浏览器过程
地址栏输入URL
URL : Uniform / Universal Resource Locator , 即统一资源定位符。它实际上就是网站网址。浏览器就是靠URL来查找资源位置。
可以把URL分割成几个部分:协议、网络地址、资源路径。
- 传送协议: URL包含协议部分,是浏览器和www万维网之间的沟通方式,它会告诉浏览器正确在网路上找到资源位置。最常见的网络传输协议的是HTTP协议(超文本传输协议)( https则是进行加密的网络传输);其他也还有ftp 、file、 https、mailto 、git 等。还有自定义的协议(私有协议),例如tencent。不同协议有不同的通讯内容格式。
- 网络地址: 指示该连接网络上哪一台计算机,可以是域名或者IP地址,可以包括端口号;
- 资源路径: 指示从服务器上获取哪一项资源。
例如: http://www.quaro.com/question/123456/
- 协议部分:http
- 网络地址:www.quaro.com
- 资源路径:/question/123456/
DNS 域名解析IP
基础概念
IP 地址:IP 协议为互联网上的每一个网络和每一台主机分配的一个逻辑地址。IP 地址如同门牌号码,通过 IP 地址才能确定一台主机位置。服务器本质也是一台主机,想要访问某个服务器,必须先知道它的 IP 地址。
域名 DN(domain name ):域名是为了识别主机名称和组织机构名称的一种具有分层的名称。 IP 地址由四个数字组成,中间用点号连接,在使用过程中难记忆且易输错,所以用我们熟悉的字母和数字组合来代替纯数字的 IP 地址,比如我们只会记住 www.baidu.com (百度域名) 而不是 220.181.112.244(百度的其中一个 IP 地址)。
计算机域名系统 DNS ( Domain Name System or Domain Name Service): 它是由域名解析器和域名服务器组成的。 域名服务器是指保存有该网络中所有主机的域名和对应IP地址,并具有将域名转换为IP地址功能的服务器。 每个域名都对应一个或多个提供相同服务的服务器的 IP 地址,只有知道服务器 IP 地址才能建立连接,所以需要通过 DNS 把域名解析成一个 IP 地址。
查找域名对应的IP地址
通过域名查找IP过程:浏览器缓存 -> 系统缓存 -> 本地DNS服务器缓存
- 浏览器搜索自己的DNS缓存(维护一张域名与IP地址对应表)
- 搜索操作系统中的DNS缓存(维护一张域名与IP地址对应表)
- 搜索操作系统的hosts文件(windows环境下,维护一张域名与IP地址对应表)
- 操作系统将域名发送到本地区域服务器(LNDS),进行查找,成功则返回结果(
递归查询),失败则发起一个迭代DNS请求(迭代查询)//迭代查询和递归查询请参考下一节 - 本地域名服务器LDNS将得到的IP地址返回给操作系统,同时也将IP地址缓存起来
- 操作系统将IP地址返回给浏览器,同时将IP地址缓存起来
DNS迭代查询和递归查询
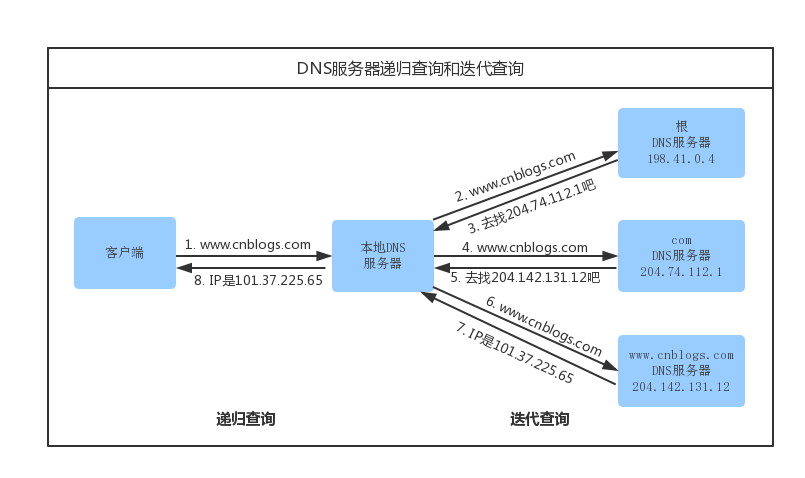
