This the multi-page printable view of this section. Click here to print.
基础知识
- 1: 操作系统
- 1.1: 基本概念
- 1.2: 抽象-进程
- 1.3: 插叙-进程 API
- 1.4: 机制-受限直接执行
- 1.5: 进程调度
- 1.6: 调度-多级反馈队列
- 1.7: 调度-比例份额
- 1.8: 多处理器调度
- 1.9: 抽象-地址空间
- 1.10: 内存接口
- 1.11: 地址转换
- 1.12: 分段
- 2: 性能之殇
- 3: IO 模型
- 3.1: Linux IO/线程 模型
- 3.2: Linux IO 零拷贝
- 3.3: Netty IO 模型
- 3.4: Redis IO 模型
- 3.5: Nginx IO 模型
- 3.6: MySQL 模型
- 4: 网络基础
- 5: TCP-IP
- 6: HTTP
- 7: HTTPS
- 7.1: 基本原理
- 8: WebSocket
- 8.1: MQTT Over WS
- 8.2: SSE WS HTTP
- 9: 信息安全
1 - 操作系统
本系列文章来自经典图书 “Operating Systems: Three Easy Pieces”, 部分是自己翻译, 部分摘抄整理自中译版 <操作系统导论>.
1.1 - 基本概念
一个正在运行的程序会做一件非常简单的事情:指令执行。处理器从内存中获取一条指令,对其进行解码,然后执行这条指令。完成这条指令后,处理器会继续执行下一条指令,以此类推,直到程序最终完成。
这就是冯诺依曼计算模型的基本概念。但实际上,在一个程序运行的同时,还有很多其他疯狂的事情正在同步进程——主要是为了让系统易于使用。
有一类软件负责让程序的运行变得更加容易,甚至允许你通知运行多个程序,允许程序共享内存,让程序能够与设备交互,以及其他类似的有趣工作。这些软件统称为操作系统,因为它们负责确保系统能够易于使用且能高效的运行。
要做到这一点,操作系统主要利用一种通用的技术——虚拟化。也就是说,操作系统将物理资源转换为更加通用、更加强大且更易于使用的虚拟形式。因此我们有时也将操作系统称为虚拟机。
为了让用户可以告诉操作系统做什么,从而利用虚拟机的功能(如运行程序、分配内存或访问文件)。操作系统还提供了一些接口供你调用。实际上,典型的操作系统会提供几百个系统调用以供程序调用。由于操作系统提供这些调用来运行程序、访问内存和设备,并进行其他相关的操作,我们有时也会说操作系统为应用程序提供了一个标准库。
最后,因为虚拟化让许多程序运行(从而共享 CPU),让许多程序可以同时访问自己的指令和数据(从而共享内存),让许多程序访问设备(共享磁盘),所以操作系统有时又被称为资源管理器。每个 CPU、内存和磁盘都是系统的资源,因此操作系统扮演的主要角色就是管理这些资源,以做到高效公平,或者实际上会考虑其他更多的指标。
虚拟化 CPU
图 2-1 展示了我们第一个程序,所做的只是调用 spin 函数,该函数会反复检查时间并在运行一秒后返回。然后它会打印出用户在命令行中传入的字符串,并一直重复上述过程。
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#include <assert.h>
#include "common.h"
int main(int argc, char *argv[]) {
if(argc != 2) {
fprintf(stderr, "usage: cpu <string>\n");
exit(1);
}
char *str = argv[1];
while(1) {
Spin(1);
pringf("s%\n", str);
}
return 0;
}
假设我们将这段代码保存为 cpu.c,并决定在一个单处理器的系统上编译运行。以下是我们看到的内容:
prompt> gcc -o cpu cpu.c -Wall
prompt> ./cpu "A"
A
A
A
A
^C
prompt>
系统开始运行时,该程序会反复检查时间,直到一秒钟过去。一秒钟过去之后,代码打印用户传入的字符串并继续。注意:该程序将永远保持执行,只有按下 CTRL + C,才能终止该程序。
现在我们做同样的事情,让我们运行同一个程序的多个不同实例,图 2-2 展示了这个稍复杂的例子的结果:
prompt> ./cpu A & ; ./cpu B & ; ./cpu C & ; ./cpu D &
[1] 7353
[2] 7354
[3] 7355
[4] 7356
A
B
D
C
A
B
D
C
A
C
B
D
...
尽管我们只有一个处理器,但这 4 个程序几乎同时都在运行。
事实证明,在硬件的一些帮助下,操作系统负责提供这种假象,即系统拥有非常多的虚拟 CPU 的假象。将单个 CPU (或其中一小部分)转换为看似无限数量的 CPU,从而让许多程序看似同时运行,这就是所谓的虚拟化 CPU,这是本书第一大部分的关注点。
需要一些接口来运行程序或终止程序,接口是大多数用户与操作系统交互的主要方式。
一次运行多个程序可能会引发各种新的问题,比如两个程序都想要在特定的时间执行,哪又该运行哪个呢?该问题由操作系统的策略来解决。操作系统的各种组件采用了一些不同的策略来解决该问题,所以我们将在学习操作系统实现的基本机制时研究这些策略。因此,操作系统承担了资源管理器的角色。
虚拟化内存
现代机器提供的物理内存模型非常简单。内存就是一个字节数组。要读取内存必须指定一个地址,才能访问存储在其中的数据。要写入或更新内存,也必须指定要写入给定数据的地址。
程序在运行时一直需要访问内存。程序将所有数据结构保存在内存中,并通过各种指令来访问这些数据,比如加载或保存,或利用其它明确的指令来在工作中访问内存。程序的每个指令都保存在内存中,因此每次读取指令都会访问内存。
下面的程序通过 malloc 来分配一些内存:
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include "common.h"
int main(int argc, char *argv[]) {
int *p = malloc(sizeof(int)); // a1
assert(p != NULL);
printf("(d%) memory address of p: %08x\n",
getpid(),(unsigned) p); // a2
*p = 0; // a3
while(1) {
Spin(1);
*p = *p + 1;
printf("(d%) p: %d\n", getpid(), *p); // a4
}
return 0;
}
该程序的输出如下:
prompt> ./mem
(2134) memory address of p: 00200000
(2134) p: 1
(2134) p: 2
(2134) p: 3
(2134) p: 4
(2134) p: 5
首先,它分配了一些内存(a1)。然后,打印出内存的地址(a2),然后将数字 0 放入新分配的内存(a3)的第一个空位中。最后,程序循环,延迟一秒钟并递增 p 中保存的地址值。在每个打印语句中,它还会打印出所谓的正在执行的进程标示符(PID)。每个运行进程都有一个唯一的 PID。
现在,我们再次运行同一个程序的多个实例,看看会发生什么。我们从示例中看到,每个正在运行的程序都在相同的地址分配了内存,但每个程序似乎都独立的更新了该地址的值。就好像每个正在运行的程序都有自己的私有内存,而不是与其他正在运行的程序共享相同的物理内存。
prompt> ./mem &; ./mem &
[1] 24113
[2] 24114
(24113) memory address of p: 00200000
(24114) memory address of p: 00200000
(24113) p: 1
(24114) p: 1
(24114) p: 2
(24113) p: 2
(24113) p: 3
(24114) p: 3
(24113) p: 4
(24114) p: 4
实际上,这正是操作系统虚拟化内存时发生的情况。每个进程访问自己的私有虚拟内存地址空间,操作系统以这种方式映射到机器的物理内存上。一个正在运行的程序中的内存引用不会影响其他进程(或操作系统本身)的地址空间。对于正在运行的程序,它完全拥有自己的物理内存。但实际情况是,物理内存是由操作系统管理的共享资源。
并发
并发问题首先会出现在操作系统本身,比如上面关于虚拟化的例子中,操作系统同时处理很多事情,它首先运行一个程序,然后再运行一个程序,等等。
同时,并发问题并不局限于操作系统本身。事实上,现代多线程程序也存在相同的问题。
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include "common.h"
4
5 volatile int counter = 0;
6 int loops;
7
8 void *worker(void *arg) {
9 int i;
10 for (i = 0; i < loops; i++) {
11 counter++;
12 }
13 return NULL;
14 }
15
16 int
17 main(int argc, char *argv[])
18 {
19 if (argc != 2) {
20 fprintf(stderr, "usage: threads <value>\n");
21 exit(1);
22 }
23 loops = atoi(argv[1]);
24 pthread_t p1, p2;
25 printf("Initial value : %d\n", counter);
26
27 Pthread_create(&p1, NULL, worker, NULL);
28 Pthread_create(&p2, NULL, worker, NULL);
29 Pthread_join(p1, NULL);
30 Pthread_join(p2, NULL);
31 printf("Final value : %d\n", counter);
32 return 0;
33 }
主程序利用 Pthread_create 创建了两个线程。你可以将线程看做与其他函数在同一内存空间中运行的函数,并且每次都有多个线程处于活动状态。在这个例子中,每个线程开始在一个名为 worker 的函数中运行,在该函数中,它只是一个递增计数器,循环 loops 次。
prompt> gcc -o thread thread.c -Wall -pthread
prompt> ./thread 1000
Initial value : 0
Final value :
你可能会猜到,两个线程完成时计数器的结果为 2000,因为每个线程都将计数器增加 1000 次。也就是说,当 loops 的输入值设为 N 时,我们预计程序的最终输出为 2N。但事实证明并非如此。
prompt> ./thread 100000
Initial value : 0
Final value : 143012 // huh??
prompt> ./thread 100000
Initial value : 0
Final value : 137298
在这次运行中我们提供 100000 作为输入值,得到的最终值却不是 200000。然后当我们再次运行该程序时,不仅得到了错误的结果,而且每次错误的结果还都不相同。事实上,如果以多次使用较高的 loops 值来运行该程序,甚至有可能得到正确的答案。
事实证明,这些奇怪的结果与指令如何执行有关。指令每次执行一条。遗憾的是,上面的程序中关键部分是增加共享计数器的地方,它需要 3 条指令:一条将计数器的值从内存加载到寄存器,一条将其递增,另一条将递增后的值保存到内存中。因为这 3 条指令并非以原子的方式执行,所以会发生如上奇怪的结果。
持久性
在系统内存中,数据容易丢失,因为像 DRAM 这样的设备已易失的方式存储数据。如果断电或系统崩溃,内存中的所有数据将会丢失。因此,我们需要硬件和软件来持久的存储数据。
硬件以某种输入/输出设备的形式出现。在现代系统中,硬盘驱动器是存储长期保存的信息的通用存储库,同时固态磁盘(SSD)也正在这个领域取得领先地位。
操作系统中管理磁盘的软件通常称为文件系统。因此它负责以可靠和高效的方式,将用户创建的任何文件存储在系统的磁盘上。
不像操作系统为 CPU 和内存提供的抽象,操作系统不会为每个应用程序创建专用的虚拟磁盘。相反,它假设用户经常需要共享文件中的信息。比如,在编写 C 程序时,你可能首先使用编辑器,之后,可以使用编译器将源代码转换为可执行文件,再之后,你可以运行新的可执行文件。因此,你可以看到文件如何在不同的进程之间共享。首先,编辑器创建一个文件,作为编译器的输入。编译器使用该输入文件创建一个新的可执行文件。最后,运行新的可执行文件。这样一个新的程序就诞生了。
1 #include <stdio.h>
2 #include <unistd.h>
3 #include <assert.h>
4 #include <fcntl.h>
5 #include <sys/types.h>
6
7 int
8 main(int argc, char *argv[])
9 {
10 int fd = open("/tmp/file", O_WRONLY | O_CREAT | O_TRUNC, S_IRWXU);
11 assert(fd > -1);
12 int rc = write(fd, "hello world\n", 13);
13 assert(rc == 13);
14 close(fd);
15 return 0;
16 }
为了完成这个任务,该程序向操作系统发出 3 个调用。第一个是对 open 的调用,它打开文件并创建。第二个是 write,将一些数据写入文件。第三个是 close,只是简单的关闭文件,从而表名程序不会再向其写入更多的数据。这些系统调用被转到称为文件系统的操作系统部分,然后操作系统处理这些请求,并向用户返回某些错误代码。
文件系统必须做很多操作:首先确定新数据将驻留在磁盘的哪个位置上,然后在文件系统所维护的各种结构中对其进行记录。这样做需要向底层存储系统发出 IO 请求,已读取现有结果或更新。所有编写过设备驱动程序的人都知道,让设备代表你来执行某项操作是一项复杂而详细的过程。它需要深入了解低级别设备接口的确切含义。幸运的是,操作系统提供了一种通过系统调用来访问设备的标准又简单的方法。因此,操作系统有时又被称为标准库。
当然,关于如何访问设备、文件系统如何在所述设备上持久的管理数据,还有更多细节。处于性能访问的考虑,大多数文件系统首先会延迟这些写操作一段时间,希望将其批量分组为较大的组。为了处理写入期间系统崩溃的问题,大多数文件系统都包含某种复杂的写入协议,如日志或写时复制,仔细排序写入磁盘的操作,以确保如果在写入序列期间发生故障,系统可以在之后恢复到合理的状态。为了使不同的通用操作更加高效,文件系统采用了许多不同的数据结构和访问方法,从简单的列表到复杂的 B 树。
设计目标
操作系统的工作是:它获得 CPU、内存、磁盘等物理资源,并对它们进行虚拟化;它处理并发相关的棘手问题;它之久的存储文件以确保文件长期安全。鉴于我们希望建立这样一个系统,所以要有一些目标,以帮助我们集中设计和实现,并在必要时进行折中。找到合适的折中是建立系统的关键。
一个最基本的目标是建立一些抽象,让系统变得易于使用。抽象对我们在计算机科学中做的每件事都有帮助。抽象使得编写一个大型程序称为可能,将其划分为更小且更易理解的部分,用 C 这样高级的语言编写这样的程序不用考虑汇编,用汇编代码则不用考虑逻辑门,用逻辑门来构建处理器则不用太多考虑晶体管。抽象是如此重要,以至于我们会忘记其重要性,但在这里我们会谨记。因此,在每一部分中,我们将讨论随着时间的推移而发展的一些主要抽象,为你提供一种思考操作系统各个部分的方法或思路。
**设计和实现操作系统的一个目标是提供高性能。**换言之,我们的目标是最小化操作系统的开销。虚拟化让系统变得易于使用是非常值得的,但也不会不计成本。因此,我们必须努力提供虚拟化和其他操作系统功能,同时避免过多的开销。这些开销会以多种形式出现:额外时间(更多指令)和额外空间(更多内存/磁盘)。如果有可能,我们会寻求解决方案以尽量减少这些形式的开销。但是完美并非总是可以实现的,我们会注意到这一点并在适当的情况下让人这种情况。
另一个设计目标是在应用程序之间、操作系统和应用程序之间提供保护。因为我们希望许多程序同时运行,所以要确保一个程序的恶意或偶然的不良行为不会损害其他程序。我们当然不希望应用程序能够损害操作系统本身。保护是操作系统基本原理之一的核心,这就是隔离。让进程彼此隔离是保护的关键,因此决定了 OS 必须执行的大部分任务。
**操作系统必须能够不间断运行。**当它失效时,系统上运行的所有应用程序也会失效。由于这种依赖性,操作系统往往力求提供高度的可靠性。随着操作系统变得越来越复杂,构建一个可靠的操作系统是一个相当大的挑战:事实上,该领域的许多正在进行的研究,正式专注于该问题。
其他目标也是有道理的:在我们日益增长的绿色世界中,能源效率非常重要;安全性对于恶意应用程序直观重要,尤其是在当前高度联网的时代。随着操作系统在越来越小的设备上运行,移动性变得越来越重要。根据系统的使用方式,操作系统将有不同的目标,因此可能至少以稍微不同的方式实现。但是我们会看到,我们将要介绍的关于如何构建操作系统的许多原则,则各种不同的设备上都很有意义。
简单历史
早期操作系统:只是一些库
一开始操作系统并没有做太多事情。基本是,它只是一些常用函数库。比如,不是让系统中每个程序员都编写低级 IO 处理代码,而是让 OS 提供这样的 API,以提升开发效率。
通常在这些老的大型机系统上,一次运行一个程序,并由操作员来控制。该操作员完成了你认为现代操作系统会做的所有事情,比如决定运行作业的顺序。如果你是一个聪明的开发人员,就会对这个操作员很好,这样他们可以将你的工作移到到队列的前端以尽快执行。
这种计算模式被称为批处理,先把一些工作准备好,然后由操作员以“分批”的方式运行。此时,计算机并没有以交互的方式被使用,因为这样做成本太高:让用户坐在计算机前使用它,大部分时间都会闲置,所以会导致设备每小时浪费数千美元。
超越库:保护
在超越常用服务的简单库的发展过程中,操作系统在管理机器方面扮演者更为重要的角色。其中一个重要方面是意识到代表操作系统运行的代码是特殊的。它控制了设备,因此对打它的凡事应该与对待正常应用程序的代码有所不同。不然的话,假设允许任何应用程序能够从磁盘的任何地方读取数据。因为任何程序都可以读取数据,隐私的概念就消失了。因此,将一个文件系统实现为一个库是没有意义的。
因此,系统调用的概念诞生了,它由 Atlas 计算系统率先采用。不是将操作系统例程作为一个库来提供,这里的想法是添加一些特殊的硬件指令和硬件状态,让操作系统过度变为正式的、受控的过程。
系统调用和过程调用的关键区别在于,系统调用将控制转移到 OS 中,同时提高硬件特权级别。用户应用程序以所谓的用户模式运行,这意味着硬件限制了应用程序的功能。比如,以用户模式运行的应用程序通常不能发起对磁盘的 IO 请求,不能访问任何物理内存页或在网络上发送数据包。在发起系统调用时(通常通过一个称为“trap”的特殊硬件指令),硬件将控制转移到预先指定的陷阱处理程序,并同时将特权级别提升到内核模式。在内核模式下,操作系统可以完全访问系统的硬件,因此可以执行诸如发起 IO 请求或为程序提供更多的内存等功能。当操作系统完成请求的服务时,他通过特殊的陷阱返回(return-from-trap)指令将控制权交还给用户,该指令返回到用户模式,同时将控制权交还给应用程序,回到应用离开的地方。
多道程序时代
操作系统的真正兴起是在大主机计算时代之后,即小型机时代。像数字设备公司的 PDP 系列这样经典机器,让计算机变得更加实惠。因此,不再是每个大型组织都需要拥有一台主机,而是组织内的一小群人可以拥有自己的计算机。毫不奇怪,这种成本下降的主要影响之一就是开发者活动的增加。更聪明的人接触到计算机,从而让计算机系统做出更有趣和漂亮的事情。
特别是,由于希望更好的利用资源,多道程序开始变得很普遍。操作系统不是一次只运行一项作业,而是将大量作业加载到内存中并在它们之间切换,从而提供 CPU 利用率。这种切换非常重要,因为 IO 设备很慢。在处理 IO 时让程序占用着 CPU 则会浪费 CPU 时间。
在 IO 进行和任务中断时,要支持多道程序和重叠运行。这一愿望使得操作系统开始创新,沿着多个方向进行概念发展。内存保护等问题开始变得重要。我们不希望一个程序能够访问另一个程序的内存。了解如何处理多道程序引入的并发问题也很关键。在中断存在的情况下,确保操作系统正常运行是一个很大的挑战。
当时主要的实际进展之一是引入了 UNIX 操作系统,主要归功与贝尔实验室和 Ken Thompson、Dennis Ritchie。UNIX 从不同的操作系统获得了很多好的想法,并让这些想法变得更简单易用。很快,该团队就向世界各地的人们发送含有 UNIX 源代码的磁带,其中很多人随后参与并加入到系统中。
摩登时代
除了小型计算机之外还有一种新型机器,更加便宜快速且适用于大众:今天我们称之为个人计算机。在苹果公司早期的机器和 IBM PC 的引领下,这种新机器很快就称为计算的主导力量,因为它们的低成本让每个桌子上都有一台机器,而不是每个工作小组共享一台小型机器。
遗憾的是,对于操作系统来说,个人计算机起初代表了一次巨大的倒退,因为早期的系统忘记了小型机时代的经验教训。比如早期的操作系统如 DOS 并不认为内存保护很重要。因此,恶意程序或者编写质量欠佳的程序可能会在整个内存中写入乱七八糟的数据。第一代 MacOS 采取合作的方式进行作业调度。因此,意外陷入无限循环的线程可能会占用整个系统,从而导致重新启动。这一代系统中遗漏的操作系统功能造成的痛苦列表很长,因此无法在这里给出完整的讨论。
幸运的是,进过一段时间的苦难后,小型计算机操作系统的老功能开始进入台式机。比如 MaxOS X 的核心是 UNIX,包括人们期望从这样一个成熟系统中获得的所有功能。Windows 在计算机历史中同样采用了许多伟大的思想,特别是从 Windows NT 开始,这是微软操作系统技术的一次伟大飞跃。即使在今天的手机上运行的操作系统(如 Linux),也更像小型机在 20 世纪 70 年代运行的,而不是像 20 世纪 80 年代 PC 运行的那种操作系统。很高兴看到在操作系统开发鼎盛时期出现的好想法已经进入了现代世界。更好的是,这些想法不断发展,为用户和应用程序提供了更多功能,让现代系统更加完善。
补充:UNIX 的重要性 在操作系统的历史中,UNIX 的重要性举足轻重。受早期系统的影响,尤其是 MIT 的 Multics 系统,UNIX 汇集了很多了不起的思想,创造了既简单又强大的系统。 最初的贝尔实验室 UNIX 的基础是统一原则,即构建小二强大的程序,这些程序可以连接在一起形成更大的工作流。在你输入命令的地方,shell 提供了诸如管道之类的原语,来支持这样的元编程,因此很容易将程序串起来完成更大规模的任务。 UNIX 环境对于程序开发人员很友好,并为新的 C 语言提供了编译器。程序员很容易编写自己的程序并将其分享,这使得 UNIX 大受欢迎。作为开源软件的早期形式,作者向所有请求的人免费提供副本,这种方式的帮助很大。 代码的可得性和可读性非常重要。用 C 语言编写的美丽的小内核吸引其他人来摆弄内核,添加新的、很酷的功能。 遗憾的是,随着公司试图维护其所有权和利润,UNIX 的传播速度有所降低,这是律师参与其中的不幸结果。很多公司开始拥有自己的 UNIX 变种。
补充:然后出现了 Linux 幸运的是,对于 UNIX 来说,一位名叫 Linus Torvalds 的年轻芬兰黑客决定编写它自己的 UNIX 版本,该版本严重依赖最初系统背后的原则和思想,但没有借用原来的代码集,从而避免了合法性问题。他征集了世界各地其他人的帮助,不久之后 Linux 就诞生了。
1.2 - 抽象-进程
进程的非正式定义非常简单:进程就是运行中的程序。程序本身没有生命周期,它只是保存在磁盘上的一些指令或静态数据。是操作系统让这些字节运行起来、让程序发挥作用。
事实表明,人们常常系统同时运行多个程序。比如:在使用计算机或笔记本的时候,我们会同时运行浏览器、邮件、游戏等。实际上,一个正常的系统可能会有上百个进程同时在运行。如果能实现这样的系统,人们就不需要考虑当时是哪个 CPU 是可用的,使用起来非常简单。因此我们的挑战是:
关键问题:如何提供有许多 CPU 的假象?
操作系统通过虚拟化 CPU 来提供这种假象。通过让一个进程只运行一个时间片,然后切换到其他进程,操作系统提供了存在多个虚拟 CPU 的假象。这就是 分时共享 CPU 技术,允许用户如愿运行多个并发进程。潜在的开销是性能损失,因为如果 CPU 必须共享,每个进程的运行过程都会慢一点。
要实现 CPU 的虚拟化并能实现的足够好,操作系统就需要一些低级机制和一些高级智能。我们将低级机制称为机制。机制是一些低级方法或协议,实现了所需要的功能。比如稍后我们将学习如何实现上下文切换,它让操作系统能够停止运行一个程序,并开始在指定的 CPU 上运行另一个程序。所有现代操作系统都采用了这种分时机制。
提示:使用分时共享(和空分共享) 分时共享是操作系统共享资源所使用的最基本的技术之一。通过运行资源由一个实体使用一小段时间,然后由另一个实体使用一小段时间,如此下去,所谓的资源(CPU/网络)可以被许多人共享。 分时共享的自然对应技术是空分共享,资源在空间上被划分给希望使用它的多个人。比如磁盘空间自然就是一个空分共享资源,因为一旦将块分配给文件,在用户删除文件之前,不可能将它分配给其它文件。
在这些机制之上,操作系统中有一些智能以策略的形式存在。策略是在操作系统内做出某种决定的算法。比如,给定一组可能的程序要在 CPU 上运行,操作系统应该运行哪个程序?操作系统中调度策略会做出这个决定,可能利用历史信息、工作负载知识、性能指标来做出决定。
抽象:进程
操作系统为正在运行的程序提供的抽象,就是所谓的进程。 一个进程只是一个正在运行的程序。在任何时刻,我们都可以清点它在执行过程中访问或影响了操作系统的哪些部分,从而概况为一个进程。
为了理解进程的构成,我们必须理解它的机器状态:程序在运行时可以读取或更新的内容。在任何时刻,机器的哪些部分对该程序的执行很重要?
进程的机器状态有一个明显的组成部分——内存。指令被保存在内存中,正在运行的程序读写的数据也保存在内存中。因此进程可以访问的内存(地址空间)是该进程的一部分。
进程的机器状态的另一部分是寄存器。许多指令明确的读取或更新寄存器,因此显然它们对于执行该进程很重要。
请注意,有一些非常特殊的寄存器构成了该机器状态的一部分。比如程序计数器告诉我们程序当前正在执行哪个指令;类似的,栈指针和先关的帧指针用户管理函数参数栈、局部变量和返回地址。
提示:分离策略和机制 在许多操作系统中,一个通用的设计范式是将高级策略与其低级机制分开。你可以将机制看成对系统的“HOW”问题提供的答案。例如操作系统如何执行上下文切换?策略为“WHICH”问题提供答案。例如操作系统现在应该运行哪个进程?将两者分开可以轻松改变策略,而不用重新考虑机制,因此这是一种模块化的形式,一种通用的软件设计原则。
最后,程序也经常访问持久存储设备。此类 IO 信息可能包含当前打开的文件列表。
进程 API
虽然讨论真实的进程 API 将会在第五章进行,但这里先介绍一下操作系统的所有接口必须包含哪些内容。所有现代操作系统都以某种形式提供这些 API。
- 创建:操作系统必须包含一些创建新进程的方法。在 shell 中键入命令或双击应用程序图标时,会调用操作系统来创建新进程,运行指定的程序。
- 销毁:由于存在创建进程接口,因此系统还提供了一个强制销毁进程的接口。当然,很多进程会在运行完成后自行退出。但是,如果它们不退出,用户可能希望终止它们,因此停止失控进程的接口非常有用。
- 等待:有时等待进程停止运行是有用的,因此经常提供某种等待接口。
- 控制:除了杀死或等待进程外,有时还可能存在其他控制。比如大多数操作系统提供了某种方法来暂停进程、恢复进程。
- 状态:通常也有一些接口可以获得有关集成的状态信息,例如运行了多长时间,或者处于什么状态。
进程创建:细节
**操作系统运行进程要做的第一件事情就是将代码和所有静态数据(如初始化变量)加载到内存中,即加载到进程的地址空间中。**程序最初以某种可执行的格式保存在磁盘上。因此,将程序和静态数据加载到内存中的过程,需要操作系统从磁盘上读取这些字节,并将它们放在内存中的某处。
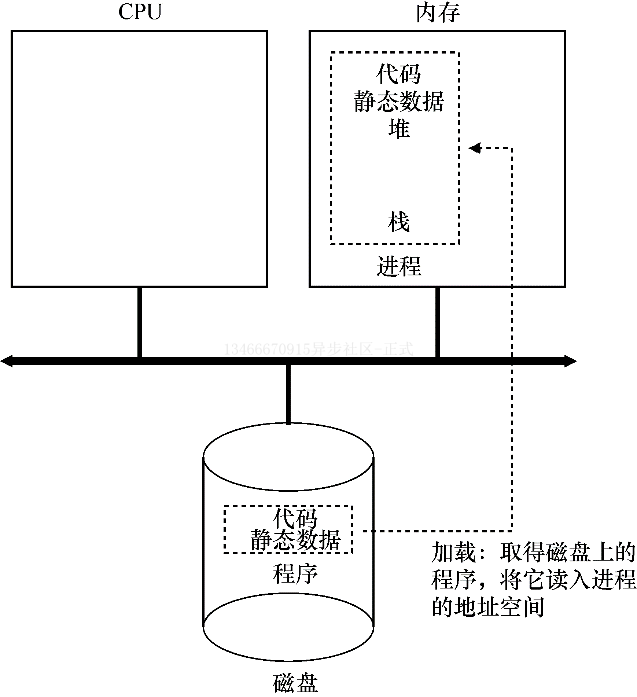
**在早期的操作系统中,加载过程会尽早(eagerly)完成,即在运行程序之前全部完成。现代操作系统则会惰性(lazily)执行该过程,即仅在程序执行期间需要的时候才会加载代码或数据片段。**要真正理解代码和数据的惰性加载过程是如何工作的,必须更多的了解分页和交换的机制,这是我们将来讨论内存虚拟化时要涉及的主题。现在,只要记住在运行任何程序之前,操作系统显然必须要执行一些工作,才能将重要的程序字节从磁盘读入内存。
将代码和静态数据加载到内存之后,操作系统在运行该进程之前还要执行一些其他操作。必须为程序的运行时栈分配一些内存。你可能已经知道,C 程序使用栈存放局部变量、函数参数和返回地址。操作系统分配这些内存并提供给进程。操作系统也可能会用参数初始化栈。具体来说,它会将参数填入 mian 函数,即 argc 和 argv 数组。
**操作系统也可能会程序的堆分配一些内存。在 C 程序中,堆用于显式请求的动态分配数据。**程序通过调用 malloc 来请求这样的内存空间,并通过调用 free 来显式释放。数据结构需要堆。起初堆会很小,随着程序的运行,通过 malloc 库 API 请求更多内存,操作系统可能会参与分配更多内存给进程,以满足这些调用。
操作系统还将执行一些其他初始化任务,特别是与输入/输出先关的任务。比如,在 UNIX 系统中,默认情况下每个进程都有 3 个打开的文件描述符,分别用于标准输入、输出和错误。这些描述符让程序轻松读取来自中断的输入以及打印输出到屏幕。
通过将代码和静态数据加载到内存中,通过创建和初始化栈以及执行与 IO 设置相关的其他工作,OS 现在终于为程序执行搭好了舞台。然后它还有最后一项任务:启动程序,在入口处执行,即 main。通过调转到 main 例程,OS 将 CPU 的控制权转移到新创建的进程中,从而程序开始执行。
进程状态
进程在特定的时间可能处于不同的状态。在早期的计算机系统中,出现了一个进程可能处于多种状态的概念。简而言之,进程可以处于以下 3 种状态之一:
- 运行:在运行状态下,进程正在处理器上运行,这意味着它正在执行指令。
- 就绪:在就绪状态下,进程已经准备好运行,但由于某种原因,操作系统选择不在此时运行它。
- 阻塞:在阻塞状态下,一个进程执行了某种操作,直到发生其他事件时才会准备开始运行。一个常见的例子就是,当进程向磁盘发起 IO 请求时,进程会被阻塞,这时其他进程可以使用该处理器。

如上图所示,可以根据操作系统的负载,让进程在就绪和运行状态之间切换。从就绪到运行意味着该进程已经被调度;从运行到就绪则意味着该进程已经被取消调度;一旦进程被阻塞,OS 将保持进程的这种状态,直到发生某种事件。此时,进程再次转入就绪状态(或立即再次运行)。
我们来看一个例子,看两个进程如何通过这些状态转换。首先想象两个正在运行的进程,每个进程只使用 CPU。在这种情况下,每个进程的状态可能如下所示:
| 时间 | Process0 | Process1 | 备注 |
|---|---|---|---|
| 1 | 运行 | 就绪 | |
| 2 | 运行 | 就绪 | |
| 3 | 运行 | 就绪 | |
| 4 | 运行 | 就绪 | Process0 现在完成 |
| 5 | — | 运行 | |
| 6 | — | 运行 | |
| 7 | — | 运行 | |
| 8 | — | 运行 | Process1 现在完成 |
在下一个例子中,第一个进程在运行一段时间之后发起 IO 请求。此时该进程被阻塞,让另一个进程有机会运行:
| 时间 | Process0 | Process1 | 备注 |
|---|---|---|---|
| 1 | 运行 | 就绪 | |
| 2 | 运行 | 就绪 | |
| 3 | 运行 | 就绪 | Process0 发起 IO |
| 4 | 运行 | 运行 | Process0 被阻塞 |
| 5 | 阻塞 | 运行 | 所以 Process1 运行 |
| 6 | 阻塞 | 运行 | |
| 7 | 就绪 | 运行 | Process0 IO 完成 |
| 8 | 就绪 | 运行 | Process1 现在完成 |
| 9 | 运行 | — | |
| 10 | 运行 | — | Process0 现在完成 |
更具体的说,Process0 发起 IO 并被阻塞,等待 IO 完成。OS 发现 Process0 不使用 CPU,因此开始运行 Process1。当 Process1 运行时,Process0 的 IO 完成,状态变为就绪。最后 Process1 结束,Process0 运行,然后完成。
请注意,即使是在这个简单的例子中,操作系统也必须做出很多决定。首先,系统必须决定在 Process0 发出 IO 时运行 Process1。这样做可以通过保持 CPU 繁忙来提供资源利用率。其次,当 IO 完成时,系统决定不立即切换为 Process0。目前还不清楚这是不是一个很好的决定。这类决策由操作系统调度程序完成,后续几章将会展开详细的讨论。
数据结构
操作系统是一个程序,和其他程序一样,它拥有一些关键的数据结构来跟踪各种相关的信息。比如,为了跟踪每个进程的状态,操作系统可能会为所有就绪的进程保留某种进程列表,以及跟踪当前正在运行的进程的一些附加信息。操作系统还必须以某种方式跟踪阻塞的进程。当 IO 事件完成时,操作系统应确保唤醒正确的进程,使其准备好再次运行。
// the registers xv6 will save and restore
// to stop and subsequently restart a process
struct context {
int eip;
int esp;
int ebx;
int ecx;
int edx;
int esi;
int edi;
int ebp;
};
// the different states a process can be in
enum proc_state { UNUSED, EMBRYO, SLEEPING,
RUNNABLE, RUNNING, ZOMBIE };
// the information xv6 tracks about each process
// including its register context and state
struct proc {
char *mem; // Start of process memory
uint sz; // Size of process memory
char *kstack; // Bottom of kernel stack
// for this process
enum proc_state state; // Process state
int pid; // Process ID
struct proc *parent; // Parent process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
struct context context; // Switch here to run process
struct trapframe *tf; // Trap frame for the
// current interrupt
};
上面的代码展示了 OS 需要跟踪 xv6 内核中每个进程的信息类型。“真正的”操作系统中存在类似的进程结构。
从上面的代码可以看到操作系统跟踪进程的一些重要信息。对于停止的进程,寄存器上下文将保存其寄存器的内容。当一个进程停止时,它的寄存器将被保存到该内存位置。通过恢复这些寄存器(将它们的值放回实际的物理寄存器中),操作系统可以恢复运行该进程。我们将在后面的章节中详细了解该技术,即上下文切换。
从上面的代码中还可以看到,除了运行、就绪、阻塞之外,进程还可能处于一些其他状态。有时候系统会有一个初始状态,表示进程在创建时处于的状态。另外,一个进程可以处于已退出但尚未清理的最终状态(UNIX 中的僵尸状态)。这个最终状态非常有用,因为它运行其他进程(通常是该进程的父进程)检查进程的返回代码,并查看刚刚完成的进程是否执行成功。完成后,父进程将进行最后一次调用,以等待子进程的完成,并告诉操作系统可以清理这个正在结束的进程的所有相关数据结构。
补充:数据结构——进程列表 操作系统充满了我们将要在本书中讨论的各种重要的数据结构。进程列表是第一个这样的结构。这种结构比较简单,但是任何能够同时运行多个程序的操作系统当然都会有这种类似的结构,以便跟踪系统中运行的所有程序。有时人们会将存储关于进程信息的个体结构称为进程控制块(PCB),这是谈论包含每个进程信息的 C 结构的一种方式。
1.3 - 插叙-进程 API
关键问题:如何创建并控制进程
fork 系统调用
系统调用 fork 用户创建新的进程,但要小心,这可能是你使用过的最奇怪的接口。具体来说,你可以运行一个程序,如下面的代码所示。
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4
5 int
6 main(int argc, char *argv[])
7 {
8 printf("hello world (pid:%d)\n", (int) getpid());
9 int rc = fork();
10 if (rc < 0) { // fork failed; exit
11 fprintf(stderr, "fork failed\n");
12 exit(1);
13 } else if (rc == 0) { // child (new process)
14 printf("hello, I am child (pid:%d)\n", (int) getpid());
15 } else { // parent goes down this path (main)
16 printf("hello, I am parent of %d (pid:%d)\n",
17 rc, (int) getpid());
18 }
19 return 0;
20 }
运行这段程序你将看到以下输出:
prompt> ./p1
hello world (pid:29146)
hello, I am parent of 29147 (pid:29146)
hello, I am child (pid:29147)
prompt>
让我们更详细的了解以下上面的程序发生了什么。当它开始运行时,进程输出一条 hello workd 信息,以及自己的进程描述符(PID)。该进程的 PID 是 29146。在 UNIX 系统中,如果要操作某个进程,就要通过 PID 来指明。到目前为止一切正常。
紧接着有趣的事情发生了。进程调用了 fork 系统调用,这是操作系统提供了创建新进程的方法。新创建的进程几乎与调用进程完全一样,对操作系统来说,这时看起来有两个完全一样的的程序在运行,并都从 fork 系统调用中返回。新创建的进程称为子进程,原来的进程称为父进程。子进程不会从 main 方法开始执行,而是直接从 fork 系统调用返回,就好像是它自己调用了 fork。
你可能已经注意到,子进程并不是完全拷贝了父进程。具体来说,虽然它拥有自己的地址空间(自己的私有内存)、寄存器、程序计数器等,但是它从 fork 返回的值是不同的。父进程获得的返回值是新创建子进程的 PID,而子进程获得的返回值是 0。这个差别非常重要,因为这样很容易来编写代码以处理两种不同的情况。
你可能还会注意到,该程序的输出是不确定的。子进程被创建后,我们就需要关心系统中的两个活动进程了:子进程和父进程。假设我们在单个 CPU 的系统上运行,那么子进程或父进程在此时都有可能运行。在上面的例子中,父进程先运行并输出信息。在其他情况下,子进程可能先运行,会有以下输出结果:
prompt> ./p1
hello world (pid:29146)
hello, I am child (pid:29147)
hello, I am parent of 29147 (pid:29146)
prompt>
CPU 调度程序决定了某个时刻哪个进程应该被执行,我们稍后将详细介绍这部分内容。由于 CPU 调度程序非常复杂,所以我们不能假设哪个进程会首先执行。事实表明,这种不确定性会导致一些有趣的问题,特别是在多线程程序中。
wait 系统调用
到目前为止,我们只是创建了一个进程,打印信息然后退出。事实表明,有时候父进程需要等待子进程执行完毕。这项任务由 wait 系统调用(或更完整的接口 waitpid)来完成。
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4 #include <sys/wait.h>
5
6 int
7 main(int argc, char *argv[])
8 {
9 printf("hello world (pid:%d)\n", (int) getpid());
10 int rc = fork();
11 if (rc < 0) { // fork failed; exit
12 fprintf(stderr, "fork failed\n");
13 exit(1);
14 } else if (rc == 0) { // child (new process)
15 printf("hello, I am child (pid:%d)\n", (int) getpid());
16 } else { // parent goes down this path (main)
17 int wc = wait(NULL);
18 printf("hello, I am parent of %d (wc:%d) (pid:%d)\n",
19 rc, wc, (int) getpid());
20 }
21 return 0;
22 }
在上面的例子中,父进程调用 wait,延迟自己的执行,直到子进程执行完毕。当子进程结束时,wait 才返回父进程。以下是输出结果:
prompt> ./p2
hello world (pid:29266)
hello, I am child (pid:29267)
hello, I am parent of 29267 (wc:29267) (pid:29266)
prompt>
通过这段代码,现在我们知道子进程总是先输出结果。其实,子进程可能只是碰巧先运行,因此会先于父进程输出结果。但是,如果碰上父进程先运行,它会立即调用 wait。该系统调用会在子进程运行结束后才返回。因此,即使父进程先于子进程运行,它也会礼貌的等待子进程运行完毕,然后 wait 返回,接着父进程才输出自己的信息。
exec 系统调用
它是创建进程 API 的重要部分。该系统调用可以让子进程执行与父进程完全不同的程序。比如上面提到的 fork,只有你想运行与父进程相同程序的考培时才有用。但是,我们经常需要运行不同的程序。
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4 #include <string.h>
5 #include <sys/wait.h>
6
7 int
8 main(int argc, char *argv[])
9 {
10 printf("hello world (pid:%d)\n", (int) getpid());
11 int rc = fork();
12 if (rc < 0) { // fork failed; exit
13 fprintf(stderr, "fork failed\n");
14 exit(1);
15 } else if (rc == 0) { // child (new process)
16 printf("hello, I am child (pid:%d)\n", (int) getpid());
17 char *myargs[3];
18 myargs[0] = strdup("wc"); // program: "wc" (word count)
19 myargs[1] = strdup("p3.c"); // argument: file to count
20 myargs[2] = NULL; // marks end of array
21 execvp(myargs[0], myargs); // runs word count
22 printf("this shouldn't print out");
23 } else { // parent goes down this path (main)
24 int wc = wait(NULL);
25 printf("hello, I am parent of %d (wc:%d) (pid:%d)\n",
26 rc, wc, (int) getpid());
27 }
28 return 0;
29 }
输出结果为:
prompt> ./p3
hello world (pid:29383)
hello, I am child (pid:29384)
29 107 1030 p3.c
hello, I am parent of 29384 (wc:29384) (pid:29383)
prompt>
在上面的例子中,子进程调用 execvp 来运行字符计数程序 wc。实际上,它针对源代码文件 p3.c 运行 wc,从而告诉我们该文件有多少行、多少单词以及多少字节。
fork 系统调用很奇怪,它的伙伴 exec 也不简单。给定可执行程序的名称以及需要的参数后,exec 会从可执行程序中加载代码和静态数据,并用它覆盖自己的代码段,堆、栈以及其他内存空间也会被重新初始化。然后操作系统就执行该程序,将参数通过 argv 传递给该进程。因此,它并没有创建新进程,而是直接将当前运行的程序替换为不同的运行程序。子进程执行 exec 后,几乎就像 p3.c 从未运行过一样。对 exec 的成功调用永远不会返回。
为什么这样设计 API
为什么设计如此奇怪的接口来完成简单的、创建新进程的任务?事实证明,这种分离 fork 和 exec 的做法在构建 UNIX shell 的时候非常有用,因此这给了 shell 在 fork 之后 exec 执行前运行代码的机会,这些代码可以在运行新程序前改变环境,从而让一系列有趣的功能得以实现。
提示:重要的是做对事(LAMPSON 定律) Lampson 在他的著名论文《Hints for Computer Systems Design》中曾经说过:“做对事。抽象和简化不能替代做对事。”有时你必须做正确的事,当你这样做时,总是好过其他方案。有许多方式来设计创建进程的 API,但 fork 和 exec 的组合既简单又极其强大。因此 UNIX 的设计师们做对了。
shell 也是一个用户程序,它首先显示一个提示符,然后等待用户输入。你可以向它输入一个命令,大多数情况下,shell 可以在文件系统中找到这个可执行程序,调用 fork 来创建新的进程,并调用 exec 的某个变体来执行这个可执行程序,调用 wait 等待该命令完成。子进程执行结束后,shell 从 wait 返回并再次输出一个提示符,等待用户输入下一条命令。
fork 和 exec 的分离,然 shell 可以方便的实现很多有用的功能。比如:
prompt> wc p3.c > newfile.txt
在上面的例子中,wc 的输出结果被重定向到文件 newfile.txt 中。shell 实现重定向的方式很简单,当完成子进程的创建后,shell 在滴啊用 exec 之前先关闭了标准输出,打开了文件 newfile.txt。这样,即将运行的程序 wc 的输出结果就被发送到该文件,而不是打印在屏幕上。
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4 #include <string.h>
5 #include <fcntl.h>
6 #include <sys/wait.h>
7
8 int
9 main(int argc, char *argv[])
10 {
11 int rc = fork();
12 if (rc < 0) { // fork failed; exit
13 fprintf(stderr, "fork failed\n");
14 exit(1);
15 } else if (rc == 0) { // child: redirect standard output to a file
16 close(STDOUT_FILENO);
17 open("./p4.output", O_CREAT|O_WRONLY|O_TRUNC, S_IRWXU);
18
19 // now exec "wc"...
20 char *myargs[3];
21 myargs[0] = strdup("wc"); // program: "wc" (word count)
22 myargs[1] = strdup("p4.c"); // argument: file to count
23 myargs[2] = NULL; // marks end of array
24 execvp(myargs[0], myargs); // runs word count
25 } else { // parent goes down this path (main)
26 int wc = wait(NULL);
27 }
28 return 0;
29 }
prompt> ./p4
prompt> cat p4.output
32 109 846 p4.c
prompt>
上面的代码展示了这样做的一个程序。重定向的工作原理,是基于对操作系统管理文件描述符方式的假设。具体来说,UNIX 系统从 0 开始寻找可以使用的文件描述符。在该例子中,STDOUT_FILENO 将成为第一个可用的文件描述符,因此在 open 被调用时,得到赋值。然后子进程像标准输出文件描述符的写入,都会被透明的转向新打开的文件,而不是屏幕。
关于这个输出,你至少会注意到两个有趣的地方。首先,当运行完 p4 程序后,好像什么也没有发生。shell 只是打印了提示符,等待用户的下一个命令。但事实并非如此,p4 确实调用了 fork 来创建新的子进程,之后调用 execvp 来执行 wc。屏幕上没有看到输出,是由于结果被重定向到 p4.output。其次,当用 cat 命令打印输出文件时,能看到运行 wc 的所有预期输出。
UNIX 管道也是用类似的方式实现的,但用的是 pipe 系统调用。在这种情况下,一个进程的输出被链接到了一个内核管道(pipe)上(队列),另一个进程的输入也被连接到了同一个管道上。因此,前一个进程的输出无缝的作为后一个进程的输入,许多命令可以用这种方式串联在一起,共同完成某项任务。比如通过将 grep、wc 命令用管道连接可以完成从一个文件查找某个词,并统计其出现次数的可能:grep -o foo file | wc -l。
最后,我们刚才只是从较高层面上简单介绍了进程 API,关于这些系统调用的细节,还有更多的内容需要学习和理解。
其他 API
除了上面提到过的 API,在 UNIX 中还有其他许多与进程交互的方式。比如可以通过 kill 系统调用向进程发送信号,包括要求进程睡眠、终止或其他有用的指令。实际上,整个信号子系统提供了一套丰富的向进程传递外部事件的途径,包括接受和执行这些信号。
此外还有很多非常有用的命令行工具。比如通过 ps 命令来查看当前运行的进程,阅读 man 手册来了解 ps 命令所能接受的参数。
1.4 - 机制-受限直接执行
为了虚拟化 CPU,操作系统需要以某种方式让许多任务共享物理 CPU,让它们看起来像是在同时运行。基本思想很简单:运行一个进程一段时间,然后运行另一个进程,如此轮换。通过这种方式分时共享 CPU,就实现了虚拟化。
然而,在构建这样的虚拟化机制时存在一些挑战。第一个是性能:如何在不增加系统开销的情况下实现虚拟化?第二个是控制权:如何有效的运行进程,同时保留对 CPU 的控制?控制权对于操作系统尤为重要,因为操作系统负责管理资源。如果没有控制权,一个进程可以简单的无限制运行并接管机器,或者访问原本没有权限的信息。因此,在保持控制权的同时获得高性能,是构建操作系统的主要挑战之一。
关键问题:如果高效可控的虚拟化 CPU 操作系统必须以高性能的方式虚拟化 CPU,同时保持对系统的控制。为此,需要硬件和操作系统的支持。操作系统通常会明智的利用硬件的支持,以便高效的实现其工作。
基本技巧:受限直接执行
为了使程序尽可能快的执行,操作系统开发人员想出了一种技术——我们称之为受限的直接执行。这个概念的“直接执行”部分很简单:只需直接在 CPU 上运行程序即可。因此,当 OS 希望启动程序运行时,它会在进程列表中为其创建一个进程条目,为其分配一些内存,将程序代码从磁盘加载到内存中,找到入口点并跳转到那里,然后开始执行用户的代码。下表展示了这种基本的直接执行协议(没有任何限制),使用正常的调用并返回跳转到程序的 mian,并在稍后回到内核。
| 操作系统 | 程序 |
|---|---|
| 在进程列表上创建条目 为程序分配内存 将程序加载到内存中 根据 argc/argv 设置程序栈 | |
| 清除寄存器 执行 call main 方法 | |
| 执行 main | |
| 释放进程的内存 将进程从进程列表中清除 |
听起来很简单,但是这种方法在我们虚拟化 CPU 时产生了一些问题。第一个问题很简单:如果我们只运行一个程序,操作系统怎么能确保程序不做任何我们不希望它做的事情,同时仍然能够高效执行?第二个问题:当我们运行一个进程时,操作系统如何让它停下来并切换到另一个进程,从而实现虚拟化 CPU 所需要的分时共享?
下面在回到这些问题时,我们将更好的了解虚拟化 CPU 需要什么。在开发这些技术时,我们还会看到标题中的“受限”部分来自哪里。如果对运行程序没有限制,操作系统无法控制任何事情,因此会成为“仅仅是一个库”——对应有抱负的操作系统而言,这真是令人悲伤的事情!
问题 1:受限制的操作
直接执行的明显优势是快速。该程序直接在硬件 CPU 上执行,因此执行速度与预期的一样快。但是,在 CPU 上运行会带来一个问题——如果进程希望执行某种受限操作,比如向磁盘发起 IO 请求或获得更多系统资源,该怎么办?
提示:采用受保护的控制权转移 硬件通过提供不同的执行模式来协助操作系统。在用户模式下,应用程序不能完全访问硬件资源。在内核模式下,操作系统可以访问机器的全部资源。还提供了陷入内核和从陷阱返回到用户模式程序的特别说明,以及一些指令,让操作系统告诉硬件陷阱表在内存中为位置。
对于 IO 和其他相关操作,一种方法就是让所有进程做所有它想做的事情。但是,这样做导致无法构建许多我们想要的系统。例如,如果我们希望构建一个在授予文件访问权限前检查权限的文件系统,就不能简单的让任何用户进程都可以向磁盘发起 IO 请求。如果这样做,一个进程就可以读写整个磁盘,这样所有的保护都将失效。
因此,我们采用的方法是引入一种新的处理器模式,称为用户模式。在用户模式下运行的代码会收到限制。比如,在用户模式下运行时,进程不能发出 IO 请求。这样做会导致处理器引发异常,操作系统可能会终止进程。
与用户模式不同的内核模式,操作系统就可以以这种模式运行。在该模式下,运行的代码可以做它喜欢的事情,包括特权操作,如果发出 IO 请求或执行所有类型的受限指令。
但是,我们仍然面临一个挑战——如果用户希望执行某种特权操作,应该怎么办?为了实现这一点,几乎所有的现代硬件都提供了用户程序执行系统调用的能力。系统调用是在 Atlas 等古老机器上开创的,它允许内核小心的向用户程序暴露某些关键功能,例如访问文件系统、创建和销毁进程、与其他进程通信,以及分配更多内存。大多数操作系统能提供几百个调用。早期的 UNIX 系统公开了更加简洁的子集,大约 20 个调用。
要执行系统调用,程序必须执行特殊的陷阱指令。该指令同时跳入内核并将特权界别提升到内核模式。一旦进入内核,系统即可以执行任何允许的特权操作,从而为调用进程执行需要的工作。完成后,操作系统调用一个特殊的从陷阱返回的指令,如你期望的那样,该指令返回到发起调用的用户程序中,同时将特权级别降低,回到用户模式。
执行陷阱时,硬件需要小心,因为它必须确保存储足够的调用者寄存器,以便在操作系统发出从陷阱返回的指令时能够正确返回。比如在 X86 上,处理器会将程序计数器、标志和其他一些寄存器推送到每个进程的内核栈上。从陷阱返回将从栈弹出这些值,并恢复执行用户模式程序。其他硬件系统使用不同的约定,但基本概念在各个平台上是类似的。
补充:为什么系统调用看起来像是过程调用? 你可能想知道,为什么系统调用(open/read)看起来完全像是 C 中典型的过程调用。也就是说,如果它看起来像是一个过程调用,系统又是如何知道它是一个系统调用呢,并做出正确的响应?原因很简单:它是一个过程调用,但隐藏在过程调用内部的是著名的陷阱指令。 更具体的说,当你调用 open 时,你正在执行对 C 库的过程调用。其中,无论是对于 open 还是提供的其他系统调用,库都使用与内核一致的调用约定来将参数放在众所周知的位置(如栈中或特定的寄存器中),将系统调用号也放在一个众所周知的位置,然后再执行上述陷阱指令。 在库中,陷阱之后的代码准备好返回值,并将控制权返回给发出系统调用的程序。因此,C 库中进行系统调用的部分是用汇编手工编码的,因为它需要仔细遵循约定,以便正确的处理参数和返回值,以及执行硬件特定的陷阱指令。 现在你知道为什么你自己不必编写汇编来陷入操作系统内核了吧,因为已经有人完成了这些工作。
还有一个重要的细节没有讨论:陷阱如何知道在 OS 内执行哪些代码?显然,发起调用的过程不能指定要跳转到的地址(就像你在进行过程调用时一样),这样做让程序可以跳转到内核中的任意位置,这显然是一个糟糕的主意。因此内核必须谨慎的控制在陷阱中执行的代码。
内核通过在启动时设置陷阱表来实现。当机器启动时,它在特权(内核)模式下执行,因此可以根据需要自由配置机器硬件。操作系统做的第一件事就是告诉硬件在发生某些异常事件时要运行哪些代码。比如,当发生磁盘中断、发生键盘中断或程序进行系统调用时,应该运行哪些代码。操作系统通常通过某种特殊的指令,通知硬件这些陷阱处理程序的位置。一旦硬件被通知,它就会记住这些处理程序的位置,直到下一次重启机器,并且硬件知道在发生系统调用和其他异常事件时要做什么(即跳转到那段代码)。
最后,能够执行指令来告诉硬件陷阱表的位置是一个非常强大的功能。因此你可能已经猜到,这也是一项特权操作。如果你试图在用户模式下执行这些指令,硬件是不会允许的。如果你可以自己设置陷阱表,你可以对系统做些什么呢?你能接管机器码?
时间线总结了该协议。我们假设每个进程都有一个内核栈,在进入内核和离开内核时,寄存器分别被保存和恢复。
下表是“受限直接运行协议”:
| 操作系统@启动(内核模式) | 硬件 | |
|---|---|---|
| 初始化陷阱表 | ||
| 记住系统调用处理程序的地址 | ||
| 操作系统@运行(内核模式) | 硬件 | 程序(应用模式) |
| 在进程列表上创建条目 为程序分配内存 将程序加载到内存中 根据 argv 设置程序栈 用寄存器/程序计数器填充内核栈 从陷阱返回 | ||
| 从内核栈恢复寄存器 转向用户模式 调到 main | ||
| 运行 main …… 执行系统调用 陷入操作系统 | ||
| 将寄存器保存到内核栈 转向内核模式 调到陷阱处理程序 | ||
| 处理陷阱 完成系统调用指定的工作 从陷阱返回 | ||
| 从内核栈恢复寄存器 转向用户模式 调到陷阱之后的程序计数器 | ||
| 从 main 返回 陷入(通过 exit) | ||
| 释放进程的内存 将进程从进程列表中清除 |
LDE 协议有两个阶段。第一个阶段(在系统引导时),内核初始化陷阱表,并且 CPU 记住他的位置以供随后使用。内核通过特权指令来执行此操作。第二个阶段(运行进程时),在使用从陷阱返回指令开始执行进程之前,内核设置了一些内容。这会将 CPU 切换到用户模式并开始运行该程序。当进程希望发出系统调用时,它会重新陷入操作系统,然后再次通过从陷阱返回,将控制权还给进程。该进程然后完成它的工作,并从 main 返回。这通常会返回到一些存根代码,它将正确退出该程序。此时,OS 清理干净,任务完成。
问题 2:进程间切换
直接执行的下一个问题是进程间切换。实际上这个问题很棘手,特别是,如果一个进程在 CPU 上运行,这就意味着这时操作系统没有运行。如果操作系统没有处于运行状态,它又怎么做事情?虽然这听起来几乎是哲学,但这是真正的问题——如果操作系统没有在 CPU 上运行,那么显然操作系统没有办法采取行动。因此,我们遇到了关键问题。
协作方式:等待系统调用
过去某些系统采用的一种方式成为“协作方式”。在这种形式下,操作系统会相信系统中的进程会合理运行。运行时间过长的进程被假定会定期放弃 CPU,以便操作系统可以决定运行其他任务。
因此你可能会问,在这个虚拟的世界中,一个友好的进程如何放弃 CPU?事实证明,大多数进程通过执行调用,将 CPU 的控制权转移给操作系统,比如打开文件并随后读取文件,或者向另一台机器发送消息或创建新的进程。像这样的系统通常包括一个显式的 yield 系统调用,它什么也不干,只是将控制权交给操作系统,以便操作系统可以运行其他进程。
如果应用程序执行了某些非法操作,也会将控制权转移给操作系统。比如,如果应用程序已 0 为除数,或者尝试访问无法访问的内存,就会陷入操作系统。操作系统将再次控制 CPU,并可能终止违规进程。
因此,在协作调度系统中,OS 通过等待系统调用,或某种非法操作发生,从而重新获得 CPU 的控制权。你也许会想到,这种被动方式是不是不太理想?比如,如果某个进程进入无线循环并且从不进行系统调用,或发生什么情况?那么操作系统又能做什么?
非协作方式:操作系统进行控制
事实证明,没有硬件的额外帮助,如果进程拒绝执行系统调用而且不出错,从而将控制权交还给操作系统,那么操作系统无法做什么事情。事实上,在协作方式中,当进程陷入无限循环时,唯一的办法就是使用古来的解决方案来处理计算机系统中的所有问题——重新启动计算机。因此,我们又遇到了请求获得 CPU 控制权的一个子问题。
关键问题:如何在没有协作的情况下获得控制权? 即使进程不协作,操作系统如何获得 CPU 控制权?操作系统如何保证流氓进程不会占有机器?
答案很简单,很多年前构建计算机系统的人都发现了:时钟中断。时钟设备可以变成为每隔几毫秒产生一次中断。产生中断时,当前正在运行的进程停止,操作系统中预先配置的中断处理程序会运行。这时,操作系统重新获得了 CPU 的控制权,因此可以做它想做的事情:停止当前进程,并启动另一个进程。
提示:利用时钟中断重新获得控制权 即使进程以非协作的方式运行,添加时钟中断也让操作系统能够在 CPU 上重新运行。因此,该硬件功能对于操作系统维持机器的控制权至关重要。
首先,正如我们之前讨论过的系统调用一样,操作系统必须通知硬件哪些代码需要在发生中断时运行。因此,在启动时,操作系统就是这样做的。其次,在启动过程中,操作系统也必须启动时钟,这当然是一项特权操作。一旦时钟开始运行,操作系统就感到安全了,因为控制权最终会归还给他,因此操作系统可以自由运行用户程序。时钟也可以关闭,在稍后对并发的讲解中我们会进行讨论。
请注意,硬件在发生中断时有一定的责任,尤其是在发生中断时,要为正在运行的程序保存足够的状态,以便随后从陷阱返回指令能够正确的恢复该程序。这一组操作与硬件在显式系统调用陷入内核时的行为非常相似,其中各种寄存器因此会被保存,因此可以很容易的从陷阱返回指令恢复。
保存和恢复上下文
既然操作系统已经重新获得了控制权,无论是通过系统调用协作,还是通过时钟中断强制执行,都必须决定:是继续运行当前正在运行的进程,还是切换到另一个进程。这个决定是由调度程序做出的,它是操作系统的一部分。我们将在接下来的几章中详细讨论调度策略。
如果决定进行切换,OS 就会执行一些底层代码,即所谓的上下文切换。上下文切换在概念上很简单:操作系统要做的就是为当前正在执行的进程保存一些寄存器的值,并未即将执行的进程恢复一些寄存器的值。这样一来,操作系统就可以确保最后执行从陷阱返回指令时,不是返回到之前运行的进程,而是继续执行另一个进程。
为了保存当前正在运行的进程的上下文,操作系统会执行一些底层汇编代码,来保存通用寄存器、程序计数器,以及当前正在运行的进程的内核栈指针,然后恢复寄存器、程序计数器,并切换内核栈,供即将运行的进程使用。通过切换栈,内核在进入切换代码调用时,是一个(被中断的)进程的上下文,返回时,是另一个(即将执行的)进程的上下文。当操作系统最终执行从陷阱返回指令时,即将执行的进程编程了当前运行的进程。至此,一次上下文切换过程完成。
| 操作系统@启动(内核模式) | 硬件 | |
|---|---|---|
| 初始化陷阱表 | ||
| 记住以下地址: 系统调用处理程序 时钟处理程序 | ||
| 启动时钟中断 | ||
| 启动时钟 每个 N 毫秒中断 CPU | ||
| 操作系统@运行(内核模式) | 硬件 | 程序(应用模式) |
| 进程 A… | ||
| 时钟中断 将寄存器(A)保存到内核栈(A) 转向内核模式 跳转陷阱处理程序 | ||
| 处理陷阱 调用 switch 例程 将寄存器(A)保存到进程结构(A) 将进程结构(B)恢复到寄存器(B) 从陷阱返回(进入 B) | ||
| 从内核栈(B)恢复到寄存器(B) 转向用户模式 调到 B 的程序计数器 | ||
| 进程 B… |
上表展示了完整的时间线。在这个例子中,进程 A 正在运行,然后被时钟中断。硬件(在内核栈中)保存其寄存器,并进入内核栈(切换到内核模式)。在时钟中断处理程序中,操作系统决定从正在运行的进程 A 切换到进程 B。此时,它调用 switch 例程,该例程仔细保存当前寄存器的值(保存到 A 的进程结构),恢复寄存器进程 B(从 B 的进程结构),然后切换上下文,具体来说是通过改变栈指针来使用 B 的内核栈(而不再是 A)。最后,操作系统从陷阱返回,恢复 B 的寄存器并开始运行 B。
请注意,在此协议中,有两种类型的寄存器保存和恢复。第一种是发生时钟中断的时候,在这种情况下,运行进程的用户寄存器由硬件隐式保存,使用的是该进程的内核栈。第二种是当操作系统决定从 A 切换到 B。在这种情况下,内核寄存器被软件(即 OS)明确的保存,但这次被存储在该进程的进程结构对应的内存中。后一个操作让系统从好像刚刚 A 陷入内核,编程好像刚刚从 B 陷入内核。
为了更好的理解如何实现这种切换,下面的代码展示了具体的实现过程。context 结构的 old 和 new 分别在老的和新的进程的进程结构中。
1 # void swtch(struct context **old, struct context *new);
2 #
3 # Save current register context in old
4 # and then load register context from new.
5 .globl swtch
6 swtch:
7 # Save old registers
8 movl 4(%esp), %eax # put old ptr into eax
9 popl 0(%eax) # save the old IP
10 movl %esp, 4(%eax) # and stack
11 movl %ebx, 8(%eax) # and other registers
12 movl %ecx, 12(%eax)
13 movl %edx, 16(%eax)
14 movl %esi, 20(%eax)
15 movl %edi, 24(%eax)
16 movl %ebp, 28(%eax)
17
18 # Load new registers
19 movl 4(%esp), %eax # put new ptr into eax
20 movl 28(%eax), %ebp # restore other registers
21 movl 24(%eax), %edi
22 movl 20(%eax), %esi
23 movl 16(%eax), %edx
24 movl 12(%eax), %ecx
25 movl 8(%eax), %ebx
26 movl 4(%eax), %esp # stack is switched here
27 pushl 0(%eax) # return addr put in place
28 ret # finally return into new ctxt
并发问题
作为细心的读者,你们可能会想到:在系统调用期间发生时钟中断会发生什么?或者,在处理一个中断时又发生了另一个中断,这时会发生什么?这不会让内核难以处理吗?
如果在中断或陷阱处理过程中发生另一个中断,那么操作系统确实需要关心发生了什么。实际上,这正是本书第二部分关于并发的主题。
补充:上下文切换的耗时 一个自然的问题是:上下文切换需要多久,或者系统调用需要多久。 随着时间的推移,结果有了很大的提高,大致跟上了处理器你的性能提升。比如,1996 年在 200-MHz P6 CPU 上运行 Linux 1.3.37,系统调用花费了 4us,上下文切换的时间大致为 6us。现代操作系统的性能几乎可以提高一个数量级,在具有 2GHz 或 3GHz 处理器的系统上的性能可以达到亚微秒级。 应该注意的是,并非所有的操作系统都会跟踪 CPU 的性能。正如 Ousterhout 所说,许多操作系统的操作都是内存密集型的,而随着时间的推移,但随着时间的推移,内存带宽并没有像处理器速度那样显著提高。因此,根据你的工作负载,购买最新的、性能好的处理器可能不会像你期望的那样加速操作系统。
为了让你开开胃,我们只是简单介绍了操作系统如何处理这些棘手的情况。操作系统可能简单的决定,在中断处理期间禁止中断。这样做可以确保在处理一个中断时,不会将其他中断交给 CPU。当然,操作系统这样做必须小心。禁用中断时间过长则可能导致中断丢失,这在技术上是不好的。
操作系统还开发了许多复杂的加锁方案,以保护对内部数据结构的并发访问。这使得多个活动可以同时在内核中进行,特别适用于多处理器。我们将在后续章节中看到,这种锁可能会变得复杂,并导致各种有趣且难发现的错误。
小结
我们已经描述了一些实现 CPU 虚拟化的关键底层机制,并将其统称为受限直接执行。基本思路很简单:就让你想运行的程序在 CPU 上运行,但首先要确保设置好硬件,以便在没有操作系统帮助的情况下限制进程可以执行的操作。
这种一般方法在现实生活中也适用。比如,有些孩子会熟悉宝宝防护房间的概念——锁好包含危险物品的柜子,并掩盖电源插座。当这些都准备妥当时,你可以让宝宝自由行动,确保房间最危险的方面受到限制。
提示:重新启动是有用的 之前我们指出,在协作式抢占时,无限循环的唯一解决方案是重启机器。虽然你可能嘲笑这种粗暴的做法,但研究表明,重启(软件)可能构建强大系统的一个非常有用的工具。 具体来说,重新启动很有用,因为它让软件回到已知的状态,很可能是经过更多测试的状态。重新启动还可以回收旧的或泄露的资源,否则这些资源可能很难处理。最后,重启很容易自动化。由于所有这些原因,在大规模互联网服务中,系统管理软件定期重启一些机器,重置它们并因此获得以上好处,这并不少见。
通过类似的方式,OS 首先在启动时设置陷阱处理程序并启动中断时钟,然后仅在受限模式下运行进程,以此为 CPU 提供宝宝防护。这样做,操作系统能确信进程可以高效运行,只在执行特权操作,或者让它们独占 CPU 时间过长并因此需要切换时,才需要操作系统干预。
至此,我们有了虚拟化 CPU 的基本机制。但一个主要问题还没有答案:在特定时间,我们应该运行哪个进程?调度程序可以解答这个问题。
1.5 - 进程调度
现在,运行进程的底层机制应该清楚了。然而,我们还不知道操作系统调度程序采用的上层策略。
事实上,调度的起源早于计算机系统。早期调度策略取自于操作管理领域,并应用于计算机。对于这个事实不必惊讶:装配线以及许多人类活动都需要调度,而且许多关注点是一样的,包括像激光一样对效率的渴望。
工作负载假设
探讨可能的策略范围之前,我们先做一些假设。这些假设与系统中运行的进程有关,有时候统称为工作负载。确定工作负载是构建调度策略的关键部分。工作负载了解的越多,你的策略就越优化。
我们这里做的工作负载的假设是不切实际的,但目前这不算问题,因为我们将来会放宽这些假设,并最终开发出我们所谓的——一个完全可操作的调度准则。
我们对操作系统中运行的进程做出如下假设:
- 每个工作运行相同的时间。
- 所有的工作同时到达。
- 一旦开始,每个工作保持运行直到完成。
- 所有的工作只使用 CPU,不执行 IO 操作。
- 每个工作的运行时间是已知的。
调度指标
除了做出工作负载假设,还需要一个东西能让我们比较不同的调度策略:调度指标。指标是我们衡量某些东西标准,在调度进程中,一些不同的指标是有意义的。
现在让我们简化一下,只用一个指标:周转时间。任务的周转时间定义为任务完成时间减去任务到达系统的时间,即:周转时间 = 完成时间 - 到达时间。
因为我们假设所有的任务都在同一时间到达,那么 到达时间=0,因此 周转时间=完成时间。随着我们放宽上述假设,该情况将会改变。
你应该注意到,周转时间是一个性能指标,这将是本章的首要关注点。另一个有趣的指标是公平,比如 Jian’s Fariness Index。性能和公平在调度系统中往往是矛盾的。比如,调度程序可以优化性能,但代价是阻止一些任务的执行,这也就降低了公平性。
先进先出
我们可以实现的最基本的算法为 FIFO,或称为先到先服务(FCFS)。FIFO 有一些积极的特性:它很简单,而且易于实现。而且,对于我们的假设,它的效果很好。
我们一起看一个简单的例子。想象一下,3 个工作 A、B、C 在大致相同的时间到达系统。因为 FIFO 必须将某个工作放在前面,所以我们假设当它们都同时到达时,A 比 B 早一点点,然后 B 比 C 早一点点。假设每个工作运行 10 秒。这些工作的平均周转周期是多少?
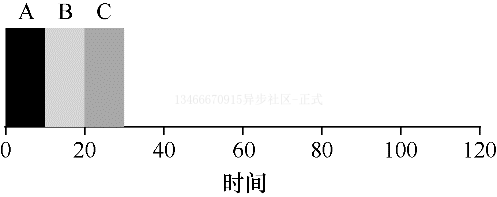
从上图可以看出,A 在 10s 时完成,B 在 20s 时完成,C 在 30s 时完成。因此这 3 个任务的平均周转时间就是 (10+20+30)/3=20。
现在让我们放宽假设 1,因此不再认为所有任务的运行时间是相同的。FIFO 表现如何?你可以构建什么样的工作负载来让 FIFO 表现的不好?
这次我们假设 3 个任务,A 运行 100s,B 和 C 都运行 10s。

如上图,A 先运行 100s,B 或 C 才有机会运行。因此,系统的平均周转时间是比较高的,达到 110s。
该问题通常被称为护航效应,一些耗时较少的潜在资源消费者被排在重量级的资源消费者之后。
提示:SJF 原则 最短任务优先代表一个总体调度原则,可以应用于所有系统,只要其中平均客户周转时间很重要。
最短任务优先
实际上这是才从运筹学中借鉴的一个想法,然后应用到计算机系统的任务调度中。这个新的调度准则被称为最短任务优先:先运行最短的任务,然后是次短的任务,以此类推。
我们用上面的例子,但以 SJF作为调度策略。下图展示的是三个任务的执行情况。它清除的表明了为什么在考虑平均周转时间的情况下,SJF 的表现会更好。这里的平均周转时间降到了 50s。
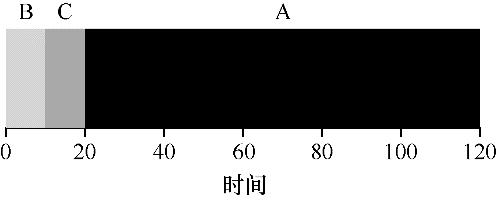
事实上,考虑到所有工作同时到达的假设,我们可以证明 SJF 确实是一个最优的调度算法。
补充:抢占式调度程序 在过去的批处理计算中,开发了一些非抢占式调度程序。这样的系统会将每项工作做完,再考虑是否允许新工作。几乎所有现代优化的调度程序都是抢占式的,非常愿意停止一个进程以运行另一个进程,这意味着调度程序采用了我们之前学习的机制。特别是调度程序可以进行上下文切换,临时停止一个运行进程,并回复或启动另一个进程。
因此我们找到了一个用 SJF 进行调度的好方法,但是我们的假设仍然是不切实际的。让我们放宽假设 2,现在假设工作可以随时到达,而不再是同时到达。
现在假设 A 在 t=0 时到达,且需要运行 100s。而 B 和 C 在 t=10 到达,且各需运行 10s。如果使用纯粹的 SJF,则会得到下面的调度过程:
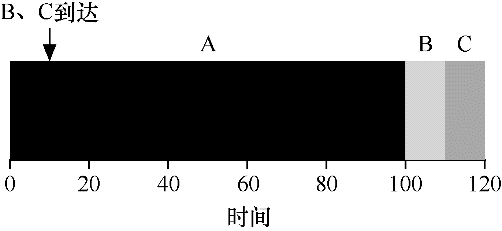
从图中可以看出,即使 B 和 C 在 A 之后不久到达,但它们仍然需要等待 A 完成之后才能开始运行,从而遭遇同样的护航问题。它们的平均周转时间为 103.33s。
最短完成时间优先
为了解决该问题,需要放款假设条件:工作必须保持运行直到完成。我们还需要调度程序本身的一些机制。你可能已经猜到,鉴于我们之前讨论过的关于时钟中断和上下文切换技术,当 B 和 C 到达时,调度程序当然可以做其他事情:它可以抢占工作 A,并决定运行另一个工作,后续稍后会继续运行工作 A。根据我们的定义,SJF 是一种非抢占式调度程序,因此存在上述问题。
幸运的是,有一个调度程序完全就是这样做的:向 SJF 添加抢占能力,称为最短完成时间优先,或抢占式最短作业优先。每当新工作进入系统时,它就会确定剩余工作和新工作中谁的剩余时间最少,然后调度该工作。因此,在我们的例子中,STCF 将抢占 A 并运行 B 和 C。只有在它们完成之后才能调度 A 的剩余时间。
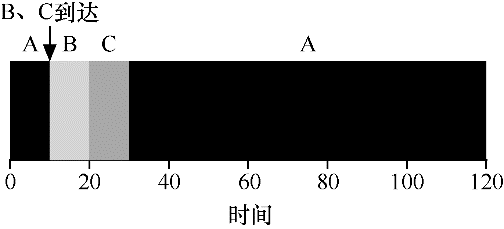
结果是平均周转时间大大减少:50s。和以前一样,考虑到我们的新架设,STCF 可证明是最优的。考虑到所有工作如果同时到达,则 SJF 是最优的,那么你应该能够看到 STCF 的最优性是符合直觉的。
新度量指标:响应时间
因此,如果我们知道任务长度,而且任务只使用 CPU,而我们唯一的衡量标准是周转时间,STCF 将是一个很好的策略。事实上,对于许多早期批处理系统,这些类型的调度算法有一定的意义。然而,引入分时系统改变了这一切。现在,用户将会坐在终端前面,同时也要求系统的交互性好。因此,一个新的度量指标诞生了:响应时间。
响应时间定义为从任务到达系统到开始首次运行的时间:响应时间=首次运行-到达时间。
比如,如果我们有上面的调度(A 在时间 0 到达,BC 在时间 10 到达),每个作业的响应时间如下:
- A:0
- B:0
- C:10
平均为 3.3s。
你可能会想到,STCF 和相关方法在响应时间上的表现并不好。比如,如果 3 个工作同时到达,第三个工作必须等待前两个工作完全运行后才能开始运行。这种方法虽然有很好的周转时间,但对于响应时间和交互性是相当糟糕的。假设你在终端前输入,不得不等待 10s 才能看到系统的回应,只是因为其他一些工作已经在你之前被调度了。
因此我们还有另一个问题:如何构建对响应时间敏感的调度程序?
轮转
为了解决这个问题,我们将介绍一种新的调度算法:轮转调度(Round-Robin)。基本思想很简单:RR 在一个时间片内运行一个工作,然后切换到运行队列中的下一个任务,而不是运行一个任务直到结束。它反复执行,直到所有任务执行完成。因此,RR 有时被称为时间切片。注意,时间片长度必须是时钟中断周期的倍数。因此,如果时钟中断是每 10ms 一次,则时间片可以是 10ms、20ms 等等。
为了更详细的理解 RR,我们来看一个例子。假设 3 个任务 ABC 同时到达,并且都希望运行 5 秒。SJF 调度程序必须运行网当前任务才能运行下一个任务。相比之下,1s 时间片的 RR 可以快速的循环工作。
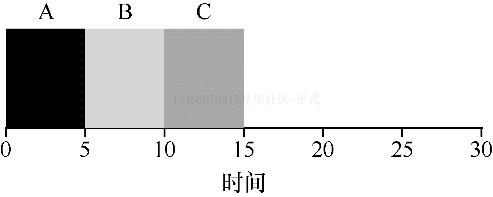
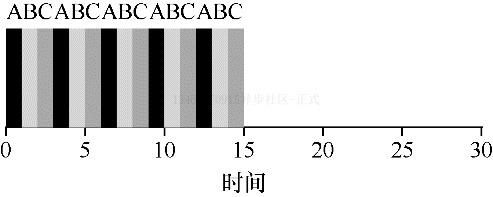
RR 的平均响应时间为 1s,而 SJF 的平均响应时间为 5s。
如果你所见,时间片长度对于 RR 是至关重要的。越短,RR 在响应时间上的表现越好。然而,时间片太短也会有问题:突然上下文切换的成本将影响整体性能。因此,系统设计者需要权衡时间片的长度,使其足够长以分摊上下文切换的成本,而又不会使系统无法及时响应。
提示:摊销和减少成本 当系统某些操作有固定成本时,通常会使用摊销技术。通过减少成本的频度(即执行较少次的操作),系统的总成本会降低。例如,如果时间片设置为 10ms,并且上下文切换时间为 1ms,那么浪费大约 10% 的时间用于上下文切换。如果要摊销这个成本,可以把时间片增加到 100ms。这时,不到 1% 的时间用于上下文切换,因此时间片带来的成本就被摊销了。
请注意,上下文切换的成本不仅仅是来自保存和恢复少量寄存器的操作系统操作。程序运行时,他们在 CPU 高速缓存、TLB、分支预测器和其他片上硬件中建立了大量的状态。切换到另一个工作会导致此状态被刷新,且与当前运行的作业相关的新状态被引入,这可能导致显著的性能成本。
如果响应时间是我们的唯一指标,那么带有合理时间片的 RR,就会是非常好的调度程序。但是周转时间呢?再来看看我们的例子。ABC 各自的运行时间为 5s,同时到达,RR 是具有 1s 时间片的调度程序。从上面的图中可以看到,平均周转时间为 14s,相当可怕。
这并不奇怪,如果周转时间是我们的指标,那么 RR 确实是最糟糕的策略之一。直观的说,这应该是有意义的:RR 所做的真是延伸每个工作,只运行每个工作一小段时间,就转向下一个工作。因为周转时间只关心作业何时完成,RR 几乎是最差的,在很多情况下甚至比简单的 FIFO 还要差。
更一般的说,任何公平的策略,即在小规模的时间内将 CPU 均为分配到活动的进程之间,在周转时间这类指标上都会表现不佳。事实上,这是固有的权衡:如果你愿意不公平,你可以运行较短的工作直到完成,但是要以响应时间为代价。如果你重视公平性,则响应时间会较短,但会以周转时间为代价。这种权衡在系统中很常见。
我们开发了两种调度程序。第一种类型(SJF/STCF)优化周转时间,但对响应时间不利。第二种类型(RR)优化响应时间,但对周转时间不利。我们还有两个假设需要放宽:作业没有 IO、每个作业的运行时间是已知的。接下来我们来解决这些假设。
提示:重叠可以提高利用率 如有可能,重叠(overlap)操作可以最大限度的提高系统的利用率。重叠在很多不同的领域很有用,包括执行磁盘 IO 或将消息发送到远程机器时。在任何一种情况下,开始操作然后切换到其他工作都是一个好主意,这也提高了系统的整体利用率和效率。
结合 IO
首先,我们将放宽假设 4:所有程序都执行 IO。想象一下没有任何输入的程序:每次都会产生相同的输出。设想一个没有输出的程序:没有人会看到它,它的运行没有意义。
调度程序显然要在工作发起 IO 请求时做出决定,因为当前正在运行的作业在 IO 期间不会使用 CPU,它被阻塞直到等待 IO 完成。如果将 IO 请求发送到磁盘驱动器,则进程可能会被阻塞几毫秒甚至更长时间,具体取决于驱动器当前的 IO 负载。因此,这时调度程序应该在 CPU 上安排其他工作。
调度程序还必须在 IO 完成时做出决定。发生这种情况时,会产生中断,操作系统运行并将发出 IO 的进程从阻塞状态转换为就绪状态。当然,它甚至可以决定在哪个时候运行该项工作。操作系统应该如何处理每项工作?
为了更好的理解这个问题,我们假设两个工作 AB,每项工作都需要 50ms 的 CPU 时间。但是有一个明显的区别,A 运行 10ms,然后发起 IO 请求,假设每个 IO 需要 10ms。而 B 只是使用 CPU 50ms,不执行 IO。调度程序先运行 A,然后运行 B。
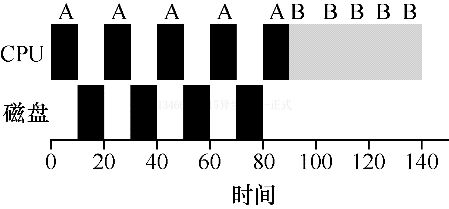
假设我们正在尝试构建 STCF 调度程序。这样的调度程序应该如何考虑这样的事实,即 A 分解成 5 个 10ms 子工作,而 B 仅仅是单个 50ms CPU 的需求?显然,仅仅运行一个工作然后运行另一个工作,而不考虑 IO,是没有意义的。
一种常见的方法是将 A 的每个 10ms 的子工作视为一项独立的工作。因此,当系统启动时,它的选择是调度 10ms 的 A,还是 50ms 的 B,对于 STCF 来说选择是明确的:选择较短的一个,这种情况下是 A。然后 A 的工作已经完成,只剩下 B,并开始运行。然后提交 A 的一个新子工作,它抢占 B 并运行 10ms。这样做可以实现重叠,一个进程在等待另一个进程 IO 完成时使用 CPU,系统因此得到更好的利用。
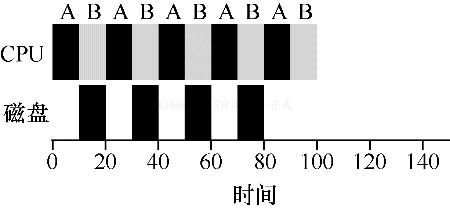
这样我们就看到了调度程序可能如何结合 IO。通过将每个 CPU 突发作为一项工作,调度程序确保“交互”的进程正常运行。当这些交互式作业正在执行 IO 时,其他 CPU 密集型作业将运行,从而更好的利用处理器。
无法预知
有了应对 IO 的基本方法,我们来到最后的假设:调度程序知道每个工作的长度。如前所述,这可能是最糟糕的假设。事实上,在一个通用的操作系统中,操作系统通常对每个作业的长度知之甚少。因此我们如何建立一个没有这种先验知识的 SJF/STCF?更进一步,我们如何能够将已经看到的一些想法与 RR 调度程序结合,以便响应时间也能表现的更好?
小结
我们介绍了调度的基本思想,并开发了两类方法。第一类是运行最短的工作,从而优化周转时间。第二类是交替运行所有工作,从而优化响应时间。但很难做到鱼与熊掌兼得,这是系统中最常见、固有的折中。我们也看到了如何将 IO 结合到场景中,但仍未解决操作系统根本无法看到未来的问题。稍后,我们将看到如何构建一个调度程序,利用最近的历史预测未来。这个调度程序被称为多级反馈队列。
1.6 - 调度-多级反馈队列
本章将介绍一种著名的调度方法——多级反馈队列(MLFQ)。1962 年,Corbato 首次提出多级反馈队列,应用于兼容分时共享系统。Corbato 因在 CTSS 中的贡献和后来的 Multics 中的贡献,获得了 ACM 颁发的图灵奖。该调度程序经过多年的一系列优化,出现在许多现代操作系统中。
多级反馈队列需要解决两方面的问题。首先需要优化周转时间。上一章我们看到,可以通过先执行较短工作来实现。然而,操作系统通常不知道工作的长度,而这又是 SJF/STCF 等算法所必须的。其次,MLFQ 希望给交互用户带来更好的交互体验,因此需要降低响应时间。然而,像轮转这样的算法虽然降低了响应时间,周转时间却很差。所以这里的问题是:通常我们对进程一无所知,应该如何构建调度程序来实现这些目标?调度程序如何在运行过程中学习进程的特征,从而做出更好的调度决策?
提示:从历史中学习 多级反馈队列是使用历史的经验来预测未来的典型实例,操作系统中有很多地方采用了这种技术。如果工作有明显的阶段性行为,因此可以预测,这种方式会很有效。当然,必须小心使用这种技术,因为它可能出错,让系统做出比一无所知还要糟的决定。
MLFQ:基本规则
为了构建这样的调度程序,本章将介绍多级反馈队列背后的基本算法。虽然对应的实现有很多,但大都类似。
MLFQ 中有许多独立的队列,每个队列有不同的优先级。任何时刻,一个工作只能存在于一个队列中。MLFQ 总是优先执行较高优先级的工作(即在较高级队列中的工作)。
当然,每个队列中可能会有多个工作,因此它们具有相同的优先级。在这种情况下,我们就对这些工作采用轮转调度。
因此,MLFQ 调度策略的关键在于如何设置优先级。MLFQ 没有为每个工作指定不变的优先级,而是根据观察到的行为调整它的优先级。比如,如果一个工作不断放弃 CPU 去等待键盘输入,这是交互型进程的可能行为,MLFQ 因此会让它保持高优先级。相反,如果一个工作长时间的占用 CPU,MLFQ 会降低其优先级。通过这种方式,MLFQ 在进程运行过程中学习其行为,从而利用工作的历史来预测它未来的行为。
至此,我们得到了 MLFQ 的两条基本规则。
- 规则 1:如果 A 的优先级 > B 的优先级,运行 A。
- 规则 2:如果 A 的优先级 = B 的优先级,轮转运行 AB。
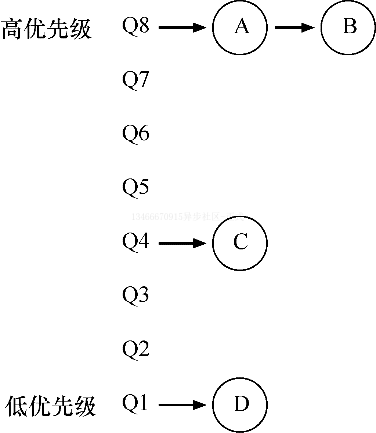
如果要在某个特定的时刻展示这些队列,可能会看到类似上面的内容。最高优先级中有两个工作 AB,工作 C 位于中等优先级队列,而 D 的优先级最低。按刚才介绍的基本规则,由于 A 和 B 有最高优先级,调度程序将交替的调度它们,可怜的 C 和 D 永远没有机会运行,太气人了!
当然,这只是展示了一些队列的静态快照,并不能让你真正明白 MLFQ 的工作原理。我们需要理解工作的优先级如何随时间变化。
尝试 1:如何改变优先级
我们必须决定,在一个工作的生命周期中,MLFQ 如何改变其优先级。要做到这一点,我们必须记得工作负载:既有时间很短、频繁放弃 CPU 的交互型工作,也有需要很多 CPU 时间、响应时间缺不重要的长时间计算密集型工作。下面是我们第一次尝试优先级调整算法。
- 规则 3:工作进入系统时,放在最高优先级。
- 规则 4a:工作用完真个时间片后,降低其优先级。
- 规则 4b:如果工作在其时间片以内主动释放 CPU,则优先级不变。
实例 1:单个长工作
如果系统中有一个需要长时间运行的工作,看看会发生什么。下图展示了在一个拥有 3 个队列的调度程序中,随着时间的推移,这个工作的运行情况。
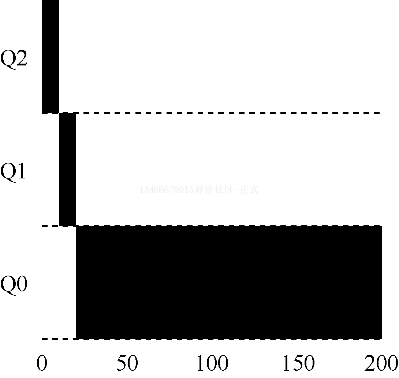
从这个例子可以看出,该工作首先进入最高优先级。执行一个 10ms 的时间片后,调度程序将工作的优先级减低 1,因此进入 Q1。在 Q1 执行一段时间后,最终降低优先级进入到系统的最低优先级队列 Q0,并一直留在那里。
实例 2:来了一个短工作
再看一个复杂的例子,看看 MLFQ 如何近似 SJF。在这个例子中有两个工作:A 是一个长时间运行的 CPU 密集型工作,B 是一个运行时间很短的交互型工作。假设 A 执行一段时间后 B 到达,会发生什么?对 B 来说,MLFQ 会近似于 SJF 吗?
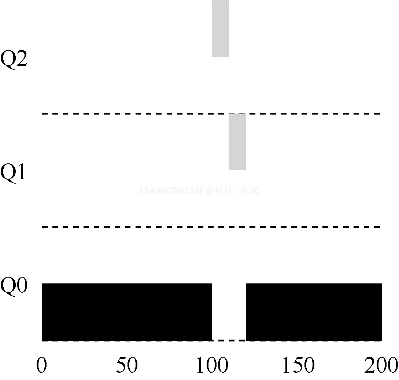
上图展示了该场景的结果。A 在最低优先级队列执行,B 在时间 100 时到达,并被加入到最高优先级队列。由于它的运行时间很短,经过两个时间片,在被移入最低优先级队列之前,B 执行完毕。然后 A 继续执行。
通过这个例子,大概可以体会到这个算法的一个主要目标:如果不知道工作是短工作还是长工作,那么就在开始的时候假设其是短工作,并赋予最高优先级。如果确定是短工作,则很快会执行完毕,否则将被慢慢移入低优先级队列,而这时该工作也被认为是长工作了。通过这种方式,MLFQ 近似于 SJF。
实例 3:结合 IO
根据规则 4b,如果进程在时间片用完之前主动放弃 CPU,则保持它的优先级不变。这条规则的意图很简单:假设交互型工作中有大量的 IO 操作,它会在时间片用完之前放弃 CPU。在这种情况下我们不想惩罚它,只是保持它的优先级不变。
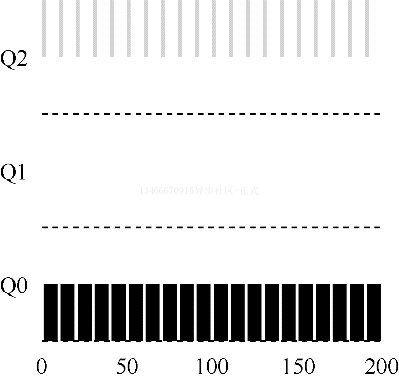
上图展示了这种运行过程,交互性工作 B 没执行 1ms 便需要进行 IO 操作,他与长时间运行的工作 A 竞争 CPU,MLFQ 算法保持 B 在最高优先级,因为 B 总是让出 CPU。如果 B 是交互型工作,MLFQ 就进一步实现了它的目标,让交互型工作快速运行。
当前 MLFQ 问题
至此我们有了基本的 MLFQ。看起来似乎不错,长时间工作可以公平的分享 CPU,又能给段工作或交互型工作很好的响应时间。然而,这种算法有一些非常严重的缺点。
首先,会有饥饿问题。如果系统有太多交互型工作,就会不断中断 CPU,导致长工作永远无法得到 CPU。即使在这种情况下,我们也希望这些厂工作保持进展。
其次,聪明的用户会重写程序来愚弄调度程序。愚弄调度程序指的是用一些卑鄙的手段欺骗调度程序,让它给你远超公平的资源。上述算法对如下的攻击束手无策:进程在时间片用完之前,调用一个 IO 操作(比如访问一个没有意义的文件),从而主动释放 CPU。如此便可以保持在高优先级,占用更多的 CPU 时间。做的好时,工作几乎可以独占 CPU。
最后,一个程序可能在不同时间表现不同。一个计算密集型的进程可能在某段时间表现为一个交互型的进程。用我们目前的方法,它不会享受系统中其他交互工作的待遇。
尝试 2:提升优先级
让我们试着改变之前的规则,看看是否能避免饥饿问题。要让 CPU 密集型工作也能保持进展(即使不多)。
一个简单的思路是周期性的提升所有工作的优先级。可以有很多方法做到,但我们这里使用最简单的一种:将所有工作放到最高优先级队列。于是有了如下的新规则:
- 规则 5:经过一段时间 S,就将系统中所有工作重新加入最高优先级队列。
新规则一下解决了两个问题。首先,进程不会饥饿——在最高优先级队列中,它会以轮转的方式,与其他高由下级工作分享 CPU,从而最终获得执行。其次,如果一个 CPU 密集型工作变成了交互型,当它优先级提升时,调度程序则会正确的对待他。
我们来看一个例子。在这种场景下,我们展示了长工作与两个交互型段工作竞争 CPU 时的行为。左图没有优先级提升,长工作在两个段工作到达后被饿死。右边每 50ms 就有一次优先级提升,因此至少能够保证长工作会取得一些进展,没过 50ms 就被提神到最高优先级,从而定期获得执行。
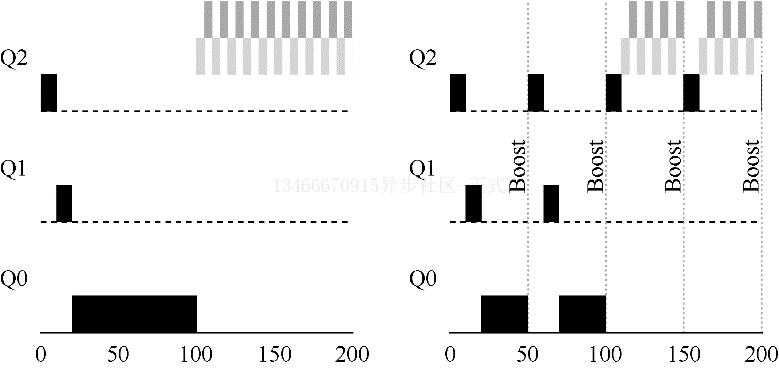
当然,添加时间段 S 导致了明显的问题:S 的值应该如何设置?德高望重的系统研究员 John Ousterhout 曾将这种值称为巫毒常量,因为似乎需要一些黑魔法才能正确设置。如果 S 设置的太高,长工作会出现一定程度的饥饿;如果设置的太低,交互型工作又得不到合适的 CPU 时间比例。
尝试 3:更好的计时方式
现在有一个问题需要解决:如何阻止调度程序被愚弄?可以看出,这里的元凶是 4a 和 4b,导致工作在时间片内释放 CPU,就保留它的优先级。那么应该怎么做?
这里的解决方案,是为 MLFQ 的每层队列提供更完善的 CPU 计时方式。调度程序应该记录一个进程在某一层中消耗的总时间,而不是在调度时重新计时。只要进程耗尽了自己的配额,就将它降低到低一级的队列中去。不论是它是一次用完的,还是拆成很多次用完。因此我们需要改变规则 4a 和 4b。
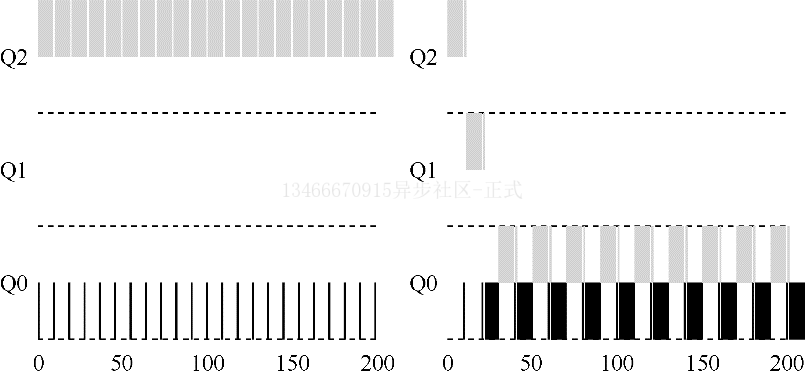
- 规则 4:一旦工作用完了其在某一层中的时间配额,无论中间主动放弃了多次 CPU,就降低其优先级。
来看一个例子。下图对比了在规则 4ab 的策略下和在新规则 4 的策略下,同样视图愚弄调度程序的进程表现。在没有规则 4 保护时,进程可以在每个时间片结束前发起一次 IO 操作,从而垄断 CPU 时间。有了这样的保护后,不论进程的 IO 行为如何,都会慢慢的降低优先级,因为无法获得超过公平的 CPU 时间比例。
MLFQ 调优及其他问题
关于 MLFQ 调度算法还有一些其他问题。其中一个大问题是如何配置一个调度程序,例如,配置多少队列?每个队列的时间片有多大?为了避免饥饿问题以及进程行为改变,应该多久提升一次进程的优先级?这些问题都没有显而易见的答案,因此只有利用度工作负载的经验,以及后续对调度程序的调优,才会得到满意的平衡。
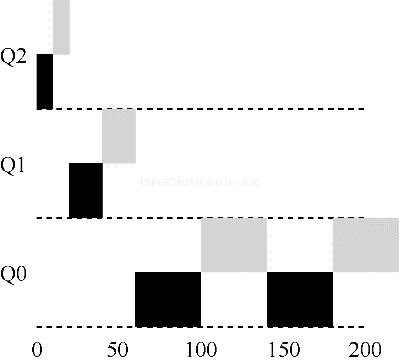
比如,大多数的 MLFQ 变体都支持不同队列可变的时间片长度。高优先等级队列通常只有较小的时间片,因此这一层的交互工作可以更快的切换。相反,低优先级队列中更多的是 CPU 密集型工作,配置更长的时间片会取得更好的效果。下图展示了一个例子,两个长工作在高优先级队列执行 10ms,中间队列执行 20ms,最后在最低优先级队列执行 40ms。
提示:避免巫毒常量 尽可能避免巫毒常量是个好主意。然而,从上面的例子可以看出,这通常很难。当然,我们也可以让系统自己去学习一个很优化的值,但这同样也不太容易。因此,通常我们会有一个写满各种参数默认值的配置文件,使得系统管理员可以方便的进行调整。然而,大多数使用者并不会去修改这些值,这时就寄希望于默认值合适了。
Solaris 的 MLFQ 实现很容易配置。它提供了一组表来决定进程在其生命周期中如何调整优先级,每层的时间片多大,以及多久提升一个工作的优先级。管理员可以通过这些表让调度程序的行为方式不同。该表默认有 60 层队列,时间片长度从 20ms 到数百 ms,每 1s 左右提升一次进程的优先级。
其他一些 MLFQ 调度程序没有使用表,甚至没有使用本章中讲到的规则,有些采用数学公式来调整优先级。比如,FreeBSD 调度程序,会基于当前进程使用了多少 CPU,通过公式计算出某个工作的当前优先级。另外,使用量会随时间衰减,这提供了期望的优先级提升,但与这里的描述方式不同。
最后,许多调度程序有些我们没有提到特征,比如,有效调度程序将最高优先级队列留给操作系统使用,因此通常的用户工作是无法得到系统的最高优先级的。有些系统允许用户给出优先级设置的建议,比如通过命令行工具 nice,可以稍微提升或降低工作的优先级,从而增加或减低它在某个时刻运行的机会。
小结
本章介绍了一种调度方式,MLFQ。总的来说就是:以史为鉴,关注进程的一贯表现,然后区别对待。
提示:尽可能多的使用建议 操作系统很少知道什么策略对系统中的单个进程或每个进程是友好的,因此提供接口并允许用户给操作系统一些提示常常很有用。我们通常称之为建议,因为操作系统不一定要关注它,但是可能会将建议考虑在内,以便做出更好的决定。这种用户建议的方式在操作系统的各个领域经常十分有用,包括调度程序、内存管理、文件系统。
- 规则 1:如果 A 的优先级 > B 的优先级,运行 A。
- 规则 2:如果 A 的优先级 = B 的优先级,轮转运行 AB。
- 规则 3:工作进入系统时,放在最高优先级。
- 规则 4:一旦工作用完了其在某一层中的时间配额(无论中间主动放弃了多少次 CPU),就降低其优先级。
- 规则 5:进过源时间 S,就将系统中所有工作放入最高优先级队列。
MLFQ 有趣的原因是:它不需要对工作的运行方式有先验知识,而是通过观察工作的运行来给出对应的优先级。通过这种方式,MLFQ 可以同时满足各种工作的需求:对于短时间运行的交互工作,获得类似于 SJF/STCF 的很好的全局性能,同时对长时间运行的 CPU 密集型负载也可以公平的不断的稳步向前。因此,很多系统都使用某种类型的 MLFQ 作为自己的基础调度程序,包括类 BSD UNIX 系统、Solaris、Windows NT 和其后的 Windows 系列操作系统。
1.7 - 调度-比例份额
在本章中,我们卡一个不同类型的调度程序——比例份额调度程序,有时也称为公平份额调度程序。基于一个简单的思想:调度程序的最终目标是确保每个工作都能获得一定比例的的 CPU 时间,而不是优化周转时间和响应时间。
比例份额调度程序有一个非常优秀的现代实例,名为彩票调度。基本思想很简单:每个一段实现,都会举行一次彩票抽奖,以确定接下来应该运行哪个进程,越是应该频繁运行的进程,越是应该拥有更多的赢得彩票的机会。
基本概念:彩票数表示份额
彩票调度背后是一个非常基本的概念:彩票数代表了进程占有某个资源的份额。一个进程拥有的彩票数占总彩票数的百分比,就是它占有资源的份额。
下面来看一个例子。假设有两个进程 AB,A 拥有 75 张彩票,B 拥有 25 张。因此我们希望 A 占用 75% 的 CPU 时间,而 B 占用 25%。
通过不断定时(比如每个时间片)的抽取彩票,彩票调度从概率上获得这种份额比例。抽取彩票的过程很简单:调度程序知道总的彩票数。调度程序抽取中奖彩票,即 0~99 之间的一个数字,拥有这个数对应的彩票的进程中奖。假设进程 A 拥有 0~74 共 75 张彩票,进程 B 拥有 75~99 共 25 张彩票,中奖的彩票就决定了运行 A 还是 B。调度程序然后加载中奖进程的状态并使其运行。
提示:利用随机性 彩票调度最精彩的地方在于利用了随机性。当你需要作出决定时,采用随机的方式常常是既简单又可靠的选择。 随机方法限度与传统的决策方式,至少有 3 点优势。第一,随机方法常常可以避免奇怪的边角情况,较传统的算法可能在处理这些情况时遇到麻烦。例如 LRU 替换策略。虽然 LRU 是很好的替换算法,但在有重复序列的负载时表现很差。但随机方法就没有这种最差情况。 第二,随机方法很轻量,几乎不需要记录任何状态。在传统的公平份额调度算法中,记录每个集成已经获得了多少的 CPU 时间需要对每个进程计时,这必须在每次运行结束后更新。而采用随机方式后每个进程只需要非常少的状态记录。 第三,随机方法很快。只要能够很快的产生随机数,做出决策就很快。因此,随机方式在对运行速递要求很高的场景非常适用。当然,越是需要快的计算速度,随机就越倾向于伪随机。
下面是彩票调度程序输出的中奖彩票:
63 85 70 39 76 17 29 41 36 39 10 99 68 83 63 62 43 0 49 49
下面是对应的调度结果:
A A A A A A A A A A A A A A A A
B B B B
从这个例子中可以看出,彩票调度中利用了随机性,这实现了从概率上满足期望的比例,但并不能保证。在上面的例子中,工作 B 运行了 20 个时间片中的 4 个,只是占了 20%,而不是期望的 25%。但是,这两个工作运行的时间越长,它们得到的 CPU 时间比例就会越接近期望。
提示:用彩票来表示份额 彩票(步长)调度的设计中,最强大最基本的机制是彩票。在这些例子中,彩票用于表示一个进程占有 CPU 的份额,但也可以用在更多的地方。比如在迅疾管理程序的虚拟管理的最新研究工作中,Waldspurger 提出了用彩票来表示用户占用操作系统内存的方法。因此,如果你需要通过什么机制来表示所有权比例,这个概念可能就是彩票。
彩票机制
彩票调度还提供了一种机制,以不同且有效的方式来调度彩票。一种方式是利用彩票货币的概念。这种方式允许拥有一组彩票的用户以它们喜欢的某种货币,将彩票分给自己的不同工作。之后操作系统再自动将这种货币兑换为正确的全局彩票。
比如,假设用户 A 和 B 每人拥有 100 张彩票。用户 A 有两个工作 A1 和 A2,他以自己的货币,给每个工作 500 张彩票(共 1000 张)。用户 B 只运行一个工作,给它 10 张彩票(共 10 张)。操作系统将进行兑换,将 A1 和 A2 拥有的 A 的货币个 500 张兑换成全局货币个 50 张。类似的,兑换给 B1 的 10 张彩票兑换成 100 张。然后会对全局彩票货币进行抽奖(共 200 张),决定哪个工作运行。
User A -> 500 (A's currency) to A1 -> 50 (global currency)
-> 500 (A's currency) to A2 -> 50 (global currency)
User B -> 10 (B's currency) to B1 -> 100 (global currency)
另一个有用的机制是彩票转让。通过转让,一个进程可以临时将自己的彩票交给另一个进程。这种机制在客户端-服务器交互的场景中尤其有用,在这种场景中,客户端进程向服务端发送消息,请求其按自己的需求执行工作,为了加速服务端的执行,客户端可以将自己的彩票转让给服务端,从而尽可能加速服务端执行自己请求的速度。服务端执行结束后会将这部分彩票归还给客户端。
最后,彩票通胀有时也很有用。利用通胀,一个进程可以临时提升或降低自己拥有的彩票的数量。当然在竞争环境中,进程之间互相不信任,这种机制就没有意义。一个贪婪的进程可能给自己非常多的彩票,从而接管机器。但是,通胀可以用于进程之间互相信任的环境。在这种情况下,如果一个进程知道它需要更多 CPU 时间,就可以增加自己的彩票,从而将自己的需求告知操作系统,这一切不需要与任何其他进程通信。
实现
彩票调度中最不可思议的部分可能是其简单的实现。只需要一个不错的随机数生成器来选择中奖彩票和一个记录系统中所有进程的数据结构,以及所有彩票的总数。
假设我们用列表记录进程。下面的例子中有 ABC 三个进程,每个进程有一定数量的彩票。

在做出调度之前,首相要从彩票总数中选择一个随机数(中奖号码)。假设选择了 300,然后遍历链表,用一个简单的计数器帮助我们找到中奖者:
1 // counter: used to track if we've found the winner yet
2 int counter = 0;
3
4 // winner: use some call to a random number generator to
5 // get a value, between 0 and the total # of tickets
6 int winner = getrandom(0, totaltickets);
7
8 // current: use this to walk through the list of jobs
9 node_t *current = head;
10
11 // loop until the sum of ticket values is > the winner
12 while (current) {
13 counter = counter + current->tickets;
14 if (counter > winner)
15 break; // found the winner
16 current = current->next;
17 }
18 // 'current' is the winner: schedule it...
这段代码从前向后遍历进程列表,将每张彩票的值加到 counter 上,直至查过 winner。这时,当前的列表元素所对应的进程就是中奖者。在我们的例子中,中奖彩票是 300。首先,计 A 的票后,counter 增加到 100。因为 100 小于 300,继续遍历。然后 counter 增加到 150 即 B 的彩票,仍然小于 300,继续遍历。最后,counter 增加到 400,因此退出遍历,current 指向中奖者 C。
要让这个过程更加高效,建议将列表项按照彩票数递减排序。这个顺序不会影响算法的正确性,但能保证用最小的迭代次数找到需要的节点,尤其当大多数彩票被少数进程掌握时。
一个例子
为了更好的理解彩票调度的运行过程,我们现在简单研究一下两个互相竞争工作的完成时间,每个工作都有相同数目的 100 张彩票,以及相同的运行时间 R。
在这种情况下,我们希望两个工作能够在大约相同的时间完成,但由于彩票调度算法的随机性,有时一个工作会先于另一个完成。为了量化这种区别,我们顶一个了一个简单的不公平指标 U,将两个工作完成时刻相除得到 U 的值。比如运行时间 R 为 10,第一个工作在时刻 10 完成,另一个在 20,U = 10/20 = 0.5。如果两个工作几乎同时完成,U 的值将接近于 1。在这种情况下我们的目标是:完美的公平调度程序可以做到 U=1。
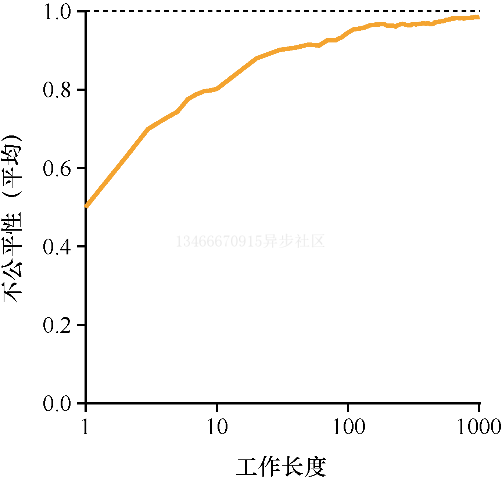
上图展示了两个工作的运行时间从 1 到 1000 变化时,30 次实验的平均 U 值。可以看出,当工作时间执行很短时,平均不公平度非常糟糕。只有当工作执行非常多的时间片时,彩票调度算法才能得到期望的结果。
如何分配彩票
关于彩票调度还有一个问题没有提到,那就是如何为工作分配彩票?这是一个非常棘手的问题,系统的运行严重依赖于彩票的分配。假设用户自己知道如何分配,因此可以给每个用户一定量的彩票,由用户按照需要自主分配自己的工作。然而这种方案似乎什么也没有解决——还是没有给出具体的分配策略。因此对于给定的一组工作,彩票分配的问题依然没有最佳答案。
为什么是不确定的
你可能还想知道,究竟为什么要利用随机性?从上面的内容可以看出,虽然随机方式可以使调度程序的实现变得简单且大致正确,但偶尔并不能产生正确的比例,尤其是在工作时间较短的情况下。由于这个原因,Waldspurger 提出了步长调度,一个确定性的公平分配算法。
步长调度也很简单。系统中的每个工作都有自己的步长,这个值与票数值成反比。在上面的例子中,ABC 这 3 个工作的票数分别是 100、50、250,我们通过用一个大数分别除以他们的票数来获得每个进程的步长。比如用 1000 除以这些票数值,得到了 3 个进程的步长分别为 100、200、40。我们称这个值为每个进程的步长。每次进程运行后,我们会让他的计数器(行程值)增加它的步长,以记录它的总体进展。
之后,调度程序使用进程的步长以及行程值来确定调度哪个进程。基本思路很简单:当需要进行调度时,选择目前拥有最小行程值的进程,并且在运行之后将该进程的行程值增加一个步长。下面是是 Waldspurger 给出的伪代码:
current = remove_min(queue); // pick client with minimum pass
schedule(current); // use resource for quantum
current->pass += current->stride; // compute next pass using stride
insert(queue, current); // put back into the queue
在我们的例子中三个进程的步长分别为 100、200、40,初始行程都是 0。因此,最初所有进程都可能被选择调度。假设选择 A,执行一个时间片后行程值为 100。然后运行 B,行程值为 200。最后运行 C,行程值为 40。这时,算法选择最小的行程值,即 C,执行并增加为 80。然后 C 会再次运行,行程增加为 120。现在需要运行 A,行程值增加到 200。然后 C 再次连续运行两次,行程值为 200。此时,所有行程值再次相等,这个过程会无限重复下去。下图展示了一段时间内的变化过程:
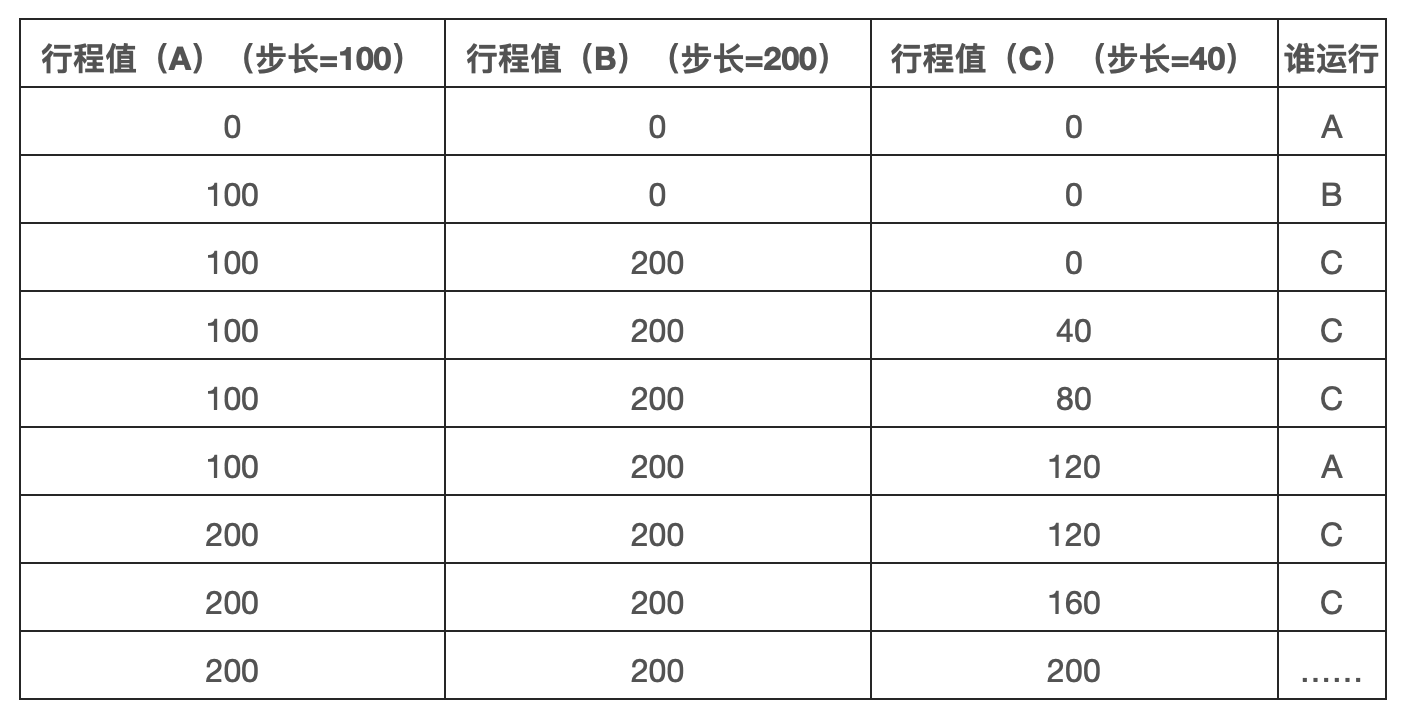
可以看出 C 运行了 5 次、A 为 2 次、B 为 1 次,真好是票数的比例——200、100、50。彩票调度算法只能一段时间后在概率上实现比例,而步长调度算法可以在每个调度周期后做到完全正确。
你可能想知道,既然有了可以精确控制的步长算法,为什么还需要彩票算法呢?好吧,彩票调度有一个步长调度没有的优势——不需要全局状态。假如有个新的进程在上面的步长调度执行过程中假如系统,应该怎样设置它的行程值呢?设置为 0 则会使其独占 CPU。而彩票调度算法不需要对每个进程记录全局状态,只需要用新进程的票数更新全局的总票数即可。因此彩票调度算法能够更加合理的处理新加入的进程。
小结
本章介绍了比例份额调度的概念,并简单讨论了两种实现:彩票调度和步长调度。彩票调度通过随机值,聪明的做到了按比例分配。步长调度算法能够确定的获得需要的比例。虽然两者都很有趣,但由于一些原因,并没有作为 CPU 调度程序被广泛使用。一个原因是这两种方式都不能很好的适合 IO;另一个原因是其中最难的票数分配问题并没有确定的解决方式。比如,如何知道浏览器进程拥有多少票数?通用调度程序(类似 MLFQ)做的更好,因此得到了广泛的应用。
结果,比例份额调度程序只有在这些问题可以相对容易解决的领域才更有用。比如虚拟数据中心,你可能会希望分配 1/4 的 CPU 周期给 Windows 虚拟机,剩余的则分配给 Linux 系统,比例分配的方式则会更加简单高效。
1.8 - 多处理器调度
过去很多年,多处理器系统只存在于高端服务器中。现在,它们越来越多的出现在个人电脑、笔记本电脑甚至移动设备上。多核处理器将多个 CPU 组装在一块芯片上,是这种扩展的根源。由于计算机的构架师们当时很难让单核 CPU 更快,同时又不增加太多功耗,所以这种多核 CPU 很快就变得流行。
当然,多核 CPU 也带来和很多困难。主要困难是典型的应用程序都只使用一个 CPU,增加更多的 CPU 并没有让这类程序运行的更快。为了解决该问题不得不重新这些程序,使之能够并行执行,或者使用多线程。多线程应用可以将工作分散到多个 CPU 上,因此 CPU 资源越多运行的也就越快。
除了应用程序,操作系统遇到的一个新的问题是多处理器调度。到目前为止,我们讨论了很多单处理器调度的原则,那么如何将这些想法扩展到多处理器上呢?
背景:多处理器架构
为了了解多处理器调度带来的新问题,必须先知道它与单 CPU 之间的基本区别。区别的核心在于对硬件缓存的使用,以及多处理器之间共享数据的方式。
在单 CPU 系统中,存在多级的硬件缓存,一般来说会让处理器更快的执行程序。缓存是很小但很快的存储设备,通常拥有内存中最热数据的备份。相比之下,内存很大且拥有所有的数据,但访问速度较慢。通过将频繁访问的数据放在缓存中,系统似乎拥有又大又快的内存。
举个例子,假设一个程序需要从内存中加载指令并读取一个值,系统只有一个 CPU,拥有较小的缓存和较大的内存。
程序第一次读取数据时,数据在内存中,因此需要花费较长的时间。处理器判断该数据可能被再次使用,因此将其放入 CPU 缓存中。如果之后程序需要再次使用该数据,CPU 会先查找缓存。因为在缓存中找到了数据,所以取数据会快的多,程序则会运行的更快。
缓存是基于局部性的概念,局部性有两种,即时间局部性和空间局部性。时间局部性指当一个数据被访问后,它很有可能在不久的将来被再次访问,比如循环代码中的数据或指令本身。而空间局部性指的是,当程序访问地址为 X 的数据时,很有可能会紧接着访问 X 周围的数据,比如遍历数组或指令的顺序执行。由于这两种局部性存在于大多数程序中,硬件系统可以很好的预测哪些数据可以放入缓存,从而运行的更快。
有趣的是,如果系统有多个处理器,并共享同一个内存,会怎样呢?

