
if (connection == null) {
openConnection();
}
return connection;
}
/**
* commit()功能 使用connection的commit()
* @throws SQLException
*/
public void commit() throws SQLException {
if (connection != null && !connection.getAutoCommit()) {
if (log.isDebugEnabled()) {
log.debug("Committing JDBC Connection [" + connection + "]");
}
connection.commit();
}
}
/**
* rollback()功能 使用connection的rollback()
* @throws SQLException
*/
public void rollback() throws SQLException {
if (connection != null && !connection.getAutoCommit()) {
if (log.isDebugEnabled()) {
log.debug("Rolling back JDBC Connection [" + connection + "]");
}
connection.rollback();
}
}
/**
* close()功能 使用connection的close()
* @throws SQLException
*/
public void close() throws SQLException {
if (connection != null) {
resetAutoCommit();
if (log.isDebugEnabled()) {
log.debug("Closing JDBC Connection [" + connection + "]");
}
connection.close();
}
}
protected void setDesiredAutoCommit(boolean desiredAutoCommit) {
try {
if (connection.getAutoCommit() != desiredAutoCommit) {
if (log.isDebugEnabled()) {
log.debug("Setting autocommit to " + desiredAutoCommit + " on JDBC Connection [" + connection + "]");
}
connection.setAutoCommit(desiredAutoCommit);
}
} catch (SQLException e) {
// Only a very poorly implemented driver would fail here,
// and there's not much we can do about that.
throw new TransactionException("Error configuring AutoCommit. "
+ "Your driver may not support getAutoCommit() or setAutoCommit(). "
+ "Requested setting: " + desiredAutoCommit + ". Cause: " + e, e);
}
}
protected void resetAutoCommit() {
try {
if (!connection.getAutoCommit()) {
// MyBatis does not call commit/rollback on a connection if just selects were performed.
// Some databases start transactions with select statements
// and they mandate a commit/rollback before closing the connection.
// A workaround is setting the autocommit to true before closing the connection.
// Sybase throws an exception here.
if (log.isDebugEnabled()) {
log.debug("Resetting autocommit to true on JDBC Connection [" + connection + "]");
}
connection.setAutoCommit(true);
}
} catch (SQLException e) {
log.debug("Error resetting autocommit to true "
+ "before closing the connection. Cause: " + e);
}
}
protected void openConnection() throws SQLException {
if (log.isDebugEnabled()) {
log.debug("Opening JDBC Connection");
}
connection = dataSource.getConnection();
if (level != null) {
connection.setTransactionIsolation(level.getLevel());
}
setDesiredAutoCommit(autoCommmit);
}
}
ManagedTransaction
ManagedTransaction让容器来管理事务Transaction的整个生命周期,意思就是说,使用ManagedTransaction的commit和rollback功能不会对事务有任何的影响,它什么都不会做,它将事务管理的权利移交给了容器来实现。看如下Managed的实现代码大家就会一目了然:
/**
*
* 让容器管理事务transaction的整个生命周期
* connection的获取延迟到getConnection()方法的调用
* 忽略所有的commit和rollback操作
* 默认情况下,可以关闭一个连接connection,也可以配置它不可以关闭一个连接
* 让容器来管理transaction的整个生命周期
* @see ManagedTransactionFactory
*/
public class ManagedTransaction implements Transaction {
private static final Log log = LogFactory.getLog(ManagedTransaction.class);
private DataSource dataSource;
private TransactionIsolationLevel level;
private Connection connection;
private boolean closeConnection;
public ManagedTransaction(Connection connection, boolean closeConnection) {
this.connection = connection;
this.closeConnection = closeConnection;
}
public ManagedTransaction(DataSource ds, TransactionIsolationLevel level, boolean closeConnection) {
this.dataSource = ds;
this.level = level;
this.closeConnection = closeConnection;
}
public Connection getConnection() throws SQLException {
if (this.connection == null) {
openConnection();
}
return this.connection;
}
public void commit() throws SQLException {
// Does nothing
}
public void rollback() throws SQLException {
// Does nothing
}
public void close() throws SQLException {
if (this.closeConnection && this.connection != null) {
if (log.isDebugEnabled()) {
log.debug("Closing JDBC Connection [" + this.connection + "]");
}
this.connection.close();
}
}
protected void openConnection() throws SQLException {
if (log.isDebugEnabled()) {
log.debug("Opening JDBC Connection");
}
this.connection = this.dataSource.getConnection();
if (this.level != null) {
this.connection.setTransactionIsolation(this.level.getLevel());
}
}
}
注意:如果我们使用MyBatis构建本地程序,即不是WEB程序,若将type设置成"MANAGED”,那么,我们执行的任何update操作,即使我们最后执行了commit操作,数据也不会保留,不会对数据库造成任何影响。因为我们将MyBatis配置成了“MANAGED”,即MyBatis自己不管理事务,而我们又是运行的本地程序,没有事务管理功能,所以对数据库的update操作都是无效的。
16 - CH16-一级缓存原理
什么是一级缓存?
每当我们使用MyBatis开启一次和数据库的会话,MyBatis会创建出一个SqlSession对象表示一次数据库会话。
在对数据库的一次会话中,我们有可能会反复地执行完全相同的查询语句,如果不采取一些措施的话,每一次查询都会查询一次数据库,而我们在极短的时间内做了完全相同的查询,那么它们的结果极有可能完全相同,由于查询一次数据库的代价很大,这有可能造成很大的资源浪费。
为了解决这一问题,减少资源的浪费,MyBatis会在表示会话的SqlSession对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候,如果判断先前有个完全一样的查询,会直接从缓存中直接将结果取出,返回给用户,不需要再进行一次数据库查询了。
如下图所示,MyBatis一次会话: 一个SqlSession对象中创建一个本地缓存(local cache),对于每一次查询,都会尝试根据查询的条件去本地缓存中查找是否在缓存中,如果在缓存中,就直接从缓存中取出,然后返回给用户;否则,从数据库读取数据,将查询结果存入缓存并返回给用户。

对于会话(Session)级别的数据缓存,我们称之为一级数据缓存,简称一级缓存。
MyBatis中的一级缓存是怎样组织的?
