版本与性能
Web性能的隐性规则是减少终端用户能够感知到的延迟;在用户之前获得页面并使交互变得尽可能的快。
至于HTTP而言,这意味着一个理想的协议交互看起来像这样:
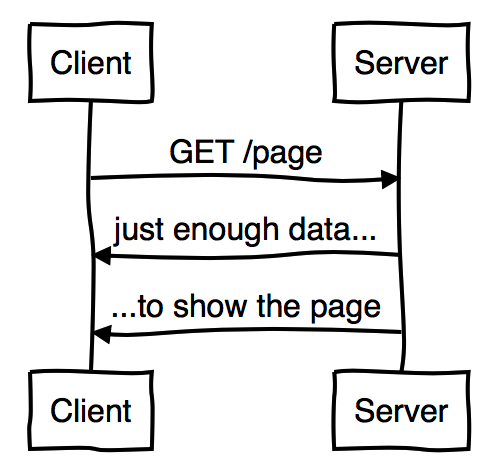
意思就是一个页面的加载过程中,需要在最少的往返次数中,发送尽可能少的数据到服务端,然后下载尽可能少的必须的数据。
额外数数据同时意味着更多的转换时间和更多的出错机会,比如拥堵或者丢包,这将严重的影响性能。
由于协议“隔阂(chattiness)”的更多往返次数会带来更多的延迟,尤其是移动网络(一个往返100ms可以作为你最好的预期)。
如果这是最理想的情况,那HTTP是如何度量的?我们又如何来提升呢?
HTTP/0.9
HTTP/0.9 诞生于 1991 年,是 HTTP 协议的最初版,构造十分简单:
- 请求端只支持 GET 请求
- 响应端只能返回 HTML 文本数据
GET /index.html
<html>
<body>
Hello World
</body>
</html>
请求示意图如下:

可以看到,HTTP/0.9 只能发送 GET 请求,且每一个请求都单独创建一个 TCP 连接,响应端只能返回 HTML 格式的数据,响应完成之后 TCP 请求断开。
这样的请求方式虽然能够满足当时的使用需求,但也还是暴露出了一些问题。
HTTP/0.9 痛点:
- 请求方式唯一,返回格式唯一
- TCP 连接无法复用
HTTP/1.0
HTTP/1.0 诞生于 1996 年,它在 HTTP/0.9 的基础上,增加了 HTTP 头部字段,极大扩展了 HTTP 的使用场景。这个版本的 HTTP 不仅可以传输文字,还能传输图像、视频、二进制文件,为互联网的迅速发展奠定了坚实的基础。
核心特点如下:
请求端增加 HTTP 协议版本,响应端增加状态码。
请求方法增加 POST、HEAD。
请求端和响应端增加头部字段。
- Content-Type 让响应数据不只限于超文本。
- Expires、Last-Modified 缓存头。
- Authorization 身份认证。
- Connection: keep-alive 支持长连接,但非标准。
GET /mypage.html HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
200 OK
Date: Tue, 15 Nov 1994 08:12:31 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/html
