This the multi-page printable view of this section. Click here to print.
网络基础
1 - 网络分层
全局网络层次
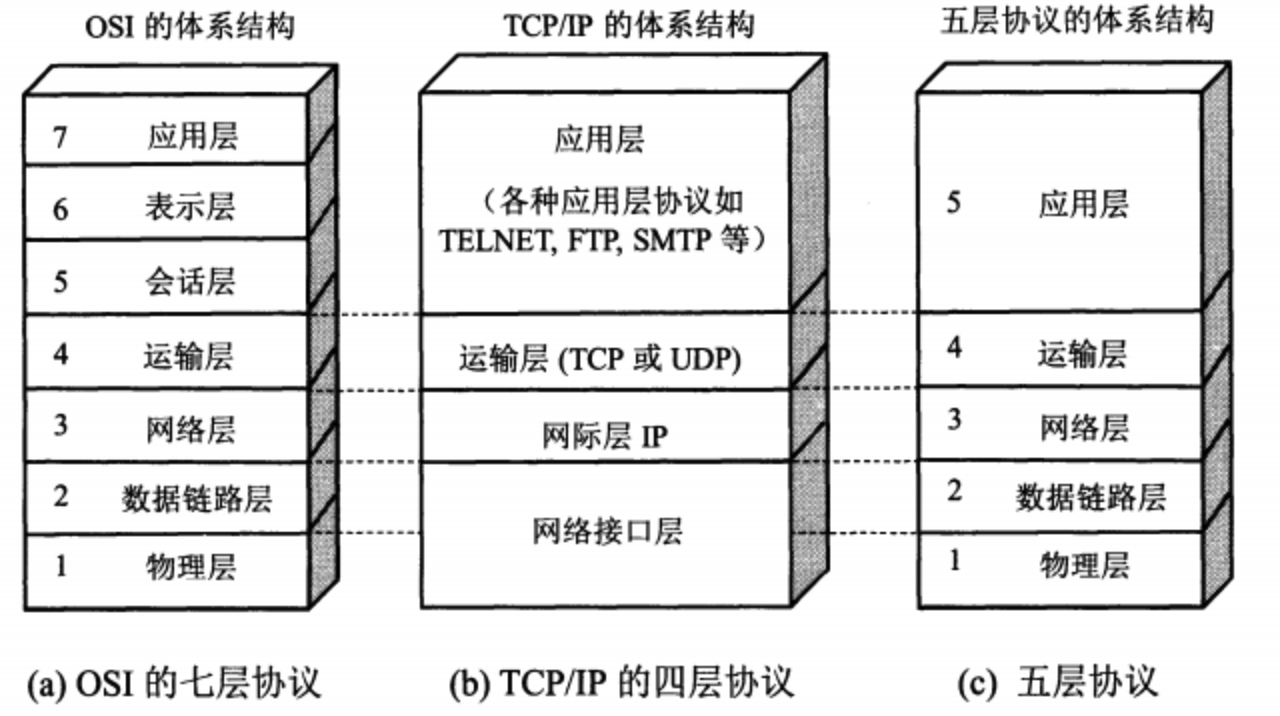
OSI 7 层
国际标准化组织ISO于1984年提出了OSI(Open System Interconnection Reference Model,开放系统互联参考模型)。OSI很快成为计算机网络通信的基础模型。
OSI依层次结构来划分:应用层(Application)、表示层(Presentation)、会话层(Session)、传输层(Transport)、网络层(Network)、数据链路层(Data Link)、物理层(Physical)。
OSI七层参考模型的各个层次的划分遵循下列原则:
- 同一层中的各网络节点都有相同的层次结构,具有同样的功能。
- 同一节点内相邻层之间通过接口(可以是逻辑接口)进行通信。
- 七层结构中的每一层使用下一层提供的服务,并且向其上层提供服务。
- 不同节点的同等层按照协议实现对等层之间的通信。

第一层:物理层(PhysicalLayer)
规定通信设备的机械的、电气的、功能的和过程的特性,用以建立、维护和拆除物理链路连接。具体地讲,机械 特性规定了网络连接时所需接插件的规格尺寸、引脚数量和排列情况等;电气特性规定了在物理连接上传输bit流时线路上信号电平的大小、阻抗匹配、传输速率 距离限制等;功能特性是指对各个信号先分配确切的信号含义,即定义了DTE和DCE之间各个线路的功能;规程特性定义了利用信号线进行bit流传输的一组 操作规程,是指在物理连接的建立、维护、交换信息是,DTE和DCE双放在各电路上的动作系列。在这一层,数据的单位称为比特(bit)。属于物理层定义的典型规范代表包括:EIA/TIA RS-232、EIA/TIA RS-449、V.35、RJ-45等。
第二层:数据链路层(DataLinkLayer)
在物理层提供比特流服务的基础上,建立相邻结点之间的数据链路,通过差错控制提供数据帧(Frame)在信道上无差错的传输,并进行各电路上的动作系列。数据链路层在不可靠的物理介质上提供可靠的传输。该层的作用包括:物理地址寻址、数据的成帧、流量控制、数据的检错、重发等。在这一层,数据的单位称为帧(frame)。数据链路层协议的代表包括:SDLC、HDLC、PPP、STP、帧中继等。
第三层:网络层(network)
在 计算机网络中进行通信的两个计算机之间可能会经过很多个数据链路,也可能还要经过很多通信子网。网络层的任务就是选择合适的网间路由和交换结点, 确保数据及时传送。网络层将数据链路层提供的帧组成数据包,包中封装有网络层包头,其中含有逻辑地址信息- -源站点和目的站点地址的网络地址。如 果你在谈论一个IP地址,那么你是在处理第3层的问题,这是“数据包”问题,而不是第2层的“帧”。IP是第3层问题的一部分,此外还有一些路由协议和地 址解析协议(ARP)。有关路由的一切事情都在这第3层处理。地址解析和路由是3层的重要目的。网络层还可以实现拥塞控制、网际互连等功能。在这一层,数据的单位称为数据包(packet)。网络层协议的代表包括:IP、IPX、RIP、OSPF等。
第四层: 传输层(Transport)
第4层的数据单元也称作数据包(packets)。但是,当你谈论TCP等具体的协议时又有特殊的叫法,TCP的数据单元称为段 (segments)而UDP协议的数据单元称为“数据报(datagrams)”。这个层负责获取全部信息,因此,它必须跟踪数据单元碎片、乱序到达的 数据包和其它在传输过程中可能发生的危险。第4层为上层提供端到端(最终用户到最终用户)的透明的、可靠的数据传输服务。所为透明的传输是指在通信过程中 传输层对上层屏蔽了通信传输系统的具体细节。传输层协议的代表包括:TCP、UDP、SPX等。
第五层: 会话层(Session)
这一层也可以称为会晤层或对话层,在会话层及以上的高层次中,数据传送的单位不再另外命名,而是统称为报文。会话层不参与具体的传输,它提供包括访问验证和会话管理在内的建立和维护应用之间通信的机制。如服务器验证用户登录便是由会话层完成的。
第六层: 表示层(Presentation)
这一层主要解决拥护信息的语法表示问题。它将欲交换的数据从适合于某一用户的抽象语法,转换为适合于OSI系统内部使用的传送语法。即提供格式化的表示和转换数据服务。数据的压缩和解压缩, 加密和解密等工作都由表示层负责。
第七层: 应用层(Application)
应用层为操作系统或网络应用程序提供访问网络服务的接口。应用层协议的代表包括:Telnet、FTP、HTTP、SNMP等。
TCP/IP 4 层
4层是指TCP/IP四层模型,主要包括:应用层、运输层、网际层和网络接口层。
体系结构 5 层
五层体系结构包括:应用层、运输层、网络层、数据链路层和物理层。
五层协议只是OSI和TCP/IP的综合,实际应用还是TCP/IP的四层结构。为了方便可以把下两层称为网络接口层。
网络层次与数据传递
数据在各层之间的传递过程
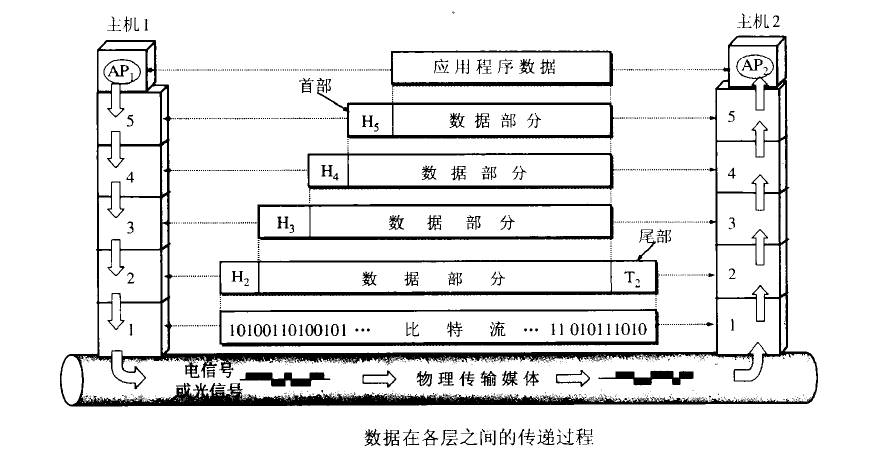
结合层次所在的协议理解
图引用自《图解HTTP》。下图就是这四层协议在数据传输过程中的工作方式,在发送端是应用层–>链路层这个方向的封包过程,每经过一层都会增加该层的头部。而接收端则是从链路层–>应用层解包的过程,每经过一层则会去掉相应的首部。
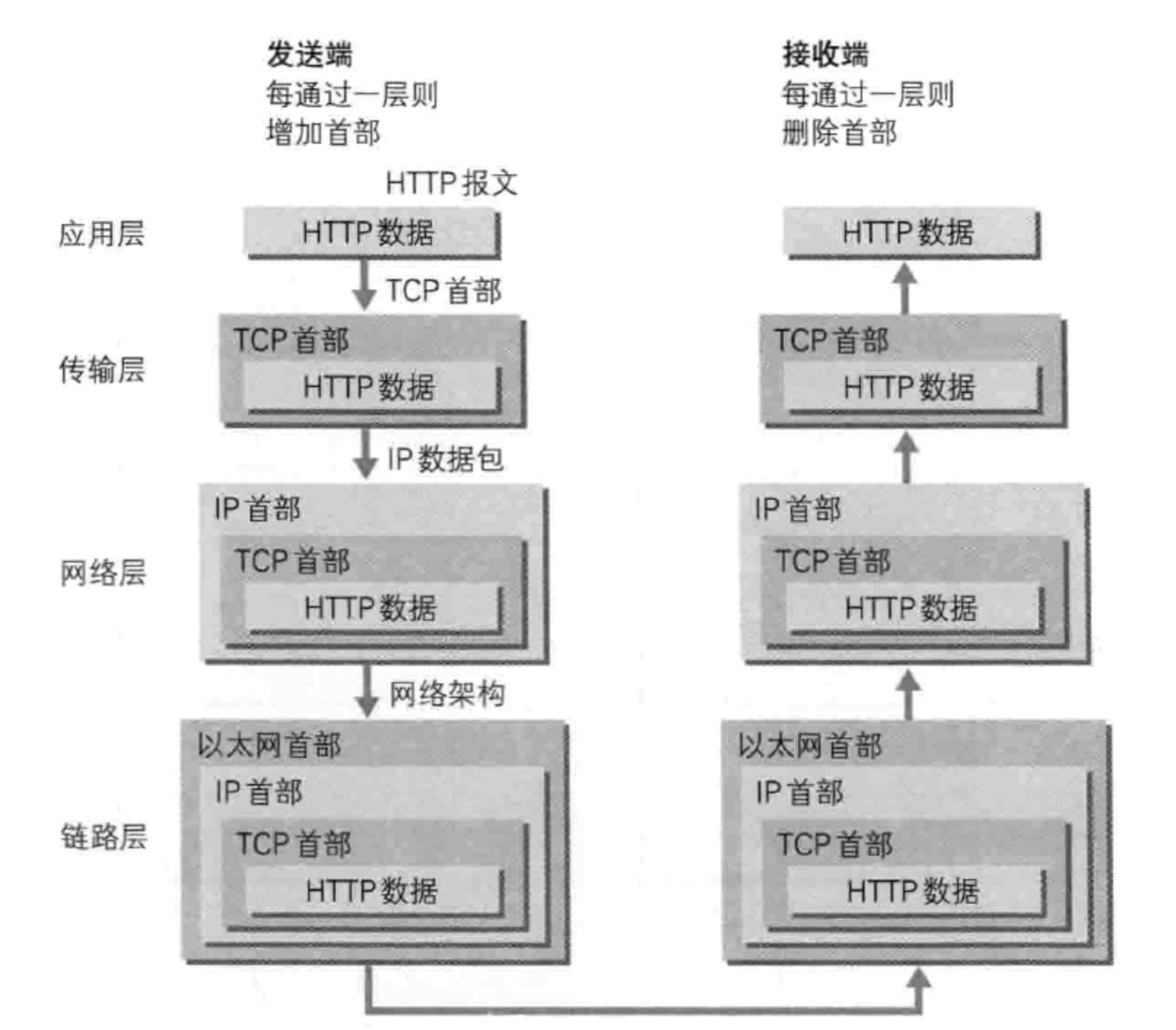
各层对应设备
OSI 七层模型通过七个层次化的结构模型使不同的系统不同的网络之间实现可靠的通讯,因此其最主要的功能就是帮助不同类型的主机实现数据传输 。完成中继功能的节点通常称为中继系统。一个设备工作在哪一层,关键看它工作时利用哪一层的数据头部信息。网桥工作时,是以MAC头部来决定转发端口的,因此显然它是数据链路层的设备。具体说:
- 物理层:网卡,网线,集线器,中继器,调制解调器
- 数据链路层:网桥,交换机
- 网络层:路由器
- 网关工作在第四层传输层及其以上 集线器是物理层设备,采用广播的形式来传输信息。
交换机就是用来进行报文交换的机器。多为链路层设备(二层交换机),能够进行地址学习,采用存储转发的形式来交换报文。
路由器的一个作用是连通不同的网络,另一个作用是选择信息传送的线路。选择通畅快捷的近路,能大大提高通信速度,减轻网络系统通信负荷,节约网络系统资源,提高网络系统畅通率。
交换机的工作原理
交换机拥有一条很高带宽的内部总线和内部交换矩阵。交换机的所有的端口都挂接在这条总线上,控制电路收到数据包以后,处理端口会查找内存中的地址对照表以确定目的MAC(网卡的硬件地址)的NIC(网卡)挂接在哪个端口上,通过内部交换矩阵迅速将数据包传送到目的端口,目的MAC若不存在则广播到所有的端口,接收端口回应后交换机会“学习”新的地址,并把它添加入内部MAC地址表中。 使用交换机也可以把网络“分段”,通过对照MAC地址表,交换机只允许必要的网络流量通过交换机。通过交换机的过滤和转发,可以有效的隔离广播风暴,减少误包和错包的出现,避免共享冲突。 交换机在同一时刻可进行多个端口对之间的数据传输。每一端口都可视为独立的网段,连接在其上的网络设备独自享有全部的带宽,无须同其他设备竞争使用。当节点A向节点D发送数据时,节点B可同时向节点C发送数据,而且这两个传输都享有网络的全部带宽,都有着自己的虚拟连接。总之,交换机是一种基于MAC地址识别,能完成封装转发数据包功能的网络设备。交换机可以"学习"MAC地址,并把其存放在内部地址表中,通过在数据帧的始发者和目标接收者之间建立临时的交换路径,使数据帧直接由源地址到达目的地址。
集线器的功能
集线器的英文称为“Hub”。集线器的主要功能是对接收到的信号进行再生整形放大,以扩大网络的传输距离,同时把所有节点集中在以它为中心的节点上。它 工作于OSI(开放系统互联参考模型)参考模型第一层,即“物理层”。集线器与网卡、网线等传输介质一样,属于局域网中的基础设备,采用 CSMA/CD(即带冲突检测的载波监听多路访问技术)介质访问控制机制。集线器每个接口简单的收发比特,收到1就转发1,收到0就转发0,不进行碰撞检 测。集线器属于纯硬件网络底层设备,基本上不具有类似于交换机的"智能记忆"能力和"学习"能力。它也不具备交换机所具有的MAC地址表,所以它发送数据 时都是没有针对性的,而是采用广播方式发送。也就是说当它要向某节点发送数据时,不是直接把数据发送到目的节点,而是把数据包发送到与集线器相连的所有节点。HUB是一个多端口的转发器,当以HUB为中心设备时,网络中某条线路产生了故障,并不影响其它线路的工作。所以HUB在局域网中得到了广泛的应用。 大多数的时候它用在星型与树型网络拓扑结构中。
路由器相关基础
路由器从功能上可以划分为:路由选择和分组转发。
路由器的分组转发
分组转发结构由三个部分组成:交换结构、一组输入端口和一组输出端口。
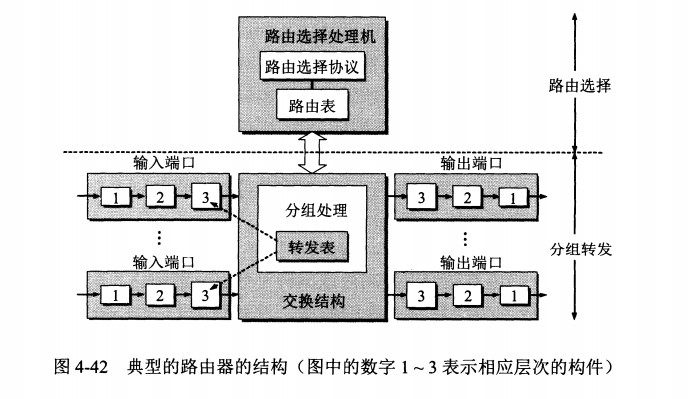
路由器分组转发流程
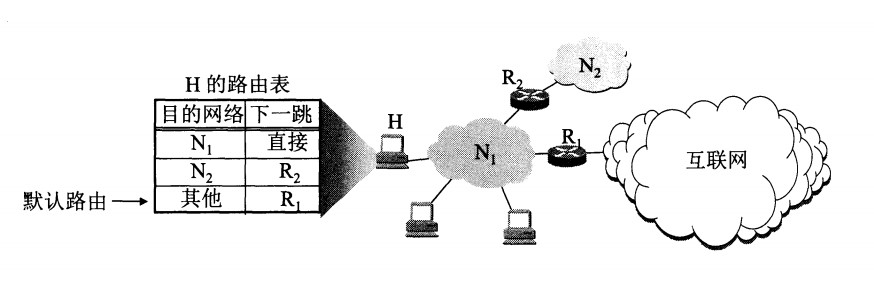
- 从数据报的首部提取目的主机的 IP 地址 D,得到目的网络地址 N。
- 若 N 就是与此路由器直接相连的某个网络地址,则进行直接交付;
- 若路由表中有目的地址为 D 的特定主机路由,则把数据报传送给表中所指明的下一跳路由器;
- 若路由表中有到达网络 N 的路由,则把数据报传送给路由表中所指明的下一跳路由器;
- 若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;
- 报告转发分组出错。
路由选择协议
路由选择协议都是自适应的,能随着网络通信量和拓扑结构的变化而自适应地进行调整。
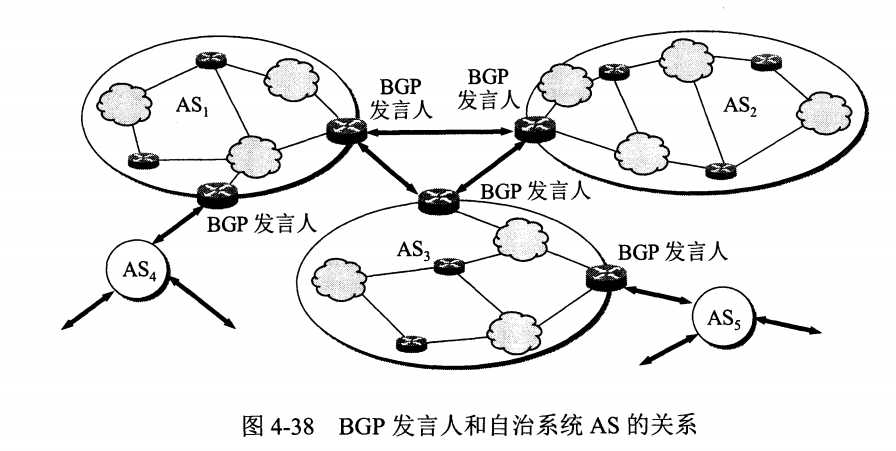
互联网可以划分为许多较小的自治系统 AS,一个 AS 可以使用一种和别的 AS 不同的路由选择协议。
可以把路由选择协议划分为两大类:
- 自治系统内部的路由选择:RIP 和 OSPF
- 自治系统间的路由选择:BGP
内部网关协议 RIP
RIP 是一种基于距离向量的路由选择协议。距离是指跳数,直接相连的路由器跳数为 1。跳数最多为 15,超过 15 表示不可达。
RIP 按固定的时间间隔仅和相邻路由器交换自己的路由表,经过若干次交换之后,所有路由器最终会知道到达本自治系统中任何一个网络的最短距离和下一跳路由器地址。
距离向量算法:
- 对地址为 X 的相邻路由器发来的 RIP 报文,先修改报文中的所有项目,把下一跳字段中的地址改为 X,并把所有的距离字段加 1;
- 对修改后的 RIP 报文中的每一个项目,进行以下步骤:
- 若原来的路由表中没有目的网络 N,则把该项目添加到路由表中;
- 否则:若下一跳路由器地址是 X,则把收到的项目替换原来路由表中的项目;否则:若收到的项目中的距离 d 小于路由表中的距离,则进行更新(例如原始路由表项为 Net2, 5, P,新表项为 Net2, 4, X,则更新);否则什么也不做。
- 若 3 分钟还没有收到相邻路由器的更新路由表,则把该相邻路由器标为不可达,即把距离置为 16。
RIP 协议实现简单,开销小。但是 RIP 能使用的最大距离为 15,限制了网络的规模。并且当网络出现故障时,要经过比较长的时间才能将此消息传送到所有路由器。
内部网关协议 OSPF
开放最短路径优先 OSPF,是为了克服 RIP 的缺点而开发出来的。
开放表示 OSPF 不受某一家厂商控制,而是公开发表的;最短路径优先表示使用了 Dijkstra 提出的最短路径算法 SPF。
OSPF 具有以下特点:
- 向本自治系统中的所有路由器发送信息,这种方法是洪泛法。
- 发送的信息就是与相邻路由器的链路状态,链路状态包括与哪些路由器相连以及链路的度量,度量用费用、距离、时延、带宽等来表示。
- 只有当链路状态发生变化时,路由器才会发送信息。
- 所有路由器都具有全网的拓扑结构图,并且是一致的。相比于 RIP,OSPF 的更新过程收敛的很快。
外部网关协议 BGP
BGP(Border Gateway Protocol,边界网关协议)
AS 之间的路由选择很困难,主要是由于:
- 互联网规模很大;
- 各个 AS 内部使用不同的路由选择协议,无法准确定义路径的度量;
- AS 之间的路由选择必须考虑有关的策略,比如有些 AS 不愿意让其它 AS 经过。
- BGP 只能寻找一条比较好的路由,而不是最佳路由。
每个 AS 都必须配置 BGP 发言人,通过在两个相邻 BGP 发言人之间建立 TCP 连接来交换路由信息。
集线器与交换机的区别
首先说HUB,也就是集线器。它的作用可以简单的理解为将一些机器连接起来组成一个局域网。而交换机(又名交换式集线器)作用与集线器大体相同。但是两者在性能上有区别:集线器采用的式共享带宽的工作方式,而交换机是独享带宽。这样在机器很多或数据量很大时,两者将会有比较明显的。
- 工作位置不同 :集线器工作在物理层,而交换机工作在数据链路层。
- 工作方式不同 : 集线器是一种广播方式,当集线器的某个端口工作时其他端口都能收听到信息。交换机工作时端口互不影响。
- 带宽不同 :集线器是所有端口共享一条带宽,在同一时刻只能有两个端口传输数据;而交换机每个端口独占一条带宽。
- 性能不同 :交换机以MAC地址进行寻址,有一定额外的寻址开销;集线器以广播方式传输数据,流量小时性能下降不明显,适用于共享总线的局域网。
路由器与交换机的区别
总的来说,路由器与交换机的主要区别体现在以下几个方面:
- 工作层次不同。最初的的交换机是工作在数据链路层,而路由器一开始就设计工作在网络层。由于交换机工作在数据链路层,所以它的工作原理比较简单,而路由器工作在网络层,可以得到更多的协议信息,路由器可以做出更加智能的转发决策。
- 数据转发所依据的对象不同。交换机是利用物理地址或者说MAC地址来确定转发数据的目的地址。而路由器则是利用IP地址来确定数据转发的地址。IP地址是在软件中实现的,描述的是设备所在的网络。MAC地址通常是硬件自带的,由网卡生产商来分配的,而且已经固化到了网卡中去,一般来说是不可更改的。而IP地址则通常由网络管理员或系统自动分配。
- 传统的交换机只能分割冲突域,不能分割广播域;而路由器可以分割广播域。由交换机连接的网段仍属于同一个广播域,广播数据包会在交换机连接的所有网段上传播,在某些情况下会导致通信拥挤和安全漏洞。连接到路由器上的网段会被分配成不同的广播域,广播数据不会穿过路由器。虽然第三层以上交换机具有VLAN功能,也可以分割广播域,但是各子广播域之间是不能通信交流的,它们之间的交流仍然需要路由器。
- 交换机负责同一个网段的通信,而路由器负责不同网段的通信。路由器提供了防火墙的服务。路由器仅仅转发特定地址的数据包,不传送不支持路由协议的数据包传送和未知目标网络数据包的传送,从而可以防止广播风暴。
路由表
路由表是指路由器或者其他互联网网络设备上存储的一张路由信息表,该表中存有到达特定网络终端的路径,在某些情况下,还有一些与这些路径相关的度量。路由器的主要工作就是为经过路由器的每个数据包寻找一条最佳的传输路径,并将该数据有效地传送到目的站点。由此可见,选择最佳路径的策略即路由算法是路由器的关键所在。为了完成这项工作,在路由器中保存着各种传输路径的相关数据——路由表(Routing Table),供路由选择时使用,表中包含的信息决定了数据转发的策略。路由表可以是由系统管理员固定设置好的,也可以由系统动态修改,可以由路由器自动调整,也可以由主机控制。
- 静态路由表:由系统管理员事先设置好固定的路由表称之为静态(static)路由表,一般是在系统安装时就根据网络的配置情况预先设定的,它不会随未来网络结构的改变而改变。
- 动态路由表:动态(Dynamic)路由表是路由器根据网络系统的运行情况而自动调整的路由表。路由器根据路由选择协议(Routing Protocol)提供的功能,自动学习和记忆网络运行情况,在需要时自动计算数据传输的最佳路径。
路由器通常依靠所建立及维护的路由表来决定如何转发。路由表能力是指路由表内所容纳路由表项数量的极限。路由表中的表项内容包括:
- destination mask pre costdestination:目的地址,用来标识IP包的目的地址或者目的网络。
- mask:网络掩码,与目的地址一起标识目的主机或者路由器所在的网段的地址。
- pre:标识路由加入IP路由表的优先级。可能到达一个目的地有多条路由,但是优先级的存在让他们先选择优先级高的路由进行利用。
- cost:路由开销,当到达一个目的地的多个路由优先级相同时,路由开销最小的将成为最优路由。
- interface:输出接口,说明IP包将从该路由器哪个接口转发。 nexthop:下一跳IP地址,说明IP包所经过的下一个路由器。
各层常见协议
2 - IP 协议
IP 及配套协议详解
因为网络层是整个互联网的核心,因此应当让网络层尽可能简单。网络层向上只提供简单灵活的、无连接的、尽最大努力交互的数据报服务。
使用 IP 协议,可以把异构的物理网络连接起来,使得在网络层看起来好像是一个统一的网络。
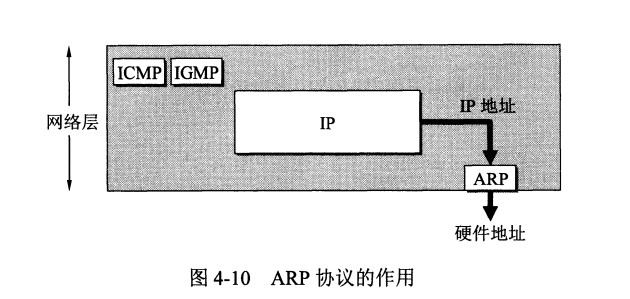
与 IP 协议配套使用的还有三个协议:
- 地址解析协议 ARP(Address Resolution Protocol)
- 网际控制报文协议 ICMP(Internet Control Message Protocol)
- 网际组管理协议 IGMP(Internet Group Management Protocol)
IP 数据报格式
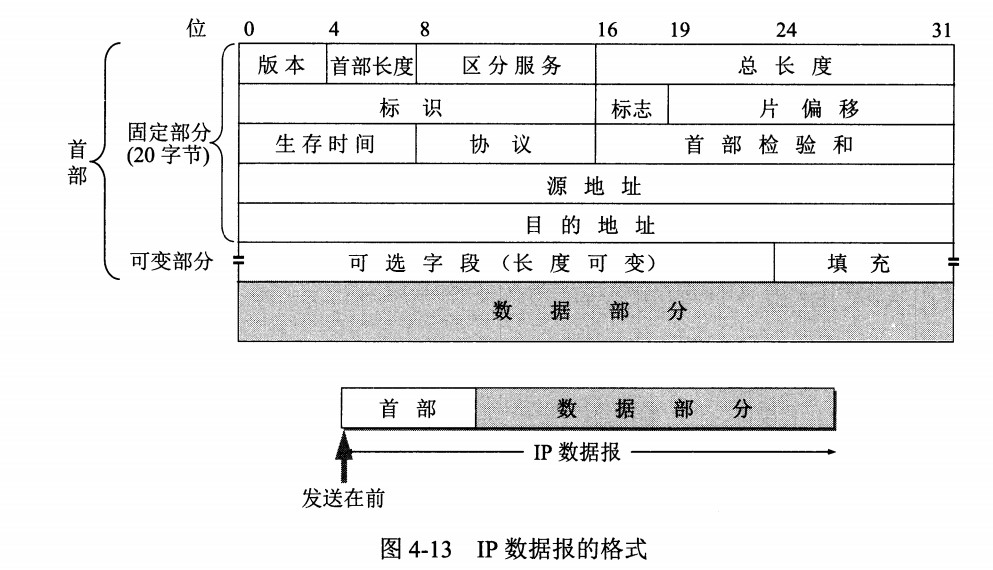
版本 : 有 4(IPv4)和 6(IPv6)两个值;
首部长度 : 占 4 位,因此最大值为 15。值为 1 表示的是 1 个 32 位字的长度,也就是 4 字节。因为固定部分长度为 20 字节,因此该值最小为 5。如果可选字段的长度不是 4 字节的整数倍,就用尾部的填充部分来填充。
区分服务 : 用来获得更好的服务,一般情况下不使用。
总长度 : 包括首部长度和数据部分长度。
生存时间 :TTL,它的存在是为了防止无法交付的数据报在互联网中不断兜圈子。以路由器跳数为单位,当 TTL 为 0 时就丢弃数据报。
协议 :指出携带的数据应该上交给哪个协议进行处理,例如 ICMP、TCP、UDP 等。
首部检验和 :因为数据报每经过一个路由器,都要重新计算检验和,因此检验和不包含数据部分可以减少计算的工作量。
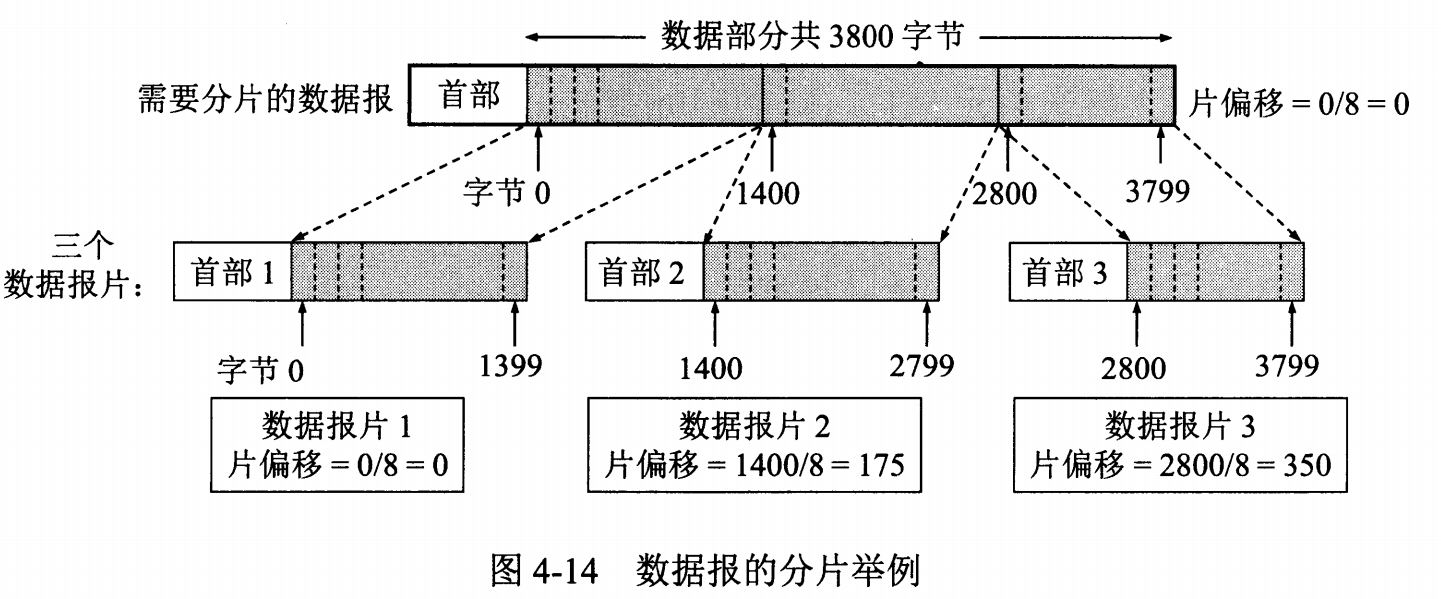
标识 : 在数据报长度过长从而发生分片的情况下,相同数据报的不同分片具有相同的标识符。
片偏移 : 和标识符一起,用于发生分片的情况。片偏移的单位为 8 字节。
IP 地址编址方式
IP 地址的编址方式经历了三个历史阶段:
- 分类
- 子网划分
- 无分类
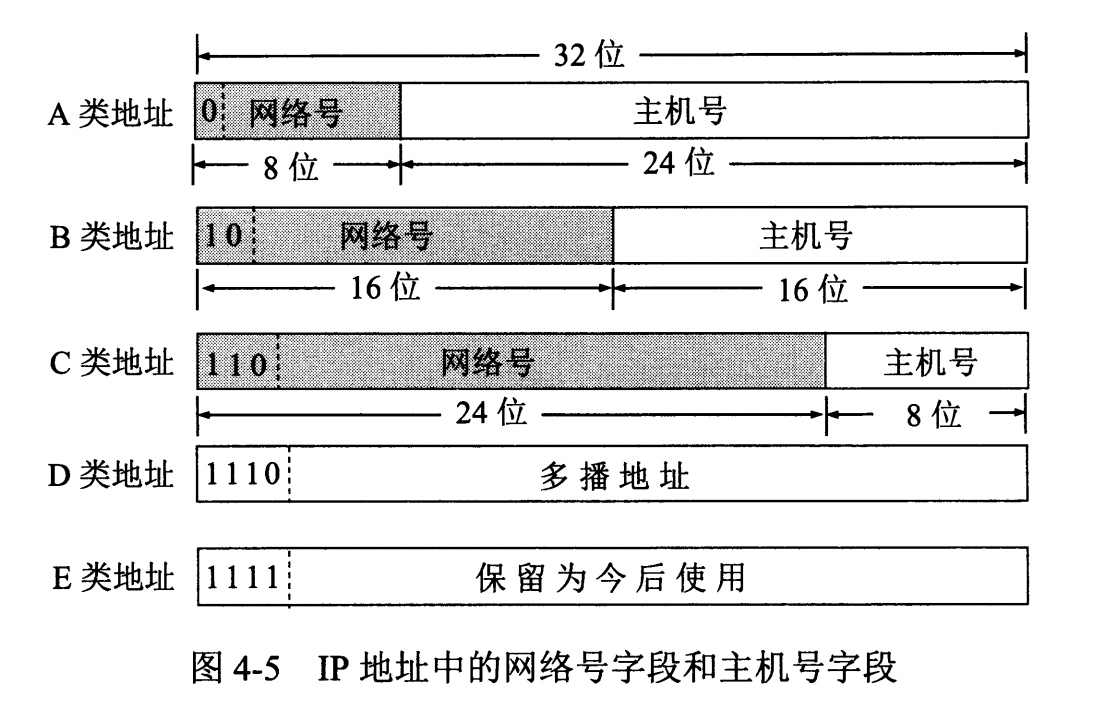
