Hikari 读作 Hi-ka-li。
1 - 基本概念
定义
- 数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个;
- 释放空闲时间超过最大空闲时间的数据库连接,来避免因为没有释放数据库连接而引起的数据库连接遗漏。
传统过程
经典的 JDBC 连接数据库的大致步骤:
- 加载 JDBC 驱动
- 创建数据库连接
- 创建 preparedStatement
- 执行 SQL 语句
- 遍历结果
- 关闭数据库连接
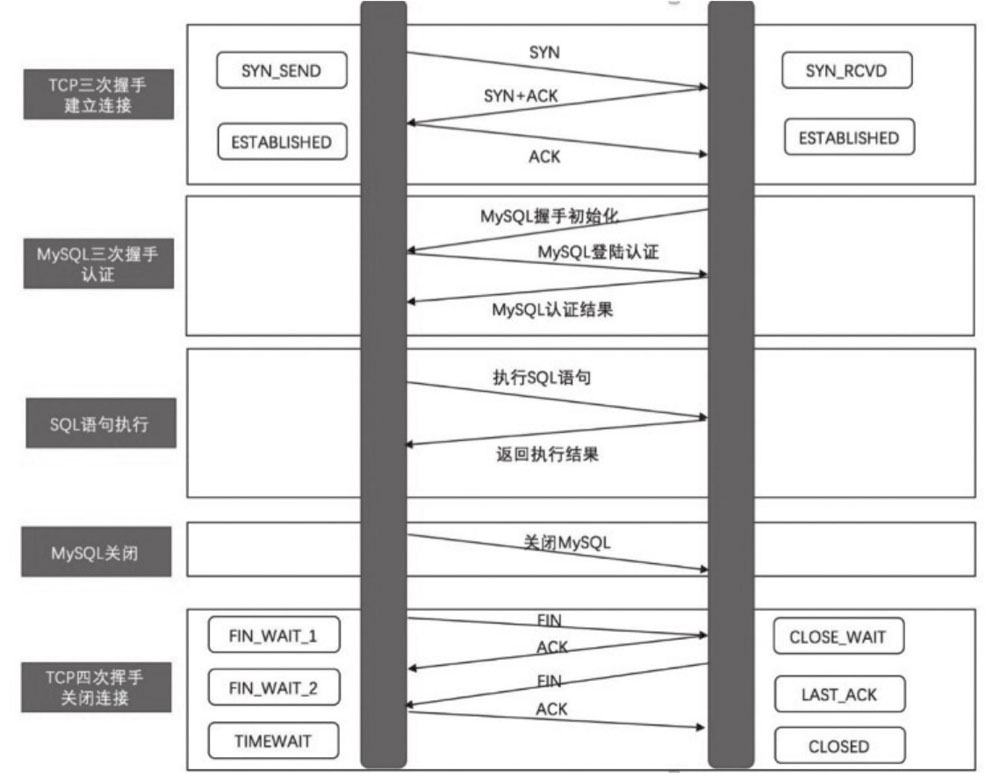
在网络层面,以访问 MySQL 为例,执行一个 SQL 语句的完整 TCP 流程包括:
- TCP 三次握手建立连接
- MySQL 三次握手认证
- SQL 语句执行
- MySQL 关闭
- TCP 四次挥手关闭连接
存在问题
这种传统连接方式的问题有:
- 创建和关闭连接的过程比较耗时,并发时系统会变得卡顿。
- 数据库同时支持的连接数有限,如果并发量很大,数据库的连接数则会被耗尽,增加了数据库负载,新的数据库连接请求将会失败。
- 这会极大的浪费数据库资源,极易造成数据库服务内存溢出、宕机。
- 为了执行一条 SQL,却产生了很多我们并不关心的网络 IO。
- 应用如果频繁的创建和关闭连接,会导致 JVM 临时对象较多,GC 频繁。
- 频繁关闭连接后,会出现大量 TIME_WAIT 的 TCP 状态(在 2 个 MSL 之后关闭)。
- 应用的响应时间和 QPS 较低。
池化优点
使用数据库连接池后,最直接的改变就是仅需在首次访问时创建连接,之后的访问直接可以复用已有连接。
- 资源重用。由于数据库连接得到复用,减少了大量创建和关闭连接带来的开销,也减少了内存碎片和数据库临时进程、线程的珊瑚粮,整体系统的运行更加平稳。
- 系统调优更简便。TIME_WAIT 的调优非常繁琐,使用了数据库连接池以后,由于资源重用,大大减少了频繁关闭连接的开销,大大降低 TIME_WAIT 的出现频率。
- 系统响应更快。数据库连接池在应用初始化的过程中一般都会提前准备好一些数据库连接,业务请求可以直接使用已经创建的连接而不需要等待创建连接的开销。初始化数据库连接配合资源重用,使得数据库连接池可以大大缩短系统整体响应时间。
- 连接管理更灵活。数据库连接池作为一款中间件,除了扮演有界缓冲的角色以外,在统一的连接管理上同样可以做很多文章。用户可以自行配置连接的最小数量、最大数量、最常空闲时间、获取连接超时间、心跳检测等。另外,用户也可以结合新的技术趋势,增加数据库连接池的动态配置、监控、故障演习等一系列实用的功能。
实现原理
在系统初始化的时候,在内存中开辟一片空间,将一定数量的数据库连接作为对象存储在对象池里,并对外提供数据库连接的获取和归还方法。
用户访问数据库时,并不是建立一个新的连接,而是从数据库连接池中取出一个已有的空闲连接对象;使用完毕归还后的连接也不会马上被关闭,而是由数据库连接池统一管理回收,为下一次借用做好准备。
如果由于高并发请求导致数据库连接池中的连接被借用完毕,其他线程就会等待,直到有连接被归还。
整个过程中,连接并不会被关闭,而是源源不断地循环使用,有借有还。数据库连接池还可以通过设置其参数来控制连接池中的初始连接数、连接的上下限数,以及每个连接的最大使用次数、最大空闲时间等,也可以通过其自身的管理机制来监视数据库连接的数量、使用情况等。
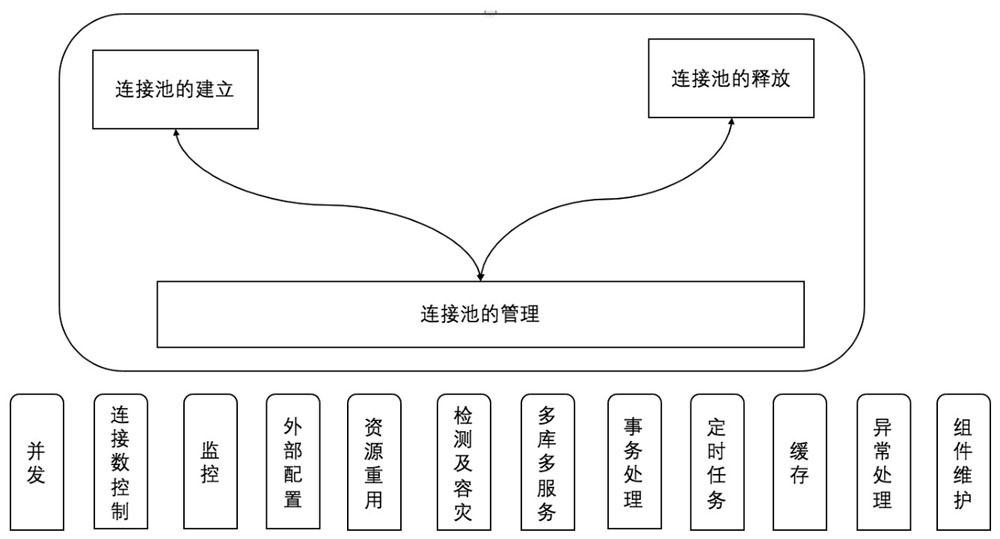
基本构成
数据库连接池的核心功能是建立和释放连接。通常完整的连接池实现会提供更多功能:
- 并发优化:锁性能优化,甚至无锁
- 连接数控制:不同的系统对连接数的要求不同
- 监控:提供管理机制来监视连接数量或用量
- 外部配置
- 资源重用
- 检测/容灾:面对网络、时间问题的自愈
- 多库:不同的数据库、不同的用户与密码、分库分表
- 事务处理:对数据库的操作符合 ALL-ALL-NOTHING 原则
- 定时任务:空闲检查、最小连接数控制
- 缓存:如 PSCache 等避免 SQL 重复解析
- 异常处理:对 JDBC 异常的统处理
- 组件维护:连接状态、JDBC 封装维护
2 - 开源实现
按采用的线程模型分类:
| 单线程 | 多线程 |
|---|---|
| c3p0 | DBCP 2.x |
| Proxool | Tomact JDBC Pool |
| XAPool | BoneCP |
| DBCP 1.x | Druid |
| Hakari |
c3p0
c3p0 具有超过 230 个 synchronize 同步块和方法,在不同的类中充斥着大量 wait() 及 notifyAll() 方法,这些导致死锁倾向的代码造成了在网络上搜索“c3p0死锁”可以查到大量的资料。由于代码量复杂等原因,c3p0 在基准测试中也始终排在最后。c3p0 在默认情况下不会在 getConnection 的时候测试连接可用性,这点也是不安全的默认配置。
但 c3p0 也提供了一些有用的功能:
- 一个将传统的基于
DriverManager的 JDBC 驱动程序调整为较新的javax.sql. DataSource方案的类,以获取数据库连接。 - 基于
DataSources的Connection和PreparedStatements的透明池,可以“包装”传统驱动程序或任意非池化数据源。
c3p0 在以下细节上进行了打磨以确保正确性:
DataSources都是可引用和可序列化的,因此其适合绑定到各种基于 JNDI 的命名服务。- 当引入
Connection和Statement时,都会仔细清理Statement和ResultSets,这是为了防止客户端使用Lazy模式。但常见的资源管理策略仅仅清理Connection而造成资源耗尽。 - 该库采用 JDBC 2 和 JDBC 3 规范定义的方法(即使这些方法与库作者的首选项冲突)。
DataSources以 JavaBean 样式编写,提供所有必需和大多数可选属性(以及一些非标准属性)和无参构造函数。- 实现了所有 JDBC 定义的内部接口(
ConnectionPoolDataSource,PooledConnection,ConnectionEvent-generating Connections等)。 - 用户可以将 c3p0 类与兼容的第三方实现混合使用(尽管并非所有 c3p0 功能都可以与
ConnectionPoolDataSource的外部实现一起使用)。
- 实现了所有 JDBC 定义的内部接口(
Proxool
Proxool 以JDBC 驱动的身份为用户提供透明的连接池服务,所以 Proxool 移植到现有代码中特别容易,用户可以轻松地使用 JDBC API、XML 或 Java 属性文件进行配置。
Proxool 在那个年代另辟蹊径,开创性地提供了连接池监控功能,便于发现连接泄漏的等性能情况及连接事件。
它的很多设计理念都被 HikariCP 认可并吸收,HikariCP 在继承过程中进行了独具匠心的打磨。例如,关于 Cglib 等字节码的代理,这也是 HikariCP 仔细打磨的地方。
XAPool
XA 是 X/Open CAE Specification(Distributed TransactionProcessing) 模型中定义的 TM(Transaction Manager) 与 RM(Resource Manager) 之间进行通信的接口。
Java 中的 javax.transaction.xa.XAResource 定义了XA接口,它依赖数据库厂商对 jdbc-driver 的具体实现。在 XA 规范中,数据库充当 RM 角色,应用需要充当 TM 的角色,即生成全局的 txId,调用 XAResource 接口,把多个本地事务协调为全局统一的分布式事务。
XAPool 是一个 XA 数据库连接池,它实现了 javax.sql.XADataSource,并提供了连接池工具。这是一款主打分布式事务的数据库连接池,它允许池对象,JDBC 连接和 XA 连接。
DBCP
Apache Commons DBCP 并不是独立实现连接池功能的,它内部依赖于 Commons 中的另一个子项目 Apache Commons Pool。数据库连接池中最核心的“池”,就是由 Pool 组件提供的,Apache Commons Pool 决定着数据库连接池的整体性能。

在2014年3月,DBCP终于更新到了2.x版本,基于新的线程模型的数据库连接池让DBCP焕然一新重获新生,稳定性得到提升,性能也有了质的提升。Apache Commons Pool 2类库是对象池技术的一种具体实现,它的出现是为了解决频繁的创建和销毁对象带来的性能损耗问题。
其原理就是建立一个对象池,池中预先生成了一些对象,需要对象的时候借用,用完后进行归还,对象不够时灵活地自动创建,对象池满后提供参数控制是阻塞还是非阻塞响应租借用。
在 SpringBoot 1.5.x 版本中,数据库连接池的默认配置是 Tomcat Pool → HikariCP →Commons DBCP → Commons DBCP2;然而在 2.x 版本中,HikariCP 被提升为默认的数据库连接池,数据库连接池的默认配置顺序是 HikariCP → Tomcat pool→ CommonsDBCP2。
Tomcat JDBC Pool
在 DBCP 2.0 之前,为什么需要一个新的连接池:
- DBCP 1.x 是单线程。为了线程安全,在对象分配或对象返回的短期内,Commons 锁定了全部池。
- DBCP 1.x 可能会变得很慢。当逻辑 CPU 数目增长,或者试图借出或归还对象的并发线程增加时,性能就会受到影响。高并发系统受到的影响会更为显著。
- DBCP 拥有 60 多个类,而 tomcat-jdbc-pool 核心只有 8 个类。因此为了未来需求变更着想,肯定需要更少的改动。我们真正需要的只是连接池本身,其余的只是附属。
- DBCP 使用静态接口,因此对于指定版本的 JRE,只能采用正确版本的 DBCP,否则就会出现 NoSuchMethodException 异常。
- 当 DBCP 可以用其他更简便的实现来替代时,实在不值得重写那 60 个类。
- Tomcat JDBC 连接池无需为库本身添加额外线程,就能异步获取连接。
- Tomcat JDBC 连接池是 Tomcat 的一个模块,依靠 Tomcat JULI 这个简化了的日志架构。
- 使用 javax.sql.PooledConnection 接口获取底层连接。
- 防止饥饿。如果池变空,线程将等待一个连接。当连接返回时,池就将唤醒正确的等待线程。大多数连接池只会一直维持饥饿状态。
Tomcat JDBC Pool 还具有其他连接池没有的特点:
- 支持高并发环境与多 核/CPU 系统。
- 接口的动态实现。支持 java.sql 与 java.sql 接口(只要JDBC驱动),甚至在利用低版本的 JDK 来编译时也支持。
- 验证间隔时间。我们不必每次使用单个连接时都进行验证,可以在借出或归还连接时进行验证,只要不低于我们所设定的间隔时间就行。
- 只执行一次查询。当与数据库建立起连接时,只执行一次可配置查询。这项功能对会话设置非常有用,因为你可能会想在连接建立的整个时段内都保持会话。
- 能够配置自定义拦截器。通过自定义拦截器来增强功能。可以使用拦截器来采集查询统计,缓存会话状态,重新连接之前失败的连接,重新查询,缓存查询结果,等等。由于可以使用大量的选项,所以这种自定义拦截器也是没有限制的,与 java.sql/javax.sql 接口的 JDK 版本没有任何关系。
- 高性能。后面将举例展示一些性能差异。
- 极其简单。它的实现非常简单,代码行数与源文件都非常少,这都有赖于从一开始研发它时,就把简洁当作重中之重。核心只有8个文件。
- 异步连接获取。可将连接请求队列化,系统返回
Future<Connection>。 - 更好地处理空闲连接。不再简单粗暴地直接关闭空闲连接,而是把连接仍然保留在池中,通过更为巧妙的算法控制空闲连接池的规模。
- 可以控制连接应被废弃的时间。当池满了即废弃,或者指定一个池使用容差值,发生超时就进行废弃处理。
- 通过查询或语句来重置废弃连接计时器。允许一个使用了很长时间的连接不会因为超时而被废弃。这一点是通过使用 ResetAbandonedTimer 来实现的。
- 经过指定时间后,关闭连接。与返回池的时间相类似。
- 当连接要被释放时,获取 JMX 通知并记录所有日志。它类似于 remove-AbandonedTimeout,但却不需要采取任何行为,只需要报告信息即可。通过 suspectTimeout 属性来实现。
- 可以通过 java.sql.Driver、javax.sql.DataSource 或 javax.sql.XADataSource 获取连接。通过 dataSource 与 dataSourceJNDI 属性实现这一点。
- 支持 XA 连接。
其缺点有:
- 默认配置也存在类似 c3p0 的问题,就是在 getConnection 的时候并不会默认测试连接可用性。
- 不完全遵守 JDBC 规范,默认也不会重置连接状态(如自动提交、事务隔离级别等),用户必须手动配置名为 ConnectionState 的 JDBCInterceptor。
- 在自动提交中,如果连接池配置了
autocommit=false,就需要在自己的事务中执行连接有效性测试isValid(),否则使用者获取的连接有可能就在一个事务进行中。 - 对于创建连接时可以在连接上运行的初始化 initSQL 也是如此,Tomcat 不会在自己的事务中封装连接测试或 initSQL。
- 连接池应该在 Connection 返回到池时或从池中取出之前,调用
clearWarnings()方法清除 SQL 警告,然而 TomcatJDBC 也没有这么做。 - JDBC 规范还规定,连接关闭时,所有没有关闭的、已经打开的 Statements 都应该自动关闭,但是默认情况下 Tomcat JDBC 并不会跟踪 Statements,除非手动配置一个 StatementFinalizer 拦截。
- 不幸的是,StatementFinalizer 使用一组 WeakReference 对象跟踪 Statements,当 JVM 受到 GC压力时,在 Tomcat 有机会关闭这些语句之前,可能会对废弃的 Statements 进行垃圾收集,这可能导致资源的泄漏,但是只有在 GC 压力下才会发生,因此可能很难追踪。
BoneCP
在 c3p0 和 DBCP 已经存在的时代,BoneCP 的出现就是为了追求极致,它几乎比下一个最快的连接池选项快 25 倍,而且 BoneCP 从不自旋锁定,因此它不会减慢应用程序速度。
BoneCP 可以说是极致数据库连接池的领军开源项目。它和 HikariCP 也是非常有渊源的,除了 HikariCP 捐赠了 BoneCP 几美金的故事以外,BoneCP 在浪潮之巅功成身退,深藏功与名,将一身衣钵传给了 HikariCP。
BoneCP 的特点如下:
- 具有高可扩展性的快速连接池。
- 在 connection 状态改变时,可配置回调机制(钩式拦截器)。
- 通过分区(Partitioning)来提升性能。
- 允许用户直接访问 connection 或 statement。
- 自动扩展 pool 容量。
- 支持 statement caching。
- 支持异步地获取connection,通过返回一个
Future<Connection>实现。 - 以异步的方式施放辅助线程,来关闭 connection 和 statement,以获得高性能。
- 在每个新获取的 connection 上,通过简单的机制,执行自定义的 statement。即通过简单的 SQL 语句来测试 connection 是否有效,对应的配置属性为 initSQL。
- 支持运行时切换数据库,而不需要停止应用。
- 能够自动地回放任何失败的事务(如数据库或网络出现故障等)。
- 支持JMX。
- 可以延迟初始化(lazy initialization)。
- 支持使用 XML 或 property 文件的配置方式。
- 支持 idle connection timeouts 和 max connection age。
- 自动检验 connection 是否活跃等等。
- 允许直接从数据库获取连接,而不通过 Driver。
- 支持 Datasouce 和 Hibernate。
- 支持通过 debugging hooks 来定位获取后未关闭的 connection。
- 支持通过 debugging 来显示被关闭了两次的 connection 的堆栈轨迹(stack locations)。
- 支持自定义 pool name。
- 代码整洁有序。
- 免费,开源,纯 Java 编写,具有完整的文档。
BoneCP 最大的一个问题是无法在 getConnection() 的时候配置数据库连接池来测试连接。然而其他每个数据库连接池大多都可以这样配置。它这样做是为了提升速度,但却牺牲了可靠性。
- 在默认配置方面,BoneCP 也不会在 Connection 返回到池时或从池中取出之前通过
Connection.clearWarnings()方法清除 SQL 警告; - 默认情况下也不会关闭废弃的、已经打开的 statements;
- 也不会在自己的事务中封装连接测试或 initSQL。
Druid
主要功能:
- 替换 DBCP 和 c3p0。Druid 提供了一个高效、功能强大、扩展性好的数据库连接池。
- 可以监控数据库访问性能。Druid 内置了一个功能强大的 StatFilter 插件,能够详细统计 SQL 的执行性能,这有助于对线上数据库访问性能进行分析。
- 数据库加密。直接把数据库密码写在配置文件中是不好的行为,容易导致安全问题。DruidDruiver 和 DruidDataSource 都支持 PasswordCallback。
- SQL 执行日志。Druid 提供了不同的 LogFilter,能够支持 Common-Logging、Log4j 和 JdkLog,用户可以按需要选择相应的 LogFilter,监控自己的应用的数据库访问情况。
- 扩展 JDBC。如果用户对 JDBC 层有编程的需求,可以通过 Druid 提供的 Filter 机制,很方便地编写 JDBC 层的扩展插件。
Druid 在监控、可扩展性、稳定性和性能方面都有明显的优势:
- 强大的监控特性,通过 Druid 提供的监控功能,可以清楚地知道连接池和 SQL 的工作情况。
- 监控 SQL 的执行时间、ResultSet 持有时间、返回行数、更新行数、错误次数、错误堆栈信息。
- SQ L执行的耗时区间分布。什么是耗时区间分布?比如,某个 SQL 执行了 1000 次,其中在 0~1 毫秒区间50次…
- 监控连接池的物理连接创建和销毁次数、逻辑连接的申请和关闭次数、非空等待次数、PSCache 命中率等。
- 方便扩展。Druid 提供了 Filter-Chain 模式的扩展 API,可以自己编写 Filter 拦截 JDBC 中的任何方法。
- Druid 集合了开源和商业数据库连接池的优秀特性,并结合阿里巴巴公司大规模苛刻生产环境的使用经验进行了优化。