即SqlSession中的缓存是怎样组织的?由于MyBatis使用SqlSession对象表示一次数据库的会话,那么,对于会话级别的一级缓存也应该是在SqlSession中控制的。
实际上, MyBatis只是一个MyBatis对外的接口,SqlSession将它的工作交给了Executor执行器这个角色来完成,负责完成对数据库的各种操作。当创建了一个SqlSession对象时,MyBatis会为这个SqlSession对象创建一个新的Executor执行器,而缓存信息就被维护在这个Executor执行器中,MyBatis将缓存和对缓存相关的操作封装成了Cache接口中。SqlSession、Executor、Cache之间的关系如下列类图所示:
如上述的类图所示,Executor接口的实现类BaseExecutor中拥有一个Cache接口的实现类PerpetualCache,则对于BaseExecutor对象而言,它将使用PerpetualCache对象维护缓存。
综上,SqlSession对象、Executor对象、Cache对象之间的关系如下图所示:

由于Session级别的一级缓存实际上就是使用PerpetualCache维护的,那么PerpetualCache是怎样实现的呢?
PerpetualCache实现原理其实很简单,其内部就是通过一个简单的HashMap<k,v> 来实现的,没有其他的任何限制。如下是PerpetualCache的实现代码:
package org.apache.ibatis.cache.impl;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.locks.ReadWriteLock;
import org.apache.ibatis.cache.Cache;
import org.apache.ibatis.cache.CacheException;
/**
* 使用简单的HashMap来维护缓存
* @author Clinton Begin
*/
public class PerpetualCache implements Cache {
private String id;
private Map<Object, Object> cache = new HashMap<Object, Object>();
public PerpetualCache(String id) {
this.id = id;
}
public String getId() {
return id;
}
public int getSize() {
return cache.size();
}
public void putObject(Object key, Object value) {
cache.put(key, value);
}
public Object getObject(Object key) {
return cache.get(key);
}
public Object removeObject(Object key) {
return cache.remove(key);
}
public void clear() {
cache.clear();
}
public ReadWriteLock getReadWriteLock() {
return null;
}
public boolean equals(Object o) {
if (getId() == null) throw new CacheException("Cache instances require an ID.");
if (this == o) return true;
if (!(o instanceof Cache)) return false;
Cache otherCache = (Cache) o;