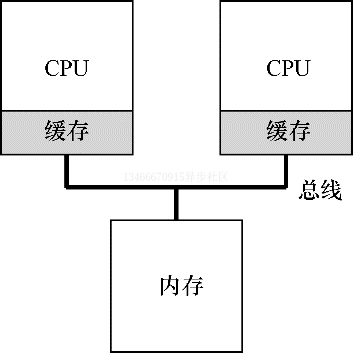
事实证明,多 CPU 的情况下缓存要复杂的多。假设运行一个在 CPU1 上的程序从内存地址 A 读取数据。由于不再 CPU1 的缓存中,所以系统会直接访问内存,得到值 D。程序然后修改了 A 处的值,只是将其缓存更新会新的值 D1。将数据写回内存比较慢,因此系统通常稍后再执行写入操作。假设这时系统中断了该程序的运行,并将其交给 CPU2,重新读取地址 A 的数据,由于 CPU2 的缓存中没有该数据,所以会直接从内存读取,得到了旧的值 D,而不是正确的 D1。
这一普遍的问题被称为缓存一致性问题,有大量的研究文献描述了解决该问题的微妙之处。这里我们仅提几个要点。
硬件提供了该问题的基本解决方案:通过监控内存访问,硬件可以保证获得正确的数据,并保证共享内存的唯一性。在基于总线的系统中,一种方式是使用总线窥探。每个缓存都通过监听链接了所有缓存和内存的总线,来发现内存访问操作。如果 CPU 发现对它放在缓存中的数据的更新,会作废本地副本,或将其更新。而回写缓存,则会让事情变得更加复杂。
同步
跨 CPU 访问(尤其是写入)时共享数据或数据结构,需要使用互斥原语才能保证正确性。比如多 CPU 并发访问一个共享队列。如果没有锁,即使有底层一致性协议,并发的从队列增加或删除元素依然不会得到正确的结果。需要使用锁来保证数据结构状态更新的原子性。
为了更具体,我们设想这样的代码序列,用于删除共享链表的一个元素。
1 typedef struct __Node_t {
2 int value;
3 struct __Node_t *next;
4 } Node_t;
5
6 int List_Pop() {
7 Node_t *tmp = head; // remember old head ...
8 int value = head->value; // ... and its value
9 head = head->next; // advance head to next pointer
10 free(tmp); // free old head
11 return value; // return value at head
12 }
假设两个 CPU 上的不同线程同时进入这个函数。如果线程 1 执行第一行,会将 head 的当前值存入它的 tmp 变量。如果线程 2 接着也执行第一行,他也会将同样的 head 值存入自己的私有 tmp 变量。tmp 变量在栈上分配,两个线程拥有各自的私有存储。因此,两个线程会尝试删除同一个链表头,而不是每个线程各移除一个元素,这导致了各种问题。
当然,让这类函数正确工作的方式是使用锁。这里只需要一个互斥锁,然后在函数开始时调用 lock,在结束时条用 unlock,确保代码的执行符合预期。我们会看到,这里依然会有问题,尤其是性能方面。具体来说,随着 CPU 数量的增加,访问同步共享的数据结构会变得很慢。
缓存亲和度
在设计多处理器调度时遇到的最后一个问题,是所谓的缓存亲和度。这个概念很简单:一个进程在某个 CPU 上运行时,会在该 CPU 的缓存中维护很多状态。下次该进程在相同的 CPU 上运行时,由于缓存中的数据而执行的更快。相反,在不同的 CPU 上执行,会由于需要重新加载数据而变慢。因此多处理器调度应该考虑到这种缓存亲和度,并尽可能将进程保持在相同的 CPU 上执行。
单队列调度
现在我们来讨论如何设计一个多处理器调度程序。最基本的方式是简单的复用单处理器调度的基本结构,将所有需要调度的工作放在一个单独的队列中,我们称之为单队列多处理器调度(SQMS)。该方法最大的优点是简单,不需要做过多的修改,就可以将原有的策略应用于多 CPU,以选择最合适的工作来运行。
然而,SQMS 有几个明显的缺陷。第一个是缺乏扩展性。为了保证在多个 CPU 上正确运行,调度程序的开发者需要在代码中通过加锁来保证原子性。在 SQMS 访问单个队列时,锁能确保得到正确的结果。
然而,锁可能带来巨大的性能损失,尤其是随着系统中的 CPU 数增加时。随着这种单个锁的争用增加,系统花费了越来越多的时间在锁的开销上,较少的时间用于系统应该完成的工作。
SQMS 的第二个主要问题是缓存亲和度。比如,假设我们有 5 个工作 ABCDE 和 4 个 CPU。调度队列如下:

一段时间后,假设每个工作依次执行一个时间片,然后选择另一个工作,下面是每个 CPU 可能的调度队列:

由于每个 CPU 都简单的从全局共享的队列中选取下一个要执行的工作,因此每个工作都不断的在不同 CPU 之间转移,这与缓存亲和度的目标背道而驰。
为了解决该问题,大多数 SQMS 调度程序都引入了一些亲和机制,尽可能让进程在同一个 CPU 上运行。保持一些工作的亲和度的同时,可能需要牺牲其他的亲和度来实现负载均衡。比如,针对同样的 5 个工作的调度如下:
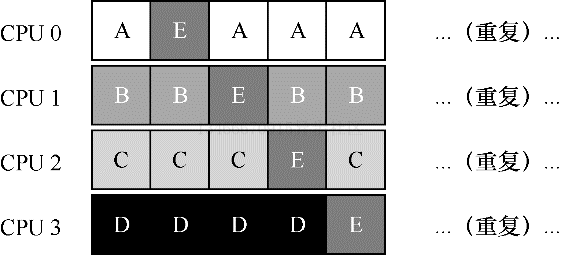
这种情况下,ABCD 都保持在同一个 CPU 上运行,只有工作 E 在不断的来回转移,从而尽可能多的获得缓存亲和度。为了公平起见,之后我们可以选择不同的工作来转移。但实现这种策略可能会很复杂。
我们看到,SQMS 调度方式有优势但也有不足。优势是能够从单 CPU 调度程序很简单的发展而来,根据定义,它只有一个队列。然而,它的扩展性不好(由于同步开销),并且不能很好的保证缓存亲和度。
多队列调度
正是由于但队列调度的这些问题,有些系统使用了多队列方案,比如每个 CPU 一个队列。我们称之为多队列多处理器调度(MQMS)。
在 MQMS 中,基本调度框架包含多个调度队列,每个队列可以使用不同的调度规则,比如轮转或者其他任何可能的算法。当一个工作进入系统后,系统会依靠一些启发性规则将其放入某个队列来调度。这样一来,每个 CPU 调度之间互相独立,就避免了但队列的方式中由于数据共享及同步带来的问题。
例如,假设系统中有两个 CPU。这时一些工作进入系统。由于每个 CPU 都有自己的调度队列,操作系统需要决定每个工作放入哪个队列。可能像下面这样:

根据不同队列的调度侧列,每个 CPU 从两个工作中选择,决定谁将运行。比如利用轮转,调度结果可能如下所示:

MQMS 比 SQMS 有明显的优势,它天生具有可扩展性。队列的数量会随着 CPU 的增加而增加,因此锁和缓存争用的开销不是大问题。此外,MQMS 天生具有良好的缓存亲和度。所有工作都保持在固定的 CPU 上,因而可以很好的利用缓存数据。
但是,如果稍加注意你可能会发现一个新的问题,即负载不均衡。假定和上面的设定一样,但假设一个工作执行完毕,现在的调度队列如下:

如果对系统中每个队列都执行轮转调度策略,会得到如下调度结果:

从上图可以看出,A 获得了 BD 两倍的 CPU 时间,这不是期望的结果。更糟的是,假设 A 和 C 都执行完毕,系统中只有 B 和 D,调度队列看起来如下:

因此 CPU 使用时间线看起来令人难过:

所以可怜的多队列多处理器调度程序应该怎么办呢?最明显的答案是让工作移动,这种技术我们称之为迁移。通过工作的跨 CPU 迁移,可以实现真正的负载均衡。
来看两个例子就更清楚了。同样,一个 CPU 空闲,另一个 CPU 有一些工作:

在这种情况下,期望的迁移很容易理解:操作系统应该讲 B 或 D 迁移到 CPU0。这次工作迁移使得负载均衡,皆大欢喜。
更棘手的情况是较早的一些例子,A 肚子留在 CPU0 上,BD 在 CPU1 上交替执行。

在这种情况下,单次迁移并不能解决问题。应该怎么做呢?答案是不断的迁移一个或多个工作。一种可能的方案是不断切换工作,如下面的时间线所示。可以看到,开始的时候 A 独享 CPU0,BD 在 CPU1。一些时间片后,B 迁移到 CPU0 与 A 竞争,D 则独享 CPU1 一段时间。这样就实现了负载均衡。

当然,还有其他不同的迁移模式。但现在是最棘手的部分:系统如何决定发起这样的迁移?
一个基本的方法是采用一种技术,名为工作窃取。通过这种方法,工作量少的队列不定期的偷看其他队列是不是比自己的工作多。如果目标队列比源队列中的工作显著较多,就从目标队列窃取一个或多个工作,实现负载均衡。
当然,这种方法也有让人抓狂的地方——如果太频繁的检查其他队列就会带来较高的开销,可扩展性不好,而这时多队列调度最初的全部目标。相反,如果检查间隔较长,又可能会带来严重的负载不均。找到合适的阈值仍然是黑魔法,这在系统策略设计中很常见。
Linux 多处理器调度
有趣的是,在构建多处理器调度程序方面,Linux 社区一直没有达成共识。一直以来,存在 3 种不同的调度程序:O(1)调度程序、完全公平调度程序(CFS)、BF 调度程序(BFS)。从 Meehean 的论文中可以找到对这些不同调度程序优缺点的对比总结。
O(1) CFS 采用多队列,而 BFS 采用单队列,这说明两种方法都可以成功。当然它们之间还有很多不同的细节。比如 O(1) 调度程序是基于优先级的,类似之前讲过的 MLFQ,随时间推移改变进程的优先级,然后调度优先级最高的进程,来实现各种调度目标。交互性得到了特别的关注。与之不同,CFS 是确定的比例调度方法,类似之前介绍的步长调度。BFS 作为 3 个算法中唯一采用单队列的算法,也是基于比例调度,但采用了更复杂的方案,称为最早合适虚拟截止时间优先算法(EEVEF)。
小结
本章介绍了多处理器调度程序的不同实现方法。其中单队列的方式比较容易构建,负载均衡较好,但在扩展性和缓存亲和度方面有着天生的缺陷。多队列的方式有很好的扩展性和缓存亲和度,但实现负载均衡却很困难,也更复杂。无论采用哪种方式,都没有简单的答案:构建一个通用的调度程序仍然是一项令人生畏的任务,因为即使很小的代码改动,也有可能导致巨大的行为差异。
1.9 - 抽象-地址空间
在早期,构建计算机操作系统非常简单。原因是用户对操作系统的期望不高。然而一些烦人的用户提出要易于使用、高性能、可靠性等,这导致了所有这些令人头疼的问题。
早期系统
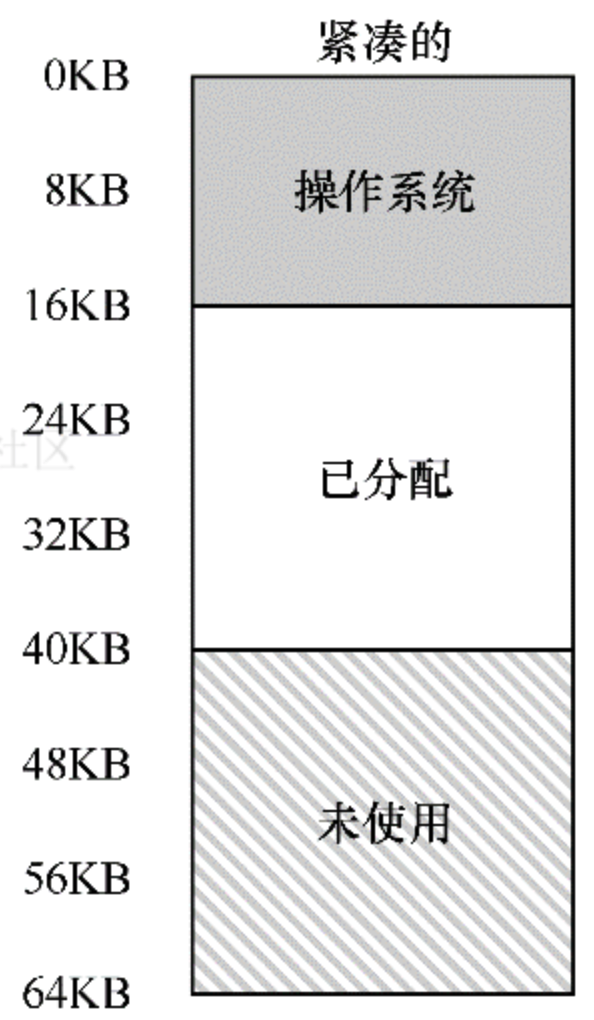
从内存来看,早期的机器并没有提供多少抽象给用户。基本上机器的物理内存看起来如下图所示:

操作系统曾经是一组函数(一个库),在内存中,然后有一个正在运行的程序(进程),目前在物理内存中,并使用剩余的内存。这里几乎没有任何抽象,用户对操作系统的要求也不多。
多道程序与分时共享
过了一段时间,由于机器昂贵,人们开始更有效的共享机器。因此多道程序系统时代开启,其中多个进程在指定时间准备运行,比如当有一个进程在等待 IO 操作的时候,操作系统会切换这些进程,这样增加了 CPU 的有效利用率。那时候,效率的提高尤其重要,因为每台机器的成本是数十万元甚至数百万元。
但很快,人们开始对机器要求更多,分时系统的时代诞生了。具体来说,很多人意识到批量计算的局限性,尤其是程序员本身,他们厌倦了长时间的编程-调试循环。交互性变得很重要,因为许多用户可能同时在使用机器,每个人都在等待他们执行的任务及时响应。
一种实现分时共享的方法,是让一个进程单独占用全部内存运行一小段时间,然后停止它,并将它所有的状态信息保存在磁盘上(包含所有的物理内存),记载其他进程的状态信息,再运行一段时间,这就实现了某种比较粗糙的机器共享。
遗憾的是,这种方法有一个大问题:太慢了,特别是当内存增长的时候。虽然保存和恢复集群器级别的状态信息相对较快,但将全部的内存信息保存到磁盘就太慢了。因此,在进程切换的时候,我们仍然将进程信息放在内存中,这样操作系统可以更有效的实现分时系统。

