CH06-缓存机制
在实际的工作项目中, 缓存成为高并发、高性能架构的关键组件 ,那么Redis为什么可以作为缓存使用呢?首先可以作为缓存的两个主要特征:
- 在分层系统中处于内存/CPU具有访问性能良好,
- 缓存数据饱和,有良好的数据淘汰机制
由于 Redis 天然就具有这两个特征,Redis 基于内存操作的,且其具有完善的数据淘汰机制,十分适合作为缓存组件。
其中,基于内存操作,容量可以为 32-96GB,且操作时间平均为 100ns,操作效率高。而且数据淘汰机制众多,在Redis 4.0 后就有 8 种了促使 Redis 作为缓存可以适用很多场景。
淘汰机制
Redis 对于缓存被写满的情况,就需要缓存数据淘汰机制,通过一定淘汰规则将一些数据刷选出来删除,让缓存服务可再使用。那么 Redis 使用哪些淘汰策略进行刷选删除数据?
在 Redis 4.0 之后,Redis 缓存淘汰策略 6+2 种,包括分成三大类:
- 不淘汰数据
- noeviction ,不进行数据淘汰,当缓存被写满后,Redis不提供服务直接返回错误。
- 在设置过期时间的键值对中,
- volatile-random ,在设置过期时间的键值对中随机删除
- volatile-ttl ,在设置过期时间的键值对,基于过期时间的先后进行删除,越早过期的越先被删除。
- volatile-lru , 基于LRU(Least Recently Used) 算法筛选设置了过期时间的键值对, 最近最少使用的原则来筛选数据
- volatile-lfu ,使用 LFU( Least Frequently Used ) 算法选择设置了过期时间的键值对, 使用频率最少的键值对,来筛选数据。
- 在所有的键值对中
- allkeys-random, 从所有键值对中随机选择并删除数据
- allkeys-lru, 使用 LRU 算法在所有数据中进行筛选
- allkeys-lfu, 使用 LFU 算法在所有数据中进行筛选
Note: LRU( 最近最少使用,Least Recently Used)算法, LRU维护一个双向链表 ,链表的头和尾分别表示 MRU 端和 LRU 端,分别代表最近最常使用的数据和最近最不常用的数据。
LRU 算法在实际实现时,需要用链表管理所有的缓存数据,这会带来额外的空间开销。而且,当有数据被访问时,需要在链表上把该数据移动到 MRU 端,如果有大量数据被访问,就会带来很多链表移动操作,会很耗时,进而会降低 Redis 缓存性能。
其中,LRU和LFU 基于Redis的对象结构redisObject的lru和refcount属性实现的:
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
// 对象最后一次被访问的时间
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
// 引用计数 * and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
Redis的LRU会使用redisObject的lru记录最近一次被访问的时间,随机选取参数maxmemory-samples 配置的数量作为候选集合,在其中选择 lru 属性值最小的数据淘汰出去。
在实际项目中,那么该如何选择数据淘汰机制呢?
- 优先选择
allkeys-lru算法,将最近最常访问的数据留在缓存中,提升应用的访问性能。 - 有顶置数据使用
volatile-lru算法 ,顶置数据不设置缓存过期时间,其他数据设置过期时间,基于LRU 规则进行筛选 。
在理解了Redis缓存淘汰机制后,来看看Redis作为缓存共有多少种模式呢?