return getId().equals(otherCache.getId());
}
public int hashCode() {
if (getId() == null) throw new CacheException("Cache instances require an ID.");
return getId().hashCode();
}
}
一级缓存的生命周期有多长?
MyBatis在开启一个数据库会话时,会创建一个新的SqlSession对象,SqlSession对象中会有一个新的Executor对象,Executor对象中持有一个新的PerpetualCache对象;当会话结束时,SqlSession对象及其内部的Executor对象还有PerpetualCache对象也一并释放掉。
- 如果SqlSession调用了close()方法,会释放掉一级缓存PerpetualCache对象,一级缓存将不可用;
- 如果SqlSession调用了clearCache(),会清空PerpetualCache对象中的数据,但是该对象仍可使用;
- SqlSession中执行了任何一个update操作(update()、delete()、insert()) ,都会清空PerpetualCache对象的数据,但是该对象可以继续使用;
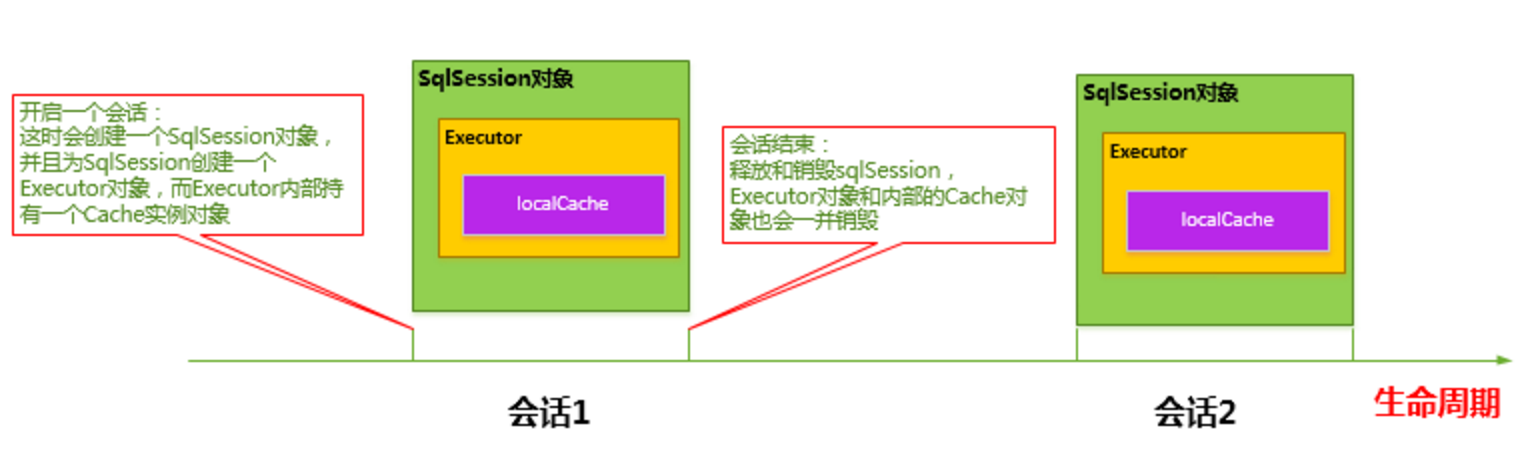
SqlSession 一级缓存的工作流程
- 对于某个查询,根据statementId,params,rowBounds来构建一个key值,根据这个key值去缓存Cache中取出对应的key值存储的缓存结果;
- 判断从Cache中根据特定的key值取的数据数据是否为空,即是否命中;
- 如果命中,则直接将缓存结果返回;
- 如果没命中:
- 去数据库中查询数据,得到查询结果;
- 将key和查询到的结果分别作为key,value对存储到Cache中;
- 将查询结果返回;
- 结束。
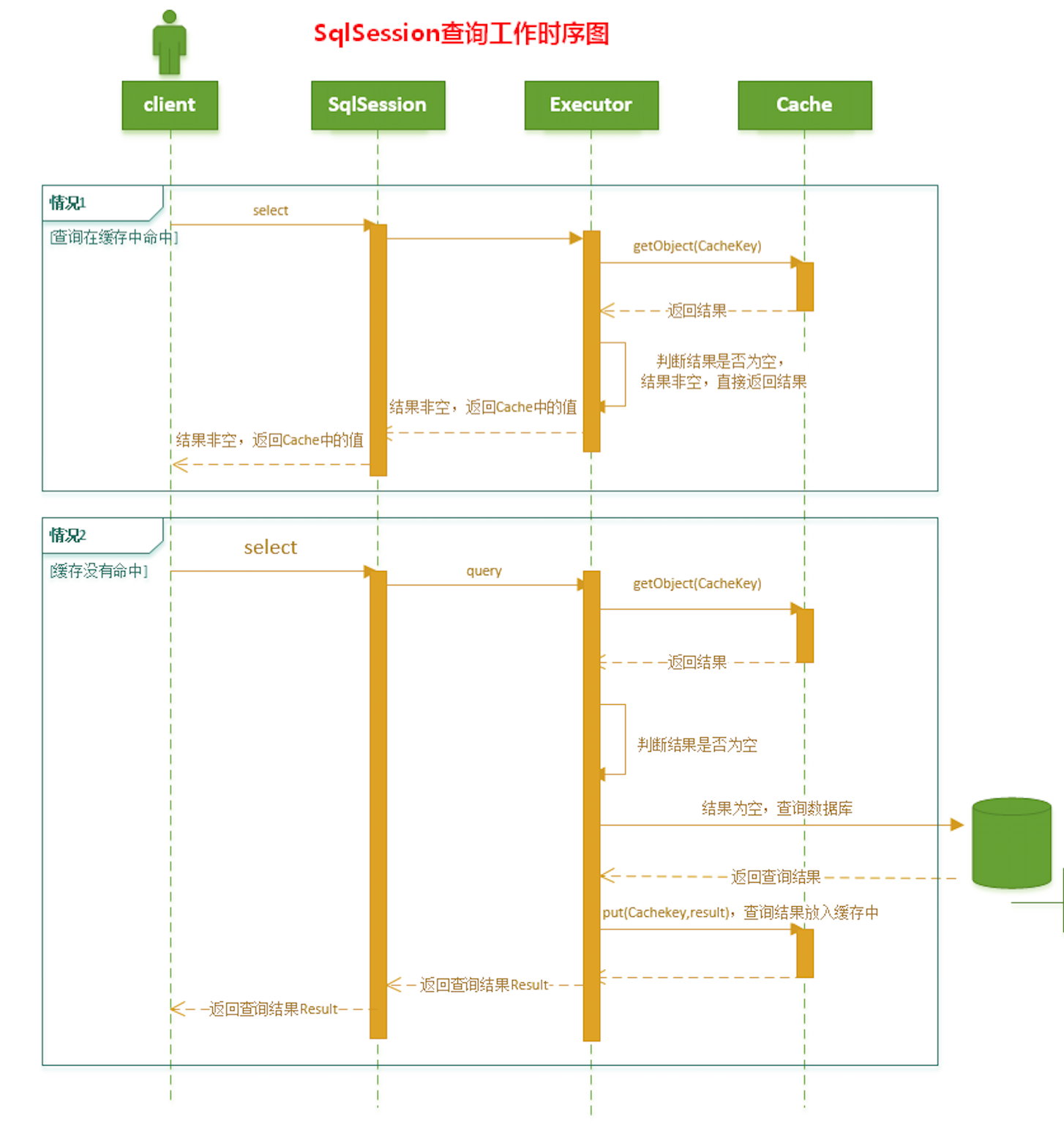
Cache接口的设计以及CacheKey的定义
如下图所示,MyBatis定义了一个org.apache.ibatis.cache.Cache接口作为其Cache提供者的SPI(Service Provider Interface) ,所有的MyBatis内部的Cache缓存,都应该实现这一接口。MyBatis定义了一个PerpetualCache实现类实现了Cache接口,实际上,在SqlSession对象里的Executor对象内维护的Cache类型实例对象,就是PerpetualCache子类创建的。
(MyBatis内部还有很多Cache接口的实现,一级缓存只会涉及到这一个PerpetualCache子类,Cache的其他实现将会放到二级缓存中介绍)。

我们知道,Cache最核心的实现其实就是一个Map,将本次查询使用的特征值作为key,将查询结果作为value存储到Map中。现在最核心的问题出现了:怎样来确定一次查询的特征值?换句话说就是:怎样判断某两次查询是完全相同的查询?也可以这样说:如何确定Cache中的key值?
MyBatis认为,对于两次查询,如果以下条件都完全一样,那么就认为它们是完全相同的两次查询:
- 传入的 statementId
- 查询时要求的结果集中的结果范围 (结果的范围通过rowBounds.offset和rowBounds.limit表示)
- 这次查询所产生的最终要传递给JDBC java.sql.Preparedstatement的Sql语句字符串(boundSql.getSql() )
- 传递给java.sql.Statement要设置的参数值
现在分别解释上述四个条件:
- 传入的statementId,对于MyBatis而言,你要使用它,必须需要一个statementId,它代表着你将执行什么样的Sql;