- 性能不是 Druid 的设计目标,但是测试数据表明,Druid 性能比 DBCP、c3p0、Proxool、JBoss 都好。
- Druid 代码将近 50 万行。
功能对比

- LRU。LRU 是一个性能关键指标,特别是 Oracle,其中每个 Connection 对应数据库端的一个进程,如果数据库连接池遵从 LRU,有助于数据库服务器优化,这是重要的指标。
- PSCache。PSCache 是数据库连接池的关键指标。在 Oracle 中,类似 SELECT NAME FROM USER WHERE ID =?这样的 SQL,启用 PSCache 和不启用 PSCache 的性能可能会相差一个数量级。
- PSCache-Oracle-Optimized。在 Oracle 10 系列的 Driver 中,如果开启 PSCache,会占用大量的内存,必须做特别的处理,启用内部的 EnterImplicitCache 等方法优化才能够减少内存的占用。
- ExceptionSorter。ExceptionSorter 是一个很重要的容错特性,如果一个连接产生了一个不可恢复的错误,必须立刻将其从连接池中去掉,否则会连续产生大量错误。
中断测试
将数据库连接池执行 getConnection() 在5秒的调用后超时,应用程序应在指定时间内获得连接,或获得异常。
3 - 配置参数
时间校准
HikariCP 在很大程度上依赖于精确的高分辨率的定时器来提高性能和可靠性,所以使用数据库连接池 HikariCP 的应用服务器最好能够与时间源做同步,比如 NTP 服务器,否则由于 HikariCP 源码对于时间的处理可能会导致一些问题。
不稳定的时间影响的不仅仅是数据库连接池,任何定时等待、并发集合的定时轮询、带有超时的 Object.wait()、Thread.sleep() 调用等,以及任何 Java 中需要测量时间的功能都会受到影响。
必要配置
dataSourceClassName
dataSourceClassName 和 jdbcUrl 是两种数据源的配置方式。
HikariCP 更加建议使用 dataSourceClassName,当然,两者都可以接受。需要注意的是,如果是 Spring Boot 自动装配的用户,需要使用 jdbcUrl 的基于配置的方式;当前已知的 MySQL DataSource 并不支持网络超时,建议改用 jdbcUrl 的方式。
jdbcUrl
表示 HikariCP 使用传统的、基于驱动管理器 DriverManager 的配置。虽然 HikariCP 作者认为两种配置方式中,基于 dataSourceClassName 的配置由于各种原因而更优越,但对于许多部署而言,几乎没有显著差异。
将此属性与“旧”驱动程序一起使用时,可能还需要设置 driverClassName 属性,但首先尝试不使用该属性。如果使用此属性,用户仍可以使用 DataSource 属性来配置驱动程序,实际上建议使用 URL 本身中指定的驱动程序参数。
username & password
username 和 password 分别表示从基础驱动程序获取 Connections 时使用的默认身份验证用户名和密码。
HikariCP 会将 username 属性和 password 属性分别配置在 Properties 文件中,从而传递给驱动 Driver 的 DriverManager.getConnection(jdbcUrl, props) 调用。
非必要配置
autoCommit
此属性控制从池返回的连接的默认自动提交行为。它是一个布尔值。默认值:true。
connectionTimeout
此属性控制客户端(即用户的程序)等待池中连接的最长毫秒数。如果在没有连接可用的情况下超过此时间,则将抛出 SQLException 异常。最低可接受的连接超时为250毫秒。默认值:30000(30秒)。这是一个很重要的问题排查指标。
idleTimeout
此属性控制连接允许被闲置在池中的最大时间。此设置仅适用于 minimumIdle 定义为比 maximumPoolSize 小的时候。一旦池到达 minimumIdle 连接的时候,空闲连接将不会退役。连接是否空闲而退役的最大变化为 +30 秒,平均变化为 +15 秒。在此超时之前,连接永远不会因空闲状态而退役。值为 0 意味着空闲连接永远不会从池中删除即永不超时。minimum 允许的最小值为 10000 毫秒(10秒)。默认值:600000(10分钟)。
许多防火墙和负载均衡器(通常位于应用程序和数据库之间)会占用套接字生存周期。通常,达到 idleTimeout 时,无论当前流量如何,都会切断连接。
HikariCP 设计之初就不支持空闲连接检测 test-while-idle,这是因为数据库管理员 DBA 往往会默认设置数据库最长连接时间是 60 秒,test-while-idle 会对数据库产生不必要的查询,这样就有可能导致数据库空闲连接出现超时的问题。
旧版本中,maxLifetime 由管家线程 HouseKeeper 强制执行,每 30 秒执行一次,因为 wait_timeout 减去 30 秒是推荐的 maxLifetime。但是最新版本的 HikariCP 对每个连接 connection 进行专用计时器任务,提供了几十毫秒(在高负载下长达几秒)的时间间隔,此时 maxLifetime 被安全地设置为 wait_timeout 减去5秒。如果连接退出,后台线程会执行添加操作,创建新的连接大约是 5 毫秒。如果 maxLifetime 是60秒,那么 idleTimeout 可以被设置为 0,显得就并不那么重要。
maxLifetime
此属性控制池中连接的最大生命周期。使用中的连接永远不会退役,除非它被关闭然后移除。在逐个连接的基础上,应用轻微的负衰减可以避免池中的大量消亡(在源码解析部分会深入分析)。HikariCP 作者强烈建议用户设置此值,并且它应比任何数据库或基础设施实施的连接时间限制短几秒。值为 0 表示没有最大生存期(无限生存期),当然这取决于 idleTimeout 设置。默认值:1800000(30分钟)。
30 分钟的默认超时是非常合理的,很多开发人员都会发现,在应用程序与很多数据库之间,会有高可用代理、负载均衡、防火墙等,通常这些组件会自动且独立地终止连接 30 分钟左右。
一般来说,可以将 maxLifetime 设置缩短到 900000 毫秒(15分钟)然而更好的方法是,确定 MySQL 配置的 wait_timeout 值是什么,并将 HikariCP 设置为比 maxLifetime 短几分钟。
connectionTestQuery
如果您的驱动程序支持 JDBC4,我们强烈建议不要设置此属性。这适用于不支持 JDBC4 的 Connection.isValid() 的“遗留”驱动程序 API。这是一个检测查询,在数据库连接池给出连接之前进行查询,以验证与数据库的连接是否仍然存在且有效。
如果你追求极致性能的话,建议不要配置该属性,因为不配置的时候会通过 ping 命令进行连接检测,性能会更高。
minimumIdle
此属性控制 HikariCP 尝试在池中维护的最小空闲连接数。若空闲连接低于此值且池中的总连接数小于 maximumPoolSize,则 HikariCP 将尽最大努力快速有效地添加其他连接。
然而,为了最大限度地提高性能和对峰值需求的响应能力,HikariCP 作者建议不要设置此值,而是允许 HikariCP 充当一个固定大小的连接池(如果 minimumIdle 未设置则默认为是 maximumPoolSize,因此即使 idleTimeout 设置为 1 分钟,一旦连接关闭,它将在池中被替换)。
如果设置这个值,那么 HikariCP 就会是一个大小可变的池,通过 minimumIdle 进行调解控制,即使使用情况上下浮动,HikariCP 也会保持 minimumIdle 连接可用。默认值:与 maximumPoolSize 相同。
minimumIdle 应始终小于或等于 maximumPoolSize。如果 minimumIdle 设置为更高的值,它将推高 maximumPoolSize 到相等的值。minimumIdle 逻辑上不能超过 maximumPoolSize,因为 maximumPoolSize 指定了后端数据库的实际连接的最大数量。
如果有比 minimumIdle 的数目更多的连接数,如果一个连接退役了,它不会被自动替换。但是如果数据库连接池被配置为固定大小的,或者连接关闭后如果空闲连接小于 minimumIdle 的数量,那么就会立即自动替换连接。
启用 HikariCP 的 metrics 采集,在可视化界面上可直观地显示连接的直方图,便于用户研究并确定正确的、合理的 minimumIdle 及 idleTimeout 等值。数据库连接池的调优最好基于经验数据,具体问题具体分析。
maximumPoolSize
此属性控制允许数据库连接池到达的最大大小,包括空闲和正在使用的连接。基本上,此值将确定到数据库后端的实际连接的最大数量。合理值最好由用户的执行环境决定。当池达到此大小且没有空闲连接可用时,对 getConnection() 的调用将阻塞到超时前 connectionTimeout 毫秒。关于连接池大小 PoolSize 的相关知识请关注本章后续内容。默认值:10。
metricRegistry
此属性仅通过编程配置或 IoC 容器可用。此属性允许用户指定池使用的 Codahale /Dropwizard 实例 MetricRegistry,来记录各种度量标准。如果用户需要使用 Prometheus 等监控的话,还需要做一些操作。
healthCheckRegistry
此属性仅通过编程配置或 IoC 容器可用。此属性允许用户指定池使用的 Codahale /Dropwizard 实例 HealthCheckRegistry,来报告当前系统的健康信息。默认值:无。
poolName
此属性表示连接池的用户定义名称,主要显示在日志记录和JMX管理控制台中,以标识池和池配置。默认值:自动生成。
非常用配置
initializationFailTimeout
如果池无法成功初始化连接,则此属性控制池是否“快速失败”。任何正数都被认为是尝试获取初始连接的毫秒数;在此期间,应用程序线程将被阻塞。如果在超时发生之前无法获取连接,则将引发异常。initializationFailTimeout超时发生在connectionTimeout阶段之后。如果值为0, HikariCP将尝试获取并验证连接。如果获得连接但验证失败,则抛出异常,而不会启动池。但是,如果无法获得连接,则池将启动,但稍后获取连接的尝试会失败。小于0的值将绕过任何初始连接尝试,并且池将在尝试在后台获取连接时立即启动。因此,以后获得连接的尝试可能会失败。默认值:1。
isolatelnternalQueries
此属性决定HikariCP是否在自己的事务中隔离内部池查询,例如连接存活测试。由于这些通常是只读查询,因此很少有必要将它们封装在自己的事务中。此属性仅在autoCommit禁用时适用。默认值:false。
allowPoolSuspension
此属性控制池是否可以通过JMX挂起和恢复。这对某些故障转移自动化方案很有用。当池被挂起时,调用getConnection()将不会超时,并将一直保持到池恢复为止。默认值:false。
readOnly
此属性控制默认情况下从池中获取的Connections是否处于只读模式。请注意,某些数据库不支持只读模式的概念,而其他数据库在Connection设置为只读时提供查询优化。是否需要此属性将在很大程度上取决于那的应用程序和数据库。默认值:false。
registerMbeans
此属性控制是否注册JMX管理Bean(“MBean”)。默认值:false。
catalog
此属性为支持catalog的数据库设置默认catalog。如果未指定此属性,则使用JDBC驱动程序定义的默认catalog。默认值:driver default。
connectionlnitSql
此属性设置一个SQL语句,该语句将在每次创建新连接之后执行,然后再将该连接添加到池中。如果此SQL无效或抛出异常,它将被视为连接失败,并将遵循标准重试逻辑。默认值:无。
driverClassName
HikariCP将尝试仅基于jdbcUrl通过DriverManager解析驱动程序,但对于某些较旧的驱动程序必须指定driverClassName。除非用户收到明显的错误消息,表明未找到驱动程序,否则可忽略此属性。默认值:无。
transactionlsolation
此属性控制从池返回的连接的默认事务隔离级别。若未指定,则用JDBC驱动程序定义的默认事务隔离级别。仅当有针对所有查询的特定隔离需求时,才使用此属性。此属性的值是Connection类的常量名,如TRANSACTION_READ_COMMITTED、TRANSACTION_REPEATABLE_READ等。默认值:driverdefault。
validationTimeout
此属性控制连接测试活性的最长时间。该值必须小于connectionTimeout。最低可接受的验证超时为250毫秒。默认值:5000。
leakDetectionThreshold
此属性控制连接在记录一条指示可能连接泄漏的消息之前流出池的时间。值为0表示禁用泄漏检测。启用泄漏检测的最低可接受值是2000(2秒)。默认值:0。
dataSource
此属性仅可通过编程配置或IoC容器获得。此属性允许用户直接设置DataSource要由池包装的实例,而不是让HikariCP通过反射构造它。这在一些依赖注入框架中很有用。指定此属性后,dataSourceClassName将忽略该属性和所有特定于DataSource的属性。默认值:无。
schema
该属性为支持schema概念数据库设置默认schema。如果未指定此属性,则使用JDBC驱动程序定义的默认模式。默认值:driver default。
threadFactory
此属性仅可通过编程配置或IoC容器获得。此属性允许设置java.util.concurrent. ThreadFactory将用于创建池使用的所有线程的实例。在注入线程只能通过应用程序容器提供的ThreadFactory创建的某些受限执行环境中使用它。默认值:无。
scheduledExecutor
仅可通过编程配置或IoC容器获得。允许设置java.util.concurrent.Scheduled-ExecutorService用于各种内部调度任务的实例。如果向HikariCP提供ScheduledThread-PoolExecutor实例,建议设置setRemoveOnCancelPolicy(true)。默认值:无。
容量设置
公式
拥有一个CPU内核的计算机可以同时执行数十或数百个线程,其实这只是操作系统的一个time-slicing(时间切片)的把戏。实际上,单核只能一次执行一个线程,然后由操作系统切换上下文,并且内核为另一个线程执行代码,依此类推。这是一个基本的计算法则,给定一个CPU资源,按顺序执行A和B总是比通过时间片“同时”执行A和B要快。一旦线程数量超过了CPU核心的数量,添加更多的线程速度就会变慢,而不是更快。
设计多线程是为了尽可能地利用CPU空闲等待时间(及IO、交互等),它的代价就是要增加部分CPU时间来实现线程切换。如果CPU空闲等待时间已经比线程切换更短(线程越多,切换消耗越大),那么线程切换会非常影响性能,成为系统瓶颈。
当我们查看数据库的主要瓶颈是什么时,它们可以归纳为3个基本类别:CPU、磁盘、网络。
可以在PostgreSQL基准测试中看到,TPS速率开始在大约50个连接处变平:
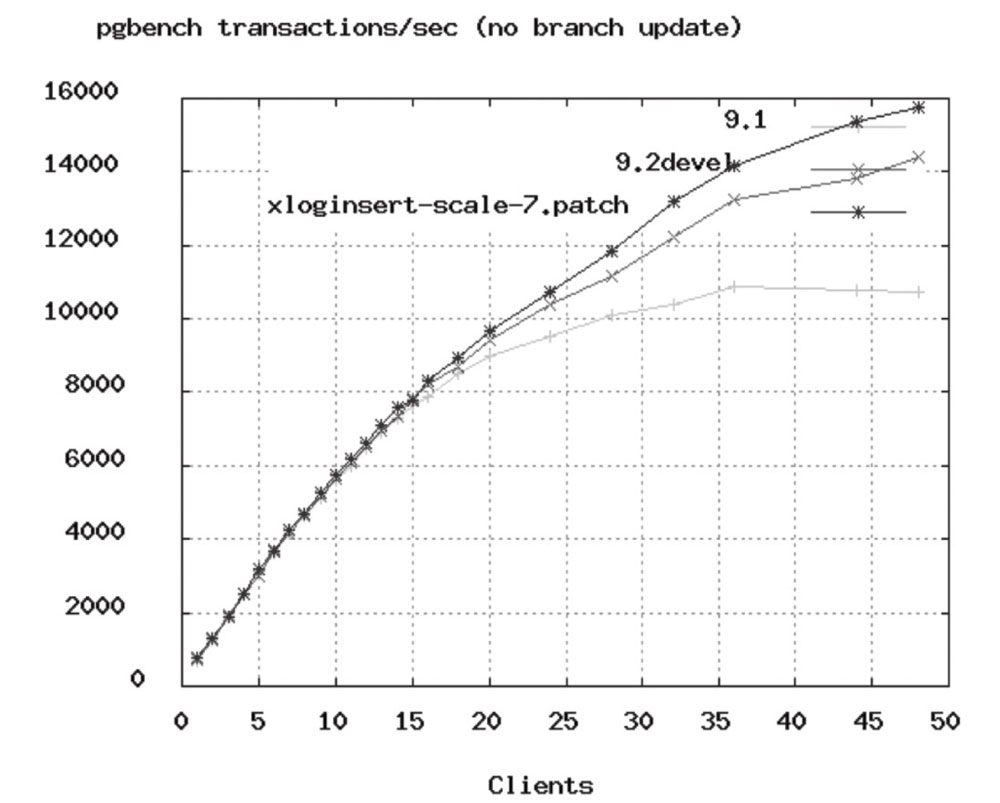
下面的公式也是由PostgreSQL项目提供的,它同样在很大程度上适用于数据库。实际生产中,用户测试应用程序,即模拟预期的负载,并在此起点周围尝试不同的池设置。
connections =((core_count×2)+ effective_spindle_count)
effective_spindle_count 就是磁盘列阵中的硬盘数。某PostgreSQL项目做过测试,拥有一个硬盘的小型4核i7服务器的连接池大小设置为:9 = ((4×2) + 1)。这样的连接池大小居然可以轻松处理3000个前端用户在6000 TPS下进行简单查询。这里的线程数指的是数据库进程中的线程,通常通过连接调度的查询将在数据库的单个线程上执行,连接和线程在大多数情况下几乎都是一对一的关系。
在公式的配置上,如果加大压力,TPS会下降,RT会上升,可以适当地根据情况进行调整加大。这时应考虑整体系统性能,同时考虑线程执行需要的等待时间,合理地设计线程数目。但是,不要过度配置你的数据库。如果一直给HikariCP增加压力,那么性能也可能会产生急剧的下降。
- 如果查询是5毫秒,则通过单个连接每秒可以处理大约200个查询。
- 如果查询是100毫秒,单个连接每秒可以处理大约10个查询。
- 对数据库而言,5台Server各自拥有一个连接和每台Server拥有5个连接几乎相同。
- 如果有慢查询和快速查询的混合,由于慢查询会锁定数据库连接池,建议长时间运行的查询使用单独的数据库连接池。
数据库连接池的大小设置针对的是单个组件、应用程序和单个数据库。在多个微服务同时访问单个共享数据库的时候,情况就会变得比较棘手,这时就需要提炼出一些应对它的方法。对于单个应用程序来说,如果同时运行任何超过10个查询会产生较低的吞吐量和较高的延迟,如果平均查询时间是2ms,那么在2ms的时间内可以满足10个查询。如果我们允许20个查询(HikariCP数据库连接池的大小为20),则在2ms内无法满足同时运行20个查询,并且由于调度程序的时间分片开销,实际上可能超过2倍。如果微服务A和微服务B同时对该数据库进行查询,并持续生成连续负载,按照10个查询的稳定性大小,服务A和服务B分别设置数据库连接池大小为5是有意义的。对于生成连续负载的N服务,最大池大小的公式很简单:(最大同时数据库查询)/ N。
但是服务A和服务B之间还有一些突发性,比如A或者B一段时间内爆发大量查询,一段时间内相对空闲,这时候最大数据库连接池大小设为5~10会比较好。微服务越多,这个就越复杂。度量标准Metrics是进行数据库连接池大小评估的很有效的工具。首先,根据对其需求的最佳预测,为每个微服务选择一个池大小,而不考虑其他服务,并收集每项服务的指标:Active connections(活动连接)、Idle connections(空闲连接)、Waiting threadcount(等待线程数)、Usage(每个连接离开池多长时间)。然后,根据这些指标找到峰值并尝试确定原因,进行分类对比,并确定总活动超过数据库容量和CPU的点是否与峰值对应。最后,通过不断重复这些过程,根据收集的指标慢慢进行匹配对比,观察分析,从而找到数据库连接池最合适的大小。
池锁
池锁代表数据库连接池由于由于竞争资源或者由于彼此通信而造成的一种阻塞的现象。
很多实际使用数据库连接池的用户在开发过程中或多或少遇到过池锁的问题。增大连接池大小可以缓解池锁问题,但是扩大池之前可以先检查一下应用层面是否能够调优,而不要直接调整连接池大小。