<html>
<body>
Hello World
</body>
</html>
请求示意图如下:
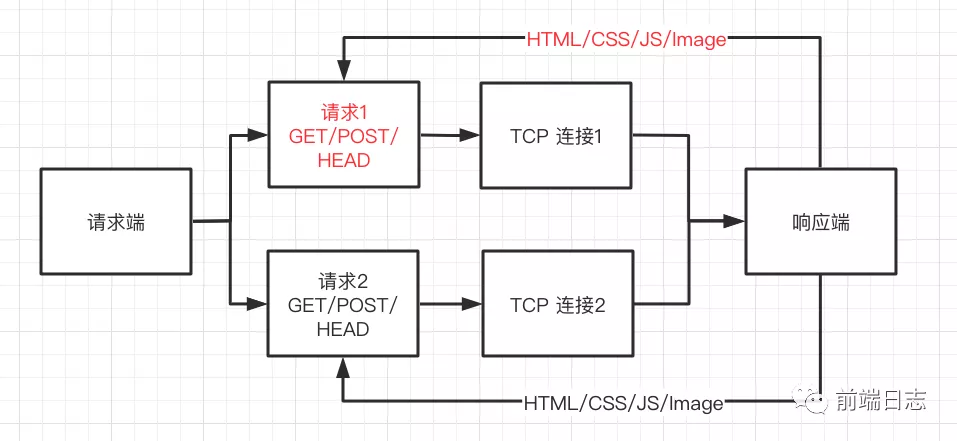
HTTP/1.0 扩展了请求方法和响应状态码,并且支持定义 HTTP 头部字段,通过 Content-Type 头,我们就能传输任何格式的数据了。同时可以看出,HTTP/1.0 仍然是一个请求对应一个 TCP 连接,不能形成复用。
HTTP/1.0 痛点:
- TCP 连接无法复用。
- HTTP 队头阻塞,一个 HTTP 请求响应结束之后,才能发起下一个 HTTP 请求。
- 一台服务器只能提供一个 HTTP 服务。
HTTP/1.1
HTTP/1.1 诞生于 1999 年,它进一步完善了 HTTP 协议,一直用到了 20 多年后的今天,仍然是使用最广的 HTTP 版本。
核心特点如下:
持久连接。
- HTTP/1.1 默认开启持久连接,在 TCP 连接建立后不立即关闭,让多个 HTTP 请求得以复用。
管线化技术。
- HTTP/1.1 中,多个 HTTP 请求不用排队发送,可以批量发送,这就解决了 HTTP 队头阻塞问题。但批量发送的 HTTP 请求,必须按照发送的顺序返回响应,相当于问题解决了一半,仍然不是最佳体验。
支持响应分块。
- HTTP/1.1 实现了流式渲染,响应端可以不用一次返回所有数据,可以将数据拆分成多个模块,产生一块数据,就发送一块数据,这样客户端就可以同步对数据进行处理,减少响应延迟,降低白屏时间。
- Bigpipe 的实现就是基于这个特性,具体是通过定义
Transfer-Encoding头来实现的。
增加 Host 头。
- HTTP/1.1 实现了虚拟主机技术,将一台服务器分成若干个主机,这样就可以在一台服务器上部署多个网站了。
- 通过配置 Host 的域名和端口号,即可支持多个 HTTP 服务:
Host: <domain>:<port>
其他扩展。
- 增加 Cache-Control、E-Tag 缓存头。
- 增加 PUT、PATCH、HEAD、 OPTIONS、DELETE 请求方法。
GET /en-US/docs/Glossary/Simple_header HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header
200 OK
Connection: Keep-Alive