1. 分类
由两部分组成,网络号和主机号,其中不同分类具有不同的网络号长度,并且是固定的。
IP 地址 ::= {< 网络号 >, < 主机号 >}
2. 子网划分
通过在主机号字段中拿一部分作为子网号,把两级 IP 地址划分为三级 IP 地址。
IP 地址 ::= {< 网络号 >, < 子网号 >, < 主机号 >}
要使用子网,必须配置子网掩码。一个 B 类地址的默认子网掩码为 255.255.0.0,如果 B 类地址的子网占两个比特,那么子网掩码为 11111111 11111111 11000000 00000000,也就是 255.255.192.0。
注意,外部网络看不到子网的存在。
3. 无分类
无分类编址 CIDR 消除了传统 A 类、B 类和 C 类地址以及划分子网的概念,使用网络前缀和主机号来对 IP 地址进行编码,网络前缀的长度可以根据需要变化。
IP 地址 ::= {< 网络前缀号 >, < 主机号 >}
CIDR 的记法上采用在 IP 地址后面加上网络前缀长度的方法,例如 128.14.35.7/20 表示前 20 位为网络前缀。
CIDR 的地址掩码可以继续称为子网掩码,子网掩码首 1 长度为网络前缀的长度。
一个 CIDR 地址块中有很多地址,一个 CIDR 表示的网络就可以表示原来的很多个网络,并且在路由表中只需要一个路由就可以代替原来的多个路由,减少了路由表项的数量。把这种通过使用网络前缀来减少路由表项的方式称为路由聚合,也称为 构成超网 。
在路由表中的项目由“网络前缀”和“下一跳地址”组成,在查找时可能会得到不止一个匹配结果,应当采用最长前缀匹配来确定应该匹配哪一个。
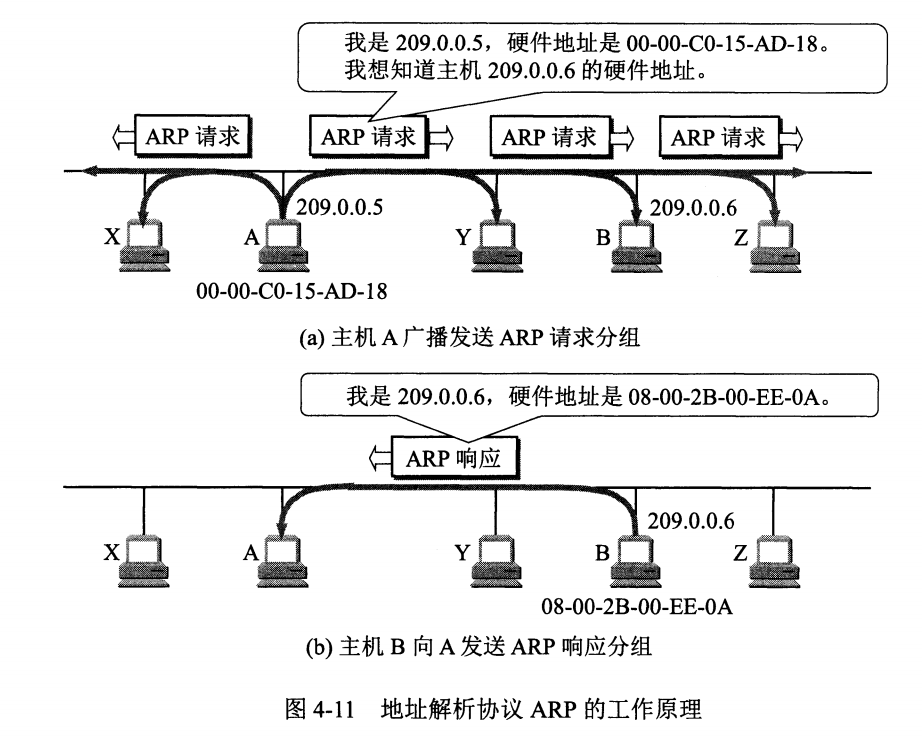
地址解析协议 ARP
网络层实现主机之间的通信,而链路层实现具体每段链路之间的通信。因此在通信过程中,IP 数据报的源地址和目的地址始终不变,而 MAC 地址随着链路的改变而改变。
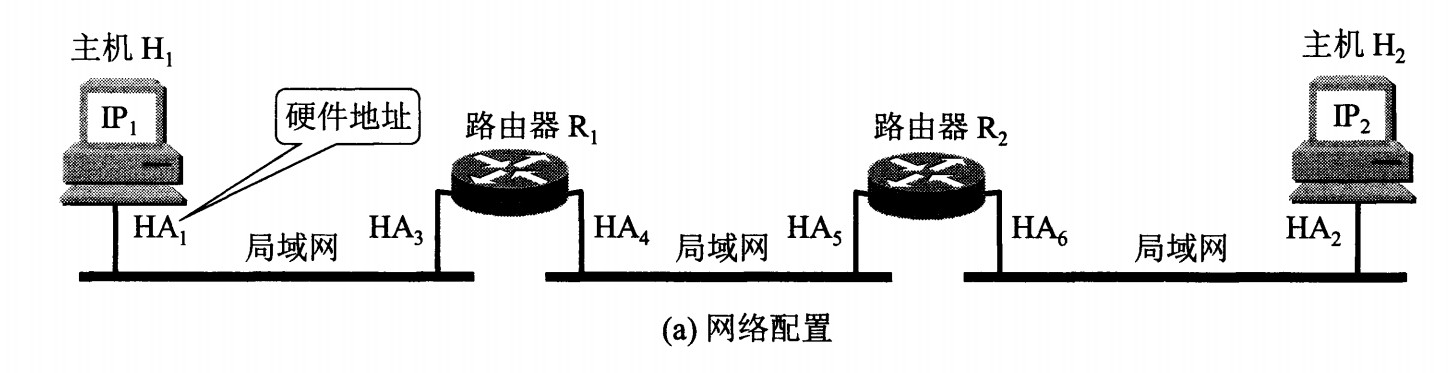
ARP 实现由 IP 地址得到 MAC 地址。
每个主机都有一个 ARP 高速缓存,里面有本局域网上的各主机和路由器的 IP 地址到 MAC 地址的映射表。
如果主机 A 知道主机 B 的 IP 地址,但是 ARP 高速缓存中没有该 IP 地址到 MAC 地址的映射,此时主机 A 通过广播的方式发送 ARP 请求分组,主机 B 收到该请求后会发送 ARP 响应分组给主机 A 告知其 MAC 地址,随后主机 A 向其高速缓存中写入主机 B 的 IP 地址到 MAC 地址的映射。
网际控制报文协议 ICMP
ICMP 是为了更有效地转发 IP 数据报和提高交付成功的机会。它封装在 IP 数据报中,但是不属于高层协议。
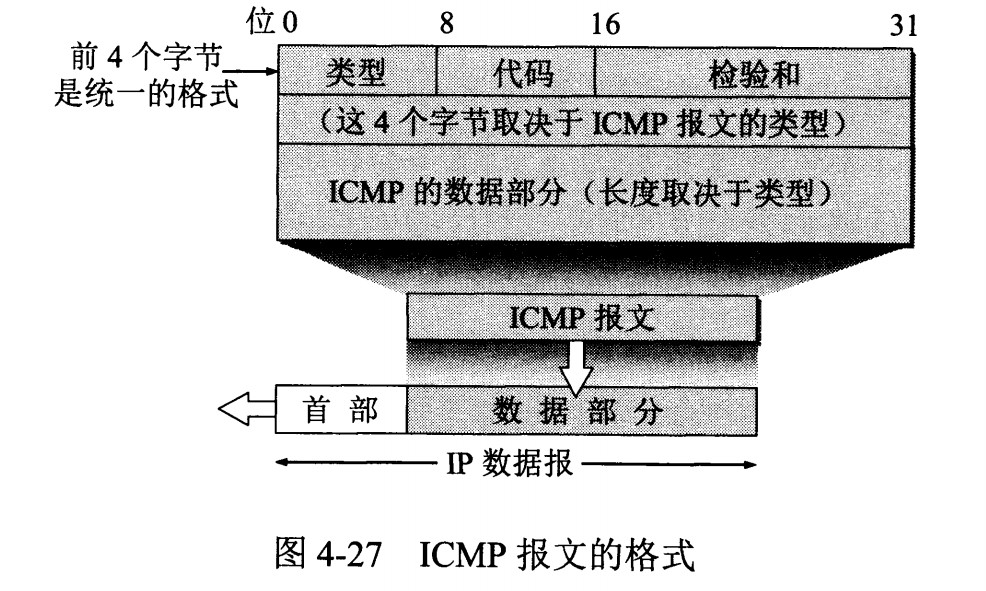
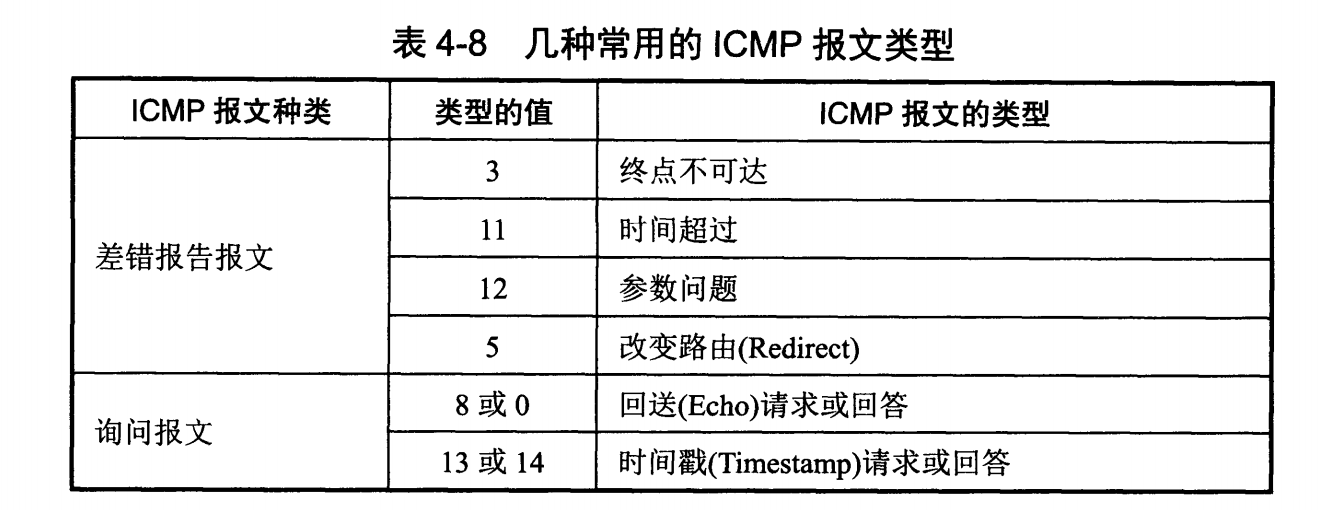
ICMP 报文分为差错报告报文和询问报文。
1. Ping
Ping 是 ICMP 的一个重要应用,主要用来测试两台主机之间的连通性。
Ping 的原理是通过向目的主机发送 ICMP Echo 请求报文,目的主机收到之后会发送 Echo 回答报文。Ping 会根据时间和成功响应的次数估算出数据包往返时间以及丢包率。
2. Traceroute
Traceroute 是 ICMP 的另一个应用,用来跟踪一个分组从源点到终点的路径。
Traceroute 发送的 IP 数据报封装的是无法交付的 UDP 用户数据报,并由目的主机发送终点不可达差错报告报文。
源主机向目的主机发送一连串的 IP 数据报。第一个数据报 P1 的生存时间 TTL 设置为 1,当 P1 到达路径上的第一个路由器 R1 时,R1 收下它并把 TTL 减 1,此时 TTL 等于 0,R1 就把 P1 丢弃,并向源主机发送一个 ICMP 时间超过差错报告报文; 源主机接着发送第二个数据报 P2,并把 TTL 设置为 2。P2 先到达 R1,R1 收下后把 TTL 减 1 再转发给 R2,R2 收下后也把 TTL 减 1,由于此时 TTL 等于 0,R2 就丢弃 P2,并向源主机发送一个 ICMP 时间超过差错报文。
不断执行这样的步骤,直到最后一个数据报刚刚到达目的主机,主机不转发数据报,也不把 TTL 值减 1。但是因为数据报封装的是无法交付的 UDP,因此目的主机要向源主机发送 ICMP 终点不可达差错报告报文。
之后源主机知道了到达目的主机所经过的路由器 IP 地址以及到达每个路由器的往返时间。
IPV6
我国在2014-2015年也逐步停止了向新用户和应用分配 IPv4 地址。 解决 IP 地址耗尽的根本措施就是采用具有更大地址空间的新版本的 IP,即 IPv6。 所引进的主要变化如下:
- 更大的地址空间。IPv6 将地址从 IPv4 的 32 位 增大到了 128 位。
- 扩展的地址层次结构。
- 灵活的首部格式。 IPv6 定义了许多可选的扩展首部。
- 改进的选项。 IPv6 允许数据报包含有选项的控制信息,其选项放在有效载荷中。
- 允许协议继续扩充。
- 支持即插即用(即自动配置)。因此 IPv6 不需要使用 DHCP。
- 支持资源的预分配。 IPv6 支持实时视像等要求,保证一定的带宽和时延的应用。
- IPv6 首部改为 8 字节对齐。首部长度必须是 8 字节的整数倍。原来的 IPv4 首部是 4 字节对齐。
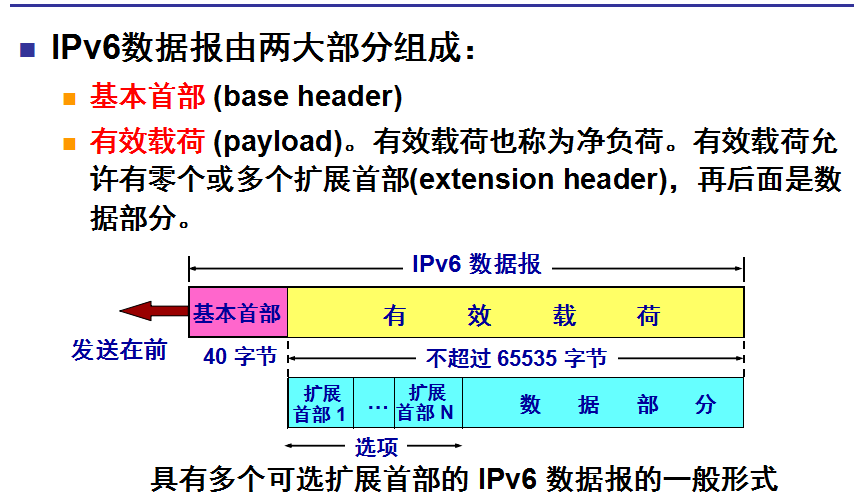
数据包格式
V4 -> V6
向 IPv6 过渡只能采用逐步演进的办法,同时,还必须使新安装的 IPv6 系统能够向后兼容:IPv6 系统必须能够接收和转发 IPv4 分组,并且能够为 IPv4 分组选择路由。
两种向 IPv6 过渡的策略:
- 使用双协议栈
- 使用隧道技术
双协议栈主机在和 IPv6 主机通信时是采用 IPv6 地址,而和 IPv4 主机通信时就采用 IPv4 地址。 根据 DNS 返回的地址类型可以确定使用 IPv4 地址还是 IPv6 地址。

在 IPv6 数据报要进入IPv4网络时,把 IPv6 数据报封装成为 IPv4 数据报,整个的 IPv6 数据报变成了 IPv4 数据报的数据部分。 当 IPv4 数据报离开 IPv4 网络中的隧道时,再把数据部分(即原来的 IPv6 数据报)交给主机的 IPv6 协议栈。
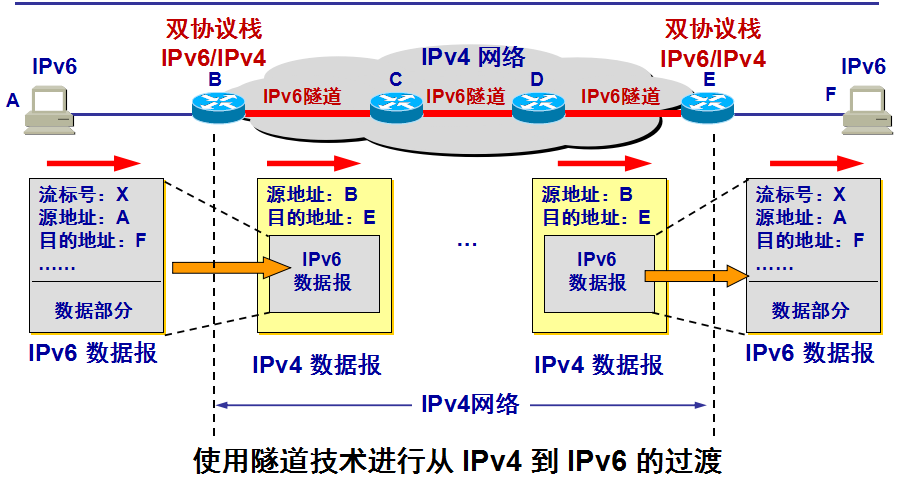
IP与Mac之间关系
- 整体与局部
信息传递时候,需要知道的其实是两个地址:终点地址(Final destination address)下一跳的地址(Next hop address)IP地址本质上是终点地址,它在跳过路由器(hop)的时候不会改变,而MAC地址则是下一跳的地址,每跳过一次路由器都会改变。这就是为什么还要用MAC地址的原因之一,它起到了记录下一跳的信息的作用。注:一般来说IP地址经过路由器是不变的,不过NAT(Network address translation)例外,这也是有些人反对NAT而支持IPV6的原因之一。
- 分层实现
如果在IP包头(header)中增加了”下一跳IP地址“这个字段,在逻辑上来说,如果IP地址够用,交换机也支持根据IP地址转发(现在的二层交换机不支持这样做),其实MAC地址并不是必要的。但用MAC地址和IP地址两个地址,用于分别表示物理地址和逻辑地址是有好处的。这样分层可以使网络层与链路层的协议更灵活地替换,网络层不一定非要用『IP』协议,链路层也不一定非用『以太网』协议。这就像OSI七层模型,TCP/IP五层模型其实也不是必要的,用双层模型甚至单层模型实现网络也不是不可以的,只是那样做很蛋疼罢了。
- 早期的『以太网』实现
早期的以太网只有集线器(hub),没有交换机(switch),所以发出去的包能被以太网内的所有机器监听到,因此要附带上MAC地址,每个机器只需要接受与自己MAC地址相匹配的包。
网络地址转换NAT
问题:在专用网上使用专用地址的主机如何与互联网上的主机通信(并不需要加密)?
采用网络地址转换 NAT。这是目前使用得最多的方法。
装有 NAT 软件的路由器叫作 NAT路由器,它至少有一个有效的外部全球IP地址,所有使用本地地址的主机在和外界通信时,都要在 NAT 路由器上将其本地地址转换成全球 IP 地址。
通过 NAT 路由器的通信必须由专用网内的主机发起。专用网内部的主机不能充当服务器用,因为互联网上的客户无法请求专用网内的服务器提供服务。
转换过程
- 内部主机 A 用本地地址 IPA 和互联网上主机 B 通信所发送的数据报必须经过 NAT 路由器。
- NAT 路由器将数据报的源地址 IPA 转换成全球地址 IPG,并把转换结果记录到NAT地址转换表中,目的地址 IPB 保持不变,然后发送到互联网。
- NAT 路由器收到主机 B 发回的数据报时,知道数据报中的源地址是 IPB 而目的地址是 IPG。
- 根据 NAT 转换表,NAT 路由器将目的地址** IPG 转换为 IPA,转发给最终的内部主机 A**。
可以看出,在内部主机与外部主机通信时,在NAT路由器上发生了两次地址转换:
- 离开专用网时:替换源地址,将内部地址替换为全球地址;
- 进入专用网时:替换目的地址,将全球地址替换为内部地址;

3 - TCP 协议
概览
首先,我们需要知道TCP在网络OSI的七层模型中的第四层——Transport层,IP在第三层——Network层,ARP在第二层——Data Link层,在第二层上的数据,我们叫Frame,在第三层上的数据叫Packet,第四层的数据叫Segment。
我们程序的数据首先会打到TCP的Segment中,然后TCP的Segment会打到IP的Packet中,然后再打到以太网Ethernet的Frame中,传到对端后,各个层解析自己的协议,然后把数据交给更高层的协议处理。
TCP 头格式
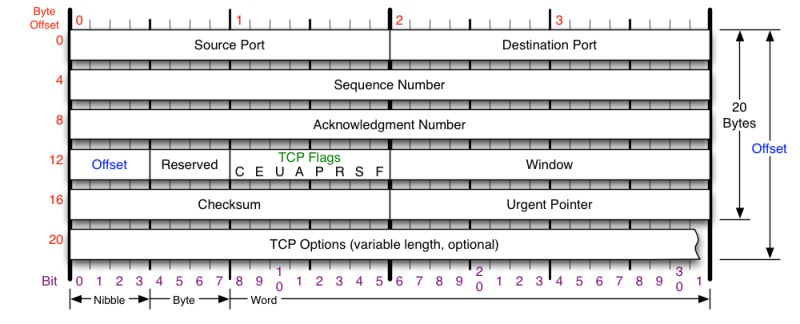
- TCP 包是没有 IP 地址的,因为已经经过了 IP 协议的处理。到这一层仅有源端口和目标端口。
- 一个 TCP 连接需要 4 个元组来标识同一个连接:
- src_ip、src_port、dst_ip、dst_port
- 准确说是 5 个元组,还有一个是协议
- 上图中 4 个重要部分:
- Sequence Number:包的序号,用于解决网络包乱序问题。
- Acknowledgement Number:ACK,用于确认收到,用于解决不丢包问题。
- Window 或 Advertised-Window:滑动窗口,用于解决流控问题。
- TCP Flag:包类型,用于操控 TCP 状态机。
其他部分的解释:
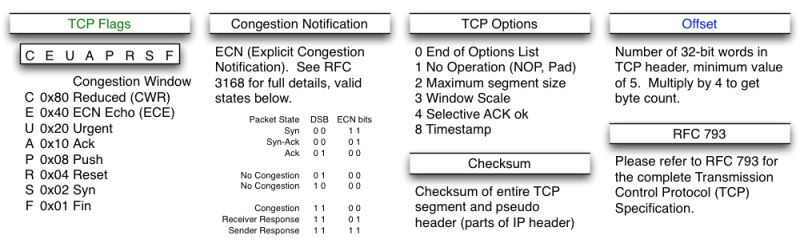
TCP 状态机
其实网络上的传输是没有连接的,包括 TCP 也一样。而 TCP 所谓的“连接”只不过是通讯双方维护的一个“连接状态”,使其看上去好像有连接一样。所以,TCP 的状态尤其重要。
下面是“TCP协议的状态机” 和 “TCP建链接”、“TCP断链接”、“传数据” 的对照图。
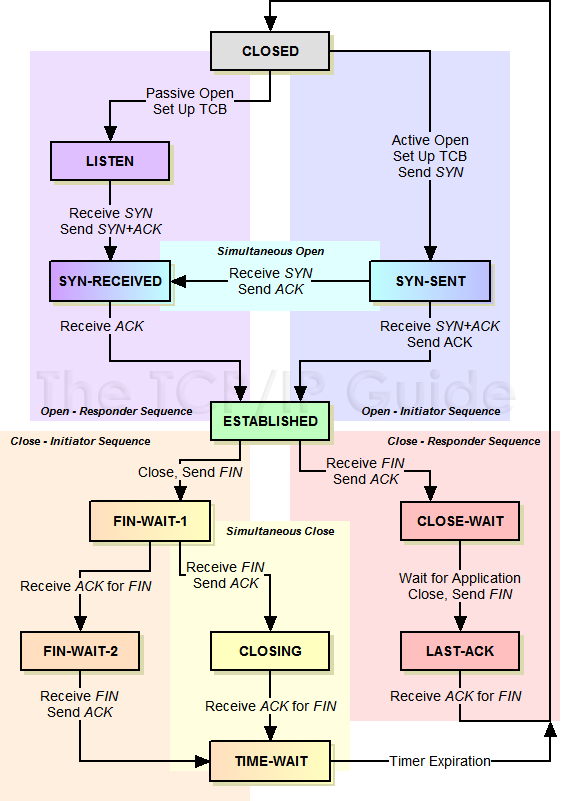
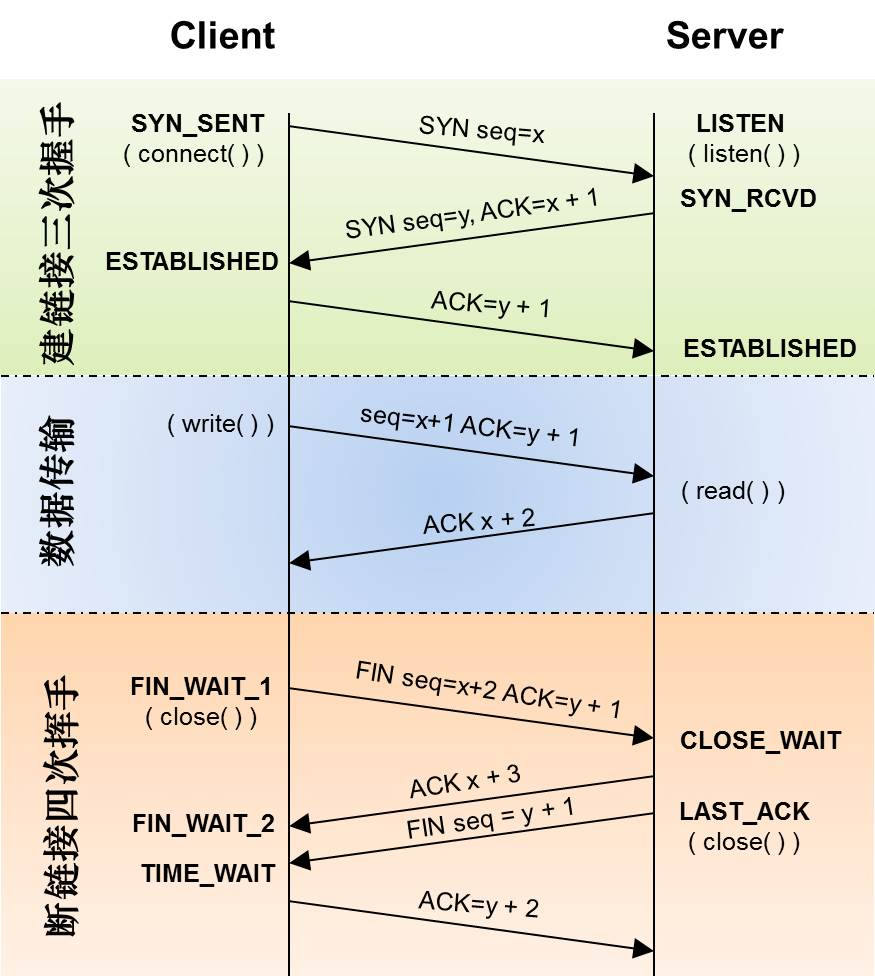
握手机制
一次握手表示向对方发送一个数据包,Client -> Server 或 Server -> Client。
建立连接:三次握手
目的是连接服务器指定端口、建立 TCP 连接,同步连接双方的序列号和确认号,交换 TCP 窗口的大小信息。
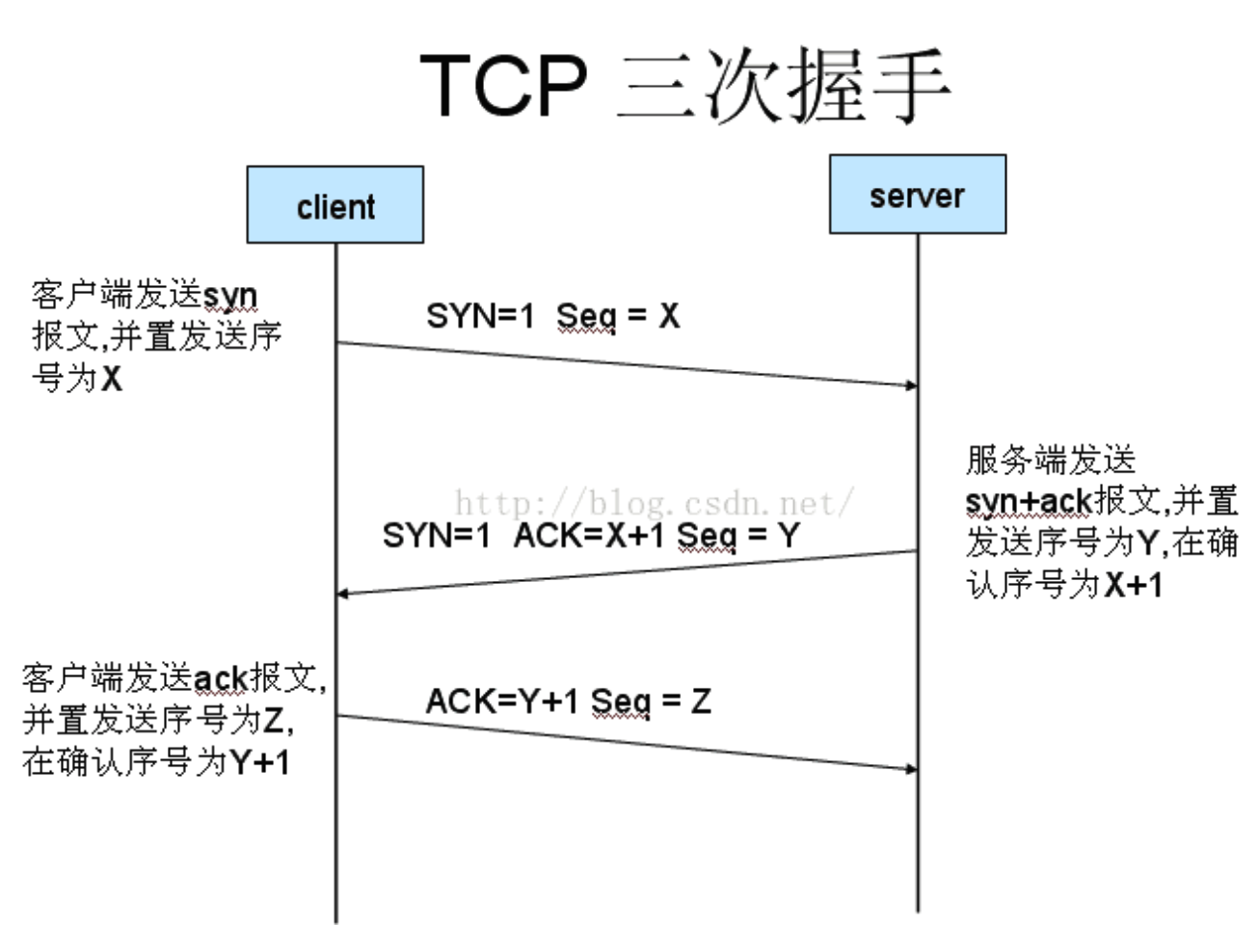
- Client -> Server:请求创建连接,SEQ=X
- Server -> Client:同意创建连接,ACK=X+1,SEQ=Y
- Client -> Server:得知同意创建,ACK=Y+1,SEQ=Z
关闭连接:四次挥手
双方均可主动发起挥手来关闭连接。
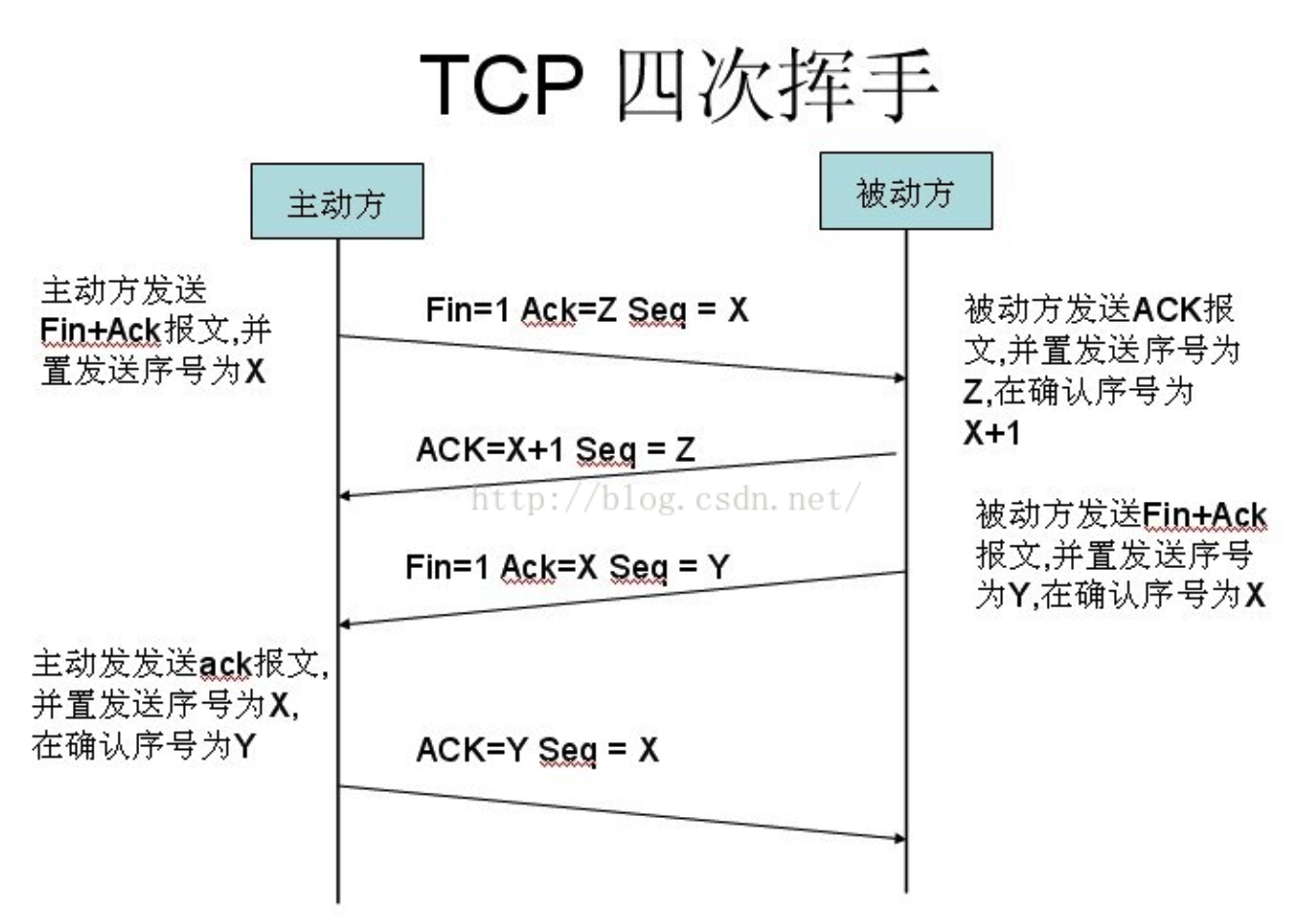
- Client -> Server:请求关闭
- Server -> Client:同意关闭
- Server -> Client:请求关闭
- Client -> Server:同意关闭
问题汇总
为什么要三次握手
为了防止已失效连接的请求报文段突然又传送到了服务端,因而产生错误。
- 为了防止无效请求发送给服务端,被服务端误以为是新建连接的请求。
假设 Client 发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达 Server。
本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新的连接请求。于是就向client发出确认报文段,同意建立连接。
假设不采用“三次握手”(没有第三次握手),那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了。
如果采用三次握手,client不会向server的确认发出确认。server由于收不到确认,就知道client并没有要求建立连接。
为什么要四次挥手
TCP协议是一种面向连接的、可靠的、基于字节流的全双工运输层通信协议。
- TCP是全双工模式,这就意味着,当主机1发出FIN报文段时,只是表示主机1已经没有数据要发送了,主机1告诉主机2,它的数据已经全部发送完毕了;
- 但是,这个时候主机1还是可以接受来自主机2的数据;
- 当主机2返回ACK报文段时,表示它已经知道主机1没有数据发送了;
- 但是主机2还是可以发送数据到主机1的;
- 当主机2也发送了FIN报文段时,这个时候就表示主机2也没有数据要发送了,就会告诉主机1,我也没有数据要发送了,之后彼此就会愉快的中断这次TCP连接。
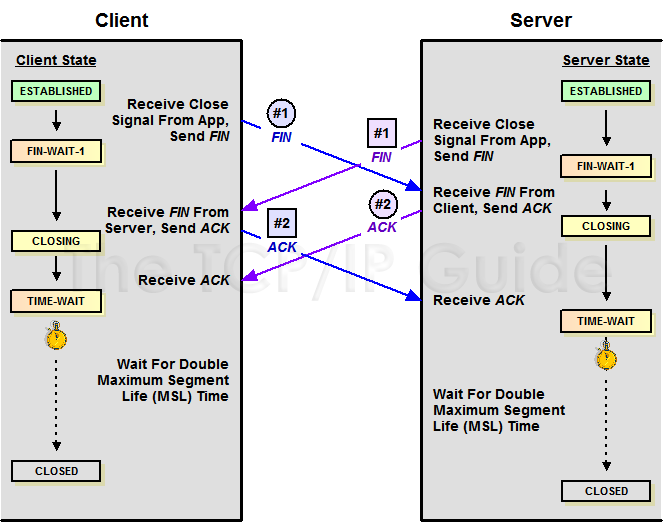
关闭时为什么要等待2MSL
MSL:报文段最大生存时间,它是任何报文段被丢弃前在网络内的最长时间。
- 保证TCP协议的全双工连接能够可靠关闭
- 保证这次连接的重复数据段从网络中消失
第一点:如果主机1直接CLOSED了,那么由于IP协议的不可靠性或者是其它网络原因,导致主机2没有收到主机1最后回复的ACK。那么主机2就会在超时之后继续发送FIN,此时由于主机1已经CLOSED了,就找不到与重发的FIN对应的连接。所以,主机1不是直接进入CLOSED,而是要保持TIME_WAIT,当再次收到FIN的时候,能够保证对方收到ACK,最后正确的关闭连接。
第二点:如果主机1直接CLOSED,然后又再向主机2发起一个新连接,我们不能保证这个新连接与刚关闭的连接的端口号是不同的。也就是说有可能新连接和老连接的端口号是相同的。一般来说不会发生什么问题,但是还是有特殊情况出现:假设新连接和已经关闭的老连接端口号是一样的,如果前一次连接的某些数据仍然滞留在网络中,这些延迟数据在建立新连接之后才到达主机2,由于新连接和老连接的端口号是一样的,TCP协议就认为那个延迟的数据是属于新连接的,这样就和真正的新连接的数据包发生混淆了。所以TCP连接还要在TIME_WAIT状态等待2倍MSL,这样可以保证本次连接的所有数据都从网络中消失。
3 次握手
- 主要目的是为了初始化 Sequence Number 的初始值。
- 通信的双方需要互相通知对方自己初始化的 Sequence Number,所以称为 SYN,全称为 Synchronize Sequence Number。
- 即图中的 x 和 y。
- 该序号会作为后续数据通信的序号,以保证应用层接收到的数据不会因为网络传输问题而乱序。
- TCP 使用这些序号来拼接数据。
4 次挥手
其实你仔细看是2次,因为TCP是全双工的,所以,发送方和接收方都需要Fin和Ack。只不过,有一方是被动的,所以看上去就成了所谓的4次挥手。如果两边同时断连接,那就会就进入到CLOSING状态,然后到达TIME_WAIT状态。下图是双方同时断连接的示意图(你同样可以对照着TCP状态机看):
相关问题
建连接时SYN超时
试想一下,如果server端接到了clien发的SYN后回了SYN-ACK后client掉线了,server端没有收到client回来的ACK,那么,这个连接处于一个中间状态,既没成功也没失败。于是,server端如果在一定时间内没有收到的TCP会重发SYN-ACK。在Linux下,默认重试次数为5次,重试的间隔时间从1s开始每次都翻倍,5次的重试时间间隔为1s, 2s, 4s, 8s, 16s,总共31s,第5次发出后还要等32s都知道第5次也超时了,所以,总共需要 1s + 2s + 4s+ 8s+ 16s + 32s = 2^6 -1 = 63s,TCP才会把断开这个连接。
SYN Flood攻击
一些恶意的人就为此制造了SYN Flood攻击——给服务器发了一个SYN后,就下线了,于是服务器需要默认等63s才会断开连接,这样,攻击者就可以把服务器的syn连接的队列耗尽,让正常的连接请求不能处理。于是,Linux下给了一个叫tcp_syncookies的参数来应对这个事——当SYN队列满了后,TCP会通过源地址端口、目标地址端口和时间戳打造出一个特别的Sequence Number发回去(又叫cookie),如果是攻击者则不会有响应,如果是正常连接,则会把这个 SYN Cookie发回来,然后服务端可以通过cookie建连接(即使你不在SYN队列中)。请注意,请先千万别用tcp_syncookies来处理正常的大负载的连接的情况。因为,synccookies是妥协版的TCP协议,并不严谨。对于正常的请求,你应该调整三个TCP参数可供你选择,第一个是:tcp_synack_retries 可以用他来减少重试次数;第二个是:tcp_max_syn_backlog,可以增大SYN连接数;第三个是:tcp_abort_on_overflow 处理不过来干脆就直接拒绝连接了。
ISN的初始化
ISN是不能hard code的,不然会出问题的——比如:如果连接建好后始终用1来做ISN,如果client发了30个segment过去,但是网络断了,于是 client重连,又用了1做ISN,但是之前连接的那些包到了,于是就被当成了新连接的包,此时,client的Sequence Number 可能是3,而Server端认为client端的这个号是30了。全乱了。RFC793中说,ISN会和一个假的时钟绑在一起,这个时钟会在每4微秒对ISN做加一操作,直到超过2^32,又从0开始。这样,一个ISN的周期大约是4.55个小时。因为,我们假设我们的TCP Segment在网络上的存活时间不会超过Maximum Segment Lifetime(缩写为MSL – Wikipedia语条),所以,只要MSL的值小于4.55小时,那么,我们就不会重用到ISN。
MSL 和 TIME_WAIT