避免池锁有一个简单的资源分配公式:
pool size = Tn x (Cm -1) + 1
Tn 是线程的最大数量,Cm 是单个线程持有的同时连接的最大数量。例如,有3个线程(Tn = 3),每个线程需要4个连接来执行某个任务(Cm = 4)。确保永不死锁的池大小是: 3 x(4-1)+ 1 = 10。
如果有10个线程(Tn = 10),每个线程需要2个连接(Cm =2)来执行某个任务,确保永不出现死锁所需的池大小是:10x(2-1)+ 1 = 11。
再比如,最多有8个线程(Tn = 8),每个线程需要3个连接来执行一些任务(Cm =3)。确保永远不可能死锁的池大小是: 8×(3-1)+ 1 = 17注意,这不一定是最佳池大小,但是是避免死锁所需的最低限度,也就是最小的池大小。
在某些环境中,使用JTA(Java事务管理器)可以显著减少从同一个Connection返回getConnection()到当前事务中已经存储Connection的线程所需的连接数。
建议
混合了长时间运行事务和非常短的事务的系统通常是最难调整任何连接池的系统。在这些情况下,创建两个池实例可以很好地工作(例如,一个用于长时间运行的事务,另一个用于“实时”查询)。
对于长期运行的外部系统,例如只允许一定数量的作业同时运行的作业执行队列,这时作业队列大小就是连接池非常合适的大小。
总结如下:连接池是综合每个应用系统的业务逻辑特性,加上应用硬件配置,加上应用部署数量,再加上DB硬件配置和最大允许连接数等测试出来的,很难用一个公式简单进行计算。连接数及超时时间设置不正确经常会带来较大的性能问题,并影响整个服务能力的稳定性。具体设置多少,要看系统的访问量,可通过反复测试,找到最佳点。压测很重要。
Fixed Pool Design
基于大量实践得到的经验值:
maximumPoolSize: 20
minimumIdle: 10
HikariCP的初始版本只支持固定大小的池。作者初衷是,HikariCP是专门为具有相当恒定负载的系统而设计的,并且倾向于连接池大小保持其运行时允许达到的最大大小,所以作者认为没有必要将代码复杂化以支持动态调整大小。
如果想要支持动态调整不同负载的最佳池大小设置,可以配合Hikari使用同为the Mutual Admiration Society成员的VladMihalcea研究的FlexyPool。当然,连接池上限受到数据库最优并发查询容量的限制,这正是HikariCP关于池大小起作用的地方。然而,在池的最小值和最大值之间,FlexyPool不断尝试递增,确保该池大小在提供服务的过程中动态负载一直是正确的。
FlexyPool具有以下默认策略:
- 在超时时递增池。此策略将增加连接获取超时时的目标连接池最大大小。连接池具有最小的大小,并可根据需要增长到最大大小。该溢出是多余的连接,让连接池增长超过其初始的缓冲区最大尺寸。每当检测到连接获取超时时,如果池未增长到其最大溢出大小,则当前请求不会失败。
- 重试尝试。此策略对于那些缺少连接获取重试机制的连接池非常有用。
核心逻辑
minIdle来指定空闲连接的最小数量,maxPoolSize指定连接池连接最大值,默认初始化的时候,是初始化minIdle大小的连接,如果minIdle与maxPool-Size值相等,那就是初始化时把连接池填满。idleTimeout用来指定空闲连接的时长,maxLifetime用来指定所有连接的时长。com.zaxxer.hikari.housekeeping.periodMs用来指定连接池空闲连接处理及连接池数补充的HouseKeeper任务的调度时间间隔。所有的连接在maxLifetime之后都得重连一次,以保证连接池的活性。
MySQL 配置
MySQL 的主要性能配置参数是:
- prepStmtCacheSize:这将设置MySQL驱动程序将为每个连接缓存的预准备语句数。默认值为保守25。我们建议将其设置为250~500。
- prepStmtCacheSqlLimit:这是驱动程序将缓存的已准备SQL语句的最大长度。MySQL的默认值是256。根据我们的经验,特别是对于像Hibernate这样的ORM框架,这个默认值远低于生成的语句长度的阈值。我们推荐的设置是2048。
- cachePrepStmts:如果事实上禁用了高速缓存,则上述任何参数都不会产生任何影响,因为它是默认情况下。必须将此参数设置为true。
- useServerPrepStmts:较新版本的MySQL支持服务器端预处理语句,这可以提供显著的性能提升。应将此属性设置为true。
HikariCP 的典型 MySQL 配置如下:
jdbcUrl=jdbc:mysql://localhost:3306/simpsons
user=test
password=test
dataSource.cachePrepStmts=true
dataSource.prepStmtCacheSize=250
dataSource.prepStmtCacheSqlLimit=2048
dataSource.useServerPrepStmts=true
dataSource.useLocalSessionState=true
dataSource.rewriteBatchedStatements=true
dataSource.cacheResultSetMetadata=true
dataSource.cacheServerConfiguration=true
dataSource.elideSetAutoCommits=true
dataSource.maintainTimeStats=false
4 - JDBC API
HikariCP JDBC Logging
HikariCP 目前并不包含 JDBC 的日志记录。因为作者认为日志记录是性能杀手,甚至检查是否启用或禁用日志记录的布尔值对 HikariCP 来说也是多余的开销,几乎每个驱动程序都支持某种类型的日志记录,并且 ORM 框架也不可避免这样去做。
对于驱动程序不支持 JDBC 直接记录,或者希望此解决方案的灵活性优于数据库供应商的产品,log4jdbc-log4j2 是一个不错的选择。
另外还有 P6spy,它似乎略微比 log4jdbc-log4j2 更易于维护。
JDBC
在 Vlad Mihalcea 的 “High-Performance JavaPersistence” 一书中给出了一张数据访问技术栈的图片,如图所示。我们可以看到 JDBC 在整个数据访问技术栈中起着非常重要的作用。
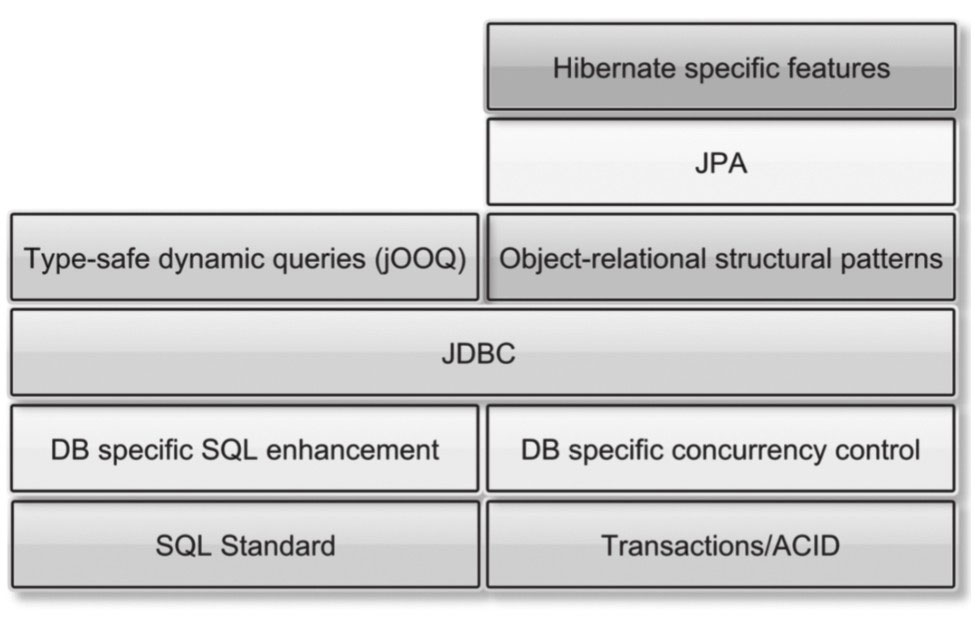
JDBC 代表 Java 数据库连接,是基于 Java 开发的系统中程序员和数据库打交道的主要途径,提供了完备的数据库操作方法接口。
JDBC 定义
JDBC,Java DataBase Connectivity。
JDBC API 是一个 Java API,可以访问任何类型表列数据,特别是存储在关系数据库中的数据。
JDBC API 由一组用 Java 编写的类和接口组成。为工具/数据库开发人员提供标准 API 的编程语言,可以使用全 Java API 编写工业级数据库应用程序。JDBC API 可以轻松地将 SQL 语句发送到关系数据库系统,并支持所有 SQL 方言。但是 JDBC 2.0 API 超越了 SQL,也使得与其他类型的数据源(例如包含表格数据的文件)进行交互成为可能。
JDBC API 的价值在于,应用程序几乎可以访问任何数据源,并可以在任何具有 Java 虚拟机的平台上运行。换句话说,使用 JDBC API,不必编写一个程序来访问 Sybase 数据库,另一个程序访问 Oracle 数据库,另一个程序访问 IBM DB2 数据库,等等。
JDBC API 是 Java 编程语言与各种数据库之间数据库无关连接的行业标准。JDBC API 为基于 SQL 的数据库访问提供了调用级 API。JDBC 技术允许您使用 Java 编程语言为需要访问企业数据的应用程序提供“一次编写,随处运行”功能。
JDBC API 是一种执行 SQL 语句的 API, JDBC 驱动才是真正的接口实现,所有的网络逻辑和特定于数据库的通信协议都隐藏于、独立于供应商的 JDBC API 后面。Sun 公司只是提供了JDBC API,每个数据库厂商都有自己的驱动来连接自己公司的数据库,如图所示。
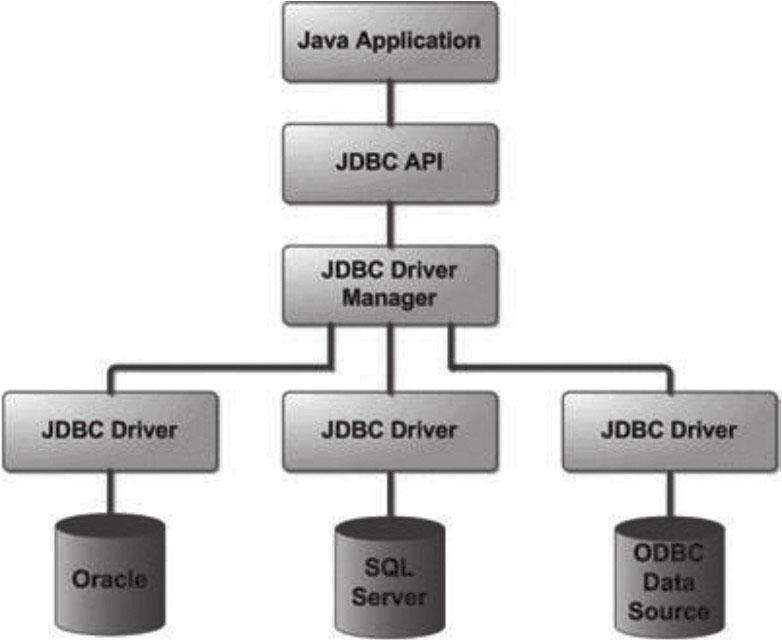
我们可以看到,JDBC API 采用了桥接的设计模式,提供了两套接口,JDBC Driver Planager 面向数据库厂商,如Oracle、SQL Seruer 等;JDBC API 面向 JDBC 使用者,如 Java Application。
JDBC 接口相当于实现化角色接口,数据库厂商实现的驱动相当于具体实现化子类,应用程序相当于抽象化角色,内部持有一个实现化角色的对象。桥接模式将实现化和抽象化解耦,从而让两个部分可以沿着不同的方向拓展,只要遵循接口即可,从而学习成本低。
JDBC 连接数据库时,在各个数据库之间进行切换,基本上不需要动太多的代码,甚至丝毫不动,原因就是 JDBC 提供了统一接口,每个数据库提供各自的实现,用一个叫作数据库驱动的程序来桥接就行了。
JDBC 定义了 4 种驱动类型:JDBC-ODBC 桥、本地 API 驱动、网络协议驱动、本地协议驱动。由于易于设置和调试,第 4 种类型本地协议驱动纯粹基于 Java 的多驱动程序,通过 Socket 连接与厂商的数据库进行通信,是首选的方案。
通过 DriverManager 获取连接:

通过 DataSource 获取连接:

由于减少了创建和关闭连接的开销,HikariCP 等数据库连接池的出现又将 JDBC 的性能大大提升了一个档次。使用数据库连接池作为 JDBC 的最佳实践已经几乎成了公认的标准。
除此之外,JDBC 的最佳实践还有如下内容:
- 使用 PrearedStatement,通过预编译的方式避免在拼接SQL时造成SQL注入,使用“? ”或其他占位符等变量绑定的形式可以使用不同的参数执行相同的查询也能防止 SQL 注入。
- 禁用自动提交,这样可以将数据库操作放在一个事务中,而不是每次执行 SQL 语句都在执行结束时提交自己独立的事务。
- JDBC 批处理可以降低数据库传输频率,进而提升性能。
- 使用列名而不是列序号获取 ResultSet 中的数据,避免 invalidColumIndexError,从而提升程序的健壮性、可读性。
- 在 Java 7 中,可以通过 Automatic ResourceManagement Block 来自动关闭资源。要记得关闭所有的Connection、Statement 等资源。
- 使用标准的 SQL 语句(如标准的ANSI SQL),避免数据库对 SQL 支持的差异。
JDBC 剖析
JDK 规定了 JDBC 的相关接口,JDBC 是 SPI(服务提供者接口) 框架的良好应用。JDBC API 主要位于 JDK 中的 java.sql 包中,扩展的内容位于 javax.sql 包中。
java.sql.* 采用传统的 C/S 体系结构思想设计它所包含的接口和类,核心类图如图所示。
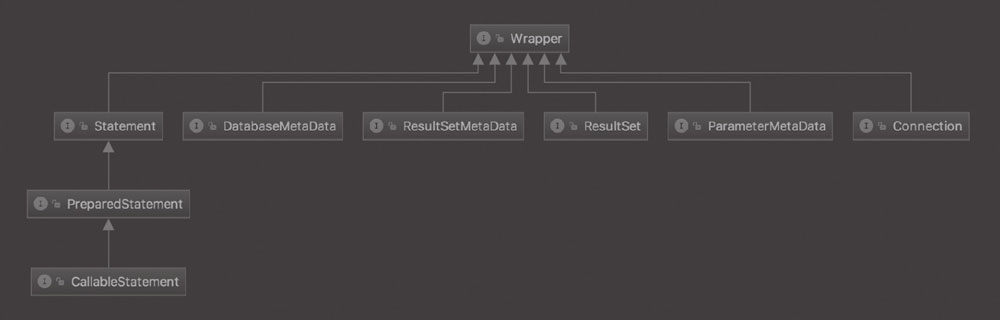
它包含生成连接、执行语句等功能,包括一些诸如批处理更新、可滚动结果集、事务隔离、封装 SQLException 等功能。java.sql.* 属于 JDBC2.0 之前,通常被称为 JDBC 内核 API; javax.sql.* 包括了 JDBC 3.0 的很多新特性,被称为 JDBC 标准扩展。
javax.sql.* 作为标准扩展,提供了很多对java.sql.*的补充和新特性。体现在 Datasource 接口提供了一种可选择性的方式去建立连接,分布式事务处理,增加 rowset,增加连接池等。

了解 JDBC,关注点更多的还是 java.sql.* 包,在这个包里,有 4 个核心接口(Driver、Connection、Statement和ResultSet)和两个核心类(DriverManager和SQLException)。类型的对象。它还提取与使用 Driver 对象相关的信息。不同的数据库有不同的装载方法。
- DriverManager:管理一组数据库驱动程序的基本服务。使用通信子协议将来自 Java 应用程序的连接请求与适当的数据库驱动程序进行匹配。在 JDBC 下识别某个子协议的第一个驱动程序将用于建立数据库连接。其初始化时用到 ServiceLoader 机制,所以可以直接用 Class.forName(driver);就可以完成加载驱动。在 DriverManager 里面,有一个 ArrayList,专门用来保存注册好的 Driver,并使用了 CopyOnWriteArrayList 来保证多线程环境下的线程安全。
- Driver:此接口处理与特定数据库服务器的通信,是每个数据库驱动都必须继承的接口。我们很少会直接与 Driver 对象进行交互。但会使用 DriverManager 对象来管理。
- Connection:此接口具有用于链接数据库的所有方法。连接(Connection)对象表示通信上下文,即,与数据库的所有通信仅通过连接对象。拥有创建 SQL 语句的方法,以完成基本的 SQL 操作,同时为数据库事务提供提交和回滚方法。
createStatement():创建向数据库发送 SQL 的 statement 对象。prepareStatement(sql):创建向数据库发送预编译 SQL 的 PrepareSatement 对象。prepareCall(sql):创建执行存储过程的 callableStatement 对象。setAutoCommit(boolean autoCommit):设置事务是否自动提交。commit():在连接上提交事务。rollback():在此连接上回滚事务。
- Statement:使用从此接口创建的对象将 SQL 语句提交到数据库。除了执行存储过程之外,一些派生接口还接受参数。它由 createStatement 创建,用于发送简单的 SQL 语句(不带参数)。除此以外,还有两种Statement:PreparedStatement 和 CallableStatement,如图上图所示.CallableStatement 继承自 PreparedStatement,PreparedStatement 继承自 Statement。
- PreparedStatement:PreparedStatement 接口扩展了 Statement 接口,它添加了比 Statement 对象更好一些的功能。此语句由 preparedStatement 创建,可以动态地提供/接受参数,进行 SQL 语句的预编译,也可以动态拼接。因为会进行预编译,所以当用动态拼接的时候,会对传入的参数进行强制转换,所以会对参数进行校验,可以避免 SQL 注入。开发的时候尽量用 preparedStatement,少用 statement。PreparedStatement 对象有能力使用提供参数数据的输入和输出流。它可以将整个文件输入数据库中,可容纳较大的值,如 CLOB 和 BLOB 数据类型的列。对于 PreparedStatement,会有一个 LRUCache 来存放,先到那里去取,取不到再创建一个新的,这个 LRUCache 的默认大小是 25。
- CallableStatement:由方法 prepareCall 创建,为所有的 DBMS 提供了一种以标准形式调用数据库储存过程的方法。
- 常用方法:
execute(String sql):运行语句,返回是否有结果集。executeQuery(String sql):运行 select 语句,返回 ResultSet 结果集。executeUpdate(String sql):运行 insert/update/delete 操作,返回更新的行数。addBatch(String sql):把多条 SQL 语句放到一个批处理中。executeBatch():向数据库发送一批 SQL 语句执行。
- ResultSet:在使用 Statement 对象执行 SQL 查询后,这些对象保存从数据库检索到的数据。它作为一个迭代器并可移动 ResultSet 对象查询的数据。但是结果集并不仅仅具有存储的功能,它同时还具有操纵数据的功能,可能完成对数据的更新等。
getString(int index)、getString(StringcolumnName):获得数据库里 varchar、char 等类型的数据对象。getFloat(int index)、getFloat(StringcolumnName):获得数据库里 Float 类型的数据对象。getDate(int index)、getDate(StringcolumnName):获得数据库里 Date 类型的数据。getBoolean(int index)、getBoolean(StringcolumnName):获得数据库里 Boolean 类型的数据。getObject(int index)、getObject(StringcolumnName):获取数据库里任意类型的数据。next():移动到下一行。previous():移动到前一行。absolute(int row):移动到指定行。beforeFirst():移动到 ResultSet 的最前面。afterLast():移动到 ResultSet 的最后面。
- SQLException:此类处理数据库应用程序中发生的任何错误。
需要强调的是,Connection、Statement 和 Result 是一种“爷—父—子”的关系,对 Connection 的管理,就是对数据库资源的管理。如果想确定某个数据库连接(Connection)是否超时,则需要确定其(所有的)子 Statement 是否超时,同样,需要确定所有相关的 ResultSet 是否超时;Statement 关闭会导致 ResultSet 关闭,但是 Connection 关闭却不一定会导致 Statement 关闭。
在数据库连接池里,Connection 关闭并不是物理关闭,只是归还连接池,所以 Statement 和 ResultSet 有可能被持有,并且实际占用相关的数据库的游标资源。所以在关闭 Connection 前,需要关闭所有相关的 Statement 和 ResultSet。这就是 HikariCP 作者所强调的 JDBC 的最基本的规范,也是他创造 HikariCP 的原因,数据库连接池一定不能违背这样的规则。
最好方案就是顺序关闭 ResultSet、Statement、Connection;在 rs.close() 和 stmt.close() 后面加上 rs= null 和 stmt = null 来防止内存泄漏;RowSet 不依赖于 Connection 和 Statement 可以作为一种传递 ResultSet 的替代方案。
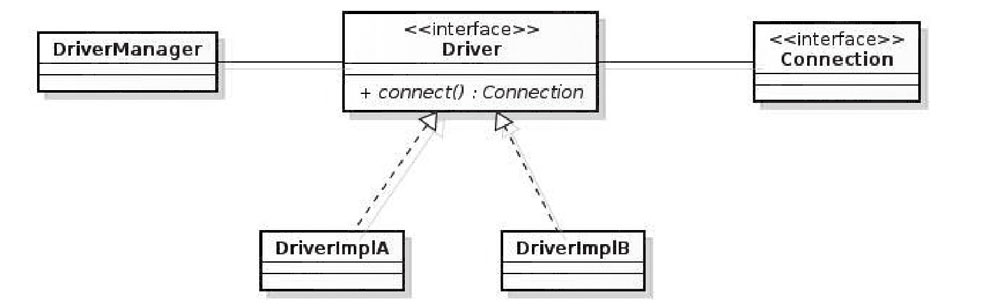
通过 DriverManger 获得 Connection,一个 Connection 对应一个实际的物理连接,每次操作都需要打开物理连接,使用完后立即关闭;这样频繁地打开/关闭连接会造成不必要的数据库系统性能消耗。