- MyBatis自身提供的分页功能是通过RowBounds来实现的,它通过rowBounds.offset和rowBounds.limit来过滤查询出来的结果集,这种分页功能是基于查询结果的再过滤,而不是进行数据库的物理分页;
- 由于MyBatis底层还是依赖于JDBC实现的,那么,对于两次完全一模一样的查询,MyBatis要保证对于底层JDBC而言,也是完全一致的查询才行。而对于JDBC而言,两次查询,只要传入给JDBC的SQL语句完全一致,传入的参数也完全一致,就认为是两次查询是完全一致的。
- 上述的第3个条件正是要求保证传递给JDBC的SQL语句完全一致;第4条则是保证传递给JDBC的参数也完全一致;即3、4两条MyBatis最本质的要求就是:调用JDBC的时候,传入的SQL语句要完全相同,传递给JDBC的参数值也要完全相同。
综上所述,CacheKey由以下条件决定:statementId + rowBounds + 传递给JDBC的SQL + 传递给JDBC的参数值;
- CacheKey的创建
对于每次的查询请求,Executor都会根据传递的参数信息以及动态生成的SQL语句,将上面的条件根据一定的计算规则,创建一个对应的CacheKey对象。
我们知道创建CacheKey的目的,就两个:
- 根据CacheKey作为key,去Cache缓存中查找缓存结果;
- 如果查找缓存命中失败,则通过此CacheKey作为key,将从数据库查询到的结果作为value,组成key,value对存储到Cache缓存中;
CacheKey的构建被放置到了Executor接口的实现类BaseExecutor中,定义如下:
/**
* 所属类: org.apache.ibatis.executor.BaseExecutor
* 功能 : 根据传入信息构建CacheKey
*/
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) throw new ExecutorException("Executor was closed.");
CacheKey cacheKey = new CacheKey();
//1.statementId
cacheKey.update(ms.getId());
//2. rowBounds.offset
cacheKey.update(rowBounds.getOffset());
//3. rowBounds.limit
cacheKey.update(rowBounds.getLimit());
//4. SQL语句
cacheKey.update(boundSql.getSql());
//5. 将每一个要传递给JDBC的参数值也更新到CacheKey中
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
for (int i = 0; i < parameterMappings.size(); i++) { // mimic DefaultParameterHandler logic
ParameterMapping parameterMapping = parameterMappings.get(i);
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
//将每一个要传递给JDBC的参数值也更新到CacheKey中
cacheKey.update(value);
}
}
return cacheKey;
}
- CacheKey的hashcode生成算法