通过上面的ISN的描述,相信你也知道MSL是怎么来的了。我们注意到,在TCP的状态图中,从TIME_WAIT状态到CLOSED状态,有一个超时设置,这个超时设置是 2*MSL(RFC793定义了MSL为2分钟,Linux设置成了30s)为什么要这有TIME_WAIT?为什么不直接给转成CLOSED状态呢?主要有两个原因:1)TIME_WAIT确保有足够的时间让对端收到了ACK,如果被动关闭的那方没有收到Ack,就会触发被动端重发Fin,一来一去正好2个MSL,2)有足够的时间让这个连接不会跟后面的连接混在一起(你要知道,有些自做主张的路由器会缓存IP数据包,如果连接被重用了,那么这些延迟收到的包就有可能会跟新连接混在一起)。你可以看看这篇文章《TIME_WAIT and its design implications for protocols and scalable client server systems》
TIME_WAIT数量太多
从上面的描述我们可以知道,TIME_WAIT是个很重要的状态,但是如果在大并发的短链接下,TIME_WAIT 就会太多,这也会消耗很多系统资源。只要搜一下,你就会发现,十有八九的处理方式都是教你设置两个参数,一个叫tcp_tw_reuse,另一个叫tcp_tw_recycle的参数,这两个参数默认值都是被关闭的,后者recyle比前者resue更为激进,resue要温柔一些。另外,如果使用tcp_tw_reuse,必需设置tcp_timestamps=1,否则无效。这里,你一定要注意,打开这两个参数会有比较大的坑——可能会让TCP连接出一些诡异的问题(因为如上述一样,如果不等待超时重用连接的话,新的连接可能会建不上。正如官方文档上说的一样“It should not be changed without advice/request of technical experts”)。
- 关于tcp_tw_reuse。官方文档上说tcp_tw_reuse 加上tcp_timestamps(又叫PAWS, for Protection Against Wrapped Sequence Numbers)可以保证协议的角度上的安全,但是你需要tcp_timestamps在两边都被打开(你可以读一下tcp_twsk_unique的源码 )。我个人估计还是有一些场景会有问题。
- 关于tcp_tw_recycle。如果是tcp_tw_recycle被打开了话,会假设对端开启了tcp_timestamps,然后会去比较时间戳,如果时间戳变大了,就可以重用。但是,如果对端是一个NAT网络的话(如:一个公司只用一个IP出公网)或是对端的IP被另一台重用了,这个事就复杂了。建链接的SYN可能就被直接丢掉了(你可能会看到connection time out的错误)(如果你想观摩一下Linux的内核代码,请参看源码 tcp_timewait_state_process)。
- 关于tcp_max_tw_buckets。这个是控制并发的TIME_WAIT的数量,默认值是180000,如果超限,那么,系统会把多的给destory掉,然后在日志里打一个警告(如:time wait bucket table overflow),官网文档说这个参数是用来对抗DDoS攻击的。也说的默认值180000并不小。这个还是需要根据实际情况考虑。
其实,TIME_WAIT表示的是你主动断连接,所以,这就是所谓的“不作死不会死”。试想,如果让对端断连接,那么这个破问题就是对方的了,呵呵。另外,如果你的服务器是于HTTP服务器,那么设置一个HTTP的KeepAlive有多重要(浏览器会重用一个TCP连接来处理多个HTTP请求),然后让客户端去断链接(你要小心,浏览器可能会非常贪婪,他们不到万不得已不会主动断连接)。
数据传输中的 Sequence Number
下图是我从Wireshark中截了个我在访问coolshell.cn时的有数据传输的图给你看一下,SeqNum是怎么变的。(使用Wireshark菜单中的Statistics ->Flow Graph… )
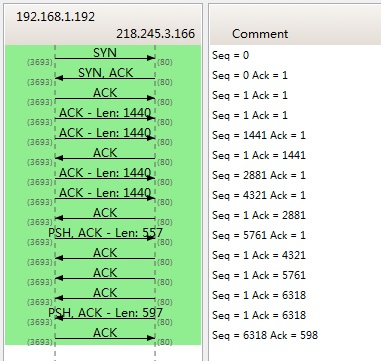
你可以看到,SeqNum的增加是和传输的字节数相关的。上图中,三次握手后,来了两个Len:1440的包,而第二个包的SeqNum就成了1441。然后第一个ACK回的是1441,表示第一个1440收到了。
注意:如果你用Wireshark抓包程序看3次握手,你会发现SeqNum总是为0,不是这样的,Wireshark为了显示更友好,使用了Relative SeqNum——相对序号,你只要在右键菜单中的protocol preference 中取消掉就可以看到“Absolute SeqNum”了
TCP 重传机制
TCP要保证所有的数据包都可以到达,所以,必需要有重传机制。
注意,接收端给发送端的Ack确认只会确认最后一个连续的包,比如,发送端发了1,2,3,4,5一共五份数据,接收端收到了1,2,于是回ack 3,然后收到了4(注意此时3没收到),此时的TCP会怎么办?我们要知道,因为正如前面所说的,SeqNum和Ack是以字节数为单位,所以ack的时候,不能跳着确认,只能确认最大的连续收到的包,不然,发送端就以为之前的都收到了。
超时重传机制
一种是不回ack,死等3,当发送方发现收不到3的ack超时后,会重传3。一旦接收方收到3后,会ack 回 4——意味着3和4都收到了。
但是,这种方式会有比较严重的问题,那就是因为要死等3,所以会导致4和5即便已经收到了,而发送方也完全不知道发生了什么事,因为没有收到Ack,所以,发送方可能会悲观地认为也丢了,所以有可能也会导致4和5的重传。
对此有两种选择:
- 一种是仅重传timeout的包。也就是第3份数据。
- 另一种是重传timeout后所有的数据,也就是第3,4,5这三份数据。
这两种方式有好也有不好。第一种会节省带宽,但是慢,第二种会快一点,但是会浪费带宽,也可能会有无用功。但总体来说都不好。因为都在等timeout,timeout可能会很长(在下篇会说TCP是怎么动态地计算出timeout的)
快速重传机制
于是,TCP引入了一种叫Fast Retransmit 的算法,不以时间驱动,而以数据驱动重传。也就是说,如果,包没有连续到达,就ack最后那个可能被丢了的包,如果发送方连续收到3次相同的ack,就重传。Fast Retransmit的好处是不用等timeout了再重传。
比如:如果发送方发出了1,2,3,4,5份数据,第一份先到送了,于是就ack回2,结果2因为某些原因没收到,3到达了,于是还是ack回2,后面的4和5都到了,但是还是ack回2,因为2还是没有收到,于是发送端收到了三个ack=2的确认,知道了2还没有到,于是就马上重转2。然后,接收端收到了2,此时因为3,4,5都收到了,于是ack回6。示意图如下:
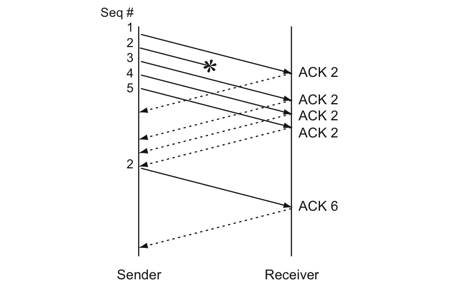
Fast Retransmit只解决了一个问题,就是timeout的问题,它依然面临一个艰难的选择,就是,是重传之前的一个还是重传所有的问题。对于上面的示例来说,是重传#2呢还是重传#2,#3,#4,#5呢?因为发送端并不清楚这连续的3个ack(2)是谁传回来的?也许发送端发了20份数据,是#6,#10,#20传来的呢。这样,发送端很有可能要重传从2到20的这堆数据(这就是某些TCP的实际的实现)。可见,这是一把双刃剑。
SACK 方法
另外一种更好的方式叫:Selective Acknowledgment (SACK)(参看RFC 2018),这种方式需要在TCP头里加一个SACK的东西,ACK还是Fast Retransmit的ACK,SACK则是汇报收到的数据碎版。参看下图:
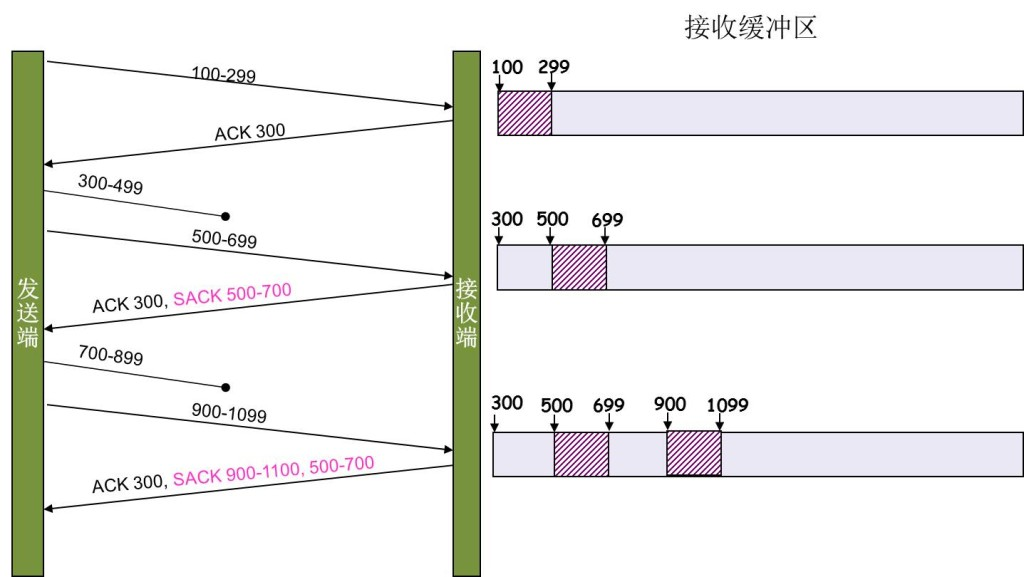
这样,在发送端就可以根据回传的SACK来知道哪些数据到了,哪些没有到。于是就优化了Fast Retransmit的算法。当然,这个协议需要两边都支持。在 Linux下,可以通过tcp_sack参数打开这个功能(Linux 2.4后默认打开)。
这里还需要注意一个问题——接收方Reneging,所谓Reneging的意思就是接收方有权把已经报给发送端SACK里的数据给丢了。这样干是不被鼓励的,因为这个事会把问题复杂化了,但是,接收方这么做可能会有些极端情况,比如要把内存给别的更重要的东西。所以,发送方也不能完全依赖SACK,还是要依赖ACK,并维护Time-Out,如果后续的ACK没有增长,那么还是要把SACK的东西重传,另外,接收端这边永远不能把SACK的包标记为Ack。
注意:SACK会消费发送方的资源,试想,如果一个攻击者给数据发送方发一堆SACK的选项,这会导致发送方开始要重传甚至遍历已经发出的数据,这会消耗很多发送端的资源。详细的东西请参看《TCP SACK的性能权衡》
Duplicate SACK – 重复收到数据的问题
Duplicate SACK又称D-SACK,其主要使用了SACK来告诉发送方有哪些数据被重复接收了。RFC-2883 里有详细描述和示例。下面举几个例子(来源于RFC-2883)
D-SACK使用了SACK的第一个段来做标志,
- 如果SACK的第一个段的范围被ACK所覆盖,那么就是D-SACK
- 如果SACK的第一个段的范围被SACK的第二个段覆盖,那么就是D-SACK
示例一:ACK丢包
下面的示例中,丢了两个ACK,所以,发送端重传了第一个数据包(3000-3499),于是接收端发现重复收到,于是回了一个SACK=3000-3500,因为ACK都到了4000意味着收到了4000之前的所有数据,所以这个SACK就是D-SACK——旨在告诉发送端我收到了重复的数据,而且我们的发送端还知道,数据包没有丢,丢的是ACK包。
Transmitted Received ACK Sent
Segment Segment (Including SACK Blocks)
3000-3499 3000-3499 3500 (ACK dropped)
3500-3999 3500-3999 4000 (ACK dropped)
3000-3499 3000-3499 4000, SACK=3000-3500
---------
示例二,网络延误
下面的示例中,网络包(1000-1499)被网络给延误了,导致发送方没有收到ACK,而后面到达的三个包触发了“Fast Retransmit算法”,所以重传,但重传时,被延误的包又到了,所以,回了一个SACK=1000-1500,因为ACK已到了3000,所以,这个SACK是D-SACK——标识收到了重复的包。
这个案例下,发送端知道之前因为“Fast Retransmit算法”触发的重传不是因为发出去的包丢了,也不是因为回应的ACK包丢了,而是因为网络延时了。
Transmitted Received ACK Sent
Segment Segment (Including SACK Blocks)
500-999 500-999 1000
1000-1499 (delayed)
1500-1999 1500-1999 1000, SACK=1500-2000
2000-2499 2000-2499 1000, SACK=1500-2500
2500-2999 2500-2999 1000, SACK=1500-3000
1000-1499 1000-1499 3000
1000-1499 3000, SACK=1000-1500
---------
可见,引入了D-SACK,有这么几个好处:
- 1)可以让发送方知道,是发出去的包丢了,还是回来的ACK包丢了。
- 2)是不是自己的timeout太小了,导致重传。
- 3)网络上出现了先发的包后到的情况(又称reordering)
- 4)网络上是不是把我的数据包给复制了。
知道这些东西可以很好得帮助TCP了解网络情况,从而可以更好的做网络上的流控。
Linux下的tcp_dsack参数用于开启这个功能(Linux 2.4后默认打开)
TCP的RTT算法
从前面的TCP重传机制我们知道Timeout的设置对于重传非常重要。
- 设长了,重发就慢,丢了老半天才重发,没有效率,性能差;
- 设短了,会导致可能并没有丢就重发。于是重发的就快,会增加网络拥塞,导致更多的超时,更多的超时导致更多的重发。
而且,这个超时时间在不同的网络的情况下,根本没有办法设置一个死的值。只能动态地设置。 为了动态地设置,TCP引入了RTT——Round Trip Time,也就是一个数据包从发出去到回来的时间。这样发送端就大约知道需要多少的时间,从而可以方便地设置Timeout——RTO(Retransmission TimeOut),以让我们的重传机制更高效。 听起来似乎很简单,好像就是在发送端发包时记下t0,然后接收端再把这个ack回来时再记一个t1,于是RTT = t1 – t0。没那么简单,这只是一个采样,不能代表普遍情况
经典算法
RFC793 中定义的经典算法是这样的:
- 1)首先,先采样RTT,记下最近好几次的RTT值。
- 2)然后做平滑计算
SRTT( Smoothed RTT)。公式为:(其中的 α 取值在0.8 到 0.9之间,这个算法英文叫Exponential weighted moving average,中文叫:加权移动平均)
SRTT = ( α * SRTT ) + ((1- α) * RTT)
3)开始计算RTO。公式如下:
RTO = min [ UBOUND, max [ LBOUND, (β * SRTT) ] ]- UBOUND是最大的timeout时间,上限值
- LBOUND是最小的timeout时间,下限值
- β 值一般在1.3到2.0之间。
Karn / Partridge 算法
但是上面的这个算法在重传的时候会出有一个终极问题——你是用第一次发数据的时间和ack回来的时间做RTT样本值,还是用重传的时间和ACK回来的时间做RTT样本值?
这个问题无论你选那头都是按下葫芦起了瓢。 如下图所示:
- 情况(a)是ack没回来,所以重传。如果你计算第一次发送和ACK的时间,那么,明显算大了。
- 情况(b)是ack回来慢了,但是导致了重传,但刚重传不一会儿,之前ACK就回来了。如果你是算重传的时间和ACK回来的时间的差,就会算短了。
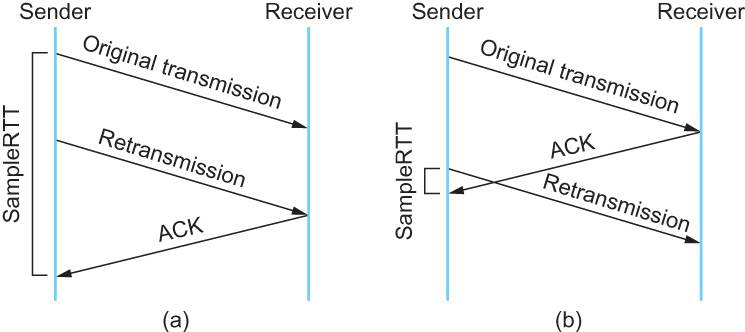
所以1987年的时候,搞了一个叫Karn / Partridge Algorithm,这个算法的最大特点是——忽略重传,不把重传的RTT做采样(你看,你不需要去解决不存在的问题)。
但是,这样一来,又会引发一个大BUG——如果在某一时间,网络闪动,突然变慢了,产生了比较大的延时,这个延时导致要重转所有的包(因为之前的RTO很小),于是,因为重转的不算,所以,RTO就不会被更新,这是一个灾难。 于是Karn算法用了一个取巧的方式——只要一发生重传,就对现有的RTO值翻倍(这就是所谓的 Exponential backoff),很明显,这种死规矩对于一个需要估计比较准确的RTT也不靠谱。
Jacobson / Karels 算法
前面两种算法用的都是“加权移动平均”,这种方法最大的毛病就是如果RTT有一个大的波动的话,很难被发现,因为被平滑掉了。所以,1988年,又有人推出来了一个新的算法,这个算法叫Jacobson / Karels Algorithm(参看RFC6289)。这个算法引入了最新的RTT的采样和平滑过的SRTT的差距做因子来计算。 公式如下:(其中的DevRTT是Deviation RTT的意思)
SRTT = SRTT + α (RTT – SRTT)—— 计算平滑RTTDevRTT = (1-β)*DevRTT + β*(|RTT-SRTT|)——计算平滑RTT和真实的差距(加权移动平均)RTO= µ * SRTT + ∂ *DevRTT—— 神一样的公式
(其中:在Linux下,α = 0.125,β = 0.25, μ = 1,∂ = 4 ——这就是算法中的“调得一手好参数”,nobody knows why, it just works…) 最后的这个算法在被用在今天的TCP协议中(Linux的源代码在:tcp_rtt_estimator)。
TCP滑动窗口
需要说明一下,如果你不了解TCP的滑动窗口这个事,你等于不了解TCP协议。我们都知道,TCP必需要解决的可靠传输以及包乱序(reordering)的问题,所以,TCP必需要知道网络实际的数据处理带宽或是数据处理速度,这样才不会引起网络拥塞,导致丢包。
所以,TCP引入了一些技术和设计来做网络流控,Sliding Window是其中一个技术。 前面我们说过,TCP头里有一个字段叫Window,又叫Advertised-Window,这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。 为了说明滑动窗口,我们需要先看一下TCP缓冲区的一些数据结构:
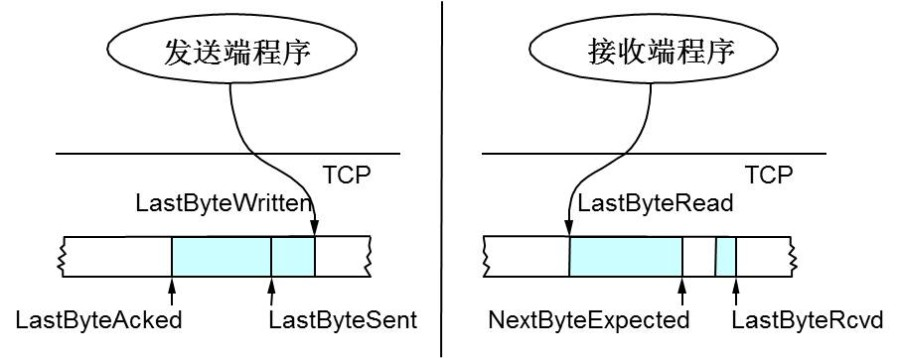
上图中,我们可以看到:
- 接收端LastByteRead指向了TCP缓冲区中读到的位置,NextByteExpected指向的地方是收到的连续包的最后一个位置,LastByteRcved指向的是收到的包的最后一个位置,我们可以看到中间有些数据还没有到达,所以有数据空白区。
- 发送端的LastByteAcked指向了被接收端Ack过的位置(表示成功发送确认),LastByteSent表示发出去了,但还没有收到成功确认的Ack,LastByteWritten指向的是上层应用正在写的地方。
于是:
- 接收端在给发送端回ACK中会汇报自己的AdvertisedWindow = MaxRcvBuffer – LastByteRcvd – 1;
- 而发送方会根据这个窗口来控制发送数据的大小,以保证接收方可以处理。
下面我们来看一下发送方的滑动窗口示意图:
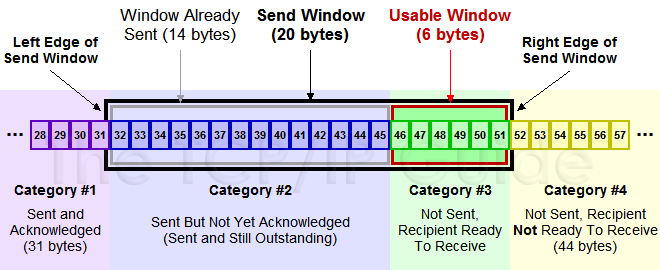
上图中分成了四个部分,分别是:(其中那个黑模型就是滑动窗口)
- #1已收到ack确认的数据。
- #2发还没收到ack的。
- #3在窗口中还没有发出的(接收方还有空间)。
- #4窗口以外的数据(接收方没空间)
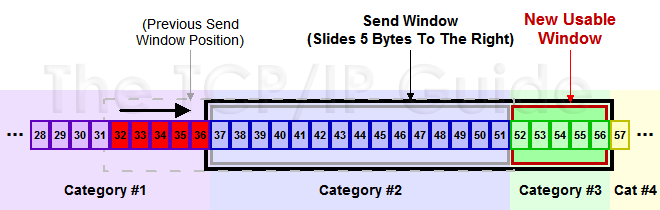
下面是个滑动后的示意图(收到36的ack,并发出了46-51的字节):
下面我们来看一个接受端控制发送端的图示:
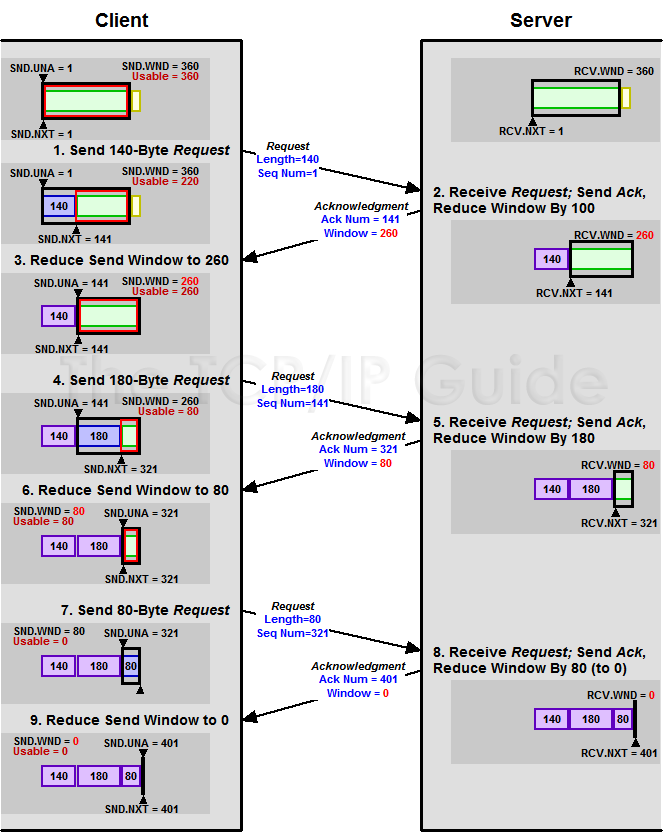
Zero Window
上图,我们可以看到一个处理缓慢的Server(接收端)是怎么把Client(发送端)的TCP Sliding Window给降成0的。此时,你一定会问,如果Window变成0了,TCP会怎么样?是不是发送端就不发数据了?是的,发送端就不发数据了,你可以想像成“Window Closed”,那你一定还会问,如果发送端不发数据了,接收方一会儿Window size 可用了,怎么通知发送端呢?