缓存模式
Redis 缓存模式基于是否接收写请求,可以分成只读缓存和读写缓存:
只读缓存:只处理读操作,所有的更新操作都在数据库中,这样数据不会有丢失的风险。
- Cache Aside模式
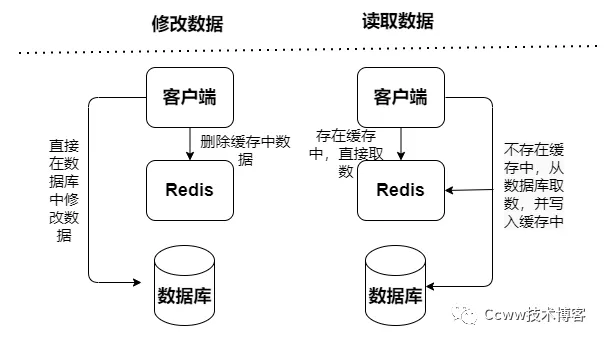
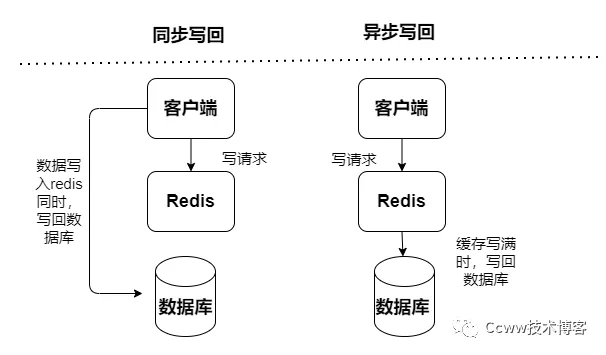
读写缓存:读写操作都在缓存中执行,出现宕机故障,会导致数据丢失。缓存写回数据到数据库有分成两种同步和异步:
同步:访问性能偏低,其更加侧重于保证数据可靠性
- Read-Throug模式
- Write-Through模式
异步:有数据丢失风险,其侧重于提供低延迟访问
- Write-Behind模式
Cache Aside 模式
查询数据先从缓存读取数据,如果缓存中不存在,则再到数据库中读取数据,获取到数据之后更新到缓存Cache中,但更新数据操作,会先去更新数据库种的数据,然后将缓存种的数据失效。
而且Cache Aside模式会存在并发风险:执行读操作未命中缓存,然后查询数据库中取数据,数据已经查询到还没放入缓存,同时一个更新写操作让缓存失效,然后读操作再把查询到数据加载缓存,导致缓存的脏数据。
Read/Write-Throug 模式
查询数据和更新数据都直接访问缓存服务,缓存服务同步方式地将数据更新到数据库。出现脏数据的概率较低,但是就强依赖缓存,对缓存服务的稳定性有较大要求,但同步更新会导致其性能不好。
Write Behind 模式
查询数据和更新数据都直接访问缓存服务,但缓存服务使用异步方式地将数据更新到数据库(通过异步任务) 速度快,效率会非常高,但是数据的一致性比较差,还可能会有数据的丢失情况,实现逻辑也较为复杂。
生产实践
在实际项目开发中根据实际的业务场景需求来进行选择缓存模式。那了解上述后,我们的应用中为什么需要使用到redis缓存呢?
在应用使用Redis缓存可以提高系统性能和并发,主要体现在
- 高性能:基于内存查询,KV结构,简单逻辑运算
- 高并发:
Mysql每秒只能支持2000左右的请求,Redis轻松每秒1W以上。让80%以上查询走缓存,20%以下查询走数据库,能让系统吞吐量有很大的提高
虽然使用Redis缓存可以大大提升系统的性能,但是使用了缓存,会出现一些问题,比如,缓存与数据库双向不一致、缓存雪崩等,对于出现的这些问题该怎么解决呢?
常见问题
使用了缓存,会出现一些问题,主要体现在:
- 缓存与数据库双写不一致
- 缓存雪崩: Redis 缓存无法处理大量的应用请求,转移到数据库层导致数据库层的压力激增;
- 缓存穿透:访问数据不存在在Redis缓存中和数据库中,导致大量访问穿透缓存直接转移到数据库导致数据库层的压力激增;
- 缓存击穿:缓存无法处理高频热点数据,导致直接高频访问数据库导致数据库层的压力激增;
数据一致性
只读缓存(Cache Aside模式)
对于只读缓存(Cache Aside模式),读操作都发生在缓存中,数据不一致只会发生在删改操作上(新增操作不会,因为新增只会在数据库处理),当发生删改操作时,缓存将数据中标志为无效和更新数据库。因此在更新数据库和删除缓存值的过程中,无论这两个操作的执行顺序谁先谁后,只要有一个操作失败了就会出现数据不一致的情况。
总结出,当不存在并发的情况使用重试机制(消息队列使用),当存在高并发的情况,使用延迟双删除(在第一次删除后,睡眠一定时间后,再进行删除),具体如下:
| 操作顺序 | 高并发 | 潜在问题 | 现象 | 应对方案 |
|---|---|---|---|---|
| 先删除缓存,再更新数据库 | 否 | 缓存删除成功,数据库更新失败 | 读到数据库的旧值 | 重试机制(数据库更新) |
| 先更新数据库,再删除缓存 | 否 | 数据库更新成功,缓存删除失败 | 读到缓存的旧值 | 重试机制(缓存删除) |
| 先删除缓存,再更新数据库 | 是 | 缓存删除后,尚未更新数据库,有并发读请求 | 并发读请求读到数据库旧值,并更新到缓存,导致之后的读请求读到旧值 | 延迟双删 |
| 先更新数据库,再删除缓存 | 是 | 数据库更新成功,尚未删除缓存 | 读到缓存的旧值 | 不一致的情况短暂存在,对业务影响较小 |
延迟双删除伪代码:
redis.delKey(X) db.update(X) Thread.sleep(N) redis.delKey(X)
读写缓存(Read/Write-Throug、Write Behind模式 )
