分段
到目前为止,我们一直假设将所有进程的地址空间完整的加载到内存中。利用基址和界限寄存器,操作系统很容易将不同进程重定位到不同的物理内存区域。但是,对于这些内存区域,你可能会注意到:栈和堆之间,有一大块空闲空间。
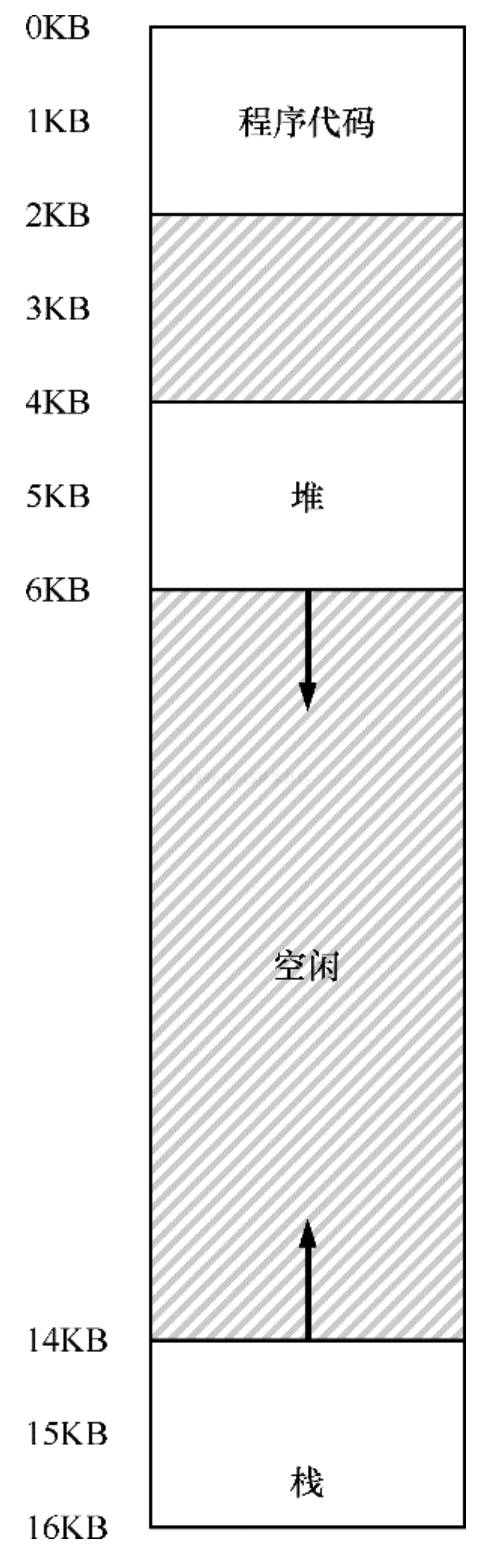
从上图可知,如果我们将整个地址空间放入物理内存,那么栈和堆之间的空间并没有被进程使用,却依然占用了实际的物理内存。因此,简单的通过基址寄存器和界限寄存器实现的虚拟内存很浪费。另外,如果剩余物理内存无法提供连续区域来放置完整的内存空间,进程便无法运行。这种基址加界限的方式看起来并不像我们想象的那样灵活。
关键问题:怎样支持大地址空间 怎样支持大的地址空间,同时栈和堆之间又可能存在大量空间空间?在之前的例子中,地址空间非常小,所以这种浪费并不明显。但假设一个 32 位 4GB 的地址空间,通常的程序只会使用几兆的内存,但需要整个地址空间都放在内存中。
分段:泛化的基址/界限
为了解决该问题,分段概念应运而生。分段并非一个新概念,它甚至可以追溯到 20 时机 60 年代初期。这个想法很简单,在 MMU 中引入不止一个基址和界限寄存器对,而是为地址空间内的每个逻辑段配置一对。一个段只是地址空间中一个连续定长的区域,在典型的地址空间中有 3 个逻辑不同的段:代码、栈、堆。分段的机制使得操作系统能够将不同的段放到不同的物理内存区域,从而避免了虚拟地址空间中未使用部分仍然占用内存。
我们来看一个例子,假设我们系统将上图中的地址空间放入物理内存。通过给每个段一对基址和界限寄存器,可以将每个段独立放入物理空间。如下图所示,64KB 的物理内存中放置了 3 个段,为操作系统保留 16KB。
