CH05-底层结构
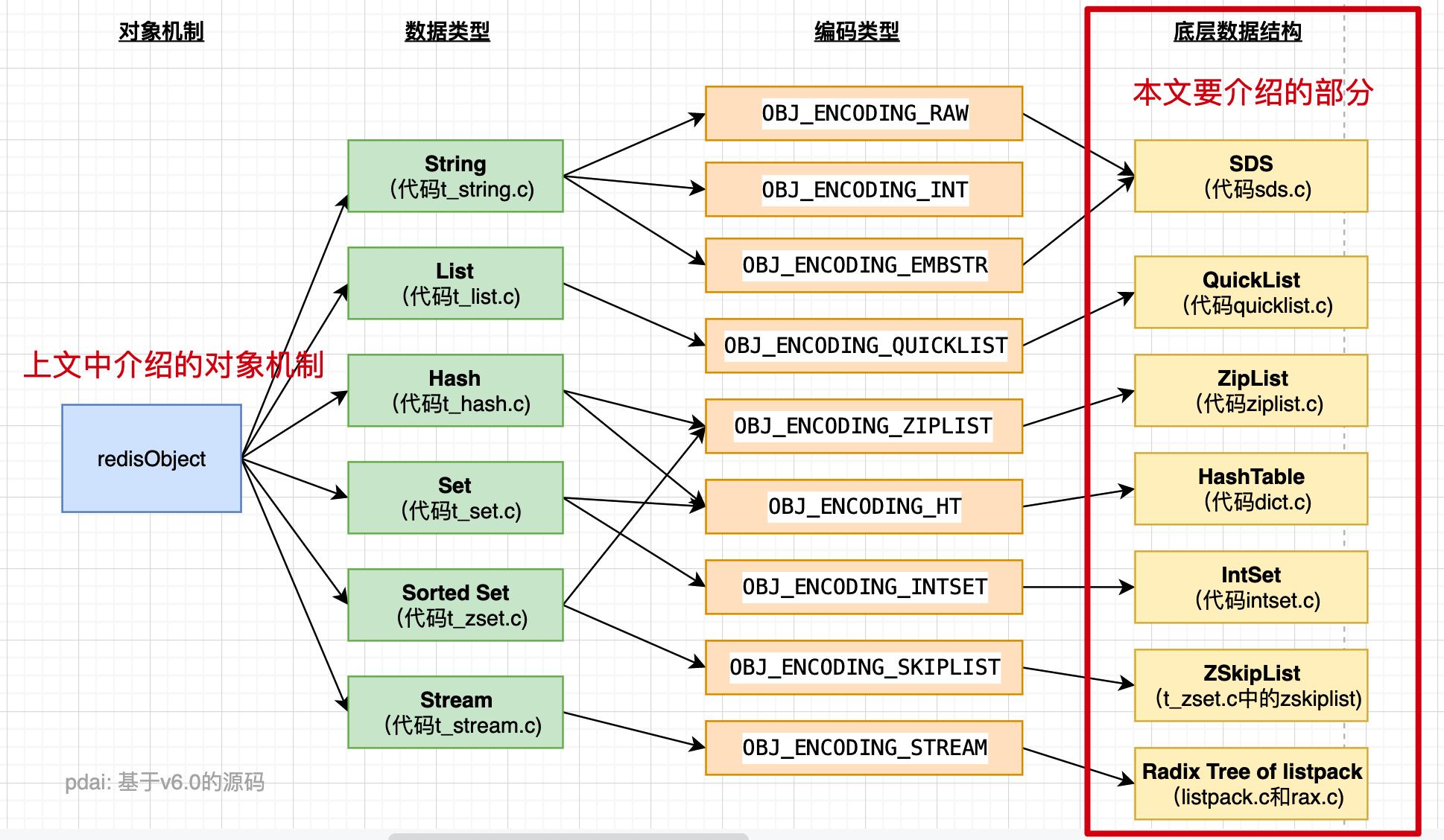
简单动态字符串:SDS
Redis 是用 C 语言写的,但是对于Redis的字符串,却不是 C 语言中的字符串(即以空字符’\0’结尾的字符数组),它是自己构建了一种名为 简单动态字符串(simple dynamic string,SDS)的抽象类型,并将 SDS 作为 Redis的默认字符串表示。
定义
这是一种用于存储二进制数据的一种结构, 具有动态扩容的特点. 其实现位于src/sds.h与src/sds.c中。

其中sdshdr是头部, buf是真实存储用户数据的地方. 另外注意, 从命名上能看出来, 这个数据结构除了能存储二进制数据, 显然是用于设计作为字符串使用的, 所以在buf中, 用户数据后总跟着一个\0. 即图中 "数据" + "\0"是为所谓的buf。
SDS有五种不同的头部. 其中sdshdr5实际并未使用到. 所以实际上有四种不同的头部, 分别如下:
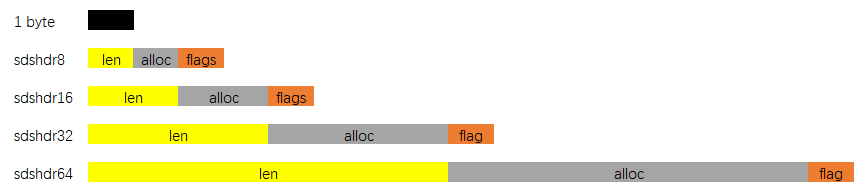
其中:
len保存了SDS保存字符串的长度buf[]数组用来保存字符串的每个元素alloc分别以uint8, uint16, uint32, uint64表示整个SDS, 除过头部与末尾的\0, 剩余的字节数.flags始终为一字节, 以低三位标示着头部的类型, 高5位未使用.
为什么使用SDS
为什么不使用C语言字符串实现,而是使用 SDS呢?这样实现有什么好处?
常数复杂度获取字符串长度
由于 len 属性的存在,我们获取 SDS 字符串的长度只需要读取 len 属性,时间复杂度为 O(1)。而对于 C 语言,获取字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O(n)。通过
strlen key命令可以获取 key 的字符串长度。杜绝缓冲区溢出
我们知道在 C 语言中使用
strcat函数来进行两个字符串的拼接,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。而对于 SDS 数据类型,在进行字符修改的时候,会首先根据记录的 len 属性检查内存空间是否满足需求,如果不满足,会进行相应的空间扩展,然后在进行修改操作,所以不会出现缓冲区溢出。减少修改字符串的内存重新分配次数