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
Date: Wed, 20 Jul 2016 10:55:30 GMT
Etag: "547fa7e369ef56031dd3bff2ace9fc0832eb251a"
Keep-Alive: timeout=5, max=1000
Last-Modified: Tue, 19 Jul 2016 00:59:33 GMT
Server: Apache
Transfer-Encoding: chunked
Vary: Cookie, Accept-Encoding
<html>
<body>
Hello World
</body>
</html>
请求示意图如下:
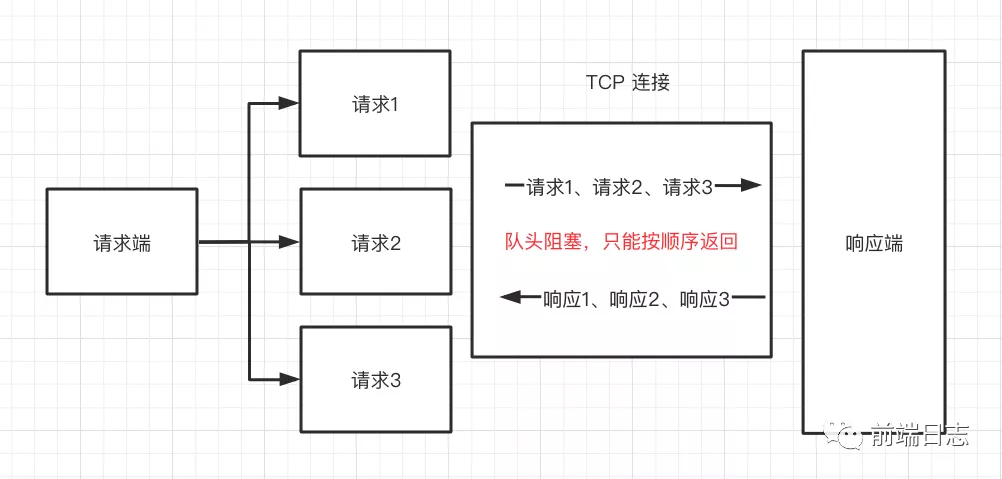
可以看到,HTTP/1.1 可以并行发起多个请求,并且也能复用同一个 TCP 连接,传输效率得到了提升。但响应端只能按照发送的顺序进行返回,为此很多浏览器会为每个域名至多打开 6 个连接,用增加队列的方式减少 HTTP 队头阻塞。
HTTP/1.1 痛点:
- HTTP 队头阻塞没有彻底解决,响应端必须按照 HTTP 的发送顺序进行返回,如果排序靠前的响应特别耗时,则会阻塞排序靠后的所有响应。
扩展阅读
多种原因说明HTTP/1.1是一个很好的协议,但遗憾的是现代的Web工作方式意味着性能并不是其中之一。一个典型的页面加载方式看起来会是这样:
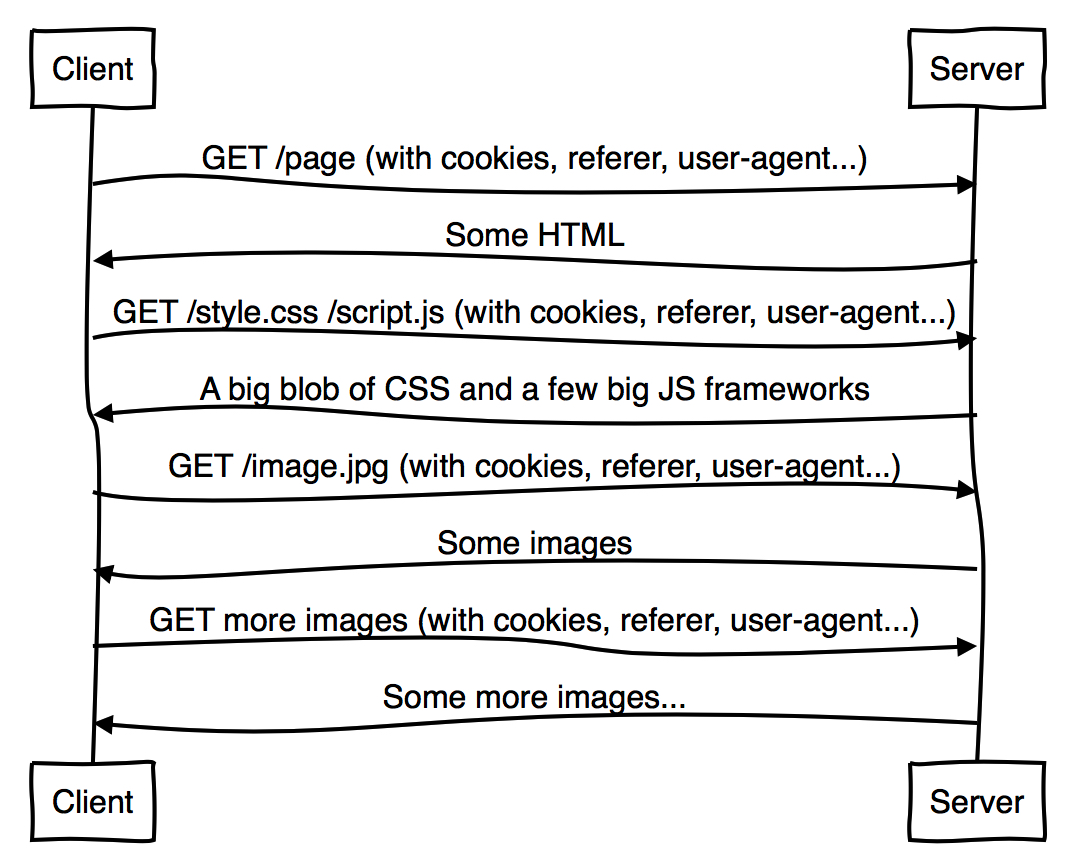
这并不是特别的理想。
Web使用的HTTP/1是非常“饶舌”的,因为客户端需要多次去请求服务端以寻求它需要的更多东西;首先是HTML,然后是CSS和Javascript。每次这样的交互都会增加新的一个或多个往返从而增加了页面加载的延迟,这与理想中的“最少的往返次数”相悖。
此外,仅对页面的请求就增加了大量的数据,这与理想中的“发送尽可能少的数据到服务端”相悖。这是因为比如Referer、User-Agent、Cookie这样的冗长Header信息会在每次请求中重复,并且又被大量的Web页面所需要的资源加倍增长。
最终,由于HTTP/1的head-of-line blocking问题(线头阻塞:队列首个packet由于他的目的端口正忙而被延迟转发),将多个资源组装到一个大的CSS代码、内嵌或连接,成为了一个普遍的最佳实践。这些都是HTTP/1中漂亮的性能hack,但是他们同样有一个损失:他们下载了远多于客户端需求的数据来显示一个页面,这与我们的理想相悖,并不能做到尽可能快的展示页面。