这样的背景下催生了数据库连接池的产生,数据库连接池提供的解决方案是:当应用启动时,主动建立足够多的数据库连接,并将这些连接组织成连接池,每次请求连接时,无须重新打开连接,而是从池中取出已有连接,使用完后并不实际关闭连接,而是将其归还给池。
所以这里需要涉及两项技术,一是连接使用 List 之类的集合进行初始化、装载和归还,二是使用动态代理来把资源归回给 List 集合。
而HikariCP之所以这么快,也主要是将这两项技术做到了极致。
JDBC 数据库连接池使用 javax.sql.DataSource 表示,DataSource 只是一个接口,其实现通常由服务器提供商(如WebLogic、WebShere)或开源组织(如 DBCP、c3p0 和 HikariCP)提供。
PreparedStatement & Statement
PreparedStatement 在企业开发中被强烈推荐使用,原因主要有以下方面:
Statement 会频繁编译 SQL。如果 JDBC 驱动支持的话(一般来说数据库系统库系统初次分析、编译时会对查询语句做最大的性能优化), PreparedStatement 可对 SQL 进行预编译,提高效率,预编译的 SQL 存储在 PreparedStatement 对象中。从这个意义上来说,PreparedStatement 比 Statement 更快,使用 PreparedStatement 也可以降低生产环境的数据库负载。
Statement 对象编译 SQL 语句时,如果 SQL 语句有变量,就需要使用分隔符来隔开,如果变量非常多,就会使 SQL 变得非常复杂。PreparedStatement 可以使用占位符,通过动态参数化的查询来简化 SQL 的编写。比如下面这个参数化查询例子,通过使用相同的 SQL 语句和不同的参数值来做查询,比创建一个不同的查询语句要好。
SELECT telephone_number FROM city WHERE username =?PreparedStatement 可防止 SQL 注入。因为 Statement 对象需要拼接,通过分隔符“++”编写永等式就可以实现 SQL 注入;而 PreparedStatement 使用占位符,就不会有 SQL 注入的问题。
JDBC & SPI
为了实现在模块装配的时候能不在程序里动态指明,需要一种服务发现机制。JDK 内置的 SPI(Service ProviderInterface)就能提供这样的一个机制:为某个接口寻找服务实现的机制。有点类似 IOC 的思想,就是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要。
JDBC 4.0 以前,开发人员还需要基于 Class.forName(“xxx”) 的方式来装载驱动,而 JDBC 4.0 基于 SPI 机制来发现驱动提供商,可以通过 META-INF/services/java.sql.Driver 文件里指定实现类的方式来暴露驱动提供者。开发者只需要编写一行代码,使用不同厂商的 jar 包,就可以轻松创建连接了。
线程池技术
池化技术,包括线程池、连接池、内存池、对象池等,其作用就是提前保存大量的资源,或者将用过的资源保存起来,等下一次需要使用该资源时再取出来重复使用。
线程池和连接池是两个不同的概念,连接池一般在客户端设置,而线程池是在如数据库这样的服务器上配置。通常来说,比较好的方式是将连接池和线程池结合起来使用。线程池具有线程复用、控制最大并发数、管理线程、保护系统4个优点,线程池的目的类似于连接池,通过复用线程来减少频繁创建和销毁线程,从而降低性能损耗。
线程池往往配合队列一起工作,限制并发处理任务的数量,从而保护系统。线程池的工作方式大同小异:先将任务提交到一个或者多个队列中,接着一定数量的线程从该队列中领取任务并执行,任务的结果再做处理,比如保存到MySQL数据库、调用别的服务等;任务完成以后,该线程会返回任务队列,等待下一个任务。
MySQL 线程池
传统方式下,MySQL 线程调度方式有两种:每个连接一个线程(One-Thread-Per-Connection)和所有连接一个线程(no-threads)。
MySQL 线程池是 MySQL 5.6 企业版的一个核心功能,是为了解决 One-Thread-Per-Connection 的实际生产常用选择的问题而引入的,通过有效管理大量客户端连接的语句执行线程数量,减少内存消耗,降低上下文切换(提高CPU Cache命中率)等来提高服务器性能。
在线程池 Thread Pool 处理方案中,最小单位是 statement,一个线程可以处理多个连接的请求,可以避免瞬间连接风暴造成的抖动。MySQL 线程池只在 Percona、MariaDB、Oracle 的 MySQL 企业版中提供,Oracle MySQL 社区版并不提供。MariaDB 在 5.5 版本中引入并最先实现线程池 Thread Pool 方案,Oracle 在 6.10 企业版本以 plugin 插件形式引入,Percona 在移植 MariaDB 的 Thread Pool 方案后又修复了一系列问题并优化了线程池性能。
使用“show variables like ‘thread%’”命令可以看到 thread_handling 的配置,默认情况是 one-thread-per-connection,即不启用线程池;将该参数设置为 pool-of-threads 即启用了线程池。
可以这么说,在 Percona 版本以后,MySQL 支持 No-Threads、One-Thread-Per-Connection 和 Pool-Threads 三种管理方式。Oracle Mysql 官方的性能测试表明:
- 在并发达到 128 个连接以后.没有线程池的 MySQL 性能会迅速降低。使用线程池以后,性能不会出现波动,会一直保持在较好的状态运行。
- 在读写模式下,128 个连接以后,有线程池的 MySQL 比没有线程池的 MySQL 性能高出 60 倍。
- 在只读模式下,512 个连接以后,有线程池的 MySQL 比没有线程池的 MySQL 性能高出 18 倍。
我们可以看到,Thread Pool 极大地提升了性能,并且解决了 One-Thread-Per-Connection 的如下 3 个问题:
- 太多的线程堆栈使 CPU 缓存在高度并行的执行工作负载中几乎无用。线程池促进了线程堆栈重用,以最小化 CPU 缓存占用空间。
- 由于太多线程并行执行,因此上下文切换开销很高。这也给操作系统调度程序带来了挑战性的任务。线程池控制活动线程的数量,以使 MySQL 服务器内的并行性保持在它可以处理的水平,并且适用于 MySQL 正在执行的服务器主机。
- 并行执行的事务太多会增加资源争用。
MySQL 线程池内部
排队理论中存在一个众所周知的关系:尝试访问共享资源的用户越多,响应时间越长,并呈指数级增长。
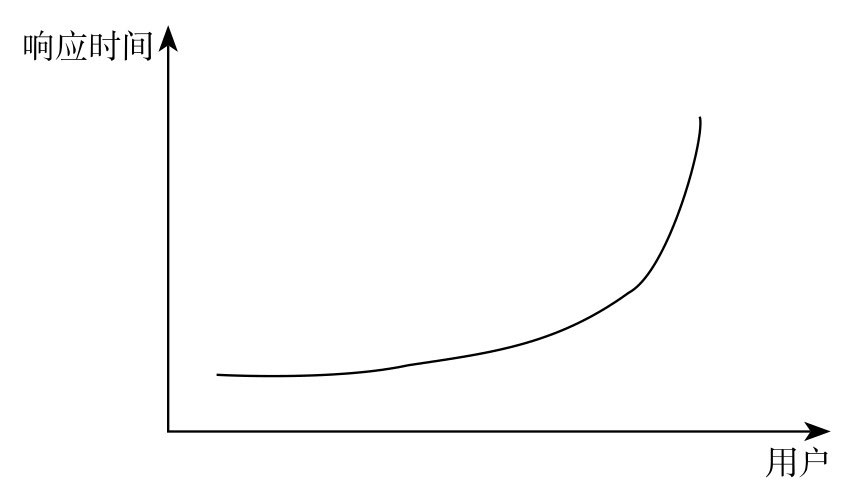
在吞吐量上,随着用户的不断增多,由于内部通信和同步,系统每秒能够处理的请求就越来越少,甚至会导致系统没有反应并且直接卡死,如图所示。众所周知的 DDoS 攻击就是类似这样的行为。
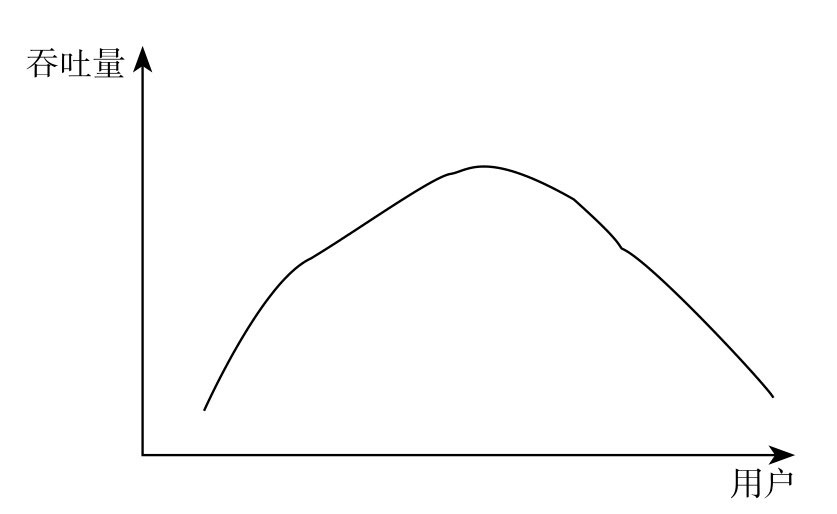
而 MySQL 线程池在面对上述困难时,旨在提供如图所示的吞吐量曲线。
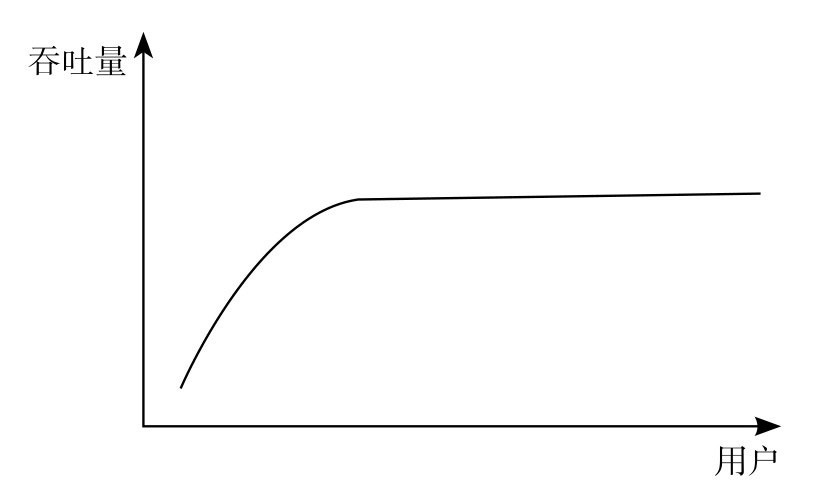
MySQL 线程池本身并不会神奇地提高性能,但是它可以保护 MySQL 突然过载的情况,打造上图所示的稳定性曲线,这是通过其限制 MySQL 内部的工作线程数量来实现的。
如图下所示,这是 MySQL Thread Pool 的架构图,MySQL 的线程池提出了一个线程组的概念,工作线程被放在了线程组内部。我们可以看到 Thread Pool 由一个 Timer 线程和多个线程组构成,每个线程组内部由优先队列、普通队列两个队列,以及一个 Listener 线程和多个工作线程组成。
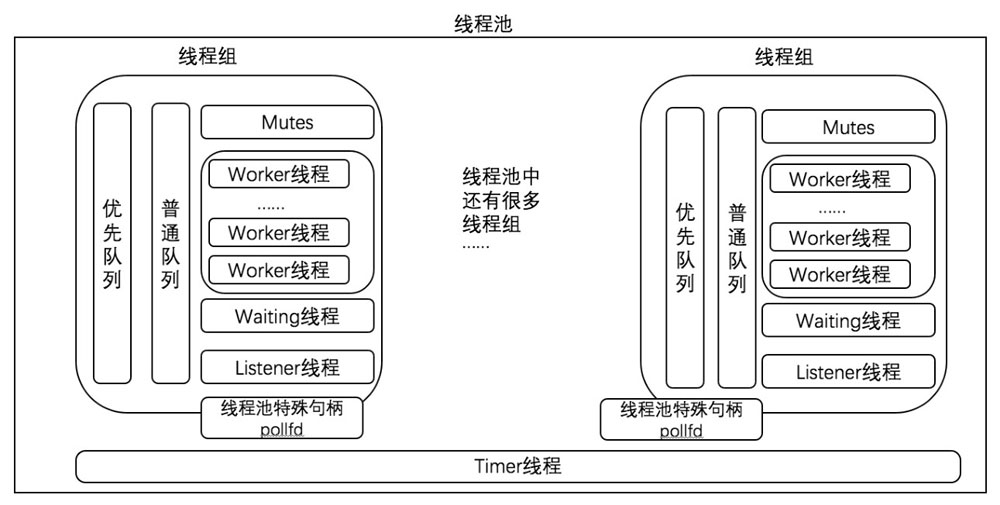
- 线程组,在初始化以后会由底层的 IO 库分配到一个特殊的句柄 pollfd,每个线程组都有一个对应的 pollfd。
- Worker 线程,是真正干活的线程,它具有活跃、空闲和等待3种状态。
- Listener 线程,主要用来监听该线程组的语句,通过 pollfd 中轮询 IO 任务来决定是 Listener 线程自身处理这些任务,还是放入队列交给并唤醒多少个 Worker 线程去处理。从这个意义上来说,Listener 线程也是可以转换为 Worker 线程的。所以,线程组中,总线程数等于正在工作且未被阻塞的线程数+工作线程任务的过程中被阻塞的个数+空闲线程的个数 + Listener 线程的个数。
- 任务队列,由普通队列和优先任务队列构成,是 Listene r每次从 pollfd 轮询出来的就绪任务。官方定义将符合连接处于事务中和连接关联的 priority tickets 值大于 0 两种情况认为是优先队列。所以可以这么认为,如果同一个事务中有两个 insert的SQL,有 1 个已经执行,那么另一个 insert0 任务就会放在高优先级中。如果是非事务引擎,或者开启了 autocommit 的事务引擎,都会放到普通队列中。还有一种情况是如果语句在普通队列中停留太久,该语句也会移到优先队列中,防止它饿死,thread_pool_prio_kickup_timer 系统变量控制了这个“停留时间”,对每个线程组来说,语句停留的最大时间为 10ms。另外,还有一个
priority tickets(thread_pool_high_prio_tickets)的设计,以优先的任务每次被放入优先队列中就对 priority tickets 减 1,以避免永久优先的问题。 - Timer 线程,是一种 Check Stall 机制,用来周期性地检查 group 是否超时或阻塞状态,并通过检测线程组的负载来进行工作线程的唤醒和创建行。创建线程必须满足两个条件:其一,如果没有空闲线程且没有活跃线程则立刻创建,这种情况可能因为没有任何工作线程或者工作线程都被阻塞了,或者是存在潜在的死锁;其二,如果距离上次创建的时间大于一定阈值才创建线程,这个阈值由线程组内的线程数决定。
介绍完 Thread Pool 架构和架构中的各个组件,我们再来看一下一次完整的用户请求是如何从数据库连接池进入 MySQL 的线程池,通过 Thread Pool 而进行运作的。
- 在初始化时,MySQL 线程池根据宿主机的 CPU 核心数设置 thread_pool_size,并分成若干 group,每个 group 各自维护客服端发起的连接。当用户的请求通过数据库连接池访问到 MySQL 服务端时,MySQL 服务端再进行
threadid % thread_pool_size取模计算,确定落在哪个线程组中。 - 线程组中的 Listener 线程监听到所在的线程组有新的请求后,检查队列中是否有请求还未处理,并决定是自己亲自转化为 Worker 线程进行处理,还是把这些任务放入队列中让 Worker 线程进行处理。在这个过程中先处理优先队列,再处理普通队列。如果任务队列不为空,Listener 线程还需要考虑应调度唤醒多少个工作线程。
在以上两步中,还有两个自检程序在运行着。一个是 Worker 线程会自己判断最大空闲时间,如果超过最大空闲时间(默认60秒)就会退出;还有一个是 Timer 线程不断进行 CheckStall 机制,用来周期性地检查 group 是否处于超时或阻塞状态,并通过检测线程组的负载来进行工作线程的唤醒和创建。
MySQL 线程池实战
基本参数:
- thread_pool_size 是线程池性能最重要的参数,其设置线程池的 group 的数量,默认为系统CPU的个数。MySQL 官方文档给出的经验性建议[插图]是:如果主引擎(primary storage engine)为InnoDB, thread_pool_size 最佳设置可能为16~36,最常见的优化值倾向于24~36;如果主引擎为 MyISAM,那么 thread_pool_size 设置应该相当低。该值设置为4~8,倾向于获取最优性能。更高值设置对性能倾向于有点负面但不显著的影响。
- thread_pool_stall_limit 表示 Timer Thread 检测 group 是否异常的时间间隔,默认是 500ms。其用来处理被阻塞和长时间运行的语句,确保服务器不会完全被阻塞。thread_pool_stall_limit 有个 6 秒的上限值,防止服务器死锁的风险。在合适范围内,该值越大,MySQL 服务器的整体处理性能就越好,因为较少数量的线程,会降低对于系统资源的征用。但是,并不是越大越好,因为该值越大,新线程的创建将等待时间越长,用户的查询延迟就会越明显。
- thread_pool_max_threads 控制线程池的最大线程数,默认为 10000。若该值为 1000,代表线程池中所能创建的最大线程数不能超过 1000。
- thread_handling 默认是 one-thread-per-connection,如果要使用连接池功能,则必须设置为 pool-of-threads。
- thread_pool_oversubscribe 用于控制单个 CPU 核心在同一时间活跃的线程数。类似于一种“超频”的概念,默认值是 3。
- thread_pool_idle_timeout 设置空闲线程销毁前的等待时间,单位为秒,默认是 60 秒。用户可以根据自己的业务场景来调整该参数的值。设置得太短,会导致线程频繁地销毁与创建;设置得太长,则会导致线程池中的线程数长时间不会下降。
- thread_pool_idle_timeout 设置空闲线程销毁前的等待时间,单位为秒,默认是 60 秒。用户可以根据自己的业务场景来调整该参数的值。设置得太短,会导致线程频繁地销毁与创建;设置得太长,则会导致线程池中的线程数长时间不会下降。
- extra_port 用于设置 MySQL 服务端口之外的端口,供管理员管理服务器。
- extra_max_connections 用于设置 extra_port 端口允许的最大连接数,通过 extra_port 端口创建的连接,采用的是 one-thread-per-connection 的方式。
- thread_pool_high_prio_mode,线程池分组内的待处理任务会放到任务队列中,等待 Worker 线程处理。每个分组有两个队列:优先队列和普通队列,Worker 线程先从优先队列取事务处理,只有当优先队列为空时才从普通队列取事务处理。通过优先队列,可以让已经开启的事务或短事务得到优先处理,及时提交释放锁等资源。该参数可设置为3种模式:
- transactions。默认的,只有一个已经开启了事务的SQL,并且 thread_pool_high_prio_tickets 不为 0,才会进入优先队列中,每个连接在 thread_pool_high_prio_tickets 次被放到优先队列后,会移到普通队列中。
- statements。单独的 SQL 总是进入优先队列。
- none。禁用优先队列功能,所有的连接都放到普通队列中处理。
- thread_pool_high_prio_tickets,当
thread_pool_high_prio_mode = transactions的时候,每个连接的任务最多被放入优先队列 thread_pool_high_prio_tickets 次,并且每放一次递减,直到小于等于 0 的时候放入普通队列,这个值默认是 4294967295。
实战经验:
- 在 Percona 5.7 的部分低版本中,如果开启了 Performance_Schema 和 ThreadPool 会出现内存泄漏问题,需要将 performance_schema 设置为 off 并重启 MySQL。
- 慢 SQL 导致线程池卡住。慢 SQL 的问题往往是压倒团队的“最后一根稻草”,慢 SQL 引发的惨痛故障不胜枚举,甚至造成资损。不符合规范的 SQL、全表查询、没建索引等都是可能造成慢 SQL 的原因,而 thread_pool_oversubscribe 可以暂时缓解这个问题。但是这咱方法治标不治本,根本解决方法还是开启 MySQL 服务端的日志,将慢SQL每天反馈给各个技术研发团队,甚至直接通过中间件过滤掉慢 SQL,不让其访问到 MySQL 服务端。
- MySQL 主备切换及容灾演练。生产数据库往往会默认设置几千个连接数,可是如果发生业务洪峰、机房故障以后迅速重连导致的连接风暴等情况,都容易将 MySQL 的最大连接数和并发线程数迅速提高到峰值。业务上可以提前做好预案及压测,技术上可以考虑通过配置中心进行 MySQL 的多机房切换、主备切换及容灾,也可以做探测脚本,在即将达到最大连接数时进行及时的扩容。
- 调度死锁解决。引入线程池解决了多线程高并发的问题,但也带来一个隐患。假设,A、B 两个事务被分配到不同的 group 中执行,A 事务已经开始,并且持有锁,但由于 A 所在的 group 比较繁忙,导致A执行一条语句后,不能立即获得调度执行;而 B 事务依赖A事务释放锁资源,虽然B事务可以被调度起来,但由于无法获得锁资源,导致 B 仍然需要等待,这就是所谓的调度死锁。由于一个 group 会同时处理多个连接,但多个连接不是对等的。比如,有的连接是第一次发送请求,而有的连接对应的事务已经开启,并且持有了部分锁资源。为了减少锁资源争用,后者显然应该比前者优先得到处理,以达到尽早释放锁资源的目的。因此在 group 里面,可以添加一个优先队列,将已经持有锁的连接,或者已经开启的事务的连接发起的请求放入优先队列,工作线程首先从优先队列获取任务执行。
- 大查询处理。假设一种场景,某个 group 里面的连接都是大查询,那么 group 里面的工作线程数很快就会达到 thread_pool_oversubscribe 参数设置值,对于后续的连接请求,则会响应不及时(没有更多的连接来处理),这时候 group 就发生了 stall。通过前面的分析知道,Timer 线程会定期检查这种情况,并创建一个新的 Worker 线程来处理请求。如果长查询来源于业务请求,则此时所有 group 都面临这种问题,此时主机可能会由于负载过大,发生 hang 住的情况。这种情况线程池本身无能为力,因为源头可能是烂 SQL 并发,或者 SQL 没有走对执行计划而导致,通过其他方法,比如 SQL 高低水位限流或者 SQL 过滤手段可以应急处理。但是,还有另外一种情况,就是 dump 任务。很多下游依赖于数据库的原始数据,通常通过 dump 命令将数据拉到下游,而这种 dump 任务通常都耗时比较长,所以也可以认为是大查询。如果 dump 任务集中在一个 group 内,并导致其他正常业务请求无法立即响应,这个是不能容忍的。因为此时数据库并没有压力,只是因为采用了线程池策略,才导致了请求响应不及时。为了解决这个问题,我们将 group 中处理 dump 任务的线程不计入 thread_pool_oversubscribe 累计值,即可避免上述问题。
