性能原理
为什么快
在 HikariCP 官网详细了介绍 HikariCP 所做的优化,总结如下:
- 优化并精简字节码、优化代码和拦截器。
- 使用 FastList 替代 ArrayList。
- 更好的并发集合类实现 ConcurrentBag。
- 其他针对 BoneCP 缺陷的优化,比如对于耗时超过一个 CPU 时间片的方法调用的研究。
精简字节码
HikariCP 的代码只有 130 Kb,它是一个轻量级数据库连接池。
HikariCP 利用了一个第三方的 Java 字节码修改类库 Javassist 来生成委托实现动态代理。
动态代理的实现在 com.zaxxer.hikari.pool.ProxyFactory 类,源码非常简单。如下所示:
public final class ProxyFactory
{
private ProxyFactory() { }
static ProxyConnection getProxyConnection(final PoolEntry poolEntry,
final Connection connection,
final FastList<Statement> openStatements,
final ProxyLeakTask leakTask,
final long now,
final boolean isReadOnly,
final boolean isAutoCommit){
//body部分被JavassistProxyFactory重新注入了
throw new IllegalStateException("You need to run the CLI build and you
need target/classes in your classpath to run.");
}
static Statement getProxyStatement(final ProxyConnection connection, final
Statement statement)
{//body部分被JavassistProxyFactory重新注入了
throw new IllegalStateException("You need to run the CLI build and you
need target/classes in your classpath to run.");
}
static CallableStatement getProxyCallableStatement(final ProxyConnection
connection, final CallableStatement statement)
{//body部分被JavassistProxyFactory重新注入了
throw new IllegalStateException("You need to run the CLI build and you
need target/classes in your classpath to run.");
}
static PreparedStatement getProxyPreparedStatement(final ProxyConnection
connection, final PreparedStatement statement)
{//body部分被JavassistProxyFactory重新注入了
throw new IllegalStateException("You need to run the CLI build and you
need target/classes in your classpath to run.");
}
static ResultSet getProxyResultSet(final ProxyConnection connection, final
ProxyStatement statement, final ResultSet resultSet)
{//body部分被JavassistProxyFactory重新注入了
throw new IllegalStateException("You need to run the CLI build and you
need target/classes in your classpath to run.");
}
}
这些代码基本代理了 JDBC 常用的核心接口,一共是 5 个:ProxyConnection、Statement、CallableStatement、PreparedStatement、ResultSet。并且每个方法都抛出了异常。其实每个方法都是抛异常之前都有一段 body,这段 body 是在编译时调用 JavassistProxyFactory 才生成的。
