JDBC API
HikariCP JDBC Logging
HikariCP 目前并不包含 JDBC 的日志记录。因为作者认为日志记录是性能杀手,甚至检查是否启用或禁用日志记录的布尔值对 HikariCP 来说也是多余的开销,几乎每个驱动程序都支持某种类型的日志记录,并且 ORM 框架也不可避免这样去做。
对于驱动程序不支持 JDBC 直接记录,或者希望此解决方案的灵活性优于数据库供应商的产品,log4jdbc-log4j2 是一个不错的选择。
另外还有 P6spy,它似乎略微比 log4jdbc-log4j2 更易于维护。
JDBC
在 Vlad Mihalcea 的 “High-Performance JavaPersistence” 一书中给出了一张数据访问技术栈的图片,如图所示。我们可以看到 JDBC 在整个数据访问技术栈中起着非常重要的作用。
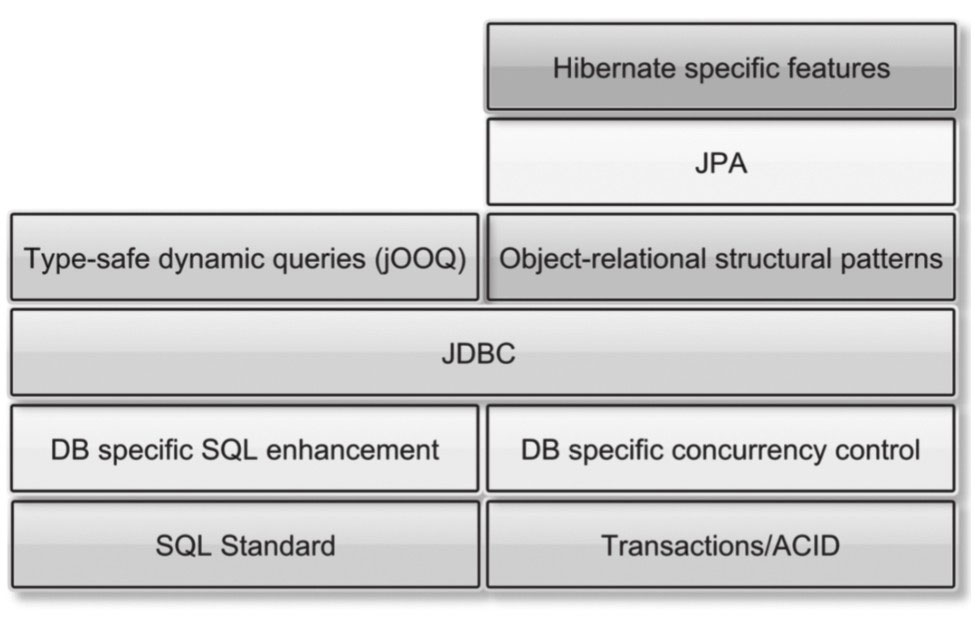
JDBC 代表 Java 数据库连接,是基于 Java 开发的系统中程序员和数据库打交道的主要途径,提供了完备的数据库操作方法接口。
JDBC 定义
JDBC,Java DataBase Connectivity。
JDBC API 是一个 Java API,可以访问任何类型表列数据,特别是存储在关系数据库中的数据。
JDBC API 由一组用 Java 编写的类和接口组成。为工具/数据库开发人员提供标准 API 的编程语言,可以使用全 Java API 编写工业级数据库应用程序。JDBC API 可以轻松地将 SQL 语句发送到关系数据库系统,并支持所有 SQL 方言。但是 JDBC 2.0 API 超越了 SQL,也使得与其他类型的数据源(例如包含表格数据的文件)进行交互成为可能。
JDBC API 的价值在于,应用程序几乎可以访问任何数据源,并可以在任何具有 Java 虚拟机的平台上运行。换句话说,使用 JDBC API,不必编写一个程序来访问 Sybase 数据库,另一个程序访问 Oracle 数据库,另一个程序访问 IBM DB2 数据库,等等。
JDBC API 是 Java 编程语言与各种数据库之间数据库无关连接的行业标准。JDBC API 为基于 SQL 的数据库访问提供了调用级 API。JDBC 技术允许您使用 Java 编程语言为需要访问企业数据的应用程序提供“一次编写,随处运行”功能。
JDBC API 是一种执行 SQL 语句的 API, JDBC 驱动才是真正的接口实现,所有的网络逻辑和特定于数据库的通信协议都隐藏于、独立于供应商的 JDBC API 后面。Sun 公司只是提供了JDBC API,每个数据库厂商都有自己的驱动来连接自己公司的数据库,如图所示。
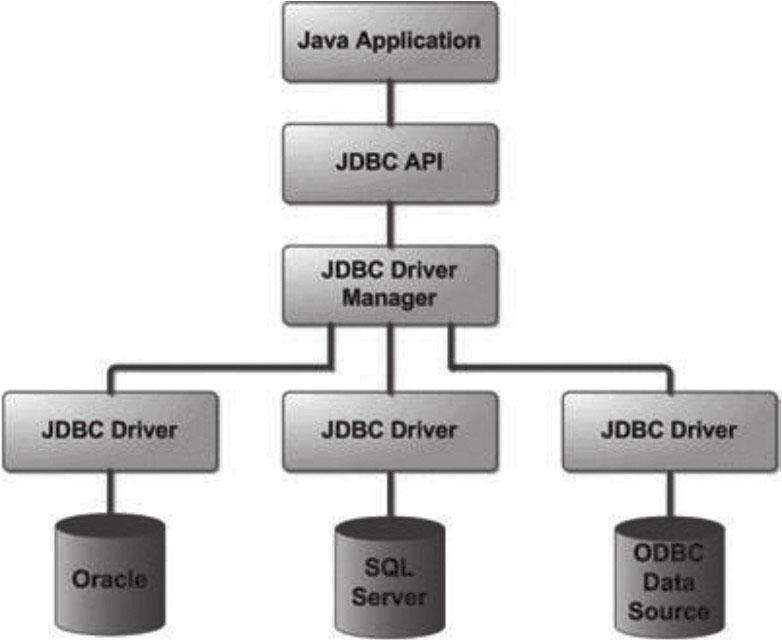
我们可以看到,JDBC API 采用了桥接的设计模式,提供了两套接口,JDBC Driver Planager 面向数据库厂商,如Oracle、SQL Seruer 等;JDBC API 面向 JDBC 使用者,如 Java Application。
JDBC 接口相当于实现化角色接口,数据库厂商实现的驱动相当于具体实现化子类,应用程序相当于抽象化角色,内部持有一个实现化角色的对象。桥接模式将实现化和抽象化解耦,从而让两个部分可以沿着不同的方向拓展,只要遵循接口即可,从而学习成本低。
JDBC 连接数据库时,在各个数据库之间进行切换,基本上不需要动太多的代码,甚至丝毫不动,原因就是 JDBC 提供了统一接口,每个数据库提供各自的实现,用一个叫作数据库驱动的程序来桥接就行了。
JDBC 定义了 4 种驱动类型:JDBC-ODBC 桥、本地 API 驱动、网络协议驱动、本地协议驱动。由于易于设置和调试,第 4 种类型本地协议驱动纯粹基于 Java 的多驱动程序,通过 Socket 连接与厂商的数据库进行通信,是首选的方案。
通过 DriverManager 获取连接:

通过 DataSource 获取连接:

由于减少了创建和关闭连接的开销,HikariCP 等数据库连接池的出现又将 JDBC 的性能大大提升了一个档次。使用数据库连接池作为 JDBC 的最佳实践已经几乎成了公认的标准。