- thread_cache_size 设置优化。每建立一个连接,都需要一个线程来与之匹配,此参数用来缓存空闲的线程,以至不被销毁。如果线程缓存中有空闲线程,这时候如果建立新连接,MySQL 就会很快地响应连接请求。MySQL 如果采用多线程来处理并发的连接,那么采用 mysqlreport 的 Threads 部分可以看到线程创建的频率非常高。一个比较好的方法就是使用持久连接,这将在一定程度上减少线程的重复创建。将 thread_cache_size 从 0 适当地提高到一定的业务需求值,虽然每秒处理的连接数不变,但是创建的线程数可以大大减少,同时提高线程池的命中率。
5 - 性能原理
为什么快
在 HikariCP 官网详细了介绍 HikariCP 所做的优化,总结如下:
- 优化并精简字节码、优化代码和拦截器。
- 使用 FastList 替代 ArrayList。
- 更好的并发集合类实现 ConcurrentBag。
- 其他针对 BoneCP 缺陷的优化,比如对于耗时超过一个 CPU 时间片的方法调用的研究。
精简字节码
HikariCP 的代码只有 130 Kb,它是一个轻量级数据库连接池。
HikariCP 利用了一个第三方的 Java 字节码修改类库 Javassist 来生成委托实现动态代理。
动态代理的实现在 com.zaxxer.hikari.pool.ProxyFactory 类,源码非常简单。如下所示:
public final class ProxyFactory
{
private ProxyFactory() { }
static ProxyConnection getProxyConnection(final PoolEntry poolEntry,
final Connection connection,
final FastList<Statement> openStatements,
final ProxyLeakTask leakTask,
final long now,
final boolean isReadOnly,
final boolean isAutoCommit){
//body部分被JavassistProxyFactory重新注入了
throw new IllegalStateException("You need to run the CLI build and you
need target/classes in your classpath to run.");
}
static Statement getProxyStatement(final ProxyConnection connection, final
Statement statement)
{//body部分被JavassistProxyFactory重新注入了
throw new IllegalStateException("You need to run the CLI build and you
need target/classes in your classpath to run.");
}
static CallableStatement getProxyCallableStatement(final ProxyConnection
connection, final CallableStatement statement)
{//body部分被JavassistProxyFactory重新注入了
throw new IllegalStateException("You need to run the CLI build and you
need target/classes in your classpath to run.");
}
static PreparedStatement getProxyPreparedStatement(final ProxyConnection
connection, final PreparedStatement statement)
{//body部分被JavassistProxyFactory重新注入了
throw new IllegalStateException("You need to run the CLI build and you
need target/classes in your classpath to run.");
}
static ResultSet getProxyResultSet(final ProxyConnection connection, final
ProxyStatement statement, final ResultSet resultSet)
{//body部分被JavassistProxyFactory重新注入了
throw new IllegalStateException("You need to run the CLI build and you
need target/classes in your classpath to run.");
}
}
这些代码基本代理了 JDBC 常用的核心接口,一共是 5 个:ProxyConnection、Statement、CallableStatement、PreparedStatement、ResultSet。并且每个方法都抛出了异常。其实每个方法都是抛异常之前都有一段 body,这段 body 是在编译时调用 JavassistProxyFactory 才生成的。
JavassistProxyFactory 存在于 com.zaxxer.hikari.util 包中,是 Javassist 的工具包,它主要有两个核心方法: generateProxyClass 方法负责生成实际使用的代理类字节码,modifyProxyFactory 对应修改工厂类中的代理类获取方法 Proxy*.java 为 HikariProxy*. java。这个工具包的作用是将 ProxyConnection、ProxyStatement、ProxyPreparedStatement、ProxyCallableStatement、ProxyResultSet 这 5 个 com.zaxxer.hikari.pool 包下代理类,利用 Javassist 重构后生成实际的 HikariCP 的对应代理类 HikariProxyConnection、HikariProxyStatement、HikariProxyPreparedStatement、HikariProxyCallableStatement、HikariProxyResultSet。
之所以使用 Javassist 生成动态代理,是因为其速度更快,比 JDK Proxy 生成的字节码更少,精简了很多不必要的字节码。
此外,HikariCP 在字节码工程中还对 JIT 进行了优化。比如,JIT 方法内联优化默认的字节码个数阈值是 35 字节,低于 35 字节才会进行优化。HikariCP 在精简字节码的时候,研究了编译器的字节码输出,甚至是 JIT 的汇编输出,以将关键部分限制为小于 JIT 内联阈值,展平了继承层次结构,阴影成员变量,消除了强制转换。
FastList
HikariCP 一个性能方面的出彩优化突破就是 FastList。我们先看一组 HikariCP 中关于 FastList 的结论:
- 当调用
Connection.prepareStatement()的时候,新的 PreparedStatement 就被添加到 FastList。 - 当调用
PreparedStatement.close()的时候,这个 statement 就从 FastList 中被移除。 - 如果调用
Connection.close()的时候,任何未明确关闭的语句都将从 FastList 移除并关闭。
但是 HikariCP 并没有拦截 PreparedStatement.addBatch() 方法,所以实际上 addBatch() 不可能添加任何内容到 FastList。executeBatch 方法即不会清除批处理,也不会将 PreparedStatement 从 FastList 中移除。唯一能够清除批处理的是 PreparedStatement.clearBatch() 方法,而唯一能够从 FastList 移除 PreparedStatement 的方法就是调用 PreparedStatement. close() 或者 Connection.close() 方法。
try (Connection con = dataSource.getConnection();
PreparedStatement stmt = con.prepareStatement(...)) {
int batchCount = 0;
for (something in somelist) {
stmt.setString(...);
stmt.setInt(...);
stmt.addBatch();
if (++batchCount == 100) {
stmt.executeBatch();
stmt.clearBatch();
batchCount = 0;
}
}
if (batchCount > 0) {
stmt.executeBatch();
stmt.clearBatch();
}
con.commit();
}
catch (SQLException e) {
// 记录异常
}
如上述代码所示,对于批处理语句执行清理的过程分为如下几步:DataSource.getConnection()、Connection.prepareStatement()、多次调用 PreparedStatement.addBatch()、PreparedStatement.executeBatch()/clearBatch() 的调用、依赖 Java 7 的 try-with-resources 语法进行资源的清理。
FastList 是一个 List 接口的精简实现,只实现了接口中必要的几个方法。JDK ArrayList 每次调用 get() 方法时都会进行 rangeCheck,检查索引是否越界,FastList 的实现中去除了这一检查,只要保证索引合法那么 rangeCheck 就成为了不必要的计算开销(当然开销极小)。
此外,HikariCP 使用 List 来保存打开的 Statement,当 Statement 关闭或 Connection 关闭时需要将对应的 Statement 从 List 中移除。通常情况下,JDBC 在同一个 Connection 创建了多个 Statement 时,后打开的 Statement 会先关闭。这种情况从尾部开始扫描将表现更好。ArrayList 的 remove(Object) 方法是从头开始遍历数组,而 FastList 是从数组的尾部开始遍历,因此更为高效,它消除了范围检查,并从尾部到头部执行移除扫描。
简而言之就是用自定义数组类型 FastList 代替 ArrayList:避免每次 get() 调用都要进行范围检查,避免调用 remove() 时的从头到尾的扫描。
ConcurrentBag
ConcurrentBag 取名来源于 C# .NET 的同名类,但是实现却不一样。它是一个 lock-free 集合,在连接池(多线程数据交互)的实现上具有比 LinkedBlockingQueue 和 LinkedTransferQueue 更优越的并发读写性能。它具有无锁设计、ThreadLocal 缓存、队列窃取、直接切换优化四大特点。
ConcurrentBag 采用了 queue-stealing 的机制获取元素:首先尝试从 ThreadLocal 中获取属于当前线程的元素来避免锁竞争,如果没有可用元素则再次从共享的 CopyOnWriteArrayList 中获取。此外,ThreadLocal 和 CopyOnWriteArrayList 在 ConcurrentBag 中都是成员变量,线程间不共享,避免了伪共享(false sharing)的发生。作者评价这款设计具有高度并发性,极低的延迟,并最大限度地减少了伪共享的发生。
ConcurrentBag 的性能提升主要源于如下 3 个组成部分:
- CopyOnWriteArrayList:负责存放 ConcurrentBag 中全部用于出借的资源。
- ThreadLocal:用于加速线程本地化资源访问。
- SynchronousQueue:用于存在资源等待线程时的第一手资源交接。
源码解析
ConcurrentBag 内部同时使用 ThreadLocal 和 CopyOnWriteArrayList 来存储元素,其中 CopyOnWriteArrayList 是线程共享的。
ConcurrentBag 采用了 queue-stealing 的机制获取元素:首先尝试从 ThreadLocal 中获取属于当前线程的元素来避免锁竞争,如果没有可用元素则扫描公共集合,再从共享的 CopyOnWriteArrayList 中获取。ThreadLocal 列表中没有被使用的 items 在借用线程没有属于自己的时候,是可以被“窃取”的。
ThreadLocal 和 CopyOnWriteArrayList 在 ConcurrentBag 中都是成员变量,线程间不共享,避免了伪共享的发生。
使用专门的 AbstractQueuedLongSynchronizer 来管理跨线程信号,这是一个 lock-less 的实现。
ConcurrentBag 通过 borrow 方法进行数据资源借用,通过 requite 方法进行资源回收,注意其中 borrow 方法只提供对象引用,不移除对象。所以从 bag 中“借用”的 items 实际上并没有从任何集合中删除,因此即使引用废弃了,垃圾收集也不会发生。因此使用时通过 borrow 取出的对象必须通过 requite 方法进行放回,否则会导致内存泄露,只有 remove 方法才能完全从 bag 中删除一个对象。
ConcurrentBag:
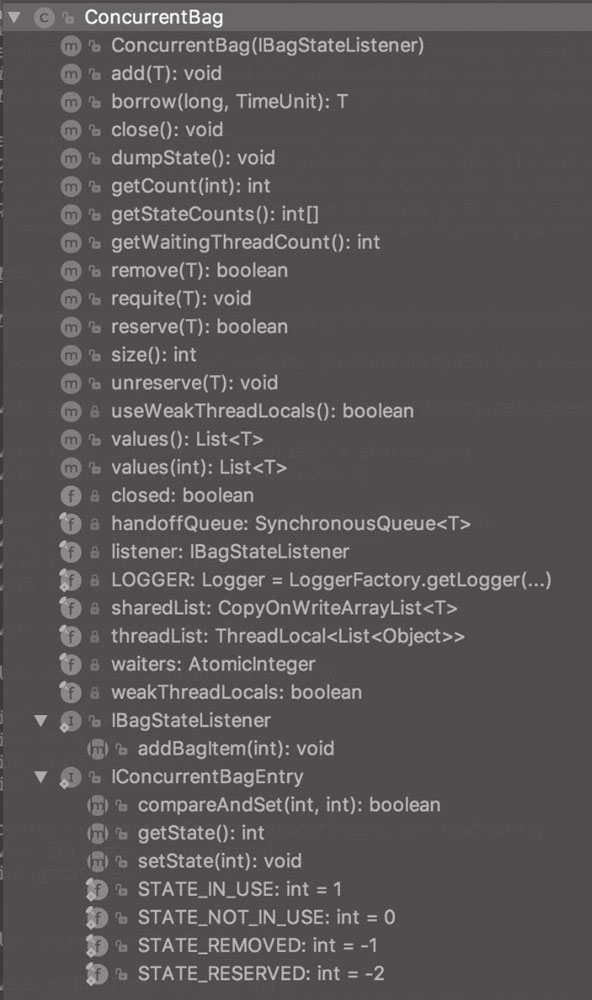
对 CopyOnWriteArrayList 的使用:通过 add 添加资源,通过 remove 方法借出资源:
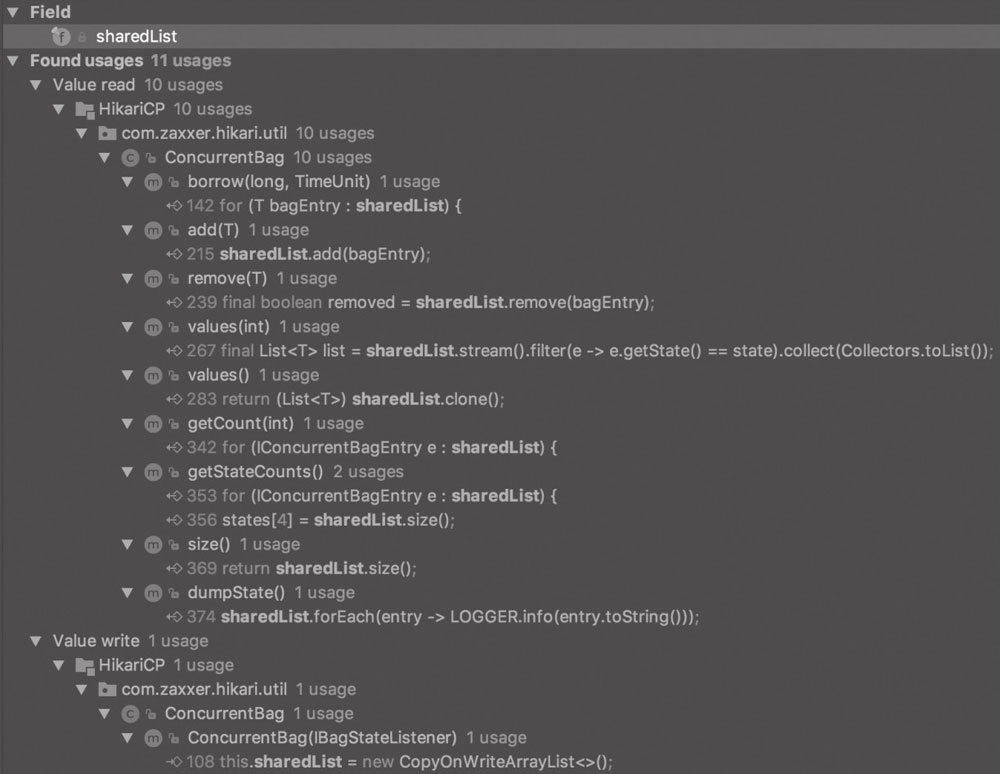
add 方法向 bag 中添加 bagEntry 对象,以供别人借用:
public void add(final T bagEntry)
{
if (closed) {
LOGGER.info("ConcurrentBag has been closed, ignoring add()");
throw new IllegalStateException("ConcurrentBag has been closed, ignoring
add()");
}
sharedList.add(bagEntry); //新添加的资源优先放入CopyOnWriteArrayList
// 当有等待资源的线程时,将资源交到某个等待线程后才返回(SynchronousQueue)
while (waiters.get() > 0 && ! handoffQueue.offer(bagEntry)) {
yield();
}
}
remove 方法从 bag 中删除一个 bagEntry,仅在 borrow(long, TimeUnit) 和 reserve(T) 时被调用:
public boolean remove(final T bagEntry){
// 如果资源正在使用且无法进行状态切换,则返回失败
if (!bagEntry.compareAndSet(STATE_IN_USE, STATE_REMOVED) &&
!bagEntry.compareAndSet(STATE_RESERVED, STATE_REMOVED) &&
!closed) {
LOGGER.warn("Attempt to remove an object from the bag that was not borrowed or reserved: {}", bagEntry);
return false;
}
final boolean removed = sharedList.remove(bagEntry); // 移出
if (! removed && ! closed) {
LOGGER.warn("Attempt to remove an object from the bag that does not exist: {}", bagEntry);
}
return removed;
}
// ConcurrentBag中通过borrow方法进行数据资源借用。
public T borrow(long timeout, final TimeUnit timeUnit) throws InterruptedException
{
// 优先查看有没有可用的本地化的资源
final List<Object> list = threadList.get();
for (int i = list.size() -1; i >= 0; i--) {
final Object entry = list.remove(i);
@SuppressWarnings("unchecked")
final T bagEntry = weakThreadLocals ? ((WeakReference<T>) entry).
get() : (T) entry;
if (bagEntry ! = null && bagEntry.compareAndSet(STATE_NOT_IN_USE,
STATE_IN_USE)) {//优先从当前线程的ThreadLocal中获取连接,若获得则直接返回
return bagEntry;
}
}
final int waiting = waiters.incrementAndGet();
try {
// 当无可用本地化资源时,遍历全部资源,查看是否存在可用资源
// 因此被一个线程本地化的资源也可能被另一个线程"抢走"
for (T bagEntry : sharedList) {
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
if (waiting > 1) {
// 因为可能"抢走"了其他线程的资源,因此提醒包裹进行资源添加
listener.addBagItem(waiting -1);
}
return bagEntry;
}
}
listener.addBagItem(waiting);
timeout = timeUnit.toNanos(timeout);
do {
final long start = currentTime();
// 若现有资源全部在使用中,则等待一个被释放的资源或者一个新资源
final T bagEntry = handoffQueue.poll(timeout, NANOSECONDS);
if (bagEntry == null ||
bagEntry.compareAndSet(STATE_NOT_IN_USE,STATE_IN_USE)) {
return bagEntry;
}