C语言由于不记录字符串的长度,所以如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。
而对于SDS,由于
len属性和alloc属性的存在,对于修改字符串SDS实现了空间预分配和惰性空间释放两种策略:空间预分配:对字符串进行空间扩展的时候,扩展的内存比实际需要的多,这样可以减少连续执行字符串增长操作所需的内存重分配次数。惰性空间释放:对字符串进行缩短操作时,程序不立即使用内存重新分配来回收缩短后多余的字节,而是使用alloc属性将这些字节的数量记录下来,等待后续使用。(当然SDS也提供了相应的API,当我们有需要时,也可以手动释放这些未使用的空间。)
二进制安全
因为C字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此C字符串无法正确存取;而所有 SDS 的API 都是以处理二进制的方式来处理
buf里面的元素,并且 SDS 不是以空字符串来判断是否结束,而是以 len 属性表示的长度来判断字符串是否结束。兼容部分 C 字符串函数
虽然 SDS 是二进制安全的,但是一样遵从每个字符串都是以空字符串结尾的惯例,这样可以重用 C 语言库<string.h> 中的一部分函数。
空间预分配补进一步理解
当执行追加操作时,比如现在给key=‘Hello World’的字符串后追加‘ again!’则这时的len=18,free由0变成了18,此时的buf='Hello World again!\0....................'(.表示空格),也就是buf的内存空间是18+18+1=37个字节,其中‘\0’占1个字节redis给字符串多分配了18个字节的预分配空间,所以下次还有append追加的时候,如果预分配空间足够,就无须在进行空间分配了。在当前版本中,当新字符串的长度小于1M时,redis会分配他们所需大小一倍的空间,当大于1M的时候,就为他们额外多分配1M的空间。
思考:这种分配策略会浪费内存资源吗?