总的来说,HTTP/1并是不是一无是处,性能上的智能。举例来说,它拥有缓存,允许你在一个新的拷贝时完全不需要网络。还有受限制的请求,当有一个老的拷贝时避免你去转换大的东西。
HTTP/2
HTTP/2 诞生于 2015 年,它的最大的特点是 All in 二进制,基于二进制的特性,对 HTTP 传输效率进行了深度优化。
HTTP/2 将一个 HTTP 请求划分为 3 个部分:
- 帧:一段二进制数据,是 HTTP/2 传输的最小单位。
- 消息:一个请求或响应对应的一个或多个帧。
- 数据流:已建立的连接内的双向字节流,可以承载一条或多条消息。
HTTP/2 核心特点如下:
请求优先级
- 多个 HTTP 请求同时发送时,会产生多个数据流,数据流中有一个优先级的标识,服务器端可以根据这个标识来决定响应的优先顺序。
多路复用
- TCP 传输时,不用按照 HTTP 的发送顺序进行响应,可以交错发送,接收端根据帧首部的标识符,就能找到对应的流,进而重新组合得到最终数据。
服务器端推送
- HTTP/2 允许服务器未经请求,主动向客户端发送资源,并缓存到客户端中,以避免二次请求。
- HTTP/1.1 中请求一个页面时,浏览器会先发送一个 HTTP 请求,然后得到响应的 HTML 内容并开始解析,如果发现有
<script src="xxxx.js">标签,则会再次发起 HTTP 请求获取对应的 JS 内容。而 HTTP/2 可以在返回 HTML 的同时,将需要用到的 JS、CSS 等内容一并返回给客户端,当浏览器解析到对应标签时,也就不需要再次发起请求了。
头部压缩
- HTTP/1.1 的头部字段包含大量信息,而且每次请求都得带上,占用了大量的字节。
- HTTP/2.0 中通信双方各自缓存一份头部字段表,如:把
Content-Type:text/html存入索引表中,后续如果要用到这个头,只需要发送对应的索引号就可以了。
除此之外,虽然 HTTP/2 没有规定必须使用 TLS 安全协议,但所有实现 HTTP/2 的 Web 浏览器都只支持配置过 TLS 的网站,这是为了鼓励大家使用更加安全的 HTTPS。
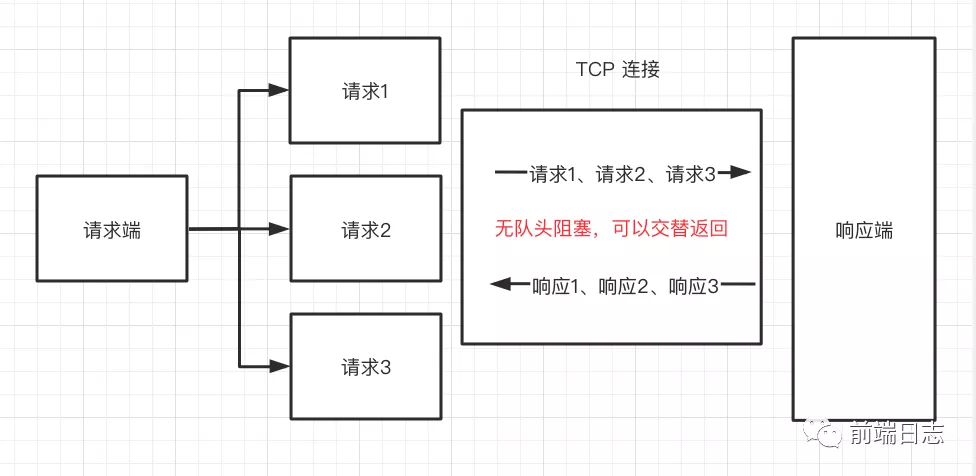
可以看到,在 HTTP/2 中发送请求时,既不需要排队发送,也不需要排队返回,彻底解决了 HTTP 队头阻塞问题。对于头部信息,资源缓存等痛点也进行了优化,似乎已经是一种很完美的方案了。