JavassistProxyFactory 存在于 com.zaxxer.hikari.util 包中,是 Javassist 的工具包,它主要有两个核心方法: generateProxyClass 方法负责生成实际使用的代理类字节码,modifyProxyFactory 对应修改工厂类中的代理类获取方法 Proxy*.java 为 HikariProxy*. java。这个工具包的作用是将 ProxyConnection、ProxyStatement、ProxyPreparedStatement、ProxyCallableStatement、ProxyResultSet 这 5 个 com.zaxxer.hikari.pool 包下代理类,利用 Javassist 重构后生成实际的 HikariCP 的对应代理类 HikariProxyConnection、HikariProxyStatement、HikariProxyPreparedStatement、HikariProxyCallableStatement、HikariProxyResultSet。
之所以使用 Javassist 生成动态代理,是因为其速度更快,比 JDK Proxy 生成的字节码更少,精简了很多不必要的字节码。
此外,HikariCP 在字节码工程中还对 JIT 进行了优化。比如,JIT 方法内联优化默认的字节码个数阈值是 35 字节,低于 35 字节才会进行优化。HikariCP 在精简字节码的时候,研究了编译器的字节码输出,甚至是 JIT 的汇编输出,以将关键部分限制为小于 JIT 内联阈值,展平了继承层次结构,阴影成员变量,消除了强制转换。
FastList
HikariCP 一个性能方面的出彩优化突破就是 FastList。我们先看一组 HikariCP 中关于 FastList 的结论:
- 当调用
Connection.prepareStatement()的时候,新的 PreparedStatement 就被添加到 FastList。 - 当调用
PreparedStatement.close()的时候,这个 statement 就从 FastList 中被移除。 - 如果调用
Connection.close()的时候,任何未明确关闭的语句都将从 FastList 移除并关闭。
但是 HikariCP 并没有拦截 PreparedStatement.addBatch() 方法,所以实际上 addBatch() 不可能添加任何内容到 FastList。executeBatch 方法即不会清除批处理,也不会将 PreparedStatement 从 FastList 中移除。唯一能够清除批处理的是 PreparedStatement.clearBatch() 方法,而唯一能够从 FastList 移除 PreparedStatement 的方法就是调用 PreparedStatement. close() 或者 Connection.close() 方法。
try (Connection con = dataSource.getConnection();
PreparedStatement stmt = con.prepareStatement(...)) {
int batchCount = 0;
for (something in somelist) {
stmt.setString(...);
stmt.setInt(...);
stmt.addBatch();
if (++batchCount == 100) {
stmt.executeBatch();
stmt.clearBatch();
batchCount = 0;
}
}
if (batchCount > 0) {
stmt.executeBatch();
stmt.clearBatch();
}
con.commit();
}
catch (SQLException e) {
// 记录异常
}
如上述代码所示,对于批处理语句执行清理的过程分为如下几步:DataSource.getConnection()、Connection.prepareStatement()、多次调用 PreparedStatement.addBatch()、PreparedStatement.executeBatch()/clearBatch() 的调用、依赖 Java 7 的 try-with-resources 语法进行资源的清理。
FastList 是一个 List 接口的精简实现,只实现了接口中必要的几个方法。JDK ArrayList 每次调用 get() 方法时都会进行 rangeCheck,检查索引是否越界,FastList 的实现中去除了这一检查,只要保证索引合法那么 rangeCheck 就成为了不必要的计算开销(当然开销极小)。