解决这个问题,TCP使用了Zero Window Probe技术,缩写为ZWP,也就是说,发送端在窗口变成0后,会发ZWP的包给接收方,让接收方来ack他的Window尺寸,一般这个值会设置成3次,第次大约30-60秒(不同的实现可能会不一样)。如果3次过后还是0的话,有的TCP实现就会发RST把链接断了。
注意:只要有等待的地方都可能出现DDoS攻击,Zero Window也不例外,一些攻击者会在和HTTP建好链发完GET请求后,就把Window设置为0,然后服务端就只能等待进行ZWP,于是攻击者会并发大量的这样的请求,把服务器端的资源耗尽。(关于这方面的攻击,大家可以移步看一下Wikipedia的SockStress词条)
另外,Wireshark中,你可以使用tcp.analysis.zero_window来过滤包,然后使用右键菜单里的follow TCP stream,你可以看到ZeroWindowProbe及ZeroWindowProbeAck的包。
Silly Window Syndrome
Silly Window Syndrome翻译成中文就是“糊涂窗口综合症”。正如你上面看到的一样,如果我们的接收方太忙了,来不及取走Receive Windows里的数据,那么,就会导致发送方越来越小。到最后,如果接收方腾出几个字节并告诉发送方现在有几个字节的window,而我们的发送方会义无反顾地发送这几个字节。
要知道,我们的TCP+IP头有40个字节,为了几个字节,要达上这么大的开销,这太不经济了。
另外,你需要知道网络上有个MTU,对于以太网来说,MTU是1500字节,除去TCP+IP头的40个字节,真正的数据传输可以有1460,这就是所谓的MSS(Max Segment Size)注意,TCP的RFC定义这个MSS的默认值是536,这是因为 RFC 791里说了任何一个IP设备都得最少接收576尺寸的大小(实际上来说576是拨号的网络的MTU,而576减去IP头的20个字节就是536)。
如果你的网络包可以塞满MTU,那么你可以用满整个带宽,如果不能,那么你就会浪费带宽。(大于MTU的包有两种结局,一种是直接被丢了,另一种是会被重新分块打包发送) 你可以想像成一个MTU就相当于一个飞机的最多可以装的人,如果这飞机里满载的话,带宽最高,如果一个飞机只运一个人的话,无疑成本增加了,也而相当二。
所以,Silly Windows Syndrome这个现像就像是你本来可以坐200人的飞机里只做了一两个人。 要解决这个问题也不难,就是避免对小的window size做出响应,直到有足够大的window size再响应,这个思路可以同时实现在sender和receiver两端。
- 如果这个问题是由Receiver端引起的,那么就会使用 David D Clark’s 方案。在receiver端,如果收到的数据导致window size小于某个值,可以直接ack(0)回sender,这样就把window给关闭了,也阻止了sender再发数据过来,等到receiver端处理了一些数据后windows size 大于等于了MSS,或者,receiver buffer有一半为空,就可以把window打开让send 发送数据过来。
- 如果这个问题是由Sender端引起的,那么就会使用著名的 Nagle’s algorithm。这个算法的思路也是延时处理,他有两个主要的条件:1)要等到 Window Size>=MSS 或是 Data Size >=MSS,2)收到之前发送数据的ack回包,他才会发数据,否则就是在攒数据。
另外,Nagle算法默认是打开的,所以,对于一些需要小包场景的程序——比如像telnet或ssh这样的交互性比较强的程序,你需要关闭这个算法。你可以在Socket设置TCP_NODELAY选项来关闭这个算法(关闭Nagle算法没有全局参数,需要根据每个应用自己的特点来关闭)
setsockopt(sock_fd, IPPROTO_TCP, TCP_NODELAY, (char *)&value,sizeof(int));
另外,网上有些文章说TCP_CORK的socket option是也关闭Nagle算法,这不对。TCP_CORK其实是更新激进的Nagle算法,完全禁止小包发送,而Nagle算法没有禁止小包发送,只是禁止了大量的小包发送。最好不要两个选项都设置。
TCP的拥塞处理 – Congestion Handling
上面我们知道了,TCP通过Sliding Window来做流控(Flow Control),但是TCP觉得这还不够,因为Sliding Window需要依赖于连接的发送端和接收端,其并不知道网络中间发生了什么。TCP的设计者觉得,一个伟大而牛逼的协议仅仅做到流控并不够,因为流控只是网络模型4层以上的事,TCP的还应该更聪明地知道整个网络上的事。
具体一点,我们知道TCP通过一个timer采样了RTT并计算RTO,但是,如果网络上的延时突然增加,那么,TCP对这个事做出的应对只有重传数据,但是,重传会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,于是,这个情况就会进入恶性循环被不断地放大。试想一下,如果一个网络内有成千上万的TCP连接都这么行事,那么马上就会形成“网络风暴”,TCP这个协议就会拖垮整个网络。这是一个灾难。
所以,TCP不能忽略网络上发生的事情,而无脑地一个劲地重发数据,对网络造成更大的伤害。对此TCP的设计理念是:TCP不是一个自私的协议,当拥塞发生的时候,要做自我牺牲。就像交通阻塞一样,每个车都应该把路让出来,而不要再去抢路了。
关于拥塞控制的论文请参看《Congestion Avoidance and Control》(PDF)
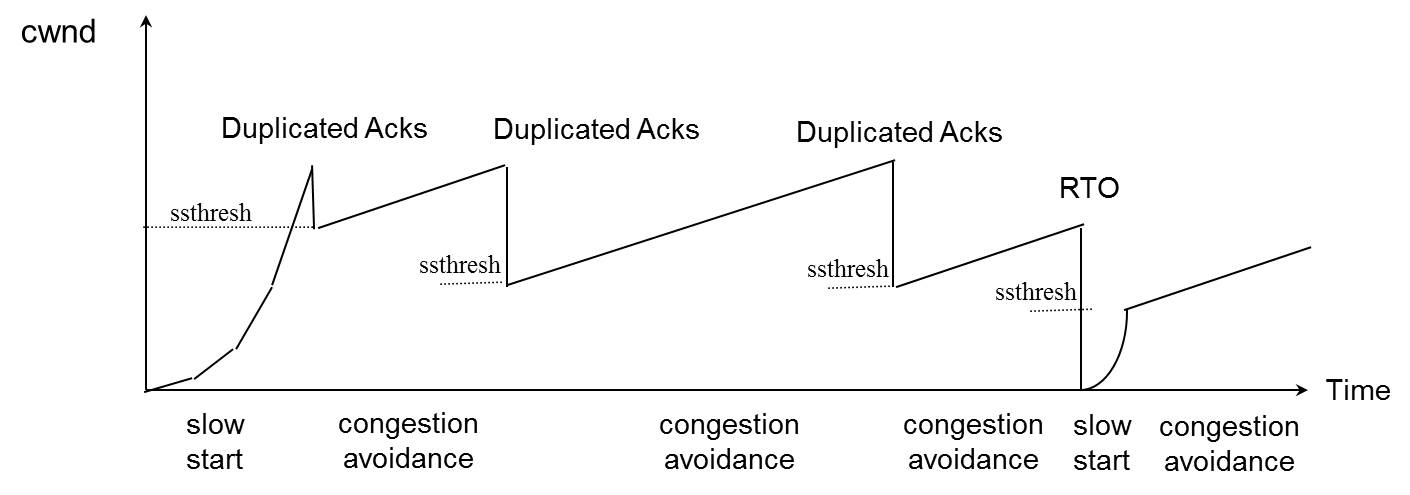
拥塞控制主要是四个算法:1)慢启动,2)拥塞避免,3)拥塞发生,4)快速恢复。这四个算法不是一天都搞出来的,这个四算法的发展经历了很多时间,到今天都还在优化中。 备注:
- 1988年,TCP-Tahoe 提出了1)慢启动,2)拥塞避免,3)拥塞发生时的快速重传
- 1990年,TCP Reno 在Tahoe的基础上增加了4)快速恢复
慢热启动算法 – Slow Start
首先,我们来看一下TCP的慢热启动。慢启动的意思是,刚刚加入网络的连接,一点一点地提速,不要一上来就像那些特权车一样霸道地把路占满。新同学上高速还是要慢一点,不要把已经在高速上的秩序给搞乱了。
慢启动的算法如下(cwnd全称Congestion Window):
1)连接建好的开始先初始化cwnd = 1,表明可以传一个MSS大小的数据。
2)每当收到一个ACK,cwnd++; 呈线性上升
3)每当过了一个RTT,cwnd = cwnd*2; 呈指数让升
4)还有一个ssthresh(slow start threshold),是一个上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”(后面会说这个算法)
所以,我们可以看到,如果网速很快的话,ACK也会返回得快,RTT也会短,那么,这个慢启动就一点也不慢。下图说明了这个过程。
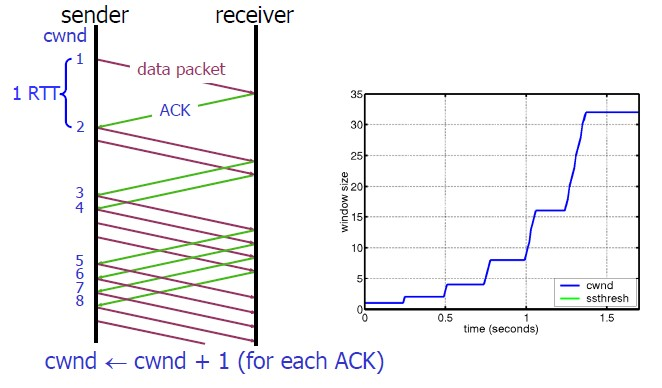
这里,我需要提一下的是一篇Google的论文《An Argument for Increasing TCP’s Initial Congestion Window》, Linux 3.0后采用了这篇论文的建议——把cwnd 初始化成了 10个MSS。 而Linux 3.0以前,比如2.6,Linux采用了RFC3390,cwnd是跟MSS的值来变的,如果MSS< 1095,则cwnd = 4;如果MSS>2190,则cwnd=2;其它情况下,则是3。
拥塞避免算法 – Congestion Avoidance
前面说过,还有一个ssthresh(slow start threshold),是一个上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”。一般来说ssthresh的值是65535,单位是字节,当cwnd达到这个值时后,算法如下:
- 1)收到一个ACK时,cwnd = cwnd + 1/cwnd
- 2)当每过一个RTT时,cwnd = cwnd + 1
这样就可以避免增长过快导致网络拥塞,慢慢的增加调整到网络的最佳值。很明显,是一个线性上升的算法。
拥塞状态时的算法
前面我们说过,当丢包的时候,会有两种情况:
- 1)等到RTO超时,重传数据包。TCP认为这种情况太糟糕,反应也很强烈。
- sshthresh = cwnd /2
- cwnd 重置为 1
- 进入慢启动过程
- 2)Fast Retransmit算法,也就是在收到3个duplicate ACK时就开启重传,而不用等到RTO超时。
- TCP Tahoe的实现和RTO超时一样。
- TCP Reno的实现是:
- cwnd = cwnd /2
- sshthresh = cwnd
- 进入快速恢复算法——Fast Recovery
上面我们可以看到RTO超时后,sshthresh会变成cwnd的一半,这意味着,如果cwnd<=sshthresh时出现的丢包,那么TCP的sshthresh就会减了一半,然后等cwnd又很快地以指数级增涨爬到这个地方时,就会成慢慢的线性增涨。我们可以看到,TCP是怎么通过这种强烈地震荡快速而小心得找到网站流量的平衡点的。
快速恢复算法 – Fast Recovery
TCP Reno
这个算法定义在RFC5681。快速重传和快速恢复算法一般同时使用。快速恢复算法是认为,你还有3个Duplicated Acks说明网络也不那么糟糕,所以没有必要像RTO超时那么强烈。 注意,正如前面所说,进入Fast Recovery之前,cwnd 和 sshthresh已被更新:
- cwnd = cwnd /2
- sshthresh = cwnd
然后,真正的Fast Recovery算法如下:
- cwnd = sshthresh + 3 * MSS (3的意思是确认有3个数据包被收到了)
- 重传Duplicated ACKs指定的数据包
- 如果再收到 duplicated Acks,那么cwnd = cwnd +1
- 如果收到了新的Ack,那么,cwnd = sshthresh ,然后就进入了拥塞避免的算法了。
如果你仔细思考一下上面的这个算法,你就会知道,上面这个算法也有问题,那就是——它依赖于3个重复的Acks。注意,3个重复的Acks并不代表只丢了一个数据包,很有可能是丢了好多包。但这个算法只会重传一个,而剩下的那些包只能等到RTO超时,于是,进入了恶梦模式——超时一个窗口就减半一下,多个超时会超成TCP的传输速度呈级数下降,而且也不会触发Fast Recovery算法了。
通常来说,正如我们前面所说的,SACK或D-SACK的方法可以让Fast Recovery或Sender在做决定时更聪明一些,但是并不是所有的TCP的实现都支持SACK(SACK需要两端都支持),所以,需要一个没有SACK的解决方案。而通过SACK进行拥塞控制的算法是FACK(后面会讲)
TCP New Reno
于是,1995年,TCP New Reno(参见 RFC 6582 )算法提出来,主要就是在没有SACK的支持下改进Fast Recovery算法的——
当sender这边收到了3个Duplicated Acks,进入Fast Retransimit模式,开发重传重复Acks指示的那个包。如果只有这一个包丢了,那么,重传这个包后回来的Ack会把整个已经被sender传输出去的数据ack回来。如果没有的话,说明有多个包丢了。我们叫这个ACK为Partial ACK。 一旦Sender这边发现了Partial ACK出现,那么,sender就可以推理出来有多个包被丢了,于是乎继续重传sliding window里未被ack的第一个包。直到再也收不到了Partial Ack,才真正结束Fast Recovery这个过程 我们可以看到,这个“Fast Recovery的变更”是一个非常激进的玩法,他同时延长了Fast Retransmit和Fast Recovery的过程。
算法示意图
下面我们来看一个简单的图示以同时看一下上面的各种算法的样子:
FACK算法
FACK全称Forward Acknowledgment 算法,论文地址在这里(PDF)Forward Acknowledgement: Refining TCP Congestion Control 这个算法是其于SACK的,前面我们说过SACK是使用了TCP扩展字段Ack了有哪些数据收到,哪些数据没有收到,他比Fast Retransmit的3 个duplicated acks好处在于,前者只知道有包丢了,不知道是一个还是多个,而SACK可以准确的知道有哪些包丢了。 所以,SACK可以让发送端这边在重传过程中,把那些丢掉的包重传,而不是一个一个的传,但这样的一来,如果重传的包数据比较多的话,又会导致本来就很忙的网络就更忙了。所以,FACK用来做重传过程中的拥塞流控。
- 这个算法会把SACK中最大的Sequence Number 保存在
snd.fack这个变量中,snd.fack的更新由ack带秋,如果网络一切安好则和snd.una一样(snd.una就是还没有收到ack的地方,也就是前面sliding window里的category #2的第一个地方) - 然后定义一个
awnd = snd.nxt – snd.fack(snd.nxt指向发送端sliding window中正在要被发送的地方——前面sliding windows图示的category#3第一个位置),这样awnd的意思就是在网络上的数据。(所谓awnd意为:actual quantity of data outstanding in the network) - 如果需要重传数据,那么,
awnd = snd.nxt – snd.fack + retran_data,也就是说,awnd是传出去的数据 + 重传的数据。 - 然后触发Fast Recovery 的条件是: (
( snd.fack – snd.una ) > (3*MSS) ) || (dupacks == 3)) 。这样一来,就不需要等到3个duplicated acks才重传,而是只要sack中的最大的一个数据和ack的数据比较长了(3个MSS),那就触发重传。在整个重传过程中cwnd不变。直到当第一次丢包的snd.nxt<=snd.una(也就是重传的数据都被确认了),然后进来拥塞避免机制——cwnd线性上涨。
我们可以看到如果没有FACK在,那么在丢包比较多的情况下,原来保守的算法会低估了需要使用的window的大小,而需要几个RTT的时间才会完成恢复,而FACK会比较激进地来干这事。 但是,FACK如果在一个网络包会被 reordering的网络里会有很大的问题。
其它拥塞控制算法简介
TCP Vegas 拥塞控制算法
这个算法1994年被提出,它主要对TCP Reno 做了些修改。这个算法通过对RTT的非常重的监控来计算一个基准RTT。然后通过这个基准RTT来估计当前的网络实际带宽,如果实际带宽比我们的期望的带宽要小或是要多的活,那么就开始线性地减少或增加cwnd的大小。如果这个计算出来的RTT大于了Timeout后,那么,不等ack超时就直接重传。(Vegas 的核心思想是用RTT的值来影响拥塞窗口,而不是通过丢包) 这个算法的论文是《TCP Vegas: End to End Congestion Avoidance on a Global Internet》这篇论文给了Vegas和 New Reno的对比:
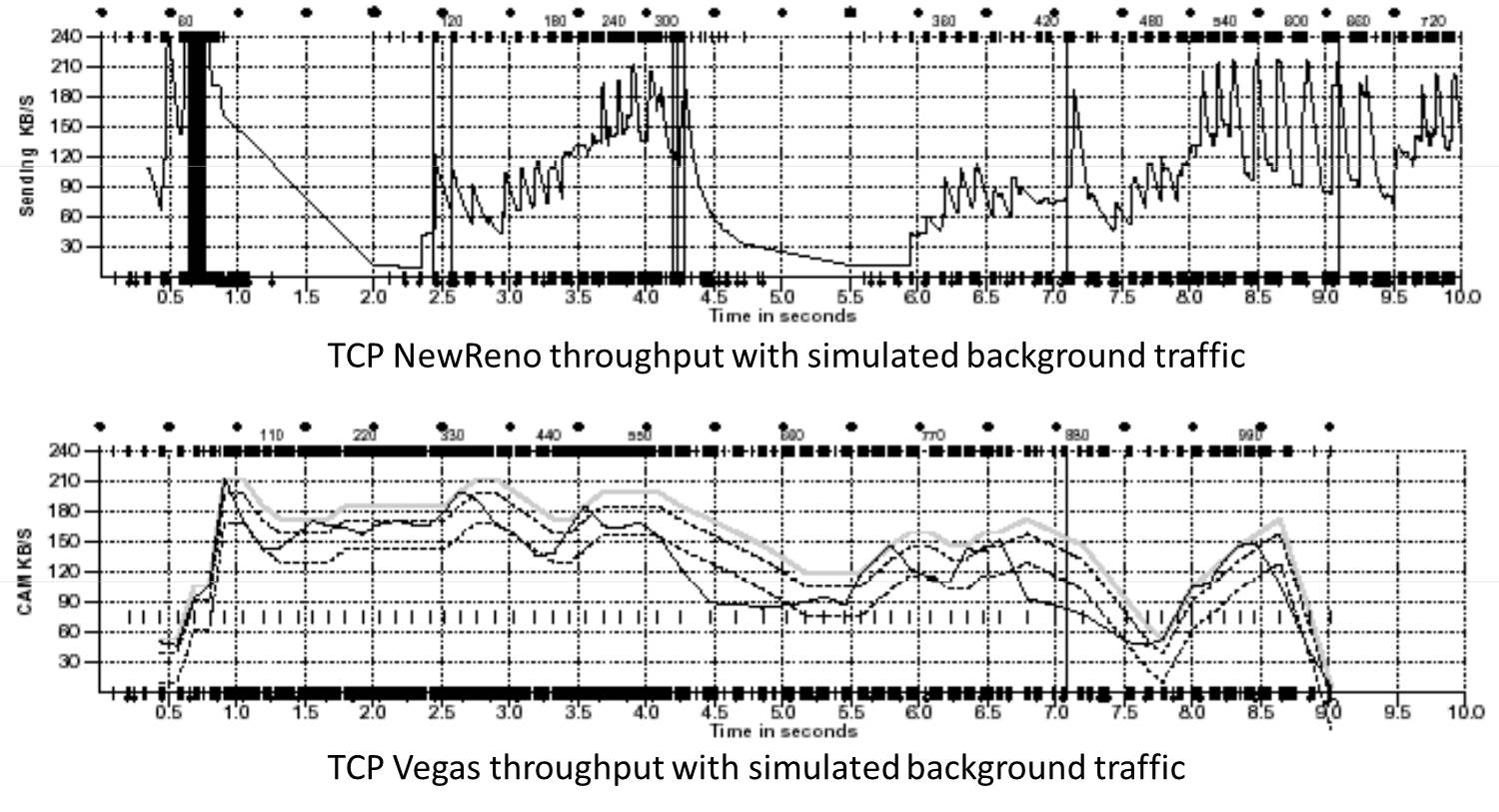
关于这个算法实现,你可以参看Linux源码:/net/ipv4/tcp_vegas.h (opens new window), /net/ipv4/tcp_vegas.c
HSTCP(High Speed TCP) 算法
这个算法来自RFC 3649。其对最基础的算法进行了更改,他使得Congestion Window涨得快,减得慢。其中:
- 拥塞避免时的窗口增长方式: cwnd = cwnd + α(cwnd) / cwnd
- 丢包后窗口下降方式:cwnd = (1- β(cwnd))*cwnd
注:α(cwnd)和β(cwnd)都是函数,如果你要让他们和标准的TCP一样,那么让α(cwnd)=1,β(cwnd)=0.5就可以了。 对于α(cwnd)和β(cwnd)的值是个动态的变换的东西。 关于这个算法的实现,你可以参看Linux源码:/net/ipv4/tcp_highspeed.c
TCP BIC 算法
2004年,产内出BIC算法。现在你还可以查得到相关的新闻《Google:美科学家研发BIC-TCP协议 速度是DSL六千倍》 BIC全称Binary Increase Congestion control,在Linux 2.6.8中是默认拥塞控制算法。BIC的发明者发这么多的拥塞控制算法都在努力找一个合适的cwnd – Congestion Window,而且BIC-TCP的提出者们看穿了事情的本质,其实这就是一个搜索的过程,所以BIC这个算法主要用的是Binary Search——二分查找来干这个事。 关于这个算法实现,你可以参看Linux源码:/net/ipv4/tcp_bic.c
TCP WestWood算法
westwood采用和Reno相同的慢启动算法、拥塞避免算法。westwood的主要改进方面:在发送端做带宽估计,当探测到丢包时,根据带宽值来设置拥塞窗口、慢启动阈值。 那么,这个算法是怎么测量带宽的?每个RTT时间,会测量一次带宽,测量带宽的公式很简单,就是这段RTT内成功被ack了多少字节。因为,这个带宽和用RTT计算RTO一样,也是需要从每个样本来平滑到一个值的——也是用一个加权移平均的公式。 另外,我们知道,如果一个网络的带宽是每秒可以发送X个字节,而RTT是一个数据发出去后确认需要的时候,所以,X * RTT应该是我们缓冲区大小。所以,在这个算法中,ssthresh的值就是est_BD * min-RTT(最小的RTT值),如果丢包是Duplicated ACKs引起的,那么如果cwnd > ssthresh,则 cwin = ssthresh。如果是RTO引起的,cwnd = 1,进入慢启动。 关于这个算法实现,你可以参看Linux源码: /net/ipv4/tcp_westwood.c
其它
更多的算法,你可以从Wikipedia的 TCP Congestion Avoidance Algorithm 词条中找到相关的线索
4 - UDP 协议
概览
UDP(User Datagram Protocol)即用户数据报协议,在网络中它与TCP协议一样用于处理数据包,是一种无连接的协议。在OSI模型中,在第四层——传输层,处于IP协议的上一层。
UDP用来支持那些需要在计算机之间传输数据的网络应用。包括网络视频会议系统在内的众多的客户/服务器模式的网络应用都需要使用UDP协议。UDP协议从问世至今已经被使用了很多年,虽然其最初的光彩已经被一些类似协议所掩盖,但是即使是在今天UDP仍然不失为一项非常实用和可行的网络传输层协议。UDP报文没有可靠性保证、顺序保证和流量控制字段等,可靠性较差。但是正因为UDP协议的控制选项较少,在数据传输过程中延迟小、数据传输效率高,适合对可靠性要求不高的应用程序,或者可以保障可靠性的应用程序,如DNS、TFTP、SNMP等。
特点
UDP提供不可靠服务,但具有TCP所没有的优势:
- UDP无连接,时间上不存在建立连接需要的时延。空间上,TCP需要在端系统中维护连接状态,需要一定的开销。此连接装入包括接收和发送缓存,拥塞控制参数和序号与确认号的参数。UDP不维护连接状态,也不跟踪这些参数,开销小。空间和时间上都具有优势。 举个例子:
- DNS如果运行在TCP之上而不是UDP,那么DNS的速度将会慢很多。
- HTTP使用TCP而不是UDP,是因为对于基于文本数据的Web网页来说,可靠性很重要。
- 同一种专用应用服务器在支持UDP时,一定能支持更多的活动客户机。
- 分组首部开销小,TCP首部20字节,UDP首部8字节。
- UDP没有拥塞控制,应用层能够更好的控制要发送的数据和发送时间,网络中的拥塞控制也不会影响主机的发送速率。某些实时应用要求以稳定的速度发送,能容 忍一些数据的丢失,但是不能允许有较大的时延(比如实时视频,直播等)
- UDP提供尽最大努力的交付,不保证可靠交付。所有维护传输可靠性的工作需要用户在应用层来完成。没有TCP的确认机制、重传机制。如果因为网络原因没有传送到对端,UDP也不会给应用层返回错误信息
- UDP是面向报文的,对应用层交下来的报文,添加首部后直接乡下交付为IP层,既不合并,也不拆分,保留这些报文的边界。对IP层交上来UDP用户数据报,在去除首部后就原封不动地交付给上层应用进程,报文不可分割,是UDP数据报处理的最小单位。 正是因为这样,UDP显得不够灵活,不能控制读写数据的次数和数量。比如我们要发送100个字节的报文,我们调用一次sendto函数就会发送100字节,对端也需要用recvfrom函数一次性接收100字节,不能使用循环每次获取10个字节,获取十次这样的做法。
- UDP常用一次性传输比较少量数据的网络应用,如DNS,SNMP等,因为对于这些应用,若是采用TCP,为连接的创建,维护和拆除带来不小的开销。UDP也常用于多媒体应用(如IP电话,实时视频会议,流媒体等)数据的可靠传输对他们而言并不重要,TCP的拥塞控制会使他们有较大的延迟,也是不可容忍的
- UDP 支持一对一、一对多、多对一和多对多的交互通信。
还要注意的是:
- IP 数据报要经过互连网中许多路由器的存储转发;UDP 用户数据报是在运输层的端到端抽象的逻辑信道中传送的。
UDP 对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。应用层交给 UDP 多长的报文,UDP 就照样发送,即一次发送一个报文。
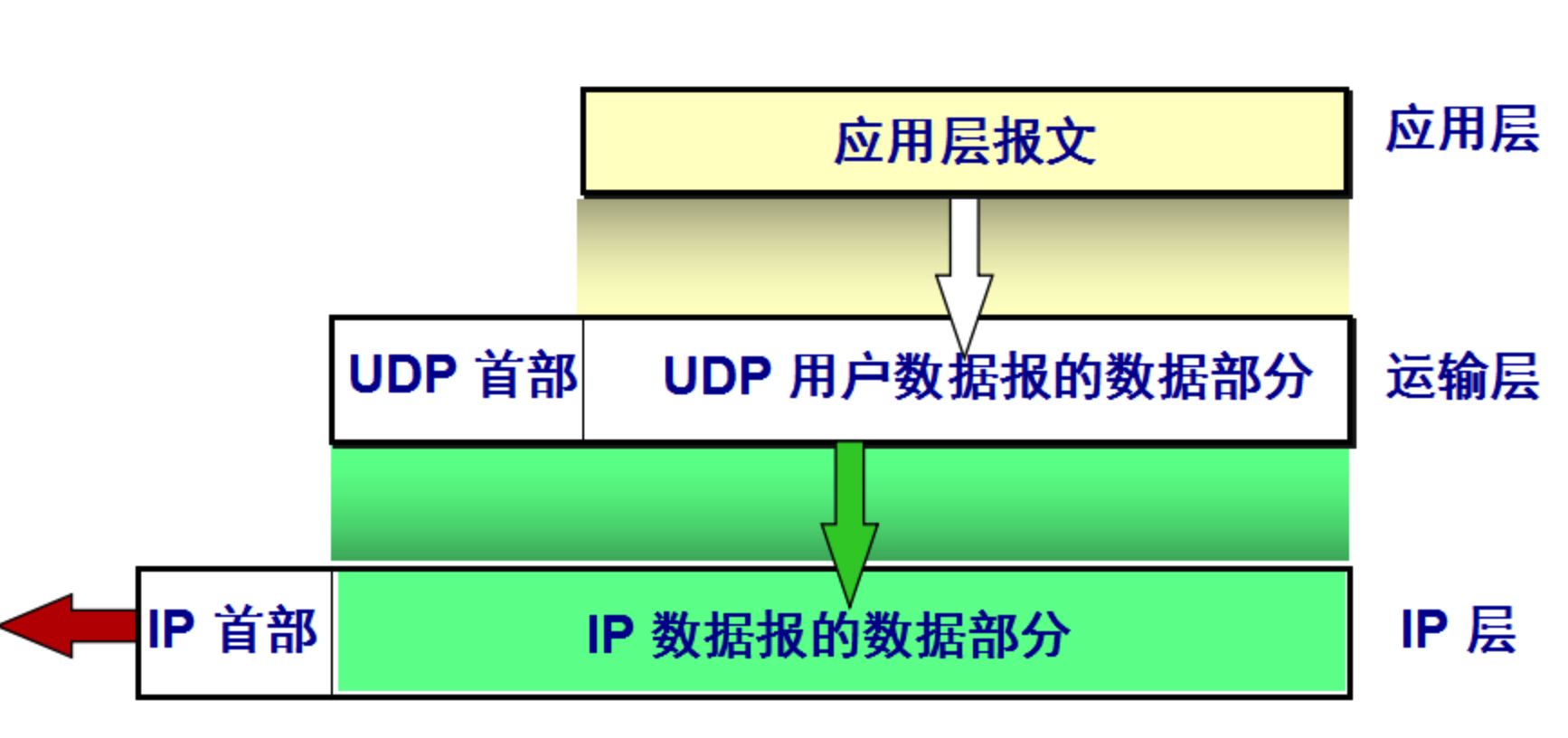
首部格式
在计算检验和时,临时把“伪首部”和 UDP 用户数据报连接在一起。伪首部仅仅是为了计算检验和。
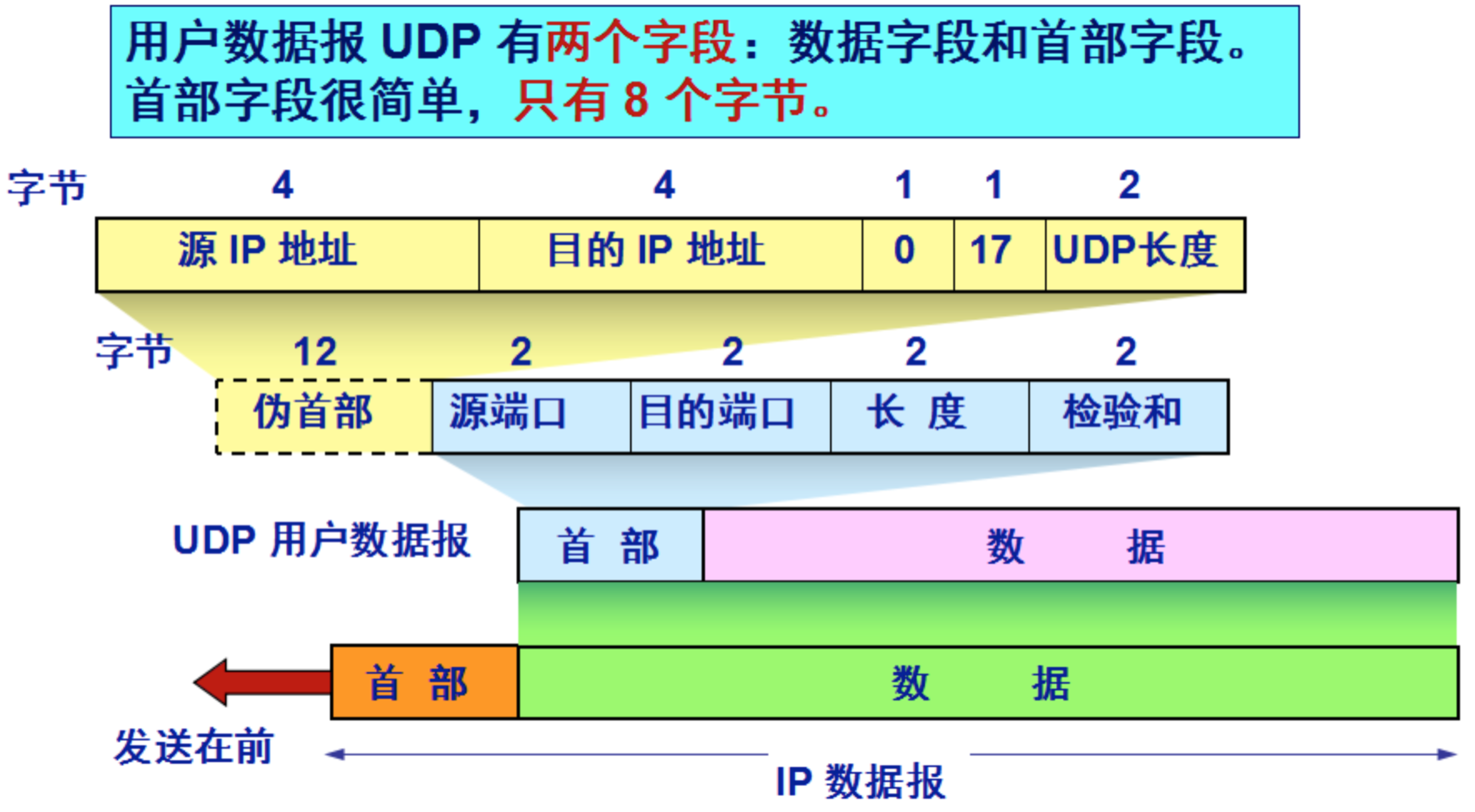
- 源端口: 占16位、源端口号。在需要对方回信时选用。不需要时可用全0。
- 目的端口: 占16位、目的端口号。这在终点交付报文时必须使用。
- 长度: 占16位、UDP用户数据报的长度,其最小值是8(仅有首部)。
- 检验和: 占16位、检测UDP用户数据报在传输中是否有错。有错就丢弃。
请注意,虽然在 UDP 之间的通信要用到其端口号,但由于 UDP 的通信是无连接的,因此不需要使用套接字。
校验
UDP校验和的计算方法和IP数据报首部校验和的计算方法相似,都使用二进制反码运算求和再取反,但不同的是:IP数据报的校验和之检验IP数据报和首部,但UDP的校验和是把首部和数据部分一起校验。
发送方,首先是把全零放入校验和字段并且添加伪首部,然后把UDP数据报看成是由许多16位的子串连接起来,若UDP数据报的数据部分不是偶数个字节,则要在数据部分末尾增加一个全零字节(此字节不发送),接下来就按照二进制反码计算出这些16位字的和。将此和的二进制反码写入校验和字段。在接收方,把收到得UDP数据报加上伪首部(如果不为偶数个字节,还需要补上全零字节)后,按二进制反码计算出这些16位字的和。当无差错时其结果全为1,。否则就表明有差错出现,接收方应该丢弃这个UDP数据报。
下图是计算UDP校验和的例子:
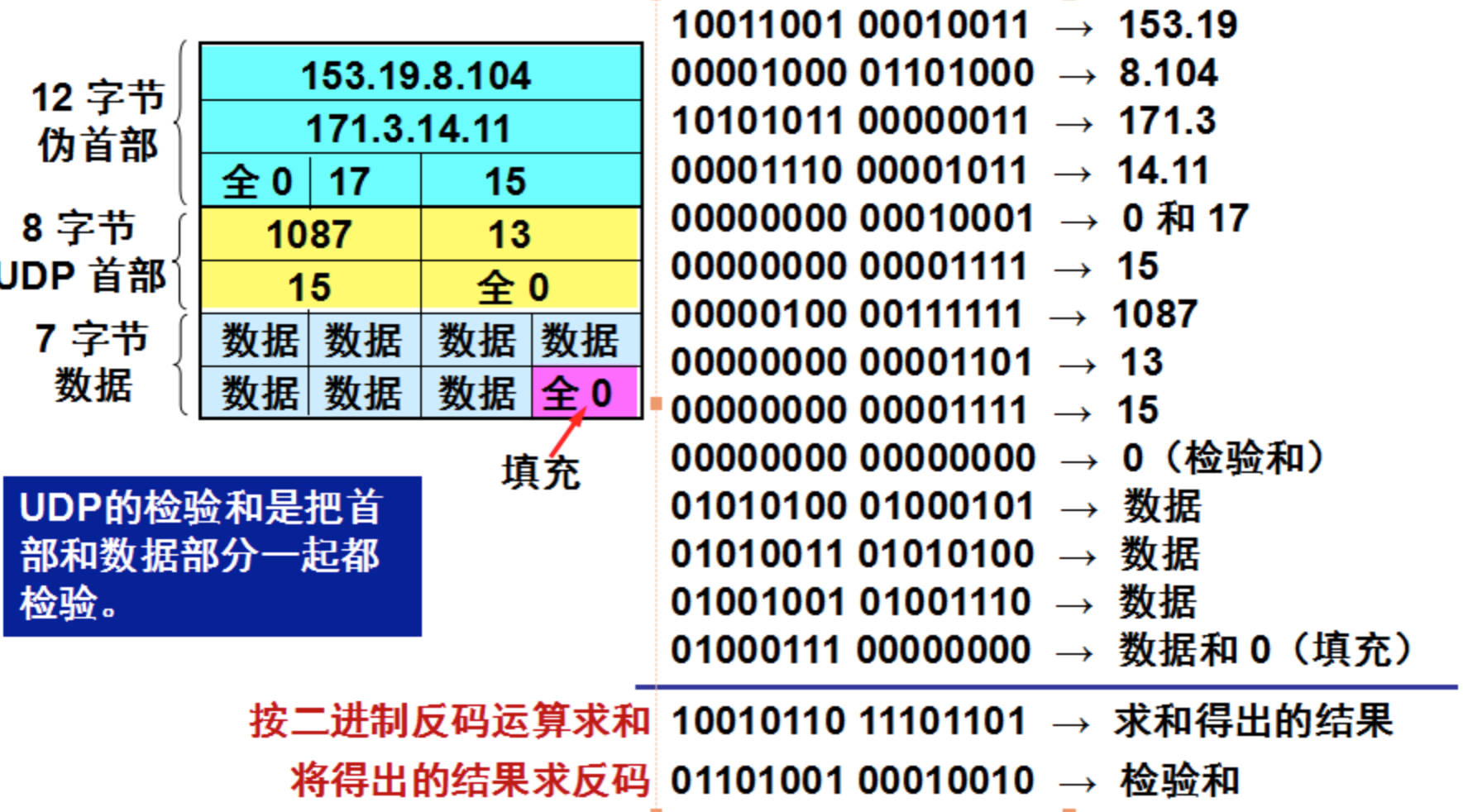
注意:
- 校验时,若UDP数据报部分的长度不是偶数个字节,则需要填入一个全0字节,但是次字节和伪首部一样,是不发送的。
- 如果UDP校验和校验出UDP数据报是错误的,可以丢弃,也可以交付上层,但是要附上错误报告,告诉上层这是错误的数据报。
- 通过伪首部,不仅可以检查源端口号,目的端口号和UDP用户数据报的数据部分,还可以检查IP数据报的源IP地址和目的地址。 这种差错检验的检错能力不强,但是简单,速度快。
5 - HTTP 协议
概念
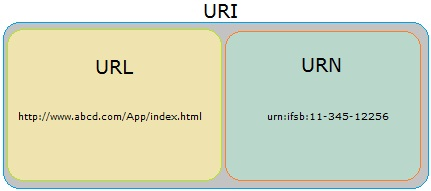
URL
URI 包含 URL 和 URN,目前 WEB 只有 URL 比较流行,所以见到的基本都是 URL。
- URI(Uniform Resource Identifier,统一资源标识符)
- URL(Uniform Resource Locator,统一资源定位符)
- URN(Uniform Resource Name,统一资源名称)
请求和响应报文
请求报文

响应报文

HTTP (请求)方法
客户端发送的 请求报文 第一行为请求行,包含了方法字段。
GET
获取资源
当前网络请求中,绝大部分使用的是 GET 方法。
HEAD
获取报文首部
和 GET 方法一样,但是不返回报文实体主体部分。
主要用于确认 URL 的有效性以及资源更新的日期时间等。
POST
传输实体主体
POST 主要用来传输数据,而 GET 主要用来获取资源。
PUT
上传文件
由于自身不带验证机制,任何人都可以上传文件,因此存在安全性问题,一般不使用该方法。
PATCH
对资源进行部分修改
PUT 也可以用于修改资源,但是只能完全替代原始资源,PATCH 允许部分修改。
DELETE
删除文件
与 PUT 功能相反,并且同样不带验证机制。
OPTIONS
查询支持的方法
查询指定的 URL 能够支持的方法。
会返回 Allow: GET, POST, HEAD, OPTIONS 这样的内容。
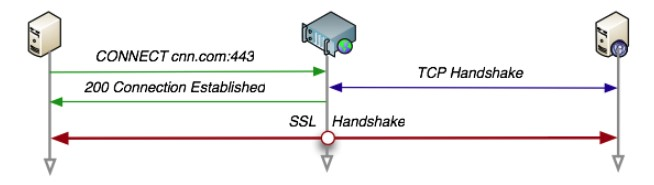
CONNECT
要求在与代理服务器通信时建立隧道
使用 SSL(Secure Sockets Layer,安全套接层)和 TLS(Transport Layer Security,传输层安全)协议把通信内容加密后经网络隧道传输。
TRACE
追踪路径
服务器会将通信路径返回给客户端。
发送请求时,在 Max-Forwards 首部字段中填入数值,每经过一个服务器就会减 1,当数值为 0 时就停止传输。
通常不会使用 TRACE,并且它容易受到 XST 攻击(Cross-Site Tracing,跨站追踪)。
HTTP (响应)状态码
服务器返回的 响应报文 中第一行为状态行,包含了状态码以及原因短语,用来告知客户端请求的结果。
服务器返回的 响应报文 中第一行为状态行,包含了状态码以及原因短语,用来告知客户端请求的结果。
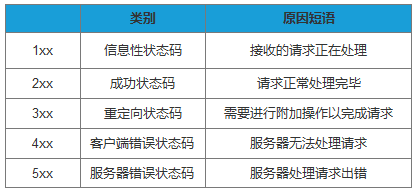
| 状态码 | 类别 | 原因短语 |
|---|---|---|
| 1XX | Informational(信息性状态码) | 接收的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
1XX 信息
- 100 Continue : 表明到目前为止都很正常,客户端可以继续发送请求或者忽略这个响应。
- 101 Switching Protocols : 表示服务端切换协议, 如从 HTTP 升级到 WebSocket 协议.