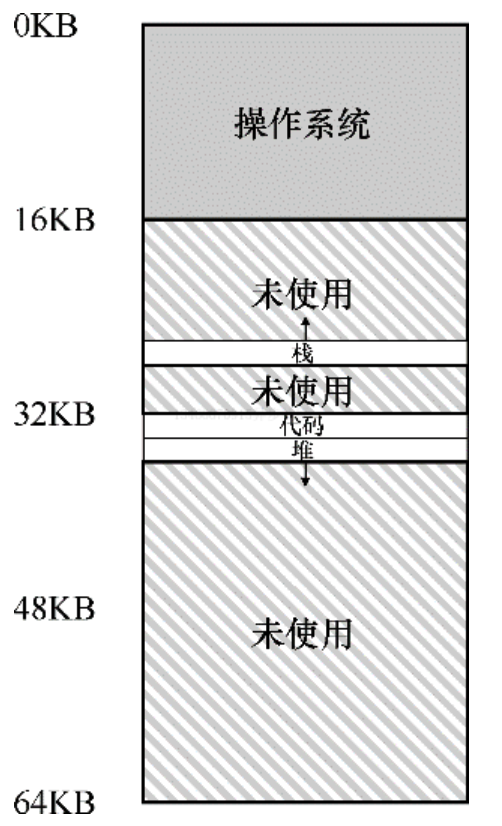
从上图可以看到,只有已使用的内存才在物理内存中分配空间,因此可以容纳巨大的地址空间,其中包含大量未使用的地址空间,有时又称为稀疏地址空间。
你会想到,需要 MMU 中的硬件结构来支持分段:在这种情况下,需要一组 3 对基址和界限寄存器。下表展示了上面例子中的寄存器值,每个界限寄存器都记录了一个段的大小。
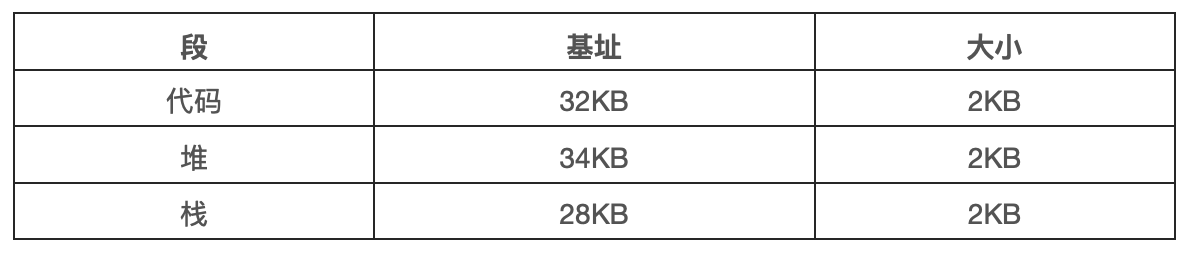
我们来看一个地址转换的例子。假设现在要引用虚拟地址 100,MMU 将基址值加上偏移量 100 得到实际的物理地址:100+32KB=32868。然后它会检查该地址是否在界限内,验证通过,于是发起对物理内存地址 32868 的引用。
补充:段错误 段错误指的是在支持分段的机器上发生了非法内存访问。有趣的是,即使在不支持分段的机器上这个术语依然保留。
来看一个堆中的地址,虚拟地址 4200。如果用虚拟地址 4200 加上堆的基址 32KB,得到 39016,这是不正确的。我们首先应该减去堆的偏移量,即该地址指的是这个段中的哪个字节。因为堆从虚拟地址 4KB 开始,4200 的偏移量实际上是 4200 减去 4096,即 104,然后用这个偏移量加上基址寄存器中的物理地址 3KB,得到真正的物理地址 34920。
如果试图访问非法的地址,如 7KB,你可以想象发生的情况:硬件会发现该地址越界,因此陷入操作系统,和可能导致终止出错进程。这就是段异常或段错误。
我们引用哪个段
硬件在地址转换时使用寄存器,它如何知道段内的偏移量呢,以及地址引用了哪个段?