HTTP/2 在 HTTP + TCP 的架构上已经优化到了极致,如果要想继续优化,那就只能从这个架构入手了。
首先需要优化的是 TCP,因为 TCP 核心是保证传输层的可靠性,传输效率其实并不好。
- TCP 也存在队头阻塞,TCP 在传输时使用序列号标识数据的顺序,一旦某个数据丢失,后面的数据需要等待这个数据重传后才能进行下一步处理。
- TCP 每一次建立都需要三次握手,释放连接需要四次挥手,无形中增加了传输时长。
- TCP 存在拥塞控制,内置了慢启动,拥塞避免等算法,传输效率并不稳定。
扩展阅读
HTTP/2试图通过几种方式去解决HTTP/1.1中的问题:
- 完全的复用意味着线头阻塞不再是问题。可以通过单个HTTP连接加载整个Web页面,而不用担心创建了多少个请求。数据浪费的优化技巧可以被丢下了。
- Header压缩移除了由于冗长头部信息引起的单个消息的消耗。现在可以将数十个甚至数百个请求合并到仅仅一些IP包中。这更接近于理想中的两种“更少的数据”。
- HTTP/2的服务端PUSH主动提供客户端的需要,避免更多的往复次数带来的消耗。
因此,HTTP/2的运作看起来会像这样:
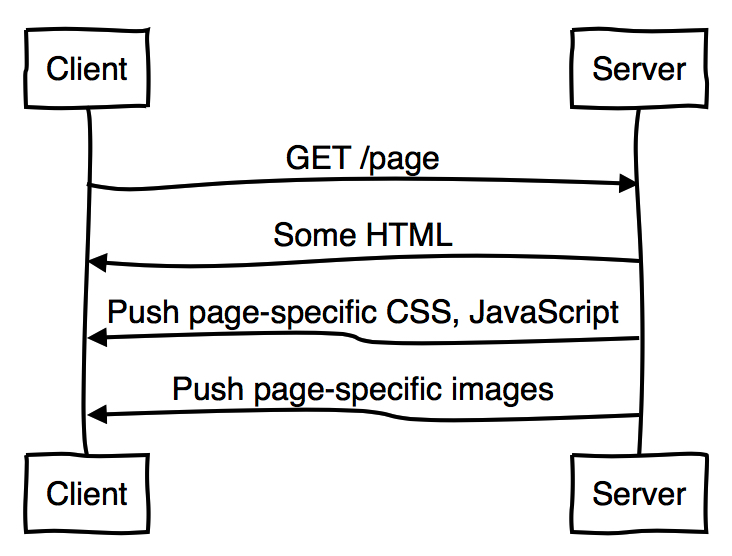
图中可以看到服务端在没有请求的情况下向客户端发送CSS、Javascript和图片。它知道客户端可能将会请求这些,因此它使用Server Push发送合成的请求/响应对到客户端,以节省一个往复次数。它不再是一个“饶舌”的协议,结果是他能更充分的使用网络。
需要注意的是,并不是说这些会更简单。HTTP/2仍然有很多存在的问题,特别是关于推送的时机。
HTTP/2 + 缓存摘要
服务端PUSH一个通常的问题是“客户端的缓存中是否已经有一个拷贝?”,因为推送天生是投机性的,总会出现你推送的东西并不是客户端需要的。
HTTP/2允许客户端在这种情况下通过RESET_STREAM取消推送。然而尽管这样,仍然会有一次往复的交互被浪费了,或许他们可以用来处理更值得的事情。记住,理想的是仅发送客户端用于显示页面仅需要的数据。
一个提议的方案是客户端使用一个紧凑的Cache Digest来告诉服务端它已经拥有的cache,从而使得服务端知道哪些是需要的。

因为缓存摘要使用Golumb Compressed Sets,它实时计算并使用少一1000个字节将浏览器缓存告诉服务端,通过连接在前几个包发送给服务端。