2XX 成功
- 200 OK
- 204 No Content : 请求已经成功处理,但是返回的响应报文不包含实体的主体部分。一般在只需要从客户端往服务器发送信息,而不需要返回数据时使用。
- 206 Partial Content : 表示客户端进行了范围请求,响应报文包含由 Content-Range 指定范围的实体内容。
3XX 重定向
- 301 Moved Permanently : 永久性重定向
- 302 Found : 临时性重定向
- 303 See Other : 和 302 有着相同的功能,但是 303 明确要求客户端应该采用 GET 方法获取资源。
- 注: 虽然 HTTP 协议规定 301、302 状态下重定向时不允许把 POST 方法改成 GET 方法,但是大多数浏览器都会在 301、302 和 303 状态下的重定向把 POST 方法改成 GET 方法。
- 304 Not Modified : 如果请求报文首部包含一些条件,例如: If-Match,If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since,如果不满足条件,则服务器会返回 304 状态码。
- 307 Temporary Redirect : 临时重定向,与 302 的含义类似,但是 307 要求浏览器不会把重定向请求的 POST 方法改成 GET 方法。
4XX 客户端错误
- 400 Bad Request : 请求报文中存在语法错误。
- 401 Unauthorized : 该状态码表示发送的请求需要有认证信息(BASIC 认证、DIGEST 认证)。如果之前已进行过一次请求,则表示用户认证失败。
- 403 Forbidden : 请求被拒绝。
- 404 Not Found
5XX 服务器错误
- 500 Internal Server Error : 服务器正在执行请求时发生错误。
- 503 Service Unavailable : 服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。
HTTP 首部
有 4 种类型的首部字段: 通用首部字段、请求首部字段、响应首部字段和实体首部字段。
通用首部字段
| 首部字段名 | 说明 |
|---|---|
| Cache-Control | 控制缓存的行为 |
| Connection | 控制不再转发给代理的首部字段、管理持久连接 |
| Date | 创建报文的日期时间 |
| Pragma | 报文指令 |
| Trailer | 报文末端的首部一览 |
| Transfer-Encoding | 指定报文主体的传输编码方式 |
| Upgrade | 升级为其他协议 |
| Via | 代理服务器的相关信息 |
| Warning | 错误通知 |
请求首部字段
| 首部字段名 | 说明 |
|---|---|
| Accept | 用户代理可处理的媒体类型 |
| Accept-Charset | 优先的字符集 |
| Accept-Encoding | 优先的内容编码 |
| Accept-Language | 优先的语言(自然语言) |
| Authorization | Web 认证信息 |
| Expect | 期待服务器的特定行为 |
| From | 用户的电子邮箱地址 |
| Host | 请求资源所在服务器 |
| If-Match | 比较实体标记(ETag) |
| If-Modified-Since | 比较资源的更新时间 |
| If-None-Match | 比较实体标记(与 If-Match 相反) |
| If-Range | 资源未更新时发送实体 Byte 的范围请求 |
| If-Unmodified-Since | 比较资源的更新时间(与 If-Modified-Since 相反) |
| Max-Forwards | 最大传输逐跳数 |
| Proxy-Authorization | 代理服务器要求客户端的认证信息 |
| Range | 实体的字节范围请求 |
| Referer | 对请求中 URI 的原始获取方 |
| TE | 传输编码的优先级 |
| User-Agent | HTTP 客户端程序的信息 |
响应首部字段
| 首部字段名 | 说明 |
|---|---|
| Accept-Ranges | 是否接受字节范围请求 |
| Age | 推算资源创建经过时间 |
| ETag | 资源的匹配信息 |
| Location | 令客户端重定向至指定 URI |
| Proxy-Authenticate | 代理服务器对客户端的认证信息 |
| Retry-After | 对再次发起请求的时机要求 |
| Server | HTTP 服务器的安装信息 |
| Vary | 代理服务器缓存的管理信息 |
| WWW-Authenticate | 服务器对客户端的认证信息 |
实体首部字段
| 首部字段名 | 说明 |
|---|---|
| Allow | 资源可支持的 HTTP 方法 |
| Content-Encoding | 实体主体适用的编码方式 |
| Content-Language | 实体主体的自然语言 |
| Content-Length | 实体主体的大小 |
| Content-Location | 替代对应资源的 URI |
| Content-MD5 | 实体主体的报文摘要 |
| Content-Range | 实体主体的位置范围 |
| Content-Type | 实体主体的媒体类型 |
| Expires | 实体主体过期的日期时间 |
| Last-Modified | 资源的最后修改日期时间 |
具体应用
Cookie
HTTP 协议是无状态的,主要是为了让 HTTP 协议尽可能简单,使得它能够处理大量事务。HTTP/1.1 引入 Cookie 来保存状态信息。
Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器之后向同一服务器再次发起请求时被携带上,用于告知服务端两个请求是否来自同一浏览器。由于之后每次请求都会需要携带 Cookie 数据,因此会带来额外的性能开销(尤其是在移动环境下)。
Cookie 曾一度用于客户端数据的存储,因为当时并没有其它合适的存储办法而作为唯一的存储手段,但现在随着现代浏览器开始支持各种各样的存储方式,Cookie 渐渐被淘汰。新的浏览器 API 已经允许开发者直接将数据存储到本地,如使用 Web storage API (本地存储和会话存储)或 IndexedDB。
1. 用途
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
2. 创建过程
服务器发送的响应报文包含 Set-Cookie 首部字段,客户端得到响应报文后把 Cookie 内容保存到浏览器中。
HTTP/1.0 200 OK
Content-type: text/html
Set-Cookie: yummy_cookie=choco
Set-Cookie: tasty_cookie=strawberry
[page content]
客户端之后对同一个服务器发送请求时,会从浏览器中取出 Cookie 信息并通过 Cookie 请求首部字段发送给服务器。
GET /sample_page.html HTTP/1.1
Host: www.example.org
Cookie: yummy_cookie=choco; tasty_cookie=strawberry
3. 分类
- 会话期 Cookie: 浏览器关闭之后它会被自动删除,也就是说它仅在会话期内有效。
- 持久性 Cookie: 指定一个特定的过期时间(Expires)或有效期(max-age)之后就成为了持久性的 Cookie。
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT;
4. JavaScript 获取 Cookie
通过 Document.cookie 属性可创建新的 Cookie,也可通过该属性访问非 HttpOnly 标记的 Cookie。
document.cookie = "yummy_cookie=choco";
document.cookie = "tasty_cookie=strawberry";
console.log(document.cookie);
5. Secure 和 HttpOnly
标记为 Secure 的 Cookie 只能通过被 HTTPS 协议加密过的请求发送给服务端。但即便设置了 Secure 标记,敏感信息也不应该通过 Cookie 传输,因为 Cookie 有其固有的不安全性,Secure 标记也无法提供确实的安全保障。
标记为 HttpOnly 的 Cookie 不能被 JavaScript 脚本调用。跨站脚本攻击 (XSS) 常常使用 JavaScript 的 Document.cookie API 窃取用户的 Cookie 信息,因此使用 HttpOnly 标记可以在一定程度上避免 XSS 攻击。
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT; Secure; HttpOnly
6. 作用域
Domain 标识指定了哪些主机可以接受 Cookie。如果不指定,默认为当前文档的主机(不包含子域名)。如果指定了 Domain,则一般包含子域名。例如,如果设置 Domain=mozilla.org,则 Cookie 也包含在子域名中(如 developer.mozilla.org)。
Path 标识指定了主机下的哪些路径可以接受 Cookie(该 URL 路径必须存在于请求 URL 中)。以字符 %x2F ("/") 作为路径分隔符,子路径也会被匹配。例如,设置 Path=/docs,则以下地址都会匹配:
- /docs
- /docs/Web/
- /docs/Web/HTTP
7. Session
除了可以将用户信息通过 Cookie 存储在用户浏览器中,也可以利用 Session 存储在服务器端,存储在服务器端的信息更加安全。
Session 可以存储在服务器上的文件、数据库或者内存中。也可以将 Session 存储在 Redis 这种内存型数据库中,效率会更高。
使用 Session 维护用户登录状态的过程如下:
- 用户进行登录时,用户提交包含用户名和密码的表单,放入 HTTP 请求报文中;
- 服务器验证该用户名和密码;
- 如果正确则把用户信息存储到 Redis 中,它在 Redis 中的 Key 称为 Session ID;
- 服务器返回的响应报文的 Set-Cookie 首部字段包含了这个 Session ID,客户端收到响应报文之后将该 Cookie 值存入浏览器中;
- 客户端之后对同一个服务器进行请求时会包含该 Cookie 值,服务器收到之后提取出 Session ID,从 Redis 中取出用户信息,继续之前的业务操作。
应该注意 Session ID 的安全性问题,不能让它被恶意攻击者轻易获取,那么就不能产生一个容易被猜到的 Session ID 值。此外,还需要经常重新生成 Session ID。在对安全性要求极高的场景下,例如转账等操作,除了使用 Session 管理用户状态之外,还需要对用户进行重新验证,比如重新输入密码,或者使用短信验证码等方式。
8. 浏览器禁用 Cookie
此时无法使用 Cookie 来保存用户信息,只能使用 Session。除此之外,不能再将 Session ID 存放到 Cookie 中,而是使用 URL 重写技术,将 Session ID 作为 URL 的参数进行传递。
9. Cookie 与 Session 选择
- Cookie 只能存储 ASCII 码字符串,而 Session 则可以存取任何类型的数据,因此在考虑数据复杂性时首选 Session;
- Cookie 存储在浏览器中,容易被恶意查看。如果非要将一些隐私数据存在 Cookie 中,可以将 Cookie 值进行加密,然后在服务器进行解密;
- 对于大型网站,如果用户所有的信息都存储在 Session 中,那么开销是非常大的,因此不建议将所有的用户信息都存储到 Session 中。
缓存
1. 优点
- 缓解服务器压力;
- 降低客户端获取资源的延迟: 缓存通常位于内存中,读取缓存的速度更快。并且缓存在地理位置上也有可能比源服务器来得近,例如浏览器缓存。
2. 实现方法
- 让代理服务器进行缓存;
- 让客户端浏览器进行缓存。
3. Cache-Control
HTTP/1.1 通过 Cache-Control 首部字段来控制缓存。
(一)禁止进行缓存
no-store 指令规定不能对请求或响应的任何一部分进行缓存。
Cache-Control: no-store
(二)强制确认缓存
no-cache 指令规定缓存服务器需要先向源服务器验证缓存资源的有效性,只有当缓存资源有效才将能使用该缓存对客户端的请求进行响应。
Cache-Control: no-cache
(三)私有缓存和公共缓存
private 指令规定了将资源作为私有缓存,只能被单独用户所使用,一般存储在用户浏览器中。
Cache-Control: private
public 指令规定了将资源作为公共缓存,可以被多个用户所使用,一般存储在代理服务器中。
Cache-Control: public
(四)缓存过期机制
max-age 指令出现在请求报文中,并且缓存资源的缓存时间小于该指令指定的时间,那么就能接受该缓存。
max-age 指令出现在响应报文中,表示缓存资源在缓存服务器中保存的时间。
Cache-Control: max-age=31536000
Expires 首部字段也可以用于告知缓存服务器该资源什么时候会过期。
- 在 HTTP/1.1 中,会优先处理 max-age 指令;
- 在 HTTP/1.0 中,max-age 指令会被忽略掉。
Expires: Wed, 04 Jul 2012 08:26:05 GMT
4. 缓存验证
需要先了解 ETag 首部字段的含义,它是资源的唯一标识。URL 不能唯一表示资源,例如 http://www.google.com/ 有中文和英文两个资源,只有 ETag 才能对这两个资源进行唯一标识。
ETag: "82e22293907ce725faf67773957acd12"
可以将缓存资源的 ETag 值放入 If-None-Match 首部,服务器收到该请求后,判断缓存资源的 ETag 值和资源的最新 ETag 值是否一致,如果一致则表示缓存资源有效,返回 304 Not Modified。
If-None-Match: "82e22293907ce725faf67773957acd12"
Last-Modified 首部字段也可以用于缓存验证,它包含在源服务器发送的响应报文中,指示源服务器对资源的最后修改时间。但是它是一种弱校验器,因为只能精确到一秒,所以它通常作为 ETag 的备用方案。如果响应首部字段里含有这个信息,客户端可以在后续的请求中带上 If-Modified-Since 来验证缓存。服务器只在所请求的资源在给定的日期时间之后对内容进行过修改的情况下才会将资源返回,状态码为 200 OK。如果请求的资源从那时起未经修改,那么返回一个不带有消息主体的 304 Not Modified 响应。
Last-Modified: Wed, 21 Oct 2015 07:28:00 GMT
If-Modified-Since: Wed, 21 Oct 2015 07:28:00 GMT
连接管理
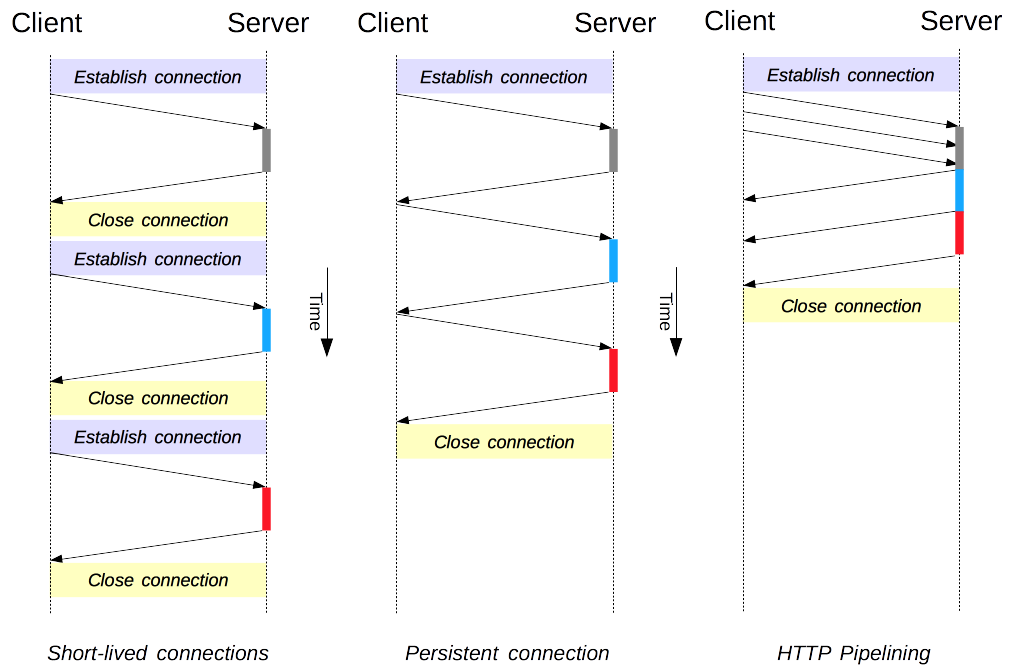
1. 短连接与长连接
当浏览器访问一个包含多张图片的 HTML 页面时,除了请求访问 HTML 页面资源,还会请求图片资源。如果每进行一次 HTTP 通信就要新建一个 TCP 连接,那么开销会很大。
长连接只需要建立一次 TCP 连接就能进行多次 HTTP 通信。
- 从 HTTP/1.1 开始默认是长连接的,如果要断开连接,需要由客户端或者服务器端提出断开,使用
Connection : close; - 在 HTTP/1.1 之前默认是短连接的,如果需要使用长连接,则使用
Connection : Keep-Alive。
2. 流水线
默认情况下,HTTP 请求是按顺序发出的,下一个请求只有在当前请求收到响应之后才会被发出。由于会受到网络延迟和带宽的限制,在下一个请求被发送到服务器之前,可能需要等待很长时间。
流水线是在同一条长连接上发出连续的请求,而不用等待响应返回,这样可以避免连接延迟。
内容协商
通过内容协商返回最合适的内容,例如根据浏览器的默认语言选择返回中文界面还是英文界面。
1. 类型
(一)服务端驱动型
客户端设置特定的 HTTP 首部字段,例如 Accept、Accept-Charset、Accept-Encoding、Accept-Language、Content-Languag,服务器根据这些字段返回特定的资源。
它存在以下问题:
- 服务器很难知道客户端浏览器的全部信息;
- 客户端提供的信息相当冗长(HTTP/2 协议的首部压缩机制缓解了这个问题),并且存在隐私风险(HTTP 指纹识别技术);
- 给定的资源需要返回不同的展现形式,共享缓存的效率会降低,而服务器端的实现会越来越复杂。
(二)代理驱动型
服务器返回 300 Multiple Choices 或者 406 Not Acceptable,客户端从中选出最合适的那个资源。
2. Vary
Vary: Accept-Language
在使用内容协商的情况下,只有当缓存服务器中的缓存满足内容协商条件时,才能使用该缓存,否则应该向源服务器请求该资源。
例如,一个客户端发送了一个包含 Accept-Language 首部字段的请求之后,源服务器返回的响应包含 Vary: Accept-Language 内容,缓存服务器对这个响应进行缓存之后,在客户端下一次访问同一个 URL 资源,并且 Accept-Language 与缓存中的对应的值相同时才会返回该缓存。
内容编码
内容编码将实体主体进行压缩,从而减少传输的数据量。
常用的内容编码有: gzip、compress、deflate、identity。
浏览器发送 Accept-Encoding 首部,其中包含有它所支持的压缩算法,以及各自的优先级。服务器则从中选择一种,使用该算法对响应的消息主体进行压缩,并且发送 Content-Encoding 首部来告知浏览器它选择了哪一种算法。由于该内容协商过程是基于编码类型来选择资源的展现形式的,在响应的 Vary 首部至少要包含 Content-Encoding。
范围请求
如果网络出现中断,服务器只发送了一部分数据,范围请求可以使得客户端只请求服务器未发送的那部分数据,从而避免服务器重新发送所有数据。
1. Range
在请求报文中添加 Range 首部字段指定请求的范围。
GET /z4d4kWk.jpg HTTP/1.1
Host: i.imgur.com
Range: bytes=0-1023
请求成功的话服务器返回的响应包含 206 Partial Content 状态码。
HTTP/1.1 206 Partial Content
Content-Range: bytes 0-1023/146515
Content-Length: 1024
...
(binary content)
2. Accept-Ranges
响应首部字段 Accept-Ranges 用于告知客户端是否能处理范围请求,可以处理使用 bytes,否则使用 none。
Accept-Ranges: bytes
3. 响应状态码
- 在请求成功的情况下,服务器会返回 206 Partial Content 状态码。
- 在请求的范围越界的情况下,服务器会返回 416 Requested Range Not Satisfiable 状态码。
- 在不支持范围请求的情况下,服务器会返回 200 OK 状态码。
分块传输编码
Chunked Transfer Coding,可以把数据分割成多块,让浏览器逐步显示页面。
多部分对象集合
一份报文主体内可含有多种类型的实体同时发送,每个部分之间用 boundary 字段定义的分隔符进行分隔,每个部分都可以有首部字段。
例如,上传多个表单时可以使用如下方式:
Content-Type: multipart/form-data; boundary=AaB03x
--AaB03x
Content-Disposition: form-data; name="submit-name"
Larry
--AaB03x
Content-Disposition: form-data; name="files"; filename="file1.txt"
Content-Type: text/plain
... contents of file1.txt ...