对于读写缓存,写操作都发生在缓存中,后再更新数据库,只要有一个操作失败了就会出现数据不一致的情况。
总结出,当不存在并发的情况使用重试机制(消息队列使用),当存在高并发的情况,使用分布锁。具体如下:
| 操作顺序 | 高 并发 | 潜在问题 | 现象 | 应对方案 |
|---|---|---|---|---|
| 先更新缓存,再更新数据库 | 否 | 缓存更新成功,数据库更新失败 | 会从缓存中读到最新值,短期影响不大 | 重试机制(数据库更新) |
| 先更新数据库,再更新缓存 | 否 | 数据库更新成功,缓存更新失败 | 会从缓存读到旧值 | 重试机制(缓存删除) |
| 先更新数据库,再更新缓存 | 写+读并发 | 线程A先更新数据库,之后线程B读取数据,之后线程A更新缓存 | B会命中缓存,读取到旧值 | A更新缓存前,对业务有短暂影响 |
| 先更新缓存,再更新数据库 | 写+读并发 | 线程A先更新缓存成功,之后线程B读取数据,此时线程B命中缓存,读取到最新值后返回,之后线程A更新数据库成功 | B会命中缓存,读取到最新值 | 业务没影响 |
| 先更新数据库,再更新缓存 | 写+写并发 | 线程A和线程B同时更新同一条数据,更新数据库的顺序是先A后B,但更新缓存时顺序是先B后A,这会导致数据库和缓存的不一致 | 数据库和缓存的不一致 | 写操作加分布式锁 |
| 先更新缓存,再更新数据库 | 写+写并发 | 线程A和线程B同时更新同一条数据,更新缓存的顺序是先A后B,但是更新数据库的顺序是先B后A,这也会导致数据库和缓存的不一致 | 数据库和缓存的不一致 | 写操作加分布式锁 |
缓存雪崩
缓存雪崩,由于缓存中有大量数据同时过期失效或者缓存出现宕机,大量的应用请求无法在 Redis 缓存中进行处理,进而发送到数据库层导致数据库层的压力激增,严重的会造成数据库宕机。
对于缓存中有大量数据同时过期,导致大量请求无法得到处理, 解决方式:
数据预热,将发生大并发访问前手动触发加载缓存不同的key, 可以避免在用户请求的时候,先查询数据库
设置不同的过期时间,让缓存失效的时间点尽量均匀
双层缓存策略, 在原始缓存上加上拷贝缓存,原始缓存失效时可以访问拷贝缓存,且原始缓存失效时间设置为短期,拷贝缓存设置为长期
服务降级 , 发生缓存雪崩时,针对不同的数据采取不同的降级方案 ,比如,非核心数据直接返回预定义信息、空值或是错误信息
对于缓存出现宕机,解决方式:
- 业务系统中实现服务熔断或请求限流机制,防止大量访问导致数据库出现宕机
缓存穿透
缓存穿透,数据在数据库和缓存中都不存在,这样就导致查询数据,在缓存中找不到对应key的value,都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。
当有大量访问请求,且其绕过缓存直接查数据库,导致数据库层的压力激增,严重的会造成数据库宕机。
对于缓存穿透,解决方式:
- 缓存空值或缺省值,当一个查询返回的数据为空时, 空结果也将进行缓存,并将它的过期时间设置比较短,下次访问直接从缓存中取值,避免了把大量请求发送给数据库处理,造成数据库出问题。
- 布隆过滤器( BloomFilter ),将所有可能查询数据
key哈希到一个足够大的bitmap中 , 在查询的时候先去BloomFilter去查询key是否存在,如果不存在就直接返回,存在再去查询缓存,缓存中没有再去查询数据库 ,从而避免了数据库层的压力激增出现宕机。
缓存击穿
缓存击穿,针对某个访问非常频繁的热点数据过期失效,导致访问无法在缓存中进行处理,进而会有导致大量的直接请求数据库,从而使得数据库层的压力激增,严重的会造成数据库宕机。
对于缓存击穿,解决方式:
- 不设置过期时间,对于访问特别频繁的热点数据,不设置过期时间。
问题总结
在大多数业务场景下,Redis缓存作为只读缓存使用。针对只读缓存来说, 优先使用先更新数据库再删除缓存的方法保证数据一致性 。
其中,缓存雪崩,缓存穿透,缓存击穿三大问题的原因和解决方式
| 问题 | 原因 | 解决方式 |
|---|---|---|
| 缓存雪崩 | 大量数据同时过期失效缓存出现宕机 | 数据预热设置不同的过期时间双层缓存策略服务降级服务熔断限流机制 |
| 缓存穿透 | 数据在数据库和缓存中都不存在 | 缓存空值或缺省值布隆过滤器( BloomFilter ) |
| 缓存击穿 | 访问非常频繁的热点数据过期失效 | 对于访问特别频繁的热点数据,不设置过期时间 |
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.