一种常见的方式是,有时称为显式方式,就是用虚拟地址的开头几位来标识不同的段,VAX/VMS 系统使用了这种技术。在我们之前的例子中有 3 个段,因此需要两位来标识。如果我们用 14 位虚拟地址的前两位来标识,那么虚拟地址如下所示:
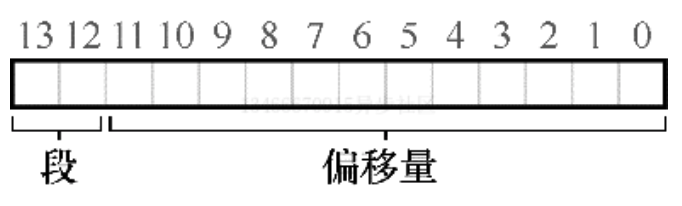
那么在我们的例子中,如果前两位是 00,硬件就知道这是属于代码段的地址,因此使用代码段的基址和界限来定位到正确的物理地址。如果前两位是 01,则是堆地址,对应的使用堆的基址和界限。下面来看一个 4200 之上的虚拟地址进行转换。虚拟地址 4200 的二进制形式如下:
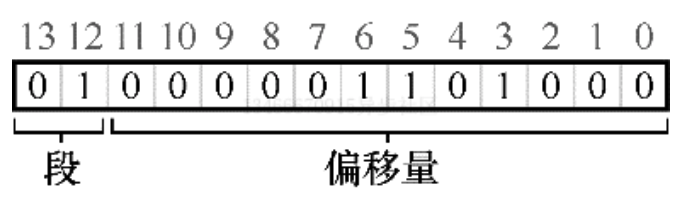
从图中可以看到,前两位 01 告诉硬件我们引用的是哪个段。剩下的 12 位是段内偏移量。因此,硬件就使用前两位来决定使用哪个段寄存器,然后用后 12 位作为段内偏移。偏移量与基址相加,硬件就得到了物理地址。请注意,偏移量也简化了对段边界的判断。我们只要检查偏移量是否小于界限,大于界限的则为非法地址。因此,如果基址和界限放在数组中,为了获得需要的物理地址,硬件或做以下操作:
1 // get top 2 bits of 14-bit VA
2 Segment = (VirtualAddress & SEG_MASK) >> SEG_SHIFT
3 // now get offset
4 Offset = VirtualAddress & OFFSET_MASK
5 if (Offset >= Bounds[Segment])
6 RaiseException(PROTECTION_FAULT)
7 else
8 PhysAddr = Base[Segment] + Offset
9 Register = AccessMempory(PhysAddr)
在我们的例子中,可以为上面的常量填上值。具体来说,SEG_MASK 为 0x3000,SEG_SHIFT 为 12,OFFSET_MASK 为 0xFFF。
你或许已经注意到,上面使用两位来区分段,但实际只有 3 个段,因此有一段的地址空间被浪费。因此有些系统中会将堆和栈作为一个段,因此只需要一位来做标识。
硬件还提供了其他方法来决定特定地址在哪个段。在隐式方式中,硬件通过地址产生的方式来确定段。比如,如果地址由程序计数器产生,那么地址在代码段。如果基于栈或基址指针,他一定在栈段。其他地址则在堆段。
栈怎么办