递归查询:客户端与服务器之间属于递归查询,即当客户机想DNS服务器发出请求后,若DNS服务器本身不能解析,会向另一个DNS服务器发出查询请求,最后将结果转交给客户端的过程。 服务器必须回答目标IP与域名的映射关系。
迭代查询:DNS服务器之间属于迭代查询。服务器接收到一次迭代查询回复一次结果,这个结果不一定死目标IP与域名的映射关系,也可以是其他DNS服务器的地址。
请求和响应数据
- TCP连接建立
- 发送http 请求
- 服务端处理
- 返回http 结果
- TCP连接关闭。
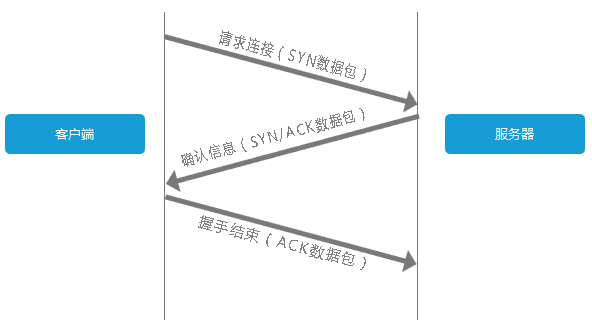
建立TCP连接(3次握手)
上一步找到IP之后,便可以开始建立TCP连接了,这里就是我们所说的TCP3次握手。
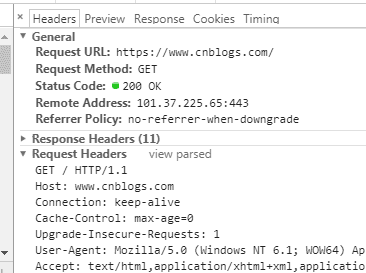
发送HTTP请求
与服务器建立了连接后,就可以向服务器发起请求了。
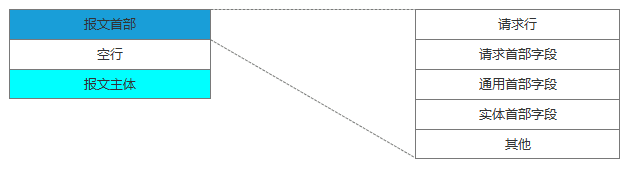
请求报文结构如下:
服务器处理请求
服务器端收到请求后的由web服务器(准确说应该是http服务器)处理请求,诸如Apache、Ngnix、IIS等。web服务器解析用户请求,知道了需要调度哪些资源文件,再通过相应的这些资源文件处理用户请求和参数,并调用数据库信息,最后将结果通过web服务器返回给浏览器客户端。
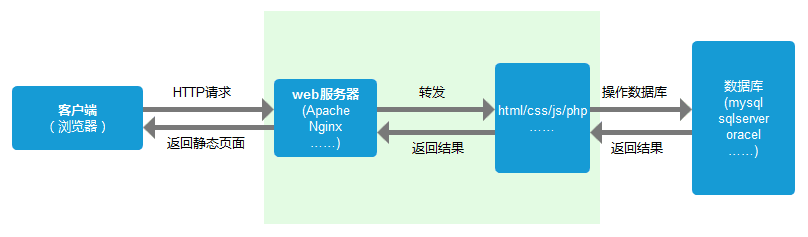
返回HTTP响应结果
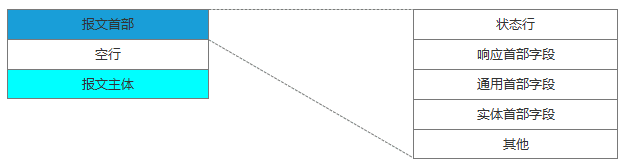
服务器处理完请求后,就会发送响应结果。响应报文的结构如下:
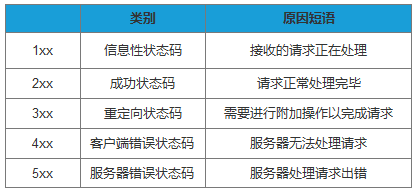
响应结果中会有对应的HTTP状态码,可分为5类:
关闭TCP连接(4次挥手)
为了避免服务器与客户端双方的资源占用和损耗,当双方没有请求或响应传递时,任意一方都可以发起关闭请求。与创建TCP连接的3次握手类似,关闭TCP连接,需要4次握手。

浏览器:加载-解析-渲染
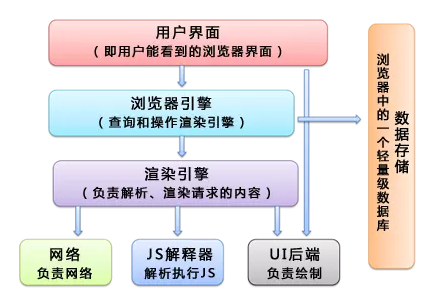
浏览器内核也称渲染引擎,主要有3种:
- Trident内核: IE
- Webkit内核:Chrome,Safari
- Gecko内核:FireFo
浏览器加载
加载过程如下:
- 当浏览器获得一个html文件时,会”自上而下“加载,并在加载过程中进行解析渲染。
- 加载过程中遇到外部css文件,浏览器另外发出一个请求,来获取css文件。
- 遇到图片资源,浏览器也会另外发出一个请求,来获取图片资源。这是异步请求,并不会影响html文档进行加载。
- 但是当文档加载过程中遇到js文件,html文档会挂起渲染(加载解析渲染同步)的线程,不仅要等待文档中js文件加载完毕,还要等待解析执行完毕,才可以恢复html文档的渲染线程。
加载外联js和css的阻塞情况:一个不太严谨但方便记忆的口诀:JS 全阻塞,CSS 半阻塞
- JS 会阻塞后续 DOM 解析以及其它资源(如 CSS,JS 或图片资源)的加载。