答:执行过APPEND 命令的字符串会带有额外的预分配空间,这些预分配空间不会被释放,除非该字符串所对应的键被删除,或者等到关闭Redis 之后,再次启动时重新载入的字符串对象将不会有预分配空间。因为执行APPEND 命令的字符串键数量通常并不多,占用内存的体积通常也不大,所以这一般并不算什么问题。另一方面,如果执行APPEND 操作的键很多,而字符串的体积又很大的话,那可能就需要修改Redis 服务器,让它定时释放一些字符串键的预分配空间,从而更有效地使用内存。
小结
redis的字符串表示为sds,而不是C字符串(以\0结尾的char*), 它是Redis 底层所使用的字符串表示,它被用在几乎所有的Redis 模块中。可以看如下对比:
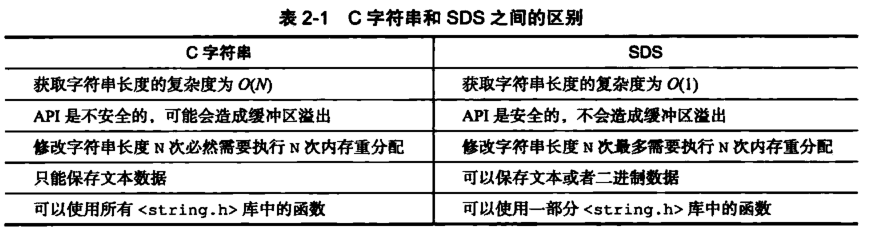
一般来说,SDS 除了保存数据库中的字符串值以外,SDS 还可以作为缓冲区(buffer):包括 AOF 模块中的AOF缓冲区以及客户端状态中的输入缓冲区
压缩列表:ZipList
ziplist是为了提高存储效率而设计的一种特殊编码的双向链表。它可以存储字符串或者整数,存储整数时是采用整数的二进制而不是字符串形式存储。他能在O(1)的时间复杂度下完成list两端的push和pop操作。但是因为每次操作都需要重新分配ziplist的内存,所以实际复杂度和ziplist的内存使用量相关。
ZipList 结构
整个ziplist在内存中的存储格式如下:

zlbytes字段的类型是uint32_t, 这个字段中存储的是整个ziplist所占用的内存的字节数zltail字段的类型是uint32_t, 它指的是ziplist中最后一个entry的偏移量. 用于快速定位最后一个entry, 以快速完成pop等操作zllen字段的类型是uint16_t, 它指的是整个ziplit中entry的数量. 这个值只占2bytes(16位): 如果ziplist中entry的数目小于65535(2的16次方), 那么该字段中存储的就是实际entry的值. 若等于或超过65535, 那么该字段的值固定为65535, 但实际数量需要一个个entry的去遍历所有entry才能得到.zlend是一个终止字节, 其值为全F, 即0xff. ziplist保证任何情况下, 一个entry的首字节都不会是255
Entry 结构
第一种情况:一般结构 <prevlen> <encoding> <entry-data>
prevlen:前一个entry的大小,编码方式见下文;
encoding:不同的情况下值不同,用于表示当前entry的类型和长度;
entry-data:真是用于存储entry表示的数据;
第二种情况:在entry中存储的是int类型时,encoding和entry-data会合并在encoding中表示,此时没有entry-data字段;
redis中,在存储数据时,会先尝试将string转换成int存储,节省空间;
此时entry结构:<prevlen> <encoding>
- prevlen编码
当前一个元素长度小于254(255用于zlend)的时候,prevlen长度为1个字节,值即为前一个entry的长度,如果长度大于等于254的时候,prevlen用5个字节表示,第一字节设置为254,后面4个字节存储一个小端的无符号整型,表示前一个entry的长度;
<prevlen from 0 to 253> <encoding> <entry> //长度小于254结构
0xFE <4 bytes unsigned little endian prevlen> <encoding> <entry> //长度大于等于254
- encoding编码
encoding的长度和值根据保存的是int还是string,还有数据的长度而定;
前两位用来表示类型,当为“11”时,表示entry存储的是int类型,其他表示存储的是string;
存储string时:
|00pppppp| :此时encoding长度为1个字节,该字节的后六位表示entry中存储的string长度,因为是6位,所以entry中存储的string长度不能超过63;
|01pppppp|qqqqqqqq| 此时encoding长度为两个字节;此时encoding的后14位用来存储string长度,长度不能超过16383;
|10000000|qqqqqqqq|rrrrrrrr|ssssssss|ttttttt| 此时encoding长度为5个字节,后面的4个字节用来表示encoding中存储的字符串长度,长度不能超过2^32 - 1;
存储int时:
|11000000| encoding为3个字节,后2个字节表示一个int16;
|11010000| encoding为5个字节,后4个字节表示一个int32;
|11100000| encoding 为9个字节,后8字节表示一个int64;
|11110000| encoding为4个字节,后3个字节表示一个有符号整型;
|11111110| encoding为2字节,后1个字节表示一个有符号整型;
|1111xxxx| encoding长度就只有1个字节,xxxx表示一个0 - 12的整数值;
|11111111| 还记得zlend么?