--AaB03x--
虚拟主机
HTTP/1.1 使用虚拟主机技术,使得一台服务器拥有多个域名,并且在逻辑上可以看成多个服务器。
通信数据转发
1. 代理
代理服务器接受客户端的请求,并且转发给其它服务器。
使用代理的主要目的是:
- 缓存
- 负载均衡
- 网络访问控制
- 访问日志记录
代理服务器分为正向代理和反向代理两种:
- 用户察觉得到正向代理的存在。
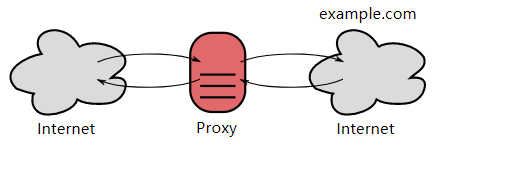
- 而反向代理一般位于内部网络中,用户察觉不到。

2. 网关
与代理服务器不同的是,网关服务器会将 HTTP 转化为其它协议进行通信,从而请求其它非 HTTP 服务器的服务。
3. 隧道
使用 SSL 等加密手段,在客户端和服务器之间建立一条安全的通信线路。
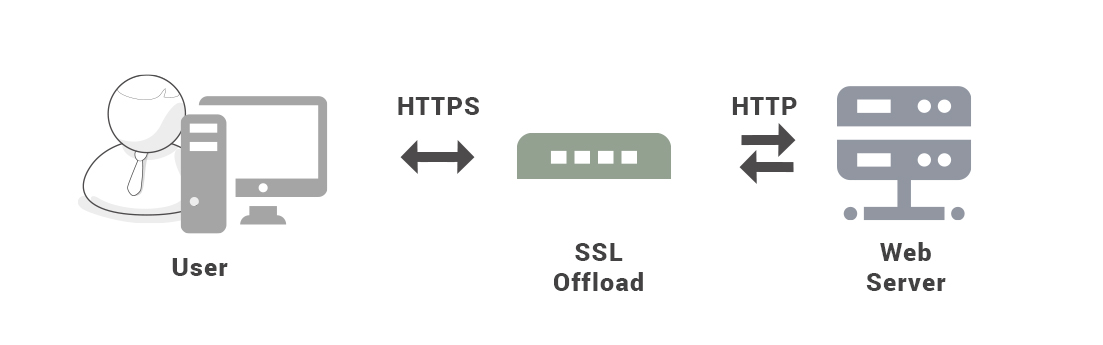
HTTPS
HTTP 有以下安全性问题:
- 使用明文进行通信,内容可能会被窃听;
- 不验证通信方的身份,通信方的身份有可能遭遇伪装;
- 无法证明报文的完整性,报文有可能遭篡改。
HTTPs 并不是新协议,而是让 HTTP 先和 SSL(Secure Sockets Layer)通信,再由 SSL 和 TCP 通信,也就是说 HTTPs 使用了隧道进行通信。
通过使用 SSL,HTTPs 具有了加密(防窃听)、认证(防伪装)和完整性保护(防篡改)。
加密
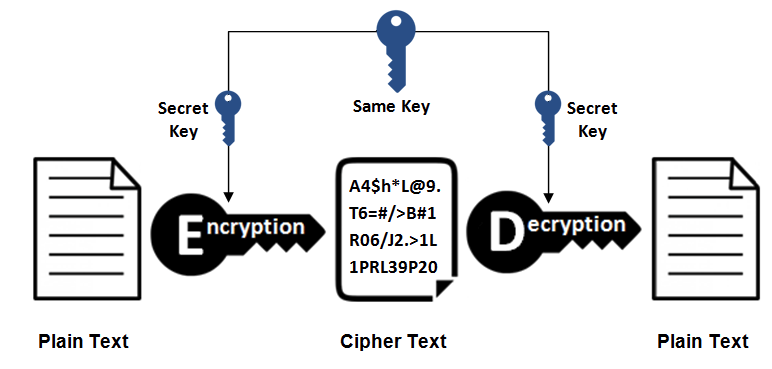
1. 对称密钥加密
对称密钥加密(Symmetric-Key Encryption),加密和解密使用同一密钥。
- 优点: 运算速度快;
- 缺点: 无法安全地将密钥传输给通信方。
2.非对称密钥加密
非对称密钥加密,又称公开密钥加密(Public-Key Encryption),加密和解密使用不同的密钥。
公开密钥所有人都可以获得,通信发送方获得接收方的公开密钥之后,就可以使用公开密钥进行加密,接收方收到通信内容后使用私有密钥解密。
非对称密钥除了用来加密,还可以用来进行签名。因为私有密钥无法被其他人获取,因此通信发送方使用其私有密钥进行签名,通信接收方使用发送方的公开密钥对签名进行解密,就能判断这个签名是否正确。
- 优点: 可以更安全地将公开密钥传输给通信发送方;
- 缺点: 运算速度慢。
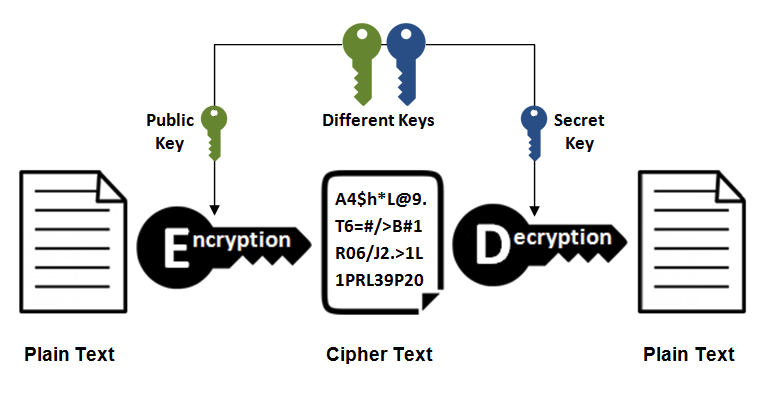
3. HTTPs 采用的加密方式
HTTPs 采用混合的加密机制,使用非对称密钥加密用于传输对称密钥来保证传输过程的安全性,之后使用对称密钥加密进行通信来保证通信过程的效率。(下图中的 Session Key 就是对称密钥)
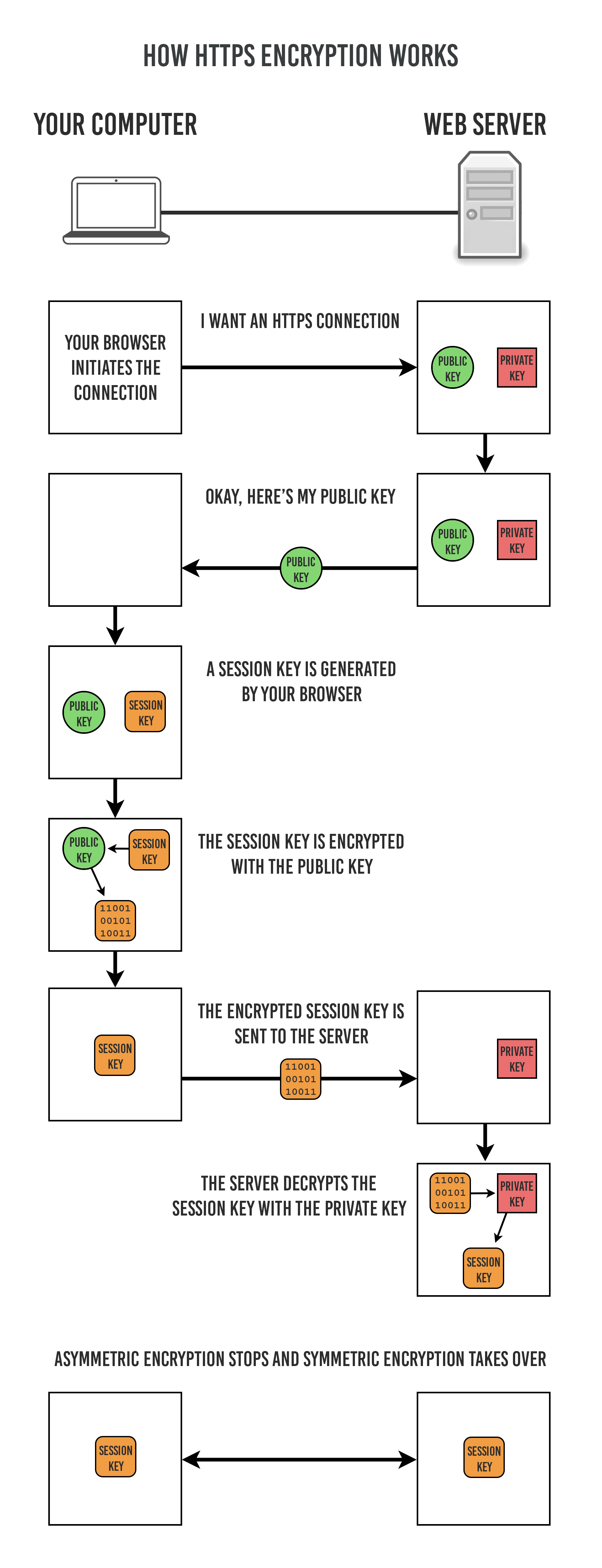
认证
通过使用 证书 来对通信方进行认证。
数字证书认证机构(CA,Certificate Authority)是客户端与服务器双方都可信赖的第三方机构。
服务器的运营人员向 CA 提出公开密钥的申请,CA 在判明提出申请者的身份之后,会对已申请的公开密钥做数字签名,然后分配这个已签名的公开密钥,并将该公开密钥放入公开密钥证书后绑定在一起。
进行 HTTPs 通信时,服务器会把证书发送给客户端。客户端取得其中的公开密钥之后,先使用数字签名进行验证,如果验证通过,就可以开始通信了。
通信开始时,客户端需要使用服务器的公开密钥将自己的私有密钥传输给服务器,之后再进行对称密钥加密。
完整性保护
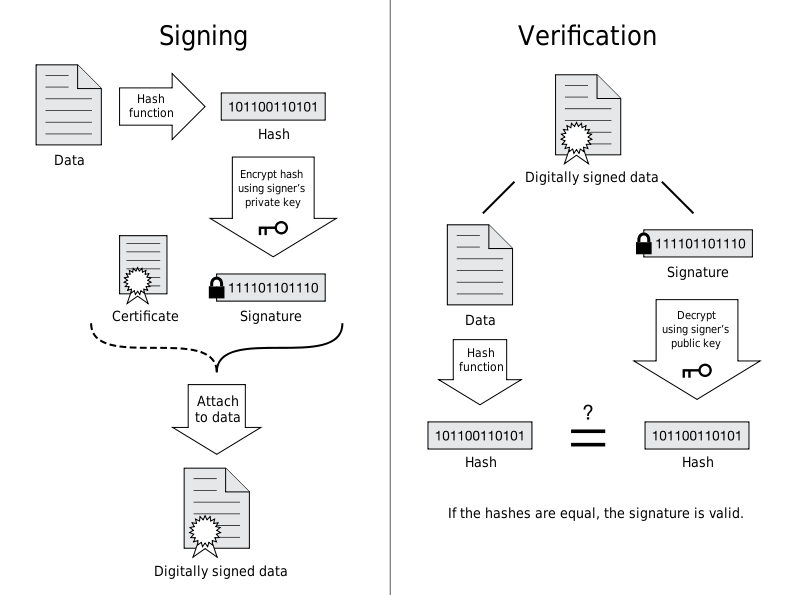
SSL 提供报文摘要功能来进行完整性保护。
HTTP 也提供了 MD5 报文摘要功能,但不是安全的。例如报文内容被篡改之后,同时重新计算 MD5 的值,通信接收方是无法意识到发生了篡改。
HTTPs 的报文摘要功能之所以安全,是因为它结合了加密和认证这两个操作。试想一下,加密之后的报文,遭到篡改之后,也很难重新计算报文摘要,因为无法轻易获取明文。
HTTPs 的缺点
- 因为需要进行加密解密等过程,因此速度会更慢;
- 需要支付证书授权的高额费用。
配置 HTTPs
HTTP/2.0
HTTP/1.x 缺陷
HTTP/1.x 实现简单是以牺牲性能为代价的:
- 客户端需要使用多个连接才能实现并发和缩短延迟;
- 不会压缩请求和响应首部,从而导致不必要的网络流量;
- 不支持有效的资源优先级,致使底层 TCP 连接的利用率低下。
二进制分帧层
HTTP/2.0 将报文分成 HEADERS 帧和 DATA 帧,它们都是二进制格式的。
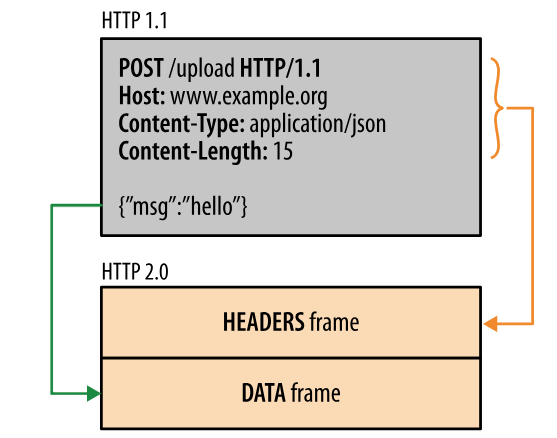
在通信过程中,只会有一个 TCP 连接存在,它承载了任意数量的双向数据流(Stream)。
- 一个数据流都有一个唯一标识符和可选的优先级信息,用于承载双向信息。
- 消息(Message)是与逻辑请求或响应消息对应的完整的一系列帧。
- 帧(Fram)是最小的通信单位,来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装。
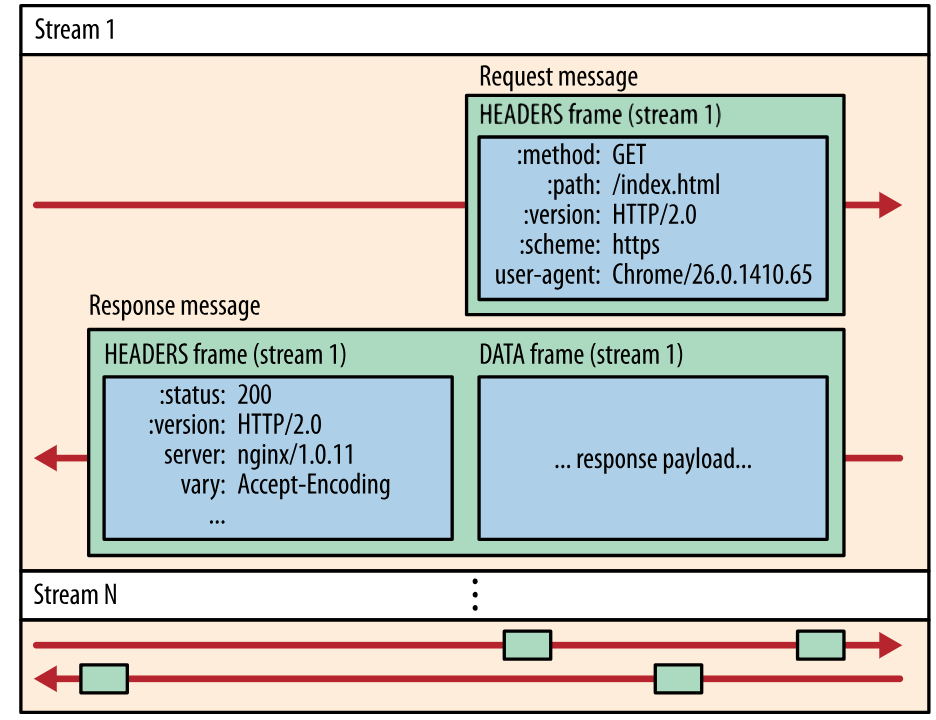
服务端推送
HTTP/2.0 在客户端请求一个资源时,会把相关的资源一起发送给客户端,客户端就不需要再次发起请求了。例如客户端请求 page.html 页面,服务端就把 script.js 和 style.css 等与之相关的资源一起发给客户端。
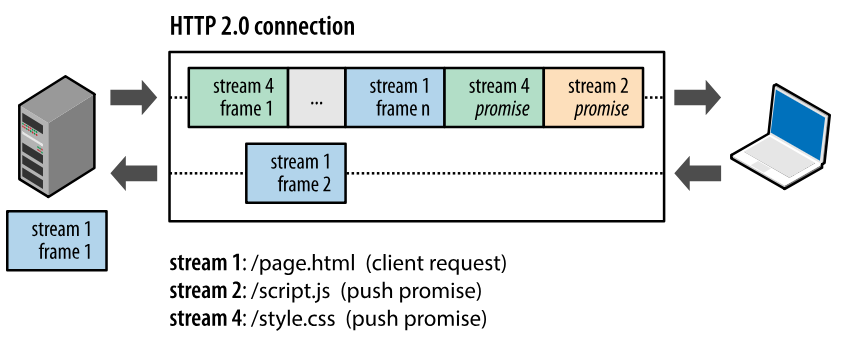
首部压缩
HTTP/1.1 的首部带有大量信息,而且每次都要重复发送。
HTTP/2.0 要求客户端和服务器同时维护和更新一个包含之前见过的首部字段表,从而避免了重复传输。
不仅如此,HTTP/2.0 也使用 Huffman 编码对首部字段进行压缩。
GET VS POST
作用
GET 用于获取资源,而 POST 用于传输实体主体。
参数
GET 和 POST 的请求都能使用额外的参数,但是 GET 的参数是以查询字符串出现在 URL 中,而 POST 的参数存储在实体主体中。不能因为 POST 参数存储在实体主体中就认为它的安全性更高,因为照样可以通过一些抓包工具(Fiddler)查看。
因为 URL 只支持 ASCII 码,因此 GET 的参数中如果存在中文等字符就需要先进行编码。例如 中文 会转换为 %E4%B8%AD%E6%96%87,而空格会转换为 %20。POST 参考支持标准字符集。
GET /test/demo_form.asp?name1=value1&name2=value2 HTTP/1.1
POST /test/demo_form.asp HTTP/1.1
Host: w3schools.com
name1=value1&name2=value2
安全
安全的 HTTP 方法不会改变服务器状态,也就是说它只是可读的。
GET 方法是安全的,而 POST 却不是,因为 POST 的目的是传送实体主体内容,这个内容可能是用户上传的表单数据,上传成功之后,服务器可能把这个数据存储到数据库中,因此状态也就发生了改变。
安全的方法除了 GET 之外还有: HEAD、OPTIONS。
不安全的方法除了 POST 之外还有 PUT、DELETE。
幂等性
幂等的 HTTP 方法,同样的请求被执行一次与连续执行多次的效果是一样的,服务器的状态也是一样的。换句话说就是,幂等方法不应该具有副作用(统计用途除外)。
所有的安全方法也都是幂等的。
在正确实现的条件下,GET,HEAD,PUT 和 DELETE 等方法都是幂等的,而 POST 方法不是。
GET /pageX HTTP/1.1 是幂等的,连续调用多次,客户端接收到的结果都是一样的:
GET /pageX HTTP/1.1
GET /pageX HTTP/1.1
GET /pageX HTTP/1.1
GET /pageX HTTP/1.1
POST /add_row HTTP/1.1 不是幂等的,如果调用多次,就会增加多行记录:
POST /add_row HTTP/1.1 -> Adds a 1nd row
POST /add_row HTTP/1.1 -> Adds a 2nd row
POST /add_row HTTP/1.1 -> Adds a 3rd row
DELETE /idX/delete HTTP/1.1 是幂等的,即便不同的请求接收到的状态码不一样:
DELETE /idX/delete HTTP/1.1 -> Returns 200 if idX exists
DELETE /idX/delete HTTP/1.1 -> Returns 404 as it just got deleted
DELETE /idX/delete HTTP/1.1 -> Returns 404
可缓存
如果要对响应进行缓存,需要满足以下条件:
- 请求报文的 HTTP 方法本身是可缓存的,包括 GET 和 HEAD,但是 PUT 和 DELETE 不可缓存,POST 在多数情况下不可缓存的。
- 响应报文的状态码是可缓存的,包括: 200, 203, 204, 206, 300, 301, 404, 405, 410, 414, and 501。
- 响应报文的 Cache-Control 首部字段没有指定不进行缓存。
XMLHttpRequest
为了阐述 POST 和 GET 的另一个区别,需要先了解 XMLHttpRequest:
XMLHttpRequest 是一个 API,它为客户端提供了在客户端和服务器之间传输数据的功能。它提供了一个通过 URL 来获取数据的简单方式,并且不会使整个页面刷新。这使得网页只更新一部分页面而不会打扰到用户。XMLHttpRequest 在 AJAX 中被大量使用。
- 在使用 XMLHttpRequest 的 POST 方法时,浏览器会先发送 Header 再发送 Data。但并不是所有浏览器会这么做,例如火狐就不会。
- 而 GET 方法 Header 和 Data 会一起发送。
HTTP/1.0 VS HTTP/1.1
HTTP/1.1 默认是长连接
HTTP/1.1 支持管线化处理
HTTP/1.1 支持同时打开多个 TCP 连接
HTTP/1.1 支持虚拟主机
HTTP/1.1 新增状态码 100
HTTP/1.1 支持分块传输编码
HTTP/1.1 新增缓存处理指令 max-age
6 - WebSocket
概览
WebSocket的出现,使得浏览器具备了实时双向通信的能力。本文由浅入深,介绍了WebSocket如何建立连接、交换数据的细节,以及数据帧的格式。此外,还简要介绍了针对WebSocket的安全攻击,以及协议是如何抵御类似攻击的。
什么是WebSocket
HTML5开始提供的一种浏览器与服务器进行全双工通讯的网络技术,属于应用层协议。它基于TCP传输协议,并复用HTTP的握手通道。
对大部分web开发者来说,上面这段描述有点枯燥,其实只要记住几点:
- WebSocket可以在浏览器里使用
- 支持双向通信
- 使用很简单
1、有哪些优点
说到优点,这里的对比参照物是HTTP协议,概括地说就是:支持双向通信,更灵活,更高效,可扩展性更好。
- 支持双向通信,实时性更强。
- 更好的二进制支持。
- 较少的控制开销。连接创建后,ws客户端、服务端进行数据交换时,协议控制的数据包头部较小。在不包含头部的情况下,服务端到客户端的包头只有2~10字节(取决于数据包长度),客户端到服务端的的话,需要加上额外的4字节的掩码。而HTTP协议每次通信都需要携带完整的头部。
- 支持扩展。ws协议定义了扩展,用户可以扩展协议,或者实现自定义的子协议。(比如支持自定义压缩算法等)
对于后面两点,没有研究过WebSocket协议规范的同学可能理解起来不够直观,但不影响对WebSocket的学习和使用。
2、需要学习哪些东西
对网络应用层协议的学习来说,最重要的往往就是连接建立过程、数据交换教程。当然,数据的格式是逃不掉的,因为它直接决定了协议本身的能力。好的数据格式能让协议更高效、扩展性更好。
下文主要围绕下面几点展开:
- 如何建立连接
- 如何交换数据
- 数据帧格式
- 如何维持连接
入门示例
在正式介绍协议细节前,先来看一个简单的例子,有个直观感受。例子包括了WebSocket服务端、WebSocket客户端(网页端)。
这里服务端用了ws这个库。相比大家熟悉的socket.io,ws实现更轻量,更适合学习的目的。
1、服务端
代码如下,监听8080端口。当有新的连接请求到达时,打印日志,同时向客户端发送消息。当收到到来自客户端的消息时,同样打印日志。
var app = require('express')();
var server = require('http').Server(app);
var WebSocket = require('ws');
var wss = new WebSocket.Server({ port: 8080 });
wss.on('connection', function connection(ws) {
console.log('server: receive connection.');
ws.on('message', function incoming(message) {
console.log('server: received: %s', message);
});
ws.send('world');
});
app.get('/', function (req, res) {
res.sendfile(__dirname + '/index.html');
});
app.listen(3000);
2、客户端
代码如下,向8080端口发起WebSocket连接。连接建立后,打印日志,同时向服务端发送消息。接收到来自服务端的消息后,同样打印日志。
<script>
var ws = new WebSocket('ws://localhost:8080');
ws.onopen = function () {
console.log('ws onopen');
ws.send('from client: hello');
};
ws.onmessage = function (e) {
console.log('ws onmessage');
console.log('from server: ' + e.data);
};
</script>
3、运行结果
可分别查看服务端、客户端的日志,这里不展开。
服务端输出:
server: receive connection.
server: received hello
客户端输出:
client: ws connection is open
client: received world
如何建立连接
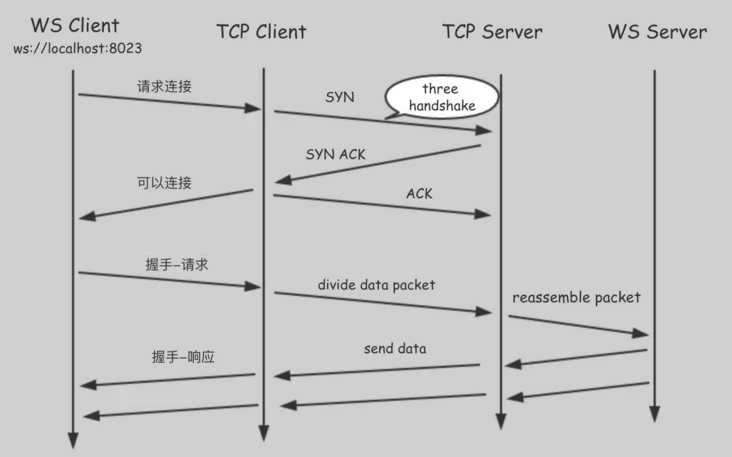
WebSocket 协议本质上是一个基于 TCP 的协议,为了建立一个 WebSocket 连接,客户端浏览器首先要向服务器发起一个 HTTP 请求,这个请求相比较平时使用的 HTTP 请求多了一些信息。
WebSocket 复用了 HTTP 的握手通道。具体指的是,客户端通过 HTTP 请求与 WebSocket 服务端协商升级协议。协议升级完成后,后续的数据交换则遵照 WebSocket 的协议。
1、客户端:申请协议升级
首先,客户端发起协议升级请求。可以看到,采用的是标准的HTTP报文格式,且只支持GET方法。
GET / HTTP/1.1
Host: localhost:8080
Origin: http://127.0.0.1:3000
Connection: Upgrade
Upgrade: websocket
Sec-WebSocket-Version: 13
Sec-WebSocket-Key: w4v7O6xFTi36lq3RNcgctw==
重点请求首部意义如下:
Connection: Upgrade:表示要升级协议Upgrade: websocket:表示要升级到websocket协议。Sec-WebSocket-Version: 13:表示websocket的版本。如果服务端不支持该版本,需要返回一个Sec-WebSocket-Versionheader,里面包含服务端支持的版本号。Sec-WebSocket-Key:与后面服务端响应首部的Sec-WebSocket-Accept是配套的,提供基本的防护,比如恶意的连接,或者无意的连接。
注意,上面请求省略了部分非重点请求首部。由于是标准的HTTP请求,类似Host、Origin、Cookie等请求首部会照常发送。在握手阶段,可以通过相关请求首部进行 安全限制、权限校验等。
2、服务端:响应协议升级
服务端返回内容如下,状态代码101表示协议切换。到此完成协议升级,后续的数据交互都按照新的协议来。
HTTP/1.1 101 Switching Protocols
Connection:Upgrade
Upgrade: websocket
Sec-WebSocket-Accept: Oy4NRAQ13jhfONC7bP8dTKb4PTU=
备注:每个header都以
\r\n结尾,并且最后一行加上一个额外的空行\r\n。此外,服务端回应的HTTP状态码只能在握手阶段使用。过了握手阶段后,就只能采用特定的错误码。
3、Sec-WebSocket-Accept的计算
Sec-WebSocket-Accept根据客户端请求首部的Sec-WebSocket-Key计算出来。
计算公式为:
- 将
Sec-WebSocket-Key跟258EAFA5-E914-47DA-95CA-C5AB0DC85B11拼接。 - 通过SHA1计算出摘要,并转成base64字符串。
伪代码如下:
>toBase64( sha1( Sec-WebSocket-Key + 258EAFA5-E914-47DA-95CA-C5AB0DC85B11 ) )
验证下前面的返回结果:
const crypto = require('crypto');
const magic = '258EAFA5-E914-47DA-95CA-C5AB0DC85B11';
const secWebSocketKey = 'w4v7O6xFTi36lq3RNcgctw==';
let secWebSocketAccept = crypto.createHash('sha1')
.update(secWebSocketKey + magic)
.digest('base64');
console.log(secWebSocketAccept);
// Oy4NRAQ13jhfONC7bP8dTKb4PTU=
数据帧格式
客户端、服务端数据的交换,离不开数据帧格式的定义。因此,在实际讲解数据交换之前,我们先来看下WebSocket的数据帧格式。
WebSocket客户端、服务端通信的最小单位是帧(frame),由1个或多个帧组成一条完整的消息(message)。
- 发送端:将消息切割成多个帧,并发送给服务端;
- 接收端:接收消息帧,并将关联的帧重新组装成完整的消息;
本节的重点,就是讲解数据帧的格式。详细定义可参考 RFC6455 5.2节 。
1、数据帧格式概览
下面给出了WebSocket数据帧的统一格式。熟悉TCP/IP协议的同学对这样的图应该不陌生。
- 从左到右,单位是比特。比如
FIN、RSV1各占据1比特,opcode占据4比特。 - 内容包括了标识、操作代码、掩码、数据、数据长度等。(下一小节会展开)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-------+-+-------------+-------------------------------+
|F|R|R|R| opcode|M| Payload len | Extended payload length |
|I|S|S|S| (4) |A| (7) | (16/64) |
|N|V|V|V| |S| | (if payload len==126/127) |
| |1|2|3| |K| | |
+-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - +
| Extended payload length continued, if payload len == 127 |
+ - - - - - - - - - - - - - - - +-------------------------------+
| |Masking-key, if MASK set to 1 |
+-------------------------------+-------------------------------+
| Masking-key (continued) | Payload Data |
+-------------------------------- - - - - - - - - - - - - - - - +
: Payload Data continued ... :
+ - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +
| Payload Data continued ... |
+---------------------------------------------------------------+
2、数据帧格式详解
针对前面的格式概览图,这里逐个字段进行讲解,如有不清楚之处,可参考协议规范,或留言交流。
FIN:1个比特。
如果是1,表示这是消息(message)的最后一个分片(fragment),如果是0,表示不是是消息(message)的最后一个分片(fragment)。
RSV1, RSV2, RSV3:各占1个比特。
一般情况下全为0。当客户端、服务端协商采用WebSocket扩展时,这三个标志位可以非0,且值的含义由扩展进行定义。如果出现非零的值,且并没有采用WebSocket扩展,连接出错。
Opcode: 4个比特。
操作代码,Opcode的值决定了应该如何解析后续的数据载荷(data payload)。如果操作代码是不认识的,那么接收端应该断开连接(fail the connection)。可选的操作代码如下:
- %x0:表示一个延续帧。当Opcode为0时,表示本次数据传输采用了数据分片,当前收到的数据帧为其中一个数据分片。
- %x1:表示这是一个文本帧(frame)
- %x2:表示这是一个二进制帧(frame)
- %x3-7:保留的操作代码,用于后续定义的非控制帧。
- %x8:表示连接断开。
- %x9:表示这是一个ping操作。
- %xA:表示这是一个pong操作。
- %xB-F:保留的操作代码,用于后续定义的控制帧。
Mask: 1个比特。
表示是否要对数据载荷进行掩码操作。从客户端向服务端发送数据时,需要对数据进行掩码操作;从服务端向客户端发送数据时,不需要对数据进行掩码操作。
如果服务端接收到的数据没有进行过掩码操作,服务端需要断开连接。
如果Mask是1,那么在Masking-key中会定义一个掩码键(masking key),并用这个掩码键来对数据载荷进行反掩码。所有客户端发送到服务端的数据帧,Mask都是1。
掩码的算法、用途在下一小节讲解。
Payload length:数据载荷的长度,单位是字节。为7位,或7+16位,或1+64位。
假设数Payload length === x,如果
- x为0~126:数据的长度为x字节。
- x为126:后续2个字节代表一个16位的无符号整数,该无符号整数的值为数据的长度。
- x为127:后续8个字节代表一个64位的无符号整数(最高位为0),该无符号整数的值为数据的长度。
此外,如果payload length占用了多个字节的话,payload length的二进制表达采用网络序(big endian,重要的位在前)。
Masking-key:0或4字节(32位)
所有从客户端传送到服务端的数据帧,数据载荷都进行了掩码操作,Mask为1,且携带了4字节的Masking-key。如果Mask为0,则没有Masking-key。
备注:载荷数据的长度,不包括mask key的长度。
Payload data:(x+y) 字节
载荷数据:包括了扩展数据、应用数据。其中,扩展数据x字节,应用数据y字节。
扩展数据:如果没有协商使用扩展的话,扩展数据数据为0字节。所有的扩展都必须声明扩展数据的长度,或者可以如何计算出扩展数据的长度。此外,扩展如何使用必须在握手阶段就协商好。如果扩展数据存在,那么载荷数据长度必须将扩展数据的长度包含在内。
应用数据:任意的应用数据,在扩展数据之后(如果存在扩展数据),占据了数据帧剩余的位置。载荷数据长度 减去 扩展数据长度,就得到应用数据的长度。
3、掩码算法
掩码键(Masking-key)是由客户端挑选出来的32位的随机数。掩码操作不会影响数据载荷的长度。掩码、反掩码操作都采用如下算法:
首先,假设:
- original-octet-i:为原始数据的第i字节。
- transformed-octet-i:为转换后的数据的第i字节。
- j:为
i mod 4的结果。 - masking-key-octet-j:为mask key第j字节。
算法描述为: original-octet-i 与 masking-key-octet-j 异或后,得到 transformed-octet-i。
j = i MOD 4 transformed-octet-i = original-octet-i XOR masking-key-octet-j
数据传递
一旦WebSocket客户端、服务端建立连接后,后续的操作都是基于数据帧的传递。
WebSocket根据opcode来区分操作的类型。比如0x8表示断开连接,0x0-0x2表示数据交互。
1、数据分片
WebSocket的每条消息可能被切分成多个数据帧。当WebSocket的接收方收到一个数据帧时,会根据FIN的值来判断,是否已经收到消息的最后一个数据帧。
FIN=1表示当前数据帧为消息的最后一个数据帧,此时接收方已经收到完整的消息,可以对消息进行处理。FIN=0,则接收方还需要继续监听接收其余的数据帧。
此外,opcode在数据交换的场景下,表示的是数据的类型。0x01表示文本,0x02表示二进制。而0x00比较特殊,表示延续帧(continuation frame),顾名思义,就是完整消息对应的数据帧还没接收完。
2、数据分片例子
直接看例子更形象些。下面例子来自MDN,可以很好地演示数据的分片。客户端向服务端两次发送消息,服务端收到消息后回应客户端,这里主要看客户端往服务端发送的消息。
第一条消息
FIN=1, 表示是当前消息的最后一个数据帧。服务端收到当前数据帧后,可以处理消息。opcode=0x1,表示客户端发送的是文本类型。
第二条消息
- FIN=0,opcode=0x1,表示发送的是文本类型,且消息还没发送完成,还有后续的数据帧。
- FIN=0,opcode=0x0,表示消息还没发送完成,还有后续的数据帧,当前的数据帧需要接在上一条数据帧之后。
- FIN=1,opcode=0x0,表示消息已经发送完成,没有后续的数据帧,当前的数据帧需要接在上一条数据帧之后。服务端可以将关联的数据帧组装成完整的消息。
Client: FIN=1, opcode=0x1, msg="hello"
Server: (process complete message immediately) Hi.
Client: FIN=0, opcode=0x1, msg="and a"
Server: (listening, new message containing text started)
Client: FIN=0, opcode=0x0, msg="happy new"
Server: (listening, payload concatenated to previous message)
Client: FIN=1, opcode=0x0, msg="year!"
Server: (process complete message) Happy new year to you too!
连接保持+心跳
WebSocket为了保持客户端、服务端的实时双向通信,需要确保客户端、服务端之间的TCP通道保持连接没有断开。然而,对于长时间没有数据往来的连接,如果依旧长时间保持着,可能会浪费包括的连接资源。
但不排除有些场景,客户端、服务端虽然长时间没有数据往来,但仍需要保持连接。这个时候,可以采用心跳来实现。
- 发送方->接收方:ping
- 接收方->发送方:pong
ping、pong的操作,对应的是WebSocket的两个控制帧,opcode分别是0x9、0xA。
举例,WebSocket服务端向客户端发送ping,只需要如下代码(采用ws模块)
ws.ping('', false, true);
Sec-WebSocket-Key/Accept的作用
前面提到了,Sec-WebSocket-Key/Sec-WebSocket-Accept在主要作用在于提供基础的防护,减少恶意连接、意外连接。
作用大致归纳如下:
- 避免服务端收到非法的websocket连接(比如http客户端不小心请求连接websocket服务,此时服务端可以直接拒绝连接)
- 确保服务端理解websocket连接。因为ws握手阶段采用的是http协议,因此可能ws连接是被一个http服务器处理并返回的,此时客户端可以通过Sec-WebSocket-Key来确保服务端认识ws协议。(并非百分百保险,比如总是存在那么些无聊的http服务器,光处理Sec-WebSocket-Key,但并没有实现ws协议。。。)
- 用浏览器里发起ajax请求,设置header时,Sec-WebSocket-Key以及其他相关的header是被禁止的。这样可以避免客户端发送ajax请求时,意外请求协议升级(websocket upgrade)
- 可以防止反向代理(不理解ws协议)返回错误的数据。比如反向代理前后收到两次ws连接的升级请求,反向代理把第一次请求的返回给cache住,然后第二次请求到来时直接把cache住的请求给返回(无意义的返回)。
- Sec-WebSocket-Key主要目的并不是确保数据的安全性,因为Sec-WebSocket-Key、Sec-WebSocket-Accept的转换计算公式是公开的,而且非常简单,最主要的作用是预防一些常见的意外情况(非故意的)。
强调:Sec-WebSocket-Key/Sec-WebSocket-Accept 的换算,只能带来基本的保障,但连接是否安全、数据是否安全、客户端/服务端是否合法的 ws客户端、ws服务端,其实并没有实际性的保证。
数据掩码的作用
WebSocket协议中,数据掩码的作用是增强协议的安全性。但数据掩码并不是为了保护数据本身,因为算法本身是公开的,运算也不复杂。除了加密通道本身,似乎没有太多有效的保护通信安全的办法。
那么为什么还要引入掩码计算呢,除了增加计算机器的运算量外似乎并没有太多的收益(这也是不少同学疑惑的点)。
答案还是两个字:安全。但并不是为了防止数据泄密,而是为了防止早期版本的协议中存在的代理缓存污染攻击(proxy cache poisoning attacks)等问题。
1、代理缓存污染攻击
下面摘自2010年关于安全的一段讲话。其中提到了代理服务器在协议实现上的缺陷可能导致的安全问题。猛击出处。
“We show, empirically, that the current version of the WebSocket consent mechanism is vulnerable to proxy cache poisoning attacks. Even though the WebSocket handshake is based on HTTP, which should be understood by most network intermediaries, the handshake uses the esoteric “Upgrade” mechanism of HTTP. In our experiment, we find that many proxies do not implement the Upgrade mechanism properly, which causes the handshake to succeed even though subsequent traffic over the socket will be misinterpreted by the proxy.”