timeout -= elapsedNanos(start);
} while (timeout > 10_000);
return null;
}
finally {
waiters.decrementAndGet();
}
}
public void requite(final T bagEntry)
{
// 将状态转为未在使用
bagEntry.setState(STATE_NOT_IN_USE);
// 判断是否存在等待线程,若存在,则直接转手资源
for (int i = 0; waiters.get() > 0; i++) {
if (bagEntry.getState() ! = STATE_NOT_IN_USE || handoffQueue.offer(bagEntry)) {
return;
}
else if ((i & 0xff) == 0xff) {
parkNanos(MICROSECONDS.toNanos(10));
}
else {
yield();
}
}
// 否则,进行资源本地化
final List<Object> threadLocalList = threadList.get();
threadLocalList.add(weakThreadLocals ? new WeakReference<>(bagEntry) :bagEntry);
}
SynchronousQueue
SynchronousQueue 来自于 JUC 并发包 java.util.concurrent,在 HikariCP 中的体现就是 ConcurrentBag 结构中的 handoffQueue,它主要用于存在资源等待线程时的第一手资源交接:
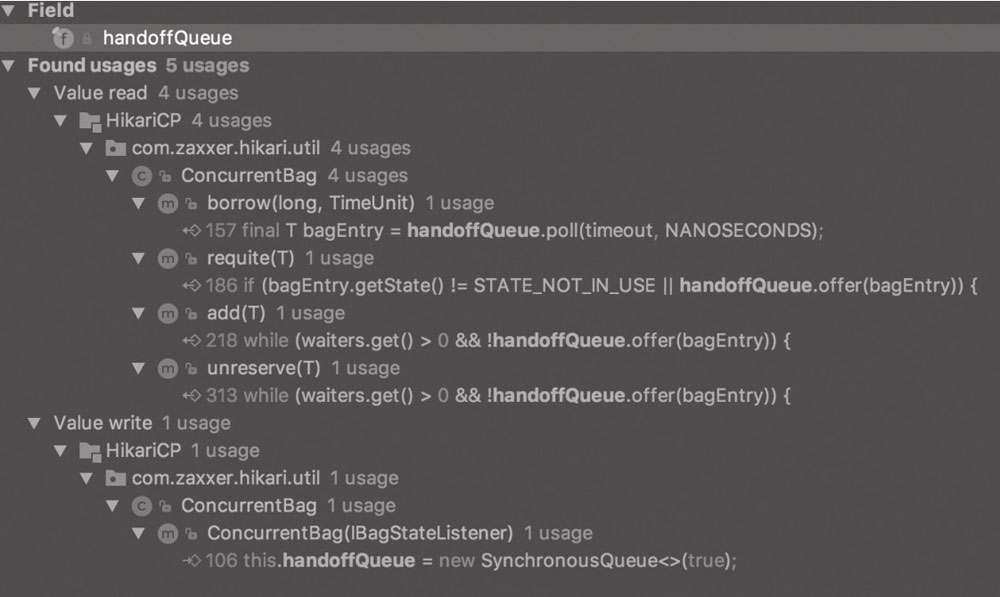
SynchronousQueue 的初始化是在 ConcurrentBag 的构造方法中,如下所示:
public ConcurrentBag(final IBagStateListener listener)
{
this.listener = listener;
this.weakThreadLocals = useWeakThreadLocals();
this.handoffQueue = new SynchronousQueue<>(true);
this.waiters = new AtomicInteger();
this.sharedList = new CopyOnWriteArrayList<>();
if (weakThreadLocals) {
this.threadList = ThreadLocal.withInitial(() -> new ArrayList<>(16));
}
else {
this.threadList = ThreadLocal.withInitial(() -> new FastList<>
(IConcurrentBagEntry.class, 16));
}
}
SynchronousQueue 提供了以下两个构造函数:
public SynchronousQueue() {
this(false);
}
public SynchronousQueue(boolean fair) {
// 通过fair值来决定公平和不公平
// 公平使用TransferQueue,不公平使用TransferStack
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}
在 HikariCP 中,选择的是公平模式 this.handoffQueue = newSynchronousQueue<>(true)。公平模式总结下来就是:队尾入队队头出队,先进先出,体现公平原则。
SynchronousQueue 是一个无存储空间的阻塞队列(是实现 newFixedThreadPool 的核心),非常适合做交换工作,生产者和消费者的线程同步以传递某些信息、事件或者任务。作为 BlockingQueue 中的一员,SynchronousQueue 的吞吐量高于 ArrayBlockingQueue 和 LinkedBlockingQueue,与其他 BlockingQueue 有着不同特性。
- SynchronousQueue 无存储空间。与其他 BlockingQueue 不同,SynchronousQueue 是一个不存储元素的 BlockingQueue。它的特点是每一个 put 操作必须要等待一个 take 操作或者 poll 方法,才能使用 off、add 方法,否则不能继续添加元素,反之亦然。
- 因为没有容量,所以对应 peek、contains、clear、isEmpty 等方法其实是无效的。例如 clear 是不执行任何操作的,contains 始终返回 false, peek 始终返回 null, peek 方法直接返回 null。
- SynchronousQueue 分为公平和不公平,默认情况下采用不公平访问策略。当然也可以通过构造函数来设置为公平访问策略。
- 若使用 TransferQueue,则队列中永远会存在一个 dummynode。
CopyOnWriteArrayList
CopyOnWriteArrayList 负责存放 ConcurrentBag 中全部用于出借的资源。顾名思义,Write 的时候总是要 Copy,也就是说对于任何可变的操作都是伴随复制这个动作的,这是 ArrayList 的一个线程安全的变体,底层通过复制数组的方式来实现。和 SynchronousQueue 一样,它也位于 java.util.concurrent 包下,为并发而生。CopyOnWriteArrayList 在遍历的时候不会抛出 ConcurrentModificationException 异常,并且遍历的时候就不用额外加锁,元素也可以为 null。
CopyOnWriteArrayList 底层是一个数组,通过 ReentrantLock 进行加锁,它初始化的时候底层是一个 Object[] array, Object array 指向一个大小为 0 的数组。一次 add 操作经历了 5 个步骤,都是在锁的保护下进行的,在添加的时候先上锁,拿到原数组并复制一个新数组(原数组大小+1),增加操作在新数组上进行,最后再将 Object array 引用指向新数组,解锁。这样做是为了避免在多线程并发add的时候,复制多个副本出来,把数据搞乱了,导致最终的数组数据不是我们期望的。这是一种写时复制的理念。
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
final transient ReentrantLock lock = new ReentrantLock(); //可重入锁
final Object[] getArray() {return array; }//非private,得到数组
final void setArray(Object[] a) {array = a; }//设置数组
public CopyOnWriteArrayList() { setArray(new Object[0]); }//初始化
public boolean add(E e) {
final ReentrantLock lock = this.lock; //1)加锁
lock.lock();
try {
Object[] elements = getArray(); //得到原数组的长度和元素
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1); //2)复制数组
newElements[len] = e; //3)将元素加入到新数组中
setArray(newElements); //4)将array引用指向到新数组
return true;
} finally {
lock.unlock(); //5)解锁
}
}
插入、删除、修改操作也都是一样,每一次的操作都是以对Object[] array进行一次复制为基础的。写加锁,读不加锁。由于所有的写操作都是在新数组进行的,这个时候如果有线程并发的写,则通过锁来控制。如果有线程并发的读,则分以下几种情况:
- 如果写操作未完成,那么直接读取原数组的数据。
- 如果写操作完成,但是引用还未指向新数组,那么也是读取原数组数据。
- 如果写操作完成,并且引用已经指向了新的数组,那么直接从新数组中读取数据。
CopyOnWriteArrayList 非常适用于数据库连接池这种读操作远远多于修改操作的场景,它反映的是 3 个十分重要的分布式理念:
- 读写分离。读取 CopyOnWriteArrayList 的时候,读取的是 CopyOnWriteArrayList 中的
Object[] array,但是修改的时候,操作的是一个新的Object[] array。读和写操作的不是同一个对象,这就是读写分离。这种技术数据库用的非常多,在高并发下为了缓解数据库的压力,即使做了缓存也要对数据库做读写分离,读的时候使用读库,写的时候使用写库,然后读库、写库之间进行一定的同步,这样就避免同一个库上读、写的 IO 操作太多。 - 最终一致。对 CopyOnWriteArrayList 来说,线程1读取集合里面的数据,未必是最新的数据。因为线程2、线程3、线程4都修改了 CopyOnWriteArrayList 里面的数据,但是线程1拿到的还是最老的那个
Object[] array,新添加进去的数据并没有,所以线程1读取的内容未必准确。不过这些数据虽然对于线程1是不一致的,但是对于之后的线程一定是一致的,它们拿到的Object[] array一定是3个线程都操作完毕之后的Object array[],这就是最终一致。最终一致对于分布式系统也非常重要,它通过容忍一定时间的数据不一致,提升整个分布式系统的可用性与分区容错性。当然,最终一致并不是任何场景都适用的,像火车站售票这种系统用户对于数据的实时性要求非常非常高,就必须做成强一致性的。 - 使用另外开辟空间的思路,来解决并发冲突。
但是它有着以下缺点:
- 因为 CopyOnWrite 的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)。如果这些对象占用的内存比较大,比如200M左右,再写入100M数据,内存就会占用300M,那么这个时候很有可能造成频繁的Yong GC和Full GC。
- 不能用于实时读的场景,像复制数组、新增元素都需要时间,所以调用一个 set 操作后,读取到数据可能还是旧的。虽 CopyOnWriteArrayList 能做到最终一致性,但是还是没法满足实时性要求。所以如果你希望写入的的数据马上能读到,就不要使用 CopyOnWrite 容器。
6 - 优化原理
获取连接
HikariCP 可以被理解为一个简单的 BlockingQueue,它实际上并没有使用 BlockingQueue,而是使用了一种被称为 ConcurrentBag 的专用集合,但在行为概念上是类似的。在这个 BlockingQueue 的模型上,可以想象你的客户端调用 HikariDataSource 的 getConnection 方法执行着如下的工作:
public Connection getConnection() throws SQLException {
return connectionQueue.poll(timeout);
}
显然会有更多的事情发生,比如抛出超时异常等,如上是基本的思路。调用 Connection.close 方法实质上返回到池的连接,同样,还有很多具体细节,但概念是相通的。
public void close() throws SQLException {
connectionQueue.put(this);
}
HikariCP 确实有几个自己的线程,有一个 HouseKeeper 管家线程定期运行以退出空闲连接,有一个调度线程可以退出到达 maxLifetime 的连接,还有一个用于添加连接的线程,以及一个用于关闭它们的线程等。接下来,我们从获取连接部分开始仔细研究源码级的原理。
获取连接是 HikariCP 的核心功能,HikariDataSource 对象首先通过 getConnection 方法获得 HikariPool 真正的 getConnection 方法,HikariPool 内部通过我们介绍过的 ConcurrentBag 的 borrow 方法获取 PoolEntry,它将首先尝试从线程的 ThreadLocal 最近使用的连接列表中获取未使用的连接。最后通过 PoolEntry 执行 Create Proxy Connection 方法创建一个物理连接并返回其代理连接 Proxy Connection。具体的时序图如图所示。
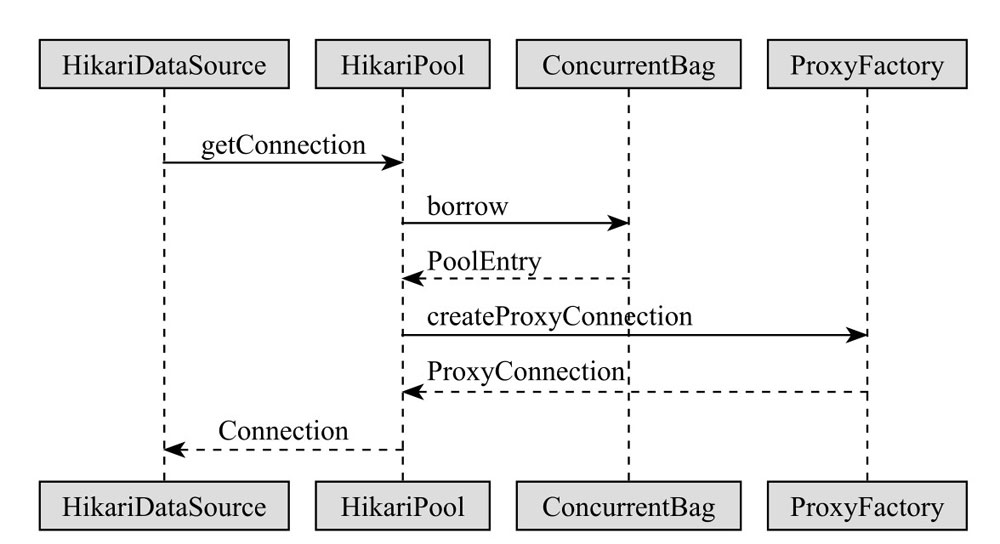
HikariDataSource,顾名思义,就是 HikariCP 对外提供给用户的定制化的 DataSource,使用 Spring 的用户可以直接将它作为数据源。用户也可以直接初始化 HikariDataSource:
HikariDataSource ds = new HikariDataSource();
ds.setJdbcUrl("jdbc:mysql://localhost:3306/simpsons");
ds.setUsername("bart");
ds.setPassword("51mp50n");
HikariDataSource 继承了 HikariConfig,并且实现了 JDCB 基础中介绍过的 javax.sql 扩展包中的 DataSource 接口。作为 DriverManager 设施的替代项,DataSource 对象是获取连接的首选方法,实现 DataSource 接口的对象通常在基于 JavaTM Naming and Directory Interface (JNDI) API 的命名服务中注册。
HikariConfig 是 HikariCP 的配置管理核心类,它实现了 HikariConfigMXBean 接口,用来对外暴露 HikariCP 配置相关的 JMX 监控和管理功能。
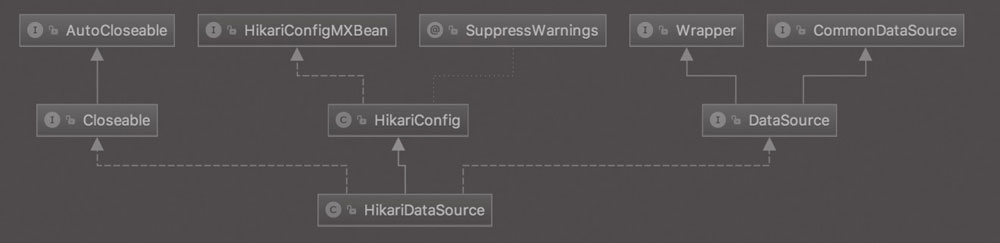
在创建连接的过程中,有几个细节性的问题可以从源码级重点关注一下。
细节:单例池初始化
HikariDataSource 获取连接 getConnection 的单例处理。大家都知道,在实现单例模式时,如果未考虑多线程的情况,很可能会造成实例化了多次并且被不同对象持有。在 JDK1.5 或者更晚的版本中,扩展了 volatile 的语义,使用了 volatile 关键字后,重排序被禁止,双重检查锁可以减少开销。如果没有 volatile 关键字则可能由于指令重排导致 HikariPool 对象 pool 在多线程下无法正确地初始化,volatile 禁止了指令重排,并强制本地线程读取主存。由于数据库连接池处于一个激烈的被频繁调用的位置,HikariCP 的源码部分就使用双重检查锁进行单例初始化。以下是 HikariDataSource 中的部分源码代码:
private final HikariPool fastPathPool;
private volatile HikariPool pool; //注意这里引入了volatile
public Connection getConnection() throws SQLException {
if (isClosed()) //检查数据源是否已经关闭,如果关闭则抛出异常
{ throw new SQLException("HikariDataSource " + this + " has been
closed."); }
if (fastPathPool ! = null) {//如果当前引用HikariPool不为空,则直接返回连接
return fastPathPool.getConnection();
}
HikariPool result = pool;
if (result == null) {//典型的双重检验锁代码
synchronized (this) {
result = pool;
if (result == null) {
validate(); //参数校验,主要是检查参数是否合法并给予默认值
try {
pool = result = new HikariPool(this); //初始化连接池
this.seal();
}
catch (PoolInitializationException pie) {
if (pie.getCause() instanceof SQLException) {
throw (SQLException) pie.getCause();
}
else {
throw pie;
}
}
LOGGER.info("{} - Start completed.", getPoolName());
}
}
}
//从连接池中返回一个连接,返回给HikariPool资源池与ConcurrentBag进行交互
return result.getConnection();
}
细节:连接有效性
另一个细节是获取连接时的有效性检查。当从资源池里面获取到资源后,需要检查该资源的有效性,如果失效,则再次获取连接,这样可以避免执行业务的时候报错。这部分的工作是由 HikariPool 做的,它通过判断 PoolEntry 是否已经被标记清除了、当前 PoolEntry 的存活时间是否过期及当前连接是否活着 3 项进行判断,如果超时则关闭这个 PoolEntry 的连接、重置超时时间、再次获取连接。这部分的核心实现在 HikariPool 的 getConnection 方法里,如下所示:
try {
long timeout = hardTimeout;
do {//从connectionBag中借用连接,借用过程中会发生创建连接、连接过期、空闲等事情
PoolEntry poolEntry = connectionBag.borrow(timeout, MILLISECONDS);
if (poolEntry == null) {
break; //中断,跳出循环,并抛出异常
}
final long now = currentTime(); //记录当前时间
if (poolEntry.isMarkedEvicted() || (elapsedMillis(poolEntry.lastAccessed, now) > aliveBypassWindowMs && ! isConnectionAlive(poolEntry.connection))) {//有效性检查
closeConnection(poolEntry, poolEntry.isMarkedEvicted() ? EVICTED_ CONNECTION_MESSAGE : DEAD_CONNECTION_MESSAGE); //关闭当前失效连接
timeout = hardTimeout - elapsedMillis(startTime); //重置超时时间
}
else {
//借用的连接若未过期未丢弃进入此逻辑,则设置metrics监控指标