- 源码中数据结构支撑
你可以看到为了操作上的简易实际还增加了几个属性
/* We use this function to receive information about a ziplist entry.
* Note that this is not how the data is actually encoded, is just what we
* get filled by a function in order to operate more easily. */
typedef struct zlentry {
unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
unsigned int prevrawlen; /* Previous entry len. */
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;
prevrawlensize表示 previous_entry_length字段的长度prevrawlen表示 previous_entry_length字段存储的内容lensize表示 encoding字段的长度len表示数据内容长度headersize表示当前元素的首部长度,即previous_entry_length字段长度与encoding字段长度之和encoding表示数据类型p表示当前元素首地址
为什么ZipList特别省内存
- ziplist节省内存是相对于普通的list来说的,如果是普通的数组,那么它每个元素占用的内存是一样的且取决于最大的那个元素(很明显它是需要预留空间的);
- 所以ziplist在设计时就很容易想到要尽量让每个元素按照实际的内容大小存储,所以增加encoding字段,针对不同的encoding来细化存储大小;
- 这时候还需要解决的一个问题是遍历元素时如何定位下一个元素呢?在普通数组中每个元素定长,所以不需要考虑这个问题;但是ziplist中每个data占据的内存不一样,所以为了解决遍历,需要增加记录上一个元素的length,所以增加了prelen字段。
为什么我们去研究ziplist特别节省内存的数据结构? 在实际应用中,大量存储字符串的优化是需要你对底层的数据结构有一定的理解的,而ziplist在场景优化的时候也被考虑采用的首选。
缺点
- ziplist也不预留内存空间, 并且在移除结点后, 也是立即缩容, 这代表每次写操作都会进行内存分配操作.
- 结点如果扩容, 导致结点占用的内存增长, 并且超过254字节的话, 可能会导致链式反应: 其后一个结点的entry.prevlen需要从一字节扩容至五字节.
- 最坏情况下, 第一个结点的扩容, 会导致整个ziplist表中的后续所有结点的entry.prevlen字段扩容.
- 虽然这个内存重分配的操作依然只会发生一次, 但代码中的时间复杂度是o(N)级别, 因为链式扩容只能一步一步的计算.
- 但这种情况的概率十分的小, 一般情况下链式扩容能连锁反映五六次就很不幸了.
- 这样的坏场景下, 其实时间复杂度并不高: 依次计算每个entry新的空间占用, 也就是o(N), 总体占用计算出来后, 只执行一次内存重分配, 与对应的memmove操作, 就可以了.
