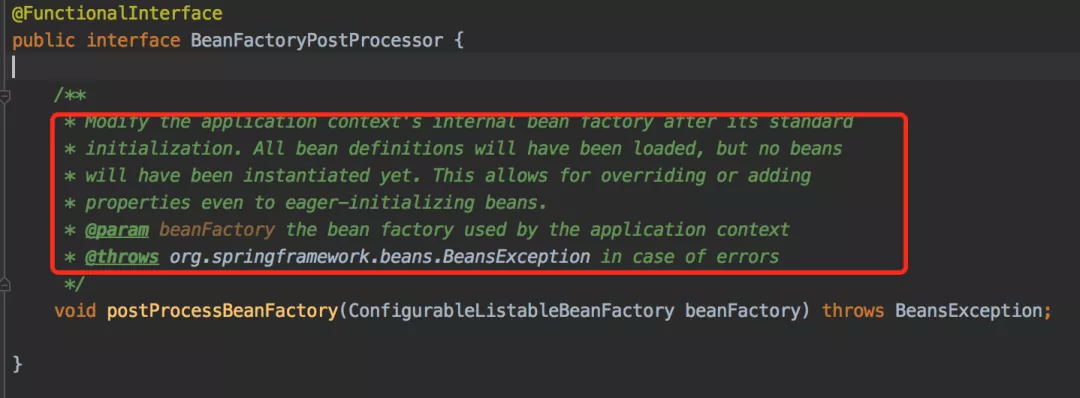
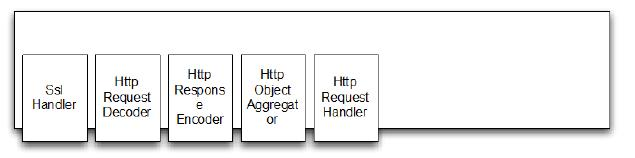
框架库
Awesome toolkits!!!
Life is too short to depend on unstable software! __Read more…
Utils
Files
Functional
- linq: LINQ to Objects for Java.
- immutables: Annotation processor to create immutable objects and builders.
Reflection
- Moo: Mapping Objects to Objects.
Concurrent
Database
- objectbox: Superfast lightweight database for objects.
ORM
SQL Parser
Distributed
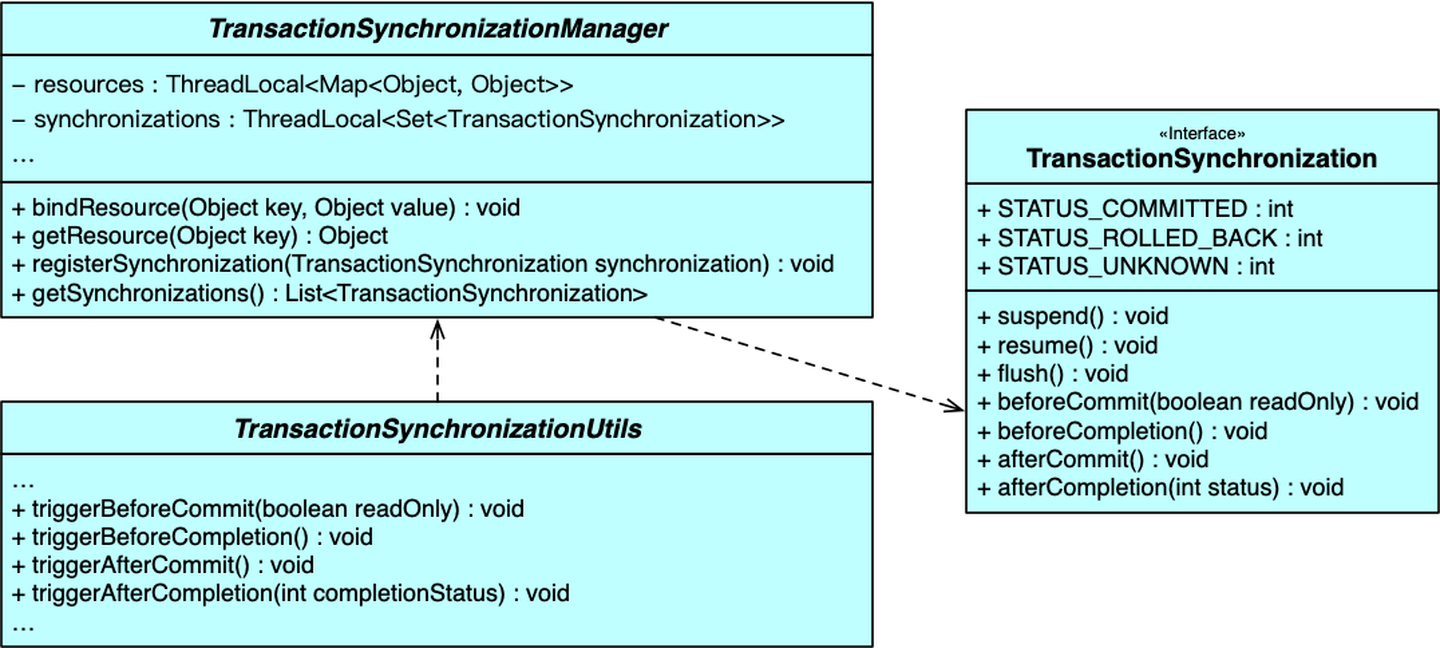
1 - Spring
1.1 - CH01-IOC
IOC 是什么
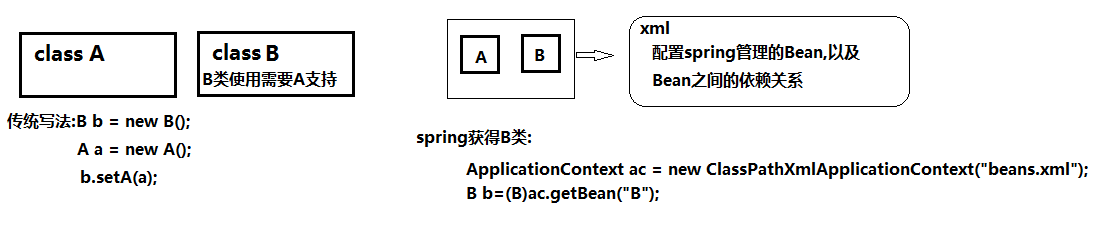
**IoC,是 Inversion of Control 的缩写,即控制反转。*他还有一个别名叫*依赖注入(Dependency Injection)有些资料也称依赖注入是IOC的一种常见方式。
IoC 不是什么技术,而是一种设计思想。在 Java 开发中,IoC 意味着将你设计好的对象交给容器控制,而不是传统的在你的对象内部直接控制。如何理解 Ioc 呢?理解 Ioc 的关键是要明确“谁控制谁,控制什么,为何是反转(有反转就应该有正转了),哪些方面反转了”,那我们来深入分析一下:
- **谁控制谁,控制什么:**传统 JavaSE 程序设计,我们直接在对象内部通过 new 进行创建对象,是程序主动去创建依赖对象;而 IoC 是有专门一个容器来创建这些对象,即由 IoC 容器来控制对象的创建;谁控制谁?当然是 IoC 容器控制了对象;控制什么?那就是主要控制了外部资源获取(不只是对象包括比如文件等)。
- **为何是反转,哪些方面反转了:**有反转就有正转,传统应用程序是由我们自己在对象中主动控制去直接获取依赖对象,也就是正转;而反转则是由容器来帮忙创建及注入依赖对象;为何是反转?因为由容器帮我们查找及注入依赖对象,对象只是被动的接受依赖对象,所以是反转;哪些方面反转了?依赖对象的获取方式被反转了。
IOC 能做什么
IoC 不是一种技术,只是一种思想,一个重要的面向对象编程的法则,它能指导我们如何设计出松耦合、更优良的程序。传统应用程序都是由我们在类内部主动创建依赖对象,从而导致类与类之间高耦合,难于测试;有了 IoC 容器后,把创建和查找依赖对象的控制权交给了容器,由容器进行注入组合对象,所以对象与对象之间是松散耦合,这样也方便测试,利于功能复用,更重要的是使得程序的整个体系结构变得非常灵活。
其实 IoC 对编程带来的最大改变不是从代码上,而是从思想上,发生了“主从换位”的变化。应用程序原本是老大,要获取什么资源都是主动出击,但是在 IoC/DI 思想中,应用程序就变成被动的了,被动的等待 IoC 容器来创建并注入它所需要的资源了。
IoC 很好的体现了面向对象设计法则之一—— 好莱坞法则:“Don’t call us,we will call you”;即由 IoC 容器帮对象找相应的依赖对象并注入,而不是由对象主动去找。
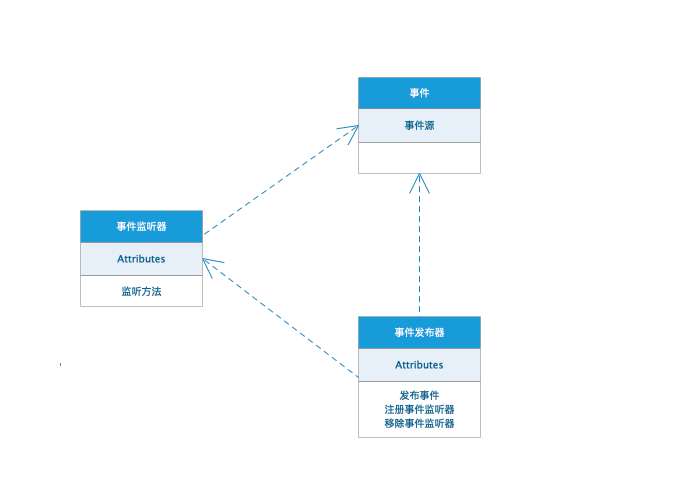
依赖注入
DI,是 Dependency Injection 的缩写,即依赖注入。依赖注入是 IoC 的最常见形式。
容器全权负责的组件的装配,它会把符合依赖关系的对象通过 JavaBean 属性或者构造函数传递给需要的对象。
DI 是组件之间依赖关系由容器在运行期决定,形象的说,即由容器动态的将某个依赖关系注入到组件之中。依赖注入的目的并非为软件系统带来更多功能,而是为了提升组件重用的频率,并为系统搭建一个灵活、可扩展的平台。通过依赖注入机制,我们只需要通过简单的配置,而无需任何代码就可指定目标需要的资源,完成自身的业务逻辑,而不需要关心具体的资源来自何处,由谁实现。
理解 DI 的关键是:“谁依赖谁,为什么需要依赖,谁注入谁,注入了什么”,那我们来深入分析一下:
- **谁依赖于谁:**当然是应用程序依赖于 IoC 容器;
- **为什么需要依赖:**应用程序需要 IoC 容器来提供对象需要的外部资源;
- **谁注入谁:**很明显是 IoC 容器注入应用程序某个对象,应用程序依赖的对象;
- 注入了什么:就是注入某个对象所需要的外部资源(包括对象、资源、常量数据)。
IOC 与 DI
其实它们是同一个概念的不同角度描述,由于控制反转概念比较含糊(可能只是理解为容器控制对象这一个层面,很难让人想到谁来维护对象关系),所以 2004 年大师级人物 Martin Fowler 又给出了一个新的名字:“依赖注入”,相对 IoC 而言,“依赖注入”明确描述了“被注入对象依赖 IoC 容器配置依赖对象”。
Martin Fowler—Inversion of Control Containers and the Dependency Injection pattern
IOC 容器
IoC 容器就是具有依赖注入功能的容器。IoC 容器负责实例化、定位、配置应用程序中的对象及建立这些对象间的依赖。应用程序无需直接在代码中 new 相关的对象,应用程序由 IoC 容器进行组装。在 Spring 中 BeanFactory 是 IoC 容器的实际代表者。
Spring IoC 容器如何知道哪些是它管理的对象呢?这就需要配置文件,Spring IoC 容器通过读取配置文件中的配置元数据,通过元数据对应用中的各个对象进行实例化及装配。一般使用基于 xml 配置文件进行配置元数据,而且 Spring 与配置文件完全解耦的,可以使用其他任何可能的方式进行配置元数据,比如注解、基于 java 文件的、基于属性文件的配置都可以
那 Spring IoC 容器管理的对象叫什么呢?
Bean
JavaBean 是一种JAVA语言写成的可重用组件。为写成JavaBean,类必须是具体的和公共的,并且具有无参数的构造器。JavaBean 通过提供符合一致性设计模式的公共方法(getter / setter 方法)将内部域暴露成员属性。众所周知,属性名称符合这种模式,其他Java 类可以通过自省机制发现和操作这些JavaBean 的属性。
一个javaBean由三部分组成:属性、方法、事件
JavaBean的任务就是: “Write once, run anywhere, reuse everywhere”,即“一次性编写,任何地方执行,任何地方重用”。
由 IoC 容器管理的那些组成你应用程序的对象我们就叫它 Bean。Bean 就是由 Spring 容器初始化、装配及管理的对象,除此之外,bean 就与应用程序中的其他对象没有什么区别了。
IOC 容器
核心接口
org.springframework.beans 和 org.springframework.context 是 IoC 容器的基础。
在 Spring 中,有两种 IoC 容器:BeanFactory 和 ApplicationContext。
BeanFactory:Spring 实例化、配置和管理对象的最基本接口。ApplicationContext:BeanFactory 的子接口。它还扩展了其他一些接口,以支持更丰富的功能,如:国际化、访问资源、事件机制、更方便的支持 AOP、在 web 应用中指定应用层上下文等。
实际开发中,更推荐使用 ApplicationContext 作为 IoC 容器的操作入口,因为它的功能远多于 FactoryBean。
常见 ApplicationContext 实现:
- ClassPathXmlApplicationContext:
ApplicationContext 的实现,从 classpath 获取配置文件;new ClassPathXmlApplicationContext("classpath.xml");
- FileSystemXmlApplicationContext:
ApplicationContext 的实现,从文件系统获取配置文件。new FileSystemXmlApplicationContext("fileSystemConfig.xml");
应用流程
使用 IoC 容器可分为三步骤:
- 配置元数据:需要配置一些元数据来告诉 Spring,你希望容器如何工作,具体来说,就是如何去初始化、配置、管理 JavaBean 对象。
- 实例化容器:由 IoC 容器解析配置的元数据。IoC 容器的 Bean Reader 读取并解析配置文件,根据定义生成 BeanDefinition 配置元数据对象,IoC 容器根据 BeanDefinition 进行实例化、配置及组装 Bean。
- 使用容器:由客户端实例化容器,获取需要的 Bean。
配置元数据
元数据(Metadata) 又称中介数据、中继数据,为描述数据的数据(data about data),主要是描述数据属性(property)的信息。
配置元数据的方式:
基于 xml 配置:Spring 的传统配置方式。在 <beans> 标签中配置元数据内容。
缺点是当 JavaBean 过多时,产生的配置文件足以让你眼花缭乱。
基于注解配置:Spring2.5 引入。可以大大简化你的配置。
基于 Java 配置:可以使用 Java 类来定义 JavaBean 。
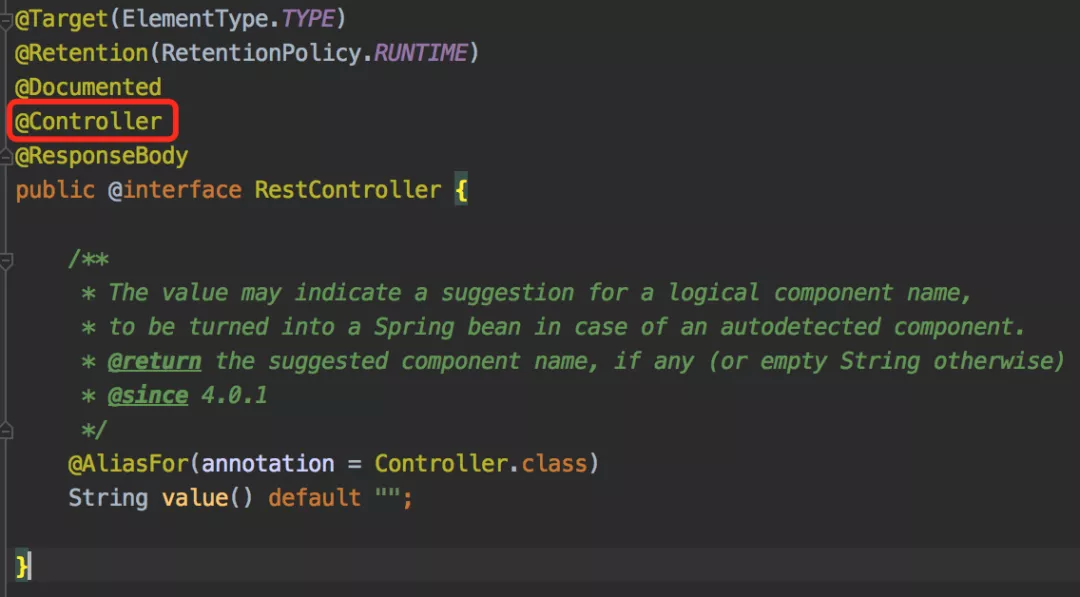
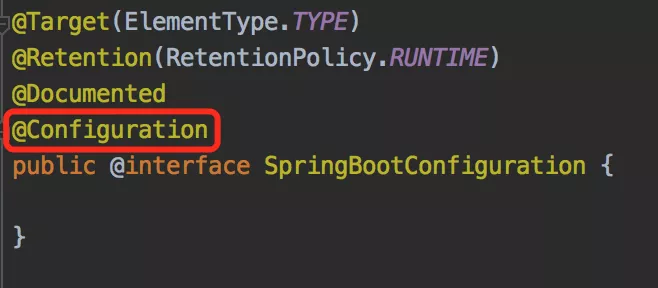
为了使用这个新特性,需要用到 @Configuration 、@Bean 、@Import 和 @DependsOn 注解。
Bean 概述
一个 Spring 容器管理一个或多个 bean。 这些 bean 根据你配置的元数据(比如 xml 形式)来创建。 Spring IoC 容器本身,并不能识别你配置的元数据。为此,要将这些配置信息转为 Spring 能识别的格式——BeanDefinition 对象。
命名 Bean
指定 id 和 name 属性不是必须的。 Spring 中,并非一定要指定 id 和 name 属性。实际上,Spring 会自动为其分配一个特殊名。 如果你需要引用声明的 bean,这时你才需要一个标识。官方推荐驼峰命名法来命名。
支持别名
可能存在这样的场景,不同系统中对于同一 bean 的命名方式不一样。 为了适配,Spring 支持 <alias> 为 bean 添加别名的功能。
<alias name="subsystemA-dataSource" alias="subsystemB-dataSource"/>
<alias name="subsystemA-dataSource" alias="myApp-dataSource" />
实例化 Bean
构造器方式
<bean id="exampleBean" class="examples.ExampleBean"/>
静态工厂方法
依赖
依赖注入 依赖注入有两种主要方式:
- 构造器注入
- Setter 注入 构造器注入有可能出现循环注入的错误。如:
class A {
public A(B b){}
}
class B {
public B(A a){}
}
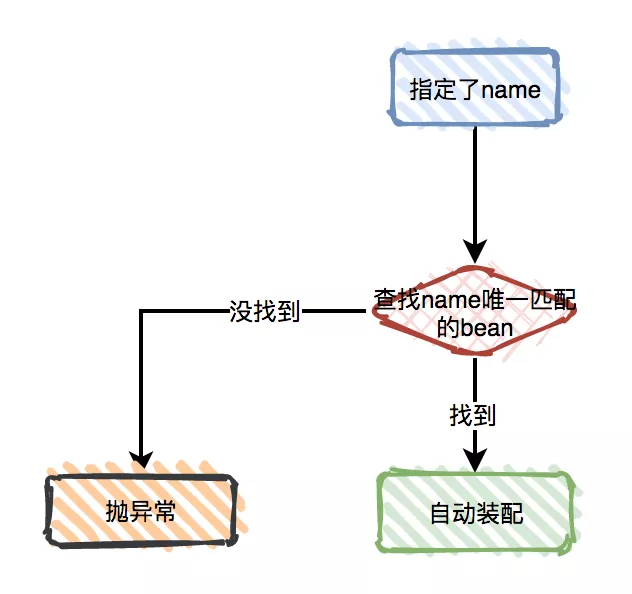
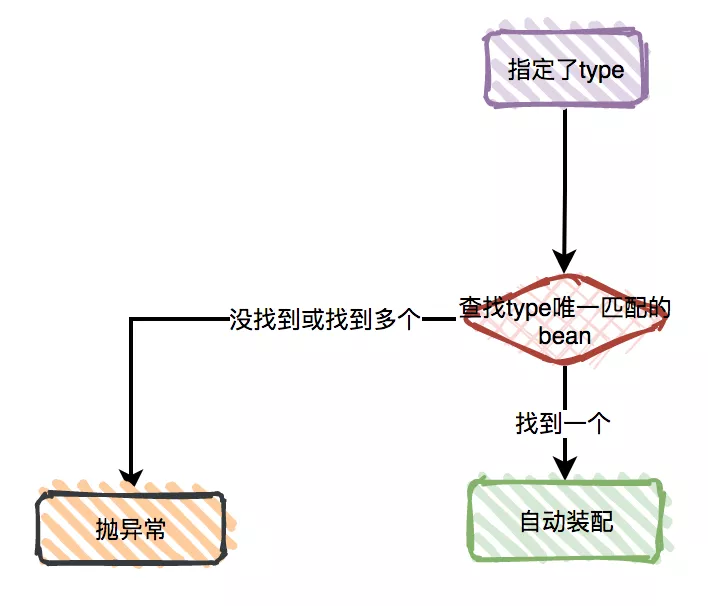
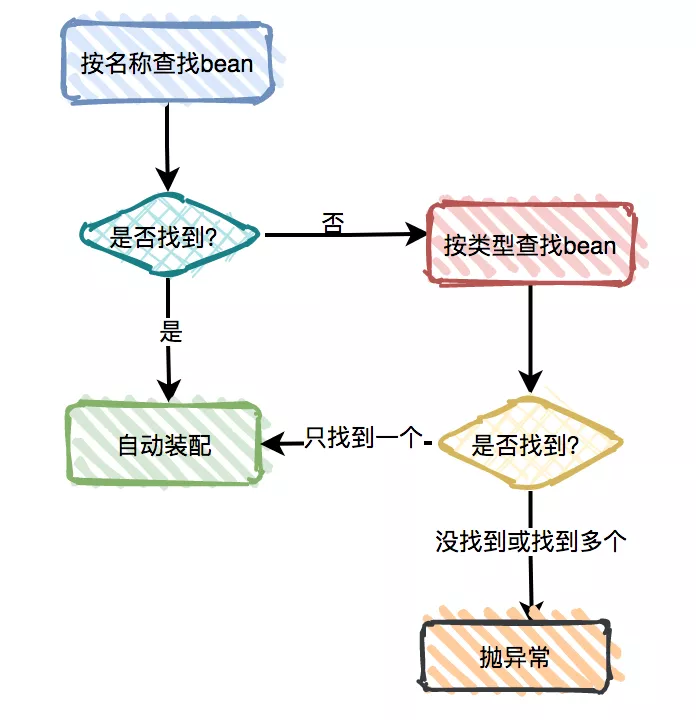
依赖和配置细节 使用 depends-on Lazy-initialized Bean 自动装配 方法注入�。
IoC 容器配置
IoC 容器的配置有三种方式:
- 基于 xml 配置
- 基于注解配置
- 基于 Java 配置
作为 Spring 传统的配置方式,xml 配置方式一般为大家所熟知。
如果厌倦了 xml 配置,Spring 也提供了注解配置方式或 Java 配置方式来简化配置。
Xml 配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<import resource="resource1.xml" />
<bean id="bean1" class=""></bean>
<bean id="bean2" class=""></bean>
<bean name="bean2" class=""></bean>
<alias alias="bean3" name="bean2"/>
<import resource="resource2.xml" />
</beans>
标签说明:
<beans> 是 Spring 配置文件的根节点。<bean> 用来定义一个 JavaBean。id 属性是它的标识,在文件中必须唯一;class 属性是它关联的类。<alias> 用来定义 Bean 的别名。<import> 用来导入其他配置文件的 Bean 定义。这是为了加载多个配置文件,当然也可以把这些配置文件构造为一个数组(new String[] {“config1.xml”, config2.xml})传给 ApplicationContext 实现类进行加载多个配置文件,那一个更适合由用户决定;这两种方式都是通过调用 Bean Definition Reader 读取 Bean 定义,内部实现没有任何区别。<import> 标签可以放在 <beans> 下的任何位置,没有顺序关系。
实例化容器
实例化容器的过程: 定位资源(XML 配置文件) 读取配置信息(Resource) 转化为 Spring 可识别的数据形式(BeanDefinition)
ApplicationContext context =
new ClassPathXmlApplicationContext(new String[] {"services.xml", "daos.xml"});
组合 xml 配置文件 配置的 Bean 功能各不相同,都放在一个 xml 文件中,不便管理。 Java 设计模式讲究职责单一原则。配置其实也是如此,功能不同的 JavaBean 应该被组织在不同的 xml 文件中。然后使用 import 标签把它们统一导入。
<import resource="classpath:spring/applicationContext.xml"/>
<import resource="/WEB-INF/spring/service.xml"/>
使用容器
使用容器的方式就是通过getBean获取 IoC 容器中的 JavaBean。 Spring 也有其他方法去获得 JavaBean,但是 Spring 并不推荐其他方式。
// create and configure beans
ApplicationContext context =
new ClassPathXmlApplicationContext(new String[] {"services.xml", "daos.xml"});
// retrieve configured instance
PetStoreService service = context.getBean("petStore", PetStoreService.class);
// use configured instance
List<String> userList = service.getUsernameList();
注解配置
Spring2.5 引入了注解。 优点:大大减少了配置,并且可以使配置更加精细——类,方法,字段都可以用注解去标记。 缺点:使用注解,不可避免产生了侵入式编程,也产生了一些问题。
- 你需要将注解加入你的源码并编译它;
- 注解往往比较分散,不易管控。
注:spring 中,先进行注解注入,然后才是 xml 注入,因此如果注入的目标相同,后者会覆盖前者。
启动注解
Spring 默认是不启用注解的。如果想使用注解,需要先在 xml 中启动注解。 启动方式:在 xml 中加入一个标签,很简单吧。
<context:annotation-config/>
注:<context:annotation-config/> 只会检索定义它的上下文。什么意思呢?就是说,如果你 为 DispatcherServlet 指定了一个WebApplicationContext,那么它只在 controller 中查找@Autowired注解,而不会检查其它的路径。
Spring 注解
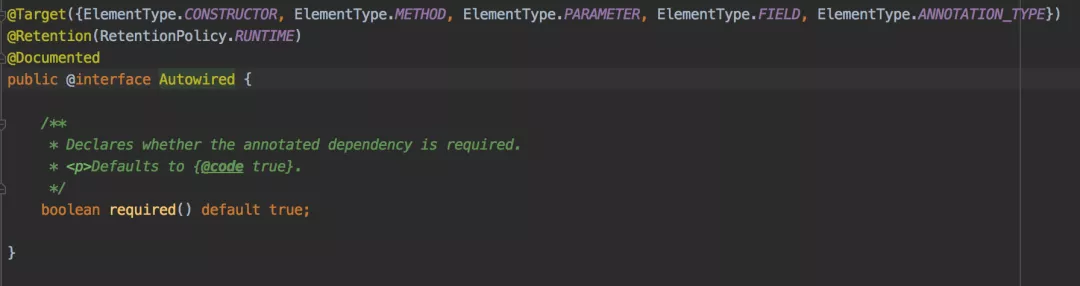
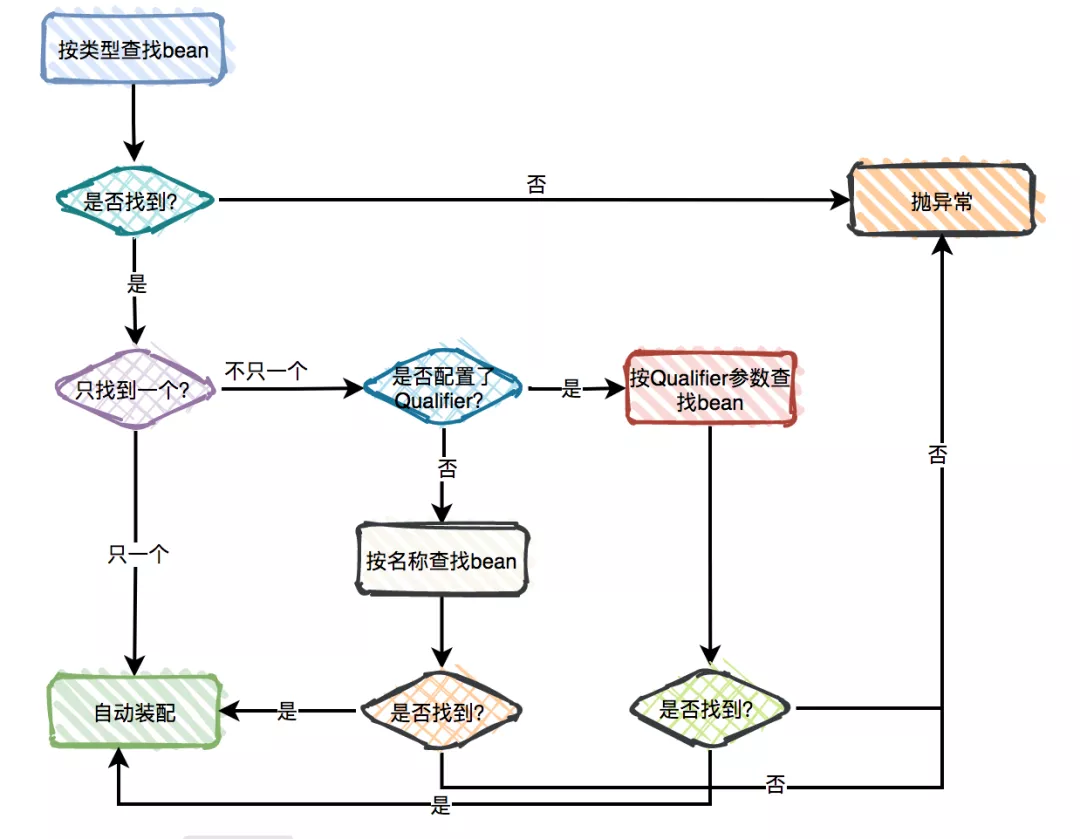
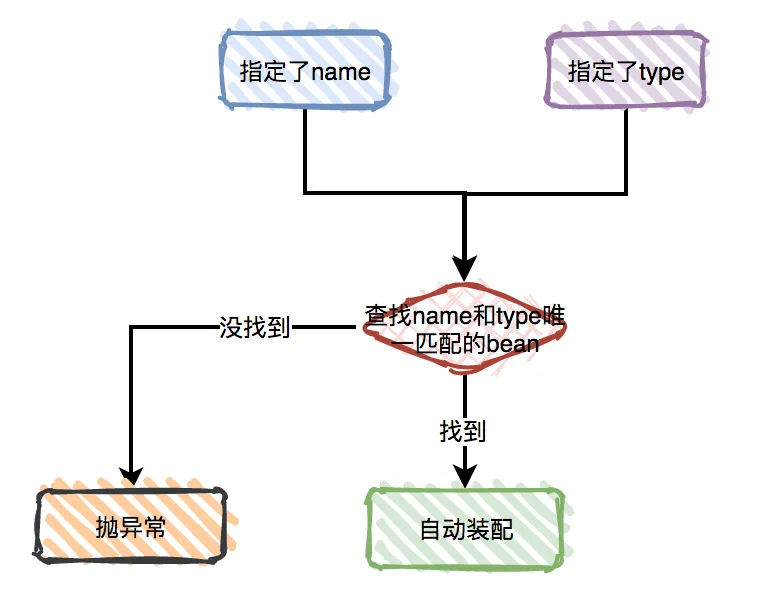
@Required:只能用于修饰 bean 属性的 setter 方法。受影响的 bean 属性必须在配置时被填充在 xml 配置文件中,否则容器将抛出BeanInitializationException。@Autowired:可用于修饰属性、setter 方法、构造方法。- 可以使用 JSR330 的注解
@Inject来替代@Autowired。
@Qualifier:如果发现有多个候选的 bean 都符合修饰类型,指定 bean 名称来锁定真正需要的那个 bean。- JSR 250 注解
@Resource@PostConstruct 和 @PreDestroy
- JSR 330 注解
Java 配置
基于 Java 配置 Spring IoC 容器,实际上是 Spring 允许用户定义一个类,在这个类中去管理 IoC 容器的配置。
为了让 Spring 识别这个定义类为一个 Spring 配置类,需要用到两个注解:@Configuration 和 @Bean。
如果你熟悉 Spring 的 xml 配置方式,你可以将 @Configuration 等价于 <beans> 标签;将 @Bean 等价于 <bean> 标签。
@Bean
@Bean 的修饰目标只能是方法或注解。
@Bean 只能定义在@Configuration 或@Component 注解修饰的类中。
@Configuration 类允许在同一个类中通过@Bean 定义内部 bean 依赖。
声明一个 bean,只需要在 bean 属性的 set 方法上标注@Bean 即可。
@Configuration
public class AnnotationConfiguration {
@Bean
public Job getPolice() {
return new Police();
}
}
public interface Job {
String work();
}
@Component("police")
public class Police implements Job {
@Override
public String work() {
return "抓罪犯";
}
}
@Configuration
@Configuration 是一个类级别的注解,用来标记被修饰类的对象是一个BeanDefinition。
@Configuration 声明 bean 是通过被 @Bean 修饰的公共方法。此外,@Configuration 允许在同一个类中通过 @Bean 定义内部 bean 依赖。
@Configuration
public class AppConfig {
@Bean
public MyService myService() {
return new MyServiceImpl();
}
}
1.2 - CH02-Spring IOC
基本概念
IoC(Inverse of Control:控制反转)是一种设计思想,就是 将原本在程序中手动创建对象的控制权,交由Spring框架来管理。 IoC 在其他语言中也有应用,并非 Spring 特有。 IoC 容器是 Spring 用来实现 IoC 的载体, IoC 容器实际上就是个Map(key,value),Map 中存放的是各种对象。
将对象之间的相互依赖关系交给 IoC 容器来管理,并由 IoC 容器完成对象的注入。这样可以很大程度上简化应用的开发,把应用从复杂的依赖关系中解放出来。 IoC 容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件/注解即可,完全不用考虑对象是如何被创建出来的。 在实际项目中一个 Service 类可能有几百甚至上千个类作为它的底层,假如我们需要实例化这个 Service,你可能要每次都要搞清这个 Service 所有底层类的构造函数,这可能会把人逼疯。如果利用 IoC 的话,你只需要配置好,然后在需要的地方引用就行了,这大大增加了项目的可维护性且降低了开发难度。
Spring IOC 通过引入 xml 配置,由 IOC 容器来管理对象的生命周期,依赖关系等。
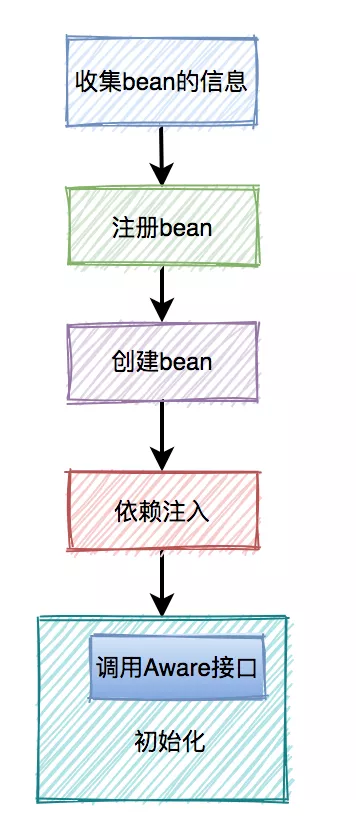
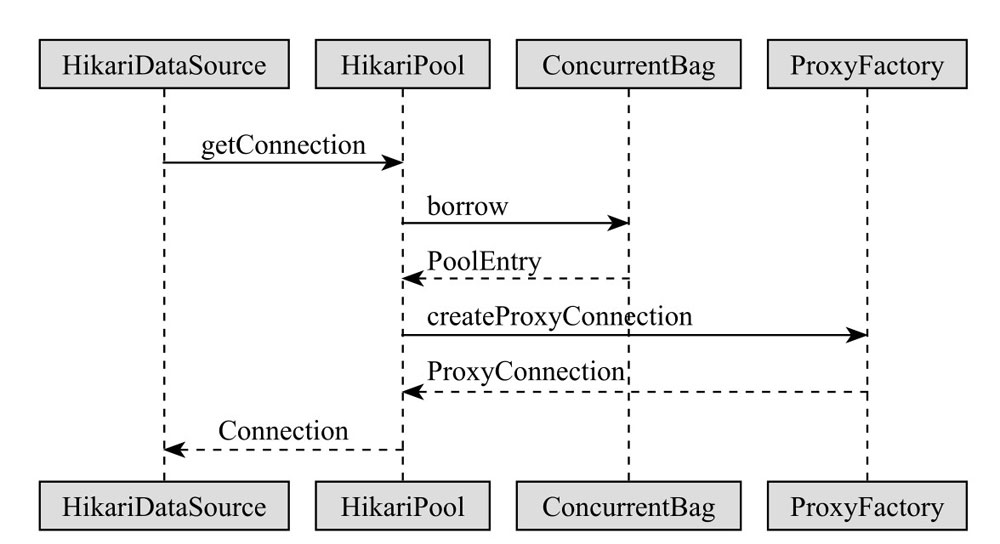
从图中可以看出,我们以前获取两个有依赖关系的对象,要用 set 方法,而用容器之后,它们之间的关系就由容器来管理。
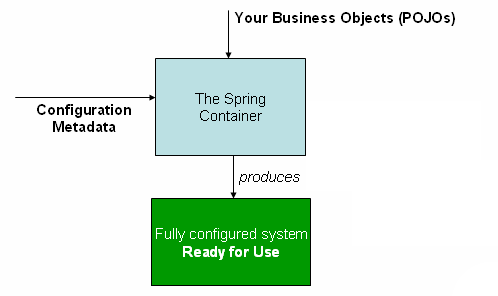
什么是 Spring IOC 容器?
Spring 框架的核心是 Spring 容器。容器创建对象,将它们装配在一起,配置它们并管理它们的完整生命周期。Spring 容器使用依赖注入来管理组成应用程序的组件。容器通过读取提供的配置元数据来接收对象进行实例化,配置和组装的指令。该元数据可以通过 XML,Java 注解或 Java 代码提供。
什么是依赖注入?
依赖注入(DI,Dependency Injection)是在编译阶段尚未知所需的功能是来自哪个的类的情况下,将其他对象所依赖的功能对象实例化的模式。这就需要一种机制用来激活相应的组件以提供特定的功能,所以依赖注入是控制反转的基础。否则如果在组件不受框架控制的情况下,框架又怎么知道要创建哪个组件?
依赖注入有以下三种实现方式:
- 构造器注入
- Setter方法注入(属性注入)
- 接口注入
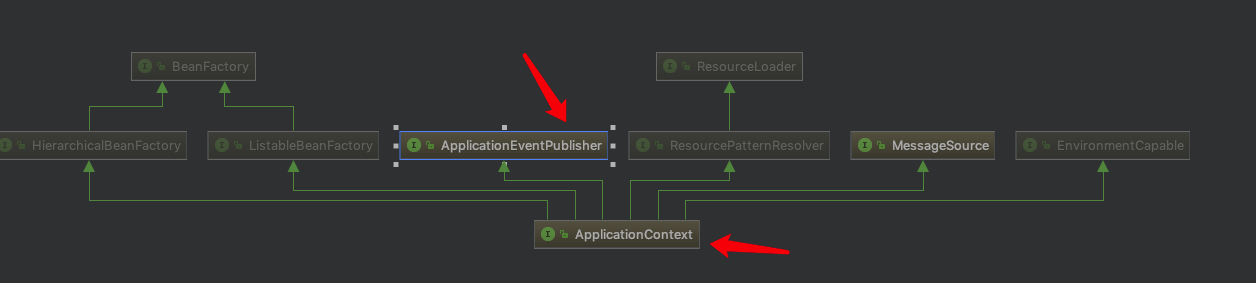
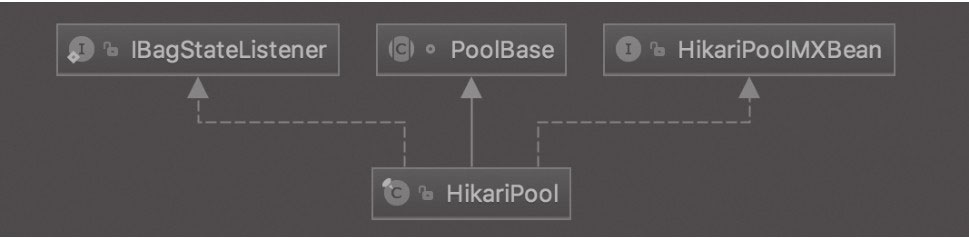
Spring 中有多少种 IOC 容器?
在 Spring IOC 容器读取 Bean 配置创建 Bean 实例之前,必须对它进行实例化。只有在容器实例化后, 才可以从 IOC 容器里获取 Bean 实例并使用。
Spring 提供了两种类型的 IOC 容器实现
- BeanFactory:IOC 容器的基本实现
- ApplicationContext:提供了更多的高级特性,是 BeanFactory 的子接口
BeanFactory 是 Spring 框架的基础设施,面向 Spring 本身;ApplicationContext 面向使用 Spring 框架的开发者,几乎所有的应用场合都直接使用 ApplicationContext 而非底层的 BeanFactory;
无论使用何种方式,配置文件是相同的。
BeanFactory
BeanFactory,从名字上可以看出来它是 bean 的工厂,它负责生产和管理各个 bean 实例。
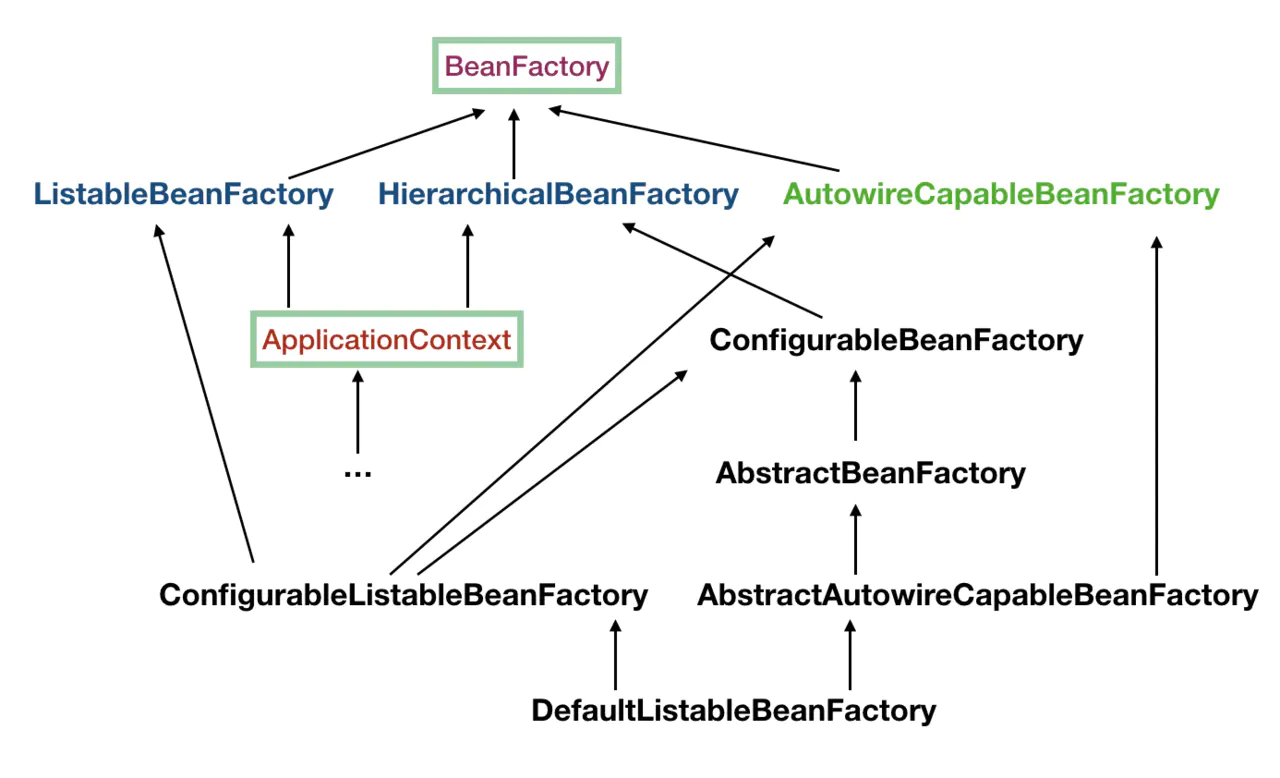
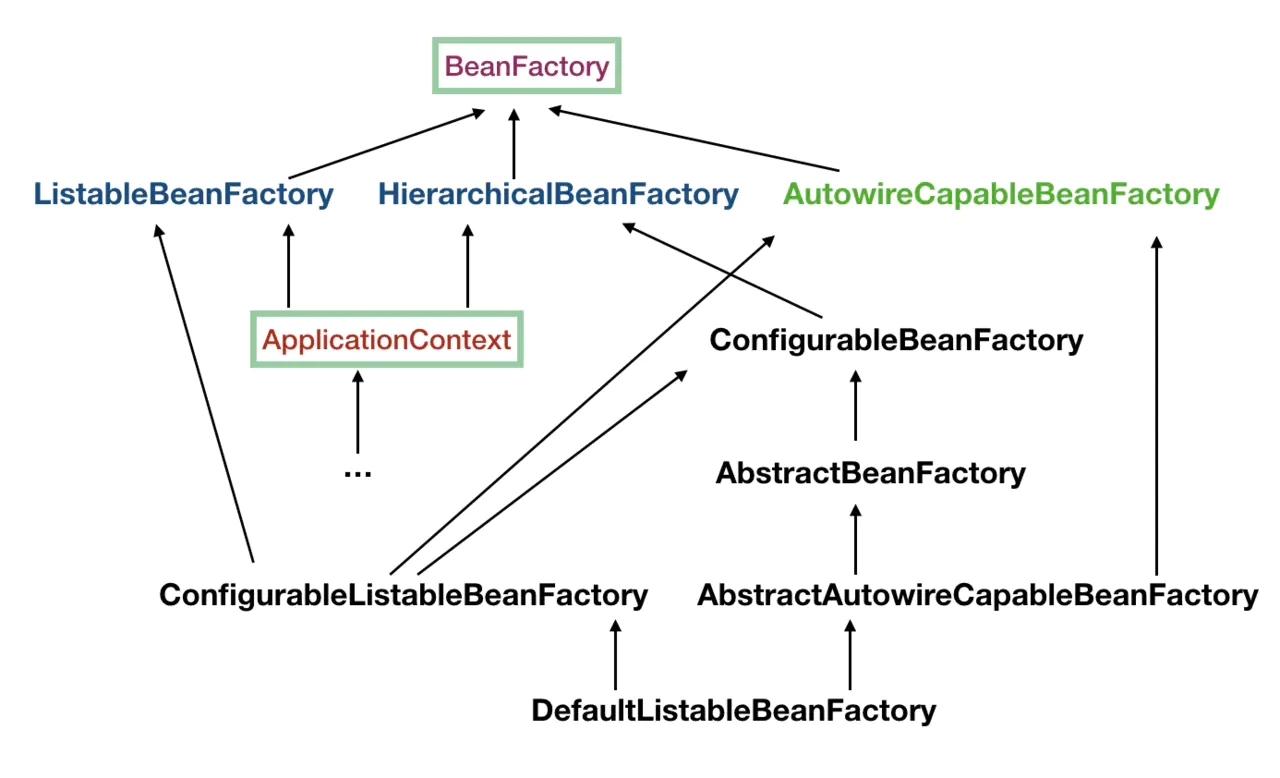
大概了解下这里提到的几个类:
- ListableBeanFactory:这个 Listable 的意思就是,通过这个接口,我们可以获取多个 Bean,大家看源码会发现,最顶层 BeanFactory 接口的方法都是获取单个 Bean 的。
- HierarchicalBeanFactory:Hierarchical 单词本身已经能说明问题了,也就是说我们可以在应用中起多个 BeanFactory,然后可以将各个 BeanFactory 设置为父子关系。
- AutowireCapableBeanFactory: 这个名字中的 Autowire 大家都非常熟悉,它就是用来自动装配 Bean 用的,但是仔细看上图,ApplicationContext 并没有继承它,不过不用担心,不使用继承,不代表不可以使用组合,如果你看到 ApplicationContext 接口定义中的最后一个方法 getAutowireCapableBeanFactory() 就知道了。
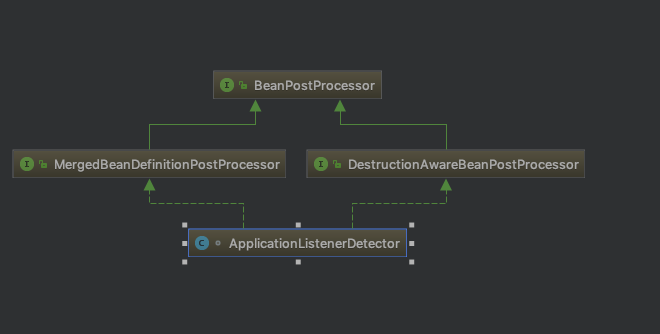
- ConfigurableListableBeanFactory :也是一个特殊的接口,看图,特殊之处在于它继承了第二层所有的三个接口,而 ApplicationContext 没有。这点之后会用到。
1.3 - CH03-Bean加载
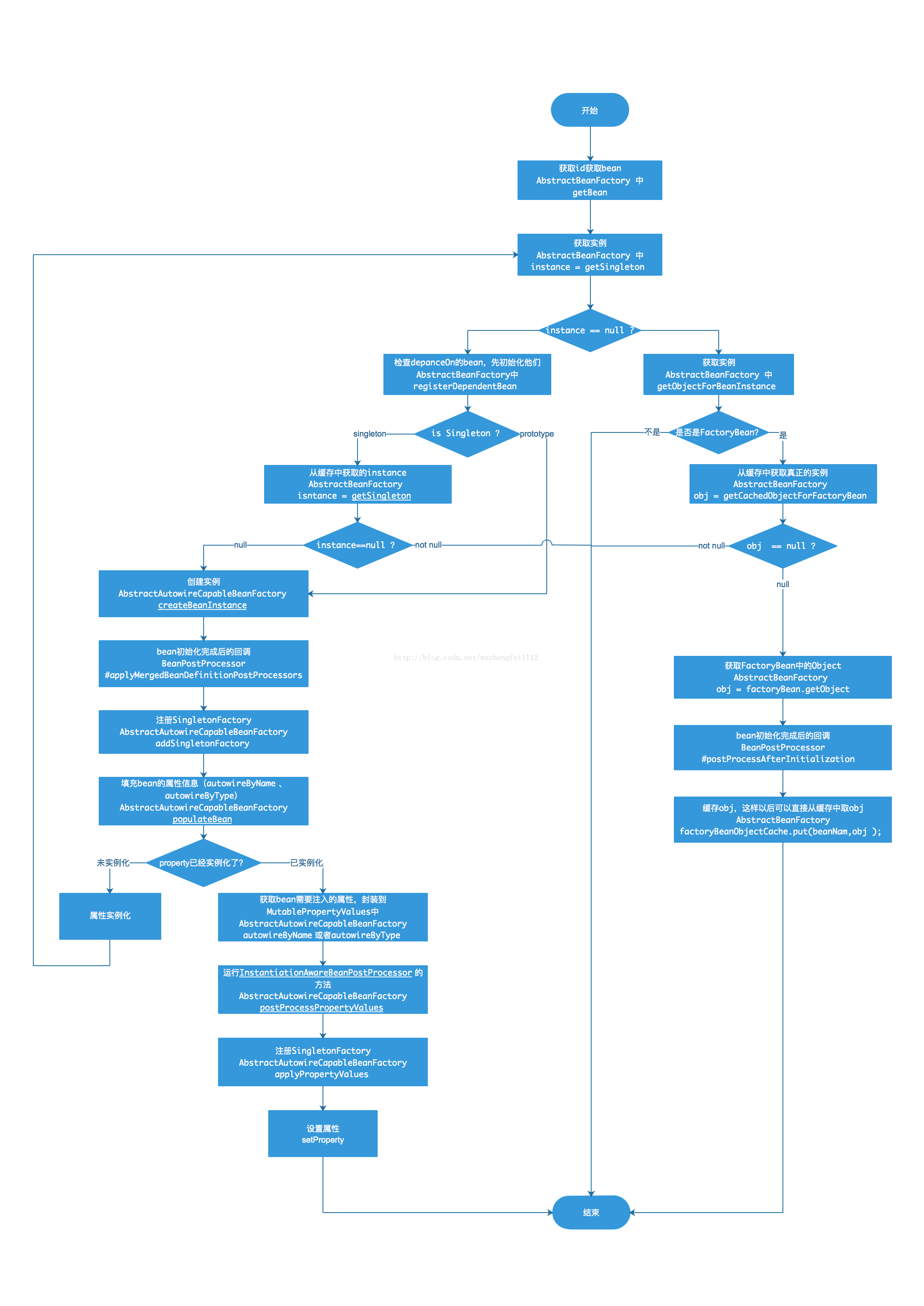
解析流程
获取流程
创建流程
1.4 - CH04-IOC源码
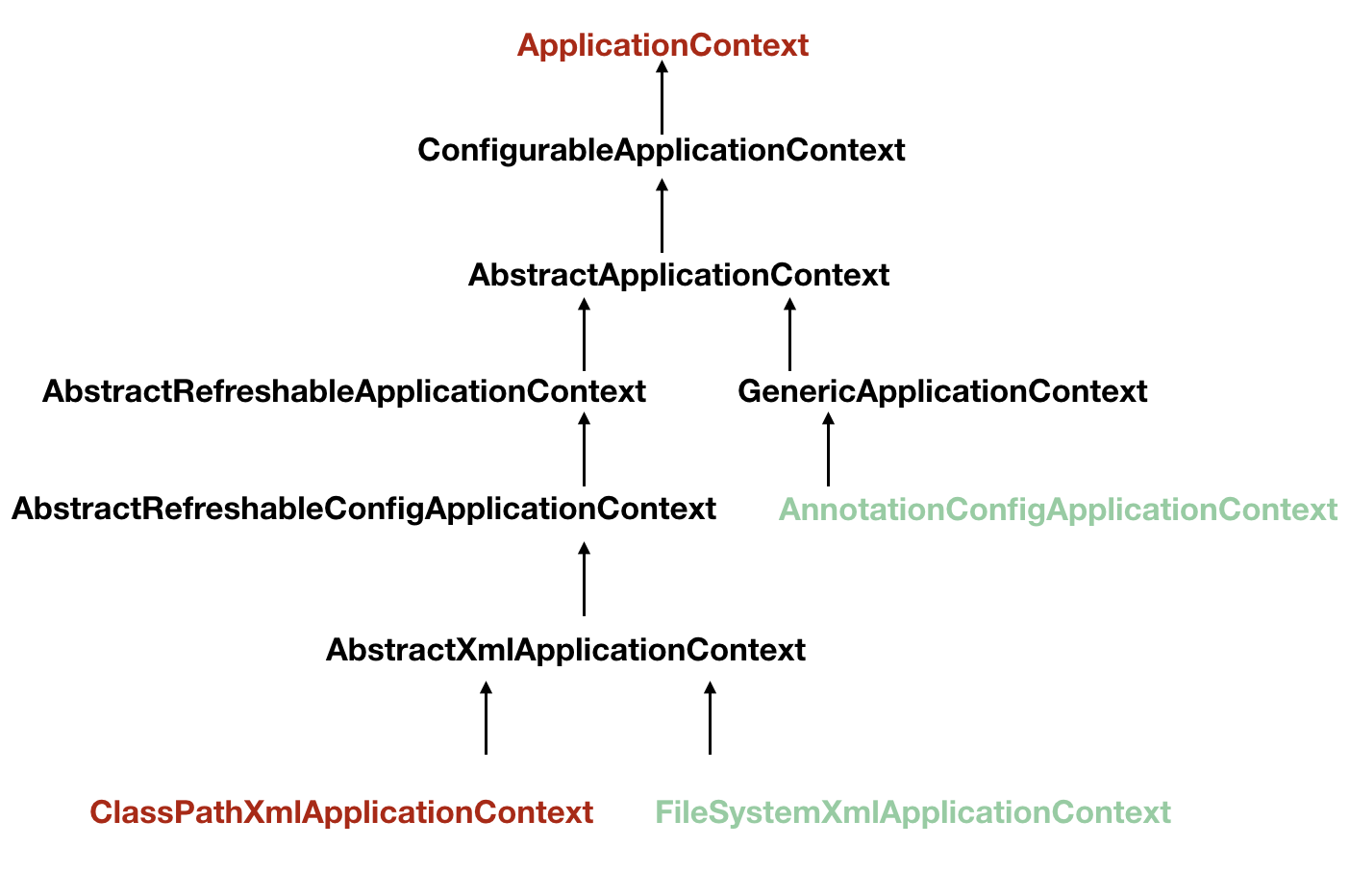
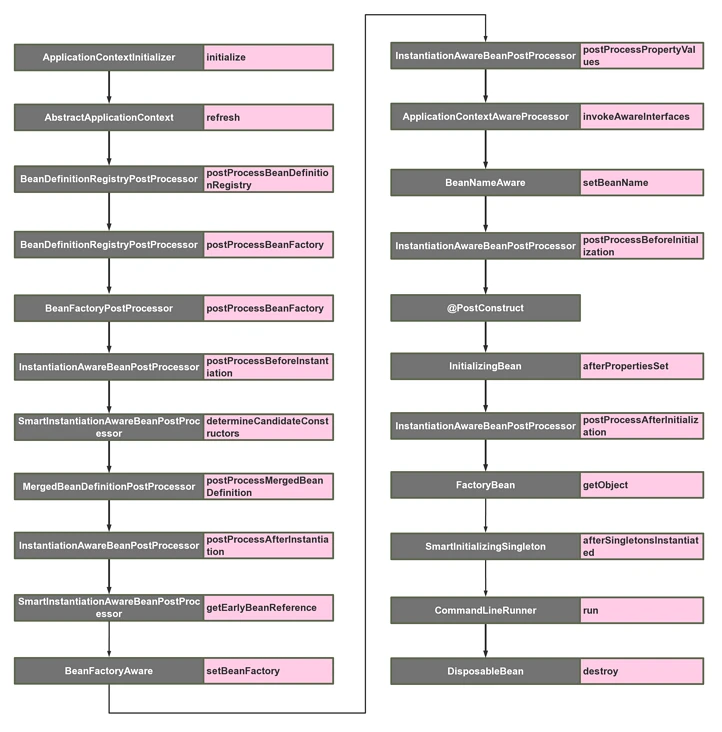
ApplicationContext 实例化 Bean 的过程
ApplicationContext ac = new ClassPathXmlApplicationContext("classpath:applicationContext.xml");
Hello hello = (Hello)ac.getBean("hello");
hello.sayHello();
这个从写法上我们可以知道从 ClassPath 中寻找 xml 配置文件,然后根据 xml 文件的内容来构建ApplicationContext 对象实例(容器),然后通过容器获取一个叫 ”hello“ 的 bean,执行该 bean 的 sayHello 方法。
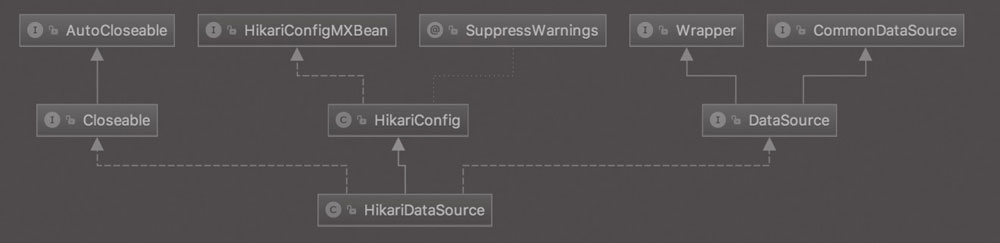
当然我们之前也知道这不是唯一的构建容器方式,我们先来看看大体的继承结构是怎么样的:
启动过程分析
第一步,我们肯定要从 ClassPathXmlApplicationContext 的构造方法说起。
public ClassPathXmlApplicationContext(
String[] configLocations, boolean refresh, @Nullable ApplicationContext parent)
throws BeansException {
super(parent);
// 根据提供的路径,处理成配置文件数组(以分号、逗号、空格、tab、换行符分割)
setConfigLocations(configLocations);
if (refresh) {
refresh();
}
}
接下来,就是 refresh(),这里简单说下为什么是 refresh(),而不是 init() 这种名字的方法。因为 ApplicationContext 建立起来以后,其实我们是可以通过调用 refresh() 这个方法重建的,refresh() 会将原来的 ApplicationContext 销毁,然后再重新执行一次初始化操作。
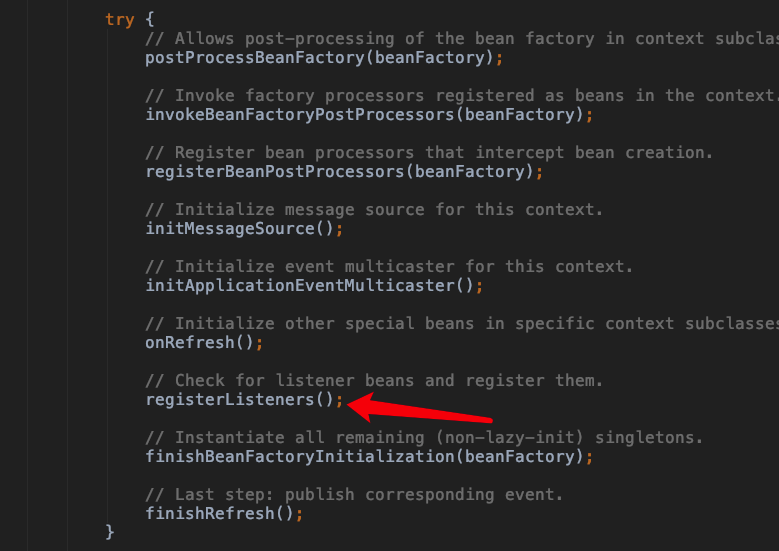
@Override
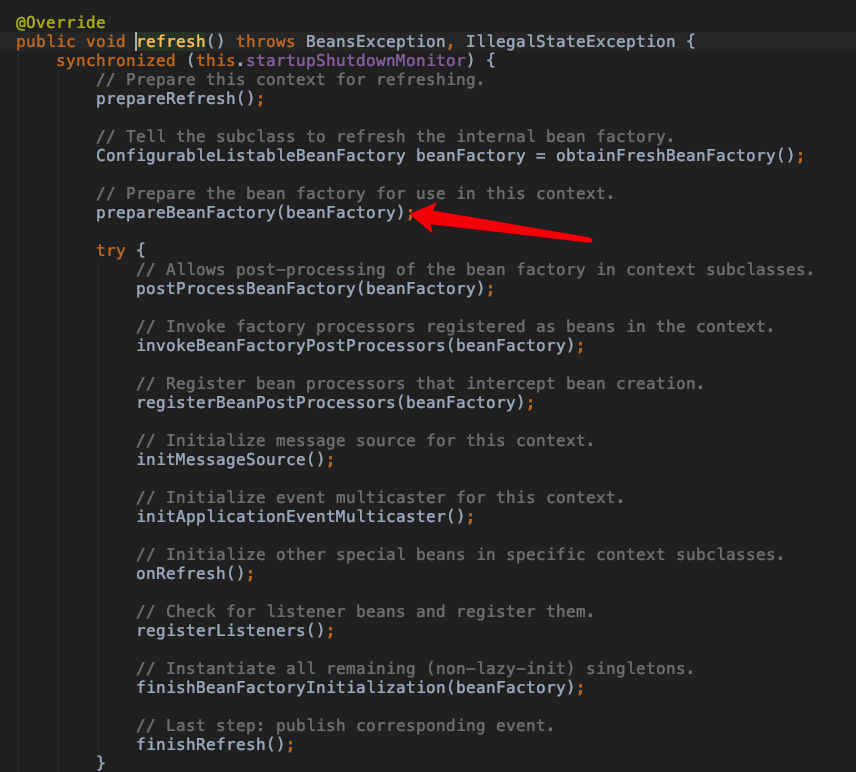
public void refresh() throws BeansException, IllegalStateException {
// 来个锁,不然 refresh() 还没结束,你又来个启动或销毁容器的操作,那不就乱套了嘛
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
// 准备工作,记录下容器的启动时间、标记“已启动”状态、处理配置文件中的占位符
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
// 这步比较关键,这步完成后,配置文件就会解析成一个个 Bean 定义,注册到 BeanFactory 中,
// 当然,这里说的 Bean 还没有初始化,只是配置信息都提取出来了,
// 注册也只是将这些信息都保存到了注册中心(说到底核心是一个 beanName-> beanDefinition 的 map)
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
// 设置 BeanFactory 的类加载器,添加几个 BeanPostProcessor,手动注册几个特殊的 bean
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
//提供给子类实现一些postProcess的注册,如AbstractRefreshableWebApplicationContext注册一些Servlet相关的
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
//调用所有BeanFactoryProcessor的postProcessBeanFactory()方法
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
//注册BeanPostProcessor,BeanPostProcessor作用是用于拦截Bean的创建
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
//初始化消息Bean
initMessageSource();
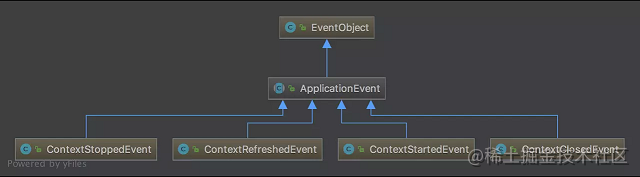
// Initialize event multicaster for this context.
//初始化上下文的事件多播组建,ApplicationEvent触发时由multicaster通知给ApplicationListener
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
//ApplicationContext初始化一些特殊的bean
onRefresh();
// Check for listener beans and register them.
//注册事件监听器,事件监听Bean统一注册到multicaster里头,ApplicationEvent事件触发后会由multicaster广播
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.(重点)
// 非延迟加载的单例Bean实例化
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.(最后,广播事件,ApplicationContext 初始化完成)
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
}
下面,我们开始一步步来肢解这个 refresh() 方法。
创建 Bean 容器前的准备工作
/**
* Prepare this context for refreshing, setting its startup date and
* active flag as well as performing any initialization of property sources.
*/
protected void prepareRefresh() {
// Switch to active.
this.startupDate = System.currentTimeMillis();
this.closed.set(false);
this.active.set(true);
if (logger.isInfoEnabled()) {
logger.info("Refreshing " + this);
}
// Initialize any placeholder property sources in the context environment.
initPropertySources();
// Validate that all properties marked as required are resolvable:
// see ConfigurablePropertyResolver#setRequiredProperties
// 校验 xml 配置文件
getEnvironment().validateRequiredProperties();
// Store pre-refresh ApplicationListeners...
if (this.earlyApplicationListeners == null) {
this.earlyApplicationListeners = new LinkedHashSet<>(this.applicationListeners);
}
else {
// Reset local application listeners to pre-refresh state.
this.applicationListeners.clear();
this.applicationListeners.addAll(this.earlyApplicationListeners);
}
// Allow for the collection of early ApplicationEvents,
// to be published once the multicaster is available...
this.earlyApplicationEvents = new LinkedHashSet<>();
}
创建 Bean 容器,加载并注册 Bean
我们回到 refresh() 方法中的下一行 obtainFreshBeanFactory()。
注意,这个方法是全文最重要的部分之一,这里将会初始化 BeanFactory、加载 Bean、注册 Bean 等等。
当然,这步结束后,Bean 并没有完成初始化。这里指的是 Bean 实例并未在这一步生成。
protected ConfigurableListableBeanFactory obtainFreshBeanFactory() {
// 关闭旧的 BeanFactory (如果有),创建新的 BeanFactory,加载 Bean 定义、注册 Bean 等等
refreshBeanFactory();
// 返回刚刚创建的 BeanFactory
ConfigurableListableBeanFactory beanFactory = getBeanFactory();
if (logger.isDebugEnabled()) {
logger.debug("Bean factory for " + getDisplayName() + ": " + beanFactory);
}
return beanFactory;
}
// AbstractRefreshableApplicationContext.java
@Override
protected final void refreshBeanFactory() throws BeansException {
// 如果 ApplicationContext 中已经加载过 BeanFactory 了,销毁所有 Bean,关闭 BeanFactory
// 注意,应用中 BeanFactory 本来就是可以多个的,这里可不是说应用全局是否有 BeanFactory,而是当前
// ApplicationContext 是否有 BeanFactory
if (hasBeanFactory()) {
destroyBeans();
closeBeanFactory();
}
try {
// 初始化一个 DefaultListableBeanFactory,为什么用这个,我们马上说。
DefaultListableBeanFactory beanFactory = createBeanFactory();
// 用于 BeanFactory 的序列化
beanFactory.setSerializationId(getId());
// 下面这两个方法很重要,别跟丢了,具体细节之后说
// 设置 BeanFactory 的两个配置属性:是否允许 Bean 覆盖、是否允许循环引用
customizeBeanFactory(beanFactory);
// 加载 Bean 到 BeanFactory 中
loadBeanDefinitions(beanFactory);
synchronized (this.beanFactoryMonitor) {
this.beanFactory = beanFactory;
}
}
catch (IOException ex) {
throw new ApplicationContextException("I/O error parsing bean definition source for " + getDisplayName(), ex);
}
}
看到这里的时候,我觉得读者就应该站在高处看 ApplicationContext 了,ApplicationContext 继承自 BeanFactory,但是它不应该被理解为 BeanFactory 的实现类,而是说其内部持有一个实例化的 BeanFactory(DefaultListableBeanFactory)。以后所有的 BeanFactory 相关的操作其实是委托给这个实例来处理的。
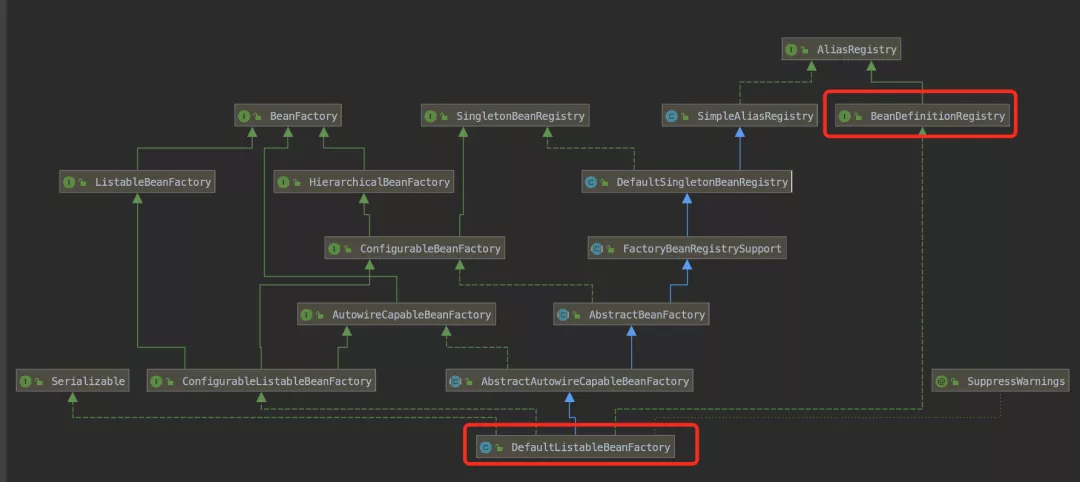
我们说说为什么选择实例化 DefaultListableBeanFactory ?前面我们说了有个很重要的接口 ConfigurableListableBeanFactory,它实现了 BeanFactory 下面一层的所有三个接口,我把之前的继承图再拿过来大家再仔细看一下:
我们可以看到 ConfigurableListableBeanFactory 只有一个实现类 DefaultListableBeanFactory,而且实现类 DefaultListableBeanFactory 还通过实现右边的 AbstractAutowireCapableBeanFactory 通吃了右路。所以结论就是,最底下这个家伙 DefaultListableBeanFactory 基本上是最牛的 BeanFactory 了,这也是为什么这边会使用这个类来实例化的原因。
如果你想要在程序运行的时候动态往 Spring IOC 容器注册新的 bean,就会使用到这个类。那我们怎么在运行时获得这个实例呢?
之前我们说过 ApplicationContext 接口能获取到 AutowireCapableBeanFactory,就是最右上角那个,然后它向下转型就能得到 DefaultListableBeanFactory 了。
在继续往下之前,我们需要先了解 BeanDefinition。我们说 BeanFactory 是 Bean 容器,那么 Bean 又是什么呢?
这里的 BeanDefinition 就是我们所说的 Spring 的 Bean,我们自己定义的各个 Bean 其实会转换成一个个 BeanDefinition 存在于 Spring 的 BeanFactory 中。
所以,如果有人问你 Bean 是什么的时候,你要知道 Bean 在代码层面上可以认为是 BeanDefinition 的实例。
BeanDefinition 中保存了我们的 Bean 信息,比如这个 Bean 指向的是哪个类、是否是单例的、是否懒加载、这个 Bean 依赖了哪些 Bean 等等。
BeanDefinition 是一个接口,用于属性承载,比如 元素标签拥有 class、scope、lazy-init 等配置。bean的定义方式有千千万万种,无论是何种标签,无论是何种资源定义,无论是何种容器,只要按照 Spring 的规范编写xml配置文件,最终的 bean 定义内部表示都将转换为内部的唯一结构:BeanDefinition。当 BeanDefinition 注册完毕以后,Spring 的 BeanFactory 就可以随时根据需要进行实例化了。
BeanDefinition 接口定义
我们来看下 BeanDefinition 的接口定义:
public interface BeanDefinition extends AttributeAccessor, BeanMetadataElement {
// 我们可以看到,默认只提供 sington 和 prototype 两种,
// 很多读者可能知道还有 request, session, globalSession, application, websocket 这几种,
// 不过,它们属于基于 web 的扩展。
String SCOPE_SINGLETON = ConfigurableBeanFactory.SCOPE_SINGLETON;
String SCOPE_PROTOTYPE = ConfigurableBeanFactory.SCOPE_PROTOTYPE;
// 比较不重要,直接跳过吧
int ROLE_APPLICATION = 0;
int ROLE_SUPPORT = 1;
int ROLE_INFRASTRUCTURE = 2;
// 设置父 Bean,这里涉及到 bean 继承,不是 java 继承。请参见附录的详细介绍
// 一句话就是:继承父 Bean 的配置信息而已
void setParentName(String parentName);
// 获取父 Bean
String getParentName();
// 设置 Bean 的类名称,将来是要通过反射来生成实例的
void setBeanClassName(String beanClassName);
// 获取 Bean 的类名称
String getBeanClassName();
// 设置 bean 的 scope
@Nullable
void setScope(String scope);
@Nullable
String getScope();
// 设置是否懒加载
void setLazyInit(boolean lazyInit);
boolean isLazyInit();
// 设置该 Bean 依赖的所有的 Bean,注意,这里的依赖不是指属性依赖(如 @Autowire 标记的),
// 是 depends-on="" 属性设置的值。
void setDependsOn(String... dependsOn);
// 返回该 Bean 的所有依赖
String[] getDependsOn();
// 设置该 Bean 是否可以注入到其他 Bean 中,只对根据类型注入有效,
// 如果根据名称注入,即使这边设置了 false,也是可以的
void setAutowireCandidate(boolean autowireCandidate);
// 该 Bean 是否可以注入到其他 Bean 中
boolean isAutowireCandidate();
// 主要的。同一接口的多个实现,如果不指定名字的话,Spring 会优先选择设置 primary 为 true 的 bean
void setPrimary(boolean primary);
// 是否是 primary 的
boolean isPrimary();
// 如果该 Bean 采用工厂方法生成,指定工厂名称。对工厂不熟悉的读者,请参加附录
// 一句话就是:有些实例不是用反射生成的,而是用工厂模式生成的
void setFactoryBeanName(String factoryBeanName);
// 获取工厂名称
String getFactoryBeanName();
// 指定工厂类中的 工厂方法名称
void setFactoryMethodName(String factoryMethodName);
// 获取工厂类中的 工厂方法名称
String getFactoryMethodName();
// 构造器参数
ConstructorArgumentValues getConstructorArgumentValues();
// Bean 中的属性值,后面给 bean 注入属性值的时候会说到
MutablePropertyValues getPropertyValues();
// 是否 singleton
boolean isSingleton();
// 是否 prototype
boolean isPrototype();
// 如果这个 Bean 是被设置为 abstract,那么不能实例化,
// 常用于作为 父bean 用于继承,其实也很少用......
boolean isAbstract();
int getRole();
String getDescription();
String getResourceDescription();
BeanDefinition getOriginatingBeanDefinition();
}
这个 BeanDefinition 其实已经包含很多的信息了,暂时不清楚所有的方法对应什么东西没关系,希望看完本文后读者可以彻底搞清楚里面的所有东西。
这里接口虽然那么多,但是没有类似 getInstance() 这种方法来获取我们定义的类的实例,真正的我们定义的类生成的实例到哪里去了呢?别着急,这个要很后面才能讲到。
有了 BeanDefinition 的概念以后,我们再往下看 refreshBeanFactory() 方法中的剩余部分:
customizeBeanFactory(beanFactory);
loadBeanDefinitions(beanFactory);
customizeBeanFactory()
customizeBeanFactory(beanFactory) 比较简单,就是配置是否允许 BeanDefinition 覆盖、是否允许循环引用。
protected void customizeBeanFactory(DefaultListableBeanFactory beanFactory) {
if (this.allowBeanDefinitionOverriding != null) {
// 是否允许 Bean 定义覆盖
beanFactory.setAllowBeanDefinitionOverriding(this.allowBeanDefinitionOverriding);
}
if (this.allowCircularReferences != null) {
// 是否允许 Bean 间的循环依赖
beanFactory.setAllowCircularReferences(this.allowCircularReferences)
}
}
BeanDefinition 的覆盖问题可能会有开发者碰到这个坑,就是在配置文件中定义 bean 时使用了相同的 id 或 name,默认情况下,allowBeanDefinitionOverriding 属性为 null,如果在同一配置文件中重复了,会抛错,但是如果不是同一配置文件中,会发生覆盖。
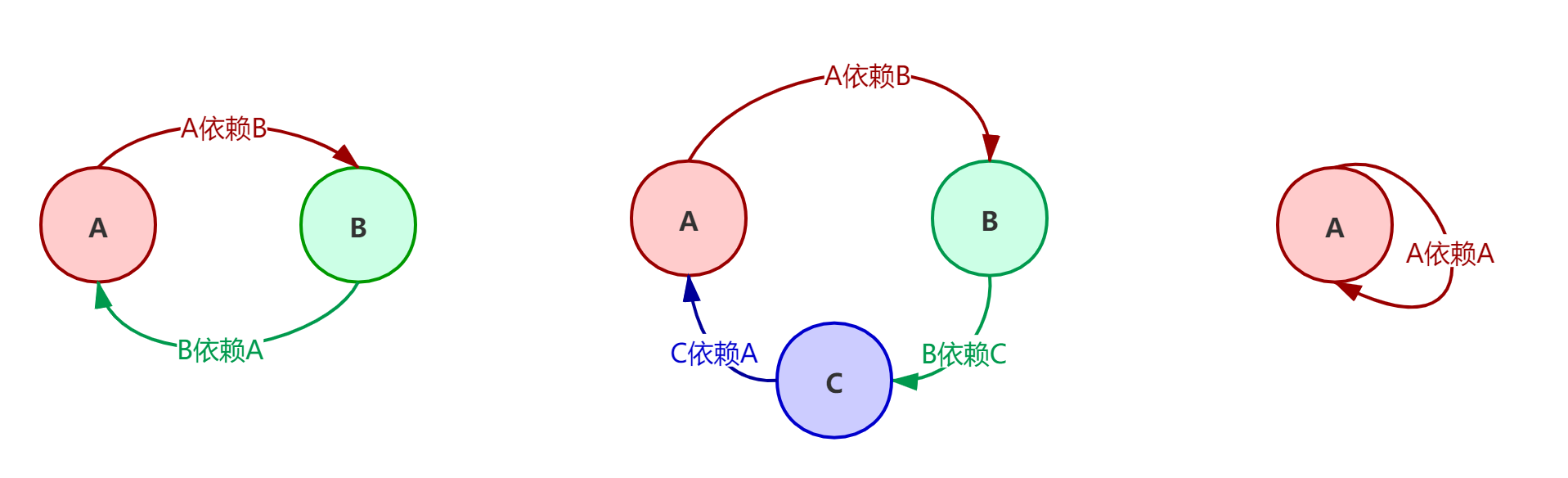
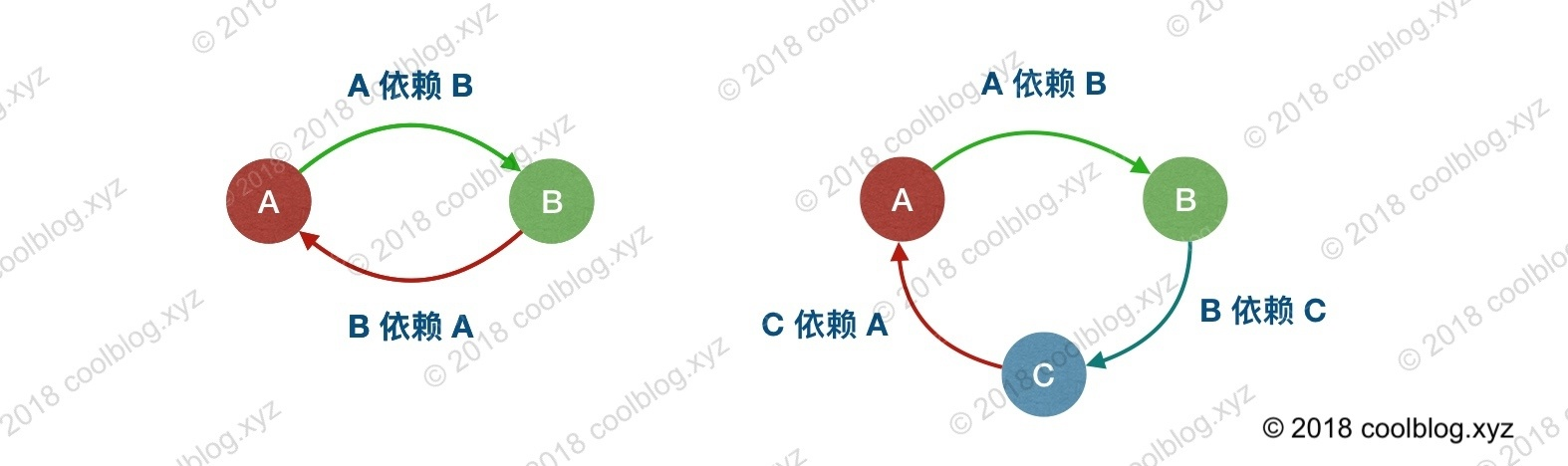
循环引用也很好理解:A 依赖 B,而 B 依赖 A。或 A 依赖 B,B 依赖 C,而 C 依赖 A。
默认情况下,Spring 允许循环依赖,当然如果你在 A 的构造方法中依赖 B,在 B 的构造方法中依赖 A 是不行的。
至于这两个属性怎么配置?我在附录中进行了介绍,尤其对于覆盖问题,很多人都希望禁止出现 Bean 覆盖,可是 Spring 默认是不同文件的时候可以覆盖的。
之后的源码中还会出现这两个属性,先有个印象就可以了。
loadBeanDefinitions():加载 Bean
接下来是最重要的 loadBeanDefinitions(beanFactory) 方法了,这个方法将根据配置,加载各个 Bean,然后放到 BeanFactory 中。
读取配置的操作在 XmlBeanDefinitionReader 中,其负责加载配置、解析。
/** 我们可以看到,此方法将通过一个 XmlBeanDefinitionReader 实例来加载各个 Bean。*/
@Override
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
// 给这个 BeanFactory 实例化一个 XmlBeanDefinitionReader
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
// Configure the bean definition reader with this context's
// resource loading environment.
beanDefinitionReader.setEnvironment(this.getEnvironment());
beanDefinitionReader.setResourceLoader(this);
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
// 初始化 BeanDefinitionReader,其实这个是提供给子类覆写的,
// 我看了一下,没有类覆写这个方法,我们姑且当做不重要吧
initBeanDefinitionReader(beanDefinitionReader);
// 重点来了,继续往下
loadBeanDefinitions(beanDefinitionReader);
}
现在还在这个类中,接下来用刚刚初始化的 Reader 开始来加载 xml 配置,这块代码读者可以选择性跳过,不是很重要。也就是说,下面这个代码块,读者可以很轻松地略过。
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws BeansException, IOException {
Resource[] configResources = getConfigResources();
if (configResources != null) {
// 往下看
reader.loadBeanDefinitions(configResources);
}
String[] configLocations = getConfigLocations();
if (configLocations != null) {
// 2
reader.loadBeanDefinitions(configLocations);
}
}
// 上面虽然有两个分支,不过第二个分支很快通过解析路径转换为 Resource 以后也会进到这里
@Override
public int loadBeanDefinitions(Resource... resources) throws BeanDefinitionStoreException {
Assert.notNull(resources, "Resource array must not be null");
int counter = 0;
// 注意这里是个 for 循环,也就是每个文件是一个 resource
for (Resource resource : resources) {
// 继续往下看
counter += loadBeanDefinitions(resource);
}
// 最后返回 counter,表示总共加载了多少的 BeanDefinition
return counter;
}
// XmlBeanDefinitionReader 303
@Override
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
return loadBeanDefinitions(new EncodedResource(resource));
}
// XmlBeanDefinitionReader 314
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isInfoEnabled()) {
logger.info("Loading XML bean definitions from " + encodedResource.getResource());
}
// 用一个 ThreadLocal 来存放配置文件资源
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet<EncodedResource>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try {
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
// 核心部分是这里,往下面看
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
inputStream.close();
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
}
finally {
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}
// 还在这个文件中,第 388 行
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
// 这里就不看了,将 xml 文件转换为 Document 对象
Document doc = doLoadDocument(inputSource, resource);
// 继续
return registerBeanDefinitions(doc, resource);
}
catch (...
}
// 还在这个文件中,第 505 行
// 返回值:返回从当前配置文件加载了多少数量的 Bean
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
int countBefore = getRegistry().getBeanDefinitionCount();
// 这里
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
return getRegistry().getBeanDefinitionCount() - countBefore;
}
// DefaultBeanDefinitionDocumentReader.java
@Override
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
logger.debug("Loading bean definitions");
Element root = doc.getDocumentElement();
// 从 xml 根节点开始解析文件
doRegisterBeanDefinitions(root);
}
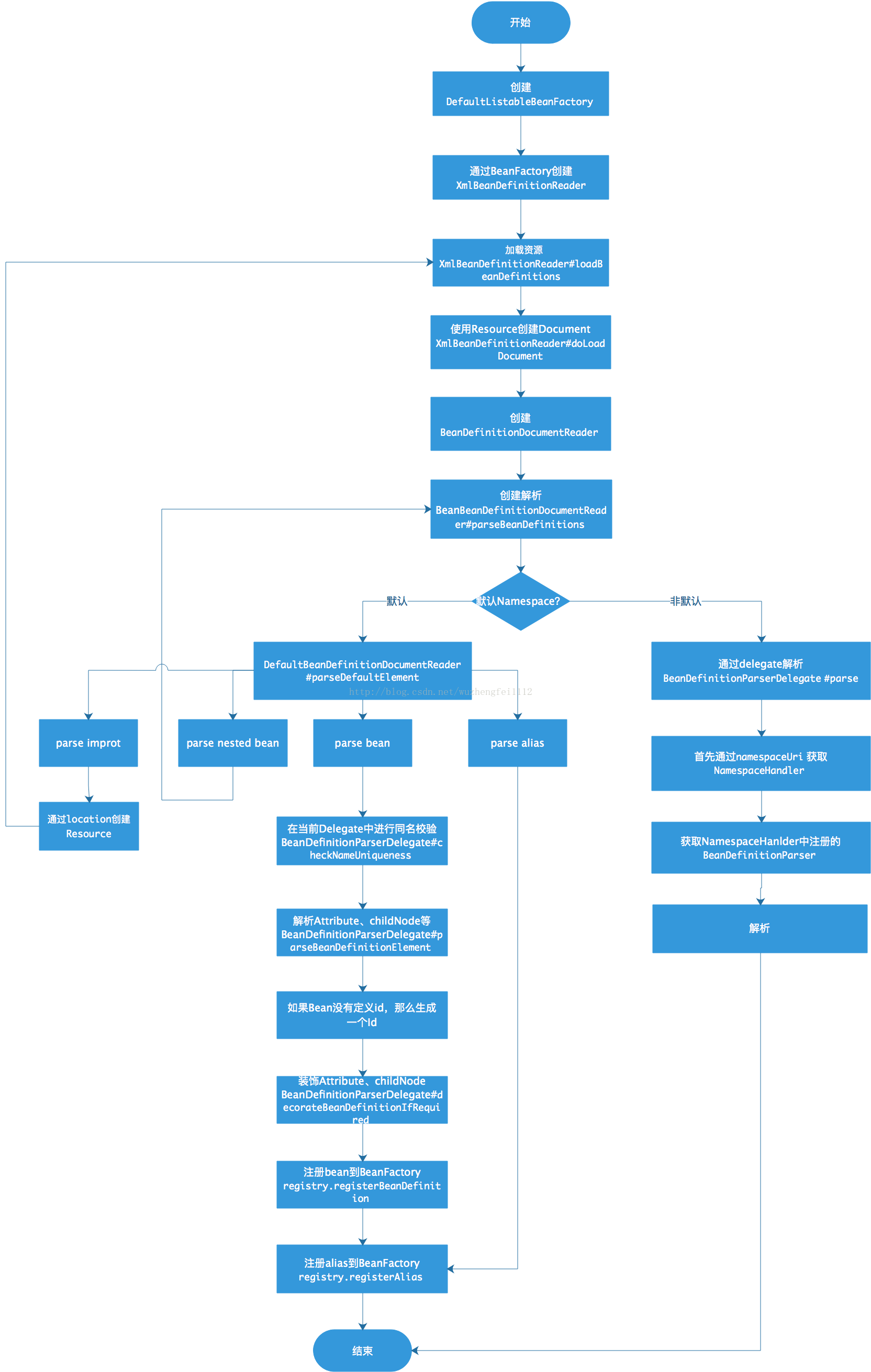
经过漫长的链路,一个配置文件终于转换为一颗 DOM 树了,注意,这里指的是其中一个配置文件,不是所有的,读者可以看到上面有个 for 循环的。下面开始从根节点开始解析:
doRegisterBeanDefinitions()
// DefaultBeanDefinitionDocumentReader.java
protected void doRegisterBeanDefinitions(Element root) {
// 我们看名字就知道,BeanDefinitionParserDelegate 必定是一个重要的类,它负责解析 Bean 定义,
// 这里为什么要定义一个 parent? 看到后面就知道了,是递归问题,
// 因为 <beans /> 内部是可以定义 <beans /> 的,所以这个方法的 root 其实不一定就是 xml 的根节点,也可以是嵌套在里面的 <beans /> 节点,从源码分析的角度,我们当做根节点就好了
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
if (this.delegate.isDefaultNamespace(root)) {
// 这块说的是根节点 <beans ... profile="dev" /> 中的 profile 是否是当前环境需要的,
// 如果当前环境配置的 profile 不包含此 profile,那就直接 return 了,不对此 <beans /> 解析
// 不熟悉 profile 为何物,不熟悉怎么配置 profile 读者的请移步附录区
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
if (logger.isInfoEnabled()) {
logger.info("Skipped XML bean definition file due to specified profiles [" + profileSpec +
"] not matching: " + getReaderContext().getResource());
}
return;
}
}
}
preProcessXml(root); // 钩子
// 往下看
parseBeanDefinitions(root, this.delegate);
postProcessXml(root); // 钩子
this.delegate = parent;
}
preProcessXml(root) 和 postProcessXml(root) 是给子类用的钩子方法,鉴于没有被使用到,也不是我们的重点,我们直接跳过。
这里涉及到了 profile 的问题,对于不了解的读者,我在附录中对 profile 做了简单的解释,读者可以参考一下。接下来,看核心解析方法
parseBeanDefinitions(root, this.delegate)
// default namespace 涉及到的就四个标签 <import />、<alias />、<bean /> 和 <beans />,
// 其他的属于 custom 的
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
// 解析 default namespace 下面的几个元素
parseDefaultElement(ele, delegate);
}
else {
// 解析其他 namespace 的元素
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}
从上面的代码,我们可以看到,对于每个配置来说,分别进入到 parseDefaultElement(ele, delegate); 和 delegate.parseCustomElement(ele); 这两个分支了。
parseDefaultElement(ele, delegate) 代表解析的节点是 <import />、<alias />、<bean />、<beans /> 这几个。
这里的四个标签之所以是 default 的,是因为它们是处于这个 namespace 下定义的:
http://www.springframework.org/schema/beans
又到初学者科普时间,不熟悉 namespace 的读者请看下面贴出来的 xml,这里的第二行 xmlns 就是咯。
<beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.springframework.org/schema/beans"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd"
default-autowire="byName">
而对于其他的标签,将进入到 delegate.parseCustomElement(element) 这个分支。如我们经常会使用到的 <mvc />、<task />、<context />、<aop />等。
这些属于扩展,如果需要使用上面这些 ”非 default“ 标签,那么上面的 xml 头部的地方也要引入相应的 namespace 和 .xsd 文件的路径,如下所示。同时代码中需要提供相应的 parser 来解析,如 MvcNamespaceHandler、TaskNamespaceHandler、ContextNamespaceHandler、AopNamespaceHandler 等。
假如读者想分析 <context:property-placeholder location="classpath:xx.properties" /> 的实现原理,就应该到 ContextNamespaceHandler 中找答案。
<beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/mvc
http://www.springframework.org/schema/mvc/spring-mvc.xsd
"
default-autowire="byName">
回过神来,看看处理 default 标签的方法:
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
// 处理 <import /> 标签
importBeanDefinitionResource(ele);
}
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
// 处理 <alias /> 标签定义
// <alias name="fromName" alias="toName"/>
processAliasRegistration(ele);
}
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
// 处理 <bean /> 标签定义,这也算是我们的重点吧
processBeanDefinition(ele, delegate);
}
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// 如果碰到的是嵌套的 <beans /> 标签,需要递归
doRegisterBeanDefinitions(ele);
}
}
如果每个标签都说,那我不吐血,你们都要吐血了。我们挑我们的重点 <bean /> 标签出来说。
processBeanDefinition 解析 bean 标签
下面是 processBeanDefinition 解析 <bean /> 标签:
// DefaultBeanDefinitionDocumentReader.java
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
// 将 <bean /> 节点中的信息提取出来,然后封装到一个 BeanDefinitionHolder 中,细节往下看
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
// 下面的几行先不要看,跳过先,跳过先,跳过先,后面会继续说的
if (bdHolder != null) {
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// Register the final decorated instance.
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
// Send registration event.
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
继续往下看怎么解析之前,我们先看下 <bean /> 标签中可以定义哪些属性:
| Property | |
|---|
| class | 类的全限定名 |
| name | 可指定 id、name(用逗号、分号、空格分隔) |
| scope | 作用域 |
| constructor arguments | 指定构造参数 |
| properties | 设置属性的值 |
| autowiring mode | no(默认值)、byName、byType、 constructor |
| lazy-initialization mode | 是否懒加载(如果被非懒加载的bean依赖了那么其实也就不能懒加载了) |
| initialization method | bean 属性设置完成后,会调用这个方法 |
| destruction method | bean 销毁后的回调方法 |
上面表格中的内容我想大家都非常熟悉吧,如果不熟悉,那就是你不够了解 Spring 的配置了。
简单地说就是像下面这样子:
<bean id="exampleBean" name="name1, name2, name3" class="com.javadoop.ExampleBean"
scope="singleton" lazy-init="true" init-method="init" destroy-method="cleanup">
<!-- 可以用下面三种形式指定构造参数 -->
<constructor-arg type="int" value="7500000"/>
<constructor-arg name="years" value="7500000"/>
<constructor-arg index="0" value="7500000"/>
<!-- property 的几种情况 -->
<property name="beanOne">
<ref bean="anotherExampleBean"/>
</property>
<property name="beanTwo" ref="yetAnotherBean"/>
<property name="integerProperty" value="1"/>
</bean>
当然,除了上面举例出来的这些,还有 factory-bean、factory-method、<lockup-method />、<replaced-method />、<meta />、<qualifier /> 这几个,大家是不是熟悉呢?自己检验一下自己对 Spring 中 bean 的了解程度。
有了以上这些知识以后,我们再继续往里看怎么解析 bean 元素,是怎么转换到 BeanDefinitionHolder 的。
// BeanDefinitionParserDelegate.java
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele) {
return parseBeanDefinitionElement(ele, null);
}
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, BeanDefinition containingBean) {
String id = ele.getAttribute(ID_ATTRIBUTE);
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
List<String> aliases = new ArrayList<String>();
// 将 name 属性的定义按照 “逗号、分号、空格” 切分,形成一个 别名列表数组,
// 当然,如果你不定义 name 属性的话,就是空的了
// 我在附录中简单介绍了一下 id 和 name 的配置,大家可以看一眼,有个20秒就可以了
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}
String beanName = id;
// 如果没有指定id, 那么用别名列表的第一个名字作为beanName
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
if (logger.isDebugEnabled()) {
logger.debug("No XML 'id' specified - using '" + beanName +
"' as bean name and " + aliases + " as aliases");
}
}
if (containingBean == null) {
checkNameUniqueness(beanName, aliases, ele);
}
// 根据 <bean ...>...</bean> 中的配置创建 BeanDefinition,然后把配置中的信息都设置到实例中,
// 细节后面细说,先知道下面这行结束后,一个 BeanDefinition 实例就出来了。
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
// 到这里,整个 <bean /> 标签就算解析结束了,一个 BeanDefinition 就形成了。
if (beanDefinition != null) {
// 如果都没有设置 id 和 name,那么此时的 beanName 就会为 null,进入下面这块代码产生
// 如果读者不感兴趣的话,我觉得不需要关心这块代码,对本文源码分析来说,这些东西不重要
if (!StringUtils.hasText(beanName)) {
try {
if (containingBean != null) {// 按照我们的思路,这里 containingBean 是 null 的
beanName = BeanDefinitionReaderUtils.generateBeanName(
beanDefinition, this.readerContext.getRegistry(), true);
}
else {
// 如果我们不定义 id 和 name,那么我们引言里的那个例子:
// 1. beanName 为:com.javadoop.example.MessageServiceImpl#0
// 2. beanClassName 为:com.javadoop.example.MessageServiceImpl
beanName = this.readerContext.generateBeanName(beanDefinition);
String beanClassName = beanDefinition.getBeanClassName();
if (beanClassName != null &&
beanName.startsWith(beanClassName) && beanName.length() > beanClassName.length() &&
!this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {
// 把 beanClassName 设置为 Bean 的别名
aliases.add(beanClassName);
}
}
if (logger.isDebugEnabled()) {
logger.debug("Neither XML 'id' nor 'name' specified - " +
"using generated bean name [" + beanName + "]");
}
}
catch (Exception ex) {
error(ex.getMessage(), ele);
return null;
}
}
String[] aliasesArray = StringUtils.toStringArray(aliases);
// 返回 BeanDefinitionHolder
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
return null;
}
然后,我们再看看怎么根据配置创建 BeanDefinition 实例的:
public AbstractBeanDefinition parseBeanDefinitionElement(
Element ele, String beanName, BeanDefinition containingBean) {
this.parseState.push(new BeanEntry(beanName));
String className = null;
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
try {
String parent = null;
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}
// 创建 BeanDefinition,然后设置类信息而已,很简单,就不贴代码了
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
// 设置 BeanDefinition 的一堆属性,这些属性定义在 AbstractBeanDefinition 中
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
/**
* 下面的一堆是解析 <bean>......</bean> 内部的子元素,
* 解析出来以后的信息都放到 bd 的属性中
*/
// 解析 <meta />
parseMetaElements(ele, bd);
// 解析 <lookup-method />
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
// 解析 <replaced-method />
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
// 解析 <constructor-arg />
parseConstructorArgElements(ele, bd);
// 解析 <property />
parsePropertyElements(ele, bd);
// 解析 <qualifier />
parseQualifierElements(ele, bd);
bd.setResource(this.readerContext.getResource());
bd.setSource(extractSource(ele));
return bd;
}
catch (ClassNotFoundException ex) {
error("Bean class [" + className + "] not found", ele, ex);
}
catch (NoClassDefFoundError err) {
error("Class that bean class [" + className + "] depends on not found", ele, err);
}
catch (Throwable ex) {
error("Unexpected failure during bean definition parsing", ele, ex);
}
finally {
this.parseState.pop();
}
return null;
}
到这里,我们已经完成了根据 <bean /> 配置创建了一个 BeanDefinitionHolder 实例。注意,是一个。
我们回到解析 <bean /> 的入口方法:
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
// 将 <bean /> 节点转换为 BeanDefinitionHolder,就是上面说的一堆
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
// 如果有自定义属性的话,进行相应的解析,先忽略
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// 我们把这步叫做 注册Bean 吧
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
// 注册完成后,发送事件,本文不展开说这个
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
大家再仔细看一下这块吧,我们后面就不回来说这个了。这里已经根据一个 <bean /> 标签产生了一个 BeanDefinitionHolder 的实例,这个实例里面也就是一个 BeanDefinition 的实例和它的 beanName、aliases 这三个信息,注意,我们的关注点始终在 BeanDefinition 上:
public class BeanDefinitionHolder implements BeanMetadataElement {
private final BeanDefinition beanDefinition;
private final String beanName;
private final String[] aliases;
...
然后我们准备注册这个 BeanDefinition,最后,把这个注册事件发送出去。
下面,我们开始说说注册 Bean 吧。
注册 Bean
// BeanDefinitionReaderUtils.java
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
String beanName = definitionHolder.getBeanName();
// 注册这个 Bean
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// 如果还有别名的话,也要根据别名全部注册一遍,不然根据别名就会找不到 Bean 了
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
// alias -> beanName 保存它们的别名信息,这个很简单,用一个 map 保存一下就可以了,
// 获取的时候,会先将 alias 转换为 beanName,然后再查找
registry.registerAlias(beanName, alias);
}
}
}
别名注册的放一边,毕竟它很简单,我们看看怎么注册 Bean。
// DefaultListableBeanFactory.java 793
@Override
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
Assert.hasText(beanName, "Bean name must not be empty");
Assert.notNull(beanDefinition, "BeanDefinition must not be null");
if (beanDefinition instanceof AbstractBeanDefinition) {
try {
((AbstractBeanDefinition) beanDefinition).validate();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(...);
}
}
// old? 还记得 “允许 bean 覆盖” 这个配置吗?allowBeanDefinitionOverriding
BeanDefinition oldBeanDefinition;
// 之后会看到,所有的 Bean 注册后会放入这个 beanDefinitionMap 中
oldBeanDefinition = this.beanDefinitionMap.get(beanName);
// 处理重复名称的 Bean 定义的情况
if (oldBeanDefinition != null) {
if (!isAllowBeanDefinitionOverriding()) {
// 如果不允许覆盖的话,抛异常
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription()...
}
else if (oldBeanDefinition.getRole() < beanDefinition.getRole()) {
// log...用框架定义的 Bean 覆盖用户自定义的 Bean
}
else if (!beanDefinition.equals(oldBeanDefinition)) {
// log...用新的 Bean 覆盖旧的 Bean
}
else {
// log...用同等的 Bean 覆盖旧的 Bean,这里指的是 equals 方法返回 true 的 Bean
}
// 覆盖
this.beanDefinitionMap.put(beanName, beanDefinition);
}
else {
// 判断是否已经有其他的 Bean 开始初始化了.
// 注意,"注册Bean" 这个动作结束,Bean 依然还没有初始化,我们后面会有大篇幅说初始化过程,
// 在 Spring 容器启动的最后,会 预初始化 所有的 singleton beans
if (hasBeanCreationStarted()) {
// Cannot modify startup-time collection elements anymore (for stable iteration)
synchronized (this.beanDefinitionMap) {
this.beanDefinitionMap.put(beanName, beanDefinition);
List<String> updatedDefinitions = new ArrayList<String>(this.beanDefinitionNames.size() + 1);
updatedDefinitions.addAll(this.beanDefinitionNames);
updatedDefinitions.add(beanName);
this.beanDefinitionNames = updatedDefinitions;
if (this.manualSingletonNames.contains(beanName)) {
Set<String> updatedSingletons = new LinkedHashSet<String>(this.manualSingletonNames);
updatedSingletons.remove(beanName);
this.manualSingletonNames = updatedSingletons;
}
}
}
else {
// 最正常的应该是进到这个分支。
// 将 BeanDefinition 放到这个 map 中,这个 map 保存了所有的 BeanDefinition
this.beanDefinitionMap.put(beanName, beanDefinition);
// 这是个 ArrayList,所以会按照 bean 配置的顺序保存每一个注册的 Bean 的名字
this.beanDefinitionNames.add(beanName);
// 这是个 LinkedHashSet,代表的是手动注册的 singleton bean,
// 注意这里是 remove 方法,到这里的 Bean 当然不是手动注册的
// 手动指的是通过调用以下方法注册的 bean :
// registerSingleton(String beanName, Object singletonObject)
// 这不是重点,解释只是为了不让大家疑惑。Spring 会在后面"手动"注册一些 Bean,
// 如 "environment"、"systemProperties" 等 bean,我们自己也可以在运行时注册 Bean 到容器中的
this.manualSingletonNames.remove(beanName);
}
// 这个不重要,在预初始化的时候会用到,不必管它。
this.frozenBeanDefinitionNames = null;
}
if (oldBeanDefinition != null || containsSingleton(beanName)) {
resetBeanDefinition(beanName);
}
}
总结一下,到这里已经初始化了 Bean 容器,<bean /> 配置也相应的转换为了一个个 BeanDefinition,然后注册了各个 BeanDefinition 到注册中心,并且发送了注册事件。
到这里是一个分水岭,前面的内容都还算比较简单,大家要清楚地知道前面都做了哪些事情。
Bean 容器实例化完成后
说到这里,我们回到 refresh() 方法,我重新贴了一遍代码,看看我们说到哪了。是的,我们才说完 obtainFreshBeanFactory() 方法。
考虑到篇幅,这里开始大幅缩减掉没必要详细介绍的部分,大家直接看下面的代码中的注释就好了。
@Override
public void refresh() throws BeansException, IllegalStateException {
// 来个锁,不然 refresh() 还没结束,你又来个启动或销毁容器的操作,那不就乱套了嘛
synchronized (this.startupShutdownMonitor) {
// 准备工作,记录下容器的启动时间、标记“已启动”状态、处理配置文件中的占位符
prepareRefresh();
// 这步比较关键,这步完成后,配置文件就会解析成一个个 Bean 定义,注册到 BeanFactory 中,
// 当然,这里说的 Bean 还没有初始化,只是配置信息都提取出来了,
// 注册也只是将这些信息都保存到了注册中心(说到底核心是一个 beanName-> beanDefinition 的 map)
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// 设置 BeanFactory 的类加载器,添加几个 BeanPostProcessor,手动注册几个特殊的 bean
// 这块待会会展开说
prepareBeanFactory(beanFactory);
try {
// 【这里需要知道 BeanFactoryPostProcessor 这个知识点,Bean 如果实现了此接口,
// 那么在容器初始化以后,Spring 会负责调用里面的 postProcessBeanFactory 方法。】
// 这里是提供给子类的扩展点,到这里的时候,所有的 Bean 都加载、注册完成了,但是都还没有初始化
// 具体的子类可以在这步的时候添加一些特殊的 BeanFactoryPostProcessor 的实现类或做点什么事
postProcessBeanFactory(beanFactory);
// 调用 BeanFactoryPostProcessor 各个实现类的 postProcessBeanFactory(factory) 回调方法
invokeBeanFactoryPostProcessors(beanFactory);
// 注册 BeanPostProcessor 的实现类,注意看和 BeanFactoryPostProcessor 的区别
// 此接口两个方法: postProcessBeforeInitialization 和 postProcessAfterInitialization
// 两个方法分别在 Bean 初始化之前和初始化之后得到执行。这里仅仅是注册,之后会看到回调这两方法的时机
registerBeanPostProcessors(beanFactory);
// 初始化当前 ApplicationContext 的 MessageSource,国际化这里就不展开说了,不然没完没了了
initMessageSource();
// 初始化当前 ApplicationContext 的事件广播器,这里也不展开了
initApplicationEventMulticaster();
// 从方法名就可以知道,典型的模板方法(钩子方法),不展开说
// 具体的子类可以在这里初始化一些特殊的 Bean(在初始化 singleton beans 之前)
onRefresh();
// 注册事件监听器,监听器需要实现 ApplicationListener 接口。这也不是我们的重点,过
registerListeners();
// 重点,重点,重点
// 初始化所有的 singleton beans
//(lazy-init 的除外)
finishBeanFactoryInitialization(beanFactory);
// 最后,广播事件,ApplicationContext 初始化完成,不展开
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
// 销毁已经初始化的 singleton 的 Beans,以免有些 bean 会一直占用资源
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// 把异常往外抛
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
}
准备 Bean 容器: prepareBeanFactory
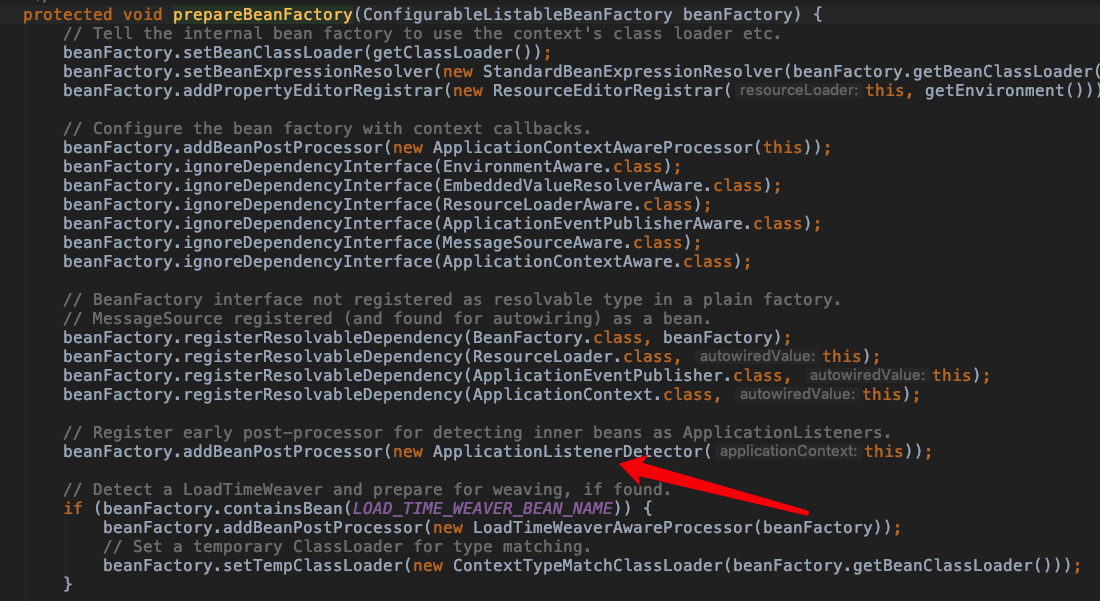
之前我们说过,Spring 把我们在 xml 配置的 bean 都注册以后,会"手动"注册一些特殊的 bean。
这里简单介绍下 prepareBeanFactory(factory) 方法:
prepareBeanFactory(factory)
/**
* Configure the factory's standard context characteristics,
* such as the context's ClassLoader and post-processors.
* @param beanFactory the BeanFactory to configure
*/
protected void prepareBeanFactory(ConfigurableListableBeanFactory beanFactory) {
// 设置 BeanFactory 的类加载器,我们知道 BeanFactory 需要加载类,也就需要类加载器,
// 这里设置为加载当前 ApplicationContext 类的类加载器
beanFactory.setBeanClassLoader(getClassLoader());
// 设置 BeanExpressionResolver
beanFactory.setBeanExpressionResolver(new StandardBeanExpressionResolver(beanFactory.getBeanClassLoader()));
//
beanFactory.addPropertyEditorRegistrar(new ResourceEditorRegistrar(this, getEnvironment()));
// 添加一个 BeanPostProcessor,这个 processor 比较简单:
// 实现了 Aware 接口的 beans 在初始化的时候,这个 processor 负责回调,
// 这个我们很常用,如我们会为了获取 ApplicationContext 而 implement ApplicationContextAware
// 注意:它不仅仅回调 ApplicationContextAware,
// 还会负责回调 EnvironmentAware、ResourceLoaderAware 等,看下源码就清楚了
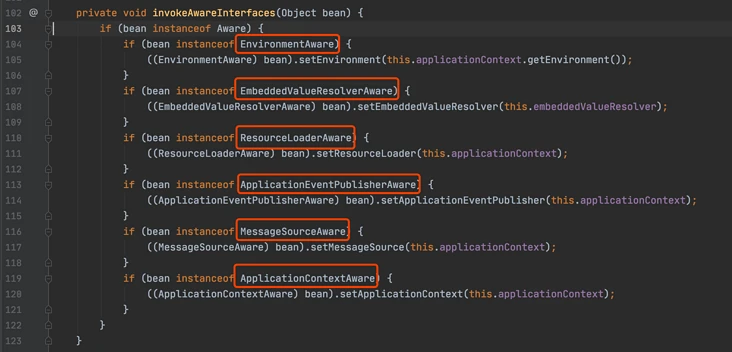
beanFactory.addBeanPostProcessor(new ApplicationContextAwareProcessor(this));
// 下面几行的意思就是,如果某个 bean 依赖于以下几个接口的实现类,在自动装配的时候忽略它们,
// Spring 会通过其他方式来处理这些依赖。
beanFactory.ignoreDependencyInterface(EnvironmentAware.class);
beanFactory.ignoreDependencyInterface(EmbeddedValueResolverAware.class);
beanFactory.ignoreDependencyInterface(ResourceLoaderAware.class);
beanFactory.ignoreDependencyInterface(ApplicationEventPublisherAware.class);
beanFactory.ignoreDependencyInterface(MessageSourceAware.class);
beanFactory.ignoreDependencyInterface(ApplicationContextAware.class);
/**
* 下面几行就是为特殊的几个 bean 赋值,如果有 bean 依赖了以下几个,会注入这边相应的值,
* 之前我们说过,"当前 ApplicationContext 持有一个 BeanFactory",这里解释了第一行
* ApplicationContext 还继承了 ResourceLoader、ApplicationEventPublisher、MessageSource
* 所以对于这几个依赖,可以赋值为 this,注意 this 是一个 ApplicationContext
* 那这里怎么没看到为 MessageSource 赋值呢?那是因为 MessageSource 被注册成为了一个普通的 bean
*/
beanFactory.registerResolvableDependency(BeanFactory.class, beanFactory);
beanFactory.registerResolvableDependency(ResourceLoader.class, this);
beanFactory.registerResolvableDependency(ApplicationEventPublisher.class, this);
beanFactory.registerResolvableDependency(ApplicationContext.class, this);
// 这个 BeanPostProcessor 也很简单,在 bean 实例化后,如果是 ApplicationListener 的子类,
// 那么将其添加到 listener 列表中,可以理解成:注册 事件监听器
beanFactory.addBeanPostProcessor(new ApplicationListenerDetector(this));
// 这里涉及到特殊的 bean,名为:loadTimeWeaver,这不是我们的重点,忽略它
// tips: ltw 是 AspectJ 的概念,指的是在运行期进行织入,这个和 Spring AOP 不一样,
// 感兴趣的读者请参考我写的关于 AspectJ 的另一篇文章 https://www.javadoop.com/post/aspectj
if (beanFactory.containsBean(LOAD_TIME_WEAVER_BEAN_NAME)) {
beanFactory.addBeanPostProcessor(new LoadTimeWeaverAwareProcessor(beanFactory));
// Set a temporary ClassLoader for type matching.
beanFactory.setTempClassLoader(new ContextTypeMatchClassLoader(beanFactory.getBeanClassLoader()));
}
/**
* 从下面几行代码我们可以知道,Spring 往往很 "智能" 就是因为它会帮我们默认注册一些有用的 bean,
* 我们也可以选择覆盖
*/
// 如果没有定义 "environment" 这个 bean,那么 Spring 会 "手动" 注册一个
if (!beanFactory.containsLocalBean(ENVIRONMENT_BEAN_NAME)) {
beanFactory.registerSingleton(ENVIRONMENT_BEAN_NAME, getEnvironment());
}
// 如果没有定义 "systemProperties" 这个 bean,那么 Spring 会 "手动" 注册一个
if (!beanFactory.containsLocalBean(SYSTEM_PROPERTIES_BEAN_NAME)) {
beanFactory.registerSingleton(SYSTEM_PROPERTIES_BEAN_NAME, getEnvironment().getSystemProperties());
}
// 如果没有定义 "systemEnvironment" 这个 bean,那么 Spring 会 "手动" 注册一个
if (!beanFactory.containsLocalBean(SYSTEM_ENVIRONMENT_BEAN_NAME)) {
beanFactory.registerSingleton(SYSTEM_ENVIRONMENT_BEAN_NAME, getEnvironment().getSystemEnvironment());
}
}
在上面这块代码中,Spring 对一些特殊的 bean 进行了处理,读者如果暂时还不能消化它们也没有关系,慢慢往下看。
初始化所有的 singleton beans
我们的重点当然是 finishBeanFactoryInitialization(beanFactory); 这个巨头了,这里会负责初始化所有的 singleton beans。
注意,后面的描述中,我都会使用初始化或预初始化来代表这个阶段,Spring 会在这个阶段完成所有的 singleton beans 的实例化。
我们来总结一下,到目前为止,应该说 BeanFactory 已经创建完成,并且所有的实现了 BeanFactoryPostProcessor 接口的 Bean 都已经初始化并且其中的 postProcessBeanFactory(factory) 方法已经得到回调执行了。而且 Spring 已经“手动”注册了一些特殊的 Bean,如 ‘environment’、‘systemProperties’ 等。
剩下的就是初始化 singleton beans 了,我们知道它们是单例的,如果没有设置懒加载,那么 Spring 会在接下来初始化所有的 singleton beans。
// AbstractApplicationContext.java 834
// 初始化剩余的 singleton beans
protected void finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory) {
// 首先,初始化名字为 conversionService 的 Bean。本着送佛送到西的精神,我在附录中简单介绍了一下 ConversionService,因为这实在太实用了
// 什么,看代码这里没有初始化 Bean 啊!
// 注意了,初始化的动作包装在 beanFactory.getBean(...) 中,这里先不说细节,先往下看吧
if (beanFactory.containsBean(CONVERSION_SERVICE_BEAN_NAME) &&
beanFactory.isTypeMatch(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class)) {
beanFactory.setConversionService(
beanFactory.getBean(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class));
}
// Register a default embedded value resolver if no bean post-processor
// (such as a PropertyPlaceholderConfigurer bean) registered any before:
// at this point, primarily for resolution in annotation attribute values.
if (!beanFactory.hasEmbeddedValueResolver()) {
beanFactory.addEmbeddedValueResolver(new StringValueResolver() {
@Override
public String resolveStringValue(String strVal) {
return getEnvironment().resolvePlaceholders(strVal);
}
});
}
// 先初始化 LoadTimeWeaverAware 类型的 Bean
// 之前也说过,这是 AspectJ 相关的内容,放心跳过吧
String[] weaverAwareNames = beanFactory.getBeanNamesForType(LoadTimeWeaverAware.class, false, false);
for (String weaverAwareName : weaverAwareNames) {
getBean(weaverAwareName);
}
// Stop using the temporary ClassLoader for type matching.
beanFactory.setTempClassLoader(null);
// 没什么别的目的,因为到这一步的时候,Spring 已经开始预初始化 singleton beans 了,
// 肯定不希望这个时候还出现 bean 定义解析、加载、注册。
beanFactory.freezeConfiguration();
// 开始初始化
beanFactory.preInstantiateSingletons();
}
从上面最后一行往里看,我们就又回到 DefaultListableBeanFactory 这个类了,这个类大家应该都不陌生了吧。
// DefaultListableBeanFactory.java 728
@Override
public void preInstantiateSingletons() throws BeansException {
if (this.logger.isDebugEnabled()) {
this.logger.debug("Pre-instantiating singletons in " + this);
}
// this.beanDefinitionNames 保存了所有的 beanNames
List<String> beanNames = new ArrayList<String>(this.beanDefinitionNames);
// 触发所有的非懒加载的 singleton beans 的初始化操作
for (String beanName : beanNames) {
// 合并父 Bean 中的配置,注意 <bean id="" class="" parent="" /> 中的 parent,用的不多吧,
// 考虑到这可能会影响大家的理解,我在附录中解释了一下 "Bean 继承",不了解的请到附录中看一下
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
// 非抽象、非懒加载的 singletons。如果配置了 'abstract = true',那是不需要初始化的
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
// 处理 FactoryBean(读者如果不熟悉 FactoryBean,请移步附录区了解)
if (isFactoryBean(beanName)) {
// FactoryBean 的话,在 beanName 前面加上 ‘&’ 符号。再调用 getBean,getBean 方法别急
final FactoryBean<?> factory = (FactoryBean<?>) getBean(FACTORY_BEAN_PREFIX + beanName);
// 判断当前 FactoryBean 是否是 SmartFactoryBean 的实现,此处忽略,直接跳过
boolean isEagerInit;
if (System.getSecurityManager() != null && factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged(new PrivilegedAction<Boolean>() {
@Override
public Boolean run() {
return ((SmartFactoryBean<?>) factory).isEagerInit();
}
}, getAccessControlContext());
}
else {
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean<?>) factory).isEagerInit());
}
if (isEagerInit) {
getBean(beanName);
}
}
else {
// 对于普通的 Bean,只要调用 getBean(beanName) 这个方法就可以进行初始化了
getBean(beanName);
}
}
}
// 到这里说明所有的非懒加载的 singleton beans 已经完成了初始化
// 如果我们定义的 bean 是实现了 SmartInitializingSingleton 接口的,那么在这里得到回调,忽略
for (String beanName : beanNames) {
Object singletonInstance = getSingleton(beanName);
if (singletonInstance instanceof SmartInitializingSingleton) {
final SmartInitializingSingleton smartSingleton = (SmartInitializingSingleton) singletonInstance;
if (System.getSecurityManager() != null) {
AccessController.doPrivileged(new PrivilegedAction<Object>() {
@Override
public Object run() {
smartSingleton.afterSingletonsInstantiated();
return null;
}
}, getAccessControlContext());
}
else {
smartSingleton.afterSingletonsInstantiated();
}
}
}
}
接下来,我们就进入到 getBean(beanName) 方法了,这个方法我们经常用来从 BeanFactory 中获取一个 Bean,而初始化的过程也封装到了这个方法里。
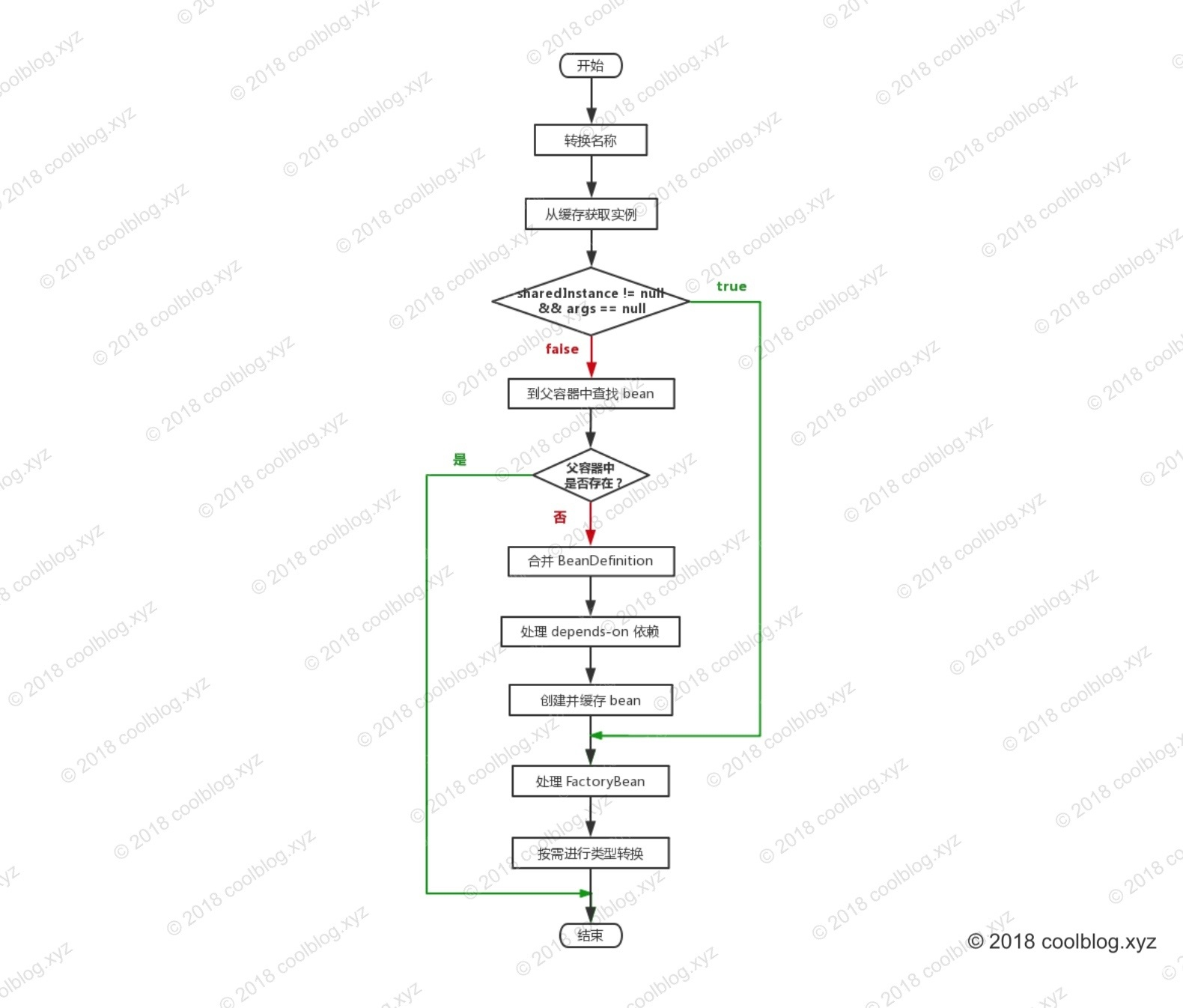
获取 Bean
容器和 Bean 已经准备好了,接着就是获取 Bean 去使用了。
俯瞰 getBean(String) 源码
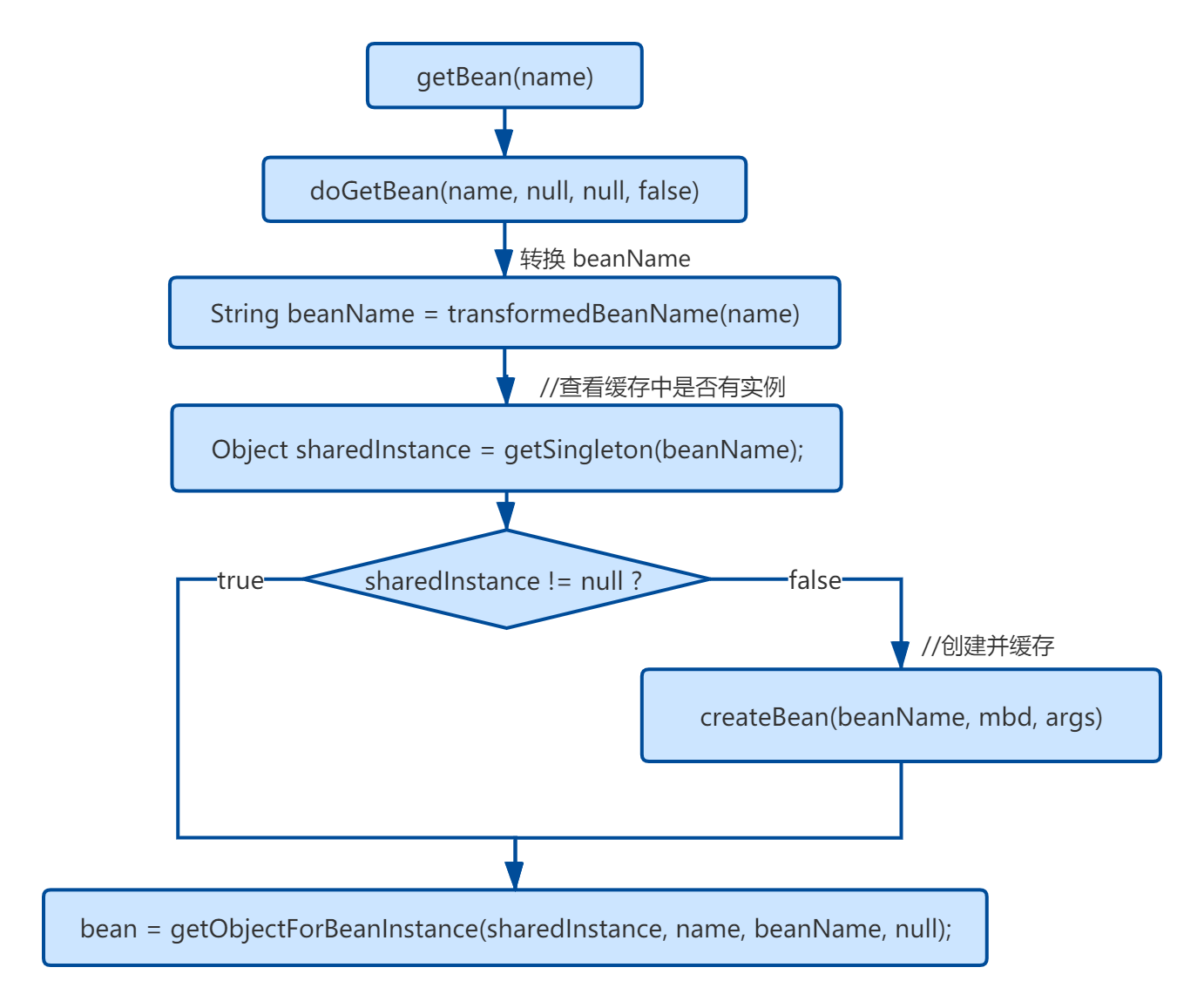
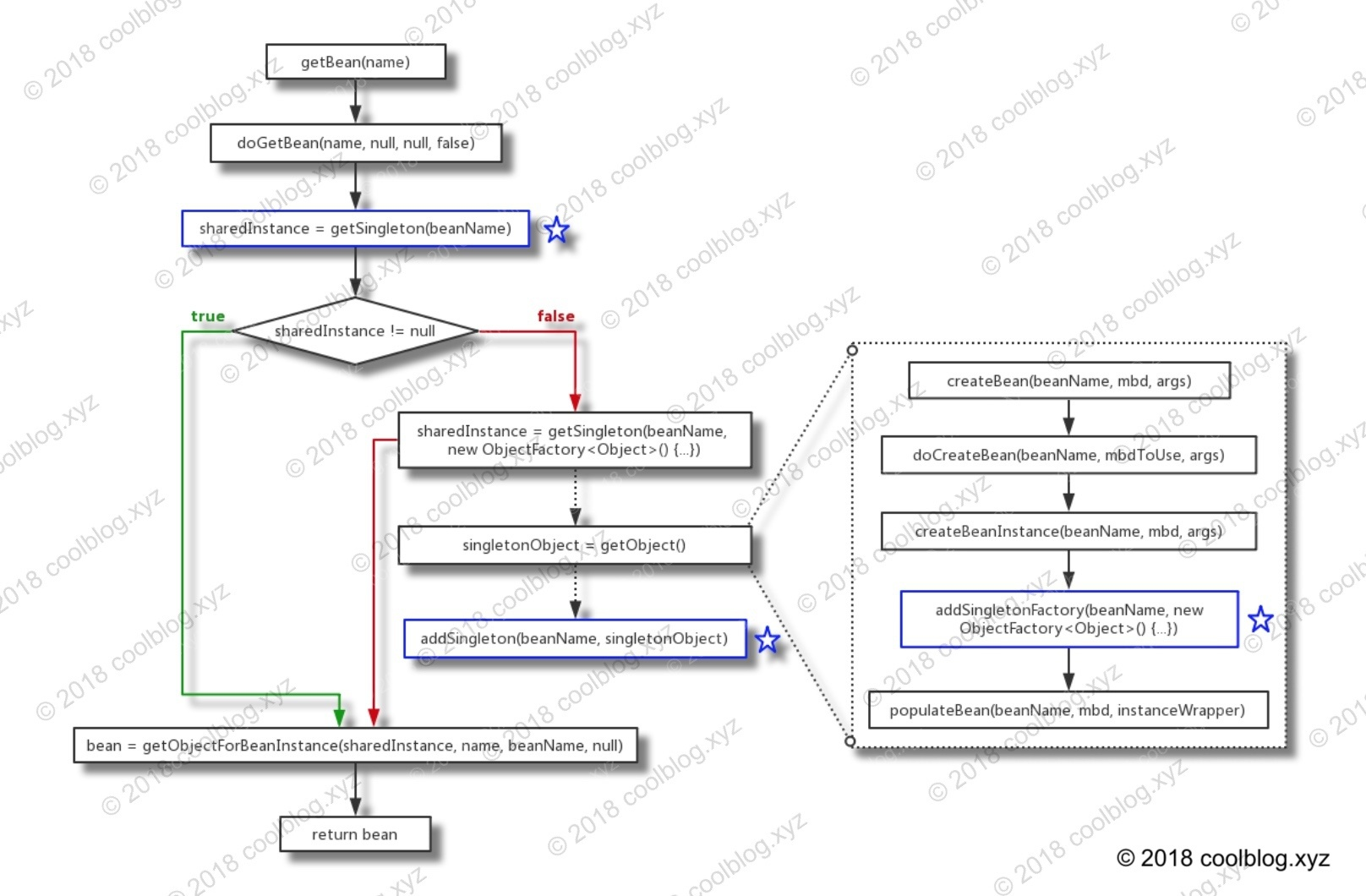
在本小节,我们先从战略上俯瞰 getBean(String) 方法的实现源码。代码如下:
public Object getBean(String name) throws BeansException {
// getBean 是一个空壳方法,所有的逻辑都封装在 doGetBean 方法中
return doGetBean(name, null, null, false);
}
protected <T> T doGetBean(
final String name, final Class<T> requiredType, final Object[] args, boolean typeCheckOnly)
throws BeansException {
/*
* 通过 name 获取 beanName。这里不使用 name 直接作为 beanName 有两点原因:
* 1. name 可能会以 & 字符开头,表明调用者想获取 FactoryBean 本身,而非 FactoryBean
* 实现类所创建的 bean。在 BeanFactory 中,FactoryBean 的实现类和其他的 bean 存储
* 方式是一致的,即 <beanName, bean>,beanName 中是没有 & 这个字符的。所以我们需要
* 将 name 的首字符 & 移除,这样才能从缓存里取到 FactoryBean 实例。
* 2. 若 name 是一个别名,则应将别名转换为具体的实例名,也就是 beanName。
*/
final String beanName = transformedBeanName(name);
// 注意跟着这个,这个是返回值
Object bean;
/*
* 从缓存中获取单例 bean。Spring 是使用 Map 作为 beanName 和 bean 实例的缓存的,所以这
* 里暂时可以把 getSingleton(beanName) 等价于 beanMap.get(beanName)。当然,实际的
* 逻辑并非如此简单,后面再细说。
*/
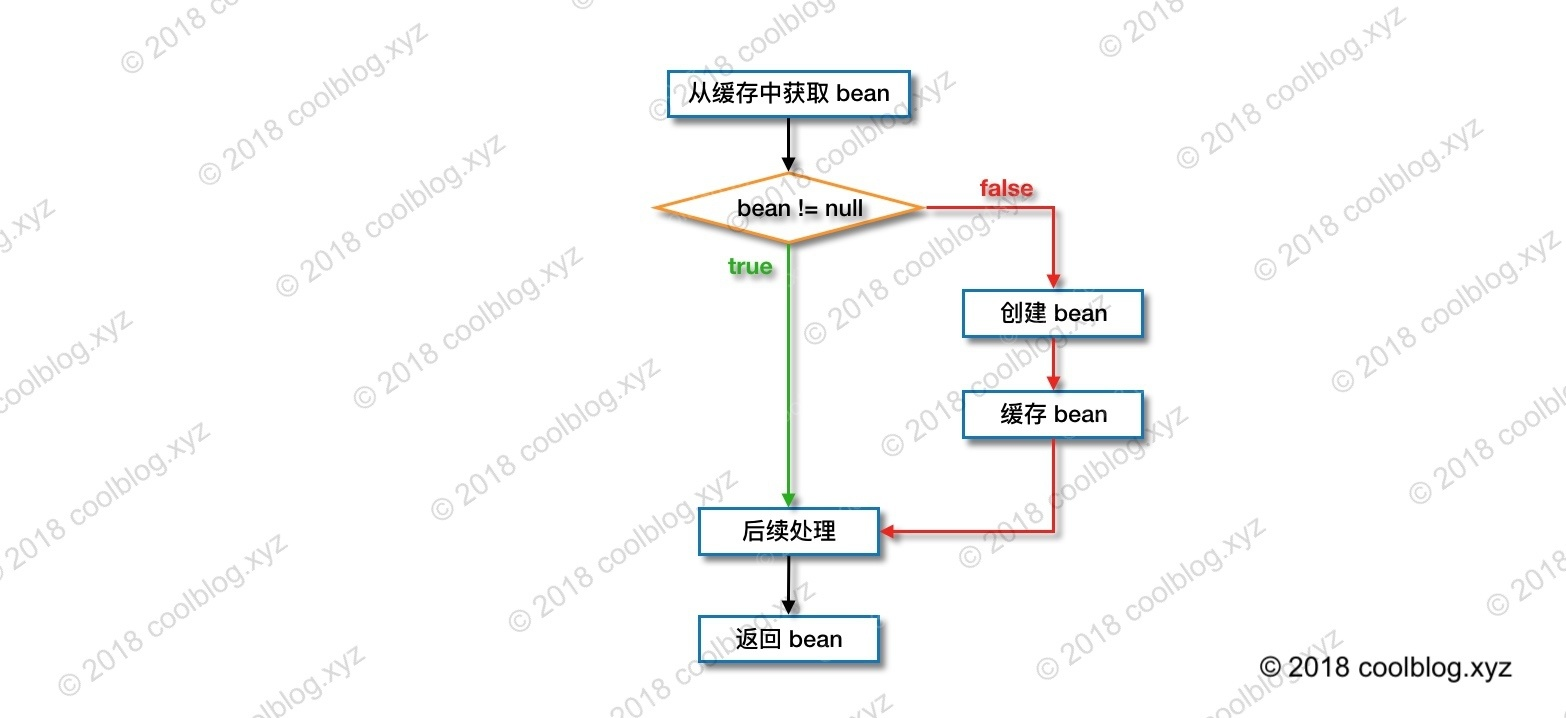
Object sharedInstance = getSingleton(beanName);
/*
* 如果 sharedInstance = null,则说明缓存里没有对应的实例,表明这个实例还没创建。
* BeanFactory 并不会在一开始就将所有的单例 bean 实例化好,而是在调用 getBean 获取
* bean 时再实例化,也就是懒加载。
* getBean 方法有很多重载,比如 getBean(String name, Object... args),我们在首次获取
* 某个 bean 时,可以传入用于初始化 bean 的参数数组(args),BeanFactory 会根据这些参数
* 去匹配合适的构造方法构造 bean 实例。当然,如果单例 bean 早已创建好,这里的 args 就没有
* 用了,BeanFactory 不会多次实例化单例 bean。
*/
if (sharedInstance != null && args == null) {
if (logger.isDebugEnabled()) {
if (isSingletonCurrentlyInCreation(beanName)) {
logger.debug("Returning eagerly cached instance of singleton bean '" + beanName +
"' that is not fully initialized yet - a consequence of a circular reference");
}
else {
logger.debug("Returning cached instance of singleton bean '" + beanName + "'");
}
}
/*
* 如果 sharedInstance 是普通的单例 bean,下面的方法会直接返回。但如果
* sharedInstance 是 FactoryBean 类型的,则需调用 getObject 工厂方法获取真正的
* bean 实例。如果用户想获取 FactoryBean 本身,这里也不会做特别的处理,直接返回
* 即可。毕竟 FactoryBean 的实现类本身也是一种 bean,只不过具有一点特殊的功能而已。
*/
bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);
}
/*
* 如果上面的条件不满足,则表明 sharedInstance 可能为空,此时 beanName 对应的 bean
* 实例可能还未创建。这里还存在另一种可能,如果当前容器有父容器,beanName 对应的 bean 实例
* 可能是在父容器中被创建了,所以在创建实例前,需要先去父容器里检查一下。
*/
else {
// BeanFactory 不缓存 Prototype 类型的 bean,无法处理该类型 bean 的循环依赖问题
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
// 如果 sharedInstance = null,则到父容器中查找 bean 实例
BeanFactory parentBeanFactory = getParentBeanFactory();
if (parentBeanFactory != null && !containsBeanDefinition(beanName)) {
// 获取 name 对应的 beanName,如果 name 是以 & 字符开头,则返回 & + beanName
String nameToLookup = originalBeanName(name);
// 根据 args 是否为空,以决定调用父容器哪个方法获取 bean
if (args != null) {
// 返回父容器的查询结果
return (T) parentBeanFactory.getBean(nameToLookup, args);
}
else {
return parentBeanFactory.getBean(nameToLookup, requiredType);
}
}
if (!typeCheckOnly) {
markBeanAsCreated(beanName);
}
/*
* 稍稍总结一下:
* 到这里的话,要准备创建 Bean 了,对于 singleton 的 Bean 来说,容器中还没创建过此 Bean;
* 对于 prototype 的 Bean 来说,本来就是要创建一个新的 Bean。
*/
try {
// 合并父 BeanDefinition 与子 BeanDefinition,后面会单独分析这个方法
final RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
checkMergedBeanDefinition(mbd, beanName, args);
// 检查是否有 dependsOn 依赖,如果有则先初始化所依赖的 bean
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
for (String dep : dependsOn) {
/*
* 检测是否存在 depends-on 循环依赖,若存在则抛异常。比如 A 依赖 B,
* B 又依赖 A,他们的配置如下:
* <bean id="beanA" class="BeanA" depends-on="beanB">
* <bean id="beanB" class="BeanB" depends-on="beanA">
*
* beanA 要求 beanB 在其之前被创建,但 beanB 又要求 beanA 先于它
* 创建。这个时候形成了循环,对于 depends-on 循环,Spring 会直接
* 抛出异常
*/
if (isDependent(beanName, dep)) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Circular depends-on relationship between '" + beanName + "' and '" + dep + "'");
}
// 注册依赖记录
registerDependentBean(dep, beanName);
try {
// 先初始化被依赖项 加载 depends-on 依赖
getBean(dep);
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"'" + beanName + "' depends on missing bean '" + dep + "'", ex);
}
}
}
// 创建 bean 实例
if (mbd.isSingleton()) {
/*
* 这里并没有直接调用 createBean 方法创建 bean 实例,而是通过
* getSingleton(String, ObjectFactory) 方法获取 bean 实例。
* getSingleton(String, ObjectFactory) 方法会在内部调用
* ObjectFactory 的 getObject() 方法创建 bean,并会在创建完成后,
* 将 bean 放入缓存中。关于 getSingleton 方法的分析,本文先不展开,我会在
* 后面的文章中进行分析
*/
sharedInstance = getSingleton(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
try {
// 创建 bean 实例
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
}
});
// 如果 bean 是 FactoryBean 类型,则调用工厂方法获取真正的 bean 实例。否则直接返回 bean 实例
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
// 创建 prototype 类型的 bean 实例
else if (mbd.isPrototype()) {
Object prototypeInstance = null;
try {
beforePrototypeCreation(beanName);
prototypeInstance = createBean(beanName, mbd, args);
}
finally {
afterPrototypeCreation(beanName);
}
bean = getObjectForBeanInstance(prototypeInstance, name, beanName, mbd);
}
// 创建其他类型的 bean 实例
else {
String scopeName = mbd.getScope();
final Scope scope = this.scopes.get(scopeName);
if (scope == null) {
throw new IllegalStateException("No Scope registered for scope name '" + scopeName + "'");
}
try {
Object scopedInstance = scope.get(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
beforePrototypeCreation(beanName);
try {
return createBean(beanName, mbd, args);
}
finally {
afterPrototypeCreation(beanName);
}
}
});
bean = getObjectForBeanInstance(scopedInstance, name, beanName, mbd);
}
catch (IllegalStateException ex) {
throw new BeanCreationException(beanName,
"Scope '" + scopeName + "' is not active for the current thread; consider " +
"defining a scoped proxy for this bean if you intend to refer to it from a singleton",
ex);
}
}
}
catch (BeansException ex) {
cleanupAfterBeanCreationFailure(beanName);
throw ex;
}
}
// 如果需要进行类型转换,则在此处进行转换。类型转换这一块我没细看,就不多说了。
if (requiredType != null && bean != null && !requiredType.isInstance(bean)) {
try {
return getTypeConverter().convertIfNecessary(bean, requiredType);
}
catch (TypeMismatchException ex) {
if (logger.isDebugEnabled()) {
logger.debug("Failed to convert bean '" + name + "' to required type '" +
ClassUtils.getQualifiedName(requiredType) + "'", ex);
}
throw new BeanNotOfRequiredTypeException(name, requiredType, bean.getClass());
}
}
// 返回 bean
return (T) bean;
}
createBean
大家应该也猜到了,接下来当然是分析 createBean 方法:
protected abstract Object createBean(String beanName, RootBeanDefinition mbd, Object[] args) throws BeanCreationException;
第三个参数 args 数组代表创建实例需要的参数,不就是给构造方法用的参数,或者是工厂 Bean 的参数嘛,不过要注意,在我们的初始化阶段,args 是 null。
这回我们要到一个新的类了 AbstractAutowireCapableBeanFactory,看类名,AutowireCapable?类名是不是也说明了点问题了。
主要是为了以下场景,采用 @Autowired 注解注入属性值:
public class MessageServiceImpl implements MessageService {
@Autowired
private UserService userService;
public String getMessage() {
return userService.getMessage();
}
}
<bean id="messageService" class="com.example.MessageServiceImpl" />
以上这种属于混用了 xml 和 注解 两种方式的配置方式,Spring 会处理这种情况。
好了,读者要知道这么回事就可以了,继续向前。
// AbstractAutowireCapableBeanFactory.java 447
/**
* Central method of this class: creates a bean instance,
* populates the bean instance, applies post-processors, etc.
* @see #doCreateBean
*/
@Override
protected Object createBean(String beanName, RootBeanDefinition mbd, Object[] args) throws BeanCreationException {
if (logger.isDebugEnabled()) {
logger.debug("Creating instance of bean '" + beanName + "'");
}
RootBeanDefinition mbdToUse = mbd;
// 确保 BeanDefinition 中的 Class 被加载
Class<?> resolvedClass = resolveBeanClass(mbd, beanName);
if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null) {
mbdToUse = new RootBeanDefinition(mbd);
mbdToUse.setBeanClass(resolvedClass);
}
// 准备方法覆写,这里又涉及到一个概念:MethodOverrides,它来自于 bean 定义中的 <lookup-method />
// 和 <replaced-method />,如果读者感兴趣,回到 bean 解析的地方看看对这两个标签的解析。
// 我在附录中也对这两个标签的相关知识点进行了介绍,读者可以移步去看看
try {
mbdToUse.prepareMethodOverrides();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(mbdToUse.getResourceDescription(),
beanName, "Validation of method overrides failed", ex);
}
try {
// 让 InstantiationAwareBeanPostProcessor 在这一步有机会返回代理,
Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
if (bean != null) {
return bean;
}
}
catch (Throwable ex) {
throw new BeanCreationException(mbdToUse.getResourceDescription(), beanName,
"BeanPostProcessor before instantiation of bean failed", ex);
}
// 重头戏,创建 bean
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
if (logger.isDebugEnabled()) {
logger.debug("Finished creating instance of bean '" + beanName + "'");
}
return beanInstance;
}
我们继续往里看 doCreateBean 这个方法:
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final Object[] args)
throws BeanCreationException {
// Instantiate the bean.
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
// 说明不是 FactoryBean,这里实例化 Bean,这里非常关键,细节之后再说
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
// 这个就是 Bean 里面的 我们定义的类 的实例,很多地方我直接描述成 "bean 实例"
final Object bean = (instanceWrapper != null ? instanceWrapper.getWrappedInstance() : null);
// 类型
Class<?> beanType = (instanceWrapper != null ? instanceWrapper.getWrappedClass() : null);
mbd.resolvedTargetType = beanType;
// 建议跳过吧,涉及接口:MergedBeanDefinitionPostProcessor
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
// MergedBeanDefinitionPostProcessor,这个我真不展开说了,直接跳过吧,很少用的
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Post-processing of merged bean definition failed", ex);
}
mbd.postProcessed = true;
}
}
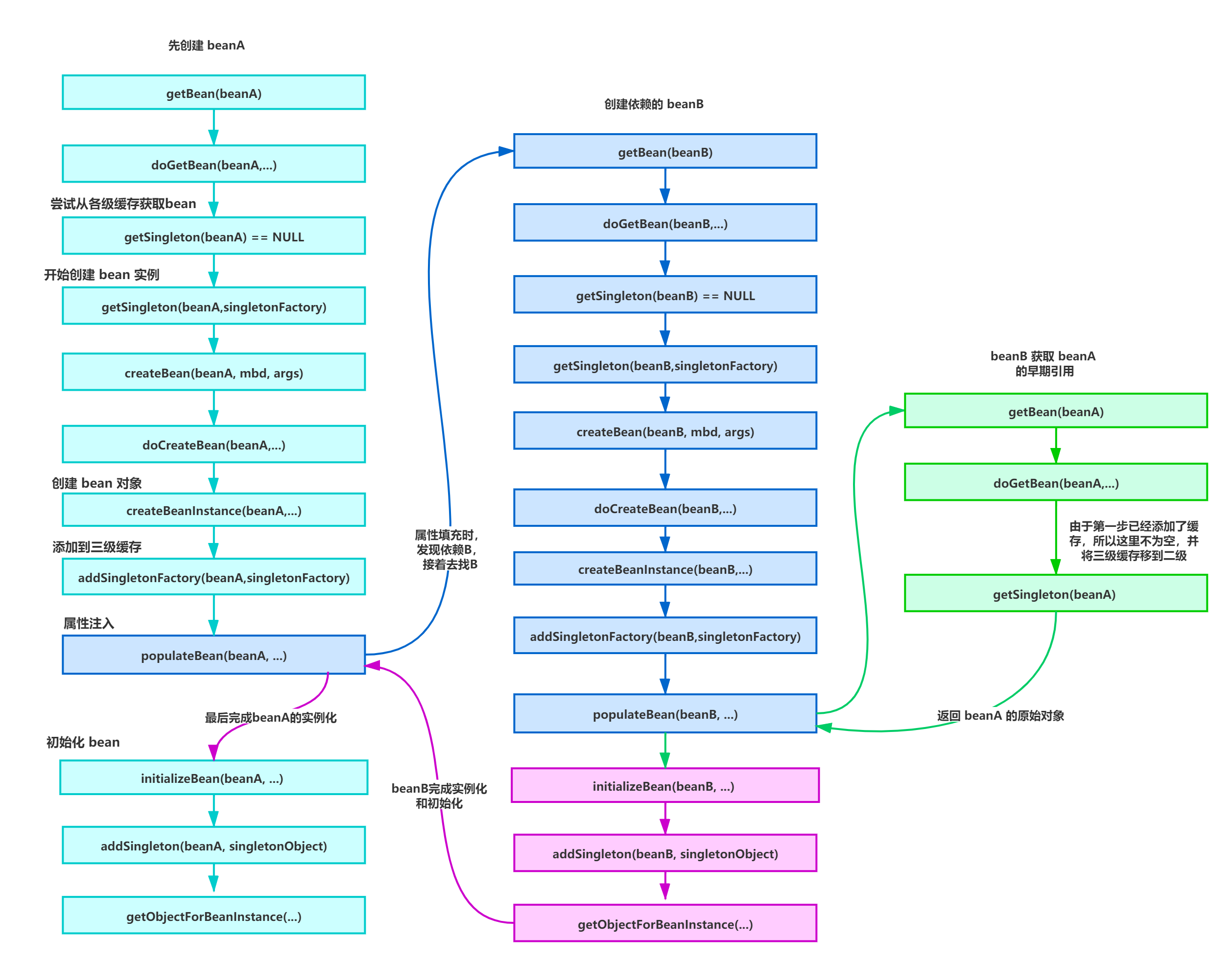
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
// 下面这块代码是为了解决循环依赖的问题
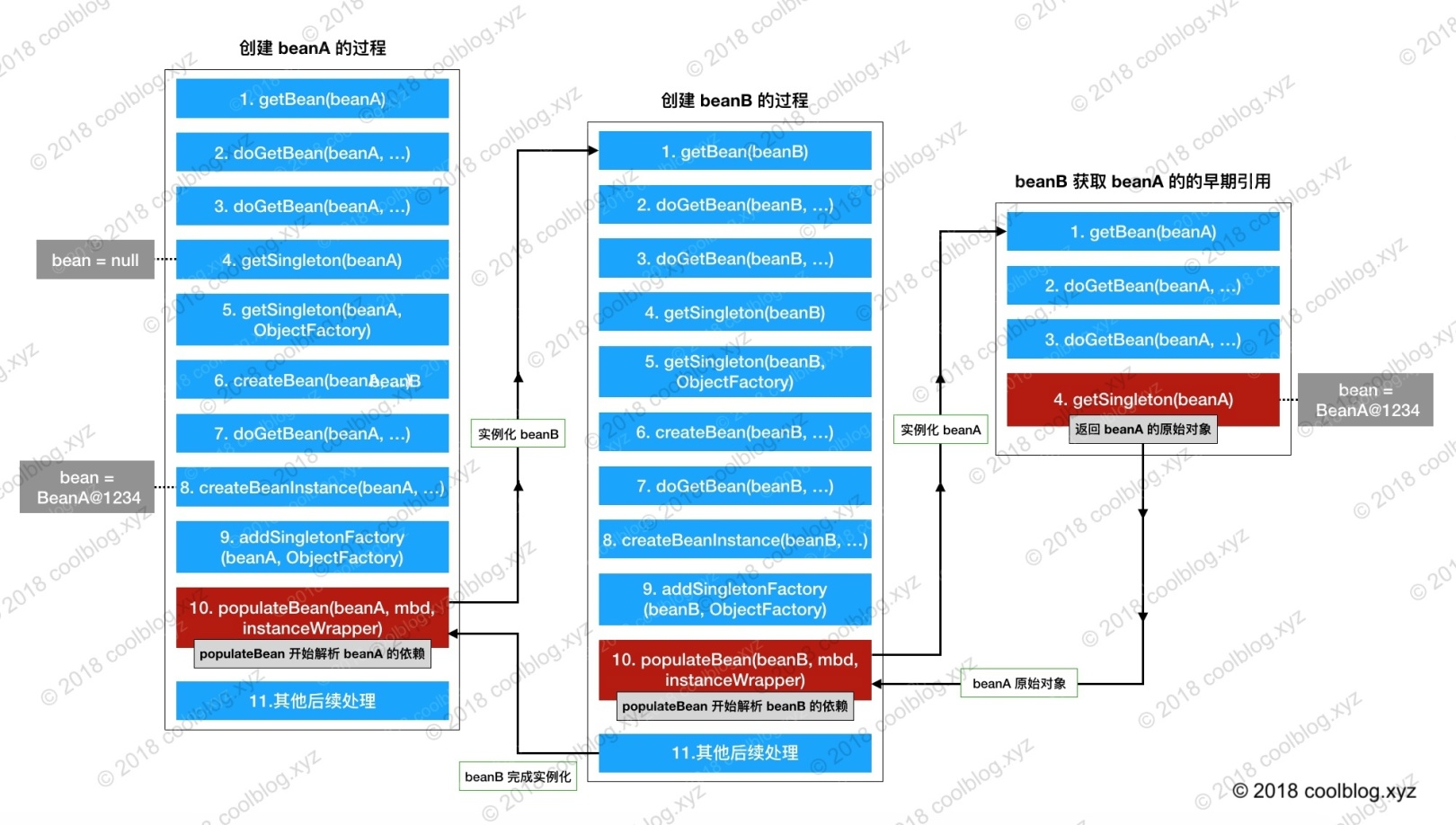
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isDebugEnabled()) {
logger.debug("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
addSingletonFactory(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
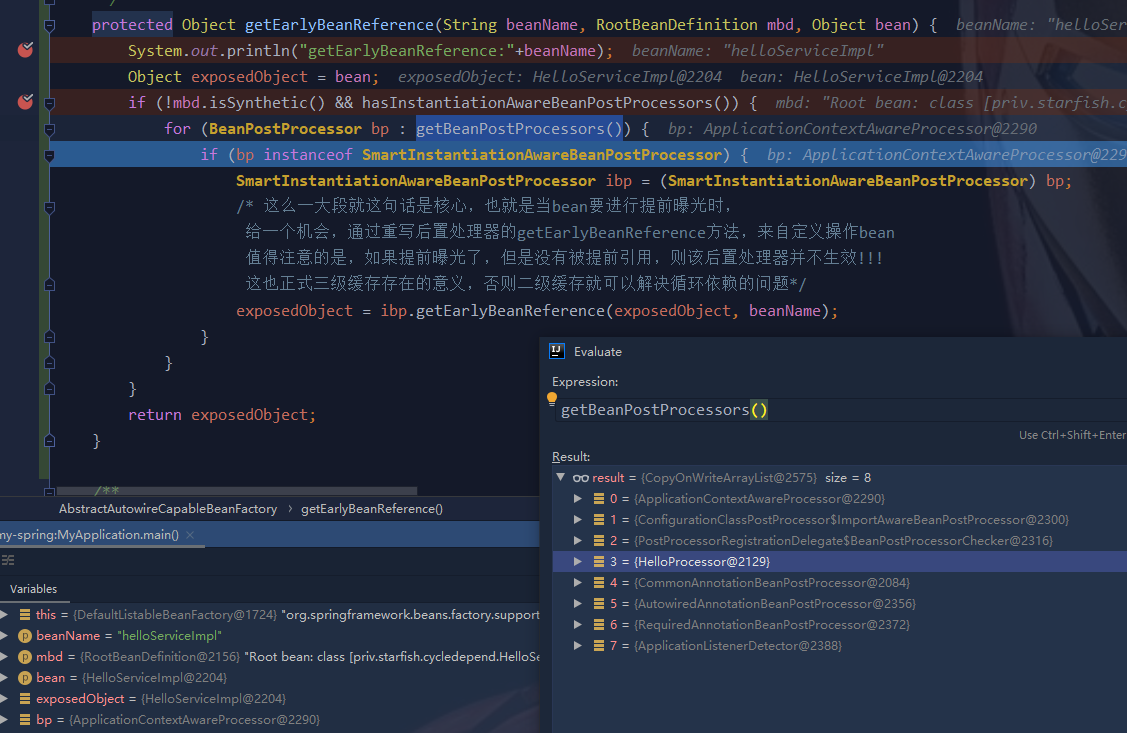
return getEarlyBeanReference(beanName, mbd, bean);
}
});
}
// Initialize the bean instance.
Object exposedObject = bean;
try {
// 这一步也是非常关键的,这一步负责属性装配,因为前面的实例只是实例化了,并没有设值,这里就是设值
populateBean(beanName, mbd, instanceWrapper);
if (exposedObject != null) {
// 还记得 init-method 吗?还有 InitializingBean 接口?还有 BeanPostProcessor 接口?
// 这里就是处理 bean 初始化完成后的各种回调
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
}
catch (Throwable ex) {
if (ex instanceof BeanCreationException && beanName.equals(((BeanCreationException) ex).getBeanName())) {
throw (BeanCreationException) ex;
}
else {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Initialization of bean failed", ex);
}
}
if (earlySingletonExposure) {
//
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
String[] dependentBeans = getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet<String>(dependentBeans.length);
for (String dependentBean : dependentBeans) {
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName,
"Bean with name '" + beanName + "' has been injected into other beans [" +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
"] in its raw version as part of a circular reference, but has eventually been " +
"wrapped. This means that said other beans do not use the final version of the " +
"bean. This is often the result of over-eager type matching - consider using " +
"'getBeanNamesOfType' with the 'allowEagerInit' flag turned off, for example.");
}
}
}
}
// Register bean as disposable.
try {
registerDisposableBeanIfNecessary(beanName, bean, mbd);
}
catch (BeanDefinitionValidationException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Invalid destruction signature", ex);
}
return exposedObject;
}
到这里,我们已经分析完了 doCreateBean 方法,总的来说,我们已经说完了整个初始化流程。
接下来我们挑 doCreateBean 中的三个细节出来说说。
一个是创建 Bean 实例的 createBeanInstance 方法,一个是依赖注入的 populateBean 方法,还有就是回调方法 initializeBean。
注意了,接下来的这三个方法要认真说那也是极其复杂的,很多地方我就点到为止了,感兴趣的读者可以自己往里看,最好就是碰到不懂的,自己写代码去调试它。
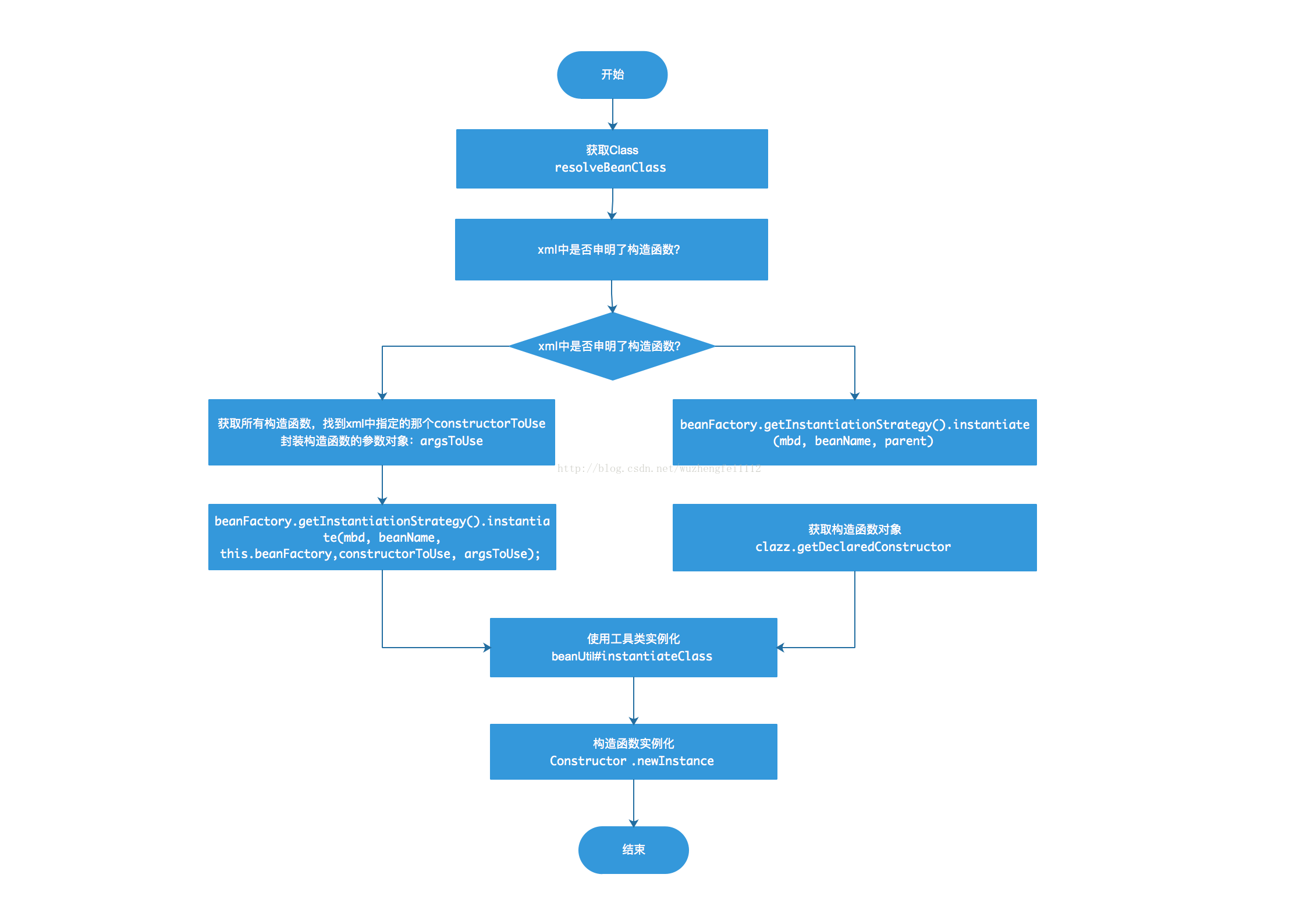
创建 Bean 实例
我们先看看 createBeanInstance 方法。需要说明的是,这个方法如果每个分支都分析下去,必然也是极其复杂冗长的,我们挑重点说。此方法的目的就是实例化我们指定的类。
protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, Object[] args) {
// 确保已经加载了此 class
Class<?> beanClass = resolveBeanClass(mbd, beanName);
// 校验一下这个类的访问权限
if (beanClass != null && !Modifier.isPublic(beanClass.getModifiers()) && !mbd.isNonPublicAccessAllowed()) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Bean class isn't public, and non-public access not allowed: " + beanClass.getName());
}
if (mbd.getFactoryMethodName() != null) {
// 采用工厂方法实例化,不熟悉这个概念的读者请看附录,注意,不是 FactoryBean
return instantiateUsingFactoryMethod(beanName, mbd, args);
}
// 如果不是第一次创建,比如第二次创建 prototype bean。
// 这种情况下,我们可以从第一次创建知道,采用无参构造函数,还是构造函数依赖注入 来完成实例化
boolean resolved = false;
boolean autowireNecessary = false;
if (args == null) {
synchronized (mbd.constructorArgumentLock) {
if (mbd.resolvedConstructorOrFactoryMethod != null) {
resolved = true;
autowireNecessary = mbd.constructorArgumentsResolved;
}
}
}
if (resolved) {
if (autowireNecessary) {
// 构造函数依赖注入
return autowireConstructor(beanName, mbd, null, null);
}
else {
// 无参构造函数
return instantiateBean(beanName, mbd);
}
}
// 判断是否采用有参构造函数
Constructor<?>[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
if (ctors != null ||
mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
// 构造函数依赖注入
return autowireConstructor(beanName, mbd, ctors, args);
}
// 调用无参构造函数
return instantiateBean(beanName, mbd);
}
挑个简单的无参构造函数构造实例来看看:
protected BeanWrapper instantiateBean(final String beanName, final RootBeanDefinition mbd) {
try {
Object beanInstance;
final BeanFactory parent = this;
if (System.getSecurityManager() != null) {
beanInstance = AccessController.doPrivileged(new PrivilegedAction<Object>() {
@Override
public Object run() {
return getInstantiationStrategy().instantiate(mbd, beanName, parent);
}
}, getAccessControlContext());
}
else {
// 实例化
beanInstance = getInstantiationStrategy().instantiate(mbd, beanName, parent);
}
// 包装一下,返回
BeanWrapper bw = new BeanWrapperImpl(beanInstance);
initBeanWrapper(bw);
return bw;
}
catch (Throwable ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Instantiation of bean failed", ex);
}
}
我们可以看到,关键的地方在于:
beanInstance = getInstantiationStrategy().instantiate(mbd, beanName, parent);
这里会进行实际的实例化过程,我们进去看看:
// SimpleInstantiationStrategy 59
@Override
public Object instantiate(RootBeanDefinition bd, String beanName, BeanFactory owner) {
// 如果不存在方法覆写,那就使用 java 反射进行实例化,否则使用 CGLIB,
// 方法覆写 请参见附录"方法注入"中对 lookup-method 和 replaced-method 的介绍
if (bd.getMethodOverrides().isEmpty()) {
Constructor<?> constructorToUse;
synchronized (bd.constructorArgumentLock) {
constructorToUse = (Constructor<?>) bd.resolvedConstructorOrFactoryMethod;
if (constructorToUse == null) {
final Class<?> clazz = bd.getBeanClass();
if (clazz.isInterface()) {
throw new BeanInstantiationException(clazz, "Specified class is an interface");
}
try {
if (System.getSecurityManager() != null) {
constructorToUse = AccessController.doPrivileged(new PrivilegedExceptionAction<Constructor<?>>() {
@Override
public Constructor<?> run() throws Exception {
return clazz.getDeclaredConstructor((Class[]) null);
}
});
}
else {
constructorToUse = clazz.getDeclaredConstructor((Class[]) null);
}
bd.resolvedConstructorOrFactoryMethod = constructorToUse;
}
catch (Throwable ex) {
throw new BeanInstantiationException(clazz, "No default constructor found", ex);
}
}
}
// 利用构造方法进行实例化
return BeanUtils.instantiateClass(constructorToUse);
}
else {
// 存在方法覆写,利用 CGLIB 来完成实例化,需要依赖于 CGLIB 生成子类,这里就不展开了。
// tips: 因为如果不使用 CGLIB 的话,存在 override 的情况 JDK 并没有提供相应的实例化支持
return instantiateWithMethodInjection(bd, beanName, owner);
}
}
到这里,我们就算实例化完成了。我们开始说怎么进行属性注入。
bean 属性注入
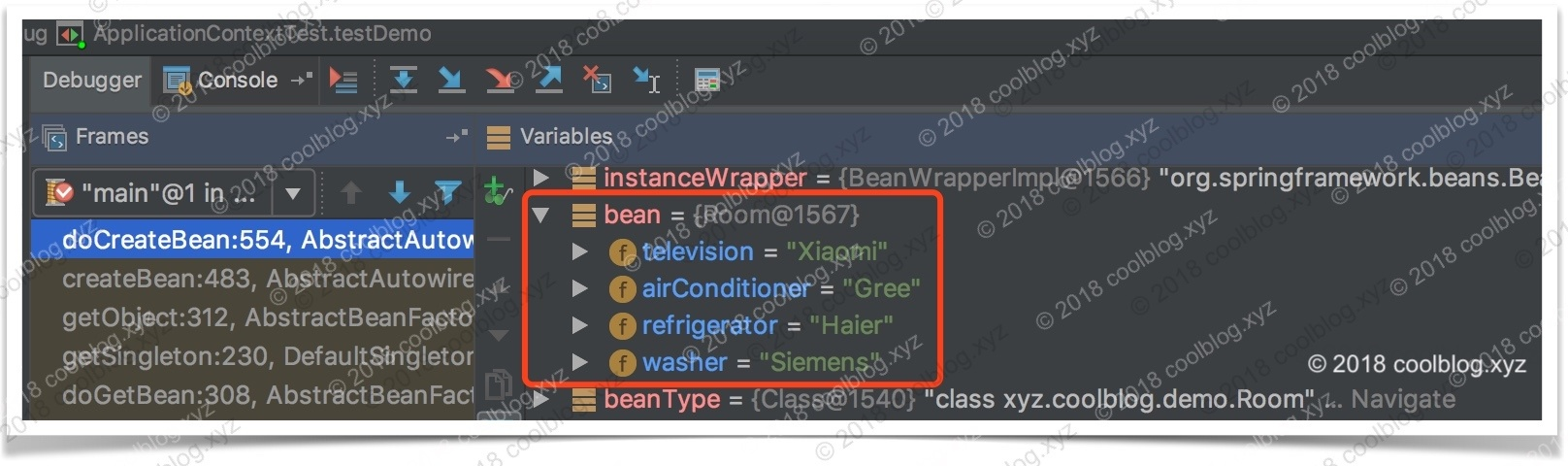
看完了 createBeanInstance(…) 方法,我们来看看 populateBean(…) 方法,该方法负责进行属性设值,处理依赖。
// AbstractAutowireCapableBeanFactory 1203
protected void populateBean(String beanName, RootBeanDefinition mbd, BeanWrapper bw) {
// bean 实例的所有属性都在这里了
PropertyValues pvs = mbd.getPropertyValues();
if (bw == null) {
if (!pvs.isEmpty()) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Cannot apply property values to null instance");
}
else {
// Skip property population phase for null instance.
return;
}
}
// 到这步的时候,bean 实例化完成(通过工厂方法或构造方法),但是还没开始属性设值,
// InstantiationAwareBeanPostProcessor 的实现类可以在这里对 bean 进行状态修改,
// 我也没找到有实际的使用,所以我们暂且忽略这块吧
boolean continueWithPropertyPopulation = true;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
// 如果返回 false,代表不需要进行后续的属性设值,也不需要再经过其他的 BeanPostProcessor 的处理
if (!ibp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {
continueWithPropertyPopulation = false;
break;
}
}
}
}
if (!continueWithPropertyPopulation) {
return;
}
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_NAME ||
mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_TYPE) {
MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
// 通过名字找到所有属性值,如果是 bean 依赖,先初始化依赖的 bean。记录依赖关系
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_NAME) {
autowireByName(beanName, mbd, bw, newPvs);
}
// 通过类型装配。复杂一些
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_TYPE) {
autowireByType(beanName, mbd, bw, newPvs);
}
pvs = newPvs;
}
boolean hasInstAwareBpps = hasInstantiationAwareBeanPostProcessors();
boolean needsDepCheck = (mbd.getDependencyCheck() != RootBeanDefinition.DEPENDENCY_CHECK_NONE);
if (hasInstAwareBpps || needsDepCheck) {
PropertyDescriptor[] filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
if (hasInstAwareBpps) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
// 这里有个非常有用的 BeanPostProcessor 进到这里: AutowiredAnnotationBeanPostProcessor
// 对采用 @Autowired、@Value 注解的依赖进行设值,这里的内容也是非常丰富的,不过本文不会展开说了,感兴趣的读者请自行研究
pvs = ibp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName);
if (pvs == null) {
return;
}
}
}
}
if (needsDepCheck) {
checkDependencies(beanName, mbd, filteredPds, pvs);
}
}
// 设置 bean 实例的属性值
applyPropertyValues(beanName, mbd, bw, pvs);
}
initializeBean
属性注入完成后,这一步其实就是处理各种回调了,这块代码比较简单。
protected Object initializeBean(final String beanName, final Object bean, RootBeanDefinition mbd) {
if (System.getSecurityManager() != null) {
AccessController.doPrivileged(new PrivilegedAction<Object>() {
@Override
public Object run() {
invokeAwareMethods(beanName, bean);
return null;
}
}, getAccessControlContext());
}
else {
// 如果 bean 实现了 BeanNameAware、BeanClassLoaderAware 或 BeanFactoryAware 接口,回调
invokeAwareMethods(beanName, bean);
}
Object wrappedBean = bean;
if (mbd == null || !mbd.isSynthetic()) {
// BeanPostProcessor 的 postProcessBeforeInitialization 回调
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
try {
// 处理 bean 中定义的 init-method,
// 或者如果 bean 实现了 InitializingBean 接口,调用 afterPropertiesSet() 方法
invokeInitMethods(beanName, wrappedBean, mbd);
}
catch (Throwable ex) {
throw new BeanCreationException(
(mbd != null ? mbd.getResourceDescription() : null),
beanName, "Invocation of init method failed", ex);
}
if (mbd == null || !mbd.isSynthetic()) {
// BeanPostProcessor 的 postProcessAfterInitialization 回调
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}
return wrappedBean;
}
大家发现没有,BeanPostProcessor 的两个回调都发生在这边,只不过中间处理了 init-method,是不是和读者原来的认知有点不一样了?
相关疑问
Spring 的 bean 在什么时候实例化?
如果你使用BeanFactory,如 XmlBeanFactory 作为 Spring Bean 的工厂类,则所有的 bean 都是在第一次使用该bean 的时候实例化 。
如果你使用 ApplicationContext 作为 Spring Bean 的工厂类,则又分为以下几种情况:
- 如果 bean 的 scope 是 singleton 的,并且 lazy-init 为 false(默认是false,所以可以不用设置),则ApplicationContext 启动的时候就实例化该 bean,并且将实例化的 bean 放在一个线程安全的 ConcurrentHashMap 结构的缓存中,下次再使用该 Bean 的时候,直接从这个缓存中取
- 如果 bean 的 scope 是 singleton 的,并且 lazy-init 为 true,则该 bean 的实例化是在第一次使用该 bean 的时候进行实例化
- 如果 bean 的 scope 是 prototype 的,则该 bean 的实例化是在第一次使用该 bean 的时候进行实例化 。
1.5 - CH05-循环依赖
创建过程
Java 对象的创建步骤很多,可以 new XXX、序列化、clone() 等等, 只是 Spring 是通过反射 + 工厂的方式创建对象并放在容器的,创建好的对象我们一般还会对对象属性进行赋值,才去使用,可以理解是分了两个步骤。
什么是循环依赖
所谓的循环依赖是指,A 依赖 B,B 又依赖 A,它们之间形成了循环依赖。或者是 A 依赖 B,B 依赖 C,C 又依赖 A,形成了循环依赖。更或者是自己依赖自己。它们之间的依赖关系如下:
这里以两个类直接相互依赖为例,他们的实现代码可能如下:
public class BeanB {
private BeanA beanA;
public void setBeanA(BeanA beanA) {
this.beanA = beanA;
}
}
public class BeanA {
private BeanB beanB;
public void setBeanB(BeanB beanB) {
this.beanB = beanB;
}
}
配置信息如下(用注解方式注入同理,只是为了方便理解,用了配置文件):
<bean id="beanA" class="priv.starfish.BeanA">
<property name="beanB" ref="beanB"/>
</bean>
<bean id="beanB" class="priv.starfish.BeanB">
<property name="beanA" ref="beanA"/>
</bean>
Spring 启动后,读取如上的配置文件,会按顺序先实例化 A,但是创建的时候又发现它依赖了 B,接着就去实例化 B ,同样又发现它依赖了 A ,这尼玛咋整?无限循环呀
Spring “肯定”不会让这种事情发生的,如前言我们说的 Spring 实例化对象分两步,第一步会先创建一个原始对象,只是没有设置属性,可以理解为"半成品"—— 官方叫 A 对象的早期引用(EarlyBeanReference),所以当实例化 B 的时候发现依赖了 A, B 就会把这个“半成品”设置进去先完成实例化,既然 B 完成了实例化,所以 A 就可以获得 B 的引用,也完成实例化了,这其实就是 Spring 解决循环依赖的思想。
源码实现
在 Spring IOC 容器读取 Bean 配置创建 Bean 实例之前, 必须对它进行实例化。只有在容器实例化后,才可以从 IOC 容器里获取 Bean 实例并使用,循环依赖问题也就是发生在实例化 Bean 的过程中的,所以我们先回顾下获取 Bean 的过程。
获取 Bean 流程
Spring IOC 容器中获取 bean 实例的简化版流程如下(排除了各种包装和检查的过程)
大概的流程顺序:
- 流程从
getBean 方法开始,getBean 是个空壳方法,所有逻辑直接到 doGetBean 方法中 transformedBeanName 将 name 转换为真正的 beanName(name 可能是 FactoryBean 以 & 字符开头或者有别名的情况,所以需要转化下)- 然后通过
getSingleton(beanName) 方法尝试从缓存中查找是不是有该实例 sharedInstance(单例在 Spring 的同一容器只会被创建一次,后续再获取 bean,就直接从缓存获取即可) - 如果有的话,sharedInstance 可能是完全实例化好的 bean,也可能是一个原始的 bean,所以再经
getObjectForBeanInstance 处理即可返回 - 当然 sharedInstance 也可能是 null,这时候就会执行创建 bean 的逻辑,将结果返回
第三步的时候我们提到了一个缓存的概念,这个就是 Spring 为了解决单例的循环依赖问题而设计的 三级缓存:
/** Cache of singleton objects: bean name --> bean instance */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name --> ObjectFactory */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name --> bean instance */
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
这三级缓存的作用分别是:
singletonObjects:完成初始化的单例对象的 cache,这里的 bean 经历过 实例化->属性填充->初始化 以及各种后置处理(一级缓存)earlySingletonObjects:存放原始的 bean 对象(完成实例化但是尚未填充属性和初始化),仅仅能作为指针提前曝光,被其他 bean 所引用,用于解决循环依赖的 (二级缓存)singletonFactories:在 bean 实例化完之后,属性填充以及初始化之前,如果允许提前曝光,Spring 会将实例化后的 bean 提前曝光,也就是把该 bean 转换成 beanFactory 并加入到 singletonFactories(三级缓存)
我们首先从缓存中试着获取 bean,就是从这三级缓存中查找:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 从 singletonObjects 获取实例,singletonObjects 中的实例都是准备好的 bean 实例,可以直接使用
Object singletonObject = this.singletonObjects.get(beanName);
//isSingletonCurrentlyInCreation() 判断当前单例bean是否正在创建中
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
// 一级缓存没有,就去二级缓存找
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
// 二级缓存也没有,就去三级缓存找
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 三级缓存有的话,就把他移动到二级缓存,.getObject() 后续会讲到
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
如果缓存没有的话,我们就要创建了,接着我们以单例对象为例,再看下创建 bean 的逻辑(大括号表示内部类调用方法):
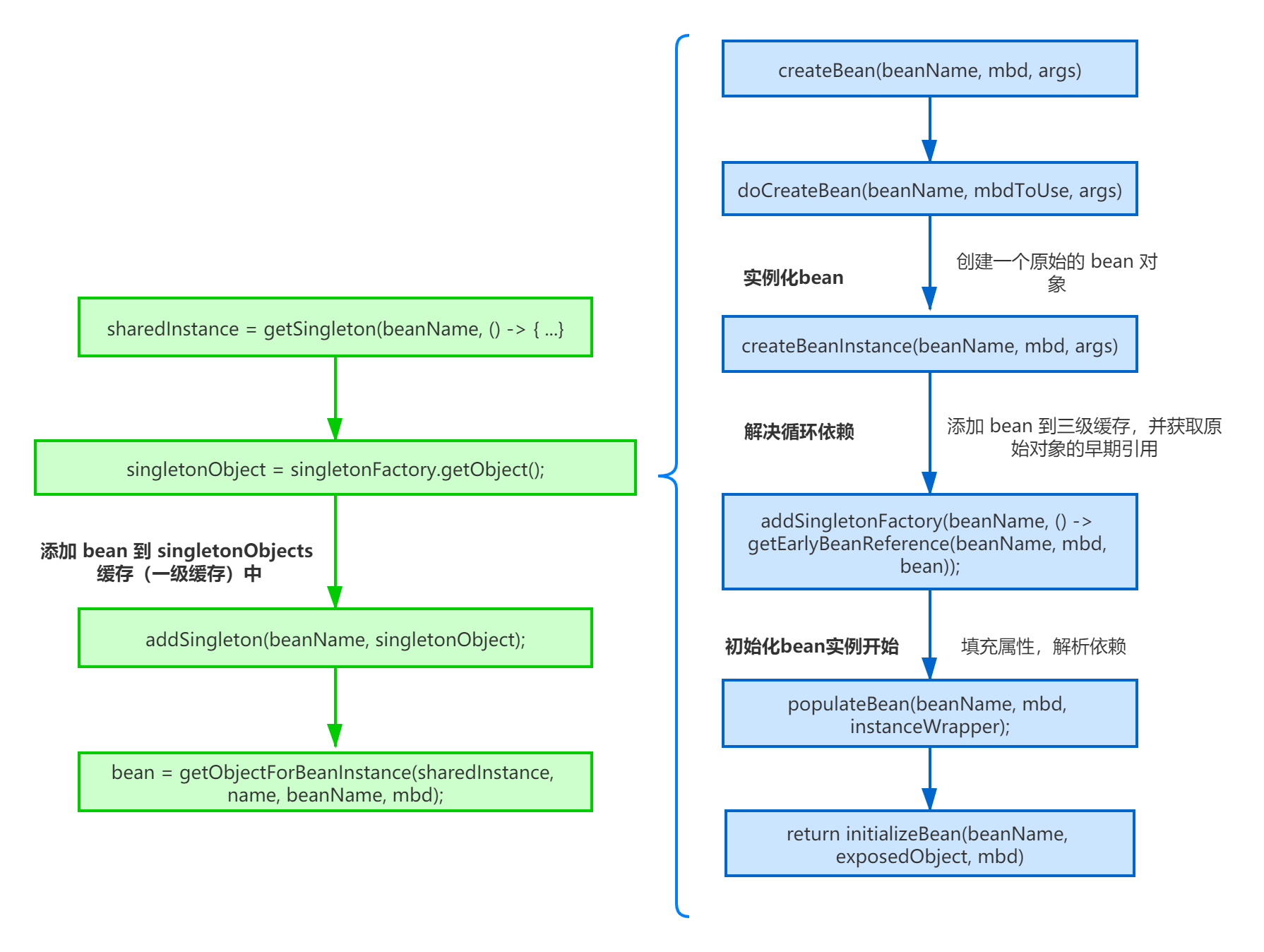
创建 bean 从以下代码开始,一个匿名内部类方法参数
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
getSingleton() 方法内部主要有两个方法
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
// 创建 singletonObject
singletonObject = singletonFactory.getObject();
// 将 singletonObject 放入缓存
addSingleton(beanName, singletonObject);
}
getObject() 匿名内部类的实现真正调用的又是 createBean(beanName, mbd, args)
往里走,主要的实现逻辑在 doCreateBean方法,先通过 createBeanInstance 创建一个原始 bean 对象
接着 addSingletonFactory 添加 bean 工厂对象到 singletonFactories 缓存(三级缓存)
通过 populateBean 方法向原始 bean 对象中填充属性,并解析依赖,假设这时候创建 A 之后填充属性时发现依赖 B,然后创建依赖对象 B 的时候又发现依赖 A,还是同样的流程,又去 getBean(A),这个时候三级缓存已经有了 beanA 的“半成品”,这时就可以把 A 对象的原始引用注入 B 对象(并将其移动到二级缓存)来解决循环依赖问题。这时候 getObject() 方法就算执行结束了,返回完全实例化的 bean
最后调用 addSingleton 把完全实例化好的 bean 对象放入 singletonObjects 缓存(一级缓存)中
Spring 解决循环依赖
流程其实上边都已经说过了,结合着上图我们再看下具体细节,用大白话再捋一捋:
- Spring 创建 bean 主要分为两个步骤,创建原始 bean 对象,接着去填充对象属性和初始化
- 每次创建 bean 之前,我们都会从缓存中查下有没有该 bean,因为是单例,只能有一个
- 当我们创建 beanA 的原始对象后,并把它放到三级缓存中,接下来就该填充对象属性了,这时候发现依赖了 beanB,接着就又去创建 beanB,同样的流程,创建完 beanB 填充属性时又发现它依赖了 beanA,又是同样的流程,不同的是,这时候可以在三级缓存中查到刚放进去的原始对象 beanA,所以不需要继续创建,用它注入 beanB,完成 beanB 的创建
- 既然 beanB 创建好了,所以 beanA 就可以完成填充属性的步骤了,接着执行剩下的逻辑,闭环完成
但是为什么需要三级缓存,二级缓存不够用吗?
跟源码的时候,发现在创建 beanB 需要引用 beanA 这个“半成品”的时候,就会触发"前期引用",即如下代码:
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 三级缓存有的话,就把他移动到二级缓存
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
singletonFactory.getObject() 是一个接口方法,这里具体的实现方法在
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
// 这么一大段就这句话是核心,也就是当bean要进行提前曝光时,
// 给一个机会,通过重写后置处理器的getEarlyBeanReference方法,来自定义操作bean
// 值得注意的是,如果提前曝光了,但是没有被提前引用,则该后置处理器并不生效!!!
// 这也正式三级缓存存在的意义,否则二级缓存就可以解决循环依赖的问题
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
它的目的是为了后置处理,如果没有 AOP 后置处理,就不会走进 if 语句,直接返回了 exposedObject ,相当于啥都没干,二级缓存就够用了。
所以又得出结论,这个三级缓存应该和 AOP 有关系,继续。
在 Spring 的源码中getEarlyBeanReference 是 SmartInstantiationAwareBeanPostProcessor 接口的默认方法,真正实现这个方法的只有**AbstractAutoProxyCreator** 这个类,用于提前曝光的 AOP 代理。
@Override
public Object getEarlyBeanReference(Object bean, String beanName) throws BeansException {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
this.earlyProxyReferences.put(cacheKey, bean);
// 对bean进行提前Spring AOP代理
return wrapIfNecessary(bean, beanName, cacheKey);
}
这么说有点干,来个小 demo 吧,我们都知道 Spring AOP、事务等都是通过代理对象来实现的,而事务的代理对象是由自动代理创建器来自动完成的。也就是说 Spring 最终给我们放进容器里面的是一个代理对象,而非原始对象,假设我们有如下一段业务代码:
@Service
public class HelloServiceImpl implements HelloService {
@Autowired
private HelloService helloService;
@Override
@Transactional
public Object hello() {
return "Hello JavaKeeper";
}
}
此 Service 类使用到了事务,所以最终会生成一个 JDK 动态代理对象 Proxy。刚好它又存在自己引用自己的循环依赖,完美符合我们的场景需求。
我们再自定义一个后置处理,来看下效果:
@Component
public class HelloProcessor implements SmartInstantiationAwareBeanPostProcessor {
@Override
public Object getEarlyBeanReference(Object bean, String beanName) throws BeansException {
System.out.println("提前曝光了:"+beanName);
return bean;
}
}
可以看到,调用方法栈中有我们自己实现的 HelloProcessor,说明这个 bean 会通过 AOP 代理处理。
再从源码看下这个自己循环自己的 bean 的创建流程:
protected Object doCreateBean( ... ){
...
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences && isSingletonCurrentlyInCreation(beanName));
// 需要提前暴露(支持循环依赖),就注册一个ObjectFactory到三级缓存
if (earlySingletonExposure) {
// 添加 bean 工厂对象到 singletonFactories 缓存中,并获取原始对象的早期引用
//匿名内部方法 getEarlyBeanReference 就是后置处理器
// SmartInstantiationAwareBeanPostProcessor 的一个方法,
// 它的功效为:保证自己被循环依赖的时候,即使被别的Bean @Autowire进去的也是代理对象
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
// 此处注意:如果此处自己被循环依赖了 那它会走上面的getEarlyBeanReference,从而创建一个代理对象从 三级缓存转移到二级缓存里
// 注意此时候对象还在二级缓存里,并没有在一级缓存。并且此时后续的这两步操作还是用的 exposedObject,它仍旧是原始对象~~~
populateBean(beanName, mbd, instanceWrapper);
exposedObject = initializeBean(beanName, exposedObject, mbd);
// 因为事务的AOP自动代理创建器在getEarlyBeanReference 创建代理后,initializeBean 就不会再重复创建了,二选一的)
// 所以经过这两大步后,exposedObject 还是原始对象,通过 getEarlyBeanReference 创建的代理对象还在三级缓存呢
...