刚才已经提到,Cache接口的实现,本质上是使用的HashMap<k,v>,而构建CacheKey的目的就是为了作为HashMap<k,v>中的key值。而HashMap是通过key值的hashcode 来组织和存储的,那么,构建CacheKey的过程实际上就是构造其hashCode的过程。下面的代码就是CacheKey的核心hashcode生成算法,感兴趣的话可以看一下:
public void update(Object object) {
if (object != null && object.getClass().isArray()) {
int length = Array.getLength(object);
for (int i = 0; i < length; i++) {
Object element = Array.get(object, i);
doUpdate(element);
}
} else {
doUpdate(object);
}
}
private void doUpdate(Object object) {
//1. 得到对象的hashcode;
int baseHashCode = object == null ? 1 : object.hashCode();
//对象计数递增
count++;
checksum += baseHashCode;
//2. 对象的hashcode 扩大count倍
baseHashCode *= count;
//3. hashCode * 拓展因子(默认37)+拓展扩大后的对象hashCode值
hashcode = multiplier * hashcode + baseHashCode;
updateList.add(object);
}
MyBatis认为的完全相同的查询,不是指使用sqlSession查询时传递给算起来Session的所有参数值完完全全相同,你只要保证statementId,rowBounds,最后生成的SQL语句,以及这个SQL语句所需要的参数完全一致就可以了。
一级缓存的性能分析
- MyBatis对会话(Session)级别的一级缓存设计的比较简单,就简单地使用了HashMap来维护,并没有对HashMap的容量和大小进行限制
读者有可能就觉得不妥了:如果我一直使用某一个SqlSession对象查询数据,这样会不会导致HashMap太大,而导致 java.lang.OutOfMemoryError错误啊? 读者这么考虑也不无道理,不过MyBatis的确是这样设计的。
MyBatis这样设计也有它自己的理由:
- 一般而言SqlSession的生存时间很短。一般情况下使用一个SqlSession对象执行的操作不会太多,执行完就会消亡;
- 对于某一个SqlSession对象而言,只要执行update操作(update、insert、delete),都会将这个SqlSession对象中对应的一级缓存清空掉,所以一般情况下不会出现缓存过大,影响JVM内存空间的问题;
- 可以手动地释放掉SqlSession对象中的缓存。
- 一级缓存是一个粗粒度的缓存,没有更新缓存和缓存过期的概念
MyBatis的一级缓存就是使用了简单的HashMap,MyBatis只负责将查询数据库的结果存储到缓存中去, 不会去判断缓存存放的时间是否过长、是否过期,因此也就没有对缓存的结果进行更新这一说了。
根据一级缓存的特性,在使用的过程中,我认为应该注意:
- 对于数据变化频率很大,并且需要高时效准确性的数据要求,我们使用SqlSession查询的时候,要控制好SqlSession的生存时间, SqlSession的生存时间越长,它其中缓存的数据有可能就越旧,从而造成和真实数据库的误差;同时对于这种情况,用户也可以手动地适时清空SqlSession中的缓存;
- 对于只执行、并且频繁执行大范围的select操作的SqlSession对象,SqlSession对象的生存时间不应过长。
17 - CH17-二级缓存原理
MyBatis的二级缓存是Application级别的缓存,它可以提高对数据库查询的效率,以提高应用的性能。