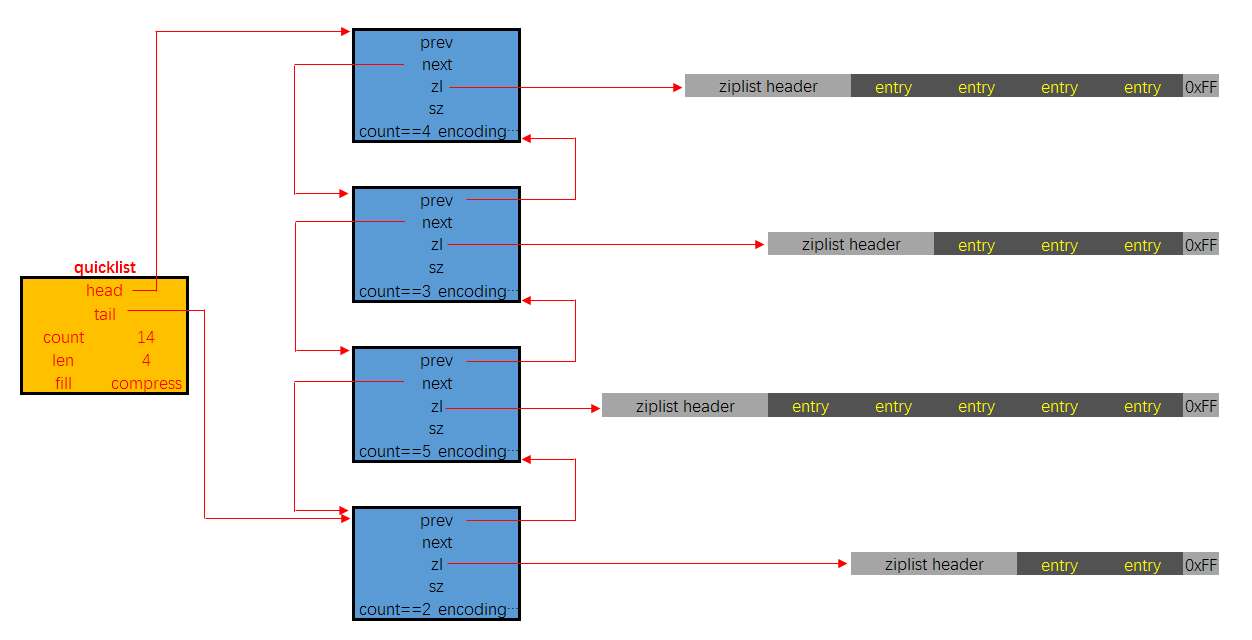
快表:QuickList
quicklist这个结构是Redis在3.2版本后新加的, 之前的版本是list(即linkedlist), 用于String数据类型中。
它是一种以ziplist为结点的双端链表结构. 宏观上, quicklist是一个链表, 微观上, 链表中的每个结点都是一个ziplist。
QuickList 结构
内部定义了6个结构体:
quicklistNode, 宏观上, quicklist是一个链表, 这个结构描述的就是链表中的结点. 它通过zl字段持有底层的ziplist. 简单来讲, 它描述了一个ziplist实例quicklistLZF, ziplist是一段连续的内存, 用LZ4算法压缩后, 就可以包装成一个quicklistLZF结构. 是否压缩quicklist中的每个ziplist实例是一个可配置项. 若这个配置项是开启的, 那么quicklistNode.zl字段指向的就不是一个ziplist实例, 而是一个压缩后的quicklistLZF实例quicklistBookmark, 在quicklist尾部增加的一个书签,它只有在大量节点的多余内存使用量可以忽略不计的情况且确实需要分批迭代它们,才会被使用。当不使用它们时,它们不会增加任何内存开销。quicklist. 这就是一个双链表的定义. head, tail分别指向头尾指针. len代表链表中的结点. count指的是整个quicklist中的所有ziplist中的entry的数目. fill字段影响着每个链表结点中ziplist的最大占用空间, compress影响着是否要对每个ziplist以LZ4算法进行进一步压缩以更节省内存空间.quicklistIter是一个迭代器quicklistEntry是对ziplist中的entry概念的封装. quicklist作为一个封装良好的数据结构, 不希望使用者感知到其内部的实现, 所以需要把ziplist.entry的概念重新包装一下.
内存布局图
更多信息
下面是有关quicklist的更多额外信息:
quicklist.fill的值影响着每个链表结点中, ziplist的长度.
- 当数值为负数时, 代表以字节数限制单个ziplist的最大长度. 具体为:
- -1 不超过4kb
- -2 不超过 8kb
- -3 不超过 16kb
- -4 不超过 32kb
- -5 不超过 64kb
- 当数值为正数时, 代表以entry数目限制单个ziplist的长度. 值即为数目. 由于该字段仅占16位, 所以以entry数目限制ziplist的容量时, 最大值为2^15个
quicklist.compress的值影响着quicklistNode.zl字段指向的是原生的ziplist, 还是经过压缩包装后的quicklistLZF
- 0 表示不压缩, zl字段直接指向ziplist
- 1 表示quicklist的链表头尾结点不压缩, 其余结点的zl字段指向的是经过压缩后的quicklistLZF
- 2 表示quicklist的链表头两个, 与末两个结点不压缩, 其余结点的zl字段指向的是经过压缩后的quicklistLZF
- 以此类推, 最大值为2^16
quicklistNode.encoding字段, 以指示本链表结点所持有的ziplist是否经过了压缩. 1代表未压缩, 持有的是原生的ziplist, 2代表压缩过quicklistNode.container字段指示的是每个链表结点所持有的数据类型是什么. 默认的实现是ziplist, 对应的该字段的值是2, 目前Redis没有提供其它实现. 所以实际上, 该字段的值恒为2quicklistNode.recompress字段指示的是当前结点所持有的ziplist是否经过了解压. 如果该字段为1即代表之前被解压过, 且需要在下一次操作时重新压缩.