// 循环依赖校验
if (earlySingletonExposure) {
// 注意此处第二个参数传的false,表示不去三级缓存里再去调用一次getObject()方法了~~~,此时代理对象还在二级缓存,所以这里拿出来的就是个 代理对象
// 最后赋值给exposedObject 然后return出去,进而最终被addSingleton()添加进一级缓存里面去
// 这样就保证了我们容器里 最终实际上是代理对象,而非原始对象~~~~~
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
}
...
}
}
非单例循环依赖
看完了单例模式的循环依赖,我们再看下非单例的情况,假设我们的配置文件是这样的:
<bean id="beanA" class="priv.starfish.BeanA" scope="prototype">
<property name="beanB" ref="beanB"/>
</bean>
<bean id="beanB" class="priv.starfish.BeanB" scope="prototype">
<property name="beanA" ref="beanA"/>
</bean>
启动 Spring,结果如下:
Error creating bean with name 'beanA' defined in class path resource [applicationContext.xml]: Cannot resolve reference to bean 'beanB' while setting bean property 'beanB';
Error creating bean with name 'beanB' defined in class path resource [applicationContext.xml]: Cannot resolve reference to bean 'beanA' while setting bean property 'beanA';
Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name 'beanA': Requested bean is currently in creation: Is there an unresolvable circular reference?
对于 prototype 作用域的 bean,Spring 容器无法完成依赖注入,因为 Spring 容器不进行缓存 prototype 作用域的 bean ,因此无法提前暴露一个创建中的bean 。
原因也挺好理解的,原型模式每次请求都会创建一个实例对象,即使加了缓存,循环引用太多的话,就比较麻烦了就,所以 Spring 不支持这种方式,直接抛出异常:
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
构造器循环依赖
如果您主要使用构造器注入,循环依赖场景是无法解决的。建议你用 setter 注入方式代替构造器注入
其实也不是说只要是构造器注入就会有循环依赖问题,Spring 在创建 Bean 的时候默认是按照自然排序来进行创建的,我们暂且把先创建的 bean 叫主 bean,上文的 A 即主 bean,只要主 bean 注入依赖 bean 的方式是 setter 方式,依赖 bean 的注入方式无所谓,都可以解决,反之亦然
所以上文我们 AB 循环依赖问题,只要 A 的注入方式是 setter ,就不会有循环依赖问题。
Spring 解决循环依赖依靠的是 Bean 的“中间态”这个概念,而这个中间态指的是已经实例化,但还没初始化的状态。实例化的过程又是通过构造器创建的,如果 A 还没创建好出来,怎么可能提前曝光,所以构造器的循环依赖无法解决,我一直认为应该先有鸡才能有蛋。
总结
B 中提前注入了一个没有经过初始化的 A 类型对象不会有问题吗?
虽然在创建 B 时会提前给 B 注入了一个还未初始化的 A 对象,但是在创建 A 的流程中一直使用的是注入到 B 中的 A 对象的引用,之后会根据这个引用对 A 进行初始化,所以这是没有问题的。
Spring 是如何解决的循环依赖?
Spring 为了解决单例的循环依赖问题,使用了三级缓存。其中一级缓存为单例池(singletonObjects),二级缓存为提前曝光对象(earlySingletonObjects),三级缓存为提前曝光对象工厂(singletonFactories)。
假设A、B循环引用,实例化 A 的时候就将其放入三级缓存中,接着填充属性的时候,发现依赖了 B,同样的流程也是实例化后放入三级缓存,接着去填充属性时又发现自己依赖 A,这时候从缓存中查找到早期暴露的 A,没有 AOP 代理的话,直接将 A 的原始对象注入 B,完成 B 的初始化后,进行属性填充和初始化,这时候 B 完成后,就去完成剩下的 A 的步骤,如果有 AOP 代理,就进行 AOP 处理获取代理后的对象 A,注入 B,走剩下的流程。
为什么要使用三级缓存呢?二级缓存能解决循环依赖吗?
如果没有 AOP 代理,二级缓存可以解决问题,但是有 AOP 代理的情况下,只用二级缓存就意味着所有 Bean 在实例化后就要完成 AOP 代理,这样违背了 Spring 设计的原则,Spring 在设计之初就是通过 AnnotationAwareAspectJAutoProxyCreator 这个后置处理器来在 Bean 生命周期的最后一步来完成 AOP 代理,而不是在实例化后就立马进行 AOP 代理。
1.6 - CH07-动态代理
代理模式是一种设计模式,能够使得在不修改源目标的前提下,额外扩展源目标的功能。即通过访问源目标的代理类,再由代理类去访问源目标。这样一来,要扩展功能,就无需修改源目标的代码了。只需要在代理类上增加就可以了。
其实代理模式的核心思想就是这么简单,在java中,代理又分静态代理和动态代理2种,其中动态代理根据不同实现又区分基于接口的的动态代理和基于子类的动态代理。
其中静态代理由于比较简单,面试中也没啥问的,在代理模式一块,问的最多就是动态代理,而且动态代理也是spring aop的核心思想,spring其他很多功能也是通过动态代理来实现的,比如拦截器,事务控制等。
熟练掌握动态代理技术,能让你业务代码更加精简而优雅。如果你需要写一些中间件的话,那动态代理技术更是必不可少的技能包。
静态代理
在说动态代理前,还是先说说静态代理。
所谓静态代理,就是通过声明一个明确的代理类来访问源对象。
我们有2个接口,Person和Animal。每个接口各有2个实现类,UML如下图:
每个实现类中代码都差不多一致,用Student来举例(其他类和这个几乎一模一样)
public class Student implements Person{
private String name;
public Student() {
}
public Student(String name) {
this.name = name;
}
@Override
public void wakeup() {
System.out.println(StrUtil.format("学生[{}]早晨醒来啦",name));
}
@Override
public void sleep() {
System.out.println(StrUtil.format("学生[{}]晚上睡觉啦",name));
}
}
假设我们现在要做一件事,就是在所有的实现类调用wakeup()前增加一行输出早安~,调用sleep()前增加一行输出晚安~。那我们只需要编写2个代理类PersonProxy和AnimalProxy:
PersonProxy:
public class PersonProxy implements Person {
private Person person;
public PersonProxy(Person person) {
this.person = person;
}
@Override
public void wakeup() {
System.out.println("早安~");
person.wakeup();
}
@Override
public void sleep() {
System.out.println("晚安~");
person.sleep();
}
}
AnimalProxy:
public class AnimalProxy implements Animal {
private Animal animal;
public AnimalProxy(Animal animal) {
this.animal = animal;
}
@Override
public void wakeup() {
System.out.println("早安~");
animal.wakeup();
}
@Override
public void sleep() {
System.out.println("晚安~");
animal.sleep();
}
}
最终执行代码为:
public static void main(String[] args) {
Person student = new Student("张三");
PersonProxy studentProxy = new PersonProxy(student);
studentProxy.wakeup();
studentProxy.sleep();
Person doctor = new Doctor("王教授");
PersonProxy doctorProxy = new PersonProxy(doctor);
doctorProxy.wakeup();
doctorProxy.sleep();
Animal dog = new Dog("旺旺");
AnimalProxy dogProxy = new AnimalProxy(dog);
dogProxy.wakeup();
dogProxy.sleep();
Animal cat = new Cat("咪咪");
AnimalProxy catProxy = new AnimalProxy(cat);
catProxy.wakeup();
catProxy.sleep();
}
输出:
早安~
学生[张三]早晨醒来啦
晚安~
学生[张三]晚上睡觉啦
早安~
医生[王教授]早晨醒来啦
晚安~
医生[王教授]晚上睡觉啦
早安~~
小狗[旺旺]早晨醒来啦
晚安~~
小狗[旺旺]晚上睡觉啦
早安~~
小猫[咪咪]早晨醒来啦
晚安~~
小猫[咪咪]晚上睡觉啦
结论:
静态代理的代码相信已经不用多说了,代码非常简单易懂。这里用了2个代理类,分别代理了Person和Animal接口。
这种模式虽然好理解,但是缺点也很明显:
- 会存在大量的冗余的代理类,这里演示了2个接口,如果有10个接口,就必须定义10个代理类。
- 不易维护,一旦接口更改,代理类和目标类都需要更改。
JDK 动态代理
动态代理,通俗点说就是:无需声明式的创建java代理类,而是在运行过程中生成"虚拟"的代理类,被ClassLoader加载。从而避免了静态代理那样需要声明大量的代理类。
JDK从1.3版本就开始支持动态代理类的创建。主要核心类只有2个:java.lang.reflect.Proxy和java.lang.reflect.InvocationHandler。
还是前面那个例子,用JDK动态代理类去实现的代码如下:
创建一个JdkProxy类,用于统一代理:
public class JdkProxy implements InvocationHandler {
private Object bean;
public JdkProxy(Object bean) {
this.bean = bean;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
if (methodName.equals("wakeup")){
System.out.println("早安~~~");
}else if(methodName.equals("sleep")){
System.out.println("晚安~~~");
}
return method.invoke(bean, args);
}
}
执行代码:
public static void main(String[] args) {
JdkProxy proxy = new JdkProxy(new Student("张三"));
Person student = (Person) Proxy.newProxyInstance(proxy.getClass().getClassLoader(), new Class[]{Person.class}, proxy);
student.wakeup();
student.sleep();
proxy = new JdkProxy(new Doctor("王教授"));
Person doctor = (Person) Proxy.newProxyInstance(proxy.getClass().getClassLoader(), new Class[]{Person.class}, proxy);
doctor.wakeup();
doctor.sleep();
proxy = new JdkProxy(new Dog("旺旺"));
Animal dog = (Animal) Proxy.newProxyInstance(proxy.getClass().getClassLoader(), new Class[]{Animal.class}, proxy);
dog.wakeup();
dog.sleep();
proxy = new JdkProxy(new Cat("咪咪"));
Animal cat = (Animal) Proxy.newProxyInstance(proxy.getClass().getClassLoader(), new Class[]{Animal.class}, proxy);
cat.wakeup();
cat.sleep();
}
讲解:
可以看到,相对于静态代理类来说,无论有多少接口,这里只需要一个代理类。核心代码也很简单。唯一需要注意的点有以下2点:
JDK动态代理是需要声明接口的,创建一个动态代理类必须得给这个”虚拟“的类一个接口。可以看到,这时候经动态代理类创造之后的每个bean已经不是原来那个对象了。
为什么这里JdkProxy还需要构造传入原有的bean呢?因为处理完附加的功能外,需要执行原有bean的方法,以完成代理的职责。
这里JdkProxy最核心的方法就是
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable
其中proxy为代理过之后的对象(并不是原对象),method为被代理的方法,args为方法的参数。
如果你不传原有的bean,直接用method.invoke(proxy, args)的话,那么就会陷入一个死循环。
可以代理什么
JDK的动态代理是也平时大家使用的最多的一种代理方式。也叫做接口代理。前几天有一个小伙伴在群里问我,动态代理是否一次可以代理一个类,多个类可不可以。
JDK动态代理说白了只是根据接口”凭空“来生成类,至于具体的执行,都被代理到了InvocationHandler 的实现类里。上述例子我是需要继续执行原有bean的逻辑,才将原有的bean构造进来。只要你需要,你可以构造进任何对象到这个代理实现类。也就是说,你可以传入多个对象,或者说你什么类都不代理。只是为某一个接口”凭空“的生成多个代理实例,这多个代理实例最终都会进入InvocationHandler的实现类来执行某一个段共同的代码。
所以,在以往的项目中的一个实际场景就是,我有多个以yaml定义的规则文件,通过对yaml文件的扫描,来为每个yaml规则文件生成一个动态代理类。而实现这个,我只需要事先定义一个接口,和定义InvocationHandler的实现类就可以了,同时把yaml解析过的对象传入。最终这些动态代理类都会进入invoke方法来执行某个共同的逻辑。
Cglib 动态代理
Spring在5.X之前默认的动态代理实现一直是jdk动态代理。但是从5.X开始,spring就开始默认使用Cglib来作为动态代理实现。并且springboot从2.X开始也转向了Cglib动态代理实现。
是什么导致了spring体系整体转投Cglib呢,jdk动态代理又有什么缺点呢?
那么我们现在就要来说下Cglib的动态代理。
Cglib是一个开源项目,它的底层是字节码处理框架ASM,Cglib提供了比jdk更为强大的动态代理。主要相比jdk动态代理的优势有:
- jdk动态代理只能基于接口,代理生成的对象只能赋值给接口变量,而Cglib就不存在这个问题,Cglib是通过生成子类来实现的,代理对象既可以赋值给实现类,又可以赋值给接口。
- Cglib速度比jdk动态代理更快,性能更好。
那何谓通过子类来实现呢?
还是前面那个例子,我们要实现相同的效果。代码如下
创建CglibProxy类,用于统一代理:
public class CglibProxy implements MethodInterceptor {
private Enhancer enhancer = new Enhancer();
private Object bean;
public CglibProxy(Object bean) {
this.bean = bean;
}
public Object getProxy(){
//设置需要创建子类的类
enhancer.setSuperclass(bean.getClass());
enhancer.setCallback(this);
//通过字节码技术动态创建子类实例
return enhancer.create();
}
//实现MethodInterceptor接口方法
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
String methodName = method.getName();
if (methodName.equals("wakeup")){
System.out.println("早安~~~");
}else if(methodName.equals("sleep")){
System.out.println("晚安~~~");
}
//调用原bean的方法
return method.invoke(bean,args);
}
}
执行代码:
public static void main(String[] args) {
CglibProxy proxy = new CglibProxy(new Student("张三"));
Student student = (Student) proxy.getProxy();
student.wakeup();
student.sleep();
proxy = new CglibProxy(new Doctor("王教授"));
Doctor doctor = (Doctor) proxy.getProxy();
doctor.wakeup();
doctor.sleep();
proxy = new CglibProxy(new Dog("旺旺"));
Dog dog = (Dog) proxy.getProxy();
dog.wakeup();
dog.sleep();
proxy = new CglibProxy(new Cat("咪咪"));
Cat cat = (Cat) proxy.getProxy();
cat.wakeup();
cat.sleep();
}
讲解:
在这里用Cglib作为代理,其思路和jdk动态代理差不多。也需要把原始bean构造传入。原因上面有说,这里不多赘述。
关键的代码在这里
//设置需要创建子类的类
enhancer.setSuperclass(bean.getClass());
enhancer.setCallback(this);
//通过字节码技术动态创建子类实例
return enhancer.create();
可以看到,Cglib"凭空"的创造了一个原bean的子类,并把Callback指向了this,也就是当前对象,也就是这个proxy对象。从而会调用intercept方法。而在intercept方法里,进行了附加功能的执行,最后还是调用了原始bean的相应方法。
在debug这个生成的代理对象时,我们也能看到,Cglib是凭空生成了原始bean的子类:
javassist 动态代理
Javassist是一个开源的分析、编辑和创建Java字节码的类库,可以直接编辑和生成Java生成的字节码。相对于bcel, asm等这些工具,开发者不需要了解虚拟机指令,就能动态改变类的结构,或者动态生成类。
在日常使用中,javassit通常被用来动态修改字节码。它也能用来实现动态代理的功能。
话不多说,还是一样的例子,我用javassist动态代理来实现一遍
创建JavassitProxy,用作统一代理:
public class JavassitProxy {
private Object bean;
public JavassitProxy(Object bean) {
this.bean = bean;
}
public Object getProxy() throws IllegalAccessException, InstantiationException {
ProxyFactory f = new ProxyFactory();
f.setSuperclass(bean.getClass());
f.setFilter(m -> ListUtil.toList("wakeup","sleep").contains(m.getName()));
Class c = f.createClass();
MethodHandler mi = (self, method, proceed, args) -> {
String methodName = method.getName();
if (methodName.equals("wakeup")){
System.out.println("早安~~~");
}else if(methodName.equals("sleep")){
System.out.println("晚安~~~");
}
return method.invoke(bean, args);
};
Object proxy = c.newInstance();
((Proxy)proxy).setHandler(mi);
return proxy;
}
}
执行代码:
public static void main(String[] args) throws Exception{
JavassitProxy proxy = new JavassitProxy(new Student("张三"));
Student student = (Student) proxy.getProxy();
student.wakeup();
student.sleep();
proxy = new JavassitProxy(new Doctor("王教授"));
Doctor doctor = (Doctor) proxy.getProxy();
doctor.wakeup();
doctor.sleep();
proxy = new JavassitProxy(new Dog("旺旺"));
Dog dog = (Dog) proxy.getProxy();
dog.wakeup();
dog.sleep();
proxy = new JavassitProxy(new Cat("咪咪"));
Cat cat = (Cat) proxy.getProxy();
cat.wakeup();
cat.sleep();
}
讲解:
熟悉的配方,熟悉的味道,大致思路也是类似的。同样把原始bean构造传入。可以看到,javassist也是用”凭空“生成子类的方式类来解决,代码的最后也是调用了原始bean的目标方法完成代理。
javaassit比较有特点的是,可以对所需要代理的方法用filter来设定,里面可以像Criteria构造器那样进行构造。其他的代码,如果你仔细看了之前的代码演示,应该能很轻易看懂了。
ByteBuddy 动态代理
ByteBuddy,字节码伙计,一听就很牛逼有不。
ByteBuddy也是一个大名鼎鼎的开源库,和Cglib一样,也是基于ASM实现。还有一个名气更大的库叫Mockito,相信不少人用过这玩意写过测试用例,其核心就是基于ByteBuddy来实现的,可以动态生成mock类,非常方便。另外ByteBuddy另外一个大的应用就是java agent,其主要作用就是在class被加载之前对其拦截,插入自己的代码。
ByteBuddy非常强大,是一个神器。可以应用在很多场景。但是这里,只介绍用ByteBuddy来做动态代理,关于其他使用方式,可能要专门写一篇来讲述,这里先给自己挖个坑。
来,还是熟悉的例子,熟悉的配方。用ByteBuddy我们再来实现一遍前面的例子
创建ByteBuddyProxy,做统一代理:
public class ByteBuddyProxy {
private Object bean;
public ByteBuddyProxy(Object bean) {
this.bean = bean;
}
public Object getProxy() throws Exception{
Object object = new ByteBuddy().subclass(bean.getClass())
.method(ElementMatchers.namedOneOf("wakeup","sleep"))
.intercept(InvocationHandlerAdapter.of(new AopInvocationHandler(bean)))
.make()
.load(ByteBuddyProxy.class.getClassLoader())
.getLoaded()
.newInstance();
return object;
}
public class AopInvocationHandler implements InvocationHandler {
private Object bean;
public AopInvocationHandler(Object bean) {
this.bean = bean;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
if (methodName.equals("wakeup")){
System.out.println("早安~~~");
}else if(methodName.equals("sleep")){
System.out.println("晚安~~~");
}
return method.invoke(bean, args);
}
}
}
执行代码:
public static void main(String[] args) throws Exception{
ByteBuddyProxy proxy = new ByteBuddyProxy(new Student("张三"));
Student student = (Student) proxy.getProxy();
student.wakeup();
student.sleep();
proxy = new ByteBuddyProxy(new Doctor("王教授"));
Doctor doctor = (Doctor) proxy.getProxy();
doctor.wakeup();
doctor.sleep();
proxy = new ByteBuddyProxy(new Dog("旺旺"));
Dog dog = (Dog) proxy.getProxy();
dog.wakeup();
dog.sleep();
proxy = new ByteBuddyProxy(new Cat("咪咪"));
Cat cat = (Cat) proxy.getProxy();
cat.wakeup();
cat.sleep();
}
讲解:
思路和之前还是一样,通过仔细观察代码,ByteBuddy也是采用了创造子类的方式来实现动态代理。
性能对比
前面介绍了4种动态代理对于同一例子的实现。对于代理的模式可以分为2种:
- JDK动态代理采用接口代理的模式,代理对象只能赋值给接口,允许多个接口
- Cglib,Javassist,ByteBuddy这些都是采用了子类代理的模式,代理对象既可以赋值给接口,又可以复制给具体实现类
Spring5.X,Springboot2.X只有都采用了Cglib作为动态代理的实现,那是不是cglib性能是最好的呢?
我这里做了一个简单而粗暴的实验,直接把上述4段执行代码进行单线程同步循环多遍,用耗时来确定他们4个的性能。应该能看出些端倪。
JDK PROXY循环10000遍所耗时:0.714970125秒
Cglib循环10000遍所耗时:0.434937833秒
Javassist循环10000遍所耗时:1.294194708秒
ByteBuddy循环10000遍所耗时:9.731999042秒
执行的结果如上
从执行结果来看,的确是cglib效果最好。至于为什么ByteBuddy执行那么慢,不一定是ByteBuddy性能差,也有可能是我测试代码写的有问题,没有找到正确的方式。所以这只能作为一个大致的参考。
看来Spring选择Cglib还是有道理的。
1.7 - CH08-定义接口
接口参数
SpringMVC中处理控制器参数的接口是HandlerMethodArgumentResolver,此接口有众多子类,分别处理不同(注解类型)的参数,下面只列举几个子类:
RequestParamMethodArgumentResolver:解析处理使用了@RequestParam注解的参数、MultipartFile类型参数和Simple类型(如long、int等类型)参数。RequestResponseBodyMethodProcessor:解析处理@RequestBody注解的参数。PathVariableMapMethodArgumentResolver:解析处理@PathVariable注解的参数。
实际上,一般在解析一个控制器的请求参数的时候,用到的是HandlerMethodArgumentResolverComposite,里面装载了所有启用的HandlerMethodArgumentResolver子类。而HandlerMethodArgumentResolver子类在解析参数的时候使用到HttpMessageConverter(实际上也是一个列表,进行遍历匹配解析)子类进行匹配解析,常见的如MappingJackson2HttpMessageConverter(使用Jackson进行序列化和反序列化)。
而HandlerMethodArgumentResolver子类到底依赖什么HttpMessageConverter实例实际上是由请求头中的Content-Type(在SpringMVC中统一命名为MediaType,见org.springframework.http.MediaType)决定的,因此我们在处理控制器的请求参数之前必须要明确外部请求的Content-Type到底是什么。上面的逻辑可以直接看源码AbstractMessageConverterMethodArgumentResolver#readWithMessageConverters,思路是比较清晰的。在@RequestMapping注解中,produces和consumes属性就是和请求的Accept或者响应的Content-Type相关的:
consumes属性:指定处理请求的提交内容类型(Content-Type),例如application/json、text/html等等,只有命中了对应的Content-Type的值才会接受该请求。produces属性:指定返回的内容类型,仅当某个请求的请求头中的(Accept)类型中包含该指定类型才返回,如果返回的是JSON数据一般考虑使用application/json;charset=UTF-8。
另外提一点,SpringMVC中默认使用Jackson作为JSON的工具包,如果不是完全理解透整套源码的运作,一般不是十分建议修改默认使用的MappingJackson2HttpMessageConverter(例如有些人喜欢使用FastJson,实现HttpMessageConverter引入FastJson做HTTP消息转换器,其实这种做法并不推荐)。
请求参数接收
其实一般的表单或者JSON数据的请求都是相对简单的,一些复杂的处理主要包括URL路径参数、文件上传、数组或者列表类型数据等。另外,关于参数类型中存在日期类型属性(例如java.util.Date、java.sql.Date、java.time.LocalDate、java.time.LocalDateTime、java.time.ZonedDateTime等等),解析的时候一般需要自定义实现的逻辑实现String-->日期类型的转换。其实道理很简单,日期相关的类型对于每个国家、每个时区甚至每个使用者来说认知都不一定相同,所以SpringMVC并没有对于日期时间类型的解析提供一个通用的解决方案。在演示一些例子可能用到下面的模特类:
@Data
public class User {
private String name;
private Integer age;
private List<Contact> contacts;
}
@Data
public class Contact {
private String name;
private String phone;
}
下面主要以HTTP的GET方法和POST方法提交在SpringMVC体系中正确处理参数的例子进行分析,还会花精力整理SpringMVC体系中独有的URL路径参数处理的一些技巧以及最常见的日期参数处理的合理实践(对于GET方法和POST方法提交的参数处理,基本囊括了其他如DELETE、PUT等方法的参数处理,随机应变即可)。
GET 方法请求参数处理
HTTP(s)协议使用GET方法进行请求的时候,提交的参数位于URL模式的Query部分,也就是URL的?标识符之后的参数,格式是key1=value1&key2=value2。GET方法请求参数可以有多种方法获取:
- 使用
@RequestParam注解处理。 - 使用对象接收,注意对象的属性名称要和
Query中的参数名称一致。 - 使用
HttpServletRequest实例提供的方法(不推荐,存在硬编码)。
假设请求的URL为http://localhost:8080/get?name=doge&age=26,那么控制器如下:
@Slf4j
@RestController
public class SampleController {
@GetMapping(path = "/get1")
public void get1(@RequestParam(name = "name") String name,
@RequestParam(name = "age") Integer age) {
log.info("name:{},age:{}", name, age);
}
@GetMapping(path = "/get2")
public void get2(UserVo vo) {
log.info("name:{},age:{}", vo.getName(), vo.getAge());
}
@GetMapping(path = "/get3")
public void get3(HttpServletRequest request) {
String name = request.getParameter("name");
String age = request.getParameter("age");
log.info("name:{},age:{}", name, age);
}
@Data
public static class UserVo {
private String name;
private Integer age;
}
}
表单参数
表单参数,一般对应于页面上<form>标签内的所有<input>标签的name-value聚合而成的参数,一般Content-Type指定为application/x-www-form-urlencoded,表单参数值也就是会进行(URL)编码。下面介绍几种常见的表单参数提交的参数形式。
对应的控制器如下:
@PostMapping(value = "/post")
public String post(@RequestParam(name = "name") String name,
@RequestParam(name = "age") Integer age) {
String content = String.format("name = %s,age = %d", name, age);
log.info(content);
return content;
}
说实话,如果有毅力的话,所有的复杂参数的提交最终都可以转化为多个单参数接收,不过这样做会产生十分多冗余的代码,而且可维护性比较低。这种情况下,用到的参数处理器是RequestParamMapMethodArgumentResolver。
我们接着写一个接口用于提交用户信息,用到的是上面提到的模特类,主要包括用户姓名、年龄和联系人信息列表,这个时候,我们目标的控制器最终编码如下:
@PostMapping(value = "/user")
public User saveUser(User user) {
log.info(user.toString());
return user;
}
加入强行指定Content-Type为application/x-www-form-urlencoded,需要构造请求参数格式如下:
因为没有使用注解,最终的参数处理器为ServletModelAttributeMethodProcessor,主要是把HttpServletRequest中的表单参数封装到MutablePropertyValues实例中,再通过参数类型实例化(通过构造反射创建User实例),反射匹配属性进行值的填充。另外,请求复杂参数里面的列表属性请求参数看起来比较奇葩,实际上和在.properties文件中添加最终映射到Map类型的参数的写法是一致的,所以对于嵌套数组或者列表类型的第一层索引要写成firstLevel[index].fieldName的形式。那么,能不能把整个请求参数塞在一个字段中提交呢?
直接这样做是不行的,因为实际提交的Form表单,key是user字符串,value实际上也是一个字符串,缺少一个String->User类型的转换器,实际上RequestParamMethodArgumentResolver依赖WebConversionService中Converter实例列表进行参数转换,而默认的Converter列表中肯定不会存在自定义转换String->User类型的转换器:
解决办法还是有的,添加一个自定义的org.springframework.core.convert.converter.Converter实现即可:
@Component
public class StringUserConverter implements Converter<String, User> {
@Autowaired
private ObjectMapper objectMapper;
@Override
public User convert(String source) {
try {
return objectMapper.readValue(source, User.class);
} catch (IOException e) {
throw new IllegalArgumentException(e);
}
}
}
上面这种做法属于曲线救国的做法,不推荐使用在生产环境,但是如果有些第三方接口的对接无法避免这种参数(这个还真碰到多,有一些远古的遗留系统比较容易出现各种奇葩的操作),可以选择这种实现方式。
极度不推荐使用在application/x-www-form-urlencoded这种媒体类型的表单提交的形式下强行使用列表或者数组类型参数,除非是为了兼容处理历史遗留系统的参数提交处理。例如提交的参数形式是:
list = ["string-1", "string-2", "string-3"]
那么表单参数的形式要写成:
| name | value |
|---|
| list[0] | string-1 |
| list[1] | string-2 |
| list[2] | string-3 |
控制器的代码如下:
@PostMapping(path = "/list")
public void list(@RequestParam(name="list") List<String> list) {
log.info(list);
}
一个更加复杂的例子如下,假设想要提交的报文格式如下:
user = [{"name":"doge-1","age": 21},{"name":"doge-2","age": 22}]
那么表单参数的形式要写成:
| name | value |
|---|
| user[0].name | doge-1 |
| user[0].age | 21 |
| user[1].name | doge-2 |
| user[1].age | 22 |
控制器的代码如下:
@PostMapping(path = "/user")
public void saveUsers(@RequestParam(name="user") List<UserVo> users) {
log.info(users);
}
@Data
public class UserVo{
private String name;
private Integer age;
}
这种传参格式其实并不灵活,甚至有可能降低开发效率和参数可读性。
JSON 参数
一般来说,直接在POST请求中的请求体提交一个JSON字符串这种方式对于SpringMVC来说是比较友好的,只需要把Content-Type设置为application/json,然后直接上传一个原始的JSON字符串即可,控制器方法参数使用@RequestBody注解处理:
后端控制器的代码也比较简单:
@PostMapping(value = "/user-2")
public User saveUser2(@RequestBody User user) {
log.info(user.toString());
return user;
}
因为使用了@RequestBody注解,最终使用到的参数处理器为RequestResponseBodyMethodProcessor,实际上会用到MappingJackson2HttpMessageConverter进行参数类型的转换,底层依赖到Jackson相关的包。推荐使用这种方式,这是最常用也是最稳健的JSON参数处理方式。
URL 路径参数
URL路径参数,或者叫请求路径参数是基于URL模板获取到的参数,例如/user/{userId}是一个URL模板(URL模板中的参数占位符是{}),实际请求的URL为/user/1,那么通过匹配实际请求的URL和URL模板就能提取到userId为1。在SpringMVC中,URL模板中的路径参数叫做Path Variable,对应注解@PathVariable,对应的参数处理器为PathVariableMethodArgumentResolver。注意一点是,@PathVariable的解析是按照value(name)属性进行匹配,和URL参数的顺序是无关的。举个简单的例子:
后台的控制器如下:
@GetMapping(value = "/user/{name}/{age}")
public String findUser1(@PathVariable(value = "age") Integer age,
@PathVariable(value = "name") String name) {
String content = String.format("name = %s,age = %d", name, age);
log.info(content);
return content;
}
这种用法被广泛使用于Representational State Transfer(REST)的软件架构风格,个人觉得这种风格是比较灵活和清晰的(从URL和请求方法就能完全理解接口的意义和功能)。下面再介绍两种相对特殊的使用方式。
其实路径参数支持正则表达式,例如我们在使用/sex/{sex}接口的时候,要求sex必须是F(Female)或者M(Male),那么我们的URL模板可以定义为/sex/{sex:M|F},代码如下:
@GetMapping(value = "/sex/{sex:M|F}")
public String findUser2(@PathVariable(value = "sex") String sex){
log.info(sex);
return sex;
}
只有/sex/F或者/sex/M的请求才会进入findUser2()控制器方法,其他该路径前缀的请求都是非法的,会返回404状态码。这里仅仅是介绍了一个最简单的URL参数正则表达式的使用方式,更强大的用法可以自行摸索。
MatrixVariable也是URL参数的一种,对应注解@MatrixVariable,不过它并不是URL中的一个值(这里的值指定是两个"/“之间的部分),而是值的一部分,它通过”;“进行分隔,通过”=“进行K-V设置。说起来有点抽象,举个例子:假如我们需要打电话给一个名字为doge,性别是男,分组是码畜的程序员,GET请求的URL可以表示为:/call/doge;gender=male;group=programmer,我们设计的控制器方法如下:
@GetMapping(value = "/call/{name}")
public String find(@PathVariable(value = "name") String name,
@MatrixVariable(value = "gender") String gender,
@MatrixVariable(value = "group") String group) {
String content = String.format("name = %s,gender = %s,group = %s", name, gender, group);
log.info(content);
return content;
}
当然,如果你按照上面的例子写好代码,尝试请求一下该接口发现是报错的:400 Bad Request - Missing matrix variable 'gender' for method parameter of type String。这是因为@MatrixVariable注解的使用是不安全的,在SpringMVC中默认是关闭对其支持。要开启对@MatrixVariable的支持,需要设置RequestMappingHandlerMapping#setRemoveSemicolonContent方法为false:
@Configuration
public class CustomMvcConfiguration implements InitializingBean {
@Autowired
private RequestMappingHandlerMapping requestMappingHandlerMapping;
@Override
public void afterPropertiesSet() throws Exception {
requestMappingHandlerMapping.setRemoveSemicolonContent(false);
}
}
除非有很特殊的需要,否则不建议使用@MatrixVariable。
文件上传
文件上传在使用POSTMAN模拟请求的时候需要选择form-data,POST方式进行提交:
假设在电脑的磁盘D盘根目录有一个图片文件叫doge.jpg,现在要通过本地服务接口把文件上传,控制器的代码如下:
@PostMapping(value = "/file1")
public String file1(@RequestPart(name = "file1") MultipartFile multipartFile) {
String content = String.format("name = %s,originName = %s,size = %d",
multipartFile.getName(), multipartFile.getOriginalFilename(), multipartFile.getSize());
log.info(content);
return content;
}
控制台输出是:
name = file1,originName = doge.jpg,size = 68727
可能有点疑惑,参数是怎么来的,我们可以用Fildder软件抓个包看下:
可知MultipartFile实例的主要属性分别来自Content-Disposition、Content-Type和Content-Length,另外,InputStream用于读取请求体的最后部分(文件的字节序列)。参数处理器用到的是RequestPartMethodArgumentResolver(记住一点,使用了@RequestPart和MultipartFile一定是使用此参数处理器)。在其他情况下,使用@RequestParam和MultipartFile或者仅仅使用MultipartFile(参数的名字必须和POST表单中的Content-Disposition描述的name一致)也可以接收上传的文件数据,主要是通过RequestParamMethodArgumentResolver进行解析处理的,它的功能比较强大,具体可以看其supportsParameter方法,这两种情况的控制器方法代码如下:
@PostMapping(value = "/file2")
public String file2(MultipartFile file1) {
String content = String.format("name = %s,originName = %s,size = %d",
file1.getName(), file1.getOriginalFilename(), file1.getSize());
log.info(content);
return content;
}
@PostMapping(value = "/file3")
public String file3(@RequestParam(name = "file1") MultipartFile multipartFile) {
String content = String.format("name = %s,originName = %s,size = %d",
multipartFile.getName(), multipartFile.getOriginalFilename(), multipartFile.getSize());
log.info(content);
return content;
}
其他参数
其他参数主要包括请求头、Cookie、Model、Map等相关参数,还有一些并不是很常用或者一些相对原生的属性值获取(例如HttpServletRequest、HttpServletResponse或者它们内置的实例方法等)不做讨论。
请求头
请求头的值主要通过@RequestHeader注解的参数获取,参数处理器是RequestHeaderMethodArgumentResolver,需要在注解中指定请求头的Key。简单实用如下:
控制器方法代码:
@PostMapping(value = "/header")
public String header(@RequestHeader(name = "Content-Type") String contentType) {
return contentType;
}
Cookie
Cookie的值主要通过@CookieValue注解的参数获取,参数处理器为ServletCookieValueMethodArgumentResolver,需要在注解中指定Cookie的Key。控制器方法代码如下:
@PostMapping(value = "/cookie")
public String cookie(@CookieValue(name = "JSESSIONID") String sessionId) {
return sessionId;
}
Model 类型参数
Model类型参数的处理器是ModelMethodProcessor,实际上处理此参数是直接返回ModelAndViewContainer实例中的Model(具体是ModelMap类型),因为要桥接不同的接口和类的功能,因此回调的实例是BindingAwareModelMap类型,此类型继承自ModelMap同时实现了Model接口。举个例子:
@GetMapping(value = "/model")
public String model(Model model, ModelMap modelMap) {
log.info("{}", model == modelMap);
return "success";
}
注意调用此接口,控制台输出INFO日志内容为:true。还要注意一点:ModelMap或者Model中添加的属性项会附加到HttpRequestServlet实例中带到页面中进行渲染,使用模板引擎的前提下可以直接在模板文件内容中直接使用占位符提取这些属性值。
@ModelAttribute 参数
@ModelAttribute注解处理的参数处理器为ModelAttributeMethodProcessor,@ModelAttribute的功能源码的注释如下:
Annotation that binds a method parameter or method return value to a named model attribute, exposed to a web view.
简单来说,就是通过key-value形式绑定方法参数或者方法返回值到Model(Map)中,区别下面三种情况:
@ModelAttribute使用在方法(返回值)上,方法没有返回值(void类型), Model(Map)参数需要自行设置。@ModelAttribute使用在方法(返回值)上,方法有返回值(非void类型),返回值会添加到Model(Map)参数,key由@ModelAttribute的value指定,否则会使用返回值类型字符串(首写字母变为小写,如返回值类型为Integer,则key为integer)。@ModelAttribute使用在方法参数中,则可以获取同一个控制器中的已经设置的@ModelAttribute对应的值。
在一个控制器(使用了@Controller的Spring组件)中,如果存在一到多个使用了@ModelAttribute的方法,这些方法总是在进入控制器方法之前执行,并且执行顺序是由加载顺序决定的(具体的顺序是带参数的优先,并且按照方法首字母升序排序),举个例子:
@Slf4j
@RestController
public class ModelAttributeController {
@ModelAttribute
public void before(Model model) {
log.info("before..........");
model.addAttribute("before", "beforeValue");
}
@ModelAttribute(value = "beforeArg")
public String beforeArg() {
log.info("beforeArg..........");
return "beforeArgValue";
}
@GetMapping(value = "/modelAttribute")
public String modelAttribute(Model model, @ModelAttribute(value = "beforeArg") String beforeArg) {
log.info("modelAttribute..........");
log.info("beforeArg..........{}", beforeArg);
log.info("{}", model);
return "success";
}
@ModelAttribute
public void after(Model model) {
log.info("after..........");
model.addAttribute("after", "afterValue");
}
@ModelAttribute(value = "afterArg")
public String afterArg() {
log.info("afterArg..........");
return "afterArgValue";
}
}
调用此接口,控制台输出日志如下:
after..........
before..........
afterArg..........
beforeArg..........
modelAttribute..........
beforeArg..........beforeArgValue
{after=afterValue, before=beforeValue, afterArg=afterArgValue, beforeArg=beforeArgValue}
可以印证排序规则和参数设置、获取的结果和前面的分析是一致的。
Errors 或 BindingResult 参数
Errors其实是BindingResult的父接口,BindingResult主要用于回调JSR参数校验异常的属性项,如果JSR303校验异常,一般会抛出MethodArgumentNotValidException异常,并且会返回400(Bad Request),见全局异常处理器DefaultHandlerExceptionResolver。Errors类型的参数处理器为ErrorsMethodArgumentResolver。举个例子:
@PostMapping(value = "/errors")
public String errors(@RequestBody @Validated ErrorsModel errors, BindingResult bindingResult) {
if (bindingResult.hasErrors()) {
for (ObjectError objectError : bindingResult.getAllErrors()) {
log.warn("name={},message={}", objectError.getObjectName(), objectError.getDefaultMessage());
}
}
return errors.toString();
}
//ErrorsModel
@Data
@NoArgsConstructor
public class ErrorsModel {
@NotNull(message = "id must not be null!")
private Integer id;
@NotEmpty(message = "errors name must not be empty!")
private String name;
}
调用接口控制台Warn日志如下:
name=errors,message=errors name must not be empty!
一般情况下,不建议用这种方式处理JSR校验异常的属性项,因为会涉及到大量的重复的硬编码工作,建议:方式一直接继承ResponseEntityExceptionHandler覆盖对应的方法或者方式二同时使用@ExceptionHandler和@(Rest)ControllerAdvice注解进行异常处理。例如:
@RestControllerAdvice
public class ApplicationRestControllerAdvice{
@ExceptionHandler(BusinessException.class)
public Response handleBusinessException(BusinessException e, HttpServletRequest request){
// 这里处理异常和返回值
}
@ExceptionHandler(MethodArgumentNotValidException.class)
public Response handleMethodArgumentNotValidException(MethodArgumentNotValidException e, HttpServletRequest request){
// 这里处理异常和返回值
}
}
值得注意的是,SpringBoot某个版本之后,把JSR303相关的依赖抽离到spring-boot-starter-validation依赖中,如果要使用JSR303相关相关校验功能,必须独立引入此starter
@Value 参数
控制器方法的参数可以是@Value注解修饰的参数,会从Environment实例中装配和转换属性值到对应的参数中(也就是参数的来源并不是请求体,而是上下文中已经加载和处理完成的环境属性值),参数处理器为ExpressionValueMethodArgumentResolver。举个例子:
@GetMapping(value = "/value")
public String value(@Value(value = "${spring.application.name}") String name) {
log.info("spring.application.name={}", name);
return name;
}
spring.application.name属性一般在配置文件中指定,在加载配置文件属性的时候添加到全局的Environment中。
Map 类型参数
Map类型参数的范围相对比较广,对应一系列的参数处理器,注意区别使用了上面提到的部分注解的Map类型和完全不使用注解的Map类型参数,两者的处理方式不相同。下面列举几个相对典型的Map类型参数处理例子。
不使用任何注解的Map<String,Object>参数
这种情况下参数实际上直接回调ModelAndViewContainer中的ModelMap实例,参数处理器为MapMethodProcessor,往Map参数中添加的属性将会带到页面中。
使用@RequestParam注解的Map<String,Object>参数
这种情况下的参数处理器为RequestParamMapMethodArgumentResolver,使用的请求方式需要指定Content-Type为x-www-form-urlencoded,不能使用application/json的方式:
控制器代码为:
@PostMapping(value = "/map")
public String mapArgs(@RequestParam Map<String, Object> map) {
log.info("{}", map);
return map.toString();
}
这种情况下的参数处理器为RequestHeaderMapMethodArgumentResolver,作用是获取请求的所有请求头的Key-Value。
使用@PathVariable注解的Map<String,Object>参数
这种情况下的参数处理器为PathVariableMapMethodArgumentResolver,作用是获取所有路径参数封装为Key-Value结构。
MultipartFile 集合:批量文件上传
批量文件上传的时候,我们一般需要接收一个MultipartFile集合,可以有两种选择:
- 使用
MultipartHttpServletRequest参数,直接调用getFiles方法获取MultipartFile列表。 - 使用
@RequestParam注解修饰MultipartFile列表,参数处理器是RequestParamMethodArgumentResolver,其实就是第1种方式的封装而已。
控制器方法代码如下:
@PostMapping(value = "/parts")
public String partArgs(@RequestParam(name = "file") List<MultipartFile> parts) {
log.info("{}", parts);
return parts.toString();
}
日期类型参数处理
日期参数处理个人认为是请求参数处理中最复杂的,因为一般日期处理的逻辑不是通用的,过多的定制化处理导致很难有一个统一的标准处理逻辑去处理和转换日期类型的参数。不过,这里介绍几个通用的方法,以应对各种奇葩的日期格式。下面介绍的例子中全部使用JDK8中引入的日期时间API,围绕java.util.Date为核心的日期时间API的使用方式类同。
统一以字符串形式接收
这种是最原始但是最奏效的方式,统一以字符串形式接收,然后自行处理类型转换,下面给个小例子:
static DateTimeFormatter FORMATTER = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
@PostMapping(value = "/date1")
public String date1(@RequestBody UserDto userDto) {
UserEntity userEntity = new UserEntity();
userEntity.setUserId(userDto.getUserId());
userEntity.setBirthdayTime(LocalDateTime.parse(userDto.getBirthdayTime(), FORMATTER));
userEntity.setGraduationTime(LocalDateTime.parse(userDto.getGraduationTime(), FORMATTER));
log.info(userEntity.toString());
return "success";
}
@Data
public class UserDto {
private String userId;
private String birthdayTime;
private String graduationTime;
}
@Data
public class UserEntity {
private String userId;
private LocalDateTime birthdayTime;
private LocalDateTime graduationTime;
}
使用字符串接收后再转换的缺点就是模板代码太多,编码风格不够简洁,重复性工作太多,如果有代码洁癖或者类似笔者这样是一个节能主义者,一般不会选用这种方式。
@DateTimeFormat注解配合@RequestBody的参数使用的时候,会发现抛出InvalidFormatException异常,提示转换失败,这是因为在处理此注解的时候,只支持Form表单提交(Content-Type为x-www-form-urlencoded),例子如下:
@Data
public class UserDto2 {
private String userId;
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime birthdayTime;
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime graduationTime;
}
@PostMapping(value = "/date2")
public String date2(UserDto2 userDto2) {
log.info(userDto2.toString());
return "success";
}
//或者像下面这样
@PostMapping(value = "/date2")
public String date2(@RequestParam("name"="userId")String userId,
@RequestParam("name"="birthdayTime") @DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss") LocalDateTime birthdayTime,
@RequestParam("name"="graduationTime") @DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss") LocalDateTime graduationTime) {
return "success";
}
而@JsonFormat注解可使用在Form表单或者JSON请求参数的场景,因此更推荐使用@JsonFormat注解,不过注意需要指定时区(timezone属性,例如在中国是东八区GMT+8),否则有可能导致出现时差,举个例子:
@PostMapping(value = "/date2")
public String date2(@RequestBody UserDto2 userDto2) {
log.info(userDto2.toString());
return "success";
}
@Data
public class UserDto2 {
private String userId;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private LocalDateTime birthdayTime;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private LocalDateTime graduationTime;
}
一般选用LocalDateTime作为日期字段参数的类型,因为它的转换相对于其他JDK8的日期时间类型简单
Jackson 序列化和反序列化定制
因为SpringMVC默认使用Jackson处理@RequestBody的参数转换,因此可以通过定制序列化器和反序列化器来实现日期类型的转换,这样我们就可以使用application/json的形式提交请求参数。这里的例子是转换请求JSON参数中的字符串为LocalDateTime类型,属于JSON反序列化,因此需要定制反序列化器:
@PostMapping(value = "/date3")
public String date3(@RequestBody UserDto3 userDto3) {
log.info(userDto3.toString());
return "success";
}
@Data
public class UserDto3 {
private String userId;
@JsonDeserialize(using = CustomLocalDateTimeDeserializer.class)
private LocalDateTime birthdayTime;
@JsonDeserialize(using = CustomLocalDateTimeDeserializer.class)
private LocalDateTime graduationTime;
}
public class CustomLocalDateTimeDeserializer extends LocalDateTimeDeserializer {
public CustomLocalDateTimeDeserializer() {
super(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
}
}
最佳实践
前面三种方式都存在硬编码等问题,其实最佳实践是直接修改MappingJackson2HttpMessageConverter中的ObjectMapper对于日期类型处理默认的序列化器和反序列化器,这样就能全局生效,不需要再使用其他注解或者定制序列化方案(当然,有些时候需要特殊处理定制),或者说,在需要特殊处理的场景才使用其他注解或者定制序列化方案。使用钩子接口Jackson2ObjectMapperBuilderCustomizer可以实现对容器中的ObjectMapper单例中的属性定制:
@Bean
public Jackson2ObjectMapperBuilderCustomizer jackson2ObjectMapperBuilderCustomizer(){
return customizer->{
customizer.serializerByType(LocalDateTime.class,new LocalDateTimeSerializer(
DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));
customizer.deserializerByType(LocalDateTime.class,new LocalDateTimeDeserializer(
DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));
};
}
这样就能定制化MappingJackson2HttpMessageConverter中持有的ObjectMapper,上面的LocalDateTime序列化和反序列化器对全局生效。
请求 URL 匹配
前面基本介绍完了主流的请求参数处理,其实SpringMVC中还会按照URL的模式进行匹配,使用的是Ant路径风格,处理工具类为org.springframework.util.AntPathMatcher,从此类的注释来看,匹配规则主要包括下面四点
:
?匹配1个字符。*匹配0个或者多个字符。**匹配路径中0个或者多个目录。- 正则支持,如
{spring:[a-z]+}将正则表达式[a-z]+匹配到的值,赋值给名为spring的路径变量。
举些例子:
’?‘形式的URL:
@GetMapping(value = "/pattern?")
public String pattern() {
return "success";
}
/pattern 404 Not Found
/patternd 200 OK
/patterndd 404 Not Found
/pattern/ 404 Not Found
/patternd/s 404 Not Found
’*‘形式的URL:
@GetMapping(value = "/pattern*")
public String pattern() {
return "success";
}
/pattern 200 OK
/pattern/ 200 OK
/patternd 200 OK
/pattern/a 404 Not Found
’**‘形式的URL:
@GetMapping(value = "/pattern/**/p")
public String pattern() {
return "success";
}
/pattern/p 200 OK
/pattern/x/p 200 OK
/pattern/x/y/p 200 OK
{spring:[a-z]+}形式的URL:
@GetMapping(value = "/pattern/{key:[a-c]+}")
public String pattern(@PathVariable(name = "key") String key) {
return "success";
}
/pattern/a 200 OK
/pattern/ab 200 OK
/pattern/abc 200 OK
/pattern 404 Not Found
/pattern/abcd 404 Not Found
上面的四种URL模式可以组合使用,千变万化。
URL匹配还遵循精确匹配原则,也就是存在两个模式对同一个URL都能够匹配成功,则选取最精确的URL匹配,进入对应的控制器方法,举个例子:
@GetMapping(value = "/pattern/**/p")
public String pattern1() {
return "success";
}
@GetMapping(value = "/pattern/p")
public String pattern2() {
return "success";
}
上面两个控制器,如果请求URL为/pattern/p,最终进入的方法为pattern2。上面的例子只是列举了SpringMVC中URL匹配的典型例子,并没有深入展开。
最后,org.springframework.util.AntPathMatcher作为一个工具类,可以单独使用,不仅仅可以用于匹配URL,也可以用于匹配系统文件路径,不过需要使用其带参数构造改变内部的pathSeparator变量,例如:
AntPathMatcher antPathMatcher = new AntPathMatcher(File.separator);
1.8 - CH09-请求过程
Spring MVC是Spring系列框架中使用频率最高的部分。不管是Spring Boot还是传统的Spring项目,只要是Web项目都会使用到Spring MVC部分。因此程序员一定要熟练掌握MVC部分。本篇博客简要分析Spring MVC处理一个请求的流程。
一个请求从客户端发出到达服务器,然后被处理的整个过程其实是非常复杂的。本博客主要介绍请求到达服务器被核心组件 DispatcherServlet 处理的整理流程(不包括Filter的处理流程)。
处理流程分析
Servlet处理一个请求时会调用service()方法,所以DispatcherServlet处理请求的方式也是从service()方法开始(debug的话建议从DispatcherServlet的service方法开始debug)。FrameworkServlet重写了HttpServlet的service方法,这个service方法后面又调用了FrameworkServlet的processRequest()方法,processRequest()调用了DispatcherServlet的doService()方法,最后调用到DispatcherServlet的doDispatcher()方法。整合处理请求的方法调用流程如上,下面看下代码:
protected void service(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
HttpMethod httpMethod = HttpMethod.resolve(request.getMethod());
if (HttpMethod.PATCH == httpMethod || httpMethod == null) {
processRequest(request, response);
}
else {
//这边调用了HttpServlet的service()方法,但由于FrameWorkServle重写了doGet、doPost等方法,所以最终还是会调用到processRequest方法
super.service(request, response);
}
}
再看看FrameworkServlet的processRequest()方法。
protected final void processRequest(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
long startTime = System.currentTimeMillis();
Throwable failureCause = null;
LocaleContext previousLocaleContext = LocaleContextHolder.getLocaleContext();
LocaleContext localeContext = buildLocaleContext(request);
RequestAttributes previousAttributes = RequestContextHolder.getRequestAttributes();
ServletRequestAttributes requestAttributes = buildRequestAttributes(request, response, previousAttributes);
WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request);
asyncManager.registerCallableInterceptor(FrameworkServlet.class.getName(), new RequestBindingInterceptor());
initContextHolders(request, localeContext, requestAttributes);
try {
//这边调用DispatcherServlet的doService()方法
doService(request, response);
}
catch (ServletException ex) {
failureCause = ex;
throw ex;
}
catch (IOException ex) {
failureCause = ex;
throw ex;
}
catch (Throwable ex) {
failureCause = ex;
throw new NestedServletException("Request processing failed", ex);
}
finally {
resetContextHolders(request, previousLocaleContext, previousAttributes);
if (requestAttributes != null) {
requestAttributes.requestCompleted();
}
if (logger.isDebugEnabled()) {
if (failureCause != null) {
this.logger.debug("Could not complete request", failureCause);
}
else {
if (asyncManager.isConcurrentHandlingStarted()) {
logger.debug("Leaving response open for concurrent processing");
}
else {
this.logger.debug("Successfully completed request");
}
}
}
publishRequestHandledEvent(request, response, startTime, failureCause);
}
}
doService()方法的具体内容会在后面讲到,这边描述下doDispatcher()的内容,参考了博客:
首先根据请求的路径找到HandlerMethod(带有Method反射属性,也就是对应Controller中的方法),然后匹配路径对应的拦截器,有了HandlerMethod和拦截器构造个HandlerExecutionChain对象。HandlerExecutionChain对象的获取是通过HandlerMapping接口提供的方法中得到。有了HandlerExecutionChain之后,通过HandlerAdapter对象进行处理得到ModelAndView对象,HandlerMethod内部handle的时候,使用各种HandlerMethodArgumentResolver实现类处理HandlerMethod的参数,使用各种HandlerMethodReturnValueHandler实现类处理返回值。 最终返回值被处理成ModelAndView对象,这期间发生的异常会被HandlerExceptionResolver接口实现类进行处理。
总结下Spring MVC处理一个请求的过程:
- 首先,搜索应用的上下文对象 WebApplicationContext 并把它作为一个属性(attribute)绑定到该请求上,以便控制器和其他组件能够使用它。
- 将地区(locale)解析器绑定到请求上,以便其他组件在处理请求(渲染视图、准备数据等)时可以获取区域相关的信息。如果你的应用不需要解析区域相关的信息;
- 将主题(theme)解析器绑定到请求上,以便其他组件(比如视图等)能够了解要渲染哪个主题文件。同样,如果你不需要使用主题相关的特性,忽略它即可如果你配置了multipart文件处理器,那么框架将查找该文件是不是multipart(分为多个部分连续上传)的。若是,则将该请求包装成一个 MultipartHttpServletRequest 对象,以便处理链中的其他组件对它做进一步的处理。关于Spring对multipart文件传输处理的支持;
- 为该请求查找一个合适的处理器。如果可以找到对应的处理器,则与该处理器关联的整条执行链(前处理器、后处理器、控制器等)都会被执行,以完成相应模型的准备或视图的渲染如果处理器返回的是一个模型(model),那么框架将渲染相应的视图。若没有返回任何模型(可能是因为前后的处理器出于某些原因拦截了请求等,比如,安全问题),则框架不会渲染任何视图,此时认为对请求的处理可能已经由处理链完成了(这个过程就是doService()和doDispatcher()做的事情)
1、 首先用户发送请求——>DispatcherServlet,前端控制器收到请求后自己不进行处理,而是委托给其他的解析器进行处理,作为统一访问点,进行全局的流程控制;
2、 DispatcherServlet——>HandlerMapping,HandlerMapping将会把请求映射为HandlerExecutionChain对象(包含一个Handler处理器(页面控制器)对象、多个HandlerInterceptor拦截器)对象,通过这种策略模式,很容易添加新的映射策略;
3、 DispatcherServlet——>HandlerAdapter,HandlerAdapter将会把处理器包装为适配器,从而支持多种类型的处理器,即适配器设计模式的应用,从而很容易支持很多类型的处理器;
4、 HandlerAdapter——>处理器功能处理方法的调用,HandlerAdapter将会根据适配的结果调用真正的处理器的功能处理方法,完成功能处理;并返回一个ModelAndView对象(包含模型数据、逻辑视图名);
5、 ModelAndView的逻辑视图名——> ViewResolver,ViewResolver将把逻辑视图名解析为具体的View,通过这种策略模式,很容易更换其他视图技术;
6、 View——>渲染,View会根据传进来的Model模型数据进行渲染,此处的Model实际是一个Map数据结构,因此很容易支持其他视图技术;
7、返回控制权给DispatcherServlet,由DispatcherServlet返回响应给用户,到此一个流程结束。
请求流程图
还是这个图比较清楚。发现根据代码不太能把这个流程说清楚。而且整个流程很长,代码很多,我就不贴代码了。这里根据这个图再把整个流程中组件的功能总结下:
DispatcherServlet:核心控制器,所有请求都会先进入DispatcherServlet进行统一分发,是不是感觉有点像外观模式的感觉;
HandlerMapping:这个组件的作用就是将用户请求的URL映射成一个HandlerExecutionChain。这个HandlerExecutionChain是HandlerMethod和HandlerInterceptor的组合。Spring在启动的时候会默认注入很多HandlerMapping组件,其中最常用的组件就是RequestMappingHandlerMapping。
上面的HandlerMethod和HandlerInterceptor组件分别对应我们Controller中的方法和拦截器。拦截器会在HandlerMethod方法执行之前执行
HandlerAdapter组件,这个组件的主要作用是用来对HandlerMethod中参数的转换,对方法的执行,以及对返回值的转换等等。这里面涉及的细节就很多了,包括HandlerMethodArgumentResolver、HandlerMethodReturnValueHandler 、RequestResponseBodyMethodProcessor 、和HttpMessageConvert等组件。
当HandlerAdapter组件执行完成之后会得到一个ModleAndView组件,这个组件代表视图模型。
得到ModleAndView后会执行拦截器的postHandle方法。
如果在上面的执行过程中发生任何异常,会由HandlerExceptionResolver进行统一处理。
最后模型解析器会对上面的到的ModleAndView进行解析,得到一个一个View返回给客户端。在返回客户端之前还会执行拦截器的afterCompletion方法。
1.9 - CH10-配置注入
直接注入
susan.test.userName=someone
@Service
public class UserService {
@Value("${susan.test.userName}")
private String userName;
public String test() {
System.out.println(userName);
return userName;
}
}
默认值
@Value(value = "${susan.test.userName:susan}")
private String userName;
静态变量
@Service
public class UserService {
private static String userName;
@Value("${susan.test.userName}")
public void setUserName(String userName) {
UserService.userName = userName;
}
public String test() {
return userName;
}
}
变量类型
在 Java 中的基本数据类型有4类8种,然我们一起回顾一下:
- 整型:byte、short、int、long
- 浮点型:float、double
- 布尔型:boolean
- 字符型:char
相对应地提供了8种包装类:
- 整型:Byte、Short、Integer、Long
- 浮点型:Float、Double
- 布尔型:Boolean
- 字符型:Character
@Value 注解对这8中基本类型和相应的包装类,有非常良好的支持,例如:
@Value("${susan.test.a:1}")
private byte a;
@Value("${susan.test.b:100}")
private short b;
@Value("${susan.test.c:3000}")
private int c;
@Value("${susan.test.d:4000000}")
private long d;
@Value("${susan.test.e:5.2}")
private float e;
@Value("${susan.test.f:6.1}")
private double f;
@Value("${susan.test.g:false}")
private boolean g;
@Value("${susan.test.h:h}")
private char h;
@Value("${susan.test.a:1}")
private byte a1;
@Value("${susan.test.b:100}")
private Short b1;
@Value("${susan.test.c:3000}")
private Integer c1;
@Value("${susan.test.d:4000000}")
private Long d1;
@Value("${susan.test.e:5.2}")
private Float e1;
@Value("${susan.test.f:6.1}")
private Double f1;
@Value("${susan.test.g:false}")
private Boolean g1;
@Value("${susan.test.h:h}")
private Character h1;
数组类型
@Value("${susan.test.array:1,2,3,4,5}")
private int[] array;
集合类型
List
susan.test.list[0]=10
susan.test.list[1]=11
susan.test.list[2]=12
susan.test.list[3]=13
@Configuration
@ConfigurationProperties(prefix = "susan.test")
@Data
public class MyConfig {
private List<String> list;
}
或:
@Value("#{'${susan.test.list}'.split(',')}")
private List<String> list;
Set
susan.test.set=10,11,12,13
@Value("#{'${susan.test.set}'.split(',')}")
private Set<String> set;
支持空值:
@Value("#{'${susan.test.set:}'.empty ? null : '${susan.test.set:}'.split(',')}")
private Set<String> set;
Map
susan.test.map={"name":"苏三", "age":"18"}
@Value("#{'${susan.test.map:}'.empty ? null : '${susan.test.map:}'}")
private Map<String, String> map;
注入 Bean
@Service
public class RoleService {
public static final int DEFAULT_AGE = 18;
public int id = 1000;
public String getRoleName() {
return "管理员";
}
public static int getParentId() {
return 2000;
}
}
@Service
public class UserService {
@Value("#{roleService.DEFAULT_AGE}")
private int myAge;
@Value("#{roleService.id}")
private int id;
@Value("#{roleService.getRoleName()}")
private String myRoleName;
@Value("#{roleService.getParentId()}")
private String myParentId;
public String test() {
System.out.println(myAge);
System.out.println(id);
System.out.println(myRoleName);
System.out.println(myParentId);
return null;
}
}
静态类
@Value("#{T(java.io.File).separator}")
private String path;
@Value("#{T(java.lang.Math).random()}")
private double randomValue;
逻辑运算
@Value("#{roleService.roleName + '' + roleService.DEFAULT_AGE}")
private String value;
@Value("#{roleService.DEFAULT_AGE > 16 and roleService.roleName.equals('苏三')}")
private String operation;
@Value("#{roleService.DEFAULT_AGE > 16 ? roleService.roleName: '苏三' }")
private String realRoleName;
${} 与 #{}
${}
用于获取配置文件中的系统属性值。
@Value(value = "${susan.test.userName:susan}")
private String userName;
通过 : 可以设置默认值。如果在配置文件中找不到susan.test.userName的配置,则注入时用默认值。
#{}
主要用于通过spring的EL表达式,获取bean的属性,或者调用bean的某个方法。还有调用类的静态常量和静态方法。
@Value("#{roleService.DEFAULT_AGE}")
private int myAge;
@Value("#{roleService.id}")
private int id;
@Value("#{roleService.getRoleName()}")
private String myRoleName;
@Value("#{T(java.lang.Math).random()}")
private double randomValue;
如果是调用类的静态方法,则需要加T(包名 + 方法名称)。
1.10 - CH11-配置绑定
使用 @Value("${property}") 注释注入配置属性有时会很麻烦,尤其是当你使用多个属性或你的数据是分层的时候。
Spring Boot 引入了一个可替换的方案 —— @ConfigurationProperties 来注入属性。
JavaBean 属性绑定
@Data
@ConfigurationProperties("my.service")
public class MyProperties {
// 我们可以简单地用一个值初始化一个字段来定义一个默认值
private boolean enabled = true;
private InetAddress remoteAddress;
private final Security security = new Security();
@Data
public static class Security {
private String username;
private String password;
// 如果这个属性配置的话,默认是“USER”
private List<String> roles = new ArrayList<>(Collections.singleton("USER"));
}
}
在配置文件中进行如下配置:
my:
service:
enabled: true
remoteAddress: 127.0.0.1
security:
username: csx
password: passwoed
roles:
- role1
- role2
最后生成的 Bean 的属性如下:
{
"enabled": true,
"remoteAddress": "127.0.0.1",
"security": {
"username": "csx",
"password": "passwoed",
"roles": [
"role1",
"role2"
]
}
}
以上的绑定当时需要提供默认的构造函数,以及get/setter方法。
并且不支持 JavaBean 中的静态成员变量的数据绑定
另外,@ConfigurationProperties 还有两个其他属性。
@ConfigurationProperties( value = "my.service",
ignoreInvalidFields = false,
ignoreUnknownFields = false)
ignoreInvalidFields:是否忽略非法值,比如将一个字符串 “foo” 赋值给 bool 值,不忽略的话会报启动异常。
ignoreUnknownFields:对于多余的配置是否会报异常。
构造函数绑定
有些情况下,我们需要绑定的 JavaBean 是不可变的(防止配置注入 Bean 以后,开发者在程序中错误地将配置改掉了)。这种情况下我们可以使用构造函数形式的绑定,只提供 getter 方法。
@Getter
@ConstructorBinding
@ConfigurationProperties("my.service")
public class MyProperties {
private boolean enabled;
private InetAddress remoteAddress;
private final Security security;
public MyProperties(boolean enabled, InetAddress remoteAddress, Security security) {
this.enabled = enabled;
this.remoteAddress = remoteAddress;
this.security = security;
}
@Getter
public static class Security {
private String username;
private String password;
private List<String> roles;
public Security(String username, String password, @DefaultValue("USER") List<String> roles) {
this.username = username;
this.password = password;
this.roles = roles;
}
}
}
@DefaultValue 可以指定默认值。
使用构造函数绑定的方式,只能 @EnableConfigurationProperties 或者 @ConfigurationPropertiesScan 的方式激活 Bean。而不能使用 @Component、@Bean 或者 @Import 的方式进行数据绑定。
如果你的类有多个构造函数,可以直接指定使用哪个。
@ConstructorBinding
public MyProperties(boolean enabled, InetAddress remoteAddress, Security security) {
this.enabled = enabled;
this.remoteAddress = remoteAddress;
this.security = security;
}
激活方式
方式一:添加 @Component 注解
上面的方式需要保证 MyProperties 能被 Spring 扫到。
@Data
@Component
@ConfigurationProperties("my.service")
public class MyProperties {
}
方式二:通过 @Bean 方法
@Configuration
public class ServiceConfig {
@Bean
public MyProperties myProperties(){
return new MyProperties();
}
}
方式三:@EnableConfigurationProperties(推荐)
@Configuration
@EnableConfigurationProperties(MyProperties.class)
public class ServiceConfig {
}
方式四:@ConfigurationPropertiesScan
@SpringBootApplication
@ConfigurationPropertiesScan({ "com.example.app", "com.example.another" })
public class MyApplication {
}
引用方式
我们通过配置在 Spring 容器中生成了配置 Bean,那么需要怎么使用他们呢?
@Service
public class MyService {
// 依赖注入
@Autowired
private MyProperties properties;
public void service(){
System.out.println(properties.getRemoteAddress());
}
}
@Service
public class MyService {
private MyProperties properties;
// 通过构造函数注入,一般推荐这种方式
public MyService(MyProperties properties) {
this.properties = properties;
}
public void service(){
System.out.println(properties.getRemoteAddress());
}
}
给第三方类绑定值
假如某些类不是你自己开发的,你也想使用 @ConfigurationProperties 的方式给他绑定值,那么可以进行下面的方式进行配置。
@Configuration(proxyBeanMethods = false)
public class ThirdPartyConfiguration {
@Bean
@ConfigurationProperties(prefix = "another")
public AnotherComponent anotherComponent() {
return new AnotherComponent();
}
}
宽松绑定原则(Relaxed Binding)
所谓的宽松绑定原则是指:并不是 JavaBean 中的属性必须要和配置文件中的一致才能绑定数据,context-path 也能绑定到 contextPath 属性上。下面举个列子:
@ConfigurationProperties(prefix = "my.main-project.person")
public class MyPersonProperties {
private String firstName;
public String getFirstName() {
return this.firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
}
下面的几种方式,都能将配置文件或者环境变量中的值绑定到 firstName 上。
| 形式 | 使用场景 |
|---|
my.main-project.person.first-name | 推荐使用在 .properties and .yml files. |
my.main-project.person.firstName | Standard camel case syntax. |
my.main-project.person.first_name | 推荐使用在 .properties and .yml files. |
MY_MAINPROJECT_PERSON_FIRSTNAME | 推荐使用在系统环境变量读取配置时使用 |
和 @Value 对比
@Value 是 Spring Framework 中的注解,而 @ConfigurationProperties 是在 Spring Boot 中引入的。
1.11 - CH12-环境变量
Environment 接口介绍
在 Spring 中,Environment 接口主要管理应用程序两个方面的内容:profile 和 properties。
profile 可以简单的等同于环境,比如说平时项目中常见的环境有开发(dev)、测试(stg)和生产(prod),Spring 启动的时候可以设置激活具体的环境。当然,这个 profile 我们还可以为其赋予很多含义,这个主要看你的业务。比如说,你开发的软件会交付给客户A,也会交付给客户B,那么这个 profile 也可以定义成客户的含义。
properties 是配置,配置的来源有很多,可以是配置文件、JVM 的参数、系统的环境变量、JNDI、Sevlet Contxet 参数以及 Map 对象等,使用 Environment 接口,可以方便的获取这些配置。
Bean Definition Profiles
使用 @Profile
Spring 容器可以根据不同的 profile 配置不同的 Bean。这个特性可以帮助你实现很多灵活的功能,比如:
- 开发环境使用内存数据库,测试和生产环境才使用关系型数据库,比如 Mysql 和 Oracle 等
- 交互给客户 A 的软件使用 A 特性,交付给客户 B 的软件使用 B 特性
@Configuration
@Profile("development")
public class StandaloneDataConfig {
@Bean
public DataSource dataSource() {
return new EmbeddedDatabaseBuilder()
.setType(EmbeddedDatabaseType.HSQL)
.addScript("classpath:com/bank/config/sql/schema.sql")
.addScript("classpath:com/bank/config/sql/test-data.sql")
.build();
}
}
@Configuration
@Profile("production")
public class JndiDataConfig {
@Bean(destroyMethod="")
public DataSource dataSource() throws Exception {
Context ctx = new InitialContext();
return (DataSource) ctx.lookup("java:comp/env/jdbc/datasource");
}
}
对比上面的两个配置,我们发现 @Profile 非常适合在两个环境下,Bean 的定义完全不一样的情况,如果两个 Bean 的定义是一样的,只是一些参数不一样的话,我们完全可以使用配置文件的方式实现。
@Profile 注解后面的表达式可以是一个简单的字符串,也可以是一个逻辑运算符。@Profile 支持如下的逻辑运算符。
- !: A logical “not” of the profile
- &: A logical “and” of the profiles
- |: A logical “or” of the profiles
说明:
If a @Configuration class is marked with @Profile, all of the @Bean methods and @Import annotations associated with that class are bypassed unless one or more of the specified profiles are active. If a @Component or @Configuration class is marked with @Profile({"p1", "p2"}), that class is not registered or processed unless profiles ‘p1’ or ‘p2’ have been activated.
使用 xml 方式配置
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jdbc="http://www.springframework.org/schema/jdbc"
xmlns:jee="http://www.springframework.org/schema/jee"
xsi:schemaLocation="...">
<!-- other bean definitions -->
<beans profile="development">
<jdbc:embedded-database id="dataSource">
<jdbc:script location="classpath:com/bank/config/sql/schema.sql"/>
<jdbc:script location="classpath:com/bank/config/sql/test-data.sql"/>
</jdbc:embedded-database>
</beans>
<beans profile="production">
<jee:jndi-lookup id="dataSource" jndi-name="java:comp/env/jdbc/datasource"/>
</beans>
</beans>
激活 profile
1. API 方式
AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext();
// 设置激活的 profile
ctx.getEnvironment().setActiveProfiles("development");
ctx.register(SomeConfig.class, StandaloneDataConfig.class, JndiDataConfig.class);
ctx.refresh();
2. 命令行方式
-Dspring.profiles.active="profile1,profile2"
3. 配置文件方式
spring:
profiles:
active: dev
默认的 profile
Spring 默认的 profile 是 default,可以通过 Environment 的 API 进行修改。
PropertySource 接口
PropertySource 接口是对任何形式的 key-value 键值对的抽象。
@PropertySource
@PropertySource 这个注解的作用是将配置文件中的键值对放入Environment。这个注解的作用和传统配置方式中的 context:place-hold一致。
@Configuration
@PropertySource("classpath:/com/myco/app.properties")
public class AppConfig {
@Autowired
Environment env;
@Bean
public TestBean testBean() {
TestBean testBean = new TestBean();
testBean.setName(env.getProperty("testbean.name"));
return testBean;
}
}
经过上面这样的配置,我们就可以使用 ${key} 这种形式来取变量的值。有时如果我们没配置 key 的值,Spring 会抛异常。这时我们可以使用 ${key:defaultvalue} 这种形式配置默认值。
1.12 - CH13-事务原理
基本概念
ACID 特性
事务(Transaction)是数据库系统中一系列操作的一个逻辑单元,所有操作要么全部成功要么全部失败。
事务是区分文件存储系统与Nosql数据库重要特性之一,其存在的意义是为了保证即使在并发情况下也能正确的执行crud操作。怎样才算是正确的呢?这时提出了事务需要保证的四个特性即ACID:
A: 原子性(atomicity)
一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
C: 一致性(consistency)
在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
I: 隔离性(isolation)
数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读已提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
D: 持久性(durability)
事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
事务隔离级别
在高并发的情况下,要完全保证其ACID特性是非常困难的,除非把所有的事务串行化执行,但带来的负面的影响将是性能大打折扣。很多时候我们有些业务对事务的要求是不一样的,所以数据库中设计了四种隔离级别,供用户基于业务进行选择。
数据库默认隔离级别:
#查看mysql 的默认隔离级别
SELECT @@tx_isolation
#设置为读未提交
set tx_isolation='read-uncommitted';
#设置为读已提交
set tx_isolation='read-committed';
#设置为可重复读
set tx_isolation='REPEATABLE-READ';
#设置为串行化
set tx_isolation='SERIALIZABLE';
脏读
一个事务读取到另一事务未提交的更新数据
# session-1
# 设置为读未提交
set tx_isolation='read-uncommitted';
BEGIN;
insert INTO `account` (accountName,user,money) VALUES ('222','cat',1000);
rollback;
commit;
# session-2
# 设置为读未提交
set tx_isolation='read-uncommitted';
SELECT * from account;
不可重复读
在同一事务中,多次读取同一数据返回的结果有所不同, 换句话说, 后续读取可以读到另一事务已提交的更新数据. 相反, “可重复读”在同一事务中多次读取数据时, 能够保证所读数据一样, 也就是后续读取不能读到另一事务已提交的更新数据。
事务B修改数据导致当前事务A前后读取数据不一致 ,侧重点在于事务B的修改。
当前事务读到了其他事务修改的数据。
# session-1
# 设置为读已提交
set tx_isolation='read-committed';
BEGIN;
SELECT * from `account`;
# 其他操作
SELECT * from `account`;
commit;
# session-2
# 设置为读已提交
set tx_isolation='read-committed';
UPDATE account SET money= money+1 where user='cat';
幻读
查询表中一条数据如果不存在就插入一条,并发的时候却发现,里面居然有两条相同的数据。
事务A修改表中数据,此时事务B插入一条新数据,事务A查询发现表中还有没修改的数据,像是出现幻觉
事务A读到了事务B新增的数据,导致结果不一致, 侧重点在于事务B新增数据
# session-1
# 设置为可重复读
set tx_isolation='REPEATABLE-READ';
BEGIN;
SELECT * FROM `account` WHERE `user` = 'cat';
#此时,另一个事务插入了数据
SELECT * FROM `account` WHERE `user` = 'cat';
insert INTO `account` (accountName,user,money) VALUES ('222','cat',1000);
SELECT * FROM `account` WHERE `user` = 'cat';
update `account` set money=money+10 where `user` = 'cat' and id=1;
SELECT * FROM `account` WHERE `user` = 'cat';
commit;
# session-2
# 设置为可重复读
set tx_isolation='REPEATABLE-READ';
insert INTO `account` (accountName,user,money) VALUES ('222','cat',1000);
传播机制
Spring 针对方法嵌套调用时事务的创建行为定义了七种事务传播机制,分别是:
- PROPAGATION_REQUIRED:
- 表示当前方法必须在一个具有事务的上下文中运行,如有客户端有事务在进行,那么被调用端将在该事务中运行,否则的话重新开启一个事务。(如果被调用端发生异常,那么调用端和被调用端事务都将回滚)
- PROPAGATION_SUPPORT:
- 表示当前方法不必需要具有一个事务上下文,但是如果有一个事务的话,它也可以在这个事务中运行。
- PROPAGATION_MANDATORY:
- 表示当前方法必须在一个事务中运行,如果没有事务,将抛出异常。
- PROPAGATION_REQUIRES_NEW:
- 表示当前方法必须运行在它自己的事务中。一个新的事务将启动,而且如果有一个现有的事务在运行的话,则这个方法将在运行期被挂起,直到新的事务提交或者回滚才恢复执行。
- PROPAGATION_NOT_SUPPORTED:
- 表示该方法不应该在一个事务中运行。如果有一个事务正在运行,他将在运行期被挂起,直到这个事务提交或者回滚才恢复执行。
- PROPAGATION_NEVER:
- 表示当方法务不应该在一个事务中运行,如果存在一个事务,则抛出异常。
- PROPAGATION_NESTED:
- 表示如果当前方法正有一个事务在运行中,则该方法应该运行在一个嵌套事务中,被嵌套的事务可以独立于被封装的事务中进行提交或者回滚。如果封装事务存在,并且外层事务抛出异常回滚,那么内层事务必须回滚,反之,内层事务并不影响外层事务。如果封装事务不存在,则同PROPAGATION_REQUIRED的一样。
基本上从字面意思就能知道每种传播机制各自的行为表现,Spring 默认的事务传播机制是PROPAGATION_REQUIRED,即如果当前存在事务,则使用当前事务,否则创建新的事务。详情可参考Spring事务传播行为。
事务行为
事务的行为包括事务开启、事务提交和事务回滚。InnoDB所有的用户SQL执行都在事务控制之内,在默认情况下,autocommit设置为true,单条SQL执行成功后,MySQL会自动提交事务,或者如果SQL执行出错,则根据异常类型执行事务提交或者回滚。可以使用START TRANSACTION(SQL标准)或者BEGIN开启事务,使用COMMIT和ROLLBACK提交和回滚事务;也可以通过设置autocommit属性来控制事务行为,当设置autocommit为false时,其后执行的多条SQL语句将在一个事务内,直到执行COMMIT或者ROLLBACK事务才会提交或者回滚。
AOP 增强
Spring使用 AOP(面向切面编程)来实现声明式事务,这里不再细说。说下动态代理和 AOP 增强。
动态代理 是Spring 实现 AOP 的默认方式,分为两种:JDK 动态代理和 CGLIB 动态代理。JDK 动态代理面向接口,通过反射生成目标代理接口的匿名实现类;CGLIB 动态代理则通过继承,使用字节码增强技术(或者objenesis类库)为目标代理类生成代理子类。Spring 默认对接口实现使用 JDK 动态代理,对具体类使用 CGLIB,同时也支持配置全局使用 CGLIB 来生成代理对象。
我们在切面配置中会使用到@Aspect注解,这里用到了 Aspectj 的切面表达式。Aspectj 是 java 语言实现的一个 AOP 框架,使用静态代理模式,拥有完善的 AOP 功能,与 Spring AOP 互为补充。Spring 采用了 Aspectj 强大的切面表达式定义方式,但是默认情况下仍然使用动态代理方式,并未使用 Aspectj 的编译器和织入器,当然也支持配置使用 Aspectj 静态代理替代动态代理方式。Aspectj 功能更强大,比方说它支持对字段、POJO 类进行增强,与之相对,Spring 只支持对 Bean 方法级别进行增强。
Spring对方法的增强有五种方式:
- 前置增强(
org.springframework.aop.BeforeAdvice):在目标方法执行之前进行增强; - 后置增强(
org.springframework.aop.AfterReturningAdvice):在目标方法执行之后进行增强; - 环绕增强(
org.aopalliance.intercept.MethodInterceptor):在目标方法执行前后都执行增强; - 异常抛出增强(
org.springframework.aop.ThrowsAdvice):在目标方法抛出异常后执行增强; - 引介增强(
org.springframework.aop.IntroductionInterceptor):为目标类添加新的方法和属性。
声明式事务的实现就是通过环绕增强的方式,在目标方法执行之前开启事务,在目标方法执行之后提交或者回滚事务,事务拦截器的继承关系图可以体现这一点:
Spring 事务抽象
统一一致的事务抽象是 Spring 框架的一大优势,无论是全局事务还是本地事务,JTA、JDBC、Hibernate 还是 JPA,Spring 都使用统一的编程模型,使得应用程序可以很容易地在全局事务与本地事务,或者不同的事务框架之间进行切换。下图是 Spring 事务抽象的核心类图:
接口PlatformTransactionManager定义了事务操作的行为,其依赖TransactionDefinition和TransactionStatus接口,其实大部分的事务属性和行为我们以MySQL数据库为例已经有过了解,这里再对应介绍下。
PlatformTransactionManager:事务管理器getTransaction方法:事务获取操作,根据事务属性定义,获取当前事务或者创建新事物;commit方法:事务提交操作,注意这里所说的提交并非直接提交事务,而是根据当前事务状态执行提交或者回滚操作;rollback方法:事务回滚操作,同样,也并非一定直接回滚事务,也有可能只是标记事务为只读,等待其他调用方执行回滚。TransactionDefinition:事务属性定义getPropagationBehavior方法:返回事务的传播属性,默认是PROPAGATION_REQUIRED;getIsolationLevel方法:返回事务隔离级别,事务隔离级别只有在创建新事务时才有效,也就是说只对应传播属性PROPAGATION_REQUIRED和PROPAGATION_REQUIRES_NEW;getTimeout方法:返回事务超时时间,以秒为单位,同样只有在创建新事务时才有效;isReadOnly方法:是否优化为只读事务,支持这项属性的事务管理器会将事务标记为只读,只读事务不允许有写操作,不支持只读属性的事务管理器需要忽略这项设置,这一点跟其他事务属性定义不同,针对其他不支持的属性设置,事务管理器应该抛出异常。getName方法:返回事务名称,声明式事务中默认值为“类的完全限定名.方法名”。TransactionStatus:当前事务状态isNewTransaction方法:当前方法是否创建了新事务(区别于使用现有事务以及没有事务);hasSavepoint方法:在嵌套事务场景中,判断当前事务是否包含保存点;setRollbackOnly和isRollbackOnly方法:只读属性设置(主要用于标记事务,等待回滚)和查询;flush方法:刷新底层会话中的修改到数据库,一般用于刷新如Hibernate/JPA的会话,是否生效由具体事务资源实现决定;isCompleted方法:判断当前事务是否已完成(已提交或者已回滚)。
部分Spring包含的对PlatformTransactionManager的实现类如下图所示:
AbstractPlatformTransactionManager抽象类实现了Spring事务的标准流程,其子类DataSourceTransactionManager是我们使用较多的JDBC单数据源事务管理器,而JtaTransactionManager是JTA(Java Transaction API)规范的实现类,另外两个则分别是JavaEE容器WebLogic和WebSphere的JTA事务管理器的具体实现。
Spring 事务切面
之前提到,Spring采用AOP来实现声明式事务,那么事务的AOP切面是如何织入的呢?这一点涉及到AOP动态代理对象的生成过程。
代理对象生成的核心类是AbstractAutoProxyCreator,实现了BeanPostProcessor接口,会在Bean初始化完成之后,通过postProcessAfterInitialization方法生成代理对象,关于BeanPostProcessor在Bean生命周期中的作用,可参考一些常用的Spring扩展接口。
看一下AbstractAutoProxyCreator类的核心代码,主要关注三个方法:postProcessAfterInitialization、wrapIfNecessary和createProxy,为了突出核心流程,以注释代替了部分代码的具体实现,后续的源码分析也采用相同的处理。
// AbstractAutoProxyCreator.class
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (bean != null) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
if (!this.earlyProxyReferences.contains(cacheKey)) {
// 创建代理对象
return wrapIfNecessary(bean, beanName, cacheKey);
}
}
return bean;
}
protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
// 参数检查,跳过已经执行过代理对象生成,或者已知的不需要生成代理对象的Bean
...
// Create proxy if we have advice.
// 查询当前Bean所有的AOP增强配置,最终是通过AOPUtils工具类实现
Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);
if (specificInterceptors != DO_NOT_PROXY) {
this.advisedBeans.put(cacheKey, Boolean.TRUE);
// 执行AOP织入,创建代理对象
Object proxy = createProxy(
bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
this.proxyTypes.put(cacheKey, proxy.getClass());
return proxy;
}
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
protected Object createProxy(Class<?> beanClass, String beanName, Object[] specificInterceptors, TargetSource targetSource) {
if (this.beanFactory instanceof ConfigurableListableBeanFactory) {
AutoProxyUtils.exposeTargetClass((ConfigurableListableBeanFactory) this.beanFactory, beanName, beanClass);
}
// 实例化代理工厂类
ProxyFactory proxyFactory = new ProxyFactory();
proxyFactory.copyFrom(this);
// 当全局使用动态代理时,设置是否需要对目标Bean强制使用CGLIB动态代理
...
// 构建AOP增强顾问,包含框架公共增强和应用程序自定义增强
// 设置proxyFactory属性,如增强、目标类、是否允许变更等
...
// 创建代理对象
return proxyFactory.getProxy(getProxyClassLoader());
}
最后是通过调用ProxyFactory#getProxy(java.lang.ClassLoader)方法来创建代理对象:
// ProxyFactory.class
public Object getProxy(ClassLoader classLoader) {
return createAopProxy().getProxy(classLoader);
}
// ProxyFactory父类ProxyCreatorSupport.class
protected final synchronized AopProxy createAopProxy() {
if (!this.active) {
activate();
}
return getAopProxyFactory().createAopProxy(this);
}
public ProxyCreatorSupport() {
this.aopProxyFactory = new DefaultAopProxyFactory();
}
ProxyFactory的父类构造器实例化了DefaultAopProxyFactory类,从其源代码我们可以看到Spring动态代理方式选择策略的实现:如果目标类optimize,proxyTargetClass属性设置为true或者未指定需要代理的接口,则使用CGLIB生成代理对象,否则使用JDK动态代理。
public class DefaultAopProxyFactory implements AopProxyFactory, Serializable {
@Override
public AopProxy createAopProxy(AdvisedSupport config) throws AopConfigException {
// 如果optimize,proxyTargetClass属性设置为true或者未指定代理接口,则使用CGLIB生成代理对象
if (config.isOptimize() || config.isProxyTargetClass() || hasNoUserSuppliedProxyInterfaces(config)) {
Class<?> targetClass = config.getTargetClass();
// 参数检查,targetClass为空抛出异常
...
// 目标类本身是接口或者代理对象,仍然使用JDK动态代理
if (targetClass.isInterface() || Proxy.isProxyClass(targetClass)) {
return new JdkDynamicAopProxy(config);
}
// Objenesis是一个可以不通过构造器创建子类的java工具类库
// 作为Spring 4.0后CGLIB的默认实现
return new ObjenesisCglibAopProxy(config);
}
else {
// 否则使用JDK动态代理
return new JdkDynamicAopProxy(config);
}
}
...
}
Spring 事务拦截
我们已经了解了AOP切面织入生成代理对象的过程,当Bean方法通过代理对象调用时,会触发对应的AOP增强拦截器,前面提到声明式事务是一种环绕增强,对应接口为MethodInterceptor,事务增强对该接口的实现为TransactionInterceptor,类图如下:
事务拦截器TransactionInterceptor在invoke方法中,通过调用父类TransactionAspectSupport的invokeWithinTransaction方法进行事务处理,该方法支持声明式事务和编程式事务。
// TransactionInterceptor.class
@Override
public Object invoke(final MethodInvocation invocation) throws Throwable {
// 获取targetClass
...
// Adapt to TransactionAspectSupport's invokeWithinTransaction...
return invokeWithinTransaction(invocation.getMethod(), targetClass, new InvocationCallback() {
@Override
public Object proceedWithInvocation() throws Throwable {
// 实际执行目标方法
return invocation.proceed();
}
});
}
// TransactionInterceptor父类TransactionAspectSupport.class
protected Object invokeWithinTransaction(Method method, Class<?> targetClass, final InvocationCallback invocation)
throws Throwable {
// If the transaction attribute is null, the method is non-transactional.
// 查询目标方法事务属性、确定事务管理器、构造连接点标识(用于确认事务名称)
final TransactionAttribute txAttr = getTransactionAttributeSource().getTransactionAttribute(method, targetClass);
final PlatformTransactionManager tm = determineTransactionManager(txAttr);
final String joinpointIdentification = methodIdentification(method, targetClass, txAttr);
if (txAttr == null || !(tm instanceof CallbackPreferringPlatformTransactionManager)) {
// 事务获取
TransactionInfo txInfo = createTransactionIfNecessary(tm, txAttr, joinpointIdentification);
Object retVal = null;
try {
// 通过回调执行目标方法
retVal = invocation.proceedWithInvocation();
}
catch (Throwable ex) {
// 目标方法执行抛出异常,根据异常类型执行事务提交或者回滚操作
completeTransactionAfterThrowing(txInfo, ex);
throw ex;
}
finally {
// 清理当前线程事务信息
cleanupTransactionInfo(txInfo);
}
// 目标方法执行成功,提交事务
commitTransactionAfterReturning(txInfo);
return retVal;
} else {
// 带回调的事务执行处理,一般用于编程式事务
...
}
}
在讲Spring事务抽象时,有提到事务抽象的核心接口为PlatformTransactionManager,它负责管理事务行为,包括事务的获取、提交和回滚。在invokeWithinTransaction方法中,我们可以看到createTransactionIfNecessary、commitTransactionAfterReturning和completeTransactionAfterThrowing都是针对该接口编程,并不依赖于特定事务管理器,这里是对Spring事务抽象的实现。
//TransactionAspectSupport.class
protected TransactionInfo createTransactionIfNecessary(
PlatformTransactionManager tm, TransactionAttribute txAttr, final String joinpointIdentification) {
...
TransactionStatus status = null;
if (txAttr != null) {
if (tm != null) {
// 获取事务
status = tm.getTransaction(txAttr);
...
}
protected void commitTransactionAfterReturning(TransactionInfo txInfo) {
if (txInfo != null && txInfo.hasTransaction()) {
...
// 提交事务
txInfo.getTransactionManager().commit(txInfo.getTransactionStatus());
}
}
protected void completeTransactionAfterThrowing(TransactionInfo txInfo, Throwable ex) {
if (txInfo != null && txInfo.hasTransaction()) {
...
if (txInfo.transactionAttribute.rollbackOn(ex)) {
try {
// 异常类型为回滚异常,执行事务回滚
txInfo.getTransactionManager().rollback(txInfo.getTransactionStatus());
}
...
} else {
try {
// 异常类型为非回滚异常,仍然执行事务提交
txInfo.getTransactionManager().commit(txInfo.getTransactionStatus());
}
...
}
protected final class TransactionInfo {
private final PlatformTransactionManager transactionManager;
...
另外,在获取事务时,AbstractPlatformTransactionManager#doBegin方法负责开启新事务,在DataSourceTransactionManager有如下代码:
@Override
protected void doBegin(Object transaction, TransactionDefinition definition) {
// 获取数据库连接con
...
if (con.getAutoCommit()) {
txObject.setMustRestoreAutoCommit(true);
if (logger.isDebugEnabled()) {
logger.debug("Switching JDBC Connection [" + con + "] to manual commit");
}
con.setAutoCommit(false);
}
...
}
这里才真正开启了数据库事务。
Spring 事务同步
提到事务传播机制时,我们经常提到一个条件“如果当前已有事务”,那么Spring是如何知道当前是否已经开启了事务呢?在AbstractPlatformTransactionManager中是这样做的:
// AbstractPlatformTransactionManager.class
@Override
public final TransactionStatus getTransaction(TransactionDefinition definition) throws TransactionException {
Object transaction = doGetTransaction();
// 参数为null时构造默认值
...
if (isExistingTransaction(transaction)) {
// Existing transaction found -> check propagation behavior to find out how to behave.
return handleExistingTransaction(definition, transaction, debugEnabled);
}
...
// 获取当前事务对象
protected abstract Object doGetTransaction() throws TransactionException;
// 判断当前事务对象是否包含活跃事务
protected boolean isExistingTransaction(Object transaction) throws TransactionException {
return false;
}
注意getTransaction方法是final的,无法被子类覆盖,保证了获取事务流程的一致和稳定。抽象方法doGetTransaction获取当前事务对象,方法isExistingTransaction判断当前事务对象是否存在活跃事务,具体逻辑由特定事务管理器实现,看下我们使用最多的DataSourceTransactionManager对应的实现:
// DataSourceTransactionManager.class
@Override
protected Object doGetTransaction() {
DataSourceTransactionObject txObject = new DataSourceTransactionObject();
txObject.setSavepointAllowed(isNestedTransactionAllowed());
ConnectionHolder conHolder =
(ConnectionHolder) TransactionSynchronizationManager.getResource(this.dataSource);
txObject.setConnectionHolder(conHolder, false);
return txObject;
}
@Override
protected boolean isExistingTransaction(Object transaction) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
return (txObject.hasConnectionHolder() && txObject.getConnectionHolder().isTransactionActive());
}
可以看到,获取当前事务对象时,使用了TransactionSynchronizationManager#getResource方法,类图如下:
TransactionSynchronizationManager通过ThreadLocal对象在当前线程记录了resources和synchronizations属性。resources是一个HashMap,用于记录当前参与事务的事务资源,方便进行事务同步,在DataSourceTransactionManager的例子中就是以dataSource作为key,保存了数据库连接,这样在同一个线程中,不同的方法调用就可以通过dataSource获取相同的数据库连接,从而保证所有操作在一个事务中进行。synchronizations属性是一个TransactionSynchronization对象的集合,AbstractPlatformTransactionManager类中定义了事务操作各个阶段的调用流程,以事务提交为例:
// AbstractPlatformTransactionManager.class
private void processCommit(DefaultTransactionStatus status) throws TransactionException {
try {
boolean beforeCompletionInvoked = false;
try {
prepareForCommit(status);
triggerBeforeCommit(status);
triggerBeforeCompletion(status);
....
else if (status.isNewTransaction()) {
// 记录日志
...
doCommit(status);
}
...
// 事务调用异常处理
...
try {
triggerAfterCommit(status);
}
finally {
triggerAfterCompletion(status, TransactionSynchronization.STATUS_COMMITTED);
}
}
}
我们可以看到,有很多trigger前缀的方法,这些方法用于在事务操作的各个阶段触发回调,从而可以精确控制在事务执行的不同阶段所要执行的操作,这些回调实际上都通过TransactionSynchronizationUtils来实现,它会遍历TransactionSynchronizationManager#synchronizations集合中的TransactionSynchronization对象,然后分别触发集合中各个元素对应方法的调用。例如:
TransactionSynchronizationManager.registerSynchronization(new TransactionSynchronizationAdapter() {
@Override
public void afterCommit() {
// do something after commit
}
});
这段代码就在当前线程的事务synchronizations属性中,添加了一个自定义同步类,如果当前存在事务,那么在事务管理器执行事务提交之后,就会触发afterCommit方法,可以通过这种方式在事务执行的不同阶段自定义一些操作。
事务不生效
1.访问权限问题
@Service
public class UserService {
@Transactional
private void add(UserModel userModel) {
saveData(userModel);
updateData(userModel);
}
}
我们可以看到add方法的访问权限被定义成了private,这样会导致事务失效,spring要求被代理方法必须是public的。
说白了,在AbstractFallbackTransactionAttributeSource类的computeTransactionAttribute方法中有个判断,如果目标方法不是public,则TransactionAttribute返回null,即不支持事务。
protected TransactionAttribute computeTransactionAttribute(Method method, @Nullable Class<?> targetClass) {
// Don't allow no-public methods as required.
if (allowPublicMethodsOnly() && !Modifier.isPublic(method.getModifiers())) {
return null;
}
// The method may be on an interface, but we need attributes from the target class.
// If the target class is null, the method will be unchanged.
Method specificMethod = AopUtils.getMostSpecificMethod(method, targetClass);
// First try is the method in the target class.
TransactionAttribute txAttr = findTransactionAttribute(specificMethod);
if (txAttr != null) {
return txAttr;
}
// Second try is the transaction attribute on the target class.
txAttr = findTransactionAttribute(specificMethod.getDeclaringClass());
if (txAttr != null && ClassUtils.isUserLevelMethod(method)) {
return txAttr;
}
if (specificMethod != method) {
// Fallback is to look at the original method.
txAttr = findTransactionAttribute(method);
if (txAttr != null) {
return txAttr;
}
// Last fallback is the class of the original method.
txAttr = findTransactionAttribute(method.getDeclaringClass());
if (txAttr != null && ClassUtils.isUserLevelMethod(method)) {
return txAttr;
}
}
return null;
}
也就是说,如果我们自定义的事务方法(即目标方法),它的访问权限不是public,而是private、default或protected的话,spring则不会提供事务功能。
2. 方法用final修饰
有时候,某个方法不想被子类重新,这时可以将该方法定义成final的。普通方法这样定义是没问题的,但如果将事务方法定义成final,例如:
@Service
public class UserService {
@Transactional
public final void add(UserModel userModel){
saveData(userModel);
updateData(userModel);
}
}
我们可以看到add方法被定义成了final的,这样会导致事务失效。
为什么?
如果你看过spring事务的源码,可能会知道spring事务底层使用了aop,也就是通过jdk动态代理或者cglib,帮我们生成了代理类,在代理类中实现的事务功能。
但如果某个方法用final修饰了,那么在它的代理类中,就无法重写该方法,而添加事务功能。
注意:如果某个方法是static的,同样无法通过动态代理,变成事务方法。
3.方法内部调用
有时候我们需要在某个Service类的某个方法中,调用另外一个事务方法,比如:
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
public void add(UserModel userModel) {
userMapper.insertUser(userModel);
updateStatus(userModel);
}
@Transactional
public void updateStatus(UserModel userModel) {
doSameThing();
}
}
我们看到在事务方法add中,直接调用事务方法updateStatus。从前面介绍的内容可以知道,updateStatus方法拥有事务的能力是因为spring aop生成代理了对象,但是这种方法直接调用了this对象的方法,所以updateStatus方法不会生成事务。
由此可见,在同一个类中的方法直接内部调用,会导致事务失效。
那么问题来了,如果有些场景,确实想在同一个类的某个方法中,调用它自己的另外一个方法,该怎么办呢?
3.1 新加一个Service方法
这个方法非常简单,只需要新加一个Service方法,把@Transactional注解加到新Service方法上,把需要事务执行的代码移到新方法中。具体代码如下:
@Servcie
public class ServiceA {
@Autowired
prvate ServiceB serviceB;
public void save(User user) {
queryData1();
queryData2();
serviceB.doSave(user);
}
}
@Servcie
public class ServiceB {
@Transactional(rollbackFor=Exception.class)
public void doSave(User user) {
addData1();
updateData2();
}
}
3.2 在该Service类中注入自己
如果不想再新加一个Service类,在该Service类中注入自己也是一种选择。具体代码如下:
@Servcie
public class ServiceA {
@Autowired
prvate ServiceA serviceA;
public void save(User user) {
queryData1();
queryData2();
serviceA.doSave(user);
}
@Transactional(rollbackFor=Exception.class)
public void doSave(User user) {
addData1();
updateData2();
}
}
可能有些人可能会有这样的疑问:这种做法会不会出现循环依赖问题?
答案:不会。
其实spring ioc内部的三级缓存保证了它,不会出现循环依赖问题。
3.3 通过AopContent类
在该Service类中使用AopContext.currentProxy()获取代理对象
上面的方法2确实可以解决问题,但是代码看起来并不直观,还可以通过在该Service类中使用AOPProxy获取代理对象,实现相同的功能。具体代码如下:
@Servcie
public class ServiceA {
public void save(User user) {
queryData1();
queryData2();
((ServiceA)AopContext.currentProxy()).doSave(user);
}
@Transactional(rollbackFor=Exception.class)
public void doSave(User user) {
addData1();
updateData2();
}
}
4.未被spring管理
在我们平时开发过程中,有个细节很容易被忽略。即使用spring事务的前提是:对象要被spring管理,需要创建bean实例。
通常情况下,我们通过@Controller、@Service、@Component、@Repository等注解,可以自动实现bean实例化和依赖注入的功能。
如果有一天,你匆匆忙忙的开发了一个Service类,但忘了加@Service注解,比如:
//@Service
public class UserService {
@Transactional
public void add(UserModel userModel) {
saveData(userModel);
updateData(userModel);
}
}
从上面的例子,我们可以看到UserService类没有加@Service注解,那么该类不会交给spring管理,所以它的add方法也不会生成事务。
5.多线程调用
在实际项目开发中,多线程的使用场景还是挺多的。如果spring事务用在多线程场景中,会有问题吗?
@Slf4j
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
@Autowired
private RoleService roleService;
@Transactional
public void add(UserModel userModel) throws Exception {
userMapper.insertUser(userModel);
new Thread(() -> {
roleService.doOtherThing();
}).start();
}
}
@Service
public class RoleService {
@Transactional
public void doOtherThing() {
System.out.println("保存role表数据");
}
}
从上面的例子中,我们可以看到事务方法add中,调用了事务方法doOtherThing,但是事务方法doOtherThing是在另外一个线程中调用的。
这样会导致两个方法不在同一个线程中,获取到的数据库连接不一样,从而是两个不同的事务。如果想doOtherThing方法中抛了异常,add方法也回滚是不可能的。
如果看过spring事务源码的朋友,可能会知道spring的事务是通过数据库连接来实现的。当前线程中保存了一个map,key是数据源,value是数据库连接。
private static final ThreadLocal<Map<Object, Object>> resources =
new NamedThreadLocal<>("Transactional resources");
我们说的同一个事务,其实是指同一个数据库连接,只有拥有同一个数据库连接才能同时提交和回滚。如果在不同的线程,拿到的数据库连接肯定是不一样的,所以是不同的事务。
6.表不支持事务
周所周知,在mysql5之前,默认的数据库引擎是myisam。
它的好处就不用多说了:索引文件和数据文件是分开存储的,对于查多写少的单表操作,性能比innodb更好。
有些老项目中,可能还在用它。
在创建表的时候,只需要把ENGINE参数设置成MyISAM即可:
CREATE TABLE `category` (
`id` bigint NOT NULL AUTO_INCREMENT,
`one_category` varchar(20) COLLATE utf8mb4_bin DEFAULT NULL,
`two_category` varchar(20) COLLATE utf8mb4_bin DEFAULT NULL,
`three_category` varchar(20) COLLATE utf8mb4_bin DEFAULT NULL,
`four_category` varchar(20) COLLATE utf8mb4_bin DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
myisam好用,但有个很致命的问题是:不支持事务。
如果只是单表操作还好,不会出现太大的问题。但如果需要跨多张表操作,由于其不支持事务,数据极有可能会出现不完整的情况。
此外,myisam还不支持行锁和外键。
所以在实际业务场景中,myisam使用的并不多。在mysql5以后,myisam已经逐渐退出了历史的舞台,取而代之的是innodb。
有时候我们在开发的过程中,发现某张表的事务一直都没有生效,那不一定是spring事务的锅,最好确认一下你使用的那张表,是否支持事务。
7.未开启事务
有时候,事务没有生效的根本原因是没有开启事务。
你看到这句话可能会觉得好笑。
开启事务不是一个项目中,最最最基本的功能吗?
为什么还会没有开启事务?
没错,如果项目已经搭建好了,事务功能肯定是有的。
但如果你是在搭建项目demo的时候,只有一张表,而这张表的事务没有生效。那么会是什么原因造成的呢?
当然原因有很多,但没有开启事务,这个原因极其容易被忽略。
如果你使用的是springboot项目,那么你很幸运。因为springboot通过DataSourceTransactionManagerAutoConfiguration类,已经默默的帮你开启了事务。
你所要做的事情很简单,只需要配置spring.datasource相关参数即可。
但如果你使用的还是传统的spring项目,则需要在applicationContext.xml文件中,手动配置事务相关参数。如果忘了配置,事务肯定是不会生效的。
具体配置如下信息:
<!-- 配置事务管理器 -->
<bean class="org.springframework.jdbc.datasource.DataSourceTransactionManager" id="transactionManager">
<property name="dataSource" ref="dataSource"></property>
</bean>
<tx:advice id="advice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="*" propagation="REQUIRED"/>
</tx:attributes>
</tx:advice>
<!-- 用切点把事务切进去 -->
<aop:config>
<aop:pointcut expression="execution(* com.susan.*.*(..))" id="pointcut"/>
<aop:advisor advice-ref="advice" pointcut-ref="pointcut"/>
</aop:config>
默默的说一句,如果在pointcut标签中的切入点匹配规则,配错了的话,有些类的事务也不会生效。
事务不回滚
1.错误的传播特性
其实,我们在使用@Transactional注解时,是可以指定propagation参数的。
该参数的作用是指定事务的传播特性,spring目前支持7种传播特性:
REQUIRED 如果当前上下文中存在事务,那么加入该事务,如果不存在事务,创建一个事务,这是默认的传播属性值。SUPPORTS 如果当前上下文存在事务,则支持事务加入事务,如果不存在事务,则使用非事务的方式执行。MANDATORY 如果当前上下文中存在事务,否则抛出异常。REQUIRES_NEW 每次都会新建一个事务,并且同时将上下文中的事务挂起,执行当前新建事务完成以后,上下文事务恢复再执行。NOT_SUPPORTED 如果当前上下文中存在事务,则挂起当前事务,然后新的方法在没有事务的环境中执行。NEVER 如果当前上下文中存在事务,则抛出异常,否则在无事务环境上执行代码。NESTED 如果当前上下文中存在事务,则嵌套事务执行,如果不存在事务,则新建事务。
如果我们在手动设置propagation参数的时候,把传播特性设置错了,比如:
@Service
public class UserService {
@Transactional(propagation = Propagation.NEVER)
public void add(UserModel userModel) {
saveData(userModel);
updateData(userModel);
}
}
我们可以看到add方法的事务传播特性定义成了Propagation.NEVER,这种类型的传播特性不支持事务,如果有事务则会抛异常。
目前只有这三种传播特性才会创建新事务:REQUIRED,REQUIRES_NEW,NESTED。
2.自己吞了异常
事务不会回滚,最常见的问题是:开发者在代码中手动try…catch了异常。比如:
@Slf4j
@Service
public class UserService {
@Transactional
public void add(UserModel userModel) {
try {
saveData(userModel);
updateData(userModel);
} catch (Exception e) {
log.error(e.getMessage(), e);
}
}
}
这种情况下spring事务当然不会回滚,因为开发者自己捕获了异常,又没有手动抛出,换句话说就是把异常吞掉了。
如果想要spring事务能够正常回滚,必须抛出它能够处理的异常。如果没有抛异常,则spring认为程序是正常的。
3.手动抛了别的异常
即使开发者没有手动捕获异常,但如果抛的异常不正确,spring事务也不会回滚。
@Slf4j
@Service
public class UserService {
@Transactional
public void add(UserModel userModel) throws Exception {
try {
saveData(userModel);
updateData(userModel);
} catch (Exception e) {
log.error(e.getMessage(), e);
throw new Exception(e);
}
}
}
上面的这种情况,开发人员自己捕获了异常,又手动抛出了异常:Exception,事务同样不会回滚。
因为spring事务,默认情况下只会回滚RuntimeException(运行时异常)和Error(错误),对于普通的Exception(非运行时异常),它不会回滚。
4.自定义了回滚异常
在使用@Transactional注解声明事务时,有时我们想自定义回滚的异常,spring也是支持的。可以通过设置rollbackFor参数,来完成这个功能。
但如果这个参数的值设置错了,就会引出一些莫名其妙的问题,例如:
@Slf4j
@Service
public class UserService {
@Transactional(rollbackFor = BusinessException.class)
public void add(UserModel userModel) throws Exception {
saveData(userModel);
updateData(userModel);
}
}
如果在执行上面这段代码,保存和更新数据时,程序报错了,抛了SqlException、DuplicateKeyException等异常。而BusinessException是我们自定义的异常,报错的异常不属于BusinessException,所以事务也不会回滚。
即使rollbackFor有默认值,但阿里巴巴开发者规范中,还是要求开发者重新指定该参数。
这是为什么呢?
因为如果使用默认值,一旦程序抛出了Exception,事务不会回滚,这会出现很大的bug。所以,建议一般情况下,将该参数设置成:Exception或Throwable。
5.嵌套事务回滚多了
public class UserService {
@Autowired
private UserMapper userMapper;
@Autowired
private RoleService roleService;
@Transactional
public void add(UserModel userModel) throws Exception {
userMapper.insertUser(userModel);
roleService.doOtherThing();
}
}
@Service
public class RoleService {
@Transactional(propagation = Propagation.NESTED)
public void doOtherThing() {
System.out.println("保存role表数据");
}
}
这种情况使用了嵌套的内部事务,原本是希望调用roleService.doOtherThing方法时,如果出现了异常,只回滚doOtherThing方法里的内容,不回滚 userMapper.insertUser里的内容,即回滚保存点。。但事实是,insertUser也回滚了。
why?
因为doOtherThing方法出现了异常,没有手动捕获,会继续往上抛,到外层add方法的代理方法中捕获了异常。所以,这种情况是直接回滚了整个事务,不只回滚单个保存点。
怎么样才能只回滚保存点呢?
@Slf4j
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
@Autowired
private RoleService roleService;
@Transactional
public void add(UserModel userModel) throws Exception {
userMapper.insertUser(userModel);
try {
roleService.doOtherThing();
} catch (Exception e) {
log.error(e.getMessage(), e);
}
}
}
可以将内部嵌套事务放在try/catch中,并且不继续往上抛异常。这样就能保证,如果内部嵌套事务中出现异常,只回滚内部事务,而不影响外部事务。
其他问题
1. 大事务问题
在使用spring事务时,有个让人非常头疼的问题,就是大事务问题。
通常情况下,我们会在方法上@Transactional注解,填加事务功能,比如:
@Service
public class UserService {
@Autowired
private RoleService roleService;
@Transactional
public void add(UserModel userModel) throws Exception {
query1();
query2();
query3();
roleService.save(userModel);
update(userModel);
}
}
@Service
public class RoleService {
@Autowired
private RoleService roleService;
@Transactional
public void save(UserModel userModel) throws Exception {
query4();
query5();
query6();
saveData(userModel);
}
}
但@Transactional注解,如果被加到方法上,有个缺点就是整个方法都包含在事务当中了。
上面的这个例子中,在UserService类中,其实只有这两行才需要事务:
roleService.save(userModel);
update(userModel);
在RoleService类中,只有这一行需要事务:
现在的这种写法,会导致所有的query方法也被包含在同一个事务当中。
如果query方法非常多,调用层级很深,而且有部分查询方法比较耗时的话,会造成整个事务非常耗时,而从造成大事务问题。
2.编程式事务
上面聊的这些内容都是基于@Transactional注解的,主要说的是它的事务问题,我们把这种事务叫做:声明式事务。
其实,spring还提供了另外一种创建事务的方式,即通过手动编写代码实现的事务,我们把这种事务叫做:编程式事务。例如:
@Autowired
private TransactionTemplate transactionTemplate;
...
public void save(final User user) {
queryData1();
queryData2();
transactionTemplate.execute((status) => {
addData1();
updateData2();
return Boolean.TRUE;
})
}
在spring中为了支持编程式事务,专门提供了一个类:TransactionTemplate,在它的execute方法中,就实现了事务的功能。
相较于@Transactional注解声明式事务,我更建议大家使用,基于TransactionTemplate的编程式事务。主要原因如下:
- 避免由于spring aop问题,导致事务失效的问题。
- 能够更小粒度的控制事务的范围,更直观。
建议在项目中少使用@Transactional注解开启事务。但并不是说一定不能用它,如果项目中有些业务逻辑比较简单,而且不经常变动,使用@Transactional注解开启事务开启事务也无妨,因为它更简单,开发效率更高,但是千万要小心事务失效的问题。
1.13 - CH14-定义 Bean
1. XML 文件配置 Bean
1.1 构造器
这种方式是以前使用最多的方式,它默认使用了无参构造器创建bean。
<bean id="personService" class="com.sue.cache.service.test7.PersonService">
</bean>
当然我们还可以使用有参的构造器,通过标签来完成配置。
<bean id="personService" class="com.sue.cache.service.test7.PersonService">
<constructor-arg index="0" value="susan"></constructor-arg>
<constructor-arg index="1" ref="baseInfo"></constructor-arg>
</bean>
其中:
- index表示下标,从0开始。
- value表示常量值
- ref表示引用另一个bean
1.2 setter 方法
除此之外,spring还提供了另外一种思路:通过setter方法设置bean所需参数,这种方式耦合性相对较低,比有参构造器使用更为广泛。
先定义Person实体:
@Data
public class Person {
private String name;
private int age;
}
它里面包含:成员变量name和age,getter/setter方法。
然后在bean.xml文件中配置bean时,加上标签设置bean所需参数。
<bean id="person" class="com.sue.cache.service.test7.Person">
<property name="name" value="susan"></constructor-arg>
<property name="age" value="18"></constructor-arg>
</bean>
1.3 静态工厂
这种方式的关键是需要定义一个工厂类,它里面包含一个创建bean的静态方法。例如:
public class SusanBeanFactory {
public static Person createPerson(String name, int age) {
return new Person(name, age);
}
}
接下来定义Person类如下:
@AllArgsConstructor
@NoArgsConstructor
@Data
public class Person {
private String name;
private int age;
}
它里面包含:成员变量name和age,getter/setter方法,无参构造器和全参构造器。
然后在bean.xml文件中配置bean时,通过factory-method参数指定静态工厂方法,同时通过<constructor-arg>设置相关参数。
<bean class="com.sue.cache.service.test7.SusanBeanFactory" factory-method="createPerson">
<constructor-arg index="0" value="susan"></constructor-arg>
<constructor-arg index="1" value="18"></constructor-arg>
</bean>
1.4 实例工厂方法
这种方式也需要定义一个工厂类,但里面包含非静态的创建bean的方法。
public class SusanBeanFactory {
public Person createPerson(String name, int age) {
return new Person(name, age);
}
}
Person类跟上面一样,就不多说了。
然后bean.xml文件中配置bean时,需要先配置工厂bean。然后在配置实例bean时,通过factory-bean参数指定该工厂bean的引用。
<bean id="susanBeanFactory" class="com.sue.cache.service.test7.SusanBeanFactory">
</bean>
<bean factory-bean="susanBeanFactory" factory-method="createPerson">
<constructor-arg index="0" value="susan"></constructor-arg>
<constructor-arg index="1" value="18"></constructor-arg>
</bean>
1.5 FactoryBean
不知道大家有没有发现,上面的实例工厂方法每次都需要创建一个工厂类,不方面统一管理。
这时我们可以使用FactoryBean接口。
public class UserFactoryBean implements FactoryBean<User> {
@Override
public User getObject() throws Exception {
return new User();
}
@Override
public Class<?> getObjectType() {
return User.class;
}
}
在它的getObject方法中可以实现我们自己的逻辑创建对象,并且在getObjectType方法中我们可以定义对象的类型。
然后在bean.xml文件中配置bean时,只需像普通的bean一样配置即可。
<bean id="userFactoryBean" class="com.sue.async.service.UserFactoryBean">
</bean>
轻松搞定,so easy。
注意:getBean(“userFactoryBean”);获取的是getObject方法中返回的对象。而getBean("&userFactoryBean");获取的才是真正的UserFactoryBean对象。
我们通过上面五种方式,在bean.xml文件中把bean配置好之后,spring就会自动扫描和解析相应的标签,并且帮我们创建和实例化bean,然后放入spring容器中。
虽说基于xml文件的方式配置bean,简单而且非常灵活,比较适合一些小项目。但如果遇到比较复杂的项目,则需要配置大量的bean,而且bean之间的关系错综复杂,这样久而久之会导致xml文件迅速膨胀,非常不利于bean的管理。
2. @Component 注解声明 Bean
为了解决bean太多时,xml文件过大,从而导致膨胀不好维护的问题。在spring2.5中开始支持:@Component、@Repository、@Service、@Controller等注解定义bean。
如果你有看过这些注解的源码的话,就会惊奇得发现:其实后三种注解也是@Component。
@Component系列注解的出现,给我们带来了极大的便利。我们不需要像以前那样在bean.xml文件中配置bean了,现在只用在类上加Component、Repository、Service、Controller,这四种注解中的任意一种,就能轻松完成bean的定义。
@Service
public class PersonService {
public String get() {
return "data";
}
}
其实,这四种注解在功能上没有特别的区别,不过在业界有个不成文的约定:
- Controller 一般用在控制层
- Service 一般用在业务层
- Repository 一般用在数据层
- Component 一般用在公共组件上
太棒了,简直一下子解放了我们的双手。
不过,需要特别注意的是,通过这种@Component扫描注解的方式定义bean的前提是:需要先配置扫描路径。
目前常用的配置扫描路径的方式如下:
- 在applicationContext.xml文件中使用
<context:component-scan>标签。例如:
<context:component-scan base-package="com.sue.cache" />
- 在springboot的启动类上加上
@ComponentScan注解,例如:
@ComponentScan(basePackages = "com.sue.cache")
@SpringBootApplication
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(WebApplicationType.SERVLET).run(args);
}
}
- 直接在
SpringBootApplication注解上加,它支持ComponentScan功能:
@SpringBootApplication(scanBasePackages = "com.sue.cache")
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(WebApplicationType.SERVLET).run(args);
}
}
当然,如果你需要扫描的类跟springboot的入口类,在同一级或者子级的包下面,无需指定scanBasePackages参数,spring默认会从入口类的同一级或者子级的包去找。
@SpringBootApplication
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(WebApplicationType.SERVLET).run(args);
}
}
此外,除了上述四种@Component注解之外,springboot还增加了@RestController注解,它是一种特殊的@Controller注解,所以也是@Component注解。
@RestController还支持@ResponseBody注解的功能,即将接口响应数据的格式自动转换成json。
@Component系列注解已经让我们爱不释手了,它目前是我们日常工作中最多的定义bean的方式。
3. JavaConfig配置 Bean
@Component系列注解虽说使用起来非常方便,但是bean的创建过程完全交给spring容器来完成,我们没办法自己控制。
spring从3.0以后,开始支持JavaConfig的方式定义bean。它可以看做spring的配置文件,但并非真正的配置文件,我们需要通过编码java代码的方式创建bean。例如:
@Configuration
public class MyConfiguration {
@Bean
public Person person() {
return new Person();
}
}
在JavaConfig类上加@Configuration注解,相当于配置了<beans>标签。而在方法上加@Bean注解,相当于配置了<bean>标签。
此外,springboot还引入了一些列的@Conditional注解,用来控制bean的创建。
@Configuration
public class MyConfiguration {
@ConditionalOnClass(Country.class)
@Bean
public Person person() {
return new Person();
}
}
@ConditionalOnClass注解的功能是当项目中存在Country类时,才实例化Person类。换句话说就是,如果项目中不存在Country类,就不实例化Person类。
这个功能非常有用,相当于一个开关控制着Person类,只有满足一定条件才能实例化。
spring中使用比较多的Conditional还有:
- ConditionalOnBean
- ConditionalOnProperty
- ConditionalOnMissingClass
- ConditionalOnMissingBean
- ConditionalOnWebApplication
下面用一张图整体认识一下@Conditional家族:
4. @Import 注解
通过前面介绍的@Configuration和@Bean相结合的方式,我们可以通过代码定义bean。但这种方式有一定的局限性,它只能创建该类中定义的bean实例,不能创建其他类的bean实例,如果我们想创建其他类的bean实例该怎么办呢?
这时可以使用@Import注解导入。
4.1 普通类
spring4.2之后@Import注解可以实例化普通类的bean实例。例如:
先定义了Role类:
@Data
public class Role {
private Long id;
private String name;
}
接下来使用@Import注解导入Role类:
@Import(Role.class)
@Configuration
public class MyConfig {
}
然后在调用的地方通过@Autowired注解注入所需的bean。
@RequestMapping("/")
@RestController
public class TestController {
@Autowired
private Role role;
@GetMapping("/test")
public String test() {
System.out.println(role);
return "test";
}
}
聪明的你可能会发现,我没有在任何地方定义过Role的bean,但spring却能自动创建该类的bean实例,这是为什么呢?
这也许正是@Import注解的强大之处。
此时,有些朋友可能会问:@Import注解能定义单个类的bean,但如果有多个类需要定义bean该怎么办呢?
恭喜你,这是个好问题,因为@Import注解也支持。
@Import({Role.class, User.class})
@Configuration
public class MyConfig {
}
甚至,如果你想偷懒,不想写这种MyConfig类,springboot也欢迎。
@Import({Role.class, User.class})
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class,
DataSourceTransactionManagerAutoConfiguration.class})
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(WebApplicationType.SERVLET).run(args);
}
}
可以将@Import加到springboot的启动类上。
这样也能生效?
springboot的启动类一般都会加@SpringBootApplication注解,该注解上加了@SpringBootConfiguration注解。
而@SpringBootConfiguration注解,上面又加了@Configuration注解
所以,springboot启动类本身带有@Configuration注解的功能。
4.2 Configuration 类
上面介绍了@Import注解导入普通类的方法,它同时也支持导入Configuration类。
先定义一个Configuration类:
@Configuration
public class MyConfig2 {
@Bean
public User user() {
return new User();
}
@Bean
public Role role() {
return new Role();
}
}
然后在另外一个Configuration类中引入前面的Configuration类:
@Import({MyConfig2.class})
@Configuration
public class MyConfig {
}
这种方式,如果MyConfig2类已经在spring指定的扫描目录或者子目录下,则MyConfig类会显得有点多余。因为MyConfig2类本身就是一个配置类,它里面就能定义bean。
但如果MyConfig2类不在指定的spring扫描目录或者子目录下,则通过MyConfig类的导入功能,也能把MyConfig2类识别成配置类。这就有点厉害了喔。
其实下面还有更高端的玩法。
swagger作为一个优秀的文档生成框架,在spring项目中越来越受欢迎。接下来,我们以swagger2为例,介绍一下它是如何导入相关类的。
众所周知,我们引入swagger相关jar包之后,只需要在springboot的启动类上加上@EnableSwagger2注解,就能开启swagger的功能。
其中@EnableSwagger2注解中导入了Swagger2DocumentationConfiguration类。
该类是一个Configuration类,它又导入了另外两个类:
- SpringfoxWebMvcConfiguration
- SwaggerCommonConfiguration
SpringfoxWebMvcConfiguration类又会导入新的Configuration类,并且通过@ComponentScan注解扫描了一些其他的路径。
SwaggerCommonConfiguration同样也通过@ComponentScan注解扫描了一些额外的路径。
如此一来,我们通过一个简单的@EnableSwagger2注解,就能轻松的导入swagger所需的一系列bean,并且拥有swagger的功能。
4.3 ImportSelector
上面提到的Configuration类,它的功能非常强大。但怎么说呢,它不太适合加复杂的判断条件,根据某些条件定义这些bean,根据另外的条件定义那些bean。
那么,这种需求该怎么实现呢?
这时就可以使用ImportSelector接口了。
首先定义一个类实现ImportSelector接口:
public class DataImportSelector implements ImportSelector {
@Override
public String[] selectImports(AnnotationMetadata importingClassMetadata) {
return new String[]{"com.sue.async.service.User", "com.sue.async.service.Role"};
}
}
重写selectImports方法,在该方法中指定需要定义bean的类名,注意要包含完整路径,而非相对路径。
然后在MyConfig类上@Import导入这个类即可:
@Import({DataImportSelector.class})
@Configuration
public class MyConfig {
}
朋友们是不是又发现了一个新大陆?
不过,这个注解还有更牛逼的用途。
@EnableAutoConfiguration注解中导入了AutoConfigurationImportSelector类,并且里面包含系统参数名称:spring.boot.enableautoconfiguration。
AutoConfigurationImportSelector类实现了ImportSelector接口。
并且重写了selectImports方法,该方法会根据某些注解去找所有需要创建bean的类名,然后返回这些类名。其中在查找这些类名之前,先调用isEnabled方法,判断是否需要继续查找。
该方法会根据ENABLED_OVERRIDE_PROPERTY的值来作为判断条件。
而这个值就是spring.boot.enableautoconfiguration。
换句话说,这里能根据系统参数控制bean是否需要被实例化,优秀。
我个人认为实现ImportSelector接口的好处主要有以下两点:
- 把某个功能的相关类,可以放到一起,方面管理和维护。
- 重写selectImports方法时,能够根据条件判断某些类是否需要被实例化,或者某个条件实例化这些bean,其他的条件实例化那些bean等。我们能够非常灵活的定制化bean的实例化。
4.4 ImportBeanDefinitionRegistrar
我们通过上面的这种方式,确实能够非常灵活的自定义bean。
但它的自定义能力,还是有限的,它没法自定义bean的名称和作用域等属性。
有需求,就有解决方案。
接下来,我们一起看看ImportBeanDefinitionRegistrar接口的神奇之处。
先定义CustomImportSelector类实现ImportBeanDefinitionRegistrar接口:
public class CustomImportSelector implements ImportBeanDefinitionRegistrar {
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
RootBeanDefinition roleBeanDefinition = new RootBeanDefinition(Role.class);
registry.registerBeanDefinition("role", roleBeanDefinition);
RootBeanDefinition userBeanDefinition = new RootBeanDefinition(User.class);
userBeanDefinition.setScope(ConfigurableBeanFactory.SCOPE_PROTOTYPE);
registry.registerBeanDefinition("user", userBeanDefinition);
}
}
重写registerBeanDefinitions方法,在该方法中我们可以获取BeanDefinitionRegistry对象,通过它去注册bean。不过在注册bean之前,我们先要创建BeanDefinition对象,它里面可以自定义bean的名称、作用域等很多参数。
然后在MyConfig类上导入上面的类:
@Import({CustomImportSelector.class})
@Configuration
public class MyConfig {
}
我们所熟悉的fegin功能,就是使用ImportBeanDefinitionRegistrar接口实现的:
5. PostProcessor
除此之外,spring还提供了专门注册bean的接口:BeanDefinitionRegistryPostProcessor。
该接口的方法postProcessBeanDefinitionRegistry上有这样一段描述:
修改应用程序上下文的内部bean定义注册表标准初始化。所有常规bean定义都将被加载,但是还没有bean被实例化。这允许进一步添加在下一个后处理阶段开始之前定义bean。
如果用这个接口来定义bean,我们要做的事情就变得非常简单了。只需定义一个类实现BeanDefinitionRegistryPostProcessor接口。
@Component
public class MyRegistryPostProcessor implements BeanDefinitionRegistryPostProcessor {
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException {
RootBeanDefinition roleBeanDefinition = new RootBeanDefinition(Role.class);
registry.registerBeanDefinition("role", roleBeanDefinition);
RootBeanDefinition userBeanDefinition = new RootBeanDefinition(User.class);
userBeanDefinition.setScope(ConfigurableBeanFactory.SCOPE_PROTOTYPE);
registry.registerBeanDefinition("user", userBeanDefinition);
}
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
}
}
重写postProcessBeanDefinitionRegistry方法,在该方法中能够获取BeanDefinitionRegistry对象,它负责bean的注册工作。
不过细心的朋友可能会发现,里面还多了一个postProcessBeanFactory方法,没有做任何实现。
这个方法其实是它的父接口:BeanFactoryPostProcessor里的方法。
在应用程序上下文的标准bean工厂之后修改其内部bean工厂初始化。所有bean定义都已加载,但没有bean将被实例化。这允许重写或添加属性甚至可以初始化bean。
@Component
public class MyPostProcessor implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
DefaultListableBeanFactory registry = (DefaultListableBeanFactory)beanFactory;
RootBeanDefinition roleBeanDefinition = new RootBeanDefinition(Role.class);
registry.registerBeanDefinition("role", roleBeanDefinition);
RootBeanDefinition userBeanDefinition = new RootBeanDefinition(User.class);
userBeanDefinition.setScope(ConfigurableBeanFactory.SCOPE_PROTOTYPE);
registry.registerBeanDefinition("user", userBeanDefinition);
}
}
既然这两个接口都能注册bean,那么他们有什么区别?
- BeanDefinitionRegistryPostProcessor 更侧重于bean的注册
- BeanFactoryPostProcessor 更侧重于对已经注册的bean的属性进行修改,虽然也可以注册bean。
此时,有些朋友可能会问:既然拿到BeanDefinitionRegistry对象就能注册bean,那通过BeanFactoryAware的方式是不是也能注册bean呢?
从下面这张图能够看出DefaultListableBeanFactory就实现了BeanDefinitionRegistry接口。
这样一来,我们如果能够获取DefaultListableBeanFactory对象的实例,然后调用它的注册方法,不就可以注册bean了?
说时迟那时快,定义一个类实现BeanFactoryAware接口:
@Component
public class BeanFactoryRegistry implements BeanFactoryAware {
@Override
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
DefaultListableBeanFactory registry = (DefaultListableBeanFactory) beanFactory;
RootBeanDefinition rootBeanDefinition = new RootBeanDefinition(User.class);
registry.registerBeanDefinition("user", rootBeanDefinition);
RootBeanDefinition userBeanDefinition = new RootBeanDefinition(User.class);
userBeanDefinition.setScope(ConfigurableBeanFactory.SCOPE_PROTOTYPE);
registry.registerBeanDefinition("user", userBeanDefinition);
}
}
重写setBeanFactory方法,在该方法中能够获取BeanFactory对象,它能够强制转换成DefaultListableBeanFactory对象,然后通过该对象的实例注册bean。
当你满怀喜悦的运行项目时,发现竟然报错了:
为什么会报错?
spring中bean的创建过程顺序大致如下:
BeanFactoryAware接口是在bean创建成功,并且完成依赖注入之后,在真正初始化之前才被调用的。在这个时候去注册bean意义不大,因为这个接口是给我们获取bean的,并不建议去注册bean,会引发很多问题。
此外,ApplicationContextRegistry和ApplicationListener接口也有类似的问题,我们可以用他们获取bean,但不建议用它们注册bean。
1.14 - CH15-注入 Bean
1. @Autowired 的默认装配
我们都知道在spring中@Autowired注解,是用来自动装配对象的。通常,我们在项目中是这样用的:
package com.sue.cache.service;
import org.springframework.stereotype.Service;
@Service
public class TestService1 {
public void test1() {
}
}
package com.sue.cache.service;
import org.springframework.stereotype.Service;
@Service
public class TestService2 {
@Autowired
private TestService1 testService1;
public void test2() {
}
}
没错,这样是能够装配成功的,因为默认情况下spring是按照类型装配的,也就是我们所说的byType方式。
此外,@Autowired注解的required参数默认是true,表示开启自动装配,有些时候我们不想使用自动装配功能,可以将该参数设置成false。
2. 相同类型的对象不止一个
上面byType方式主要针对相同类型的对象只有一个的情况,此时对象类型是唯一的,可以找到正确的对象。
但如果相同类型的对象不只一个时,会发生什么?
在项目的test目录下,建了一个同名的类TestService1:
package com.sue.cache.service.test;
import org.springframework.stereotype.Service;
@Service
public class TestService1 {
public void test1() {
}
}
重新启动项目时:
Caused by: org.springframework.context.annotation.ConflictingBeanDefinitionException: Annotation-specified bean name 'testService1' for bean class [com.sue.cache.service.test.TestService1] conflicts with existing, non-compatible bean definition of same name and class [com.sue.cache.service.TestService1]
结果报错了,报类类名称有冲突,直接导致项目启动不来。
注意,这种情况不是相同类型的对象在Autowired时有两个导致的,非常容易产生混淆。这种情况是因为spring的@Service方法不允许出现相同的类名,因为spring会将类名的第一个字母转换成小写,作为bean的名称,比如:testService1,而默认情况下bean名称必须是唯一的。
下面看看如何产生两个相同的类型bean:
public class TestService1 {
public void test1() {
}
}
@Service
public class TestService2 {
@Autowired
private TestService1 testService1;
public void test2() {
}
}
@Configuration
public class TestConfig {
@Bean("test1")
public TestService1 test1() {
return new TestService1();
}
@Bean("test2")
public TestService1 test2() {
return new TestService1();
}
}
在TestConfig类中手动创建TestService1实例,并且去掉TestService1类上原有的@Service注解。
重新启动项目:
果然报错了,提示testService1是单例的,却找到两个对象。
其实还有一个情况会产生两个相同的类型bean:
public interface IUser {
void say();
}
@Service
public class User1 implements IUser{
@Override
public void say() {
}
}
@Service
public class User2 implements IUser{
@Override
public void say() {
}
}
@Service
public class UserService {
@Autowired
private IUser user;
}
项目重新启动时:
报错了,提示跟上面一样,testService1是单例的,却找到两个对象。
第二种情况在实际的项目中出现得更多一些,后面的例子,我们主要针对第二种情况。
3. @Qualifier 和 @Primary
显然在spring中,按照Autowired默认的装配方式:byType,是无法解决上面的问题的,这时可以改用按名称装配:byName。
只需在代码上加上@Qualifier注解即可:
@Service
public class UserService {
@Autowired
@Qualifier("user1")
private IUser user;
}
只需这样调整之后,项目就能正常启动了。
Qualifier意思是合格者,一般跟Autowired配合使用,需要指定一个bean的名称,通过bean名称就能找到需要装配的bean。
除了上面的@Qualifier注解之外,还能使用@Primary注解解决上面的问题。在User1上面加上@Primary注解:
@Primary
@Service
public class User1 implements IUser{
@Override
public void say() {
}
}
去掉UserService上的@Qualifier注解:
@Service
public class UserService {
@Autowired
private IUser user;
}
重新启动项目,一样能正常运行。
当我们使用自动配置的方式装配Bean时,如果这个Bean有多个候选者,假如其中一个候选者具有@Primary注解修饰,该候选者会被选中,作为自动配置的值。
4. @Autowired 的使用范围
上面的实例中@Autowired注解,都是使用在成员变量上,但@Autowired的强大之处,远非如此。
先看看@Autowired注解的定义:
从图中可以看出该注解能够使用在5种目标类型上:
4.1 成员变量
在成员变量上使用Autowired注解:
@Service
public class UserService {
@Autowired
private IUser user;
}
这种方式可能是平时用得最多的。
4.2 构造器
在构造器上使用Autowired注解:
@Service
public class UserService {
private IUser user;
@Autowired
public UserService(IUser user) {
this.user = user;
System.out.println("user:" + user);
}
}
注意,在构造器上加Autowired注解,实际上还是使用了Autowired装配方式,并非构造器装配。
4.3 方法
在普通方法上加Autowired注解:
@Service
public class UserService {
@Autowired
public void test(IUser user) {
user.say();
}
}
spring会在项目启动的过程中,自动调用一次加了@Autowired注解的方法,我们可以在该方法做一些初始化的工作。
也可以在setter方法上Autowired注解:
@Service
public class UserService {
private IUser user;
@Autowired
public void setUser(IUser user) {
this.user = user;
}
}
4.4 参数
可以在构造器的入参上加Autowired注解:
@Service
public class UserService {
private IUser user;
public UserService(@Autowired IUser user) {
this.user = user;
System.out.println("user:" + user);
}
}
也可以在非静态方法的入参上加Autowired注解:
@Service
public class UserService {
public void test(@Autowired IUser user) {
user.say();
}
}
4.5 注解
这种方式其实用得不多,我就不过多介绍了。
5. @Autowired的高端玩法
其实上面举的例子都是通过@Autowired自动装配单个实例,但这里我会告诉你,它也能自动装配多个实例,怎么回事呢?
将UserService方法调整一下,用一个List集合接收IUser类型的参数:
@Service
public class UserService {
@Autowired
private List<IUser> userList;
@Autowired
private Set<IUser> userSet;
@Autowired
private Map<String, IUser> userMap;
public void test() {
System.out.println("userList:" + userList);
System.out.println("userSet:" + userSet);
System.out.println("userMap:" + userMap);
}
}
增加一个controller:
@RequestMapping("/u")
@RestController
public class UController {
@Autowired
private UserService userService;
@RequestMapping("/test")
public String test() {
userService.test();
return "success";
}
}
调用该接口后:
从上图中看出:userList、userSet和userMap都打印出了两个元素,说明@Autowired会自动把相同类型的IUser对象收集到集合中。
6. @Autowired一定能装配成功?
前面介绍了@Autowired注解这么多牛逼之处,其实有些情况下,即使使用了@Autowired装配的对象还是null,到底是什么原因呢?
6.1 没有加@Service注解
在类上面忘了加@Controller、@Service、@Component、@Repository等注解,spring就无法完成自动装配的功能,例如:
public class UserService {
@Autowired
private IUser user;
public void test() {
user.say();
}
}
这种情况应该是最常见的错误了,不会因为你长得帅,就不会犯这种低级的错误。
6.2 注入Filter或Listener
web应用启动的顺序是:listener->filter->servlet。
接下来看看这个案例:
public class UserFilter implements Filter {
@Autowired
private IUser user;
@Override
public void init(FilterConfig filterConfig) throws ServletException {
user.say();
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
}
@Override
public void destroy() {
}
}
@Configuration
public class FilterConfig {
@Bean
public FilterRegistrationBean filterRegistrationBean() {
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new UserFilter());
bean.addUrlPatterns("/*");
return bean;
}
}
程序启动会报错:
tomcat无法正常启动。
什么原因呢?
众所周知,springmvc的启动是在DisptachServlet里面做的,而它是在listener和filter之后执行。如果我们想在listener和filter里面@Autowired某个bean,肯定是不行的,因为filter初始化的时候,此时bean还没有初始化,无法自动装配。
如果工作当中真的需要这样做,我们该如何解决这个问题呢?
public class UserFilter implements Filter {
private IUser user;
@Override
public void init(FilterConfig filterConfig) throws ServletException {
ApplicationContext applicationContext = WebApplicationContextUtils.getWebApplicationContext(filterConfig.getServletContext());
this.user = ((IUser)(applicationContext.getBean("user1")));
user.say();
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
}
@Override
public void destroy() {
}
}
答案是使用WebApplicationContextUtils.getWebApplicationContext获取当前的ApplicationContext,再通过它获取到bean实例。
6.3 注解未被@ComponentScan扫描
通常情况下,@Controller、@Service、@Component、@Repository、@Configuration等注解,是需要通过@ComponentScan注解扫描,收集元数据的。
但是,如果没有加@ComponentScan注解,或者@ComponentScan注解扫描的路径不对,或者路径范围太小,会导致有些注解无法收集,到后面无法使用@Autowired完成自动装配的功能。
有个好消息是,在springboot项目中,如果使用了@SpringBootApplication注解,它里面内置了@ComponentScan注解的功能。
6.4 循环依赖问题
如果A依赖于B,B依赖于C,C又依赖于A,这样就形成了一个死循环。
spring的bean默认是单例的,如果单例bean使用@Autowired自动装配,大多数情况,能解决循环依赖问题。
但是如果bean是多例的,会出现循环依赖问题,导致bean自动装配不了。
还有有些情况下,如果创建了代理对象,即使bean是单例的,依然会出现循环依赖问题。
如果你对循环依赖问题比较感兴趣,也可以看一下我的另一篇专题《》,里面介绍的非常详细。
7. @Autowired和 @Resouce 的区别
@Autowired功能虽说非常强大,但是也有些不足之处。比如:比如它跟spring强耦合了,如果换成了JFinal等其他框架,功能就会失效。而@Resource是JSR-250提供的,它是Java标准,绝大部分框架都支持。
除此之外,有些场景使用@Autowired无法满足的要求,改成@Resource却能解决问题。接下来,我们重点看看@Autowired和@Resource的区别。
- @Autowired默认按byType自动装配,而@Resource默认byName自动装配。
- @Autowired只包含一个参数:required,表示是否开启自动准入,默认是true。而@Resource包含七个参数,其中最重要的两个参数是:name 和 type。
- @Autowired如果要使用byName,需要使用@Qualifier一起配合。而@Resource如果指定了name,则用byName自动装配,如果指定了type,则用byType自动装配。
- @Autowired能够用在:构造器、方法、参数、成员变量和注解上,而@Resource能用在:类、成员变量和方法上。
- @Autowired是spring定义的注解,而@Resource是JSR-250定义的注解。
此外,它们的装配顺序不同。
@Autowired的装配顺序如下:
@Resource的装配顺序如下:
如果同时指定了name和type:
如果指定了name:
如果指定了type:
如果既没有指定name,也没有指定type:
1.15 - CH16-拦截器
拦截器是Spring MVC中强大的控件,它可以在进入处理器之前做一些操作,或者在处理器完成后进行操作,甚至是在渲染视图后进行操作。
拦截器概述
- 对于任何优秀的MVC框架,都会提供一些通用的操作,如请求数据的封装、类型转换、数据校验、解析上传的文件、防止表单的多次提交等。早期的MVC框架将这些操作都写死在核心控制器中,而这些常用的操作又不是所有的请求都需要实现的,这就导致了框架的灵活性不足,可扩展性降低
- SpringMVC提供了Interceptor拦截器机制,类似于Servlet中的Filter过滤器,用于拦截用户的请求并做出相应的处理。比如通过拦截器来进行用户权限验证,或者用来判断用户是否已经登录。Spring MVC拦截器是可插拔式的设计,需要某一功能拦截器,只需在配置文件中应用该拦截器即可;如果不需要这个功能拦截器,只需在配置文件中取消应用该拦截器。
- 在Spring MVC中定义一个拦截器有两种方法:实现HandlerInterceptor接口,实现WebRequestInterceptor接口.
区别于过滤器 Filter
Spring 的拦截器与 Servlet 的 Filter 有相似之处,比如二者都是 AOP 编程思想的体现,都能实现权限检查、日志记录等。不同的是:
- 使用范围不同:Filter 是 Servlet 规范规定的,只能用于 Web 程序中。而拦截器既可以用于 Web 程序,又可以用于 Application、Swing 程序中。
- 规范不同:Filter 是在 Serlvet 规范中定义的,是 Servlet 容器支持的。而拦截器是在 Spring 容器内的,是 Spring 框架支持的。
- 使用的资源不同:同其他代码块一样,拦截器也是一个 Spring 组件,归 Spring 管理,配置在 Spring 文件中,因此能使用 Spring 里的任何资源、对象。比如 Service 对象、数据源、事务管理等,通过 IoC 注入到烂机器即可;而 Filter 不能。
- 深度不同:Filter 只在 Servlet 前后起作用。而拦截器能够深入到方法前后、异常抛出前后等,因此烂机器的使用具有更大的弹性。因此在 Spring 程序中优先使用拦截器。
过滤器流程
应用层次
过滤器(Filter) :可以拿到原始的http请求,但是拿不到你请求的控制器和请求控制器中的方法的信息。
拦截器(Interceptor):可以拿到你请求的控制器和方法,却拿不到请求方法的参数。
切片(Aspect): 可以拿到方法的参数,但是却拿不到http请求和响应的对象
三大器对比
实现 HandlerInterceptor 接口
首先来看看HandlerInterceor接口的源码,该接口位于org.springframework.web.servlet的包中,定义了三个方法,若要实现该接口,就要实现其三个方法:
preHandle()方法:该方法在执行控制器方法之前执行。返回值为Boolean类型,如果返回false,表示拦截请求,不再向下执行,如果返回true,表示放行,程序继续向下执行(如果后面没有其他Interceptor,就会执行controller方法)。所以此方法可对请求进行判断,决定程序是否继续执行,或者进行一些初始化操作及对请求进行预处理。
postHandle()方法:该方法在执行控制器方法调用之后,且在返回ModelAndView之前执行。由于该方法会在DispatcherServlet进行返回视图渲染之前被调用,所以此方法多被用于处理返回的视图,可通过此方法对请求域中的模型和视图做进一步的修改。
afterCompletion()方法:该方法在执行完控制器之后执行,由于是在Controller方法执行完毕后执行该方法,所以该方法适合进行一些资源清理,记录日志信息等处理操作。
实现了HandlerInterceptor接口之后,需要在Spring的类加载配置文件中配置拦截器实现类,才能使拦截器起到拦截的效果,加载配置有两种方式:
针对HandlerMapping配置,样例代码如下:
这里为BeanNameUrlHandlerMapping处理器配置了一个interceptors拦截器链,该拦截器链包含了myInterceptor1和myInterceptor2两个拦截器,具体实现分别对应下面id为myInterceptor1和myInterceptor2的bean配置。
优点:此种配置的优点是针对具体的处理器映射器进行拦截操作
缺点:缺点是如果使用多个处理器映射器,就要在多处添加拦截器的配置信息,比较繁琐
针对全局配置,样例代码如下:
在上面的配置中,可在mvc:interceptors标签下配置多个拦截器其子元素 bean 定义的是全局拦截器,它会拦截所有的请求;而mvc:interceptor元素中定义的是指定元素的拦截器,它会对指定路径下的请求生效,其子元素必须按照mvc:mapping –> mvc:exclude-mapping –> bean的顺序,否则文件会报错。
实现 WebRequestInterceptor 接口
WebRequestInterceptor中也定义了三个方法,也是通过这三个方法来实现拦截的。这三个方法都传递了同一个参数WebRequest, WebRequest 是Spring 定义的一个接口,它里面的方法定义都基本跟HttpServletRequest 一样,在WebRequestInterceptor 中对WebRequest 进行的所有操作都将同步到HttpServletRequest 中,然后在当前请求中一直传递。三个方法如下:
(1) preHandle(WebRequest request) :WebRequestInterceptor的该方法返回值为void,不是boolean。所以该方法不能用于请求阻断,一般用于资源准备。
(2) postHandle(WebRequest request, ModelMap model):preHandle 中准备的数据都可以通过参数WebRequest访问。ModelMap 是Controller 处理之后返回的Model 对象,可以通过改变它的属性来改变Model 对象模型,达到改变视图渲染效果的目的。
(3) afterCompletion(WebRequest request, Exception ex) :。Exception 参数表示的是当前请求的异常对象,如果Controller 抛出的异常已经被处理过,则Exception对象为null 。
单个拦截器执行流程
运行程序时,拦截器的执行时有一定顺序的,该顺序与配置文件中所定义的拦截的顺序相关。如果程序中只定义了一个拦截器,则该单个拦截器在程序中的执行流程如图所示。
程序首先执行拦截器类中的preHandle()方法,如果该方法返回值是true,则程序会继续向下执行处理器中的方法,否则不再向下执行;在业务控制器类Controller处理完请求后,会执行postHandle()方法,而后会通过DispatcherServlet向客户端返回相应;在DispatcherServlet处理完请求后,才会执行afterCompletion()方法。
单个拦截器的执行流程
下面在springmvc-6的项目中通过示例来演示单个拦截器的执行流程,步骤如下:
(1) 在src目录下的com.springmvc.controller包中的UserController类中,新建一个hello()方法,并使用@RequestMapping注解进行映射。
package com.springmvc.controller;
import java.util.Locale;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.context.i18n.LocaleContextHolder;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.validation.annotation.Validated;
import org.springframework.web.bind.annotation.ModelAttribute;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.servlet.i18n.CookieLocaleResolver;
import org.springframework.web.servlet.i18n.SessionLocaleResolver;
import org.springframework.web.servlet.support.RequestContext;
import com.springmvc.entity.User;
@Controller
public class UserController {
@RequestMapping("/hello")
public String hello() {
System.out.println("Hello!Controller控制器类执行hello方法");
return "hello";
}
}
(2) 在src目录下,新建一个com.springmvc.interceptor包,创建拦截器类MyInterceptor,实现HandlerInterceptor接口。
package com.springmvc.interceptor;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.web.servlet.HandlerInterceptor;
import org.springframework.web.servlet.ModelAndView;
public class MyInterceptor implements HandlerInterceptor{
public boolean preHandle(HttpServletRequest request, HttpServletResponse response,
Object handler)
throws Exception {
System.out.println("MyInterceptor 拦截器执行preHandle()方法");
return true;
}
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex)
throws Exception {
System.out.println("MyInterceptor 拦截器执行afterCompletion方法");
}
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler,ModelAndView modelAndView) throws Exception {
System.out.println("MyInterceptor 拦截器执行postHandle()方法");
}
}
(3) 在springmvc.xml的配置文件中,添加拦截器配置代码。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/mvc
http://www.springframework.org/schema/mvc/spring-mvc.xsd
">
<!-- 配置自动扫描的包 -->
<context:component-scan base-package="com.springmvc"/>
<!-- 自动注册处理器映射器和处理器适配器 -->
<mvc:annotation-driven/>
<!-- 配置视图解析器,将控制器方法返回的逻辑视图解析为物理视图 -->
<bean class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="prefix" value="/ch11/"></property>
<property name="suffix" value=".jsp"></property>
</bean>
<!-- 如果不想经过控制器类的处理方法直接转发到页面,可以通过mvc:view-controller元素来实现 -->
<mvc:view-controller path="/success" view-name="success"/>
<mvc:view-controller path="/index" view-name="index"/>
<mvc:default-servlet-handler/>
<mvc:interceptors>
<!-- 使用bean直接定义在mvc:interceptors下面的拦截器将拦截所有请求 -->
<bean class="com.springmvc.interceptor.MyInterceptor"/>
</mvc:interceptors>
</beans>
(4) 在ch11文件夹中,创建一个hello.jsp页面文件,在主体部分编写“拦截器执行过程完成!”提示信息。
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
拦截器执行过程完成!
</body>
</html>
(5) 重启Tomcat,访问http://localhost:8080/springmvc-6/hello,浏览器会跳转到hello.jsp页面,控制台的输出结果。
多个拦截器执行流程
在一个Web工程中,甚至在一个HandlerMapping处理器适配器中都可以配置多个拦截器,每个拦截器都按照提前配置好的顺序执行。它们内部的执行规律并不像多个普通Java类一样,它们的设计模式是基于“责任链”的模式。
下面通过图例来描述多个拦截器的执行流程,假设有两个拦截器MyInterceptor1和MyInterceptor2,将MyInterceptor1配置在前,如图所示。
当多个拦截器同时工作时,它们的preHandle()方法会按照配置文件中拦截器的配置顺序执行,而它们的postHandle()方法和afterCompletion()方法则会按照配置顺序的反序执行
多个拦截器的执行流程
修改单个拦截器执行流程的实例,来演示多个拦截器的执行,步骤如下:
(1) 在com.springmvc.interceptor包中,新建两个拦截器类MyInterceptor1和MyInterceptor2,这两个拦截器类均实现了HandlerInterceptor接口,其代码与MyInterceptor相似。
MyInterceptor1
package com.springmvc.interceptor;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.web.servlet.HandlerInterceptor;
import org.springframework.web.servlet.ModelAndView;
public class MyInterceptor1 implements HandlerInterceptor{
public boolean preHandle(HttpServletRequest request, HttpServletResponse response,
Object handler)
throws Exception {
System.out.println("MyInterceptor1 拦截器执行preHandle()方法");
return true;
}
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex)
throws Exception {
System.out.println("MyInterceptor1 拦截器执行afterCompletion方法");
}
public void postHandle(HttpServletRequest request, HttpServletResponse response,
Object handler,
ModelAndView modelAndView) throws Exception {
System.out.println("MyInterceptor1 拦截器执行postHandle()方法");
}
}
MyInterceptor2
package com.springmvc.interceptor;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.web.servlet.HandlerInterceptor;
import org.springframework.web.servlet.ModelAndView;
public class MyInterceptor2 implements HandlerInterceptor{
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
throws Exception {
System.out.println("MyInterceptor2 拦截器执行preHandle()方法");
return true;
}
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex)
throws Exception {
System.out.println("MyInterceptor2 拦截器执行afterCompletion方法");
}
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler,
ModelAndView modelAndView) throws Exception {
System.out.println("MyInterceptor2 拦截器执行postHandle()方法");
}
}
(2) 在springmvc.xml的配置文件中,首先注释掉前面配置的MyInterceptor拦截器,而后在mvc:interceptors元素内配置上面所定义的的两个拦截器。
<mvc:interceptors>
<!-- 定义多个拦截器 -->
<mvc:interceptor><!-- 拦截器1 -->
<mvc:mapping path="/**"/><!-- 配置拦截器所作用的路径 -->
<!-- 定义在<mvc:interceptor>下面的拦截器表示对匹配路径请求才进行拦截 -->
<bean class="com.springmvc.interceptor.MyInterceptor1"></bean>
</mvc:interceptor>
<mvc:interceptor><!-- 拦截器2 -->
<mvc:mapping path="/hello"/>
<bean class="com.springmvc.interceptor.MyInterceptor2"></bean>
</mvc:interceptor>
</mvc:interceptors>
(3) 重启Tomcat,访问 http://localhost:8080/springmvc-6/hello ,程序正确运行后,浏览器会跳转到hello.jsp页面,控制台输出内容如图所示。
实例:用户登录权限验证
在springmvc-6项目中完成使用拦截器实现用户登录权限验证,步骤如下:
(1) 在com.springmvc.controller包中,在控制器UserController类中,注释以前的方法,并在该类中定义向主页跳转、向登录页跳转、执行用户登录等操作的方法。
//向用户登录页面的跳转方法
@RequestMapping(value="/login",method=RequestMethod.GET)
public String loginPage() {
System.out.println("用户从login的请求到登录跳转login.jsp");
return "login";
}
//用户实现登录的方法
@RequestMapping(value="/login",method=RequestMethod.POST)
public String login(User user,Model model,HttpSession session) {
String loginName=user.getLoginName();
String password=user.getPassword();
if(loginName.equals("mary") && password.equals("123456")) {
System.out.println("用户登录成功");
//将用户添加至session中保存
session.setAttribute("current_user", user);
//重新定向到主页的index跳转方法
return "redirect:/index";
}
model.addAttribute("message", "账号或者密码错误,请重新登录");
//跳转到登录页面
return "login";
}
//向主页跳转的方法
@RequestMapping(value="/index",method=RequestMethod.GET)
public String indexPage() {
System.out.println("用户从index请求到主页跳转index.jsp页面");
//跳转到主页面
return "index";
}
//用户退出登录的方法
@RequestMapping(value="/logout",method=RequestMethod.GET)
public String logout(HttpSession session) {
//清除session
session.invalidate();
System.out.println("退出功能实现, 清除session,重定向到login请求");
return "redirect:/login";//重定向到登录页面的跳转方法
}
(2) 在com.springmvc.interceptor包中,新建LoginInterceptor的拦截器类。
package com.springmvc.interceptor;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.web.servlet.HandlerInterceptor;
import org.springframework.web.servlet.ModelAndView;
//登录的拦截器类
public class loginInterceptor implements HandlerInterceptor {
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
throws Exception {
//获取请求的URI
String url=request.getRequestURI();
if(!url.toLowerCase().contains("login")) {
//非登录请求,获取session,判断是否有用户数据
if(request.getSession().getAttribute("current_user")!=null) {
//已经登录,放行
return true;
}else {
//没有登录则跳转到登录页面
request.setAttribute("message", "您还没有登录,请先登录");
request.getRequestDispatcher("/ch11/login.jsp").forward(request, response);
}
}else {
return true;//登录请求,放行
}
return false;//默认拦截
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response,
Object handler,ModelAndView modelAndView) throws Exception {
HandlerInterceptor.super.postHandle(request, response, handler, modelAndView);
}
public void afterCompletion(HttpServletRequest request, HttpServletResponse response,
Object handler, Exception ex)throws Exception {
HandlerInterceptor.super.afterCompletion(request, response, handler, ex);
}
}
(3) 在springmvc.xml的配置文件中,首先注释前面配置过的拦截器,而后在mvc:interceptors元素内配置上面所定义的的LoginInterceptor拦截器。
<!-- 登录拦截器 -->
<mvc:interceptors>
<mvc:interceptor>
<mvc:mapping path="/**"/><!--配置拦截器所作用的路径 -->
<bean class="com.springmvc.interceptor.loginInterceptor"></bean>
</mvc:interceptor>
</mvc:interceptors>
(4) 在ch11文件夹中,新建登录页login.jsp和主页index.jsp。
login.jsp
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>登录页面</title>
</head>
<body>
<font color="red">${requestScope.message }</font><br/><br/>
<h3>登录页面</h3>
<form action="${pageContext.request.contextPath }/login" method="post">
账号:<input type="text" name="loginName"/><br/><br/>
密码:<input type="password" name="password"/><br/><br/>
<input type="submit" value="登录"/>
</form>
</body>
</html>
主页index.jsp
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>主页面</title>
</head>
<body>
欢迎: ${sessionScope.current_user.loginName }
<a href="${pageContext.request.contextPath }/logout">退出</a>
</body>
</html>
(5) 重启Tomcat,访问 http://localhost:8080/springmvc-6/index,运行界面如图所示。
1.16 - CH17-监听器
观察者模式
在讲解事件监听机制前,我们先回顾下设计模式中的观察者模式,因为事件监听机制可以说是在典型观察者模式基础上的进一步抽象和改进。我们可以在JDK或者各种开源框架比如Spring中看到它的身影,从这个意义上说,事件监听机制也可以看做一种对传统观察者模式的具体实现,不同的框架对其实现方式会有些许差别。
典型的观察者模式将有依赖关系的对象抽象为了观察者和主题两个不同的角色,多个观察者同时观察一个主题,两者只通过抽象接口保持松耦合状态,这样双方可以相对独立的进行扩展和变化:比如可以很方便的增删观察者,修改观察者中的更新逻辑而不用修改主题中的代码。但是这种解耦进行的并不彻底,这具体体现在以下几个方面:
- 1.抽象主题需要依赖抽象观察者,而这种依赖关系完全可以去除。
- 2.主题需要维护观察者列表,并对外提供动态增删观察者的接口,
- 3.主题状态改变时需要由自己去通知观察者进行更新。
我们可以把主题(Subject)替换成事件(event),把对特定主题进行观察的观察者(Observer)替换成对特定事件进行监听的监听器(EventListener),而把原有主题中负责维护主题与观察者映射关系以及在自身状态改变时通知观察者的职责从中抽出,放入一个新的角色事件发布器(EventPublisher)中,事件监听模式的轮廓就展现在了我们眼前,如下图所示
常见事件监听机制的主要角色如下
- 事件及事件源:对应于观察者模式中的主题。事件源发生某事件是特定事件监听器被触发的原因。
- 事件监听器:对应于观察者模式中的观察者。监听器监听特定事件,并在内部定义了事件发生后的响应逻辑。
- 事件发布器:事件监听器的容器,对外提供发布事件和增删事件监听器的接口,维护事件和事件监听器之间的映射关系,并在事件发生时负责通知相关监听器。
Spring框架对事件的发布与监听提供了相对完整的支持,它扩展了JDK中对自定义事件监听提供的基础框架,并与Spring的IOC特性作了整合,使得用户可以根据自己的业务特点进行相关的自定义,并依托Spring容器方便的实现监听器的注册和事件的发布。因为Spring的事件监听依托于JDK提供的底层支持,为了更好的理解,先来看下JDK中为用户实现自定义事件监听提供的基础框架。
JDK中对事件监听机制的支持
JDK为用户实现自定义事件监听提供了两个基础的类。一个是代表所有可被监听事件的事件基类java.util.EventObject,所有自定义事件类型都必须继承该类,类结构如下所示
public class EventObject implements java.io.Serializable {
private static final long serialVersionUID = 5516075349620653480L;
/**
* The object on which the Event initially occurred.
*/
protected transient Object source;
/**
* Constructs a prototypical Event.
*
* @param source The object on which the Event initially occurred.
* @exception IllegalArgumentException if source is null.
*/
public EventObject(Object source) {
if (source == null)
throw new IllegalArgumentException("null source");
this.source = source;
}
/**
* The object on which the Event initially occurred.
*
* @return The object on which the Event initially occurred.
*/
public Object getSource() {
return source;
}
/**
* Returns a String representation of this EventObject.
*
* @return A a String representation of this EventObject.
*/
public String toString() {
return getClass().getName() + "[source=" + source + "]";
}
}
该类内部有一个Object类型的source变量,逻辑上表示发生该事件的事件源,实际中可以用来存储包含该事件的一些相关信息。
另一个则是对所有事件监听器进行抽象的接口java.util.EventListener,这是一个标记接口,内部没有任何抽象方法,所有自定义事件监听器都必须实现该标记接口
/**
* A tagging interface that all event listener interfaces must extend.
* @since JDK1.1
*/
public interface EventListener {
}
以上就是JDK为我们实现自定义事件监听提供的底层支持。针对具体业务场景,我们通过扩展java.util.EventObject来自定义事件类型,同时通过扩展java.util.EventListener来定义在特定事件发生时被触发的事件监听器。当然,不要忘了还要定义一个事件发布器来管理事件监听器并提供发布事件的功能。
基于JDK实现对任务执行结果的监听
想象我们正在做一个关于Spark的任务调度系统,我们需要把任务提交到集群中并监控任务的执行状态,当任务执行完毕(成功或者失败),除了必须对数据库进行更新外,还可以执行一些额外的工作:比如将任务执行结果以邮件的形式发送给用户。这些额外的工作后期还有较大的变动可能:比如还需要以短信的形式通知用户,对于特定的失败任务需要通知相关运维人员进行排查等等,所以不宜直接写死在主流程代码中。最好的方式自然是以事件监听的方式动态的增删对于任务执行结果的处理逻辑。为此我们可以基于JDK提供的事件框架,打造一个能够对任务执行结果进行监听的弹性系统。
任务结束事件的事件源
因为要对任务执行结束这一事件进行监听,所以必须对任务这一概念进行定义,如下
/**
* @author: takumiCX
* @create: 2018-11-02
**/
@Data
public class Task {
private String name;
private TaskFinishStatus status;
}
任务包含任务名和任务状态,其中任务状态是个枚举常量,只有成功和失败两种取值。
/**
* @author: takumiCX
* @create: 2018-11-02
**/
public enum TaskFinishStatus {
SUCCEDD,
FAIL;
}
任务结束事件TaskFinishEvent
自定义事件类型TaskFinishEvent继承自JDK中的EventObject,构造时会传入Task作为事件源。
/**
* @author: takumiCX
* @create: 2018-11-02
**/
public class TaskFinishEvent extends EventObject {
/**
* Constructs a prototypical Event.
*
* @param source The object on which the Event initially occurred.
* @throws IllegalArgumentException if source is null.
*/
public TaskFinishEvent(Object source) {
super(source);
}
}
该事件的监听器抽象
继承标记接口EventListner表示该接口的实现类是一个监听器,同时在内部定义了事件发生时的响应方法onTaskFinish(event),接收一个TaskFinishEvent作为参数。
/**
* @author: takumiCX
* @create: 2018-11-02
**/
public interface TaskFinishEventListner extends EventListener {
void onTaskFinish(TaskFinishEvent event);
}
- 邮件服务监听器
该邮件服务监听器将在监听到任务结束事件时将任务的执行结果发送给用户。
/**
* @author: takumiCX
* @create: 2018-11-03
**/
@Data
public class MailTaskFinishListener implements TaskFinishEventListner {
private String emial;
@Override
public void onTaskFinish(TaskFinishEvent event) {
System.out.println("Send Emial to "+emial+" Task:"+event.getSource());
}
}
自定义事件发布器
/**
* @author: takumiCX
* @create: 2018-11-03
**/
public class TaskFinishEventPublisher {
private List<TaskFinishEventListner> listners=new ArrayList<>();
//注册监听器
public synchronized void register(TaskFinishEventListner listner){
if(!listners.contains(listner)){
listners.add(listner);
}
}
//移除监听器
public synchronized boolean remove(TaskFinishEventListner listner){
return listners.remove(listner);
}
//发布任务结束事件
public void publishEvent(TaskFinishEvent event){
for(TaskFinishEventListner listner:listners){
listner.onTaskFinish(event);
}
}
}
测试代码
/**
* @author: takumiCX
* @create: 2018-11-03
**/
public class TestTaskFinishListener {
public static void main(String[] args) {
//事件源
Task source = new Task("用户统计", TaskFinishStatus.SUCCEDD);
//任务结束事件
TaskFinishEvent event = new TaskFinishEvent(source);
//邮件服务监听器
MailTaskFinishListener mailListener = new MailTaskFinishListener("takumiCX@163.com");
//事件发布器
TaskFinishEventPublisher publisher = new TaskFinishEventPublisher();
//注册邮件服务监听器
publisher.register(mailListener);
//发布事件
publisher.publishEvent(event);
}
}
如果后期因为需求变动需要在任务结束时将结果以短信的方式发送给用户,则可以再添加一个短信服务监听器
/**
* @author: takumiCX
* @create: 2018-11-03
**/
@Data
@AllArgsConstructor
public class SmsTaskFinishListener implements TaskFinishEventListner {
private String address;
@Override
public void onTaskFinish(TaskFinishEvent event) {
System.out.println("Send Message to "+address+" Task:"+event.getSource());
}
}
在测试代码中添加如下代码向事件发布器注册该监听器
SmsTaskFinishListener smsListener = new SmsTaskFinishListener("123456789");
//注册短信服务监听器
publisher.register(smsListener);
基于JDK的支持要实现对自定义事件的监听还是比较麻烦的,要做的工作比较多。而且自定义的事件发布器也不能提供对所有事件的统一发布支持。基于Spring框架实现自定义事件监听则要简单很多,功能也更加强大。
Spring容器对事件监听机制的支持
基本抽象
Spring容器,具体而言是ApplicationContext接口定义的容器提供了一套相对完善的事件发布和监听框架,其遵循了JDK中的事件监听标准,并使用容器来管理相关组件,使得用户不用关心事件发布和监听的具体细节,降低了开发难度也简化了开发流程。下面看看对于事件监听机制中的各主要角色,Spring框架中是如何定义的,以及相关的类体系结构
事件
Spring为容器内事件定义了一个抽象类ApplicationEvent,该类继承了JDK中的事件基类EventObject。因而自定义容器内事件除了需要继承ApplicationEvent之外,还要传入事件源作为构造参数。
事件监听器
Spring定义了一个ApplicationListener接口作为为事件监听器的抽象,接口定义如下
public interface ApplicationListener<E extends ApplicationEvent> extends EventListener {
/**
* Handle an application event.
* @param event the event to respond to
*/
void onApplicationEvent(E event);
}
- 该接口继承了JDK中表示事件监听器的标记接口EventListener,内部只定义了一个抽象方法onApplicationEvent(evnt),当监听的事件在容器中被发布,该方法将被调用。
- 同时,该接口是一个泛型接口,其实现类可以通过传入泛型参数指定该事件监听器要对哪些事件进行监听。这样有什么好处?这样所有的事件监听器就可以由一个事件发布器进行管理,并对所有事件进行统一发布,而具体的事件和事件监听器之间的映射关系,则可以通过反射读取泛型参数类型的方式进行匹配,稍后我们会对原理进行讲解。
- 最后,所有的事件监听器都必须向容器注册,容器能够对其进行识别并委托容器内真正的事件发布器进行管理。
事件发布器
ApplicationContext接口继承了ApplicationEventPublisher接口,从而提供了对外发布事件的能力,如下所示
那么是否可以说ApplicationContext,即容器本身就担当了事件发布器的角色呢?其实这是不准确的,容器本身仅仅是对外提供了事件发布的接口,真正的工作其实是委托给了具体容器内部一个ApplicationEventMulticaster对象,其定义在AbstractApplicationContext抽象类内部,如下所示
/** Helper class used in event publishing */
private ApplicationEventMulticaster applicationEventMulticaster;
所以,真正的事件发布器是ApplicationEventMulticaster,这是一个接口,定义了事件发布器需要具备的基本功能:管理事件监听器以及发布事件。其默认实现类是
SimpleApplicationEventMulticaster,该组件会在容器启动时被自动创建,并以单例的形式存在,管理了所有的事件监听器,并提供针对所有容器内事件的发布功能。
基于Spring实现对任务执行结果的监听
业务场景在2.1中已经介绍过了,这里就不在啰嗦。基于Spring框架来实现对自定义事件的监听流程十分简单,只需要三部:1.自定义事件类 2.自定义事件监听器并向容器注册 3.发布事件
1.自定任务结束事件
定义一个任务结束事件TaskFinishEvent2,该类继承抽象类ApplicationEvent来遵循容器事件规范。
/**
* @author: takumiCX
* @create: 2018-11-04
**/
public class TaskFinishEvent2 extends ApplicationEvent {
/**
* Create a new ApplicationEvent.
*
* @param source the object on which the event initially occurred (never {@code null})
*/
public TaskFinishEvent2(Object source) {
super(source);
}
}
2.自定义邮件服务监听器并向容器注册
该类实现了容器事件规范定义的监听器接口,通过泛型参数指定对上面定义的任务结束事件进行监听,通过@Component注解向容器进行注册
/**
* @author: takumiCX
* @create: 2018-11-04
**/
@Component
public class MailTaskFinishListener2 implements ApplicationListener<TaskFinishEvent2> {
private String emial="takumiCX@163.com";
@Override
public void onApplicationEvent(TaskFinishEvent2 event) {
System.out.println("Send Emial to "+emial+" Task:"+event.getSource());
}
}
3.发布事件
从上面对Spring事件监听机制的类结构分析可知,发布事件的功能定义在ApplicationEventPublisher接口中,而ApplicationContext继承了该接口,所以最好的方法是通过实现ApplicationContextAware接口获取ApplicationContext实例,然后调用其发布事件方法。如下所示定义了一个发布容器事件的代理类
/**
* @author: takumiCX
* @create: 2018-11-04
**/
@Component
public class EventPublisher implements ApplicationContextAware {
private ApplicationContext applicationContext;
//发布事件
public void publishEvent(ApplicationEvent event){
applicationContext.publishEvent(event);
}
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext=applicationContext;
}
}
在此基础上,还可以自定义一个短信服务监听器,在任务执行结束时发送短信通知用户。过程和上面自定义邮件服务监听器类似:实现ApplicationListner接口并重写抽象方法,然后通过注解或者xml的方式向容器注册。
Spring事件监听源码解析
Spring事件监听机制离不开容器IOC特性提供的支持,比如容器会自动创建事件发布器,自动识别用户注册的监听器并进行管理,在特定的事件发布后会找到对应的事件监听器并对其监听方法进行回调。Spring帮助用户屏蔽了关于事件监听机制背后的很多细节,使用户可以专注于业务层面进行自定义事件开发。然而我们还是忍不住对其背后的实现原理进行一番探讨,比如:
- 1.事件发布器ApplicationEventMulticaster是何时被初始化的,初始化过程中都做了什么?
- 2.注册事件监听器的过程是怎样的,容器怎么识别出它们并进行管理?
- 3.容器发布事件的流程是怎样的?它如何根据发布的事件找到对应的事件监听器,事件和由该事件触发的监听器之间的匹配规则是怎样的?
为了对以上问题进行解答,我们不得不深入源码层面一探究竟。
1. 初始化事件发布器流程
真正的事件发布器是ApplicationEventMulticaster,它定义在AbstractApplicationContext中,并在ApplicationContext容器启动的时候进行初始化。在容器启动的refrsh()方法中可以找到初始化事件发布器的入口方法,如下图所示
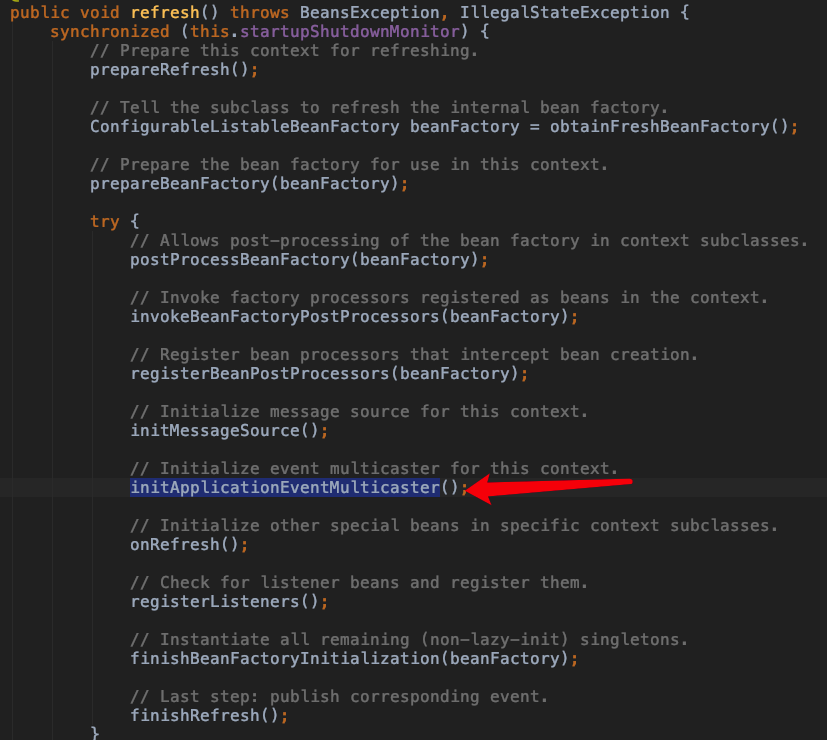
protected void initApplicationEventMulticaster() {
ConfigurableListableBeanFactory beanFactory = getBeanFactory();
// 判断beanFactory里是否定义了id为applicationEventMulticaster的bean,默认是没有的
if (beanFactory.containsLocalBean(APPLICATION_EVENT_MULTICASTER_BEAN_NAME)) {
this.applicationEventMulticaster =
beanFactory.getBean(APPLICATION_EVENT_MULTICASTER_BEAN_NAME, ApplicationEventMulticaster.class);
if (logger.isDebugEnabled()) {
logger.debug("Using ApplicationEventMulticaster [" + this.applicationEventMulticaster + "]");
}
}
else {
//一般情况会走这里,创建一个SimpleApplicationEventMulticaster并交由容器管理
this.applicationEventMulticaster = new SimpleApplicationEventMulticaster(beanFactory);
beanFactory.registerSingleton(APPLICATION_EVENT_MULTICASTER_BEAN_NAME, this.applicationEventMulticaster);
if (logger.isDebugEnabled()) {
logger.debug("Unable to locate ApplicationEventMulticaster with name '" +
APPLICATION_EVENT_MULTICASTER_BEAN_NAME +
"': using default [" + this.applicationEventMulticaster + "]");
}
}
}
这里会根据核心容器beanFactory中是否有id为applicationEventMulticaster的bean分两种情况:
- 1.容器中已有id为applicationEventMulticaster的bean
直接从容器缓存获取或是创建该bean实例,并交由成员变量applicationEventMulticaster保存。
当用户自定义了事件发布器并向容器注册时会执行该流程。
- 2.容器中不存在applicationEventMulticaster的bean
这是容器默认的执行流程,会创建一个SimpleApplicationEventMulticaster,其仅在实现事件发布器基本功能(管理事件监听器以及发布容器事件)的前提下,增加了可以设置任务执行器
Executor和错误处理器ErrorHandler的功能,当设置Executor为线程池时,则会以异步的方式对事件监听器进行回调,而ErrorHandler允许我们在回调方法执行错误时进行自定义处理。默认情况下,
这两个变量都为null。
public class SimpleApplicationEventMulticaster extends AbstractApplicationEventMulticaster {
private Executor taskExecutor;
private ErrorHandler errorHandler;
public abstract class AbstractApplicationEventMulticaster
implements ApplicationEventMulticaster, BeanClassLoaderAware, BeanFactoryAware {
private final ListenerRetriever defaultRetriever = new ListenerRetriever(false);
final Map<ListenerCacheKey, ListenerRetriever> retrieverCache =
new ConcurrentHashMap<ListenerCacheKey, ListenerRetriever>(64);
private ClassLoader beanClassLoader;
private BeanFactory beanFactory;
private Object retrievalMutex = this.defaultRetriever;
之后会调用beanFactory.registerSingleton方法将创建的SimpleApplicationEventMulticaster实例注册为容器的单实例bean。
初始化事件发布器的工作非常简单,一句话总结:由容器实例化用户自定义的事件发布器或者由容器帮我们创建一个简单的事件发布器并交由容器管理。
2. 注册事件监听器流程
注册事件监听器的流程在初始化事件发布器之后,如下图所示
其关键代码如下所示
// uninitialized to let post-processors apply to them!
//获取实现ApplicationListener接口的所有bean的beanName
String[] listenerBeanNames = getBeanNamesForType(ApplicationListener.class, true, false);
for (String listenerBeanName : listenerBeanNames) {
//将监听器的beanName保存到事件发布器中
getApplicationEventMulticaster().addApplicationListenerBean(listenerBeanName);
}
首先遍历beanFactory中所有的bean,获取所有实现ApplicationListener接口的bean的beanName,并将这些beanName注册到ApplicationEventMulticaster中
@Override
public void addApplicationListenerBean(String listenerBeanName) {
synchronized (this.retrievalMutex) {
//保存所有监听器的beanName
this.defaultRetriever.applicationListenerBeans.add(listenerBeanName);
//清除维护事件和监听器映射关系的缓存
this.retrieverCache.clear();
}
}
defaultRetriever是定义在抽象类AbstractApplicationEventMulticaster中的成员,用来保存所有事件监听器及其beanName
private final ListenerRetriever defaultRetriever = new ListenerRetriever(false);
其以内部类形式定义在AbstractApplicationEventMulticaster中
/**
* Helper class that encapsulates a specific set of target listeners,
* allowing for efficient retrieval of pre-filtered listeners.
* <p>An instance of this helper gets cached per event type and source type.
*/
private class ListenerRetriever {
//保存所有事件监听器
public final Set<ApplicationListener<?>> applicationListeners;
//保存所有事件监听器的beanName
public final Set<String> applicationListenerBeans;
向事件发布器注册监听器的beanName,其实就是将beanName加入ListenerRetriever的集合中。
其实看到这里会有一个疑问,registerListeners()方法只是找到了所有监听器的beanName并将其保存到了事件发布器ApplicationEventMulticaster中,那么真正的事件监听器实例是何时被创建并被加入到事件发布器中的?
这里我们不得不退回到启动容器的refresh()方法中,在初始化beanFactory之后,初始化事件发布器之前,容器在prepareBeanFactory(beanFactory)方法中又注册了一些重要组件,其中就包括一个特殊的BeanPostProcessor:ApplicationListenerDetector,正如其类名暗示的那样,这是一个事件监听器的探测器。
该类实现了BeanPostProcessor接口,如下图所示
ApplicationListenerDetector实现了BeanPostProcessor接口,可以在容器级别对所有bean的生命周期过程进行增强。这里主要是为了能够在初始化所有bean后识别出所有的事件监听器bean并
将其注册到事件发布器中
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) {
//判断该bean是否实现了ApplicationListener接口
if (this.applicationContext != null && bean instanceof ApplicationListener) {
// potentially not detected as a listener by getBeanNamesForType retrieval
Boolean flag = this.singletonNames.get(beanName);
if (Boolean.TRUE.equals(flag)) {
// singleton bean (top-level or inner): register on the fly
//将实现了ApplicationListener接口的bean注册到事件发布器applicationEventMulticaster中
this.applicationContext.addApplicationListener((ApplicationListener<?>) bean);
}
else if (Boolean.FALSE.equals(flag)) {
if (logger.isWarnEnabled() && !this.applicationContext.containsBean(beanName)) {
// inner bean with other scope - can't reliably process events
logger.warn("Inner bean '" + beanName + "' implements ApplicationListener interface " +
"but is not reachable for event multicasting by its containing ApplicationContext " +
"because it does not have singleton scope. Only top-level listener beans are allowed " +
"to be of non-singleton scope.");
}
this.singletonNames.remove(beanName);
}
}
return bean;
}
在初始化所有的bean后,该ApplicationListenerDetector的postProcessAfterInitialization(Object bean, String beanName)方法会被作用在每一个bean上,通过判断传入的bean
是否是ApplicationListener实例进行过滤,然后将找到的事件监听器bean注册到事件发布器中。
3. 容器事件发布流程
这里为了简化源码阅读的工作量,对一些细节和分支情形做了忽略,只考虑主流程,如上图箭头所示,这里调用了事件发布器的multicastEvent()方法进行事件发布,需要传入事件event和事件类型
eventType作为参数。不过通常这个eventType参数为null,因为事件的类型信息完全可以通过反射的方式从event对象中获得。继续跟进源码
@Override
public void multicastEvent(final ApplicationEvent event, ResolvableType eventType) {
//获取事件类型
ResolvableType type = (eventType != null ? eventType : resolveDefaultEventType(event));
//遍历所有和事件匹配的事件监听器
for (final ApplicationListener<?> listener : getApplicationListeners(event, type)) {
//获取事件发布器内的任务执行器,默认该方法返回null
Executor executor = getTaskExecutor();
if (executor != null) {
//异步回调监听方法
executor.execute(new Runnable() {
@Override
public void run() {
invokeListener(listener, event);
}
});
}
else {
//同步回调监听方法
invokeListener(listener, event);
}
}
}
首先通过传入的参数或者通过调用resolveDefaultEventType(event)方法获取事件的事件类型信息,之后会通过
getApplicationListeners(event, type)方法得到所有和该事件类型匹配的事件监听器,其实现逻辑后面会细说,这里先跳过。对于匹配的每一个监听器,视事件发布器内是否设置了
任务执行器实例Executor,决定以何种方式对监听器的监听方法进行回调。
- 若执行器实例Executor未设置,则进行同步回调,即在当前线程执行监听器的回调方法
- 若用户设置了Executor实例(通常而言是线程池),则会进行异步回调,监听器的监听方法会交由线程池中的线程去执行。
默认情况下容器不会为用户创建执行器实例,因而对监听器的回调是同步进行的,即所有监听器的监听方法都在推送事件的线程中被执行,通常这也是处理业务逻辑的线程,若其中一个监听器回调执行
阻塞,则会阻塞整个业务处理的线程,造成严重的后果。而异步回调的方式,虽然不会导致业务处理线程被阻塞,但是不能共享一些业务线程的上下文资源,比如类加载器,事务等等。因而究竟选择哪种回调
方式,要视具体业务场景而定。
好了,现在可以来探究下困扰我们很久的一个问题了,那就是:如何根据事件类型找到匹配的所有事件监听器?这部分逻辑在getApplicationListeners方法中
protected Collection<ApplicationListener<?>> getApplicationListeners(
ApplicationEvent event, ResolvableType eventType) {
//获取事件中的事件源对象
Object source = event.getSource();
//获取事件源类型
Class<?> sourceType = (source != null ? source.getClass() : null);
//以事件类型和事件源类型为参数构建一个cacheKey,用于从缓存map中获取与之匹配的监听器列表
ListenerCacheKey cacheKey = new ListenerCacheKey(eventType, sourceType);
// Quick check for existing entry on ConcurrentHashMap...
ListenerRetriever retriever = this.retrieverCache.get(cacheKey);
if (retriever != null) {
//从缓存中获取监听器列表
return retriever.getApplicationListeners();
}
if (this.beanClassLoader == null ||
(ClassUtils.isCacheSafe(event.getClass(), this.beanClassLoader) &&
(sourceType == null || ClassUtils.isCacheSafe(sourceType, this.beanClassLoader)))) {
// Fully synchronized building and caching of a ListenerRetriever
synchronized (this.retrievalMutex) {
retriever = this.retrieverCache.get(cacheKey);
if (retriever != null) {
return retriever.getApplicationListeners();
}
retriever = new ListenerRetriever(true);
//查找所有与发布事件匹配的监听器列表
Collection<ApplicationListener<?>> listeners =
retrieveApplicationListeners(eventType, sourceType, retriever);
//将匹配结果缓存到map中
this.retrieverCache.put(cacheKey, retriever);
return listeners;
}
}
else {
// No ListenerRetriever caching -> no synchronization necessary
return retrieveApplicationListeners(eventType, sourceType, null);
}
}
整个流程可以概括为:
- 1.首先从缓存map中查找,这个map定义在事件发布器的抽象类中
final Map<ListenerCacheKey, ListenerRetriever> retrieverCache =
new ConcurrentHashMap<ListenerCacheKey, ListenerRetriever>(64);
ListenerCacheKey由事件类型eventType和事件源类型sourceType构成,ListenerRetriever内部则维护了一个监听器列表。当所发布的事件类型和事件源类型与Map中的key匹配时,
将直接返回value中的监听器列表作为匹配结果,通常这发生在事件不是第一次发布时,能避免遍历所有监听器并进行过滤,如果事件时第一次发布,则会执行流程2。
- 2.遍历所有的事件监听器,并根据事件类型和事件源类型进行匹配。
Collection<ApplicationListener<?>> listeners =
retrieveApplicationListeners(eventType, sourceType, retriever);
/**
* Actually retrieve the application listeners for the given event and source type.
* @param eventType the event type
* @param sourceType the event source type
* @param retriever the ListenerRetriever, if supposed to populate one (for caching purposes)
* @return the pre-filtered list of application listeners for the given event and source type
*/
private Collection<ApplicationListener<?>> retrieveApplicationListeners(
ResolvableType eventType, Class<?> sourceType, ListenerRetriever retriever) {
//这是存放匹配的监听器的列表
LinkedList<ApplicationListener<?>> allListeners = new LinkedList<ApplicationListener<?>>();
Set<ApplicationListener<?>> listeners;
Set<String> listenerBeans;
synchronized (this.retrievalMutex) {
listeners = new LinkedHashSet<ApplicationListener<?>>(this.defaultRetriever.applicationListeners);
listenerBeans = new LinkedHashSet<String>(this.defaultRetriever.applicationListenerBeans);
}
//遍历所有的监听器
for (ApplicationListener<?> listener : listeners) {
//判断该事件监听器是否匹配
if (supportsEvent(listener, eventType, sourceType)) {
if (retriever != null) {
retriever.applicationListeners.add(listener);
}
//将匹配的监听器加入列表
allListeners.add(listener);
}
}
//这部分可以跳过
if (!listenerBeans.isEmpty()) {
BeanFactory beanFactory = getBeanFactory();
for (String listenerBeanName : listenerBeans) {
try {
Class<?> listenerType = beanFactory.getType(listenerBeanName);
if (listenerType == null || supportsEvent(listenerType, eventType)) {
ApplicationListener<?> listener =
beanFactory.getBean(listenerBeanName, ApplicationListener.class);
if (!allListeners.contains(listener) && supportsEvent(listener, eventType, sourceType)) {
if (retriever != null) {
retriever.applicationListenerBeans.add(listenerBeanName);
}
allListeners.add(listener);
}
}
}
catch (NoSuchBeanDefinitionException ex) {
// Singleton listener instance (without backing bean definition) disappeared -
// probably in the middle of the destruction phase
}
}
}
//对匹配的监听器列表进行排序
AnnotationAwareOrderComparator.sort(allListeners);
return allListeners;
}
判断监听器是否匹配的逻辑在supportsEvent(listener, eventType, sourceType)中,
protected boolean supportsEvent(ApplicationListener<?> listener, ResolvableType eventType, Class<?> sourceType) {
//对原始的ApplicationListener进行一层适配器包装成为GenericApplicationListener
GenericApplicationListener smartListener = (listener instanceof GenericApplicationListener ?
(GenericApplicationListener) listener : new GenericApplicationListenerAdapter(listener));
//判断监听器是否支持该事件类型以及该事件源类型
return (smartListener.supportsEventType(eventType) && smartListener.supportsSourceType(sourceType));
}
首先对原始的ApplicationListener进行一层适配器包装成GenericApplicationListener,便于后面使用该接口中定义的方法判断监听器是否支持传入的事件类型或事件源类型
public interface GenericApplicationListener extends ApplicationListener<ApplicationEvent>, Ordered {
/**
* Determine whether this listener actually supports the given event type.
*/
boolean supportsEventType(ResolvableType eventType); //判断是否支持该事件类型
/**
* Determine whether this listener actually supports the given source type.
*/
boolean supportsSourceType(Class<?> sourceType); //判断是否支持该事件源类型
}
smartListener.supportsEventType(eventType)用来判断监听器是否支持该事件类型,因为我们的监听器实例通常都不是SmartApplicationListener类型,所以直接看下面箭头所指的方法就好
declaredEventType是监听器泛型的实际类型,而eventType是发布的事件的类型
declaredEventType.isAssignableFrom(eventType)当以下两种情况返回true
- 1.declaredEventType和eventType类型相同
- 2.declaredEventType是eventType的父类型
只要监听器泛型的实际类型和发布的事件类型一样或是它的父类型,则该监听器将被成功匹配。
而对于事件源类型而言,通常默认会直接返回true,也就是说事件源的类型通常对于判断匹配的监听器没有意义。
这里查找到所有匹配的监听器返回后会将匹配关系缓存到retrieverCache这个map中
Collection<ApplicationListener<?>> listeners =
retrieveApplicationListeners(eventType, sourceType, retriever);
//将匹配结果缓存到map中
this.retrieverCache.put(cacheKey, retriever);
return listeners;
梳理下容器事件发布的整个流程,可以总结如下
1.17 - CH18-设计模式
简单工厂
实现方式
BeanFactory。Spring中的BeanFactory就是简单工厂模式的体现,根据传入一个唯一的标识来获得Bean对象,但是否是在传入参数后创建还是传入参数前创建这个要根据具体情况来定。
实质
由一个工厂类根据传入的参数,动态决定应该创建哪一个产品类。
实现原理
设计意义
- 松耦合。可以将原来硬编码的依赖,通过Spring这个beanFactory这个工长来注入依赖,也就是说原来只有依赖方和被依赖方,现在我们引入了第三方——Spring这个beanFactory,由它来解决bean之间的依赖问题,达到了松耦合的效果。
- bean的额外处理。通过Spring接口的暴露,在实例化bean的阶段我们可以进行一些额外的处理,这些额外的处理只需要让bean实现对应的接口即可,那么spring就会在bean的生命周期调用我们实现的接口来处理该bean。
工厂方法
实现方式
FactoryBean接口。
实现原理
实现了FactoryBean接口的bean是一类叫做factory的bean。其特点是,spring会在使用getBean()调用获得该bean时,会自动调用该bean的getObject()方法,所以返回的不是factory这个bean,而是这个bean.getOjbect()方法的返回值。
实例
典型的例子有Spring与MyBatis的结合。
我们看上面该bean,因为实现了FactoryBean接口,所以返回的不是SqlSessionFactoryBean的实例,而是它的 SqlSessionFactoryBean.getObject()的返回值。
单例模式
在我们的系统中,有一些对象其实我们只需要一个,比如说:线程池、缓存、对话框、注册表、日志对象、充当打印机、显卡等设备驱动程序的对象。事实上,这一类对象只能有一个实例,如果制造出多个实例就可能会导致一些问题的产生,比如:程序的行为异常、资源使用过量、或者不一致性的结果。
使用单例模式的好处:
- 对于频繁使用的对象,可以省略创建对象所花费的时间,这对于那些重量级对象而言,是非常可观的一笔系统开销;
- 由于 new 操作的次数减少,因而对系统内存的使用频率也会降低,这将减轻 GC 压力,缩短 GC 停顿时间。
Spring 中 bean 的默认作用域就是 singleton(单例)的。 除了 singleton 作用域,Spring 中 bean 还有下面几种作用域:
- prototype : 每次请求都会创建一个新的 bean 实例。
- request : 每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP request内有效。
- session : 每一次HTTP请求都会产生一个新的 bean,该bean仅在当前 HTTP session 内有效。
- global-session: 全局session作用域,仅仅在基于portlet的web应用中才有意义,Spring5已经没有了。Portlet是能够生成语义代码(例如:HTML)片段的小型Java Web插件。它们基于portlet容器,可以像servlet一样处理HTTP请求。但是,与 servlet 不同,每个 portlet 都有不同的会话
Spring 实现单例的方式:
- xml :
<bean id="userService" class="top.snailclimb.UserService" scope="singleton"/> - 注解:
@Scope(value = "singleton")
Spring 通过 ConcurrentHashMap 实现单例注册表的特殊方式实现单例模式。Spring 实现单例的核心代码如下
// 通过 ConcurrentHashMap(线程安全) 实现单例注册表
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(64);
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "'beanName' must not be null");
synchronized (this.singletonObjects) {
// 检查缓存中是否存在实例
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
//...省略了很多代码
try {
singletonObject = singletonFactory.getObject();
}
//...省略了很多代码
// 如果实例对象在不存在,我们注册到单例注册表中。
addSingleton(beanName, singletonObject);
}
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
}
//将对象添加到单例注册表
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
this.singletonObjects.put(beanName, (singletonObject != null ? singletonObject : NULL_OBJECT));
}
}
}
代理模式
代理模式在 AOP 中的应用
AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性。
Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么Spring AOP会使用JDK Proxy,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候Spring AOP会使用Cglib ,这时候Spring AOP会使用 Cglib 生成一个被代理对象的子类来作为代理,如下图所示:
当然你也可以使用 AspectJ ,Spring AOP 已经集成了AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。
使用 AOP 之后我们可以把一些通用功能抽象出来,在需要用到的地方直接使用即可,这样大大简化了代码量。我们需要增加新功能时也方便,这样也提高了系统扩展性。日志功能、事务管理等等场景都用到了 AOP 。
Spring AOP 和 AspectJ AOP 有什么区别?