除此之外,JDBC 的最佳实践还有如下内容:
- 使用 PrearedStatement,通过预编译的方式避免在拼接SQL时造成SQL注入,使用“? ”或其他占位符等变量绑定的形式可以使用不同的参数执行相同的查询也能防止 SQL 注入。
- 禁用自动提交,这样可以将数据库操作放在一个事务中,而不是每次执行 SQL 语句都在执行结束时提交自己独立的事务。
- JDBC 批处理可以降低数据库传输频率,进而提升性能。
- 使用列名而不是列序号获取 ResultSet 中的数据,避免 invalidColumIndexError,从而提升程序的健壮性、可读性。
- 在 Java 7 中,可以通过 Automatic ResourceManagement Block 来自动关闭资源。要记得关闭所有的Connection、Statement 等资源。
- 使用标准的 SQL 语句(如标准的ANSI SQL),避免数据库对 SQL 支持的差异。
JDBC 剖析
JDK 规定了 JDBC 的相关接口,JDBC 是 SPI(服务提供者接口) 框架的良好应用。JDBC API 主要位于 JDK 中的 java.sql 包中,扩展的内容位于 javax.sql 包中。
java.sql.* 采用传统的 C/S 体系结构思想设计它所包含的接口和类,核心类图如图所示。
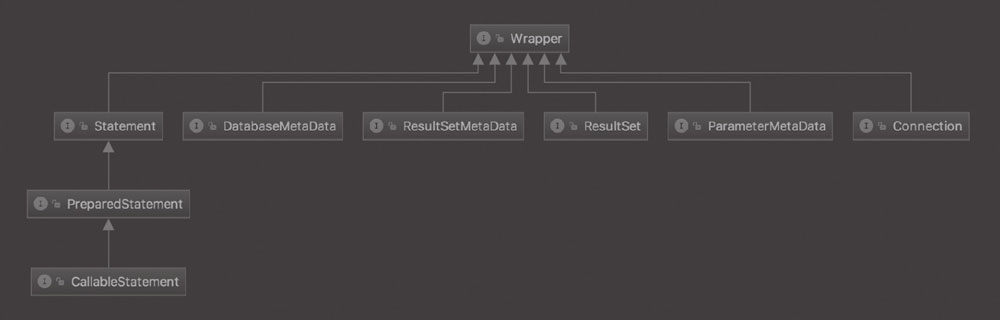
它包含生成连接、执行语句等功能,包括一些诸如批处理更新、可滚动结果集、事务隔离、封装 SQLException 等功能。java.sql.* 属于 JDBC2.0 之前,通常被称为 JDBC 内核 API; javax.sql.* 包括了 JDBC 3.0 的很多新特性,被称为 JDBC 标准扩展。
javax.sql.* 作为标准扩展,提供了很多对java.sql.*的补充和新特性。体现在 Datasource 接口提供了一种可选择性的方式去建立连接,分布式事务处理,增加 rowset,增加连接池等。

了解 JDBC,关注点更多的还是 java.sql.* 包,在这个包里,有 4 个核心接口(Driver、Connection、Statement和ResultSet)和两个核心类(DriverManager和SQLException)。类型的对象。它还提取与使用 Driver 对象相关的信息。不同的数据库有不同的装载方法。
- DriverManager:管理一组数据库驱动程序的基本服务。使用通信子协议将来自 Java 应用程序的连接请求与适当的数据库驱动程序进行匹配。在 JDBC 下识别某个子协议的第一个驱动程序将用于建立数据库连接。其初始化时用到 ServiceLoader 机制,所以可以直接用 Class.forName(driver);就可以完成加载驱动。在 DriverManager 里面,有一个 ArrayList,专门用来保存注册好的 Driver,并使用了 CopyOnWriteArrayList 来保证多线程环境下的线程安全。
- Driver:此接口处理与特定数据库服务器的通信,是每个数据库驱动都必须继承的接口。我们很少会直接与 Driver 对象进行交互。但会使用 DriverManager 对象来管理。
- Connection:此接口具有用于链接数据库的所有方法。连接(Connection)对象表示通信上下文,即,与数据库的所有通信仅通过连接对象。拥有创建 SQL 语句的方法,以完成基本的 SQL 操作,同时为数据库事务提供提交和回滚方法。
createStatement():创建向数据库发送 SQL 的 statement 对象。prepareStatement(sql):创建向数据库发送预编译 SQL 的 PrepareSatement 对象。prepareCall(sql):创建执行存储过程的 callableStatement 对象。setAutoCommit(boolean autoCommit):设置事务是否自动提交。commit():在连接上提交事务。rollback():在此连接上回滚事务。