metricsTracker.recordBorrowTimeoutStats(startTime);
//最核心部分,通过代理创建连接
return poolEntry.createProxyConnection(leakTaskFactory.schedule(poolEntry), now);
}
} while (timeout > 0L); //只要超时时间大于0则不断重试
throw createTimeoutException(startTime); //抛出创建连接超时异常
}
在上述代码中,有效性检查的部分是 isConnectionAlive,在这里用户可以自行配置心跳语句的检测,如果追求极致性能,那么使用 JDBC4 的用户还是强烈建议不要配置心跳语句,而是采用 HikariCP 默认的 com.mysql.jdbc. JDBC4Connection 的 isValid 实现,因为它的实现是 ping 命令,一般来说原生 ping 命令的性能是 select 1 的两倍。刚才我们看到的 HikariPool 的 getConnection 方法,其心跳语句检测的 isConnectionAlive 是在其父类中实现的,核心代码如下:
boolean isConnectionAlive(final Connection connection)
{
try {
try {
setNetworkTimeout(connection, validationTimeout);
final int validationSeconds = (int) Math.max(1000L, validationTimeout) / 1000;
if (isUseJdbc4Validation) {//如果是JDBC4,则直接使用ping命令进行验证
return connection.isValid(validationSeconds); //性能可以大大提升
}
try (Statement statement = connection.createStatement()) {
if (isNetworkTimeoutSupported ! = TRUE) {
setQueryTimeout(statement, validationSeconds);
}
statement.execute(config.getConnectionTestQuery()); //否则执行测试语句验证
}
}
finally {
setNetworkTimeout(connection, networkTimeout);
if (isIsolateInternalQueries && ! isAutoCommit) {
connection.rollback();
}
}
return true;
}
catch (Exception e) {
lastConnectionFailure.set(e);
logger.warn("{} - Failed to validate connection {} ({}). Possiblyconsider using a shorter maxLifetime value.",
poolName, connection, e.getMessage());
return false;
}
}
上述代码中有一个 validationTimeout 属性,默认值是 5000 毫秒,所以默认情况下 final int validationSeconds = (int)Math.max(1000L, validationTimeout) / 1000 它的值应该为 1~5 秒。又由于 validationTimeout 的值必须小于 connectionTimeout(默认值30000毫秒,如果小于250毫秒,则被重置回30秒),所以默认情况下,调整 validationTimeout 却不调整 connectionTimeou t情况下,validationSeconds 的默认峰值应该是 30 毫秒。
如果是 JDBC4 的话,使用 isUseJdbc4Validation(就是 config.getConnectionTestQuery()== null 的时候),用 connection.isValid(validationSeconds) 来验证连接的有效性,否则的话则用 connectionTestQuery 查询语句来查询验证。
细节:创建形式
第 3 个细节就是连接的创建。连接的创建可以同步创建,也可以异步创建,这与 HikariCP 的配置息息相关,这也是 HikariCP 作者别具匠心的设计之处。
过程总结
- 实现了 JDBC 扩展包 javax.sql 的 DataSource 接口的 HikariDataSource,执行 getConnection 方法时会进行 Double-checked_locking 单例、配置检查等流程,再向 HikariPool 资源池请求获取连接。
- HikariPool 则向其 lock-free 的资源集合 ConcurrentBag 借用 PoolEntry,若没有 poolEntry 则超时抛出异常,若有 poolEntry 则创建一个 JDBC 代理连接 ProxyConnection。
- ProxyConnection 是由 ProxyFactory 产生的,它是一个生产标准 JDBC 接口代理的工厂类,HikariDataSource 最终获取的 Connection 连接就是代理工厂返回的 JDBC 物理连接,而 poolEntry 就是对这个物理连接的一对一封装。
连接有效性
Java.sql.Connection 的 isValid() 和 isClosed() 区别:
- isValid:如果连接尚未关闭并且仍然有效,则返回true。驱动程序将提交一个关于该连接的查询,或者使用其他某种能确切验证在调用此方法时连接是否仍然有效的机制。由驱动程序提交的用来验证该连接的查询将在当前事务的上下文中执行。
- 参数:timeout。等待用来验证连接是否完成的数据库操作的时间,以秒为单位。如果在操作完成之前超时期满,则此方法返回 false。0值表示不对数据库操作应用超时值。
- 返回:如果连接有效,则返回 true,否则返回 false。
- isClosed:查询此 Connection 对象是否已经被关闭。如果在连接上调用了 close 方法或者发生某些严重的错误,则连接被关闭。只有在调用了 Connection.close 方法之后被调用时,此方法才保证返回 true。通常不能调用此方法确定到数据库的连接是有效的还是无效的。通过捕获在试图进行某一操作时可能抛出的异常,典型的客户端可以确定某一连接是无效的。
- 返回:如果此 Connection 对象是关闭的,则返回 true;如果它仍然处于打开状态,则返回 false。
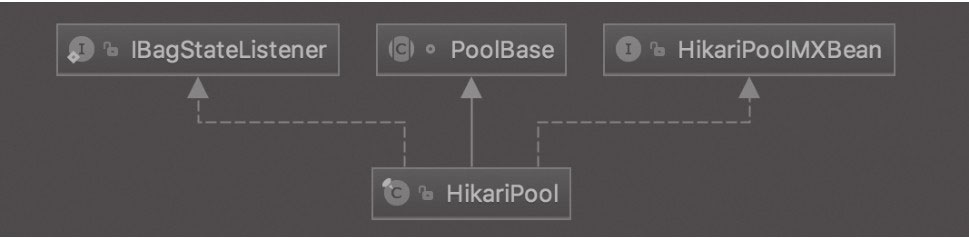
连接监控
HikariPool 继承了 PoolBase,实现了 HikariPoolMXBean 接口用于对外暴露 HikariCP 连接池相关的监控管理功能:
归还连接
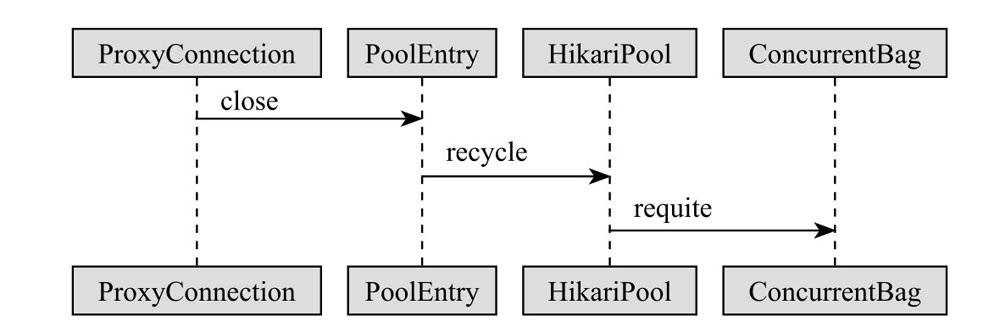
连接的归还和连接的借用是两个大致相反的过程,归还部分的源码如下所示:
public final void close() throws SQLException
{
closeStatements(); //由于关闭语句可能导致连接被驱逐,所以优先执行
if (delegate ! = ClosedConnection.CLOSED_CONNECTION) {
leakTask.cancel();
try {
if (isCommitStateDirty && ! isAutoCommit) {
delegate.rollback(); //如果存在脏提交或者没有自动提交,则连接回滚
lastAccess = currentTime();
LOGGER.debug("{} - Executed rollback on connection {} due to dirty commit state on close().", poolEntry.getPoolName(), delegate);
}
if (dirtyBits ! = 0) {
poolEntry.resetConnectionState(this, dirtyBits);
lastAccess = currentTime();
}
delegate.clearWarnings();
}
catch (SQLException e) {
//当连接中止时,通常会抛出不适用于应用程序的异常
if (! poolEntry.isMarkedEvicted()) {
throw checkException(e);
}
}
finally {//这里开始调用PoolEntry的recycle方法
delegate = ClosedConnection.CLOSED_CONNECTION;
poolEntry.recycle(lastAccess);
}
}
}
在 ProxyConnection 代理层获取到的连接,进行归还时调用了代理层的 close 方法。HikariCP 归还连接是一系列没有返回值的 void 操作,ProxyConnection 的 close 方法并没有直接调用 JDBC 的 close 方法,而是依次调用了 PoolEnry 的 recycle 方法、HikariPool 的 recycle 方法及 ConcurrentBag 的 requite 方法,这一系列方法传递的参数都是 PoolEntry。
数据库连接池 HikariCP 的 close 方法返回的连接其实是封装在这个 ProxyConnection 代理连接中的,当调用它的时候,它只返回与池的连接,但是依然保持与数据库的基础连接是打开的。数据库连接池通常都是以这种方式工作的,数据库连接池的性能优势就是来自于连接保持打开,通过代理连接,对用户来说是透明的。如果需要关闭这个连接,可以将它先转换为 ProxyConnection,然后调用它的 unwrap 方法,最后关闭这个内部连接。
public final <T> T unwrap(Class<T> iface) throws SQLException{
//ProxyConnection内部提供的unwrap方法
if (iface.isInstance(delegate)) {
return (T) delegate;
} else if (delegate ! = null) {
return delegate.unwrap(iface);
}
throw new SQLException("Wrapped connection is not an instance of " + iface);
}
unwrap 是一个很有意思的工具,如果你想跳过代理获取数据库的源信息,那么还可以直接使用 JDBC 的 unwrap 的 API 来获取(这里不是 ProxyConnection 的 unwrap )。如下所示:
((ConnectionProperties) connection.unwrap(ConnectionProperties.class))
.setNullCatalogMeansCurrent(false);
在归还连接的代码中,也存在很多细节。比如代理层的 close 方法第 1 行就这么讲究:
closeStatements(); //由于关闭语句可能导致连接被驱逐,所以优先执行
本书前面章节介绍的 HikariCP 诞生的理由——很多数据库连接池违反了 JDBC 规范。当 Connection 连接 close 或者 return 时,清除警告或回滚未提交的事务时,一些数据库连接池并不会自动关闭语句 Statement,并且它们也不会重置用户更改过的属性,如自动提交或事务隔离级别等,从而导致下一个消费者获得“脏”连接。
JDBC 最佳实践中有一条就是最顺序关闭 ResultSet、Statement、Connection。因此,在 HikariCP 中,ProxyConnection 的源码中,它的 close 方法覆盖了 java.sql.Connection 的方法,覆盖 JDBC 的 close 方法时,第一件事就是关闭了 Statement 语句。
private synchronized void closeStatements(){
final int size = openStatements.size();
if (size > 0) {
for (int i = 0; i < size && delegate ! = ClosedConnection.CLOSED_CONNECTION; i++){
try (Statement ignored = openStatements.get(i)) {
//自动资源清理
}
catch (SQLException e) {
LOGGER.warn("{} - Connection {} marked as broken because of an exception closing open statements during Connection.close()",poolEntry.getPoolName(), delegate);
leakTask.cancel();
poolEntry.evict("(exception closing Statements during Connection.close())");
delegate = ClosedConnection.CLOSED_CONNECTION;
}
}
openStatements.clear();
}
}
在上述 closeStatements 的具体方法实现里,在执行 clear 之前,将所有不是关闭状态的 Statement 都遍历了一遍,进行了资源的自动清理,对于遇到异常的连接,PoolEntry 对象标记具体问题原因是关闭 Statement 时产生的,并将连接设置为关闭状态。
从 ProxyConnection 覆盖 JDBC 的 close 方法,一步步调用到了 ConcurrentBag 的 requite 方法放回,就像后者方法前的注释说的那样:“有借必有还。如果你只借不还,那么就会导致内存泄漏。”
结合连接时序图和归还连接时序图我们可以发现,PoolEntry 对象通过 borrow 方法从 ConcurrentBag 中取出,再通过 requite 方法被放回,有借有还。当线程调用 getConnection 的时候,会调用 ConcurrentBag 的 borrow 方法,它将首先尝试从该线程的 ThreadLocal 最近使用的连接列表中获取未使用的连接。
当关闭连接时,又会通过 remove 方法删除 PoolEntry。ConcurrentBag 就是 HikariCP 的数据库连接存储结构,它在 HikariCP 中起着举足轻重的作用,其性能直接决定 HikariCP 的整体性能。
关闭连接
在可以热部署的 Web 应用程序中,关闭 DataSource 非常重要。通常可以调用 HikariDataSource 实例的 shutdown 或者 close 方法,也可以配置 Spring 或其他 IOC 容器来指定 destroy 方法。一旦 Connection 进入关闭连接阶段,它立即从池中被移除,但是仍然和数据库 DB 有活动连接,直到 Connection.close 完成。HikariCP 永远不会杀死正在使用的连接,除非池本身被关闭。
关闭分为 HikariDataSouce 和 HikariPool 两种关闭,这两者截然不同。
HikariDatasource 作为 HikariCP 对外对使用方提供的 DataSource,它的 close 方法是粗暴的 shutdown 操作。其 close 方法就是直接关闭数据源及其连接池,源码如下所示:
public void close(){
if (isShutdown.getAndSet(true)) {
return;
}
HikariPool p = pool;
if (p ! = null) {
try {
LOGGER.info("{} - Shutdown initiated...", getPoolName());
p.shutdown();
LOGGER.info("{} - Shutdown completed.", getPoolName());
}
catch (InterruptedException e) {
LOGGER.warn("{} - Interrupted during closing", getPoolName(), e);
Thread.currentThread().interrupt();
}
}
}
HikariDataSouce 的 close 直接调用了 HikariPool 的 shutdown 操作,其具体实现在 HikariPool 的 shutdown 方法里,不但关闭连接池,还关闭了所有空闲连接,中止或关闭活动连接。此外,它还会进行直接取消定时任务、关闭 ConcurrentBag 等一系列清理工作,可以认为就是一个 shutdown 的强硬操作。HikariPool 的 shutdown 源码如下所示:
public synchronized void shutdown() throws InterruptedException {
try {
poolState = POOL_SHUTDOWN;
if (addConnectionExecutor == null) { //如果连接池从未启动
return;
}
logPoolState("Before shutdown ");
if (houseKeeperTask ! = null) {//关闭houseKeeper的任务
houseKeeperTask.cancel(false);
houseKeeperTask = null;
}
softEvictConnections(); //软驱逐连接
addConnectionExecutor.shutdown(); //关闭增加连接线程池
addConnectionExecutor.awaitTermination(getLoginTimeout(), SECONDS);
destroyHouseKeepingExecutorService();
connectionBag.close(); //关闭connectionBag
final ExecutorService assassinExecutor = createThreadPoolExecutor(
config.getMaximumPoolSize(),
poolName + " connection assassinator",
config.getThreadFactory(),
new ThreadPoolExecutor.CallerRunsPolicy());
try {
final long start = currentTime();
do {