Spring AOP 属于运行时增强,而 AspectJ 是编译时增强。 Spring AOP 基于代理(Proxying),而 AspectJ 基于字节码操作(Bytecode Manipulation)。
Spring AOP 已经集成了 AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。AspectJ 相比于 Spring AOP 功能更加强大,但是 Spring AOP 相对来说更简单,
如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择 AspectJ ,它比Spring AOP 快很多。
模板方法
模板方法模式是一种行为设计模式,它定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。 模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤的实现方式。
public abstract class Template {
//这是我们的模板方法
public final void TemplateMethod(){
PrimitiveOperation1();
PrimitiveOperation2();
PrimitiveOperation3();
}
protected void PrimitiveOperation1(){
//当前类实现
}
//被子类实现的方法
protected abstract void PrimitiveOperation2();
protected abstract void PrimitiveOperation3();
}
public class TemplateImpl extends Template {
@Override
public void PrimitiveOperation2() {
//当前类实现
}
@Override
public void PrimitiveOperation3() {
//当前类实现
}
}
复制代码
Spring 中 jdbcTemplate、hibernateTemplate 等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。一般情况下,我们都是使用继承的方式来实现模板模式,但是 Spring 并没有使用这种方式,而是使用Callback 模式与模板方法模式配合,既达到了代码复用的效果,同时增加了灵活性。
管擦者模式
观察者模式是一种对象行为型模式。它表示的是一种对象与对象之间具有依赖关系,当一个对象发生改变的时候,这个对象所依赖的对象也会做出反应。Spring 事件驱动模型就是观察者模式很经典的一个应用。Spring 事件驱动模型非常有用,在很多场景都可以解耦我们的代码。比如我们每次添加商品的时候都需要重新更新商品索引,这个时候就可以利用观察者模式来解决这个问题。
Spring 事件驱动模型中的三种角色
事件角色
ApplicationEvent (org.springframework.context包下)充当事件的角色,这是一个抽象类,它继承了java.util.EventObject并实现了 java.io.Serializable接口。
Spring 中默认存在以下事件,他们都是对 ApplicationContextEvent 的实现(继承自ApplicationContextEvent):
ContextStartedEvent:ApplicationContext 启动后触发的事件;ContextStoppedEvent:ApplicationContext 停止后触发的事件;ContextRefreshedEvent:ApplicationContext 初始化或刷新完成后触发的事件;ContextClosedEvent:ApplicationContext 关闭后触发的事件。
事件监听者角色
ApplicationListener 充当了事件监听者角色,它是一个接口,里面只定义了一个 onApplicationEvent()方法来处理ApplicationEvent。ApplicationListener接口类源码如下,可以看出接口定义看出接口中的事件只要实现了 ApplicationEvent就可以了。所以,在 Spring中我们只要实现 ApplicationListener 接口实现 onApplicationEvent() 方法即可完成监听事件
package org.springframework.context;
import java.util.EventListener;
@FunctionalInterface
public interface ApplicationListener<E extends ApplicationEvent> extends EventListener {
void onApplicationEvent(E var1);
}
复制代码
事件发布者角色
ApplicationEventPublisher 充当了事件的发布者,它也是一个接口。
@FunctionalInterface
public interface ApplicationEventPublisher {
default void publishEvent(ApplicationEvent event) {
this.publishEvent((Object)event);
}
void publishEvent(Object var1);
}
复制代码
ApplicationEventPublisher 接口的publishEvent()这个方法在AbstractApplicationContext类中被实现,阅读这个方法的实现,你会发现实际上事件真正是通过ApplicationEventMulticaster来广播出去的。具体内容过多,就不在这里分析了,后面可能会单独写一篇文章提到。
Spring 的事件流程总结
- 定义一个事件: 实现一个继承自
ApplicationEvent,并且写相应的构造函数; - 定义一个事件监听者:实现
ApplicationListener 接口,重写 onApplicationEvent() 方法; - 使用事件发布者发布消息: 可以通过
ApplicationEventPublisher 的 publishEvent() 方法发布消息。
Example:
// 定义一个事件,继承自ApplicationEvent并且写相应的构造函数
public class DemoEvent extends ApplicationEvent{
private static final long serialVersionUID = 1L;
private String message;
public DemoEvent(Object source,String message){
super(source);
this.message = message;
}
public String getMessage() {
return message;
}
// 定义一个事件监听者,实现ApplicationListener接口,重写 onApplicationEvent() 方法;
@Component
public class DemoListener implements ApplicationListener<DemoEvent>{
//使用onApplicationEvent接收消息
@Override
public void onApplicationEvent(DemoEvent event) {
String msg = event.getMessage();
System.out.println("接收到的信息是:"+msg);
}
}
// 发布事件,可以通过ApplicationEventPublisher 的 publishEvent() 方法发布消息。
@Component
public class DemoPublisher {
@Autowired
ApplicationContext applicationContext;
public void publish(String message){
//发布事件
applicationContext.publishEvent(new DemoEvent(this, message));
}
}
复制代码
当调用 DemoPublisher 的 publish() 方法的时候,比如 demoPublisher.publish("你好") ,控制台就会打印出:接收到的信息是:你好 。
适配器模式
适配器模式(Adapter Pattern) 将一个接口转换成客户希望的另一个接口,适配器模式使接口不兼容的那些类可以一起工作,其别名为包装器(Wrapper)。
spring AOP中的适配器模式
我们知道 Spring AOP 的实现是基于代理模式,但是 Spring AOP 的增强或通知(Advice)使用到了适配器模式,与之相关的接口是AdvisorAdapter 。Advice 常用的类型有:BeforeAdvice(目标方法调用前,前置通知)、AfterAdvice(目标方法调用后,后置通知)、AfterReturningAdvice(目标方法执行结束后,return之前)等等。每个类型Advice(通知)都有对应的拦截器:MethodBeforeAdviceInterceptor、AfterReturningAdviceAdapter、AfterReturningAdviceInterceptor。Spring预定义的通知要通过对应的适配器,适配成 MethodInterceptor接口(方法拦截器)类型的对象(如:MethodBeforeAdviceInterceptor 负责适配 MethodBeforeAdvice)。
spring MVC中的适配器模式
在Spring MVC中,DispatcherServlet 根据请求信息调用 HandlerMapping,解析请求对应的 Handler。解析到对应的 Handler(也就是我们平常说的 Controller 控制器)后,开始由HandlerAdapter 适配器处理。HandlerAdapter 作为期望接口,具体的适配器实现类用于对目标类进行适配,Controller 作为需要适配的类。
为什么要在 Spring MVC 中使用适配器模式? Spring MVC 中的 Controller 种类众多,不同类型的 Controller通过不同的方法来对请求进行处理。如果不利用适配器模式的话,DispatcherServlet 直接获取对应类型的 Controller,需要的自行来判断,像下面这段代码一样:
if(mappedHandler.getHandler() instanceof MultiActionController){
((MultiActionController)mappedHandler.getHandler()).xxx
}else if(mappedHandler.getHandler() instanceof XXX){
...
}else if(...){
...
}
复制代码
假如我们再增加一个 Controller类型就要在上面代码中再加入一行 判断语句,这种形式就使得程序难以维护,也违反了设计模式中的开闭原则 – 对扩展开放,对修改关闭。
装饰者模式
装饰者模式可以动态地给对象添加一些额外的属性或行为。相比于使用继承,装饰者模式更加灵活。简单点儿说就是当我们需要修改原有的功能,但我们又不愿直接去修改原有的代码时,设计一个Decorator套在原有代码外面。其实在 JDK 中就有很多地方用到了装饰者模式,比如 InputStream家族,InputStream 类下有 FileInputStream (读取文件)、BufferedInputStream (增加缓存,使读取文件速度大大提升)等子类都在不修改InputStream 代码的情况下扩展了它的功能。
Spring 中配置 DataSource 的时候,DataSource 可能是不同的数据库和数据源。我们能否根据客户的需求在少修改原有类的代码下动态切换不同的数据源?这个时候就要用到装饰者模式(这一点我自己还没太理解具体原理)。Spring 中用到的包装器模式在类名上含有 Wrapper或者 Decorator。这些类基本上都是动态地给一个对象添加一些额外的职责
策略模式
实现方式:Spring框架的资源访问Resource接口。该接口提供了更强的资源访问能力,Spring框架本身大量使用了Resource接口来访问底层资源。
Resource接口介绍
source接口是具体资源访问策略的抽象,也是所有资源访问类所实现的接口。
Resource接口主要提供了如下几个方法:
- getInputStream():定位并打开资源,返回资源对应的输入流。每次调用都返回新的输入流。调用者必须负责关闭输入流。
- exists():返回Resource所指向的资源是否存在。
- isOpen():返回资源文件是否打开,如果资源文件不能多次读取,每次读取结束应该显式关闭,以防止资源泄漏。
- getDescription():返回资源的描述信息,通常用于资源处理出错时输出该信息,通常是全限定文件名或实际URL。
- getFile:返回资源对应的File对象。
- getURL:返回资源对应的URL对象。
最后两个方法通常无须使用,仅在通过简单方式访问无法实现时,Resource提供传统的资源访问的功能。
Resource接口本身没有提供访问任何底层资源的实现逻辑,针对不同的底层资源,Spring将会提供不同的Resource实现类,不同的实现类负责不同的资源访问逻辑。
Spring为Resource接口提供了如下实现类:
- UrlResource:访问网络资源的实现类。
- ClassPathResource:访问类加载路径里资源的实现类。
- FileSystemResource:访问文件系统里资源的实现类。
- ServletContextResource:访问相对于ServletContext路径里的资源的实现类.
- InputStreamResource:访问输入流资源的实现类。
- ByteArrayResource:访问字节数组资源的实现类。
这些Resource实现类,针对不同的的底层资源,提供了相应的资源访问逻辑,并提供便捷的包装,以利于客户端程序的资源访问。
1.18 - CH19-Servlet
Servlet
Servlet(Server Applet),全称Java Servlet。是用Java编写的服务器端程序。其主要功能在于交互式地浏览和修改数据,生成动态Web内容。狭义的Servlet是指Java语言实现的一个接口,广义的Servlet是指任何实现了这个Servlet接口的类,一般情况下,人们将Servlet理解为后者。
web开发的本质就一句话:客户端和服务器交换数据。于是你使用 Java 的 Socket 套接字进行编程,去处理客户端来的 tcp 请求,经过编解码处理读取请求体,获取请求行,然后找到请求行对应的处理逻辑步入服务器的处理中,处理完毕把对应的结果返回给当前的 Socket 链接,响应完毕,关闭 Socket。
以上过程,你有没有发现其实是两个部分:
- 建立连接,传输数据,关闭连接,你肯定知道这些步骤不是你所开发的web服务去处理的,而是tomcat容器帮你做了这些事情。
- 拿到请求行之后去找对应的 url 路由,这一部分是谁做的呢?在如今 SpringBoot 横行的时代,去配置化已经成为趋势,编程越来越简单导致的后果就是越来越难以理解事物最开始的样子。还记得 SpringMVC工程中的 web.xml文件吗?是否还记得在web.xml中有这么一段配置呢:
<servlet>
<servlet-name>SpringMVC</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet
</servlet-class>
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath*:/spring/SpringMVC-servlet.xml</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>SpringMVC</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
Spring 的核心就是一个 Servlet,它拦截了所有的请求,将请求交给 DispatcherServlet 去处理。
我们再来问一遍,Servlet 到底是什么,它就是一段处理 web 请求的逻辑,并不是很高深的东西。
再来看 Java 中的 Servlet,它只是一个接口:
package javax.servlet;
import java.io.IOException;
public interface Servlet {
public void init(ServletConfig config) throws ServletException;
public ServletConfig getServletConfig();
public void service(ServletRequest req, ServletResponse res)
throws ServletException, IOException;
public String getServletInfo();
public void destroy();
}
Servlet 接口规定请求从容器到达 web 服务端的规范,最重要的三个步骤是:
- init():初始化请求的时候要做什么;
- service():拿到请求的时候要做什么;
- destory():处理完请求销毁的时候要做什么。
所有实现 Servlet 的实现方都是在这个规范的基础上进行开发。那么 Servlet 中的数据是从哪里来的呢?答案就是 Servlet 容器。容器才是真正与客户端打交道的那一方。Servlet容器只有一个,而 Servlet 可以有多个。常见的Servlet容器Tomcat,它监听了客户端的请求端口,根据请求行信息确定将请求交给哪个Servlet 处理,找到处理的Servlet之后,调用该Servlet的 service() 方法,处理完毕将对应的处理结果包装成ServletResponse 对象返回给客户端。
Servlet 容器
上面说过,Servlet 只是一个处理请求的应用程序,光有Servlet是无法运行起来的,需要有一个 main 方法去调用你的这段 Servlet 程序才行。所以这里出现了Servlet 容器的概念。Servlet容器的主要作用是:
- 建立连接;
- 调用Servlet处理请求;
- 响应请求给客户端;
- 释放连接;
这上面的四步,如果是你来设计的话是否可以用一个模板方法搞定,1,3,4都是固定的步骤,不会因为请求不同而有很大的变化。2却会因为对应的请求不同需要业务逻辑自己去实现不同的处理。所以这里抽象出来了 Servlet,Servlet想怎么玩就怎么玩,这是你自己的事情。容器帮你做的是你不想做的脏活累活。
另外,既然叫做容器肯定是能装多个Servlet,并且可以管理Servlet的声明周期。这些功能应该是容器必备的。
上面提到了 web.xml 中的 DispatcherServlet,它是 Spring 中定义的一个 Servlet,实现了 Servlet 接口,本质也是一个 Servlet。只是它是 HttpServlet 的继承者,主要处理 http 请求。所以 Spring 程序本质是就是一个 Servlet。SpringMVC 帮你做了本该你去实现的逻辑,你看不到并不代表它不是。
好啦,以上通俗的语言解释了什么是 Servlet,什么是 Servlet 容器,以及 Servlet 和 Servlet 容器之间的关系。
Tomcat
Tomcat是啥呢?本质上是一个 Servlet 容器,实现了对 Java Servlet 规范的支持。同时 Tomcat 也提供了处理HTTP请求的能力,所以也可以作为一个Web服务器。了解到Tomcat有 Web服务器和 Servlet容器的功能,那么 Tomcat总体是如何设计的呢?我们来看一张简图:
Java web 应用如果部署到 Tomcat 中,一个Tomcat就表示一个服务。一个 Server 服务器可以包含多个 Service 服务,Tomcat 默认的 Service 服务是 Catalina,而一个 Service 服务可以包含多个连接器,因为 Tomcat 支持多种网络协议,包括 HTTP/1.1、HTTP/2、AJP 等等,一个 Service 服务还会包括一个容器,容器外部会有一层 Engine 引擎所包裹,负责与处理连接器的请求与响应,连接器与容器之间通过 ServletRequest 和 ServletResponse 对象进行交流。
Tomcat容器的设计提现在一个核心文件中:server.xml。这个文件充分展示了Tomcat的高度抽象设计:
<Server port="8005" shutdown="SHUTDOWN">
<Service name="Catalina">
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443"/>
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443"/>
<Engine name="Catalina" defaultHost="localhost">
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true">
</Host>
</Engine>
</Service>
</Server>
其中:
Server 组件是管理 tomcat 实例的组件,可以监听一个端口,从此端口上可以远程向该实例发送 shutdown 关闭命令。
Service 组件是一个逻辑组件,用于绑定 connector 和 container,有了 service 表示可以向外提供服务,就像是一般的 daemon 类服务的 service。可以认为一个 service 就启动一个JVM,更严格地说,一个 engine 组件才对应一个 JVM (定义负载均衡时,jvmRoute 就定义在 Engine 组件上用来标识这个 JVM ),只不过 connector 也工作在 JVM 中。
小故事:
是否关注到 Service name = Catalina,实际上 Tomcat 的前身就是 Catalina,这是一个岛的名字,而
Catalina 只是一个 Servlet 容器,为Servlet和 JavaServer Pages(JSP)实现了Sun Microsystems的规范。
Tomcat 的作者 詹姆斯·邓肯·戴维森,Sun Microsystems 的软件架构师在后来 Sun Microsystems 向 Apache Software Foundation 捐赠该项目中发挥了重要作用。当时他认为许多开源项目都有与 O’Reilly 相关的书籍,封面上有动物,所以他想以动物命名。后来这位老哥想到了猫。他认为这只动物代表着某种可以自己生存的东西,当2003年 O’Reilly 发行带有雪豹的 Tomcat 书籍时,他希望看到动物封面的愿望终于实现了。
Connector 组件是监听组件,它有四个作用:
- 开启监听套接字,监听外界请求,并和客户端建立 TCP 连接;
- 使用 protocolHandler 解析请求中的协议和端口等信息,如 http 协议、AJP 协议;
- 根据解析到的信息,使用 processer 将分析后的请求转发给绑定的 Engine;
- 接收响应数据并返回给客户端。
上面的 server.xml 配置我们能看到有两个 Connector。
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443"/>
这个 Connector 表示通过 8080 端口使用 HTTP/1.1版本的协议来访问 Tomcat。
我们知道 80 端口是为 HTTP(HyperText Transport Protocol) 即 超文本传输协议 开放的,主要用于万维网传输信息的协议。而我们一般在 Tomcat 中监听的是一个非 80 端口。那为啥不直接在 Tomcat 中写上 80 端口,即所有 HTTP 请求都可以收到。这是因为在生产环境中,一般不会直接暴露原始服务给外网,一方面是安全性,另一方面是 负载均衡处理 和 静态资源处理。所以会在原始服务上加一层代理,代理来监听 80 端口,再将服务暴露端口的请求转发给对应服务。
第二个 Connector:
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443"/>
这个 Connector 监听 8009 端口的 AJP 协议连接。AJP 协议负责和其他的 HTTP 服务器(如 Apache )建立连接;在把 Tomcat 与其他 HTTP 服务器集成时,就需要用到这个连接器。之所以使用 Tomcat 和其他服务器集成,是因为 Tomcat 可以用作 Servlet/JSP 容器,但是对静态资源的处理速度较慢,不如 Apache 和 IIS 等 HTTP 服务器。因此常常将 Tomcat 与 Apache 等集成,前者作 Servlet 容器,后者处理静态资源,而 AJP 协议便负责 Tomcat 和 Apache 的连接。
Container 表示一类组件,在配置文件(server.xml)中没有体现出来。它包含4个容器类组件:Engine容器、Host容器、Context容器 和 wrapper容器。
Engine 容器用于从 Connector 组件处接收已建立的 TCP 连接,还用于接收客户端发送的 HTTP 请求并分析请求,然后按照分析的结果将相关参数传递给匹配出的虚拟主机。Engine 还用于指定默认的虚拟主机。
Host 容器定义虚拟主机,对应了服务器中一个网络名实体(如”www.baidu.com”,或IP地址”23.0.32.1”)。为了使用户可以通过域名连接 Tomcat 服务器,这个域名应该在域名服务器已经注册过。
比如上例中的配置:
<Host name="localhost" appBase="webapps" unpackWARs="true" autoDeploy="true">
name=localhost 表示当前对应的请求是本机,这是因为已经配置了Nginx代理的原因,如果没有配置代理,那么这里就必须是真实的IP 或者域名。注意后面的 appBase,appBase表示当前 web资源所在的目录。
Context 容器主要是根据 path 和 docBase 获取一些信息,将结果交给其内的 wrapper 组件进行处理(它提供wrapper运行的环境,所以它叫上下文context)。一般来说,都采用默认的标准 wrapper 类,因此在 Context 容器中几乎不会出现 wrapper 组件。
wrapper 容器对应 Servlet 的处理过程。它开启 Servlet 的生命周期,根据 Context 给出的信息以及解析 web.xml 中的映射关系,负责装载相关的类,初始化 servlet 对象 init()、执行 servlet 代码 service() 以及服务结束时 servlet 对象的销毁 destory()。
根据上面描述的 tomcat 组件体系结构,处理请求的大致过程其实很容易推导出来:
CopyClient(request)-->Connector-->Engine-->Host-->Context-->Wrapper(response data)-->Connector(response header)-->Client
可以看到宏观上 Tomcat 设计的真是非常精妙,层叠式的容器设计呈现出一种美感。Connector 和 Container 两大组件涵盖主要功能,这种复合组件化的设计思想我们是否可以应用在业务系统中呢。
1.19 - CH20-缓存注解
@Cacheable
@Cacheable 的作用 主要针对方法配置,能够根据方法的请求参数对其结果进行缓存
@Cacheable 作用和配置方法
| 参数 | 解释 | 示例 |
|---|
| value | 缓存的名称,在spring配置文件中定义,必须指定至少一个 | 例如: @Cacheable(value="mycache") @Cacheable(value={"cache1","cache2"} |
| key | 缓存的key,可以为空,如果指定要按照SpEL表达式编写,如果不指定,则缺省按照方法的所有参数进行组合 | @Cacheable(value="testcache",key="#userName") |
| condition | 缓存的条件,可以为空,使用SpEL编写,返回true或者false,只有为true才进行缓存 | @Cacheable(value="testcache",condition="#userName.length()>2") |
实例
@Cacheable(value=”accountCache”),这个注释的意思是,当调用这个方法的时候,会从一个名叫 accountCache 的缓存中查询,如果没有,则执行实际的方法(即查询数据库),并将执行的结果存入缓存中,否则返回缓存中的对象。这里的缓存中的 key 就是参数 userName,value 就是 Account 对象。“accountCache”缓存是在 spring*.xml 中定义的名称。
@Cacheable(value="accountCache")// 使用了一个缓存名叫 accountCache
public Account getAccountByName(String userName) {
// 方法内部实现不考虑缓存逻辑,直接实现业务
System.out.println("real query account."+userName);
return getFromDB(userName);
}
@CachePut
@CachePut 的作用 主要针对方法配置,能够根据方法的请求参数对其结果进行缓存,和 @Cacheable 不同的是,它每次都会触发真实方法的调用。
@CachePut 作用和配置方法
| 参数 | 解释 | example |
|---|
| value | 缓存的名称,在spring配置文件中定义,必须指定至少一个 | @CachePut(value=”my cache”) |
| key | 缓存的key,可以为空,如果指定要按照SpEL表达式编写,如果不指定,则缺省按照方法的所有参数进行组合 | @CachePut(value="testcache",key="#userName") |
| condition | 缓存的条件,可以为空,使用SpEL编写,返回true或者false,只有为true才进行缓存 | @CachePut(value="testcache",condition="#userName.length()>2") |
实例
@CachePut 注释,这个注释可以确保方法被执行,同时方法的返回值也被记录到缓存中,实现缓存与数据库的同步更新。
@CachePut(value="accountCache",key="#account.getName()")// 更新accountCache 缓存
public Account updateAccount(Account account) {
return updateDB(account);
}
@CacheEvict
@CachEvict 的作用 主要针对方法配置,能够根据一定的条件对缓存进行清空
@CacheEvict 作用和配置方法
| 参数 | 解释 | example |
|---|
| value | 缓存的名称,在 spring 配置文件中定义,必须指定至少一个 | @CacheEvict(value="my cache") |
| key | 缓存的key,可以为空,如果指定要按照SpEL表达式编写,如果不指定,则缺省按照方法的所有参数进行组合 | @CacheEvict(value="testcache",key="#userName") |
| condition | 缓存的条件,可以为空,使用SpEL编写,返回true或者false,只有为true才进行缓存 | @CacheEvict(value="testcache",condition="#userName.length()>2") |
| allEntries | 是否清空所有缓存内容,缺省为false,如果指定为true,则方法调用后将立即清空所有缓存 | @CachEvict(value="testcache",allEntries=true) |
| beforeInvocation | 是否在方法执行前就清空,缺省为false,如果指定为true,则在方法还没有执行的时候就清空缓存,缺省情况下,如果方法执行抛出异常,则不会清空缓存 | @CachEvict(value="testcache",beforeInvocation=true) |
实例
@CacheEvict(value="accountCache",key="#account.getName()")// 清空accountCache 缓存
public void updateAccount(Account account) {
updateDB(account);
}
@CacheEvict(value="accountCache",allEntries=true)// 清空accountCache 缓存
public void reload() {
reloadAll()
}
@Cacheable(value="accountCache",condition="#userName.length() <=4")// 缓存名叫 accountCache
public Account getAccountByName(String userName) {
// 方法内部实现不考虑缓存逻辑,直接实现业务
return getFromDB(userName);
}
@CacheConfig
所有的 @Cacheable 里面都有一个value=“xxx”的属性,这显然如果方法多了,写起来也是挺累的,如果可以一次性声明完 那就省事了,
所以,有了 @CacheConfig 这个配置,@CacheConfig is a class-level annotation that allows to share the cache names,如果你在你的方法写别的名字,那么依然以方法的名字为准。
@CacheConfig("books")
public class BookRepositoryImpl implements BookRepository {
@Cacheable
public Book findBook(ISBN isbn) {...}
}
条件缓存
下面提供一些常用的条件缓存
//@Cacheable将在执行方法之前( #result还拿不到返回值)判断condition,如果返回true,则查缓存;
@Cacheable(value = "user", key = "#id", condition = "#id lt 10")
public User conditionFindById(final Long id)
//@CachePut将在执行完方法后(#result就能拿到返回值了)判断condition,如果返回true,则放入缓存;
@CachePut(value = "user", key = "#id", condition = "#result.username ne 'zhang'")
public User conditionSave(final User user)
//@CachePut将在执行完方法后(#result就能拿到返回值了)判断unless,如果返回false,则放入缓存;(即跟condition相反)
@CachePut(value = "user", key = "#user.id", unless = "#result.username eq 'zhang'")
public User conditionSave2(final User user)
//@CacheEvict, beforeInvocation=false表示在方法执行之后调用(#result能拿到返回值了);且判断condition,如果返回true,则移除缓存;
@CacheEvict(value = "user", key = "#user.id", beforeInvocation = false, condition = "#result.username ne 'zhang'")
public User conditionDelete(final User user)
@Caching
有时候我们可能组合多个Cache注解使用;比如用户新增成功后,我们要添加id–>user;username—>user;email—>user的缓存;此时就需要@Caching组合多个注解标签了。
@Caching(put = {
@CachePut(value = "user", key = "#user.id"),
@CachePut(value = "user", key = "#user.username"),
@CachePut(value = "user", key = "#user.email")
})
public User save(User user) {
自定义缓存注解
比如之前的那个@Caching组合,会让方法上的注解显得整个代码比较乱,此时可以使用自定义注解把这些注解组合到一个注解中,如:
@Caching(put = {
@CachePut(value = "user", key = "#user.id"),
@CachePut(value = "user", key = "#user.username"),
@CachePut(value = "user", key = "#user.email")
})
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
public @interface UserSaveCache {
}
这样我们在方法上使用如下代码即可,整个代码显得比较干净。
@UserSaveCache
public User save(User user)
扩展
比如findByUsername时,不应该只放username–>user,应该连同id—>user和email—>user一起放入;这样下次如果按照id查找直接从缓存中就命中了
@Caching(
cacheable = {
@Cacheable(value = "user", key = "#username")
},
put = {
@CachePut(value = "user", key = "#result.id", condition = "#result != null"),
@CachePut(value = "user", key = "#result.email", condition = "#result != null")
}
)
public User findByUsername(final String username) {
System.out.println("cache miss, invoke find by username, username:" + username);
for (User user : users) {
if (user.getUsername().equals(username)) {
return user;
}
}
return null;
}
其实对于:id—>user;username—->user;email—>user;更好的方式可能是:id—>user;username—>id;email—>id;保证user只存一份;如:
@CachePut(value="cacheName", key="#user.username", cacheValue="#user.username")
public void save(User user)
@Cacheable(value="cacheName", key="#user.username", cacheValue="#caches[0].get(#caches[0].get(#username).get())")
public User findByUsername(String username)
SpEL 上下文数据
Spring Cache提供了一些供我们使用的SpEL上下文数据,下表直接摘自Spring官方文档:
| 名称 | 位置 | 描述 | 示例 |
|---|
| methodName | root对象 | 当前被调用的方法名 | #root.methodName |
| method | root对象 | 当前被调用的方法 | #root.method.name |
| target | root对象 | 当前被调用的目标对象 | #root.target |
| targetClass | root对象 | 当前被调用的目标对象类 | #root.targetClass |
| args | root对象 | 当前被调用的方法的参数列表 | #root.args[0] |
| caches | root对象 | 当前方法调用使用的缓存列表(如@Cacheable(value={“cache1”, “cache2”})),则有两个cache | #root.caches[0].name |
| argument name | 执行上下文 | 当前被调用的方法的参数,如findById(Long id),我们可以通过#id拿到参数 | #user.id |
| result | 执行上下文 | 方法执行后的返回值(仅当方法执行之后的判断有效,如‘unless’,’cache evict’的beforeInvocation=false) | #result |
@CacheEvict(value = "user",
key = "#user.id",
condition = "#root.target.canCache() and #root.caches[0].get(#user.id).get().username ne #user.username",
beforeInvocation = true)
public void conditionUpdate(User user)
1.20 - CH21-跨域问题
什么是跨域
很多人对跨域有一种误解,以为这是前端的事,和后端没关系,其实不是这样的,说到跨域,就不得不说说浏览器的同源策略。
同源策略是由 Netscape 提出的一个著名的安全策略,它是浏览器最核心也最基本的安全功能,现在所有支持 JavaScript 的浏览器都会使用这个策略。所谓同源是指协议、域名以及端口要相同。
同源策略是基于安全方面的考虑提出来的,这个策略本身没问题,但是我们在实际开发中,由于各种原因又经常有跨域的需求,传统的跨域方案是 JSONP,JSONP 虽然能解决跨域但是有一个很大的局限性,那就是只支持 GET 请求,不支持其他类型的请求,在 RESTful 时代这几乎就没什么用。
而今天我们说的 CORS(跨域源资源共享)(CORS,Cross-origin resource sharing)是一个 W3C 标准,它是一份浏览器技术的规范,提供了 Web 服务从不同网域传来沙盒脚本的方法,以避开浏览器的同源策略,这是 JSONP 模式的现代版。
在 Spring 框架中,对于 CORS 也提供了相应的解决方案,在 Spring Boot 中,这一方案得倒了简化,无论是单纯的跨域,还是结合 Spring Security 之后的跨域,都变得非常容易了。
解决方案
首先创建两个普通的 Spring Boot 项目,这个就不用我多说,第一个命名为 provider 提供服务,第二个命名为 consumer 消费服务,第一个配置端口为 8080,第二个配置配置为 8081,然后在 provider 上提供两个 hello 接口,一个 get,一个 post,如下:
@RestController
public class HelloController {
@GetMapping("/hello")
public String hello() {
return "hello";
}
@PostMapping("/hello")
public String hello2() {
return "post hello";
}
}
在 consumer 的 resources/static 目录下创建一个 html 文件,发送一个简单的 ajax 请求,如下:
<div id="app"></div>
<input type="button" onclick="btnClick()" value="get_button">
<input type="button" onclick="btnClick2()" value="post_button">
<script>
function btnClick() {
$.get('http://localhost:8080/hello', function (msg) {
$("#app").html(msg);
});
}
function btnClick2() {
$.post('http://localhost:8080/hello', function (msg) {
$("#app").html(msg);
});
}
</script>
然后分别启动两个项目,发送请求按钮,观察浏览器控制台如下:
Access to XMLHttpRequest at 'http://localhost:8080/hello' from origin 'http://localhost:8081' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource.
可以看到,由于同源策略的限制,请求无法发送成功。
使用 CORS 可以在前端代码不做任何修改的情况下,实现跨域,那么接下来看看在 provider 中如何配置。首先可以通过 @CrossOrigin 注解配置某一个方法接受某一个域的请求,如下:
@RestController
public class HelloController {
@CrossOrigin(value = "http://localhost:8081")
@GetMapping("/hello")
public String hello() {
return "hello";
}
@CrossOrigin(value = "http://localhost:8081")
@PostMapping("/hello")
public String hello2() {
return "post hello";
}
}
这个注解表示这两个接口接受来自 http://localhost:8081 地址的请求,配置完成后,重启 provider ,再次发送请求,浏览器控制台就不会报错了,consumer 也能拿到数据了。
此时观察浏览器请求网络控制台,可以看到响应头中多了如下信息:
这个表示服务端愿意接收来自 http://localhost:8081 的请求,拿到这个信息后,浏览器就不会再去限制本次请求的跨域了。
provider 上,每一个方法上都去加注解未免太麻烦了,有的小伙伴想到可以讲注解直接加在 Controller 上,不过每个 Controller 都要加还是麻烦,在 Spring Boot 中,还可以通过全局配置一次性解决这个问题,全局配置只需要在 SpringMVC 的配置类中重写 addCorsMappings 方法即可,如下:
@Configuration
public class WebMvcConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**")
.allowedOrigins("http://localhost:8081")
.allowedMethods("*")
.allowedHeaders("*");
}
}
/** 表示本应用的所有方法都会去处理跨域请求,allowedMethods 表示允许通过的请求数,allowedHeaders 则表示允许的请求头。经过这样的配置之后,就不必在每个方法上单独配置跨域了。
存在的问题
了解了整个 CORS 的工作过程之后,我们通过 Ajax 发送跨域请求,虽然用户体验提高了,但是也有潜在的威胁存在,常见的就是 CSRF(Cross-site request forgery)跨站请求伪造。跨站请求伪造也被称为 one-click attack 或者 session riding,通常缩写为 CSRF 或者 XSRF,是一种挟制用户在当前已登录的 Web 应用程序上执行非本意的操作的攻击方法。
关于 CSRF 攻击的具体介绍和防御办法,大家可以参考松哥之前的文章,这里就不重复介绍了:
Spring Security
如果使用了 Spring Security,上面的跨域配置会失效,因为请求被 Spring Security 拦截了。
当引入了 Spring Security 的时候,我们有两种办法开启 Spring Security 对跨域的支持。
方式一
方式一就是在上一小节的基础上,添加 Spring Security 对于 CORS 的支持,只需要添加如下配置即可:
@Configuration
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.anyRequest().authenticated()
.and()
.formLogin()
.permitAll()
.and()
.httpBasic()
.and()
.cors()
.and()
.csrf()
.disable();
}
}
一个 .cors 就开启了 Spring Security 对 CORS 的支持。
方式二
方式二则是去除第二小节的跨域配置,直接在 Spring Security 中做全局配置,如下:
@Configuration
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.anyRequest().authenticated()
.and()
.formLogin()
.permitAll()
.and()
.httpBasic()
.and()
.cors()
.configurationSource(corsConfigurationSource())
.and()
.csrf()
.disable();
}
@Bean
CorsConfigurationSource corsConfigurationSource() {
UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource();
CorsConfiguration configuration = new CorsConfiguration();
configuration.setAllowCredentials(true);
configuration.setAllowedOrigins(Arrays.asList("*"));
configuration.setAllowedMethods(Arrays.asList("*"));
configuration.setAllowedHeaders(Arrays.asList("*"));
configuration.setMaxAge(Duration.ofHours(1));
source.registerCorsConfiguration("/**",configuration);
return source;
}
}
通过 CorsConfigurationSource 实例对跨域信息作出详细配置,例如允许的请求来源、允许的请求方法、允许通过的请求头、探测请求的有效期、需要处理的路径等等。
使用这种方式就可以去掉第二小节的跨域配置了。
OAuth2
还有一种情况就是 OAuth2 允许跨域,如果用户要访问 OAuth2 端点,例如 /oauth/token ,出现了跨域该怎么配置呢?
这个解决方案松哥在之前的 【用 Swagger 测试接口,怎么在请求头中携带 Token?】 一文中已经有过介绍,主要是配置一个 CorsFilter,大家可以参考该篇文章,我这里就把核心配置类列出来:
@Configuration
public class GlobalCorsConfiguration {
@Bean
public CorsFilter corsFilter() {
CorsConfiguration corsConfiguration = new CorsConfiguration();
corsConfiguration.setAllowCredentials(true);
corsConfiguration.addAllowedOrigin("*");
corsConfiguration.addAllowedHeader("*");
corsConfiguration.addAllowedMethod("*");
UrlBasedCorsConfigurationSource urlBasedCorsConfigurationSource = new UrlBasedCorsConfigurationSource();
urlBasedCorsConfigurationSource.registerCorsConfiguration("/**", corsConfiguration);
return new CorsFilter(urlBasedCorsConfigurationSource);
}
}
然后在 SecurityConfig 中开启跨域支持:
@Configuration
@Order(Ordered.HIGHEST_PRECEDENCE)
public class SecurityConfig extends WebSecurityConfigurerAdapter {
...
...
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.requestMatchers().antMatchers(HttpMethod.OPTIONS, "/oauth/**")
.and()
.csrf().disable().formLogin()
.and()
.cors();
}
}
1.21 - CH22-SpEL表达式
简介
Spring表达式语言是一个支持查询和操作运行时对象图功能的强大的表达式语言。它的语法类似于传统 EL,但提供额外的功能,最出色的就是函数调用和字符串模板函数。
尽管有其他可选的 Java 表达式语言,如 OGNL, MVEL,JBoss EL 等等,但 Spel 创建的初衷是了给 Spring 社区提供一种简单而高效的表达式语言,一种可贯穿整个 Spring 产品组的语言。这种语言的特性应基于 Spring 产品的需求而设计。
应用过程
声明一个字符串值:
ExpressionParser parser = new SpelExpressionParser();
Expression exp = parser.parseExpression("'Hello World'");
String message = (String) exp.getValue();
消息变量的值是简单的“hello world”。
接口ExpressionParser负责解析表达式字符串。这个字符串例子是通过单引号扩起来的一个字符串声明。
接口Expression负责解析之前被定义的字符串表达式。
调用字符串的“concat”方法:
ExpressionParser parser = new SpelExpressionParser();
Expression exp = parser.parseExpression("'Hello World'.concat('!')");
String message = (String) exp.getValue();
获取 String 的“bytes”属性:
ExpressionParser parser = new SpelExpressionParser();
// invokes getBytes()
Expression exp = parser.parseExpression("'Hello World'.bytes");
byte[] bytes = (byte[]) exp.getValue();
获取或设置嵌套属性:
ExpressionParser parser = new SpelExpressionParser();
// invokes getBytes().length
Expression exp = parser.parseExpression("'Hello World'.bytes.length");
int length = (Integer) exp.getValue();
构造字符串:
ExpressionParser parser = new SpelExpressionParser();
Expression exp = parser.parseExpression("new String('hello world').toUpperCase()");
String message = exp.getValue(String.class);
注意这里调用的方法 public <T> T getValue(Class<T> desiredResultType)。使用这种方法没必要实例化表达式的值的结果类型. 如果该值不能被转换为类型T或使用已注册的类型转换器转换,那么一个EvaluationException会抛出。
SpEL比较常见的用途是针对一个特定的对象实例(称为root object)提供被解析的表达式字符串。
// Create and set a calendar
GregorianCalendar c = new GregorianCalendar();
c.set(1856, 7, 9);
// The constructor arguments are name, birthday, and nationality.
Inventor tesla = new Inventor("Nikola Tesla", c.getTime(), "Serbian");
ExpressionParser parser = new SpelExpressionParser();
Expression exp = parser.parseExpression("name");
EvaluationContext context = new StandardEvaluationContext(tesla);
String name = (String) exp.getValue(context);
在最后一行,该字符串变量name的值将被设定为“Nikola Tesla”。 类StandardEvaluationContext是可以指定哪些对象的“name” 属性将被解析。如果root object不太可能改变. ,就可以简单地在评估上下文中设置一次。如果root object反复变化 ,它可以在每次调用getValue,如 接下来的例子说明:
/ Create and set a calendar
GregorianCalendar c = new GregorianCalendar();
c.set(1856, 7, 9);
// The constructor arguments are name, birthday, and nationality.
Inventor tesla = new Inventor("Nikola Tesla", c.getTime(), "Serbian");
ExpressionParser parser = new SpelExpressionParser();
Expression exp = parser.parseExpression("name");
String name = (String) exp.getValue(tesla);
在这种情况下,inventor tesla已直接应用到getValue和 表达式计算基础架构创建和管理一个默认的解析环境 在内部 - 它不要求再次解析。
StandardEvaluationContext 的构造成本较为昂贵,在重复使用它时将会创建状态缓存,使得后续的解析将会变得更快。出于这个原因,应该尽可能复用实例,而不是每个表达式求值时创建新实例。
在某些情况下,它可以是理想的使用配置解析上下文,但仍然在每次调用getValue提供不同的root object。 getValue允许既要在同一个调用中指定。在这些情况下对root object通过调用要考虑到覆盖任何(这可能为空)在解析范围内的指定。
在SpEL的独立使用的时候,需要创建parser,parse expressions, 同时可能需要提供解析的context和root context object。然而,更常见的 用法是只提供一个SpEL表达式字符串作为配置文件的一部分, 例如,对于Spring的bean或Spring Web Flow的定义。在这种情况下,解析器 求值的context,root object和所有预定义变量都设置了隐式, 没有什么要用户去指定了,除了声明表达式.
作为最后一个例子,使用了一个boolean运算符去调用 inventor object 在前面的例子中。
Expression exp = parser.parseExpression("name == 'Nikola Tesla'");
boolean result = exp.getValue(context, Boolean.class); // evaluates to true
EvaluationContext 接口
当计算表达式解析properties, methods, fields,并帮助执行类型转换, 使用接口EvaluationContext 这是一个开箱即用的实现, StandardEvaluationContext,使用反射来操纵对象, 内部会缓存java.lang.reflect的Method,Field,和Constructor实例 提高性能。
该StandardEvaluationContext是你可以指定root object通过使用 setRootObject()或传递root object到构造函数. 你也可以指定变量和函数使用方法的setVariable()和registerFunction()的表达式。
StandardEvaluationContext也是在那里你可以自定义的注册 ConstructorResolvers, MethodResolvers, 和 PropertyAccessors 来扩展 SpEL 求值表达式的逻辑。
类型转换
默认情况下,SpEL使用Spring-core的转换服务( org.springframework.core.convert。ConversionService)。这种转换服务的许多转换器内置了常用的转换,但也完全可扩展类型之间特定转换。此外,它拥有的关键能力是泛型感知。这意味着,当与通用类型的工作表达式,SpEL将尝试转换他遇到的维持对任何对象类型的正确性
这做法是什么意思呢?假设分配,使用的 setValue(),正在使用 以设置一个 List属性。该属性的类型实际上是List<Boolean>。SpEL 将认识到,需要在列表中的元素之前,必须转换成Boolean 一个简单的例子:
class Simple {
public List<Boolean> booleanList = new ArrayList<Boolean>();
}
Simple simple = new Simple();
simple.booleanList.add(true);
StandardEvaluationContext simpleContext = new StandardEvaluationContext(simple);
// false is passed in here as a string. SpEL and the conversion service will
// correctly recognize that it needs to be a Boolean and convert it
parser.parseExpression("booleanList[0]").setValue(simpleContext, "false");
// b will be false
Boolean b = simple.booleanList.get(0);
解析器配置
用一个parser configuration object去配置SpEL解析器是可能的, (org.springframework.expression.spel.SpelParserConfiguration)。配置对象控制的一些表达组件的行为。例如,如果数据为索引到指定索引处的数组或集合的元素是null 它可以自动地创建的元素。当用表达式组合一个链式属性引用时这将非常有用. 如果索引到一个数组或列表 并指定一个索引超出数组的当前大小或 自动增长的数组或队列去容纳
class Demo {
public List<String> list;
}
// Turn on:
// - auto null reference initialization
// - auto collection growing
SpelParserConfiguration config = new SpelParserConfiguration(true,true);
ExpressionParser parser = new SpelExpressionParser(config);
Expression expression = parser.parseExpression("list[3]");
Demo demo = new Demo();
Object o = expression.getValue(demo);
// demo.list will now be a real collection of 4 entries
// Each entry is a new empty String
另外,也可以配置一个SpEL表达式编译器的行为。
SpEl 编译
Spring Framework 4.1 包含了一个基本的表达式编译器. 表达式通常 解释其执行过程中提供了大量的动态灵活性,但 不提供最佳性能。对于偶尔使用的表达 这是好的,而是由其他组件,如Spring集成使用时, 性能是非常重要的,并没有为活力提供真正的需要。
新使用SpEL编译旨在解决这一需要。然后该 编译器将执行这体现了中动态生成一个真正的Java类 表达行为,并用它来实现更快的表达 式执行。由于缺乏各种表达式编译器 使用过程中的一个评估收集的评价的信息 当执行编译的表达。例如,它不知道的类型 参考表达,但在第一属性参考 解释执行会发现它是什么。当然,基于该 编译这些信息可能会造成的麻烦后,如果类型 各种表达元件随着时间而改变。出于这个原因汇编 是最适合返回执行不会改变其表达式类型的信息。
对于基本的表达是这样的:
someArray[0].someProperty.someOtherProperty < 0.1
其中涉及数组访问,部分属性引用和数字运算,性能 增益可以很明显的。在50000迭代一个例子微基准来看,它是 使用了75ms用来执行翻译,而仅仅3ms编译表达式的version。
编译器配置
编译器默认是并未开启的,但有两种方式打开 它。它被打开用parser configuration process 或者 通过系统属性将SpEL使用嵌入另一个组件中。本节 讨论这两个选项。
重要的是要明白,编译器可工作在几个模式下,查看详细可以用过一个enum (org.springframework.expression.spel.SpelCompilerMode). 模式如下:
OFF - 编译器被关闭;这是默认的。IMMEDIATE - 在直接模式下,表达式尽快编制。 这是一个典型的首个编译选项。如果编译错误的表达式 (通常是由于一个类型变化,如上面所描述的)调用者将会得到一个异常。MIXED - 在混合模式下,随着时间的推移,表达式默默地解释和编译之间切换。 经过解释运行的一些数字后,他们就会切换去编译源码 ,如果出现问题,编译形式(如一种变化,如 如上所述),那么表达式将自动切换回解释形式 。一段时间后,可能产生另一种形式的编制,并切换到它。基本上 相比用户IMMEDIATE模式,不同之处在于对于异常的处理,混合模式是隐式的(原话是: Basically the exception that the user gets
in IMMEDIATE mode is instead handled internally。)。
IMMEDIATE 模式的存在是因为MIXED模式可能会导致问题的表达式 有副作用。如果在后面的部分是一个编译表达的摧毁 可能已经做了一些这已经影响到了系统的状态。如果这 已经发生的调用可能不希望它默默地重新运行在解释模式 因为表达的一部分可能运行两次。
选择模式后,使用SpelParserConfiguration配置解析器:
SpelParserConfiguration config = new SpelParserConfiguration(SpelCompilerMode.IMMEDIATE,
this.getClass().getClassLoader());
SpelExpressionParser parser = new SpelExpressionParser(config);
Expression expr = parser.parseExpression("payload");
MyMessage message = new MyMessage();
Object payload = expr.getValue(message);
当指定编译器模式,也可以指定一个类加载器(传递null是允许的)。 编译表达式将在根据任何被供应创建一个子类加载器来限定。 确保如果指定一个类加载器就可以看到所有涉及的类型是很重要的 表达式求值的过程。 如果没有指定,那么默认的类加载器将使用(一般为上下文类加载器 这是在表达式求值运行的线程)。
来配置编译器的第二种方法是用于当使用SpEL嵌入里面的一些其它 组件和它可能无法通过配置对象来配置。 在这些情况下,有可能使用一个系统属性。属性 spring.expression.compiler.mode可设置到SpelCompilerMode 枚举值(off,immediate或mixed)之一。
编译器限制
随着Spring框架4.1的基本编制框架到位。然而,该框架 还没有支持编译每一种表情式。最初的重点一直是共同的表达 有可能在性能关键上下文中使用。这些种类的表达不能被编译 这些情况:
- 涉及赋值表达式
- 依托转换服务表达式
- 使用自定义解析器或访问表达式
- 使用选择或投影表达式
未来将支持越来越多类型的表达式。
定义bean的beandef表达支持
SpEL表达式可以与XML或基于注释的配置元数据使用 定义BeanDefinitions。在这两种情况下,以定义表达式语法的 形式#{<表达式字符串>}。
基于XML的配置
一个属性或构造带参数的值可以使用表达式如下所示进行设置。
<bean id="numberGuess" class="org.spring.samples.NumberGuess">
<property name="randomNumber" value="#{ T(java.lang.Math).random() * 100.0 }"/>
<!-- other properties -->
</bean>
变量systemProperties是预定义的,所以你可以在你的表达式使用 如下所示。请注意,您不必用``#前缀的预定义变量 符号于该上下文。
<bean id="taxCalculator" class="org.spring.samples.TaxCalculator">
<property name="defaultLocale" value="#{ systemProperties['user.region'] }"/>
<!-- other properties -->
</bean>
还可以参考其他bean属性的名字,例如。
<bean id="numberGuess" class="org.spring.samples.NumberGuess">
<property name="randomNumber" value="{ T(java.lang.Math).random() * 100.0 }"/>
<!-- other properties -->
</bean>
<bean id="shapeGuess" class="org.spring.samples.ShapeGuess">
<property name="initialShapeSeed" value="{ numberGuess.randomNumber }"/>
<!-- other properties -->
</bean>
基于注解的配置
@Value注解可以放在字段,方法和方法/构造 参数里,以指定默认值。
这里是一个例子,设置一个字段变量的缺省值。
public static class FieldValueTestBean
@Value("#{ systemProperties['user.region'] }")
private String defaultLocale;
public void setDefaultLocale(String defaultLocale) {
this.defaultLocale = defaultLocale;
}
public String getDefaultLocale() {
return this.defaultLocale;
}
}
等效的属性setter方法如下所示。
public static class PropertyValueTestBean
private String defaultLocale;
@Value("#{ systemProperties['user.region'] }")
public void setDefaultLocale(String defaultLocale) {
this.defaultLocale = defaultLocale;
}
public String getDefaultLocale() {
return this.defaultLocale;
}
}
自动装配方法和构造也可以使用@ Value注解。
public class SimpleMovieLister {
private MovieFinder movieFinder;
private String defaultLocale;
@Autowired
public void configure(MovieFinder movieFinder,
@Value("#{ systemProperties['user.region'] }") String defaultLocale) {
this.movieFinder = movieFinder;
this.defaultLocale = defaultLocale;
}
// ...
}
public class MovieRecommender {
private String defaultLocale;
private CustomerPreferenceDao customerPreferenceDao;
@Autowired
public MovieRecommender(CustomerPreferenceDao customerPreferenceDao,
@Value("#{systemProperties['user.country']}") String defaultLocale) {
this.customerPreferenceDao = customerPreferenceDao;
this.defaultLocale = defaultLocale;
}
// ...
}
字面量表达式
ExpressionParser parser = new SpelExpressionParser();
// evals to "Hello World"
String helloWorld = (String) parser.parseExpression("'Hello World'").getValue();
double avogadrosNumber = (Double) parser.parseExpression("6.0221415E+23").getValue();
// evals to 2147483647
int maxValue = (Integer) parser.parseExpression("0x7FFFFFFF").getValue();
boolean trueValue = (Boolean) parser.parseExpression("true").getValue();
Object nullValue = parser.parseExpression("null").getValue();
数字支持使用负号,指数符号和小数点。 默认情况下,实数使用Double.parseDouble()。
属性/数组/列表/映射/索引器
用属性引用引导很简单:只要用一个.表示嵌套 属性值。实现Inventor类, pupin和tesla, 被添加 被添加。在章节classes 的例子. 使用表达式引导 “down” 同时获取 Tesla’s 出生年 和 Pupin’s 出生城市
// evals to 1856
int year = (Integer) parser.parseExpression("Birthdate.Year + 1900").getValue(context);
String city = (String) parser.parseExpression("placeOfBirth.City").getValue(context);
不区分大小写允许的属性名称的第一个字母。 数组和列表使用方括号获得内容。
ExpressionParser parser = new SpelExpressionParser();
// Inventions Array
StandardEvaluationContext teslaContext = new StandardEvaluationContext(tesla);
// evaluates to "Induction motor"
String invention = parser.parseExpression("inventions[3]").getValue(
teslaContext, String.class);
// Members List
StandardEvaluationContext societyContext = new StandardEvaluationContext(ieee);
// evaluates to "Nikola Tesla"
String name = parser.parseExpression("Members[0].Name").getValue(
societyContext, String.class);
// List and Array navigation
// evaluates to "Wireless communication"
String invention = parser.parseExpression("Members[0].Inventions[6]").getValue(
societyContext, String.class);
通过在方括号内指定文字键值可以获取映射的内容。 在下面的示例中,由于 Officer 映射的键是字符串,因此我们可以指定字符串文字:
// Officer's Dictionary
Inventor pupin = parser.parseExpression("Officers['president']").getValue(
societyContext, Inventor.class);
// evaluates to "Idvor"
String city = parser.parseExpression("Officers['president'].PlaceOfBirth.City").getValue(
societyContext, String.class);
// setting values
parser.parseExpression("Officers['advisors'][0].PlaceOfBirth.Country").setValue(
societyContext, "Croatia");
内联列表
您可以使用 {} 表示法在表达式中直接表达列表。
// evaluates to a Java list containing the four numbers
List numbers = (List) parser.parseExpression("{1,2,3,4}").getValue(context);
List listOfLists = (List) parser.parseExpression("{{'a','b'},{'x','y'}}").getValue(context);
{} 本身表示一个空列表。出于性能原因,如果列表本身完全由固定文字组成,则会创建一个常量列表来表示该表达式(而不是在每次求值时都建立一个新列表)。
内联映射
您也可以使用 {key:value} 表示法在表达式中直接表达映射。以下示例显示了如何执行此操作:
// evaluates to a Java map containing the two entries
Map inventorInfo = (Map) parser.parseExpression("{name:'Nikola',dob:'10-July-1856'}").getValue(context);
Map mapOfMaps = (Map) parser.parseExpression("{name:{first:'Nikola',last:'Tesla'},dob:{day:10,month:'July',year:1856}}").getValue(context);
{:} 本身意味着一个空的映射。出于性能原因,如果映射图本身由固定的文字或其他嵌套的常量结构(列表或映射)组成,则会创建一个常量映射来表示该表达式(而不是在每次求值时都构建一个新的映射)。映射键的引号是可选的。上面的示例使用的是不带引号的键。
构建数组
您可以使用熟悉的 Java 语法来构建数组,可以选择提供一个初始化程序,以在构造时填充该数组。 以下示例显示了如何执行此操作:
int[] numbers1 = (int[]) parser.parseExpression("new int[4]").getValue(context);
// Array with initializer
int[] numbers2 = (int[]) parser.parseExpression("new int[]{1,2,3}").getValue(context);
// Multi dimensional array
int[][] numbers3 = (int[][]) parser.parseExpression("new int[4][5]").getValue(context);
构造多维数组时,当前无法提供初始化程序。
方法
您可以使用典型的 Java 编程语法来调用方法。 您还可以在文字上调用方法。 还支持变量参数。 下面的示例演示如何调用方法:
// string literal, evaluates to "bc"
String bc = parser.parseExpression("'abc'.substring(1, 3)").getValue(String.class);
// evaluates to true
boolean isMember = parser.parseExpression("isMember('Mihajlo Pupin')").getValue(
societyContext, Boolean.class);
运算符
Spring 表达式语言支持以下几种运算符:
关系运算符
使用标准运算符表示法支持关系运算符(等于,不等于,小于,小于或等于,大于和大于或等于)。 以下清单显示了一些运算符示例:
// evaluates to true
boolean trueValue = parser.parseExpression("2 == 2").getValue(Boolean.class);
// evaluates to false
boolean falseValue = parser.parseExpression("2 < -5.0").getValue(Boolean.class);
// evaluates to true
boolean trueValue = parser.parseExpression("'black' < 'block'").getValue(Boolean.class);
对 null 的大于和小于比较遵循一个简单的规则:null 被视为无(不是零)。结果,任何其他值始终大于 null(X > null 始终为 true),并且其他任何值都不小于零(X < null 始终为 false)。
如果您需要数字比较,请避免使用基于数字的 null 比较,而建议使用零进行比较(例如,X > 0 或 X < 0)。
除了标准的关系运算符外,SpEL 还支持 instanceof 和基于正则表达式的匹配运算符。 以下清单显示了两个示例:
// evaluates to false
boolean falseValue = parser.parseExpression(
"'xyz' instanceof T(Integer)").getValue(Boolean.class);
// evaluates to true
boolean trueValue = parser.parseExpression(
"'5.00' matches '^-?\\d+(\\.\\d{2})?$'").getValue(Boolean.class);
//evaluates to false
boolean falseValue = parser.parseExpression(
"'5.0067' matches '^-?\\d+(\\.\\d{2})?$'").getValue(Boolean.class);
请注意原始类型,因为它们会立即被包装为包装器类型,因此,按预期方式,1 instanceof T(int) 的计算结果为 false,而 1 instanceof T(Integer) 的计算结果为 true。
每个符号运算符也可以指定为纯字母等效项。 这样可以避免使用的符号对于嵌入表达式的文档类型具有特殊含义的问题(例如在 XML 文档中)。等效的文字是:
- lt (<)
- gt (>)
- le (<=)
- ge (>=)
- eq (==)
- ne (!=)
- div (/)
- mod (%)
- not (!)
所有的文本运算符都不区分大小写。
逻辑运算符
SpEL 支持以下逻辑运算符:
下面的示例演示如何使用逻辑运算符
// -- AND --
// evaluates to false
boolean falseValue = parser.parseExpression("true and false").getValue(Boolean.class);
// evaluates to true
String expression = "isMember('Nikola Tesla') and isMember('Mihajlo Pupin')";
boolean trueValue = parser.parseExpression(expression).getValue(societyContext, Boolean.class);
// -- OR --
// evaluates to true
boolean trueValue = parser.parseExpression("true or false").getValue(Boolean.class);
// evaluates to true
String expression = "isMember('Nikola Tesla') or isMember('Albert Einstein')";
boolean trueValue = parser.parseExpression(expression).getValue(societyContext, Boolean.class);
// -- NOT --
// evaluates to false
boolean falseValue = parser.parseExpression("!true").getValue(Boolean.class);
// -- AND and NOT --
String expression = "isMember('Nikola Tesla') and !isMember('Mihajlo Pupin')";
boolean falseValue = parser.parseExpression(expression).getValue(societyContext, Boolean.class);
数学运算符
您可以在数字和字符串上使用加法运算符。 您只能对数字使用减法,乘法和除法运算符。 您还可以使用模数(%)和指数幂(^)运算符。 强制执行标准运算符优先级。 以下示例显示了正在使用的数学运算符:
// Addition
int two = parser.parseExpression("1 + 1").getValue(Integer.class); // 2
String testString = parser.parseExpression(
"'test' + ' ' + 'string'").getValue(String.class); // 'test string'
// Subtraction
int four = parser.parseExpression("1 - -3").getValue(Integer.class); // 4
double d = parser.parseExpression("1000.00 - 1e4").getValue(Double.class); // -9000
// Multiplication
int six = parser.parseExpression("-2 * -3").getValue(Integer.class); // 6
double twentyFour = parser.parseExpression("2.0 * 3e0 * 4").getValue(Double.class); // 24.0
// Division
int minusTwo = parser.parseExpression("6 / -3").getValue(Integer.class); // -2
double one = parser.parseExpression("8.0 / 4e0 / 2").getValue(Double.class); // 1.0
// Modulus
int three = parser.parseExpression("7 % 4").getValue(Integer.class); // 3
int one = parser.parseExpression("8 / 5 % 2").getValue(Integer.class); // 1
// Operator precedence
int minusTwentyOne = parser.parseExpression("1+2-3*8").getValue(Integer.class); // -21
赋值运算符
要设置属性,请使用赋值运算符(=)。 这通常在对 setValue 的调用内完成,但也可以在对 getValue 的调用内完成。 下面的清单显示了使用赋值运算符的两种方法:
Inventor inventor = new Inventor();
EvaluationContext context = SimpleEvaluationContext.forReadWriteDataBinding().build();
parser.parseExpression("Name").setValue(context, inventor, "Aleksandar Seovic");
// alternatively
String aleks = parser.parseExpression(
"Name = 'Aleksandar Seovic'").getValue(context, inventor, String.class);
类型
您可以使用特殊的 T 运算符来指定 java.lang.Class(类型)的实例。静态方法也可以通过使用此运算符来调用。StandardEvaluationContext 使用 TypeLocator 查找类型,而 StandardTypeLocator(可以替换)是在了解 java.lang 包的情况下构建的。 这意味着对 Java.lang 中的类型的 T()
引用不需要完全限定,但是所有其他类型引用都必须是完全限定的。下面的示例演示如何使用 T 运算符:
Class dateClass = parser.parseExpression("T(java.util.Date)").getValue(Class.class);
Class stringClass = parser.parseExpression("T(String)").getValue(Class.class);
boolean trueValue = parser.parseExpression(
"T(java.math.RoundingMode).CEILING < T(java.math.RoundingMode).FLOOR")
.getValue(Boolean.class);
构造器
您可以使用 new 运算符来调用构造函数。 除基本类型(int,float 等)和 String 以外的所有其他类都应使用完全限定的类名。 下面的示例演示如何使用 new 运算符调用构造函数:
Inventor einstein = p.parseExpression(
"new org.spring.samples.spel.inventor.Inventor('Albert Einstein', 'German')")
.getValue(Inventor.class);
//create new inventor instance within add method of List
p.parseExpression(
"Members.add(new org.spring.samples.spel.inventor.Inventor(
'Albert Einstein', 'German'))").getValue(societyContext);
变量
您可以使用 #variableName 语法在表达式中引用变量。 通过在 EvaluationContext 实现上使用 setVariable 方法设置变量。
有效的变量名称必须由以下一个或多个受支持的字符组成。
- 字母:
A 到 Z 和 a 到 z - 数字:
0 到 9 - 下划线:
_ - 美元符号:
$
以下示例显示了如何使用变量。
Inventor tesla = new Inventor("Nikola Tesla", "Serbian");
EvaluationContext context = SimpleEvaluationContext.forReadWriteDataBinding().build();
context.setVariable("newName", "Mike Tesla");
parser.parseExpression("Name = #newName").getValue(context, tesla);
System.out.println(tesla.getName()) // "Mike Tesla"
#this 和 #root 变量
#this 变量始终是定义的,并且引用当前的评估对象(反对解决不合格的引用)。#root 变量也是始终定义,并引用根上下文对象。尽管 #this可能随表达式的组成部分的求值而变化,但 #root 始终引用根。 以下示例说明如何使用 #this 和 #root 变量:
// create an array of integers
List<Integer> primes = new ArrayList<Integer>();
primes.addAll(Arrays.asList(2,3,5,7,11,13,17));
// create parser and set variable 'primes' as the array of integers
ExpressionParser parser = new SpelExpressionParser();
EvaluationContext context = SimpleEvaluationContext.forReadOnlyDataAccess();
context.setVariable("primes", primes);
// all prime numbers > 10 from the list (using selection ?{...})
// evaluates to [11, 13, 17]
List<Integer> primesGreaterThanTen = (List<Integer>) parser.parseExpression(
"#primes.?[#this>10]").getValue(context);
函数
您可以通过注册可以在表达式字符串中调用的用户定义函数来扩展 SpEL。该函数通过 EvaluationContext 注册。下面的示例显示如何注册用户定义的函数:
Method method = ...;
EvaluationContext context = SimpleEvaluationContext.forReadOnlyDataBinding().build();
context.setVariable("myFunction", method);
例如,考虑以下用于反转字符串的实用程序方法:
public abstract class StringUtils {
public static String reverseString(String input) {
StringBuilder backwards = new StringBuilder(input.length());
for (int i = 0; i < input.length(); i++) {
backwards.append(input.charAt(input.length() - 1 - i));
}
return backwards.toString();
}
}
然后,您可以注册并使用前面的方法,如以下示例所示:
ExpressionParser parser = new SpelExpressionParser();
EvaluationContext context = SimpleEvaluationContext.forReadOnlyDataBinding().build();
context.setVariable("reverseString",
StringUtils.class.getDeclaredMethod("reverseString", String.class));
String helloWorldReversed = parser.parseExpression(
"#reverseString('hello')").getValue(context, String.class);
Bean 引用
如果评估上下文已使用 bean 解析器配置,则可以使用@符号从表达式中查找 bean。 以下示例显示了如何执行此操作:
ExpressionParser parser = new SpelExpressionParser();
StandardEvaluationContext context = new StandardEvaluationContext();
context.setBeanResolver(new MyBeanResolver());
// This will end up calling resolve(context,"something") on MyBeanResolver during evaluation
Object bean = parser.parseExpression("@something").getValue(context);
要访问工厂 bean 本身,您应该在 bean 名称前加上&符号。 以下示例显示了如何执行此操作:
ExpressionParser parser = new SpelExpressionParser();
StandardEvaluationContext context = new StandardEvaluationContext();
context.setBeanResolver(new MyBeanResolver());
// This will end up calling resolve(context,"&foo") on MyBeanResolver during evaluation
Object bean = parser.parseExpression("&foo").getValue(context);
三元表达式
您可以使用三元运算符在表达式内部执行 if-then-else 条件逻辑。 以下清单显示了一个最小的示例:
String falseString = parser.parseExpression(
"false ? 'trueExp' : 'falseExp'").getValue(String.class);
在这种情况下,布尔值 false 导致返回字符串值’falseExp’。 一个更现实的示例如下:
parser.parseExpression("Name").setValue(societyContext, "IEEE");
societyContext.setVariable("queryName", "Nikola Tesla");
expression = "isMember(#queryName)? #queryName + ' is a member of the ' " +
"+ Name + ' Society' : #queryName + ' is not a member of the ' + Name + ' Society'";
String queryResultString = parser.parseExpression(expression)
.getValue(societyContext, String.class);
// queryResultString = "Nikola Tesla is a member of the IEEE Society"
有关三元运算符的更短语法,请参阅关于 Elvis 运算符的下一部分。
Elvis 运算符
Elvis 运算符是三元运算符语法的简化,并且在 Groovy 语言中使用。 使用三元运算符语法,通常必须将变量重复两次,如以下示例所示:
String name = "Elvis Presley";
String displayName = (name != null ? name : "Unknown");
相反,您可以使用 Elvis 运算符(其命名类似于 Elvis 的发型)。 以下示例显示了如何使用 Elvis 运算符:
ExpressionParser parser = new SpelExpressionParser();
String name = parser.parseExpression("name?:'Unknown'").getValue(new Inventor(), String.class);
System.out.println(name); // 'Unknown'
以下显示了一个更复杂的示例:
ExpressionParser parser = new SpelExpressionParser();
EvaluationContext context = SimpleEvaluationContext.forReadOnlyDataBinding().build();
Inventor tesla = new Inventor("Nikola Tesla", "Serbian");
String name = parser.parseExpression("Name?:'Elvis Presley'").getValue(context, tesla, String.class);
System.out.println(name); // Nikola Tesla
tesla.setName(null);
name = parser.parseExpression("Name?:'Elvis Presley'").getValue(context, tesla, String.class);
System.out.println(name); // Elvis Presley
您可以使用 Elvis 运算符在表达式中应用默认值。 以下示例显示了如何在 @Value 表达式中使用 Elvis 运算符:
> @Value("#{systemProperties['pop3.port'] ?: 25}")
>
上例将注入系统属性 pop3.port,为空将注入 25。
安全导航运算符
安全导航运算符用于避免 NullPointerException,它来自 Groovy 语言。通常,当您引用一个对象时,可能需要在访问该对象的方法或属性之前验证其是否为 null。为了避免这种情况,安全导航运算符返回 null 而不是引发异常。 下面的示例演示如何使用安全导航操作符:
ExpressionParser parser = new SpelExpressionParser();
EvaluationContext context = SimpleEvaluationContext.forReadOnlyDataBinding().build();
Inventor tesla = new Inventor("Nikola Tesla", "Serbian");
tesla.setPlaceOfBirth(new PlaceOfBirth("Smiljan"));
String city = parser.parseExpression("PlaceOfBirth?.City").getValue(context, tesla, String.class);
System.out.println(city); // Smiljan
tesla.setPlaceOfBirth(null);
city = parser.parseExpression("PlaceOfBirth?.City").getValue(context, tesla, String.class);
System.out.println(city); // null - does not throw NullPointerException!!!
集合选择
选择是一种强大的表达语言功能,可让您通过从源集合中进行选择来将其转换为另一个集合。
选择使用 .?[selectionExpression] 的语法。 它过滤集合并返回一个包含原始元素子集的新集合。例如,通过选择,我们可以轻松地获得 Serbian inventors 的列表,如以下示例所示:
List<Inventor> list = (List<Inventor>) parser.parseExpression(
"Members.?[Nationality == 'Serbian']").getValue(societyContext);
在列表和映射上都可以选择。对于列表,将针对每个单独的列表元素评估选择标准。针对映射,针对每个映射条目(Java 类型 Map.Entry 的对象)评估选择标准。每个映射条目都有其键和值,可作为属性访问以供选择。
以下表达式返回一个新映射,该映射由原始映射中条目值小于 27 的那些元素组成:
Map newMap = parser.parseExpression("map.?[value<27]").getValue();
除了返回所有选定的元素外,您只能检索第一个或最后一个值。为了获得与选择匹配的第一个条目,语法为 .^[selectionExpression]。要获取最后一个匹配选择,语法为 .$[selectionExpression]。
集合投影
投影使集合可以驱动子表达式的求值,结果是一个新的集合。投影的语法为 .![projectionExpression]。例如,假设我们有一个 inventor 列表,但是想要他们出生的城市列表。实际上,我们希望为 inventor 列表中的每个条目计算“placeOfBirth.city”。 下面的示例使用投影来做到这一点:
// returns ['Smiljan', 'Idvor' ]
List placesOfBirth = (List)parser.parseExpression("Members.![placeOfBirth.city]");
您还可以使用映射来驱动投影,在这种情况下,将针对映射中的每个条目(表示为 Java Map.Entry)对投影表达式进行评估。 跨映射的投影结果是一个列表,其中包含针对每个映射条目的投影表达式的评估。
表达式模板
表达式模板允许将文字文本与一个或多个评估块混合。每个评估块均以您可以定义的前缀和后缀字符分隔。常见的选择是使用 #{ } 作为分隔符,如以下示例所示:
String randomPhrase = parser.parseExpression(
"random number is #{T(java.lang.Math).random()}",
new TemplateParserContext()).getValue(String.class);
// evaluates to "random number is 0.7038186818312008"
通过将文字文本 'random number is ' 与评估 #{ } 分隔符内的表达式的结果(在本例中为调用 random() 方法的结果)相连接来评估字符串。parseExpression() 方法的第二个参数的类型为 ParserContext。ParserContext 接口用于影响表达式的解析方式,以支持表达式模板功能。TemplateParserContext 的定义如下:
public class TemplateParserContext implements ParserContext {
public String getExpressionPrefix() {
return "#{";
}
public String getExpressionSuffix() {
return "}";
}
public boolean isTemplate() {
return true;
}
}
示例类
本节列出了本章示例中使用的类。
Inventor.java
package org.spring.samples.spel.inventor;
import java.util.Date;
import java.util.GregorianCalendar;
public class Inventor {
private String name;
private String nationality;
private String[] inventions;
private Date birthdate;
private PlaceOfBirth placeOfBirth;
public Inventor(String name, String nationality) {
GregorianCalendar c= new GregorianCalendar();
this.name = name;
this.nationality = nationality;
this.birthdate = c.getTime();
}
public Inventor(String name, Date birthdate, String nationality) {
this.name = name;
this.nationality = nationality;
this.birthdate = birthdate;
}
public Inventor() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getNationality() {
return nationality;
}
public void setNationality(String nationality) {
this.nationality = nationality;
}
public Date getBirthdate() {
return birthdate;
}
public void setBirthdate(Date birthdate) {
this.birthdate = birthdate;
}
public PlaceOfBirth getPlaceOfBirth() {
return placeOfBirth;
}
public void setPlaceOfBirth(PlaceOfBirth placeOfBirth) {
this.placeOfBirth = placeOfBirth;
}
public void setInventions(String[] inventions) {
this.inventions = inventions;
}
public String[] getInventions() {
return inventions;
}
}
PlaceOfBirth.java
package org.spring.samples.spel.inventor;
public class PlaceOfBirth {
private String city;
private String country;
public PlaceOfBirth(String city) {
this.city=city;
}
public PlaceOfBirth(String city, String country) {
this(city);
this.country = country;
}
public String getCity() {
return city;
}
public void setCity(String s) {
this.city = s;
}
public String getCountry() {
return country;
}
public void setCountry(String country) {
this.country = country;
}
}
Society.java
package org.spring.samples.spel.inventor;
import java.util.*;
public class Society {
private String name;
public static String Advisors = "advisors";
public static String President = "president";
private List<Inventor> members = new ArrayList<Inventor>();
private Map officers = new HashMap();
public List getMembers() {
return members;
}
public Map getOfficers() {
return officers;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public boolean isMember(String name) {
for (Inventor inventor : members) {
if (inventor.getName().equals(name)) {
return true;
}
}
return false;
}
}
2 - Spring IOC
Spring 模块结构
Spring 是分模块开发的,Spring 包含了很多模块,其中最为核心的是 bean 容器相关模块。像 AOP、MVC、Data 等模块都要依赖 bean 容器。这里先看一下 Spring 框架的结构图:
从上图中可以看出Core Container处于整个框架的最底层(忽略 Test 模块),在其之上有 AOP、Data、Web 等模块。既然 Spring 容器是最核心的部分,那么大家如果要读 Spring 的源码,容器部分必须先弄懂。
Spring IOC 特性介绍
alias
alias 的中文意思是“别名”,在 Spring 中,我们可以使用 alias 标签给 bean 起个别名。比如下面的配置:
<bean id="hello" class="xyz.coolblog.service.Hello">
<property name="content" value="hello"/>
</bean>
<alias name="hello" alias="alias-hello"/>
<alias name="alias-hello" alias="double-alias-hello"/>
这里我们给hello这个 beanName 起了一个别名alias-hello,然后又给别名alias-hello起了一个别名double-alias-hello。我们可以通过这两个别名获取到hello这个 bean 实例,比如下面的测试代码:
public class ApplicationContextTest {
@Test
public void testAlias() {
String configLocation = "application-alias.xml";
ApplicationContext applicationContext = new ClassPathXmlApplicationContext(configLocation);
System.out.println(" alias-hello -> " + applicationContext.getBean("alias-hello"));
System.out.println("double-alias-hello -> " + applicationContext.getBean("double-alias-hello"));
}
}
autowire
autowire 即自动注入的意思,通过使用 autowire 特性,我们就不用再显式的配置 bean 之间的依赖了。把依赖的发现和注入都交给 Spring 去处理,省时又省力。autowire 几个可选项,比如 byName、byType 和 constructor 等。autowire 是一个常用特性,相信大家都比较熟悉了,所以本节我们就 byName 为例,快速结束 autowire 特性的介绍。
当 bean 配置中的 autowire = byName 时,Spring 会首先通过反射获取该 bean 所依赖 bean 的名字(beanName),然后再通过调用 BeanFactory.getName(beanName) 方法即可获取对应的依赖实例。autowire = byName 原理大致就是这样,接下来我们来演示一下。
public class Service {
private Dao mysqlDao;
private Dao mongoDao;
// 忽略 getter/setter
@Override
public String toString() {
return super.toString() + "\n\t\t\t\t\t{" +
"mysqlDao=" + mysqlDao +
", mongoDao=" + mongoDao +
'}';
}
}
public interface Dao {}
public class MySqlDao implements Dao {}
public class MongoDao implements Dao {}
配置如下:
<bean name="mongoDao" class="xyz.coolblog.autowire.MongoDao"/>
<bean name="mysqlDao" class="xyz.coolblog.autowire.MySqlDao"/>
<!-- 非自动注入,手动配置依赖 -->
<bean name="service-without-autowire" class="xyz.coolblog.autowire.Service" autowire="no">
<property name="mysqlDao" ref="mysqlDao"/>
<property name="mongoDao" ref="mongoDao"/>
</bean>
<!-- 通过设置 autowire 属性,我们就不需要像上面那样显式配置依赖了 -->
<bean name="service-with-autowire" class="xyz.coolblog.autowire.Service" autowire="byName"/>
测试代码如下:
String configLocation = "application-autowire.xml";
ApplicationContext applicationContext = new ClassPathXmlApplicationContext(configLocation);
System.out.println("service-without-autowire -> " + applicationContext.getBean("service-without-autowire"));
System.out.println("service-with-autowire -> " + applicationContext.getBean("service-with-autowire"));
两种方式配置方式都能完成解决 bean 之间的依赖问题。只不过使用 autowire 会更加省力一些,配置文件也不会冗长。这里举的例子比较简单,假使一个 bean 依赖了十几二十个 bean,再手动去配置,恐怕就很难受了。
FactoryBean
FactoryBean?看起来是不是很像 BeanFactory 孪生兄弟。不错,他们看起来很像,但是他们是不一样的。FactoryBean 是一种工厂 bean,与普通的 bean 不一样,FactoryBean 是一种可以产生 bean 的 bean,好吧说起来很绕嘴。FactoryBean 是一个接口,我们可以实现这个接口。下面演示一下:
public class HelloFactoryBean implements FactoryBean<Hello> {
@Override
public Hello getObject() throws Exception {
Hello hello = new Hello();
hello.setContent("hello");
return hello;
}
@Override
public Class<?> getObjectType() {
return Hello.class;
}
@Override
public boolean isSingleton() {
return true;
}
}
配置如下:
<bean id="helloFactory" class="xyz.coolblog.service.HelloFactoryBean"/>
测试代码如下:
public class ApplicationContextTest {
@Test
public void testFactoryBean() {
String configLocation = "application-factory-bean.xml";
ApplicationContext applicationContext = new ClassPathXmlApplicationContext(configLocation);
System.out.println("helloFactory -> " + applicationContext.getBean("helloFactory"));
System.out.println("&helloFactory -> " + applicationContext.getBean("&helloFactory"));
}
}
当我们调用 getBean(“helloFactory”) 时,ApplicationContext 会返回一个 Hello 对象,该对象是 HelloFactoryBean 的 getObject 方法所创建的。如果我们想获取 HelloFactoryBean 本身,则可以在 helloFactory 前加上一个前缀&,即&helloFactory。
factory-method
介绍完 FactoryBean,本节再来看看了一个和工厂相关的特性 – factory-method。factory-method 可用于标识静态工厂的工厂方法(工厂方法是静态的),直接举例说明吧:
public class StaticHelloFactory {
public static Hello getHello() {
Hello hello = new Hello();
hello.setContent("created by StaticHelloFactory");
return hello;
}
}
配置如下:
<bean id="staticHelloFactory" class="xyz.coolblog.service.StaticHelloFactory" factory-method="getHello"/>
测试代码如下:
public class ApplicationContextTest {
@Test
public void testFactoryMethod() {
String configLocation = "application-factory-method.xml";
ApplicationContext applicationContext = new ClassPathXmlApplicationContext(configLocation);
System.out.println("staticHelloFactory -> " + applicationContext.getBean("staticHelloFactory"));
}
}
对于非静态工厂,需要使用 factory-bean 和 factory-method 两个属性配合。关于 factory-bean 这里就不继续说了,留给大家自己去探索吧。
lookup-method
我们通过 BeanFactory getBean 方法获取 bean 实例时,对于 singleton 类型的 bean,BeanFactory 每次返回的都是同一个 bean。对于 prototype 类型的 bean,BeanFactory 则会返回一个新的 bean。
现在考虑这样一种情况,一个 singleton 类型的 bean 中有一个 prototype 类型的成员变量。BeanFactory 在实例化 singleton 类型的 bean 时,会向其注入一个 prototype 类型的实例。但是 singleton 类型的 bean 只会实例化一次,那么它内部的 prototype 类型的成员变量也就不会再被改变。
但如果我们每次从 singleton bean 中获取这个 prototype 成员变量时,都想获取一个新的对象。这个时候怎么办?
举个例子,我们有一个新闻提供类(NewsProvider),这个类中有一个新闻类(News)成员变量。我们每次调用 getNews 方法都想获取一条新的新闻。这里我们有两种方式实现这个需求,一种方式是让 NewsProvider 类实现 ApplicationContextAware 接口(实现 BeanFactoryAware 接口也是可以的),每次调用 NewsProvider 的 getNews 方法时,都从 ApplicationContext 中获取一个新的 News 实例,返回给调用者。第二种方式就是这里的 lookup-method 了,Spring 会在运行时对 NewsProvider 进行增强,使其 getNews 可以每次都返回一个新的实例。说完了背景和解决方案,接下来就来写点测试代码验证一下。
在演示两种处理方式前,我们先来看看不使用任何处理方式,BeanFactory 所返回的 bean 实例情况。相关类定义如下:
public class News {
// 仅演示使用,News 类中无成员变量
}
public class NewsProvider {
private News news;
public News getNews() {
return news;
}
public void setNews(News news) {
this.news = news;
}
}
配置信息如下:
<bean id="news" class="xyz.coolblog.lookupmethod.News" scope="prototype"/>
<bean id="newsProvider" class="xyz.coolblog.lookupmethod.NewsProvider">
<property name="news" ref="news"/>
</bean>
测试代码如下:
String configLocation = "application-lookup-method.xml";
ApplicationContext applicationContext = new ClassPathXmlApplicationContext(configLocation);
NewsProvider newsProvider = (NewsProvider) applicationContext.getBean("newsProvider");
System.out.println(newsProvider.getNews());
System.out.println(newsProvider.getNews());
从测试结果中可以看出,newsProvider.getNews() 方法两次返回的结果都是一样的,这个是不满足要求的。
实现 ApplicationContextAware 接口
我们让 NewsProvider 实现 ApplicationContextAware 接口,实现代码如下:
public class NewsProvider implements ApplicationContextAware {
private ApplicationContext applicationContext;
private News news;
/** 每次都从 applicationContext 中获取一个新的 bean */
public News getNews() {
return applicationContext.getBean("news", News.class);
}
public void setNews(News news) {
this.news = news;
}
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
}
使用 lookup-method 特性
使用 lookup-method 特性,配置文件需要改一下。如下:
<bean id="news" class="xyz.coolblog.lookupmethod.News" scope="prototype"/>
<bean id="newsProvider" class="xyz.coolblog.lookupmethod.NewsProvider">
<lookup-method name="getNews" bean="news"/>
</bean>
NewsProvider 的代码沿用 4.5.1 小节之前贴的代码。测试代码稍微变一下,如下:
String configLocation = "application-lookup-method.xml";
ApplicationContext applicationContext = new ClassPathXmlApplicationContext(configLocation);
NewsProvider newsProvider = (NewsProvider) applicationContext.getBean("newsProvider");
System.out.println("newsProvider -> " + newsProvider);
System.out.println("news 1 -> " + newsProvider.getNews());
System.out.println("news 2 -> " + newsProvider.getNews());
depends-on
当一个 bean 直接依赖另一个 bean,可以使用 <ref/> 标签进行配置。不过如某个 bean 并不直接依赖于 其他 bean,但又需要其他 bean 先实例化好,这个时候就需要使用 depends-on 特性了。depends-on 特性比较简单,就不演示了。仅贴一下配置文件的内容,如下:
这里有两个简单的类,其中 Hello 需要 World 在其之前完成实例化。相关配置如下:
<bean id="hello" class="xyz.coolblog.depnedson.Hello" depends-on="world"/>
<bean id="world" class="xyz.coolblog.depnedson.World" />
BeanPostProcessor
BeanPostProcessor 是 bean 实例化时的后置处理器,包含两个方法,其源码如下:
public interface BeanPostProcessor {
// bean 初始化前的回调方法
Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException;
// bean 初始化后的回调方法
Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException;
}
BeanPostProcessor 是 Spring 框架的一个扩展点,通过实现 BeanPostProcessor 接口,我们就可插手 bean 实例化的过程。比如大家熟悉的 AOP 就是在 bean 实例后期间将切面逻辑织入 bean 实例中的,AOP 也正是通过 BeanPostProcessor 和 IOC 容器建立起了联系。这里我来演示一下 BeanPostProcessor 的使用方式,如下:
/**
* 日志后置处理器,将会在 bean 创建前、后打印日志
*/
public class LoggerBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println("Before " + beanName + " Initialization");
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("After " + beanName + " Initialization");
return bean;
}
}
配置如下:
<bean class="xyz.coolblog.beanpostprocessor.LoggerBeanPostProcessor"/>
<bean id="hello" class="xyz.coolblog.service.Hello"/>
<bean id="world" class="xyz.coolblog.service.World"/>
测试代码如下:
public class ApplicationContextTest {
@Test
public void testBeanPostProcessor() {
String configLocation = "application-bean-post-processor.xml";
ApplicationContext applicationContext = new ClassPathXmlApplicationContext(configLocation);
}
}
与 BeanPostProcessor 类似的还有一个叫 BeanFactoryPostProcessor 拓展点,顾名思义,用户可以通过这个拓展点插手容器启动的过程。不过这个不属于本系列文章范畴,暂时先不细说了。
BeanFactoryAware
Spring 中定义了一些列的 Aware 接口,比如这里的 BeanFactoryAware,以及 BeanNameAware 和 BeanClassLoaderAware 等等。通过实现这些 Aware 接口,我们可以在运行时获取一些配置信息或者其他一些信息。比如实现 BeanNameAware 接口,我们可以获取 bean 的配置名称(beanName)。通过实现 BeanFactoryAware 接口,我们可以在运行时获取 BeanFactory 实例。关于 Aware 类型接口的使用,可以参考实现 ApplicationContextAware 接口一节中的叙述,这里就不演示了。
Reference
2.1 - CH01-获取单例 Bean
getBean
public Object getBean(String name) throws BeansException {
// getBean 是一个空壳方法,所有的逻辑都封装在 doGetBean 方法中
return doGetBean(name, null, null, false);
}
protected <T> T doGetBean(
final String name, final Class<T> requiredType, final Object[] args, boolean typeCheckOnly)
throws BeansException {
/*
* 通过 name 获取 beanName。这里不使用 name 直接作为 beanName 有两点原因:
* 1. name 可能会以 & 字符开头,表明调用者想获取 FactoryBean 本身,而非 FactoryBean
* 实现类所创建的 bean。在 BeanFactory 中,FactoryBean 的实现类和其他的 bean 存储
* 方式是一致的,即 <beanName, bean>,beanName 中是没有 & 这个字符的。所以我们需要
* 将 name 的首字符 & 移除,这样才能从缓存里取到 FactoryBean 实例。
* 2. 若 name 是一个别名,则应将别名转换为具体的实例名,也就是 beanName。
*/
final String beanName = transformedBeanName(name);
Object bean;
/*
* 从缓存中获取单例 bean。Spring 是使用 Map 作为 beanName 和 bean 实例的缓存的,所以这
* 里暂时可以把 getSingleton(beanName) 等价于 beanMap.get(beanName)。当然,实际的
* 逻辑并非如此简单,后面再细说。
*/
Object sharedInstance = getSingleton(beanName);
/*
* 如果 sharedInstance = null,则说明缓存里没有对应的实例,表明这个实例还没创建。
* BeanFactory 并不会在一开始就将所有的单例 bean 实例化好,而是在调用 getBean 获取
* bean 时再实例化,也就是懒加载。
* getBean 方法有很多重载,比如 getBean(String name, Object... args),我们在首次获取
* 某个 bean 时,可以传入用于初始化 bean 的参数数组(args),BeanFactory 会根据这些参数
* 去匹配合适的构造方法构造 bean 实例。当然,如果单例 bean 早已创建好,这里的 args 就没有
* 用了,BeanFactory 不会多次实例化单例 bean。
*/
if (sharedInstance != null && args == null) {
if (logger.isDebugEnabled()) {
if (isSingletonCurrentlyInCreation(beanName)) {
logger.debug("Returning eagerly cached instance of singleton bean '" + beanName +
"' that is not fully initialized yet - a consequence of a circular reference");
}
else {
logger.debug("Returning cached instance of singleton bean '" + beanName + "'");
}
}
/*
* 如果 sharedInstance 是普通的单例 bean,下面的方法会直接返回。但如果
* sharedInstance 是 FactoryBean 类型的,则需调用 getObject 工厂方法获取真正的
* bean 实例。如果用户想获取 FactoryBean 本身,这里也不会做特别的处理,直接返回
* 即可。毕竟 FactoryBean 的实现类本身也是一种 bean,只不过具有一点特殊的功能而已。
*/
bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);
}
/*
* 如果上面的条件不满足,则表明 sharedInstance 可能为空,此时 beanName 对应的 bean
* 实例可能还未创建。这里还存在另一种可能,如果当前容器有父容器,beanName 对应的 bean 实例
* 可能是在父容器中被创建了,所以在创建实例前,需要先去父容器里检查一下。
*/
else {
// BeanFactory 不缓存 Prototype 类型的 bean,无法处理该类型 bean 的循环依赖问题
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
// 如果 sharedInstance = null,则到父容器中查找 bean 实例
BeanFactory parentBeanFactory = getParentBeanFactory();
if (parentBeanFactory != null && !containsBeanDefinition(beanName)) {
// 获取 name 对应的 beanName,如果 name 是以 & 字符开头,则返回 & + beanName
String nameToLookup = originalBeanName(name);
// 根据 args 是否为空,以决定调用父容器哪个方法获取 bean
if (args != null) {
return (T) parentBeanFactory.getBean(nameToLookup, args);
}
else {
return parentBeanFactory.getBean(nameToLookup, requiredType);
}
}
if (!typeCheckOnly) {
markBeanAsCreated(beanName);
}
try {
// 合并父 BeanDefinition 与子 BeanDefinition,后面会单独分析这个方法
final RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
checkMergedBeanDefinition(mbd, beanName, args);
// 检查是否有 dependsOn 依赖,如果有则先初始化所依赖的 bean
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
for (String dep : dependsOn) {
/*
* 检测是否存在 depends-on 循环依赖,若存在则抛异常。比如 A 依赖 B,
* B 又依赖 A,他们的配置如下:
* <bean id="beanA" class="BeanA" depends-on="beanB">
* <bean id="beanB" class="BeanB" depends-on="beanA">
*
* beanA 要求 beanB 在其之前被创建,但 beanB 又要求 beanA 先于它
* 创建。这个时候形成了循环,对于 depends-on 循环,Spring 会直接
* 抛出异常
*/
if (isDependent(beanName, dep)) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Circular depends-on relationship between '" + beanName + "' and '" + dep + "'");
}
// 注册依赖记录
registerDependentBean(dep, beanName);
try {
// 加载 depends-on 依赖
getBean(dep);
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"'" + beanName + "' depends on missing bean '" + dep + "'", ex);
}
}
}
// 创建 bean 实例
if (mbd.isSingleton()) {
/*
* 这里并没有直接调用 createBean 方法创建 bean 实例,而是通过
* getSingleton(String, ObjectFactory) 方法获取 bean 实例。
* getSingleton(String, ObjectFactory) 方法会在内部调用
* ObjectFactory 的 getObject() 方法创建 bean,并会在创建完成后,
* 将 bean 放入缓存中。关于 getSingleton 方法的分析,本文先不展开,我会在
* 后面的文章中进行分析
*/
sharedInstance = getSingleton(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
try {
// 创建 bean 实例
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
}
});
// 如果 bean 是 FactoryBean 类型,则调用工厂方法获取真正的 bean 实例。否则直接返回 bean 实例
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
// 创建 prototype 类型的 bean 实例
else if (mbd.isPrototype()) {
Object prototypeInstance = null;
try {
beforePrototypeCreation(beanName);
prototypeInstance = createBean(beanName, mbd, args);
}
finally {
afterPrototypeCreation(beanName);
}
bean = getObjectForBeanInstance(prototypeInstance, name, beanName, mbd);
}
// 创建其他类型的 bean 实例
else {
String scopeName = mbd.getScope();
final Scope scope = this.scopes.get(scopeName);
if (scope == null) {
throw new IllegalStateException("No Scope registered for scope name '" + scopeName + "'");
}
try {
Object scopedInstance = scope.get(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
beforePrototypeCreation(beanName);
try {
return createBean(beanName, mbd, args);
}
finally {
afterPrototypeCreation(beanName);
}
}
});
bean = getObjectForBeanInstance(scopedInstance, name, beanName, mbd);
}
catch (IllegalStateException ex) {
throw new BeanCreationException(beanName,
"Scope '" + scopeName + "' is not active for the current thread; consider " +
"defining a scoped proxy for this bean if you intend to refer to it from a singleton",
ex);
}
}
}
catch (BeansException ex) {
cleanupAfterBeanCreationFailure(beanName);
throw ex;
}
}
// 如果需要进行类型转换,则在此处进行转换。类型转换这一块我没细看,就不多说了。
if (requiredType != null && bean != null && !requiredType.isInstance(bean)) {
try {
return getTypeConverter().convertIfNecessary(bean, requiredType);
}
catch (TypeMismatchException ex) {
if (logger.isDebugEnabled()) {
logger.debug("Failed to convert bean '" + name + "' to required type '" +
ClassUtils.getQualifiedName(requiredType) + "'", ex);
}
throw new BeanNotOfRequiredTypeException(name, requiredType, bean.getClass());
}
}
// 返回 bean
return (T) bean;
}
执行流程
- 转换 beanName
- 从缓存中获取实例
- 如果实例不为空,且 args=null,调用 getObjectForBeanInstance 方法,并按 name 规则返回相应 bean 实例
- 如果实例为空,则到父容器中查找 beanName 对应的 bean 实例,存在则直接返回
- 如果父容器中不存在,则进行下一步操作——合并 BeanDefinition
- 处理 depends-on 依赖
- 创建并缓存 bean
- 调用 getObjectForBeanInstance 方法,并按那么规则返回对应 bean 实例
- 按需转换 bean 类型,并返回转换后的 bean 实例
beanName 转换
在获取 bean 实例之前,Spring 第一件要做的事情是对参数 name 进行转换。转换的目的主要是为了解决两个问题,第一个是处理以字符 & 开头的 name,防止 BeanFactory 无法找到与 name 对应的 bean 实例。第二个是处理别名问题,Spring 不会存储 <别名, bean 实例> 这种映射,仅会存储 <beanName, bean>。所以,同样是为了避免 BeanFactory 找不到 name 对应的 bean 的实例,对于别名也要进行转换。接下来,我们来简单分析一下转换的过程,如下:
protected String transformedBeanName(String name) {
// 这里调用了两个方法:BeanFactoryUtils.transformedBeanName(name) 和 canonicalName
return canonicalName(BeanFactoryUtils.transformedBeanName(name));
}
/** 该方法用于处理 & 字符 */
public static String transformedBeanName(String name) {
Assert.notNull(name, "'name' must not be null");
String beanName = name;
// 循环处理 & 字符。比如 name = "&&&&&helloService",最终会被转成 helloService
while (beanName.startsWith(BeanFactory.FACTORY_BEAN_PREFIX)) {
beanName = beanName.substring(BeanFactory.FACTORY_BEAN_PREFIX.length());
}
return beanName;
}
/** 该方法用于转换别名 */
public String canonicalName(String name) {
String canonicalName = name;
String resolvedName;
/*
* 这里使用 while 循环进行处理,原因是:可能会存在多重别名的问题,即别名指向别名。比如下面
* 的配置:
* <bean id="hello" class="service.Hello"/>
* <alias name="hello" alias="aliasA"/>
* <alias name="aliasA" alias="aliasB"/>
*
* 上面的别名指向关系为 aliasB -> aliasA -> hello,对于上面的别名配置,aliasMap 中数据
* 视图为:aliasMap = [<aliasB, aliasA>, <aliasA, hello>]。通过下面的循环解析别名
* aliasB 最终指向的 beanName
*/
do {
resolvedName = this.aliasMap.get(canonicalName);
if (resolvedName != null) {
canonicalName = resolvedName;
}
}
while (resolvedName != null);
return canonicalName;
}
从缓存获取 bean 实例
对于单例 bean,Spring 容器只会实例化一次。后续再次获取时,只需直接从缓存里获取即可,无需且不能再次实例化(否则单例就没意义了)。从缓存中取 bean 实例的方法是getSingleton(String),下面我们就来看看这个方法实现方式吧。如下:
public Object getSingleton(String beanName) {
return getSingleton(beanName, true);
}
/**
* 这里解释一下 allowEarlyReference 参数,allowEarlyReference 表示是否允许其他 bean 引用
* 正在创建中的 bean,用于处理循环引用的问题。关于循环引用,这里先简单介绍一下。先看下面的配置:
*
* <bean id="hello" class="xyz.coolblog.service.Hello">
* <property name="world" ref="world"/>
* </bean>
* <bean id="world" class="xyz.coolblog.service.World">
* <property name="hello" ref="hello"/>
* </bean>
*
* 如上所示,hello 依赖 world,world 又依赖于 hello,他们之间形成了循环依赖。Spring 在构建
* hello 这个 bean 时,会检测到它依赖于 world,于是先去实例化 world。实例化 world 时,发现
* world 依赖 hello。这个时候容器又要去初始化 hello。由于 hello 已经在初始化进程中了,为了让
* world 能完成初始化,这里先让 world 引用正在初始化中的 hello。world 初始化完成后,hello
* 就可引用到 world 实例,这样 hello 也就能完成初始了。关于循环依赖,我后面会专门写一篇文章讲
* 解,这里先说这么多。
*/
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 从 singletonObjects 获取实例,singletonObjects 中缓存的实例都是完全实例化好的 bean,可以直接使用
Object singletonObject = this.singletonObjects.get(beanName);
/*
* 如果 singletonObject = null,表明还没创建,或者还没完全创建好。
* 这里判断 beanName 对应的 bean 是否正在创建中
*/
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
// 从 earlySingletonObjects 中获取提前曝光的 bean,用于处理循环引用
singletonObject = this.earlySingletonObjects.get(beanName);
// 如果如果 singletonObject = null,且允许提前曝光 bean 实例,则从相应的 ObjectFactory 获取一个原始的(raw)bean(尚未填充属性)
if (singletonObject == null && allowEarlyReference) {
// 获取相应的工厂类
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 提前曝光 bean 实例,用于解决循环依赖
singletonObject = singletonFactory.getObject();
// 放入缓存中,如果还有其他 bean 依赖当前 bean,其他 bean 可以直接从 earlySingletonObjects 取结果
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
上面的代码虽然不长,但是涉及到了好几个缓存集合。如果不知道这些缓存的用途是什么,上面源码可能就很难弄懂了。这几个缓存集合用的很频繁,在后面的代码中还会出现,所以这里介绍一下。如下:
| 缓存 | 用途 |
|---|
| singletonObjects | 用于存放完全初始化好的 bean,从该缓存中取出的 bean 可以直接使用 |
| earlySingletonObjects | 用于存放还在初始化中的 bean,用于解决循环依赖 |
| singletonFactories | 用于存放 bean 工厂。bean 工厂所产生的 bean 是还未完成初始化的 bean。如代码所示,bean 工厂所生成的对象最终会被缓存到 earlySingletonObjects 中 |
合并 BeanDefinition
Spring 支持配置继承,在 标签中可以使用parent属性配置父类 bean。这样子类 bean 可以继承父类 bean 的配置信息,同时也可覆盖父类中的配置。比如下面的配置:
<bean id="hello" class="xyz.coolblog.innerbean.Hello">
<property name="content" value="hello"/>
</bean>
<bean id="hello-child" parent="hello">
<property name="content" value="I`m hello-child"/>
</bean>
如上所示,hello-child 配置继承自 hello。hello-child 未配置 class 属性,这里我们让它继承父配置中的 class 属性。然后我们写点代码测试一下,如下:
String configLocation = "application-parent-bean.xml";
ApplicationContext applicationContext = new ClassPathXmlApplicationContext(configLocation);
System.out.println("hello -> " + applicationContext.getBean("hello"));
System.out.println("hello-child -> " + applicationContext.getBean("hello-child"));
hello-child 在未配置 class 的属性下也可以实例化成功,表明它成功继承了父配置的 class 属性。
看完代码演示,接下来我们来看看源码吧。如下:
protected RootBeanDefinition getMergedLocalBeanDefinition(String beanName) throws BeansException {
// 检查缓存中是否存在“已合并的 BeanDefinition”,若有直接返回即可
RootBeanDefinition mbd = this.mergedBeanDefinitions.get(beanName);
if (mbd != null) {
return mbd;
}
// 调用重载方法
return getMergedBeanDefinition(beanName, getBeanDefinition(beanName));
}
protected RootBeanDefinition getMergedBeanDefinition(String beanName, BeanDefinition bd)
throws BeanDefinitionStoreException {
// 继续调用重载方法
return getMergedBeanDefinition(beanName, bd, null);
}
protected RootBeanDefinition getMergedBeanDefinition(
String beanName, BeanDefinition bd, BeanDefinition containingBd)
throws BeanDefinitionStoreException {
synchronized (this.mergedBeanDefinitions) {
RootBeanDefinition mbd = null;
// 我暂时还没去详细了解 containingBd 的用途,尽管从方法的注释上可以知道 containingBd 的大致用途,但没经过详细分析,就不多说了。见谅
if (containingBd == null) {
mbd = this.mergedBeanDefinitions.get(beanName);
}
if (mbd == null) {
// bd.getParentName() == null,表明无父配置,这时直接将当前的 BeanDefinition 升级为 RootBeanDefinition
if (bd.getParentName() == null) {
if (bd instanceof RootBeanDefinition) {
mbd = ((RootBeanDefinition) bd).cloneBeanDefinition();
}
else {
mbd = new RootBeanDefinition(bd);
}
}
else {
BeanDefinition pbd;
try {
String parentBeanName = transformedBeanName(bd.getParentName());
/*
* 判断父类 beanName 与子类 beanName 名称是否相同。若相同,则父类 bean 一定
* 在父容器中。原因也很简单,容器底层是用 Map 缓存 <beanName, bean> 键值对
* 的。同一个容器下,使用同一个 beanName 映射两个 bean 实例显然是不合适的。
* 有的朋友可能会觉得可以这样存储:<beanName, [bean1, bean2]> ,似乎解决了
* 一对多的问题。但是也有问题,调用 getName(beanName) 时,到底返回哪个 bean
* 实例好呢?
*/
if (!beanName.equals(parentBeanName)) {
/*
* 这里再次调用 getMergedBeanDefinition,只不过参数值变为了
* parentBeanName,用于合并父 BeanDefinition 和爷爷辈的
* BeanDefinition。如果爷爷辈的 BeanDefinition 仍有父
* BeanDefinition,则继续合并
*/
pbd = getMergedBeanDefinition(parentBeanName);
}
else {
// 获取父容器,并判断,父容器的类型,若不是 ConfigurableBeanFactory 则判抛出异常
BeanFactory parent = getParentBeanFactory();
if (parent instanceof ConfigurableBeanFactory) {
pbd = ((ConfigurableBeanFactory) parent).getMergedBeanDefinition(parentBeanName);
}
else {
throw new NoSuchBeanDefinitionException(parentBeanName,
"Parent name '" + parentBeanName + "' is equal to bean name '" + beanName +
"': cannot be resolved without an AbstractBeanFactory parent");
}
}
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanDefinitionStoreException(bd.getResourceDescription(), beanName,
"Could not resolve parent bean definition '" + bd.getParentName() + "'", ex);
}
// 以父 BeanDefinition 的配置信息为蓝本创建 RootBeanDefinition,也就是“已合并的 BeanDefinition”
mbd = new RootBeanDefinition(pbd);
// 用子 BeanDefinition 中的属性覆盖父 BeanDefinition 中的属性
mbd.overrideFrom(bd);
}
// 如果用户未配置 scope 属性,则默认将该属性配置为 singleton
if (!StringUtils.hasLength(mbd.getScope())) {
mbd.setScope(RootBeanDefinition.SCOPE_SINGLETON);
}
if (containingBd != null && !containingBd.isSingleton() && mbd.isSingleton()) {
mbd.setScope(containingBd.getScope());
}
if (containingBd == null && isCacheBeanMetadata()) {
// 缓存合并后的 BeanDefinition
this.mergedBeanDefinitions.put(beanName, mbd);
}
}
return mbd;
}
}
FactoryBean 获取 bean
在经过前面这么多的步骤处理后,到这里差不多就接近 doGetBean 方法的尾声了。在本节中,我们来看看从 FactoryBean 实现类中获取 bean 实例的过程。
protected Object getObjectForBeanInstance(
Object beanInstance, String name, String beanName, RootBeanDefinition mbd) {
// 如果 name 以 & 开头,但 beanInstance 却不是 FactoryBean,则认为有问题。
if (BeanFactoryUtils.isFactoryDereference(name) && !(beanInstance instanceof FactoryBean)) {
throw new BeanIsNotAFactoryException(transformedBeanName(name), beanInstance.getClass());
}
/*
* 如果上面的判断通过了,表明 beanInstance 可能是一个普通的 bean,也可能是一个
* FactoryBean。如果是一个普通的 bean,这里直接返回 beanInstance 即可。如果是
* FactoryBean,则要调用工厂方法生成一个 bean 实例。
*/
if (!(beanInstance instanceof FactoryBean) || BeanFactoryUtils.isFactoryDereference(name)) {
return beanInstance;
}
Object object = null;
if (mbd == null) {
/*
* 如果 mbd 为空,则从缓存中加载 bean。FactoryBean 生成的单例 bean 会被缓存
* 在 factoryBeanObjectCache 集合中,不用每次都创建
*/
object = getCachedObjectForFactoryBean(beanName);
}
if (object == null) {
// 经过前面的判断,到这里可以保证 beanInstance 是 FactoryBean 类型的,所以可以进行类型转换
FactoryBean<?> factory = (FactoryBean<?>) beanInstance;
// 如果 mbd 为空,则判断是否存在名字为 beanName 的 BeanDefinition
if (mbd == null && containsBeanDefinition(beanName)) {
// 合并 BeanDefinition
mbd = getMergedLocalBeanDefinition(beanName);
}
// synthetic 字面意思是"合成的"。通过全局查找,我发现在 AOP 相关的类中会将该属性设为 true。
// 所以我觉得该字段可能表示某个 bean 是不是被 AOP 增强过,也就是 AOP 基于原始类合成了一个新的代理类。
// 不过目前只是猜测,没有深究。如果有朋友知道这个字段的具体意义,还望不吝赐教
boolean synthetic = (mbd != null && mbd.isSynthetic());
// 调用 getObjectFromFactoryBean 方法继续获取实例
object = getObjectFromFactoryBean(factory, beanName, !synthetic);
}
return object;
}
protected Object getObjectFromFactoryBean(FactoryBean<?> factory, String beanName, boolean shouldPostProcess) {
/*
* FactoryBean 也有单例和非单例之分,针对不同类型的 FactoryBean,这里有两种处理方式:
* 1. 单例 FactoryBean 生成的 bean 实例也认为是单例类型。需放入缓存中,供后续重复使用
* 2. 非单例 FactoryBean 生成的 bean 实例则不会被放入缓存中,每次都会创建新的实例
*/
if (factory.isSingleton() && containsSingleton(beanName)) {
synchronized (getSingletonMutex()) {
// 从缓存中取 bean 实例,避免多次创建 bean 实例
Object object = this.factoryBeanObjectCache.get(beanName);
if (object == null) {
// 使用工厂对象中创建实例
object = doGetObjectFromFactoryBean(factory, beanName);
Object alreadyThere = this.factoryBeanObjectCache.get(beanName);
if (alreadyThere != null) {
object = alreadyThere;
}
else {
// shouldPostProcess 等价于上一个方法中的 !synthetic,用于表示是否应用后置处理
if (object != null && shouldPostProcess) {
if (isSingletonCurrentlyInCreation(beanName)) {
return object;
}
beforeSingletonCreation(beanName);
try {
// 应用后置处理
object = postProcessObjectFromFactoryBean(object, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(beanName,
"Post-processing of FactoryBean's singleton object failed", ex);
}
finally {
afterSingletonCreation(beanName);
}
}
// 这里的 beanName 对应于 FactoryBean 的实现类, FactoryBean 的实现类也会被实例化,并被缓存在 singletonObjects 中
if (containsSingleton(beanName)) {
// FactoryBean 所创建的实例会被缓存在 factoryBeanObjectCache 中,供后续调用使用
this.factoryBeanObjectCache.put(beanName, (object != null ? object : NULL_OBJECT));
}
}
}
return (object != NULL_OBJECT ? object : null);
}
}
// 获取非单例实例
else {
// 从工厂类中获取实例
Object object = doGetObjectFromFactoryBean(factory, beanName);
if (object != null && shouldPostProcess) {
try {
// 应用后置处理
object = postProcessObjectFromFactoryBean(object, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(beanName, "Post-processing of FactoryBean's object failed", ex);
}
}
return object;
}
}
private Object doGetObjectFromFactoryBean(final FactoryBean<?> factory, final String beanName)
throws BeanCreationException {
Object object;
try {
// if 分支的逻辑是 Java 安全方面的代码,可以忽略,直接看 else 分支的代码
if (System.getSecurityManager() != null) {
AccessControlContext acc = getAccessControlContext();
try {
object = AccessController.doPrivileged(new PrivilegedExceptionAction<Object>() {
@Override
public Object run() throws Exception {
return factory.getObject();
}
}, acc);
}
catch (PrivilegedActionException pae) {
throw pae.getException();
}
}
else {
// 调用工厂方法生成 bean 实例
object = factory.getObject();
}
}
catch (FactoryBeanNotInitializedException ex) {
throw new BeanCurrentlyInCreationException(beanName, ex.toString());
}
catch (Throwable ex) {
throw new BeanCreationException(beanName, "FactoryBean threw exception on object creation", ex);
}
if (object == null && isSingletonCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(
beanName, "FactoryBean which is currently in creation returned null from getObject");
}
return object;
}
getObjectForBeanInstance 及它所调用的方法主要做了如下几件事情:
- 检测参数 beanInstance 的类型,如果是非 FactoryBean 类型的 bean,直接返回
- 检测 FactoryBean 实现类是否单例类型,针对单例和非单例类型进行不同处理
- 对于单例 FactoryBean,先从缓存里获取 FactoryBean 生成的实例
- 若缓存未命中,则调用 FactoryBean.getObject() 方法生成实例,并放入缓存中
- 对于非单例的 FactoryBean,每次直接创建新的实例即可,无需缓存
- 如果 shouldPostProcess = true,不管是单例还是非单例 FactoryBean 生成的实例,都要进行后置处理
2.2 - CH02-创建单例 Bean
对于已实例化好的单例 bean,getBean(String) 方法并不会再一次去创建,而是从缓存中获取。如果某个 bean 还未实例化,这个时候就无法命中缓存。此时,就要根据 bean 的配置信息去创建这个 bean 了。相较于getBean(String)方法的实现逻辑,创建 bean 的方法createBean(String, RootBeanDefinition, Object[])及其所调用的方法逻辑上更为复杂一些。
创建入口
在正式分析createBean(String, RootBeanDefinition, Object[])方法前,我们先来看看 createBean 方法是在哪里被调用的。如下:
public T doGetBean(...) {
// 省略不相关代码
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
// 省略不相关代码
}
上面是 doGetBean 方法的代码片段,从中可以发现 createBean 方法。createBean 方法被匿名工厂类的 getObject 方法包裹,但这个匿名工厂类对象并未直接调用 getObject 方法。而是将自身作为参数传给了getSingleton(String, ObjectFactory)方法,那么我们接下来再去看看一下 getSingleton(String, ObjectFactory) 方法的实现。如下:
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "'beanName' must not be null");
synchronized (this.singletonObjects) {
// 从缓存中获取单例 bean,若不为空,则直接返回,不用再初始化
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
if (this.singletonsCurrentlyInDestruction) {
throw new BeanCreationNotAllowedException(beanName,
"Singleton bean creation not allowed while singletons of this factory are in destruction " +
"(Do not request a bean from a BeanFactory in a destroy method implementation!)");
}
if (logger.isDebugEnabled()) {
logger.debug("Creating shared instance of singleton bean '" + beanName + "'");
}
/*
* 将 beanName 添加到 singletonsCurrentlyInCreation 集合中,
* 用于表明 beanName 对应的 bean 正在创建中
*/
beforeSingletonCreation(beanName);
boolean newSingleton = false;
boolean recordSuppressedExceptions = (this.suppressedExceptions == null);
if (recordSuppressedExceptions) {
this.suppressedExceptions = new LinkedHashSet<Exception>();
}
try {
// 通过 getObject 方法调用 createBean 方法创建 bean 实例
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
catch (IllegalStateException ex) {
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
throw ex;
}
}
catch (BeanCreationException ex) {
if (recordSuppressedExceptions) {
for (Exception suppressedException : this.suppressedExceptions) {
ex.addRelatedCause(suppressedException);
}
}
throw ex;
}
finally {
if (recordSuppressedExceptions) {
this.suppressedExceptions = null;
}
// 将 beanName 从 singletonsCurrentlyInCreation 移除
afterSingletonCreation(beanName);
}
if (newSingleton) {
/*
* 将 <beanName, singletonObject> 键值对添加到 singletonObjects 集合中,
* 并从其他集合(比如 earlySingletonObjects)中移除 singletonObject 记录
*/
addSingleton(beanName, singletonObject);
}
}
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
}
流程如下:
- 先从 singletonObjects 集合获取 bean 实例,若不为空,则直接返回
- 若为空,进入创建 bean 实例阶段。先将 beanName 添加到 singletonsCurrentlyInCreation
- 通过 getObject 方法调用 createBean 方法创建 bean 实例
- 将 beanName 从 singletonsCurrentlyInCreation 集合中移除
- 将 <beanName, singletonObject> 映射缓存到 singletonObjects 集合中
从上面的分析中,我们知道了 createBean 方法在何处被调用的。那么接下来我们一起深入 createBean 方法的源码中,来看看这个方法具体都做了什么事情。
创建流程
createBean 和 getBean 方法类似,基本上都是空壳方法,只不过 createBean 的逻辑稍微多点,多做了一些事情。下面我们一起看看这个方法的实现逻辑,如下:
protected Object createBean(String beanName, RootBeanDefinition mbd, Object[] args) throws BeanCreationException {
if (logger.isDebugEnabled()) {
logger.debug("Creating instance of bean '" + beanName + "'");
}
RootBeanDefinition mbdToUse = mbd;
// 解析 bean 的类型
Class<?> resolvedClass = resolveBeanClass(mbd, beanName);
if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null) {
mbdToUse = new RootBeanDefinition(mbd);
mbdToUse.setBeanClass(resolvedClass);
}
try {
// 处理 lookup-method 和 replace-method 配置,Spring 将这两个配置统称为 override method
mbdToUse.prepareMethodOverrides();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(mbdToUse.getResourceDescription(),
beanName, "Validation of method overrides failed", ex);
}
try {
// 在 bean 初始化前应用后置处理,如果后置处理返回的 bean 不为空,则直接返回
Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
if (bean != null) {
return bean;
}
}
catch (Throwable ex) {
throw new BeanCreationException(mbdToUse.getResourceDescription(), beanName,
"BeanPostProcessor before instantiation of bean failed", ex);
}
// 调用 doCreateBean 创建 bean
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
if (logger.isDebugEnabled()) {
logger.debug("Finished creating instance of bean '" + beanName + "'");
}
return beanInstance;
}
流程如下:
- 解析 bean 类型
- 处理 lookup-method 和 replace-method 配置
- 在 bean 初始化前应用后置处理,若后置处理返回的 bean 不为空,则直接返回
- 若上一步后置处理返回的 bean 为空,则调用 doCreateBean 创建 bean 实例
验证准备 override 方法
当用户配置了 lookup-method 和 replace-method 时,Spring 需要对目标 bean 进行增强。在增强之前,需要做一些准备工作,也就是 prepareMethodOverrides 中的逻辑。下面来看看这个方法的源码:
public void prepareMethodOverrides() throws BeanDefinitionValidationException {
MethodOverrides methodOverrides = getMethodOverrides();
if (!methodOverrides.isEmpty()) {
Set<MethodOverride> overrides = methodOverrides.getOverrides();
synchronized (overrides) {
// 循环处理每个 MethodOverride 对象
for (MethodOverride mo : overrides) {
prepareMethodOverride(mo);
}
}
}
}
protected void prepareMethodOverride(MethodOverride mo) throws BeanDefinitionValidationException {
// 获取方法名为 mo.getMethodName() 的方法数量,当方法重载时,count 的值就会大于1
int count = ClassUtils.getMethodCountForName(getBeanClass(), mo.getMethodName());
// count = 0,表明根据方法名未找到相应的方法,此时抛出异常
if (count == 0) {
throw new BeanDefinitionValidationException(
"Invalid method override: no method with name '" + mo.getMethodName() +
"' on class [" + getBeanClassName() + "]");
}
// 若 count = 1,表明仅存在已方法名为 mo.getMethodName(),这意味着方法不存在重载
else if (count == 1) {
// 方法不存在重载,则将 overloaded 成员变量设为 false
mo.setOverloaded(false);
}
}
上面的源码中,prepareMethodOverrides方法循环调用了prepareMethodOverride方法,并没其他的太多逻辑。主要准备工作都是在 prepareMethodOverride 方法中进行的,所以我们重点关注一下这个方法。
prepareMethodOverride 这个方法主要用于获取指定方法的方法数量 count,并根据 count 的值进行相应的处理。count = 0 时,表明方法不存在,此时抛出异常。count = 1 时,设置 MethodOverride 对象的overloaded成员变量为 false。这样做的目的在于,提前标注名称mo.getMethodName()的方法不存在重载,在使用 CGLIB 增强阶段就不需要进行校验,直接找到某个方法进行增强即可。
实例化前的后置处理
后置处理是 Spring 的一个拓展点,用户通过实现 BeanPostProcessor 接口,并将实现类配置到 Spring 的配置文件中(或者使用注解),即可在 bean 初始化前后进行自定义操作。
protected Object resolveBeforeInstantiation(String beanName, RootBeanDefinition mbd) {
Object bean = null;
// 检测是否解析过,mbd.beforeInstantiationResolved 的值在下面的代码中会被设置
if (!Boolean.FALSE.equals(mbd.beforeInstantiationResolved)) {
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
Class<?> targetType = determineTargetType(beanName, mbd);
if (targetType != null) {
// 应用前置处理
bean = applyBeanPostProcessorsBeforeInstantiation(targetType, beanName);
if (bean != null) {
// 应用后置处理
bean = applyBeanPostProcessorsAfterInitialization(bean, beanName);
}
}
}
// 设置 mbd.beforeInstantiationResolved
mbd.beforeInstantiationResolved = (bean != null);
}
return bean;
}
protected Object applyBeanPostProcessorsBeforeInstantiation(Class<?> beanClass, String beanName) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
// InstantiationAwareBeanPostProcessor 一般在 Spring 框架内部使用,不建议用户直接使用
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
// bean 初始化前置处理
Object result = ibp.postProcessBeforeInstantiation(beanClass, beanName);
if (result != null) {
return result;
}
}
}
return null;
}
public Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
for (BeanPostProcessor beanProcessor : getBeanPostProcessors()) {
// bean 初始化后置处理
result = beanProcessor.postProcessAfterInitialization(result, beanName);
if (result == null) {
return result;
}
}
return result;
}
在 resolveBeforeInstantiation 方法中,当前置处理方法返回的 bean 不为空时,后置处理才会被执行。前置处理器是 InstantiationAwareBeanPostProcessor 类型的,该种类型的处理器一般用在 Spring 框架内部,比如 AOP 模块中的AbstractAutoProxyCreator抽象类间接实现了这个接口中的 postProcessBeforeInstantiation方法,所以 AOP 可以在这个方法中生成为目标类的代理对象。
调用 doCreateBean
在 Spring 中,做事情的方法基本上都是以do开头的,doCreateBean 也不例外。那下面我们就来看看这个方法都做了哪些事情。
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final Object[] args)
throws BeanCreationException {
/*
* BeanWrapper 是一个基础接口,由接口名可看出这个接口的实现类用于包裹 bean 实例。
* 通过 BeanWrapper 的实现类可以方便的设置/获取 bean 实例的属性
*/
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
// 从缓存中获取 BeanWrapper,并清理相关记录
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
/*
* 创建 bean 实例,并将实例包裹在 BeanWrapper 实现类对象中返回。createBeanInstance
* 中包含三种创建 bean 实例的方式:
* 1. 通过工厂方法创建 bean 实例
* 2. 通过构造方法自动注入(autowire by constructor)的方式创建 bean 实例
* 3. 通过无参构造方法方法创建 bean 实例
*
* 若 bean 的配置信息中配置了 lookup-method 和 replace-method,则会使用 CGLIB
* 增强 bean 实例。关于这个方法,后面会专门写一篇文章介绍,这里先说这么多。
*/
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
// 此处的 bean 可以认为是一个原始的 bean 实例,暂未填充属性
final Object bean = (instanceWrapper != null ? instanceWrapper.getWrappedInstance() : null);
Class<?> beanType = (instanceWrapper != null ? instanceWrapper.getWrappedClass() : null);
mbd.resolvedTargetType = beanType;
// 这里又遇到后置处理了,此处的后置处理是用于处理已“合并的 BeanDefinition”。关于这种后置处理器具体的实现细节就不深入理解了,大家有兴趣可以自己去看
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Post-processing of merged bean definition failed", ex);
}
mbd.postProcessed = true;
}
}
/*
* earlySingletonExposure 是一个重要的变量,这里要说明一下。该变量用于表示是否提前暴露
* 单例 bean,用于解决循环依赖。earlySingletonExposure 由三个条件综合而成,如下:
* 条件1:mbd.isSingleton() - 表示 bean 是否是单例类型
* 条件2:allowCircularReferences - 是否允许循环依赖
* 条件3:isSingletonCurrentlyInCreation(beanName) - 当前 bean 是否处于创建的状态中
*
* earlySingletonExposure = 条件1 && 条件2 && 条件3
* = 单例 && 是否允许循环依赖 && 是否存于创建状态中。
*/
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isDebugEnabled()) {
logger.debug("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
// 添加工厂对象到 singletonFactories 缓存中
addSingletonFactory(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
// 获取早期 bean 的引用,如果 bean 中的方法被 AOP 切点所匹配到,此时 AOP 相关逻辑会介入
return getEarlyBeanReference(beanName, mbd, bean);
}
});
}
Object exposedObject = bean;
try {
// 向 bean 实例中填充属性,populateBean 方法也是一个很重要的方法,后面会专门写文章分析
populateBean(beanName, mbd, instanceWrapper);
if (exposedObject != null) {
/*
* 进行余下的初始化工作,详细如下:
* 1. 判断 bean 是否实现了 BeanNameAware、BeanFactoryAware、
* BeanClassLoaderAware 等接口,并执行接口方法
* 2. 应用 bean 初始化前置操作
* 3. 如果 bean 实现了 InitializingBean 接口,则执行 afterPropertiesSet
* 方法。如果用户配置了 init-method,则调用相关方法执行自定义初始化逻辑
* 4. 应用 bean 初始化后置操作
*
* 另外,AOP 相关逻辑也会在该方法中织入切面逻辑,此时的 exposedObject 就变成了
* 一个代理对象了
*/
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
}
catch (Throwable ex) {
if (ex instanceof BeanCreationException && beanName.equals(((BeanCreationException) ex).getBeanName())) {
throw (BeanCreationException) ex;
}
else {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Initialization of bean failed", ex);
}
}
if (earlySingletonExposure) {
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
// 若 initializeBean 方法未改变 exposedObject 的引用,则此处的条件为 true。
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
// 下面的逻辑我也没完全搞懂,就不分析了。见谅。
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
String[] dependentBeans = getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet<String>(dependentBeans.length);
for (String dependentBean : dependentBeans) {
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName,
"Bean with name '" + beanName + "' has been injected into other beans [" +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
"] in its raw version as part of a circular reference, but has eventually been " +
"wrapped. This means that said other beans do not use the final version of the " +
"bean. This is often the result of over-eager type matching - consider using " +
"'getBeanNamesOfType' with the 'allowEagerInit' flag turned off, for example.");
}
}
}
}
try {
// 注册销毁逻辑
registerDisposableBeanIfNecessary(beanName, bean, mbd);
}
catch (BeanDefinitionValidationException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Invalid destruction signature", ex);
}
return exposedObject;
}
执行流程:
- 从缓存中获取 BeanWrapper 实现类对象,并清理相关记录
- 若未命中缓存,则创建 bean 实例,并将实例包裹在 BeanWrapper 实现类对象中返回
- 应用 MergedBeanDefinitionPostProcessor 后置处理器相关逻辑
- 根据条件决定是否提前暴露 bean 的早期引用(early reference),用于处理循环依赖问题
- 调用 populateBean 方法向 bean 实例中填充属性
- 调用 initializeBean 方法完成余下的初始化工作
- 注册销毁逻辑
由此也可了解到创建一个 bean 还是很复杂的,这中间要做的事情繁多。比如填充属性、对 BeanPostProcessor 拓展点提供支持等。
2.3 - CH03-创建原始 Bean 对象
createBeanInstance
protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, Object[] args) {
Class<?> beanClass = resolveBeanClass(mbd, beanName);
/*
* 检测类的访问权限。默认情况下,对于非 public 的类,是允许访问的。
* 若禁止访问,这里会抛出异常
*/
if (beanClass != null && !Modifier.isPublic(beanClass.getModifiers()) && !mbd.isNonPublicAccessAllowed()) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Bean class isn't public, and non-public access not allowed: " + beanClass.getName());
}
/*
* 如果工厂方法不为空,则通过工厂方法构建 bean 对象。这种构建 bean 的方式
* 就不深入分析了,有兴趣的朋友可以自己去看一下。
*/
if (mbd.getFactoryMethodName() != null) {
// 通过“工厂方法”的方式构建 bean 对象
return instantiateUsingFactoryMethod(beanName, mbd, args);
}
/*
* 当多次构建同一个 bean 时,可以使用此处的快捷路径,即无需再次推断应该使用哪种方式构造实例,
* 以提高效率。比如在多次构建同一个 prototype 类型的 bean 时,就可以走此处的捷径。
* 这里的 resolved 和 mbd.constructorArgumentsResolved 将会在 bean 第一次实例
* 化的过程中被设置,在后面的源码中会分析到,先继续往下看。
*/
boolean resolved = false;
boolean autowireNecessary = false;
if (args == null) {
synchronized (mbd.constructorArgumentLock) {
if (mbd.resolvedConstructorOrFactoryMethod != null) {
resolved = true;
autowireNecessary = mbd.constructorArgumentsResolved;
}
}
}
if (resolved) {
if (autowireNecessary) {
// 通过“构造方法自动注入”的方式构造 bean 对象
return autowireConstructor(beanName, mbd, null, null);
}
else {
// 通过“默认构造方法”的方式构造 bean 对象
return instantiateBean(beanName, mbd);
}
}
// 由后置处理器决定返回哪些构造方法,这里不深入分析了
Constructor<?>[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
/*
* 下面的条件分支条件用于判断使用什么方式构造 bean 实例,有两种方式可选 - 构造方法自动
* 注入和默认构造方法。判断的条件由4部分综合而成,如下:
*
* 条件1:ctors != null -> 后置处理器返回构造方法数组是否为空
*
* 条件2:mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_CONSTRUCTOR
* -> bean 配置中的 autowire 属性是否为 constructor
* 条件3:mbd.hasConstructorArgumentValues()
* -> constructorArgumentValues 是否存在元素,即 bean 配置文件中
* 是否配置了 <construct-arg/>
* 条件4:!ObjectUtils.isEmpty(args)
* -> args 数组是否存在元素,args 是由用户调用
* getBean(String name, Object... args) 传入的
*
* 上面4个条件,只要有一个为 true,就会通过构造方法自动注入的方式构造 bean 实例
*/
if (ctors != null ||
mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
// 通过“构造方法自动注入”的方式构造 bean 对象
return autowireConstructor(beanName, mbd, ctors, args);
}
// 通过“默认构造方法”的方式构造 bean 对象
return instantiateBean(beanName, mbd);
}
流程如下:
- 检测类的访问权限,若禁止访问,则抛出异常
- 若工厂方法不为空,则通过工厂方法构建 bean 对象,并返回结果
- 若构造方式已解析过,则走快捷路径构建 bean 对象,并返回结果
- 如第三步不满足,则通过组合条件决定使用哪种方式构建 bean 对象
这里有三种构造 bean 对象的方式,如下:
- 通过“工厂方法”的方式构造 bean 对象
- 通过“构造方法自动注入”的方式构造 bean 对象
- 通过“默认构造方法”的方式构造 bean 对象
创建:构造方法自动注入
protected BeanWrapper autowireConstructor(
String beanName, RootBeanDefinition mbd, Constructor<?>[] ctors, Object[] explicitArgs) {
// 创建 ConstructorResolver 对象,并调用其 autowireConstructor 方法
return new ConstructorResolver(this).autowireConstructor(beanName, mbd, ctors, explicitArgs);
}
public BeanWrapper autowireConstructor(final String beanName, final RootBeanDefinition mbd,
Constructor<?>[] chosenCtors, final Object[] explicitArgs) {
// 创建 BeanWrapperImpl 对象
BeanWrapperImpl bw = new BeanWrapperImpl();
this.beanFactory.initBeanWrapper(bw);
Constructor<?> constructorToUse = null;
ArgumentsHolder argsHolderToUse = null;
Object[] argsToUse = null;
// 确定参数值列表(argsToUse)
if (explicitArgs != null) {
argsToUse = explicitArgs;
}
else {
Object[] argsToResolve = null;
synchronized (mbd.constructorArgumentLock) {
// 获取已解析的构造方法
constructorToUse = (Constructor<?>) mbd.resolvedConstructorOrFactoryMethod;
if (constructorToUse != null && mbd.constructorArgumentsResolved) {
// 获取已解析的构造方法参数列表
argsToUse = mbd.resolvedConstructorArguments;
if (argsToUse == null) {
// 若 argsToUse 为空,则获取未解析的构造方法参数列表
argsToResolve = mbd.preparedConstructorArguments;
}
}
}
if (argsToResolve != null) {
// 解析参数列表
argsToUse = resolvePreparedArguments(beanName, mbd, bw, constructorToUse, argsToResolve);
}
}
if (constructorToUse == null) {
boolean autowiring = (chosenCtors != null ||
mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_CONSTRUCTOR);
ConstructorArgumentValues resolvedValues = null;
int minNrOfArgs;
if (explicitArgs != null) {
minNrOfArgs = explicitArgs.length;
}
else {
ConstructorArgumentValues cargs = mbd.getConstructorArgumentValues();
resolvedValues = new ConstructorArgumentValues();
/*
* 确定构造方法参数数量,比如下面的配置:
* <bean id="persion" class="xyz.coolblog.autowire.Person">
* <constructor-arg index="0" value="xiaoming"/>
* <constructor-arg index="1" value="1"/>
* <constructor-arg index="2" value="man"/>
* </bean>
*
* 此时 minNrOfArgs = maxIndex + 1 = 2 + 1 = 3,除了计算 minNrOfArgs,
* 下面的方法还会将 cargs 中的参数数据转存到 resolvedValues 中
*/
minNrOfArgs = resolveConstructorArguments(beanName, mbd, bw, cargs, resolvedValues);
}
// 获取构造方法列表
Constructor<?>[] candidates = chosenCtors;
if (candidates == null) {
Class<?> beanClass = mbd.getBeanClass();
try {
candidates = (mbd.isNonPublicAccessAllowed() ?
beanClass.getDeclaredConstructors() : beanClass.getConstructors());
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Resolution of declared constructors on bean Class [" + beanClass.getName() +
"] from ClassLoader [" + beanClass.getClassLoader() + "] failed", ex);
}
}
// 按照构造方法的访问权限级别和参数数量进行排序
AutowireUtils.sortConstructors(candidates);
int minTypeDiffWeight = Integer.MAX_VALUE;
Set<Constructor<?>> ambiguousConstructors = null;
LinkedList<UnsatisfiedDependencyException> causes = null;
for (Constructor<?> candidate : candidates) {
Class<?>[] paramTypes = candidate.getParameterTypes();
/*
* 下面的 if 分支的用途是:若匹配到到合适的构造方法了,提前结束 for 循环
* constructorToUse != null 这个条件比较好理解,下面分析一下条件 argsToUse.length > paramTypes.length:
* 前面说到 AutowireUtils.sortConstructors(candidates) 用于对构造方法进行
* 排序,排序规则如下:
* 1. 具有 public 访问权限的构造方法排在非 public 构造方法前
* 2. 参数数量多的构造方法排在前面
*
* 假设现在有一组构造方法按照上面的排序规则进行排序,排序结果如下(省略参数名称):
*
* 1. public Hello(Object, Object, Object)
* 2. public Hello(Object, Object)
* 3. public Hello(Object)
* 4. protected Hello(Integer, Object, Object, Object)
* 5. protected Hello(Integer, Object, Object)
* 6. protected Hello(Integer, Object)
*
* argsToUse = [num1, obj2],可以匹配上的构造方法2和构造方法6。由于构造方法2有
* 更高的访问权限,所以没理由不选他(尽管后者在参数类型上更加匹配)。由于构造方法3
* 参数数量 < argsToUse.length,参数数量上不匹配,也不应该选。所以
* argsToUse.length > paramTypes.length 这个条件用途是:在条件
* constructorToUse != null 成立的情况下,通过判断参数数量与参数值数量
* (argsToUse.length)是否一致,来决定是否提前终止构造方法匹配逻辑。
*/
if (constructorToUse != null && argsToUse.length > paramTypes.length) {
break;
}
/*
* 构造方法参数数量低于配置的参数数量,则忽略当前构造方法,并重试。比如
* argsToUse = [obj1, obj2, obj3, obj4],上面的构造方法列表中,
* 构造方法1、2和3显然不是合适选择,忽略之。
*/
if (paramTypes.length < minNrOfArgs) {
continue;
}
ArgumentsHolder argsHolder;
if (resolvedValues != null) {
try {
/*
* 判断否则方法是否有 ConstructorProperties 注解,若有,则取注解中的
* 值。比如下面的代码:
*
* public class Persion {
* private String name;
* private Integer age;
*
* @ConstructorProperties(value = {"coolblog", "20"})
* public Persion(String name, Integer age) {
* this.name = name;
* this.age = age;
* }
* }
*/
String[] paramNames = ConstructorPropertiesChecker.evaluate(candidate, paramTypes.length);
if (paramNames == null) {
ParameterNameDiscoverer pnd = this.beanFactory.getParameterNameDiscoverer();
if (pnd != null) {
/*
* 获取构造方法参数名称列表,比如有这样一个构造方法:
* public Person(String name, int age, String sex)
*
* 调用 getParameterNames 方法返回 paramNames = [name, age, sex]
*/
paramNames = pnd.getParameterNames(candidate);
}
}
/*
* 创建参数值列表,返回 argsHolder 会包含进行类型转换后的参数值,比如下
* 面的配置:
*
* <bean id="persion" class="xyz.coolblog.autowire.Person">
* <constructor-arg name="name" value="xiaoming"/>
* <constructor-arg name="age" value="1"/>
* <constructor-arg name="sex" value="man"/>
* </bean>
*
* Person 的成员变量 age 是 Integer 类型的,但由于在 Spring 配置中
* 只能配成 String 类型,所以这里要进行类型转换。
*/
argsHolder = createArgumentArray(beanName, mbd, resolvedValues, bw, paramTypes, paramNames,
getUserDeclaredConstructor(candidate), autowiring);
}
catch (UnsatisfiedDependencyException ex) {
if (this.beanFactory.logger.isTraceEnabled()) {
this.beanFactory.logger.trace(
"Ignoring constructor [" + candidate + "] of bean '" + beanName + "': " + ex);
}
if (causes == null) {
causes = new LinkedList<UnsatisfiedDependencyException>();
}
causes.add(ex);
continue;
}
}
else {
if (paramTypes.length != explicitArgs.length) {
continue;
}
argsHolder = new ArgumentsHolder(explicitArgs);
}
/*
* 计算参数值(argsHolder.arguments)每个参数类型与构造方法参数列表
* (paramTypes)中参数的类型差异量,差异量越大表明参数类型差异越大。参数类型差异
* 越大,表明当前构造方法并不是一个最合适的候选项。引入差异量(typeDiffWeight)
* 变量目的:是将候选构造方法的参数列表类型与参数值列表类型的差异进行量化,通过量化
* 后的数值筛选出最合适的构造方法。
*
* 讲完差异量,再来说说 mbd.isLenientConstructorResolution() 条件。
* 官方的解释是:返回构造方法的解析模式,有宽松模式(lenient mode)和严格模式
* (strict mode)两种类型可选。具体的细节没去研究,就不多说了。
*/
int typeDiffWeight = (mbd.isLenientConstructorResolution() ?
argsHolder.getTypeDifferenceWeight(paramTypes) : argsHolder.getAssignabilityWeight(paramTypes));
if (typeDiffWeight < minTypeDiffWeight) {
constructorToUse = candidate;
argsHolderToUse = argsHolder;
argsToUse = argsHolder.arguments;
minTypeDiffWeight = typeDiffWeight;
ambiguousConstructors = null;
}
/*
* 如果两个构造方法与参数值类型列表之间的差异量一致,那么这两个方法都可以作为
* 候选项,这个时候就出现歧义了,这里先把有歧义的构造方法放入
* ambiguousConstructors 集合中
*/
else if (constructorToUse != null && typeDiffWeight == minTypeDiffWeight) {
if (ambiguousConstructors == null) {
ambiguousConstructors = new LinkedHashSet<Constructor<?>>();
ambiguousConstructors.add(constructorToUse);
}
ambiguousConstructors.add(candidate);
}
}
// 若上面未能筛选出合适的构造方法,这里将抛出 BeanCreationException 异常
if (constructorToUse == null) {
if (causes != null) {
UnsatisfiedDependencyException ex = causes.removeLast();
for (Exception cause : causes) {
this.beanFactory.onSuppressedException(cause);
}
throw ex;
}
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Could not resolve matching constructor " +
"(hint: specify index/type/name arguments for simple parameters to avoid type ambiguities)");
}
/*
* 如果 constructorToUse != null,且 ambiguousConstructors 也不为空,表明解析
* 出了多个的合适的构造方法,此时就出现歧义了。Spring 不会擅自决定使用哪个构造方法,
* 所以抛出异常。
*/
else if (ambiguousConstructors != null && !mbd.isLenientConstructorResolution()) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Ambiguous constructor matches found in bean '" + beanName + "' " +
"(hint: specify index/type/name arguments for simple parameters to avoid type ambiguities): " +
ambiguousConstructors);
}
if (explicitArgs == null) {
/*
* 缓存相关信息,比如:
* 1. 已解析出的构造方法对象 resolvedConstructorOrFactoryMethod
* 2. 构造方法参数列表是否已解析标志 constructorArgumentsResolved
* 3. 参数值列表 resolvedConstructorArguments 或 preparedConstructorArguments
*
* 这些信息可用在其他地方,用于进行快捷判断
*/
argsHolderToUse.storeCache(mbd, constructorToUse);
}
}
try {
Object beanInstance;
if (System.getSecurityManager() != null) {
final Constructor<?> ctorToUse = constructorToUse;
final Object[] argumentsToUse = argsToUse;
beanInstance = AccessController.doPrivileged(new PrivilegedAction<Object>() {
@Override
public Object run() {
return beanFactory.getInstantiationStrategy().instantiate(
mbd, beanName, beanFactory, ctorToUse, argumentsToUse);
}
}, beanFactory.getAccessControlContext());
}
else {
/*
* 调用实例化策略创建实例,默认情况下使用反射创建实例。如果 bean 的配置信息中
* 包含 lookup-method 和 replace-method,则通过 CGLIB 增强 bean 实例
*/
beanInstance = this.beanFactory.getInstantiationStrategy().instantiate(
mbd, beanName, this.beanFactory, constructorToUse, argsToUse);
}
// 设置 beanInstance 到 BeanWrapperImpl 对象中
bw.setBeanInstance(beanInstance);
return bw;
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Bean instantiation via constructor failed", ex);
}
}
该方法的核心逻辑是根据参数值类型筛选合适的构造方法。解析出合适的构造方法后,剩下的工作就是构建 bean 对象了,这个工作交给了实例化策略去做。下面罗列一下这个方法的工作流程吧:
- 创建 BeanWrapperImpl 对象
- 解析构造方法参数,并算出 minNrOfArgs
- 获取构造方法列表,并排序
- 遍历排序好的构造方法列表,筛选合适的构造方法
- 获取构造方法参数列表中每个参数的名称
- 再次解析参数,此次解析会将
<constructor-arg/> value 属性值进行类型转换,由 String 转为合适的类型。 - 计算构造方法参数列表与参数值列表之间的类型差异量,以筛选出更为合适的构造方法
- 缓存已筛选出的构造方法以及参数值列表,若再次创建 bean 实例时,可直接使用,无需再次进行筛选
- 使用初始化策略创建 bean 对象
- 将 bean 对象放入 BeanWrapperImpl 对象中,并返回该对象
创建:默认构造方法
protected BeanWrapper instantiateBean(final String beanName, final RootBeanDefinition mbd) {
try {
Object beanInstance;
final BeanFactory parent = this;
// if 条件分支里的一大坨是 Java 安全相关的代码,可以忽略,直接看 else 分支
if (System.getSecurityManager() != null) {
beanInstance = AccessController.doPrivileged(new PrivilegedAction<Object>() {
@Override
public Object run() {
return getInstantiationStrategy().instantiate(mbd, beanName, parent);
}
}, getAccessControlContext());
}
else {
/*
* 调用实例化策略创建实例,默认情况下使用反射创建对象。如果 bean 的配置信息中
* 包含 lookup-method 和 replace-method,则通过 CGLIB 创建 bean 对象
*/
beanInstance = getInstantiationStrategy().instantiate(mbd, beanName, parent);
}
// 创建 BeanWrapperImpl 对象
BeanWrapper bw = new BeanWrapperImpl(beanInstance);
initBeanWrapper(bw);
return bw;
}
catch (Throwable ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Instantiation of bean failed", ex);
}
}
public Object instantiate(RootBeanDefinition bd, String beanName, BeanFactory owner) {
// 检测 bean 配置中是否配置了 lookup-method 或 replace-method,若配置了,则需使用 CGLIB 构建 bean 对象
if (bd.getMethodOverrides().isEmpty()) {
Constructor<?> constructorToUse;
synchronized (bd.constructorArgumentLock) {
constructorToUse = (Constructor<?>) bd.resolvedConstructorOrFactoryMethod;
if (constructorToUse == null) {
final Class<?> clazz = bd.getBeanClass();
if (clazz.isInterface()) {
throw new BeanInstantiationException(clazz, "Specified class is an interface");
}
try {
if (System.getSecurityManager() != null) {
constructorToUse = AccessController.doPrivileged(new PrivilegedExceptionAction<Constructor<?>>() {
@Override
public Constructor<?> run() throws Exception {
return clazz.getDeclaredConstructor((Class[]) null);
}
});
}
else {
// 获取默认构造方法
constructorToUse = clazz.getDeclaredConstructor((Class[]) null);
}
// 设置 resolvedConstructorOrFactoryMethod
bd.resolvedConstructorOrFactoryMethod = constructorToUse;
}
catch (Throwable ex) {
throw new BeanInstantiationException(clazz, "No default constructor found", ex);
}
}
}
// 通过无参构造方法创建 bean 对象
return BeanUtils.instantiateClass(constructorToUse);
}
else {
// 使用 GCLIG 创建 bean 对象
return instantiateWithMethodInjection(bd, beanName, owner);
}
}
上面就是通过默认构造方法创建 bean 对象的过程,比较简单,就不多说了。最后我们再来看看简单看看通过无参构造方法刚创建 bean 对象的代码(通过 CGLIB 创建 bean 对象的方式就不看了)是怎样的,如下:
public static <T> T instantiateClass(Constructor<T> ctor, Object... args) throws BeanInstantiationException {
Assert.notNull(ctor, "Constructor must not be null");
try {
// 设置构造方法为可访问
ReflectionUtils.makeAccessible(ctor);
// 通过反射创建 bean 实例,这里的 args 是一个没有元素的空数组
return ctor.newInstance(args);
}
catch (InstantiationException ex) {
throw new BeanInstantiationException(ctor, "Is it an abstract class?", ex);
}
catch (IllegalAccessException ex) {
throw new BeanInstantiationException(ctor, "Is the constructor accessible?", ex);
}
catch (IllegalArgumentException ex) {
throw new BeanInstantiationException(ctor, "Illegal arguments for constructor", ex);
}
catch (InvocationTargetException ex) {
throw new BeanInstantiationException(ctor, "Constructor threw exception", ex.getTargetException());
}
}
2.4 - CH04-解决循环依赖
循环依赖
所谓的循环依赖是指,A 依赖 B,B 又依赖 A,它们之间形成了循环依赖。或者是 A 依赖 B,B 依赖 C,C 又依赖 A。它们之间的依赖关系如下:
这里以两个类直接相互依赖为例,他们的实现代码可能如下:
public class BeanB {
private BeanA beanA;
// 省略 getter/setter
}
public class BeanA {
private BeanB beanB;
}
配置文件:
<bean id="beanA" class="xyz.coolblog.BeanA">
<property name="beanB" ref="beanB"/>
</bean>
<bean id="beanB" class="xyz.coolblog.BeanB">
<property name="beanA" ref="beanA"/>
</bean>
IOC 容器在读到上面的配置时,会按照顺序,先去实例化 beanA。然后发现 beanA 依赖于 beanB,接在又去实例化 beanB。实例化 beanB 时,发现 beanB 又依赖于 beanA。
如果容器不处理循环依赖的话,容器会无限执行上面的流程,直到内存溢出,程序崩溃。当然,Spring 是不会让这种情况发生的。在容器再次发现 beanB 依赖于 beanA 时,容器会获取 beanA 对象的一个早期的引用(early reference),并把这个早期引用注入到 beanB 中,让 beanB 先完成实例化。beanB 完成实例化,beanA 就可以获取到 beanB 的引用,beanA 随之完成实例化。这里大家可能不知道“早期引用”是什么意思,这里先别着急,我会在下一章进行说明。
缓存介绍
/** Cache of singleton objects: bean name --> bean instance */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(256);
/** Cache of singleton factories: bean name --> ObjectFactory */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<String, ObjectFactory<?>>(16);
/** Cache of early singleton objects: bean name --> bean instance */
private final Map<String, Object> earlySingletonObjects = new HashMap<String, Object>(16);
根据缓存变量上面的注释,大家应该能大致了解他们的用途。我这里简单说明一下吧:
| 缓存 | 用途 |
|---|
| singletonObjects | 用于存放完全初始化好的 bean,从该缓存中取出的 bean 可以直接使用 |
| earlySingletonObjects | 存放原始的 bean 对象(尚未填充属性),用于解决循环依赖 |
| singletonFactories | 存放 bean 工厂对象,用于解决循环依赖 |
上一章提到了”早期引用“,所谓的”早期引用“是指向原始对象的引用。所谓的原始对象是指刚创建好的对象,但还未填充属性。这样讲大家不知道大家听明白了没,不过没听明白也不要紧。简单做个实验就知道了,这里我们先定义一个对象 Room:
/** Room 包含了一些电器 */
public class Room {
private String television;
private String airConditioner;
private String refrigerator;
private String washer;
// 省略 getter/setter
}
配置文件:
<bean id="room" class="xyz.coolblog.demo.Room">
<property name="television" value="Xiaomi"/>
<property name="airConditioner" value="Gree"/>
<property name="refrigerator" value="Haier"/>
<property name="washer" value="Siemens"/>
</bean>
下图依次是原始 bean 和完全初始化后的 bean:
这里的 bean 和上面的 bean 指向的是同一个对象Room@1567,但现在这个对象所有字段都是 null,我们把这种对象成为原始的对象。形象点说,上面的 bean 对象是一个装修好的房子,可以拎包入住了。而这里的 bean 对象还是个毛坯房,还要装修一下(填充属性)才行。
Bean 获取过程回顾
开始流程图中只有一条执行路径,在条件 sharedInstance != null 这里出现了岔路,形成了绿色和红色两条路径。在上图中,读取/添加缓存的方法我用蓝色的框和☆标注了出来。至于虚线的箭头,和虚线框里的路径,这个下面会说到。
我来按照上面的图,分析一下整个流程的执行顺序。这个流程从 getBean 方法开始,getBean 是个空壳方法,所有逻辑都在 doGetBean 方法中。doGetBean 首先会调用 getSingleton(beanName) 方法获取 sharedInstance,sharedInstance 可能是完全实例化好的 bean,也可能是一个原始的 bean,当然也有可能是 null。如果不为 null,则走绿色的那条路径。再经 getObjectForBeanInstance 这一步处理后,绿色的这条执行路径就结束了。
我们再来看一下红色的那条执行路径,也就是 sharedInstance = null 的情况。在第一次获取某个 bean 的时候,缓存中是没有记录的,所以这个时候要走创建逻辑。上图中的 getSingleton(beanName,
new ObjectFactory<Object>() {...}) 方法会创建一个 bean 实例,上图虚线路径指的是 getSingleton 方法内部调用的两个方法,其逻辑如下:
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
// 省略部分代码
singletonObject = singletonFactory.getObject();
// ...
addSingleton(beanName, singletonObject);
}
如上所示,getSingleton 会在内部先调用 getObject 方法创建 singletonObject,然后再调用 addSingleton 将 singletonObject 放入缓存中。getObject 在内部代用了 createBean 方法,createBean 方法基本上也属于空壳方法,更多的逻辑是写在 doCreateBean 方法中的。doCreateBean 方法中的逻辑很多,其首先调用了 createBeanInstance 方法创建了一个原始的 bean 对象,随后调用 addSingletonFactory 方法向缓存中添加单例 bean 工厂,从该工厂可以获取原始对象的引用,也就是所谓的“早期引用”。再之后,继续调用 populateBean 方法向原始 bean 对象中填充属性,并解析依赖。getObject 执行完成后,会返回完全实例化好的 bean。紧接着再调用 addSingleton 把完全实例化好的 bean 对象放入缓存中。到这里,红色执行路径差不多也就要结束的。
我这里没有把 getObject、addSingleton 方法和 getSingleton(String, ObjectFactory) 并列画在红色的路径里,目的是想简化一下方法的调用栈(都画进来有点复杂)。我们可以进一步简化上面的调用流程,比如下面:
这个流程看起来是不是简单多了,命中缓存走绿色路径,未命中走红色的创建路径。
源码分析
protected <T> T doGetBean(
final String name, final Class<T> requiredType, final Object[] args, boolean typeCheckOnly)
throws BeansException {
// ......
// 从缓存中获取 bean 实例
Object sharedInstance = getSingleton(beanName);
// ......
}
public Object getSingleton(String beanName) {
return getSingleton(beanName, true);
}
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 从 singletonObjects 获取实例,singletonObjects 中的实例都是准备好的 bean 实例,可以直接使用
Object singletonObject = this.singletonObjects.get(beanName);
// 判断 beanName 对应的 bean 是否正在创建中
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
// 从 earlySingletonObjects 中获取提前曝光的 bean
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
// 获取相应的 bean 工厂
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 提前曝光 bean 实例(raw bean),用于解决循环依赖
singletonObject = singletonFactory.getObject();
// 将 singletonObject 放入缓存中,并将 singletonFactory 从缓存中移除
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
上面的源码中,doGetBean 所调用的方法 getSingleton(String) 是一个空壳方法,其主要逻辑在 getSingleton(String, boolean) 中。该方法逻辑比较简单,首先从 singletonObjects 缓存中获取 bean 实例。若未命中,再去 earlySingletonObjects 缓存中获取原始 bean 实例。如果仍未命中,则从 singletonFactory 缓存中获取 ObjectFactory 对象,然后再调用 getObject 方法获取原始 bean 实例的应用,也就是早期引用。获取成功后,将该实例放入 earlySingletonObjects 缓存中,并将 ObjectFactory 对象从 singletonFactories 移除。看完这个方法,我们再来看看 getSingleton(String, ObjectFactory) 方法,这个方法也是在 doGetBean 中被调用的。这次我会把 doGetBean 的代码多贴一点出来,如下:
protected <T> T doGetBean(
final String name, final Class<T> requiredType, final Object[] args, boolean typeCheckOnly)
throws BeansException {
// ......
Object bean;
// 从缓存中获取 bean 实例
Object sharedInstance = getSingleton(beanName);
// 这里先忽略 args == null 这个条件
if (sharedInstance != null && args == null) {
// 进行后续的处理
bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);
} else {
// ......
// mbd.isSingleton() 用于判断 bean 是否是单例模式
if (mbd.isSingleton()) {
// 再次获取 bean 实例
sharedInstance = getSingleton(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
try {
// 创建 bean 实例,createBean 返回的 bean 是完全实例化好的
return createBean(beanName, mbd, args);
} catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
}
});
// 进行后续的处理
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
// ......
}
// ......
// 返回 bean
return (T) bean;
}
这里的代码逻辑和我在 回顾获取 bean 的过程 一节的最后贴的主流程图已经很接近了,对照那张图和代码中的注释,大家应该可以理解 doGetBean 方法了。继续往下看:
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
synchronized (this.singletonObjects) {
// ......
// 调用 getObject 方法创建 bean 实例
singletonObject = singletonFactory.getObject();
newSingleton = true;
if (newSingleton) {
// 添加 bean 到 singletonObjects 缓存中,并从其他集合中将 bean 相关记录移除
addSingleton(beanName, singletonObject);
}
// ......
// 返回 singletonObject
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
}
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
// 将 <beanName, singletonObject> 映射存入 singletonObjects 中
this.singletonObjects.put(beanName, (singletonObject != null ? singletonObject : NULL_OBJECT));
// 从其他缓存中移除 beanName 相关映射
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
上面的代码中包含两步操作,第一步操作是调用 getObject 创建 bean 实例,第二步是调用 addSingleton 方法将创建好的 bean 放入缓存中。代码逻辑并不复杂,相信大家都能看懂。那么接下来我们继续往下看,这次分析的是 doCreateBean 中的一些逻辑。如下:
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final Object[] args)
throws BeanCreationException {
BeanWrapper instanceWrapper = null;
// ......
// ☆ 创建 bean 对象,并将 bean 对象包裹在 BeanWrapper 对象中返回
instanceWrapper = createBeanInstance(beanName, mbd, args);
// 从 BeanWrapper 对象中获取 bean 对象,这里的 bean 指向的是一个原始的对象
final Object bean = (instanceWrapper != null ? instanceWrapper.getWrappedInstance() : null);
/*
* earlySingletonExposure 用于表示是否”提前暴露“原始对象的引用,用于解决循环依赖。
* 对于单例 bean,该变量一般为 true。更详细的解释可以参考我之前的文章
*/
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
// ☆ 添加 bean 工厂对象到 singletonFactories 缓存中
addSingletonFactory(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
/*
* 获取原始对象的早期引用,在 getEarlyBeanReference 方法中,会执行 AOP
* 相关逻辑。若 bean 未被 AOP 拦截,getEarlyBeanReference 原样返回
* bean,所以大家可以把
* return getEarlyBeanReference(beanName, mbd, bean)
* 等价于:
* return bean;
*/
return getEarlyBeanReference(beanName, mbd, bean);
}
});
}
Object exposedObject = bean;
// ......
// ☆ 填充属性,解析依赖
populateBean(beanName, mbd, instanceWrapper);
// ......
// 返回 bean 实例
return exposedObject;
}
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
// 将 singletonFactory 添加到 singletonFactories 缓存中
this.singletonFactories.put(beanName, singletonFactory);
// 从其他缓存中移除相关记录,即使没有
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
上面的代码简化了不少,不过看起来仍有点复杂。好在,上面代码的主线逻辑比较简单,由三个方法组成。如下:
1. 创建原始 bean 实例 → createBeanInstance(beanName, mbd, args)
2. 添加原始对象工厂对象到 singletonFactories 缓存中
→ addSingletonFactory(beanName, new ObjectFactory<Object>{...})
3. 填充属性,解析依赖 → populateBean(beanName, mbd, instanceWrapper)
关键步骤
在上面的方法调用中,有几个关键的地方,下面一一列举出来:
1. 创建原始 bean 对象
instanceWrapper = createBeanInstance(beanName, mbd, args);
final Object bean = (instanceWrapper != null ? instanceWrapper.getWrappedInstance() : null);
假设 beanA 先被创建,创建后的原始对象为 BeanA@1234,上面代码中的 bean 变量指向就是这个对象。
2. 暴露早期引用
addSingletonFactory(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
return getEarlyBeanReference(beanName, mbd, bean);
}
});
beanA 指向的原始对象创建好后,就开始把指向原始对象的引用通过 ObjectFactory 暴露出去。getEarlyBeanReference 方法的第三个参数 bean 指向的正是 createBeanInstance 方法创建出原始 bean 对象 BeanA@1234。
3. 解析依赖
populateBean(beanName, mbd, instanceWrapper);
populateBean 用于向 beanA 这个原始对象中填充属性,当它检测到 beanA 依赖于 beanB 时,会首先去实例化 beanB。beanB 在此方法处也会解析自己的依赖,当它检测到 beanA 这个依赖,于是调用 BeanFactry.getBean(“beanA”) 这个方法,从容器中获取 beanA。
4. 获取早期引用
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
// ☆ 从缓存中获取早期引用
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// ☆ 从 SingletonFactory 中获取早期引用
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
接着上面的步骤讲,populateBean 调用 BeanFactry.getBean(“beanA”) 以获取 beanB 的依赖。getBean(“beanA”) 会先调用 getSingleton(“beanA”),尝试从缓存中获取 beanA。此时由于 beanA 还没完全实例化好,于是 this.singletonObjects.get(“beanA”) 返回 null。接着 this.earlySingletonObjects.get(“beanA”) 也返回空,因为 beanA 早期引用还没放入到这个缓存中。最后调用 singletonFactory.getObject() 返回 singletonObject,此时 singletonObject != null。singletonObject 指向 BeanA@1234,也就是 createBeanInstance 创建的原始对象。此时 beanB 获取到了这个原始对象的引用,beanB 就能顺利完成实例化。beanB 完成实例化后,beanA 就能获取到 beanB 所指向的实例,beanA 随之也完成了实例化工作。由于 beanB.beanA 和 beanA 指向的是同一个对象 BeanA@1234,所以 beanB 中的 beanA 此时也处于可用状态了。
以上的过程对应下面的流程图:
2.5 - CH05-原始 Bean 属性填充
populateBean 源码
本节,我们先来看一下填充属性的方法,即 populateBean。该方法并不复杂,但它所调用的一些方法比较复杂。不过好在我们这里只需要知道这些方法都有什么用就行了,暂时不用纠结细节。好了,下面看源码吧。
protected void populateBean(String beanName, RootBeanDefinition mbd, BeanWrapper bw) {
// 获取属性列表
PropertyValues pvs = mbd.getPropertyValues();
if (bw == null) {
if (!pvs.isEmpty()) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Cannot apply property values to null instance");
}
else {
return;
}
}
boolean continueWithPropertyPopulation = true;
/*
* 在属性被填充前,给 InstantiationAwareBeanPostProcessor 类型的后置处理器一个修改
* bean 状态的机会。关于这段后置引用,官方的解释是:让用户可以自定义属性注入。比如用户实现一
* 个 InstantiationAwareBeanPostProcessor 类型的后置处理器,并通过
* postProcessAfterInstantiation 方法向 bean 的成员变量注入自定义的信息。当然,如果无
* 特殊需求,直接使用配置中的信息注入即可。另外,Spring 并不建议大家直接实现
* InstantiationAwareBeanPostProcessor 接口,如果想实现这种类型的后置处理器,更建议
* 通过继承 InstantiationAwareBeanPostProcessorAdapter 抽象类实现自定义后置处理器。
*/
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
if (!ibp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {
continueWithPropertyPopulation = false;
break;
}
}
}
}
/*
* 如果上面设置 continueWithPropertyPopulation = false,表明用户可能已经自己填充了
* bean 的属性,不需要 Spring 帮忙填充了。此时直接返回即可
*/
if (!continueWithPropertyPopulation) {
return;
}
// 根据名称或类型注入依赖
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_NAME ||
mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_TYPE) {
MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
// 通过属性名称注入依赖
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_NAME) {
autowireByName(beanName, mbd, bw, newPvs);
}
// 通过属性类型注入依赖
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_TYPE) {
autowireByType(beanName, mbd, bw, newPvs);
}
pvs = newPvs;
}
boolean hasInstAwareBpps = hasInstantiationAwareBeanPostProcessors();
boolean needsDepCheck = (mbd.getDependencyCheck() != RootBeanDefinition.DEPENDENCY_CHECK_NONE);
/*
* 这里又是一种后置处理,用于在 Spring 填充属性到 bean 对象前,对属性的值进行相应的处理,
* 比如可以修改某些属性的值。这时注入到 bean 中的值就不是配置文件中的内容了,
* 而是经过后置处理器修改后的内容
*/
if (hasInstAwareBpps || needsDepCheck) {
PropertyDescriptor[] filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
if (hasInstAwareBpps) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
// 对属性进行后置处理
pvs = ibp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName);
if (pvs == null) {
return;
}
}
}
}
if (needsDepCheck) {
checkDependencies(beanName, mbd, filteredPds, pvs);
}
}
// 应用属性值到 bean 对象中
applyPropertyValues(beanName, mbd, bw, pvs);
}
上面的源码注释的比较详细了,下面我们来总结一下这个方法的执行流程。如下:
- 获取属性列表 pvs
- 在属性被填充到 bean 前,应用后置处理自定义属性填充
- 根据名称或类型解析相关依赖
- 再次应用后置处理,用于动态修改属性列表 pvs 的内容
- 将属性应用到 bean 对象中
注意第 3 步,也就是根据名称或类型解析相关依赖(autowire)。该逻辑只会解析依赖,并不会将解析出的依赖立即注入到 bean 对象中。所有的属性值是在 applyPropertyValues 方法中统一被注入到 bean 对象中的。
在下面的章节中,我将会对 populateBean 方法中比较重要的几个方法调用进行分析,也就是第3步和第5步中的三个方法。好了,本节先到这里。
autowireByName
protected void autowireByName(
String beanName, AbstractBeanDefinition mbd, BeanWrapper bw, MutablePropertyValues pvs) {
/*
* 获取非简单类型属性的名称,且该属性未被配置在配置文件中。这里从反面解释一下什么是"非简单类型"
* 属性,我们先来看看 Spring 认为的"简单类型"属性有哪些,如下:
* 1. CharSequence 接口的实现类,比如 String
* 2. Enum
* 3. Date
* 4. URI/URL
* 5. Number 的继承类,比如 Integer/Long
* 6. byte/short/int... 等基本类型
* 7. Locale
* 8. 以上所有类型的数组形式,比如 String[]、Date[]、int[] 等等
*
* 除了要求非简单类型的属性外,还要求属性未在配置文件中配置过,也就是 pvs.contains(pd.getName()) = false。
*/
String[] propertyNames = unsatisfiedNonSimpleProperties(mbd, bw);
for (String propertyName : propertyNames) {
// 检测是否存在与 propertyName 相关的 bean 或 BeanDefinition。若存在,则调用 BeanFactory.getBean 方法获取 bean 实例
if (containsBean(propertyName)) {
// 从容器中获取相应的 bean 实例
Object bean = getBean(propertyName);
// 将解析出的 bean 存入到属性值列表(pvs)中
pvs.add(propertyName, bean);
registerDependentBean(propertyName, beanName);
if (logger.isDebugEnabled()) {
logger.debug("Added autowiring by name from bean name '" + beanName +
"' via property '" + propertyName + "' to bean named '" + propertyName + "'");
}
}
else {
if (logger.isTraceEnabled()) {
logger.trace("Not autowiring property '" + propertyName + "' of bean '" + beanName +
"' by name: no matching bean found");
}
}
}
}
autowireByName 方法的逻辑比较简单,该方法首先获取非简单类型属性的名称,然后再根据名称到容器中获取相应的 bean 实例,最后再将获取到的 bean 添加到属性列表中即可。既然这个方法比较简单,那我也就不多说了,继续下面的分析。
autowireByType
本节我们来分析一下 autowireByName 的孪生兄弟 autowireByType,相较于 autowireByName,autowireByType 则要复杂一些,复杂之处在于解析依赖的过程。不过也没关系,如果我们不过于纠结细节,我们完全可以把一些复杂的地方当做一个黑盒,我们只需要要知道这个黑盒有什么用即可。这样可以在很大程度上降低源码分析的难度。好了,其他的就不多说了,咱们来分析源码吧。
protected void autowireByType(
String beanName, AbstractBeanDefinition mbd, BeanWrapper bw, MutablePropertyValues pvs) {
TypeConverter converter = getCustomTypeConverter();
if (converter == null) {
converter = bw;
}
Set<String> autowiredBeanNames = new LinkedHashSet<String>(4);
// 获取非简单类型的属性
String[] propertyNames = unsatisfiedNonSimpleProperties(mbd, bw);
for (String propertyName : propertyNames) {
try {
PropertyDescriptor pd = bw.getPropertyDescriptor(propertyName);
// 如果属性类型为 Object,则忽略,不做解析
if (Object.class != pd.getPropertyType()) {
/*
* 获取 setter 方法(write method)的参数信息,比如参数在参数列表中的
* 位置,参数类型,以及该参数所归属的方法等信息
*/
MethodParameter methodParam = BeanUtils.getWriteMethodParameter(pd);
// Do not allow eager init for type matching in case of a prioritized post-processor.
boolean eager = !PriorityOrdered.class.isAssignableFrom(bw.getWrappedClass());
// 创建依赖描述对象
DependencyDescriptor desc = new AutowireByTypeDependencyDescriptor(methodParam, eager);
/*
* 下面的方法用于解析依赖。过程比较复杂,先把这里看成一个黑盒,我们只要知道这
* 个方法可以帮我们解析出合适的依赖即可。
*/
Object autowiredArgument = resolveDependency(desc, beanName, autowiredBeanNames, converter);
if (autowiredArgument != null) {
// 将解析出的 bean 存入到属性值列表(pvs)中
pvs.add(propertyName, autowiredArgument);
}
for (String autowiredBeanName : autowiredBeanNames) {
registerDependentBean(autowiredBeanName, beanName);
if (logger.isDebugEnabled()) {
logger.debug("Autowiring by type from bean name '" + beanName + "' via property '" +
propertyName + "' to bean named '" + autowiredBeanName + "'");
}
}
autowiredBeanNames.clear();
}
}
catch (BeansException ex) {
throw new UnsatisfiedDependencyException(mbd.getResourceDescription(), beanName, propertyName, ex);
}
}
}
如上所示,autowireByType 的代码本身并不复杂。和 autowireByName 一样,autowireByType 首先也是获取非简单类型属性的名称。然后再根据属性名获取属性描述符,并由属性描述符获取方法参数对象 MethodParameter,随后再根据 MethodParameter 对象获取依赖描述符对象,整个过程为 beanName → PropertyDescriptor → MethodParameter → DependencyDescriptor。在获取到依赖描述符对象后,再根据依赖描述符解析出合适的依赖。最后将解析出的结果存入属性列表 pvs 中即可。
关于 autowireByType 方法中出现的几种描述符对象,大家自己去看一下他们的实现吧,我就不分析了。接下来,我们来分析一下解析依赖的方法 resolveDependency。如下:
public Object resolveDependency(DependencyDescriptor descriptor, String requestingBeanName,
Set<String> autowiredBeanNames, TypeConverter typeConverter) throws BeansException {
descriptor.initParameterNameDiscovery(getParameterNameDiscoverer());
if (javaUtilOptionalClass == descriptor.getDependencyType()) {
return new OptionalDependencyFactory().createOptionalDependency(descriptor, requestingBeanName);
}
else if (ObjectFactory.class == descriptor.getDependencyType() ||
ObjectProvider.class == descriptor.getDependencyType()) {
return new DependencyObjectProvider(descriptor, requestingBeanName);
}
else if (javaxInjectProviderClass == descriptor.getDependencyType()) {
return new Jsr330ProviderFactory().createDependencyProvider(descriptor, requestingBeanName);
}
else {
Object result = getAutowireCandidateResolver().getLazyResolutionProxyIfNecessary(
descriptor, requestingBeanName);
if (result == null) {
// 解析依赖
result = doResolveDependency(descriptor, requestingBeanName, autowiredBeanNames, typeConverter);
}
return result;
}
}
public Object doResolveDependency(DependencyDescriptor descriptor, String beanName,
Set<String> autowiredBeanNames, TypeConverter typeConverter) throws BeansException {
InjectionPoint previousInjectionPoint = ConstructorResolver.setCurrentInjectionPoint(descriptor);
try {
// 该方法最终调用了 beanFactory.getBean(String, Class),从容器中获取依赖
Object shortcut = descriptor.resolveShortcut(this);
// 如果容器中存在所需依赖,这里进行断路操作,提前结束依赖解析逻辑
if (shortcut != null) {
return shortcut;
}
Class<?> type = descriptor.getDependencyType();
// 处理 @value 注解
Object value = getAutowireCandidateResolver().getSuggestedValue(descriptor);
if (value != null) {
if (value instanceof String) {
String strVal = resolveEmbeddedValue((String) value);
BeanDefinition bd = (beanName != null && containsBean(beanName) ? getMergedBeanDefinition(beanName) : null);
value = evaluateBeanDefinitionString(strVal, bd);
}
TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
return (descriptor.getField() != null ?
converter.convertIfNecessary(value, type, descriptor.getField()) :
converter.convertIfNecessary(value, type, descriptor.getMethodParameter()));
}
// 解析数组、list、map 等类型的依赖
Object multipleBeans = resolveMultipleBeans(descriptor, beanName, autowiredBeanNames, typeConverter);
if (multipleBeans != null) {
return multipleBeans;
}
/*
* 按类型查找候选列表,如果某个类型已经被实例化,则返回相应的实例。
* 比如下面的配置:
*
* <bean name="mongoDao" class="xyz.coolblog.autowire.MongoDao" primary="true"/>
* <bean name="service" class="xyz.coolblog.autowire.Service" autowire="byType"/>
* <bean name="mysqlDao" class="xyz.coolblog.autowire.MySqlDao"/>
*
* MongoDao 和 MySqlDao 均实现自 Dao 接口,Service 对象(不是接口)中有一个 Dao
* 类型的属性。现在根据类型自动注入 Dao 的实现类。这里有两个候选 bean,一个是
* mongoDao,另一个是 mysqlDao,其中 mongoDao 在 service 之前实例化,
* mysqlDao 在 service 之后实例化。此时 findAutowireCandidates 方法会返回如下的结果:
*
* matchingBeans = [ <mongoDao, Object@MongoDao>, <mysqlDao, Class@MySqlDao> ]
*
* 注意 mysqlDao 还未实例化,所以返回的是 MySqlDao.class。
*
* findAutowireCandidates 这个方法逻辑比较复杂,我简单说一下它的工作流程吧,如下:
* 1. 从 BeanFactory 中获取某种类型 bean 的名称,比如上面的配置中
* mongoDao 和 mysqlDao 均实现了 Dao 接口,所以他们是同一种类型的 bean。
* 2. 遍历上一步得到的名称列表,并判断 bean 名称对应的 bean 是否是合适的候选项,
* 若合适则添加到候选列表中,并在最后返回候选列表
*
* findAutowireCandidates 比较复杂,我并未完全搞懂,就不深入分析了。见谅
*/
Map<String, Object> matchingBeans = findAutowireCandidates(beanName, type, descriptor);
if (matchingBeans.isEmpty()) {
if (isRequired(descriptor)) {
// 抛出 NoSuchBeanDefinitionException 异常
raiseNoMatchingBeanFound(type, descriptor.getResolvableType(), descriptor);
}
return null;
}
String autowiredBeanName;
Object instanceCandidate;
if (matchingBeans.size() > 1) {
/*
* matchingBeans.size() > 1,则表明存在多个可注入的候选项,这里判断使用哪一个
* 候选项。比如下面的配置:
*
* <bean name="mongoDao" class="xyz.coolblog.autowire.MongoDao" primary="true"/>
* <bean name="mysqlDao" class="xyz.coolblog.autowire.MySqlDao"/>
*
* mongoDao 的配置中存在 primary 属性,所以 mongoDao 会被选为最终的候选项。如
* 果两个 bean 配置都没有 primary 属性,则需要根据优先级选择候选项。优先级这一块
* 的逻辑没细看,不多说了。
*/
autowiredBeanName = determineAutowireCandidate(matchingBeans, descriptor);
if (autowiredBeanName == null) {
if (isRequired(descriptor) || !indicatesMultipleBeans(type)) {
// 抛出 NoUniqueBeanDefinitionException 异常
return descriptor.resolveNotUnique(type, matchingBeans);
}
else {
return null;
}
}
// 根据解析出的 autowiredBeanName,获取相应的候选项
instanceCandidate = matchingBeans.get(autowiredBeanName);
}
else { // 只有一个候选项,直接取出来即可
Map.Entry<String, Object> entry = matchingBeans.entrySet().iterator().next();
autowiredBeanName = entry.getKey();
instanceCandidate = entry.getValue();
}
if (autowiredBeanNames != null) {
autowiredBeanNames.add(autowiredBeanName);
}
// 返回候选项实例,如果实例是 Class 类型,则调用 beanFactory.getBean(String, Class) 获取相应的 bean。否则直接返回即可
return (instanceCandidate instanceof Class ?
descriptor.resolveCandidate(autowiredBeanName, type, this) : instanceCandidate);
}
finally {
ConstructorResolver.setCurrentInjectionPoint(previousInjectionPoint);
}
}
由上面的代码可以看出,doResolveDependency 这个方法还是挺复杂的。这里我就不继续分析 doResolveDependency 所调用的方法了,对于这些方法,我也是似懂非懂。好了,本节的最后我们来总结一下 doResolveDependency 的执行流程吧,如下:
- 首先将 beanName 和 requiredType 作为参数,并尝试从 BeanFactory 中获取与此对于的 bean。若获取成功,就可以提前结束 doResolveDependency 的逻辑。
- 处理 @value 注解
- 解析数组、List、Map 等类型的依赖,如果解析结果不为空,则返回结果
- 根据类型查找合适的候选项
- 如果候选项的数量为0,则抛出异常。为1,直接从候选列表中取出即可。若候选项数量 > 1,则在多个候选项中确定最优候选项,若无法确定则抛出异常
- 若候选项是 Class 类型,表明候选项还没实例化,此时通过 BeanFactory.getBean 方法对其进行实例化。若候选项是非 Class 类型,则表明已经完成了实例化,此时直接返回即可。
applyPropertyValues
经过了上面的流程,现在终于可以将属性值注入到 bean 对象中了。当然,这里还不能立即将属性值注入到对象中,因为在 Spring 配置文件中属性值都是以 String 类型进行配置的,所以 Spring 框架需要对 String 类型进行转换。除此之外,对于 ref 属性,这里还需要根据 ref 属性值解析依赖。还有一些其他操作,这里就不多说了,更多的信息我们一起在源码探寻。
protected void applyPropertyValues(String beanName, BeanDefinition mbd, BeanWrapper bw, PropertyValues pvs) {
if (pvs == null || pvs.isEmpty()) {
return;
}
if (System.getSecurityManager() != null && bw instanceof BeanWrapperImpl) {
((BeanWrapperImpl) bw).setSecurityContext(getAccessControlContext());
}
MutablePropertyValues mpvs = null;
List<PropertyValue> original;
if (pvs instanceof MutablePropertyValues) {
mpvs = (MutablePropertyValues) pvs;
// 如果属性列表 pvs 被转换过,则直接返回即可
if (mpvs.isConverted()) {
try {
bw.setPropertyValues(mpvs);
return;
}
catch (BeansException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Error setting property values", ex);
}
}
original = mpvs.getPropertyValueList();
}
else {
original = Arrays.asList(pvs.getPropertyValues());
}
TypeConverter converter = getCustomTypeConverter();
if (converter == null) {
converter = bw;
}
BeanDefinitionValueResolver valueResolver = new BeanDefinitionValueResolver(this, beanName, mbd, converter);
List<PropertyValue> deepCopy = new ArrayList<PropertyValue>(original.size());
boolean resolveNecessary = false;
// 遍历属性列表
for (PropertyValue pv : original) {
// 如果属性值被转换过,则就不需要再次转换
if (pv.isConverted()) {
deepCopy.add(pv);
}
else {
String propertyName = pv.getName();
Object originalValue = pv.getValue();
/*
* 解析属性值。举例说明,先看下面的配置:
*
* <bean id="macbook" class="MacBookPro">
* <property name="manufacturer" value="Apple"/>
* <property name="width" value="280"/>
* <property name="cpu" ref="cpu"/>
* <property name="interface">
* <list>
* <value>USB</value>
* <value>HDMI</value>
* <value>Thunderbolt</value>
* </list>
* </property>
* </bean>
*
* 上面是一款电脑的配置信息,每个 property 配置经过下面的方法解析后,返回如下结果:
* propertyName = "manufacturer", resolvedValue = "Apple"
* propertyName = "width", resolvedValue = "280"
* propertyName = "cpu", resolvedValue = "CPU@1234" 注:resolvedValue 是一个对象
* propertyName = "interface", resolvedValue = ["USB", "HDMI", "Thunderbolt"]
*
* 如上所示,resolveValueIfNecessary 会将 ref 解析为具体的对象,将 <list>
* 标签转换为 List 对象等。对于 int 类型的配置,这里并未做转换,所以
* width = "280",还是字符串。除了解析上面几种类型,该方法还会解析 <set/>、
* <map/>、<array/> 等集合配置
*/
Object resolvedValue = valueResolver.resolveValueIfNecessary(pv, originalValue);
Object convertedValue = resolvedValue;
/*
* convertible 表示属性值是否可转换,由两个条件合成而来。第一个条件不难理解,解释
* 一下第二个条件。第二个条件用于检测 propertyName 是否是 nested 或者 indexed,
* 直接举例说明吧:
*
* public class Room {
* private Door door = new Door();
* }
*
* room 对象里面包含了 door 对象,如果我们想向 door 对象中注入属性值,则可以这样配置:
*
* <bean id="room" class="xyz.coolblog.Room">
* <property name="door.width" value="123"/>
* </bean>
*
* isNestedOrIndexedProperty 会根据 propertyName 中是否包含 . 或 [ 返回
* true 和 false。包含则返回 true,否则返回 false。关于 nested 类型的属性,我
* 没在实践中用过,所以不知道上面举的例子是不是合理。若不合理,欢迎指正,也请多多指教。
* 关于 nested 类型的属性,大家还可以参考 Spring 的官方文档:
* https://docs.spring.io/spring/docs/4.3.17.RELEASE/spring-framework-reference/htmlsingle/#beans-beans-conventions
*/
boolean convertible = bw.isWritableProperty(propertyName) &&
!PropertyAccessorUtils.isNestedOrIndexedProperty(propertyName);
// 对于一般的属性,convertible 通常为 true
if (convertible) {
// 对属性值的类型进行转换,比如将 String 类型的属性值 "123" 转为 Integer 类型的 123
convertedValue = convertForProperty(resolvedValue, propertyName, bw, converter);
}
/*
* 如果 originalValue 是通过 autowireByType 或 autowireByName 解析而来,
* 那么此处条件成立,即 (resolvedValue == originalValue) = true
*/
if (resolvedValue == originalValue) {
if (convertible) {
// 将 convertedValue 设置到 pv 中,后续再次创建同一个 bean 时,就无需再次进行转换了
pv.setConvertedValue(convertedValue);
}
deepCopy.add(pv);
}
/*
* 如果原始值 originalValue 是 TypedStringValue,且转换后的值
* convertedValue 不是 Collection 或数组类型,则将转换后的值存入到 pv 中。
*/
else if (convertible && originalValue instanceof TypedStringValue &&
!((TypedStringValue) originalValue).isDynamic() &&
!(convertedValue instanceof Collection || ObjectUtils.isArray(convertedValue))) {
pv.setConvertedValue(convertedValue);
deepCopy.add(pv);
}
else {
resolveNecessary = true;
deepCopy.add(new PropertyValue(pv, convertedValue));
}
}
}
if (mpvs != null && !resolveNecessary) {
mpvs.setConverted();
}
try {
// 将所有的属性值设置到 bean 实例中
bw.setPropertyValues(new MutablePropertyValues(deepCopy));
}
catch (BeansException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Error setting property values", ex);
}
}
以上就是 applyPropertyValues 方法的源码,配合着我写的注释,应该可以理解这个方法的流程。这个方法也调用了很多其他的方法,如果大家跟下去的话,会发现这些方法的调用栈也是很深的,比较复杂。这里说一下 bw.setPropertyValues 这个方法,如果大家跟到这个方法的调用栈的最底部,会发现这个方法是通过调用对象的 setter 方法进行属性设置的。这里贴一下简化后的代码:
public class BeanWrapperImpl extends AbstractNestablePropertyAccessor implements BeanWrapper {
// 省略部分代码
private class BeanPropertyHandler extends PropertyHandler {
@Override
public void setValue(final Object object, Object valueToApply) throws Exception {
// 获取 writeMethod,也就是 setter 方法
final Method writeMethod = this.pd.getWriteMethod();
if (!Modifier.isPublic(writeMethod.getDeclaringClass().getModifiers()) && !writeMethod.isAccessible()) {
writeMethod.setAccessible(true);
}
final Object value = valueToApply;
// 调用 setter 方法,getWrappedInstance() 返回的是 bean 对象
writeMethod.invoke(getWrappedInstance(), value);
}
}
}
好了,本节的最后来总结一下 applyPropertyValues 方法的执行流程吧,如下:
- 检测属性值列表是否已转换过的,若转换过,则直接填充属性,无需再次转换
- 遍历属性值列表 pvs,解析原始值 originalValue,得到解析值 resolvedValue
- 对解析后的属性值 resolvedValue 进行类型转换
- 将类型转换后的属性值设置到 PropertyValue 对象中,并将 PropertyValue 对象存入 deepCopy 集合中
- 将 deepCopy 中的属性信息注入到 bean 对象中
2.6 - CH06-后续初始化工作
initializeBean
protected Object initializeBean(final String beanName, final Object bean, RootBeanDefinition mbd) {
if (System.getSecurityManager() != null) {
AccessController.doPrivileged(new PrivilegedAction<Object>() {
@Override
public Object run() {
invokeAwareMethods(beanName, bean);
return null;
}
}, getAccessControlContext());
}
else {
// 若 bean 实现了 BeanNameAware、BeanFactoryAware、BeanClassLoaderAware 等接口,则向 bean 中注入相关对象
invokeAwareMethods(beanName, bean);
}
Object wrappedBean = bean;
if (mbd == null || !mbd.isSynthetic()) {
// 执行 bean 初始化前置操作
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
try {
/*
* 调用初始化方法:
* 1. 若 bean 实现了 InitializingBean 接口,则调用 afterPropertiesSet 方法
* 2. 若用户配置了 bean 的 init-method 属性,则调用用户在配置中指定的方法
*/
invokeInitMethods(beanName, wrappedBean, mbd);
}
catch (Throwable ex) {
throw new BeanCreationException(
(mbd != null ? mbd.getResourceDescription() : null),
beanName, "Invocation of init method failed", ex);
}
if (mbd == null || !mbd.isSynthetic()) {
// 执行 bean 初始化后置操作,AOP 会在此处向目标对象中织入切面逻辑
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}
return wrappedBean;
}
以上就是 initializeBean 方法的逻辑,很简单是不是。该方法做了如下几件事情:
- 检测 bean 是否实现了 *Aware 类型接口,若实现,则向 bean 中注入相应的对象
- 执行 bean 初始化前置操作
- 执行初始化操作
- 执行 bean 初始化后置操作
在上面的流程中,我们又发现了后置处理器的踪影。如果大家阅读过 Spring 的源码,会发现后置处理器在 Spring 源码中多次出现过。后置处理器是 Spring 拓展点之一,通过实现后置处理器 BeanPostProcessor 接口,我们就可以插手 bean 的初始化过程。比如大家所熟悉的 AOP 就是在后置处理 postProcessAfterInitialization 方法中向目标对象中织如切面逻辑的。关于“前置处理”和“后置处理”相关的源码,这里就不分析了,大家有兴趣自己去看一下。接下来分析一下 invokeAwareMethods 和 invokeInitMethods 方法,如下:
private void invokeAwareMethods(final String beanName, final Object bean) {
if (bean instanceof Aware) {
if (bean instanceof BeanNameAware) {
// 注入 beanName 字符串
((BeanNameAware) bean).setBeanName(beanName);
}
if (bean instanceof BeanClassLoaderAware) {
// 注入 ClassLoader 对象
((BeanClassLoaderAware) bean).setBeanClassLoader(getBeanClassLoader());
}
if (bean instanceof BeanFactoryAware) {
// 注入 BeanFactory 对象
((BeanFactoryAware) bean).setBeanFactory(AbstractAutowireCapableBeanFactory.this);
}
}
}
invokeAwareMethods 方法的逻辑很简单,一句话总结:根据 bean 所实现的 Aware 的类型,向 bean 中注入不同类型的对象。
protected void invokeInitMethods(String beanName, final Object bean, RootBeanDefinition mbd)
throws Throwable {
// 检测 bean 是否是 InitializingBean 类型的
boolean isInitializingBean = (bean instanceof InitializingBean);
if (isInitializingBean && (mbd == null || !mbd.isExternallyManagedInitMethod("afterPropertiesSet"))) {
if (logger.isDebugEnabled()) {
logger.debug("Invoking afterPropertiesSet() on bean with name '" + beanName + "'");
}
if (System.getSecurityManager() != null) {
try {
AccessController.doPrivileged(new PrivilegedExceptionAction<Object>() {
@Override
public Object run() throws Exception {
((InitializingBean) bean).afterPropertiesSet();
return null;
}
}, getAccessControlContext());
}
catch (PrivilegedActionException pae) {
throw pae.getException();
}
}
else {
// 如果 bean 实现了 InitializingBean,则调用 afterPropertiesSet 方法执行初始化逻辑
((InitializingBean) bean).afterPropertiesSet();
}
}
if (mbd != null) {
String initMethodName = mbd.getInitMethodName();
if (initMethodName != null && !(isInitializingBean && "afterPropertiesSet".equals(initMethodName)) &&
!mbd.isExternallyManagedInitMethod(initMethodName)) {
// 调用用户自定义的初始化方法
invokeCustomInitMethod(beanName, bean, mbd);
}
}
}
2.7 - CH07-生命周期扩展
Spring的核心思想就是容器,当容器refresh的时候,外部看上去风平浪静,其实内部则是一片惊涛骇浪,汪洋一片。Springboot更是封装了Spring,遵循约定大于配置,加上自动装配的机制。很多时候我们只要引用了一个依赖,几乎是零配置就能完成一个功能的装配。
我非常喜欢这种自动装配的机制,所以在自己开发中间件和公共依赖工具的时候也会用到这个特性。让使用者以最小的代价接入。想要把自动装配玩的转,就必须要了解spring对于bean的构造生命周期以及各个扩展接口。当然了解了bean的各个生命周期也能促进我们加深对spring的理解。业务代码也能合理利用这些扩展点写出更加漂亮的代码。
0. 扩展点调用顺序图
1. ApplicationContextInitializer
org.springframework.context.ApplicationContextInitializer
这是整个spring容器在刷新之前初始化ConfigurableApplicationContext的回调接口,简单来说,就是在容器刷新之前调用此类的initialize方法。这个点允许被用户自己扩展。用户可以在整个spring容器还没被初始化之前做一些事情。
可以想到的场景可能为,在最开始激活一些配置,或者利用这时候 class 还没被类加载器加载的时机,进行动态字节码注入等操作。
扩展方式为:
public class TestApplicationContextInitializer implements ApplicationContextInitializer {
@Override
public void initialize(ConfigurableApplicationContext applicationContext) {
System.out.println("[ApplicationContextInitializer]");
}
}
因为这时候spring容器还没被初始化,所以想要自己的扩展的生效,有以下三种方式:
- 在启动类中用
springApplication.addInitializers(new TestApplicationContextInitializer())语句加入 - 配置文件配置
context.initializer.classes=com.example.demo.TestApplicationContextInitializer - Spring SPI扩展,在spring.factories中加入
org.springframework.context.ApplicationContextInitializer=com.example.demo.TestApplicationContextInitializer
2. BeanDefinitionRegistryPostProcessor
org.springframework.beans.factory.support.BeanDefinitionRegistryPostProcessor
这个接口在读取项目中的beanDefinition之后执行,提供一个补充的扩展点
使用场景:你可以在这里动态注册自己的beanDefinition,可以加载classpath之外的bean
扩展方式为:
public class TestBeanDefinitionRegistryPostProcessor implements BeanDefinitionRegistryPostProcessor {
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException {
System.out.println("[BeanDefinitionRegistryPostProcessor] postProcessBeanDefinitionRegistry");
}
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
System.out.println("[BeanDefinitionRegistryPostProcessor] postProcessBeanFactory");
}
}
3. BeanFactoryPostProcessor
org.springframework.beans.factory.config.BeanFactoryPostProcessor
这个接口是beanFactory的扩展接口,调用时机在spring在读取beanDefinition信息之后,实例化bean之前。
在这个时机,用户可以通过实现这个扩展接口来自行处理一些东西,比如修改已经注册的beanDefinition的元信息。
扩展方式为:
public class TestBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
System.out.println("[BeanFactoryPostProcessor]");
}
}
4. InstantiationAwareBeanPostProcessor
org.springframework.beans.factory.config.InstantiationAwareBeanPostProcessor
该接口继承了BeanPostProcess接口,区别如下:
BeanPostProcess接口只在bean的初始化阶段进行扩展(注入spring上下文前后),而InstantiationAwareBeanPostProcessor接口在此基础上增加了3个方法,把可扩展的范围增加了实例化阶段和属性注入阶段。
该类主要的扩展点有以下5个方法,主要在bean生命周期的两大阶段:实例化阶段和初始化阶段,下面一起进行说明,按调用顺序为:
postProcessBeforeInstantiation:实例化bean之前,相当于new这个bean之前postProcessAfterInstantiation:实例化bean之后,相当于new这个bean之后postProcessPropertyValues:bean已经实例化完成,在属性注入时阶段触发,@Autowired,@Resource等注解原理基于此方法实现postProcessBeforeInitialization:初始化bean之前,相当于把bean注入spring上下文之前postProcessAfterInitialization:初始化bean之后,相当于把bean注入spring上下文之后
使用场景:这个扩展点非常有用 ,无论是写中间件和业务中,都能利用这个特性。比如对实现了某一类接口的bean在各个生命期间进行收集,或者对某个类型的bean进行统一的设值等等。
扩展方式为:
public class TestInstantiationAwareBeanPostProcessor implements InstantiationAwareBeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println("[TestInstantiationAwareBeanPostProcessor] before initialization " + beanName);
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("[TestInstantiationAwareBeanPostProcessor] after initialization " + beanName);
return bean;
}
@Override
public Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException {
System.out.println("[TestInstantiationAwareBeanPostProcessor] before instantiation " + beanName);
return null;
}
@Override
public boolean postProcessAfterInstantiation(Object bean, String beanName) throws BeansException {
System.out.println("[TestInstantiationAwareBeanPostProcessor] after instantiation " + beanName);
return true;
}
@Override
public PropertyValues postProcessPropertyValues(PropertyValues pvs, PropertyDescriptor[] pds, Object bean, String beanName) throws BeansException {
System.out.println("[TestInstantiationAwareBeanPostProcessor] postProcessPropertyValues " + beanName);
return pvs;
}
5. SmartInstantiationAwareBeanPostProcessor
org.springframework.beans.factory.config.SmartInstantiationAwareBeanPostProcessor
该扩展接口有3个触发点方法:
predictBeanType:该触发点发生在postProcessBeforeInstantiation之前(在图上并没有标明,因为一般不太需要扩展这个点),这个方法用于预测Bean的类型,返回第一个预测成功的Class类型,如果不能预测返回null;当你调用BeanFactory.getType(name)时当通过bean的名字无法得到bean类型信息时就调用该回调方法来决定类型信息。determineCandidateConstructors:该触发点发生在postProcessBeforeInstantiation之后,用于确定该bean的构造函数之用,返回的是该bean的所有构造函数列表。用户可以扩展这个点,来自定义选择相应的构造器来实例化这个bean。getEarlyBeanReference:该触发点发生在postProcessAfterInstantiation之后,当有循环依赖的场景,当bean实例化好之后,为了防止有循环依赖,会提前暴露回调方法,用于bean实例化的后置处理。这个方法就是在提前暴露的回调方法中触发。
扩展方式为:
public class TestSmartInstantiationAwareBeanPostProcessor implements SmartInstantiationAwareBeanPostProcessor {
@Override
public Class<?> predictBeanType(Class<?> beanClass, String beanName) throws BeansException {
System.out.println("[TestSmartInstantiationAwareBeanPostProcessor] predictBeanType " + beanName);
return beanClass;
}
@Override
public Constructor<?>[] determineCandidateConstructors(Class<?> beanClass, String beanName) throws BeansException {
System.out.println("[TestSmartInstantiationAwareBeanPostProcessor] determineCandidateConstructors " + beanName);
return null;
}
@Override
public Object getEarlyBeanReference(Object bean, String beanName) throws BeansException {
System.out.println("[TestSmartInstantiationAwareBeanPostProcessor] getEarlyBeanReference " + beanName);
return bean;
}
}
6. BeanFactoryAware
org.springframework.beans.factory.BeanFactoryAware
这个类只有一个触发点,发生在bean的实例化之后,注入属性之前,也就是Setter之前。这个类的扩展点方法为setBeanFactory,可以拿到BeanFactory这个属性。
使用场景为,你可以在bean实例化之后,但还未初始化之前,拿到 BeanFactory,在这个时候,可以对每个bean作特殊化的定制。也或者可以把BeanFactory拿到进行缓存,日后使用。
扩展方式为:
public class TestBeanFactoryAware implements BeanFactoryAware {
@Override
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
System.out.println("[TestBeanFactoryAware] " + beanFactory.getBean(TestBeanFactoryAware.class).getClass().getSimpleName());
}
}
7. ApplicationContextAwareProcessor
org.springframework.context.support.ApplicationContextAwareProcessor
该类本身并没有扩展点,但是该类内部却有6个扩展点可供实现 ,这些类触发的时机在bean实例化之后,初始化之前:
可以看到,该类用于执行各种驱动接口,在bean实例化之后,属性填充之后,通过执行以上红框标出的扩展接口,来获取对应容器的变量。所以这里应该来说是有6个扩展点,这里就放一起来说了
EnvironmentAware:用于获取EnviromentAware的一个扩展类,这个变量非常有用, 可以获得系统内的所有参数。当然个人认为这个Aware没必要去扩展,因为spring内部都可以通过注入的方式来直接获得。EmbeddedValueResolverAware:用于获取StringValueResolver的一个扩展类, StringValueResolver用于获取基于String类型的properties的变量,一般我们都用@Value的方式去获取,如果实现了这个Aware接口,把StringValueResolver缓存起来,通过这个类去获取String类型的变量,效果是一样的。ResourceLoaderAware:用于获取ResourceLoader的一个扩展类,ResourceLoader可以用于获取classpath内所有的资源对象,可以扩展此类来拿到ResourceLoader对象。ApplicationEventPublisherAware:用于获取ApplicationEventPublisher的一个扩展类,ApplicationEventPublisher可以用来发布事件,结合ApplicationListener来共同使用,下文在介绍ApplicationListener时会详细提到。这个对象也可以通过spring注入的方式来获得。MessageSourceAware:用于获取MessageSource的一个扩展类,MessageSource主要用来做国际化。ApplicationContextAware:用来获取ApplicationContext的一个扩展类,ApplicationContext应该是很多人非常熟悉的一个类了,就是spring上下文管理器,可以手动的获取任何在spring上下文注册的bean,我们经常扩展这个接口来缓存spring上下文,包装成静态方法。同时ApplicationContext也实现了BeanFactory,MessageSource,ApplicationEventPublisher等接口,也可以用来做相关接口的事情。
8. BeanNameAware
org.springframework.beans.factory.BeanNameAware
可以看到,这个类也是Aware扩展的一种,触发点在bean的初始化之前,也就是postProcessBeforeInitialization之前,这个类的触发点方法只有一个:setBeanName
使用场景为:用户可以扩展这个点,在初始化bean之前拿到spring容器中注册的的beanName,来自行修改这个beanName的值。
扩展方式为:
public class NormalBeanA implements BeanNameAware{
public NormalBeanA() {
System.out.println("NormalBean constructor");
}
@Override
public void setBeanName(String name) {
System.out.println("[BeanNameAware] " + name);
}
}
9. @PostConstruct
javax.annotation.PostConstruct
这个并不算一个扩展点,其实就是一个标注。其作用是在bean的初始化阶段,如果对一个方法标注了@PostConstruct,会先调用这个方法。这里重点是要关注下这个标准的触发点,这个触发点是在postProcessBeforeInitialization之后,InitializingBean.afterPropertiesSet之前。
使用场景:用户可以对某一方法进行标注,来进行初始化某一个属性
扩展方式为:
public class NormalBeanA {
public NormalBeanA() {
System.out.println("NormalBean constructor");
}
@PostConstruct
public void init(){
System.out.println("[PostConstruct] NormalBeanA");
}
}
10. InitializingBean
org.springframework.beans.factory.InitializingBean
这个类,顾名思义,也是用来初始化bean的。InitializingBean接口为bean提供了初始化方法的方式,它只包括afterPropertiesSet方法,凡是继承该接口的类,在初始化bean的时候都会执行该方法。这个扩展点的触发时机在postProcessAfterInitialization之前。
使用场景:用户实现此接口,来进行系统启动的时候一些业务指标的初始化工作。
扩展方式为:
public class NormalBeanA implements InitializingBean{
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("[InitializingBean] NormalBeanA");
}
}
11. FactoryBean
org.springframework.beans.factory.FactoryBean
一般情况下,Spring通过反射机制利用bean的class属性指定支线类去实例化bean,在某些情况下,实例化Bean过程比较复杂,如果按照传统的方式,则需要在bean中提供大量的配置信息。配置方式的灵活性是受限的,这时采用编码的方式可能会得到一个简单的方案。Spring为此提供了一个org.springframework.bean.factory.FactoryBean的工厂类接口,用户可以通过实现该接口定制实例化Bean的逻辑。FactoryBean接口对于Spring框架来说占用重要的地位,Spring自身就提供了70多个FactoryBean的实现。它们隐藏了实例化一些复杂bean的细节,给上层应用带来了便利。从Spring3.0开始,FactoryBean开始支持泛型,即接口声明改为FactoryBean<T>的形式
使用场景:用户可以扩展这个类,来为要实例化的bean作一个代理,比如为该对象的所有的方法作一个拦截,在调用前后输出一行log,模仿ProxyFactoryBean的功能。
扩展方式为:
public class TestFactoryBean implements FactoryBean<TestFactoryBean.TestFactoryInnerBean> {
@Override
public TestFactoryBean.TestFactoryInnerBean getObject() throws Exception {
System.out.println("[FactoryBean] getObject");
return new TestFactoryBean.TestFactoryInnerBean();
}
@Override
public Class<?> getObjectType() {
return TestFactoryBean.TestFactoryInnerBean.class;
}
@Override
public boolean isSingleton() {
return true;
}
public static class TestFactoryInnerBean{
}
}
12. SmartInitializingSingleton
org.springframework.beans.factory.SmartInitializingSingleton
这个接口中只有一个方法afterSingletonsInstantiated,其作用是是 在spring容器管理的所有单例对象(非懒加载对象)初始化完成之后调用的回调接口。其触发时机为postProcessAfterInitialization之后。
使用场景:用户可以扩展此接口在对所有单例对象初始化完毕后,做一些后置的业务处理。
扩展方式为:
public class TestSmartInitializingSingleton implements SmartInitializingSingleton {
@Override
public void afterSingletonsInstantiated() {
System.out.println("[TestSmartInitializingSingleton]");
}
}
13. CommandLineRunner
org.springframework.boot.CommandLineRunner
这个接口也只有一个方法:run(String... args),触发时机为整个项目启动完毕后,自动执行。如果有多个CommandLineRunner,可以利用@Order来进行排序。
使用场景:用户扩展此接口,进行启动项目之后一些业务的预处理。
扩展方式为:
public class TestCommandLineRunner implements CommandLineRunner {
@Override
public void run(String... args) throws Exception {
System.out.println("[TestCommandLineRunner]");
}
}
14. DisposableBean
org.springframework.beans.factory.DisposableBean
这个扩展点也只有一个方法:destroy(),其触发时机为当此对象销毁时,会自动执行这个方法。比如说运行applicationContext.registerShutdownHook时,就会触发这个方法。
扩展方式为:
public class NormalBeanA implements DisposableBean {
@Override
public void destroy() throws Exception {
System.out.println("[DisposableBean] NormalBeanA");
}
}
15. ApplicationListener
org.springframework.context.ApplicationListener
准确的说,这个应该不算spring&springboot当中的一个扩展点,ApplicationListener可以监听某个事件的event,触发时机可以穿插在业务方法执行过程中,用户可以自定义某个业务事件。但是spring内部也有一些内置事件,这种事件,可以穿插在启动调用中。我们也可以利用这个特性,来自己做一些内置事件的监听器来达到和前面一些触发点大致相同的事情。
接下来罗列下spring主要的内置事件:
ContextRefreshedEvent
ApplicationContext 被初始化或刷新时,该事件被发布。这也可以在 ConfigurableApplicationContext接口中使用 refresh() 方法来发生。此处的初始化是指:所有的Bean被成功装载,后处理Bean被检测并激活,所有Singleton Bean 被预实例化,ApplicationContext容器已就绪可用。
ContextStartedEvent
当使用 ConfigurableApplicationContext (ApplicationContext子接口)接口中的 start() 方法启动 ApplicationContext 时,该事件被发布。你可以调查你的数据库,或者你可以在接受到这个事件后重启任何停止的应用程序。
ContextStoppedEvent
当使用 ConfigurableApplicationContext 接口中的 stop() 停止 ApplicationContext 时,发布这个事件。你可以在接受到这个事件后做必要的清理的工作
ContextClosedEvent
当使用 ConfigurableApplicationContext接口中的 close()方法关闭 ApplicationContext 时,该事件被发布。一个已关闭的上下文到达生命周期末端;它不能被刷新或重启
RequestHandledEvent
这是一个 web-specific 事件,告诉所有 bean HTTP 请求已经被服务。只能应用于使用DispatcherServlet的Web应用。在使用Spring作为前端的MVC控制器时,当Spring处理用户请求结束后,系统会自动触发该事件
总结
我们从这些spring&springboot的扩展点当中,大致可以窥视到整个bean的生命周期。在业务开发或者写中间件业务的时候,可以合理利用spring提供给我们的扩展点,在spring启动的各个阶段内做一些事情。以达到自定义初始化的目的。
2.8 - CH08-控制加载顺序
springboot遵从约定大于配置的原则,极大程度的解决了配置繁琐的问题。在此基础上,又提供了spi机制,用spring.factories可以完成一个小组件的自动装配功能。
在一般业务场景,可能你不大关心一个bean是如何被注册进spring容器的。只需要把需要注册进容器的bean声明为@Component即可,spring会自动扫描到这个Bean完成初始化并加载到spring上下文容器。
而当你在项目启动时需要提前做一个业务的初始化工作时,或者你正在开发某个中间件需要完成自动装配时。你会声明自己的Configuration类,但是可能你面对的是好几个有互相依赖的Bean。如果不加以控制,这时候可能会报找不到依赖的错误。
但是你明明已经把相关的Bean都注册进spring上下文了呀。这时候你需要通过一些手段来控制springboot中的bean加载顺序。
几个误区
在正式说如何控制加载顺序之前,先说2个误区。
在标注了@Configuration的类中,写在前面的@Bean一定会被先注册
这个不存在的,spring在以前xml的时代,也不存在写在前面一定会被先加载的逻辑。因为xml不是渐进的加载,而是全部parse好,再进行依赖分析和注册。到了springboot中,只是省去了xml被parse成spring内部对象的这一过程,但是加载方式并没有大的改变。
利用@Order这个标注能进行加载顺序的控制
严格的说,不是所有的Bean都可以通过@Order这个标注进行顺序的控制。你把@Order这个标注加在普通的方法上或者类上一点鸟用都没有。
那@Order能控制哪些bean的加载顺序呢,我们先看看官方的解释:
{@code @Order} defines the sort order for an annotated component. Since Spring 4.0, annotation-based ordering is supported for many kinds of components in Spring, even for collection injection where the order values of the target components are taken into account (either from their target class or from their {@code @Bean} method). While such order values may influence priorities at injection points, please be aware that they do not influence singleton startup order which is an orthogonal concern determined by dependency relationships and {@code @DependsOn} declarations (influencing a runtime-determined dependency graph).