- Statement:使用从此接口创建的对象将 SQL 语句提交到数据库。除了执行存储过程之外,一些派生接口还接受参数。它由 createStatement 创建,用于发送简单的 SQL 语句(不带参数)。除此以外,还有两种Statement:PreparedStatement 和 CallableStatement,如图上图所示.CallableStatement 继承自 PreparedStatement,PreparedStatement 继承自 Statement。
- PreparedStatement:PreparedStatement 接口扩展了 Statement 接口,它添加了比 Statement 对象更好一些的功能。此语句由 preparedStatement 创建,可以动态地提供/接受参数,进行 SQL 语句的预编译,也可以动态拼接。因为会进行预编译,所以当用动态拼接的时候,会对传入的参数进行强制转换,所以会对参数进行校验,可以避免 SQL 注入。开发的时候尽量用 preparedStatement,少用 statement。PreparedStatement 对象有能力使用提供参数数据的输入和输出流。它可以将整个文件输入数据库中,可容纳较大的值,如 CLOB 和 BLOB 数据类型的列。对于 PreparedStatement,会有一个 LRUCache 来存放,先到那里去取,取不到再创建一个新的,这个 LRUCache 的默认大小是 25。
- CallableStatement:由方法 prepareCall 创建,为所有的 DBMS 提供了一种以标准形式调用数据库储存过程的方法。
- 常用方法:
execute(String sql):运行语句,返回是否有结果集。executeQuery(String sql):运行 select 语句,返回 ResultSet 结果集。executeUpdate(String sql):运行 insert/update/delete 操作,返回更新的行数。addBatch(String sql):把多条 SQL 语句放到一个批处理中。executeBatch():向数据库发送一批 SQL 语句执行。
- ResultSet:在使用 Statement 对象执行 SQL 查询后,这些对象保存从数据库检索到的数据。它作为一个迭代器并可移动 ResultSet 对象查询的数据。但是结果集并不仅仅具有存储的功能,它同时还具有操纵数据的功能,可能完成对数据的更新等。
getString(int index)、getString(StringcolumnName):获得数据库里 varchar、char 等类型的数据对象。getFloat(int index)、getFloat(StringcolumnName):获得数据库里 Float 类型的数据对象。getDate(int index)、getDate(StringcolumnName):获得数据库里 Date 类型的数据。getBoolean(int index)、getBoolean(StringcolumnName):获得数据库里 Boolean 类型的数据。getObject(int index)、getObject(StringcolumnName):获取数据库里任意类型的数据。next():移动到下一行。previous():移动到前一行。absolute(int row):移动到指定行。beforeFirst():移动到 ResultSet 的最前面。afterLast():移动到 ResultSet 的最后面。
- SQLException:此类处理数据库应用程序中发生的任何错误。
需要强调的是,Connection、Statement 和 Result 是一种“爷—父—子”的关系,对 Connection 的管理,就是对数据库资源的管理。如果想确定某个数据库连接(Connection)是否超时,则需要确定其(所有的)子 Statement 是否超时,同样,需要确定所有相关的 ResultSet 是否超时;Statement 关闭会导致 ResultSet 关闭,但是 Connection 关闭却不一定会导致 Statement 关闭。