在上图中,有 3 个进程 ABC,每个进程拥有从 512KB 物理内存中切分出来给他们使用的一小部分内存。假定只有一个 CPU,操作系统选择运行其中一个进程,同时其他进程则在队列中等待运行。
随着分时系统变得更加流行,人们对操作系统又有了新要求。特别是多个程序同时驻留在内存中,使保护称为重要问题。人们不希望一个进程可以读写其他进程的内存。
地址空间
然而,我们必须将这些烦人的用户的需求放在心上。因此操作系统需要提供一个易用的物理内存抽象。这个抽象叫做地址空间,是运行的程序能够看到的系统中的内存。理解这个基本的抽象系统内存抽象,是了解内存虚拟化的关键。
一个进程的地址空间包含运行程序的所有内存状态。比如:程序的代码必须在内存中,因此它们也在地址空间中。当程序在运行时,利用栈来保存当前的函数调用信息,分配空间给局部变量,传递参数和函数返回值。最后,堆用户管理动态分配的、用户管理的内存,就像你从 C 语言中调用 malloc 或面向对象语言中调用 new 关键字获得内存。当然,还有其他的东西(如静态初始化的变量),但现在假设只有这 3 部分:代码、堆、栈。
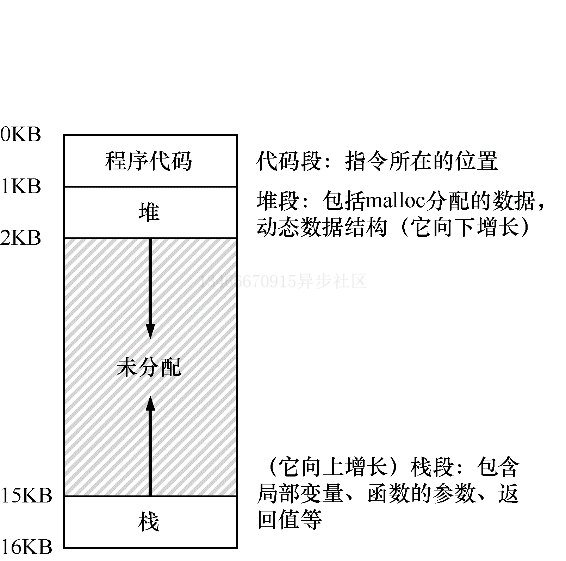
上图是一个很小的地址空间。程序代码位于地址空间的顶部。代码是静态的,所以可以将其放在地址空间的顶部,我们知道程序在运行时,代码不会再需要额外的空间。
接下来在程序运行时,地址空间有两个区域可能增长,那就是堆和栈。把它们放在底部,是因为它们都希望能够增长。通过将它们放在地址空间的两端,我们可以运行这样的增长:它们只需要在相反的方向上增长。因此堆在代码之下 1KB 开始并向下增长,栈从 16KB 开始并向上增长。然而,堆和栈的这种放置方式只是一种约定,如果你愿意,可以用不同的方式来安排地址空间,当多个线程在地址空间中共存时,就没有像这样分配空间的好办法了。
当然,当我们描述地址空间时,所描述的是操作系统提供给运行程序的抽象。程序不再物理地址 0~16KB 的内存中,而是加载在任意的物理地址。回顾前图中的进程 ABC,你可以看到每个进程如何加载到内存中的不同地址。因此问题来了?
关键问题:如何虚拟化内存 操作系统如何在单一的物理内存上为多个运行的进程构建一个私有的、可能很大的地址空间的抽象?
当操作系统这样做时,我们说操作系统在虚拟化内存,因为运行的程序认为它被加载到特定地址的内存中,并且具有非常大的地址空间。现实很不一样。
比如,当前图中的进程 A 尝试在地址 0 执行加载操作时,然而操作系统在硬件的支持下,处于某种原因,必须确保不是加载到物理地址 0,而是物理地址 320KB,即 A 载入内存的地址。这是内存虚拟化的关键,这是世界上每个现代计算机系统的基础。
提示:隔离原则 隔离是构建可靠系统的关键原则。如果两个实体相互隔离,这意味着一个实体的失败不会影响另一个实体。操作系统力求让进程彼此隔离,从而防止互相造成伤害。通过内存隔离,操作系统进一步确保运行程序不会影响底层操作系统的操作。一些现代操作系统通过将某些部分与操作系统的其他部分分离,实现进一步的隔离。这样的微内核可以比整体内核提供更大的可靠性。
目标
补充:你看到的所有地址都不是真的 编写过打印指针的 C 程序吗?你看到的值是虚拟地址。有没有想过你的程序代码到底在哪里?你也可以将其打印出来,但它也是一个虚拟地址。实际上,作为用户级程序的成员,可以看到的任何地址都是虚拟地址。只有操作系统通过精妙的内存虚拟化技术,知道这些指令和数据所在的物理内存地址。所以永远不要忘记:如果你在程序中打印一个地址,那是一个虚拟地址。虚拟地址只是提供地址如何在内存中分布的假象,只有操作系统才知道物理地址。
在这一章中我们将触及操作系统的工作——虚拟化内存。操作系统不仅虚拟化内存,而且还遵循了一定的风格。为了确保操作系统这样做,我们需要一些目标来指导。
虚拟内存系统的一个主要目标是透明。操作系统实现虚拟内存的方式,应该让运行的程序看不见。因此,程序不应该感知到内存被虚拟化的事实。相反,程序的行为就好像它拥有自己的私有物理地址。在幕后,操作系统和硬件完成了所有的工作,让不同的工作复用内存,从而实现了这种假象。
虚拟内存的另一个目标是效率。操作系统应该追求虚拟化尽可能高效,包括时间上和空间上的高效。在实现高效虚拟化时,操作系统将不得不依赖硬件支持,包括 TLB 这样的硬件功能。
1 #include <stdio.h>
2 #include <stdlib.h>
3 int main(int argc, char *argv[]) {
4 printf("location of code : %p\n", (void *) main);
5 printf("location of heap : %p\n", (void *) malloc(1));
6 int x = 3;
7 printf("location of stack : %p\n", (void *) &x);
8 return x;
9 }
最后,虚拟内存的第三个目标是保护。操作系统应该确保进程受到保护,不会受其他进程影响,操作系统本省也不会受进程影响。当一个进程执行加载、存储或指令提取时,它不应该以任何方式访问或影响任何其他进程或操作系统本身的内存内容。因此,保护让我们能够在进程之间提供隔离性,每个进程都应该在自己的独立环境中运行,避免其他出错或恶意进程的影响。
在接下来的章节中,我们将重点介绍虚拟化内存所需的基本机制,包括硬件和操作系统的支持。我们还将研究一些相关的策略,包括如何管理可用内存,以及值空间不足的情况下该释放那些内存。
小结
我们介绍了操作系统的一个重要子系统:虚拟内存。虚拟内存负责为程序提供一个聚到的、稀疏的、私有的地址空间假象。其中保存了程序的所有指令和数据。操作系统在专门硬件的帮助下,通过每一个虚拟内存的索引,将其转换为物理地址,物理内存根据获得的物理地址来获取所需的信息。操作系统会同时对许多进程执行此操作,并且确保程序之间互相不影响,也不会影响操作系统。真个方法需要大量的机制和策略。
1.10 - 内存接口
在本章中,我们将介绍 UNIX 操作系统的内存管理接口。操作系统提供的接口非常简洁,因此本章简明扼要。
内存类型
在运行一个 C 程序的时候,会分配两种类型的内存。第一种称为栈内存,它的申请和释放操作是编译器来隐式管理的,所以有时也称为自动内存。
C 申请栈内存很容易。比如,假设需要在 func 函数中为一个整形变量 x 申请空间。为了声明这样一块内存,只需要这样做:
void func() {
int x; // declares an integer on the stack
...
}
编译器将完成剩下的工作,确保你进入 func 函数的时候,在栈上开辟空间。当你从该函数退出时,编译器释放内存。因此,如果你希望某些信息存在于函数调用之外,建议不要将其放在栈上。
就是这种对长期内存的需求,所以我们才需要第二种类型的内存,即堆内存。其中所有的申请和释放操作都有程序员显式完成。毫无疑问,这是一项艰巨的任务。这确实导致了很多缺陷。但如果小心并加以注意,就会正确的使用这些接口,没有太多的麻烦。下面的例子展示了如何在堆上分配一个整数,并得到指向它的指针:
void func() {
int *x = (int *) malloc(sizeof(int));
...
}
关于这一段代码有两点说明。首先,你可能会注意到栈和堆的分配都发生在同一行:首先编译器看到指针的声明 (int * x),知道为一个整形指针分配空间,随后,当程序调用 malloc 时,它会在堆上请求整数的空间,函数返回这样一个整数的地址,然后将其存储在栈中一共程序使用。
因为它的显式特性,以及它富于变化的用法,堆内存对用户和系统提出了更大的挑战。所以这也是我们接下来要讨论的重点。
malloc 调用
malloc 函数非常简单:传入要申请的堆空间的大小,它成功就返回一个指向新申请空间的指针,失败就返回 NULL。
man 手册展示了使用 malloc 需要怎么做,在命令行输入 man malloc 即可:
#include <stdlib.h>
...
void *malloc(size_t size);
从这段信息可以看到,只要包含头文件 stdlib.h 就可以使用 malloc 了。但实际上,甚至都不要这样做,因为 C 库是程序默认链接的,其中就有 malloc 的代码,加上头文件只是让编译器检查你是否正确调用了 malloc。
malloc 只需要一个 size_t 类型参数,该参数表示你需要多少个字节。然而,大多数程序员并不会直接传入数字。实际上,这样做会被认为是不好的形式。替代方案是使用各种函数或宏。比如为了给双精度浮点分配空间会这样做:
double *d = (double *) malloc(sizeof(double));
对 malloc 的调用是用 sizeof 操作符来申请正确大小的空间。在 C 中,这通常被认为是编译时操作符,意味着这个大小是在编译时已经知道的,因此被替换为一个数,再作为 malloc 的参数。处于这个原因,sizeof 被正确的认为是一个操作符,而不是一个函数调用,因为函数调用发生在运行时。
你可以可以传入一个变量的名字给 sizeof,但在一些情况下,可能得不到你想要的结果,所以要小心使用。
另一个需要注意的地方是使用字符串。如果为一个字符串分配空间,请使用以下惯用法:malloc(strlen(s) + 1),它使用函数 strlen 获取字符串的长度并加上 1,以便给字符串结束符留出空间。这里使用 sizeof 可能会导致麻烦。
你也许注意到 malloc 返回一个指向 void 类型的指针。这样做只是 C 中传回地址的形式,让程序员决定如何处理它。程序员进一步使用所谓的强制类型转换,在我们上面的例子中,程序员将返回类型的 malloc 强制转换为指向 double 的指针。强制类型转换实际上没干什么,只是告诉编译器和其他可能正在读你代码的程序员:是的,我知道正在做什么。通过强制转换 malloc 的结果,程序员只是在给人一些信息,并非必须。
free 调用
事实证明,分配内存是等式的简单部分。知道何时、如何以及是否释放内存是困难的部分。要释放不再使用的堆内存,程序员只需调用 free。
int *x = malloc(10 * sizeof(int));
...
free(x);
该函数接收一个参数,即一个由 malloc 返回的指针。因此你会注意到,分配区域的大小不会被传入,必须由内存分配库自己来记录追踪。
常见错误
在使用 malloc 和 free 时会出现一些常见的错误。以下是我们在教授本科操作系统课程时反复看到的情形。所有使用的这些例子都可以通过编译器编译并运行。对于构建一个正确的 C 程序来说,通过编译是必要的,但这还远远不够,你会懂的。
实际上,正确的内存管理就是这样一个问题,许多新语言都支持自动内存管理。在这样的语言中,当你调用类似 malloc 的机制来分配内存时,你永远不需要调用某些东西来释放空间。实际上,来及收集器会运行,找出你不再引用的内存并将其释放。
忘记分配内存
许多例程在调用之前,都希望你为它们分配内存,比如 strcpy(dst,src) 将源字符串中的字符串复制到目标指针。但是,如果不小心,你可能会这样做:
char *src = "hello";
char *dst; // oops! unallocated
strcoy(dst, src); // segfault and die
运行这段代码将会导致段错误,这是一个很奇怪的术语,表示你对内存犯了一个错误。
正确的代码应该向下面这样:
char *src = "hello";
char *dst = (char *)malloc(strlen(src)+1);
strcpy(dst, src);
``
或者你可以使用 strdup 来让生活更加轻松。
### 没有分配足够的内存
另一个相关的错误是没有分配足够的内存,有时称为缓冲区溢出。在上面的例子中,一个常见的错误是为目标缓冲区仅仅留出几乎足够的空间:
```c
char *src = "hello";
char *dst = (char *) malloc(strlen(src)); // too small!
strcpy(dst, src); // work properly
奇怪的是,这个程序通常看起来会正确运行,这取决于如何实现 malloc 和许多其他细节。在某些情况下,当字符串拷贝执行时,它会在超过分配空间的末尾处写入一个字节,但在某些情况下,这是无害的,可能会覆盖不再使用的变量。在某些情况下,这些溢出可能具有令人难以置信的危害,实际上是系统中许多安全漏洞的来源。在其他情况下,malloc 库总是分配一些额外空间,因此你的程序实际上不会在其他某个变量的值上涂写,并能工作的很好。还有一些情况,该程序确实会发生故障和崩溃。因此,我们学到了另一个宝贵的教训:即使它正确运行过一次,也不意味着它是正确的。
忘记初始化分配的内存
在这个错误中,你正确的调用 malloc,但忘记在新分配的数据类型中填写数值。不要这样做。如果你忘记了,你成程序最终会遇到未初始化的读取,它从堆中读取了一些未知的数值。谁知道都是些什么数值!如果走运,读到的值使程序仍然有效。如果不走运,将会读到一些有害的数值。
忘记释放内存
另一个常见错误是内存泄露,如果忘记释放内存,就会发生。在长时间运行的程序或系统中,这是一个巨大的问题。因为缓慢泄露的内存会导致内存不足,此时需要重新启动。因此一般来说,当你用完一段内存后应该确保将其释放。请注意,使用垃圾回收语言在这里没有什么帮助:如果你仍然持有对某块内存的引用,那么垃圾收集器就不会将其释放,因此即使在较现代的语言中,内存泄露仍然是一个问题。
在某些情况下,不调用 free 似乎是合理的。比如你的程序运行时间很短,很快就会退出。在这种情况下,当进程死亡时,操作系统将清理其分配的所有内存,因此将不会发生内存泄露。虽然这肯定有效,但这可能是一个坏习惯,所以请谨慎使用这种策略。
在用完之前释放内存
有时候程序会提前释放内存,这种错误被称为悬挂指针,正如你猜测的那样,这也是不对的。随后的使用可能会导致程序错误或覆盖有效的内存。
反复释放内存
程序有时还会不止一次的释放内存,这种操作被称为重复释放。这样做的结果是未定义的。正如你所能想到的那样,内存分配库可能会感到困惑,并且会做出各种奇怪的事情,崩溃是常见的结果。
错误的调用 free
我们讨论的最后一个问题是 free 的错误调用。free 期望你只传入之前从 malloc 得到的指针。如果传入一些其他值,就会发生错误。因此这种无效的释放是危险的。
底层操作系统支持
你可能已经注意到,在讨论 malloc 和 free 时,我们没有提到系统调用。原因很简单:它们不是系统调用,而是库调用。因此 malloc 库管理虚拟地址空间,但是它本身是建立在一些系统调用之上的,这些系统调用会进入操作系统,来请求更多内存或释放内存。
一个这样的系统条用叫做 brk,它被用来改变程序分断的位置:堆结束的位置。它需要一个参数,从而根据新分断是大于还是小于当前分断,来增加或减少堆的大小。另一个调用 sbrk 要求传入一个增量,但目的类似。
请注意,你不应该直接调用 brk 或 sbrk。它们被内存分配库使用。如果你尝试使用它们,很可能会犯一些错误。
最后,你还可以通过 mmap 调用从操作系统获取内存。通过传入正确的参数,mmap 可以在程序中创建一个匿名内存区域——该区域不与任何特定文件关联,而是与交换空间关联,稍后将详细讨论。这种内存也可以像堆一样被管理。
其他调用
内存分配库还支持一些其他调用。比如 calloc 分配内存,并在返回之前将其置零。如果你认为内存已归零并忘记自己初始化它,这可以放置出现一些错误。当你为某些东西分配空间,然后还需要添加一些东西时,例程 realloc 也会很有用。realloc 创建一个新的更大的内存区域,将旧区域复制到其中,并返回新区域的指针。
1.11 - 地址转换
在实现 CPU 虚拟化时,我们遵循的一般准则被称为受限直接访问(LDE)。LDE 背后的想法很简单:让程序运行的大部分指令直接访问硬件,只在一些关键点由操作系统介入,以确保“在正确的时间地点,做正确的事情”。为了实现高效的虚拟化,操作系统应该尽量让程序自己运行,同时通过在关键点的及时介入,来保持对硬件的控制。高效和控制是现代操作系统的两个主要目标。
在实现虚拟内存时,我们将追求类似的战略,在实现高效和控制的同时,提供期望的虚拟化。高效决定了我们要利用硬件的支持,这在开始的时候非常初级,但会逐渐变得相当复杂。控制意味着操作系统要确保应用程序只能访问它自己的内存空间。因此,要保护应用程序不会互相影响且不影响操作系统本身,我们还是需要硬件的帮助。最后,我们对虚拟内存还有一点要求,即灵活性。具体来说,我们希望程序能够以任何方式访问它自己的地址空间,从而让操作系统更易编程。所以关键问题在于:
关键问题:如何高效、灵活的虚拟化内存
我们利用了一种通用技术,有时被称为硬件的地址转换,简称地址转换。它可以被看做是受限执行这种一般方法的补充。利用地址转换,硬件对每次的内存访问都进行处理,将指令中的虚拟地址转换为实际存储数据的物理地址。因此,在每次内存引用时,硬件都会进行地址转换,将应用程序的内存引用重定位到内存中实际的位置。
当然,仅仅依靠硬件不足以实现虚拟内存,因为它只提供了底层机制来提供效率。操作系统必须在关键的位置介入,设置好硬件,以便完成正确的地址转换。因此它必须管理内存,记录被占用和空闲的内存位置,并明智而谨慎的介入,保持对内存使用的控制。
同样,所有这些工作都是为了创造一种美丽的假象:每个程序都拥有私有的内存,那里存放着它自己的代码和数据。虚拟现实的背后是丑陋的物理现实:许多程序其实是在同一时间共享着内存,就像 CPU 在不同的程序之间切换运行。通过虚拟化,操作系统将丑陋的机器现实转换为一种有用的、强大的、且易于使用的抽象。
假设
我们先假设用户的地址空间必须连续的存放在物理内存中。同时为了简单,我们假设地址空间不是很大,小于物理内存的大小。最后,假设每个地址空间的大小完全一样。
实例
为了更好的理解地址转换的实现,我们先来看一个例子。设想一个进程的地址空间如下图所示。这里我们需要检查一小段代码,它从内存加载一个值,对其加 3,让后再放回内存。

void func() {
int x;
x = x + 3;
}
编译器将这段代码转换为类似如下汇编代码:
128: movl 0x0(%ebx), %eax ;load 0+ebx into eax
132: addl $0x03, %eax ;add 3 to eax register
135: movl %eax, 0x0(%ebx) ;store eax back to mem
这段代码相对简单,它假定 x 的地址已经存入寄存去 ebx,之后通过 movl 指令将该地址的值加载到通用寄存器 eax。下一条指令对 eax 的值加 3。最后一条指令将 eax 中的值写回到内存的同一位置。
提示:介入很强大 介入是一种很常见又很强大的技术,计算机系统中使用介入常常能带来很好的效果。在虚拟内存中,硬件可以介入到每次内存访问中,将进程提供的虚拟地址转换为数据实际存储的物理地址。但是,一般化的介入技术有更加广阔的应用空间,实际上几乎所有良好定义的接口都应该提供介入机制,以便增加功能或在其他方面提升系统。这种方式最基本的特点是透明,介入完成时通常不需要改动接口的客户端,因此客户端不需要任何改动。
在前面的图中,可以看到代码和数据都位于进程的地址空间,3 条指令序列位于地址 128,变量 x 的值位于地址 15KB。如前图所示,x 的初始值为 3000。
如果这 3 条指令执行,从进程的角度来看,发生了以下几次内存访问:
- 从内存 128 获得指令。
- 执行指令(从地址 15KB 加载数据)。
- 从地址 132 获得命令。
- 执行命令(没有内存访问)。
- 从地址 135 获得指令。
- 执行指令(新值存入地址 15KB)。
从程序的角度来看,它的地址空间从 0 开始到 16KB 结束。它包含的所有内存引用都应该在该范围呢。然而,对虚拟内存来说,操作系统希望将该进程地址空间放在物理内存的其他位置,并不一定从地址 0 开始。因此我们遇到如下问题:怎样在内存中重定位该进程,同时对该进程透明?怎样提供一种虚拟地址空间从 0 开始的假象,而实际上地址空间位于另外某个物理地址?
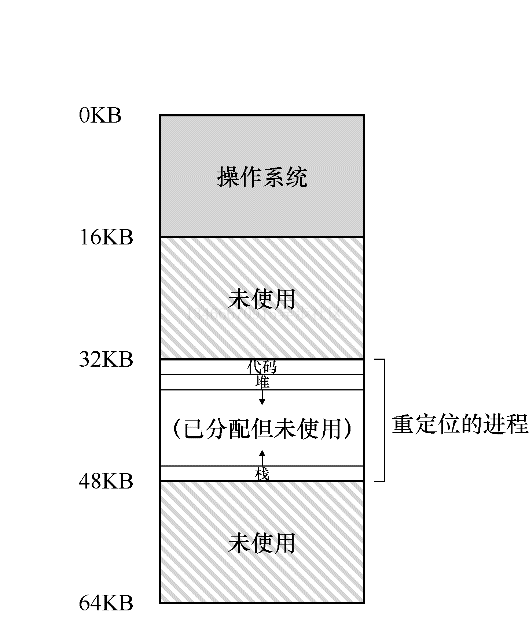
上图展示了一个例子,说明该进程的地址空间被放入物理内存后可能的样子。从上图可以看到,操作系统将第一块物理内存留给了自己,并将上述例子中的进程地址空间重定位到从 32KB 开始的物理内存地址。剩下的两块内存空闲。
硬件动态重定位
为了更好的理解基于硬件的地址转换,我们先来讨论他的第一次应用。在 20 世纪 50 年代后期,它首次出现在分时系统中,那时只是一个简单的思想,称为地址加界限机制,有时又称为动态重定位,我们将交叉使用这两个术语。
具体来说,每个 CPU 需要两个硬件寄存器:基址寄存器和界限寄存器,或称为限制寄存器。这两个寄存器能够支持我们将地址空间放在屋里内存的任何位置,同时又能确保进程只能访问自己的地址空间。
采用这种方式,在编写和编译程序时假设地址空间从 0 开始。但是,当程序真正执行时,操作系统会决定其在物理内存中的实际加载地址,并将其实地址记录在基址寄存器中。在上面的例子中,操作系统决定加载在物理地址 32KB 的进程,因此将基址寄存器设置为这个值。
当进程运行时,有趣的事情发生了。现在,该进程产生的所有内存引用,都会被处理器通过以下方式转换为物理地址:
physical address = virtual address + base
补充:基于软件的重定位 在早期,在硬件支持重定位之前,一些系统曾经采用基于软件的重定位方式。基本技术被称为静态重定位,其中一个名为加载程序的软件接收将要运行的可执行程序,将它的地址重写到物理内存中期望的便宜位置。 然而,静态重定位存在很多问题,首先也是最重要的是不提供访问保护,进程中的错误地址可能导致对其他进程或操作系统内存的非法访问,一般来说,需要硬件支持来实现真正的访问保护。静态重定位的另一个缺点是一旦完成,稍后很难将内存空间重定位到其他位置。
进程中使用的内存引用都是虚拟地址,硬件接下来将虚拟地址加上基址寄存器中的内容,得到物理地址,再发给内存系统。
为了更好的理解,我们来追踪一条指令执行的过程。
128: movl 0x0(%ebx), %eax
程序计数器首先被设置为 128.当硬件需要获取该指令时,它先将该值加上基址寄存器中的 32KB(32768),得到实际的物理地址为 32896,然后硬件从该地址获取指令。接下来,处理器开始执行该指令。这时,进程发起从虚拟地址 15KB 的加载,处理器同样将虚拟地址加上基址寄存器的内容(32KB),得到最终的物理地址为 47KB,从而获得需要的数据。
将虚拟地址转换为物理地址,这正是所谓的地址转换技术。也就是说,硬件取得进程认为要访问的地址,将它转换成数据实际位于的物理地址。由于这种重定位是在运行时发生的,而且我们甚至可以在进程开始运行后改变其地址空间,这种技术一般被称为动态重定位。
提示:基于硬件的动态重定位 在动态定位的过程中,只有很少的硬件参与,但获得了很好的效果。一个基址寄存器将虚拟地址转换为物理地址,一个界限寄存器将确保这个地址在进程地址空间的范围内。它们一起提供了简单高效的虚拟内存机制。
现在你可能会问,界限寄存器去哪了?不是基址加上界限机制吗?正如你猜测的那样,界限寄存器提供了访问保护。在上面的例子中,界限寄存器被设置为 16KB。如果进程需要访问超过了该界限或者为负数的虚拟地址,CPU 将触发异常,进程可能被终止。界限寄存器的用处在于,它确保了进程产生的所有地址都在进程地址的界限内。
这种基址寄存器配合界限寄存器的硬件结构位于芯片内,每个 CPU 一对。有时我们将 CPU 的这个负责地址转换的部分统称为内存管理单元(MMU)。随着我们开发更加复杂的内存管理技术,MMU 也将拥有更为复杂的电路和功能。
关于界限寄存器再补充一点,它通常有两种使用方式。像上面这种方式中,它记录地址空间的大小,硬件在将虚拟地址与基址寄存器内容求和前,就检查这个界限。另一种方式是界限寄存器中记录地址空间结束的物理地址,硬件在转化虚拟地址到物理地址之后采取检查该界限。这两种方式在逻辑上是等价的。简单起见,我们这里假设采用第一种方式。
转换示例
为了更好的理解基址加界限的地址转换机制,我们来看一个例子。设想一个进程拥有 4KB 大小的地址空间,它被加载到从 16KB 开始的物理内存中。一些转换过程如下:
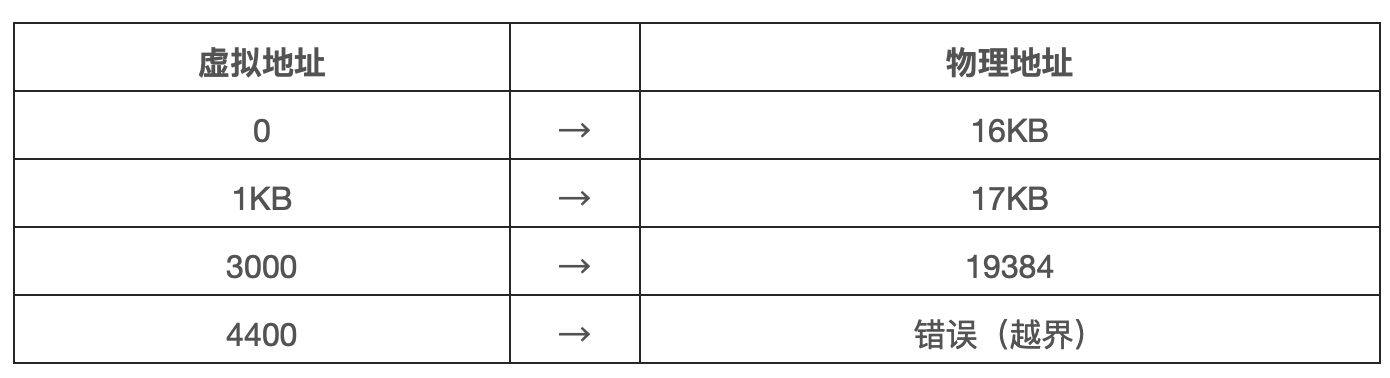
从例子可以看出,通过基址加虚拟地址(可以看做是地址空间的偏移量)的方式,很容易得到物理地址。虚拟地址过大或为负数,均会导致异常。
补充:数据结构——空闲列表 操心系统必须记录哪些空闲内存没有被使用,以便能够为进程分配内存。很多不同的数据结构可以用于这项任务,其中最简单的是空闲列表。它实际上是一个列表,记录了当前没有被使用的物理内存的范围。
硬件支持总结
首先,正如在 CPU 虚拟化中提到的,我们需要两种 CPU 模式。操作系统在特权模式运行,可以访问整个机器资源。应用程序在用户模式,只能执行有限的操作。只要一个位,也许保存在处理器状态字中,就能说明当前 CPU 的运行模式。在一些特殊的时刻,CPU 会切换状态,如系统调用、中断、异常。下图则是动态重定位的硬件要求:
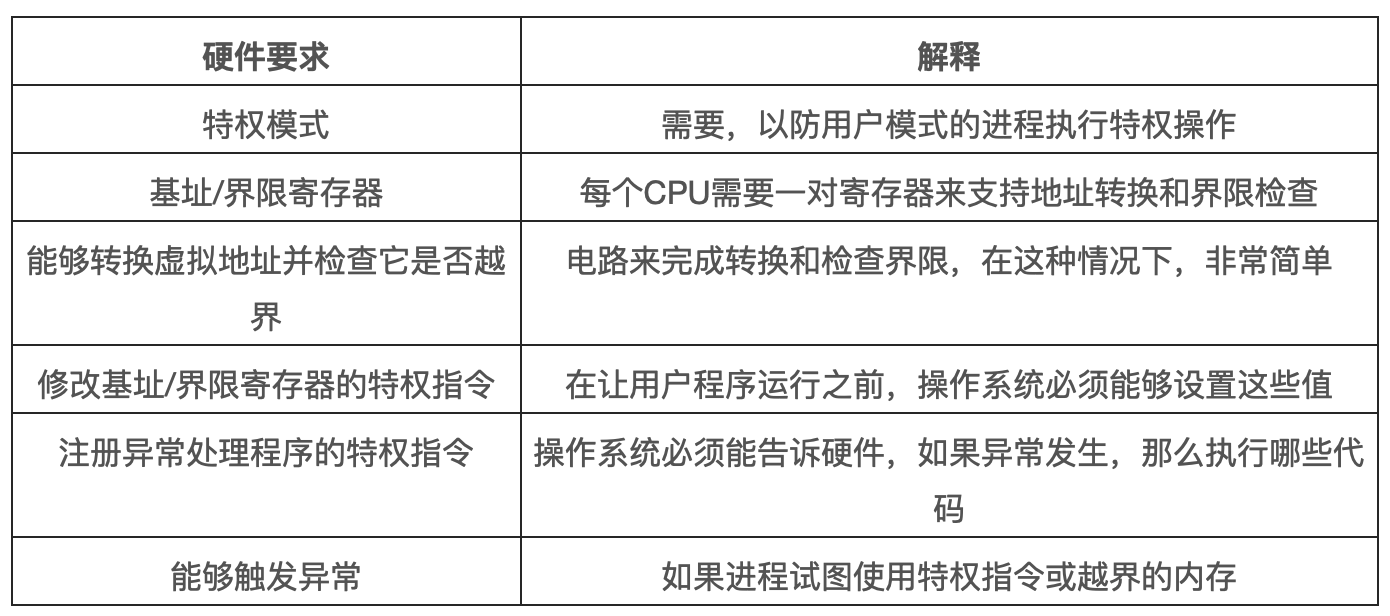
硬件还必须提供基址和界限寄存器,因此每个 CPU 的内存管理单元都需要这两个额外的寄存器。用户程序运行时,硬件会转换每个地址,即将用户程序产生的虚拟地址加上基址寄存器的内容。硬件也必须能够检查地址是否有效,通过界限寄存器和 CPU 内的一些电路来实现。
硬件应该提供一些特殊指令,用于修改基址寄存器和界限寄存器,允许操作系统在切换进程时改变它们。这些指令是特权指令,只有在内核模式下才能修改这些寄存器。
最后,在用户程序尝试非法访问内存时,CPU 必须能够产生异常。在这种情况下,CPU 应该阻止用户程序的执行,并安排操作系统的越界异常处理程序来处理。操作系统的处理程序会做出正确的响应,比如在这种情况下终止进程。类似的,如果用户程序尝试修改基址或者界限寄存器,CPU 也应该产生异常,并调用“用户模式尝试执行特权指令”的异常处理程序。CPU 还必须提供一种方法,来通知它这些处理程序的位置,因此又需要一些特权指令。
操作系统的问题
为了支持动态重定位,硬件添加了新的功能,使得操作系统有了一些必须处理的新问题。硬件支持和操作系统管理结合在了一起,实现了一个简单的虚拟内存。具体来说,在一些关键时刻需要操作系统的接入,以实现基址和界限方式的虚拟内存。如下表。

第一,在进程创建时,操作系统必须采取行动,为进程的地址空间找到内存空间。由于我们假设每个进程的地址空间小于物理内存的大小,并且大小相同,这对操作系统来说很容易实现。它可以把整个物理内存看做一组槽块,并标记为空闲或已用。当新进程创建时,操作系统加锁这个数据结构,为新的地址空间找到位置,并将其标记与已用。如果地址空间可变,那么就会变得复杂,我们将在后续章节中讨论。
我们来看一个例子,在前一节的图中,操作系统将物理内存的第一个槽块分配给自己,然后将例子中的进程重定位到物理内存地址 32KB。另两个槽块空闲,因此空闲列表中就包含了这两个空闲槽块。
第二,在进程终止时,操作系统也必须做一些工作,回收进程的所有内存,以便给其他进程或操作系统使用。在进程终止时,操作系统会将这些内存放回到空闲列表,并根据需要清除相关的数据结构。
第三,在上下文切换时,操作系统也必须执行一些操作。每个 CPU 毕竟只有一个基址寄存器和一个界限寄存器,但对于每个运行的程序,它们的值都不同,因为每个程序被加载到内存中不同的物理地址。因此,在切换进程时,操作系统必须保存和恢复基址和界限寄存器。具体来说,当操作系统决定中止当前进程时,它必须将当前基址寄存器和界限寄存器中的内存保存在内存中,放在每个进程都拥有的结果中,如进程结构或进程控制块中。类似的,当操作系统恢复执行某个进程时,也必须给基址寄存器和界限寄存器恢复正确的值。
需要注意,当进程停止时,操作系统可以改变其地址空间的物理位置,这很容易。要移动进程的地址空间,操作系统首先让进程停止运行,然后将地址空间拷贝到新的位置,最后更新保存的基址寄存器,指向新的位置。当进程恢复执行时,它的新基址寄存器会被恢复,它再次开始运行,显然它的指令和数据都在新的内存位置了。
第四,操作系统必须提供异常处理程序,或需要一些调用的函数。操作系统在启动时加载这些处理程序。比如,当一个进程视图越界访问内存时,CPU 会触发异常。在这种异常产生时,操作系统必须准备采取行动。通常操作系统会做出充满敌意的反应:终止错误进程。操作系统应该尽力保护它运行的机器,因此它不会对那些企图访问非法地址或执行非法指令的进程客气。
下表展按时间线展示了大多数硬件与操作系统的交互。可以看出,操作系统在启动时做了什么,为我们准备好机器,然后在进程开始运行时发生了什么。请注意,地址转换过程完全由硬件处理,没有操作系统的介入。在这个时候,发生时钟中断,操作系统切换到进程 B 运行,它执行了“错误的加载”,这时操作系统必须介入,终止该进程,清理并释放进程 B 占用的内存,将它从进程表中移除。从表中可以看出,我们仍然遵循受限直接访问的基本方法,大多数情况下,操作系统正确设置硬件后,就任凭进程直接运行在 CPU 上,只有进程行为不端时才介入。
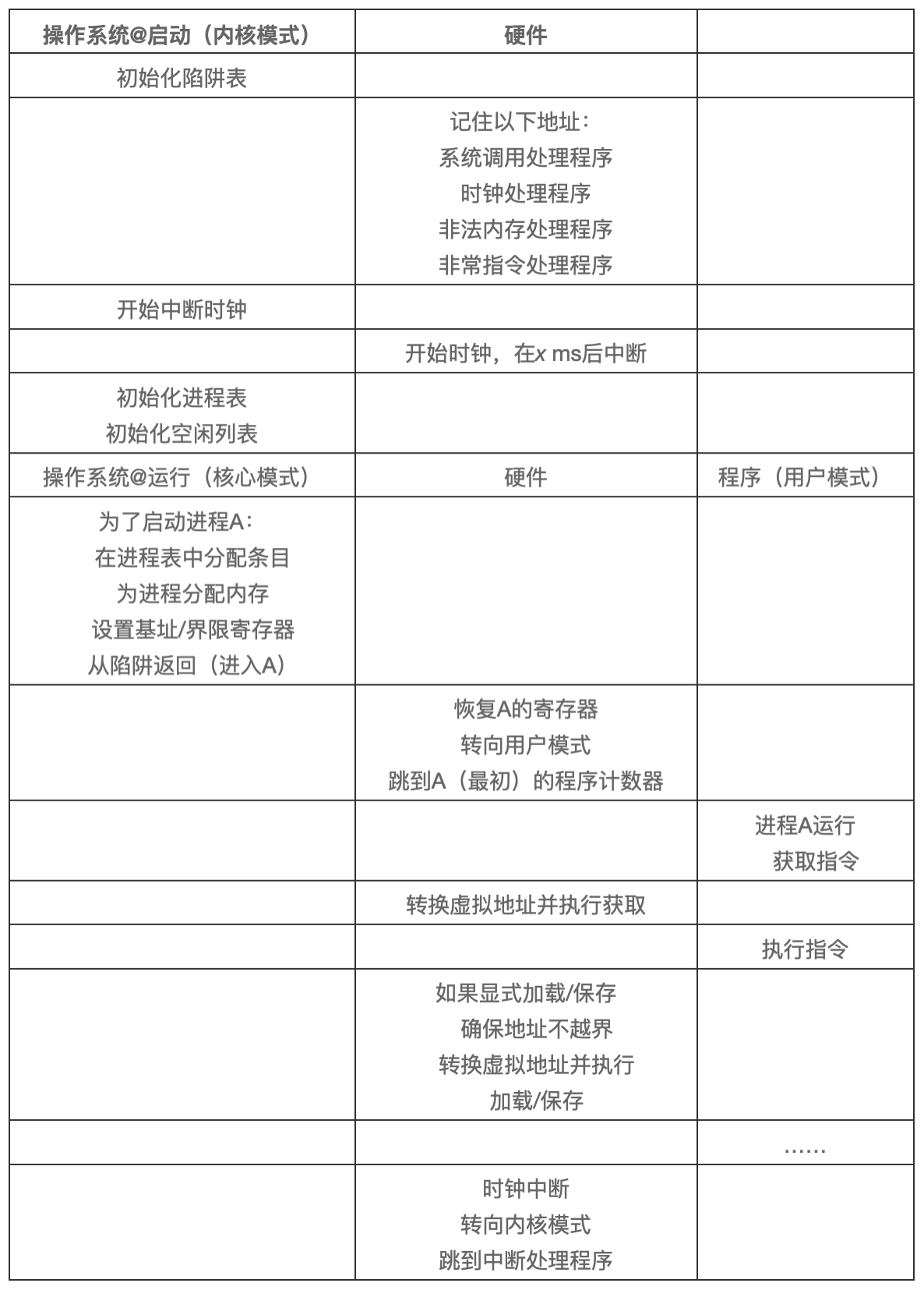
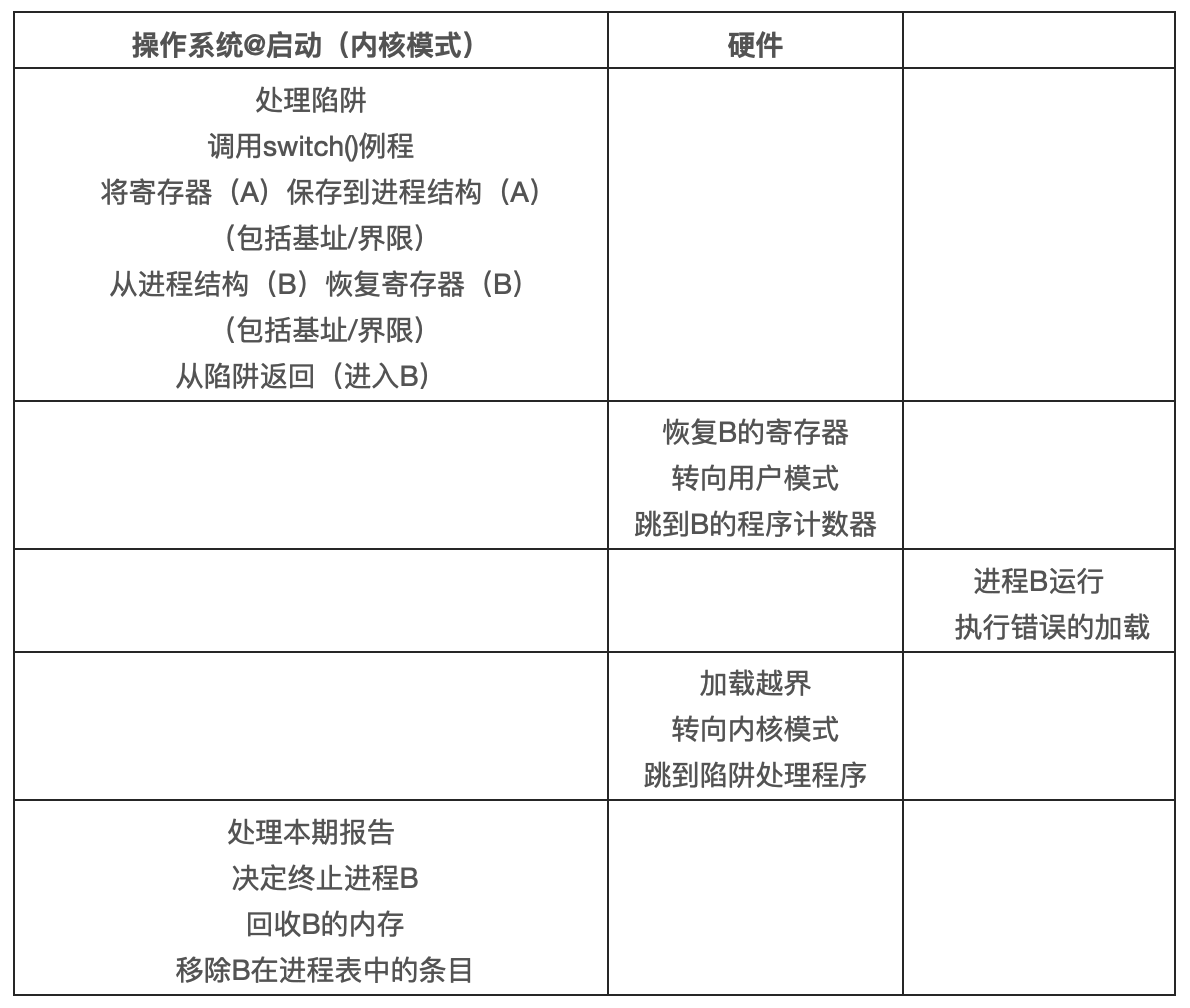
小结
本章通过虚拟内存使用的一种特殊机制,即地址转换,扩展了受限直接访问的概念。利用地址转换,操作系统可以控制进程的所有内存访问,确保访问在地址空间的界限内。该技术高效的关键在于硬件支持,硬件快速的将所有内存访问操作中的虚拟地址转换为物理地址。所有的这一切对进程来说是透明的,进程并不知道自己使用的内存引用已经被重定位。
我们还看到了一种特殊的虚拟化方式,称为基址界限的动态重定位。基址界限的虚拟化方式非常高效,因为只需要非常少的硬件逻辑,就可以将虚拟地址和寄存器地址相加,并检查进程产生的地址是否越界。基址界限也提供了保护,操作系统和硬件的协作,确保没有进程能够访问到其他地址空间的内容。保护肯定是操作系统最重要的目标之一。没有保护,操作系统也就无法控制机器。
遗憾的是,这个简单动态重定位技术有效率低下的问题。比如前面的例子中,重定位的进程使用了从 32KB 到 48KB 的物理内存,但由于该进程的栈区和堆区并不是很大,导致这块内存区域中大量的空间被浪费。这种浪费通常称为内部碎片,指的是已经分配的内存单元内部未有使用的空间,造成了浪费。在我们当前的方式中,即使有足够的内存容纳更多进程,但我们目前要求将地址空间放在固定的槽块中,因此会出现内存碎片。所以我们还需要一些复杂的机制,以便更好的利用物理内存,避免内部碎片。第一次尝试是将基址界限的概念稍微泛化,得到分段(segmentation)的概念。
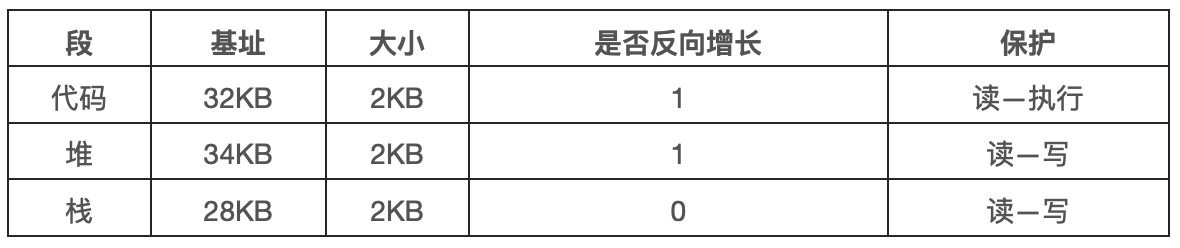
1.12 - 分段
到目前为止,我们一直假设将所有进程的地址空间完整的加载到内存中。利用基址和界限寄存器,操作系统很容易将不同进程重定位到不同的物理内存区域。但是,对于这些内存区域,你可能会注意到:栈和堆之间,有一大块空闲空间。
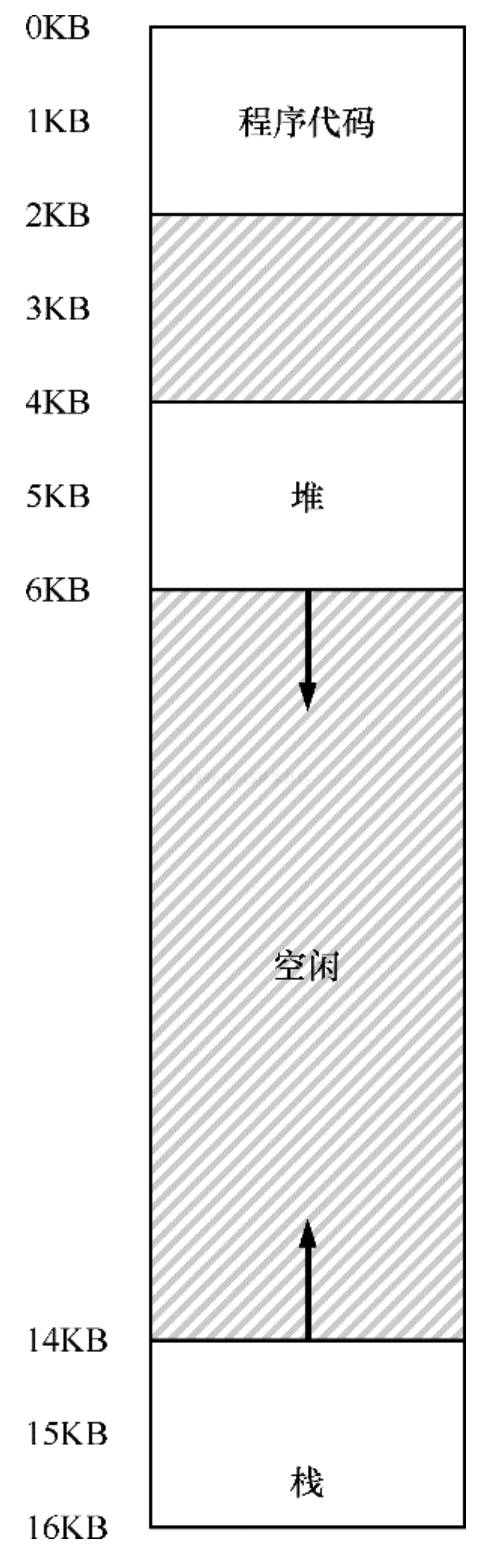
从上图可知,如果我们将整个地址空间放入物理内存,那么栈和堆之间的空间并没有被进程使用,却依然占用了实际的物理内存。因此,简单的通过基址寄存器和界限寄存器实现的虚拟内存很浪费。另外,如果剩余物理内存无法提供连续区域来放置完整的内存空间,进程便无法运行。这种基址加界限的方式看起来并不像我们想象的那样灵活。
关键问题:怎样支持大地址空间 怎样支持大的地址空间,同时栈和堆之间又可能存在大量空间空间?在之前的例子中,地址空间非常小,所以这种浪费并不明显。但假设一个 32 位 4GB 的地址空间,通常的程序只会使用几兆的内存,但需要整个地址空间都放在内存中。
分段:泛化的基址/界限
为了解决该问题,分段概念应运而生。分段并非一个新概念,它甚至可以追溯到 20 时机 60 年代初期。这个想法很简单,在 MMU 中引入不止一个基址和界限寄存器对,而是为地址空间内的每个逻辑段配置一对。一个段只是地址空间中一个连续定长的区域,在典型的地址空间中有 3 个逻辑不同的段:代码、栈、堆。分段的机制使得操作系统能够将不同的段放到不同的物理内存区域,从而避免了虚拟地址空间中未使用部分仍然占用内存。
我们来看一个例子,假设我们系统将上图中的地址空间放入物理内存。通过给每个段一对基址和界限寄存器,可以将每个段独立放入物理空间。如下图所示,64KB 的物理内存中放置了 3 个段,为操作系统保留 16KB。
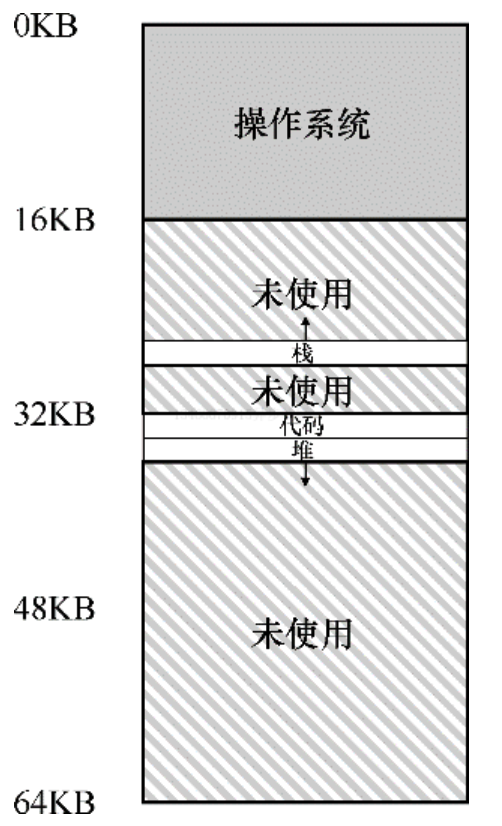
从上图可以看到,只有已使用的内存才在物理内存中分配空间,因此可以容纳巨大的地址空间,其中包含大量未使用的地址空间,有时又称为稀疏地址空间。
你会想到,需要 MMU 中的硬件结构来支持分段:在这种情况下,需要一组 3 对基址和界限寄存器。下表展示了上面例子中的寄存器值,每个界限寄存器都记录了一个段的大小。
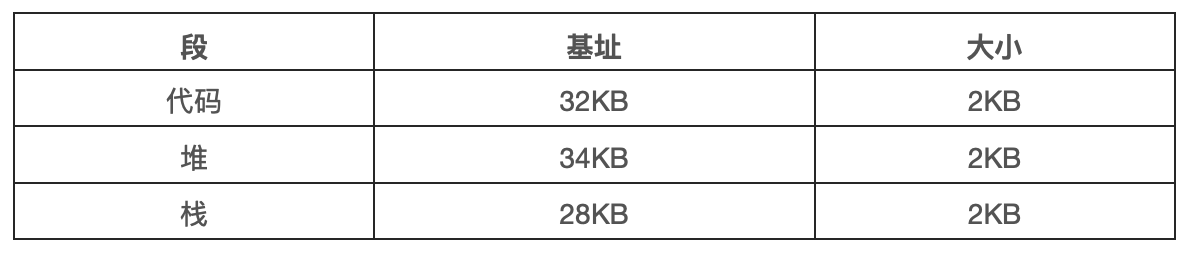
我们来看一个地址转换的例子。假设现在要引用虚拟地址 100,MMU 将基址值加上偏移量 100 得到实际的物理地址:100+32KB=32868。然后它会检查该地址是否在界限内,验证通过,于是发起对物理内存地址 32868 的引用。
补充:段错误 段错误指的是在支持分段的机器上发生了非法内存访问。有趣的是,即使在不支持分段的机器上这个术语依然保留。
来看一个堆中的地址,虚拟地址 4200。如果用虚拟地址 4200 加上堆的基址 32KB,得到 39016,这是不正确的。我们首先应该减去堆的偏移量,即该地址指的是这个段中的哪个字节。因为堆从虚拟地址 4KB 开始,4200 的偏移量实际上是 4200 减去 4096,即 104,然后用这个偏移量加上基址寄存器中的物理地址 3KB,得到真正的物理地址 34920。
如果试图访问非法的地址,如 7KB,你可以想象发生的情况:硬件会发现该地址越界,因此陷入操作系统,和可能导致终止出错进程。这就是段异常或段错误。
我们引用哪个段
硬件在地址转换时使用寄存器,它如何知道段内的偏移量呢,以及地址引用了哪个段?
一种常见的方式是,有时称为显式方式,就是用虚拟地址的开头几位来标识不同的段,VAX/VMS 系统使用了这种技术。在我们之前的例子中有 3 个段,因此需要两位来标识。如果我们用 14 位虚拟地址的前两位来标识,那么虚拟地址如下所示:
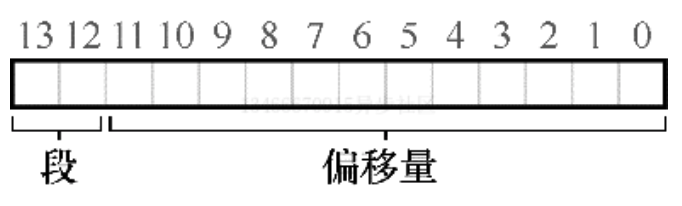
那么在我们的例子中,如果前两位是 00,硬件就知道这是属于代码段的地址,因此使用代码段的基址和界限来定位到正确的物理地址。如果前两位是 01,则是堆地址,对应的使用堆的基址和界限。下面来看一个 4200 之上的虚拟地址进行转换。虚拟地址 4200 的二进制形式如下:
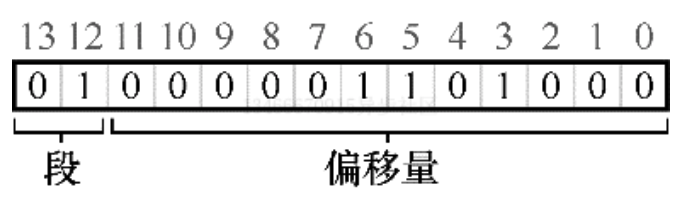
从图中可以看到,前两位 01 告诉硬件我们引用的是哪个段。剩下的 12 位是段内偏移量。因此,硬件就使用前两位来决定使用哪个段寄存器,然后用后 12 位作为段内偏移。偏移量与基址相加,硬件就得到了物理地址。请注意,偏移量也简化了对段边界的判断。我们只要检查偏移量是否小于界限,大于界限的则为非法地址。因此,如果基址和界限放在数组中,为了获得需要的物理地址,硬件或做以下操作:
1 // get top 2 bits of 14-bit VA
2 Segment = (VirtualAddress & SEG_MASK) >> SEG_SHIFT
3 // now get offset
4 Offset = VirtualAddress & OFFSET_MASK
5 if (Offset >= Bounds[Segment])
6 RaiseException(PROTECTION_FAULT)
7 else
8 PhysAddr = Base[Segment] + Offset
9 Register = AccessMempory(PhysAddr)
在我们的例子中,可以为上面的常量填上值。具体来说,SEG_MASK 为 0x3000,SEG_SHIFT 为 12,OFFSET_MASK 为 0xFFF。
你或许已经注意到,上面使用两位来区分段,但实际只有 3 个段,因此有一段的地址空间被浪费。因此有些系统中会将堆和栈作为一个段,因此只需要一位来做标识。
硬件还提供了其他方法来决定特定地址在哪个段。在隐式方式中,硬件通过地址产生的方式来确定段。比如,如果地址由程序计数器产生,那么地址在代码段。如果基于栈或基址指针,他一定在栈段。其他地址则在堆段。
栈怎么办
到目前为止,我们一直没有将地址空间中的一个重要部分:栈。在前面的例子中,栈被定位到物理地址 28KB。但有一点关键区别,它反向增长。在物理内存中,它始于 28KB,增长回到 26KB,响应虚拟地址从 16KB 到 14KB。地址转换必须有所不同。
首先,我们需要一点硬件支持。除了基址和界限外,硬件还需要知道段的增长方向(使用 1 位来区分)。在下表中,我们更新了硬件的视图。
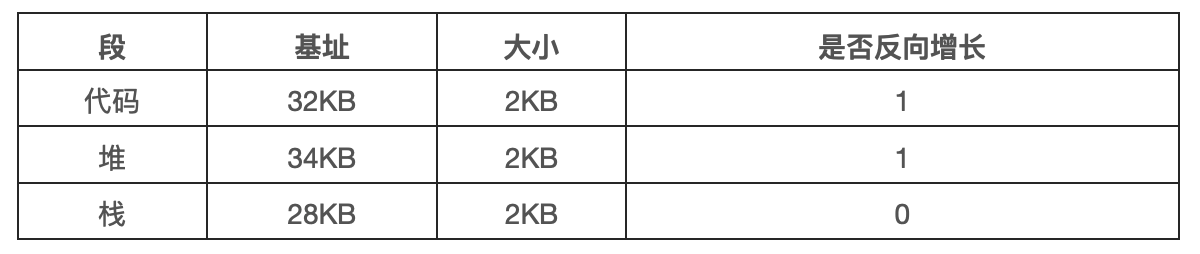
硬件理解段可以反向增长后,这种虚拟地址的地址转化必须有所不同。下面来看一个例子。
在该例子中,假设要访问虚拟地址 15KB,它映射到物理地址为 27KB。该虚拟地址的二进制形式为 11 1100 0000 0000(十六进制 0x3C00)。硬件利用前两位 11 来指定段,但然后我们要处理偏移量 3KB。为了得到正确的反向偏移,我们必须从 3KB 中减去最大的段地址:在这个例子中,段可以是 4KB,因此正确的偏移量是 3KB 减去 4KB,即 -1KB。只要用这个偏移量加上基址 28KB,就能得到正确的物理地址 27KB。用户可以进行越界检查,确保反向偏移量的绝对值小于段的大小。
支持共享
随着分段机制的不断改进,系统设计人员很快意识到,通过再多一点的硬件支持,就能实现新的效率提升。具体来说,要节省内存,有时候在地址空间之间共享某些内存段是有用的。尤其是,代码共享很常见,今天的系统仍然在用。
为了支持共享,需要一些额外的支持,这就是保护位。基本为每个段增加了一个位,标识程序是否能够读写该段,或执行其中的代码。通过将代码段标记为只读,同样的代码可以被多个进程共享,而不用担心破坏隔离。虽然每个进程都认为自己独占这块内存,但操作系统秘密的共享了内存,进程不能修改这些内存,所以假象得以保持。
下表展示了一个例子,是硬件记录的额外信息。可以看到,代码段的权限是可读和可执行,因此物理内存中的一个段可以映射到多个虚拟地址空间。
有了保护位,前面描述的硬件算法也必须改变。除了检查地址是否越界,还需要检查特定访问是否允许。如果用户试图写入只读段,或从非执行段执行指令,硬件会触发异常,并让操作系统来处理出错进程。
分段粒度
到目前为止,我们的例子大多针对只有很少几个段的系统(代码、堆、栈)。我们可以认为这种分段是粗粒度的,因为它将地址空间分为较大的、粗粒度的块。但是,一些早期的系统更灵活,允许将地址空间划分为大量较小的段,被称为细粒度分段。
支持大量分段需要硬件的支持,并在内存中保存某种段表。这种分段表通常支持创建非常多的段,因此系统使用段的方式比之前讨论的方式更加灵活。比如,像 Burroughs B5000 这样的早期机器可以支持成千上万的段,有了操作系统和硬件的支持,编译器可以将代码段和数据段划分为许多不同的部分。当时的考虑是,通过耕细粒度的分段,操作系统可以更好的了解哪些段在使用、哪些段未被使用,从更加高效的利用内存。
操作系统支持
现在你应该了解了基本的分段原理。系统运行时,地址空间中的不同段被重定位到物理内存中。与我们之前介绍的整个地址空间只有一个基址/界限寄存器对的方式相比,节省了大量物理内存。具体来说,栈和堆之间没有使用的区域就不再需要分配物理内存,让我们可以将更多的地址空间放入物理内存。
然而,分段带来了一些新的问题。我们先介绍必须关注的操作系统相关的问题。第一个是老问题:操作系统在上下文切换时应该怎么做?你可能已经猜到了:各个段寄存器中的内存必须被保存和恢复。显然,每个进程都有自己独立的虚拟地址空间,操作系统必须在进程运行之前,确保这些寄存器被正确的赋值。
第二个问题更重要,即管理物理内存的空闲空间。新的地址空间被创建时,操作系统需要在物理内存中为它的段找到空间。之前,我们假设所有的地址空间大小相同,物理内存可以被认为是一些槽块,进程可以放进去。现在,每个进程都有一些段,每个段的大小也可能不同。
一般会遇到的问题是,物理内存很快充满了很多小的空闲空间,因而很难分配给新的段,或扩大已有的段。这种问题被称为外部碎片,如下图所示。

在这个例子中,一个进程需要分配一个 20KB 的段。当前只有 24KB 空闲,但并不连续。因此,操作系统无法满足这个 20KB 的请求。
该问题的一种解决方案是紧凑物理内存,重新安排原有的段。比如,操作系统先中止运行的进程,将它们的数据复制到连续的内存区域中去,改变它们的段寄存器中的值,指向新的物理地址,从而得到足够大的连续空闲空间。这样做,操作系统能让新的内存分配请求成功。但是,内存紧凑的成本很高,因为拷贝是内存密集型的,一般会占用大量的处理器时间。如下图所示。
一种跟简单的方案是利用空闲列表管理算法,试图保留大的内存块用于分配。相关的算法可能有成千上百种,包括传统的最优匹配、最坏匹配、首次匹配、伙伴算法等。Wilson 等人做过一个很好的调查。
小结
分段解决了一些问题,帮助我们实现了高效的虚拟内存。不只是动态重定位,通过避免地址空间的逻辑段之间潜在的大量内存浪费,分段能够更好的支持稀疏地址空间。它还很快,因为分段需要的算法很简单,很适合由硬件完成,地址转换的开销极小。分段还有一个附加好处是代码共享。如果代码放在独立的段中,这样段就可以被多个运行的程序共享。
但我们已经知道,在内存中分配不同大小的段会导致一些问题,我们希望客服。首先,是我们上面讨论的外部碎片。由于段的大小不同,空闲内存被割裂成各种奇怪的大小,因此满足内存分配请求可能会很难。用户可以尝试采用聪明的算法,或定义紧凑内存,但问题很根本,难以避免。
第二个问题也许更重要,分段还是不足以支持更一般化的稀疏地址空间。比如,如果有一个很大但是稀疏的堆,都在一个逻辑段中,整个堆仍然必须完整的加载到内存中。换言之,如果使用地址空间的方式不能很好的匹配底层分段的设计目标,分段就不能很好的工作。因此我们需要找到新的解决方案。
2 - 性能之殇
本文来自: 岁寒-性能之殇
Reference
电子计算机与信息技术是最近几十年人类科技发展最快的领域,无可争议地改变了每个人的生活:从生活方式到战争方式,从烹饪方式到国家治理方式,都被计算机和信息技术彻底地改变了。如果说核武器彻底改变了国与国之间相处的模式,那么计算机与信息技术则彻底改变了人类这个物种本身,人类的进化也进入了一个新的阶段。
简单的说,生物进化之前还有化学进化。然而细胞一经诞生,中心法则的分子进化就趋于停滞了:38 亿年来,中心法则再没有新的变动,所有的蛋白质都由 20 种标准氨基酸连成,连碱基与氨基酸的对应关系也沿袭至今,所有现代生物都共用一套标准遗传密码。正如中心法则是化学进化的产物,却因为开创了生物进化而停止了化学进化,人类是生物进化的产物,也因为开创了文化进化和技术进化而停止了生物进化——进化已经走上了更高的难度。
Abstract
本文的目标是在我有限的认知范围内,讨论一下人们为了提升性能而做出的各种努力,这其中包含硬件层面的 CPU、RAM、磁盘,操作系统层面的并发、并行、事件驱动,软件层面的多进程、多线程,网络层面的分布式,等等。事实上,上述名词并不局限于某一固定层面,计算机从 CPU 内的门电路到显示器中的某行字,是靠层层协作才得以实现的;计算机科学中的很多概念,都跨越了层次;事件驱动就是由 CPU 和操作系统协作完成测。
2.1 - 冯诺依曼瓶颈
天才冯·诺依曼
冯·诺依曼于 1903年12月28日出生在奥匈帝国的布达佩斯,1957年2月8日卒于美国,终年 53 岁。在他短暂的一生中,他取得了绝大的成就,远不止于世人熟知的“冯·诺依曼架构”。
约翰·冯·诺伊曼,出生于匈牙利的美国籍犹太人数学家家庭,现代电子计算机与博弈论的重要创始人,在泛函分析、遍历理论、几何学、拓扑学和数值分析等众多数学领域及计算机学、量子力学和经济学中都有重大贡献。
出列对计算机科学的贡献,他还有一个称号不为大众所熟知:“博弈论之父”。博弈论被认为是 20 世纪经济学领域最伟大的成果之一。(说到博弈论,我相信很多人第一个想到的肯定跟我一些样,那么就是“纳什均衡”)。
冯·诺依曼架构
冯·诺依曼由于在曼哈顿工程中需要进行大量的运算,从而使用了当时最先进的两台计算机 Mark I 和 ENIAC,在使用 Mark I 和 ENIAC 的过程中,他意识到了存储程序的重要性,从而提出了存储程序逻辑架构。
“冯·诺依曼架构”定义如下:
- 以运算单元为中心。
- 采用存储程序原理。
- 存储器是按地址访问、线性编址的空间。
- 控制流由指令流产生。
- 指令码由操作码和地址码组成。
- 数据以二进制编码。
优势
冯·诺依曼架构第一次将存储器和运算器分开,指令和数据均放置在存储器中,为计算机的通用性奠定了基础。虽然在规范中计算单元依然是核心,但冯·诺依曼架构事实上导致了以存储器为核心的现代计算机的诞生。
注:请各位在心里明确一件事情,“存储器指的是内存,即 RAM。”而磁盘在理论上属于输入输出设备。
该架构的另一项重要共现是使用二进制取代十进制,大幅降低了运算电路的复杂性。这为晶体管时代超大规模集成电路的诞生提供了最重要的基础,让我们实现了今天手腕上 Apple Watch 的运算性能能够远超早期大型计算机的壮举,这也是摩尔定律得以实现的基础。
瓶颈
冯·诺依曼架构为计算机大提速铺平了道路,却也埋下了一个隐患:在内存容量指数级增长以后,CPU 和内存之间的数据传输带宽称为了瓶颈。
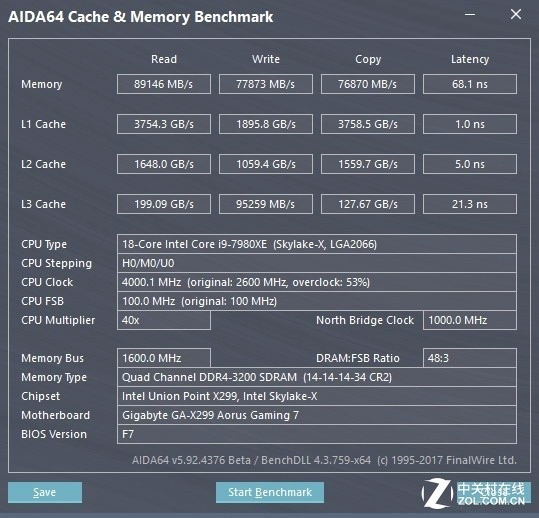
上图是 i9-7980XE 18 核 36 线程的民用最强 CPU,其配合超频过的 DDR4 3200MHz 内存,测试出的内存读取速度是 90GB/s。看起来是不是很快?看看图中的 L1 Cache,3.7TB/s。
我们再来算算时间。这颗 CPU 的最大睿频是 4.4GHz,就是说 CPU 执行一条指令需要的时间是 0.000000000227273 秒,即 0.22ns,而内存的延迟是 68.1ns。换句话说,只要去内存里读取一个字节,就需要 CPU 等待 300 个时钟周期,何其的浪费 CPU 时间啊。
CPU 的 L1/L2/L3 三级缓存是使用和 CPU 同样的 14 纳米工艺执照的硅半导体,每个 bit 都是用 6 个场效应管(即通俗讲的三极管)构成,成本高昂且非常占用 CPU 的核心面积,故不能做成很大的容量。
除此之外,三级缓存对计算机速度的提升来源于计算机内存的“局部性”,相关内容后续再展开讨论。
接下来
下一篇文章,我们将讨论分支预测、流水线与多个 CPU,看看那些上古大神为了提升性能都迸发出了什么奇思妙想,又都搞出了什么奇技淫巧。
2.2 - CPU实现
CPU 硬件为了提高性能,逐步发展出了指令流水线(分支预测)和多核 CPU,本文我们将简单的探讨它们的原理和效果。
指令流水线
在一台纯粹的图灵机中,指令是一个接一个顺序执行的。而现实世界中的通用计算机所用的很多基础算法都是可以并行的,如加法器和乘法器,它们可以很容易的被切分成能够同时运行的多个指令,这样就可以大大提升性能。
指令流水线,说白了是就是 CPU 电路层面的编发。
Intel Core i7 自 Sandy Bridge(2010)架构以来一直都是 14 级流水线设计。基于 Cedar Mill 架构的最后一代奔腾 4,在 2006 年就拥有 3.8GHz 的超高频率,却因为其长达 31 级的流水线而成了为样子货,被 AMD 1GHz 的芯片按在地上摩擦。
流水线是现代 RISC(精简指令集) 核心的一个重要设计,它极大地提高了性能。
对于一条指令的执行过程,通常分为:取指令、指令译码、取操作数、运算、写结果。前面三步由控制器完成,后面两步由运算器完成。按照传统的做法,当控制器工作的时候运算器在休息,在运算器工作的时候控制器在休息。流水线的做法就是当控制器完成第一条指令的操作后,直接开始开始第二条指令的操作,同时运算器开始第一条指令的操作。这样就形成了流水线系统,这是一条2级流水线。
RISC 机器的五层流水线示意图
下图形象的展示了流水线是如何提高性能的。
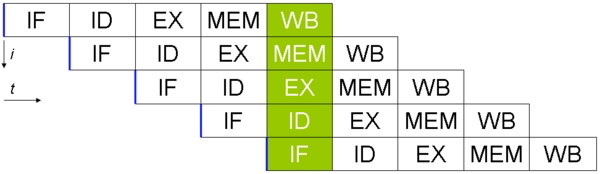
缺点
指令流水线通过硬件层面的并发来提高性能,却也带来了一些无法避免的缺点。
- 设计难度高,一步小心就成了高频低能的奔腾 4。
- 并发导致每条指令的执行时间变长。
- 优化难度大,有时候两行代码的顺序变动可能导致数倍的性能差异,这对编译器提出了更高的要求。
- 如果多次分支预测失败,将会导致严重的性能损失。
分支预测
指令形成流水线以后,就需要一种高效的调控来保证硬件层面的并发效果:最佳情况是每条流水线里的十几个指令都是正确的,这样完全不浪费时钟周期。而分支预测就是干这个的。
分支预测器猜测条件表达式两路分支中那一路最优可能发生,然后推测执行这一路的指令,来避免流水线停顿造成时间的浪费。但是,如果后来发现分支预测错误,那么流水线中推测执行的那些中间结果就要全部被放弃,重新获取正确的分支路线上的指令开始执行,这就带来了是一个时钟周期的延迟,这个时候,该 CPU 核心就是完全在浪费时间。
幸运的是,当下主流的 CPU 在现代编译器的配合下,能够越来越高的完成这项工作。
还记得那个让 Intel CPU 性能跌 30% 的漏洞补丁吗,那个漏洞就是 CPU 设计的时候,分支预测设计的不完善导致的。
多核 CPU
多核 CPU 的每个核心拥有自己独立的运算单元、寄存器、一二级缓存,所有核心共用同一条内存总线,同一段内存。
多核 CPU 的出现,标志着人类的集成电路工艺遇到了一个严酷的瓶颈,无法再大规模提升单核性能,只能通过多核类聊以自慰。实际上,多核 CPU 性能的提升极其有限,还不如增加一点点单核频率所能提升的性能多。
优势
多核 CPU 的优势很明显,就是可以并行地执行多个图灵机,可以显而易见地提升性能。只不过由于使用同一条内存总线,实际带来的效果有限,并且需要操作系统和编译器的密切配合才行。
题外话: AMD64 技术可以运行 32 位的操作系统和应用程序,所用的方法是依旧使用 32 位宽的内存总线,每计算一次要取两次内存,性能提升也非常有限,不过好处就是可以使用大于 4GB 的内存了。大家应该都没忘记第一篇文章中提到的冯·诺依曼架构拥有 CPU 和内存通信带宽不足的弱点。(注:AMD64 技术是和 Intel 交叉授权的专利,i7 也是这么设计的)
劣势
多核 CPU 劣势其实更加明显,但是人类也没有办法,谁不想用 20GHz 的 CPU 呢,谁想用这八核的 i7 呀。
- 内存读写效率不变,甚至有降低的风险。
- 操作系统复杂度提升很多倍,计算资源的管理变得非常复杂。
- 依赖操作系统的进步:微软以肉眼可见的速度,在这十几年间大幅提升了 Windows 的多核效率和安全性:XP 只是能利用,7 可以自动调配一个进程在多个核心上游走,2008R2 解决了依赖 CPU0 调度导致司机的 BUG,8 可以利用多核心启动,10 优化了杀死进程依赖 CPU0 的问题。
超线程技术:Intel 的超线程技术是将 CPU 核心内部再分出两个逻辑核心,只增加了 5% 的裸面积,就带来了 15%~30% 的性能提升。
怀念过去
Intel 肯定怀念摩尔定律提出时候的黄金年代,只依靠工艺的进步,就能一两年就性能翻番。AMD 肯定怀念 K8 的黄金一代,1G 战 4G,靠的就是把内存控制器从北桥芯片移到 CPU 内部,提升了 CPU 和内存的通信效率,自然性能倍增。而今天,人类的技术已经到达了一个瓶颈,只能通过不断的提升 CPU 和操作系统的复杂度来获得微弱的性能提升,呜呼哀哉。
不过我们也不能放弃希望,AMD RX VAGA64 显卡拥有 2048 位的显存位宽,理论极限还是很恐怖的,这可能就是未来内存的发展方向。
2.3 - 事件驱动
Event-Driven(事件驱动)这个词这几年随着 Node.js 的大热也成了一个热词,似乎已经成了“高性能”的代名词,殊不知事件驱动其实是通用计算机的胎记,是一种与生俱来的能力。本文我们就要一起了解一下事件驱动的价值和本质。
通用计算机中的时间驱动
首先我们定义当下最火的 x86 PC 机为典型的通用电子计算机:可以写文章,可以打游戏,可以上网聊天,可以读U盘,可以打印,可以设计三维模型,可以编辑渲染视频,可以作路由器,还可以控制巨大的工业机器。那么,这种计算机的事件驱动能力就很容易理解了:
- 假设 Chrome 正在播放 Youtube 视频,你按下了键盘上的空格键,视频暂停了。这个操作就是事件驱动:计算机获得了你单机空格的事件,于是把视频暂停了。
- 假设你正在跟人聊 QQ,别人发了一段文字给你,计算机获得了网络传输事件,于是将信息提取出来显示到了屏幕上,这也是事件驱动。
事件驱动的实现方式
事件驱动本质是由 CPU 提供的,因为 CPU 作为控制器+运算器,它需要随时响应意外事件,如上面例子中的键盘和网络。
CPU 对于意外事件的响应是依靠 Execption Control Flow(异常控制流)来实现的。
强大的异常控制流
异常控制流是 CPU 的核心功能,它是以下听起来高大上的功能的基础。
时间片
CPU 时间片的分配也是利用异常控制流来实现的,它让多个进程在宏观上位于同一个 CPU 核心上同时运行,而我们知道在微观上任一个时刻,每个 CPU 核心都只能运行一条指令。
虚拟内存
这里的虚拟内存不是 Windows 的虚拟内存,是 Linux 虚拟内存,即逻辑内存。
逻辑内存是用一段内存和一段磁盘上的存储空间放在一起组成的一个逻辑内存空间,对外依然表现为“线性数组内存空间”。逻辑内存引出了现代计算机的一个重要性能观念:
内存局部性天然的让相邻指令需要读写的内存空间也相邻,于是可以把一个进程的内存放到磁盘上,再把一小部分的“热数据”放到内存中,让其作为磁盘的缓存,这样可以在降低很少性能的情况下,大幅提升计算机能够同时运行的进程数量,从而大幅提升性能。
虚拟内存的本质其实是使用缓存+乐观的手段来提升计算机的性能。
系统调用
系统调用是进程向操作系统索取资源的通道,这也是利用异常控制流来实现的。
硬件中断
键盘点击、鼠标移动、网络接收到数据、麦克风有声音输入、插入 U 盘这些操作全部需要 CPU 暂时停下手头的工作,来做出响应。
进程、线程
进程的创建、管理和销毁全部都是基于异常控制流实现的,其生命周期的钩子函数也是操作系统依赖异常控制流实现的。在 Linux 上线程和进程没有功能上的区别。
编程语言中的 try-catch
C++ 编译成二进制程序,其异常控制语句是直接基于异常控制流实现的。Java 这种硬虚拟机语言,PHP 这种软虚拟机语言,其异常控制流的一部分也是基于最底层的异常控制流来实现的,另一部分可以用逻辑判断来实现。
基于异常控制流的事件驱动
其实现在人们讨论的事件驱动,是由 Linux 内核提供的 epoll,是 2002年10月18日伴随着 kernel 2.5.44 发布的,是 Linux 首次将操作系统中的 IO 事件和异常控制流暴露给了进程,实现了本文开头提的事件驱动。
Kqueue
FreeBSD 4.1 版本于 2000 年发布,一起携带的 Kqueue 是 BSD 系统中事件驱动的 API 提供者。BSD 系统如今已遍地开花,从 macOS 到 iOS,从 watchOS 到 PS4 游戏机,都受到了 Kqueue 的蒙荫。
epoll 是什么
操作系统本身就是事件驱动的,所以 epoll 并不是什么新发明,而只是把本来不给用户空间的 API 暴露给了用户空间而已。
epoll 做了什么
网络 IO 是一种纯异步的 IO 模型,所以 Nginx 和 Node.js 都基于 epoll 实现了完全的事件驱动,活得好了相比于 select/epoll 巨量的性能提升。而磁盘 IO 就没有这么幸运的,因此磁盘本身也是单体阻塞资源:即,有进程在写磁盘的时候,其他写入请求只能等待,就是天王老子来了也不行,磁盘做不到呀。所以磁盘 IO 是基于 epoll 实现的非阻塞 IO,但是其底层依旧是异步阻塞,即便这样,性能也已经爆棚了。Node 的磁盘 IO 性能远超其他解释型语言,过去几年在 web 后端霸占了一些对磁盘 IO 要求较高的领域。
2.4 - Unix进程模型
Unix 系统 1969 年诞生于 AT&T 旗下的贝尔实验室。1971 年,Ken Thompson(Unix之父) 和 Dennis Ritchie(C语言之父)共同发明了 C 语言,并在 1973 年用 C 语言重写了 Unix。
Unix 自诞生起就是多用户、多任务的分时操作系统,其引入的“进程”概念是计算机科学中最成功的概念之一,几乎所有现代操作系统都是这一概念的受益者。但是进程也有局限,由于 AT&T 是做电话交换起家,所以 Unix 进程在设计之初就是延续的电话交换这个业务需求:保证电话交换的效率,就够了。
1984年,Richard Stallman 发起了 GNU 项目,目标是创建一个完全自由且向下兼容 Unix 的操作系统。之后 Linus Torvalds 与 1991 年发布了 Linux 内核,和 GNU 结合在了一起形成了 GNU/Linux 这个当下最成功的开源操作系统。所以 Redhat、CentOS、Ubuntu 这些如雷贯耳的 Linux 服务器操作系统,他们的内存模型也是高度类似 Unix 的。
Unix 进程模型
进程是操作系统提供的一种抽象,每个进程在自己看来都是一个独立的图灵机:独占 CPU 核心,一个一个地运行指令,读写内存。进程是计算机科学中最重要的概念之一,是进程使多用户、多任务成为了可能。
上下文切换
操作系统使用上下文切换让一个 CPU 核心上可以同时运行多个进程:在宏观时间尺度,例如 5 秒内,一台电脑的用户会认为他的桌面进程、音乐播放进程、鼠标响应进程、浏览器进程是在同时运行的。
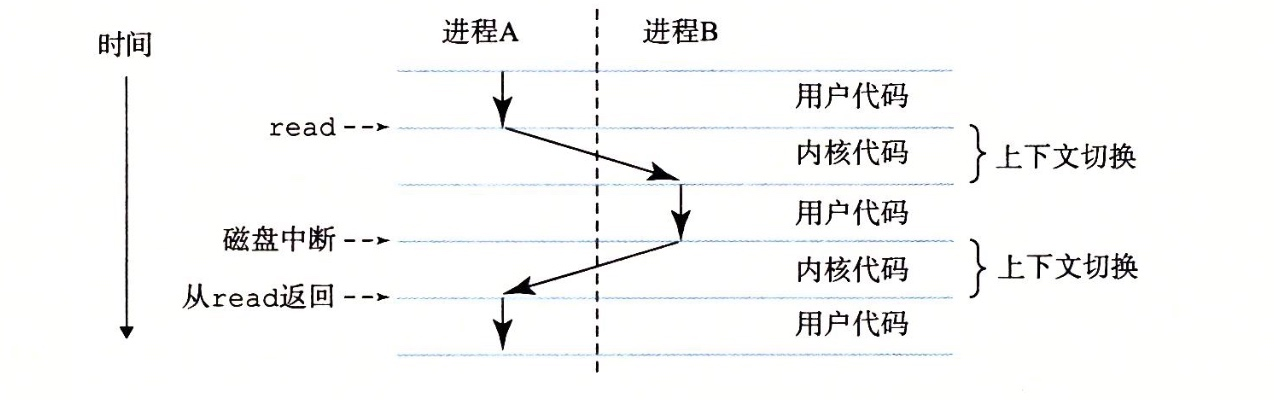
上下文切换的过程
假设你正在运行网易云音乐进程,你突然想搜歌,假设焦点已经位于搜索框内:
- 当前进程是网易云音乐,它正在播放音乐。
- 你突然打字,CPU 接到键盘发起的中断信号(异常控制流中的一个异常),准备调起键盘处理进程。
- 将网易云音乐进程的寄存器、栈指针、程序计数器保存到内存中。
- 将键盘处理进程的寄存器、栈指针、程序计数器从内存中读出来,写入到 CPU 内部相应的模块中。
- 执行程序计数器的指令,键盘处理程序开始处理键盘输入。
- 完成了一次上下文切换。
名词解释
- 寄存器:CPU 核心中用于暂时存储指令、地址和数据的电路,和内核频率一样,速度极快。
- 栈指针:该进程所拥有的栈的指针。
- 程序计数器:简称 PC,它存储着内核将要执行的下一个指令的内存地址。程序计数器是图灵机的核心组成部分。还记得冯·诺依曼架构吗,它的一大创造就是把指令和数据都存在内存里,让计算机获得了极大的自由度。
Unix 进程模型的局限
Unix 进程模型十分的清晰,上下文切换使用了一个非常简单的操作就实现了多个进程的宏观同时运行,是一个伟大的杰作。但是它却存在着一个潜在的缺陷,这个缺陷在 Unix 诞生数十年之后才渐渐浮出水面。
致命的内存
进程切换过程中需要分别写、读一些内存,该操作在 Unix 刚发明的时候没有发现有什么性能问题,但是 CPU 裹挟着摩尔定律一路狂奔,2000 年,ADM 领先 Intel 两天发布了第一款 1GHz 的微处理器 “AMD Athlon 1GHz”,此时一个指令的执行时间已经低于 1ns,而其内存延迟高达 60ns,这导致了一个之前不曾出现过的问题:
上下文切换读写内存的时间成为了整个系统的性能瓶颈。
软件定义一切
我们将在下一篇文章中探讨 SDN(软件定义网络),着这里我们先来看一下“软件定义一切”整个概念。
当下,不仅有软件定义网络,还有软件定义存储,甚至还出现了软件定义基础架构(这不就是云计算吗)。是什么导致了软件越来越强势,开始倾如过去只有专业的硬件设备才能提高的高性能高稳定性服务呢?我认为,就是通用计算机的发展导致的,确切的说,是 CPU 和网络的发展导致的。
当前的民用级 CPU 性能已经爆表,因为规模巨大,所以其价格也要显著低于同性能的专用处理器:40G 路由设备的价格大约是自建 40G 软路由价格的二十分之一。
2.5 - DPDK-SDN-大页内存
上文我们说到,当今的 x86 通用微处理器已经拥有了十分强大的性能,得益于其庞大的销量,其价格与专用 CPU 相比也有着巨大的优势,于是,软件定义一切诞生了!
软路由
说到软路由,很多人都露出了会心的微笑,因为其拥有低廉的价格、超多的功能、够用的性能和科学上网能力。现在网上能买到的软路由,其本质就是一个 x86 PC 加上多个网口,大多是基于 Linux 或 BSD 内核,使用 Intel 低端被动散热 CPU 打造出的千兆路由器,几百块就能实现千兆的性能,最重要的是拥有 QOS、多路拨号、负载均衡、防火墙、VPN 组网、科学上网等强大功能,传统路由器抛开科学上网不谈,其他功能也不是几百块就搞得定的。
软路由的弱点
软路由便宜,功能强大,但是也有弱点。它最大的弱点其实是性能:传统 *UNIX 网络栈的性能实在是不高。
软路由的 NAT 延迟比硬路由明显更大,而且几百块的软路由 NAT 性能也不够,跑到千兆都难,而几百块的硬路由跑到千兆很容易。那怎么办呢?改操作系统啊。
SDN
软件定义网络,其本质就是使用计算机科学中最常用的“虚拟机”构想,将传统由硬件实现的 交换、网关、路由、NAT 等网络流量控制流程交由软件来统一管理:可以实现硬件不动,网络结构瞬间变化,避免了传统的停机维护调试的烦恼,也为大规模公有云计算铺平了道路。
虚拟机
虚拟机的思想自底向上完整地贯穿了计算机的每一个部分,硬件层有三个场效应管虚拟出的 SRAM、多个内存芯片虚拟出的一个“线性数组内存”,软件层有 jvm 虚拟机,PHP 虚拟机(解释器)。自然而然的,当网络成为了更大规模计算的瓶颈的时候,人们就会想,为什么网络不能虚拟呢?
OpenFlow
最开始,SDN 还是基于硬件来实施的。Facebook 和 Google 使用的都是 OpenFlow 协议,作用在数据链路层(使用 MAC 地址通信的那一层,也就是普通交换机工作的那一层),它可以统一管理所有网关、交换等设备,让网络架构实时地做出改变,这对这种规模的公司所拥有的巨大的数据中心非常重要。
DPDK
DPDK 是 SDN 更前沿的方向:使用 x86 通用 CPU 实现 10Gbps 甚至 40Gbps 的超高速网关(路由器)。
DPDK 是什么
Intel DPDK 全称为 Intel Data Plane Development Kit,直译为“英特尔数据平面开发工具集”,它可以摆脱类 UNIX 网络数据包处理机制的局限,实现超高速的网络包处理。

DPDK 的价值
当下,一台 40G 核心网管路由器动辄数十万,而 40G 网卡也不会超过一万块,而一颗性能足够的 Intel CPU 也只需要几万块,软路由的性价比优势是巨大的。
实际上,阿里云和腾讯云也已经基于 DPDK 研发出了自用的 SDN,已经创造了很大的经济价值。
怎么做到的?
DPDK 使用自研的数据链路层(MAC地址)和网络层(ip地址)处理功能(协议栈),抛弃操作系统(Linux,BSD 等)提供的网络处理功能(协议栈),直接接管物理网卡,在用户态处理数据包,并且配合大页内存和 NUMA 等技术,大幅提升了网络性能。有论文做过实测,10G 网卡使用 Linux 网络协议栈只能跑到 2G 多,而 DPDK 分分钟跑满。
用户态网络栈
上篇文章我们已经说到,Unix 进程在网络数据包过来的时候,要进行一次上下文切换,需要分别读写一次内存,当系统网络栈处理完数据把数据交给用户态的进程如 Nginx 去处理还会出现一次上下文切换,还要分别读写一次内存。夭寿啦,一共 1200 个 CPU 周期呀,太浪费了。
而用户态协议栈的意思就是把这块网卡完全交给一个位于用户态的进程去处理,CPU 看待这个网卡就像一个假肢一样,这个网卡数据包过来的时候也不会引发系统中断了,不会有上下文切换,一切都如丝般顺滑。当然,实现起来难度不小,因为 Linux 还是分时系统,一不小心就把 CPU 时间占完了,所以需要小心地处理阻塞和缓存问题。
NUMA
NUMA 来源于 AMD Opteron 微架构,其特点是将 CPU 直接和某几根内存使用总线电路连接在一起,这样 CPU 在读取自己拥有的内存的时候就会很快,代价就是读取别 U 的内存的时候就会比较慢。这个技术伴随着服务器 CPU 核心数越来越多,内存总量越来越大的趋势下诞生的,因为传统的模型中不仅带宽不足,而且极易被抢占,效率下降的厉害。
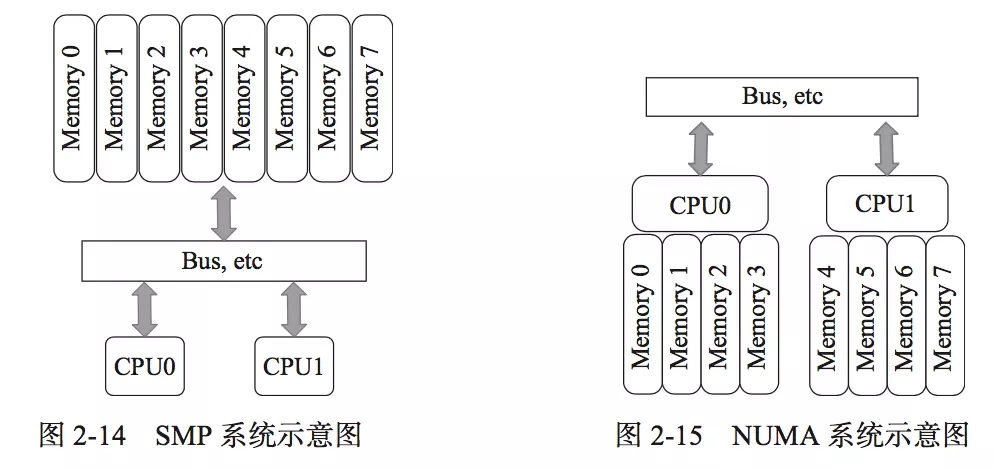
NUMA 利用的就是电子计算机(图灵机 + 冯·诺依曼架构)天生就带的涡轮:局部性。
细说大页内存
内存分页
为了实现虚拟内存管理机制,前人们发明了内存分页机制。这个技术诞生的时候,内存分页的默认大小是 4KB,而到了今天,绝大多数操作系统还是用的这个数字,但是内存的容量已经增长了不知道多少倍了。
TLB miss
TLB(Translation Lookaside Buffers)转换检测缓冲区,是内存控制器中为增加虚拟地址到物理地址的翻译速度而设立的一组电子元件,最近十几年已经随着内存控制器被集成到了 CPU 内部,每颗 CPU 的 TLB 都有固定的长度。
如果缓存未命中(TLB miss),则要付出 20-30 个 CPU 周期的带价。假设应用程序需要 2MB 的内存,如果操作系统以 4KB 作为分页的单位,则需要 512 个页面,进而在 TLB 中需要 512 个表项,同时也需要 512 个页表项,操作系统需要经历至少 512 次 TLB Miss 和 512 次缺页中断才能将 2MB 应用程序空间全部映射到物理内存;然而,当操作系统采用 2MB 作为分页的基本单位时,只需要一次 TLB Miss 和一次缺页中断,就可以为 2MB 的应用程序空间建立虚实映射,并在运行过程中无需再经历 TLB Miss 和缺页中断。
大页内存
大页内存 HugePage 是一种非常有效的减少 TLB miss 的方式,让我们来进行一个简单的计算。
2013 年发布的 Intel Haswell i7-4770 是当年的民用旗舰 CPU,其在使用 64 位 Windows 系统时,可以提供 1024 长度的 TLB,如果内存页的大小是 4KB,那么总缓存内存容量为 4MB,如果内存页的大小是 2MB,那么总缓存内存容量为 2GB。显然后者的 TLB miss 概率会低得多。
DPDK 支持 1G 的内存分页配置,这种模式下,一次性缓存的内存容量高达 1TB,绝对够用了。
不过大页内存的效果没有理论上那么惊人,DPDK 实测有 10%~15% 的性能提升,原因依旧是那个天生就带的涡轮:局部性。
2.6 - 局部性与乐观
冯·诺依曼架构中,指令和数据均存储在内存中,彻底打开了计算机“通用”的大门。这个结构中,“线性数组”内存天生携带了一个涡轮:局部性。
局部性分类
空间局部性
空间局部性是最容易理解的局部性:如果一段内存被使用,那么之后,离他最近的内存也最容易被使用,无论是数据还是指令都是这样。举一个浅显易懂的例子:
循环处理一个 Array,当处理完了 [2] 之后,下一个访问的就是 [3],他们在内存里是相邻的。
时间局部性
如果一个变量所在的内存被访问过,那么接下来这一段内存很可能被再次访问,例子也非常简单:
$a = [];
if ( !$b ) {
$a[] = $b;
}
在一个 function 内,一个内存地址很可能被访问、修改多次。
乐观
“乐观”作为一种思考问题的方式广泛存在于计算机中,从硬件设计、内存管理、应用软件到数据库均广泛运用了这种思考方式,并给我们带来了十分可观的性能收益。
乐观的 CPU
第一篇文章中的三级缓存和第二篇文章中的分支预测与流水线,均是乐观思想的代表。
乐观的虚拟内存
虚拟内存依据计算机内存的局部性,将磁盘作为内存的本体,将内存作为磁盘的缓存,用很小的性能代价带来了数十倍并发进程数,是乐观思想的集大成者。
乐观的缓存
Java 经典面试题 LRU 缓存实现,也是乐观思想的一种表达。
同样,鸟哥的 yac 也是这一思想的强烈体现。
设计 Yac 的经验假设:
- 对于一个应用来说, 同名的 Cache 键, 对应的 Value 大小几乎相当。
- 不同的键名的个数是有限的。
- Cache 的读次数, 远远大于写的次数。
- Cache 不是数据库, 即使 Cache 失效也不会带来致命错误。
Yac 的限制:
- key 的长度最大不能超过 48 个字符. (我想这个应该是能满足大家的需求的, 如果你非要用长 Key, 可以 MD5 以后再存)
- Value 的最大长度不能超过 64M, 压缩后的长度不能超过 1M。
- 当内存不够的时候, Yac 会有比较明显的踢出率, 所以如果要使用 Yac, 那么尽量多给点内存吧。
乐观锁
乐观锁在并发控制和数据库设计里都拥有重要地位,其本质就是在特定的需求下,假定不会冲突,冲突之后再浪费较长时间处理,比直接每次请求都浪费较短时间检测,总体的性能高。乐观锁在算法领域有着非常丰富而成熟的应用。
乐观的分布式计算
分布式计算的核心思想就是乐观,由 95% 可靠的 PC 机组成的分布式系统,起可靠性也不会达到 99.99%,但是绝大多数场景下,99% 的可靠性就够了,毕竟拿 PC 机做分布式比小型机便宜得多嘛。下一篇文章我会详细介绍分布式计算的性能之殇,此处不再赘述。
乐观的代价
乐观给了我们很多的好处,总结起来就是一句话:以微小的性能损失换来大幅的性能提升。但是,人在河边走,哪有不湿鞋。每一个 2015 年 6 月入 A 股的散户,都觉得大盘还能再翻一番,岂不知一周之后,就是股灾了。
乐观的代价来自于“微小的性能损失”,就跟房贷市场中“微小的风险”一样,当大环境小幅波动的时候,他确实能承担压力,稳住系统,但是怕就怕突然雪崩:
- 虚拟内存中的内存的局部性突然大幅失效,磁盘读写速度成了内存读写速度,系统卡死。
- 分布式数据库的六台机器中的 master 挂了,系统在一秒内选举出了新的 master,你以为系统会稳定运行?master 挂掉的原因就是压力过大,这样就会导致新的 master 瞬间又被打挂,然后一台一台地继续,服务彻底失效。
2.7 - 共同的瓶颈
分布式计算是这些年的热门话题,各种大数据框架层出不穷,容器技术也奋起直追,各类数据库(Redis、ELasticsearch、MongoDB)也大搞分布式,可以说是好不热闹。分布式计算在大热的同时,也存在着两台机器也要硬上 Hadoop 的“面向简历编程”,接下来我就剖析一下分布式计算的本质,以及我的理解和体会。
分布式计算的本质
分布式计算来源于人们日益增长的性能需求与落后的 x86 基础架构之间的矛盾。恰似设计模式是面向对象对现实问题的一种妥协。
x86 服务器
x86 服务器,俗称 PC 服务器、微机服务器,近二十年以迅雷不及掩耳盗铃之势全面抢占了绝大部分的服务器市场,它和小型机比只有一个优势,其他的全是缺点,性能、可靠性、可扩展性、占地面积都不如小型机,但是一个优势就决定了每年 2000 多亿美元的 IDC 市场被 x86 服务器占领了 90%,这个优势就是价格。毕竟有钱能使磨推鬼嘛。
现有的分布式计算,无论是 Hadoop 之类的大数据平台,还是 HBase 这样的分布式数据库,无论是 Docker 这种容器排布,还是 Redis 这种朴素分布式数据库,其本质都是因为 x86 的扩展性不够好,导致大家只能自己想办法利用网络来自己构建一个宏观上更强性能更高负载能力的计算机。
分布式计算,是一种新的计算机结构
基于网络的 x86 服务器分布式计算,其本质是把网络当做总线,设计了一套新的计算机体系结构:
- 每台机器就等于一个运算器加一个存储器。
- master 节点就是控制器和输入设备、输出设备。
x86 分布式计算的弱点
上古时代,小型机的扩展能力是非常变态的,到今天,基于小型机的 Oracle 数据库系统依旧能做到惊人的性能和可靠性。实际上单颗 x86 CPU 的性能已经远超 IBM 小型机用的 PowerPC,但是当数量来到几百颗,x86 服务器集群就败下阵来,原因也非常简单:
- 小型机是专门设计的硬件和专门设计的软件,只面向这种规模(例如几百颗 CPU)的计算。
- 小型机是完全闭源的,不需要考虑扩展性,特定的几种硬件在稳定性上前进了一大步。
- x86 的 IO 性能被架构锁死了,各种总线、PCI、PCIe、USB、SATA、以太网,为了个人计算机的便利性,牺牲了很多的性能和可靠性。
- 小型机使用总线通信,可以实现极高的信息传递效率,极其有效的监控以及极高的故障隔离速度。
- x86 服务器基于网络的分布式具有天然的缺陷:
- 操作系统决定了网络性能不足。
- 网络需要使用事件驱动处理,比总线电路的延迟高几个数量级。
- PC 机的硬件不够可靠,故障率高。
- 很难有效监控,隔离故障速度慢。
x86 分布式计算的基本套路
Google 系大数据处理框架
2003 年到 2004 年间,Google 发表了 MapReduce、GFS(Google File System)和 BigTable 三篇技术论文,提出了一套全新的分布式计算理论。MapReduce 是分布式计算框架,GFS(Google File System)是分布式文件系统,BigTable 是基于 GFS 的数据存储系统,这三大组件组成了 Google 的分布式计算模型。
Hadoop、Spark、Storm 是目前最重要的三大分布式计算系统,他们都是承袭 Google 的思路实现并且一步一步发展到今天的。
MapReduce 的基本原理也十分简单:将可以并行执行的任务切分开来,分配到不同的机器上去处理,最终再汇总结果。而 GFS 是基于 Master-Slave 架构的分布式文件系统,其 master 只扮演控制者的角色,操控着所有的 slave 干活。
Redis/MongoDB 的分布式
Redis 有两个不同的分布式方案。Redis Cluster 是官方提供的工具,它通过特殊的协议,实现了每台机器都拥有数据存储和分布式调节功能,性能没有损失。缺点就是缺乏统一管理,运维不友好。Codis 是一个非常火的 Redis 集群搭建方案,其基本原理可以简单地描述如下:通过一个 proxy 层,完全隔离掉了分布式调节功能,底层的多台机器可以任意水平扩展,运维十分友好。
MongoDB 官方提供了一套完整的分布式部署的方案,提供了 mongos 控制中心,config server 配置存储,以及众多的 shard(其底层一般依然有两台互为主从强数据一致性的 mongod)。这三个组件可以任意部署在任意的机器上,MongoDB 提供了 master 选举功能,在检测到 master 异常后会自动选举出新的 master 节点。
问题和瓶颈
人们费这么大的劲研究基于网络的 x86 服务器分布式计算,目的是什么?还不是为了省钱,想用一大票便宜的 PC 机替换掉昂贵的小型机、大型机。虽然人们已经想尽了办法,但还是有一些顽固问题无法彻底解决。
master 失效问题
无论怎样设计,master 失效必然会导致服务异常,因为网络本身不够可靠,所以监控系统的容错要做的比较高,所以基于网络的分布式系统的故障恢复时间一般在秒级。而小型机的单 CPU 故障对外是完全无感的。
现行的选举机制主要以节点上的数据以及节点数据之间的关系为依据,通过一顿猛如虎的数学操作,选举出一个新的 master。逻辑上,选举没有任何问题,如果 master 因为硬件故障而失效,新的 master 会自动顶替上,并在短时间内恢复工作。
而自然界总是狠狠地打人类的脸:
- 硬件故障概率极低,大部分 master 失效都不是因为硬件故障。
- 如果是流量过大导致的 master 失效,那么选举出新的 master 也无济于事:提升集群规模才是解决之道。
- 即使能够及时地在一分钟之内顶替上 master 的工作,那这一分钟的异常也可能导致雪崩式的 cache miss,从磁盘缓存到虚拟内存,从 TLB 到三级缓存,再到二级缓存和一级缓存,全部失效。如果每一层的失效会让系统响应时间增加五倍的话,那最终的总响应时长将是惊人的。
系统规模问题
无论是 Master-Slave 模式还是 Proxy 模式,整个系统的流量最终还是要落到一个特定的资源上。当然这个资源可能是多台机器,但是依旧无法解决一个严重的问题:系统规模越大,其本底性能损失就越大。
这其实是我们所在的这个宇宙空间的一个基本规律。我一直认为,这个宇宙里只有一个自然规律:熵增。既然我们这个宇宙是一个熵增宇宙,那么这个问题就无法解决。
超级计算机
超级计算机可以看成一个规模特别巨大的分布式计算系统,他的性能瓶颈从目前的眼光来看,是超多计算核心(数百万)的调节效率问题。其本质是通信速率不够快,信息传递的太慢,让数百万核心一起工作,传递命令和数据的工作占据了绝大多数的运行时间。
神经网络
深度学习这几年大火,其原因就是卷积神经网络(CNN)造就的 AlphaGo 打败了人类,计算机在这个无法穷举的游戏里彻底赢了。伴随着 Google 帝国的强大推力,深度学习,机器学习,乃至人工智能,这几个词在过去的两年大火,特别是在中美两国。现在拿手机拍张照背后都有机器学习你敢信?
机器学习的瓶颈,本质也是数据交换:机器学习需要极多的计算,而计算速度的瓶颈现在就在运算器和存储器的通信上,这也是显卡搞深度学习比 CPU 快数十倍的原因:显存和 GPU 信息交换的速度极快。
九九归一
分布式系统的性能问题,表现为多个方面,但是归根到底,其原因只是一个非常单纯的矛盾:人们日益增长的性能需求和数据一致性之间的矛盾。一旦需要强数据一致性,那就必然存在一个限制速度的瓶颈,这个瓶颈就是信息传递的速度决定的。
同样,超级计算机和神经网络的瓶颈也都是信息传递的速度。
那么,信息传递速度的瓶颈在哪里呢?
我个人认为,信息传递的瓶颈最表层是人类的硬件制造水平决定的,再往底层去是冯·诺依曼架构决定的,再往底层去是图灵机的逻辑模型决定的。可是图灵机是计算机可行的理论基础呀,所以,还是怪这个熵增宇宙吧,为什么规模越大维护成本越高呢,你也是个成熟的宇宙了,该学会自己把自己变成熵减宇宙了。
3 - IO 模型
3.1 - Linux IO/线程 模型
用户空间与内核空间
我们知道现在的操作系统都是采用虚拟存储器,那么对 32 位操作系统来说,它的寻址空间即虚拟存储空间为 4G,2 的 32 次方。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核,保证内核的的安全,操作系统将虚拟内存空间划分为两部分,一部分是内核空间,一部分是用户空间。
针对 Linux 操作系统而言,将最高的 1G 字节,即从虚拟地址 0xC0000000 到 0xFFFFFFFF 供内核使用,称为内核空间。而较低的 3G 字节,即从虚拟地址 0x00000000 到 0xBFFFFFFF,供进程使用,称为用户空间。每个进程都可以通过系统调用进入内核,因此 Linux 内核由系统内的所有进程共享。于是,从具体进程的角度看,每个进程可以拥有 4G 字节的虚拟空间。
有了用户空间和内核空间,整个 Linux 内部结构可以分为三个部分,从最底层到最上层依次是:硬件、内核空间、用户空间。
需要注意的细节是,从上图可以看出内核的组成:
- 内核空间中存放的是内核代码和数据,而进程的用户空间存放的是用户程序的代码和数据。不管是内核空间还是用户空间,都处于虚拟空间之中。
- Linux 使用两级保护机制:0 级供内核使用,3 级供用户程序使用。
服务端处理网络请求的流程
为了 OS 的安全性等考虑,进程是无法直接操作 IO 设备的,其必须通过系统调用来请求内核以协助完成 IO 动作,而内核会为每个 IO 设备维护一个 buffer。
整个请求过程为:
- 用户进程发起请求;
- 内核接收到请求后;
- 从 IO 设备中获取数据到 buffer 中;
- 再将 buffer 中的数据 copy 到用户进程的地址空间;
- 该用户进程获取到数据后再响应客户端。
服务端处理网络请求的典型流程图如下:
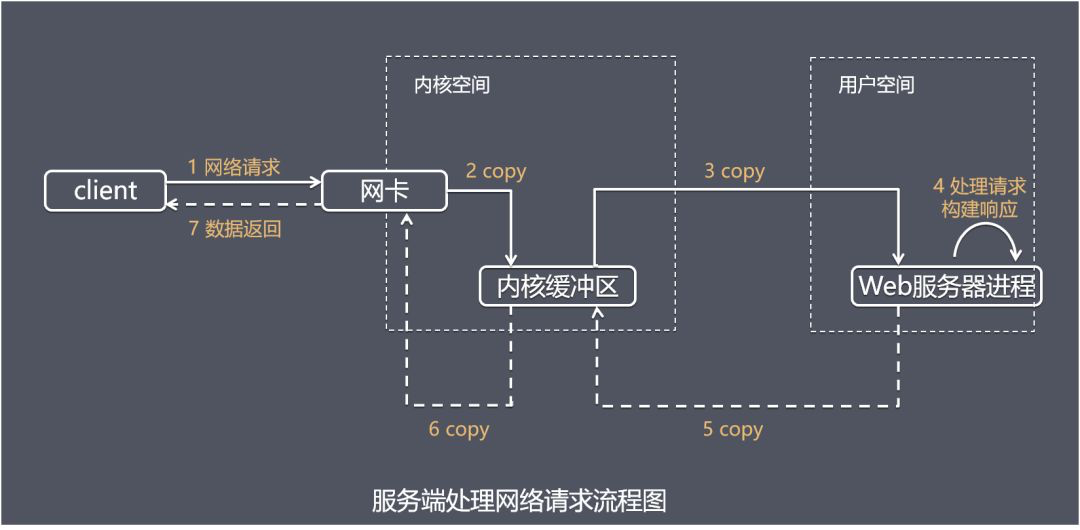
在请求过程中,数据从 IO 设备输入至 buffer 需要时间,从 buffer 复制将数据复制到用户进程也需要时间。因此根据在这两段时间内等待方式的不同,IO 动作可以分为以下五种:
- 阻塞 IO,Blocking IO
- 非阻塞 IO,Non-Blocking IO
- IO 复用,IO Multiplexing
- 信号驱动的 IO,Signal Driven IO
- 异步 IO,Asynchrnous IO
更多细节参考 <Unix 网络编程>,6.2 节 “IO Models”。
设计服务端并发模型时,主要有如下两个关键点:
- 服务器如何管理连接,获取请求数据。
- 服务器如何处理请求。
以上两个关键点最终都与操作系统的 I/O 模型以及线程(进程)模型相关,下面详细介绍这两个模型。
阻塞/非阻塞、同步/异步
阻塞/非阻塞:
- 阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
- 非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
区别:
- 两者的最大区别在于被调用方在收到请求到返回结果之前的这段时间内,调用方是否一直在等待。
- 阻塞是指调用方一直在等待而且别的事情什么都不做;非阻塞是指调用方先去忙别的事情。
同步/异步:
- 同步处理是指被调用方得到最终结果之后才返回给调用方;
- 异步处理是指被调用方先返回应答,然后再计算调用结果,计算完最终结果后再通知并返回给调用方。
区别与联系
阻塞、非阻塞和同步、异步其实针对的对象是不一样的:
- 阻塞、非阻塞的讨论对象是调用者。
- 同步、异步的讨论对象是被调用者。
Linux 网络 I/O 模型
recvfrom 函数
recvfrom 函数(经 Socket 接收数据),这里把它视为系统调用。一个输入操作通常包括两个不同的阶段:
- 等待数据准就绪。
- 从内核向应用进程复制数据。
对于一个套接字上的输入操作,第一步通常涉及等待数据从网络中到达。当所等待分组到达时,它被复制到内核中的某个缓冲区。第二步就是把数据从内核缓冲区复制到应用进程缓冲区。
实际应用程序在通过系统调用完成上面的 2 步操作时,调用方式的阻塞、非阻塞,操作系统在处理应用程序请求时处理方式的同步、异步,可以分为 5 种 I/O 模型。
阻塞式 IO
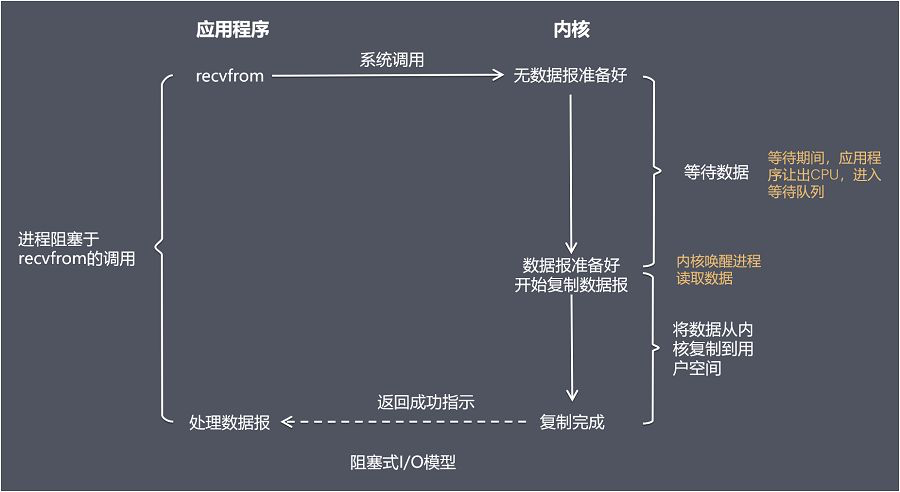
在阻塞式 IO 模型中,应用程序从调用 recvfrom 开始到它返回有数据报准备好这段时间是阻塞的,recvfrom 返回成功后,应用程序开始处理数据报。
- 优点:程序实现简单,在阻塞等待数据期间,进程、线程挂起,基本不会占用 CPU 资源。
- 每个连接需要独立的进程、线程单独处理,当并发请求量大时为了维护程序,内存、线程切换开销很大,这种模型在实际生产中很少使用。
非阻塞 IO
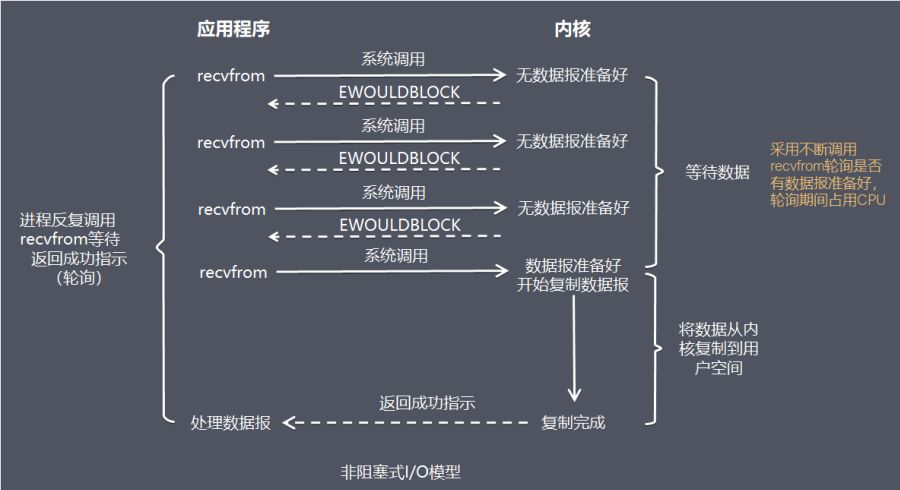
在非阻塞 IO 模型中,应用程序把一个套接口设置为非阻塞,就是告诉内核,当所有请求的 IO 操作无法完成时,不要将进程睡眠。
而是返回一个错误,应用程序基于 IO 操作函数,将会不断的轮询数据是否已经准备就绪,直到数据准备就绪。
- 优点:不会阻塞在内核的等待数据过程,每次发起的 IO 请求可以立即返回,不会阻塞等待,实时性比较好。
- 缺点:轮询将会不断的询问内核,这将占用大量的 CPU 时间,系统资源利用率较低,所以一般 Web 服务器不会使用这种 IO 模型。
IO 多路复用

在 IO 复用模型中,会用到 Select、Poll、Epoll 函数,这些函数会使进程阻塞,但是和阻塞 IO 有所不同。
这些函数可以同时阻塞多个 IO 操作,而且可以同时对多个读、写操作的 IO 函数进行检测,直到有数据可读或可写时,才会真正调用 IO 操作函数。
- 优点:可以基于一个阻塞对象,同时在多个描述符上等待就绪,而不是使用多个线程(每个文件描述符一个线程),这样可以大大节省系统资源。
- 当连接数较少时效率比“多线程+阻塞IO”的模式效率低,可能延迟更大,因为单个连接处理需要 2 次系统调用,占用时间会增加。
信号驱动 IO
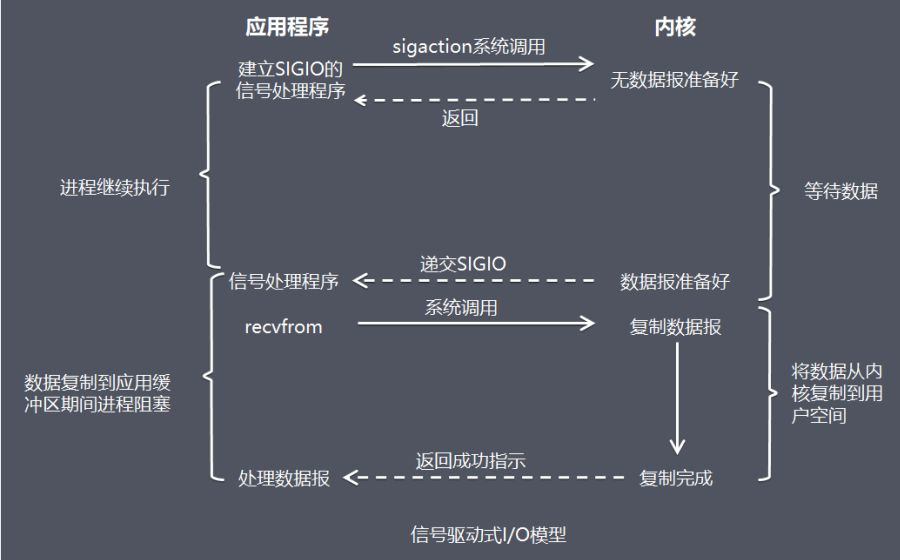
在信号驱动 IO 模型中,应用程序使用套接口进行信号驱动 IO,并安装一个信号处理函数,进程继续运行并不阻塞。
当数据准备好时,进程会收到一个 SIGIO 信号,可以在信号处理函数中调用 IO 操作函数处理数据。
- 优点:线程没有在等待数据时被阻塞,可以提高资源利用率。
- 缺点:信号 IO 模式在大量 IO 操作时可能会因为信号队列溢出而导致无法通知。
信号驱动 IO 尽管对于处理 UDP 套接字来说有用,即这种信号通知意味着到达了一个数据报,或者返回一个异步错误。
但是,对于 TCP 而言,信号驱动 IO 方式近乎无用。因为导致这种通知的条件为数众多,逐个进行判断会消耗很大的资源,与前几种方式相比优势尽失。
异步 IO
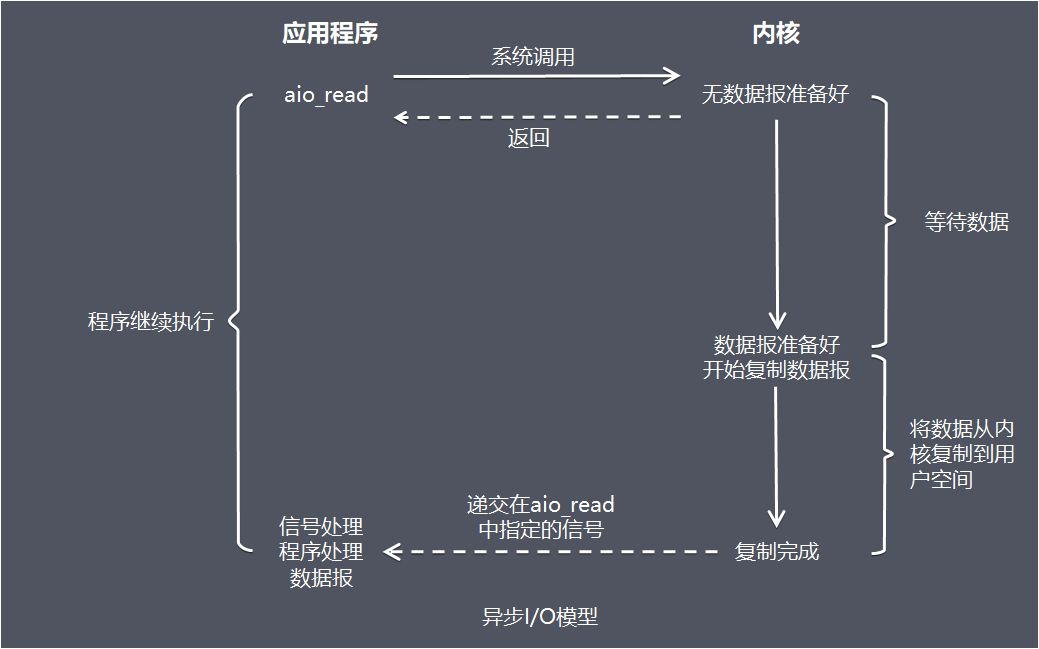
由 POSIX 规范定义,应用程序告知内核启动某个操作,并让内核在整个操作完成后(包括将数据从内核拷贝到应用程序的缓冲区)通知应用程序。
这种模型与信号驱动模型的主要区别在于:信号驱动 IO 是由内核通知应用程序合适启动一个 IO 操作,而异步 IO 模型是由内核通知应用程序 IO 操作合适完成。
- 优点:异步 IO 能够充分利用 DMA 特性,让 IO 操作与计算重叠。
- 缺点:需要实现真正的异步 IO,操作系统需要做大量的工作。当前 Windows 下通过 IOCP 实现了真正的异步 IO。
而在 Linux 系统下直到 2.6 版本才引入,目前 AIO 并不完善,因此在 Linux 下实现并发网络编程时都是以 IO 复用模型为主。
IO 模型对比

从上图可以看出,越往后,阻塞越少,理论上效率也最优。
这五种模型中,前四种属于同步 IO,因为其中真正的 IO 操作(recvfrom 函数调用)将阻塞进程/线程,只有异步 IO 模型才与 POSIX 定义的异步 IO 相匹配。
进程/线程模型
介绍完服务器如何基于 IO 模型管理连接、获取输入数据,下面介绍服务器如何基于进程、线程模型来处理请求。
传统阻塞 IO 服务模型
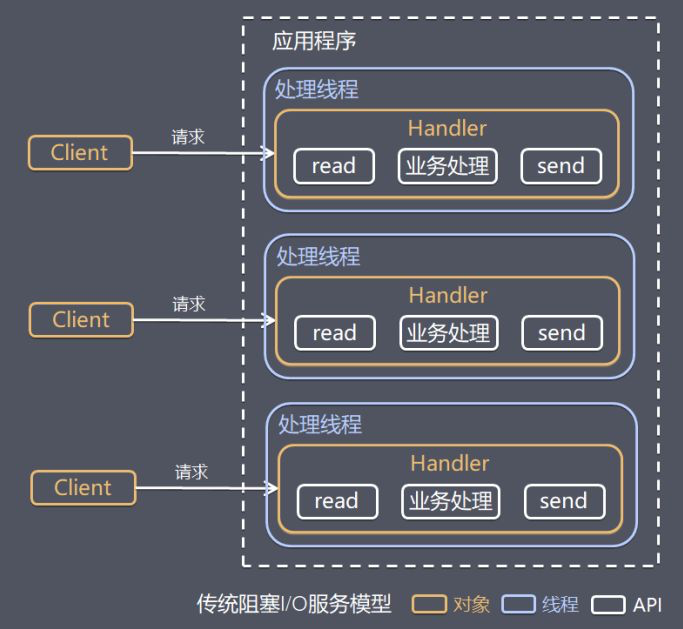
特点:
- 采用阻塞式 IO 模型获取输入数据。
- 每个连接都需要独立的线程完成数据输入的读取、业务处理、数据返回操作。
存在问题:
- 当请求的并发数较大时,需要创建大量线程来处理连接,系统资源占用较大。
- 当连接建立后,如果当前线程暂时没有数据可读,则线程就阻塞在 Read 操作上,造成线程资源浪费。
Reactor 模式
针对传统阻塞 IO 服务模型的 2 个缺点,比较常见的有如下解决方案:
- 基于 IO 复用模型,多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象上等待,无需阻塞等待所有连接。
- 当某条连接有新的数据可处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务处理。
- 基于线程池复用线程资源,不必再为每个连接创建线程,将连接完成后的业务处理任务分配给线程进行处理,一个线程可以多个连接的业务。
IO 复用模式结合线程池,就是 Reactor 模式的基本设计思想,如下图:
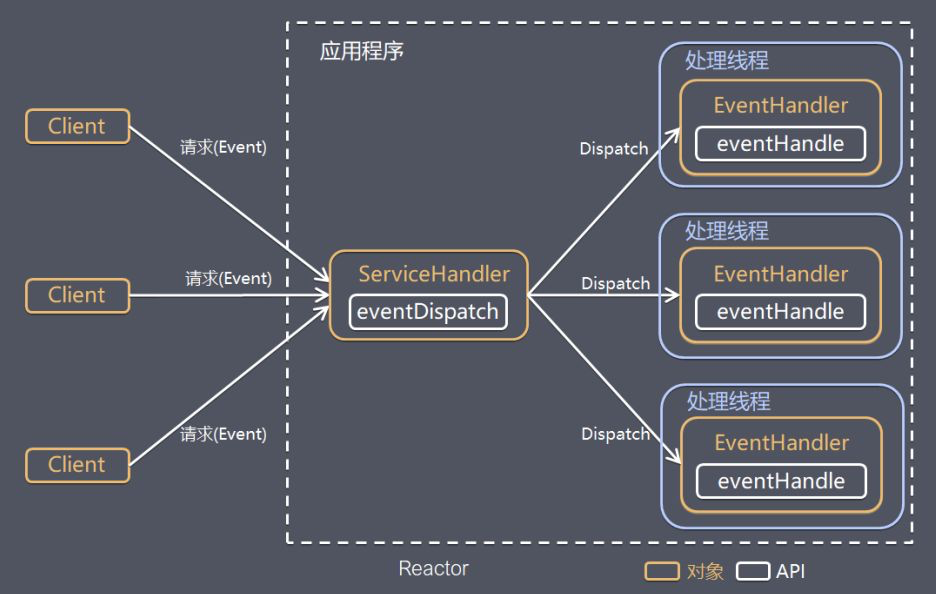
Reactor 模式,是指通过一个或多个输入同时传递给服务器来处理服务请求的事件驱动处理模式。
服务端程序处理传入的多路请求,并将它们同步分派给请求对应的处理线程,Reactor 模式也叫 Dispatcher 模式。
即 IO 多路复用以统一的方式监听事件,收到事件后分发(Dispatch 给某线程),是编写高性能服务器的必备技术之一。
Reactor 模式有两个关键组件构成:
- Reactor:在一个单独的线程中运行,负责监听和分发事件,分发给适当的处理程序对 IO 事件做出反应。它就像公司的电话接线员,接听来自客户的电话并将线路转移给适当的联系人。
- Handlers:处理程序执行 IO 事件需要完成的实际组件,类似于客户想要与之交谈的客服坐席。Reactor 通过调度适当的处理程序来响应 IO 事件,处理程序执行非阻塞操作。
根据 Reactor 的数量和处理资源池线程的数量不同,有 3 种典型的实现:
- 单 Reactor 单线程
- 单 Reactor 多线程
- 主从 Reactor 多线程
单 Reactor 单线程
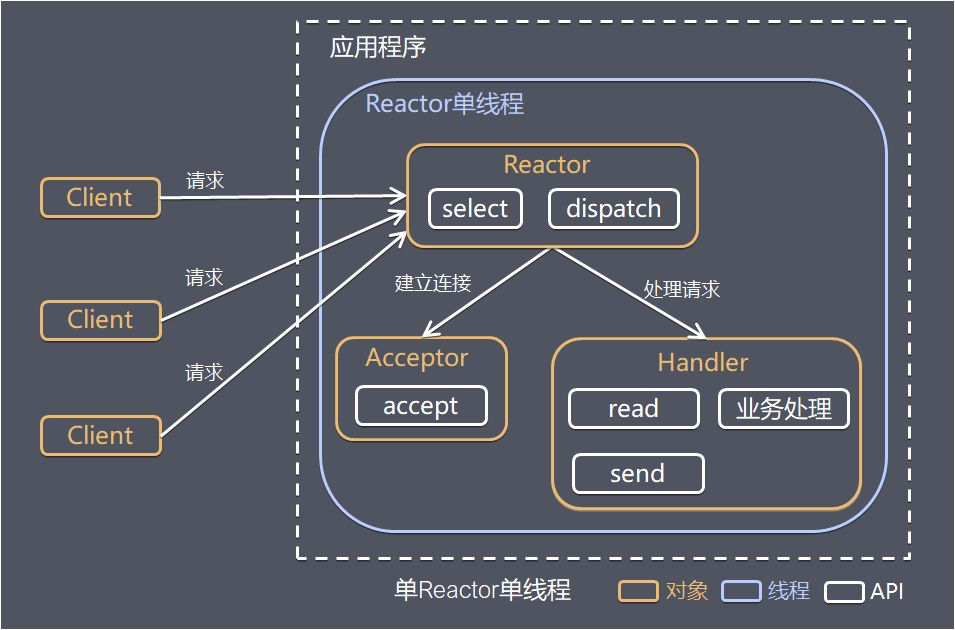
其中,Select 是前面 IO 复用模型介绍的标准网络编程 API,可以实现应用程序通过一个阻塞多向监听多路连接请求,其他方案的示意图也类似。
方案说明:
Reactor 对象通过 Select 监听客户端请求事件,收到事件后通过 Dispatch 进行分发。
如果是“建立连接”请求事件,则由 Acceptor 通过 Accept 处理连接请求,同时创建一个 Handler 对象来处理连接完成后的后续业务处理。
如果不是“建立连接”事件,则 Reactor 会分发调用“连接”对应的 Handler 来响应。
Handler 会完成 “Read->业务处理->Send” 的完整业务流程。
优点:模型简单,没有多线程、进程通信、竞争的问题,全部都在一个线程中完成。
缺点:性能问题,只有一个线程,无法完全发挥多个 CPU 的性能。Handler 在处理某个连接上的业务时,整个进程无法处理其他连接事件,很容易导致性能瓶颈。
可靠性问题、线程意外跑飞、进入死循环,或导致整个系统的通信模块不可用,不能接收或处理外部消息,造成节点故障。
应用场景:客户端的数量有限,业务处理非常快,比如 Redis,业务处理的时间复杂度为 O(1)。
单 Reactor 多线程
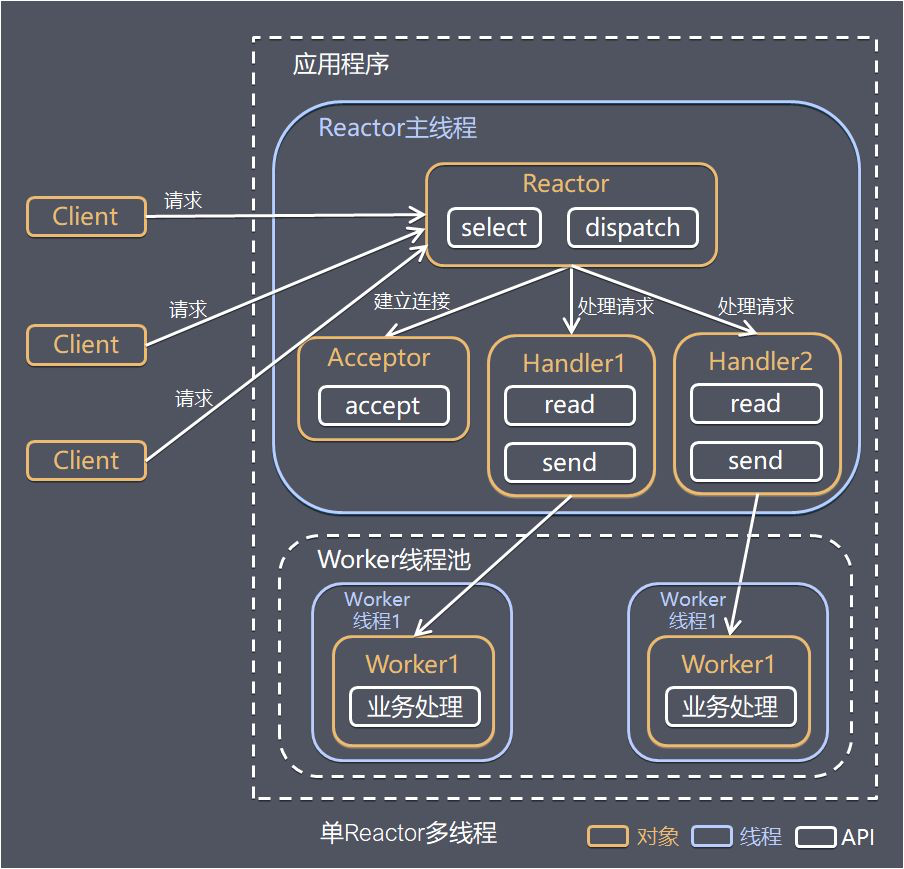
Reactor 对象通过 Select 监控客户端请求事件,收到事件后通过 Dispatch 进行分发。
如果是建立连接请求事件,则由 Acceptor 通过 Accept 处理连接请求,同时创建一个 Handler 对象处理连接完成后续的各种事件。
如果不是建立连接事件,则 Reactor 会分发调用连接对应的 Handler 来响应。
Handler 只负责响应事件,不做具体业务处理,通过 Read 读取数据后,会分发给后面的 Worker 线程池进行业务处理。
Worker 线程池会分配独立的线程完成真正的业务处理,如何将响应结果发给 Handler 进行处理。
Handler 收到响应结果后通过 Send 将响应结果返回给 Client。
优点:可以充分利用多核 CPU 的处理能力。
缺点:
- 多线程数据共享和访问比较复杂;
- Reactor 承担所有事件的监听和响应,在单线程中运行,高并发场景下容易成为性能瓶颈。
主从 Reactor 多线程
针对单 Reactor 多线程模型中,Reactor 在单线程中运行,高并发场景下容易成为性能瓶颈,可以让 Reactor 在多线程中运行。
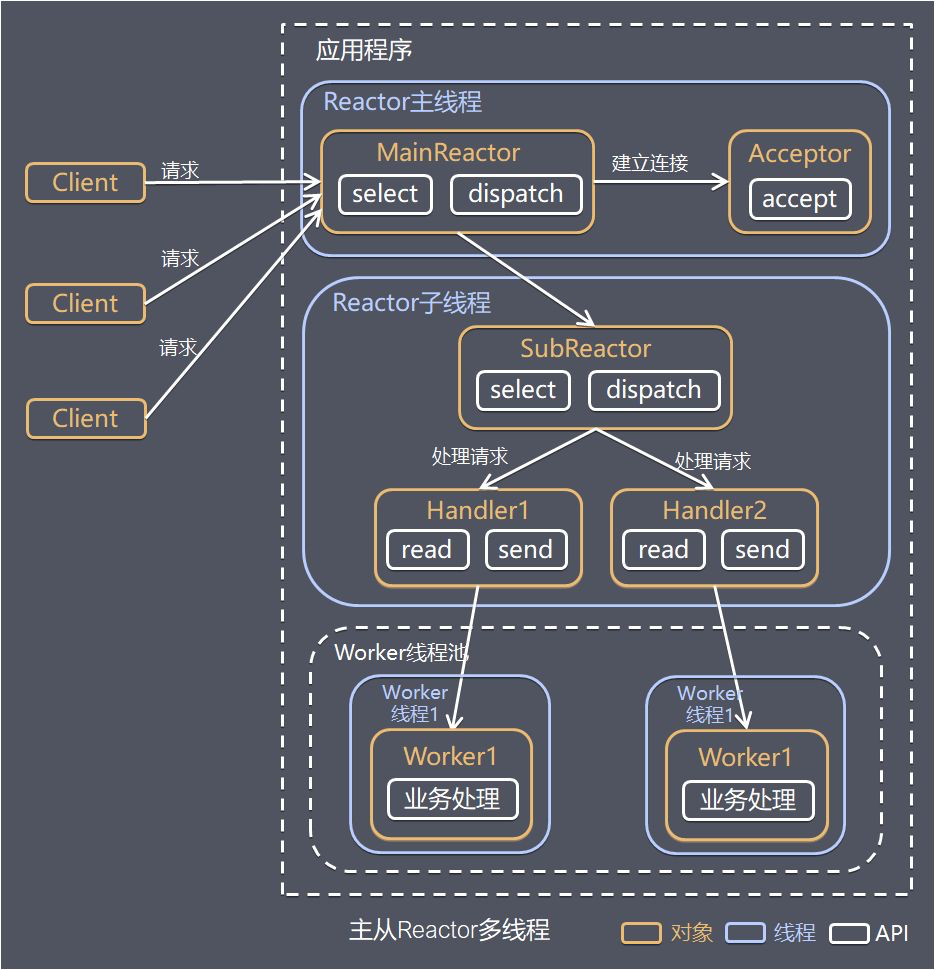
Reactor 主线程 MainReactor 对象通过 Select 监控建立连接事件,收到事件后通过 Acceptor 接收,处理建立连接事件。
Acceptor 处理建立连接事件后,MainReactor 将连接分配 Reactor 子线程给 SubReactor 进行处理。
SubReactor 将连接加入连接队列进行监听,并创建一个 Handler 用于处理各种连接事件。
当有新的事件发生时,SubReactor 会调用连接对应的 Handler 进行响应。
Handler 通过 Read 读取数据后,会分发给后面的 Worker 线程池进行业务处理。
Worker 线程池会分配独立的线程完成真正的业务处理,如何将响应结果发给 Handler 进行处理。
Handler 收到响应结果后通过 Send 将响应结果返回给 Client。
优点:父线程与子线程的数据交互简单、职责明确,父线程只需要接收新连接,子线程完成后续的业务处理。
父线程与子线程的数据交互简单,Reactor 主线程只需要把新连接传递给子线程即可,子线程无需返回数据。
这种模型在很多项目中广泛使用,包括 Nginx 主从 Reactor 多线程模型,Memcached 主从多线程。
Reactor 模式总结
三种模式可以用一个比喻来理解:餐厅常常雇佣接待员负责迎接顾客,当顾客入座后,侍应生专门为这张桌子服务。
- 单 Reactor 单线程:接待员和侍应生是同一个人,全程为顾客服务。
- 单 Reactor 多线程:一个接待员、多个侍应生,接待员只负责接待。
- 主从 Reactor:多个接待员,多个侍应生。
Reactor 模式具有如下的优点:
- 响应快:不必为单个同步时间所阻塞,虽然 Reactor 本身依然是同步的。
- 编程相对简单:可以最大程度的避免复杂的多线程及同步问题,并且避免了多线程的切换开销。
- 可扩展性:可以方便的通过增加 Reactor 实例个数来充分利用 CPU 资源。
- 可复用性:Reactor 模型本身与具体事件处理逻辑无关,具有很高的复用性。
Proactor 模型
在 Reactor 模式中,Reactor 等待某个事件、可应用或操作的状态发生(比如文件描述符可读、Socket 可读写)。
然后把该事件传递给事先注册的 Handler(事件处理函数或回调函数),由后者来做实际的读写操作。
其中的读写操作都需要应用程序同步操作,所以 Reactor 是非阻塞同步网络模型。
如果把 IO 操作改为异步,即交给操作系统来完成 IO 操作,就能进一步提升性能,这就是异步网络模型 Proactor。
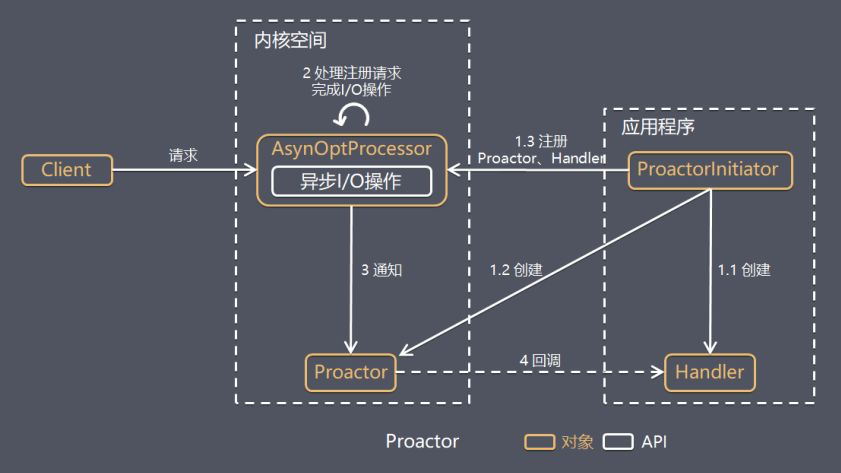
Proactor 是和异步 I/O 相关的,详细方案如下:
- ProactorInitiator 创建 Proactor 和 Handler 对象,并将 Proactor 和 Handler 都通过 AsyOptProcessor(Asynchronous Operation Processor) 注册到内核。
- AsyOptProcessor 处理注册请求,并处理 I/O 操作。
- AsyOptProcessor 完成 I/O 操作后通知 Proactor。
- Proactor 根据不同的事件类型回调不同的 Handler 进行业务处理。
- Handler 完成业务处理。
可以看出 Proactor 和 Reactor 的区别:
- Reactor 是在事件发生时就通知事先注册的事件(读写在应用程序线程中处理完成)。
- Proactor 是在事件发生时基于异步 I/O 完成读写操作(由内核完成),待 I/O 操作完成后才回调应用程序的处理器来进行业务处理。
理论上 Proactor 比 Reactor 效率更高,异步 I/O 更加充分发挥 DMA(Direct Memory Access,直接内存存取)的优势,但是有如下缺点:
- 编程复杂性:由于异步操作流程的事件的初始化和事件完成在时间和空间上都是相互分离的,因此开发异步应用程序更加复杂。应用程序还可能因为反向的流控而变得更加难以 Debug。
- 内存使用:缓冲区在读或写操作的时间段内必须保持住,可能造成持续的不确定性,并且每个并发操作都要求有独立的缓存,相比 Reactor 模式,在 Socket 已经准备好读或写前,是不要求开辟缓存的。
- 操作系统支持,Windows 下通过 IOCP 实现了真正的异步 I/O,而在 Linux 系统下,Linux 2.6 才引入,目前异步 I/O 还不完善。
因此在 Linux 下实现高并发网络编程都是以 Reactor 模型为主。
3.2 - Linux IO 零拷贝
CPU 并不执行将数据从一个存储区域拷贝到另一个存储区域这样的任务。通常用于在网络传输文件时节省 CPU 周期和内存带宽。
缓存 IO
缓存 IO 又被称为标准 IO,大多数文件系统的默认 IO 操作都是缓存 IO。在 Linux 的缓存 IO 机制中,操作系统会将 IO 的数据缓存在文件系统的页缓存(page cache)中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
缓存 IO 的缺点:数据在传输过程中需要在应用程序地址空间和内核间进行多次数据复制操作,这些数据复制所带来的 CPU 及内存开销是非常大的。
零拷贝技术分类
零拷贝技术的发展很多样化,现有的零拷贝技术种类也非常多,而当前并没有一个适合于所有场景的零拷贝技术出现。对于 Linux 来说,现有的零拷贝技术也比较多,这些零拷贝技术大部分存在于不同的 Linux 内核版本,有些旧的技术在不同的 Linux 内核版本间得到了很大的发展或者已经渐渐被新的技术所代替。
本文针对这些零拷贝技术所适用的不同场景对它们进行了划分。概括起来,Linux 中的零拷贝技术主要有下面这几种:
- 直接 I/O:对于这种数据传输方式来说,应用程序可以直接访问硬件存储,操作系统内核只是辅助数据传输:这类零拷贝技术针对的是操作系统内核并不需要对数据进行直接处理的情况,数据可以在应用程序地址空间的缓冲区和磁盘之间直接进行传输,完全不需要 Linux 操作系统内核提供的页缓存的支持。
- 在数据传输的过程中,避免数据在操作系统内核地址空间的缓冲区和用户应用程序地址空间的缓冲区之间进行拷贝。有的时候,应用程序在数据进行传输的过程中不需要对数据进行访问,那么,将数据从 Linux 的页缓存拷贝到用户进程的缓冲区中就可以完全避免,传输的数据在页缓存中就可以得到处理。在某些特殊的情况下,这种零拷贝技术可以获得较好的性能。Linux 中提供类似的系统调用主要有 mmap(),sendfile() 以及 splice()。
- 对数据在 Linux 的页缓存和用户进程的缓冲区之间的传输过程进行优化。该零拷贝技术侧重于灵活地处理数据在用户进程的缓冲区和操作系统的页缓存之间的拷贝操作。这种方法延续了传统的通信方式,但是更加灵活。在Linux 中,该方法主要利用了写时复制技术。
前两类方法的目的主要是为了避免应用程序地址空间和操作系统内核地址空间这两者之间的缓冲区拷贝操作。这两类零拷贝技术通常适用在某些特殊的情况下,比如要传送的数据不需要经过操作系统内核的处理或者不需要经过应用程序的处理。第三类方法则继承了传统的应用程序地址空间和操作系统内核地址空间之间数据传输的概念,进而针对数据传输本身进行优化。我们知道,硬件和软件之间的数据传输可以通过使用 DMA 来进行,DMA 进行数据传输的过程中几乎不需要CPU参与,这样就可以把 CPU 解放出来去做更多其他的事情,但是当数据需要在用户地址空间的缓冲区和 Linux 操作系统内核的页缓存之间进行传输的时候,并没有类似DMA 这种工具可以使用,CPU 需要全程参与到这种数据拷贝操作中,所以这第三类方法的目的是可以有效地改善数据在用户地址空间和操作系统内核地址空间之间传递的效率。
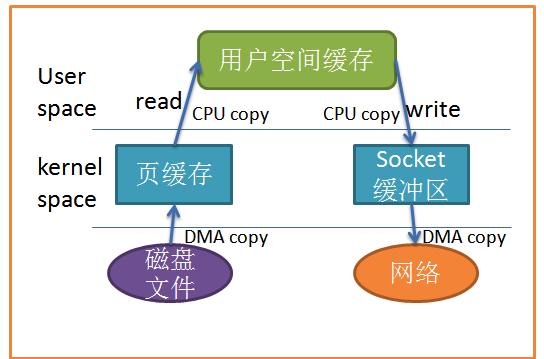
当应用程序访问某块数据时,操作系统首先会检查,是不是最近访问过此文件,文件内容是否缓存在内核缓冲区,如果是,操作系统则直接根据read系统调用提供的buf地址,将内核缓冲区的内容拷贝到buf所指定的用户空间缓冲区中去。如果不是,操作系统则首先将磁盘上的数据拷贝的内核缓冲区,这一步目前主要依靠DMA来传输,然后再把内核缓冲区上的内容拷贝到用户缓冲区中。 接下来,write系统调用再把用户缓冲区的内容拷贝到网络堆栈相关的内核缓冲区中,最后socket再把内核缓冲区的内容发送到网卡上。
从上图中可以看出,共产生了四次数据拷贝,即使使用了DMA来处理了与硬件的通讯,CPU仍然需要处理两次数据拷贝,与此同时,在用户态与内核态也发生了多次上下文切换,无疑也加重了CPU负担。
在此过程中,我们没有对文件内容做任何修改,那么在内核空间和用户空间来回拷贝数据无疑就是一种浪费,而零拷贝主要就是为了解决这种低效性。
mmap:让数据传输不需要经过user space
我们减少拷贝次数的一种方法是调用mmap()来代替read调用:
buf = mmap(diskfd, len);
write(sockfd, buf, len);
应用程序调用 mmap(),磁盘上的数据会通过 DMA被拷贝的内核缓冲区,接着操作系统会把这段内核缓冲区与应用程序共享,这样就不需要把内核缓冲区的内容往用户空间拷贝。应用程序再调用 write(),操作系统直接将内核缓冲区的内容拷贝到 socket缓冲区中,这一切都发生在内核态,最后, socket缓冲区再把数据发到网卡去。
如下图:
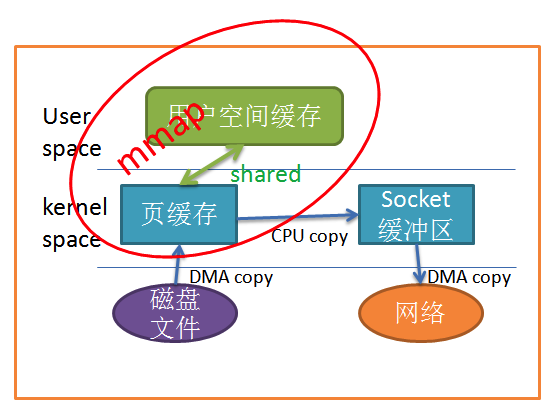
使用mmap替代read很明显减少了一次拷贝,当拷贝数据量很大时,无疑提升了效率。但是使用 mmap是有代价的。当你使用 mmap时,你可能会遇到一些隐藏的陷阱。例如,当你的程序 map了一个文件,但是当这个文件被另一个进程截断(truncate)时, write系统调用会因为访问非法地址而被 SIGBUS信号终止。 SIGBUS信号默认会杀死你的进程并产生一个 coredump,如果你的服务器这样被中止了,那会产生一笔损失。
通常我们使用以下解决方案避免这种问题:
- 为SIGBUS信号建立信号处理程序:当遇到 SIGBUS信号时,信号处理程序简单地返回, write系统调用在被中断之前会返回已经写入的字节数,并且 errno会被设置成success,但是这是一种糟糕的处理办法,因为你并没有解决问题的实质核心。
- 使用文件租借锁:通常我们使用这种方法,在文件描述符上使用租借锁,我们为文件向内核申请一个租借锁,当其它进程想要截断这个文件时,内核会向我们发送一个实时的 RT_SIGNAL_LEASE信号,告诉我们内核正在破坏你加持在文件上的读写锁。这样在程序访问非法内存并且被 SIGBUS杀死之前,你的 write系统调用会被中断。 write会返回已经写入的字节数,并且置 errno为success。 我们应该在 mmap文件之前加锁,并且在操作完文件后解锁:
if(fcntl(diskfd, F_SETSIG, RT_SIGNAL_LEASE) == -1){
perror("kernel lease set signal");
return -1;
}
/* l_type can be F_RDLCK_F_WRLCK 加锁 */
/* l_type can be F_UNLCK 解锁 */
if(fcntl(diskfd, F_SETLEASE, l_type)){
perror("kernel lease set_type");
return -1;
}
Reference
3.3 - Netty IO 模型
本文基于Netty4.1展开介绍相关理论模型,使用场景,基本组件、整体架构,知其然且知其所以然,希望给大家在实际开发实践、学习开源项目提供参考。
简介
Netty是 一个异步事件驱动的网络应用程序框架,用于快速开发可维护的高性能协议服务器和客户端。
JDK原生NIO程序的问题
JDK原生也有一套网络应用程序API,但是存在一系列问题,主要如下:
- NIO的类库和API繁杂,使用麻烦,你需要熟练掌握Selector、ServerSocketChannel、SocketChannel、ByteBuffer等
- 需要具备其它的额外技能做铺垫,例如熟悉Java多线程编程,因为NIO编程涉及到Reactor模式,你必须对多线程和网路编程非常熟悉,才能编写出高质量的NIO程序
- 可靠性能力补齐,开发工作量和难度都非常大。例如客户端面临断连重连、网络闪断、半包读写、失败缓存、网络拥塞和异常码流的处理等等,NIO编程的特点是功能开发相对容易,但是可靠性能力补齐工作量和难度都非常大
- JDK NIO的BUG,例如臭名昭著的epoll bug,它会导致Selector空轮询,最终导致CPU 100%。官方声称在JDK1.6版本的update18修复了该问题,但是直到JDK1.7版本该问题仍旧存在,只不过该bug发生概率降低了一些而已,它并没有被根本解决
Netty 的特点
Netty对JDK自带的NIO的API进行封装,解决上述问题,主要特点有:
- 设计优雅
- 适用于各种传输类型的统一API - 阻塞和非阻塞Socket
- 基于灵活且可扩展的事件模型,可以清晰地分离关注点
- 高度可定制的线程模型 - 单线程,一个或多个线程池
- 真正的无连接数据报套接字支持(自3.1起)
- 使用方便
- 详细记录的Javadoc,用户指南和示例
- 没有其他依赖项,JDK 5(Netty 3.x)或6(Netty 4.x)就足够了
- 高性能
- 吞吐量更高,延迟更低
- 减少资源消耗
- 最小化不必要的内存复制
- 安全
- 完整的SSL / TLS和StartTLS支持
- 社区活跃,不断更新
- 社区活跃,版本迭代周期短,发现的BUG可以被及时修复,同时,更多的新功能会被加入
Netty常见使用场景
Netty常见的使用场景如下:
- 互联网行业
- 在分布式系统中,各个节点之间需要远程服务调用,高性能的RPC框架必不可少,Netty作为异步高新能的通信框架,往往作为基础通信组件被这些RPC框架使用。
- 典型的应用有:阿里分布式服务框架Dubbo的RPC框架使用Dubbo协议进行节点间通信,Dubbo协议默认使用Netty作为基础通信组件,用于实现各进程节点之间的内部通信。
- 游戏行业
- 无论是手游服务端还是大型的网络游戏,Java语言得到了越来越广泛的应用。Netty作为高性能的基础通信组件,它本身提供了TCP/UDP和HTTP协议栈。
- 非常方便定制和开发私有协议栈,账号登录服务器,地图服务器之间可以方便的通过Netty进行高性能的通信
- 大数据领域
- 经典的Hadoop的高性能通信和序列化组件Avro的RPC框架,默认采用Netty进行跨界点通信,它的Netty Service基于Netty框架二次封装实现
Netty 的高性能设计
Netty作为异步事件驱动的网络,高性能之处主要来自于其I/O模型和线程处理模型,前者决定如何收发数据,后者决定如何处理数据。
IO 模型
用什么样的通道将数据发送给对方,BIO、NIO或者AIO,I/O模型在很大程度上决定了框架的性能
阻塞 IO
传统阻塞型I/O(BIO)可以用下图表示:
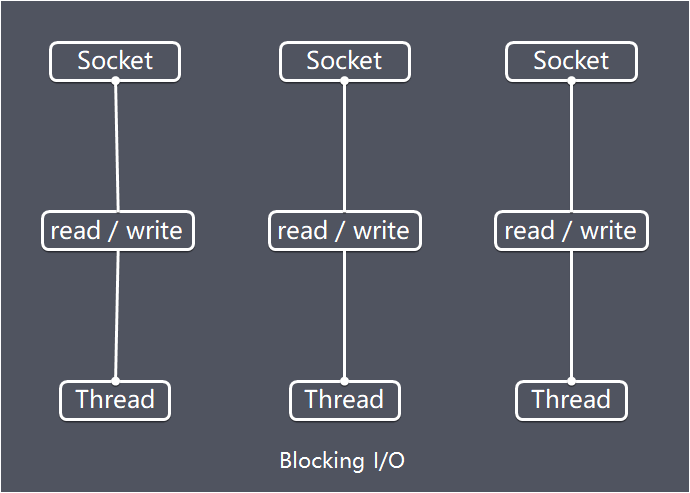
特点:
- 每个请求都需要独立的线程完成数据read,业务处理,数据write的完整操作
问题:
- 当并发数较大时,需要创建大量线程来处理连接,系统资源占用较大
- 连接建立后,如果当前线程暂时没有数据可读,则线程就阻塞在read操作上,造成线程资源浪费
IO 复用模型
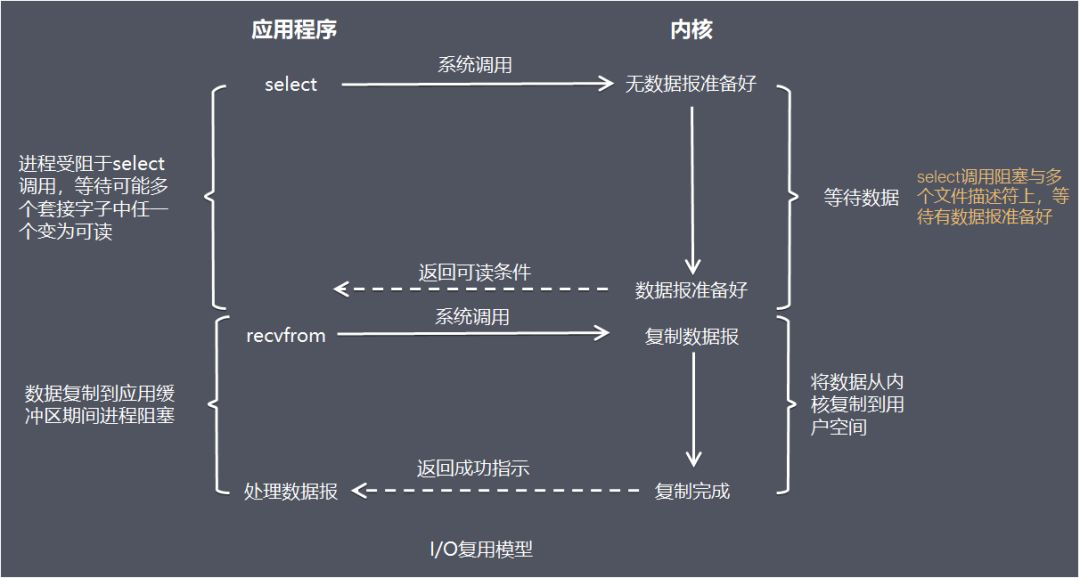
在I/O复用模型中,会用到select,这个函数也会使进程阻塞,但是和阻塞I/O所不同的的,这两个函数可以同时阻塞多个I/O操作,而且可以同时对多个读操作,多个写操作的I/O函数进行检测,直到有数据可读或可写时,才真正调用I/O操作函数。
Netty的非阻塞I/O的实现关键是基于I/O复用模型,这里用Selector对象表示:
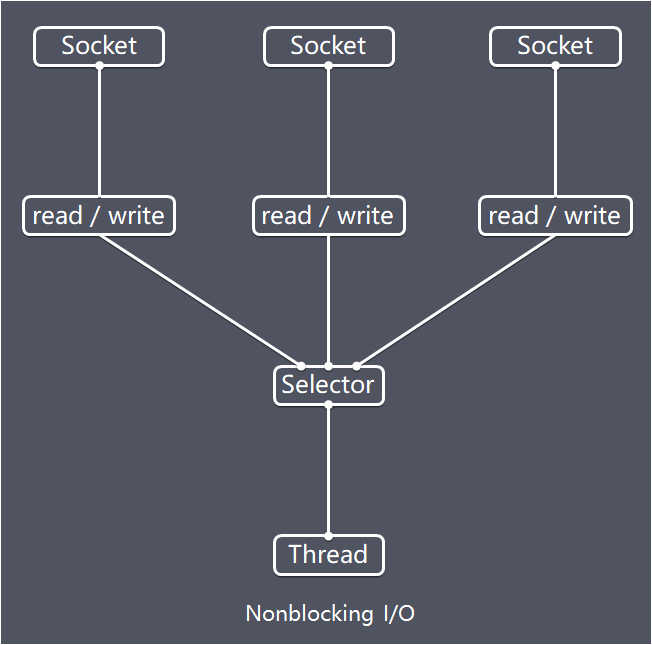
Netty的IO线程NioEventLoop由于聚合了多路复用器Selector,可以同时并发处理成百上千个客户端连接。当线程从某客户端Socket通道进行读写数据时,若没有数据可用时,该线程可以进行其他任务。线程通常将非阻塞 IO 的空闲时间用于在其他通道上执行 IO 操作,所以单独的线程可以管理多个输入和输出通道。