最开始@Order注解用于切面的优先级指定;在 4.0 之后对它的功能进行了增强,支持集合的注入时,指定集合中 bean 的顺序,并且特别指出了,它对于但实例的 bean 之间的顺序,没有任何影响。
目前用的比较多的有以下3点:
- 控制AOP的类的加载顺序,也就是被
@Aspect标注的类 - 控制
ApplicationListener实现类的加载顺序 - 控制
CommandLineRunner实现类的加载顺序
控制方法
@DependsOn
@DependsOn注解可以用来控制bean的创建顺序,该注解用于声明当前bean依赖于另外一个bean。所依赖的bean会被容器确保在当前bean实例化之前被实例化。
示例:
@Configuration
public class BeanOrderConfiguration {
@Bean
@DependsOn("beanB")
public BeanA beanA(){
System.out.println("bean A init");
return new BeanA();
}
@Bean
public BeanB beanB(){
System.out.println("bean B init");
return new BeanB();
}
@Bean
@DependsOn({"beanD","beanE"})
public BeanC beanC(){
System.out.println("bean C init");
return new BeanC();
}
@Bean
@DependsOn("beanE")
public BeanD beanD(){
System.out.println("bean D init");
return new BeanD();
}
@Bean
public BeanE beanE(){
System.out.println("bean E init");
return new BeanE();
}
}
以上代码bean的加载顺序为:
bean B init
bean A init
bean E init
bean D init
bean C init
@DependsOn的使用:
- 直接或者间接标注在带有
@Component注解的类上面; - 直接或者间接标注在带有
@Bean注解的方法上面; - 使用
@DependsOn注解到类层面仅仅在使用 component-scanning 方式时才有效,如果带有@DependsOn注解的类通过XML方式使用,该注解会被忽略,<bean depends-on="..."/>这种方式会生效。
参数注入
在@Bean标注的方法上,如果你传入了参数,springboot会自动会为这个参数在spring上下文里寻找这个类型的引用。并先初始化这个类的实例。
利用此特性,我们也可以控制bean的加载顺序。
示例:
@Bean
public BeanA beanA(BeanB demoB){
System.out.println("bean A init");
return new BeanA();
}
@Bean
public BeanB beanB(){
System.out.println("bean B init");
return new BeanB();
}
以上结果,beanB先于beanA被初始化加载。
需要注意的是,springboot会按类型去寻找。如果这个类型有多个实例被注册到spring上下文,那你就需要加上@Qualifier("Bean的名称")来指定
生命周期中的扩展点
在spring体系中,从容器到Bean实例化&初始化都是有生命周期的,并且提供了很多的扩展点,允许你在这些步骤时进行逻辑的扩展。
这些可扩展点的加载顺序由spring自己控制,大多数是无法进行干预的。我们可以利用这一点,扩展spring的扩展点。在相应的扩展点加入自己的业务初始化代码。从来达到顺序的控制。
这个注解用来指定配置文件的加载顺序。但是在实际测试中发现,以下这样使用是不生效的:
@Configuration
@AutoConfigureOrder(2)
public class BeanOrderConfiguration1 {
@Bean
public BeanA beanA(){
System.out.println("bean A init");
return new BeanA();
}
}
@Configuration
@AutoConfigureOrder(1)
public class BeanOrderConfiguration2 {
@Bean
public BeanB beanB(){
System.out.println("bean B init");
return new BeanB();
}
}
无论你2个数字填多少,都不会改变其加载顺序结果。
那这个@AutoConfigureOrder到底是如何使用的呢。
经过测试发现,@AutoConfigureOrder只能改变外部依赖的@Configuration的顺序。如何理解是外部依赖呢。
能被你工程内部scan到的包,都是内部的Configuration,而spring引入外部的Configuration,都是通过spring特有的spi文件:spring.factories
换句话说,@AutoConfigureOrder能改变spring.factories中的@Configuration的顺序。
具体使用方式:
@Configuration
@AutoConfigureOrder(10)
public class BeanOrderConfiguration1 {
@Bean
public BeanA beanA(){
System.out.println("bean A init");
return new BeanA();
}
}
@Configuration
@AutoConfigureOrder(1)
public class BeanOrderConfiguration2 {
@Bean
public BeanB beanB(){
System.out.println("bean B init");
return new BeanB();
}
}
spring.factories:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.example.demo.BeanOrderConfiguration1,\
com.example.demo.BeanOrderConfiguration2
3.1 - AOP 理论
什么是 AOP
AOP(Aspect-Oriented Programming), 即 面向切面编程, 它与 OOP( Object-Oriented Programming, 面向对象编程) 相辅相成, 提供了与 OOP 不同的抽象软件结构的视角.
在 OOP 中, 我们以类(class)作为我们的基本单元, 而 AOP 中的基本单元是 Aspect(切面)。
术语
切面:Aspect
aspect 由 pointcount 和 advice 组成, 它既包含了横切逻辑的定义, 也包括了连接点的定义. Spring AOP就是负责实施切面的框架, 它将切面所定义的横切逻辑织入到切面所指定的连接点中.
AOP的工作重心在于如何将增强织入目标对象的连接点上, 这里包含两个工作:
- 如何通过 pointcut 和 advice 定位到特定的 joinpoint 上
- 如何在 advice 中编写切面代码.
可以简单地认为, 使用 @Aspect 注解的类就是切面.
增强:advice
由 aspect 添加到特定的 join point(即满足 point cut 规则的 join point) 的一段代码.
许多 AOP框架, 包括 Spring AOP, 会将 advice 模拟为一个拦截器(interceptor), 并且在 join point 上维护多个 advice, 进行层层拦截.
例如 HTTP 鉴权的实现, 我们可以为每个使用 RequestMapping 标注的方法织入 advice, 当 HTTP 请求到来时, 首先进入到 advice 代码中, 在这里我们可以分析这个 HTTP 请求是否有相应的权限, 如果有, 则执行 Controller, 如果没有, 则抛出异常. 这里的 advice 就扮演着鉴权拦截器的角色了.
连接点:join point
a point during the execution of a program, such as the execution of a method or the handling of an exception. In Spring AOP, a join point always represents a method execution.
程序运行中的一些时间点、时机, 例如一个方法的执行, 或者是一个异常的处理.
在 Spring AOP 中, join point 总是方法的执行点, 即只有方法连接点.
切点:point cut
匹配 join point 的谓词(a predicate that matches join points).
Advice 是和特定的 point cut 关联的, 并且在 point cut 相匹配的 join point 中执行.
在 Spring 中, 所有的方法都可以认为是 joinpoint, 但是我们并不希望在所有的方法上都添加 Advice, 而 pointcut 的作用就是提供一组规则(使用 AspectJ pointcut expression language 来描述) 来匹配joinpoint, 给满足规则的 joinpoint 添加 Advice.
区别:joint point 与 point cut
在 Spring AOP 中, 所有的方法执行都是 join point. 而 point cut 是一个描述信息, 它修饰的是 join point, 通过 point cut, 我们就可以确定哪些 join point 可以被织入 Advice. 因此 join point 和 point cut 本质上就是两个不同纬度上的东西.
advice 是在 join point 上执行的, 而 point cut 规定了哪些 join point 可以执行哪些 advice
introduction
为一个类型添加额外的方法或字段. Spring AOP 允许我们为 目标对象 引入新的接口(和对应的实现). 例如我们可以使用 introduction 来为一个 bean 实现 IsModified 接口, 并以此来简化 caching 的实现.
目标对象:Target
织入 advice 的目标对象. 目标对象也被称为 advised object.
因为 Spring AOP 使用运行时代理的方式来实现 aspect, 因此 adviced object 总是一个代理对象(proxied object)。
注意, adviced object 指的不是原来的类, 而是织入 advice 后所产生的代理类.
AOP Proxy
一个类被 AOP 织入 advice, 就会产生一个结果类, 它是融合了原类和增强逻辑的代理类.
在 Spring AOP 中, 一个 AOP 代理是一个 JDK 动态代理对象或 CGLIB 代理对象.
织入:Weaving
将 aspect 和其他对象连接起来, 并创建 adviced object 的过程.
根据不同的实现技术, AOP织入有三种方式:
- 编译器织入, 这要求有特殊的Java编译器.
- 类装载期织入, 这需要有特殊的类装载器.
- 动态代理织入, 在运行期为目标类添加增强(Advice)生成子类的方式.
Spring 采用动态代理织入, 而AspectJ采用编译器织入和类装载期织入.
advice 类型
- before advice:在 join point 前被执行的 advice. 虽然 before advice 是在 join point 前被执行, 但是它并不能够阻止 join point 的执行, 除非发生了异常(即我们在 before advice 代码中, 不能人为地决定是否继续执行 join point 中的代码)
- after return advice:在一个 join point 正常返回后执行的 advice
- after throwing advice:当一个 join point 抛出异常后执行的 advice
- after(final) advice:无论一个 join point 是正常退出还是发生了异常, 都会被执行的 advice.
- around advice:在 join point 前和 joint point 退出后都执行的 advice. 这个是最常用的 advice.
关于 AOP Proxy
Spring AOP 默认使用标准的 JDK 动态代理(dynamic proxy)技术来实现 AOP 代理, 通过它, 我们可以为任意的接口实现代理.
如果需要为一个类实现代理, 那么可以使用 CGLIB 代理. 当一个业务逻辑对象没有实现接口时, 那么Spring AOP 就默认使用 CGLIB 来作为 AOP 代理了.
即如果我们需要为一个方法织入 advice, 但是这个方法不是一个接口所提供的方法, 则此时 Spring AOP 会使用 CGLIB 来实现动态代理.
鉴于此, Spring AOP 建议基于接口编程, 对接口进行 AOP 而不是类.
@AspectJ 支持
@AspectJ 是一种使用 Java 注解来实现 AOP 的编码风格.
@AspectJ 风格的 AOP 是 AspectJ Project 在 AspectJ 5 中引入的, 并且 Spring 也支持 @AspectJ 的 AOP 风格.
开启 @AspectJ 支持
@AspectJ 可以以 XML 的方式或以注解的方式来开启, 并且不论以哪种方式开启 @ASpectJ, 我们都必须保证 aspectjweaver.jar 在 classpath 中.
通过 Java Configuration 方式开启 @AspectJ
@Configuration
@EnableAspectJAutoProxy
public class AppConfig {
}
通过 XML 方式开启 @AspectJ
定义切面 aspect
当使用注解 @Aspect 标注一个 Bean 后, 那么 Spring 框架会自动收集这些 Bean, 并添加到 Spring AOP 中, 例如:
@Aspect
@Component
public class MyTest {
}
注意, 仅仅使用@Aspect 注解, 并不能将一个 Java 对象转换为 Bean, 因此我们还需要使用类似 @Component 之类的
注解.注意, 如果一个 类被@Aspect 标注, 则这个类就不能是其他 aspect 的 advised object 了, 因为使用 @Aspect 后, 这个类就会被排除在 auto-proxying 机制之外.
声明 pointcut
一个 pointcut 的声明由两部分组成:
- 一个方法签名, 包括方法名和相关参数
- 一个 pointcut 表达式, 用来指定哪些方法执行是我们感兴趣的(即因此可以织入 advice).
在 @AspectJ 风格的 AOP 中, 我们使用一个方法来描述 pointcut, 即:
@Pointcut("execution(* com.xys.service.UserService.*(..))") // 切点表达式
private void dataAccessOperation() {} // 切点前面
这个方法必须无返回值.
这个方法本身就是 pointcut signature, pointcut 表达式使用@Pointcut 注解指定.
上面我们简单地定义了一个 pointcut, 这个 pointcut 所描述的是: 匹配所有在包 com.xys.service.UserService 下的所有方法的执行.
切点标志符 designator
AspectJ5 的切点表达式由标志符(designator)和操作参数组成. 如 “execution( greetTo(..))” 的切点表达式, execution 就是 标志符, 而圆括号里的 greetTo(..) 就是操作参数
execution
匹配 join point 的执行, 例如 “execution(* hello(..))” 表示匹配所有目标类中的 hello() 方法. 这个是最基本的 pointcut 标志符.
within
匹配特定包下的所有 join point, 例如 within(com.xys.*) 表示 com.xys 包中的所有连接点, 即包中的所有类的所有方法. 而 within(com.xys.service.*Service) 表示在 com.xys.service 包中所有以 Service 结尾的类的所有的连接点.
this 与 target
this 的作用是匹配一个 bean, 这个 bean(Spring AOP proxy) 是一个给定类型的实例(instance of). 而 target 匹配的是一个目标对象(target object, 即需要织入 advice 的原始的类), 此对象是一个给定类型的实例(instance of).
bean
匹配 bean 名字为指定值的 bean 下的所有方法, 例如:
bean(*Service) // 匹配名字后缀为 Service 的 bean 下的所有方法
bean(myService) // 匹配名字为 myService 的 bean 下的所有方法
args
匹配参数满足要求的的方法.
例如:
@Pointcut("within(com.xys.demo2.*)")
public void pointcut2() {
}
@Before(value = "pointcut2() && args(name)")
public void doSomething(String name) {
logger.info("---page: {}---", name);
}
@Service
public class NormalService {
private Logger logger = LoggerFactory.getLogger(getClass());
public void someMethod() {
logger.info("---NormalService: someMethod invoked---");
}
public String test(String name) {
logger.info("---NormalService: test invoked---");
return "服务一切正常";
}
}
当 NormalService.test 执行时, 则 advice doSomething 就会执行, test 方法的参数 name 就会传递到 doSomething 中.
常用例子:
// 匹配只有一个参数 name 的方法
@Before(value = "aspectMethod() && args(name)")
public void doSomething(String name) {
}
// 匹配第一个参数为 name 的方法
@Before(value = "aspectMethod() && args(name, ..)")
public void doSomething(String name) {
}
// 匹配第二个参数为 name 的方法
Before(value = "aspectMethod() && args(*, name, ..)")
public void doSomething(String name) {
}
@annotation
匹配由指定注解所标注的方法, 例如:
@Pointcut("@annotation(com.xys.demo1.AuthChecker)")
public void pointcut() {
}
则匹配由注解 AuthChecker 所标注的方法.
常见切点表达式
匹配方法签名
// 匹配指定包中的所有的方法
execution(* com.xys.service.*(..))
// 匹配当前包中的指定类的所有方法
execution(* UserService.*(..))
// 匹配指定包中的所有 public 方法
execution(public * com.xys.service.*(..))
// 匹配指定包中的所有 public 方法, 并且返回值是 int 类型的方法
execution(public int com.xys.service.*(..))
// 匹配指定包中的所有 public 方法, 并且第一个参数是 String, 返回值是 int 类型的方法
execution(public int com.xys.service.*(String name, ..))
匹配类型签名
// 匹配指定包中的所有的方法, 但不包括子包
within(com.xys.service.*)
// 匹配指定包中的所有的方法, 包括子包
within(com.xys.service..*)
// 匹配当前包中的指定类中的方法
within(UserService)
// 匹配一个接口的所有实现类中的实现的方法
within(UserDao+)
匹配 Bean 名字
// 匹配以指定名字结尾的 Bean 中的所有方法
bean(*Service)
切点表达式组合
// 匹配以 Service 或 ServiceImpl 结尾的 bean
bean(*Service || *ServiceImpl)
// 匹配名字以 Service 结尾, 并且在包 com.xys.service 中的 bean
bean(*Service) && within(com.xys.service.*)
声明 advice
advice 是和一个 pointcut 表达式关联在一起的, 并且会在匹配的 join point 的方法执行的前/后/周围 运行. pointcut 表达式可以是简单的一个 pointcut 名字的引用, 或者是完整的 pointcut 表达式.
下面我们以几个简单的 advice 为例子, 来看一下一个 advice 是如何声明的.
Before advice
/**
* @author xiongyongshun
* @version 1.0
* @created 16/9/9 13:13
*/
@Component
@Aspect
public class BeforeAspectTest {
// 定义一个 Pointcut, 使用 切点表达式函数 来描述对哪些 Join point 使用 advise.
@Pointcut("execution(* com.xys.service.UserService.*(..))")
public void dataAccessOperation() {
}
}
@Component
@Aspect
public class AdviseDefine {
// 定义 advise
@Before("com.xys.aspect.PointcutDefine.dataAccessOperation()")
public void doBeforeAccessCheck(JoinPoint joinPoint) {
System.out.println("*****Before advise, method: " + joinPoint.getSignature().toShortString() + " *****");
}
}
这里, @Before 引用了一个 pointcut, 即 “com.xys.aspect.PointcutDefine.dataAccessOperation()” 是一个 pointcut 的名字.
如果我们在 advice 在内置 pointcut, 则可以:
@Component
@Aspect
public class AdviseDefine {
// 将 pointcut 和 advice 同时定义
@Before("within(com.xys.service..*)")
public void doAccessCheck(JoinPoint joinPoint) {
System.out.println("*****doAccessCheck, Before advise, method: " + joinPoint.getSignature().toShortString() + " *****");
}
}
around advice
around advice 比较特别, 它可以在一个方法的之前之前和之后添加不同的操作, 并且甚至可以决定何时, 如何, 是否调用匹配到的方法.
@Component
@Aspect
public class AdviseDefine {
// 定义 advise
@Around("com.xys.aspect.PointcutDefine.dataAccessOperation()")
public Object doAroundAccessCheck(ProceedingJoinPoint pjp) throws Throwable {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
// 开始
Object retVal = pjp.proceed();
stopWatch.stop();
// 结束
System.out.println("invoke method: " + pjp.getSignature().getName() + ", elapsed time: " + stopWatch.getTotalTimeMillis());
return retVal;
}
}
around advice 和前面的 before advice 差不多, 只是我们把注解 @Before 改为了 @Around 了.
3.2 - AOP 实战
Spring AOP 实战
看了上面这么多的理论知识, 不知道大家有没有觉得枯燥哈. 不过不要急, 俗话说理论是实践的基础, 对 Spring AOP 有了基本的理论认识后, 我们来看一下下面几个具体的例子吧.
下面的几个例子是我在工作中所遇见的比较常用的 Spring AOP 的使用场景, 我精简了很多有干扰我们学习的注意力的细枝末节, 以力求整个例子的简洁性.
HTTP 接口鉴权
首先让我们来想象一下如下场景: 我们需要提供的 HTTP RESTful 服务, 这个服务会提供一些比较敏感的信息, 因此对于某些接口的调用会进行调用方权限的校验, 而某些不太敏感的接口则不设置权限, 或所需要的权限比较低(例如某些监控接口, 服务状态接口等).
实现这样的需求的方法有很多, 例如我们可以在每个 HTTP 接口方法中对服务请求的调用方进行权限的检查, 当调用方权限不符时, 方法返回错误. 当然这样做并无不可, 不过如果我们的 api 接口很多, 每个接口都进行这样的判断, 无疑有很多冗余的代码, 并且很有可能有某个粗心的家伙忘记了对调用者的权限进行验证, 这样就会造成潜在的 bug.
那么除了上面的所说的方法外, 还有没有别的比较优雅的方式来实现呢? 当然有啦, 不然我在这啰嗦半天干嘛呢, 它就是我们今天的主角: AOP.
让我们来提炼一下我们的需求:
- 可以定制地为某些指定的 HTTP RESTful api 提供权限验证功能.
- 当调用方的权限不符时, 返回错误.
根据上面所提出的需求, 我们可以进行如下设计:
- 提供一个特殊的注解
AuthChecker, 这个是一个方法注解, 有此注解所标注的 Controller 需要进行调用方权限的认证. - 利用 Spring AOP, 以 @annotation 切点标志符来匹配有注解
AuthChecker 所标注的 joinpoint. - 在 advice 中, 简单地检查调用者请求中的 Cookie 中是否有我们指定的 token, 如果有, 则认为此调用者权限合法, 允许调用, 反之权限不合法, 范围错误.
根据上面的设计, 我们来看一下具体的源码吧.
首先是 AuthChecker 注解的定义:
AuthChecker.java:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface AuthChecker {
}
AuthChecker 注解是一个方法注解, 它用于注解 RequestMapping 方法.
有了注解的定义, 那我们再来看一下 aspect 的实现吧:
HttpAopAdviseDefine.java:
@Component
@Aspect
public class HttpAopAdviseDefine {
// 定义一个 Pointcut, 使用 切点表达式函数 来描述对哪些 Join point 使用 advise.
@Pointcut("@annotation(com.xys.demo1.AuthChecker)")
public void pointcut() {
}
// 定义 advise
@Around("pointcut()")
public Object checkAuth(ProceedingJoinPoint joinPoint) throws Throwable {
HttpServletRequest request = ((ServletRequestAttributes) RequestContextHolder.getRequestAttributes())
.getRequest();
// 检查用户所传递的 token 是否合法
String token = getUserToken(request);
if (!token.equalsIgnoreCase("123456")) {
return "错误, 权限不合法!";
}
return joinPoint.proceed();
}
private String getUserToken(HttpServletRequest request) {
Cookie[] cookies = request.getCookies();
if (cookies == null) {
return "";
}
for (Cookie cookie : cookies) {
if (cookie.getName().equalsIgnoreCase("user_token")) {
return cookie.getValue();
}
}
return "";
}
}
在这个 aspect 中, 我们首先定义了一个 pointcut, 以 @annotation 切点标志符来匹配有注解 AuthChecker 所标注的 joinpoint, 即:
// 定义一个 Pointcut, 使用 切点表达式函数 来描述对哪些 Join point 使用 advise.
@Pointcut("@annotation(com.xys.demo1.AuthChecker)")
public void pointcut() {
}
然后再定义一个 advice:
// 定义 advise
@Around("pointcut()")
public Object checkAuth(ProceedingJoinPoint joinPoint) throws Throwable {
HttpServletRequest request = ((ServletRequestAttributes) RequestContextHolder.getRequestAttributes())
.getRequest();
// 检查用户所传递的 token 是否合法
String token = getUserToken(request);
if (!token.equalsIgnoreCase("123456")) {
return "错误, 权限不合法!";
}
return joinPoint.proceed();
}
当被 AuthChecker 注解所标注的方法调用前, 会执行我们的这个 advice, 而这个 advice 的处理逻辑很简单, 即从 HTTP 请求中获取名为 user_token 的 cookie 的值, 如果它的值是 123456, 则我们认为此 HTTP 请求合法, 进而调用 joinPoint.proceed() 将 HTTP 请求转交给相应的控制器处理; 而如果user_token cookie 的值不是 123456, 或为空, 则认为此 HTTP 请求非法, 返回错误.
接下来我们来写一个模拟的 HTTP 接口:
DemoController.java:
@RestController
public class DemoController {
@RequestMapping("/aop/http/alive")
public String alive() {
return "服务一切正常";
}
@AuthChecker
@RequestMapping("/aop/http/user_info")
public String callSomeInterface() {
return "调用了 user_info 接口.";
}
}
注意到上面我们提供了两个 HTTP 接口, 其中 接口 /aop/http/alive 是没有 AuthChecker 标注的, 而 /aop/http/user_info 接口则用到了 @AuthChecker 标注. 那么自然地, 当请求了 /aop/http/user_info 接口时, 就会触发我们所设置的权限校验逻辑.
接下来我们来验证一下, 我们所实现的功能是否有效吧.
首先在 Postman 中, 调用 /aop/http/alive 接口, 请求头中不加任何参数:
可以看到, 我们的 HTTP 请求完全没问题.
那么再来看一下请求 /aop/http/user_info 接口会怎样呢:
当我们请求 /aop/http/user_info 接口时, 服务返回一个权限异常的错误, 为什么会这样呢? 自然就是我们的权限认证系统起了作为: 当一个方法被调用并且这个方法有 AuthChecker 标注时, 那么首先会执行到我们的 around advice, 在这个 advice 中, 我们会校验 HTTP 请求的 cookie 字段中是否有携带 user_token 字段时, 如果没有, 则返回权限错误.
那么为了能够正常地调用 /aop/http/user_info 接口, 我们可以在 Cookie 中添加 user_token=123456, 这样我们可以愉快的玩耍了:
注意, Postman 默认是不支持 Cookie 的, 所以为了实现添加 Cookie 的功能, 我们需要安装 Postman 的 interceptor 插件. 安装方法可以看官网的文章
方法调用日志
第二个 AOP 实例是记录一个方法调用的log. 这应该是一个很常见的功能了.
首先假设我们有如下需求:
- 某个服务下的方法的调用需要有 log: 记录调用的参数以及返回结果.
- 当方法调用出异常时, 有特殊处理, 例如打印异常 log, 报警等.
根据上面的需求, 我们可以使用 before advice 来在调用方法前打印调用的参数, 使用 after returning advice 在方法返回打印返回的结果. 而当方法调用失败后, 可以使用 after throwing advice 来做相应的处理.
那么我们来看一下 aspect 的实现:
@Component
@Aspect
public class LogAopAdviseDefine {
private Logger logger = LoggerFactory.getLogger(getClass());
// 定义一个 Pointcut, 使用 切点表达式函数 来描述对哪些 Join point 使用 advise.
@Pointcut("within(NeedLogService)")
public void pointcut() {
}
// 定义 advise
@Before("pointcut()")
public void logMethodInvokeParam(JoinPoint joinPoint) {
logger.info("---Before method {} invoke, param: {}---", joinPoint.getSignature().toShortString(), joinPoint.getArgs());
}
@AfterReturning(pointcut = "pointcut()", returning = "retVal")
public void logMethodInvokeResult(JoinPoint joinPoint, Object retVal) {
logger.info("---After method {} invoke, result: {}---", joinPoint.getSignature().toShortString(), joinPoint.getArgs());
}
@AfterThrowing(pointcut = "pointcut()", throwing = "exception")
public void logMethodInvokeException(JoinPoint joinPoint, Exception exception) {
logger.info("---method {} invoke exception: {}---", joinPoint.getSignature().toShortString(), exception.getMessage());
}
}
第一步, 自然是定义一个 pointcut, 以 within 切点标志符来匹配类 NeedLogService 下的所有 joinpoint, 即:
@Pointcut("within(NeedLogService)")
public void pointcut() {
}
接下来根据我们前面的设计, 我们分别定义了三个 advice, 第一个是一个 before advice:
@Before("pointcut()")
public void logMethodInvokeParam(JoinPoint joinPoint) {
logger.info("---Before method {} invoke, param: {}---", joinPoint.getSignature().toShortString(), joinPoint.getArgs());
}
它在一个符合要求的 joinpoint 方法调用前执行, 打印调用的方法名和调用的参数.
第二个是 after return advice:
@AfterReturning(pointcut = "pointcut()", returning = "retVal")
public void logMethodInvokeResult(JoinPoint joinPoint, Object retVal) {
logger.info("---After method {} invoke, result: {}---", joinPoint.getSignature().toShortString(), joinPoint.getArgs());
}
这个 advice 会在方法调用成功后打印出方法名还反的参数.
最后一个是 after throw advice:
@AfterThrowing(pointcut = "pointcut()", throwing = "exception")
public void logMethodInvokeException(JoinPoint joinPoint, Exception exception) {
logger.info("---method {} invoke exception: {}---", joinPoint.getSignature().toShortString(), exception.getMessage());
}
这个 advice 会在指定的 joinpoint 抛出异常时执行, 打印异常的信息.
接下来我们再写两个 Service 类:
NeedLogService.java:
@Service
public class NeedLogService {
private Logger logger = LoggerFactory.getLogger(getClass());
private Random random = new Random(System.currentTimeMillis());
public int logMethod(String someParam) {
logger.info("---NeedLogService: logMethod invoked, param: {}---", someParam);
return random.nextInt();
}
public void exceptionMethod() throws Exception {
logger.info("---NeedLogService: exceptionMethod invoked---");
throw new Exception("Something bad happened!");
}
}
NormalService.java:
@Service
public class NormalService {
private Logger logger = LoggerFactory.getLogger(getClass());
public void someMethod() {
logger.info("---NormalService: someMethod invoked---");
}
}
根据我们 pointcut 的规则, 类 NeedLogService 下的所有方法都会被织入 advice, 而类 NormalService 则不会.
最后我们分别调用这几个方法:
@PostConstruct
public void test() {
needLogService.logMethod("xys");
try {
needLogService.exceptionMethod();
} catch (Exception e) {
// Ignore
}
normalService.someMethod();
}
我们可以看到有如下输出:
---Before method NeedLogService.logMethod(..) invoke, param: [xys]---
---NeedLogService: logMethod invoked, param: xys---
---After method NeedLogService.logMethod(..) invoke, result: [xys]---
---Before method NeedLogService.exceptionMethod() invoke, param: []---
---NeedLogService: exceptionMethod invoked---
---method NeedLogService.exceptionMethod() invoke exception: Something bad happened!---
---NormalService: someMethod invoked---
根据 log, 我们知道, NeedLogService.logMethod 执行的前后确实有 advice 执行了, 并且在 NeedLogService.exceptionMethod 抛出异常后, logMethodInvokeException 这个 advice 也被执行了. 而由于 pointcut 的匹配规则, 在 NormalService 类中的方法则不会织入 advice.
方法耗时统计
作为程序员, 我们都知道服务监控对于一个服务能够长期稳定运行的重要性, 因此很多公司都有自己内部的监控报警系统, 或者是使用一些开源的系统, 例如小米的 Falcon 监控系统.
那么在程序监控中, AOP 有哪些用武之地呢? 我们来假想一下如下场景:
有一天, leader 对小王说, “小王啊, 你负责的那个服务不太稳定啊, 经常有超时发生! 你有对这些服务接口进行过耗时统计吗?”
耗时统计? 小王嘀咕了, 小声的回答到: “还没有加呢.”
leader: “你看着办吧, 我明天要看到各个时段的服务接口调用的耗时分布!”
小王这就犯难了, 虽然说计算一个方法的调用耗时并不是一个很难的事情, 但是整个服务有二十来个接口呢, 一个一个地添加统计代码, 那还不是要累死人了.
看着同事一个一个都下班回家了, 小王眉头更加紧了. 不过此时小王灵机一动: “噫, 有了!”.
小王想到了一个好方法, 立即动手, 吭哧吭哧地几分钟就搞定了.
那么小王的解决方法是什么呢? 自然是我们的主角 AOP 啦.
首先让我们来提炼一下需求:
- 为服务中的每个方法调用进行调用耗时记录.
- 将方法调用的时间戳, 方法名, 调用耗时上报到监控平台
有了需求, 自然设计实现就很简单了. 首先我们可以使用 around advice, 然后在方法调用前, 记录一下开始时间, 然后在方法调用结束后, 记录结束时间, 它们的时间差就是方法的调用耗时.
我们来看一下具体的 aspect 实现:
ExpiredAopAdviseDefine.java:
@Component
@Aspect
public class ExpiredAopAdviseDefine {
private Logger logger = LoggerFactory.getLogger(getClass());
// 定义一个 Pointcut, 使用 切点表达式函数 来描述对哪些 Join point 使用 advise.
@Pointcut("within(SomeService)")
public void pointcut() {
}
// 定义 advise
// 定义 advise
@Around("pointcut()")
public Object methodInvokeExpiredTime(ProceedingJoinPoint pjp) throws Throwable {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
// 开始
Object retVal = pjp.proceed();
stopWatch.stop();
// 结束
// 上报到公司监控平台
reportToMonitorSystem(pjp.getSignature().toShortString(), stopWatch.getTotalTimeMillis());
return retVal;
}
public void reportToMonitorSystem(String methodName, long expiredTime) {
logger.info("---method {} invoked, expired time: {} ms---", methodName, expiredTime);
//
}
}
aspect 一开始定义了一个 pointcut, 匹配 SomeService 类下的所有的方法.
接着呢, 定义了一个 around advice:
@Around("pointcut()")
public Object methodInvokeExpiredTime(ProceedingJoinPoint pjp) throws Throwable {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
// 开始
Object retVal = pjp.proceed();
stopWatch.stop();
// 结束
// 上报到公司监控平台
reportToMonitorSystem(pjp.getSignature().toShortString(), stopWatch.getTotalTimeMillis());
return retVal;
}
advice 中的代码也很简单, 它使用了 Spring 提供的 StopWatch 来统计一段代码的执行时间. 首先我们先调用 stopWatch.start() 开始计时, 然后通过 pjp.proceed() 来调用我们实际的服务方法, 当调用结束后, 通过 stopWatch.stop() 来结束计时.
接着我们来写一个简单的服务, 这个服务提供一个 someMethod 方法用于模拟一个耗时的方法调用:
SomeService.java:
@Service
public class SomeService {
private Logger logger = LoggerFactory.getLogger(getClass());
private Random random = new Random(System.currentTimeMillis());
public void someMethod() {
logger.info("---SomeService: someMethod invoked---");
try {
// 模拟耗时任务
Thread.sleep(random.nextInt(500));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
这样当 SomeService 类下的方法调用时, 我们所提供的 advice 就会被执行, 因此就可以自动地为我们统计此方法的调用耗时, 并自动上报到监控系统中了.
看到 AOP 的威力了吧, 我们这里仅仅使用了寥寥数语就把一个需求完美地解决了, 并且还与原来的业务逻辑完全解耦, 扩展及其方便.
总结
通过上面的几个简单例子, 我们对 Spring AOP 的使用应该有了一个更为深入的了解了. 其实 Spring AOP 的使用的地方不止这些, 例如 Spring 的 声明式事务 就是在 AOP 之上构建的. 读者朋友也可以根据自己的实际业务场景, 合理使用 Spring AOP, 发挥它的强大功能!
4 - Mybatis
参考自 <MyBatis 技术内幕>。
4.1 - CH01-整体架构
MyBatis 是一款旨在帮助开发人员屏蔽底层重复性原生 JDBC 代码的持久化框架,其支持通过映射文件配置或注解将 ResultSet 映射为 Java 对象。相对于其它 ORM 框架,MyBatis 更为轻量级,支持定制化 SQL
和动态 SQL,方便优化查询性能,同时包含了良好的缓存机制。
整体架构
基础支持层
- 反射模块:提供封装的反射 API,方便上层调用。
- 类型转换:为简化配置文件提供了别名机制,并且实现了 Java 类型和 JDBC 类型的互转。
- 日志模块:能够集成多种第三方日志框架。
- 资源加载模块:对类加载器进行封装,提供加载类文件和其它资源文件的功能。
- 数据源模块:提供数据源实现并能够集成第三方数据源模块。
- 事务管理:可以和 Spring 集成开发,对事务进行管理。
- 缓存模块:提供一级缓存和二级缓存,将部分请求拦截在缓存层。
- Binding 模块:在调用 SqlSession 相应方法执行数据库操作时,需要指定映射文件中的 SQL 节点,MyBatis 通过 Binding 模块将自定义 Mapper 接口与映射文件关联,避免拼写等错误导致在运行时才发现相应异常。
核心处理层
- 配置解析:MyBatis 初始化时会加载配置文件、映射文件和 Mapper 接口的注解信息,解析后会以对象的形式保存到 Configuration 对象中。
- SQL 解析与 scripting 模块:MyBatis 支持通过配置实现动态 SQL,即根据不同入参生成 SQL。
- SQL 执行与结果解析:Executor 负责维护缓存和事务管理,并将数据库相关操作委托给 StatementHandler,ParmeterHadler 负责完成 SQL 语句的实参绑定并通过 Statement 对象执行 SQL,通过 ResultSet 返回结果,交由 ResultSetHandler 处理。
- 插件:支持开发者通过插件接口对 MyBatis 进行扩展。
接口层
SqlSession 接口定义了暴露给应用程序调用的 API,接口层在收到请求时会调用核心处理层的相应模块完成具体的数据库操作。
4.2 - CH02-反射模块
MyBatis 在进行参数处理、结果映射时等操作时,会涉及大量的反射操作。为了简化这些反射相关操作,MyBatis 在 org.apache.ibatis.reflection 包下提供了专门的反射模块,对反射操作做了近一步封装,提供了更为简洁的 API。
缓存类的元信息
MyBatis 提供 Reflector 类来缓存类的字段名和 getter/setter 方法的元信息,使得反射时有更好的性能。使用方式是将原始类对象传入其构造方法,生成 Reflector 对象。
public Reflector(Class<?> clazz) {
type = clazz;
// 如果存在,记录无参构造方法
addDefaultConstructor(clazz);
// 记录字段名与get方法、get方法返回值的映射关系
addGetMethods(clazz);
// 记录字段名与set方法、set方法参数的映射关系
addSetMethods(clazz);
// 针对没有getter/setter方法的字段,通过Filed对象的反射来设置和读取字段值
addFields(clazz);
// 可读的字段名
readablePropertyNames = getMethods.keySet().toArray(new String[getMethods.keySet().size()]);
// 可写的字段名
writablePropertyNames = setMethods.keySet().toArray(new String[setMethods.keySet().size()]);
// 保存一份所有字段名大写与原始字段名的映射
for (String propName : readablePropertyNames) {
caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);
}
for (String propName : writablePropertyNames) {
caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);
}
}
addGetMethods 和 addSetMethods 分别获取类的所有方法,从符合 getter/setter 规范的方法中解析出字段名,并记录方法的参数类型、返回值类型等信息:
private void addGetMethods(Class<?> cls) {
// 字段名-get方法
Map<String, List<Method>> conflictingGetters = new HashMap<>();
// 获取类的所有方法,及其实现接口的方法,并根据方法签名去重
Method[] methods = getClassMethods(cls);
for (Method method : methods) {
if (method.getParameterTypes().length > 0) {
// 过滤有参方法
continue;
}
String name = method.getName();
if ((name.startsWith("get") && name.length() > 3)
|| (name.startsWith("is") && name.length() > 2)) {
// 由get属性获取对应的字段名(去除前缀,首字母转小写)
name = PropertyNamer.methodToProperty(name);
addMethodConflict(conflictingGetters, name, method);
}
}
// 保证每个字段只对应一个get方法
resolveGetterConflicts(conflictingGetters);
}
对 getter/setter 方法进行去重是通过类似 java.lang.String#getSignature:java.lang.reflect.Method 的方法签名来实现的,如果子类在实现过程中,参数、返回值使用了不同的类型(使用原类型的子类),则会导致方法签名不一致,同一字段就会对应不同的 getter/setter 方法,因此需要进行去重。
private void resolveGetterConflicts(Map<String, List<Method>> conflictingGetters) {
for (Entry<String, List<Method>> entry : conflictingGetters.entrySet()) {
Method winner = null;
// 属性名
String propName = entry.getKey();
for (Method candidate : entry.getValue()) {
if (winner == null) {
winner = candidate;
continue;
}
// 字段对应了多个get方法
Class<?> winnerType = winner.getReturnType();
Class<?> candidateType = candidate.getReturnType();
if (candidateType.equals(winnerType)) {
// 返回值类型相同
if (!boolean.class.equals(candidateType)) {
throw new ReflectionException(
"Illegal overloaded getter method with ambiguous type for property "
+ propName + " in class " + winner.getDeclaringClass()
+ ". This breaks the JavaBeans specification and can cause unpredictable results.");
} else if (candidate.getName().startsWith("is")) {
// 返回值为boolean的get方法可能有多个,如getIsSave和isSave,优先取is开头的
winner = candidate;
}
} else if (candidateType.isAssignableFrom(winnerType)) {
// OK getter type is descendant
// 可能会出现接口中的方法返回值是List,子类实现方法返回值是ArrayList,使用子类返回值方法
} else if (winnerType.isAssignableFrom(candidateType)) {
winner = candidate;
} else {
throw new ReflectionException(
"Illegal overloaded getter method with ambiguous type for property "
+ propName + " in class " + winner.getDeclaringClass()
+ ". This breaks the JavaBeans specification and can cause unpredictable results.");
}
}
// 记录字段名对应的get方法对象和返回值类型
addGetMethod(propName, winner);
}
}
去重的方式是使用更规范的方法以及使用子类的方法。在确认字段名对应的唯一 getter/setter 方法后,记录方法名对应的方法、参数、返回值等信息。MethodInvoker 可用于调用 Method 类的 invoke 方法来执行 getter/setter 方法(addSetMethods 记录映射关系的方式与 addGetMethods 大致相同)。
private void addGetMethod(String name, Method method) {
// 过滤$开头、serialVersionUID的get方法和getClass()方法
if (isValidPropertyName(name)) {
// 字段名-对应get方法的MethodInvoker对象
getMethods.put(name, new MethodInvoker(method));
Type returnType = TypeParameterResolver.resolveReturnType(method, type);
// 字段名-运行时方法的真正返回类型
getTypes.put(name, typeToClass(returnType));
}
}
接下来会执行 addFields 方法,此方法针对没有 getter/setter 方法的字段,通过包装为 SetFieldInvoker 在需要时通过 Field 对象的反射来设置和读取字段值。
private void addFields(Class<?> clazz) {
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) {
if (!setMethods.containsKey(field.getName())) {
// issue #379 - removed the check for final because JDK 1.5 allows
// modification of final fields through reflection (JSR-133). (JGB)
// pr #16 - final static can only be set by the classloader
int modifiers = field.getModifiers();
if (!(Modifier.isFinal(modifiers) && Modifier.isStatic(modifiers))) {
// 非final的static变量,没有set方法,可以通过File对象做赋值操作
addSetField(field);
}
}
if (!getMethods.containsKey(field.getName())) {
addGetField(field);
}
}
if (clazz.getSuperclass() != null) {
// 递归查找父类
addFields(clazz.getSuperclass());
}
}
抽象字段赋值与读取
Invoker 接口用于抽象设置和读取字段值的操作。对于有 getter/setter 方法的字段,通过 MethodInvoker 反射执行;对应其它字段,通过 GetFieldInvoker 和 SetFieldInvoker 操作 Field 对象的 getter/setter 方法反射执行。
/**
* 用于抽象设置和读取字段值的操作
*
* {@link MethodInvoker} 反射执行getter/setter方法
* {@link GetFieldInvoker} {@link SetFieldInvoker} 反射执行Field对象的get/set方法
*
* @author Clinton Begin
*/
public interface Invoker {
/**
* 通过反射设置或读取字段值
*
* @param target
* @param args
* @return
* @throws IllegalAccessException
* @throws InvocationTargetException
*/
Object invoke(Object target, Object[] args) throws IllegalAccessException, InvocationTargetException;
/**
* 字段类型
*
* @return
*/
Class<?> getType();
}
解析参数类型
针对 Java-Type 体系的多种实现,TypeParameterResolver 提供一系列方法来解析指定类中的字段、方法返回值或方法参数的类型。
Type 接口包含 4 个子接口和 1 个实现类:
- Class:原始类型
- ParameterizedType:泛型类型,如:List
- TypeVariable:泛型类型变量,如: List 中的 T
- GenericArrayType:组成元素是 ParameterizedType 或 TypeVariable 的数组类型,如:List[]、T[]
- WildcardType:通配符泛型类型变量,如:List 中的 ?
TypeParameterResolver 分别提供 resolveFieldType、resolveReturnType、resolveParamTypes 方法用于解析字段类型、方法返回值类型和方法入参类型,这些方法均调用 resolveType 来获取类型信息:
/**
* 获取类型信息
*
* @param type 根据是否有泛型信息签名选择传入泛型类型或简单类型
* @param srcType 引用字段/方法的类(可能是子类,字段和方法在父类声明)
* @param declaringClass 字段/方法声明的类
* @return
*/
private static Type resolveType(Type type, Type srcType, Class<?> declaringClass) {
if (type instanceof TypeVariable) {
// 泛型类型变量,如:List<T> 中的 T
return resolveTypeVar((TypeVariable<?>) type, srcType, declaringClass);
} else if (type instanceof ParameterizedType) {
// 泛型类型,如:List<String>
return resolveParameterizedType((ParameterizedType) type, srcType, declaringClass);
} else if (type instanceof GenericArrayType) {
// TypeVariable/ParameterizedType 数组类型
return resolveGenericArrayType((GenericArrayType) type, srcType, declaringClass);
} else {
// 原始类型,直接返回
return type;
}
}
resolveTypeVar 用于解析泛型类型变量参数类型,如果字段或方法在当前类中声明,则返回泛型类型的上界或 Object 类型;如果在父类中声明,则递归解析父类;父类也无法解析,则递归解析实现的接口。
private static Type resolveTypeVar(TypeVariable<?> typeVar, Type srcType, Class<?> declaringClass) {
Type result;
Class<?> clazz;
if (srcType instanceof Class) {
// 原始类型
clazz = (Class<?>) srcType;
} else if (srcType instanceof ParameterizedType) {
// 泛型类型,如 TestObj<String>
ParameterizedType parameterizedType = (ParameterizedType) srcType;
// 取原始类型TestObj
clazz = (Class<?>) parameterizedType.getRawType();
} else {
throw new IllegalArgumentException("The 2nd arg must be Class or ParameterizedType, but was: " + srcType.getClass());
}
if (clazz == declaringClass) {
// 字段就是在当前引用类中声明的
Type[] bounds = typeVar.getBounds();
if (bounds.length > 0) {
// 返回泛型类型变量上界,如:T extends String,则返回String
return bounds[0];
}
// 没有上界返回Object
return Object.class;
}
// 字段/方法在父类中声明,递归查找父类泛型
Type superclass = clazz.getGenericSuperclass();
result = scanSuperTypes(typeVar, srcType, declaringClass, clazz, superclass);
if (result != null) {
return result;
}
// 递归泛型接口
Type[] superInterfaces = clazz.getGenericInterfaces();
for (Type superInterface : superInterfaces) {
result = scanSuperTypes(typeVar, srcType, declaringClass, clazz, superInterface);
if (result != null) {
return result;
}
}
return Object.class;
}
通过调用 scanSuperTypes 实现递归解析:
private static Type scanSuperTypes(TypeVariable<?> typeVar, Type srcType, Class<?> declaringClass, Class<?> clazz, Type superclass) {
if (superclass instanceof ParameterizedType) {
// 父类是泛型类型
ParameterizedType parentAsType = (ParameterizedType) superclass;
Class<?> parentAsClass = (Class<?>) parentAsType.getRawType();
// 父类中的泛型类型变量集合
TypeVariable<?>[] parentTypeVars = parentAsClass.getTypeParameters();
if (srcType instanceof ParameterizedType) {
// 子类可能对父类泛型变量做过替换,使用替换后的类型
parentAsType = translateParentTypeVars((ParameterizedType) srcType, clazz, parentAsType);
}
if (declaringClass == parentAsClass) {
// 字段/方法在当前父类中声明
for (int i = 0; i < parentTypeVars.length; i++) {
if (typeVar == parentTypeVars[i]) {
// 使用变量对应位置的真正类型(可能已经被替换),如父类 A<T>,子类 B extends A<String>,则返回String
return parentAsType.getActualTypeArguments()[i];
}
}
}
// 字段/方法声明的类是当前父类的父类,继续递归
if (declaringClass.isAssignableFrom(parentAsClass)) {
return resolveTypeVar(typeVar, parentAsType, declaringClass);
}
} else if (superclass instanceof Class && declaringClass.isAssignableFrom((Class<?>) superclass)) {
// 父类是原始类型,继续递归父类
return resolveTypeVar(typeVar, superclass, declaringClass);
}
return null;
}
解析方法返回值和方法参数的逻辑大致与解析字段类型相同,MyBatis 源码的TypeParameterResolverTest 类提供了相关的测试用例。
元信息工厂
MyBatis 还提供 ReflectorFactory 接口用于实现 Reflector 容器,其默认实现为 DefaultReflectorFactory,其中可以使用 classCacheEnabled 属性来配置是否使用缓存。
public class DefaultReflectorFactory implements ReflectorFactory {
/**
* 是否缓存Reflector类信息
*/
private boolean classCacheEnabled = true;
/**
* Reflector缓存容器
*/
private final ConcurrentMap<Class<?>, Reflector> reflectorMap = new ConcurrentHashMap<>();
public DefaultReflectorFactory() {
}
@Override
public boolean isClassCacheEnabled() {
return classCacheEnabled;
}
@Override
public void setClassCacheEnabled(boolean classCacheEnabled) {
this.classCacheEnabled = classCacheEnabled;
}
/**
* 获取类的Reflector信息
*
* @param type
* @return
*/
@Override
public Reflector findForClass(Class<?> type) {
if (classCacheEnabled) {
// synchronized (type) removed see issue #461
// 如果缓存Reflector信息,放入缓存容器
return reflectorMap.computeIfAbsent(type, Reflector::new);
} else {
return new Reflector(type);
}
}
}
对象创建工厂
ObjectFactory 接口是 MyBatis 对象创建工厂,其默认实现 DefaultObjectFactory 通过构造器反射创建对象,支持使用无参构造器和有参构造器。
属性工具集
MyBatis 在映射文件定义 resultMap 支持如下形式:
<resultMap id="map" type="Order">
<result property="orders[0].items[0].name" column="col1"/>
<result property="orders[0].items[1].name" column="col2"/>
...
</resultMap>
orders[0].items[0].name 这样的表达式是由 PropertyTokenizer 解析的,其构造方法能够对表达式进行解析;同时还实现了 Iterator 接口,能够迭代解析表达式。
public PropertyTokenizer(String fullname) {
// orders[0].items[0].name
int delim = fullname.indexOf('.');
if (delim > -1) {
// name = orders[0]
name = fullname.substring(0, delim);
// children = items[0].name
children = fullname.substring(delim + 1);
} else {
name = fullname;
children = null;
}
// orders[0]
indexedName = name;
delim = name.indexOf('[');
if (delim > -1) {
// 0
index = name.substring(delim + 1, name.length() - 1);
// order
name = name.substring(0, delim);
}
}
/**
* 是否有children表达式继续迭代
*
* @return
*/
@Override
public boolean hasNext() {
return children != null;
}
/**
* 分解出的 . 分隔符的 children 表达式可以继续迭代
* @return
*/
@Override
public PropertyTokenizer next() {
return new PropertyTokenizer(children);
}
PropertyNamer 可以根据 getter/setter 规范解析字段名称;PropertyCopier 则支持对有相同父类的对象,通过反射拷贝字段值。
封装类信息
MetaClass 类依赖 PropertyTokenizer 和 Reflector 查找表达式是否可以匹配 Java 对象中的字段,以及对应字段是否有 getter/setter 方法。
/**
* 验证传入的表达式,是否存在指定的字段
*
* @param name
* @param builder
* @return
*/
private StringBuilder buildProperty(String name, StringBuilder builder) {
// 映射文件表达式迭代器
PropertyTokenizer prop = new PropertyTokenizer(name);
if (prop.hasNext()) {
// 复杂表达式,如name = items[0].name,则prop.getName() = items
String propertyName = reflector.findPropertyName(prop.getName());
if (propertyName != null) {
builder.append(propertyName);
// items.
builder.append(".");
// 加载内嵌字段类型对应的MetaClass
MetaClass metaProp = metaClassForProperty(propertyName);
// 迭代子字段
metaProp.buildProperty(prop.getChildren(), builder);
}
} else {
// 非复杂表达式,获取字段名,如:userid->userId
String propertyName = reflector.findPropertyName(name);
if (propertyName != null) {
builder.append(propertyName);
}
}
return builder;
}
包装字段对象
相对于 MetaClass 关注类信息,MetalObject 关注的是对象的信息,除了保存传入的对象本身,还会为对象指定一个 ObjectWrapper 将对象包装起来。ObejctWrapper 体系如下:
ObjectWrapper 的默认实现包括了对 Map、Collection 和普通 JavaBean 的包装。MyBatis 还支持通过 ObjectWrapperFactory 接口对 ObejctWrapper 进行扩展,生成自定义的包装类。MetaObject 对对象的具体操作,就委托给真正的 ObjectWrapper 处理。
private MetaObject(Object object, ObjectFactory objectFactory, ObjectWrapperFactory objectWrapperFactory, ReflectorFactory reflectorFactory) {
this.originalObject = object;
this.objectFactory = objectFactory;
this.objectWrapperFactory = objectWrapperFactory;
this.reflectorFactory = reflectorFactory;
// 根据传入object类型不同,指定不同的wrapper
if (object instanceof ObjectWrapper) {
this.objectWrapper = (ObjectWrapper) object;
} else if (objectWrapperFactory.hasWrapperFor(object)) {
this.objectWrapper = objectWrapperFactory.getWrapperFor(this, object);
} else if (object instanceof Map) {
this.objectWrapper = new MapWrapper(this, (Map) object);
} else if (object instanceof Collection) {
this.objectWrapper = new CollectionWrapper(this, (Collection) object);
} else {
this.objectWrapper = new BeanWrapper(this, object);
}
}
例如赋值操作,BeanWrapper 的实现如下:
@Override
public void set(PropertyTokenizer prop, Object value) {
if (prop.getIndex() != null) {
// 当前表达式是集合,如:items[0],就需要获取items集合对象
Object collection = resolveCollection(prop, object);
// 在集合的指定索引上赋值
setCollectionValue(prop, collection, value);
} else {
// 解析完成,通过Invoker接口做赋值操作
setBeanProperty(prop, object, value);
}
}
protected Object resolveCollection(PropertyTokenizer prop, Object object) {
if ("".equals(prop.getName())) {
return object;
} else {
// 在对象信息中查到此字段对应的集合对象
return metaObject.getValue(prop.getName());
}
}
根据 PropertyTokenizer 对象解析出的当前字段是否存在 index 索引来判断字段是否为集合。如果当前字段对应集合,则需要在对象信息中查到此字段对应的集合对象:
public Object getValue(String name) {
PropertyTokenizer prop = new PropertyTokenizer(name);
if (prop.hasNext()) {
// 如果表达式仍可迭代,递归寻找字段对应的对象
MetaObject metaValue = metaObjectForProperty(prop.getIndexedName());
if (metaValue == SystemMetaObject.NULL_META_OBJECT) {
return null;
} else {
return metaValue.getValue(prop.getChildren());
}
} else {
// 字段解析完成
return objectWrapper.get(prop);
}
}
如果字段是简单类型,BeanWrapper 获取字段对应的对象逻辑如下:
@Override
public Object get(PropertyTokenizer prop) {
if (prop.getIndex() != null) {
// 集合类型,递归获取
Object collection = resolveCollection(prop, object);
return getCollectionValue(prop, collection);
} else {
// 解析完成,反射读取
return getBeanProperty(prop, object);
}
}
可以看到,仍然是会判断表达式是否迭代完成,如果未解析完字段会不断递归,直至找到对应的类型。前面说到 Reflector 创建过程中将对字段的读取和赋值操作通过 Invoke 接口抽象出来,针对最终获取的字段,此时就会调用 Invoke 接口对字段反射读取对象值:
/**
* 通过Invoker接口反射执行读取操作
*
* @param prop
* @param object
*/
private Object getBeanProperty(PropertyTokenizer prop, Object object) {
try {
Invoker method = metaClass.getGetInvoker(prop.getName());
try {
return method.invoke(object, NO_ARGUMENTS);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
} catch (RuntimeException e) {
throw e;
} catch (Throwable t) {
throw new ReflectionException("Could not get property '" + prop.getName() + "' from " + object.getClass() + ". Cause: " + t.toString(), t);
}
}
对象读取完毕再通过 setCollectionValue 方法对集合指定索引进行赋值或通过 setBeanProperty 方法对简单类型反射赋值。MapWrapper 的操作与 BeanWrapper 大致相同,CollectionWrapper 相对更会简单,只支持对原始集合对象进行添加操作。
总结
MyBatis 根据自身需求,对反射 API 做了近一步封装。其目的是简化反射操作,为对象字段的读取和赋值提供更好的性能。
- org.apache.ibatis.reflection.Reflector:缓存类的字段名和 getter/setter 方法的元信息,使得反射时有更好的性能。
- org.apache.ibatis.reflection.invoker.Invoker:用于抽象设置和读取字段值的操作。
- org.apache.ibatis.reflection.TypeParameterResolver:针对 Java-Type 体系的多种实现,解析指定类中的字段、方法返回值或方法参数的类型。
- org.apache.ibatis.reflection.ReflectorFactory:反射信息创建工厂抽象接口。
- org.apache.ibatis.reflection.DefaultReflectorFactory:默认的反射信息创建工厂。
- org.apache.ibatis.reflection.factory.ObjectFactory:MyBatis 对象创建工厂,其默认实现 DefaultObjectFactory 通过构造器反射创建对象。
- org.apache.ibatis.reflection.property:property 工具包,针对映射文件表达式进行解析和 Java 对象的反射赋值。
- org.apache.ibatis.reflection.MetaClass:依赖 PropertyTokenizer 和 Reflector 查找表达式是否可以匹配 Java 对象中的字段,以及对应字段是否有 getter/setter 方法。
- org.apache.ibatis.reflection.MetaObject:对原始对象进行封装,将对象操作委托给 ObjectWrapper 处理。
- org.apache.ibatis.reflection.wrapper.ObjectWrapper:对象包装类,封装对象的读取和赋值等操作。
4.3 - CH03-基础支持模块
类型转换
JDBC 规范定义的数据类型与 Java 数据类型并不是完全对应的,所以在 PrepareStatement 为 SQL 语句绑定参数时,需要从 Java 类型转为 JDBC 类型;而从结果集中获取数据时,则需要将 JDBC 类型转为 Java 类型。
类型转换操作
MyBatis 中的所有类型转换器都继承自 BaseTypeHandler 抽象类,此类实现了 TypeHandler 接口。接口中定义了 1 个向 PreparedStatement 对象中设置参数的方法和 3 个从结果集中取值的方法:
public interface TypeHandler<T> {
/**
* 为PreparedStatement对象设置参数
*
* @param ps SQL 预编译对象
* @param i 参数索引
* @param parameter 参数值
* @param jdbcType 参数 JDBC类型
* @throws SQLException
*/
void setParameter(PreparedStatement ps, int i, T parameter, JdbcType jdbcType) throws SQLException;
/**
* 根据列名从结果集中取值
*
* @param rs 结果集
* @param columnName 列名
* @return
* @throws SQLException
*/
T getResult(ResultSet rs, String columnName) throws SQLException;
/**
* 根据索引从结果集中取值
* @param rs 结果集
* @param columnIndex 索引
* @return
* @throws SQLException
*/
T getResult(ResultSet rs, int columnIndex) throws SQLException;
/**
* 根据索引从存储过程函数中取值
*
* @param cs 存储过程对象
* @param columnIndex 索引
* @return
* @throws SQLException
*/
T getResult(CallableStatement cs, int columnIndex) throws SQLException;
}
BaseTypeHandler 及其实现
BaseTypeHandler 实现了 TypeHandler 接口,针对 null 和异常处理做了封装,但是具体逻辑封装成 4 个抽象方法仍交由相应的类型转换器子类实现,以 IntegerTypeHandler 为例,其实现如下:
public class IntegerTypeHandler extends BaseTypeHandler<Integer> {
@Override
public void setNonNullParameter(PreparedStatement ps, int i, Integer parameter, JdbcType jdbcType)
throws SQLException {
ps.setInt(i, parameter);
}
@Override
public Integer getNullableResult(ResultSet rs, String columnName)
throws SQLException {
int result = rs.getInt(columnName);
// 如果列值为空值返回控制否则返回原值
return result == 0 && rs.wasNull() ? null : result;
}
@Override
public Integer getNullableResult(ResultSet rs, int columnIndex)
throws SQLException {
int result = rs.getInt(columnIndex);
return result == 0 && rs.wasNull() ? null : result;
}
@Override
public Integer getNullableResult(CallableStatement cs, int columnIndex)
throws SQLException {
int result = cs.getInt(columnIndex);
return result == 0 && cs.wasNull() ? null : result;
}
}
其实现主要是调用 JDBC API 设置查询参数或取值,并对 null 等特定情况做特殊处理。
类型转换注册器
TypeHandlerRegistry 是 TypeHandler 的注册类,在其无参构造方法中维护了 JavaType、JdbcType 和 TypeHandler 的关系。其主要使用的容器如下:
/**
* JdbcType - TypeHandler对象
* 用于将Jdbc类型转为Java类型
*/
private final Map<JdbcType, TypeHandler<?>> jdbcTypeHandlerMap = new EnumMap<>(JdbcType.class);
/**
* JavaType - JdbcType - TypeHandler对象
* 用于将Java类型转为指定的Jdbc类型
*/
private final Map<Type, Map<JdbcType, TypeHandler<?>>> typeHandlerMap = new ConcurrentHashMap<>();
/**
* TypeHandler类型 - TypeHandler对象
* 注册所有的TypeHandler类型
*/
private final Map<Class<?>, TypeHandler<?>> allTypeHandlersMap = new HashMap<>();
别名注册
别名转换器注册
TypeAliasRegistry 提供了多种方式用于为 Java 类型注册别名。包括直接指定别名、注解指定别名、为指定包下类型注册别名:
/**
* 注册指定包下所有类型别名
*
* @param packageName
*/
public void registerAliases(String packageName) {
registerAliases(packageName, Object.class);
}
/**
* 注册指定包下指定类型的别名
*
* @param packageName
* @param superType
*/
public void registerAliases(String packageName, Class<?> superType) {
ResolverUtil<Class<?>> resolverUtil = new ResolverUtil<>();
// 找出该包下superType所有的子类
resolverUtil.find(new ResolverUtil.IsA(superType), packageName);
Set<Class<? extends Class<?>>> typeSet = resolverUtil.getClasses();
for (Class<?> type : typeSet) {
// Ignore inner classes and interfaces (including package-info.java)
// Skip also inner classes. See issue #6
if (!type.isAnonymousClass() && !type.isInterface() && !type.isMemberClass()) {
registerAlias(type);
}
}
}
/**
* 注册类型别名,默认为简单类名,优先从Alias注解获取
*
* @param type
*/
public void registerAlias(Class<?> type) {
String alias = type.getSimpleName();
// 从Alias注解读取别名
Alias aliasAnnotation = type.getAnnotation(Alias.class);
if (aliasAnnotation != null) {
alias = aliasAnnotation.value();
}
registerAlias(alias, type);
}
/**
* 注册类型别名
*
* @param alias 别名
* @param value 类型
*/
public void registerAlias(String alias, Class<?> value) {
if (alias == null) {
throw new TypeException("The parameter alias cannot be null");
}
// issue #748
String key = alias.toLowerCase(Locale.ENGLISH);
if (typeAliases.containsKey(key) && typeAliases.get(key) != null && !typeAliases.get(key).equals(value)) {
throw new TypeException("The alias '" + alias + "' is already mapped to the value '" + typeAliases.get(key).getName() + "'.");
}
typeAliases.put(key, value);
}
/**
* 注册类型别名
* @param alias 别名
* @param value 指定类型全名
*/
public void registerAlias(String alias, String value) {
try {
registerAlias(alias, Resources.classForName(value));
} catch (ClassNotFoundException e) {
throw new TypeException("Error registering type alias " + alias + " for " + value + ". Cause: " + e, e);
}
}
所有别名均注册到名为 typeAliases 的容器中。TypeAliasRegistry 的无参构造方法默认为一些常用类型注册了别名,如 Integer、String、byte[] 等。
日志配置
MyBatis 支持与多种日志工具集成,包括 Slf4j、log4j、log4j2、commons-logging 等。这些第三方工具类对应日志的实现各有不同,MyBatis 通过适配器模式抽象了这些第三方工具的集成过程,按照一定的优先级选择具体的日志工具,并将真正的日志实现委托给选择的日志工具。
日志适配接口
Log 接口是 MyBatis 的日志适配接口,支持 trace、debug、warn、error 四种级别。
日志工厂
LogFactory 负责对第三方日志工具进行适配,在类加载时会通过静态代码块按顺序选择合适的日志实现。
static {
// 按顺序加载日志实现,如果有某个第三方日志实现可以成功加载,则不继续加载其它实现
tryImplementation(LogFactory::useSlf4jLogging);
tryImplementation(LogFactory::useCommonsLogging);
tryImplementation(LogFactory::useLog4J2Logging);
tryImplementation(LogFactory::useLog4JLogging);
tryImplementation(LogFactory::useJdkLogging);
tryImplementation(LogFactory::useNoLogging);
}
/**
* 初始化 logConstructor
*
* @param runnable
*/
private static void tryImplementation(Runnable runnable) {
if (logConstructor == null) {
try {
// 同步执行
runnable.run();
} catch (Throwable t) {
// ignore
}
}
}
/**
* 配置第三方日志实现适配器
*
* @param implClass
*/
private static void setImplementation(Class<? extends Log> implClass) {
try {
Constructor<? extends Log> candidate = implClass.getConstructor(String.class);
Log log = candidate.newInstance(LogFactory.class.getName());
if (log.isDebugEnabled()) {
log.debug("Logging initialized using '" + implClass + "' adapter.");
}
logConstructor = candidate;
} catch (Throwable t) {
throw new LogException("Error setting Log implementation. Cause: " + t, t);
}
}
tryImplementation 按顺序加载第三方日志工具的适配实现,如 Slf4j 的适配器 Slf4jImpl:
public Slf4jImpl(String clazz) {
Logger logger = LoggerFactory.getLogger(clazz);
if (logger instanceof LocationAwareLogger) {
try {
// check for slf4j >= 1.6 method signature
logger.getClass().getMethod("log", Marker.class, String.class, int.class, String.class, Object[].class, Throwable.class);
log = new Slf4jLocationAwareLoggerImpl((LocationAwareLogger) logger);
return;
} catch (SecurityException | NoSuchMethodException e) {
// fail-back to Slf4jLoggerImpl
}
}
// Logger is not LocationAwareLogger or slf4j version < 1.6
log = new Slf4jLoggerImpl(logger);
}
如果 Slf4jImpl 能成功执行构造方法,则 LogFactory 的 logConstructor 被成功赋值,MyBatis 就找到了合适的日志实现,可以通过 getLog 方法获取 Log 对象。
JDBC 日志代理
org.apache.ibatis.logging.jdbc 包提供了 Connection、PrepareStatement、Statement、ResultSet 类中的相关方法执行的日志记录代理。BaseJdbcLogger 在创建时整理了 PreparedStatement 执行的相关方法名,并提供容器保存列值:
/**
* PreparedStatement 接口中的 set* 方法名称集合
*/
protected static final Set<String> SET_METHODS;
/**
* PreparedStatement 接口中的 部分执行方法
*/
protected static final Set<String> EXECUTE_METHODS = new HashSet<>();
/**
* 列名-列值
*/
private final Map<Object, Object> columnMap = new HashMap<>();
/**
* 列名集合
*/
private final List<Object> columnNames = new ArrayList<>();
/**
* 列值集合
*/
private final List<Object> columnValues = new ArrayList<>();
static {
SET_METHODS = Arrays.stream(PreparedStatement.class.getDeclaredMethods())
.filter(method -> method.getName().startsWith("set"))
.filter(method -> method.getParameterCount() > 1)
.map(Method::getName)
.collect(Collectors.toSet());
EXECUTE_METHODS.add("execute");
EXECUTE_METHODS.add("executeUpdate");
EXECUTE_METHODS.add("executeQuery");
EXECUTE_METHODS.add("addBatch");
}
protected void setColumn(Object key, Object value) {
columnMap.put(key, value);
columnNames.add(key);
columnValues.add(value);
}
ConnectionLogger、PreparedStatementLogger、StatementLogger、ResultSetLogger 都继承自 BaseJdbcLogger,并实现了 InvocationHandler 接口,在运行时通过 JDK 动态代理实现代理类,针对相关方法执行打印日志。如下是 ConnectionLogger 对 InvocationHandler 接口的实现:
@Override
public Object invoke(Object proxy, Method method, Object[] params)
throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, params);
}
if ("prepareStatement".equals(method.getName())) {
if (isDebugEnabled()) {
debug(" Preparing: " + removeBreakingWhitespace((String) params[0]), true);
}
PreparedStatement stmt = (PreparedStatement) method.invoke(connection, params);
// 执行创建PreparedStatement方法,使用PreparedStatementLogger代理
stmt = PreparedStatementLogger.newInstance(stmt, statementLog, queryStack);
return stmt;
} else if ("prepareCall".equals(method.getName())) {
if (isDebugEnabled()) {
debug(" Preparing: " + removeBreakingWhitespace((String) params[0]), true);
}
PreparedStatement stmt = (PreparedStatement) method.invoke(connection, params);
stmt = PreparedStatementLogger.newInstance(stmt, statementLog, queryStack);
return stmt;
} else if ("createStatement".equals(method.getName())) {
Statement stmt = (Statement) method.invoke(connection, params);
stmt = StatementLogger.newInstance(stmt, statementLog, queryStack);
return stmt;
} else {
return method.invoke(connection, params);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
如果执行 prepareStatement 方法创建 PrepareStatement 对象,则会使用动态代理创建 PreparedStatementLogger 对象增强原有对象。在 PreparedStatementLogger 的代理逻辑中,如果执行的是 executeQuery 或 getResultSet 方法,其返回值 ResultSet 也会包装为 ResultSetLogger 作为代理,其代理逻辑为如果执行 ResultSet 的 next 方法,会打印结果集的行。
资源加载
Resources 与 ClassLoaderWrapper
MyBatis 提供工具类 Resources 用于工具加载,其底层是通过 ClassLoaderWrapper 实现的。ClassLoaderWrapper 组合了一系列的 ClassLoader:
ClassLoader[] getClassLoaders(ClassLoader classLoader) {
return new ClassLoader[]{
// 指定 ClassLoader
classLoader,
// 默认 ClassLoader,默认为 null
defaultClassLoader,
// 当前线程对应的 ClassLoader
Thread.currentThread().getContextClassLoader(),
// 当前类对应的 ClassLoader
getClass().getClassLoader(),
// 默认为 SystemClassLoader
systemClassLoader};
}
当加载资源时会按组合的 ClassLoader 顺序依次尝试加载资源,例如 classForName 方法的实现:
Class<?> classForName(String name, ClassLoader[] classLoader) throws ClassNotFoundException {
// 按组合顺序依次加载
for (ClassLoader cl : classLoader) {
if (null != cl) {
try {
// 类加载
Class<?> c = Class.forName(name, true, cl);
if (null != c) {
return c;
}
} catch (ClassNotFoundException e) {
// we'll ignore this until all classloaders fail to locate the class
}
}
}
throw new ClassNotFoundException("Cannot find class: " + name);
}
加载指定包下的类
ResolverUtil 的 find 方法用于按条件加载指定包下的类。
public ResolverUtil<T> find(Test test, String packageName) {
// 包名.替换为/
String path = getPackagePath(packageName);
try {
// 虚拟文件系统加载文件路径
List<String> children = VFS.getInstance().list(path);
for (String child : children) {
if (child.endsWith(".class")) {
// 如果指定class文件符合条件,加入容器
addIfMatching(test, child);
}
}
} catch (IOException ioe) {
log.error("Could not read package: " + packageName, ioe);
}
return this;
}
ResolverUtil 还提供了一个内部接口 Test 用于判断指定类型是否满足条件,在 ResolverUtil 有两个默认实现:IsA 用于判断是否为指定类型的子类;AnnotatedWith 用于判断类上是否有指定注解。
/**
* A Test that checks to see if each class is assignable to the provided class. Note
* that this test will match the parent type itself if it is presented for matching.
*
* 判断是否为子类
*/
public static class IsA implements Test {
private Class<?> parent;
/** Constructs an IsA test using the supplied Class as the parent class/interface. */
public IsA(Class<?> parentType) {
this.parent = parentType;
}
/** Returns true if type is assignable to the parent type supplied in the constructor. */
@Override
public boolean matches(Class<?> type) {
return type != null && parent.isAssignableFrom(type);
}
}
/**
* A Test that checks to see if each class is annotated with a specific annotation. If it
* is, then the test returns true, otherwise false.
*
* 判断类上是否有指定注解
*/
public static class AnnotatedWith implements Test {
private Class<? extends Annotation> annotation;
/** Constructs an AnnotatedWith test for the specified annotation type. */
public AnnotatedWith(Class<? extends Annotation> annotation) {
this.annotation = annotation;
}
/** Returns true if the type is annotated with the class provided to the constructor. */
@Override
public boolean matches(Class<?> type) {
return type != null && type.isAnnotationPresent(annotation);
}
}
如果要加载的类复合条件,则将加载的类对象加入容器。
protected void addIfMatching(Test test, String fqn) {
try {
String externalName = fqn.substring(0, fqn.indexOf('.')).replace('/', '.');
ClassLoader loader = getClassLoader();
if (log.isDebugEnabled()) {
log.debug("Checking to see if class " + externalName + " matches criteria [" + test + "]");
}
// 加载类
Class<?> type = loader.loadClass(externalName);
if (test.matches(type)) {
// 符合条件,加入容器
matches.add((Class<T>) type);
}
} catch (Throwable t) {
log.warn("Could not examine class '" + fqn + "'" + " due to a " +
t.getClass().getName() + " with message: " + t.getMessage());
}
}
数据源实现
MyBatis 提供了自己的数据源实现,分别为非池化数据源 UnpooledDataSource 和池化数据源 PooledDataSource。两个数据源都实现了 javax.sql.DataSource 接口并分别由 UnpooledDataSourceFactory 和 PooledDataSourceFactory 工厂类创建。两个工厂类又都实现了 DataSourceFactory 接口。
DataSourceFactory 实现
UnpooledDataSourceFactory 实现了 DataSourceFactory 接口的 setProperties 和 getDataSource 方法,分别用于在创建数据源工厂后配置数据源属性和获取数据源,PooledDataSourceFactory 继承了其实现:
public UnpooledDataSourceFactory() {
this.dataSource = new UnpooledDataSource();
}
/**
* 创建数据源工厂后配置数据源属性
*
* @param props
*/
@Override
public void setProperties(Properties properties) {
Properties driverProperties = new Properties();
// 数据源对象信息
MetaObject metaDataSource = SystemMetaObject.forObject(dataSource);
for (Object key : properties.keySet()) {
String propertyName = (String) key;
if (propertyName.startsWith(DRIVER_PROPERTY_PREFIX)) {
// 数据源驱动相关属性
String value = properties.getProperty(propertyName);
driverProperties.setProperty(propertyName.substring(DRIVER_PROPERTY_PREFIX_LENGTH), value);
} else if (metaDataSource.hasSetter(propertyName)) {
// 属性在数据源类中有相应的set方法
String value = (String) properties.get(propertyName);
// 转换类型
Object convertedValue = convertValue(metaDataSource, propertyName, value);
// 反射赋值
metaDataSource.setValue(propertyName, convertedValue);
} else {
throw new DataSourceException("Unknown DataSource property: " + propertyName);
}
}
if (driverProperties.size() > 0) {
metaDataSource.setValue("driverProperties", driverProperties);
}
}
/**
* 获取数据源
*
* @return
*/
@Override
public DataSource getDataSource() {
return dataSource;
}
非池化数据源
UnpooledDataSource 在静态语句块中从数据源驱动管理器 DriverManager 获取所有已注册驱动并放入本地容器:
static {
// 从数据库驱动类中获取所有驱动
Enumeration<Driver> drivers = DriverManager.getDrivers();
while (drivers.hasMoreElements()) {
Driver driver = drivers.nextElement();
registeredDrivers.put(driver.getClass().getName(), driver);
}
}
此数据源获取连接的实现为调用 doGetConnection 方法,每次获取连接时先校验当前驱动是否注册,如果已注册则直接创建新连接,并配置自动提交属性和默认事务隔离级别:
/**
* 获取连接
*
* @param properties
* @return
* @throws SQLException
*/
private Connection doGetConnection(Properties properties) throws SQLException {
// 校验当前驱动是否注册,如果未注册,加载驱动并注册
initializeDriver();
// 获取数据库连接
Connection connection = DriverManager.getConnection(url, properties);
// 配置自动提交和默认事务隔离级别属性
configureConnection(connection);
return connection;
}
/**
* 校验当前驱动是否注册
*
* @throws SQLException
*/
private synchronized void initializeDriver() throws SQLException {
if (!registeredDrivers.containsKey(driver)) {
// 当前驱动还未注册
Class<?> driverType;
try {
// 加载驱动类
if (driverClassLoader != null) {
driverType = Class.forName(driver, true, driverClassLoader);
} else {
driverType = Resources.classForName(driver);
}
// DriverManager requires the driver to be loaded via the system ClassLoader.
// http://www.kfu.com/~nsayer/Java/dyn-jdbc.html
Driver driverInstance = (Driver)driverType.newInstance();
// 注册驱动
DriverManager.registerDriver(new DriverProxy(driverInstance));
registeredDrivers.put(driver, driverInstance);
} catch (Exception e) {
throw new SQLException("Error setting driver on UnpooledDataSource. Cause: " + e);
}
}
}
/**
* 配置自动提交和默认事务隔离级别属性
*
* @param conn
* @throws SQLException
*/
private void configureConnection(Connection conn) throws SQLException {
if (autoCommit != null && autoCommit != conn.getAutoCommit()) {
conn.setAutoCommit(autoCommit);
}
if (defaultTransactionIsolationLevel != null) {
conn.setTransactionIsolation(defaultTransactionIsolationLevel);
}
}
池化数据源
数据库连接的创建是十分耗时的,在高并发环境下,频繁地创建和关闭连接会为系统带来很大的开销。而使用连接池实现对数据库连接的重用可以显著提高性能,避免反复创建连接。MyBatis 实现的连接池包含了维护连接队列、创建和保存连接、归还连接等功能。
池化连接
PooledConnection 是 MyBatis 的池化连接实现。其构造方法中传入了驱动管理器创建的真正连接,并通过 JDK 动态代理创建了连接的代理对象:
public PooledConnection(Connection connection, PooledDataSource dataSource) {
this.hashCode = connection.hashCode();
// 真正的数据库连接
this.realConnection = connection;
// 数据源对象
this.dataSource = dataSource;
// 连接创建时间
this.createdTimestamp = System.currentTimeMillis();
// 连接上次使用时间
this.lastUsedTimestamp = System.currentTimeMillis();
// 数据源有效标志
this.valid = true;
// 创建连接代理
this.proxyConnection = (Connection) Proxy.newProxyInstance(Connection.class.getClassLoader(), IFACES, this);
}
连接代理的逻辑如下,如果执行 close 方法,并不会真正的关闭连接,而是当作空闲连接交给数据源处理,根据连接池的状态选择将连接放入空闲队列或关闭连接;如果执行其它方法,则会判断当前连接是否有效,如果是无效连接会抛出异常:
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
if (CLOSE.hashCode() == methodName.hashCode() && CLOSE.equals(methodName)) {
// 调用连接关闭方法代理逻辑:处理空闲连接,放入空闲队列或关闭
dataSource.pushConnection(this);
return null;
}
try {
if (!Object.class.equals(method.getDeclaringClass())) {
// issue #579 toString() should never fail
// throw an SQLException instead of a Runtime
// 执行其它方法,验证连接是否有效,如果是无效连接,抛出异常
checkConnection();
}
return method.invoke(realConnection, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
连接池状态
PoolState 维护了数据库连接池状态。其内部维护了两个容器,分别为空闲连接集合和活跃连接集合。
/**
* 空闲连接集合
*/
protected final List<PooledConnection> idleConnections = new ArrayList<>();
/**
* 活跃连接集合
*/
protected final List<PooledConnection> activeConnections = new ArrayList<>();
获取连接
池化数据源 PooledDataSource 是依赖 UnpooledDataSource 实现的。其获取连接的方式是调用 popConnection 方法。在获取连接池同步锁后按照以下顺序尝试获取可用连接:
- 从空闲队列获取连接
- 活跃连接池未满,创建新连接
- 检查最早的活跃连接是否超时
- 等待释放连接
private PooledConnection popConnection(String username, String password) throws SQLException {
// 等待连接标志
boolean countedWait = false;
// 待获取的池化连接
PooledConnection conn = null;
long t = System.currentTimeMillis();
int localBadConnectionCount = 0;
while (conn == null) {
// 循环获取连接
synchronized (state) {
// 获取连接池的同步锁
if (!state.idleConnections.isEmpty()) {
// Pool has available connection 连接池中有空闲连接
conn = state.idleConnections.remove(0);
if (log.isDebugEnabled()) {
log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
}
} else {
// Pool does not have available connection 连接池无可用连接
if (state.activeConnections.size() < poolMaximumActiveConnections) {
// Can create new connection 活跃连接数小于设定的最大连接数,创建新的连接(从驱动管理器创建新的连接)
conn = new PooledConnection(dataSource.getConnection(), this);
if (log.isDebugEnabled()) {
log.debug("Created connection " + conn.getRealHashCode() + ".");
}
} else {
// Cannot create new connection 活跃连接数到达最大连接数
PooledConnection oldestActiveConnection = state.activeConnections.get(0);
// 查询最早入队的活跃连接使用时间(即使用时间最长的活跃连接使用时间)
long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
if (longestCheckoutTime > poolMaximumCheckoutTime) {
// Can claim overdue connection 超出活跃连接最大使用时间
state.claimedOverdueConnectionCount++;
// 超时连接累计使用时长
state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
state.accumulatedCheckoutTime += longestCheckoutTime;
// 活跃连接队列移除当前连接
state.activeConnections.remove(oldestActiveConnection);
if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
try {
// 创建的连接未自动提交,执行回滚
oldestActiveConnection.getRealConnection().rollback();
} catch (SQLException e) {
/*
Just log a message for debug and continue to execute the following
statement like nothing happened.
Wrap the bad connection with a new PooledConnection, this will help
to not interrupt current executing thread and give current thread a
chance to join the next competition for another valid/good database
connection. At the end of this loop, bad {@link @conn} will be set as null.
*/
log.debug("Bad connection. Could not roll back");
}
}
// 包装新的池化连接
conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
// 设置原连接无效
oldestActiveConnection.invalidate();
if (log.isDebugEnabled()) {
log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
}
} else {
// Must wait
try {
// 存活连接有效
if (!countedWait) {
state.hadToWaitCount++;
countedWait = true;
}
if (log.isDebugEnabled()) {
log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
}
long wt = System.currentTimeMillis();
// 释放锁等待连接,{@link PooledDataSource#pushConnection} 如果有连接空闲,会唤醒等待
state.wait(poolTimeToWait);
// 记录等待时长
state.accumulatedWaitTime += System.currentTimeMillis() - wt;
} catch (InterruptedException e) {
break;
}
}
}
}
if (conn != null) {
// ping to server and check the connection is valid or not
if (conn.isValid()) {
// 连接有效
if (!conn.getRealConnection().getAutoCommit()) {
// 非自动提交的连接,回滚上次任务
conn.getRealConnection().rollback();
}
conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
// 设置连接新的使用时间
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
// 添加到活跃连接集合队尾
state.activeConnections.add(conn);
// 连接请求次数+1
state.requestCount++;
// 请求连接花费的时间
state.accumulatedRequestTime += System.currentTimeMillis() - t;
} else {
// 未获取到连接
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
}
// 因为没有空闲连接导致获取连接失败次数+1
state.badConnectionCount++;
// 本次请求获取连接失败数+1
localBadConnectionCount++;
conn = null;
if (localBadConnectionCount > (poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)) {
// 超出获取连接失败的可容忍次数,抛出异常
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Could not get a good connection to the database.");
}
throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
}
}
}
}
}
if (conn == null) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
return conn;
}
如果暂时获取不到可用连接,则当前线程进入等待,等待新的空闲连接产生唤醒等待或等待超时后重新尝试获取连接。当尝试次数到达指定上限,会抛出异常跳出等待。
判断连接有效性
如果可以从连接池中获取连接,会调用 PooledConnection#isValid 方法判断连接是否有效,其逻辑为 PooledConnection 对象自身维护的标志有效且连接存活。判断连接存活的实现如下:
protected boolean pingConnection(PooledConnection conn) {
boolean result = true;
try {
// 连接是否关闭
result = !conn.getRealConnection().isClosed();
} catch (SQLException e) {
if (log.isDebugEnabled()) {
log.debug("Connection " + conn.getRealHashCode() + " is BAD: " + e.getMessage());
}
result = false;
}
if (result) {
if (poolPingEnabled) {
// 使用语句检测连接是否可用开关开启
if (poolPingConnectionsNotUsedFor >= 0 && conn.getTimeElapsedSinceLastUse() > poolPingConnectionsNotUsedFor) {
// 距上次连接使用经历时长超过设置的阈值
try {
if (log.isDebugEnabled()) {
log.debug("Testing connection " + conn.getRealHashCode() + " ...");
}
// 验证连接是否可用
Connection realConn = conn.getRealConnection();
try (Statement statement = realConn.createStatement()) {
statement.executeQuery(poolPingQuery).close();
}
if (!realConn.getAutoCommit()) {
// 未自动提交执行回滚
realConn.rollback();
}
result = true;
if (log.isDebugEnabled()) {
log.debug("Connection " + conn.getRealHashCode() + " is GOOD!");
}
} catch (Exception e) {
log.warn("Execution of ping query '" + poolPingQuery + "' failed: " + e.getMessage());
try {
// 抛出异常,连接不可用,关闭连接
conn.getRealConnection().close();
} catch (Exception e2) {
//ignore
}
result = false;
if (log.isDebugEnabled()) {
log.debug("Connection " + conn.getRealHashCode() + " is BAD: " + e.getMessage());
}
}
}
}
}
return result;
}
默认调用 Connection#isClosed 方法判断连接是否存活,如果连接存活,则可以选择执行 SQL 语句来进一步判断连接的有效性。是否进一步验证、验证使用的 SQL 语句、验证的时间条件,都是可配置的。
处理空闲连接
在池化连接的代理连接执行关闭操作时,会转为对空闲连接的处理,其实现逻辑如下:
protected void pushConnection(PooledConnection conn) throws SQLException {
synchronized (state) {
// 获取连接池状态同步锁,活跃连接队列移除当前连接
state.activeConnections.remove(conn);
if (conn.isValid()) {
// 连接有效
if (state.idleConnections.size() < poolMaximumIdleConnections && conn.getConnectionTypeCode() == expectedConnectionTypeCode) {
// 空闲连接数小于最大空闲连接数,累计连接使用时长
state.accumulatedCheckoutTime += conn.getCheckoutTime();
if (!conn.getRealConnection().getAutoCommit()) {
// 未自动提交连接回滚上次事务
conn.getRealConnection().rollback();
}
// 包装成新的代理连接
PooledConnection newConn = new PooledConnection(conn.getRealConnection(), this);
// 将新连接放入空闲队列
state.idleConnections.add(newConn);
// 设置相关统计时间戳
newConn.setCreatedTimestamp(conn.getCreatedTimestamp());
newConn.setLastUsedTimestamp(conn.getLastUsedTimestamp());
// 老连接设置失效
conn.invalidate();
if (log.isDebugEnabled()) {
log.debug("Returned connection " + newConn.getRealHashCode() + " to pool.");
}
// 唤醒等待连接的线程,通知有新连接可以使用
state.notifyAll();
} else {
// 空闲连接数达到最大空闲连接数
state.accumulatedCheckoutTime += conn.getCheckoutTime();
if (!conn.getRealConnection().getAutoCommit()) {
// 未自动提交连接回滚上次事务
conn.getRealConnection().rollback();
}
// 关闭多余的连接
conn.getRealConnection().close();
if (log.isDebugEnabled()) {
log.debug("Closed connection " + conn.getRealHashCode() + ".");
}
// 连接设置失效
conn.invalidate();
}
} else {
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") attempted to return to the pool, discarding connection.");
}
// 连接无效次数+1
state.badConnectionCount++;
}
}
}
如果当前空闲连接数小于最大空闲连接数,则将空闲连接放入空闲队列,否则关闭连接。
处理配置变更
在相关配置变更后,MyBatis 会调用 forceCloseAll 关闭连接池中所有存活的连接:
public void forceCloseAll() {
synchronized (state) {
// 获取连接池状态同步锁
expectedConnectionTypeCode = assembleConnectionTypeCode(dataSource.getUrl(), dataSource.getUsername(), dataSource.getPassword());
for (int i = state.activeConnections.size(); i > 0; i--) {
try {
// 移除活跃连接
PooledConnection conn = state.activeConnections.remove(i - 1);
// 原连接置为无效
conn.invalidate();
Connection realConn = conn.getRealConnection();
if (!realConn.getAutoCommit()) {
// 未提交连接回滚当前事务
realConn.rollback();
}
// 关闭连接
realConn.close();
} catch (Exception e) {
// ignore
}
}
for (int i = state.idleConnections.size(); i > 0; i--) {
try {
// 移除空闲连接
PooledConnection conn = state.idleConnections.remove(i - 1);
// 原连接置为无效
conn.invalidate();
Connection realConn = conn.getRealConnection();
if (!realConn.getAutoCommit()) {
// 未提交连接回滚当前事务
realConn.rollback();
}
// 关闭连接
realConn.close();
} catch (Exception e) {
// ignore
}
}
}
if (log.isDebugEnabled()) {
log.debug("PooledDataSource forcefully closed/removed all connections.");
}
}
缓存实现
Cache 是 MyBatis 的缓存抽象接口,其要求实现如下方法:
public interface Cache {
/**
* 缓存对象 id
*
* @return The identifier of this cache
*/
String getId();
/**
* 设置缓存
*
* @param key Can be any object but usually it is a {@link CacheKey}
* @param value The result of a select.
*/
void putObject(Object key, Object value);
/**
* 获取缓存
*
* @param key The key
* @return The object stored in the cache.
*/
Object getObject(Object key);
/**
* 移除缓存
*
* @param key The key
* @return Not used
*/
Object removeObject(Object key);
/**
* 清空缓存
*
* Clears this cache instance.
*/
void clear();
/**
* Optional. This method is not called by the core.
* 获取缓存项数量
*
* @return The number of elements stored in the cache (not its capacity).
*/
int getSize();
/**
* 获取读写锁
*
* @return A ReadWriteLock
*/
ReadWriteLock getReadWriteLock();
}
基础实现
PerpetualCache 类是基础实现类,核心是基于 HashMap 作为缓存维护容器。在此基础上,MyBatis 实现了多种缓存装饰器,用于满足不同的需求。
缓存装饰器
同步操作
SynchronizedCache 针对缓存操作方法加上了 synchronized 关键字用于进行同步操作。
阻塞操作
BlockingCache 在执行获取缓存操作时对 key 加锁,直到写缓存后释放锁,保证了相同 key 同一时刻只有一个线程执行数据库操作,其它线程在缓存层阻塞。
/**
* 写缓存完成后释放锁
*/
@Override
public void putObject(Object key, Object value) {
try {
delegate.putObject(key, value);
} finally {
releaseLock(key);
}
}
@Override
public Object getObject(Object key) {
// 获取锁
acquireLock(key);
Object value = delegate.getObject(key);
if (value != null) {
// 缓存不为空则释放锁,否则继续持有锁,在进行数据库操作后写缓存释放锁
releaseLock(key);
}
return value;
}
/**
* 删除指定 key 对应的缓存,并释放锁
*
* @param key The key
* @return
*/
@Override
public Object removeObject(Object key) {
// despite of its name, this method is called only to release locks
releaseLock(key);
return null;
}
/**
* 获取已有的锁或创建新锁
*
* @param key
* @return
*/
private ReentrantLock getLockForKey(Object key) {
return locks.computeIfAbsent(key, k -> new ReentrantLock());
}
/**
* 根据 key 获取锁
*
* @param key
*/
private void acquireLock(Object key) {
Lock lock = getLockForKey(key);
if (timeout > 0) {
try {
boolean acquired = lock.tryLock(timeout, TimeUnit.MILLISECONDS);
if (!acquired) {
throw new CacheException("Couldn't get a lock in " + timeout + " for the key " + key + " at the cache " + delegate.getId());
}
} catch (InterruptedException e) {
throw new CacheException("Got interrupted while trying to acquire lock for key " + key, e);
}
} else {
lock.lock();
}
}
/**
* 释放锁
*
* @param key
*/
private void releaseLock(Object key) {
ReentrantLock lock = locks.get(key);
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
日志记录
LoggingCache 是缓存日志装饰器。查询缓存时会记录查询日志并统计命中率。
/**
* 查询缓存时记录查询日志并统计命中率
*
* @param key The key
* @return
*/
@Override
public Object getObject(Object key) {
// 查询数+1
requests++;
final Object value = delegate.getObject(key);
if (value != null) {
// 命中数+1
hits++;
}
if (log.isDebugEnabled()) {
log.debug("Cache Hit Ratio [" + getId() + "]: " + getHitRatio());
}
return value;
}
定时清理
ScheduledCache 是缓存定时清理装饰器。在执行缓存相关操作时会根据设置的时间间隔判断是否需要清除全部的缓存。
/**
* 操作缓存时判断是否需要清除所有缓存。
*
* @return
*/
private boolean clearWhenStale() {
if (System.currentTimeMillis() - lastClear > clearInterval) {
clear();
return true;
}
return false;
}
序列化与反序列化
SerializedCache 是缓存序列化装饰器,其在写入时会将值序列化成对象流,并在读取时进行反序列化。
事务操作
TransactionalCache 是事务缓存装饰器。在事务提交后再将缓存写入,如果发生回滚则不写入。
先进先出
FifoCache 是先进先出缓存装饰器。其按写缓存顺序维护了一个缓存 key 队列,如果缓存项超出指定大小,则删除最先入队的缓存。
/**
* 按写缓存顺序维护缓存 key 队列,缓存项超出指定大小,删除最先入队的缓存
*
* @param key
*/
private void cycleKeyList(Object key) {
keyList.addLast(key);
if (keyList.size() > size) {
Object oldestKey = keyList.removeFirst();
delegate.removeObject(oldestKey);
}
}
最近最久未使用
LruCache 是缓存最近最久未使用装饰器。其基于 LinkedHashMap 维护了 key 的 LRU 顺序。
public void setSize(final int size) {
// LinkedHashMap 在执行 get 方法后会将对应的 entry 移到队尾来维护使用顺序
keyMap = new LinkedHashMap<Object, Object>(size, .75F, true) {
private static final long serialVersionUID = 4267176411845948333L;
@Override
protected boolean removeEldestEntry(Map.Entry<Object, Object> eldest) {
boolean tooBig = size() > size;
if (tooBig) {
// 超出缓存项数量限制,获取最近最久未使用的key
eldestKey = eldest.getKey();
}
return tooBig;
}
};
}
/**
* 更新缓存后检查是否需要删除最近最久未使用的缓存项
*/
@Override
public void putObject(Object key, Object value) {
delegate.putObject(key, value);
cycleKeyList(key);
}
private void cycleKeyList(Object key) {
keyMap.put(key, key);
if (eldestKey != null) {
delegate.removeObject(eldestKey);
eldestKey = null;
}
}
软引用缓存
SoftCache 是缓存软引用装饰器,其使用了软引用 + 强引用队列的方式维护缓存。在写缓存操作中,写入的数据其实时缓存项的软引用包装对象,在 Full GC 时,如果没有一个强引用指向被包装的缓存项或缓存值,并且系统内存不足,缓存项就会被 GC,被回收对象进入指定的引用队列。
/**
* 引用队列,用于记录已经被 GC 的 SoftEntry 对象
*/
private final ReferenceQueue<Object> queueOfGarbageCollectedEntries;
/**
* 写入缓存。
* 不直接写缓存的值,而是写入缓存项对应的软引用
*/
@Override
public void putObject(Object key, Object value) {
removeGarbageCollectedItems();
// 在 Full GC 时,如果没有一个强引用指向被包装的缓存项或缓存值,并且系统内存不足,缓存项就会被回收,被回收对象进入指定的引用队列
delegate.putObject(key, new SoftEntry(key, value, queueOfGarbageCollectedEntries));
}
/**
* 查询已被 GC 的软引用,删除对应的缓存项
*/
private void removeGarbageCollectedItems() {
SoftEntry sv;
while ((sv = (SoftEntry) queueOfGarbageCollectedEntries.poll()) != null) {
delegate.removeObject(sv.key);
}
}
/**
* 封装软引用对象
*/
private static class SoftEntry extends SoftReference<Object> {
private final Object key;
SoftEntry(Object key, Object value, ReferenceQueue<Object> garbageCollectionQueue) {
// 声明 value 为软引用对象
super(value, garbageCollectionQueue);
// key 为强引用
this.key = key;
}
}
在读取缓存时,如果软引用被回收,则删除对应的缓存项;否则将缓存项放入一个强引用队列中,该队列会将最新读取的缓存项放入队首,使得真正的缓存项有了强引用指向,其软引用包装就不会被垃圾回收。队列有数量限制,当超出限制时会删除队尾的缓存项。
/**
* 获取缓存。
* 如果软引用被回收则删除对应的缓存项,如果未回收则加入到有数量限制的 LRU 队列中
*
* @param key The key
* @return
*/
@Override
public Object getObject(Object key) {
Object result = null;
@SuppressWarnings("unchecked") // assumed delegate cache is totally managed by this cache
SoftReference<Object> softReference = (SoftReference<Object>) delegate.getObject(key);
if (softReference != null) {
result = softReference.get();
if (result == null) {
// 软引用已经被回收,删除对应的缓存项
delegate.removeObject(key);
} else {
// 如果未被回收,增将软引用加入到 LRU 队列
// See #586 (and #335) modifications need more than a read lock
synchronized (hardLinksToAvoidGarbageCollection) {
// 将对应的软引用
hardLinksToAvoidGarbageCollection.addFirst(result);
if (hardLinksToAvoidGarbageCollection.size() > numberOfHardLinks) {
// 超出数量限制,删除最近最久未使用的软引用对象
hardLinksToAvoidGarbageCollection.removeLast();
}
}
}
}
return result;
}
弱引用缓存
WeakCache 是缓存弱引用装饰器,使用弱引用 + 强引用队列的方式维护缓存,其实现方式与 SoftCache 是一致的。
Binding 模块
为了避免因拼写等错误导致在运行期才发现执行方法找不到对应的 SQL 语句,MyBatis 使用 Binding 模块在启动时对执行方法校验,如果找不到对应的语句,则会抛出 BindingException。
MyBatis 一般将执行数据库操作的方法所在的接口称为 Mapper,MapperRegistry 用来注册 Mapper 接口类型与其代理创建工厂的映射,其提供 addMapper 和 addMappers 接口用于注册。Mapper 接口代理工厂是通过 MapperProxyFactory 创建,创建过程依赖 MapperProxy 提供的 JDK 动态代理:
protected T newInstance(MapperProxy<T> mapperProxy) {
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
/**
* 使用 Mapper 代理封装 SqlSession 相关操作
*
* @param sqlSession
* @return
*/
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
MapperProxy 的代理逻辑如下,在 Mapper 接口中的方法真正执行时,会为指定的非 default 方法创建方法信息和 SQL 执行信息缓存:
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) {
// Object中的方法,直接执行
return method.invoke(this, args);
} else if (isDefaultMethod(method)) {
// 当前方法是接口中的非abstract、非static的public方法,即高版本JDK中的default方法
return invokeDefaultMethod(proxy, method, args);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
// 缓存 Mapper接口 对应的方法和 SQL 执行信息
final MapperMethod mapperMethod = cachedMapperMethod(method);
// 执行 SQL
return mapperMethod.execute(sqlSession, args);
}
/**
* 缓存 Mapper接口 对应的方法和 SQL 执行信息
*
* @param method
* @return
*/
private MapperMethod cachedMapperMethod(Method method) {
return methodCache.computeIfAbsent(method, k -> new MapperMethod(mapperInterface, method, sqlSession.getConfiguration()));
}
缓存通过 MapperMethod 类来保存,其构造方法创建了 SqlCommand 和 MethodSignature 对象。
public MapperMethod(Class<?> mapperInterface, Method method, Configuration config) {
// SQL 执行信息
this.command = new SqlCommand(config, mapperInterface, method);
// 获取方法参数和返回值相关信息
this.method = new MethodSignature(config, mapperInterface, method);
}
SqlCommand 会根据接口和方法名找到对应的 SQL statement 对象:
private MappedStatement resolveMappedStatement(Class<?> mapperInterface, String methodName,
Class<?> declaringClass, Configuration configuration) {
// statementId 为接口名与方法名组合
String statementId = mapperInterface.getName() + "." + methodName;
if (configuration.hasStatement(statementId)) {
// 配置中存在此 statementId,返回对应的 statement
return configuration.getMappedStatement(statementId);
} else if (mapperInterface.equals(declaringClass)) {
// 此方法就是在对应接口中声明的
return null;
}
// 递归查找父类
for (Class<?> superInterface : mapperInterface.getInterfaces()) {
if (declaringClass.isAssignableFrom(superInterface)) {
MappedStatement ms = resolveMappedStatement(superInterface, methodName,
declaringClass, configuration);
if (ms != null) {
return ms;
}
}
}
return null;
}
而 MethodSignature 会获取方法相关信息,如返回值类型、是否返回 void、是否返回多值等。对于 Param 注解的解析也会保存下来(MyBatis 使用 Param 注解重置参数名)。
总结
MyBatis 提供了一系列工具和实现,用于为整个框架提供基础支持。
- 类型转换
- org.apache.ibatis.type.TypeHandler:类型转换器接口,抽象 JDBC 类型和 Java 类型互转逻辑。
- org.apache.ibatis.type.BaseTypeHandler:TypeHandler 的抽象实现,针对 null 和异常处理做了封装,具体逻辑仍由相应的类型转换器实现。
- org.apache.ibatis.type.TypeHandlerRegistry:TypeHandler 注册类,维护 JavaType、JdbcType 和 TypeHandler 关系。
- 别名注册
- org.apache.ibatis.type.TypeAliasRegistry:别名注册类。注册常用类型的别名,并提供多种注册别名的方式。
- 日志配置
- org.apache.ibatis.logging.Log:MyBatis 日志适配接口,支持 trace、debug、warn、error 四种级别。
- org.apache.ibatis.logging.LogFactory:MyBatis 日志工厂,负责适配第三方日志实现。
- org.apache.ibatis.logging.jdbc:SQL 执行日志工具包,针对执行 Connection、PrepareStatement、Statement、ResultSet 类中的相关方法,提供日志记录工具。
- 资源加载
- org.apache.ibatis.io.Resources:MyBatis 封装的资源加载工具类。
- org.apache.ibatis.io.ClassLoaderWrapper:资源加载底层实现。组合多种 ClassLoader 按顺序尝试加载资源。
- org.apache.ibatis.io.ResolverUtil:按条件加载指定包下的类。
- 数据源实现
- org.apache.ibatis.datasource.DataSourceFactory:数据源创建工厂接口。
- org.apache.ibatis.datasource.unpooled.UnpooledDataSourceFactory:非池化数据源工厂。
- org.apache.ibatis.datasource.pooled.PooledDataSourceFactory:池化数据源工厂。
- org.apache.ibatis.datasource.unpooled.UnpooledDataSource:非池化数据源。
- org.apache.ibatis.datasource.pooled.PooledDataSource:池化数据源。
- org.apache.ibatis.datasource.pooled.PooledConnection:池化连接。
- org.apache.ibatis.datasource.pooled.PoolState:连接池状态。
- 事务实现
- org.apache.ibatis.transaction.Transaction:事务抽象接口
- org.apache.ibatis.session.TransactionIsolationLevel:事务隔离级别。
- org.apache.ibatis.transaction.TransactionFactory:事务创建工厂抽象接口。
- org.apache.ibatis.transaction.jdbc.JdbcTransaction:封装 JDBC 数据库事务操作。
- org.apache.ibatis.transaction.managed.ManagedTransaction:数据库事务操作依赖外部管理。
- 缓存实现
- org.apache.ibatis.cache.Cache:缓存抽象接口。
- org.apache.ibatis.cache.impl.PerpetualCache:使用 HashMap 作为缓存实现容器的 Cache 基本实现。
- org.apache.ibatis.cache.decorators.BlockingCache:缓存阻塞装饰器。保证相同 key 同一时刻只有一个线程执行数据库操作,其它线程在缓存层阻塞。
- org.apache.ibatis.cache.decorators.FifoCache:缓存先进先出装饰器。按写缓存顺序维护缓存 key 队列,缓存项超出指定大小,删除最先入队的缓存。
- org.apache.ibatis.cache.decorators.LruCache:缓存最近最久未使用装饰器。基于 LinkedHashMap 维护了 key 的 LRU 顺序。
- org.apache.ibatis.cache.decorators.LoggingCache:缓存日志装饰器。查询缓存时记录查询日志并统计命中率。
- org.apache.ibatis.cache.decorators.ScheduledCache:缓存定时清理装饰器。
- org.apache.ibatis.cache.decorators.SerializedCache:缓存序列化装饰器。
- org.apache.ibatis.cache.decorators.SynchronizedCache:缓存同步装饰器。在缓存操作方法上使用 synchronized 关键字同步。
- org.apache.ibatis.cache.decorators.TransactionalCache:事务缓存装饰器。在事务提交后再将缓存写入,如果发生回滚则不写入。
- org.apache.ibatis.cache.decorators.SoftCache:缓存软引用装饰器。使用软引用 + 强引用队列的方式维护缓存。
- org.apache.ibatis.cache.decorators.WeakCache:缓存弱引用装饰器。使用弱引用 + 强引用队列的方式维护缓存。
- Binding
- org.apache.ibatis.binding.MapperRegistry: Mapper 接口注册类,管理 Mapper 接口类型和其代理创建工厂的映射。
- org.apache.ibatis.binding.MapperProxyFactory:Mapper 接口代理创建工厂。
- org.apache.ibatis.binding.MapperProxy:Mapper 接口方法代理逻辑,封装 SqlSession 相关操作。
- org.apache.ibatis.binding.MapperMethod:封装 Mapper 接口对应的方法和 SQL 执行信息。
4.4 - CH04-运行配置解析
在 Spring 与 MyBatis 的集成中,通常需要声明一个 sqlSessionFactory 用于初始化 MyBatis:
<!-- 注册 sqlSessionFactory -->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="configLocation" value="classpath:config/mybatis-config.xml"/>
<property name="typeAliasesPackage" value="com.wch.base.domain"/>
<property name="mapperLocations" value="classpath:mapper/*.xml"/>
</bean>
在 bean 初始化的时候会调用 SqlSessionFactoryBean 的 afterPropertiesSet 方法,在此方法中 MyBatis 使用 XMLConfigBuilder 对配置进行解析。
BaseBuilder 体系
XMLConfigBuilder 是 XML 配置解析的入口,继承自 BaseBuilder,其为 MyBatis 初始化提供了一系列工具方法,如别名转换、类型转换、类加载等。
全局配置对象
XMLConfigBuilder 在构造方法中创建了 Configuration 对象,这个对象中用于保存 MyBatis 相关的全部配置,包括运行行为、类型容器、别名容器、注册 Mapper、注册 statement 等。通过 XMLConfigBuilder 的 parse 方法可以看出,配置解析的目的就是为了获取 Configuration 对象。
private XMLConfigBuilder(XPathParser parser, String environment, Properties props) {
// 创建全局配置
super(new Configuration());
ErrorContext.instance().resource("SQL Mapper Configuration");
// 设置自定义配置
this.configuration.setVariables(props);
// 解析标志
this.parsed = false;
// 指定环境
this.environment = environment;
// 包装配置 InputStream 的 XPathParser
this.parser = parser;
}
public Configuration parse() {
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
parsed = true;
// 读取 configuration 元素并解析
parseConfiguration(parser.evalNode("/configuration"));
return configuration;
}
解析配置文件
配置解析分为多步,详情可参考 XML 配置。MyBatis 源码内置 mybatis-config.xsd 文件用于定义配置文件书写规则。
private void parseConfiguration(XNode root) {
try {
//issue #117 read properties first
// 解析 properties 元素
propertiesElement(root.evalNode("properties"));
// 加载 settings 配置并验证是否有效
Properties settings = settingsAsProperties(root.evalNode("settings"));
// 配置自定义虚拟文件系统实现
loadCustomVfs(settings);
// 配置自定义日志实现
loadCustomLogImpl(settings);
// 解析 typeAliases 元素
typeAliasesElement(root.evalNode("typeAliases"));
// 解析 plugins 元素
pluginElement(root.evalNode("plugins"));
// 解析 objectFactory 元素
objectFactoryElement(root.evalNode("objectFactory"));
// 解析 objectWrapperFactory 元素
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
// 解析 reflectorFactory 元素
reflectorFactoryElement(root.evalNode("reflectorFactory"));
// 将 settings 配置设置到全局配置中
settingsElement(settings);
// read it after objectFactory and objectWrapperFactory issue #631
// 解析 environments 元素
environmentsElement(root.evalNode("environments"));
// 解析 databaseIdProvider 元素
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
// 解析 typeHandlers 元素
typeHandlerElement(root.evalNode("typeHandlers"));
// 解析 mappers 元素
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
解析 properties 元素
properties 元素用于将自定义配置传递给 MyBatis,例如:
<properties resource="com/wch/mybatis/config.properties">
<property name="username" value="wch"/>
<property name="password" value="Noop"/>
</properties>
其加载逻辑为将不同配置转为 Properties 对象,并设置到全局配置中:
private void propertiesElement(XNode context) throws Exception {
if (context != null) {
// 获取子元素属性
Properties defaults = context.getChildrenAsProperties();
// 读取 resource 属性
String resource = context.getStringAttribute("resource");
// 读取 url 属性
String url = context.getStringAttribute("url");
if (resource != null && url != null) {
// 不可均为空
throw new BuilderException("The properties element cannot specify both a URL and a resource based property file reference. Please specify one or the other.");
}
// 加载指定路径文件,转为 properties
if (resource != null) {
defaults.putAll(Resources.getResourceAsProperties(resource));
} else if (url != null) {
defaults.putAll(Resources.getUrlAsProperties(url));
}
// 添加创建配置的附加属性
Properties vars = configuration.getVariables();
if (vars != null) {
defaults.putAll(vars);
}
parser.setVariables(defaults);
// 设置到全局配置中
configuration.setVariables(defaults);
}
}
解析 settings 元素
setteings 元素中的各子元素定义了 MyBatis 的运行时行为,例如:
<settings>
<!-- 缓存开关 -->
<setting name="cacheEnabled" value="true"/>
<!-- 懒加载开关 -->
<setting name="lazyLoadingEnabled" value="false"/>
<!-- 允许自动生成主键 -->
<setting name="useGeneratedKeys" value="false"/>
<!-- 驼峰命名开关 -->
<setting name="mapUnderscoreToCamelCase" value="true"/>
...
</settings>
这些配置在 Configuration 类中都有对应的 setter 方法。settings 元素的解析方法对配置进行了验证:
private Properties settingsAsProperties(XNode context) {
if (context == null) {
return new Properties();
}
// 获取子元素配置
Properties props = context.getChildrenAsProperties();
// Check that all settings are known to the configuration class
// 获取 Configuration 类的相关信息
MetaClass metaConfig = MetaClass.forClass(Configuration.class, localReflectorFactory);
for (Object key : props.keySet()) {
if (!metaConfig.hasSetter(String.valueOf(key))) {
// 验证对应的 setter 方法存在,保证配置是有效的
throw new BuilderException("The setting " + key + " is not known. Make sure you spelled it correctly (case sensitive).");
}
}
return props;
}
如果不存在对应的配置,会抛出 BuilderException 异常,如果自定义配置都是生效的,随后会调用 settingsElement 方法将这些运行时行为设置到全局配置中。
解析 typeAliases 元素
typeAliases 元素用于定义类别名:
<typeAliases>
<package name="com.wch.mybatis.User"/>
<typeAlias alias="User" type="com.wch.mybatis.User"/>
<typeAlias type="com.wch.mybatis.Item"/>
</typeAliases>
如果使用 package 元素注册别名,则对应包下的所有类都会注册到 TypeAliasRegistry 别名注册容器中;如果使用 typeAlias 元素,则会注册指定类到别名容器中。注册逻辑如下,如果没有指定别名,则优先从类的 Alias 注解获取别名,如果未在类上定义,则默认使用简单类名:
/**
* 注册指定包下所有类型别名
*
* @param packageName
*/
public void registerAliases(String packageName) {
registerAliases(packageName, Object.class);
}
/**
* 注册指定包下指定类型的别名
*
* @param packageName
* @param superType
*/
public void registerAliases(String packageName, Class<?> superType) {
ResolverUtil<Class<?>> resolverUtil = new ResolverUtil<>();
// 找出该包下superType所有的子类
resolverUtil.find(new ResolverUtil.IsA(superType), packageName);
Set<Class<? extends Class<?>>> typeSet = resolverUtil.getClasses();
for (Class<?> type : typeSet) {
// Ignore inner classes and interfaces (including package-info.java)
// Skip also inner classes. See issue #6
if (!type.isAnonymousClass() && !type.isInterface() && !type.isMemberClass()) {
registerAlias(type);
}
}
}
/**
* 注册类型别名,默认为简单类名,优先从 Alias 注解获取
*
* @param type
*/
public void registerAlias(Class<?> type) {
String alias = type.getSimpleName();
// 从Alias注解读取别名
Alias aliasAnnotation = type.getAnnotation(Alias.class);
if (aliasAnnotation != null) {
alias = aliasAnnotation.value();
}
registerAlias(alias, type);
}
/**
* 注册类型别名
*
* @param alias 别名
* @param value 类型
*/
public void registerAlias(String alias, Class<?> value) {
if (alias == null) {
throw new TypeException("The parameter alias cannot be null");
}
// issue #748
String key = alias.toLowerCase(Locale.ENGLISH);
if (typeAliases.containsKey(key) && typeAliases.get(key) != null && !typeAliases.get(key).equals(value)) {
throw new TypeException("The alias '" + alias + "' is already mapped to the value '" + typeAliases.get(key).getName() + "'.");
}
typeAliases.put(key, value);
}
解析 plugins 元素
插件是 MyBatis 提供的扩展机制之一,通过添加自定义插件可以实现在 SQL 执行过程中的某个时机进行拦截。 plugins 元素用于定义调用拦截器:
<plugins>
<plugin interceptor="com.wch.mybatis.ExamplePlugin">
<property name="name" value="ExamplePlugin"/>
</plugin>
</plugins>
指定的 interceptor 需要实现 org.apache.ibatis.plugin.Interceptor 接口,在创建对象后被加到全局配置过滤器链中:
private void pluginElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
// 获取 interceptor 属性
String interceptor = child.getStringAttribute("interceptor");
// 从子元素中读取属性配置
Properties properties = child.getChildrenAsProperties();
// 加载指定拦截器并创建实例
Interceptor interceptorInstance = (Interceptor) resolveClass(interceptor).newInstance();
interceptorInstance.setProperties(properties);
// 加入全局配置拦截器链
configuration.addInterceptor(interceptorInstance);
}
}
}
objectFactory、 objectWrapperFactory、reflectorFactory 元素的解析方式与 plugins 元素类似 ,指定的子类对象创建后被设置到全局对象中。
解析 environments 元素
在实际生产中,一个项目可能会分为多个不同的环境,通过配置enviroments 元素可以定义不同的数据环境,并在运行时使用指定的环境:
<environments default="development">
<environment id="development">
<transactionManager type="JDBC">
<property name="" value=""/>
</transactionManager>
<dataSource type="UNPOOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
<environment id="prd">
...
</environment>
</environments>
在解析过程中,只有被 default 属性指定的数据环境才会被加载:
private void environmentsElement(XNode context) throws Exception {
if (context != null) {
if (environment == null) {
// 获取指定的数据源名
environment = context.getStringAttribute("default");
}
for (XNode child : context.getChildren()) {
// 环境配置 id
String id = child.getStringAttribute("id");
if (isSpecifiedEnvironment(id)) {
// 加载指定环境配置
// 解析 transactionManager 元素并创建事务工厂实例
TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));
// 解析 dataSource 元素并创建数据源工厂实例
DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));
// 创建数据源
DataSource dataSource = dsFactory.getDataSource();
// 创建环境
Environment.Builder environmentBuilder = new Environment.Builder(id)
.transactionFactory(txFactory)
.dataSource(dataSource);
// 将环境配置信息设置到全局配置中
configuration.setEnvironment(environmentBuilder.build());
}
}
}
}
/**
* 解析 transactionManager 元素并创建事务工厂实例
*
* @param context
* @return
* @throws Exception
*/
private TransactionFactory transactionManagerElement(XNode context) throws Exception {
if (context != null) {
// 指定事务工厂类型
String type = context.getStringAttribute("type");
// 从子元素读取属性配置
Properties props = context.getChildrenAsProperties();
// 加载事务工厂并创建实例
TransactionFactory factory = (TransactionFactory) resolveClass(type).newInstance();
factory.setProperties(props);
return factory;
}
throw new BuilderException("Environment declaration requires a TransactionFactory.");
}
/**
* 解析 dataSource 元素并创建数据源工厂实例
*
* @param context
* @return
* @throws Exception
*/
private DataSourceFactory dataSourceElement(XNode context) throws Exception {
if (context != null) {
// 指定数据源工厂类型
String type = context.getStringAttribute("type");
// 从子元素读取属性配置
Properties props = context.getChildrenAsProperties();
// 加载数据源工厂并创建实例
DataSourceFactory factory = (DataSourceFactory) resolveClass(type).newInstance();
factory.setProperties(props);
return factory;
}
throw new BuilderException("Environment declaration requires a DataSourceFactory.");
}
解析 databaseIdProvider 元素
MyBatis 支持通过 databaseIdProvider 元素来指定支持的数据库的 databaseId,这样在映射配置文件中指定 databaseId 就能够与对应的数据源进行匹配:
<databaseIdProvider type="DB_VENDOR">
<property name="SQL Server" value="sqlserver"/>
<property name="DB2" value="db2"/>
<property name="Oracle" value="oracle" />
</databaseIdProvider>
在根据指定类型解析出对应的 DatabaseIdProvider 后,MyBatis 会根据数据源获取对应的厂商信息:
private void databaseIdProviderElement(XNode context) throws Exception {
DatabaseIdProvider databaseIdProvider = null;
if (context != null) {
String type = context.getStringAttribute("type");
// awful patch to keep backward compatibility
if ("VENDOR".equals(type)) {
type = "DB_VENDOR";
}
// 从子元素读取属性配置
Properties properties = context.getChildrenAsProperties();
// 加载数据库厂商信息配置类并创建实例
databaseIdProvider = (DatabaseIdProvider) resolveClass(type).newInstance();
databaseIdProvider.setProperties(properties);
}
Environment environment = configuration.getEnvironment();
if (environment != null && databaseIdProvider != null) {
// 获取数据库厂商标识
String databaseId = databaseIdProvider.getDatabaseId(environment.getDataSource());
configuration.setDatabaseId(databaseId);
}
}
因为 DB_VENDOR 被指定为 VendorDatabaseIdProvider 的别名,所以默认的获取厂商信息的逻辑如下,当通过 property 属性指定了数据库产品名则使用指定的名称,否则使用数据库元信息对应的产品名。
/**
* 根据数据源获取对应的厂商信息
*
* @param dataSource
* @return
*/
@Override
public String getDatabaseId(DataSource dataSource) {
if (dataSource == null) {
throw new NullPointerException("dataSource cannot be null");
}
try {
return getDatabaseName(dataSource);
} catch (Exception e) {
LogHolder.log.error("Could not get a databaseId from dataSource", e);
}
return null;
}
@Override
public void setProperties(Properties p) {
this.properties = p;
}
/**
* 如果传入的属性配置包含当前数据库产品名,返回指定的值,否则返回数据库产品名
*
* @param dataSource
* @return
* @throws SQLException
*/
private String getDatabaseName(DataSource dataSource) throws SQLException {
String productName = getDatabaseProductName(dataSource);
if (this.properties != null) {
for (Map.Entry<Object, Object> property : properties.entrySet()) {
if (productName.contains((String) property.getKey())) {
return (String) property.getValue();
}
}
// no match, return null
return null;
}
return productName;
}
/**
* 获取数据库产品名
*
* @param dataSource
* @return
* @throws SQLException
*/
private String getDatabaseProductName(DataSource dataSource) throws SQLException {
Connection con = null;
try {
con = dataSource.getConnection();
DatabaseMetaData metaData = con.getMetaData();
return metaData.getDatabaseProductName();
} finally {
if (con != null) {
try {
con.close();
} catch (SQLException e) {
// ignored
}
}
}
}
解析 typeHandlers 元素
typeHandlers 元素用于配置自定义类型转换器:
<typeHandlers>
<typeHandler handler="com.wch.mybatis.ExampleTypeHandler"/>
</typeHandlers>
如果配置的是 package 元素,则会将包下的所有类注册为类型转换器;如果配置的是 typeHandler 元素,则会根据 javaType、jdbcType、handler 属性注册类型转换器。
private void typeHandlerElement(XNode parent) {
if (parent != null) {
for (XNode child : parent.getChildren()) {
if ("package".equals(child.getName())) {
// 注册指定包下的类作为类型转换器,如果声明了 MappedTypes 注解则注册为指定 java 类型的转换器
String typeHandlerPackage = child.getStringAttribute("name");
typeHandlerRegistry.register(typeHandlerPackage);
} else {
// 获取相关属性
String javaTypeName = child.getStringAttribute("javaType");
String jdbcTypeName = child.getStringAttribute("jdbcType");
String handlerTypeName = child.getStringAttribute("handler");
// 加载指定 java 类型类对象
Class<?> javaTypeClass = resolveClass(javaTypeName);
// 加载指定 JDBC 类型并创建实例
JdbcType jdbcType = resolveJdbcType(jdbcTypeName);
// 加载指定类型转换器类对象
Class<?> typeHandlerClass = resolveClass(handlerTypeName);
if (javaTypeClass != null) {
// 注册类型转换器
if (jdbcType == null) {
typeHandlerRegistry.register(javaTypeClass, typeHandlerClass);
} else {
typeHandlerRegistry.register(javaTypeClass, jdbcType, typeHandlerClass);
}
} else {
typeHandlerRegistry.register(typeHandlerClass);
}
}
}
}
}
解析 mappers 元素
mappers 元素用于定义 Mapper 映射文件和 Mapper 调用接口:
<mappers>
<mapper resource="com/wch/mybatis/UserMapper.xml"/>
<mapper url="file://mappers/ItemMapper.xml"/>
<mapper class="com.wch.mybatis.UserMapper"/>
<package name="com.wch.mybatis.mappers"/>
</mappers>
如果定义的是 mapper 元素并指定了 class 属性,或定义了 package 元素,则会将指定类型在 MapperRegistry 中注册为 Mapper 接口,并使用 MapperAnnotationBuilder 对接口方法进行解析;如果定义的是 mapper 元素并指定了 resource、或 url 属性,则会使用 XMLMapperBuilder 解析。对于 Mapper 接口和映射文件将在下一章进行分析。
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
if ("package".equals(child.getName())) {
// 注册指定包名下的类为 Mapper 接口
String mapperPackage = child.getStringAttribute("name");
configuration.addMappers(mapperPackage);
} else {
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
if (resource != null && url == null && mapperClass == null) {
// 加载指定资源
ErrorContext.instance().resource(resource);
InputStream inputStream = Resources.getResourceAsStream(resource);
// 加载指定 Mapper 文件并解析
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url != null && mapperClass == null) {
// 加载指定 URL
ErrorContext.instance().resource(url);
InputStream inputStream = Resources.getUrlAsStream(url);
// 加载指定 Mapper 文件并解析
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url == null && mapperClass != null) {
// 注册指定类为 Mapper 接口
Class<?> mapperInterface = Resources.classForName(mapperClass);
configuration.addMapper(mapperInterface);
} else {
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
}
总结
XMLConfigBuilder 是 XML 配置解析的入口,通常 MyBatis 启动时会使用此类解析配置文件获取运行时行为。
- org.apache.ibatis.builder.BaseBuilder:为 MyBatis 初始化过程提供一系列工具方法。如别名转换、类型转换、类加载等。
- org.apache.ibatis.builder.xml.XMLConfigBuilder:XML 配置解析入口。
- org.apache.ibatis.session.Configuration:MyBatis 全局配置,包括运行行为、类型容器、别名容器、注册 Mapper、注册 statement 等。
- org.apache.ibatis.mapping.VendorDatabaseIdProvider:根据数据源获取对应的厂商信息。
4.5 - CH05-通用配置解析
在上章的配置解析中可以看到 MyBatis 在解析完运行时行为相关配置后会继续解析 Mapper 映射文件和接口,其中参数映射的解析入口为 XMLMapperBuilder 。
映射文件解析
XMLMapperBuilder 调用 parse 方法解析 Mapper 映射文件。
public void parse() {
if (!configuration.isResourceLoaded(resource)) {
// 解析 mapper 元素
configurationElement(parser.evalNode("/mapper"));
// 加入已解析队列
configuration.addLoadedResource(resource);
// Mapper 映射文件与对应 namespace 的接口进行绑定
bindMapperForNamespace();
}
// 重新引用配置
parsePendingResultMaps();
parsePendingCacheRefs();
parsePendingStatements();
}
解析 mapper 元素
mapper 元素通常需要指定 namespace 用于唯一区别映射文件,不同映射文件支持通过其它映射文件的 namespace 来引用其配置。mapper 元素下可以配置二级缓存(cache、cache-ref)、返回值映射(resultMap)、sql fragments(sql)、statement(select、insert、update、delete)等,MyBatis 源码提供 mybatis-mapper.xsd 文件用于规范映射文件书写规则。
private void configurationElement(XNode context) {
try {
// 获取元素对应的 namespace 名称
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
// 设置 Mapper 文件对应的 namespace 名称
builderAssistant.setCurrentNamespace(namespace);
// 解析 cache-ref 元素
cacheRefElement(context.evalNode("cache-ref"));
// 解析 cache 元素,会覆盖 cache-ref 配置
cacheElement(context.evalNode("cache"));
// 解析 parameterMap 元素(废弃)
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
// 解析 resultMap 元素
resultMapElements(context.evalNodes("/mapper/resultMap"));
// 解析 sql 元素
sqlElement(context.evalNodes("/mapper/sql"));
// 解析 select|insert|update|delete 元素
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
}
}
解析 cache 元素
如果要为某命名空间开启二级缓存功能,可以通过配置 cache 元素,示例配置如下:
<cache type=“PERPETUAL” eviction="LRU" flushInterval="60000" size="512" readOnly="true" blocking="true">
<property name="name" value="cache"/>
</cache>
cache 元素的解析逻辑如下:
private void cacheElement(XNode context) {
if (context != null) {
// 获取缓存类型,默认为 PERPETUAL
String type = context.getStringAttribute("type", "PERPETUAL");
// Configuration 构造方法中已为默认的缓存实现注册别名,从别名转换器中获取类对象
Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type);
// 获取失效类型,默认为 LRU
String eviction = context.getStringAttribute("eviction", "LRU");
Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction);
// 缓存刷新时间间隔
Long flushInterval = context.getLongAttribute("flushInterval");
// 缓存项大小
Integer size = context.getIntAttribute("size");
// 是否将序列化成二级制数据
boolean readWrite = !context.getBooleanAttribute("readOnly", false);
// 缓存不命中进入数据库查询时是否加锁(保证同一时刻相同缓存key只有一个线程执行数据库查询任务)
boolean blocking = context.getBooleanAttribute("blocking", false);
// 从子元素中加载属性
Properties props = context.getChildrenAsProperties();
// 创建缓存配置
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
}
}
在第三章基础支持模块中已经详细介绍了 MyBatis 实现的各种缓存。从 cache 元素中获取缓存参数配置后会交由 MapperBuilderAssistant#useNewCache 方法处理。MapperBuilderAssistant 方法是一个映射文件解析工具,它负责将映射文件各个元素解析的参数生成配置对象,最终设置到全局配置类 Configuration 中。
public Cache useNewCache(Class<? extends Cache> typeClass,
Class<? extends Cache> evictionClass,
Long flushInterval,
Integer size,
boolean readWrite,
boolean blocking,
Properties props) {
Cache cache = new CacheBuilder(currentNamespace)
// 基础缓存配置
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
// 失效类型,默认 LRU
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
// 定时清理缓存时间间隔
.clearInterval(flushInterval)
// 缓存项大小
.size(size)
// 是否将缓存系列化成二级制数据
.readWrite(readWrite)
// 缓存不命中进入数据库查询时是否加锁(保证同一时刻相同缓存key只有一个线程执行数据库查询任务)
.blocking(blocking)
.properties(props)
.build();
// 设置到全局配置中
configuration.addCache(cache);
currentCache = cache;
return cache;
}
解析 cache-ref 元素
如果希望引用其它 namespace 的缓存配置,可以通过 cache-ref 元素配置:
<cache-ref namespace="com.wch.mybatis.OtherMapper" />
其解析逻辑是将当前 namespace 与引用缓存配置的 namespace 在全局配置中进行绑定。
private void cacheRefElement(XNode context) {
if (context != null) {
// 当前 namespace - 引用缓存配置的 namespace,在全局配置中进行绑定
configuration.addCacheRef(builderAssistant.getCurrentNamespace(), context.getStringAttribute("namespace"));
// 获取缓存配置解析器
CacheRefResolver cacheRefResolver = new CacheRefResolver(builderAssistant, context.getStringAttribute("namespace"));
try {
// 解析获得引用的缓存配置
cacheRefResolver.resolveCacheRef();
} catch (IncompleteElementException e) {
// 指定引用的 namespace 缓存还未加载,暂时放入集合,等待全部 namespace 都加载完成后重新引用
configuration.addIncompleteCacheRef(cacheRefResolver);
}
}
}
由于存在被引用配置还未被加载,因而无法从全局配置中获取的情况,MyBatis 定义了 IncompleteElementException 在此时抛出,未解析完成的缓存解析对象会被加入到全局配置中的 incompleteCacheRefs 集合中,用于后续处理。
public Cache useCacheRef(String namespace) {
if (namespace == null) {
throw new BuilderException("cache-ref element requires a namespace attribute.");
}
try {
unresolvedCacheRef = true;
// 从全局配置中获取缓存配置
Cache cache = configuration.getCache(namespace);
if (cache == null) {
throw new IncompleteElementException("No cache for namespace '" + namespace + "' could be found.");
}
currentCache = cache;
unresolvedCacheRef = false;
return cache;
} catch (IllegalArgumentException e) {
// 可能指定引用的 namespace 缓存还未加载,抛出异常
throw new IncompleteElementException("No cache for namespace '" + namespace + "' could be found.", e);
}
}
MyBatis 允许 resultMap、cache-ref、statement 元素延迟加载,以 cache-ref 重新引用的方法 parsePendingCacheRefs 为例,其重新引用逻辑如下:
private void parsePendingCacheRefs() {
// 从全局配置中获取未解析的缓存引用配置
Collection<CacheRefResolver> incompleteCacheRefs = configuration.getIncompleteCacheRefs();
synchronized (incompleteCacheRefs) {
Iterator<CacheRefResolver> iter = incompleteCacheRefs.iterator();
while (iter.hasNext()) {
try {
// 逐个重新引用缓存配置
iter.next().resolveCacheRef();
// 引用成功,删除集合元素
iter.remove();
} catch (IncompleteElementException e) {
// 引用的缓存配置不存在
// Cache ref is still missing a resource...
}
}
}
}
解析 resultMap 元素
resultMap 元素用于定义结果集与结果对象(JavaBean 对象)之间的映射规则。resultMap 下除了 discriminator 的其它元素,都会被解析成 ResultMapping 对象,其解析过程如下:
private ResultMap resultMapElement(XNode resultMapNode, List<ResultMapping> additionalResultMappings, Class<?> enclosingType) throws Exception {
ErrorContext.instance().activity("processing " + resultMapNode.getValueBasedIdentifier());
// 获取返回值类型
String type = resultMapNode.getStringAttribute("type",
resultMapNode.getStringAttribute("ofType",
resultMapNode.getStringAttribute("resultType",
resultMapNode.getStringAttribute("javaType"))));
// 加载返回值类对象
Class<?> typeClass = resolveClass(type);
if (typeClass == null) {
// association 和 case 元素没有显式地指定返回值类型
typeClass = inheritEnclosingType(resultMapNode, enclosingType);
}
Discriminator discriminator = null;
List<ResultMapping> resultMappings = new ArrayList<>();
resultMappings.addAll(additionalResultMappings);
// 加载子元素
List<XNode> resultChildren = resultMapNode.getChildren();
for (XNode resultChild : resultChildren) {
if ("constructor".equals(resultChild.getName())) {
// 解析 constructor 元素
processConstructorElement(resultChild, typeClass, resultMappings);
} else if ("discriminator".equals(resultChild.getName())) {
// 解析 discriminator 元素
discriminator = processDiscriminatorElement(resultChild, typeClass, resultMappings);
} else {
// 解析 resultMap 元素下的其它元素
List<ResultFlag> flags = new ArrayList<>();
if ("id".equals(resultChild.getName())) {
// id 元素增加标志
flags.add(ResultFlag.ID);
}
// 解析元素映射关系
resultMappings.add(buildResultMappingFromContext(resultChild, typeClass, flags));
}
}
String id = resultMapNode.getStringAttribute("id",
resultMapNode.getValueBasedIdentifier());
// extend resultMap id
String extend = resultMapNode.getStringAttribute("extends");
// 是否设置自动映射
Boolean autoMapping = resultMapNode.getBooleanAttribute("autoMapping");
// resultMap 解析器
ResultMapResolver resultMapResolver = new ResultMapResolver(builderAssistant, id, typeClass, extend, discriminator, resultMappings, autoMapping);
try {
// 解析生成 ResultMap 对象并设置到全局配置中
return resultMapResolver.resolve();
} catch (IncompleteElementException e) {
// 异常稍后处理
configuration.addIncompleteResultMap(resultMapResolver);
throw e;
}
}
以下从不同元素配置的角度分别分析 MyBatis 解析规则。
id & result
id 和 result 元素都会将一个列的值映射到一个简单数据类型字段,不同的是 id 元素对应对象的标识属性,在比较对象时会用到。此外还可以设置 typeHandler 属性用于自定义类型转换逻辑。
buildResultMappingFromContext 方法负责将 resultMap 子元素解析为 ResultMapping 对象:
/**
* 解析 resultMap 子元素映射关系
*/
private ResultMapping buildResultMappingFromContext(XNode context, Class<?> resultType, List<ResultFlag> flags) throws Exception {
String property;
if (flags.contains(ResultFlag.CONSTRUCTOR)) {
// constructor 子元素,通过 name 获取参数名
property = context.getStringAttribute("name");
} else {
property = context.getStringAttribute("property");
}
// 列名
String column = context.getStringAttribute("column");
// java 类型
String javaType = context.getStringAttribute("javaType");
// jdbc 类型
String jdbcType = context.getStringAttribute("jdbcType");
// 嵌套的 select id
String nestedSelect = context.getStringAttribute("select");
// 获取嵌套的 resultMap id
String nestedResultMap = context.getStringAttribute("resultMap",
processNestedResultMappings(context, Collections.emptyList(), resultType));
// 获取指定的不为空才创建实例的列
String notNullColumn = context.getStringAttribute("notNullColumn");
// 列前缀
String columnPrefix = context.getStringAttribute("columnPrefix");
// 类型转换器
String typeHandler = context.getStringAttribute("typeHandler");
// 集合的多结果集
String resultSet = context.getStringAttribute("resultSet");
// 指定外键对应的列名
String foreignColumn = context.getStringAttribute("foreignColumn");
// 是否懒加载
boolean lazy = "lazy".equals(context.getStringAttribute("fetchType", configuration.isLazyLoadingEnabled() ? "lazy" : "eager"));
// 加载返回值类型
Class<?> javaTypeClass = resolveClass(javaType);
// 加载类型转换器类型
Class<? extends TypeHandler<?>> typeHandlerClass = resolveClass(typeHandler);
// 加载 jdbc 类型对象
JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);
return builderAssistant.buildResultMapping(resultType, property, column, javaTypeClass, jdbcTypeEnum, nestedSelect, nestedResultMap, notNullColumn, columnPrefix, typeHandlerClass, flags, resultSet, foreignColumn, lazy);
}
ResultMapping 对象保存了列名与 JavaBean 中字段名的对应关系,并明确了 Java 类型和 JDBC 类型,如果指定了类型转换器则使用指定的转化器将结果集字段映射为 Java 对象字段;否则根据 Java 类型和 JDBC 类型到类型转换器注册类中寻找适合的类型转换器。最终影响映射的一系列因素都被保存到 ResultMapping 对象中并加入到全局配置。
constructor
使用 constructor 元素允许返回值对象使用指定的构造方法创建而不是默认的构造方法。
<constructor>
<idArg name="id" column="id"/>
<arg name="productId" column="product_id"/>
</constructor>
在解析 constructor 元素时,MyBatis 特别指定了将 constructor 子元素解析为 ResultMapping 对象。
...
// 加载子元素
List<XNode> resultChildren = resultMapNode.getChildren();
for (XNode resultChild : resultChildren) {
if ("constructor".equals(resultChild.getName())) {
// 解析 constructor 元素
processConstructorElement(resultChild, typeClass, resultMappings);
}
...
}
...
/**
* 解析 constructor 元素下的子元素
*/
private void processConstructorElement(XNode resultChild, Class<?> resultType, List<ResultMapping> resultMappings) throws Exception {
// 获取子元素
List<XNode> argChildren = resultChild.getChildren();
for (XNode argChild : argChildren) {
List<ResultFlag> flags = new ArrayList<>();
// 标明此元素在 constructor 元素中
flags.add(ResultFlag.CONSTRUCTOR);
if ("idArg".equals(argChild.getName())) {
// 此元素映射 id
flags.add(ResultFlag.ID);
}
// 解析子元素映射关系
resultMappings.add(buildResultMappingFromContext(argChild, resultType, flags));
}
}
解析 constructor 子元素的逻辑与解析 id、result 元素的逻辑是一致的。
association
association 用于配置非简单类型的映射关系。其不仅支持在当前查询中做嵌套映射:
<resultMap id="userResult" type="User">
<id property="id" column="user_id" />
<association property="product" column="product_id" resultMap="productResult"/>
</resultMap>
也支持通过 select 属性嵌套其它查询:
<resultMap id="userResult" type="User">
<id property="id" column="user_id" />
<association property="product" column="product_id" select="queryProduct"/>
</resultMap>
在解析 resultMap 子元素方法 buildResultMappingFromContext 的逻辑中,MyBatis 会尝试获取每个子元素的 resultMap 属性,如果未指定,则会调用 processNestedResultMappings 方法,在此方法中对于 asociation 元素来说,如果指定了 select 属性,则映射时只需要获取对应 select 语句的 resultMap;如果未指定,则需要重新调用 resultMapElement 解析结果集映射关系。
private ResultMapping buildResultMappingFromContext(XNode context, Class<?> resultType, List<ResultFlag> flags) throws Exception {
...
// 尝试获取嵌套的 resultMap id
String nestedResultMap = context.getStringAttribute("resultMap", processNestedResultMappings(context, Collections.emptyList(), resultType));
...
}
/**
* 处理嵌套的 resultMap,获取 id
*
* @param context
* @param resultMappings
* @param enclosingType
* @return
* @throws Exception
*/
private String processNestedResultMappings(XNode context, List<ResultMapping> resultMappings, Class<?> enclosingType) throws Exception {
if ("association".equals(context.getName())
|| "collection".equals(context.getName())
|| "case".equals(context.getName())) {
if (context.getStringAttribute("select") == null) {
// 如果是 association、collection 或 case 元素并且没有 select 属性
// collection 元素没有指定 resultMap 或 javaType 属性,需要验证 resultMap 父元素对应的返回值类型是否有对当前集合的赋值入口
validateCollection(context, enclosingType);
ResultMap resultMap = resultMapElement(context, resultMappings, enclosingType);
return resultMap.getId();
}
}
return null;
}
在 resultMapElement 方法中调用了 inheritEnclosingType 针对未定义返回类型的元素的返回值类型解析:
private ResultMap resultMapElement(XNode resultMapNode, List<ResultMapping> additionalResultMappings, Class<?> enclosingType) throws Exception {
...
// 获取返回值类型
String type = resultMapNode.getStringAttribute("type",
resultMapNode.getStringAttribute("ofType",
resultMapNode.getStringAttribute("resultType",
resultMapNode.getStringAttribute("javaType"))));
// 加载返回值类对象
Class<?> typeClass = resolveClass(type);
if (typeClass == null) {
// association 等元素没有显式地指定返回值类型
typeClass = inheritEnclosingType(resultMapNode, enclosingType);
}
}
protected Class<?> inheritEnclosingType(XNode resultMapNode, Class<?> enclosingType) {
if ("association".equals(resultMapNode.getName()) && resultMapNode.getStringAttribute("resultMap") == null) {
// association 元素没有指定 resultMap 属性
String property = resultMapNode.getStringAttribute("property");
if (property != null && enclosingType != null) {
// 根据反射信息确定字段的类型
MetaClass metaResultType = MetaClass.forClass(enclosingType, configuration.getReflectorFactory());
return metaResultType.getSetterType(property);
}
} else if ("case".equals(resultMapNode.getName()) && resultMapNode.getStringAttribute("resultMap") == null) {
// case 元素返回值属性与 resultMap 父元素相同
return enclosingType;
}
return null;
}
在 inheritEnclosingType 方法中,如果未定义 resultMap 属性,则会通过反射工具 MetaClass 获取父元素 resultMap 返回类型的类信息,association 元素对应的字段名称的 setter 方法的参数就是其返回值类型。由此 association 元素必定可以关联到其结果集映射。
collection
collection 元素用于配置集合属性的映射关系,其解析过程与 association 元素大致相同,重要的区别是 collection 元素使用 ofType 属性指定集合元素类型,例如需要映射的 Java 集合为 List users,则配置示例如下:
<collection property="users" column="
user_id" ofType="com.wch.mybatis.User" javaType="ArrayList" select="queryUsers"/>
javaType熟悉指定的是字段类型,而 ofType 属性指定的才是需要映射的集合存储的类型。
discriminator
discriminator 支持对一个查询可能出现的不同结果集做鉴别,根据具体的条件为 resultMap 动态选择返回值类型。
<discriminator javaType="int" column="type">
<case value="1" resultType="Apple"/>
<case value="2" resultType="Banana"/>
</discriminator>
discriminator 元素的解析是通过 processDiscriminatorElement 方法完成的:
private Discriminator processDiscriminatorElement(XNode context, Class<?> resultType, List<ResultMapping> resultMappings) throws Exception {
// 获取需要鉴别的字段的相关信息
String column = context.getStringAttribute("column");
String javaType = context.getStringAttribute("javaType");
String jdbcType = context.getStringAttribute("jdbcType");
String typeHandler = context.getStringAttribute("typeHandler");
Class<?> javaTypeClass = resolveClass(javaType);
Class<? extends TypeHandler<?>> typeHandlerClass = resolveClass(typeHandler);
JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);
Map<String, String> discriminatorMap = new HashMap<>();
// 解析 discriminator 的 case 子元素
for (XNode caseChild : context.getChildren()) {
// 解析不同列值对应的不同 resultMap
String value = caseChild.getStringAttribute("value");
String resultMap = caseChild.getStringAttribute("resultMap", processNestedResultMappings(caseChild, resultMappings, resultType));
discriminatorMap.put(value, resultMap);
}
return builderAssistant.buildDiscriminator(resultType, column, javaTypeClass, jdbcTypeEnum, typeHandlerClass, discriminatorMap);
}
创建 ResultMap
在 resultMap 各子元素解析完成,ResultMapResolver 负责将生成的 ResultMapping 集合解析为 ResultMap 对象:
public ResultMap addResultMap(String id, Class<?> type, String extend, Discriminator discriminator, List<ResultMapping> resultMappings, Boolean autoMapping) {
id = applyCurrentNamespace(id, false);
extend = applyCurrentNamespace(extend, true);
if (extend != null) {
if (!configuration.hasResultMap(extend)) {
throw new IncompleteElementException("Could not find a parent resultmap with id '" + extend + "'");
}
// 获取继承的 ResultMap 对象
ResultMap resultMap = configuration.getResultMap(extend);
List<ResultMapping> extendedResultMappings = new ArrayList<>(resultMap.getResultMappings());
extendedResultMappings.removeAll(resultMappings);
// Remove parent constructor if this resultMap declares a constructor.
boolean declaresConstructor = false;
for (ResultMapping resultMapping : resultMappings) {
if (resultMapping.getFlags().contains(ResultFlag.CONSTRUCTOR)) {
// 当前 resultMap 指定了构造方法
declaresConstructor = true;
break;
}
}
if (declaresConstructor) {
// 移除继承的 ResultMap 的构造器映射对象
extendedResultMappings.removeIf(resultMapping -> resultMapping.getFlags().contains(ResultFlag.CONSTRUCTOR));
}
resultMappings.addAll(extendedResultMappings);
}
ResultMap resultMap = new ResultMap.Builder(configuration, id, type, resultMappings, autoMapping).discriminator(discriminator).build();
configuration.addResultMap(resultMap);
return resultMap;
}
如果当前 ResultMap 指定了 extend 属性,MyBatis 会从全局配置中获取被继承的 ResultMap 的相关映射关系,加入到当前映射关系中。但是如果被继承的 ResultMap 指定了构造器映射关系,当前 ResultMap 会选择移除。
解析 sql 元素
sql 元素用于定义可重用的 SQL 代码段,这些代码段可以通过 include 元素进行引用。
<sql id="baseColumns">
id, name, value
</sql>
<sql id="other">
${alias}
</sql>
<select id="query" resultType="Product">
SELECT
<include refid="baseColumns">,
<include refid="other">
<property name="alias" value="other"/>
</include>
FROM
t_something
</select>
对 sql 元素的解析逻辑如下,符合 databaseId 要求的 sql 元素才会被加载到全局配置中。
private void sqlElement(List<XNode> list) {
if (configuration.getDatabaseId() != null) {
sqlElement(list, configuration.getDatabaseId());
}
sqlElement(list, null);
}
/**
* 解析 sql 元素,将对应的 sql 片段设置到全局配置中
*/
private void sqlElement(List<XNode> list, String requiredDatabaseId) {
for (XNode context : list) {
String databaseId = context.getStringAttribute("databaseId");
String id = context.getStringAttribute("id");
id = builderAssistant.applyCurrentNamespace(id, false);
if (databaseIdMatchesCurrent(id, databaseId, requiredDatabaseId)) {
// 符合当前 databaseId 的 sql fragment,加入到全局配置中
sqlFragments.put(id, context);
}
}
}
/**
* 判断 sql 元素是否满足加载条件
*
* @param id
* @param databaseId
* @param requiredDatabaseId
* @return
*/
private boolean databaseIdMatchesCurrent(String id, String databaseId, String requiredDatabaseId) {
if (requiredDatabaseId != null) {
// 如果指定了当前数据源的 databaseId
if (!requiredDatabaseId.equals(databaseId)) {
// 被解析 sql 元素的 databaseId 需要符合
return false;
}
} else {
if (databaseId != null) {
// 全局未指定 databaseId,不会加载指定了 databaseId 的 sql 元素
return false;
}
// skip this fragment if there is a previous one with a not null databaseId
if (this.sqlFragments.containsKey(id)) {
XNode context = this.sqlFragments.get(id);
if (context.getStringAttribute("databaseId") != null) {
return false;
}
}
}
return true;
}
总结
MyBatis 能够轻松实现列值转换为 Java 对象依靠的是其强大的参数映射功能,能够支持集合、关联类型、嵌套等复杂场景的映射。同时缓存配置、sql 片段配置,也为开发者方便的提供了配置入口。
- org.apache.ibatis.builder.annotation.MapperAnnotationBuilder:解析 Mapper 接口。
- org.apache.ibatis.builder.xml.XMLMapperBuilder:解析 Mapper 文件。
- org.apache.ibatis.builder.MapperBuilderAssistant:Mapper 文件解析工具。生成元素对象并设置到全局配置中。
- org.apache.ibatis.builder.CacheRefResolver:缓存引用配置解析器,应用其它命名空间缓存配置到当前命名空间下。
- org.apache.ibatis.builder.IncompleteElementException:当前映射文件引用了其它命名空间下的配置,而该配置还未加载到全局配置中时会抛出此异常。
- org.apache.ibatis.mapping.ResultMapping:返回值字段映射关系对象。
- org.apache.ibatis.builder.ResultMapResolver:ResultMap 解析器。
- org.apache.ibatis.mapping.ResultMap:返回值映射对象。
4.6 - CH06-语句解析
Mapper 映射文件解析的最后一步是解析所有 statement 元素,即 select、insert、update、delete 元素,这些元素中可能会包含动态 SQL,即使用 ${} 占位符或 if、choose、where 等元素动态组成的 SQL。动态 SQL 功能正是 MyBatis 强大的所在,其解析过程也是十分复杂的。
解析工具
为了方便 statement 的解析,MyBatis 提供了一些解析工具。
Token 解析
MyBatis 支持使用 ${} 或 #{} 类型的 token 作为动态参数,不仅文本中可以使用 token,xml 元素中的属性等也可以使用。
GenericTokenParser
GenericTokenParser 是 MyBatis 提供的通用 token 解析器,其解析逻辑是根据指定的 token 前缀和后缀搜索 token,并使用传入的 TokenHandler 对文本进行处理。
public String parse(String text) {
if (text == null || text.isEmpty()) {
return "";
}
// search open token 搜索 token 前缀
int start = text.indexOf(openToken);
if (start == -1) {
// 没有 token 前缀,返回原文本
return text;
}
char[] src = text.toCharArray();
// 当前解析偏移量
int offset = 0;
// 已解析文本
final StringBuilder builder = new StringBuilder();
// 当前占位符内的表达式
StringBuilder expression = null;
while (start > -1) {
if (start > 0 && src[start - 1] == '\\') {
// 如果待解析属性前缀被转义,则去掉转义字符,加入已解析文本
// this open token is escaped. remove the backslash and continue.
builder.append(src, offset, start - offset - 1).append(openToken);
// 更新解析偏移量
offset = start + openToken.length();
} else {
// found open token. let's search close token.
if (expression == null) {
expression = new StringBuilder();
} else {
expression.setLength(0);
}
// 前缀前面的部分加入已解析文本
builder.append(src, offset, start - offset);
// 更新解析偏移量
offset = start + openToken.length();
// 获取对应的后缀索引
int end = text.indexOf(closeToken, offset);
while (end > -1) {
if (end > offset && src[end - 1] == '\\') {
// 后缀被转义,加入已解析文本
// this close token is escaped. remove the backslash and continue.
expression.append(src, offset, end - offset - 1).append(closeToken);
offset = end + closeToken.length();
// 寻找下一个后缀
end = text.indexOf(closeToken, offset);
} else {
// 找到后缀,获取占位符内的表达式
expression.append(src, offset, end - offset);
offset = end + closeToken.length();
break;
}
}
if (end == -1) {
// 找不到后缀,前缀之后的部分全部加入已解析文本
// close token was not found.
builder.append(src, start, src.length - start);
offset = src.length;
} else {
// 能够找到后缀,追加 token 处理器处理后的文本
builder.append(handler.handleToken(expression.toString()));
// 更新解析偏移量
offset = end + closeToken.length();
}
}
// 寻找下一个前缀,重复解析表达式
start = text.indexOf(openToken, offset);
}
if (offset < src.length) {
// 将最后的部分加入已解析文本
builder.append(src, offset, src.length - offset);
}
// 返回解析后的文本
return builder.toString();
}
由于 GenericTokenParser 的 token 前后缀和具体解析逻辑都是可指定的,因此基于 GenericTokenParser 可以实现对不同 token 的定制化解析。
TokenHandler
TokenHandler 是 token 处理器抽象接口。实现此接口可以定义 token 以何种方式被解析。
public interface TokenHandler {
/**
* 对 token 进行解析
*
* @param content 待解析 token
* @return
*/
String handleToken(String content);
}
PropertyParser
PropertyParser 是 token 解析的一种具体实现,其指定对 ${} 类型 token 进行解析,具体解析逻辑由其内部类 VariableTokenHandler 实现:
/**
* 对 ${} 类型 token 进行解析
*
* @param string
* @param variables
* @return
*/
public static String parse(String string, Properties variables) {
VariableTokenHandler handler = new VariableTokenHandler(variables);
GenericTokenParser parser = new GenericTokenParser("${", "}", handler);
return parser.parse(string);
}
/**
* 根据配置属性对 ${} token 进行解析
*/
private static class VariableTokenHandler implements TokenHandler {
/**
* 预先设置的属性
*/
private final Properties variables;
/**
* 是否运行使用默认值,默认为 false
*/
private final boolean enableDefaultValue;
/**
* 默认值分隔符号,即如待解析属性 ${key:default},key 的默认值为 default
*/
private final String defaultValueSeparator;
private VariableTokenHandler(Properties variables) {
this.variables = variables;
this.enableDefaultValue = Boolean.parseBoolean(getPropertyValue(KEY_ENABLE_DEFAULT_VALUE, ENABLE_DEFAULT_VALUE));
this.defaultValueSeparator = getPropertyValue(KEY_DEFAULT_VALUE_SEPARATOR, DEFAULT_VALUE_SEPARATOR);
}
private String getPropertyValue(String key, String defaultValue) {
return (variables == null) ? defaultValue : variables.getProperty(key, defaultValue);
}
@Override
public String handleToken(String content) {
if (variables != null) {
String key = content;
if (enableDefaultValue) {
// 如待解析属性 ${key:default},key 的默认值为 default
final int separatorIndex = content.indexOf(defaultValueSeparator);
String defaultValue = null;
if (separatorIndex >= 0) {
key = content.substring(0, separatorIndex);
defaultValue = content.substring(separatorIndex + defaultValueSeparator.length());
}
if (defaultValue != null) {
// 使用默认值
return variables.getProperty(key, defaultValue);
}
}
if (variables.containsKey(key)) {
// 不使用默认值
return variables.getProperty(key);
}
}
// 返回原文本
return "${" + content + "}";
}
}
VariableTokenHandler 实现了 TokenHandler 接口,其构造方法允许传入一组 Properties 用于获取 token 表达式的值。如果开启了使用默认值,则表达式 ${key:default} 会在 key 没有映射值的时候使用 default 作为默认值。
特殊容器
StrictMap
Configuration 中的 StrictMap 继承了 HashMap,相对于 HashMap,其存取键值的要求更为严格。put 方法不允许添加相同的 key,并获取最后一个 . 后的部分作为 shortKey,如果 shortKey 也重复了,其会向容器中添加一个 Ambiguity 对象,当使用 get 方法获取这个 shortKey 对应的值时,就会抛出异常。get 方法对于不存在的 key 也会抛出异常。
public V put(String key, V value) {
if (containsKey(key)) {
// 重复 key 异常
throw new IllegalArgumentException(name + " already contains value for " + key
+ (conflictMessageProducer == null ? "" : conflictMessageProducer.apply(super.get(key), value)));
}
if (key.contains(".")) {
// 获取最后一个 . 后的部分作为 shortKey
final String shortKey = getShortName(key);
// shortKey 不允许重复,否则在获取时异常
if (super.get(shortKey) == null) {
super.put(shortKey, value);
} else {
super.put(shortKey, (V) new Ambiguity(shortKey));
}
}
return super.put(key, value);
}
public V get(Object key) {
V value = super.get(key);
if (value == null) {
// key 不存在抛异常
throw new IllegalArgumentException(name + " does not contain value for " + key);
}
// 重复的 key 抛异常
if (value instanceof Ambiguity) {
throw new IllegalArgumentException(((Ambiguity) value).getSubject() + " is ambiguous in " + name
+ " (try using the full name including the namespace, or rename one of the entries)");
}
return value;
}
ContextMap
ContextMap 是 DynamicContext 的静态内部类,用于保存 sql 上下文中的绑定参数。
static class ContextMap extends HashMap<String, Object> {
private static final long serialVersionUID = 2977601501966151582L;
/**
* 参数对象
*/
private MetaObject parameterMetaObject;
public ContextMap(MetaObject parameterMetaObject) {
this.parameterMetaObject = parameterMetaObject;
}
@Override
public Object get(Object key) {
// 先根据 key 查找原始容器
String strKey = (String) key;
if (super.containsKey(strKey)) {
return super.get(strKey);
}
// 再进入参数对象查找
if (parameterMetaObject != null) {
// issue #61 do not modify the context when reading
return parameterMetaObject.getValue(strKey);
}
return null;
}
}
OGNL 参数
OgnlCache
OGNL 工具支持通过字符串表达式调用 Java 方法,但是其实现需要对 OGNL 表达式进行编译,为了提高性能,MyBatis 提供 OgnlCache 工具类用于对 OGNL 表达式编译结果进行缓存。
/**
* 根据 ognl 表达式和参数计算值
*
* @param expression
* @param root
* @return
*/
public static Object getValue(String expression, Object root) {
try {
Map context = Ognl.createDefaultContext(root, MEMBER_ACCESS, CLASS_RESOLVER, null);
return Ognl.getValue(parseExpression(expression), context, root);
} catch (OgnlException e) {
throw new BuilderException("Error evaluating expression '" + expression + "'. Cause: " + e, e);
}
}
/**
* 编译 ognl 表达式并放入缓存
*
* @param expression
* @return
* @throws OgnlException
*/
private static Object parseExpression(String expression) throws OgnlException {
Object node = expressionCache.get(expression);
if (node == null) {
// 编译 ognl 表达式
node = Ognl.parseExpression(expression);
// 放入缓存
expressionCache.put(expression, node);
}
return node;
}
ExpressionEvaluator
ExpressionEvaluator 是 OGNL 表达式计算工具,evaluateBoolean 和 evaluateIterable 方法分别根据传入的表达式和参数计算出一个 boolean 值或一个可迭代对象。
/**
* 计算 ognl 表达式 true / false
*
* @param expression
* @param parameterObject
* @return
*/
public boolean evaluateBoolean(String expression, Object parameterObject) {
// 根据 ognl 表达式和参数计算值
Object value = OgnlCache.getValue(expression, parameterObject);
// true / false
if (value instanceof Boolean) {
return (Boolean) value;
}
// 不为 0
if (value instanceof Number) {
return new BigDecimal(String.valueOf(value)).compareTo(BigDecimal.ZERO) != 0;
}
// 不为 null
return value != null;
}
/**
* 计算获得一个可迭代的对象
*
* @param expression
* @param parameterObject
* @return
*/
public Iterable<?> evaluateIterable(String expression, Object parameterObject) {
Object value = OgnlCache.getValue(expression, parameterObject);
if (value == null) {
throw new BuilderException("The expression '" + expression + "' evaluated to a null value.");
}
if (value instanceof Iterable) {
// 已实现 Iterable 接口
return (Iterable<?>) value;
}
if (value.getClass().isArray()) {
// 数组转集合
// the array may be primitive, so Arrays.asList() may throw
// a ClassCastException (issue 209). Do the work manually
// Curse primitives! :) (JGB)
int size = Array.getLength(value);
List<Object> answer = new ArrayList<>();
for (int i = 0; i < size; i++) {
Object o = Array.get(value, i);
answer.add(o);
}
return answer;
}
if (value instanceof Map) {
// Map 获取 entry
return ((Map) value).entrySet();
}
throw new BuilderException("Error evaluating expression '" + expression + "'. Return value (" + value + ") was not iterable.");
}
解析逻辑
MyBastis 中调用 XMLStatementBuilder#parseStatementNode 方法解析单个 statement 元素。此方法中除了逐个获取元素属性,还对 include 元素、selectKey 元素进行解析,创建了 sql 生成对象 SqlSource,并将 statement 的全部信息聚合到 MappedStatement 对象中。
public void parseStatementNode() {
// 获取 id
String id = context.getStringAttribute("id");
// 自定义数据库厂商信息
String databaseId = context.getStringAttribute("databaseId");
if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) {
// 不符合当前数据源对应的数据厂商信息的语句不加载
return;
}
// 获取元素名
String nodeName = context.getNode().getNodeName();
// 元素名转为对应的 SqlCommandType 枚举
SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
// 是否为查询
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
// 获取 flushCache 属性,查询默认为 false,其它默认为 true
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
// 获取 useCache 属性,查询默认为 true,其它默认为 false
boolean useCache = context.getBooleanAttribute("useCache", isSelect);
// 获取 resultOrdered 属性,默认为 false
boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false);
// Include Fragments before parsing
XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant);
// 解析 include 属性
includeParser.applyIncludes(context.getNode());
// 参数类型
String parameterType = context.getStringAttribute("parameterType");
Class<?> parameterTypeClass = resolveClass(parameterType);
// 获取 Mapper 语法类型
String lang = context.getStringAttribute("lang");
// 默认使用 XMLLanguageDriver
LanguageDriver langDriver = getLanguageDriver(lang);
// Parse selectKey after includes and remove them.
// 解析 selectKey 元素
processSelectKeyNodes(id, parameterTypeClass, langDriver);
// 获取 KeyGenerator
// Parse the SQL (pre: <selectKey> and <include> were parsed and removed)
KeyGenerator keyGenerator;
String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX;
keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true);
if (configuration.hasKeyGenerator(keyStatementId)) {
// 获取解析完成的 KeyGenerator 对象
keyGenerator = configuration.getKeyGenerator(keyStatementId);
} else {
// 如果开启了 useGeneratedKeys 属性,并且为插入类型的 sql 语句、配置了 keyProperty 属性,则可以批量自动设置属性
keyGenerator = context.getBooleanAttribute("useGeneratedKeys",
configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType))
? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
}
// 生成有效 sql 语句和参数绑定对象
SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
// sql 类型
StatementType statementType = StatementType.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString()));
// 分批获取数据的数量
Integer fetchSize = context.getIntAttribute("fetchSize");
// 执行超时时间
Integer timeout = context.getIntAttribute("timeout");
// 参数映射
String parameterMap = context.getStringAttribute("parameterMap");
// 返回值类型
String resultType = context.getStringAttribute("resultType");
Class<?> resultTypeClass = resolveClass(resultType);
// 返回值映射 map
String resultMap = context.getStringAttribute("resultMap");
// 结果集类型
String resultSetType = context.getStringAttribute("resultSetType");
ResultSetType resultSetTypeEnum = resolveResultSetType(resultSetType);
// 插入、更新生成键值的字段
String keyProperty = context.getStringAttribute("keyProperty");
// 插入、更新生成键值的列
String keyColumn = context.getStringAttribute("keyColumn");
// 指定多结果集名称
String resultSets = context.getStringAttribute("resultSets");
// 新增 MappedStatement
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
}
语法驱动
LanguageDriver 是 statement 创建语法驱动,默认实现为 XMLLanguageDriver,其提供 createSqlSource 方法用于使用 XMLScriptBuilder 创建 sql 生成对象。
递归解析 include
include 元素是 statement 元素的子元素,通过 refid 属性可以指向在别处定义的 sql fragments。
public void applyIncludes(Node source) {
Properties variablesContext = new Properties();
Properties configurationVariables = configuration.getVariables();
// 拷贝全局配置中设置的额外配置属性
Optional.ofNullable(configurationVariables).ifPresent(variablesContext::putAll);
applyIncludes(source, variablesContext, false);
}
/**
* 递归解析 statement 元素中的 include 元素
*
* Recursively apply includes through all SQL fragments.
* @param source Include node in DOM tree
* @param variablesContext Current context for static variables with values
*/
private void applyIncludes(Node source, final Properties variablesContext, boolean included) {
if (source.getNodeName().equals("include")) {
// include 元素,从全局配置中找对应的 sql 节点并 clone
Node toInclude = findSqlFragment(getStringAttribute(source, "refid"), variablesContext);
// 读取 include 子元素中的 property 元素,获取全部属性
Properties toIncludeContext = getVariablesContext(source, variablesContext);
applyIncludes(toInclude, toIncludeContext, true);
if (toInclude.getOwnerDocument() != source.getOwnerDocument()) {
toInclude = source.getOwnerDocument().importNode(toInclude, true);
}
source.getParentNode().replaceChild(toInclude, source);
while (toInclude.hasChildNodes()) {
toInclude.getParentNode().insertBefore(toInclude.getFirstChild(), toInclude);
}
toInclude.getParentNode().removeChild(toInclude);
} else if (source.getNodeType() == Node.ELEMENT_NODE) {
if (included && !variablesContext.isEmpty()) {
// replace variables in attribute values
// include 指向的 sql clone 节点,逐个对属性进行解析
NamedNodeMap attributes = source.getAttributes();
for (int i = 0; i < attributes.getLength(); i++) {
Node attr = attributes.item(i);
attr.setNodeValue(PropertyParser.parse(attr.getNodeValue(), variablesContext));
}
}
// statement 元素中可能包含 include 子元素
NodeList children = source.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
applyIncludes(children.item(i), variablesContext, included);
}
} else if (included && source.getNodeType() == Node.TEXT_NODE
&& !variablesContext.isEmpty()) {
// replace variables in text node
// 替换元素值,如果使用了 ${} 占位符,会对 token 进行解析
source.setNodeValue(PropertyParser.parse(source.getNodeValue(), variablesContext));
}
}
/**
* 从全局配置中找对应的 sql fragment
*
* @param refid
* @param variables
* @return
*/
private Node findSqlFragment(String refid, Properties variables) {
// 解析 refid
refid = PropertyParser.parse(refid, variables);
// namespace.refid
refid = builderAssistant.applyCurrentNamespace(refid, true);
try {
// 从全局配置中找对应的 sql fragment
XNode nodeToInclude = configuration.getSqlFragments().get(refid);
return nodeToInclude.getNode().cloneNode(true);
} catch (IllegalArgumentException e) {
// sql fragments 定义在全局配置中的 StrictMap 中,获取不到会抛出异常
throw new IncompleteElementException("Could not find SQL statement to include with refid '" + refid + "'", e);
}
}
private String getStringAttribute(Node node, String name) {
return node.getAttributes().getNamedItem(name).getNodeValue();
}
/**
* Read placeholders and their values from include node definition.