在数据库连接池里,Connection 关闭并不是物理关闭,只是归还连接池,所以 Statement 和 ResultSet 有可能被持有,并且实际占用相关的数据库的游标资源。所以在关闭 Connection 前,需要关闭所有相关的 Statement 和 ResultSet。这就是 HikariCP 作者所强调的 JDBC 的最基本的规范,也是他创造 HikariCP 的原因,数据库连接池一定不能违背这样的规则。
最好方案就是顺序关闭 ResultSet、Statement、Connection;在 rs.close() 和 stmt.close() 后面加上 rs= null 和 stmt = null 来防止内存泄漏;RowSet 不依赖于 Connection 和 Statement 可以作为一种传递 ResultSet 的替代方案。
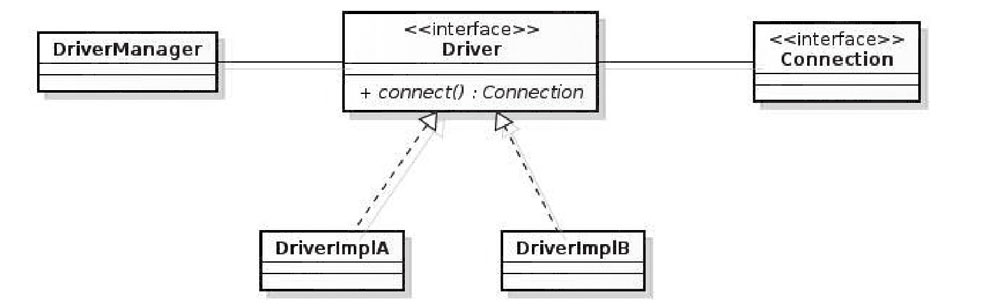
通过 DriverManger 获得 Connection,一个 Connection 对应一个实际的物理连接,每次操作都需要打开物理连接,使用完后立即关闭;这样频繁地打开/关闭连接会造成不必要的数据库系统性能消耗。
这样的背景下催生了数据库连接池的产生,数据库连接池提供的解决方案是:当应用启动时,主动建立足够多的数据库连接,并将这些连接组织成连接池,每次请求连接时,无须重新打开连接,而是从池中取出已有连接,使用完后并不实际关闭连接,而是将其归还给池。
所以这里需要涉及两项技术,一是连接使用 List 之类的集合进行初始化、装载和归还,二是使用动态代理来把资源归回给 List 集合。
而HikariCP之所以这么快,也主要是将这两项技术做到了极致。
JDBC 数据库连接池使用 javax.sql.DataSource 表示,DataSource 只是一个接口,其实现通常由服务器提供商(如WebLogic、WebShere)或开源组织(如 DBCP、c3p0 和 HikariCP)提供。
PreparedStatement & Statement
PreparedStatement 在企业开发中被强烈推荐使用,原因主要有以下方面:
Statement 会频繁编译 SQL。如果 JDBC 驱动支持的话(一般来说数据库系统库系统初次分析、编译时会对查询语句做最大的性能优化), PreparedStatement 可对 SQL 进行预编译,提高效率,预编译的 SQL 存储在 PreparedStatement 对象中。从这个意义上来说,PreparedStatement 比 Statement 更快,使用 PreparedStatement 也可以降低生产环境的数据库负载。
Statement 对象编译 SQL 语句时,如果 SQL 语句有变量,就需要使用分隔符来隔开,如果变量非常多,就会使 SQL 变得非常复杂。PreparedStatement 可以使用占位符,通过动态参数化的查询来简化 SQL 的编写。比如下面这个参数化查询例子,通过使用相同的 SQL 语句和不同的参数值来做查询,比创建一个不同的查询语句要好。
SELECT telephone_number FROM city WHERE username =?PreparedStatement 可防止 SQL 注入。因为 Statement 对象需要拼接,通过分隔符“++”编写永等式就可以实现 SQL 注入;而 PreparedStatement 使用占位符,就不会有 SQL 注入的问题。
JDBC & SPI
为了实现在模块装配的时候能不在程序里动态指明,需要一种服务发现机制。JDK 内置的 SPI(Service ProviderInterface)就能提供这样的一个机制:为某个接口寻找服务实现的机制。有点类似 IOC 的思想,就是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要。
JDBC 4.0 以前,开发人员还需要基于 Class.forName(“xxx”) 的方式来装载驱动,而 JDBC 4.0 基于 SPI 机制来发现驱动提供商,可以通过 META-INF/services/java.sql.Driver 文件里指定实现类的方式来暴露驱动提供者。开发者只需要编写一行代码,使用不同厂商的 jar 包,就可以轻松创建连接了。
线程池技术