quicklist的具体实现代码篇幅很长, 这里就不贴代码片断了, 从内存布局上也能看出来, 由于每个结点持有的ziplist是有上限长度的, 所以在与操作时要考虑的分支情况比较多。
quicklist有自己的优点, 也有缺点, 对于使用者来说, 其使用体验类似于线性数据结构, list作为最传统的双链表, 结点通过指针持有数据, 指针字段会耗费大量内存. ziplist解决了耗费内存这个问题. 但引入了新的问题: 每次写操作整个ziplist的内存都需要重分配. quicklist在两者之间做了一个平衡. 并且使用者可以通过自定义quicklist.fill, 根据实际业务情况, 经验主义调参.
字典:Dict
数据结构
哈希表结构定义:
typedef struct dictht{
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
//总是等于 size-1
unsigned long sizemask;
//该哈希表已有节点的数量
unsigned long used;
}dictht
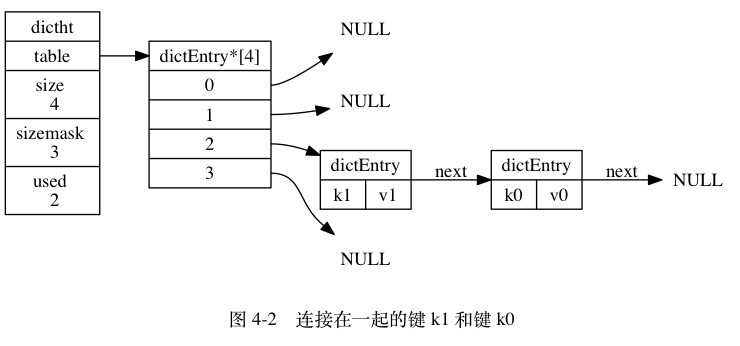
哈希表是由数组 table 组成,table 中每个元素都是指向 dict.h/dictEntry 结构,dictEntry 结构定义如下:
typedef struct dictEntry{
//键
void *key;
//值
union{
void *val;
uint64_tu64;
int64_ts64;
}v;
//指向下一个哈希表节点,形成链表
struct dictEntry *next;
}dictEntry
key 用来保存键,val 属性用来保存值,值可以是一个指针,也可以是uint64_t整数,也可以是int64_t整数。
注意这里还有一个指向下一个哈希表节点的指针,我们知道哈希表最大的问题是存在哈希冲突,如何解决哈希冲突,有开放地址法和链地址法。这里采用的便是链地址法,通过next这个指针可以将多个哈希值相同的键值对连接在一起,用来解决哈希冲突。
要点理解
- 哈希算法:Redis计算哈希值和索引值方法如下:
#1、使用字典设置的哈希函数,计算键 key 的哈希值
hash = dict->type->hashFunction(key);
#2、使用哈希表的sizemask属性和第一步得到的哈希值,计算索引值
index = hash & dict->ht[x].sizemask;
解决哈希冲突:这个问题上面我们介绍了,方法是链地址法。通过字典里面的 *next 指针指向下一个具有相同索引值的哈希表节点。
扩容和收缩:当哈希表保存的键值对太多或者太少时,就要通过 rerehash(重新散列)来对哈希表进行相应的扩展或者收缩。具体步骤:
1、如果执行扩展操作,会基于原哈希表创建一个大小等于
ht[0].used*2n的哈希表(也就是每次扩展都是根据原哈希表已使用的空间扩大一倍创建另一个哈希表)。相反如果执行的是收缩操作,每次收缩是根据已使用空间缩小一倍创建一个新的哈希表。2、重新利用上面的哈希算法,计算索引值,然后将键值对放到新的哈希表位置上。
3、所有键值对都迁徙完毕后,释放原哈希表的内存空间。
触发扩容的条件:
1、服务器目前没有执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于1。
2、服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于5。
ps:负载因子 = 哈希表已保存节点数量 / 哈希表大小。
渐近式 rehash
- 什么叫渐进式 rehash?也就是说扩容和收缩操作不是一次性、集中式完成的,而是分多次、渐进式完成的。如果保存在Redis中的键值对只有几个几十个,那么 rehash 操作可以瞬间完成,但是如果键值对有几百万,几千万甚至几亿,那么要一次性的进行 rehash,势必会造成Redis一段时间内不能进行别的操作。所以Redis采用渐进式 rehash,这样在进行渐进式rehash期间,字典的删除查找更新等操作可能会在两个哈希表上进行,第一个哈希表没有找到,就会去第二个哈希表上进行查找。但是进行 增加操作,一定是在新的哈希表上进行的。