*
* 读取 include 子元素中的 property 元素
* @param node Include node instance
* @param inheritedVariablesContext Current context used for replace variables in new variables values
* @return variables context from include instance (no inherited values)
*/
private Properties getVariablesContext(Node node, Properties inheritedVariablesContext) {
Map<String, String> declaredProperties = null;
// 解析 include 元素中的 property 子元素
NodeList children = node.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node n = children.item(i);
if (n.getNodeType() == Node.ELEMENT_NODE) {
// include 运行包含 property 元素
String name = getStringAttribute(n, "name");
// Replace variables inside
String value = PropertyParser.parse(getStringAttribute(n, "value"), inheritedVariablesContext);
if (declaredProperties == null) {
declaredProperties = new HashMap<>();
}
if (declaredProperties.put(name, value) != null) {
// 不允许添加同名属性
throw new BuilderException("Variable " + name + " defined twice in the same include definition");
}
}
}
if (declaredProperties == null) {
return inheritedVariablesContext;
} else {
// 聚合属性配置
Properties newProperties = new Properties();
newProperties.putAll(inheritedVariablesContext);
newProperties.putAll(declaredProperties);
return newProperties;
}
}
在开始解析前,从全局配置中获取全部的属性配置,如果 include 元素中有 property 元素,解析并获取键值,放入 variablesContext 中,在后续处理中针对可能出现的 ${} 类型 token 使用 PropertyParser 进行解析。
因为解析 statement 元素前已经加载过 sql 元素,因此会根据 include 元素的 refid 属性查找对应的 sql fragments,如果全局配置中无法找到就会抛出异常;如果能够找到则克隆 sql 元素并插入到当前 xml 文档中。
解析 selectKey
selectKey 用于指定 sql 在 insert 或 update 语句执行前或执行后生成或获取列值,在 MyBatis 中 selectKey 也被当做 statement 语句进行解析并设置到全局配置中。单个 selectKey 元素会以SelectKeyGenerator 对象的形式进行保存用于后续调用。
private void parseSelectKeyNode(String id, XNode nodeToHandle, Class<?> parameterTypeClass, LanguageDriver langDriver, String databaseId) {
// 返回值类型
String resultType = nodeToHandle.getStringAttribute("resultType");
Class<?> resultTypeClass = resolveClass(resultType);
StatementType statementType = StatementType.valueOf(nodeToHandle.getStringAttribute("statementType", StatementType.PREPARED.toString()));
// 对应字段名
String keyProperty = nodeToHandle.getStringAttribute("keyProperty");
// 对应列名
String keyColumn = nodeToHandle.getStringAttribute("keyColumn");
// 是否在父sql执行前执行
boolean executeBefore = "BEFORE".equals(nodeToHandle.getStringAttribute("order", "AFTER"));
//defaults
boolean useCache = false;
boolean resultOrdered = false;
KeyGenerator keyGenerator = NoKeyGenerator.INSTANCE;
Integer fetchSize = null;
Integer timeout = null;
boolean flushCache = false;
String parameterMap = null;
String resultMap = null;
ResultSetType resultSetTypeEnum = null;
// 创建 sql 生成对象
SqlSource sqlSource = langDriver.createSqlSource(configuration, nodeToHandle, parameterTypeClass);
SqlCommandType sqlCommandType = SqlCommandType.SELECT;
// 将 KeyGenerator 生成 sql 作为 MappedStatement 加入全局对象
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, null);
id = builderAssistant.applyCurrentNamespace(id, false);
MappedStatement keyStatement = configuration.getMappedStatement(id, false);
// 包装为 SelectKeyGenerator 对象
configuration.addKeyGenerator(id, new SelectKeyGenerator(keyStatement, executeBefore));
}
在 selectKey 解析完成后,按指定的 namespace 规则从全局配置中获取 SelectKeyGenerator 对象,等待创建 MappedStatement 对象。如果未指定 selectKey 元素,但是全局配置中开启了 useGeneratedKeys,并且指定 insert 元素的 useGeneratedKeys 属性为 true,则 MyBatis 会指定 Jdbc3KeyGenerator 作为 useGeneratedKeys 的默认实现。
创建 sql 生成对象
SqlSource
SqlSource 是 sql 生成抽象接口,其提供 getBoundSql 方法用于根据参数生成有效 sql 语句和参数绑定对象 BoundSql。在生成 statement 元素的解析结果 MappedStatement 对象前,需要先创建 sql 生成对象,即 SqlSource 对象。
public interface SqlSource {
/**
* 根据参数生成有效 sql 语句和参数绑定对象
*
* @param parameterObject
* @return
*/
BoundSql getBoundSql(Object parameterObject);
}
SqlNode
SqlNode 是 sql 节点抽象接口。sql 节点指的是 statement 中的组成部分,如果简单文本、if 元素、where 元素等。SqlNode 提供 apply 方法用于判断当前 sql 节点是否可以加入到生效的 sql 语句中。
public interface SqlNode {
/**
* 根据条件判断当前 sql 节点是否可以加入到生效的 sql 语句中
*
* @param context
* @return
*/
boolean apply(DynamicContext context);
}
DynamicContext
DynamicContext 是动态 sql 上下文,用于保存绑定参数和生效 sql 节点。DynamicContext 使用 ContextMap 作为参数绑定容器。由于动态 sql 是根据参数条件组合生成 sql,DynamicContext 还提供了对 sqlBuilder 修改和访问方法,用于添加有效 sql 节点和生成 sql 文本。
/**
* 生效的 sql 部分,以空格相连
*/
private final StringJoiner sqlBuilder = new StringJoiner(" ");
public void appendSql(String sql) {
sqlBuilder.add(sql);
}
public String getSql() {
return sqlBuilder.toString().trim();
}
节点解析
将 statement 元素转为 sql 生成对象依赖于 LanguageDriver 的 createSqlSource 方法,此方法中创建 XMLScriptBuilder 对象,并调用 parseScriptNode 方法对 sql 组成节点逐个解析并进行组合。
public SqlSource parseScriptNode() {
// 递归解析各 sql 节点
MixedSqlNode rootSqlNode = parseDynamicTags(context);
SqlSource sqlSource;
if (isDynamic) {
// 动态 sql
sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
} else {
// 原始文本 sql
sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
}
return sqlSource;
}
/**
* 处理 statement 各 SQL 组成部分,并进行组合
*/
protected MixedSqlNode parseDynamicTags(XNode node) {
// SQL 各组成部分
List<SqlNode> contents = new ArrayList<>();
// 遍历子元素
NodeList children = node.getNode().getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
XNode child = node.newXNode(children.item(i));
if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
// 解析 sql 文本
String data = child.getStringBody("");
TextSqlNode textSqlNode = new TextSqlNode(data);
if (textSqlNode.isDynamic()) {
// 判断是否为动态 sql,包含 ${} 占位符即为动态 sql
contents.add(textSqlNode);
isDynamic = true;
} else {
// 静态 sql 元素
contents.add(new StaticTextSqlNode(data));
}
} else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628
// 如果是子元素
String nodeName = child.getNode().getNodeName();
// 获取支持的子元素语法处理器
NodeHandler handler = nodeHandlerMap.get(nodeName);
if (handler == null) {
throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
}
// 根据子元素标签类型使用对应的处理器处理子元素
handler.handleNode(child, contents);
// 包含标签元素,认定为动态 SQL
isDynamic = true;
}
}
return new MixedSqlNode(contents);
}
parseDynamicTags 方法会对 sql 各组成部分进行分解,如果 statement 元素包含 ${} 类型 token 或含有标签子元素,则认为当前 statement 是动态 sql,随后 isDynamic 属性会被设置为 true。对于文本节点,如 sql 纯文本和仅含 ${} 类型 token 的文本,会被包装为 StaticTextSqlNode 或 TextSqlNode 加入到 sql 节点容器中,而其它元素类型的 sql 节点会经过 NodeHandler 的 handleNode 方法处理过之后才能加入到节点容器中。nodeHandlerMap 定义了不同动态 sql 元素节点与 NodeHandler 的关系:
private void initNodeHandlerMap() {
nodeHandlerMap.put("trim", new TrimHandler());
nodeHandlerMap.put("where", new WhereHandler());
nodeHandlerMap.put("set", new SetHandler());
nodeHandlerMap.put("foreach", new ForEachHandler());
nodeHandlerMap.put("if", new IfHandler());
nodeHandlerMap.put("choose", new ChooseHandler());
nodeHandlerMap.put("when", new IfHandler());
nodeHandlerMap.put("otherwise", new OtherwiseHandler());
nodeHandlerMap.put("bind", new BindHandler());
}
MixedSqlNode
MixedSqlNode 中定义了一个 SqlNode 集合,用于保存 statement 中包含的全部 sql 节点。其生成有效 sql 的逻辑为逐个判断节点是否有效。
/**
* 组合 SQL 各组成部分
*
* @author Clinton Begin
*/
public class MixedSqlNode implements SqlNode {
/**
* SQL 各组装成部分
*/
private final List<SqlNode> contents;
public MixedSqlNode(List<SqlNode> contents) {
this.contents = contents;
}
@Override
public boolean apply(DynamicContext context) {
// 逐个判断各个 sql 节点是否能生效
contents.forEach(node -> node.apply(context));
return true;
}
}
StaticTextSqlNode
StaticTextSqlNode 中仅包含静态 sql 文本,在组装时会直接追加到 sql 上下文的有效 sql 中:
@Override
public boolean apply(DynamicContext context) {
context.appendSql(text);
return true;
}
TextSqlNode
TextSqlNode 中的 sql 文本包含 ${} 类型 token,使用 GenericTokenParser 搜索到 token 后会使用 BindingTokenParser 对 token 进行解析,解析后的文本会被追加到生效 sql 中。
@Override
public boolean apply(DynamicContext context) {
// 搜索 ${} 类型 token 节点
GenericTokenParser parser = createParser(new BindingTokenParser(context, injectionFilter));
// 解析 token 并追加解析后的文本到生效 sql 中
context.appendSql(parser.parse(text));
return true;
}
private GenericTokenParser createParser(TokenHandler handler) {
return new GenericTokenParser("${", "}", handler);
}
private static class BindingTokenParser implements TokenHandler {
private DynamicContext context;
private Pattern injectionFilter;
public BindingTokenParser(DynamicContext context, Pattern injectionFilter) {
this.context = context;
this.injectionFilter = injectionFilter;
}
@Override
public String handleToken(String content) {
// 获取绑定参数
Object parameter = context.getBindings().get("_parameter");
if (parameter == null) {
context.getBindings().put("value", null);
} else if (SimpleTypeRegistry.isSimpleType(parameter.getClass())) {
context.getBindings().put("value", parameter);
}
// 计算 ognl 表达式的值
Object value = OgnlCache.getValue(content, context.getBindings());
String srtValue = value == null ? "" : String.valueOf(value); // issue #274 return "" instead of "null"
checkInjection(srtValue);
return srtValue;
}
}
IfSqlNode
if 标签用于在 test 条件生效时才追加标签内的文本。
<if test="userId > 0">
AND user_id = #{userId}
</if>
IfSqlNode 保存了 if 元素下的节点内容和 test 表达式,在生成有效 sql 时会根据 OGNL 工具计算 test 表达式是否生效。
@Override
public boolean apply(DynamicContext context) {
// 根据 test 表达式判断当前节点是否生效
if (evaluator.evaluateBoolean(test, context.getBindings())) {
contents.apply(context);
return true;
}
return false;
}
TrimSqlNode
trim 标签用于解决动态 sql 中由于条件不同不能拼接正确语法的问题。
SELECT * FROM test
<trim prefix="WHERE" prefixOverrides="AND|OR">
<if test="a > 0">
a = #{a}
</if>
<if test="b > 0">
OR b = #{b}
</if>
<if test="c > 0">
AND c = #{c}
</if>
</trim>
如果没有 trim 标签,这个 statement 的有效 sql 最终可能会是这样的:
SELECT * FROM test OR b = #{b}
但是加上 trim 标签,生成的 sql 语法是正确的:
SELECT * FROM test WHERE b = #{b}
prefix 属性用于指定 trim 节点生成的 sql 语句的前缀,prefixOverrides 则会指定生成的 sql 语句的前缀需要去除的部分,多个需要去除的前缀可以使用 | 隔开。suffix 与 suffixOverrides 的功能类似,但是作用于后缀。
TrimSqlNode 首先调用 parseOverrides 对 prefixOverrides 和 suffixOverrides 进行解析,通过 | 分隔,分别加入字符串集合。
private static List<String> parseOverrides(String overrides) {
if (overrides != null) {
// 解析 token,按 | 分隔
final StringTokenizer parser = new StringTokenizer(overrides, "|", false);
final List<String> list = new ArrayList<>(parser.countTokens());
while (parser.hasMoreTokens()) {
// 保存为字符串集合
list.add(parser.nextToken().toUpperCase(Locale.ENGLISH));
}
return list;
}
return Collections.emptyList();
}
在调用包含的 SqlNode 的 apply 方法后还会调用 FilteredDynamicContext 的 applyAll 方法处理前缀和后缀。
@Override
public boolean apply(DynamicContext context) {
FilteredDynamicContext filteredDynamicContext = new FilteredDynamicContext(context);
boolean result = contents.apply(filteredDynamicContext);
// 加上前缀和和后缀,并去除多余字段
filteredDynamicContext.applyAll();
return result;
}
对于已经生成的 sql 文本,分别根据规则加上和去除指定前缀和后缀。
public void applyAll() {
sqlBuffer = new StringBuilder(sqlBuffer.toString().trim());
String trimmedUppercaseSql = sqlBuffer.toString().toUpperCase(Locale.ENGLISH);
if (trimmedUppercaseSql.length() > 0) {
// 加上前缀和和后缀,并去除多余字段
applyPrefix(sqlBuffer, trimmedUppercaseSql);
applySuffix(sqlBuffer, trimmedUppercaseSql);
}
delegate.appendSql(sqlBuffer.toString());
}
private void applyPrefix(StringBuilder sql, String trimmedUppercaseSql) {
if (!prefixApplied) {
prefixApplied = true;
if (prefixesToOverride != null) {
// 文本最前去除多余字段
for (String toRemove : prefixesToOverride) {
if (trimmedUppercaseSql.startsWith(toRemove)) {
sql.delete(0, toRemove.trim().length());
break;
}
}
}
// 在文本最前插入前缀和空格
if (prefix != null) {
sql.insert(0, " ");
sql.insert(0, prefix);
}
}
}
private void applySuffix(StringBuilder sql, String trimmedUppercaseSql) {
if (!suffixApplied) {
suffixApplied = true;
if (suffixesToOverride != null) {
// 文本最后去除多余字段
for (String toRemove : suffixesToOverride) {
if (trimmedUppercaseSql.endsWith(toRemove) || trimmedUppercaseSql.endsWith(toRemove.trim())) {
int start = sql.length() - toRemove.trim().length();
int end = sql.length();
sql.delete(start, end);
break;
}
}
}
// 文本最后插入空格和后缀
if (suffix != null) {
sql.append(" ");
sql.append(suffix);
}
}
}
WhereSqlNode
where 元素与 trim 元素的功能类似,区别在于 where 元素不提供属性配置可以处理的前缀和后缀。
WhereSqlNode 继承了 TrimSqlNode,并指定了需要添加和删除的前缀。
public class WhereSqlNode extends TrimSqlNode {
private static List<String> prefixList = Arrays.asList("AND ","OR ","AND\n", "OR\n", "AND\r", "OR\r", "AND\t", "OR\t");
public WhereSqlNode(Configuration configuration, SqlNode contents) {
// 默认添加 WHERE 前缀,去除 AND、OR 等前缀
super(configuration, contents, "WHERE", prefixList, null, null);
}
}
因此,生成的 sql 语句会自动在最前加上 WHERE,并去除前缀中包含的 AND、OR 等字符串。
SetSqlNode
set 标签用于 update 语句中。
UPDATE test
<set>
<if test="a > 0">
a = #{a},
</if>
<if test="b > 0">
b = #{b}
</if>
</set>
SetSqlNode 同样继承自 TrimSqlNode,并指定默认添加 SET 前缀,去除 , 前缀和后缀。
public class SetSqlNode extends TrimSqlNode {
private static final List<String> COMMA = Collections.singletonList(",");
public SetSqlNode(Configuration configuration,SqlNode contents) {
// 默认添加 SET 前缀,去除 , 前缀和后缀
super(configuration, contents, "SET", COMMA, null, COMMA);
}
}
ForEachSqlNode
foreach 元素用于指定对集合循环添加 sql 语句。
<foreach collection="list" item="item" index="index" open="(" close=")" separator=",">
AND itm = #{item} AND idx #{index}
</foreach>
ForEachSqlNode 解析生成有效 sql 的逻辑如下,除了计算 collection 表达式的值、添加前缀、后缀外,还将参数与索引进行了绑定。
@Override
public boolean apply(DynamicContext context) {
// 获取绑定参数
Map<String, Object> bindings = context.getBindings();
// 计算 ognl 表达式获取可迭代对象
final Iterable<?> iterable = evaluator.evaluateIterable(collectionExpression, bindings);
if (!iterable.iterator().hasNext()) {
return true;
}
boolean first = true;
// 添加动态语句前缀
applyOpen(context);
// 迭代索引
int i = 0;
for (Object o : iterable) {
DynamicContext oldContext = context;
// 首个元素
if (first || separator == null) {
context = new PrefixedContext(context, "");
} else {
context = new PrefixedContext(context, separator);
}
int uniqueNumber = context.getUniqueNumber();
// Issue #709
if (o instanceof Map.Entry) {
// entry 集合项索引为 key,集合项为 value
@SuppressWarnings("unchecked")
Map.Entry<Object, Object> mapEntry = (Map.Entry<Object, Object>) o;
applyIndex(context, mapEntry.getKey(), uniqueNumber);
applyItem(context, mapEntry.getValue(), uniqueNumber);
} else {
// 绑定集合项索引关系
applyIndex(context, i, uniqueNumber);
// 绑定集合项关系
applyItem(context, o, uniqueNumber);
}
// 对解析的表达式进行替换,如 idx = #{index} AND itm = #{item} 替换为 idx = #{__frch_index_1} AND itm = #{__frch_item_1}
contents.apply(new FilteredDynamicContext(configuration, context, index, item, uniqueNumber));
if (first) {
first = !((PrefixedContext) context).isPrefixApplied();
}
context = oldContext;
i++;
}
// 添加动态语句后缀
applyClose(context);
// 移除原始的表达式
context.getBindings().remove(item);
context.getBindings().remove(index);
return true;
}
/**
* 绑定集合项索引关系
*
* @param context
* @param o
* @param i
*/
private void applyIndex(DynamicContext context, Object o, int i) {
if (index != null) {
context.bind(index, o);
context.bind(itemizeItem(index, i), o);
}
}
/**
* 绑定集合项关系
*
* @param context
* @param o
* @param i
*/
private void applyItem(DynamicContext context, Object o, int i) {
if (item != null) {
context.bind(item, o);
context.bind(itemizeItem(item, i), o);
}
}
对于循环中的 #{} 类型 token,ForEachSqlNode 在内部类 FilteredDynamicContext 中定义了解析规则:
@Override
public void appendSql(String sql) {
GenericTokenParser parser = new GenericTokenParser("#{", "}", content -> {
// 对解析的表达式进行替换,如 idx = #{index} AND itm = #{item} 替换为 idx = #{__frch_index_1} AND itm = #{__frch_item_1}
String newContent = content.replaceFirst("^\\s*" + item + "(?![^.,:\\s])", itemizeItem(item, index));
if (itemIndex != null && newContent.equals(content)) {
newContent = content.replaceFirst("^\\s*" + itemIndex + "(?![^.,:\\s])", itemizeItem(itemIndex, index));
}
return "#{" + newContent + "}";
});
delegate.appendSql(parser.parse(sql));
}
类似 idx = #{index} AND itm = #{item} 会被替换为 idx = #{__frch_index_1} AND itm = #{__frch_item_1},而 ForEachSqlNode 也做了参数与索引的绑定,因此在替换时可以快速绑定参数。
ChooseSqlNode
choose 元素用于生成带默认 sql 文本的语句,当 when 元素中的条件都不生效,就可以使用 otherwise 元素的默认文本。
<choose>
<when test="a > 0">
AND a = #{a}
</when>
<otherwise>
AND b = #{b}
</otherwise>
</choose>
ChooseSqlNode 是由 choose 节点和 otherwise 节点组合而成的,在生成有效 sql 于语句时会逐个计算 when 节点的 test 表达式,如果返回 true 则生效当前 when 语句中的 sql。如果均不生效则使用 otherwise 语句对应的默认 sql 文本。
@Override
public boolean apply(DynamicContext context) {
// when 节点根据 test 表达式判断是否生效
for (SqlNode sqlNode : ifSqlNodes) {
if (sqlNode.apply(context)) {
return true;
}
}
// when 节点如果都未生效,且存在 otherwise 节点,则使用 otherwise 节点
if (defaultSqlNode != null) {
defaultSqlNode.apply(context);
return true;
}
return false;
}
VarDeclSqlNode
bind 元素用于绑定一个 OGNL 表达式到一个动态 sql 变量中。
<bind name="pattern" value="'%' + _parameter.getTitle() + '%'" />
VarDeclSqlNode 会计算表达式的值并将参数名和值绑定到参数容器中。
@Override
public boolean apply(DynamicContext context) {
// 解析 ognl 表达式
final Object value = OgnlCache.getValue(expression, context.getBindings());
// 绑定参数
context.bind(name, value);
return true;
}
创建解析对象与生成可执行 sql
statemen 解析完毕后会创建 MappedStatement 对象,statement 的相关属性以及生成的 sql 创建对象都会被保存到该对象中。MappedStatement 还提供了 getBoundSql 方法用于获取可执行 sql 和参数绑定对象,即 BoundSql 对象。
public BoundSql getBoundSql(Object parameterObject) {
// 生成可执行 sql 和参数绑定对象
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
// 获取参数映射
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings == null || parameterMappings.isEmpty()) {
boundSql = new BoundSql(configuration, boundSql.getSql(), parameterMap.getParameterMappings(), parameterObject);
}
// check for nested result maps in parameter mappings (issue #30)
// 检查是否有嵌套的 resultMap
for (ParameterMapping pm : boundSql.getParameterMappings()) {
String rmId = pm.getResultMapId();
if (rmId != null) {
ResultMap rm = configuration.getResultMap(rmId);
if (rm != null) {
hasNestedResultMaps |= rm.hasNestedResultMaps();
}
}
}
return boundSql;
}
BoundSql 对象由 DynamicSqlSource 的 getBoundSql 方法生成,在验证各个 sql 节点,生成了有效 sql 后会继续调用 SqlSourceBuilder 将 sql 解析为 StaticSqlSource,即可执行 sql。
@Override
public BoundSql getBoundSql(Object parameterObject) {
DynamicContext context = new DynamicContext(configuration, parameterObject);
// 验证各 sql 节点,生成有效 sql
rootSqlNode.apply(context);
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
// 将生成的 sql 文本解析为 StaticSqlSource
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
context.getBindings().forEach(boundSql::setAdditionalParameter);
return boundSql;
}
此时的 sql 文本中仍包含 #{} 类型 token,需要通过 ParameterMappingTokenHandler 进行解析。
public SqlSource parse(String originalSql, Class<?> parameterType, Map<String, Object> additionalParameters) {
ParameterMappingTokenHandler handler = new ParameterMappingTokenHandler(configuration, parameterType, additionalParameters);
// 创建 #{} 类型 token 搜索对象
GenericTokenParser parser = new GenericTokenParser("#{", "}", handler);
// 解析 token
String sql = parser.parse(originalSql);
// 创建静态 sql 生成对象,并绑定参数
return new StaticSqlSource(configuration, sql, handler.getParameterMappings());
}
token 的具体解析逻辑为根据表达式的参数名生成对应的参数映射对象,并将表达式转为预编译 sql 的占位符 ?。
@Override
public String handleToken(String content) {
// 创建参数映射对象
parameterMappings.add(buildParameterMapping(content));
// 将表达式转为预编译 sql 占位符
return "?";
}
最终解析完成的 sql 与参数映射关系集合包装为 StaticSqlSource 对象,该对象在随后的逻辑中通过构造方法创建了 BoundSql 对象。
接口解析
除了使用 xml 方式配置 statement,MyBatis 同样支持使用 Java 注解配置。但是相对于 xml 的映射方式,将动态 sql 写在 Java 代码中是不合适的。如果在配置文件中指定了需要注册 Mapper 接口的类或包,MyBatis 会扫描相关类进行注册;在 Mapper 文件解析完成后也会尝试加载 namespace 的同名类,如果存在,则注册为 Mapper 接口。
无论是绑定还是直接注册 Mapper 接口,都是调用 MapperAnnotationBuilder#parse 方法来解析的。此方法中的解析方式与上述 xml 解析方式大致相同,区别只在于相关配置参数是从注解中获取而不是从 xml 元素属性中获取。
public <T> void addMapper(Class<T> type) {
if (type.isInterface()) {
if (hasMapper(type)) {
// 不允许相同接口重复注册
throw new BindingException("Type " + type + " is already known to the MapperRegistry.");
}
boolean loadCompleted = false;
try {
knownMappers.put(type, new MapperProxyFactory<>(type));
// It's important that the type is added before the parser is run
// otherwise the binding may automatically be attempted by the
// mapper parser. If the type is already known, it won't try.
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
parser.parse();
loadCompleted = true;
} finally {
if (!loadCompleted) {
knownMappers.remove(type);
}
}
}
}
总结
statement 解析的最终目的是为每个 statement 创建一个 MappedStatement 对象保存相关定义,在 sql 执行时根据传入参数动态获取可执行 sql 和参数绑定对象。
org.apache.ibatis.builder.xml.XMLStatementBuilder:解析 Mapper 文件中的 select|insert|update|delete 元素。org.apache.ibatis.parsing.GenericTokenParser.GenericTokenParser:搜索指定格式 token 并进行解析。org.apache.ibatis.parsing.TokenHandler:token 处理器抽象接口。定义 token 以何种方式被解析。org.apache.ibatis.parsing.PropertyParser:${} 类型 token 解析器。org.apache.ibatis.session.Configuration.StrictMap:封装 HashMap,对键值存取有严格要求。org.apache.ibatis.builder.xml.XMLIncludeTransformer:include 元素解析器。org.apache.ibatis.mapping.SqlSource:sql 生成抽象接口。根据传入参数生成有效 sql 语句和参数绑定对象。org.apache.ibatis.scripting.xmltags.XMLScriptBuilder:解析 statement 各个 sql 节点并进行组合。org.apache.ibatis.scripting.xmltags.SqlNode:sql 节点抽象接口。用于判断当前 sql 节点是否可以加入到生效的 sql 语句中。org.apache.ibatis.scripting.xmltags.DynamicContext:动态 sql 上下文。用于保存绑定参数和生效 sql 节点。org.apache.ibatis.scripting.xmltags.OgnlCache:ognl 缓存工具,缓存表达式编译结果。org.apache.ibatis.scripting.xmltags.ExpressionEvaluator:ognl 表达式计算工具。org.apache.ibatis.scripting.xmltags.MixedSqlNode:sql 节点组合对象。org.apache.ibatis.scripting.xmltags.StaticTextSqlNode:静态 sql 节点对象。org.apache.ibatis.scripting.xmltags.TextSqlNode:${} 类型 sql 节点对象。org.apache.ibatis.scripting.xmltags.IfSqlNode:if 元素 sql 节点对象。org.apache.ibatis.scripting.xmltags.TrimSqlNode:trim 元素 sql 节点对象。org.apache.ibatis.scripting.xmltags.WhereSqlNode:where 元素 sql 节点对象。org.apache.ibatis.scripting.xmltags.SetSqlNode:set 元素 sql 节点对象。org.apache.ibatis.scripting.xmltags.ForEachSqlNode:foreach 元素 sql 节点对象。org.apache.ibatis.scripting.xmltags.ChooseSqlNode:choose 元素 sql 节点对象。org.apache.ibatis.scripting.xmltags.VarDeclSqlNode:bind 元素 sql 节点对象。org.apache.ibatis.mapping.MappedStatement:statement 解析对象。org.apache.ibatis.mapping.BoundSql:可执行 sql 和参数绑定对象。org.apache.ibatis.scripting.xmltags.DynamicSqlSource:根据参数动态生成有效 sql 和绑定参数。org.apache.ibatis.builder.SqlSourceBuilder:解析 #{} 类型 token 并绑定参数对象。
4.7 - CH07-接口层
sql 会话创建工厂
SqlSessionFactoryBuilder 经过复杂的解析逻辑之后,会根据全局配置创建 DefaultSqlSessionFactory,该类是 sql 会话创建工厂抽象接口 SqlSessionFactory 的默认实现,其提供了若干 openSession 方法用于打开一个会话,在会话中进行相关数据库操作。这些 openSession 方法最终都会调用 openSessionFromDataSource 或 openSessionFromConnection 创建会话,即基于数据源配置创建还是基于已有连接对象创建。
基于数据源配置创建会话
要使用数据源打开一个会话需要先从全局配置中获取当前生效的数据源环境配置,如果没有生效配置或没用设置可用的事务工厂,就会创建一个 ManagedTransactionFactory 实例作为默认事务工厂实现,其与 MyBatis 提供的另一个事务工厂实现 JdbcTransactionFactory 的区别在于其生成的事务实现 ManagedTransaction 的提交和回滚方法是空实现,即希望将事务管理交由外部容器管理。
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
final Environment environment = configuration.getEnvironment();
// 获取事务工厂
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
// 创建事务配置
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
// 创建执行器
final Executor executor = configuration.newExecutor(tx, execType);
// 创建 sql 会话
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
/**
* 获取生效数据源环境配置的事务工厂
*/
private TransactionFactory getTransactionFactoryFromEnvironment(Environment environment) {
if (environment == null || environment.getTransactionFactory() == null) {
// 未配置数据源环境或事务工厂,默认使用 ManagedTransactionFactory
return new ManagedTransactionFactory();
}
return environment.getTransactionFactory();
}
随后会根据入参传入的 execType 选择对应的执行器 Executor,execType 的取值来源于 ExecutorType,这是一个枚举类。在下一章将会详细分析各类 Executor 的作用及其实现。
获取到事务工厂配置和执行器对象后会结合传入的数据源自动提交属性创建 DefaultSqlSession,即 sql 会话对象。
基于数据连接创建会话
基于连接创建会话的流程大致与基于数据源配置创建相同,区别在于自动提交属性 autoCommit 是从连接对象本身获取的。
private SqlSession openSessionFromConnection(ExecutorType execType, Connection connection) {
try {
// 获取自动提交配置
boolean autoCommit;
try {
autoCommit = connection.getAutoCommit();
} catch (SQLException e) {
// Failover to true, as most poor drivers
// or databases won't support transactions
autoCommit = true;
}
final Environment environment = configuration.getEnvironment();
// 获取事务工厂
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
// 创建事务配置
final Transaction tx = transactionFactory.newTransaction(connection);
// 创建执行器
final Executor executor = configuration.newExecutor(tx, execType);
// 创建 sql 会话
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
sql 会话
SqlSession 是 MyBatis 面向用户编程的接口,其提供了一系列方法用于执行相关数据库操作,默认实现为 DefaultSqlSession,在该类中,增删查改对应的操作最终会调用 selectList、select 和 update 方法,其分别用于普通查询、执行存储过程和修改数据库记录。
/**
* 查询结果集
*/
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
/**
* 调用存储过程
*/
@Override
public void select(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
executor.query(ms, wrapCollection(parameter), rowBounds, handler);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
/**
* 修改
*/
@Override
public int update(String statement, Object parameter) {
try {
dirty = true;
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.update(ms, wrapCollection(parameter));
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error updating database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
以上操作均是根据传入的 statement 名称到全局配置中查找对应的 MappedStatement 对象,并将操作委托给执行器对象 executor 完成。select、selectMap 等方法则是对 selectList 方法返回的结果集做处理来实现的。
此外,提交和回滚方法也是基于 executor 实现的。
/**
* 提交事务
*/
@Override
public void commit(boolean force) {
try {
executor.commit(isCommitOrRollbackRequired(force));
dirty = false;
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error committing transaction. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
/**
* 回滚事务
*/
@Override
public void rollback(boolean force) {
try {
executor.rollback(isCommitOrRollbackRequired(force));
dirty = false;
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error rolling back transaction. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
/**
* 非自动提交且事务未提交 || 强制提交或回滚 时返回 true
*/
private boolean isCommitOrRollbackRequired(boolean force) {
return (!autoCommit && dirty) || force;
}
在执行 update 方法时,会设置 dirty 属性为 true ,意为事务还未提交,当事务提交或回滚后才会将 dirty 属性修改为 false。如果当前会话不是自动提交且 dirty 熟悉为 true,或者设置了强制提交或回滚的标志,则会将强制标志提交给 executor 处理。
sql 会话管理器
SqlSessionManager 同时实现了 SqlSessionFactory 和 SqlSession 接口,使得其既能够创建 sql 会话,又能够执行 sql 会话的相关数据库操作。
/**
* sql 会话创建工厂
*/
private final SqlSessionFactory sqlSessionFactory;
/**
* sql 会话代理对象
*/
private final SqlSession sqlSessionProxy;
/**
* 保存线程对应 sql 会话
*/
private final ThreadLocal<SqlSession> localSqlSession = new ThreadLocal<>();
private SqlSessionManager(SqlSessionFactory sqlSessionFactory) {
this.sqlSessionFactory = sqlSessionFactory;
this.sqlSessionProxy = (SqlSession) Proxy.newProxyInstance(
SqlSessionFactory.class.getClassLoader(),
new Class[]{SqlSession.class},
new SqlSessionInterceptor());
}
@Override
public SqlSession openSession() {
return sqlSessionFactory.openSession();
}
/**
* 设置当前线程对应的 sql 会话
*/
public void startManagedSession() {
this.localSqlSession.set(openSession());
}
/**
* sql 会话代理逻辑
*/
private class SqlSessionInterceptor implements InvocationHandler {
public SqlSessionInterceptor() {
// Prevent Synthetic Access
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 获取当前线程对应的 sql 会话对象并执行对应方法
final SqlSession sqlSession = SqlSessionManager.this.localSqlSession.get();
if (sqlSession != null) {
try {
return method.invoke(sqlSession, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
} else {
// 如果当前线程没有对应的 sql 会话,默认创建不自动提交的 sql 会话
try (SqlSession autoSqlSession = openSession()) {
try {
final Object result = method.invoke(autoSqlSession, args);
autoSqlSession.commit();
return result;
} catch (Throwable t) {
autoSqlSession.rollback();
throw ExceptionUtil.unwrapThrowable(t);
}
}
}
}
}
SqlSessionManager 的构造方法要求 SqlSessionFactory 对象作为入参传入,其各个创建会话的方法实际是由该传入对象完成的。执行 sql 会话的操作由 sqlSessionProxy 对象完成,这是一个由 JDK 动态代理创建的对象,当执行方法时会去 ThreadLocal 对象中查找当前线程有没有对应的 sql 会话对象,如果有则使用已有的会话对象执行,否则创建新的会话对象执行,而线程对应的会话对象需要使用 startManagedSession 方法来维护。
之所以 SqlSessionManager 需要为每个线程维护会话对象,是因为 DefaultSqlSession 是非线程安全的,多线程操作会导致执行错误。如上文中提到的 dirty 属性,其修改是没有经过任何同步操作的。
总结
SqlSession 是 MyBatis 提供的面向开发者编程的接口,其提供了一系列数据库相关操作,并屏蔽了底层细节。使用 MyBatis 的正确方式应该是像 SqlSessionManager 那样为每个线程创建 sql 会话对象,避免造成线程安全问题。
org.apache.ibatis.session.SqlSessionFactory:sql 会话创建工厂。org.apache.ibatis.session.defaults.DefaultSqlSessionFactory: sql 会话创建工厂默认实现。org.apache.ibatis.session.SqlSession:sql 会话。org.apache.ibatis.session.defaults.DefaultSqlSession:sql 会话默认实现。org.apache.ibatis.session.SqlSessionManager:sql 会话管理器。
4.8 - CH08-执行器
执行器 Executor 是 MyBatis 的核心接口之一,接口层提供的相关数据库操作,都是基于 Executor 的子类实现的。
创建执行器
在创建 sql 会话时,MyBatis 会调用 Configuration#newExecutor 方法创建执行器。枚举类 ExecutorType 定义了三种执行器类型,即 SIMPLE、REUSE 和 Batch,这些执行器的主要区别在于:
SIMPLE 在每次执行完成后都会关闭 statement 对象;REUSE 会在本地维护一个容器,当前 statement 创建完成后放入容器中,当下次执行相同的 sql 时会复用 statement 对象,执行完毕后也不会关闭;BATCH 会将修改操作记录在本地,等待程序触发或有下一次查询时才批量执行修改操作。
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
// 默认类型为 simple
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
if (cacheEnabled) {
// 如果全局缓存打开,使用 CachingExecutor 代理执行器
executor = new CachingExecutor(executor);
}
// 应用插件
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
执行器创建后,如果全局缓存配置是有效的,则会将执行器装饰为 CachingExecutor。
基础执行器
SimpleExecutor、ReuseExecutor、BatchExecutor 均继承自 BaseExecutor。BaseExecutor 实现了 Executor 的全部方法,对缓存、事务、连接处理等提供了一些模板方法,但是针对具体的数据库操作留下了四个抽象方法交由子类实现。
/**
* 更新
*/
protected abstract int doUpdate(MappedStatement ms, Object parameter)
throws SQLException;
/**
* 刷新 statement
*/
protected abstract List<BatchResult> doFlushStatements(boolean isRollback)
throws SQLException;
/**
* 查询
*/
protected abstract <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql)
throws SQLException;
/**
* 查询获取游标对象
*/
protected abstract <E> Cursor<E> doQueryCursor(MappedStatement ms, Object parameter, RowBounds rowBounds, BoundSql boundSql)
throws SQLException;
基础执行器的查询逻辑如下:
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
// 非嵌套查询且设置强制刷新时清除缓存
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
// 缓存不为空,组装存储过程出参
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 无本地缓存,执行数据库查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
// 全局配置语句不共享缓存
clearLocalCache();
}
}
return list;
}
/**
* 查询本地缓存,组装存储过程结果集
*/
private void handleLocallyCachedOutputParameters(MappedStatement ms, CacheKey key, Object parameter, BoundSql boundSql) {
if (ms.getStatementType() == StatementType.CALLABLE) {
// 存储过程类型,查询缓存
final Object cachedParameter = localOutputParameterCache.getObject(key);
if (cachedParameter != null && parameter != null) {
final MetaObject metaCachedParameter = configuration.newMetaObject(cachedParameter);
final MetaObject metaParameter = configuration.newMetaObject(parameter);
for (ParameterMapping parameterMapping : boundSql.getParameterMappings()) {
if (parameterMapping.getMode() != ParameterMode.IN) {
// 参数类型为 OUT 或 INOUT 的,组装结果集
final String parameterName = parameterMapping.getProperty();
final Object cachedValue = metaCachedParameter.getValue(parameterName);
metaParameter.setValue(parameterName, cachedValue);
}
}
}
}
}
/**
* 查询数据库获取结果集
*/
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 放一个 placeHolder 标志
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 执行查询
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
// 查询结果集放入本地缓存
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
// 如果是存储过程查询,将存储过程结果集放入本地缓存
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
执行查询时 MyBatis 首先会根据 CacheKey 查询本地缓存,CacheKey 由本次查询的参数生成,本地缓存由 PerpetualCache 实现,这就是 MyBatis 的一级缓存。一级缓存维护对象 localCache 是基础执行器的本地变量,因此只有相同 sql 会话的查询才能共享一级缓存。当一级缓存中没有对应的数据,基础执行器最终会调用 doQuery 方法交由子类去获取数据。
而执行 update 等其它操作时,则会首先清除本地的一级缓存再交由子类执行具体的操作:
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 清空本地缓存
clearLocalCache();
// 调用子类执行器逻辑
return doUpdate(ms, parameter);
}
简单执行器
简单执行器是 MyBatis 的默认执行器。其封装了对 JDBC 的操作,对于查询方法 doQuery 的实现如下,其主要包括创建 statement 处理器、创建 statement、执行查询、关闭 statement。
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 创建 statement 处理器
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 创建 statement
stmt = prepareStatement(handler, ms.getStatementLog());
// 执行查询
return handler.query(stmt, resultHandler);
} finally {
// 关闭 statement
closeStatement(stmt);
}
}
创建 statement 处理器
全局配置类 Configuration 提供了方法 newStatementHandler 用于创建 statement 处理器:
/**
* 创建 statement 处理器
*/
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// StatementHandler 包装对象,根据 statement 类型创建代理处理器,并将实际操作委托给代理处理器处理
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
// 应用插件
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
实际每次创建的 statement 处理器对象都是由 RoutingStatementHandler 创建的,RoutingStatementHandler 根据当前 MappedStatement 的类型创建具体的 statement 类型处理器。StatementType 定义了 3 个 statement 类型枚举,分别对应 JDBC 的普通语句、预编译语句和存储过程语句。
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// 根据 statement 类型选择对应的 statementHandler
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}
创建 statement
简单执行器中的 Statement 对象是根据上述步骤中生成的 statement 处理器获取的。
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
// 获取代理连接对象
Connection connection = getConnection(statementLog);
// 创建 statement 对象
stmt = handler.prepare(connection, transaction.getTimeout());
// 设置 statement 参数
handler.parameterize(stmt);
return stmt;
}
@Override
public Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException {
ErrorContext.instance().sql(boundSql.getSql());
Statement statement = null;
try {
// 从连接中创建 statement 对象
statement = instantiateStatement(connection);
// 设置超时时间
setStatementTimeout(statement, transactionTimeout);
// 设置分批获取数据数量
setFetchSize(statement);
return statement;
} catch (SQLException e) {
closeStatement(statement);
throw e;
} catch (Exception e) {
closeStatement(statement);
throw new ExecutorException("Error preparing statement. Cause: " + e, e);
}
}
执行查询
创建 statement 对象完成即可通过 JDBC 的 API 执行数据库查询,并从 statement 对象中获取查询结果,根据配置进行转换。
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
// 执行查询
ps.execute();
// 处理结果集
return resultSetHandler.handleResultSets(ps);
}
/**
* 处理结果集
*/
@Override
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
// 多结果集
final List<Object> multipleResults = new ArrayList<>();
int resultSetCount = 0;
ResultSetWrapper rsw = getFirstResultSet(stmt);
// statement 对应的所有 ResultMap 对象
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
// 验证结果集不为空时,ResultMap 数量不能为 0
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
// 逐个获取 ResultMap
ResultMap resultMap = resultMaps.get(resultSetCount);
// 转换结果集,放到 multipleResults 容器中
handleResultSet(rsw, resultMap, multipleResults, null);
// 获取下一个待处理的结果集
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
// statement 配置的多结果集类型
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
return collapseSingleResultList(multipleResults);
}
关闭连接
查询完成后 statement 对象会被关闭。
/**
* 关闭 statement
*
* @param statement
*/
protected void closeStatement(Statement statement) {
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {
// ignore
}
}
}
简单执行器中的其它数据库执行方法与 doQuery 方法实现类似。
复用执行器
ReuseExecutor 相对于 SimpleExecutor 实现了对 statment 对象的复用,其在本地维护了 statementMap 用于保存 sql 语句和 statement 对象的关系。当调用 prepareStatement 方法获取 statement 对象时首先会查找本地是否有对应的 statement 对象,如果有则进行复用,负责重新创建并将 statement 对象放入本地缓存。
/**
* 创建 statement 对象
*
* @param handler
* @param statementLog
* @return
* @throws SQLException
*/
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
BoundSql boundSql = handler.getBoundSql();
String sql = boundSql.getSql();
if (hasStatementFor(sql)) {
// 如果本地容器中包含当前 sql 对应的 statement 对象,进行复用
stmt = getStatement(sql);
applyTransactionTimeout(stmt);
} else {
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
putStatement(sql, stmt);
}
handler.parameterize(stmt);
return stmt;
}
private boolean hasStatementFor(String sql) {
try {
return statementMap.keySet().contains(sql) && !statementMap.get(sql).getConnection().isClosed();
} catch (SQLException e) {
return false;
}
}
private Statement getStatement(String s) {
return statementMap.get(s);
}
private void putStatement(String sql, Statement stmt) {
statementMap.put(sql, stmt);
}
提交或回滚会导致执行器调用 doFlushStatements 方法,复用执行器会因此批量关闭本地的 statement 对象。
/**
* 批量关闭 statement 对象
*
* @param isRollback
* @return
*/
@Override
public List<BatchResult> doFlushStatements(boolean isRollback) {
for (Statement stmt : statementMap.values()) {
closeStatement(stmt);
}
statementMap.clear();
return Collections.emptyList();
}
批量执行器
BatchExecutor 相对于 SimpleExecutor ,其 update 操作是批量执行的。
@Override
public int doUpdate(MappedStatement ms, Object parameterObject) throws SQLException {
final Configuration configuration = ms.getConfiguration();
final StatementHandler handler = configuration.newStatementHandler(this, ms, parameterObject, RowBounds.DEFAULT, null, null);
final BoundSql boundSql = handler.getBoundSql();
final String sql = boundSql.getSql();
final Statement stmt;
if (sql.equals(currentSql) && ms.equals(currentStatement)) {
// 如果当前 sql 与上次传入 sql 相同且为相同的 MappedStatement,复用 statement 对象
int last = statementList.size() - 1;
// 获取最后一个 statement 对象
stmt = statementList.get(last);
// 设置超时时间
applyTransactionTimeout(stmt);
// 设置参数
handler.parameterize(stmt);//fix Issues 322
// 获取批量执行结果对象
BatchResult batchResult = batchResultList.get(last);
batchResult.addParameterObject(parameterObject);
} else {
// 创建新的 statement 对象
Connection connection = getConnection(ms.getStatementLog());
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt); //fix Issues 322
currentSql = sql;
currentStatement = ms;
statementList.add(stmt);
batchResultList.add(new BatchResult(ms, sql, parameterObject));
}
// 执行 JDBC 批量添加 sql 语句操作
handler.batch(stmt);
return BATCH_UPDATE_RETURN_VALUE;
}
/**
* 批量执行 sql
*
* @param isRollback
* @return
* @throws SQLException
*/
@Override
public List<BatchResult> doFlushStatements(boolean isRollback) throws SQLException {
try {
// 批量执行结果
List<BatchResult> results = new ArrayList<>();
if (isRollback) {
return Collections.emptyList();
}
for (int i = 0, n = statementList.size(); i < n; i++) {
Statement stmt = statementList.get(i);
applyTransactionTimeout(stmt);
BatchResult batchResult = batchResultList.get(i);
try {
// 设置执行影响行数
batchResult.setUpdateCounts(stmt.executeBatch());
MappedStatement ms = batchResult.getMappedStatement();
List<Object> parameterObjects = batchResult.getParameterObjects();
KeyGenerator keyGenerator = ms.getKeyGenerator();
if (Jdbc3KeyGenerator.class.equals(keyGenerator.getClass())) {
Jdbc3KeyGenerator jdbc3KeyGenerator = (Jdbc3KeyGenerator) keyGenerator;
// 设置数据库生成的主键
jdbc3KeyGenerator.processBatch(ms, stmt, parameterObjects);
} else if (!NoKeyGenerator.class.equals(keyGenerator.getClass())) { //issue #141
for (Object parameter : parameterObjects) {
keyGenerator.processAfter(this, ms, stmt, parameter);
}
}
// Close statement to close cursor #1109
closeStatement(stmt);
} catch (BatchUpdateException e) {
StringBuilder message = new StringBuilder();
message.append(batchResult.getMappedStatement().getId())
.append(" (batch index #")
.append(i + 1)
.append(")")
.append(" failed.");
if (i > 0) {
message.append(" ")
.append(i)
.append(" prior sub executor(s) completed successfully, but will be rolled back.");
}
throw new BatchExecutorException(message.toString(), e, results, batchResult);
}
results.add(batchResult);
}
return results;
} finally {
for (Statement stmt : statementList) {
closeStatement(stmt);
}
currentSql = null;
statementList.clear();
batchResultList.clear();
}
}
执行器提交或回滚事务时会调用 doFlushStatements,从而批量执行提交的 sql 语句并最终批量关闭 statement 对象。
缓存执行器与二级缓存
CachingExecutor 对基础执行器进行了装饰,其作用就是为查询提供二级缓存。所谓的二级缓存是由 CachingExecutor 维护的,相对默认内置的一级缓存而言的缓存。二者区别如下:
- 一级缓存由基础执行器维护,且不可关闭。二级缓存的配置是开发者可干预的,在
xml 文件或注解中针对 namespace 的缓存配置就是二级缓存配置。 - 一级缓存在执行器中维护,即不同
sql 会话不能共享一级缓存。二级缓存则是根据 namespace 维护,不同 sql 会话是可以共享二级缓存的。
CachingExecutor 中的方法大多是通过直接调用其代理的执行器来实现的,而查询操作则会先查询二级缓存。
/**
* 缓存事务管理器
*/
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 查询二级缓存配置
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
// 当前 statement 配置使用二级缓存
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// 二级缓存中没用数据,调用代理执行器
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 将查询结果放入二级缓存
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
// 无二级缓存配置,调用代理执行器获取结果
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
private void flushCacheIfRequired(MappedStatement ms) {
Cache cache = ms.getCache();
if (cache != null && ms.isFlushCacheRequired()) {
// 存在 namespace 对应的缓存配置,且当前 statement 配置了刷新缓存,执行清空缓存操作
// 非 select 语句配置了默认刷新
tcm.clear(cache);
}
}
如果对应的 statement 的二级缓存配置有效,则会先通过缓存事务管理器 TransactionalCacheManager 查询二级缓存,如果没有命中则查询一级缓存,仍没有命中才会执行数据库查询。
缓存事务管理器
缓存执行器对二级缓存的维护是基于缓存事务管理器 TransactionalCacheManager 的,其内部维护了一个 Map 容器,用于保存 namespace 缓存配置与事务缓存对象的映射关系。
public class TransactionalCacheManager {
/**
* 缓存配置 - 缓存事务对象
*/
private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<>();
/**
* 清除缓存
*
* @param cache
*/
public void clear(Cache cache) {
getTransactionalCache(cache).clear();
}
/**
* 获取缓存
*/
public Object getObject(Cache cache, CacheKey key) {
return getTransactionalCache(cache).getObject(key);
}
/**
* 写缓存
*/
public void putObject(Cache cache, CacheKey key, Object value) {
getTransactionalCache(cache).putObject(key, value);
}
/**
* 缓存提交
*/
public void commit() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.commit();
}
}
/**
* 缓存回滚
*/
public void rollback() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.rollback();
}
}
/**
* 获取或新建事务缓存对象
*/
private TransactionalCache getTransactionalCache(Cache cache) {
return transactionalCaches.computeIfAbsent(cache, TransactionalCache::new);
}
}
缓存配置映射的事务缓存对象就是前文中提到过的事务缓存装饰器 TransactionalCache。getTransactionalCache 会从维护容器中查找对应的事务缓存对象,如果找不到就创建一个事务缓存对象,即通过事务缓存对象装饰当前缓存配置。
查询缓存时,如果缓存未命中,则将对应的 key 放入未命中队列,执行数据库查询完毕后写缓存时并不是立刻写到缓存配置的本地容器中,而是暂时放入待提交队列中,当触发事务提交时才将提交队列中的缓存数据写到缓存配置中。如果发生回滚,则提交队列中的数据会被清空,从而保证了数据的一致性。
@Override
public Object getObject(Object key) {
// issue #116
Object object = delegate.getObject(key);
if (object == null) {
// 放入未命中缓存的 key 的队列
entriesMissedInCache.add(key);
}
// issue #146
if (clearOnCommit) {
return null;
} else {
return object;
}
}
@Override
public void putObject(Object key, Object object) {
// 缓存先写入待提交容器
entriesToAddOnCommit.put(key, object);
}
/**
* 事务提交
*/
public void commit() {
if (clearOnCommit) {
delegate.clear();
}
// 提交缓存
flushPendingEntries();
reset();
}
/**
* 事务回滚
*/
public void rollback() {
unlockMissedEntries();
reset();
}
/**
* 事务提交,提交待提交的缓存。
*/
private void flushPendingEntries() {
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}
/**
* 事务回滚,清理未命中缓存。
*/
private void unlockMissedEntries() {
for (Object entry : entriesMissedInCache) {
try {
delegate.removeObject(entry);
} catch (Exception e) {
log.warn("Unexpected exception while notifiying a rollback to the cache adapter."
+ "Consider upgrading your cache adapter to the latest version. Cause: " + e);
}
}
}
二级缓存与一级缓存的互斥性
使用二级缓存要求无论是否配置了事务自动提交,在执行完成后, sql 会话必须手动提交事务才能触发事务缓存管理器维护缓存到缓存配置中,否则二级缓存无法生效。而缓存执行器在触发事务提交时,不仅会调用事务缓存管理器提交,还会调用代理执行器提交事务:
@Override
public void commit(boolean required) throws SQLException {
// 代理执行器提交
delegate.commit(required);
// 事务缓存管理器提交
tcm.commit();
}
代理执行器的事务提交方法继承自 BaseExecutor,其 commit 方法中调用了 clearLocalCache 方法清除本地一级缓存。因此二级缓存和一级缓存的使用是互斥的。
@Override
public void commit(boolean required) throws SQLException {
if (closed) {
throw new ExecutorException("Cannot commit, transaction is already closed");
}
// 清除本地一级缓存
clearLocalCache();
flushStatements();
if (required) {
transaction.commit();
}
}
总结
MyBatis 提供若干执行器封装底层 JDBC 操作和结果集转换,并嵌入 sql 会话维度的一级缓存和 namespace 维度的二级缓存。接口层可以通过调用不同类型的执行器来完成 sql 相关操作。
org.apache.ibatis.executor.Executor:数据库操作执行器抽象接口。org.apache.ibatis.executor.BaseExecutor:执行器基础抽象实现。org.apache.ibatis.executor.SimpleExecutor:简单类型执行器。org.apache.ibatis.executor.ReuseExecutor:statement 复用执行器。org.apache.ibatis.executor.BatchExecutor:批量执行器。org.apache.ibatis.executor.CachingExecutor:二级缓存执行器。org.apache.ibatis.executor.statement.StatementHandler:statement 处理器抽象接口。org.apache.ibatis.executor.statement.BaseStatementHandler:statement 处理器基础抽象实现。org.apache.ibatis.executor.statement.RoutingStatementHandler:statement 处理器路由对象。org.apache.ibatis.executor.statement.SimpleStatementHandler:简单 statement 处理器。org.apache.ibatis.executor.statement.PreparedStatementHandler:预编译 statement 处理器。org.apache.ibatis.executor.statement.CallableStatementHandler:存储过程 statement 处理器。org.apache.ibatis.cache.TransactionalCacheManager:缓存事务管理器。
4.9 - CH09-集成 Spring
mybatis-spring 是 MyBatis 的一个子项目,用于帮助开发者将 MyBatis 无缝集成到 Spring 中。它允许 MyBatis 参与到 Spring 的事务管理中,创建映射器 mapper 和 SqlSession 并注入到 Spring bean 中。
SqlSessionFactoryBean
在 MyBatis 的基础用法中,是通过 SqlSessionFactoryBuilder 来创建 SqlSessionFactory,最终获得执行接口 SqlSession 的,而在 mybatis-spring 中,则使用 SqlSessionFactoryBean 来创建。其使用方式如下:
@Bean
public SqlSessionFactory sqlSessionFactory(DataSource dataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
// 设置配置文件路径
bean.setConfigLocation(new ClassPathResource("config/mybatis-config.xml"));
// 别名转化类所在的包
bean.setTypeAliasesPackage("com.wch.domain");
// 设置数据源
bean.setDataSource(dataSource);
// 设置 mapper 文件路径
bean.setMapperLocations(new ClassPathResource("mapper/*.xml"));
// 获取 SqlSessionFactory 对象
return bean.getObject();
}
SqlSessionFactoryBean 实现了 FactoryBean 接口,因此可以通过其 getObject 方法获取 SqlSessionFactory 对象。
@Override
public SqlSessionFactory getObject() throws Exception {
if (this.sqlSessionFactory == null) {
afterPropertiesSet();
}
return this.sqlSessionFactory;
}
@Override
public void afterPropertiesSet() throws Exception {
notNull(dataSource, "Property 'dataSource' is required");
notNull(sqlSessionFactoryBuilder, "Property 'sqlSessionFactoryBuilder' is required");
state((configuration == null && configLocation == null) || !(configuration != null && configLocation != null),
"Property 'configuration' and 'configLocation' can not specified with together");
this.sqlSessionFactory = buildSqlSessionFactory();
}
protected SqlSessionFactory buildSqlSessionFactory() throws Exception {
final Configuration targetConfiguration;
XMLConfigBuilder xmlConfigBuilder = null;
if (this.configuration != null) {
// 使用已配置的全局配置对象和附加属性
targetConfiguration = this.configuration;
if (targetConfiguration.getVariables() == null) {
targetConfiguration.setVariables(this.configurationProperties);
} else if (this.configurationProperties != null) {
targetConfiguration.getVariables().putAll(this.configurationProperties);
}
} else if (this.configLocation != null) {
// 使用配置文件路径加载全局配置
xmlConfigBuilder = new XMLConfigBuilder(this.configLocation.getInputStream(), null, this.configurationProperties);
targetConfiguration = xmlConfigBuilder.getConfiguration();
} else {
// 新建全局配置对象
LOGGER.debug(
() -> "Property 'configuration' or 'configLocation' not specified, using default MyBatis Configuration");
targetConfiguration = new Configuration();
Optional.ofNullable(this.configurationProperties).ifPresent(targetConfiguration::setVariables);
}
// 设置对象创建工厂、对象包装工厂、虚拟文件系统实现
Optional.ofNullable(this.objectFactory).ifPresent(targetConfiguration::setObjectFactory);
Optional.ofNullable(this.objectWrapperFactory).ifPresent(targetConfiguration::setObjectWrapperFactory);
Optional.ofNullable(this.vfs).ifPresent(targetConfiguration::setVfsImpl);
// 以包的维度注册别名转换器
if (hasLength(this.typeAliasesPackage)) {
// 扫描之类包下的符合条件的类对象
scanClasses(this.typeAliasesPackage, this.typeAliasesSuperType).stream()
// 过滤匿名类
.filter(clazz -> !clazz.isAnonymousClass())
// 过滤接口
.filter(clazz -> !clazz.isInterface())
// 过滤成员类
.filter(clazz -> !clazz.isMemberClass()).
// 注册别名转换器
forEach(targetConfiguration.getTypeAliasRegistry()::registerAlias);
}
// 以类的维度注册别名转换器
if (!isEmpty(this.typeAliases)) {
Stream.of(this.typeAliases).forEach(typeAlias -> {
// 注册类对象到别名转换器
targetConfiguration.getTypeAliasRegistry().registerAlias(typeAlias);
LOGGER.debug(() -> "Registered type alias: '" + typeAlias + "'");
});
}
// 设置插件
if (!isEmpty(this.plugins)) {
Stream.of(this.plugins).forEach(plugin -> {
targetConfiguration.addInterceptor(plugin);
LOGGER.debug(() -> "Registered plugin: '" + plugin + "'");
});
}
// 以包的维度注册类型转换器
if (hasLength(this.typeHandlersPackage)) {
// 扫描指定包下 TypeHandler 的子类
scanClasses(this.typeHandlersPackage, TypeHandler.class).stream().
// 过滤匿名类
filter(clazz -> !clazz.isAnonymousClass())
// 过滤接口
.filter(clazz -> !clazz.isInterface())
// 过滤抽象类
.filter(clazz -> !Modifier.isAbstract(clazz.getModifiers()))
// 注册类对象到类型转换器
.forEach(targetConfiguration.getTypeHandlerRegistry()::register);
}
// 以类的维度注册类型转换器
if (!isEmpty(this.typeHandlers)) {
Stream.of(this.typeHandlers).forEach(typeHandler -> {
// 注册类对象到类型转换器
targetConfiguration.getTypeHandlerRegistry().register(typeHandler);
LOGGER.debug(() -> "Registered type handler: '" + typeHandler + "'");
});
}
// 注册脚本语言驱动
if (!isEmpty(this.scriptingLanguageDrivers)) {
Stream.of(this.scriptingLanguageDrivers).forEach(languageDriver -> {
targetConfiguration.getLanguageRegistry().register(languageDriver);
LOGGER.debug(() -> "Registered scripting language driver: '" + languageDriver + "'");
});
}
Optional.ofNullable(this.defaultScriptingLanguageDriver)
.ifPresent(targetConfiguration::setDefaultScriptingLanguage);
// 配置数据库产品识别转换器
if (this.databaseIdProvider != null) {// fix #64 set databaseId before parse mapper xmls
try {
targetConfiguration.setDatabaseId(this.databaseIdProvider.getDatabaseId(this.dataSource));
} catch (SQLException e) {
throw new NestedIOException("Failed getting a databaseId", e);
}
}
// 设置缓存配置
Optional.ofNullable(this.cache).ifPresent(targetConfiguration::addCache);
// 如果设置了配置文件路径,则解析并加载到全局配置中
if (xmlConfigBuilder != null) {
try {
xmlConfigBuilder.parse();
LOGGER.debug(() -> "Parsed configuration file: '" + this.configLocation + "'");
} catch (Exception ex) {
throw new NestedIOException("Failed to parse config resource: " + this.configLocation, ex);
} finally {
ErrorContext.instance().reset();
}
}
// 设置数据源环境
targetConfiguration.setEnvironment(new Environment(this.environment,
this.transactionFactory == null ? new SpringManagedTransactionFactory() : this.transactionFactory,
this.dataSource));
// 解析 xml statement 文件
if (this.mapperLocations != null) {
if (this.mapperLocations.length == 0) {
LOGGER.warn(() -> "Property 'mapperLocations' was specified but matching resources are not found.");
} else {
for (Resource mapperLocation : this.mapperLocations) {
if (mapperLocation == null) {
continue;
}
try {
XMLMapperBuilder xmlMapperBuilder = new XMLMapperBuilder(mapperLocation.getInputStream(),
targetConfiguration, mapperLocation.toString(), targetConfiguration.getSqlFragments());
xmlMapperBuilder.parse();
} catch (Exception e) {
throw new NestedIOException("Failed to parse mapping resource: '" + mapperLocation + "'", e);
} finally {
ErrorContext.instance().reset();
}
LOGGER.debug(() -> "Parsed mapper file: '" + mapperLocation + "'");
}
}
} else {
LOGGER.debug(() -> "Property 'mapperLocations' was not specified.");
}
// 创建 sql 会话工厂
return this.sqlSessionFactoryBuilder.build(targetConfiguration);
}
buildSqlSessionFactory 方法会分别对配置文件、别名转换类、mapper 文件等进行解析,逐步配置全局配置对象,并最终调用 SqlSessionFactoryBuilder 创建 SqlSessionFactory 对象。
SqlSessionTemplatge
在前章分析 MyBatis 接口层时说到 SqlSessionManager 通过 JDK 动态代理为每个线程创建不同的 SqlSession 来解决 DefaultSqlSession 的线程不安全问题。mybatis-spring 的实现与 SqlSessionManager 大致相同,但是其提供了更好的方式与 Spring 事务集成。
SqlSessionTemplate 实现了 SqlSession 接口,但是都是委托给成员对象 sqlSessionProxy 来实现的。sqlSessionProxy 在构造方法中使用 JDK 动态代理初始化为代理类。
public SqlSessionTemplate(SqlSessionFactory sqlSessionFactory, ExecutorType executorType,
PersistenceExceptionTranslator exceptionTranslator) {
notNull(sqlSessionFactory, "Property 'sqlSessionFactory' is required");
notNull(executorType, "Property 'executorType' is required");
this.sqlSessionFactory = sqlSessionFactory;
this.executorType = executorType;
this.exceptionTranslator = exceptionTranslator;
this.sqlSessionProxy = (SqlSession) newProxyInstance(SqlSessionFactory.class.getClassLoader(),
new Class[] { SqlSession.class }, new SqlSessionInterceptor());
}
sqlSessionProxy 的代理逻辑如下。
private class SqlSessionInterceptor implements InvocationHandler {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 获取 sqlSession
SqlSession sqlSession = getSqlSession(SqlSessionTemplate.this.sqlSessionFactory,
SqlSessionTemplate.this.executorType, SqlSessionTemplate.this.exceptionTranslator);
try {
// 执行原始调用
Object result = method.invoke(sqlSession, args);
if (!isSqlSessionTransactional(sqlSession, SqlSessionTemplate.this.sqlSessionFactory)) {
// 如果事务没有交给外部事务管理器管理,进行提交
sqlSession.commit(true);
}
return result;
} catch (Throwable t) {
Throwable unwrapped = unwrapThrowable(t);
if (SqlSessionTemplate.this.exceptionTranslator != null && unwrapped instanceof PersistenceException) {
// 异常为 PersistenceException,使用配置的 exceptionTranslator 来包装异常
closeSqlSession(sqlSession, SqlSessionTemplate.this.sqlSessionFactory);
sqlSession = null;
Throwable translated = SqlSessionTemplate.this.exceptionTranslator
.translateExceptionIfPossible((PersistenceException) unwrapped);
if (translated != null) {
unwrapped = translated;
}
}
throw unwrapped;
} finally {
if (sqlSession != null) {
// 关闭 sql session
closeSqlSession(sqlSession, SqlSessionTemplate.this.sqlSessionFactory);
}
}
}
}
获取 SqlSession
在执行原始调用前会先根据 SqlSessionUtils#getSqlSession 方法获取 SqlSession,如果通过事务同步管理器 TransactionSynchronizationManager 获取不到 SqlSession,就会使用 SqlSessionFactory 新建一个 SqlSession,并尝试将获取的 SqlSession 注册到 TransactionSynchronizationManager 中。
public static SqlSession getSqlSession(SqlSessionFactory sessionFactory, ExecutorType executorType,
PersistenceExceptionTranslator exceptionTranslator) {
// SqlSessionFactory 和 ExecutorType 参数不可为 null
notNull(sessionFactory, NO_SQL_SESSION_FACTORY_SPECIFIED);
notNull(executorType, NO_EXECUTOR_TYPE_SPECIFIED);
// 尝试从事务同步管理器中获取 SqlSessionHolder
SqlSessionHolder holder = (SqlSessionHolder) TransactionSynchronizationManager.getResource(sessionFactory);
// 获取 SqlSession
SqlSession session = sessionHolder(executorType, holder);
if (session != null) {
return session;
}
// 新建 SqlSession
LOGGER.debug(() -> "Creating a new SqlSession");
session = sessionFactory.openSession(executorType);
// 将新建的 SqlSession 注册到事务同步管理器中
registerSessionHolder(sessionFactory, executorType, exceptionTranslator, session);
return session;
}
事务同步管理器
每次获取 SqlSession 时是新建还是从事务同步管理器中获取决于事务同步管理器是否开启。事务同步管理器用于维护当前线程的同步资源,如判断当前线程是否已经开启了一个事务就需要查询事务同步管理器,以便后续根据事务传播方式决定是新开启一个事务或加入当前事务。Spring 支持使用注解开启事务或编程式事务。
注解开启事务
在 Spring 工程中可以通过添加 EnableTransactionManagement 注解来开启 Spring 事务管理。EnableTransactionManagement 注解的参数 mode = AdviceMode.PROXY 默认指定了加载代理事务管理器配置 ProxyTransactionManagementConfiguration,在此配置中其默认地对使用 Transactional 注解的方法进行 AOP 代理。在代理逻辑中,会调用 AbstractPlatformTransactionManager#getTransaction 方法获取当前线程对应的事务,根据当前线程是否有活跃事务、事务传播属性等来配置事务。如果是新创建事务,就会调用 TransactionSynchronizationManager#initSynchronization 方法来初始化当前线程在事务同步管理器中的资源。
编程式事务
编程开启事务的方式与注解式其实是一样的,区别在于编程式需要手动开启事务,其最终也会为当前线程在事务同步管理器中初始化资源。
// 手动开启事务
TransactionStatus txStatus = transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
// invoke...
} catch (Exception e) {
transactionManager.rollback(txStatus);
throw e;
}
transactionManager.commit(txStatus);
SqlSession 注册
如果当前方法开启了事务,那么创建的 SqlSession 就会被注册到事务同步管理器中。SqlSession 会首先被包装为 SqlSessionHolder,其还包含了 SqlSession 对应的执行器类型、异常处理器。
// ...
holder = new SqlSessionHolder(session, executorType, exceptionTranslator);
TransactionSynchronizationManager.bindResource(sessionFactory, holder);
// ...
随后 SqlSessionHolder 对象通过 TransactionSynchronizationManager#bindResource 方法绑定到事务同步管理器中,其实现为将 SqlSessionFactory 和 SqlSessionHolder 绑定到 ThreadLocal 中,从而完成了线程到 SqlSessionFactory 到 SqlSession 的映射。
事务提交与回滚
如果事务是交给 Spring 事务管理器管理的,那么Spring 会自动在执行成功或异常后对当前事务进行提交或回滚。如果没有配置 Spring 事务管理,那么将会调用 SqlSession 的 commit 方法对事务进行提交。
if (!isSqlSessionTransactional(sqlSession, SqlSessionTemplate.this.sqlSessionFactory)) {
// 未被事务管理器管理,设置提交
sqlSession.commit(true);
}
而 SqlSessionTemplate 是不允许用来显式地提交或回滚的,其提交或回滚的方法实现为直接抛出 UnsupportedOperationException 异常。
关闭 SqlSession
在当前调用结束后 SqlSessionTemplate 会调动 closeSqlSession 方法来关闭 SqlSession,如果事务同步管理器中存在当前线程绑定的 SqlSessionHolder,即当前调用被事务管理器管理,则将 SqlSession 的持有释放掉。如果没被事务管理器管理,则会真实地关闭 SqlSession。
public static void closeSqlSession(SqlSession session, SqlSessionFactory sessionFactory) {
notNull(session, NO_SQL_SESSION_SPECIFIED);
notNull(sessionFactory, NO_SQL_SESSION_FACTORY_SPECIFIED);
SqlSessionHolder holder = (SqlSessionHolder) TransactionSynchronizationManager.getResource(sessionFactory);
if ((holder != null) && (holder.getSqlSession() == session)) {
// 被事务管理器管理,释放 SqlSession
LOGGER.debug(() -> "Releasing transactional SqlSession [" + session + "]");
holder.released();
} else {
// 真实地关闭 SqlSesion
LOGGER.debug(() -> "Closing non transactional SqlSession [" + session + "]");
session.close();
}
}
映射器
单个映射器
在 MyBatis 的基础用法中,MyBatis 配置文件支持使用 mappers 标签的子元素 mapper 或 package 来指定需要扫描的 mapper 接口。被扫描到的接口类将被注册到 MapperRegistry 中,通过 MapperRegistry#getMapper 方法可以获得 Mapper 接口的代理类。
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
// 生成 mapper 接口的代理类
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
通过代理类的方式可以使得 statement 的 id 直接与接口方法的全限定名关联,消除了 mapper 接口实现类的样板代码。但是此种方式在每次获取 mapper 代理类的时候都需要指定 sqlSession 对象,而 mybatis-spring 中的 sqlSession 对象是 SqlSessionTemplate 代理创建的,为了适配代理逻辑,mybatis-spring 提供了 MapperFactoryBean 来创建代理类。
@Bean
public UserMapper userMapper(SqlSessionFactory sqlSessionFactory) throws Exception {
MapperFactoryBean<UserMapper> factoryBean = new MapperFactoryBean<>(UserMapper.class);
factoryBean.setSqlSessionFactory(sqlSessionFactory);
return factoryBean.getObject();
}
MapperFactoryBean 继承了 SqlSessionDaoSupport,其会根据传入的 SqlSessionFactory 来创建 SqlSessionTemplate,并使用 SqlSessionTemplate 来生成代理类。
@Override
public T getObject() throws Exception {
// 使用 SqlSessionTemplate 来创建代理类
return getSqlSession().getMapper(this.mapperInterface);
}
public SqlSession getSqlSession() {
return this.sqlSessionTemplate;
}
批量映射器
每次手动获取单个映射器的效率是低下的,MyBatis 还提供了 MapperScan 注解用于批量扫描 mapper 接口并通过 MapperFactoryBean 创建代理类,注册为 Spring bean。
@Configuration
@MapperScan("org.mybatis.spring.sample.mapper")
public class AppConfig {
// ...
}
MapperScan 注解解析后注册 Spring bean 的逻辑是由 MapperScannerConfigure 实现的,其实现 了 BeanDefinitionRegistryPostProcessor 接口的 postProcessBeanDefinitionRegistry 方法。
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) {
// ...
ClassPathMapperScanner scanner = new ClassPathMapperScanner(registry);
// ...
scanner.scan(
StringUtils.tokenizeToStringArray(this.basePackage, ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS));
}
扫描逻辑由 ClassPathMapperScanner 提供,其继承了 ClassPathBeanDefinitionScanner 扫描指定包下的类并注册为 BeanDefinitionHolder 的能力。
public int scan(String... basePackages) {
int beanCountAtScanStart = this.registry.getBeanDefinitionCount();
// 扫描指定包并注册 bean definion
doScan(basePackages);
// Register annotation config processors, if necessary.
if (this.includeAnnotationConfig) {
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
return (this.registry.getBeanDefinitionCount() - beanCountAtScanStart);
}
@Override
public Set<BeanDefinitionHolder> doScan(String... basePackages) {
// 扫描指定包已经获取的 bean 定义
Set<BeanDefinitionHolder> beanDefinitions = super.doScan(basePackages);
if (beanDefinitions.isEmpty()) {
LOGGER.warn(() -> "No MyBatis mapper was found in '" + Arrays.toString(basePackages)
+ "' package. Please check your configuration.");
} else {
// 增强 bean 配置
processBeanDefinitions(beanDefinitions);
}
return beanDefinitions;
}
private void processBeanDefinitions(Set<BeanDefinitionHolder> beanDefinitions) {
GenericBeanDefinition definition;
for (BeanDefinitionHolder holder : beanDefinitions) {
definition = (GenericBeanDefinition) holder.getBeanDefinition();
// ...
// 设置 bean class 类型为 MapperFactoryBean
definition.setBeanClass(this.mapperFactoryBeanClass);
// ...
}
}
获取到指定 bean 的定义后,重新设置 beanClass 为 MapperFactoryBean,因此在随后的 bean 初始化中,这些被扫描的 mapper 接口可以创建代理类并被注册到 Spring 容器中。
映射器注册完成后,就可以使用引用 Spring bean 的配置来使用 mapper 接口。
总结
mybatis-spring 提供了与 Spring 集成的更高层次的封装。
SqlSessionFactoryBean 遵循 Spring FactoryBean 的定义,使得 SqlSessionFactory 注册在 Spring 容器中。SqlSessionTemplate 是 SqlSession 另一种线程安全版本的实现,并且能够更好地与 Spring 事务管理集成。MapperFactoryBean 是生成 mapper 接口代理类的 SqlSessionTemplate 版本实现。MapperScannerConfigurer 简化了生成 mapper 接口代理的逻辑,指定扫描的包即可将生成 mapper 接口代理类并注册为 Spring bean。
4.10 - CH10-整体流程
1. 通过 Resource 加载配置
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.IOException;
import java.io.InputStream;
public class MyBatisUtils {
private static SqlSessionFactory sqlSessionFactory;
static {
try {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
public static SqlSession getSqlSession() {
return sqlSessionFactory.openSession();
}
}
2. 实例化 sqlSessionFactoryBuilder 构造器
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
3. 通过 build 中 XmlConfigBuilder 类解析文件流以及环境和属性
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
var5 = this.build(parser.parse());
4. 将配置信息存放到 Configuration 中
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
5. 实例化 SqlSessionFactory 实现类 DefaultSqlSessionFactory
6. 由 TransactionFactory 创建一个 Transaction 事务对象
7. 创建执行器 Excutor,执行 mapper
8. 创建 SqlSession 接口实现类 DefaultSqlSession
SqlSession sqlSession = MybatisUtils.getSqlSession()
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
9. 执行 CRUD
10. 判断是否成功,失败则回滚到事务提交器
11. 提交事务
12. 关闭
4.11 - CH11-插件机制
MyBatis支持用插件对四大核心组件进行拦截,对MyBatis来说插件就是拦截器,用来增强核心组件的功能,增强功能本质上是借助于底层的动态代理实现的,换句话说,MyBatis中的四大对象都是代理对象。
Executor:用于执行增删改查操作的执行器类StatementHandler:处理数据库SQL语句的类ParameterHandler:处理SQL的参数的类ResultSetHandler:处理SQL的返回结果集的类
以下是这四种处理各自能够拦截的方法:
| 对象 | 描述 | 可拦截方法 | 方法作用 |
|---|
| Executor | 上层对象,包含 SQL 执行全过程 | update | 执行 update/insert/delete |
| | query | 执行 query |
| | flushStatements | 在 commit 时自动调用,SimpleExecutor/ReuseExecutor/BatchExecutor 处理不同 |
| | commit | 提交事务 |
| | rollback | 回滚事务 |
| | getTransaction | 获取事务 |
| | close | 结束事务 |
| | isClosed | 判断事务是否关闭 |
| StatementHandler | 执行 SQL 的过程,常用拦截对象 | prepare | SQL 预编译 |
| | parameterize | 设置 SQL 参数 |
| | batch | 批处理 |
| | update | 增删改操作 |
| | query | 查询操作 |
| ParameterHandler | SQL 参数组装过程 | getParameterObject | 获取参数 |
| | setParameters | 设置参数 |
| ResultSetHandler | 执行 SQL 结果的组装 | handleResultSets | 处理结果集 |
| | handleOutputParameters | 处理存储过程出参 |
插件原理
MyBatis的插件借助于责任链的模式进行对拦截的处理- 使用
动态代理对目标对象进行包装,达到拦截的目的
拦截
插件具体是如何拦截并附加额外的功能的呢?以ParameterHandler来说:
public ParameterHandlernewParameterHandler(
MappedStatement mappedStatement,
Object object,
BoundSql sql,
InterceptorChain interceptorChain){
ParameterHandler parameterHandler =
mappedStatement.getLang().createParameterHandler(mappedStatement,object,sql);
parameterHandler = (ParameterHandler) interceptorChain.pluginAll(parameterHandler);
return parameterHandler;
}
public Object pluginAll(Objecttarget){
for(Interceptorinterceptor:interceptors){
target = interceptor.plugin(target);
}
return target;
}
interceptorChain保存了所有的拦截器(interceptors),是MyBatis初始化的时候创建的。
调用拦截器链中的拦截器依次的对目标进行拦截或增强。
interceptor.plugin(target) 中的 target 就可以理解为MyBatis中的四大组件,返回的target是被重重代理后的对象。
插件接口Interceptor
intercept()方法,插件的核心方法plugin()方法,生成target的代理对象setProperties()方法,传递插件所需参数
插件实例
插件开发需要以下步骤
- 自定义插件需要实现上述接口
- 增加@Intercepts注解(声明是哪个核心组件的插件,以及对哪些方法进行扩展)
- 在xml文件中配置插件
**
*插件签名,告诉MyBatis插件用来拦截那个对象的哪个方法
**/
@Intercepts({
@Signature(type=StatementHandler.class,method="parameterize",args=Statement.class)
})
public class MyInterceptsimplementsInterceptor {
/**
*拦截目标对象的目标方法
*
*@paraminvocation
*@return
*@throwsThrowable
*/
@Override
public Object intercept(Invocation invocation) throws Throwable{
System.out.println("进入自定义的拦截器,拦截目标对象"+invocation+invocation.getMethod()+invocation.getTarget());
return invocation.proceed();
}
/**
*包装目标对象为目标对象创建代理对象
*
*@Paramtarget为要拦截的对象
*@Return代理对象
*/
@Override
public Object plugin(Object target){
System.out.println("自定义plugin方法,将要包装的目标对象"+target.toString()+target.getClass());
returnPlugin.wrap(target,this);
}
/**
*获取配置文件的属性
*
*@paramproperties
*/
@Override
public void setProperties(Properties properties){
System.out.println("自定义插件的初始化参数"+properties);
}
}
在mybatis-config.xml中配置插件
<!--自定义插件-->
<plugins>
<plugininterceptor="com.boxuegu.javaee.mybatissourcelearn.MyIntercepts">
<propertyname="test"value="testvalue"/>
</plugin>
</plugins>
调用查询方法,查询方法会返回ResultSet
public class Test{
public static void main(String[]args){
//1.加载配置文件
String resource="mybatis-config.xml";
InputStream inputStream=null;
try{
inputStream=Resources.getResourceAsStream(resource);
}catch(IOExceptione){
e.printStackTrace();
}
//2.获取sqlSessionFactory
SqlSessionFactory sqlSessionFactory=
new SqlSessionFactoryBuilder().build(inputStream);
//3.获取sqlSession
SqlSession sqlSession=sqlSessionFactory.openSession();
try{
//通过xml文件直接执行sql语句
//Employeeemployee=sqlSession.selectOne("com.boxuegu.javaee.mybatissourcelearn.dao.EmployeeMapper.getEmployeeById",1);
//alt+shift+Lintroducelocalvariables;
Thread thread=newThread(()->System.out.println("test"));
//4.获取mapper接口实现
EmployeeMapper mapper=sqlSession.getMapper(EmployeeMapper.class);
System.out.println("mapper::::"+mapper.getClass());
//5.执行sql语句
Employee employee=mapper.getEmployeeById(1);
System.out.println(employee);
}finally{
sqlSession.close();
}
}
}
分页插件
MyBatis 自带的 RowBounds 是一次查询所有结果,然后再内存中计算并提取分页,最终返回指定页数的数据。
这种分页方式对于数据量小的还好,如果数据量大就有很大性能影响了。因为这种方式是将数据全部查询出来放到内存里,再进行分页长度的截取,是一种伪分页,是一种逻辑分页。
因此通常会使用 PageHelper 插件:
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.3.0</version>
</dependency>
在 mybatis-config.xml 中配置插件:
<plugins>
<plugininterceptor="com.github.pagehelper.PageInterceptor" />
</plugins>
执行分页查询:
PageHelper.startPage(/*pageNum*/ 2, /*pageSize*/ 4);
List<User> users = userMapper.findAll();
PageInfo<User> pageInfo = new PageInfo(list);
// return pageInfo to controller
实现原理
PageHelper是利用Mybatis的插件原理,对Executor接口的query方法进行了拦截。
@Intercepts({
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class}),
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class, CacheKey.class, BoundSql.class}),
})
public class PageInterceptor implements Interceptor {
//...
}
在创建Executor时,如果有插件对Executor进行拦截,则会对Executor对象生成代理,在执行相对应的方法时进行增强处理。
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
// 根据数据库操作类型创建市级执行器
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
// 根据配置文件中的 settings 节点cacheEnabled配置项确定是否启用缓存
if (cacheEnabled) { // 如果配置启用该缓存
// 使用CachingExecutor装饰实际的执行器
executor = new CachingExecutor(executor);
}
// 为执行器增加拦截器(插件),以启用各个拦截器的功能
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
当程序走到DefaultSqlSession中时,会调用Executor的query方法,此时就会触发PageHelper的代理,进入PageHelper的逻辑:
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
/**
* 获取查询语句
* 设置MappedStatement映射,见{@link XMLStatementBuilder#parseStatementNode()}
*/
MappedStatement ms = configuration.getMappedStatement(statement);
/**
* 交由执行器进行查询,由于全局配置cacheEnabled默认是打开的,因此此处的executor通常都是CachingExecutor
* 获取executor,见{@link Configuration#newExecutor(org.apache.ibatis.transaction.Transaction, org.apache.ibatis.session.ExecutorType)}
*/
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
PageHelper拦截器PageInterceptor执行流程:
@Override
public Object intercept(Invocation invocation) throws Throwable {
try {
...
//调用方法判断是否需要进行分页,如果不需要,直接返回结果
if (!dialect.skip(ms, parameter, rowBounds)) {
//判断是否需要进行count查询
if (dialect.beforeCount(ms, parameter, rowBounds)) {
//查询总数
Long count = count(executor, ms, parameter, rowBounds, null, boundSql);
//处理查询总数,返回true时继续分页查询,false时直接返回
if (!dialect.afterCount(count, parameter, rowBounds)) {
//当查询总数为0时,直接返回空的结果
return dialect.afterPage(new ArrayList(), parameter, rowBounds);
}
}
// 生成不同方言对应的分页 SQL 并执行
resultList = ExecutorUtil.pageQuery(dialect, executor,
ms, parameter, rowBounds, resultHandler, boundSql, cacheKey);
} else {
//rowBounds有参数值,不使用分页插件处理时,仍然支持默认的内存分页
resultList = executor.query(ms, parameter, rowBounds, resultHandler, cacheKey, boundSql);
}
// 将查询结果设置到Page对象中
return dialect.afterPage(resultList, parameter, rowBounds);
} finally {
if(dialect != null){
dialect.afterAll();
}
}
}
ExecutorUtil.pageQuery主要是基于不同的数据库方言生成分页查询 SQL,比如最简单的是在原 SQL 后追加 LIMIT ? OFFSET ?。
多插件开发
- 创建代理对象时,按照插件配置的顺序进行包装
- 执行目标方法后,是按照代理的逆向进行执行
总结
1.遵循插件尽量不使用的原则,因为会修改底层设计
2.插件是生成的层层代理对象的责任链模式,使用反射机制实现
3.插件的编写要考虑全面,特别是多个插件层层代理的时候
4.12 - CH12-代码生成
运行方式
Mybatis-Generator的运行方式有很多种:
- 基于
mybatis-generator-core-x.x.x.jar和其XML配置文件,通过命令行运行。 - 通过
Ant的Task结合其XML配置文件运行。 - 通过
Maven插件运行。 - 通过
Java代码和其XML配置文件运行。 - 通过
Java代码和编程式配置运行。 - 通过
Eclipse Feature运行。
这里只介绍通过Maven插件运行和通过Java代码和其XML配置文件运行这两种方式,两种方式有个特点:都要提前编写好XML配置文件。个人感觉XML配置文件相对直观,后文会花大量篇幅去说明XML配置文件中的配置项及其作用。这里先注意一点:默认的配置文件为ClassPath:generatorConfig.xml。
通过编码和配置文件运行
通过编码方式去运行插件先需要引入mybatis-generator-core依赖,编写本文的时候最新的版本为:
<dependency>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-core</artifactId>
<version>1.4.0</version>
</dependency>
假设编写好的XML配置文件是ClassPath下的generator-configuration.xml,那么使用代码生成器的编码方式大致如下:
List<String> warnings = new ArrayList<>();
// 如果已经存在生成过的文件是否进行覆盖
boolean overwrite = true;
File configFile = new File("ClassPath路径/generator-configuration.xml");
ConfigurationParser cp = new ConfigurationParser(warnings);
Configuration config = cp.parseConfiguration(configFile);
DefaultShellCallback callback = new DefaultShellCallback(overwrite);
MyBatisGenerator generator = new MyBatisGenerator(config, callback, warnings);
generator.generate(null);
通过 Maven 插件运行
如果使用Maven插件,那么不需要引入mybatis-generator-core依赖,只需要引入一个Maven的插件mybatis-generator-maven-plugin:
<plugins>
<plugin>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-maven-plugin</artifactId>
<version>1.4.0</version>
<executions>
<execution>
<id>Generate MyBatis Artifacts</id>
<goals>
<goal>generate</goal>
</goals>
</execution>
</executions>
<configuration>
<!-- 输出详细信息 -->
<verbose>true</verbose>
<!-- 覆盖生成文件 -->
<overwrite>true</overwrite>
<!-- 定义配置文件 -->
<configurationFile>${basedir}/src/main/resources/generator-configuration.xml</configurationFile>
</configuration>
</plugin>
</plugins>
XML 配置详解
XML配置文件才是Mybatis-Generator的核心,它用于控制代码生成的所有行为。所有非标签独有的公共配置的Key可以在mybatis-generator-core的PropertyRegistry类中找到。下面是一个相对完整的配置文件的模板:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<properties resource="db.properties"/>
<classPathEntry location="/Program Files/IBM/SQLLIB/java/db2java.zip" />
<context id="DB2Tables" targetRuntime="MyBatis3">
<jdbcConnection driverClass="COM.ibm.db2.jdbc.app.DB2Driver"
connectionURL="jdbc:db2:TEST"
userId="db2admin"
password="db2admin">
</jdbcConnection>
<plugin type="org.mybatis.generator.plugins.SerializablePlugin"/>
<commentGenerator>
<property name="suppressDate" value="true"/>
<property name="suppressAllComments" value="true"/>
</commentGenerator>
<javaTypeResolver>
<property name="forceBigDecimals" value="false" />
</javaTypeResolver>
<javaModelGenerator targetPackage="test.model" targetProject="\MBGTestProject\src">
<property name="enableSubPackages" value="true" />
<property name="trimStrings" value="true" />
</javaModelGenerator>
<sqlMapGenerator targetPackage="test.xml" targetProject="\MBGTestProject\src">
<property name="enableSubPackages" value="true" />
</sqlMapGenerator>
<javaClientGenerator type="XMLMAPPER" targetPackage="test.dao" targetProject="\MBGTestProject\src">
<property name="enableSubPackages" value="true" />
</javaClientGenerator>
<table schema="DB2ADMIN" tableName="ALLTYPES" domainObjectName="Customer" >
<property name="useActualColumnNames" value="true"/>
<generatedKey column="ID" sqlStatement="DB2" identity="true" />
<columnOverride column="DATE_FIELD" property="startDate" />
<ignoreColumn column="FRED" />
<columnOverride column="LONG_VARCHAR_FIELD" jdbcType="VARCHAR" />
</table>
</context>
</generatorConfiguration>
配置文件中,最外层的标签为<generatorConfiguration>,它的子标签包括:
- 0或者1个
<properties>标签,用于指定全局配置文件,下面可以通过占位符的形式读取<properties>指定文件中的值。 - 0或者N个
<classPathEntry>标签,<classPathEntry>只有一个location属性,用于指定数据源驱动包(jar或者zip)的绝对路径,具体选择什么驱动包取决于连接什么类型的数据源。 - 1或者N个
<context>标签,用于运行时的解析模式和具体的代码生成行为,所以这个标签里面的配置是最重要的。
下面分别列举和分析一下<context>标签和它的主要子标签的一些属性配置和功能。
context 标签
<context>标签在mybatis-generator-core中对应的实现类为org.mybatis.generator.config.Context,它除了大量的子标签配置之外,比较主要的属性是:
id:Context示例的唯一ID,用于输出错误信息时候作为唯一标记。targetRuntime:用于执行代码生成模式。defaultModelType:控制 Domain 类的生成行为。执行引擎为 MyBatis3DynamicSql 或者 MyBatis3Kotlin 时忽略此配置,可选值:conditional:默认值,类似hierarchical,但是只有一个主键的时候会合并所有属性生成在同一个类。flat:所有内容全部生成在一个对象中。hierarchical:键生成一个XXKey对象,Blob等单独生成一个对象,其他简单属性在一个对象中。
targetRuntime属性的可选值比较多,这里做个简单的小结:
属性:
- MyBatis3DynamicSql:默认值,兼容 JDK8+ 和 MyBatis 3.4.2+,不会生成 XML 映射文件,忽略
<sqlMapGenerator> 的配置项,也就是 Mapper 全部注解化,依赖于 MyBatis Dynamic SQL 类库。 - MyBatis3Kotlin:行为类似于 MyBatis3DynamicSql,不过兼容 Kotlin 的代码生成。
- MyBatis3:提供基本的基于动态 SQL 的 CRUD 方法和 XXXByExample 方法,会生成 XML 映射文件。
- MyBatis3Simple:提供基本的基于动态 SQL 的 CRUD 方法,会生成 XML 映射文件。
- MyBatis3DynamicSqlV1:已经过时,不推荐使用。
笔者偏向于把SQL文件和代码分离,所以一般选用MyBatis3或者MyBatis3Simple。例如:
<context id="default" targetRuntime="MyBatis3">
<context>标签支持0或N个<property>标签,<property>的可选属性有:
| property属性 | 功能描述 | 默认值 | 备注 |
|---|
autoDelimitKeywords | 是否使用分隔符号括住数据库关键字 | false | 例如MySQL中会使用反引号括住关键字 |
beginningDelimiter | 分隔符号的开始符号 | " | |
endingDelimiter | 分隔符号的结束号 | " | |
javaFileEncoding | 文件的编码 | 系统默认值 | 来源于java.nio.charset.Charset |
javaFormatter | 类名和文件格式化器 | DefaultJavaFormatter | 见JavaFormatter和DefaultJavaFormatter |
targetJava8 | 是否JDK8和启动其特性 | true | |
kotlinFileEncoding | Kotlin文件编码 | 系统默认值 | 来源于java.nio.charset.Charset |
kotlinFormatter | Kotlin类名和文件格式化器 | DefaultKotlinFormatter | 见KotlinFormatter和DefaultKotlinFormatter |
xmlFormatter | XML文件格式化器 | DefaultXmlFormatter | 见XmlFormatter和DefaultXmlFormatter |
jdbcConnection 标签
<jdbcConnection>标签用于指定数据源的连接信息,它在mybatis-generator-core中对应的实现类为org.mybatis.generator.config.JDBCConnectionConfiguration,主要属性包括:
| 属性 | 功能描述 | 是否必须 |
|---|
driverClass | 数据源驱动的全类名 | Y |
connectionURL | JDBC的连接URL | Y |
userId | 连接到数据源的用户名 | N |
password | 连接到数据源的密码 | N |
<commentGenerator>标签是可选的,用于控制生成的实体的注释内容。它在mybatis-generator-core中对应的实现类为org.mybatis.generator.internal.DefaultCommentGenerator,可以通过可选的type属性指定一个自定义的CommentGenerator实现。<commentGenerator>标签支持0或N个<property>标签,<property>的可选属性有:
| property属性 | 功能描述 | 默认值 |
|---|
suppressAllComments | 是否生成注释 | false |
suppressDate | 是否在注释中添加生成的时间戳 | false |
dateFormat | 配合suppressDate使用,指定输出时间戳的格式 | java.util.Date#toString() |
addRemarkComments | 是否输出表和列的Comment信息 | false |
笔者建议保持默认值,也就是什么注释都不输出,生成代码干净的实体。
javaTypeResolver 标签
<javaTypeResolver>标签是<context>的子标签,用于解析和计算数据库列类型和Java类型的映射关系,该标签只包含一个type属性,用于指定org.mybatis.generator.api.JavaTypeResolver接口的实现类。<javaTypeResolver>标签支持0或N个<property>标签,<property>的可选属性有:
| property属性 | 功能描述 | 默认值 |
|---|
forceBigDecimals | 是否强制把所有的数字类型强制使用java.math.BigDecimal类型表示 | false |
useJSR310Types | 是否支持JSR310,主要是JSR310的新日期类型 | false |
如果useJSR310Types属性设置为true,那么生成代码的时候类型映射关系如下(主要针对日期时间类型):
| 数据库(JDBC)类型 | Java类型 |
|---|
DATE | java.time.LocalDate |
TIME | java.time.LocalTime |
TIMESTAMP | java.time.LocalDateTime |
TIME_WITH_TIMEZONE | java.time.OffsetTime |
TIMESTAMP_WITH_TIMEZONE | java.time.OffsetDateTime |
引入mybatis-generator-core后,可以查看JavaTypeResolver的默认实现为JavaTypeResolverDefaultImpl,从它的源码可以得知一些映射关系:
BIGINT --> Long
BIT --> Boolean
INTEGER --> Integer
SMALLINT --> Short
TINYINT --> Byte
......
有些时候,我们希望INTEGER、SMALLINT和TINYINT都映射为Integer,那么我们需要覆盖JavaTypeResolverDefaultImpl的构造方法:
public class DefaultJavaTypeResolver extends JavaTypeResolverDefaultImpl {
public DefaultJavaTypeResolver() {
super();
typeMap.put(Types.SMALLINT, new JdbcTypeInformation("SMALLINT",
new FullyQualifiedJavaType(Integer.class.getName())));
typeMap.put(Types.TINYINT, new JdbcTypeInformation("TINYINT",
new FullyQualifiedJavaType(Integer.class.getName())));
}
}
注意一点的是这种自定义实现JavaTypeResolver接口的方式使用编程式运行MBG会相对方便,如果需要使用Maven插件运行,那么需要把上面的DefaultJavaTypeResolver类打包到插件中。
javaModelGenerator 标签
<javaModelGenerator标签>标签是<context>的子标签,主要用于控制实体(Model)类的代码生成行为。它支持的属性如下:
| 属性 | 功能描述 | 是否必须 | 备注 |
|---|
targetPackage | 生成的实体类的包名 | Y | 例如club.throwable.model |
targetProject | 生成的实体类文件相对于项目(根目录)的位置 | Y | 例如src/main/java |
<javaModelGenerator标签>标签支持0或N个<property>标签,<property>的可选属性有:
| property属性 | 功能描述 | 默认值 | 备注 |
|---|
constructorBased | 是否生成一个带有所有字段属性的构造函数 | false | MyBatis3Kotlin模式下忽略此属性配置 |
enableSubPackages | 是否允许通过Schema生成子包 | false | 如果为true,例如包名为club.throwable,如果Schema为xyz,那么实体类文件最终会生成在club.throwable.xyz目录 |
exampleTargetPackage | 生成的伴随实体类的Example类的包名 | - | - |
exampleTargetProject | 生成的伴随实体类的Example类文件相对于项目(根目录)的位置 | - | - |
immutable | 是否不可变 | false | 如果为true,则不会生成Setter方法,所有字段都使用final修饰,提供一个带有所有字段属性的构造函数 |
rootClass | 为生成的实体类添加父类 | - | 通过value指定父类的全类名即可 |
trimStrings | Setter方法是否对字符串类型进行一次trim操作 | false | - |
javaClientGenerator 标签
<javaClientGenerator>标签是<context>的子标签,主要用于控制Mapper接口的代码生成行为。它支持的属性如下:
| 属性 | 功能描述 | 是否必须 | 备注 |
|---|
type | Mapper接口生成策略 | Y | <context>标签的targetRuntime属性为MyBatis3DynamicSql或者MyBatis3Kotlin时此属性配置忽略 |
targetPackage | 生成的Mapper接口的包名 | Y | 例如club.throwable.mapper |
targetProject | 生成的Mapper接口文件相对于项目(根目录)的位置 | Y | 例如src/main/java |
type属性的可选值如下:
ANNOTATEDMAPPER:Mapper接口生成的时候依赖于注解和SqlProviders(也就是纯注解实现),不会生成XML映射文件。XMLMAPPER:Mapper接口生成接口方法,对应的实现代码生成在XML映射文件中(也就是纯映射文件实现)。MIXEDMAPPER:Mapper接口生成的时候复杂的方法实现生成在XML映射文件中,而简单的实现通过注解和SqlProviders实现(也就是注解和映射文件混合实现)。
注意两点:
<context>标签的targetRuntime属性指定为MyBatis3Simple的时候,type只能选用ANNOTATEDMAPPER或者XMLMAPPER。<context>标签的targetRuntime属性指定为MyBatis3的时候,type可以选用ANNOTATEDMAPPER、XMLMAPPER或者MIXEDMAPPER。
<javaClientGenerator>标签支持0或N个<property>标签,<property>的可选属性有:
| property属性 | 功能描述 | 默认值 | 备注 |
|---|
enableSubPackages | 是否允许通过Schema生成子包 | false | 如果为true,例如包名为club.throwable,如果Schema为xyz,那么Mapper接口文件最终会生成在club.throwable.xyz目录 |
useLegacyBuilder | 是否通过SQL Builder生成动态SQL | false | |
rootInterface | 为生成的Mapper接口添加父接口 | - | 通过value指定父接口的全类名即可 |
sqlMapGenerator 标签
<sqlMapGenerator>标签是<context>的子标签,主要用于控制XML映射文件的代码生成行为。它支持的属性如下:
| 属性 | 功能描述 | 是否必须 | 备注 |
|---|
targetPackage | 生成的XML映射文件的包名 | Y | 例如mappings |
targetProject | 生成的XML映射文件相对于项目(根目录)的位置 | Y | 例如src/main/resources |
<sqlMapGenerator>标签支持0或N个<property>标签,<property>的可选属性有:
| property属性 | 功能描述 | 默认值 | 备注 |
|---|
enableSubPackages | 是否允许通过Schema生成子包 | false | - |
plugin 标签
<plugin>标签是<context>的子标签,用于引入一些插件对代码生成的一些特性进行扩展,该标签只包含一个type属性,用于指定org.mybatis.generator.api.Plugin接口的实现类。内置的插件实现见Supplied Plugins。例如:引入org.mybatis.generator.plugins.SerializablePlugin插件会让生成的实体类自动实现java.io.Serializable接口并且添加serialVersionUID属性。
table 标签
<table> 标签是 <context> 的子标签,主要用于配置要生成代码的数据库表格,定制一些代码生成行为等等。它支持的属性众多,列举如下:
| 属性 | 功能描述 | 是否必须 | 备注 |
|---|
tableName | 数据库表名称 | Y | 例如t_order |
schema | 数据库Schema | N | - |
catalog | 数据库Catalog | N | - |
alias | 表名称标签 | N | 如果指定了此值,则查询列的时候结果格式为alias_column |
domainObjectName | 表对应的实体类名称,可以通过.指定包路径 | N | 如果指定了bar.User,则包名为bar,实体类名称为User |
mapperName | 表对应的Mapper接口类名称,可以通过.指定包路径 | N | 如果指定了bar.UserMapper,则包名为bar,Mapper接口类名称为UserMapper |
sqlProviderName | 动态SQL提供类SqlProvider的类名称 | N | - |
enableInsert | 是否允许生成insert方法 | N | 默认值为true,执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
enableSelectByPrimaryKey | 是否允许生成selectByPrimaryKey方法 | N | 默认值为true,执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
enableSelectByExample | 是否允许生成selectByExample方法 | N | 默认值为true,执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
enableUpdateByPrimaryKey | 是否允许生成updateByPrimaryKey方法 | N | 默认值为true,执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
enableDeleteByPrimaryKey | 是否允许生成deleteByPrimaryKey方法 | N | 默认值为true,执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
enableDeleteByExample | 是否允许生成deleteByExample方法 | N | 默认值为true,执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
enableCountByExample | 是否允许生成countByExample方法 | N | 默认值为true,执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
enableUpdateByExample | 是否允许生成updateByExample方法 | N | 默认值为true,执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
selectByPrimaryKeyQueryId | value指定对应的主键列提供列表查询功能 | N | 执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
selectByExampleQueryId | value指定对应的查询ID提供列表查询功能 | N | 执行引擎为MyBatis3DynamicSql或者MyBatis3Kotlin时忽略此配置 |
modelType | 覆盖<context>的defaultModelType属性 | N | 见<context>的defaultModelType属性 |
escapeWildcards | 是否对通配符进行转义 | N | - |
delimitIdentifiers | 标记匹配表名称的时候是否需要使用分隔符去标记生成的SQL | N | - |
delimitAllColumns | 是否所有的列都添加分隔符 | N | 默认值为false,如果设置为true,所有列名会添加起始和结束分隔符 |
<table> 标签支持0或N个 <property> 标签,<property> 的可选属性有:
| property属性 | 功能描述 | 默认值 | 备注 |
|---|
constructorBased | 是否为实体类生成一个带有所有字段的构造函数 | false | 执行引擎为MyBatis3Kotlin的时候此属性忽略 |
ignoreQualifiersAtRuntime | 是否在运行时忽略别名 | false | 如果为true,则不会在生成表的时候把schema和catalog作为表的前缀 |
immutable | 实体类是否不可变 | false | 执行引擎为MyBatis3Kotlin的时候此属性忽略 |
modelOnly | 是否仅仅生成实体类 | false | - |
rootClass | 如果配置此属性,则实体类会继承此指定的超类 | - | 如果有主键属性会把主键属性在超类生成 |
rootInterface | 如果配置此属性,则实体类会实现此指定的接口 | - | 执行引擎为MyBatis3Kotlin或者MyBatis3DynamicSql的时候此属性忽略 |
runtimeCatalog | 指定运行时的Catalog | - | 当生成表和运行时的表的Catalog不一样的时候可以使用该属性进行配置 |
runtimeSchema | 指定运行时的Schema | - | 当生成表和运行时的表的Schema不一样的时候可以使用该属性进行配置 |
runtimeTableName | 指定运行时的表名称 | - | 当生成表和运行时的表的表名称不一样的时候可以使用该属性进行配置 |
selectAllOrderByClause | 指定字句内容添加到selectAll()方法的order by子句之中 | - | 执行引擎为MyBatis3Simple的时候此属性才适用 |
trimStrings | 实体类的字符串类型属性会做trim处理 | - | 执行引擎为MyBatis3Kotlin的时候此属性忽略 |
useActualColumnNames | 是否使用列名作为实体类的属性名 | false | - |
useColumnIndexes | XML映射文件中生成的ResultMap使用列索引定义而不是列名称 | false | 执行引擎为MyBatis3Kotlin或者MyBatis3DynamicSql的时候此属性忽略 |
useCompoundPropertyNames | 是否把列名和列备注拼接起来生成实体类属性名 | false | - |
<table> 标签还支持众多的非 property 的子标签:
- 0或1个
<generatedKey>用于指定主键生成的规则,指定此标签后会生成一个<selectKey>标签:
<!-- column:指定主键列 -->
<!-- sqlStatement:查询主键的SQL语句,例如填写了MySql,则使用SELECT LAST_INSERT_ID() -->
<!-- type:可选值为pre或者post,pre指定selectKey标签的order为BEFORE,post指定selectKey标签的order为AFTER -->
<!-- identity:true的时候,指定selectKey标签的order为AFTER -->
<generatedKey column="id" sqlStatement="MySql" type="post" identity="true" />
- 0或1个
<domainObjectRenamingRule>用于指定实体类重命名规则:
<!-- searchString中正则命中的实体类名部分会替换为replaceString -->
<domainObjectRenamingRule searchString="^Sys" replaceString=""/>
<!-- 例如 SysUser会变成User -->
<!-- 例如 SysUserMapper会变成UserMapper -->
- 0或1个
<columnRenamingRule>用于指定列重命名规则:
<!-- searchString中正则命中的列名部分会替换为replaceString -->
<columnRenamingRule searchString="^CUST_" replaceString=""/>
<!-- 例如 CUST_BUSINESS_NAME会变成BUSINESS_NAME(useActualColumnNames=true) -->
<!-- 例如 CUST_BUSINESS_NAME会变成businessName(useActualColumnNames=false) -->
- 0或N个
<columnOverride>用于指定具体列的覆盖映射规则:
<!-- column:指定要覆盖配置的列 -->
<!-- property:指定要覆盖配置的属性 -->
<!-- delimitedColumnName:是否为列名添加定界符,例如`{column}` -->
<!-- isGeneratedAlways:是否一定生成此列 -->
<columnOverride column="customer_name" property="customerName" javaType="" jdbcType="" typeHandler="" delimitedColumnName="" isGeneratedAlways="">
<!-- 覆盖table或者javaModelGenerator级别的trimStrings属性配置 -->
<property name="trimStrings" value="true"/>
<columnOverride/>
- 0或N个
<ignoreColumn>用于指定忽略生成的列:
<ignoreColumn column="version" delimitedColumnName="false"/>
应用实例
如果需要深度定制一些代码生成行为,建议引入mybatis-generator-core并且通过编程式执行代码生成方法,否则可以选用Maven插件。假设我们在本地数据local有一张t_order表如下:
CREATE TABLE `t_order`
(
id BIGINT UNSIGNED PRIMARY KEY COMMENT '主键',
order_id VARCHAR(64) NOT NULL COMMENT '订单ID',
create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
amount DECIMAL(10, 2) NOT NULL DEFAULT 0 COMMENT '金额',
order_status TINYINT NOT NULL DEFAULT 0 COMMENT '订单状态',
UNIQUE uniq_order_id (`order_id`)
) COMMENT '订单表';
假设项目的结构如下:
mbg-sample
- main
- java
- club
- throwable
- resources
下面会基于此前提举三个例子。编写基础的XML配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<!-- 驱动包绝对路径 -->
<classPathEntry
location="I:\Develop\Maven-Repository\mysql\mysql-connector-java\5.1.48\mysql-connector-java-5.1.48.jar"/>
<context id="default" targetRuntime="这里选择合适的引擎">
<property name="javaFileEncoding" value="UTF-8"/>
<!-- 不输出注释 -->
<commentGenerator>
<property name="suppressDate" value="true"/>
<property name="suppressAllComments" value="true"/>
</commentGenerator>
<jdbcConnection driverClass="com.mysql.jdbc.Driver"
connectionURL="jdbc:mysql://localhost:3306/local"
userId="root"
password="root">
</jdbcConnection>
<!-- 不强制把所有的数字类型转化为BigDecimal -->
<javaTypeResolver>
<property name="forceBigDecimals" value="false"/>
</javaTypeResolver>
<javaModelGenerator targetPackage="club.throwable.entity" targetProject="src/main/java">
<property name="enableSubPackages" value="true"/>
</javaModelGenerator>
<sqlMapGenerator targetPackage="mappings" targetProject="src/main/resources">
<property name="enableSubPackages" value="true"/>
</sqlMapGenerator>
<javaClientGenerator type="这里选择合适的Mapper类型" targetPackage="club.throwable.dao" targetProject="src/main/java">
<property name="enableSubPackages" value="true"/>
</javaClientGenerator>
<table tableName="t_order"
enableCountByExample="false"
enableDeleteByExample="false"
enableSelectByExample="false"
enableUpdateByExample="false"
domainObjectName="Order"
mapperName="OrderMapper">
<generatedKey column="id" sqlStatement="MySql"/>
</table>
</context>
</generatorConfiguration>
纯注解
使用纯注解需要引入mybatis-dynamic-sql:
<dependency>
<groupId>org.mybatis.dynamic-sql</groupId>
<artifactId>mybatis-dynamic-sql</artifactId>
<version>1.1.4</version>
</dependency>
需要修改两个位置:
<context id="default" targetRuntime="MyBatis3DynamicSql">
...
<javaClientGenerator type="ANNOTATEDMAPPER"
...
运行结果会生成三个类:
// club.throwable.entity
public class Order {
@Generated("org.mybatis.generator.api.MyBatisGenerator")
private Long id;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
private String orderId;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
private Date createTime;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
private BigDecimal amount;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
private Byte orderStatus;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public Long getId() {
return id;
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public void setId(Long id) {
this.id = id;
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public String getOrderId() {
return orderId;
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public void setOrderId(String orderId) {
this.orderId = orderId;
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public Date getCreateTime() {
return createTime;
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public void setCreateTime(Date createTime) {
this.createTime = createTime;
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public BigDecimal getAmount() {
return amount;
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public void setAmount(BigDecimal amount) {
this.amount = amount;
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public Byte getOrderStatus() {
return orderStatus;
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public void setOrderStatus(Byte orderStatus) {
this.orderStatus = orderStatus;
}
}
// club.throwable.dao
public final class OrderDynamicSqlSupport {
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public static final Order order = new Order();
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public static final SqlColumn<Long> id = order.id;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public static final SqlColumn<String> orderId = order.orderId;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public static final SqlColumn<Date> createTime = order.createTime;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public static final SqlColumn<BigDecimal> amount = order.amount;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public static final SqlColumn<Byte> orderStatus = order.orderStatus;
@Generated("org.mybatis.generator.api.MyBatisGenerator")
public static final class Order extends SqlTable {
public final SqlColumn<Long> id = column("id", JDBCType.BIGINT);
public final SqlColumn<String> orderId = column("order_id", JDBCType.VARCHAR);
public final SqlColumn<Date> createTime = column("create_time", JDBCType.TIMESTAMP);
public final SqlColumn<BigDecimal> amount = column("amount", JDBCType.DECIMAL);
public final SqlColumn<Byte> orderStatus = column("order_status", JDBCType.TINYINT);
public Order() {
super("t_order");
}
}
}
@Mapper
public interface OrderMapper {
@Generated("org.mybatis.generator.api.MyBatisGenerator")
BasicColumn[] selectList = BasicColumn.columnList(id, orderId, createTime, amount, orderStatus);
@Generated("org.mybatis.generator.api.MyBatisGenerator")
@SelectProvider(type=SqlProviderAdapter.class, method="select")
long count(SelectStatementProvider selectStatement);
@Generated("org.mybatis.generator.api.MyBatisGenerator")
@DeleteProvider(type=SqlProviderAdapter.class, method="delete")
int delete(DeleteStatementProvider deleteStatement);
@Generated("org.mybatis.generator.api.MyBatisGenerator")
@InsertProvider(type=SqlProviderAdapter.class, method="insert")
@SelectKey(statement="SELECT LAST_INSERT_ID()", keyProperty="record.id", before=true, resultType=Long.class)
int insert(InsertStatementProvider<Order> insertStatement);
@Generated("org.mybatis.generator.api.MyBatisGenerator")
@SelectProvider(type=SqlProviderAdapter.class, method="select")
@Results(id="OrderResult", value = {
@Result(column="id", property="id", jdbcType=JdbcType.BIGINT, id=true),
@Result(column="order_id", property="orderId", jdbcType=JdbcType.VARCHAR),
@Result(column="create_time", property="createTime", jdbcType=JdbcType.TIMESTAMP),
@Result(column="amount", property="amount", jdbcType=JdbcType.DECIMAL),
@Result(column="order_status", property="orderStatus", jdbcType=JdbcType.TINYINT)
})
Optional<Order> selectOne(SelectStatementProvider selectStatement);
@Generated("org.mybatis.generator.api.MyBatisGenerator")
@SelectProvider(type=SqlProviderAdapter.class, method="select")
@Results(id="OrderResult", value = {
@Result(column="id", property="id", jdbcType=JdbcType.BIGINT, id=true),
@Result(column="order_id", property="orderId", jdbcType=JdbcType.VARCHAR),
@Result(column="create_time", property="createTime", jdbcType=JdbcType.TIMESTAMP),
@Result(column="amount", property="amount", jdbcType=JdbcType.DECIMAL),
@Result(column="order_status", property="orderStatus", jdbcType=JdbcType.TINYINT)
})
List<Order> selectMany(SelectStatementProvider selectStatement);
@Generated("org.mybatis.generator.api.MyBatisGenerator")
@UpdateProvider(type=SqlProviderAdapter.class, method="update")
int update(UpdateStatementProvider updateStatement);
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default long count(CountDSLCompleter completer) {
return MyBatis3Utils.countFrom(this::count, order, completer);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default int delete(DeleteDSLCompleter completer) {
return MyBatis3Utils.deleteFrom(this::delete, order, completer);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default int deleteByPrimaryKey(Long id_) {
return delete(c ->
c.where(id, isEqualTo(id_))
);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default int insert(Order record) {
return MyBatis3Utils.insert(this::insert, record, order, c ->
c.map(id).toProperty("id")
.map(orderId).toProperty("orderId")
.map(createTime).toProperty("createTime")
.map(amount).toProperty("amount")
.map(orderStatus).toProperty("orderStatus")
);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default int insertSelective(Order record) {
return MyBatis3Utils.insert(this::insert, record, order, c ->
c.map(id).toProperty("id")
.map(orderId).toPropertyWhenPresent("orderId", record::getOrderId)
.map(createTime).toPropertyWhenPresent("createTime", record::getCreateTime)
.map(amount).toPropertyWhenPresent("amount", record::getAmount)
.map(orderStatus).toPropertyWhenPresent("orderStatus", record::getOrderStatus)
);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default Optional<Order> selectOne(SelectDSLCompleter completer) {
return MyBatis3Utils.selectOne(this::selectOne, selectList, order, completer);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default List<Order> select(SelectDSLCompleter completer) {
return MyBatis3Utils.selectList(this::selectMany, selectList, order, completer);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default List<Order> selectDistinct(SelectDSLCompleter completer) {
return MyBatis3Utils.selectDistinct(this::selectMany, selectList, order, completer);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default Optional<Order> selectByPrimaryKey(Long id_) {
return selectOne(c ->
c.where(id, isEqualTo(id_))
);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default int update(UpdateDSLCompleter completer) {
return MyBatis3Utils.update(this::update, order, completer);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
static UpdateDSL<UpdateModel> updateAllColumns(Order record, UpdateDSL<UpdateModel> dsl) {
return dsl.set(id).equalTo(record::getId)
.set(orderId).equalTo(record::getOrderId)
.set(createTime).equalTo(record::getCreateTime)
.set(amount).equalTo(record::getAmount)
.set(orderStatus).equalTo(record::getOrderStatus);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
static UpdateDSL<UpdateModel> updateSelectiveColumns(Order record, UpdateDSL<UpdateModel> dsl) {
return dsl.set(id).equalToWhenPresent(record::getId)
.set(orderId).equalToWhenPresent(record::getOrderId)
.set(createTime).equalToWhenPresent(record::getCreateTime)
.set(amount).equalToWhenPresent(record::getAmount)
.set(orderStatus).equalToWhenPresent(record::getOrderStatus);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default int updateByPrimaryKey(Order record) {
return update(c ->
c.set(orderId).equalTo(record::getOrderId)
.set(createTime).equalTo(record::getCreateTime)
.set(amount).equalTo(record::getAmount)
.set(orderStatus).equalTo(record::getOrderStatus)
.where(id, isEqualTo(record::getId))
);
}
@Generated("org.mybatis.generator.api.MyBatisGenerator")
default int updateByPrimaryKeySelective(Order record) {
return update(c ->
c.set(orderId).equalToWhenPresent(record::getOrderId)
.set(createTime).equalToWhenPresent(record::getCreateTime)
.set(amount).equalToWhenPresent(record::getAmount)
.set(orderStatus).equalToWhenPresent(record::getOrderStatus)
.where(id, isEqualTo(record::getId))
);
}
}
极简 XML 映射文件
极简XML映射文件生成只需要简单修改配置文件:
<context id="default" targetRuntime="MyBatis3Simple">
...
<javaClientGenerator type="XMLMAPPER"
...
生成三个文件:
// club.throwable.entity
public class Order {
private Long id;
private String orderId;
private Date createTime;
private BigDecimal amount;
private Byte orderStatus;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public Date getCreateTime() {
return createTime;
}
public void setCreateTime(Date createTime) {
this.createTime = createTime;
}
public BigDecimal getAmount() {
return amount;
}
public void setAmount(BigDecimal amount) {
this.amount = amount;
}
public Byte getOrderStatus() {
return orderStatus;
}
public void setOrderStatus(Byte orderStatus) {
this.orderStatus = orderStatus;
}
}
// club.throwable.dao
public interface OrderMapper {
int deleteByPrimaryKey(Long id);
int insert(Order record);
Order selectByPrimaryKey(Long id);
List<Order> selectAll();
int updateByPrimaryKey(Order record);
}
// mappings
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="club.throwable.dao.OrderMapper">
<resultMap id="BaseResultMap" type="club.throwable.entity.Order">
<id column="id" jdbcType="BIGINT" property="id"/>
<result column="order_id" jdbcType="VARCHAR" property="orderId"/>
<result column="create_time" jdbcType="TIMESTAMP" property="createTime"/>
<result column="amount" jdbcType="DECIMAL" property="amount"/>
<result column="order_status" jdbcType="TINYINT" property="orderStatus"/>
</resultMap>
<delete id="deleteByPrimaryKey" parameterType="java.lang.Long">
delete
from t_order
where id = #{id,jdbcType=BIGINT}
</delete>
<insert id="insert" parameterType="club.throwable.entity.Order">
<selectKey keyProperty="id" order="AFTER" resultType="java.lang.Long">
SELECT LAST_INSERT_ID()
</selectKey>
insert into t_order (order_id, create_time, amount,
order_status)
values (#{orderId,jdbcType=VARCHAR}, #{createTime,jdbcType=TIMESTAMP}, #{amount,jdbcType=DECIMAL},
#{orderStatus,jdbcType=TINYINT})
</insert>
<update id="updateByPrimaryKey" parameterType="club.throwable.entity.Order">
update t_order
set order_id = #{orderId,jdbcType=VARCHAR},
create_time = #{createTime,jdbcType=TIMESTAMP},
amount = #{amount,jdbcType=DECIMAL},
order_status = #{orderStatus,jdbcType=TINYINT}
where id = #{id,jdbcType=BIGINT}
</update>
<select id="selectByPrimaryKey" parameterType="java.lang.Long" resultMap="BaseResultMap">
select id, order_id, create_time, amount, order_status
from t_order
where id = #{id,jdbcType=BIGINT}
</select>
<select id="selectAll" resultMap="BaseResultMap">
select id, order_id, create_time, amount, order_status
from t_order
</select>
<resultMap id="BaseResultMap" type="club.throwable.entity.Order">
<id column="id" jdbcType="BIGINT" property="id"/>
<result column="order_id" jdbcType="VARCHAR" property="orderId"/>
<result column="create_time" jdbcType="TIMESTAMP" property="createTime"/>
<result column="amount" jdbcType="DECIMAL" property="amount"/>
<result column="order_status" jdbcType="TINYINT" property="orderStatus"/>
</resultMap>
<delete id="deleteByPrimaryKey" parameterType="java.lang.Long">
delete
from t_order
where id = #{id,jdbcType=BIGINT}
</delete>
<insert id="insert" parameterType="club.throwable.entity.Order">
<selectKey keyProperty="id" order="BEFORE" resultType="java.lang.Long">
SELECT LAST_INSERT_ID()
</selectKey>
insert into t_order (id, order_id, create_time,
amount, order_status)
values (#{id,jdbcType=BIGINT}, #{orderId,jdbcType=VARCHAR}, #{createTime,jdbcType=TIMESTAMP},
#{amount,jdbcType=DECIMAL}, #{orderStatus,jdbcType=TINYINT})
</insert>
<update id="updateByPrimaryKey" parameterType="club.throwable.entity.Order">
update t_order
set order_id = #{orderId,jdbcType=VARCHAR},
create_time = #{createTime,jdbcType=TIMESTAMP},
amount = #{amount,jdbcType=DECIMAL},
order_status = #{orderStatus,jdbcType=TINYINT}
where id = #{id,jdbcType=BIGINT}
</update>
<select id="selectByPrimaryKey" parameterType="java.lang.Long" resultMap="BaseResultMap">
select id, order_id, create_time, amount, order_status
from t_order
where id = #{id,jdbcType=BIGINT}
</select>
<select id="selectAll" resultMap="BaseResultMap">
select id, order_id, create_time, amount, order_status
from t_order
</select>
</mapper>
编程式自定义类型映射
笔者喜欢把所有的非长整型的数字,统一使用Integer接收,因此需要自定义类型映射。编写映射器如下:
public class DefaultJavaTypeResolver extends JavaTypeResolverDefaultImpl {
public DefaultJavaTypeResolver() {
super();
typeMap.put(Types.SMALLINT, new JdbcTypeInformation("SMALLINT",
new FullyQualifiedJavaType(Integer.class.getName())));
typeMap.put(Types.TINYINT, new JdbcTypeInformation("TINYINT",
new FullyQualifiedJavaType(Integer.class.getName())));
}
}
此时最好使用编程式运行代码生成器,修改XML配置文件:
<javaTypeResolver type="club.throwable.mbg.DefaultJavaTypeResolver">
<property name="forceBigDecimals" value="false"/>
</javaTypeResolver>
...
运行方法代码如下:
public class Main {
public static void main(String[] args) throws Exception {
List<String> warnings = new ArrayList<>();
// 如果已经存在生成过的文件是否进行覆盖
boolean overwrite = true;
ConfigurationParser cp = new ConfigurationParser(warnings);
Configuration config = cp.parseConfiguration(Main.class.getResourceAsStream("/generator-configuration.xml"));
DefaultShellCallback callback = new DefaultShellCallback(overwrite);
MyBatisGenerator generator = new MyBatisGenerator(config, callback, warnings);
generator.generate(null);
}
}
数据库的order_status是TINYINT类型,生成出来的文件中的orderStatus字段全部替换使用Integer类型定义。
总结
本文相对详尽地介绍了Mybatis Generator的使用方式,具体分析了XML配置文件中主要标签以及标签属性的功能。因为Mybatis在Java的ORM框架体系中还会有一段很长的时间处于主流地位,了解Mybatis Generator可以简化CRUD方法模板代码、实体以及Mapper接口代码生成,从而解放大量生产力。Mybatis Generator有不少第三方的扩展,例如tk.mapper或者mybatis-plus自身的扩展,可能附加的功能不一样,但是基本的使用是一致的。
引用
原文地址:https://www.cnblogs.com/throwable/p/12046848.html
4.13 - CH13-多数据源
如果要在查询端实现数据库的主从访问,或者业务较复杂,需要访问不同的数据库,则需要实现多数据源的集成与切换。
配置文件
mybatis.config-location=classpath:mybatis/mybatis-config.xml
spring.datasource.test1.jdbc-url=jdbc:mysql://localhost:3306/test1?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true
spring.datasource.test1.username=root
spring.datasource.test1.password=root
spring.datasource.test1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.test2.jdbc-url=jdbc:mysql://localhost:3306/test2?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true
spring.datasource.test2.username=root
spring.datasource.test2.password=root
spring.datasource.test2.driver-class-name=com.mysql.cj.jdbc.Driver
一个 test1 库和一个 test2 库,其中 test1 位主库,在使用的过程中必须指定主库,不然会报错。
数据源配置
@Configuration
@MapperScan(basePackages = "com.neo.mapper.test1", sqlSessionTemplateRef = "test1SqlSessionTemplate")
public class DataSource1Config {
@Bean(name = "test1DataSource")
@ConfigurationProperties(prefix = "spring.datasource.test1")
@Primary
public DataSource testDataSource() {
return DataSourceBuilder.create().build();
}
@Bean(name = "test1SqlSessionFactory")
@Primary
public SqlSessionFactory testSqlSessionFactory(@Qualifier("test1DataSource") DataSource dataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mybatis/mapper/test1/*.xml"));
return bean.getObject();
}
@Bean(name = "test1TransactionManager")
@Primary
public DataSourceTransactionManager testTransactionManager(@Qualifier("test1DataSource") DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
@Bean(name = "test1SqlSessionTemplate")
@Primary
public SqlSessionTemplate testSqlSessionTemplate(@Qualifier("test1SqlSessionFactory") SqlSessionFactory sqlSessionFactory) throws Exception {
return new SqlSessionTemplate(sqlSessionFactory);
}
}
最关键的地方就是这块了,一层一层注入,首先创建 DataSource,然后创建 SqlSessionFactory 再创建事务,最后包装到 SqlSessionTemplate 中。其中需要指定分库的 mapper 文件地址,以及分库dao层代码:
@MapperScan(basePackages = "com.neo.mapper.test1", sqlSessionTemplateRef = "test1SqlSessionTemplate")
这块的注解就是指明了扫描 dao 层,并且给 dao 层注入指定的 SqlSessionTemplate。所有@Bean都需要按照命名指定正确。
dao & mapper
dao 层和 xml 需要按照库来分在不同的目录,比如:test1 库 dao 层在 com.neo.mapper.test1 包下,test2 库在com.neo.mapper.test2:
public interface User1Mapper {
List<UserEntity> getAll();
UserEntity getOne(Long id);
void insert(UserEntity user);
void update(UserEntity user);
void delete(Long id);
}
mapper:
<mapper namespace="com.neo.mapper.test1.User1Mapper" >
<resultMap id="BaseResultMap" type="com.neo.model.User" >
<id column="id" property="id" jdbcType="BIGINT" />
<result column="userName" property="userName" jdbcType="VARCHAR" />
<result column="passWord" property="passWord" jdbcType="VARCHAR" />
<result column="user_sex" property="userSex" javaType="com.neo.enums.UserSexEnum"/>
<result column="nick_name" property="nickName" jdbcType="VARCHAR" />
</resultMap>
<sql id="Base_Column_List" >
id, userName, passWord, user_sex, nick_name
</sql>
<select id="getAll" resultMap="BaseResultMap" >
SELECT
<include refid="Base_Column_List" />
FROM users
</select>
<select id="getOne" parameterType="java.lang.Long" resultMap="BaseResultMap" >
SELECT
<include refid="Base_Column_List" />
FROM users
WHERE id = #{id}
</select>
<insert id="insert" parameterType="com.neo.model.User" >
INSERT INTO
users
(userName,passWord,user_sex)
VALUES
(#{userName}, #{passWord}, #{userSex})
</insert>
<update id="update" parameterType="com.neo.model.User" >
UPDATE
users
SET
<if test="userName != null">userName = #{userName},</if>
<if test="passWord != null">passWord = #{passWord},</if>
nick_name = #{nickName}
WHERE
id = #{id}
</update>
<delete id="delete" parameterType="java.lang.Long" >
DELETE FROM
users
WHERE
id =#{id}
</delete>
</mapper>
测试验证
测试可以使用 SpringBootTest,也可以放到 Controller中,这里只贴 Controller 层的使用:
@RestController
public class UserController {
@Autowired
private User1Mapper user1Mapper;
@Autowired
private User2Mapper user2Mapper;
@RequestMapping("/getUsers")
public List<UserEntity> getUsers() {
List<UserEntity> users=user1Mapper.getAll();
return users;
}
@RequestMapping("/getUser")
public UserEntity getUser(Long id) {
UserEntity user=user2Mapper.getOne(id);
return user;
}
@RequestMapping("/add")
public void save(UserEntity user) {
user2Mapper.insert(user);
}
@RequestMapping(value="update")
public void update(UserEntity user) {
user2Mapper.update(user);
}
@RequestMapping(value="/delete/{id}")
public void delete(@PathVariable("id") Long id) {
user1Mapper.delete(id);
}
}
4.14 - CH14-常用片段
容器循环 foreach
foreach 元素的属性主要有:
- item:集合中元素迭代时的别名
- index:集合中元素迭代时的索引
- open:常用语where语句中,表示以什么开始,比如以’(‘开始
- separator:表示在每次进行迭代时的分隔符
- close 常用语where语句中,表示以什么结束
在使用 foreach 的时候最关键的也是最容易出错的就是 collection 属性,该属性是必须指定的,但是在不同情况下,该属性的值是不一样的,主要有一下 3 种情况:
- 如果传入的是单参数且参数类型是一个 List 的时候,collection 属性值为 list。
- 如果传入的是单参数且参数类型是一个 array 数组的时候,collection 的属性值为 array。
- 如果传入的参数是多个的时候,我们就需要把它们封装成一个 Map 了,当然单参数也可以封装成 map,实际上如果你在传入参数的时候,在 MyBatis 里面也是会把它封装成一个 Map 的,map 的 key 就是参数名,所以这个时候 collection 属性值就是传入的 List 或 array 对象在自己封装的 map 里面的 key.
针对最后一条,我们看一下官方的说法:
注意:你可以将一个 List 实例或者数组作为参数对象传给 MyBatis,当你这么做的时候,MyBatis 会自动将它包装在一个 Map 中并以名称为键。List 实例将会以 “list” 作为键,而数组实例的键将是 “array”。
所以,不管是多参数还是单参数的 list,array 类型,都可以封装为 map 进行传递。如果传递的是一个 List,则 mybatis 会封装为一个 list 为 key,list 值为 object 的 map,如果是 array,则封装成一个 array 为 key,array 的值为 object 的 map,如果自己封装呢,则 colloection里 放的是自己封装的 map 里的 key 值。
//mapper中我们要为这个方法传递的是一个容器,将容器中的元素一个一个的
//拼接到xml的方法中就要使用这个forEach这个标签了
public List<Entity> queryById(List<String> userids);
//对应的xml中如下
<select id="queryById" resultMap="BaseReslutMap" >
select * FROM entity
where id in
<foreach collection="userids" item="userid" index="index" open="(" separator="," close=")">
#{userid}
</foreach>
</select>
foreach array
public List<StudentEntity> getStudentListByClassIds_foreach_array(String[] classIds);
<!-- 7.1 foreach(循环array参数) - 作为where中in的条件 -->
<select id="getStudentListByClassIds_foreach_array" resultMap="resultMap_studentEntity">
SELECT ST.STUDENT_ID,
ST.STUDENT_NAME,
ST.STUDENT_SEX,
ST.STUDENT_BIRTHDAY,
ST.STUDENT_PHOTO,
ST.CLASS_ID,
ST.PLACE_ID
FROM STUDENT_TBL ST
WHERE ST.CLASS_ID IN
<foreach collection="array" item="classIds" open="(" separator="," close=")">
#{classIds}
</foreach>
</select>
foreach list
public List<StudentEntity> getStudentListByClassIds_foreach_list(List<String> classIdList);
<!-- 7.2 foreach(循环List<String>参数) - 作为where中in的条件 -->
<select id="getStudentListByClassIds_foreach_list" resultMap="resultMap_studentEntity">
SELECT ST.STUDENT_ID,
ST.STUDENT_NAME,
ST.STUDENT_SEX,
ST.STUDENT_BIRTHDAY,
ST.STUDENT_PHOTO,
ST.CLASS_ID,
ST.PLACE_ID
FROM STUDENT_TBL ST
WHERE ST.CLASS_ID IN
<foreach collection="list" item="classIdList" open="(" separator="," close=")">
#{classIdList}
</foreach>
</select>
模糊查询 concat
//比如说我们想要进行条件查询,但是几个条件不是每次都要使用,那么我们就可以
//通过判断是否拼接到sql中
<select id="queryById" resultMap="BascResultMap" parameterType="entity">
SELECT * from entity
<where>
<if test="name!=null">
name like concat('%',concat(#{name},'%'))
</if>
</where>
</select>
choose、when、otherwise
choose 标签是按顺序判断其内部 when 标签中的 test 条件出否成立,如果有一个成立,则 choose 结束。当 choose 中所有 when 的条件都不满则时,则执行 otherwise 中的 sql。类似于 Java 的 switch 语句,choose 为 switch,when 为 case,otherwise 则为 default。
例如下面例子,同样把所有可以限制的条件都写上,方面使用。choose 会从上到下选择一个 when 标签的 test 为 true 的 sql 执行。安全考虑,我们使用 where 将 choose 包起来,放置关键字多于错误。
<!-- choose(判断参数) - 按顺序将实体类 User 第一个不为空的属性作为:where条件 -->
<select id="getUserList_choose" resultMap="resultMap_user" parameterType="com.yiibai.pojo.User">
SELECT *
FROM User u
<where>
<choose>
<when test="username !=null ">
u.username LIKE CONCAT(CONCAT('%', #{username, jdbcType=VARCHAR}),'%')
</when >
<when test="sex != null and sex != '' ">
AND u.sex = #{sex, jdbcType=INTEGER}
</when >
<when test="birthday != null ">
AND u.birthday = #{birthday, jdbcType=DATE}
</when >
<otherwise>
</otherwise>
</choose>
</where>
</select>
selectKey
在insert语句中,在Oracle经常使用序列、在MySQL中使用函数来自动生成插入表的主键,而且需要方法能返回这个生成主键。使用myBatis的selectKey标签可以实现这个效果。
下面例子,使用 mysql 数据库自定义函数 nextval(‘student’),用来生成一个 key,并把他设置到传入的实体类中的 studentId 属性上。所以在执行完此方法后,边可以通过这个实体类获取生成的 key。
<!-- 插入学生 自动主键-->
<insert id="createStudentAutoKey" parameterType="com.demo.model.StudentEntity" keyProperty="studentId">
<selectKey keyProperty="studentId" resultType="String" order="BEFORE">
select nextval('student')
</selectKey>
INSERT INTO STUDENT_TBL(STUDENT_ID,
STUDENT_NAME,
STUDENT_SEX,
STUDENT_BIRTHDAY,
STUDENT_PHOTO,
CLASS_ID,
PLACE_ID)
VALUES (#{studentId},
#{studentName},
#{studentSex},
#{studentBirthday},
#{studentPhoto, javaType=byte[], jdbcType=BLOB, typeHandler=org.apache.ibatis.type.BlobTypeHandler},
#{classId},
#{placeId})
</insert>
调用接口方法,和获取自动生成 key:
StudentEntity entity = new StudentEntity();
entity.setStudentName("黎明你好");
entity.setStudentSex(1);
entity.setStudentBirthday(DateUtil.parse("1985-05-28"));
entity.setClassId("20000001");
entity.setPlaceId("70000001");
this.dynamicSqlMapper.createStudentAutoKey(entity);
System.out.println("新增学生ID: " + entity.getStudentId());
if
if 标签可用在许多类型的 sql 语句中,我们以查询为例。首先看一个很普通的查询:
<!-- 查询学生list,like姓名 -->
<select id="getStudentListLikeName" parameterType="StudentEntity" resultMap="studentResultMap">
SELECT * from STUDENT_TBL ST
WHERE ST.STUDENT_NAME LIKE CONCAT(CONCAT('%', #{studentName}),'%')
</select>
但是此时如果 studentName 为 null,此语句很可能报错或查询结果为空。此时我们使用 if 动态 sql 语句先进行判断,如果值为 null 或等于空字符串,我们就不进行此条件的判断,增加灵活性。
参数为实体类 StudentEntity。将实体类中所有的属性均进行判断,如果不为空则执行判断条件。
<!-- 2 if(判断参数) - 将实体类不为空的属性作为where条件 -->
<select id="getStudentList_if" resultMap="resultMap_studentEntity" parameterType="liming.student.manager.data.model.StudentEntity">
SELECT ST.STUDENT_ID,
ST.STUDENT_NAME,
ST.STUDENT_SEX,
ST.STUDENT_BIRTHDAY,
ST.STUDENT_PHOTO,
ST.CLASS_ID,
ST.PLACE_ID
FROM STUDENT_TBL ST
WHERE
<if test="studentName !=null ">
ST.STUDENT_NAME LIKE CONCAT(CONCAT('%', #{studentName, jdbcType=VARCHAR}),'%')
</if>
<if test="studentSex != null and studentSex != '' ">
AND ST.STUDENT_SEX = #{studentSex, jdbcType=INTEGER}
</if>
<if test="studentBirthday != null ">
AND ST.STUDENT_BIRTHDAY = #{studentBirthday, jdbcType=DATE}
</if>
<if test="classId != null and classId!= '' ">
AND ST.CLASS_ID = #{classId, jdbcType=VARCHAR}
</if>
<if test="classEntity != null and classEntity.classId !=null and classEntity.classId !=' ' ">
AND ST.CLASS_ID = #{classEntity.classId, jdbcType=VARCHAR}
</if>
<if test="placeId != null and placeId != '' ">
AND ST.PLACE_ID = #{placeId, jdbcType=VARCHAR}
</if>
<if test="placeEntity != null and placeEntity.placeId != null and placeEntity.placeId != '' ">
AND ST.PLACE_ID = #{placeEntity.placeId, jdbcType=VARCHAR}
</if>
<if test="studentId != null and studentId != '' ">
AND ST.STUDENT_ID = #{studentId, jdbcType=VARCHAR}
</if>
</select>
使用时比较灵活,new 一个这样的实体类,我们需要限制那个条件,只需要附上相应的值就会 where 这个条件,相反不去赋值就可以不在 where 中判断。
public void select_test_2_1() {
StudentEntity entity = new StudentEntity();
entity.setStudentName("");
entity.setStudentSex(1);
entity.setStudentBirthday(DateUtil.parse("1985-05-28"));
entity.setClassId("20000001");
//entity.setPlaceId("70000001");
List<StudentEntity> list = this.dynamicSqlMapper.getStudentList_if(entity);
for (StudentEntity e : list) {
System.out.println(e.toString());
}
}
if + where
当 where 中的条件使用的 if 标签较多时,这样的组合可能会导致错误。我们以在 3.1 中的查询语句为例子,当 java 代码按如下方法调用时:
@Test
public void select_test_2_1() {
StudentEntity entity = new StudentEntity();
entity.setStudentName(null);
entity.setStudentSex(1);
List<StudentEntity> list = this.dynamicSqlMapper.getStudentList_if(entity);
for (StudentEntity e : list) {
System.out.println(e.toString());
}
}
如果上面例子,参数studentName为null,将不会进行STUDENT_NAME列的判断,则会直接导“WHERE AND”关键字多余的错误SQL。
这时我们可以使用where动态语句来解决。这个“where”标签会知道如果它包含的标签中有返回值的话,它就插入一个‘where’。此外,如果标签返回的内容是以AND 或OR 开头的,则它会剔除掉。
上面例子修改为:
<!-- 3 select - where/if(判断参数) - 将实体类不为空的属性作为where条件 -->
<select id="getStudentList_whereIf" resultMap="resultMap_studentEntity" parameterType="liming.student.manager.data.model.StudentEntity">
SELECT ST.STUDENT_ID,
ST.STUDENT_NAME,
ST.STUDENT_SEX,
ST.STUDENT_BIRTHDAY,
ST.STUDENT_PHOTO,
ST.CLASS_ID,
ST.PLACE_ID
FROM STUDENT_TBL ST
<where>
<if test="studentName !=null ">
ST.STUDENT_NAME LIKE CONCAT(CONCAT('%', #{studentName, jdbcType=VARCHAR}),'%')
</if>
<if test="studentSex != null and studentSex != '' ">
AND ST.STUDENT_SEX = #{studentSex, jdbcType=INTEGER}
</if>
<if test="studentBirthday != null ">
AND ST.STUDENT_BIRTHDAY = #{studentBirthday, jdbcType=DATE}
</if>
<if test="classId != null and classId!= '' ">
AND ST.CLASS_ID = #{classId, jdbcType=VARCHAR}
</if>
<if test="classEntity != null and classEntity.classId !=null and classEntity.classId !=' ' ">
AND ST.CLASS_ID = #{classEntity.classId, jdbcType=VARCHAR}
</if>
<if test="placeId != null and placeId != '' ">
AND ST.PLACE_ID = #{placeId, jdbcType=VARCHAR}
</if>
<if test="placeEntity != null and placeEntity.placeId != null and placeEntity.placeId != '' ">
AND ST.PLACE_ID = #{placeEntity.placeId, jdbcType=VARCHAR}
</if>
<if test="studentId != null and studentId != '' ">
AND ST.STUDENT_ID = #{studentId, jdbcType=VARCHAR}
</if>
</where>
</select>
if + set
当update语句中没有使用if标签时,如果有一个参数为null,都会导致错误。
当在update语句中使用if标签时,如果前面的if没有执行,则或导致逗号多余错误。使用set标签可以将动态的配置SET 关键字,和剔除追加到条件末尾的任何不相关的逗号。使用if+set标签修改后,如果某项为null则不进行更新,而是保持数据库原值。
如下示例:
<!-- 4 if/set(判断参数) - 将实体类不为空的属性更新 -->
<update id="updateStudent_if_set" parameterType="liming.student.manager.data.model.StudentEntity">
UPDATE STUDENT_TBL
<set>
<if test="studentName != null and studentName != '' ">
STUDENT_TBL.STUDENT_NAME = #{studentName},
</if>
<if test="studentSex != null and studentSex != '' ">
STUDENT_TBL.STUDENT_SEX = #{studentSex},
</if>
<if test="studentBirthday != null ">
STUDENT_TBL.STUDENT_BIRTHDAY = #{studentBirthday},
</if>
<if test="studentPhoto != null ">
STUDENT_TBL.STUDENT_PHOTO = #{studentPhoto, javaType=byte[], jdbcType=BLOB, typeHandler=org.apache.ibatis.type.BlobTypeHandler},
</if>
<if test="classId != '' ">
STUDENT_TBL.CLASS_ID = #{classId}
</if>
<if test="placeId != '' ">
STUDENT_TBL.PLACE_ID = #{placeId}
</if>
</set>
WHERE STUDENT_TBL.STUDENT_ID = #{studentId};
</update>
if + trim 代替 where/set
trim是更灵活的去处多余关键字的标签,他可以实践where和set的效果。
trim 代替 where
<!-- 5.1if/trim代替where(判断参数) -将实体类不为空的属性作为where条件-->
<select id="getStudentList_if_trim" resultMap="resultMap_studentEntity">
SELECT ST.STUDENT_ID,
ST.STUDENT_NAME,
ST.STUDENT_SEX,
ST.STUDENT_BIRTHDAY,
ST.STUDENT_PHOTO,
ST.CLASS_ID,
ST.PLACE_ID
FROM STUDENT_TBL ST
<trim prefix="WHERE" prefixOverrides="AND|OR">
<if test="studentName !=null ">
ST.STUDENT_NAME LIKE CONCAT(CONCAT('%', #{studentName, jdbcType=VARCHAR}),'%')
</if>
<if test="studentSex != null and studentSex != '' ">
AND ST.STUDENT_SEX = #{studentSex, jdbcType=INTEGER}
</if>
<if test="studentBirthday != null ">
AND ST.STUDENT_BIRTHDAY = #{studentBirthday, jdbcType=DATE}
</if>
<if test="classId != null and classId!= '' ">
AND ST.CLASS_ID = #{classId, jdbcType=VARCHAR}
</if>
<if test="classEntity != null and classEntity.classId !=null and classEntity.classId !=' ' ">
AND ST.CLASS_ID = #{classEntity.classId, jdbcType=VARCHAR}
</if>
<if test="placeId != null and placeId != '' ">
AND ST.PLACE_ID = #{placeId, jdbcType=VARCHAR}
</if>
<if test="placeEntity != null and placeEntity.placeId != null and placeEntity.placeId != '' ">
AND ST.PLACE_ID = #{placeEntity.placeId, jdbcType=VARCHAR}
</if>
<if test="studentId != null and studentId != '' ">
AND ST.STUDENT_ID = #{studentId, jdbcType=VARCHAR}
</if>
</trim>
</select>
trim 代替 set
<!-- 5.2 if/trim代替set(判断参数) - 将实体类不为空的属性更新 -->
<update id="updateStudent_if_trim" parameterType="liming.student.manager.data.model.StudentEntity">
UPDATE STUDENT_TBL
<trim prefix="SET" suffixOverrides=",">
<if test="studentName != null and studentName != '' ">
STUDENT_TBL.STUDENT_NAME = #{studentName},
</if>
<if test="studentSex != null and studentSex != '' ">
STUDENT_TBL.STUDENT_SEX = #{studentSex},
</if>
<if test="studentBirthday != null ">
STUDENT_TBL.STUDENT_BIRTHDAY = #{studentBirthday},
</if>
<if test="studentPhoto != null ">
STUDENT_TBL.STUDENT_PHOTO = #{studentPhoto, javaType=byte[], jdbcType=BLOB, typeHandler=org.apache.ibatis.type.BlobTypeHandler},
</if>
<if test="classId != '' ">
STUDENT_TBL.CLASS_ID = #{classId},
</if>
<if test="placeId != '' ">
STUDENT_TBL.PLACE_ID = #{placeId}
</if>
</trim>
WHERE STUDENT_TBL.STUDENT_ID = #{studentId}
</update>
sql 复用
sql片段标签:通过该标签可定义能复用的sql语句片段,在执行sql语句标签中直接引用即可。这样既可以提高编码效率,还能有效简化代码,提高可读性
需要配置的属性:id="" »>表示需要改sql语句片段的唯一标识
引用:通过标签引用,refid="" 中的值指向需要引用的中的id=“”属性
<!--定义sql片段-->
<sql id="orderAndItem">
o.order_id,o.cid,o.address,o.create_date,o.orderitem_id,i.orderitem_id,i.product_id,i.count
</sql>
<select id="findOrderAndItemsByOid" parameterType="java.lang.String" resultMap="BaseResultMap">
select
<!--引用sql片段-->
<include refid="orderAndItem" />
from ordertable o
join orderitem i on o.orderitem_id = i.orderitem_id
where o.order_id = #{orderId}
</select>
upsert
基于唯一键冲突
<select id="createRecord" parameterType="map" resultType="long" flushCache="true">
INSERT INTO MYTABLE (id, name, creator, description)
VALUES (nextval('my_seq'), #{name}, #{creator}, #{description})
ON CONFLICT ON CONSTRAINT (name, creator)
DO UPDATE SET
name = #{name},
creator = #{creator},
description = #{description}
RETURNING id
</insert>
基于主键
<insert id="AddTeacher" parameterType="com.mycompany.entity.Teacher">
<selectKey keyProperty="count" resultType="int" order="BEFORE">
select count(*) from Teacher where teacher_id = #{teacherId}
</selectKey>
<if test="count > 0">
update event
<set>
<if test="teacherName!= null" >
teacher_name= #{teacherName},
</if>
</set>
<where>
teacher_id = #{teacherId}
</where>
</if>
<if test="count==0">
insert into teacher(teacher_id,teacher_name) values (#{teacherId},#{teacherName})
</if>
</insert>
基于唯一键冲突批量执行
public interface ExcelDataMapper {
/**
* 根据excel解析的实体,插入到数据库。
*
* @param dbColumnToValueMap <code>Map<String, String></code> 表示excel解析的实体。
*/
int insert(@Param("dbColumnToValueMap") Map<String, Object> dbColumnToValueMap);
}
<insert id="upsert" parameterType="map">
insert into excel_data_info
<foreach collection="dbColumnToValueMap.keys" item="key" open="(" close=")" separator=",">
${key}
</foreach>
values
<foreach collection="dbColumnToValueMap.keys" item="key" open="(" close=")" separator=",">
#{dbColumnToValueMap[${key}]}
</foreach>
on duplicate key update
<foreach collection="dbColumnToValueMap.keys" item="key" separator="," >
<if test=" key != 'id' ">
${key} = #{dbColumnToValueMap[${key}]}
</if>
</foreach>
</insert>
4.15 - CH15-事务管理原理
概述
对数据库的事务而言,应该具有以下几点:创建(create)、提交(commit)、回滚(rollback)、关闭(close)。对应地,MyBatis将事务抽象成了Transaction接口:
MyBatis的事务管理分为两种形式:
- 使用JDBC的事务管理机制:即利用java.sql.Connection对象完成对事务的提交(commit())、回滚(rollback())、关闭(close())等。
- 使用MANAGED的事务管理机制:这种机制MyBatis自身不会去实现事务管理,而是让程序的容器如(JBOSS,Weblogic)来实现对事务的管理。
这两者的类图如下所示:
事务配置
在 MyBatis 中有两种类型的事务管理器(也就是 type="[JDBC|MANAGED]"):
- JDBC – 这个配置直接使用了 JDBC 的提交和回滚设施,它依赖从数据源获得的连接来管理事务作用域。
- MANAGED – 这个配置几乎没做什么。它从不提交或回滚一个连接,而是让容器来管理事务的整个生命周期(比如 JEE 应用服务器的上下文)。 默认情况下它会关闭连接。然而一些容器并不希望连接被关闭,因此需要将 closeConnection 属性设置为 false 来阻止默认的关闭行为。例如:
<transactionManager type="MANAGED">
<property name="closeConnection" value="false"/>
</transactionManager>
如果你正在使用 Spring + MyBatis,则没有必要配置事务管理器,因为 Spring 模块会使用自带的管理器来覆盖前面的配置。
这两种事务管理器类型都不需要设置任何属性。它们其实是类型别名,换句话说,你可以用 TransactionFactory 接口实现类的全限定名或类型别名代替它们。
public interface TransactionFactory {
default void setProperties(Properties props) { // 从 3.5.2 开始,该方法为默认方法
// 空实现
}
Transaction newTransaction(Connection conn);
Transaction newTransaction(DataSource dataSource, TransactionIsolationLevel level, boolean autoCommit);
}
在事务管理器实例化后,所有在 XML 中配置的属性将会被传递给 setProperties() 方法。你的实现还需要创建一个 Transaction 接口的实现类,这个接口也很简单:
public interface Transaction {
Connection getConnection() throws SQLException;
void commit() throws SQLException;
void rollback() throws SQLException;
void close() throws SQLException;
Integer getTimeout() throws SQLException;
}
使用这两个接口,你可以完全自定义 MyBatis 对事务的处理。
事务的配置、创建和使用
事务的配置
我们在使用MyBatis时,一般会在MyBatisXML配置文件中定义类似如下的信息:
<environment>节点定义了连接某个数据库的信息,其子节点<transactionManager> 的type 会决定我们用什么类型的事务管理机制。
事务工厂的创建
MyBatis事务的创建是交给TransactionFactory 事务工厂来创建的,如果我们将<transactionManager>的type 配置为"JDBC",那么,在MyBatis初始化解析 <environment>节点时,会根据type=“JDBC"创建一个JdbcTransactionFactory工厂,其源码如下:
/**
* 解析<transactionManager>节点,创建对应的TransactionFactory
* @param context
* @return
* @throws Exception
*/
private TransactionFactory transactionManagerElement(XNode context) throws Exception {
if (context != null) {
String type = context.getStringAttribute("type");
Properties props = context.getChildrenAsProperties();
/*
* 在Configuration初始化的时候,会通过以下语句,给JDBC和MANAGED对应的工厂类
* typeAliasRegistry.registerAlias("JDBC", JdbcTransactionFactory.class);
* typeAliasRegistry.registerAlias("MANAGED", ManagedTransactionFactory.class);
* 下述的resolveClass(type).newInstance()会创建对应的工厂实例
*/
TransactionFactory factory = (TransactionFactory) resolveClass(type).newInstance();
factory.setProperties(props);
return factory;
}
throw new BuilderException("Environment declaration requires a TransactionFactory.");
}
@pdai: 代码已经复制到剪贴板
如上述代码所示,如果type = “JDBC”,则MyBatis会创建一个JdbcTransactionFactory.class 实例;如果type=“MANAGED”,则MyBatis会创建一个MangedTransactionFactory.class实例。
MyBatis对<transactionManager>节点的解析会生成TransactionFactory实例;而对<dataSource>解析会生成datasouce实例,作为<environment>节点,会根据TransactionFactory和DataSource实例创建一个Environment对象,代码如下所示:
private void environmentsElement(XNode context) throws Exception {
if (context != null) {
if (environment == null) {
environment = context.getStringAttribute("default");
}
for (XNode child : context.getChildren()) {
String id = child.getStringAttribute("id");
//是和默认的环境相同时,解析之
if (isSpecifiedEnvironment(id)) {
//1.解析<transactionManager>节点,决定创建什么类型的TransactionFactory
TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));
//2. 创建dataSource
DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));
DataSource dataSource = dsFactory.getDataSource();
//3. 使用了Environment内置的构造器Builder,传递id 事务工厂TransactionFactory和数据源DataSource
Environment.Builder environmentBuilder = new Environment.Builder(id)
.transactionFactory(txFactory)
.dataSource(dataSource);
configuration.setEnvironment(environmentBuilder.build());
}
}
}
}
Environment表示着一个数据库的连接,生成后的Environment对象会被设置到Configuration实例中,以供后续的使用。
上述一直在讲事务工厂TransactionFactory来创建的Transaction,现在让我们看一下MyBatis中的TransactionFactory的定义吧。
事务工厂 TransactionFactory
事务工厂Transaction定义了创建Transaction的两个方法:一个是通过指定的Connection对象创建Transaction,另外是通过数据源DataSource来创建Transaction。与JDBC 和MANAGED两种Transaction相对应,TransactionFactory有两个对应的实现的子类:
事务Transaction的创建
通过事务工厂TransactionFactory很容易获取到Transaction对象实例。我们以JdbcTransaction为例,看一下JdbcTransactionFactory是怎样生成JdbcTransaction的,代码如下:
public class JdbcTransactionFactory implements TransactionFactory {
public void setProperties(Properties props) {
}
/**
* 根据给定的数据库连接Connection创建Transaction
* @param conn Existing database connection
* @return
*/
public Transaction newTransaction(Connection conn) {
return new JdbcTransaction(conn);
}
/**
* 根据DataSource、隔离级别和是否自动提交创建Transacion
*
* @param ds
* @param level Desired isolation level
* @param autoCommit Desired autocommit
* @return
*/
public Transaction newTransaction(DataSource ds, TransactionIsolationLevel level, boolean autoCommit) {
return new JdbcTransaction(ds, level, autoCommit);
}
}
如上说是,JdbcTransactionFactory会创建JDBC类型的Transaction,即JdbcTransaction。类似地,ManagedTransactionFactory也会创建ManagedTransaction。下面我们会分别深入JdbcTranaction 和ManagedTransaction,看它们到底是怎样实现事务管理的。
JdbcTranscation
JdbcTransaction直接使用JDBC的提交和回滚事务管理机制。它依赖与从dataSource中取得的连接connection 来管理transaction 的作用域,connection对象的获取被延迟到调用getConnection()方法。如果autocommit设置为on,开启状态的话,它会忽略commit和rollback。
直观地讲,就是JdbcTransaction是使用的java.sql.Connection 上的commit和rollback功能,JdbcTransaction只是相当于对java.sql.Connection事务处理进行了一次包装(wrapper),Transaction的事务管理都是通过java.sql.Connection实现的。JdbcTransaction的代码实现如下:
public class JdbcTransaction implements Transaction {
private static final Log log = LogFactory.getLog(JdbcTransaction.class);
//数据库连接
protected Connection connection;
//数据源
protected DataSource dataSource;
//隔离级别
protected TransactionIsolationLevel level;
//是否为自动提交
protected boolean autoCommmit;
public JdbcTransaction(DataSource ds, TransactionIsolationLevel desiredLevel, boolean desiredAutoCommit) {
dataSource = ds;
level = desiredLevel;
autoCommmit = desiredAutoCommit;
}
public JdbcTransaction(Connection connection) {
this.connection = connection;
}
public Connection getConnection() throws SQLException {
if (connection == null) {
openConnection();
}
return connection;
}
/**
* commit()功能 使用connection的commit()
* @throws SQLException
*/
public void commit() throws SQLException {
if (connection != null && !connection.getAutoCommit()) {
if (log.isDebugEnabled()) {
log.debug("Committing JDBC Connection [" + connection + "]");
}
connection.commit();
}
}
/**
* rollback()功能 使用connection的rollback()
* @throws SQLException
*/
public void rollback() throws SQLException {
if (connection != null && !connection.getAutoCommit()) {
if (log.isDebugEnabled()) {
log.debug("Rolling back JDBC Connection [" + connection + "]");
}
connection.rollback();
}
}
/**
* close()功能 使用connection的close()
* @throws SQLException
*/
public void close() throws SQLException {
if (connection != null) {
resetAutoCommit();
if (log.isDebugEnabled()) {
log.debug("Closing JDBC Connection [" + connection + "]");
}
connection.close();
}
}
protected void setDesiredAutoCommit(boolean desiredAutoCommit) {
try {
if (connection.getAutoCommit() != desiredAutoCommit) {
if (log.isDebugEnabled()) {
log.debug("Setting autocommit to " + desiredAutoCommit + " on JDBC Connection [" + connection + "]");
}
connection.setAutoCommit(desiredAutoCommit);
}
} catch (SQLException e) {
// Only a very poorly implemented driver would fail here,
// and there's not much we can do about that.
throw new TransactionException("Error configuring AutoCommit. "
+ "Your driver may not support getAutoCommit() or setAutoCommit(). "
+ "Requested setting: " + desiredAutoCommit + ". Cause: " + e, e);
}
}
protected void resetAutoCommit() {
try {
if (!connection.getAutoCommit()) {
// MyBatis does not call commit/rollback on a connection if just selects were performed.
// Some databases start transactions with select statements
// and they mandate a commit/rollback before closing the connection.
// A workaround is setting the autocommit to true before closing the connection.
// Sybase throws an exception here.
if (log.isDebugEnabled()) {
log.debug("Resetting autocommit to true on JDBC Connection [" + connection + "]");
}
connection.setAutoCommit(true);
}
} catch (SQLException e) {
log.debug("Error resetting autocommit to true "
+ "before closing the connection. Cause: " + e);
}
}
protected void openConnection() throws SQLException {
if (log.isDebugEnabled()) {
log.debug("Opening JDBC Connection");
}
connection = dataSource.getConnection();
if (level != null) {
connection.setTransactionIsolation(level.getLevel());
}
setDesiredAutoCommit(autoCommmit);
}
}
ManagedTransaction
ManagedTransaction让容器来管理事务Transaction的整个生命周期,意思就是说,使用ManagedTransaction的commit和rollback功能不会对事务有任何的影响,它什么都不会做,它将事务管理的权利移交给了容器来实现。看如下Managed的实现代码大家就会一目了然:
/**
*
* 让容器管理事务transaction的整个生命周期
* connection的获取延迟到getConnection()方法的调用
* 忽略所有的commit和rollback操作
* 默认情况下,可以关闭一个连接connection,也可以配置它不可以关闭一个连接
* 让容器来管理transaction的整个生命周期
* @see ManagedTransactionFactory
*/
public class ManagedTransaction implements Transaction {
private static final Log log = LogFactory.getLog(ManagedTransaction.class);
private DataSource dataSource;
private TransactionIsolationLevel level;
private Connection connection;
private boolean closeConnection;
public ManagedTransaction(Connection connection, boolean closeConnection) {
this.connection = connection;
this.closeConnection = closeConnection;
}
public ManagedTransaction(DataSource ds, TransactionIsolationLevel level, boolean closeConnection) {
this.dataSource = ds;
this.level = level;
this.closeConnection = closeConnection;
}
public Connection getConnection() throws SQLException {
if (this.connection == null) {
openConnection();
}
return this.connection;
}
public void commit() throws SQLException {
// Does nothing
}
public void rollback() throws SQLException {
// Does nothing
}
public void close() throws SQLException {
if (this.closeConnection && this.connection != null) {
if (log.isDebugEnabled()) {
log.debug("Closing JDBC Connection [" + this.connection + "]");
}
this.connection.close();
}
}
protected void openConnection() throws SQLException {
if (log.isDebugEnabled()) {
log.debug("Opening JDBC Connection");
}
this.connection = this.dataSource.getConnection();
if (this.level != null) {
this.connection.setTransactionIsolation(this.level.getLevel());
}
}
}
注意:如果我们使用MyBatis构建本地程序,即不是WEB程序,若将type设置成"MANAGED”,那么,我们执行的任何update操作,即使我们最后执行了commit操作,数据也不会保留,不会对数据库造成任何影响。因为我们将MyBatis配置成了“MANAGED”,即MyBatis自己不管理事务,而我们又是运行的本地程序,没有事务管理功能,所以对数据库的update操作都是无效的。
4.16 - CH16-一级缓存原理
什么是一级缓存?
每当我们使用MyBatis开启一次和数据库的会话,MyBatis会创建出一个SqlSession对象表示一次数据库会话。
在对数据库的一次会话中,我们有可能会反复地执行完全相同的查询语句,如果不采取一些措施的话,每一次查询都会查询一次数据库,而我们在极短的时间内做了完全相同的查询,那么它们的结果极有可能完全相同,由于查询一次数据库的代价很大,这有可能造成很大的资源浪费。
为了解决这一问题,减少资源的浪费,MyBatis会在表示会话的SqlSession对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候,如果判断先前有个完全一样的查询,会直接从缓存中直接将结果取出,返回给用户,不需要再进行一次数据库查询了。
如下图所示,MyBatis一次会话: 一个SqlSession对象中创建一个本地缓存(local cache),对于每一次查询,都会尝试根据查询的条件去本地缓存中查找是否在缓存中,如果在缓存中,就直接从缓存中取出,然后返回给用户;否则,从数据库读取数据,将查询结果存入缓存并返回给用户。
对于会话(Session)级别的数据缓存,我们称之为一级数据缓存,简称一级缓存。
MyBatis中的一级缓存是怎样组织的?
即SqlSession中的缓存是怎样组织的?由于MyBatis使用SqlSession对象表示一次数据库的会话,那么,对于会话级别的一级缓存也应该是在SqlSession中控制的。
实际上, MyBatis只是一个MyBatis对外的接口,SqlSession将它的工作交给了Executor执行器这个角色来完成,负责完成对数据库的各种操作。当创建了一个SqlSession对象时,MyBatis会为这个SqlSession对象创建一个新的Executor执行器,而缓存信息就被维护在这个Executor执行器中,MyBatis将缓存和对缓存相关的操作封装成了Cache接口中。SqlSession、Executor、Cache之间的关系如下列类图所示:
如上述的类图所示,Executor接口的实现类BaseExecutor中拥有一个Cache接口的实现类PerpetualCache,则对于BaseExecutor对象而言,它将使用PerpetualCache对象维护缓存。
综上,SqlSession对象、Executor对象、Cache对象之间的关系如下图所示:
由于Session级别的一级缓存实际上就是使用PerpetualCache维护的,那么PerpetualCache是怎样实现的呢?
PerpetualCache实现原理其实很简单,其内部就是通过一个简单的HashMap<k,v> 来实现的,没有其他的任何限制。如下是PerpetualCache的实现代码:
package org.apache.ibatis.cache.impl;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.locks.ReadWriteLock;
import org.apache.ibatis.cache.Cache;
import org.apache.ibatis.cache.CacheException;
/**
* 使用简单的HashMap来维护缓存
* @author Clinton Begin
*/
public class PerpetualCache implements Cache {
private String id;
private Map<Object, Object> cache = new HashMap<Object, Object>();
public PerpetualCache(String id) {
this.id = id;
}
public String getId() {
return id;
}
public int getSize() {
return cache.size();
}
public void putObject(Object key, Object value) {
cache.put(key, value);
}
public Object getObject(Object key) {
return cache.get(key);
}
public Object removeObject(Object key) {
return cache.remove(key);
}
public void clear() {
cache.clear();
}
public ReadWriteLock getReadWriteLock() {
return null;
}
public boolean equals(Object o) {
if (getId() == null) throw new CacheException("Cache instances require an ID.");
if (this == o) return true;
if (!(o instanceof Cache)) return false;
Cache otherCache = (Cache) o;
return getId().equals(otherCache.getId());
}
public int hashCode() {
if (getId() == null) throw new CacheException("Cache instances require an ID.");
return getId().hashCode();
}
}
一级缓存的生命周期有多长?
MyBatis在开启一个数据库会话时,会创建一个新的SqlSession对象,SqlSession对象中会有一个新的Executor对象,Executor对象中持有一个新的PerpetualCache对象;当会话结束时,SqlSession对象及其内部的Executor对象还有PerpetualCache对象也一并释放掉。
- 如果SqlSession调用了close()方法,会释放掉一级缓存PerpetualCache对象,一级缓存将不可用;
- 如果SqlSession调用了clearCache(),会清空PerpetualCache对象中的数据,但是该对象仍可使用;
- SqlSession中执行了任何一个update操作(update()、delete()、insert()) ,都会清空PerpetualCache对象的数据,但是该对象可以继续使用;
SqlSession 一级缓存的工作流程
- 对于某个查询,根据statementId,params,rowBounds来构建一个key值,根据这个key值去缓存Cache中取出对应的key值存储的缓存结果;
- 判断从Cache中根据特定的key值取的数据数据是否为空,即是否命中;
- 如果命中,则直接将缓存结果返回;
- 如果没命中:
- 去数据库中查询数据,得到查询结果;
- 将key和查询到的结果分别作为key,value对存储到Cache中;
- 将查询结果返回;
- 结束。
Cache接口的设计以及CacheKey的定义
如下图所示,MyBatis定义了一个org.apache.ibatis.cache.Cache接口作为其Cache提供者的SPI(Service Provider Interface) ,所有的MyBatis内部的Cache缓存,都应该实现这一接口。MyBatis定义了一个PerpetualCache实现类实现了Cache接口,实际上,在SqlSession对象里的Executor对象内维护的Cache类型实例对象,就是PerpetualCache子类创建的。
(MyBatis内部还有很多Cache接口的实现,一级缓存只会涉及到这一个PerpetualCache子类,Cache的其他实现将会放到二级缓存中介绍)。
我们知道,Cache最核心的实现其实就是一个Map,将本次查询使用的特征值作为key,将查询结果作为value存储到Map中。现在最核心的问题出现了:怎样来确定一次查询的特征值?换句话说就是:怎样判断某两次查询是完全相同的查询?也可以这样说:如何确定Cache中的key值?
MyBatis认为,对于两次查询,如果以下条件都完全一样,那么就认为它们是完全相同的两次查询:
- 传入的 statementId
- 查询时要求的结果集中的结果范围 (结果的范围通过rowBounds.offset和rowBounds.limit表示)
- 这次查询所产生的最终要传递给JDBC java.sql.Preparedstatement的Sql语句字符串(boundSql.getSql() )
- 传递给java.sql.Statement要设置的参数值
现在分别解释上述四个条件:
- 传入的statementId,对于MyBatis而言,你要使用它,必须需要一个statementId,它代表着你将执行什么样的Sql;
- MyBatis自身提供的分页功能是通过RowBounds来实现的,它通过rowBounds.offset和rowBounds.limit来过滤查询出来的结果集,这种分页功能是基于查询结果的再过滤,而不是进行数据库的物理分页;
- 由于MyBatis底层还是依赖于JDBC实现的,那么,对于两次完全一模一样的查询,MyBatis要保证对于底层JDBC而言,也是完全一致的查询才行。而对于JDBC而言,两次查询,只要传入给JDBC的SQL语句完全一致,传入的参数也完全一致,就认为是两次查询是完全一致的。
- 上述的第3个条件正是要求保证传递给JDBC的SQL语句完全一致;第4条则是保证传递给JDBC的参数也完全一致;即3、4两条MyBatis最本质的要求就是:调用JDBC的时候,传入的SQL语句要完全相同,传递给JDBC的参数值也要完全相同。
综上所述,CacheKey由以下条件决定:statementId + rowBounds + 传递给JDBC的SQL + 传递给JDBC的参数值;
对于每次的查询请求,Executor都会根据传递的参数信息以及动态生成的SQL语句,将上面的条件根据一定的计算规则,创建一个对应的CacheKey对象。
我们知道创建CacheKey的目的,就两个:
- 根据CacheKey作为key,去Cache缓存中查找缓存结果;
- 如果查找缓存命中失败,则通过此CacheKey作为key,将从数据库查询到的结果作为value,组成key,value对存储到Cache缓存中;
CacheKey的构建被放置到了Executor接口的实现类BaseExecutor中,定义如下:
/**
* 所属类: org.apache.ibatis.executor.BaseExecutor
* 功能 : 根据传入信息构建CacheKey
*/
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) throw new ExecutorException("Executor was closed.");
CacheKey cacheKey = new CacheKey();
//1.statementId
cacheKey.update(ms.getId());
//2. rowBounds.offset
cacheKey.update(rowBounds.getOffset());
//3. rowBounds.limit
cacheKey.update(rowBounds.getLimit());
//4. SQL语句
cacheKey.update(boundSql.getSql());
//5. 将每一个要传递给JDBC的参数值也更新到CacheKey中
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
for (int i = 0; i < parameterMappings.size(); i++) { // mimic DefaultParameterHandler logic
ParameterMapping parameterMapping = parameterMappings.get(i);
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
//将每一个要传递给JDBC的参数值也更新到CacheKey中
cacheKey.update(value);
}
}
return cacheKey;
}
刚才已经提到,Cache接口的实现,本质上是使用的HashMap<k,v>,而构建CacheKey的目的就是为了作为HashMap<k,v>中的key值。而HashMap是通过key值的hashcode 来组织和存储的,那么,构建CacheKey的过程实际上就是构造其hashCode的过程。下面的代码就是CacheKey的核心hashcode生成算法,感兴趣的话可以看一下:
public void update(Object object) {
if (object != null && object.getClass().isArray()) {
int length = Array.getLength(object);
for (int i = 0; i < length; i++) {
Object element = Array.get(object, i);
doUpdate(element);
}
} else {
doUpdate(object);
}
}
private void doUpdate(Object object) {
//1. 得到对象的hashcode;
int baseHashCode = object == null ? 1 : object.hashCode();
//对象计数递增
count++;
checksum += baseHashCode;
//2. 对象的hashcode 扩大count倍
baseHashCode *= count;
//3. hashCode * 拓展因子(默认37)+拓展扩大后的对象hashCode值
hashcode = multiplier * hashcode + baseHashCode;
updateList.add(object);
}
MyBatis认为的完全相同的查询,不是指使用sqlSession查询时传递给算起来Session的所有参数值完完全全相同,你只要保证statementId,rowBounds,最后生成的SQL语句,以及这个SQL语句所需要的参数完全一致就可以了。
一级缓存的性能分析
- MyBatis对会话(Session)级别的一级缓存设计的比较简单,就简单地使用了HashMap来维护,并没有对HashMap的容量和大小进行限制
读者有可能就觉得不妥了:如果我一直使用某一个SqlSession对象查询数据,这样会不会导致HashMap太大,而导致 java.lang.OutOfMemoryError错误啊? 读者这么考虑也不无道理,不过MyBatis的确是这样设计的。
MyBatis这样设计也有它自己的理由:
- 一般而言SqlSession的生存时间很短。一般情况下使用一个SqlSession对象执行的操作不会太多,执行完就会消亡;
- 对于某一个SqlSession对象而言,只要执行update操作(update、insert、delete),都会将这个SqlSession对象中对应的一级缓存清空掉,所以一般情况下不会出现缓存过大,影响JVM内存空间的问题;
- 可以手动地释放掉SqlSession对象中的缓存。
- 一级缓存是一个粗粒度的缓存,没有更新缓存和缓存过期的概念
MyBatis的一级缓存就是使用了简单的HashMap,MyBatis只负责将查询数据库的结果存储到缓存中去, 不会去判断缓存存放的时间是否过长、是否过期,因此也就没有对缓存的结果进行更新这一说了。
根据一级缓存的特性,在使用的过程中,我认为应该注意:
- 对于数据变化频率很大,并且需要高时效准确性的数据要求,我们使用SqlSession查询的时候,要控制好SqlSession的生存时间, SqlSession的生存时间越长,它其中缓存的数据有可能就越旧,从而造成和真实数据库的误差;同时对于这种情况,用户也可以手动地适时清空SqlSession中的缓存;
- 对于只执行、并且频繁执行大范围的select操作的SqlSession对象,SqlSession对象的生存时间不应过长。
4.17 - CH17-二级缓存原理
MyBatis的二级缓存是Application级别的缓存,它可以提高对数据库查询的效率,以提高应用的性能。
整体设计与工作模式
当开一个会话时,一个SqlSession对象会使用一个Executor对象来完成会话操作,MyBatis的二级缓存机制的关键就是对这个Executor对象做文章。如果用户配置了"cacheEnabled=true",那么MyBatis在为SqlSession对象创建Executor对象时,会对Executor对象加上一个装饰者:CachingExecutor,这时SqlSession使用CachingExecutor对象来完成操作请求。CachingExecutor对于查询请求,会先判断该查询请求在Application级别的二级缓存中是否有缓存结果,如果有查询结果,则直接返回缓存结果;如果缓存中没有,再交给真正的Executor对象来完成查询操作,之后CachingExecutor会将真正Executor返回的查询结果放置到缓存中,然后在返回给用户。
CachingExecutor是Executor的装饰者,以增强Executor的功能,使其具有缓存查询的功能,这里用到了设计模式中的装饰者模式,CachingExecutor和Executor的接口的关系如下类图所示:
二级缓存的划分
MyBatis并不是简单地对整个Application就只有一个Cache缓存对象,它将缓存划分的更细,即是Mapper级别的,即每一个Mapper都可以拥有一个Cache对象,具体如下:
- 为每一个Mapper分配一个Cache缓存对象(使用
<cache>节点配置)
MyBatis将Application级别的二级缓存细分到Mapper级别,即对于每一个Mapper.xml,如果在其中使用了<cache> 节点,则MyBatis会为这个Mapper创建一个Cache缓存对象,如下图所示:
注:上述的每一个Cache对象,都会有一个自己所属的namespace命名空间,并且会将Mapper的 namespace作为它们的ID;
- 多个Mapper共用一个Cache缓存对象(使用
<cache-ref>节点配置)
如果你想让多个Mapper公用一个Cache的话,你可以使用<cache-ref namespace="">节点,来指定你的这个Mapper使用到了哪一个Mapper的Cache缓存。
必须要具备的条件
MyBatis对二级缓存的支持粒度很细,它会指定某一条查询语句是否使用二级缓存。
虽然在Mapper中配置了<cache>,并且为此Mapper分配了Cache对象,这并不表示我们使用Mapper中定义的查询语句查到的结果都会放置到Cache对象之中,我们必须指定Mapper中的某条选择语句是否支持缓存,即如下所示,在<select> 节点中配置useCache=“true”,Mapper才会对此Select的查询支持缓存特性,否则,不会对此Select查询,不会经过Cache缓存。如下所示,Select语句配置了useCache=“true”,则表明这条Select语句的查询会使用二级缓存。
<select id="selectByMinSalary" resultMap="BaseResultMap" parameterType="java.util.Map" useCache="true">
总之,要想使某条Select查询支持二级缓存,你需要保证:
- MyBatis支持二级缓存的总开关:全局配置变量参数 cacheEnabled=true
- 该select语句所在的Mapper,配置了
<cache> 或<cached-ref>节点,并且有效 - 该select语句的参数 useCache=true
一级缓存和二级缓存的使用顺序
请注意,如果你的MyBatis使用了二级缓存,并且你的Mapper和select语句也配置使用了二级缓存,那么在执行select查询的时候,MyBatis会先从二级缓存中取输入,其次才是一级缓存,即MyBatis查询数据的顺序是:二级缓存 ———> 一级缓存 ——> 数据库。
二级缓存实现的选择
MyBatis对二级缓存的设计非常灵活,它自己内部实现了一系列的Cache缓存实现类,并提供了各种缓存刷新策略如LRU,FIFO等等;另外,MyBatis还允许用户自定义Cache接口实现,用户是需要实现org.apache.ibatis.cache.Cache接口,然后将Cache实现类配置在<cache type="">节点的type属性上即可;除此之外,MyBatis还支持跟第三方内存缓存库如Memecached的集成,总之,使用MyBatis的二级缓存有三个选择:
- MyBatis自身提供的缓存实现;
- 用户自定义的Cache接口实现;
- 跟第三方内存缓存库的集成;
MyBatis自身提供的二级缓存的实现
MyBatis自身提供了丰富的,并且功能强大的二级缓存的实现,它拥有一系列的Cache接口装饰者,可以满足各种对缓存操作和更新的策略。
MyBatis定义了大量的Cache的装饰器来增强Cache缓存的功能,如下类图所示。
对于每个Cache而言,都有一个容量限制,MyBatis各供了各种策略来对Cache缓存的容量进行控制,以及对Cache中的数据进行刷新和置换。MyBatis主要提供了以下几个刷新和置换策略:
- LRU:(Least Recently Used),最近最少使用算法,即如果缓存中容量已经满了,会将缓存中最近最少被使用的缓存记录清除掉,然后添加新的记录;
- FIFO:(First in first out),先进先出算法,如果缓存中的容量已经满了,那么会将最先进入缓存中的数据清除掉;
- Scheduled:指定时间间隔清空算法,该算法会以指定的某一个时间间隔将Cache缓存中的数据清空;
如何细粒度地控制你的MyBatis二级缓存
一个关于MyBatis的二级缓存的实际问题
现有AMapper.xml中定义了对数据库表 ATable 的CRUD操作,BMapper定义了对数据库表BTable的CRUD操作;
假设 MyBatis 的二级缓存开启,并且 AMapper 中使用了二级缓存,AMapper对应的二级缓存为ACache;
除此之外,AMapper 中还定义了一个跟BTable有关的查询语句,类似如下所述:
<select id="selectATableWithJoin" resultMap="BaseResultMap" useCache="true">
select * from ATable left join BTable on ....
</select>
执行以下操作:
- 执行AMapper中的"selectATableWithJoin" 操作,此时会将查询到的结果放置到AMapper对应的二级缓存ACache中;
- 执行BMapper中对BTable的更新操作(update、delete、insert)后,BTable的数据更新;
- 再执行1完全相同的查询,这时候会直接从AMapper二级缓存ACache中取值,将ACache中的值直接返回;
好,问题就出现在第3步上:
由于AMapper的“selectATableWithJoin” 对应的SQL语句需要和BTable进行join查找,而在第 2 步BTable的数据已经更新了,但是第 3 步查询的值是第 1 步的缓存值,已经极有可能跟真实数据库结果不一样,即ACache中缓存数据过期了!
总结来看,就是:
对于某些使用了 join连接的查询,如果其关联的表数据发生了更新,join连接的查询由于先前缓存的原因,导致查询结果和真实数据不同步;
从MyBatis的角度来看,这个问题可以这样表述:
对于某些表执行了更新(update、delete、insert)操作后,如何去清空跟这些表有关联的查询语句所造成的缓存;
当前MyBatis二级缓存的工作机制
MyBatis二级缓存的一个重要特点:即松散的Cache缓存管理和维护
一个Mapper中定义的增删改查操作只能影响到自己关联的Cache对象。如上图所示的Mapper namespace1中定义的若干CRUD语句,产生的缓存只会被放置到相应关联的Cache1中,即Mapper namespace2,namespace3,namespace4 中的CRUD的语句不会影响到Cache1。
可以看出,Mapper之间的缓存关系比较松散,相互关联的程度比较弱。
现在再回到上面描述的问题,如果我们将AMapper和BMapper共用一个Cache对象,那么,当BMapper执行更新操作时,可以清空对应Cache中的所有的缓存数据,这样的话,数据不是也可以保持最新吗?