整体设计与工作模式
当开一个会话时,一个SqlSession对象会使用一个Executor对象来完成会话操作,MyBatis的二级缓存机制的关键就是对这个Executor对象做文章。如果用户配置了"cacheEnabled=true",那么MyBatis在为SqlSession对象创建Executor对象时,会对Executor对象加上一个装饰者:CachingExecutor,这时SqlSession使用CachingExecutor对象来完成操作请求。CachingExecutor对于查询请求,会先判断该查询请求在Application级别的二级缓存中是否有缓存结果,如果有查询结果,则直接返回缓存结果;如果缓存中没有,再交给真正的Executor对象来完成查询操作,之后CachingExecutor会将真正Executor返回的查询结果放置到缓存中,然后在返回给用户。
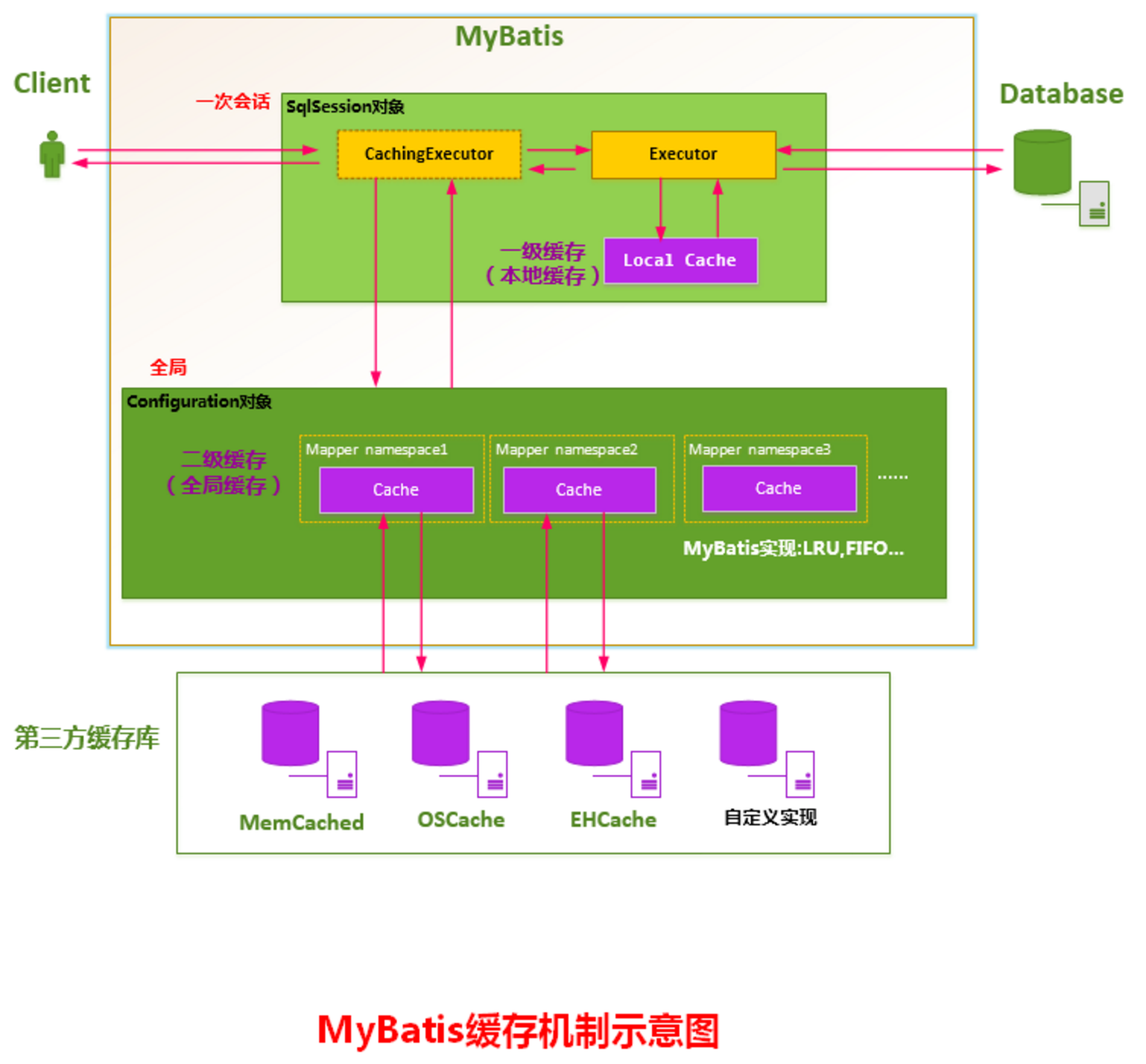
CachingExecutor是Executor的装饰者,以增强Executor的功能,使其具有缓存查询的功能,这里用到了设计模式中的装饰者模式,CachingExecutor和Executor的接口的关系如下类图所示:
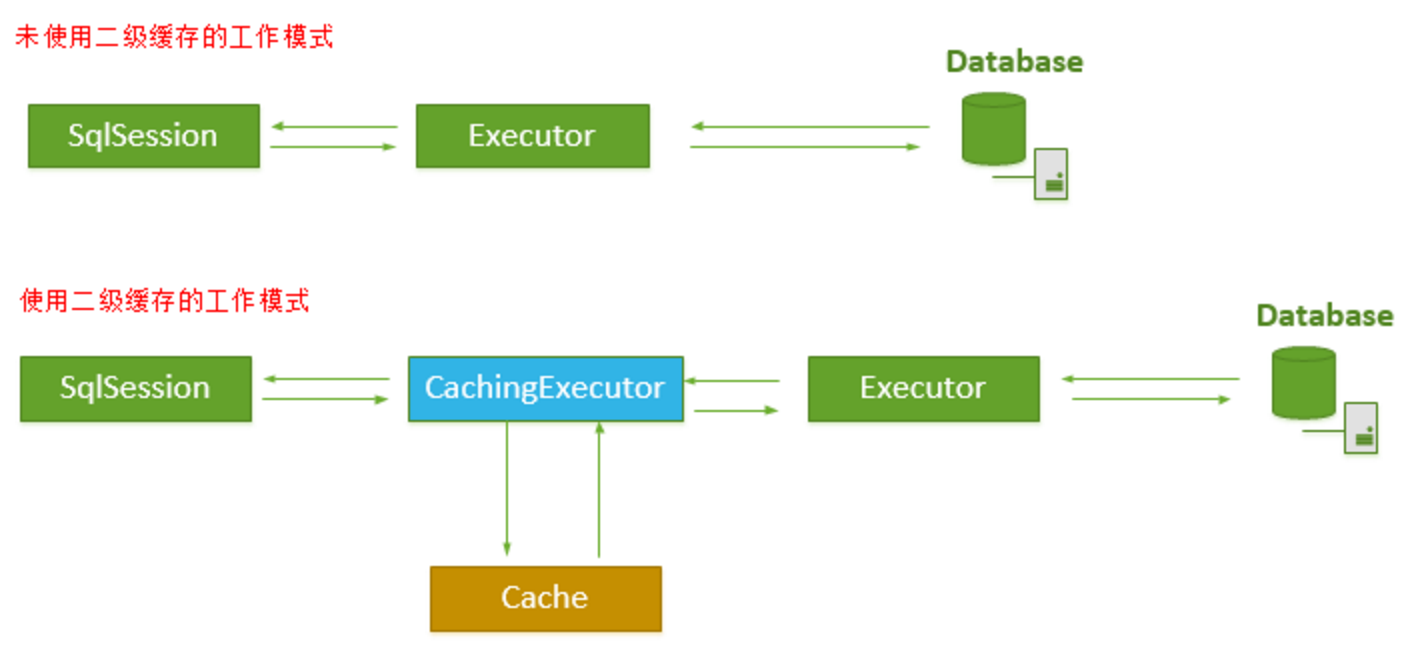
二级缓存的划分
MyBatis并不是简单地对整个Application就只有一个Cache缓存对象,它将缓存划分的更细,即是Mapper级别的,即每一个Mapper都可以拥有一个Cache对象,具体如下:
- 为每一个Mapper分配一个Cache缓存对象(使用
<cache>节点配置)
MyBatis将Application级别的二级缓存细分到Mapper级别,即对于每一个Mapper.xml,如果在其中使用了<cache> 节点,则MyBatis会为这个Mapper创建一个Cache缓存对象,如下图所示:
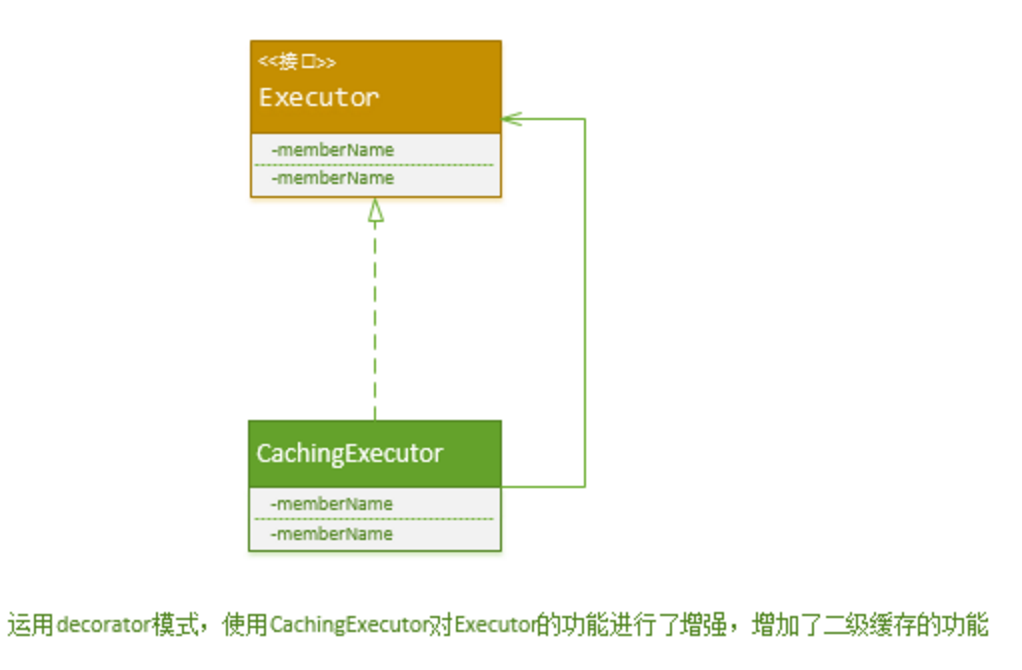
注:上述的每一个Cache对象,都会有一个自己所属的namespace命名空间,并且会将Mapper的 namespace作为它们的ID;
- 多个Mapper共用一个Cache缓存对象(使用
<cache-ref>节点配置)
如果你想让多个Mapper公用一个Cache的话,你可以使用<cache-ref namespace="">节点,来指定你的这个Mapper使用到了哪一个Mapper的Cache缓存。
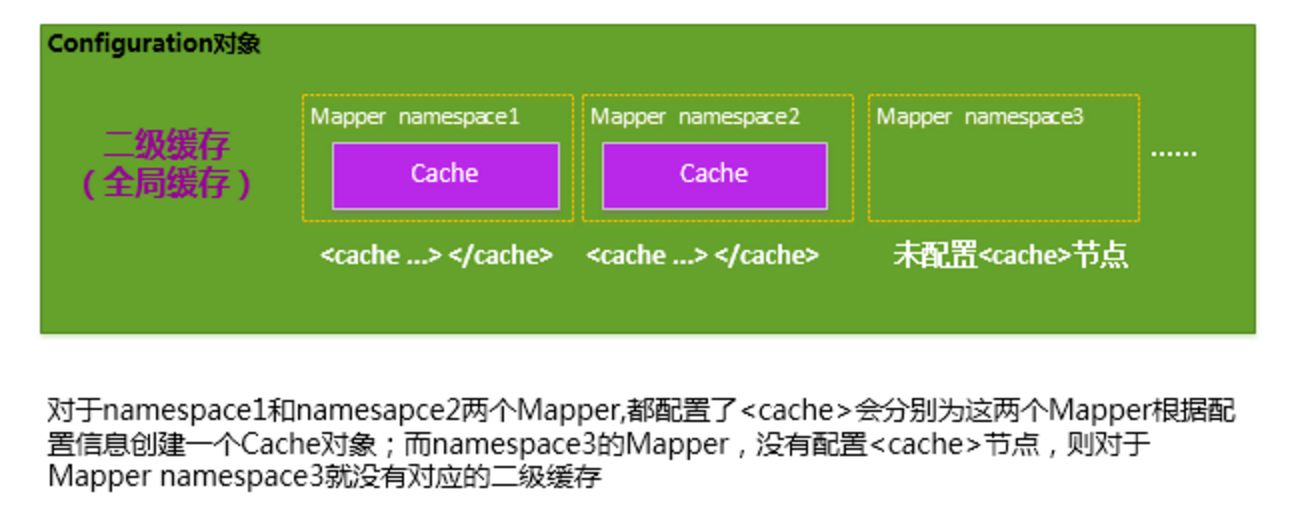
必须要具备的条件
MyBatis对二级缓存的支持粒度很细,它会指定某一条查询语句是否使用二级缓存。
虽然在Mapper中配置了<cache>,并且为此Mapper分配了Cache对象,这并不表示我们使用Mapper中定义的查询语句查到的结果都会放置到Cache对象之中,我们必须指定Mapper中的某条选择语句是否支持缓存,即如下所示,在<select> 节点中配置useCache=“true”,Mapper才会对此Select的查询支持缓存特性,否则,不会对此Select查询,不会经过Cache缓存。如下所示,Select语句配置了useCache=“true”,则表明这条Select语句的查询会使用二级缓存。
<select id="selectByMinSalary" resultMap="BaseResultMap" parameterType="java.util.Map" useCache="true">
总之,要想使某条Select查询支持二级缓存,你需要保证:
- MyBatis支持二级缓存的总开关:全局配置变量参数 cacheEnabled=true
- 该select语句所在的Mapper,配置了