- CSS不阻塞DOM的加载和解析(它只阻塞DOM的渲染呈现。这里谈加载),不会阻塞其它资源(如图片)的加载,但是会阻塞 后续JS 文件的执行(原因之一是,js执行代码可能会依赖到css样式。css只阻塞执行而不阻塞js的加载)。
- 鉴于上面的特性,当css后面存在js的时候,css会间接地阻塞js后面资源的加载(css阻塞js,js阻塞其他资源 )。
- 现代浏览器会进行 prefetch 优化,浏览器在获得 html 文档之后会对页面上引用的资源进行提前下载
外联js文件使用defer属性和asyn可以达到异步非阻塞加载的效果,由于现代浏览器都存在 prefetch,所以 defer, async 可能并没有太多的用途,可以作为了解扩展知识,仅仅将脚本文件放到 body 底部(但还是在</body>之前)就可以起到很不错的优化效果(遵循先解析再渲染再执行script这个顺序)。当把js放在最后的时候,其实浏览器将自动忽略</body>标签,从而自动在最后的最后补上</body>。
浏览器解析和渲染
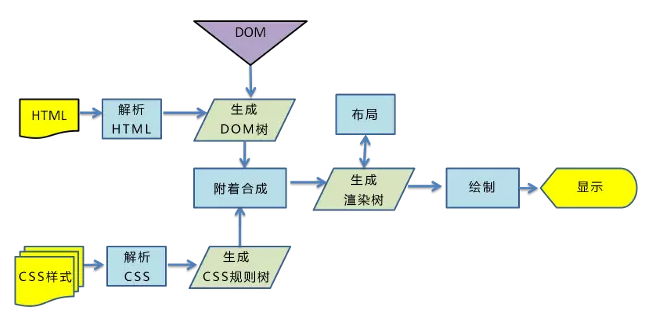
步骤如下:
- 解析html,生成dom树
- 解析css,生成cssom树
- 将dom树和cssom树合并,生成渲染树
- 遍历渲染树,开始布局和计算
- 绘制渲染树,显示到屏幕
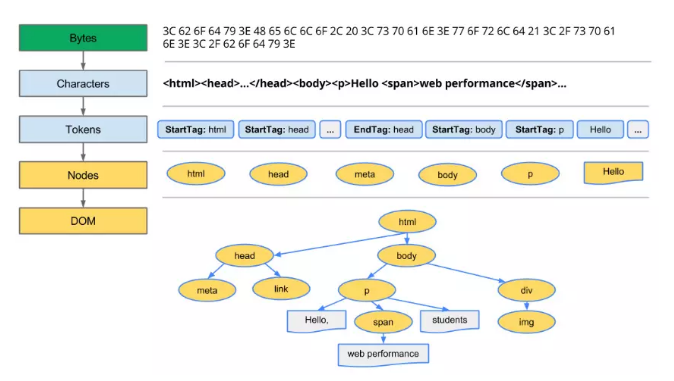
解析html,生成dom树
当浏览器接收到服务器响应来的HTML文档后,会自上而下扫描文档,开始解析,遍历文档节点,生成DOM树。
整个构建过程其实包括: 字节 -> 字符 -> 令牌 -> 节点对象 -> 对象模型,下面是示例代码和配图:
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<link href="style.css" rel="stylesheet">
<title>Critical Path</title>
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg"></div>
</body>
</html>
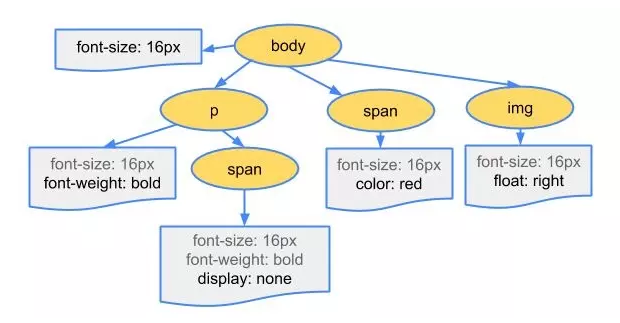
解析css,生成cssom树
- 每个css文件都被分析成一个stylesheet对象,每个对象都包含CSS规则。
- css规则对象包含对应于css语法的选择器和声明对象以及其他对象。
构建过程没有什么特别的差别,下面是示例代码和配图:
body { font-size: 16px }
p { font-weight: bold }
span { color: red }
p span { display: none }
img { float: right }
将dom树和cssom树合并,生成渲染树
- 浏览器会先从dom树的根节点开始遍历每个可见节点,找到其适配的CSS样式规则并应用。
- 将dom树与cssom树结合在一起,这就是渲染树。
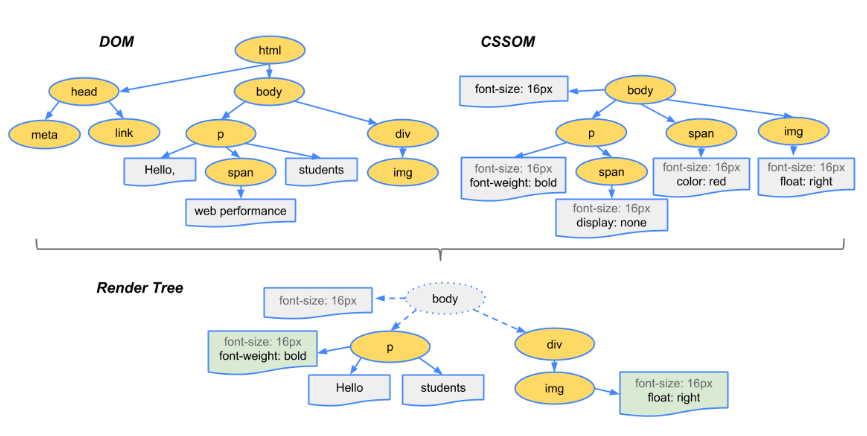
- 每一个渲染对象都对应着dom节点,但是非视觉(隐藏,不占位)dom元素不会插入渲染树,如