确实这个也是一种解决方案,不过,它会使缓存的使用效率变的很低!AMapper和BMapper的任意的更新操作都会将共用的Cache清空,会频繁地清空Cache,导致Cache实际的命中率和使用率就变得很低了,所以这种策略实际情况下是不可取的。
最理想的解决方案就是:
对于某些表执行了更新(update、delete、insert)操作后,如何去清空跟这些表有关联的查询语句所造成的缓存; 这样,就是以很细的粒度管理MyBatis内部的缓存,使得缓存的使用率和准确率都能大大地提升。
4.18 - CH18-性能优化
动态条件
通过传入参数动态组装条件语句时,条件可能均为空,常见做法是使用 where 1=1 作为占位符,避免所有条件为空时语法错误:
<select id="getFruitInfo" resultType="Fruit">
SELECT * FROM Fruit
WHERE 1=1
<if test="id!= null">
and id = #{id}
</if>
<if test="name!= null">
and name = #{name}
</if>
</select>
如果 id 和 name 均为 null,则整个语句变成了:
SELECT * FROM Fruit WHERE 1=1
这时数据库就无法使用索引等查询优化策略,被迫对每行数据进行扫描,如果表很大,则性能消耗巨大,推荐的做法是使用 WHERE 标签:
<select id="getFruitInfo" resultType="Fruit">
SELECT * FROM Fruit
<WHERE>
<if test="id!= null">
id = #{id}
</if>
<if test="name!= null">
and name = #{name}
</if>
</WHERE>
</select>
where 元素知道只有在一个以上的 if 条件有值的情况下才去插入 “where” 子句,且最后的内容如果是 “AND” 或 “OR” 开头的,where 元素也能识别并将它们去除。
批量插入
在使用 foreach 执行批量插入时,如果条目很多,会生成一个很长的 sql 语句,然后再使用实际的条目数据带入,构造出要执行的 sql,这个过程会很慢。
推荐的做法是使用 BATCH 模式执行批量插入:
@Service
public class PersonService {
@Autowired
private SqlSessionFactory sqlSessionFactory;
public void insertPersions(List<Person> persons) {
try (SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH)) {
PersonMapper mapper = session.getMapper(PersonMapper.class);
for (Person person : persons) {
mapper.insert(person);
}
session.commit();
session.clearCache();
}
}
}
WHERE IN foreach
<select id="getUserInfo" resultType="com.test.UserList">
SELECT age FROM user
WHERE
<if test="userName!= null and userName.size() >0">
user_name IN
<foreach collection="userName" item="value" separator="," open="(" close=")">
#{value}
</foreach>
</if>
</select>
但列表可能为空,所以总是在调用之前判空。或者有些同学会以如下方式兼容:
<select id="getUserInfo" resultType="com.test.UserList">
SELECT age FROM user
WHERE
<if test="userName!= null and userName.size() >0">
user_name IN
<foreach collection="userName" item="value" separator="," open="(" close=")">
#{value}
</foreach>
</if>
<if test="userName!= null and userName.size() ==0">
1=2
</if>
<if test="userName!= null and userName.size() ==1">
user_name = #{users[0].userName}
</if>
</select>
基于 IN 的性能问题,可以将 IN 改为 JOIN。
5 - Hikari
Hikari 读作 Hi-ka-li。
5.1 - 基本概念
定义
- 数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个;
- 释放空闲时间超过最大空闲时间的数据库连接,来避免因为没有释放数据库连接而引起的数据库连接遗漏。
传统过程
经典的 JDBC 连接数据库的大致步骤:
- 加载 JDBC 驱动
- 创建数据库连接
- 创建 preparedStatement
- 执行 SQL 语句
- 遍历结果
- 关闭数据库连接
在网络层面,以访问 MySQL 为例,执行一个 SQL 语句的完整 TCP 流程包括:
- TCP 三次握手建立连接
- MySQL 三次握手认证
- SQL 语句执行
- MySQL 关闭
- TCP 四次挥手关闭连接
存在问题
这种传统连接方式的问题有:
- 创建和关闭连接的过程比较耗时,并发时系统会变得卡顿。
- 数据库同时支持的连接数有限,如果并发量很大,数据库的连接数则会被耗尽,增加了数据库负载,新的数据库连接请求将会失败。
- 这会极大的浪费数据库资源,极易造成数据库服务内存溢出、宕机。
- 为了执行一条 SQL,却产生了很多我们并不关心的网络 IO。
- 应用如果频繁的创建和关闭连接,会导致 JVM 临时对象较多,GC 频繁。
- 频繁关闭连接后,会出现大量 TIME_WAIT 的 TCP 状态(在 2 个 MSL 之后关闭)。
- 应用的响应时间和 QPS 较低。
池化优点
使用数据库连接池后,最直接的改变就是仅需在首次访问时创建连接,之后的访问直接可以复用已有连接。
- 资源重用。由于数据库连接得到复用,减少了大量创建和关闭连接带来的开销,也减少了内存碎片和数据库临时进程、线程的珊瑚粮,整体系统的运行更加平稳。
- 系统调优更简便。TIME_WAIT 的调优非常繁琐,使用了数据库连接池以后,由于资源重用,大大减少了频繁关闭连接的开销,大大降低 TIME_WAIT 的出现频率。
- 系统响应更快。数据库连接池在应用初始化的过程中一般都会提前准备好一些数据库连接,业务请求可以直接使用已经创建的连接而不需要等待创建连接的开销。初始化数据库连接配合资源重用,使得数据库连接池可以大大缩短系统整体响应时间。
- 连接管理更灵活。数据库连接池作为一款中间件,除了扮演有界缓冲的角色以外,在统一的连接管理上同样可以做很多文章。用户可以自行配置连接的最小数量、最大数量、最常空闲时间、获取连接超时间、心跳检测等。另外,用户也可以结合新的技术趋势,增加数据库连接池的动态配置、监控、故障演习等一系列实用的功能。
实现原理
在系统初始化的时候,在内存中开辟一片空间,将一定数量的数据库连接作为对象存储在对象池里,并对外提供数据库连接的获取和归还方法。
用户访问数据库时,并不是建立一个新的连接,而是从数据库连接池中取出一个已有的空闲连接对象;使用完毕归还后的连接也不会马上被关闭,而是由数据库连接池统一管理回收,为下一次借用做好准备。
如果由于高并发请求导致数据库连接池中的连接被借用完毕,其他线程就会等待,直到有连接被归还。
整个过程中,连接并不会被关闭,而是源源不断地循环使用,有借有还。数据库连接池还可以通过设置其参数来控制连接池中的初始连接数、连接的上下限数,以及每个连接的最大使用次数、最大空闲时间等,也可以通过其自身的管理机制来监视数据库连接的数量、使用情况等。
基本构成
数据库连接池的核心功能是建立和释放连接。通常完整的连接池实现会提供更多功能:
- 并发优化:锁性能优化,甚至无锁
- 连接数控制:不同的系统对连接数的要求不同
- 监控:提供管理机制来监视连接数量或用量
- 外部配置
- 资源重用
- 检测/容灾:面对网络、时间问题的自愈
- 多库:不同的数据库、不同的用户与密码、分库分表
- 事务处理:对数据库的操作符合 ALL-ALL-NOTHING 原则
- 定时任务:空闲检查、最小连接数控制
- 缓存:如 PSCache 等避免 SQL 重复解析
- 异常处理:对 JDBC 异常的统处理
- 组件维护:连接状态、JDBC 封装维护
5.2 - 开源实现
按采用的线程模型分类:
| 单线程 | 多线程 |
|---|
| c3p0 | DBCP 2.x |
| Proxool | Tomact JDBC Pool |
| XAPool | BoneCP |
| DBCP 1.x | Druid |
| Hakari |
c3p0
c3p0 具有超过 230 个 synchronize 同步块和方法,在不同的类中充斥着大量 wait() 及 notifyAll() 方法,这些导致死锁倾向的代码造成了在网络上搜索“c3p0死锁”可以查到大量的资料。由于代码量复杂等原因,c3p0 在基准测试中也始终排在最后。c3p0 在默认情况下不会在 getConnection 的时候测试连接可用性,这点也是不安全的默认配置。
但 c3p0 也提供了一些有用的功能:
- 一个将传统的基于
DriverManager 的 JDBC 驱动程序调整为较新的 javax.sql. DataSource 方案的类,以获取数据库连接。 - 基于
DataSources 的 Connection 和 PreparedStatements 的透明池,可以“包装”传统驱动程序或任意非池化数据源。
c3p0 在以下细节上进行了打磨以确保正确性:
DataSources 都是可引用和可序列化的,因此其适合绑定到各种基于 JNDI 的命名服务。- 当引入
Connection 和 Statement 时,都会仔细清理 Statement 和 ResultSets,这是为了防止客户端使用Lazy模式。但常见的资源管理策略仅仅清理 Connection 而造成资源耗尽。 - 该库采用 JDBC 2 和 JDBC 3 规范定义的方法(即使这些方法与库作者的首选项冲突)。
DataSources 以 JavaBean 样式编写,提供所有必需和大多数可选属性(以及一些非标准属性)和无参构造函数。- 实现了所有 JDBC 定义的内部接口(
ConnectionPoolDataSource, PooledConnection,ConnectionEvent-generating Connections等)。 - 用户可以将 c3p0 类与兼容的第三方实现混合使用(尽管并非所有 c3p0 功能都可以与
ConnectionPoolDataSource 的外部实现一起使用)。
Proxool
Proxool 以JDBC 驱动的身份为用户提供透明的连接池服务,所以 Proxool 移植到现有代码中特别容易,用户可以轻松地使用 JDBC API、XML 或 Java 属性文件进行配置。
Proxool 在那个年代另辟蹊径,开创性地提供了连接池监控功能,便于发现连接泄漏的等性能情况及连接事件。
它的很多设计理念都被 HikariCP 认可并吸收,HikariCP 在继承过程中进行了独具匠心的打磨。例如,关于 Cglib 等字节码的代理,这也是 HikariCP 仔细打磨的地方。
XAPool
XA 是 X/Open CAE Specification(Distributed TransactionProcessing) 模型中定义的 TM(Transaction Manager) 与 RM(Resource Manager) 之间进行通信的接口。
Java 中的 javax.transaction.xa.XAResource 定义了XA接口,它依赖数据库厂商对 jdbc-driver 的具体实现。在 XA 规范中,数据库充当 RM 角色,应用需要充当 TM 的角色,即生成全局的 txId,调用 XAResource 接口,把多个本地事务协调为全局统一的分布式事务。
XAPool 是一个 XA 数据库连接池,它实现了 javax.sql.XADataSource,并提供了连接池工具。这是一款主打分布式事务的数据库连接池,它允许池对象,JDBC 连接和 XA 连接。
DBCP
Apache Commons DBCP 并不是独立实现连接池功能的,它内部依赖于 Commons 中的另一个子项目 Apache Commons Pool。数据库连接池中最核心的“池”,就是由 Pool 组件提供的,Apache Commons Pool 决定着数据库连接池的整体性能。
在2014年3月,DBCP终于更新到了2.x版本,基于新的线程模型的数据库连接池让DBCP焕然一新重获新生,稳定性得到提升,性能也有了质的提升。Apache Commons Pool 2类库是对象池技术的一种具体实现,它的出现是为了解决频繁的创建和销毁对象带来的性能损耗问题。
其原理就是建立一个对象池,池中预先生成了一些对象,需要对象的时候借用,用完后进行归还,对象不够时灵活地自动创建,对象池满后提供参数控制是阻塞还是非阻塞响应租借用。
在 SpringBoot 1.5.x 版本中,数据库连接池的默认配置是 Tomcat Pool → HikariCP →Commons DBCP → Commons DBCP2;然而在 2.x 版本中,HikariCP 被提升为默认的数据库连接池,数据库连接池的默认配置顺序是 HikariCP → Tomcat pool→ CommonsDBCP2。
Tomcat JDBC Pool
在 DBCP 2.0 之前,为什么需要一个新的连接池:
- DBCP 1.x 是单线程。为了线程安全,在对象分配或对象返回的短期内,Commons 锁定了全部池。
- DBCP 1.x 可能会变得很慢。当逻辑 CPU 数目增长,或者试图借出或归还对象的并发线程增加时,性能就会受到影响。高并发系统受到的影响会更为显著。
- DBCP 拥有 60 多个类,而 tomcat-jdbc-pool 核心只有 8 个类。因此为了未来需求变更着想,肯定需要更少的改动。我们真正需要的只是连接池本身,其余的只是附属。
- DBCP 使用静态接口,因此对于指定版本的 JRE,只能采用正确版本的 DBCP,否则就会出现 NoSuchMethodException 异常。
- 当 DBCP 可以用其他更简便的实现来替代时,实在不值得重写那 60 个类。
- Tomcat JDBC 连接池无需为库本身添加额外线程,就能异步获取连接。
- Tomcat JDBC 连接池是 Tomcat 的一个模块,依靠 Tomcat JULI 这个简化了的日志架构。
- 使用 javax.sql.PooledConnection 接口获取底层连接。
- 防止饥饿。如果池变空,线程将等待一个连接。当连接返回时,池就将唤醒正确的等待线程。大多数连接池只会一直维持饥饿状态。
Tomcat JDBC Pool 还具有其他连接池没有的特点:
- 支持高并发环境与多 核/CPU 系统。
- 接口的动态实现。支持 java.sql 与 java.sql 接口(只要JDBC驱动),甚至在利用低版本的 JDK 来编译时也支持。
- 验证间隔时间。我们不必每次使用单个连接时都进行验证,可以在借出或归还连接时进行验证,只要不低于我们所设定的间隔时间就行。
- 只执行一次查询。当与数据库建立起连接时,只执行一次可配置查询。这项功能对会话设置非常有用,因为你可能会想在连接建立的整个时段内都保持会话。
- 能够配置自定义拦截器。通过自定义拦截器来增强功能。可以使用拦截器来采集查询统计,缓存会话状态,重新连接之前失败的连接,重新查询,缓存查询结果,等等。由于可以使用大量的选项,所以这种自定义拦截器也是没有限制的,与 java.sql/javax.sql 接口的 JDK 版本没有任何关系。
- 高性能。后面将举例展示一些性能差异。
- 极其简单。它的实现非常简单,代码行数与源文件都非常少,这都有赖于从一开始研发它时,就把简洁当作重中之重。核心只有8个文件。
- 异步连接获取。可将连接请求队列化,系统返回
Future<Connection>。 - 更好地处理空闲连接。不再简单粗暴地直接关闭空闲连接,而是把连接仍然保留在池中,通过更为巧妙的算法控制空闲连接池的规模。
- 可以控制连接应被废弃的时间。当池满了即废弃,或者指定一个池使用容差值,发生超时就进行废弃处理。
- 通过查询或语句来重置废弃连接计时器。允许一个使用了很长时间的连接不会因为超时而被废弃。这一点是通过使用 ResetAbandonedTimer 来实现的。
- 经过指定时间后,关闭连接。与返回池的时间相类似。
- 当连接要被释放时,获取 JMX 通知并记录所有日志。它类似于 remove-AbandonedTimeout,但却不需要采取任何行为,只需要报告信息即可。通过 suspectTimeout 属性来实现。
- 可以通过 java.sql.Driver、javax.sql.DataSource 或 javax.sql.XADataSource 获取连接。通过 dataSource 与 dataSourceJNDI 属性实现这一点。
- 支持 XA 连接。
其缺点有:
- 默认配置也存在类似 c3p0 的问题,就是在 getConnection 的时候并不会默认测试连接可用性。
- 不完全遵守 JDBC 规范,默认也不会重置连接状态(如自动提交、事务隔离级别等),用户必须手动配置名为 ConnectionState 的 JDBCInterceptor。
- 在自动提交中,如果连接池配置了
autocommit=false,就需要在自己的事务中执行连接有效性测试 isValid(),否则使用者获取的连接有可能就在一个事务进行中。 - 对于创建连接时可以在连接上运行的初始化 initSQL 也是如此,Tomcat 不会在自己的事务中封装连接测试或 initSQL。
- 连接池应该在 Connection 返回到池时或从池中取出之前,调用
clearWarnings() 方法清除 SQL 警告,然而 TomcatJDBC 也没有这么做。 - JDBC 规范还规定,连接关闭时,所有没有关闭的、已经打开的 Statements 都应该自动关闭,但是默认情况下 Tomcat JDBC 并不会跟踪 Statements,除非手动配置一个 StatementFinalizer 拦截。
- 不幸的是,StatementFinalizer 使用一组 WeakReference 对象跟踪 Statements,当 JVM 受到 GC压力时,在 Tomcat 有机会关闭这些语句之前,可能会对废弃的 Statements 进行垃圾收集,这可能导致资源的泄漏,但是只有在 GC 压力下才会发生,因此可能很难追踪。
BoneCP
在 c3p0 和 DBCP 已经存在的时代,BoneCP 的出现就是为了追求极致,它几乎比下一个最快的连接池选项快 25 倍,而且 BoneCP 从不自旋锁定,因此它不会减慢应用程序速度。
BoneCP 可以说是极致数据库连接池的领军开源项目。它和 HikariCP 也是非常有渊源的,除了 HikariCP 捐赠了 BoneCP 几美金的故事以外,BoneCP 在浪潮之巅功成身退,深藏功与名,将一身衣钵传给了 HikariCP。
BoneCP 的特点如下:
- 具有高可扩展性的快速连接池。
- 在 connection 状态改变时,可配置回调机制(钩式拦截器)。
- 通过分区(Partitioning)来提升性能。
- 允许用户直接访问 connection 或 statement。
- 自动扩展 pool 容量。
- 支持 statement caching。
- 支持异步地获取connection,通过返回一个
Future<Connection> 实现。 - 以异步的方式施放辅助线程,来关闭 connection 和 statement,以获得高性能。
- 在每个新获取的 connection 上,通过简单的机制,执行自定义的 statement。即通过简单的 SQL 语句来测试 connection 是否有效,对应的配置属性为 initSQL。
- 支持运行时切换数据库,而不需要停止应用。
- 能够自动地回放任何失败的事务(如数据库或网络出现故障等)。
- 支持JMX。
- 可以延迟初始化(lazy initialization)。
- 支持使用 XML 或 property 文件的配置方式。
- 支持 idle connection timeouts 和 max connection age。
- 自动检验 connection 是否活跃等等。
- 允许直接从数据库获取连接,而不通过 Driver。
- 支持 Datasouce 和 Hibernate。
- 支持通过 debugging hooks 来定位获取后未关闭的 connection。
- 支持通过 debugging 来显示被关闭了两次的 connection 的堆栈轨迹(stack locations)。
- 支持自定义 pool name。
- 代码整洁有序。
- 免费,开源,纯 Java 编写,具有完整的文档。
BoneCP 最大的一个问题是无法在 getConnection() 的时候配置数据库连接池来测试连接。然而其他每个数据库连接池大多都可以这样配置。它这样做是为了提升速度,但却牺牲了可靠性。
- 在默认配置方面,BoneCP 也不会在 Connection 返回到池时或从池中取出之前通过
Connection.clearWarnings() 方法清除 SQL 警告; - 默认情况下也不会关闭废弃的、已经打开的 statements;
- 也不会在自己的事务中封装连接测试或 initSQL。
Druid
主要功能:
- 替换 DBCP 和 c3p0。Druid 提供了一个高效、功能强大、扩展性好的数据库连接池。
- 可以监控数据库访问性能。Druid 内置了一个功能强大的 StatFilter 插件,能够详细统计 SQL 的执行性能,这有助于对线上数据库访问性能进行分析。
- 数据库加密。直接把数据库密码写在配置文件中是不好的行为,容易导致安全问题。DruidDruiver 和 DruidDataSource 都支持 PasswordCallback。
- SQL 执行日志。Druid 提供了不同的 LogFilter,能够支持 Common-Logging、Log4j 和 JdkLog,用户可以按需要选择相应的 LogFilter,监控自己的应用的数据库访问情况。
- 扩展 JDBC。如果用户对 JDBC 层有编程的需求,可以通过 Druid 提供的 Filter 机制,很方便地编写 JDBC 层的扩展插件。
Druid 在监控、可扩展性、稳定性和性能方面都有明显的优势:
- 强大的监控特性,通过 Druid 提供的监控功能,可以清楚地知道连接池和 SQL 的工作情况。
- 监控 SQL 的执行时间、ResultSet 持有时间、返回行数、更新行数、错误次数、错误堆栈信息。
- SQ L执行的耗时区间分布。什么是耗时区间分布?比如,某个 SQL 执行了 1000 次,其中在 0~1 毫秒区间50次…
- 监控连接池的物理连接创建和销毁次数、逻辑连接的申请和关闭次数、非空等待次数、PSCache 命中率等。
- 方便扩展。Druid 提供了 Filter-Chain 模式的扩展 API,可以自己编写 Filter 拦截 JDBC 中的任何方法。
- Druid 集合了开源和商业数据库连接池的优秀特性,并结合阿里巴巴公司大规模苛刻生产环境的使用经验进行了优化。
- 性能不是 Druid 的设计目标,但是测试数据表明,Druid 性能比 DBCP、c3p0、Proxool、JBoss 都好。
功能对比
- LRU。LRU 是一个性能关键指标,特别是 Oracle,其中每个 Connection 对应数据库端的一个进程,如果数据库连接池遵从 LRU,有助于数据库服务器优化,这是重要的指标。
- PSCache。PSCache 是数据库连接池的关键指标。在 Oracle 中,类似 SELECT NAME FROM USER WHERE ID =?这样的 SQL,启用 PSCache 和不启用 PSCache 的性能可能会相差一个数量级。
- PSCache-Oracle-Optimized。在 Oracle 10 系列的 Driver 中,如果开启 PSCache,会占用大量的内存,必须做特别的处理,启用内部的 EnterImplicitCache 等方法优化才能够减少内存的占用。
- ExceptionSorter。ExceptionSorter 是一个很重要的容错特性,如果一个连接产生了一个不可恢复的错误,必须立刻将其从连接池中去掉,否则会连续产生大量错误。
中断测试
将数据库连接池执行 getConnection() 在5秒的调用后超时,应用程序应在指定时间内获得连接,或获得异常。
5.3 - 配置参数
时间校准
HikariCP 在很大程度上依赖于精确的高分辨率的定时器来提高性能和可靠性,所以使用数据库连接池 HikariCP 的应用服务器最好能够与时间源做同步,比如 NTP 服务器,否则由于 HikariCP 源码对于时间的处理可能会导致一些问题。
不稳定的时间影响的不仅仅是数据库连接池,任何定时等待、并发集合的定时轮询、带有超时的 Object.wait()、Thread.sleep() 调用等,以及任何 Java 中需要测量时间的功能都会受到影响。
必要配置
dataSourceClassName
dataSourceClassName 和 jdbcUrl 是两种数据源的配置方式。
HikariCP 更加建议使用 dataSourceClassName,当然,两者都可以接受。需要注意的是,如果是 Spring Boot 自动装配的用户,需要使用 jdbcUrl 的基于配置的方式;当前已知的 MySQL DataSource 并不支持网络超时,建议改用 jdbcUrl 的方式。
jdbcUrl
表示 HikariCP 使用传统的、基于驱动管理器 DriverManager 的配置。虽然 HikariCP 作者认为两种配置方式中,基于 dataSourceClassName 的配置由于各种原因而更优越,但对于许多部署而言,几乎没有显著差异。
将此属性与“旧”驱动程序一起使用时,可能还需要设置 driverClassName 属性,但首先尝试不使用该属性。如果使用此属性,用户仍可以使用 DataSource 属性来配置驱动程序,实际上建议使用 URL 本身中指定的驱动程序参数。
username & password
username 和 password 分别表示从基础驱动程序获取 Connections 时使用的默认身份验证用户名和密码。
HikariCP 会将 username 属性和 password 属性分别配置在 Properties 文件中,从而传递给驱动 Driver 的 DriverManager.getConnection(jdbcUrl, props) 调用。
非必要配置
autoCommit
此属性控制从池返回的连接的默认自动提交行为。它是一个布尔值。默认值:true。
connectionTimeout
此属性控制客户端(即用户的程序)等待池中连接的最长毫秒数。如果在没有连接可用的情况下超过此时间,则将抛出 SQLException 异常。最低可接受的连接超时为250毫秒。默认值:30000(30秒)。这是一个很重要的问题排查指标。
idleTimeout
此属性控制连接允许被闲置在池中的最大时间。此设置仅适用于 minimumIdle 定义为比 maximumPoolSize 小的时候。一旦池到达 minimumIdle 连接的时候,空闲连接将不会退役。连接是否空闲而退役的最大变化为 +30 秒,平均变化为 +15 秒。在此超时之前,连接永远不会因空闲状态而退役。值为 0 意味着空闲连接永远不会从池中删除即永不超时。minimum 允许的最小值为 10000 毫秒(10秒)。默认值:600000(10分钟)。
许多防火墙和负载均衡器(通常位于应用程序和数据库之间)会占用套接字生存周期。通常,达到 idleTimeout 时,无论当前流量如何,都会切断连接。
HikariCP 设计之初就不支持空闲连接检测 test-while-idle,这是因为数据库管理员 DBA 往往会默认设置数据库最长连接时间是 60 秒,test-while-idle 会对数据库产生不必要的查询,这样就有可能导致数据库空闲连接出现超时的问题。
旧版本中,maxLifetime 由管家线程 HouseKeeper 强制执行,每 30 秒执行一次,因为 wait_timeout 减去 30 秒是推荐的 maxLifetime。但是最新版本的 HikariCP 对每个连接 connection 进行专用计时器任务,提供了几十毫秒(在高负载下长达几秒)的时间间隔,此时 maxLifetime 被安全地设置为 wait_timeout 减去5秒。如果连接退出,后台线程会执行添加操作,创建新的连接大约是 5 毫秒。如果 maxLifetime 是60秒,那么 idleTimeout 可以被设置为 0,显得就并不那么重要。
maxLifetime
此属性控制池中连接的最大生命周期。使用中的连接永远不会退役,除非它被关闭然后移除。在逐个连接的基础上,应用轻微的负衰减可以避免池中的大量消亡(在源码解析部分会深入分析)。HikariCP 作者强烈建议用户设置此值,并且它应比任何数据库或基础设施实施的连接时间限制短几秒。值为 0 表示没有最大生存期(无限生存期),当然这取决于 idleTimeout 设置。默认值:1800000(30分钟)。
30 分钟的默认超时是非常合理的,很多开发人员都会发现,在应用程序与很多数据库之间,会有高可用代理、负载均衡、防火墙等,通常这些组件会自动且独立地终止连接 30 分钟左右。
一般来说,可以将 maxLifetime 设置缩短到 900000 毫秒(15分钟)然而更好的方法是,确定 MySQL 配置的 wait_timeout 值是什么,并将 HikariCP 设置为比 maxLifetime 短几分钟。
connectionTestQuery
如果您的驱动程序支持 JDBC4,我们强烈建议不要设置此属性。这适用于不支持 JDBC4 的 Connection.isValid() 的“遗留”驱动程序 API。这是一个检测查询,在数据库连接池给出连接之前进行查询,以验证与数据库的连接是否仍然存在且有效。
如果你追求极致性能的话,建议不要配置该属性,因为不配置的时候会通过 ping 命令进行连接检测,性能会更高。
minimumIdle
此属性控制 HikariCP 尝试在池中维护的最小空闲连接数。若空闲连接低于此值且池中的总连接数小于 maximumPoolSize,则 HikariCP 将尽最大努力快速有效地添加其他连接。
然而,为了最大限度地提高性能和对峰值需求的响应能力,HikariCP 作者建议不要设置此值,而是允许 HikariCP 充当一个固定大小的连接池(如果 minimumIdle 未设置则默认为是 maximumPoolSize,因此即使 idleTimeout 设置为 1 分钟,一旦连接关闭,它将在池中被替换)。
如果设置这个值,那么 HikariCP 就会是一个大小可变的池,通过 minimumIdle 进行调解控制,即使使用情况上下浮动,HikariCP 也会保持 minimumIdle 连接可用。默认值:与 maximumPoolSize 相同。
minimumIdle 应始终小于或等于 maximumPoolSize。如果 minimumIdle 设置为更高的值,它将推高 maximumPoolSize 到相等的值。minimumIdle 逻辑上不能超过 maximumPoolSize,因为 maximumPoolSize 指定了后端数据库的实际连接的最大数量。
如果有比 minimumIdle 的数目更多的连接数,如果一个连接退役了,它不会被自动替换。但是如果数据库连接池被配置为固定大小的,或者连接关闭后如果空闲连接小于 minimumIdle 的数量,那么就会立即自动替换连接。
启用 HikariCP 的 metrics 采集,在可视化界面上可直观地显示连接的直方图,便于用户研究并确定正确的、合理的 minimumIdle 及 idleTimeout 等值。数据库连接池的调优最好基于经验数据,具体问题具体分析。
maximumPoolSize
此属性控制允许数据库连接池到达的最大大小,包括空闲和正在使用的连接。基本上,此值将确定到数据库后端的实际连接的最大数量。合理值最好由用户的执行环境决定。当池达到此大小且没有空闲连接可用时,对 getConnection() 的调用将阻塞到超时前 connectionTimeout 毫秒。关于连接池大小 PoolSize 的相关知识请关注本章后续内容。默认值:10。
metricRegistry
此属性仅通过编程配置或 IoC 容器可用。此属性允许用户指定池使用的 Codahale /Dropwizard 实例 MetricRegistry,来记录各种度量标准。如果用户需要使用 Prometheus 等监控的话,还需要做一些操作。
healthCheckRegistry
此属性仅通过编程配置或 IoC 容器可用。此属性允许用户指定池使用的 Codahale /Dropwizard 实例 HealthCheckRegistry,来报告当前系统的健康信息。默认值:无。
poolName
此属性表示连接池的用户定义名称,主要显示在日志记录和JMX管理控制台中,以标识池和池配置。默认值:自动生成。
非常用配置
initializationFailTimeout
如果池无法成功初始化连接,则此属性控制池是否“快速失败”。任何正数都被认为是尝试获取初始连接的毫秒数;在此期间,应用程序线程将被阻塞。如果在超时发生之前无法获取连接,则将引发异常。initializationFailTimeout超时发生在connectionTimeout阶段之后。如果值为0, HikariCP将尝试获取并验证连接。如果获得连接但验证失败,则抛出异常,而不会启动池。但是,如果无法获得连接,则池将启动,但稍后获取连接的尝试会失败。小于0的值将绕过任何初始连接尝试,并且池将在尝试在后台获取连接时立即启动。因此,以后获得连接的尝试可能会失败。默认值:1。
isolatelnternalQueries
此属性决定HikariCP是否在自己的事务中隔离内部池查询,例如连接存活测试。由于这些通常是只读查询,因此很少有必要将它们封装在自己的事务中。此属性仅在autoCommit禁用时适用。默认值:false。
allowPoolSuspension
此属性控制池是否可以通过JMX挂起和恢复。这对某些故障转移自动化方案很有用。当池被挂起时,调用getConnection()将不会超时,并将一直保持到池恢复为止。默认值:false。
readOnly
此属性控制默认情况下从池中获取的Connections是否处于只读模式。请注意,某些数据库不支持只读模式的概念,而其他数据库在Connection设置为只读时提供查询优化。是否需要此属性将在很大程度上取决于那的应用程序和数据库。默认值:false。
registerMbeans
此属性控制是否注册JMX管理Bean(“MBean”)。默认值:false。
catalog
此属性为支持catalog的数据库设置默认catalog。如果未指定此属性,则使用JDBC驱动程序定义的默认catalog。默认值:driver default。
connectionlnitSql
此属性设置一个SQL语句,该语句将在每次创建新连接之后执行,然后再将该连接添加到池中。如果此SQL无效或抛出异常,它将被视为连接失败,并将遵循标准重试逻辑。默认值:无。
driverClassName
HikariCP将尝试仅基于jdbcUrl通过DriverManager解析驱动程序,但对于某些较旧的驱动程序必须指定driverClassName。除非用户收到明显的错误消息,表明未找到驱动程序,否则可忽略此属性。默认值:无。
transactionlsolation
此属性控制从池返回的连接的默认事务隔离级别。若未指定,则用JDBC驱动程序定义的默认事务隔离级别。仅当有针对所有查询的特定隔离需求时,才使用此属性。此属性的值是Connection类的常量名,如TRANSACTION_READ_COMMITTED、TRANSACTION_REPEATABLE_READ等。默认值:driverdefault。
validationTimeout
此属性控制连接测试活性的最长时间。该值必须小于connectionTimeout。最低可接受的验证超时为250毫秒。默认值:5000。
leakDetectionThreshold
此属性控制连接在记录一条指示可能连接泄漏的消息之前流出池的时间。值为0表示禁用泄漏检测。启用泄漏检测的最低可接受值是2000(2秒)。默认值:0。
dataSource
此属性仅可通过编程配置或IoC容器获得。此属性允许用户直接设置DataSource要由池包装的实例,而不是让HikariCP通过反射构造它。这在一些依赖注入框架中很有用。指定此属性后,dataSourceClassName将忽略该属性和所有特定于DataSource的属性。默认值:无。
schema
该属性为支持schema概念数据库设置默认schema。如果未指定此属性,则使用JDBC驱动程序定义的默认模式。默认值:driver default。
threadFactory
此属性仅可通过编程配置或IoC容器获得。此属性允许设置java.util.concurrent. ThreadFactory将用于创建池使用的所有线程的实例。在注入线程只能通过应用程序容器提供的ThreadFactory创建的某些受限执行环境中使用它。默认值:无。
scheduledExecutor
仅可通过编程配置或IoC容器获得。允许设置java.util.concurrent.Scheduled-ExecutorService用于各种内部调度任务的实例。如果向HikariCP提供ScheduledThread-PoolExecutor实例,建议设置setRemoveOnCancelPolicy(true)。默认值:无。
容量设置
公式
拥有一个CPU内核的计算机可以同时执行数十或数百个线程,其实这只是操作系统的一个time-slicing(时间切片)的把戏。实际上,单核只能一次执行一个线程,然后由操作系统切换上下文,并且内核为另一个线程执行代码,依此类推。这是一个基本的计算法则,给定一个CPU资源,按顺序执行A和B总是比通过时间片“同时”执行A和B要快。一旦线程数量超过了CPU核心的数量,添加更多的线程速度就会变慢,而不是更快。
设计多线程是为了尽可能地利用CPU空闲等待时间(及IO、交互等),它的代价就是要增加部分CPU时间来实现线程切换。如果CPU空闲等待时间已经比线程切换更短(线程越多,切换消耗越大),那么线程切换会非常影响性能,成为系统瓶颈。
当我们查看数据库的主要瓶颈是什么时,它们可以归纳为3个基本类别:CPU、磁盘、网络。
可以在PostgreSQL基准测试中看到,TPS速率开始在大约50个连接处变平:
下面的公式也是由PostgreSQL项目提供的,它同样在很大程度上适用于数据库。实际生产中,用户测试应用程序,即模拟预期的负载,并在此起点周围尝试不同的池设置。
connections =((core_count×2)+ effective_spindle_count)
effective_spindle_count 就是磁盘列阵中的硬盘数。某PostgreSQL项目做过测试,拥有一个硬盘的小型4核i7服务器的连接池大小设置为:9 = ((4×2) + 1)。这样的连接池大小居然可以轻松处理3000个前端用户在6000 TPS下进行简单查询。这里的线程数指的是数据库进程中的线程,通常通过连接调度的查询将在数据库的单个线程上执行,连接和线程在大多数情况下几乎都是一对一的关系。
在公式的配置上,如果加大压力,TPS会下降,RT会上升,可以适当地根据情况进行调整加大。这时应考虑整体系统性能,同时考虑线程执行需要的等待时间,合理地设计线程数目。但是,不要过度配置你的数据库。如果一直给HikariCP增加压力,那么性能也可能会产生急剧的下降。
- 如果查询是5毫秒,则通过单个连接每秒可以处理大约200个查询。
- 如果查询是100毫秒,单个连接每秒可以处理大约10个查询。
- 对数据库而言,5台Server各自拥有一个连接和每台Server拥有5个连接几乎相同。
- 如果有慢查询和快速查询的混合,由于慢查询会锁定数据库连接池,建议长时间运行的查询使用单独的数据库连接池。
数据库连接池的大小设置针对的是单个组件、应用程序和单个数据库。在多个微服务同时访问单个共享数据库的时候,情况就会变得比较棘手,这时就需要提炼出一些应对它的方法。对于单个应用程序来说,如果同时运行任何超过10个查询会产生较低的吞吐量和较高的延迟,如果平均查询时间是2ms,那么在2ms的时间内可以满足10个查询。如果我们允许20个查询(HikariCP数据库连接池的大小为20),则在2ms内无法满足同时运行20个查询,并且由于调度程序的时间分片开销,实际上可能超过2倍。如果微服务A和微服务B同时对该数据库进行查询,并持续生成连续负载,按照10个查询的稳定性大小,服务A和服务B分别设置数据库连接池大小为5是有意义的。对于生成连续负载的N服务,最大池大小的公式很简单:(最大同时数据库查询)/ N。
但是服务A和服务B之间还有一些突发性,比如A或者B一段时间内爆发大量查询,一段时间内相对空闲,这时候最大数据库连接池大小设为5~10会比较好。微服务越多,这个就越复杂。度量标准Metrics是进行数据库连接池大小评估的很有效的工具。首先,根据对其需求的最佳预测,为每个微服务选择一个池大小,而不考虑其他服务,并收集每项服务的指标:Active connections(活动连接)、Idle connections(空闲连接)、Waiting threadcount(等待线程数)、Usage(每个连接离开池多长时间)。然后,根据这些指标找到峰值并尝试确定原因,进行分类对比,并确定总活动超过数据库容量和CPU的点是否与峰值对应。最后,通过不断重复这些过程,根据收集的指标慢慢进行匹配对比,观察分析,从而找到数据库连接池最合适的大小。
池锁
池锁代表数据库连接池由于由于竞争资源或者由于彼此通信而造成的一种阻塞的现象。
很多实际使用数据库连接池的用户在开发过程中或多或少遇到过池锁的问题。增大连接池大小可以缓解池锁问题,但是扩大池之前可以先检查一下应用层面是否能够调优,而不要直接调整连接池大小。
避免池锁有一个简单的资源分配公式:
pool size = Tn x (Cm -1) + 1
Tn 是线程的最大数量,Cm 是单个线程持有的同时连接的最大数量。例如,有3个线程(Tn = 3),每个线程需要4个连接来执行某个任务(Cm = 4)。确保永不死锁的池大小是: 3 x(4-1)+ 1 = 10。
如果有10个线程(Tn = 10),每个线程需要2个连接(Cm =2)来执行某个任务,确保永不出现死锁所需的池大小是:10x(2-1)+ 1 = 11。
再比如,最多有8个线程(Tn = 8),每个线程需要3个连接来执行一些任务(Cm =3)。确保永远不可能死锁的池大小是: 8×(3-1)+ 1 = 17注意,这不一定是最佳池大小,但是是避免死锁所需的最低限度,也就是最小的池大小。
在某些环境中,使用JTA(Java事务管理器)可以显著减少从同一个Connection返回getConnection()到当前事务中已经存储Connection的线程所需的连接数。
建议
混合了长时间运行事务和非常短的事务的系统通常是最难调整任何连接池的系统。在这些情况下,创建两个池实例可以很好地工作(例如,一个用于长时间运行的事务,另一个用于“实时”查询)。
对于长期运行的外部系统,例如只允许一定数量的作业同时运行的作业执行队列,这时作业队列大小就是连接池非常合适的大小。
总结如下:连接池是综合每个应用系统的业务逻辑特性,加上应用硬件配置,加上应用部署数量,再加上DB硬件配置和最大允许连接数等测试出来的,很难用一个公式简单进行计算。连接数及超时时间设置不正确经常会带来较大的性能问题,并影响整个服务能力的稳定性。具体设置多少,要看系统的访问量,可通过反复测试,找到最佳点。压测很重要。
Fixed Pool Design
基于大量实践得到的经验值:
maximumPoolSize: 20
minimumIdle: 10
HikariCP的初始版本只支持固定大小的池。作者初衷是,HikariCP是专门为具有相当恒定负载的系统而设计的,并且倾向于连接池大小保持其运行时允许达到的最大大小,所以作者认为没有必要将代码复杂化以支持动态调整大小。
如果想要支持动态调整不同负载的最佳池大小设置,可以配合Hikari使用同为the Mutual Admiration Society成员的VladMihalcea研究的FlexyPool。当然,连接池上限受到数据库最优并发查询容量的限制,这正是HikariCP关于池大小起作用的地方。然而,在池的最小值和最大值之间,FlexyPool不断尝试递增,确保该池大小在提供服务的过程中动态负载一直是正确的。
FlexyPool具有以下默认策略:
- 在超时时递增池。此策略将增加连接获取超时时的目标连接池最大大小。连接池具有最小的大小,并可根据需要增长到最大大小。该溢出是多余的连接,让连接池增长超过其初始的缓冲区最大尺寸。每当检测到连接获取超时时,如果池未增长到其最大溢出大小,则当前请求不会失败。
- 重试尝试。此策略对于那些缺少连接获取重试机制的连接池非常有用。
核心逻辑
minIdle来指定空闲连接的最小数量,maxPoolSize指定连接池连接最大值,默认初始化的时候,是初始化minIdle大小的连接,如果minIdle与maxPool-Size值相等,那就是初始化时把连接池填满。idleTimeout用来指定空闲连接的时长,maxLifetime用来指定所有连接的时长。com.zaxxer.hikari.housekeeping.periodMs用来指定连接池空闲连接处理及连接池数补充的HouseKeeper任务的调度时间间隔。所有的连接在maxLifetime之后都得重连一次,以保证连接池的活性。
MySQL 配置
MySQL 的主要性能配置参数是:
- prepStmtCacheSize:这将设置MySQL驱动程序将为每个连接缓存的预准备语句数。默认值为保守25。我们建议将其设置为250~500。
- prepStmtCacheSqlLimit:这是驱动程序将缓存的已准备SQL语句的最大长度。MySQL的默认值是256。根据我们的经验,特别是对于像Hibernate这样的ORM框架,这个默认值远低于生成的语句长度的阈值。我们推荐的设置是2048。
- cachePrepStmts:如果事实上禁用了高速缓存,则上述任何参数都不会产生任何影响,因为它是默认情况下。必须将此参数设置为true。
- useServerPrepStmts:较新版本的MySQL支持服务器端预处理语句,这可以提供显著的性能提升。应将此属性设置为true。
HikariCP 的典型 MySQL 配置如下:
jdbcUrl=jdbc:mysql://localhost:3306/simpsons
user=test
password=test
dataSource.cachePrepStmts=true
dataSource.prepStmtCacheSize=250
dataSource.prepStmtCacheSqlLimit=2048
dataSource.useServerPrepStmts=true
dataSource.useLocalSessionState=true
dataSource.rewriteBatchedStatements=true
dataSource.cacheResultSetMetadata=true
dataSource.cacheServerConfiguration=true
dataSource.elideSetAutoCommits=true
dataSource.maintainTimeStats=false
5.4 - JDBC API
HikariCP JDBC Logging
HikariCP 目前并不包含 JDBC 的日志记录。因为作者认为日志记录是性能杀手,甚至检查是否启用或禁用日志记录的布尔值对 HikariCP 来说也是多余的开销,几乎每个驱动程序都支持某种类型的日志记录,并且 ORM 框架也不可避免这样去做。
对于驱动程序不支持 JDBC 直接记录,或者希望此解决方案的灵活性优于数据库供应商的产品,log4jdbc-log4j2 是一个不错的选择。
另外还有 P6spy,它似乎略微比 log4jdbc-log4j2 更易于维护。
JDBC
在 Vlad Mihalcea 的 “High-Performance JavaPersistence” 一书中给出了一张数据访问技术栈的图片,如图所示。我们可以看到 JDBC 在整个数据访问技术栈中起着非常重要的作用。
JDBC 代表 Java 数据库连接,是基于 Java 开发的系统中程序员和数据库打交道的主要途径,提供了完备的数据库操作方法接口。
JDBC 定义
JDBC,Java DataBase Connectivity。
JDBC API 是一个 Java API,可以访问任何类型表列数据,特别是存储在关系数据库中的数据。
JDBC API 由一组用 Java 编写的类和接口组成。为工具/数据库开发人员提供标准 API 的编程语言,可以使用全 Java API 编写工业级数据库应用程序。JDBC API 可以轻松地将 SQL 语句发送到关系数据库系统,并支持所有 SQL 方言。但是 JDBC 2.0 API 超越了 SQL,也使得与其他类型的数据源(例如包含表格数据的文件)进行交互成为可能。
JDBC API 的价值在于,应用程序几乎可以访问任何数据源,并可以在任何具有 Java 虚拟机的平台上运行。换句话说,使用 JDBC API,不必编写一个程序来访问 Sybase 数据库,另一个程序访问 Oracle 数据库,另一个程序访问 IBM DB2 数据库,等等。
JDBC API 是 Java 编程语言与各种数据库之间数据库无关连接的行业标准。JDBC API 为基于 SQL 的数据库访问提供了调用级 API。JDBC 技术允许您使用 Java 编程语言为需要访问企业数据的应用程序提供“一次编写,随处运行”功能。
JDBC API 是一种执行 SQL 语句的 API, JDBC 驱动才是真正的接口实现,所有的网络逻辑和特定于数据库的通信协议都隐藏于、独立于供应商的 JDBC API 后面。Sun 公司只是提供了JDBC API,每个数据库厂商都有自己的驱动来连接自己公司的数据库,如图所示。
我们可以看到,JDBC API 采用了桥接的设计模式,提供了两套接口,JDBC Driver Planager 面向数据库厂商,如Oracle、SQL Seruer 等;JDBC API 面向 JDBC 使用者,如 Java Application。
JDBC 接口相当于实现化角色接口,数据库厂商实现的驱动相当于具体实现化子类,应用程序相当于抽象化角色,内部持有一个实现化角色的对象。桥接模式将实现化和抽象化解耦,从而让两个部分可以沿着不同的方向拓展,只要遵循接口即可,从而学习成本低。
JDBC 连接数据库时,在各个数据库之间进行切换,基本上不需要动太多的代码,甚至丝毫不动,原因就是 JDBC 提供了统一接口,每个数据库提供各自的实现,用一个叫作数据库驱动的程序来桥接就行了。
JDBC 定义了 4 种驱动类型:JDBC-ODBC 桥、本地 API 驱动、网络协议驱动、本地协议驱动。由于易于设置和调试,第 4 种类型本地协议驱动纯粹基于 Java 的多驱动程序,通过 Socket 连接与厂商的数据库进行通信,是首选的方案。
通过 DriverManager 获取连接:
通过 DataSource 获取连接:
由于减少了创建和关闭连接的开销,HikariCP 等数据库连接池的出现又将 JDBC 的性能大大提升了一个档次。使用数据库连接池作为 JDBC 的最佳实践已经几乎成了公认的标准。
除此之外,JDBC 的最佳实践还有如下内容:
- 使用 PrearedStatement,通过预编译的方式避免在拼接SQL时造成SQL注入,使用“? ”或其他占位符等变量绑定的形式可以使用不同的参数执行相同的查询也能防止 SQL 注入。
- 禁用自动提交,这样可以将数据库操作放在一个事务中,而不是每次执行 SQL 语句都在执行结束时提交自己独立的事务。
- JDBC 批处理可以降低数据库传输频率,进而提升性能。
- 使用列名而不是列序号获取 ResultSet 中的数据,避免 invalidColumIndexError,从而提升程序的健壮性、可读性。
- 在 Java 7 中,可以通过 Automatic ResourceManagement Block 来自动关闭资源。要记得关闭所有的Connection、Statement 等资源。
- 使用标准的 SQL 语句(如标准的ANSI SQL),避免数据库对 SQL 支持的差异。
JDBC 剖析
JDK 规定了 JDBC 的相关接口,JDBC 是 SPI(服务提供者接口) 框架的良好应用。JDBC API 主要位于 JDK 中的 java.sql 包中,扩展的内容位于 javax.sql 包中。
java.sql.* 采用传统的 C/S 体系结构思想设计它所包含的接口和类,核心类图如图所示。
它包含生成连接、执行语句等功能,包括一些诸如批处理更新、可滚动结果集、事务隔离、封装 SQLException 等功能。java.sql.* 属于 JDBC2.0 之前,通常被称为 JDBC 内核 API; javax.sql.* 包括了 JDBC 3.0 的很多新特性,被称为 JDBC 标准扩展。
javax.sql.* 作为标准扩展,提供了很多对java.sql.*的补充和新特性。体现在 Datasource 接口提供了一种可选择性的方式去建立连接,分布式事务处理,增加 rowset,增加连接池等。
了解 JDBC,关注点更多的还是 java.sql.* 包,在这个包里,有 4 个核心接口(Driver、Connection、Statement和ResultSet)和两个核心类(DriverManager和SQLException)。类型的对象。它还提取与使用 Driver 对象相关的信息。不同的数据库有不同的装载方法。
- DriverManager:管理一组数据库驱动程序的基本服务。使用通信子协议将来自 Java 应用程序的连接请求与适当的数据库驱动程序进行匹配。在 JDBC 下识别某个子协议的第一个驱动程序将用于建立数据库连接。其初始化时用到 ServiceLoader 机制,所以可以直接用 Class.forName(driver);就可以完成加载驱动。在 DriverManager 里面,有一个 ArrayList,专门用来保存注册好的 Driver,并使用了 CopyOnWriteArrayList 来保证多线程环境下的线程安全。
- Driver:此接口处理与特定数据库服务器的通信,是每个数据库驱动都必须继承的接口。我们很少会直接与 Driver 对象进行交互。但会使用 DriverManager 对象来管理。
- Connection:此接口具有用于链接数据库的所有方法。连接(Connection)对象表示通信上下文,即,与数据库的所有通信仅通过连接对象。拥有创建 SQL 语句的方法,以完成基本的 SQL 操作,同时为数据库事务提供提交和回滚方法。
createStatement():创建向数据库发送 SQL 的 statement 对象。prepareStatement(sql):创建向数据库发送预编译 SQL 的 PrepareSatement 对象。prepareCall(sql):创建执行存储过程的 callableStatement 对象。setAutoCommit(boolean autoCommit):设置事务是否自动提交。commit():在连接上提交事务。rollback():在此连接上回滚事务。
- Statement:使用从此接口创建的对象将 SQL 语句提交到数据库。除了执行存储过程之外,一些派生接口还接受参数。它由 createStatement 创建,用于发送简单的 SQL 语句(不带参数)。除此以外,还有两种Statement:PreparedStatement 和 CallableStatement,如图上图所示.CallableStatement 继承自 PreparedStatement,PreparedStatement 继承自 Statement。
- PreparedStatement:PreparedStatement 接口扩展了 Statement 接口,它添加了比 Statement 对象更好一些的功能。此语句由 preparedStatement 创建,可以动态地提供/接受参数,进行 SQL 语句的预编译,也可以动态拼接。因为会进行预编译,所以当用动态拼接的时候,会对传入的参数进行强制转换,所以会对参数进行校验,可以避免 SQL 注入。开发的时候尽量用 preparedStatement,少用 statement。PreparedStatement 对象有能力使用提供参数数据的输入和输出流。它可以将整个文件输入数据库中,可容纳较大的值,如 CLOB 和 BLOB 数据类型的列。对于 PreparedStatement,会有一个 LRUCache 来存放,先到那里去取,取不到再创建一个新的,这个 LRUCache 的默认大小是 25。
- CallableStatement:由方法 prepareCall 创建,为所有的 DBMS 提供了一种以标准形式调用数据库储存过程的方法。
- 常用方法:
execute(String sql):运行语句,返回是否有结果集。executeQuery(String sql):运行 select 语句,返回 ResultSet 结果集。executeUpdate(String sql):运行 insert/update/delete 操作,返回更新的行数。addBatch(String sql):把多条 SQL 语句放到一个批处理中。executeBatch():向数据库发送一批 SQL 语句执行。
- ResultSet:在使用 Statement 对象执行 SQL 查询后,这些对象保存从数据库检索到的数据。它作为一个迭代器并可移动 ResultSet 对象查询的数据。但是结果集并不仅仅具有存储的功能,它同时还具有操纵数据的功能,可能完成对数据的更新等。
getString(int index)、getString(StringcolumnName):获得数据库里 varchar、char 等类型的数据对象。getFloat(int index)、getFloat(StringcolumnName):获得数据库里 Float 类型的数据对象。getDate(int index)、getDate(StringcolumnName):获得数据库里 Date 类型的数据。getBoolean(int index)、getBoolean(StringcolumnName):获得数据库里 Boolean 类型的数据。getObject(int index)、getObject(StringcolumnName):获取数据库里任意类型的数据。next():移动到下一行。previous():移动到前一行。absolute(int row):移动到指定行。beforeFirst():移动到 ResultSet 的最前面。afterLast():移动到 ResultSet 的最后面。
- SQLException:此类处理数据库应用程序中发生的任何错误。
需要强调的是,Connection、Statement 和 Result 是一种“爷—父—子”的关系,对 Connection 的管理,就是对数据库资源的管理。如果想确定某个数据库连接(Connection)是否超时,则需要确定其(所有的)子 Statement 是否超时,同样,需要确定所有相关的 ResultSet 是否超时;Statement 关闭会导致 ResultSet 关闭,但是 Connection 关闭却不一定会导致 Statement 关闭。
在数据库连接池里,Connection 关闭并不是物理关闭,只是归还连接池,所以 Statement 和 ResultSet 有可能被持有,并且实际占用相关的数据库的游标资源。所以在关闭 Connection 前,需要关闭所有相关的 Statement 和 ResultSet。这就是 HikariCP 作者所强调的 JDBC 的最基本的规范,也是他创造 HikariCP 的原因,数据库连接池一定不能违背这样的规则。
最好方案就是顺序关闭 ResultSet、Statement、Connection;在 rs.close() 和 stmt.close() 后面加上 rs= null 和 stmt = null 来防止内存泄漏;RowSet 不依赖于 Connection 和 Statement 可以作为一种传递 ResultSet 的替代方案。
通过 DriverManger 获得 Connection,一个 Connection 对应一个实际的物理连接,每次操作都需要打开物理连接,使用完后立即关闭;这样频繁地打开/关闭连接会造成不必要的数据库系统性能消耗。
这样的背景下催生了数据库连接池的产生,数据库连接池提供的解决方案是:当应用启动时,主动建立足够多的数据库连接,并将这些连接组织成连接池,每次请求连接时,无须重新打开连接,而是从池中取出已有连接,使用完后并不实际关闭连接,而是将其归还给池。
所以这里需要涉及两项技术,一是连接使用 List 之类的集合进行初始化、装载和归还,二是使用动态代理来把资源归回给 List 集合。
而HikariCP之所以这么快,也主要是将这两项技术做到了极致。
JDBC 数据库连接池使用 javax.sql.DataSource 表示,DataSource 只是一个接口,其实现通常由服务器提供商(如WebLogic、WebShere)或开源组织(如 DBCP、c3p0 和 HikariCP)提供。
PreparedStatement & Statement
PreparedStatement 在企业开发中被强烈推荐使用,原因主要有以下方面:
Statement 会频繁编译 SQL。如果 JDBC 驱动支持的话(一般来说数据库系统库系统初次分析、编译时会对查询语句做最大的性能优化), PreparedStatement 可对 SQL 进行预编译,提高效率,预编译的 SQL 存储在 PreparedStatement 对象中。从这个意义上来说,PreparedStatement 比 Statement 更快,使用 PreparedStatement 也可以降低生产环境的数据库负载。
Statement 对象编译 SQL 语句时,如果 SQL 语句有变量,就需要使用分隔符来隔开,如果变量非常多,就会使 SQL 变得非常复杂。PreparedStatement 可以使用占位符,通过动态参数化的查询来简化 SQL 的编写。比如下面这个参数化查询例子,通过使用相同的 SQL 语句和不同的参数值来做查询,比创建一个不同的查询语句要好。
SELECT telephone_number FROM city WHERE username =?
PreparedStatement 可防止 SQL 注入。因为 Statement 对象需要拼接,通过分隔符“++”编写永等式就可以实现 SQL 注入;而 PreparedStatement 使用占位符,就不会有 SQL 注入的问题。
JDBC & SPI
为了实现在模块装配的时候能不在程序里动态指明,需要一种服务发现机制。JDK 内置的 SPI(Service ProviderInterface)就能提供这样的一个机制:为某个接口寻找服务实现的机制。有点类似 IOC 的思想,就是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要。
JDBC 4.0 以前,开发人员还需要基于 Class.forName(“xxx”) 的方式来装载驱动,而 JDBC 4.0 基于 SPI 机制来发现驱动提供商,可以通过 META-INF/services/java.sql.Driver 文件里指定实现类的方式来暴露驱动提供者。开发者只需要编写一行代码,使用不同厂商的 jar 包,就可以轻松创建连接了。
线程池技术
池化技术,包括线程池、连接池、内存池、对象池等,其作用就是提前保存大量的资源,或者将用过的资源保存起来,等下一次需要使用该资源时再取出来重复使用。
线程池和连接池是两个不同的概念,连接池一般在客户端设置,而线程池是在如数据库这样的服务器上配置。通常来说,比较好的方式是将连接池和线程池结合起来使用。线程池具有线程复用、控制最大并发数、管理线程、保护系统4个优点,线程池的目的类似于连接池,通过复用线程来减少频繁创建和销毁线程,从而降低性能损耗。
线程池往往配合队列一起工作,限制并发处理任务的数量,从而保护系统。线程池的工作方式大同小异:先将任务提交到一个或者多个队列中,接着一定数量的线程从该队列中领取任务并执行,任务的结果再做处理,比如保存到MySQL数据库、调用别的服务等;任务完成以后,该线程会返回任务队列,等待下一个任务。
MySQL 线程池
传统方式下,MySQL 线程调度方式有两种:每个连接一个线程(One-Thread-Per-Connection)和所有连接一个线程(no-threads)。
MySQL 线程池是 MySQL 5.6 企业版的一个核心功能,是为了解决 One-Thread-Per-Connection 的实际生产常用选择的问题而引入的,通过有效管理大量客户端连接的语句执行线程数量,减少内存消耗,降低上下文切换(提高CPU Cache命中率)等来提高服务器性能。
在线程池 Thread Pool 处理方案中,最小单位是 statement,一个线程可以处理多个连接的请求,可以避免瞬间连接风暴造成的抖动。MySQL 线程池只在 Percona、MariaDB、Oracle 的 MySQL 企业版中提供,Oracle MySQL 社区版并不提供。MariaDB 在 5.5 版本中引入并最先实现线程池 Thread Pool 方案,Oracle 在 6.10 企业版本以 plugin 插件形式引入,Percona 在移植 MariaDB 的 Thread Pool 方案后又修复了一系列问题并优化了线程池性能。
使用“show variables like ‘thread%’”命令可以看到 thread_handling 的配置,默认情况是 one-thread-per-connection,即不启用线程池;将该参数设置为 pool-of-threads 即启用了线程池。
可以这么说,在 Percona 版本以后,MySQL 支持 No-Threads、One-Thread-Per-Connection 和 Pool-Threads 三种管理方式。Oracle Mysql 官方的性能测试表明:
- 在并发达到 128 个连接以后.没有线程池的 MySQL 性能会迅速降低。使用线程池以后,性能不会出现波动,会一直保持在较好的状态运行。
- 在读写模式下,128 个连接以后,有线程池的 MySQL 比没有线程池的 MySQL 性能高出 60 倍。
- 在只读模式下,512 个连接以后,有线程池的 MySQL 比没有线程池的 MySQL 性能高出 18 倍。
我们可以看到,Thread Pool 极大地提升了性能,并且解决了 One-Thread-Per-Connection 的如下 3 个问题:
- 太多的线程堆栈使 CPU 缓存在高度并行的执行工作负载中几乎无用。线程池促进了线程堆栈重用,以最小化 CPU 缓存占用空间。
- 由于太多线程并行执行,因此上下文切换开销很高。这也给操作系统调度程序带来了挑战性的任务。线程池控制活动线程的数量,以使 MySQL 服务器内的并行性保持在它可以处理的水平,并且适用于 MySQL 正在执行的服务器主机。
- 并行执行的事务太多会增加资源争用。
MySQL 线程池内部
排队理论中存在一个众所周知的关系:尝试访问共享资源的用户越多,响应时间越长,并呈指数级增长。
在吞吐量上,随着用户的不断增多,由于内部通信和同步,系统每秒能够处理的请求就越来越少,甚至会导致系统没有反应并且直接卡死,如图所示。众所周知的 DDoS 攻击就是类似这样的行为。
而 MySQL 线程池在面对上述困难时,旨在提供如图所示的吞吐量曲线。
MySQL 线程池本身并不会神奇地提高性能,但是它可以保护 MySQL 突然过载的情况,打造上图所示的稳定性曲线,这是通过其限制 MySQL 内部的工作线程数量来实现的。
如图下所示,这是 MySQL Thread Pool 的架构图,MySQL 的线程池提出了一个线程组的概念,工作线程被放在了线程组内部。我们可以看到 Thread Pool 由一个 Timer 线程和多个线程组构成,每个线程组内部由优先队列、普通队列两个队列,以及一个 Listener 线程和多个工作线程组成。
- 线程组,在初始化以后会由底层的 IO 库分配到一个特殊的句柄 pollfd,每个线程组都有一个对应的 pollfd。
- Worker 线程,是真正干活的线程,它具有活跃、空闲和等待3种状态。
- Listener 线程,主要用来监听该线程组的语句,通过 pollfd 中轮询 IO 任务来决定是 Listener 线程自身处理这些任务,还是放入队列交给并唤醒多少个 Worker 线程去处理。从这个意义上来说,Listener 线程也是可以转换为 Worker 线程的。所以,线程组中,总线程数等于正在工作且未被阻塞的线程数+工作线程任务的过程中被阻塞的个数+空闲线程的个数 + Listener 线程的个数。
- 任务队列,由普通队列和优先任务队列构成,是 Listene r每次从 pollfd 轮询出来的就绪任务。官方定义将符合连接处于事务中和连接关联的 priority tickets 值大于 0 两种情况认为是优先队列。所以可以这么认为,如果同一个事务中有两个 insert的SQL,有 1 个已经执行,那么另一个 insert0 任务就会放在高优先级中。如果是非事务引擎,或者开启了 autocommit 的事务引擎,都会放到普通队列中。还有一种情况是如果语句在普通队列中停留太久,该语句也会移到优先队列中,防止它饿死,thread_pool_prio_kickup_timer 系统变量控制了这个“停留时间”,对每个线程组来说,语句停留的最大时间为 10ms。另外,还有一个
priority tickets(thread_pool_high_prio_tickets) 的设计,以优先的任务每次被放入优先队列中就对 priority tickets 减 1,以避免永久优先的问题。 - Timer 线程,是一种 Check Stall 机制,用来周期性地检查 group 是否超时或阻塞状态,并通过检测线程组的负载来进行工作线程的唤醒和创建行。创建线程必须满足两个条件:其一,如果没有空闲线程且没有活跃线程则立刻创建,这种情况可能因为没有任何工作线程或者工作线程都被阻塞了,或者是存在潜在的死锁;其二,如果距离上次创建的时间大于一定阈值才创建线程,这个阈值由线程组内的线程数决定。
介绍完 Thread Pool 架构和架构中的各个组件,我们再来看一下一次完整的用户请求是如何从数据库连接池进入 MySQL 的线程池,通过 Thread Pool 而进行运作的。
- 在初始化时,MySQL 线程池根据宿主机的 CPU 核心数设置 thread_pool_size,并分成若干 group,每个 group 各自维护客服端发起的连接。当用户的请求通过数据库连接池访问到 MySQL 服务端时,MySQL 服务端再进行
threadid % thread_pool_size 取模计算,确定落在哪个线程组中。 - 线程组中的 Listener 线程监听到所在的线程组有新的请求后,检查队列中是否有请求还未处理,并决定是自己亲自转化为 Worker 线程进行处理,还是把这些任务放入队列中让 Worker 线程进行处理。在这个过程中先处理优先队列,再处理普通队列。如果任务队列不为空,Listener 线程还需要考虑应调度唤醒多少个工作线程。
在以上两步中,还有两个自检程序在运行着。一个是 Worker 线程会自己判断最大空闲时间,如果超过最大空闲时间(默认60秒)就会退出;还有一个是 Timer 线程不断进行 CheckStall 机制,用来周期性地检查 group 是否处于超时或阻塞状态,并通过检测线程组的负载来进行工作线程的唤醒和创建。
MySQL 线程池实战
基本参数:
- thread_pool_size 是线程池性能最重要的参数,其设置线程池的 group 的数量,默认为系统CPU的个数。MySQL 官方文档给出的经验性建议[插图]是:如果主引擎(primary storage engine)为InnoDB, thread_pool_size 最佳设置可能为16~36,最常见的优化值倾向于24~36;如果主引擎为 MyISAM,那么 thread_pool_size 设置应该相当低。该值设置为4~8,倾向于获取最优性能。更高值设置对性能倾向于有点负面但不显著的影响。
- thread_pool_stall_limit 表示 Timer Thread 检测 group 是否异常的时间间隔,默认是 500ms。其用来处理被阻塞和长时间运行的语句,确保服务器不会完全被阻塞。thread_pool_stall_limit 有个 6 秒的上限值,防止服务器死锁的风险。在合适范围内,该值越大,MySQL 服务器的整体处理性能就越好,因为较少数量的线程,会降低对于系统资源的征用。但是,并不是越大越好,因为该值越大,新线程的创建将等待时间越长,用户的查询延迟就会越明显。
- thread_pool_max_threads 控制线程池的最大线程数,默认为 10000。若该值为 1000,代表线程池中所能创建的最大线程数不能超过 1000。
- thread_handling 默认是 one-thread-per-connection,如果要使用连接池功能,则必须设置为 pool-of-threads。
- thread_pool_oversubscribe 用于控制单个 CPU 核心在同一时间活跃的线程数。类似于一种“超频”的概念,默认值是 3。
- thread_pool_idle_timeout 设置空闲线程销毁前的等待时间,单位为秒,默认是 60 秒。用户可以根据自己的业务场景来调整该参数的值。设置得太短,会导致线程频繁地销毁与创建;设置得太长,则会导致线程池中的线程数长时间不会下降。
- thread_pool_idle_timeout 设置空闲线程销毁前的等待时间,单位为秒,默认是 60 秒。用户可以根据自己的业务场景来调整该参数的值。设置得太短,会导致线程频繁地销毁与创建;设置得太长,则会导致线程池中的线程数长时间不会下降。
- extra_port 用于设置 MySQL 服务端口之外的端口,供管理员管理服务器。
- extra_max_connections 用于设置 extra_port 端口允许的最大连接数,通过 extra_port 端口创建的连接,采用的是 one-thread-per-connection 的方式。
- thread_pool_high_prio_mode,线程池分组内的待处理任务会放到任务队列中,等待 Worker 线程处理。每个分组有两个队列:优先队列和普通队列,Worker 线程先从优先队列取事务处理,只有当优先队列为空时才从普通队列取事务处理。通过优先队列,可以让已经开启的事务或短事务得到优先处理,及时提交释放锁等资源。该参数可设置为3种模式:
- transactions。默认的,只有一个已经开启了事务的SQL,并且 thread_pool_high_prio_tickets 不为 0,才会进入优先队列中,每个连接在 thread_pool_high_prio_tickets 次被放到优先队列后,会移到普通队列中。
- statements。单独的 SQL 总是进入优先队列。
- none。禁用优先队列功能,所有的连接都放到普通队列中处理。
- thread_pool_high_prio_tickets,当
thread_pool_high_prio_mode = transactions 的时候,每个连接的任务最多被放入优先队列 thread_pool_high_prio_tickets 次,并且每放一次递减,直到小于等于 0 的时候放入普通队列,这个值默认是 4294967295。
实战经验:
- 在 Percona 5.7 的部分低版本中,如果开启了 Performance_Schema 和 ThreadPool 会出现内存泄漏问题,需要将 performance_schema 设置为 off 并重启 MySQL。
- 慢 SQL 导致线程池卡住。慢 SQL 的问题往往是压倒团队的“最后一根稻草”,慢 SQL 引发的惨痛故障不胜枚举,甚至造成资损。不符合规范的 SQL、全表查询、没建索引等都是可能造成慢 SQL 的原因,而 thread_pool_oversubscribe 可以暂时缓解这个问题。但是这咱方法治标不治本,根本解决方法还是开启 MySQL 服务端的日志,将慢SQL每天反馈给各个技术研发团队,甚至直接通过中间件过滤掉慢 SQL,不让其访问到 MySQL 服务端。
- MySQL 主备切换及容灾演练。生产数据库往往会默认设置几千个连接数,可是如果发生业务洪峰、机房故障以后迅速重连导致的连接风暴等情况,都容易将 MySQL 的最大连接数和并发线程数迅速提高到峰值。业务上可以提前做好预案及压测,技术上可以考虑通过配置中心进行 MySQL 的多机房切换、主备切换及容灾,也可以做探测脚本,在即将达到最大连接数时进行及时的扩容。
- 调度死锁解决。引入线程池解决了多线程高并发的问题,但也带来一个隐患。假设,A、B 两个事务被分配到不同的 group 中执行,A 事务已经开始,并且持有锁,但由于 A 所在的 group 比较繁忙,导致A执行一条语句后,不能立即获得调度执行;而 B 事务依赖A事务释放锁资源,虽然B事务可以被调度起来,但由于无法获得锁资源,导致 B 仍然需要等待,这就是所谓的调度死锁。由于一个 group 会同时处理多个连接,但多个连接不是对等的。比如,有的连接是第一次发送请求,而有的连接对应的事务已经开启,并且持有了部分锁资源。为了减少锁资源争用,后者显然应该比前者优先得到处理,以达到尽早释放锁资源的目的。因此在 group 里面,可以添加一个优先队列,将已经持有锁的连接,或者已经开启的事务的连接发起的请求放入优先队列,工作线程首先从优先队列获取任务执行。
- 大查询处理。假设一种场景,某个 group 里面的连接都是大查询,那么 group 里面的工作线程数很快就会达到 thread_pool_oversubscribe 参数设置值,对于后续的连接请求,则会响应不及时(没有更多的连接来处理),这时候 group 就发生了 stall。通过前面的分析知道,Timer 线程会定期检查这种情况,并创建一个新的 Worker 线程来处理请求。如果长查询来源于业务请求,则此时所有 group 都面临这种问题,此时主机可能会由于负载过大,发生 hang 住的情况。这种情况线程池本身无能为力,因为源头可能是烂 SQL 并发,或者 SQL 没有走对执行计划而导致,通过其他方法,比如 SQL 高低水位限流或者 SQL 过滤手段可以应急处理。但是,还有另外一种情况,就是 dump 任务。很多下游依赖于数据库的原始数据,通常通过 dump 命令将数据拉到下游,而这种 dump 任务通常都耗时比较长,所以也可以认为是大查询。如果 dump 任务集中在一个 group 内,并导致其他正常业务请求无法立即响应,这个是不能容忍的。因为此时数据库并没有压力,只是因为采用了线程池策略,才导致了请求响应不及时。为了解决这个问题,我们将 group 中处理 dump 任务的线程不计入 thread_pool_oversubscribe 累计值,即可避免上述问题。
- thread_cache_size 设置优化。每建立一个连接,都需要一个线程来与之匹配,此参数用来缓存空闲的线程,以至不被销毁。如果线程缓存中有空闲线程,这时候如果建立新连接,MySQL 就会很快地响应连接请求。MySQL 如果采用多线程来处理并发的连接,那么采用 mysqlreport 的 Threads 部分可以看到线程创建的频率非常高。一个比较好的方法就是使用持久连接,这将在一定程度上减少线程的重复创建。将 thread_cache_size 从 0 适当地提高到一定的业务需求值,虽然每秒处理的连接数不变,但是创建的线程数可以大大减少,同时提高线程池的命中率。
5.5 - 性能原理
为什么快
在 HikariCP 官网详细了介绍 HikariCP 所做的优化,总结如下:
- 优化并精简字节码、优化代码和拦截器。
- 使用 FastList 替代 ArrayList。
- 更好的并发集合类实现 ConcurrentBag。
- 其他针对 BoneCP 缺陷的优化,比如对于耗时超过一个 CPU 时间片的方法调用的研究。
精简字节码
HikariCP 的代码只有 130 Kb,它是一个轻量级数据库连接池。
HikariCP 利用了一个第三方的 Java 字节码修改类库 Javassist 来生成委托实现动态代理。
动态代理的实现在 com.zaxxer.hikari.pool.ProxyFactory 类,源码非常简单。如下所示:
public final class ProxyFactory
{
private ProxyFactory() { }
static ProxyConnection getProxyConnection(final PoolEntry poolEntry,
final Connection connection,
final FastList<Statement> openStatements,
final ProxyLeakTask leakTask,
final long now,
final boolean isReadOnly,
final boolean isAutoCommit){
//body部分被JavassistProxyFactory重新注入了
throw new IllegalStateException("You need to run the CLI build and you
need target/classes in your classpath to run.");
}
static Statement getProxyStatement(final ProxyConnection connection, final
Statement statement)
{//body部分被JavassistProxyFactory重新注入了
throw new IllegalStateException("You need to run the CLI build and you
need target/classes in your classpath to run.");
}
static CallableStatement getProxyCallableStatement(final ProxyConnection
connection, final CallableStatement statement)
{//body部分被JavassistProxyFactory重新注入了
throw new IllegalStateException("You need to run the CLI build and you
need target/classes in your classpath to run.");
}
static PreparedStatement getProxyPreparedStatement(final ProxyConnection
connection, final PreparedStatement statement)
{//body部分被JavassistProxyFactory重新注入了
throw new IllegalStateException("You need to run the CLI build and you
need target/classes in your classpath to run.");
}
static ResultSet getProxyResultSet(final ProxyConnection connection, final
ProxyStatement statement, final ResultSet resultSet)
{//body部分被JavassistProxyFactory重新注入了
throw new IllegalStateException("You need to run the CLI build and you
need target/classes in your classpath to run.");
}
}
这些代码基本代理了 JDBC 常用的核心接口,一共是 5 个:ProxyConnection、Statement、CallableStatement、PreparedStatement、ResultSet。并且每个方法都抛出了异常。其实每个方法都是抛异常之前都有一段 body,这段 body 是在编译时调用 JavassistProxyFactory 才生成的。
JavassistProxyFactory 存在于 com.zaxxer.hikari.util 包中,是 Javassist 的工具包,它主要有两个核心方法: generateProxyClass 方法负责生成实际使用的代理类字节码,modifyProxyFactory 对应修改工厂类中的代理类获取方法 Proxy*.java 为 HikariProxy*. java。这个工具包的作用是将 ProxyConnection、ProxyStatement、ProxyPreparedStatement、ProxyCallableStatement、ProxyResultSet 这 5 个 com.zaxxer.hikari.pool 包下代理类,利用 Javassist 重构后生成实际的 HikariCP 的对应代理类 HikariProxyConnection、HikariProxyStatement、HikariProxyPreparedStatement、HikariProxyCallableStatement、HikariProxyResultSet。
之所以使用 Javassist 生成动态代理,是因为其速度更快,比 JDK Proxy 生成的字节码更少,精简了很多不必要的字节码。
此外,HikariCP 在字节码工程中还对 JIT 进行了优化。比如,JIT 方法内联优化默认的字节码个数阈值是 35 字节,低于 35 字节才会进行优化。HikariCP 在精简字节码的时候,研究了编译器的字节码输出,甚至是 JIT 的汇编输出,以将关键部分限制为小于 JIT 内联阈值,展平了继承层次结构,阴影成员变量,消除了强制转换。
FastList
HikariCP 一个性能方面的出彩优化突破就是 FastList。我们先看一组 HikariCP 中关于 FastList 的结论:
- 当调用
Connection.prepareStatement() 的时候,新的 PreparedStatement 就被添加到 FastList。 - 当调用
PreparedStatement.close() 的时候,这个 statement 就从 FastList 中被移除。 - 如果调用
Connection.close() 的时候,任何未明确关闭的语句都将从 FastList 移除并关闭。
但是 HikariCP 并没有拦截 PreparedStatement.addBatch() 方法,所以实际上 addBatch() 不可能添加任何内容到 FastList。executeBatch 方法即不会清除批处理,也不会将 PreparedStatement 从 FastList 中移除。唯一能够清除批处理的是 PreparedStatement.clearBatch() 方法,而唯一能够从 FastList 移除 PreparedStatement 的方法就是调用 PreparedStatement. close() 或者 Connection.close() 方法。
try (Connection con = dataSource.getConnection();
PreparedStatement stmt = con.prepareStatement(...)) {
int batchCount = 0;
for (something in somelist) {
stmt.setString(...);
stmt.setInt(...);
stmt.addBatch();
if (++batchCount == 100) {
stmt.executeBatch();
stmt.clearBatch();
batchCount = 0;
}
}
if (batchCount > 0) {
stmt.executeBatch();
stmt.clearBatch();
}
con.commit();
}
catch (SQLException e) {
// 记录异常
}
如上述代码所示,对于批处理语句执行清理的过程分为如下几步:DataSource.getConnection()、Connection.prepareStatement()、多次调用 PreparedStatement.addBatch()、PreparedStatement.executeBatch()/clearBatch() 的调用、依赖 Java 7 的 try-with-resources 语法进行资源的清理。
FastList 是一个 List 接口的精简实现,只实现了接口中必要的几个方法。JDK ArrayList 每次调用 get() 方法时都会进行 rangeCheck,检查索引是否越界,FastList 的实现中去除了这一检查,只要保证索引合法那么 rangeCheck 就成为了不必要的计算开销(当然开销极小)。
此外,HikariCP 使用 List 来保存打开的 Statement,当 Statement 关闭或 Connection 关闭时需要将对应的 Statement 从 List 中移除。通常情况下,JDBC 在同一个 Connection 创建了多个 Statement 时,后打开的 Statement 会先关闭。这种情况从尾部开始扫描将表现更好。ArrayList 的 remove(Object) 方法是从头开始遍历数组,而 FastList 是从数组的尾部开始遍历,因此更为高效,它消除了范围检查,并从尾部到头部执行移除扫描。
简而言之就是用自定义数组类型 FastList 代替 ArrayList:避免每次 get() 调用都要进行范围检查,避免调用 remove() 时的从头到尾的扫描。
ConcurrentBag
ConcurrentBag 取名来源于 C# .NET 的同名类,但是实现却不一样。它是一个 lock-free 集合,在连接池(多线程数据交互)的实现上具有比 LinkedBlockingQueue 和 LinkedTransferQueue 更优越的并发读写性能。它具有无锁设计、ThreadLocal 缓存、队列窃取、直接切换优化四大特点。
ConcurrentBag 采用了 queue-stealing 的机制获取元素:首先尝试从 ThreadLocal 中获取属于当前线程的元素来避免锁竞争,如果没有可用元素则再次从共享的 CopyOnWriteArrayList 中获取。此外,ThreadLocal 和 CopyOnWriteArrayList 在 ConcurrentBag 中都是成员变量,线程间不共享,避免了伪共享(false sharing)的发生。作者评价这款设计具有高度并发性,极低的延迟,并最大限度地减少了伪共享的发生。
ConcurrentBag 的性能提升主要源于如下 3 个组成部分:
- CopyOnWriteArrayList:负责存放 ConcurrentBag 中全部用于出借的资源。
- ThreadLocal:用于加速线程本地化资源访问。
- SynchronousQueue:用于存在资源等待线程时的第一手资源交接。
源码解析
ConcurrentBag 内部同时使用 ThreadLocal 和 CopyOnWriteArrayList 来存储元素,其中 CopyOnWriteArrayList 是线程共享的。
ConcurrentBag 采用了 queue-stealing 的机制获取元素:首先尝试从 ThreadLocal 中获取属于当前线程的元素来避免锁竞争,如果没有可用元素则扫描公共集合,再从共享的 CopyOnWriteArrayList 中获取。ThreadLocal 列表中没有被使用的 items 在借用线程没有属于自己的时候,是可以被“窃取”的。
ThreadLocal 和 CopyOnWriteArrayList 在 ConcurrentBag 中都是成员变量,线程间不共享,避免了伪共享的发生。
使用专门的 AbstractQueuedLongSynchronizer 来管理跨线程信号,这是一个 lock-less 的实现。
ConcurrentBag 通过 borrow 方法进行数据资源借用,通过 requite 方法进行资源回收,注意其中 borrow 方法只提供对象引用,不移除对象。所以从 bag 中“借用”的 items 实际上并没有从任何集合中删除,因此即使引用废弃了,垃圾收集也不会发生。因此使用时通过 borrow 取出的对象必须通过 requite 方法进行放回,否则会导致内存泄露,只有 remove 方法才能完全从 bag 中删除一个对象。
ConcurrentBag:
对 CopyOnWriteArrayList 的使用:通过 add 添加资源,通过 remove 方法借出资源:
add 方法向 bag 中添加 bagEntry 对象,以供别人借用:
public void add(final T bagEntry)
{
if (closed) {
LOGGER.info("ConcurrentBag has been closed, ignoring add()");
throw new IllegalStateException("ConcurrentBag has been closed, ignoring
add()");
}
sharedList.add(bagEntry); //新添加的资源优先放入CopyOnWriteArrayList
// 当有等待资源的线程时,将资源交到某个等待线程后才返回(SynchronousQueue)
while (waiters.get() > 0 && ! handoffQueue.offer(bagEntry)) {
yield();
}
}
remove 方法从 bag 中删除一个 bagEntry,仅在 borrow(long, TimeUnit) 和 reserve(T) 时被调用:
public boolean remove(final T bagEntry){
// 如果资源正在使用且无法进行状态切换,则返回失败
if (!bagEntry.compareAndSet(STATE_IN_USE, STATE_REMOVED) &&
!bagEntry.compareAndSet(STATE_RESERVED, STATE_REMOVED) &&
!closed) {
LOGGER.warn("Attempt to remove an object from the bag that was not borrowed or reserved: {}", bagEntry);
return false;
}
final boolean removed = sharedList.remove(bagEntry); // 移出
if (! removed && ! closed) {
LOGGER.warn("Attempt to remove an object from the bag that does not exist: {}", bagEntry);
}
return removed;
}
// ConcurrentBag中通过borrow方法进行数据资源借用。
public T borrow(long timeout, final TimeUnit timeUnit) throws InterruptedException
{
// 优先查看有没有可用的本地化的资源
final List<Object> list = threadList.get();
for (int i = list.size() -1; i >= 0; i--) {
final Object entry = list.remove(i);
@SuppressWarnings("unchecked")
final T bagEntry = weakThreadLocals ? ((WeakReference<T>) entry).
get() : (T) entry;
if (bagEntry ! = null && bagEntry.compareAndSet(STATE_NOT_IN_USE,
STATE_IN_USE)) {//优先从当前线程的ThreadLocal中获取连接,若获得则直接返回
return bagEntry;
}
}
final int waiting = waiters.incrementAndGet();
try {
// 当无可用本地化资源时,遍历全部资源,查看是否存在可用资源
// 因此被一个线程本地化的资源也可能被另一个线程"抢走"
for (T bagEntry : sharedList) {
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
if (waiting > 1) {
// 因为可能"抢走"了其他线程的资源,因此提醒包裹进行资源添加
listener.addBagItem(waiting -1);
}
return bagEntry;
}
}
listener.addBagItem(waiting);
timeout = timeUnit.toNanos(timeout);
do {
final long start = currentTime();
// 若现有资源全部在使用中,则等待一个被释放的资源或者一个新资源
final T bagEntry = handoffQueue.poll(timeout, NANOSECONDS);
if (bagEntry == null ||
bagEntry.compareAndSet(STATE_NOT_IN_USE,STATE_IN_USE)) {
return bagEntry;
}
timeout -= elapsedNanos(start);
} while (timeout > 10_000);
return null;
}
finally {
waiters.decrementAndGet();
}
}
public void requite(final T bagEntry)
{
// 将状态转为未在使用
bagEntry.setState(STATE_NOT_IN_USE);
// 判断是否存在等待线程,若存在,则直接转手资源
for (int i = 0; waiters.get() > 0; i++) {
if (bagEntry.getState() ! = STATE_NOT_IN_USE || handoffQueue.offer(bagEntry)) {
return;
}
else if ((i & 0xff) == 0xff) {
parkNanos(MICROSECONDS.toNanos(10));
}
else {
yield();
}
}
// 否则,进行资源本地化
final List<Object> threadLocalList = threadList.get();
threadLocalList.add(weakThreadLocals ? new WeakReference<>(bagEntry) :bagEntry);
}
SynchronousQueue
SynchronousQueue 来自于 JUC 并发包 java.util.concurrent,在 HikariCP 中的体现就是 ConcurrentBag 结构中的 handoffQueue,它主要用于存在资源等待线程时的第一手资源交接:
SynchronousQueue 的初始化是在 ConcurrentBag 的构造方法中,如下所示:
public ConcurrentBag(final IBagStateListener listener)
{
this.listener = listener;
this.weakThreadLocals = useWeakThreadLocals();
this.handoffQueue = new SynchronousQueue<>(true);
this.waiters = new AtomicInteger();
this.sharedList = new CopyOnWriteArrayList<>();
if (weakThreadLocals) {
this.threadList = ThreadLocal.withInitial(() -> new ArrayList<>(16));
}
else {
this.threadList = ThreadLocal.withInitial(() -> new FastList<>
(IConcurrentBagEntry.class, 16));
}
}
SynchronousQueue 提供了以下两个构造函数:
public SynchronousQueue() {
this(false);
}
public SynchronousQueue(boolean fair) {
// 通过fair值来决定公平和不公平
// 公平使用TransferQueue,不公平使用TransferStack
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}
在 HikariCP 中,选择的是公平模式 this.handoffQueue = newSynchronousQueue<>(true)。公平模式总结下来就是:队尾入队队头出队,先进先出,体现公平原则。
SynchronousQueue 是一个无存储空间的阻塞队列(是实现 newFixedThreadPool 的核心),非常适合做交换工作,生产者和消费者的线程同步以传递某些信息、事件或者任务。作为 BlockingQueue 中的一员,SynchronousQueue 的吞吐量高于 ArrayBlockingQueue 和 LinkedBlockingQueue,与其他 BlockingQueue 有着不同特性。
- SynchronousQueue 无存储空间。与其他 BlockingQueue 不同,SynchronousQueue 是一个不存储元素的 BlockingQueue。它的特点是每一个 put 操作必须要等待一个 take 操作或者 poll 方法,才能使用 off、add 方法,否则不能继续添加元素,反之亦然。
- 因为没有容量,所以对应 peek、contains、clear、isEmpty 等方法其实是无效的。例如 clear 是不执行任何操作的,contains 始终返回 false, peek 始终返回 null, peek 方法直接返回 null。
- SynchronousQueue 分为公平和不公平,默认情况下采用不公平访问策略。当然也可以通过构造函数来设置为公平访问策略。
- 若使用 TransferQueue,则队列中永远会存在一个 dummynode。
CopyOnWriteArrayList
CopyOnWriteArrayList 负责存放 ConcurrentBag 中全部用于出借的资源。顾名思义,Write 的时候总是要 Copy,也就是说对于任何可变的操作都是伴随复制这个动作的,这是 ArrayList 的一个线程安全的变体,底层通过复制数组的方式来实现。和 SynchronousQueue 一样,它也位于 java.util.concurrent 包下,为并发而生。CopyOnWriteArrayList 在遍历的时候不会抛出 ConcurrentModificationException 异常,并且遍历的时候就不用额外加锁,元素也可以为 null。
CopyOnWriteArrayList 底层是一个数组,通过 ReentrantLock 进行加锁,它初始化的时候底层是一个 Object[] array, Object array 指向一个大小为 0 的数组。一次 add 操作经历了 5 个步骤,都是在锁的保护下进行的,在添加的时候先上锁,拿到原数组并复制一个新数组(原数组大小+1),增加操作在新数组上进行,最后再将 Object array 引用指向新数组,解锁。这样做是为了避免在多线程并发add的时候,复制多个副本出来,把数据搞乱了,导致最终的数组数据不是我们期望的。这是一种写时复制的理念。
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
final transient ReentrantLock lock = new ReentrantLock(); //可重入锁
final Object[] getArray() {return array; }//非private,得到数组
final void setArray(Object[] a) {array = a; }//设置数组
public CopyOnWriteArrayList() { setArray(new Object[0]); }//初始化
public boolean add(E e) {
final ReentrantLock lock = this.lock; //1)加锁
lock.lock();
try {
Object[] elements = getArray(); //得到原数组的长度和元素
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1); //2)复制数组
newElements[len] = e; //3)将元素加入到新数组中
setArray(newElements); //4)将array引用指向到新数组
return true;
} finally {
lock.unlock(); //5)解锁
}
}
插入、删除、修改操作也都是一样,每一次的操作都是以对Object[] array进行一次复制为基础的。写加锁,读不加锁。由于所有的写操作都是在新数组进行的,这个时候如果有线程并发的写,则通过锁来控制。如果有线程并发的读,则分以下几种情况:
- 如果写操作未完成,那么直接读取原数组的数据。
- 如果写操作完成,但是引用还未指向新数组,那么也是读取原数组数据。
- 如果写操作完成,并且引用已经指向了新的数组,那么直接从新数组中读取数据。
CopyOnWriteArrayList 非常适用于数据库连接池这种读操作远远多于修改操作的场景,它反映的是 3 个十分重要的分布式理念:
- 读写分离。读取 CopyOnWriteArrayList 的时候,读取的是 CopyOnWriteArrayList 中的
Object[] array,但是修改的时候,操作的是一个新的 Object[] array。读和写操作的不是同一个对象,这就是读写分离。这种技术数据库用的非常多,在高并发下为了缓解数据库的压力,即使做了缓存也要对数据库做读写分离,读的时候使用读库,写的时候使用写库,然后读库、写库之间进行一定的同步,这样就避免同一个库上读、写的 IO 操作太多。 - 最终一致。对 CopyOnWriteArrayList 来说,线程1读取集合里面的数据,未必是最新的数据。因为线程2、线程3、线程4都修改了 CopyOnWriteArrayList 里面的数据,但是线程1拿到的还是最老的那个
Object[] array,新添加进去的数据并没有,所以线程1读取的内容未必准确。不过这些数据虽然对于线程1是不一致的,但是对于之后的线程一定是一致的,它们拿到的 Object[] array 一定是3个线程都操作完毕之后的 Object array[],这就是最终一致。最终一致对于分布式系统也非常重要,它通过容忍一定时间的数据不一致,提升整个分布式系统的可用性与分区容错性。当然,最终一致并不是任何场景都适用的,像火车站售票这种系统用户对于数据的实时性要求非常非常高,就必须做成强一致性的。 - 使用另外开辟空间的思路,来解决并发冲突。
但是它有着以下缺点:
- 因为 CopyOnWrite 的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)。如果这些对象占用的内存比较大,比如200M左右,再写入100M数据,内存就会占用300M,那么这个时候很有可能造成频繁的Yong GC和Full GC。
- 不能用于实时读的场景,像复制数组、新增元素都需要时间,所以调用一个 set 操作后,读取到数据可能还是旧的。虽 CopyOnWriteArrayList 能做到最终一致性,但是还是没法满足实时性要求。所以如果你希望写入的的数据马上能读到,就不要使用 CopyOnWrite 容器。
5.6 - 优化原理
获取连接
HikariCP 可以被理解为一个简单的 BlockingQueue,它实际上并没有使用 BlockingQueue,而是使用了一种被称为 ConcurrentBag 的专用集合,但在行为概念上是类似的。在这个 BlockingQueue 的模型上,可以想象你的客户端调用 HikariDataSource 的 getConnection 方法执行着如下的工作:
public Connection getConnection() throws SQLException {
return connectionQueue.poll(timeout);
}
显然会有更多的事情发生,比如抛出超时异常等,如上是基本的思路。调用 Connection.close 方法实质上返回到池的连接,同样,还有很多具体细节,但概念是相通的。
public void close() throws SQLException {
connectionQueue.put(this);
}
HikariCP 确实有几个自己的线程,有一个 HouseKeeper 管家线程定期运行以退出空闲连接,有一个调度线程可以退出到达 maxLifetime 的连接,还有一个用于添加连接的线程,以及一个用于关闭它们的线程等。接下来,我们从获取连接部分开始仔细研究源码级的原理。
获取连接是 HikariCP 的核心功能,HikariDataSource 对象首先通过 getConnection 方法获得 HikariPool 真正的 getConnection 方法,HikariPool 内部通过我们介绍过的 ConcurrentBag 的 borrow 方法获取 PoolEntry,它将首先尝试从线程的 ThreadLocal 最近使用的连接列表中获取未使用的连接。最后通过 PoolEntry 执行 Create Proxy Connection 方法创建一个物理连接并返回其代理连接 Proxy Connection。具体的时序图如图所示。
HikariDataSource,顾名思义,就是 HikariCP 对外提供给用户的定制化的 DataSource,使用 Spring 的用户可以直接将它作为数据源。用户也可以直接初始化 HikariDataSource:
HikariDataSource ds = new HikariDataSource();
ds.setJdbcUrl("jdbc:mysql://localhost:3306/simpsons");
ds.setUsername("bart");
ds.setPassword("51mp50n");
HikariDataSource 继承了 HikariConfig,并且实现了 JDCB 基础中介绍过的 javax.sql 扩展包中的 DataSource 接口。作为 DriverManager 设施的替代项,DataSource 对象是获取连接的首选方法,实现 DataSource 接口的对象通常在基于 JavaTM Naming and Directory Interface (JNDI) API 的命名服务中注册。
HikariConfig 是 HikariCP 的配置管理核心类,它实现了 HikariConfigMXBean 接口,用来对外暴露 HikariCP 配置相关的 JMX 监控和管理功能。
在创建连接的过程中,有几个细节性的问题可以从源码级重点关注一下。
细节:单例池初始化
HikariDataSource 获取连接 getConnection 的单例处理。大家都知道,在实现单例模式时,如果未考虑多线程的情况,很可能会造成实例化了多次并且被不同对象持有。在 JDK1.5 或者更晚的版本中,扩展了 volatile 的语义,使用了 volatile 关键字后,重排序被禁止,双重检查锁可以减少开销。如果没有 volatile 关键字则可能由于指令重排导致 HikariPool 对象 pool 在多线程下无法正确地初始化,volatile 禁止了指令重排,并强制本地线程读取主存。由于数据库连接池处于一个激烈的被频繁调用的位置,HikariCP 的源码部分就使用双重检查锁进行单例初始化。以下是 HikariDataSource 中的部分源码代码:
private final HikariPool fastPathPool;
private volatile HikariPool pool; //注意这里引入了volatile
public Connection getConnection() throws SQLException {
if (isClosed()) //检查数据源是否已经关闭,如果关闭则抛出异常
{ throw new SQLException("HikariDataSource " + this + " has been
closed."); }
if (fastPathPool ! = null) {//如果当前引用HikariPool不为空,则直接返回连接
return fastPathPool.getConnection();
}
HikariPool result = pool;
if (result == null) {//典型的双重检验锁代码
synchronized (this) {
result = pool;
if (result == null) {
validate(); //参数校验,主要是检查参数是否合法并给予默认值
try {
pool = result = new HikariPool(this); //初始化连接池
this.seal();
}
catch (PoolInitializationException pie) {
if (pie.getCause() instanceof SQLException) {
throw (SQLException) pie.getCause();
}
else {
throw pie;
}
}
LOGGER.info("{} - Start completed.", getPoolName());
}
}
}
//从连接池中返回一个连接,返回给HikariPool资源池与ConcurrentBag进行交互
return result.getConnection();
}
细节:连接有效性
另一个细节是获取连接时的有效性检查。当从资源池里面获取到资源后,需要检查该资源的有效性,如果失效,则再次获取连接,这样可以避免执行业务的时候报错。这部分的工作是由 HikariPool 做的,它通过判断 PoolEntry 是否已经被标记清除了、当前 PoolEntry 的存活时间是否过期及当前连接是否活着 3 项进行判断,如果超时则关闭这个 PoolEntry 的连接、重置超时时间、再次获取连接。这部分的核心实现在 HikariPool 的 getConnection 方法里,如下所示:
try {
long timeout = hardTimeout;
do {//从connectionBag中借用连接,借用过程中会发生创建连接、连接过期、空闲等事情
PoolEntry poolEntry = connectionBag.borrow(timeout, MILLISECONDS);
if (poolEntry == null) {
break; //中断,跳出循环,并抛出异常
}
final long now = currentTime(); //记录当前时间
if (poolEntry.isMarkedEvicted() || (elapsedMillis(poolEntry.lastAccessed, now) > aliveBypassWindowMs && ! isConnectionAlive(poolEntry.connection))) {//有效性检查
closeConnection(poolEntry, poolEntry.isMarkedEvicted() ? EVICTED_ CONNECTION_MESSAGE : DEAD_CONNECTION_MESSAGE); //关闭当前失效连接
timeout = hardTimeout - elapsedMillis(startTime); //重置超时时间
}
else {
//借用的连接若未过期未丢弃进入此逻辑,则设置metrics监控指标
metricsTracker.recordBorrowTimeoutStats(startTime);
//最核心部分,通过代理创建连接
return poolEntry.createProxyConnection(leakTaskFactory.schedule(poolEntry), now);
}
} while (timeout > 0L); //只要超时时间大于0则不断重试
throw createTimeoutException(startTime); //抛出创建连接超时异常
}
在上述代码中,有效性检查的部分是 isConnectionAlive,在这里用户可以自行配置心跳语句的检测,如果追求极致性能,那么使用 JDBC4 的用户还是强烈建议不要配置心跳语句,而是采用 HikariCP 默认的 com.mysql.jdbc. JDBC4Connection 的 isValid 实现,因为它的实现是 ping 命令,一般来说原生 ping 命令的性能是 select 1 的两倍。刚才我们看到的 HikariPool 的 getConnection 方法,其心跳语句检测的 isConnectionAlive 是在其父类中实现的,核心代码如下:
boolean isConnectionAlive(final Connection connection)
{
try {
try {
setNetworkTimeout(connection, validationTimeout);
final int validationSeconds = (int) Math.max(1000L, validationTimeout) / 1000;
if (isUseJdbc4Validation) {//如果是JDBC4,则直接使用ping命令进行验证
return connection.isValid(validationSeconds); //性能可以大大提升
}
try (Statement statement = connection.createStatement()) {
if (isNetworkTimeoutSupported ! = TRUE) {
setQueryTimeout(statement, validationSeconds);
}
statement.execute(config.getConnectionTestQuery()); //否则执行测试语句验证
}
}
finally {
setNetworkTimeout(connection, networkTimeout);
if (isIsolateInternalQueries && ! isAutoCommit) {
connection.rollback();
}
}
return true;
}
catch (Exception e) {
lastConnectionFailure.set(e);
logger.warn("{} - Failed to validate connection {} ({}). Possiblyconsider using a shorter maxLifetime value.",
poolName, connection, e.getMessage());
return false;
}
}
上述代码中有一个 validationTimeout 属性,默认值是 5000 毫秒,所以默认情况下 final int validationSeconds = (int)Math.max(1000L, validationTimeout) / 1000 它的值应该为 1~5 秒。又由于 validationTimeout 的值必须小于 connectionTimeout(默认值30000毫秒,如果小于250毫秒,则被重置回30秒),所以默认情况下,调整 validationTimeout 却不调整 connectionTimeou t情况下,validationSeconds 的默认峰值应该是 30 毫秒。
如果是 JDBC4 的话,使用 isUseJdbc4Validation(就是 config.getConnectionTestQuery()== null 的时候),用 connection.isValid(validationSeconds) 来验证连接的有效性,否则的话则用 connectionTestQuery 查询语句来查询验证。
细节:创建形式
第 3 个细节就是连接的创建。连接的创建可以同步创建,也可以异步创建,这与 HikariCP 的配置息息相关,这也是 HikariCP 作者别具匠心的设计之处。
过程总结
- 实现了 JDBC 扩展包 javax.sql 的 DataSource 接口的 HikariDataSource,执行 getConnection 方法时会进行 Double-checked_locking 单例、配置检查等流程,再向 HikariPool 资源池请求获取连接。
- HikariPool 则向其 lock-free 的资源集合 ConcurrentBag 借用 PoolEntry,若没有 poolEntry 则超时抛出异常,若有 poolEntry 则创建一个 JDBC 代理连接 ProxyConnection。
- ProxyConnection 是由 ProxyFactory 产生的,它是一个生产标准 JDBC 接口代理的工厂类,HikariDataSource 最终获取的 Connection 连接就是代理工厂返回的 JDBC 物理连接,而 poolEntry 就是对这个物理连接的一对一封装。
连接有效性
Java.sql.Connection 的 isValid() 和 isClosed() 区别:
- isValid:如果连接尚未关闭并且仍然有效,则返回true。驱动程序将提交一个关于该连接的查询,或者使用其他某种能确切验证在调用此方法时连接是否仍然有效的机制。由驱动程序提交的用来验证该连接的查询将在当前事务的上下文中执行。
- 参数:timeout。等待用来验证连接是否完成的数据库操作的时间,以秒为单位。如果在操作完成之前超时期满,则此方法返回 false。0值表示不对数据库操作应用超时值。
- 返回:如果连接有效,则返回 true,否则返回 false。
- isClosed:查询此 Connection 对象是否已经被关闭。如果在连接上调用了 close 方法或者发生某些严重的错误,则连接被关闭。只有在调用了 Connection.close 方法之后被调用时,此方法才保证返回 true。通常不能调用此方法确定到数据库的连接是有效的还是无效的。通过捕获在试图进行某一操作时可能抛出的异常,典型的客户端可以确定某一连接是无效的。
- 返回:如果此 Connection 对象是关闭的,则返回 true;如果它仍然处于打开状态,则返回 false。
连接监控
HikariPool 继承了 PoolBase,实现了 HikariPoolMXBean 接口用于对外暴露 HikariCP 连接池相关的监控管理功能:
归还连接
连接的归还和连接的借用是两个大致相反的过程,归还部分的源码如下所示:
public final void close() throws SQLException
{
closeStatements(); //由于关闭语句可能导致连接被驱逐,所以优先执行
if (delegate ! = ClosedConnection.CLOSED_CONNECTION) {
leakTask.cancel();
try {
if (isCommitStateDirty && ! isAutoCommit) {
delegate.rollback(); //如果存在脏提交或者没有自动提交,则连接回滚
lastAccess = currentTime();
LOGGER.debug("{} - Executed rollback on connection {} due to dirty commit state on close().", poolEntry.getPoolName(), delegate);
}
if (dirtyBits ! = 0) {
poolEntry.resetConnectionState(this, dirtyBits);
lastAccess = currentTime();
}
delegate.clearWarnings();
}
catch (SQLException e) {
//当连接中止时,通常会抛出不适用于应用程序的异常
if (! poolEntry.isMarkedEvicted()) {
throw checkException(e);
}
}
finally {//这里开始调用PoolEntry的recycle方法
delegate = ClosedConnection.CLOSED_CONNECTION;
poolEntry.recycle(lastAccess);
}
}
}
在 ProxyConnection 代理层获取到的连接,进行归还时调用了代理层的 close 方法。HikariCP 归还连接是一系列没有返回值的 void 操作,ProxyConnection 的 close 方法并没有直接调用 JDBC 的 close 方法,而是依次调用了 PoolEnry 的 recycle 方法、HikariPool 的 recycle 方法及 ConcurrentBag 的 requite 方法,这一系列方法传递的参数都是 PoolEntry。
数据库连接池 HikariCP 的 close 方法返回的连接其实是封装在这个 ProxyConnection 代理连接中的,当调用它的时候,它只返回与池的连接,但是依然保持与数据库的基础连接是打开的。数据库连接池通常都是以这种方式工作的,数据库连接池的性能优势就是来自于连接保持打开,通过代理连接,对用户来说是透明的。如果需要关闭这个连接,可以将它先转换为 ProxyConnection,然后调用它的 unwrap 方法,最后关闭这个内部连接。
public final <T> T unwrap(Class<T> iface) throws SQLException{
//ProxyConnection内部提供的unwrap方法
if (iface.isInstance(delegate)) {
return (T) delegate;
} else if (delegate ! = null) {
return delegate.unwrap(iface);
}
throw new SQLException("Wrapped connection is not an instance of " + iface);
}
unwrap 是一个很有意思的工具,如果你想跳过代理获取数据库的源信息,那么还可以直接使用 JDBC 的 unwrap 的 API 来获取(这里不是 ProxyConnection 的 unwrap )。如下所示:
((ConnectionProperties) connection.unwrap(ConnectionProperties.class))
.setNullCatalogMeansCurrent(false);
在归还连接的代码中,也存在很多细节。比如代理层的 close 方法第 1 行就这么讲究:
closeStatements(); //由于关闭语句可能导致连接被驱逐,所以优先执行
本书前面章节介绍的 HikariCP 诞生的理由——很多数据库连接池违反了 JDBC 规范。当 Connection 连接 close 或者 return 时,清除警告或回滚未提交的事务时,一些数据库连接池并不会自动关闭语句 Statement,并且它们也不会重置用户更改过的属性,如自动提交或事务隔离级别等,从而导致下一个消费者获得“脏”连接。
JDBC 最佳实践中有一条就是最顺序关闭 ResultSet、Statement、Connection。因此,在 HikariCP 中,ProxyConnection 的源码中,它的 close 方法覆盖了 java.sql.Connection 的方法,覆盖 JDBC 的 close 方法时,第一件事就是关闭了 Statement 语句。
private synchronized void closeStatements(){
final int size = openStatements.size();
if (size > 0) {
for (int i = 0; i < size && delegate ! = ClosedConnection.CLOSED_CONNECTION; i++){
try (Statement ignored = openStatements.get(i)) {
//自动资源清理
}
catch (SQLException e) {
LOGGER.warn("{} - Connection {} marked as broken because of an exception closing open statements during Connection.close()",poolEntry.getPoolName(), delegate);
leakTask.cancel();
poolEntry.evict("(exception closing Statements during Connection.close())");
delegate = ClosedConnection.CLOSED_CONNECTION;
}
}
openStatements.clear();
}
}
在上述 closeStatements 的具体方法实现里,在执行 clear 之前,将所有不是关闭状态的 Statement 都遍历了一遍,进行了资源的自动清理,对于遇到异常的连接,PoolEntry 对象标记具体问题原因是关闭 Statement 时产生的,并将连接设置为关闭状态。
从 ProxyConnection 覆盖 JDBC 的 close 方法,一步步调用到了 ConcurrentBag 的 requite 方法放回,就像后者方法前的注释说的那样:“有借必有还。如果你只借不还,那么就会导致内存泄漏。”
结合连接时序图和归还连接时序图我们可以发现,PoolEntry 对象通过 borrow 方法从 ConcurrentBag 中取出,再通过 requite 方法被放回,有借有还。当线程调用 getConnection 的时候,会调用 ConcurrentBag 的 borrow 方法,它将首先尝试从该线程的 ThreadLocal 最近使用的连接列表中获取未使用的连接。
当关闭连接时,又会通过 remove 方法删除 PoolEntry。ConcurrentBag 就是 HikariCP 的数据库连接存储结构,它在 HikariCP 中起着举足轻重的作用,其性能直接决定 HikariCP 的整体性能。
关闭连接
在可以热部署的 Web 应用程序中,关闭 DataSource 非常重要。通常可以调用 HikariDataSource 实例的 shutdown 或者 close 方法,也可以配置 Spring 或其他 IOC 容器来指定 destroy 方法。一旦 Connection 进入关闭连接阶段,它立即从池中被移除,但是仍然和数据库 DB 有活动连接,直到 Connection.close 完成。HikariCP 永远不会杀死正在使用的连接,除非池本身被关闭。
关闭分为 HikariDataSouce 和 HikariPool 两种关闭,这两者截然不同。
HikariDatasource 作为 HikariCP 对外对使用方提供的 DataSource,它的 close 方法是粗暴的 shutdown 操作。其 close 方法就是直接关闭数据源及其连接池,源码如下所示:
public void close(){
if (isShutdown.getAndSet(true)) {
return;
}
HikariPool p = pool;
if (p ! = null) {
try {
LOGGER.info("{} - Shutdown initiated...", getPoolName());
p.shutdown();
LOGGER.info("{} - Shutdown completed.", getPoolName());
}
catch (InterruptedException e) {
LOGGER.warn("{} - Interrupted during closing", getPoolName(), e);
Thread.currentThread().interrupt();
}
}
}
HikariDataSouce 的 close 直接调用了 HikariPool 的 shutdown 操作,其具体实现在 HikariPool 的 shutdown 方法里,不但关闭连接池,还关闭了所有空闲连接,中止或关闭活动连接。此外,它还会进行直接取消定时任务、关闭 ConcurrentBag 等一系列清理工作,可以认为就是一个 shutdown 的强硬操作。HikariPool 的 shutdown 源码如下所示:
public synchronized void shutdown() throws InterruptedException {
try {
poolState = POOL_SHUTDOWN;
if (addConnectionExecutor == null) { //如果连接池从未启动
return;
}
logPoolState("Before shutdown ");
if (houseKeeperTask ! = null) {//关闭houseKeeper的任务
houseKeeperTask.cancel(false);
houseKeeperTask = null;
}
softEvictConnections(); //软驱逐连接
addConnectionExecutor.shutdown(); //关闭增加连接线程池
addConnectionExecutor.awaitTermination(getLoginTimeout(), SECONDS);
destroyHouseKeepingExecutorService();
connectionBag.close(); //关闭connectionBag
final ExecutorService assassinExecutor = createThreadPoolExecutor(
config.getMaximumPoolSize(),
poolName + " connection assassinator",
config.getThreadFactory(),
new ThreadPoolExecutor.CallerRunsPolicy());
try {
final long start = currentTime();
do {
abortActiveConnections(assassinExecutor);
softEvictConnections();
} while (getTotalConnections() > 0 && elapsedMillis(start) < SECONDS.toMillis(10));
}
finally {
assassinExecutor.shutdown();
assassinExecutor.awaitTermination(10L, SECONDS);
}
shutdownNetworkTimeoutExecutor();
closeConnectionExecutor.shutdown();
closeConnectionExecutor.awaitTermination(10L, SECONDS);
}
finally {
logPoolState("After shutdown ");
handleMBeans(this, false);
metricsTracker.close();
}
}
与 HikariDataSource 对外提供的 close 接口不同,HikariPool 提供的内部 closeConnection 方法才是我们通常意义上理解的数据库连接池内部的连接关闭逻辑。
当 HikariPool 执行 closeConnection 方法时,首先先从 ConcurrentBag 中移除 PoolEntry,然后 PoolEntry 自身 close,接着独立线程池 closeConnectionExecutor(本质是ThreadPoolExecutor) 调用 JDBC 的方法进行物理连接的关闭。如果 poolState 的状态为 0,还会使用另一个独立线程池 addConnectionExecutor(与 closeConnectionExecutor 对称,本质上也是 ThreadPoolExecutor)进行新连接的生成,fillPool 补足到 HikariCP 的配置值。其核心源码如下所示:
void closeConnection(final PoolEntry poolEntry, final String closureReason)
{
if (connectionBag.remove(poolEntry)) {//ConcurrentBag移除poolEntry
final Connection connection = poolEntry.close(); //poolEntry关闭
closeConnectionExecutor.execute(() -> {
quietlyCloseConnection(connection, closureReason); //jdbc关闭连接
if (poolState == POOL_NORMAL) {
fillPool(); //填充连接池
}
});
}
}
我们可以看到 HikariCP 使用了线程池 closeConnectionExecutor 进行了物理连接的关闭。其实在 HikariCP 的源码里,closeConnectionExecutor 还有一个孪生兄弟 addConnectionExecutor,在 com.zaxxer.hikari.pool.HikariPool 的源码中构造函数初始化的时候就可以看到 public HikariPool(final HikariConfigconfig)。
private final ThreadPoolExecutor addConnectionExecutor;
private final ThreadPoolExecutor closeConnectionExecutor;
//......
LinkedBlockingQueue<Runnable> addQueue =
new LinkedBlockingQueue<>(config.getMaximumPoolSize()
);
this.addConnectionQueue = unmodifiableCollection(addQueue);
this.addConnectionExecutor = createThreadPoolExecutor(
addQueue,
poolName + "connection adder",
threadFactory,
new ThreadPoolExecutor.DiscardPolicy()
);
this.closeConnectionExecutor = createThreadPoolExecutor(
config.getMaximumPoolSize(),
poolName + " connection closer",
threadFactory, newThreadPoolExecutor.CallerRunsPolicy()
);
addConnectionExecutor 和 closeConnectionExecuto r的初始化就是命中了Java 5 种线程池、4 种拒绝策略、3 种阻塞队列的知识点。addConnectionExecutor 用于创建物理连接,它使用了 DiscardPolicy 策略,默认情况下它就是丢弃被拒绝的任务,实际上就是任务满了就不会抛出异常;而 closeConnectionExecutor 用了 CallerRunsPolicy 策略,如果添加到线程池失败,主线程会直接在 execute 方法的调用线程中运行被拒绝的任务,若执行程序已关闭,则会丢弃该任务。
使用 HikariCP 的用户可能经常会看到类似 connection isevicted or dead 这样的异常,其实这是合理的,关闭死连接对于连接池的资源清理至关重要。
HikariCP 关闭连接的 5 种情况:
- 连接验证失败。这对应用程序是不可见的。连接已停用并已替换。用户会看到一条日志消息:“Failed tovalidate connection…”。
- 连接达到了其 maxLifetime。这对应用程序是不可见的。连接已停用并已替换。用户会看到一个关闭原因:“connection has passed maxLifetime”,或者如果在到达时 maxLifetime 正在使用该连接,用户会晚一点看到原因:“connection is evicted or dead”。
- 用户手动驱逐连接。这对应用程序是不可见的。连接已停用并已替换。用户会看到关闭的原因:“connectionevicted by user”。
- JDBC 调用引发了无法恢复的问题 SQLException。这应该对应用程序可见。用户会看到关闭的原因:“connection is broken”。
生成连接
独立的线程池 addConnectionExecutor 用于创建物理连接,它是在 HikariPool 的构造函数中被初始化的。HikariPool 中的 addConnectionExecutor 在 addBagItem() 和 fillPool() 的时候进行新的物理连接的创建。addBagItem 代表向我们之前介绍的 HikariCP 的数据结构 ConcurrentBag 中放置 Bag 项,它的源码实现其实是在 ConcurrentBag 的 borrrow 也就是连接的借用时执行的。核心代码如下所示:
try {
for (T bagEntry : sharedList) {
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
//如果我们已经窃取了另一个等待着的连接,那么请求会新增另一个bag
if (waiting > 1) {
listener.addBagItem(waiting -1);
}
return bagEntry;
}
}
listener.addBagItem(waiting);
在上述代码中,有两处分别执行了 listener.addBagItem(waiting-1) 和 listener.addBagItem(waiting),当有并发连接产生时,如果存在等待的连接或者连接已经不可用,则会进行物理连接的创建。
另一个 addConnectionExecutor 在 addBagItem() 来源于 HikariPool 的 fillPool 的方法,它是来源于 HikariPool 内部的单独线程 HouseKeeper,用来将当前的数据库连接池从当前的空闲连接填充到最小空闲连接的指标。
private synchronized void fillPool()
{
final int connectionsToAdd = Math.min(config.getMaximumPoolSize() -
getTotalConnections(), config.getMinimumIdle() - getIdleConnections())
- addConnectionQueue.size();
for (int i = 0; i < connectionsToAdd; i++) {
addConnectionExecutor.submit((i < connectionsToAdd -1) ?
poolEntryCreator : postFillPoolEntryCreator);
}
}
PoolEntry 是一个封装了物理连接的对象,在 HikariPool 中定义了两个 PoolEntry,分别代表我们刚才介绍的连接生成的两种场景(addBagItem 和 fillPool):
private final PoolEntryCreator poolEntryCreator = new PoolEntryCreator(null
/*logging prefix*/);
private final PoolEntryCreator postFillPoolEntryCreator = new PoolEntryCreator
("After adding ");
addConnectionExecutor 线程调用 HikariPool 的 createPoolEntry 方法进行连接生成,HikariPool 继承的父类 PoolBase 提供的 newPoolEntry 会先进行物理连接的创建,创建完成以后的连接会被封装为 PoolEntry 后放入ConcurrentBag。createPoolEntry 的源码如下所示:
private PoolEntry createPoolEntry()
{
try {
final PoolEntry poolEntry = newPoolEntry();
final long maxLifetime = config.getMaxLifetime();
if (maxLifetime > 0) {
// 设置maxlifetime的2.5%的差额
final long variance = maxLifetime > 10_000 ? ThreadLocalRandom.
current().nextLong( maxLifetime / 40 ) : 0; //随机数
final long lifetime = maxLifetime - variance;
poolEntry.setFutureEol(houseKeepingExecutorService.schedule(
() -> {//设置异步任务
if (softEvictConnection(poolEntry, "(connection has passed
maxLifetime)", false /* not owner */)) {
addBagItem(connectionBag.getWaitingThreadCount());
}
},
lifetime, MILLISECONDS));
}
return poolEntry;
}
catch (ConnectionSetupException e) {
if (poolState == POOL_NORMAL) {
//如果shutdown()同时运行,我们检查POOL_NORMAL以避免消息泛滥
logger.error("{} - Error thrown while acquiring connection from data
source", poolName, e.getCause());
lastConnectionFailure.set(e); //设置上一次连接失败的异常
}
return null;
}
HikariCP 的 maxLifetime 默认是 1800000毫秒(30分钟)。在上述代码中,有一段重要的随机数逻辑,这段代码主要就是根据 maxLifetime 的 2.5% 来设置一个差额,如下所示:
// 设置maxlifetime的2.5%的差额
final long variance = maxLifetime > 10_000 ? ThreadLocalRandom.current().
nextLong( maxLifetime / 40 ) : 0; //随机数
连接生成的时候让每个连接的最大存活时间错开一点,防止同时过期,加一点点随机因素,防止一件事情大量同时发生,比如防止 HikariCP 的连接同时大量死亡。如果 maxLifetime 大于 10000 就是大于 10 秒钟,就执行这个策略,用 maxLifetime 的 2.5% 的时间和 0 之间的随机数来随机设定一个 variance,在 maxLifetime - variance 之后触发 evict。比如,配置 maxLifetime 为 15 分钟时,HikariCP 为每个连接最大寿命注入了 2.5% 的变化,寿命为 15 分钟时,相当于 22.5 秒的变化。一些连接可能在 14 分 38 秒退休,其他连接可能在 14 分 53 秒退休等。
在创建 poolEntry 的时候,注册了一个延时任务,在连接存活将要到达 maxLifetime 之前触发 evit(标记连接池中的连接不可用),用来防止出现大面积连接因为 maxLifetim e是一样的而同时失效,从而造成 HikariCP 数据库连接池不稳定的情况。
在 HikariCP 的 3.3.1 版本中,修复了一个 issue 1287 “setcore pool size before max pool size”,这正是与我们介绍的连接生成 addConnectionExecutor 有关系的。提交这个 issue 的用户反馈:他在执行大量并发耗时查询(查询10~30秒)的时候,启动时的有尖峰请求,在尖峰需求完毕以前池中无空闲连接的情况下反应非常慢,获得新的连接是一个严重阻塞的过程。
根据这个用户的问题,HikariCP 3.3.1 版本在 HikariPool 的初始化过程中统一将 addConnectionExecutor.setMaximumPoolSize 挪到了 addConnectionExecutor.setCorePoolSize 的后面。其源码如下所示:
if (Boolean.getBoolean("com.zaxxer.hikari.blockUntilFilled") &&
config.getInitializationFailTimeout() > 1) { addConnectionExecutor.
setCorePoolSize(Runtime.getRuntime().availableProcessors()); addConnectionExecutor.
setMaximumPoolSize(Runtime.getRuntime().availableProcessors());
final long startTime = currentTime();
while (elapsedMillis(startTime) < config.getInitializationFailTimeout()
&& getTotalConnections() < config.getMinimumIdle()) {
quietlySleep(MILLISECONDS.toMillis(100));
}
addConnectionExecutor.setCorePoolSize(1);
addConnectionExecutor.setMaximumPoolSize(1);
}
com.zaxxer.hikari.blockUntilFilled 是 HikariCP 新版本的一个新功能,它是 HikariCP 官方文档没有提供的系统属性,它的作用是阻塞应用程序直到数据库连接池达到 minimumIdle 值的大小。这个行为在 HikariCP 旧版本期间是单线程的,所以就有可能出现初始化时大量并发连接的长慢查询容易导致 HikariCP 的 getConnection 方法产生阻塞;在 3.3.0 版本中可以进行调整,如果 com.zaxxer.hikari.blockUntilFilled 的属性为 true,并且 initializationFailTimeout 大于 1,则池将由多个线程填充。这线程数由 Runtime.getRuntime().availableProcessors() 确定。初始化后,线程数会在池的生命周期内下降回 1。
那么为什么又要将 setMaximumPoolSize 挪到 setCorePoolSize 后面呢?因为这里有一个 Bug,根据 ThreadPoolExecutor 文档,需要在设置最大池大小之前设置核心池大小,因为在将最大池大小设置为低于核心池大小的值时会抛出 IllegalArgumentException。而这个修复是在 HikariCP 3.3.1 版本中调整的。
setMaximumPoolSize 文档:
public void setMaximumPoolSize(int maximumPoolSize)
Sets the maximum allowed number of threads. This overrides any value set in
the constructor. If the new value is smaller than the current value, excess existing
threads will be terminated when they next become idle.
Parameters:
maximumPoolSize - the new maximum
Throws:
IllegalArgumentException - if the new maximum is less than or equal to zero,
or less than the core pool size
See Also:
getMaximumPoolSize()
5.7 - 参数解析
Working in Progress
5.8 - 动态代理
Working in Progress
5.9 - 应用实践
Working in Progress
5.10 - 监控度量
Working in Progress
5.11 - 常见问题
Working in Progress
5.12 - 扩展技术
Working in Progress
6 - Udf Modeling
6.1 - Transport UDF at Linkedin
如何使用户能够仅编写一次 UDF,并在任何引擎中复用,同时又不牺牲性能。
Transport UDF at Linkedin
在统一数据视图一文中,我们介绍了 Dali 的新型架构,它使得数据和逻辑在 Linkedin 的各种环境中能够被无缝访问和共享。Dali 通过采用物理与逻辑独立的原则来实现这一目标。物理独立性指的是用户能够透明的访问数据,无论其物理位置、存储格式、分区策略,甚至是跨机房的分片策略。逻辑独立性指的是 Dali 的用户自定义逻辑能够用于任何引擎或数据处理框架,而无论其语言接口或数据处理能力如何。作为一个数据和逻辑的共享层,Dali 致力于实现这些目标,同时致力于为其服务的关键任务系统提供几乎相同的性能保证。
这里将介绍逻辑独立性的实现原理:可翻译和可移植的 UDF,或者称为可传输的 UDF。
Dali 中的逻辑以 SQL 视图的形式表示。一个 SQL 视图由一系列应用在输入数据集(基本数据集或其他视图)的逻辑转换构成。在 Linkedin,Dali 视图广泛用于汇总和聚合数据、清除数据噪音、提取感兴趣的或相关信息、应用隐私过滤器,或用于组合来自不同源头的数据以从这些数据中创建洞察力和业务价值。UDF 被广泛的应用于当单纯的 SQL 无法表达应用需要的转换逻辑时,并且通常涉及诸如 Java 这种命令式语言中所表达的相当复杂的操作。只有在视图逻辑和 UDF 定义都能够跨引擎移植时,才能实现真正的逻辑独立性。虽然用于表达视图转换的关系代数表达式可以映射到不同数据处理引擎的不同声明性语言结构,但 UDF 定义却不同,它是命令式且不透明的,因此这也是挑战所在。
UDF 的 API 在数据处理引擎之间存在很大的差异,因为这些 API 必须考虑每个引擎所选择的 内部数据表示,并且必须提供 将数据表示连接到关系模式的能力。这种差异则给应用程序开发人员带来了负担,一旦需要进行引擎迁移或者跨引擎共享相同的逻辑,他们必须学习 UDF 的 API 和每个引擎的数据模型,然后在不同的引擎上以不同的 API 来重新实现相同的逻辑。这引入了我们称之为“UDF 非规范化”的概念,即有害的冗余,这会对生产力和工艺产生负面的影响。
基于这些挑战,问题则变成了:我们如何使用户能够仅编写一次 UDF,并在任何引擎中复用,同时又不牺牲性能。为了解决这个问题,我们将可翻译、可移植的 UDF 构建为一个框架,名为 Transport。虽然在一开始这似乎是一个疯狂而模糊的想法,但到目前为止,我们已经有很多用户在生产中使用了这些功能,我们目前覆盖了 3 个引擎(Hive/Presto/Spark)和一种数据格式(Avro),并且仍在扩展其他处理引擎。
Transport 是一套 API 和框架。用户使用可翻译的 UDF API 来实现 UDF,然后框架再将这些 UDF 转换为各种目标引擎特定的原生 UDF。比如,用于可以基于 Transport UDF API 实现自己的 UDF,框架可以透明的将这些 UDF 转换为原生的 Hive UDF,就像用户直接编写的就是 Hive UDF。现在,如果用户想要在其他引擎中使用这些 UDF 也同样没有问题。比如,如果用户想要在 Presto 查询中使用相同的 UDF,框架同样可以透明的将这些 UDF 转换为 Presto 原生的 UDF,就像用户直接编写的就是 Presto UDF 一样。
在解释 Transport 的工作原理之前,我们先来浏览一下该想法背后的动机,主要有两点:UDF API 的差异性和复杂性。
UDF API 的差异性
数据处理世界中有很多引擎,每个都有各自的特性以满足某个特定的应用场景。同样,每个引擎也都拥有与其他引擎完全不同的 UDF API,这里具体列举其中一些主要的不同点,包括 3 个比较流行的引擎:Hive、Presto、Spark。
UDF 类型验证与推断
UDF API 通常会为用户提供一些手段来指定 UDF 预期的数据类型(如类型验证)、UDF 的输出类型与输入类型的关联关系(类型推断)。比如 Presto 的 UDF API 使用类型签名来描述 UDF 对类型的预期要求,而 Hive 和 Spark 则要求用户通过遍历给定的类型对象树来编写命令式的代码来表示类型验证和推断。
引擎内部数据模型
不同的平台使用不同的数据模型来表示执行引擎中处理的数据,同样也会将这些数据模型直接暴露给 UDF API。比如,Presto 的 UDF 使用 Presto 的 Type Object、Block、Slice、Long、boolean、double 等数据类型来描述数据,而 Hive 的 UDF 使用 ObjectInspectors 和 Objects。其他引擎也类似。
UDF 的定义 API
此外,用户定义 UDF 的方式也随着引擎的不同的不同。比如,Presto 使用特殊的类型注解来声明一个表示 UDF 的类。Hive UDF 类则需要继承 GenericUDF 抽象类,而 Spark UDF 实现则使用 SQL API 或 Expression API。
UDF 的 API 特性
最后,UDF API 提供的特性集也不尽相同。比如,Hive UDF 提供了将文件添加到 MapReduce 分布式缓存的钩子,允许在不同工作程序上执行的 UDF 处理这些文件。Presto 或 Spark 的 UDF 则不提供这种功能。即使多个引擎中都存在某个功能,其在 API 中的表达方式也会有所不同。Presto UDF 允许用户声明哪些参数可以为空,而 Hive 和 Spark UDF 将 null 直接委托给用户。Presto 通过在使用相同名称的情况下多次实现 UDF 来实现 UDF 重载。在 Hive 和 Spark 中,用户使用相同的类,但需要手动检查输入类型是否是符合预期的类型。
UDF API 的复杂性
当前引擎的 API 具有不同程度的复杂性和对 UDF 开发者技能集的期望。比如,Hive UDF 要求开发者理解 Object 和 ObjectInspector 模型。期望用户在 UDF 初始化时捕获输入的 ObjectInspectors,并以树遍历的方式逐级检查来验证它是否符合预期类型。此外,还期望用户通过捕获输入的 ObjectInspectors 子树并从中创建新的 ObjectInspectors 树来显式绑定参数,以作为输出 ObjectInspectors 返回。比如 UDF 期望类型为 Map[String, Array[K]] => Map[K, K],在查询执行时,会使用 Map[String, Array[K]] 来调用 UDF,下面的对象检查器树会被传给 UDF 的初始化方法:
需要由开发者来完成树遍历的工作,验证上面的蓝色节点是否符合用户预期,然后再捕获灰色节点的值(或子树),这里是 K,然后通过将绿色节点添加到从 K 子树捕获的内容来构建下面的树,从而构造返回类型,如下图所示:
此外在 Hive 中,甚至是单个类的 ObjectInspectors(如 StringObjectInspector)也具有该类相同顶级 ObjectInspector 类的变体和不同实现。编写 Hive UDF 的用户必须了解这些差异,并且不同的实现不可互换。处理这些可互换性检查和保证时会带来大量的代码复杂性。
在 Presto UDF 中可以发现另一种形式的 API 复杂性。Presto UDF 允许用户通过 Block API 处理容器数据类型,如 Array、Map、Struct,Block API 是用于操作字节数组的 API。因此,用户会接触到字节数组内复杂数据类型的物理布局,并且必须编写多个步骤的低级操作来表示在这些容器类型上的简单高级操作。另一个例子是使用依赖项注入来解析与泛型类型数组相对应的具体运行时类型,以及解析 UDF 依赖项。此外,当 UDF 期望顶级泛型类型(即它可以采用任何类型)时,必须为每个匹配的顶级具体类型的每个实例重新实现,实现数量的增加使得泛型参数的数量呈指数级增长。虽然通过编写代码生成的 UDF 可以缓解这个问题,但也仍然是一种复杂的方法。
可传输的 UDF
在物理和逻辑独立性的驱动下,以及 API 差异和复杂性问题的推动下,我们设计的 Transport UDF API,它支持用户专注于 UDF 逻辑,而不是实现和遵守特定于平台的接口。用户编写一次逻辑就可以在任何平台上运行。
高阶想法是为用户提供一个用于实现 UDF 的标准数据 API。该标准数据 API 可以由任何平台、使用其在原生 UDF 中使用的原生数据类型来实现。比如,Map 对象将在 Presto 中显示为 PrestoMapType 以及 Block 数据类型。在 Hive 中则是 MapObjectInspector 和一个 Object。这些标准数据 API 被操作仅可传输 UDF API,来表达标准数据上的实际逻辑。
可传输 UDF API 可以通过类型签名来操作泛型容器类型,如 Array[T] 或 Map[K,V]。可传输 UDF 被构造为抽象类,并被表达实际逻辑的具体 UDF 继承。最后,可以从自动生成的特定于平台的包装器来调用这些 UDF API。这意味着,可传输 UDF API 实现是一个独立于平台的中间表示逻辑。它也有两个特定于平台的外观,可以很容易的提供给用户。一个外观向下,这是特定于平台的标准数据 API 实现,另一个外观向上,这是特定于平台的自动生成的包装器。该家头如图所示:
示例
如上所述,用户所要做的就是定义可传输 UDF。在下面的例子中,接收两个数组作为输入来构造一个 Map——第一个数组作为 Map 的键,第二个数组作为 Map 的值。
public class MapFromTwoArraysFunction
extends StdUDF2<StdArray, StdArray, StdMap>
implements TopLevelStdUDF {
private StdType _mapType;
@Override
public List<String> getInputParameterSignatures() {
return ImmutableList.of("array(K)", "array(V)");
}
@Override
public String getOutputParameterSignature() {
return "map(K,V)";
}
@Override
public void init(StdFactory stdFactory) {
super.init(stdFactory);
_mapType = getStdFactory().createStdType(getOutputParameterSignature());
}
@Override
public StdMap eval(StdArray a1, StdArray a2) {
if (a1.size() != a2.size()) {
return null;
}
StdMap map = getStdFactory().createMap(_mapType);
for (int i = 0; i < a1.size(); i++) {
map.put(a1.get(i), a2.get(i));
}
return map;
}
@Override
public String getFunctionName() {
return "map_from_two_arrays";
}
@Override
public String getFunctionDescription() {
return "A function to create a map out of two arrays";
}
}
在上面的例子中,StdMap 和 StdArray 作为接口为 Map 和 Array 对象提供了高阶操作方法。基于 UDF 所要执行的引擎,这些接口会以不同的方式来处理特定引擎的原生数据类型。getStdFactory() 方法会以给定的数据类型来创建对象,比如上面的例子中,Map 的键类型以第一个数组的元素类型为准,Map 的值类型以第二个数组的元素类型为准。StdUDF2 是一个抽象类,表示一个接收两个参数的 UDF,被具体 UDF 的输入输出类型来参数化。
总结
Transport 作为定义 UDF 的 API 和框架,在不牺牲任何性能的同时能够在不同平台上像使用原生 UDF 一样来复用 UDF。这是实现物理与逻辑独立性目标的第一步。被当前 UDF 的差异性和复杂性所驱动。在 LinkedIn,事实证明,可传输 UDF 是提供开发人员工作效率的强大工具,使他们能够共享 UDF 逻辑并确保跨引擎的数据处理一致性。
UDF 的其他应用场景与问题
统一数据处理 API:Apache Beam
在 Apache Beam 的技术愿景中,希望可以使用任意语言 Beam SDK 编写 Beam Pipeline,然后可以运行在任何 Runner 中(每个 Runner 对应一个底层的大数据引擎,例如 Flink Runner、Spark Runner)的能力。设计中通过两个可移植的层来实现这个目标:
- Runner API 层提供了 SDK 和 Runner 无关的 Pipeline 定义。
- Fn API 层,允许 Runner 调用使用特定语言 SDK 编写的 UDF(用户自定义函数)。
通用数据处理框架:Apache Nifi
Nifi 中预定义了大量的 Processor,并支持自定义。Processor 本身仍然可以被看做是扩展了 Nifi 执行上下文的 Function。
Nifi 提供了表达式来操作 FlowFile 的属性,用于配置处理器。表达式有 Antlr 解析,其中的执行函数由 Evaluator 类建模,Evaluator 的建模过程也与 Function 抽象类似,值得借鉴。
流式计算引擎:Apache Flink
Flink 中将函数分为 3 类:
- Scalar Functions,将零个、一个或多个标量值转换到一个标量值。
- Table Functions,将零个、一个或多个标量值转换到多个数据行。
- Aggregation Functions,将一个表转换为一个标量值。
用户自定义并注册函数之后,可以直接在 Table、SQL API 中使用。
流式计算引擎:Aliyun(Antfin) MaxCompute
MaxCompute 与 Flink 类似将函数分为三类,但通过注解或反射来获得函数的类型签名。
规则引擎:Drools
如果业务逻辑复杂,通常会使用规则引擎来代替大量的 if-else 语句。在 Drools 规则定义中,when 部分的断言函数和字段引用、then 部分的数据操作函数都需要应用到函数建模来实现业务特定的计算逻辑。
when
$s : Order(amout > 500 && amout <= 1000)
then
$s.setScore(500);
update($s);
消息路由规则:Apache Camel
Camel 中提供了各种 DSL 或 XML 配置来完成路由规则的定义,如:
from("file:src/data?noop=true")
.choice()
.when(xpath("/person/city = 'London'"))
.to("file:target/messages/uk")
.otherwise()
.to("file:target/messages/others");
对函数的应用主要集中在 when 部分的数据引用与值判定,这里使用的是 xpath 表达式。
有限状态机
在有限状态机中,需要定义状态的迁移条件,迁移条件中包含对领域模型的数据引用、求值与判定,同样需要使用函数建模。
业务应用集成
总的来说,需要在各个层次和维度上,面向业务场景或业务层框架提供一组通用的函数建模 API,以提升业务开发和框架开发的效率。比如:
- 定义较为宽泛的类型系统,以支持对各种引擎、框架中 UDF 的集成。
- 为原生类型提供预定义的函数(或称为算子),以便直接引用来(动态)构建更加复杂的函数。
- 支持基于原生类型构建复杂类型,并为这些复杂类型定义函数。
- 支持直接以代码形式,定义、注册、调用类型安全的函数。
- 支持以字符串表达式形式来定义函数,以满足动态(定义、更新、执行)场景。
- 支持以类似 IDE GUI Plugin 插件的形式定义、引用、执行函数。
- 支持函数式的、类型安全的链式调用、组合、柯里化。
- 提供良好的扩展机制,以优雅的、类型安全的方式扩展、引用函数。
- 提供良好的集成机制,以简便的方式将函数适配到其他框架、引擎以实现复用。
- 提供良好的测试机制,使得函数可测试、且能简化测试过程。
References
6.2 - Flink Type System
为什么以及如何构建一个类型系统。
Flink 在内部构建了一套自己的类型系统,因为 Flink 需要推导那些在分布式计算过程中被传输和存储的数据的相关类型信息。就像数据库对表结构的引用一样。在大多数情况下,Flink 均使用自己的这套类型系统来无缝的推导类型信息。基于丰富的类型类型信息,Flink 可以完成更多功能的实现,如:
- 使用 POJO 类型,并通过对其字段名的引用来执行 grouping、joining、aggregating。类型信息能够帮助 Flink 在早期完成检查(拼写错误或类型兼容性),而非在运行时导致失败。
- Flink 对类型信息了解越多,序列化和数据布局结构则会更好。这对于 Flink 中内存的应用范式是非常重要的(尽可能在堆内外处理序列化数据,以使得序列化过程变得廉价)。
- 避免用户在大多数情况下对序列化框架的担心,同时避免对类型的手动注册过程。
类型层级
- Basic
- Java Primitive Types
- void/String/Date/BigDecimal/BigInteger
- Array
- Array of Primitive
- Array of Object
- Composite
- Java Tuple, max 25 fields
- Scala case class/tuple, max 22 fields
- Row, tuples with any number fields
- POJO, bean-like class
- Auxiliary
- Generic
抽象结构
可以看到,抽象结构与类型层级定义基本对应。TypeInformation 是所有类型的基类。
module: flink-core
package: org.apache.flink.api.common.typeinfo
Comments on TypeInformation class:
- 这是 Flink 类型系统的核心类。对于一个用户函数来说(UDF),Flink 需要一个类型信息来作为该函数的输入输出类型。该类型信息类作为一个工具来生成对应类型的序列化器和比较器,并用于执行语义检查,比如当一些字段在作为 joing 或 grouping 的键时,检查这些字段是否在该类型中存在。
- 该类型信息同时连接了编程语言对象模型和逻辑扁平模式(ligical flat schema)。它将类型的字段映射到扁平模式的列(字段)。
类型提取
TypeExtractor 类可以根据方法签名、子类信息等蛛丝马迹自动提取或恢复类型信息。
module: flink-core
package: org.apache.flink.api.java.typeutils
s
Comments on TypeExtractor class:
一个对类进行反射分析的工具类,用于检测转换函数的返回类型。
该类可以从 function、operator、Class、实例等对象中提取类型信息。
由于 Java 中的类型擦除机制,自动提起并不是很有效,因此有些情况下(比如由 URLClassLoader 动态加载的类)仍然需要手动处理。比如下面的示例中使用 returns 方法来声明返回类型:
inputDS
.groupBy(gourpKeys:_*)
.reduce(new DistinctReduce)
.setCombineHint(CombineHint.HASH)
.name(newName="distinct")
.returns(inputDS.getType)
returns 方法接收 3 种类型的参数:
- 字符串描述的类名,如 “String”。
- 用于泛型类型参数的 TypeHint。
- Java 原生 Class 对象。
类型注册
ExecutionEnvironment 提供的 registerType 方法可以用来向 Flink 注册子类信息(Flink 认识父类,但不一定认识子类的一些独特特性,因此需要注册)。以 Flink-ML 为例:
def registerFlinkMLTypes(env:ExecutionEnvironment):Unit = {
// Vector types
env.registerType(classOf[org.apache.flink.ml.math.DenseVector])
env.registerType(classOf[org.apache.flink.ml.math.SparseVector])
// Matrix types
env.registerType(classOf[org.apache.flink.ml.math.DenseVector])
env.registerType(classOf[org.apache.flink.ml.math.SparseVector])
// Breeze Vector types
env.registerType(classOf[breeze.linalg.DenseVector[_]])
env.registerType(classOf[breeze.linalg.SparseVector[_]])
}
在 registerType 方法内部,会使用 TypeExtractor 来提取类型信息。上面注册过程中调用的方法是:
public void registerType(Class<?> type) {
if(type == null) {
throw new NullPointException(...);
}
TypeInformation<?> typeInfo = TypeExtractor.createTypeInfo(type);
if(typeInfo instanceof PojoTypeInfo) {
config.registerPojoType(type);
} else {
config.registerKryoType(type);
}
}
可以发现,获取到的类型信息属于 PojoTypeInfo 及其子类,那么将其注册到一起;否则统一交给 Kryo 去处理,Flink 并不过问(这种情况下性能会变差)。
类型声明
通过 TypeInformation.of() 方法可以非常方便的创建类型信息对象。
- 对于非泛型类,直接传入 Class 对象即可:
Outer o = new Outer(a:10, new Inner(x:4L), (short) 12);
PojoTypeInfo<Outer> typeInfo = (PojoTypeInfo<Outer>) TypeInformation.of(Outer.class);
- 对于泛型类,需要借助 TypeHint 来保存泛型类型信息。
final TypeInfomation<Tuple2<Integer,Integer>> resultType =
TypeInformation.of(new TypeHint<Tuple2<Integer,Integer>>(){});
- TypeHint 的原理是创建一个匿名子类,运行时 TypeExtractor 可以通过
getGenericSuperclass().getActuralTypeArguments() 方法来回去保存的实际类型。
- 预定义常量。如 BasicTypeInfo 中定义了一系列常用原生类型的类型信息实例。或者直接使用更简单的 Types 类。
- 自定义 TypeInfo 和 TypeInfoFactory。
- 通过自定义 TypeInfo 为任意类提供 Flink 原生内存管理(而非 Kryo),可令存储更紧凑,运行时也更高效。
- 开发者在自定义类上使用 @TypeInfo 注解,随后创建相应的 TypeInfoFactory 并覆盖 createTypeInfo 方法。
- 注意需要继承 TypeInformation 类,为每个字段定义类型,并覆盖元数据方法,例如 isBasicType、isTupleType、元数(对于一维的 Row 类型,等于字段的个数)等等,从而为 TypeExtractor 提供决策依据。
类型序列化
Flink 自带了很多 TypeSerializer 子类,大多数情况下各种自定义类型都是常用类型的排列组合,因而可以直接复用。
如果不能满足,可以继承 TypeSerializer 及其子类来实现自己的特定类型的序列化器。
Kryo 序列化
陷阱与缺陷
- Lambda 函数的类型提取?
- Kryo 的 JavaSerializer 在 Flink 下存在 Bug?
类型机制与内存管理
下面以 StringSerializer 为例,来看下 Flink 是如何紧凑管理内存的。下面是 StringSerializer 的序列化方法:
@Override
public void serialize(String record, DataOutputView target) throws IOException {
StringValue.writeString(record, target);
}
然后是具体的序列化过程:
public static final void writeString(CharSequence cs, DataOutput out) thorws IOException {
if(cs != null) {
// the length we write is offset by one, because a length of zero indicates a null value
int lenToWrite = cs.length() + 1;
if(lenToWrite < 0) {
throw new IllegalArgumentException();
}
// write the length, variable-length ecdoded
while(lenToWrite >= HIGH_BIT) {
out.write(b:lenToWrite | HIGH_BIT);
lenToWrite >>>= 7;
}
out.write(lenToWrite);
for(int i=0; i<cs.length(); i++) {
int c = cs.charAt(i);
while(c >= HIGH_BIT) {
out.write(b:c | HIGH_BIT);
c >>>= 7;
}
out.write(c);
}
} else {
out.write(b:0);
}
}
可以看到,Flink 对于内存管理是非常细致的,层次分明,代码也容易理解。
Reference
7 - Parboiled
Parboiled 是一个轻量、易用、强大且优雅的解析库,用于解析任意任意输入文本,基于 “解析表达式文法(PEGs)”,同时支持 Java 和 Scala。PEGs 是一种针对形式特定语法的上下文无关文法,是对正则表达式的很好替代,通过 CFGs 来构建解析器通常也会比传统的方式要有很多优势。
7.1 - CH01-Motivation
Parboiled 的诞生源自对 JVM 上现有解析器构建工具的挫败感。
近年来流行动态语言(如 Ruby、Groovy)的巨大增长,很大一部分原因是它们将自身作为 DSL 的模型。虽然这些语言(甚至是一些静态类型的语言,如 Scala)具有简洁灵活的语法,通常直接可以用作内部 DSL 的基础,但相当笨拙的 Java 语法使得内部 DSL 非常缺乏吸引力。
对于很多项目来说,一个很小的 DSL 久能够构建出一个优雅的“用户接口”,以在没有 GUI 的情况下提供丰富的表现力以及灵活性。在 Java 中,内部 DSL 并不在规划之内,你不得不为外部 DSL 构建一个解析器以获得便利。尽管外部 DSL 并非解析器的唯一用例,像 Java 中这样对语言的传统解析支持工具并不出众。很多时候支持 DSL 并非项目的核心目标(如下编译器实现中),而是解决各种问题之一的优雅方案。因此,你可能并不希望将太多时间用于上下文无关的文法、词法理论以及错综复杂的外部解析器生成器。您只想以某种方式指定解析语法的外观并使其快速轻松地工作。这也就是 Parboiled 存在的原因。
下面是一些传统解析器生成器的缺点:
- 专有性,以非 Java 语法的形式保存在单独的项目文件(如外部 DSL)。
- 对文法文件没有 IDE 内置支持(语法高亮、内联检查、重构、代码导航等)。
- 运行外部解析器生成器需要特殊的构建步骤。
- “谜不可触”,在你项目中生成的 Java 源文件需要与文法规范保持同步。
- 通过词法分析(令牌生成)和令牌解析阶段中的分离解析过程进行更复杂的设计和维护。
- 综合占用(ANTLR 分发的生成器加上运行时占用多余 1.8 MB)。
7.2 - CH02-Features
- 以 Java、Scala 源码的形式定义文法。
- 没有外部的、非 Java/Scala 源码格式的文件。
- 无需学习额外的特有语法。
- 无需破坏 IDE 支持。
- 真实世界可读。
- 来自PEG的完整表现力。
- 支持强大且灵活的解析器动作。
- 游戏的解析错误包括与恢复。
- 高性能。
- 非常易于集成。
- 无需管理外部的解析器生成器。
- 没有特殊的步骤使你的构建过程复杂化。
- 你的项目结构中不再有“谜不可触”的、生成的源文件。
- 开放、轻量的结构使得非常易于集成到现有项目结构。
- 轻量、易用。
- 仅有一个解析阶段(词法分析代码不是必须的)。
- 少量且简单的 API。
- 整个库仅占用 300/450 KB,依赖较少。
虽然 Parboiled 最初设计的速度低于易用性和可维护性,但其解析性能自早期版本以来已显着改善,现在对于大多数应用程序来说已经足够了。它可以以近似的速率解析其自身的 Java 5 源码。以每秒 55,000 行或每秒 200 万个字符的速度运行(2.4 GHz Intel Core i5 单核,OS/X Java 6)。
7.3 - CH03-Java Example
首先是一个计算器的文法定义:
Expression <- Term (('+' / '-') Term)*
Term <- Factor (('*' / '/') Factor)*
Factor <- Number / '(' Expression ')'
Number <- [0-9]+
然后是基于 Java 代码的解析器定义:
@BuildParseTree
class CalculatorParser extends BaseParser<Object> {
Rule Expression() {
return Sequence(
Term(),
ZeroOrMore(AnyOf("+-"), Term())
);
}
Rule Term() {
return Sequence(
Factor(),
ZeroOrMore(AnyOf("*/"), Factor())
);
}
Rule Factor() {
return FirstOf(
Number(),
Sequence('(', Expression(), ')')
);
}
Rule Number() {
return OneOrMore(CharRange('0', '9'));
}
}
最后是对该解析器的应用:
String input = "1+2";
CalculatorParser parser = Parboiled.createParser(CalculatorParser.class);
ParsingResult<?> result = new ReportingParseRunner(parser.Expression()).run(input);
String parseTreePrintOut = ParseTreeUtils.printNodeTree(result);
System.out.println(parseTreePrintOut);
第 2 行创建了一个解释器实例,其方法可以被用于各种不同的 ParserRunner 来执行实际的解析过程并创建 ParsingResult。ParsingResult 对象除了包含输入是否匹配的信息之外,还包含表达式的解析树的根(如果启用了解析书构建)、结果值、解析错误列表。理解解析器是如何处理输入的方式是使用 ParseTreeUtils.printNodeTree,如上面示例中第 4~5 行那样。
通常来说,Parboiled 会在 Java 语法的约束下使你的规则规范尽可能的可读。
7.4 - CH04-Scala Example
首先是一个计算器的文法定义:
Expression <- Term (('+' / '-') Term)*
Term <- Factor (('*' / '/') Factor)*
Factor <- Number / '(' Expression ')'
Number <- [0-9]+
然后是基于 Scala 代码的解析器定义:
import org.parboiled.scala._
class SimpleCalculator extends Parser {
def Expression:Rule0 = rule { Term ~ zeroOrMore(anyOf("+-") ~ Term) }
def Term = rule { Factor ~ zeroOrMore(anyOf("*/") ~ Factor) }
def Factor = rule { Number | "(" ~ Expression ~ ")" }
def Number = rule { oneOrMore("0" - "9") }
}
最后是对该解析器的应用:
val input = "1+2"
val parser = new SimpleCalculator { override val buildParseTree = true }
val result = ReportingParseRunner(parser.Expression).run(input)
val parseTreePrintOut = org.parboiled.support.ParseTreeUtils.printNodeTree(result)
println(parseTreePrintOut)
7.5 - CH05-Comparison
如果你将解析需求想象为一个光谱,一边是“脏且快”的正则表达式,一边是像 ANTLR 一样完整的解析器生成器,Parboiled 则旨在填补两端之间的巨大空间。对于非常简单的用例,正则表达式可能是一个具有最小开销的适当解决方案。然而,正则表达式可以很快变成丑陋的混乱、难以阅读理解并最终难以维护。在许多情况下,它们也缺乏表达能力来解析像嵌套构造这样需要递归规则定义的东西。它们也不会生成正确的错误消息或从输入的错误中恢复,而这可以在开发过程中节省大量时间。
在光谱的另一端,像 ANTLR 和 Rats! 这样强大的工具当然也有其适用场景。当必须解析那些用复杂语言编写的大量源码时,解析器生成器可能是合适的工具。比如,你可能想要使用现有的语法,或者需要一些发展多年的企业工具的完整特性集。
然而,当你需要定义自己的语法,并且对解析器生成器没有丰富的经验,Parboiled 则可以快速简便的帮你达到目的。Parboiled 可以用于小的任务,如解析日期与时间;也可以用于复杂的任务,如解析 Java 源码或像 Markdown 这样的标记语言。占用小、轻量的架构使其很容易与其他应用集成,同时又能为多种定制需求提供良好的基础。
7.6 - CH06-Concepts
纵观全局
Parboiled 提供了一个递归下降的 PEG 解析器实现来操作你指定的 PEG 规则。
你的语法规范可以包含解析器动作,这些动作可以在解析过程中的任意一点执行额外的逻辑,比如使用自定义条件来增强输入识别,或者构造抽象语法树(AST)。
两个阶段
你的代码会在两个阶段与 Parboiled 交互。在第一个阶段——“规则构造”阶段,Parboiled 会基于你定义的 Java/Scala 代码为解析器规则构建一个树(一个有向图)。该阶段与实际的输入阶段没有依赖,仅需要在整个 JVM 的生命周期中执行一次,即构建过的规则树是可复用的。第二个阶段是实际的解析阶段,使用第一阶段中的规则来处理特定的输入文本。最终的执行结构将包含以下信息:
- 一个布尔值来表示输入是否与根规则匹配。
- 可能遇到的所有解析错误。
- 由你的解析器动作构造的一个或多个值对象。
规则构造
在执行由 Java/Scala 定义的规则代码时将触发规则构造。Parboiled 分别为 Java 和 Scala 提供了单独的 DSL 来使得规则的定义过程与语言本身结合的更加舒适。
在 Java 中你需要实现一个自定义类来继承 BaseParser 类,并定义一些方法来返回 Rule 实例。这些方法可以通过调用其他自定义方法、终止符、预定义原语、动作表达式来构造规则实例。由于 Java 语法的限制,Parboiled 则使用了一个名为“解析器扩展(Parser Extension)”的过程来支持比其他方式更加简洁的规则构造代码。
因为 Scala 本身就富有较强的表现力,因此 Parboiled 并不需要为 Scala 再提供一个单独的解析器扩展步骤。在 Scala 中,你可以直接通过 Scala 语言元素来构造解析器规则树。
解析动作
为了避免你的解析器仅仅是一个“识别器”(一段仅能检测输入是否与定义的语法匹配的代码),在你的解析器中需要包含一些动作。解析器动作是一段自定义的代码,在规则执行期间的一些特定点被执行。除了检查解析器状态(如查看匹配的输入文本片段),解析器动作通常用于构造“值”(如 AST 节点),并可以作为语义谓词主动影响解析过程。
值栈
在规则执行阶段,你的解析器动作可以利用“值栈”来组织自定义对象的构造,如 AST 节点。值栈是一个简单的栈结构,作为一个临时存储为自定义对象提供服务。使用值栈的方式取决于你使用的是 Parboiled Java 还是 Parboiled Scala。
解析树
在规则执行阶段 Parboiled 能够以可选的方式构造一个解析树,其节点对应于已识别的规则。每个解析树 Node 包含一个对应规则的 Matcher,同时,被匹配的输入文本(位置)也会作为当前值栈的栈顶元素。该解析树可以被看做是输入对已匹配规则的记录,在调试过程中尤其有用。
解析执行器
ParseRunner 的职责是“监管”解析的执行过程,并能以可选的方式提供额外的逻辑,尤其重要的是对非法输入字符的处理(基于语法)。当你使用 Parboiled 执行解析时可以选择一下 5 种预定义的 ParseRunner:
- BasicParseRunner,最快最基本的 ParseRunner,不执行错误处理。
- ReportingParseRunner,为输入的第一个错误创建衣蛾 InvalidInputError。
- RecoveringParseRunner,最复杂的 ParseRunner,报告输入中的所有错误,并尝试从错误中恢复。
- TracingParseRunner,为每条匹配的或未匹配的规则有选择的打印追踪信息。
- ProfilingParseRunner,在你的解析器处理一个或多个输入时生成详细的统计信息。
Rule Tree
像大多数解析相关的程序一样,Parboiled 严重依赖于图和树结构。第一个这样的结构会在解析过程中创建,即规则“树”。该规则树这时尚未与实际的输入产生依赖。解析输入会在解析执行的过程中被解析器消费并被应用到规则树上,该过程可以以可选的方式生成一个解析树。
假设以下示例语法:
a ← b ‘a’ c
b ← ‘b’ d
c ← ‘c’ d
d ← ‘d’ c?
如果你将该语法转换为一个图,仅将规则作为图的节点,规则引用作为有向边,这时该语法可以用以下结构来表示:
你会发现该图存在一个环,同时节点 d 拥有两个父亲,这也就是为什么该图不是一个树而仅仅是一个有向图。很多真实世界的语法的大多部分都像是一个树,带有非常清晰的规则到子规则层级引用。虽然回环(递归)并不十分罕见,但与“常规”分层引用相比,它们的数量确实很少。
因此这样的原因(以及对许多人而言,“树”是一种更常见的心理图景),你可能会选择将这样的规则图看做是带有两个特殊异常的规则树:多父亲、回环。
顺便提一下,PEG 语法的这种有向图特性几乎与方法调用在 JVM 中的工作方式一致:方法调用其他方法,可能包括调用堆栈祖先。这也是为什么 Parboiled 会或多或少的将规则声明映射到 Java/Scala 的方法调用。你的每个解析器规则方法都会构造一个规则对象,并在构造过程中潜在的调用其他规则构造方法。
然而这里还有两个问题:
- Java/Scala 方法递归到方法自身或其祖先时需要一种方式来终止递归。通常这是通过一些逻辑实现的,可以在逻辑中通过一些条件来退出递归。然而规则声明无法做到这一点,只有解析的输入文本(是有限的)将会终止任何规则递归。因此为了防止用于构造规则的 Java/Scala 方法出现无限递归,需要采取一些技巧。
- 当一个规则构造方法被调用多次时(可能被多起其他规则构造方法调用),通常会为每次调用创建结构相同的全新的规则实例。虽然这不是什么问题,但在规模较大的语法中则会比较低效,这时一个大型的规则树中会包含很多重复的规则实例。
Parboiled 在 Java 中通过重写解析类的规则方法来、并注入开发者不可见的代码来解决这两个问题。这些代码会确保每个方法仅会被调用一次,即背个规则仅被创建一次,后续的调用则会返回已创建的相同规则实例。如果规则的创建过程递归会自身,则插入代理规则以防止无限递归。所有这些事情都在幕后透明地发生,开发者无需关心。
Parboiled 在 Scala 中则不需要重写实际的字节码,而是将实际的规则创建代码封装到一个函数块,并作为主规则构建方法的参数。
最后,当你调用你的顶级规则方法并传给所选的 ParseRunner 时,则会得到一个规则树,没有重复节点,正确的链接关系,甚至还有递归。
Mathcers
你可能已经在 Javadoc API 文档中看到 Rule 接口仅仅是一个外观接口,带有很少的方法以指定特殊的规则属性。所有实现该接口的类被定义在 org.parboiled.matchers 中。有一个用于所有规则原语的 Matcher 实现,它实现了实际规则类型的逻辑。因此规则树实际上是一个 Matcher 树。然而,大多时候你不必了解这些内部细节,仅需关注于解析器规则和值栈。
Value Stack
在规则执行阶段,你的解析器动作可以利用“值栈”来组织自定义对象(如 AST 节点)的构造。值栈是一个简单的栈结构,作为临时存储服务于自定义对象。
通常,规则可以以任何方式修改值栈。可以创建新的值并推到栈上,或者消费已有的值,或者转换已有的值并重新推到栈上,等等。Parboiled 解析引擎并不关心你的规则和解析器动作与值栈之间的交互。
有两个特殊异常:
规则未匹配
如果规则因任何原因未匹配成功,则将值栈重置为执行该失败规则之前的状态。这意味着失败的规则无法修改值栈(这包括失败的语义判定动作)。
此行为的原因是使您不仅可以将动作放在一系列规则的最后位置。考虑如下规则:
Rule ← ‘a’ ‘b’ action ‘c’
假设匹配规则 “b” 之后将一个新值推到栈上。如果因为最终的元素 “c” 不能匹配到规则而导致规则序列失败,该值栈仍然会包含刚才被动作推入的新值。即使您的规则逻辑可能能够处理这些情况,这也会使动作设计复杂化并使解析器逻辑更加脆弱。
事实上,当规则不匹配时 Parboiled 重置堆栈的行为使得你可以自由的放置解析器动作,并将值栈用于规则内临时存储,这在很多情况下都非常方便。
语义判定
Test 和 TestNot 规则永远不会影响值栈。Parboiled 会使用一个以保存的快照将值栈重置回 Test/TestNot 规则匹配之前的状态。因此,您可以确定语法判定永远不会“混乱”您的值栈设置,即使它们包含解析器动作或引用其他规则。
Parse Tree
Parboiled 在规则执行阶段以可选的方式支持构建一个解析树。查看解析树可以更好的理解你的解析器对输入的消费过程,因此有助于解析器的开发和调试。
由 Parboiled 创建的解析树由一系列实现 Node 接口的不可变对象组成。除了基本的树节点功能(父亲、儿子)之外,该接口定义了节点名、所匹配输入文本的起始终止位置,以及一个自定义值对象。一些工具类为解析树提供了额外的处理方法,有 ParseTreeUtils、TreeUtils、GraphUtils。
需要注意的是解析树的节点是不可变的,即一旦被创建则不再能被修改。这实际上意味着它们的子节点结构和它们的值对象“引用”不能被修改。(尽管它们的值对象可以是可变的,或者仍然能够被修改。)整个解析树会从底向上被构建,先从叶子节点开始。通常来说,如果开启了解析树构建选项,匹配成功的每个规则都会创建一个解析树节点,该节点将匹配成功的子规则所创建的节点作为子节点。匹配失败的规则不会创建节点。解析树可以被认为是“已匹配规则的记录”。Parboiled 将解析树节点的 value 字段值设置为节点构造时值栈的栈顶元素。因此产看解析树值对象可以为你提供解析器如何使用值栈的线索。
或许对解析树最有用的使用方式是使用 ParseTreeUtils 的 printNodeTree 来将其打印出来。
在 Java 中开启解析树构建
可以在解析器实现类上添加 @BuildParseTree 注解来开启解析树构建。还可以在解析器方法上使用 @SuppressNode/@SuppresssSubnodes/@SkipNode 来对解析树进行微调。
在 Scala 中开启解析树构建
在 Scala 中,Parser 特质拥有一个 buildParseTree 标记方法,将其设置为 true 则可以开启解析树构建。最简单的方式是在解析器类的构造方法上调用 .withParseTreeBuilding() 方法。类似 Java API,可以使用 Parser$RuleOption 中的选项来对解析树的构建过程进行微调。
AST Construction
和解析树与语法之间的紧密关联关系相反,你想要构造的抽象语法树(AST)则完全取决于你的项目需要。这就是为什么 Parboiled 采用非常开放和灵活的方法来支持它。
事实上对 AST 节点的类型没有任何约束。Parboiled 没有提供任何不变或可变的对象来使用,因此也不会强制你使用什么。可以查看 org.parboiled.trees 包来开始。
通常你可以使用解析器值栈来作为构造 AST 的“工作台”。对于 Java API 可以参考 Calculators 示例,Scala API 可以参考 JSON Parser 示例。
Error Handling
对非法输入的适当处理是任何要被应用到真实项目的解析器的关键特性,这也是正则比倒是的最大缺陷之一。比如,如果用户在自定义 DSL 中提供了输入,你可以清楚的知道其中的语法或语义错误。语义错误可以被更高级的应用程序捕获并报告,但是语法错误必须在解析器中直接被捕获并报告。Parboiled 通过提供 4 种不同的 ParseRunner 实现来支持你选择处理解析错误的方式。
BasicParseRunner
这是最简单的实现。它不会执行任何错误处理,如果输入与指定的语法规则无效,则会简单的导致解析过程不匹配。这时,它的行为就像正则表达式引擎一样。它只执行一次解析,是确定指定输入是否符合解析器语法定义的最快方式。
RecordingParseRunner
比 BasicParseRunner 多一点特性:跟踪输入字符流中成功匹配的最远输入位置。如果给定的语法根规则不匹配,则紧随其后的位置必须是错误位置。和 BasicParseRunner 一样,仅执行一次解析运行。
ReportingParseRunner
不提供任何错误恢复功能,但是会在发现输入中的第一个匹配错误时报告错误。它在无错误输入上执行一次解析运行,但如果输入包含解析错误,则内部触发另外两次运行。在第二次运行期间,它会记录第一个解析错误的位置,并且在第三次运行期间,它会“监视”解析器尝试匹配错误字符时的行为,以便为用户创建有意义的错误消息。然后实例化一个 InvalidInputError 并将其添加到 ParsingResult 中返回的错误解析列表中。
RecoveringParseRunner
这是 4 种 ParseRunner 实现中最复杂的一个,它提供了自动的、只能的错误恢复,并且即便是存在解析错误也能完整的解析整个输入文本。Parboiled 提供的这种策略与 ANTLR 类似。如果可能的话,Parboiled 会在识别到非法输入时尝试进行单字符删除、插入或替换。如果仍然失败,Parboiled 会在当前规则堆栈中找到合适的重新同步规则,并是由所有非法字符,知道解析器可以重新同步以继续解析为止。
解析错误恢复细节
类似于 ReportingParseRunner,RecoveringParseRunner 首先会尝试一次快速的基本运行以发现输入是否存在错误。如果整个输入没有任何错误则直接结束执行。
如果首次运行出现错误,RecoveringParseRunner 则会执行以下算法来尝试克服错误:
- 首先执行一次“记录运行”以检测当前错误的位置。
- 然后执行一次“报告运行”,并将有意义的 InvalidInputError 添加到解析错误列表。
- 然后当前错误位置的字符会被临时性的删除,随后再次执行“记录运行”来发现下个错误的位置,以此类推。如果没有发现更多错误,则表示所有错误已被解决,然后直接结束解析。
- 在“报告运行”期间,运行器会收集所有在预期字符发生错误的规则并失败。对于所有这些规则,运行期会尝试插入临时性的“虚拟”字符到输入字符流,然后执行一次“记录运行”来检测下个错误的位置。如果这些插入的字符能够使得完整运行整个输入文本,则直接结束解析。
- 运行器尝试使用一个配件“虚拟”字符来替换错误字符(像上一步一些样)。如果这样能够使得错误得到解决则直接结束解析。
- 在这一步中,运行器知道没有单个字符恢复能够完全修复错误输入。但是它现在知道是否有一个动作(单个字符删除、插入、替换)允许解析器能够继续解析直到超出错误的位置。如果是这种情况,则可以通过单个字符恢复来克服错误,并且运行器应用允许解析器继续解析最远输入流的修复。因此,如果有可用的话,运行器总是选择最好的单字符修复。
- 如果没有单字符修复能够使得将下一个错误位置推送到当前错误位置之外,则会强制运行程序重新同步并重新执行“记录运行”以确定下一个错误的位置。为了做到这一点,运行器首先识别重新同步规则,该规则是作为序列并且已经匹配至少一个字符的第一个父规则。运行器确定运行哪些字符在合法解析中遵循此重新同步规则,并跳过所有不符合条件的字符。
- 既然最佳单字符修复或重新同步已经克服了当前的解析错误,则运行器继续解析到下一个错误并从步骤 1 开始从该错误中恢复。
动作设计的后果
由于上述概述的解析错误恢复策略允许解析即使已存在错误,如果你决定使用 RecoveringParseRunner,解析器动作应该能够处理一些意外情况。
单字符修复通常不会对你的动作产生任何影响,因为解析器动作所能看到的匹配输入文本已经包含错误更正,即排除掉了非法字符,并且在错误恢复期间插入的虚拟字符也包含在其结果中。但是,通过重新同步进行错误恢复会导致不匹配的规则序列“神奇的”匹配,即使并非是所有序列子规则都匹配或甚至运行。由于这会抛弃预期的值栈设置,因此在重新同步期间,Parboiled 会在重新同步序列中执行所有低限度要求的解析器动作。所有这些动作都会看到空匹配,因此可以提供有意义的默认值。
7.7 - CH07-Java APIs
Parboiled Java 的应用步骤:
- 安装依赖。
- 确定要解析器值栈中要参数化的类型,继承 BaseParser 实现自定义解析类。
- 在该解析类中添加返回类型为 Rule 的规则方法。
- 通过
Parboiled.createParser 创建解析器实例。 - 调用解析器的根规则方法来创建规则树。
- 选择 ParseRunner 的特定实现,调用其 run 方法并传入根规则和输入文本。
- 查看 ParsingResult 对象的属性。
Rule Construction
一个 PEG 由任意数量的规则组成,规则又可以由其他规则、终止符、或下表中的原语规则组成:
| Name | Common Notation | Primitive |
|---|
| Sequence | a b | Sequence(a, b) |
| Ordered Choice | a | b | FisrtOf(a, b) |
| Zero-Or-More | a * | ZeroOrMore(a) |
| One-Or-More | a + | OneOrMore(a) |
| Optional | a ? | Optional(a) |
| And-Predicate | & a | Test(a) |
| Non-Predicate | ! a | TestNot(a) |
这些原语实际是 BaseParser 类的实例方法,即所有自定义解析器的必要父类。这些原语规则创建方法可以接收一个或多个 Object 参数,这些参数的类型可以是:
- 一个 Rule 实例
- 一个字符字面量
- 一个字符串字面量
- 一个字符数组
- 一个动作表达式
- 实现了 Action 接口的类的实例
除了以上原语方法,还有以下原语可供使用:
| Method/Field | Description |
|---|
| ANY | 匹配任何除了 EOI 的单个字符 |
| NOTHING | 不匹配任何,总是失败 |
| EMPTY | 不匹配任何,总是成功 |
| EOI | 匹配特殊的 EOI 字符 |
| Ch(char) | 创建一个匹配单个字符的规则 |
| CharRange(char, char) | 匹配给定的字符范围 |
| AnyOf(string) | 匹配给定字符串中的任意字符 |
| NoneOf(string) | 不匹配给定字符串中的任意字符和 EOI |
| IgnoreCase(char) | 匹配单个字符且忽略大小写 |
| IgnoreCase(String) | 匹配整个字符串且胡烈大小写 |
| String(string) | 创建一个匹配整个字符串的 |
Parser Action Expressions
Parboiled Java 的解析器可以在规则定义的任意位置包含解析器动作。这些动作可以分为 4 类。
“Regular” objects implementing the Action interface
如果你的动作代码较多,则可以将其封装到一个实现了 Action 接口的自定义类中,然后再在规则定义方法中使用该自定义类的实例。
class MyParser extends BaseParser<Object> {
Action myAction = new MyActionClass();
Rule MyRule() {
return Sequence(
...,
myAction,
...
);
}
}
如果使用这种方式,你的自定义动作类也可以实现 SkippableAction 接口以告诉解析器引擎在执行内部的语法判定时是否跳过这些动作。
Anonymous inner classes implementing the Action interface
更多时候动作仅会包含少量的代码,这时可以直接使用匿名类:
class MyParser extends BaseParser<Object> {
Rule MyRule() {
return Sequence(
...,
new Action() {
public boolean run(Context context) {
...; // arbitrary action code
return true; // could also return false to stop matching the Sequence and continue looking for other matching alternatives
}
},
...
);
}
}
Explicit action expressions
虽然匿名类要比独立的动作类定义简单一点,但仍然显得冗余。可以继续简化为一个布尔表达式:
class MyParser extends BaseParser<Object> {
Rule MyRule() {
return Sequence(
...,
ACTION(...), // the argument being the boolean expression to wrap
...
);
}
}
BaseParser.ACTION 是一个特殊的标记方法,其告诉 Parboiled 将参数表达式封装到一个单独的、自动创建的动作类中,类似上面匿名类的例子。这样的动作表达式中可以包含对本地变量的访问代码或方法参数、读写非私有的解析器字段、调用非私有的解析器方法。
此外,如果动作表达式中调用实现了 ContextAware 接口的类对象方法,将自动在调用方法之前插入 setContext 方法。比如你想将所有的动作代码移出到解析器类之外以简化实现:
class MyParser extends BaseParser<Object> {
MyActions actions = new MyActions();
Rule MyRule() {
return Sequence(
...,
ACTION(actions.someAction()),
...
);
}
}
如果 MyActions 实现了 ContextAware 接口,Parboiled 将会自动在内部转换为类似下列清单的代码:
class MyParser extends BaseParser<Object> {
MyActions actions = new MyActions();
Rule MyRule() {
return Sequence(
...,
new Action() {
public boolean run(Context context) {
actions.setContext(context);
return actions.someAction();
}
},
...
);
}
}
注意 BaseParser 已经继承了 BaseActions,其实现了 ContextAware 接口,所以解析器类中的所有动作方法可以通过 getContext 方法获得当前的上下文。
Implicit action expressions
大多数情况下,Parboiled 可以自动识别你的规则定义中哪些是动作表达式。比如下面的规则定义中包含了一个隐式的动作表达式:
Rule Number() {
return Sequence(
OneOrMore(CharRange('0', '9')),
Math.random() < 0.5 ? extractIntegerValue(match()) : someObj.doSomething()
);
}
Parboiled 的检测逻辑如下:
BaseParser 中所有的默认规则创建器方法都拥有通用的 Java Object 参数,Java 编译器会自动将原始布尔表达式的结果作为一个 Boolean 对象传递。这是通过在布尔动作表达式的代码之后隐式地插入对 Boolean.valueOf 的调用来实现的。Parboiled 会在你的规则方法字节码中查找这些调用然后将其当做隐式动作表达式来处理,如果其结果直接被用作规则创建方法的参数的话。也可以通过 @ExplicitActionsOnly 注解(定义在解析类或规则方法上)来关闭该功能。
Return Values
动作表达式均为布尔表达式。其返回值将影响对当前值的解析进度。如果动作表达式的结果为 false,解析将继续,就像替换动作表达式的假设解析规则失败一样。因此,你可以将动作表达式视作可以(匹配)成功或(匹配)失败的“规则”,具体则取决于其返回值。
Value Stack
在任何特定的解析项目中,解析器动作都希望能够以某种方式来创建对应输入文本结构的自定义对象。Parboiled Java 提供了两种工具来在解析器规则中管理创建的自定义对象:
值栈是一个简单的栈结构,作为一个临时存储为你的自定义对象提供服务。你的解析器动作可以将对象推到栈上、推出栈、推出再推入栈交换对象,等等。值栈的实现隐藏在 ValueStack 接口下面,其定义了操作值栈的一系列方法。
所有的解析器动作可以通过当前 context 的 getValueStack 来获得当前值栈。为了简化值栈操作的冗余,BaseActions 类(BaseParser)的父类提供了一些值栈操作的快捷方法,可以直接在解析器动作表达式中内联使用。
在解析器规则中使用值栈的方式通常有以下几种:
- 匹配分隔符、空格或其他辅助结构的规则通常不会影响值栈。
- 较底层的规则会从匹配到的输入中创建基本对象并推到栈上。
- 调用一个或多个底层规则的高级别规则,会从栈上推出值对象,然后创建高级别的对象并重新推到栈上。
- 根规则作为最高级别的规则会创建自定义结构的根对象。
大多时候,但一个规则被完整处理过后,最多会推一个对象到栈上(尽管在处理过程中会推多个对象到栈上)。那么你可以认为:如果规则匹配,一个规则会在栈上创建一个特定类型的对象,否则则不会影响栈。
规则定义须知
一条重要的原则是一个规则总是应该确保其对值栈的操作是“稳定的行为”,而无论输入是什么。因此,如果一个规则将一个特定类型的值对象推到栈上,则其应该为所有可能的输入都推一个值到栈上。如果不然,那么引用该规则之外的规则时将无法在规则匹配之后会值栈的状态进行假设,这将使动作设计复杂化。以下讨论着眼于各种 PEG 原语以及在使用影响值栈的解析器操作时需要注意的事项。
Sequence 规则
由于它们不提供任何可选组件,因此关于值栈操作,序列规则相当直接。它们的最终结果本质上是稳定的,仅包括所有子操作的串联。
FirstOf 规则
FirstOf 规则提供了几种替代子规则匹配。为了向外部提供稳定的“输出”,重要的是所有替代方案都表现出兼容的值堆栈行为。考虑以下例子:
Rule R() {
return FirstOf(A(), B(), C());
}
如果子规则 A 将推一个对象到栈,则 B 和 C 也需要这样做。
Optional 规则
Optional 规则的子规则通常不应该在值栈中添加或删除对象。由于 Optional 规则始终会匹配成功,即使其子规则不匹配,对值栈上的对象数量的任何影响都将违反“稳定行为”的原则。但是,Optional 规则可以很好的转换值栈上的内容,而避免不稳定的行为。
Rule R() {
return Sequence(
Number(), // number adds an Integer object to the stack
Optional(
'+',
Number(), // another Integer object on the stack
push(pop() + pop()) // pop two and repush one Integer
)
);
}
该规则的行为始终是稳定的,因为它总是会将一个值推送到栈上。
ZeroOrMore/OneOrMore 规则
与 Optional 规则类似,不能添加或删除值栈的元素,而可以修改值栈的元素内容。
Action Variables
对值栈的操作需要一些设计素养,同时为了类型安全,值栈中仅能使用一个较为宽泛的通用类型,然后再在解析器动作使用使用强制类型转换,这会带来维护成本。为了提供更多的灵活性,提供了动作变量功能。
通常,一个规则方法会在规则的子结构中包含多个动作表达式,以协同的方式来构造出最终规则。在很多情况下如果能够通过一个通用的临时辅助变量来访问规则中所有的动作,则会大有帮助。考虑如下例子:
Rule Verbatim() {
StringVar text = new StringVar("");
StringVar temp = new StringVar("");
return Sequence(
OneOrMore(
ZeroOrMore(BlankLine(), temp.append("\n")),
NonblankIndentedLine(), text.append(temp.getAndSet(""), pop().getText())
),
push(new VerbatimNode(text.get()))
);
}
该规则用于解析 Markdown 的逐行结构,其中包含一行或多行的缩进文本。这些缩进行可以通过完全的空行来拆分,如果其跟随的有最少一个缩进行则也可以被匹配。该规则的工作是创建一个 AST 节点并初始化为匹配到的文本(不带有行缩进)。
为了能够构建该 AST 节点的文本参数,如果能够访问一个字符串变量——作为构建字符串的临时容器,则会非常有帮助。在通常的 Java 方法中可以使用一个本地变量,然而,因为规则方法仅包含规则的构造代码而非规则实际运行的代码,因此本地变量起不了作用。因为本地变量仅能在规则的构造期间而非运行期间可见。
这就是为什么 Parboiled Java 提供了一个名为 Var 的类,它可以用作规则执行阶段的本地变量。Var 对象包装一个任意类型的值,可以拥有初始值,支持对值的读写,可以在嵌套规则方法之间传递。每轮规则调用(如规则匹配重试)都会接受到自己的 Var 域,因此递归规则中的动作也会像预期一样运行。此外,Var 类还定义了一系列简便的辅助方法来简化其在动作表达式中的应用过程。
如下所示:
Rule A() {
Var<Integer> i = new Var<Integer>();
return Sequence(
...,
i.set(42),
B(i),
action(i.get())
);
}
Rule B(Var<Integer> i) {
return Sequence(
...,
i.set(26)
);
}
规则方法 A 传递一个其域内定义的 Var 作为参数到规则方法 B,规则方法 B 内的动作向该 Var 写入一个新值,规则方法 A 中所有运行在 B 之后的动作都能看到该新写入的 Var 的值。上面的例子中,A 中的 action 读取 Var 值时会得到 26。
Parser Extension
当你首次调用 Parboiled.createParser 来构造你的解析器实例时,Parboiled Java 会在内部运行解析器扩展逻辑来为你的解析器类增加所有可能的特殊功能。因为你定义的解析器类一定不是 private 和 final 的,因此可以被子类化。新创建的类与你原有的解析器类处于同一个包下,使用原有的类名并加上 $$parboiled 后缀。
自动穿件的解析器子类会覆写所有返回 Rule 实例的方法。这些覆写会在某个点将调用为派给父方法(即原始解析器类中的方法),或者甚至完全重写而不会父类方法做任何调用。
以下规则方法扩展需要完全重写而不会对父方法执行委派调用:
以下规则方法扩展可以无需方法重写而应用,如果方法中没有上面列出的转换时也可以调用父方法:
- @Label
- @Cache
- @SuppressNode
- @SuppressSubnodes
- @SkipNode
- @MemoMismatches
通常你不必担心是否需要进行方法覆写的问题。然而在调试环节,当你需要在规则方法中添加断点以追踪执行过程时,如果你的规则方法被重写,则端点就无法没命中。因此,比如你需要调试一个带有隐式或显式动作表达式的规则方法时,需要临时将动作表达式改写为显式匿名内部 Action 类,来避免对该规则方法的完全重写。
解析器扩展逻辑不会触碰那些不返回 Rule 实例的方法则,而是直接保留。
Examples
7.8 - CH08-Scala APIs
与 Java 的区别在于规则的构造过程,在 Scala 中使用了特殊的 Scala DSL 构造。相比 Java API,Scala API 更具优势:
- 更加简明的规则构建 DSL(Scala 语言的丰富表现力)。
- 通过对值栈的进一步抽象隐藏了值栈,增加了类型安全性(Scala Type Inference)。
- 高阶规则构造。
- 更快的初次规则构建(不再有昂贵的解析器扩展步骤)。
Rule Construction
一个 PEG 由任意数量的规则组成,规则又可以由其他规则、终止符、或下表中的原语规则组成:
| Name | Common Notation | Primitive |
|---|
| Sequence | a b | a ~ b |
| Ordered Choice | a | b | a | b |
| Zero-Or-More | a * | zeroOrMore(a) |
| One-Or-More | a + | oneOrMore(a) |
| Optional | a ? | optional(a) |
| And-Predicate | & a | &(a) |
| Non-Predicate | ! a | !a |
除了以上原语方法,还有以下原语可供使用:
| Method/Field | Description |
|---|
| ANY | 匹配任何除了 EOI 的单个字符 |
| NOTHING | 不匹配任何,总是失败 |
| EMPTY | 不匹配任何,总是成功 |
| EOI | 匹配特殊的 EOI 字符 |
| ch(Char) | 创建一个匹配单个字符的规则 |
| {String} ~ {String} | 匹配给定的字符范围 |
| anyOf(String) | 匹配给定字符串中的任意字符 |
| ignoreCase(Char) | 匹配单个字符且忽略大小写 |
| ignoreCase(String) | 匹配整个字符串且胡烈大小写 |
| str(String) | 创建一个匹配整个字符串的 |
| nTimes(Int, Rule) | 创建一个匹配子规则 N 次的规则 |
Parser Actions
在 Parboiled Java 中需要以布尔表达式的形式设置解析器动作,然后再被自动转换为解析器动作规则。没有进一步的动作类型来支持 Parboiled Java 对值栈操作元素数量进行区分。这意味着 Java 开发者不能依赖编译器来检测解析器动作对值栈操作的一致性(主要是元素数量)。因此在动作的设计期间需要更多对人的规范约束。
在 Parboiled Scala 中,Scala 的类型推断能力使得解析器动作支持比 Java 中更高级别的抽象。在 Scala 解析器动作中,无需对值栈进行操作,而是将其指定为函数。因此,它们不仅仅是简单的代码块,其本身就是类型。
根据规则中包含的解析器动作,规则的实际类型会发生变化。对值栈没有任何影响的规则类型为 Rule0。将类型为 A 的值对象推送到值栈的规则具有类型 Rule1[A]。导致类型分别为 A 和 B 的两个值对象被推送到值栈的规则类型为 Rule2[A,B]。导致类型为 Z 的一个值对象从堆栈中弹出的规则具有类型 PopRule1[Z]。目前共 15 种具体的规则类型。
这种稍微复杂的类结构允许 Scala 在规则类型中进行编码,以确定规则如何影响解析器值堆栈,并确保所有解析器操作正确地协同工作以生成解析器最终结果值。请注意,这不会对值对象的类型施加任何限制!
支持 3 种形式的解析器动作:
- 动作操作符
- push/test/run 方法
- 独立动作
Action Operators
共定义了 9 种动作操作符。每种都会链接一个动作函数到语法规则结构,但与它们的动作函数参数的类型和语义不同。下表是一个概览:
| Action Result | Action Argument(String) | Action Argument(Value Object Pop) | Action Argument(Value Object Peek) | Action Argument(Char) | Action Argument(IndexRange) |
|---|
| Value Object | ~> | ~~> | ~~~> | ~:> | ~» |
| Boolean | ~? | ~~? | ~~~? | | |
| Unit | ~% | ~~% | ~~~% | | |
以单个 ~ 字符起始的操作符通常是解析器动作接收已匹配输入文本的方式。其参数是一个类型为 String => ... 的函数。该操作符内部会创建一个新的动作规则,在运行时,将与紧邻的规则匹配的输入文本作为参数传递给该函数。
以 ~~ 和 ~~~ 字符起始的操作符接收一个或多个值对象作为参数。
以 > 字符结尾的操作符创建一个或多个新的值对象,在动作函数运行之后推送到值栈。这些动作结构值的类型会被编码到操作符的返回类型。
以 ? 字符结尾的操作符接收一个返回布尔值的函数作为语义判定。如果动作函数返回 false 则停止当前规则序列的求值,即为匹配,然后强制解析器回退并查找其他匹配可能。
以 % 字符结尾的操作符支持你运行任意逻辑而不会对处理过程产生影响。其动作函数返回 Unit,一旦解析器经过,它们就会被运行。
push/test/run 方法
上述讨论的动作操作符均为将你的动作链接到当前的解析处理过程,要么是接收已匹配的输入文本作为参数,要么是生成新的栈值元素。但有时你的动作并不需要任何输入,因为其在规则结构中的位置就是其需要的所有上下文。这时你可以使用 push/test/run 方法来实现与上述讨论的操作符相同的功能,这些方法由 Parser 特质提供。
由这些方法构造的动作规则可以通过被链接在一起。如下所示:
def JsonTrue = rule { "true" ~ push(True) }
独立动作
独立动作是以 Context 对象作为参数的独立函数。它们可以像普通规则一样被使用,因为 Parser 特质提供了以下两种隐式转换:
| Method | Semantics |
|---|
| toRunAction(f:(Context[Any]) => Unit):Rule0 | 通用非判断动作 |
| toTestAction(f:(Context[Any]) => Boolean):Rule0 | 通用语义判定动作 |
当前解析的 Context 为通用动作提供了对解析器的所有状态访问能力。它们可以通过 getValueStack 方法来修改解析器的值栈。但并不推荐这种用法,因为这将导致 Scala 编译器无法有效的验证值栈操作的一致性。
“withContext” 动作
Parser 特质提供的另一个便利的工具是 withContext 方法,通过该方法,你可以包装一个动作函数然后再将其传递给动作操作符。该方法支持你的动作函数除了其常规的参数之外还能接收当前解析器的 Context。
withContext 的签名类似如下定义:
def withContext[A, B, R](f: (A, B, Context[_]) => R): ((A, B) => R)
因此,被该方法包装的动作函数在外部会显示为一个函数,比如,弹出值栈的两个对象并生成一个新的值。但是,在内部你的动作同样也可以接受到当前上下文的实例,比如可以查看当前输入位置以及行号。
Parser Tesing
从 0.9.9.0 开始提供了一个 ParboiledTest 特质来简化测试的开发工作。Parboiled 使用它来完成内部测试,你可以参考 WithContextTest 来查看应用方式。
Examples
7.9 - CH09-Advanced Topics
8 - Netty
Netty In Action Essential.
8.1 - CH01-Netty 概览
什么是 Netty
Netty 是一个利用 Java 的高级网络的能力,隐藏其背后的复杂性而提供一个易于使用的 API 的客户端/服务器框架。Netty 提供高性能和可扩展性,让你可以自由地专注于你真正感兴趣的东西,你的独特应用!
在这一章我们将解释 Netty 在处理一些高并发的网络问题体现的价值。然后,我们将介绍基本概念和构成 Netty 的工具包,我们将在这本书的其余部分深入研究。
一些历史
在网络发展初期,需要花很多时间来学习 socket 的复杂,寻址等等,在 C socket 库上进行编码,并需要在不同的操作系统上做不同的处理。
Java 早期版本(1995-2002)介绍了足够的面向对象的糖衣来隐藏一些复杂性,但实现复杂的客户端-服务器协议仍然需要大量的样板代码(和进行大量的监视才能确保他们是对的)。
这些早期的 Java API(java.net)只能通过原生的 socket 库来支持所谓的“blocking(阻塞)”的功能。一个简单的例子
Listing 1.1 Blocking I/O Example
ServerSocket serverSocket = new ServerSocket(portNumber); //1
Socket clientSocket = serverSocket.accept(); //2
BufferedReader in = //3
new BufferedReader(new InputStreamReader(clientSocket.getInputStream()));
PrintWriter out =
new PrintWriter(clientSocket.getOutputStream(), true);
String request, response;
while ((request = in.readLine()) != null) { //4
if ("Done".equals(request)) { //5
break;
}
}
response = processRequest(request); //6
out.println(response); //7
//8
ServerSocket 创建并监听端口的连接请求
accept() 调用阻塞,直到一个连接被建立了。返回一个新的 Socket 用来处理 客户端和服务端的交互
流被创建用于处理 socket 的输入和输出数据。BufferedReader 读取从字符输入流里面的本文。PrintWriter 打印格式化展示的对象读到本文输出流
处理循环开始 readLine() 阻塞,读取字符串直到最后是换行或者输入终止。
如果客户端发送的是“Done”处理循环退出
执行方法处理请求,返回服务器的响应
响应发回客户端
处理循环继续
显然,这段代码限制每次只能处理一个连接。为了实现多个并行的客户端我们需要分配一个新的 Thread 给每个新的客户端 Socket(当然需要更多的代码)。但考虑使用这种方法来支持大量的同步,长连接。在任何时间点多线程可能处于休眠状态,等待输入或输出数据。这很容易使得资源的大量浪费,对性能产生负面影响。当然,有一种替代方案。
除了示例中所示阻塞调用,原生 socket 库同时也包含了非阻塞 I/O 的功能。这使我们能够确定任何一个 socket 中是否有数据准备读或写。我们还可以设置标志,因为读/写调用如果没有数据立即返回;就是说,如果一个阻塞被调用后就会一直阻塞,直到处理完成。通过这种方法,会带来更大的代码的复杂性成本,其实我们可以获得更多的控制权来如何利用网络资源。
JAVA NIO
在 2002 年,Java 1.4 引入了非阻塞 API 在 java.nio 包(NIO)。
“New"还是"Nonblocking”?
NIO 最初是为 New Input/Output 的缩写。然而,Java 的 API 已经存在足够长的时间,它不再是新的。现在普遍使用的缩写来表示Nonblocking I/O (非阻塞 I/O)。另一方面,一般(包括作者)指阻塞 I/O 为 OIO 或 Old Input/Output。你也可能会遇到普通 I/O。
我们已经展示了在 Java 的 I/O 阻塞一例例子。图 1.1 展示了方法 必须扩大到处理多个连接:给每个连接创建一个线程,有些连接是空闲的!显然,这种方法的可扩展性将是受限于可以在 JVM 中创建的线程数。
当你的应用中连接数比较少,这个方案还是可以接受。当并发连接超过10000 时,context-switching(上下文切换)开销将是明显的。此外,每个线程都有一个默认的堆栈内存分配了 128K 和 1M 之间的空间。考虑到整体的内存和操作系统需要处理 100000 个或更多的并发连接资源,这似乎是一个不理想的解决方案。
SELECTOR
相比之下,图1.2 显示了使用非阻塞I/O,主要是消除了这些方法 约束。在这里,我们介绍了“Selector”,这是 Java 的无阻塞 I/O 实现的关键。
Selector 最终决定哪一组注册的 socket 准备执行 I/O。正如我们之前所解释的那样,这 I/O 操作设置为非阻塞模式。通过通知,一个线程可以同时处理多个并发连接。(通常一个 Selector 由一个线程处理,但具体实施可以使用多个线程。)因此,每次读或写操作执行能立即检查完成。总体而言,该模型提供了比 阻塞 I/O 模型 更好的资源使用,因为
- 可以用较少的线程处理更多连接,这意味着更少的开销在内存和上下文切换上
- 当没有 I/O 处理时,线程可以被重定向到其他任务上。
你可以直接用这些 Java API 构建的 NIO 建立你的应用程序,但这样做正确和安全是无法保证的。实现可靠和可扩展的 event-processing(事件处理器)来处理和调度数据并保证尽可能有效地,这是一个繁琐和容易出错的任务,最好留给专家 - Netty。
整体构成
正如我们前面解释的,非阻塞 I/O 不迫使我们等待完成的操作。在这种能力的基础上,真正的异步 I/O 起到了更进一步的作用:一个异步方法完成时立即返回并直接或稍后通知用户。
正如我们将看到的,在一个网络环境的异步模型可以更有效地利用资源,可以快速连续执行多个调用。
Channel
Channel 是 NIO 基本的结构。它代表了一个用于连接到实体如硬件设备、文件、网络套接字或程序组件,能够执行一个或多个不同的 I/O 操作(例如读或写)的开放连接。
现在,把 Channel 想象成一个可以“打开”或“关闭”,“连接”或“断开”和作为传入和传出数据的运输工具。
Callback (回调)
callback (回调)是一个简单的方法,提供给另一种方法作为引用,这样后者就可以在某个合适的时间调用前者。这种技术被广泛使用在各种编程的情况下,最常见的方法之一通知给其他人操作已完成。
Netty 内部使用回调处理事件时。一旦这样的回调被触发,事件可以由接口 ChannelHandler 的实现来处理。如下面的代码,一旦一个新的连接建立了,调用 channelActive(),并将打印一条消息。
Listing 1.2 ChannelHandler triggered by a callback
public class ConnectHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception { //1
System.out.println(
"Client " + ctx.channel().remoteAddress() + " connected");
}
}
- 当建立一个新的连接时调用 ChannelActive()
Future
Future 提供了另外一种通知应用操作已经完成的方式。这个对象作为一个异步操作结果的占位符,它将在将来的某个时候完成并提供结果。
JDK 附带接口 java.util.concurrent.Future ,但所提供的实现只允许您手动检查操作是否完成或阻塞了。这是很麻烦的,所以 Netty 提供自己了的实现,ChannelFuture,用于在执行异步操作时使用。
ChannelFuture 提供多个附件方法来允许一个或者多个 ChannelFutureListener 实例。这个回调方法 operationComplete() 会在操作完成时调用。事件监听者能够确认这个操作是否成功或者是错误。如果是后者,我们可以检索到产生的 Throwable。简而言之, ChannelFutureListener 提供的通知机制不需要手动检查操作是否完成的。
每个 Netty 的 outbound I/O 操作都会返回一个 ChannelFuture;这样就不会阻塞。这就是 Netty 所谓的“自底向上的异步和事件驱动”。
下面例子简单的演示了作为 I/O 操作的一部分 ChannelFuture 的返回。当调用 connect() 将会直接是非阻塞的,并且调用在背后完成。由于线程是非阻塞的,所以无需等待操作完成,而可以去干其他事,因此这令资源利用更高效。
Listing 1.3 Callback in action
Channel channel = ...;
//不会阻塞
ChannelFuture future = channel.connect(
new InetSocketAddress("192.168.0.1", 25));
1.异步连接到远程地址
下面代码描述了如何利用 ChannelFutureListener 。首先,连接到远程地址。接着,通过 ChannelFuture 调用 connect() 来 注册一个新ChannelFutureListener。当监听器被通知连接完成,我们检查状态。如果是成功,就写数据到 Channel,否则我们检索 ChannelFuture 中的Throwable。
注意,错误的处理取决于你的项目。当然,特定的错误是需要加以约束 的。例如,在连接失败的情况下你可以尝试连接到另一个。
Listing 1.4 Callback in action
Channel channel = ...;
//不会阻塞
ChannelFuture future = channel.connect( //1
new InetSocketAddress("192.168.0.1", 25));
future.addListener(new ChannelFutureListener() { //2
@Override
public void operationComplete(ChannelFuture future) {
if (future.isSuccess()) { //3
ByteBuf buffer = Unpooled.copiedBuffer(
"Hello", Charset.defaultCharset()); //4
ChannelFuture wf = future.channel().writeAndFlush(buffer); //5
// ...
} else {
Throwable cause = future.cause(); //6
cause.printStackTrace();
}
}
});
异步连接到远程对等。调用立即返回并提供 ChannelFuture。
操作完成后通知注册一个 ChannelFutureListener 。
当 operationComplete() 调用时检查操作的状态。
如果成功就创建一个 ByteBuf 来保存数据。
异步发送数据到远程。再次返回ChannelFuture。
如果有一个错误则抛出 Throwable,描述错误原因。
Event 和 Handler
Netty 使用不同的事件来通知我们更改的状态或操作的状态。这使我们能够根据发生的事件触发适当的行为。
这些行为可能包括:
由于 Netty 是一个网络框架,事件很清晰的跟入站或出站数据流相关。因为一些事件可能触发传入的数据或状态的变化包括:
出站事件是由于在未来操作将触发一个动作。这些包括:
- 打开或关闭一个连接到远程
- 写或冲刷数据到 socket
每个事件都可以分配给用户实现处理程序类的方法。这说明了事件驱动的范例可直接转换为应用程序构建块。
图1.3显示了一个事件可以由一连串的事件处理器来处理
Netty 还提供了一组丰富的预定义的处理程序,您可以开箱即用。这些是各种协议的编解码器包括 HTTP 和 SSL/TLS。在内部,ChannelHandler 使用事件和 future 本身,使得消费者的具有 Netty 的抽象。
整合
FUTURE, CALLBACK 和 HANDLER
Netty 的异步编程模型是建立在 future 和 callback 的概念上的。所有这些元素的协同为自己的设计提供了强大的力量。
拦截操作和转换入站或出站数据只需要您提供回调或利用 future 操作返回的。这使得链操作简单、高效,促进编写可重用的、通用的代码。一个 Netty 的设计的主要目标是促进“关注点分离”:你的业务逻辑从网络基础设施应用程序中分离。
SELECTOR, EVENT 和 EVENT LOOP
Netty 通过触发事件从应用程序中抽象出 Selector,从而避免手写调度代码。EventLoop 分配给每个 Channel 来处理所有的事件,包括
- 注册有趣的事件
- 调度事件到 ChannelHandler
- 安排进一步行动
该 EventLoop 本身是由只有一个线程驱动,它给一个 Channel 处理所有的 I/O 事件,并且在 EventLoop 的生命周期内不会改变。这个简单而强大的线程模型消除你可能对你的 ChannelHandler 同步的任何关注,这样你就可以专注于提供正确的回调逻辑来执行。该 API 是简单和紧凑。
关于本书
我们开始通过讨论阻塞和非阻塞处理之间的差异来了解到后一种方法的优点。然后,我们转移到了的 Netty的功能,设计和效益的概述。这些包括了Netty 的异步模型,包括回调,future 及其组合使用。我们还谈到了Netty 的线程模型,事件是如何被使用的,以及它们如何被拦截和处理。展望未来,我们将更加深入探索如何使用这些丰富的工具集用来满足特殊需求的应用。
一路上,我们将介绍公司的工程师自己的案例研究解释为什么他们选择的Netty 以及他们如何使用它。
因此,让我们开始吧。在下一章中,我们将深入研究了 Netty 的 API 的基础知识,编程模型,开始写 echo(回声)服务器和客户端。
8.2 - CH02-应用实例
在本章中,我们会确保你有一个工作的发展环境并通过构建一个简单的客户端和服务器进行测试。虽然我们不会开始学习的 Netty 框架的细节,直到下一个章节,在这里我们将采取仔细看看的重要我们在引进触及的 API 方面;即通过 ChannelHandler 来实现应用的逻辑。
开发环境
如果你已经有了 Maven 的开发环境,那你可以跳过本节。
本书例子需要 JDK 和 Apache Maven,都可以免费下载到。
1.安装配置 JDK
建议用 JDK 7+
2.下载 IDE
JAVA 的 IDE 很多,主流的有
3.下载安装 Maven
4.配置工具
确保系统环境变量有 JAVA_HOME 和 M2_HOME
Netty Client/Server
在本节中,我们将构建一个完整的的 Netty客 户端和服务器。虽然你可能集中在写客户端是浏览器的基于 Web 的服务,接下来你将会获得更完整了解 Netty 的 API 是如何实现客户端和服务器的。
图中显示了连接到服务器的多个并发的客户端。在理论上,客户端可以支持的连接数只受限于使用的 JDK 版本中的制约。
echo(回声)客户端和服务器之间的交互是很简单的;客户端后,建立一个连接发送一个或多个消息发送到服务器,其中每相呼应消息返回给客户端。诚然,这个应用程序并不是非常有用。但这项工作是为了更好的理解请求 - 响应交互本身,这是一个基本的模式的客户端/服务器系统。
我们将通过检查服务器端代码开始。
Echo Server
所以 Netty 服务器都需要下面这些:
- 一个服务器 handler:这个组件实现了服务器的业务逻辑,决定了连接创建后和接收到信息后该如何处理
- Bootstrapping: 这个是配置服务器的启动代码。最少需要设置服务器绑定的端口,用来监听连接请求。
通过 ChannelHandler 来实现服务器的逻辑
Echo Server 将会将接受到的数据的拷贝发送给客户端。因此,我们需要实现 ChannelInboundHandler 接口,用来定义处理入站事件的方法。由于我们的应用很简单,只需要继承 ChannelInboundHandlerAdapter 就行了。这个类 提供了默认 ChannelInboundHandler 的实现,所以只需要覆盖下面的方法:
- channelRead() - 每个信息入站都会调用
- channelReadComplete() - 通知处理器最后的 channelread() 是当前批处理中的最后一条消息时调用
- exceptionCaught()- 读操作时捕获到异常时调用
EchoServerHandler 代码如下:
Listing 2.2 EchoServerHandler
@Sharable //1
public class EchoServerHandler extends
ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx,
Object msg) {
ByteBuf in = (ByteBuf) msg;
System.out.println("Server received: " + in.toString(CharsetUtil.UTF_8)); //2
ctx.write(in); //3
}
@Override
public void channelReadComplete(ChannelHandlerContext ctx) throws Exception {
ctx.writeAndFlush(Unpooled.EMPTY_BUFFER)//4
.addListener(ChannelFutureListener.CLOSE);
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx,
Throwable cause) {
cause.printStackTrace(); //5
ctx.close(); //6
}
}
@Sharable 标识这类的实例之间可以在 channel 里面共享
日志消息输出到控制台
将所接收的消息返回给发送者。注意,这还没有冲刷数据
冲刷所有待审消息到远程节点。关闭通道后,操作完成
打印异常堆栈跟踪
关闭通道
这种使用 ChannelHandler 的方式体现了关注点分离的设计原则,并简化业务逻辑的迭代开发的要求。处理程序很简单;它的每一个方法可以覆盖到“hook(钩子)”在活动周期适当的点。很显然,我们覆盖 channelRead因为我们需要处理所有接收到的数据。
覆盖 exceptionCaught 使我们能够应对任何 Throwable 的子类型。在这种情况下我们记录,并关闭所有可能处于未知状态的连接。它通常是难以 从连接错误中恢复,所以干脆关闭远程连接。当然,也有可能的情况是可以从错误中恢复的,所以可以用一个更复杂的措施来尝试识别和处理 这样的情况。
如果异常没有被捕获,会发生什么?
每个 Channel 都有一个关联的 ChannelPipeline,它代表了 ChannelHandler 实例的链。适配器处理的实现只是将一个处理方法调用转发到链中的下一个处理器。因此,如果一个 Netty 应用程序不覆盖exceptionCaught ,那么这些错误将最终到达 ChannelPipeline,并且结束警告将被记录。出于这个原因,你应该提供至少一个 实现 exceptionCaught 的 ChannelHandler。
关键点要牢记:
- ChannelHandler 是给不同类型的事件调用
- 应用程序实现或扩展 ChannelHandler 挂接到事件生命周期和 提供自定义应用逻辑。
引导服务器
了解到业务核心处理逻辑 EchoServerHandler 后,下面要引导服务器自身了。
- 监听和接收进来的连接请求
- 配置 Channel 来通知一个关于入站消息的 EchoServerHandler 实例
Transport(传输)
在本节中,你会遇到“transport(传输)”一词。在网络的多层视图协议里面,传输层提供了用于端至端或主机到主机的通信服务。互联网通信的基础是 TCP 传输。当我们使用术语“NIO transport”我们指的是一个传输的实现,它是大多等同于 TCP ,除了一些由 Java NIO 的实现提供了服务器端的性能增强。Transport 详细在第4章中讨论。
Listing 2.3 EchoServer
public class EchoServer {
private final int port;
public EchoServer(int port) {
this.port = port;
}
public static void main(String[] args) throws Exception {
if (args.length != 1) {
System.err.println(
"Usage: " + EchoServer.class.getSimpleName() +
" <port>");
return;
}
int port = Integer.parseInt(args[0]); //1
new EchoServer(port).start(); //2
}
public void start() throws Exception {
NioEventLoopGroup group = new NioEventLoopGroup(); //3
try {
ServerBootstrap b = new ServerBootstrap();
b.group(group) //4
.channel(NioServerSocketChannel.class) //5
.localAddress(new InetSocketAddress(port)) //6
.childHandler(new ChannelInitializer<SocketChannel>() { //7
@Override
public void initChannel(SocketChannel ch)
throws Exception {
ch.pipeline().addLast(
new EchoServerHandler());
}
});
ChannelFuture f = b.bind().sync(); //8
System.out.println(EchoServer.class.getName() + " started and listen on " + f.channel().localAddress());
f.channel().closeFuture().sync(); //9
} finally {
group.shutdownGracefully().sync(); //10
}
}
}
设置端口值(抛出一个 NumberFormatException 如果该端口参数的格式不正确)
呼叫服务器的 start() 方法
创建 EventLoopGroup
创建 ServerBootstrap
指定使用 NIO 的传输 Channel
设置 socket 地址使用所选的端口
添加 EchoServerHandler 到 Channel 的 ChannelPipeline
绑定的服务器;sync 等待服务器关闭
关闭 channel 和 块,直到它被关闭
关机的 EventLoopGroup,释放所有资源。
在这个例子中,代码创建 ServerBootstrap 实例(步骤4)。由于我们使用在 NIO 传输,我们已指定 NioEventLoopGroup(3)接受和处理新连接,指定 NioServerSocketChannel(5)为信道类型。在此之后,我们设置本地地址是 InetSocketAddress 与所选择的端口(6)如。服务器将绑定到此地址来监听新的连接请求。
第七步是关键:在这里我们使用一个特殊的类,ChannelInitializer 。当一个新的连接被接受,一个新的子 Channel 将被创建, ChannelInitializer 会添加我们EchoServerHandler 的实例到 Channel 的 ChannelPipeline。正如我们如前所述,这个处理器将被通知如果有入站信息。
虽然 NIO 是可扩展性,但它的正确配置是不简单的。特别是多线程,要正确处理也非易事。幸运的是,Netty 的设计封装了大部分复杂性,尤其是通过抽象,例如 EventLoopGroup,SocketChannel 和 ChannelInitializer,其中每一个将在更详细地在第3章中讨论。
在步骤8,我们绑定的服务器,等待绑定完成。 (调用 sync() 的原因是当前线程阻塞)在第9步的应用程序将等待服务器 Channel 关闭(因为我们 在 Channel 的 CloseFuture 上调用 sync())。现在,我们可以关闭下 EventLoopGroup 并释放所有资源,包括所有创建的线程(10)。
NIO 用于在本实施例,因为它是目前最广泛使用的传输,归功于它的可扩展性和彻底的不同步。但不同的传输的实现是也是可能的。例如,如果本实施例中使用的 OIO 传输,我们将指定 OioServerSocketChannel 和 OioEventLoopGroup。 Netty 的架构,包括更关于传输信息,将包含在第4章。在此期间,让我们回顾下在服务器上执行,我们只研究重要步骤。
服务器的主代码组件是
- EchoServerHandler 实现了的业务逻辑
- 在 main() 方法,引导了服务器
执行后者所需的步骤是:
- 创建 ServerBootstrap 实例来引导服务器并随后绑定
- 创建并分配一个 NioEventLoopGroup 实例来处理事件的处理,如接受新的连接和读/写数据。
- 指定本地 InetSocketAddress 给服务器绑定
- 通过 EchoServerHandler 实例给每一个新的 Channel 初始化
- 最后调用 ServerBootstrap.bind() 绑定服务器
这样服务器初始化完成,可以被使用了。
Echo Client
客户端要做的是:
- 连接服务器
- 发送信息
- 发送的每个信息,等待和接收从服务器返回的同样的信息
- 关闭连接
用 ChannelHandler 实现客户端逻辑
跟写服务器一样,我们提供 ChannelInboundHandler 来处理数据。下面例子,我们用 SimpleChannelInboundHandler 来处理所有的任务,需要覆盖三个方法:
- channelActive() - 服务器的连接被建立后调用
- channelRead0() - 数据后从服务器接收到调用
- exceptionCaught() - 捕获一个异常时调用
Listing 2.4 ChannelHandler for the client
@Sharable //1
public class EchoClientHandler extends
SimpleChannelInboundHandler<ByteBuf> {
@Override
public void channelActive(ChannelHandlerContext ctx) {
ctx.writeAndFlush(Unpooled.copiedBuffer("Netty rocks!", //2
CharsetUtil.UTF_8));
}
@Override
public void channelRead0(ChannelHandlerContext ctx,
ByteBuf in) {
System.out.println("Client received: " + in.toString(CharsetUtil.UTF_8)); //3
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx,
Throwable cause) { //4
cause.printStackTrace();
ctx.close();
}
}
@Sharable标记这个类的实例可以在 channel 里共享
当被通知该 channel 是活动的时候就发送信息
记录接收到的消息
记录日志错误并关闭 channel
建立连接后该 channelActive() 方法被调用一次。逻辑很简单:一旦建立了连接,字节序列被发送到服务器。该消息的内容并不重要;在这里,我们使用了 Netty 编码字符串 “Netty rocks!” 通过覆盖这种方法,我们确保东西被尽快写入到服务器。
接下来,我们覆盖方法 channelRead0()。这种方法会在接收到数据时被调用。注意,由服务器所发送的消息可以以块的形式被接收。即,当服务器发送 5 个字节是不是保证所有的 5 个字节会立刻收到 - 即使是只有 5 个字节,channelRead0() 方法可被调用两次,第一次用一个ByteBuf(Netty的字节容器)装载3个字节和第二次一个 ByteBuf 装载 2 个字节。唯一要保证的是,该字节将按照它们发送的顺序分别被接收。 (注意,这是真实的,只有面向流的协议如TCP)。
第三个方法重写是 exceptionCaught()。正如在 EchoServerHandler (清单2.2),所述的记录 Throwable 并且关闭通道,在这种情况下终止 连接到服务器。
SimpleChannelInboundHandler vs. ChannelInboundHandler
何时用这2个要看具体业务的需要。在客户端,当 channelRead0() 完成,我们已经拿到的入站的信息。当方法返回,SimpleChannelInboundHandler 会小心的释放对 ByteBuf(保存信息) 的引用。而在 EchoServerHandler,我们需要将入站的信息返回给发送者,write() 是异步的在 channelRead()返回时,可能还没有完成。所以,我们使用 ChannelInboundHandlerAdapter,无需释放信息。最后在 channelReadComplete() 我们调用 ctxWriteAndFlush() 来释放信息。详见第5、6章
引导客户端
客户端引导需要 host 、port 两个参数连接服务器。
Listing 2.5 Main class for the client
public class EchoClient {
private final String host;
private final int port;
public EchoClient(String host, int port) {
this.host = host;
this.port = port;
}
public void start() throws Exception {
EventLoopGroup group = new NioEventLoopGroup();
try {
Bootstrap b = new Bootstrap(); //1
b.group(group) //2
.channel(NioSocketChannel.class) //3
.remoteAddress(new InetSocketAddress(host, port)) //4
.handler(new ChannelInitializer<SocketChannel>() { //5
@Override
public void initChannel(SocketChannel ch)
throws Exception {
ch.pipeline().addLast(
new EchoClientHandler());
}
});
ChannelFuture f = b.connect().sync(); //6
f.channel().closeFuture().sync(); //7
} finally {
group.shutdownGracefully().sync(); //8
}
}
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println(
"Usage: " + EchoClient.class.getSimpleName() +
" <host> <port>");
return;
}
final String host = args[0];
final int port = Integer.parseInt(args[1]);
new EchoClient(host, port).start();
}
}
创建 Bootstrap
指定 EventLoopGroup 来处理客户端事件。由于我们使用 NIO 传输,所以用到了 NioEventLoopGroup 的实现
使用的 channel 类型是一个用于 NIO 传输
设置服务器的 InetSocketAddress
当建立一个连接和一个新的通道时,创建添加到 EchoClientHandler 实例 到 channel pipeline
连接到远程;等待连接完成
阻塞直到 Channel 关闭
8.调用 shutdownGracefully() 来关闭线程池和释放所有资源
与以前一样,在这里使用了 NIO 传输。请注意,您可以在 客户端和服务器 使用不同的传输 ,例如 NIO 在服务器端和 OIO 客户端。在第四章中,我们将研究一些具体的因素和情况,这将导致 您可以选择一种传输,而不是另一种。
让我们回顾一下我们在本节所介绍的要点
- 一个 Bootstrap 被创建来初始化客户端
- 一个 NioEventLoopGroup 实例被分配给处理该事件的处理,这包括创建新的连接和处理入站和出站数据
- 一个 InetSocketAddress 为连接到服务器而创建
- 一个 EchoClientHandler 将被安装在 pipeline 当连接完成时
- 之后 Bootstrap.connect()被调用连接到远程的 - 本例就是 echo(回声)服务器。
编译运行
编译
本例涉及到多模块 Maven 项目的组织
在例子 chapter2 目录下,执行
输出如下
Listing 2.6 Build Output
chapter2>mvn clean package
[INFO] Scanning for projects...
[INFO] --------------------------------------------------------------------
[INFO] Reactor Build Order:
[INFO]
[INFO] Echo Client and Server
[INFO] Echo Client
[INFO] Echo Server
[INFO]
[INFO] --------------------------------------------------------------------
[INFO] Building Echo Client and Server 1.0-SNAPSHOT
[INFO] --------------------------------------------------------------------
[INFO]
[INFO] --- maven-clean-plugin:2.5:clean (default-clean) @ echo-parent ---
[INFO]
[INFO] --------------------------------------------------------------------
[INFO] Building Echo Client 1.0-SNAPSHOT
[INFO] --------------------------------------------------------------------
[INFO]
[INFO] --- maven-clean-plugin:2.5:clean (default-clean) @ echo-client ---
[INFO]
[INFO] --- maven-compiler-plugin:3.1:compile (default-compile)
@ echo-client ---
[INFO] Changes detected - recompiling the module!
[INFO] --------------------------------------------------------------------
[INFO] Reactor Summary:
[INFO]
[INFO] Echo Client and Server ......................... SUCCESS [ 0.118 s]
[INFO] Echo Client .................................... SUCCESS [ 1.219 s]
[INFO] Echo Server .................................... SUCCESS [ 0.110 s]
[INFO] --------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] --------------------------------------------------------------------
[INFO] Total time: 1.561 s
[INFO] Finished at: 2014-06-08T17:39:15-05:00
[INFO] Final Memory: 14M/245M
[INFO] --------------------------------------------------------------------
注意事项:
- Maven Reactor 构建顺序:先是 父 POM,然后是子项目
- Netty artifact 没在用户的本地存储库中找到,所以 Maven 就会从互联网上下载
- clean 和 compile 在构建生命周期的运行。事后 mavensurefire-plugin 插件运行,但不会有测试类存在。最后 mavenjar-plugin 执行
这段说明了项目已经成功编译。
运行 Echo 服务器 和 客户端
我们使用 exec-maven-plugin 来运行项目。
在 chapter2/Server 目录,执行
输出如下:
[INFO] Scanning for projects...