由于读写操作都是非阻塞的,这就可以充分提升IO线程的运行效率,避免由于频繁I/O阻塞导致的线程挂起,一个I/O线程可以并发处理N个客户端连接和读写操作,这从根本上解决了传统同步阻塞I/O一连接一线程模型,架构的性能、弹性伸缩能力和可靠性都得到了极大的提升。
基于 Buffer
传统的I/O是面向字节流或字符流的,以流式的方式顺序地从一个Stream 中读取一个或多个字节, 因此也就不能随意改变读取指针的位置。
在NIO中, 抛弃了传统的 I/O流, 而是引入了Channel和Buffer的概念. 在NIO中, 只能从Channel中读取数据到Buffer中或将数据 Buffer 中写入到 Channel。
基于buffer操作不像传统IO的顺序操作, NIO 中可以随意地读取任意位置的数据。
线程模型
数据报如何读取?读取之后的编解码在哪个线程进行,编解码后的消息如何派发,线程模型的不同,对性能的影响也非常大。
事件驱动模型
通常,我们设计一个事件处理模型的程序有两种思路
- 轮询方式
- 线程不断轮询访问相关事件发生源有没有发生事件,有发生事件就调用事件处理逻辑。
- 事件驱动方式
- 发生事件,主线程把事件放入事件队列,在另外线程不断循环消费事件列表中的事件,调用事件对应的处理逻辑处理事件。事件驱动方式也被称为消息通知方式,其实是设计模式中观察者模式的思路。
以GUI的逻辑处理为例,说明两种逻辑的不同:
- 轮询方式
- 线程不断轮询是否发生按钮点击事件,如果发生,调用处理逻辑
- 事件驱动方式
- 发生点击事件把事件放入事件队列,在另外线程消费的事件列表中的事件,根据事件类型调用相关事件处理逻辑
这里借用O’Reilly 大神关于事件驱动模型解释图
主要包括4个基本组件:
- 事件队列(event queue):接收事件的入口,存储待处理事件
- 分发器(event mediator):将不同的事件分发到不同的业务逻辑单元
- 事件通道(event channel):分发器与处理器之间的联系渠道
- 事件处理器(event processor):实现业务逻辑,处理完成后会发出事件,触发下一步操作
可以看出,相对传统轮询模式,事件驱动有如下优点:
- 可扩展性好,分布式的异步架构,事件处理器之间高度解耦,可以方便扩展事件处理逻辑
- 高性能,基于队列暂存事件,能方便并行异步处理事件
Reactor 线程模型
Reactor是反应堆的意思,Reactor模型,是指通过一个或多个输入同时传递给服务处理器的服务请求的事件驱动处理模式。 服务端程序处理传入多路请求,并将它们同步分派给请求对应的处理线程,Reactor模式也叫Dispatcher模式,即I/O多了复用统一监听事件,收到事件后分发(Dispatch给某进程),是编写高性能网络服务器的必备技术之一。
Reactor模型中有2个关键组成:
- Reactor
- Reactor在一个单独的线程中运行,负责监听和分发事件,分发给适当的处理程序来对IO事件做出反应。 它就像公司的电话接线员,它接听来自客户的电话并将线路转移到适当的联系人
- Handlers
- 处理程序执行I/O事件要完成的实际事件,类似于客户想要与之交谈的公司中的实际官员。Reactor通过调度适当的处理程序来响应I/O事件,处理程序执行非阻塞操作

取决于Reactor的数量和Hanndler线程数量的不同,Reactor模型有3个变种
- 单Reactor单线程
- 单Reactor多线程
- 主从Reactor多线程
可以这样理解,Reactor就是一个执行while (true) { selector.select(); …}循环的线程,会源源不断的产生新的事件,称作反应堆很贴切。
Netty 线程模型
Netty主要基于主从Reactors多线程模型(如下图)做了一定的修改,其中主从Reactor多线程模型有多个Reactor:MainReactor和SubReactor:
- MainReactor负责客户端的连接请求,并将请求转交给SubReactor
- SubReactor负责相应通道的IO读写请求
- 非IO请求(具体逻辑处理)的任务则会直接写入队列,等待worker threads进行处理
这里引用Doug Lee大神的Reactor介绍:Scalable IO in Java里面关于主从Reactor多线程模型的图
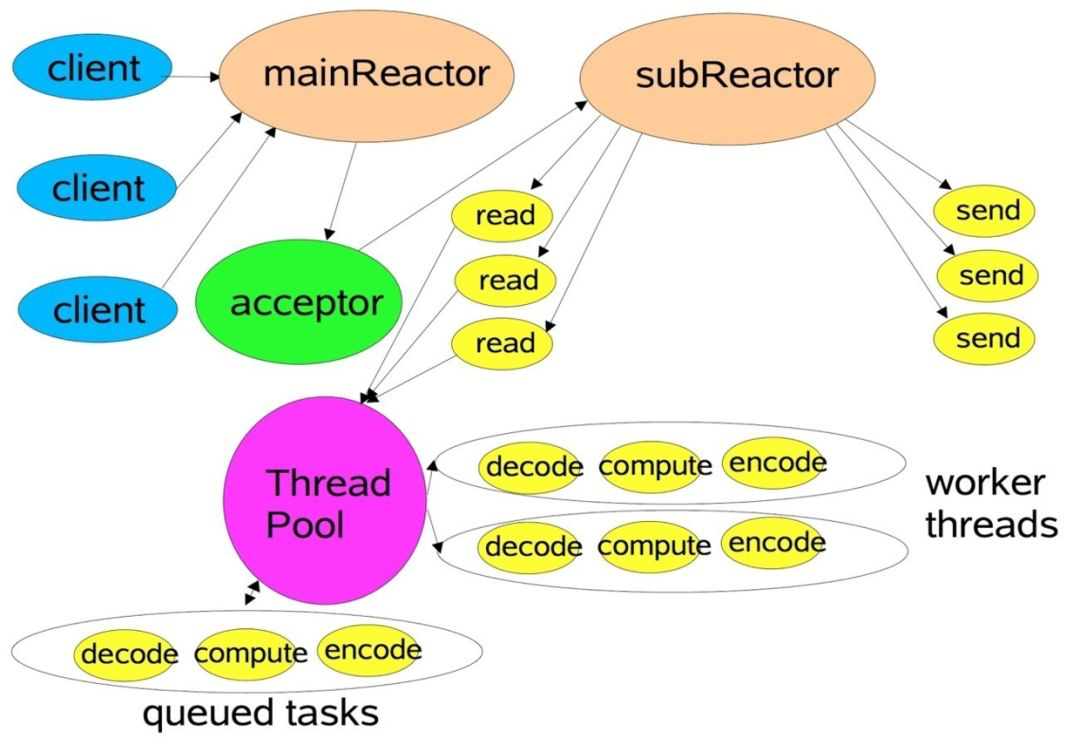
特别说明的是: 虽然Netty的线程模型基于主从Reactor多线程,借用了MainReactor和SubReactor的结构,但是实际实现上,SubReactor和Worker线程在同一个线程池中:
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
ServerBootstrap server = new ServerBootstrap();
server.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
上面代码中的bossGroup 和workerGroup是Bootstrap构造方法中传入的两个对象,这两个group均是线程池
- bossGroup线程池则只是在bind某个端口后,获得其中一个线程作为MainReactor,专门处理端口的accept事件,每个端口对应一个boss线程
- workerGroup线程池会被各个SubReactor和worker线程充分利用
异步处理
异步的概念和同步相对。当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。
Netty中的I/O操作是异步的,包括bind、write、connect等操作会简单的返回一个ChannelFuture,调用者并不能立刻获得结果,通过Future-Listener机制,用户可以方便的主动获取或者通过通知机制获得IO操作结果。
当future对象刚刚创建时,处于非完成状态,调用者可以通过返回的ChannelFuture来获取操作执行的状态,注册监听函数来执行完成后的操,常见有如下操作:
- 通过isDone方法来判断当前操作是否完成
- 通过isSuccess方法来判断已完成的当前操作是否成功
- 通过getCause方法来获取已完成的当前操作失败的原因
- 通过isCancelled方法来判断已完成的当前操作是否被取消
- 通过addListener方法来注册监听器,当操作已完成(isDone方法返回完成),将会通知指定的监听器;如果future对象已完成,则理解通知指定的监听器
例如下面的的代码中绑定端口是异步操作,当绑定操作处理完,将会调用相应的监听器处理逻辑
serverBootstrap.bind(port).addListener(future -> {
if (future.isSuccess()) {
System.out.println(new Date() + ": 端口[" + port + "]绑定成功!");
} else {
System.err.println("端口[" + port + "]绑定失败!");
}
});
相比传统阻塞I/O,执行I/O操作后线程会被阻塞住, 直到操作完成;异步处理的好处是不会造成线程阻塞,线程在I/O操作期间可以执行别的程序,在高并发情形下会更稳定和更高的吞吐量。
Netty 的架构设计
功能特性

模块组件
Bootstrap、ServerBootstrap
Bootstrap意思是引导,一个Netty应用通常由一个Bootstrap开始,主要作用是配置整个Netty程序,串联各个组件,Netty中Bootstrap类是客户端程序的启动引导类,ServerBootstrap是服务端启动引导类。
Future、ChannelFuture
正如前面介绍,在Netty中所有的IO操作都是异步的,不能立刻得知消息是否被正确处理,但是可以过一会等它执行完成或者直接注册一个监听,具体的实现就是通过Future和ChannelFutures,他们可以注册一个监听,当操作执行成功或失败时监听会自动触发注册的监听事件。
Channel
Netty网络通信的组件,能够用于执行网络I/O操作。
Channel为用户提供:
当前网络连接的通道的状态(例如是否打开?是否已连接?)
网络连接的配置参数 (例如接收缓冲区大小)
提供异步的网络I/O操作(如建立连接,读写,绑定端口),异步调用意味着任何I / O调用都将立即返回,并且不保证在调用结束时所请求的I / O操作已完成。调用立即返回一个ChannelFuture实例,通过注册监听器到ChannelFuture上,可以I / O操作成功、失败或取消时回调通知调用方。
支持关联I/O操作与对应的处理程序
不同协议、不同的阻塞类型的连接都有不同的 Channel 类型与之对应,下面是一些常用的 Channel 类型
NioSocketChannel,异步的客户端 TCP Socket 连接
NioServerSocketChannel,异步的服务器端 TCP Socket 连接
NioDatagramChannel,异步的 UDP 连接
NioSctpChannel,异步的客户端 Sctp 连接
NioSctpServerChannel,异步的 Sctp 服务器端连接
这些通道涵盖了 UDP 和 TCP网络 IO以及文件 IO.
Selector
Netty基于Selector对象实现I/O多路复用,通过 Selector, 一个线程可以监听多个连接的Channel事件, 当向一个Selector中注册Channel 后,Selector 内部的机制就可以自动不断地查询(select) 这些注册的Channel是否有已就绪的I/O事件(例如可读, 可写, 网络连接完成等),这样程序就可以很简单地使用一个线程高效地管理多个 Channel 。
NioEventLoop
NioEventLoop中维护了一个线程和任务队列,支持异步提交执行任务,线程启动时会调用NioEventLoop的run方法,执行I/O任务和非I/O任务:
- I/O任务 即selectionKey中ready的事件,如accept、connect、read、write等,由processSelectedKeys方法触发。
- 非IO任务 添加到taskQueue中的任务,如register0、bind0等任务,由runAllTasks方法触发。
两种任务的执行时间比由变量ioRatio控制,默认为50,则表示允许非IO任务执行的时间与IO任务的执行时间相等。
NioEventLoopGroup
NioEventLoopGroup,主要管理eventLoop的生命周期,可以理解为一个线程池,内部维护了一组线程,每个线程(NioEventLoop)负责处理多个Channel上的事件,而一个Channel只对应于一个线程。
ChannelHandler
ChannelHandler是一个接口,处理I / O事件或拦截I / O操作,并将其转发到其ChannelPipeline(业务处理链)中的下一个处理程序。
ChannelHandler本身并没有提供很多方法,因为这个接口有许多的方法需要实现,方便使用期间,可以继承它的子类:
- ChannelInboundHandler用于处理入站I / O事件
- ChannelOutboundHandler用于处理出站I / O操作
或者使用以下适配器类:
ChannelInboundHandlerAdapter用于处理入站I / O事件
ChannelOutboundHandlerAdapter用于处理出站I / O操作
ChannelDuplexHandler用于处理入站和出站事件
ChannelHandlerContext
保存Channel相关的所有上下文信息,同时关联一个ChannelHandler对象
ChannelPipline
保存ChannelHandler的List,用于处理或拦截Channel的入站事件和出站操作。 ChannelPipeline实现了一种高级形式的拦截过滤器模式,使用户可以完全控制事件的处理方式,以及Channel中各个的ChannelHandler如何相互交互。
下图引用Netty的Javadoc4.1中ChannelPipline的说明,描述了ChannelPipeline中ChannelHandler通常如何处理I/O事件。 I/O事件由ChannelInboundHandler或ChannelOutboundHandler处理,并通过调用ChannelHandlerContext中定义的事件传播方法(例如ChannelHandlerContext.fireChannelRead(Object)和ChannelOutboundInvoker.write(Object))转发到其最近的处理程序。

入站事件由自下而上方向的入站处理程序处理,如图左侧所示。 入站Handler处理程序通常处理由图底部的I / O线程生成的入站数据。 通常通过实际输入操作(例如SocketChannel.read(ByteBuffer))从远程读取入站数据。
出站事件由上下方向处理,如图右侧所示。 出站Handler处理程序通常会生成或转换出站传输,例如write请求。 I/O线程通常执行实际的输出操作,例如SocketChannel.write(ByteBuffer)。
在 Netty 中每个 Channel 都有且仅有一个 ChannelPipeline 与之对应, 它们的组成关系如下:
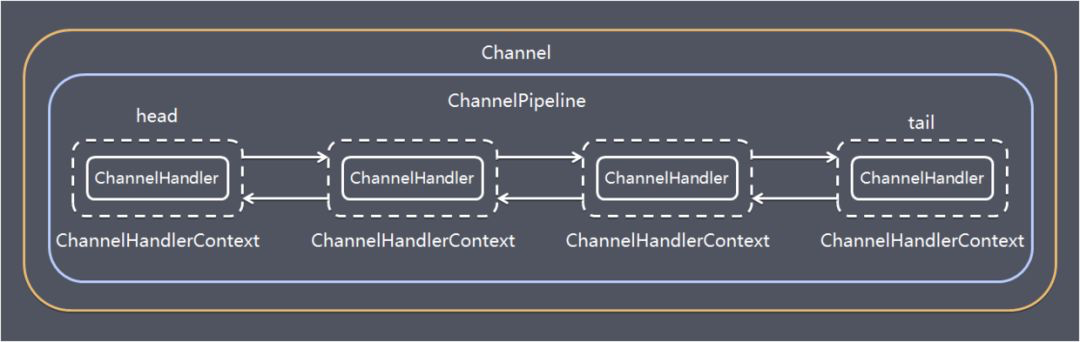
一个 Channel 包含了一个 ChannelPipeline, 而 ChannelPipeline 中又维护了一个由 ChannelHandlerContext 组成的双向链表, 并且每个 ChannelHandlerContext 中又关联着一个 ChannelHandler。入站事件和出站事件在一个双向链表中,入站事件会从链表head往后传递到最后一个入站的handler,出站事件会从链表tail往前传递到最前一个出站的handler,两种类型的handler互不干扰。
Netty 工作流程
初始化并启动Netty服务端过程如下:
public static void main(String[] args) {
// 创建mainReactor
NioEventLoopGroup boosGroup = new NioEventLoopGroup();
// 创建工作线程组
NioEventLoopGroup workerGroup = new NioEventLoopGroup();
final ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap
// 组装NioEventLoopGroup
.group(boosGroup, workerGroup)
// 设置channel类型为NIO类型
.channel(NioServerSocketChannel.class)
// 设置连接配置参数
.option(ChannelOption.SO_BACKLOG, 1024)
.childOption(ChannelOption.SO_KEEPALIVE, true)
.childOption(ChannelOption.TCP_NODELAY, true)
// 配置入站、出站事件handler
.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) {
// 配置入站、出站事件channel
ch.pipeline().addLast(...);
ch.pipeline().addLast(...);
}
});
// 绑定端口
int port = 8080;
serverBootstrap.bind(port).addListener(future -> {
if (future.isSuccess()) {
System.out.println(new Date() + ": 端口[" + port + "]绑定成功!");
} else {
System.err.println("端口[" + port + "]绑定失败!");
}
});
}
基本过程如下:
初始化创建2个NioEventLoopGroup,其中boosGroup用于Accetpt连接建立事件并分发请求, workerGroup用于处理I/O读写事件和业务逻辑
基于ServerBootstrap(服务端启动引导类),配置EventLoopGroup、Channel类型,连接参数、配置入站、出站事件handler
绑定端口,开始工作
结合上面的介绍的Netty Reactor模型,介绍服务端Netty的工作架构图:
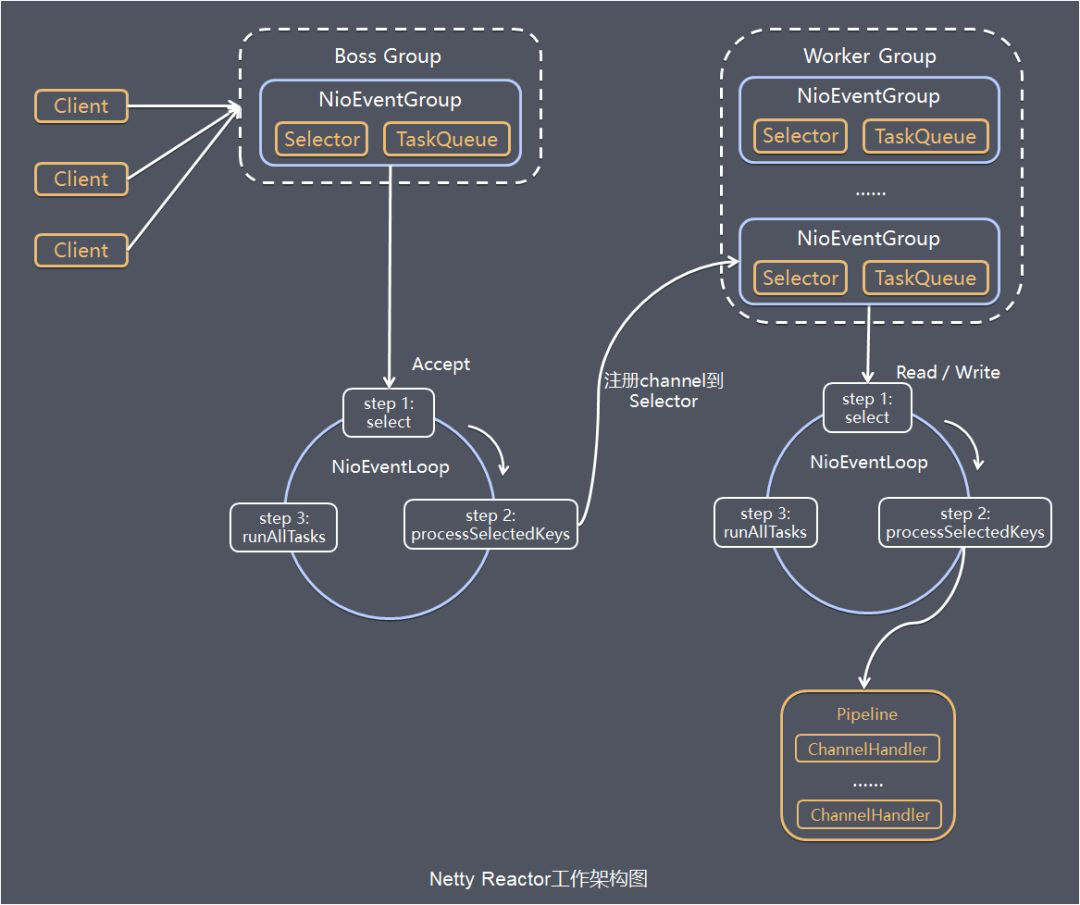
server端包含1个Boss NioEventLoopGroup和1个Worker NioEventLoopGroup,NioEventLoopGroup相当于1个事件循环组,这个组里包含多个事件循环NioEventLoop,每个NioEventLoop包含1个selector和1个事件循环线程。
每个Boss NioEventLoop循环执行的任务包含3步:
- 1 轮询accept事件
- 2 处理accept I/O事件,与Client建立连接,生成NioSocketChannel,并将NioSocketChannel注册到某个Worker NioEventLoop的Selector上 *3 处理任务队列中的任务,runAllTasks。任务队列中的任务包括用户调用eventloop.execute或schedule执行的任务,或者其它线程提交到该eventloop的任务。
每个Worker NioEventLoop循环执行的任务包含3步:
- 1 轮询read、write事件;
- 2 处I/O事件,即read、write事件,在NioSocketChannel可读、可写事件发生时进行处理
- 3 处理任务队列中的任务,runAllTasks。
其中任务队列中的task有3种典型使用场景
1 用户程序自定义的普通任务
ctx.channel().eventLoop().execute(new Runnable() { @Override public void run() { //... } });2 非当前reactor线程调用channel的各种方法 例如在推送系统的业务线程里面,根据用户的标识,找到对应的channel引用,然后调用write类方法向该用户推送消息,就会进入到这种场景。最终的write会提交到任务队列中后被异步消费。
3 用户自定义定时任务
ctx.channel().eventLoop().schedule(new Runnable() { @Override public void run() { } }, 60, TimeUnit.SECONDS);
总结
现在稳定推荐使用的主流版本还是Netty4,Netty5 中使用了 ForkJoinPool,增加了代码的复杂度,但是对性能的改善却不明显,所以这个版本不推荐使用,官网也没有提供下载链接。
Netty 入门门槛相对较高,其实是因为这方面的资料较少,并不是因为他有多难,大家其实都可以像搞透 Spring 一样搞透 Netty。在学习之前,建议先理解透整个框架原理结构,运行过程,可以少走很多弯路。
3.4 - Redis IO 模型
Redis 是一个事件驱动的内存数据库,服务器需要处理两种类型的事件。
- 文件事件
- 时间事件
文件事件(FileEvent)
Redis 服务器通过 socket 实现与客户端(或其他redis服务器)的交互,文件事件就是服务器对 socket 操作的抽象。 Redis 服务器,通过监听这些 socket 产生的文件事件并处理这些事件,实现对客户端调用的响应。
Reactor
Redis 基于 Reactor 模式开发了自己的事件处理器。
这里就先展开讲一讲 Reactor 模式。看下图:
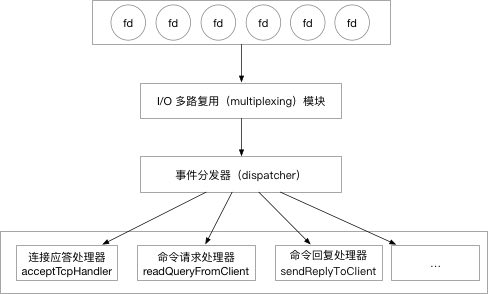
“I/O 多路复用模块”会监听多个 FD ,当这些FD产生,accept,read,write 或 close 的文件事件。会向“文件事件分发器(dispatcher)”传送事件。
文件事件分发器(dispatcher)在收到事件之后,会根据事件的类型将事件分发给对应的 handler。
我们顺着图,从上到下的逐一讲解 Redis 是怎么实现这个 Reactor 模型的。
I/O 多路复用模块
Redis 的 I/O 多路复用模块,其实是封装了操作系统提供的 select,epoll,avport 和 kqueue 这些基础函数。向上层提供了一个统一的接口,屏蔽了底层实现的细节。
| 操作系统 | I/O多路复用 |
|---|---|
| Solaris | avport |
| LINUX | epoll |
| Mac | kqueue |
| Other | select |
下面以Linux epoll为例,看看使用 Redis 是怎么利用 linux 提供的 epoll 实现I/O 多路复用。
Redis 对文件事件,封装epoll向上提供的接口:
/*
* 事件状态
*/
typedef struct aeApiState {
// epoll_event 实例描述符
int epfd;
// 事件槽
struct epoll_event *events;
} aeApiState;
/*
* 创建一个新的 epoll
*/
static int aeApiCreate(aeEventLoop *eventLoop)
/*
* 调整事件slot的大小
*/
static int aeApiResize(aeEventLoop *eventLoop, int setsize)
/*
* 释放epoll实例和事件slot
*/
static void aeApiFree(aeEventLoop *eventLoop)
/*
* 关联给定事件到fd
*/
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask)
/*
* 从fd中删除给定事件
*/
static void aeApiDelEvent(aeEventLoop *eventLoop, int fd, int mask)
/*
* 获取可执行事件
*/
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp)
所以看看这个ae_peoll.c 如何对 epoll 进行封装的:
aeApiCreate()是对epoll.epoll_create()的封装。aeApiAddEvent()和aeApiDelEvent()是对epoll.epoll_ctl()的封装。aeApiPoll()是对epoll_wait()的封装。
这样 Redis 的利用 epoll 实现的 I/O 复用器就比较清晰了。
再往上一层次我们需要看看 ae.c 是怎么封装的?
首先需要关注的是事件处理器的数据结构:
typedef struct aeFileEvent {
// 监听事件类型掩码,
// 值可以是 AE_READABLE 或 AE_WRITABLE ,
// 或者 AE_READABLE | AE_WRITABLE
int mask; /* one of AE_(READABLE|WRITABLE) */
// 读事件处理器
aeFileProc *rfileProc;
// 写事件处理器
aeFileProc *wfileProc;
// 多路复用库的私有数据
void *clientData;
} aeFileEvent;
mask 就是可以理解为事件的类型。
除了使用 ae_epoll.c 提供的方法外, ae.c 还增加 “增删查” 的几个 API。
- 增:
aeCreateFileEvent - 删:
aeDeleteFileEvent - 查: 查包括两个维度
aeGetFileEvents获取某个 fd 的监听类型和aeWait等待某个fd 直到超时或者达到某个状态。
事件分发器(dispatcher)
Redis 的事件分发器 ae.c/aeProcessEvents 不但处理文件事件还处理时间事件,所以这里只贴与文件分发相关的出部分代码,dispather 根据 mask 调用不同的事件处理器。
//从 epoll 中获关注的事件
numevents = aeApiPoll(eventLoop, tvp);
for (j = 0; j < numevents; j++) {
// 从已就绪数组中获取事件
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
int mask = eventLoop->fired[j].mask;
int fd = eventLoop->fired[j].fd;
int rfired = 0;
// 读事件
if (fe->mask & mask & AE_READABLE) {
// rfired 确保读/写事件只能执行其中一个
rfired = 1;
fe->rfileProc(eventLoop,fd,fe->clientData,mask);
}
// 写事件
if (fe->mask & mask & AE_WRITABLE) {
if (!rfired || fe->wfileProc != fe->rfileProc)
fe->wfileProc(eventLoop,fd,fe->clientData,mask);
}
processed++;
}
可以看到这个分发器,根据 mask 的不同将事件分别分发给了读事件和写事件。
文件事件处理器的类型
Redis 有大量的事件处理器类型,我们就讲解处理一个简单命令涉及到的3个处理器:
- acceptTcpHandler 连接应答处理器,负责处理连接相关的事件,当有client 连接到Redis的时候们就会产生 AE_READABLE 事件。引发它执行。
- readQueryFromClient 命令请求处理器,负责读取通过 sokect 发送来的命令。
- sendReplyToClient 命令回复处理器,当Redis处理完命令,就会产生 AE_WRITEABLE 事件,将数据回复给 client。
文件事件实现总结
我们按照开始给出的 Reactor 模型,从上到下讲解了文件事件处理器的实现,下面将会介绍时间时间的实现。
时间事件(TimeEvent)
Reids 有很多操作需要在给定的时间点进行处理,时间事件就是对这类定时任务的抽象。
先看时间事件的数据结构:
/* Time event structure
*
* 时间事件结构
*/
typedef struct aeTimeEvent {
// 时间事件的唯一标识符
long long id; /* time event identifier. */
// 事件的到达时间
long when_sec; /* seconds */
long when_ms; /* milliseconds */
// 事件处理函数
aeTimeProc *timeProc;
// 事件释放函数
aeEventFinalizerProc *finalizerProc;
// 多路复用库的私有数据
void *clientData;
// 指向下个时间事件结构,形成链表
struct aeTimeEvent *next;
} aeTimeEvent;
看见 next 我们就知道这个 aeTimeEvent 是一个链表结构。看图:
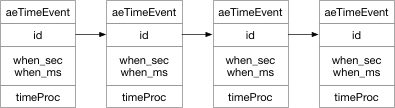
注意这是一个按照id倒序排列的链表,并没有按照事件顺序排序。
processTimeEvent
Redis 使用这个函数处理所有的时间事件,我们整理一下执行思路:
- 记录最新一次执行这个函数的时间,用于处理系统时间被修改产生的问题。
- 遍历链表找出所有 when_sec 和 when_ms 小于现在时间的事件。
- 执行事件对应的处理函数。
- 检查事件类型,如果是周期事件则刷新该事件下一次的执行事件。
- 否则从列表中删除事件。
综合调度器(aeProcessEvents)
综合调度器是 Redis 统一处理所有事件的地方。我们梳理一下这个函数的简单逻辑:
// 1. 获取离当前时间最近的时间事件
shortest = aeSearchNearestTimer(eventLoop);
// 2. 获取间隔时间
timeval = shortest - nowTime;
// 如果timeval 小于 0,说明已经有需要执行的时间事件了。
if(timeval < 0){
timeval = 0
}
// 3. 在 timeval 时间内,取出文件事件。
numevents = aeApiPoll(eventLoop, timeval);
// 4.根据文件事件的类型指定不同的文件处理器
if (AE_READABLE) {
// 读事件
rfileProc(eventLoop,fd,fe->clientData,mask);
}
// 写事件
if (AE_WRITABLE) {
wfileProc(eventLoop,fd,fe->clientData,mask);
}
以上的伪代码就是整个 Redis 事件处理器的逻辑。
我们可以再看看谁执行了这个 aeProcessEvents:
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
// 如果有需要在事件处理前执行的函数,那么运行它
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
// 开始处理事件
aeProcessEvents(eventLoop, AE_ALL_EVENTS);
}
}
然后我们再看看是谁调用了 aeMain:
int main(int argc, char **argv) {
//一些配置和准备
...
aeMain(server.el);
//结束后的回收工作
...
}
我们在 Redis 的 main 方法中找个了它。
这个时候我们整理出的思路就是:
- Redis 的 main() 方法执行了一些配置和准备以后就调用
aeMain()方法。 eaMain()while(true) 的调用aeProcessEvents()。
所以我们说 Redis 是一个事件驱动的程序,期间我们发现,Redis 没有 fork 过任何线程。所以也可以说 Redis 是一个基于事件驱动的单线程应用。
3.5 - Nginx IO 模型
Nginx以其高性能,稳定性,丰富的功能,简单的配置和低资源消耗而闻名。本文从底层原理分析Nginx为什么这么快!
进程模型
Nginx 服务器在运行过程中:
- 多进程:一个 Master 进程、多个 Worker 进程。
- Master进程:管理 Worker 进程。
- 对外接口:接收外部的操作(信号);
- 对内转发:根据外部的操作的不同,通过信号管理 Worker;
- 监控:监控 Worker 进程的运行状态,Worker 进程异常终止后,自动重启 Worker 进程。
- Worker进程:所有 Worker 进程都是平等的。
- 处理网络请求,由Worker进程处理。
- Worker进程数量:在nginx.conf中配置,一般设置为核心数,充分利用 CPU 资源。
- 同时,避免进程数量过多,避免进程竞争 CPU 资源,增加上下文切换的损耗。
思考
- 请求是连接到 Nginx,Master 进程负责处理和转发?
- 如何选定哪个 Worker 进程处理请求?请求的处理结果,是否还要经过 Master 进程?
请求处理过程
HTTP 连接建立和请求处理过程如下:
- Nginx 启动时,Master 进程,加载配置文件。
- Master 进程,初始化监听的 Socket。
- Master 进程,Fork 出多个 Worker 进程。
- Worker 进程,竞争新的连接,获胜方通过三次握手,建立 Socket 连接,并处理请求。
高性能高并发
Nginx 为什么拥有高性能并且能够支撑高并发?
- Nginx采用多进程+异步非阻塞方式(IO 多路复用 Epoll)。
- 请求的完整过程:建立连接→读取请求→解析请求→处理请求→响应请求。
- 请求的完整过程对应到底层就是:读写Socket事件。
事件处理模型
Request:Nginx中HTTP请求。
基本的HTTP Web Server工作模式:
- 接收请求:逐行读取请求行和请求头,判断段有请求体后,读取请求体。
- 处理请求:获取对应的资源
- 返回响应:根据处理结果,生成相应的 HTTP 请求(响应行、响应头、响应体)。
Nginx也是这个套路,整体流程一致:
模块化体系结构
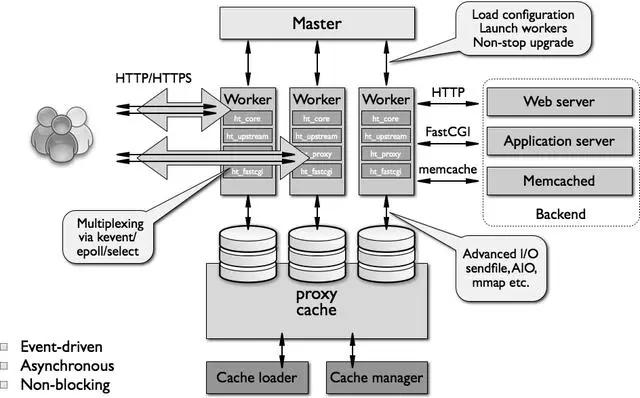
Nginx的模块根据其功能基本上可以分为以下几种类型:
- event module:
- 搭建了独立于操作系统的事件处理机制的框架,及提供了各具体事件的处理。包括 ngx_events_module,ngx_event_core_module 和 ngx_epoll_module 等。
- Nginx 具体使用何种事件处理模块,这依赖于具体的操作系统和编译选项。
- phase handler:
- 此类型的模块也被直接称为 handler 模块。主要负责处理客户端请求并产生待响应内容,比如 ngx_http_static_module 模块,负责客户端的静态页面请求处理并将对应的磁盘文件准备为响应内容输出。
- output filter:
- 也称为 filter 模块,主要是负责对输出的内容进行处理,可以对输出进行修改。
- 例如: 可以实现对输出的所有 html 页面增加预定义的 footbar 一类的工作,或者对输出的图片的 URL 进行替换之类的工作。
- upstream:
- upstream 模块实现反向代理的功能,将真正的请求转发到后端服务器上,并从后端服务器上读取响应,发回客户端。
- upstream 模块是一种特殊的 handler,只不过响应内容不是真正由自己产生的,而是从后端服务器上读取的。
- load-balancer:
- 负载均衡模块,实现特定的算法,在众多的后端服务器中,选择一个服务器出来作为某个请求的转发服务器。
Nginx vs Apache
Nginx:
- IO 多路复用,Epoll(freebsd 上是 kqueue)
- 高性能
- 高并发
- 占用系统资源少
Apache:
- 阻塞+多进程/多线程
- 更稳定,Bug 少
- 模块更丰富
最大连接数
基础背景:
- Nginx 是多进程模型,Worker 进程用于处理请求。
- 单个进程的连接数(文件描述符 fd),有上限(nofile):ulimit -n。
- Nginx 上配置单个 Worker 进程的最大连接数:worker_connections 上限为 nofile。
- Nginx 上配置 Worker 进程的数量:worker_processes。
因此,Nginx 的最大连接数:
Nginx 作为通用服务器时,最大的连接数:Worker进程数量 * 单个Worker进程的最大连接数。
Nginx 作为反向代理服务器时,能够服务的最大连接数:(Worker 进程数量 * 单个 Worker 进程的最大连接数)/ 2。
Nginx 反向代理时,会建立 Client 的连接和后端 Web Server 的连接,占用 2 个连接。
3.6 - MySQL 模型
MySQL启动Socket监听
看源码,首先就需要找到其入口点,mysqld的入口点为mysqld_main,跳过了各种配置文件的加载 之后,我们来到了network_init初始化网络环节,如下图所示:

下面是其调用栈:
mysqld_main (MySQL Server Entry Point)
|-network_init (初始化网络)
/* 建立tcp套接字 */
|-create_socket (AF_INET)
|-mysql_socket_bind (AF_INET)
|-mysql_socket_listen (AF_INET)
/* 建立UNIX套接字*/
|-mysql_socket_socket (AF_UNIX)
|-mysql_socket_bind (AF_UNIX)
|-mysql_socket_listen (AF_UNIX)
值得注意的是,在tcp socket的初始化过程中,考虑到了ipv4/v6的两种情况:
// 首先创建ipv4连接
ip_sock= create_socket(ai, AF_INET, &a);
// 如果无法创建ipv4连接,则尝试创建ipv6连接
if(mysql_socket_getfd(ip_sock) == INVALID_SOCKET)
ip_sock= create_socket(ai, AF_INET6, &a);
如果我们以很快的速度 stop/start mysql,会出现上一个mysql的listen port没有被release导致无法当前mysql的socket无法bind的情况,在此种情况下mysql会循环等待,其每次等待时间为当前重试次数retry * retry/3 +1秒,一直到设置的–port-open-timeout(默认为0)为止,如下图所示:
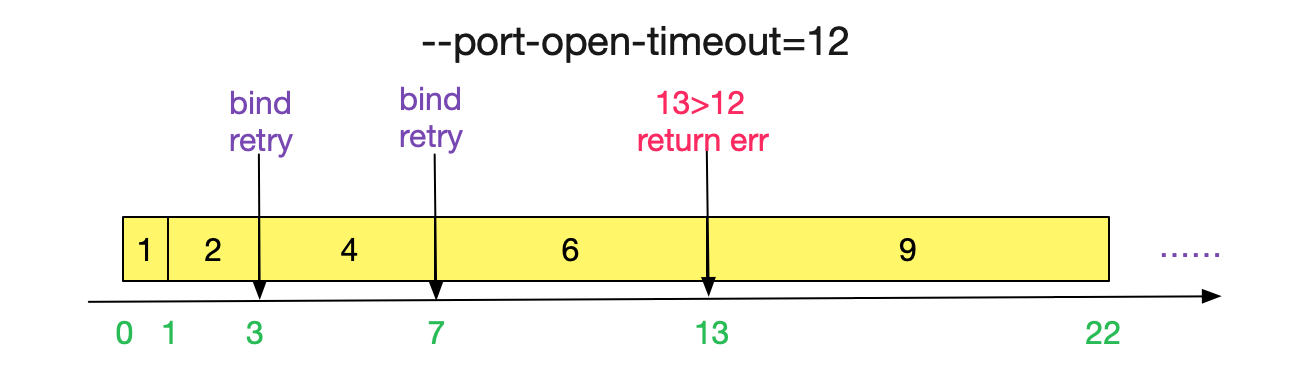
MySQL新建连接处理循环
通过 handle_connections_sockets 处理 MySQL 的新建连接循环,根据操作系统的配置通过 poll/select 处理循环(非epoll,这样可移植性较高,且mysql瓶颈不在网络上)。 MySQL通过线程池的模式处理连接(一个连接对应一个线程,连接关闭后将线程归还到池中)。
如下图所示:

对应的调用栈如下所示:
handle_connections_sockets
|->poll/select
|->new_sock=mysql_socket_accept(...sock...) /*从listen socket中获取新连接*/
|->new THD 连接线程上下文 /* 如果获取不到足够内存,则shutdown new_sock*/
|->mysql_socket_getfd(sock) 从socket中获取
/** 设置为NONBLOCK和环境有关 **/
|->fcntl(mysql_socket_getfd(sock), F_SETFL, flags | O_NONBLOCK);
|->mysql_socket_vio_new
|->vio_init (VIO_TYPE_TCPIP)
|->(vio->write = vio_write)
/* 默认用的是vio_read */
|->(vio->read=(flags & VIO_BUFFERED_READ) ?vio_read_buff :vio_read;)
|->(vio->viokeepalive = vio_keepalive) /*tcp层面的keepalive*/
|->.....
|->mysql_net_init
|->设置超时时间,最大packet等参数
|->create_new_thread(thd) /* 实际是从线程池拿,不够再新建pthread线程 */
|->最大连接数限制
|->create_thread_to_handle_connection
|->首先看下线程池是否有空闲线程
|->mysql_cond_signal(&COND_thread_cache) /* 有则发送信号 */
/** 这边的hanlde_one_connection是mysql连接的主要处理函数 */
|->mysql_thread_create(...handle_one_connection...)
MySQL 的 VIO
如上图代码中,每新建一个连接,都随之新建一个 vio(mysql_socket_vio_new->vio_init),在vio_init的过程中,初始化了一堆回掉函数,如下图所示:
我们关注点在vio_read和vio_write上,如上面代码所示,在笔者所处机器的环境下将MySQL连接的socket设置成了非阻塞模式(O_NONBLOCK)模式。所以在vio的代码里面采用了nonblock代码的编写模式,如下面源码所示:
vio_read
size_t vio_read(Vio *vio, uchar *buf, size_t size)
{
while ((ret= mysql_socket_recv(vio->mysql_socket, (SOCKBUF_T *)buf, size, flags)) == -1)
{
......
// 如果上面获取的数据为空,则通过select的方式去获取读取事件,并设置超时timeout时间
if ((ret= vio_socket_io_wait(vio, VIO_IO_EVENT_READ)))
break;
}
}
即通过while循环去读取socket中的数据,如果读取为空,则通过vio_socket_io_wait去等待(借助于select的超时机制),其源码如下所示:
vio_socket_io_wait
|->vio_io_wait
|-> (ret= select(fd + 1, &readfds, &writefds, &exceptfds,
(timeout >= 0) ? &tm : NULL))
笔者在jdk源码中看到java的connection time out也是通过这,select(…wait_time)的方式去实现连接超时的。 由上述源码可以看出,这个mysql的read_timeout是针对每次socket recv(而不是整个packet的),所以可能出现超过read_timeout MySQL仍旧不会报错的情况,如下图所示:
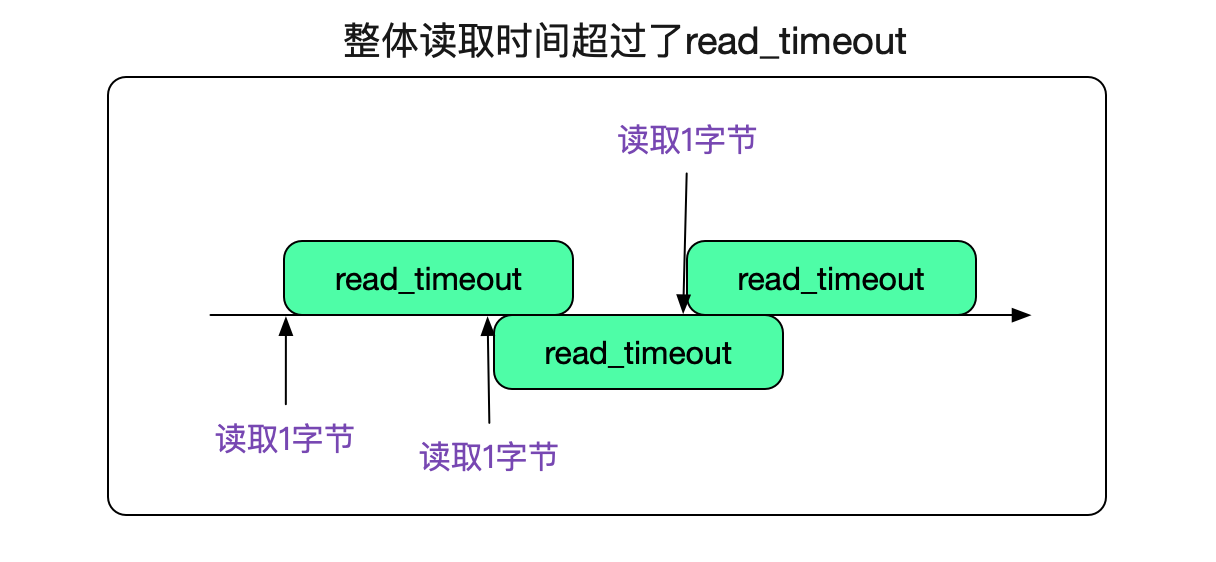
vio_write
vio_write实现模式和vio_read一致,也是通过select来实现超时时间的判定,如下面源码所示:
size_t vio_write(Vio *vio, const uchar* buf, size_t size)
{
while ((ret= mysql_socket_send(vio->mysql_socket, (SOCKBUF_T *)buf, size, flags)) == -1)
{
int error= socket_errno;
/* The operation would block? */
// 处理EAGAIN和EWOULDBLOCK返回,NON_BLOCK模式都必须处理
if (error != SOCKET_EAGAIN && error != SOCKET_EWOULDBLOCK)
break;
/* Wait for the output buffer to become writable.*/
if ((ret= vio_socket_io_wait(vio, VIO_IO_EVENT_WRITE)))
break;
}
}
MySQL 的连接线程处理
从上面的代码:
mysql_thread_create(...handle_one_connection...)
可以发现,MySQL每个线程的处理函数为handle_one_connection,其过程如下图所示:
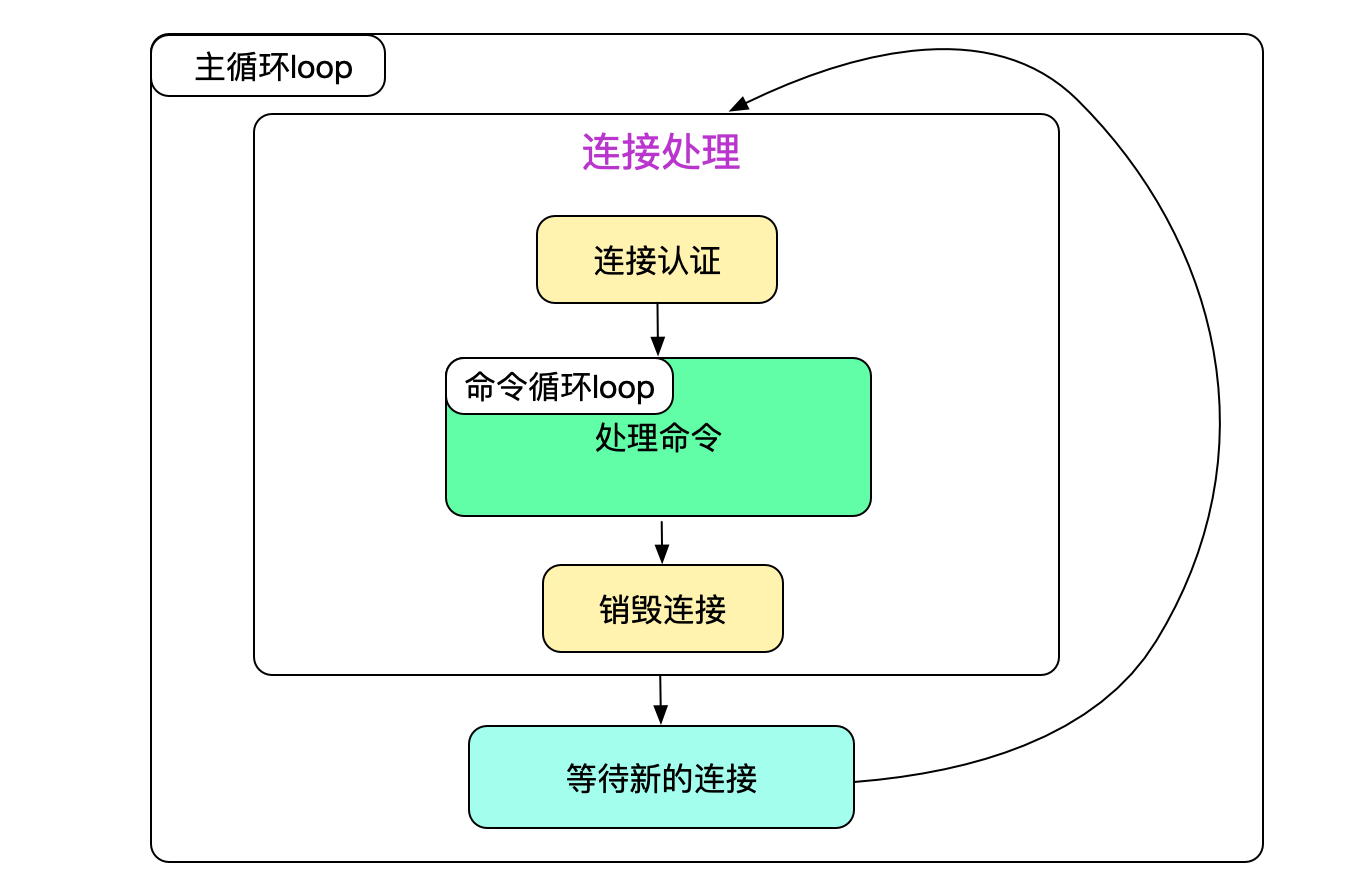
代码如下所示:
for(;;){
// 这边做了连接的handshake和auth的工作
rc= thd_prepare_connection(thd);
// 和通常的线程处理一样,一个无限循环获取连接请求
while(thd_is_connection_alive(thd))
{
if(do_command(thd))
break;
}
// 出循环之后,连接已经被clientdu端关闭或者出现异常
// 这边做了连接的销毁动作
end_connection(thd);
end_thread:
...
// 这边调用end_thread做清理动作,并将当前线程返还给线程池重用
// end_thread对应为one_thread_per_connection_end
if (MYSQL_CALLBACK_ELSE(thread_scheduler, end_thread, (thd, 1), 0))
return;
...
// 这边current_thd是个宏定义,其实是current_thd();
// 主要是从线程上下文中获取新塞进去的thd
// my_pthread_getspecific_ptr(THD*,THR_THD);
thd= current_thd;
...
}
mysql的每个woker线程通过无限循环去处理请求。
线程的归还过程
MySQL通过调用one_thread_per_connection_end(即上面的end_thread)去归还连接。
MYSQL_CALLBACK_ELSE(...end_thread)
one_thread_per_connection_end
|->thd->release_resources()
|->......
|->block_until_new_connection
线程在新连接尚未到来之前,等待在信号量上(下面代码是C/C++ mutex condition的标准使用模式):
static bool block_until_new_connection()
{
mysql_mutex_lock(&LOCK_thread_count);
......
while (!abort_loop && !wake_pthread && !kill_blocked_pthreads_flag)
mysql_cond_wait(&x1, &LOCK_thread_count);
......
// 从等待列表中获取需要处理的THD
thd= waiting_thd_list->front();
waiting_thd_list->pop_front();
......
// 将thd放入到当前线程上下文中
// my_pthread_setspecific_ptr(THR_THD, this)
thd->store_globals();
......
mysql_mutex_unlock(&LOCK_thread_count);
.....
}
整个过程如下图所示:

由于MySQL的调用栈比较深,所以将thd放入线程上下文中能够有效的在调用栈中减少传递参数的数量。
总结
MySQL的网络IO模型采用了经典的线程池技术,虽然性能上不及reactor模型,但好在其瓶颈并不在网络IO上,采用这种方法无疑可以节省大量的精力去专注于处理sql等其它方面的优化。
4 - 网络基础
4.1 - 网络分层
全局网络层次
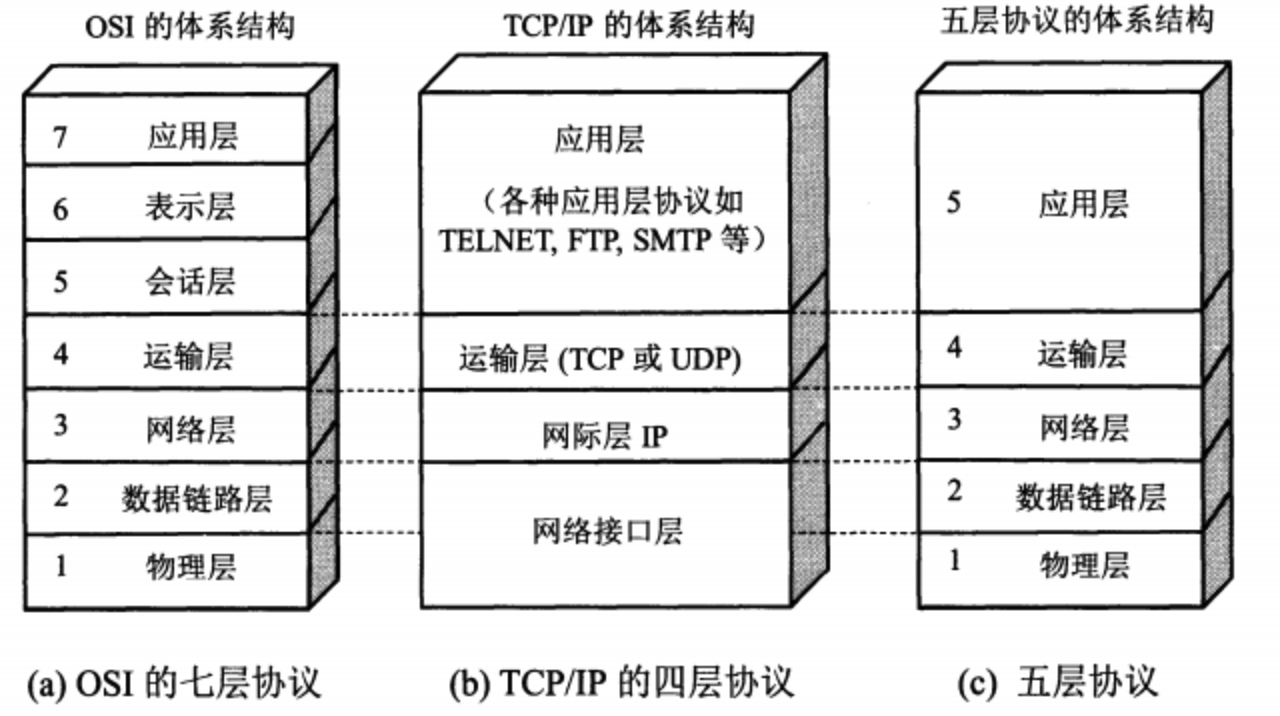
OSI 7 层
国际标准化组织ISO于1984年提出了OSI(Open System Interconnection Reference Model,开放系统互联参考模型)。OSI很快成为计算机网络通信的基础模型。
OSI依层次结构来划分:应用层(Application)、表示层(Presentation)、会话层(Session)、传输层(Transport)、网络层(Network)、数据链路层(Data Link)、物理层(Physical)。
OSI七层参考模型的各个层次的划分遵循下列原则:
- 同一层中的各网络节点都有相同的层次结构,具有同样的功能。
- 同一节点内相邻层之间通过接口(可以是逻辑接口)进行通信。
- 七层结构中的每一层使用下一层提供的服务,并且向其上层提供服务。
- 不同节点的同等层按照协议实现对等层之间的通信。

第一层:物理层(PhysicalLayer)
规定通信设备的机械的、电气的、功能的和过程的特性,用以建立、维护和拆除物理链路连接。具体地讲,机械 特性规定了网络连接时所需接插件的规格尺寸、引脚数量和排列情况等;电气特性规定了在物理连接上传输bit流时线路上信号电平的大小、阻抗匹配、传输速率 距离限制等;功能特性是指对各个信号先分配确切的信号含义,即定义了DTE和DCE之间各个线路的功能;规程特性定义了利用信号线进行bit流传输的一组 操作规程,是指在物理连接的建立、维护、交换信息是,DTE和DCE双放在各电路上的动作系列。在这一层,数据的单位称为比特(bit)。属于物理层定义的典型规范代表包括:EIA/TIA RS-232、EIA/TIA RS-449、V.35、RJ-45等。
第二层:数据链路层(DataLinkLayer)
在物理层提供比特流服务的基础上,建立相邻结点之间的数据链路,通过差错控制提供数据帧(Frame)在信道上无差错的传输,并进行各电路上的动作系列。数据链路层在不可靠的物理介质上提供可靠的传输。该层的作用包括:物理地址寻址、数据的成帧、流量控制、数据的检错、重发等。在这一层,数据的单位称为帧(frame)。数据链路层协议的代表包括:SDLC、HDLC、PPP、STP、帧中继等。
第三层:网络层(network)
在 计算机网络中进行通信的两个计算机之间可能会经过很多个数据链路,也可能还要经过很多通信子网。网络层的任务就是选择合适的网间路由和交换结点, 确保数据及时传送。网络层将数据链路层提供的帧组成数据包,包中封装有网络层包头,其中含有逻辑地址信息- -源站点和目的站点地址的网络地址。如 果你在谈论一个IP地址,那么你是在处理第3层的问题,这是“数据包”问题,而不是第2层的“帧”。IP是第3层问题的一部分,此外还有一些路由协议和地 址解析协议(ARP)。有关路由的一切事情都在这第3层处理。地址解析和路由是3层的重要目的。网络层还可以实现拥塞控制、网际互连等功能。在这一层,数据的单位称为数据包(packet)。网络层协议的代表包括:IP、IPX、RIP、OSPF等。
第四层: 传输层(Transport)
第4层的数据单元也称作数据包(packets)。但是,当你谈论TCP等具体的协议时又有特殊的叫法,TCP的数据单元称为段 (segments)而UDP协议的数据单元称为“数据报(datagrams)”。这个层负责获取全部信息,因此,它必须跟踪数据单元碎片、乱序到达的 数据包和其它在传输过程中可能发生的危险。第4层为上层提供端到端(最终用户到最终用户)的透明的、可靠的数据传输服务。所为透明的传输是指在通信过程中 传输层对上层屏蔽了通信传输系统的具体细节。传输层协议的代表包括:TCP、UDP、SPX等。
第五层: 会话层(Session)
这一层也可以称为会晤层或对话层,在会话层及以上的高层次中,数据传送的单位不再另外命名,而是统称为报文。会话层不参与具体的传输,它提供包括访问验证和会话管理在内的建立和维护应用之间通信的机制。如服务器验证用户登录便是由会话层完成的。
第六层: 表示层(Presentation)
这一层主要解决拥护信息的语法表示问题。它将欲交换的数据从适合于某一用户的抽象语法,转换为适合于OSI系统内部使用的传送语法。即提供格式化的表示和转换数据服务。数据的压缩和解压缩, 加密和解密等工作都由表示层负责。
第七层: 应用层(Application)
应用层为操作系统或网络应用程序提供访问网络服务的接口。应用层协议的代表包括:Telnet、FTP、HTTP、SNMP等。
TCP/IP 4 层
4层是指TCP/IP四层模型,主要包括:应用层、运输层、网际层和网络接口层。
体系结构 5 层
五层体系结构包括:应用层、运输层、网络层、数据链路层和物理层。
五层协议只是OSI和TCP/IP的综合,实际应用还是TCP/IP的四层结构。为了方便可以把下两层称为网络接口层。
网络层次与数据传递
数据在各层之间的传递过程
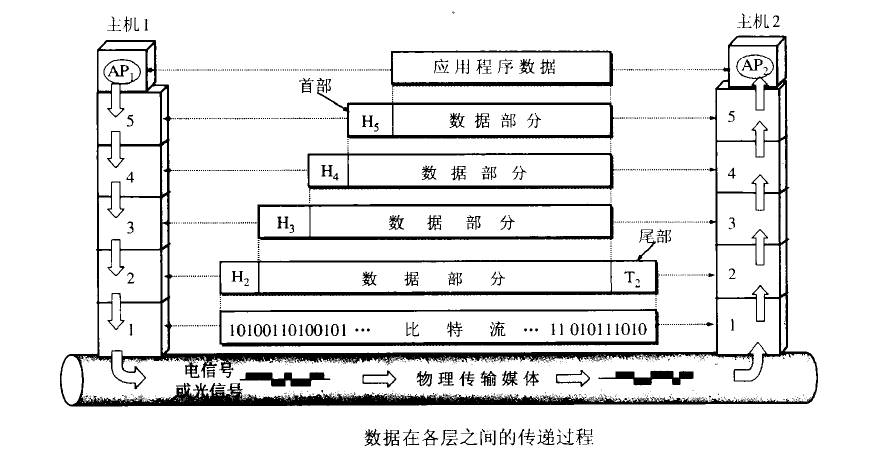
结合层次所在的协议理解
图引用自《图解HTTP》。下图就是这四层协议在数据传输过程中的工作方式,在发送端是应用层–>链路层这个方向的封包过程,每经过一层都会增加该层的头部。而接收端则是从链路层–>应用层解包的过程,每经过一层则会去掉相应的首部。
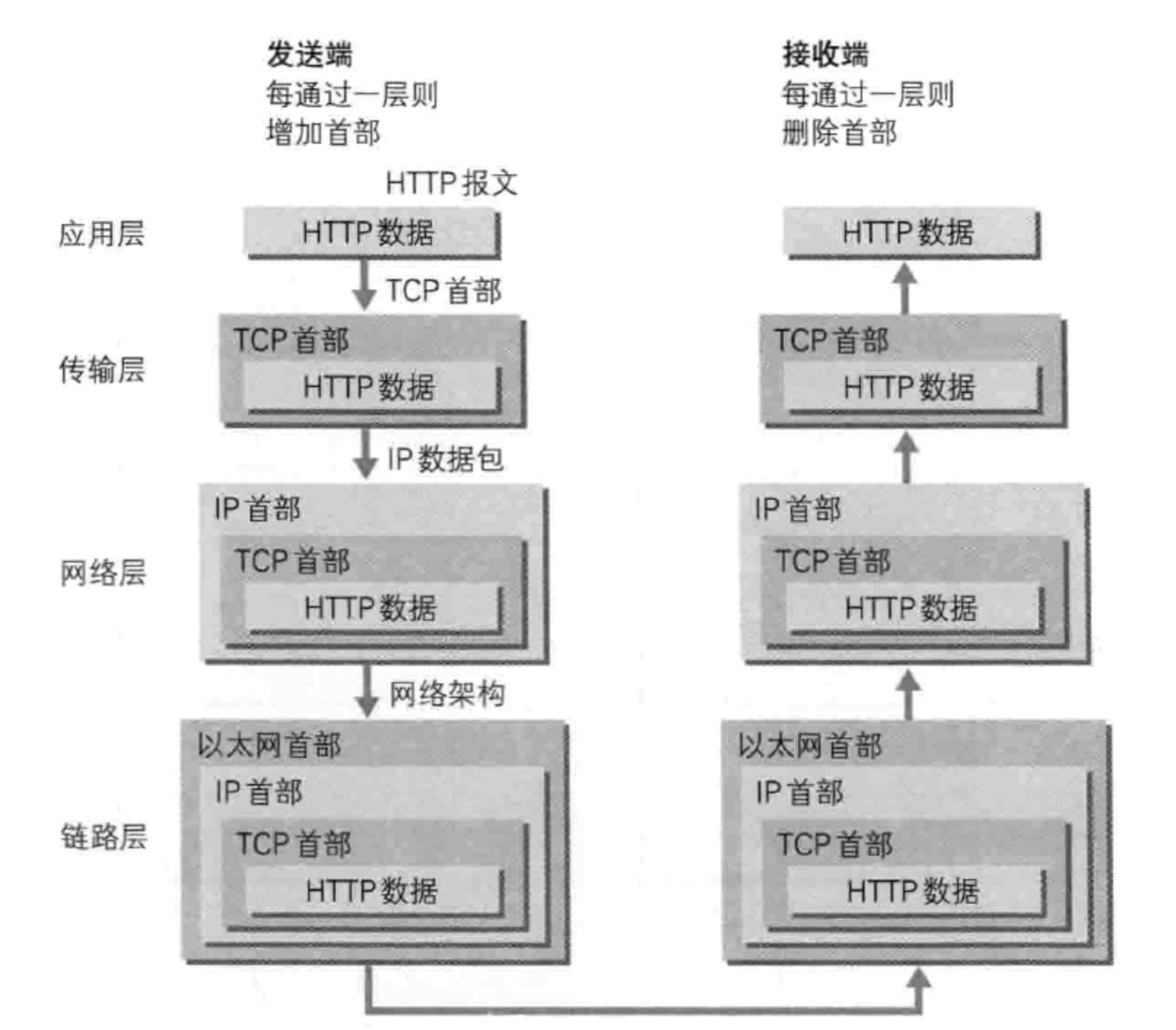
各层对应设备
OSI 七层模型通过七个层次化的结构模型使不同的系统不同的网络之间实现可靠的通讯,因此其最主要的功能就是帮助不同类型的主机实现数据传输 。完成中继功能的节点通常称为中继系统。一个设备工作在哪一层,关键看它工作时利用哪一层的数据头部信息。网桥工作时,是以MAC头部来决定转发端口的,因此显然它是数据链路层的设备。具体说:
- 物理层:网卡,网线,集线器,中继器,调制解调器
- 数据链路层:网桥,交换机
- 网络层:路由器
- 网关工作在第四层传输层及其以上 集线器是物理层设备,采用广播的形式来传输信息。
交换机就是用来进行报文交换的机器。多为链路层设备(二层交换机),能够进行地址学习,采用存储转发的形式来交换报文。
路由器的一个作用是连通不同的网络,另一个作用是选择信息传送的线路。选择通畅快捷的近路,能大大提高通信速度,减轻网络系统通信负荷,节约网络系统资源,提高网络系统畅通率。
交换机的工作原理
交换机拥有一条很高带宽的内部总线和内部交换矩阵。交换机的所有的端口都挂接在这条总线上,控制电路收到数据包以后,处理端口会查找内存中的地址对照表以确定目的MAC(网卡的硬件地址)的NIC(网卡)挂接在哪个端口上,通过内部交换矩阵迅速将数据包传送到目的端口,目的MAC若不存在则广播到所有的端口,接收端口回应后交换机会“学习”新的地址,并把它添加入内部MAC地址表中。 使用交换机也可以把网络“分段”,通过对照MAC地址表,交换机只允许必要的网络流量通过交换机。通过交换机的过滤和转发,可以有效的隔离广播风暴,减少误包和错包的出现,避免共享冲突。 交换机在同一时刻可进行多个端口对之间的数据传输。每一端口都可视为独立的网段,连接在其上的网络设备独自享有全部的带宽,无须同其他设备竞争使用。当节点A向节点D发送数据时,节点B可同时向节点C发送数据,而且这两个传输都享有网络的全部带宽,都有着自己的虚拟连接。总之,交换机是一种基于MAC地址识别,能完成封装转发数据包功能的网络设备。交换机可以"学习"MAC地址,并把其存放在内部地址表中,通过在数据帧的始发者和目标接收者之间建立临时的交换路径,使数据帧直接由源地址到达目的地址。
集线器的功能
集线器的英文称为“Hub”。集线器的主要功能是对接收到的信号进行再生整形放大,以扩大网络的传输距离,同时把所有节点集中在以它为中心的节点上。它 工作于OSI(开放系统互联参考模型)参考模型第一层,即“物理层”。集线器与网卡、网线等传输介质一样,属于局域网中的基础设备,采用 CSMA/CD(即带冲突检测的载波监听多路访问技术)介质访问控制机制。集线器每个接口简单的收发比特,收到1就转发1,收到0就转发0,不进行碰撞检 测。集线器属于纯硬件网络底层设备,基本上不具有类似于交换机的"智能记忆"能力和"学习"能力。它也不具备交换机所具有的MAC地址表,所以它发送数据 时都是没有针对性的,而是采用广播方式发送。也就是说当它要向某节点发送数据时,不是直接把数据发送到目的节点,而是把数据包发送到与集线器相连的所有节点。HUB是一个多端口的转发器,当以HUB为中心设备时,网络中某条线路产生了故障,并不影响其它线路的工作。所以HUB在局域网中得到了广泛的应用。 大多数的时候它用在星型与树型网络拓扑结构中。
路由器相关基础
路由器从功能上可以划分为:路由选择和分组转发。
路由器的分组转发
分组转发结构由三个部分组成:交换结构、一组输入端口和一组输出端口。
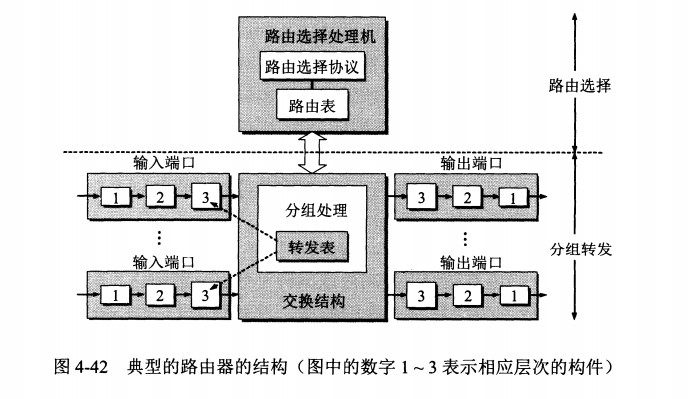
路由器分组转发流程
- 从数据报的首部提取目的主机的 IP 地址 D,得到目的网络地址 N。
- 若 N 就是与此路由器直接相连的某个网络地址,则进行直接交付;
- 若路由表中有目的地址为 D 的特定主机路由,则把数据报传送给表中所指明的下一跳路由器;
- 若路由表中有到达网络 N 的路由,则把数据报传送给路由表中所指明的下一跳路由器;
- 若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;
- 报告转发分组出错。
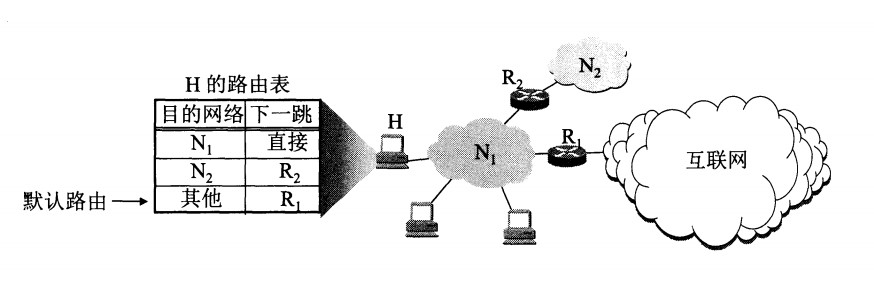
路由选择协议
路由选择协议都是自适应的,能随着网络通信量和拓扑结构的变化而自适应地进行调整。
互联网可以划分为许多较小的自治系统 AS,一个 AS 可以使用一种和别的 AS 不同的路由选择协议。
可以把路由选择协议划分为两大类:
- 自治系统内部的路由选择:RIP 和 OSPF
- 自治系统间的路由选择:BGP
内部网关协议 RIP
RIP 是一种基于距离向量的路由选择协议。距离是指跳数,直接相连的路由器跳数为 1。跳数最多为 15,超过 15 表示不可达。
RIP 按固定的时间间隔仅和相邻路由器交换自己的路由表,经过若干次交换之后,所有路由器最终会知道到达本自治系统中任何一个网络的最短距离和下一跳路由器地址。
距离向量算法:
- 对地址为 X 的相邻路由器发来的 RIP 报文,先修改报文中的所有项目,把下一跳字段中的地址改为 X,并把所有的距离字段加 1;
- 对修改后的 RIP 报文中的每一个项目,进行以下步骤:
- 若原来的路由表中没有目的网络 N,则把该项目添加到路由表中;
- 否则:若下一跳路由器地址是 X,则把收到的项目替换原来路由表中的项目;否则:若收到的项目中的距离 d 小于路由表中的距离,则进行更新(例如原始路由表项为 Net2, 5, P,新表项为 Net2, 4, X,则更新);否则什么也不做。
- 若 3 分钟还没有收到相邻路由器的更新路由表,则把该相邻路由器标为不可达,即把距离置为 16。
RIP 协议实现简单,开销小。但是 RIP 能使用的最大距离为 15,限制了网络的规模。并且当网络出现故障时,要经过比较长的时间才能将此消息传送到所有路由器。
内部网关协议 OSPF
开放最短路径优先 OSPF,是为了克服 RIP 的缺点而开发出来的。
开放表示 OSPF 不受某一家厂商控制,而是公开发表的;最短路径优先表示使用了 Dijkstra 提出的最短路径算法 SPF。
OSPF 具有以下特点:
- 向本自治系统中的所有路由器发送信息,这种方法是洪泛法。
- 发送的信息就是与相邻路由器的链路状态,链路状态包括与哪些路由器相连以及链路的度量,度量用费用、距离、时延、带宽等来表示。
- 只有当链路状态发生变化时,路由器才会发送信息。
- 所有路由器都具有全网的拓扑结构图,并且是一致的。相比于 RIP,OSPF 的更新过程收敛的很快。
外部网关协议 BGP
BGP(Border Gateway Protocol,边界网关协议)
AS 之间的路由选择很困难,主要是由于:
- 互联网规模很大;
- 各个 AS 内部使用不同的路由选择协议,无法准确定义路径的度量;
- AS 之间的路由选择必须考虑有关的策略,比如有些 AS 不愿意让其它 AS 经过。
- BGP 只能寻找一条比较好的路由,而不是最佳路由。
每个 AS 都必须配置 BGP 发言人,通过在两个相邻 BGP 发言人之间建立 TCP 连接来交换路由信息。
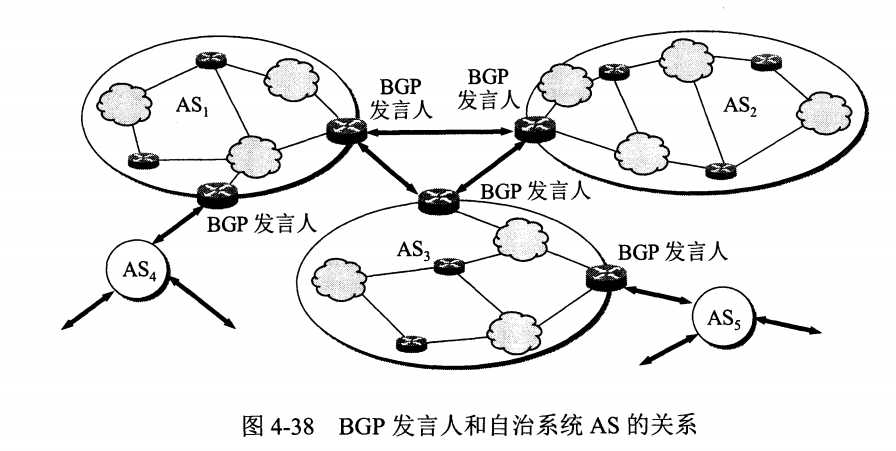
集线器与交换机的区别
首先说HUB,也就是集线器。它的作用可以简单的理解为将一些机器连接起来组成一个局域网。而交换机(又名交换式集线器)作用与集线器大体相同。但是两者在性能上有区别:集线器采用的式共享带宽的工作方式,而交换机是独享带宽。这样在机器很多或数据量很大时,两者将会有比较明显的。
- 工作位置不同 :集线器工作在物理层,而交换机工作在数据链路层。
- 工作方式不同 : 集线器是一种广播方式,当集线器的某个端口工作时其他端口都能收听到信息。交换机工作时端口互不影响。
- 带宽不同 :集线器是所有端口共享一条带宽,在同一时刻只能有两个端口传输数据;而交换机每个端口独占一条带宽。
- 性能不同 :交换机以MAC地址进行寻址,有一定额外的寻址开销;集线器以广播方式传输数据,流量小时性能下降不明显,适用于共享总线的局域网。
路由器与交换机的区别
总的来说,路由器与交换机的主要区别体现在以下几个方面:
- 工作层次不同。最初的的交换机是工作在数据链路层,而路由器一开始就设计工作在网络层。由于交换机工作在数据链路层,所以它的工作原理比较简单,而路由器工作在网络层,可以得到更多的协议信息,路由器可以做出更加智能的转发决策。
- 数据转发所依据的对象不同。交换机是利用物理地址或者说MAC地址来确定转发数据的目的地址。而路由器则是利用IP地址来确定数据转发的地址。IP地址是在软件中实现的,描述的是设备所在的网络。MAC地址通常是硬件自带的,由网卡生产商来分配的,而且已经固化到了网卡中去,一般来说是不可更改的。而IP地址则通常由网络管理员或系统自动分配。
- 传统的交换机只能分割冲突域,不能分割广播域;而路由器可以分割广播域。由交换机连接的网段仍属于同一个广播域,广播数据包会在交换机连接的所有网段上传播,在某些情况下会导致通信拥挤和安全漏洞。连接到路由器上的网段会被分配成不同的广播域,广播数据不会穿过路由器。虽然第三层以上交换机具有VLAN功能,也可以分割广播域,但是各子广播域之间是不能通信交流的,它们之间的交流仍然需要路由器。
- 交换机负责同一个网段的通信,而路由器负责不同网段的通信。路由器提供了防火墙的服务。路由器仅仅转发特定地址的数据包,不传送不支持路由协议的数据包传送和未知目标网络数据包的传送,从而可以防止广播风暴。
路由表
路由表是指路由器或者其他互联网网络设备上存储的一张路由信息表,该表中存有到达特定网络终端的路径,在某些情况下,还有一些与这些路径相关的度量。路由器的主要工作就是为经过路由器的每个数据包寻找一条最佳的传输路径,并将该数据有效地传送到目的站点。由此可见,选择最佳路径的策略即路由算法是路由器的关键所在。为了完成这项工作,在路由器中保存着各种传输路径的相关数据——路由表(Routing Table),供路由选择时使用,表中包含的信息决定了数据转发的策略。路由表可以是由系统管理员固定设置好的,也可以由系统动态修改,可以由路由器自动调整,也可以由主机控制。
- 静态路由表:由系统管理员事先设置好固定的路由表称之为静态(static)路由表,一般是在系统安装时就根据网络的配置情况预先设定的,它不会随未来网络结构的改变而改变。
- 动态路由表:动态(Dynamic)路由表是路由器根据网络系统的运行情况而自动调整的路由表。路由器根据路由选择协议(Routing Protocol)提供的功能,自动学习和记忆网络运行情况,在需要时自动计算数据传输的最佳路径。
路由器通常依靠所建立及维护的路由表来决定如何转发。路由表能力是指路由表内所容纳路由表项数量的极限。路由表中的表项内容包括:
- destination mask pre costdestination:目的地址,用来标识IP包的目的地址或者目的网络。
- mask:网络掩码,与目的地址一起标识目的主机或者路由器所在的网段的地址。
- pre:标识路由加入IP路由表的优先级。可能到达一个目的地有多条路由,但是优先级的存在让他们先选择优先级高的路由进行利用。
- cost:路由开销,当到达一个目的地的多个路由优先级相同时,路由开销最小的将成为最优路由。
- interface:输出接口,说明IP包将从该路由器哪个接口转发。 nexthop:下一跳IP地址,说明IP包所经过的下一个路由器。
各层常见协议
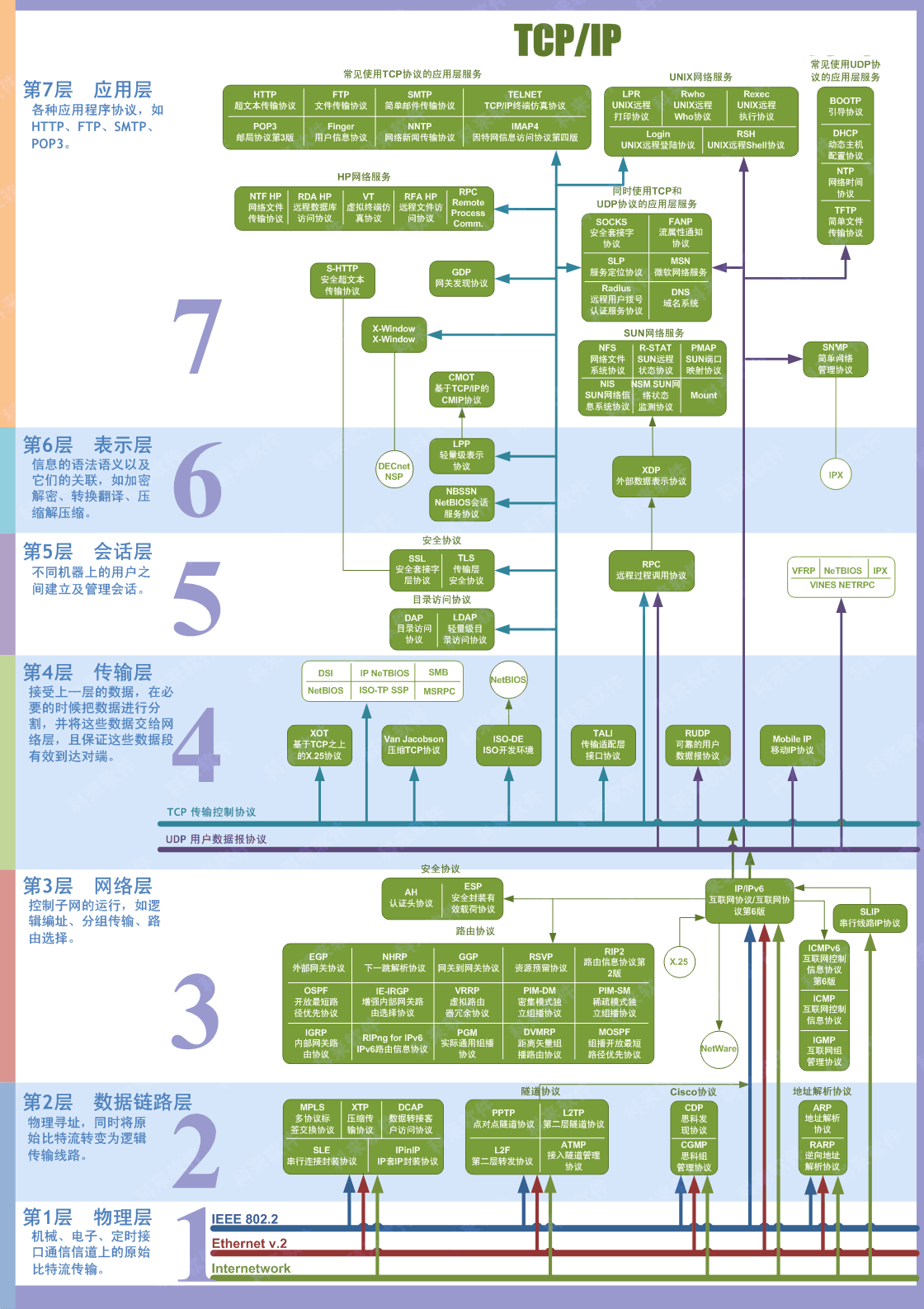
4.2 - IP 协议
IP 及配套协议详解
因为网络层是整个互联网的核心,因此应当让网络层尽可能简单。网络层向上只提供简单灵活的、无连接的、尽最大努力交互的数据报服务。
使用 IP 协议,可以把异构的物理网络连接起来,使得在网络层看起来好像是一个统一的网络。
与 IP 协议配套使用的还有三个协议:
- 地址解析协议 ARP(Address Resolution Protocol)
- 网际控制报文协议 ICMP(Internet Control Message Protocol)
- 网际组管理协议 IGMP(Internet Group Management Protocol)
IP 数据报格式
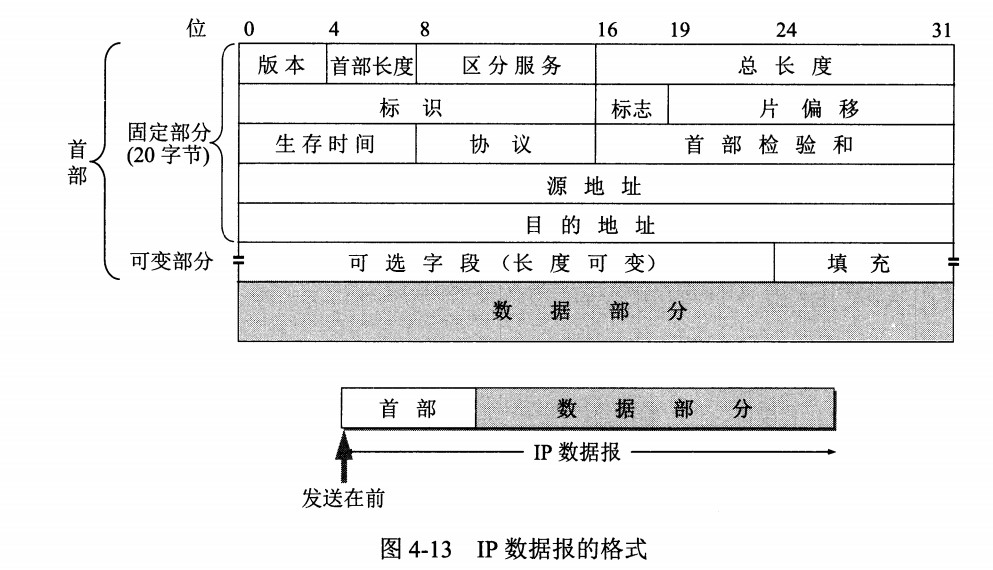
版本 : 有 4(IPv4)和 6(IPv6)两个值;
首部长度 : 占 4 位,因此最大值为 15。值为 1 表示的是 1 个 32 位字的长度,也就是 4 字节。因为固定部分长度为 20 字节,因此该值最小为 5。如果可选字段的长度不是 4 字节的整数倍,就用尾部的填充部分来填充。
区分服务 : 用来获得更好的服务,一般情况下不使用。
总长度 : 包括首部长度和数据部分长度。
生存时间 :TTL,它的存在是为了防止无法交付的数据报在互联网中不断兜圈子。以路由器跳数为单位,当 TTL 为 0 时就丢弃数据报。
协议 :指出携带的数据应该上交给哪个协议进行处理,例如 ICMP、TCP、UDP 等。
首部检验和 :因为数据报每经过一个路由器,都要重新计算检验和,因此检验和不包含数据部分可以减少计算的工作量。
标识 : 在数据报长度过长从而发生分片的情况下,相同数据报的不同分片具有相同的标识符。
片偏移 : 和标识符一起,用于发生分片的情况。片偏移的单位为 8 字节。
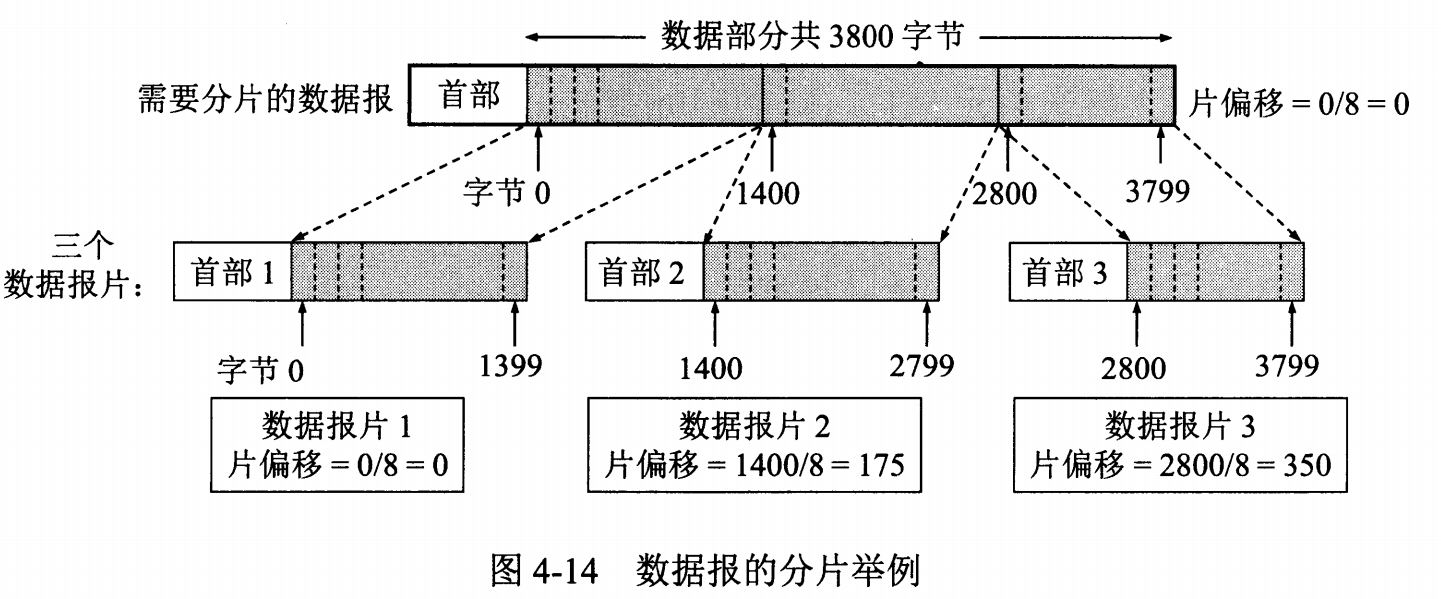
IP 地址编址方式
IP 地址的编址方式经历了三个历史阶段:
- 分类
- 子网划分
- 无分类
1. 分类
由两部分组成,网络号和主机号,其中不同分类具有不同的网络号长度,并且是固定的。
IP 地址 ::= {< 网络号 >, < 主机号 >}
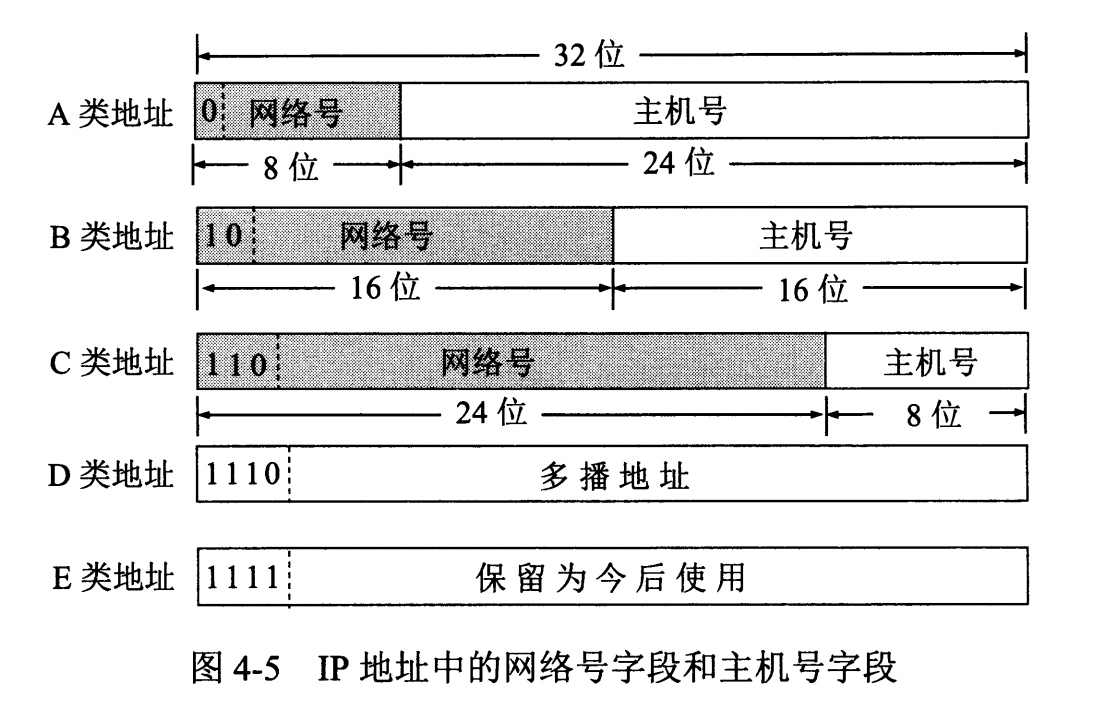
2. 子网划分
通过在主机号字段中拿一部分作为子网号,把两级 IP 地址划分为三级 IP 地址。
IP 地址 ::= {< 网络号 >, < 子网号 >, < 主机号 >}
要使用子网,必须配置子网掩码。一个 B 类地址的默认子网掩码为 255.255.0.0,如果 B 类地址的子网占两个比特,那么子网掩码为 11111111 11111111 11000000 00000000,也就是 255.255.192.0。
注意,外部网络看不到子网的存在。
3. 无分类
无分类编址 CIDR 消除了传统 A 类、B 类和 C 类地址以及划分子网的概念,使用网络前缀和主机号来对 IP 地址进行编码,网络前缀的长度可以根据需要变化。
IP 地址 ::= {< 网络前缀号 >, < 主机号 >}
CIDR 的记法上采用在 IP 地址后面加上网络前缀长度的方法,例如 128.14.35.7/20 表示前 20 位为网络前缀。
CIDR 的地址掩码可以继续称为子网掩码,子网掩码首 1 长度为网络前缀的长度。
一个 CIDR 地址块中有很多地址,一个 CIDR 表示的网络就可以表示原来的很多个网络,并且在路由表中只需要一个路由就可以代替原来的多个路由,减少了路由表项的数量。把这种通过使用网络前缀来减少路由表项的方式称为路由聚合,也称为 构成超网 。
在路由表中的项目由“网络前缀”和“下一跳地址”组成,在查找时可能会得到不止一个匹配结果,应当采用最长前缀匹配来确定应该匹配哪一个。
地址解析协议 ARP
网络层实现主机之间的通信,而链路层实现具体每段链路之间的通信。因此在通信过程中,IP 数据报的源地址和目的地址始终不变,而 MAC 地址随着链路的改变而改变。
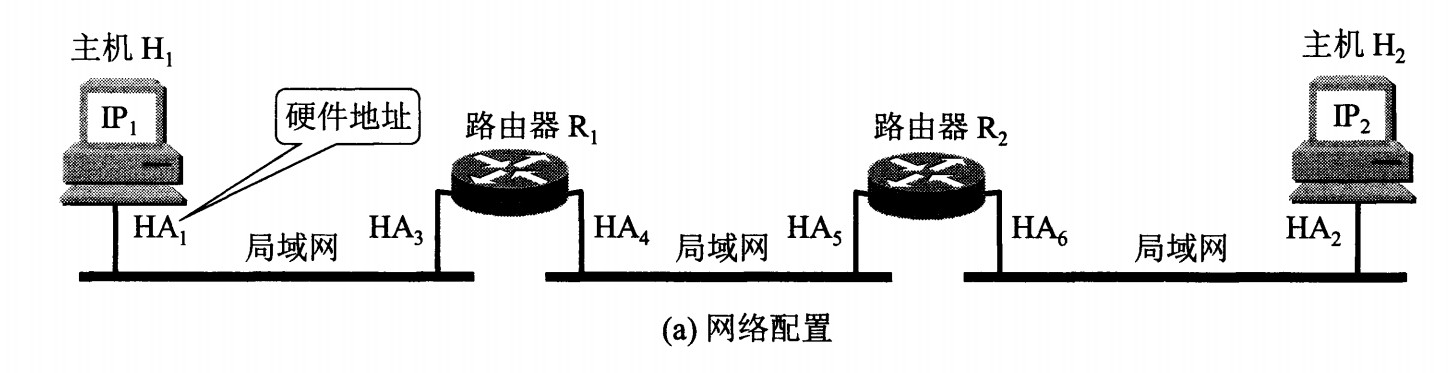
ARP 实现由 IP 地址得到 MAC 地址。
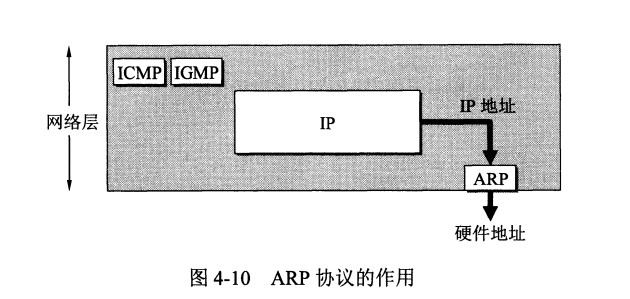
每个主机都有一个 ARP 高速缓存,里面有本局域网上的各主机和路由器的 IP 地址到 MAC 地址的映射表。
如果主机 A 知道主机 B 的 IP 地址,但是 ARP 高速缓存中没有该 IP 地址到 MAC 地址的映射,此时主机 A 通过广播的方式发送 ARP 请求分组,主机 B 收到该请求后会发送 ARP 响应分组给主机 A 告知其 MAC 地址,随后主机 A 向其高速缓存中写入主机 B 的 IP 地址到 MAC 地址的映射。
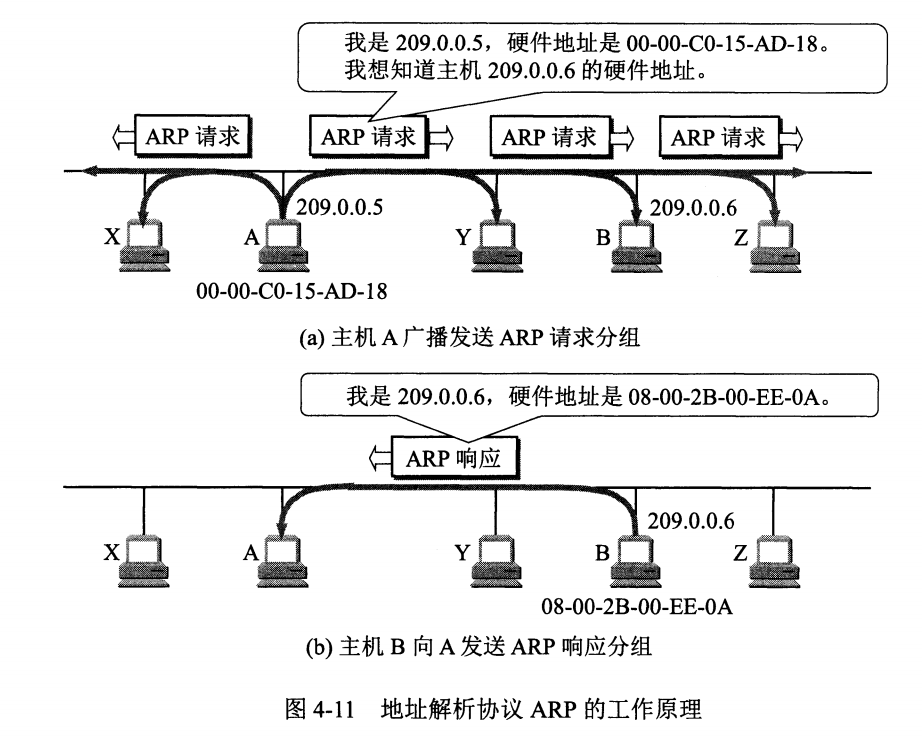
网际控制报文协议 ICMP
ICMP 是为了更有效地转发 IP 数据报和提高交付成功的机会。它封装在 IP 数据报中,但是不属于高层协议。
ICMP 报文分为差错报告报文和询问报文。
1. Ping
Ping 是 ICMP 的一个重要应用,主要用来测试两台主机之间的连通性。
Ping 的原理是通过向目的主机发送 ICMP Echo 请求报文,目的主机收到之后会发送 Echo 回答报文。Ping 会根据时间和成功响应的次数估算出数据包往返时间以及丢包率。
2. Traceroute
Traceroute 是 ICMP 的另一个应用,用来跟踪一个分组从源点到终点的路径。
Traceroute 发送的 IP 数据报封装的是无法交付的 UDP 用户数据报,并由目的主机发送终点不可达差错报告报文。
源主机向目的主机发送一连串的 IP 数据报。第一个数据报 P1 的生存时间 TTL 设置为 1,当 P1 到达路径上的第一个路由器 R1 时,R1 收下它并把 TTL 减 1,此时 TTL 等于 0,R1 就把 P1 丢弃,并向源主机发送一个 ICMP 时间超过差错报告报文; 源主机接着发送第二个数据报 P2,并把 TTL 设置为 2。P2 先到达 R1,R1 收下后把 TTL 减 1 再转发给 R2,R2 收下后也把 TTL 减 1,由于此时 TTL 等于 0,R2 就丢弃 P2,并向源主机发送一个 ICMP 时间超过差错报文。
不断执行这样的步骤,直到最后一个数据报刚刚到达目的主机,主机不转发数据报,也不把 TTL 值减 1。但是因为数据报封装的是无法交付的 UDP,因此目的主机要向源主机发送 ICMP 终点不可达差错报告报文。
之后源主机知道了到达目的主机所经过的路由器 IP 地址以及到达每个路由器的往返时间。
IPV6
我国在2014-2015年也逐步停止了向新用户和应用分配 IPv4 地址。 解决 IP 地址耗尽的根本措施就是采用具有更大地址空间的新版本的 IP,即 IPv6。 所引进的主要变化如下:
- 更大的地址空间。IPv6 将地址从 IPv4 的 32 位 增大到了 128 位。
- 扩展的地址层次结构。
- 灵活的首部格式。 IPv6 定义了许多可选的扩展首部。
- 改进的选项。 IPv6 允许数据报包含有选项的控制信息,其选项放在有效载荷中。
- 允许协议继续扩充。
- 支持即插即用(即自动配置)。因此 IPv6 不需要使用 DHCP。
- 支持资源的预分配。 IPv6 支持实时视像等要求,保证一定的带宽和时延的应用。
- IPv6 首部改为 8 字节对齐。首部长度必须是 8 字节的整数倍。原来的 IPv4 首部是 4 字节对齐。
数据包格式
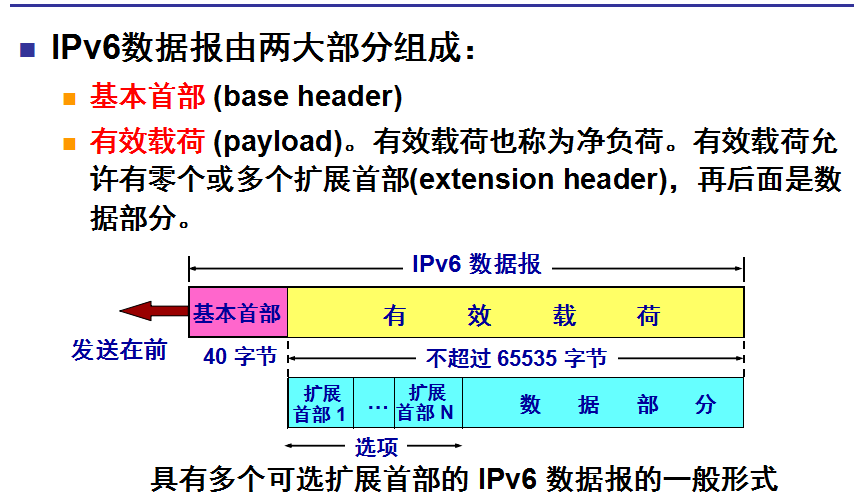
V4 -> V6
向 IPv6 过渡只能采用逐步演进的办法,同时,还必须使新安装的 IPv6 系统能够向后兼容:IPv6 系统必须能够接收和转发 IPv4 分组,并且能够为 IPv4 分组选择路由。
两种向 IPv6 过渡的策略:
- 使用双协议栈
- 使用隧道技术
双协议栈主机在和 IPv6 主机通信时是采用 IPv6 地址,而和 IPv4 主机通信时就采用 IPv4 地址。 根据 DNS 返回的地址类型可以确定使用 IPv4 地址还是 IPv6 地址。

在 IPv6 数据报要进入IPv4网络时,把 IPv6 数据报封装成为 IPv4 数据报,整个的 IPv6 数据报变成了 IPv4 数据报的数据部分。 当 IPv4 数据报离开 IPv4 网络中的隧道时,再把数据部分(即原来的 IPv6 数据报)交给主机的 IPv6 协议栈。
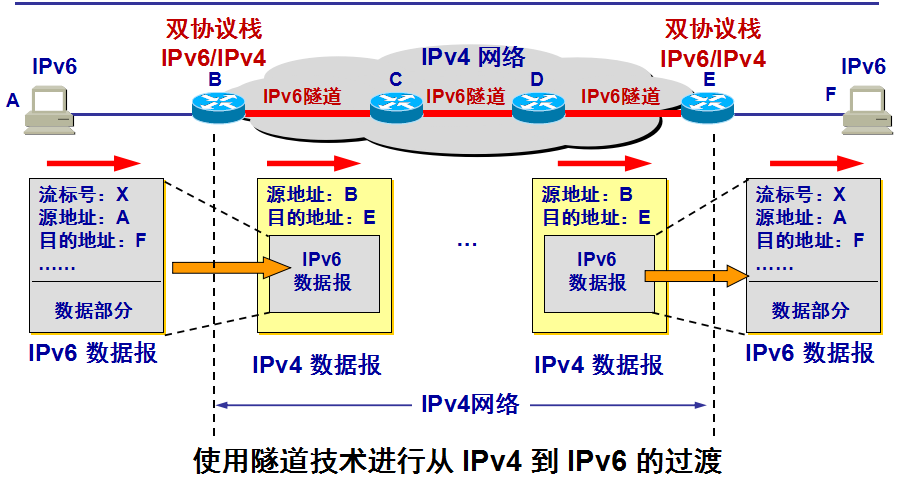
IP与Mac之间关系
- 整体与局部
信息传递时候,需要知道的其实是两个地址:终点地址(Final destination address)下一跳的地址(Next hop address)IP地址本质上是终点地址,它在跳过路由器(hop)的时候不会改变,而MAC地址则是下一跳的地址,每跳过一次路由器都会改变。这就是为什么还要用MAC地址的原因之一,它起到了记录下一跳的信息的作用。注:一般来说IP地址经过路由器是不变的,不过NAT(Network address translation)例外,这也是有些人反对NAT而支持IPV6的原因之一。
- 分层实现
如果在IP包头(header)中增加了”下一跳IP地址“这个字段,在逻辑上来说,如果IP地址够用,交换机也支持根据IP地址转发(现在的二层交换机不支持这样做),其实MAC地址并不是必要的。但用MAC地址和IP地址两个地址,用于分别表示物理地址和逻辑地址是有好处的。这样分层可以使网络层与链路层的协议更灵活地替换,网络层不一定非要用『IP』协议,链路层也不一定非用『以太网』协议。这就像OSI七层模型,TCP/IP五层模型其实也不是必要的,用双层模型甚至单层模型实现网络也不是不可以的,只是那样做很蛋疼罢了。
- 早期的『以太网』实现
早期的以太网只有集线器(hub),没有交换机(switch),所以发出去的包能被以太网内的所有机器监听到,因此要附带上MAC地址,每个机器只需要接受与自己MAC地址相匹配的包。
网络地址转换NAT
问题:在专用网上使用专用地址的主机如何与互联网上的主机通信(并不需要加密)?
采用网络地址转换 NAT。这是目前使用得最多的方法。
装有 NAT 软件的路由器叫作 NAT路由器,它至少有一个有效的外部全球IP地址,所有使用本地地址的主机在和外界通信时,都要在 NAT 路由器上将其本地地址转换成全球 IP 地址。
通过 NAT 路由器的通信必须由专用网内的主机发起。专用网内部的主机不能充当服务器用,因为互联网上的客户无法请求专用网内的服务器提供服务。
转换过程
- 内部主机 A 用本地地址 IPA 和互联网上主机 B 通信所发送的数据报必须经过 NAT 路由器。
- NAT 路由器将数据报的源地址 IPA 转换成全球地址 IPG,并把转换结果记录到NAT地址转换表中,目的地址 IPB 保持不变,然后发送到互联网。
- NAT 路由器收到主机 B 发回的数据报时,知道数据报中的源地址是 IPB 而目的地址是 IPG。
- 根据 NAT 转换表,NAT 路由器将目的地址** IPG 转换为 IPA,转发给最终的内部主机 A**。
可以看出,在内部主机与外部主机通信时,在NAT路由器上发生了两次地址转换:
- 离开专用网时:替换源地址,将内部地址替换为全球地址;
- 进入专用网时:替换目的地址,将全球地址替换为内部地址;

4.3 - TCP 协议
概览
首先,我们需要知道TCP在网络OSI的七层模型中的第四层——Transport层,IP在第三层——Network层,ARP在第二层——Data Link层,在第二层上的数据,我们叫Frame,在第三层上的数据叫Packet,第四层的数据叫Segment。
我们程序的数据首先会打到TCP的Segment中,然后TCP的Segment会打到IP的Packet中,然后再打到以太网Ethernet的Frame中,传到对端后,各个层解析自己的协议,然后把数据交给更高层的协议处理。
TCP 头格式
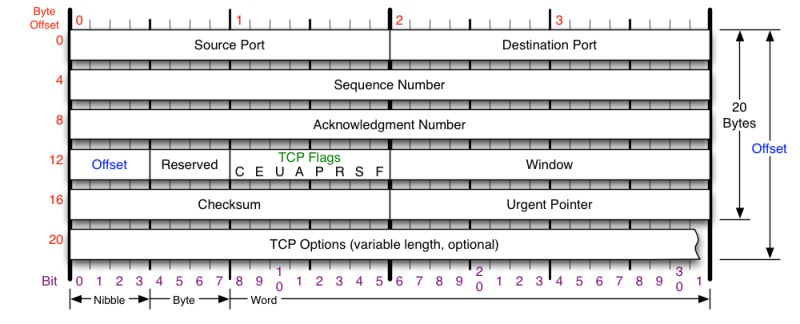
- TCP 包是没有 IP 地址的,因为已经经过了 IP 协议的处理。到这一层仅有源端口和目标端口。
- 一个 TCP 连接需要 4 个元组来标识同一个连接:
- src_ip、src_port、dst_ip、dst_port
- 准确说是 5 个元组,还有一个是协议
- 上图中 4 个重要部分:
- Sequence Number:包的序号,用于解决网络包乱序问题。
- Acknowledgement Number:ACK,用于确认收到,用于解决不丢包问题。
- Window 或 Advertised-Window:滑动窗口,用于解决流控问题。
- TCP Flag:包类型,用于操控 TCP 状态机。
其他部分的解释:
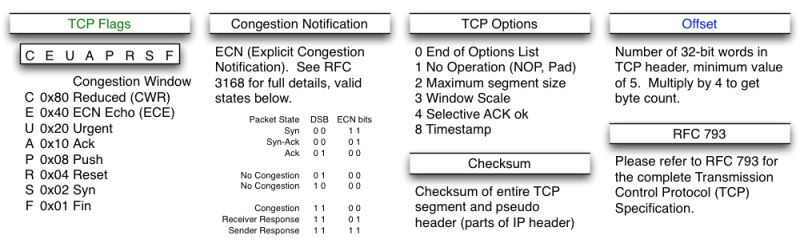
TCP 状态机
其实网络上的传输是没有连接的,包括 TCP 也一样。而 TCP 所谓的“连接”只不过是通讯双方维护的一个“连接状态”,使其看上去好像有连接一样。所以,TCP 的状态尤其重要。
下面是“TCP协议的状态机” 和 “TCP建链接”、“TCP断链接”、“传数据” 的对照图。
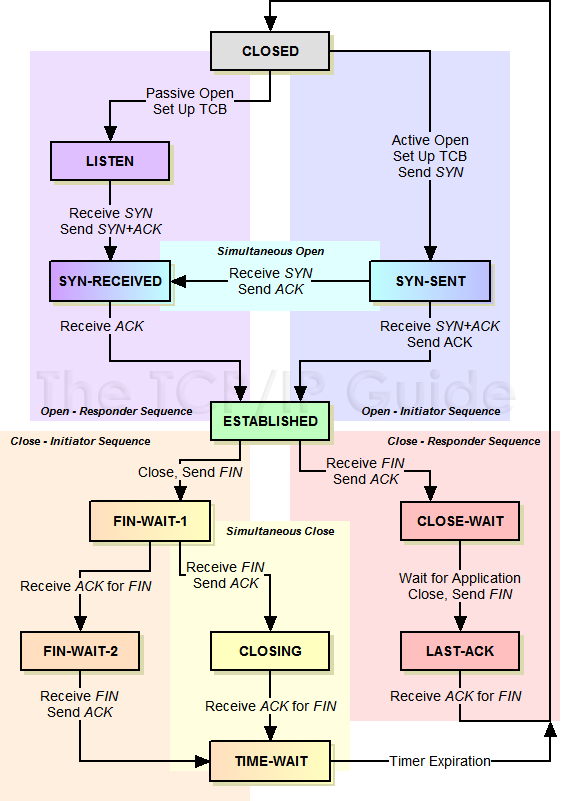
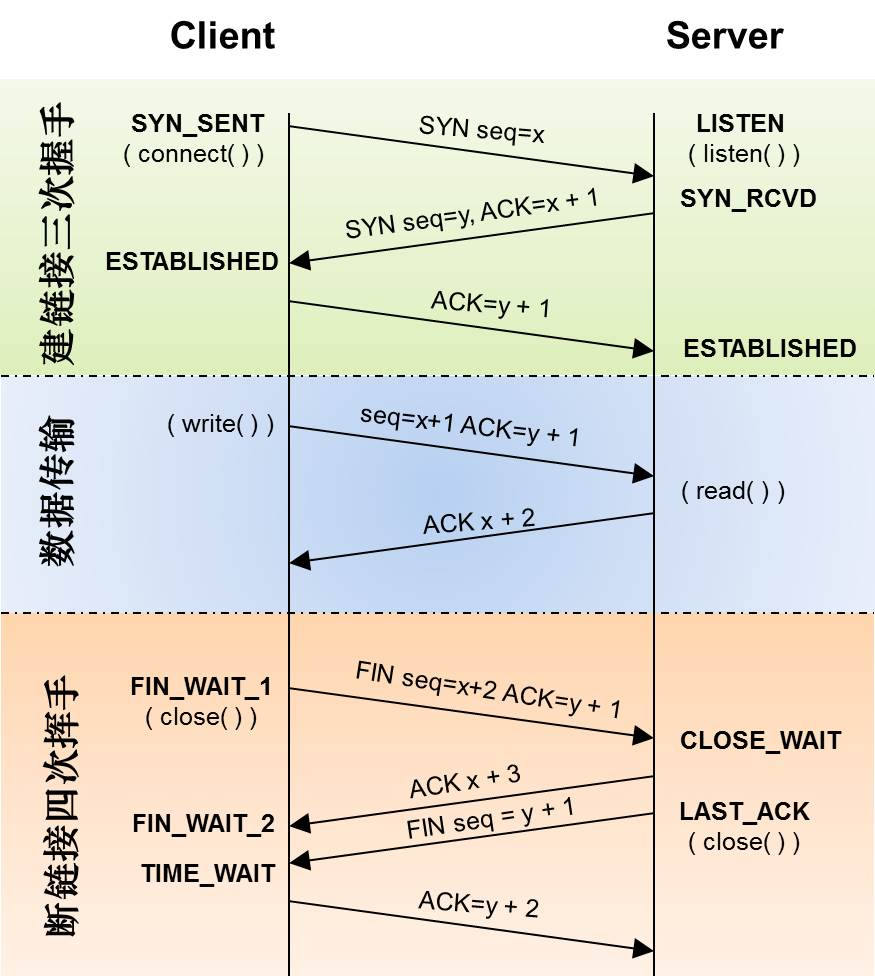
握手机制
一次握手表示向对方发送一个数据包,Client -> Server 或 Server -> Client。
建立连接:三次握手
目的是连接服务器指定端口、建立 TCP 连接,同步连接双方的序列号和确认号,交换 TCP 窗口的大小信息。
- Client -> Server:请求创建连接,SEQ=X
- Server -> Client:同意创建连接,ACK=X+1,SEQ=Y
- Client -> Server:得知同意创建,ACK=Y+1,SEQ=Z
关闭连接:四次挥手
双方均可主动发起挥手来关闭连接。
- Client -> Server:请求关闭
- Server -> Client:同意关闭
- Server -> Client:请求关闭
- Client -> Server:同意关闭
问题汇总
为什么要三次握手
为了防止已失效连接的请求报文段突然又传送到了服务端,因而产生错误。
- 为了防止无效请求发送给服务端,被服务端误以为是新建连接的请求。
假设 Client 发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达 Server。
本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新的连接请求。于是就向client发出确认报文段,同意建立连接。
假设不采用“三次握手”(没有第三次握手),那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了。
如果采用三次握手,client不会向server的确认发出确认。server由于收不到确认,就知道client并没有要求建立连接。
为什么要四次挥手
TCP协议是一种面向连接的、可靠的、基于字节流的全双工运输层通信协议。
- TCP是全双工模式,这就意味着,当主机1发出FIN报文段时,只是表示主机1已经没有数据要发送了,主机1告诉主机2,它的数据已经全部发送完毕了;
- 但是,这个时候主机1还是可以接受来自主机2的数据;
- 当主机2返回ACK报文段时,表示它已经知道主机1没有数据发送了;
- 但是主机2还是可以发送数据到主机1的;
- 当主机2也发送了FIN报文段时,这个时候就表示主机2也没有数据要发送了,就会告诉主机1,我也没有数据要发送了,之后彼此就会愉快的中断这次TCP连接。
关闭时为什么要等待2MSL
MSL:报文段最大生存时间,它是任何报文段被丢弃前在网络内的最长时间。
- 保证TCP协议的全双工连接能够可靠关闭
- 保证这次连接的重复数据段从网络中消失
第一点:如果主机1直接CLOSED了,那么由于IP协议的不可靠性或者是其它网络原因,导致主机2没有收到主机1最后回复的ACK。那么主机2就会在超时之后继续发送FIN,此时由于主机1已经CLOSED了,就找不到与重发的FIN对应的连接。所以,主机1不是直接进入CLOSED,而是要保持TIME_WAIT,当再次收到FIN的时候,能够保证对方收到ACK,最后正确的关闭连接。
第二点:如果主机1直接CLOSED,然后又再向主机2发起一个新连接,我们不能保证这个新连接与刚关闭的连接的端口号是不同的。也就是说有可能新连接和老连接的端口号是相同的。一般来说不会发生什么问题,但是还是有特殊情况出现:假设新连接和已经关闭的老连接端口号是一样的,如果前一次连接的某些数据仍然滞留在网络中,这些延迟数据在建立新连接之后才到达主机2,由于新连接和老连接的端口号是一样的,TCP协议就认为那个延迟的数据是属于新连接的,这样就和真正的新连接的数据包发生混淆了。所以TCP连接还要在TIME_WAIT状态等待2倍MSL,这样可以保证本次连接的所有数据都从网络中消失。
3 次握手
- 主要目的是为了初始化 Sequence Number 的初始值。
- 通信的双方需要互相通知对方自己初始化的 Sequence Number,所以称为 SYN,全称为 Synchronize Sequence Number。
- 即图中的 x 和 y。
- 该序号会作为后续数据通信的序号,以保证应用层接收到的数据不会因为网络传输问题而乱序。
- TCP 使用这些序号来拼接数据。
4 次挥手
其实你仔细看是2次,因为TCP是全双工的,所以,发送方和接收方都需要Fin和Ack。只不过,有一方是被动的,所以看上去就成了所谓的4次挥手。如果两边同时断连接,那就会就进入到CLOSING状态,然后到达TIME_WAIT状态。下图是双方同时断连接的示意图(你同样可以对照着TCP状态机看):
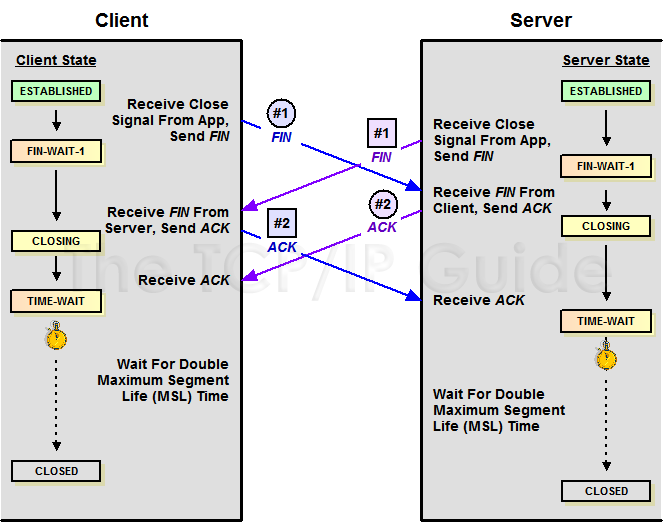
相关问题
建连接时SYN超时
试想一下,如果server端接到了clien发的SYN后回了SYN-ACK后client掉线了,server端没有收到client回来的ACK,那么,这个连接处于一个中间状态,既没成功也没失败。于是,server端如果在一定时间内没有收到的TCP会重发SYN-ACK。在Linux下,默认重试次数为5次,重试的间隔时间从1s开始每次都翻倍,5次的重试时间间隔为1s, 2s, 4s, 8s, 16s,总共31s,第5次发出后还要等32s都知道第5次也超时了,所以,总共需要 1s + 2s + 4s+ 8s+ 16s + 32s = 2^6 -1 = 63s,TCP才会把断开这个连接。
SYN Flood攻击
一些恶意的人就为此制造了SYN Flood攻击——给服务器发了一个SYN后,就下线了,于是服务器需要默认等63s才会断开连接,这样,攻击者就可以把服务器的syn连接的队列耗尽,让正常的连接请求不能处理。于是,Linux下给了一个叫tcp_syncookies的参数来应对这个事——当SYN队列满了后,TCP会通过源地址端口、目标地址端口和时间戳打造出一个特别的Sequence Number发回去(又叫cookie),如果是攻击者则不会有响应,如果是正常连接,则会把这个 SYN Cookie发回来,然后服务端可以通过cookie建连接(即使你不在SYN队列中)。请注意,请先千万别用tcp_syncookies来处理正常的大负载的连接的情况。因为,synccookies是妥协版的TCP协议,并不严谨。对于正常的请求,你应该调整三个TCP参数可供你选择,第一个是:tcp_synack_retries 可以用他来减少重试次数;第二个是:tcp_max_syn_backlog,可以增大SYN连接数;第三个是:tcp_abort_on_overflow 处理不过来干脆就直接拒绝连接了。
ISN的初始化
ISN是不能hard code的,不然会出问题的——比如:如果连接建好后始终用1来做ISN,如果client发了30个segment过去,但是网络断了,于是 client重连,又用了1做ISN,但是之前连接的那些包到了,于是就被当成了新连接的包,此时,client的Sequence Number 可能是3,而Server端认为client端的这个号是30了。全乱了。RFC793中说,ISN会和一个假的时钟绑在一起,这个时钟会在每4微秒对ISN做加一操作,直到超过2^32,又从0开始。这样,一个ISN的周期大约是4.55个小时。因为,我们假设我们的TCP Segment在网络上的存活时间不会超过Maximum Segment Lifetime(缩写为MSL – Wikipedia语条),所以,只要MSL的值小于4.55小时,那么,我们就不会重用到ISN。
MSL 和 TIME_WAIT
通过上面的ISN的描述,相信你也知道MSL是怎么来的了。我们注意到,在TCP的状态图中,从TIME_WAIT状态到CLOSED状态,有一个超时设置,这个超时设置是 2*MSL(RFC793定义了MSL为2分钟,Linux设置成了30s)为什么要这有TIME_WAIT?为什么不直接给转成CLOSED状态呢?主要有两个原因:1)TIME_WAIT确保有足够的时间让对端收到了ACK,如果被动关闭的那方没有收到Ack,就会触发被动端重发Fin,一来一去正好2个MSL,2)有足够的时间让这个连接不会跟后面的连接混在一起(你要知道,有些自做主张的路由器会缓存IP数据包,如果连接被重用了,那么这些延迟收到的包就有可能会跟新连接混在一起)。你可以看看这篇文章《TIME_WAIT and its design implications for protocols and scalable client server systems》
TIME_WAIT数量太多
从上面的描述我们可以知道,TIME_WAIT是个很重要的状态,但是如果在大并发的短链接下,TIME_WAIT 就会太多,这也会消耗很多系统资源。只要搜一下,你就会发现,十有八九的处理方式都是教你设置两个参数,一个叫tcp_tw_reuse,另一个叫tcp_tw_recycle的参数,这两个参数默认值都是被关闭的,后者recyle比前者resue更为激进,resue要温柔一些。另外,如果使用tcp_tw_reuse,必需设置tcp_timestamps=1,否则无效。这里,你一定要注意,打开这两个参数会有比较大的坑——可能会让TCP连接出一些诡异的问题(因为如上述一样,如果不等待超时重用连接的话,新的连接可能会建不上。正如官方文档上说的一样“It should not be changed without advice/request of technical experts”)。
- 关于tcp_tw_reuse。官方文档上说tcp_tw_reuse 加上tcp_timestamps(又叫PAWS, for Protection Against Wrapped Sequence Numbers)可以保证协议的角度上的安全,但是你需要tcp_timestamps在两边都被打开(你可以读一下tcp_twsk_unique的源码 )。我个人估计还是有一些场景会有问题。
- 关于tcp_tw_recycle。如果是tcp_tw_recycle被打开了话,会假设对端开启了tcp_timestamps,然后会去比较时间戳,如果时间戳变大了,就可以重用。但是,如果对端是一个NAT网络的话(如:一个公司只用一个IP出公网)或是对端的IP被另一台重用了,这个事就复杂了。建链接的SYN可能就被直接丢掉了(你可能会看到connection time out的错误)(如果你想观摩一下Linux的内核代码,请参看源码 tcp_timewait_state_process)。
- 关于tcp_max_tw_buckets。这个是控制并发的TIME_WAIT的数量,默认值是180000,如果超限,那么,系统会把多的给destory掉,然后在日志里打一个警告(如:time wait bucket table overflow),官网文档说这个参数是用来对抗DDoS攻击的。也说的默认值180000并不小。这个还是需要根据实际情况考虑。
其实,TIME_WAIT表示的是你主动断连接,所以,这就是所谓的“不作死不会死”。试想,如果让对端断连接,那么这个破问题就是对方的了,呵呵。另外,如果你的服务器是于HTTP服务器,那么设置一个HTTP的KeepAlive有多重要(浏览器会重用一个TCP连接来处理多个HTTP请求),然后让客户端去断链接(你要小心,浏览器可能会非常贪婪,他们不到万不得已不会主动断连接)。
数据传输中的 Sequence Number
下图是我从Wireshark中截了个我在访问coolshell.cn时的有数据传输的图给你看一下,SeqNum是怎么变的。(使用Wireshark菜单中的Statistics ->Flow Graph… )
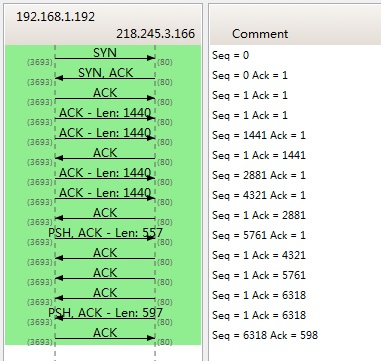
你可以看到,SeqNum的增加是和传输的字节数相关的。上图中,三次握手后,来了两个Len:1440的包,而第二个包的SeqNum就成了1441。然后第一个ACK回的是1441,表示第一个1440收到了。
注意:如果你用Wireshark抓包程序看3次握手,你会发现SeqNum总是为0,不是这样的,Wireshark为了显示更友好,使用了Relative SeqNum——相对序号,你只要在右键菜单中的protocol preference 中取消掉就可以看到“Absolute SeqNum”了
TCP 重传机制
TCP要保证所有的数据包都可以到达,所以,必需要有重传机制。
注意,接收端给发送端的Ack确认只会确认最后一个连续的包,比如,发送端发了1,2,3,4,5一共五份数据,接收端收到了1,2,于是回ack 3,然后收到了4(注意此时3没收到),此时的TCP会怎么办?我们要知道,因为正如前面所说的,SeqNum和Ack是以字节数为单位,所以ack的时候,不能跳着确认,只能确认最大的连续收到的包,不然,发送端就以为之前的都收到了。
超时重传机制
一种是不回ack,死等3,当发送方发现收不到3的ack超时后,会重传3。一旦接收方收到3后,会ack 回 4——意味着3和4都收到了。
但是,这种方式会有比较严重的问题,那就是因为要死等3,所以会导致4和5即便已经收到了,而发送方也完全不知道发生了什么事,因为没有收到Ack,所以,发送方可能会悲观地认为也丢了,所以有可能也会导致4和5的重传。
对此有两种选择:
- 一种是仅重传timeout的包。也就是第3份数据。
- 另一种是重传timeout后所有的数据,也就是第3,4,5这三份数据。
这两种方式有好也有不好。第一种会节省带宽,但是慢,第二种会快一点,但是会浪费带宽,也可能会有无用功。但总体来说都不好。因为都在等timeout,timeout可能会很长(在下篇会说TCP是怎么动态地计算出timeout的)
快速重传机制
于是,TCP引入了一种叫Fast Retransmit 的算法,不以时间驱动,而以数据驱动重传。也就是说,如果,包没有连续到达,就ack最后那个可能被丢了的包,如果发送方连续收到3次相同的ack,就重传。Fast Retransmit的好处是不用等timeout了再重传。
比如:如果发送方发出了1,2,3,4,5份数据,第一份先到送了,于是就ack回2,结果2因为某些原因没收到,3到达了,于是还是ack回2,后面的4和5都到了,但是还是ack回2,因为2还是没有收到,于是发送端收到了三个ack=2的确认,知道了2还没有到,于是就马上重转2。然后,接收端收到了2,此时因为3,4,5都收到了,于是ack回6。示意图如下:
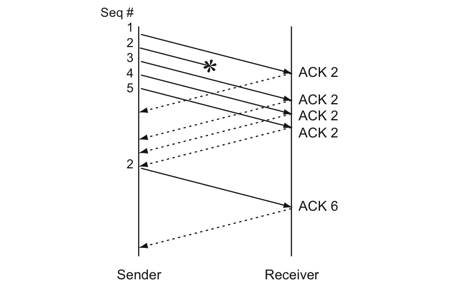
Fast Retransmit只解决了一个问题,就是timeout的问题,它依然面临一个艰难的选择,就是,是重传之前的一个还是重传所有的问题。对于上面的示例来说,是重传#2呢还是重传#2,#3,#4,#5呢?因为发送端并不清楚这连续的3个ack(2)是谁传回来的?也许发送端发了20份数据,是#6,#10,#20传来的呢。这样,发送端很有可能要重传从2到20的这堆数据(这就是某些TCP的实际的实现)。可见,这是一把双刃剑。
SACK 方法
另外一种更好的方式叫:Selective Acknowledgment (SACK)(参看RFC 2018),这种方式需要在TCP头里加一个SACK的东西,ACK还是Fast Retransmit的ACK,SACK则是汇报收到的数据碎版。参看下图:
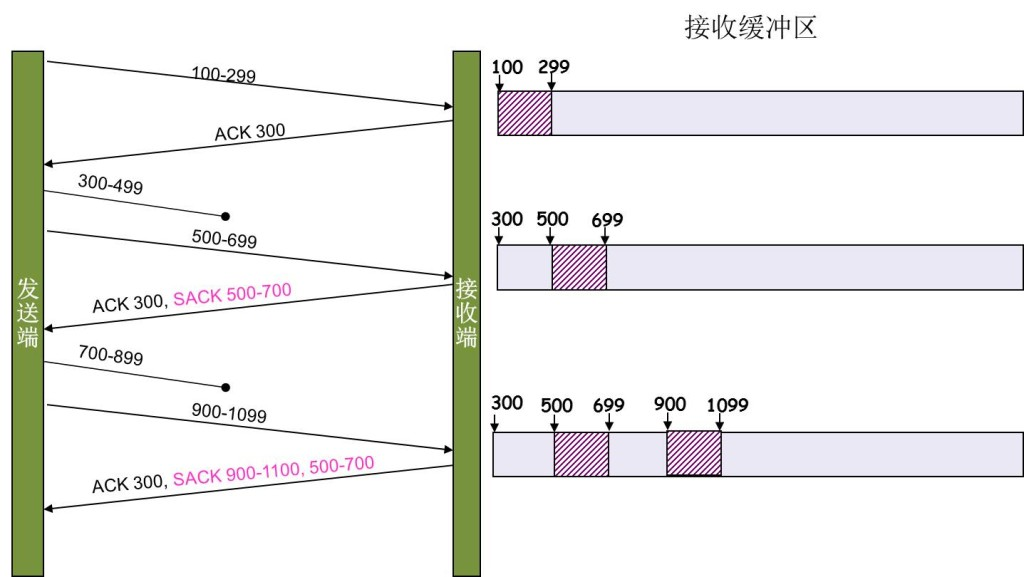
这样,在发送端就可以根据回传的SACK来知道哪些数据到了,哪些没有到。于是就优化了Fast Retransmit的算法。当然,这个协议需要两边都支持。在 Linux下,可以通过tcp_sack参数打开这个功能(Linux 2.4后默认打开)。
这里还需要注意一个问题——接收方Reneging,所谓Reneging的意思就是接收方有权把已经报给发送端SACK里的数据给丢了。这样干是不被鼓励的,因为这个事会把问题复杂化了,但是,接收方这么做可能会有些极端情况,比如要把内存给别的更重要的东西。所以,发送方也不能完全依赖SACK,还是要依赖ACK,并维护Time-Out,如果后续的ACK没有增长,那么还是要把SACK的东西重传,另外,接收端这边永远不能把SACK的包标记为Ack。
注意:SACK会消费发送方的资源,试想,如果一个攻击者给数据发送方发一堆SACK的选项,这会导致发送方开始要重传甚至遍历已经发出的数据,这会消耗很多发送端的资源。详细的东西请参看《TCP SACK的性能权衡》
Duplicate SACK – 重复收到数据的问题
Duplicate SACK又称D-SACK,其主要使用了SACK来告诉发送方有哪些数据被重复接收了。RFC-2883 里有详细描述和示例。下面举几个例子(来源于RFC-2883)
D-SACK使用了SACK的第一个段来做标志,
- 如果SACK的第一个段的范围被ACK所覆盖,那么就是D-SACK
- 如果SACK的第一个段的范围被SACK的第二个段覆盖,那么就是D-SACK
示例一:ACK丢包
下面的示例中,丢了两个ACK,所以,发送端重传了第一个数据包(3000-3499),于是接收端发现重复收到,于是回了一个SACK=3000-3500,因为ACK都到了4000意味着收到了4000之前的所有数据,所以这个SACK就是D-SACK——旨在告诉发送端我收到了重复的数据,而且我们的发送端还知道,数据包没有丢,丢的是ACK包。
Transmitted Received ACK Sent
Segment Segment (Including SACK Blocks)
3000-3499 3000-3499 3500 (ACK dropped)
3500-3999 3500-3999 4000 (ACK dropped)
3000-3499 3000-3499 4000, SACK=3000-3500
---------
示例二,网络延误
下面的示例中,网络包(1000-1499)被网络给延误了,导致发送方没有收到ACK,而后面到达的三个包触发了“Fast Retransmit算法”,所以重传,但重传时,被延误的包又到了,所以,回了一个SACK=1000-1500,因为ACK已到了3000,所以,这个SACK是D-SACK——标识收到了重复的包。
这个案例下,发送端知道之前因为“Fast Retransmit算法”触发的重传不是因为发出去的包丢了,也不是因为回应的ACK包丢了,而是因为网络延时了。
Transmitted Received ACK Sent
Segment Segment (Including SACK Blocks)
500-999 500-999 1000
1000-1499 (delayed)
1500-1999 1500-1999 1000, SACK=1500-2000
2000-2499 2000-2499 1000, SACK=1500-2500
2500-2999 2500-2999 1000, SACK=1500-3000
1000-1499 1000-1499 3000
1000-1499 3000, SACK=1000-1500
---------
可见,引入了D-SACK,有这么几个好处:
- 1)可以让发送方知道,是发出去的包丢了,还是回来的ACK包丢了。
- 2)是不是自己的timeout太小了,导致重传。
- 3)网络上出现了先发的包后到的情况(又称reordering)
- 4)网络上是不是把我的数据包给复制了。
知道这些东西可以很好得帮助TCP了解网络情况,从而可以更好的做网络上的流控。
Linux下的tcp_dsack参数用于开启这个功能(Linux 2.4后默认打开)
TCP的RTT算法
从前面的TCP重传机制我们知道Timeout的设置对于重传非常重要。
- 设长了,重发就慢,丢了老半天才重发,没有效率,性能差;
- 设短了,会导致可能并没有丢就重发。于是重发的就快,会增加网络拥塞,导致更多的超时,更多的超时导致更多的重发。
而且,这个超时时间在不同的网络的情况下,根本没有办法设置一个死的值。只能动态地设置。 为了动态地设置,TCP引入了RTT——Round Trip Time,也就是一个数据包从发出去到回来的时间。这样发送端就大约知道需要多少的时间,从而可以方便地设置Timeout——RTO(Retransmission TimeOut),以让我们的重传机制更高效。 听起来似乎很简单,好像就是在发送端发包时记下t0,然后接收端再把这个ack回来时再记一个t1,于是RTT = t1 – t0。没那么简单,这只是一个采样,不能代表普遍情况
经典算法
RFC793 中定义的经典算法是这样的:
- 1)首先,先采样RTT,记下最近好几次的RTT值。
- 2)然后做平滑计算
SRTT( Smoothed RTT)。公式为:(其中的 α 取值在0.8 到 0.9之间,这个算法英文叫Exponential weighted moving average,中文叫:加权移动平均)
SRTT = ( α * SRTT ) + ((1- α) * RTT)
3)开始计算RTO。公式如下:
RTO = min [ UBOUND, max [ LBOUND, (β * SRTT) ] ]- UBOUND是最大的timeout时间,上限值
- LBOUND是最小的timeout时间,下限值
- β 值一般在1.3到2.0之间。
Karn / Partridge 算法
但是上面的这个算法在重传的时候会出有一个终极问题——你是用第一次发数据的时间和ack回来的时间做RTT样本值,还是用重传的时间和ACK回来的时间做RTT样本值?
这个问题无论你选那头都是按下葫芦起了瓢。 如下图所示:
- 情况(a)是ack没回来,所以重传。如果你计算第一次发送和ACK的时间,那么,明显算大了。
- 情况(b)是ack回来慢了,但是导致了重传,但刚重传不一会儿,之前ACK就回来了。如果你是算重传的时间和ACK回来的时间的差,就会算短了。
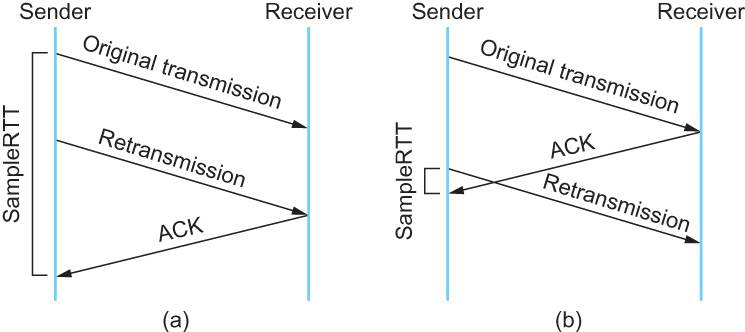
所以1987年的时候,搞了一个叫Karn / Partridge Algorithm,这个算法的最大特点是——忽略重传,不把重传的RTT做采样(你看,你不需要去解决不存在的问题)。
但是,这样一来,又会引发一个大BUG——如果在某一时间,网络闪动,突然变慢了,产生了比较大的延时,这个延时导致要重转所有的包(因为之前的RTO很小),于是,因为重转的不算,所以,RTO就不会被更新,这是一个灾难。 于是Karn算法用了一个取巧的方式——只要一发生重传,就对现有的RTO值翻倍(这就是所谓的 Exponential backoff),很明显,这种死规矩对于一个需要估计比较准确的RTT也不靠谱。
Jacobson / Karels 算法
前面两种算法用的都是“加权移动平均”,这种方法最大的毛病就是如果RTT有一个大的波动的话,很难被发现,因为被平滑掉了。所以,1988年,又有人推出来了一个新的算法,这个算法叫Jacobson / Karels Algorithm(参看RFC6289)。这个算法引入了最新的RTT的采样和平滑过的SRTT的差距做因子来计算。 公式如下:(其中的DevRTT是Deviation RTT的意思)
SRTT = SRTT + α (RTT – SRTT)—— 计算平滑RTTDevRTT = (1-β)*DevRTT + β*(|RTT-SRTT|)——计算平滑RTT和真实的差距(加权移动平均)RTO= µ * SRTT + ∂ *DevRTT—— 神一样的公式
(其中:在Linux下,α = 0.125,β = 0.25, μ = 1,∂ = 4 ——这就是算法中的“调得一手好参数”,nobody knows why, it just works…) 最后的这个算法在被用在今天的TCP协议中(Linux的源代码在:tcp_rtt_estimator)。
TCP滑动窗口
需要说明一下,如果你不了解TCP的滑动窗口这个事,你等于不了解TCP协议。我们都知道,TCP必需要解决的可靠传输以及包乱序(reordering)的问题,所以,TCP必需要知道网络实际的数据处理带宽或是数据处理速度,这样才不会引起网络拥塞,导致丢包。
所以,TCP引入了一些技术和设计来做网络流控,Sliding Window是其中一个技术。 前面我们说过,TCP头里有一个字段叫Window,又叫Advertised-Window,这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。 为了说明滑动窗口,我们需要先看一下TCP缓冲区的一些数据结构:
上图中,我们可以看到:
- 接收端LastByteRead指向了TCP缓冲区中读到的位置,NextByteExpected指向的地方是收到的连续包的最后一个位置,LastByteRcved指向的是收到的包的最后一个位置,我们可以看到中间有些数据还没有到达,所以有数据空白区。
- 发送端的LastByteAcked指向了被接收端Ack过的位置(表示成功发送确认),LastByteSent表示发出去了,但还没有收到成功确认的Ack,LastByteWritten指向的是上层应用正在写的地方。
于是:
- 接收端在给发送端回ACK中会汇报自己的AdvertisedWindow = MaxRcvBuffer – LastByteRcvd – 1;
- 而发送方会根据这个窗口来控制发送数据的大小,以保证接收方可以处理。
下面我们来看一下发送方的滑动窗口示意图:
上图中分成了四个部分,分别是:(其中那个黑模型就是滑动窗口)
- #1已收到ack确认的数据。
- #2发还没收到ack的。
- #3在窗口中还没有发出的(接收方还有空间)。
- #4窗口以外的数据(接收方没空间)
下面是个滑动后的示意图(收到36的ack,并发出了46-51的字节):
下面我们来看一个接受端控制发送端的图示:
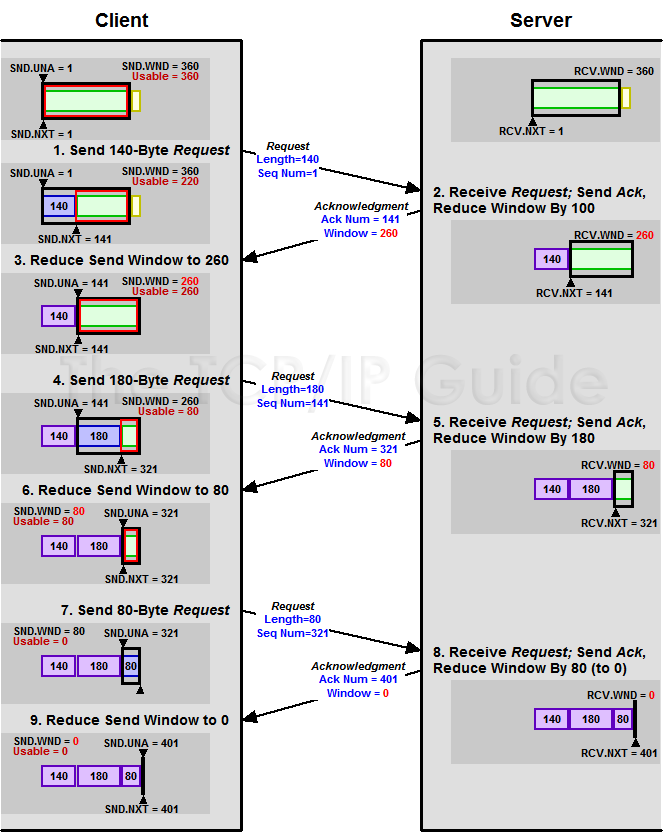
Zero Window
上图,我们可以看到一个处理缓慢的Server(接收端)是怎么把Client(发送端)的TCP Sliding Window给降成0的。此时,你一定会问,如果Window变成0了,TCP会怎么样?是不是发送端就不发数据了?是的,发送端就不发数据了,你可以想像成“Window Closed”,那你一定还会问,如果发送端不发数据了,接收方一会儿Window size 可用了,怎么通知发送端呢?
解决这个问题,TCP使用了Zero Window Probe技术,缩写为ZWP,也就是说,发送端在窗口变成0后,会发ZWP的包给接收方,让接收方来ack他的Window尺寸,一般这个值会设置成3次,第次大约30-60秒(不同的实现可能会不一样)。如果3次过后还是0的话,有的TCP实现就会发RST把链接断了。
注意:只要有等待的地方都可能出现DDoS攻击,Zero Window也不例外,一些攻击者会在和HTTP建好链发完GET请求后,就把Window设置为0,然后服务端就只能等待进行ZWP,于是攻击者会并发大量的这样的请求,把服务器端的资源耗尽。(关于这方面的攻击,大家可以移步看一下Wikipedia的SockStress词条)
另外,Wireshark中,你可以使用tcp.analysis.zero_window来过滤包,然后使用右键菜单里的follow TCP stream,你可以看到ZeroWindowProbe及ZeroWindowProbeAck的包。
Silly Window Syndrome
Silly Window Syndrome翻译成中文就是“糊涂窗口综合症”。正如你上面看到的一样,如果我们的接收方太忙了,来不及取走Receive Windows里的数据,那么,就会导致发送方越来越小。到最后,如果接收方腾出几个字节并告诉发送方现在有几个字节的window,而我们的发送方会义无反顾地发送这几个字节。
要知道,我们的TCP+IP头有40个字节,为了几个字节,要达上这么大的开销,这太不经济了。
另外,你需要知道网络上有个MTU,对于以太网来说,MTU是1500字节,除去TCP+IP头的40个字节,真正的数据传输可以有1460,这就是所谓的MSS(Max Segment Size)注意,TCP的RFC定义这个MSS的默认值是536,这是因为 RFC 791里说了任何一个IP设备都得最少接收576尺寸的大小(实际上来说576是拨号的网络的MTU,而576减去IP头的20个字节就是536)。
如果你的网络包可以塞满MTU,那么你可以用满整个带宽,如果不能,那么你就会浪费带宽。(大于MTU的包有两种结局,一种是直接被丢了,另一种是会被重新分块打包发送) 你可以想像成一个MTU就相当于一个飞机的最多可以装的人,如果这飞机里满载的话,带宽最高,如果一个飞机只运一个人的话,无疑成本增加了,也而相当二。
所以,Silly Windows Syndrome这个现像就像是你本来可以坐200人的飞机里只做了一两个人。 要解决这个问题也不难,就是避免对小的window size做出响应,直到有足够大的window size再响应,这个思路可以同时实现在sender和receiver两端。
- 如果这个问题是由Receiver端引起的,那么就会使用 David D Clark’s 方案。在receiver端,如果收到的数据导致window size小于某个值,可以直接ack(0)回sender,这样就把window给关闭了,也阻止了sender再发数据过来,等到receiver端处理了一些数据后windows size 大于等于了MSS,或者,receiver buffer有一半为空,就可以把window打开让send 发送数据过来。
- 如果这个问题是由Sender端引起的,那么就会使用著名的 Nagle’s algorithm。这个算法的思路也是延时处理,他有两个主要的条件:1)要等到 Window Size>=MSS 或是 Data Size >=MSS,2)收到之前发送数据的ack回包,他才会发数据,否则就是在攒数据。
另外,Nagle算法默认是打开的,所以,对于一些需要小包场景的程序——比如像telnet或ssh这样的交互性比较强的程序,你需要关闭这个算法。你可以在Socket设置TCP_NODELAY选项来关闭这个算法(关闭Nagle算法没有全局参数,需要根据每个应用自己的特点来关闭)
setsockopt(sock_fd, IPPROTO_TCP, TCP_NODELAY, (char *)&value,sizeof(int));
另外,网上有些文章说TCP_CORK的socket option是也关闭Nagle算法,这不对。TCP_CORK其实是更新激进的Nagle算法,完全禁止小包发送,而Nagle算法没有禁止小包发送,只是禁止了大量的小包发送。最好不要两个选项都设置。
TCP的拥塞处理 – Congestion Handling
上面我们知道了,TCP通过Sliding Window来做流控(Flow Control),但是TCP觉得这还不够,因为Sliding Window需要依赖于连接的发送端和接收端,其并不知道网络中间发生了什么。TCP的设计者觉得,一个伟大而牛逼的协议仅仅做到流控并不够,因为流控只是网络模型4层以上的事,TCP的还应该更聪明地知道整个网络上的事。
具体一点,我们知道TCP通过一个timer采样了RTT并计算RTO,但是,如果网络上的延时突然增加,那么,TCP对这个事做出的应对只有重传数据,但是,重传会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,于是,这个情况就会进入恶性循环被不断地放大。试想一下,如果一个网络内有成千上万的TCP连接都这么行事,那么马上就会形成“网络风暴”,TCP这个协议就会拖垮整个网络。这是一个灾难。