此外,HikariCP 使用 List 来保存打开的 Statement,当 Statement 关闭或 Connection 关闭时需要将对应的 Statement 从 List 中移除。通常情况下,JDBC 在同一个 Connection 创建了多个 Statement 时,后打开的 Statement 会先关闭。这种情况从尾部开始扫描将表现更好。ArrayList 的 remove(Object) 方法是从头开始遍历数组,而 FastList 是从数组的尾部开始遍历,因此更为高效,它消除了范围检查,并从尾部到头部执行移除扫描。
简而言之就是用自定义数组类型 FastList 代替 ArrayList:避免每次 get() 调用都要进行范围检查,避免调用 remove() 时的从头到尾的扫描。
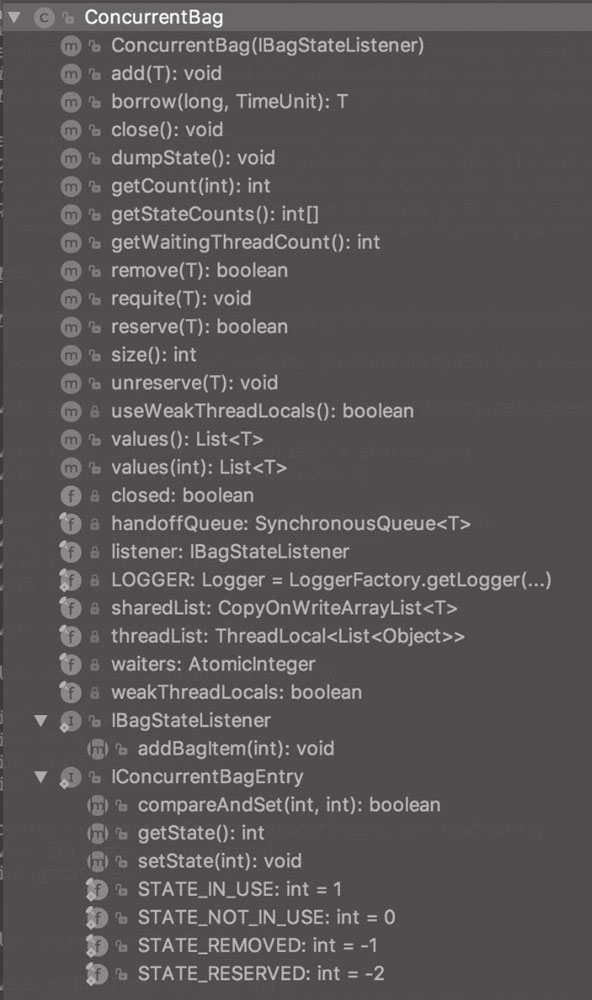
ConcurrentBag
ConcurrentBag 取名来源于 C# .NET 的同名类,但是实现却不一样。它是一个 lock-free 集合,在连接池(多线程数据交互)的实现上具有比 LinkedBlockingQueue 和 LinkedTransferQueue 更优越的并发读写性能。它具有无锁设计、ThreadLocal 缓存、队列窃取、直接切换优化四大特点。
ConcurrentBag 采用了 queue-stealing 的机制获取元素:首先尝试从 ThreadLocal 中获取属于当前线程的元素来避免锁竞争,如果没有可用元素则再次从共享的 CopyOnWriteArrayList 中获取。此外,ThreadLocal 和 CopyOnWriteArrayList 在 ConcurrentBag 中都是成员变量,线程间不共享,避免了伪共享(false sharing)的发生。作者评价这款设计具有高度并发性,极低的延迟,并最大限度地减少了伪共享的发生。
ConcurrentBag 的性能提升主要源于如下 3 个组成部分:
- CopyOnWriteArrayList:负责存放 ConcurrentBag 中全部用于出借的资源。
- ThreadLocal:用于加速线程本地化资源访问。
- SynchronousQueue:用于存在资源等待线程时的第一手资源交接。
源码解析
ConcurrentBag 内部同时使用 ThreadLocal 和 CopyOnWriteArrayList 来存储元素,其中 CopyOnWriteArrayList 是线程共享的。
ConcurrentBag 采用了 queue-stealing 的机制获取元素:首先尝试从 ThreadLocal 中获取属于当前线程的元素来避免锁竞争,如果没有可用元素则扫描公共集合,再从共享的 CopyOnWriteArrayList 中获取。ThreadLocal 列表中没有被使用的 items 在借用线程没有属于自己的时候,是可以被“窃取”的。
ThreadLocal 和 CopyOnWriteArrayList 在 ConcurrentBag 中都是成员变量,线程间不共享,避免了伪共享的发生。
使用专门的 AbstractQueuedLongSynchronizer 来管理跨线程信号,这是一个 lock-less 的实现。
ConcurrentBag 通过 borrow 方法进行数据资源借用,通过 requite 方法进行资源回收,注意其中 borrow 方法只提供对象引用,不移除对象。所以从 bag 中“借用”的 items 实际上并没有从任何集合中删除,因此即使引用废弃了,垃圾收集也不会发生。因此使用时通过 borrow 取出的对象必须通过 requite 方法进行放回,否则会导致内存泄露,只有 remove 方法才能完全从 bag 中删除一个对象。
ConcurrentBag:
对 CopyOnWriteArrayList 的使用:通过 add 添加资源,通过 remove 方法借出资源:
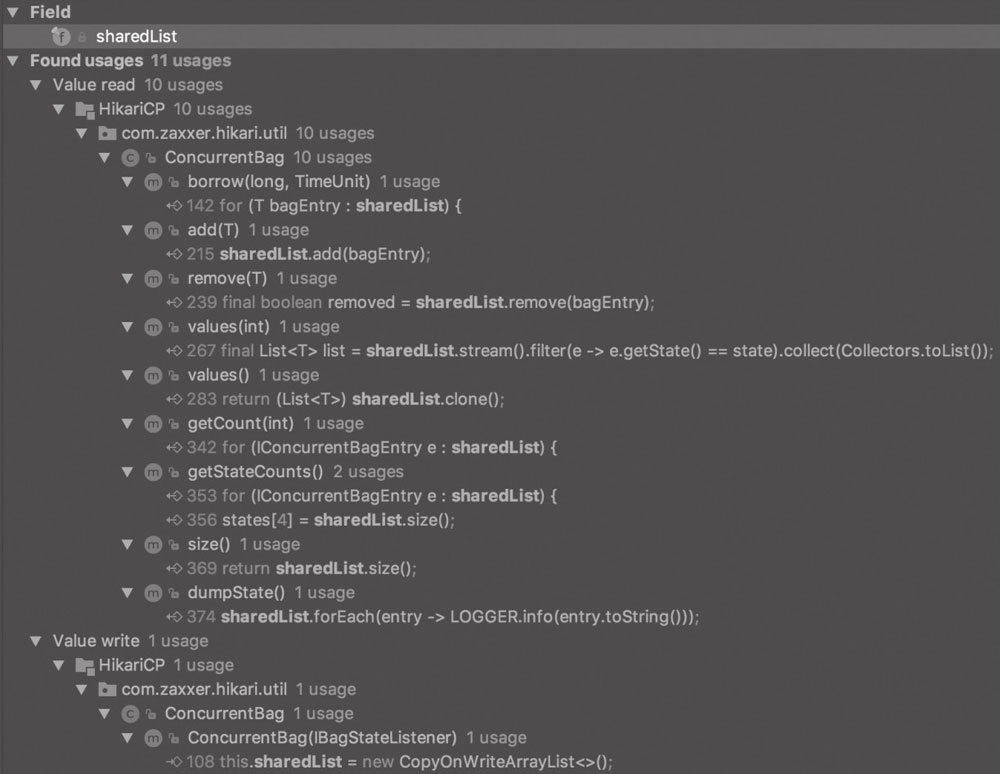
add 方法向 bag 中添加 bagEntry 对象,以供别人借用:
public void add(final T bagEntry)
{
if (closed) {
LOGGER.info("ConcurrentBag has been closed, ignoring add()");
throw new IllegalStateException("ConcurrentBag has been closed, ignoring
add()");
}
sharedList.add(bagEntry); //新添加的资源优先放入CopyOnWriteArrayList
// 当有等待资源的线程时,将资源交到某个等待线程后才返回(SynchronousQueue)
while (waiters.get() > 0 && ! handoffQueue.offer(bagEntry)) {
yield();
}
}
remove 方法从 bag 中删除一个 bagEntry,仅在 borrow(long, TimeUnit) 和 reserve(T) 时被调用:
public boolean remove(final T bagEntry){
// 如果资源正在使用且无法进行状态切换,则返回失败
if (!bagEntry.compareAndSet(STATE_IN_USE, STATE_REMOVED) &&
!bagEntry.compareAndSet(STATE_RESERVED, STATE_REMOVED) &&
!closed) {
LOGGER.warn("Attempt to remove an object from the bag that was not borrowed or reserved: {}", bagEntry);
return false;
}
final boolean removed = sharedList.remove(bagEntry); // 移出
if (! removed && ! closed) {
LOGGER.warn("Attempt to remove an object from the bag that does not exist: {}", bagEntry);
}
return removed;
}
// ConcurrentBag中通过borrow方法进行数据资源借用。
public T borrow(long timeout, final TimeUnit timeUnit) throws InterruptedException
{
// 优先查看有没有可用的本地化的资源
final List<Object> list = threadList.get();
for (int i = list.size() -1; i >= 0; i--) {
final Object entry = list.remove(i);
@SuppressWarnings("unchecked")
final T bagEntry = weakThreadLocals ? ((WeakReference<T>) entry).
get() : (T) entry;
if (bagEntry ! = null && bagEntry.compareAndSet(STATE_NOT_IN_USE,
STATE_IN_USE)) {//优先从当前线程的ThreadLocal中获取连接,若获得则直接返回
return bagEntry;
}
}
final int waiting = waiters.incrementAndGet();
try {
// 当无可用本地化资源时,遍历全部资源,查看是否存在可用资源
// 因此被一个线程本地化的资源也可能被另一个线程"抢走"
for (T bagEntry : sharedList) {
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
if (waiting > 1) {
// 因为可能"抢走"了其他线程的资源,因此提醒包裹进行资源添加
listener.addBagItem(waiting -1);
}
return bagEntry;
}
}
listener.addBagItem(waiting);
timeout = timeUnit.toNanos(timeout);
do {
final long start = currentTime();
// 若现有资源全部在使用中,则等待一个被释放的资源或者一个新资源
final T bagEntry = handoffQueue.poll(timeout, NANOSECONDS);
if (bagEntry == null ||
bagEntry.compareAndSet(STATE_NOT_IN_USE,STATE_IN_USE)) {
return bagEntry;
}
timeout -= elapsedNanos(start);
} while (timeout > 10_000);
return null;
}
finally {
waiters.decrementAndGet();
}
}
public void requite(final T bagEntry)
{
// 将状态转为未在使用
bagEntry.setState(STATE_NOT_IN_USE);
// 判断是否存在等待线程,若存在,则直接转手资源
for (int i = 0; waiters.get() > 0; i++) {
if (bagEntry.getState() ! = STATE_NOT_IN_USE || handoffQueue.offer(bagEntry)) {
return;
}
else if ((i & 0xff) == 0xff) {
parkNanos(MICROSECONDS.toNanos(10));
}
else {
yield();
}
}
// 否则,进行资源本地化