到目前为止,我们一直没有将地址空间中的一个重要部分:栈。在前面的例子中,栈被定位到物理地址 28KB。但有一点关键区别,它反向增长。在物理内存中,它始于 28KB,增长回到 26KB,响应虚拟地址从 16KB 到 14KB。地址转换必须有所不同。
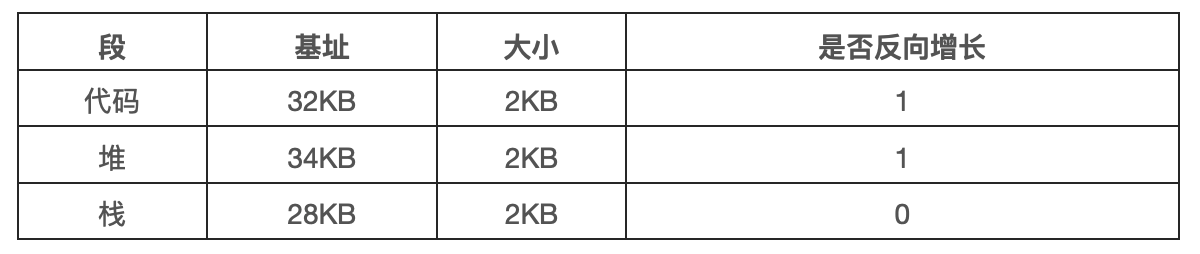
首先,我们需要一点硬件支持。除了基址和界限外,硬件还需要知道段的增长方向(使用 1 位来区分)。在下表中,我们更新了硬件的视图。
硬件理解段可以反向增长后,这种虚拟地址的地址转化必须有所不同。下面来看一个例子。
在该例子中,假设要访问虚拟地址 15KB,它映射到物理地址为 27KB。该虚拟地址的二进制形式为 11 1100 0000 0000(十六进制 0x3C00)。硬件利用前两位 11 来指定段,但然后我们要处理偏移量 3KB。为了得到正确的反向偏移,我们必须从 3KB 中减去最大的段地址:在这个例子中,段可以是 4KB,因此正确的偏移量是 3KB 减去 4KB,即 -1KB。只要用这个偏移量加上基址 28KB,就能得到正确的物理地址 27KB。用户可以进行越界检查,确保反向偏移量的绝对值小于段的大小。
支持共享
随着分段机制的不断改进,系统设计人员很快意识到,通过再多一点的硬件支持,就能实现新的效率提升。具体来说,要节省内存,有时候在地址空间之间共享某些内存段是有用的。尤其是,代码共享很常见,今天的系统仍然在用。
为了支持共享,需要一些额外的支持,这就是保护位。基本为每个段增加了一个位,标识程序是否能够读写该段,或执行其中的代码。通过将代码段标记为只读,同样的代码可以被多个进程共享,而不用担心破坏隔离。虽然每个进程都认为自己独占这块内存,但操作系统秘密的共享了内存,进程不能修改这些内存,所以假象得以保持。
下表展示了一个例子,是硬件记录的额外信息。可以看到,代码段的权限是可读和可执行,因此物理内存中的一个段可以映射到多个虚拟地址空间。
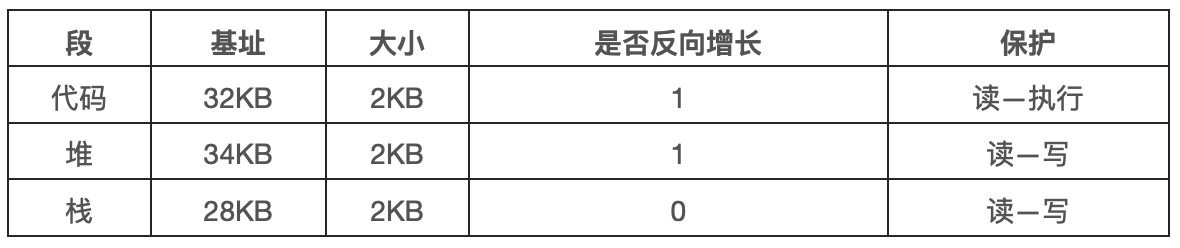
有了保护位,前面描述的硬件算法也必须改变。除了检查地址是否越界,还需要检查特定访问是否允许。如果用户试图写入只读段,或从非执行段执行指令,硬件会触发异常,并让操作系统来处理出错进程。
分段粒度
到目前为止,我们的例子大多针对只有很少几个段的系统(代码、堆、栈)。我们可以认为这种分段是粗粒度的,因为它将地址空间分为较大的、粗粒度的块。但是,一些早期的系统更灵活,允许将地址空间划分为大量较小的段,被称为细粒度分段。