<cache>或<cached-ref>节点,并且有效 - 该select语句的参数 useCache=true
一级缓存和二级缓存的使用顺序
请注意,如果你的MyBatis使用了二级缓存,并且你的Mapper和select语句也配置使用了二级缓存,那么在执行select查询的时候,MyBatis会先从二级缓存中取输入,其次才是一级缓存,即MyBatis查询数据的顺序是:二级缓存 ———> 一级缓存 ——> 数据库。
二级缓存实现的选择
MyBatis对二级缓存的设计非常灵活,它自己内部实现了一系列的Cache缓存实现类,并提供了各种缓存刷新策略如LRU,FIFO等等;另外,MyBatis还允许用户自定义Cache接口实现,用户是需要实现org.apache.ibatis.cache.Cache接口,然后将Cache实现类配置在<cache type="">节点的type属性上即可;除此之外,MyBatis还支持跟第三方内存缓存库如Memecached的集成,总之,使用MyBatis的二级缓存有三个选择:
- MyBatis自身提供的缓存实现;
- 用户自定义的Cache接口实现;
- 跟第三方内存缓存库的集成;
MyBatis自身提供的二级缓存的实现
MyBatis自身提供了丰富的,并且功能强大的二级缓存的实现,它拥有一系列的Cache接口装饰者,可以满足各种对缓存操作和更新的策略。
MyBatis定义了大量的Cache的装饰器来增强Cache缓存的功能,如下类图所示。
对于每个Cache而言,都有一个容量限制,MyBatis各供了各种策略来对Cache缓存的容量进行控制,以及对Cache中的数据进行刷新和置换。MyBatis主要提供了以下几个刷新和置换策略:
- LRU:(Least Recently Used),最近最少使用算法,即如果缓存中容量已经满了,会将缓存中最近最少被使用的缓存记录清除掉,然后添加新的记录;
- FIFO:(First in first out),先进先出算法,如果缓存中的容量已经满了,那么会将最先进入缓存中的数据清除掉;
- Scheduled:指定时间间隔清空算法,该算法会以指定的某一个时间间隔将Cache缓存中的数据清空;
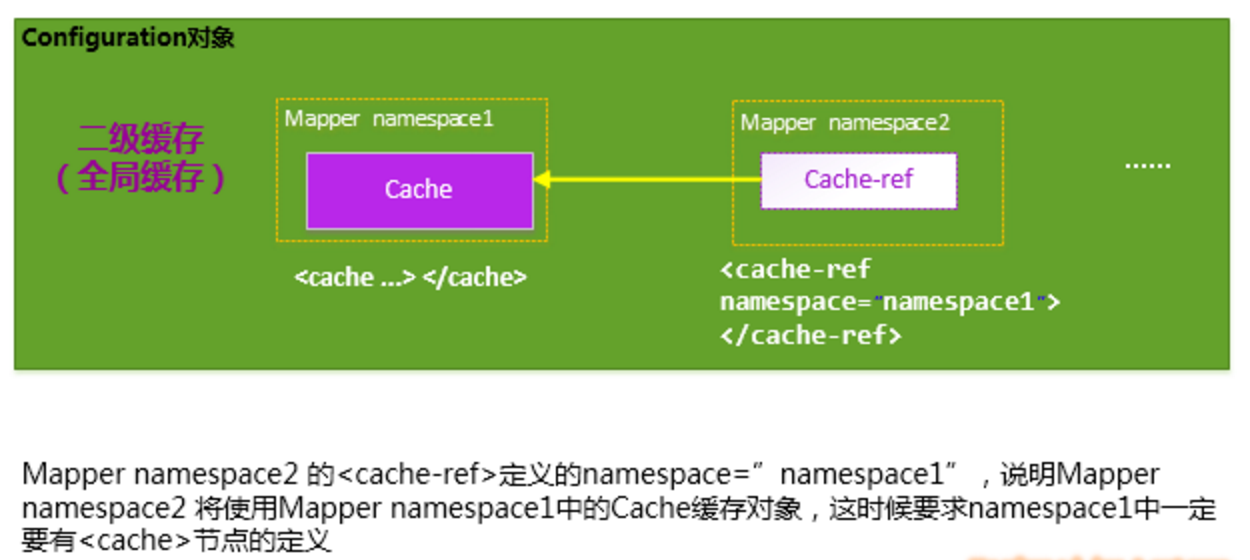
如何细粒度地控制你的MyBatis二级缓存
一个关于MyBatis的二级缓存的实际问题
现有AMapper.xml中定义了对数据库表 ATable 的CRUD操作,BMapper定义了对数据库表BTable的CRUD操作;
假设 MyBatis 的二级缓存开启,并且 AMapper 中使用了二级缓存,AMapper对应的二级缓存为ACache;
除此之外,AMapper 中还定义了一个跟BTable有关的查询语句,类似如下所述:
<select id="selectATableWithJoin" resultMap="BaseResultMap" useCache="true">
select * from ATable left join BTable on ....
</select>
执行以下操作:
- 执行AMapper中的"selectATableWithJoin" 操作,此时会将查询到的结果放置到AMapper对应的二级缓存ACache中;
- 执行BMapper中对BTable的更新操作(update、delete、insert)后,BTable的数据更新;
- 再执行1完全相同的查询,这时候会直接从AMapper二级缓存ACache中取值,将ACache中的值直接返回;
好,问题就出现在第3步上:
由于AMapper的“selectATableWithJoin” 对应的SQL语句需要和BTable进行join查找,而在第 2 步BTable的数据已经更新了,但是第 3 步查询的值是第 1 步的缓存值,已经极有可能跟真实数据库结果不一样,即ACache中缓存数据过期了!