final List<Object> threadLocalList = threadList.get();
threadLocalList.add(weakThreadLocals ? new WeakReference<>(bagEntry) :bagEntry);
}
SynchronousQueue
SynchronousQueue 来自于 JUC 并发包 java.util.concurrent,在 HikariCP 中的体现就是 ConcurrentBag 结构中的 handoffQueue,它主要用于存在资源等待线程时的第一手资源交接:
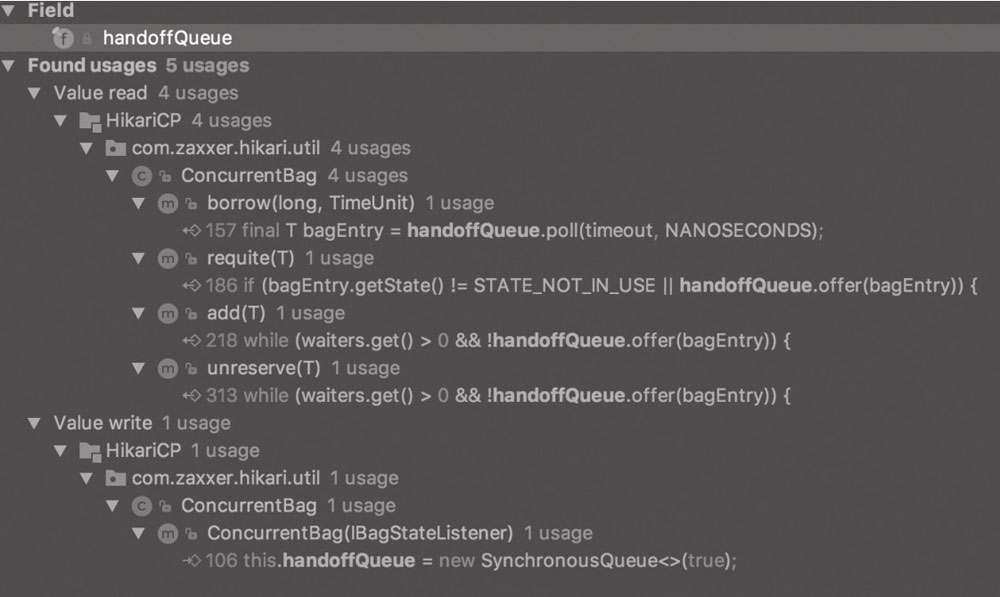
SynchronousQueue 的初始化是在 ConcurrentBag 的构造方法中,如下所示:
public ConcurrentBag(final IBagStateListener listener)
{
this.listener = listener;
this.weakThreadLocals = useWeakThreadLocals();
this.handoffQueue = new SynchronousQueue<>(true);
this.waiters = new AtomicInteger();
this.sharedList = new CopyOnWriteArrayList<>();
if (weakThreadLocals) {
this.threadList = ThreadLocal.withInitial(() -> new ArrayList<>(16));
}
else {
this.threadList = ThreadLocal.withInitial(() -> new FastList<>
(IConcurrentBagEntry.class, 16));
}
}
SynchronousQueue 提供了以下两个构造函数:
public SynchronousQueue() {
this(false);
}
public SynchronousQueue(boolean fair) {
// 通过fair值来决定公平和不公平
// 公平使用TransferQueue,不公平使用TransferStack
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}
在 HikariCP 中,选择的是公平模式 this.handoffQueue = newSynchronousQueue<>(true)。公平模式总结下来就是:队尾入队队头出队,先进先出,体现公平原则。
SynchronousQueue 是一个无存储空间的阻塞队列(是实现 newFixedThreadPool 的核心),非常适合做交换工作,生产者和消费者的线程同步以传递某些信息、事件或者任务。作为 BlockingQueue 中的一员,SynchronousQueue 的吞吐量高于 ArrayBlockingQueue 和 LinkedBlockingQueue,与其他 BlockingQueue 有着不同特性。
- SynchronousQueue 无存储空间。与其他 BlockingQueue 不同,SynchronousQueue 是一个不存储元素的 BlockingQueue。它的特点是每一个 put 操作必须要等待一个 take 操作或者 poll 方法,才能使用 off、add 方法,否则不能继续添加元素,反之亦然。
- 因为没有容量,所以对应 peek、contains、clear、isEmpty 等方法其实是无效的。例如 clear 是不执行任何操作的,contains 始终返回 false, peek 始终返回 null, peek 方法直接返回 null。
- SynchronousQueue 分为公平和不公平,默认情况下采用不公平访问策略。当然也可以通过构造函数来设置为公平访问策略。
- 若使用 TransferQueue,则队列中永远会存在一个 dummynode。
CopyOnWriteArrayList
CopyOnWriteArrayList 负责存放 ConcurrentBag 中全部用于出借的资源。顾名思义,Write 的时候总是要 Copy,也就是说对于任何可变的操作都是伴随复制这个动作的,这是 ArrayList 的一个线程安全的变体,底层通过复制数组的方式来实现。和 SynchronousQueue 一样,它也位于 java.util.concurrent 包下,为并发而生。CopyOnWriteArrayList 在遍历的时候不会抛出 ConcurrentModificationException 异常,并且遍历的时候就不用额外加锁,元素也可以为 null。