<head>元素或声明display: none;的元素。 - 渲染对象与dom节点不是简单的一对一的关系,一个dom可以对应一个渲染对象,但一个dom元素也可能对应多个渲染对象,因为有很多元素不止包含一个css盒子。(如当文本被折行时,会产生多个行盒,这些行会生成多个渲染对象;又如行内元素同时包含块元素和行内元素,则会创建一个匿名块级盒包含内部行内元素,此时一个dom对应多个渲染对象)
遍历渲染树,开始布局和计算
布局阶段会从渲染树的根节点开始遍历,然后确定每个节点对象在页面上的确切大小与位置。 布局阶段的输出是一个盒子模型,它会精确地捕获每个元素在屏幕内的确切位置与大小,所有相对的测量值也都会被转换为屏幕内的绝对像素值。
绘制渲染树,显示到屏幕
在绘制阶段,浏览器会立即发出Paint Setup与Paint事件,开始将渲染树绘制成像素,绘制所需的时间跟CSS样式的复杂度成正比,绘制完成后,用户就可以看到页面的最终呈现效果了。
Repaint和Reflow
当用户在浏览网页时进行交互或通过 js 脚本改变页面结构时,以上的部分操作有可能重复运行,此过程称为 Repaint 或 Reflow。
Repaint
当元素改变的时候,将不会影响元素在页面当中的位置(比如 background-color, border-color, visibility),浏览器仅仅会应用新的样式重绘此元素,此过程称为 Repaint。
Reflow
当元素改变的时候,将会影响文档内容或结构,或元素位置,此过程称为 Reflow。( HTML 使用的是 flow based layout ,也就是流式布局,所以,如果某元件的几何尺寸发生了变化,需要重新布局,也就叫 Reflow。)
Reflow 的成本比 Repaint 的成本高得多的多。我们应当尽量避免Reflow。
如何优化浏览器渲染过程
针对html
- html文档结构层次尽量少,最好不深于6层
- 首屏html可以少量,主体结构动态插入
- 尽量减少将 DOM 节点属性值放在循环当中,会导致大量读写此属性值。
- 创建有效的 HTML 和 CSS ,不要忘记指定文档编码,比如
<meta charset="utf-8">。
针对css
- 使用媒体查询,减少初次cssom树的构建量
- 尽量用id和class,不要过渡层叠
- 样式结构层次尽量简单
- 尽可能的为产生动画的 HTML 元素使用 fixed 或 absolute 的 position ,那么修改他们的 CSS 是不会 Reflow 的。
针对js
- 使用defer和async,避免对文档的阻塞
- 可以的话,动态插入js,避免阻塞
- 不要通过 JS 逐条修改 DOM 的样式,提前定义好 CSS 的 Class 进行操作。
针对引入位置
- css放到head,让cssom树先行构建;js放到
</body>前,保证dom树先行构建,不被阻塞 避免js文件的插入跟在css文件之后,避免css解析对js执行的延迟,造成阻塞
针对资源载入
- 对页面资源进行压缩,对传输进行gzip压缩
- 利用link标签的rel属性进行预解析,运用http缓存
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.