池化技术,包括线程池、连接池、内存池、对象池等,其作用就是提前保存大量的资源,或者将用过的资源保存起来,等下一次需要使用该资源时再取出来重复使用。
线程池和连接池是两个不同的概念,连接池一般在客户端设置,而线程池是在如数据库这样的服务器上配置。通常来说,比较好的方式是将连接池和线程池结合起来使用。线程池具有线程复用、控制最大并发数、管理线程、保护系统4个优点,线程池的目的类似于连接池,通过复用线程来减少频繁创建和销毁线程,从而降低性能损耗。
线程池往往配合队列一起工作,限制并发处理任务的数量,从而保护系统。线程池的工作方式大同小异:先将任务提交到一个或者多个队列中,接着一定数量的线程从该队列中领取任务并执行,任务的结果再做处理,比如保存到MySQL数据库、调用别的服务等;任务完成以后,该线程会返回任务队列,等待下一个任务。
MySQL 线程池
传统方式下,MySQL 线程调度方式有两种:每个连接一个线程(One-Thread-Per-Connection)和所有连接一个线程(no-threads)。
MySQL 线程池是 MySQL 5.6 企业版的一个核心功能,是为了解决 One-Thread-Per-Connection 的实际生产常用选择的问题而引入的,通过有效管理大量客户端连接的语句执行线程数量,减少内存消耗,降低上下文切换(提高CPU Cache命中率)等来提高服务器性能。
在线程池 Thread Pool 处理方案中,最小单位是 statement,一个线程可以处理多个连接的请求,可以避免瞬间连接风暴造成的抖动。MySQL 线程池只在 Percona、MariaDB、Oracle 的 MySQL 企业版中提供,Oracle MySQL 社区版并不提供。MariaDB 在 5.5 版本中引入并最先实现线程池 Thread Pool 方案,Oracle 在 6.10 企业版本以 plugin 插件形式引入,Percona 在移植 MariaDB 的 Thread Pool 方案后又修复了一系列问题并优化了线程池性能。
使用“show variables like ‘thread%’”命令可以看到 thread_handling 的配置,默认情况是 one-thread-per-connection,即不启用线程池;将该参数设置为 pool-of-threads 即启用了线程池。
可以这么说,在 Percona 版本以后,MySQL 支持 No-Threads、One-Thread-Per-Connection 和 Pool-Threads 三种管理方式。Oracle Mysql 官方的性能测试表明:
- 在并发达到 128 个连接以后.没有线程池的 MySQL 性能会迅速降低。使用线程池以后,性能不会出现波动,会一直保持在较好的状态运行。
- 在读写模式下,128 个连接以后,有线程池的 MySQL 比没有线程池的 MySQL 性能高出 60 倍。
- 在只读模式下,512 个连接以后,有线程池的 MySQL 比没有线程池的 MySQL 性能高出 18 倍。
我们可以看到,Thread Pool 极大地提升了性能,并且解决了 One-Thread-Per-Connection 的如下 3 个问题:
- 太多的线程堆栈使 CPU 缓存在高度并行的执行工作负载中几乎无用。线程池促进了线程堆栈重用,以最小化 CPU 缓存占用空间。
- 由于太多线程并行执行,因此上下文切换开销很高。这也给操作系统调度程序带来了挑战性的任务。线程池控制活动线程的数量,以使 MySQL 服务器内的并行性保持在它可以处理的水平,并且适用于 MySQL 正在执行的服务器主机。
- 并行执行的事务太多会增加资源争用。
MySQL 线程池内部
排队理论中存在一个众所周知的关系:尝试访问共享资源的用户越多,响应时间越长,并呈指数级增长。
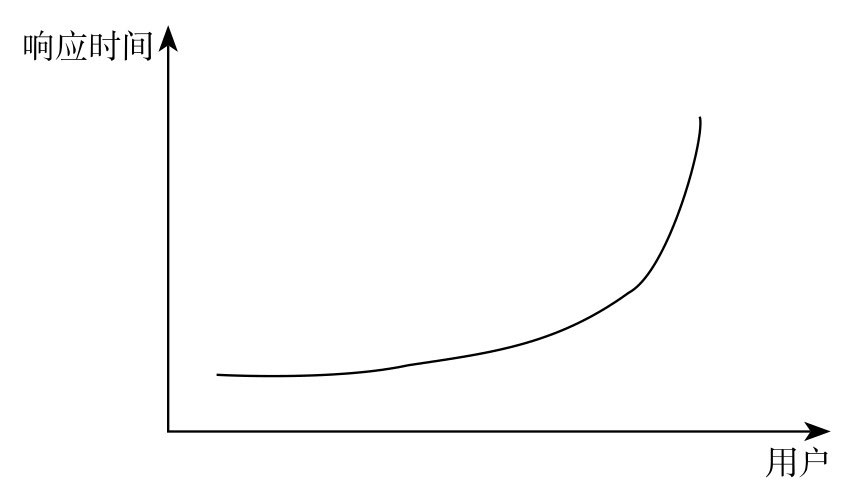
在吞吐量上,随着用户的不断增多,由于内部通信和同步,系统每秒能够处理的请求就越来越少,甚至会导致系统没有反应并且直接卡死,如图所示。众所周知的 DDoS 攻击就是类似这样的行为。
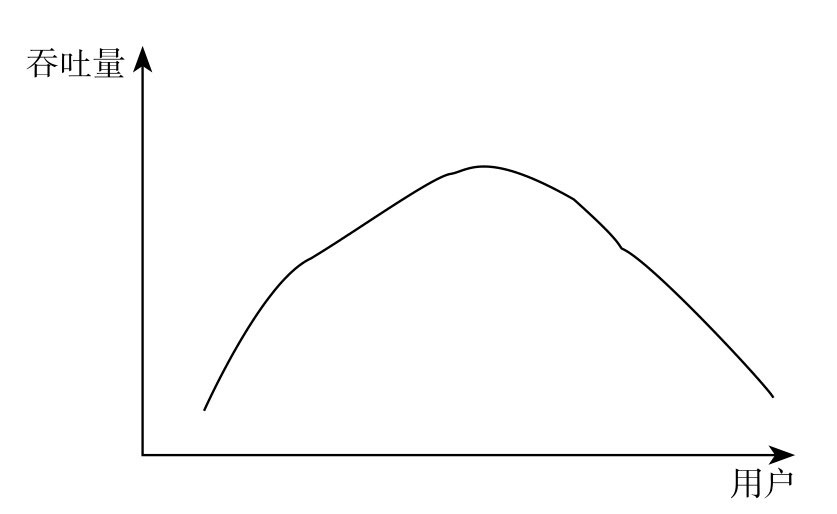