所以,TCP不能忽略网络上发生的事情,而无脑地一个劲地重发数据,对网络造成更大的伤害。对此TCP的设计理念是:TCP不是一个自私的协议,当拥塞发生的时候,要做自我牺牲。就像交通阻塞一样,每个车都应该把路让出来,而不要再去抢路了。
关于拥塞控制的论文请参看《Congestion Avoidance and Control》(PDF)
拥塞控制主要是四个算法:1)慢启动,2)拥塞避免,3)拥塞发生,4)快速恢复。这四个算法不是一天都搞出来的,这个四算法的发展经历了很多时间,到今天都还在优化中。 备注:
- 1988年,TCP-Tahoe 提出了1)慢启动,2)拥塞避免,3)拥塞发生时的快速重传
- 1990年,TCP Reno 在Tahoe的基础上增加了4)快速恢复
慢热启动算法 – Slow Start
首先,我们来看一下TCP的慢热启动。慢启动的意思是,刚刚加入网络的连接,一点一点地提速,不要一上来就像那些特权车一样霸道地把路占满。新同学上高速还是要慢一点,不要把已经在高速上的秩序给搞乱了。
慢启动的算法如下(cwnd全称Congestion Window):
1)连接建好的开始先初始化cwnd = 1,表明可以传一个MSS大小的数据。
2)每当收到一个ACK,cwnd++; 呈线性上升
3)每当过了一个RTT,cwnd = cwnd*2; 呈指数让升
4)还有一个ssthresh(slow start threshold),是一个上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”(后面会说这个算法)
所以,我们可以看到,如果网速很快的话,ACK也会返回得快,RTT也会短,那么,这个慢启动就一点也不慢。下图说明了这个过程。
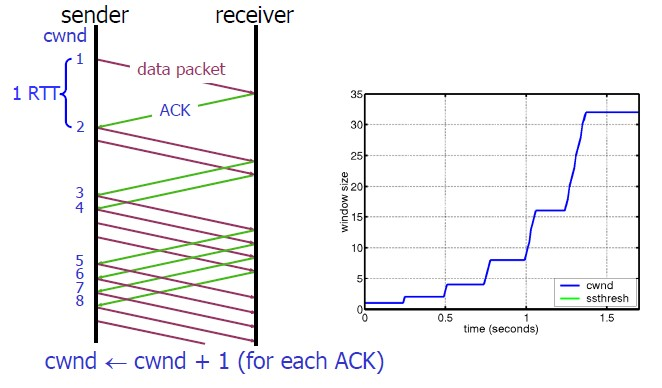
这里,我需要提一下的是一篇Google的论文《An Argument for Increasing TCP’s Initial Congestion Window》, Linux 3.0后采用了这篇论文的建议——把cwnd 初始化成了 10个MSS。 而Linux 3.0以前,比如2.6,Linux采用了RFC3390,cwnd是跟MSS的值来变的,如果MSS< 1095,则cwnd = 4;如果MSS>2190,则cwnd=2;其它情况下,则是3。
拥塞避免算法 – Congestion Avoidance
前面说过,还有一个ssthresh(slow start threshold),是一个上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”。一般来说ssthresh的值是65535,单位是字节,当cwnd达到这个值时后,算法如下:
- 1)收到一个ACK时,cwnd = cwnd + 1/cwnd
- 2)当每过一个RTT时,cwnd = cwnd + 1
这样就可以避免增长过快导致网络拥塞,慢慢的增加调整到网络的最佳值。很明显,是一个线性上升的算法。
拥塞状态时的算法
前面我们说过,当丢包的时候,会有两种情况:
- 1)等到RTO超时,重传数据包。TCP认为这种情况太糟糕,反应也很强烈。
- sshthresh = cwnd /2
- cwnd 重置为 1
- 进入慢启动过程
- 2)Fast Retransmit算法,也就是在收到3个duplicate ACK时就开启重传,而不用等到RTO超时。
- TCP Tahoe的实现和RTO超时一样。
- TCP Reno的实现是:
- cwnd = cwnd /2
- sshthresh = cwnd
- 进入快速恢复算法——Fast Recovery
上面我们可以看到RTO超时后,sshthresh会变成cwnd的一半,这意味着,如果cwnd<=sshthresh时出现的丢包,那么TCP的sshthresh就会减了一半,然后等cwnd又很快地以指数级增涨爬到这个地方时,就会成慢慢的线性增涨。我们可以看到,TCP是怎么通过这种强烈地震荡快速而小心得找到网站流量的平衡点的。
快速恢复算法 – Fast Recovery
TCP Reno
这个算法定义在RFC5681。快速重传和快速恢复算法一般同时使用。快速恢复算法是认为,你还有3个Duplicated Acks说明网络也不那么糟糕,所以没有必要像RTO超时那么强烈。 注意,正如前面所说,进入Fast Recovery之前,cwnd 和 sshthresh已被更新:
- cwnd = cwnd /2
- sshthresh = cwnd
然后,真正的Fast Recovery算法如下:
- cwnd = sshthresh + 3 * MSS (3的意思是确认有3个数据包被收到了)
- 重传Duplicated ACKs指定的数据包
- 如果再收到 duplicated Acks,那么cwnd = cwnd +1
- 如果收到了新的Ack,那么,cwnd = sshthresh ,然后就进入了拥塞避免的算法了。
如果你仔细思考一下上面的这个算法,你就会知道,上面这个算法也有问题,那就是——它依赖于3个重复的Acks。注意,3个重复的Acks并不代表只丢了一个数据包,很有可能是丢了好多包。但这个算法只会重传一个,而剩下的那些包只能等到RTO超时,于是,进入了恶梦模式——超时一个窗口就减半一下,多个超时会超成TCP的传输速度呈级数下降,而且也不会触发Fast Recovery算法了。
通常来说,正如我们前面所说的,SACK或D-SACK的方法可以让Fast Recovery或Sender在做决定时更聪明一些,但是并不是所有的TCP的实现都支持SACK(SACK需要两端都支持),所以,需要一个没有SACK的解决方案。而通过SACK进行拥塞控制的算法是FACK(后面会讲)
TCP New Reno
于是,1995年,TCP New Reno(参见 RFC 6582 )算法提出来,主要就是在没有SACK的支持下改进Fast Recovery算法的——
当sender这边收到了3个Duplicated Acks,进入Fast Retransimit模式,开发重传重复Acks指示的那个包。如果只有这一个包丢了,那么,重传这个包后回来的Ack会把整个已经被sender传输出去的数据ack回来。如果没有的话,说明有多个包丢了。我们叫这个ACK为Partial ACK。 一旦Sender这边发现了Partial ACK出现,那么,sender就可以推理出来有多个包被丢了,于是乎继续重传sliding window里未被ack的第一个包。直到再也收不到了Partial Ack,才真正结束Fast Recovery这个过程 我们可以看到,这个“Fast Recovery的变更”是一个非常激进的玩法,他同时延长了Fast Retransmit和Fast Recovery的过程。
算法示意图
下面我们来看一个简单的图示以同时看一下上面的各种算法的样子:
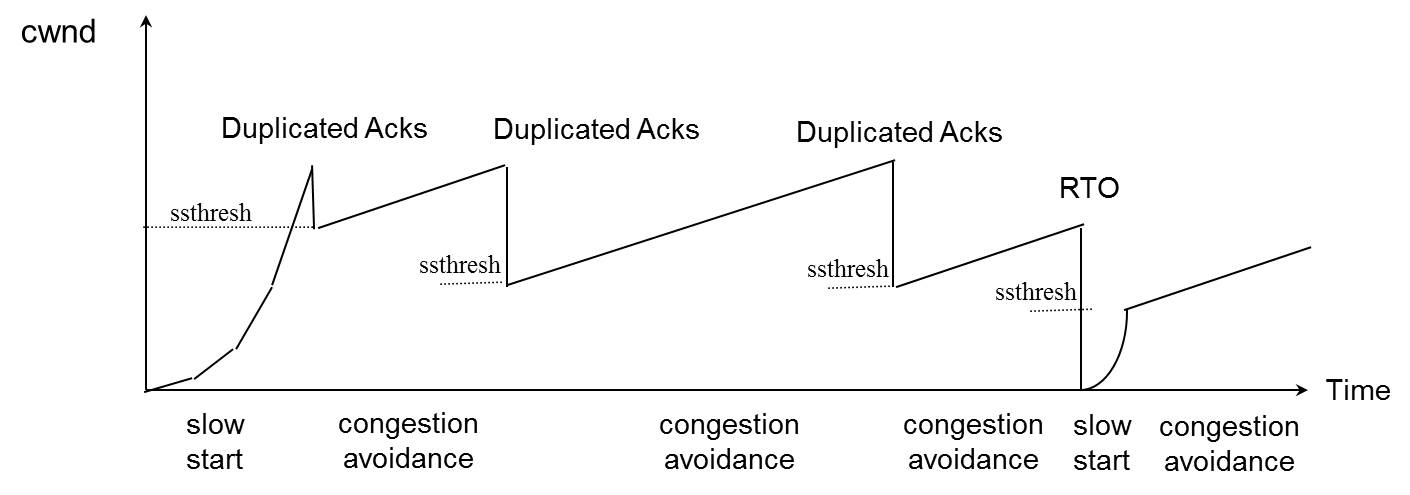
FACK算法
FACK全称Forward Acknowledgment 算法,论文地址在这里(PDF)Forward Acknowledgement: Refining TCP Congestion Control 这个算法是其于SACK的,前面我们说过SACK是使用了TCP扩展字段Ack了有哪些数据收到,哪些数据没有收到,他比Fast Retransmit的3 个duplicated acks好处在于,前者只知道有包丢了,不知道是一个还是多个,而SACK可以准确的知道有哪些包丢了。 所以,SACK可以让发送端这边在重传过程中,把那些丢掉的包重传,而不是一个一个的传,但这样的一来,如果重传的包数据比较多的话,又会导致本来就很忙的网络就更忙了。所以,FACK用来做重传过程中的拥塞流控。
- 这个算法会把SACK中最大的Sequence Number 保存在
snd.fack这个变量中,snd.fack的更新由ack带秋,如果网络一切安好则和snd.una一样(snd.una就是还没有收到ack的地方,也就是前面sliding window里的category #2的第一个地方) - 然后定义一个
awnd = snd.nxt – snd.fack(snd.nxt指向发送端sliding window中正在要被发送的地方——前面sliding windows图示的category#3第一个位置),这样awnd的意思就是在网络上的数据。(所谓awnd意为:actual quantity of data outstanding in the network) - 如果需要重传数据,那么,
awnd = snd.nxt – snd.fack + retran_data,也就是说,awnd是传出去的数据 + 重传的数据。 - 然后触发Fast Recovery 的条件是: (
( snd.fack – snd.una ) > (3*MSS) ) || (dupacks == 3)) 。这样一来,就不需要等到3个duplicated acks才重传,而是只要sack中的最大的一个数据和ack的数据比较长了(3个MSS),那就触发重传。在整个重传过程中cwnd不变。直到当第一次丢包的snd.nxt<=snd.una(也就是重传的数据都被确认了),然后进来拥塞避免机制——cwnd线性上涨。
我们可以看到如果没有FACK在,那么在丢包比较多的情况下,原来保守的算法会低估了需要使用的window的大小,而需要几个RTT的时间才会完成恢复,而FACK会比较激进地来干这事。 但是,FACK如果在一个网络包会被 reordering的网络里会有很大的问题。
其它拥塞控制算法简介
TCP Vegas 拥塞控制算法
这个算法1994年被提出,它主要对TCP Reno 做了些修改。这个算法通过对RTT的非常重的监控来计算一个基准RTT。然后通过这个基准RTT来估计当前的网络实际带宽,如果实际带宽比我们的期望的带宽要小或是要多的活,那么就开始线性地减少或增加cwnd的大小。如果这个计算出来的RTT大于了Timeout后,那么,不等ack超时就直接重传。(Vegas 的核心思想是用RTT的值来影响拥塞窗口,而不是通过丢包) 这个算法的论文是《TCP Vegas: End to End Congestion Avoidance on a Global Internet》这篇论文给了Vegas和 New Reno的对比:
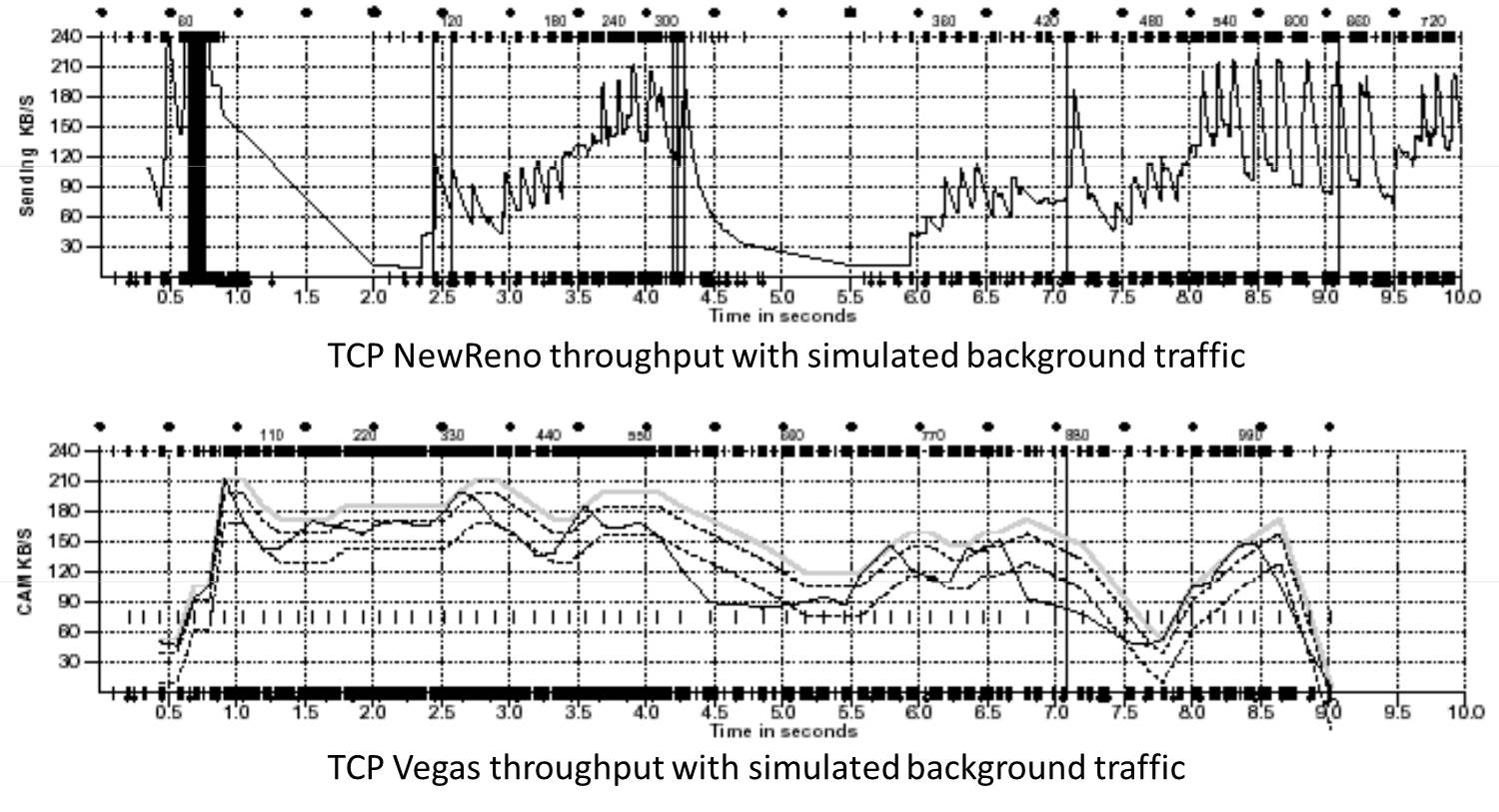
关于这个算法实现,你可以参看Linux源码:/net/ipv4/tcp_vegas.h (opens new window), /net/ipv4/tcp_vegas.c
HSTCP(High Speed TCP) 算法
这个算法来自RFC 3649。其对最基础的算法进行了更改,他使得Congestion Window涨得快,减得慢。其中:
- 拥塞避免时的窗口增长方式: cwnd = cwnd + α(cwnd) / cwnd
- 丢包后窗口下降方式:cwnd = (1- β(cwnd))*cwnd
注:α(cwnd)和β(cwnd)都是函数,如果你要让他们和标准的TCP一样,那么让α(cwnd)=1,β(cwnd)=0.5就可以了。 对于α(cwnd)和β(cwnd)的值是个动态的变换的东西。 关于这个算法的实现,你可以参看Linux源码:/net/ipv4/tcp_highspeed.c
TCP BIC 算法
2004年,产内出BIC算法。现在你还可以查得到相关的新闻《Google:美科学家研发BIC-TCP协议 速度是DSL六千倍》 BIC全称Binary Increase Congestion control,在Linux 2.6.8中是默认拥塞控制算法。BIC的发明者发这么多的拥塞控制算法都在努力找一个合适的cwnd – Congestion Window,而且BIC-TCP的提出者们看穿了事情的本质,其实这就是一个搜索的过程,所以BIC这个算法主要用的是Binary Search——二分查找来干这个事。 关于这个算法实现,你可以参看Linux源码:/net/ipv4/tcp_bic.c
TCP WestWood算法
westwood采用和Reno相同的慢启动算法、拥塞避免算法。westwood的主要改进方面:在发送端做带宽估计,当探测到丢包时,根据带宽值来设置拥塞窗口、慢启动阈值。 那么,这个算法是怎么测量带宽的?每个RTT时间,会测量一次带宽,测量带宽的公式很简单,就是这段RTT内成功被ack了多少字节。因为,这个带宽和用RTT计算RTO一样,也是需要从每个样本来平滑到一个值的——也是用一个加权移平均的公式。 另外,我们知道,如果一个网络的带宽是每秒可以发送X个字节,而RTT是一个数据发出去后确认需要的时候,所以,X * RTT应该是我们缓冲区大小。所以,在这个算法中,ssthresh的值就是est_BD * min-RTT(最小的RTT值),如果丢包是Duplicated ACKs引起的,那么如果cwnd > ssthresh,则 cwin = ssthresh。如果是RTO引起的,cwnd = 1,进入慢启动。 关于这个算法实现,你可以参看Linux源码: /net/ipv4/tcp_westwood.c
其它
更多的算法,你可以从Wikipedia的 TCP Congestion Avoidance Algorithm 词条中找到相关的线索
4.4 - UDP 协议
概览
UDP(User Datagram Protocol)即用户数据报协议,在网络中它与TCP协议一样用于处理数据包,是一种无连接的协议。在OSI模型中,在第四层——传输层,处于IP协议的上一层。
UDP用来支持那些需要在计算机之间传输数据的网络应用。包括网络视频会议系统在内的众多的客户/服务器模式的网络应用都需要使用UDP协议。UDP协议从问世至今已经被使用了很多年,虽然其最初的光彩已经被一些类似协议所掩盖,但是即使是在今天UDP仍然不失为一项非常实用和可行的网络传输层协议。UDP报文没有可靠性保证、顺序保证和流量控制字段等,可靠性较差。但是正因为UDP协议的控制选项较少,在数据传输过程中延迟小、数据传输效率高,适合对可靠性要求不高的应用程序,或者可以保障可靠性的应用程序,如DNS、TFTP、SNMP等。
特点
UDP提供不可靠服务,但具有TCP所没有的优势:
- UDP无连接,时间上不存在建立连接需要的时延。空间上,TCP需要在端系统中维护连接状态,需要一定的开销。此连接装入包括接收和发送缓存,拥塞控制参数和序号与确认号的参数。UDP不维护连接状态,也不跟踪这些参数,开销小。空间和时间上都具有优势。 举个例子:
- DNS如果运行在TCP之上而不是UDP,那么DNS的速度将会慢很多。
- HTTP使用TCP而不是UDP,是因为对于基于文本数据的Web网页来说,可靠性很重要。
- 同一种专用应用服务器在支持UDP时,一定能支持更多的活动客户机。
- 分组首部开销小,TCP首部20字节,UDP首部8字节。
- UDP没有拥塞控制,应用层能够更好的控制要发送的数据和发送时间,网络中的拥塞控制也不会影响主机的发送速率。某些实时应用要求以稳定的速度发送,能容 忍一些数据的丢失,但是不能允许有较大的时延(比如实时视频,直播等)
- UDP提供尽最大努力的交付,不保证可靠交付。所有维护传输可靠性的工作需要用户在应用层来完成。没有TCP的确认机制、重传机制。如果因为网络原因没有传送到对端,UDP也不会给应用层返回错误信息
- UDP是面向报文的,对应用层交下来的报文,添加首部后直接乡下交付为IP层,既不合并,也不拆分,保留这些报文的边界。对IP层交上来UDP用户数据报,在去除首部后就原封不动地交付给上层应用进程,报文不可分割,是UDP数据报处理的最小单位。 正是因为这样,UDP显得不够灵活,不能控制读写数据的次数和数量。比如我们要发送100个字节的报文,我们调用一次sendto函数就会发送100字节,对端也需要用recvfrom函数一次性接收100字节,不能使用循环每次获取10个字节,获取十次这样的做法。
- UDP常用一次性传输比较少量数据的网络应用,如DNS,SNMP等,因为对于这些应用,若是采用TCP,为连接的创建,维护和拆除带来不小的开销。UDP也常用于多媒体应用(如IP电话,实时视频会议,流媒体等)数据的可靠传输对他们而言并不重要,TCP的拥塞控制会使他们有较大的延迟,也是不可容忍的
- UDP 支持一对一、一对多、多对一和多对多的交互通信。
还要注意的是:
- IP 数据报要经过互连网中许多路由器的存储转发;UDP 用户数据报是在运输层的端到端抽象的逻辑信道中传送的。
UDP 对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。应用层交给 UDP 多长的报文,UDP 就照样发送,即一次发送一个报文。
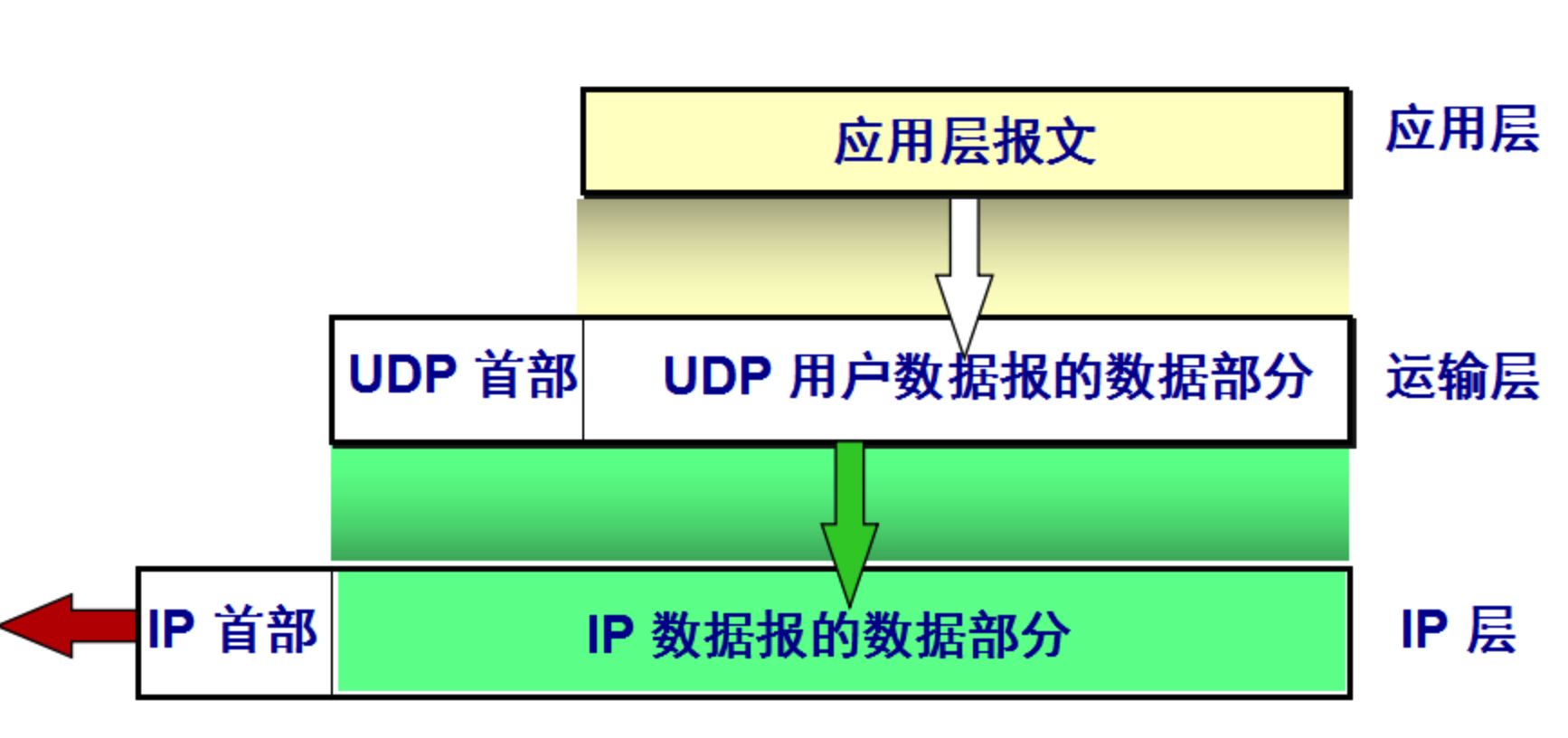
首部格式
在计算检验和时,临时把“伪首部”和 UDP 用户数据报连接在一起。伪首部仅仅是为了计算检验和。
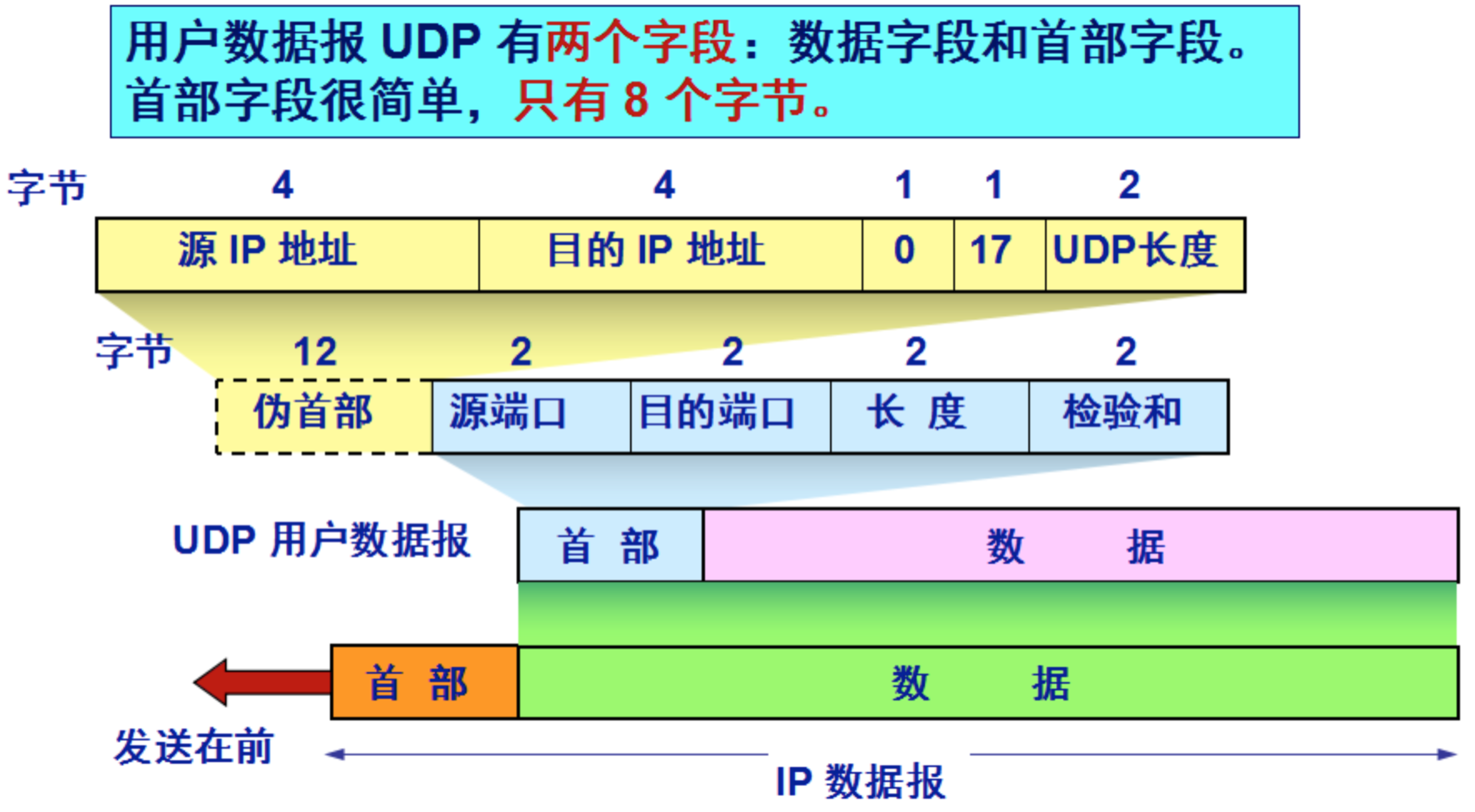
- 源端口: 占16位、源端口号。在需要对方回信时选用。不需要时可用全0。
- 目的端口: 占16位、目的端口号。这在终点交付报文时必须使用。
- 长度: 占16位、UDP用户数据报的长度,其最小值是8(仅有首部)。
- 检验和: 占16位、检测UDP用户数据报在传输中是否有错。有错就丢弃。
请注意,虽然在 UDP 之间的通信要用到其端口号,但由于 UDP 的通信是无连接的,因此不需要使用套接字。
校验
UDP校验和的计算方法和IP数据报首部校验和的计算方法相似,都使用二进制反码运算求和再取反,但不同的是:IP数据报的校验和之检验IP数据报和首部,但UDP的校验和是把首部和数据部分一起校验。
发送方,首先是把全零放入校验和字段并且添加伪首部,然后把UDP数据报看成是由许多16位的子串连接起来,若UDP数据报的数据部分不是偶数个字节,则要在数据部分末尾增加一个全零字节(此字节不发送),接下来就按照二进制反码计算出这些16位字的和。将此和的二进制反码写入校验和字段。在接收方,把收到得UDP数据报加上伪首部(如果不为偶数个字节,还需要补上全零字节)后,按二进制反码计算出这些16位字的和。当无差错时其结果全为1,。否则就表明有差错出现,接收方应该丢弃这个UDP数据报。
下图是计算UDP校验和的例子:
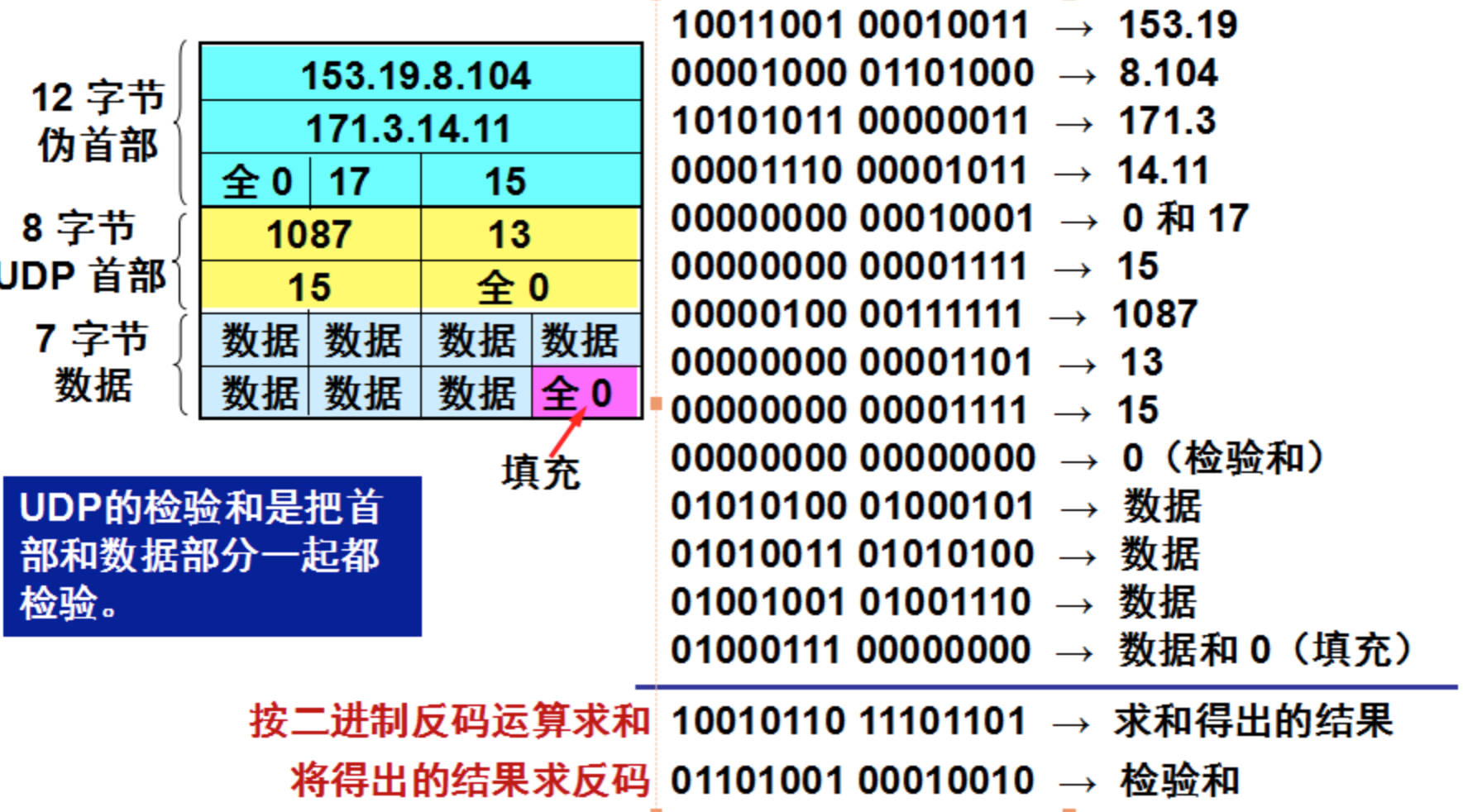
注意:
- 校验时,若UDP数据报部分的长度不是偶数个字节,则需要填入一个全0字节,但是次字节和伪首部一样,是不发送的。
- 如果UDP校验和校验出UDP数据报是错误的,可以丢弃,也可以交付上层,但是要附上错误报告,告诉上层这是错误的数据报。
- 通过伪首部,不仅可以检查源端口号,目的端口号和UDP用户数据报的数据部分,还可以检查IP数据报的源IP地址和目的地址。 这种差错检验的检错能力不强,但是简单,速度快。
4.5 - HTTP 协议
概念
URL
URI 包含 URL 和 URN,目前 WEB 只有 URL 比较流行,所以见到的基本都是 URL。
- URI(Uniform Resource Identifier,统一资源标识符)
- URL(Uniform Resource Locator,统一资源定位符)
- URN(Uniform Resource Name,统一资源名称)
请求和响应报文
请求报文

响应报文

HTTP (请求)方法
客户端发送的 请求报文 第一行为请求行,包含了方法字段。
GET
获取资源
当前网络请求中,绝大部分使用的是 GET 方法。
HEAD
获取报文首部
和 GET 方法一样,但是不返回报文实体主体部分。
主要用于确认 URL 的有效性以及资源更新的日期时间等。
POST
传输实体主体
POST 主要用来传输数据,而 GET 主要用来获取资源。
PUT
上传文件
由于自身不带验证机制,任何人都可以上传文件,因此存在安全性问题,一般不使用该方法。
PATCH
对资源进行部分修改
PUT 也可以用于修改资源,但是只能完全替代原始资源,PATCH 允许部分修改。
DELETE
删除文件
与 PUT 功能相反,并且同样不带验证机制。
OPTIONS
查询支持的方法
查询指定的 URL 能够支持的方法。
会返回 Allow: GET, POST, HEAD, OPTIONS 这样的内容。
CONNECT
要求在与代理服务器通信时建立隧道
使用 SSL(Secure Sockets Layer,安全套接层)和 TLS(Transport Layer Security,传输层安全)协议把通信内容加密后经网络隧道传输。
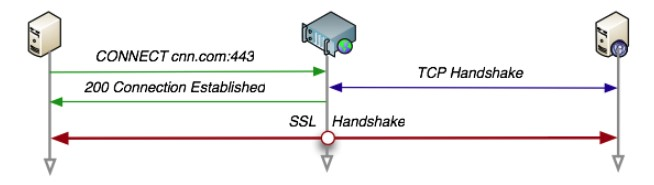
TRACE
追踪路径
服务器会将通信路径返回给客户端。
发送请求时,在 Max-Forwards 首部字段中填入数值,每经过一个服务器就会减 1,当数值为 0 时就停止传输。
通常不会使用 TRACE,并且它容易受到 XST 攻击(Cross-Site Tracing,跨站追踪)。
HTTP (响应)状态码
服务器返回的 响应报文 中第一行为状态行,包含了状态码以及原因短语,用来告知客户端请求的结果。
服务器返回的 响应报文 中第一行为状态行,包含了状态码以及原因短语,用来告知客户端请求的结果。
| 状态码 | 类别 | 原因短语 |
|---|---|---|
| 1XX | Informational(信息性状态码) | 接收的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
1XX 信息
- 100 Continue : 表明到目前为止都很正常,客户端可以继续发送请求或者忽略这个响应。
- 101 Switching Protocols : 表示服务端切换协议, 如从 HTTP 升级到 WebSocket 协议.
2XX 成功
- 200 OK
- 204 No Content : 请求已经成功处理,但是返回的响应报文不包含实体的主体部分。一般在只需要从客户端往服务器发送信息,而不需要返回数据时使用。
- 206 Partial Content : 表示客户端进行了范围请求,响应报文包含由 Content-Range 指定范围的实体内容。
3XX 重定向
- 301 Moved Permanently : 永久性重定向
- 302 Found : 临时性重定向
- 303 See Other : 和 302 有着相同的功能,但是 303 明确要求客户端应该采用 GET 方法获取资源。
- 注: 虽然 HTTP 协议规定 301、302 状态下重定向时不允许把 POST 方法改成 GET 方法,但是大多数浏览器都会在 301、302 和 303 状态下的重定向把 POST 方法改成 GET 方法。
- 304 Not Modified : 如果请求报文首部包含一些条件,例如: If-Match,If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since,如果不满足条件,则服务器会返回 304 状态码。
- 307 Temporary Redirect : 临时重定向,与 302 的含义类似,但是 307 要求浏览器不会把重定向请求的 POST 方法改成 GET 方法。
4XX 客户端错误
- 400 Bad Request : 请求报文中存在语法错误。
- 401 Unauthorized : 该状态码表示发送的请求需要有认证信息(BASIC 认证、DIGEST 认证)。如果之前已进行过一次请求,则表示用户认证失败。
- 403 Forbidden : 请求被拒绝。
- 404 Not Found
5XX 服务器错误
- 500 Internal Server Error : 服务器正在执行请求时发生错误。
- 503 Service Unavailable : 服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。
HTTP 首部
有 4 种类型的首部字段: 通用首部字段、请求首部字段、响应首部字段和实体首部字段。
通用首部字段
| 首部字段名 | 说明 |
|---|---|
| Cache-Control | 控制缓存的行为 |
| Connection | 控制不再转发给代理的首部字段、管理持久连接 |
| Date | 创建报文的日期时间 |
| Pragma | 报文指令 |
| Trailer | 报文末端的首部一览 |
| Transfer-Encoding | 指定报文主体的传输编码方式 |
| Upgrade | 升级为其他协议 |
| Via | 代理服务器的相关信息 |
| Warning | 错误通知 |
请求首部字段
| 首部字段名 | 说明 |
|---|---|
| Accept | 用户代理可处理的媒体类型 |
| Accept-Charset | 优先的字符集 |
| Accept-Encoding | 优先的内容编码 |
| Accept-Language | 优先的语言(自然语言) |
| Authorization | Web 认证信息 |
| Expect | 期待服务器的特定行为 |
| From | 用户的电子邮箱地址 |
| Host | 请求资源所在服务器 |
| If-Match | 比较实体标记(ETag) |
| If-Modified-Since | 比较资源的更新时间 |
| If-None-Match | 比较实体标记(与 If-Match 相反) |
| If-Range | 资源未更新时发送实体 Byte 的范围请求 |
| If-Unmodified-Since | 比较资源的更新时间(与 If-Modified-Since 相反) |
| Max-Forwards | 最大传输逐跳数 |
| Proxy-Authorization | 代理服务器要求客户端的认证信息 |
| Range | 实体的字节范围请求 |
| Referer | 对请求中 URI 的原始获取方 |
| TE | 传输编码的优先级 |
| User-Agent | HTTP 客户端程序的信息 |
响应首部字段
| 首部字段名 | 说明 |
|---|---|
| Accept-Ranges | 是否接受字节范围请求 |
| Age | 推算资源创建经过时间 |
| ETag | 资源的匹配信息 |
| Location | 令客户端重定向至指定 URI |
| Proxy-Authenticate | 代理服务器对客户端的认证信息 |
| Retry-After | 对再次发起请求的时机要求 |
| Server | HTTP 服务器的安装信息 |
| Vary | 代理服务器缓存的管理信息 |
| WWW-Authenticate | 服务器对客户端的认证信息 |
实体首部字段
| 首部字段名 | 说明 |
|---|---|
| Allow | 资源可支持的 HTTP 方法 |
| Content-Encoding | 实体主体适用的编码方式 |
| Content-Language | 实体主体的自然语言 |
| Content-Length | 实体主体的大小 |
| Content-Location | 替代对应资源的 URI |
| Content-MD5 | 实体主体的报文摘要 |
| Content-Range | 实体主体的位置范围 |
| Content-Type | 实体主体的媒体类型 |
| Expires | 实体主体过期的日期时间 |
| Last-Modified | 资源的最后修改日期时间 |
具体应用
Cookie
HTTP 协议是无状态的,主要是为了让 HTTP 协议尽可能简单,使得它能够处理大量事务。HTTP/1.1 引入 Cookie 来保存状态信息。
Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器之后向同一服务器再次发起请求时被携带上,用于告知服务端两个请求是否来自同一浏览器。由于之后每次请求都会需要携带 Cookie 数据,因此会带来额外的性能开销(尤其是在移动环境下)。
Cookie 曾一度用于客户端数据的存储,因为当时并没有其它合适的存储办法而作为唯一的存储手段,但现在随着现代浏览器开始支持各种各样的存储方式,Cookie 渐渐被淘汰。新的浏览器 API 已经允许开发者直接将数据存储到本地,如使用 Web storage API (本地存储和会话存储)或 IndexedDB。
1. 用途
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
2. 创建过程
服务器发送的响应报文包含 Set-Cookie 首部字段,客户端得到响应报文后把 Cookie 内容保存到浏览器中。
HTTP/1.0 200 OK
Content-type: text/html
Set-Cookie: yummy_cookie=choco
Set-Cookie: tasty_cookie=strawberry
[page content]
客户端之后对同一个服务器发送请求时,会从浏览器中取出 Cookie 信息并通过 Cookie 请求首部字段发送给服务器。
GET /sample_page.html HTTP/1.1
Host: www.example.org
Cookie: yummy_cookie=choco; tasty_cookie=strawberry
3. 分类
- 会话期 Cookie: 浏览器关闭之后它会被自动删除,也就是说它仅在会话期内有效。
- 持久性 Cookie: 指定一个特定的过期时间(Expires)或有效期(max-age)之后就成为了持久性的 Cookie。
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT;
4. JavaScript 获取 Cookie
通过 Document.cookie 属性可创建新的 Cookie,也可通过该属性访问非 HttpOnly 标记的 Cookie。
document.cookie = "yummy_cookie=choco";
document.cookie = "tasty_cookie=strawberry";
console.log(document.cookie);
5. Secure 和 HttpOnly
标记为 Secure 的 Cookie 只能通过被 HTTPS 协议加密过的请求发送给服务端。但即便设置了 Secure 标记,敏感信息也不应该通过 Cookie 传输,因为 Cookie 有其固有的不安全性,Secure 标记也无法提供确实的安全保障。
标记为 HttpOnly 的 Cookie 不能被 JavaScript 脚本调用。跨站脚本攻击 (XSS) 常常使用 JavaScript 的 Document.cookie API 窃取用户的 Cookie 信息,因此使用 HttpOnly 标记可以在一定程度上避免 XSS 攻击。
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT; Secure; HttpOnly
6. 作用域
Domain 标识指定了哪些主机可以接受 Cookie。如果不指定,默认为当前文档的主机(不包含子域名)。如果指定了 Domain,则一般包含子域名。例如,如果设置 Domain=mozilla.org,则 Cookie 也包含在子域名中(如 developer.mozilla.org)。
Path 标识指定了主机下的哪些路径可以接受 Cookie(该 URL 路径必须存在于请求 URL 中)。以字符 %x2F ("/") 作为路径分隔符,子路径也会被匹配。例如,设置 Path=/docs,则以下地址都会匹配:
- /docs
- /docs/Web/
- /docs/Web/HTTP
7. Session
除了可以将用户信息通过 Cookie 存储在用户浏览器中,也可以利用 Session 存储在服务器端,存储在服务器端的信息更加安全。
Session 可以存储在服务器上的文件、数据库或者内存中。也可以将 Session 存储在 Redis 这种内存型数据库中,效率会更高。
使用 Session 维护用户登录状态的过程如下:
- 用户进行登录时,用户提交包含用户名和密码的表单,放入 HTTP 请求报文中;
- 服务器验证该用户名和密码;
- 如果正确则把用户信息存储到 Redis 中,它在 Redis 中的 Key 称为 Session ID;
- 服务器返回的响应报文的 Set-Cookie 首部字段包含了这个 Session ID,客户端收到响应报文之后将该 Cookie 值存入浏览器中;
- 客户端之后对同一个服务器进行请求时会包含该 Cookie 值,服务器收到之后提取出 Session ID,从 Redis 中取出用户信息,继续之前的业务操作。
应该注意 Session ID 的安全性问题,不能让它被恶意攻击者轻易获取,那么就不能产生一个容易被猜到的 Session ID 值。此外,还需要经常重新生成 Session ID。在对安全性要求极高的场景下,例如转账等操作,除了使用 Session 管理用户状态之外,还需要对用户进行重新验证,比如重新输入密码,或者使用短信验证码等方式。
8. 浏览器禁用 Cookie
此时无法使用 Cookie 来保存用户信息,只能使用 Session。除此之外,不能再将 Session ID 存放到 Cookie 中,而是使用 URL 重写技术,将 Session ID 作为 URL 的参数进行传递。
9. Cookie 与 Session 选择
- Cookie 只能存储 ASCII 码字符串,而 Session 则可以存取任何类型的数据,因此在考虑数据复杂性时首选 Session;
- Cookie 存储在浏览器中,容易被恶意查看。如果非要将一些隐私数据存在 Cookie 中,可以将 Cookie 值进行加密,然后在服务器进行解密;
- 对于大型网站,如果用户所有的信息都存储在 Session 中,那么开销是非常大的,因此不建议将所有的用户信息都存储到 Session 中。
缓存
1. 优点
- 缓解服务器压力;
- 降低客户端获取资源的延迟: 缓存通常位于内存中,读取缓存的速度更快。并且缓存在地理位置上也有可能比源服务器来得近,例如浏览器缓存。
2. 实现方法
- 让代理服务器进行缓存;
- 让客户端浏览器进行缓存。
3. Cache-Control
HTTP/1.1 通过 Cache-Control 首部字段来控制缓存。
(一)禁止进行缓存
no-store 指令规定不能对请求或响应的任何一部分进行缓存。
Cache-Control: no-store
(二)强制确认缓存
no-cache 指令规定缓存服务器需要先向源服务器验证缓存资源的有效性,只有当缓存资源有效才将能使用该缓存对客户端的请求进行响应。
Cache-Control: no-cache
(三)私有缓存和公共缓存
private 指令规定了将资源作为私有缓存,只能被单独用户所使用,一般存储在用户浏览器中。
Cache-Control: private
public 指令规定了将资源作为公共缓存,可以被多个用户所使用,一般存储在代理服务器中。
Cache-Control: public
(四)缓存过期机制
max-age 指令出现在请求报文中,并且缓存资源的缓存时间小于该指令指定的时间,那么就能接受该缓存。
max-age 指令出现在响应报文中,表示缓存资源在缓存服务器中保存的时间。
Cache-Control: max-age=31536000
Expires 首部字段也可以用于告知缓存服务器该资源什么时候会过期。
- 在 HTTP/1.1 中,会优先处理 max-age 指令;
- 在 HTTP/1.0 中,max-age 指令会被忽略掉。
Expires: Wed, 04 Jul 2012 08:26:05 GMT
4. 缓存验证
需要先了解 ETag 首部字段的含义,它是资源的唯一标识。URL 不能唯一表示资源,例如 http://www.google.com/ 有中文和英文两个资源,只有 ETag 才能对这两个资源进行唯一标识。
ETag: "82e22293907ce725faf67773957acd12"
可以将缓存资源的 ETag 值放入 If-None-Match 首部,服务器收到该请求后,判断缓存资源的 ETag 值和资源的最新 ETag 值是否一致,如果一致则表示缓存资源有效,返回 304 Not Modified。
If-None-Match: "82e22293907ce725faf67773957acd12"
Last-Modified 首部字段也可以用于缓存验证,它包含在源服务器发送的响应报文中,指示源服务器对资源的最后修改时间。但是它是一种弱校验器,因为只能精确到一秒,所以它通常作为 ETag 的备用方案。如果响应首部字段里含有这个信息,客户端可以在后续的请求中带上 If-Modified-Since 来验证缓存。服务器只在所请求的资源在给定的日期时间之后对内容进行过修改的情况下才会将资源返回,状态码为 200 OK。如果请求的资源从那时起未经修改,那么返回一个不带有消息主体的 304 Not Modified 响应。
Last-Modified: Wed, 21 Oct 2015 07:28:00 GMT
If-Modified-Since: Wed, 21 Oct 2015 07:28:00 GMT
连接管理
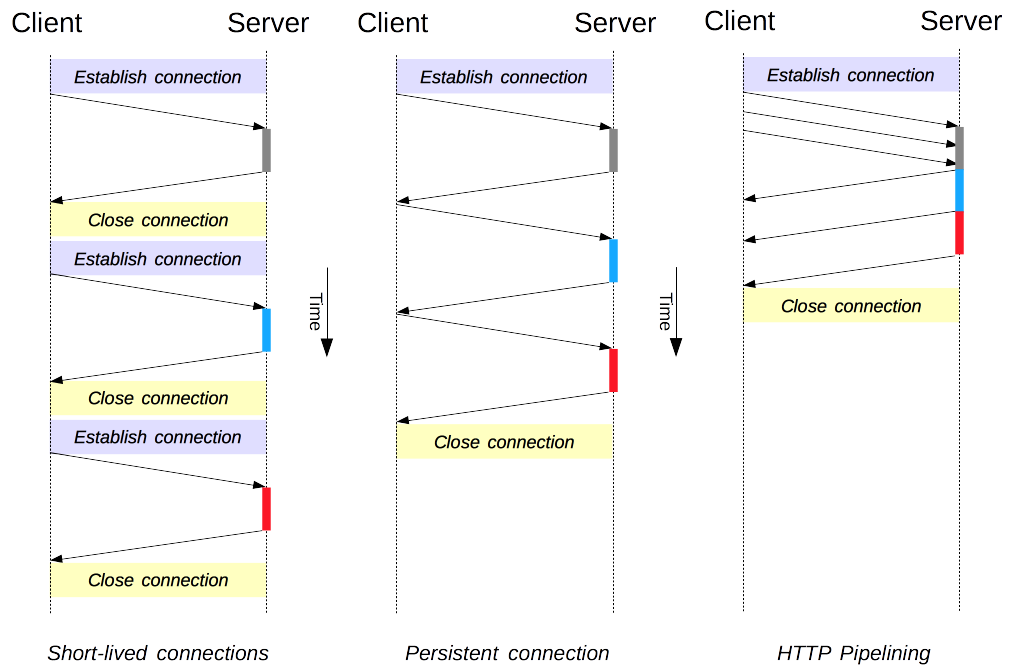
1. 短连接与长连接
当浏览器访问一个包含多张图片的 HTML 页面时,除了请求访问 HTML 页面资源,还会请求图片资源。如果每进行一次 HTTP 通信就要新建一个 TCP 连接,那么开销会很大。
长连接只需要建立一次 TCP 连接就能进行多次 HTTP 通信。
- 从 HTTP/1.1 开始默认是长连接的,如果要断开连接,需要由客户端或者服务器端提出断开,使用
Connection : close; - 在 HTTP/1.1 之前默认是短连接的,如果需要使用长连接,则使用
Connection : Keep-Alive。
2. 流水线
默认情况下,HTTP 请求是按顺序发出的,下一个请求只有在当前请求收到响应之后才会被发出。由于会受到网络延迟和带宽的限制,在下一个请求被发送到服务器之前,可能需要等待很长时间。
流水线是在同一条长连接上发出连续的请求,而不用等待响应返回,这样可以避免连接延迟。
内容协商
通过内容协商返回最合适的内容,例如根据浏览器的默认语言选择返回中文界面还是英文界面。
1. 类型
(一)服务端驱动型
客户端设置特定的 HTTP 首部字段,例如 Accept、Accept-Charset、Accept-Encoding、Accept-Language、Content-Languag,服务器根据这些字段返回特定的资源。
它存在以下问题:
- 服务器很难知道客户端浏览器的全部信息;
- 客户端提供的信息相当冗长(HTTP/2 协议的首部压缩机制缓解了这个问题),并且存在隐私风险(HTTP 指纹识别技术);
- 给定的资源需要返回不同的展现形式,共享缓存的效率会降低,而服务器端的实现会越来越复杂。
(二)代理驱动型
服务器返回 300 Multiple Choices 或者 406 Not Acceptable,客户端从中选出最合适的那个资源。
2. Vary
Vary: Accept-Language
在使用内容协商的情况下,只有当缓存服务器中的缓存满足内容协商条件时,才能使用该缓存,否则应该向源服务器请求该资源。
例如,一个客户端发送了一个包含 Accept-Language 首部字段的请求之后,源服务器返回的响应包含 Vary: Accept-Language 内容,缓存服务器对这个响应进行缓存之后,在客户端下一次访问同一个 URL 资源,并且 Accept-Language 与缓存中的对应的值相同时才会返回该缓存。
内容编码
内容编码将实体主体进行压缩,从而减少传输的数据量。
常用的内容编码有: gzip、compress、deflate、identity。
浏览器发送 Accept-Encoding 首部,其中包含有它所支持的压缩算法,以及各自的优先级。服务器则从中选择一种,使用该算法对响应的消息主体进行压缩,并且发送 Content-Encoding 首部来告知浏览器它选择了哪一种算法。由于该内容协商过程是基于编码类型来选择资源的展现形式的,在响应的 Vary 首部至少要包含 Content-Encoding。
范围请求
如果网络出现中断,服务器只发送了一部分数据,范围请求可以使得客户端只请求服务器未发送的那部分数据,从而避免服务器重新发送所有数据。
1. Range
在请求报文中添加 Range 首部字段指定请求的范围。
GET /z4d4kWk.jpg HTTP/1.1
Host: i.imgur.com
Range: bytes=0-1023
请求成功的话服务器返回的响应包含 206 Partial Content 状态码。
HTTP/1.1 206 Partial Content
Content-Range: bytes 0-1023/146515
Content-Length: 1024
...
(binary content)
2. Accept-Ranges
响应首部字段 Accept-Ranges 用于告知客户端是否能处理范围请求,可以处理使用 bytes,否则使用 none。
Accept-Ranges: bytes
3. 响应状态码
- 在请求成功的情况下,服务器会返回 206 Partial Content 状态码。
- 在请求的范围越界的情况下,服务器会返回 416 Requested Range Not Satisfiable 状态码。
- 在不支持范围请求的情况下,服务器会返回 200 OK 状态码。
分块传输编码
Chunked Transfer Coding,可以把数据分割成多块,让浏览器逐步显示页面。
多部分对象集合
一份报文主体内可含有多种类型的实体同时发送,每个部分之间用 boundary 字段定义的分隔符进行分隔,每个部分都可以有首部字段。
例如,上传多个表单时可以使用如下方式:
Content-Type: multipart/form-data; boundary=AaB03x
--AaB03x
Content-Disposition: form-data; name="submit-name"
Larry
--AaB03x
Content-Disposition: form-data; name="files"; filename="file1.txt"
Content-Type: text/plain
... contents of file1.txt ...
--AaB03x--
虚拟主机
HTTP/1.1 使用虚拟主机技术,使得一台服务器拥有多个域名,并且在逻辑上可以看成多个服务器。
通信数据转发
1. 代理
代理服务器接受客户端的请求,并且转发给其它服务器。
使用代理的主要目的是:
- 缓存
- 负载均衡
- 网络访问控制
- 访问日志记录
代理服务器分为正向代理和反向代理两种:
- 用户察觉得到正向代理的存在。
- 而反向代理一般位于内部网络中,用户察觉不到。

2. 网关
与代理服务器不同的是,网关服务器会将 HTTP 转化为其它协议进行通信,从而请求其它非 HTTP 服务器的服务。
3. 隧道
使用 SSL 等加密手段,在客户端和服务器之间建立一条安全的通信线路。
HTTPS
HTTP 有以下安全性问题:
- 使用明文进行通信,内容可能会被窃听;
- 不验证通信方的身份,通信方的身份有可能遭遇伪装;
- 无法证明报文的完整性,报文有可能遭篡改。
HTTPs 并不是新协议,而是让 HTTP 先和 SSL(Secure Sockets Layer)通信,再由 SSL 和 TCP 通信,也就是说 HTTPs 使用了隧道进行通信。
通过使用 SSL,HTTPs 具有了加密(防窃听)、认证(防伪装)和完整性保护(防篡改)。
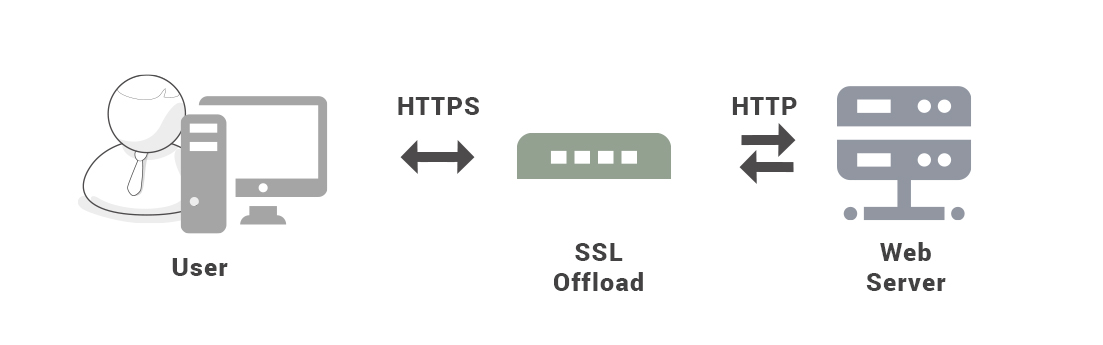
加密
1. 对称密钥加密
对称密钥加密(Symmetric-Key Encryption),加密和解密使用同一密钥。
- 优点: 运算速度快;
- 缺点: 无法安全地将密钥传输给通信方。
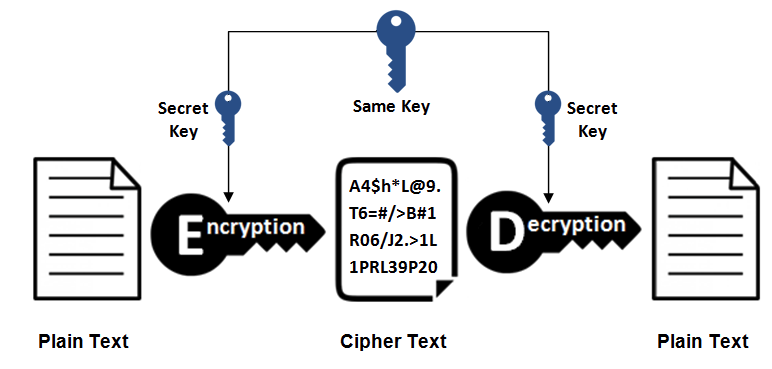
2.非对称密钥加密
非对称密钥加密,又称公开密钥加密(Public-Key Encryption),加密和解密使用不同的密钥。
公开密钥所有人都可以获得,通信发送方获得接收方的公开密钥之后,就可以使用公开密钥进行加密,接收方收到通信内容后使用私有密钥解密。
非对称密钥除了用来加密,还可以用来进行签名。因为私有密钥无法被其他人获取,因此通信发送方使用其私有密钥进行签名,通信接收方使用发送方的公开密钥对签名进行解密,就能判断这个签名是否正确。
- 优点: 可以更安全地将公开密钥传输给通信发送方;
- 缺点: 运算速度慢。
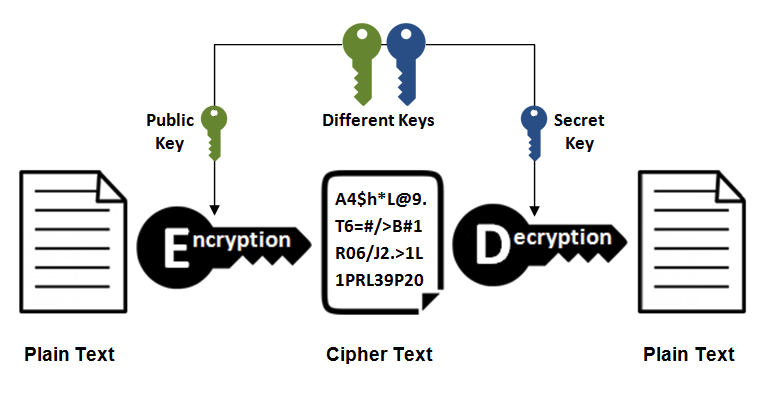
3. HTTPs 采用的加密方式
HTTPs 采用混合的加密机制,使用非对称密钥加密用于传输对称密钥来保证传输过程的安全性,之后使用对称密钥加密进行通信来保证通信过程的效率。(下图中的 Session Key 就是对称密钥)
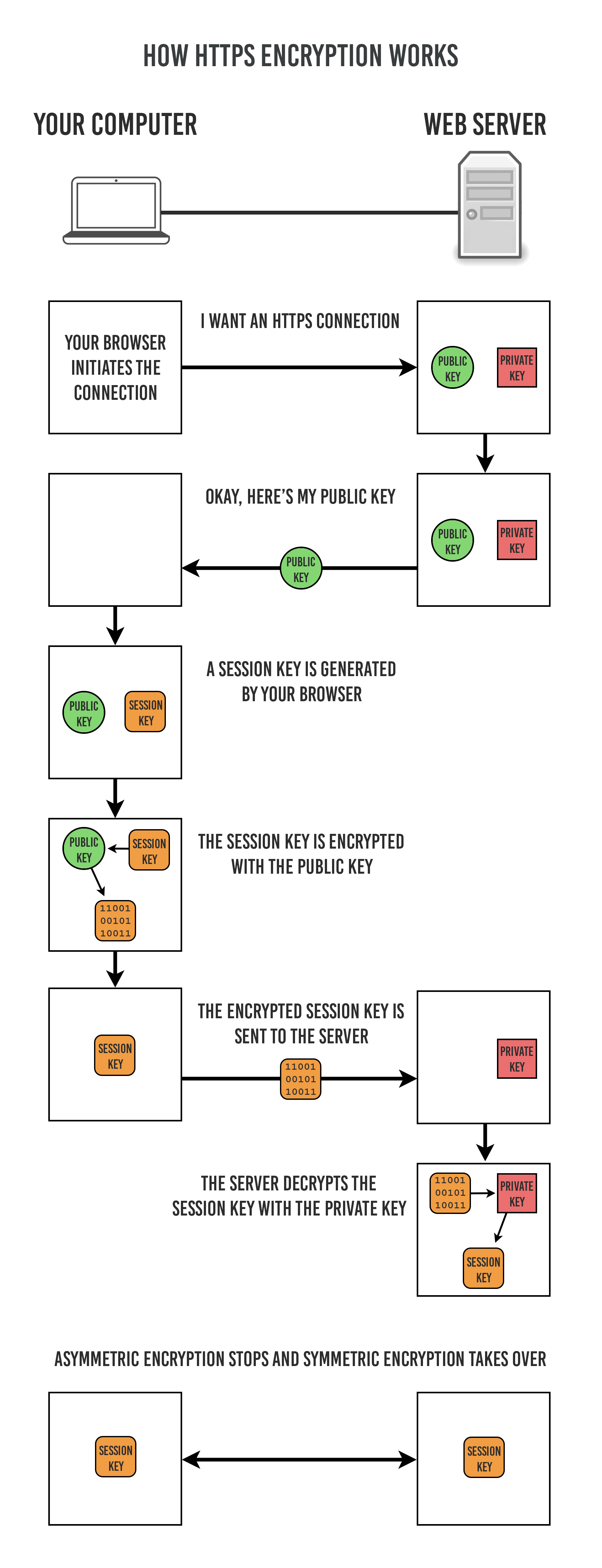
认证
通过使用 证书 来对通信方进行认证。
数字证书认证机构(CA,Certificate Authority)是客户端与服务器双方都可信赖的第三方机构。
服务器的运营人员向 CA 提出公开密钥的申请,CA 在判明提出申请者的身份之后,会对已申请的公开密钥做数字签名,然后分配这个已签名的公开密钥,并将该公开密钥放入公开密钥证书后绑定在一起。
进行 HTTPs 通信时,服务器会把证书发送给客户端。客户端取得其中的公开密钥之后,先使用数字签名进行验证,如果验证通过,就可以开始通信了。
通信开始时,客户端需要使用服务器的公开密钥将自己的私有密钥传输给服务器,之后再进行对称密钥加密。
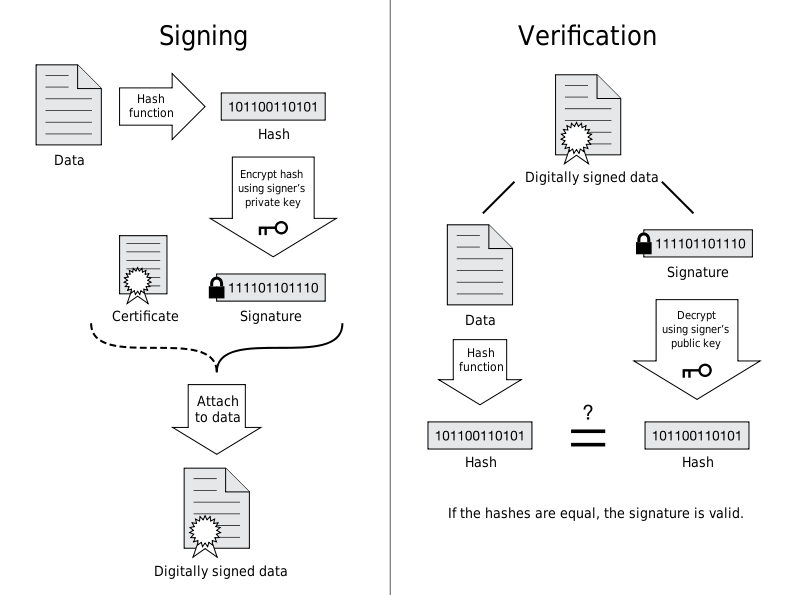
完整性保护
SSL 提供报文摘要功能来进行完整性保护。
HTTP 也提供了 MD5 报文摘要功能,但不是安全的。例如报文内容被篡改之后,同时重新计算 MD5 的值,通信接收方是无法意识到发生了篡改。
HTTPs 的报文摘要功能之所以安全,是因为它结合了加密和认证这两个操作。试想一下,加密之后的报文,遭到篡改之后,也很难重新计算报文摘要,因为无法轻易获取明文。
HTTPs 的缺点
- 因为需要进行加密解密等过程,因此速度会更慢;
- 需要支付证书授权的高额费用。
配置 HTTPs
HTTP/2.0
HTTP/1.x 缺陷
HTTP/1.x 实现简单是以牺牲性能为代价的:
- 客户端需要使用多个连接才能实现并发和缩短延迟;
- 不会压缩请求和响应首部,从而导致不必要的网络流量;
- 不支持有效的资源优先级,致使底层 TCP 连接的利用率低下。
二进制分帧层
HTTP/2.0 将报文分成 HEADERS 帧和 DATA 帧,它们都是二进制格式的。
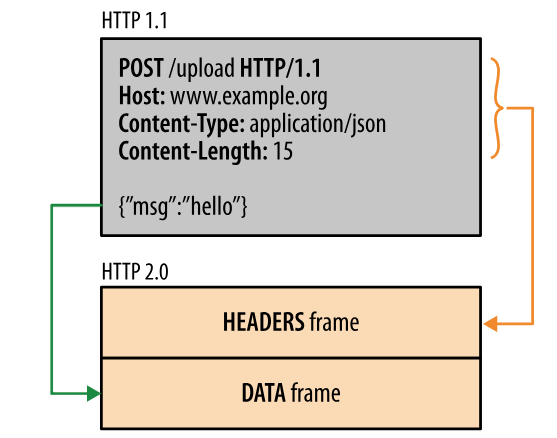
在通信过程中,只会有一个 TCP 连接存在,它承载了任意数量的双向数据流(Stream)。
- 一个数据流都有一个唯一标识符和可选的优先级信息,用于承载双向信息。
- 消息(Message)是与逻辑请求或响应消息对应的完整的一系列帧。
- 帧(Fram)是最小的通信单位,来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装。
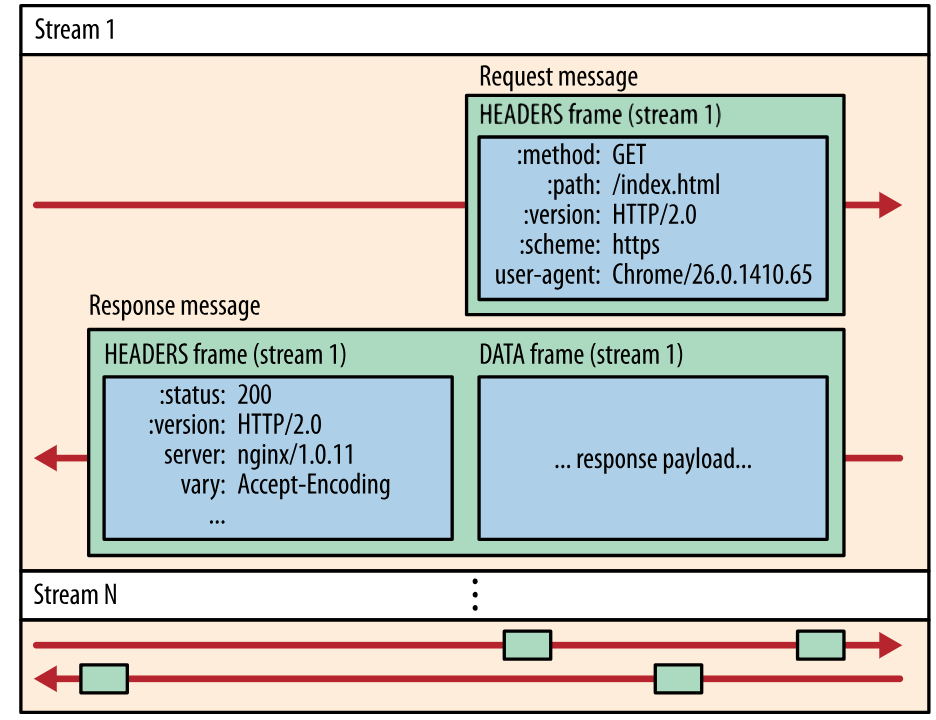
服务端推送
HTTP/2.0 在客户端请求一个资源时,会把相关的资源一起发送给客户端,客户端就不需要再次发起请求了。例如客户端请求 page.html 页面,服务端就把 script.js 和 style.css 等与之相关的资源一起发给客户端。
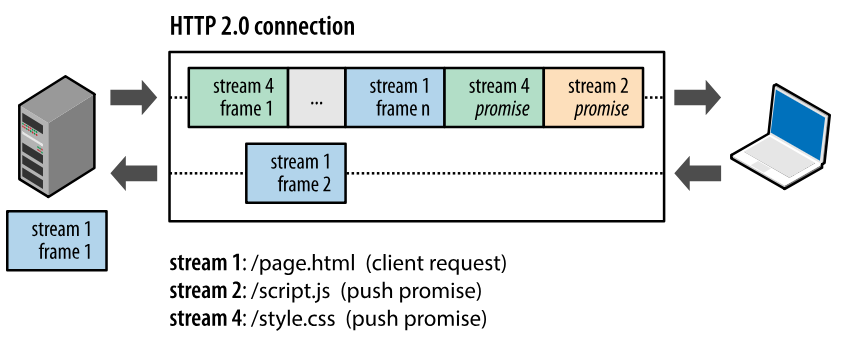
首部压缩
HTTP/1.1 的首部带有大量信息,而且每次都要重复发送。
HTTP/2.0 要求客户端和服务器同时维护和更新一个包含之前见过的首部字段表,从而避免了重复传输。
不仅如此,HTTP/2.0 也使用 Huffman 编码对首部字段进行压缩。
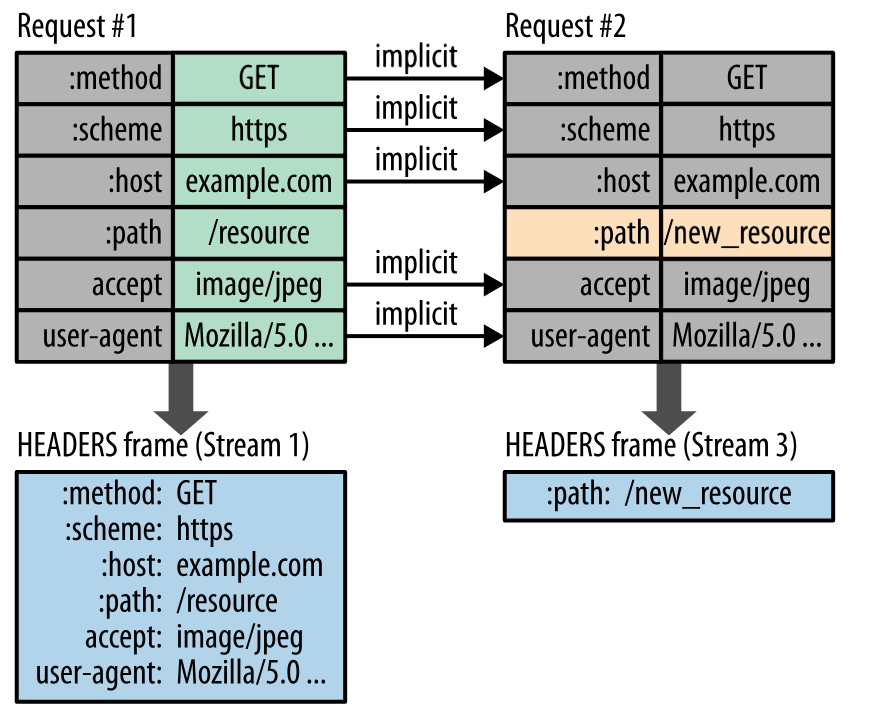
GET VS POST
作用
GET 用于获取资源,而 POST 用于传输实体主体。
参数
GET 和 POST 的请求都能使用额外的参数,但是 GET 的参数是以查询字符串出现在 URL 中,而 POST 的参数存储在实体主体中。不能因为 POST 参数存储在实体主体中就认为它的安全性更高,因为照样可以通过一些抓包工具(Fiddler)查看。
因为 URL 只支持 ASCII 码,因此 GET 的参数中如果存在中文等字符就需要先进行编码。例如 中文 会转换为 %E4%B8%AD%E6%96%87,而空格会转换为 %20。POST 参考支持标准字符集。
GET /test/demo_form.asp?name1=value1&name2=value2 HTTP/1.1
POST /test/demo_form.asp HTTP/1.1
Host: w3schools.com
name1=value1&name2=value2
安全
安全的 HTTP 方法不会改变服务器状态,也就是说它只是可读的。
GET 方法是安全的,而 POST 却不是,因为 POST 的目的是传送实体主体内容,这个内容可能是用户上传的表单数据,上传成功之后,服务器可能把这个数据存储到数据库中,因此状态也就发生了改变。
安全的方法除了 GET 之外还有: HEAD、OPTIONS。
不安全的方法除了 POST 之外还有 PUT、DELETE。
幂等性
幂等的 HTTP 方法,同样的请求被执行一次与连续执行多次的效果是一样的,服务器的状态也是一样的。换句话说就是,幂等方法不应该具有副作用(统计用途除外)。
所有的安全方法也都是幂等的。
在正确实现的条件下,GET,HEAD,PUT 和 DELETE 等方法都是幂等的,而 POST 方法不是。
GET /pageX HTTP/1.1 是幂等的,连续调用多次,客户端接收到的结果都是一样的:
GET /pageX HTTP/1.1
GET /pageX HTTP/1.1
GET /pageX HTTP/1.1
GET /pageX HTTP/1.1
POST /add_row HTTP/1.1 不是幂等的,如果调用多次,就会增加多行记录:
POST /add_row HTTP/1.1 -> Adds a 1nd row
POST /add_row HTTP/1.1 -> Adds a 2nd row
POST /add_row HTTP/1.1 -> Adds a 3rd row
DELETE /idX/delete HTTP/1.1 是幂等的,即便不同的请求接收到的状态码不一样:
DELETE /idX/delete HTTP/1.1 -> Returns 200 if idX exists
DELETE /idX/delete HTTP/1.1 -> Returns 404 as it just got deleted
DELETE /idX/delete HTTP/1.1 -> Returns 404
可缓存
如果要对响应进行缓存,需要满足以下条件:
- 请求报文的 HTTP 方法本身是可缓存的,包括 GET 和 HEAD,但是 PUT 和 DELETE 不可缓存,POST 在多数情况下不可缓存的。
- 响应报文的状态码是可缓存的,包括: 200, 203, 204, 206, 300, 301, 404, 405, 410, 414, and 501。
- 响应报文的 Cache-Control 首部字段没有指定不进行缓存。
XMLHttpRequest
为了阐述 POST 和 GET 的另一个区别,需要先了解 XMLHttpRequest:
XMLHttpRequest 是一个 API,它为客户端提供了在客户端和服务器之间传输数据的功能。它提供了一个通过 URL 来获取数据的简单方式,并且不会使整个页面刷新。这使得网页只更新一部分页面而不会打扰到用户。XMLHttpRequest 在 AJAX 中被大量使用。
- 在使用 XMLHttpRequest 的 POST 方法时,浏览器会先发送 Header 再发送 Data。但并不是所有浏览器会这么做,例如火狐就不会。
- 而 GET 方法 Header 和 Data 会一起发送。
HTTP/1.0 VS HTTP/1.1
HTTP/1.1 默认是长连接
HTTP/1.1 支持管线化处理
HTTP/1.1 支持同时打开多个 TCP 连接
HTTP/1.1 支持虚拟主机
HTTP/1.1 新增状态码 100
HTTP/1.1 支持分块传输编码
HTTP/1.1 新增缓存处理指令 max-age
4.6 - WebSocket
概览
WebSocket的出现,使得浏览器具备了实时双向通信的能力。本文由浅入深,介绍了WebSocket如何建立连接、交换数据的细节,以及数据帧的格式。此外,还简要介绍了针对WebSocket的安全攻击,以及协议是如何抵御类似攻击的。
什么是WebSocket
HTML5开始提供的一种浏览器与服务器进行全双工通讯的网络技术,属于应用层协议。它基于TCP传输协议,并复用HTTP的握手通道。
对大部分web开发者来说,上面这段描述有点枯燥,其实只要记住几点:
- WebSocket可以在浏览器里使用
- 支持双向通信
- 使用很简单
1、有哪些优点
说到优点,这里的对比参照物是HTTP协议,概括地说就是:支持双向通信,更灵活,更高效,可扩展性更好。
- 支持双向通信,实时性更强。
- 更好的二进制支持。
- 较少的控制开销。连接创建后,ws客户端、服务端进行数据交换时,协议控制的数据包头部较小。在不包含头部的情况下,服务端到客户端的包头只有2~10字节(取决于数据包长度),客户端到服务端的的话,需要加上额外的4字节的掩码。而HTTP协议每次通信都需要携带完整的头部。
- 支持扩展。ws协议定义了扩展,用户可以扩展协议,或者实现自定义的子协议。(比如支持自定义压缩算法等)
对于后面两点,没有研究过WebSocket协议规范的同学可能理解起来不够直观,但不影响对WebSocket的学习和使用。
2、需要学习哪些东西
对网络应用层协议的学习来说,最重要的往往就是连接建立过程、数据交换教程。当然,数据的格式是逃不掉的,因为它直接决定了协议本身的能力。好的数据格式能让协议更高效、扩展性更好。
下文主要围绕下面几点展开:
- 如何建立连接
- 如何交换数据
- 数据帧格式
- 如何维持连接
入门示例
在正式介绍协议细节前,先来看一个简单的例子,有个直观感受。例子包括了WebSocket服务端、WebSocket客户端(网页端)。
这里服务端用了ws这个库。相比大家熟悉的socket.io,ws实现更轻量,更适合学习的目的。
1、服务端
代码如下,监听8080端口。当有新的连接请求到达时,打印日志,同时向客户端发送消息。当收到到来自客户端的消息时,同样打印日志。
var app = require('express')();
var server = require('http').Server(app);
var WebSocket = require('ws');
var wss = new WebSocket.Server({ port: 8080 });
wss.on('connection', function connection(ws) {
console.log('server: receive connection.');
ws.on('message', function incoming(message) {
console.log('server: received: %s', message);
});
ws.send('world');
});
app.get('/', function (req, res) {
res.sendfile(__dirname + '/index.html');
});
app.listen(3000);
2、客户端
代码如下,向8080端口发起WebSocket连接。连接建立后,打印日志,同时向服务端发送消息。接收到来自服务端的消息后,同样打印日志。
<script>
var ws = new WebSocket('ws://localhost:8080');
ws.onopen = function () {
console.log('ws onopen');
ws.send('from client: hello');
};
ws.onmessage = function (e) {
console.log('ws onmessage');
console.log('from server: ' + e.data);
};
</script>
3、运行结果
可分别查看服务端、客户端的日志,这里不展开。
服务端输出:
server: receive connection.
server: received hello
客户端输出:
client: ws connection is open
client: received world
如何建立连接
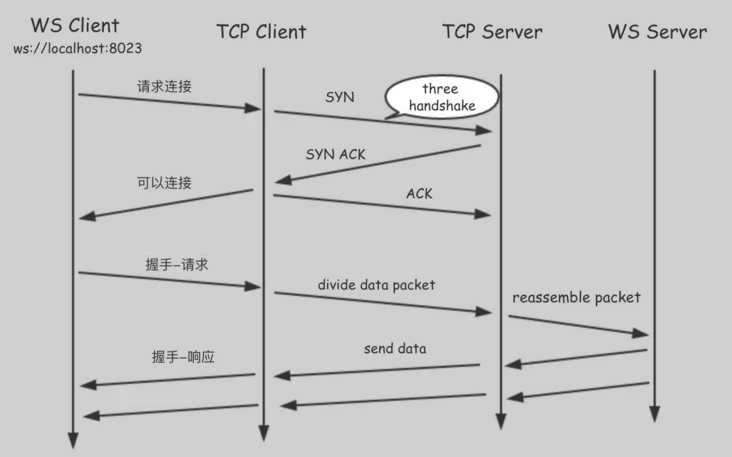
WebSocket 协议本质上是一个基于 TCP 的协议,为了建立一个 WebSocket 连接,客户端浏览器首先要向服务器发起一个 HTTP 请求,这个请求相比较平时使用的 HTTP 请求多了一些信息。
WebSocket 复用了 HTTP 的握手通道。具体指的是,客户端通过 HTTP 请求与 WebSocket 服务端协商升级协议。协议升级完成后,后续的数据交换则遵照 WebSocket 的协议。
1、客户端:申请协议升级
首先,客户端发起协议升级请求。可以看到,采用的是标准的HTTP报文格式,且只支持GET方法。
GET / HTTP/1.1
Host: localhost:8080
Origin: http://127.0.0.1:3000
Connection: Upgrade
Upgrade: websocket
Sec-WebSocket-Version: 13
Sec-WebSocket-Key: w4v7O6xFTi36lq3RNcgctw==
重点请求首部意义如下:
Connection: Upgrade:表示要升级协议Upgrade: websocket:表示要升级到websocket协议。Sec-WebSocket-Version: 13:表示websocket的版本。如果服务端不支持该版本,需要返回一个Sec-WebSocket-Versionheader,里面包含服务端支持的版本号。Sec-WebSocket-Key:与后面服务端响应首部的Sec-WebSocket-Accept是配套的,提供基本的防护,比如恶意的连接,或者无意的连接。
注意,上面请求省略了部分非重点请求首部。由于是标准的HTTP请求,类似Host、Origin、Cookie等请求首部会照常发送。在握手阶段,可以通过相关请求首部进行 安全限制、权限校验等。
2、服务端:响应协议升级
服务端返回内容如下,状态代码101表示协议切换。到此完成协议升级,后续的数据交互都按照新的协议来。
HTTP/1.1 101 Switching Protocols
Connection:Upgrade
Upgrade: websocket
Sec-WebSocket-Accept: Oy4NRAQ13jhfONC7bP8dTKb4PTU=
备注:每个header都以
\r\n结尾,并且最后一行加上一个额外的空行\r\n。此外,服务端回应的HTTP状态码只能在握手阶段使用。过了握手阶段后,就只能采用特定的错误码。
3、Sec-WebSocket-Accept的计算
Sec-WebSocket-Accept根据客户端请求首部的Sec-WebSocket-Key计算出来。
计算公式为:
- 将
Sec-WebSocket-Key跟258EAFA5-E914-47DA-95CA-C5AB0DC85B11拼接。 - 通过SHA1计算出摘要,并转成base64字符串。
伪代码如下:
>toBase64( sha1( Sec-WebSocket-Key + 258EAFA5-E914-47DA-95CA-C5AB0DC85B11 ) )
验证下前面的返回结果:
const crypto = require('crypto');
const magic = '258EAFA5-E914-47DA-95CA-C5AB0DC85B11';
const secWebSocketKey = 'w4v7O6xFTi36lq3RNcgctw==';
let secWebSocketAccept = crypto.createHash('sha1')
.update(secWebSocketKey + magic)
.digest('base64');
console.log(secWebSocketAccept);
// Oy4NRAQ13jhfONC7bP8dTKb4PTU=
数据帧格式
客户端、服务端数据的交换,离不开数据帧格式的定义。因此,在实际讲解数据交换之前,我们先来看下WebSocket的数据帧格式。
WebSocket客户端、服务端通信的最小单位是帧(frame),由1个或多个帧组成一条完整的消息(message)。
- 发送端:将消息切割成多个帧,并发送给服务端;
- 接收端:接收消息帧,并将关联的帧重新组装成完整的消息;
本节的重点,就是讲解数据帧的格式。详细定义可参考 RFC6455 5.2节 。
1、数据帧格式概览
下面给出了WebSocket数据帧的统一格式。熟悉TCP/IP协议的同学对这样的图应该不陌生。
- 从左到右,单位是比特。比如
FIN、RSV1各占据1比特,opcode占据4比特。 - 内容包括了标识、操作代码、掩码、数据、数据长度等。(下一小节会展开)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-------+-+-------------+-------------------------------+
|F|R|R|R| opcode|M| Payload len | Extended payload length |
|I|S|S|S| (4) |A| (7) | (16/64) |
|N|V|V|V| |S| | (if payload len==126/127) |
| |1|2|3| |K| | |
+-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - +
| Extended payload length continued, if payload len == 127 |
+ - - - - - - - - - - - - - - - +-------------------------------+
| |Masking-key, if MASK set to 1 |
+-------------------------------+-------------------------------+
| Masking-key (continued) | Payload Data |
+-------------------------------- - - - - - - - - - - - - - - - +
: Payload Data continued ... :
+ - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +
| Payload Data continued ... |
+---------------------------------------------------------------+
2、数据帧格式详解
针对前面的格式概览图,这里逐个字段进行讲解,如有不清楚之处,可参考协议规范,或留言交流。
FIN:1个比特。
如果是1,表示这是消息(message)的最后一个分片(fragment),如果是0,表示不是是消息(message)的最后一个分片(fragment)。
RSV1, RSV2, RSV3:各占1个比特。
一般情况下全为0。当客户端、服务端协商采用WebSocket扩展时,这三个标志位可以非0,且值的含义由扩展进行定义。如果出现非零的值,且并没有采用WebSocket扩展,连接出错。
Opcode: 4个比特。
操作代码,Opcode的值决定了应该如何解析后续的数据载荷(data payload)。如果操作代码是不认识的,那么接收端应该断开连接(fail the connection)。可选的操作代码如下:
- %x0:表示一个延续帧。当Opcode为0时,表示本次数据传输采用了数据分片,当前收到的数据帧为其中一个数据分片。
- %x1:表示这是一个文本帧(frame)
- %x2:表示这是一个二进制帧(frame)
- %x3-7:保留的操作代码,用于后续定义的非控制帧。
- %x8:表示连接断开。
- %x9:表示这是一个ping操作。
- %xA:表示这是一个pong操作。
- %xB-F:保留的操作代码,用于后续定义的控制帧。
Mask: 1个比特。
表示是否要对数据载荷进行掩码操作。从客户端向服务端发送数据时,需要对数据进行掩码操作;从服务端向客户端发送数据时,不需要对数据进行掩码操作。
如果服务端接收到的数据没有进行过掩码操作,服务端需要断开连接。
如果Mask是1,那么在Masking-key中会定义一个掩码键(masking key),并用这个掩码键来对数据载荷进行反掩码。所有客户端发送到服务端的数据帧,Mask都是1。
掩码的算法、用途在下一小节讲解。
Payload length:数据载荷的长度,单位是字节。为7位,或7+16位,或1+64位。
假设数Payload length === x,如果
- x为0~126:数据的长度为x字节。
- x为126:后续2个字节代表一个16位的无符号整数,该无符号整数的值为数据的长度。
- x为127:后续8个字节代表一个64位的无符号整数(最高位为0),该无符号整数的值为数据的长度。
此外,如果payload length占用了多个字节的话,payload length的二进制表达采用网络序(big endian,重要的位在前)。
Masking-key:0或4字节(32位)
所有从客户端传送到服务端的数据帧,数据载荷都进行了掩码操作,Mask为1,且携带了4字节的Masking-key。如果Mask为0,则没有Masking-key。
备注:载荷数据的长度,不包括mask key的长度。
Payload data:(x+y) 字节
载荷数据:包括了扩展数据、应用数据。其中,扩展数据x字节,应用数据y字节。
扩展数据:如果没有协商使用扩展的话,扩展数据数据为0字节。所有的扩展都必须声明扩展数据的长度,或者可以如何计算出扩展数据的长度。此外,扩展如何使用必须在握手阶段就协商好。如果扩展数据存在,那么载荷数据长度必须将扩展数据的长度包含在内。
应用数据:任意的应用数据,在扩展数据之后(如果存在扩展数据),占据了数据帧剩余的位置。载荷数据长度 减去 扩展数据长度,就得到应用数据的长度。
3、掩码算法
掩码键(Masking-key)是由客户端挑选出来的32位的随机数。掩码操作不会影响数据载荷的长度。掩码、反掩码操作都采用如下算法:
首先,假设:
- original-octet-i:为原始数据的第i字节。
- transformed-octet-i:为转换后的数据的第i字节。
- j:为
i mod 4的结果。 - masking-key-octet-j:为mask key第j字节。
算法描述为: original-octet-i 与 masking-key-octet-j 异或后,得到 transformed-octet-i。
j = i MOD 4 transformed-octet-i = original-octet-i XOR masking-key-octet-j
数据传递
一旦WebSocket客户端、服务端建立连接后,后续的操作都是基于数据帧的传递。
WebSocket根据opcode来区分操作的类型。比如0x8表示断开连接,0x0-0x2表示数据交互。
1、数据分片
WebSocket的每条消息可能被切分成多个数据帧。当WebSocket的接收方收到一个数据帧时,会根据FIN的值来判断,是否已经收到消息的最后一个数据帧。
FIN=1表示当前数据帧为消息的最后一个数据帧,此时接收方已经收到完整的消息,可以对消息进行处理。FIN=0,则接收方还需要继续监听接收其余的数据帧。
此外,opcode在数据交换的场景下,表示的是数据的类型。0x01表示文本,0x02表示二进制。而0x00比较特殊,表示延续帧(continuation frame),顾名思义,就是完整消息对应的数据帧还没接收完。
2、数据分片例子
直接看例子更形象些。下面例子来自MDN,可以很好地演示数据的分片。客户端向服务端两次发送消息,服务端收到消息后回应客户端,这里主要看客户端往服务端发送的消息。
第一条消息
FIN=1, 表示是当前消息的最后一个数据帧。服务端收到当前数据帧后,可以处理消息。opcode=0x1,表示客户端发送的是文本类型。
第二条消息
- FIN=0,opcode=0x1,表示发送的是文本类型,且消息还没发送完成,还有后续的数据帧。
- FIN=0,opcode=0x0,表示消息还没发送完成,还有后续的数据帧,当前的数据帧需要接在上一条数据帧之后。
- FIN=1,opcode=0x0,表示消息已经发送完成,没有后续的数据帧,当前的数据帧需要接在上一条数据帧之后。服务端可以将关联的数据帧组装成完整的消息。
Client: FIN=1, opcode=0x1, msg="hello"
Server: (process complete message immediately) Hi.
Client: FIN=0, opcode=0x1, msg="and a"
Server: (listening, new message containing text started)
Client: FIN=0, opcode=0x0, msg="happy new"
Server: (listening, payload concatenated to previous message)
Client: FIN=1, opcode=0x0, msg="year!"
Server: (process complete message) Happy new year to you too!
连接保持+心跳
WebSocket为了保持客户端、服务端的实时双向通信,需要确保客户端、服务端之间的TCP通道保持连接没有断开。然而,对于长时间没有数据往来的连接,如果依旧长时间保持着,可能会浪费包括的连接资源。
但不排除有些场景,客户端、服务端虽然长时间没有数据往来,但仍需要保持连接。这个时候,可以采用心跳来实现。
- 发送方->接收方:ping
- 接收方->发送方:pong
ping、pong的操作,对应的是WebSocket的两个控制帧,opcode分别是0x9、0xA。
举例,WebSocket服务端向客户端发送ping,只需要如下代码(采用ws模块)
ws.ping('', false, true);
Sec-WebSocket-Key/Accept的作用
前面提到了,Sec-WebSocket-Key/Sec-WebSocket-Accept在主要作用在于提供基础的防护,减少恶意连接、意外连接。
作用大致归纳如下:
- 避免服务端收到非法的websocket连接(比如http客户端不小心请求连接websocket服务,此时服务端可以直接拒绝连接)
- 确保服务端理解websocket连接。因为ws握手阶段采用的是http协议,因此可能ws连接是被一个http服务器处理并返回的,此时客户端可以通过Sec-WebSocket-Key来确保服务端认识ws协议。(并非百分百保险,比如总是存在那么些无聊的http服务器,光处理Sec-WebSocket-Key,但并没有实现ws协议。。。)
- 用浏览器里发起ajax请求,设置header时,Sec-WebSocket-Key以及其他相关的header是被禁止的。这样可以避免客户端发送ajax请求时,意外请求协议升级(websocket upgrade)
- 可以防止反向代理(不理解ws协议)返回错误的数据。比如反向代理前后收到两次ws连接的升级请求,反向代理把第一次请求的返回给cache住,然后第二次请求到来时直接把cache住的请求给返回(无意义的返回)。
- Sec-WebSocket-Key主要目的并不是确保数据的安全性,因为Sec-WebSocket-Key、Sec-WebSocket-Accept的转换计算公式是公开的,而且非常简单,最主要的作用是预防一些常见的意外情况(非故意的)。
强调:Sec-WebSocket-Key/Sec-WebSocket-Accept 的换算,只能带来基本的保障,但连接是否安全、数据是否安全、客户端/服务端是否合法的 ws客户端、ws服务端,其实并没有实际性的保证。
数据掩码的作用
WebSocket协议中,数据掩码的作用是增强协议的安全性。但数据掩码并不是为了保护数据本身,因为算法本身是公开的,运算也不复杂。除了加密通道本身,似乎没有太多有效的保护通信安全的办法。
那么为什么还要引入掩码计算呢,除了增加计算机器的运算量外似乎并没有太多的收益(这也是不少同学疑惑的点)。
答案还是两个字:安全。但并不是为了防止数据泄密,而是为了防止早期版本的协议中存在的代理缓存污染攻击(proxy cache poisoning attacks)等问题。
1、代理缓存污染攻击
下面摘自2010年关于安全的一段讲话。其中提到了代理服务器在协议实现上的缺陷可能导致的安全问题。猛击出处。
“We show, empirically, that the current version of the WebSocket consent mechanism is vulnerable to proxy cache poisoning attacks. Even though the WebSocket handshake is based on HTTP, which should be understood by most network intermediaries, the handshake uses the esoteric “Upgrade” mechanism of HTTP. In our experiment, we find that many proxies do not implement the Upgrade mechanism properly, which causes the handshake to succeed even though subsequent traffic over the socket will be misinterpreted by the proxy.”
Huang, L-S., Chen, E., Barth, A., Rescorla, E., and C. Jackson, “Talking to Yourself for Fun and Profit”, 2010,
在正式描述攻击步骤之前,我们假设有如下参与者:
- 攻击者、攻击者自己控制的服务器(简称“邪恶服务器”)、攻击者伪造的资源(简称“邪恶资源”)
- 受害者、受害者想要访问的资源(简称“正义资源”)
- 受害者实际想要访问的服务器(简称“正义服务器”)
- 中间代理服务器
攻击步骤一:
- 攻击者浏览器 向 邪恶服务器 发起WebSocket连接。根据前文,首先是一个协议升级请求。
- 协议升级请求 实际到达 代理服务器。
- 代理服务器 将协议升级请求转发到 邪恶服务器。
- 邪恶服务器 同意连接,代理服务器 将响应转发给 攻击者。
由于 upgrade 的实现上有缺陷,代理服务器 以为之前转发的是普通的HTTP消息。因此,当协议服务器 同意连接,代理服务器 以为本次会话已经结束。
攻击步骤二:
- 攻击者 在之前建立的连接上,通过WebSocket的接口向 邪恶服务器 发送数据,且数据是精心构造的HTTP格式的文本。其中包含了 正义资源 的地址,以及一个伪造的host(指向正义服务器)。(见后面报文)
- 请求到达 代理服务器 。虽然复用了之前的TCP连接,但 代理服务器 以为是新的HTTP请求。
- 代理服务器 向 邪恶服务器 请求 邪恶资源。
- 邪恶服务器 返回 邪恶资源。代理服务器 缓存住 邪恶资源(url是对的,但host是 正义服务器 的地址)。
到这里,受害者可以登场了:
- 受害者 通过 代理服务器 访问 正义服务器 的 正义资源。
- 代理服务器 检查该资源的url、host,发现本地有一份缓存(伪造的)。
- 代理服务器 将 邪恶资源 返回给 受害者。
- 受害者 卒。
附:前面提到的精心构造的“HTTP请求报文”。
Client → Server:
POST /path/of/attackers/choice HTTP/1.1 Host: host-of-attackers-choice.com Sec-WebSocket-Key: <connection-key>
Server → Client:
HTTP/1.1 200 OK
Sec-WebSocket-Accept: <connection-key>
2、当前解决方案
最初的提案是对数据进行加密处理。基于安全、效率的考虑,最终采用了折中的方案:对数据载荷进行掩码处理。
需要注意的是,这里只是限制了浏览器对数据载荷进行掩码处理,但是坏人完全可以实现自己的WebSocket客户端、服务端,不按规则来,攻击可以照常进行。
但是对浏览器加上这个限制后,可以大大增加攻击的难度,以及攻击的影响范围。如果没有这个限制,只需要在网上放个钓鱼网站骗人去访问,一下子就可以在短时间内展开大范围的攻击。
项目示例
4.7 - DNS 服务
概览
域名系统并不像电话号码通讯录那么简单,通讯录主要是单个个体在使用,同一个名字出现在不同个体的通讯录里并不会出现问题,但域名是群体中所有人都在用的,必须要保持唯一性。
为了达到唯一性的目的,因特网在命名的时候采用了层次结构的命名方法。每一个域名(本文只讨论英文域名)都是一个标号序列(labels),用字母(A-Z,a-z,大小写等价)、数字(0-9)和连接符(-)组成,标号序列总长度不能超过255个字符,它由点号分割成一个个的标号(label),每个标号应该在63个字符之内,每个标号都可以看成一个层次的域名。级别最低的域名写在左边,级别最高的域名写在右边。
域名服务主要是基于UDP实现的,服务器的端口号为53。
域名层级结构
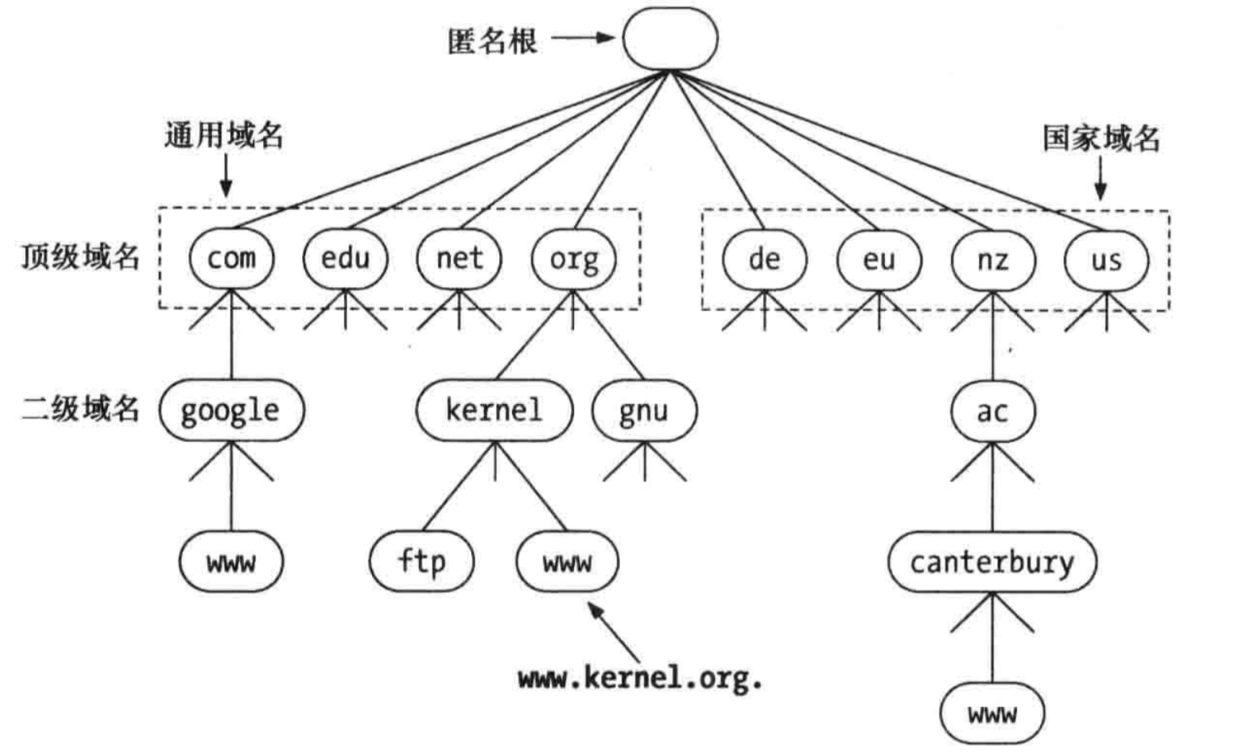
注意:最开始的域名最后都是带了点号的,比如
www.kernel.org.,最后面的点号表示根域名服务器,后来发现所有的网址都要加上最后的点,就简化了写法,干脆所有的都不加即www.kernel.org,但是你在网址后面加上点号也是可以正常解析的。
域名服务器
有域名结构还不行,还需要有一个东西去解析域名,手机通讯录是由通讯录软件解析的,域名需要由遍及全世界的域名服务器去解析,域名服务器实际上就是装有域名系统的主机。由高向低进行层次划分,可分为以下几大类:
- 根域名服务器:最高层次的域名服务器,也是最重要的域名服务器,本地域名服务器如果解析不了域名就会向根域名服务器求助。全球共有13个不同IP地址的根域名服务器,它们的名称用一个英文字母命名,从a一直到m。这些服务器由各种组织控制,并由 ICANN(互联网名称和数字地址分配公司)授权,由于每分钟都要解析的名称数量多得令人难以置信,所以实际上每个根服务器都有镜像服务器,每个根服务器与它的镜像服务器共享同一个 IP 地址,中国大陆地区内只有6组根服务器镜像(F,I(3台),J,L)。当你对某个根服务器发出请求时,请求会被路由到该根服务器离你最近的镜像服务器。所有的根域名服务器都知道所有的顶级域名服务器的域名和地址,如果向根服务器发出对 “pdai.tech” 的请求,则根服务器是不能在它的记录文件中找到与 “pdai.tech” 匹配的记录。但是它会找到 “tech” 的顶级域名记录,并把负责 “tech” 地址的顶级域名服务器的地址发回给请求者。
- 顶级域名服务器:负责管理在该顶级域名服务器下注册的二级域名。当根域名服务器告诉查询者顶级域名服务器地址时,查询者紧接着就会到顶级域名服务器进行查询。比如还是查询"pdai.tech",根域名服务器已经告诉了查询者"tech"顶级域名服务器的地址,“tech"顶级域名服务器会找到 “pdai.tech”的域名服务器的记录,域名服务器检查其区域文件,并发现它有与 “pdai.tech” 相关联的区域文件。在此文件的内部,有该主机的记录。此记录说明此主机所在的 IP 地址,并向请求者返回最终答案。
- 权限域名服务器:负责一个区的域名解析工作
- 本地域名服务器:当一个主机发出DNS查询请求的时候,这个查询请求首先就是发给本地域名服务器的。
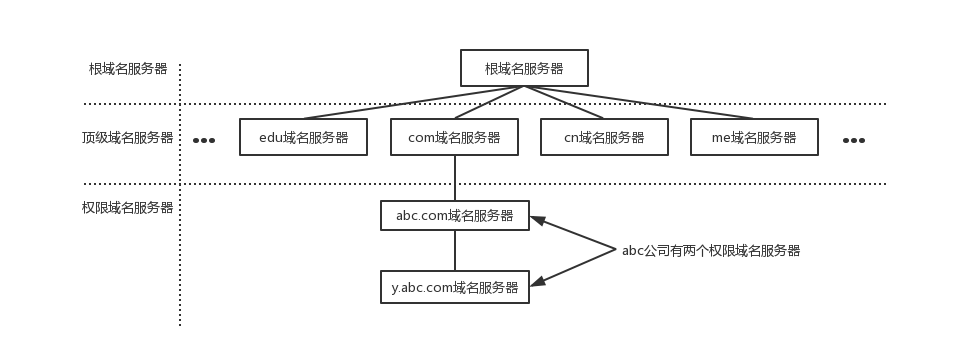
DNS 解析流程
.com.fi国际金融域名DNS解析的步骤一共分为9步,如果每次解析都要走完9个步骤,大家浏览网站的速度也不会那么快,现在之所以能保持这么快的访问速度,其实一般的解析都是跑完第4步就可以了。除非一个地区完全是第一次访问(在都没有缓存的情况下)才会走完9个步骤,这个情况很少。
- 1、本地客户机提出域名解析请求,查找本地HOST文件后将该请求发送给本地的域名服务器。
- 2、将请求发送给本地的域名服务器。
- 3、当本地的域名服务器收到请求后,就先查询本地的缓存。
- 4、如果有该纪录项,则本地的域名服务器就直接把查询的结果返回浏览器。
- 5、如果本地DNS缓存中没有该纪录,则本地域名服务器就直接把请求发给根域名服务器。
- 6、然后根域名服务器再返回给本地域名服务器一个所查询域(根的子域)的主域名服务器的地址。
- 7、本地服务器再向上一步返回的域名服务器发送请求,然后接受请求的服务器查询自己的缓存,如果没有该纪录,则返回相关的下级的域名服务器的地址。
- 8、重复第7步,直到找到正确的纪录。
- 9、本地域名服务器把返回的结果保存到缓存,以备下一次使用,同时还将结果返回给客户机。
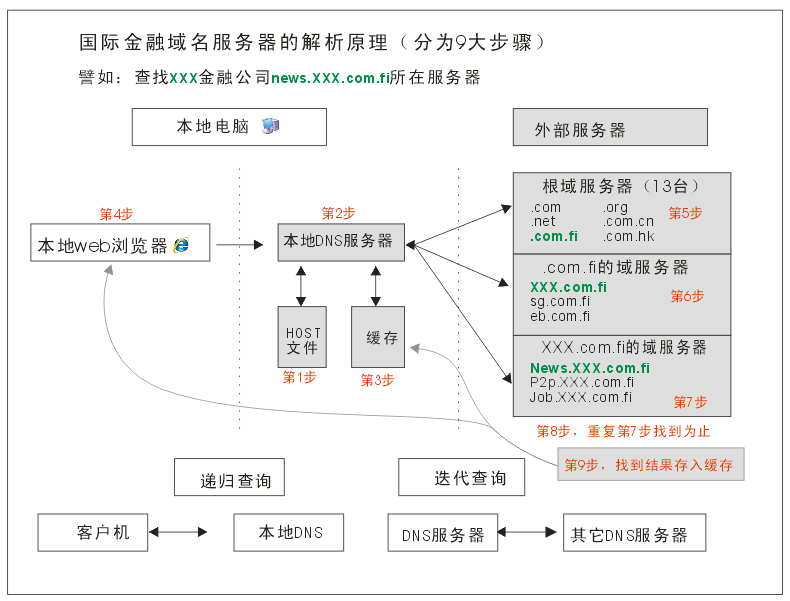
递归查询:在该模式下DNS服务器接收到客户机请求,必须使用一个准确的查询结果回复客户机。如果DNS服务器本地没有存储查询DNS信息,那么该服务器会询问其他服务器,并将返回的查询结果提交给客户机。
迭代查询:DNS所在服务器若没有可以响应的结果,会向客户机提供其他能够解析查询请求的DNS服务器地址,当客户机发送查询请求时,DNS服务器并不直接回复查询结果,而是告诉客户机另一台DNS服务器地址,客户机再向这台DNS服务器提交请求,依次循环直到返回查询的结果为止。
为什么DNS通常基于UDP
使用基于UDP的DNS协议只要一个请求、一个应答就好了
而使用基于TCP的DNS协议要三次握手、发送数据以及应答、四次挥手
明显基于TCP协议的DNS更浪费网络资源!
当然以上只是从数据包的数量以及占有网络资源的层面来进行的分析,那数据一致性层面呢?
DNS数据包不是那种大数据包,所以使用UDP不需要考虑分包,如果丢包那么就是全部丢包,如果收到了数据,那就是收到了全部数据!所以只需要考虑丢包的情况,那就算是丢包了,重新请求一次就好了。而且DNS的报文允许填入序号字段,对于请求报文和其对应的应答报文,这个字段是相同的,通过它可以区分DNS应答是对应的哪个请求
DNS通常是基于UDP的,但当数据长度大于512字节的时候,为了保证传输质量,就会使用基于TCP的实现方式
DNS 查询
dig 查询
用
dig可以查看整个过程,看下下面的返回就能理解的
- dig www.sina.com
- dig +trace www.sina.com // 分级查询
域名与IP之间的对应关系,称为"记录”(record)。根据使用场景,“记录"可以分成不同的类型(type),前面已经看到了有A记录和NS记录。
常见的DNS记录类型如下。
- A:地址记录(Address),返回域名指向的IP地址。
- NS:域名服务器记录(Name Server),返回保存下一级域名信息的服务器地址。该记录只能设置为域名,不能设置为IP地址。
- MX:邮件记录(Mail eXchange),返回接收电子邮件的服务器地址。
- CNAME:规范名称记录(Canonical Name),返回另一个域名,即当前查询的域名是另一个域名的跳转,详见下文。
- PTR:逆向查询记录(Pointer Record),只用于从IP地址查询域名,详见下文。
一般来说,为了服务的安全可靠,至少应该有两条NS记录,而A记录和MX记录也可以有多条,这样就提供了服务的冗余性,防止出现单点失败。
CNAME记录主要用于域名的内部跳转,为服务器配置提供灵活性,用户感知不到。
host查询
pdaiMbp:/ pdai$ host www.sina.com
www.sina.com is an alias for us.sina.com.cn.
us.sina.com.cn is an alias for spool.grid.sinaedge.com.
spool.grid.sinaedge.com has address 115.238.190.240
spool.grid.sinaedge.com has IPv6 address 240e:f7:a000:221::75:71
nslookup查询
pdaiMbp:/ pdai$ nslookup
> www.sina.com
Server: 192.168.3.1
Address: 192.168.3.1#53
Non-authoritative answer:
www.sina.com canonical name = us.sina.com.cn.
us.sina.com.cn canonical name = spool.grid.sinaedge.com.
Name: spool.grid.sinaedge.com
Address: 115.238.190.240
whois查询
pdaiMbp:/ pdai$ whois www.sina.com
在线工具查询
https://www.nslookuptool.com/chs/
DNS 调度原理
本节转自:【网易MC】DNS 调度原理解析
现在,大部分应用和业务都采用域名作为服务的入口,因此用 DNS 来负载均衡和区域调度是非常普遍的做法,网易云也有着一套基于 DNS 的调度系统。某些用户在进行直播推流时用的并不是网易云的直播 SDK,而是一些第三方的推流软件,如obs,这样就不能使用我们的 GSLB 全局调度服务器来调度。对于这些用户,我们使用 DNS 调度的方式,对不同地域的请求返回不同解析结果,将请求调度到离用户最近的服务器节点,从而减少延迟访问。
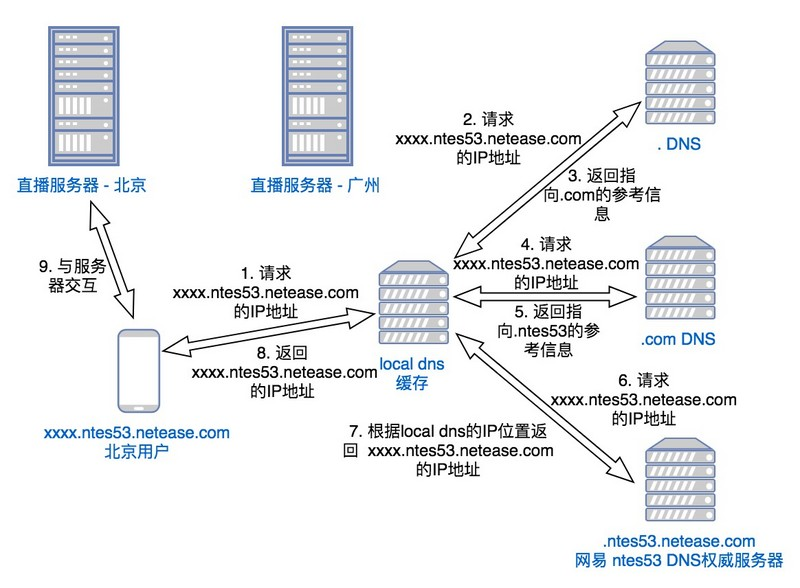
咋一看,DNS 调度这么简单方便,那为什么不让所有的用户都走 DNS 调度呢?想知道原因?来,我们继续讲。
地理位置调度不准确
在 DNS 解析过程中,与权威服务器通信的只有 DNS 缓存服务器,所以权威服务器只能根据 DNS 缓存服务器的IP来进行调度。因此 DNS 调度有一个前提:假定用户使用的缓存DNS与用户本身在同个网络内,即至少在同一个 AS(自治域)内,在该前提下,DNS 的解析才是准确的。通常情况下,用户使用 ISP 提供的本地缓存(简称 local DNS),local DNS 一般与用户在同个网络内,这时候 DNS 调度是有效的。
但近些年,不少互联网厂商推广基于 BGP Anycast 的公共 DNS (Public DNS),而这些Anycaset IP 的节点一般是远少于各个ISP的节点,例如可能广州电信用户使用了某公共 DNS,但该公共 DNS 里用户最近的是上海电信节点,甚至更极端的如 Google DNS 8.8.8.8,在中国大陆没有节点(最近的是台湾)。而不幸的是国内有不少用户使用了 Google DNS,这其实降低了他们的网络访问体验。总的来说,使用公共 DNS,实际上破坏了上文的前提,导致 DNS 区域调度失效,用户以为得到了更快更安全的 DNS 解析,但实际得到了错误的解析,增加了网络访问延迟。
传统 DNS 协议的区域调度过程示例如下图,假定某业务以 foo.163.com 对外提供服务,在北京和东京各有一个节点,业务期望国内大陆的用户访问北京节点,而非大陆用户则访问东京节点。因为权威是根据 DNS 缓存来决定返回的结果,所以当用户使用不用的 DNS 缓存时,可能会解析到不同的结果。
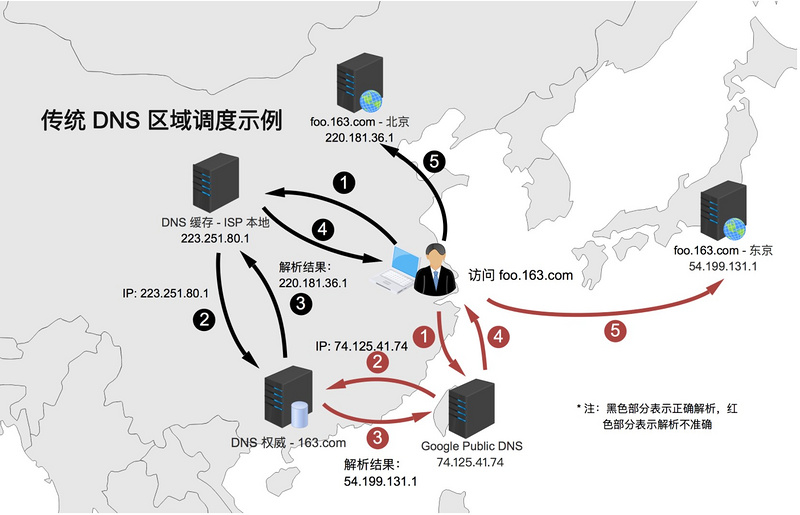
2011 年,Google 为首的几家公司在提出了一个 DNS 的扩展方案 edns-client-subnet (以下简称 ECS),该扩展方案的核心思想是通过在 DNS 请求报文里加入原始请求的 IP(即 client 的 IP),使得权威能根据该信息返回正确的结果。目前,该方案仍处于草案阶段。该方案很好地解决了上述提到的 remote DNS 导致解析不准确的问题,但也带了一些问题:
- 至少需要 cache 和权威都支持,才能完成完整的 ECS 解析
- ECS 给 cache 增加了很大的缓存压力,因为理论上可能需要为每个IP段分配空间去缓存解析结果
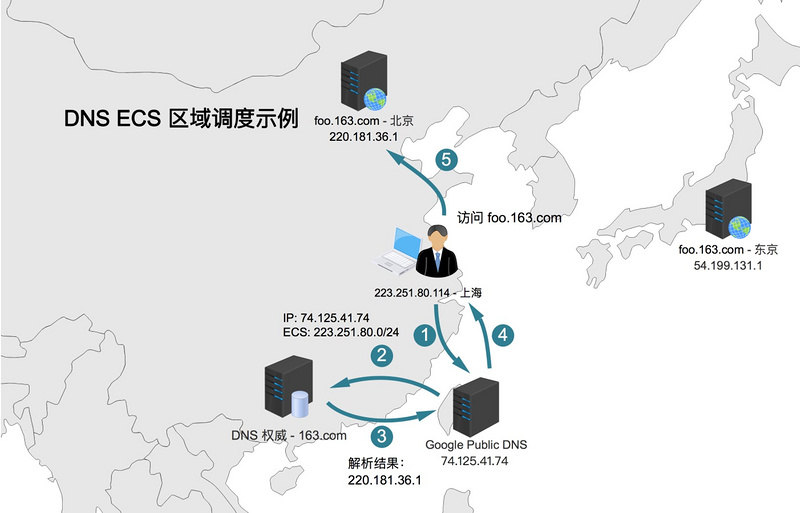
规则变更生效时间不确定
当缓存服务器向权威服务器查询得到记录之后,会将其缓存起来,在缓存有效期内,如果收到相同记录的查询,缓存服务器会直接返回给客户端,而不需要再次向权威查询,当有效期过后,缓存则是需要再次发起查询。这个缓存有效期即是 TTL。
虽然 DNS 的缓存机制在大多数情况下缩短了客户端的记录解析时间,但缓存也意味着生效同步的延迟。当权威服务器的记录变更时,需要等待一段时间才能让所有客户端能解析到新的结果,因为很可能缓存服务器还缓存着旧的记录。
我们将权威的记录变更到全网生效这个过程称为 propagation,它的时间是不确定的,理论上的最大值即是 TTL 的值,对于记录变更或删除,这个时间是记录原本的 TTL,对于记录新增则是域的 nTTL 值。
如果一个域名记录原本的 TTL 是 18000,可以认为,变更该记录理论上需要等待 5 个小时才能保证记录能生效到全网。假设该域名的业务方希望缩短切换的时间,正确的做法是,至少提前5个小时修改记录,仅改小 TTL,例如改为5分钟,等待该变更同步到全网之后,再进行修改指向的操作,确认无误再将 TTL 修改为原本的值。
虽然 DNS 协议标准里建议缓存服务器应该记住或者缩短 TTL 的值,但实际上,有一些DNS缓存会修改权威服务器的 TTL,将其变大,这在国内几大运营商中是很常见的。例如,某域记录的 TTL 值实际上设置为 60,但在运营商的 DNS 缓存上,却变成 600 或者更大的值,甚至还有一些 DNS 缓存是不遵循 TTL 机制。这些都会影响域名的实际生效时间。
高可用
为避免受 DNS 缓存的影响,需要保证 DNS 中 A 记录的 IP 节点高可用性。对此,网易云DNS 调度系统采用的方案是在同一区域的多台直播服务器节点之间做负载均衡,对外只暴露一个虚 IP,这样,即使某台服务器宕机,负载均衡能迅速感知到,排除故障节点,而对 DNS 而言,因为虚 IP 不变而不受影响。
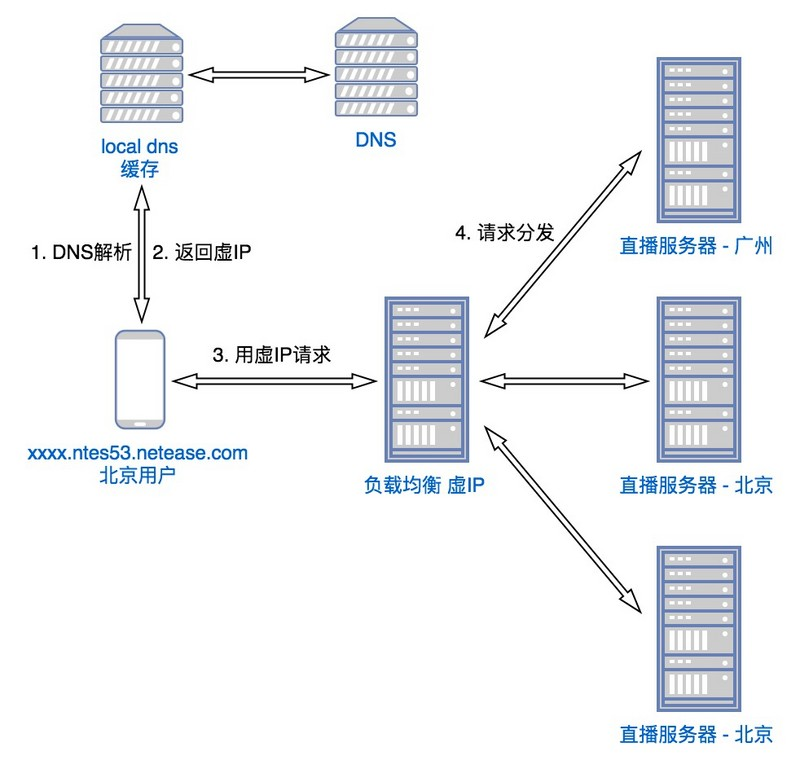
安全相关
犯罪分子会抓住任何互联网服务或协议的漏洞发动攻击,这当然也包括域名系统( DNS )。他们会注册一次性域名用于垃圾邮件活动和僵尸网络管理,还会盗用域名进行钓鱼和恶意软件下载。他们会注入恶意查询代码以利用域名服务器的漏洞或扰乱域名解析过程。他们会注入伪造的响应污染解析器缓存或强化 DDOS 攻击。他们甚至将 DNS 用作数据渗漏或恶意软件更新的隐蔽通道。
你可能没办法了解每一个新的 DNS 漏洞攻击,但是可以使用防火墙、网络入侵监测系统或域名解析器报告可疑的 DNS 行为迹象,作为主动防范的措施。
先讲下最常用的手段:DNS劫持和DNS污染。
什么是DNS劫持
DNS劫持就是通过劫持了DNS服务器,通过某些手段取得某域名的解析记录控制权,进而修改此域名的解析结果,导致对该域名的访问由原IP地址转入到修改后的指定IP,其结果就是对特定的网址不能访问或访问的是假网址,从而实现窃取资料或者破坏原有正常服务的目的。DNS劫持通过篡改DNS服务器上的数据返回给用户一个错误的查询结果来实现的。
DNS劫持症状:在某些地区的用户在成功连接宽带后,首次打开任何页面都指向ISP提供的“电信互联星空”、“网通黄页广告”等内容页面。还有就是曾经出现过用户访问Google域名的时候出现了百度的网站。这些都属于DNS劫持。
什么是DNS污染
DNS污染是一种让一般用户由于得到虚假目标主机IP而不能与其通信的方法,是一种DNS缓存投毒攻击(DNS cache poisoning)。其工作方式是:由于通常的DNS查询没有任何认证机制,而且DNS查询通常基于的UDP是无连接不可靠的协议,因此DNS的查询非常容易被篡改,通过对UDP端口53上的DNS查询进行入侵检测,一经发现与关键词相匹配的请求则立即伪装成目标域名的解析服务器(NS,Name Server)给查询者返回虚假结果。
而DNS污染则是发生在用户请求的第一步上,直接从协议上对用户的DNS请求进行干扰。
DNS污染症状:目前一些被禁止访问的网站很多就是通过DNS污染来实现的,例如YouTube、Facebook等网站。
解决方法:
- 对于DNS劫持,可以采用使用国外免费公用的DNS服务器解决。例如OpenDNS(208.67.222.222)或GoogleDNS(8.8.8.8)。
- 对于DNS污染,可以说,个人用户很难单单靠设置解决,通常可以使用VPN或者域名远程解析的方法解决,但这大多需要购买付费的VPN或SSH等,也可以通过修改Hosts的方法,手动设置域名正确的IP地址。
为什么要DNS流量监控
预示网络中正出现可疑或恶意代码的 DNS 组合查询或流量特征。例如:
- 1.来自伪造源地址的 DNS 查询、或未授权使用且无出口过滤地址的 DNS 查询,若同时观察到异常大的 DNS 查询量或使用 TCP 而非 UDP 进行 DNS 查询,这可能表明网络内存在被感染的主机,受到了 DDoS 攻击。
- 2.异常 DNS 查询可能是针对域名服务器或解析器(根据目标 IP 地址确定)的漏洞攻击的标志。与此同时,这些查询也可能表明网络中有不正常运行的设备。原因可能是恶意软件或未能成功清除恶意软件。
- 3.在很多情况下,DNS 查询要求解析的域名如果是已知的恶意域名,或具有域名生成算法( DGA )(与非法僵尸网络有关)常见特征的域名,或者向未授权使用的解析器发送的查询,都是证明网络中存在被感染主机的有力证据。
- 4.DNS 响应也能显露可疑或恶意数据在网络主机间传播的迹象。例如,DNS 响应的长度或组合特征可以暴露恶意或非法行为。例如,响应消息异常巨大(放大攻击),或响应消息的 Answer Section 或 Additional Section 非常可疑(缓存污染,隐蔽通道)。
- 5.针对自身域名组合的 DNS 响应,如果解析至不同于你发布在授权区域中的 IP 地址,或来自未授权区域主机的域名服务器的响应,或解析为名称错误( NXDOMAIN )的对区域主机名的肯定响应,均表明域名或注册账号可能被劫持或 DNS 响应被篡改。
- 6.来自可疑 IP 地址的 DNS 响应,例如来自分配给宽带接入网络 IP 段的地址、非标准端口上出现的 DNS 流量,异常大量的解析至短生存时间( TTL )域名的响应消息,或异常大量的包含“ name error ”( NXDOMAIN )的响应消息,往往是主机被僵尸网络控制、运行恶意软件或被感染的表现。
DNS 流量监控
如何借助网络入侵检测系统、流量分析和日志数据在网络防火墙上应用这些机制以检测此类威胁?
防火墙
我们从最常用的安全系统开始吧,那就是防火墙。所有的防火墙都允许自定义规则以防止 IP 地址欺骗。添加一条规则,拒绝接收来自指定范围段以外的 IP 地址的 DNS 查询,从而避免域名解析器被 DDOS 攻击用作开放的反射器。
接下来,启动 DNS 流量检测功能,监测是否存在可疑的字节模式或异常 DNS 流量,以阻止域名服务器软件漏洞攻击。具备本功能的常用防火墙的介绍资料在许多网站都可以找到(例如 Palo Alto、思科、沃奇卫士等)。Sonicwall 和 Palo Alto 还可以监测并拦截特定的 DNS 隧道流量。
入侵检测系统
无论你使用 Snort、Suricata 还是 OSSEC,都可以制定规则,要求系统对未授权客户的 DNS 请求发送报告。你也可以制定规则来计数或报告 NXDomain 响应、包含较小 TTL 数值记录的响应、通过 TCP 发起的 DNS 查询、对非标准端口的 DNS 查询和可疑的大规模 DNS 响应等。DNS 查询或响应信息中的任何字段、任何数值基本上都“能检测”。唯一能限制你的,就是你的想象力和对 DNS 的熟悉程度。防火墙的 IDS (入侵检测系统)对大多数常见检测项目都提供了允许和拒绝两种配置规则。
流量分析工具
Wireshark 和 Bro 的实际案例都表明,被动流量分析对识别恶意软件流量很有效果。捕获并过滤客户端与解析器之间的 DNS 数据,保存为 PCAP (网络封包)文件。创建脚本程序搜索这些网络封包,以寻找你正在调查的某种可疑行为。或使用 PacketQ (最初是 DNS2DB )对网络封包直接进行 SQL 查询。
(记住:除了自己的本地解析器之外,禁止客户使用任何其他解析器或非标准端口。)
DNS 被动复制
该方法涉及对解析器使用传感器以创建数据库,使之包含通过给定解析器或解析器组进行的所有 DNS 交易(查询/响应)。在分析中包含 DNS 被动数据对识别恶意软件域名有着重要作用,尤其适用于恶意软件使用由算法生成的域名的情况。将 Suricata 用做 IDS (入侵检测系统)引擎的 Palo Alto 防火墙和安全管理系统,正是结合使用被动 DNS 与 IPS (入侵防御系统)以防御已知恶意域名的安全系统范例。
解析器日志记录
本地解析器的日志文件是调查 DNS 流量的最后一项,也可能是最明显的数据来源。在开启日志记录的情况下,你可以使用 Splunk 加 getwatchlist 或是 OSSEC 之类的工具收集 DNS 服务器的日志,并搜索已知恶意域名。
尽管本文提到了不少资料链接、案例分析和实际例子,但也只是涉及了众多监控 DNS 流量方法中的九牛一毛,疏漏在所难免,要想全面快捷及时有效监控 DNS 流量,不妨试试 DNS 服务器监控。
DNS 服务器监控
应用管理器可对域名系统( DNS )进行全面深入的可用性和性能监控,也可监控 DNS 监控器的个别属性,比如响应时间、记录类型、可用记录、搜索字段、搜索值、搜索值状态以及搜索时间等。
DNS 中被监控的一些关键组件:
| 指标 | 描述 |
|---|---|
| 响应时间 | 给出 DNS 监控器的响应时间,以毫秒表示 |
| 记录类型 | 显示记录类型连接到 DNS 服务器的耗时 |
| 可用记录 | 根据可用记录类型输出 True 或 False |
| 搜索字段 | 显示用于 DNS 服务器的字段类型 |
| 搜索值 | 显示在DNS 服务器中执行的搜索值 |
| 搜索值状态 | 根据输出信息显示搜索值状态:Success (成功)或 Failed (失败) |
| 搜索时间 | DNS 服务器中的搜索执行时间 |
监控可用性和响应时间等性能统计数据。这些数据可绘制成性能图表和报表,即时可用,还可以按照可用性和完善性对报表进行分组显示。
若 DNS 服务器或系统内任何特定属性出现问题,会根据配置好的阈值生成通知和警告,并根据配置自动执行相关操作。目前,国内外 DNS 监控工具主要有 New relic、appDynamic、OneAPM。
4.8 - 浏览器过程
地址栏输入URL
URL : Uniform / Universal Resource Locator , 即统一资源定位符。它实际上就是网站网址。浏览器就是靠URL来查找资源位置。
可以把URL分割成几个部分:协议、网络地址、资源路径。
- 传送协议: URL包含协议部分,是浏览器和www万维网之间的沟通方式,它会告诉浏览器正确在网路上找到资源位置。最常见的网络传输协议的是HTTP协议(超文本传输协议)( https则是进行加密的网络传输);其他也还有ftp 、file、 https、mailto 、git 等。还有自定义的协议(私有协议),例如tencent。不同协议有不同的通讯内容格式。
- 网络地址: 指示该连接网络上哪一台计算机,可以是域名或者IP地址,可以包括端口号;
- 资源路径: 指示从服务器上获取哪一项资源。
例如: http://www.quaro.com/question/123456/
- 协议部分:http
- 网络地址:www.quaro.com
- 资源路径:/question/123456/
DNS 域名解析IP
基础概念
IP 地址:IP 协议为互联网上的每一个网络和每一台主机分配的一个逻辑地址。IP 地址如同门牌号码,通过 IP 地址才能确定一台主机位置。服务器本质也是一台主机,想要访问某个服务器,必须先知道它的 IP 地址。
域名 DN(domain name ):域名是为了识别主机名称和组织机构名称的一种具有分层的名称。 IP 地址由四个数字组成,中间用点号连接,在使用过程中难记忆且易输错,所以用我们熟悉的字母和数字组合来代替纯数字的 IP 地址,比如我们只会记住 www.baidu.com (百度域名) 而不是 220.181.112.244(百度的其中一个 IP 地址)。
计算机域名系统 DNS ( Domain Name System or Domain Name Service): 它是由域名解析器和域名服务器组成的。 域名服务器是指保存有该网络中所有主机的域名和对应IP地址,并具有将域名转换为IP地址功能的服务器。 每个域名都对应一个或多个提供相同服务的服务器的 IP 地址,只有知道服务器 IP 地址才能建立连接,所以需要通过 DNS 把域名解析成一个 IP 地址。
查找域名对应的IP地址
通过域名查找IP过程:浏览器缓存 -> 系统缓存 -> 本地DNS服务器缓存
- 浏览器搜索自己的DNS缓存(维护一张域名与IP地址对应表)
- 搜索操作系统中的DNS缓存(维护一张域名与IP地址对应表)
- 搜索操作系统的hosts文件(windows环境下,维护一张域名与IP地址对应表)
- 操作系统将域名发送到本地区域服务器(LNDS),进行查找,成功则返回结果(
递归查询),失败则发起一个迭代DNS请求(迭代查询)//迭代查询和递归查询请参考下一节 - 本地域名服务器LDNS将得到的IP地址返回给操作系统,同时也将IP地址缓存起来
- 操作系统将IP地址返回给浏览器,同时将IP地址缓存起来
DNS迭代查询和递归查询
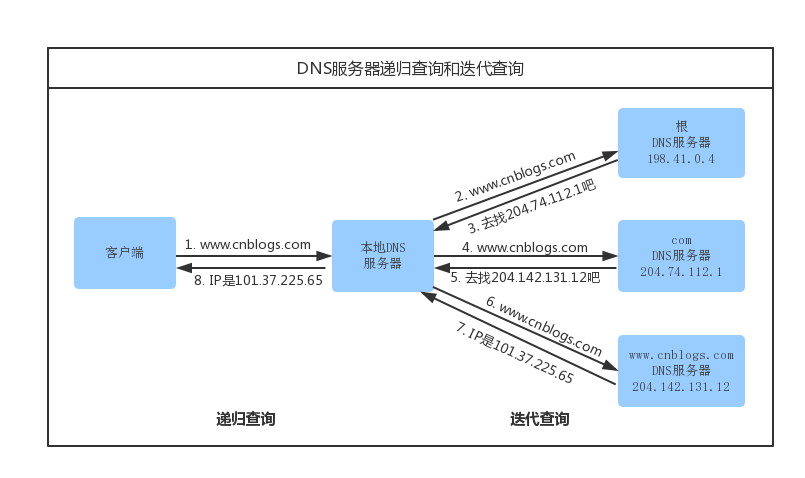
递归查询:客户端与服务器之间属于递归查询,即当客户机想DNS服务器发出请求后,若DNS服务器本身不能解析,会向另一个DNS服务器发出查询请求,最后将结果转交给客户端的过程。 服务器必须回答目标IP与域名的映射关系。
迭代查询:DNS服务器之间属于迭代查询。服务器接收到一次迭代查询回复一次结果,这个结果不一定死目标IP与域名的映射关系,也可以是其他DNS服务器的地址。
请求和响应数据
- TCP连接建立
- 发送http 请求
- 服务端处理
- 返回http 结果
- TCP连接关闭。
建立TCP连接(3次握手)
上一步找到IP之后,便可以开始建立TCP连接了,这里就是我们所说的TCP3次握手。
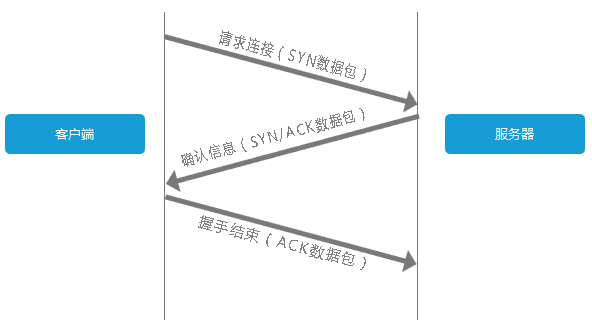
发送HTTP请求
与服务器建立了连接后,就可以向服务器发起请求了。
请求报文结构如下:
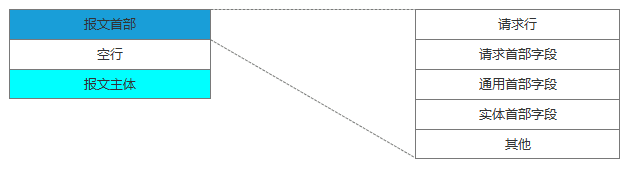
服务器处理请求
服务器端收到请求后的由web服务器(准确说应该是http服务器)处理请求,诸如Apache、Ngnix、IIS等。web服务器解析用户请求,知道了需要调度哪些资源文件,再通过相应的这些资源文件处理用户请求和参数,并调用数据库信息,最后将结果通过web服务器返回给浏览器客户端。
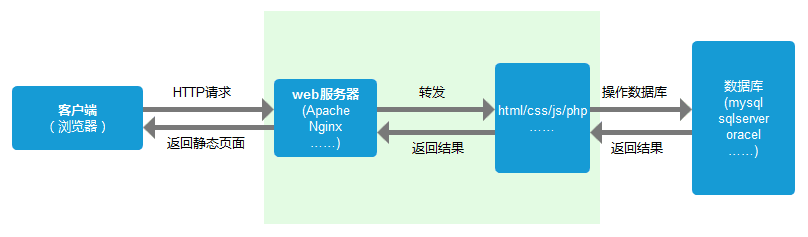
返回HTTP响应结果
服务器处理完请求后,就会发送响应结果。响应报文的结构如下:
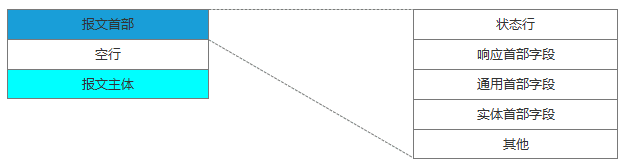
响应结果中会有对应的HTTP状态码,可分为5类:
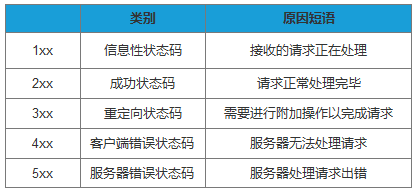
关闭TCP连接(4次挥手)
为了避免服务器与客户端双方的资源占用和损耗,当双方没有请求或响应传递时,任意一方都可以发起关闭请求。与创建TCP连接的3次握手类似,关闭TCP连接,需要4次握手。

浏览器:加载-解析-渲染
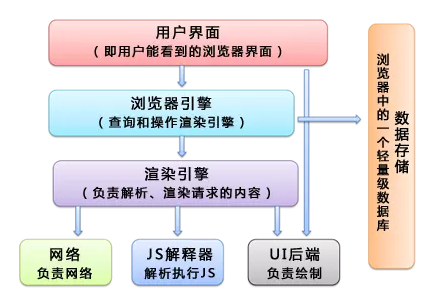
浏览器内核也称渲染引擎,主要有3种:
- Trident内核: IE
- Webkit内核:Chrome,Safari
- Gecko内核:FireFo
浏览器加载
加载过程如下:
- 当浏览器获得一个html文件时,会”自上而下“加载,并在加载过程中进行解析渲染。
- 加载过程中遇到外部css文件,浏览器另外发出一个请求,来获取css文件。
- 遇到图片资源,浏览器也会另外发出一个请求,来获取图片资源。这是异步请求,并不会影响html文档进行加载。
- 但是当文档加载过程中遇到js文件,html文档会挂起渲染(加载解析渲染同步)的线程,不仅要等待文档中js文件加载完毕,还要等待解析执行完毕,才可以恢复html文档的渲染线程。
加载外联js和css的阻塞情况:一个不太严谨但方便记忆的口诀:JS 全阻塞,CSS 半阻塞
- JS 会阻塞后续 DOM 解析以及其它资源(如 CSS,JS 或图片资源)的加载。
- CSS不阻塞DOM的加载和解析(它只阻塞DOM的渲染呈现。这里谈加载),不会阻塞其它资源(如图片)的加载,但是会阻塞 后续JS 文件的执行(原因之一是,js执行代码可能会依赖到css样式。css只阻塞执行而不阻塞js的加载)。
- 鉴于上面的特性,当css后面存在js的时候,css会间接地阻塞js后面资源的加载(css阻塞js,js阻塞其他资源 )。
- 现代浏览器会进行 prefetch 优化,浏览器在获得 html 文档之后会对页面上引用的资源进行提前下载
外联js文件使用defer属性和asyn可以达到异步非阻塞加载的效果,由于现代浏览器都存在 prefetch,所以 defer, async 可能并没有太多的用途,可以作为了解扩展知识,仅仅将脚本文件放到 body 底部(但还是在</body>之前)就可以起到很不错的优化效果(遵循先解析再渲染再执行script这个顺序)。当把js放在最后的时候,其实浏览器将自动忽略</body>标签,从而自动在最后的最后补上</body>。
浏览器解析和渲染
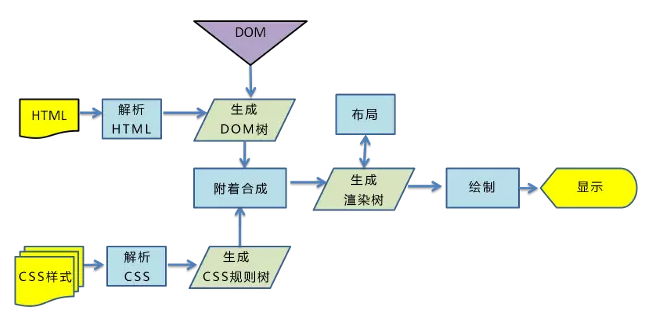
步骤如下:
- 解析html,生成dom树
- 解析css,生成cssom树
- 将dom树和cssom树合并,生成渲染树
- 遍历渲染树,开始布局和计算