Huang, L-S., Chen, E., Barth, A., Rescorla, E., and C. Jackson, “Talking to Yourself for Fun and Profit”, 2010,
在正式描述攻击步骤之前,我们假设有如下参与者:
- 攻击者、攻击者自己控制的服务器(简称“邪恶服务器”)、攻击者伪造的资源(简称“邪恶资源”)
- 受害者、受害者想要访问的资源(简称“正义资源”)
- 受害者实际想要访问的服务器(简称“正义服务器”)
- 中间代理服务器
攻击步骤一:
- 攻击者浏览器 向 邪恶服务器 发起WebSocket连接。根据前文,首先是一个协议升级请求。
- 协议升级请求 实际到达 代理服务器。
- 代理服务器 将协议升级请求转发到 邪恶服务器。
- 邪恶服务器 同意连接,代理服务器 将响应转发给 攻击者。
由于 upgrade 的实现上有缺陷,代理服务器 以为之前转发的是普通的HTTP消息。因此,当协议服务器 同意连接,代理服务器 以为本次会话已经结束。
攻击步骤二:
- 攻击者 在之前建立的连接上,通过WebSocket的接口向 邪恶服务器 发送数据,且数据是精心构造的HTTP格式的文本。其中包含了 正义资源 的地址,以及一个伪造的host(指向正义服务器)。(见后面报文)
- 请求到达 代理服务器 。虽然复用了之前的TCP连接,但 代理服务器 以为是新的HTTP请求。
- 代理服务器 向 邪恶服务器 请求 邪恶资源。
- 邪恶服务器 返回 邪恶资源。代理服务器 缓存住 邪恶资源(url是对的,但host是 正义服务器 的地址)。
到这里,受害者可以登场了:
- 受害者 通过 代理服务器 访问 正义服务器 的 正义资源。
- 代理服务器 检查该资源的url、host,发现本地有一份缓存(伪造的)。
- 代理服务器 将 邪恶资源 返回给 受害者。
- 受害者 卒。
附:前面提到的精心构造的“HTTP请求报文”。
Client → Server:
POST /path/of/attackers/choice HTTP/1.1 Host: host-of-attackers-choice.com Sec-WebSocket-Key: <connection-key>
Server → Client:
HTTP/1.1 200 OK
Sec-WebSocket-Accept: <connection-key>
2、当前解决方案
最初的提案是对数据进行加密处理。基于安全、效率的考虑,最终采用了折中的方案:对数据载荷进行掩码处理。
需要注意的是,这里只是限制了浏览器对数据载荷进行掩码处理,但是坏人完全可以实现自己的WebSocket客户端、服务端,不按规则来,攻击可以照常进行。
但是对浏览器加上这个限制后,可以大大增加攻击的难度,以及攻击的影响范围。如果没有这个限制,只需要在网上放个钓鱼网站骗人去访问,一下子就可以在短时间内展开大范围的攻击。
项目示例
7 - DNS 服务
概览
域名系统并不像电话号码通讯录那么简单,通讯录主要是单个个体在使用,同一个名字出现在不同个体的通讯录里并不会出现问题,但域名是群体中所有人都在用的,必须要保持唯一性。
为了达到唯一性的目的,因特网在命名的时候采用了层次结构的命名方法。每一个域名(本文只讨论英文域名)都是一个标号序列(labels),用字母(A-Z,a-z,大小写等价)、数字(0-9)和连接符(-)组成,标号序列总长度不能超过255个字符,它由点号分割成一个个的标号(label),每个标号应该在63个字符之内,每个标号都可以看成一个层次的域名。级别最低的域名写在左边,级别最高的域名写在右边。
域名服务主要是基于UDP实现的,服务器的端口号为53。
域名层级结构
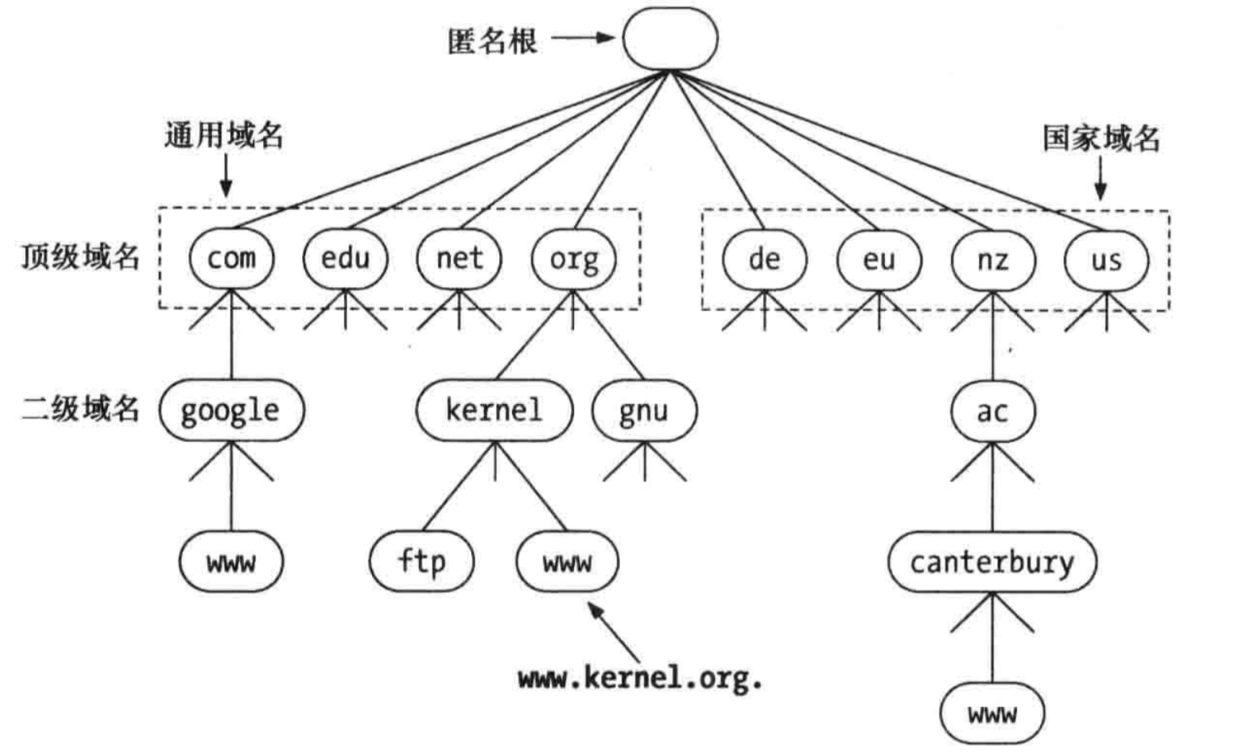
注意:最开始的域名最后都是带了点号的,比如
www.kernel.org.,最后面的点号表示根域名服务器,后来发现所有的网址都要加上最后的点,就简化了写法,干脆所有的都不加即www.kernel.org,但是你在网址后面加上点号也是可以正常解析的。
域名服务器
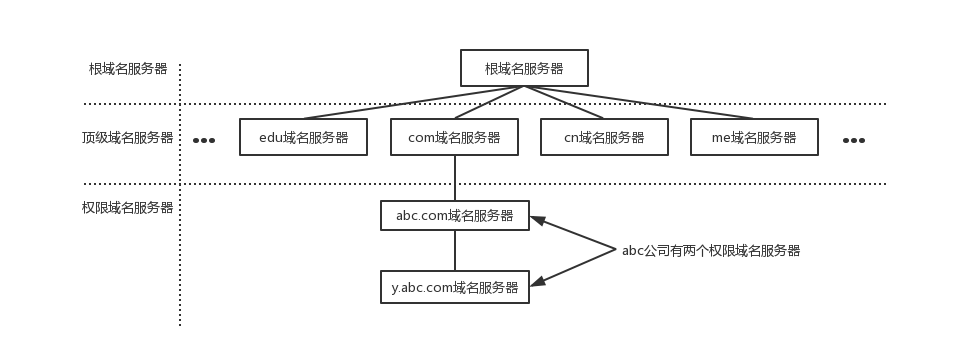
有域名结构还不行,还需要有一个东西去解析域名,手机通讯录是由通讯录软件解析的,域名需要由遍及全世界的域名服务器去解析,域名服务器实际上就是装有域名系统的主机。由高向低进行层次划分,可分为以下几大类:
- 根域名服务器:最高层次的域名服务器,也是最重要的域名服务器,本地域名服务器如果解析不了域名就会向根域名服务器求助。全球共有13个不同IP地址的根域名服务器,它们的名称用一个英文字母命名,从a一直到m。这些服务器由各种组织控制,并由 ICANN(互联网名称和数字地址分配公司)授权,由于每分钟都要解析的名称数量多得令人难以置信,所以实际上每个根服务器都有镜像服务器,每个根服务器与它的镜像服务器共享同一个 IP 地址,中国大陆地区内只有6组根服务器镜像(F,I(3台),J,L)。当你对某个根服务器发出请求时,请求会被路由到该根服务器离你最近的镜像服务器。所有的根域名服务器都知道所有的顶级域名服务器的域名和地址,如果向根服务器发出对 “pdai.tech” 的请求,则根服务器是不能在它的记录文件中找到与 “pdai.tech” 匹配的记录。但是它会找到 “tech” 的顶级域名记录,并把负责 “tech” 地址的顶级域名服务器的地址发回给请求者。
- 顶级域名服务器:负责管理在该顶级域名服务器下注册的二级域名。当根域名服务器告诉查询者顶级域名服务器地址时,查询者紧接着就会到顶级域名服务器进行查询。比如还是查询"pdai.tech",根域名服务器已经告诉了查询者"tech"顶级域名服务器的地址,“tech"顶级域名服务器会找到 “pdai.tech”的域名服务器的记录,域名服务器检查其区域文件,并发现它有与 “pdai.tech” 相关联的区域文件。在此文件的内部,有该主机的记录。此记录说明此主机所在的 IP 地址,并向请求者返回最终答案。
- 权限域名服务器:负责一个区的域名解析工作
- 本地域名服务器:当一个主机发出DNS查询请求的时候,这个查询请求首先就是发给本地域名服务器的。
DNS 解析流程
.com.fi国际金融域名DNS解析的步骤一共分为9步,如果每次解析都要走完9个步骤,大家浏览网站的速度也不会那么快,现在之所以能保持这么快的访问速度,其实一般的解析都是跑完第4步就可以了。除非一个地区完全是第一次访问(在都没有缓存的情况下)才会走完9个步骤,这个情况很少。
- 1、本地客户机提出域名解析请求,查找本地HOST文件后将该请求发送给本地的域名服务器。
- 2、将请求发送给本地的域名服务器。
- 3、当本地的域名服务器收到请求后,就先查询本地的缓存。
- 4、如果有该纪录项,则本地的域名服务器就直接把查询的结果返回浏览器。
- 5、如果本地DNS缓存中没有该纪录,则本地域名服务器就直接把请求发给根域名服务器。
- 6、然后根域名服务器再返回给本地域名服务器一个所查询域(根的子域)的主域名服务器的地址。
- 7、本地服务器再向上一步返回的域名服务器发送请求,然后接受请求的服务器查询自己的缓存,如果没有该纪录,则返回相关的下级的域名服务器的地址。
- 8、重复第7步,直到找到正确的纪录。
- 9、本地域名服务器把返回的结果保存到缓存,以备下一次使用,同时还将结果返回给客户机。
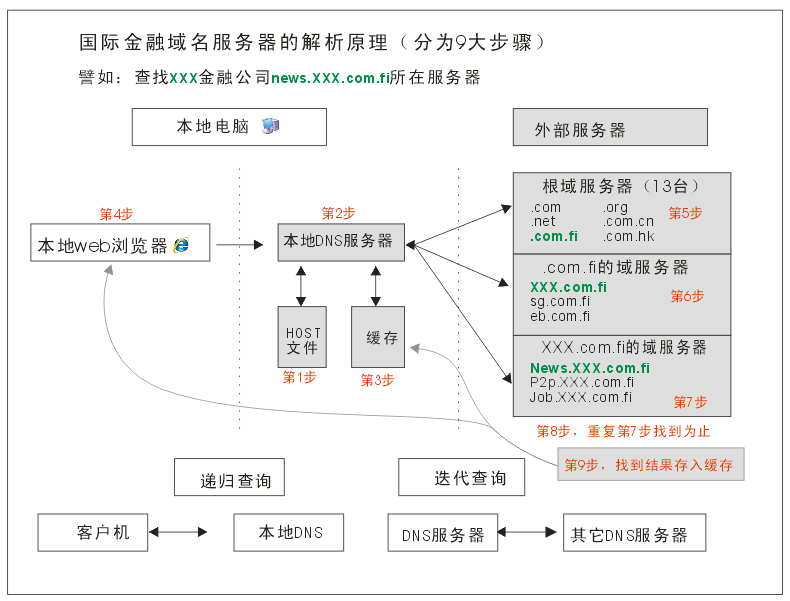
递归查询:在该模式下DNS服务器接收到客户机请求,必须使用一个准确的查询结果回复客户机。如果DNS服务器本地没有存储查询DNS信息,那么该服务器会询问其他服务器,并将返回的查询结果提交给客户机。
迭代查询:DNS所在服务器若没有可以响应的结果,会向客户机提供其他能够解析查询请求的DNS服务器地址,当客户机发送查询请求时,DNS服务器并不直接回复查询结果,而是告诉客户机另一台DNS服务器地址,客户机再向这台DNS服务器提交请求,依次循环直到返回查询的结果为止。
为什么DNS通常基于UDP
使用基于UDP的DNS协议只要一个请求、一个应答就好了
而使用基于TCP的DNS协议要三次握手、发送数据以及应答、四次挥手
明显基于TCP协议的DNS更浪费网络资源!
当然以上只是从数据包的数量以及占有网络资源的层面来进行的分析,那数据一致性层面呢?
DNS数据包不是那种大数据包,所以使用UDP不需要考虑分包,如果丢包那么就是全部丢包,如果收到了数据,那就是收到了全部数据!所以只需要考虑丢包的情况,那就算是丢包了,重新请求一次就好了。而且DNS的报文允许填入序号字段,对于请求报文和其对应的应答报文,这个字段是相同的,通过它可以区分DNS应答是对应的哪个请求
DNS通常是基于UDP的,但当数据长度大于512字节的时候,为了保证传输质量,就会使用基于TCP的实现方式
DNS 查询
dig 查询
用
dig可以查看整个过程,看下下面的返回就能理解的
- dig www.sina.com
- dig +trace www.sina.com // 分级查询
域名与IP之间的对应关系,称为"记录”(record)。根据使用场景,“记录"可以分成不同的类型(type),前面已经看到了有A记录和NS记录。
常见的DNS记录类型如下。
- A:地址记录(Address),返回域名指向的IP地址。
- NS:域名服务器记录(Name Server),返回保存下一级域名信息的服务器地址。该记录只能设置为域名,不能设置为IP地址。
- MX:邮件记录(Mail eXchange),返回接收电子邮件的服务器地址。
- CNAME:规范名称记录(Canonical Name),返回另一个域名,即当前查询的域名是另一个域名的跳转,详见下文。
- PTR:逆向查询记录(Pointer Record),只用于从IP地址查询域名,详见下文。
一般来说,为了服务的安全可靠,至少应该有两条NS记录,而A记录和MX记录也可以有多条,这样就提供了服务的冗余性,防止出现单点失败。
CNAME记录主要用于域名的内部跳转,为服务器配置提供灵活性,用户感知不到。
host查询
pdaiMbp:/ pdai$ host www.sina.com
www.sina.com is an alias for us.sina.com.cn.
us.sina.com.cn is an alias for spool.grid.sinaedge.com.
spool.grid.sinaedge.com has address 115.238.190.240
spool.grid.sinaedge.com has IPv6 address 240e:f7:a000:221::75:71
nslookup查询
pdaiMbp:/ pdai$ nslookup
> www.sina.com
Server: 192.168.3.1
Address: 192.168.3.1#53
Non-authoritative answer:
www.sina.com canonical name = us.sina.com.cn.
us.sina.com.cn canonical name = spool.grid.sinaedge.com.
Name: spool.grid.sinaedge.com
Address: 115.238.190.240
whois查询
pdaiMbp:/ pdai$ whois www.sina.com
在线工具查询
https://www.nslookuptool.com/chs/
DNS 调度原理
本节转自:【网易MC】DNS 调度原理解析
现在,大部分应用和业务都采用域名作为服务的入口,因此用 DNS 来负载均衡和区域调度是非常普遍的做法,网易云也有着一套基于 DNS 的调度系统。某些用户在进行直播推流时用的并不是网易云的直播 SDK,而是一些第三方的推流软件,如obs,这样就不能使用我们的 GSLB 全局调度服务器来调度。对于这些用户,我们使用 DNS 调度的方式,对不同地域的请求返回不同解析结果,将请求调度到离用户最近的服务器节点,从而减少延迟访问。
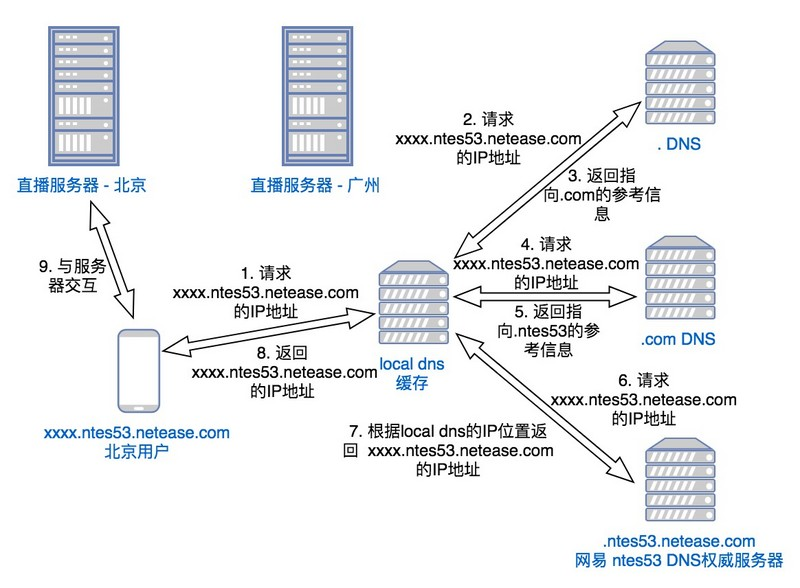
咋一看,DNS 调度这么简单方便,那为什么不让所有的用户都走 DNS 调度呢?想知道原因?来,我们继续讲。
地理位置调度不准确
在 DNS 解析过程中,与权威服务器通信的只有 DNS 缓存服务器,所以权威服务器只能根据 DNS 缓存服务器的IP来进行调度。因此 DNS 调度有一个前提:假定用户使用的缓存DNS与用户本身在同个网络内,即至少在同一个 AS(自治域)内,在该前提下,DNS 的解析才是准确的。通常情况下,用户使用 ISP 提供的本地缓存(简称 local DNS),local DNS 一般与用户在同个网络内,这时候 DNS 调度是有效的。
但近些年,不少互联网厂商推广基于 BGP Anycast 的公共 DNS (Public DNS),而这些Anycaset IP 的节点一般是远少于各个ISP的节点,例如可能广州电信用户使用了某公共 DNS,但该公共 DNS 里用户最近的是上海电信节点,甚至更极端的如 Google DNS 8.8.8.8,在中国大陆没有节点(最近的是台湾)。而不幸的是国内有不少用户使用了 Google DNS,这其实降低了他们的网络访问体验。总的来说,使用公共 DNS,实际上破坏了上文的前提,导致 DNS 区域调度失效,用户以为得到了更快更安全的 DNS 解析,但实际得到了错误的解析,增加了网络访问延迟。
传统 DNS 协议的区域调度过程示例如下图,假定某业务以 foo.163.com 对外提供服务,在北京和东京各有一个节点,业务期望国内大陆的用户访问北京节点,而非大陆用户则访问东京节点。因为权威是根据 DNS 缓存来决定返回的结果,所以当用户使用不用的 DNS 缓存时,可能会解析到不同的结果。
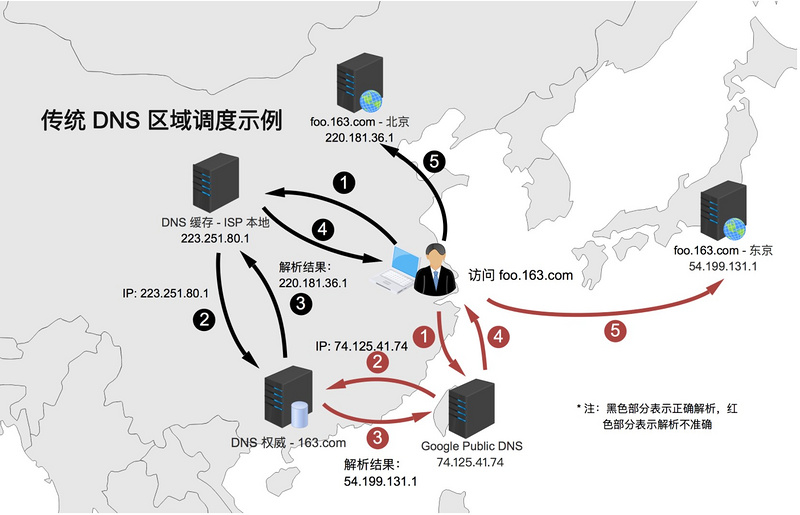
2011 年,Google 为首的几家公司在提出了一个 DNS 的扩展方案 edns-client-subnet (以下简称 ECS),该扩展方案的核心思想是通过在 DNS 请求报文里加入原始请求的 IP(即 client 的 IP),使得权威能根据该信息返回正确的结果。目前,该方案仍处于草案阶段。该方案很好地解决了上述提到的 remote DNS 导致解析不准确的问题,但也带了一些问题:
- 至少需要 cache 和权威都支持,才能完成完整的 ECS 解析
- ECS 给 cache 增加了很大的缓存压力,因为理论上可能需要为每个IP段分配空间去缓存解析结果
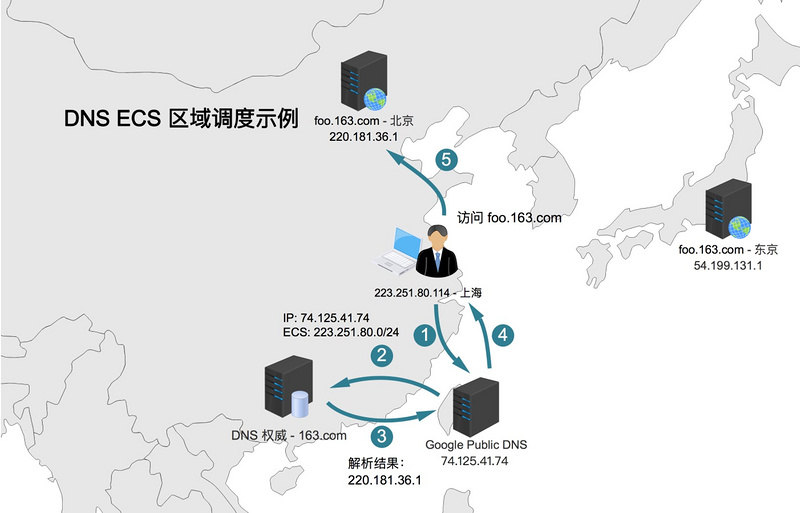
规则变更生效时间不确定
当缓存服务器向权威服务器查询得到记录之后,会将其缓存起来,在缓存有效期内,如果收到相同记录的查询,缓存服务器会直接返回给客户端,而不需要再次向权威查询,当有效期过后,缓存则是需要再次发起查询。这个缓存有效期即是 TTL。
虽然 DNS 的缓存机制在大多数情况下缩短了客户端的记录解析时间,但缓存也意味着生效同步的延迟。当权威服务器的记录变更时,需要等待一段时间才能让所有客户端能解析到新的结果,因为很可能缓存服务器还缓存着旧的记录。
我们将权威的记录变更到全网生效这个过程称为 propagation,它的时间是不确定的,理论上的最大值即是 TTL 的值,对于记录变更或删除,这个时间是记录原本的 TTL,对于记录新增则是域的 nTTL 值。
如果一个域名记录原本的 TTL 是 18000,可以认为,变更该记录理论上需要等待 5 个小时才能保证记录能生效到全网。假设该域名的业务方希望缩短切换的时间,正确的做法是,至少提前5个小时修改记录,仅改小 TTL,例如改为5分钟,等待该变更同步到全网之后,再进行修改指向的操作,确认无误再将 TTL 修改为原本的值。
虽然 DNS 协议标准里建议缓存服务器应该记住或者缩短 TTL 的值,但实际上,有一些DNS缓存会修改权威服务器的 TTL,将其变大,这在国内几大运营商中是很常见的。例如,某域记录的 TTL 值实际上设置为 60,但在运营商的 DNS 缓存上,却变成 600 或者更大的值,甚至还有一些 DNS 缓存是不遵循 TTL 机制。这些都会影响域名的实际生效时间。
高可用
为避免受 DNS 缓存的影响,需要保证 DNS 中 A 记录的 IP 节点高可用性。对此,网易云DNS 调度系统采用的方案是在同一区域的多台直播服务器节点之间做负载均衡,对外只暴露一个虚 IP,这样,即使某台服务器宕机,负载均衡能迅速感知到,排除故障节点,而对 DNS 而言,因为虚 IP 不变而不受影响。
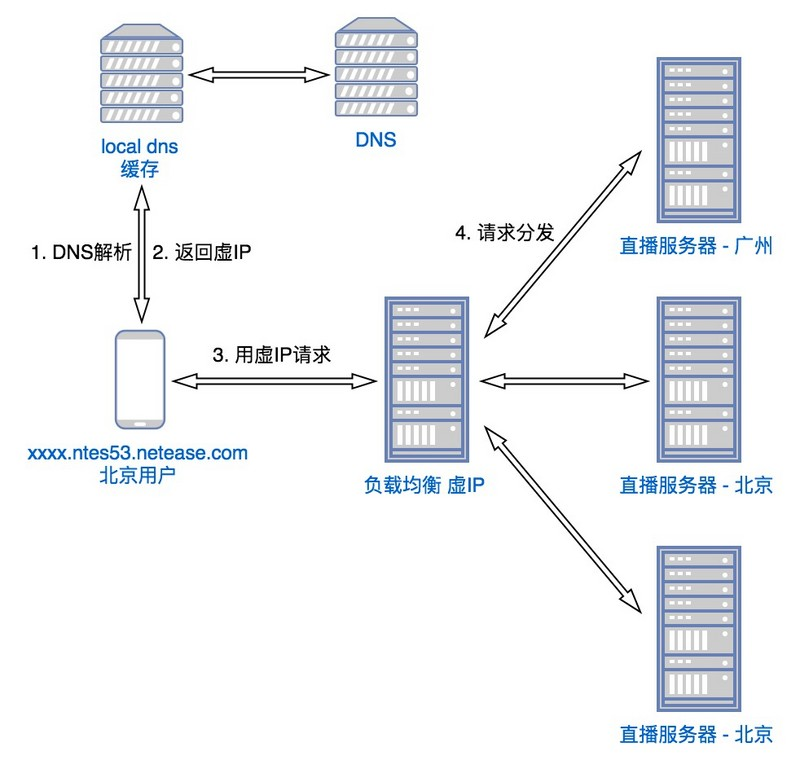
安全相关
犯罪分子会抓住任何互联网服务或协议的漏洞发动攻击,这当然也包括域名系统( DNS )。他们会注册一次性域名用于垃圾邮件活动和僵尸网络管理,还会盗用域名进行钓鱼和恶意软件下载。他们会注入恶意查询代码以利用域名服务器的漏洞或扰乱域名解析过程。他们会注入伪造的响应污染解析器缓存或强化 DDOS 攻击。他们甚至将 DNS 用作数据渗漏或恶意软件更新的隐蔽通道。
你可能没办法了解每一个新的 DNS 漏洞攻击,但是可以使用防火墙、网络入侵监测系统或域名解析器报告可疑的 DNS 行为迹象,作为主动防范的措施。
先讲下最常用的手段:DNS劫持和DNS污染。
什么是DNS劫持
DNS劫持就是通过劫持了DNS服务器,通过某些手段取得某域名的解析记录控制权,进而修改此域名的解析结果,导致对该域名的访问由原IP地址转入到修改后的指定IP,其结果就是对特定的网址不能访问或访问的是假网址,从而实现窃取资料或者破坏原有正常服务的目的。DNS劫持通过篡改DNS服务器上的数据返回给用户一个错误的查询结果来实现的。
DNS劫持症状:在某些地区的用户在成功连接宽带后,首次打开任何页面都指向ISP提供的“电信互联星空”、“网通黄页广告”等内容页面。还有就是曾经出现过用户访问Google域名的时候出现了百度的网站。这些都属于DNS劫持。
什么是DNS污染
DNS污染是一种让一般用户由于得到虚假目标主机IP而不能与其通信的方法,是一种DNS缓存投毒攻击(DNS cache poisoning)。其工作方式是:由于通常的DNS查询没有任何认证机制,而且DNS查询通常基于的UDP是无连接不可靠的协议,因此DNS的查询非常容易被篡改,通过对UDP端口53上的DNS查询进行入侵检测,一经发现与关键词相匹配的请求则立即伪装成目标域名的解析服务器(NS,Name Server)给查询者返回虚假结果。
而DNS污染则是发生在用户请求的第一步上,直接从协议上对用户的DNS请求进行干扰。
DNS污染症状:目前一些被禁止访问的网站很多就是通过DNS污染来实现的,例如YouTube、Facebook等网站。
解决方法:
- 对于DNS劫持,可以采用使用国外免费公用的DNS服务器解决。例如OpenDNS(208.67.222.222)或GoogleDNS(8.8.8.8)。
- 对于DNS污染,可以说,个人用户很难单单靠设置解决,通常可以使用VPN或者域名远程解析的方法解决,但这大多需要购买付费的VPN或SSH等,也可以通过修改Hosts的方法,手动设置域名正确的IP地址。
为什么要DNS流量监控
预示网络中正出现可疑或恶意代码的 DNS 组合查询或流量特征。例如:
- 1.来自伪造源地址的 DNS 查询、或未授权使用且无出口过滤地址的 DNS 查询,若同时观察到异常大的 DNS 查询量或使用 TCP 而非 UDP 进行 DNS 查询,这可能表明网络内存在被感染的主机,受到了 DDoS 攻击。
- 2.异常 DNS 查询可能是针对域名服务器或解析器(根据目标 IP 地址确定)的漏洞攻击的标志。与此同时,这些查询也可能表明网络中有不正常运行的设备。原因可能是恶意软件或未能成功清除恶意软件。
- 3.在很多情况下,DNS 查询要求解析的域名如果是已知的恶意域名,或具有域名生成算法( DGA )(与非法僵尸网络有关)常见特征的域名,或者向未授权使用的解析器发送的查询,都是证明网络中存在被感染主机的有力证据。
- 4.DNS 响应也能显露可疑或恶意数据在网络主机间传播的迹象。例如,DNS 响应的长度或组合特征可以暴露恶意或非法行为。例如,响应消息异常巨大(放大攻击),或响应消息的 Answer Section 或 Additional Section 非常可疑(缓存污染,隐蔽通道)。
- 5.针对自身域名组合的 DNS 响应,如果解析至不同于你发布在授权区域中的 IP 地址,或来自未授权区域主机的域名服务器的响应,或解析为名称错误( NXDOMAIN )的对区域主机名的肯定响应,均表明域名或注册账号可能被劫持或 DNS 响应被篡改。
- 6.来自可疑 IP 地址的 DNS 响应,例如来自分配给宽带接入网络 IP 段的地址、非标准端口上出现的 DNS 流量,异常大量的解析至短生存时间( TTL )域名的响应消息,或异常大量的包含“ name error ”( NXDOMAIN )的响应消息,往往是主机被僵尸网络控制、运行恶意软件或被感染的表现。
DNS 流量监控
如何借助网络入侵检测系统、流量分析和日志数据在网络防火墙上应用这些机制以检测此类威胁?