现在,我们避免了额外的往复次数,相关的数据浪费,直接嵌入和一些相似的hack,和非必须请求的数据浪费。这使我们里理想更进一步!
缓存摘要只是一个提议,但在HTTP社区中已经表现出很明显的兴趣。
HTTP/3
HTTP/3 目前还在草案阶段,它的主要特点是对传输层进行了优化,使用 QUIC 替换 TCP,彻底规避了 TCP 传输的效率问题。
QUIC 由 Google 提出的基于 UDP 进行多路复用的传输协议。QUIC 没有连接的概念,不需要三次握手,在应用程序层面,实现了 TCP 的可靠性,TLS 的安全性和 HTTP2 的并发性。在设备支持层面,只需要客户端和服务端的应用程序支持 QUIC 协议即可,无操作系统和中间设备的限制。
HTTP/3 核心特点如下:
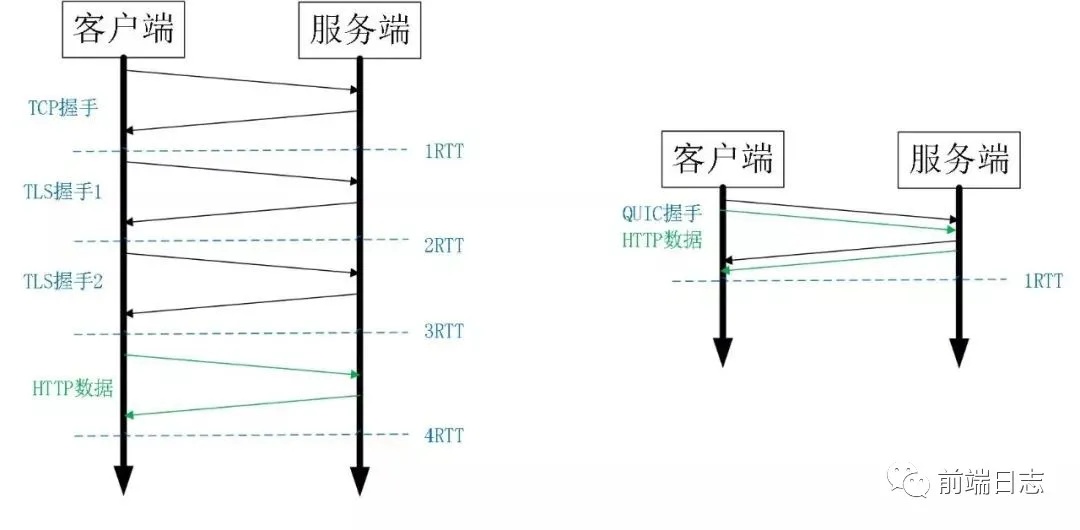
传输层连接更快
HTTP/3 基于 QUIC 协议,可以实现 0-RTT 建立连接,而 TCP 需要 3-RTT 才能建立连接。
传输层多路复用
图中的 Stream 之间相互独立,如果 Stream2 丢了一个 Pakcet,不会影响 Stream3 和 Stream4 正常读取。
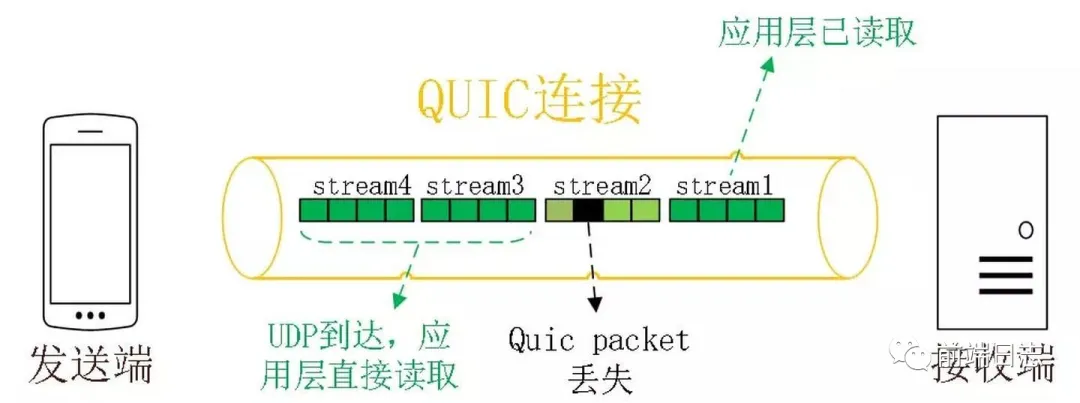
HTTP/3 传输层使用 QUIC 协议,数据在传输时会被拆分成了多个 packet 包,每一个 packet 包都可以独立、交错发送,不用按顺序发送,也就避免了 TCP 队头阻塞。
改进的拥塞控制
- 单调递增的 Packet Number。在 TCP 中,每一个数据包都有一个序列号标识(seq),如果接收端超时没有收到,就会要求重发标识为 seq 的包,如果这时超时的包也接收到了,则无法区分哪个是超时的包,哪个是重传的包。QUIC 中的每一个包的标识(Packet Number)都是单调递增的,重传的 Packet Number 一定大于超时的 Packet Number,这样就能区分开了。
- 不允许 Reneging。在 TCP 中,如果接收方内存不够或 Buffer 溢出,则可能会把已接收的包丢弃(Reneging),这种行为对数据重传产生了很大的干扰,在 QUIC 中是明确禁止的。在 QUIC 中,一个包只要被确认,就一定是被正确接收了。
- 更多的 ACK 块。一般来说,接收方收到发送方的消息后都会发送一个 ACK 标识,表示收到了数据。但每收到一个数据就发送一个 ACK 效率太低了,通常是收到多个数据后再统一回复 ACK。TCP 中每收到 3 个数据包就要返回一个 ACK,而 QUIC 最多可以收到 256 个包之后,才返回 ACK。在丢包率比较严重的网络下,更多的 ACK 块可以减少重传量,提升网络效率。