整数集:IntSet
整数集合(intset)是集合类型的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis 就会使用整数集合作为集合键的底层实现。
结构
首先看源码结构
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
encoding表示编码方式,的取值有三个:INTSET_ENC_INT16, INTSET_ENC_INT32, INTSET_ENC_INT64length代表其中存储的整数的个数contents指向实际存储数值的连续内存区域, 就是一个数组;整数集合的每个元素都是 contents 数组的一个数组项(item),各个项在数组中按值得大小从小到大有序排序,且数组中不包含任何重复项。(虽然 intset 结构将 contents 属性声明为 int8_t 类型的数组,但实际上 contents 数组并不保存任何 int8_t 类型的值,contents 数组的真正类型取决于 encoding 属性的值)
内存布局

content数组里面每个元素的数据类型是由encoding来决定的,那么如果原来的数据类型是int16, 当我们再插入一个int32类型的数据时怎么办呢?这就是下面要说的intset的升级。
升级
当在一个int16类型的整数集合中插入一个int32类型的值,整个集合的所有元素都会转换成32类型。 整个过程有三步:
- 根据新元素的类型(比如int32),扩展整数集合底层数组的空间大小,并为新元素分配空间。
- 将底层数组现有的所有元素都转换成与新元素相同的类型, 并将类型转换后的元素放置到正确的位上, 而且在放置元素的过程中, 需要继续维持底层数组的有序性质不变。
- 最后改变encoding的值,length+1。
那么如果我们删除掉刚加入的int32类型时,会不会做一个降级操作呢?
不会。主要还是减少开销的权衡。
跳表:ZSkipList
跳跃表结构在 Redis 中的运用场景只有一个,那就是作为有序列表 (Zset) 的使用。跳跃表的性能可以保证在查找,删除,添加等操作的时候在对数期望时间内完成,这个性能是可以和平衡树来相比较的,而且在实现方面比平衡树要优雅,这就是跳跃表的长处。
跳跃表的缺点就是需要的存储空间比较大,属于利用空间来换取时间的数据结构。
跳跃表
对于于一个单链表来讲,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高,是 O(n)。比如查找12,需要7次查找:

如果我们增加如下两级索引,那么它搜索次数就变成了3次:

Redis 跳跃表
redis跳跃表并没有在单独的类(比如skplist.c)中定义,而是其定义在server.h中, 如下:
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
内存布局:
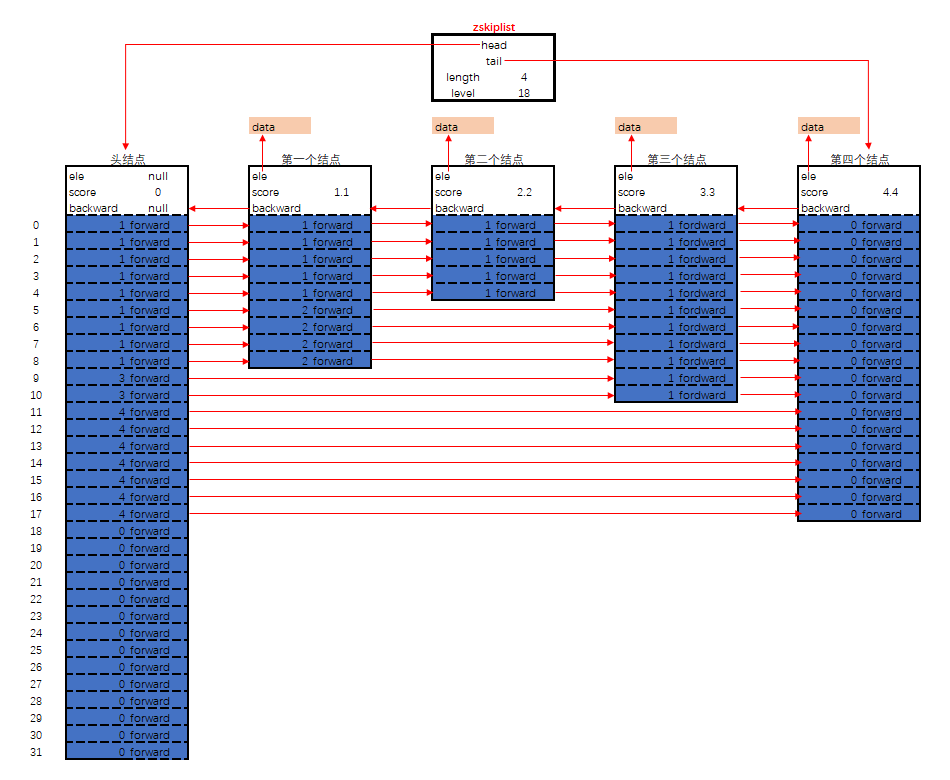
zskiplist的核心设计要点
头结点不持有任何数据, 且其level[]的长度为32
每个结点
ele字段,持有数据,是sds类型score字段, 其标示着结点的得分, 结点之间凭借得分来判断先后顺序, 跳跃表中的结点按结点的得分升序排列.backward指针, 这是原版跳跃表中所没有的. 该指针指向结点的前一个紧邻结点.level字段, 用以记录所有结点(除过头结点外);每个结点中最多持有32个zskiplistLevel结构. 实际数量在结点创建时, 按幂次定律随机生成(不超过32). 每个zskiplistLevel中有两个字段