CopyOnWriteArrayList 底层是一个数组,通过 ReentrantLock 进行加锁,它初始化的时候底层是一个 Object[] array, Object array 指向一个大小为 0 的数组。一次 add 操作经历了 5 个步骤,都是在锁的保护下进行的,在添加的时候先上锁,拿到原数组并复制一个新数组(原数组大小+1),增加操作在新数组上进行,最后再将 Object array 引用指向新数组,解锁。这样做是为了避免在多线程并发add的时候,复制多个副本出来,把数据搞乱了,导致最终的数组数据不是我们期望的。这是一种写时复制的理念。
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
final transient ReentrantLock lock = new ReentrantLock(); //可重入锁
final Object[] getArray() {return array; }//非private,得到数组
final void setArray(Object[] a) {array = a; }//设置数组
public CopyOnWriteArrayList() { setArray(new Object[0]); }//初始化
public boolean add(E e) {
final ReentrantLock lock = this.lock; //1)加锁
lock.lock();
try {
Object[] elements = getArray(); //得到原数组的长度和元素
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1); //2)复制数组
newElements[len] = e; //3)将元素加入到新数组中
setArray(newElements); //4)将array引用指向到新数组
return true;
} finally {
lock.unlock(); //5)解锁
}
}
插入、删除、修改操作也都是一样,每一次的操作都是以对Object[] array进行一次复制为基础的。写加锁,读不加锁。由于所有的写操作都是在新数组进行的,这个时候如果有线程并发的写,则通过锁来控制。如果有线程并发的读,则分以下几种情况:
- 如果写操作未完成,那么直接读取原数组的数据。
- 如果写操作完成,但是引用还未指向新数组,那么也是读取原数组数据。
- 如果写操作完成,并且引用已经指向了新的数组,那么直接从新数组中读取数据。
CopyOnWriteArrayList 非常适用于数据库连接池这种读操作远远多于修改操作的场景,它反映的是 3 个十分重要的分布式理念:
- 读写分离。读取 CopyOnWriteArrayList 的时候,读取的是 CopyOnWriteArrayList 中的
Object[] array,但是修改的时候,操作的是一个新的Object[] array。读和写操作的不是同一个对象,这就是读写分离。这种技术数据库用的非常多,在高并发下为了缓解数据库的压力,即使做了缓存也要对数据库做读写分离,读的时候使用读库,写的时候使用写库,然后读库、写库之间进行一定的同步,这样就避免同一个库上读、写的 IO 操作太多。 - 最终一致。对 CopyOnWriteArrayList 来说,线程1读取集合里面的数据,未必是最新的数据。因为线程2、线程3、线程4都修改了 CopyOnWriteArrayList 里面的数据,但是线程1拿到的还是最老的那个
Object[] array,新添加进去的数据并没有,所以线程1读取的内容未必准确。不过这些数据虽然对于线程1是不一致的,但是对于之后的线程一定是一致的,它们拿到的Object[] array一定是3个线程都操作完毕之后的Object array[],这就是最终一致。最终一致对于分布式系统也非常重要,它通过容忍一定时间的数据不一致,提升整个分布式系统的可用性与分区容错性。当然,最终一致并不是任何场景都适用的,像火车站售票这种系统用户对于数据的实时性要求非常非常高,就必须做成强一致性的。 - 使用另外开辟空间的思路,来解决并发冲突。
但是它有着以下缺点:
- 因为 CopyOnWrite 的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)。如果这些对象占用的内存比较大,比如200M左右,再写入100M数据,内存就会占用300M,那么这个时候很有可能造成频繁的Yong GC和Full GC。
- 不能用于实时读的场景,像复制数组、新增元素都需要时间,所以调用一个 set 操作后,读取到数据可能还是旧的。虽 CopyOnWriteArrayList 能做到最终一致性,但是还是没法满足实时性要求。所以如果你希望写入的的数据马上能读到,就不要使用 CopyOnWrite 容器。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.