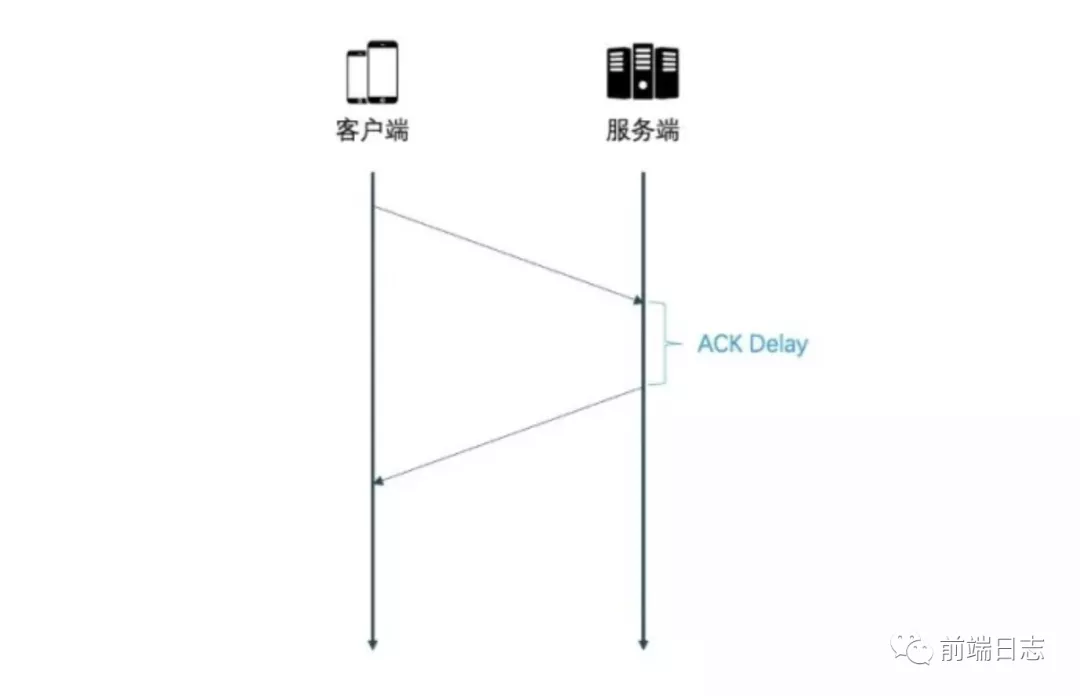
- Ack Delay。TCP 计算 RTT 时没有考虑接收方处理数据的延迟,如下图所示,这段延迟即 ACK Delay。QUIC 考虑了这段延迟,使得 RTT 的计算更加准确。
优化的流量控制
- Stream 级别的流量控制中,
接收窗口 = 最大接收窗口- 已接收数据。 - Connection 级别的流量控制中,
接收窗口 = Stream1接收窗口 + Stream2接收窗口 + ... + StreamN接收窗口。 - TCP 通过滑动窗口来控制流量,如果某一个包丢失了,滑动窗口并不能跨过丢失的包继续滑动,而是会卡在丢失的位置,等待数据重传后,才能继续滑动。
- QUIC 流量控制的核心是:不能建立太多的连接,以免响应端处理不过来;不能让某一个连接占用大量的资源,让其他连接没有资源可用。为此 QUIC 流量控制分为 2 个级别:连接级别(Connection Level)和 Stream 级别(Stream Level)。
加密认证的报文
- TCP 头部没有经过任何加密和认证,在传输过程中很容易被中间网络设备篡改,注入和窃听。
- QUIC 中报文都是经过加密和认证的,在传输过程中保证了数据的安全。
连接迁移
- TCP 连接是由(源 IP,源端口,目的 IP,目的端口)组成,这四者中一旦有一项发生改变,这个连接也就不能用了。如果我们从 5G 网络切换到 WiFi 网络,IP 地址就会改变,这个时候 TCP 连接也自然断掉了。
- QUIC 使用客户端生成的 64 位 ID 来表示一条连接,只要 ID 不变,这条连接也就一直维持着,不会中断。
前向纠错机制
- 发送端需要发送三个包,QUIC 在传输时会计算出这三个包的异或值,并单独发出一个校验包,也就是总共发出了四个包。
- 如果某一个包(非校验包)传输时丢失了,则可以通过另外三个包计算出丢失数据包的内容。
- 当然这种技术只能用在丢失一个包的情况下,如果丢失了多个包,就只能进行重传了。
- QUIC 中发送数据时,除了发送本身的数据包,还会发送验证包,以减少数据丢失导致的重传。