forward字段指向比自己得分高的某个结点(不一定是紧邻的), 并且, 若当前zskiplistLevel实例在level[]中的索引为X, 则其forward字段指向的结点, 其level[]字段的容量至少是X+1. 这也是上图中, 为什么forward指针总是画的水平的原因.span字段代表forward字段指向的结点, 距离当前结点的距离. 紧邻的两个结点之间的距离定义为1.
为什么不选择平衡树或哈希表
作者:
There are a few reasons:
They are not very memory intensive. It’s up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees. A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
About the Append Only durability & speed, I don’t think it is a good idea to optimize Redis at cost of more code and more complexity for a use case that IMHO should be rare for the Redis target (fsync() at every command). Almost no one is using this feature even with ACID SQL databases, as the performance hint is big anyway. About threads: our experience shows that Redis is mostly I/O bound. I’m using threads to serve things from Virtual Memory. The long term solution to exploit all the cores, assuming your link is so fast that you can saturate a single core, is running multiple instances of Redis (no locks, almost fully scalable linearly with number of cores), and using the “Redis Cluster” solution that I plan to develop in the future.
简而言之就是实现简单且达到了类似效果。
skiplist和各种平衡树(如AVL、红黑树等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做单个key的查找,不适宜做范围查找。所谓范围查找,指的是查找那些大小在指定的两个值之间的所有节点。
在做范围查找的时候,平衡树比skiplist操作要复杂。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在skiplist上进行范围查找就非常简单,只需要在找到小值之后,对第1层链表进行若干步的遍历就可以实现。
平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
从内存占用上来说,skiplist比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
查找单个key,skiplist和平衡树的时间复杂度都为O(log n),大体相当;而哈希表在保持较低的哈希值冲突概率的前提下,查找时间复杂度接近O(1),性能更高一些。所以我们平常使用的各种Map或dictionary结构,大都是基于哈希表实现的。
从算法实现难度上来比较,skiplist比平衡树要简单得多。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.