abortActiveConnections(assassinExecutor);
softEvictConnections();
} while (getTotalConnections() > 0 && elapsedMillis(start) < SECONDS.toMillis(10));
}
finally {
assassinExecutor.shutdown();
assassinExecutor.awaitTermination(10L, SECONDS);
}
shutdownNetworkTimeoutExecutor();
closeConnectionExecutor.shutdown();
closeConnectionExecutor.awaitTermination(10L, SECONDS);
}
finally {
logPoolState("After shutdown ");
handleMBeans(this, false);
metricsTracker.close();
}
}
与 HikariDataSource 对外提供的 close 接口不同,HikariPool 提供的内部 closeConnection 方法才是我们通常意义上理解的数据库连接池内部的连接关闭逻辑。
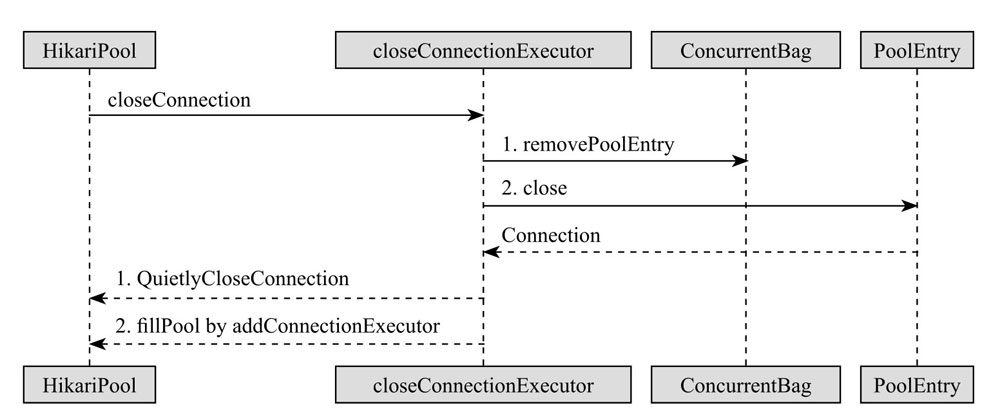
当 HikariPool 执行 closeConnection 方法时,首先先从 ConcurrentBag 中移除 PoolEntry,然后 PoolEntry 自身 close,接着独立线程池 closeConnectionExecutor(本质是ThreadPoolExecutor) 调用 JDBC 的方法进行物理连接的关闭。如果 poolState 的状态为 0,还会使用另一个独立线程池 addConnectionExecutor(与 closeConnectionExecutor 对称,本质上也是 ThreadPoolExecutor)进行新连接的生成,fillPool 补足到 HikariCP 的配置值。其核心源码如下所示:
void closeConnection(final PoolEntry poolEntry, final String closureReason)
{
if (connectionBag.remove(poolEntry)) {//ConcurrentBag移除poolEntry
final Connection connection = poolEntry.close(); //poolEntry关闭
closeConnectionExecutor.execute(() -> {
quietlyCloseConnection(connection, closureReason); //jdbc关闭连接
if (poolState == POOL_NORMAL) {
fillPool(); //填充连接池
}
});
}
}
我们可以看到 HikariCP 使用了线程池 closeConnectionExecutor 进行了物理连接的关闭。其实在 HikariCP 的源码里,closeConnectionExecutor 还有一个孪生兄弟 addConnectionExecutor,在 com.zaxxer.hikari.pool.HikariPool 的源码中构造函数初始化的时候就可以看到 public HikariPool(final HikariConfigconfig)。
private final ThreadPoolExecutor addConnectionExecutor;
private final ThreadPoolExecutor closeConnectionExecutor;
//......
LinkedBlockingQueue<Runnable> addQueue =
new LinkedBlockingQueue<>(config.getMaximumPoolSize()
);
this.addConnectionQueue = unmodifiableCollection(addQueue);
this.addConnectionExecutor = createThreadPoolExecutor(
addQueue,
poolName + "connection adder",
threadFactory,
new ThreadPoolExecutor.DiscardPolicy()
);
this.closeConnectionExecutor = createThreadPoolExecutor(
config.getMaximumPoolSize(),
poolName + " connection closer",
threadFactory, newThreadPoolExecutor.CallerRunsPolicy()
);
addConnectionExecutor 和 closeConnectionExecuto r的初始化就是命中了Java 5 种线程池、4 种拒绝策略、3 种阻塞队列的知识点。addConnectionExecutor 用于创建物理连接,它使用了 DiscardPolicy 策略,默认情况下它就是丢弃被拒绝的任务,实际上就是任务满了就不会抛出异常;而 closeConnectionExecutor 用了 CallerRunsPolicy 策略,如果添加到线程池失败,主线程会直接在 execute 方法的调用线程中运行被拒绝的任务,若执行程序已关闭,则会丢弃该任务。
使用 HikariCP 的用户可能经常会看到类似 connection isevicted or dead 这样的异常,其实这是合理的,关闭死连接对于连接池的资源清理至关重要。
HikariCP 关闭连接的 5 种情况:
- 连接验证失败。这对应用程序是不可见的。连接已停用并已替换。用户会看到一条日志消息:“Failed tovalidate connection…”。
- 连接达到了其 maxLifetime。这对应用程序是不可见的。连接已停用并已替换。用户会看到一个关闭原因:“connection has passed maxLifetime”,或者如果在到达时 maxLifetime 正在使用该连接,用户会晚一点看到原因:“connection is evicted or dead”。
- 用户手动驱逐连接。这对应用程序是不可见的。连接已停用并已替换。用户会看到关闭的原因:“connectionevicted by user”。
- JDBC 调用引发了无法恢复的问题 SQLException。这应该对应用程序可见。用户会看到关闭的原因:“connection is broken”。
生成连接
独立的线程池 addConnectionExecutor 用于创建物理连接,它是在 HikariPool 的构造函数中被初始化的。HikariPool 中的 addConnectionExecutor 在 addBagItem() 和 fillPool() 的时候进行新的物理连接的创建。addBagItem 代表向我们之前介绍的 HikariCP 的数据结构 ConcurrentBag 中放置 Bag 项,它的源码实现其实是在 ConcurrentBag 的 borrrow 也就是连接的借用时执行的。核心代码如下所示:
try {
for (T bagEntry : sharedList) {
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
//如果我们已经窃取了另一个等待着的连接,那么请求会新增另一个bag
if (waiting > 1) {
listener.addBagItem(waiting -1);
}
return bagEntry;
}
}
listener.addBagItem(waiting);
在上述代码中,有两处分别执行了 listener.addBagItem(waiting-1) 和 listener.addBagItem(waiting),当有并发连接产生时,如果存在等待的连接或者连接已经不可用,则会进行物理连接的创建。
另一个 addConnectionExecutor 在 addBagItem() 来源于 HikariPool 的 fillPool 的方法,它是来源于 HikariPool 内部的单独线程 HouseKeeper,用来将当前的数据库连接池从当前的空闲连接填充到最小空闲连接的指标。
private synchronized void fillPool()
{
final int connectionsToAdd = Math.min(config.getMaximumPoolSize() -
getTotalConnections(), config.getMinimumIdle() - getIdleConnections())
- addConnectionQueue.size();
for (int i = 0; i < connectionsToAdd; i++) {
addConnectionExecutor.submit((i < connectionsToAdd -1) ?
poolEntryCreator : postFillPoolEntryCreator);
}
}
PoolEntry 是一个封装了物理连接的对象,在 HikariPool 中定义了两个 PoolEntry,分别代表我们刚才介绍的连接生成的两种场景(addBagItem 和 fillPool):
private final PoolEntryCreator poolEntryCreator = new PoolEntryCreator(null
/*logging prefix*/);
private final PoolEntryCreator postFillPoolEntryCreator = new PoolEntryCreator
("After adding ");
addConnectionExecutor 线程调用 HikariPool 的 createPoolEntry 方法进行连接生成,HikariPool 继承的父类 PoolBase 提供的 newPoolEntry 会先进行物理连接的创建,创建完成以后的连接会被封装为 PoolEntry 后放入ConcurrentBag。createPoolEntry 的源码如下所示:
private PoolEntry createPoolEntry()
{
try {
final PoolEntry poolEntry = newPoolEntry();
final long maxLifetime = config.getMaxLifetime();
if (maxLifetime > 0) {
// 设置maxlifetime的2.5%的差额
final long variance = maxLifetime > 10_000 ? ThreadLocalRandom.
current().nextLong( maxLifetime / 40 ) : 0; //随机数
final long lifetime = maxLifetime - variance;
poolEntry.setFutureEol(houseKeepingExecutorService.schedule(
() -> {//设置异步任务
if (softEvictConnection(poolEntry, "(connection has passed
maxLifetime)", false /* not owner */)) {
addBagItem(connectionBag.getWaitingThreadCount());
}
},
lifetime, MILLISECONDS));
}
return poolEntry;
}
catch (ConnectionSetupException e) {
if (poolState == POOL_NORMAL) {
//如果shutdown()同时运行,我们检查POOL_NORMAL以避免消息泛滥
logger.error("{} - Error thrown while acquiring connection from data
source", poolName, e.getCause());
lastConnectionFailure.set(e); //设置上一次连接失败的异常
}
return null;
}
HikariCP 的 maxLifetime 默认是 1800000毫秒(30分钟)。在上述代码中,有一段重要的随机数逻辑,这段代码主要就是根据 maxLifetime 的 2.5% 来设置一个差额,如下所示:
// 设置maxlifetime的2.5%的差额
final long variance = maxLifetime > 10_000 ? ThreadLocalRandom.current().
nextLong( maxLifetime / 40 ) : 0; //随机数
连接生成的时候让每个连接的最大存活时间错开一点,防止同时过期,加一点点随机因素,防止一件事情大量同时发生,比如防止 HikariCP 的连接同时大量死亡。如果 maxLifetime 大于 10000 就是大于 10 秒钟,就执行这个策略,用 maxLifetime 的 2.5% 的时间和 0 之间的随机数来随机设定一个 variance,在 maxLifetime - variance 之后触发 evict。比如,配置 maxLifetime 为 15 分钟时,HikariCP 为每个连接最大寿命注入了 2.5% 的变化,寿命为 15 分钟时,相当于 22.5 秒的变化。一些连接可能在 14 分 38 秒退休,其他连接可能在 14 分 53 秒退休等。
在创建 poolEntry 的时候,注册了一个延时任务,在连接存活将要到达 maxLifetime 之前触发 evit(标记连接池中的连接不可用),用来防止出现大面积连接因为 maxLifetim e是一样的而同时失效,从而造成 HikariCP 数据库连接池不稳定的情况。
在 HikariCP 的 3.3.1 版本中,修复了一个 issue 1287 “setcore pool size before max pool size”,这正是与我们介绍的连接生成 addConnectionExecutor 有关系的。提交这个 issue 的用户反馈:他在执行大量并发耗时查询(查询10~30秒)的时候,启动时的有尖峰请求,在尖峰需求完毕以前池中无空闲连接的情况下反应非常慢,获得新的连接是一个严重阻塞的过程。
根据这个用户的问题,HikariCP 3.3.1 版本在 HikariPool 的初始化过程中统一将 addConnectionExecutor.setMaximumPoolSize 挪到了 addConnectionExecutor.setCorePoolSize 的后面。其源码如下所示:
if (Boolean.getBoolean("com.zaxxer.hikari.blockUntilFilled") &&
config.getInitializationFailTimeout() > 1) { addConnectionExecutor.
setCorePoolSize(Runtime.getRuntime().availableProcessors()); addConnectionExecutor.
setMaximumPoolSize(Runtime.getRuntime().availableProcessors());
final long startTime = currentTime();
while (elapsedMillis(startTime) < config.getInitializationFailTimeout()
&& getTotalConnections() < config.getMinimumIdle()) {
quietlySleep(MILLISECONDS.toMillis(100));
}
addConnectionExecutor.setCorePoolSize(1);
addConnectionExecutor.setMaximumPoolSize(1);
}
com.zaxxer.hikari.blockUntilFilled 是 HikariCP 新版本的一个新功能,它是 HikariCP 官方文档没有提供的系统属性,它的作用是阻塞应用程序直到数据库连接池达到 minimumIdle 值的大小。这个行为在 HikariCP 旧版本期间是单线程的,所以就有可能出现初始化时大量并发连接的长慢查询容易导致 HikariCP 的 getConnection 方法产生阻塞;在 3.3.0 版本中可以进行调整,如果 com.zaxxer.hikari.blockUntilFilled 的属性为 true,并且 initializationFailTimeout 大于 1,则池将由多个线程填充。这线程数由 Runtime.getRuntime().availableProcessors() 确定。初始化后,线程数会在池的生命周期内下降回 1。
那么为什么又要将 setMaximumPoolSize 挪到 setCorePoolSize 后面呢?因为这里有一个 Bug,根据 ThreadPoolExecutor 文档,需要在设置最大池大小之前设置核心池大小,因为在将最大池大小设置为低于核心池大小的值时会抛出 IllegalArgumentException。而这个修复是在 HikariCP 3.3.1 版本中调整的。
setMaximumPoolSize 文档:
public void setMaximumPoolSize(int maximumPoolSize)
Sets the maximum allowed number of threads. This overrides any value set in
the constructor. If the new value is smaller than the current value, excess existing
threads will be terminated when they next become idle.
Parameters:
maximumPoolSize - the new maximum
Throws:
IllegalArgumentException - if the new maximum is less than or equal to zero,
or less than the core pool size
See Also:
getMaximumPoolSize()
7 - 参数解析
Working in Progress
8 - 动态代理
Working in Progress
9 - 应用实践
Working in Progress
10 - 监控度量
Working in Progress
11 - 常见问题
Working in Progress
12 - 扩展技术
Working in Progress