- 绘制渲染树,显示到屏幕
解析html,生成dom树
当浏览器接收到服务器响应来的HTML文档后,会自上而下扫描文档,开始解析,遍历文档节点,生成DOM树。
整个构建过程其实包括: 字节 -> 字符 -> 令牌 -> 节点对象 -> 对象模型,下面是示例代码和配图:
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<link href="style.css" rel="stylesheet">
<title>Critical Path</title>
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg"></div>
</body>
</html>
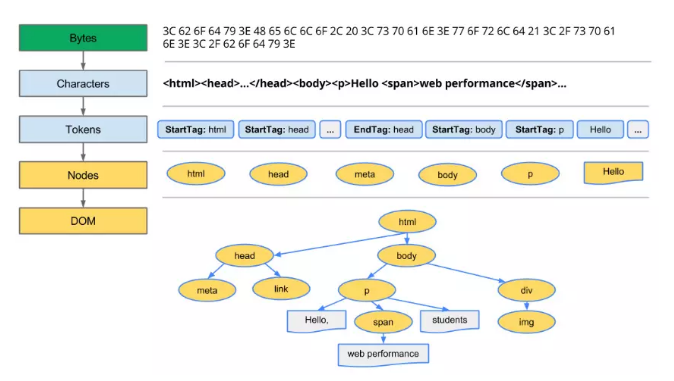
解析css,生成cssom树
- 每个css文件都被分析成一个stylesheet对象,每个对象都包含CSS规则。
- css规则对象包含对应于css语法的选择器和声明对象以及其他对象。
构建过程没有什么特别的差别,下面是示例代码和配图:
body { font-size: 16px }
p { font-weight: bold }
span { color: red }
p span { display: none }
img { float: right }
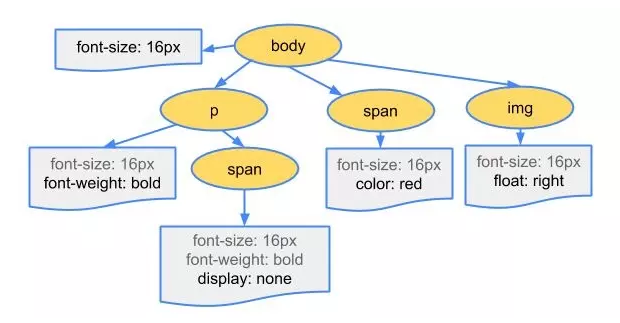
将dom树和cssom树合并,生成渲染树
- 浏览器会先从dom树的根节点开始遍历每个可见节点,找到其适配的CSS样式规则并应用。
- 将dom树与cssom树结合在一起,这就是渲染树。
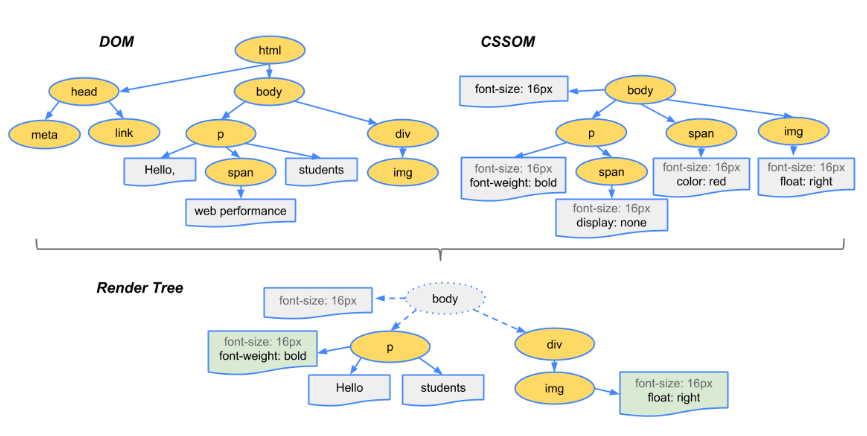
- 每一个渲染对象都对应着dom节点,但是非视觉(隐藏,不占位)dom元素不会插入渲染树,如
<head>元素或声明display: none;的元素。 - 渲染对象与dom节点不是简单的一对一的关系,一个dom可以对应一个渲染对象,但一个dom元素也可能对应多个渲染对象,因为有很多元素不止包含一个css盒子。(如当文本被折行时,会产生多个行盒,这些行会生成多个渲染对象;又如行内元素同时包含块元素和行内元素,则会创建一个匿名块级盒包含内部行内元素,此时一个dom对应多个渲染对象)
遍历渲染树,开始布局和计算
布局阶段会从渲染树的根节点开始遍历,然后确定每个节点对象在页面上的确切大小与位置。 布局阶段的输出是一个盒子模型,它会精确地捕获每个元素在屏幕内的确切位置与大小,所有相对的测量值也都会被转换为屏幕内的绝对像素值。
绘制渲染树,显示到屏幕
在绘制阶段,浏览器会立即发出Paint Setup与Paint事件,开始将渲染树绘制成像素,绘制所需的时间跟CSS样式的复杂度成正比,绘制完成后,用户就可以看到页面的最终呈现效果了。
Repaint和Reflow
当用户在浏览网页时进行交互或通过 js 脚本改变页面结构时,以上的部分操作有可能重复运行,此过程称为 Repaint 或 Reflow。
Repaint
当元素改变的时候,将不会影响元素在页面当中的位置(比如 background-color, border-color, visibility),浏览器仅仅会应用新的样式重绘此元素,此过程称为 Repaint。
Reflow
当元素改变的时候,将会影响文档内容或结构,或元素位置,此过程称为 Reflow。( HTML 使用的是 flow based layout ,也就是流式布局,所以,如果某元件的几何尺寸发生了变化,需要重新布局,也就叫 Reflow。)
Reflow 的成本比 Repaint 的成本高得多的多。我们应当尽量避免Reflow。
如何优化浏览器渲染过程
针对html
- html文档结构层次尽量少,最好不深于6层
- 首屏html可以少量,主体结构动态插入
- 尽量减少将 DOM 节点属性值放在循环当中,会导致大量读写此属性值。
- 创建有效的 HTML 和 CSS ,不要忘记指定文档编码,比如
<meta charset="utf-8">。
针对css
- 使用媒体查询,减少初次cssom树的构建量
- 尽量用id和class,不要过渡层叠
- 样式结构层次尽量简单
- 尽可能的为产生动画的 HTML 元素使用 fixed 或 absolute 的 position ,那么修改他们的 CSS 是不会 Reflow 的。
针对js
- 使用defer和async,避免对文档的阻塞
- 可以的话,动态插入js,避免阻塞
- 不要通过 JS 逐条修改 DOM 的样式,提前定义好 CSS 的 Class 进行操作。
针对引入位置
- css放到head,让cssom树先行构建;js放到
</body>前,保证dom树先行构建,不被阻塞 避免js文件的插入跟在css文件之后,避免css解析对js执行的延迟,造成阻塞
针对资源载入
- 对页面资源进行压缩,对传输进行gzip压缩
- 利用link标签的rel属性进行预解析,运用http缓存
4.9 - 概念术语
主机
计算机网络上任何一种能够连接网络的设备都被称为主机或者说端系统,比如手机、平板电脑、电视、游戏机、汽车等,随着 5G 的到来,将会有越来越多的终端设备接入网络。
通信链路
通信链路是由物理链路(同轴电缆、双绞线、光纤等)连接到一起组成的一种物理通路。
传输速率
单位是 bit/s 或者 bps ,用来度量不同链路从一个端系统到另一个端系统传输数据的速率。
分组
当一台端系统向另外一台端系统发送数据时,通常会将数据进行分片,然后为每段加上首部字节,从而形成计算机网络的专业术语:分组。这些分组通过网络发送到端系统,然后再进行数据处理。
路由器
它和链路层交换机一样,都是一种交换机,主要用于转发数据的目的。
路径
一个分组所经历一系列通信链路和分组交换机称为通过这个网络的路径。
因特网服务商
也叫 ISP,不是 lsp。这个好理解,就是网络运营商,移动、电信、联通。
网络协议
网络协议是计算机网络中进行数据交换而建立的规则、标准或者约定。
IP
网际协议,它规定了路由器和端系统之间发送和接收的分组格式。
TCP/IP 协议簇
不仅仅只有 TCP 协议和 IP 协议,而是以 TCP、IP 协议为主的一系列协议,比如 ICMP 协议、ARP 协议、UDP 协议、DNS 协议、SMTP 协议等。
分布式应用程序
多个端系统之间相互交换数据的端系统被称为分布式应用程序。
套接字接口
指的就是 socket 接口,这个接口规定了端系统之间通过因特网进行数据交换的方式。
协议
协议定义了两个以上通信实体之间交换报文格式和顺序所遵从的标准。
客户端
在客户-服务器架构中扮演请求方的角色,通常是 PC,智能手机等端系统。
服务器
在客户-服务器架构中扮演服务方的角色,通常是大型服务器集群扮演服务器的角色。
转发表
路由内部记录报文路径的映射关系的一种记录。
时延
时延指的是一个报文或者分组从网络的一端传递到另一端所需要的时间,时延分类有发送时延、传播时延、处理时延、排队时延,总时延 = 发送时延+传播时延+处理时延+排队时延。
丢包
在计算机网络中指的是分组出现丢失的现象。
吞吐量
吞吐量在计算机网络中指的是单位时间内成功传输数据的数量。
报文
通常指的是应用层的分组。
报文段
通常把运输层的分组称为报文段。
数据报
通常将网络层的分组称为数据报。
帧
一般把链路层的分组称为帧。
客户-服务体系
它是一种面向网络应用的体系结构。把系统中的不同端系统区分为客户和服务器两类,客户向服务器发出服务请求,由服务器完成所请求的服务,并把处理结果回送给客户。在客户-服务器体系结构中,有一个总是打开的主机称为 服务器(Server),它提供来自于 客户(client) 的服务。我们最常见的服务器就是 Web 服务器,Web 服务器服务于来自 浏览器 的请求。
CIDR
使用任意长度分割 IP 地址的网络标识和主机标识
P2P 体系 对等体系结构,相当于没有服务器了,大家都是客户机,每个客户既能发送请求,也能对请求作出响应。
## IP 地址
IP 地址就是网际协议地址,在互联网中唯一标识主机的一种地址。每一台入网的设备都会有一个 IP 地址,这个 IP 又分为内网 IP 和公网 IP。
端口号
在同一台主机内,端口号用于标识不同应用程序进程。
URI
它的全称是(Uniform Resource Identifier),中文名称是统一资源标识符,使用它就能够唯一地标记互联网上资源。
URL
它的全称是(Uniform Resource Locator),中文名称是统一资源定位符,它实际上是 URI 的一个子集。
HTML
HTML 称为超文本标记语言,是一种标识性的语言。它包括一系列标签.通过这些标签可以将网络上的文档格式统一,使分散的 Internet 资源连接为一个逻辑整体。HTML 文本是由 HTML 命令组成的描述性文本,HTML 命令可以说明文字,图形、动画、声音、表格、链接等。
Web 页面
Web 页面也叫做 Web Page,它是由对象组成,一个对象(object) 简单来说就是一个文件,这个文件可以是 HTML 文件、一个图片、一段 Java 应用程序等,它们都可以通过 URI 来找到。一个 Web 页面包含了很多对象,Web 页面可以说是对象的集合体。
Web 服务器
Web 服务器的正式名称叫做 Web Server,Web 服务器可以向浏览器等 Web 客户端提供文档,也可以放置网站文件,让全世界浏览;可以放置数据文件,让全世界下载。目前最主流的三个 Web 服务器是 Apache、 Nginx 、IIS。
CDN
CDN 的全称是Content Delivery Network,即内容分发网络,它应用了 HTTP 协议里的缓存和代理技术,代替源站响应客户端的请求。CDN 是构建在现有网络基础之上的网络,它依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。
WAF
WAF 是一种 应用程序防护系统,它是一种通过执行一系列针对 HTTP / HTTPS的安全策略来专门为 Web 应用提供保护的一款产品,它是应用层面的防火墙,专门检测 HTTP 流量,是防护 Web 应用的安全技术。
WebService
WebService 是一种 Web 应用程序,WebService 是一种跨编程语言和跨操作系统平台的远程调用技术。
HTTP
TCP/IP 协议簇的一种,它是一个在计算机世界里专门在两点之间传输文字、图片、音频、视频等超文本数据的约定和规范。
Session
Session 其实就是客户端会话的缓存,主要是为了弥补 HTTP 无状态的特性而设计的。服务器可以利用 Session 存储客户端在同一个会话期间的一些操作记录。当客户端请求服务端时,服务端会为这次请求开辟一块内存空间,这个对象便是 Session 对象,存储结构为 ConcurrentHashMap。
Cookie
HTTP 协议中的 Cookie 包括 Web Cookie 和浏览器 Cookie,它是服务器发送到 Web 浏览器的一小块数据。服务器发送到浏览器的 Cookie,浏览器会进行存储,并与下一个请求一起发送到服务器。通常,它用于判断两个请求是否来自于同一个浏览器,例如用户保持登录状态。
SMTP 协议
提供电子邮件服务的协议叫做 SMTP 协议, SMTP 在传输层也使用了 TCP 协议。SMTP 协议主要用于系统之间的邮件信息传递,并提供有关来信的通知。
DNS 协议
由于 IP 地址是计算机能够识别的地址,而我们人类不方便记忆这种地址,所以为了方便人类的记忆,使用 DNS 协议,来把我们容易记忆的网络地址映射称为主机能够识别的 IP 地址。
TELNET 协议
远程登陆协议,它允许用户(Telnet 客户端)通过一个协商过程来与一个远程设备进行通信,它为用户提供了在本地计算机上完成远程主机工作的能力。
SSH 协议
SSH 是一种建立在应用层上的安全加密协议。因为 TELNET 有一个非常明显的缺点,那就是在主机和远程主机的发送数据包的过程中是明文传输,未经任何安全加密,这样的后果是容易被互联网上不法分子嗅探到数据包来搞一些坏事,为了数据的安全性,我们一般使用 SSH 进行远程登录。
FTP 协议
文件传输协议,是应用层协议之一。FTP 协议包括两个组成部分,分为 FTP 服务器和 FTP 客户端。其中 FTP 服务器用来存储文件,用户可以使用 FTP 客户端通过 FTP 协议访问位于 FTP 服务器上的资源。FTP 协议传输效率很高,一般用来传输大文件。
MIME 类型
它表示的是互联网的资源类型,一般类型有 超文本标记语言文本 .html text/html、xml文档 .xml text/xml、普通文本 .txt text/plain、PNG图像 .png image/png、GIF图形 .gif image/gif、JPEG图形 .jpeg,.jpg image/jpeg、AVI 文件 .avi video/x-msvideo 等。
多路分解
在接收端,运输层会检查源端口号和目的端口号等字段,然后标识出接收的套接字,从而将运输层报文段的数据交付到正确套接字的过程被称为多路分解。
多路复用
在发送方,从不同的套接字中收集数据块,然后为数据块封装上首部信息从而生成报文段,然后将报文段传递给网络层的过程被称为多路复用。
周知端口号
在主机的应用程序中,从 0 - 1023 的端口号是受限制的,被称为周知端口号,这些端口号一般不能占用。
单向数据传输
数据的流向只能是单向的,也就是从发送端 -> 接收端。
双向数据传输
数据的流向是双向的,又叫做全双工通信,发送端和接收端可以相互发送数据。
面向连接的
面向连接指的是应用进程在向另一个应用进程发送数据前,需要先进行握手,即它们必须先相互发送预备报文段,用来建立确保数据传输的参数。
三次握手
TCP 连接的建立需要经过三个报文段的发送,这种连接的建立过程被称为三次握手。
最大报文段长度
即 MSS,它指的是从缓存中取出并放入报文段中的最大值。
最大传输单元
即 MTU,它指的是通信双方能够接收有效载荷的大小,MSS 通常会根据 MTU 来设。
冗余 ACK
就是再次确认某个报文段的 ACK,报文段的丢失会导致冗余 ACK 的出现。
快速重传
即在报文段定时器过期之前重传丢失的报文段。
选择确认
在报文段出现丢失的情况下,TCP 能够选择确认失序的报文段,这个机制通常和重传一起使用。
拥塞控制
拥塞控制说的是,当某一段时间网络中的分组过多,使得接收端来不及处理,从而引起部分甚至整个网络性能下降的现象时采取的一种抑制发送端发送数据,等过一段时间或者网络情况改善后再继续发送报文段的一种方法。
四次挥手
TCP 断开链接需要经过四个报文段的发送,这种断开过程是四次挥手。
路由选择算法
网络层中决定分组发送路径的一种算法。
转发
它指的是将分组从一个输入链路转移到合适的输出链路的动作。
分组调度
分组调度讨论的是分组如何经输出链路传输的问题,主要有三种调度方式:先进先出、优先级排队和"循环和加权公平排队"。
IPv4
网际协议的第四个版本,也是被广泛使用的一个版本。IPv4 是一种无连接的协议,无连接不保证数据的可靠性交付。使用 32 位的地址。
IPv6
网际协议的第六个版本,IPv6 的地址长度是 128 位,由于 IPv4 最大的问题在于网络地址资源不足,严重制约了互联网的应用和发展。IPv6 的使用,不仅能解决网络地址资源数量的问题,而且也解决了多种接入设备连入互联网的障碍。
接口
主机和物理链路之间的边界。
ARP 协议
ARP 是一种解决地址问题的协议,通过 IP 位线索,可以定位下一个用来接收数据的网络设备的 MAC 地址。如果目标主机与主机不在同一个链路上时,可以通过 ARP 查找下一跳路由的地址。不过 ARP 只适用于 IPv4 ,不适用于 IPv6。
RARP
RARP 就是将 ARP 协议反过来,通过 MAC 地址定位 IP 地址的一种协议。
代理 ARP
用于解决 ARP 包被路由器隔离的情况,通过代理 ARP 可以实现将 ARP 请求转发给临近的网段。
ICMP 协议
Internet 报文控制协议,如果在 IP 通信过程中由于某个 IP 包由于某种原因未能到达目标主机,那么将会发送 ICMP 消息,ICMP 实际上是 IP 的一部分。
DHCP 协议
DHCP 是一种动态主机配置协议。使用 DHCP 就能实现自动设置 IP 地址、统一管理 IP 地址分配,实现即插即用。
NAT 协议
网络地址转换协议,它指的是所有本地地址的主机在接入网络时,都会要在 NAT 路由器上将其转换成为全球 IP 地址,才能和其他主机进行通信。
IP 隧道
IP 隧道技术说的是由路由器把网络层协议封装到另一个协议中从而跨过网络传输到另外一个路由器的过程。
单播
单播最大的特点就是 1 对 1,早期的固定电话就是单播的一个例子
广播
我们一般小时候经常会广播体操,这就是广播的一个事例,主机和与他连接的所有端系统相连,主机将信号发送给所有的端系统。
多播
多播与广播很类似,也是将消息发送给多个接收主机,不同之处在于多播需要限定在某一组主机作为接收端。
任播
任播是在特定的多台主机中选出一个接收端的通信方式。虽然和多播很相似,但是行为与多播不同,任播是从许多目标机群中选出一台最符合网络条件的主机作为目标主机发送消息。然后被选中的特定主机将返回一个单播信号,然后再与目标主机进行通信。
IGP
内部网关协议,一般用于企业内部自己搭建的路由自治系统。
EGP
外部网关协议,EGP 通常用于在网络主机之间相互交换路由信息。
RIP
一种距离向量型路由协议,广泛应用于 LAN 网。
OSPF
是根据 OSI 的 IS-IS 协议提出的一种链路状态型协议。这种协议还能够有效的解决网络环路问题。
MPLS
它是一种标记交换技术,标记交换会对每个 IP 数据包都设定一个标记,然后根据这个标记进行转发。
节点
一般指链路层协议中的设备。
链路
一般把沿着通信路径连接相邻节点的通信信道称为链路。
MAC 协议
媒体访问控制协议,它规定了帧在链路上传输的规则。
奇偶校验位
一种差错检测方式,多用于计算机硬件的错误检测中,奇偶校验通常用在数据通信中来保证数据的有效性。
向前纠错
接收方检测和纠正差错的能力被称为向前纠错。
以太网
以太网是一种当今最普遍的局域网技术,它规定了物理层的连线、电子信号和 MAC 协议的内容。
VLAN
虚拟局域网(VLAN)是一组逻辑上的设备和用户,这些设备和用户并不受物理位置的限制,可以根据功能、部门及应用等因素将它们组织起来,相互之间的通信就好像它们在同一个网段中一样,所以称为虚拟局域网。
基站
无线网络的基础设施。
5 - TCP-IP
5.1 - 握手机制
一次握手表示向对方发送一个数据包,Client -> Server 或 Server -> Client。
建立连接:三次握手
目的是连接服务器指定端口、建立 TCP 连接,同步连接双方的序列号和确认号,交换 TCP 窗口的大小信息。
- Client -> Server:请求创建连接,SEQ=X
- Server -> Client:同意创建连接,ACK=X+1,SEQ=Y
- Client -> Server:得知同意创建,ACK=Y+1,SEQ=Z
关闭连接:四次挥手
双方均可主动发起挥手来关闭连接。
- Client -> Server:请求关闭
- Server -> Client:同意关闭
- Server -> Client:请求关闭
- Client -> Server:同意关闭
问题汇总
为什么要三次握手
为了防止已失效连接的请求报文段突然又传送到了服务端,因而产生错误。
Client 发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达 Server。
本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新的连接请求。于是就向client发出确认报文段,同意建立连接。
假设不采用“三次握手”,那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了。
如果采用三次握手,client不会向server的确认发出确认。server由于收不到确认,就知道client并没有要求建立连接。
为什么要四次挥手
TCP协议是一种面向连接的、可靠的、基于字节流的运输层通信协议。
TCP是全双工模式,这就意味着,当主机1发出FIN报文段时,只是表示主机1已经没有数据要发送了,主机1告诉主机2,它的数据已经全部发送完毕了;但是,这个时候主机1还是可以接受来自主机2的数据;当主机2返回ACK报文段时,表示它已经知道主机1没有数据发送了,但是主机2还是可以发送数据到主机1的;当主机2也发送了FIN报文段时,这个时候就表示主机2也没有数据要发送了,就会告诉主机1,我也没有数据要发送了,之后彼此就会愉快的中断这次TCP连接。
关闭时为什么要等待2MSL
MSL:报文段最大生存时间,它是任何报文段被丢弃前在网络内的最长时间。
- 保证TCP协议的全双工连接能够可靠关闭
- 保证这次连接的重复数据段从网络中消失
第一点:如果主机1直接CLOSED了,那么由于IP协议的不可靠性或者是其它网络原因,导致主机2没有收到主机1最后回复的ACK。那么主机2就会在超时之后继续发送FIN,此时由于主机1已经CLOSED了,就找不到与重发的FIN对应的连接。所以,主机1不是直接进入CLOSED,而是要保持TIME_WAIT,当再次收到FIN的时候,能够保证对方收到ACK,最后正确的关闭连接。
第二点:如果主机1直接CLOSED,然后又再向主机2发起一个新连接,我们不能保证这个新连接与刚关闭的连接的端口号是不同的。也就是说有可能新连接和老连接的端口号是相同的。一般来说不会发生什么问题,但是还是有特殊情况出现:假设新连接和已经关闭的老连接端口号是一样的,如果前一次连接的某些数据仍然滞留在网络中,这些延迟数据在建立新连接之后才到达主机2,由于新连接和老连接的端口号是一样的,TCP协议就认为那个延迟的数据是属于新连接的,这样就和真正的新连接的数据包发生混淆了。所以TCP连接还要在TIME_WAIT状态等待2倍MSL,这样可以保证本次连接的所有数据都从网络中消失。
5.2 - 协议栈精要
TCP/IP 精要
《TCP/IP详解学习笔记》系列文章的学习整理,点击标题查看原文。
基本概念
为什么会有TCP/IP协议
为了可以在多个单机的计算机之间进行通信,可以使用电线将他们连接在一起。但是简单的连接在一起还不够,好比语言不同的两个人见面后并不能正确的交流信息。因此需要定义一些共通的东西来进行交流,TCP/IP就是为此而生。
TCP/IP不是一个协议,而是一个协议簇的统称。里面包含了IP协议、IMCP协议、TCP协议,以及我们更加熟悉的HTTP、FTP、POP3协议等。计算机有了这些,就好像大家都统一使用英语来交流一样。
TCP/IP协议分层
协议分层经常会提到IOS-OSI七层协议经典架构,但是TCP/IP协议族的结构稍有不同。如图:
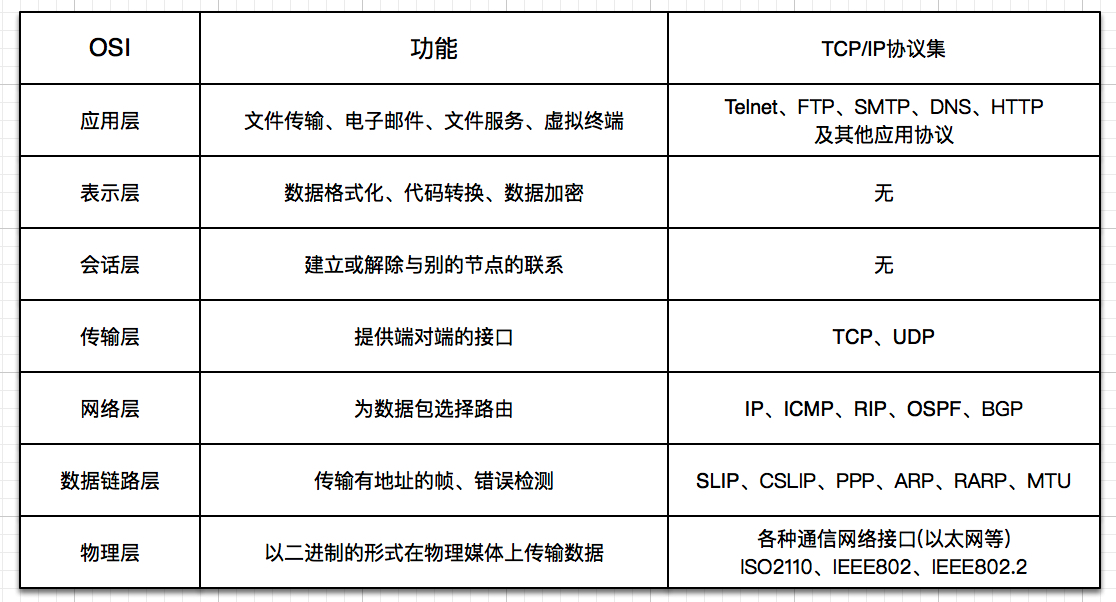
TCP/IP协议族按照层次由上到下,层层包装。最上面是应用层,里面包含HTTP、FTP等我们熟悉的协议。第二层是传输层,著名的TCP和UDP协议就在这层。第三层是网络层,包含IP协议,负责对数据加上IP信息和其他数据以确定传输的目标。第四层叫做数据链路层,为待传送的数据加入一个以太网协议头,并进行CRC编码,为最后的数据传输做准备。再往下则是硬件层次了,负责网络的传输,这个层次的定义包括网线的制式,网卡的定义等。
发送数据的主机从上自下将数据按照协议封装,而接收数据的主机则按照协议将得到的数据包解开,最后拿到需要的数据。
基本常识
互联网地址
网络上每一个节点都必须有一个独立的internet地址(即IP地址),现在常用的是IPV4地址,又被分为5类,常用的是B类地址。需要注意的是IP地址是网络号+主机号的组合,这非常重要。
域名系统
域名系统是一个分布的数据库,它提供将主机名(即网址)转换成IP地址。
RFC
RFC就是TCP/IP协议栈的标准文档,文档中可以看到一个很长的定义列表,现在一共有4000多个协议的定义,然而我们要学习使用的也就10多个。
端口号
这个号码是用在TCP和UDP上的一个逻辑号码,并不是一个硬件端口。平时所说的封掉某个端口,也只是在IP层次上把带有这个号码的IP包给过滤掉而已。
应用编程接口
现在常用的编程接口有socket和TLI。
数据链路层
数据链路层有三个目的:
- 为IP模块发送和接收IP数据报
- 为ARP模块发送ARP请求和接收ARP应答
- 为RARP发送RARP请求和接收RARP应答
ARP叫做地址解析协议,是用IP地址换MAC地址的一种协议,而RARP叫做逆地址解析协议。
数据链路层的协议还是很多的,有我们最常用的以太网(网卡)协议,也有不太常用的令牌环,还有FDDI,还有国内现在相当普及的PPP(adsl宽带),以及一个loopback协议。
在Linux终端中使用ifconfig -a命令,这个命令通常会得到如下结果:
lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> mtu 16384
options=3<RXCSUM,TXCSUM>
inet6 ::1 prefixlen 128
inet 127.0.0.1 netmask 0xff000000
inet6 fe80::1%lo0 prefixlen 64 scopeid 0x1
nd6 options=1<PERFORMNUD>
gif0: flags=8010<POINTOPOINT,MULTICAST> mtu 1280
stf0: flags=0<> mtu 1280
en0: flags=8863<UP,BROADCAST,SMART,RUNNING,SIMPLEX,MULTICAST> mtu 1500
ether ac:bc:32:8e:41:57
inet6 fe80::aebc:32ff:fe8e:4157%en0 prefixlen 64 scopeid 0x4
inet 192.168.10.203 netmask 0xffffff00 broadcast 192.168.10.255
inet6 fd3d:5f4e:424b::aebc:32ff:fe8e:4157 prefixlen 64 autoconf
inet6 fd3d:5f4e:424b::806d:59f8:8422:b7ca prefixlen 64 autoconf temporary
nd6 options=1<PERFORMNUD>
media: autoselect
status: active
其中,eth0就是以太网接口,而lo则是lookback接口。这也说明这个主机在网络链路层上至少支持lookback协议和以太网协议。
以太网的定义是指:数字设备公司、英特尔公司和Xerox公司在1982年联合公布的一个标准,这个标准里面使用了一种称作CSMA/CD的接入方法。而IEEE802提供的标准集802.3(还有一部分定义在802.2中)也提供了一个CSMA/CD的标准。这两个标准稍有不同,TCP/IP对这种情况的处理方式如下:
- 以太网的IP数据报封装在RFC894中定义,而IEEE802网络的IP数据报封装在RFC1042中定义。
- 一台主机一定要能发送和接收RFC894定义的数据报。
- 一台主机可以接收RFC894和RFC1042的封装格式的混合数据报。
- 一台主机也许能够发送RFC1042数据报。如果主机能够同时发送两种类型的分组数据,那么发送的分组必须是可以设置的,而且默认的情况下必须是RFC894分组。
可见,RFC1042在TCP/IP里处于一个配角的地位。
PPP(点对点协议)是SLIP的替代品。他们都提供了一种低速接入的解决方案。而每一种数据链路层协议,都有一个MTU(最大传输单元)定义,在这个定义下面,如果IP数据报过大,则要进行分片(fragmentation),使得每片都小于MTU。注意PPP和MTU并不是一个物理定义,而是指一个逻辑定义(个人认为就是用程序控制)。可以用netstat打印MTU的结果,比如命令netstat -in,可以看到各协议的MTU值。
环回接口(lookback),平时我们用127.0.0.1测试本机服务器是否可以使用,走的就是这个环回接口。对于环回接口,有如下三点值得注意:
- 传给换回地址(127.0.0.1)的任何数据均作为IP输入
- 传给广播地址或多播地址的数据报复制一份传给环回接口,然后发送到以太网上。这是因为广播传送和多播传送的定义包含主机本身
- 任何传给主机IP地址的数据均送到环回接口
IP,ARP,RARP
这三个协议均属于网络层。ARP协议用于找到目标主机的Ethernet网卡MAC地址,IP要承载发送的消息。数据链路层可以从ARP得到数据的传送信息,而从IP得到要传输的数据的信息。
IP协议
IP协议用于将多个包交换网络连接起来,它在源地址可目标地址之间传送一种称为数据包的东西,并提供对数据包大小的重新组装功能,以适应不同网络对包大小的要求。
IP协议实现两个基本功能:寻址和分段。IP可以根据数据包包头中包括的目的地址将数据报传送到目的地址,在此过程中IP负责选择传送的道路,称为路由。如果有些网络内只能传输小数据报,IP可以将数据报重新组装并在包头域内注明。
IP协议是TCP/IP协议栈的核心,所有的TCP、UDP、IMCP、IGCP的数据都是以IP数据格式传输的。要注意的是,IP不是可靠的协议,就是说,IP协议没有提供一种数据未到达以后的处理机制,这被认为是上层协议–即TCP和UDP要做的事情。所以也就出现了TCP是一个可靠的协议,而UDP就没有那么可靠的区别。
IP协议头
其中8位的TTL字段规定该数据报在穿过多少个路由之后才被丢弃(即它不保证数据被送达),某个IP数据包没穿过一个路由,该数据报的TTL值就会减少1,当该数据报的TTL值为0,它就会自动被丢弃。这个字段的值最大为255,也就是说一个协议包在路由里穿行255次就会被丢弃,根据系统的不同,这个值的大小也不一样,一般是32或64。Tracrouter这个工具就是用这个原理工作的,其-m选项要求最大值是255,也就是说这个TTL在IP协议里面只有8bit。
先在的IP版本号是4,即成为IPV4,同时还有现在使用越来越广泛的IPV6。
IP路由选择
当一个IP数据包准备好之后,IP数据包(或路由器)是如何将数据包送到目的地的呢?它是如何选择一个合适的路径来“送货”?
最特殊的情况是主机和目的主机直连,这时主机根本不用寻找路由,直接将数据传送过去。至于是怎么直接传递的,会用到ARP协议。
稍微一般一点的情况是,主机通过若干个路由器和目的主机连接。那么路由器要用IP包的信息来为IP包找到一个合适的目标进行传递,比如合适的主机,或者合适的路由。路由或主机将会用如下的方式来处理一个IP数据包:
- 如果IP数据包的TTL值已经为0,则丢弃该IP数据包;
- 搜索路由表,有限搜索匹配主机,如果能找到和IP地址完全一致的目标主机,则将该包发向目标主机;
- 搜索路由表,如果匹配主机失败,则匹配同子网的路由器,这需要
子网掩码(参考下面一节的子网寻址)的协助。如果找到路由器,则发送该数据包; - 搜索路由器,如果匹配相同子网路由器失败,则匹配同网号路哟器。如果找到,则发送该数据包;
- 搜索路由表,如果以上都失败,就搜索默认路由,如果默认路由存在,则发包;
- 如果都失败,丢弃该包。
这在一起说明,IP包是不可靠的,因为它不保证送达。
子网寻址
IP地址的定义是网络号+主机号。但是现在所有的主机都要求子网编址,也就是说,把主机号再细分成子网号+主机号。最终一个IP地址就成为:网络号码+子网号+主机号。例如一个B类地址:210.30.109.134。一般情况下,这个IP地址的红色部分就是网络号,蓝色部分就是子网号,绿色部分就是主机号。至于有多少位代表子网号这个问题,没有一个硬性的规定,取而代之的子网掩码,在校园网的设定里面有一个225.225.225.0的东西,就是子网掩码。
ARP协议
在数据链路层的以太网协议中,每一个数据包都有一个MAC地址头。每一块以太网卡都有一个MAC地址,这个地址是唯一的,那么IP包是如何知道这个MAC地址呢,这就是ARP的工作。
ARP(地址解析)协议是一种解析协议,本来主机是不知道这个IP对应的是哪个主机的哪个接口,当主机发送一个IP包的时候,首先会查一下自己的ARP告诉缓存(IP-MAC地址对应缓存),如果查询的IP-MAC不存在,那么主机就发送一个ARP协议广播包,这个广播包中包含待查询的IP地址,而直接收到这个广播包的所有主机都会查询自己的IP地址,如果其中一个主机发现自己符合条件,那么就准备好一个包含自己MAC地址的ARP包传送给发送ARP广播的主机,然后广播主机拿到ARP包后会更新自己的ARP缓存。发送广播的主机就会用新的ARP缓存数据准备好数据链路层的数据包发送工作。
一个典型的ARP缓存信息如下,在系统中使用arp -a命令。
这个高速缓存的时限是20分钟。
ICMP协议
由于IP协议并不是一个可靠的协议,因此保证数据送达的工作就会由其他模块来完成,其中一个重要的模块就是IMCP(网络控制报文)协议。
当IP数据包发生错误,比如主机不可达、路由不可达等,ICMP就会将错误信息封包,然后传送回给主机。给主机一个处理错误的机会,这也就是为什么说建立在IP层以上的协议是能够做到安全的原因。ICMP数据包由8bit的错误类型+8bit的代码+16bit的校验和组成。而前16bit就组成了ICMP要传递的信息。
尽管在大多数情况下,错误的包传送应该给出ICMP报文,但是在特殊情况下,是不产生ICMP报文的:
- ICMP错误报文不会产生ICMP错误报文(出ICMP查询报文),防止ICMP的无线产生和传送
- 目的地址是广播地址或多播地址的IP数据包
- 作为链路层广播的数据包
- 不是IP分片的第一片
- 原地址不是单个主机的数据包
这里的一切规定,都是为了防止ICMP报文的无线传播而定义的。
ICMP协议大致分两类,一种是查询报文,一种是错误报文。其中查询报文的用途:
- ping查询
- 子网掩码查询
- 时间戳查询
ICMP的应用-ping
ping可以说是ICMP的最注明应用,可以通过ping一个网址来查看其是否可用。
原理是用类型码为0的ICMP发请求,收到请求的主机则用类型码为8的ICMP回应。ping程序来计算时间间隔,并计算有多少包被送达。用户就可以判断大致的网络情况。
ping还给我们一个看到目的主机路由的机会,这是因为,ICMP的ping请求数据包在没经过一个路由的时候,路由器会把自己的IP放到该数据包中。而目的主机则会把这个IP列表复制到回应ICMP数据包中发回给主机。但是这个信息比较有限,如果想要查看更详细的路由,可以使用tracerouter。
ICMP的应用-tracerouter
Tracerouter用来侦测主机到目的主机之间所经路由情况的重要工具,也是最便利的工具。
它的原理是,它收到目的主机的IP后,首先给目的主机发送一个TTL=1的UDP数据包,而经过的第一个路由器收到这个包之后就自动把TTL减1,这时TTL为0,路由器就把这个包丢弃了,并同时产生一个主机不可达的ICMP数据包给主机。主机收到这个数据包以后再发一个TTL=2的UDP数据包给目的主机,然后刺激第二个路由器给主机发送ICMP数据包。如此往复直到到达目的主机,这样,tracerouter就拿到了所有路由IP,从而避免了IP头只能记录有限路由IP的问题。
但是tracerouter是如何直到是否到达目的主机了呢。这就涉及到一个技巧问题,TCP和UDP协议有一个端口号定义,普通的网络程序只监控少数几个号码较小的端口,如80、23等。而tracerouter发送的端口号>30000,所以到达主机的时候,目的主机只能发送一个端口不可达的ICMP数据报给主机,主机接收到这个报告以后就知道主机到了。
IP选路、动态选路
UDP协议
UDP是传输层协议,和TCP处于同一个分层中,但是于TCP不同,UDP不提供超时重传,出错重传等功能,也就是说它是不可靠协议。
协议头
UDP端口号
由于很多软件要用到UDP协议,所以UDP协议必须通过某个标志用以区分不同的程序所需要的数据包,这就是端口号的功能。例如一个UDP程序在A系统中注册了3000端口,以后从外部传进来的端口号为3000的数据包就会交给该程序。
UDP检验和
这是一个可选的选项,并不是所有的系统都对UDP数据包加以检验和数据(相对TCP的必须来说),但是RFC中标准要求,发送端应该计算校验和。
UDP校验和覆盖UDP协议头和数据,这个IP的检验和是不同的,IP协议的检验和只是覆盖IP数据头,并不覆盖所有的数据。UDP和TCP都包含一个伪首部,这是为了计算校验和而设置的。伪首部甚至包含IP地址这样IP协议里面都有的数据,目的是让UDP两次检查数据是否正确到达目的地。如果发送端没有打开校验和选项,而接收端计算校验和有差错,那么UDP数据将会被悄悄的丢掉(不保证送达),而不会产生任何错误报文。
UDP长度
UDP可以很长,长达65535字节。但是一般网络在传输的时候,一次传输不了那么长的协议(MTU),就只好对数据分片,当然,这些是对UDP上层协议透明的,UDP不需要关心IP层如何对数据分片。
IP分片
IP是在从上层接到数据以后,根据IP地址来判断从哪个接口发送数据,并进行MTU查询,如果数据大小超过MTU就进行分片。数据的分片对上层和下层透明,而数据在到达目的地后会重新组装,IP层提供了足够的信息进行数据的再组装。
UDP服务器设计
UDP协议的特性将会影响我们的服务器程序设计,大致总结如下:
- 关于客户IP和地址:服务器必须有根据客户IP地址和端口号判断数据包是否合法的能力;
- 关于目的地址:服务器必须要有过滤广播地址的能力;
- 关于数据输入:通常服务器系统的每一个端口都会和一块输入缓冲区对应,进来的数据根据先来后到的原则等待服务器的处理,所以难免会出现缓冲区溢出的问题,这种情况可能会出现UDP被丢弃,而应用服务器并不知道这个问题;
- 服务器应该限制本地IP地址,就是说他应该可以把自己绑定到某一个网络接口的某一个端口上。
广播与多播、IGMP协议
单播、多播、组播
单播
单播是对特定的主机进行数据的传送。例如给某一个主机发送IP数据包。这时,数据链路层给出的数据头里面是非常具体的目的地址,对于以太网来说就是MAC地址。现在的具有路由功能的主机应该可以将单播数据定向转发,而目的主机的网络接口则可以过滤掉和自己MAC地址不一致的数据。
广播
广播是主机针对某一网络上的所有主机发送数据。这个网络可能是网络、子网,或所有子网。如果是网络,例如A类地址的广播就是netid.255.255.255,如果是子网,则是netid.netid.subnetid.255,如果是所有子网(B类IP),则是netid.netid.255.255。广播所用的MAC地址是FF-FF-FF-FF-FF-FF,网络内所有的主机都会收到这个广播数据,网卡只要把MAC地址为FF-FF-FF-FF-FF-FF的数据交给内核就行了。一般来说,ARP或者路由协议RIP应该是广播的形式播发的。
多播
可以说广播的多播的特例,多播就是给一组特定的主机(多播组)发送数据。这样,数据的播发范围会小一些,多播的MAC地址是最高字节的低位为1,例如:01-00-00-00-00-00,多播组的IP是D类IP,规定是224.0.0.0-239.255.255.255。
IGMP协议
IGMP协议的作用在于,让其他所有需要知道自己处于哪个多播组的主机和路由器知道自己的状态。一般多播路由器根本不需要知道某一个多播组里有多少个主机,而只需要知道自己的子网内还有没有处于某个多播组的主机就行了。只要某一个多播组还有一台主机,多播路由器就会把数据传输过去,这样,接受方就会通过网卡过滤功能来得到自己想要的数据。为了知道多播组的信息,多播路由器需要定时的发送IGMP查询,各个多播组里面的主机需要根据查询来回复自己的状态。路由器来决定有几个多播组,自己要对某一个多播组发送什么样的数据。
TCP协议
TCP和UDP同样处于运输层,但是TCP和UDP最不同的地方是,TCP提供了一种可靠的的数据传输服务,TCP是面向连接的,也就是说,利用TCP通信的两台主机首先要精力一个拨打电话的过程,等到通信准备就绪才开始传输数据,最后结束通话。所以TCP要比UDP可靠的多,UDP是直接把数据发过去,而不管对方是不是在收信,就算是UDP无法送达,也不会产生ICMP差错报文。
TCP保证可靠性的工作原理:
- 应用数据被分割成TCP认为最适合发送的数据块。
- 当TCP发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段,如果不能及时收到这个确认,将重发这个报文段。
- 当TCP收到发自TCP另一端的数据,它将发送一个确认。这个确认不是立即发送的,通常推迟几分之一秒。
- TCP将保持它首部和数据的校验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP将丢弃这个报文段和不确认收到此报文段。
- 既然TCP报文段作为IP数据报来传输,而IP数据报的到达可能输失序,因此TCP报文段的到达也可能会失序。如果必要,TCP将对收到的数据进行重新排序,将收到数据以正确的顺序交给应用层。
- TCP还能提供流量控制。TCP连接的每一方都有固定大小的缓冲空间。TCP的接收端只允许另一端发送 接收端缓冲区所能接纳的数据。这将放置比较块的主机致使比较慢主机的缓冲区溢出。
由此可见,TCP中保持可靠性的方式就是超时重发。最可靠的方式就是只要不得到确认,就重新发送数据报,直到得到对方的确认为止。
TCP和UDP的首部一样。都有发送端口号和接收端口号。显然TCP的首部信息会更多,提供了发送和确认所需要的所有必要的信息。可以想象一个TCP数据的发送过程:
- 双方建立连接
- 发送方给接收方TCP数据报,然后等待对方的确认TCP数据报,有则发送下一个,没有则等待重发
- 接收方等待发送方的数据报,如果得到数据并检查无误,就发送ACK数据报,并等待下一个数据报
- 终止连接
DNS域名系统
DNS系统介绍
DNS的全称是“Domain Name Syetem”。它负责把FQDN翻译成一个IP,最初是一个巨大的host.txt文件,最终发展到现在的分布式数据库。
DNS是一个巨大的树,最上方是一个无名树根,下一层是“arpa,com,edu,gov,int,mil,us,cn”等。其中arpa是域名反解析树的顶端。
一个独立管理的DNS子树叫做zone,最常见的区域就是二级域名,比如说.com.cn,还可以把这个二级域名划分成更小的区域,比如sina.com.cn。
DNS系统是一个分布式数据库,当一个数据库发现并没有某查询所需要的数据时,它将把查询转发出去,而转发的目的地通常是根服务器,根服务器从上自下层层转发查询,直到找到目标为止。DNS的另一特点是使用高速缓存,DNS把查询过的数据缓存在某处,以便于下次查询时使用。
DNS协议
DNS协议定义了一个既可以查询也可以响应的报文格式,各个字段的解释如下:
- 最前面的16个bit唯一的标识了问题号码,用于查询端区别自己的查询
- 紧接着的16歌bit又可以做进一步的细分,标示了报文的性质和一些细节,比如说是查询报文还是响应报文,需要递归查询与否
- 查询问题后面有查询类型,包括“A,NS,CNAME,HINFO,MX”
- 响应报文可以回复多个IP,也就是说,域名可以和多个IP地址对应,并且有很多CNAME
反向查询
正向是指通过域名查询IP,反向是指通过IP查询域名。例如用host命令,host ip就可以得到服务器的域名,host domainname得到IP地址。
DNS服务器高速缓存
BIND9默认作为一个高速缓存服务器,其将所有的查询都交到服务器上去,然后得到的结果放在本地的缓存区,以加速查询。
用UDP还是TCP
DNS服务器同时支持UDP和TCP两种协议的查询方式,而且端口都是53,大多数都是UDP查询,需要TCP查询的一般有两种情况:
- 当查询过大以至于产生了数据截断(TC标志为1),这时,需要利用TCP的分片能力来进行数据传输
- 当master和slave服务器之间通信,辅服务器要拿到主服务器的zone信息的时候。
TCP数据包内容
TCP处于7层模型中的传输层,主要是用来建立可靠的连接。而建立连接的基础,就是其非常丰富的报文。首先,TCP3次握手用的报文就是绿色部分的TCP Flags内容。通过发送ACK、SYN包实现。具体涉及的Tag详见:
- Source Port/Destination Post:即客户端和服务端端口号,端口号用于区分主机中不同的进程,通过结合源IP和目的IP,得出唯一的TCP连接;
- Sequence Number(seqNumber):一般由客户端发送,用来表示报文段中第一个数据字节在数据流中的序号,主要用来解决网络包乱序问题;
- Acknowledgment Number(ACK):就是用来存放客户端发来的seqNumber的下一个信号(seqNumber+1)。只有当TCP flags中的ACK为1时才有效。主要用来解决不丢包的问题。
- TCP flags:TCP中有6个首部,用来控制TCP连接的状态,取值为0或1。分别是:URG、ACK、PSH、RST、SYN、FIN:
- URG为1时,用来保证TCP连接不被中断。并且将该次TCP内容数据的紧急程度提升(即告诉计算机,首先处理该连接)
- ACK通常是服务端返回的。用来表示应答是否有效。
- PSH表示当数据包得到后,立马给应用程序使用(PUSH到最顶端)
- RST用来确保TCP连接的安全。该flag用来表示一个连接复位的请求。如果发生错误连接,则reset一次,重新连。同时可以用来拒绝非法数据包。
- SYN同步的意思,通常由客户端发出,用来建立连接。第一次握手时:SYN为1,ACK为0;第二次握手时:SYN为1,ACK为1。
- FIN用来表示是否结束该次TCP连接。通常当你的数据发送完后,会自动带上FIN然后断开连接。
TCP连接的建立与终止
TCP是一个面向连接的协议,所以在连接双方发送数据前,都需要建立一条连接。TCP连接的建立需要3次握手,终止需要4次握手。
建立连接
在建立连接时,客户端首先向服务器申请打开某一个端口(用SYN段等于1的TCP报文),然后服务器返回一个ACK报文通知客户端请求报文收到,客户端收到确认报文以后再次发送一个确认报文确认刚才服务器发出的确认报文,至此,连接建立完成,被称为3次握手。如果打算让双发都做好准备的话,一定要发送三次报文,而且只需要三次报文就可以了。
结束连接
TCP有一个特别的概念叫做half-close,TCP的连接是全双工(可以同时接收和发送)连接,因此在关闭连接的时候,必须关闭传个送两个方向上的连接。客户端给服务器一个FIN为1的TCP报文,然后服务器返回一个确认ACK报文,并且发送一个FIN报文,当客户机回复ACK报文后,连接就结束了。
最大报文长度
在建立连接时,通信的双方要互相确认对方的最大报文长度(MSS),以便通信,一般这个SYN长度是MTU长度减去固定IP首都和TCP首部长度。对于一个以太网,一般可以达到1460字节。当然如果对于非本地的IP,这个MSS可能只有536字节,而且,如果中间的传输网络的MSS更小的话,这个值会变得更小。
TCP的状态迁移图
包含两个部分,服务器状态和客户端状态,如果从某一个角度会更加清晰,这里面的服务器和客户端都不是绝对的,发送数据的就是客户端,接收数据的就是服务器。
另一种描述方式:
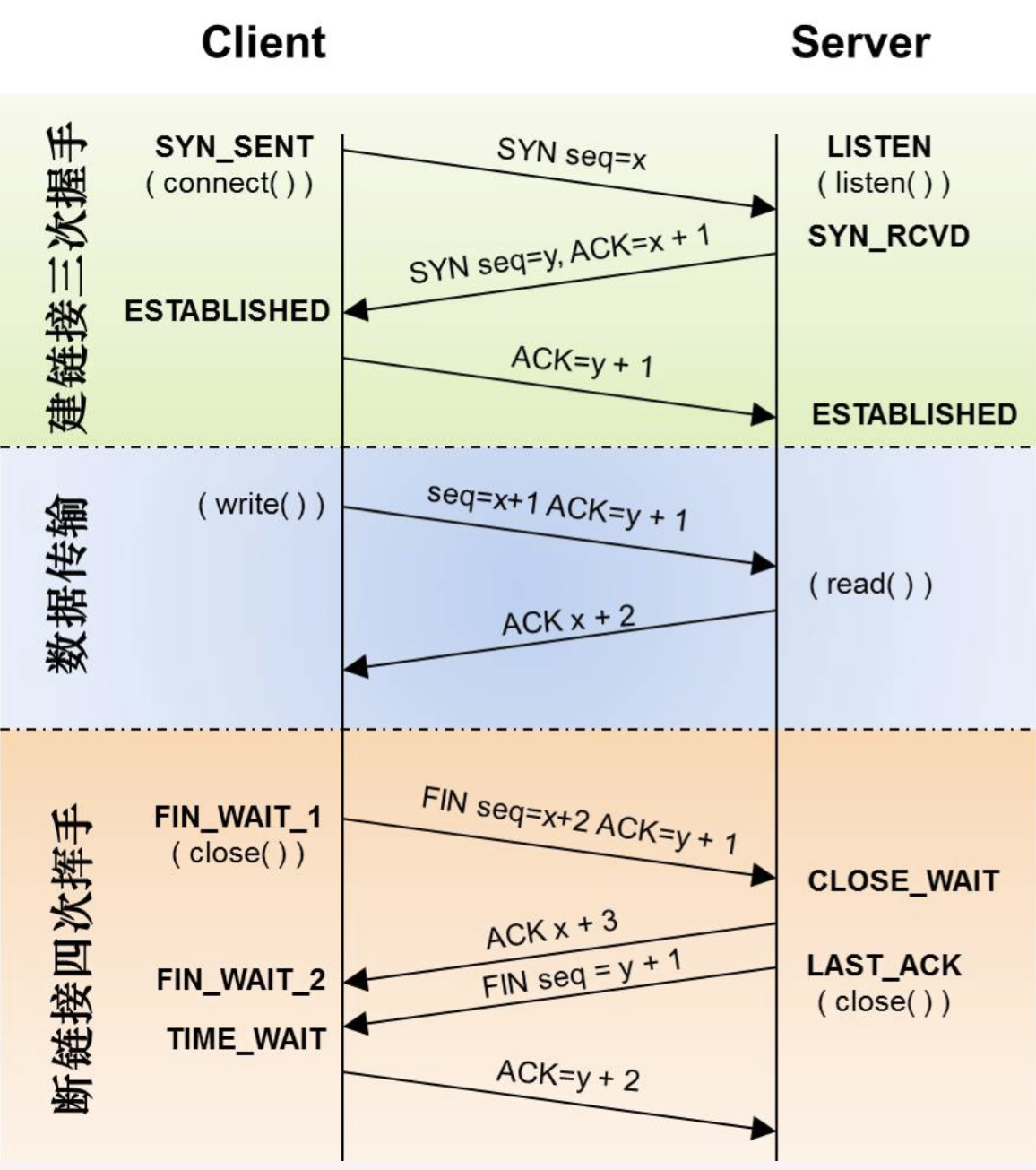
客户端路线
客户端状态可以用一下流程来表示:
CLOSER --> SYN_SENT -->ESTABLISHED --> FIN_WAIT_1 --> FIN_WAIT_2 --> TIME_WAIT -- CLOSED
该流程是在程序正常时应该有的流程,在建立连接时,当客户端收到SYN的ACK报文以后,客户端就打开了数据交互的连接。而结束连接则通常是客户端主动结束的,客户端结束应用程序以后,需要经历FIN_WAIT_1、FIN_WAIT_2等状态,这些状态的迁移就是前面提到的结束连接的4次握手。
服务器路线
服务器状态的流程:
CLOSED --> LISTEN --> SYN收到 --> ESTABLISHED --> CLOSE_WAIT --> LAST_ACK --> CLOSED
在建立连接的时候,服务器端就是在三次握手之后才进入数据交互状态,而关闭连接则是在关闭连接的第二次握手之后,而不是第四次握手之后。关闭以后还要等待客户端给出最后的ACK才能进入初始状态。
建立连接的三次握手流程
- 第一次握手:客户端向服务端发送一个SYN包,并且添加上seqNumber(假设为x),然后进入
SYN_SEND状态,并且等待服务器的确认; - 第二次握手:服务器接收SYN包,并进行确认,如果该请求有效,则将TCP flags中的ACK标记为1,然后将AckNumber置为(seqNumber+1),并且再添加上自己的seqNumber(y),完成后,返回给客户端。服务器进入
SYN_RECV状态(这里服务端是发送SYN+ACK包); - 第三次握手:客户端接收ACK+SYN报文后,获取到服务器发送的AckNumber(y),并且将新头部的AckNumber变为(y+1),然后发送给服务端,完成TCP的三次握手,建立连接。此时服务器和客户端都进入
ESTABLISHED状态。
关闭连接的四次挥手流程
- 第一次挥手:A机感觉此时如果keepalive比较浪费资源,则它提出了分手的请求。设置SeqNumber和AckNumber之后,向B机发送FIN包,表示我这已经没有数据给你了,然后A机进入
FIN_WAIT_1状态; - 第二次挥手:B机收到了A机的FIN包,已经知道了A机没有数据再发送了。此时B会给A发送一个ACK包,并且将AckNumber变为A传输来的SeqNumber+1。当A接收到之后,则变为
FIN_WAIT_2状态。表示已经得到B机的许可,可以进行关闭操作。不过此时,B机还是可以向A机发送请求的。 - 第三次挥手:B机向A机发送FIN包,请求关闭,相当于告诉A机,我这里也没有你要的数据了。然后B进入
CLOSE_WAIT状态(同时带上SeqNumber); - 第四次挥手:A接收到B的FIN包之后,然后同样,发送一个ACK包给B。B接收到之后就断开了。而A会等待2MSL的时间之后,如果没有回复,确保服务端确实是关闭了。然后A机也可以关闭连接。A、B都进入
CLOSE状态。
2MSL的意思是2 x MSL。MSL的其实是 ”Maximum Segment Lifetime“,报文最大生存时间。RFC793中规定为2分钟,实际应用中常用的是30秒、1分钟等。同样上面的TIME_WAIT状态其实也就是2MSL状态,如果超过该时间,则会将报文丢弃,直接进入CLOSE状态。
其他状态迁移
图中还有一些其他状态的迁移,针对服务端和客户端两方面总结如下:
LISTEN --> SYN_SENT:指服务器有时候也需要打开连接SYN --> SYN收到:服务器和客户端在SYN_SENT状态下如果收到SYN数据报,则都需要发送SYN的ACK数据报并把自己的状态调整到SYN收到状态,准备进入ESTABLISHEDSYN_SENT --> CLOSED:才发送超时的情况下,会返回到CLOSED状态SYN收到 --> LISTEN:如果收到RST包,会返回到LISTEN状态SYN收到 --> FIN_WAIT_1:这个迁移是说,可以不用到ESTABLISHED状态,可以直接跳转到FIN_WAIT_1状态并等待关闭
2MSL等待状态
图中有一个TIME_WAIT等待状态,又称为2MSL状态,说的是在TIME_WAIT_2发送了最后一个ACK数据报以后,要进入TIME_WAIT状态,这个状态是防止最后一次握手的数据报没有传送到对方那里准备的(注意这不是4次握手,这是第4次握手的保险状态),这个状态在很大程度上都保证了双方都可以正常结束,但是也伴随着问题。
由于插口的2MSL状态(插口是IP和端口对的意思,socket),使得应用程序在2MSL时间内无法再次使用同一个插口对,对于客户端程序还好,但是对于服务器程序,例如httpd,他总是要使用同一个端口来进行服务,而在2MSL时间内,启动httpd就会出现错误(插口被使用)。为了避免这个错误,服务器给出了一个平静时间的概念,在2MSL时间内,虽然可以重新启动服务器,但是这个服务器还是要平静的等待2MSL时间的过去才能进行下一次连接。
FIN_WAIT_2状态
这是著名的半关闭状态,在关闭连接时,客户端和服务器两次握手之后的状态。这个状态下,应用程序还有接收数据的能力,但是已经无法发送数据,但是也有一种可能,客户端一直处于FIN_WAIT_2状态,而服务器一直出去WAIT_CLOSE状态,而直到应用层来决定关闭这个状态。
RST,同时打开和同时关闭
RST是另一种关闭连接的方式,应用程序可以判断RST包的真实性,即是否为异常终止。而同时开发和同时关闭时两种特殊的TCP状态,发生的概率很小。
TCP服务器设计
在前面的UDP服务器设计中,完全不需要所谓的并发机制,它只需要建立一个数据输入队列就可以。但是TCP不同,TCP服务器对于每一个连接都需要建立一个独立的进程(或者轻量级的线程),来宝成对话的独立性。所以TCP服务器是并发的。而TCP服务器还需要配备一个呼入连接请求队列,来为每一个连接请求建立对话进程,这也就是为什么各种TCP服务器都有一个最大连接数的限制。而根据源主机的IP和端口号,服务器可以很轻松的区别不同的会话,来进行数据的分发。
TCP交互数据流、成块数据流
目前建立在TCP协议上的网络协议很多,有telnet、ssh、ftp、http等。这些协议又可以根据数据吞吐量大致分为两类:
- 交互数据类型:例如telnet、ssh,这种协议通常只做小流量的数据交换,比如按下键盘,回显文字等;
- 数据成块类型:例如ftp。这种类型的协议要求TCP尽量的运载数据,把数据的吞吐量做到最大,并尽可能的提高效率。
TCP的交互流数据
对于交互性要求比较高的应用,TCP给出了两个策略来提高效率和减少网络负担:捎带ACK、Nagle算法(一次尽量多的发数据)。通常在网络速度很快的情况下,比如用lo接口进行telnet通信,当按下字母键并要求回显的时候,客户端和服务器将经历发送按键数据 --> 服务器发送按键数据的ACK --> 服务器端发送回显数据 --> 客户端发送回显数据的ACK的过程,而其中的数据流将是40bit + 41bit + 41bit + 40bit = 162bit,如果在广域网里面,这种小分组的TCP流量将会造成很大的网络负担。
捎带ACK的发送方式
这个策略是说,当主机收到远程主机的TCP数据报的时候,通常不马上发送ACK数据报,而是登上一个短暂的时间,如果这段时间内主机还有发送到远程主机的TCP数据报,那么就把这个ACK数据报捎带着发过去,把原本两个数据报整合成一个发送。一般这个时间是200ms。可以很明显的看到这个策略把TCP的数据报的利用率提高很多。
Nagle算法
Nagle算法是指,当A给B发送了一个TCP数据报并进入等待B的ACK数据报的状态时,TCP的输出缓冲区中只能有一个TCP数据报,并且,这个数据报不断的收集后来的数据,整合成一个大的数据报,等到B的ACK包一到,就把这些数据一股脑的发送出去。
在编写接口程序的时候,可以通过TCP_NODELAY来关闭这个算法。同时使用这个算法需要据情况而定,比如基于TCP的X窗口协议,如果处理鼠标事件还是用这个算法的话延迟就会非常大了。
TCP的成块流数据
对于FTP这样对数据吞吐量有较高的要求,将总是希望每次尽量多的发送数据到对方主机,就算是有点延迟也无所谓。TCP也提供了一整套的策略来支持这样的需求。TCP协议中有16个bit表示窗口的大小,这是这些策略的核心。
传输数据是ACK的问题
在解释滑动窗口前,需要看看ACK的应答策略,一般来说,发送端发送一个TCP数据报,那么接收端就应该发送一个ACK数据报。但是事实上并不是这样,发送端将会连续发送数据尽量填满接收方的缓冲区,而接收方只要对这些数据发送一个ACK报文来回应就可以了,这就是ACK的累积特性,这个特性大大减少了发送端和接收端的负担。
滑动窗口
滑动窗口本质上是描述接收方的TCP数据报缓冲区大小的数据,发送方根据这个数据来计算自己最多能发送多长的数据。如果发送方收到接收方的窗口大小为0的TCP数据报,那么发送方将停止发送数据,等到接收方发送窗口大小不为0的数据报的到来。
关于滑动窗口协议,还有三个术语:
- 框框合拢:当窗口从左边向右边靠近的时候,这种现象发生在数据报被发送和确认的时候;
- 窗口张开:当窗口的右边沿向右边移动的时候,这种现象发生在接收端处理了数据以后;
- 窗口收缩:当窗口的右边沿向左边移动的时候,这种现象不常发生。
TCP就是利用这个窗口,慢慢的从数据的左边移动到右边,把处于窗口范围内的数据发送出去(但不是发送所有,只是处于窗口内的数据可以发送)。这就是窗口的意义。窗口的大小是可以通过socket来指定的,4096并不是最理想的窗口大小,而16384则可以使吞吐量大大的增加。
数据拥堵
上面的策略用于局域网内传输还可以,但是用在广域网中就可能出现问题,最大的问题就是当传输时出现了瓶颈(比如一定要经过一个slip低速链路)所产生的大量数据拥堵问题,为了解决这个问题,TCP发送方需要确认连接双方的线路的数据最大吞吐量是多少。
拥堵窗口的原理很简单,TCP发送方首先发送一个数据报,然后等待对方的回应,得到回应后就把这个窗口的大小加倍,然后连续发送两个数据报,等到对方回应以后,再把这个窗口加倍(先是2的指数倍,到了一定程度后变成线性增长,即慢启动),发送更多的数据报,直到出现超时错误。这样,发送端就了解了通信双方的线路承载能力,也就确定了拥堵窗口的大小,发送方就用这个拥堵窗口的大小发送数据。比如下载的时候一开始很慢,慢慢加速后变成匀速。
TCP的超时与重传
超时重传是TCP保证数据可靠性的另一个重要机制。其原理是在发送某一个数据以后就开启一个计时器,在一定的时间内如果没有得到发出数据的ACK报文,就重新发送数据,直到发送成功。
超时
超时时间的计算是超时的核心部分,TCP要求这个算法能大致估算出当前的网络状况,虽然这确实很困难。要求精确的原因有两个:1、定时长久会造成网络利用率不高;2、定时太短会造成多次重传,使得网络拥堵。所以书中(《TCP/IP详解:卷一》)给出了一套经验公式,和其他的保证计时器准确的措施。
递推公式概述
最早的TCP计算网络状况的公式:
R<-aR+(1-a)M
RTP=Rb
其中a是一个经验系数0.1,b通常为2,注意这是经验,没有推导过程,这个数值是可以被修改的。这个公式是说用旧的RTT(R)和新的RTT(M)综合到一起考虑新的RTT(R)的大小。但是,这种估计在网络变化很大的情况下完全不能做出灵敏的反应,于是就有下面的修正公式:
Err=M-A
A<-A+gErr
D<-D+h(|Err|-D)
RTO=A+4D
详细解释参考P228。这个递推公式甚至提到了方差这种统计概念,使得偏差更小。而且,必须要指出的是,这两组公司更新,都是在数据成功传输的情况下才进行,在发生数据重新传输的情况下,并不使用上面的公式进行网络国际,理由很简单,因为程序已经不再正常状态下了,估计出来的数据也是没有意义的。
RTO的初始化
RTO的初始化是由公式决定的,例如最初的公式,初始的值应该是1。而修正公式,初始RTO应该是A+4D。
RTO的更新
当输出传输正常的情况下,我们就会用上面的公式来更新各个数据,并重开定时器,来保证下一个数据被顺利传输。要注意的是:**重传的情况下,RTO不用上面的公式计算,而是采用一种叫”指数退避“的方式。**例如:当RTO为1S的情况下,发生了数据重传,我们就用RTO=2S的定时器来重新传输数据,下一次用4S。一直增加到64S为止。
估计器的初始化
在这里,SYN用的估计器初始化似乎和传输用的估计器不一样???
估计器的更新
Karn算法
应该称为一个策略,说的是更新RTO和估计器的时机选择问题。
计时器的使用
- 一个连接中,有且仅有一个测量定时器被使用。也就是说,如果TCP连续发出三组数据,只有一组数据会被测量;
- ACK数据报不会被测量,原因很简单,没有ACK的ACK回应可以供结束定时器测量。
重传
有了超时就有重传,但是会根据一定的策略重传,而不是将数据简单的发送。
重传时发送数据的大小
前面曾经提到过,数据在传输时不能只是用一种窗口协议,我们还需要有一个拥堵窗口来控制数据的流量,使得数据不会一下子都跑到网络中引起拥堵。也提到过,拥堵窗口最初使用指数增长的速度来增加自身的窗口,直到发生超时重传,在进行一次微调。但是没有提到,如何进行微调,拥塞避免算法和慢启动门限就是为此而生。
慢启动门限是说,当拥堵窗口超过这个门限的时候,就使用拥塞避免算法,而在门限以内就使用慢启动算法。所以这个标准才叫做门限,通常,拥塞窗口记做cwnd,慢启动门限记做ssthresh。
算法概要:
- 对一个给定的连接,初始化cwnd为1个报文段,ssthresh为65535字节;
- TCP输出历程的输出不能超过cwnd和接收方通告窗口的大小。拥塞避免是发送方使用的流量控制,而通告窗口则是接收方进行的流量控制。前者是发送发感受到网络拥堵的估计,而后者则与接收方在该连接上的可用缓存大小有关;
- 当拥堵发生时(超时或收到重复确认),sshthresh被设置为当前窗口大小的一半(cwnd和接收方通告窗口大小的最小值,但最少为2个报文段)。此外,如果是超时引起了阻塞,则cwnd被设置为一个报文段(这就是慢启动)。
- 当心的数据被对方确认时,就增加cwnd,但增加的方法依赖于我们是否正在进行慢启动或拥塞避免。如果cwnd小于或等于ssthresh,则正在进行慢启动,否则正在进行拥塞避免。慢启动一直持续到我们回到拥发生时所处位置的半时候才停止(因为我们记录了在步骤2中给我们制造麻烦的窗口大小的一半),然后转为执行拥塞避免。
快速重传和快速恢复算法
这是数据丢包的情况下给出的一种修补机制。一般来说,重传发生在超时之后,但是如果发送端收到超过3个以上的重复ACK的情况下,就应该意识到,数据丢了,需要重新传递。这个机制是不需要等到重传计时器溢出的,所以叫做快速重传,而重新传递以后,因为走的不是慢启动而是拥塞避免算法,所以又被称为快速恢复算法。流程如下:
- 当收到3个重复的ACK时,将ssthresh设置为当前拥堵窗口cwnd的一半,重传丢失的报文段。设置cwnd为ssthresh加上3倍的报文段大小;
- 每次收到另一个重复的ACK时,cwnd增加1个报文段大小并发送一个分组(如果新的cwnd允许发送);
- 当下一个确认新数据的ACK到达时,设置cwnd为ssthresh(在第一步中设置的值)。这个ACK应该是在重传后的一个往返时间内对步骤1中重传的确认。另外,这个ACK应该是对丢失的分组和收到的第一个重复的ACK之间的所有中间报文段的确认。这一步采用的是拥塞避免,因为当分组丢失时我们将当前的速率减半。
ICMP会引起重新传递吗
不会,TCP会坚持自己的定时器,但是TCP会保留下ICMP的错误并通知用户。
重新分组
TCP为了提高自己的效率。允许再重新传输的时候,只要传输包含重传数据报文的报文就可以,而不用只重传需要传输的报文。
TCP坚持定时器、TCP保活定时器
TCP一共提供了四个主要的定时器,前面已经说过最复杂的超时定时器,另外的三个是:
- 坚持定时器
- 保活定时器
- 2MSL定时器
坚持定时器
当TCP服务器收到了客户端的0滑动窗口报文时,就启动一个定时器计时,并在定时器溢出的时候想客户端查询窗口是否已经增大,如果得到非0的窗口就重新开始发送数据,如果得到0窗口就再开一个新的定时器准备下一次查询。通过观察可知,TCP的坚持定时器使用1、2、4、8、16、…64秒这样的普通指数退避序列来作为每一次的溢出时间。
糊涂窗口综合征
TCP的窗口协议,会引起一种叫做糊涂窗口综合征的问题,具体表现为,当客户端通告一个小的非0窗口时,服务器立即发送小数据给客户端并充满气缓冲区,一来二去就会让网络中充满小TCP数据报,从而影响网络利用率。对于发送方和接收端的这种糊涂行为,TCP给出了一些建议、规定:
- 接收方不通告小窗口。通常的算法是接收方不通告一个比当前窗口大的窗口(可以为0),除非窗口可以增加一个报文段大小(也就是将要接收的MSS),或者可以增加接收方缓存空间的一半,不论实际有多少;
- 发送方避免出现糊涂窗口综合症的措施是只有一下条件之一满足时才发送数据:
- 可以发送一个满长度的报文段
- 可以发送至少是接收方通告窗口大小一半的报文段
- 可以发送任何数据并且不希望接收ACK(也就是说,我们还没有未被确认的数据)或者该连接上不能使用Nagle算法
可以发现TCP的很多规定都是为了在一次发送中发送尽量多的数据,例如捎带ACK的策略,Nagle算法,重传时发送包含数据报文的策略,等等。
保活定时器
保活定时器更加简单,还记得FTP或者HTTP服务器都有Session Time机制吗?因为TCP是面向连接的,所以就会出现只连接不传数据的”半开放连接“,服务器当然要检测这种连接并且在某些情况下释放这些连接,这就是保活定时器的作用。其时限根据服务器的实现不同而不同。另外,当其中一端如果崩溃并重启的情况时,如果收到该端”前生“的保活探查,则要发送一个RST数据报文帮助另一端结束连接。
5.3 - 调优参数
Linux-TCP/IP 参数优化
相关参数释义
关于 Linux 下 TCP/IP 协议栈的参数调优,在/etc/sysctl.conf修改,执行命令sysctl -p可以永久生效,在/proc/sys/net/ipv4/修改会在重启后失效。
/proc/sys/net/ipv4/文件:
| 名称 | 默认值 | 建议值 | 描述 |
|---|---|---|---|
| tcp_syn_retries | 5 | 1 | 对于一个新建连接,内核要发送多少个 SYN 连接请求才决定放弃。不应该大于255,默认值是5,对应于180秒左右时间。。(对于大负载而物理通信良好的网络而言,这个值偏高,可修改为2.这个值仅仅是针对对外的连接,对进来的连接,是由tcp_retries1决定的) |
| tcp_synack_retries | 5 | 1 | 对于远端的连接请求SYN,内核会发送SYN + ACK数据报,以确认收到上一个 SYN连接请求包。这是所谓的三次握手( threeway handshake)机制的第二个步骤。这里决定内核在放弃连接之前所送出的 SYN+ACK 数目。不应该大于255,默认值是5,对应于180秒左右时间。 |
| tcp_keepalive_time | 7200 | 600 | TCP发送keepalive探测消息的间隔时间(秒),用于确认TCP连接是否有效。防止两边建立连接但不发送数据的攻击。 |
| tcp_keepalive_probes | 9 | 3 | TCP发送keepalive探测消息的间隔时间(秒),用于确认TCP连接是否有效。 |
| tcp_keepalive_intvl | 75 | 15 | 探测消息未获得响应时,重发该消息的间隔时间(秒)。默认值为75秒。 (对于普通应用来说,这个值有一些偏大,可以根据需要改小.特别是web类服务器需要改小该值,15是个比较合适的值) |
| tcp_retries1 | 3 | 3 | 放弃回应一个TCP连接请求前﹐需要进行多少次重试。RFC 规定最低的数值是3 |
| tcp_retries2 | 15 | 5 | 在丢弃激活(已建立通讯状况)的TCP连接之前﹐需要进行多少次重试。默认值为15,根据RTO的值来决定,相当于13-30分钟(RFC1122规定,必须大于100秒).(这个值根据目前的网络设置,可以适当地改小,我的网络内修改为了5) |
| tcp_orphan_retries | 7 | 3 | 在近端丢弃TCP连接之前﹐要进行多少次重试。默认值是7个﹐相当于 50秒 - 16分钟﹐视 RTO 而定。如果您的系统是负载很大的web服务器﹐那么也许需要降低该值﹐这类 sockets 可能会耗费大量的资源。另外参的考tcp_max_orphans。(事实上做NAT的时候,降低该值也是好处显著的,我本人的网络环境中降低该值为3) |
| tcp_fin_timeout | 60 | 2 | 对于本端断开的socket连接,TCP保持在FIN-WAIT-2状态的时间。对方可能会断开连接或一直不结束连接或不可预料的进程死亡。默认值为 60 秒。 |
| tcp_max_tw_buckets | 180000 | 36000 | 系统在同时所处理的最大 timewait sockets 数目。如果超过此数的话﹐time-wait socket 会被立即砍除并且显示警告信息。之所以要设定这个限制﹐纯粹为了抵御那些简单的 DoS 攻击﹐不过﹐如果网络条件需要比默认值更多﹐则可以提高它(或许还要增加内存)。(事实上做NAT的时候最好可以适当地增加该值) |
| tcp_tw_recycle | 0 | 1 | 打开快速 TIME-WAIT sockets 回收。除非得到技术专家的建议或要求﹐请不要随意修改这个值。(做NAT的时候,建议打开它) |
| tcp_tw_reuse | 0 | 1 | 表示是否允许重新应用处于TIME-WAIT状态的socket用于新的TCP连接(这个对快速重启动某些服务,而启动后提示端口已经被使用的情形非常有帮助) |
| tcp_max_orphans | 8192 | 32768 | 系统所能处理不属于任何进程的TCP sockets最大数量。假如超过这个数量﹐那么不属于任何进程的连接会被立即reset,并同时显示警告信息。之所以要设定这个限制﹐纯粹为了抵御那些简单的 DoS 攻击﹐千万不要依赖这个或是人为的降低这个限制。如果内存大更应该增加这个值。(这个值Redhat AS版本中设置为32768,但是很多防火墙修改的时候,建议该值修改为2000) |
| tcp_abort_on_overflow | 0 | 0 | 当守护进程太忙而不能接受新的连接,就象对方发送reset消息,默认值是false。这意味着当溢出的原因是因为一个偶然的猝发,那么连接将恢复状态。只有在你确信守护进程真的不能完成连接请求时才打开该选项,该选项会影响客户的使用。(对待已经满载的sendmail,apache这类服务的时候,这个可以很快让客户端终止连接,可以给予服务程序处理已有连接的缓冲机会,所以很多防火墙上推荐打开它) |
| tcp_syncookies | 0 | 1 | 只有在内核编译时选择了CONFIG_SYNCOOKIES时才会发生作用。当出现syn等候队列出现溢出时象对方发送syncookies。目的是为了防止syn flood攻击。 |
| tcp_stdurg | 0 | 0 | 使用 TCP urg pointer 字段中的主机请求解释功能。大部份的主机都使用老旧的 BSD解释,因此如果您在 Linux 打开它﹐或会导致不能和它们正确沟通。 |
| tcp_max_syn_backlog | 1024 | 16384 | 对于那些依然还未获得客户端确认的连接请求﹐需要保存在队列中最大数目。对于超过 128Mb 内存的系统﹐默认值是 1024 ﹐低于 128Mb 的则为 128。如果服务器经常出现过载﹐可以尝试增加这个数字。警告﹗假如您将此值设为大于 1024﹐最好修改include/net/tcp.h里面的TCP_SYNQ_HSIZE﹐以保持TCP_SYNQ_HSIZE16(SYN Flood攻击利用TCP协议散布握手的缺陷,伪造虚假源IP地址发送大量TCP-SYN半打开连接到目标系统,最终导致目标系统Socket队列资源耗尽而无法接受新的连接。为了应付这种攻击,现代Unix系统中普遍采用多连接队列处理的方式来缓冲(而不是解决)这种攻击,是用一个基本队列处理正常的完全连接应用(Connect()和Accept() ),是用另一个队列单独存放半打开连接。这种双队列处理方式和其他一些系统内核措施(例如Syn-Cookies/Caches)联合应用时,能够比较有效的缓解小规模的SYN Flood攻击(事实证明) |
| tcp_window_scaling | 1 | 1 | 该文件表示设置tcp/ip会话的滑动窗口大小是否可变。参数值为布尔值,为1时表示可变,为0时表示不可变。tcp/ip通常使用的窗口最大可达到 65535 字节,对于高速网络,该值可能太小,这时候如果启用了该功能,可以使tcp/ip滑动窗口大小增大数个数量级,从而提高数据传输的能力(RFC 1323)。(对普通地百M网络而言,关闭会降低开销,所以如果不是高速网络,可以考虑设置为0) |
| tcp_timestamps | 1 | 1 | Timestamps 用在其它一些东西中﹐可以防范那些伪造的 sequence 号码。一条1G的宽带线路或许会重遇到带 out-of-line数值的旧sequence 号码(假如它是由于上次产生的)。Timestamp 会让它知道这是个 ‘旧封包’。(该文件表示是否启用以一种比超时重发更精确的方法(RFC 1323)来启用对 RTT 的计算;为了实现更好的性能应该启用这个选项。) |
| tcp_sack | 1 | 1 | 使用 Selective ACK﹐它可以用来查找特定的遗失的数据报— 因此有助于快速恢复状态。该文件表示是否启用有选择的应答(Selective Acknowledgment),这可以通过有选择地应答乱序接收到的报文来提高性能(这样可以让发送者只发送丢失的报文段)。(对于广域网通信来说这个选项应该启用,但是这会增加对 CPU 的占用。) |
| tcp_fack | 1 | 1 | 打开FACK拥塞避免和快速重传功能。(注意,当tcp_sack设置为0的时候,这个值即使设置为1也无效)(这个是TCP连接靠谱的核心功能) |
| tcp_dsack | 1 | 1 | 允许TCP发送"两个完全相同"的SACK。 |
| tcp_ecn | 0 | 0 | TCP的直接拥塞通告功能。 |
| tcp_reordering | 3 | 6 | TCP流中重排序的数据报最大数量。 (一般有看到推荐把这个数值略微调整大一些,比如5) |
| tcp_retrans_collapse | 1 | 0 | 对于某些有bug的打印机提供针对其bug的兼容性。(一般不需要这个支持,可以关闭它) |
| tcp_wmem:min | 4096 | 8192 | 发送缓存设置. 为TCP socket预留用于发送缓冲的内存最小值。每个tcp socket都可以在建议以后都可以使用它。默认值为4096(4K)。 |
| tcp_wmem:default | 16384 | 131072 | 为TCP socket预留用于发送缓冲的内存数量,默认情况下该值会影响其它协议使用的net.core.wmem_default 值,一般要低于net.core.wmem_default的值。默认值为16384(16K)。 |
| tcp_wmem:max | 131072 | 16777216 | 用于TCP socket发送缓冲的内存最大值。该值不会影响net.core.wmem_max,“静态"选择参数SOSNDBUF则不受该值影响。默认值为131072(128K)。(对于服务器而言,增加这个参数的值对于发送数据很有帮助,在我的网络环境中,修改为了51200 131072 204800,分别对应min、default、max。) |
| tcprmem:min | 4096 | 32768 | 接收缓存设置。同tcp_wmem。 |
| tcprmem:default | 87380 | 131072 | 接收缓存设置。同tcp_wmem。 |
| tcprmem:max | 174760 | 16777216 | 接收缓存设置。同tcp_wmem。 |
| tcp_mem:min | 根据内存计算 | 786432 | low:当TCP使用了低于该值的内存页面数时,TCP不会考虑释放内存。即低于此值没有内存压力。(理想情况下,这个值应与指定给 tcp_wmem 的第 2 个值相匹配 - 这第 2 个值表明,最大页面大小乘以最大并发请求数除以页大小 (131072 300 / 4096)。 ) |
| tcp_mem:default | 根据内存计算 | 1048576 | pressure:当TCP使用了超过该值的内存页面数量时,TCP试图稳定其内存使用,进入pressure模式,当内存消耗低于low值时则退出pressure状态。(理想情况下这个值应该是 TCP 可以使用的总缓冲区大小的最大值 (204800 300 / 4096)。 ) |
| tcp_mem:max | 根据内存计算 | 1572864 | high:允许所有tcp sockets用于排队缓冲数据报的页面量。(如果超过这个值,TCP 连接将被拒绝,这就是为什么不要令其过于保守 (512000 300 / 4096) 的原因了。 在这种情况下,提供的价值很大,它能处理很多连接,是所预期的 2.5 倍;或者使现有连接能够传输 2.5 倍的数据。 我的网络里为192000 300000 732000)。一般情况下这些值是在系统启动时根据系统内存数量计算得到的。 |
| tcp_app_win | 31 | 31 | 保留max(window/2^tcp_app_win, mss)数量的窗口由于应用缓冲。当为0时表示不需要缓冲。 |
| tcp_adv_win_scale | 2 | 2 | 计算缓冲开销bytes/2^tcp_adv_win_scale(如果tcp_adv_win_scale > 0)或者bytes-bytes/2^(-tcp_adv_win_scale)(如果tcp_adv_win_scale BOOLEAN>0) |
| tcp_low_latency | 0 | 0 | 允许 TCP/IP 栈适应在高吞吐量情况下低延时的情况;这个选项一般情形是的禁用。(但在构建Beowulf 集群的时候,打开它很有帮助) |
| tcp_bic | 0 | 0 | 为快速长距离网络启用 Binary Increase Congestion;这样可以更好地利用以 GB 速度进行操作的链接;对于 WAN 通信应该启用这个选项。 |
| ip_forward | 0 | - | NAT必须开启IP转发支持,把该值写1 |
| ip_local_port_range:min | 32768 | 1024 | 表示用于向外连接的端口范围,默认比较小,这个范围同样会间接用于NAT表规模。 |
| ip_local_port_range:max | 61000 | 65000 | 同上 |
| ip_conntrack_max | 65535 | 65535 | 系统支持的最大ipv4连接数,默认65536(事实上这也是理论最大值),同时这个值和你的内存大小有关,如果内存128M,这个值最大8192,1G以上内存这个值都是默认65536 |
/proc/sys/net/ipv4/netfilter/文件,该文件需要打开防火墙再会存在。
| 名称 | 默认值 | 建议值 | 描述 |
|---|---|---|---|
| ip_conntrack_max | 65536 | 65536 | 系统支持的最大ipv4连接数,默认65536(事实上这也是理论最大值),同时这个值和你的内存大小有关,如果内存128M,这个值最大8192,1G以上内存这个值都是默认65536,这个值受/proc/sys/net/ipv4/ip_conntrack_max限制 |
| ip_conntrack_tcp_timeout_established | 432000 | 180 | 已建立的tcp连接的超时时间,默认432000,也就是5天。影响:这个值过大将导致一些可能已经不用的连接常驻于内存中,占用大量链接资源,从而可能导致NAT ip_conntrack: table full的问题。建议:对于NAT负载相对本机的 NAT表大小很紧张的时候,可能需要考虑缩小这个值,以尽早清除连接,保证有可用的连接资源;如果不紧张,不必修改 |
| ip_conntrack_tcp_timeout_time_wait | 120 | 120 | time_wait状态超时时间,超过该时间就清除该连接 |
| ip_conntrack_tcp_timeout_close_wait | 60 | 60 | close_wait状态超时时间,超过该时间就清除该连接 |
| ip_conntrack_tcp_timeout_fin_wait | 120 | 120 | fin_wait状态超时时间,超过该时间就清除该连接 |
/proc/sys/net/core/文件:
| 名称 | 默认值 | 建议值 | 描述 |
|---|---|---|---|
| netdev_max_backlog | 1024 | 1024 | 每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目,对重负载服务器而言,该值需要调高一点。 |
| somaxconn | 128 | 16384 | 用来限制监听(LISTEN)队列最大数据包的数量,超过这个数量就会导致链接超时或者触发重传机制。web应用中listen函数的backlog默认会给我们内核参数的net.core.somaxconn限制到128,而nginx定义的NGX_LISTEN_BACKLOG默认为511,所以有必要调整这个值。对繁忙的服务器,增加该值有助于网络性能 |
| wmem_default | 129024 | 129024 | 默认的发送窗口大小(以字节为单位) |
| rmem_default | 129024 | 129024 | 默认的接收窗口大小(以字节为单位) |
| rmem_max | 129024 | 873200 | 最大的TCP数据接收缓冲 |
| wmem_max | 129024 | 873200 | 最大的TCP数据发送缓冲 |
| online | String | AA | AA |
| online | String | AA | AA |
| online | String | AA | AA |
| online | String | AA | AA |
| online | String | AA | AA |
生产环境参数优化
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_intvl =15
net.ipv4.tcp_retries2 = 5
net.ipv4.tcp_fin_timeout = 2
net.ipv4.tcp_max_tw_buckets = 36000
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_max_orphans = 32768
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.tcp_wmem = 8192 131072 16777216
net.ipv4.tcp_rmem = 32768 131072 16777216
net.ipv4.tcp_mem = 786432 1048576 1572864
net.ipv4.ip_local_port_range = 1024 65000
net.ipv4.ip_conntrack_max = 65536
net.ipv4.netfilter.ip_conntrack_max=65536
net.ipv4.netfilter.ip_conntrack_tcp_timeout_established=180
net.core.somaxconn = 16384
net.core.netdev_max_backlog = 16384
优化实例
sudops网站提供的优化例子,相关参数仅供参考,具体数值还需要根据机器性能,应用场景等实际情况来做更细微调整。
net.core.netdev_max_backlog = 400000
#该参数决定了,网络设备接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
net.core.optmem_max = 10000000
#该参数指定了每个套接字所允许的最大缓冲区的大小
net.core.rmem_default = 10000000
#指定了接收套接字缓冲区大小的缺省值(以字节为单位)。
net.core.rmem_max = 10000000
#指定了接收套接字缓冲区大小的最大值(以字节为单位)。
net.core.somaxconn = 100000
#Linux kernel参数,表示socket监听的backlog(监听队列)上限
net.core.wmem_default = 11059200
#定义默认的发送窗口大小;对于更大的 BDP 来说,这个大小也应该更大。
net.core.wmem_max = 11059200
#定义发送窗口的最大大小;对于更大的 BDP 来说,这个大小也应该更大。
net.ipv4.conf.all.rp_filter = 1
net.ipv4.conf.default.rp_filter = 1
#严谨模式 1 (推荐)
#松散模式 0
net.ipv4.tcp_congestion_control = bic
#默认推荐设置是 htcp
net.ipv4.tcp_window_scaling = 0
#关闭tcp_window_scaling
#启用 RFC 1323 定义的 window scaling;要支持超过 64KB 的窗口,必须启用该值。
net.ipv4.tcp_ecn = 0
#把TCP的直接拥塞通告(tcp_ecn)关掉
net.ipv4.tcp_sack = 1
#关闭tcp_sack
#启用有选择的应答(Selective Acknowledgment),
#这可以通过有选择地应答乱序接收到的报文来提高性能(这样可以让发送者只发送丢失的报文段);
#(对于广域网通信来说)这个选项应该启用,但是这会增加对 CPU 的占用。
net.ipv4.tcp_max_tw_buckets = 10000
#表示系统同时保持TIME_WAIT套接字的最大数量
net.ipv4.tcp_max_syn_backlog = 8192
#表示SYN队列长度,默认1024,改成8192,可以容纳更多等待连接的网络连接数。
net.ipv4.tcp_syncookies = 1
#表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
net.ipv4.tcp_timestamps = 1
#开启TCP时间戳
#以一种比重发超时更精确的方法(请参阅 RFC 1323)来启用对 RTT 的计算;为了实现更好的性能应该启用这个选项。
net.ipv4.tcp_tw_reuse = 1
#表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcp_tw_recycle = 1
#表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。
net.ipv4.tcp_fin_timeout = 10
#表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间。
net.ipv4.tcp_keepalive_time = 1800
#表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时,改为30分钟。
net.ipv4.tcp_keepalive_probes = 3
#如果对方不予应答,探测包的发送次数
net.ipv4.tcp_keepalive_intvl = 15
#keepalive探测包的发送间隔
net.ipv4.tcp_mem
#确定 TCP 栈应该如何反映内存使用;每个值的单位都是内存页(通常是 4KB)。
#第一个值是内存使用的下限。
#第二个值是内存压力模式开始对缓冲区使用应用压力的上限。
#第三个值是内存上限。在这个层次上可以将报文丢弃,从而减少对内存的使用。对于较大的 BDP 可以增大这些值(但是要记住,其单位是内存页,而不是字节)。
net.ipv4.tcp_rmem
#与 tcp_wmem 类似,不过它表示的是为自动调优所使用的接收缓冲区的值。
net.ipv4.tcp_wmem = 30000000 30000000 30000000
#为自动调优定义每个 socket 使用的内存。
#第一个值是为 socket 的发送缓冲区分配的最少字节数。
#第二个值是默认值(该值会被 wmem_default 覆盖),缓冲区在系统负载不重的情况下可以增长到这个值。
#第三个值是发送缓冲区空间的最大字节数(该值会被 wmem_max 覆盖)。
net.ipv4.ip_local_port_range = 1024 65000
#表示用于向外连接的端口范围。缺省情况下很小:32768到61000,改为1024到65000。
net.ipv4.netfilter.ip_conntrack_max=204800
#设置系统对最大跟踪的TCP连接数的限制
net.ipv4.tcp_slow_start_after_idle = 0
#关闭tcp的连接传输的慢启动,即先休止一段时间,再初始化拥塞窗口。
net.ipv4.route.gc_timeout = 100
#路由缓存刷新频率,当一个路由失败后多长时间跳到另一个路由,默认是300。
net.ipv4.tcp_syn_retries = 1
#在内核放弃建立连接之前发送SYN包的数量。
net.ipv4.icmp_echo_ignore_broadcasts = 1
# 避免放大攻击
net.ipv4.icmp_ignore_bogus_error_responses = 1
# 开启恶意icmp错误消息保护
net.inet.udp.checksum=1
#防止不正确的udp包的攻击
net.ipv4.conf.default.accept_source_route = 0
#是否接受含有源路由信息的ip包。参数值为布尔值,1表示接受,0表示不接受。
#在充当网关的linux主机上缺省值为1,在一般的linux主机上缺省值为0。
#从安全性角度出发,建议你关闭该功能。
5.4 - 理解网络栈
我们不敢想象离开了 TCP/IP 互联网服务会变成什么样子。所有我们在 NHN 上开发和使用的互联网服务都基于一个一致的基础,TCP/IP。理解数据是如何在网络上传输的,能够帮助你通过调优来提升性能、排除故障,或者是将其引入到新的技术中去。
本文将基于 Linux OS 和硬件层中的数据流及控制流来介绍网络栈的整体操作方案。
TCP/IP 的关键特性
怎样才能设计一个用来快速传输数据的网络协议,同时能够保证数据顺序又不丢失数据?
TCP/IP 就是以这样的初衷来设计的。以下是理解网络栈所必须的 TCP/IP 的关键特性。
TCP 与 IP 从技术上讲,由于 TCP 和 IP 拥有不同的层次结构,正确的方式是将它们分开来介绍。然而,这里我们会将其看做一个整体。
1、面向连接
首先,一个连接在两个端点之间(local and remote)被创建,然后数据才会被传输。这里的 “TCP 连接标识符” 是两个端点的地址的结合体,其结构如下:
<local IP address, local port number, remote IP address, remote port number>
2、双向字节流
双向的数据通信通过字节流(byte stream)来完成。
3、有序抵达
一个接收者以发送者发送的顺序来接收数据。为此,必须确保数据的顺序。为了标记顺序,使用了一个 32 位的整形数据类型。
4、通过 ACK 确保可靠性
当一个发送者在将数据发送给一个接收者之后没能收到一个 ACK(确认应答) 时,发送者 TCP 将会重新发送该数据给接收者。因此,发送方将会缓存那些没有得到接收者返回 ACK 的数据。
5、流控(Flow Control)
发送者竟会根据接收者的承受能力发送尽可能多的数据。接收者会将其能够接收的数据的最大字节数(unused buffer size, receive window)发送给发送者。发送者将会根据接收者的接收窗口所能支持的大小,尽可能发送更多的数据。
6、拥堵控制(Congestion Control)
拥堵窗口 以独立于接收窗口的方式来使用,通过限制网络上的数据流量来避免网络拥堵。与接收窗口一样,发送者通过一些算法来根据接收者拥堵窗口所能支持的最大字节数来发送尽可能多的数据,这些算法有 TCP Vegas、Westwood、BIC、CUBIC。与流控不同,拥堵控制仅由发送方实现。
数据传输
就像其名字中的提示一样,一个网络“栈”拥有很多层。下面的图示中展示了各层的类型:
可见有多个不同的层,并且归类为三种不同的空间:
- 用户空间
- 内核空间
- 设备空间
用户与内核空间的任务会由 CPU 来完成执行。用户与内核空间又被称为 “Host” 以与设备空间加以区分。这里的设备是网络适配器(Network Interface Card, NIC),它会发送或接收数据包。这比通常称呼的 “网卡(LAN Card)” 更为准确。
让我们看一下用户空间。首先,应用会创建用来发送的数据(User Data)并通过 write() 系统调用来发送数据。这里假定 socket(fd) 已经被创建过了。当执行了系统调用,则会切换到内核空间。
POSIX 系列的操作系统,包括 Linux 和 Unix,通过一个文件描述符将 socket 保留给应用。在 POSIX 系列的操作系统中,socket 只是文件的一种。文件层会执行一个简单的检查,并通过连接到文件构造体的 socket 构造体来调用 socket 函数。
内核 socket 拥有两个缓冲区:
- 一个是用于发送的 socket 发送缓冲区
- 一个是用于接收的 socket 接收缓冲区
当“系统写”被调用,处于用户空间的数据会被复制到内核内存并被添加到“socket 发送缓冲区”的末端,以按照数据添加的顺序进行发送。就像上图中浅灰色的方块引用着 socket 缓冲区中的数据。然后 TCP 被调用。
这里有一个关联到 socket 的 TCP 控制块(TCP Control Block, TCB) 结构,TCB 包含着用于处理 TCP 连接的必要信息。TCP 中的数据包括:连接状态(LISTEN, ESTABLISHED, TIME_WAIT),接收窗口,拥堵窗口,序列号,重发计时器,等等。
如果 TCP 的当前状态运行数据传输,一个新的 TCP 段(segment, 即数据包) 会被创建。如果因为流控或类似的原因不能进行数据传输,系统调用就此终止并将模式(mode)返回给用户模式,即将控制权交给应用。
下面是两个 TCP 段,其结构如下图所示:
- TCP 头
- 负荷(payload)
负荷中包含了保存在未进行应答确认的 socket 发送缓冲区中的数据。负荷的最大长度即为接收窗口、拥堵窗口、最大分段值(MSS),这三者中的最大值。
然后,TCP 的校验和(checksum)被计算。在这个校验和计算中,包含了虚拟(pseudo)头信息,如 IP 地址、分段长度、协议号。根据 TCP 的状态,可以传输一个或更多的数据包。
事实上,由于现在的网络栈采用无负载(offload)的校验和,因此 TCP 校验和是由 NIC 计算的,而非内核。然而我们为了方便,这里假设是由内核完成的 TCP 校验和计算。
被创建的 TCP 分段会进入到 IP 层。IP 层将 IP 头添加到 TCP 分段,并执行 IP 路由。IP 路由 是为了搜索下一个跳板 IP 以最终能够抵达目的 IP。
在 IP 层计算并添加了 IP 头校验和之后,它会将数据发送到以太网(Ethernet)层。以太网层将会根据**地址解析协议(Address Resolution Protocol,ARP)**搜索下一个跳板 IP 的 MAC 地址。让后将以太网头添加到数据包。以太网数据包的添加则完成了主机(host)数据包的创建。
在 IP 路由执行之后,传输接口会得到 IP 路由的结果。该接口用于将数据包发送给下一个跳板 IP 或直接 IP。因此,网络适配器(NIC) 设备被调用。
这时,如果运行了一个数据包捕获程序,比如 tcpdump 或 Wireshark,内核将会把数据包数据复制到这些程序使用的内存中。这样,直接就能在设备上捕获接收到的数据包。通常来说,流量整形器(shaper)功能会被时限为运行在这一层上。
设备通过由 NIC 厂商定义的设备 NIC 通信协议来请求数据包的传输。
在接收到数据包传输请求之后,NIC 会将数据包从主内存复制到其自身的内存,然后发送给网线。这时,为了遵循以太网标准,会在数据包中添加 IFG(InterFrame Gap)、报头、CRC。IFG 和报头用于识别数据包的开始,CRC 则与 TCP 和 IP 的校验和一样用于保护数据。数据包的传输会基于以太网的速度和以太网的流控被启动。
当 NIC 发送一个数据包时,NIC 会使主机 CPU 中断。每次中断都拥有自己的中断号,然后 OS 通过该中断号查找合适的设备来处理该中断。在设备启动时会注册一个函数(中断处理器)来处理该中断。OS 调用该中断处理器,然后中断处理器将被传输的数据包返回给 OS。
到目前为止,我们已经讨论了当应用执行一次写入时贯穿内核与设备的整个数据传输过程。然而,再没有一个来自应用的直接写请求的情况下,内核可以直接通过调用 TCP 来传输一个数据包。比如,当接收了一个 ACK 且接收窗口被扩充,内核创建一个包含 socket 缓冲区中剩余数据的 TCP 分段,并将其发送给接收者。
数据接收
现在让我们看一下数据是如何被接收的。数据接收是网络栈用来处理传入的数据包的步骤。下图展示了网络栈如何处理一个接收到的数据包:
首先,NIC 将数据包写人到它的内存。它通过执行 CRC 检查来验证其有效性,然后将其发送给主机(host)的内存缓冲区。该缓冲区是一块已经由驱动程序向内核请求过的专门用于接收数据包的内存。一旦该内存被分配,驱动程序则会将其地址和大小发送给 NIC。如果是 NIC 已经接收到一个数据包但又没有分配可用的主机内存缓冲区,则 NIC 会将该数据包丢弃。
将数据包发送给主机内存缓冲区之后,NIC 会向主机 OS 发送一个中断(interrupt)。
然后,驱动器会检查它是否能够继续处理新的数据包。截止目前,驱动器与 NIC 使用的的通信协议由厂商定义。
当驱动器需要向上层发送数据包时,该数据包的结构必须被包装为一个 OS 使用的数据包结构,以便 OS 能够理解该数据包。比如,Linux 中的 sk_buff,BSD 系列内核中的 mbuf,微软 Windows 中的 NET_BUFFER_LIST,这些均是对应到各个 OS 的数据包结构。然后,驱动程序将被包装过的数据包发送给上层。
以太网层会检查该数据包的有效性,然后根据以太网头部中的以太网类型(ethertype)的值多路分解(de-multiplexes)上层协议(网络协议)。 比如 IPv4 的以太网类型协议是 0x0800。然后移除掉数据包的以太网头部并将其发送被 IP 层。
IP 层同样会检查数据包的有效性,或者说是检查 IP 头部的校验和。它将逻辑性的检测是否需要执行 IP 路由并使本机系统来处理该数据包,还是将其发送给其他的系统。如果该数据包必须由本机系统来处理,IP 层会通过查阅 IP 头部的原始值来多路分解上层协议(传输协议)。TCP 的原始值是 6。然后移除掉数据包的 IP 头部并将其发送给 TCP 层。
向下层一样,TCP 层会通过检查 TCP 校验和来验证数据包的有效性。如前面提到的,由于当前的网络栈使用的是无负载(offload)校验和,因此 TCP 的校验和由 NIC 完成计算,而非内核。
然后开始搜索数据包关联的 TCP 控制块(TCB)。这时,<source IP, source port, target IP, target port> 会作为数据包的标示符。在搜索连接之后,它会执行协议来处理数据包。如果接收到的是新的数据包,会将其数据添加到 socket 接收缓冲区。根据 TCP 的状态,它可以发送一个新的 TCP 数据包,比如一个 ACK 数据包。现在,TCP/IP 对数据包的接收已经处理完成。
Socket 接收缓冲区的大小是 TCP 的接收窗口大小。确定的一点是,当接收窗口很大的时候 TCP 的吞吐会随之增长。在过去,socket 的缓冲区的大小会由应用或 OS 的配置来调整。最新的网络栈会拥有自动调整 socket 接收缓冲区大小的功能,比如调整接收窗口。
当应用调用了系统读(system read)调用,空间会被切换到内核空间,socket 缓冲区中的数据则会被复制到用户空间的内存。然后被复制过的数据会被从 socket 缓冲区移除。然后 TCP 被调用。因为 socket 缓冲区中出现了新的空间,TCP 则会增长接收窗口的大小。然后根据协议的状态发送一个数据包。如果没有需要传输的数据包,系统调用则会被终止。
网络栈开发指南
目前已经介绍的网络栈层次的功能都是非常基础的功能。上世纪 90 年代初的网络栈功能并没有比上面所介绍的功能多。然而,最新的网络栈则拥有更多的功能,因为网络栈的实现也变得更加高级,所以也更加复杂。
最新的网络栈按用途分类如下。
数据包处理步骤控制(Manipulation)
这是一个类似网络过滤器(NetFilter, NAT, 防火墙)或流量控制的功能。通过在基本的处理流程中插入用户可控的代码,基于用户的配置,该功能能够完成不同的工作。
协议性能
其目的在于提升 TCP 协议在给定网络环境下的吞吐量、延迟和稳定性。通过一些拥堵控制算法和额外的 TCP 功能来实现,比如经典的 SACK。协议的提升在这里不会做过多讨论,因为已经超出了本文的范围。
数据包处理效率
数据包处理效率的目的在于,通过减少系统处理数据包时的 CPU 周期、内存使用、内存访问,来提高每秒能够处理的数据包的最大数量。已经有多种尝试来减少系统中的延迟。这些尝试包括栈并行处理、头部预测、zero-copy、single-copy、无负载校验和、TSO、LRO、RSS 等等。
网络栈中的控制流程
现在让我们更加详细的看一下 Linux 网络栈的内部流程。网络栈更像是一个子系统,一个网络栈根本上来说是以时间驱动的方式运行,并对发生的事件做出相应。因此,并没有单独的线程来执行网络栈。上面在对网络栈层次的讨论中展示了其简化版的流程,下图中阐述了更加准确的控制流程。
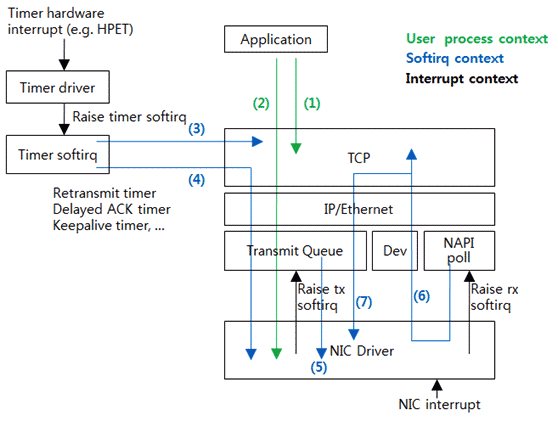
Flow(1),一个应用调用了系统调用来执行(使用) TCP。比如,调用了系统读或系统写,然后执行 TCP。然而,这里并没有数据包传输。
Flow(2) 与 Flow(1)类似,但它在执行 TCP 之后需要对数据包进行传输。它会创建一个数据包并将其向下发送给驱动设备。驱动设备之前会有一个队列。数据包首先会进入到队列,然后队列的实现结构决定了将数据包发送给驱动设备的时机。这便是 Linux 的排队机制(qdisc)。Linux 的流量控制功能便是对 qdisc 的控制。默认的 qdisc 是一个简单的先进先出(FIFO)队列。通过使用一个另外的 qdisc,操作者可以实现多种效果,比如人造丢包、包延迟、传输速度控制等等。在 Flow(1) 和 Flow(2) 中,应用的处理线程同样会用来执行驱动设备。
Flow(3) 展示了 TCP 所使用的计时器(timer)过期的场景。比如,当 TIME_WAIT 计时器过期时,TCP 会被调用以删除连接。
Flow(4) 与 Flow(3) 类似,即 TCP 使用的计时器过期,且 TCP 执行结果的数据包需要被传输。比如,当重复计时器(retransmit timer)过期时,为得到 ACK 的数据包将会被重新传输。
Flow(3) 和 Flow(4) 展示了执行计时器软中断请求(softiq)的步骤,它处理了计时器中断。
当 NIC 驱动设备接收到一个中断,它会释放已传输的数据包。大多数情况下,驱动设备的执行会在这里终止。Flow(5) 展示的是数据包在传输队列中的累积。驱动设备会请求软中断(softiq),软中断处理器会执行传输队列来将累积的数据包发送给驱动设备。
当 NIC 驱动设备收到了一个中断并发现了一个新接收到的数据包,它会请求软中断。软中断会调用驱动是被来处理数据包并将其发送给上层。在 Linux 中,向上面展示的对接收到的数据包的处理被称为 New API(NAPI)。这个过程类似于轮询,因为驱动设备并未直接将数据包发送给上层,但是上层会直接得到该数据报。这里实际的代码会被称为 NAPI poll 或 poll。
Flow(6) 展示了 TCP 的执行完成,而 Flow(7) 展示了仍需要处理额外的数据包。Flow(5,6,7) 都是由处理了 NIC 中断的软中断请求执行。
如何处理中断、接收数据包
中断的处理是相当复杂的;然而,你需要了解与数据包接收处理相关的性能问题。下图展示了中断的处理步骤:
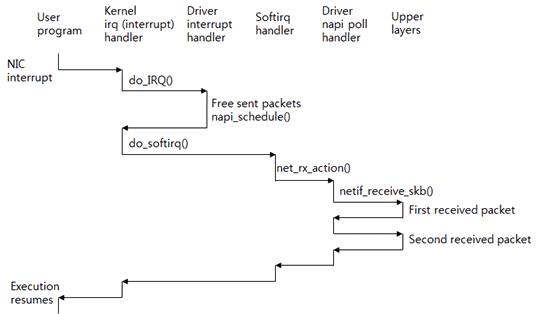
假如 CPU 0 正在处理一个应用程序(用户程序)。这时,NIC 收到一个数据包并为 CPU 0 生成一个中断。然后 CPU 执行了内核的中断处理器(irq)。这个处理器会引用该中断的序号,然后调用驱动设备的中断处理器。驱动设备首先会释放掉已经传输过的数据包,然后调用napi_schedule()来处理接收到数据包。该函数会请求 softirq(软中断)。
在驱动设备的中断处理器的执行终止后,控制权会传递给内核处理器。内核处理器会为 softirq 执行中断处理器。
在中断上下文被处理之后,softirq(软中断)上线文会被执行。中断上下文与软中断上下文会被同一个线程处理,但是,两个上下文使用不同的栈。同时,中断上下文会阻塞硬件中断,但软中断上下文则允许硬件中断。
处理接收到的数据包的软终端处理器为 net_rx_action() 函数。该函数会对驱动设备调用 poll() 函数。然后 poll() 函数会调用 netif_receive_skb() 函数将接收到的数据包一个接一个的发送给上层。在处理完软中断之后,应用会中停止点重启执行,以便能够请求一个系统调用。
然而,接收到中断的 CPU 会从头到尾的处理接收到的数据。在 Linux、BSD、微软中的处理步骤基本如此。
如果你检查服务器的 CPU 利用率,有时你会发现服务器的众多 CPU 中仅有一个 CPU 在艰难的处理软中断。这种现象的发生则是因为目前我们已经解释过的对接收到的数据包的处理方式。为了解决这个问题,出现了多队列 NIC、RSS、RPS。
数据结构
下面是一些关键的数据结构。
sk_buff 结构
首先是表述数据包的 sk_buff 或 skb。下图展示了 sk_buff 的一部分结构。由于函数已经发生了进化因此变得更加复杂。然而其基本功能则十分简单,任何人都能理解。
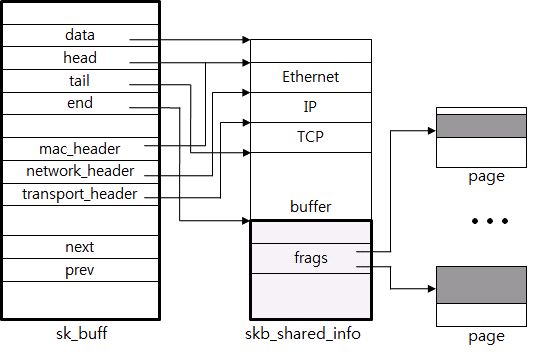
包数据与元数据
该结构直接包含了包数据或者通过一个指针来引用包数据。上图中,一些(由以太网至缓冲区)数据包通过数据指针引用,一些额外的数据(frags)则引用了实际的数据页(page)。
一些必要的信息比如头部、荷载长度则被保存在元数据区。比如上图中,mac_header、network_header、transport_header 拥有相同的指针数据,并分别指向以太网头、IP 头、TCP 头的起始位置。这种方式使得 TCP 协议的处理变得简单。
如何添加或删除头部
头部在经过各个网络栈的层时会被添加或删除。指针的使用则为了更加高效的处理。比如,想要移除以太网头部,仅需要递增对应的头部指针。
如何合并或拆分数据包
链接列表用于高效的处理类似从 socket 缓冲区、数据包链中添加或删除数据包的荷载数据这样的任务。next 指针、prev 指针则用于此目的。
快速分配与释放
因为数据包一旦创建就需要分配该结构,所以使用了快速分配器(allocator)。比如,如果数据在 10GB 带宽的以太网中传输,每秒则会有多余 1 百万的数据包被创建和删除。
TCP 控制块(TCB)
然后,是一个用于表示 TCP 连接的结构,前面我们笼统的称之为 TCB。Linux 使用 tcp_sock 来表示该结构。在下图中,你可以看到文件、socket、tcp_sock 之间的关系。
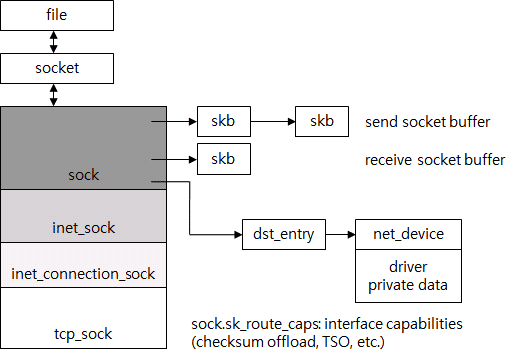