[INFO]
[INFO] --------------------------------------------------------------------
[INFO] Building Echo Server 1.0-SNAPSHOT
[INFO] --------------------------------------------------------------------
[INFO]
[INFO] >>> exec-maven-plugin:1.2.1:java (default-cli) @ echo-server >>>
[INFO]
[INFO] <<< exec-maven-plugin:1.2.1:java (default-cli) @ echo-server <<<
[INFO]
[INFO] --- exec-maven-plugin:1.2.1:java (default-cli) @ echo-server ---
nettyinaction.echo.EchoServer started and listening for connections on
/0:0:0:0:0:0:0:0:9999
在 chapter2/Client 目录,执行
输出如下:
[INFO] Scanning for projects...
[INFO]
[INFO] --------------------------------------------------------------------
[INFO] Building Echo Client 1.0-SNAPSHOT
[INFO] --------------------------------------------------------------------
[INFO]
[INFO] >>> exec-maven-plugin:1.2.1:java (default-cli) @ echo-client >>>
[INFO]
[INFO] <<< exec-maven-plugin:1.2.1:java (default-cli) @ echo-client <<<
[INFO]
[INFO] --- exec-maven-plugin:1.2.1:java (default-cli) @ echo-client ---
Client received: Netty rocks!
[INFO] --------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] --------------------------------------------------------------------
[INFO] Total time: 3.907 s
[INFO] Finished at: 2014-06-08T18:26:14-05:00
[INFO] Final Memory: 8M/245M
[INFO] --------------------------------------------------------------------
在服务器的控制台输出:
Server received: Netty rocks!
发生了什么事:
- 客户端连接后,它发送消息:“Netty rocks!”
- 服务器输出接收到消息并将其返回给客户端
- 客户输出接收到的消息并退出。
每次运行客户端,你会看到在服务器的控制台输出:
Server received: Netty rocks!
现在,我们看下错误的情况。在控制台 输入 Ctrl-C 来关闭服务器。而后运行客户端,此时输出如下:
[INFO] Scanning for projects...
[INFO]
[INFO] --------------------------------------------------------------------
[INFO] Building Echo Client 1.0-SNAPSHOT
[INFO] --------------------------------------------------------------------
[INFO]
[INFO] >>> exec-maven-plugin:1.2.1:java (default-cli) @ echo-client >>>
[INFO]
[INFO] <<< exec-maven-plugin:1.2.1:java (default-cli) @ echo-client <<<
[INFO]
[INFO] --- exec-maven-plugin:1.2.1:java (default-cli) @ echo-client ---
[WARNING]
java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke
(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke
(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.codehaus.mojo.exec.ExecJavaMojo$1.run(ExecJavaMojo.java:297)
at java.lang.Thread.run(Thread.java:744)
Caused by: java.net.ConnectException: Connection refused:
no further information: localhost/127.0.0.1:9999
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect
(SocketChannelImpl.java:739)
at io.netty.channel.socket.nio.NioSocketChannel
.doFinishConnect(NioSocketChannel.java:191)
at io.netty.channel.nio.
AbstractNioChannel$AbstractNioUnsafe.finishConnect(
AbstractNioChannel.java:279)
at io.netty.channel.nio.NioEventLoop
.processSelectedKey(NioEventLoop.java:511)
at io.netty.channel.nio.NioEventLoop
.processSelectedKeysOptimized(NioEventLoop.java:461)
at io.netty.channel.nio.NioEventLoop
.processSelectedKeys(NioEventLoop.java:378)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:350)
at io.netty.util.concurrent
.SingleThreadEventExecutor$2.run
(SingleThreadEventExecutor.java:101)
... 1 more
[INFO] --------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] --------------------------------------------------------------------
[INFO] Total time: 3.728 s
[INFO] Finished at: 2014-06-08T18:49:13-05:00
[INFO] Final Memory: 8M/245M
[INFO] --------------------------------------------------------------------
[ERROR] Failed to execute goal org.codehaus.mojo:exec-maven-plugin:1.2.1:java
(default-cli) on project echo-client: An exception occured while executing the
Java class. null: InvocationTargetException: Connection refused: no further
information:
localhost/127.0.0.1:9999 -> [Help 1]
发生了啥?客户端尝试连接服务器,但服务器是关闭的,所以引发了一个 java.net.ConnectException ,这个异常被 EchoClientHandler 的 exceptionCaught() 触发,打印出异常信息,并关闭 channel。
总结
在本章中,您构建并运行你的第一 个Netty 的客户端和服务器。虽然这是一个简单的应用程序,它可以扩展到几千个并发连接。
在下面的章节中,我们会看到的更多 Netty 如何简化可扩展和多线程的例子。我们还将更深入的了解 Netty 支持的关注点分离的构建理念;通过提供正确的抽象将业务逻辑从网络逻辑中解耦,Netty 可以很容易地跟上迅速发展的要求,而不损害系统的稳定性。
在下一章中,我们将提供的 Netty 的架构的概述。
8.3 - CH04-Transport
本章将涵盖很多 transport(传输),他们的用例以及 API:
- NIO
- OIO
- Local(本地)
- Embedded(内嵌)
网络应用程序提供了人与系统通信的信道,但是,当然 他们也将大量的数据从一个地方移到到另一个地方。如何做到这一点取决于具体的网络传输,但转移始终是相同的:字节通过线路。传输的概念帮助我们抽象掉的底层数据转移的机制。所有人都需要知道的是,字节在被发送和接收。
如果你已经做过 Java中 的网络编程,你可能会发现在某些时候你必须支持比预期更多的并发连接。如果你再尝试从阻塞切换到非阻塞传输,则可能遇会到的问题,因为 Java 的公开的网络 API 来处理这两种情况有很大的不同。
Netty 在传输层是统一的API,这使得比你用 JDK 实现更简单。你无需重构整个代码库。总之,你可以省下时间去做其他更富有成效的事。
在本章中,我们将研究这个统一的 API,与 JDK 进行演示对比,可以见它具有更大的易用性。我们将介绍不同的 捆绑在 Netty 的传输实现和适当的的用例。吸收这些信息后,你就知道如何选择适合您的应用的最佳选择。
本章的唯一前提是 Java 编程语言的知识。 最好是有网络框架或网络编程的经验,但也不是必需的。
让我们看看现实世界传输是如何工作的。
案例研究
为了让你想象 Transport 如何工作,我会从一个简单的应用程序开始,这个应用程序什么都不做,只是接受客户端连接并发送“Hi!”字符串消息到客户端,发送完了就断开连接。
JDK 实现 I/O 和 NIO
我们将不用 Netty 实现只用 JDK API 来实现 I/O 和 NIO。下面这个例子,是使用阻塞 IO 实现的例子:
Listing 4.1 Blocking networking without Netty
public class PlainOioServer {
public void serve(int port) throws IOException {
final ServerSocket socket = new ServerSocket(port); //1
try {
for (;;) {
final Socket clientSocket = socket.accept(); //2
System.out.println("Accepted connection from " + clientSocket);
new Thread(new Runnable() { //3
@Override
public void run() {
OutputStream out;
try {
out = clientSocket.getOutputStream();
out.write("Hi!\r\n".getBytes(Charset.forName("UTF-8"))); //4
out.flush();
clientSocket.close(); //5
} catch (IOException e) {
e.printStackTrace();
try {
clientSocket.close();
} catch (IOException ex) {
// ignore on close
}
}
}
}).start(); //6
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
绑定服务器到指定的端口。
接受一个连接。
创建一个新的线程来处理连接。
将消息发送到连接的客户端。
一旦消息被写入和刷新时就 关闭连接。
启动线程。
上面的方式可以工作正常,但是这种阻塞模式在大连接数的情况就会有很严重的问题,如客户端连接超时,服务器响应严重延迟,性能无法扩展。为了解决这种情况,我们可以使用异步网络处理所有的并发连接,但问题在于 NIO 和 OIO 的 API 是完全不同的,所以一个用OIO开发的网络应用程序想要使用NIO重构代码几乎是重新开发。
下面代码是使用 NIO 实现的例子:
Listing 4.2 Asynchronous networking without Netty
public class PlainNioServer {
public void serve(int port) throws IOException {
ServerSocketChannel serverChannel = ServerSocketChannel.open();
serverChannel.configureBlocking(false);
ServerSocket ss = serverChannel.socket();
InetSocketAddress address = new InetSocketAddress(port);
ss.bind(address); //1
Selector selector = Selector.open(); //2
serverChannel.register(selector, SelectionKey.OP_ACCEPT); //3
final ByteBuffer msg = ByteBuffer.wrap("Hi!\r\n".getBytes());
for (;;) {
try {
selector.select(); //4
} catch (IOException ex) {
ex.printStackTrace();
// handle exception
break;
}
Set<SelectionKey> readyKeys = selector.selectedKeys(); //5
Iterator<SelectionKey> iterator = readyKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
try {
if (key.isAcceptable()) { //6
ServerSocketChannel server =
(ServerSocketChannel)key.channel();
SocketChannel client = server.accept();
client.configureBlocking(false);
client.register(selector, SelectionKey.OP_WRITE |
SelectionKey.OP_READ, msg.duplicate()); //7
System.out.println(
"Accepted connection from " + client);
}
if (key.isWritable()) { //8
SocketChannel client =
(SocketChannel)key.channel();
ByteBuffer buffer =
(ByteBuffer)key.attachment();
while (buffer.hasRemaining()) {
if (client.write(buffer) == 0) { //9
break;
}
}
client.close(); //10
}
} catch (IOException ex) {
key.cancel();
try {
key.channel().close();
} catch (IOException cex) {
// 在关闭时忽略
}
}
}
}
}
}
绑定服务器到制定端口
打开 selector 处理 channel
注册 ServerSocket 到 ServerSocket ,并指定这是专门意接受 连接。
等待新的事件来处理。这将阻塞,直到一个事件是传入。
从收到的所有事件中 获取 SelectionKey 实例。
检查该事件是一个新的连接准备好接受。
接受客户端,并用 selector 进行注册。
检查 socket 是否准备好写数据。
将数据写入到所连接的客户端。如果网络饱和,连接是可写的,那么这个循环将写入数据,直到该缓冲区是空的。
关闭连接。
如你所见,即使它们实现的功能是一样,但是代码完全不同。下面我们将用Netty 来实现相同的功能。
Netty 实现 I/O 和 NIO
下面代码是使用Netty作为网络框架编写的一个阻塞 IO 例子:
Listing 4.3 Blocking networking with Netty
public class NettyOioServer {
public void server(int port) throws Exception {
final ByteBuf buf = Unpooled.unreleasableBuffer(
Unpooled.copiedBuffer("Hi!\r\n", Charset.forName("UTF-8")));
EventLoopGroup group = new OioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap(); //1
b.group(group) //2
.channel(OioServerSocketChannel.class)
.localAddress(new InetSocketAddress(port))
.childHandler(new ChannelInitializer<SocketChannel>() {//3
@Override
public void initChannel(SocketChannel ch)
throws Exception {
ch.pipeline().addLast(new ChannelInboundHandlerAdapter() { //4
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
ctx.writeAndFlush(buf.duplicate()).addListener(ChannelFutureListener.CLOSE);//5
}
});
}
});
ChannelFuture f = b.bind().sync(); //6
f.channel().closeFuture().sync();
} finally {
group.shutdownGracefully().sync(); //7
}
}
}
创建一个 ServerBootstrap
使用 OioEventLoopGroup 允许阻塞模式(Old-IO)
指定 ChannelInitializer 将给每个接受的连接调用
添加的 ChannelHandler 拦截事件,并允许他们作出反应
写信息到客户端,并添加 ChannelFutureListener 当一旦消息写入就关闭连接
绑定服务器来接受连接
释放所有资源
下面代码是使用 Netty NIO 实现。
Netty NIO 版本
下面是 Netty NIO 的代码,只是改变了一行代码,就从 OIO 传输 切换到了 NIO。
Listing 4.4 Asynchronous networking with Netty
public class NettyNioServer {
public void server(int port) throws Exception {
final ByteBuf buf = Unpooled.unreleasableBuffer(
Unpooled.copiedBuffer("Hi!\r\n", Charset.forName("UTF-8")));
NioEventLoopGroup group = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap(); //1
b.group(new NioEventLoopGroup(), new NioEventLoopGroup())
.channel(NioServerSocketChannel.class)
.localAddress(new InetSocketAddress(port))
.childHandler(new ChannelInitializer<SocketChannel>() { //3
@Override
public void initChannel(SocketChannel ch)
throws Exception {
ch.pipeline().addLast(new ChannelInboundHandlerAdapter() { //4
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
ctx.writeAndFlush(buf.duplicate()) //5
.addListener(ChannelFutureListener.CLOSE);
}
});
}
});
ChannelFuture f = b.bind().sync(); //6
f.channel().closeFuture().sync();
} finally {
group.shutdownGracefully().sync(); //7
}
}
}
创建一个 ServerBootstrap
使用 OioEventLoopGroup 允许阻塞模式(Old-IO)
指定 ChannelInitializer 将给每个接受的连接调用
添加的 ChannelInboundHandlerAdapter() 接收事件并进行处理
写信息到客户端,并添加 ChannelFutureListener 当一旦消息写入就关闭连接
绑定服务器来接受连接
释放所有资源
因为 Netty 使用相同的 API 来实现每个传输,它并不关心你使用什么来实现。Netty 通过操作接口Channel 、ChannelPipeline 和 ChannelHandler来实现。
现在你了解到了用 基于 Netty 传输的好处。下面就来看下传输的 API.
Transport API
Transport API 的核心是 Channel 接口,用于所有的出站操作,见下图
如上图所示,每个 Channel 都会分配一个 ChannelPipeline 和ChannelConfig。ChannelConfig 负责设置并存储 Channel 的配置,并允许在运行期间更新它们。传输一般有特定的配置设置,可能实现了 ChannelConfig. 的子类型。
ChannelPipeline 容纳了使用的 ChannelHandler 实例,这些ChannelHandler 将处理通道传递的“入站”和“出站”数据以及事件。ChannelHandler 的实现允许你改变数据状态和传输数据。
现在我们可以使用 ChannelHandler 做下面一些事情:
- 传输数据时,将数据从一种格式转换到另一种格式
- 异常通知
- Channel 变为 active(活动) 或 inactive(非活动) 时获得通知* Channel 被注册或注销时从 EventLoop 中获得通知
- 通知用户特定事件
Intercepting Filter(拦截过滤器)
ChannelPipeline 实现了常用的 Intercepting Filter(拦截过滤器)设计模式。UNIX管道是另一例子:命令链接在一起,一个命令的输出连接到 的下一行中的输入。
你还可以在运行时根据需要添加 ChannelHandler 实例到ChannelPipeline 或从 ChannelPipeline 中删除,这能帮助我们构建高度灵活的 Netty 程序。例如,你可以支持 STARTTLS 协议,只需通过加入适当的 ChannelHandler(这里是 SslHandler)到的ChannelPipeline 中,当被请求这个协议时。
此外,访问指定的 ChannelPipeline 和 ChannelConfig,你能在Channel 自身上进行操作。Channel 提供了很多方法,如下列表:
Table 4.1 Channel main methods
| 方法名称 | 描述 |
|---|
| eventLoop() | 返回分配给Channel的EventLoop |
| pipeline() | 返回分配给Channel的ChannelPipeline |
| isActive() | 返回Channel是否激活,已激活说明与远程连接对等 |
| localAddress() | 返回已绑定的本地SocketAddress |
| remoteAddress() | 返回已绑定的远程SocketAddress |
| write() | 写数据到远程客户端,数据通过ChannelPipeline传输过去 |
| flush() | 刷新先前的数据 |
| writeAndFlush(…) | 一个方便的方法用户调用write(…)而后调用y flush() |
后面会越来越熟悉这些方法,现在只需要记住我们的操作都是在相同的接口上运行,Netty 的高灵活性让你可以以不同的传输实现进行重构。
写数据到远程已连接客户端可以调用Channel.write()方法,如下代码:
Listing 4.5 Writing to a channel
Channel channel = ...; // 获取channel的引用
ByteBuf buf = Unpooled.copiedBuffer("your data", CharsetUtil.UTF_8); //1
ChannelFuture cf = channel.writeAndFlush(buf); //2
cf.addListener(new ChannelFutureListener() { //3
@Override
public void operationComplete(ChannelFuture future) {
if (future.isSuccess()) { //4
System.out.println("Write successful");
} else {
System.err.println("Write error"); //5
future.cause().printStackTrace();
}
}
});
创建 ByteBuf 保存写的数据
写数据,并刷新
添加 ChannelFutureListener 即可写操作完成后收到通知,
写操作没有错误完成
写操作完成时出现错误
Channel 是线程安全(thread-safe)的,它可以被多个不同的线程安全的操作,在多线程环境下,所有的方法都是安全的。正因为 Channel 是安全的,我们存储对Channel的引用,并在学习的时候使用它写入数据到远程已连接的客户端,使用多线程也是如此。下面的代码是一个简单的多线程例子:
Listing 4.6 Using the channel from many threads
final Channel channel = ...; // 获取channel的引用
final ByteBuf buf = Unpooled.copiedBuffer("your data",
CharsetUtil.UTF_8).retain(); //1
Runnable writer = new Runnable() { //2
@Override
public void run() {
channel.writeAndFlush(buf.duplicate());
}
};
Executor executor = Executors.newCachedThreadPool();//3
//写进一个线程
executor.execute(writer); //4
//写进另外一个线程
executor.execute(writer); //5
创建一个 ByteBuf 保存写的数据
创建 Runnable 用于写数据到 channel
获取 Executor 的引用使用线程来执行任务
手写一个任务,在一个线程中执行
手写另一个任务,在另一个线程中执行
内置 Transport
Netty 自带了一些传输协议的实现,虽然没有支持所有的传输协议,但是其自带的已足够我们来使用。Netty应用程序的传输协议依赖于底层协议,本节我们将学习Netty中的传输协议。
Netty中的传输方式有如下几种:
Table 4.1 Provided transports
| 方法名称 | 包 | 描述 |
|---|
| NIO | io.netty.channel.socket.nio | 基于java.nio.channels的工具包,使用选择器作为基础的方法。 |
| OIO | io.netty.channel.socket.oio | 基于java.net的工具包,使用阻塞流。 |
| Local | io.netty.channel.local | 用来在虚拟机之间本地通信。 |
| Embedded | io.netty.channel.embedded | 嵌入传输,它允许在没有真正网络的传输中使用 ChannelHandler,可以非常有用的来测试ChannelHandler的实现。 |
NIO-Nonblocking I/O
NIO传输是目前最常用的方式,它通过使用选择器提供了完全异步的方式操作所有的 I/O,NIO 从Java 1.4才被提供。
NIO 中,我们可以注册一个通道或获得某个通道的改变的状态,通道状态有下面几种改变:
- 一个新的 Channel 被接受并已准备好
- Channel 连接完成
- Channel 中有数据并已准备好读取
- Channel 发送数据出去
处理完改变的状态后需重新设置他们的状态,用一个线程来检查是否有已准备好的 Channel,如果有则执行相关事件。在这里可能只同时一个注册的事件而忽略其他的。选择器所支持的操作在 SelectionKey 中定义,具体如下:
Table 4.2 Selection operation bit-set
| 方法名称 | 描述 |
|---|
| OP_ACCEPT | 有新连接时得到通知 |
| OP_CONNECT | 连接完成后得到通知 |
| OP_REA | 准备好读取数据时得到通知 |
| OP_WRITE | 写入更多数据到通道时得到通知,大部分时间 |
这是可能的,但有时 socket 缓冲区完全填满了。这通常发生在你写数据的速度太快了超过了远程节点的处理能力。
新信道注册 WITH 选择器
选择处理的状态变化的通知
以前注册的通道
Selector.select()方法阻塞,直到新的状态变化接收或配置的超时 已过
检查是否有状态变化
处理所有的状态变化
在选择器操作的同一个线程执行其他任务
有一种功能,目前仅适用于 NIO 传输叫什么 “zero-file-copy (零文件拷贝)”,这使您能够快速,高效地通过移动数据到从文件系统传输内容 网络协议栈而无需复制从内核空间到用户空间。这可以使 FT P或 HTTP 协议有很大的不同。
然而,并非所有的操作系统都支持此功能。此外,你不能用它实现数据加密或压缩文件系统 - 仅支持文件的原生内容。另一方面,传送的文件原本已经加密的是完全有效的。
接下来,我们将讨论的是 OIO ,它提供了一个阻塞传输。
OIO-Old blocking I/O
Netty 中,该 OIO 传输代表了一种妥协。它通过了 Netty 的通用 API 访问但不是异步,而是构建在 java.net 的阻塞实现上。任何人下面讨论这一点可能会认为,这个协议并没有很大优势。但它确实有它有效的用途。
假设你需要的端口使用该做阻塞调用库(例如 JDBC)。它可能不适合非阻塞。相反,你可以在短期内使用 OIO 传输,后来移植到纯异步的传输上。让我们看看它是如何工作的。
在 java.net API,你通常有一个线程接受新的连接到达监听在ServerSocket,并创建一个新的线程来处理新的 Socket 。这是必需的,因为在一个特定的 socket的每个 I/O 操作可能会阻塞在任何时间。在一个线程处理多个 socket 易造成阻塞操作,一个 socket 占用了所有的其他人。
鉴于此,你可能想知道 Netty 是如何用相同的 API 来支持 NIO 的异步传输。这里的 Netty 利用了 SO_TIMEOUT 标志,可以设置在一个 Socket。这 timeout 指定最大 毫秒数量用于等待 I/O 的操作完成。如果操作在指定的时间内失败,SocketTimeoutException 会被抛出。 Netty中捕获该异常并继续处理循环。在接下来的事件循环运行,它再次尝试。像 Netty 的异步架构来支持 OIO 的话,这其实是唯一的办法。当 SocketTimeoutException 抛出时,执行 stack trace。
线程分配给 Socket
Socket 连接到远程
读操作(可能会阻塞)
读完成
处理可读的字节
执行提交到 socket 的其他任务
再次尝试读
本地 Transport 与 JVM 交互
Netty 提供了“本地”传输,为运行在同一个 Java 虚拟机上的服务器和客户之间提供异步通信。此传输支持所有的 Netty 常见的传输实现的 API。
在此传输中,与服务器 Channel 关联的 SocketAddress 不是“绑定”到一个物理网络地址中,而它被存储在注册表中,只要服务器是运行的。当 Channel 关闭时它会注销。由于传输不接受“真正的”网络通信,它不能与其他传输实现互操作。因此,客户端是希望连接到使用当地的交通必须使用它,以及一个服务器。除此限制之外,它的使用是与其他的传输是相同的。
内嵌 Transport
Netty中 还提供了可以嵌入 ChannelHandler 实例到其他的 ChannelHandler 的传输,使用它们就像辅助类,增加了灵活性的方法,使您可以与你的 ChannelHandler 互动。
该嵌入技术通常用于测试 ChannelHandler 的实现,但它也可用于将功能添加到现有的 ChannelHandler 而无需更改代码。嵌入传输的关键是Channel 的实现,称为“EmbeddedChannel”。
第10章描述了使用 EmbeddedChannel 来测试 ChannelHandlers。
支持情况
前面说了,并不是所有传输都支持核心协议,这会限制你的选择,具体看下表
| Transport | TCP | UDP | SCTP* | UDT |
|---|
| NIO | X | X | X | X |
| OIO | X | X | X | X |
| Epoll(Linux) | X | X | - | - |
*指目前仅在 Linux 上的支持。
在 Linux 上启用 SCTP
注意 SCTP 需要 kernel 支持,举例 Ubuntu:
sudo apt-get install libsctp1
Fedora 使用 yum:
sudo yum install kernel-modules-extra.x86_64 lksctp-tools.x86_64
虽然只有 SCTP 具有这些特殊的要求,对应的特定的传输也有推荐的配置。想想也是,一个服务器平台可能会需要支持较高的数量的并发连接比单个客户端的话。
下面是你可能遇到的用例:
- OIO-在低连接数、需要低延迟时、阻塞时使用
- NIO-在高连接数时使用
- Local-在同一个JVM内通信时使用
- Embedded-测试ChannelHandler时使用
总结
在本章中,我们研究了传输,他们的实现和使用,以及展示了如何用 Netty来开发。
我们介绍了 Netty 的传输,并解释他们的行为。我们还知道了他们的最低要求,因为不是所有的传输都使用相同的 Java 版本的工作或者可能是仅在特定的操作系统可用。最后,我们讲了匹配传输到特定的用例。
在下一章中,我们的重点是 ByteBuf 和 ByteBufHolder,Netty 中的数据容器。我们将介绍如何使用它们,如何从中获得最佳的性能。
8.4 - CH05-Buffer
正如我们先前所指出的,网络数据的基本单位永远是 byte(字节)。Java NIO 提供 ByteBuffer 作为字节的容器,但这个类是过于复杂,有点 难以使用。
Netty 中 ByteBuffer 替代是 ByteBuf,一个强大的实现,解决 JDK 的 API 的限制,以及为网络应用程序开发者一个更好的工具。 但 ByteBuf 并不仅仅暴露操作一个字节序列的方法;这也是专门的Netty 的 ChannelPipeline 的语义设计。
在本章中,我们会说明相比于 JDK 的 API,ByteBuf 所提供的卓越的功能和灵活性。这也将使我们能够更好地理解了 Netty 的数据处理。
Buffer API
主要包括
Netty 使用 reference-counting(引用计数)来判断何时可以释放 ByteBuf 或 ByteBufHolder 和其他相关资源,从而可以利用池和其他技巧来提高性能和降低内存的消耗。这一点上不需要开发人员做任何事情,但是在开发 Netty 应用程序时,尤其是使用 ByteBuf 和 ByteBufHolder 时,你应该尽可能早地释放池资源。 Netty 缓冲 API 提供了几个优势:
- 可以自定义缓冲类型
- 通过一个内置的复合缓冲类型实现零拷贝
- 扩展性好,比如 StringBuilder
- 不需要调用 flip() 来切换读/写模式
- 读取和写入索引分开
- 方法链
- 引用计数
- Pooling(池)
ByteBuf - 字节数据的容器
因为所有的网络通信最终都是基于底层的字节流传输,因此一个高效、方便、易用的数据接口是必要的,而 Netty 的 ByteBuf 满足这些需求。
ByteBuf 是一个很好的经过优化的数据容器,我们可以将字节数据有效的添加到 ByteBuf 中或从 ByteBuf 中获取数据。ByteBuf 有2部分:一个用于读,一个用于写。我们可以按顺序的读取数据,也可以通过调整读取数据的索引或者直接将读取位置索引作为参数传递给get方法来重复读取数据。
ByteBuf 如何在工作?
写入数据到 ByteBuf 后,writerIndex(写入索引)增加。开始读字节后,readerIndex(读取索引)增加。你可以读取字节,直到写入索引和读取索引处在相同的位置,ByteBuf 变为不可读。当访问数据超过数组的最后位,则会抛出 IndexOutOfBoundsException。
调用 ByteBuf 的 “read” 或 “write” 开头的任何方法都会提升 相应的索引。另一方面,“set” 、 “get"操作字节将不会移动索引位置;他们只会操作相关的通过参数传入方法的相对索引。
可以给ByteBuf指定一个最大容量值,这个值限制着ByteBuf的容量。任何尝试将写入索引超过这个值的行为都将导致抛出异常。ByteBuf 的默认最大容量限制是 Integer.MAX_VALUE。
ByteBuf 类似于一个字节数组,最大的区别是读和写的索引可以用来控制对缓冲区数据的访问。下图显示了一个容量为16的空的 ByteBuf 的布局和状态,writerIndex 和 readerIndex 都在索引位置 0 :
ByteBuf 使用模式
HEAP BUFFER(堆缓冲区)
最常用的模式是 ByteBuf 将数据存储在 JVM 的堆空间,这是通过将数据存储在数组的实现。堆缓冲区可以快速分配,当不使用时也可以快速释放。它还提供了直接访问数组的方法,通过 ByteBuf.array() 来获取 byte[]数据。 这种方法,正如清单5.1中所示的那样,是非常适合用来处理遗留数据的。
Listing 5.1 Backing array
ByteBuf heapBuf = ...;
if (heapBuf.hasArray()) { //1
byte[] array = heapBuf.array(); //2
int offset = heapBuf.arrayOffset() + heapBuf.readerIndex(); //3
int length = heapBuf.readableBytes();//4
handleArray(array, offset, length); //5
}
1.检查 ByteBuf 是否有支持数组。
2.如果有的话,得到引用数组。
3.计算第一字节的偏移量。
4.获取可读的字节数。
5.使用数组,偏移量和长度作为调用方法的参数。
注意:
- 访问非堆缓冲区 ByteBuf 的数组会导致UnsupportedOperationException, 可以使用 ByteBuf.hasArray()来检查是否支持访问数组。
- 这个用法与 JDK 的 ByteBuffer 类似
DIRECT BUFFER(直接缓冲区)
“直接缓冲区”是另一个 ByteBuf 模式。对象的所有内存分配发生在 堆,对不对?好吧,并非总是如此。在 JDK1.4 中被引入 NIO 的ByteBuffer 类允许 JVM 通过本地方法调用分配内存,其目的是
这就解释了为什么“直接缓冲区”对于那些通过 socket 实现数据传输的应用来说,是一种非常理想的方式。如果你的数据是存放在堆中分配的缓冲区,那么实际上,在通过 socket 发送数据之前,JVM 需要将先数据复制到直接缓冲区。
但是直接缓冲区的缺点是在内存空间的分配和释放上比堆缓冲区更复杂,另外一个缺点是如果要将数据传递给遗留代码处理,因为数据不是在堆上,你可能不得不作出一个副本,如下:
Listing 5.2 Direct buffer data access
ByteBuf directBuf = ...
if (!directBuf.hasArray()) { //1
int length = directBuf.readableBytes();//2
byte[] array = new byte[length]; //3
directBuf.getBytes(directBuf.readerIndex(), array); //4
handleArray(array, 0, length); //5
}
1.检查 ByteBuf 是不是由数组支持。如果不是,这是一个直接缓冲区。
2.获取可读的字节数
3.分配一个新的数组来保存字节
4.字节复制到数组
5.将数组,偏移量和长度作为参数调用某些处理方法
显然,这比使用数组要多做一些工作。因此,如果你事前就知道容器里的数据将作为一个数组被访问,你可能更愿意使用堆内存。
COMPOSITE BUFFER(复合缓冲区)
最后一种模式是复合缓冲区,我们可以创建多个不同的 ByteBuf,然后提供一个这些 ByteBuf 组合的视图。复合缓冲区就像一个列表,我们可以动态的添加和删除其中的 ByteBuf,JDK 的 ByteBuffer 没有这样的功能。
Netty 提供了 ByteBuf 的子类 CompositeByteBuf 类来处理复合缓冲区,CompositeByteBuf 只是一个视图。
警告
CompositeByteBuf.hasArray() 总是返回 false,因为它可能既包含堆缓冲区,也包含直接缓冲区
例如,一条消息由 header 和 body 两部分组成,将 header 和 body 组装成一条消息发送出去,可能 body 相同,只是 header 不同,使用CompositeByteBuf 就不用每次都重新分配一个新的缓冲区。下图显示CompositeByteBuf 组成 header 和 body:
Figure 5.2 CompositeByteBuf holding a header and body
下面代码显示了使用 JDK 的 ByteBuffer 的一个实现。两个 ByteBuffer 的数组创建保存消息的组件,第三个创建用于保存所有数据的副本。
Listing 5.3 Composite buffer pattern using ByteBuffer
// 使用数组保存消息的各个部分
ByteBuffer[] message = { header, body };
// 使用副本来合并这两个部分
ByteBuffer message2 = ByteBuffer.allocate(
header.remaining() + body.remaining());
message2.put(header);
message2.put(body);
message2.flip();
这种做法显然是低效的;分配和复制操作不是最优的方法,操纵数组使代码显得很笨拙。
下面看使用 CompositeByteBuf 的改进版本
Listing 5.4 Composite buffer pattern using CompositeByteBuf
CompositeByteBuf messageBuf = ...;
ByteBuf headerBuf = ...; // 可以支持或直接
ByteBuf bodyBuf = ...; // 可以支持或直接
messageBuf.addComponents(headerBuf, bodyBuf);
// ....
messageBuf.removeComponent(0); // 移除头 //2
for (int i = 0; i < messageBuf.numComponents(); i++) { //3
System.out.println(messageBuf.component(i).toString());
}
1.追加 ByteBuf 实例的 CompositeByteBuf
2.删除 索引1的 ByteBuf
3.遍历所有 ByteBuf 实例。
清单5.4 所示,你可以简单地把 CompositeByteBuf 当作一个可迭代遍历的容器。 CompositeByteBuf 不允许访问其内部可能存在的支持数组,也不允许直接访问数据,这一点类似于直接缓冲区模式,如图5.5所示。
Listing 5.5 Access data
CompositeByteBuf compBuf = ...;
int length = compBuf.readableBytes(); //1
byte[] array = new byte[length]; //2
compBuf.getBytes(compBuf.readerIndex(), array); //3
handleArray(array, 0, length); //4
1.得到的可读的字节数。
2.分配一个新的数组,数组长度为可读字节长度。
3.读取字节到数组
4.使用数组,把偏移量和长度作为参数
Netty 尝试使用 CompositeByteBuf 优化 socket I/O 操作,消除 原生 JDK 中可能存在的的性能低和内存消耗问题。虽然这是在Netty 的核心代码中进行的优化,并且是不对外暴露的,但是作为开发者还是应该意识到其影响。
CompositeByteBuf API
CompositeByteBuf 提供了大量的附加功能超出了它所继承的 ByteBuf。请参阅的 Netty 的 Javadoc 文档 API。
字节级别的操作
除了基本的读写操作, ByteBuf 还提供了它所包含的数据的修改方法。
随机访问索引
ByteBuf 使用zero-based 的 indexing(从0开始的索引),第一个字节的索引是 0,最后一个字节的索引是 ByteBuf 的 capacity - 1,下面代码是遍历 ByteBuf 的所有字节:
Listing 5.6 Access data
ByteBuf buffer = ...;
for (int i = 0; i < buffer.capacity(); i++) {
byte b = buffer.getByte(i);
System.out.println((char) b);
}
注意通过索引访问时不会推进 readerIndex (读索引)和 writerIndex(写索引),我们可以通过 ByteBuf 的 readerIndex(index) 或 writerIndex(index) 来分别推进读索引或写索引
顺序访问索引
ByteBuf 提供两个指针变量支付读和写操作,读操作是使用 readerIndex(),写操作时使用 writerIndex()。这和JDK的ByteBuffer不同,ByteBuffer只有一个方法来设置索引,所以需要使用 flip() 方法来切换读和写模式。
ByteBuf 一定符合:0 <= readerIndex <= writerIndex <= capacity。
1.字节,可以被丢弃,因为它们已经被读
2.还没有被读的字节是:“readable bytes(可读字节)”
3.空间可加入多个字节的是:“writeable bytes(写字节)”
可丢弃字节的字节
标有“可丢弃字节”的段包含已经被读取的字节。他们可以被丢弃,通过调用discardReadBytes() 来回收空间。这个段的初始大小存储在readerIndex,为 0,当“read”操作被执行时递增(“get”操作不会移动 readerIndex)。
图5.4示出了在 图5.3 中的缓冲区中调用 discardReadBytes() 所示的结果。你可以看到,在丢弃字节段的空间已变得可用写。需要注意的是不能保证对可写的段之后的内容在 discardReadBytes() 方法之后已经被调用。
1.字节尚未被读出(readerIndex 现在 0)。 2.可用的空间,由于空间被回收而增大。
ByteBuf.discardReadBytes() 可以用来清空 ByteBuf 中已读取的数据,从而使 ByteBuf 有多余的空间容纳新的数据,但是discardReadBytes() 可能会涉及内存复制,因为它需要移动 ByteBuf 中可读的字节到开始位置,这样的操作会影响性能,一般在需要马上释放内存的时候使用收益会比较大。
可读字节
ByteBuf 的“可读字节”分段存储的是实际数据。新分配,包装,或复制的缓冲区的 readerIndex 的默认值为 0 。任何操作,其名称以 “read” 或 “skip” 开头的都将检索或跳过该数据在当前 readerIndex ,并且通过读取的字节数来递增。
如果所谓的读操作是一个指定 ByteBuf 参数作为写入的对象,并且没有一个目标索引参数,目标缓冲区的 writerIndex 也会增加了。例如:
如果试图从缓冲器读取已经用尽的可读的字节,则抛出IndexOutOfBoundsException。清单5.8显示了如何读取所有可读字节。
Listing 5.7 Read all data
//遍历缓冲区的可读字节
ByteBuf buffer= ...;
while (buffer.isReadable()) {
System.out.println(buffer.readByte());
}
这段是未定义内容的地方,准备好写。一个新分配的缓冲区的 writerIndex 的默认值是 0 。任何操作,其名称 “write"开头的操作在当前的 writerIndex 写入数据时,递增字节写入的数量。如果写操作的目标也是 ByteBuf ,且未指定源索引,则源缓冲区的 readerIndex 将增加相同的量。例如:
writeBytes(ByteBuf dest);
如果试图写入超出目标的容量,则抛出 IndexOutOfBoundException。
下面的例子展示了填充随机整数到缓冲区中,直到耗尽空间。该方法writableBytes() 被用在这里确定是否存在足够的缓冲空间。
Listing 5.8 Write data
//填充随机整数到缓冲区中
ByteBuf buffer = ...;
while (buffer.writableBytes() >= 4) {
buffer.writeInt(random.nextInt());
}
索引管理
在 JDK 的 InputStream 定义了 mark(int readlimit) 和 reset()方法。这些是分别用来标记流中的当前位置和复位流到该位置。
同样,您可以设置和重新定位ByteBuf readerIndex 和 writerIndex 通过调用 markReaderIndex(), markWriterIndex(), resetReaderIndex() 和 resetWriterIndex()。这些类似于InputStream 的调用,所不同的是,没有 readlimit 参数来指定当标志变为无效。
您也可以通过调用 readerIndex(int) 或 writerIndex(int) 将指标移动到指定的位置。在尝试任何无效位置上设置一个索引将导致 IndexOutOfBoundsException 异常。
调用 clear() 可以同时设置 readerIndex 和 writerIndex 为 0。注意,这不会清除内存中的内容。让我们看看它是如何工作的。 (图5.5图重复5.3 )
调用之前,包含3个段,下面显示了调用之后
现在 整个 ByteBuf 空间都是可写的了。
clear() 比 discardReadBytes() 更低成本,因为他只是重置了索引,而没有内存拷贝。
查询操作
有几种方法,以确定在所述缓冲器中的指定值的索引。最简单的是使用 indexOf() 方法。更复杂的搜索执行以 ByteBufProcessor 为参数的方法。这个接口定义了一个方法,boolean process(byte value),它用来报告输入值是否是一个正在寻求的值。
ByteBufProcessor 定义了很多方便实现共同目标值。例如,假设您的应用程序需要集成所谓的“Flash sockets”,将使用 NULL 结尾的内容。调用
forEachByte(ByteBufProcessor.FIND_NUL)
通过减少的,因为少量的 “边界检查”的处理过程中执行了,从而使 消耗 Flash 数据变得 编码工作量更少、效率更高。
下面例子展示了寻找一个回车符,\ r的一个例子。
Listing 5.9 Using ByteBufProcessor to find \r
ByteBuf buffer = ...;
int index = buffer.forEachByte(ByteBufProcessor.FIND_CR);
衍生的缓冲区
“衍生的缓冲区”是代表一个专门的展示 ByteBuf 内容的“视图”。这种视图是由 duplicate(), slice(), slice(int, int),readOnly(), 和 order(ByteOrder) 方法创建的。所有这些都返回一个新的 ByteBuf 实例包括它自己的 reader, writer 和标记索引。然而,内部数据存储共享就像在一个 NIO 的 ByteBuffer。这使得衍生的缓冲区创建、修改其 内容,以及修改其“源”实例更廉价。
ByteBuf 拷贝
如果需要已有的缓冲区的全新副本,使用 copy() 或者 copy(int, int)。不同于派生缓冲区,这个调用返回的 ByteBuf 有数据的独立副本。
若需要操作某段数据,使用 slice(int, int),下面展示了用法:
Listing 5.10 Slice a ByteBuf
Charset utf8 = Charset.forName("UTF-8");
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8); //1
ByteBuf sliced = buf.slice(0, 14); //2
System.out.println(sliced.toString(utf8)); //3
buf.setByte(0, (byte) 'J'); //4
assert buf.getByte(0) == sliced.getByte(0);
1.创建一个 ByteBuf 保存特定字节串。
2.创建从索引 0 开始,并在 14 结束的 ByteBuf 的新 slice。
3.打印 Netty in Action
4.更新索引 0 的字节。
5.断言成功,因为数据是共享的,并以一个地方所做的修改将在其他地方可见。
下面看下如何将一个 ByteBuf 段的副本不同于 slice。
Listing 5.11 Copying a ByteBuf
Charset utf8 = Charset.forName("UTF-8");
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8); //1
ByteBuf copy = buf.copy(0, 14); //2
System.out.println(copy.toString(utf8)); //3
buf.setByte(0, (byte) 'J'); //4
assert buf.getByte(0) != copy.getByte(0);
1.创建一个 ByteBuf 保存特定字节串。
2.创建从索引0开始和 14 结束 的 ByteBuf 的段的拷贝。
3.打印 Netty in Action
4.更新索引 0 的字节。
5.断言成功,因为数据不是共享的,并以一个地方所做的修改将不影响其他。
代码几乎是相同的,但所 衍生的 ByteBuf 效果是不同的。因此,使用一个 slice 可以尽可能避免复制内存。
读/写操作
读/写操作主要由2类:
- gget()/set() 操作从给定的索引开始,保持不变
- read()/write() 操作从给定的索引开始,与字节访问的数量来适用,递增当前的写索引或读索引
ByteBuf 的各种读写方法或其他一些检查方法可以看 ByteBuf 的 API,下面是常见的 get() 操作:
Table 5.1 get() operations
| 方法名称 | 描述 |
|---|
| getBoolean(int) | 返回当前索引的 Boolean 值 |
| getByte(int) getUnsignedByte(int) | 返回当前索引的(无符号)字节 |
| getMedium(int) getUnsignedMedium(int) | 返回当前索引的 (无符号) 24-bit 中间值 |
| getInt(int) getUnsignedInt(int) | 返回当前索引的(无符号) 整型 |
| getLong(int) getUnsignedLong(int) | 返回当前索引的 (无符号) Long 型 |
| getShort(int) getUnsignedShort(int) | 返回当前索引的 (无符号) Short 型 |
| getBytes(int, …) | 字节 |
常见 set() 操作如下
Table 5.2 set() operations
| 方法名称 | 描述 |
|---|
| setBoolean(int, boolean) | 在指定的索引位置设置 Boolean 值 |
| setByte(int, int) | 在指定的索引位置设置 byte 值 |
| setMedium(int, int) | 在指定的索引位置设置 24-bit 中间 值 |
| setInt(int, int) | 在指定的索引位置设置 int 值 |
| setLong(int, long) | 在指定的索引位置设置 long 值 |
| setShort(int, int) | 在指定的索引位置设置 short 值 |
下面是用法:
Listing 5.12 get() and set() usage
Charset utf8 = Charset.forName("UTF-8");
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8); //1
System.out.println((char)buf.getByte(0)); //2
int readerIndex = buf.readerIndex(); //3
int writerIndex = buf.writerIndex();
buf.setByte(0, (byte)'B'); //4
System.out.println((char)buf.getByte(0)); //5
assert readerIndex == buf.readerIndex(); //6
assert writerIndex == buf.writerIndex();
1.创建一个新的 ByteBuf 给指定 String 保存字节
2.打印的第一个字符,N
3.存储当前 readerIndex 和 writerIndex
4.更新索引 0 的字符B
5.打印出的第一个字符,现在B
6.这些断言成功,因为这些操作永远不会改变索引
现在,让我们来看看 read() 操作,对当前 readerIndex 或 writerIndex 进行操作。这些用于从 ByteBuf 读取就好像它是一个流。 (对应的 write() 操作用于“追加”到 ByteBuf )。下面展示了常见的 read() 方法。
Table 5.3 read() operations
| 方法名称 | 描述 |
|---|
| readBoolean() | Reads the Boolean value at the current readerIndex and increases the readerIndex by 1. |
| readByte() readUnsignedByte() | Reads the (unsigned) byte value at the current readerIndex and increases the readerIndex by 1. |
| readMedium() readUnsignedMedium() | Reads the (unsigned) 24-bit medium value at the current readerIndex and increases the readerIndex by 3. |
| readInt() readUnsignedInt() | Reads the (unsigned) int value at the current readerIndex and increases the readerIndex by 4. |
| readLong() readUnsignedLong() | Reads the (unsigned) int value at the current readerIndex and increases the readerIndex by 8. |
| readShort() readUnsignedShort() | Reads the (unsigned) int value at the current readerIndex and increases the readerIndex by 2. |
| readBytes(int,int, …) | Reads the value on the current readerIndex for the given length into the given object. Also increases the readerIndex by the length. |
每个 read() 方法都对应一个 write()。
Table 5.4 Write operations
| 方法名称 | 描述 |
|---|
| writeBoolean(boolean) | Writes the Boolean value on the current writerIndex and increases the writerIndex by 1. |
| writeByte(int) | Writes the byte value on the current writerIndex and increases the writerIndex by 1. |
| writeMedium(int) | Writes the medium value on the current writerIndex and increases the writerIndex by 3. |
| writeInt(int) | Writes the int value on the current writerIndex and increases the writerIndex by 4. |
| writeLong(long) | Writes the long value on the current writerIndex and increases the writerIndex by 8. |
| writeShort(int) | Writes the short value on the current writerIndex and increases thewriterIndex by 2. |
| writeBytes(int,…) | Transfers the bytes on the current writerIndex from given resources. |
Listing 5.13 read()/write() operations on the ByteBuf
Charset utf8 = Charset.forName("UTF-8");
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8); //1
System.out.println((char)buf.readByte()); //2
int readerIndex = buf.readerIndex(); //3
int writerIndex = buf.writerIndex(); //4
buf.writeByte((byte)'?'); //5
assert readerIndex == buf.readerIndex();
assert writerIndex != buf.writerIndex();
1.创建一个新的 ByteBuf 保存给定 String 的字节。
2.打印的第一个字符,N
3.存储当前的 readerIndex
4.保存当前的 writerIndex
5.更新索引0的字符 B
6.此断言成功,因为 writeByte() 在 5 移动了 writerIndex
更多操作
Table 5.5 Other useful operations
| 方法名称 | 描述 |
|---|
| isReadable() | Returns true if at least one byte can be read. |
| isWritable() | Returns true if at least one byte can be written. |
| readableBytes() | Returns the number of bytes that can be read. |
| writablesBytes() | Returns the number of bytes that can be written. |
| capacity() | Returns the number of bytes that the ByteBuf can hold. After this it will try to expand again until maxCapacity() is reached. |
| maxCapacity() | Returns the maximum number of bytes the ByteBuf can hold. |
| hasArray() | Returns true if the ByteBuf is backed by a byte array. |
| array() | Returns the byte array if the ByteBuf is backed by a byte array, otherwise throws an |
UnsupportedOperationException.
ByteBufHolder
我们经常遇到需要另外存储除有效的实际数据各种属性值。 HTTP 响应是一个很好的例子;与内容一起的字节的还有状态码, cookies,等。
Netty 提供 ByteBufHolder 处理这种常见的情况。 ByteBufHolder 还提供对于 Netty 的高级功能,如缓冲池,其中保存实际数据的 ByteBuf 可以从池中借用,如果需要还可以自动释放。
ByteBufHolder 有那么几个方法。到底层的这些支持接入数据和引用计数。表5.7所示的方法(忽略了那些从继承 ReferenceCounted 的方法)。
Table 5.7 ByteBufHolder operations
| 名称 | 描述 |
|---|
| data() | 返回 ByteBuf 保存的数据 |
| copy() | 制作一个 ByteBufHolder 的拷贝,但不共享其数据(所以数据也是拷贝). |
如果你想实现一个“消息对象”有效负载存储在 ByteBuf,使用ByteBufHolder 是一个好主意。
ByteBuf 分配
本节介绍 ByteBuf 实例管理的几种方式:
ByteBufAllocator
为了减少分配和释放内存的开销,Netty 通过支持池类 ByteBufAllocator,可用于分配的任何 ByteBuf 我们已经描述过的类型的实例。是否使用池是由应用程序决定的,表5.8列出了 ByteBufAllocator 提供的操作。
Table 5.8 ByteBufAllocator methods
| 名称 | 描述 |
|---|
| buffer() buffer(int) buffer(int, int) | Return a ByteBuf with heap-based or direct data storage. |
| heapBuffer() heapBuffer(int) heapBuffer(int, int) | Return a ByteBuf with heap-based storage. |
| directBuffer() directBuffer(int) directBuffer(int, int) | Return a ByteBuf with direct storage. |
| compositeBuffer() compositeBuffer(int) heapCompositeBuffer() heapCompositeBuffer(int) directCompositeBuffer()directCompositeBuffer(int) | Return a CompositeByteBuf that can be expanded by adding heapbased or direct buffers. |
| ioBuffer() | Return a ByteBuf that will be used for I/O operations on a socket. |
通过一些方法接受整型参数允许用户指定 ByteBuf 的初始和最大容量值。你可能还记得,ByteBuf 存储可以扩大到其最大容量。
得到一个 ByteBufAllocator 的引用很简单。你可以得到从 Channel (在理论上,每 Channel 可具有不同的 ByteBufAllocator ),或通过绑定到的 ChannelHandler 的 ChannelHandlerContext 得到它,用它实现了你数据处理逻辑。
下面的列表说明获得 ByteBufAllocator 的两种方式。
Listing 5.15 Obtain ByteBufAllocator reference
Channel channel = ...;
ByteBufAllocator allocator = channel.alloc(); //1
....
ChannelHandlerContext ctx = ...;
ByteBufAllocator allocator2 = ctx.alloc(); //2
...
1.从 channel 获得 ByteBufAllocator
2.从 ChannelHandlerContext 获得 ByteBufAllocator
Netty 提供了两种 ByteBufAllocator 的实现,一种是 PooledByteBufAllocator,用ByteBuf 实例池改进性能以及内存使用降到最低,此实现使用一个“jemalloc”内存分配。其他的实现不池化 ByteBuf 情况下,每次返回一个新的实例。
Netty 默认使用 PooledByteBufAllocator,我们可以通过 ChannelConfig 或通过引导设置一个不同的实现来改变。更多细节在后面讲述 ,见 [Chapter 9, “Bootstrapping Netty Applications”](https://waylau.com/essential-netty-in-action/CORE FUNCTIONS/Bootstrapping.html)
Unpooled (非池化)缓存
当未引用 ByteBufAllocator 时,上面的方法无法访问到 ByteBuf。对于这个用例 Netty 提供一个实用工具类称为 Unpooled,,它提供了静态辅助方法来创建非池化的 ByteBuf 实例。表5.9列出了最重要的方法
Table 5.9 Unpooled helper class
| 名称 | 描述 |
|---|
| buffer() buffer(int) buffer(int, int) | Returns an unpooled ByteBuf with heap-based storage |
| directBuffer() directBuffer(int) directBuffer(int, int) | Returns an unpooled ByteBuf with direct storage |
| wrappedBuffer() | Returns a ByteBuf, which wraps the given data. |
| copiedBuffer() | Returns a ByteBuf, which copies the given data |
在 非联网项目,该 Unpooled 类也使得它更容易使用的 ByteBuf API,获得一个高性能的可扩展缓冲 API,而不需要 Netty 的其他部分的。
ByteBufUtil
ByteBufUtil 静态辅助方法来操作 ByteBuf,因为这个 API 是通用的,与使用池无关,这些方法已经在外面的分配类实现。
也许最有价值的是 hexDump() 方法,这个方法返回指定 ByteBuf 中可读字节的十六进制字符串,可以用于调试程序时打印 ByteBuf 的内容。一个典型的用途是记录一个 ByteBuf 的内容进行调试。十六进制字符串相比字节而言对用户更友好。 而且十六进制版本可以很容易地转换回实际字节表示。
另一个有用方法是 使用 boolean equals(ByteBuf, ByteBuf),用来比较 ByteBuf 实例是否相等。在 实现自己 ByteBuf 的子类时经常用到。
引用计数器
Netty 4 引入了 引用计数器给 ByteBuf 和 ByteBufHolder(两者都实现了 ReferenceCounted 接口)
引用计数本身并不复杂;它在特定的对象上跟踪引用的数目。实现了ReferenceCounted 的类的实例会通常开始于一个活动的引用计数器为 1。活动的引用计数器大于0的对象被保证不被释放。当数量引用减少到0,该实例将被释放。需要注意的是“释放”的语义是特定于具体的实现。最起码,一个对象,它已被释放应不再可用。
这种技术就是诸如 PooledByteBufAllocator 这种减少内存分配开销的池化的精髓部分。
Listing 5.16 Reference counting
Channel channel = ...;
ByteBufAllocator allocator = channel.alloc(); //1
....
ByteBuf buffer = allocator.directBuffer(); //2
assert buffer.refCnt() == 1; //3
...
1.从 channel 获取 ByteBufAllocator
2.从 ByteBufAllocator 分配一个 ByteBuf
3.检查引用计数器是否是 1
Listing 5.17 Release reference counted object
ByteBuf buffer = ...;
boolean released = buffer.release(); //1
...
1.release()将会递减对象引用的数目。当这个引用计数达到0时,对象已被释放,并且该方法返回 true。
如果尝试访问已经释放的对象,将会抛出 IllegalReferenceCountException 异常。
需要注意的是一个特定的类可以定义自己独特的方式其释放计数的“规则”。 例如,release() 可以将引用计数器直接计为 0 而不管当前引用的对象数目。
谁负责 release?
在一般情况下,最后访问的对象负责释放它。在第6章我们会解释 ChannelHandler 和 ChannelPipeline 的相关概念。
总结
这一章专门讨论了 Netty 基于 ByteBuf 的数据容器。我们开始说明了Netty 比 JDK 更多的优点。我们还突出适合具体情况的 API 的可用变型。
在下一章中,重点是 ChannelHandler,它提供了数据处理逻辑的载体。 ChannelHandler 大量使用了 ByteBuf。
8.5 - CH06-ChannelHandler 与 ChannelPipeline
本章主要内容
- Channel
- ChannelHandler
- ChannePipeline
- ChannelHandlerContext
我们在上一章研究的 bytebuf 是一个容器用来“包装”数据。在本章我们将探讨这些容器如何通过应用程序来移动,传入和传出,以及他们的内容是如何处理的。
Netty 提供了应用开发的数据处理方面的强大支持。我们已经看到了channelhandler 如何链接在一起 ChannelPipeline 使用结构处理更加灵活和模块化。
在这一章中,下面我们会遇到各种各样 Channelhandler,ChannelPipeline 的使用案例,以及重要的相关的类Channelhandlercontext 。我们将展示如何将这些基本组成的框架可以帮助我们写干净可重用的处理实现。
ChannelHandler 家族
在我们深入研究 Channelhandler 内部之前,让我们花几分钟了解下这个领域的 Netty 组件模型的基础。这里提供一个 Channelhandler 及其子类的研究有价值的背景。
Channel 生命周期
Channel 有个简单但强大的状态模型,与 ChannelInboundHandler API 密切相关。下面表格是 Channel 的四个状态
Table 6.1 Channel lifeycle states
| 状态 | 描述 |
|---|
| channelUnregistered | channel创建但未注册到一个 EventLoop. |
| channelRegistered | channel 注册到一个 EventLoop. |
| channelActive | channel 的活动的(连接到了它的 remote peer(远程对等方)),现在可以接收和发送数据了 |
| channelInactive | channel 没有连接到 remote peer(远程对等方) |
Channel 的正常的生命周期如下图,当这些状态变化出现,对应的事件将会生成,这样与 ChannelPipeline 中的 ChannelHandler 的交互就能及时响应
Figure 6.1 Channel State Model
ChannelHandler 生命周期
ChannelHandler 定义的生命周期操作如下表,当 ChannelHandler 添加到 ChannelPipeline,或者从 ChannelPipeline 移除后,这些将会调用。每个方法都会带 ChannelHandlerContext 参数
Table 6.2 ChannelHandler lifecycle methods
| 类型 | 描述 |
|---|
| handlerAdded | 当 ChannelHandler 添加到 ChannelPipeline 调用 |
| handlerRemoved | 当 ChannelHandler 从 ChannelPipeline 移除时调用 |
| exceptionCaught | 当 ChannelPipeline 执行发生错误时调用 |
ChannelHandler 子接口
Netty 提供2个重要的 ChannelHandler 子接口:
- ChannelInboundHandler - 处理进站数据,并且所有状态都更改
- ChannelOutboundHandler - 处理出站数据,允许拦截各种操作
ChannelHandler 适配器
Netty 提供了一个简单的 ChannelHandler 框架实现,给所有声明方法签名。这个类 ChannelHandlerAdapter 的方法,主要推送事件 到 pipeline 下个 ChannelHandler 直到 pipeline 的结束。这个类 也作为 ChannelInboundHandlerAdapter 和ChannelOutboundHandlerAdapter 的基础。所有三个适配器类的目的是作为自己的实现的起点;您可以扩展它们,覆盖你需要自定义的方法。
ChannelInboundHandler
ChannelInboundHandler 的生命周期方法在下表中,当接收到数据或者与之关联的 Channel 状态改变时调用。之前已经注意到了,这些方法与 Channel 的生命周期接近
Table 6.3 ChannelInboundHandler methods
| 类型 | 描述 |
|---|
| channelRegistered | Invoked when a Channel is registered to its EventLoop and is able to handle I/O. |
| channelUnregistered | Invoked when a Channel is deregistered from its EventLoop and cannot handle any I/O. |
| channelActive | Invoked when a Channel is active; the Channel is connected/bound and ready. |
| channelInactive | Invoked when a Channel leaves active state and is no longer connected to its remote peer. |
| channelReadComplete | Invoked when a read operation on the Channel has completed. |
| channelRead | Invoked if data are read from the Channel. |
| channelWritabilityChanged | Invoked when the writability state of the Channel changes. The user can ensure writes are not done too fast (with risk of an OutOfMemoryError) or can resume writes when the Channel becomes writable again.Channel.isWritable() can be used to detect the actual writability of the channel. The threshold for writability can be set via Channel.config().setWriteHighWaterMark() and Channel.config().setWriteLowWaterMark(). |
| userEventTriggered(…) | Invoked when a user calls Channel.fireUserEventTriggered(…) to pass a pojo through the ChannelPipeline. This can be used to pass user specific events through the ChannelPipeline and so allow handling those events. |
注意,ChannelInboundHandler 实现覆盖了 channelRead() 方法处理进来的数据用来响应释放资源。Netty 在 ByteBuf 上使用了资源池,所以当执行释放资源时可以减少内存的消耗。
Listing 6.1 Handler to discard data
@ChannelHandler.Sharable
public class DiscardHandler extends ChannelInboundHandlerAdapter { //1
@Override
public void channelRead(ChannelHandlerContext ctx,
Object msg) {
ReferenceCountUtil.release(msg); //2
}
}
扩展 ChannelInboundHandlerAdapter
ReferenceCountUtil.release() 来丢弃收到的信息
Netty 用一个 WARN-level 日志条目记录未释放的资源,使其能相当简单地找到代码中的违规实例。然而,由于手工管理资源会很繁琐,您可以通过使用 SimpleChannelInboundHandler 简化问题。如下:
Listing 6.2 Handler to discard data
@ChannelHandler.Sharable
public class SimpleDiscardHandler extends SimpleChannelInboundHandler<Object> { //1
@Override
public void channelRead0(ChannelHandlerContext ctx,
Object msg) {
// No need to do anything special //2
}
}
扩展 SimpleChannelInboundHandler
不需做特别的释放资源的动作
注意 SimpleChannelInboundHandler 会自动释放资源,而无需存储任何信息的引用。
更多详见 “Error! Reference source not found..” 一节
ChannelOutboundHandler
ChannelOutboundHandler 提供了出站操作时调用的方法。这些方法会被 Channel, ChannelPipeline, 和 ChannelHandlerContext 调用。
ChannelOutboundHandler 另个一个强大的方面是它具有在请求时延迟操作或者事件的能力。比如,当你在写数据到 remote peer 的过程中被意外暂停,你可以延迟执行刷新操作,然后在迟些时候继续。
下面显示了 ChannelOutboundHandler 的方法(继承自 ChannelHandler 未列出来)
Table 6.4 ChannelOutboundHandler methods
| 类型 | 描述 |
|---|
| bind | Invoked on request to bind the Channel to a local address |
| connect | Invoked on request to connect the Channel to the remote peer |
| disconnect | Invoked on request to disconnect the Channel from the remote peer |
| close | Invoked on request to close the Channel |
| deregister | Invoked on request to deregister the Channel from its EventLoop |
| read | Invoked on request to read more data from the Channel |
| flush | Invoked on request to flush queued data to the remote peer through the Channel |
| write | Invoked on request to write data through the Channel to the remote peer |
几乎所有的方法都将 ChannelPromise 作为参数,一旦请求结束要通过 ChannelPipeline 转发的时候,必须通知此参数。
ChannelPromise vs. ChannelFuture
ChannelPromise 是 特殊的 ChannelFuture,允许你的 ChannelPromise 及其 操作 成功或失败。所以任何时候调用例如 Channel.write(…) 一个新的 ChannelPromise将会创建并且通过 ChannelPipeline传递。这次写操作本身将会返回 ChannelFuture, 这样只允许你得到一次操作完成的通知。Netty 本身使用 ChannelPromise 作为返回的 ChannelFuture 的通知,事实上在大多数时候就是 ChannelPromise 自身(ChannelPromise 扩展了 ChannelFuture)
如前所述,ChannelOutboundHandlerAdapter 提供了一个实现了 ChannelOutboundHandler 所有基本方法的实现的框架。 这些简单事件转发到下一个 ChannelOutboundHandler 管道通过调用 ChannelHandlerContext 相关的等效方法。你可以根据需要自己实现想要的方法。
资源管理
当你通过 ChannelInboundHandler.channelRead(…) 或者 ChannelOutboundHandler.write(…) 来处理数据,重要的是在处理资源时要确保资源不要泄漏。
Netty 使用引用计数器来处理池化的 ByteBuf。所以当 ByteBuf 完全处理后,要确保引用计数器被调整。
引用计数的权衡之一是用户时必须小心使用消息。当 JVM 仍在 GC(不知道有这样的消息引用计数)这个消息,以至于可能是之前获得的这个消息不会被放回池中。因此很可能,如果你不小心释放这些消息,很可能会耗尽资源。
为了让用户更加简单的找到遗漏的释放,Netty 包含了一个 ResourceLeakDetector ,将会从已分配的缓冲区 1% 作为样品来检查是否存在在应用程序泄漏。因为 1% 的抽样,开销很小。
对于检测泄漏,您将看到类似于下面的日志消息。
LEAK: ByteBuf.release() was not called before it’s garbage-collected. Enable advanced leak reporting to find out where the leak occurred. To enable advanced
leak reporting, specify the JVM option ’-Dio.netty.leakDetectionLevel=advanced’ or call ResourceLeakDetector.setLevel()
Relaunch your application with the JVM option mentioned above, then you’ll see the recent locations of your application where the leaked buffer was accessed. The following output shows a leak from our unit test (XmlFrameDecoderTest.testDecodeWithXml()):
Running io.netty.handler.codec.xml.XmlFrameDecoderTest
15:03:36.886 [main] ERROR io.netty.util.ResourceLeakDetector - LEAK:
ByteBuf.release() was not called before it’s garbage-collected.
Recent access records: 1
#1:
io.netty.buffer.AdvancedLeakAwareByteBuf.toString(AdvancedLeakAwareByteBuf.java:697)
io.netty.handler.codec.xml.XmlFrameDecoderTest.testDecodeWithXml(XmlFrameDecoderTest.java:157)
io.netty.handler.codec.xml.XmlFrameDecoderTest.testDecodeWithTwoMessages(XmlFrameDecoderTest.java:133)
泄漏检测等级
Netty 现在定义了四种泄漏检测等级,可以按需开启,见下表
Table 6.5 Leak detection levels
| Level Description | DISABLED |
|---|
| Disables | Leak detection completely. While this even eliminates the 1 % overhead you should only do this after extensive testing. |
| SIMPLE | Tells if a leak was found or not. Again uses the sampling rate of 1%, the default level and a good fit for most cases. |
| ADVANCED | Tells if a leak was found and where the message was accessed, using the sampling rate of 1%. |
| PARANOID | Same as level ADVANCED with the main difference that every access is sampled. This it has a massive impact on performance. Use this only in the debugging phase. |
修改检测等级,只需修改 io.netty.leakDetectionLevel 系统属性,举例
# java -Dio.netty.leakDetectionLevel=paranoid
这样,我们就能在 ChannelInboundHandler.channelRead(…) 和 ChannelOutboundHandler.write(…) 避免泄漏。
当你处理 channelRead(…) 操作,并在消费消息(不是通过 ChannelHandlerContext.fireChannelRead(…) 来传递它到下个 ChannelInboundHandler) 时,要释放它,如下:
Listing 6.3 Handler that consume inbound data
@ChannelHandler.Sharable
public class DiscardInboundHandler extends ChannelInboundHandlerAdapter { //1
@Override
public void channelRead(ChannelHandlerContext ctx,
Object msg) {
ReferenceCountUtil.release(msg); //2
}
}
- 继承 ChannelInboundHandlerAdapter
- 使用 ReferenceCountUtil.release(…) 来释放资源
所以记得,每次处理消息时,都要释放它。
SimpleChannelInboundHandler -消费入站消息更容易
使用入站数据和释放它是一项常见的任务,Netty 为你提供了一个特殊的称为 SimpleChannelInboundHandler 的 ChannelInboundHandler 的实现。该实现将自动释放一个消息,一旦这个消息被用户通过channelRead0() 方法消费。
当你在处理写操作,并丢弃消息时,你需要释放它。现在让我们看下实际是如何操作的。
Listing 6.4 Handler to discard outbound data
@ChannelHandler.Sharable public class DiscardOutboundHandler extends ChannelOutboundHandlerAdapter { //1
@Override
public void write(ChannelHandlerContext ctx,
Object msg, ChannelPromise promise) {
ReferenceCountUtil.release(msg); //2
promise.setSuccess(); //3
}
}
- 继承 ChannelOutboundHandlerAdapter
- 使用 ReferenceCountUtil.release(…) 来释放资源
- 通知 ChannelPromise 数据已经被处理
重要的是,释放资源并通知 ChannelPromise。如果,ChannelPromise 没有被通知到,这可能会引发 ChannelFutureListener 不会被处理的消息通知的状况。
所以,总结下:如果消息是被 消耗/丢弃 并不会被传入下个 ChannelPipeline 的 ChannelOutboundHandler ,调用 ReferenceCountUtil.release(message) 。一旦消息经过实际的传输,在消息被写或者 Channel 关闭时,它将会自动释放。
ChannelPipeline
如果我们认为 ChannelPipeline 只是一系列 ChannelHandler 实例,用于拦截 流经一个 Channel 的入站和出站事件,然后很容易理解 这些 ChannelHandler 可以提供的交互的核心应用程序的数据 和事件处理逻辑。
每一个创建新 Channel ,分配一个新的 ChannelPipeline。这个关联是 永久性的;Channel 既不能附上另一个 ChannelPipeline 也不能分离 当前这个。这是一个 Netty 的固定方面的组件生命周期,开发人员无需特别处理。
根据它的起源,一个事件将由 ChannelInboundHandler 或 ChannelOutboundHandler 处理。随后它将调用 ChannelHandlerContext 实现转发到下一个相同的超类型的处理程序。
ChannelHandlerContext
一个 ChannelHandlerContext 使 ChannelHandler 与 ChannelPipeline 和 其他处理程序交互。一个处理程序可以通知下一个 ChannelPipeline 中的 ChannelHandler 甚至动态修改 ChannelPipeline 的归属。
下图展示了用于入站和出站 ChannelHandler 的 典型 ChannelPipeline 布局。
Figure 6.2 ChannelPipeline and ChannelHandlers
上图说明了 ChannelPipeline 主要是一系列 ChannelHandler。通过ChannelPipeline ChannelPipeline 还提供了方法传播事件本身。如果一个入站事件被触发,它将被传递的从 ChannelPipeline 开始到结束。举个例子,在这个图中出站 I/O 事件将从 ChannelPipeline 右端开始一直处理到左边。
ChannelPipeline 相对论
你可能会说,从 ChannelPipeline 事件传递的角度来看,ChannelPipeline 的“开始” 取决于是否入站或出站事件。然而,Netty 总是指 ChannelPipeline 入站口(图中的左边)为“开始”,出站口(右边)作为“结束”。当我们完成使用 ChannelPipeline.add() 添加混合入站和出站处理程序,每个 ChannelHandler 的“顺序”是它的地位从“开始”到“结束”正如我们刚才定义的。因此,如果我们在图6.1处理程序按顺序从左到右第一个ChannelHandler被一个入站事件将是#1,第一个处理程序被出站事件将是#5*
随着管道传播事件,它决定下个 ChannelHandler 是否是相匹配的方向运动的类型。如果没有,ChannelPipeline 跳过 ChannelHandler 并继续下一个合适的方向。记住,一个处理程序可能同时实现ChannelInboundHandler 和 ChannelOutboundHandler 接口。
修改 ChannelPipeline
ChannelHandler 可以实时修改 ChannelPipeline 的布局,通过添加、移除、替换其他 ChannelHandler(也可以从 ChannelPipeline 移除 ChannelHandler 自身)。这个 是 ChannelHandler 重要的功能之一。
Table 6.6 ChannelHandler methods for modifying a ChannelPipeline
| 名称 | 描述 |
|---|
| addFirst addBefore addAfter addLast | 添加 ChannelHandler 到 ChannelPipeline. |
| Remove | 从 ChannelPipeline 移除 ChannelHandler. |
| Replace | 在 ChannelPipeline 替换另外一个 ChannelHandler |
下面展示了操作
Listing 6.5 Modify the ChannelPipeline
ChannelPipeline pipeline = null; // get reference to pipeline;
FirstHandler firstHandler = new FirstHandler(); //1
pipeline.addLast("handler1", firstHandler); //2
pipeline.addFirst("handler2", new SecondHandler()); //3
pipeline.addLast("handler3", new ThirdHandler()); //4
pipeline.remove("handler3"); //5
pipeline.remove(firstHandler); //6
pipeline.replace("handler2", "handler4", new ForthHandler()); //6
- 创建一个 FirstHandler 实例
- 添加该实例作为 “handler1” 到 ChannelPipeline
- 添加 SecondHandler 实例作为 “handler2” 到 ChannelPipeline 的第一个槽,这意味着它将替换之前已经存在的 “handler1”
- 添加 ThirdHandler 实例作为"handler3" 到 ChannelPipeline 的最后一个槽
- 通过名称移除 “handler3”
- 通过引用移除 FirstHandler (因为只有一个,所以可以不用关联名字 “handler1”).
- 将作为"handler2"的 SecondHandler 实例替换为作为 “handler4"的 FourthHandler
以后我们将看到,这种轻松添加、移除和替换 ChannelHandler 能力, 适合非常灵活的实现逻辑。
ChannelHandler 执行 ChannelPipeline 和阻塞
通常每个 ChannelHandler 添加到 ChannelPipeline 将处理事件 传递到 EventLoop( I/O 的线程)。至关重要的是不要阻塞这个线程, 它将会负面影响的整体处理I/O。 有时可能需要使用阻塞 api 接口来处理遗留代码。对于这个情况下,ChannelPipeline 已有 add() 方法,它接受一个EventExecutorGroup。如果一个定制的 EventExecutorGroup 传入事件将由含在这个 EventExecutorGroup 中的 EventExecutor之一来处理,并且从 Channel 的 EventLoop 本身离开。一个默认实现,称为来自 Netty 的 DefaultEventExecutorGroup
除了上述操作,其他访问 ChannelHandler 的方法如下:
Table 6.7 ChannelPipeline operations for retrieving ChannelHandlers
| 名称 | 描述 |
|---|
| get(…) | Return a ChannelHandler by type or name |
| context(…) | Return the ChannelHandlerContext bound to a ChannelHandler. |
| names() iterator() | Return the names or of all the ChannelHander in the ChannelPipeline. |
发送事件
ChannelPipeline API 有额外调用入站和出站操作的方法。下表列出了入站操作,用于通知 ChannelPipeline 中 ChannelInboundHandlers 正在发生的事件
Table 6.8 Inbound operations on ChannelPipeline
| 名称 | 描述 |
|---|
| fireChannelRegistered | Calls channelRegistered(ChannelHandlerContext) on the next ChannelInboundHandler in the ChannelPipeline. |
| fireChannelUnregistered | Calls channelUnregistered(ChannelHandlerContext) on the next ChannelInboundHandler in the ChannelPipeline. |
| fireChannelActive | Calls channelActive(ChannelHandlerContext) on the next ChannelInboundHandler in the ChannelPipeline. |
| fireChannelInactive | Calls channelInactive(ChannelHandlerContext)on the next ChannelInboundHandler in the ChannelPipeline. |
| fireExceptionCaught | Calls exceptionCaught(ChannelHandlerContext, Throwable) on the next ChannelHandler in the ChannelPipeline. |
| fireUserEventTriggered | Calls userEventTriggered(ChannelHandlerContext, Object) on the next ChannelInboundHandler in the ChannelPipeline. |
| fireChannelRead | Calls channelRead(ChannelHandlerContext, Object msg) on the next ChannelInboundHandler in the ChannelPipeline. |
| fireChannelReadComplete | Calls channelReadComplete(ChannelHandlerContext) on the next ChannelStateHandler in the ChannelPipeline. |
在出站方面,处理一个事件将导致底层套接字的一些行动。下表列出了ChannelPipeline API 出站的操作。
Table 6.9 Outbound operations on ChannelPipeline
| 名称 | 描述 |
|---|
| bind | Bind the Channel to a local address. This will call bind(ChannelHandlerContext, SocketAddress, ChannelPromise) on the next ChannelOutboundHandler in the ChannelPipeline. |
| connect | Connect the Channel to a remote address. This will call connect(ChannelHandlerContext, SocketAddress, ChannelPromise) on the next ChannelOutboundHandler in the ChannelPipeline. |
| disconnect | Disconnect the Channel. This will call disconnect(ChannelHandlerContext, ChannelPromise) on the next ChannelOutboundHandler in the ChannelPipeline. |
| close | Close the Channel. This will call close(ChannelHandlerContext,ChannelPromise) on the next ChannelOutboundHandler in the ChannelPipeline. |
| deregister | Deregister the Channel from the previously assigned EventExecutor (the EventLoop). This will call deregister(ChannelHandlerContext,ChannelPromise) on the next ChannelOutboundHandler in the ChannelPipeline. |
| flush | Flush all pending writes of the Channel. This will call flush(ChannelHandlerContext) on the next ChannelOutboundHandler in the ChannelPipeline. write |
| writeAndFlush | Convenience method for calling write() then flush(). |
| read | Requests to read more data from the Channel. This will call read(ChannelHandlerContext) on the next ChannelOutboundHandler in the ChannelPipeline. |
总结下:
- 一个 ChannelPipeline 是用来保存关联到一个 Channel 的ChannelHandler
- 可以修改 ChannelPipeline 通过动态添加和删除 ChannelHandler
- ChannelPipeline 有着丰富的API调用动作来回应入站和出站事件。
ChannelHandlerContext
接口 ChannelHandlerContext 代表 ChannelHandler 和ChannelPipeline 之间的关联,并在 ChannelHandler 添加到 ChannelPipeline 时创建一个实例。ChannelHandlerContext 的主要功能是管理通过同一个 ChannelPipeline 关联的 ChannelHandler 之间的交互。
ChannelHandlerContext 有许多方法,其中一些也出现在 Channel 和ChannelPipeline 本身。然而,如果您通过Channel 或ChannelPipeline 的实例来调用这些方法,他们就会在整个 pipeline中传播 。相比之下,一样的 的方法在 ChannelHandlerContext的实例上调用, 就只会从当前的 ChannelHandler 开始并传播到相关管道中的下一个有处理事件能力的 ChannelHandler 。
ChannelHandlerContext API 总结如下:
Table 6.10 ChannelHandlerContext API
| 名称 | 描述 |
|---|
| bind | Request to bind to the given SocketAddress and return a ChannelFuture. |
| channel | Return the Channel which is bound to this instance. |
| close | Request to close the Channel and return a ChannelFuture. |
| connect | Request to connect to the given SocketAddress and return a ChannelFuture. |
| deregister | Request to deregister from the previously assigned EventExecutor and return a ChannelFuture. |
| disconnect | Request to disconnect from the remote peer and return a ChannelFuture. |
| executor | Return the EventExecutor that dispatches events. |
| fireChannelActive | A Channel is active (connected). |
| fireChannelInactive | A Channel is inactive (closed). |
| fireChannelRead | A Channel received a message. |
| fireChannelReadComplete | Triggers a channelWritabilityChanged event to the next |
ChannelInboundHandler. handler | Returns the ChannelHandler bound to this instance. isRemoved | Returns true if the associated ChannelHandler was removed from the ChannelPipeline. name | Returns the unique name of this instance. pipeline | Returns the associated ChannelPipeline. read | Request to read data from the Channel into the first inbound buffer. Triggers a channelRead event if successful and notifies the handler of channelReadComplete. write | Request to write a message via this instance through the pipeline.
其他注意注意事项:
- ChannelHandlerContext 与 ChannelHandler 的关联从不改变,所以缓存它的引用是安全的。
- 正如我们前面指出的,ChannelHandlerContext 所包含的事件流比其他类中同样的方法都要短,利用这一点可以尽可能高地提高性能。
使用 ChannelHandler
本节,我们将说明 ChannelHandlerContext的用法 ,以及ChannelHandlerContext, Channel 和 ChannelPipeline 这些类中方法的不同表现。下图展示了 ChannelPipeline, Channel, ChannelHandler 和 ChannelHandlerContext 的关系
- Channel 绑定到 ChannelPipeline
- ChannelPipeline 绑定到 包含 ChannelHandler 的 Channel
- ChannelHandler
- 当添加 ChannelHandler 到 ChannelPipeline 时,ChannelHandlerContext 被创建
Figure 6.3 Channel, ChannelPipeline, ChannelHandler and ChannelHandlerContext
下面展示了, 从 ChannelHandlerContext 获取到 Channel 的引用,通过调用 Channel 上的 write() 方法来触发一个 写事件到通过管道的的流中
Listing 6.6 Accessing the Channel from a ChannelHandlerContext
ChannelHandlerContext ctx = context;
Channel channel = ctx.channel(); //1
channel.write(Unpooled.copiedBuffer("Netty in Action",
CharsetUtil.UTF_8)); //2
- 得到与 ChannelHandlerContext 关联的 Channel 的引用
- 通过 Channel 写缓存
下面展示了 从 ChannelHandlerContext 获取到 ChannelPipeline 的相同示例
Listing 6.7 Accessing the ChannelPipeline from a ChannelHandlerContext
ChannelHandlerContext ctx = context;
ChannelPipeline pipeline = ctx.pipeline(); //1
pipeline.write(Unpooled.copiedBuffer("Netty in Action", CharsetUtil.UTF_8)); //2
- 得到与 ChannelHandlerContext 关联的 ChannelPipeline 的引用
- 通过 ChannelPipeline 写缓冲区
流在两个清单6.6和6.7是一样的,如图6.4所示。重要的是要注意,虽然在 Channel 或者 ChannelPipeline 上调用write() 都会把事件在整个管道传播,但是在 ChannelHandler 级别上,从一个处理程序转到下一个却要通过在 ChannelHandlerContext 调用方法实现。
- 事件传递给 ChannelPipeline 的第一个 ChannelHandler
- ChannelHandler 通过关联的 ChannelHandlerContext 传递事件给 ChannelPipeline 中的 下一个
- ChannelHandler 通过关联的 ChannelHandlerContext 传递事件给 ChannelPipeline 中的 下一个
Figure 6.4 Event propagation via the Channel or the ChannelPipeline
为什么你可能会想从 ChannelPipeline 一个特定的点开始传播一个事件?
- 通过减少 ChannelHandler 不感兴趣的事件的传递,从而减少开销
- 排除掉特定的对此事件感兴趣的处理程序的处理
想要实现从一个特定的 ChannelHandler 开始处理,你必须引用与 此ChannelHandler的前一个ChannelHandler 关联的 ChannelHandlerContext 。这个ChannelHandlerContext 将会调用与自身关联的 ChannelHandler 的下一个ChannelHandler 。
下面展示了使用场景
Listing 6.8 Events via ChannelPipeline
ChannelHandlerContext ctx = context;
ctx.write(Unpooled.copiedBuffer("Netty in Action", CharsetUtil.UTF_8));
- 获得 ChannelHandlerContext 的引用
- write() 将会把缓冲区发送到下一个 ChannelHandler
如下所示,消息将会从下一个ChannelHandler开始流过 ChannelPipeline ,绕过所有在它之前的ChannelHandler。
- ChannelHandlerContext 方法调用
- 事件发送到了下一个 ChannelHandler
- 经过最后一个ChannelHandler后,事件从 ChannelPipeline 移除
Figure 6.5 Event flow for operations triggered via the ChannelHandlerContext
我们刚刚描述的用例是一种常见的情形,当我们想要调用某个特定的 ChannelHandler操作时,它尤其有用。
ChannelHandler 和 ChannelHandlerContext 的高级用法
正如我们在清单6.6中看到的,通过调用ChannelHandlerContext的 pipeline() 方法,你可以得到一个封闭的 ChannelPipeline 引用。这使得可以在运行时操作 pipeline 的 ChannelHandler ,这一点可以被利用来实现一些复杂的需求,例如,添加一个 ChannelHandler 到 pipeline 来支持动态协议改变。
其他高级用例可以实现通过保持一个 ChannelHandlerContext 引用供以后使用,这可能发生在任何 ChannelHandler 方法,甚至来自不同的线程。清单6.9显示了此模式被用来触发一个事件。
Listing 6.9 ChannelHandlerContext usage
public class WriteHandler extends ChannelHandlerAdapter {
private ChannelHandlerContext ctx;
@Override
public void handlerAdded(ChannelHandlerContext ctx) {
this.ctx = ctx; //1
}
public void send(String msg) {
ctx.writeAndFlush(msg); //2
}
}
- 存储 ChannelHandlerContext 的引用供以后使用
- 使用之前存储的 ChannelHandlerContext 来发送消息
因为 ChannelHandler 可以属于多个 ChannelPipeline ,它可以绑定多个 ChannelHandlerContext 实例。然而,ChannelHandler 用于这种用法必须添加 @Sharable 注解。否则,试图将它添加到多个 ChannelPipeline 将引发一个异常。此外,它必须既是线程安全的又能安全地使用多个同时的通道(比如,连接)。
清单6.10显示了此模式的正确实现。
Listing 6.10 A shareable ChannelHandler
@ChannelHandler.Sharable //1
public class SharableHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
System.out.println("channel read message " + msg);
ctx.fireChannelRead(msg); //2
}
}
- 添加 @Sharable 注解
- 日志方法调用, 并专递到下一个 ChannelHandler
上面这个 ChannelHandler 实现符合所有包含在多个管道的要求;它通过@Sharable 注解,并不持有任何状态。而下面清单6.11中列出的情况则恰恰相反,它会造成问题。
Listing 6.11 Invalid usage of @Sharable
@ChannelHandler.Sharable //1
public class NotSharableHandler extends ChannelInboundHandlerAdapter {
private int count;
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
count++; //2
System.out.println("inboundBufferUpdated(...) called the "
+ count + " time"); //3
ctx.fireChannelRead(msg);
}
}
- 添加 @Sharable
- count 字段递增
- 日志方法调用, 并专递到下一个 ChannelHandler
这段代码的问题是它持有状态:一个实例变量保持了方法调用的计数。将这个类的一个实例添加到 ChannelPipeline 并发访问通道时很可能产生错误。(当然,这个简单的例子中可以通过在 channelRead() 上添加 synchronized 来纠正 )
总之,使用@Sharable的话,要确定 ChannelHandler 是线程安全的。
为什么共享 ChannelHandler
常见原因是要在多个 ChannelPipelines 上安装一个 ChannelHandler 以此来实现跨多个渠道收集统计数据的目的。
我们的讨论 ChannelHandlerContext 及与其他框架组件关系的 到此结束。接下来我们将解析 Channel 状态模型,准备仔细看看ChannelHandler 本身。
总结
本章带你深入窥探了一下 Netty 的数据处理组件: ChannelHandler。我们讨论了 ChannelHandler 之间是如何链接的以及它在像ChannelInboundHandler 和 ChannelOutboundHandler这样的化身中是如何与 ChannelPipeline 交互的。
下一章将集中在 Netty 的编解码器的抽象上,这种抽象使得编写一个协议编码器和解码器比使用原始 ChannelHandler 接口更容易。
8.6 - CH07-Codec 框架
本章介绍
- Decoder(解码器)
- Encoder(编码器)
- Codec(编解码器)
在前面的章节中,我们讨论了连接到拦截操作或数据处理链的不同方式,展示了如何使用 ChannelHandler 及其相关的类来实现几乎任何一种应用程序所需的逻辑。但正如标准架构模式通常有专门的框架,通用处理模式很适合使用目标实现,可以节省我们大量的开发时间和精力。
在这一章,我们将研究编码和解码——数据从一种特定协议格式到另一种格式的转换。这种处理模式是由通常被称为“codecs(编解码器)”的组件来处理的。Netty提供了一些组件,利用它们可以很容易地为各种不同协议编写编解码器。例如,如果您正在构建一个基于 Netty 的邮件服务器,你可以使用POP3, IMAP 和 SMTP 的现成的实现。
什么是 Codec
编写一个网络应用程序需要实现某种 codec (编解码器),codec的作用就是将原始字节数据与目标程序数据格式进行互转。网络中都是以字节码的数据形式来传输数据的,codec 由两部分组成:decoder(解码器)和encoder(编码器)
编码器和解码器一个字节序列转换为另一个业务对象。我们如何区分?
想到一个“消息”是一个结构化的字节序列,语义为一个特定的应用程序——它的“数据”。encoder 是组件,转换消息格式适合传输(就像字节流),而相应的 decoder 转换传输数据回到程序的消息格式。逻辑上,“从”消息转换来是当作操作 outbound(出站)数据,而转换“到”消息是处理 inbound(入站)数据。
我们看看 Netty 的提供的类实现的 codec 。
解码器负责将消息从字节或其他序列形式转成指定的消息对象,编码器则相反;解码器负责处理“入站”数据,编码器负责处理“出站”数据。编码器和解码器的结构很简单,消息被编码后解码后会自动通过ReferenceCountUtil.release(message)释放,如果不想释放消息可以使用ReferenceCountUtil.retain(message),这将会使引用数量增加而没有消息发布,大多数时候不需要这么做。
Decoder(解码器)
本节,会提供几个类用于 decoder 的实现,并介绍一些具体的例子,这些例子会告诉你什么时候可能用到他们以及怎么来用他们。
Netty 提供了丰富的解码器抽象基类,我们可以很容易的实现这些基类来自定义解码器。主要分两类:
- 解码字节到消息(ByteToMessageDecoder 和 ReplayingDecoder)
- 解码消息到消息(MessageToMessageDecoder)
decoder 负责将“入站”数据从一种格式转换到另一种格式,Netty的解码器是一种 ChannelInboundHandler 的抽象实现。实践中使用解码器很简单,就是将入站数据转换格式后传递到 ChannelPipeline 中的下一个ChannelInboundHandler 进行处理;这样的处理是很灵活的,我们可以将解码器放在 ChannelPipeline 中,重用逻辑。
ByteToMessageDecoder
ByteToMessageDecoder 是用于将字节转为消息(或其他字节序列)。
你不能确定远端是否会一次发送完一个完整的“信息”,因此这个类会缓存入站的数据,直到准备好了用于处理。表7.1说明了它的两个最重要的方法。
Table 7.1 ByteToMessageDecoder API
| 方法名称 | 描述 |
|---|
| Decode | This is the only abstract method you need to implement. It is called with a ByteBuf having the incoming bytes and a List into which decoded messages are added. decode() is called repeatedly until the List is empty on return. The contents of the List are then passed to the next handler in the pipeline. |
| decodeLast | The default implementation provided simply calls decode().This method is called once, when the Channel goes inactive. Override to provide special |
handling
假设我们接收一个包含简单整数的字节流,每个都单独处理。在本例中,我们将从入站 ByteBuf 读取每个整数并将其传递给 pipeline 中的下一个ChannelInboundHandler。“解码”字节流成整数我们将扩展ByteToMessageDecoder,实现类为“ToIntegerDecoder”,如图7.1所示。
Figure 7.1 ToIntegerDecoder
每次从入站的 ByteBuf 读取四个字节,解码成整形,并添加到一个 List (本例是指 Integer),当不能再添加数据到 lsit 时,它所包含的内容就会被发送到下个 ChannelInboundHandler
Listing 7.1 ByteToMessageDecoder that decodes to Integer
public class ToIntegerDecoder extends ByteToMessageDecoder { //1
@Override
public void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out)
throws Exception {
if (in.readableBytes() >= 4) { //2
out.add(in.readInt()); //3
}
}
}
- 实现继承了 ByteToMessageDecode 用于将字节解码为消息
- 检查可读的字节是否至少有4个 ( int 是4个字节长度)
- 从入站 ByteBuf 读取 int , 添加到解码消息的 List 中
尽管 ByteToMessageDecoder 简化了这个模式,你会发现它还是有点烦人,在实际的读操作(这里 readInt())之前,必须要验证输入的 ByteBuf 要有足够的数据。在下一节中,我们将看看 ReplayingDecoder,一个特殊的解码器。
章节5和6中提到,应该特别注意引用计数。对于编码器和解码器来说,这个过程非常简单。一旦一个消息被编码或解码它自动被调用ReferenceCountUtil.release(message) 。如果你稍后还需要用到这个引用而不是马上释放,你可以调用 ReferenceCountUtil.retain(message)。这将增加引用计数,防止消息被释放。
ReplayingDecoder
ReplayingDecoder 是 byte-to-message 解码的一种特殊的抽象基类,读取缓冲区的数据之前需要检查缓冲区是否有足够的字节,使用ReplayingDecoder就无需自己检查;若ByteBuf中有足够的字节,则会正常读取;若没有足够的字节则会停止解码。
ByteToMessageDecoder 和 ReplayingDecoder
注意到 ReplayingDecoder 继承自 ByteToMessageDecoder ,所以API 跟表 7.1 是相同的
也正因为这样的包装使得 ReplayingDecoder 带有一定的局限性:
- 不是所有的标准 ByteBuf 操作都被支持,如果调用一个不支持的操作会抛出 UnreplayableOperationException
- ReplayingDecoder 略慢于 ByteToMessageDecoder
如果这些限制是可以接受你可能更喜欢使用 ReplayingDecoder。下面是一个简单的准则:
如果不引入过多的复杂性 使用 ByteToMessageDecoder 。否则,使用ReplayingDecoder。
Listing 7.2 ReplayingDecoder
public class ToIntegerDecoder2 extends ReplayingDecoder<Void> { //1
@Override
public void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out)
throws Exception {
out.add(in.readInt()); //2
}
}
- 实现继承自 ReplayingDecoder 用于将字节解码为消息
- 从入站 ByteBuf 读取整型,并添加到解码消息的 List 中
如果我们比较清单7.1和7.2很明显,实现使用 ReplayingDecoder 更简单。
更多 Decoder
下面是更加复杂的使用场景: io.netty.handler.codec.LineBasedFrameDecoder 通过结束控制符("\n" 或 “\r\n”).解析入站数据。 io.netty.handler.codec.http.HttpObjectDecoder 用于 HTTP 数据解码
MessageToMessageDecoder
用于从一种消息解码为另外一种消息(例如,POJO 到 POJO),下表展示了方法:
Table 7.2 MessageToMessageDecoder API
| 方法名称 | 描述 |
|---|
| decode | decode is the only abstract method you need to implement. It is called for each inbound message to be decoded to another format . The decoded messages are then passed to the next ChannelInboundHandler in the pipeline. |
| decodeLast | The default implementation provided simply calls decode().This method is called once, when the Channel goes inactive. Override to provide special |
handling
将 Integer 转为 String,我们提供了 IntegerToStringDecoder,继承自 MessageToMessageDecoder。
因为这是一个参数化的类,实现的签名是:
public class IntegerToStringDecoder extends MessageToMessageDecoder<Integer>
decode() 方法的签名是
protected void decode( ChannelHandlerContext ctx,
Integer msg, List<Object> out ) throws Exception
也就是说,入站消息是按照在类定义中声明的参数类型(这里是 Integer) 而不是 ByteBuf来解析的。在之前的例子,解码消息(这里是String)将被添加到List,并传递到下个 ChannelInboundHandler。 这是如图7.2所示。
Figure 7.2 IntegerToStringDecoder
实现如下:
Listing 7.3 MessageToMessageDecoder - Integer to String
public class IntegerToStringDecoder extends
MessageToMessageDecoder<Integer> { //1
@Override
public void decode(ChannelHandlerContext ctx, Integer msg, List<Object> out)
throws Exception {
out.add(String.valueOf(msg)); //2
}
}
- 实现继承自 MessageToMessageDecoder
- 通过 String.valueOf() 转换 Integer 消息字符串
正如我们上面指出的,decode()方法的消息参数的类型是由给这个类指定的泛型的类型(这里是Integer)确定的。
HttpObjectAggregator
更多复杂的示例,请查看类 io.netty.handler.codec.http.HttpObjectAggregator,继承自MessageToMessageDecoder
在解码时处理太大的帧
Netty 是异步框架需要缓冲区字节在内存中,直到你能够解码它们。因此,你不能让你的解码器缓存太多的数据以免耗尽可用内存。为了解决这个共同关心的问题, Netty 提供了一个 TooLongFrameException ,通常由解码器在帧太长时抛出。
为了避免这个问题,你可以在你的解码器里设置一个最大字节数阈值,如果超出,将导致 TooLongFrameException 抛出(并由 ChannelHandler.exceptionCaught() 捕获)。然后由译码器的用户决定如何处理它。虽然一些协议,比如 HTTP、允许这种情况下有一个特殊的响应,有些可能没有,事件唯一的选择可能就是关闭连接。
如清单7.4所示 ByteToMessageDecoder 可以利用 TooLongFrameException 通知其他 ChannelPipeline 中的 ChannelHandler。
Listing 7.4 SafeByteToMessageDecoder encodes shorts into a ByteBuf
public class SafeByteToMessageDecoder extends ByteToMessageDecoder { //1
private static final int MAX_FRAME_SIZE = 1024;
@Override
public void decode(ChannelHandlerContext ctx, ByteBuf in,
List<Object> out) throws Exception {
int readable = in.readableBytes();
if (readable > MAX_FRAME_SIZE) { //2
in.skipBytes(readable); //3
throw new TooLongFrameException("Frame too big!");
}
// do something
}
}
- 实现继承 ByteToMessageDecoder 来将字节解码为消息
- 检测缓冲区数据是否大于 MAX_FRAME_SIZE
- 忽略所有可读的字节,并抛出 TooLongFrameException 来通知 ChannelPipeline 中的 ChannelHandler 这个帧数据超长
这种保护是很重要的,尤其是当你解码一个有可变帧大小的协议的时候。
到这里我们解释了解码器常见用例和 Netty 提供的用于构建它们的抽象基类。但解码器只是一方面。另一方面,还需要完成 Codec API,我们有编码器,用于转换消息到出站数据。这将是我们下一个话题。
Encoder(编码器)
回顾之前的定义,encoder 是用来把出站数据从一种格式转换到另外一种格式,因此它实现了 ChanneOutboundHandler 。正如你所期望的一样,类似于 decoder,Netty 也提供了一组类来帮助你写 encoder,当然这些类提供的是与 decoder 相反的方法,如下所示:
MessageToByteEncoder
之前我们学习了如何使用 ByteToMessageDecoder 来将字节转换成消息,现在我们使用 MessageToByteEncoder 实现相反的效果。
Table 7.3 MessageToByteEncoder API
| 方法名称 | 描述 |
|---|
| encode | The encode method is the only abstract method you need to implement. It is called with the outbound message, which this class will encodes to a ByteBuf. The ByteBuf is then forwarded to the next ChannelOutboundHandler in the ChannelPipeline. |
这个类只有一个方法,而 decoder 却是有两个,原因就是 decoder 经常需要在 Channel 关闭时产生一个“最后的消息”。出于这个原因,提供了decodeLast(),而 encoder 没有这个需求。
下面示例,我们想产生 Short 值,并想将他们编码成 ByteBuf 来发送到 线上,我们提供了 ShortToByteEncoder 来实现该目的。
Figure 7.3 ShortToByteEncoder
上图展示了,encoder 收到了 Short 消息,编码他们,并把他们写入 ByteBuf。 ByteBuf 接着前进到下一个 pipeline 的ChannelOutboundHandler。每个 Short 将占用 ByteBuf 的两个字节
Listing 7.5 ShortToByteEncoder encodes shorts into a ByteBuf
public class ShortToByteEncoder extends
MessageToByteEncoder<Short> { //1
@Override
public void encode(ChannelHandlerContext ctx, Short msg, ByteBuf out)
throws Exception {
out.writeShort(msg); //2
}
}
- 实现继承自 MessageToByteEncoder
- 写 Short 到 ByteBuf
Netty 提供很多 MessageToByteEncoder 类来帮助你的实现自己的 encoder 。其中 WebSocket08FrameEncoder 就是个不错的范例。可以在 io.netty.handler.codec.http.websocketx 包找到。
MessageToMessageEncoder
我们已经知道了如何将入站数据从一个消息格式解码成另一个格式。现在我们需要一种方法来将出站数据从一种消息编码成另一种消息。MessageToMessageEncoder 提供此功能,见表7.4,同样的只有一个方法,因为不需要产生“最后的消息”。
Table 7.4 MessageToMessageEncoder API
| 方法名称 | 描述 |
|---|
| encode | The encode method is the only abstract method you need to implement. It is called for each message written with write(…) to encode the message to one or multiple new outbound messages. The encoded messages are then forwarded |
下面例子,我们将要解码 Integer 消息到 String 消息。可简单使用 MessageToMessageEncoder
Figure 7.4 IntegerToStringEncoder
encoder 从出站字节流提取 Integer,以 String 形式传递给ChannelPipeline 中的下一个 ChannelOutboundHandler 。清单7.6 显示了细节。
Listing 7.6 IntegerToStringEncoder encodes integer to string
public class IntegerToStringEncoder extends
MessageToMessageEncoder<Integer> { //1
@Override
public void encode(ChannelHandlerContext ctx, Integer msg, List<Object> out)
throws Exception {
out.add(String.valueOf(msg)); //2
}
}
- 实现继承自 MessageToMessageEncoder
- 转 Integer 为 String,并添加到 MessageBuf
更复杂 的 MessageToMessageEncoder 应用案例,可以查看 io.netty.handler.codec.protobuf 包下的 ProtobufEncoder
抽象 Codec(编解码器)类
虽然我们一直把解码器和编码器作为不同的实体来讨论,但你有时可能会发现把入站和出站的数据和信息转换都放在同一个类中更实用。Netty的抽象编解码器类就是用于这个目的,他们把一些成对的解码器和编码器组合在一起,以此来提供对于字节和消息都相同的操作。(这些类实现了 ChannelInboundHandler 和 ChannelOutboundHandler )。
您可能想知道是否有时候使用单独的解码器和编码器会比使用这些组合类要好,最简单的答案是,紧密耦合的两个函数减少了他们的可重用性,但是把他们分开实现就会更容易扩展。当我们研究抽象编解码器类时,我们也会拿它和对应的独立的解码器和编码器做对比。
ByteToMessageCodec
我们需要解码字节到消息,也许是一个 POJO,然后转回来。ByteToMessageCodec 将为我们处理这个问题,因为它结合了ByteToMessageDecoder 和 MessageToByteEncoder。表7.5中列出的重要方法。
Table 7.5 ByteToMessageCodec API
| 方法名称 | 描述 |
|---|
| decode | This method is called as long as bytes are available to be consumed. It converts the inbound ByteBuf to the specified message format and forwards them to the next ChannelInboundHandler in the pipeline. |
| decodeLast | The default implementation of this method delegates to decode(). It is called only be called once, when the Channel goes inactive. For special handling it can be oerridden. |
| encode | This method is called for each message to be written through the ChannelPipeline. The encoded messages are contained in a ByteBuf which |
什么会是一个好的 ByteToMessageCodec 用例?任何一个请求/响应协议都可能是,例如 SMTP。编解码器将读取入站字节并解码到一个自定义的消息类型 SmtpRequest 。当接收到一个 SmtpResponse 会产生,用于编码为字节进行传输。
MessageToMessageCodec
7.3.2节中我们看到的一个例子使用 MessageToMessageEncoder 从一个消息格式转换到另一个地方。现在让我们看看 MessageToMessageCodec 是如何处理 单个类 的往返。
在进入细节之前,让我们看看表7.6中的重要方法。
Table 7.6 Methods of MessageToMessageCodec
| 方法名称 | 描述 |
|---|
| decode | This method is called with the inbound messages of the codec and decodes them to messages. Those messages are forwarded to the next ChannelInboundHandler in the ChannelPipeline |
| decodeLast | Default implementation delegates to decode().decodeLast will only be called one time, which is when the Channel goes inactive. If you need special handling here you may override decodeLast() to implement it. |
| encode | The encode method is called for each outbound message to be moved through the ChannelPipeline. The encoded messages are forwarded to the next ChannelOutboundHandler in the pipeline |
MessageToMessageCodec 是一个参数化的类,定义如下:
public abstract class MessageToMessageCodec<INBOUND,OUTBOUND>
上面所示的完整签名的方法都是这样的
protected abstract void encode(ChannelHandlerContext ctx,
OUTBOUND msg, List<Object> out)
protected abstract void decode(ChannelHandlerContext ctx,
INBOUND msg, List<Object> out)
encode() 处理出站消息类型 OUTBOUND 到 INBOUND,而 decode() 则相反。我们在哪里可能使用这样的编解码器?
在现实中,这是一个相当常见的用例,往往涉及两个来回转换的数据消息传递API 。这是常有的事,当我们不得不与遗留或专有的消息格式进行互操作。
如清单7.7所示这样的可能性。在这个例子中,WebSocketConvertHandler 是一个静态嵌套类,继承了参数为 WebSocketFrame(类型为 INBOUND)和 WebSocketFrame(类型为 OUTBOUND)的 MessageToMessageCode
Listing 7.7 MessageToMessageCodec
public class WebSocketConvertHandler extends MessageToMessageCodec<WebSocketFrame, WebSocketConvertHandler.WebSocketFrame> { //1
public static final WebSocketConvertHandler INSTANCE = new WebSocketConvertHandler();
@Override
protected void encode(ChannelHandlerContext ctx, WebSocketFrame msg, List<Object> out) throws Exception {
ByteBuf payload = msg.getData().duplicate().retain();
switch (msg.getType()) { //2
case BINARY:
out.add(new BinaryWebSocketFrame(payload));
break;
case TEXT:
out.add(new TextWebSocketFrame(payload));
break;
case CLOSE:
out.add(new CloseWebSocketFrame(true, 0, payload));
break;
case CONTINUATION:
out.add(new ContinuationWebSocketFrame(payload));
break;
case PONG:
out.add(new PongWebSocketFrame(payload));
break;
case PING:
out.add(new PingWebSocketFrame(payload));
break;
default:
throw new IllegalStateException("Unsupported websocket msg " + msg);
}
}
@Override
protected void decode(ChannelHandlerContext ctx, io.netty.handler.codec.http.websocketx.WebSocketFrame msg, List<Object> out) throws Exception {
if (msg instanceof BinaryWebSocketFrame) { //3
out.add(new WebSocketFrame(WebSocketFrame.FrameType.BINARY, msg.content().copy()));
} else if (msg instanceof CloseWebSocketFrame) {
out.add(new WebSocketFrame(WebSocketFrame.FrameType.CLOSE, msg.content().copy()));
} else if (msg instanceof PingWebSocketFrame) {
out.add(new WebSocketFrame(WebSocketFrame.FrameType.PING, msg.content().copy()));
} else if (msg instanceof PongWebSocketFrame) {
out.add(new WebSocketFrame(WebSocketFrame.FrameType.PONG, msg.content().copy()));
} else if (msg instanceof TextWebSocketFrame) {
out.add(new WebSocketFrame(WebSocketFrame.FrameType.TEXT, msg.content().copy()));
} else if (msg instanceof ContinuationWebSocketFrame) {
out.add(new WebSocketFrame(WebSocketFrame.FrameType.CONTINUATION, msg.content().copy()));
} else {
throw new IllegalStateException("Unsupported websocket msg " + msg);
}
}
public static final class WebSocketFrame { //4
public enum FrameType { //5
BINARY,
CLOSE,
PING,
PONG,
TEXT,
CONTINUATION
}
private final FrameType type;
private final ByteBuf data;
public WebSocketFrame(FrameType type, ByteBuf data) {
this.type = type;
this.data = data;
}
public FrameType getType() {
return type;
}
public ByteBuf getData() {
return data;
}
}
}
- 编码 WebSocketFrame 消息转为 WebSocketFrame 消息
- 检测 WebSocketFrame 的 FrameType 类型,并且创建一个新的响应的 FrameType 类型的 WebSocketFrame
- 通过 instanceof 来检测正确的 FrameType
- 自定义消息类型 WebSocketFrame
- 枚举类明确了 WebSocketFrame 的类型
CombinedChannelDuplexHandler
如前所述,结合解码器和编码器在一起可能会牺牲可重用性。为了避免这种方式,并且部署一个解码器和编码器到 ChannelPipeline 作为逻辑单元而不失便利性。
关键是下面的类:
public class CombinedChannelDuplexHandler<I extends ChannelInboundHandler,O extends ChannelOutboundHandler>
这个类是扩展 ChannelInboundHandler 和 ChannelOutboundHandler 参数化的类型。这提供了一个容器,单独的解码器和编码器类合作而无需直接扩展抽象的编解码器类。我们将在下面的例子说明这一点。首先查看 ByteToCharDecoder ,如清单7.8所示。
Listing 7.8 ByteToCharDecoder
public class ByteToCharDecoder extends
ByteToMessageDecoder { //1
@Override
public void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out)
throws Exception {
if (in.readableBytes() >= 2) { //2
out.add(in.readChar());
}
}
}
- 继承 ByteToMessageDecoder
- 写 char 到 MessageBuf
decode() 方法从输入数据中提取两个字节,并将它们作为一个 char 写入 List 。(注意,实现扩展 ByteToMessageDecoder 因为它从 ByteBuf 读取字符。)
现在看一下清单7.9中,把字符转换为字节的编码器。
Listing 7.9 CharToByteEncoder
public class CharToByteEncoder extends
MessageToByteEncoder<Character> { //1
@Override
public void encode(ChannelHandlerContext ctx, Character msg, ByteBuf out)
throws Exception {
out.writeChar(msg); //2
}
}
- 继承 MessageToByteEncoder
- 写 char 到 ByteBuf
这个实现继承自 MessageToByteEncoder 因为他需要编码 char 消息 到 ByteBuf。这将直接将字符串写为 ByteBuf。
现在我们有编码器和解码器,将他们组成一个编解码器。见下面的 CombinedChannelDuplexHandler.
Listing 7.10 CombinedByteCharCodec
public class CombinedByteCharCodec extends CombinedChannelDuplexHandler<ByteToCharDecoder, CharToByteEncoder> {
public CombinedByteCharCodec() {
super(new ByteToCharDecoder(), new CharToByteEncoder());
}
}
- CombinedByteCharCodec 的参数是解码器和编码器的实现用于处理进站字节和出站消息
- 传递 ByteToCharDecoder 和 CharToByteEncoder 实例到 super 构造函数来委托调用使他们结合起来。
正如你所看到的,它可能是用上述方式来使程序更简单、更灵活,而不是使用一个以上的编解码器类。它也可以归结到你个人喜好或风格。
总结
在这一章里,我们研究了 Netty 的 codec API 来编写解码器和编码器。我们还学习了为什么最好使用这个而不是纯ChannelHandler API。
我们看到不同的抽象编解码器类提供支持来处理在一个类中实现解码和编码。另一方面,如果我们需要更大的灵活性,希望结合现有实现我们也可以选择结合他们无需扩展抽象编解码器的任何类。
在下一章,我们将讨论 ChannelHandler 的实现和编解码器,他们是 Netty 本身的一部分,您可以开箱即用的处理特定的协议和任务。
8.7 - CH08-内置 ChannelHandler 与 Codec
本章介绍
- 使用 SSL/TLS 加密 Netty 程序
- 构建 Netty HTTP/HTTPS 程序
- 处理空闲连接和超时
- 解码分隔符和基于长度的协议
- 写大数据
- 序列化数据
Netty 提供了很多共同协议的编解码器和处理程序,您可以几乎“开箱即用”的使用他们,而无需花在相当乏味的基础设施问题。在这一章里,我们将探索这些工具和他们的好处。这包括支持 SSL/TLS,WebSocket 和 谷歌SPDY,通过数据压缩使 HTTP 有更好的性能。
使用 SSL/TLS 加密 Netty 程序
今天数据隐私是一个十分关注的问题,作为开发人员,我们需要准备好解决这个问题。至少我们需要熟悉加密协议 SSL 和 TLS 等之上的其他协议实现数据安全。作为一个 HTTPS 网站的用户,你是安全。当然,这些协议是广泛不基于 http 的应用程序,例如安全SMTP(SMTPS)邮件服务,甚至关系数据库系统。
为了支持 SSL/TLS,Java 提供了 javax.net.ssl API 的类SslContext 和 SslEngine 使它相对简单的实现解密和加密。Netty 的利用该 API 命名 SslHandler 的 ChannelHandler 实现, 有一个内部 SslEngine 做实际的工作。
图8.1显示了一个使用 SslHandler 数据流图。
- 加密的入站数据被 SslHandler 拦截,并被解密
- 前面加密的数据被 SslHandler 解密
- 平常数据传过 SslHandler
- SslHandler 加密数据并它传递出站
Figure 8.1 Data flow through SslHandler for decryption and encryption
如清单8.1所示一个 SslHandler 使用 ChannelInitializer 添加到 ChannelPipeline。(回想一下,当 Channel 注册时 ChannelInitializer 用于设置 ChannelPipeline 。)
Listing 8.1 Add SSL/TLS support
public class SslChannelInitializer extends ChannelInitializer<Channel> {
private final SslContext context;
private final boolean startTls;
public SslChannelInitializer(SslContext context,
boolean client, boolean startTls) { //1
this.context = context;
this.startTls = startTls;
}
@Override
protected void initChannel(Channel ch) throws Exception {
SSLEngine engine = context.newEngine(ch.alloc()); //2
engine.setUseClientMode(client); //3
ch.pipeline().addFirst("ssl", new SslHandler(engine, startTls)); //4
}
}
- 使用构造函数来传递 SSLContext 用于使用(startTls 是否启用)
- 从 SslContext 获得一个新的 SslEngine 。给每个 SslHandler 实例使用一个新的 SslEngine
- 设置 SslEngine 是 client 或者是 server 模式
- 添加 SslHandler 到 pipeline 作为第一个处理器
在大多数情况下,SslHandler 将成为 ChannelPipeline 中的第一个 ChannelHandler 。这将确保所有其他 ChannelHandler 应用他们的逻辑到数据后加密后才发生,从而确保他们的变化是安全的。
SslHandler 有很多有用的方法,如表8.1所示。例如,在握手阶段两端相互验证,商定一个加密方法。您可以配置 SslHandler 修改其行为或提供 在SSL/TLS 握手完成后发送通知,这样所有数据都将被加密。 SSL/TLS 握手将自动执行。
Table 8.1 SslHandler methods
| 名称 | 描述 |
|---|
| setHandshakeTimeout(…) setHandshakeTimeoutMillis(…) getHandshakeTimeoutMillis() | Set and get the timeout, after which the handshake ChannelFuture is notified of failure. |
| setCloseNotifyTimeout(…) setCloseNotifyTimeoutMillis(…) getCloseNotifyTimeoutMillis() | Set and get the timeout after which the close notify will time out and the connection will close. This also results in having the close notify ChannelFuture fail. |
| handshakeFuture() | Returns a ChannelFuture that will be notified once the handshake is complete. If the handshake was done before it will return a ChannelFuture that contains the result of the previous handshake. |
| close(…) | Send the close_notify to request close and destroy the underlying SslEngine. |
构建 Netty HTTP/HTTPS 应用
HTTP/HTTPS 是最常见的一种协议,在智能手机里广泛应用。虽然每家公司都有一个主页,您可以通过HTTP或HTTPS访问,这不是它唯一的使用。许多组织通过 HTTP(S) 公开 WebService API ,旨在用于缓解独立的平台带来的弊端 。 让我们看一下 Netty 提供的 ChannelHandler,是如何允许您使用 HTTP 和 HTTPS 而无需编写自己的编解码器。
HTTP Decoder, Encoder 和 Codec
HTTP 是请求-响应模式,客户端发送一个 HTTP 请求,服务就响应此请求。Netty 提供了简单的编码、解码器来简化基于这个协议的开发工作。图8.2和图8.3显示 HTTP 请求和响应的方法是如何生产和消费的
- HTTP Request 第一部分是包含的头信息
- HttpContent 里面包含的是数据,可以后续有多个 HttpContent 部分
- LastHttpContent 标记是 HTTP request 的结束,同时可能包含头的尾部信息
- 完整的 HTTP request
Figure 8.2 HTTP request component parts
- HTTP response 第一部分是包含的头信息
- HttpContent 里面包含的是数据,可以后续有多个 HttpContent 部分
- LastHttpContent 标记是 HTTP response 的结束,同时可能包含头的尾部信息
- 完整的 HTTP response
Figure 8.3 HTTP response component parts
如图8.2和8.3所示的 HTTP 请求/响应可能包含不止一个数据部分,它总是终止于 LastHttpContent 部分。FullHttpRequest 和FullHttpResponse 消息是特殊子类型,分别表示一个完整的请求和响应。所有类型的 HTTP 消息(FullHttpRequest ,LastHttpContent 以及那些如清单8.2所示)实现 HttpObject 接口。
表8.2概述 HTTP 解码器和编码器的处理和生产这些消息。
Table 8.2 HTTP decoder and encoder
| 名称 | 描述 |
|---|
| HttpRequestEncoder | Encodes HttpRequest , HttpContent and LastHttpContent messages to bytes. |
| HttpResponseEncoder | Encodes HttpResponse, HttpContent and LastHttpContent messages to bytes. |
| HttpRequestDecoder | Decodes bytes into HttpRequest, HttpContent and LastHttpContent messages. |
| HttpResponseDecoder | Decodes bytes into HttpResponse, HttpContent and LastHttpContent messages. |
清单8.2所示的是将支持 HTTP 添加到您的应用程序是多么简单。仅仅添加正确的 ChannelHandler 到 ChannelPipeline 中
Listing 8.2 Add support for HTTP
public class HttpPipelineInitializer extends ChannelInitializer<Channel> {
private final boolean client;
public HttpPipelineInitializer(boolean client) {
this.client = client;
}
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
if (client) {
pipeline.addLast("decoder", new HttpResponseDecoder()); //1
pipeline.addLast("encoder", new HttpRequestEncoder()); //2
} else {
pipeline.addLast("decoder", new HttpRequestDecoder()); //3
pipeline.addLast("encoder", new HttpResponseEncoder()); //4
}
}
}
- client: 添加 HttpResponseDecoder 用于处理来自 server 响应
- client: 添加 HttpRequestEncoder 用于发送请求到 server
- server: 添加 HttpRequestDecoder 用于接收来自 client 的请求
- server: 添加 HttpResponseEncoder 用来发送响应给 client
HTTP消息聚合
安装 ChannelPipeline 中的初始化之后,你能够对不同 HttpObject 消息进行操作。但由于 HTTP 请求和响应可以由许多部分组合而成,你需要聚合他们形成完整的消息。为了消除这种繁琐任务, Netty 提供了一个聚合器,合并消息部件到 FullHttpRequest 和 FullHttpResponse 消息。这样您总是能够看到完整的消息内容。
这个操作有一个轻微的成本,消息段需要缓冲,直到完全可以将消息转发到下一个 ChannelInboundHandler 管道。但好处是,你不必担心消息碎片。
实现自动聚合只需添加另一个 ChannelHandler 到 ChannelPipeline。清单8.3显示了这是如何实现的。
Listing 8.3 Automatically aggregate HTTP message fragments
public class HttpAggregatorInitializer extends ChannelInitializer<Channel> {
private final boolean client;
public HttpAggregatorInitializer(boolean client) {
this.client = client;
}
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
if (client) {
pipeline.addLast("codec", new HttpClientCodec()); //1
} else {
pipeline.addLast("codec", new HttpServerCodec()); //2
}
pipeline.addLast("aggegator", new HttpObjectAggregator(512 * 1024)); //3
}
}
- client: 添加 HttpClientCodec
- server: 添加 HttpServerCodec 作为我们是 server 模式时
- 添加 HttpObjectAggregator 到 ChannelPipeline, 使用最大消息值是 512kb
HTTP 压缩
使用 HTTP 时建议压缩数据以减少传输流量,压缩数据会增加 CPU 负载,现在的硬件设施都很强大,大多数时候压缩数据时一个好主意。Netty 支持“gzip”和“deflate”,为此提供了两个 ChannelHandler 实现分别用于压缩和解压。看下面代码:
客户端可以通过提供下面的头显示支持加密模式。然而服务器不是,所以不得不压缩它发送的数据。
GET /encrypted-area HTTP/1.1
Host: www.example.com
Accept-Encoding: gzip, deflate
下面是一个例子
Listing 8.4 Automatically compress HTTP messages
public class HttpAggregatorInitializer extends ChannelInitializer<Channel> {
private final boolean isClient;
public HttpAggregatorInitializer(boolean isClient) {
this.isClient = isClient;
}
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
if (isClient) {
pipeline.addLast("codec", new HttpClientCodec()); //1
pipeline.addLast("decompressor",new HttpContentDecompressor()); //2
} else {
pipeline.addLast("codec", new HttpServerCodec()); //3
pipeline.addLast("compressor",new HttpContentCompressor()); //4
}
}
}
- client: 添加 HttpClientCodec
- client: 添加 HttpContentDecompressor 用于处理来自服务器的压缩的内容
- server: HttpServerCodec
- server: HttpContentCompressor 用于压缩来自 client 支持的 HttpContentCompressor
压缩与依赖
注意,Java 6或者更早版本,如果要压缩数据,需要添加 jzlib 到 classpath
<dependency>
<groupId>com.jcraft</groupId>
<artifactId>jzlib</artifactId>
<version>1.1.3</version>
</dependency>
使用 HTTPS
启用 HTTPS,只需添加 SslHandler
Listing 8.5 Using HTTPS
public class HttpsCodecInitializer extends ChannelInitializer<Channel> {
private final SslContext context;
private final boolean client;
public HttpsCodecInitializer(SslContext context, boolean client) {
this.context = context;
this.client = client;
}
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
SSLEngine engine = context.newEngine(ch.alloc());
pipeline.addFirst("ssl", new SslHandler(engine)); //1
if (client) {
pipeline.addLast("codec", new HttpClientCodec()); //2
} else {
pipeline.addLast("codec", new HttpServerCodec()); //3
}
}
}
- 添加 SslHandler 到 pipeline 来启用 HTTPS
- client: 添加 HttpClientCodec
- server: 添加 HttpServerCodec ,如果是 server 模式的话
上面的代码就是一个很好的例子,解释了 Netty 的架构是如何让“重用”变成了“杠杆”。我们可以添加一个新的功能,甚至是一样重要的加密支持,几乎没有工作量,只需添加一个ChannelHandler 到 ChannelPipeline。
WebSocket
HTTP 是不错的协议,但是如果需要实时发布信息怎么做?有个做法就是客户端一直轮询请求服务器,这种方式虽然可以达到目的,但是其缺点很多,也不是优秀的解决方案,为了解决这个问题,便出现了 WebSocket。
WebSocket 允许数据双向传输,而不需要请求-响应模式。早期的WebSocket 只能发送文本数据,然后现在不仅可以发送文本数据,也可以发送二进制数据,这使得可以使用 WebSocket 构建你想要的程序。下图是WebSocket 的通信示例图:
WebSocket 规范及其实现是为了一个更有效的解决方案。简单的说, 一个WebSocket 提供一个 TCP 连接两个方向的交通。结合 WebSocket API 它提供了一个替代 HTTP 轮询双向通信从页面到远程服务器。
也就是说,WebSocket 提供真正的双向客户机和服务器之间的数据交换。 我们不会对内部太多的细节,但我们应该提到,虽然最早实现仅限于文本数据,但现在不再是这样,WebSocket可以用于任意数据,就像一个正常的套接字。
图8.4给出了一个通用的 WebSocket 协议。在这种情况下的通信开始于普通 HTTP ,并“升级”为双向 WebSocket。
- Client (HTTP) 与 Server 通讯
- Server (HTTP) 与 Client 通讯
- Client 通过 HTTP(s) 来进行 WebSocket 握手,并等待确认
- 连接协议升级至 WebSocket
Figure 8.4 WebSocket protocol
添加应用程序支持 WebSocket 只需要添加适当的客户端或服务器端WebSocket ChannelHandler 到管道。这个类将处理特殊 WebSocket 定义的消息类型,称为“帧。“如表8.3所示,这些可以归类为“数据”和“控制”帧。
Table 8.3 WebSocketFrame types
| 名称 | 描述 |
|---|
| BinaryWebSocketFrame | Data frame: binary data |
| TextWebSocketFrame | Data frame: text data |
| ContinuationWebSocketFrame | Data frame: text or binary data that belongs to a previous BinaryWebSocketFrame or TextWebSocketFrame |
| CloseWebSocketFrame | Control frame: a CLOSE request, close status code and a phrase |
| PingWebSocketFrame | Control frame: requests the send of a PongWebSocketFrame |
| PongWebSocketFrame | Control frame: sent as response to a PingWebSocketFrame |
由于 Netty 的主要是一个服务器端技术重点在这里创建一个 WebSocket server 。清单8.6使用 WebSocketServerProtocolHandler 提出了一个简单的例子。该类处理协议升级握手以及三个“控制”帧 Close, Ping 和 Pong。Text 和 Binary 数据帧将被传递到下一个处理程序(由你实现)进行处理。
Listing 8.6 Support WebSocket on the server
public class WebSocketServerInitializer extends ChannelInitializer<Channel> {
@Override
protected void initChannel(Channel ch) throws Exception {
ch.pipeline().addLast(
new HttpServerCodec(),
new HttpObjectAggregator(65536), //1
new WebSocketServerProtocolHandler("/websocket"), //2
new TextFrameHandler(), //3
new BinaryFrameHandler(), //4
new ContinuationFrameHandler()); //5
}
public static final class TextFrameHandler extends SimpleChannelInboundHandler<TextWebSocketFrame> {
@Override
public void channelRead0(ChannelHandlerContext ctx, TextWebSocketFrame msg) throws Exception {
// Handle text frame
}
}
public static final class BinaryFrameHandler extends SimpleChannelInboundHandler<BinaryWebSocketFrame> {
@Override
public void channelRead0(ChannelHandlerContext ctx, BinaryWebSocketFrame msg) throws Exception {
// Handle binary frame
}
}
public static final class ContinuationFrameHandler extends SimpleChannelInboundHandler<ContinuationWebSocketFrame> {
@Override
public void channelRead0(ChannelHandlerContext ctx, ContinuationWebSocketFrame msg) throws Exception {
// Handle continuation frame
}
}
}
- 添加 HttpObjectAggregator 用于提供在握手时聚合 HttpRequest
- 添加 WebSocketServerProtocolHandler 用于处理色好给你寄握手如果请求是发送到"/websocket." 端点,当升级完成后,它将会处理Ping, Pong 和 Close 帧
- TextFrameHandler 将会处理 TextWebSocketFrames
- BinaryFrameHandler 将会处理 BinaryWebSocketFrames
- ContinuationFrameHandler 将会处理ContinuationWebSocketFrames
加密 WebSocket 只需插入 SslHandler 到作为 pipline 第一个 ChannelHandler
详见 [Chapter 11 WebSocket]。
SPDY
SPDY(读作“SPeeDY”)是Google 开发的基于 TCP 的应用层协议,用以最小化网络延迟,提升网络速度,优化用户的网络使用体验。SPDY 并不是一种用于替代 HTTP 的协议,而是对 HTTP 协议的增强。SPDY 实现技术:
- 压缩报头
- 加密所有
- 多路复用连接
- 提供支持不同的传输优先级
SPDY 主要有5个版本:
- 1 - 初始化版本,但没有使用
- 2 - 新特性,包含服务器推送
- 3 - 新特性包含流控制和更新压缩
- 3.1 - 会话层流程控制
- 4.0 - 流量控制,并与 HTTP 2.0 更加集成
SPDY 被很多浏览器支持,包括 Google Chrome, Firefox, 和 Opera
Netty 支持 版本 2 和 3 (包含3.1)的支持。这些版本被广泛应用,可以支持更多的用户。更多内容详见 [Chapter 12]。
空闲连接以及超时
检测空闲连接和超时是为了及时释放资源。常见的方法发送消息用于测试一个不活跃的连接来,通常称为“心跳”,到远端来确定它是否还活着。(一个更激进的方法是简单地断开那些指定的时间间隔的不活跃的连接)。
处理空闲连接是一项常见的任务,Netty 提供了几个 ChannelHandler 实现此目的。表8.4概述。
Table 8.4 ChannelHandlers for idle connections and timeouts
| 名称 | 描述 |
|---|
| IdleStateHandler | 如果连接闲置时间过长,则会触发 IdleStateEvent 事件。在 ChannelInboundHandler 中可以覆盖 userEventTriggered(…) 方法来处理 IdleStateEvent。 |
| ReadTimeoutHandler | 在指定的时间间隔内没有接收到入站数据则会抛出 ReadTimeoutException 并关闭 Channel。ReadTimeoutException 可以通过覆盖 ChannelHandler 的 exceptionCaught(…) 方法检测到。 |
| WriteTimeoutHandler | WriteTimeoutException 可以通过覆盖 ChannelHandler 的 exceptionCaught(…) 方法检测到。 |
详细看下 IdleStateHandler,下面是一个例子,当超过60秒没有数据收到时,就会得到通知,此时就发送心跳到远端,如果没有回应,连接就关闭。
Listing 8.7 Sending heartbeats
public class IdleStateHandlerInitializer extends ChannelInitializer<Channel> {
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new IdleStateHandler(0, 0, 60, TimeUnit.SECONDS)); //1
pipeline.addLast(new HeartbeatHandler());
}
public static final class HeartbeatHandler extends ChannelInboundHandlerAdapter {
private static final ByteBuf HEARTBEAT_SEQUENCE = Unpooled.unreleasableBuffer(
Unpooled.copiedBuffer("HEARTBEAT", CharsetUtil.ISO_8859_1)); //2
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
if (evt instanceof IdleStateEvent) {
ctx.writeAndFlush(HEARTBEAT_SEQUENCE.duplicate())
.addListener(ChannelFutureListener.CLOSE_ON_FAILURE); //3
} else {
super.userEventTriggered(ctx, evt); //4
}
}
}
}
- IdleStateHandler 将通过 IdleStateEvent 调用 userEventTriggered ,如果连接没有接收或发送数据超过60秒钟
- 心跳发送到远端
- 发送的心跳并添加一个侦听器,如果发送操作失败将关闭连接
- 事件不是一个 IdleStateEvent 的话,就将它传递给下一个处理程序
总而言之,这个例子说明了如何使用 IdleStateHandler 测试远端是否还活着,如果不是就关闭连接释放资源。
解码分隔符和基于长度的协议
使用 Netty 时会遇到需要解码以分隔符和长度为基础的协议,本节讲解Netty 如何解码这些协议。
分隔符协议
经常需要处理分隔符协议或创建基于它们的协议,例如SMTP、POP3、IMAP、Telnet等等。Netty 附带的解码器可以很容易的提取一些序列分隔:
Table 8.5 Decoders for handling delimited and length-based protocols
| 名称 | 描述 |
|---|
| DelimiterBasedFrameDecoder | 接收ByteBuf由一个或多个分隔符拆分,如NUL或换行符 |
| LineBasedFrameDecoder | 接收ByteBuf以分割线结束,如"\n"和"\r\n" |
下图显示了使用"\r\n"分隔符的处理:
- 字节流
- 第一帧
- 第二帧
Figure 8.5 Handling delimited frames
下面展示了如何用 LineBasedFrameDecoder 处理
Listing 8.8 Handling line-delimited frames
public class LineBasedHandlerInitializer extends ChannelInitializer<Channel> {
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new LineBasedFrameDecoder(65 * 1024)); //1
pipeline.addLast(new FrameHandler()); //2
}
public static final class FrameHandler extends SimpleChannelInboundHandler<ByteBuf> {
@Override
public void channelRead0(ChannelHandlerContext ctx, ByteBuf msg) throws Exception { //3
// Do something with the frame
}
}
}
- 添加一个 LineBasedFrameDecoder 用于提取帧并把数据包转发到下一个管道中的处理程序,在这种情况下就是 FrameHandler
- 添加 FrameHandler 用于接收帧
- 每次调用都需要传递一个单帧的内容
使用 DelimiterBasedFrameDecoder 可以方便处理特定分隔符作为数据结构体的这类情况。如下:
- 传入的数据流是一系列的帧,每个由换行(“\n”)分隔
- 每帧包括一系列项目,每个由单个空格字符分隔
- 一帧的内容代表一个“命令”:一个名字后跟一些变量参数
清单8.9中显示了的实现的方式。定义以下类:
- 类 Cmd - 存储帧的内容,其中一个 ByteBuf 用于存名字,另外一个存参数
- 类 CmdDecoder - 从重写方法 decode() 中检索一行,并从其内容中构建一个 Cmd 的实例
- 类 CmdHandler - 从 CmdDecoder 接收解码 Cmd 对象和对它的一些处理。
所以关键的解码器是扩展了 LineBasedFrameDecoder
Listing 8.9 Decoder for the command and the handler
public class CmdHandlerInitializer extends ChannelInitializer<Channel> {
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new CmdDecoder(65 * 1024));//1
pipeline.addLast(new CmdHandler()); //2
}
public static final class Cmd { //3
private final ByteBuf name;
private final ByteBuf args;
public Cmd(ByteBuf name, ByteBuf args) {
this.name = name;
this.args = args;
}
public ByteBuf name() {
return name;
}
public ByteBuf args() {
return args;
}
}
public static final class CmdDecoder extends LineBasedFrameDecoder {
public CmdDecoder(int maxLength) {
super(maxLength);
}
@Override
protected Object decode(ChannelHandlerContext ctx, ByteBuf buffer) throws Exception {
ByteBuf frame = (ByteBuf) super.decode(ctx, buffer); //4
if (frame == null) {
return null; //5
}
int index = frame.indexOf(frame.readerIndex(), frame.writerIndex(), (byte) ' '); //6
return new Cmd(frame.slice(frame.readerIndex(), index), frame.slice(index +1, frame.writerIndex())); //7
}
}
public static final class CmdHandler extends SimpleChannelInboundHandler<Cmd> {
@Override
public void channelRead0(ChannelHandlerContext ctx, Cmd msg) throws Exception {
// Do something with the command //8
}
}
}
- 添加一个 CmdDecoder 到管道;将提取 Cmd 对象和转发到在管道中的下一个处理器
- 添加 CmdHandler 将接收和处理 Cmd 对象
- 命令也是 POJO
- super.decode() 通过结束分隔从 ByteBuf 提取帧
- frame 是空时,则返回 null
- 找到第一个空字符的索引。首先是它的命令名;接下来是参数的顺序
- 从帧先于索引以及它之后的片段中实例化一个新的 Cmd 对象
- 处理通过管道的 Cmd 对象
基于长度的协议
基于长度的协议协议在帧头文件里定义了一个帧编码的长度,而不是结束位置用一个特殊的分隔符来标记。表8.6列出了 Netty 提供的两个解码器,用于处理这种类型的协议。
Table 8.6 Decoders for length-based protocols
| 名称 | 描述 |
|---|
| FixedLengthFrameDecoder | 提取固定长度 |
| LengthFieldBasedFrameDecoder | 读取头部长度并提取帧的长度 |
如下图所示,FixedLengthFrameDecoder 的操作是提取固定长度每帧8字节
- 字节流 stream
- 4个帧,每个帧8个字节
大部分时候帧的大小被编码在头部,这种情况可以使用LengthFieldBasedFrameDecoder,它会读取头部长度并提取帧的长度。下图显示了它是如何工作的:
- 长度 “0x000C” (12) 被编码在帧的前两个字节
- 后面的12个字节就是内容
- 提取没有头文件的帧内容
Figure 8.7 Message that has frame size encoded in the header
LengthFieldBasedFrameDecoder 提供了几个构造函数覆盖各种各样的头长字段配置情况。清单8.10显示了使用三个参数的构造函数是maxFrameLength,lengthFieldOffset lengthFieldLength。在这 情况下,帧的长度被编码在帧的前8个字节。
Listing 8.10 Decoder for the command and the handler
public class LineBasedHandlerInitializer extends ChannelInitializer<Channel> {
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new LineBasedFrameDecoder(65 * 1024)); //1
pipeline.addLast(new FrameHandler()); //2
}
public static final class FrameHandler extends SimpleChannelInboundHandler<ByteBuf> {
@Override
public void channelRead0(ChannelHandlerContext ctx, ByteBuf msg) throws Exception {
// Do something with the frame //3
}
}
}
- 添加一个 LengthFieldBasedFrameDecoder ,用于提取基于帧编码长度8个字节的帧。
- 添加一个 FrameHandler 用来处理每帧
- 处理帧数据
总而言之,本部分探讨了 Netty 提供的编解码器支持协议,包括定义特定的分隔符的字节流的结构或协议帧的长度。这些编解码器非常有用。
写大型数据
由于网络的原因,如何有效的写大数据在异步框架是一个特殊的问题。因为写操作是非阻塞的,即便是在数据不能写出时,只是通知 ChannelFuture 完成了。当这种情况发生时,你必须停止写操作或面临内存耗尽的风险。所以写时,会产生大量的数据,我们需要做好准备来处理的这种情况下的缓慢的连接远端导致延迟释放内存的问题你。作为一个例子让我们考虑写一个文件的内容到网络。
在我们的讨论传输(见4.2节)时,我们提到了 NIO 的“zero-copy(零拷贝)”功能,消除移动一个文件的内容从文件系统到网络堆栈的复制步骤。所有这一切发生在 Netty 的核心,因此所有所需的应用程序代码是使用 interface FileRegion 的实现,在 Netty 的API 文档中定义如下为一个通过 Channel 支持 zero-copy 文件传输的文件区域。
下面演示了通过 zero-copy 将文件内容从 FileInputStream 创建 DefaultFileRegion 并写入 使用 Channel
Listing 8.11 Transferring file contents with FileRegion
FileInputStream in = new FileInputStream(file); //1
FileRegion region = new DefaultFileRegion(in.getChannel(), 0, file.length()); //2
channel.writeAndFlush(region).addListener(new ChannelFutureListener() { //3
@Override
public void operationComplete(ChannelFuture future) throws Exception {
if (!future.isSuccess()) {
Throwable cause = future.cause(); //4
// Do something
}
}
});
- 获取 FileInputStream
- 创建一个新的 DefaultFileRegion 用于文件的完整长度
- 发送 DefaultFileRegion 并且注册一个 ChannelFutureListener
- 处理发送失败
只是看到的例子只适用于直接传输一个文件的内容,没有执行的数据应用程序的处理。在相反的情况下,将数据从文件系统复制到用户内存是必需的,您可以使用 ChunkedWriteHandler。这个类提供了支持异步写大数据流不引起高内存消耗。
这个关键是 interface ChunkedInput,实现如下:
| 名称 | 描述 |
|---|
| ChunkedFile | 当你使用平台不支持 zero-copy 或者你需要转换数据,从文件中一块一块的获取数据 |
| ChunkedNioFile | 与 ChunkedFile 类似,处理使用了NIOFileChannel |
| ChunkedStream | 从 InputStream 中一块一块的转移内容 |
| ChunkedNioStream | 从 ReadableByteChannel 中一块一块的转移内容 |
清单 8.12 演示了使用 ChunkedStream,实现在实践中最常用。 所示的类被实例化一个 File 和一个 SslContext。当 initChannel() 被调用来初始化显示的处理程序链的通道。
当通道激活时,WriteStreamHandler 从文件一块一块的写入数据作为ChunkedStream。最后将数据通过 SslHandler 加密后传播。
Listing 8.12 Transfer file content with FileRegion
public class ChunkedWriteHandlerInitializer extends ChannelInitializer<Channel> {
private final File file;
private final SslContext sslCtx;
public ChunkedWriteHandlerInitializer(File file, SslContext sslCtx) {
this.file = file;
this.sslCtx = sslCtx;
}
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new SslHandler(sslCtx.createEngine()); //1
pipeline.addLast(new ChunkedWriteHandler());//2
pipeline.addLast(new WriteStreamHandler());//3
}
public final class WriteStreamHandler extends ChannelInboundHandlerAdapter { //4
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
super.channelActive(ctx);
ctx.writeAndFlush(new ChunkedStream(new FileInputStream(file)));
}
}
}
- 添加 SslHandler 到 ChannelPipeline.
- 添加 ChunkedWriteHandler 用来处理作为 ChunkedInput 传进的数据
- 当连接建立时,WriteStreamHandler 开始写文件的内容
- 当连接建立时,channelActive() 触发使用 ChunkedInput 来写文件的内容 (插图显示了 FileInputStream;也可以使用任何 InputStream )
ChunkedInput 所有被要求使用自己的 ChunkedInput 实现,是安装ChunkedWriteHandler 在管道中
在本节中,我们讨论
- 如何采用zero-copy(零拷贝)功能高效地传输文件
- 如何使用 ChunkedWriteHandler 编写大型数据而避免 OutOfMemoryErrors 错误。
在下一节中我们将研究几种不同方法来序列化 POJO。
序列化数据
JDK 提供了 ObjectOutputStream 和 ObjectInputStream 通过网络将原始数据类型和 POJO 进行序列化和反序列化。API并不复杂,可以应用到任何对象,支持 java.io.Serializable 接口。但它也不是非常高效的。在本节中,我们将看到 Netty 所提供的。
JDK 序列化
如果程序与端对端间的交互是使用 ObjectOutputStream 和 ObjectInputStream,并且主要面临的问题是兼容性,那么, JDK 序列化 是不错的选择。
表8.8列出了序列化类,Netty 提供了与 JDK 的互操作。
Table 8.8 JDK Serialization codecs
| 名称 | 描述 |
|---|
| CompatibleObjectDecoder | 该解码器使用 JDK 序列化,用于与非 Netty 进行互操作。 |
| CompatibleObjectEncoder | 该编码器使用 JDK 序列化,用于与非 Netty 进行互操作。 |
| ObjectDecoder | 基于 JDK 序列化来使用自定义序列化解码。外部依赖被排除在外时,提供了一个速度提升。否则选择其他序列化实现 |
| ObjectEncoder | 基于 JDK 序列化来使用自定义序列化编码。外部依赖被排除在外时,提供了一个速度提升。否则选择其他序列化实现 |
JBoss Marshalling 序列化
如果可以使用外部依赖 JBoss Marshalling 是个明智的选择。比 JDK 序列化快3倍且更加简练。
JBoss Marshalling 是另一个序列化 API,修复的许多 JDK序列化 API 中发现的问题,它与 java.io.Serializable 完全兼容。并添加了一些新的可调参数和附加功能,所有这些都可插入通过工厂配置外部化,类/实例查找表,类决议,对象替换,等等)
下表展示了 Netty 支持 JBoss Marshalling 的编解码器。
Table 8.9 JBoss Marshalling codecs
| 名称 | 描述 |
|---|
| CompatibleMarshallingDecoder | 为了与使用 JDK 序列化的端对端间兼容。 |
| CompatibleMarshallingEncoder | 为了与使用 JDK 序列化的端对端间兼容。 |
| MarshallingDecoder | 使用自定义序列化用于解码,必须使用 |
MarshallingEncoder MarshallingEncoder | 使用自定义序列化用于编码,必须使用 MarshallingDecoder
下面展示了使用 MarshallingDecoder 和 MarshallingEncoder
Listing 8.13 Using JBoss Marshalling
public class MarshallingInitializer extends ChannelInitializer<Channel> {
private final MarshallerProvider marshallerProvider;
private final UnmarshallerProvider unmarshallerProvider;
public MarshallingInitializer(UnmarshallerProvider unmarshallerProvider,
MarshallerProvider marshallerProvider) {
this.marshallerProvider = marshallerProvider;
this.unmarshallerProvider = unmarshallerProvider;
}
@Override
protected void initChannel(Channel channel) throws Exception {
ChannelPipeline pipeline = channel.pipeline();
pipeline.addLast(new MarshallingDecoder(unmarshallerProvider));
pipeline.addLast(new MarshallingEncoder(marshallerProvider));
pipeline.addLast(new ObjectHandler());
}
public static final class ObjectHandler extends SimpleChannelInboundHandler<Serializable> {
@Override
public void channelRead0(ChannelHandlerContext channelHandlerContext, Serializable serializable) throws Exception {
// Do something
}
}
}
ProtoBuf 序列化
ProtoBuf 来自谷歌,并且开源了。它使编解码数据更加紧凑和高效。它已经绑定各种编程语言,使它适合跨语言项目。
下表展示了 Netty 支持 ProtoBuf 的 ChannelHandler 实现。
Table 8.10 ProtoBuf codec
| 名称 | 描述 |
|---|
| ProtobufDecoder | 使用 ProtoBuf 来解码消息 |
| ProtobufEncoder | 使用 ProtoBuf 来编码消息 |
| ProtobufVarint32FrameDecoder | 在消息的整型长度域中,通过 “Base 128 Varints“将接收到的 ByteBuf 动态的分割 |
用法见下面
Listing 8.14 Using Google Protobuf
public class ProtoBufInitializer extends ChannelInitializer<Channel> {
private final MessageLite lite;
public ProtoBufInitializer(MessageLite lite) {
this.lite = lite;
}
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new ProtobufVarint32FrameDecoder());
pipeline.addLast(new ProtobufEncoder());
pipeline.addLast(new ProtobufDecoder(lite));
pipeline.addLast(new ObjectHandler());
}
public static final class ObjectHandler extends SimpleChannelInboundHandler<Object> {
@Override
public void channelRead0(ChannelHandlerContext ctx, Object msg) throws Exception {
// Do something with the object
}
}
}
- 添加 ProtobufVarint32FrameDecoder 用来分割帧
- 添加 ProtobufEncoder 用来处理消息的编码
- 添加 ProtobufDecoder 用来处理消息的解码
- 添加 ObjectHandler 用来处理解码了的消息
本章在这最后一节中,我们探讨了 Netty 支持的不同的序列化的专门的解码器和编码器。这些是标准 JDK 序列化 API,JBoss Marshalling 和谷歌ProtoBuf。
总结
Netty 的提供了编解码器和处理程序,可以组合和扩展来实现一个非常广泛的处理场景。此外,他们在许多大型系统被证明是健壮的组件。 请注意我们只介绍最常见的例子。API文档提供完整的描述。
8.8 - CH09-Bootstraping
本章介绍:
- 引导客户端和服务器
- 从Channel引导客户端
- 添加 ChannelHandler
- 使用 ChannelOption 和属性
正如我们所见,ChannelPipeline 、ChannelHandler和编解码器提供工具,我们可以处理一个广泛的数据处理需求。但是你可能会问,“我创建了组件后,如何将其组装形成一个应用程序?”
答案是“bootstrapping(引导)”。到目前为止我们使用这个词有点模糊,时间可以来定义它。在最简单的条件下,引导就是配置应用程序的过程。但正如我们看到的,不仅仅如此;Netty 的引导客户端和服务器的类从网络基础设施使您的应用程序代码在后台可以连接和启动所有的组件。简而言之,引导使你的 Netty 应用程序完整。
Bootstrap 类型
Netty 的包括两种不同类型的引导。而不仅仅是当作的“服务器”和“客户”的引导,更有用的是考虑他们的目的是支持的应用程序功能。从这个意义上讲,“服务器”应用程序把一个“父”管道接受连接和创建“子”管道,而“客户端”很可能只需要一个单一的、非“父”对所有网络交互的管道(对于无连接的比如 UDP 协议也是一样)。
如图9.1所示,两个引导实现自一个名为 AbstractBootstrap 的超类。
Figure 9.1 Bootstrap hierarchy
前面的章节介绍的许多我们共同关注的话题,同样适用于客户端和服务器。这些都是由 AbstractBootstrap 处理,从而防止重复的功能和代码。专业引导类可以完全专注于它们独特的需要关心的地方。
克隆引导类
我们经常需要创建多个通道具有相似或相同的设置。支持这种模式而不需要为每个通道创建和配置一个新的引导实例, AbstractBootstrap 已经被标记为 Cloneable。调用 clone() 在一个已经配置引导将返回另一个引导实例并且是立即可用。
注意,因为这将创建只是 EventLoopGroup 浅拷贝,后者将会共享所有的克隆管道。这是可以接受的,因为往往是克隆的管道是 short-lived(短暂的,典型示例是管道创建用于 HTTP 请求)
下面内容将会关注 Bootstrap 和 ServerBootstrap。
引导客户端和无连接协议
当需要引导客户端或一些无连接协议时,需要使用Bootstrap类。 在本节中,我们将回顾可用的各种方法引导客户端,引导线程,和可用的管道实现。
客户端引导方法
下表是 Bootstrap 的常用方法,其中很多是继承自 AbstractBootstrap。
Table 9.1 Bootstrap methods
| 名称 | 描述 |
|---|
| group | 设置 EventLoopGroup 用于处理所有的 Channel 的事件 |
| channel channelFactory | channel() 指定 Channel 的实现类。如果类没有提供一个默认的构造函数,你可以调用 channelFactory() 来指定一个工厂类被 bind() 调用。 |
| localAddress | 指定应该绑定到本地地址 Channel。如果不提供,将由操作系统创建一个随机的。或者,您可以使用 bind() 或 connect()指定localAddress |
| option | 设置 ChannelOption 应用于 新创建 Channel 的 ChannelConfig。这些选项将被 bind 或 connect 设置在通道,这取决于哪个被首先调用。这个方法在创建管道后没有影响。所支持 ChannelOption 取决于使用的管道类型。请参考9.6节和 ChannelConfig 的 API 文档 的 Channel 类型使用。 |
| attr | 这些选项将被 bind 或 connect 设置在通道,这取决于哪个被首先调用。这个方法在创建管道后没有影响。请参考9.6节。 |
| handler | 设置添加到 ChannelPipeline 中的 ChannelHandler 接收事件通知。 |
| clone | 创建一个当前 Bootstrap的克隆拥有原来相同的设置。 |
| remoteAddress | 设置远程地址。此外,您可以通过 connect() 指定 |
| connect | 连接到远端,返回一个 ChannelFuture, 用于通知连接操作完成 |
| bind | 将通道绑定并返回一个 ChannelFuture,用于通知绑定操作完成后,必须调用 Channel.connect() 来建立连接。 |
如何引导客户端
Bootstrap 类负责创建管道给客户或应用程序,利用无连接协议和在调用 bind() 或 connect() 之后。
下图展示了如何工作
- 当 bind() 调用时,Bootstrap 将创建一个新的管道, 当 connect() 调用在 Channel 来建立连接
- Bootstrap 将创建一个新的管道, 当 connect() 调用时
- 新的 Channel
Figure 9.2 Bootstrap process
下面演示了引导客户端,使用的是 NIO TCP 传输
Listing 9.1 Bootstrapping a client
EventLoopGroup group = new NioEventLoopGroup();
Bootstrap bootstrap = new Bootstrap(); //1
bootstrap.group(group) //2
.channel(NioSocketChannel.class) //3
.handler(new SimpleChannelInboundHandler<ByteBuf>() { //4
@Override
protected void channeRead0(
ChannelHandlerContext channelHandlerContext,
ByteBuf byteBuf) throws Exception {
System.out.println("Received data");
byteBuf.clear();
}
});
ChannelFuture future = bootstrap.connect(
new InetSocketAddress("www.manning.com", 80)); //5
future.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture channelFuture)
throws Exception {
if (channelFuture.isSuccess()) {
System.out.println("Connection established");
} else {
System.err.println("Connection attempt failed");
channelFuture.cause().printStackTrace();
}
}
});
- 创建一个新的 Bootstrap 来创建和连接到新的客户端管道
- 指定 EventLoopGroup
- 指定 Channel 实现来使用
- 设置处理器给 Channel 的事件和数据
- 连接到远端主机
注意 Bootstrap 提供了一个“流利”语法——示例中使用的方法(除了connect()) 由 Bootstrap 返回实例本身的引用链接他们。
兼容性
Channel 的实现和 EventLoop 的处理过程在 EventLoopGroup 中必须兼容,哪些 Channel 是和 EventLoopGroup 是兼容的可以查看 API 文档。经验显示,相兼容的实现一般在同一个包下面,例如使用NioEventLoop,NioEventLoopGroup 和 NioServerSocketChannel 在一起。请注意,这些都是前缀“Nio”,然后不会用这些代替另一个实现和另一个前缀,如“Oio”,也就是说 OioEventLoopGroup 和NioServerSocketChannel 是不相容的。
Channel 和 EventLoopGroup 的 EventLoop 必须相容,例如NioEventLoop、NioEventLoopGroup、NioServerSocketChannel是相容的,但是 OioEventLoopGroup 和 NioServerSocketChannel 是不相容的。从类名可以看出前缀是“Nio”的只能和“Nio”的一起使用。
EventLoop 和 EventLoopGroup
记住,EventLoop 分配给该 Channel 负责处理 Channel 的所有操作。当你执行一个方法,该方法返回一个 ChannelFuture ,它将在 分配给 Channel 的 EventLoop 执行。
EventLoopGroup 包含许多 EventLoops 和分配一个 EventLoop 通道时注册。我们将在15章更详细地讨论这个话题。
清单9.2所示的结果,试图使用一个 Channel 类型与一个 EventLoopGroup 兼容。
Listing 9.2 Bootstrap client with incompatible EventLoopGroup
EventLoopGroup group = new NioEventLoopGroup();
Bootstrap bootstrap = new Bootstrap(); //1
bootstrap.group(group) //2
.channel(OioSocketChannel.class) //3
.handler(new SimpleChannelInboundHandler<ByteBuf>() { //4
@Override
protected void channelRead0(
ChannelHandlerContext channelHandlerContext,
ByteBuf byteBuf) throws Exception {
System.out.println("Reveived data");
byteBuf.clear();
}
});
ChannelFuture future = bootstrap.connect(
new InetSocketAddress("www.manning.com", 80)); //5
future.syncUninterruptibly();
- 创建新的 Bootstrap 来创建新的客户端管道
- 注册 EventLoopGroup 用于获取 EventLoop
- 指定要使用的 Channel 类。通知我们使用 NIO 版本用于 EventLoopGroup , OIO 用于 Channel
- 设置处理器用于管道的 I/O 事件和数据
- 尝试连接到远端。当 NioEventLoopGroup 和 OioSocketChannel 不兼容时,会抛出 IllegalStateException 异常
IllegalStateException 显示如下:
Listing 9.3 IllegalStateException thrown because of invalid configuration
Exception in thread "main" java.lang.IllegalStateException: incompatible event loop
type: io.netty.channel.nio.NioEventLoop
at
io.netty.channel.AbstractChannel$AbstractUnsafe.register(AbstractChannel.java:5
71)
...
出现 IllegalStateException 的其他情况是,在 bind() 或 connect() 调用前 调用需要设置参数的方法调用失败时,包括:
- group()
- channel() 或 channnelFactory()
- handler()
handler() 方法尤为重要,因为这些 ChannelPipeline 需要适当配置。 一旦提供了这些参数,应用程序将充分利用 Netty 的能力。
引导服务器
服务器的引导共用了客户端引导的一些逻辑。
引导服务器的方法
下表显示了 ServerBootstrap 的方法
Table 9.2 Methods of ServerBootstrap‘
| 名称 | 描述 |
|---|
| group | 设置 EventLoopGroup 用于 ServerBootstrap。这个 EventLoopGroup 提供 ServerChannel 的 I/O 并且接收 Channel |
| channel channelFactory | channel() 指定 Channel 的实现类。如果管道没有提供一个默认的构造函数,你可以提供一个 ChannelFactory。 |
| localAddress | 指定 ServerChannel 实例化的类。如果不提供,将由操作系统创建一个随机的。或者,您可以使用 bind() 或 connect()指定localAddress |
| option | 指定一个 ChannelOption 来用于新创建的 ServerChannel 的 ChannelConfig 。这些选项将被设置在管道的 bind() 或 connect(),这取决于谁首先被调用。在此调用这些方法之后设置或更改 ChannelOption 是无效的。所支持 ChannelOption 取决于使用的管道类型。请参考9.6节和 ChannelConfig 的 API 文档 的 Channel 类型使用。 |
| childOption | 当管道已被接受,指定一个 ChannelOption 应用于 Channel 的 ChannelConfig。 |
| attr | 指定 ServerChannel 的属性。这些属性可以被 管道的 bind() 设置。当调用 bind() 之后,修改它们不会生效。 |
| childAttr | 应用属性到接收到的管道上。后续调用没有效果。 |
| handler | 设置添加到 ServerChannel 的 ChannelPipeline 中的 ChannelHandler。 具体详见 childHandler() 描述 |
| childHandler | 设置添加到接收到的 Channel 的 ChannelPipeline 中的 ChannelHandler。handler() 和 childHandler()之间的区别是前者是接收和处理ServerChannel,同时 childHandler() 添加处理器用于处理和接收 Channel。后者代表一个套接字绑定到一个远端。 |
| clone | 克隆 ServerBootstrap 用于连接到不同的远端,通过设置相同的原始 ServerBoostrap。 |
| bind | 绑定 ServerChannel 并且返回一个 ChannelFuture,用于 通知连接操作完成了(结果可以是成功或者失败) |
如何引导一个服务器
ServerBootstrap 中的 childHandler(), childAttr() 和 childOption() 是常用的服务器应用的操作。具体来说,ServerChannel实现负责创建子 Channel,它代表接受连接。因此 引导 ServerChannel 的 ServerBootstrap ,提供这些方法来简化接收的 Channel 对 ChannelConfig 应用设置的任务。
图9.3显示了 ServerChannel 创建 ServerBootstrap 在 bind(),后者管理大量的子 Channel。
- 当调用 bind() 后 ServerBootstrap 将创建一个新的管道,这个管道将会在绑定成功后接收子管道
- 接收新连接给每个子管道
- 接收连接的 Channel
Figure 9.3 ServerBootstrap
记住 child* 的方法都是操作在子的 Channel,被 ServerChannel 管理。
清单9.4 ServerBootstrap 时会创建一个 NioServerSocketChannel实例 bind() 。这个 NioServerChannel 负责接受新连接和创建NioSocketChannel 实例。
Listing 9.4 Bootstrapping a server
NioEventLoopGroup group = new NioEventLoopGroup();
ServerBootstrap bootstrap = new ServerBootstrap(); //1
bootstrap.group(group) //2
.channel(NioServerSocketChannel.class) //3
.childHandler(new SimpleChannelInboundHandler<ByteBuf>() { //4
@Override
protected void channelRead0(ChannelHandlerContext ctx,
ByteBuf byteBuf) throws Exception {
System.out.println("Reveived data");
byteBuf.clear();
}
}
);
ChannelFuture future = bootstrap.bind(new InetSocketAddress(8080)); //5
future.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture channelFuture)
throws Exception {
if (channelFuture.isSuccess()) {
System.out.println("Server bound");
} else {
System.err.println("Bound attempt failed");
channelFuture.cause().printStackTrace();
}
}
}
);
- 创建要给新的 ServerBootstrap 来创建新的 SocketChannel 管道并绑定他们
- 指定 EventLoopGroup 用于从注册的 ServerChannel 中获取EventLoop 和接收到的管道
- 指定要使用的管道类
- 设置子处理器用于处理接收的管道的 I/O 和数据
- 通过配置引导来绑定管道
从 Channel 引导客户端
有时你可能需要引导客户端 Channel 从另一个 Channel。这可能发生,如果您正在编写一个代理或从其他系统需要检索数据。后一种情况是常见的,因为许多 Netty 的应用程序集成现有系统,例如 web 服务或数据库。
你当然可以创建一个新的 Bootstrap 并使用它如9.2.1节所述,这个解决方案不一定有效。至少,你需要创建另一个 EventLoop 给新客户端 Channel 的,并且 Channel 将会需要在不同的 Thread 间进行上下文切换。
幸运的是,由于 EventLoop 继承自 EventLoopGroup ,您可以通过传递 接收到的 Channel 的 EventLoop 到 Bootstrap 的 group() 方法。这允许客户端 Channel 来操作 相同的 EventLoop,这样就能消除了额外的线程创建和所有相关的上下文切换的开销。
为什么共享 EventLoop 呢?
当你分享一个 EventLoop ,你保证所有 Channel 分配给 EventLoop 将使用相同的线程,消除上下文切换和相关的开销。(请记住,一个EventLoop分配给一个线程执行操作。)
共享一个 EventLoop 描述如下:
- 当 bind() 调用时,ServerBootstrap 创建一个新的ServerChannel 。 当绑定成功后,这个管道就能接收子管道了
- ServerChannel 接收新连接并且创建子管道来服务它们
- Channel 用于接收到的连接
- 管道自己创建了 Bootstrap,用于当 connect() 调用时创建一个新的管道
- 新管道连接到远端
- 在 EventLoop 接收通过 connect() 创建后就在管道间共享
Figure 9.4 EventLoop shared between channels with ServerBootstrap and Bootstrap
实现 EventLoop 共享,包括设置 EventLoop 引导通过Bootstrap.eventLoop() 方法。这是清单9.5所示。
ServerBootstrap bootstrap = new ServerBootstrap(); //1
bootstrap.group(new NioEventLoopGroup(), //2
new NioEventLoopGroup()).channel(NioServerSocketChannel.class) //3
.childHandler( //4
new SimpleChannelInboundHandler<ByteBuf>() {
ChannelFuture connectFuture;
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
Bootstrap bootstrap = new Bootstrap();//5
bootstrap.channel(NioSocketChannel.class) //6
.handler(new SimpleChannelInboundHandler<ByteBuf>() { //7
@Override
protected void channelRead0(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
System.out.println("Reveived data");
}
});
bootstrap.group(ctx.channel().eventLoop()); //8
connectFuture = bootstrap.connect(new InetSocketAddress("www.manning.com", 80)); //9
}
@Override
protected void channelRead0(ChannelHandlerContext channelHandlerContext, ByteBuf byteBuf) throws Exception {
if (connectFuture.isDone()) {
// do something with the data //10
}
}
});
ChannelFuture future = bootstrap.bind(new InetSocketAddress(8080)); //11
future.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture channelFuture) throws Exception {
if (channelFuture.isSuccess()) {
System.out.println("Server bound");
} else {
System.err.println("Bound attempt failed");
channelFuture.cause().printStackTrace();
}
}
});
- 创建一个新的 ServerBootstrap 来创建新的 SocketChannel 管道并且绑定他们
- 指定 EventLoopGroups 从 ServerChannel 和接收到的管道来注册并获取 EventLoops
- 指定 Channel 类来使用
- 设置处理器用于处理接收到的管道的 I/O 和数据
- 创建一个新的 Bootstrap 来连接到远程主机
- 设置管道类
- 设置处理器来处理 I/O
- 使用相同的 EventLoop 作为分配到接收的管道
- 连接到远端
- 连接完成处理业务逻辑 (比如, proxy)
- 通过配置了的 Bootstrap 来绑定到管道
注意,新的 EventLoop 会创建一个新的 Thread。出于该原因,EventLoop 实例应该尽量重用。或者限制实例的数量来避免耗尽系统资源。
在一个引导中添加多个 ChannelHandler
在所有的例子代码中,我们在引导过程中通过 handler() 或childHandler() 都只添加了一个 ChannelHandler 实例,对于简单的程序可能足够,但是对于复杂的程序则无法满足需求。例如,某个程序必须支持多个协议,如 HTTP、WebSocket。若在一个 ChannelHandle r中处理这些协议将导致一个庞大而复杂的 ChannelHandler。Netty 通过添加多个 ChannelHandler,从而使每个 ChannelHandler 分工明确,结构清晰。
Netty 的一个优势是可以在 ChannelPipeline 中堆叠很多ChannelHandler 并且可以最大程度的重用代码。如何添加多个ChannelHandler 呢?Netty 提供 ChannelInitializer 抽象类用来初始化 ChannelPipeline 中的 ChannelHandler。ChannelInitializer是一个特殊的 ChannelHandler,通道被注册到 EventLoop 后就会调用ChannelInitializer,并允许将 ChannelHandler 添加到CHannelPipeline;完成初始化通道后,这个特殊的 ChannelHandler 初始化器会从 ChannelPipeline 中自动删除。
听起来很复杂,其实很简单,看下面代码:
Listing 9.6 Bootstrap and using ChannelInitializer
ServerBootstrap bootstrap = new ServerBootstrap();//1
bootstrap.group(new NioEventLoopGroup(), new NioEventLoopGroup()) //2
.channel(NioServerSocketChannel.class) //3
.childHandler(new ChannelInitializerImpl()); //4
ChannelFuture future = bootstrap.bind(new InetSocketAddress(8080)); //5
future.sync();
final class ChannelInitializerImpl extends ChannelInitializer<Channel> { //6
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline(); //7
pipeline.addLast(new HttpClientCodec());
pipeline.addLast(new HttpObjectAggregator(Integer.MAX_VALUE));
}
}
- 创建一个新的 ServerBootstrap 来创建和绑定新的 Channel
- 指定 EventLoopGroups 从 ServerChannel 和接收到的管道来注册并获取 EventLoops
- 指定 Channel 类来使用
- 设置处理器用于处理接收到的管道的 I/O 和数据
- 通过配置的引导来绑定管道
- ChannelInitializer 负责设置 ChannelPipeline
- 实现 initChannel() 来添加需要的处理器到 ChannelPipeline。一旦完成了这方法 ChannelInitializer 将会从 ChannelPipeline 删除自身。
通过 ChannelInitializer, Netty 允许你添加你程序所需的多个 ChannelHandler 到 ChannelPipeline
使用Netty 的 ChannelOption 和属性
比较麻烦的是创建通道后不得不手动配置每个通道,为了避免这种情况,Netty 提供了 ChannelOption 来帮助引导配置。这些选项会自动应用到引导创建的所有通道,可用的各种选项可以配置底层连接的详细信息,如通道“keep-alive(保持活跃)”或“timeout(超时)”的特性。
Netty 应用程序通常会与组织或公司其他的软件进行集成,在某些情况下,Netty 的组件如 Channel 在 Netty 正常生命周期外使用; Netty 的提供了抽象 AttributeMap 集合,这是由 Netty 的管道和引导类,和 AttributeKey,常见类用于插入和检索属性值。属性允许您安全的关联任何数据项与客户端和服务器的 Channel。
例如,考虑一个服务器应用程序跟踪用户和 Channel 之间的关系。这可以通过存储用户 ID 作为 Channel 的一个属性。类似的技术可以用来路由消息到基于用户 ID 或关闭基于用户活动的一个管道。
清单9.7展示了如何使用 ChannelOption 配置 Channel 和一个属性来存储一个整数值。
Listing 9.7 Using Attributes
final AttributeKey<Integer> id = new AttributeKey<Integer>("ID"); //1
Bootstrap bootstrap = new Bootstrap(); //2
bootstrap.group(new NioEventLoopGroup()) //3
.channel(NioSocketChannel.class) //4
.handler(new SimpleChannelInboundHandler<ByteBuf>() { //5
@Override
public void channelRegistered(ChannelHandlerContext ctx) throws Exception {
Integer idValue = ctx.channel().attr(id).get(); //6
// do something with the idValue
}
@Override
protected void channelRead0(ChannelHandlerContext channelHandlerContext, ByteBuf byteBuf) throws Exception {
System.out.println("Reveived data");
}
});
bootstrap.option(ChannelOption.SO_KEEPALIVE, true).option(ChannelOption.CONNECT_TIMEOUT_MILLIS, 5000); //7
bootstrap.attr(id, 123456); //8
ChannelFuture future = bootstrap.connect(new InetSocketAddress("www.manning.com", 80)); //9
future.syncUninterruptibly();
- 新建一个 AttributeKey 用来存储属性值
- 新建 Bootstrap 用来创建客户端管道并连接他们
- 指定 EventLoopGroups 从和接收到的管道来注册并获取 EventLoop
- 指定 Channel 类
- 设置处理器来处理管道的 I/O 和数据
- 检索 AttributeKey 的属性及其值
- 设置 ChannelOption 将会设置在管道在连接或者绑定
- 存储 id 属性
- 通过配置的 Bootstrap 来连接到远程主机
关闭之前已经引导的客户端或服务器
引导您的应用程序启动并运行,但是迟早你也需要关闭它。当然你可以让 JVM处理所有退出但这不会满足“优雅”的定义,是指干净地释放资源。关闭一个Netty 的应用程序并不复杂,但有几件事要记住。
主要是记住关闭 EventLoopGroup,将处理任何悬而未决的事件和任务并随后释放所有活动线程。这只是一种叫EventLoopGroup.shutdownGracefully()。这个调用将返回一个 Future 用来通知关闭完成。注意,shutdownGracefully()也是一个异步操作,所以你需要阻塞,直到它完成或注册一个侦听器直到返回的 Future 来通知完成。
清单9.9定义了“优雅地关闭”
Listing 9.9 Graceful shutdown
EventLoopGroup group = new NioEventLoopGroup() //1
Bootstrap bootstrap = new Bootstrap(); //2
bootstrap.group(group)
.channel(NioSocketChannel.class);
...
...
Future<?> future = group.shutdownGracefully(); //3
// block until the group has shutdown
future.sync();
- 创建 EventLoopGroup 用于处理 I/O
- 创建一个新的 Bootstrap 并且配置他
- 最终优雅的关闭 EventLoopGroup 释放资源。这个也会关闭中当前使用的 Channel
或者,您可以调用 Channel.close() 显式地在所有活动管道之前调用EventLoopGroup.shutdownGracefully()。但是在所有情况下,记得关闭EventLoopGroup 本身
总结
在本章中,您了解了如何引导基于 Netty 服务器和客户端应用程序(包括那些使用无连接协议),如何指定管道的配置选项,以及如何使用属性信息附加到一个管道。
在下一章,我们将研究如何测试你 ChannelHandler 实现以确保其正确性。
8.9 - CH10-单元测试
本章介绍
学会了使用一个或多个 ChannelHandler 处理接收/发送数据消息,但是如何测试它们呢?Netty 提供了2个额外的类使得测试 ChannelHandler变得很容易,本章讲解如何测试 Netty 程序。测试使用 JUnit4,如果不会用可以慢慢了解。JUnit4 很简单,但是功能很强大。
本章将重点讲解测试已实现的 ChannelHandler 和编解码器
总览
我们已经知道,ChannelHandler 实现可以串联在一起,以构建ChannelPipeline 的处理逻辑。我们先前解释说,这个设计方法 支持潜在的复杂的分解处理成小和可重用的组件,其中每个一个定义良好的处理任务或步骤。在这一章里,我们将展示它简化了测试。
Netty 的促进 ChannelHandler 的测试通过的所谓“嵌入式”传输。这是由一个特殊 Channel 实现,EmbeddedChannel,它提供了一个简单的方法通过管道传递事件。
想法很简单:你入站或出站数据写入一个E mbeddedChannel 然后检查是否达到 ChannelPipeline 的结束。这样你可以确定消息编码或解码和ChannelHandler 是否操作被触发。
在表10.1中列出了相关方法。
| 名称 | 职责 |
|---|
| writeInbound | 写一个入站消息到 EmbeddedChannel。 如果数据能从 EmbeddedChannel 通过 readInbound() 读到,则返回 true |
| readInbound | 从 EmbeddedChannel 读到入站消息。任何返回遍历整个ChannelPipeline。如果读取还没有准备,则此方法返回 null |
| writeOutbound | 写一个出站消息到 EmbeddedChannel。 如果数据能从 EmbeddedChannel 通过 readOutbound() 读到,则返回 true |
| readOutbound | 从 EmbeddedChannel 读到出站消息。任何返回遍历整个ChannelPipeline。如果读取还没有准备,则此方法返回 null |
| Finish | 如果从入站或者出站中能读到数据,标记 EmbeddedChannel 完成并且返回。这同时会调用 EmbeddedChannel 的关闭方法 |
测试入站和出站数据
处理入站数据由 ChannelInboundHandler 处理并且表示数据从远端读取。出站数据由 ChannelOutboundHandler 处理并且表示数据写入远端。 根据 ChannelHandler 测试你会选择 writeInbound(),writeOutbound(), 或者两者都有。
图10.1显示了数据流如何通过 ChannelPipeline 使用 EmbeddedChannel 的方法。
Figure 10.1 EmbeddedChannel data flow
如上图所示,使用 writeOutbound() 写消息到 Channel,消息在出站方法通过 ChannelPipeline,之后就可以使用 readOutbound() 读取消息。着同样使用与入站,使用 writeInbound() 和 readInbound()。处在
每种情况下,消息是通过 ChannelPipeline 并被有关ChannelInboundHandler 或 ChannelOutboundHandler 进行处理。如果消息是不消耗您可以使用 readInbound() 或 readOutbound() 适当的读到 Channel 处理后的消息。
让我们仔细看一下这两个场景,看看他们如何适用于测试您的应用程序逻辑。
测试 ChannelHandler
本节,将使用 EmbeddedChannel 来测试 ChannelHandler
测试入站消息
我们来编写一个简单的 ByteToMessageDecoder 实现,有足够的数据可以读取时将产生固定大小的包,如果没有足够的数据可以读取,则会等待下一个数据块并再次检查是否可以产生一个完整包。
如图所示,它可能会占用一个以上的“event”以获取足够的字节产生一个数据包,并将它传递到 ChannelPipeline 中的下一个 ChannelHandler,
Figure 10.2 Decoding via FixedLengthFrameDecoder
实现如下:
Listing 10.1 FixedLengthFrameDecoder implementation
public class FixedLengthFrameDecoder extends ByteToMessageDecoder { //1
private final int frameLength;
public FixedLengthFrameDecoder(int frameLength) { //2
if (frameLength <= 0) {
throw new IllegalArgumentException(
"frameLength must be a positive integer: " + frameLength);
}
this.frameLength = frameLength;
}
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
if (in.readableBytes() >= frameLength) { //3
ByteBuf buf = in.readBytes(frameLength);//4
out.add(buf); //5
}
}
}
- 继承 ByteToMessageDecoder 用来处理入站的字节并将他们解码为消息
- 指定产出的帧的长度
- 检查是否有足够的字节用于读到下个帧
- 从 ByteBuf 读取新帧
- 添加帧到解码好的消息 List
下面是单元测试的例子,使用 EmbeddedChannel
Listing 10.2 Test the FixedLengthFrameDecoder
public class FixedLengthFrameDecoderTest {
@Test //1
public void testFramesDecoded() {
ByteBuf buf = Unpooled.buffer(); //2
for (int i = 0; i < 9; i++) {
buf.writeByte(i);
}
ByteBuf input = buf.duplicate();
EmbeddedChannel channel = new EmbeddedChannel(new FixedLengthFrameDecoder(3)); //3
Assert.assertFalse(channel.writeInbound(input.readBytes(2))); //4
Assert.assertTrue(channel.writeInbound(input.readBytes(7)));
Assert.assertTrue(channel.finish()); //5
ByteBuf read = (ByteBuf) channel.readInbound();
Assert.assertEquals(buf.readSlice(3), read);
read.release();
read = (ByteBuf) channel.readInbound();
Assert.assertEquals(buf.readSlice(3), read);
read.release();
read = (ByteBuf) channel.readInbound();
Assert.assertEquals(buf.readSlice(3), read);
read.release();
Assert.assertNull(channel.readInbound());
buf.release();
}
@Test
public void testFramesDecoded2() {
ByteBuf buf = Unpooled.buffer();
for (int i = 0; i < 9; i++) {
buf.writeByte(i);
}
ByteBuf input = buf.duplicate();
EmbeddedChannel channel = new EmbeddedChannel(new FixedLengthFrameDecoder(3));
Assert.assertFalse(channel.writeInbound(input.readBytes(2)));
Assert.assertTrue(channel.writeInbound(input.readBytes(7)));
Assert.assertTrue(channel.finish());
ByteBuf read = (ByteBuf) channel.readInbound();
Assert.assertEquals(buf.readSlice(3), read);
read.release();
read = (ByteBuf) channel.readInbound();
Assert.assertEquals(buf.readSlice(3), read);
read.release();
read = (ByteBuf) channel.readInbound();
Assert.assertEquals(buf.readSlice(3), read);
read.release();
Assert.assertNull(channel.readInbound());
buf.release();
}
}
- 测试增加 @Test 注解
- 新建 ByteBuf 并用字节填充它
- 新增 EmbeddedChannel 并添加 FixedLengthFrameDecoder 用于测试
- 写数据到 EmbeddedChannel
- 标记 channel 已经完成
- 读产生的消息并且校验
如上面代码,testFramesDecoded() 方法想测试一个 ByteBuf,这个ByteBuf 包含9个可读字节,被解码成包含了3个可读字节的 ByteBuf。你可能注意到,它写入9字节到通道是通过调用 writeInbound() 方法,之后再执行 finish() 来将 EmbeddedChannel 标记为已完成,最后调用readInbound() 方法来获取 EmbeddedChannel 中的数据,直到没有可读字节。testFramesDecoded2() 方法采取同样的方式,但有一个区别就是入站ByteBuf分两步写的,当调用 writeInbound(input.readBytes(2)) 后返回 false 时,FixedLengthFrameDecoder 值会产生输出,至少有3个字节是可读,testFramesDecoded2() 测试的工作相当于testFramesDecoded()。
Testing outbound messages
测试的处理出站消息类似于我们刚才看到的一切。这个例子将使用的实现MessageToMessageEncoder:AbsIntegerEncoder。
- 当收到 flush() 它将从 ByteBuf 读取4字节整数并给每个执行Math.abs()。
- 每个整数接着写入 ChannelHandlerPipeline
图10.3显示了逻辑。
Figure 10.3 Encoding via AbsIntegerEncoder
示例如下:
Listing 10.3 AbsIntegerEncoder
public class AbsIntegerEncoder extends MessageToMessageEncoder<ByteBuf> { //1
@Override
protected void encode(ChannelHandlerContext channelHandlerContext, ByteBuf in, List<Object> out) throws Exception {
while (in.readableBytes() >= 4) { //2
int value = Math.abs(in.readInt());//3
out.add(value); //4
}
}
}
- 继承 MessageToMessageEncoder 用于编码消息到另外一种格式
- 检查是否有足够的字节用于编码
- 读取下一个输入 ByteBuf 产出的 int 值,并计算绝对值
- 写 int 到编码的消息 List
在前面的示例中,我们将使用 EmbeddedChannel 测试代码。清单10.4
Listing 10.4 Test the AbsIntegerEncoder
public class AbsIntegerEncoderTest {
@Test //1
public void testEncoded() {
ByteBuf buf = Unpooled.buffer(); //2
for (int i = 1; i < 10; i++) {
buf.writeInt(i * -1);
}
EmbeddedChannel channel = new EmbeddedChannel(new AbsIntegerEncoder()); //3
Assert.assertTrue(channel.writeOutbound(buf)); //4
Assert.assertTrue(channel.finish()); //5
for (int i = 1; i < 10; i++) {
Assert.assertEquals(i, channel.readOutbound()); //6
}
Assert.assertNull(channel.readOutbound());
}
}
- 用 @Test 标记
- 新建 ByteBuf 并写入负整数
- 新建 EmbeddedChannel 并安装 AbsIntegerEncoder 来测试
- 写 ByteBuf 并预测 readOutbound() 产生的数据
- 标记 channel 已经完成
- 读取产生到的消息,检查负值已经
- 编码为绝对值
测试异常处理
有时候传输的入站或出站数据不够,通常这种情况也需要处理,例如抛出一个异常。这可能是你错误的输入或处理大的资源或其他的异常导致。我们来写一个实现,如果输入字节超出限制长度就抛出TooLongFrameException,这样的功能一般用来防止资源耗尽。看下图:
在图10.4最大帧大小被设置为3个字节。
Figure 10.4 Decoding via FrameChunkDecoder
上图显示帧的大小被限制为3字节,若输入的字节超过3字节,则超过的字节被丢弃并抛出 TooLongFrameException。在 ChannelPipeline 中的其他ChannelHandler 实现可以处理 TooLongFrameException 或者忽略异常。处理异常在 ChannelHandler.exceptionCaught() 方法中完成,ChannelHandler 提供了一些具体的实现,看下面代码:
public class FrameChunkDecoder extends ByteToMessageDecoder { //1
private final int maxFrameSize;
public FrameChunkDecoder(int maxFrameSize) {
this.maxFrameSize = maxFrameSize;
}
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
int readableBytes = in.readableBytes(); //2
if (readableBytes > maxFrameSize) {
// discard the bytes //3
in.clear();
throw new TooLongFrameException();
}
ByteBuf buf = in.readBytes(readableBytes); //4
out.add(buf); //5
}
}
- 继承 ByteToMessageDecoder 用于解码入站字节到消息
- 指定最大需要的帧产生的体积
- 如果帧太大就丢弃并抛出一个 TooLongFrameException 异常
- 同时从 ByteBuf 读到新帧
- 添加帧到解码消息 List
示例如下:
Listing 10.6 Testing FixedLengthFrameDecoder
public class FrameChunkDecoderTest {
@Test //1
public void testFramesDecoded() {
ByteBuf buf = Unpooled.buffer(); //2
for (int i = 0; i < 9; i++) {
buf.writeByte(i);
}
ByteBuf input = buf.duplicate();
EmbeddedChannel channel = new EmbeddedChannel(new FrameChunkDecoder(3)); //3
Assert.assertTrue(channel.writeInbound(input.readBytes(2))); //4
try {
channel.writeInbound(input.readBytes(4)); //5
Assert.fail(); //6
} catch (TooLongFrameException e) {
// expected
}
Assert.assertTrue(channel.writeInbound(input.readBytes(3))); //7
Assert.assertTrue(channel.finish()); //8
ByteBuf read = (ByteBuf) channel.readInbound();
Assert.assertEquals(buf.readSlice(2), read); //9
read.release();
read = (ByteBuf) channel.readInbound();
Assert.assertEquals(buf.skipBytes(4).readSlice(3), read);
read.release();
buf.release();
}
}
- 使用 @Test 注解
- 新建 ByteBuf 写入 9 个字节
- 新建 EmbeddedChannel 并安装一个 FixedLengthFrameDecoder 用于测试
- 写入 2 个字节并预测生产的新帧(消息)
- 写一帧大于帧的最大容量 (3) 并检查一个 TooLongFrameException 异常
- 如果异常没有被捕获,测试将失败。注意如果类实现 exceptionCaught() 并且处理了异常 exception,那么这里就不会捕捉异常
- 写剩余的 2 个字节预测一个帧
- 标记 channel 完成
- 读到的产生的消息并且验证值。注意 assertEquals(Object,Object)测试使用 equals() 是否相当,不是对象的引用是否相当
即使我们使用 EmbeddedChannel 和 ByteToMessageDecoder。
应该指出的是,同样的可以做每个 ChannelHandler 的实现,将抛出一个异常。
乍一看,这看起来很类似于测试我们写在清单10.2中,但它有一个有趣的转折,即 TooLongFrameException 的处理。这里使用的 try/catch 块是 EmbeddedChannel 的一种特殊的特性。如果其中一个“write*“编写方法产生一个受控异常将被包装在一个 RuntimeException。这使得测试更加容易,如果异常处理的一部分处理。
总结
使用测试工具,如JUnit单元测试是一个非常有效的方式保证代码的正确性,提高其可维护性。在本章中,您了解了如何测试定制 ChannelHandler 来验证他们的工作。
在接下来的章节我们将专注于写 Netty “真实世界” 的应用程序。即使我们任何进一步的测试代码的例子,但希望你能记住我们的测试方法的探讨及其重要性。
8.10 - CH11-Websocket
本章涵盖了如下内容:
- WebSockets
- ChannelHandler, Decoder 和 Encoder
- 引导你的应用程序
real-time web(实时web)是一组技术和实践,使用户能够实时地接收 到作者发布的信息,而不需要用户用他们的软件定期检查更新源。
HTTP 的请求/响应的设计并不能满足实时的需求,而 WebSocket 协议从设计以来就提供双向数据传输,允许客户和服务器在任何时间发送消息,并要求它们能够异步处理消息。最新的浏览器都将 WebSockets 作为HTML5的一种客户端API来支持的。
Netty 中对于 WebSocket 的支持包括正在使用的所有主要的实现,所以在你的下一个应用程序中采用它会非常简单。像往常使用Netty一样,你可以充分利用这种协议,而不必担心其内部实现细节。 我们将通过开发基于 WebSocket 的实时聊天应用证明这一点。
WebSocket 程序示例
为了说明实时功能的特点,我们使用 WebSocket 协议来实现一个基于浏览器的实时聊天程序,就像你在 Facebook 中用文字聊天一样。但是我们这里要更进一步,我们要让不同的用户可以同时互相交谈。
程序逻辑如图 11.1 所示
#1客户端/用户连接到服务器,并且是聊天的一部分
#2聊天消息通过 WebSocket 进行交换
#3消息双向发送
#4服务器处理所有的客户端/用户
逻辑很简单:
- 1.客户端发送一个消息。
- 2.消息被广播到所有其他连接的客户端。
这正如你所想的聊天室的工作方式:每个人都可以跟其他人聊天。此例子将仅提供服务器端,浏览器充当客户端,通过访问网页来聊天。正如您接下来要看到的,WebSocket 让这一切变得简单。
添加 WebSocket 支持
WebSocket 使用一种被称作“Upgrade handshake(升级握手)”的机制将标准的 HTTP 或HTTPS 协议转为 WebSocket。因此,使用 WebSocket 的应用程序将始终以 HTTP/S 开始,然后进行升级。这种升级发生在什么时候取决于具体的应用;可以在应用启动的时候,或者当一个特定的 URL 被请求的时候。
在我们的应用中,仅当 URL 请求以“/ws”结束时,我们才升级协议为WebSocket。否则,服务器将使用基本的 HTTP/S。一旦连接升级,之后的数据传输都将使用 WebSocket 。
下面看下服务器的逻辑图
Figure 11.2 Server logic
#1客户端/用户连接到服务器并加入聊天
#2 HTTP 请求页面或 WebSocket 升级握手
#3服务器处理所有客户端/用户
#4响应 URI “/”的请求,转到 index.html
#5如果访问的是 URI“/ws” ,处理 WebSocket 升级握手
#6升级握手完成后 ,通过 WebSocket 发送聊天消息
处理 HTTP 请求
本节我们将实现此应用中用于处理 HTTP 请求的组件,这个组件托管着可供客户端访问的聊天室页面,并且显示客户端发送的消息。
下面就是这个 HttpRequestHandler 的代码,它是一个用来处理 FullHttpRequest 消息的 ChannelInboundHandler 的实现类。注意看它是怎么实现忽略符合 “/ws” 格式的 URI 请求的。
Listing 11.1 HTTPRequestHandler
public class HttpRequestHandler extends SimpleChannelInboundHandler<FullHttpRequest> { //1
private final String wsUri;
private static final File INDEX;
static {
URL location = HttpRequestHandler.class.getProtectionDomain().getCodeSource().getLocation();
try {
String path = location.toURI() + "index.html";
path = !path.contains("file:") ? path : path.substring(5);
INDEX = new File(path);
} catch (URISyntaxException e) {
throw new IllegalStateException("Unable to locate index.html", e);
}
}
public HttpRequestHandler(String wsUri) {
this.wsUri = wsUri;
}
@Override
public void channelRead0(ChannelHandlerContext ctx, FullHttpRequest request) throws Exception {
if (wsUri.equalsIgnoreCase(request.getUri())) {
ctx.fireChannelRead(request.retain()); //2
} else {
if (HttpHeaders.is100ContinueExpected(request)) {
send100Continue(ctx); //3
}
RandomAccessFile file = new RandomAccessFile(INDEX, "r");//4
HttpResponse response = new DefaultHttpResponse(request.getProtocolVersion(), HttpResponseStatus.OK);
response.headers().set(HttpHeaders.Names.CONTENT_TYPE, "text/html; charset=UTF-8");
boolean keepAlive = HttpHeaders.isKeepAlive(request);
if (keepAlive) { //5
response.headers().set(HttpHeaders.Names.CONTENT_LENGTH, file.length());
response.headers().set(HttpHeaders.Names.CONNECTION, HttpHeaders.Values.KEEP_ALIVE);
}
ctx.write(response); //6
if (ctx.pipeline().get(SslHandler.class) == null) { //7
ctx.write(new DefaultFileRegion(file.getChannel(), 0, file.length()));
} else {
ctx.write(new ChunkedNioFile(file.getChannel()));
}
ChannelFuture future = ctx.writeAndFlush(LastHttpContent.EMPTY_LAST_CONTENT); //8
if (!keepAlive) {
future.addListener(ChannelFutureListener.CLOSE); //9
}
}
}
private static void send100Continue(ChannelHandlerContext ctx) {
FullHttpResponse response = new DefaultFullHttpResponse(HttpVersion.HTTP_1_1, HttpResponseStatus.CONTINUE);
ctx.writeAndFlush(response);
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause)
throws Exception {
cause.printStackTrace();
ctx.close();
}
}
1.扩展 SimpleChannelInboundHandler 用于处理 FullHttpRequest信息
2.如果请求是一次升级了的 WebSocket 请求,则递增引用计数器(retain)并且将它传递给在 ChannelPipeline 中的下个 ChannelInboundHandler
3.处理符合 HTTP 1.1的 “100 Continue” 请求
4.读取 index.html
5.判断 keepalive 是否在请求头里面
6.写 HttpResponse 到客户端
7.写 index.html 到客户端,根据 ChannelPipeline 中是否有 SslHandler 来决定使用 DefaultFileRegion 还是 ChunkedNioFile
8.写并刷新 LastHttpContent 到客户端,标记响应完成
9.如果 请求头中不包含 keepalive,当写完成时,关闭 Channel
HttpRequestHandler 做了下面几件事,
- 如果该 HTTP 请求被发送到URI “/ws”,则调用 FullHttpRequest 上的 retain(),并通过调用 fireChannelRead(msg) 转发到下一个 ChannelInboundHandler。retain() 的调用是必要的,因为 channelRead() 完成后,它会调用 FullHttpRequest 上的 release() 来释放其资源。 (请参考我们先前在第6章中关于 SimpleChannelInboundHandler 的讨论)
- 如果客户端发送的 HTTP 1.1 头是“Expect: 100-continue” ,则发送“100 Continue”的响应。
- 在 头被设置后,写一个 HttpResponse 返回给客户端。注意,这不是 FullHttpResponse,这只是响应的第一部分。另外,这里我们也不使用 writeAndFlush(), 这个是在留在最后完成。
- 如果传输过程既没有要求加密也没有要求压缩,那么把 index.html 的内容存储在一个 DefaultFileRegion 里就可以达到最好的效率。这将利用零拷贝来执行传输。出于这个原因,我们要检查 ChannelPipeline 中是否有一个 SslHandler。如果是的话,我们就使用 ChunkedNioFile。
- 写 LastHttpContent 来标记响应的结束,并终止它
- 如果不要求 keepalive ,添加 ChannelFutureListener 到 ChannelFuture 对象的最后写入,并关闭连接。注意,这里我们调用 writeAndFlush() 来刷新所有以前写的信息。
这里展示了应用程序的第一部分,用来处理纯的 HTTP 请求和响应。接下来我们将处理 WebSocket 的 frame(帧),用来发送聊天消息。
WebSocket frame
WebSockets 在“帧”里面来发送数据,其中每一个都代表了一个消息的一部分。一个完整的消息可以利用了多个帧。
处理 WebSocket frame
WebSocket “Request for Comments” (RFC) 定义了六种不同的 frame; Netty 给他们每个都提供了一个 POJO 实现 ,见下表:
Table 11.1 WebSocketFrame types
| 名称 | 描述 |
|---|
| BinaryWebSocketFrame | contains binary data |
| TextWebSocketFrame | contains text data |
| ContinuationWebSocketFrame | contains text or binary data that belongs to a previous BinaryWebSocketFrame or TextWebSocketFrame |
| CloseWebSocketFrame | represents a CLOSE request and contains close status code and a phrase |
| PingWebSocketFrame | requests the transmission of a PongWebSocketFrame |
| PongWebSocketFrame | sent as a response to a PingWebSocketFrame |
我们的程序只需要使用下面4个帧类型:
- CloseWebSocketFrame
- PingWebSocketFrame
- PongWebSocketFrame
- TextWebSocketFrame
在这里我们只需要处理 TextWebSocketFrame,其他的会由 WebSocketServerProtocolHandler 自动处理。
下面代码展示了 ChannelInboundHandler 处理 TextWebSocketFrame,同时也将跟踪在 ChannelGroup 中所有活动的 WebSocket 连接
Listing 11.2 Handles Text frames
public class TextWebSocketFrameHandler extends SimpleChannelInboundHandler<TextWebSocketFrame> { //1
private final ChannelGroup group;
public TextWebSocketFrameHandler(ChannelGroup group) {
this.group = group;
}
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception { //2
if (evt == WebSocketServerProtocolHandler.ServerHandshakeStateEvent.HANDSHAKE_COMPLETE) {
ctx.pipeline().remove(HttpRequestHandler.class); //3
group.writeAndFlush(new TextWebSocketFrame("Client " + ctx.channel() + " joined"));//4
group.add(ctx.channel()); //5
} else {
super.userEventTriggered(ctx, evt);
}
}
@Override
public void channelRead0(ChannelHandlerContext ctx, TextWebSocketFrame msg) throws Exception {
group.writeAndFlush(msg.retain()); //6
}
}
1.扩展 SimpleChannelInboundHandler 用于处理 TextWebSocketFrame 信息
2.覆写userEventTriggered() 方法来处理自定义事件
3.如果接收的事件表明握手成功,就从 ChannelPipeline 中删除HttpRequestHandler ,因为接下来不会接受 HTTP 消息了
4.写一条消息给所有的已连接 WebSocket 客户端,通知它们建立了一个新的 Channel 连接
5.添加新连接的 WebSocket Channel 到 ChannelGroup 中,这样它就能收到所有的信息
6.保留收到的消息,并通过 writeAndFlush() 传递给所有连接的客户端。
上面显示了 TextWebSocketFrameHandler 仅作了几件事:
- 当WebSocket 与新客户端已成功握手完成,通过写入信息到 ChannelGroup 中的 Channel 来通知所有连接的客户端,然后添加新 Channel 到 ChannelGroup
- 如果接收到 TextWebSocketFrame,调用 retain() ,并将其写、刷新到 ChannelGroup,使所有连接的 WebSocket Channel 都能接收到它。和以前一样,retain() 是必需的,因为当 channelRead0()返回时,TextWebSocketFrame 的引用计数将递减。由于所有操作都是异步的,writeAndFlush() 可能会在以后完成,我们不希望它访问无效的引用。
由于 Netty 在其内部处理了其余大部分功能,唯一剩下的需要我们去做的就是为每一个新创建的 Channel 初始化 ChannelPipeline 。要完成这个,我们需要一个ChannelInitializer
初始化 ChannelPipeline
接下来,我们需要安装我们上面实现的两个 ChannelHandler 到 ChannelPipeline。为此,我们需要继承 ChannelInitializer 并且实现 initChannel()。看下面 ChatServerInitializer 的代码实现
Listing 11.3 Init the ChannelPipeline
public class ChatServerInitializer extends ChannelInitializer<Channel> { //1
private final ChannelGroup group;
public ChatServerInitializer(ChannelGroup group) {
this.group = group;
}
@Override
protected void initChannel(Channel ch) throws Exception { //2
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new HttpServerCodec());
pipeline.addLast(new HttpObjectAggregator(64 * 1024));
pipeline.addLast(new ChunkedWriteHandler());
pipeline.addLast(new HttpRequestHandler("/ws"));
pipeline.addLast(new WebSocketServerProtocolHandler("/ws"));
pipeline.addLast(new TextWebSocketFrameHandler(group));
}
}
1.扩展 ChannelInitializer
2.添加 ChannelHandler 到 ChannelPipeline
initChannel() 方法用于设置所有新注册的 Channel 的ChannelPipeline,安装所有需要的 ChannelHandler。总结如下:
Table 11.2 ChannelHandlers for the WebSockets Chat server
| ChannelHandler | 职责 |
|---|
| HttpServerCodec | Decode bytes to HttpRequest, HttpContent, LastHttpContent.Encode HttpRequest, HttpContent, LastHttpContent to bytes. |
| ChunkedWriteHandler | Write the contents of a file. |
| HttpObjectAggregator | This ChannelHandler aggregates an HttpMessage and its following HttpContents into a single FullHttpRequest or FullHttpResponse (depending on whether it is being used to handle requests or responses).With this installed the next ChannelHandler in the pipeline will receive only full HTTP requests. |
| HttpRequestHandler | Handle FullHttpRequests (those not sent to “/ws” URI). |
| WebSocketServerProtocolHandler | As required by the WebSockets specification, handle the WebSocket Upgrade handshake, PingWebSocketFrames,PongWebSocketFrames and CloseWebSocketFrames. |
| TextWebSocketFrameHandler | Handles TextWebSocketFrames and handshake completion events |
该 WebSocketServerProtocolHandler 处理所有规定的 WebSocket 帧类型和升级握手本身。如果握手成功所需的 ChannelHandler 被添加到管道,而那些不再需要的则被去除。管道升级之前的状态如下图。这代表了 ChannelPipeline 刚刚经过 ChatServerInitializer 初始化。
Figure 11.3 ChannelPipeline before WebSockets Upgrade
握手升级成功后 WebSocketServerProtocolHandler 替换HttpRequestDecoder 为 WebSocketFrameDecoder,HttpResponseEncoder 为WebSocketFrameEncoder。 为了最大化性能,WebSocket 连接不需要的 ChannelHandler 将会被移除。其中就包括了 HttpObjectAggregator 和 HttpRequestHandler
下图,展示了 ChannelPipeline 经过这个操作完成后的情况。注意 Netty 目前支持四个版本 WebSocket 协议,每个通过其自身的方式实现类。选择正确的版本WebSocketFrameDecoder 和 WebSocketFrameEncoder 是自动进行的,这取决于在客户端(在这里指浏览器)的支持(在这个例子中,我们假设使用版本是 13 的 WebSocket 协议,从而图中显示的是 WebSocketFrameDecoder13 和 WebSocketFrameEncoder13)。
Figure 11.4 ChannelPipeline after WebSockets Upgrade
引导
最后一步是 引导服务器,设置 ChannelInitializer
public class ChatServer {
private final ChannelGroup channelGroup = new DefaultChannelGroup(ImmediateEventExecutor.INSTANCE);//1
private final EventLoopGroup group = new NioEventLoopGroup();
private Channel channel;
public ChannelFuture start(InetSocketAddress address) {
ServerBootstrap bootstrap = new ServerBootstrap(); //2
bootstrap.group(group)
.channel(NioServerSocketChannel.class)
.childHandler(createInitializer(channelGroup));
ChannelFuture future = bootstrap.bind(address);
future.syncUninterruptibly();
channel = future.channel();
return future;
}
protected ChannelInitializer<Channel> createInitializer(ChannelGroup group) { //3
return new ChatServerInitializer(group);
}
public void destroy() { //4
if (channel != null) {
channel.close();
}
channelGroup.close();
group.shutdownGracefully();
}
public static void main(String[] args) throws Exception{
if (args.length != 1) {
System.err.println("Please give port as argument");
System.exit(1);
}
int port = Integer.parseInt(args[0]);
final ChatServer endpoint = new ChatServer();
ChannelFuture future = endpoint.start(new InetSocketAddress(port));
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
endpoint.destroy();
}
});
future.channel().closeFuture().syncUninterruptibly();
}
}
1.创建 DefaultChannelGroup 用来 保存所有连接的的 WebSocket channel
2.引导 服务器
3.创建 ChannelInitializer
4.处理服务器关闭,包括释放所有资源
测试程序
使用下面命令启动服务器:
mvn -PChatServer clean package exec:exec
其中项目中的 pom.xml 是配置了 9999 端口。你也可以通过下面的方法修改属性
mvn -PChatServer -Dport=1111 clean package exec:exec
下面是控制台的主要输出(删除了部分行)
Listing 11.5 Compile and start the ChatServer
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building ChatServer 1.0-SNAPSHOT
[INFO] ------------------------------------------------------------------------
...