可以看出,QUIC 丢掉了 TCP 的包袱,基于 UDP,实现了一个安全高效可靠的 HTTP 通信协议。凭借着 0-RTT 建立连接、传输层多路复用、连接迁移、改进的拥塞控制、流量控制等特性,QUIC 在绝大多数场景下获得了比 HTTP/2 更好的效果,HTTP/3 真是未来可期。
TCP
目前为止,并没有谈到浏览器加载Web页面所使用的其他协议对性能的影响。
然而,真正的问题要比下面图片暗示的要多,TCP在HTTP开始前需要三次握手,来协定一个新连接的参数。

这意味着一个连接的创建所需要的最少往返次数,这使每个新连接的创建增加了额外的。
TCP Fast Open技术(在TCP3次握手的同时也进行数据交换)允许应用在SYN和SYN+ACK包中发送数据以避免这样的消耗。遗憾的是,仅被Linux和OSX支持。并且,社区的开发刚刚起步,在HTTP中使用TFO仍然有很多棘手的问题。
换句话说,TFO并不能保证随着SYN包发出的数据只会出现一次,很容易重复甚至引起恶意的回复攻击。因此,在一个TFO连接上的第一次请求就使用HTTP POST并不是一个明智的选择。更有问题的是,需要GET同样是有副作用的,但是浏览器并没有很好的方式来区分这些URL。
TLS
TLS提供了另一种在TCP握手完成之后启动连接的方式。它看起来会是这样:
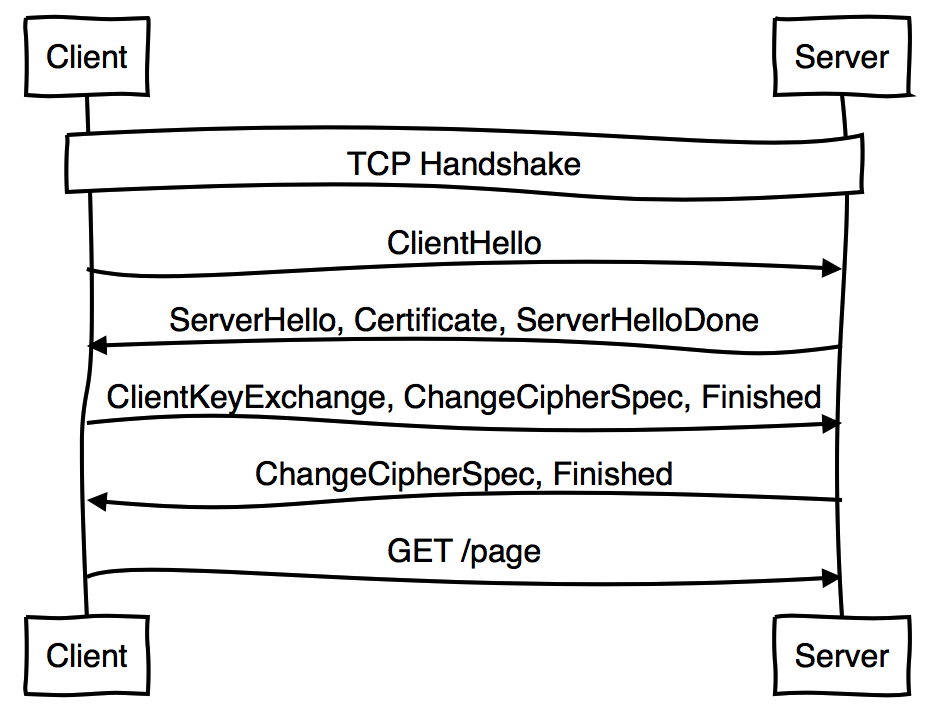
在HTTP能够发送数据前需要两次完整的往复交互。在客户端达到服务端之前,session tickets允许你可以避免一次往复次数:
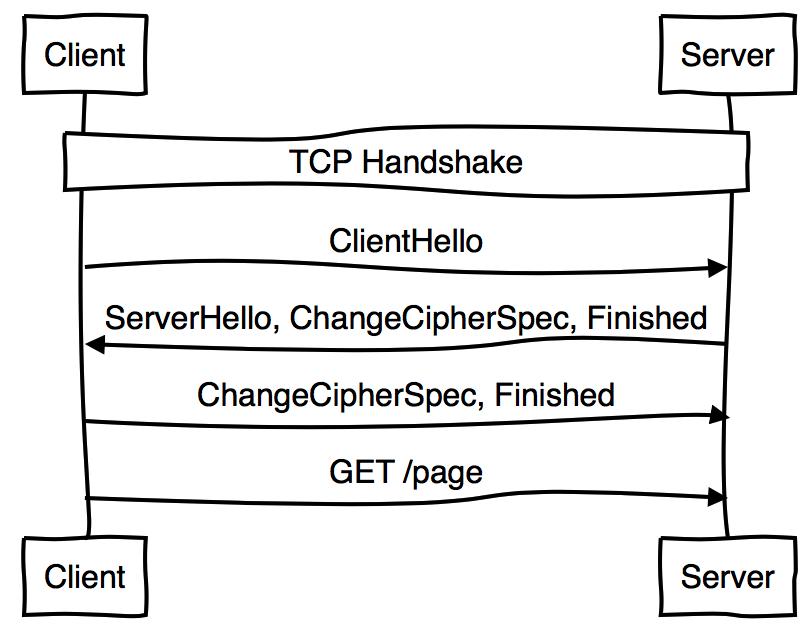
很快,TLS将支持在客户端到达服务端之前提供“0往复次数”(zero round trip)的握手,换言之,HTTP可以在第一次往复中发送数据,避免额外的消耗。然而,和TFO一样,你需要能够确保第一次往复中发送的数据不会造成任何不好的影响。
HTTP/next
TFO和TLS 1.3都是用来减少开启服务端连接的消耗。另一种方式尽量重用已开启的连接。
最后,这个讨论是如何使用HTTP/2的连接来使合并更加激烈(aggressively),不仅仅是它是否能够帮助减少开启新连接的消耗,并且是能够使已存在的连接更加高效,就像TCP一样长寿命并且繁忙。
这些事情包括向客户端推送证书,以证明该连接能够跟他初始协定的一样被更多的源使用。
另外一个更彻底的改变正在被讨论:使用UDP替换TCP,比如QUIC(Goole定制的一种基于UDP的低延迟互联网传输协议)。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.