当触发了一个系统调用时,它会在文件描述符中搜索该应用使用的触发了该调用的文件。对于 Unix 系列的 OS 来说,文件以及用于通用文件系统存储的驱动设备均被抽象为文件。因此,该结构仅包含了最少的信息。对于一个 socket,一个单独的 socket 结构保存了 socket 相关的信息,然后文件以指针的形式引用该 socket。然后 socket 又以同样的方式引用了 tcp_sock。tcp_sock 又被划分为 into_sock、inet_sock 等等,以支持不同类型的特定 TCP 协议。可以被看做是一种多态。
所有被 TCP 协议使用的状态信息均被保存在 tcp_sock 中。比如,序列号、接收窗口、阻塞控制、重发计时器。
Socket 发送缓存区、socket接收缓冲区实际上是 sk_buff 列表,其中包含的是 tcp_sock。同时引用了 dst_entry、IP 路由结构,以避免过度频繁的路由。dst_entry 支持对 ARP 结构的简单搜索,比如目的地的 MAC 地址。dst_entry 是路由表的一部分。而路由表的结构则太过复杂了,本文不再讨论。用于数据包传输的 NIC 则通过 dst_entry 进行搜索。而 NIC 则被表示为 net_device 结构。
因此通过搜索文件,可以使用指针非常容易的找到用于处理 TCP 连接所必须的所有结构(从文件到驱动设备)。结构的大小则是 TCP 连接所使用的内存大小,仅占用很少的几个 KB(包含包数据)。随着功能的增加,内存占用也会逐渐增加。
最后,让我们看一下 TCP 连接的查找表。这是一个用于搜索数据包所归属的 TCP 连接的哈希表。哈希值使用数据包的 <source IP, target IP, source port, target port> 作为输入,基于 Jenkins 哈希算法来计算。据说哈希算法的选择是基于对防御哈希表攻击的考虑。
跟随代码:如何传输数据
我们将通过跟随实际的 Linux 内核源码来检查网络栈中所执行的关键任务。这里我们将遵循两个常用的路径。
首先,这个路径用于在应用调用一个系统写调用时传输数据。
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf, ...)
{
struct file *file;
[...]
file = fget_light(fd, &fput_needed);
[...] ===>
ret = filp->f_op->aio_write(&kiocb, &iov, 1, kiocb.ki_pos);
struct file_operations {
[...]
ssize_t (*aio_read) (struct kiocb *, const struct iovec *, ...)
ssize_t (*aio_write) (struct kiocb *, const struct iovec *, ...)
[...]
};
static const struct file_operations socket_file_ops = {
[...]
.aio_read = sock_aio_read,
.aio_write = sock_aio_write,
[...]
};
当系统调用系统写时,内核会执行文件层的 write() 函数。首先,文件描述符 fd 的实际文件结构会被取到。然后 aio_wirte 被调用。这是一个函数指针。在文件结构中,你会看到 file_operattions 结构体。该结构通常被称为函数表,包含了 aio_read 和 aio_write 这样的函数指针。socket 的实际函数表是 socket_file_ops。socket 使用的 aio_write 函数实际是 sock_aio_write。函数表的目的与 Java 中的接口类似。它被普遍的用于内核对代码的抽象或重构。
static ssize_t sock_aio_write(struct kiocb *iocb, const struct iovec *iov, ..)
{
[...]
struct socket *sock = file->private_data;
[...] ===>
return sock->ops->sendmsg(iocb, sock, msg, size);
struct socket {
[...]
struct file *file;
struct sock *sk;
const struct proto_ops *ops;
};
const struct proto_ops inet_stream_ops = {
.family = PF_INET,
[...]
.connect = inet_stream_connect,
.accept = inet_accept,
.listen = inet_listen, .sendmsg = tcp_sendmsg,
.recvmsg = inet_recvmsg,
[...]
};
struct proto_ops {
[...]
int (*connect) (struct socket *sock, ...)
int (*accept) (struct socket *sock, ...)
int (*listen) (struct socket *sock, int len);
int (*sendmsg) (struct kiocb *iocb, struct socket *sock, ...)
int (*recvmsg) (struct kiocb *iocb, struct socket *sock, ...)
[...]
};
socket_aio_write() 函数重文件得到 socket 结构体并调用 sendmsg。它同样是一个函数指针。socket 结构体包含了 proto_ops 函数表。IPV4 TCP 对 proto_ops 的实现是 inet_stream_ops,对 sendmsg 函数的实现是 tcp_sendmsg。
int tcp_sendmsg(struct kiocb *iocb, struct socket *sock,
struct msghdr *msg, size_t size)
{
struct sock *sk = sock->sk;
struct iovec *iov;
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
[...]
mss_now = tcp_send_mss(sk, &size_goal, flags);
/* Ok commence sending. */
iovlen = msg->msg_iovlen;
iov = msg->msg_iov;
copied = 0;
[...]
while (--iovlen >= 0) {
int seglen = iov->iov_len;
unsigned char __user *from = iov->iov_base;
iov++;
while (seglen > 0) {
int copy = 0;
int max = size_goal;
[...]
skb = sk_stream_alloc_skb(sk,
select_size(sk, sg),
sk->sk_allocation);
if (!skb)
goto wait_for_memory;
/*
* Check whether we can use HW checksum.
*/
if (sk->sk_route_caps & NETIF_F_ALL_CSUM)
skb->ip_summed = CHECKSUM_PARTIAL;
[...]
skb_entail(sk, skb);
[...]
/* Where to copy to? */
if (skb_tailroom(skb) > 0) {
/* We have some space in skb head. Superb! */
if (copy > skb_tailroom(skb))
copy = skb_tailroom(skb);
if ((err = skb_add_data(skb, from, copy)) != 0)
goto do_fault;
[...]
if (copied)
tcp_push(sk, flags, mss_now, tp->nonagle);
[...]
}
tcp_sendmsg 从 socket 得到 tcp_sock(i.e. TCB),并将应用请求用来传输的数据复制到 socket 发送缓冲区。当把数据复制到 sk_buff 时,一个 sk_buff 又会包含多少字节呢?一个 sk_buff 复制并包含 MSS(tcp_send_mss) 个字节以帮助实际创建数据包的代码。Maximum Segment Size(MSS) 实际表示了一个 TCP 包能够包含的最大荷载大小。通过使用 TSO 和 GSO,sk_buff 能够保存比 MSS 更多的数据。这些将会在后续详细讨论,而非在本文。
sk_stream_alloc_skb 函数创建了一个新的 sk_buff, skb_entail 将新创建的 sk_buff 添加到 send_socket_buffer 的头部。skb_add_data 函数会将实际的应用数据复制到 sk_buff 的数据缓冲区。通过几次这样的重复(创建 skb_buff 并添加到 socket 发送缓冲区),所有数据都会被复制。因此,以 MSS 为大小的 sk_buffs 会以列表的形式保存在 socket 发送缓冲区中。最终,tcp_push 被调用以使得这些数据能够以一个数据包的形式被传输,然后数据包被发送。
static inline void tcp_push(struct sock *sk, int flags, int mss_now, ...)
[...] ===>
static int tcp_write_xmit(struct sock *sk, unsigned int mss_now, ...)
int nonagle,
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
[...]
while ((skb = tcp_send_head(sk))) {
[...]
cwnd_quota = tcp_cwnd_test(tp, skb);
if (!cwnd_quota)
break;
if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now)))
break;
[...]
if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp)))
break;
/* Advance the send_head. This one is sent out.
* This call will increment packets_out.
*/
tcp_event_new_data_sent(sk, skb);
[...]
tcp_push 函数会基于 TCP 允许的范围尽可能多的传输 socket 发送缓冲区中的 sk_buffs。首先,tcp_send_head 被调用以得到 socket 发送缓冲区中的第一个 sk_buff,然后执行 tcp_cwnd_test 和 tcp_snd_wnd_test 来检查正在接收的 TCP 的阻塞窗口和接收窗口是否允许新数据包的传输。然后,tcp_transmit_skb 函数被调用以创建一个数据包。
static int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb,
int clone_it, gfp_t gfp_mask)
{
const struct inet_connection_sock *icsk = inet_csk(sk);
struct inet_sock *inet;
struct tcp_sock *tp;
[...]
if (likely(clone_it)) {
if (unlikely(skb_cloned(skb)))
skb = pskb_copy(skb, gfp_mask);
else
skb = skb_clone(skb, gfp_mask);
if (unlikely(!skb))
return -ENOBUFS;
}
[...]
skb_push(skb, tcp_header_size);
skb_reset_transport_header(skb);
skb_set_owner_w(skb, sk);
/* Build TCP header and checksum it. */
th = tcp_hdr(skb);
th->source = inet->inet_sport;
th->dest = inet->inet_dport;
th->seq = htonl(tcb->seq);
th->ack_seq = htonl(tp->rcv_nxt);
[...]
icsk->icsk_af_ops->send_check(sk, skb);
[...]
err = icsk->icsk_af_ops->queue_xmit(skb);
if (likely(err <= 0))
return err;
tcp_enter_cwr(sk, 1);
return net_xmit_eval(err);
}
tcp_transmit_skb 创建了对应 sk_buff 的副本(pskb_copy)。这次,并未复制应用的完整数据,而仅仅是元数据。然后调用 skb_push 来保护头部数据空间并记录头部数据值。send_check 计算了 TCP 的校验和。基于无负载(offload)校验和,荷载数据并未被计算。最终,queue_xmit 被调用以将数据包发送给 IP 层。IPV4 的 queue_xmit 由 ip_queue_xmit 函数实现。
int ip_queue_xmit(struct sk_buff *skb)
[...]
rt = (struct rtable *)__sk_dst_check(sk, 0);
[...]
/* OK, we know where to send it, allocate and build IP header. */
skb_push(skb, sizeof(struct iphdr) + (opt ? opt->optlen : 0));
skb_reset_network_header(skb);
iph = ip_hdr(skb);
*((__be16 *)iph) = htons((4 << 12) | (5 << 8) | (inet->tos & 0xff));
if (ip_dont_fragment(sk, &rt->dst) && !skb->local_df)
iph->frag_off = htons(IP_DF);
else
iph->frag_off = 0;
iph->ttl = ip_select_ttl(inet, &rt->dst);
iph->protocol = sk->sk_protocol;
iph->saddr = rt->rt_src;
iph->daddr = rt->rt_dst;
[...]
res = ip_local_out(skb);
[...] ===>
int __ip_local_out(struct sk_buff *skb)
[...]
ip_send_check(iph);
return nf_hook(NFPROTO_IPV4, NF_INET_LOCAL_OUT, skb, NULL,
skb_dst(skb)->dev, dst_output);
[...] ===>
int ip_output(struct sk_buff *skb)
{
struct net_device *dev = skb_dst(skb)->dev;
[...]
skb->dev = dev;
skb->protocol = htons(ETH_P_IP);
return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING, skb, NULL, dev,
ip_finish_output,
[...] ===>
static int ip_finish_output(struct sk_buff *skb)
[...]
if (skb->len > ip_skb_dst_mtu(skb) && !skb_is_gso(skb))
return ip_fragment(skb, ip_finish_output2);
else
return ip_finish_output2(skb);
ip_queue_xmit 函数会执行一些 IP 层要求的函数。__sk_dst_check 检查被缓存的路由是否有效。如果没有缓存的路由或者缓存的路由无效,它会执行 IP 路由。然后调用 skb_push 来保护 IP 头部空间并记录 IP 头部字段值。之后,随着函数的调用,ip_send_check 会计算 IP 头部的校验和并调用网络过滤器(netfilter)函数。如果 ip_finish_output 函数需要 IP 分片则会创建 IP 片段。当使用 TCP 时并不需要 IP 分片。因此,ip_finish_output2 会被调用,它添加了以太网(Ethernet)头部。最终,一个数据包完成。
int dev_queue_xmit(struct sk_buff *skb)
[...] ===>
static inline int __dev_xmit_skb(struct sk_buff *skb, struct Qdisc *q, ...)
[...]
if (...) {
....
} else
if ((q->flags & TCQ_F_CAN_BYPASS) && !qdisc_qlen(q) &&
qdisc_run_begin(q)) {
[...]
if (sch_direct_xmit(skb, q, dev, txq, root_lock)) {
[...] ===>
int sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q, ...)
[...]
HARD_TX_LOCK(dev, txq, smp_processor_id());
if (!netif_tx_queue_frozen_or_stopped(txq))
ret = dev_hard_start_xmit(skb, dev, txq);
HARD_TX_UNLOCK(dev, txq);
[...]
}
int dev_hard_start_xmit(struct sk_buff *skb, struct net_device *dev, ...)
[...]
if (!list_empty(&ptype_all))
dev_queue_xmit_nit(skb, dev);
[...]
rc = ops->ndo_start_xmit(skb, dev);
[...]
}
已完成的数据包由 dev_queue_xmit 函数来传输。首先,数据包通过 qdisc(队列规则) 来传递。如果使用的是默认的 qdisc 且队列为空,sch_direct_xmit 函数被调用以将数据包直接下发给驱动设备,从而跳过队列。dev_hard_start_xmit 函数会调用实际的驱动设备。在调用驱动设备之前,首先对驱动设备的 TX 加锁。这么做是为了避免多个线程对驱动设备的同时访问。由于内核锁住了驱动设备的 TX,驱动设备的传输代码则无需再进行加锁。这些与并行编程紧密相关,我们下次再进行讨论。
ndo_start_xmit 函数调用了驱动设备代码。就在之前,你会看到 ptype_all 和 dev_queue_xmit_nit。ptype_all 是一个包含了一些模块的列表,比如数据包捕获。如果捕获程序正在运行,数据包则会被 ptype_all 复制到另外的程序。因此,tcpdump 所展示的数据包正式要传输给驱动设备的数据包。如果使用了无负载校验和或 TSO,NIC 会篡改数据包。因此 tcpdump 得到的数据包会与传输到网线上的数据包有所不同。在完成数据包的传输之后,驱动设备中断处理器会返回 sk_buff。
跟随代码:如何接收数据
大体的执行路线为接收一个数据包,然后将数据添加到 socket 接收缓冲区。在执行完驱动设备处理器之后,紧接着会首先执行 napi 拉取处理。
static void net_rx_action(struct softirq_action *h)
{
struct softnet_data *sd = &__get_cpu_var(softnet_data);
unsigned long time_limit = jiffies + 2;
int budget = netdev_budget;
void *have;
local_irq_disable();
while (!list_empty(&sd->poll_list)) {
struct napi_struct *n;
[...]
n = list_first_entry(&sd->poll_list, struct napi_struct,
poll_list);
if (test_bit(NAPI_STATE_SCHED, &n->state)) {
work = n->poll(n, weight);
trace_napi_poll(n);
}
[...]
}
int netif_receive_skb(struct sk_buff *skb)
[...] ===>
static int __netif_receive_skb(struct sk_buff *skb)
{
struct packet_type *ptype, *pt_prev;
[...]
__be16 type;
[...]
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (!ptype->dev || ptype->dev == skb->dev) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
}
[...]
type = skb->protocol;
list_for_each_entry_rcu(ptype,
&ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) {
if (ptype->type == type &&
(ptype->dev == null_or_dev || ptype->dev == skb->dev ||
ptype->dev == orig_dev)) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
}
if (pt_prev) {
ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
[...]
};
前面已经提到过,net_rx_action 是接收数据包的软中断处理器。首先,请求过 napi 拉取的驱动设备从 poll_list 中被找到,然后驱动设备的拉取处理器被调用。驱动设备使用 sk_buff 包装接收到的数据包,然后调用 netif_receive_skb。
如果有一个请求所有数据包的模块,netif_receive_skb 会将所有的数据包发送给该模块。像数据包传输中一样,数据包会被传输给注册到 ptype_all 列表的模块。数据包在这里被捕获。
然后,会基于数据包的类型将其传输给上层。以太网(Ethernet)数据包的头部中拥用 2-byte 的以太网类型字段,其值表示了数据包的类型。驱动设备会将该值记录到 sk_buff(sk->protocol) 中。每种协议都拥有各自的 packet_type 结构体,并将该结构体的指针注册到名为 ptype_base 的哈希表。IPV4 使用 ip_packet_type,其 Type 字段的值是 IPV4 以太网类型(ETH_P_IP)。因此,IPV4 数据包会调用 ip_rcv 函数。
int ip_rcv(struct sk_buff *skb, struct net_device *dev, ...)
{
struct iphdr *iph;
u32 len;
[...]
iph = ip_hdr(skb);
[...]
if (iph->ihl < 5 || iph->version != 4)
goto inhdr_error;
if (!pskb_may_pull(skb, iph->ihl*4))
goto inhdr_error;
iph = ip_hdr(skb);
if (unlikely(ip_fast_csum((u8 *)iph, iph->ihl)))
goto inhdr_error;
len = ntohs(iph->tot_len);
if (skb->len < len) {
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INTRUNCATEDPKTS);
goto drop;
} else if (len < (iph->ihl*4))
goto inhdr_error;
[...]
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, skb, dev, NULL,
ip_rcv_finish);
[...] ===>
int ip_local_deliver(struct sk_buff *skb)
[...]
if (ip_hdr(skb)->frag_off & htons(IP_MF | IP_OFFSET)) {
if (ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, skb, skb->dev, NULL,
ip_local_deliver_finish);
[...] ===>
static int ip_local_deliver_finish(struct sk_buff *skb)
[...]
__skb_pull(skb, ip_hdrlen(skb));
[...]
int protocol = ip_hdr(skb)->protocol;
int hash, raw;
const struct net_protocol *ipprot;
[...]
hash = protocol & (MAX_INET_PROTOS - 1);
ipprot = rcu_dereference(inet_protos[hash]);
if (ipprot != NULL) {
[...]
ret = ipprot->handler(skb);
[...] ===>
static const struct net_protocol tcp_protocol = {
.handler = tcp_v4_rcv,
[...]
};
ip_rcv 函数会执行 IP 层所必须的一些任务。它会检验数据包,比如长度和头部校验和。在流经网络过滤器码时,它会执行 ip_local_deliver 函数。如有必要,它会装配 IP 分段。然后,通过网络过滤器码调用 ip_local_deliver_finish。ip_local_deliver_finish 函数会通过 __skb_pull 移除掉 IP 头部,然后搜索协议值与 IP 头部的协议值一样的上层协议。类似于 ptype_base,每个传输协议都会将其各自的 net_protocol 结构体注册到 inet_protos。IPV4 TCP 使用 tcp_protocol 并调用注册为一个处理器的 tcp_v4_rcv。
当数据包来到 TCP 层,数据包处理流程会基于 TCP 状态和数据包类型变化。这里,我们将会看到这样的数据包处理步骤:预期的下一个数据包已经以 ESTABLISHED 的 TCP 连接状态被接收到。当没有丢失的或乱序抵达的数据包时,接收数据的服务端将会频繁执行这样的路线。
int tcp_v4_rcv(struct sk_buff *skb)
{
const struct iphdr *iph;
struct tcphdr *th;
struct sock *sk;
[...]
th = tcp_hdr(skb);
if (th->doff < sizeof(struct tcphdr) / 4)
goto bad_packet;
if (!pskb_may_pull(skb, th->doff * 4))
goto discard_it;
[...]
th = tcp_hdr(skb);
iph = ip_hdr(skb);
TCP_SKB_CB(skb)->seq = ntohl(th->seq);
TCP_SKB_CB(skb)->end_seq = (TCP_SKB_CB(skb)->seq + th->syn + th->fin +
skb->len - th->doff * 4);
TCP_SKB_CB(skb)->ack_seq = ntohl(th->ack_seq);
TCP_SKB_CB(skb)->when = 0;
TCP_SKB_CB(skb)->flags = iph->tos;
TCP_SKB_CB(skb)->sacked = 0;
sk = __inet_lookup_skb(&tcp_hashinfo, skb, th->source, th->dest);
[...]
ret = tcp_v4_do_rcv(sk, skb);
首先,tcp_v4_rcv 函数首先会验证接收到的数据包。如果头部大小大于数据偏移,即 th->doff < sizeof(struct tcphdr) / 4,则出现头部错误。然后,__inet_lookup_skb 会从 TCP 连接哈希表中查找数据包对应的 TCP 连接。基于找到的 sock 结构体,所有必要的结构体和 sock 都会被找到,比如 tcp_sock。
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
[...]
if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */
sock_rps_save_rxhash(sk, skb->rxhash);
if (tcp_rcv_established(sk, skb, tcp_hdr(skb), skb->len)) {
[...] ===>
int tcp_rcv_established(struct sock *sk, struct sk_buff *skb,
[...]
/*
* Header prediction.
*/
if ((tcp_flag_word(th) & TCP_HP_BITS) == tp->pred_flags &&
TCP_SKB_CB(skb)->seq == tp->rcv_nxt &&
!after(TCP_SKB_CB(skb)->ack_seq, tp->snd_nxt))) {
[...]
if ((int)skb->truesize > sk->sk_forward_alloc)
goto step5;
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPHPHITS);
/* Bulk data transfer: receiver */
__skb_pull(skb, tcp_header_len);
__skb_queue_tail(&sk->sk_receive_queue, skb);
skb_set_owner_r(skb, sk);
tp->rcv_nxt = TCP_SKB_CB(skb)->end_seq;
[...]
if (!copied_early || tp->rcv_nxt != tp->rcv_wup)
__tcp_ack_snd_check(sk, 0);
[...]
step5:
if (th->ack && tcp_ack(sk, skb, FLAG_SLOWPATH) < 0)
goto discard;
tcp_rcv_rtt_measure_ts(sk, skb);
/* Process urgent data. */
tcp_urg(sk, skb, th);
/* step 7: process the segment text */
tcp_data_queue(sk, skb);
tcp_data_snd_check(sk);
tcp_ack_snd_check(sk);
return 0;
[...]
}
实际的协议会从 tcp_v4_do_rcv 函数执行。如果 TCP 处于 ESTABLISHED 状态,则调用 tcp_rcv_esablished 函数。ESTABLISHED 状态会被单独的处理和优化,因为这是最常见的状态。tcp_rcv_esablished 函数首先会执行头部预测代码,在通常场景中,头部预测也会被快速地执行以进行检测。这里的通常场景指的是没有需要传输的数据,而已接收到的数据包其实是需要下次被接收的数据包,比如,序列号是正在接收的 TCP 所预期的序列号。这时,通过将数据添加到 socket 缓冲区并发送 ACK 类完成该步骤。
接着你会看到实际大小(truesize)与 sk_forward_alloc 的比较语句,用来检查 socket 接收缓冲区中是否有自由空间来添加新的数据包数据。如果有,则“命中”头部预测(预测成功)。然后调用 __skb_pull 来移除 TCP 头部。之后,调用 __skb_queue_tail 将数据包添加到 socket 接收缓冲区。最终,__tcp_ack_snd_check 会被调用以发送 ACK,如果需要的话。通过以上方式,数据包的处理完成。
如果没有足够的自由空间,会执行一个较慢的路线。tcp_data_queue 会重新申请缓冲空间并将数据包添加到 socket 缓冲区。这时,如果可能的话,socket 接收缓冲区大大小会被自动增长。与快速路线不同的是,如果可能的话,tcp_data_snd_check 会被调用以传输一个新的数据包。最终,__tcp_ack_snd_check 会被调用以发送 ACK,如果需要的话。
这两种执行路线的代码规模并不大,这是基于对常见场景的优化实现的。换句话说,这意味着不常见的场景的处理会显著变慢。乱系抵达就是非常见场景的一种。
驱动设备与 NIC 之间如何通信
驱动设备与 NIC 之间的通信是网络栈的底层部分,多数人并不关心这一块。然而,NIC 正在执行越来越多的任务以解决性能问题。理解基本的操作模式将有助于你理解额外的技术。
驱动设备与 NIC 之间进行的是 异步 通信。首先,驱动设备会请求一个数据包传输调用,然后 CPU 并不等待响应,而是执行另一个任务。然后,NIC 发送数据包并提醒 CPU,驱动设备返回接收到的数据包结果。数据包接收与传输一样,也是异步的。首先,驱动设备数据包接收调用,CPU 则会去指定别的任务。然后,NIC 接收数据包并提醒 CPU,驱动设备会处理接收到的数据包并返回结果。
因此,需要一个地方来保存请求和响应。大多数情况下,NIC 会使用 环(ring) 结构体,ring 类似于普通的队列结构,带有固定的条目数量,一个条目保存一个请求或响应数据。这些条目会按顺序依次被使用。固定的数量以及按顺序的复用,因此称此结构为 ring。
下图展示了数据包的传输步骤,你可以看到 ring 是如何被使用的。
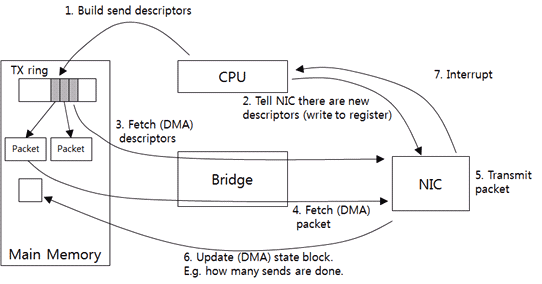
驱动设备从上层接收数据包并穿件 NIC 能够理解的发送描述符。发送描述不默认会包含数据包大小及其内存地址。因为 NIC 需要物理地址来访问内存,驱动设备需要将虚拟地址转换为物理地址。然后,驱动设备将发送描述符添加到 TX ring(1)。TX ring 是一个发送描述符 ring。
接着,驱动设备会通知 NIC 新的请求(2)。驱动设备直接将注册数据写入到指定的 NIC 内存地址。这样,程序化(programmed) IO(PIO) 则成为 CPU 直接将数据发送给驱动设备的传输方法。
被通知的 NIC 从主机内存中获得 TX ring 的发送描述符(3)。由于驱动设备直接访问内存而无需 CPU 的干预,这种访问被称为 Direct Memory Acess(DMA)。
在得到发送描述符之后,NIC 会检测数据包地址、大小,然后从主机内存中得到实际额的数据包(4)。基于无负载校验和(offload checksum),NIC 会在从内存得到数据包时计算校验和。因此,很少会出现开销。
NIC 发送数据(5) 并将发送的数据包的需要写入到内存(6)。然后,它会发送一个中断(7)。驱动设备读取所发送的数据包的序号,然后返回到目前为止已发送的数据包。
下图展示了接收数据包的步骤。
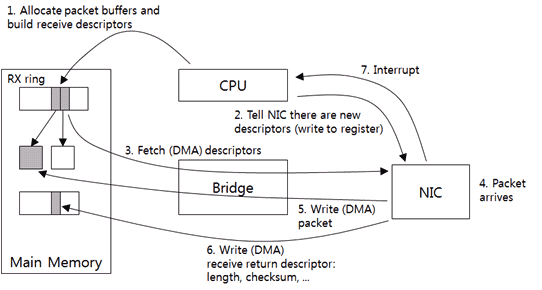
首先,驱动设备会分配主机内存缓冲以接收数据包,然后创建一个接收描述符。接收描述符默认会包含缓存大小及内存地址。像发送描述符一样,它会在接收描述符中保存 DMA 需要使用的物理地址。然后,将接收描述符添加到 TX ring(1)。描述符作为一个接收请求,RX ring 作为一个接收请求 ring。
通过 PIO,驱动设备会通知 NIC 有一个新的描述符(2)。NIC 从 RX ring 中得到新的描述符,并将描述符中的缓冲带下、位置保存到 NIC 内存(3)。
在数据被接收到之后(4),NIC 会将接收到的数据包发送给主机内存缓冲区(5)。如果存在无负载校验和函数,NIC 会在此刻计算校验和。所接收数据包的实际大小、校验和结果以及其他一些信息会被保存到另一个单独的 ring(6),即“接收返回 ring”。接收返回 ring 中包含了接收请求处理的结果,比如响应。然后 NIC 发送一个中断(7)。驱动设备从接收返回 ring 中获得数据包信息并处理接收到的数据包。如有必要,它会分配新的内存并重复步骤 (1)、(2)。
为了调优网络栈,很多人指出对 ring 和中断的设置进行调整。当 TX ring 很大时,大量发送请求可以被一次处理完成。当 RX ring 很大时,大量数据包的接收可以被一次处理完成。对于带有较大爆发的数据包传输、接收来说,一个大的 ring 将会有助于负载。在大多数情况下,NIC 会使用一个计时器来减少中断的数量,因为 CPU 可能需要遭受大量处理中断的开销。为了避免主机系统中大量中断的泛滥,中断可以被收集并在发送或接收数据包时定期发送(中断合并)。
栈缓冲区与流控
流控会在网络栈的多个阶段中执行,下图中展示了用于发送数据的缓冲区。
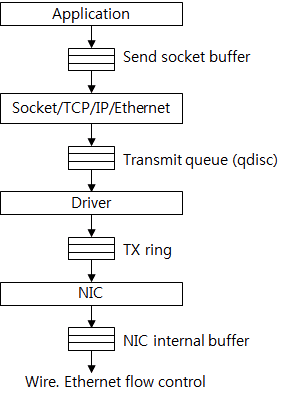
首先,一个应用创建数据并将其添加到 socket 发送缓冲区。如果缓冲区中没有自由空间,系统调用则会失败,或者应用线程会发生阻塞。因此,必须使用 socket 缓冲区大小限制来控制数据流入内核的速度。
TCP 创建并通过传输数据队列(qdisc) 将其发送到驱动设备。这是一个典型的 FIFO 队列类型,队列的最大长度是 txqueuelen 的值,该值可以通过 ifconfig 命令来检查。通常它可以承载数千个数据包。
TX ring 介于驱动设备和 NIC 之间。如前面提到的,它被认为是一个传输请求队列。如果队列中没有可用的自由空间,没有传输请求会被创建,数据包也会被累积到传输队列中。如果基类了太多数据包,多余的数据包则会被丢弃。
NIC 将需要发送的数据包保存到内部缓冲。来自该缓冲的数据包速度受物理速度的影响,比如 1 Gb/s 的 NIC 无法提供 10 GB/s 的性能。同时基于以太网的流控,如果 NIC 接收缓冲中没有可用的自由空间,数据包传输将会被停止。
下图展示了接收数据所流经的缓冲。数据包首先被保存到 NIC 的接收缓冲。基于流控的视角,驱动设备与 NIC 之间的 RX ring 被认为是一个数据包 缓冲。驱动设备从 RX ring 获取传入的数据包并将其发送给上层。由于被服务系统使用的 NIC 驱动设备默认使用 NAPI,驱动设备与上层之间没有缓冲。因此,可以认为是上层直接从 RX ring 直接获得数据包。荷载数据被保存的 socket 接收缓冲区。然后应用从 socket 接收缓冲区获取这些数据。
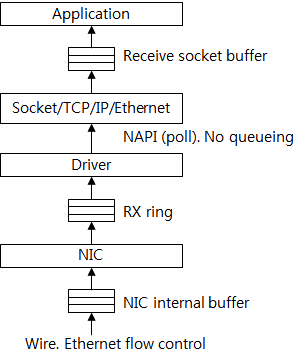
不支持 NAPI 的驱动设备会将数据包保存的后备(backlog)队列。然后,NAPI 来获取这些数据包。因此,后备队列可以被看做是上层和驱动设备间的缓冲。
如果内核对数据包的处理速度慢于 NIC 中数据包流的速度, RX ring 会变满。然后 NIC 的缓冲变满。当使用了以太网流控时,NIC 会发送一个请求给传输 NIC 以停止传输,或者丢去数据包。
在 socket 接收缓冲区中不会出现因为空间不足而丢弃数据包,因为 TCP 支持端到端的流控。对于大多数工作而言吞吐量是重中之重,提升 ring 和 socket 缓冲区大小将大有帮助。增加大小能够在快速传输或接收大量数据包时减少因为空间不足引起的错误。
总结
一开始,我计划仅向大家介绍有助于开发网络程序、执行性能测试、故障排除相关的内容。尽管我有初步计划,但本文件中的描述数量并不小。我希望本文能帮助您开发网络应用程序并监视他们的性能。TCP/IP协议本身很复杂,有很多例外。不过,您不必了解 OS 中 TCP/IP 相关的每一行代码以了解性能并分析这些现象。仅了解它的上下文就会对你很有帮助。
随着系统性能和 OS 网络栈实现的不断进化,最新的服务能够为任意程序提供 10-20 Gb/s 的 TCP 吞吐。这些时间以来,已经有太多性能相关的技术类型,比如 TSO, LRO, RSS, GSO, GRO, UFO, XPS, IOAT, DDIO, TOE,就像字母汤(alphabet soup),让我们变得困惑。
在下一篇文章中,我将从性能的角度解释网络堆栈,并讨论该技术的问题和影响。
Reference
5.5 - RFC-1180
1、介绍
本教程仅包含 TCP/IP 各个关键点的一个视图,因此它是 TCP/IP 技术的“骨架”。这里省略了其发展与资助历史、商业用例,以及与 ISO OSI 作为对比的前景。事实上,也省略了大量的技术信息。剩下的是在 TCP/IP 环境中工作的专业人员所必须理解的最小信息。这些专业人员包括系统管理员、系统程序员以及网络管理员。
本教程使用 Unix TCP/IP 环境作为示例,但是各个要点适用于所有 TCP/IP 实现。
注意,本备忘录的目的在于解释,而非定义。如果对协议的正确规范有任何疑问,请参考定义 RFC 的实际标准。
下一节是对 TCP/IP 的概览,接着是对各个组件的详细描述。
2、TCP/IP 概览
“TCP/IP”,这个通用的术语通常表示任何、所有与 TCP 和 IP 相关的特定协议。它可以包含其他协议、应用,甚至是网络媒介。协议相关的例子有:UDP、ARP、ICMP。应用相关的例子有:TELNET、FTP、rcp。一个更加准确的术语应该是“互联网(internet)技术”。一个使用互联网技术的网络则被称为“互联网”。
2.1、基本结构
想要理解该技术,你首先得理解下面的逻辑结构:
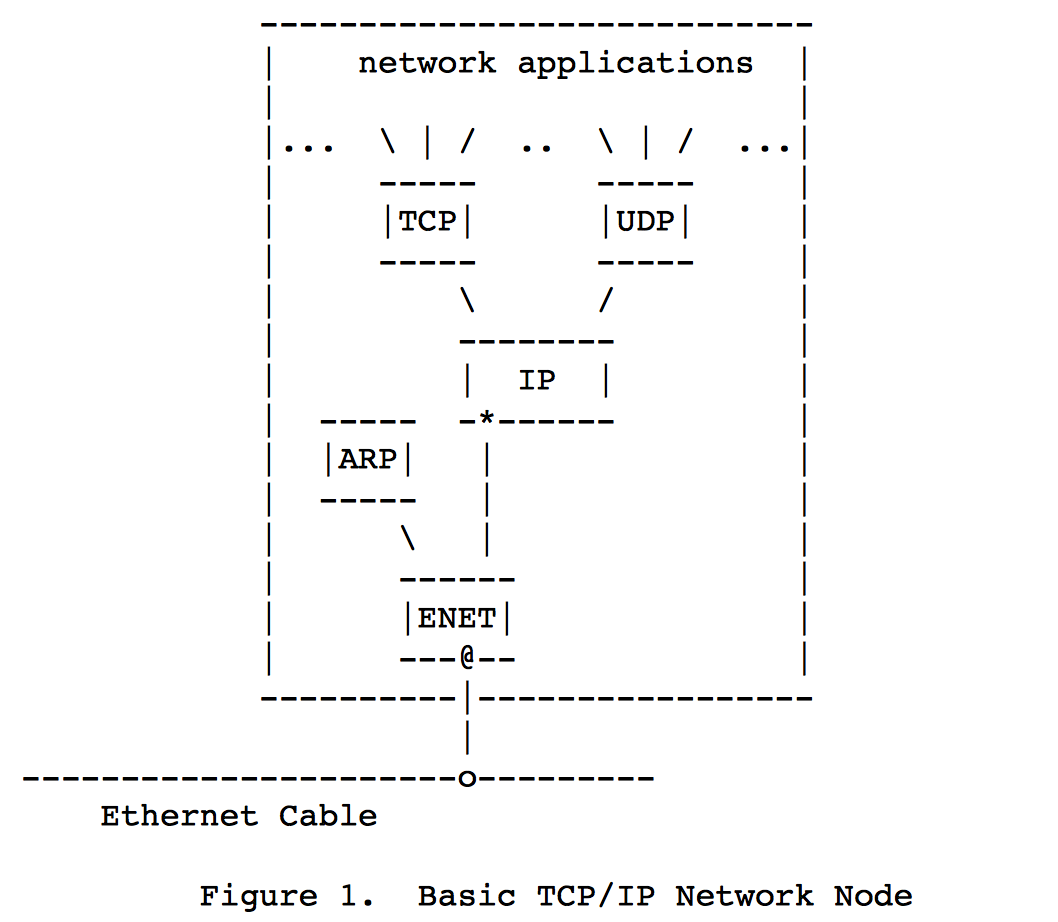
这是一个互联网上的计算机内部的分层协议的逻辑结构。每个使用拥有这样一个逻辑结构的互联网技术的计算机都能够进行通信。该逻辑结构用于判断处于互联网上的计算机的行为。这些方框表示数据通过计算机时的处理过程,连接方框的线段则表示数据的路径。处于底部的水平线表示以太网电缆;“o” 表示收发器(transceiver),“*” 表示 IP 地址;“@” 表示以太网地址。对该逻辑结构的理解是对互联网技术本质的理解;它将贯穿于整个教程。
2.2、术语
流经互联网的数据单元的名称,取决于它在协议栈中的位置。总的来说:如果它处于以太网(Ethernet),则被称为 “以太网帧(frame)”;如果它处于以太网驱动设备和 IP 模块之间,则被称为 “IP 数据包(packet)”;如果它处于 IP 模块和 UDP 模块之间,则被称为 “UDP 数据报文(datagram)”;如果它处于 IP 模块和 TCP 模块之间,则被称为 “TCP 段(segment)”,或者更通常的称为“传输消息”;如果它处于网络应用之中,则被称为 ”应用消息“。
这些定义是不完善的。实际的定义会在不同出版物之间发生变化。更加明确的定义可以在 “小节 1.3.3 RFC 1122” 中找到。
驱动设备(driver)是一种在网络接口硬件之间通信的软件。模块(module)是一种与驱动设备、网络应用、或者另一个模块进行通信的软件。
这些术语,驱动设备、模块、以太网帧、IP 数据包、UDP 数据报、TCP 消息、应用消息,会适当的使用于整个教程中。
2.3、数据流
让我们顺着数据在图一中所展示的、通过协议栈向下流动的方向。对于一个使用 TCP(Transmission Control Protocol) 的应用,数据会在应用和 TCP 模块之间传递。对于使用 UDP(User Datagram Protocl) 的应用,数据会在应用和 UDP 模块之间传递。FTP(File Transfer Protocol) 是一个使用 TCP 的典型应用。在本例中它的协议栈是 FTP/TCP/IP/ENET。SNMP(Simple Network Management Protocol) 是一个使用 UDP 的应用。它在本例中的协议栈是 SNMP/UDP/IP/ENET。
TCP 模块、UDP 模块以及以太网驱动设备,都是多对一的多路转接器(multiplexer)。作为多路转接器,它们会将多种输入转换为一种输出。它们同时又是一对多的反-多路转接器(de-multiplexer)。作为反-多路转接器,它们可以根据协议头部中的类型字段,将一种输入转换为多种输出。

如果一个以太网帧从网络向上来到以太网驱动设备,数据包可以被传递到上游的 ARP(Address Resolution Protocol) 模块或 IP(Internet Protocol) 模块。以太网帧中的类型字段的值会用于判断是将以太网帧传递给 ARP 还是 IP 模块。
如果一个 IP 数据包向上来到 IP 模块,数据单元会被传递到上游的 TCP 或 UDP,这取决于 IP 头部中协议字段的值。
如果一个 UDP 数据报向上来到 UDP 模块,应用消息会基于 UDP 头部中端口字段的值传递给上游的网络应用。如果 TCP 消息向上来到 TCP 模块,应用消息会基于 TCP 头部中端口字段的值传递给上游的网络应用。
向下游的多路转接会比较易于执行,因为从每个起始点开始仅有一个下游路径;每个协议模块会在数据单元中添加各自的头部信息,因此数据包能够在目的计算机中进行反多路转接。
通过 TCP 或 UDP 从应用中传出的数据会聚集到 IP 模块上,让后通过低层的网络接口驱动设备向下发送。
尽管互联网技术支持多种不同的网络媒体,但是本教程中的所有示例都会使用以太网(Ethernet),因为它是 IP 协议下使用的最普遍的物理网络。图一中的计算机拥有单个以太网连接。6 字节的以太网地址对于一个以太网中的每个接口来说是唯一的,并位于以太网驱动设备的低层接口。
该计算机(图一)同样拥有一个 4 字节的 IP 地址,该地址位于 IP 模块的低层接口。每个 IP 地址对于互联网来说必须是唯一的。
一个运行中的计算机总是知道它自己的 IP 地址和以太网地址。
2.4、两个网络接口
如果一个计算机被连接到两个单独的以太网,像下图(3)中一样:
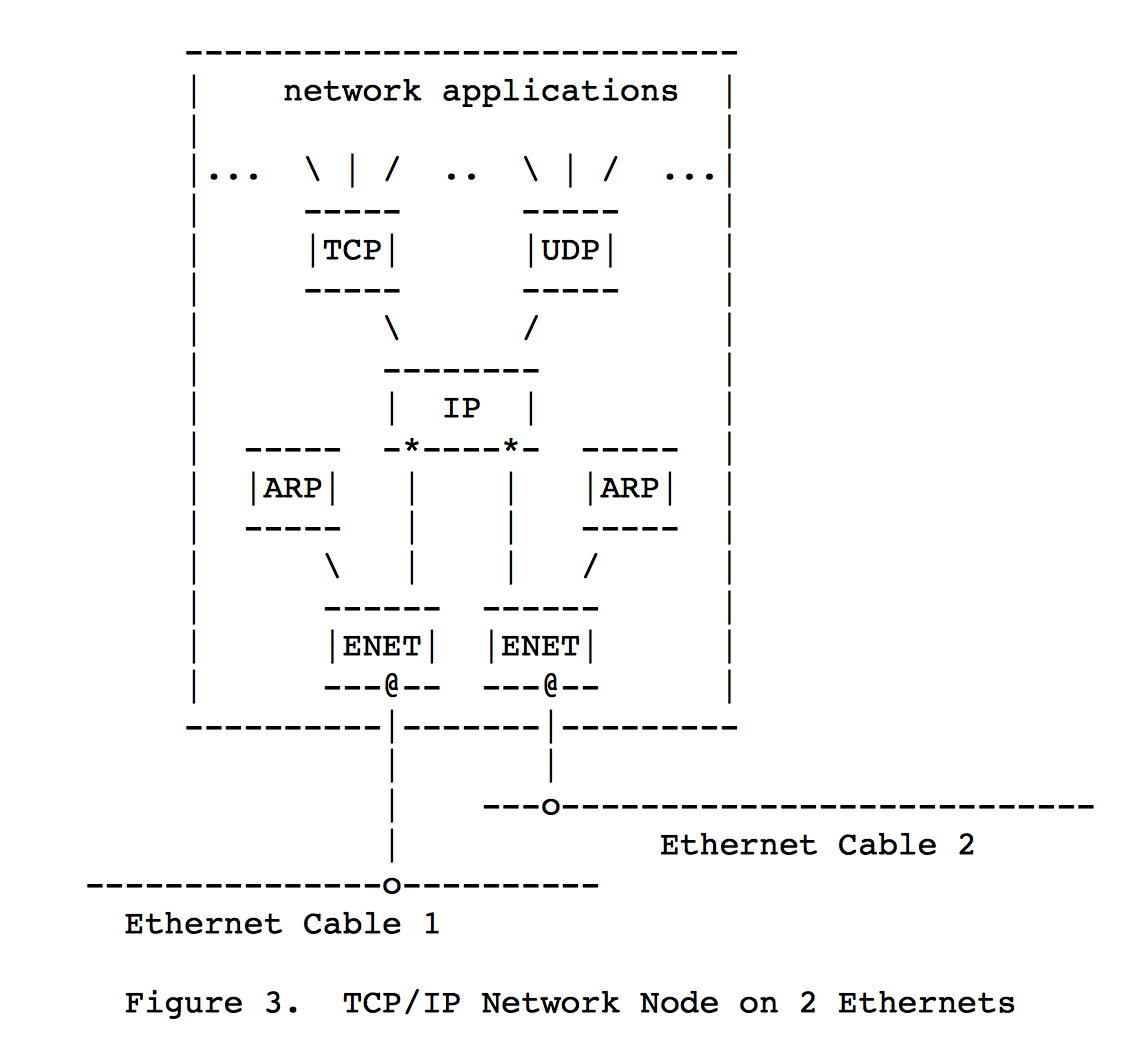
请注意该计算机拥有两个以太网地址和 IP 地址。
从图中的结构可以发现,该计算机拥有两个物理网络接口,IP 模块同时作为多对多的多路转接器和多对多的反多路转接器。

它会在任意一个方向上执行多路转接以适应传入和传出的数据。一个伴随多于一个网络接口的 IP 模块比我们一开始的例子要复杂的多,它可以将数据转发到另一个网络。数据可以到达任意网络接口,也可以从任意其他的网络接口被发出。
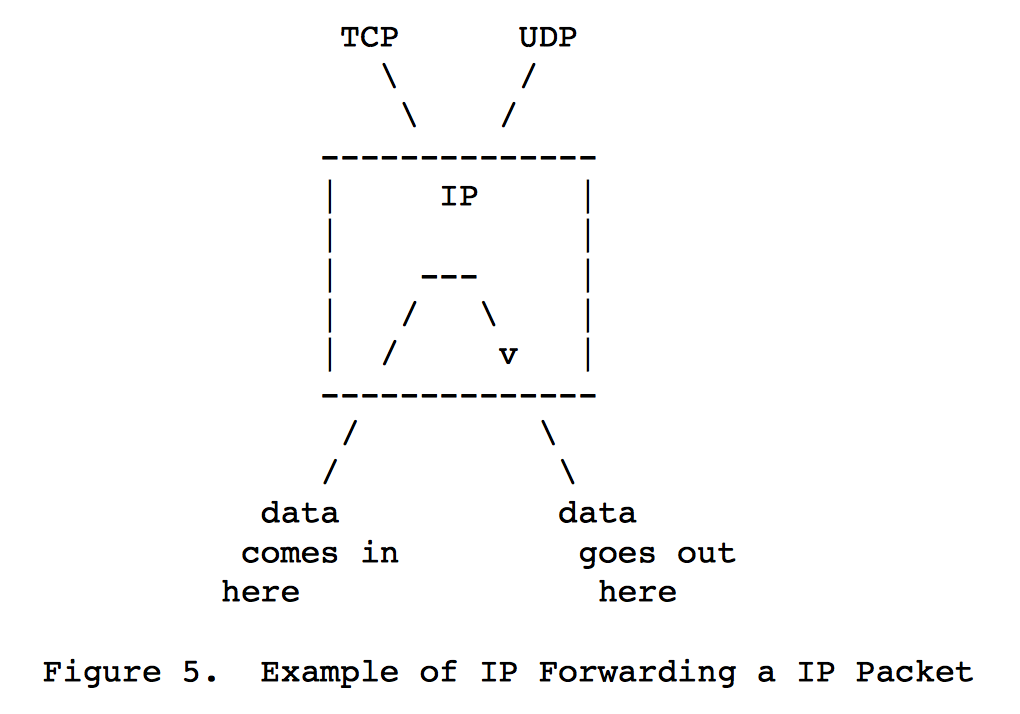
将一个 IP 数据包发送到另外一个网络的过程被称为 IP 数据包的”转发“。一个专门用来转发 IP 数据包的计算机被称为 ”IP-路由器(router)“。
从图中你可以发现,被转发的 IP 数据包绝不会接触到 IP 路由器中的 TCP 或 UDP 模块。有些 IP 路由器的实现中甚至并不拥有 TCP 或 UDP 模块。
2.5、IP 创建了一个单一逻辑网络
IP 模块是互联网技术成功的核心。在消息向下流经协议栈时,每个模块都会添加各自的头部信息到消息中。当消息由协议栈向上传输到应用时,每个模块或驱动设备都会从消息中删除对应的头部信息。IP 头部中包含了 IP 地址,它从多个物理网络构建了一个单个逻辑网络。这种物理网络的互联也即名称的来源:Internet(因特网、互联网)。限制了 IP 数据包分组范围的一组相互关联的物理网络则称为”互联网“。
2.6、物理网络独立性
IP 对网络应用隐藏了底层的网络硬件。如果你发明了一个新的物理网络,你可以通过实现一个能够连接到互联网底层 IP 的驱动设备来将其投入使用。因此,网络应用能够保持不被硬件技术的改变所影响,从而保持完整。
2.7、互操作性
如果互联网之上的两个计算机能够通信,它们被称为可以”互操作“;如果一个互联网技术的实现很好,则被称为拥有”互操作性“。通用计算机用户受益于互联网的安装,因为计算机在市场上的互操作性。通常来说,如果你购买了一台计算机,它将会进行互操作。如果一台计算机不拥有互操作性,或者不能添加互操作性,它将在市场中占有一个狭小而特殊的地位。
2.8、概览之后
基于设置的背景,我们将回答以下问题:
- 当发出一个 IP 数据包时,目标以太网地址是如何确定的?
- 当发出一个 IP 数据包时,IP 模块如何知道使用多个低层网络接口中的哪一个?
- 一台计算机中的客户端如何连接到另一台计算机中的服务端?
- 为什么同时存在 TCP 和 UDP,而不是仅有一个或另一个?
- 有哪些可用的网络应用程序?
这些将会在补习完以外网之后进行解释。
3、以太网
本节是对以太网(Ethernet)技术的简要概览。
一个以太网帧包含了目的地址、来源地址、类型字段以及数据。
一个以太网地址占用 6 个字节。每个驱动设备都有各自的以太网地址,并使用目的地址来监听以太网帧。所有的驱动设备同时还会监听一个十六进制的通配地址 ”FF-FF-FF-FF-FF-FF-FF“,称为”广播“地址。
以太网使用了 CSMA/CD(Carrier Sense and Multiple Access with Collision Detection, 基带冲突检测的载波监听多路访问技术),CSMA/CD 意味着所有驱动设备的通信都基于一个单独的媒介,而同一时间仅能有一个驱动设备执行发送,但所有驱动设备能够同时进行接收。如果两个驱动设备尝试在一个瞬间同时发送,则会被检测到传输碰撞,然后两个驱动设备均会等待一个随机很短的周期来再次尝试发送。
3.1、人类类比
以太网技术的一个很好的类比是一组人在一个小的、全黑的房间中进行讨论。在这个类比中,物理网络媒介是空气中的声波,来替代同轴电缆中的电信号。
每个人都能听到其他人说话的声音(载波侦听)。房间中的所有人都有相同的能力进行谈话(多路访问),但是他们都没有长篇大论,因为他们都很有礼貌。如果一个人很无礼,他则会被要求离开房间(比如抛出网络)。
当别人正在说话时,则没人再会说话。如果两个人在同一瞬间开始说话,则两个人都会知道这种状况的发生,因为他们听到了一些他们没有说过的事情(冲突检测)。当两个人意识到这个状态,都会开始等待一段时间,然后其中一个会再次开始谈话。其他人则会等待正在说话的人结束,然后开始自己的发言。
每个人都拥有唯一的名字(唯一的以太网地址)以避免混淆。每个人每次开始谈话时,都会以他要进行谈话的人的名字以及自己的名字(以太网目的地址与源地址)作为谈话消息的开场白。比如,“Hello Jane, this is Jack, ..blah blah blah…"。如果发送者想要对所有人说话则会说 ”everyone“(广播地址),比如,”Hello Everyone, this is Jack, ..blah blah blah…“。
4、ARP
当发出一个 IP 数据包时,目的以太网地址又是如何被识别的呢?
ARP(Address Resolution Protocol) 用于将 IP 地址翻译为以太网地址。这种翻译仅应用于传出的数据包,因为这也就是 IP 头部和以太网头部被创建的时机。
4.1、用于地址翻译的 ARP 表
翻译通过一个表查找过程来执行。该表被称为 ARP 表,被保存在内存中,而每个计算机包含一行。一列用于保存 IP 地址,一列用于保存以太网地址。当把 IP 地址翻译为以太网地址时,会在表中搜索一个匹配的 IP 地址。下面是一个简化的 ARP 表:

人们约定,在书写 4 字节的 IP 地址时,每个字节按照 10 进制的形式,并且各个字节间使用句号分割。同时约定,在书写 6 进制的以太网地址时,每个字节按照 16 进制的形式,并且每个字节间使用端横杠或冒号分割。
ARP 表是必不可少的,因为 IP 地址及以太网地址在被选择时是各自独立的;你无法使用一个算法来将 IP 地址翻译为以太网地址。IP 地址由网络管理员基于计算机在互联网上的位置进行选择。当计算机被移动到互联网的另一个部分,IP 地址也必须随着改变。而以太网地址则由制造厂商基于该厂商所注册的以太网地址空间进行选择。当以太网硬件接口板改变时,以太网地址随之改变。
4.2、典型翻译场景
在常规的网络应用操作中,比如 TELNET,发送一个应用消息给 TCP,然后 TCP 将对应的 TCP 消息发送给 IP 模块。应用、TCP 模块、IP 模块会知道目的 IP 地址。这时 IP 数据包模块已经被构造并准备好发送给以太网驱动设备,但是首先得识别目的以太网地址。
而 ARP 表则就是为了查找目的以太网地址。
4.3、ARP 请求-响应对
但是 ARP 表首先又是如何被填充的呢?答案是”基于需要“的基础,由 ARP 自动完成填充。
当 ARP 表不能用于转换一个地址时会发生两件事:
- 一个带有以太网广播地址的 ARP 请求被发送到网络上的所有计算机;
- 需要被传出的 IP 数据包被排队。
所有计算机的以太网接口都会接收到这个广播的以太网帧。每个以太网驱动设备会检查以太网帧中的类型字段并将 ARP 数据包发送给 ARP 模块。ARP 请求数据包中会说”如果你的 IP 地址与这个目标 IP 地址匹配,请告诉我你的以太网地址“。一个 ARP 请求数据包的具体格式会像下面这样:
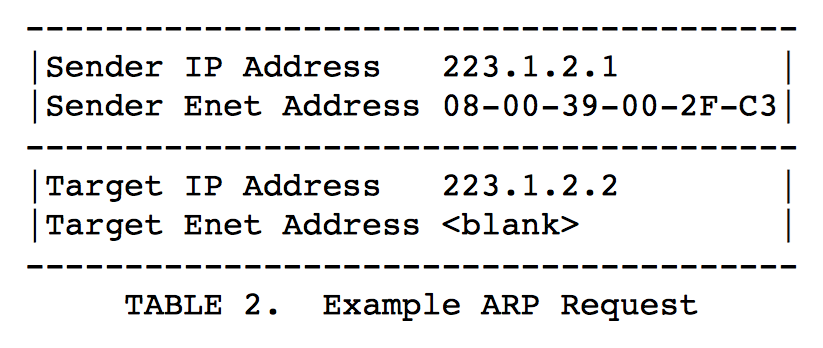
每个 ARP 模块会检查对 IP 地址进行检查,以确定目标 IP 地址与自身的 IP 地址是否匹配,然后直接向源以太网地址发送一个响应。ARP 响应中会说”是的,那个目标 IP 地址就是我,让我告诉你我的以太网地址“。一个 ARP 响应数据包中会包含与请求中对调的发送者、目标字段内容。看起来会是这样:
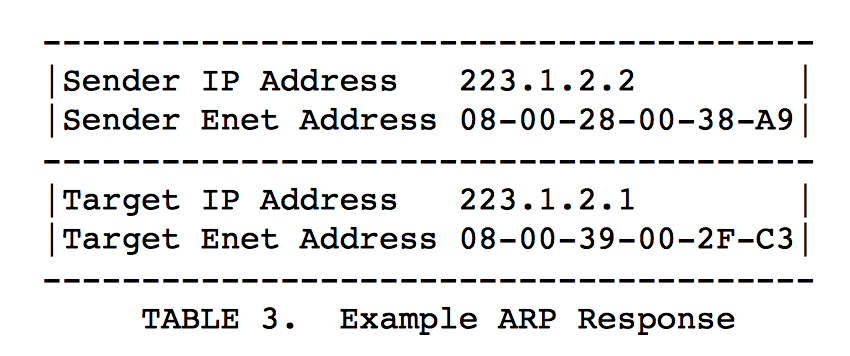
该响应会被原始的发送者计算机收到。以太网驱动设备会查看以太网帧中的类型字段然后将 ARP 数据包发送给 ARP 模块。ARP 模块检查 ARP 数据包并将发送者的 IP 地址添加到自己的 ARP 表中。
被更新后的 ARP 表看起来会是这样:

4.4、场景延续
新的翻译现在已经被自动安装到表中,从它被需要到完成仅需要数毫秒。如果你还记得上面的第二步,将要被传出的 IP 数据包目前正在被排队。接着,IP 地址到以太网地址的翻译会通过查找 ARP 表来执行,然后以太网帧被发送到以太网。因此,基于新的 3、4、5 步,发送者计算机的情况应该是这样的:
- 一个带有以太网广播地址的 ARP 请求被发送到网络上的所有计算机;
- 需要被传出的 IP 数据包被排队;
- 用于 ARP 表的、带有 IP 到以太网地址翻译的 ARP 响应返回;
- 对于被排队的 IP 数据包,ARP 表会被用于将 IP 地址转换到以太网地址;
- 以太网帧被发送到以太网。
总的来说,当基于 ARP 表的翻译无法完成,一个数据包会被排队。翻译数据会基于 ARP 请求、响应快速被填充,然后 IP 数据包被传送出去。
每个计算机的每个以太网接口都有一个单独的 ARP 表。如果目标计算机不存在,则不会有 ARP 响应、ARP 表中也不会存在对应的条目。IP 模块会删除掉需要发送到该地址的 IP 数据包。上层协议也无法识别一个断开的以太网与属于目标 IP 的地址的计算机的缺失之前的区别。
有些 IP 和 ARP 的实现不会在等到 ARP 响应的时候将 IP 数据包排队。取而代之的是 IP 数据包会被删除,对于丢失的 IP 数据包的恢复则会留给 TCP 模块或 UDP 网络应用来完成。恢复通过超时和重发来完成。被重新发送的消息则能够被成功发送出去,因为该消息的第一个副本已经使得 ARP 表被填充。
5、因特网协议
IP 模块是因特网技术的核心,而 IP 的精髓是其路由表。IP 使用这个内存中的表来制定有关 IP 数据包路由的所有决定。IP 路由表的内容有网络管理员定义。
立即路由表示是如何被使用的既是对因特网原理的理解。这些理解对成功的 IP 网络管理及维护是必须的。
想要更好的理解路由表,我们首先要拥有一个对路由概览,然后是学习 IP 网络地址,然后再查看各个细节。
5.1、直接路由
下图是一个包含三台计算机的小型因特网:A、B、C。每个计算机都拥有相同的、最开始的图一中所示的 TCP/IP 协议栈。每个计算机的以太网接口都拥有各自的以太网地址。每台计算机都拥有各自的、由网络管理员设置到 IP 接口的 IP 地址,同时网络管理员还在以太网上设置了 IP 网络编号。

当 A 向 B 发送一个 IP 数据包时,IP 头部中包含了 A 的 IP 地址来作为 IP 源地址,以太网头部中包含了 A 的以太网地址作为源以太网地址。同时,IP 头部中包含了 B 的 IP 地址作为目的 IP 地址,以太网头部中包含了 B 的以太网地址作为目的以太网地址。

在这个简单场景中,IP 是算一项开销,因为 IP 为由以太网提供的服务增加了很少的能力,相反,IP 却增加了消耗,需要额外的 CPU 处理、网络带宽用于生成、传输、解析 IP 头部。
当 B 的 IP 模块收到了来自 A 的 IP 数据包,它会对比目的 IP 地址与自身的 IP 地址,如果匹配,则会将数据包传递给上层协议。
这种 A 和 B 之间的通信称为直接路由。
5.2、间接路由
下图展示了一种更加贴近现实的因特网视图。它通过一个称为计算机 D 的 IP 路由器将 3 个以太网和 3 个 IP 网络组合,进而连接在一起。每个 IP 网络都拥有 4 台计算机;每台计算机都拥有各自的 IP 地址和以太网地址。
除了计算机 D,其他每个计算机都拥有图一中所示的相同的 TCP/IP 协议栈。计算机 D 是 IP 路由器;它被连接到 3 个网络,因此拥有 3 个 IP 地址及 3 个以太网地址。计算机 D 拥有类似图 3 中的 TCP/IP 洗衣栈,除此之外,他拥有 3 个 ARP 模块及 3 个以太网驱动设备,而非图 3 中的两个。但是注意计算机 D 仅有一个 IP 模块。
网络管理员已经为每个以太网设置了一个唯一的序号,称为 IP 网络序号。IP 网络序号并未在图中展示,其中仅展示了网络名。
当 A 发送一个 IP 数据包给 B 时,处理过程与上面的单个网络相同。位于同一个 IP 网络中的任意计算机之间的通信都与前面介绍过的直接路由的例子匹配。
当 D 与 A 通信时是直接通信。当 D 与 E 通信时是直接通信。当 D 与 H 通信时是直接通信。这是因为这些计算机对都处于同于一个 IP 网络。
然而,当计算机 A 与一个处于 IP 路由器源端的计算机通信时,通信则不再是直接的。这种通信被称为”间接“通信。
这种对 IP 数据包的路由由 IP 模块完成,并会透明的出现于 TCP、UDP 及网络应用中。
如果 A 向 E 发送一个 IP 数据包,源 IP 地址、以太网地址则为 A 的相应地址。目的 IP 地址则为 E 的相应地址,但是 A 的 IP 模块会将数据包发送给 D 以进行转发,这是目的以太网地址则为 D 的相应地址。

D 的 IP 模块接收到 IP 数据包并对目标 IP 地址进行判断,发现并非自己的 IP 地址,然后直接将 IP 数据包发送给 E。

总的来说,对于直接通信,源 IP 地址、源以太网地址都是发送者的对应地址,目标 IP 地址、以太网地址都是接收者的对应地址。对于间接通信,IP 地址与以太网地址不会像这样结对出现。
该示例因特网也是相当简单的一个。真实的网络通常因为各种因素变得复杂,最终拥有多个 IP 路由器以及多种类型的物理网络。
5.3、IP 模块路由规则
上面的概览已经展示了发生了什么,而不是如何发生的。现在让我们审查一下 IP 模块使用的一些规则、算法。
- 对于一个传出的 IP 数据包,从上层输入 IP,IP 必须决定是以直接还是间接的方式发送数据包,同时 IP 必须选择一个低层网络接口。这些选择的确定都基于对路由表的查询。
- 对于一个传入的 IP 数据包,从低层接口输入 IP,IP 必须决定是将 IP 数据包转发还是传递到上层。如果 IP 数据包被转发,则又会被当做是一个传出数据包。
- 当传入的 IP 数据包抵达时,它永远不会再通过相同的网络接口被转发回去。
这些决定会在 IP 数据包被低层网络接口处理及 ARP 表被商议之前确定。
5.4、IP 地址
网络管理员会根据计算机所附属的 IP 网络将 IP 地址设置到计算机。4 字节 IP 地址的一部分是网络 IP 序号,其他部分是计算机 IP 序号(或主机号)。对于表一种的计算机,其 IP 地址为 223.1.2.1,其网络序号为 223.1.2,主机序号为数字 1。
本教程中所有示例的 IP 地址都是 C 类地址,这意味着前三段为网络序号,最后一段为主机号码。网络地址的最高位是 110,C 类 IP 地址中网络序号的标识长度为 24 位,主机序号的长度为 8 位。因此可以有 2,097,152 个 C 类网络地址,每个网络中可以有 254 个主机。
IP 地址空间由 NIC(Network Information Center) 负责管理。所有连接到唯一一个万维网的因特网必须使用有 NIC 设定的网络序号。如果你在组建自己的因特网且不打算连接到因特网上,你也仍然需要从 NIC 获得网络序号。如果你选择使用自己的序号,一旦你的网络连接到其他网络则会存在出现混乱的风险。
5.5、命名
人们通过名称来引用到计算机,而非序号。一个名为 alpha 的计算机的 IP 地址或许为 223.1.2.1。对于小的网络,这种名称到地址的翻译数据通常会保存在各个计算机的 hosts 文件中。而对于大的网络,这种翻译数据文件被保存在一个服务器,并在需要的时候通过跨越网络来访问。文件中的几行可能看起来会是这样:
223.1.2.1 alpha
223.1.2.2 beta
223.1.2.3 gamma
223.1.2.4 delta
223.1.3.2 epsilon
223.1.4.2 iota
IP 地址作为第一列,计算机名作为第二列。
大多数情况下,你可以在所有计算机上安装完全相同的 hosts 文件。你会注意到 ”delta“ 在文件中仅有一条,尽管他可能拥有 3 个 IP 地址。Delta 可以通过其中任意一个 IP 地址抵达,使用哪一个是无关紧要的。当 delta 接收到一个 IP 数据包时它会查看目标地址,它会认出任意一个它自己的 IP 地址。
IP 网络同样也提供了名称。如果你拥有 3 个 IP 网络,你的用于注释这些名称的 ”networks“ 文件看起来会是这样:
223.1.2 development
223.1.3 accounting
223.1.4 factory
IP 网络序号是第一列,名称位于第二列。
从本例中你可以看到,alpha 是位于开发网络的计算机编号 1,beta 是位于开发网络的计算机编号 2,等等。同样你也可以说成是:alpha 是 develop.1,beta 是 develop.2,等等。
上面的 hosts 文件对用户来说是足够满足使用的,但是网络管理员可能将 delta 那一行替换为:
223.1.2.4 devnetrouter delta
223.1.3.1 facnetrouter
223.1.4.1 accnetrouter
hosts 文件中新增加的三行为 delta 的每个 IP 地址提供了更有意义的名称。事实上,第一个 IP 地址拥有两个名字:delta 与 devnetrouter 代表了相同的意义。在实践中,delta 会作为计算机的通用名称,而其他 3 个名称则仅用于对 IP 路由表的管理工作。
这些文件会被网络管理命令或网络应用使用以便提供有意义的名称。这些对因特网上的操作来说并非必要的,但是会使相关工作变得更加简单。
5.6、IP 路由表
IP 又是如何知道在发出一个 IP 数据包时使用哪个底层网络接口呢?IP 模块会从目的 IP 地址中解析出 IP 网络编号,然后作为一个键来搜索路由表。
路由表会为每个路径包含一行。路由表中主要的列包括:IP 网络编号、直接/间接标识、路由器 IP 地址、接口编号。该表会被每个传出的 IP 数据包通过 IP 引用。
在大多数计算机中,路由表可以通过 route 命令来修改。路由表的内容有网络管理员来定义,因为网络管理员为每个计算机设置了对应的 IP 地址。
5.7、直接路由细节
5.8、直接路由场景
5.9、间接路由细节
5.10、间接路由场景
5.11、路由总结
5.12、管理路由
6、用户数据报协议-UDF
6.1、端口
6.1、校验和
7、传输控制协议-TCP
8、网络应用
8.1、TELNET
8.2、FTP
8.3、rsh
8.4、NFS
8.5、SNMP
8.6、X-Window
9、其他信息
10、相关引用
5.6 - 可靠性疑问
TCP 是可靠的传输协议,不会丢包、乱序,其在理论上是非常可靠的,但在实际应用中需要区分场景。
- 发送方能不能知道已发送的数据对方是不是都收到了?或者收到多少?不能。
- 如果怀疑对方没收到,有没有办法可以确认对方没有收到?不能。
- 需要发送 123,对方会不会却收到 1223?会的。
第一个问题
众所周知 TCP 拥有 ACK,ACK 就是用来确认对方接收到了多少字节。但是 ACK 是 OS 的操作,OS 收到之后并不会通知用户程序。发送的流程如下:
- 应用程序把待发送的数据交给操作系统
- 操作系统把数据接收到自己的 buffer 里,接收完成后通知应用程序发送完成
- 操作系统进行实际的发送操作
- 操作系统收到对方的 ACK
如果在执行第二步之后,网络出现了暂时性故障,TCP 断开了连接,会发生什么?如果是网络游戏则很简单,可以将用户踢下线,让其重新登录。但如果是比较严肃的场景,当然希望能够支持 TCP 重连,但是重连后如何知道哪些数据已发送、哪些数据已丢失。
以Windows I/O completion ports举个例子。一般的网络库实现是这样的:在调用WSASend之前,malloc一个WSABuffer,把待发送数据填进去。等到收到操作系统的发送成功的通知后,把buffer释放掉(或者转给下一个Send用)。在这样的设计下,就意味着一旦遇上网络故障,丢失的数据就再也找不回来了。你可以reconnect,但是你没办法resend,因为buffer已经被释放掉了。所以这种管理buffer的方式是一个很失败的设计,释放buffer应当是在收到response之后。
方案:不要依赖于操作系统的发送成功通知,也不要依赖于TCP的ACK,如果你希望保证对方能收到,那就在应用层设计一个答复消息。再或者说,one-way RPC都是不可靠的,无论传输层是TCP还是UDP,都有可能会丢。
第二个问题
这是设计应用层协议的人很需要考虑的,简单来说,”成功一定意味着成功,而失败则未必意味着失败“。比如正在通过网银转账,这是出现“网络超时,转账操作可能失败”,这时并不能确定是否转账成功。即“失败”的定义可以包含多个层次。
方案:采用positioned write。即在客户端发给服务器的请求里加上文件偏移量(offset)。缺点是:若你想要多个客户端同时追加写入同一个文件,那几乎是不可能的。
第三个问题
方案:在应用层给每个message标记一个id,让接收者去重即可。
如何正确关闭连接
简单来说,谁是收到最后一条消息的人,谁来主动关闭 TCP 连接。另一方在 recv 返回 0 字节之后 close,千万不要主动 close。
在协议设计上,分两种情况:
- 协议是一问一答,类似于 HTTP,且发问的总是同一方。一方只问,另一方只答;
- 有显示 EOF 的消息通知对方 shutdown。
如果不满足以上两点的任何一点,那么就没有任何一方能够判断它收到的消息是不是最后一条。
5.7 - 握手详解
概览
TCP 基本认识
- TCP 头部格式
- 为什么需要 TCP 协议?TCP 工作在那一层?
- 什么是 TCP?
- 什么是 TCP 连接?
- 如何唯一确定一个 TCP 连接?
- TCP 最大连接数?
- UDP 与 TCP 的区别?各自应用场景?
- 为什么 UDP 头部没有“首部长度”字段,而 TCP 头部有“首部长度”字段?
- 为什么 UDP 头部有“包长度”字段,而 TCP 头部没有“包长度”字段?
TCP 建立连接
- TCP 三次握手过程和状态变迁
- 如何在 Linux 系统中查看 TCP 状态?
- 为什么是三次握手?不是两次或四次?
- 为什么客户端和服务端的初始需要 ISN 是不同的?
- 初始序号 ISN 是如何随机生成的?
- 既然 IP 层会分片,为什么 TCP 层还需要 MSS?
- 什么是 SYN 攻击?如何避免 SYN 攻击?
TCP 断开连接
- TCP 四次挥手过程和状态变迁
- 为什么挥手需要四次?
- 为什么 TIME_WAIT 等待的时间是 2MSL?
- 为什么需要 TIME_WAIT 状态?
- TIME_WAIT 过程有什么危害?
- 如何优化 TIME_WAIT?
- 如何已经建立了连接,但是客户端突然出现故障了怎么办?
Socket 编程
- 针对 TCP 应该如何 Socket 编程?
- Listen 时候参数 backlog 的意义?
- accept 发送在三次握手的哪一步?
- 客户端调用 close 了,连接断开的流程是什么?
1. TCP 基本认识
1.1 TCP 头部格式
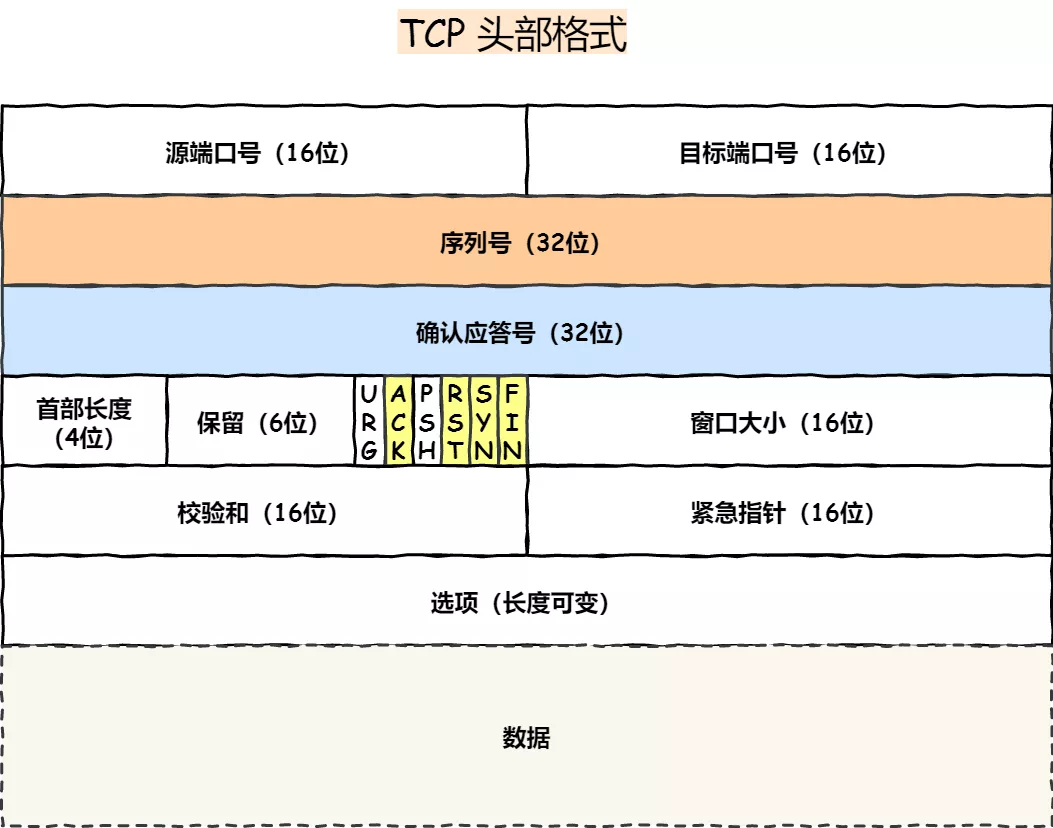
- 序列号:在建立连接时由计算机生成的随机数作为其初始值,通过 SYN 包传给接收端主机,每发送一次数据,就「累加」一次该「数据字节数」的大小。用来解决网络包乱序问题。
- 确认应答号:指下一次「期望」收到的数据的序列号,发送端收到这个确认应答以后可以认为在这个序号以前的数据都已经被正常接收。用来解决不丢包的问题。
- 控制位:
- ACK:该位为
1时,「确认应答」的字段变为有效,TCP 规定除了最初建立连接时的SYN包之外该位必须设置为1。 - RST:该位为
1时,表示 TCP 连接中出现异常必须强制断开连接。 - SYC:该位为
1时,表示希望建立连,并在其「序列号」的字段进行序列号初始值的设定。 - FIN:该位为
1时,表示今后不会再有数据发送,希望断开连接。当通信结束希望断开连接时,通信双方的主机之间就可以相互交换FIN位置为 1 的 TCP 段。
- ACK:该位为
1.2 为什么需要 TCP 协议?TCP 工作在那一层?
IP 层是「不可靠」的,它不保证网络包的交付、不保证网络包的按序交付、也不保证网络包中的数据的完整性。
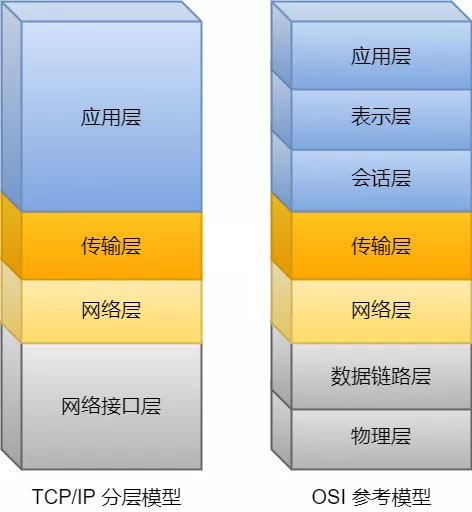
如果需要保障网络数据包的可靠性,那么就需要由上层(传输层)的 TCP 协议来负责。
因为 TCP 是一个工作在传输层的可靠数据传输的服务,它能确保接收端接收的网络包是无损坏、无间隔、非冗余和按序的。
1.3 什么是 TCP?
TCP 是面向连接的、可靠的、基于字节流的传输层通信协议。
- 面向连接:一定是「一对一」才能连接,不能像 UDP 协议 可以一个主机同时向多个主机发送消息,也就是一对多是无法做到的;
- 可靠的:无论的网络链路中出现了怎样的链路变化,TCP 都可以保证一个报文一定能够到达接收端;
- 字节流:消息是「没有边界」的,所以无论我们消息有多大都可以进行传输。并且消息是「有序的」,当「前一个」消息没有收到的时候,即使它先收到了后面的字节已经收到,那么也不能扔给应用层去处理,同时对「重复」的报文会自动丢弃。
1.4 什么是 TCP 连接?
我们来看看 RFC 793 是如何定义「连接」的:
Connections:
The reliability and flow control mechanisms described above require that TCPs initialize and maintain certain status information for each data stream.
The combination of this information, including sockets, sequence numbers, and window sizes, is called a connection.
简单来说就是,用于保证可靠性和流量控制维护的某些状态信息,这些信息的组合,包括 Socket、序列号和窗口大小称为连接。
建立一个 TCP 连接是需要客户端与服务器端达成上述三个信息的共识:
- Socket:由 IP 地址和端口号组成
- 序列号:用来解决乱序问题等
- 窗口大小:用来做流量控制
1.5 如何唯一确定一个 TCP 连接?
TCP 四元组可以唯一的确定一个连接,四元组包括如下:
- 源地址
- 源端口
- 目的地址
- 目的端口
源地址和目的地址的字段(32位)是在 IP 头部中,作用是通过 IP 协议发送报文给对方主机。
源端口和目的端口的字段(16位)是在 TCP 头部中,作用是告诉 TCP 协议应该把报文发给哪个进程。
1.6 TCP 的最大连接数是多少?
服务器通常固定在某个本地端口上监听,等待客户端的连接请求。因此,客户端 IP 和 端口是可变的,其理论值计算公式如下:

对 IPv4,客户端的 IP 数最多为 2 的 32 次方,客户端的端口数最多为 2 的 16 次方,也就是服务端单机最大 TCP 连接数,约为 2 的 48 次方。
当然,服务端最大并发 TCP 连接数远不能达到理论上限。
- 首先主要是文件描述符限制,Socket 都是文件,所以首先要通过
ulimit配置文件描述符的数目; - 另一个是内存限制,每个 TCP 连接都要占用一定内存,操作系统是有限的。
1.7 UDP 与 TCP 的区别?各自应用场景?
UDP 不提供复杂的控制机制,利用 IP 提供面向「无连接」的通信服务。
UDP 协议真的非常简,头部只有 8 个字节( 64 位),UDP 的头部格式如下:
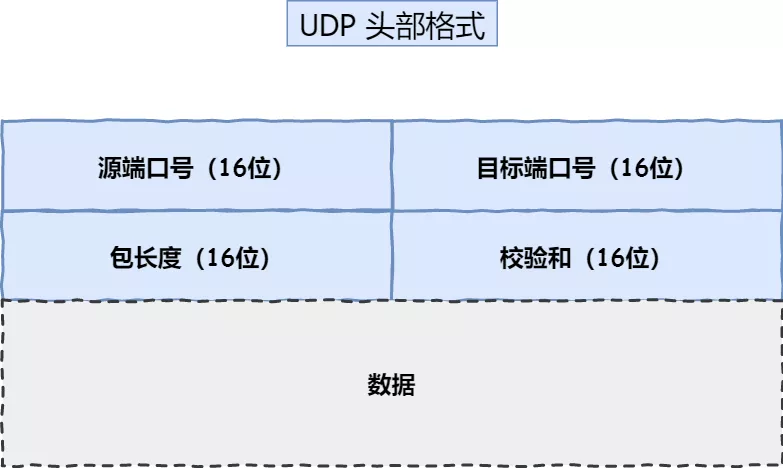
- 目标和源端口:主要是告诉 UDP 协议应该把报文发给哪个进程。
- 包长度:该字段保存了 UDP 首部的长度跟数据的长度之和。
- 校验和:校验和是为了提供可靠的 UDP 首部和数据而设计。
TCP 和 UDP 区别:
- 连接
- TCP 是面向连接的传输层协议,传输数据前先要建立连接。
- UDP 是不需要连接,即刻传输数据。
- 服务对象
- TCP 是一对一的两点服务,即一条连接只有两个端点。
- UDP 支持一对一、一对多、多对多的交互通信
- 可靠性
- TCP 是可靠交付数据的,数据可以无差错、不丢失、不重复、按需到达。
- UDP 是尽最大努力交付,不保证可靠交付数据。
- 拥塞控制、流量控制
- TCP 有拥塞控制和流量控制机制,保证数据传输的安全性。
- UDP 则没有,即使网络非常拥堵了,也不会影响 UDP 的发送速率。
- 首部开销
- TCP 首部长度较长,会有一定的开销,首部在没有使用「选项」字段时是
20个字节,如果使用了「选项」字段则会变长的。 - UDP 首部只有 8 个字节,并且是固定不变的,开销较小。
- TCP 首部长度较长,会有一定的开销,首部在没有使用「选项」字段时是
TCP 和 UDP 应用场景:
由于 TCP 是面向连接,能保证数据的可靠性交付,因此经常用于:
FTP文件传输HTTP/HTTPS
由于 UDP 面向无连接,它可以随时发送数据,再加上UDP本身的处理既简单又高效,因此经常用于:
包总量较少的通信,如
DNS、SNMP等视频、音频等多媒体通信
广播通信
1.8 头部字段:首部长度
为什么 UDP 头部没有「首部长度」字段,而 TCP 头部有「首部长度」字段呢?
原因是 TCP 有可变长的「选项」字段,而 UDP 头部长度则是不会变化的,无需多一个字段去记录 UDP 的首部长度。
1.9 头部字段:包长度
为什么 UDP 头部有「包长度」字段,而 TCP 头部则没有「包长度」字段呢?
先说说 TCP 是如何计算负载数据长度:

其中 IP 总长度 和 IP 首部长度,在 IP 首部格式是已知的。TCP 首部长度,则是在 TCP 首部格式已知的,所以就可以求得 TCP 数据的长度。
大家这时就奇怪了问:“ UDP 也是基于 IP 层的呀,那 UDP 的数据长度也可以通过这个公式计算呀?为何还要有「包长度」呢?”
这么一问,确实感觉 UDP 「包长度」是冗余的。
因为为了网络设备硬件设计和处理方便,首部长度需要是 4字节的整数倍。
如果去掉 UDP 「包长度」字段,那 UDP 首部长度就不是 4 字节的整数倍了,所以小林觉得这可能是为了补全 UDP 首部长度是 4 字节的整数倍,才补充了「包长度」字段。
2. TCP 建立连接
2.1 TCP 三次握手过程和状态变迁
TCP 是面向连接的协议,所以使用 TCP 前必须先建立连接,而建立连接是通过三次握手而进行的。
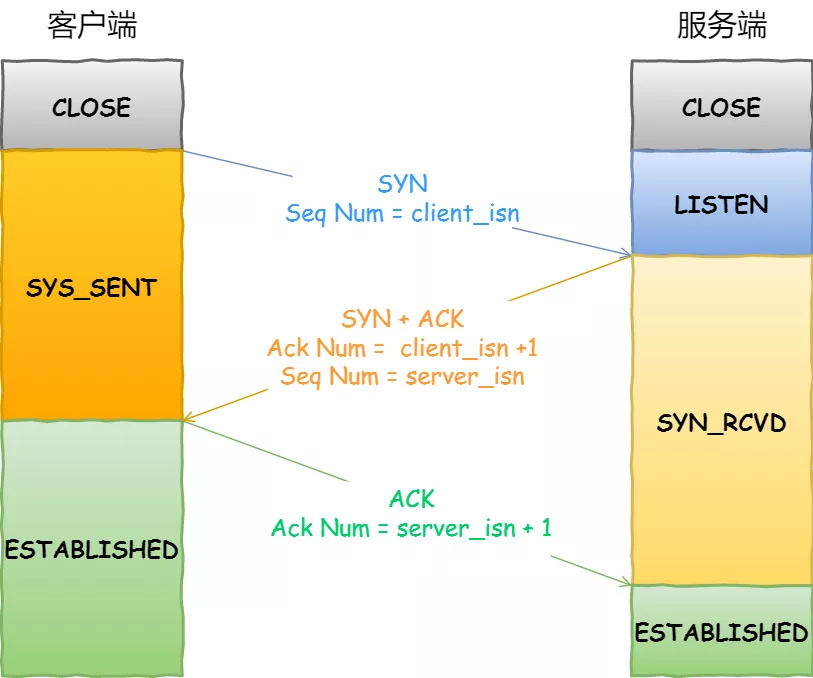
- 一开始,客户端和服务端都处于
CLOSED状态。先是服务端主动监听某个端口,处于LISTEN状态
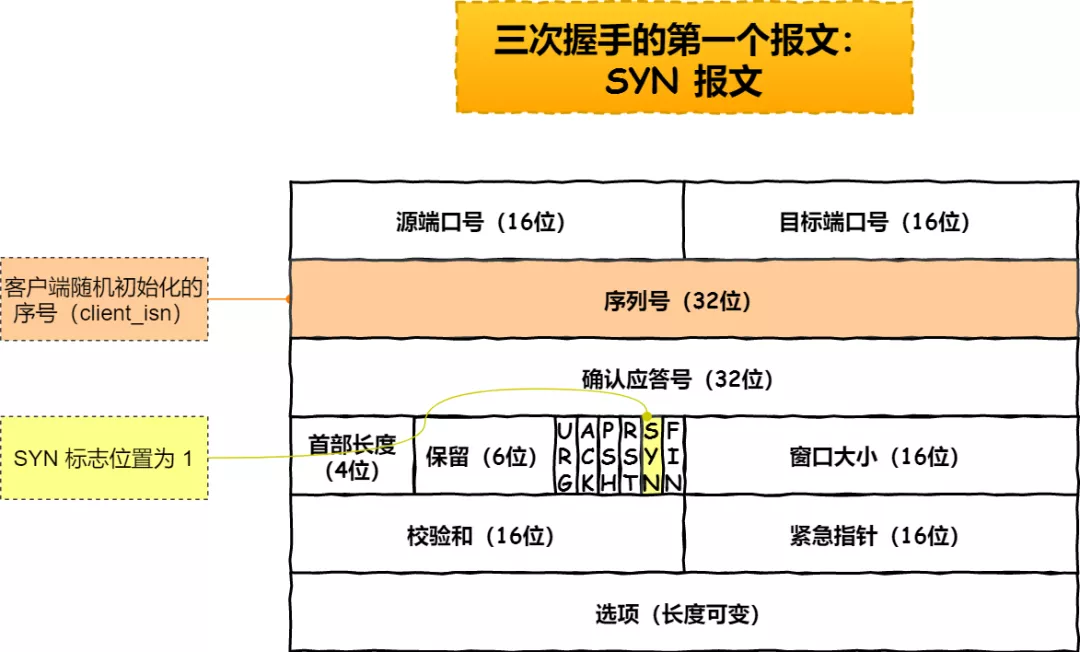
- 客户端会随机初始化序号(
client_isn),将此序号置于 TCP 首部的「序号」字段中,同时把SYN标志位置为1,表示SYN报文。接着把第一个 SYN 报文发送给服务端,表示向服务端发起连接,该报文不包含应用层数据,之后客户端处于SYN-SENT状态。
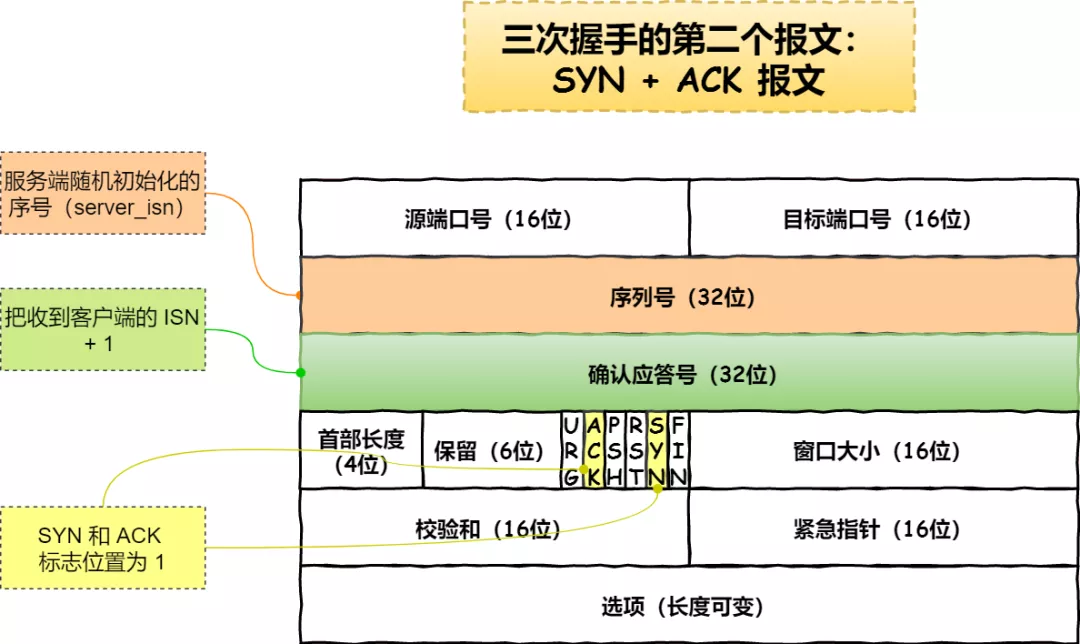
- 服务端收到客户端的
SYN报文后,首先服务端也随机初始化自己的序号(server_isn),将此序号填入 TCP 首部的「序号」字段中,其次把 TCP 首部的「确认应答号」字段填入client_isn + 1, 接着把SYN和ACK标志位置为1。最后把该报文发给客户端,该报文也不包含应用层数据,之后服务端处于SYN-RCVD状态。
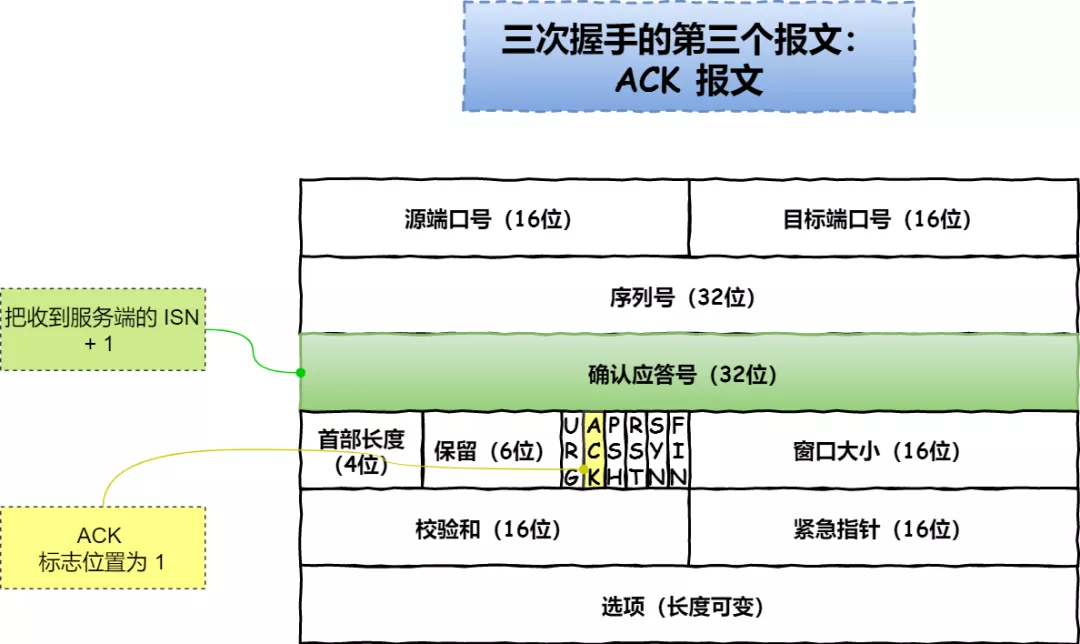
客户端收到服务端报文后,还要向服务端回应最后一个应答报文,首先该应答报文 TCP 首部
ACK标志位置为1,其次「确认应答号」字段填入server_isn + 1,最后把报文发送给服务端,这次报文可以携带客户到服务器的数据,之后客户端处于ESTABLISHED状态。服务器收到客户端的应答报文后,也进入
ESTABLISHED状态。
从上面的过程可以发现第三次握手是可以携带数据的,前两次握手是不可以携带数据的,这也是面试常问的题。
一旦完成三次握手,双方都处于 ESTABLISHED 状态,此致连接就已建立完成,客户端和服务端就可以相互发送数据了。
2.2 如何在 Linux 系统中查看 TCP 状态?
TCP 的连接状态查看,在 Linux 可以通过 netstat -napt 命令查看。

2.3 为什么是三次握手?不是两次、四次?
相信大家比较常回答的是:“因为三次握手才能保证双方具有接收和发送的能力。”
这回答是没问题,但这回答是片面的,并没有说出主要的原因。
在前面我们知道了什么是 TCP 连接:
- 用于保证可靠性和流量控制维护的某些状态信息,这些信息的组合,包括Socket、序列号和窗口大小称为连接。
所以,重要的是为什么三次握手才可以初始化Socket、序列号和窗口大小并建立 TCP 连接。
接下来以三个方面分析三次握手的原因:
- 三次握手才可以阻止历史重复连接的初始化(主要原因)
- 三次握手才可以同步双方的初始序列号
- 三次握手才可以避免资源浪费
原因一:避免历史连接
我们来看看 RFC 793 指出的 TCP 连接使用三次握手的首要原因:
The principle reason for the three-way handshake is to prevent old duplicate connection initiations from causing confusion.
简单来说,三次握手的首要原因是为了防止旧的重复连接初始化造成混乱。
网络环境是错综复杂的,往往并不是如我们期望的一样,先发送的数据包,就先到达目标主机,反而它很骚,可能会由于网络拥堵等乱七八糟的原因,会使得旧的数据包,先到达目标主机,那么这种情况下 TCP 三次握手是如何避免的呢?
客户端连续发送多次 SYN 建立连接的报文,在网络拥堵等情况下:
- 一个「旧 SYN 报文」比「最新的 SYN 」 报文早到达了服务端;
- 那么此时服务端就会回一个
SYN + ACK报文给客户端; - 客户端收到后可以根据自身的上下文,判断这是一个历史连接(序列号过期或超时),那么客户端就会发送
RST报文给服务端,表示中止这一次连接。
如果是两次握手连接,就不能判断当前连接是否是历史连接,三次握手则可以在客户端(发送方)准备发送第三次报文时,客户端因有足够的上下文来判断当前连接是否是历史连接:
- 如果是历史连接(序列号过期或超时),则第三次握手发送的报文是
RST报文,以此中止历史连接; - 如果不是历史连接,则第三次发送的报文是
ACK报文,通信双方就会成功建立连接;
所以, TCP 使用三次握手建立连接的最主要原因是防止历史连接初始化了连接。
原因二:同步双方初始序列号
TCP 协议的通信双方, 都必须各自维护一个「序列号」, 序列号是可靠传输的一个关键因素,它的作用:
- 接收方可以去除重复的数据;
- 接收方可以根据数据包的序列号按序接收;
- 可以标识发送出去的数据包中, 哪些是已经被对方收到的;
可见,序列号在 TCP 连接中占据着非常重要的作用,所以当客户端发送携带「初始序列号」的 SYN 报文的时候,需要服务端回一个 ACK 应答报文,表示客户端的 SYN 报文已被服务端成功接收,那当服务端发送「初始序列号」给客户端的时候,依然也要得到客户端的应答回应,这样一来一回,才能确保双方的初始序列号能被可靠的同步。
四次握手其实也能够可靠的同步双方的初始化序号,但由于第二步和第三步可以优化成一步,所以就成了「三次握手」。
而两次握手只保证了一方的初始序列号能被对方成功接收,没办法保证双方的初始序列号都能被确认接收。
原因三:避免资源浪费
如果只有「两次握手」,当客户端的 SYN 请求连接在网络中阻塞,客户端没有接收到 ACK 报文,就会重新发送 SYN ,由于没有第三次握手,服务器不清楚客户端是否收到了自己发送的建立连接的 ACK 确认信号,所以每收到一个 SYN 就只能先主动建立一个连接,这会造成什么情况呢?
如果客户端的 SYN 阻塞了,重复发送多次 SYN 报文,那么服务器在收到请求后就会建立多个冗余的无效链接,造成不必要的资源浪费。
即两次握手会造成消息滞留情况下,服务器重复接受无用的连接请求 SYN 报文,而造成重复分配资源。
总结
TCP 建立连接时,通过三次握手能防止历史连接的建立,能减少双方不必要的资源开销,能帮助双方同步初始化序列号。序列号能够保证数据包不重复、不丢弃和按序传输。
不使用「两次握手」和「四次握手」的原因:
- 「两次握手」:无法防止历史连接的建立,会造成双方资源的浪费,也无法可靠的同步双方序列号;
- 「四次握手」:三次握手就已经理论上最少可靠连接建立,所以不需要使用更多的通信次数。
2.4 为什么客户端和服务端的初始序列号 ISN 是不相同的?
因为网络中的报文会延迟、会复制重发、也有可能丢失,这样会造成的不同连接之间产生互相影响,所以为了避免互相影响,客户端和服务端的初始序列号是随机且不同的。
2.5 初始序列号 ISN 是如何随机产生的?
起始 ISN 是基于时钟的,每 4 毫秒 + 1,转一圈要 4.55 个小时。
RFC1948 中提出了一个较好的初始化序列号 ISN 随机生成算法。
ISN = M + F (localhost, localport, remotehost, remoteport)
M是一个计时器,这个计时器每隔 4 毫秒加 1。F是一个 Hash 算法,根据源 IP、目的 IP、源端口、目的端口生成一个随机数值。要保证 Hash 算法不能被外部轻易推算得出,用 MD5 算法是一个比较好的选择。
2.6 既然 IP 层会分片,为什么 TCP 层还需要 MSS 呢?
我们先来认识下 MTU 和 MSS
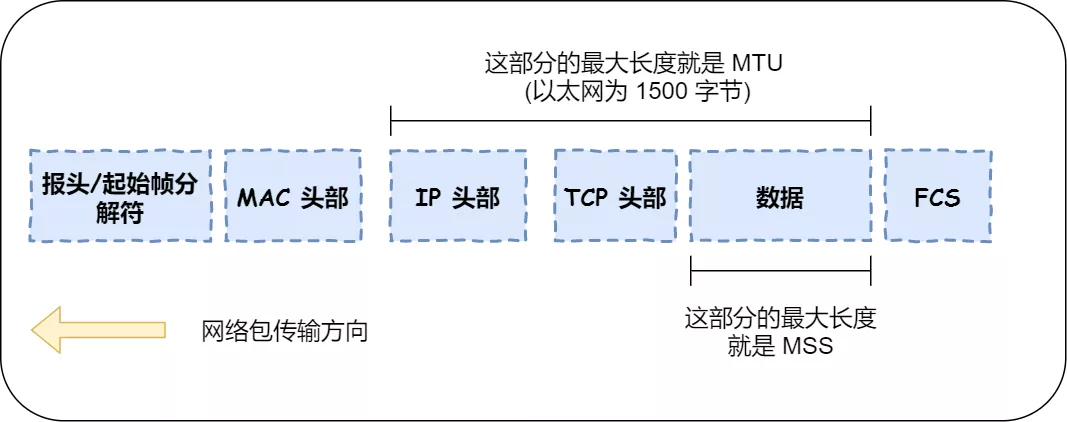
MTU:一个网络包的最大长度,以太网中一般为1500字节;MSS:除去 IP 和 TCP 头部之后,一个网络包所能容纳的 TCP 数据的最大长度;
如果TCP 的整个报文(头部 + 数据)交给 IP 层进行分片,会有什么异常呢?
当 IP 层有一个超过 MTU 大小的数据(TCP 头部 + TCP 数据)要发送,那么 IP 层就要进行分片,把数据分片成若干片,保证每一个分片都小于 MTU。把一份 IP 数据报进行分片以后,由目标主机的 IP 层来进行重新组装后,在交给上一层 TCP 传输层。
这看起来井然有序,但这存在隐患的,那么当如果一个 IP 分片丢失,整个 IP 报文的所有分片都得重传。
因为 IP 层本身没有超时重传机制,它由传输层的 TCP 来负责超时和重传。
当接收方发现 TCP 报文(头部 + 数据)的某一片丢失后,则不会响应 ACK 给对方,那么发送方的 TCP 在超时后,就会重发「整个 TCP 报文(头部 + 数据)」。
因此,可以得知由 IP 层进行分片传输,是非常没有效率的。
所以,为了达到最佳的传输效能 TCP 协议在建立连接的时候通常要协商双方的 MSS 值,当 TCP 层发现数据超过 MSS 时,则就先会进行分片,当然由它形成的 IP 包的长度也就不会大于 MTU ,自然也就不用 IP 分片了。

经过 TCP 层分片后,如果一个 TCP 分片丢失后,进行重发时也是以 MSS 为单位,而不用重传所有的分片,大大增加了重传的效率。
2.7 什么是 SYN 攻击?如何避免 SYN 攻击?
SYN 攻击
我们都知道 TCP 连接建立是需要三次握手,假设攻击者短时间伪造不同 IP 地址的 SYN 报文,服务端每接收到一个 SYN 报文,就进入SYN_RCVD 状态,但服务端发送出去的 ACK + SYN 报文,无法得到未知 IP 主机的 ACK 应答,久而久之就会占满服务端的 SYN 接收队列(未连接队列),使得服务器不能为正常用户服务。
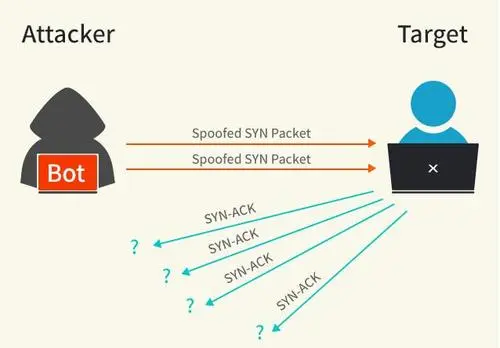
避免 SYN 攻击方式一
其中一种解决方式是通过修改 Linux 内核参数,控制队列大小和当队列满时应做什么处理。
当网卡接收数据包的速度大于内核处理的速度时,会有一个队列保存这些数据包。控制该队列的最大值如下参数:
net.core.netdev_max_backlog
SYN_RCVD 状态连接的最大个数:
net.ipv4.tcp_max_syn_backlog
超出处理能时,对新的 SYN 直接回 RST,丢弃连接:
net.ipv4.tcp_abort_on_overflow
避免 SYN 攻击方式二
我们先来看下Linux 内核的 SYN (未完成连接建立)队列与 Accpet (已完成连接建立)队列是如何工作的?
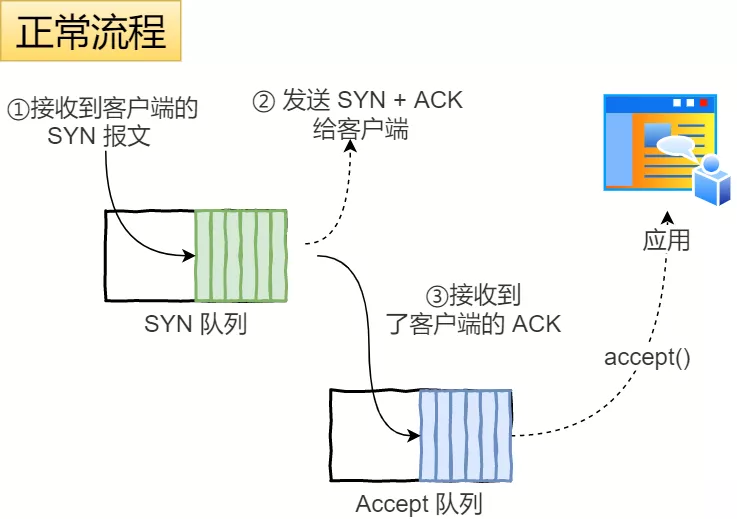
正常流程:
- 当服务端接收到客户端的 SYN 报文时,会将其加入到内核的「 SYN 队列」;
- 接着发送 SYN + ACK 给客户端,等待客户端回应 ACK 报文;
- 服务端接收到 ACK 报文后,从「 SYN 队列」移除放入到「 Accept 队列」;
- 应用通过调用
accpet()socket 接口,从「 Accept 队列」取出的连接。
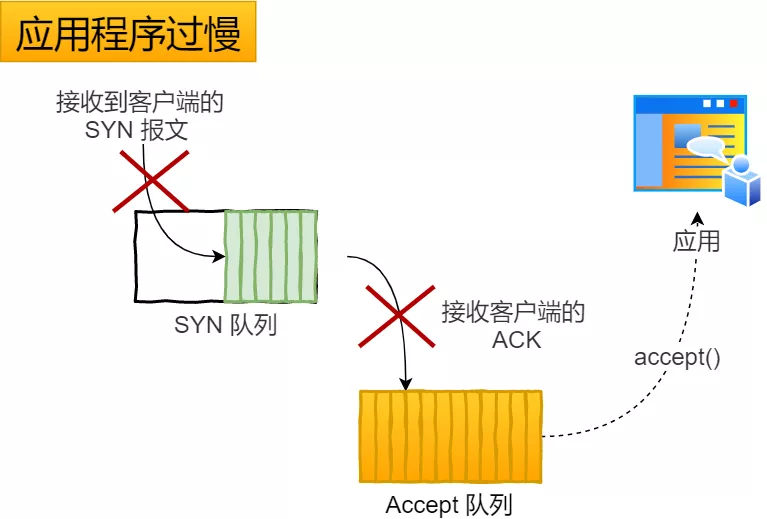
应用程序过慢:
- 如果应用程序过慢时,就会导致「 Accept 队列」被占满。
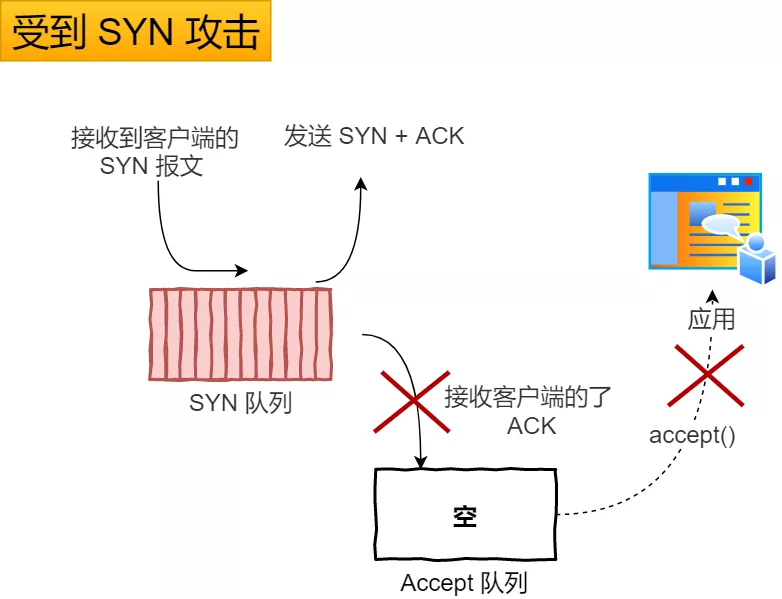
受到 SYN 攻击:
- 如果不断受到 SYN 攻击,就会导致「 SYN 队列」被占满。
tcp_syncookies 的方式可以应对 SYN 攻击的方法:net.ipv4.tcp_syncookies = 1
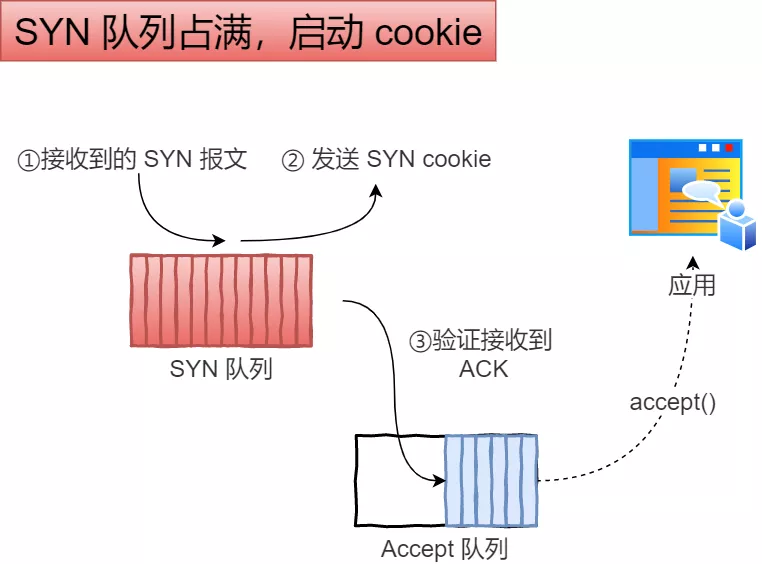
- 当 「 SYN 队列」满之后,后续服务器收到 SYN 包,不进入「 SYN 队列」;
- 计算出一个
cookie值,再以 SYN + ACK 中的「序列号」返回客户端, - 服务端接收到客户端的应答报文时,服务器会检查这个 ACK 包的合法性。如果合法,直接放入到「 Accept 队列」。
- 最后应用通过调用
accpet()socket 接口,从「 Accept 队列」取出的连接。
3. TCP 断开连接
3.1 TCP 四次挥手过程和状态变迁
天下没有不散的宴席,对于 TCP 连接也是这样, TCP 断开连接是通过四次挥手方式。
双方都可以主动断开连接,断开连接后主机中的「资源」将被释放。
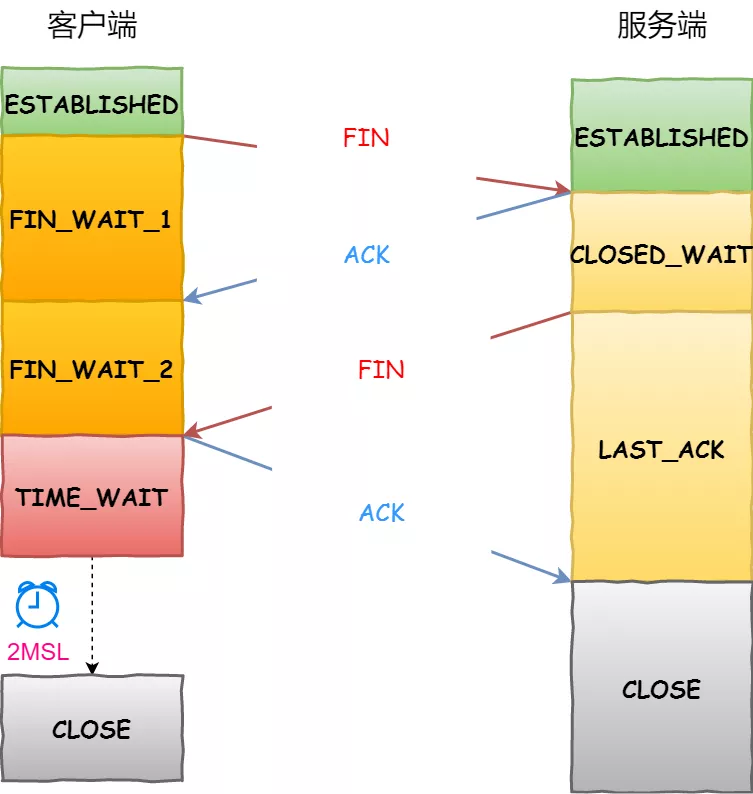
- 客户端打算关闭连接,此时会发送一个 TCP 首部
FIN标志位被置为1的报文,也即FIN报文,之后客户端进入FIN_WAIT_1状态。 - 服务端收到该报文后,就向客户端发送
ACK应答报文,接着服务端进入CLOSED_WAIT状态。 - 客户端收到服务端的
ACK应答报文后,之后进入FIN_WAIT_2状态。 - 等待服务端处理完数据后,也向客户端发送
FIN报文,之后服务端进入LAST_ACK状态。 - 客户端收到服务端的
FIN报文后,回一个ACK应答报文,之后进入TIME_WAIT状态 - 服务器收到了
ACK应答报文后,就进入了CLOSE状态,至此服务端已经完成连接的关闭。 - 客户端在经过
2MSL一段时间后,自动进入CLOSE状态,至此客户端也完成连接的关闭。
你可以看到,每个方向都需要一个 FIN 和一个 ACK,因此通常被称为四次挥手。
这里一点需要注意是:主动关闭连接的,才有 TIME_WAIT 状态。
3.2 为什么挥手需要四次?
再来回顾下四次挥手双方发 FIN 包的过程,就能理解为什么需要四次了。
- 关闭连接时,客户端向服务端发送
FIN时,仅仅表示客户端不再发送数据了但是还能接收数据。 - 服务器收到客户端的
FIN报文时,先回一个ACK应答报文,而服务端可能还有数据需要处理和发送,等服务端不再发送数据时,才发送FIN报文给客户端来表示同意现在关闭连接。
从上面过程可知,服务端通常需要等待完成数据的发送和处理,所以服务端的 ACK 和 FIN 一般都会分开发送,从而比三次握手导致多了一次。
3.3 为什么 TIME_WAIT 等待的时间是 2MSL?
MSL 是 Maximum Segment Lifetime,报文最大生存时间,它是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。因为 TCP 报文基于是 IP 协议的,而 IP 头中有一个 TTL 字段,是 IP 数据报可以经过的最大路由数,每经过一个处理他的路由器此值就减 1,当此值为 0 则数据报将被丢弃,同时发送 ICMP 报文通知源主机。
MSL 与 TTL 的区别:MSL 的单位是时间,而 TTL 是经过路由跳数。所以 MSL 应该要大于等于 TTL 消耗为 0 的时间,以确保报文已被自然消亡。
TIME_WAIT 等待 2 倍的 MSL,比较合理的解释是:网络中可能存在来自发送方的数据包,当这些发送方的数据包被接收方处理后又会向对方发送响应,所以一来一回需要等待 2 倍的时间。
比如,如果被动关闭方没有收到断开连接的最后的 ACK 报文,就会触发超时重发 Fin 报文,另一方接收到 FIN 后,会重发 ACK 给被动关闭方, 一来一去正好 2 个 MSL。
2MSL 的时间是从客户端接收到 FIN 后发送 ACK 开始计时的。如果在 TIME-WAIT 时间内,因为客户端的 ACK 没有传输到服务端,客户端又接收到了服务端重发的 FIN 报文,那么 2MSL 时间将重新计时。
在 Linux 系统里 2MSL 默认是 60 秒,那么一个 MSL 也就是 30 秒。Linux 系统停留在 TIME_WAIT 的时间为固定的 60 秒。
其定义在 Linux 内核代码里的名称为 TCP_TIMEWAIT_LEN:
#define TCP_TIMEWAIT_LEN (60*HZ) /* how long to wait to destroy TIME-WAIT
state, about 60 seconds */
如果要修改 TIME_WAIT 的时间长度,只能修改 Linux 内核代码里 TCP_TIMEWAIT_LEN 的值,并重新编译 Linux 内核。
3.4 为什么需要 TIME_WAIT 状态?
主动发起关闭连接的一方,才会有 TIME-WAIT 状态。
需要 TIME-WAIT 状态,主要是两个原因:
- 防止具有相同「四元组」的「旧」数据包被收到;
- 保证「被动关闭连接」的一方能被正确的关闭,即保证最后的 ACK 能让被动关闭方接收,从而帮助其正常关闭;
原因一:防止旧连接的数据包
假设 TIME-WAIT 没有等待时间或时间过短,被延迟的数据包抵达后会发生什么呢?
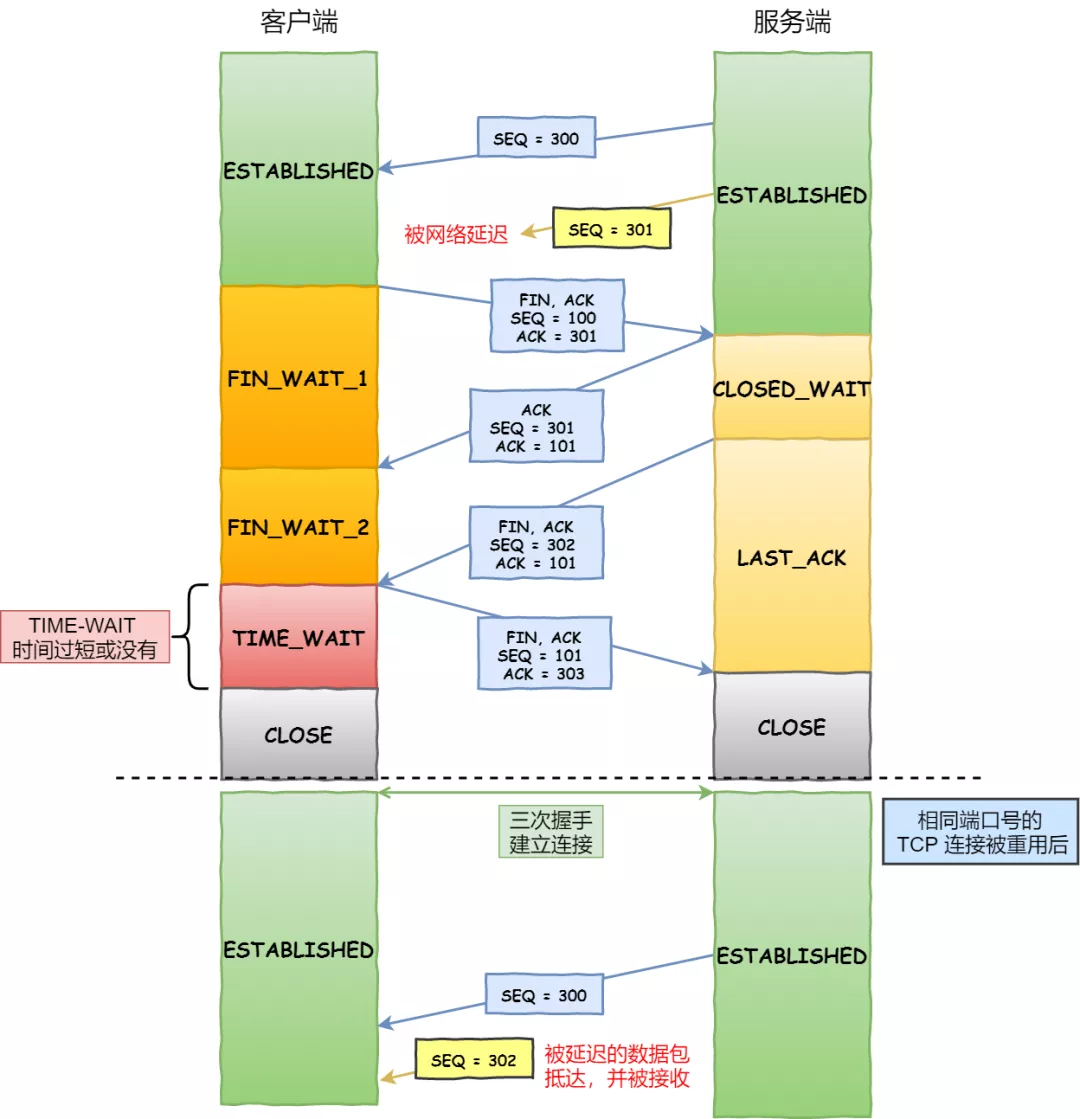
- 如上图黄色框框服务端在关闭连接之前发送的
SEQ = 301报文,被网络延迟了。 - 这时有相同端口的 TCP 连接被复用后,被延迟的
SEQ = 301抵达了客户端,那么客户端是有可能正常接收这个过期的报文,这就会产生数据错乱等严重的问题。
所以,TCP 就设计出了这么一个机制,经过 2MSL 这个时间,足以让两个方向上的数据包都被丢弃,使得原来连接的数据包在网络中都自然消失,再出现的数据包一定都是新建立连接所产生的。
原因二:保证连接正确关闭
在 RFC 793 指出 TIME-WAIT 另一个重要的作用是:
TIME-WAIT - represents waiting for enough time to pass to be sure the remote TCP received the acknowledgment of its connection termination request.
也就是说,TIME-WAIT 作用是等待足够的时间以确保最后的 ACK 能让被动关闭方接收,从而帮助其正常关闭。
假设 TIME-WAIT 没有等待时间或时间过短,断开连接会造成什么问题呢?
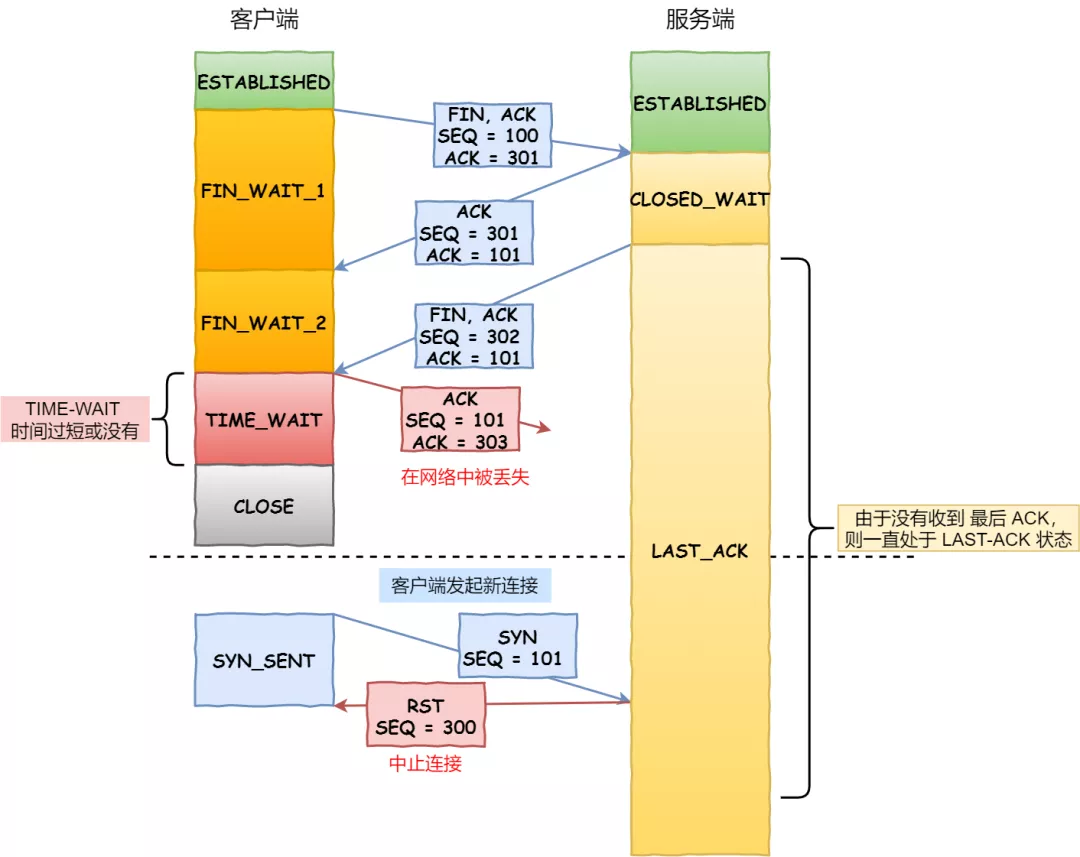
- 如上图红色框框客户端四次挥手的最后一个
ACK报文如果在网络中被丢失了,此时如果客户端TIME-WAIT过短或没有,则就直接进入了CLOSE状态了,那么服务端则会一直处在LASE-ACK状态。 - 当客户端发起建立连接的
SYN请求报文后,服务端会发送RST报文给客户端,连接建立的过程就会被终止。
如果 TIME-WAIT 等待足够长的情况就会遇到两种情况:
- 服务端正常收到四次挥手的最后一个
ACK报文,则服务端正常关闭连接。 - 服务端没有收到四次挥手的最后一个
ACK报文时,则会重发FIN关闭连接报文并等待新的ACK报文。
所以客户端在 TIME-WAIT 状态等待 2MSL 时间后,就可以保证双方的连接都可以正常的关闭。
3.5 TIME_WAIT 过多有什么危害?
如果服务器有处于 TIME-WAIT 状态的 TCP,则说明是由服务器方主动发起的断开请求。
过多的 TIME-WAIT 状态主要的危害有两种:
- 第一是内存资源占用;
- 第二是对端口资源的占用,一个 TCP 连接至少消耗一个本地端口;
第二个危害是会造成严重的后果的,要知道,端口资源也是有限的,一般可以开启的端口为 32768~61000,也可以通过如下参数设置指定 net.ipv4.ip_local_port_range。
如果服务端 TIME_WAIT 状态过多,占满了所有端口资源,则会导致无法创建新连接。
3.6 如何优化 TIME_WAIT?
这里给出优化 TIME-WAIT 的几个方式,都是有利有弊:
- 打开
net.ipv4.tcp_tw_reuse和net.ipv4.tcp_timestamps选项; net.ipv4.tcp_max_tw_buckets- 程序中使用 SO_LINGER ,应用强制使用 RST 关闭。
方式一:net.ipv4.tcp_tw_reuse 和 tcp_timestamps
如下的 Linux 内核参数开启后,则可以复用处于 TIME_WAIT 的 socket 为新的连接所用。
net.ipv4.tcp_tw_reuse = 1
使用这个选项,还有一个前提,需要打开对 TCP 时间戳的支持,即
net.ipv4.tcp_timestamps=1(默认即为 1)
这个时间戳的字段是在 TCP 头部的「选项」里,用于记录 TCP 发送方的当前时间戳和从对端接收到的最新时间戳。
由于引入了时间戳,我们在前面提到的 2MSL 问题就不复存在了,因为重复的数据包会因为时间戳过期被自然丢弃。
温馨提醒:net.ipv4.tcp_tw_reuse要慎用,因为使用了它就必然要打开时间戳的支持 net.ipv4.tcp_timestamps,当客户端与服务端主机时间不同步时,客户端的发送的消息会被直接拒绝掉。
方式二:net.ipv4.tcp_max_tw_buckets
这个值默认为 18000,当系统中处于 TIME_WAIT 的连接一旦超过这个值时,系统就会将所有的 TIME_WAIT 连接状态重置。
这个方法过于暴力,而且治标不治本,带来的问题远比解决的问题多,不推荐使用。
方式三:程序中使用 SO_LINGER
我们可以通过设置 socket 选项,来设置调用 close 关闭连接行为。
struct linger so_linger;
so_linger.l_onoff = 1;
so_linger.l_linger = 0;
setsockopt(s, SOL_SOCKET, SO_LINGER, &so_linger,sizeof(so_linger));
如果l_onoff为非 0, 且l_linger值为 0,那么调用close后,会立该发送一个RST标志给对端,该 TCP 连接将跳过四次挥手,也就跳过了TIME_WAIT状态,直接关闭。
但这为跨越TIME_WAIT状态提供了一个可能,不过是一个非常危险的行为,不值得提倡。
3.7 如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP 有一个机制是保活机制。这个机制的原理是这样的:
定义一个时间段,在这个时间段内,如果没有任何连接相关的活动,TCP 保活机制会开始作用,每隔一个时间间隔,发送一个探测报文,该探测报文包含的数据非常少,如果连续几个探测报文都没有得到响应,则认为当前的 TCP 连接已经死亡,系统内核将错误信息通知给上层应用程序。
在 Linux 内核可以有对应的参数可以设置保活时间、保活探测的次数、保活探测的时间间隔,以下都为默认值:
net.ipv4.tcp_keepalive_time=7200
net.ipv4.tcp_keepalive_intvl=75
net.ipv4.tcp_keepalive_probes=9
- tcp_keepalive_time=7200:表示保活时间是 7200 秒(2小时),也就 2 小时内如果没有任何连接相关的活动,则会启动保活机制
- tcp_keepalive_intvl=75:表示每次检测间隔 75 秒;
- tcp_keepalive_probes=9:表示检测 9 次无响应,认为对方是不可达的,从而中断本次的连接。
也就是说在 Linux 系统中,最少需要经过 2 小时 11 分 15 秒才可以发现一个「死亡」连接。
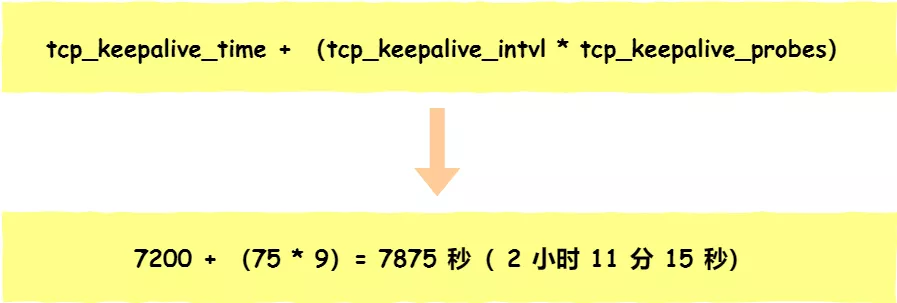
这个时间是有点长的,我们也可以根据实际的需求,对以上的保活相关的参数进行设置。
如果开启了 TCP 保活,需要考虑以下几种情况:
第一种,对端程序是正常工作的。当 TCP 保活的探测报文发送给对端, 对端会正常响应,这样 TCP 保活时间会被重置,等待下一个 TCP 保活时间的到来。
第二种,对端程序崩溃并重启。当 TCP 保活的探测报文发送给对端后,对端是可以响应的,但由于没有该连接的有效信息,会产生一个 RST 报文,这样很快就会发现 TCP 连接已经被重置。
第三种,是对端程序崩溃,或对端由于其他原因导致报文不可达。当 TCP 保活的探测报文发送给对端后,石沉大海,没有响应,连续几次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡。
4. Socket 编程
4.1 针对 TCP 应该如何 Socket 编程?
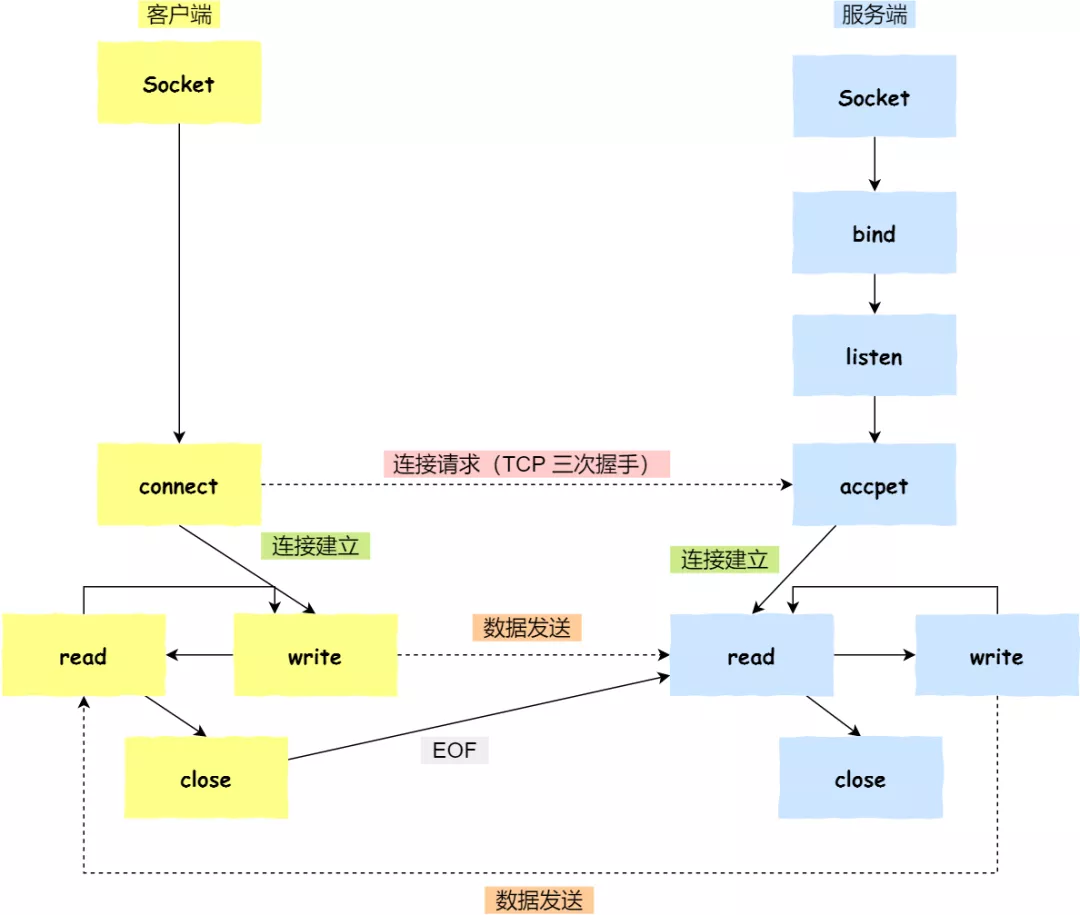
- 服务端和客户端初始化
socket,得到文件描述符; - 服务端调用
bind,将绑定在 IP 地址和端口; - 服务端调用
listen,进行监听; - 服务端调用
accept,等待客户端连接; - 客户端调用
connect,向服务器端的地址和端口发起连接请求; - 服务端
accept返回用于传输的socket的文件描述符; - 客户端调用
write写入数据;服务端调用read读取数据; - 客户端断开连接时,会调用
close,那么服务端read读取数据的时候,就会读取到了EOF,待处理完数据后,服务端调用close,表示连接关闭。
这里需要注意的是,服务端调用 accept 时,连接成功了会返回一个已完成连接的 socket,后续用来传输数据。
所以,监听的 socket 和真正用来传送数据的 socket,是「两个」 socket,一个叫作监听 socket,一个叫作已完成连接 socket。
成功连接建立之后,双方开始通过 read 和 write 函数来读写数据,就像往一个文件流里面写东西一样。
4.2 listen 时候参数 backlog 的意义?
Linux内核中会维护两个队列:
- 未完成连接队列(SYN 队列):接收到一个 SYN 建立连接请求,处于 SYN_RCVD 状态;
- 已完成连接队列(Accpet 队列):已完成 TCP 三次握手过程,处于 ESTABLISHED 状态;
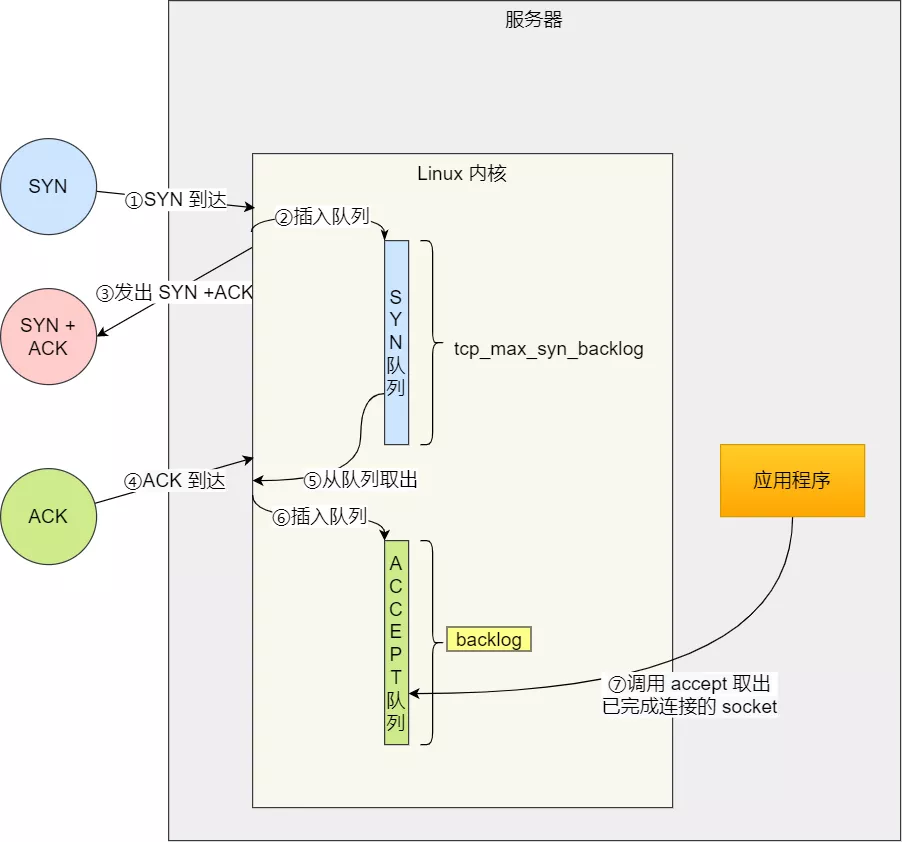
int listen (int socketfd, int backlog)
- 参数一 socketfd 为 socketfd 文件描述符
- 参数二 backlog,这参数在历史有一定的变化
在早期 Linux 内核 backlog 是 SYN 队列大小,也就是未完成的队列大小。
在 Linux 内核 2.2 之后,backlog 变成 accept 队列,也就是已完成连接建立的队列长度,所以现在通常认为 backlog 是 accept 队列。
4.3 accept 发送在三次握手的哪一步?
我们先看看客户端连接服务端时,发送了什么?
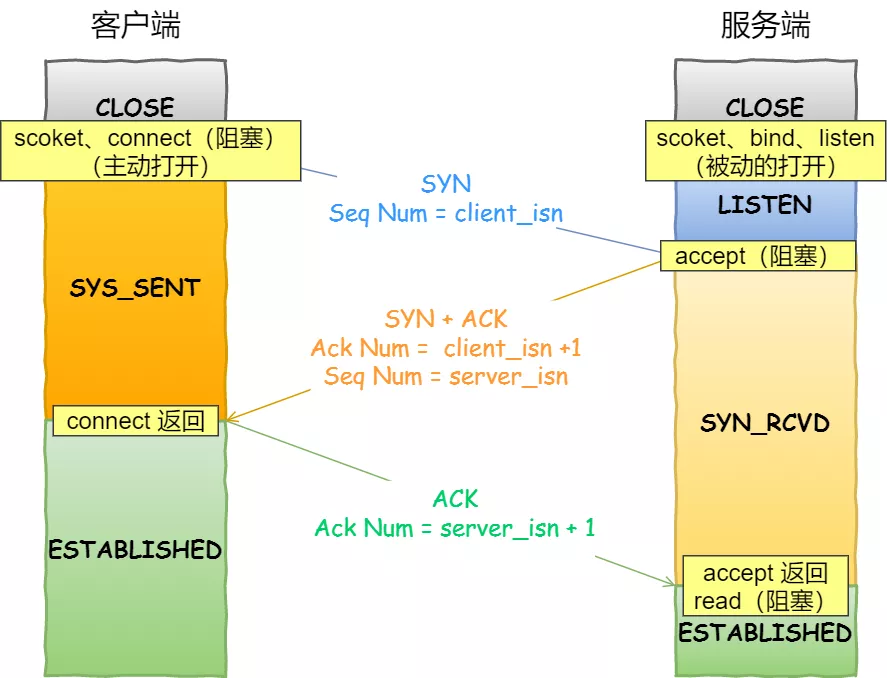
- 客户端的协议栈向服务器端发送了 SYN 包,并告诉服务器端当前发送序列号 client_isn,客户端进入 SYNC_SENT 状态;
- 服务器端的协议栈收到这个包之后,和客户端进行 ACK 应答,应答的值为 client_isn+1,表示对 SYN 包 client_isn 的确认,同时服务器也发送一个 SYN 包,告诉客户端当前我的发送序列号为 server_isn,服务器端进入 SYNC_RCVD 状态;
- 客户端协议栈收到 ACK 之后,使得应用程序从
connect调用返回,表示客户端到服务器端的单向连接建立成功,客户端的状态为 ESTABLISHED,同时客户端协议栈也会对服务器端的 SYN 包进行应答,应答数据为 server_isn+1; - 应答包到达服务器端后,服务器端协议栈使得
accept阻塞调用返回,这个时候服务器端到客户端的单向连接也建立成功,服务器端也进入 ESTABLISHED 状态。
从上面的描述过程,我们可以得知客户端 connect 成功返回是在第二次握手,服务端 accept 成功返回是在三次握手成功之后。
4.4 客户端调用 close 了,连接是断开的流程是什么?
我们看看客户端主动调用了 close,会发生什么?
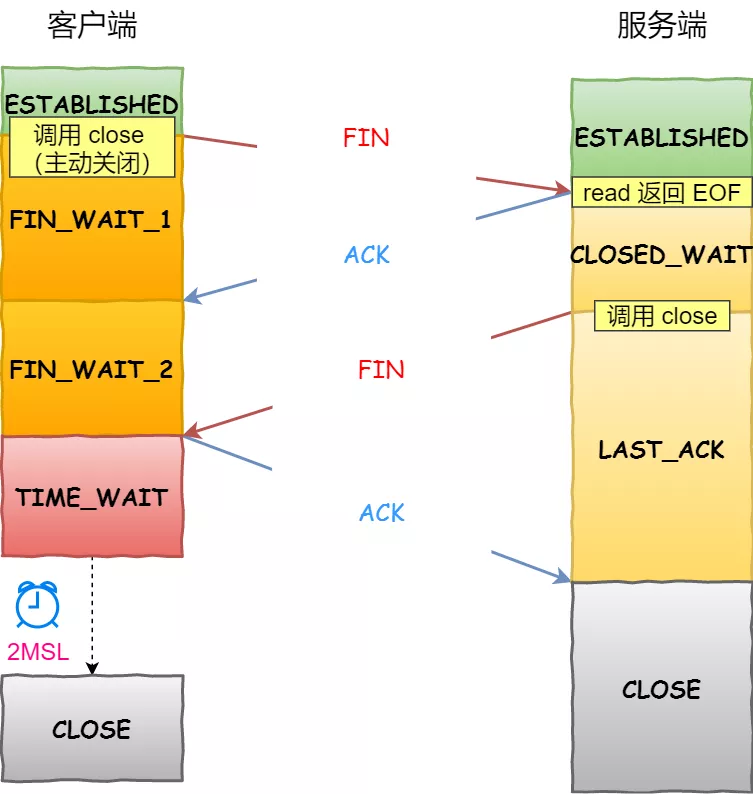
- 客户端调用
close,表明客户端没有数据需要发送了,则此时会向服务端发送 FIN 报文,进入 FIN_WAIT_1 状态; - 服务端接收到了 FIN 报文,TCP 协议栈会为 FIN 包插入一个文件结束符
EOF到接收缓冲区中,应用程序可以通过read调用来感知这个 FIN 包。这个EOF会被放在已排队等候的其他已接收的数据之后,这就意味着服务端需要处理这种异常情况,因为 EOF 表示在该连接上再无额外数据到达。此时,服务端进入 CLOSE_WAIT 状态; - 接着,当处理完数据后,自然就会读到
EOF,于是也调用close关闭它的套接字,这会使得会发出一个 FIN 包,之后处于 LAST_ACK 状态; - 客户端接收到服务端的 FIN 包,并发送 ACK 确认包给服务端,此时客户端将进入 TIME_WAIT 状态;
- 服务端收到 ACK 确认包后,就进入了最后的 CLOSE 状态;
- 客户端进过
2MSL时间之后,也进入 CLOSED 状态;
6 - HTTP
6.1 - HTTP 概述
HTTP - 因特网的多媒体信使
HTTP 使用的是可靠的数据传输协议,能够保证数据在传输过程中不会被损坏或产生混乱。
Web客户端和服务器
Web 内容都是存在 Web 服务器上,Web 服务器使用的是 HTTP 协议,因此也称为 HTTP 服务器。
HTTP 客户端,例如浏览器向 HTTP 服务器发送请求,服务器在 HTTP 响应中会送所请求的数据。
资源
Web 服务器是 Web 资源的宿主。Web 资源是 Web 内容的源头。
资源可以是静态文件,如:文本文件、HTML文件、word文件、JPEG文件、AVI文件等等。也可以是根据需要生成内容的软件程序。
媒体类型
HTTP 为因特网上数千种不同的数据类型都打上了名为 MIME 类型(MIME type)的数据格式标签。
Web 服务器会为所有 HTTP 对象数据附加一个 MIME 类型。Web 客户端从服务器取回一个对象时会查看相关的 MIME 类型以决定如何处理这个对象。
MIME 类型是一种文本标记,表示一种主要的对象类型和一个特定的子类型,中间由一个斜杠分割。
text/html:HTML 格式的文本文档text/plain:普通的 ASCII 文本文档image/jpeg:JPEG 格式的图片image/gif:GIF 格式的图片video/quicktime:Apple 的 QuickTime 电影application/vnd.ms-powerpoint:微软的 PowerPoint 演示文件- ….
URI
每个 Web 服务器资源都有一个名字,称为 统一资源标识符。 URI 有两种形式:URL 和 URN。