而 MySQL 线程池在面对上述困难时,旨在提供如图所示的吞吐量曲线。
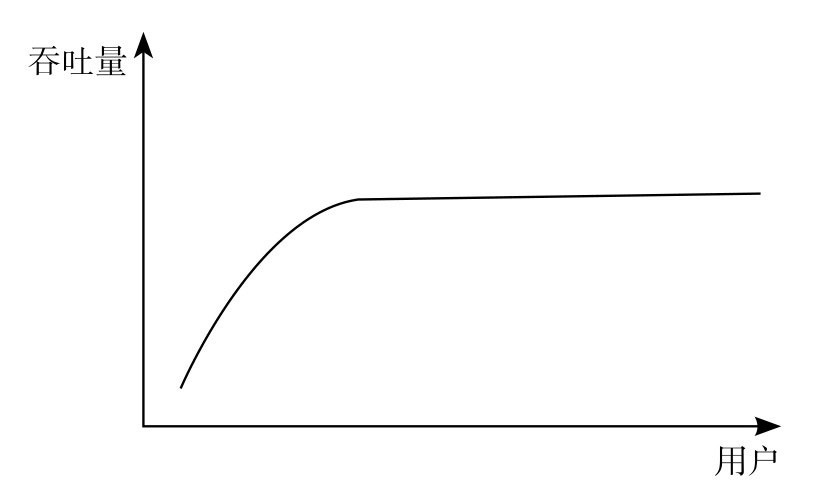
MySQL 线程池本身并不会神奇地提高性能,但是它可以保护 MySQL 突然过载的情况,打造上图所示的稳定性曲线,这是通过其限制 MySQL 内部的工作线程数量来实现的。
如图下所示,这是 MySQL Thread Pool 的架构图,MySQL 的线程池提出了一个线程组的概念,工作线程被放在了线程组内部。我们可以看到 Thread Pool 由一个 Timer 线程和多个线程组构成,每个线程组内部由优先队列、普通队列两个队列,以及一个 Listener 线程和多个工作线程组成。
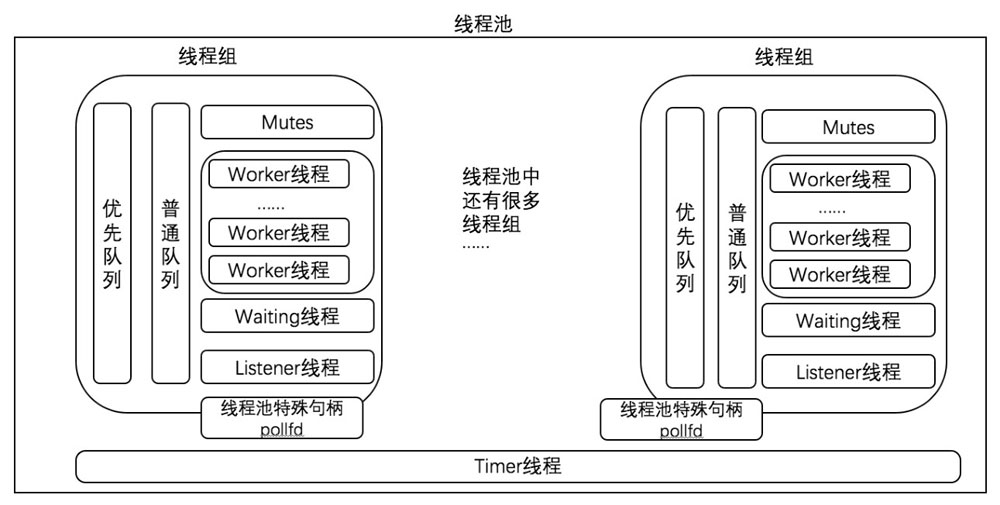
- 线程组,在初始化以后会由底层的 IO 库分配到一个特殊的句柄 pollfd,每个线程组都有一个对应的 pollfd。
- Worker 线程,是真正干活的线程,它具有活跃、空闲和等待3种状态。
- Listener 线程,主要用来监听该线程组的语句,通过 pollfd 中轮询 IO 任务来决定是 Listener 线程自身处理这些任务,还是放入队列交给并唤醒多少个 Worker 线程去处理。从这个意义上来说,Listener 线程也是可以转换为 Worker 线程的。所以,线程组中,总线程数等于正在工作且未被阻塞的线程数+工作线程任务的过程中被阻塞的个数+空闲线程的个数 + Listener 线程的个数。
- 任务队列,由普通队列和优先任务队列构成,是 Listene r每次从 pollfd 轮询出来的就绪任务。官方定义将符合连接处于事务中和连接关联的 priority tickets 值大于 0 两种情况认为是优先队列。所以可以这么认为,如果同一个事务中有两个 insert的SQL,有 1 个已经执行,那么另一个 insert0 任务就会放在高优先级中。如果是非事务引擎,或者开启了 autocommit 的事务引擎,都会放到普通队列中。还有一种情况是如果语句在普通队列中停留太久,该语句也会移到优先队列中,防止它饿死,thread_pool_prio_kickup_timer 系统变量控制了这个“停留时间”,对每个线程组来说,语句停留的最大时间为 10ms。另外,还有一个
priority tickets(thread_pool_high_prio_tickets)的设计,以优先的任务每次被放入优先队列中就对 priority tickets 减 1,以避免永久优先的问题。 - Timer 线程,是一种 Check Stall 机制,用来周期性地检查 group 是否超时或阻塞状态,并通过检测线程组的负载来进行工作线程的唤醒和创建行。创建线程必须满足两个条件:其一,如果没有空闲线程且没有活跃线程则立刻创建,这种情况可能因为没有任何工作线程或者工作线程都被阻塞了,或者是存在潜在的死锁;其二,如果距离上次创建的时间大于一定阈值才创建线程,这个阈值由线程组内的线程数决定。
介绍完 Thread Pool 架构和架构中的各个组件,我们再来看一下一次完整的用户请求是如何从数据库连接池进入 MySQL 的线程池,通过 Thread Pool 而进行运作的。
- 在初始化时,MySQL 线程池根据宿主机的 CPU 核心数设置 thread_pool_size,并分成若干 group,每个 group 各自维护客服端发起的连接。当用户的请求通过数据库连接池访问到 MySQL 服务端时,MySQL 服务端再进行
threadid % thread_pool_size取模计算,确定落在哪个线程组中。 - 线程组中的 Listener 线程监听到所在的线程组有新的请求后,检查队列中是否有请求还未处理,并决定是自己亲自转化为 Worker 线程进行处理,还是把这些任务放入队列中让 Worker 线程进行处理。在这个过程中先处理优先队列,再处理普通队列。如果任务队列不为空,Listener 线程还需要考虑应调度唤醒多少个工作线程。
在以上两步中,还有两个自检程序在运行着。一个是 Worker 线程会自己判断最大空闲时间,如果超过最大空闲时间(默认60秒)就会退出;还有一个是 Timer 线程不断进行 CheckStall 机制,用来周期性地检查 group 是否处于超时或阻塞状态,并通过检测线程组的负载来进行工作线程的唤醒和创建。