防火墙
我们从最常用的安全系统开始吧,那就是防火墙。所有的防火墙都允许自定义规则以防止 IP 地址欺骗。添加一条规则,拒绝接收来自指定范围段以外的 IP 地址的 DNS 查询,从而避免域名解析器被 DDOS 攻击用作开放的反射器。
接下来,启动 DNS 流量检测功能,监测是否存在可疑的字节模式或异常 DNS 流量,以阻止域名服务器软件漏洞攻击。具备本功能的常用防火墙的介绍资料在许多网站都可以找到(例如 Palo Alto、思科、沃奇卫士等)。Sonicwall 和 Palo Alto 还可以监测并拦截特定的 DNS 隧道流量。
入侵检测系统
无论你使用 Snort、Suricata 还是 OSSEC,都可以制定规则,要求系统对未授权客户的 DNS 请求发送报告。你也可以制定规则来计数或报告 NXDomain 响应、包含较小 TTL 数值记录的响应、通过 TCP 发起的 DNS 查询、对非标准端口的 DNS 查询和可疑的大规模 DNS 响应等。DNS 查询或响应信息中的任何字段、任何数值基本上都“能检测”。唯一能限制你的,就是你的想象力和对 DNS 的熟悉程度。防火墙的 IDS (入侵检测系统)对大多数常见检测项目都提供了允许和拒绝两种配置规则。
流量分析工具
Wireshark 和 Bro 的实际案例都表明,被动流量分析对识别恶意软件流量很有效果。捕获并过滤客户端与解析器之间的 DNS 数据,保存为 PCAP (网络封包)文件。创建脚本程序搜索这些网络封包,以寻找你正在调查的某种可疑行为。或使用 PacketQ (最初是 DNS2DB )对网络封包直接进行 SQL 查询。
(记住:除了自己的本地解析器之外,禁止客户使用任何其他解析器或非标准端口。)
DNS 被动复制
该方法涉及对解析器使用传感器以创建数据库,使之包含通过给定解析器或解析器组进行的所有 DNS 交易(查询/响应)。在分析中包含 DNS 被动数据对识别恶意软件域名有着重要作用,尤其适用于恶意软件使用由算法生成的域名的情况。将 Suricata 用做 IDS (入侵检测系统)引擎的 Palo Alto 防火墙和安全管理系统,正是结合使用被动 DNS 与 IPS (入侵防御系统)以防御已知恶意域名的安全系统范例。
解析器日志记录
本地解析器的日志文件是调查 DNS 流量的最后一项,也可能是最明显的数据来源。在开启日志记录的情况下,你可以使用 Splunk 加 getwatchlist 或是 OSSEC 之类的工具收集 DNS 服务器的日志,并搜索已知恶意域名。
尽管本文提到了不少资料链接、案例分析和实际例子,但也只是涉及了众多监控 DNS 流量方法中的九牛一毛,疏漏在所难免,要想全面快捷及时有效监控 DNS 流量,不妨试试 DNS 服务器监控。
DNS 服务器监控
应用管理器可对域名系统( DNS )进行全面深入的可用性和性能监控,也可监控 DNS 监控器的个别属性,比如响应时间、记录类型、可用记录、搜索字段、搜索值、搜索值状态以及搜索时间等。
DNS 中被监控的一些关键组件:
| 指标 | 描述 |
|---|---|
| 响应时间 | 给出 DNS 监控器的响应时间,以毫秒表示 |
| 记录类型 | 显示记录类型连接到 DNS 服务器的耗时 |
| 可用记录 | 根据可用记录类型输出 True 或 False |
| 搜索字段 | 显示用于 DNS 服务器的字段类型 |
| 搜索值 | 显示在DNS 服务器中执行的搜索值 |
| 搜索值状态 | 根据输出信息显示搜索值状态:Success (成功)或 Failed (失败) |
| 搜索时间 | DNS 服务器中的搜索执行时间 |
监控可用性和响应时间等性能统计数据。这些数据可绘制成性能图表和报表,即时可用,还可以按照可用性和完善性对报表进行分组显示。
若 DNS 服务器或系统内任何特定属性出现问题,会根据配置好的阈值生成通知和警告,并根据配置自动执行相关操作。目前,国内外 DNS 监控工具主要有 New relic、appDynamic、OneAPM。
8 - 浏览器过程
地址栏输入URL
URL : Uniform / Universal Resource Locator , 即统一资源定位符。它实际上就是网站网址。浏览器就是靠URL来查找资源位置。
可以把URL分割成几个部分:协议、网络地址、资源路径。
- 传送协议: URL包含协议部分,是浏览器和www万维网之间的沟通方式,它会告诉浏览器正确在网路上找到资源位置。最常见的网络传输协议的是HTTP协议(超文本传输协议)( https则是进行加密的网络传输);其他也还有ftp 、file、 https、mailto 、git 等。还有自定义的协议(私有协议),例如tencent。不同协议有不同的通讯内容格式。
- 网络地址: 指示该连接网络上哪一台计算机,可以是域名或者IP地址,可以包括端口号;
- 资源路径: 指示从服务器上获取哪一项资源。
例如: http://www.quaro.com/question/123456/
- 协议部分:http
- 网络地址:www.quaro.com
- 资源路径:/question/123456/
DNS 域名解析IP
基础概念
IP 地址:IP 协议为互联网上的每一个网络和每一台主机分配的一个逻辑地址。IP 地址如同门牌号码,通过 IP 地址才能确定一台主机位置。服务器本质也是一台主机,想要访问某个服务器,必须先知道它的 IP 地址。
域名 DN(domain name ):域名是为了识别主机名称和组织机构名称的一种具有分层的名称。 IP 地址由四个数字组成,中间用点号连接,在使用过程中难记忆且易输错,所以用我们熟悉的字母和数字组合来代替纯数字的 IP 地址,比如我们只会记住 www.baidu.com (百度域名) 而不是 220.181.112.244(百度的其中一个 IP 地址)。
计算机域名系统 DNS ( Domain Name System or Domain Name Service): 它是由域名解析器和域名服务器组成的。 域名服务器是指保存有该网络中所有主机的域名和对应IP地址,并具有将域名转换为IP地址功能的服务器。 每个域名都对应一个或多个提供相同服务的服务器的 IP 地址,只有知道服务器 IP 地址才能建立连接,所以需要通过 DNS 把域名解析成一个 IP 地址。
查找域名对应的IP地址
通过域名查找IP过程:浏览器缓存 -> 系统缓存 -> 本地DNS服务器缓存
- 浏览器搜索自己的DNS缓存(维护一张域名与IP地址对应表)
- 搜索操作系统中的DNS缓存(维护一张域名与IP地址对应表)
- 搜索操作系统的hosts文件(windows环境下,维护一张域名与IP地址对应表)
- 操作系统将域名发送到本地区域服务器(LNDS),进行查找,成功则返回结果(
递归查询),失败则发起一个迭代DNS请求(迭代查询)//迭代查询和递归查询请参考下一节 - 本地域名服务器LDNS将得到的IP地址返回给操作系统,同时也将IP地址缓存起来
- 操作系统将IP地址返回给浏览器,同时将IP地址缓存起来
DNS迭代查询和递归查询
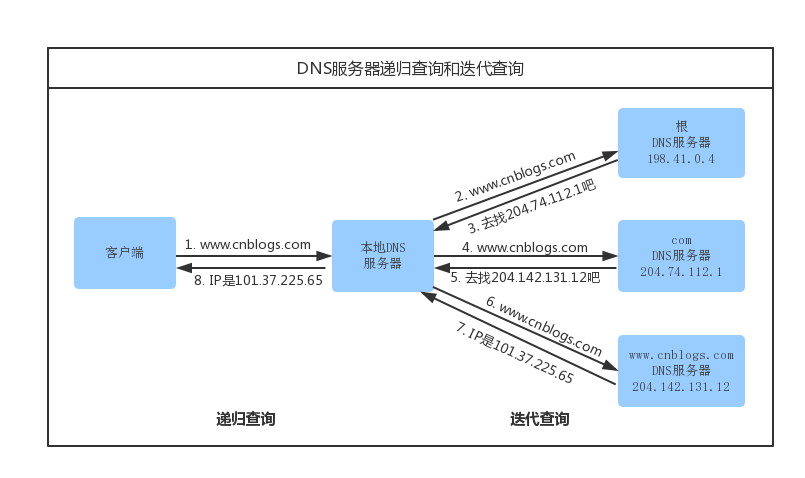
递归查询:客户端与服务器之间属于递归查询,即当客户机想DNS服务器发出请求后,若DNS服务器本身不能解析,会向另一个DNS服务器发出查询请求,最后将结果转交给客户端的过程。 服务器必须回答目标IP与域名的映射关系。
迭代查询:DNS服务器之间属于迭代查询。服务器接收到一次迭代查询回复一次结果,这个结果不一定死目标IP与域名的映射关系,也可以是其他DNS服务器的地址。
请求和响应数据
- TCP连接建立
- 发送http 请求
- 服务端处理
- 返回http 结果
- TCP连接关闭。
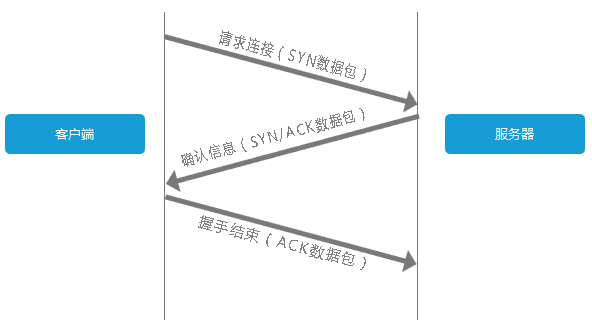
建立TCP连接(3次握手)
上一步找到IP之后,便可以开始建立TCP连接了,这里就是我们所说的TCP3次握手。
发送HTTP请求
与服务器建立了连接后,就可以向服务器发起请求了。
请求报文结构如下:
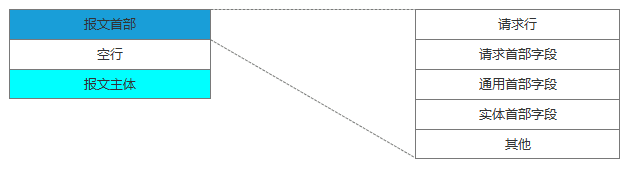
服务器处理请求
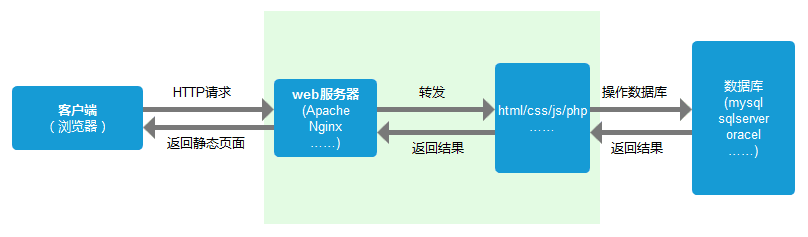
服务器端收到请求后的由web服务器(准确说应该是http服务器)处理请求,诸如Apache、Ngnix、IIS等。web服务器解析用户请求,知道了需要调度哪些资源文件,再通过相应的这些资源文件处理用户请求和参数,并调用数据库信息,最后将结果通过web服务器返回给浏览器客户端。
返回HTTP响应结果
服务器处理完请求后,就会发送响应结果。响应报文的结构如下:
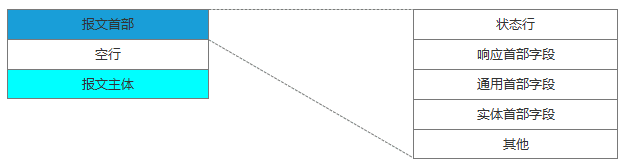
响应结果中会有对应的HTTP状态码,可分为5类:
关闭TCP连接(4次挥手)
为了避免服务器与客户端双方的资源占用和损耗,当双方没有请求或响应传递时,任意一方都可以发起关闭请求。与创建TCP连接的3次握手类似,关闭TCP连接,需要4次握手。

浏览器:加载-解析-渲染
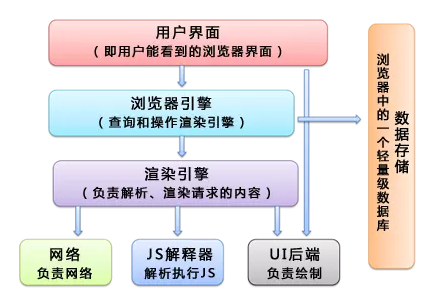
浏览器内核也称渲染引擎,主要有3种:
- Trident内核: IE
- Webkit内核:Chrome,Safari
- Gecko内核:FireFo
浏览器加载
加载过程如下:
- 当浏览器获得一个html文件时,会”自上而下“加载,并在加载过程中进行解析渲染。
- 加载过程中遇到外部css文件,浏览器另外发出一个请求,来获取css文件。
- 遇到图片资源,浏览器也会另外发出一个请求,来获取图片资源。这是异步请求,并不会影响html文档进行加载。
- 但是当文档加载过程中遇到js文件,html文档会挂起渲染(加载解析渲染同步)的线程,不仅要等待文档中js文件加载完毕,还要等待解析执行完毕,才可以恢复html文档的渲染线程。
加载外联js和css的阻塞情况:一个不太严谨但方便记忆的口诀:JS 全阻塞,CSS 半阻塞
- JS 会阻塞后续 DOM 解析以及其它资源(如 CSS,JS 或图片资源)的加载。
- CSS不阻塞DOM的加载和解析(它只阻塞DOM的渲染呈现。这里谈加载),不会阻塞其它资源(如图片)的加载,但是会阻塞 后续JS 文件的执行(原因之一是,js执行代码可能会依赖到css样式。css只阻塞执行而不阻塞js的加载)。
- 鉴于上面的特性,当css后面存在js的时候,css会间接地阻塞js后面资源的加载(css阻塞js,js阻塞其他资源 )。
- 现代浏览器会进行 prefetch 优化,浏览器在获得 html 文档之后会对页面上引用的资源进行提前下载
外联js文件使用defer属性和asyn可以达到异步非阻塞加载的效果,由于现代浏览器都存在 prefetch,所以 defer, async 可能并没有太多的用途,可以作为了解扩展知识,仅仅将脚本文件放到 body 底部(但还是在</body>之前)就可以起到很不错的优化效果(遵循先解析再渲染再执行script这个顺序)。当把js放在最后的时候,其实浏览器将自动忽略</body>标签,从而自动在最后的最后补上</body>。
浏览器解析和渲染
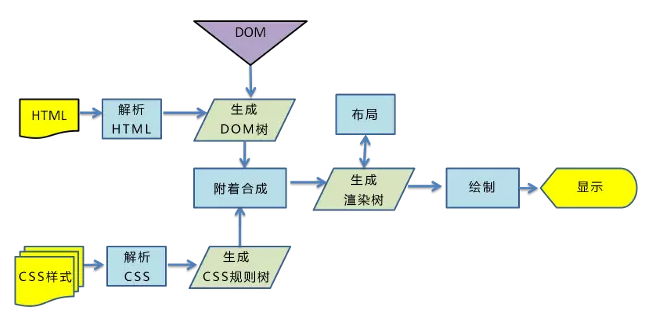
步骤如下:
- 解析html,生成dom树
- 解析css,生成cssom树
- 将dom树和cssom树合并,生成渲染树
- 遍历渲染树,开始布局和计算
- 绘制渲染树,显示到屏幕
解析html,生成dom树
当浏览器接收到服务器响应来的HTML文档后,会自上而下扫描文档,开始解析,遍历文档节点,生成DOM树。
整个构建过程其实包括: 字节 -> 字符 -> 令牌 -> 节点对象 -> 对象模型,下面是示例代码和配图:
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<link href="style.css" rel="stylesheet">
<title>Critical Path</title>
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg"></div>
</body>
</html>
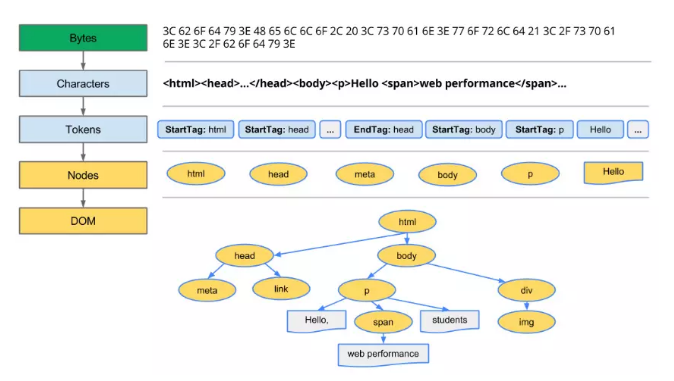
解析css,生成cssom树
- 每个css文件都被分析成一个stylesheet对象,每个对象都包含CSS规则。
- css规则对象包含对应于css语法的选择器和声明对象以及其他对象。
构建过程没有什么特别的差别,下面是示例代码和配图:
body { font-size: 16px }
p { font-weight: bold }
span { color: red }
p span { display: none }
img { float: right }
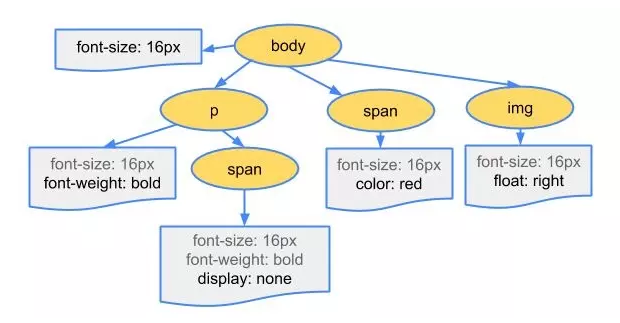
将dom树和cssom树合并,生成渲染树
- 浏览器会先从dom树的根节点开始遍历每个可见节点,找到其适配的CSS样式规则并应用。
- 将dom树与cssom树结合在一起,这就是渲染树。
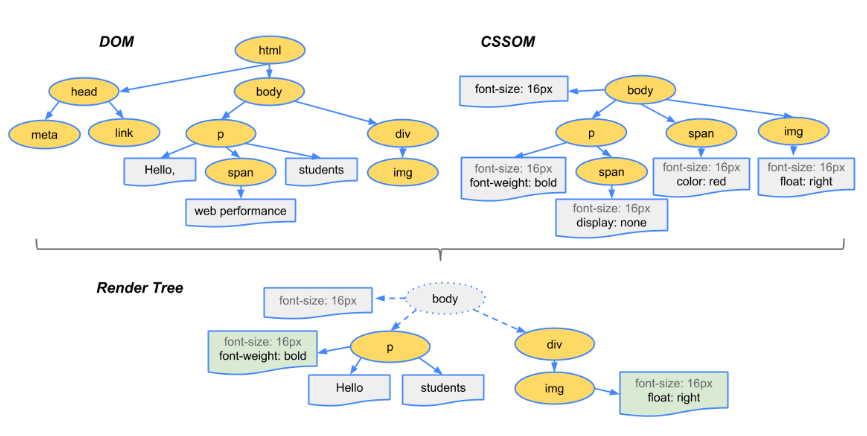
- 每一个渲染对象都对应着dom节点,但是非视觉(隐藏,不占位)dom元素不会插入渲染树,如
<head>元素或声明display: none;的元素。 - 渲染对象与dom节点不是简单的一对一的关系,一个dom可以对应一个渲染对象,但一个dom元素也可能对应多个渲染对象,因为有很多元素不止包含一个css盒子。(如当文本被折行时,会产生多个行盒,这些行会生成多个渲染对象;又如行内元素同时包含块元素和行内元素,则会创建一个匿名块级盒包含内部行内元素,此时一个dom对应多个渲染对象)
遍历渲染树,开始布局和计算
布局阶段会从渲染树的根节点开始遍历,然后确定每个节点对象在页面上的确切大小与位置。 布局阶段的输出是一个盒子模型,它会精确地捕获每个元素在屏幕内的确切位置与大小,所有相对的测量值也都会被转换为屏幕内的绝对像素值。
绘制渲染树,显示到屏幕
在绘制阶段,浏览器会立即发出Paint Setup与Paint事件,开始将渲染树绘制成像素,绘制所需的时间跟CSS样式的复杂度成正比,绘制完成后,用户就可以看到页面的最终呈现效果了。
Repaint和Reflow
当用户在浏览网页时进行交互或通过 js 脚本改变页面结构时,以上的部分操作有可能重复运行,此过程称为 Repaint 或 Reflow。
Repaint
当元素改变的时候,将不会影响元素在页面当中的位置(比如 background-color, border-color, visibility),浏览器仅仅会应用新的样式重绘此元素,此过程称为 Repaint。
Reflow
当元素改变的时候,将会影响文档内容或结构,或元素位置,此过程称为 Reflow。( HTML 使用的是 flow based layout ,也就是流式布局,所以,如果某元件的几何尺寸发生了变化,需要重新布局,也就叫 Reflow。)
Reflow 的成本比 Repaint 的成本高得多的多。我们应当尽量避免Reflow。
如何优化浏览器渲染过程
针对html
- html文档结构层次尽量少,最好不深于6层
- 首屏html可以少量,主体结构动态插入
- 尽量减少将 DOM 节点属性值放在循环当中,会导致大量读写此属性值。
- 创建有效的 HTML 和 CSS ,不要忘记指定文档编码,比如
<meta charset="utf-8">。
针对css
- 使用媒体查询,减少初次cssom树的构建量
- 尽量用id和class,不要过渡层叠
- 样式结构层次尽量简单
- 尽可能的为产生动画的 HTML 元素使用 fixed 或 absolute 的 position ,那么修改他们的 CSS 是不会 Reflow 的。
针对js
- 使用defer和async,避免对文档的阻塞
- 可以的话,动态插入js,避免阻塞
- 不要通过 JS 逐条修改 DOM 的样式,提前定义好 CSS 的 Class 进行操作。
针对引入位置
- css放到head,让cssom树先行构建;js放到
</body>前,保证dom树先行构建,不被阻塞 避免js文件的插入跟在css文件之后,避免css解析对js执行的延迟,造成阻塞
针对资源载入
- 对页面资源进行压缩,对传输进行gzip压缩
- 利用link标签的rel属性进行预解析,运用http缓存
9 - 概念术语
主机
计算机网络上任何一种能够连接网络的设备都被称为主机或者说端系统,比如手机、平板电脑、电视、游戏机、汽车等,随着 5G 的到来,将会有越来越多的终端设备接入网络。
通信链路
通信链路是由物理链路(同轴电缆、双绞线、光纤等)连接到一起组成的一种物理通路。
传输速率
单位是 bit/s 或者 bps ,用来度量不同链路从一个端系统到另一个端系统传输数据的速率。
分组
当一台端系统向另外一台端系统发送数据时,通常会将数据进行分片,然后为每段加上首部字节,从而形成计算机网络的专业术语:分组。这些分组通过网络发送到端系统,然后再进行数据处理。
路由器
它和链路层交换机一样,都是一种交换机,主要用于转发数据的目的。
路径
一个分组所经历一系列通信链路和分组交换机称为通过这个网络的路径。
因特网服务商
也叫 ISP,不是 lsp。这个好理解,就是网络运营商,移动、电信、联通。
网络协议
网络协议是计算机网络中进行数据交换而建立的规则、标准或者约定。
IP
网际协议,它规定了路由器和端系统之间发送和接收的分组格式。
TCP/IP 协议簇
不仅仅只有 TCP 协议和 IP 协议,而是以 TCP、IP 协议为主的一系列协议,比如 ICMP 协议、ARP 协议、UDP 协议、DNS 协议、SMTP 协议等。
分布式应用程序
多个端系统之间相互交换数据的端系统被称为分布式应用程序。
套接字接口
指的就是 socket 接口,这个接口规定了端系统之间通过因特网进行数据交换的方式。
协议
协议定义了两个以上通信实体之间交换报文格式和顺序所遵从的标准。
客户端
在客户-服务器架构中扮演请求方的角色,通常是 PC,智能手机等端系统。
服务器
在客户-服务器架构中扮演服务方的角色,通常是大型服务器集群扮演服务器的角色。
转发表
路由内部记录报文路径的映射关系的一种记录。
时延
时延指的是一个报文或者分组从网络的一端传递到另一端所需要的时间,时延分类有发送时延、传播时延、处理时延、排队时延,总时延 = 发送时延+传播时延+处理时延+排队时延。
丢包
在计算机网络中指的是分组出现丢失的现象。
吞吐量
吞吐量在计算机网络中指的是单位时间内成功传输数据的数量。
报文
通常指的是应用层的分组。
报文段
通常把运输层的分组称为报文段。
数据报
通常将网络层的分组称为数据报。
帧
一般把链路层的分组称为帧。
客户-服务体系
它是一种面向网络应用的体系结构。把系统中的不同端系统区分为客户和服务器两类,客户向服务器发出服务请求,由服务器完成所请求的服务,并把处理结果回送给客户。在客户-服务器体系结构中,有一个总是打开的主机称为 服务器(Server),它提供来自于 客户(client) 的服务。我们最常见的服务器就是 Web 服务器,Web 服务器服务于来自 浏览器 的请求。
CIDR
使用任意长度分割 IP 地址的网络标识和主机标识
P2P 体系 对等体系结构,相当于没有服务器了,大家都是客户机,每个客户既能发送请求,也能对请求作出响应。
## IP 地址
IP 地址就是网际协议地址,在互联网中唯一标识主机的一种地址。每一台入网的设备都会有一个 IP 地址,这个 IP 又分为内网 IP 和公网 IP。
端口号
在同一台主机内,端口号用于标识不同应用程序进程。
URI
它的全称是(Uniform Resource Identifier),中文名称是统一资源标识符,使用它就能够唯一地标记互联网上资源。
URL
它的全称是(Uniform Resource Locator),中文名称是统一资源定位符,它实际上是 URI 的一个子集。
HTML
HTML 称为超文本标记语言,是一种标识性的语言。它包括一系列标签.通过这些标签可以将网络上的文档格式统一,使分散的 Internet 资源连接为一个逻辑整体。HTML 文本是由 HTML 命令组成的描述性文本,HTML 命令可以说明文字,图形、动画、声音、表格、链接等。
Web 页面
Web 页面也叫做 Web Page,它是由对象组成,一个对象(object) 简单来说就是一个文件,这个文件可以是 HTML 文件、一个图片、一段 Java 应用程序等,它们都可以通过 URI 来找到。一个 Web 页面包含了很多对象,Web 页面可以说是对象的集合体。
Web 服务器
Web 服务器的正式名称叫做 Web Server,Web 服务器可以向浏览器等 Web 客户端提供文档,也可以放置网站文件,让全世界浏览;可以放置数据文件,让全世界下载。目前最主流的三个 Web 服务器是 Apache、 Nginx 、IIS。
CDN
CDN 的全称是Content Delivery Network,即内容分发网络,它应用了 HTTP 协议里的缓存和代理技术,代替源站响应客户端的请求。CDN 是构建在现有网络基础之上的网络,它依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。
WAF
WAF 是一种 应用程序防护系统,它是一种通过执行一系列针对 HTTP / HTTPS的安全策略来专门为 Web 应用提供保护的一款产品,它是应用层面的防火墙,专门检测 HTTP 流量,是防护 Web 应用的安全技术。
WebService
WebService 是一种 Web 应用程序,WebService 是一种跨编程语言和跨操作系统平台的远程调用技术。
HTTP
TCP/IP 协议簇的一种,它是一个在计算机世界里专门在两点之间传输文字、图片、音频、视频等超文本数据的约定和规范。
Session
Session 其实就是客户端会话的缓存,主要是为了弥补 HTTP 无状态的特性而设计的。服务器可以利用 Session 存储客户端在同一个会话期间的一些操作记录。当客户端请求服务端时,服务端会为这次请求开辟一块内存空间,这个对象便是 Session 对象,存储结构为 ConcurrentHashMap。
Cookie
HTTP 协议中的 Cookie 包括 Web Cookie 和浏览器 Cookie,它是服务器发送到 Web 浏览器的一小块数据。服务器发送到浏览器的 Cookie,浏览器会进行存储,并与下一个请求一起发送到服务器。通常,它用于判断两个请求是否来自于同一个浏览器,例如用户保持登录状态。
SMTP 协议
提供电子邮件服务的协议叫做 SMTP 协议, SMTP 在传输层也使用了 TCP 协议。SMTP 协议主要用于系统之间的邮件信息传递,并提供有关来信的通知。
DNS 协议
由于 IP 地址是计算机能够识别的地址,而我们人类不方便记忆这种地址,所以为了方便人类的记忆,使用 DNS 协议,来把我们容易记忆的网络地址映射称为主机能够识别的 IP 地址。
TELNET 协议
远程登陆协议,它允许用户(Telnet 客户端)通过一个协商过程来与一个远程设备进行通信,它为用户提供了在本地计算机上完成远程主机工作的能力。
SSH 协议
SSH 是一种建立在应用层上的安全加密协议。因为 TELNET 有一个非常明显的缺点,那就是在主机和远程主机的发送数据包的过程中是明文传输,未经任何安全加密,这样的后果是容易被互联网上不法分子嗅探到数据包来搞一些坏事,为了数据的安全性,我们一般使用 SSH 进行远程登录。
FTP 协议
文件传输协议,是应用层协议之一。FTP 协议包括两个组成部分,分为 FTP 服务器和 FTP 客户端。其中 FTP 服务器用来存储文件,用户可以使用 FTP 客户端通过 FTP 协议访问位于 FTP 服务器上的资源。FTP 协议传输效率很高,一般用来传输大文件。
MIME 类型
它表示的是互联网的资源类型,一般类型有 超文本标记语言文本 .html text/html、xml文档 .xml text/xml、普通文本 .txt text/plain、PNG图像 .png image/png、GIF图形 .gif image/gif、JPEG图形 .jpeg,.jpg image/jpeg、AVI 文件 .avi video/x-msvideo 等。
多路分解
在接收端,运输层会检查源端口号和目的端口号等字段,然后标识出接收的套接字,从而将运输层报文段的数据交付到正确套接字的过程被称为多路分解。
多路复用
在发送方,从不同的套接字中收集数据块,然后为数据块封装上首部信息从而生成报文段,然后将报文段传递给网络层的过程被称为多路复用。
周知端口号
在主机的应用程序中,从 0 - 1023 的端口号是受限制的,被称为周知端口号,这些端口号一般不能占用。
单向数据传输
数据的流向只能是单向的,也就是从发送端 -> 接收端。
双向数据传输
数据的流向是双向的,又叫做全双工通信,发送端和接收端可以相互发送数据。
面向连接的
面向连接指的是应用进程在向另一个应用进程发送数据前,需要先进行握手,即它们必须先相互发送预备报文段,用来建立确保数据传输的参数。
三次握手
TCP 连接的建立需要经过三个报文段的发送,这种连接的建立过程被称为三次握手。
最大报文段长度
即 MSS,它指的是从缓存中取出并放入报文段中的最大值。
最大传输单元
即 MTU,它指的是通信双方能够接收有效载荷的大小,MSS 通常会根据 MTU 来设。
冗余 ACK
就是再次确认某个报文段的 ACK,报文段的丢失会导致冗余 ACK 的出现。
快速重传
即在报文段定时器过期之前重传丢失的报文段。
选择确认
在报文段出现丢失的情况下,TCP 能够选择确认失序的报文段,这个机制通常和重传一起使用。
拥塞控制
拥塞控制说的是,当某一段时间网络中的分组过多,使得接收端来不及处理,从而引起部分甚至整个网络性能下降的现象时采取的一种抑制发送端发送数据,等过一段时间或者网络情况改善后再继续发送报文段的一种方法。
四次挥手
TCP 断开链接需要经过四个报文段的发送,这种断开过程是四次挥手。
路由选择算法
网络层中决定分组发送路径的一种算法。
转发
它指的是将分组从一个输入链路转移到合适的输出链路的动作。
分组调度
分组调度讨论的是分组如何经输出链路传输的问题,主要有三种调度方式:先进先出、优先级排队和"循环和加权公平排队"。
IPv4
网际协议的第四个版本,也是被广泛使用的一个版本。IPv4 是一种无连接的协议,无连接不保证数据的可靠性交付。使用 32 位的地址。
IPv6
网际协议的第六个版本,IPv6 的地址长度是 128 位,由于 IPv4 最大的问题在于网络地址资源不足,严重制约了互联网的应用和发展。IPv6 的使用,不仅能解决网络地址资源数量的问题,而且也解决了多种接入设备连入互联网的障碍。
接口
主机和物理链路之间的边界。
ARP 协议
ARP 是一种解决地址问题的协议,通过 IP 位线索,可以定位下一个用来接收数据的网络设备的 MAC 地址。如果目标主机与主机不在同一个链路上时,可以通过 ARP 查找下一跳路由的地址。不过 ARP 只适用于 IPv4 ,不适用于 IPv6。
RARP
RARP 就是将 ARP 协议反过来,通过 MAC 地址定位 IP 地址的一种协议。
代理 ARP
用于解决 ARP 包被路由器隔离的情况,通过代理 ARP 可以实现将 ARP 请求转发给临近的网段。
ICMP 协议
Internet 报文控制协议,如果在 IP 通信过程中由于某个 IP 包由于某种原因未能到达目标主机,那么将会发送 ICMP 消息,ICMP 实际上是 IP 的一部分。
DHCP 协议
DHCP 是一种动态主机配置协议。使用 DHCP 就能实现自动设置 IP 地址、统一管理 IP 地址分配,实现即插即用。
NAT 协议
网络地址转换协议,它指的是所有本地地址的主机在接入网络时,都会要在 NAT 路由器上将其转换成为全球 IP 地址,才能和其他主机进行通信。
IP 隧道
IP 隧道技术说的是由路由器把网络层协议封装到另一个协议中从而跨过网络传输到另外一个路由器的过程。
单播
单播最大的特点就是 1 对 1,早期的固定电话就是单播的一个例子
广播
我们一般小时候经常会广播体操,这就是广播的一个事例,主机和与他连接的所有端系统相连,主机将信号发送给所有的端系统。
多播
多播与广播很类似,也是将消息发送给多个接收主机,不同之处在于多播需要限定在某一组主机作为接收端。
任播
任播是在特定的多台主机中选出一个接收端的通信方式。虽然和多播很相似,但是行为与多播不同,任播是从许多目标机群中选出一台最符合网络条件的主机作为目标主机发送消息。然后被选中的特定主机将返回一个单播信号,然后再与目标主机进行通信。
IGP
内部网关协议,一般用于企业内部自己搭建的路由自治系统。
EGP
外部网关协议,EGP 通常用于在网络主机之间相互交换路由信息。
RIP
一种距离向量型路由协议,广泛应用于 LAN 网。
OSPF
是根据 OSI 的 IS-IS 协议提出的一种链路状态型协议。这种协议还能够有效的解决网络环路问题。
MPLS
它是一种标记交换技术,标记交换会对每个 IP 数据包都设定一个标记,然后根据这个标记进行转发。
节点
一般指链路层协议中的设备。
链路
一般把沿着通信路径连接相邻节点的通信信道称为链路。
MAC 协议
媒体访问控制协议,它规定了帧在链路上传输的规则。
奇偶校验位
一种差错检测方式,多用于计算机硬件的错误检测中,奇偶校验通常用在数据通信中来保证数据的有效性。
向前纠错
接收方检测和纠正差错的能力被称为向前纠错。
以太网
以太网是一种当今最普遍的局域网技术,它规定了物理层的连线、电子信号和 MAC 协议的内容。
VLAN
虚拟局域网(VLAN)是一组逻辑上的设备和用户,这些设备和用户并不受物理位置的限制,可以根据功能、部门及应用等因素将它们组织起来,相互之间的通信就好像它们在同一个网段中一样,所以称为虚拟局域网。
基站
无线网络的基础设施。