[INFO]
[INFO] --- maven-jar-plugin:2.4:jar (default-jar) @ netty-in-action ---
[INFO] Building jar: D:/netty-in-action/chapter11/target/chat-server-1.0-SNAPSHOT.jar
[INFO]
[INFO] --- exec-maven-plugin:1.2.1:exec (default-cli) @ chat-server ---
Starting ChatServer on port 9999
可以在浏览器中通过 http://localhost:9999 地址访问程序。图11.5展示了此程序在Chrome浏览器下的用户界面。
Figure 11.5 WebSockets ChatServer demonstration
图中显示了两个已经连接了的客户端。第一个客户端是通过上面的图形界面连接的,第二个是通过Chrome浏览器底部的命令行连接的。 你可以注意到,这两个客户端都在发送消息,每条消息都会显示在两个客户端上。
如何加密?
在实际场景中,加密是必不可少的。在Netty中实现加密并不麻烦,你只需要向 ChannelPipeline 中添加 SslHandler ,然后配置一下即可。如下:
Listing 11.6 Add encryption to the ChannelPipeline
public class SecureChatServerIntializer extends ChatServerInitializer { //1
private final SslContext context;
public SecureChatServerIntializer(ChannelGroup group, SslContext context) {
super(group);
this.context = context;
}
@Override
protected void initChannel(Channel ch) throws Exception {
super.initChannel(ch);
SSLEngine engine = context.newEngine(ch.alloc());
engine.setUseClientMode(false);
ch.pipeline().addFirst(new SslHandler(engine)); //2
}
}
1.扩展 ChatServerInitializer 来实现加密
2.向 ChannelPipeline 中添加SslHandler
最后修改 ChatServer,使用 SecureChatServerInitializer 并传入 SSLContext
Listing 11.7 Add encryption to the ChatServer
public class SecureChatServer extends ChatServer {//1
private final SslContext context;
public SecureChatServer(SslContext context) {
this.context = context;
}
@Override
protected ChannelInitializer<Channel> createInitializer(ChannelGroup group) {
return new SecureChatServerIntializer(group, context); //2
}
public static void main(String[] args) throws Exception{
if (args.length != 1) {
System.err.println("Please give port as argument");
System.exit(1);
}
int port = Integer.parseInt(args[0]);
SelfSignedCertificate cert = new SelfSignedCertificate();
SslContext context = SslContext.newServerContext(cert.certificate(), cert.privateKey());
final SecureChatServer endpoint = new SecureChatServer(context);
ChannelFuture future = endpoint.start(new InetSocketAddress(port));
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
endpoint.destroy();
}
});
future.channel().closeFuture().syncUninterruptibly();
}
}
1.扩展 ChatServer
2.返回先前创建的 SecureChatServerInitializer 来启用加密
这样,就在所有的通信中使用了 SSL/TLS 加密。和前面一样,你可以使用Maven拉取应用需要的所有依赖,并启动它,如下所示。
Listing 11.8 Start the SecureChatServer
$ mvn -PSecureChatServer clean package exec:exec
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building ChatServer 1.0-SNAPSHOT
[INFO] ------------------------------------------------------------------------
...
[INFO]
[INFO] --- maven-jar-plugin:2.4:jar (default-jar) @ netty-in-action ---
[INFO] Building jar: D:/netty-in-action/chapter11/target/chat-server-1.0-SNAPSHOT.jar
[INFO]
[INFO] --- exec-maven-plugin:1.2.1:exec (default-cli) @ chat-server ---
Starting SecureChatServer on port 9999
现在你可以通过 HTTPS 地址: https://localhost:9999 来访问SecureChatServer 了。
总结
在本章中,我们学习了如何使用 Netty 中的 WebSocket 来管理 Web 应用程序中的实时数据。我们讲了所支持的数据类型,并讨论了你可能会遇到的问题。虽然 WebSockets 并不能在所有情况下使用,但应该清楚,它代表了 web 技术发展上的一个重要进步。
接下来我们来谈谈“Web2.0”开发中的另一项技术。也许你还没有听说过“SPDY”,但只要你读了下一章,你就很可能在你将来的开发中很好的运用这门技术了。
8.11 - CH12-SPDY
本章介绍
- SPDY 总览
- ChannelHandler, Decoder, 和 Encoder
- 引导一个基于 Netty 的应用
- 测试 SPDY/HTTPS
SPDY(读作“speedy”)是一个谷歌开发的开放的网络协议,主要运用于 web 内容传输。SPDY 操纵 HTTP 流量,目标是减少 web 页面加载延迟,提高网络安全。SPDY 达到通过压缩、多路复用和优先级来减少延迟,虽然这取决于网络和网站部署条件的组合。“SPDY”这个名字是谷歌的一个商标,不是一个首字母缩写。(摘自http://en.wikipedia.org/wiki/SPDY)
Netty 的包支持 SPDY。正如我们已经看到在其他情况下,这种支持将使您能够使用 SPDY 无需担心所有的内部细节。在这一章里,我们将提供你需要的所有信息关于在您的应用程序中启用 SPDY ,并同时支持 SPDY 和 HTTP。
SPDY 背景
Google 开发 SPDY 是为了解决扩展性的问题。主要的任务是加载内容的速度更快,做了如下工作:
- 每个头都是压缩的,消息体的压缩是可选的,因为它可能对代理服务器有问题
- 所有的加密都使用 TLS 每个连接多个转移是可能的 数据集可以单独设置优先级,使关键内容先被转移
下表是与 HTTP 的对比
Table 12.1 Comparison of SPDY and HTTP
| 浏览器 | HTTP 1.1 | SPDY |
|---|
| 加密 | Not by default | Yes |
| Header 压缩 | No | Yes |
| 全双工 | No | Yes |
| Server push | No | Yes |
| 优先级 | No | Yes |
一些使用场合和指标显示,可以 SPDY 让页面加载速度比H TTP 原先快50%。
现在 SPDY 的协议草案规范是 1, 2 和 3, Netty 支持 2和3,主要考虑到这个是被广大浏览器所支持的版本。 现在很多浏览器都支持 SPDY,见下表:
Table 12.2 Browsers that support SPDY
| 浏览器 | 版本 |
|---|
| Chrome | 19+ |
| Chromium | 19+ |
| Mozilla Firefox | 11+ (从 13 起默认开启) |
| Opera | 12.10+ |
示例程序
编写一个简单的服务器应用程序,向您展示如何将 SPDY 集成到你的下一个应用程序。它只会提供一些静态内容回客户机。这些内容将取决于所使用协议是 HTTPS 或 SPDY 。如果 服务器提供 SPDY 是可以被客户端浏览器所支持,则自动切换到 SPDY 。图12.1显示了应用程序的流程
对于这个应用程序只编写一个服务器组件处理 HTTPS 和 SPDY。为了演示其功能使用两个不同的 web 浏览器,一个支持 SPDY,另外一个不支持。
实现
SPDY 使用 TLS 的扩展称为 Next Protocol Negotiation (NPN)。在Java 中,我们有两种不同的方式选择的基于 NPN 的协议:
- 使用 ssl_npn,NPN 的开源 SSL 提供者。
- 使用通过 Jetty 的 NPN 扩展库。
在这个例子中使用 Jetty 库。如果你想使用 ssl_npn,请参阅https://github.com/benmmurphy/ssl_npn项目文档
Jetty NPN 库
Jetty NPN 库是一个外部的库,而不是 Netty 的本身的一部分。它用于处理 Next Protocol Negotiation, 这是用于检测客户端是否支持 SPDY。
集成 Next Protocol Negotiation
Jetty 库提供了一个接口称为 ServerProvider,确定所使用的协议和选择哪个钩子。这个的实现可能取决于不同版本的 HTTP 和 SPDY 版本的支持。下面的清单显示了将用于我们的示例应用程序的实现。
Listing 12.1 Implementation of ServerProvider
public class DefaultServerProvider implements NextProtoNego.ServerProvider {
private static final List<String> PROTOCOLS =
Collections.unmodifiableList(Arrays.asList("spdy/2", "spdy/3", "http/1.1")); //1
private String protocol;
@Override
public void unsupported() {
protocol = "http/1.1"; //2
}
@Override
public List<String> protocols() {
return PROTOCOLS; //3
}
@Override
public void protocolSelected(String protocol) {
this.protocol = protocol; //4
}
public String getSelectedProtocol() {
return protocol; //5
}
}
- 定义所有的 ServerProvider 实现的协议
- 设置如果 SPDY 协议失败了就转到 http/1.1
- 返回支持的协议的列表
- 设置选择的协议
- 返回选择的协议
在 ServerProvider 的实现,我们支持下面的3种协议:
如果客户端不支持 SPDY ,则默认使用 HTTP 1.1
实现各种 ChannelHandler
第一个 ChannelInboundHandler 是用于不支持 SPDY 的情况下处理客户端 HTTP 请求,如果不支持 SPDY 就回滚使用默认的 HTTP 协议。
清单12.2显示了HTTP流量的处理程序。
Listing 12.2 Implementation that handles HTTP
@ChannelHandler.Sharable
public class HttpRequestHandler extends SimpleChannelInboundHandler<FullHttpRequest> {
@Override
public void channelRead0(ChannelHandlerContext ctx, FullHttpRequest request) throws Exception { //1
if (HttpHeaders.is100ContinueExpected(request)) {
send100Continue(ctx); //2
}
FullHttpResponse response = new DefaultFullHttpResponse(request.getProtocolVersion(), HttpResponseStatus.OK); //3
response.content().writeBytes(getContent().getBytes(CharsetUtil.UTF_8)); //4
response.headers().set(HttpHeaders.Names.CONTENT_TYPE, "text/plain; charset=UTF-8"); //5
boolean keepAlive = HttpHeaders.isKeepAlive(request);
if (keepAlive) { //6
response.headers().set(HttpHeaders.Names.CONTENT_LENGTH, response.content().readableBytes());
response.headers().set(HttpHeaders.Names.CONNECTION, HttpHeaders.Values.KEEP_ALIVE);
}
ChannelFuture future = ctx.writeAndFlush(response); //7
if (!keepAlive) {
future.addListener (ChannelFutureListener.CLOSE); //8
}
}
protected String getContent() { //9
return "This content is transmitted via HTTP\r\n";
}
private static void send100Continue(ChannelHandlerContext ctx) { //10
FullHttpResponse response = new DefaultFullHttpResponse(HttpVersion.HTTP_1_1, HttpResponseStatus.CONTINUE);
ctx.writeAndFlush(response);
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause)
throws Exception { //11
cause.printStackTrace();
ctx.close();
}
}
- 重写 channelRead0() ,可以被所有的接收到的 FullHttpRequest 调用
- 检查如果接下来的响应是预期的,就写入
- 新建 FullHttpResponse,用于对请求的响应
- 生成响应的内容,将它写入 payload
- 设置头文件,这样客户端就能知道如何与 响应的 payload 交互
- 检查请求设置是否启用了 keepalive;如果是这样,将标题设置为符合HTTP RFC
- 写响应给客户端,并获取到 Future 的引用,用于写完成时,获取到通知
- 如果响应不是 keepalive,在写完成时关闭连接
- 返回内容作为响应的 payload
- Helper 方法生成了100 持续的响应,并写回给客户端
- 若执行阶段抛出异常,则关闭管道
这就是 Netty 处理标准的 HTTP 。你可能需要分别处理特定 URI ,应对不同的状态代码,这取决于资源存在与否,但基本的概念将是相同的。
我们的下一个任务将会提供一个组件来支持 SPDY 作为首选协议。 Netty 提供了简单的处理 SPDY 方法。这些将使您能够重用FullHttpRequest 和 FullHttpResponse 消息,通过 SPDY 透明地接收和发送他们。
HttpRequestHandler 虽然是我们可以重用代码,我们将改变我们的内容写回客户端只是强调协议变化;通常您会返回相同的内容。下面的清单展示了实现,它扩展了先前的 HttpRequestHandler。
Listing 12.3 Implementation that handles SPDY
@ChannelHandler.Sharable
public class SpdyRequestHandler extends HttpRequestHandler { //1
@Override
protected String getContent() {
return "This content is transmitted via SPDY\r\n"; //2
}
}
- 继承 HttpRequestHandler 这样就能共享相同的逻辑
- 生产内容写到 payload。这个重写了 HttpRequestHandler 的 getContent() 的实现
SpdyRequestHandler 继承自 HttpRequestHandler,但区别是:写入的内容的 payload 状态的响应是在 SPDY 写的。
我们可以实现两个处理程序逻辑,将选择一个相匹配的协议。然而添加以前写过的处理程序到 ChannelPipeline 是不够的;正确的编解码器还需要补充。它的责任是检测传输字节数,然后使用 FullHttpResponse 和 FullHttpRequest 的抽象进行工作。
Netty 的附带一个基类,完全能做这个。所有您需要做的是实现逻辑选择协议和选择适当的处理程序。
清单12.4显示了实现,它使用 Netty 的提供的抽象基类。
public class DefaultSpdyOrHttpChooser extends SpdyOrHttpChooser {
public DefaultSpdyOrHttpChooser(int maxSpdyContentLength, int maxHttpContentLength) {
super(maxSpdyContentLength, maxHttpContentLength);
}
@Override
protected SelectedProtocol getProtocol(SSLEngine engine) {
DefaultServerProvider provider = (DefaultServerProvider) NextProtoNego.get(engine); //1
String protocol = provider.getSelectedProtocol();
if (protocol == null) {
return SelectedProtocol.UNKNOWN; //2
}
switch (protocol) {
case "spdy/2":
return SelectedProtocol.SPDY_2; //3
case "spdy/3.1":
return SelectedProtocol.SPDY_3_1; //4
case "http/1.1":
return SelectedProtocol.HTTP_1_1; //5
default:
return SelectedProtocol.UNKNOWN; //6
}
}
@Override
protected ChannelInboundHandler createHttpRequestHandlerForHttp() {
return new HttpRequestHandler(); //7
}
@Override
protected ChannelInboundHandler createHttpRequestHandlerForSpdy() {
return new SpdyRequestHandler(); //8
}
}
- 使用 NextProtoNego 用于获取 DefaultServerProvider 的引用, 用于 SSLEngine
- 协议不能被检测到。一旦字节已经准备好读,检测过程将重新开始。
- SPDY 2 被检测到
- SPDY 3 被检测到
- HTTP 1.1 被检测到
- 未知协议被检测到
- 将会被调用给 FullHttpRequest 消息添加处理器。该方法只会在不支持 SPDY 时调用,那么将会使用 HTTPS
- 将会被调用给 FullHttpRequest 消息添加处理器。该方法在支持 SPDY 时调用
该实现要注意检测正确的协议并设置 ChannelPipeline 。它可以处理SPDY 版本 2、3 和 HTTP 1.1,但可以很容易地修改 SPDY 支持额外的版本。
设置 ChannelPipeline
通过实现 ChannelInitializer 将所有的处理器连接到一起。正如你所了解的那样,这将设置 ChannelPipeline 并添加所有需要的ChannelHandler 的。
SPDY 需要两个 ChannelHandler:
- SslHandler,用于检测 SPDY 是否通过 TLS 扩展
- DefaultSpdyOrHttpChooser,用于当协议被检测到时,添加正确的 ChannelHandler 到 ChannelPipeline
除了添加 ChannelHandler 到 ChannelPipeline, ChannelInitializer 还有另一个责任;即,分配之前创建的 DefaultServerProvider 通过 SslHandler 到 SslEngine 。这将通过Jetty NPN 类库的 NextProtoNego helper 类实现
Listing 12.5 Implementation that handles SPDY
public class SpdyChannelInitializer extends ChannelInitializer<SocketChannel> { //1
private final SslContext context;
public SpdyChannelInitializer(SslContext context) //2 {
this.context = context;
}
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
SSLEngine engine = context.newEngine(ch.alloc()); //3
engine.setUseClientMode(false); //4
NextProtoNego.put(engine, new DefaultServerProvider()); //5
NextProtoNego.debug = true;
pipeline.addLast("sslHandler", new SslHandler(engine)); //6
pipeline.addLast("chooser", new DefaultSpdyOrHttpChooser(1024 * 1024, 1024 * 1024));
}
}
- 继承 ChannelInitializer 是一个简单的开始
- 传递 SSLContext 用于创建 SSLEngine
- 新建 SSLEngine,用于新的管道和连接
- 配置 SSLEngine 用于非客户端使用
- 通过 NextProtoNego helper 类绑定 DefaultServerProvider 到 SSLEngine
- 添加 SslHandler 到 ChannelPipeline 这将会在协议检测到时保存在 ChannelPipeline
- 添加 DefaultSpyOrHttpChooser 到 ChannelPipeline 。这个实现将会监测协议。添加正确的 ChannelHandler 到 ChannelPipeline,并且移除自身
实际的 ChannelPipeline 设置将会在 DefaultSpdyOrHttpChooser 实现之后完成,因为在这一点上它可能只需要知道客户端是否支持 SPDY
为了说明这一点,让我们总结一下,看看不同 ChannelPipeline 状态期间与客户连接的生命周期。图12.2显示了在 Channel 初始化后的 ChannelPipeline。
Figure 12.2 ChannelPipeline after connection
现在,这取决于客户端是否支持 SPDY,管道将修改DefaultSpdyOrHttpChooser 来处理协议。之后并不需要添加所需的 ChannelHandler 到 ChannelPipeline,所以删除本身。这个逻辑是由抽象 SpdyOrHttpChooser 类封装,DefaultSpdyOrHttpChooser 父类。
图12.3显示了支持 SPDY 的 ChannelPipeline 用于连接客户端的配置。
Figure 12.3 ChannelPipeline if SPDY is supported
每个 ChannelHandler 负责的一小部分工作,这个就是对基于 Netty 构造的应用程序最完美的诠释。每个 ChannelHandler 的职责如表12.3所示。
Table 12.3 Responsibilities of the ChannelHandlers when SPDY is used
| 名称 | 职责 |
|---|
| SslHandler | 加解密两端交换的数据 |
| SpdyFrameDecoder | 从接收到的 SPDY 帧中解码字节 |
| SpdyFrameEncoder | 编码 SPDY 帧到字节 |
| SpdySessionHandler | 处理 SPDY session |
| SpdyHttpEncoder | 编码 HTTP 消息到 SPDY 帧 |
| SpdyHttpDecoder | 解码 SDPY 帧到 HTTP 消息 |
| SpdyHttpResponseStreamIdHandler | 处理基于 SPDY ID 请求和响应之间的映射关系 |
| SpdyRequestHandler | 处理 FullHttpRequest, 用于从 SPDY 帧中解码,因此允许 SPDY 透明传输使用 |
当协议是 HTTP(s) 时,ChannelPipeline 看起来相当不同,如图13.4所示。
Figure 12.3 ChannelPipeline if SPDY is not supported
和之前一样,每个 ChannelHandler 都有职责,定义在表12.4
Table 12.4 Responsibilities of the ChannelHandlers when HTTP is used
| 名称 | 职责 |
|---|
| SslHandler | 加解密两端交换的数据 |
| HttpRequestDecoder | 从接收到的 HTTP 请求中解码字节 |
| HttpResponseEncoder | 编码 HTTP 响应到字节 |
HttpObjectAggregator 处理 SPDY session HttpRequestHandler | 解码时处理 FullHttpRequest
所有东西组合在一起
所有的 ChannelHandler 实现已经准备好,现在组合成一个 SpdyServer
Listing 12.6 SpdyServer implementation
public class SpdyServer {
private final NioEventLoopGroup group = new NioEventLoopGroup(); //1
private final SslContext context;
private Channel channel;
public SpdyServer(SslContext context) { //2
this.context = context;
}
public ChannelFuture start(InetSocketAddress address) {
ServerBootstrap bootstrap = new ServerBootstrap(); //3
bootstrap.group(group)
.channel(NioServerSocketChannel.class)
.childHandler(new SpdyChannelInitializer(context)); //4
ChannelFuture future = bootstrap.bind(address); //5
future.syncUninterruptibly();
channel = future.channel();
return future;
}
public void destroy() { //6
if (channel != null) {
channel.close();
}
group.shutdownGracefully();
}
public static void main(String[] args) throws Exception {
if (args.length != 1) {
System.err.println("Please give port as argument");
System.exit(1);
}
int port = Integer.parseInt(args[0]);
SelfSignedCertificate cert = new SelfSignedCertificate();
SslContext context = SslContext.newServerContext(cert.certificate(), cert.privateKey()); //7
final SpdyServer endpoint = new SpdyServer(context);
ChannelFuture future = endpoint.start(new InetSocketAddress(port));
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
endpoint.destroy();
}
});
future.channel().closeFuture().syncUninterruptibly();
}
}
- 构建新的 NioEventLoopGroup 用于处理 I/O
- 传递 SSLContext 用于加密
- 新建 ServerBootstrap 用于配置服务器
- 配置 ServerBootstrap
- 绑定服务器用于接收指定地址的连接
- 销毁服务器,用于关闭管道和 NioEventLoopGroup
- 从 BogusSslContextFactory 获取 SSLContext 。这是一个虚拟实现进行测试。真正的实现将为 SslContext 配置适当的密钥存储库。
启动 SpdyServer 并测试
请注意,当您使用 Jetty NPN 库需要提供它的位置通过 bootclasspath 的 JVM 参数。这一步是必需的,这样才能访问 SslEngine接口。(-Xbootclasspath 选项允许您覆盖标准 JDK 附带的实现类)。
下面的清单显示了特殊的参数(-Xbootclasspath)使用。
Listing 12.7 SpdyServer implementation
java -Xbootclasspath/p:<path_to_npn_boot_jar> ....
最简单的方式是使用 Maven 项目管理:
Listing 12.8 Compile and start SpdyServer with Maven
$ mvn clean package exec:exec -Pchapter12-SpdyServer
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building netty-in-action 0.1-SNAPSHOT
[INFO] ------------------------------------------------------------------------
...
...
...
[INFO]
[INFO] --- maven-jar-plugin:2.4:jar (default-jar) @ netty-in-action ---
[INFO] Building jar: /Users/norman/Documents/workspace-intellij/netty-in-actionprivate/
target/netty-in-action-0.1-SNAPSHOT.jar
[INFO]
[INFO] --- exec-maven-plugin:1.2.1:exec (default-cli) @ netty-in-action ---
可以用2个浏览器进行测试,一个支持 SPDY 一个不支持,这里我们用的是 Google Chrome (支持 SPDY) 和 Safari。
浏览器访问 https://127.0.0.1:9999,会显示 SpdyRequestHandler 的处理结果,如下图
Figure 12.4 SPDY supported by Google Chrome
Google Chrome 的一个很好的功能是可以统计数据,可以很好的看到连接情况。 在浏览器中访问 chrome://net-internals/#spdy 可以看到详细的统计数据
Figure 12.5 SPDY statistics
若不支持 SPDY ,比如我们用 Safari 浏览器访问 https://127.0.0.1:9999 ,则响应将会用 HttpRequestHandler 处理
Figure 12.7 SPDY not supported by Safari
总结
在这一章里,你学习了如何在基于Netty应用程序同时简单的使用 SPDY 和 HTTP(s) 。这提供了一个基础,您可以受益于性能于 SPDY 提供的增强,同时允许现有客户访问您的应用程序。
您学习了如何使用 Netty 提供的 SPDY 助手类,如何使用 Google Chrome获取更多的运行时信息协议。
一路上我们看到了再次修改 ChannelPipeline 如何帮助您构建强大的多路复用器在单个连接的生命周期切换协议。
下一章你学习如何利用高性能、无连接的 UDP。
8.12 - CH13-UDP 广播
本章介绍
- UDP 介绍
- ChannelHandler, Decoder, 和 Encoder
- 引导基于 Netty 的应用
前面的章节都是在示例中使用 TCP 协议,这一章,我们将使用UDP。UDP是一种无连接协议,若需要很高的性能和对数据的完成性没有严格要求,那使用 UDP 是一个很好的方法。最著名的基于UDP协议的是用来域名解析的DNS。这一章将给你一个好的理解的无连接协议所以你能够做出明智的决定何时使用 UDP 在您的应用程序。
我们将首先从一个 UDP 的概述,其特点和局限性开始讲解。之后,我们将在本章描述了示例应用程序的开发。
UDP 基础
面向连接的传输协议(如TCP)管理建立一个两个网络端点之间调用(或“连接”),命令和可靠的消息传输在调用的生命周期期间,最后有序在调用终止时终止。与此相反,在这样一个无连接协议 UDP 没有持久连接的概念,每个消息(UDP 数据报)是一个独立的传播。
此外,UDP 没有 TCP 的纠错机制,其中每个对等承认它接收的数据包并由发送方传送包。
以此类推,一个 TCP 连接就像一个电话交谈,一系列的命令消息流在两个方向上。UDP,另一方面,就像把一堆明信片丢进信箱。我们不能知道他们到达目的地的顺序,以及他们是否能够到达。
虽然 UDP 存在某些方面的的局限性,这也解释了为什么它是如此远远快于TCP:所有的握手和消息管理的开销已被消灭。显然,UDP 是一种只适合应用程序可以处理或容忍丢失消息,而不是例如处理金钱交易。
UDP 广播
我们所有的例子这一点利用传输方式称为“单播”:“将消息发送给一个网络拥有唯一地址的目的地”,这种模式支持连接和无连接协议。
然而,UDP 提供了额外的传输模式对多个接收者发送消息:
- 多播:传送给一组主机
- 广播:传送到网络上的所有主机(或子网)
示例应用程序在本章将说明使用 UDP 广播发送消息,可以接收到所有主机在同一网络。为此我们将使用特殊的“有限广播”或“零”网络地址255.255.255.255。消息发送到这个地址是规定要在本地网络(0.0.0.0)的所有主机和从不转发到其他网络通过路由器。
下一节将讨论示例应用程序的设计。
UDP 示例
我们的示例应用程序将打开一个文件,将每一行作为消息通过 UDP 发到指定的端口。如果你熟悉类 UNIX 操作系统,可以认为这是一个非常标准的简化版本 “syslog(系统日志)”。“UDP ,是一个完美的适合这样的应用程序,因为偶尔丢失一行日志文件可以被容忍,因为文件本身存储在文件系统中。此外,应用程序提供了非常有价值的能力有效地处理大量的数据。
UDP 广播使添加新事件“监视器”接收日志消息一样简单开始一个指定的端口上侦听器程序。然而,这种轻松的访问也提出了一个潜在的安全问题,指出为什么 UD P广播往往是在安全的环境中使用。还要注意广播消息可能只能在本地网络,因为路由器经常阻止他们。
Publish/Subscribe(发布/订阅)
应用程序,如 syslog 通常归类为“发布/订阅”;生产者或服务发布事件和多个订阅者可以收到它们。
整体看下这个应用,如下图:
- 应用监听新文件内容
- 事件通过 UDP 广播
- 事件监视器监听并显示内容
Figure 13.1 Application overview
应用程序有两个组件:广播器和监视器或(可能有多个实例)。为了简单起见我们不会添加身份验证、验证、加密。
在下一节中我们将开始探索实现中,我们还将讨论 UDP 和 TCP 应用程序开发之间的差异。
EventLog 的 POJO
在消息应用里面,数据一般以 POJO 形式呈现。这可能保存配置或处理信息除了实际的消息数据。在这个应用程序里,消息的单元是一个“事件”。由于数据来自一个日志文件,我们将称之为 LogEvent。
清单13.1显示了这个简单的POJO的细节。
Listing 13.1 LogEvent message
public final class LogEvent {
public static final byte SEPARATOR = (byte) ':';
private final InetSocketAddress source;
private final String logfile;
private final String msg;
private final long received;
public LogEvent(String logfile, String msg) { //1
this(null, -1, logfile, msg);
}
public LogEvent(InetSocketAddress source, long received, String logfile, String msg) { //2
this.source = source;
this.logfile = logfile;
this.msg = msg;
this.received = received;
}
public InetSocketAddress getSource() { //3
return source;
}
public String getLogfile() { //4
return logfile;
}
public String getMsg() { //5
return msg;
}
public long getReceivedTimestamp() { //6
return received;
}
}
- 构造器用于出站消息
- 构造器用于入站消息
- 返回发送 LogEvent 的 InetSocketAddress 的资源
- 返回用于发送 LogEvent 的日志文件的名称
- 返回消息的内容
- 返回 LogEvent 接收到的时间
写广播器
本节,我们将写一个广播器。下图展示了广播一个 DatagramPacket 在每个日志实体里面的方法
- 日志文件
- 日志文件中的日志实体
- 一个 DatagramPacket 保持一个单独的日志实体
Figure 13.2 Log entries sent with DatagramPackets
图13.3表示一个 LogEventBroadcaster 的 ChannelPipeline 的高级视图,说明了 LogEvent 是如何流转的。
Figure 13.3 LogEventBroadcaster: ChannelPipeline and LogEvent flow
正如我们所看到的,所有的数据传输都封装在 LogEvent 消息里。LogEventBroadcaster 写这些通过在本地端的管道,发送它们通过ChannelPipeline 转换(编码)为一个定制的 ChannelHandler 的DatagramPacket 信息。最后,他们通过 UDP 广播并被远程接收。
编码器和解码器
编码器和解码器将消息从一种格式转换为另一种,深度探讨在第7章中进行。我们探索 Netty 提供的基础类来简化和实现自定义 ChannelHandler 如 LogEventEncoder 在这个应用程序中。
下面展示了 编码器的实现
Listing 13.2 LogEventEncoder
public class LogEventEncoder extends MessageToMessageEncoder<LogEvent> {
private final InetSocketAddress remoteAddress;
public LogEventEncoder(InetSocketAddress remoteAddress) { //1
this.remoteAddress = remoteAddress;
}
@Override
protected void encode(ChannelHandlerContext channelHandlerContext, LogEvent logEvent, List<Object> out) throws Exception {
byte[] file = logEvent.getLogfile().getBytes(CharsetUtil.UTF_8); //2
byte[] msg = logEvent.getMsg().getBytes(CharsetUtil.UTF_8);
ByteBuf buf = channelHandlerContext.alloc().buffer(file.length + msg.length + 1);
buf.writeBytes(file);
buf.writeByte(LogEvent.SEPARATOR); //3
buf.writeBytes(msg); //4
out.add(new DatagramPacket(buf, remoteAddress)); //5
}
}
- LogEventEncoder 创建了 DatagramPacket 消息类发送到指定的 InetSocketAddress
- 写文件名到 ByteBuf
- 添加一个 SEPARATOR
- 写一个日志消息到 ByteBuf
- 添加新的 DatagramPacket 到出站消息
为什么使用 MessageToMessageEncoder?
当然我们可以编写自己的自定义 ChannelOutboundHandler 来转换 LogEvent 对象到 DatagramPackets。但是继承自MessageToMessageEncoder 为我们简化和做了大部分的工作。
为了实现 LogEventEncoder,我们只需要定义服务器的运行时配置,我们称之为“bootstrapping(引导)”。这包括设置各种 ChannelOption 并安装需要的 ChannelHandler 到 ChannelPipeline 中。完成的 LogEventBroadcaster 类,如清单13.3所示。
Listing 13.3 LogEventBroadcaster
public class LogEventBroadcaster {
private final Bootstrap bootstrap;
private final File file;
private final EventLoopGroup group;
public LogEventBroadcaster(InetSocketAddress address, File file) {
group = new NioEventLoopGroup();
bootstrap = new Bootstrap();
bootstrap.group(group)
.channel(NioDatagramChannel.class)
.option(ChannelOption.SO_BROADCAST, true)
.handler(new LogEventEncoder(address)); //1
this.file = file;
}
public void run() throws IOException {
Channel ch = bootstrap.bind(0).syncUninterruptibly().channel(); //2
System.out.println("LogEventBroadcaster running");
long pointer = 0;
for (;;) {
long len = file.length();
if (len < pointer) {
// file was reset
pointer = len; //3
} else if (len > pointer) {
// Content was added
RandomAccessFile raf = new RandomAccessFile(file, "r");
raf.seek(pointer); //4
String line;
while ((line = raf.readLine()) != null) {
ch.writeAndFlush(new LogEvent(null, -1, file.getAbsolutePath(), line)); //5
}
pointer = raf.getFilePointer(); //6
raf.close();
}
try {
Thread.sleep(1000); //7
} catch (InterruptedException e) {
Thread.interrupted();
break;
}
}
}
public void stop() {
group.shutdownGracefully();
}
public static void main(String[] args) throws Exception {
if (args.length != 2) {
throw new IllegalArgumentException();
}
LogEventBroadcaster broadcaster = new LogEventBroadcaster(new InetSocketAddress("255.255.255.255",
Integer.parseInt(args[0])), new File(args[1])); //8
try {
broadcaster.run();
} finally {
broadcaster.stop();
}
}
}
- 引导 NioDatagramChannel 。为了使用广播,我们设置 SO_BROADCAST 的 socket 选项
- 绑定管道。注意当使用 Datagram Channel 时,是没有连接的
- 如果需要,可以设置文件的指针指向文件的最后字节
- 设置当前文件的指针,这样不会把旧的发出去
- 写一个 LogEvent 到管道用于保存文件名和文件实体。(我们期望每个日志实体是一行长度)
- 存储当前文件的位置,这样,我们可以稍后继续
- 睡 1 秒。如果其他中断退出循环就重新启动它。
- 构造一个新的实例 LogEventBroadcaster 并启动它
这就是程序的完整的第一部分。可以使用 “netcat” 程序查看程序的结果。在 UNIX/Linux 系统,可以使用 “nc”, 在 Windows 环境下,可以在 http://nmap.org/ncat找到
Netcat 是完美的第一个测试我们的应用程序;它只是监听指定的端口上接收并打印所有数据到标准输出。将其设置为在端口 9999 上监听 UDP 数据如下:
现在我们需要启动 LogEventBroadcaster。清单13.4显示了如何使用 mvn 编译和运行广播器。pom的配置。pom.xml 配置指向一个文件/var/log/syslog(假设是UNIX / Linux环境)和端口设置为 9999。文件中的条目将通过 UDP 广播到端口,在你开始 netcat 后打印到控制台。
Listing 13.4 Compile and start the LogEventBroadcaster
$ mvn clean package exec:exec -Pchapter13-LogEventBroadcaster
[INFO] Scanning for projects...
[INFO]
[INFO] --------------------------------------------------------------------
[INFO] Building netty-in-action 0.1-SNAPSHOT
[INFO] --------------------------------------------------------------------
...
...
[INFO]
[INFO] --- maven-jar-plugin:2.4:jar (default-jar) @ netty-in-action ---
[INFO] Building jar: /Users/norman/Documents/workspace-intellij/netty-in-actionprivate/
target/netty-in-action-0.1-SNAPSHOT.jar
[INFO]
[INFO] --- exec-maven-plugin:1.2.1:exec (default-cli) @ netty-in-action -
LogEventBroadcaster running
当调用 mvn 时,在系统属性中改变文件和端口值,指定你想要的。清单13.5 设置日志文件 到 /var/log/mail.log 和端口 8888。
Listing 13.5 Compile and start the LogEventBroadcaster
$ mvn clean package exec:exec -Pchapter13-LogEventBroadcaster /
-Dlogfile=/var/log/mail.log -Dport=8888 -....
....
[INFO]
[INFO] --- exec-maven-plugin:1.2.1:exec (default-cli) @ netty-in-action -
LogEventBroadcaster running
当看到 “LogEventBroadcaster running” 说明程序运行成功了。
netcat 只用于测试,但不适合生产环境中使用。
写监视器
这一节我们编写一个监视器:EventLogMonitor ,也就是用来接收事件的程序,用来代替 netcat 。EventLogMonitor 做下面事情:
- 接收 LogEventBroadcaster 广播的 UDP DatagramPacket
- 解码 LogEvent 消息
- 输出 LogEvent 消息
和之前一样,将实现自定义 ChannelHandler 的逻辑。图13.4描述了LogEventMonitor 的 ChannelPipeline 并表明了 LogEvent 的流经情况。
Figure 13.4 LogEventMonitor
图中显示我们的两个自定义 ChannelHandlers,LogEventDecoder 和 LogEventHandler。首先是负责将网络上接收到的 DatagramPacket 解码到 LogEvent 消息。清单13.6显示了实现。
Listing 13.6 LogEventDecoder
public class LogEventDecoder extends MessageToMessageDecoder<DatagramPacket> {
@Override
protected void decode(ChannelHandlerContext ctx, DatagramPacket datagramPacket, List<Object> out) throws Exception {
ByteBuf data = datagramPacket.content(); //1
int i = data.indexOf(0, data.readableBytes(), LogEvent.SEPARATOR); //2
String filename = data.slice(0, i).toString(CharsetUtil.UTF_8); //3
String logMsg = data.slice(i + 1, data.readableBytes()).toString(CharsetUtil.UTF_8); //4
LogEvent event = new LogEvent(datagramPacket.recipient(), System.currentTimeMillis(),
filename,logMsg); //5
out.add(event);
}
}
- 获取 DatagramPacket 中数据的引用
- 获取 SEPARATOR 的索引
- 从数据中读取文件名
- 读取数据中的日志消息
- 构造新的 LogEvent 对象并将其添加到列表中
第二个 ChannelHandler 将执行一些首先创建的 LogEvent 消息。在这种情况下,我们只会写入 system.out。在真实的应用程序可能用到一个单独的日志文件或放到数据库。
下面的清单显示了 LogEventHandler。
Listing 13.7 LogEventHandler
public class LogEventHandler extends SimpleChannelInboundHandler<LogEvent> { //1
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
cause.printStackTrace(); //2
ctx.close();
}
@Override
public void channelRead0(ChannelHandlerContext channelHandlerContext, LogEvent event) throws Exception {
StringBuilder builder = new StringBuilder(); //3
builder.append(event.getReceivedTimestamp());
builder.append(" [");
builder.append(event.getSource().toString());
builder.append("] [");
builder.append(event.getLogfile());
builder.append("] : ");
builder.append(event.getMsg());
System.out.println(builder.toString()); //4
}
}
- 继承 SimpleChannelInboundHandler 用于处理 LogEvent 消息
- 在异常时,输出消息并关闭 channel
- 建立一个 StringBuilder 并构建输出
- 打印出 LogEvent 的数据
LogEventHandler 打印出 LogEvent 的一个易读的格式,包括以下:
- 收到时间戳以毫秒为单位
- 发送方的 InetSocketAddress,包括IP地址和端口
- LogEvent 生成绝对文件名
- 实际的日志消息,代表在日志文件中一行
现在我们需要安装处理程序到 ChannelPipeline ,如图13.4所示。下一个清单显示了这是如何实现 LogEventMonitor 类的一部分。
Listing 13.8 LogEventMonitor
public class LogEventMonitor {
private final Bootstrap bootstrap;
private final EventLoopGroup group;
public LogEventMonitor(InetSocketAddress address) {
group = new NioEventLoopGroup();
bootstrap = new Bootstrap();
bootstrap.group(group) //1
.channel(NioDatagramChannel.class)
.option(ChannelOption.SO_BROADCAST, true)
.handler(new ChannelInitializer<Channel>() {
@Override
protected void initChannel(Channel channel) throws Exception {
ChannelPipeline pipeline = channel.pipeline();
pipeline.addLast(new LogEventDecoder()); //2
pipeline.addLast(new LogEventHandler());
}
}).localAddress(address);
}
public Channel bind() {
return bootstrap.bind().syncUninterruptibly().channel(); //3
}
public void stop() {
group.shutdownGracefully();
}
public static void main(String[] args) throws Exception {
if (args.length != 1) {
throw new IllegalArgumentException("Usage: LogEventMonitor <port>");
}
LogEventMonitor monitor = new LogEventMonitor(new InetSocketAddress(Integer.parseInt(args[0]))); //4
try {
Channel channel = monitor.bind();
System.out.println("LogEventMonitor running");
channel.closeFuture().await();
} finally {
monitor.stop();
}
}
}
- 引导 NioDatagramChannel。设置 SO_BROADCAST socket 选项。
- 添加 ChannelHandler 到 ChannelPipeline
- 绑定的通道。注意,在使用 DatagramChannel 是没有连接,因为这些 无连接
- 构建一个新的 LogEventMonitor
运行 LogEventBroadcaster 和 LogEventMonitor
如上所述,我们将使用 Maven 来运行应用程序。这一次你需要打开两个控制台窗口给每个项目。用 Ctrl-C 可以停止它。
首先我们将启动 LogEventBroadcaster 如清单13.4所示,除了已经构建项目以下命令即可(使用默认值):
$ mvn exec:exec -Pchapter13-LogEventBroadcaster
和之前一样,这将通过 UDP 广播日志消息。
现在,在一个新窗口,构建和启动 LogEventMonitor 接收和显示广播消息。
Listing 13.9 Compile and start the LogEventBroadcaster
$ mvn clean package exec:exec -Pchapter13-LogEventMonitor
[INFO] Scanning for projects...
[INFO]
[INFO] --------------------------------------------------------------------
[INFO] Building netty-in-action 0.1-SNAPSHOT
[INFO] --------------------------------------------------------------------
...
[INFO]
[INFO] --- maven-jar-plugin:2.4:jar (default-jar) @ netty-in-action ---
[INFO] Building jar: /Users/norman/Documents/workspace-intellij/netty-in-actionprivate/
target/netty-in-action-0.1-SNAPSHOT.jar
[INFO]
[INFO] --- exec-maven-plugin:1.2.1:exec (default-cli) @ netty-in-action ---
LogEventMonitor running
当看到 “LogEventMonitor running” 说明程序运行成功了。
控制台将显示任何事件被添加到日志文件中,如下所示。消息的格式是由LogEventHandler 创建。
Listing 13.10 LogEventMonitor output
1364217299382 [/192.168.0.38:63182] [/var/log/messages] : Mar 25 13:55:08 dev-linux
dhclient: DHCPREQUEST of 192.168.0.50 on eth2 to 192.168.0.254 port 67
1364217299382 [/192.168.0.38:63182] [/var/log/messages] : Mar 25 13:55:08 dev-linux
dhclient: DHCPACK of 192.168.0.50 from 192.168.0.254
1364217299382 [/192.168.0.38:63182] [/var/log/messages] : Mar 25 13:55:08 dev-linux
dhclient: bound to 192.168.0.50 -- renewal in 270 seconds.
1364217299382 [/192.168.0.38:63182] [[/var/log/messages] : Mar 25 13:59:38 dev-linux
dhclient: DHCPREQUEST of 192.168.0.50 on eth2 to 192.168.0.254 port 67
1364217299382 [/192.168.0.38:63182] [/[/var/log/messages] : Mar 25 13:59:38 dev-linux
dhclient: DHCPACK of 192.168.0.50 from 192.168.0.254
1364217299382 [/192.168.0.38:63182] [/var/log/messages] : Mar 25 13:59:38 dev-linux
dhclient: bound to 192.168.0.50 -- renewal in 259 seconds.
1364217299383 [/192.168.0.38:63182] [/var/log/messages] : Mar 25 14:03:57 dev-linux
dhclient: DHCPREQUEST of 192.168.0.50 on eth2 to 192.168.0.254 port 67
1364217299383 [/192.168.0.38:63182] [/var/log/messages] : Mar 25 14:03:57 dev-linux
dhclient: DHCPACK of 192.168.0.50 from 192.168.0.254
1364217299383 [/192.168.0.38:63182] [/var/log/messages] : Mar 25 14:03:57 dev-linux
dhclient: bound to 192.168.0.50 -- renewal in 285 seconds.
若你没有访问 UNIX syslog 的权限,可以创建 自定义的文件,手动填入内容。下面是 UNIX 命令用 touch 创建一个空文件
再次启动 LogEventBroadcaster,设置系统属性
$ mvn exec:exec -Pchapter13-LogEventBroadcaster -Dlogfile=~/mylog.log
当 LogEventBroadcaster 运行时,你可以手动的添加消息到文件来查看广播到 LogEventMonitor 控制台的内容。使用 echo 和输出的文件
$ echo ’Test log entry’ >> ~/mylog.log
你可以启动任意个监视器实例,他们都会收到相同的消息。
总结
本章提供了一个无连接的传输协议,如UDP的介绍。我们看到,在 Netty的您可以从 TCP 切换到 UDP 的同时使用相同的 API。您还了解了如何通过专门的 ChannelHandler 来组织处理逻辑。我们通过独立的解码器的逻辑来处理消息对象。
在下一章中我们将探讨用 Netty 实现可重用的编解码器。
8.13 - CH14-自定义编解码器
本章介绍:
本章讲述 Netty 中如何轻松实现定制的编解码器,由于 Netty 架构的灵活性,这些编解码器易于重用和测试。为了更容易实现,使用 Memcached 作为协议例子是因为它更方便我们实现。
Memcached 是来自 Memcached.org 的免费开源、高性能、分布式的内存对象缓存系统,其目的是加速动态 Web 应用程序的响应,减轻数据库负载;Memcache 实际上是一个以 key-value 存储任意数据的内存小块。可能有人会问“为什么使用 Memcached?”,因为 Memcached 协议非常简单,便于讲解。
编解码器的范围
我们将只实现 Memcached 协议的一个子集,这足够我们进行添加、检索、删除对象;在 Memcached 中是通过执行 SET,GET,DELETE 命令来实现的。Memcached 支持很多其他的命令,但我们只使用其中三个命令,简单的东西,我们才会理解的更清楚。
Memcached 有一个二进制和纯文本协议,它们都可以用来与 Memcached 服务器通信,使用什么类型的协议取决于服务器支持哪些协议。本章主要关注实现二进制协议,因为二进制在网络编程中最常用。
实现 Memcached 编解码器
当想要实现一个给定协议的编解码器,我们应该花一些事件来了解它的运作原理。通常情况下,协议本身都有一些详细的记录。在这里你会发现多少细节?幸运的是 Memcached 的二进制协议可以很好的扩展。
在 RFC 中有相应的规范,可以在 https://code.google.com/p/Memcached/wiki/MemcacheBinaryProtocol 找到 。
我们不会实现 Memcached 的所有命令,只会实现三种操作:SET,GET 和 DELETE。这样做事为了让事情变得简单。
Memcached 二进制协议
我们说,要实现 Memcached 的 GET, SET, 和 DELETE 操作。我们仅仅关注这些,但 memcached 协议有一个通用的结构,只有少数参数改变为了改变一个请求或响应的意义。这意味着您可以轻松地扩展实现添加其他命令。一般协议有 24 字节头用于请求和响应。这个头可以分解如下表14.1中。
Table 14.1 Sample Memcached header byte structure
| Field | Byte offset | Value |
|---|
| Magic | 0 | 0x80 用于请求 0x81 用于响应 |
| OpCode | 1 | 0x01…0x1A |
| Key length | 2 和 3 | 1…32,767 |
| Extra length | 4 | 0x00, x04, 或 0x08 |
| Data type | 5 | 0x00 |
| Reserved | 6 和 7 | 0x00 |
| Total body length | 8-11 | 所有 body 的长度 |
| Opaque | 12-15 | 任何带带符号的 32-bit 整数; 这个也包含在响应中,因此更容易将请求映射到响应。 |
| CAS | 16-23 | 数据版本检查 |
注意每个部分使用的字节数。这告诉你接下来你应该用什么数据类型。例如,如果字节的偏移量只是 byte 0,那么旧使用一个 Java byte来表示它;如果它是6和7(2字节),你使用一个Java short;如果它是 12-15(4字节),你使用一个Java int,等等。
- 请求(只有显示头)
- 响应
Figure 14.2 Real-world Memcached request and response headers
在图14.2中,高亮显示的第一部分代表请求打到 Memcached (只显示请求头),在这种情况下是告诉 Memcached 来 SET 键是“a”而值是“abc”。第部分是响应。
突出显示的部分中的每一行代表4个字节;因为有6行,这意味着请求头是由24个字节,正如我们之前说的。回顾表14.1中,您可以头在一个真正的请求中看到头文件中的信息。现在,这是所有你需要知道的关于 Memcached 二进制协议。在下一节中,我们需要看看多么我们可以开始制作 Netty 这些请求。
Netty 编码器和解码器
Netty 的是一个复杂和先进的框架,但它并不玄幻。当我们请求一些设置了 key 的给定值时,我们知道 Request 类的一个实例被创建来代表这个请求。但 Netty 并不知道 Request 对象是如何转成 Memcached 所期望的。Memcached 所期望的是字节序列;忽略使用的协议,数据在网络上传输永远是字节序列。
将 Request 对象转为 Memcached 所需的字节序列,Netty 需要用 MemcachedRequest 来编码成另外一种格式。这里所说的另外一种格式不单单是从对象转为字节,也可以是从对象转为对象,或者是从对象转为字符串等。编码器的内容可以详见第七章。
Netty 提供了一个抽象类称为 MessageToByteEncoder。它提供了一个抽象方法,将一条消息(在本例中我们 MemcachedRequest 对象)转为字节。你显示什么信息实现通过使用 Java 泛型可以处理;例如 , MessageToByteEncoder 说这个编码器要编码的对象类型是 MemcachedRequest
MessageToByteEncoder 和 Java 泛型
使用 MessageToByteEncoder 可以绑定特定的参数类型。如果你有多个不同的消息类型,在相同的编码器里,也可以使用MessageToByteEncoder,注意检查消息的类型即可
这也适用于解码器,除了解码器将一系列字节转换回一个对象。 这个 Netty 的提供了 ByteToMessageDecoder 类,而不是提供一个编码方法用来实现解码。在接下来的两个部分你看看如何实现一个 Memcached 解码器和编码器。在你做之前,应该意识到在使用 Netty 时,你不总是需要自己提供编码器和解码器。自所以现在这么做是因为 Netty 没有对 Memcached 内置支持。而 HTTP 以及其他标准的协议,Netty 已经是提供的了。
编码器和解码器
记住,编码器处理出站,而解码器处理入站。这基本上意味着编码器将编码数据,写入远端。解码器将从远端读取处理数据。重要的是要记住,出站和入站是两个不同的方向。
请注意,为了程序简单,我们的编码器和解码器不检查任何值的最大大小。在实际实现中你需要一些验证检查,如果检测到违反协议,则使用 EncoderException 或 DecoderException(或一个子类)。
实现 Memcached 编码器
本节我们将简要介绍编码器的实现。正如我们提到的,编码器负责编码消息为字节序列。这些字节可以通过网络发送到远端。为了发送请求,我们首先创建 MemcachedRequest 类,稍后编码器实现会编码为一系列字节。下面的清单显示了我们的 MemcachedRequest 类
Listing 14.1 Implementation of a Memcached request
public class MemcachedRequest { //1
private static final Random rand = new Random();
private final int magic = 0x80;//fixed so hard coded
private final byte opCode; //the operation e.g. set or get
private final String key; //the key to delete, get or set
private final int flags = 0xdeadbeef; //random
private final int expires; //0 = item never expires
private final String body; //if opCode is set, the value
private final int id = rand.nextInt(); //Opaque
private final long cas = 0; //data version check...not used
private final boolean hasExtras; //not all ops have extras
public MemcachedRequest(byte opcode, String key, String value) {
this.opCode = opcode;
this.key = key;
this.body = value == null ? "" : value;
this.expires = 0;
//only set command has extras in our example
hasExtras = opcode == Opcode.SET;
}
public MemcachedRequest(byte opCode, String key) {
this(opCode, key, null);
}
public int magic() { //2
return magic;
}
public int opCode() { //3
return opCode;
}
public String key() { //4
return key;
}
public int flags() { //5
return flags;
}
public int expires() { //6
return expires;
}
public String body() { //7
return body;
}
public int id() { //8
return id;
}
public long cas() { //9
return cas;
}
public boolean hasExtras() { //10
return hasExtras;
}
}
- 这个类将会发送请求到 Memcached server
- 幻数,它可以用来标记文件或者协议的格式
- opCode,反应了响应的操作已经创建了
- 执行操作的 key
- 使用的额外的 flag
- 表明到期时间
- body
- 请求的 id。这个id将在响应中回显。
- compare-and-check 的值
- 如果有额外的使用,将返回 true
你如果想实现 Memcached 的其余部分协议,你只需要将 client.op*(op* 任何新的操作添加)转换为其中一个方法请求。我们需要两个更多的支持类,在下一个清单所示
Listing 14.2 Possible Memcached operation codes and response statuses
public class Status {
public static final short NO_ERROR = 0x0000;
public static final short KEY_NOT_FOUND = 0x0001;
public static final short KEY_EXISTS = 0x0002;
public static final short VALUE_TOO_LARGE = 0x0003;
public static final short INVALID_ARGUMENTS = 0x0004;
public static final short ITEM_NOT_STORED = 0x0005;
public static final short INC_DEC_NON_NUM_VAL = 0x0006;
}
public class Opcode {
public static final byte GET = 0x00;
public static final byte SET = 0x01;
public static final byte DELETE = 0x04;
}
一个 Opcode 告诉 Memcached 要执行哪些操作。每个操作都由一个字节表示。同样的,当 Memcached 响应一个请求,响应头中包含两个字节代表响应状态。状态和 Opcode 类表示这些 Memcached 的构造。这些操作码可以使用当你构建一个新的 MemcachedRequest 指定哪个行动应该由它引发的。
但现在可以集中精力在编码器上:
Listing 14.3 MemcachedRequestEncoder implementation
public class MemcachedRequestEncoder extends
MessageToByteEncoder<MemcachedRequest> { //1
@Override
protected void encode(ChannelHandlerContext ctx, MemcachedRequest msg,
ByteBuf out) throws Exception { //2
byte[] key = msg.key().getBytes(CharsetUtil.UTF_8);
byte[] body = msg.body().getBytes(CharsetUtil.UTF_8);
//total size of the body = key size + content size + extras size //3
int bodySize = key.length + body.length + (msg.hasExtras() ? 8 : 0);
//write magic byte //4
out.writeByte(msg.magic());
//write opcode byte //5
out.writeByte(msg.opCode());
//write key length (2 byte) //6
out.writeShort(key.length); //key length is max 2 bytes i.e. a Java short //7
//write extras length (1 byte)
int extraSize = msg.hasExtras() ? 0x08 : 0x0;
out.writeByte(extraSize);
//byte is the data type, not currently implemented in Memcached but required //8
out.writeByte(0);
//next two bytes are reserved, not currently implemented but are required //9
out.writeShort(0);
//write total body length ( 4 bytes - 32 bit int) //10
out.writeInt(bodySize);
//write opaque ( 4 bytes) - a 32 bit int that is returned in the response //11
out.writeInt(msg.id());
//write CAS ( 8 bytes)
out.writeLong(msg.cas()); //24 byte header finishes with the CAS //12
if (msg.hasExtras()) {
//write extras (flags and expiry, 4 bytes each) - 8 bytes total //13
out.writeInt(msg.flags());
out.writeInt(msg.expires());
}
//write key //14
out.writeBytes(key);
//write value //15
out.writeBytes(body);
}
}
- 该类是负责编码 MemachedRequest 为一系列字节
- 转换的 key 和实际请求的 body 到字节数组
- 计算 body 大小
- 写幻数到 ByteBuf 字节
- 写 opCode 作为字节
- 写 key 长度z作为 short
- 编写额外的长度作为字节
- 写数据类型,这总是0,因为目前不是在 Memcached,但可用于使用 后来的版本
- 为保留字节写为 short ,后面的 Memcached 版本可能使用
- 写 body 的大小作为 long
- 写 opaque 作为 int
- 写 cas 作为 long。这个是头文件的最后部分,在 body 的开始
- 编写额外的 flag 和到期时间为 int
- 写 key
- 这个请求完成后 写 body。
总结,编码器 使用 Netty 的 ByteBuf 处理请求,编码 MemcachedRequest 成一套正确排序的字节。详细步骤为:
- 写幻数字节。
- 写 opcode 字节。
- 写 key 长度(2字节)。
- 写额外的长度(1字节)。
- 写数据类型(1字节)。
- 为保留字节写 null 字节(2字节)。
- 写 body 长度(4字节- 32位整数)。
- 写 opaque(4个字节,一个32位整数在响应中返回)。
- 写 CAS(8个字节)。
- 写 额外的(flag 和 到期,4字节)= 8个字节
- 写 key
- 写 值
无论你放入什么到输出缓冲区( 调用 ByteBuf) Netty 的将向服务器发送被写入请求。下一节将展示如何进行反向通过解码器工作。
实现 Memcached 编码器
将 MemcachedRequest 对象转为 字节序列,Memcached 仅需将字节转到响应对象返回即可。
先见一个 POJO:
Listing 14.7 Implementation of a MemcachedResponse
public class MemcachedResponse { //1
private final byte magic;
private final byte opCode;
private byte dataType;
private final short status;
private final int id;
private final long cas;
private final int flags;
private final int expires;
private final String key;
private final String data;
public MemcachedResponse(byte magic, byte opCode,
byte dataType, short status,
int id, long cas,
int flags, int expires, String key, String data) {
this.magic = magic;
this.opCode = opCode;
this.dataType = dataType;
this.status = status;
this.id = id;
this.cas = cas;
this.flags = flags;
this.expires = expires;
this.key = key;
this.data = data;
}
public byte magic() { //2
return magic;
}
public byte opCode() { //3
return opCode;
}
public byte dataType() { //4
return dataType;
}
public short status() { //5
return status;
}
public int id() { //6
return id;
}
public long cas() { //7
return cas;
}
public int flags() { //8
return flags;
}
public int expires() { //9
return expires;
}
public String key() { //10
return key;
}
public String data() { //11
return data;
}
}
- 该类,代表从 Memcached 服务器返回的响应
- 幻数
- opCode,这反映了创建操作的响应
- 数据类型,这表明这个是基于二进制还是文本
- 响应的状态,这表明如果请求是成功的
- 惟一的 id
- compare-and-set 值
- 使用额外的 flag
- 表示该值存储的一个有效期
- 响应创建的 key
- 实际数据
下面为 MemcachedResponseDecoder, 使用了 ByteToMessageDecoder 基类,用于将 字节序列转为 MemcachedResponse
Listing 14.4 MemcachedResponseDecoder class
public class MemcachedResponseDecoder extends ByteToMessageDecoder { //1
private enum State { //2
Header,
Body
}
private State state = State.Header;
private int totalBodySize;
private byte magic;
private byte opCode;
private short keyLength;
private byte extraLength;
private short status;
private int id;
private long cas;
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in,
List<Object> out) {
switch (state) { //3
case Header:
if (in.readableBytes() < 24) {
return;//response header is 24 bytes //4
}
magic = in.readByte(); //5
opCode = in.readByte();
keyLength = in.readShort();
extraLength = in.readByte();
in.skipBytes(1);
status = in.readShort();
totalBodySize = in.readInt();
id = in.readInt(); //referred to in the protocol spec as opaque
cas = in.readLong();
state = State.Body;
case Body:
if (in.readableBytes() < totalBodySize) {
return; //until we have the entire payload return //6
}
int flags = 0, expires = 0;
int actualBodySize = totalBodySize;
if (extraLength > 0) { //7
flags = in.readInt();
actualBodySize -= 4;
}
if (extraLength > 4) { //8
expires = in.readInt();
actualBodySize -= 4;
}
String key = "";
if (keyLength > 0) { //9
ByteBuf keyBytes = in.readBytes(keyLength);
key = keyBytes.toString(CharsetUtil.UTF_8);
actualBodySize -= keyLength;
}
ByteBuf body = in.readBytes(actualBodySize); //10
String data = body.toString(CharsetUtil.UTF_8);
out.add(new MemcachedResponse( //1
magic,
opCode,
status,
id,
cas,
flags,
expires,
key,
data
));
state = State.Header;
}
}
}
- 类负责创建的 MemcachedResponse 读取字节
- 代表当前解析状态,这意味着我们需要解析的头或 body
- 根据解析状态切换
- 如果不是至少24个字节是可读的,它不可能读整个头部,所以返回这里,等待再通知一次数据准备阅读
- 阅读所有头的字段
- 检查是否足够的数据是可读用来读取完整的响应的 body。长度是从头读取
- 检查如果有任何额外的 flag 用于读,如果是这样做
- 检查如果响应包含一个 expire 字段,有就读它
- 检查响应是否包含一个 key ,有就读它
- 读实际的 body 的 payload
- 从前面读取字段和数据构造一个新的 MemachedResponse
所以在实现发生了什么事?我们知道一个 Memcached 响应有24位头;我们不知道是否所有数据,响应将被包含在输入 ByteBuf ,当解码方法调用时。这是因为底层网络堆栈可能将数据分解成块。所以确保我们只解码当我们有足够的数据,这段代码检查是否可用可读的字节的数量至少是24。一旦我们有24个字节,我们可以确定整个消息有多大,因为这个信息包含在24位头。
当我们解码整个消息,我们创建一个 MemcachedResponse 并将其添加到输出列表。任何对象添加到该列表将被转发到下一个ChannelInboundHandler 在 ChannelPipeline,因此允许处理。
测试编解码器
编码器和解码器完成,但仍有一些缺失:测试。
没有测试你只看到如果编解码器工作对一些真正的服务器运行时,这并不是你应该是依靠什么。第十章所示,为一个自定义编写测试 ChannelHandler通常是通过 EmbeddedChannel。
所以这正是现在做测试我们定制的编解码器,其中包括一个编码器和解码器。让重新开始编码器。后面的清单显示了简单的编写单元测试。
Listing 14.5 MemcachedRequestEncoderTest class
public class MemcachedRequestEncoderTest {
@Test
public void testMemcachedRequestEncoder() {
MemcachedRequest request = new MemcachedRequest(Opcode.SET, "key1", "value1"); //1
EmbeddedChannel channel = new EmbeddedChannel(new MemcachedRequestEncoder()); //2
channel.writeOutbound(request); //3
ByteBuf encoded = (ByteBuf) channel.readOutbound();
Assert.assertNotNull(encoded); //4
Assert.assertEquals(request.magic(), encoded.readUnsignedByte()); //5
Assert.assertEquals(request.opCode(), encoded.readByte()); //6
Assert.assertEquals(4, encoded.readShort());//7
Assert.assertEquals((byte) 0x08, encoded.readByte()); //8
Assert.assertEquals((byte) 0, encoded.readByte());//9
Assert.assertEquals(0, encoded.readShort());//10
Assert.assertEquals(4 + 6 + 8, encoded.readInt());//11
Assert.assertEquals(request.id(), encoded.readInt());//12
Assert.assertEquals(request.cas(), encoded.readLong());//13
Assert.assertEquals(request.flags(), encoded.readInt()); //14
Assert.assertEquals(request.expires(), encoded.readInt()); //15
byte[] data = new byte[encoded.readableBytes()]; //16
encoded.readBytes(data);
Assert.assertArrayEquals((request.key() + request.body()).getBytes(CharsetUtil.UTF_8), data);
Assert.assertFalse(encoded.isReadable()); //17
Assert.assertFalse(channel.finish());
Assert.assertNull(channel.readInbound());
}
}
- 新建 MemcachedRequest 用于编码为 ByteBuf
- 新建 EmbeddedChannel 用于保持 MemcachedRequestEncoder 到测试
- 写请求到 channel 并且判断是否产生了编码的消息
- 检查 ByteBuf 是否 null
- 判断 magic 是否正确写入 ByteBuf
- 判断 opCode (SET) 是否写入正确
- 检查 key 是否写入长度正确
- 检查写入的请求是否额外包含
- 检查数据类型是否写
- 检查是否保留数据插入
- 检查 body 的整体大小 计算方式是 key.length + body.length + extras
- 检查是否正确写入 id
- 检查是否正确写入 Compare and Swap (CAS)
- 检查是否正确的 flag
- 检查是否正确设置到期时间的
- 检查 key 和 body 是否正确
- 检查是否可读
Listing 14.6 MemcachedResponseDecoderTest class
public class MemcachedResponseDecoderTest {
@Test
public void testMemcachedResponseDecoder() {
EmbeddedChannel channel = new EmbeddedChannel(new MemcachedResponseDecoder()); //1
byte magic = 1;
byte opCode = Opcode.SET;
byte[] key = "Key1".getBytes(CharsetUtil.US_ASCII);
byte[] body = "Value".getBytes(CharsetUtil.US_ASCII);
int id = (int) System.currentTimeMillis();
long cas = System.currentTimeMillis();
ByteBuf buffer = Unpooled.buffer(); //2
buffer.writeByte(magic);
buffer.writeByte(opCode);
buffer.writeShort(key.length);
buffer.writeByte(0);
buffer.writeByte(0);
buffer.writeShort(Status.KEY_EXISTS);
buffer.writeInt(body.length + key.length);
buffer.writeInt(id);
buffer.writeLong(cas);
buffer.writeBytes(key);
buffer.writeBytes(body);
Assert.assertTrue(channel.writeInbound(buffer)); //3
MemcachedResponse response = (MemcachedResponse) channel.readInbound();
assertResponse(response, magic, opCode, Status.KEY_EXISTS, 0, 0, id, cas, key, body);//4
}
@Test
public void testMemcachedResponseDecoderFragments() {
EmbeddedChannel channel = new EmbeddedChannel(new MemcachedResponseDecoder()); //5
byte magic = 1;
byte opCode = Opcode.SET;
byte[] key = "Key1".getBytes(CharsetUtil.US_ASCII);
byte[] body = "Value".getBytes(CharsetUtil.US_ASCII);
int id = (int) System.currentTimeMillis();
long cas = System.currentTimeMillis();
ByteBuf buffer = Unpooled.buffer(); //6
buffer.writeByte(magic);
buffer.writeByte(opCode);
buffer.writeShort(key.length);
buffer.writeByte(0);
buffer.writeByte(0);
buffer.writeShort(Status.KEY_EXISTS);
buffer.writeInt(body.length + key.length);
buffer.writeInt(id);
buffer.writeLong(cas);
buffer.writeBytes(key);
buffer.writeBytes(body);
ByteBuf fragment1 = buffer.readBytes(8); //7
ByteBuf fragment2 = buffer.readBytes(24);
ByteBuf fragment3 = buffer;
Assert.assertFalse(channel.writeInbound(fragment1)); //8
Assert.assertFalse(channel.writeInbound(fragment2)); //9
Assert.assertTrue(channel.writeInbound(fragment3)); //10
MemcachedResponse response = (MemcachedResponse) channel.readInbound();
assertResponse(response, magic, opCode, Status.KEY_EXISTS, 0, 0, id, cas, key, body);//11
}
private static void assertResponse(MemcachedResponse response, byte magic, byte opCode, short status, int expires, int flags, int id, long cas, byte[] key, byte[] body) {
Assert.assertEquals(magic, response.magic());
Assert.assertArrayEquals(key, response.key().getBytes(CharsetUtil.US_ASCII));
Assert.assertEquals(opCode, response.opCode());
Assert.assertEquals(status, response.status());
Assert.assertEquals(cas, response.cas());
Assert.assertEquals(expires, response.expires());
Assert.assertEquals(flags, response.flags());
Assert.assertArrayEquals(body, response.data().getBytes(CharsetUtil.US_ASCII));
Assert.assertEquals(id, response.id());
}
}
- 新建 EmbeddedChannel ,持有 MemcachedResponseDecoder 到测试
- 创建一个新的 Buffer 并写入数据,与二进制协议的结构相匹配
- 写缓冲区到 EmbeddedChannel 和检查是否一个新的MemcachedResponse 创建由声明返回值
- 判断 MemcachedResponse 和预期的值
- 创建一个新的 EmbeddedChannel 持有 MemcachedResponseDecoder 到测试
- 创建一个新的 Buffer 和写入数据的二进制协议的结构相匹配
- 缓冲分割成三个片段
- 写的第一个片段 EmbeddedChannel 并检查,没有新的MemcachedResponse 创建,因为并不是所有的数据都是准备好了
- 写第二个片段 EmbeddedChannel 和检查,没有新的MemcachedResponse 创建,因为并不是所有的数据都是准备好了
- 写最后一段到 EmbeddedChannel 和检查新的 MemcachedResponse 是否创建,因为我们终于收到所有数据
- 判断 MemcachedResponse 与预期的值
总结
阅读本章后,您应该能够创建自己的编解码器针对你最喜欢的协议。这包括写编码器和解码器,从字节转换为你的 POJO,反之亦然。这一章展示了如何使用一个协议规范实现和提取所需的信息。
它还向您展示了如何编写单元测试完成你的工作的编码器和解码器,确保一切工作如预期而不需要一个完整的 Memcached 服务器运行。这允许轻松集成测试到构建系统的中。
8.14 - CH15-EventLoop 与线程模型
本章介绍
- 线程模型的总览
- EventLoop
- 并发
- 任务执行
- 任务调度
线程模型定义了应用或者框架如何执行你的代码,所以选择线程模型极其重要。Netty 提供了一个简单强大的线程模型来帮助我们简化代码。所有 ChannelHandler,包括业务逻辑,都保证由一个 Thread 同时执行特定的 Channel。这并不意味着Netty不能使用多线程,只是 Netty 限制每个Channel 都由一个 Thread 处理,这种设计适用于非阻塞 IO 操作。
读完本章就会深刻理解 Netty 的线程模型以及 Nett y团队为什么会选择这样的线程模型,这些信息可以让我们在使用 Netty 时让程序由最好的性能。此外,Netty 提供的线程模型还可以让我们编写整洁简单的代码,以保持代码的整洁性;我们还会学习 Netty 团队的经验,过去使用其他的线程模型,现在我们将使用 Netty 提供的更容易更强大的线程模型来开发。
本章假设如下:
- 你明白线程是什么以及如何使用,并有使用线程的工作经验。若不是这样,就请花些时间来了解清楚这些知识。推荐一本书:《Java Concurrency in Practice(Java 并发编程实战)》(Brian Goetz)。
- 你了解多线程应用程序及其设计,也包括如何保证线程安全和获取最佳性能。
线程模型的总览
本节将简单介绍一般的线程模型,Netty 中如何使用指定的线程模型,以及Netty 过去不同的版本中使用的线程模型。你会更好的理解不同的线程模型的所有利弊。
一个线程模型指定代码执行,给开发人员如何执行他们代码的信息。这很重要,因为它允许开发人员事先知道如何保护他们的代码免受并发执行的副作用。若没有这个知识背景,即使是最好的开发人员都只能是碰运气,希望到最后都能这么幸运,但这几乎是不可能的。进入更多的细节之前,提供一个更好的理解主题的回顾这些天大多数应用程序做什么。
大多数现代应用程序使用多个线程调度工作,因此让应用程序使用所有可用的系统资源以有效的方式。这使得很多有意义,因为大部分硬件有不止一个甚至多个CPU核心。如果一切都只有一个 Thread 执行,不可能完全使用所提供的资源。为了解决这个问题,许多应用程序执行多个 Thread 的运行代码。在早期的 Java,这样做是通过简单地按需创建新 Thread 时,并行工作需要做。
但很快就发现,这不是完美的,因为创建 Thread 和回收会给他们带来的开销。在 Java 5 中,我们终于有了所谓的线程池,经常缓存 Thread,用来消除创建和回收 Thread 的开销。这些池由 Executor 接口提供。Java 5 提供了许多有用的实现,在其内部发生显著的变化,但思想都一脉相承的。创建 Thread 和重用他们提交一个任务时执行。这可以帮助创建和回收线程的开销降到最低。
下图显示使用一个线程池执行一个任务,提交一个任务后会使用线程池中空闲的线程来执行,完成任务后释放线程并将线程重新放回线程池:
- Runnable 表示要执行的任务。这可能是任何东西,从一个数据库调用文件系统清理。
- 之前 runnable 移交到线程池。
- 闲置的线程被用来执行任务。当一个线程运行结束之后,它将回到闲置线程的列表新任务需要运行时被重用。
- 线程执行任务
Figure 15.1 Executor execution logic
这个修复 Thread 创建和回收的开销,不需要每个新任务创建和销毁新的 Thread 。
但使用多个 Thread 提供了资源和管理成本,作为一个副作用,引入了太多的上下文切换。这种会随着运行的线程的数量和任务执行的数量的增加而恶化。尽管使用多个线程在开始时似乎不是一个问题,但一旦你把真正工作负载放在系统上,可以会遭受到重击。
除了这些技术的限制和问题,其他问题可能发生在相关的维护应用程序/框架在未来或在项目的生命周期里。有效地说,增加应用程序的复杂性取决于对比。当状态简单时,写一个多线程应用程序是一个辛苦的工作!你能解决这个问题吗?在实际的场景中需要多个 Thread 规模;这是一个事实。让我们看看 Netty 是解决这个问题。
EventLoop
事件循环所做的正如它的名字所说的。它运行在一个循环里,直到它的终止。这符合网络框架的设计,因为他们需要在一个循环为一个特定的连接运行事件。这不是 Netty 发明新的东西;其他框架和实现已经这样做了。
下面的清单显示了典型的 EventLoop 逻辑。请注意这是为了更好的说明这个想法而不是单单展示 Netty 实现本身。
Listing 14.1 Execute task in EventLoop
while (!terminated) {
List<Runnable> readyEvents = blockUntilEventsReady(); //1
for (Runnable ev: readyEvents) {
ev.run(); //2
}
}
- 阻塞直到事件可以运行
- 循环所有事件,并运行他们
在 Netty 中使用 EventLoop 接口代表事件循环,EventLoop 是从EventExecutor 和 ScheduledExecutorService 扩展而来,所以可以将任务直接交给 EventLoop 执行。类关系图如下:
Figure 15.2 EventLoop class hierarchy
EventLoop 是完全由一个 Thread,从未改变。为了更合理利用资源,根据配置和可用的内核, Netty 可以使用多个 EventLoop。
事件/任务执行顺序
一个重要的细节关于事件和任务的执行顺序是,事件/任务执行顺序按照FIFO(先进先出)。这是必要的,因为否则事件不能按顺序处理,所处理的字节将不能保证正确的顺序。这将导致问题,所以这个不是所允许的设计。
Netty 4 中的 I/O 和事件处理
Netty 使用 I/O 事件,b被各种 I/O 操作运输本身所触发。 这些 I/O 操作,例如网络 API 的一部分,由Java 和底层操作系统提供。
一个区别在于,一些操作(或者事件)是由 Netty 的本身的传输实现触发的,一些是由用户自己。例如读事件通常是由传输本身在读取一些数据时触发。相比之下,写事件通常是由用户本身,例如,当调用 Channel.write(…)。
究竟需要做一次处理一个事件取决于事件的性质。经常会读网络栈的数据转移到您的应用程序。有时它会在另一个方向做同样的事情,例如,把数据从应用程序到网络堆栈(内核)发送到它的远端。但不限于这种类型的事务;重要的是,所使用的逻辑是通用的,灵活地处理各种各样的用例。
I/O 和事件处理的一个重要的事情在 Netty 4,是每一个 I/O 操作和事件总是由 EventLoop 本身处理,以及分配给 EventLoop 的 Thread。
我们应该注意,Netty 不总是使用我们描述的线程模型(通过 EventLoop 抽象)。在下一节中,你会了解 Netty 3 中使用的线程模型。这将帮助你理解为什么现在用新的线程模型以及为什么使用取代了 Netty 3 中仍然使用的旧模式。
Netty 3 中的 I/O 操作
在以前的版本中,线程模型是不同的。Netty 保证只将入站(以前称为 upstream)事件在执行 I/O Thread 执行 (I/O Thread 现在在 Netty 4 叫 EventLoop )。所有的出站(以前称为 downstream)事件被调用Thread 处理,这可能是 I/O Thread 也可以能是其他 Thread。 这听起来像一个好主意,但原来是容易出错,因为处理 ChannelHandler需要小心的出站事件同步,因为它没有保证只有一个线程运行在同一时间。这可能会发生如果你触发 downstream 事件同时在一个管道时;例如,您 调用 Channel.write(..) 在不同的线程。
除了需要负担同步 ChannelHandler,这个线程模型的另一个问题是你可能需要去掉一个入站事件作为一个出站事件的结果,例如 Channel.write(..) 操作导致异常。在这种情况下,exceptionCaught 必须生成并抛出去。乍看之下这不像是一个问题,但我们知道, exceptionCaught 由入站事件涉及,会让你知道问题出在哪里。问题是,事实上,你现在的情况是在调用 Thread 上执行,但 exceptionCaught 事件必须交给工作线程来执行,这样上下文切换是必须的。
相比之下,Netty 4 新线程模型根本没有这些问题,因为一切都在同一个EventLoop 在同一 Thread 中 执行。这消除了需要同步ChannelHandler ,并且使它更容易为用户理解执行。
现在你知道 EventLoop 如何执行任务,它的时间来快速浏览下 Netty 的各种内部功能。
Netty 线程模型的内部
Netty 的内部实现使其线程模型表现优异,它会检查正在执行的 Thread 是否是已分配给实际 Channel (和 EventLoop),在 Channel 的生命周期内,EventLoop 负责处理所有的事件。
如果 Thread 是相同的 EventLoop 中的一个,讨论的代码块被执行;如果线程不同,它安排一个任务并在一个内部队列后执行。通常是通过EventLoop 的 Channel 只执行一次下一个事件,这允许直接从任何线程与通道交互,同时还确保所有的 ChannelHandler 是线程安全,不需要担心并发访问问题。
下图显示在 EventLoop 中调度任务执行逻辑,这适合 Netty 的线程模型:
- 应在 EventLoop 中执行的任务
- 任务传递到执行方法后,执行检查来检测调用线程是否是与分配给 EventLoop 是一样的
- 线程是一样的,说明你在 EventLoop 里,这意味着可以直接执行的任务
- 线程与 EventLoop 分配的不一样。当 EventLoop 事件执行时,队列的任务再次执行一次
15.5 EventLoop execution logic/flow
设计是非常重要的,以确保不要把任何长时间运行的任务放在执行队列中,因为长时间运行的任务会阻止其他在相同线程上执行的任务。这多少会影响整个系统依赖于 EventLoop 实现用于特殊传输的实现。
传输之间的切换在你的代码库中可能没有任何改变,重要的是:切勿阻塞 I/O 线程。如果你必须做阻塞调用(或执行需要长时间才能完成的任务),使用 EventExecutor。
下一节将讲解一个在应用程序中经常使用的功能,就是调度执行任务(定期执行)。Java对这个需求提供了解决方案,但 Netty 提供了几个更好的方案
调度任务执行
每隔一段时间需要调度任务执行,也许你想注册一个任务在客户端完成连接5分钟后执行,一个常见的用例是发送一个消息“你还活着?”到远端通,如果远端没有反应,则可以关闭通道(连接)和释放资源。
本节介绍使用强大的 EventLoop 实现任务调度,还会简单介绍 Java API的任务调度,以方便和 Netty 比较加深理解。
使用普通的 Java API 调度任务
在 Java 中使用 JDK 提供的 ScheduledExecutorService 实现任务调度。使用 Executors 提供的静态方法创建 ScheduledExecutorService,有如下方法
Table 15.1 java.util.concurrent.Executors-Static methods to create a ScheduledExecutorService
| 方法 | 描述 | |
|---|
| newScheduledThreadPool(int corePoolSize) newScheduledThreadPool(int corePoolSize,ThreadFactorythreadFactory) | | 创建一个新的 |
ScheduledThreadExecutorService 用于调度命令来延迟或者周期性的执行。 corePoolSize 用于计算线程的数量 newSingleThreadScheduledExecutor() newSingleThreadScheduledExecutor(ThreadFact orythreadFactory) | 新建一个 ScheduledThreadExecutorService 可以用于调度命令来延迟或者周期性的执行。它将使用一个线程来执行调度的任务
下面的 ScheduledExecutorService 调度任务 60 执行一次
Listing 15.4 Schedule task with a ScheduledExecutorService
ScheduledExecutorService executor = Executors
.newScheduledThreadPool(10); //1
ScheduledFuture<?> future = executor.schedule(
new Runnable() { //2
@Override
public void run() {
System.out.println("Now it is 60 seconds later"); //3
}
}, 60, TimeUnit.SECONDS); //4
// do something
//
executor.shutdown(); //5
- 新建 ScheduledExecutorService 使用10个线程
- 新建 runnable 调度执行
- 稍后运行
- 调度任务60秒后执行
- 关闭 ScheduledExecutorService 来释放任务完成的资源
使用 EventLoop 调度任务
使用 ScheduledExecutorService 工作的很好,但是有局限性,比如在一个额外的线程中执行任务。如果需要执行很多任务,资源使用就会很严重;对于像 Netty 这样的高性能的网络框架来说,严重的资源使用是不能接受的。Netty 对这个问题提供了很好的方法。
Netty 允许使用 EventLoop 调度任务分配到通道,如下面代码:
Listing 15.5 Schedule task with EventLoop
Channel ch = null; // Get reference to channel
ScheduledFuture<?> future = ch.eventLoop().schedule(
new Runnable() {
@Override
public void run() {
System.out.println("Now its 60 seconds later");
}
}, 60, TimeUnit.SECONDS);
- 新建 runnable 用于执行调度
- 稍后执行
- 调度任务60秒后运行
如果想任务每隔多少秒执行一次,看下面代码:
Listing 15.6 Schedule a fixed task with the EventLoop
Channel ch = null; // Get reference to channel
ScheduledFuture<?> future = ch.eventLoop().scheduleAtFixedRate(
new Runnable() {
@Override
public void run() {
System.out.println("Run every 60 seconds");
}
}, 60, 60, TimeUnit.SECONDS);
- 新建 runnable 用于执行调度
- 将运行直到 ScheduledFuture 被取消
- 调度任务60秒运行
取消操作,可以使用 ScheduledFuture 返回每个异步操作。 ScheduledFuture 提供一个方法用于取消一个调度了的任务或者检查它的状态。一个简单的取消操作如下:
ScheduledFuture<?> future = ch.eventLoop()
.scheduleAtFixedRate(..); //1
// Some other code that runs...
future.cancel(false); //2
- 调度任务并获取返回的 ScheduledFuture
- 取消任务,阻止它再次运行
调度的内部实现
Netty 内部实现其实是基于George Varghese 提出的 “Hashed and hierarchical timing wheels: Data structures to efficiently implement timer facility(散列和分层定时轮:数据结构有效实现定时器)”。这种实现只保证一个近似执行,也就是说任务的执行可能不是100%准确;在实践中,这已经被证明是一个可容忍的限制,不影响多数应用程序。所以,定时执行任务不可能100%准确的按时执行。
为了更好的理解它是如何工作,我们可以这样认为:
- 在指定的延迟时间后调度任务;
- 任务被插入到 EventLoop 的 Schedule-Task-Queue(调度任务队列);
- 如果任务需要马上执行,EventLoop 检查每个运行;
- 如果有一个任务要执行,EventLoop 将立刻执行它,并从队列中删除;
- EventLoop 等待下一次运行,从第4步开始一遍又一遍的重复。
因为这样的实现计划执行不可能100%正确,对于多数用例不可能100%准备的执行计划任务;在 Netty 中,这样的工作几乎没有资源开销。
但是如果需要更准确的执行呢?很容易,你需要使用ScheduledExecutorService 的另一个实现,这不是 Netty 的内容。记住,如果不遵循 Netty 的线程模型协议,你将需要自己同步并发访问。
I/O EventLoop/Thread 分配细节
Netty 的使用一个包含 EventLoop 的 EventLoopGroup 为 Channel 的 I/O 和事件服务。EventLoop 创建并分配方式不同基于传输的实现。异步实现使用只有少数 EventLoop(和 Threads)共享于 Channel 之间 。这允许最小线程数服务多个 Channel,不需要为他们每个人都有一个专门的 Thread。
图15.7显示了如何使用 EventLoopGroup。
.jpg)
- 所有的 EventLoop 由 EventLoopGroup 分配。这里它将使用三个EventLoop 实例
- 这个 EventLoop 处理所有分配给它管道的事件和任务。每个EventLoop 绑定到一个 Thread
- 管道绑定到 EventLoop,所以所有操作总是被同一个线程在 Channel 的生命周期执行。一个管道属于一个连接
Figure 15.7 Thread allocation for nonblocking transports (such as NIO and AIO)
如图所述,使用有 3个 EventLoop (每个都有一个 Thread ) EventLoopGroup 。EventLoop (同时也是 Thread )直接当 EventLoopGroup 创建时分配。这样保证资源是可以使用的
这三个 EventLoop 实例将会分配给每个新创建的 Channel。这是通过EventLoopGroup 实现,管理 EventLoop 实例。实际实现会照顾所有EventLoop 实例上均匀的创建 Channel (同样是不同的 Thread)。
一旦 Channel 是分配给一个 EventLoop,它将使用这个 EventLoop 在它的生命周期里和同样的线程。你可以,也应该,依靠这个,因为它可以确保你不需要担心同步(包括线程安全、可见性和同步)在你 ChannelHandler实现。
但是这也会影响使用 ThreadLocal,例如,经常使用的应用程序。因为一个EventLoop 通常影响多个 Channel,ThreadLocal 将相同的 Channel 分配给 EventLoop。因此,它适合状态跟踪等等。它仍然可以用于共享重或昂贵的对象之间的 Channel ,不再需要保持状态,因此它可以用于每个事件,而不需要依赖于先前 ThreadLocal 的状态。
EventLoop 和 Channel
我们应该注意,在 Netty 4 , Channel 可能从 EventLoop 注销稍后又从不同 EventLoop 注册。这个功能是不赞成,因为它在实践中没有很好的工作
语义跟其他传输略有不同,如 OIO(Old Blocking I/O)运输,可以看到如图14.8所示。
.jpg)
- 所有 EventLoop 从 EventLoopGroup 分配。每个新的 channel 将会获得新的 EventLoop
- EventLoop 分配给 channel 用于执行所有事件和任务
- Channel 绑定到 EventLoop。一个 channel 属于一个连接
Figure 15.8 Thread allocation of blocking transports (such as OIO)
你可能会注意到这里,一个 EventLoop (也是一个 Thread)创建每个 Channel。你可能被用来从开发网络应用程序是基于常规阻塞I/O在使用java.io.* 包。但即使语义变化在这种情况下,有一件事仍然是相同的:每个 I/O 通道将由一次只有一个线程来处理,这是一个线程增强 Channel 的 EventLoop。可以依靠这个硬性的规则,使 Netty 的框架很容易与其他网络框架进行比较。
总结
在这一章里,你知道 Netty 使用哪个线程模型。你学会了使用线程模型的优缺点以及当使用 Netty 它们如何简化你的生活。
除了学习的内部运作,您获得了洞察力,知道如何可以执行自己的任务在 EventLoop(I/O Thread) 和 Netty 一样。你学会了如何在一大堆任务中安排任务。您还了解了如何验证一个任务是否执行以及如何取消它。
你现在知道 Netty 使用的各个先前版本的线程模型,你获得了更多的背景信息知道为什么新线程模型是更强大的。
你对 Netty 的线程模型有了深入了解,从而帮助您最大限度地提高您的应用程序性能,同时最小化所需的代码。关于线程池和并发访问的更多信息,请参阅 Java Concurrency in Practice (Brian Goetz)。他的书将会给你一个更深层次的了解,即使是最复杂的应用程序必须处理多线程的用例场景。
8.15 -
type: docs
title: “CH03-Netty 总览”
linkTitle: “CH03-Netty 总览”
weight: 3
本章主要了解 Netty 的架构模型,核心组件包括:
- Bootstrap 和 ServerBootstrap
- Channel
- ChannelHandler
- ChannelPipeline
- EventLoop
- ChannelFuture
这个目标是提供一个深入研究的上下文,如果你有一个很好的把握它 组织原则,可以避免迷失。
快速浏览
下面枚举所有的 Netty 应用程序的基本构建模块,包括客户端和服务器。
BOOTSTRAP
Netty 应用程序通过设置 bootstrap(引导)类的开始,该类提供了一个 用于应用程序网络层配置的容器。
CHANNEL
底层网络传输 API 必须提供给应用 I/O操作的接口,如读,写,连接,绑定等等。对于我们来说,这是结构几乎总是会成为一个“socket”。 Netty 中的接口 Channel 定义了与 socket 丰富交互的操作集:bind, close, config, connect, isActive, isOpen, isWritable, read, write 等等。 Netty 提供大量的 Channel 实现来专门使用。这些包括 AbstractChannel,AbstractNioByteChannel,AbstractNioChannel,EmbeddedChannel, LocalServerChannel,NioSocketChannel 等等。
CHANNELHANDLER
ChannelHandler 支持很多协议,并且提供用于数据处理的容器。我们已经知道 ChannelHandler 由特定事件触发。 ChannelHandler 可专用于几乎所有的动作,包括将一个对象转为字节(或相反),执行过程中抛出的异常处理。
常用的一个接口是 ChannelInboundHandler,这个类型接收到入站事件(包括接收到的数据)可以处理应用程序逻辑。当你需要提供响应时,你也可以从 ChannelInboundHandler 冲刷数据。一句话,业务逻辑经常存活于一个或者多个 ChannelInboundHandler。
CHANNELPIPELINE
ChannelPipeline 提供了一个容器给 ChannelHandler 链并提供了一个API 用于管理沿着链入站和出站事件的流动。每个 Channel 都有自己的ChannelPipeline,当 Channel 创建时自动创建的。 ChannelHandler 是如何安装在 ChannelPipeline? 主要是实现了ChannelHandler 的抽象 ChannelInitializer。ChannelInitializer子类 通过 ServerBootstrap 进行注册。当它的方法 initChannel() 被调用时,这个对象将安装自定义的 ChannelHandler 集到 pipeline。当这个操作完成时,ChannelInitializer 子类则 从 ChannelPipeline 自动删除自身。
EVENTLOOP
EventLoop 用于处理 Channel 的 I/O 操作。一个单一的 EventLoop通常会处理多个 Channel 事件。一个 EventLoopGroup 可以含有多于一个的 EventLoop 和 提供了一种迭代用于检索清单中的下一个。
CHANNELFUTURE
Netty 所有的 I/O 操作都是异步。因为一个操作可能无法立即返回,我们需要有一种方法在以后确定它的结果。出于这个目的,Netty 提供了接口 ChannelFuture,它的 addListener 方法注册了一个 ChannelFutureListener ,当操作完成时,可以被通知(不管成功与否)。
更多关于 ChannelFuture
想想一个 ChannelFuture 对象作为一个未来执行操作结果的占位符。何时执行取决于几个因素,因此不可能预测与精确。但我们可以肯定的是,它会被执行。此外,所有的操作返回 ChannelFuture 对象和属于同一个 Channel 将在以正确的顺序被执行,在他们被调用后。
Channel, Event 和 I/O
Netty 是一个非阻塞、事件驱动的网络框架。Netty 实际上是使用 Threads(多线程)处理 I/O 事件,对于熟悉多线程编程的读者可能会需要关注同步代码。这样的方式不好,因为同步会影响程序的性能,Netty 的设计保证程序处理事件不会有同步。图 Figure 3.1 展示了,你不需要在 Channel 之间共享 ChannelHandler 实例的原因:
该图显示,一个 EventLoopGroup 具有一个或多个 EventLoop。想象 EventLoop 作为一个 Thread 给 Channel 执行工作。 (事实上,一个 EventLoop 是势必为它的生命周期一个线程。)
当创建一个 Channel,Netty 通过 一个单独的 EventLoop 实例来注册该 Channel(并同样是一个单独的 Thread)的通道的使用寿命。这就是为什么你的应用程序不需要同步 Netty 的 I/O操作;所有 Channel 的 I/O 始终用相同的线程来执行。
我们将在第15章进一步讨论 EventLoop 和 EventLoopGroup。
Bootstrapping
Bootstrapping(引导) 是 Netty 中配置程序的过程,当你需要连接客户端或服务器绑定指定端口时需要使用 Bootstrapping。
如前面所述,Bootstrapping 有两种类型,一种是用于客户端的Bootstrap,一种是用于服务端的ServerBootstrap。不管程序使用哪种协议,无论是创建一个客户端还是服务器都需要使用“引导”。
面向连接 vs. 无连接
请记住,这个讨论适用于 TCP 协议,它是“面向连接”的。这样协议保证该连接的端点之间的消息的有序输送。无连接协议发送的消息,无法保证顺序和成功性
两种 Bootstrapping 之间有一些相似之处,也有一些不同。Bootstrap 和 ServerBootstrap 之间的差异如下:
Table 3.1 Comparison of Bootstrap classes
| 分类 | Bootstrap | ServerBootstrap |
|---|
| 网络功能 | 连接到远程主机和端口 | 绑定本地端口 |
| EventLoopGroup 数量 | 1 | 2 |
Bootstrap用来连接远程主机,有1个EventLoopGroup
ServerBootstrap用来绑定本地端口,有2个EventLoopGroup
事件组(Groups),传输(transports)和处理程序(handlers)分别在本章后面讲述,我们在这里只讨论两种"引导"的差异(Bootstrap和ServerBootstrap)。第一个差异很明显,“ServerBootstrap”监听在服务器监听一个端口轮询客户端的“Bootstrap”或DatagramChannel是否连接服务器。通常需要调用“Bootstrap”类的connect()方法,但是也可以先调用bind()再调用connect()进行连接,之后使用的Channel包含在bind()返回的ChannelFuture中。
一个 ServerBootstrap 可以认为有2个 Channel 集合,第一个集合包含一个单例 ServerChannel,代表持有一个绑定了本地端口的 socket;第二集合包含所有创建的 Channel,处理服务器所接收到的客户端进来的连接。下图形象的描述了这种情况:
与 ServerChannel 相关 EventLoopGroup 分配一个 EventLoop 是 负责创建 Channels 用于传入的连接请求。一旦连接接受,第二个EventLoopGroup 分配一个 EventLoop 给它的 Channel。
ChannelHandler 和 ChannelPipeline
ChannelPipeline 是 ChannelHandler 链的容器。
在许多方面的 ChannelHandler 是在您的应用程序的核心,尽管有时它 可能并不明显。ChannelHandler 支持广泛的用途,使它难以界定。因此,最好是把它当作一个通用的容器,处理进来的事件(包括数据)并且通过ChannelPipeline。下图展示了 ChannelInboundHandler 和 ChannelOutboundHandler 继承自父接口 ChannelHandler。
Netty 中有两个方向的数据流,图3.4 显示的入站(ChannelInboundHandler)和出站(ChannelOutboundHandler)之间有一个明显的区别:若数据是从用户应用程序到远程主机则是“出站(outbound)”,相反若数据时从远程主机到用户应用程序则是“入站(inbound)”。
为了使数据从一端到达另一端,一个或多个 ChannelHandler 将以某种方式操作数据。这些 ChannelHandler 会在程序的“引导”阶段被添加ChannelPipeline中,并且被添加的顺序将决定处理数据的顺序。
图 3.4 同样展示了进站和出站的处理器都可以被安装在相同的 pipeline 。本例子中,如果消息或任何其他入站事件被读到,将从 pipeline 头部开始,传递到第一个 ChannelInboundHandler。该处理器可能会或可能不会实际修改数据,取决于其特定的功能,在这之后 该数据将被传递到链中的下一个 ChannelInboundHandler。最后,将数据 到达 pipeline 的尾部,此时所有处理结束。
数据的出站运动(即,数据被“写入”)在概念上是相同的。在这种情况下的数据从尾部流过 ChannelOutboundHandlers 的链,直到它到达头部。超过这点,出站数据将到达的网络传输,在这里显示为一个 socket。通常,这将触发一个写入操作。
更多 Inbound 、 Outbound Handler
一个事件可以通过使用 ChanneHandlerContext 被转发到下一个处理器中的当前链传递到每个方法。因为这是你通常想要的而不是 Netty 提供的抽象基类 ChannelInboundHandlerAdapter 和ChannelOutboundHandlerAdapter。 每个这些提供了一个方法的实现和简单地通过调用 ChannelHandlerContext 的方法来传递事件到下一个处理器。然后,您可以根据实际需求重写方法。
所以,如果出站和入站操作是不同的,当 ChannelPipeline 中有混合处理器时将发生什么?虽然入站和出站处理器都扩展了 ChannelHandler,Netty 的 ChannelInboundHandler 的实现 和 ChannelOutboundHandler 之间的是有区别的,从而保证数据传递只从一个处理器到下一个处理器保证正确的类型。
当 ChannelHandler 被添加到的 ChannelPipeline 它得到一个 ChannelHandlerContext,它代表一个 ChannelHandler 和 ChannelPipeline 之间的“绑定”。它通常是安全保存对此对象的引用,除了当协议中的使用的是不面向连接(例如,UDP)。而该对象可以被用来获得 底层 Channel,它主要是用来写出站数据。
还有,实际上,在 Netty 发送消息有两种方式。您可以直接写消息给 Channel 或写入 ChannelHandlerContext 对象。主要的区别是, 前一种方法会导致消息从 ChannelPipeline的尾部开始,而 后者导致消息从 ChannelPipeline 下一个处理器开始。
深入 ChannelHandler
正如我们之前所说,有很多不同类型的 ChannelHandler 。每个 ChannelHandler 做什么取决于其超类。 Netty 提供了一些默认的处理程序实现形式的“adapter(适配器)”类。这些旨在简化开发处理逻辑。我们已经看到,在 pipeline 中每个的 ChannelHandler 负责转发事件到链中的下一个处理器。这些适配器类(及其子类)会自动帮你实现,所以你只需要实现该特定的方法和事件。
为什么用适配器?
有几个适配器类,可以减少编写自定义 ChannelHandlers ,因为他们提供对应接口的所有方法的默认实现。(也有类似的适配器,用于创建编码器和解码器,这我们将在稍后讨论。)这些都是创建自定义处理器时,会经常调用的适配器:ChannelHandlerAdapter、ChannelInboundHandlerAdapter、ChannelOutboundHandlerAdapter、ChannelDuplexHandlerAdapter
下面解释下三个 ChannelHandler 的子类型:编码器、解码器以及 ChannelInboundHandlerAdapter 的子类SimpleChannelInboundHandler
编码器、解码器
当您发送或接收消息时,Netty 数据转换就发生了。入站消息将从字节转为一个Java对象;也就是说,“解码”。如果该消息是出站相反会发生:“编码”,从一个Java对象转为字节。其原因是简单的:网络数据是一系列字节,因此需要从那类型进行转换。
不同类型的抽象类用于提供编码器和解码器的,这取决于手头的任务。例如,应用程序可能并不需要马上将消息转为字节。相反,该消息将被转换 一些其他格式。一个编码器将仍然可以使用,但它也将衍生自不同的超类,
在一般情况下,基类将有一个名字类似 ByteToMessageDecoder 或 MessageToByteEncoder。在一种特殊类型的情况下,你可能会发现类似 ProtobufEncoder 和 ProtobufDecoder,用于支持谷歌的 protocol buffer。
严格地说,其他处理器可以做编码器和解码器能做的事。但正如适配器类简化创建通道处理器,所有的编码器/解码器适配器类 都实现自 ChannelInboundHandler 或 ChannelOutboundHandler。
对于入站数据,channelRead 方法/事件被覆盖。这种方法在每个消息从入站 Channel 读入时调用。该方法将调用特定解码器的“解码”方法,并将解码后的消息转发到管道中下个的 ChannelInboundHandler。
出站消息是类似的。编码器将消息转为字节,转发到下个的 ChannelOutboundHandler。
SimpleChannelHandler
也许最常见的处理器是接收到解码后的消息并应用一些业务逻辑到这些数据。要创建这样一个 ChannelHandler,你只需要扩展基类SimpleChannelInboundHandler 其中 T 是想要进行处理的类型。这样的处理器,你将覆盖基类的一个或多个方法,将获得被作为输入参数传递所有方法的 ChannelHandlerContext 的引用。
在这种类型的处理器方法中的最重要是 channelRead0(ChannelHandlerContext,T)。在这个调用中,T 是将要处理的消息。 你怎么做,完全取决于你,但无论如何你不能阻塞 I/O线程,因为这可能是不利于高性能。
阻塞操作
I/O 线程一定不能完全阻塞,因此禁止任何直接阻塞操作在你的 ChannelHandler, 有一种方法来实现这一要求。你可以指定一个 EventExecutorGroup 当添加 ChannelHandler 到ChannelPipeline。此 EventExecutorGroup 将用于获得EventExecutor,将执行所有的 ChannelHandler 的方法。这EventExecutor 将从 I/O 线程使用不同的线程,从而释放EventLoop。
总结
在本章中,我们提出了 Netty 的关键部件和概念的概述,以及他们是如何结合在一起的。许多下面的章节都致力于深入研究各个组件和概念,应该可以帮助你了解全貌。
下一章将探讨 Netty 并提供不同的传输,以及如何选择最适合您应用程序的传输。
10 - Thymeleaf
Thymeleaf Tutorials.
10.1 - CH01-介绍
什么是 Thymeleaf
Thymeleaf 是面向 Web 和独立环境的现代服务器端 Java 模板引擎,能够处理 HTML、XML、JavaScript、CSS 甚至纯文本。
Thymeleaf 的主要目标是提供一个优雅和高度可维护的创建模板的方式。 为了实现这一点,它建立在自然模板( Natural Templates)的概念上,将其逻辑注入到模板文件中,不会影响模板被用作设计原型。 这改善了设计的沟通,弥合了设计和开发团队之间的差距。
Thymeleaf 的设计从一开始就遵从 Web 标准,特别是 HTML5,这样就能创建完全符合验证的模板。
处理模版
Thymeleaf 能处理以下 6 种类型的模版,我们称之为模版模式(Template Mode):
- HTML
- XML
- TEXT
- JAVASCRIPT
- CSS
- RAW
其中包含有两种标记模板模式(HTML和XML),三种文本模板模式(TEXT、JAVASCRIPT和CSS)和一个无操作模板模式(RAW)。
HTML 模板模式将允许任何类型的 HTML输入,包括HTML5、HTML4和XHTML。将不执行验证或对格式进行严格检查,这样就能尽可能的将模板代码/结构进行输出。
XML 模板模式将允许XML输入。在这种情况下,代码预期格式是良好的——没有未关闭的标签,没有引用属性等,如果找到为符合格式要求,解析器将抛出异常。请注意,不会执行验证(针对DTD或XML架构)。
TEXT 模板模式将允许对非标记性质的模板使用特殊语法。此类模板的示例可能是文本电子邮件或模板文档。请注意,HTML或XML模板也可以作为TEXT处理,在这种情况下,它们将不会被解析为标记,并且每个标签DOCTYPE、注释等将被视为纯文本。
JAVASCRIPT 模板模式将允许在Thymeleaf应用程序中处理JavaScript文件。这意味着能够使用JavaScript文件中的模型数据与HTML文件中可以完成的方式相同,但可以使用特定于JavaScript的集成,例如专门的转义或自然脚本(natural scripting)。 JAVASCRIPT模板模式被认为是文本模式,因此使用与TEXT模板模式相同的特殊语法。
CSS 模板模式将允许处理涉及Thymeleaf应用程序的CSS文件。与JAVASCRIPT模式类似,CSS模板模式也是文本模式,并使用TEXT模板模式下的特殊处理语法。
RAW 模板模式根本不会处理模板。它用于将未经修改的资源(文件、URL响应等)插入正在处理的模板中。例如,HTML格式的外部不受控制的资源可以包含在应用程序模板中,安全地知道这些资源可能包含的任何Thymeleaf代码将不会被执行。
标准方言
Thymeleaf是一个非常可扩展的模板引擎,实际上它更像是一个模板引擎框架(template engine framework)),允许您定义和自定义您的模板。
将一些逻辑应用于标记工件(例如标签、某些文本、注释或只有占位符)的一个对象被称为处理器(processor)。方言(dialect)通常包括这些处理器的集合以及一些额外的工件。Thymeleaf 的核心库提供了一种称为标准方言(Standard Dialect)的方言,提供给用户开箱即用的功能。
当然,如果用户希望在利用库的高级功能的同时定义自己的处理逻辑,用户也可以创建自己的方言(甚至扩展标准的方言)。也可以将Thymeleaf配置为同时使用几种方言。
官方的 thymeleaf-spring3 和 thymeleaf-spring4 集成包都定义了一种称为“SpringStandard Dialect”的方言,与标准方言大致相同,但是对于 Spring 框架中的某些功能则更加友好,例如, 想通过使用Spring Expression Language 或 SpringEL 而不是 OGNL。所以如果你是一个Spring MVC用户,这里的所有东西都能够在你的Spring应用程序中使用。
标准方言的大多数处理器是属性处理器。这样,即使在处理之前,浏览器也可以正确地显示HTML模板文件,因为它们将简单地忽略其他属性。对比JSP,在浏览器中会直接显示的代码片断:
<form:inputText name="userName" value="${user.name}" />
Thymeleaf 标准方言将允许我们实现与以下功能相同的功能::
<input type="text" name="userName" value="James Carrot" th:value="${user.name}" />
浏览器不仅可以正确显示这些信息,而且还可以(可选地)在浏览器中静态打开原型时显示的值(可选地)指定一个值属性(在这种情况下为“James Carrot”),将在模板处理期间由${user.name}的计算得到的值代替。
这有助于您的设计师和开发人员处理相同的模板文件,并减少将静态原型转换为工作模板文件所需的工作量。这样的功能是称为 自然模板(Natural Templating) 的功能.
10.2 - CH02-使用文本
先看一个页面示例:
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>Good Thymes Virtual Grocery</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<link rel="stylesheet" type="text/css" media="all"
href="../../css/gtvg.css" th:href="@{/css/gtvg.css}" />
</head>
<body>
<p th:text="#{home.welcome}">Welcome to our grocery store!</p>
</body>
</html>
首先,注意到的这个文件是HTML5的,可以由任何浏览器正确显示,因为它不包含任何非HTML标签(浏览器会忽略他们所不能理解的属性,如 th:text)。
但是您也可能会注意到,这个模板并不是一个真正有效的HTML5文档,因为HTML5规范不允许在th:*形式中使用这些非标准属性。 事实上,我们甚至在我们的 <html> 标签中添加了一个xmlns:th 属性,这也不属于 HTML5 语言:
<html xmlns:th="http://www.thymeleaf.org">
它在模板处理中根本没有任何影响,但我们的 IDE 会提示诸如“缺少th:*属性命名空间定义”等字样的告警。
如果我们想让这些模板对于 HTML5 验证是有效的,需要做简单地修改,将属性语法,改为data-前缀,(:)改为 (-) 即可:
<!DOCTYPE html>
<html>
<head>
<title>Good Thymes Virtual Grocery</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<link rel="stylesheet" type="text/css" media="all"
href="../../css/gtvg.css" data-th-href="@{/css/gtvg.css}" />
</head>
<body>
<p data-th-text="#{home.welcome}">Welcome to our grocery store!</p>
</body>
</html>
这样,data-前缀就符合 HTML5 中的规范了。
注:在实际开发过程中,由于th:*的辨识度往往必data-th-*这种方式更高,所以很多人仍然是选择使用th:*,这也是可以理解的。本书的示例大多也是采用th:*方式。
使用 th:text 和外部化文本
外部化文本是从模板文件中提取模板代码的片段,以便它们可以保存在单独的文件(通常为 .properties 文件)中,并且可以轻松地替换为使用其他语言编写的等效文本(称为国际化或简单的i18n) 。文本的外部化片段通常称为“消息(messages)”。
消息总是具有标识它们的 key,而Thymeleaf允许您指定文本应与 #{...}语法对应的特定消息:
<p th:text="#{home.welcome}">Welcome to our grocery store!</p>
我们在这里可以看到的其实是Thymeleaf标准方言的两个不同功能:
th:text属性,它评估其值表达式并将结果设置为主机标签的主体,有效地替换了代码中我们看到的“Welcome to our grocery store!”文本。#{home.welcome}表达式指示 th:text 属性使用的文本应该是key 为home.welcome 所对应于的消息。
Thymeleaf中外部化文本的位置是完全可配置的,它将取决于正在使用的具体的 org.thymeleaf.messageresolver.IMessageResolver实现。通常,将使用基于 .properties文件的实现,但是如果我们想要(例如)从数据库获取消息,我们可以创建自己的实现。
但是,我们在初始化期间尚未为模板引擎指定消息解析器,这意味着我们的应用程序正在使用由org.thymeleaf.messageresolver.StandardMessageResolver实现的标准消息解析器。
标准消息解析器期望在 /WEB-INF/templates/home.html中找到与该模板相同的文件夹中的属性文件的消息,例如:
/WEB-INF/templates/home_en.properties 为英文文本/WEB-INF/templates/home_es.properties 西班牙语文本/WEB-INF/templates/home_pt_BR.properties葡萄牙语(巴西)语言/WEB-INF/templates/home.properties 为默认文本(如果语言环境不匹配)
我们来看看我们的 home_es.properties 文件:
home.welcome=¡Bienvenido a nuestra tienda de comestibles!
上下文
为了执行模版,我们创建了HomeController类,它实现了 IGTVGController 接口:
public class HomeController implements IGTVGController {
public void process(
final HttpServletRequest request, final HttpServletResponse response,
final ServletContext servletContext, final ITemplateEngine templateEngine)
throws Exception {
WebContext ctx =
new WebContext(request, response, servletContext, request.getLocale());
templateEngine.process("home", ctx, response.getWriter());
}
}
首先是 *上下文(context)*的创建。 Thymeleaf 上下文对象实现了 org.thymeleaf.context.IContext接口。上下文包含了执行模版引擎的所有数据变量 map,同时也引用了外部消息的区域设置。
public interface IContext {
public Locale getLocale();
public boolean containsVariable(final String name);
public Set<String> getVariableNames();
public Object getVariable(final String name);
}
这个接口有一个专门的扩展,org.thymeleaf.context.IWebContext,用于基于ServletAPI的Web应用程序(如SpringMVC)中。
public interface IWebContext extends IContext {
public HttpServletRequest getRequest();
public HttpServletResponse getResponse();
public HttpSession getSession();
public ServletContext getServletContext();
}
Thymeleaf 核心库提供了这些接口的每个实现:
org.thymeleaf.context.Context 实现了 IContextorg.thymeleaf.context.WebContext 实现了 IWebContext
而在控制器代码中可以看到,WebContext是我们使用的。 实际上我们必须,因为使用一个ServletContextTemplateResolver要求我们使用实现 IWebContext 的上下文。
WebContext ctx = new WebContext(request, response, servletContext, request.getLocale());
只需要这四个构造函数参数中的三个,因为如果没有指定,那么将使用系统的默认语言环境(尽管不应该在实际应用程序中发生)。
有一些专门的表达式,能够从我们的模板中的 WebContext 获取请求参数和请求、会话和应用程序属性。 例如:
${x} 将返回存储在Thymeleaf上下文中的变量 x 或作为 请求属性(request attribute)${param.x} 将返回一个名为 x的请求参数(request parameter)(可能是多值的)${session.x} 将返回一个名为 x的 会话属性(session attribute)${application.x} 将返回一个名为x的servlet上下文属性 (servlet context attribute)
执行模版引擎
随着我们的上下文对象准备就绪,现在我们可以告诉模板引擎使用上下文来处理模板(通过它的名字),并传递一个响应写入器,以便可以将响应写入它:
templateEngine.process("home", ctx, response.getWriter());
在西班牙环境下,输出如下 :
<!DOCTYPE html>
<html>
<head>
<title>Good Thymes Virtual Grocery</title>
<meta content="text/html; charset=UTF-8" http-equiv="Content-Type"/>
<link rel="stylesheet" type="text/css" media="all" href="/gtvg/css/gtvg.css" />
</head>
<body>
<p>¡Bienvenido a nuestra tienda de comestibles!</p>
</body>
</html>
非转义文本
如果我们的消息中包含特殊字符,比如html标签,如下
home.welcome=Welcome to our <b>fantastic</b> grocery store!
那么,执行模版,将会得到如下输出:
<p>Welcome to our <b>fantastic</b> grocery store!</p>
这是th:text 属性的默认行为。 但我们希望 Thymeleaf 能如实输出HTML标签,我们可以使用th:utext,即“unescaped text(非转义文本)”:
<p th:utext="#{home.welcome}">Welcome to our grocery store!</p>
这样就能输出符合我们预期的文本了:
<p>Welcome to our <b>fantastic</b> grocery store!</p>
使用和显示变量
我们控制器如下:
public void process(
final HttpServletRequest request, final HttpServletResponse response,
final ServletContext servletContext, final ITemplateEngine templateEngine)
throws Exception {
SimpleDateFormat dateFormat = new SimpleDateFormat("dd MMMM yyyy");
Calendar cal = Calendar.getInstance();
WebContext ctx =
new WebContext(request, response, servletContext, request.getLocale());
ctx.setVariable("today", dateFormat.format(cal.getTime()));
templateEngine.process("home", ctx, response.getWriter());
}
添加了一个名为 today 的String 变量到我们的上下文中,我们在模版中显示:
<body>
<p th:utext="#{home.welcome}">Welcome to our grocery store!</p>
<p>Today is: <span th:text="${today}">13 February 2011</span></p>
</body>
正如你所看到的,我们仍然使用th:text属性,但是这个时候语法有点不同,不是 #{...},我们使用 ${...}。 这是一个变量表达式,它包含一个名为OGNL(Object-Graph Navigation Language)的表达式。
${today} 表达式只是意味着“获取名为 today 的变量”,但是这些表达式可能可以更复杂(例如 ${user.name} 表示变量为 user的变量,调用其 getName() 方法。
10.3 - CH03-表达式
Thymeleaf 标准表达式( Standard Expression)语法,是 Thymeleaf 标准方言(Standard Dialect)的最重要组成部分之一。
标准表达式
Thymeleaf 提供了多种标准表达式包括:
- 简单表达式:
- Variable expressions(变量表达式)
${...} - Selection expressions(选择表达式)
*{...} - Message (i18n) expressions(消息表达式)
#{...} - Link (URL) expressions(链接表达式)
@{...} - Fragment expressions(片段表达式)
~{...}
- 字面量:
- 文本:
'one text'、'Another one!'等; - 数值:0、34、3.0、12.3 等;
- 布尔:true、false
- Null:null
- Literal token(字面标记): one、sometext、 main等;
- 文本操作:
- 字符串拼接:
+ - 文本替换:
|The name is ${name}|
- 算术操作:
- 二元运算符:
+、-、 *、/、% - 减号(单目运算符):
-
- 布尔操作:
- 二元运算符:
and、or - 布尔否定(一元运算符):
!、not
- 比较和等价:
- 比较:
>、<、>=、<=(gt、lt、ge、le) - 等价:
==、!=(eq、ne)
- 条件运算符:
- If-then:
(if) ? (then) - If-then-else:
(if) ? (then) : (else) - Default:
(value) ?: (defaultvalue)
- 特殊标记:
下面的这个示例,涵盖了上述大部分表达式:
'User is of type ' + (${user.isAdmin()} ? 'Administrator' : (${user.type}
消息表达式
消息表达式(通常称为文本外化、国际化或i18n)允许我们从外部源(.properties文件)检索特定于语言环境的消息,通过 key 引用它们(可选)应用一组参数。
在Spring应用程序中,这将自动与Spring的MessageSource机制集成。
#{main.title}
#{message.entrycreated(${entryId})}
在模版中的应用如下:
<table>
...
<th th:text="#{header.address.city}">...</th>
<th th:text="#{header.address.country}">...</th>
...
</table>
请注意,如果希望消息 key 由上下文变量的值确定,或者要将变量指定为参数,则可以在消息表达式中使用变量表达式:
#{${config.adminWelcomeKey}(${session.user.name})}
变量表达式
变量表达式可以是OGNL表达式或者是 Spring EL,如果集成了Spring的话,可以在上下文变量(context variables )中执行。
有关OGNL语法和功能的详细信息,请阅读OGNL语言指南 在 Spring MVC 启用的应用程序中,OGNL将被替换为SpringEL,但其语法与OGNL非常相似(实际上,在大多数常见情况下完全相同)。
在Spring术语中,变量表达式也称为模型属性(model attributes)。 他们看起来像这样:
他们作为属性值或作为属性的一部分:
<span th:text="${book.author.name}">
上面的表达式在在OGNL和SpringEL中等价于:
((Book)context.getVariable("book")).getAuthor().getName()
这些变量表达式不仅涉及输出,还包括更复杂的处理,如条件判断、迭代等:
<li th:each="book : ${books}">
这里${books}从上下文中选择名为books的变量,并将其评估为可在th:each循环中使用的迭代器(iterable)。
更多 OGNL 的功能有:
/*
* 使用点(.)来访问属性,等价于调用属性的 getter
*/
${person.father.name}
/*
* 访问属性也可以使用([])块
*/
${person['father']['name']}
/*
* 如果对象是一个map,则点和块语法等价于调用其get(...)方法
*/
${countriesByCode.ES}
${personsByName['Stephen Zucchini'].age}
/*
* 在块语法中,也可以通过索引来访问数组或者集合
*/
${personsArray[0].name}
/*
* 可以调用方法,同时也支持参数
*/
${person.createCompleteName()}
${person.createCompleteNameWithSeparator('-')}
表达式预设对象
当对上下文变量评估 OGNL 表达式时,某些对象可用于表达式以获得更高的灵活性。 这些对象将被引用(按照OGNL标准),以#符号开始:
#ctx:上下文对象。#vars:上下文变量。#locale:上下文区域设置。#request:HttpServletRequest 对象(仅在 Web 上下文中)。#response:HttpServletResponse 对象(仅在 Web 上下文中)。#session:HttpSession对象(仅在 Web 上下文中)。#servletContext:ServletContext对象(仅在 Web 上下文中)。
所以我们可以这样做:
Established locale country: <span th:text="${#locale.country}">US</span>.
完整内容可以参考后文[表达式基本对象]部分。
表达式工具对象
除了上面这些基本的对象之外,Thymeleaf 将为我们提供一组工具对象,这些对象将帮助我们在表达式中执行常见任务:
#execInfo: 模版执行的信息#messages: 在变量内获取外部消息的方法 表达式,与使用#{...}语法获得的方式相同。.#uris: 用于转义 URL/URI 部分的方法#conversions: 执行已配置的 conversion service#dates: java.util.Date对象的方法,比如格式化,组件提取等#calendars:类似于#dates,但是对应于java.util.Calendar对象#numbers: 格式化数字对象的方法。#strings: String对象的方法,包括 contains、startsWith、prepending/appending等 等等#objects: 对象通常的方法#bools: 布尔判断的方法#arrays: array 方法#lists: list 方法#sets: set 方法#maps: map 方法#aggregates:在数组或集合上创建聚合的方法#ids: 用于处理可能重复的id属性的方法(例如,作为迭代的结果)。
下面是一个格式化日期的例子:
<p>
Today is: <span th:text="${#calendars.format(today,'dd MMMM yyyy')}">13 May 2011</span>
</p>
完整内容可以参考后文[表达式工具对象]部分。
选择表达式
选择表达式与变量表达式很像,区别在于它们是在当前选择的对象而不是整个上下文变量映射上执行。 他们看起来像这样:
它们所作用的对象由th:object属性指定:
<div th:object="${book}">
...
<span th:text="*{title}">...</span>
...
</div>
这等价于:
{
// th:object="${book}"
final Book selection = (Book) context.getVariable("book");
// th:text="*{title}"
output(selection.getTitle());
}
链接表达式
链接表达式旨在构建 URL 并向其添加有用的上下文和会话信息(通常称为URL重写的过程)。
因此,对于部署在Web服务器的/myapp上下文中的Web应用程序,可以使用以下表达式:
<a th:href="@{/order/list}">...</a>
可以转成:
<a href="/myapp/order/list">...</a>
cookie没有启用下,如果我们需要保持会话,可以这样:
<a href="/myapp/order/list;jsessionid=23fa31abd41ea093">...</a>
URL 可以携带参数:
<a th:href="@{/order/details(id=${orderId},type=${orderType})}">...</a>
结果如下:
<!-- Note ampersands (&) should be HTML-escaped in tag attributes... -->
<a href="/myapp/order/details?id=23&type=online">...</a>
链接表达式可以是相对的,在这种情况下,应用程序上下文将不会作为URL的前缀:
<a th:href="@{../documents/report}">...</a>
也 可以是服务器相对(同样,没有应用程序上下文前缀):
<a th:href="@{~/contents/main}">...</a>
和协议相对(就像绝对URL,但浏览器将使用在显示的页面中使用的相同的HTTP或HTTPS协议):
<a th:href="@{//static.mycompany.com/res/initial}">...</a>
当然,Link表达式可以是绝对的:
<a th:href="@{http://www.mycompany.com/main}">...</a>
在绝对(或协议相对)的URL等里面,Thymeleaf链接表达式添加的是什么值? 答案是,可能是由响应过滤器定义的URL重写。在基于Servlet的Web应用程序中,对于每个输出的URL(上下文相对、相对、绝对…)Thymeleaf将总是调用HttpServletResponse.encodeUrl(…) 机制 在显示URL之前。 这意味着过滤器可以通过包装HttpServletResponse对象(通常使用的机制)来为应用程序执行定制的URL重写。
片段表达式
片段表达式是 3.x 版本新增的内容。
片段段表达式是一种表示标记片段并将其移动到模板周围的简单方法。 正是由于这些表达式,片段可以被复制,或者作为参数传递给其他模板等等。
最常见的用法是使用th:insert或th:replace:插入片段:
<div th:insert="~{commons :: main}">...</div>
但是它们可以在任何地方使用,就像任何其他变量一样:
<div th:with="frag=~{footer :: #main/text()}">
<p th:insert="${frag}">
</div>
片段表达式可以有参数。
字面量
本文
文本文字只是在单引号之间指定的字符串。 他们可以包含任何字符,但您应该避免其中的任何单引号使用\'。
<p>
Now you are looking at a <span th:text="'working web application'">template file</span>.
</p>
数字
数字文字就是数字。
<p>The year is <span th:text="2013">1492</span>.</p>
<p>In two years, it will be <span th:text="2013 + 2">1494</span>.</p>
布尔
布尔文字为“true”和“false”。 例如::
<div th:if="${user.isAdmin()} == false"> ...
在这个例子中,== false写在大括号之外,Thymeleaf 会做处理。如果是写在大括号内,那就是由 OGNL/SpringEL 引擎负责处理:
<div th:if="${user.isAdmin() == false}"> ...
null
null 字面量使用如下:
<div th:if="${variable.something} == null"> ...
字面量标记
数字、布尔和 null 字面实际上是*字面量标记(literal tokens)*的特殊情况。
这些标记允许在标准表达式中进行一点简化。 他们工作与文字文字('...')完全相同,但只允许使用字母(A-Z)和a-z'),数字(0-9),括号([和]),点(.),连字符(-) 和下划线(_`)。 所以没有空白,没有逗号等
标记不需任何引号。 所以我们可以这样做:
<div th:class="content">...</div>
用来代替:
<div th:class="'content'">...</div>
附加文本
无论是文字,还是评估变量或消息表达式的结果,都可以使用 + 操作符轻松地附加文本:
<span th:text="'The name of the user is ' + ${user.name}">
字面量替换
字面量替换允许容易地格式化包含变量值的字符串,而不需要使用 '...' + '...'附加文字。
这些替换必须被(|)包围,如:
<span th:text="|Welcome to our application, ${user.name}!|">
其等价于:
<span th:text="'Welcome to our application, ' + ${user.name} + '!'">
字面量替换可以与其他类型的表达式相结合:
<span th:text="${onevar} + ' ' + |${twovar}, ${threevar}|">
|...| 字面量替换只允许使用变量/消息表达式(${...}, *{...}, #{...}), 其他字面量 ('...')、布尔/数字标记、条件表达式等是不允许的
算术运算
支持算术运算:+, -, *, / 和 %。
<div th:with="isEven=(${prodStat.count} % 2 == 0)">
请注意,这些运算符也可以在OGNL变量表达式本身中应用(在这种情况下将由OGNL执行,而不是Thymeleaf标准表达式引擎):
<div th:with="isEven=${prodStat.count % 2 == 0}">
请注意,其中一些运算符存在文本别名:div (/)、 mod (%)。
比较与相等
表达式中的值可以与>, <, >= 和 <= 号进行比较,并且可以使用== 和 != 运算符来检查是否相等。 请注意, < 和 >符号不应该在XML属性值中使用,因此它们应被替换为< 和>。
<div th:if="${prodStat.count} > 1">
<span th:text="'Execution mode is ' + ( (${execMode} == 'dev')? 'Development' : 'Production')">
一个更简单的替代方案可能是使用一些这些运算符存在的文本别名:gt (>), lt (<), ge (>=), le (<=), not (!). eq (==), neq/ne (!=)
条件表达式
条件表达式仅用于评估两个表达式中的一个,这取决于评估条件(本身就是另一个表达式)的结果。
我们来看一个示例 th:class 片段 :
<tr th:class="${row.even}? 'even' : 'odd'">
...
</tr>
条件表达式(condition,then和else)的所有三个部分都是自己的表达式,这意味着它们可以是变量(${...}, *{...}),消息 (#{...}) ,(@{...}) 或字面量('...')。
条件表达式也可以使用括号嵌套:
<tr th:class="${row.even}? (${row.first}? 'first' : 'even') : 'odd'">
...
</tr>
else表达式也可以省略,在这种情况下,如果条件为false,则返回null值:
<tr th:class="${row.even}? 'alt'">
...
</tr>
默认表达式
默认表达式(default expression)是一种特殊的条件值,没有then 部分。它相当于某些语言中的Elvis operator存在,比如 Groovy。指定两个表达式,如果第一个不是 null,则使用第二个。
查看如下示例:
<div th:object="${session.user}">
...
<p>Age: <span th:text="*{age}?: '(no age specified)'">27</span>.</p>
</div>
这相当于:
<p>Age: <span th:text="*{age != null}? *{age} : '(no age specified)'">27</span>.</p>
与条件表达式一样,它们之间可以包含嵌套表达式:
<p>
Name:
<span th:text="*{firstName}?: (*{admin}? 'Admin' : #{default.username})">Sebastian</span>
</p>
无操作标记
无操作标记由下划线符号(_)表示。表示什么也不做,这允许开发人员使用原型中的文本默认值。 例如,:
<span th:text="${user.name} ?: 'no user authenticated'">...</span>
我们可以直接使用*’no user authenticated’* 作为原型文本,这样代码从设计的角度来看起来很简洁:
<span th:text="${user.name} ?: _">no user authenticated</span>
数据转换及格式化
Thymeleaf 的双大括号为变量表达式($ {...})和选择表达式(* {...})提供了数据转换服务:
它看上去是这样的:
<td th:text="${{user.lastAccessDate}}">...</td>
注意到双括号吗?:$ {{...}}。这意味着Thymeleaf可以通过转换服务将结果转换为String。
假设user.lastAccessDate类型为java.util.Calendar,如果转换服务 (“IStandardConversionService”的实现)已经被注册并且包含有效的Calendar - > String的 转换,则它将被应用。
“IStandardConversionService”(“StandardConversionService”)的默认实现类)只需在转换为“String”的任何对象上执行.toString()。有关更多信息如何注册一个自定义转换服务实现,看看[更多配置](#more-on-configuration)部分。
表达式预处理
表达式预处理(expression preprocessing),它被定义在下划线_之间:
#{selection.__${sel.code}__}
我们看到的变量表达式${sel.code}将先被执行,假如结果是"ALL",那么_之间的值"ALL"将被看做表达式的一部分被执行,在这里会变成selection.ALL。
10.4 - CH04-设置属性值
设置任意属性值
th:attr 用于设置属性:
<form action="subscribe.html" th:attr="action=@{/subscribe}">
<fieldset>
<input type="text" name="email" />
<input type="submit" value="Subscribe!" th:attr="value=#{subscribe.submit}"/>
</fieldset>
</form>
th:attr会将表达式的结果,设置到相应的属性中去。上面模板结果如下:
<form action="/gtvg/subscribe">
<fieldset>
<input type="text" name="email" />
<input type="submit" value="¡Suscríbe!"/>
</fieldset>
</form>
我们也能同时设置多个属性值:
<img src="../../images/gtvglogo.png"
th:attr="src=@{/images/gtvglogo.png},title=#{logo},alt=#{logo}" />
输出如下:
<img src="/gtgv/images/gtvglogo.png" title="Logo de Good Thymes" alt="Logo de Good Thymes" />
设置值到指定的属性
现在,你可能会想到像:
<input type="submit" value="Subscribe!" th:attr="value=#{subscribe.submit}"/>
上面可以指定一个属性的值,但看上去有点丑陋,且并不是最优雅的方式。 通常,你将使用其他任务的th:*属性 设置特定的标签属性(而不仅仅是像“th:attr”这样的任意属性)。
例如,要设置value属性,使用th:value:
<input type="submit" value="Subscribe!" th:value="#{subscribe.submit}"/>
要设置 action 属性,使用th:action:
<form action="subscribe.html" th:action="@{/subscribe}">
Thymeleaf 提供了很多属性,每个都针对特定的HTML5属性:
th:abbr | th:accept | th:accept-charset |
|---|
th:accesskey | th:action | th:align |
th:alt | th:archive | th:audio |
th:autocomplete | th:axis | th:background |
th:bgcolor | th:border | th:cellpadding |
th:cellspacing | th:challenge | th:charset |
th:cite | th:class | th:classid |
th:codebase | th:codetype | th:cols |
th:colspan | th:compact | th:content |
th:contenteditable | th:contextmenu | th:data |
th:datetime | th:dir | th:draggable |
th:dropzone | th:enctype | th:for |
th:form | th:formaction | th:formenctype |
th:formmethod | th:formtarget | th:fragment |
th:frame | th:frameborder | th:headers |
th:height | th:high | th:href |
th:hreflang | th:hspace | th:http-equiv |
th:icon | th:id | th:inline |
th:keytype | th:kind | th:label |
th:lang | th:list | th:longdesc |
th:low | th:manifest | th:marginheight |
th:marginwidth | th:max | th:maxlength |
th:media | th:method | th:min |
th:name | th:onabort | th:onafterprint |
th:onbeforeprint | th:onbeforeunload | th:onblur |
th:oncanplay | th:oncanplaythrough | th:onchange |
th:onclick | th:oncontextmenu | th:ondblclick |
th:ondrag | th:ondragend | th:ondragenter |
th:ondragleave | th:ondragover | th:ondragstart |
th:ondrop | th:ondurationchange | th:onemptied |
th:onended | th:onerror | th:onfocus |
th:onformchange | th:onforminput | th:onhashchange |
th:oninput | th:oninvalid | th:onkeydown |
th:onkeypress | th:onkeyup | th:onload |
th:onloadeddata | th:onloadedmetadata | th:onloadstart |
th:onmessage | th:onmousedown | th:onmousemove |
th:onmouseout | th:onmouseover | th:onmouseup |
th:onmousewheel | th:onoffline | th:ononline |
th:onpause | th:onplay | th:onplaying |
th:onpopstate | th:onprogress | th:onratechange |
th:onreadystatechange | th:onredo | th:onreset |
th:onresize | th:onscroll | th:onseeked |
th:onseeking | th:onselect | th:onshow |
th:onstalled | th:onstorage | th:onsubmit |
th:onsuspend | th:ontimeupdate | th:onundo |
th:onunload | th:onvolumechange | th:onwaiting |
th:optimum | th:pattern | th:placeholder |
th:poster | th:preload | th:radiogroup |
th:rel | th:rev | th:rows |
th:rowspan | th:rules | th:sandbox |
th:scheme | th:scope | th:scrolling |
th:size | th:sizes | th:span |
th:spellcheck | th:src | th:srclang |
th:standby | th:start | th:step |
th:style | th:summary | th:tabindex |
th:target | th:title | th:type |
th:usemap | th:value | th:valuetype |
th:vspace | th:width | th:wrap |
th:xmlbase | th:xmllang | th:xmlspace |
同时设置多个值
th:alt-title 和 th:lang-xmllang 是两个特殊的属性,可以同时设置同一个值到两个属性:
th:alt-title 用于设置 alt 和 titleth:lang-xmllang 用于设置 lang 和 xml:lang
<img src="../../images/gtvglogo.png"
th:attr="src=@{/images/gtvglogo.png},title=#{logo},alt=#{logo}" />
等价于:
<img src="../../images/gtvglogo.png"
th:src="@{/images/gtvglogo.png}" th:alt-title="#{logo}" />
最终结果都是:
<img src="../../images/gtvglogo.png"
th:src="@{/images/gtvglogo.png}" th:title="#{logo}" th:alt="#{logo}" />
附加和添加前缀
th:attrappend 和 th:attrprepend 用于附加和添加前缀属性。例如
<input type="button" value="Do it!" class="btn" th:attrappend="class=${' ' + cssStyle}" />
执行模版, cssStyle 变量设置为 "warning"时,输出如下:
<input type="button" value="Do it!" class="btn warning" />
同时,有 th:classappend 和 th:styleappend 用于设置CSS 的 class 和 style。例如:
<tr th:each="prod : ${prods}" class="row" th:classappend="${prodStat.odd}? 'odd'">
固定值布尔属性
HTML具有布尔属性的概念,没有值的属性意味着该值为“true”。 在XHTML中,这些属性只取一个值,即它本身。
例如,checked:
<input type="checkbox" name="option2" checked /> <!-- HTML -->
<input type="checkbox" name="option1" checked="checked" /> <!-- XHTML -->
标准方言包括允许您通过评估条件来设置这些属性,如果评估为true,则该属性将被设置为其固定值,如果评估为false,则不会设置该属性:
<input type="checkbox" name="active" th:checked="${user.active}" />
标准方言中存在以下固定值布尔属性:
th:async | th:autofocus | th:autoplay |
|---|
th:checked | th:controls | th:declare |
th:default | th:defer | th:disabled |
th:formnovalidate | th:hidden | th:ismap |
th:loop | th:multiple | th:novalidate |
th:nowrap | th:open | th:pubdate |
th:readonly | th:required | th:reversed |
th:scoped | th:seamless | th:selected |
默认属性处理器
提供 “默认属性处理器(default attribute processor)”,当标准方言没有提供的属性时,也可以设置其属性。比如:
<span th:whatever="${user.name}">...</span>
th:whatever 不是标准方言中提供的属性,则最终输出如下:
<span whatever="John Apricot">...</span>
支持对HTML5 友好的属性及元素名称
data-{prefix}-{name}语法在HTML5中编写自定义属性的标准方式,不需要开发人员使用任何名称空间的名字,如th:*。 Thymeleaf使这种语法自动提供给所有的方言(而不只是标准方言)。
<table>
<tr data-th-each="user : ${users}">
<td data-th-text="${user.login}">...</td>
<td data-th-text="${user.name}">...</td>
</tr>
</table>
10.5 - CH05-迭代器
基本的迭
th:each将循环 array 或 list 中的元素并重复打印一组标签,语法相当于 Java foreach 表达式:
<li th:each="book : ${books}" th:text="${book.title}">En las Orillas del Sar</li>
可以使用th:each属性进行遍历的对象包括:
- 任何实现
java.util.Iterable的对象 - 任何实现
java.util.Enumeration的对象 - 任何实现
java.util.Iterator的对象,其值将被迭代器返回,而不需要在内存中缓存所有的值 - 任何实现
java.util.Map的对象。 迭代映射时,迭代变量 将是java.util.Map.Entry类 - 任何数组
- 任何其他对象将被视为包含对象本身的单值列表
状态变量
Thymeleaf 提供 状态变量(status variable) 来跟踪迭代器的状态。
th:each属性中,定义了如下状态变量:
index 属性是当前 迭代器索引(iteration index),从0开始count 属性是当前 迭代器索引(iteration index),从1开始size 属性是迭代器元素的总数current 是当前 迭代变量(iter variable)even/odd 判断当前迭代器是否是 even 或 oddfirst 判断当前迭代器是否是第一个last 判断当前迭代器是否是最后
看下面的例子:
<table>
<tr>
<th>NAME</th>
<th>PRICE</th>
<th>IN STOCK</th>
</tr>
<tr th:each="prod,iterStat : ${prods}" th:class="${iterStat.odd}? 'odd'">
<td th:text="${prod.name}">Onions</td>
<td th:text="${prod.price}">2.41</td>
<td th:text="${prod.inStock}? #{true} : #{false}">yes</td>
</tr>
</table>
状态变量(在本示例中为“iterStat”)在th:each中定义了。
我们来看看模板的处理后的结果:
<!DOCTYPE html>
<html>
<head>
<title>Good Thymes Virtual Grocery</title>
<meta content="text/html; charset=UTF-8" http-equiv="Content-Type"/>
<link rel="stylesheet" type="text/css" media="all" href="/gtvg/css/gtvg.css" />
</head>
<body>
<h1>Product list</h1>
<table>
<tr>
<th>NAME</th>
<th>PRICE</th>
<th>IN STOCK</th>
</tr>
<tr class="odd">
<td>Fresh Sweet Basil</td>
<td>4.99</td>
<td>yes</td>
</tr>
<tr>
<td>Italian Tomato</td>
<td>1.25</td>
<td>no</td>
</tr>
<tr class="odd">
<td>Yellow Bell Pepper</td>
<td>2.50</td>
<td>yes</td>
</tr>
<tr>
<td>Old Cheddar</td>
<td>18.75</td>
<td>yes</td>
</tr>
</table>
<p>
<a href="/gtvg/" shape="rect">Return to home</a>
</p>
</body>
</html>
请注意,我们的迭代状态变量已经运行良好,建立只有奇数行具有 “odd” CSS 类。
如果您没有明确设置状态变量,则 Thymeleaf 将始终创建一个状态变量,可以通过后缀“Stat”获取到迭代变量的名称:
<table>
<tr>
<th>NAME</th>
<th>PRICE</th>
<th>IN STOCK</th>
</tr>
<tr th:each="prod : ${prods}" th:class="${prodStat.odd}? 'odd'">
<td th:text="${prod.name}">Onions</td>
<td th:text="${prod.price}">2.41</td>
<td th:text="${prod.inStock}? #{true} : #{false}">yes</td>
</tr>
</table>
10.6 - CH06-条件语句
“if” 和 “unless”
th:if 属性用法如下:
<a href="comments.html"
th:href="@{/product/comments(prodId=${prod.id})}"
th:if="${not #lists.isEmpty(prod.comments)}">view</a>
请注意,th:if 属性不仅是将评估布尔条件。 它的功能有点超出这一点,它将按照这些规则评估指定的表达式:
- 如果值不为 null:
- 如果值为布尔值,则为true。
- 如果值是数字,并且不为零
- 如果值是一个字符且不为零
- 如果value是String,而不是“false”,“off”或“no”
- 如果值不是布尔值,数字,字符或字符串。
- 如果值为null,则th:if 将为 false。
另外,th:if有一个相反的属性th:unless,前面的例子改为:
<a href="comments.html"
th:href="@{/comments(prodId=${prod.id})}"
th:unless="${#lists.isEmpty(prod.comments)}">view</a>
switch 语句
switch 语句使用th:switch / th:case 属性集合来实现:
<div th:switch="${user.role}">
<p th:case="'admin'">User is an administrator</p>
<p th:case="#{roles.manager}">User is a manager</p>
</div>
请注意,只要一个th:case属性被评估为’true’,每个其他同一个 switch 语句中的th:case属性将被评估为false。
th:case="*"来设置默认选项:
<div th:switch="${user.role}">
<p th:case="'admin'">User is an administrator</p>
<p th:case="#{roles.manager}">User is a manager</p>
<p th:case="*">User is some other thing</p>
</div>
10.7 - CH07-模板布局
包含模板片段
定义和引用片段
在我们的模板中,我们经常需要从其他模板中添加 html 页面片段,如页脚、标题、菜单…
为了做到这一点,Thymeleaf 需要我们来定义这些“片段”,可以使用th:fragment属性来完成。我们定义了/WEB-INF/templates/footer.html页面
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<body>
<div th:fragment="copy">
© 2017 <a href="https://waylau.com">waylau.com</a>
</div>
</body>
</html>
如果,我们想引用这个 copy 代码片段,我们可以用 th:insert 或 th:replace 属性 (th:include 也是可以,但自 Thymeleaf 3.0 以来就不再推荐):
<body>
...
<div th:insert="~{footer :: copy}"></div>
</body>
注意th:insert需要一个片段表达式(〜{...})。 在上面的例子中,非复杂片段表达式,(〜{,})包围是完全可选,所以上面的代码将等效于:
<body>
...
<div th:insert="footer :: copy"></div>
</body>
片段规范语法
"~{templatename::selector}" 名为templatename的模板上的指定标记选择器。 selector可以只是一个片段名。"~{templatename}" : 包含完整的模版 templatename~{::selector}" or "~{this::selector}" 相同模版中的代码片段
不使用 th:fragment
不使用 th:fragment也可以引用HTML片段,比如:
...
<div id="copy-section">
© 2017 <a href="https://waylau.com">waylau.com</a>
</div>
...
通过 id 也可以引用到页面片段:
<body>
...
<div th:insert="~{footer :: #copy-section}"></div>
</body>
th:insert、 th:replace 、th:include三者区别
th:insert是最简单的:它将简单地插入指定的片段作为正文 的主标签。th:replace用指定实际片段来替换其主标签。th:include类似于th:insert,但不是插入片段它只插入此片段的内容。
所以
<footer th:fragment="copy">
© 2017 <a href="https://waylau.com">waylau.com</a>
</footer>
三种方式引用该片段
<body>
...
<div th:insert="footer :: copy"></div>
<div th:replace="footer :: copy"></div>
<div th:include="footer :: copy"></div>
</body>
结果为:
<body>
...
<div>
<footer>
© 2017 <a href="https://waylau.com">waylau.com</a>
</footer>
</div>
<footer>
© 2017 <a href="https://waylau.com">waylau.com</a>
</footer>
<div>
© 2017 <a href="https://waylau.com">waylau.com</a>
</div>
</body>
10.8 - CH08-局部变量
在迭代器中,我们可以使用局部变量prod:
<tr th:each="prod : ${prods}">
...
</tr>
Thymeleaf 为您提供了一种在不使用迭代的情况下声明局部变量的方法th:with属性,其语法与属性值类似:
<div th:with="firstPer=${persons[0]}">
<p>
The name of the first person is <span th:text="${firstPer.name}">Julius Caesar</span>.
</p>
</div>
当th:with被处理时,firstPer变量创建为局部变量,并添加到来自上下文的变量 map 中,以便它是可用于评估以及在上下文中声明的任何其他变量,但只能在包含<div>标签的范围内。
可以同时定义多个变量,赋值语法为:
<div th:with="firstPer=${persons[0]},secondPer=${persons[1]}">
<p>
The name of the first person is <span th:text="${firstPer.name}">Julius Caesar</span>.
</p>
<p>
But the name of the second person is
<span th:text="${secondPer.name}">Marcus Antonius</span>.
</p>
</div>
th:with属性允许重用在同一属性中定义的变量:
<div th:with="company=${user.company + ' Co.'},account=${accounts[company]}">...</div>
10.9 - CH09-属性优先级
当在同一个标签中写入多个th:*属性时,会发生什么? 对于下面的例子:
<ul>
<li th:each="item : ${items}" th:text="${item.description}">
Item description here...
</li>
</ul>
我们期望th:each属性在th:text之前执行,从而可以得到了我们想要的结果,但是鉴于 HTML/XML标准并未对标签中的属性的顺序给出任何的定义,所以必须在属性中建立*优先级(precedence)*机制 以确保这将按预期工作。
所以,所有的Thymeleaf属性定义一个数字优先级,它建立了它们在标签中执行的顺序。 这个是列表:
| Order | Feature | Attributes |
|---|
| 1 | Fragment inclusion | th:insert th:replace |
| 2 | Fragment iteration | th:each |
| 3 | Conditional evaluation | th:if th:unless th:switch th:case |
| 4 | Local variable definition | th:object th:with |
| 5 | General attribute modification | th:attr th:attrprepend th:attrappend |
| 6 | Specific attribute modification | th:value th:href th:src ... |
| 7 | Text (tag body modification) | th:text th:utext |
| 8 | Fragment specification | th:fragment |
| 9 | Fragment removal | th:remove |
这个优先机制意味着如果属性位置被反转,上述迭代片段将给出完全相同的结果(尽管它的可读性稍差):
<ul>
<li th:text="${item.description}" th:each="item : ${items}">Item description here...</li>
</ul>
10.10 - CH10-注释及注释块
标准 HTML/XML 注释
标准 HTML/XML 注释<!-- ... --> 可以在模版中使用:
<!-- User info follows -->
<div th:text="${...}">
...
</div>
Thymeleaf 解析器级注释块
解析器级注释块是当 Thymeleaf 解析它的模板时,这些代码将被简单地从中删除。 他们看起来像这样:
<!--/* This code will be removed at Thymeleaf parsing time! */-->
Thymeleaf将删除<!--/* 和 */-->之间的所有内容,所以这些注释块也可以用于在模板静态打开时显示代码,当Thymeleaf处理它会被删除:
<!--/*-->
<div>
you can see me only before Thymeleaf processes me!
</div>
<!--*/-->
这在原型中设计中有很多 <tr>时,非常适用:
<table>
<tr th:each="x : ${xs}">
...
</tr>
<!--/*-->
<tr>
...
</tr>
<tr>
...
</tr>
<!--*/-->
</table>
原型注释块
原型注释块是指,当模版静态打开时(比如原型设计),原型注释块所注释的代码将被注释,而在模版执行时,这些注释的代码,就能被显示出来。
<span>hello!</span>
<!--/*/
<div th:text="${...}">
...
</div>
/*/-->
<span>goodbye!</span>
Thymeleaf 的解析系统将简单地删除<!--/*/ 和 /*/--> 标记,但保留所注释的内容。 那么什么时候执行模板,Thymeleaf 实际上会看到:
<span>hello!</span>
<div th:text="${...}">
...
</div>
<span>goodbye!</span>
与解析器级注释块一样,此功能与方言无关。
合成th:block标签
标准方言中包含的唯一的元素处理器(不是属性)是th:block。
th:block只是一个属性容器,允许模板开发人员指定他们想要的任何属性。 Thymeleaf 将执行这些属性,然后简单地制作块,而不是让其内容消失。
因此,例如,当为每个元素创建需要多个<tr> 的迭代时,这可能是有用的:
<table>
<th:block th:each="user : ${users}">
<tr>
<td th:text="${user.login}">...</td>
<td th:text="${user.name}">...</td>
</tr>
<tr>
<td colspan="2" th:text="${user.address}">...</td>
</tr>
</th:block>
</table>
当与原型注释块组合使用时尤其有用:
<table>
<!--/*/ <th:block th:each="user : ${users}"> /*/-->
<tr>
<td th:text="${user.login}">...</td>
<td th:text="${user.name}">...</td>
</tr>
<tr>
<td colspan="2" th:text="${user.address}">...</td>
</tr>
<!--/*/ </th:block> /*/-->
</table>
10.11 - CH11-内联
表达式内联
虽然标准方言使我们能够使用标签属性来做几乎所有的事情,但是有些情况下我们更喜欢将表达式直接写入我们的HTML文本。 例如,我们可以喜欢写这个:
<p>Hello, [[${session.user.name}]]!</p>
来代替:
<p>Hello, <span th:text="${session.user.name}">Sebastian</span>!</p>
[[...]] 或 [(...)] 被称为 内联表达式(inlined expressions),分别对应于 th:text 和 th:utext 属性。
<p>The message is "[(${msg})]"</p>
这个的结果显示, <b> 标签不会被转义:
<p>The message is "This is <b>great!</b>"</p>
如果是这样:
<p>The message is "[[${msg}]]"</p>
则结果会被转义:
<p>The message is "This is <b>great!</b>"</p>
内联与自然模板
虽然内联看上去比自然模板更加简洁,但它并不总是适用,比如当您静态打开HTML文件时,会逐字显示,因为内联无法将它们用作设计原型了!
禁用内联
有时,我们想禁用这种机制,比如,想输出 [[...]] 或 [(...)] 文本内容,而不是将其视为表达式。 为此,我们将使用 th:inline="none":
<p th:inline="none">A double array looks like this: [[1, 2, 3], [4, 5]]!</p>
结果为:
<p>A double array looks like this: [[1, 2, 3], [4, 5]]!</p>
文本内联
文本内联与我们拥有的表达式内联功能非常相似,但实际上拥有了更多的能力。 为了启用它我们使用th:inline="text"。
文本内联不仅允许我们使用相同的内联表达式,而且实际上可以处理在“TEXT”模板模式下的标签体。
我们将在下一章中看到关于[文本模板模式]的更多信息。
JavaScript 内联
<script th:inline="javascript">
...
var username = [[${session.user.name}]];
...
</script>
结果为:
<script th:inline="javascript">
...
var username = "Sebastian \"Fruity\" Applejuice";
...
</script>
JavaScript 自然模版
我们可以在JavaScript中包装(转义)内联的表达式注释如下:
<script th:inline="javascript">
...
var username = /*[[${session.user.name}]]*/ "Gertrud Kiwifruit";
...
</script>
Thymeleaf 将会忽略所有注释之后分号之前的内容(就是例子中的'Gertrud Kiwifruit')。所以结果输出如下:
<script th:inline="javascript">
...
var username = "Sebastian \"Fruity\" Applejuice";
...
</script>
高级内联评估和JavaScript序列化
关于JavaScript内联的一个重要的事情是这个表达式评估是非常智能的,并不仅限于字符串的处理。Thymeleaf 会正确写入 JavaScript 语法中的以下几种对象:
- String
- Number
- Boolean
- Array
- Collection
- Map
- Bean (有 getter and setter 方法的对象)
例如,如果我们有以下代码:
<script th:inline="javascript">
...
var user = /*[[${session.user}]]*/ null;
...
</script>
那个 ${session.user} 表达式将评估为一个User对象,Thymeleaf 将正确转换为 JavaScript 语法:
<script th:inline="javascript">
...
var user = {"age":null,"firstName":"John","lastName":"Apricot",
"name":"John Apricot","nationality":"Antarctica"};
...
</script>
这个 JavaScript 序列化的方式是通过实现org.thymeleaf.standard.serializer.IStandardJavaScriptSerializer 接口来实现的,可以在 StandardDialect的实例配置被用于模板引擎。
此JS序列化机制的默认实现将会查找在类路径中[Jackson 库],如果存在,将会使用它。如果没有,它将应用一个内置的序列化机制。这涵盖了大多数场景的需求,并产生了类似的结果(但是 相比较 Jackson 而言不够灵活)。
CSS 内联
Thymeleaf 允许使用 CSS <style>标签,比如:
<style th:inline="css">
...
</style>
比如,我们想设置两个变量到不同的String值:
classname = 'main elems'
align = 'center'
我们可以这么做:
<style th:inline="css">
.[[${classname}]] {
text-align: [[${align}]];
}
</style>
结果为:
<style th:inline="css">
.main\ elems {
text-align: center;
}
</style>
请注意,CSS 内联中还包含一些智能处理,就像JavaScript 内联一样。具体来说,通过转义表达式来输出表达式,如 [[${classname}]] 将被转义为CSS 标识符。 这就是为什么我们的 classname = 'main elems'在上面的代码片段中变成了main\ elems。
CSS 自然模版
与JavaScript 类似,也有 CSS 自然模版,用法如下:
<style th:inline="css">
.main\ elems {
text-align: /*[[${align}]]*/ left;
}
</style>
11.1 - Gateway 请求过程
一 前言
最近通过深入学习Spring Cloud Gateway发现这个框架的架构设计非常简单、有效,很多组件的设计都非常值得学习,本文就Spring Cloud Gateway做一个简单的介绍,以及针对一次请求Spring Cloud Gateway的处理流程做一个较为详细的分析。
二 简介
Spring Cloud Gateway 即Spring官方推出的一款API网关,该框架包含了Spring5、SpringBoot2、Project Reactor,其中底层通信框架用的netty。Spring Cloud Gateway在推出之初的时候,Netflix公司已经推出了类似功能的API网关框架ZUUL,但ZUUL有一个缺点是通信方式是阻塞的,虽然后来升级到了非阻塞式的ZUUL2,但是由于Spring Cloud Gateway已经推出一段时间,同时自身也面临资料少、维护性较差的因素没有被广泛应用。
1 关键术语
在使用Spring Cloud Gateway的时候需要理解三个模块,即
Route:
即一套路由规则,是集URI、predicate、filter等属性的一个元数据类。
Predicate:
这是Java8函数式编程的一个方法,这里可以看做是满足什么条件的时候,route规则进行生效。
Filter:
filter可以认为是Spring Cloud Gateway最核心的模块,熔断、安全、逻辑执行、网络调用都是filter来完成的,其中又细分为gateway filter和global filter,区别在于是具体一个route规则生效还是所有route规则都生效。
可以先上一段代码来看看:
@RequestMapping("/paramTest")
public Object paramTest(@RequestParam Map<String,Object> param) {
return param.get("name");
}
@Bean
public RouteLocator customRouteLocator(RouteLocatorBuilder builder) {
return builder.routes()
.route("path_route", r ->
r.path("/get")
.filters(f -> f.addRequestParameter("name", "value"))
.uri("forward:///paramTest"))
.build();
}
- route方法代表的就是一个路由规则;
- path方法代表的就是一个predicate,背后的现实是PathRoutePredicateFactory,在这段代码的含义即当路径包含/get的时候,当前规则生效。
- filters方法的意思即给当前路由规则添加一个增加请求参数的filter,每次请求都对参数里添加 name:value 的键值对;
- uri 方法的含义即最终路由到哪里去,这里的forward前缀会将请求交给spring mvc的DispatcherHandler进行路由,进行本机的逻辑调用,除了forward以外还可以使用http、https前缀进行http调用,lb前缀可以在配置注册中心后进行rpc调用。
上图是Spring Cloud Gateway官方文档给出的一个工作原理图,Spring Cloud Gateway 接收到请求后进行路由规则的匹配,然后交给web handler 进行处理,web handler 会执行一系列的filter逻辑。
三 流程分析
1 接受请求
Spring Cloud Gateway的底层框架是netty,接受请求的关键类是ReactorHttpHandlerAdapter,做的事情很简单,就是将netty的请求、响应转为http的请求、响应并交给一个http handler执行后面的逻辑,下图为该类的源码仅保留核心逻辑。
@Override
public Mono< Void> apply(HttpServerRequest request, HttpServerResponse response) {
NettyDataBufferFactory bufferFactory = new NettyDataBufferFactory(response.alloc());
ServerHttpRequest adaptedRequest;
ServerHttpResponse adaptedResponse;
//转换请求
try {
adaptedRequest = new ReactorServerHttpRequest(request, bufferFactory);
adaptedResponse = new ReactorServerHttpResponse(response, bufferFactory);
}
catch (URISyntaxException ex) {
if (logger.isWarnEnabled()) {
...
}
...
return this.httpHandler.handle(adaptedRequest, adaptedResponse)
.doOnError(ex -> logger.warn("Handling completed with error: " + ex.getMessage()))
.doOnSuccess(aVoid -> logger.debug("Handling completed with success"));
}
2 WEB过滤器链
http handler做的事情第一是将request 和 response转为一个exchange,这个exchange非常核心,是各个filter之间参数流转的载体,该类包含request、response、attributes(扩展字段),接着做的事情就是web filter链的执行,其中的逻辑主要是监控。
其中WebfilterChainParoxy 又会引出新的一条filter链,主要是安全、日志、认证相关的逻辑,由此可见Spring Cloud Gateway的过滤器设计是层层嵌套,扩展性很强。
3 寻找路由规则
核心类是RoutePredicateHandlerMapping,逻辑也非常简单,就是把所有的route规则的predicate遍历一遍看哪个predicate能够命中,核心代码是:
return this.routeLocator.getRoutes()
.filter(route -> {
...
return route.getPredicate().test(exchange);
})
因为我这里用的是path进行过滤,所以背后的逻辑是PathRoutePredicateFactory来完成的,除了PathRoutePredicateFactory还有很多predicate规则。
这些路由规则都能从官方文档上找到影子。
4 核心过滤器链执行
找到路由规则后下一步就是执行了,这里的核心类是FilteringWebHandler,其中的源码为:
做的事情很简单:
- 获取route级别的过滤器
- 获取全局过滤器
- 两种过滤器放在一起并根据order进行排序
- 执行过滤器链
因为我的配置里包含了一个添加请求参数的逻辑,所以红线箭头处就是我配置的gateway filter名为 AddRequestParameterGatewayFilterFactory,其余全是Gloabl Filter,这些过滤器的功能主要是url解析,请求转发,响应回写等逻辑,因为我们这里用的是forward schema,所以请求转发会由ForwardRoutingFilter进行执行。
5 请求转发
ForwardRoutingFilter做的事情也很简单,直接复用了spring mvc的能力,将请求提交给dispatcherHandler进行处理,dispatcherHandler会根据path前缀找到需要目标处理器执行逻辑。
@Override
public Mono< Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
URI requestUrl = exchange.getRequiredAttribute(GATEWAY_REQUEST_URL_ATTR);
String scheme = requestUrl.getScheme();
if (isAlreadyRouted(exchange) || !"forward".equals(scheme)) {
return chain.filter(exchange);
}
setAlreadyRouted(exchange);
//TODO: translate url?
if (log.isTraceEnabled()) {
log.trace("Forwarding to URI: "+requestUrl);
}
return this.dispatcherHandler.handle(exchange);
}
6 响应回写
响应回写的核心类是NettyWriteResponseFilter,但是大家可以注意到执行器链中NettyWriteResponseFilter的排序是在最前面的,按道理这种响应处理的类应该是在靠后才对,这里的设计比较巧妙。大家可以看到chain.filter(exchange).then(),意思就是执行到我的时候直接跳过下一个,等后面的过滤器都执行完后才执行这段逻辑,这种行为控制的方法值得学习。
@Override
public Mono< Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// NOTICE: nothing in "pre" filter stage as CLIENT_RESPONSE_ATTR is not added
// until the WebHandler is run
return chain.filter(exchange).then(Mono.defer(() -> {
HttpClientResponse clientResponse = exchange.getAttribute(CLIENT_RESPONSE_ATTR);
if (clientResponse == null) {
return Mono.empty();
}
log.trace("NettyWriteResponseFilter start");
ServerHttpResponse response = exchange.getResponse();
NettyDataBufferFactory factory = (NettyDataBufferFactory) response.bufferFactory();
//TODO: what if it's not netty
final Flux< NettyDataBuffer> body = clientResponse.receive()
.retain() //TODO: needed?
.map(factory::wrap);
MediaType contentType = response.getHeaders().getContentType();
return (isStreamingMediaType(contentType) ?
response.writeAndFlushWith(body.map(Flux::just)) : response.writeWith(body));
}));
}
四 总结
整体读完Spring Cloud Gateway请求流程代码后,有几点感受:
- 过滤器是Spring Cloud Gateway最核心的设计,甚至于可以夸张说Spring Cloud Gateway是一个过滤器链执行框架而不是一个API网关,因为API网关实际的请求转发、请求响应回写都是在过滤器中做的,这些是Spring Cloud Gateway感知不到的逻辑。
- Spring Cloud Gateway路由规则获取的模块具备优化的空间,因为是循环遍历进行获取的,如果每个route规则较多,predicate规则较复杂,就可以考虑用map进行优化了,当日route规则,predicate规则也不会很复杂,兼顾到代码的可读性,当前方式也没有什么问题。
- 作为API网关框架,内置了非常多的过滤器,如果有过滤器的卸载功能可能会更好,用户可用根据实际情况卸载不必要的功能,背后减少的逻辑开销,在调用量极大的API网关场景,收益也会很可观。
13 - Guava
13.1 - RateLimiter
常见的限流算法有令牌桶算法,漏桶算法,与计数器算法。本文主要对三个算法的基本原理及 Google Guava 包中令牌桶算法的实现 RateLimiter 进行介绍,下一篇文章介绍最近写的一个以 RateLimiter 为参考的分布式限流实现及计数器限流实现。
令牌桶算法
令牌桶算法的原理就是以一个恒定的速度往桶里放入令牌,每一个请求的处理都需要从桶里先获取一个令牌,当桶里没有令牌时,则请求不会被处理,要么排队等待,要么降级处理,要么直接拒绝服务。当桶里令牌满时,新添加的令牌会被丢弃或拒绝。
令牌桶算法的处理示意图如下:
令牌桶算法主要是可以控制请求的平均处理速率,它允许预消费,即可以提前消费令牌,以应对突发请求,但是后面的请求需要为预消费买单(等待更长的时间),以满足请求处理的平均速率是一定的。
漏桶算法
漏桶算法的原理是水(请求)先进入漏桶中,漏桶以一定的速度出水(处理请求),当水流入速度大于流出速度导致水在桶内逐渐堆积直到桶满时,水会溢出(请求被拒绝)。
漏桶算法的处理示意图如下:
漏桶算法主要是控制请求的处理速率,平滑网络上的突发流量,请求可以以任意速度进入漏桶中,但请求的处理则以恒定的速度进行。
计算器算法
计数器算法是限流算法中最简单的一种算法,限制在一个时间窗口内,至多处理多少个请求。比如每分钟最多处理10个请求,则从第一个请求进来的时间为起点,60s的时间窗口内只允许最多处理10个请求。下一个时间窗口又以前一时间窗口过后第一个请求进来的时间为起点。常见的比如一分钟内只能获取一次短信验证码的功能可以通过计数器算法来实现。
Guava RateLimiter
Guava是Google开源的一个工具包,其中的RateLimiter是实现了令牌桶算法的一个限流工具类。
如下测试代码示例了RateLimiter的用法:
public static void main(String[] args) {
RateLimiter rateLimiter = RateLimiter.create(1); //创建一个每秒产生一个令牌的令牌桶
for(int i=1;i<=5;i++) {
double waitTime = rateLimiter.acquire(i); //一次获取i个令牌
System.out.println("acquire:" + i + " waitTime:" + waitTime);
}
}
运行后,输出如下,
acquire:1 waitTime:0.0
acquire:2 waitTime:0.997729
acquire:3 waitTime:1.998076
acquire:4 waitTime:3.000303
acquire:5 waitTime:4.000223
第一次获取一个令牌时,等待0s立即可获取到(这里之所以不需要等待是因为令牌桶的预消费特性),第二次获取两个令牌,等待时间1s,这个1s就是前面获取一个令牌时因为预消费没有等待延到这次来等待的时间,这次获取两个又是预消费,所以下一次获取(取3个时)就要等待这次预消费需要的2s了,依此类推。可见预消费不需要等待的时间都由下一次来买单,以保障一定的平均处理速率(上例为1s一次)。
RateLimiter有两种实现:
- SmoothBursty: 令牌的生成速度恒定。使用
RateLimiter.create(double permitsPerSecond) 创建的是 SmoothBursty 实例。 - SmoothWarmingUp:令牌的生成速度持续提升,直到达到一个稳定的值。WarmingUp,顾名思义就是有一个热身的过程。使用
RateLimiter.create(double permitsPerSecond, long warmupPeriod, TimeUnit unit) 时创建就是 SmoothWarmingUp 实例,其中 warmupPeriod 就是热身达到稳定速度的时间。
类结构如下:
关键属性及方法解析(以 SmoothBursty 为例):
关键属性
/** 桶中当前拥有的令牌数. */
double storedPermits;
/** 桶中最多可以保存多少秒存入的令牌数 */
double maxBurstSeconds;
/** 桶中能存储的最大令牌数,等于storedPermits*maxBurstSeconds. */
double maxPermits;
/** 放入令牌的时间间隔*/
double stableIntervalMicros;
/** 下次可获取令牌的时间点,可以是过去也可以是将来的时间点*/
private long nextFreeTicketMicros = 0L;
关键方法
调用 RateLimiter.create(double permitsPerSecond) 方法时,创建的是 SmoothBursty 实例,默认设置 maxBurstSeconds 为 1s。SleepingStopwatch 是guava中的一个时钟类实现。
@VisibleForTesting
static RateLimiter create(double permitsPerSecond, SleepingStopwatch stopwatch) {
RateLimiter rateLimiter = new SmoothBursty(stopwatch, 1.0 /* maxBurstSeconds */);
rateLimiter.setRate(permitsPerSecond);
return rateLimiter;
}
SmoothBursty(SleepingStopwatch stopwatch, double maxBurstSeconds) {
super(stopwatch);
this.maxBurstSeconds = maxBurstSeconds;
}
并通过调用 SmoothBursty.doSetRate(double, long) 方法进行初始化,该方法中:
- 调用
resync(nowMicros) 对 storedPermits 与 nextFreeTicketMicros 进行了调整——如果当前时间晚于 nextFreeTicketMicros,则计算这段时间内产生的令牌数,累加到 storedPermits 上,并更新下次可获取令牌时间 nextFreeTicketMicros 为当前时间。 - 计算 stableIntervalMicros 的值,1/permitsPerSecond。
- 调用
doSetRate(double, double) 方法计算 maxPermits 值(maxBurstSeconds*permitsPerSecond),并根据旧的 maxPermits 值对 storedPermits 进行调整。
源码如下所示
@Override
final void doSetRate(double permitsPerSecond, long nowMicros) {
resync(nowMicros);
double stableIntervalMicros = SECONDS.toMicros(1L) / permitsPerSecond;
this.stableIntervalMicros = stableIntervalMicros;
doSetRate(permitsPerSecond, stableIntervalMicros);
}
/** Updates {@code storedPermits} and {@code nextFreeTicketMicros} based on the current time. */
void resync(long nowMicros) {
// if nextFreeTicket is in the past, resync to now
if (nowMicros > nextFreeTicketMicros) {
double newPermits = (nowMicros - nextFreeTicketMicros) / coolDownIntervalMicros();
storedPermits = min(maxPermits, storedPermits + newPermits);
nextFreeTicketMicros = nowMicros;
}
}
@Override
void doSetRate(double permitsPerSecond, double stableIntervalMicros) {
double oldMaxPermits = this.maxPermits;
maxPermits = maxBurstSeconds * permitsPerSecond;
if (oldMaxPermits == Double.POSITIVE_INFINITY) {
// if we don't special-case this, we would get storedPermits == NaN, below
storedPermits = maxPermits;
} else {
storedPermits =
(oldMaxPermits == 0.0)
? 0.0 // initial state
: storedPermits * maxPermits / oldMaxPermits;
}
}
调用 acquire(int) 方法获取指定数量的令牌时,
- 调用
reserve(int) 方法,该方法最终调用 reserveEarliestAvailable(int, long) 来更新下次可取令牌时间点与当前存储的令牌数,并返回本次可取令牌的时间点,根据该时间点计算需要等待的时间 - 阻塞等待1中返回的等待时间
- 返回等待的时间(秒)
源码如下所示
/** 获取指定数量(permits)的令牌,阻塞直到获取到令牌,返回等待的时间*/
@CanIgnoreReturnValue
public double acquire(int permits) {
long microsToWait = reserve(permits);
stopwatch.sleepMicrosUninterruptibly(microsToWait);
return 1.0 * microsToWait / SECONDS.toMicros(1L);
}
final long reserve(int permits) {
checkPermits(permits);
synchronized (mutex()) {
return reserveAndGetWaitLength(permits, stopwatch.readMicros());
}
}
/** 返回需要等待的时间*/
final long reserveAndGetWaitLength(int permits, long nowMicros) {
long momentAvailable = reserveEarliestAvailable(permits, nowMicros);
return max(momentAvailable - nowMicros, 0);
}
/** 针对此次需要获取的令牌数更新下次可取令牌时间点与存储的令牌数,返回本次可取令牌的时间点*/
@Override
final long reserveEarliestAvailable(int requiredPermits, long nowMicros) {
resync(nowMicros); // 更新当前数据
long returnValue = nextFreeTicketMicros;
double storedPermitsToSpend = min(requiredPermits, this.storedPermits); // 本次可消费的令牌数
double freshPermits = requiredPermits - storedPermitsToSpend; // 需要新增的令牌数
long waitMicros =
storedPermitsToWaitTime(this.storedPermits, storedPermitsToSpend)
+ (long) (freshPermits * stableIntervalMicros); // 需要等待的时间
this.nextFreeTicketMicros = LongMath.saturatedAdd(nextFreeTicketMicros, waitMicros); // 更新下次可取令牌的时间点
this.storedPermits -= storedPermitsToSpend; // 更新当前存储的令牌数
return returnValue;
}
acquire(int) 方法是获取不到令牌时一直阻塞,直到获取到令牌,tryAcquire(int,long,TimeUnit) 方法则是在指定超时时间内尝试获取令牌,如果获取到或超时时间到则返回是否获取成功
- 先判断是否能在指定超时时间内获取到令牌,通过
nextFreeTicketMicros <= timeoutMicros + nowMicros 是否为true来判断,即可取令牌时间早于当前时间加超时时间则可取(预消费的特性),否则不可获取。 - 如果不可获取,立即返回false。
- 如果可获取,则调用
reserveAndGetWaitLength(permits, nowMicros) 来更新下次可取令牌时间点与当前存储的令牌数,返回等待时间(逻辑与前面相同),并阻塞等待相应的时间,返回true。
源码如下所示
public boolean tryAcquire(int permits, long timeout, TimeUnit unit) {
long timeoutMicros = max(unit.toMicros(timeout), 0);
checkPermits(permits);
long microsToWait;
synchronized (mutex()) {
long nowMicros = stopwatch.readMicros();
if (!canAcquire(nowMicros, timeoutMicros)) { //判断是否能在超时时间内获取指定数量的令牌
return false;
} else {
microsToWait = reserveAndGetWaitLength(permits, nowMicros);
}
}
stopwatch.sleepMicrosUninterruptibly(microsToWait);
return true;
}
private boolean canAcquire(long nowMicros, long timeoutMicros) {
return queryEarliestAvailable(nowMicros) - timeoutMicros <= nowMicros; //只要可取时间小于当前时间+超时时间,则可获取(可预消费的特性!)
}
@Override
final long queryEarliestAvailable(long nowMicros) {
return nextFreeTicketMicros;
}
以上就是 SmoothBursty 实现的基本处理流程。注意两点:
- RateLimiter 通过限制后面请求的等待时间,来支持一定程度的突发请求——预消费的特性。
- RateLimiter 令牌桶的实现并不是起一个线程不断往桶里放令牌,而是以一种延迟计算的方式(参考
resync函数),在每次获取令牌之前计算该段时间内可以产生多少令牌,将产生的令牌加入令牌桶中并更新数据来实现,比起一个线程来不断往桶里放令牌高效得多。(想想如果需要针对每个用户限制某个接口的访问,则针对每个用户都得创建一个RateLimiter,并起一个线程来控制令牌存放的话,如果在线用户数有几十上百万,起线程来控制是一件多么恐怖的事情)
单机局限
本文介绍了限流的三种基本算法,其中令牌桶算法与漏桶算法主要用来限制请求处理的速度,可将其归为限速,计数器算法则是用来限制一个时间窗口内请求处理的数量,可将其归为限量(对速度不限制)。
Guava 的 RateLimiter 是令牌桶算法的一种实现,但 RateLimiter 只适用于单机应用,在分布式环境下就不适用了。虽然已有一些开源项目可用于分布式环境下的限流管理,如阿里的Sentinel,但对于小型项目来说,引入Sentinel可能显得有点过重。
分布式实现
基于 Redis 脚本分别实现:
- 基于RateLimiter令牌桶算法的限速控制(严格限制访问速度)
- 基于Lua脚本的限量控制(限制一个时间窗口内的访问量,对访问速度没有严格限制)
限速控制
1. 令牌桶模型
首先定义令牌桶模型,与RateLimiter中类似,包括几个关键属性与关键方法。其中关键属性定义如下,
@Data
public class RedisPermits {
/**
* 最大存储令牌数
*/
private double maxPermits;
/**
* 当前存储令牌数
*/
private double storedPermits;
/**
* 添加令牌的时间间隔/毫秒
*/
private double intervalMillis;
/**
* 下次请求可以获取令牌的时间,可以是过去(令牌积累)也可以是将来的时间(令牌预消费)
*/
private long nextFreeTicketMillis;
//...
关键方法定义与RateLimiter也大同小异,方法注释基本已描述各方法用途,不再赘述。
/**
* 构建Redis令牌数据模型
*
* @param permitsPerSecond 每秒放入的令牌数
* @param maxBurstSeconds maxPermits由此字段计算,最大存储maxBurstSeconds秒生成的令牌
* @param nextFreeTicketMillis 下次请求可以获取令牌的起始时间,默认当前系统时间
*/
public RedisPermits(double permitsPerSecond, double maxBurstSeconds, Long nextFreeTicketMillis) {
this.maxPermits = permitsPerSecond * maxBurstSeconds;
this.storedPermits = maxPermits;
this.intervalMillis = TimeUnit.SECONDS.toMillis(1) / permitsPerSecond;
this.nextFreeTicketMillis = nextFreeTicketMillis;
}
/**
* 基于当前时间,若当前时间晚于nextFreeTicketMicros,则计算该段时间内可以生成多少令牌,将生成的令牌加入令牌桶中并更新数据
*/
public void resync(long nowMillis) {
if (nowMillis > nextFreeTicketMillis) {
double newPermits = (nowMillis - nextFreeTicketMillis) / intervalMillis;
storedPermits = Math.min(maxPermits, storedPermits + newPermits);
nextFreeTicketMillis = nowMillis;
}
}
/**
* 保留指定数量令牌,并返回需要等待的时间
*/
public long reserveAndGetWaitLength(long nowMillis, int permits) {
resync(nowMillis);
double storedPermitsToSpend = Math.min(permits, storedPermits); // 可以消耗的令牌数
double freshPermits = permits - storedPermitsToSpend; // 需要等待的令牌数
long waitMillis = (long) (freshPermits * intervalMillis); // 需要等待的时间
nextFreeTicketMillis = LongMath.saturatedAdd(nextFreeTicketMillis, waitMillis);
storedPermits -= storedPermitsToSpend;
return waitMillis;
}
/**
* 在超时时间内,是否有指定数量的令牌可用
*/
public boolean canAcquire(long nowMillis, int permits, long timeoutMillis) {
return queryEarliestAvailable(nowMillis, permits) <= timeoutMillis;
}
/**
* 指定数量令牌数可用需等待的时间
*
* @param permits 需保留的令牌数
* @return 指定数量令牌可用的等待时间,如果为0或负数,表示当前可用
*/
private long queryEarliestAvailable(long nowMillis, int permits) {
resync(nowMillis);
double storedPermitsToSpend = Math.min(permits, storedPermits); // 可以消耗的令牌数
double freshPermits = permits - storedPermitsToSpend; // 需要等待的令牌数
long waitMillis = (long) (freshPermits * intervalMillis); // 需要等待的时间
return LongMath.saturatedAdd(nextFreeTicketMillis - nowMillis, waitMillis);
}
2. 令牌桶控制类
Guava RateLimiter中的控制都在RateLimiter及其子类中(如SmoothBursty),本处涉及到分布式环境下的同步,因此将其解耦,令牌桶模型存储于Redis中,对其同步操作的控制放置在如下控制类,其中同步控制使用到了分布式锁。
@Slf4j
public class RedisRateLimiter {
/**
* 获取一个令牌,阻塞一直到获取令牌,返回阻塞等待时间
*
* @return time 阻塞等待时间/毫秒
*/
public long acquire(String key) throws IllegalArgumentException {
return acquire(key, 1);
}
/**
* 获取指定数量的令牌,如果令牌数不够,则一直阻塞,返回阻塞等待的时间
*
* @param permits 需要获取的令牌数
* @return time 等待的时间/毫秒
* @throws IllegalArgumentException tokens值不能为负数或零
*/
public long acquire(String key, int permits) throws IllegalArgumentException {
long millisToWait = reserve(key, permits);
log.info("acquire {} permits for key[{}], waiting for {}ms", permits, key, millisToWait);
try {
Thread.sleep(millisToWait);
} catch (InterruptedException e) {
log.error("Interrupted when trying to acquire {} permits for key[{}]", permits, key, e);
}
return millisToWait;
}
/**
* 在指定时间内获取一个令牌,如果获取不到则一直阻塞,直到超时
*
* @param timeout 最大等待时间(超时时间),为0则不等待立即返回
* @param unit 时间单元
* @return 获取到令牌则true,否则false
* @throws IllegalArgumentException
*/
public boolean tryAcquire(String key, long timeout, TimeUnit unit) throws IllegalArgumentException {
return tryAcquire(key, 1, timeout, unit);
}
/**
* 在指定时间内获取指定数量的令牌,如果在指定时间内获取不到指定数量的令牌,则直接返回false,
* 否则阻塞直到能获取到指定数量的令牌
*
* @param permits 需要获取的令牌数
* @param timeout 最大等待时间(超时时间)
* @param unit 时间单元
* @return 如果在指定时间内能获取到指定令牌数,则true,否则false
* @throws IllegalArgumentException tokens为负数或零,抛出异常
*/
public boolean tryAcquire(String key, int permits, long timeout, TimeUnit unit) throws IllegalArgumentException {
long timeoutMillis = Math.max(unit.toMillis(timeout), 0);
checkPermits(permits);
long millisToWait;
boolean locked = false;
try {
locked = lock.lock(key + LOCK_KEY_SUFFIX, WebUtil.getRequestId(), 60, 2, TimeUnit.SECONDS);
if (locked) {
long nowMillis = getNowMillis();
RedisPermits permit = getPermits(key, nowMillis);
if (!permit.canAcquire(nowMillis, permits, timeoutMillis)) {
return false;
} else {
millisToWait = permit.reserveAndGetWaitLength(nowMillis, permits);
permitsRedisTemplate.opsForValue().set(key, permit, expire, TimeUnit.SECONDS);
}
} else {
return false; //超时获取不到锁,也返回false
}
} finally {
if (locked) {
lock.unLock(key + LOCK_KEY_SUFFIX, WebUtil.getRequestId());
}
}
if (millisToWait > 0) {
try {
Thread.sleep(millisToWait);
} catch (InterruptedException e) {
}
}
return true;
}
/**
* 保留指定的令牌数待用
*
* @param permits 需保留的令牌数
* @return time 令牌可用的等待时间
* @throws IllegalArgumentException tokens不能为负数或零
*/
private long reserve(String key, int permits) throws IllegalArgumentException {
checkPermits(permits);
try {
lock.lock(key + LOCK_KEY_SUFFIX, WebUtil.getRequestId(), 60, 2, TimeUnit.SECONDS);
long nowMillis = getNowMillis();
RedisPermits permit = getPermits(key, nowMillis);
long waitMillis = permit.reserveAndGetWaitLength(nowMillis, permits);
permitsRedisTemplate.opsForValue().set(key, permit, expire, TimeUnit.SECONDS);
return waitMillis;
} finally {
lock.unLock(key + LOCK_KEY_SUFFIX, WebUtil.getRequestId());
}
}
/**
* 获取令牌桶
*
* @return
*/
private RedisPermits getPermits(String key, long nowMillis) {
RedisPermits permit = permitsRedisTemplate.opsForValue().get(key);
if (permit == null) {
permit = new RedisPermits(permitsPerSecond, maxBurstSeconds, nowMillis);
}
return permit;
}
/**
* 获取redis服务器时间
*/
private long getNowMillis() {
String luaScript = "return redis.call('time')";
DefaultRedisScript<List> redisScript = new DefaultRedisScript<>(luaScript, List.class);
List<String> now = (List<String>)stringRedisTemplate.execute(redisScript, null);
return now == null ? System.currentTimeMillis() : Long.valueOf(now.get(0))*1000+Long.valueOf(now.get(1))/1000;
}
//...
}
其中:
- acquire 是阻塞方法,如果没有可用的令牌,则一直阻塞直到获取到令牌。
- tryAcquire 则是非阻塞方法,如果在指定超时时间内获取不到指定数量的令牌,则直接返回false,不阻塞等待。
- getNowMillis 获取Redis服务器时间,避免业务服务器时间不一致导致的问题,如果业务服务器能保障时间同步,则可从本地获取提高效率。
3. 令牌桶控制工厂类
工厂类负责管理令牌桶控制类,将其缓存在本地,这里使用了Guava中的Cache,一方面避免每次都新建控制类提高效率,另一方面通过控制缓存的最大容量来避免像用户粒度的限流占用过多的内存。
public class RedisRateLimiterFactory {
private PermitsRedisTemplate permitsRedisTemplate;
private StringRedisTemplate stringRedisTemplate;
private DistributedLock distributedLock;
private Cache<String, RedisRateLimiter> cache = CacheBuilder.newBuilder()
.initialCapacity(100) //初始大小
.maximumSize(10000) // 缓存的最大容量
.expireAfterAccess(5, TimeUnit.MINUTES) // 缓存在最后一次访问多久之后失效
.concurrencyLevel(Runtime.getRuntime().availableProcessors()) // 设置并发级别
.build();
public RedisRateLimiterFactory(PermitsRedisTemplate permitsRedisTemplate, StringRedisTemplate stringRedisTemplate, DistributedLock distributedLock) {
this.permitsRedisTemplate = permitsRedisTemplate;
this.stringRedisTemplate = stringRedisTemplate;
this.distributedLock = distributedLock;
}
/**
* 创建RateLimiter
*
* @param key RedisRateLimiter本地缓存key
* @param permitsPerSecond 每秒放入的令牌数
* @param maxBurstSeconds 最大存储maxBurstSeconds秒生成的令牌
* @param expire 该令牌桶的redis tty/秒
* @return RateLimiter
*/
public RedisRateLimiter build(String key, double permitsPerSecond, double maxBurstSeconds, int expire) {
if (cache.getIfPresent(key) == null) {
synchronized (this) {
if (cache.getIfPresent(key) == null) {
cache.put(key, new RedisRateLimiter(permitsRedisTemplate, stringRedisTemplate, distributedLock, permitsPerSecond,
maxBurstSeconds, expire));
}
}
}
return cache.getIfPresent(key);
}
}
4. 注解支持
定义注解 @RateLimit 如下,表示以每秒rate的速率放置令牌,最多保留burst秒的令牌,取令牌的超时时间为timeout,limitType用于控制key类型,目前支持:
- IP, 根据客户端IP限流
- USER, 根据用户限流,对于Spring Security可从SecurityContextHolder中获取当前用户信息,如userId
- METHOD, 根据方法名全局限流,className.methodName,注意避免同时对同一个类中的同名方法做限流控制,否则需要修改获取key的逻辑
- CUSTOM,自定义,支持表达式解析,如#{id}, #{user.id}
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface RateLimit {
String key() default "";
String prefix() default "rateLimit:"; //key前缀
int expire() default 60; // 表示令牌桶模型RedisPermits redis key的过期时间/秒
double rate() default 1.0; // permitsPerSecond值
double burst() default 1.0; // maxBurstSeconds值
int timeout() default 0; // 超时时间/秒
LimitType limitType() default LimitType.METHOD;
}
通过切面的前置增强来为添加了 @RateLimit 注解的方法提供限流控制,如下
@Aspect
@Slf4j
public class RedisLimitAspect {
//...
@Before(value = "@annotation(rateLimit)")
public void rateLimit(JoinPoint point, RateLimit rateLimit) throws Throwable {
String key = getKey(point, rateLimit.limitType(), rateLimit.key(), rateLimit.prefix());
RedisRateLimiter redisRateLimiter = redisRateLimiterFactory.build(key, rateLimit.rate(), rateLimit.burst(), rateLimit.expire());
if(!redisRateLimiter.tryAcquire(key, rateLimit.timeout(), TimeUnit.SECONDS)){
ExceptionUtil.rethrowClientSideException(LIMIT_MESSAGE);
}
}
//...
限量控制
1. 限量控制类
限制一个时间窗口内的访问量,可使用计数器算法,借助Lua脚本执行的原子性来实现。
Lua脚本逻辑:
- 以需要控制的对象为key(如方法,用户ID,或IP等),当前访问次数为Value,时间窗口值为缓存的过期时间
- 如果key存在则将其增1,判断当前值是否大于访问量限制值,如果大于则返回0,表示该时间窗口内已达访问量上限,如果小于则返回1表示允许访问
- 如果key不存在,则将其初始化为1,并设置过期时间,返回1表示允许访问
public class RedisCountLimiter {
private StringRedisTemplate stringRedisTemplate;
private static final String LUA_SCRIPT = "local c \nc = redis.call('get',KEYS[1]) \nif c and redis.call('incr',KEYS[1]) > tonumber(ARGV[1]) then return 0 end"
+ " \nif c then return 1 else \nredis.call('set', KEYS[1], 1) \nredis.call('expire', KEYS[1], tonumber(ARGV[2])) \nreturn 1 end";
private static final int SUCCESS_RESULT = 1;
private static final int FAIL_RESULT = 0;
public RedisCountLimiter(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
/**
* 是否允许访问
*
* @param key redis key
* @param limit 限制次数
* @param expire 时间段/秒
* @return 获取成功true,否则false
* @throws IllegalArgumentException
*/
public boolean tryAcquire(String key, int limit, int expire) throws IllegalArgumentException {
RedisScript<Number> redisScript = new DefaultRedisScript<>(LUA_SCRIPT, Number.class);
Number result = stringRedisTemplate.execute(redisScript, Collections.singletonList(key), String.valueOf(limit), String.valueOf(expire));
if(result != null && result.intValue() == SUCCESS_RESULT) {
return true;
}
return false;
}
}
2. 注解支持
定义注解 @CountLimit 如下,表示在period时间窗口内,最多允许访问limit次,limitType用于控制key类型,取值与 @RateLimit 同。
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface CountLimit {
String key() default "";
String prefix() default "countLimit:"; //key前缀
int limit() default 1; // expire时间段内限制访问次数
int period() default 1; // 表示时间段/秒
LimitType limitType() default LimitType.METHOD;
}
同样采用前值增强来为添加了 @CountLimit 注解的方法提供限流控制,如下
@Before(value = "@annotation(countLimit)")
public void countLimit(JoinPoint point, CountLimit countLimit) throws Throwable {
String key = getKey(point, countLimit.limitType(), countLimit.key(), countLimit.prefix());
if (!redisCountLimiter.tryAcquire(key, countLimit.limit(), countLimit.period())) {
ExceptionUtil.rethrowClientSideException(LIMIT_MESSAGE);
}
}