MySQL 线程池实战
基本参数:
- thread_pool_size 是线程池性能最重要的参数,其设置线程池的 group 的数量,默认为系统CPU的个数。MySQL 官方文档给出的经验性建议[插图]是:如果主引擎(primary storage engine)为InnoDB, thread_pool_size 最佳设置可能为16~36,最常见的优化值倾向于24~36;如果主引擎为 MyISAM,那么 thread_pool_size 设置应该相当低。该值设置为4~8,倾向于获取最优性能。更高值设置对性能倾向于有点负面但不显著的影响。
- thread_pool_stall_limit 表示 Timer Thread 检测 group 是否异常的时间间隔,默认是 500ms。其用来处理被阻塞和长时间运行的语句,确保服务器不会完全被阻塞。thread_pool_stall_limit 有个 6 秒的上限值,防止服务器死锁的风险。在合适范围内,该值越大,MySQL 服务器的整体处理性能就越好,因为较少数量的线程,会降低对于系统资源的征用。但是,并不是越大越好,因为该值越大,新线程的创建将等待时间越长,用户的查询延迟就会越明显。
- thread_pool_max_threads 控制线程池的最大线程数,默认为 10000。若该值为 1000,代表线程池中所能创建的最大线程数不能超过 1000。
- thread_handling 默认是 one-thread-per-connection,如果要使用连接池功能,则必须设置为 pool-of-threads。
- thread_pool_oversubscribe 用于控制单个 CPU 核心在同一时间活跃的线程数。类似于一种“超频”的概念,默认值是 3。
- thread_pool_idle_timeout 设置空闲线程销毁前的等待时间,单位为秒,默认是 60 秒。用户可以根据自己的业务场景来调整该参数的值。设置得太短,会导致线程频繁地销毁与创建;设置得太长,则会导致线程池中的线程数长时间不会下降。
- thread_pool_idle_timeout 设置空闲线程销毁前的等待时间,单位为秒,默认是 60 秒。用户可以根据自己的业务场景来调整该参数的值。设置得太短,会导致线程频繁地销毁与创建;设置得太长,则会导致线程池中的线程数长时间不会下降。
- extra_port 用于设置 MySQL 服务端口之外的端口,供管理员管理服务器。
- extra_max_connections 用于设置 extra_port 端口允许的最大连接数,通过 extra_port 端口创建的连接,采用的是 one-thread-per-connection 的方式。
- thread_pool_high_prio_mode,线程池分组内的待处理任务会放到任务队列中,等待 Worker 线程处理。每个分组有两个队列:优先队列和普通队列,Worker 线程先从优先队列取事务处理,只有当优先队列为空时才从普通队列取事务处理。通过优先队列,可以让已经开启的事务或短事务得到优先处理,及时提交释放锁等资源。该参数可设置为3种模式:
- transactions。默认的,只有一个已经开启了事务的SQL,并且 thread_pool_high_prio_tickets 不为 0,才会进入优先队列中,每个连接在 thread_pool_high_prio_tickets 次被放到优先队列后,会移到普通队列中。
- statements。单独的 SQL 总是进入优先队列。
- none。禁用优先队列功能,所有的连接都放到普通队列中处理。
- thread_pool_high_prio_tickets,当
thread_pool_high_prio_mode = transactions的时候,每个连接的任务最多被放入优先队列 thread_pool_high_prio_tickets 次,并且每放一次递减,直到小于等于 0 的时候放入普通队列,这个值默认是 4294967295。
实战经验:
- 在 Percona 5.7 的部分低版本中,如果开启了 Performance_Schema 和 ThreadPool 会出现内存泄漏问题,需要将 performance_schema 设置为 off 并重启 MySQL。
- 慢 SQL 导致线程池卡住。慢 SQL 的问题往往是压倒团队的“最后一根稻草”,慢 SQL 引发的惨痛故障不胜枚举,甚至造成资损。不符合规范的 SQL、全表查询、没建索引等都是可能造成慢 SQL 的原因,而 thread_pool_oversubscribe 可以暂时缓解这个问题。但是这咱方法治标不治本,根本解决方法还是开启 MySQL 服务端的日志,将慢SQL每天反馈给各个技术研发团队,甚至直接通过中间件过滤掉慢 SQL,不让其访问到 MySQL 服务端。
- MySQL 主备切换及容灾演练。生产数据库往往会默认设置几千个连接数,可是如果发生业务洪峰、机房故障以后迅速重连导致的连接风暴等情况,都容易将 MySQL 的最大连接数和并发线程数迅速提高到峰值。业务上可以提前做好预案及压测,技术上可以考虑通过配置中心进行 MySQL 的多机房切换、主备切换及容灾,也可以做探测脚本,在即将达到最大连接数时进行及时的扩容。
- 调度死锁解决。引入线程池解决了多线程高并发的问题,但也带来一个隐患。假设,A、B 两个事务被分配到不同的 group 中执行,A 事务已经开始,并且持有锁,但由于 A 所在的 group 比较繁忙,导致A执行一条语句后,不能立即获得调度执行;而 B 事务依赖A事务释放锁资源,虽然B事务可以被调度起来,但由于无法获得锁资源,导致 B 仍然需要等待,这就是所谓的调度死锁。由于一个 group 会同时处理多个连接,但多个连接不是对等的。比如,有的连接是第一次发送请求,而有的连接对应的事务已经开启,并且持有了部分锁资源。为了减少锁资源争用,后者显然应该比前者优先得到处理,以达到尽早释放锁资源的目的。因此在 group 里面,可以添加一个优先队列,将已经持有锁的连接,或者已经开启的事务的连接发起的请求放入优先队列,工作线程首先从优先队列获取任务执行。
- 大查询处理。假设一种场景,某个 group 里面的连接都是大查询,那么 group 里面的工作线程数很快就会达到 thread_pool_oversubscribe 参数设置值,对于后续的连接请求,则会响应不及时(没有更多的连接来处理),这时候 group 就发生了 stall。通过前面的分析知道,Timer 线程会定期检查这种情况,并创建一个新的 Worker 线程来处理请求。如果长查询来源于业务请求,则此时所有 group 都面临这种问题,此时主机可能会由于负载过大,发生 hang 住的情况。这种情况线程池本身无能为力,因为源头可能是烂 SQL 并发,或者 SQL 没有走对执行计划而导致,通过其他方法,比如 SQL 高低水位限流或者 SQL 过滤手段可以应急处理。但是,还有另外一种情况,就是 dump 任务。很多下游依赖于数据库的原始数据,通常通过 dump 命令将数据拉到下游,而这种 dump 任务通常都耗时比较长,所以也可以认为是大查询。如果 dump 任务集中在一个 group 内,并导致其他正常业务请求无法立即响应,这个是不能容忍的。因为此时数据库并没有压力,只是因为采用了线程池策略,才导致了请求响应不及时。为了解决这个问题,我们将 group 中处理 dump 任务的线程不计入 thread_pool_oversubscribe 累计值,即可避免上述问题。
- thread_cache_size 设置优化。每建立一个连接,都需要一个线程来与之匹配,此参数用来缓存空闲的线程,以至不被销毁。如果线程缓存中有空闲线程,这时候如果建立新连接,MySQL 就会很快地响应连接请求。MySQL 如果采用多线程来处理并发的连接,那么采用 mysqlreport 的 Threads 部分可以看到线程创建的频率非常高。一个比较好的方法就是使用持久连接,这将在一定程度上减少线程的重复创建。将 thread_cache_size 从 0 适当地提高到一定的业务需求值,虽然每秒处理的连接数不变,但是创建的线程数可以大大减少,同时提高线程池的命中率。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.