URL
统一资源定位符,即 URL,是资源标识符最常见的形式,描述了一台特定服务器上某资源的特定位置。
URL 基本都遵循一种标准格式,即由三部分组成:
- 第一部分:方案,说明了资源使用的协议类型,通常是 HTTP 协议(http://)。
- 第二部分:服务器的因特网地址,比如:www.joes.com 。
- 第三部分:其余部分指定了 Web 服务器上的某个资源,比如:/pictures/image.gif 。
现在几乎所有的 URI 都是 URL。
URN
URI 的第二种形式是统一资源名,即 URN。作为特定内容的唯一名称使用,与目前的资源所在地无关。无论这个资源位于何处,都可以使用多种协议,仅通过名字就能访问该资源。
事务
一个 HTTP 事务由一条请求命令和一个响应结果组成。这种通信是通过名为 HTTP 报文的格式化数据块进行的。
方法
HTTP 支持集中不同的请求命令,这些命令被称为 HTTP 方法,该方法告诉服务器要执行什么动作。
| HTTP方法 | 描述 |
|---|---|
| GET | 从服务器向客户端发送命名资源 |
| PUT | 将来自客户端的数据存储到一个命名的服务器资源中去 |
| DELETE | 从服务器中删除命名资源 |
| POST | 将客户端数据发送到一个服务器网关应用程序 |
| HEAD | 仅发送命名资源响应中的HTTP首部 |
状态码
每条 HTTP 响应报文都会携带一个状态码。是一个三位数字,以告诉客户端请求是否成功,或者是否要采取其他动作。
伴随每个状态码,还会有一条原因短语,对状态码进行描述。
报文
HTTP 报文有多行简单的字符串组成。都是纯文本。对应请求和响应分为请求报文和响应报文。
HTTP 报文的三个部分:
- 起始行:即报文第一行,在请求报文中说明要做什么,在响应报文中说明出现了什么情况;
- 首部字段:起始行后面有零个或多个首部字段。每个首部字段包含一个名字和一个值,使用冒号分割。以一个空行结束;
- 主体:空行之后就是可选的报文主体,包含了所有类型的数据。起始行与首部字段都是结构化的文本,而主体中可以包含任意的二进制数据,或者文本。
连接
TCP/IP
HTTP 是一个应用层协议,无需操心网络通信的具体细节,它把联网的细节都交给了因特网传输协议 TCP/IP。
TCP提供了:
- 无差错的数据传输;
- 按序传输,数据总是按照顺序到达;
- 为分段的数据流,可以在任意时刻以任意尺寸将数据发送出去。
连接、IP地址及端口号
HTTP 客户端需要使用**网际协议(Internet Protocol, IP)**地址和端口号在客户端和服务器之间建立一条TCP连接。
Web的结构组件
- 代理:位于客户端和服务器之间的 HTTP 中间实体;
- 缓存:HTTP 的仓库,使常用页面的副本能够保存在离客户端更近的地方;
- 网关:连接其他应用程序的特殊 Web 服务器;
- 隧道:对 HTTP 通信报文进行盲转发的特殊代理;
- Agent 代理:发起自动 HTTP 请求的半智能 Web 客户端。
6.2 - URL 与资源
URL 就是因特网资源的标准化名称。URL 指向一条电子信息片段,告诉你它们位于何处,以及如何与之交互。
浏览因特网资源
URI 是一个更通用的概念,由两个主要的子集 URL 和 URN 构成,URL 是通过描述资源的位置来标识资源,URN 是通过名字来标识资源,与资源的位置无关。
HTTP 规范将更通用的概念 URI作为其资源标示符,但实际上,HTTP 应用程序处理的只是 URI 的子集 URL。
URL 由三部分构成:方案(协议)、服务器位置、资源路径。
URL 为应用程序提供了一种访问资源的手段。定义了用户所需的资源以及如何获取它。
URL的语法
根据方案的不同,URL 语法会随之变化,但大部分都建立在由 9 部分构成的同样格式上:
<scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag>
几乎没有哪个 URL 完整包含了这 9 部分,其中最主要的就是方案、主机、路径。
通用 URL 组件总结:
| 组件 | 描述 | 默认值 |
|---|---|---|
| 方案 | 访问服务器以获取资源时要使用哪种协议 | 无 |
| 用户 | 某些方案访问资源时需要的用户名 | 匿名 |
| 密码 | 用户名后面可能要包含的密码,中间由冒号(:)分割 | <E-mail 地址> |
| 主机 | 资源宿主服务器的主机名或点分IP地址 | 无 |
| 端口 | 资源宿主服务器正在监听的端口号。很多方案有默认的端口号,比如HTTP为80 | 每个方案特有 |
| 路径 | 服务器上资源的本地名,由一个斜杠(/)将其与前面的URL组件分割 | 无 |
| 参数 | 某些方案会使用这个组件来指定输入参数,参数为名/值对,URL 中可以包含多个参数字段,它们相互之间以及与路径 的其余部分之间用分号(;)分隔 | 无 |
| 查询 | 某些方案会用这个组件传递参数以激活应用程序,查询组 件的内容没有通用格式。 用字符“?”将其与 URL 的其余 部分分隔开来 | 无 |
| 片段 | 一小片或一部分资源的名字,引用对象时, 不会将 frag 字 段传送给服务器;这个字段是在客户端内部使用的。 通过 字符“#”将其与 URL 的其余部分分隔开来 | 无 |
方案 - 使用什么协议
方案是规定如何访问指定资源的主要标识符,告诉负责解析 URL 的应用程序使用什么协议。
方案组件必须以一个字母符号开始,由第一个冒号(:)与 URL 的其他部分分割。大小写无关。
主机与端口
主机组件标识了因特网上能够访问资源的宿主机器。 端口组件标识了服务器正在监听的网络端口。
用户名和密码
有些服务器需要输入用户名和密码才能访问资源,比如 FTP。
ftp://ftp.prep.ai.mit.edu/pub/gnu
ftp://anonymous@ftp.prep.ai.mit.edu/pub/gnu
ftp://anonymous:my_passwd@ftp.prep.ai.mit.edu/pub/gnu
http://joe:joespasswd@www.joes-hardware.com/sales_info.txt
- 第一个例子并没有用户和密码组件,只有方案、主机、路径。
- 第二个例子指定了
anonymous为用户名。 - 第三个例子指定了
anonymous为用户,my_passwd为密码,中间用冒号(:)分割。
路径
说明了资源位于服务器的什么地方,通常像一个分级的文件系统路径,是服务器定位资源时所需的信息。
参数
参数组件,向应用程序提供它们所需的输入参数,以便正确的与服务器进行交互。为应用程序提供了访问资源所需的所有附加信息。
ftp://prep.ai.mit.edu/pub/gnu;type=d
这个例子中,有一个参数type=d,参数名为type,值为d。
HTTP URL 的路径可以分成若干路径段,每段都可以有自己的参数:
http://www.joes-hardware.com/hammers;sale=false/index.html;graphics=true
这个例子有两个路径段,hammers和index.html,hammers路径段有参数sale,值为false,index.html路径段有参数graphics,值为true。
查询字符串
URL 的查询组件和标识网关资源的 URL 路径组件一起被发送给网关资源。由问号(?)与其他组件分割,由一系列“名/值”对构成,个“名/值”对使用&分割。
http://www.joes-hardware.com/inventory-check.cgi?item=12731&color=blue
片段
有些资源,比如 HTML,除了资源级别的划分,还可以更进一步的进行划分。为了引用部分资源或资源的一个片段,URL 支持使用片段组件来表示一个资源内部的片段。
片段挂在 URL 的最右边,使用#与其他组件分割:
http://www.joes-hardware.com/tools.html#drills
即引用资源tools.html的一部分,这部分的名字为drills。
HTTP 服务器只处理整个对象,而不是对象的片段,客户端不能将片段传送给服务器。浏览器从服务器获得了整个片段之后,会根据片段来显示你感兴趣的那部分资源。
URL快捷方式
相对URL
URL 有两种方式:绝对、相对。
绝对 URL 中包含有访问资源所需的全部信息。相对 URL 必须根据基础 URL 进行解析,以获取访问资源所需的全部信息。
为保持一组资源的可移植性提供了便捷。
- 基础URL
- 在资源中显式提供
- 封装资源的基础URL
- 没有基础URL
- 解析相对引用
自动扩展URL
有些浏览器会在用户提交 URL 之后,或者在用户输入的时候尝试自动扩展 URL,以为用户提供便利。
- 主机名扩展
- 历史扩展
各种令人头疼的字符
URL字符集
URL 的设计者将转义序列集成到 US-ASCII 字符集,以实现可移植性和完整性。
编码机制
为了避开安全字符集表示法带来的限制,通过一种“转义”表示法来表示不安全的字符,这种转义表示法包含一个百分号(%),后跟两个表示字符 ASCII 码的十六进制数,以此来表示不安全的字符。
比如:
| 字符 | ASCII码 | 示例URL |
|---|---|---|
~ | 126(0x7E) | http://www.joes-hardware.com/%7Ejoe |
空格 | 32(0x20) | http://www.joes-hardware.com/more%20tools.html |
% | 37(0x25) | http://www.joes-hardware.com/100%25satisfaction.html |
字符限制
在 URL 中存在一些保留字符具有特殊含义。
这些字符有:%、/、.、..、#、?、;、:、$,+、@ & =、{}|\^~[]、<>"、0x00-0x1F, 0x7F、>0x7F。
方案
| 方案 | 描述 |
|---|---|
| http | 超文本传输协议方案,除了没有用户名和密码之外, 与通用的URL格式相符。端口默认为 80。 |
| https | 方案 https 与方案 http 是一对。 唯一的区别在于方案 https 使用了网景的 SSL,SSL 为 HTTP 连接提供了端到端的加密机制。其语法与 HTTP 的语法相同,默认端口为 443。 |
| mailto | Mailto URL 指向的是 E-mail 地址。 |
| ftp | 文件传输协议 URL 可以用来从 FTP 服务器上下载或向其上载文件, 并获取 FTP 服务器 上的目录结构内容的列表。 |
| rtsp,rtspu | RTSP URL 是可以通过实时流传输协议(Real Time Streaming Protocol)解析的音 / 视频 媒体资源的标识符。方案 rtspu 中的 u 表示它是使用 UDP 协议来获取资源的。 |
| file | 方案 file 表示一台指定主机上可直接访问的文件。 |
| news | 根据 RFC 1036 的定义, 方案 news 用来访问一些特定的文章或新闻组。 |
| telnet | 用于访问交互式业务。它表示的并不是对象自身,而是可通过 telnet 协议访问的交互式应用程序(资源)。 |
6.3 - HTTP 报文
报文流
HTTP 报文即 HTTP 应用程序之间发送的数据块。以一些文本形式的元信息开头以描述报文的内容及含义,后跟可选的数据部分。
报文流入源端服务器
**流入(inbound)和流出(outbound)用于描述事物处理(transaction)**的方向。
首先报文流入源端服务器,工作完成后,会流回用户的 Agent 代理(如浏览器)。
报文向下游流动
所有报文(请求、响应)发送者都在接收者的上游,所有报文都会向下游流动。
报文的组成部分
HTTP 报文为简单的格式化数据块,包含:起始行、首部、主体。
起始行和首部是由行分割 ASCII 文本。每行都以一个由两个字符组成的终止符作为结束:回车符(ASCII 13)和换行符(ASCII 10)。这个终止序列称为 CRLF。
主体是一个可选的数据块,可是是文本或二进制数据,或为空。首部中会给出主体的信息,比如类型或长度。
报文的语法
所有报文分为两类:请求报文、响应报文。
请求报文格式:
<method> <request-URL> <version>
<headers>
<entity-body>
响应报文格式:
<version> <status> <reason-phrase>
<headers>
<entity-body>
- 方法:客户端希望服务器对资源执行的操作。
- 请求 URL:命名了所请求的资源或 URL 路径组件的完整 URL。
- 版本:报文所使用的 HTTP 版本:
HTTP/<major>.<minor>。 - 状态码:这个三位数字描述了请求过程中发生的情况。
- 原因短语:数字状态码的可读版本,包含行终止序列之前的所有文本。
- 首部:可以有零个或多个首部。每个首部都包含一个名字, 后面跟着一个冒号(:), 然后是一个可选的空格, 接着是一个值, 最后是一个 CRLF。最后由一个空行 CRLF 结束,表示首部结束,后面是主体。
- 实体的主体部分:包含一个由任意数据组成的数据块。
起始行
所有 HTTP 报文都以起始行开始,请求报文中说明要做什么,响应报文中说明发生了什么。
请求行:请求服务器对资源进行一些操作
响应行:承载了状态信息和操作产生的所有结果数据
方法:
方法 描述 是否包含主体 GET 从服务器获取一份文档 否 HEAD 只从服务器获取文档的首部 否 POST 向服务器发送需要处理的数据 是 PUT 将请求的主体部分存储在服务器上 是 TRACE 对可能经过代理服务器传送到服务器上去的报文进行追踪 否 OPTIONS 决定可以在服务器上执行哪些方法 否 DELETE 从服务器上删除一份文档 否 状态码:
整体范围 已定义范围 分类 100 ~ 199 100 ~ 101 信息提示 200 ~ 299 200 ~ 206 成功 300 ~ 399 300 ~ 305 重定向 400 ~ 499 400 ~ 415 客户端错误 500 ~ 599 500 ~ 505 服务端错误 原因短语
版本号
首部
- 首部分类
- 通用首部:出现在请求报文、响应报文
- 请求首部:请求信息
- 响应首部:响应信息
- 实体首部:实体信息
- 扩展首部:尚未定义的新首部
- 首部延续行:将较长的首部分为多行,多出来的行前使用空格或制表符(Tab)
实体的主体部分
方法
HEAD
与 GET 方法类似,但在响应中只返回首部,不返回主体部分。这允许客户端在未获取实际资源的情况下检查资源:
- 在不获取资源的情况下了解资源
- 通过查看响应中的状态码判断资源是否存在
- 通过查看首部,判断资源是否被修改
OPTIONS
询问服务器通常支持 哪些方法,或者对某些特殊资源支持哪些方法。
状态码
信息状态码
| 状态码 | 原因短语 | 含义 |
|---|---|---|
| 100 | Continue | 说明收到了请求的初始部分,请客户端继续. |
| 101 | Switching Protocols | 说明服务器正在根据客户端的指定,将协议切换成Update首部所列的协议 |
成功状态码
| 状态码 | 原因短语 | 含义 |
|---|---|---|
| 200 | OK | 请求没有问题,实体的主体部分包含了所请求的资源. |
| 201 | Created | 用于创建服务器对象的请求(比如PUT),响应体的实体主体部分中应该包含各种引用了已创建资源的URL,Location首部包含的则是最具体的引用. |
| 202 | Accepted | 请求已被接受,但服务器还未对其执行任何动作.不能保证服务器会完成这个请求;只表示接受请求时,它看起来是有效的. |
| 203 | Non-Authoritative Information | 实体首部包含的信息不是来自于源端服务器,而是来自资源的一个副本. |
| 204 | No Content | 响应报文中用于若干首部和一个状态行,但没有实体的主题部分.主要用于在浏览器不转为显示新文档的情况下,对其进行更行. |
| 205 | Reset Content | 另一个主要用于浏览器的代码,负责告诉浏览器清除当前页中的所有HTML表单元素. |
| 206 | Partial Content | 成功执行了一个部分或Range(范围)请求. |
重定向状态码
| 状态码 | 原因短语 | 含义 |
|---|---|---|
| 300 | Multiple Choices | 客户点请求一个实际指向多个资源的URL时会返回这个状态码,比如服务器上有某个HTML的英语和法语版本.返回这个状态码时会有一个选项列表,这样用户就可以选择他希望使用的那一项了. |
| 301 | Moved Permanently | 在请求的URL已被移除时使用.响应的Location首部中应该包含资源现在所处的URL. |
| 302 | Found | 与301状态码类似,但是客户端应该使用Location首部给出的URL来临时定位资源. |
| 303 | See Other | 告诉客户端应该使用另一个URL来获取资源,新的URL位于响应报文的Location首部. |
| 304 | Not Modified | 客户端可以通过所包含的请求首部,使其请求变成有条件的. |
| 305 | Use Proxy | 用来说明必须通过一个代理访问资源,代理的位置有Location首部给出. |
| 306 | (未使用) | 当前未使用. |
| 307 | Temporary Redirect | 与301状态码类似,但是客户端应该使用Location首部给出的URL来临时定位资源. |
客户端错误状态码
| 状态码 | 原因短语 | 含义 |
|---|---|---|
| 400 | Bad Request | 用于告诉客户端它发错了一个错误请求. |
| 401 | Unauthorized | 与适当的首部一起返回,在这些首部中请求客户端在获取对资源的访问权之前,对自己进行认证. |
| 402 | Payment Required | 还未使用,但已保留. |
| 403 | Forbidden | 用于说明请求被服务器拒绝了. |
| 404 | Not Found | 用于说明服务器无法找到所请求的URL. |
| 405 | Method Not Allowed | 发起的请求中带有所请求的URL不支持的方法时,使用此状态码.应该在响应中包含Allow首部,以告诉客户端所请求的资源有哪些可以使用的方法. |
| 406 | Not Acceptable | 客户端可以指定参数来说明他们愿意接受什么类型的实体. |
| 407 | Proxy Authentication Required | 与401状态码类似,但用于要求对资源进行认证的代理服务器. |
| 408 | Request Timeout | 如果客户端完成请求所花的时间太长,服务器可以返回此状态码,并关闭连接. |
| 409 | Conflict | 用于说明请求可能在资源上引发一些冲突. |
| 410 | Gone | 与401类似,只是服务器曾经拥有该资源. |
| 411 | Length Required | 服务器要求在请求报文中包含Content-Length首部. |
| 412 | Precondition Failed | 客户端发起了条件请求,且其中一个条件失败了的时候使用. |
| 413 | Request Entity Too Large | 客户端发送的实体主体部分比服务器能够或者希望处理的要大时,使用此状态码. |
| 414 | Request URI Too Long | 客户端所发请求中的请求URL比服务器能够或希望处理的要大时,使用此状态码. |
| 415 | Unsupported Media Type | 服务器无法理解或支持客户端所发实体的内容类型. |
| 416 | Requested Range Not Satistiable | 请求报文所请求的是指定资源的某个范围,而此范围无效或无法满足时,使用此状态码. |
| 417 | Expectation Failed | 请求的Expect请求首部包含了一起期望,但服务器无法满足此期望. |
服务器错误状态码
| 状态码 | 原因短语 | 含义 |
|---|---|---|
| 500 | Internal Server Error | 服务器遇到一个妨碍它为请求提供服务的错误时,使用此代码. |
| 501 | Not Implement | 客户端发起的请求超出服务器的能力范围. |
| 502 | Bad Gateway | 作为代理或网关使用的服务器从请求响应链的下一条链路上收到了一条伪响应. |
| 503 | Service Unavailable | 服务器现在无法为请求提供服务. |
| 504 | Gateway Timeout | 与状态码408类似,只是这里的响应来自一个网关或代理,他们在等待另一服务器对其请求进行响应时超时了. |
| 505 | HTTP Version Not Supperted | 服务器收到的请求使用了它无法或不愿意支持的协议版本时. |
首部
首部和方法配合工作,共同决定了客户端和服务器能做什么事情.
- 通用首部: 客户端和服务器都可以使用的通用首部.可以在客户端或服务器和其他应用程序之间提供一些非常有用的通用功能,提供了报文相关的最基本信息.比如Date首部.
- 请求首部: 是请求报文特有的.为服务器提供了一些额外信息,比如客户端希望接收什么类型的数据.
- 响应首部: 响应报文有自己的首部集,以便为客户端提供信息.
- 实体首部: 指的是用于应对实体主体部分的首部.比如,可以用实体首部来说明实体主体部分的数据类型.
- 扩展首部: 是非标准的首部,有应用程序开发正创建,但还未添加到已批准的HTTP规范中.
通用首部
| 首部 | 描述 |
|---|---|
| Connection | 允许客户端和服务器指定与请求/响应连接有关的选项 |
| Date | 提供日期和时间标志,说明报文是什么时间创建的 |
| MIME-Version | 给出了发送端使用的 MIME 版本 |
| Trailer | 如果报文采用了分块传输编码方式,就可以用这个首部列出位于报文拖挂(trailer)部分的首部集合 |
| Transfer-Encoding | 告知接收端为了保证报文的可靠传输,对报文采用了什么编码方式 |
| Update | 给出了发送端可能想要“升级”使用的新版本或协议 |
| Via | 显示了报文经过的中间节点(代理、网关) |
通用缓存首部
| 首部 | 描述 |
|---|---|
| Cache-Control | 用于随报文传送缓存指示 |
| Pragma | 另一种随报文传送指示的方式,但并不专用于缓存 |
| Connection | AAAA |
请求首部
只在请求报文才有意义的首部.用于说明谁或什么在发送请求,请求源自何处,或者客户端的喜好和能力.服务器可以根据请求首部给出的客户端信息,试着为客户端提供更好的响应.
| 首部 | 描述 |
|---|---|
| Client-IP | 提供了运行客户端的机器的 IP 地址 |
| From | 提供了客户端用户的 E-mail 地址 |
| Host | 给出了接收请求的服务器的主机名和端口号 |
| Referer | 提供了包含当前请求 URI 的文档的 URL |
| UA-Color | 提供了与客户端显示器的显示颜色有关的信息 |
| UA-CPU | 给出了客户端 CPU 的类型或制造商 |
| UA-Disp | 提供了与客户端显示器(屏幕)能力有关的信息 |
| UA-OS | 给出了运行在客户端机器上的操作系统名称及版本 |
| UA-Pixels | 提供了客户端显示器的像素信息 |
| User-Agent | 将发起请求的应用程序名称告知服务器 |
Accept首部
Accept首部为客户端提供了一种将喜好和能力告诉服务器的方式.
| 首部 | 描述 |
|---|---|
| Accept | 告诉服务器能够发送那些媒体类型 |
| Accept-Charset | 能够发送那些字符集 |
| Accept-Encoding | 能够发送哪些编码方式 |
| Accept-Language | 能够发送那些语言 |
| TE | 能够使用哪些扩展传输编码 |
条件请求首部
有时客户端希望为请求加上某些限制.
| 首部 | 描述 |
|---|---|
| Expect | 允许客户端列出某请求所要求的服务器行为 |
| If-Match | 如果实体标记与文档当前的实体标记匹配,就获取这份文档 |
| If-Modified-Since | 除非在某个指定的日期之后资源被修改过,否则就限制这个请求 |
| If-None-Match | 如果提供的实体标记与当前文档的实体标记不相符,就获取文档 |
| If-Range | 允许对文档的某个范围进行条件请求 |
| If-Unmodified-Since | 除非在某个指定日期之后资源没有被修改过,否则就限制这个请求 |
| Range | 如果服务器支持范围请求,就请求资源的指定范围 |
安全请求首部
HTTP本身就支持一种简单的机制,可以对请求进行质询/响应认证.这种机制要求客户端在获取特定资源之前,相对自身进行认证,这样就可以使事务稍微安全一些.
| 首部 | 描述 |
|---|---|
| Authorization | 包含了客户端提供给服务器,以便对其自身进行认证的数据 |
| Cookie | 客户端用它向服务器传送一个令牌——它并不是真正的安全首部,但确实隐含了安全功能 |
| Cookie2 | 用来说明请求端支持的 cookie 版本 |
代理请求首部
| 首部 | 描述 |
|---|---|
| Max-Forward | 在通往源端服务器的路径上, 将请求转发给其他代理或网关的最大次数——与Trace方法一同使用 |
| Proxy-Authorization | 与Authorization首部相同,但这个首部是在与代理进行认证时使用 |
| Proxy-Connection | 与 Connection 首部相同,但这个首部是在与代理建立连接时使用的 |
响应首部
响应报文有自己的响应首部集.为客户端提供了一些额外信息,比如谁在发送响应,响应者的功能,甚至于响应相关的一些特殊指令.这些首部有助于客户端处理响应,并在将来发起更好的请求.
| 首部 | 描述 |
|---|---|
| Age | (从最初创建开始)响应持续时间 |
| Public | 服务器为其资源支持的请求方法列表 |
| Retry-After | 如果资源不可用的话,在此日期或时间重试 |
| Server | 服务器应用程序软件的名称和版本 |
| Title | 对 HTML 文档来说,就是 HTML 文档的源端给出的标题 |
| Warning | 比原因短语中更详细一些的警告报文 |
协商首部
服务器可以用他们来传递与可协商资源有关的信息.
| 首部 | 描述 |
|---|---|
| Accept-Ranges | 对此资源来说,服务器可接受的范围类型 |
| Vary | 服务器查看的其他首部的列表,可能会使响应发生变化;也就是说,这是一个首部列表,服务器会根据这些首部的内容挑选出最适合的资源版本发送给客户端 |
安全响应首部
上面已经提到请求端的安全首部,本质上这里说的就是 HTTP 的质询 / 响应认证机制的响应侧.
| 首部 | 描述 |
|---|---|
| Proxy-Authenticate | 来自代理的对客户端的质询列表 |
| Set-Cookie | 不是真正的安全首部,但隐含有安全功能;可以在客户端设置一个令牌,以便服务器对客户端进行标识 |
| Set-Cookie2 | 与 Set-Cookie 类似, RFC 2965 Cookie 定义 |
| WWW-Authenticate | 来自服务器的对客户端的质询列表 |
实体首部
有很多首部可以用来描述HTTP报文的负荷.由于请求和响应报文中都可能包含实体部分,所以在这两种类型的报文中都可能出现这些首部.
实体首部提供了有关实体及其内容的大量信息,从有关对象类型的信息,到能够对资源使用的各种有效的请求方法.总之,实体首部可以告知报文的接收者它在对什么进行处理.
| 首部 | 描述 |
|---|---|
| Allow | 列出了可以对此实体执行的请求方法 |
| Location | 告知客户端实体实际上位于何处;用于将接收端定向到资源的(可能是新的)位置(URL)上去 |
内容首部
提供了与实体内容有关的特定信息,说明了其类型,尺寸以及处理它需要的其他有用信息.
| 首部 | 描述 |
|---|---|
| Content-Base | 解析主体中的相对 URL 时使用的基础URL |
| Content-Encoding | 对主体执行的任意编码方式 |
| Content-Language | 理解主体时最适宜使用的自然语言 |
| Content-Length | 主体的长度或尺寸 |
| Content-Location | 资源实际所处的位置 |
| Content-MD5 | 主体的 MD5 校验和 |
| Content-Range | 在整个资源中此实体表示的字节范围 |
| Content-Type | 这个主体的对象类型 |
实体缓存首部
通过缓存首部说明了如何或什么时候进行缓存.
| 首部 | 描述 |
|---|---|
| ETag | 与此实体相关的实体标记 |
| Expires | 实体不再有效,要从原始的源端再次获取此实体的日期和时间 |
| Last-Modified | 这个实体最后一次被修改的日期和时间 |
6.4 - 连接管理
TCP连接
HTTP 通信由 TCP/IP 承载。
TCP的可靠数据管道
TCP 为 HTTP 提供了一条可靠的比特传输管道。TCP 会按序、无差错的承载 HTTP 数据。
一次 HTTP 请求过程:
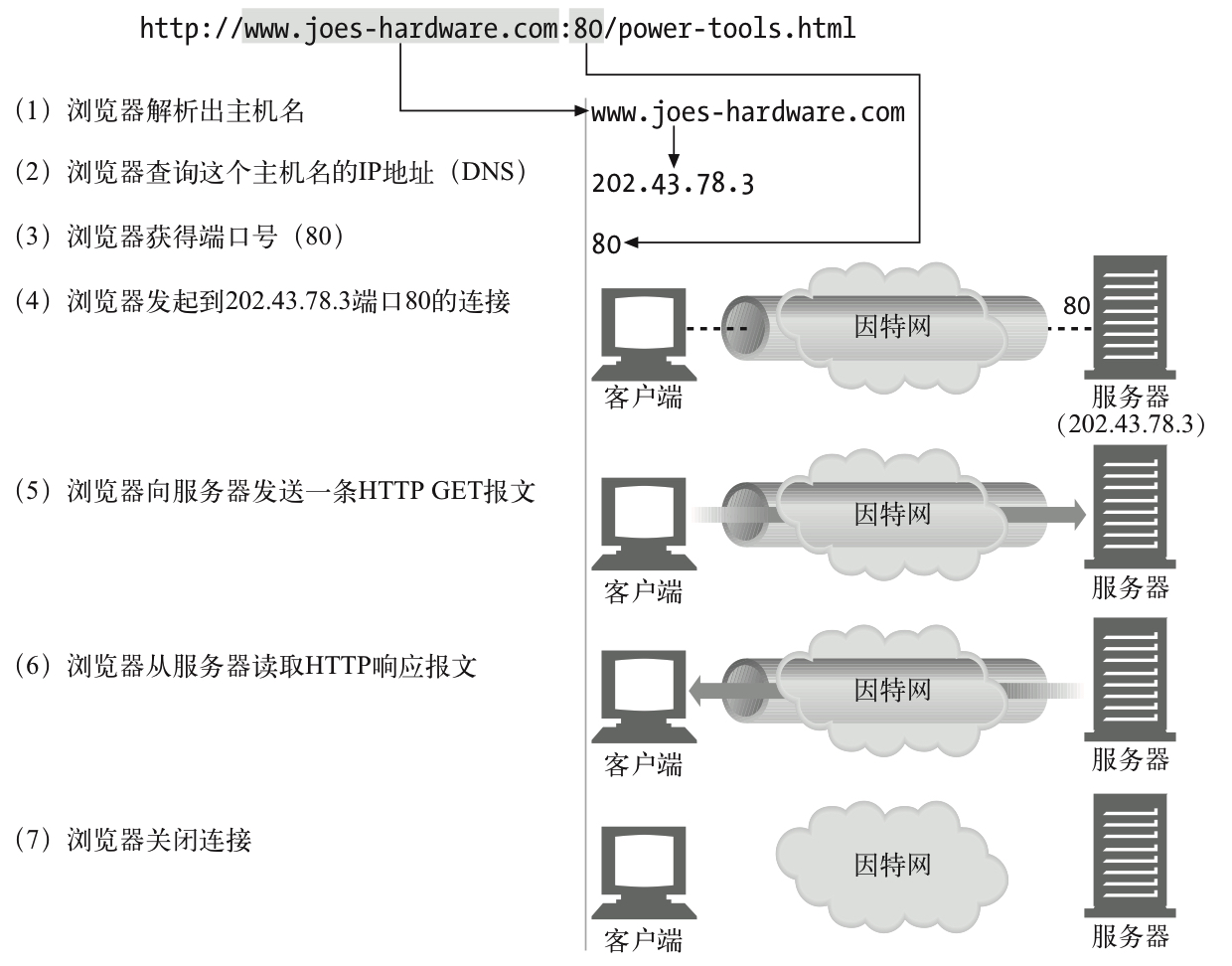
TCP流是分段的、由IP分组传送
HTTP 发送一条报文时,会以流的形式将报文数据的内容通过一条打开的 TCP 连接按序传输。TCP 收到数据流以后,将数据流分成段,并将段封装在 IP分组(IP数据报) 中,通过因特网传输。
每个 TCP 段都由 IP 分组承载,从一个 IP地址发往另一个 IP地址。每个 IP分组中包括:
- 一个 IP 分组首部(通常20字节)
- 一个 TCP 段首部(通常20字节)
- 一个 TCP 数据块(0 或多个字节)
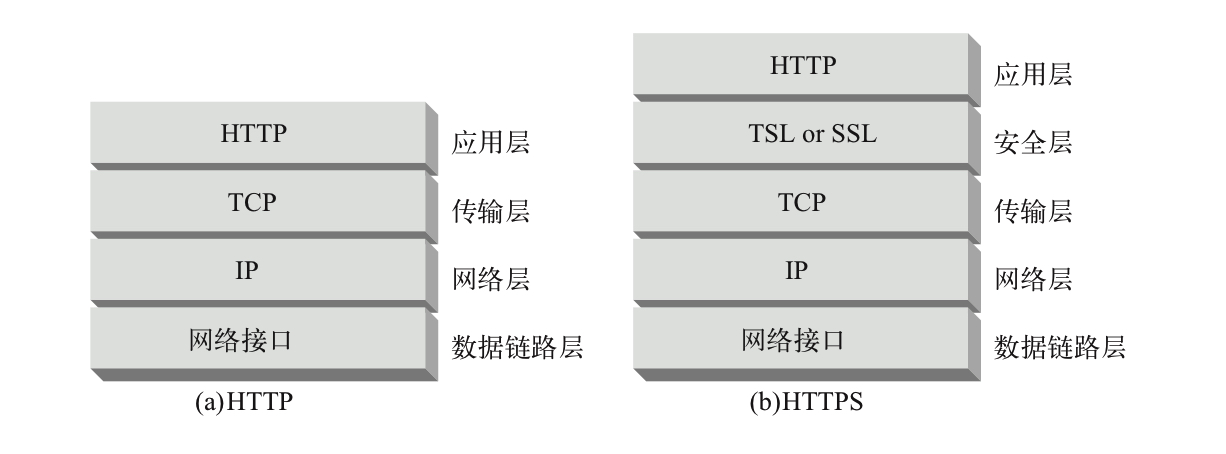
保持TCP连接持续不断的运行
TCP 通过端口号来保持连接持续不断的运行。
TCP连接是通过 4 个值来识别的:< 源 IP 地址、源端口号、目的 IP 地址、目的端口号 >
这 4 个值共同定义了一条连接。
一个 IP 分组:
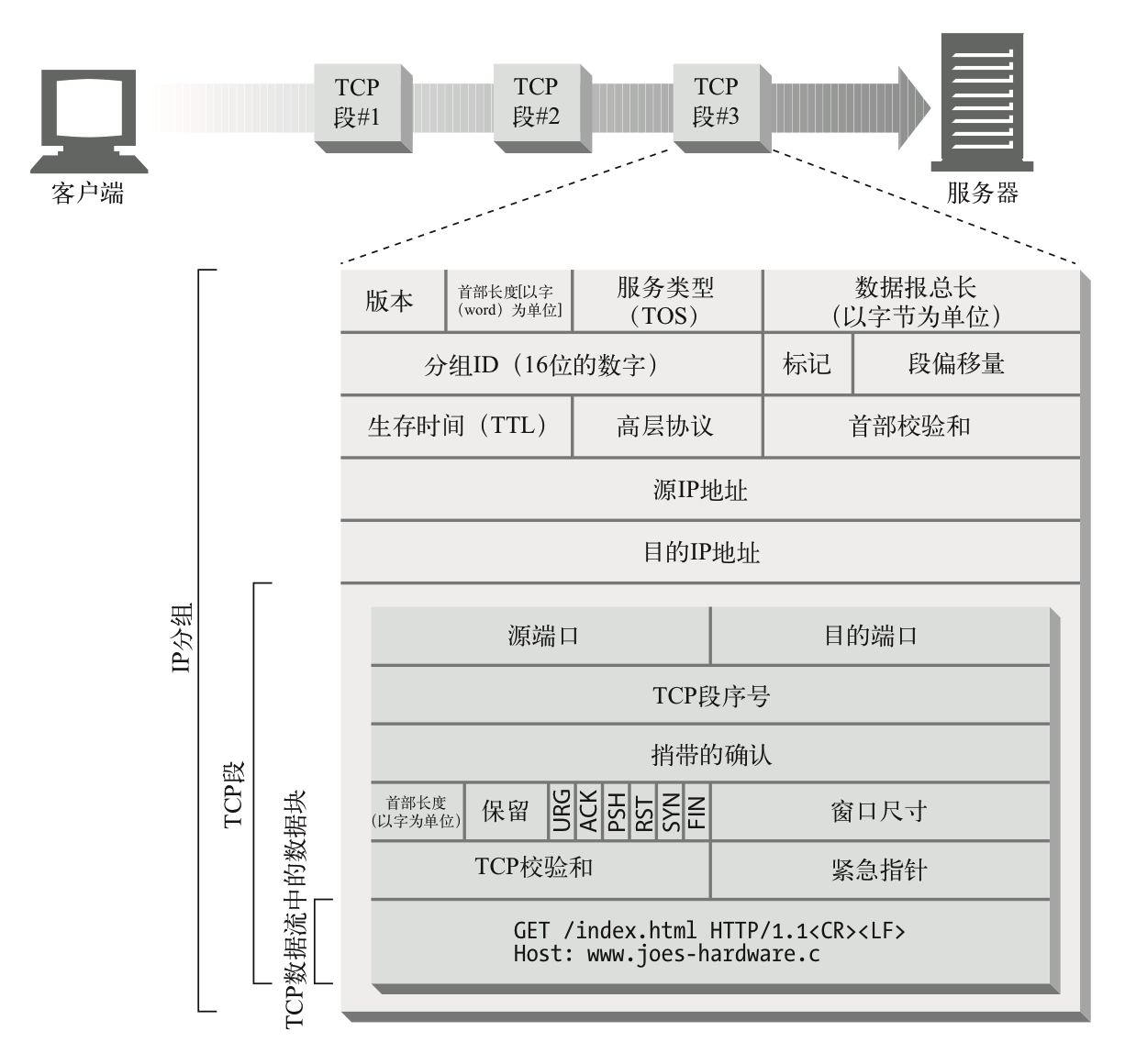
用TCP套接字编程
OS 提供了操作 TCP 连接的 API。该 API 向 HTTP 隐藏了所有 TCP 和 IP 的细节。
TCP 套接字通信过程:
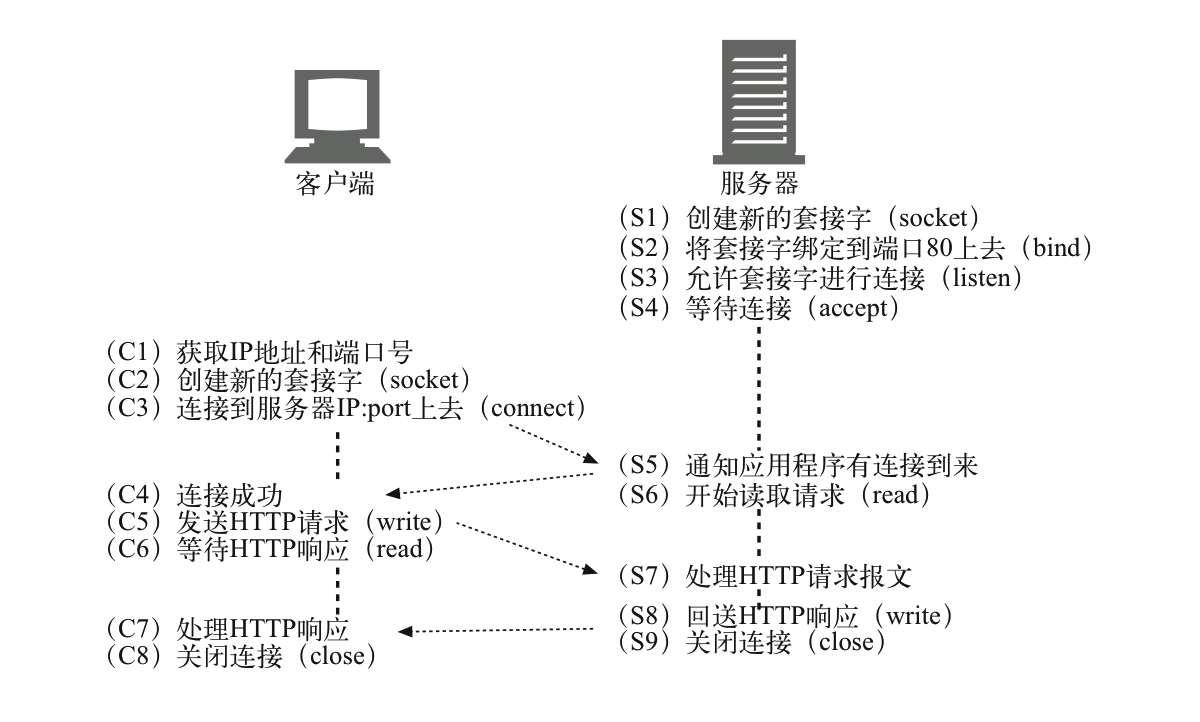
TCP性能
HTTP事务的时延
主要原因:
- 客户端根据 URL 确定服务器的 IP 和端口号,即DNS解析时间。
- 客户端向服务器发送一条 TCP 连接请求,并等待服务器返回一个接收应答。即建立 TCP连接的时间。
- 客户端通过已建立的 TCP 管道发送 HTTP 请求,即 HTTP 报文的传输和处理时间。
- 服务器返回 HTTP 响应,即 HTTP 报文传输时间。
性能聚焦区域
- TCP 连接建立握手
- TCP 慢启动拥塞控制
- 数据聚集的 Ngale 算法
- 用于捎带 ACK 的 TCP 延迟确认算法
- TIME_WAIT 时延和端口耗尽
HTTP连接的处理
常被误解的Connection首部
Connection 首部承载 3 种不同类型的标签:
- HTTP 首部字段名,列出只与此连接有关的首部;
- 任意标签值,用于描述此连接的非标准选项;
- 值 close,说明操作完成之后需关闭这条持久连接。
串行事务处理时延
一个页面包含多个元素需要加载时,如果每个事务都要(串行的建立)一条新的连接,那么连接时延和慢启动时延就会叠加起来。
一些提供 HTTP 连接性能的方法:
- 并行连接:通过多条 TCP 连接发起并发的 HTTP 请求。
- 每个事物打开/关闭新的连接,耗费时间和带宽
- TCP 慢启动的特性导致每条新连接的性能下降
- 受内存与带宽限制,可打开的并行连接数有限
- 持久连接:重用 TCP 连接,以消除连接及关闭延时。
- 管理多个持久连接的操作复杂度
- HTTP/1.0+ Keep-Alive
- HTTP/1.1 默认开启持久连接
- 管道化连接:通过共享的 TCP 连接发起并发的 HTTP 请求。将多条请求放入队列,当第一条请求发出后,队列中的请求就可以发送了。
- 复用的连接:交替传送请求和响应报文。
关闭连接
- 完全关闭与半关闭:套接字调用
close()会将 TCP 连接的输入输出信道都关闭,称为完全关闭。调用shutdown()单独关闭输入或输出信道,称为半关闭。 - TCP 关闭及重置错误
- 正常关闭:首先关闭输出信道,然后等待另一端关闭输出信道,当两端都确认不再发送任何数据之后,连接被完全关闭。
6.5 - 版本与性能
Web性能的隐性规则是减少终端用户能够感知到的延迟;在用户之前获得页面并使交互变得尽可能的快。
至于HTTP而言,这意味着一个理想的协议交互看起来像这样:
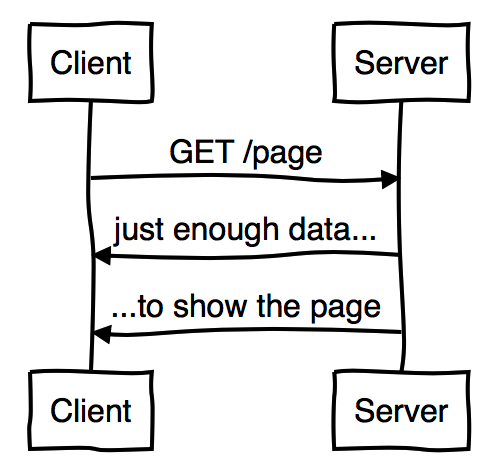
意思就是一个页面的加载过程中,需要在最少的往返次数中,发送尽可能少的数据到服务端,然后下载尽可能少的必须的数据。
额外数数据同时意味着更多的转换时间和更多的出错机会,比如拥堵或者丢包,这将严重的影响性能。
由于协议“隔阂(chattiness)”的更多往返次数会带来更多的延迟,尤其是移动网络(一个往返100ms可以作为你最好的预期)。
如果这是最理想的情况,那HTTP是如何度量的?我们又如何来提升呢?
HTTP/0.9
HTTP/0.9 诞生于 1991 年,是 HTTP 协议的最初版,构造十分简单:
- 请求端只支持 GET 请求
- 响应端只能返回 HTML 文本数据
GET /index.html
<html>
<body>
Hello World
</body>
</html>
请求示意图如下:

可以看到,HTTP/0.9 只能发送 GET 请求,且每一个请求都单独创建一个 TCP 连接,响应端只能返回 HTML 格式的数据,响应完成之后 TCP 请求断开。
这样的请求方式虽然能够满足当时的使用需求,但也还是暴露出了一些问题。
HTTP/0.9 痛点:
- 请求方式唯一,返回格式唯一
- TCP 连接无法复用
HTTP/1.0
HTTP/1.0 诞生于 1996 年,它在 HTTP/0.9 的基础上,增加了 HTTP 头部字段,极大扩展了 HTTP 的使用场景。这个版本的 HTTP 不仅可以传输文字,还能传输图像、视频、二进制文件,为互联网的迅速发展奠定了坚实的基础。
核心特点如下:
请求端增加 HTTP 协议版本,响应端增加状态码。
请求方法增加 POST、HEAD。
请求端和响应端增加头部字段。
- Content-Type 让响应数据不只限于超文本。
- Expires、Last-Modified 缓存头。
- Authorization 身份认证。
- Connection: keep-alive 支持长连接,但非标准。
GET /mypage.html HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
200 OK
Date: Tue, 15 Nov 1994 08:12:31 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/html
<html>
<body>
Hello World
</body>
</html>
请求示意图如下:
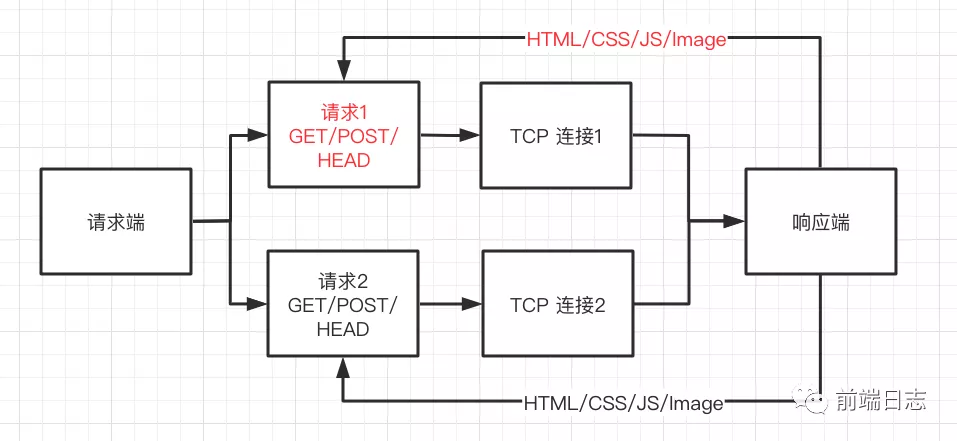
HTTP/1.0 扩展了请求方法和响应状态码,并且支持定义 HTTP 头部字段,通过 Content-Type 头,我们就能传输任何格式的数据了。同时可以看出,HTTP/1.0 仍然是一个请求对应一个 TCP 连接,不能形成复用。
HTTP/1.0 痛点:
- TCP 连接无法复用。
- HTTP 队头阻塞,一个 HTTP 请求响应结束之后,才能发起下一个 HTTP 请求。
- 一台服务器只能提供一个 HTTP 服务。
HTTP/1.1
HTTP/1.1 诞生于 1999 年,它进一步完善了 HTTP 协议,一直用到了 20 多年后的今天,仍然是使用最广的 HTTP 版本。
核心特点如下:
持久连接。
- HTTP/1.1 默认开启持久连接,在 TCP 连接建立后不立即关闭,让多个 HTTP 请求得以复用。
管线化技术。
- HTTP/1.1 中,多个 HTTP 请求不用排队发送,可以批量发送,这就解决了 HTTP 队头阻塞问题。但批量发送的 HTTP 请求,必须按照发送的顺序返回响应,相当于问题解决了一半,仍然不是最佳体验。
支持响应分块。
- HTTP/1.1 实现了流式渲染,响应端可以不用一次返回所有数据,可以将数据拆分成多个模块,产生一块数据,就发送一块数据,这样客户端就可以同步对数据进行处理,减少响应延迟,降低白屏时间。
- Bigpipe 的实现就是基于这个特性,具体是通过定义
Transfer-Encoding头来实现的。
增加 Host 头。
- HTTP/1.1 实现了虚拟主机技术,将一台服务器分成若干个主机,这样就可以在一台服务器上部署多个网站了。
- 通过配置 Host 的域名和端口号,即可支持多个 HTTP 服务:
Host: <domain>:<port>
其他扩展。
- 增加 Cache-Control、E-Tag 缓存头。
- 增加 PUT、PATCH、HEAD、 OPTIONS、DELETE 请求方法。
GET /en-US/docs/Glossary/Simple_header HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header
200 OK
Connection: Keep-Alive
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
Date: Wed, 20 Jul 2016 10:55:30 GMT
Etag: "547fa7e369ef56031dd3bff2ace9fc0832eb251a"
Keep-Alive: timeout=5, max=1000
Last-Modified: Tue, 19 Jul 2016 00:59:33 GMT
Server: Apache
Transfer-Encoding: chunked
Vary: Cookie, Accept-Encoding
<html>
<body>
Hello World
</body>
</html>
请求示意图如下:
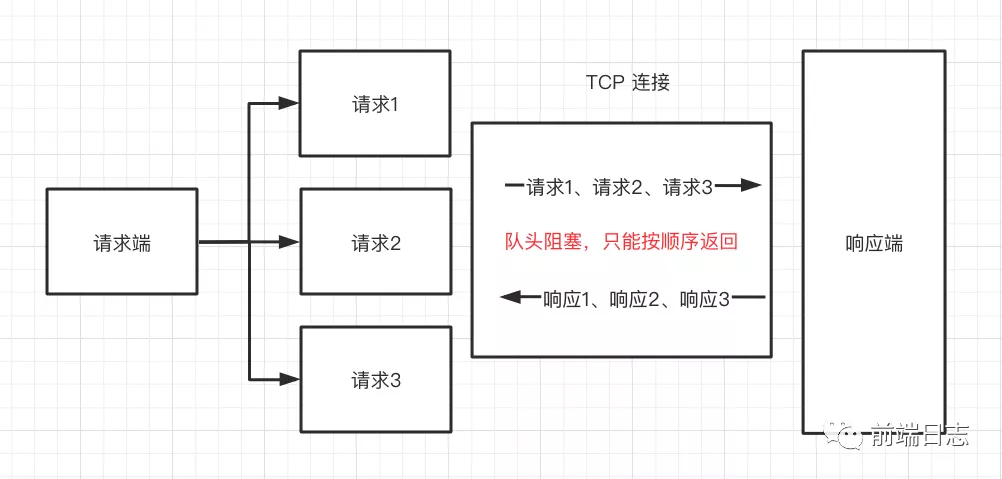
可以看到,HTTP/1.1 可以并行发起多个请求,并且也能复用同一个 TCP 连接,传输效率得到了提升。但响应端只能按照发送的顺序进行返回,为此很多浏览器会为每个域名至多打开 6 个连接,用增加队列的方式减少 HTTP 队头阻塞。
HTTP/1.1 痛点:
- HTTP 队头阻塞没有彻底解决,响应端必须按照 HTTP 的发送顺序进行返回,如果排序靠前的响应特别耗时,则会阻塞排序靠后的所有响应。
扩展阅读
多种原因说明HTTP/1.1是一个很好的协议,但遗憾的是现代的Web工作方式意味着性能并不是其中之一。一个典型的页面加载方式看起来会是这样:
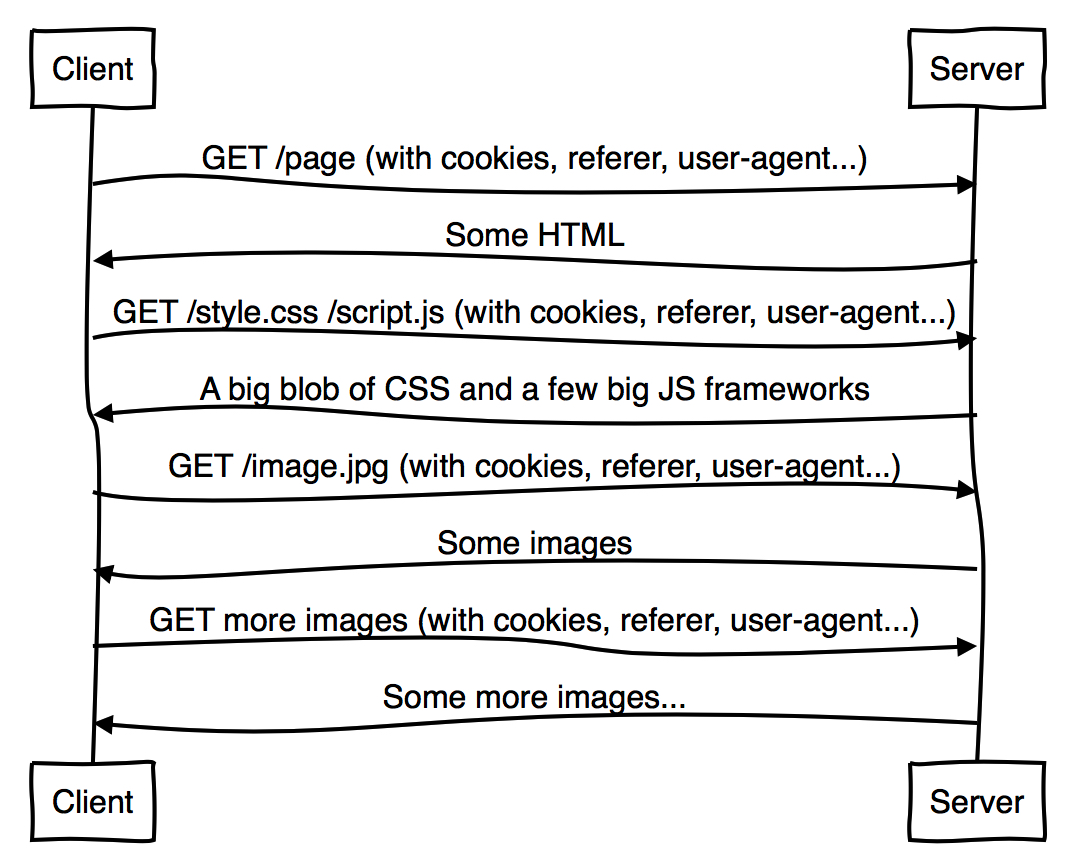
这并不是特别的理想。
Web使用的HTTP/1是非常“饶舌”的,因为客户端需要多次去请求服务端以寻求它需要的更多东西;首先是HTML,然后是CSS和Javascript。每次这样的交互都会增加新的一个或多个往返从而增加了页面加载的延迟,这与理想中的“最少的往返次数”相悖。
此外,仅对页面的请求就增加了大量的数据,这与理想中的“发送尽可能少的数据到服务端”相悖。这是因为比如Referer、User-Agent、Cookie这样的冗长Header信息会在每次请求中重复,并且又被大量的Web页面所需要的资源加倍增长。
最终,由于HTTP/1的head-of-line blocking问题(线头阻塞:队列首个packet由于他的目的端口正忙而被延迟转发),将多个资源组装到一个大的CSS代码、内嵌或连接,成为了一个普遍的最佳实践。这些都是HTTP/1中漂亮的性能hack,但是他们同样有一个损失:他们下载了远多于客户端需求的数据来显示一个页面,这与我们的理想相悖,并不能做到尽可能快的展示页面。
总的来说,HTTP/1并是不是一无是处,性能上的智能。举例来说,它拥有缓存,允许你在一个新的拷贝时完全不需要网络。还有受限制的请求,当有一个老的拷贝时避免你去转换大的东西。
HTTP/2
HTTP/2 诞生于 2015 年,它的最大的特点是 All in 二进制,基于二进制的特性,对 HTTP 传输效率进行了深度优化。
HTTP/2 将一个 HTTP 请求划分为 3 个部分:
- 帧:一段二进制数据,是 HTTP/2 传输的最小单位。
- 消息:一个请求或响应对应的一个或多个帧。
- 数据流:已建立的连接内的双向字节流,可以承载一条或多条消息。
HTTP/2 核心特点如下:
请求优先级
- 多个 HTTP 请求同时发送时,会产生多个数据流,数据流中有一个优先级的标识,服务器端可以根据这个标识来决定响应的优先顺序。
多路复用
- TCP 传输时,不用按照 HTTP 的发送顺序进行响应,可以交错发送,接收端根据帧首部的标识符,就能找到对应的流,进而重新组合得到最终数据。
服务器端推送
- HTTP/2 允许服务器未经请求,主动向客户端发送资源,并缓存到客户端中,以避免二次请求。
- HTTP/1.1 中请求一个页面时,浏览器会先发送一个 HTTP 请求,然后得到响应的 HTML 内容并开始解析,如果发现有
<script src="xxxx.js">标签,则会再次发起 HTTP 请求获取对应的 JS 内容。而 HTTP/2 可以在返回 HTML 的同时,将需要用到的 JS、CSS 等内容一并返回给客户端,当浏览器解析到对应标签时,也就不需要再次发起请求了。
头部压缩
- HTTP/1.1 的头部字段包含大量信息,而且每次请求都得带上,占用了大量的字节。
- HTTP/2.0 中通信双方各自缓存一份头部字段表,如:把
Content-Type:text/html存入索引表中,后续如果要用到这个头,只需要发送对应的索引号就可以了。
除此之外,虽然 HTTP/2 没有规定必须使用 TLS 安全协议,但所有实现 HTTP/2 的 Web 浏览器都只支持配置过 TLS 的网站,这是为了鼓励大家使用更加安全的 HTTPS。
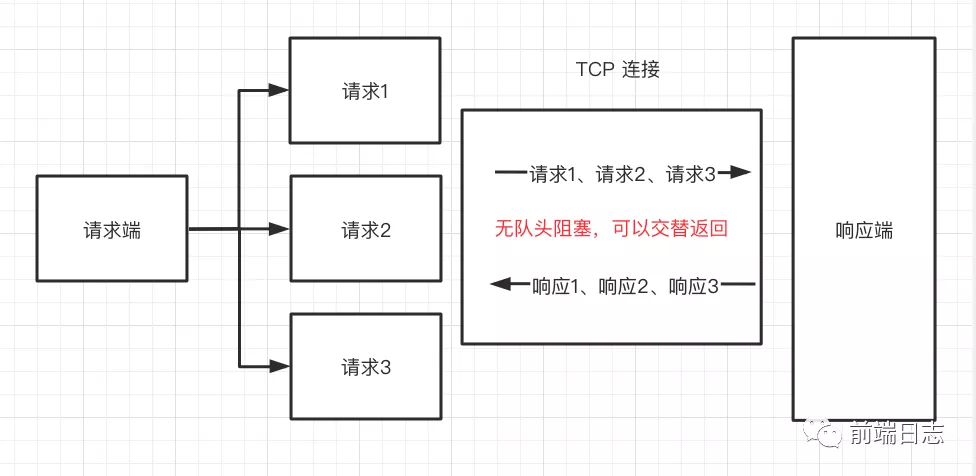
可以看到,在 HTTP/2 中发送请求时,既不需要排队发送,也不需要排队返回,彻底解决了 HTTP 队头阻塞问题。对于头部信息,资源缓存等痛点也进行了优化,似乎已经是一种很完美的方案了。
HTTP/2 在 HTTP + TCP 的架构上已经优化到了极致,如果要想继续优化,那就只能从这个架构入手了。
首先需要优化的是 TCP,因为 TCP 核心是保证传输层的可靠性,传输效率其实并不好。
- TCP 也存在队头阻塞,TCP 在传输时使用序列号标识数据的顺序,一旦某个数据丢失,后面的数据需要等待这个数据重传后才能进行下一步处理。
- TCP 每一次建立都需要三次握手,释放连接需要四次挥手,无形中增加了传输时长。
- TCP 存在拥塞控制,内置了慢启动,拥塞避免等算法,传输效率并不稳定。
扩展阅读
HTTP/2试图通过几种方式去解决HTTP/1.1中的问题:
- 完全的复用意味着线头阻塞不再是问题。可以通过单个HTTP连接加载整个Web页面,而不用担心创建了多少个请求。数据浪费的优化技巧可以被丢下了。
- Header压缩移除了由于冗长头部信息引起的单个消息的消耗。现在可以将数十个甚至数百个请求合并到仅仅一些IP包中。这更接近于理想中的两种“更少的数据”。
- HTTP/2的服务端PUSH主动提供客户端的需要,避免更多的往复次数带来的消耗。
因此,HTTP/2的运作看起来会像这样:
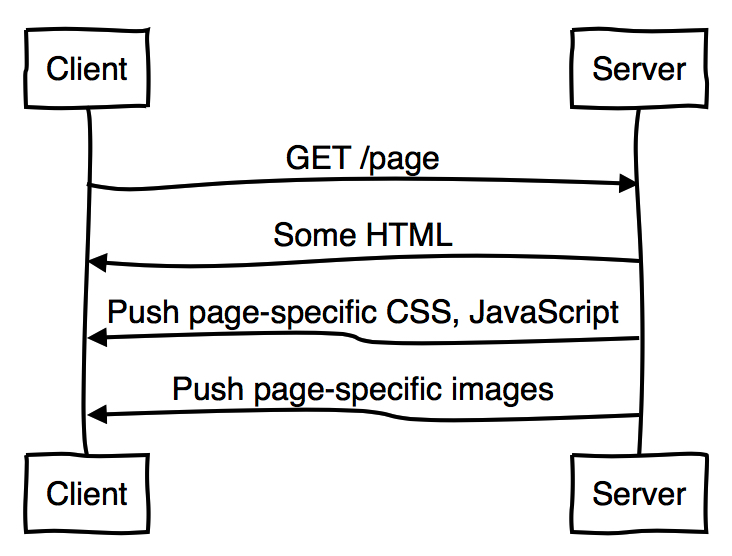
图中可以看到服务端在没有请求的情况下向客户端发送CSS、Javascript和图片。它知道客户端可能将会请求这些,因此它使用Server Push发送合成的请求/响应对到客户端,以节省一个往复次数。它不再是一个“饶舌”的协议,结果是他能更充分的使用网络。
需要注意的是,并不是说这些会更简单。HTTP/2仍然有很多存在的问题,特别是关于推送的时机。
HTTP/2 + 缓存摘要
服务端PUSH一个通常的问题是“客户端的缓存中是否已经有一个拷贝?”,因为推送天生是投机性的,总会出现你推送的东西并不是客户端需要的。
HTTP/2允许客户端在这种情况下通过RESET_STREAM取消推送。然而尽管这样,仍然会有一次往复的交互被浪费了,或许他们可以用来处理更值得的事情。记住,理想的是仅发送客户端用于显示页面仅需要的数据。
一个提议的方案是客户端使用一个紧凑的Cache Digest来告诉服务端它已经拥有的cache,从而使得服务端知道哪些是需要的。

因为缓存摘要使用Golumb Compressed Sets,它实时计算并使用少一1000个字节将浏览器缓存告诉服务端,通过连接在前几个包发送给服务端。
现在,我们避免了额外的往复次数,相关的数据浪费,直接嵌入和一些相似的hack,和非必须请求的数据浪费。这使我们里理想更进一步!
缓存摘要只是一个提议,但在HTTP社区中已经表现出很明显的兴趣。
HTTP/3
HTTP/3 目前还在草案阶段,它的主要特点是对传输层进行了优化,使用 QUIC 替换 TCP,彻底规避了 TCP 传输的效率问题。
QUIC 由 Google 提出的基于 UDP 进行多路复用的传输协议。QUIC 没有连接的概念,不需要三次握手,在应用程序层面,实现了 TCP 的可靠性,TLS 的安全性和 HTTP2 的并发性。在设备支持层面,只需要客户端和服务端的应用程序支持 QUIC 协议即可,无操作系统和中间设备的限制。
HTTP/3 核心特点如下:
传输层连接更快
HTTP/3 基于 QUIC 协议,可以实现 0-RTT 建立连接,而 TCP 需要 3-RTT 才能建立连接。
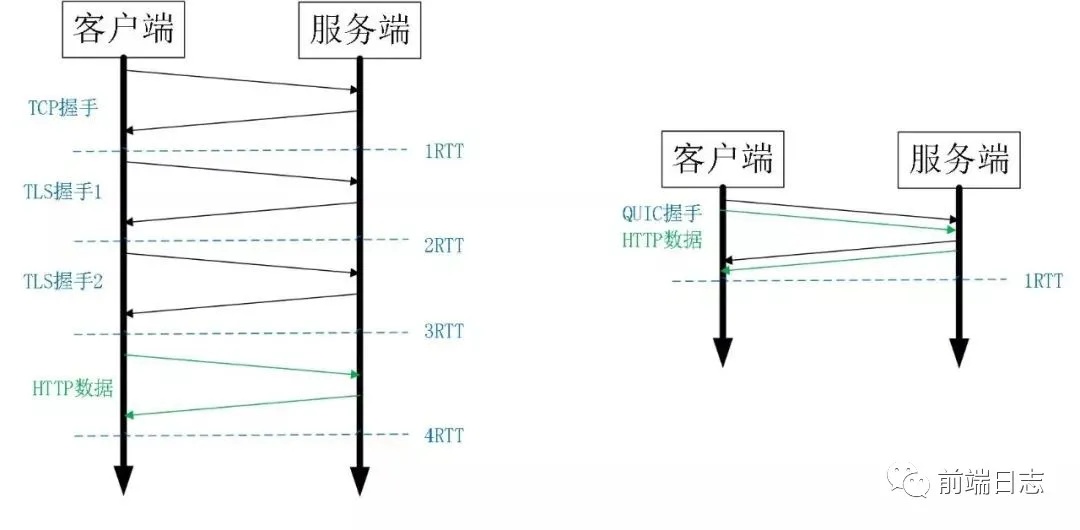
传输层多路复用
图中的 Stream 之间相互独立,如果 Stream2 丢了一个 Pakcet,不会影响 Stream3 和 Stream4 正常读取。
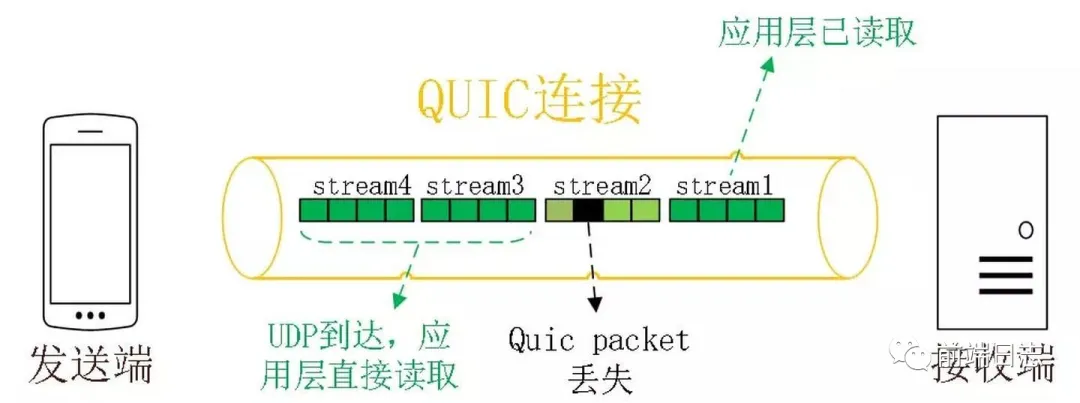
HTTP/3 传输层使用 QUIC 协议,数据在传输时会被拆分成了多个 packet 包,每一个 packet 包都可以独立、交错发送,不用按顺序发送,也就避免了 TCP 队头阻塞。
改进的拥塞控制
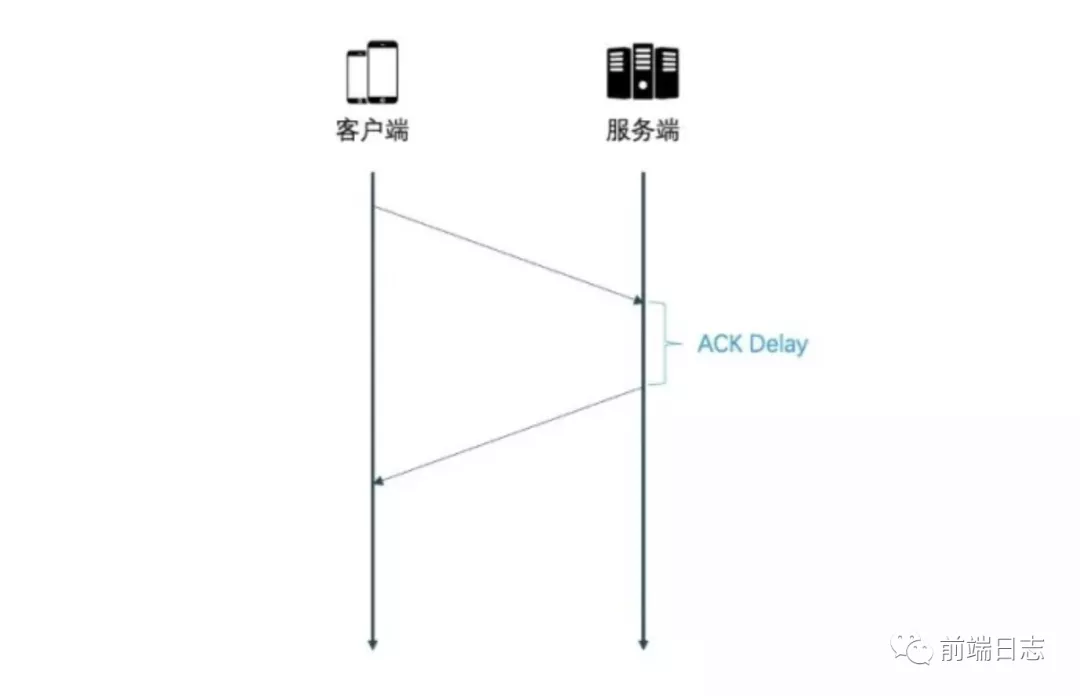
- 单调递增的 Packet Number。在 TCP 中,每一个数据包都有一个序列号标识(seq),如果接收端超时没有收到,就会要求重发标识为 seq 的包,如果这时超时的包也接收到了,则无法区分哪个是超时的包,哪个是重传的包。QUIC 中的每一个包的标识(Packet Number)都是单调递增的,重传的 Packet Number 一定大于超时的 Packet Number,这样就能区分开了。
- 不允许 Reneging。在 TCP 中,如果接收方内存不够或 Buffer 溢出,则可能会把已接收的包丢弃(Reneging),这种行为对数据重传产生了很大的干扰,在 QUIC 中是明确禁止的。在 QUIC 中,一个包只要被确认,就一定是被正确接收了。
- 更多的 ACK 块。一般来说,接收方收到发送方的消息后都会发送一个 ACK 标识,表示收到了数据。但每收到一个数据就发送一个 ACK 效率太低了,通常是收到多个数据后再统一回复 ACK。TCP 中每收到 3 个数据包就要返回一个 ACK,而 QUIC 最多可以收到 256 个包之后,才返回 ACK。在丢包率比较严重的网络下,更多的 ACK 块可以减少重传量,提升网络效率。
- Ack Delay。TCP 计算 RTT 时没有考虑接收方处理数据的延迟,如下图所示,这段延迟即 ACK Delay。QUIC 考虑了这段延迟,使得 RTT 的计算更加准确。
优化的流量控制
- Stream 级别的流量控制中,
接收窗口 = 最大接收窗口- 已接收数据。 - Connection 级别的流量控制中,
接收窗口 = Stream1接收窗口 + Stream2接收窗口 + ... + StreamN接收窗口。 - TCP 通过滑动窗口来控制流量,如果某一个包丢失了,滑动窗口并不能跨过丢失的包继续滑动,而是会卡在丢失的位置,等待数据重传后,才能继续滑动。
- QUIC 流量控制的核心是:不能建立太多的连接,以免响应端处理不过来;不能让某一个连接占用大量的资源,让其他连接没有资源可用。为此 QUIC 流量控制分为 2 个级别:连接级别(Connection Level)和 Stream 级别(Stream Level)。
加密认证的报文
- TCP 头部没有经过任何加密和认证,在传输过程中很容易被中间网络设备篡改,注入和窃听。
- QUIC 中报文都是经过加密和认证的,在传输过程中保证了数据的安全。
连接迁移
- TCP 连接是由(源 IP,源端口,目的 IP,目的端口)组成,这四者中一旦有一项发生改变,这个连接也就不能用了。如果我们从 5G 网络切换到 WiFi 网络,IP 地址就会改变,这个时候 TCP 连接也自然断掉了。
- QUIC 使用客户端生成的 64 位 ID 来表示一条连接,只要 ID 不变,这条连接也就一直维持着,不会中断。
前向纠错机制
- 发送端需要发送三个包,QUIC 在传输时会计算出这三个包的异或值,并单独发出一个校验包,也就是总共发出了四个包。
- 如果某一个包(非校验包)传输时丢失了,则可以通过另外三个包计算出丢失数据包的内容。
- 当然这种技术只能用在丢失一个包的情况下,如果丢失了多个包,就只能进行重传了。
- QUIC 中发送数据时,除了发送本身的数据包,还会发送验证包,以减少数据丢失导致的重传。
可以看出,QUIC 丢掉了 TCP 的包袱,基于 UDP,实现了一个安全高效可靠的 HTTP 通信协议。凭借着 0-RTT 建立连接、传输层多路复用、连接迁移、改进的拥塞控制、流量控制等特性,QUIC 在绝大多数场景下获得了比 HTTP/2 更好的效果,HTTP/3 真是未来可期。
TCP
目前为止,并没有谈到浏览器加载Web页面所使用的其他协议对性能的影响。
然而,真正的问题要比下面图片暗示的要多,TCP在HTTP开始前需要三次握手,来协定一个新连接的参数。

这意味着一个连接的创建所需要的最少往返次数,这使每个新连接的创建增加了额外的。
TCP Fast Open技术(在TCP3次握手的同时也进行数据交换)允许应用在SYN和SYN+ACK包中发送数据以避免这样的消耗。遗憾的是,仅被Linux和OSX支持。并且,社区的开发刚刚起步,在HTTP中使用TFO仍然有很多棘手的问题。
换句话说,TFO并不能保证随着SYN包发出的数据只会出现一次,很容易重复甚至引起恶意的回复攻击。因此,在一个TFO连接上的第一次请求就使用HTTP POST并不是一个明智的选择。更有问题的是,需要GET同样是有副作用的,但是浏览器并没有很好的方式来区分这些URL。
TLS
TLS提供了另一种在TCP握手完成之后启动连接的方式。它看起来会是这样:
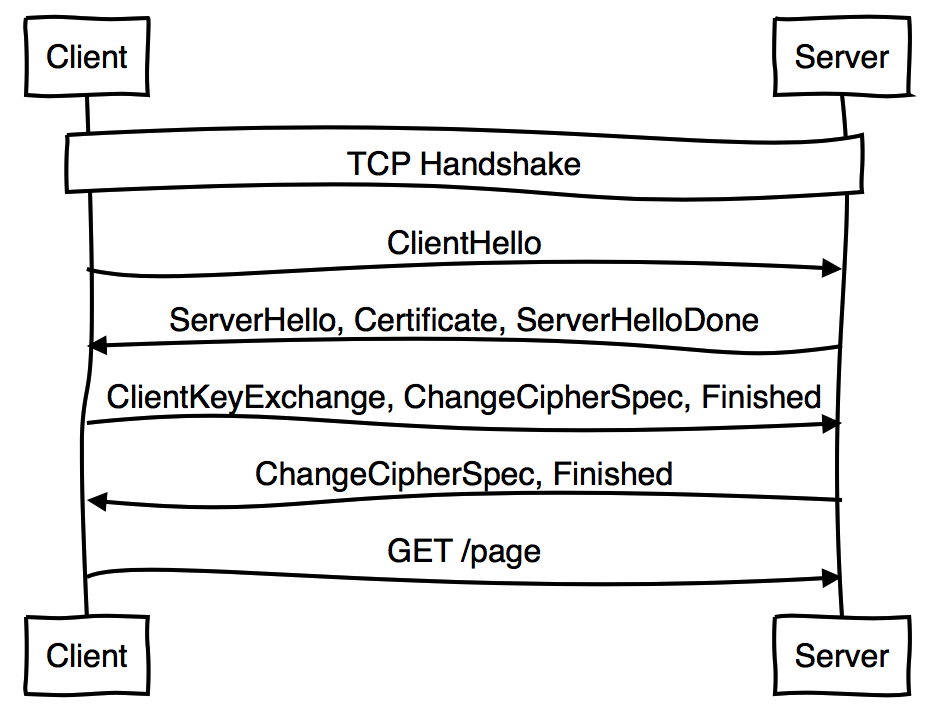
在HTTP能够发送数据前需要两次完整的往复交互。在客户端达到服务端之前,session tickets允许你可以避免一次往复次数:
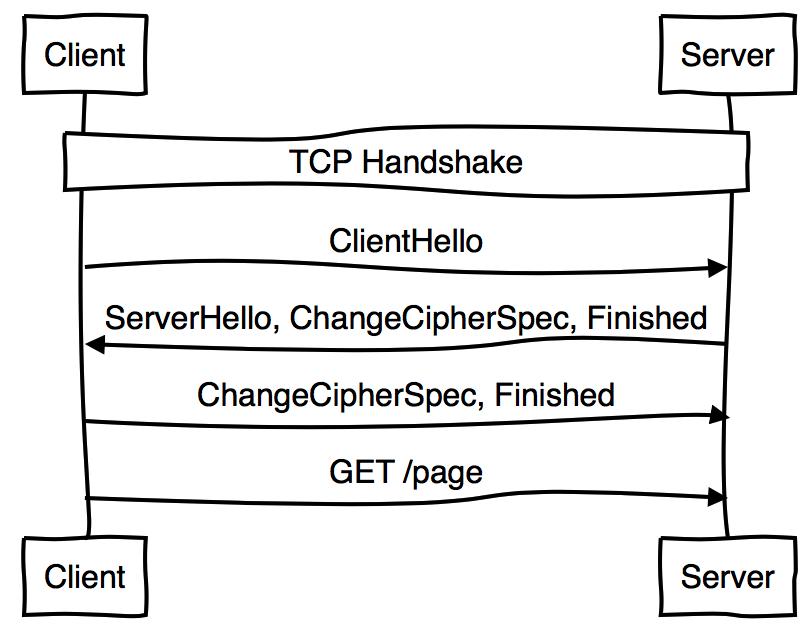
很快,TLS将支持在客户端到达服务端之前提供“0往复次数”(zero round trip)的握手,换言之,HTTP可以在第一次往复中发送数据,避免额外的消耗。然而,和TFO一样,你需要能够确保第一次往复中发送的数据不会造成任何不好的影响。
HTTP/next
TFO和TLS 1.3都是用来减少开启服务端连接的消耗。另一种方式尽量重用已开启的连接。
最后,这个讨论是如何使用HTTP/2的连接来使合并更加激烈(aggressively),不仅仅是它是否能够帮助减少开启新连接的消耗,并且是能够使已存在的连接更加高效,就像TCP一样长寿命并且繁忙。
这些事情包括向客户端推送证书,以证明该连接能够跟他初始协定的一样被更多的源使用。
另外一个更彻底的改变正在被讨论:使用UDP替换TCP,比如QUIC(Goole定制的一种基于UDP的低延迟互联网传输协议)。
7 - HTTPS
7.1 - 基本原理
HTTP 不安全
HTTP 之所以被 HTTPS 取代,最大的原因就是不安全,至于为什么不安全,看了下面这张图就一目了然了。
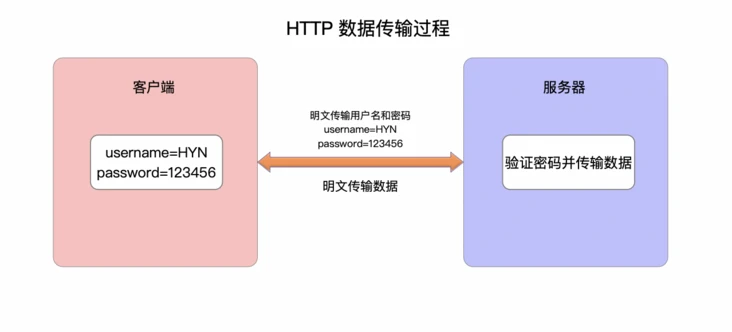
由图可见,HTTP 在传输数据的过程中,所有的数据都是明文传输,自然没有安全性可言,特别是一些敏感数据,比如用户密码和信用卡信息等,一旦被第三方获取,后果不堪设想。这里可能有人会说,我在前端页面对敏感数据进行加密不就行了,比如 MD5 加盐加密。这么想就太简单了。
首先 MD5 并不是加密算法,其全称是 Message Digest Algorithm MD5,意为信息摘要算法,是一种不可逆的哈希算法,也就是说经过前端 MD5 处理过的数据在服务器端是无法复原的。这里以密码举例,前端把用户密码通过 MD5 进行处理,并把得到的哈希值发送给服务器,服务器由于无法复原密码,就会直接用这个哈希值处理用户请求。所以第三方在获取这个哈希值后,可以绕过前端登录页面直接访问服务器,造成安全问题。另外,MD5 算法本身的安全性也存在缺陷,这里就不展开谈了。
总之 MD5,SHA-1 之类的哈希算法并不能让 HTTP 变得更安全。要想让 HTTP 更安全,只能使用真正的加密算法,因为加密算法可以用密钥加密或还原数据,只要确保密钥不被第三方获取,那就能确保数据传输的安全了。而这正是 HTTPS 的解决方案,那下面就来了解一下加密算法吧。
加密算法
HTTPS 解决数据传输安全问题的方案就是使用加密算法,具体来说是混合加密算法,也就是对称加密和非对称加密的混合使用,这里有必要先了解一下这两种加密算法的区别和优缺点。
对称加密
对称加密,顾名思义就是加密和解密都是使用同一个密钥,常见的对称加密算法有 DES、3DES 和 AES 等,其优缺点如下:
- 优点:算法公开、计算量小、加密速度快、加密效率高,适合加密比较大的数据。
- 缺点:
- 交易双方需要使用相同的密钥,也就无法避免密钥的传输,而密钥在传输过程中无法保证不被截获,因此对称加密的安全性得不到保证。
- 每对用户每次使用对称加密算法时,都需要使用其他人不知道的惟一密钥,这会使得发收信双方所拥有的钥匙数量急剧增长,密钥管理成为双方的负担。对称加密算法在分布式网络系统上使用较为困难,主要是因为密钥管理困难,使用成本较高。
如果直接将对称加密算法用在 HTTP 中,会是下面的效果:
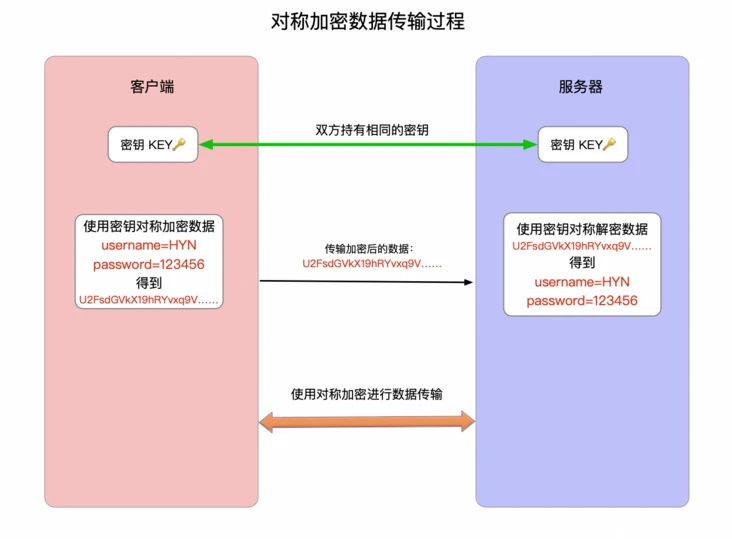
从图中可以看出,被加密的数据在传输过程中是无规则的乱码,即便被第三方截获,在没有密钥的情况下也无法解密数据,也就保证了数据的安全。但是有一个致命的问题,那就是既然双方要使用相同的密钥,那就必然要在传输数据之前先由一方把密钥传给另一方,那么在此过程中密钥就很有可能被截获,这样一来加密的数据也会被轻松解密。那如何确保密钥在传输过程中的安全呢?这就要用到非对称加密了。
非对称加密
非对称加密,顾名思义,就是加密和解密需要使用两个不同的密钥:公钥(public key)和私钥(private key)。公钥与私钥是一对,如果用公钥对数据进行加密,只有用对应的私钥才能解密;如果用私钥对数据进行加密,那么只有用对应的公钥才能解密。非对称加密算法实现机密信息交换的基本过程是:甲方生成一对密钥并将其中的一把作为公钥对外公开;得到该公钥的乙方使用公钥对机密信息进行加密后再发送给甲方;甲方再用自己保存的私钥对加密后的信息进行解密。如果对公钥和私钥不太理解,可以想象成一把钥匙和一个锁头,只是全世界只有你一个人有这把钥匙,你可以把锁头给别人,别人可以用这个锁把重要的东西锁起来,然后发给你,因为只有你一个人有这把钥匙,所以只有你才能看到被这把锁锁起来的东西。常用的非对称加密算法是 RSA 算法,其优缺点如下:
- 优点:算法公开,加密和解密使用不同的钥匙,私钥不需要通过网络进行传输,安全性很高。
- 缺点:计算量比较大,加密和解密速度相比对称加密慢很多。
由于非对称加密的强安全性,可以用它完美解决对称加密的密钥泄露问题,效果图如下:
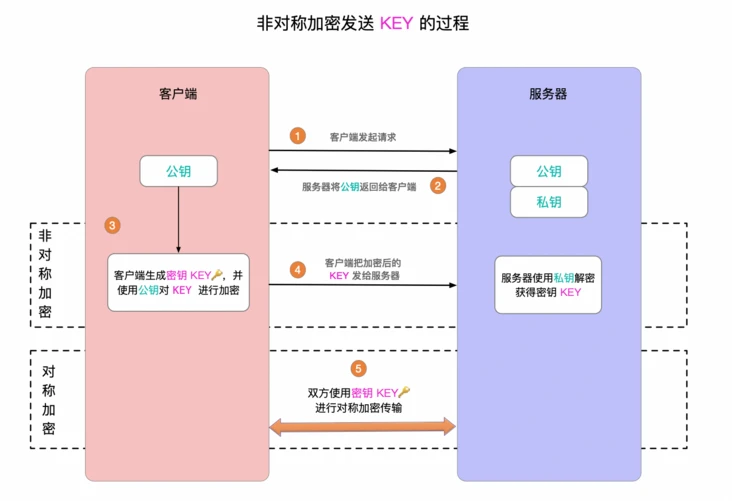
在上述过程中,客户端在拿到服务器的公钥后,会生成一个随机码 (用 KEY 表示,这个 KEY 就是后续双方用于对称加密的密钥),然后客户端使用公钥把 KEY 加密后再发送给服务器,服务器使用私钥将其解密,这样双方就有了同一个密钥 KEY,然后双方再使用 KEY 进行对称加密交互数据。在非对称加密传输 KEY 的过程中,即便第三方获取了公钥和加密后的 KEY,在没有私钥的情况下也无法破解 KEY (私钥存在服务器,泄露风险极小),也就保证了接下来对称加密的数据安全。而上面这个流程图正是 HTTPS 的雏形,HTTPS 正好综合了这两种加密算法的优点,不仅保证了通信安全,还保证了数据传输效率。
HTTPS 应用过程
先看一下维基百科对 HTTPS 的定义
Hypertext Transfer Protocol Secure (HTTPS) is an extension of the Hypertext Transfer Protocol (HTTP). It is used for secure communication over a computer network, and is widely used on the Internet. In HTTPS, the communication protocol is encrypted using Transport Layer Security (TLS) or, formerly, its predecessor, Secure Sockets Layer (SSL). The protocol is therefore also often referred to as HTTP over TLS, or HTTP over SSL.
HTTPS (Hypertext Transfer Protocol Secure) 是基于 HTTP 的扩展,用于计算机网络的安全通信,已经在互联网得到广泛应用。在 HTTPS 中,原有的 HTTP 协议会得到 TLS (安全传输层协议) 或其前辈 SSL (安全套接层) 的加密。因此 HTTPS 也常指 HTTP over TLS 或 HTTP over SSL。
可见HTTPS 并非独立的通信协议,而是对 HTTP 的扩展,保证了通信安全,二者关系如下:

也就是说 HTTPS = HTTP + SSL / TLS。
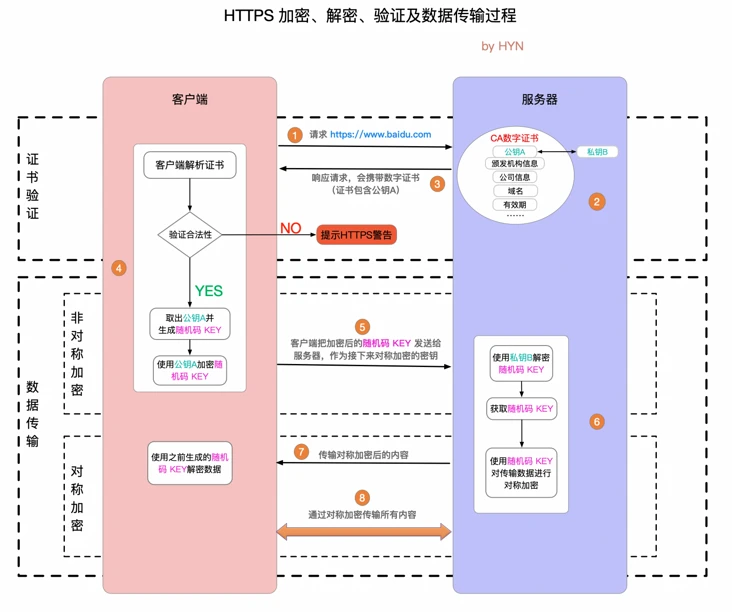
看上去眼花缭乱,不要怕,且听我细细道来。HTTPS 的整个通信过程可以分为两大阶段:证书验证和数据传输阶段,数据传输阶段又可以分为非对称加密和对称加密两个阶段。具体流程按图中的序号讲解。
- 客户端请求 HTTPS 网址,然后连接到 server 的 443 端口 (HTTPS 默认端口,类似于 HTTP 的80端口)。
- 采用 HTTPS 协议的服务器必须要有一套数字 CA (Certification Authority)证书,证书是需要申请的,并由专门的数字证书认证机构(CA)通过非常严格的审核之后颁发的电子证书 (当然了是要钱的,安全级别越高价格越贵)。颁发证书的同时会产生一个私钥和公钥。私钥由服务端自己保存,不可泄漏。公钥则是附带在证书的信息中,可以公开的。证书本身也附带一个证书电子签名,这个签名用来验证证书的完整性和真实性,可以防止证书被篡改。
- 服务器响应客户端请求,将证书传递给客户端,证书包含公钥和大量其他信息,比如证书颁发机构信息,公司信息和证书有效期等。Chrome 浏览器点击地址栏的锁标志再点击证书就可以看到证书详细信息。
- 客户端解析证书并对其进行验证。如果证书不是可信机构颁布,或者证书中的域名与实际域名不一致,或者证书已经过期,就会向访问者显示一个警告,由其选择是否还要继续通信。就像下面这样:

- 如果证书没有问题,客户端就会从服务器证书中取出服务器的公钥A。然后客户端还会生成一个随机码 KEY,并使用公钥A将其加密。
- 客户端把加密后的随机码 KEY 发送给服务器,作为后面对称加密的密钥。
- 服务器在收到随机码 KEY 之后会使用私钥B将其解密。经过以上这些步骤,客户端和服务器终于建立了安全连接,完美解决了对称加密的密钥泄露问题,接下来就可以用对称加密愉快地进行通信了。
- 服务器使用密钥 (随机码 KEY)对数据进行对称加密并发送给客户端,客户端使用相同的密钥 (随机码 KEY)解密数据。
- 双方使用对称加密愉快地传输所有数据。
数字签名与证书
黑客虽然拿不到会话密钥,无法破解密文,但可以通过窃听收集到足够多的密文,再尝试着修改、重组后发给网站。因为没有完整性保证,服务器只能“照单全收”,然后他就可以通过服务器的响应获取进一步的线索,最终就会破解出明文。
另外,黑客也可以伪造身份发布公钥。如果你拿到了假的公钥,混合加密就完全失效了。你以为自己是在和“某宝”通信,实际上网线的另一端却是黑客,银行卡号、密码等敏感信息就在“安全”的通信过程中被窃取了。
所以,在机密性的基础上还必须加上完整性、身份认证等特性,才能实现真正的安全。
摘要算法
实现完整性的手段主要是摘要算法(Digest Algorithm),也就是常说的散列函数、哈希函数(Hash Function)。
你可以把摘要算法近似地理解成一种特殊的压缩算法,它能够把任意长度的数据“压缩”成固定长度、而且独一无二的“摘要”字符串,就好像是给这段数据生成了一个数字“指纹”。
换一个角度,也可以把摘要算法理解成特殊的“单向”加密算法,它只有算法,没有密钥,加密后的数据无法解密,不能从摘要逆推出原文。
摘要算法实际上是把数据从一个“大空间”映射到了“小空间”,所以就存在“冲突”(collision,也叫碰撞)的可能性,就如同现实中的指纹一样,可能会有两份不同的原文对应相同的摘要。好的摘要算法必须能够“抵抗冲突”,让这种可能性尽量地小。
因为摘要算法对输入具有“单向性”和“雪崩效应”,输入的微小不同会导致输出的剧烈变化,所以也被 TLS 用来生成伪随机数(PRF,pseudo random function)。
你一定在日常工作中听过、或者用过 MD5(Message-Digest 5)、SHA-1(Secure Hash Algorithm 1),它们就是最常用的两个摘要算法,能够生成 16 字节和 20 字节长度的数字摘要。但这两个算法的安全强度比较低,不够安全,在 TLS 里已经被禁止使用了。
目前 TLS 推荐使用的是 SHA-1 的后继者:SHA-2。
SHA-2 实际上是一系列摘要算法的统称,总共有 6 种,常用的有 SHA224、SHA256、SHA384,分别能够生成 28 字节、32 字节、48 字节的摘要。
完整性
摘要算法保证了“数字摘要”和原文是完全等价的。所以,我们只要在原文后附上它的摘要,就能够保证数据的完整性。
比如,你发了条消息:“转账 1000 元”,然后再加上一个 SHA-2 的摘要。网站收到后也计算一下消息的摘要,把这两份“指纹”做个对比,如果一致,就说明消息是完整可信的,没有被修改。
如果黑客在中间哪怕改动了一个标点符号,摘要也会完全不同,网站计算比对就会发现消息被窜改,是不可信的。
不过摘要算法不具有机密性,如果明文传输,那么黑客可以修改消息后把摘要也一起改了,网站还是鉴别不出完整性。
所以,真正的完整性必须要建立在机密性之上,在混合加密系统里用会话密钥加密消息和摘要,这样黑客无法得知明文,也就没有办法动手脚了。
这有个术语,叫哈希消息认证码(HMAC)。
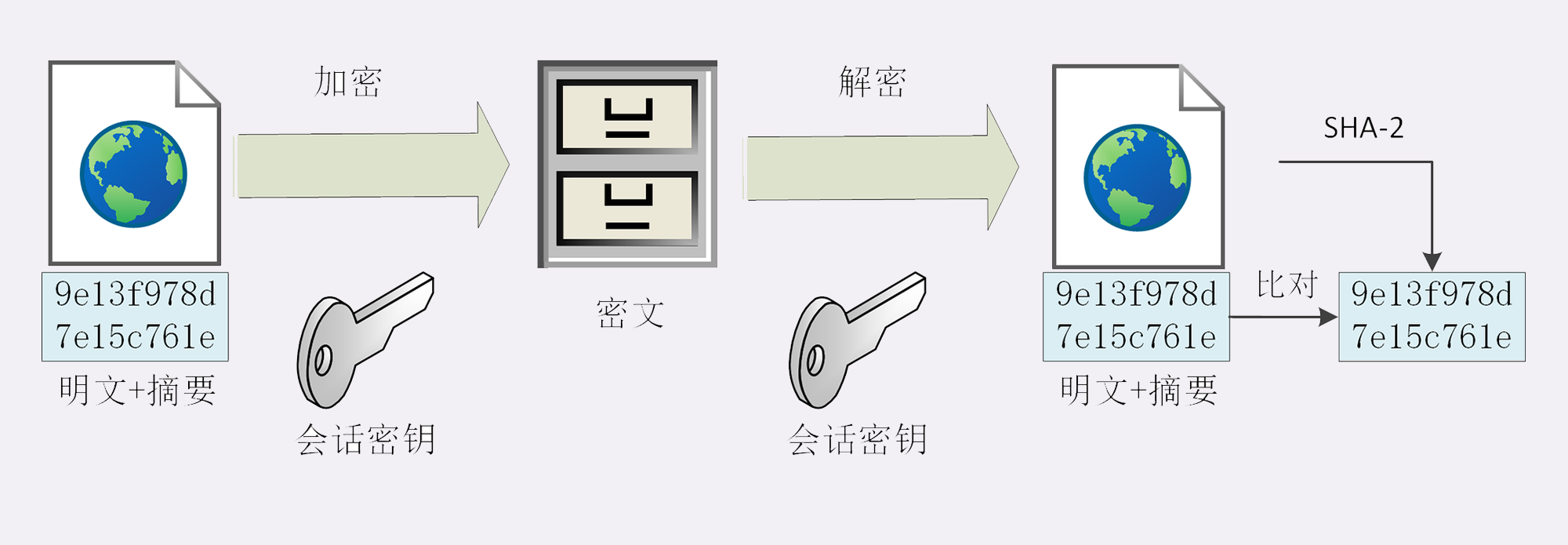
数字签名
加密算法结合摘要算法,我们的通信过程可以说是比较安全了。但这里还有漏洞,就是通信的两个端点(endpoint)。
就像一开始所说的,黑客可以伪装成网站来窃取信息。而反过来,他也可以伪装成你,向网站发送支付、转账等消息,网站没有办法确认你的身份,钱可能就这么被偷走了。
现实生活中,解决身份认证的手段是签名和印章,只要在纸上写下签名或者盖个章,就能够证明这份文件确实是由本人而不是其他人发出的。
在这里,使用非对称加密里的“私钥”再加上摘要算法,就能够实现“数字签名”,同时实现“身份认证”和“不可否认”。
数字签名的原理其实很简单,就是把公钥私钥的用法反过来,之前是公钥加密、私钥解密,现在是私钥加密、公钥解密。
但又因为非对称加密效率太低,所以私钥只加密原文的摘要,这样运算量就小的多,而且得到的数字签名也很小,方便保管和传输。
签名和公钥一样完全公开,任何人都可以获取。但这个签名只有用私钥对应的公钥才能解开,拿到摘要后,再比对原文验证完整性,就可以像签署文件一样证明消息确实是你发的。
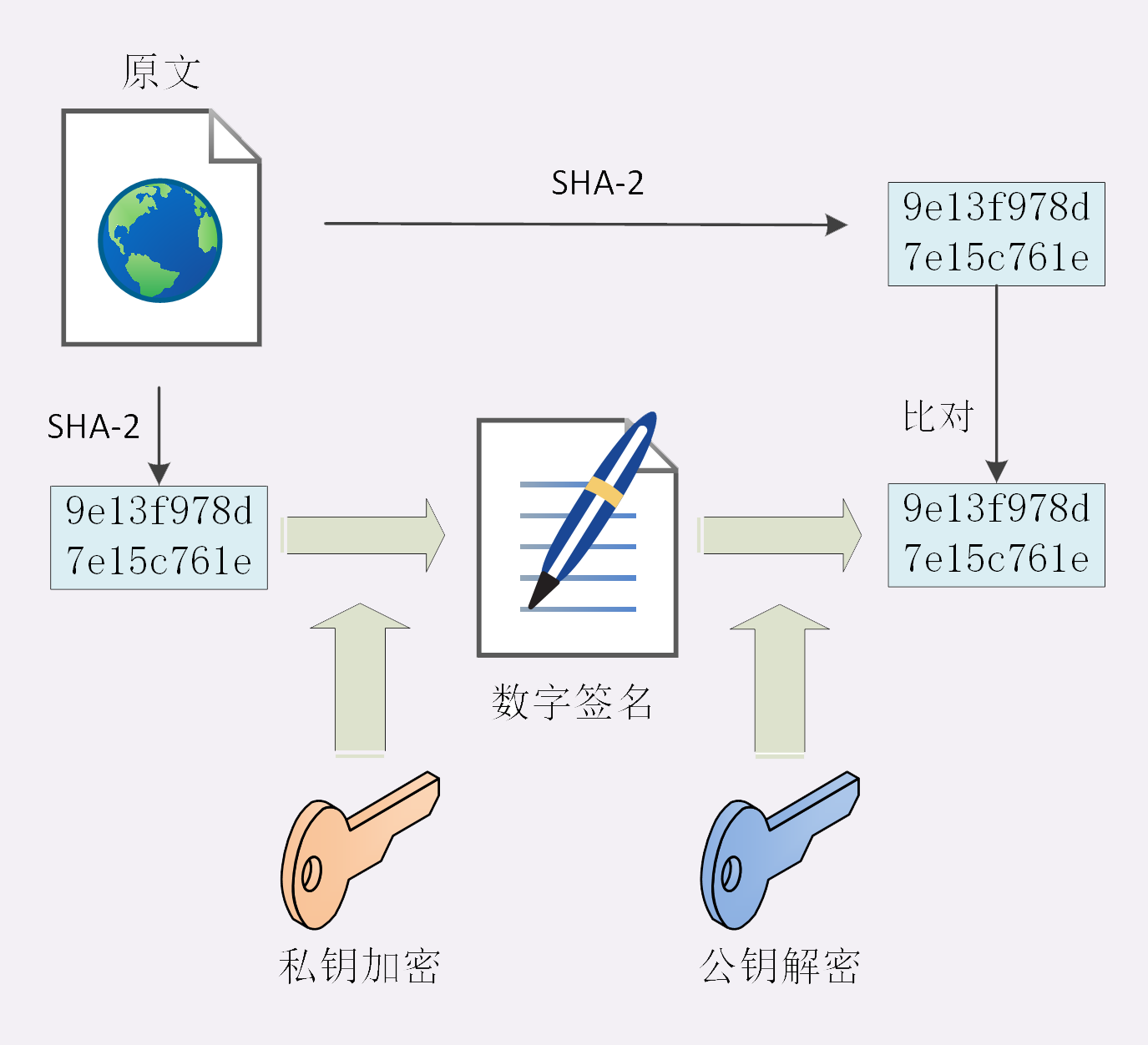
数字证书和 CA
到现在,综合使用对称加密、非对称加密和摘要算法,是不是已经完美了呢?
不是的,这里还有一个“公钥的信任”问题。因为谁都可以发布公钥,我们还缺少防止黑客伪造公钥的手段,也就是说,怎么来判断这个公钥就是你或者某宝的公钥呢?
真是“按下葫芦又起了瓢”,安全还真是个麻烦事啊,“一环套一环”的。
我们可以用类似密钥交换的方法来解决公钥认证问题,用别的私钥来给公钥签名,显然,这又会陷入“无穷递归”。但这次实在是“没招”了,要终结这个“死循环”,就必须引入“外力”,找一个公认的可信第三方,让它作为“信任的起点,递归的终点”,构建起公钥的信任链。
这个“第三方”就是我们常说的 CA(Certificate Authority,证书认证机构)。它就像网络世界里的公安局、教育部、公证中心,具有极高的可信度,由它来给各个公钥签名,用自身的信誉来保证公钥无法伪造,是可信的。CA 对公钥的签名认证也是有格式的,不是简单地把公钥绑定在持有者身份上就完事了,还要包含序列号、用途、颁发者、有效时间等等,把这些打成一个包再签名,完整地证明公钥关联的各种信息,形成“数字证书”(Certificate)。
知名的 CA 全世界就那么几家,比如 DigiCert、VeriSign、Entrust、Let’s Encrypt 等,它们签发的证书分 DV、OV、EV 三种,区别在于可信程度。
DV 是最低的,只是域名级别的可信,背后是谁不知道。EV 是最高的,经过了法律和审计的严格核查,可以证明网站拥有者的身份(在浏览器地址栏会显示出公司的名字,例如 Apple、GitHub 的网站)。
不过,CA 怎么证明自己呢?
这还是信任链的问题。小一点的 CA 可以让大 CA 签名认证,但链条的最后,也就是Root CA,就只能自己证明自己了,这个就叫“自签名证书”(Self-Signed Certificate)或者“根证书”(Root Certificate)。你必须相信,否则整个证书信任链就走不下去了。
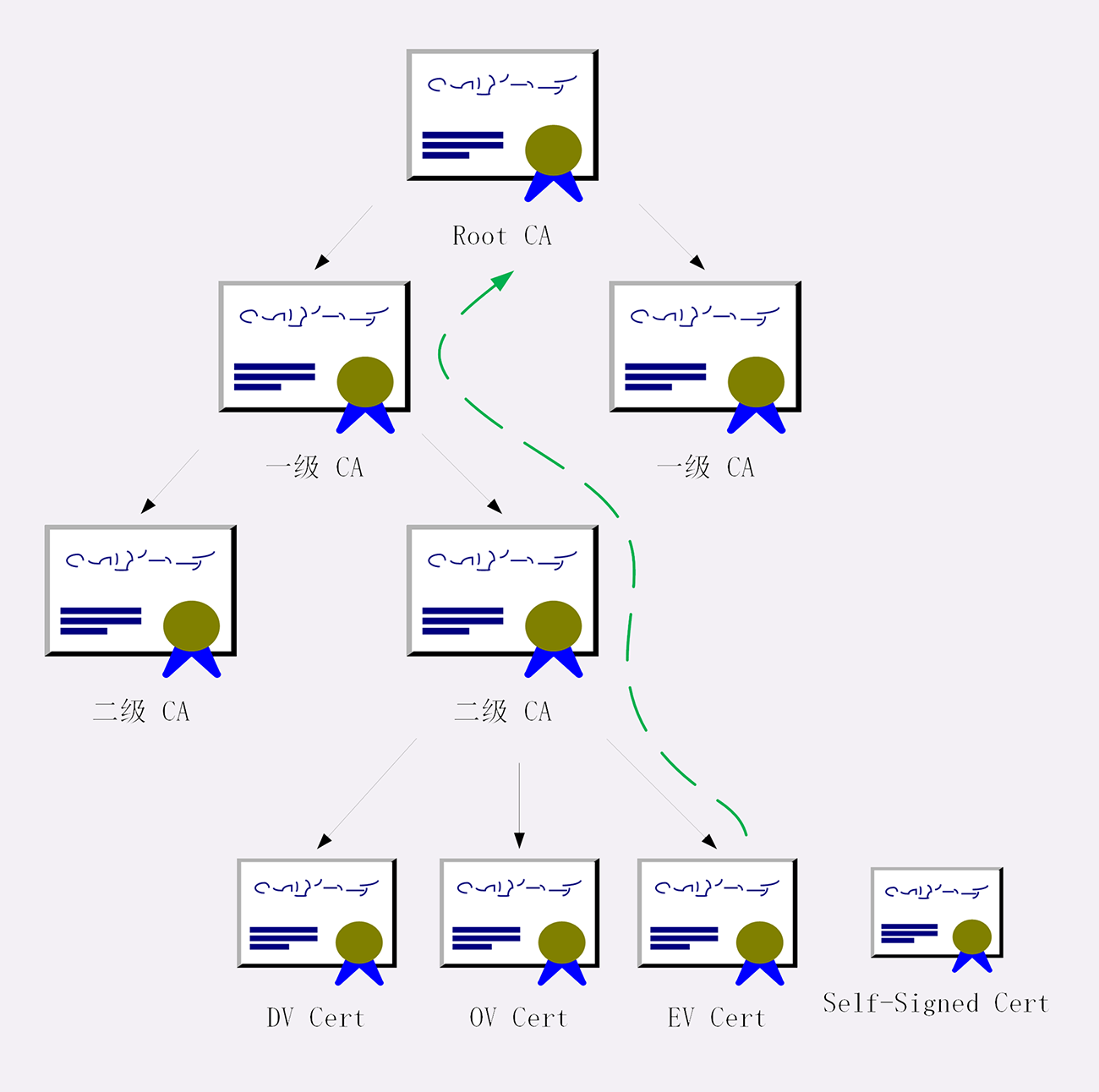
有了这个证书体系,操作系统和浏览器都内置了各大 CA 的根证书,上网的时候只要服务器发过来它的证书,就可以验证证书里的签名,顺着证书链(Certificate Chain)一层层地验证,直到找到根证书,就能够确定证书是可信的,从而里面的公钥也是可信的。
证书体系的弱点
证书体系(PKI,Public Key Infrastructure)虽然是目前整个网络世界的安全基础设施,但绝对的安全是不存在的,它也有弱点,还是关键的“信任”二字。
如果 CA 失误或者被欺骗,签发了错误的证书,虽然证书是真的,可它代表的网站却是假的。
还有一种更危险的情况,CA 被黑客攻陷,或者 CA 有恶意,因为它(即根证书)是信任的源头,整个信任链里的所有证书也就都不可信了。
这两种事情并不是“耸人听闻”,都曾经实际出现过。所以,需要再给证书体系打上一些补丁。
针对第一种,开发出了 CRL(证书吊销列表,Certificate revocation list)和 OCSP(在线证书状态协议,Online Certificate Status Protocol),及时废止有问题的证书。
对于第二种,因为涉及的证书太多,就只能操作系统或者浏览器从根上“下狠手”了,撤销对 CA 的信任,列入“黑名单”,这样它颁发的所有证书就都会被认为是不安全的。
HTTPS 建立连接
当你在浏览器地址栏里键入“https”开头的 URI,再按下回车,会发生什么呢?
浏览器首先要从 URI 里提取出协议名和域名。因为协议名是“https”,所以浏览器就知道了端口号是默认的 443,它再用 DNS 解析域名,得到目标的 IP 地址,然后就可以使用三次握手与网站建立 TCP 连接了。
在 HTTP 协议里,建立连接后,浏览器会立即发送请求报文。但现在是 HTTPS 协议,它需要再用另外一个“握手”过程,在 TCP 上建立安全连接,之后才是收发 HTTP 报文。
这个“握手”过程与 TCP 有些类似,是 HTTPS 和 TLS 协议里最重要、最核心的部分,懂了它,你就可以自豪地说自己“掌握了 HTTPS”。
TLS 协议的组成
在讲 TLS 握手之前,我先简单介绍一下 TLS 协议的组成。
TLS 包含几个子协议,你也可以理解为它是由几个不同职责的模块组成,比较常用的有记录协议、警报协议、握手协议、变更密码规范协议等。
- 记录协议(Record Protocol)规定了 TLS 收发数据的基本单位:记录(record)。它有点像是 TCP 里的 segment,所有的其他子协议都需要通过记录协议发出。但多个记录数据可以在一个 TCP 包里一次性发出,也并不需要像 TCP 那样返回 ACK。
- 警报协议(Alert Protocol)的职责是向对方发出警报信息,有点像是 HTTP 协议里的状态码。比如,protocol_version 就是不支持旧版本,bad_certificate 就是证书有问题,收到警报后另一方可以选择继续,也可以立即终止连接。
- 握手协议(Handshake Protocol)是 TLS 里最复杂的子协议,要比 TCP 的 SYN/ACK 复杂的多,浏览器和服务器会在握手过程中协商 TLS 版本号、随机数、密码套件等信息,然后交换证书和密钥参数,最终双方协商得到会话密钥,用于后续的混合加密系统。
- 最后一个是变更密码规范协议(Change Cipher Spec Protocol),它非常简单,就是一个“通知”,告诉对方,后续的数据都将使用加密保护。那么反过来,在它之前,数据都是明文的。
下面的这张图简要地描述了 TLS 的握手过程,其中每一个“框”都是一个记录,多个记录组合成一个 TCP 包发送。所以,最多经过两次消息往返(4 个消息)就可以完成握手,然后就可以在安全的通信环境里发送 HTTP 报文,实现 HTTPS 协议。

ECDHE 握手过程
刚才你看到的是握手过程的简要图,又画了一个详细图,下面我就用这个图来仔细剖析 TLS 的握手过程。
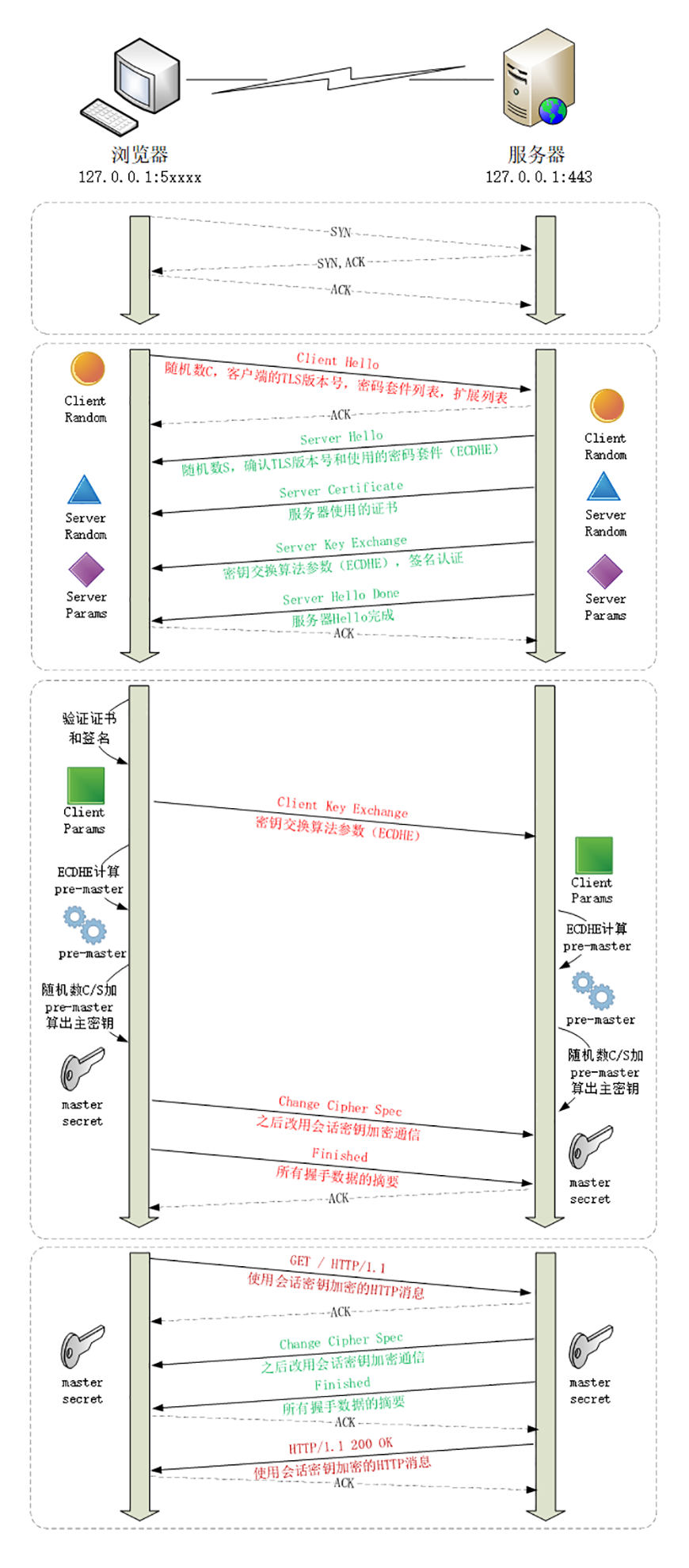
在 TCP 建立连接之后,浏览器会首先发一个“Client Hello”消息,也就是跟服务器“打招呼”。里面有客户端的版本号、支持的密码套件,还有一个随机数(Client Random),用于后续生成会话密钥。

Handshake Protocol: Client Hello
Version: TLS 1.2 (0x0303)
Random: 1cbf803321fd2623408dfe…
Cipher Suites (17 suites)
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 (0xc02f)
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (0xc030)
这个的意思就是:“我这边有这些这些信息,你看看哪些是能用的,关键的随机数可得留着。”复制代码
作为“礼尚往来”,服务器收到“Client Hello”后,会返回一个“Server Hello”消息。把版本号对一下,也给出一个随机数(Server Random),然后从客户端的列表里选一个作为本次通信使用的密码套件,在这里它选择了“TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384”。
Handshake Protocol: Server Hello
Version: TLS 1.2 (0x0303)
Random: 0e6320f21bae50842e96…
Cipher Suite: TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (0xc030)
这个的意思就是:“版本号对上了,可以加密,你的密码套件挺多,我选一个最合适的吧,用椭圆曲线加 RSA、AES、SHA384。我也给你一个随机数,你也得留着。”复制代码
然后,服务器为了证明自己的身份,就把证书也发给了客户端(Server Certificate)。
接下来是一个关键的操作,因为服务器选择了 ECDHE 算法,所以它会在证书后发送“Server Key Exchange”消息,里面是椭圆曲线的公钥(Server Params),用来实现密钥交换算法,再加上自己的私钥签名认证。
Handshake Protocol: Server Key Exchange
EC Diffie-Hellman Server Params
Curve Type: named_curve (0x03)
Named Curve: x25519 (0x001d)
Pubkey: 3b39deaf00217894e...
Signature Algorithm: rsa_pkcs1_sha512 (0x0601)
Signature: 37141adac38ea4...
这相当于说:“刚才我选的密码套件有点复杂,所以再给你个算法的参数,和刚才的随机数一样有用,别丢了。为了防止别人冒充,我又盖了个章。”复制代码
之后是“Server Hello Done”消息,服务器说:“我的信息就是这些,打招呼完毕。”
这样第一个消息往返就结束了(两个 TCP 包),结果是客户端和服务器通过明文共享了三个信息:Client Random、Server Random 和 Server Params。
客户端这时也拿到了服务器的证书,那这个证书是不是真实有效的呢?
这就要用到第 25 讲里的知识了,开始走证书链逐级验证,确认证书的真实性,再用证书公钥验证签名,就确认了服务器的身份:“刚才跟我打招呼的不是骗子,可以接着往下走。”
然后,客户端按照密码套件的要求,也生成一个椭圆曲线的公钥(Client Params),用“Client Key Exchange”消息发给服务器。
Handshake Protocol: Client Key Exchange
EC Diffie-Hellman Client Params
Pubkey: 8c674d0e08dc27b5eaa…
现在客户端和服务器手里都拿到了密钥交换算法的两个参数(Client Params、Server Params),就用 ECDHE 算法一阵算,算出了一个新的东西,叫“Pre-Master”,其实也是一个随机数。
至于具体的计算原理和过程,因为太复杂就不细说了,但算法可以保证即使黑客截获了之前的参数,也是绝对算不出这个随机数的。
现在客户端和服务器手里有了三个随机数:Client Random、Server Random 和 Pre-Master。用这三个作为原始材料,就可以生成用于加密会 话的主密钥,叫“Master Secret”。而黑客因为拿不到“Pre-Master”,所以也就得不到主密钥。
为什么非得这么麻烦,非要三个随机数呢?
这就必须说 TLS 的设计者考虑得非常周到了,他们不信任客户端或服务器伪随机数的可靠性,为了保证真正的“完全随机”“不可预测”,把三个不可靠的随机数混合起来,那么“随机”的程度就非常高了,足够让黑客难以猜测。
你一定很想知道“Master Secret”究竟是怎么算出来的吧,贴一下 RFC 里的公式:
master_secret = PRF(pre_master_secret, "master secret",ClientHello.random + ServerHello.random)
这里的“PRF”就是伪随机数函数,它基于密码套件里的最后一个参数,比如这次的 SHA384,通过摘要算法来再一次强化“Master Secret”的随机性。复制代码
主密钥有 48 字节,但它也不是最终用于通信的会话密钥,还会再用 PRF 扩展出更多的密钥,比如客户端发送用的会话密钥(client_write_key)、服务器发送用的会话密钥(server_write_key)等等,避免只用一个密钥带来的安全隐患。
有了主密钥和派生的会话密钥,握手就快结束了。客户端发一个“Change Cipher Spec”,然后再发一个“Finished”消息,把之前所有发送的数据做个摘要,再加密一下,让服务器做个验证。
意思就是告诉服务器:“后面都改用对称算法加密通信了啊,用的就是打招呼时说的 AES,加密对不对还得你测一下。”
服务器也是同样的操作,发“Change Cipher Spec”和“Finished”消息,双方都验证加密解密 OK,握手正式结束,后面就收发被加密的 HTTP 请求和响应了。
RSA 握手过程
整个握手过程可真是够复杂的,但你可能会问了,好像这个过程和其他地方看到的不一样呢?
刚才说的其实是如今主流的 TLS 握手过程,这与传统的握手有两点不同。
第一个,使用 ECDHE 实现密钥交换,而不是 RSA,所以会在服务器端发出“Server Key Exchange”消息。
第二个,因为使用了 ECDHE,客户端可以不用等到服务器发回“Finished”确认握手完毕,立即就发出 HTTP 报文,省去了一个消息往返的时间浪费。这个叫“TLS False Start”,意思就是“抢跑”,和“TCP Fast Open”有点像,都是不等连接完全建立就提前发应用数据,提高传输的效率。
这里我也画了个图。
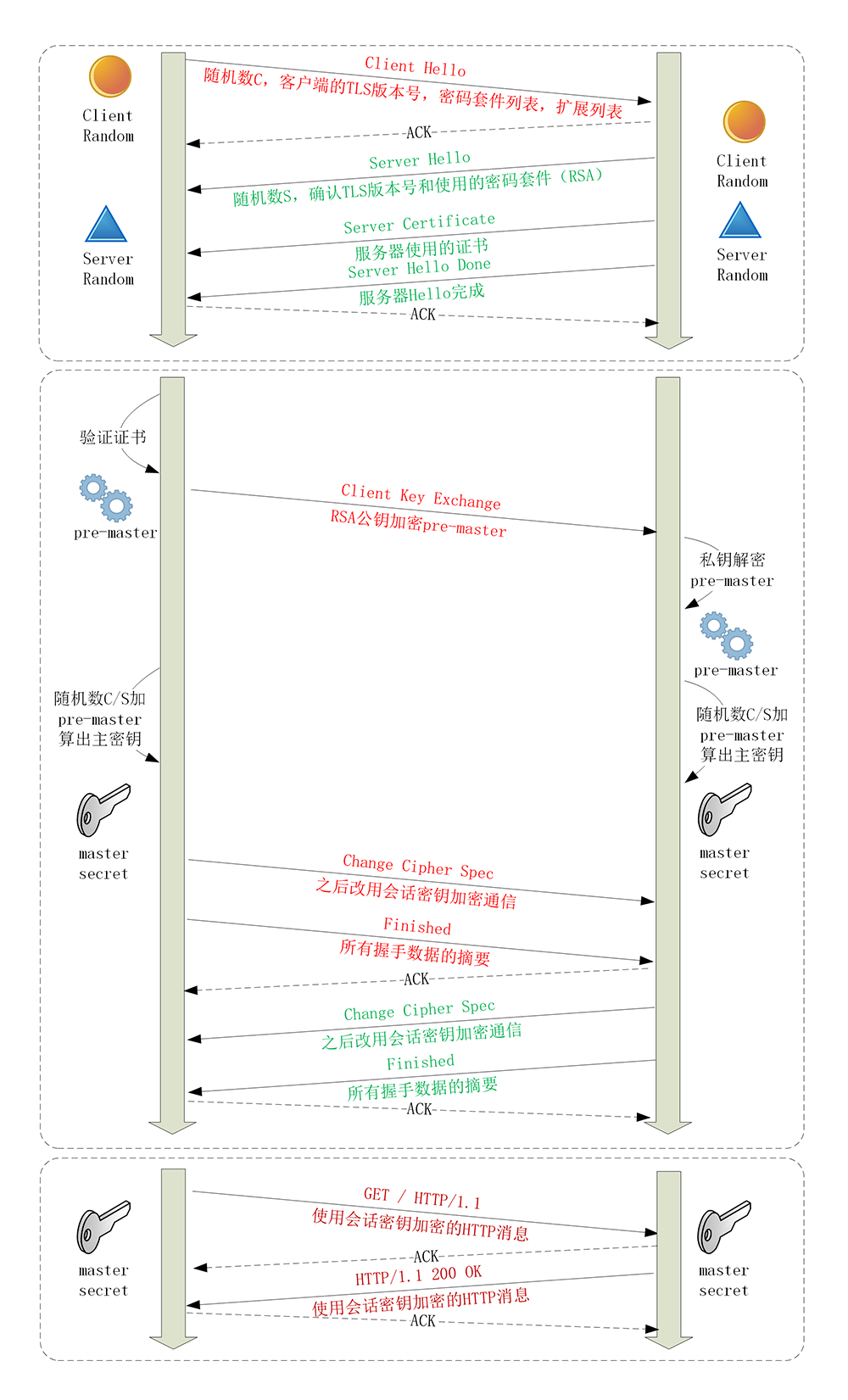
大体的流程没有变,只是“Pre-Master”不再需要用算法生成,而是客户端直接生成随机数,然后用服务器的公钥加密,通过“Client Key Exchange”消息发给服务器。服务器再用私钥解密,这样双方也实现了共享三个随机数,就可以生成主密钥。
双向认证
到这里 TLS 握手就基本讲完了。
不过上面说的是“单向认证”握手过程,只认证了服务器的身份,而没有认证客户端的身份。这是因为通常单向认证通过后已经建立了安全通信,用账号、密码等简单的手段就能够确认用户的真实身份。
但为了防止账号、密码被盗,有的时候(比如网上银行)还会使用 U 盾给用户颁发客户端证书,实现“双向认证”,这样会更加安全。
双向认证的流程也没有太多变化,只是在“Server Hello Done”之后,“Client Key Exchange”之前,客户端要发送“Client Certificate”消息,服务器收到后也把证书链走一遍,验证客户端的身份。
8 - WebSocket
8.1 - MQTT Over WS
8.2 - SSE WS HTTP
9 - 信息安全
9.1 - 单向散列
原文链接:单向散列函数
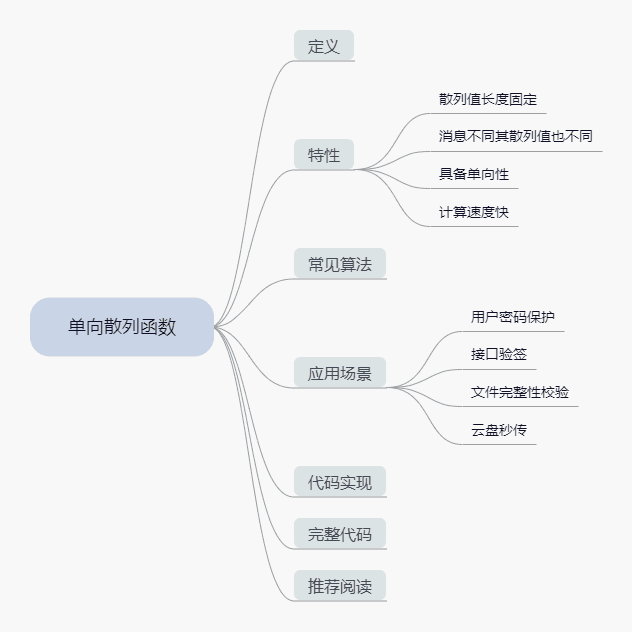
1. 定义
单向散列函数(one-way hash function)是指对不同的输入值,通过单向散列函数进行计算,得到固定长度的输出值。这个输入值称为消息(message),输出值称为散列值(hash value)。

单向散列函数也被称为消息摘要函数(message digest function)、哈希函数或者杂凑函数。输入的消息也称为原像(pre-image)。输出的散列值也称为消息摘要(message digest)或者指纹(fingerprint),相当于该消息的身份证。
单向散列函数有多种实现算法,常见的有:MD5、SHA-1、SHA-2和 SHA-3。
2. 特性
通过上面的定义,我们对单向散列函数的了解还是模糊的。下面介绍单向散列函数的特性,加深一下印象。
2.1 散列值长度固定
无论消息的长度有多少,使用同一算法计算出的散列值长度总是固定的。比如 MD5 算法,无论输入多少,产生的散列值长度总是 128 比特(16字节)。
然而比特是计算机能够识别的单位,而我们人类更习惯于使用十六进制字符串来表示(一个字节占用两位十六进制字符)。
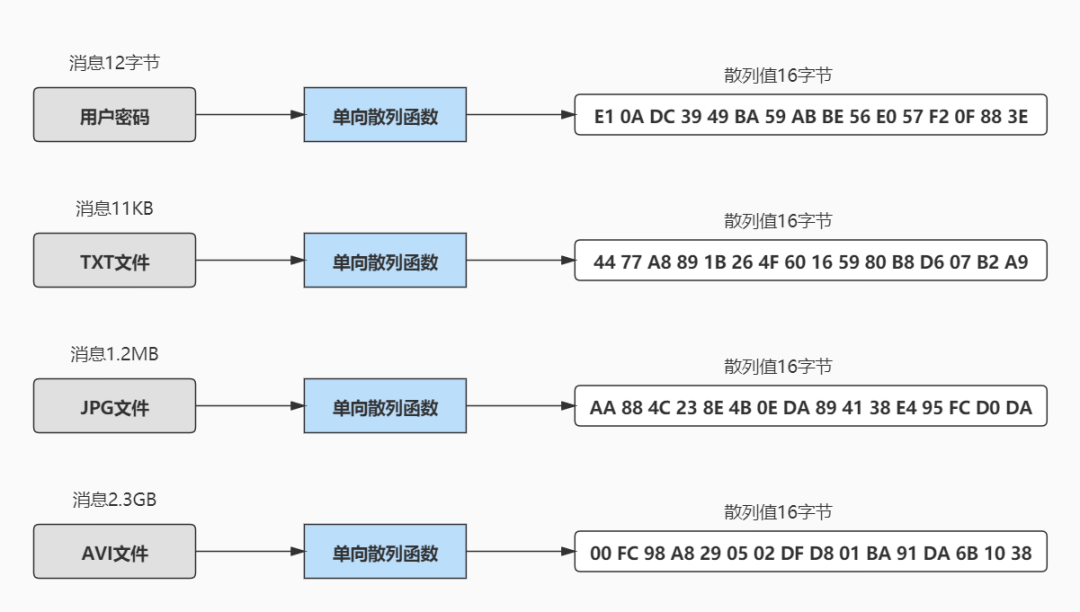
2.2 消息不同其散列值也不同
使用相同的消息,产生的散列值一定相同。
使用不同的消息,产生的散列值也不相同。哪怕只有一个比特的差别,得到的散列值也会有很大区别。
这一特性也叫做抗碰撞性,对于抗碰撞性弱的算法,我们不应该使用。
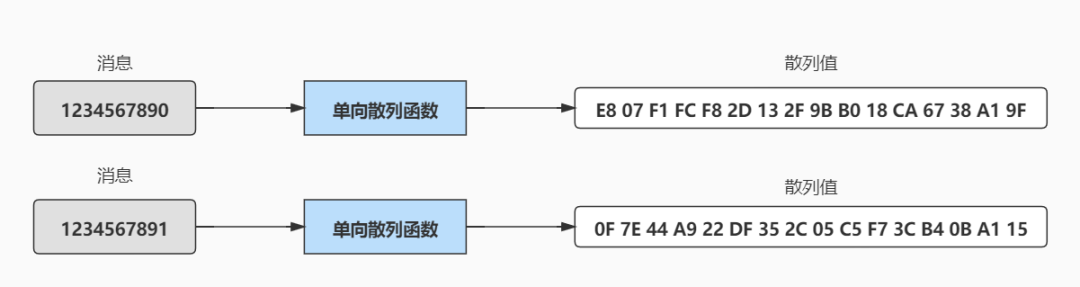
2.3 具备单向性
只能通过消息计算出散列值,无法通过散列值反算出消息。
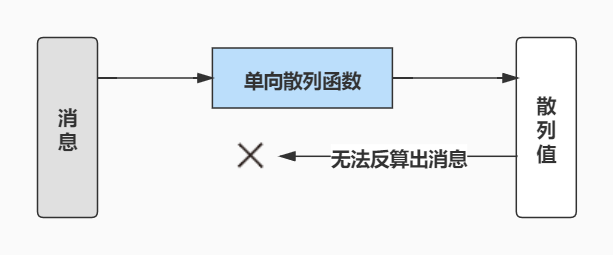
2.4 计算速度快
计算散列值的速度快。尽管消息越长,计算散列值的时间也越长,但也会在短时间内完成。
3. 常见算法
MD5 与 SHA-1 算法已被攻破,不应该被用于新的用途;SHA-2 与 SHA-3 还是安全的,可以使用。
SHA-2包括:SHA-224、SHA-256、SHA-384、SHA-512、SHA-512/224、SHA-512/256。
SHA-3包括:SHA3-224、SHA3-256、SHA3-384、SHA3-512。
| 算法名称 | 散列值长度 | 是否安全 |
|---|---|---|
| MD5 | 128 | 不安全 |
| SHA-1 | 160 | 不安全 |
| SHA-224 | 224 | 安全 |
| SHA-256 | 256 | 安全 |
| SHA-384 | 384 | 安全 |
| SHA-512 | 512 | 安全 |
| SHA-512/224 | 224 | 安全 |
| SHA-512/256 | 256 | 安全 |
| SHA3-224 | 224 | 安全 |
| SHA3-256 | 256 | 安全 |
| SHA3-384 | 384 | 安全 |
| SHA3-512 | 512 | 安全 |
4. 应用场景
单向散列函数并不能确保信息的机密性,它是一种保证信息完整性的密码技术。下面来看它的应用场景。
4.1 用户密码保护
用户在设置密码时,不记录密码本身,只记录密码的散列值,只有用户自己知道密码的明文。校验密码时,只要输入的密码正确,得到的散列值一定是一样的,表示校验正确。
为了防止彩虹表破解,还可以为密码进行加盐处理,只要验证密码时,使用相同的盐即可完成校验。

使用散列值存储密码的好处是:即使数据库被盗,也无法将密文反推出明文是什么,使密码保存更安全。
4.2 接口验签
为了保证接口的安全,可以采用签名的方式发送。
发送者与接收者要有一个共享秘钥。当发送者向接收者发送请求时,参数中附加上签名(签名由共享秘钥 *+* 业务参数,进行单向散列函数加密生成)。接收者收到后,使用相同的方式生成签名,再与收到的签名进行比对,如果一致,验签成功。
这样即可以验证业务参数是否被篡改,又能验明发送者的身份。

4.3 文件完整性校验
文件被挂载到网站时,同时也附上其散列值和算法,比如 Tomcat 官网。
用户下载后,计算其散列值,对比结果是否相同,从而校验文件的完整性。
4.4 云盘秒传
当我们将自己喜欢的视频放到网盘上时,发现只用了几秒的时间就上传成功了,而这个文件有几个G大小,是怎么做到的呢?
其实这个“秒传”功能可以利用单向散列函数来实现。
当我们上传一个文件时,云盘客户端会先为该文件生成一个散列值。拿着这个散列值去数据库中匹配,如果匹配到,说明该文件已经在云服务器存在。只需将该散列值与用户进行关联,便可完成本次“上传”。
这样,一个文件在云服务器上只会存一份,大大节约了云服务器的空间。
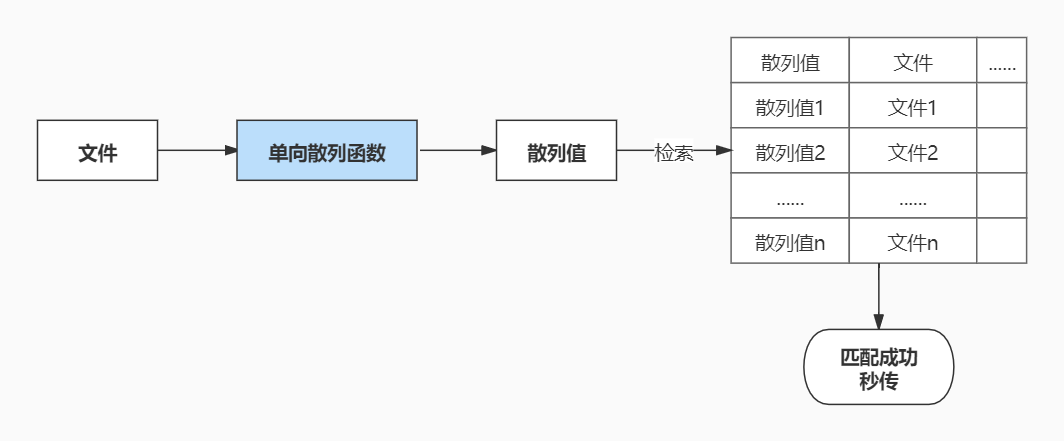
5. 代码实现
JDK的 java.security.MessageDigest 类为我们提供了消息摘要算法,用于 MD5和SHA的散列值生成。下面代码做了简单的封装,便于直接使用。
public class MDUtil {
/**
* MD5 加密
*
* @param data 要加密的数据
* @return 32位十六进制字符串
*/
public static String MD5(byte[] data) {
try {
MessageDigest md = MessageDigest.getInstance("MD5");
byte[] bytes = md.digest(data);
return bytesToHexString(bytes);
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
return "";
}
/**
* MD5 加密
*
* @param data 要加密的数据
* @return 32位十六进制字符串
*/
public static String MD5(String data) {
return MD5(data.getBytes());
}
/**
* SHA-1 加密
*
* @param data 要加密的数据
* @return 40位十六进制字符串
*/
public static String SHA1(byte[] data) {
try {
MessageDigest md = MessageDigest.getInstance("SHA-1");
byte[] bytes = md.digest(data);
return bytesToHexString(bytes);
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
return "";
}
/**
* SHA-1 加密
*
* @param data 要加密的数据
* @return 40位十六进制字符串
*/
public static String SHA1(String data) {
return SHA1(data.getBytes());
}
/**
* SHA-224 加密
*
* @param data 要加密的数据
* @return 56位十六进制字符串
*/
public static String SHA224(byte[] data) {
try {
MessageDigest md = MessageDigest.getInstance("SHA-224");
byte[] bytes = md.digest(data);
return bytesToHexString(bytes);
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
return "";
}
/**
* SHA-224 加密
*
* @param data 要加密的数据
* @return 56位十六进制字符串
*/
public static String SHA224(String data) {
return SHA224(data.getBytes());
}
/**
* SHA-256 加密
*
* @param data 要加密的数据
* @return 64位十六进制字符串
*/
public static String SHA256(byte[] data) {
try {
MessageDigest md = MessageDigest.getInstance("SHA-256");
byte[] bytes = md.digest(data);
return bytesToHexString(bytes);
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
return "";
}
/**
* SHA-256 加密
*
* @param data 要加密的数据
* @return 64位十六进制字符串
*/
public static String SHA256(String data) {
return SHA256(data.getBytes());
}
/**
* SHA-384 加密
*
* @param data 要加密的数据
* @return 96位十六进制字符串
*/
public static String SHA384(byte[] data) {
try {
MessageDigest md = MessageDigest.getInstance("SHA-384");
byte[] bytes = md.digest(data);
return bytesToHexString(bytes);
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
return "";
}
/**
* SHA-384 加密
*
* @param data 要加密的数据
* @return 96位十六进制字符串
*/
public static String SHA384(String data) {
return SHA384(data.getBytes());
}
/**
* SHA-512 加密
*
* @param data 要加密的数据
* @return 128位十六进制字符串
*/
public static String SHA512(byte[] data) {
try {
MessageDigest md = MessageDigest.getInstance("SHA-512");
byte[] bytes = md.digest(data);
return bytesToHexString(bytes);
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
return "";
}
/**
* SHA-512 加密
*
* @param data 要加密的数据
* @return 128位十六进制字符串
*/
public static String SHA512(String data) {
return SHA512(data.getBytes());
}
/**
* 将字节数组转换为十六进制字符串
*
* @param bytes 字节数组
* @return 十六进制字符串
*/
private static String bytesToHexString(byte[] bytes) {
StringBuilder hexValue = new StringBuilder();
for (byte b : bytes) {
int val = b & 0xFF;
if (val < 16) {
hexValue.append("0");
}
hexValue.append(Integer.toHexString(val));
}
return hexValue.toString();
}
}
下面分别使用这些算法计算“123456”的散列值:
public static void main(String[] args) {
System.out.println("MD5\t\t" + MDUtil.MD5("123456"));
System.out.println("SHA-1\t" + MDUtil.SHA1("123456"));
System.out.println("SHA-224\t" + MDUtil.SHA224("123456"));
System.out.println("SHA-256\t" + MDUtil.SHA256("123456"));
System.out.println("SHA-384\t" + MDUtil.SHA384("123456"));
System.out.println("SHA-512\t" + MDUtil.SHA512("123456"));
}
输出结果:
MD5 e10adc3949ba59abbe56e057f20f883e
SHA-1 7c4a8d09ca3762af61e59520943dc26494f8941b
SHA-224 f8cdb04495ded47615258f9dc6a3f4707fd2405434fefc3cbf4ef4e6
SHA-256 8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92
SHA-384 0a989ebc4a77b56a6e2bb7b19d995d185ce44090c13e2984b7ecc6d446d4b61ea9991b76a4c2f04b1b4d244841449454
SHA-512 ba3253876aed6bc22d4a6ff53d8406c6ad864195ed144ab5c87621b6c233b548baeae6956df346ec8c17f5ea10f35ee3cbc514797ed7ddd3145464e2a0bab413
我用的是Java8,还不支持 SHA-3,所以上面代码只封装了MD5、SHA-1和SHA-2。

从Java9开始支持SHA-3

9.2 - 对称加密
原文链接:对称加密
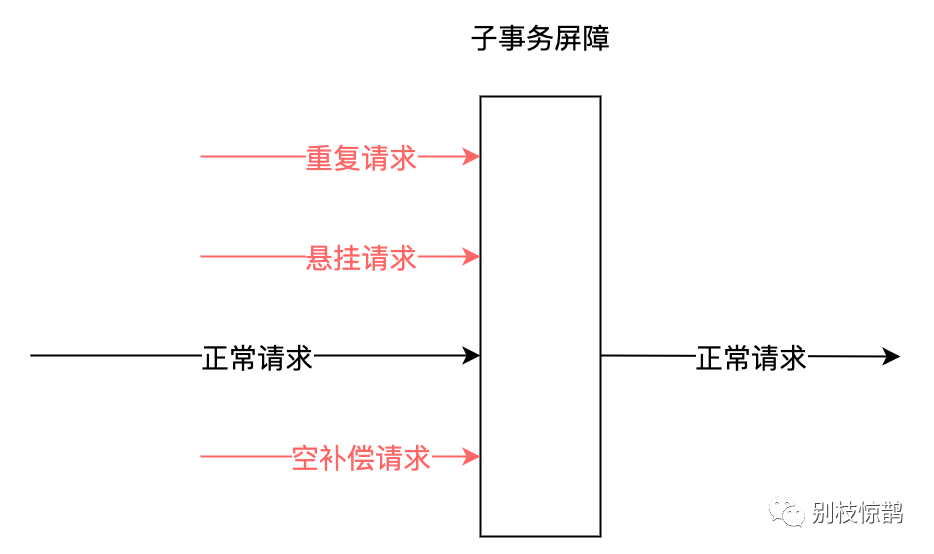
加密、解密和密钥
加密(Encrypt)是从明文生成密文的步骤,解密(Decrypt)是从密文还原成明文的步骤,而这两个步骤都需要用到密钥(Key)。这和我们现实中,用钥匙上锁和开锁是一样的。
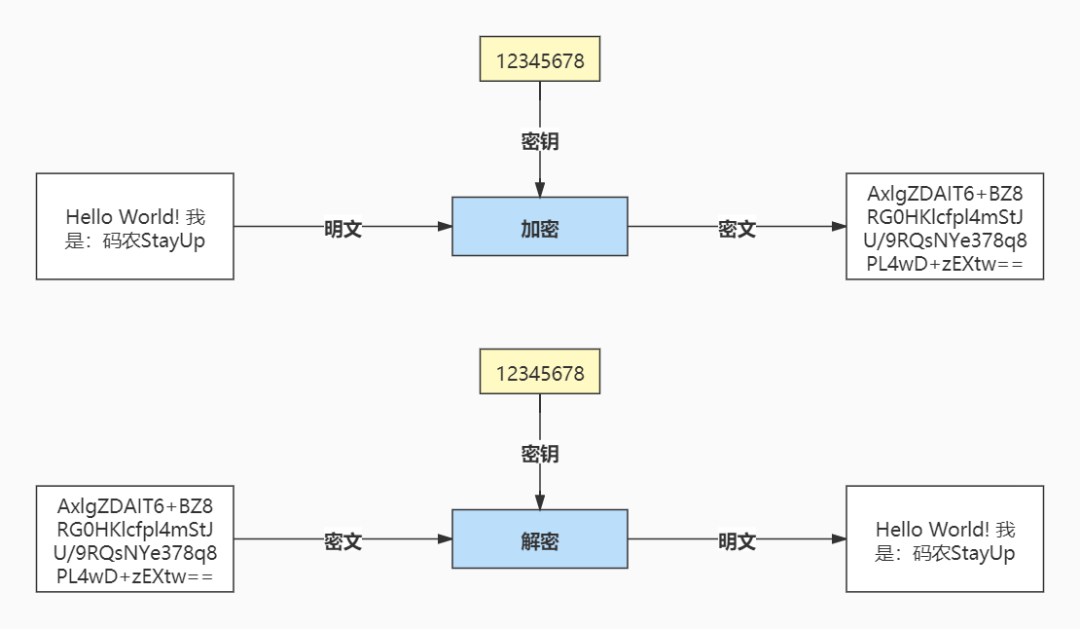
什么是对称加密
对称加密(Symmetric Cryptography)是密码学中的一类加密算法,这类算法在加密和解密时,使用相同的密钥。
对称加密又称为共享密钥加密,其最大的缺点是,对称加密的安全性依赖于密钥,一旦泄露,就意味着任何人都能解密消息。
对称加密的优点是加密速度快,所以在很多场合被使用。
常见算法
本节介绍对称加密的一些常见算法,包括DES、3DES和AES。
DES算法
DES(Data Encryption Standard,中文:数据加密标准),是一种对称加密算法。该算法在1976年被美国联邦政府的国家标准局确定为联邦资料处理标准(FIPS),并于1977年被发布,随后在国际上广泛流传开来。然而,随着计算机的进步,DES 已经能够被暴力破解,所以该算法已经不安全了。
DES是一种分组密码(Block Cipher,或者叫块加密),即将明文按64比特进行分组加密,每组生成64位比特的密文。它的密钥长度为56比特(从规格上来说,密钥长度是64比特,但由于每隔7比特会设置一个用于错误检查的比特,因此实际长度为56比特)。
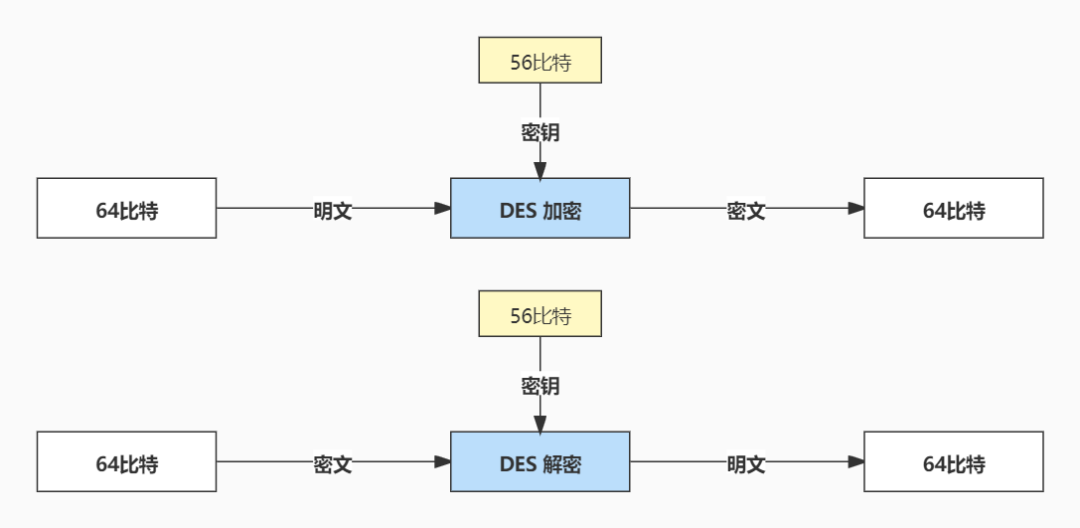
3DES算法
三重数据加密算法(Triple Data Encryption Algorithm,缩写为TDEA),简称3DES(Triple-DES),是DES的增强版,相当于对每组数据应用了三次DES算法。
由于DES算法的密钥长度过短,容易被暴力破解,为了解决这一问题,设计出了该算法。它使用简单的方法,通过增加DES密钥长度的方式来避免类似攻击,而不是一种全新的密码算法。
该算法在每次应用DES时,使用不同的密钥,所以有三把独立密钥。这三把密钥组成一起,是一个长度为168(56 + 56 + 56)比特的密钥,所以3DES算法的密钥总长度为168比特。
3DES的加密过程,并不是进行三次DES加密(加密→加密→加密),而是以密钥1、密钥2、密钥3的顺序,进行加密→解密→加密的过程。
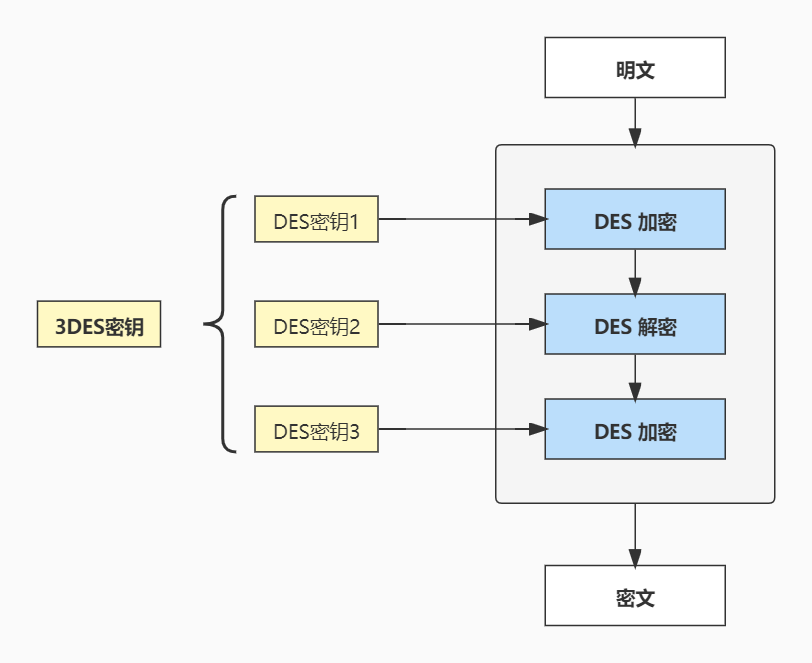
3DES的解密过程和加密正好相反,是以密钥3、密钥2、密钥1的顺序,进行解密→加密→解密的操作。
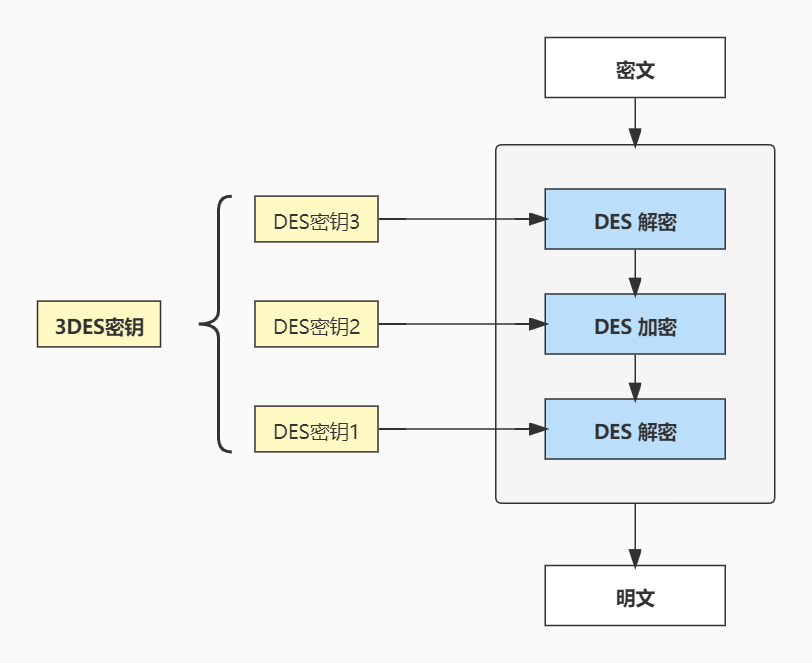
AES算法
AES(Advanced Encryption Standard),即高级加密标准,是取代DES算法的一种新的对称加密算法。AES算法是从全世界的企业和密码学家,提交的对称密码算法中竞选出来的,最终 Rijndael 加密算法胜出,所以AES又称为 Rijndael 加密算法。
AES也是一种分组密码,它的分组长度为128比特,密钥长度可以为128比特、192比特或256比特。
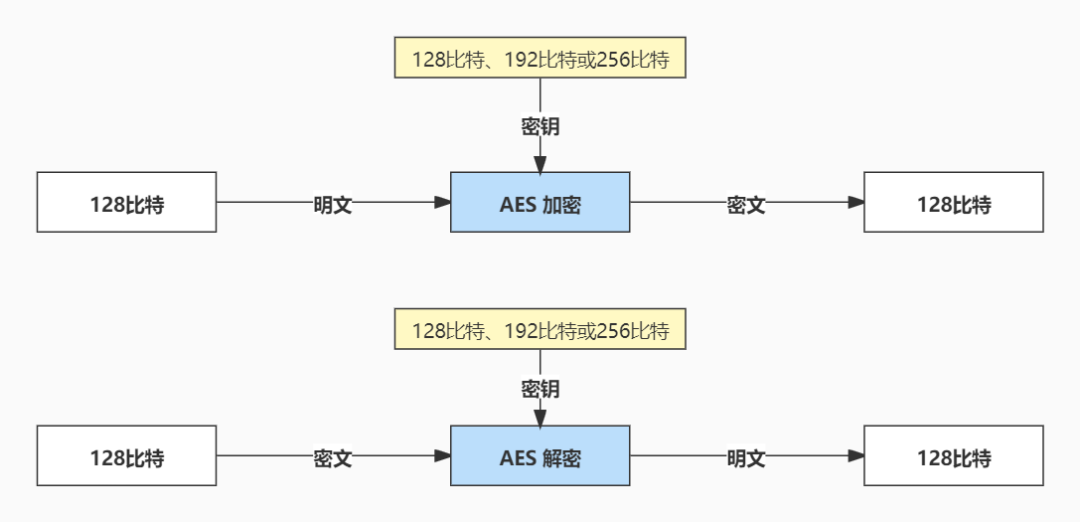
分组密码的模式
上面介绍的DES、3DES和AES都属于分组密码,它们只能加密固定长度的明文。如果需要加密更长的明文,就需要对分组密码进行迭代,而分组密码的迭代方法称为分组密码的模式(Model)。简而一句话:分组密码的模式,就是分组密码的迭代方式。
分组密码有很多种模式,这里主要介绍以下几种:ECB、CBC、CFB、OFB、CTR。
明文分组与密文分组
在下面对模式的介绍时,会用到两个术语,这里先介绍一下:
在分组密码中,我们称每组的明文为明文分组,每组生成的密文称为密文分组。
若将所有的明文分组合并起来就是完整的明文(先忽略填充),将所以的密文分组合并起来就是完整的密文。
ECB模式
ECB(Electronic CodeBook)模式,即电子密码本模式。该模式是将明文分组,加密后直接成为密文分组,分组之间没有关系。
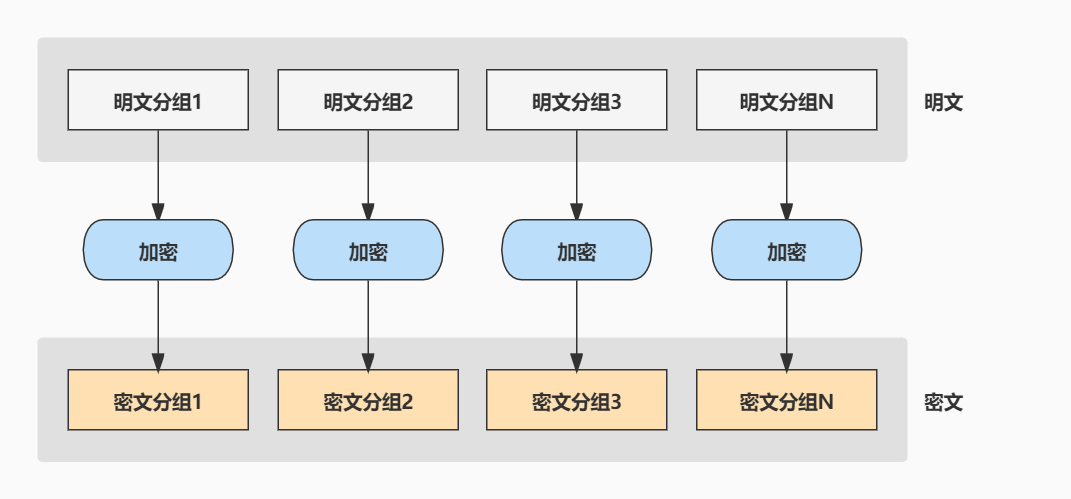
ECB模式是所有模式中最简单的一种,该模式的明文分组与密文分组是一一对应的关系,若明文分组相同,其密文分组也一定相同。因此,ECB模式也是最不安全的模式。
CBC模式
CBC(Cipher Block Chaining)模式,即密码分组链接模式。该模式首先将明文分组与前一个密文分组进行XOR运算,然后再进行加密。只有第一个明文分组特殊,需要提前为其生成一个与分组长度相同的比特序列,进行XOR运算,这个比特序列称为初始化向量(Initialization Vector),简称IV。
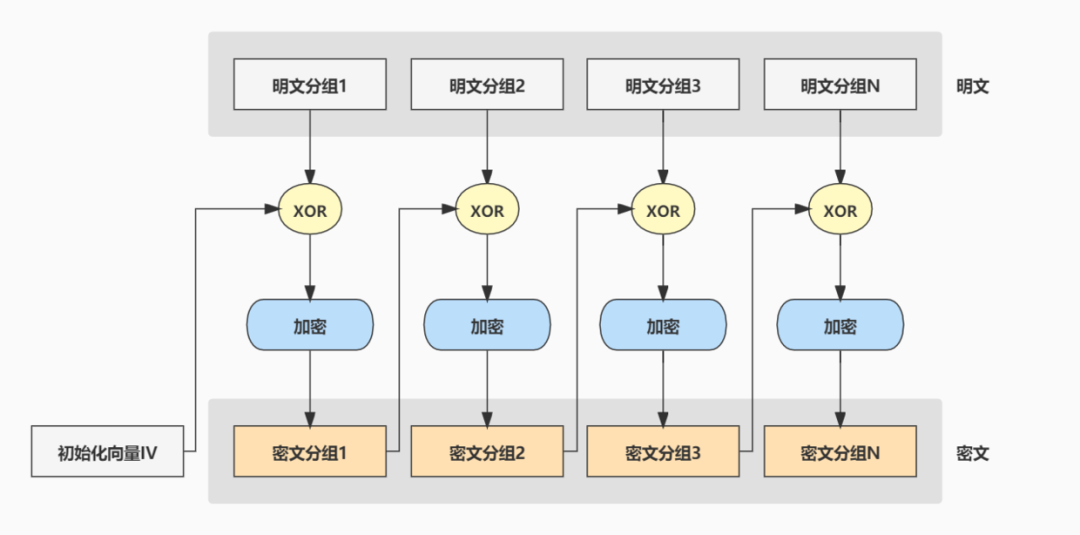
CFB模式
CFB(Cipher FeedBack)模式,即密文反馈模式。该模式首先将前一个密文分组进行加密,再与当前明文分组进行XOR运算,来生成密文分组。同样CFB模式也需要一个IV。
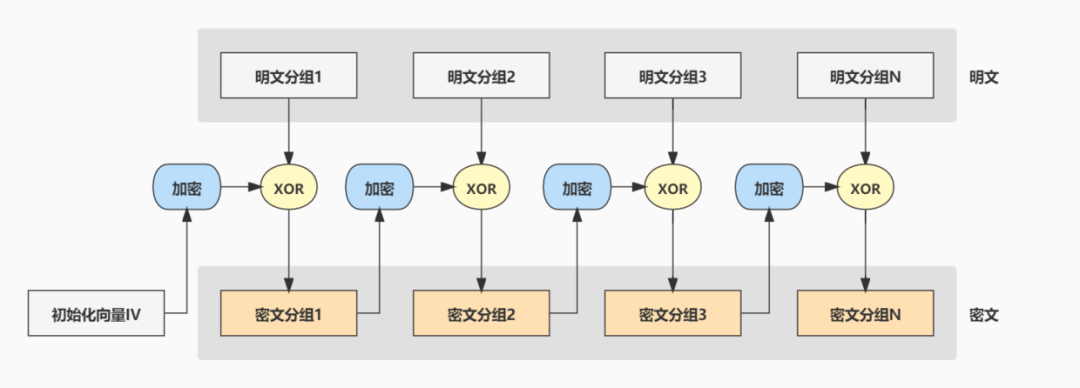
OFB模式
OFB(Output FeedBack)模式,即输出反馈模式。该模式会产生一个密钥流,即将密码算法的前一个输出值,做为当前密码算法的输入值。该输入值再与明文分组进行XOR运行,计算得出密文分组。该模式需要一个IV,进行加密后做为第一个分组的输入。
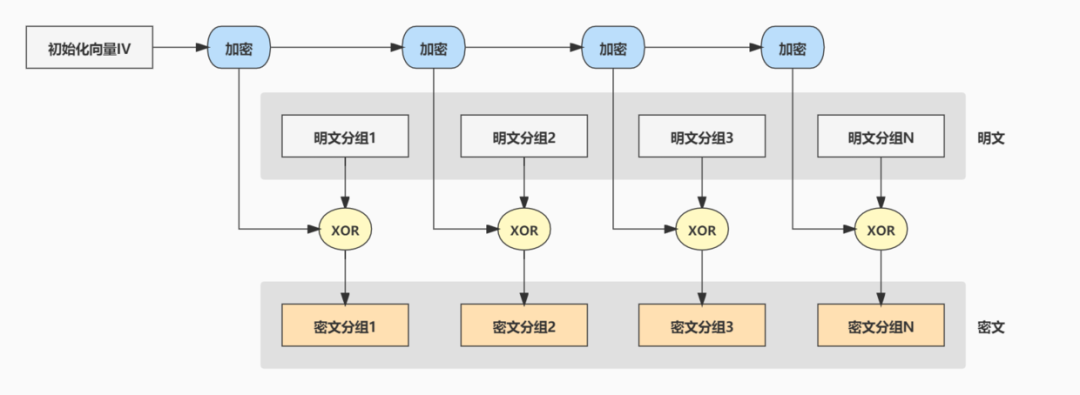
CTR模式
CTR(CounTeR)模式,即计数器模式。该模式也会产生一个密钥流,它通过递增一个计数器来产生连续的密钥流。对该计数器进行加密,再与明文分组进行XOR运算,计算得出密文分组。

分组密码的填充
在分组密码中,当数据长度不符合分组长度时,需要按一定的方式,将尾部明文分组进行填充,这种将尾部分组数据填满的方法称为填充(Padding)。
No Padding
即不填充,要求明文的长度,必须是加密算法分组长度的整数倍。
... | DD DD DD DD DD DD DD DD | DD DD DD DD DD DD DD DD |
ANSI X9.23
在填充字节序列中,最后一个字节填充为需要填充的字节长度,其余字节填充0。
... | DD DD DD DD DD DD DD DD | DD DD DD DD 00 00 00 04 |
ISO 10126
在填充字节序列中,最后一个字节填充为需要填充的字节长度,其余字节填充随机数。
... | DD DD DD DD DD DD DD DD | DD DD DD DD 81 A6 23 04 |
PKCS#5和PKCS#7
在填充字节序列中,每个字节填充为需要填充的字节长度。
... | DD DD DD DD DD DD DD DD | DD DD DD DD 04 04 04 04 |
ISO/IEC 7816-4
在填充字节序列中,第一个字节填充固定值80,其余字节填充0。若只需填充一个字节,则直接填充80。
... | DD DD DD DD DD DD DD DD | DD DD DD DD 80 00 00 00 |
... | DD DD DD DD DD DD DD DD | DD DD DD DD DD DD DD 80 |
Zero Padding
在填充字节序列中,每个字节填充为0。
... | DD DD DD DD DD DD DD DD | DD DD DD DD 00 00 00 00 |
Java代码实现
Java在底层已经封装好了对称加密的实现, 我们只需要使用即可。现在介绍几个重要的类:
SecureRandom类
SecureRandom类是一个强安全的随机数生成器(Random Number Generator,简称:RNG),加密相关的推荐使用此随机数生成器。
我们可以通过构造方法生成一个实例,或者向构造方法传递一个种子来创建实例。
SecureRandom random = new SecureRandom();
KeyGenerator类
KeyGenerator类是对称密码的密钥生成器,需要指定加密算法,来生成相应的密钥。
Java中支持的算法:
AES(128)DES(56)DESede(168)HmacSHA1HmacSHA256
下面是一些标准算法的介绍:
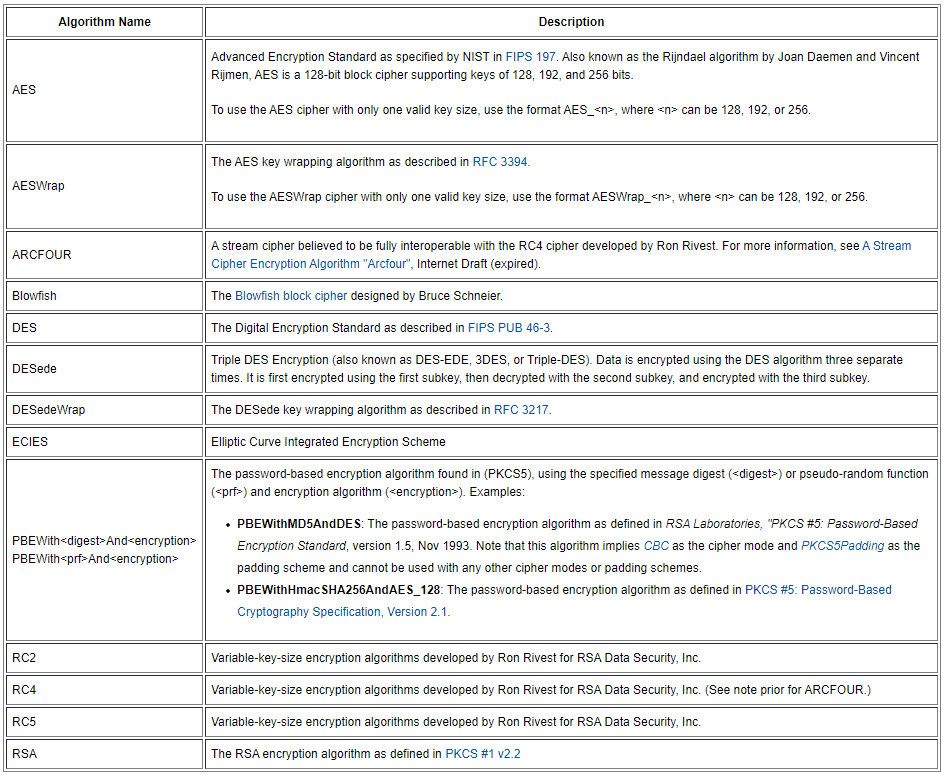
生成密钥代码如下:
/**
* 通过密码和算法获取 Key 对象
*
* @param key 密钥
* @param algorithm 算法,例如:AES (128)、DES (56)、DESede (168)、HmacSHA1、HmacSHA256
* @return 密钥 Key
* @throws Exception
*/
private static Key getKey(byte[] key, String algorithm) throws Exception {
// 通过算法获取 KeyGenerator 对象
KeyGenerator keyGenerator = KeyGenerator.getInstance(algorithm);
// 使用密钥做为随机数,初始化 KeyGenerator 对象
keyGenerator.init(new SecureRandom(key));
// 生成 Key
return keyGenerator.generateKey();
}
Cipher类
Cipher类提供了加密和解密的功能。该类需要指定一个转换(Transformation)来创建一个实例,转换的命名方式:算法名称/工作模式/填充方式。
下面是Java支持的转换:
AES/CBC/NoPadding(128)AES/CBC/PKCS5Padding(128)AES/ECB/NoPadding(128)AES/ECB/PKCS5Padding(128)DES/CBC/NoPadding(56)DES/CBC/PKCS5Padding(56)DES/ECB/NoPadding(56)DES/ECB/PKCS5Padding(56)DESede/CBC/NoPadding(168)DESede/CBC/PKCS5Padding(168)DESede/ECB/NoPadding(168)DESede/ECB/PKCS5Padding(168)RSA/ECB/PKCS1Padding(1024, 2048)RSA/ECB/OAEPWithSHA-1AndMGF1Padding(1024, 2048)RSA/ECB/OAEPWithSHA-256AndMGF1Padding(1024, 2048)
下面是一些标准的模式:

下面是一些标准的填充:

加密代码如下:
private static final String DES_ALGORITHM = "DES";
private static final String DES_TRANSFORMATION = "DES/ECB/PKCS5Padding";
/**
* DES 加密
*
* @param data 原始数据
* @param key 密钥
* @return 密文
*/
private static byte[] encryptDES(byte[] data, byte[] key) throws Exception {
// 获取 DES Key
Key secretKey = getKey(key, DES_ALGORITHM);
// 通过标准转换获取 Cipher 对象, 由该对象完成实际的加密操作
Cipher cipher = Cipher.getInstance(DES_TRANSFORMATION);
// 通过加密模式、密钥,初始化 Cipher 对象
cipher.init(Cipher.ENCRYPT_MODE, secretKey);
// 生成密文
return cipher.doFinal(data);
}
解密代码如下:
private static final String DES_ALGORITHM = "DES";
private static final String DES_TRANSFORMATION = "DES/ECB/PKCS5Padding";
/**
* DES 解密
*
* @param data 密文
* @param key 密钥
* @return 原始数据
*/
private static byte[] decryptDES(byte[] data, byte[] key) throws Exception {
// 获取 DES Key
Key secretKey = getKey(key, DES_ALGORITHM);
// 通过标准转换获取 Cipher 对象, 由该对象完成实际的加密操作
Cipher cipher = Cipher.getInstance(DES_TRANSFORMATION);
// 通过解密模式、密钥,初始化 Cipher 对象
cipher.init(Cipher.DECRYPT_MODE, secretKey);
// 生成原始数据
return cipher.doFinal(data);
}