总结来看,就是:
对于某些使用了 join连接的查询,如果其关联的表数据发生了更新,join连接的查询由于先前缓存的原因,导致查询结果和真实数据不同步;
从MyBatis的角度来看,这个问题可以这样表述:
对于某些表执行了更新(update、delete、insert)操作后,如何去清空跟这些表有关联的查询语句所造成的缓存;
当前MyBatis二级缓存的工作机制
MyBatis二级缓存的一个重要特点:即松散的Cache缓存管理和维护
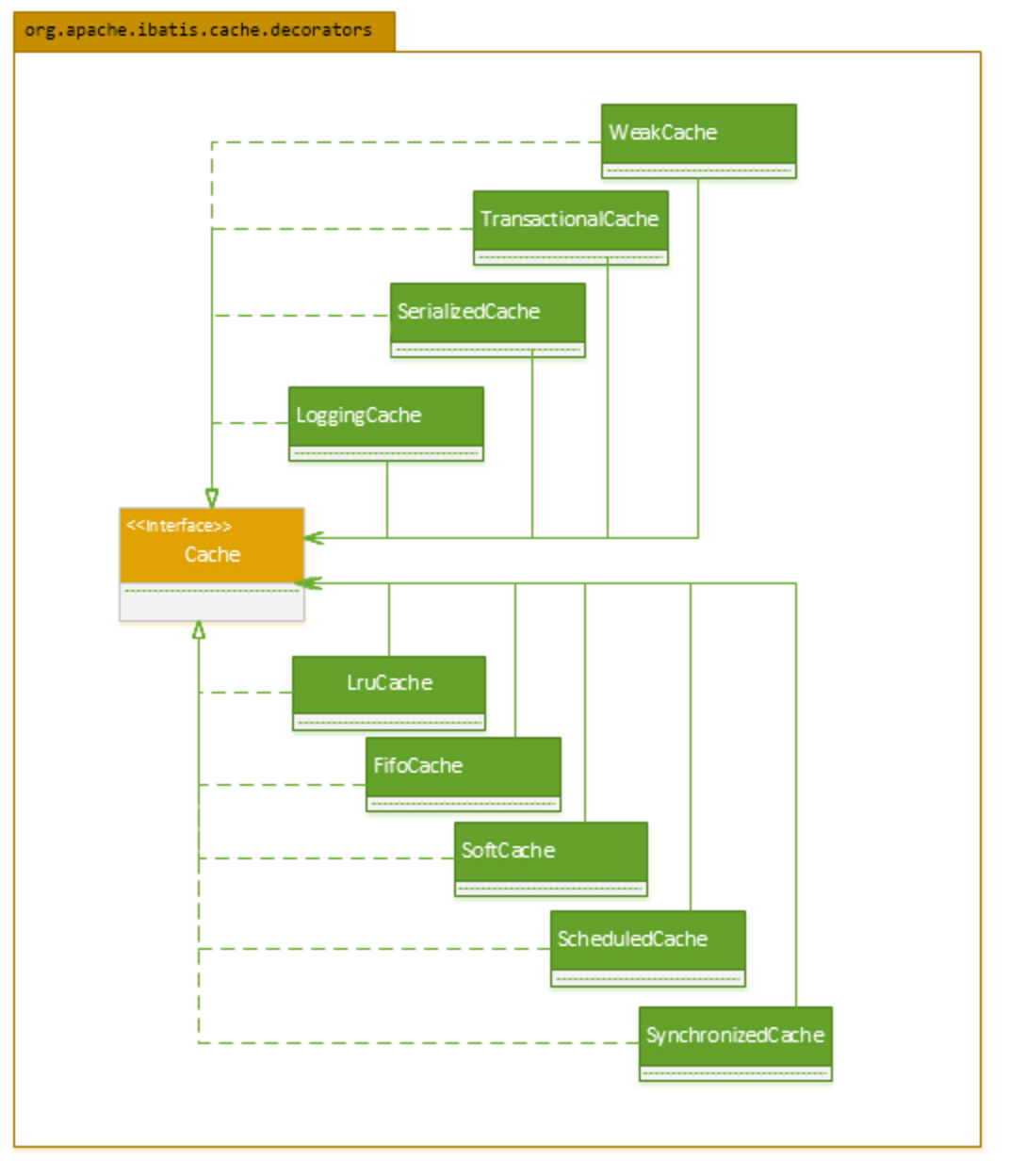
一个Mapper中定义的增删改查操作只能影响到自己关联的Cache对象。如上图所示的Mapper namespace1中定义的若干CRUD语句,产生的缓存只会被放置到相应关联的Cache1中,即Mapper namespace2,namespace3,namespace4 中的CRUD的语句不会影响到Cache1。
可以看出,Mapper之间的缓存关系比较松散,相互关联的程度比较弱。
现在再回到上面描述的问题,如果我们将AMapper和BMapper共用一个Cache对象,那么,当BMapper执行更新操作时,可以清空对应Cache中的所有的缓存数据,这样的话,数据不是也可以保持最新吗?
确实这个也是一种解决方案,不过,它会使缓存的使用效率变的很低!AMapper和BMapper的任意的更新操作都会将共用的Cache清空,会频繁地清空Cache,导致Cache实际的命中率和使用率就变得很低了,所以这种策略实际情况下是不可取的。
最理想的解决方案就是:
对于某些表执行了更新(update、delete、insert)操作后,如何去清空跟这些表有关联的查询语句所造成的缓存; 这样,就是以很细的粒度管理MyBatis内部的缓存,使得缓存的使用率和准确率都能大大地提升。
18 - CH18-性能优化
动态条件
通过传入参数动态组装条件语句时,条件可能均为空,常见做法是使用 where 1=1 作为占位符,避免所有条件为空时语法错误:
<select id="getFruitInfo" resultType="Fruit">
SELECT * FROM Fruit
WHERE 1=1
<if test="id!= null">
and id = #{id}
</if>
<if test="name!= null">
and name = #{name}
</if>
</select>
如果 id 和 name 均为 null,则整个语句变成了:
SELECT * FROM Fruit WHERE 1=1
这时数据库就无法使用索引等查询优化策略,被迫对每行数据进行扫描,如果表很大,则性能消耗巨大,推荐的做法是使用 WHERE 标签:
<select id="getFruitInfo" resultType="Fruit">
SELECT * FROM Fruit
<WHERE>
<if test="id!= null">
id = #{id}
</if>
<if test="name!= null">
and name = #{name}
</if>
</WHERE>
</select>
where 元素知道只有在一个以上的 if 条件有值的情况下才去插入 “where” 子句,且最后的内容如果是 “AND” 或 “OR” 开头的,where 元素也能识别并将它们去除。
批量插入
在使用 foreach 执行批量插入时,如果条目很多,会生成一个很长的 sql 语句,然后再使用实际的条目数据带入,构造出要执行的 sql,这个过程会很慢。
推荐的做法是使用 BATCH 模式执行批量插入:
@Service
public class PersonService {
@Autowired
private SqlSessionFactory sqlSessionFactory;
public void insertPersions(List<Person> persons) {
try (SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH)) {
PersonMapper mapper = session.getMapper(PersonMapper.class);
for (Person person : persons) {
mapper.insert(person);
}
session.commit();
session.clearCache();
}
}
}
WHERE IN foreach
<select id="getUserInfo" resultType="com.test.UserList">
SELECT age FROM user
WHERE
<if test="userName!= null and userName.size() >0">
user_name IN
<foreach collection="userName" item="value" separator="," open="(" close=")">
#{value}
</foreach>
</if>
</select>
但列表可能为空,所以总是在调用之前判空。或者有些同学会以如下方式兼容:
<select id="getUserInfo" resultType="com.test.UserList">
SELECT age FROM user
WHERE
<if test="userName!= null and userName.size() >0">
user_name IN
<foreach collection="userName" item="value" separator="," open="(" close=")">
#{value}
</foreach>
</if>
<if test="userName!= null and userName.size() ==0">
1=2
</if>
<if test="userName!= null and userName.size() ==1">
user_name = #{users[0].userName}
</if>
</select>
基于 IN 的性能问题,可以将 IN 改为 JOIN。