支持大量分段需要硬件的支持,并在内存中保存某种段表。这种分段表通常支持创建非常多的段,因此系统使用段的方式比之前讨论的方式更加灵活。比如,像 Burroughs B5000 这样的早期机器可以支持成千上万的段,有了操作系统和硬件的支持,编译器可以将代码段和数据段划分为许多不同的部分。当时的考虑是,通过耕细粒度的分段,操作系统可以更好的了解哪些段在使用、哪些段未被使用,从更加高效的利用内存。
操作系统支持
现在你应该了解了基本的分段原理。系统运行时,地址空间中的不同段被重定位到物理内存中。与我们之前介绍的整个地址空间只有一个基址/界限寄存器对的方式相比,节省了大量物理内存。具体来说,栈和堆之间没有使用的区域就不再需要分配物理内存,让我们可以将更多的地址空间放入物理内存。
然而,分段带来了一些新的问题。我们先介绍必须关注的操作系统相关的问题。第一个是老问题:操作系统在上下文切换时应该怎么做?你可能已经猜到了:各个段寄存器中的内存必须被保存和恢复。显然,每个进程都有自己独立的虚拟地址空间,操作系统必须在进程运行之前,确保这些寄存器被正确的赋值。
第二个问题更重要,即管理物理内存的空闲空间。新的地址空间被创建时,操作系统需要在物理内存中为它的段找到空间。之前,我们假设所有的地址空间大小相同,物理内存可以被认为是一些槽块,进程可以放进去。现在,每个进程都有一些段,每个段的大小也可能不同。
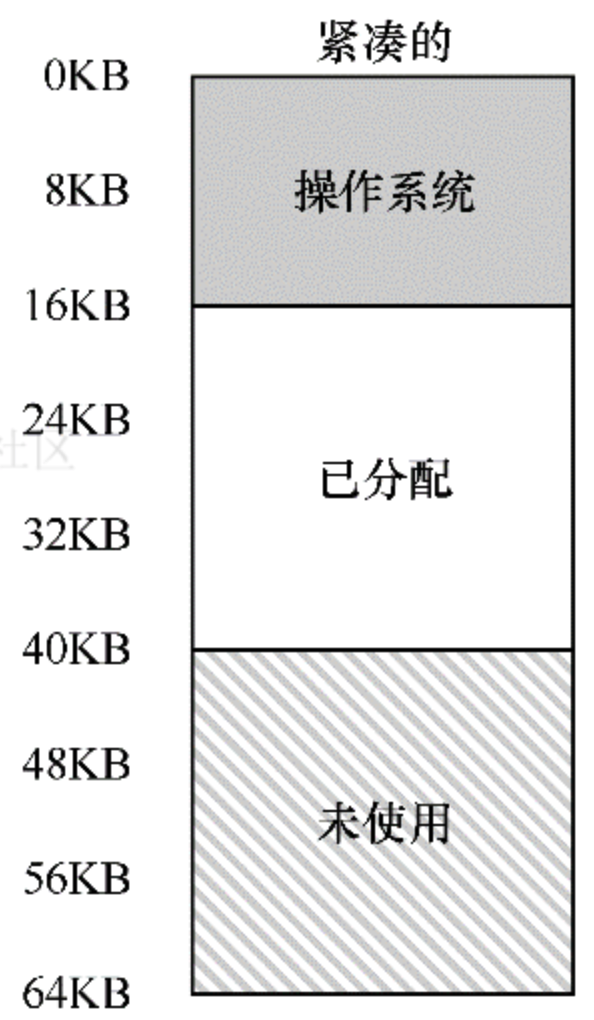
一般会遇到的问题是,物理内存很快充满了很多小的空闲空间,因而很难分配给新的段,或扩大已有的段。这种问题被称为外部碎片,如下图所示。

在这个例子中,一个进程需要分配一个 20KB 的段。当前只有 24KB 空闲,但并不连续。因此,操作系统无法满足这个 20KB 的请求。
该问题的一种解决方案是紧凑物理内存,重新安排原有的段。比如,操作系统先中止运行的进程,将它们的数据复制到连续的内存区域中去,改变它们的段寄存器中的值,指向新的物理地址,从而得到足够大的连续空闲空间。这样做,操作系统能让新的内存分配请求成功。但是,内存紧凑的成本很高,因为拷贝是内存密集型的,一般会占用大量的处理器时间。如下图所示。
一种跟简单的方案是利用空闲列表管理算法,试图保留大的内存块用于分配。相关的算法可能有成千上百种,包括传统的最优匹配、最坏匹配、首次匹配、伙伴算法等。Wilson 等人做过一个很好的调查。
小结
分段解决了一些问题,帮助我们实现了高效的虚拟内存。不只是动态重定位,通过避免地址空间的逻辑段之间潜在的大量内存浪费,分段能够更好的支持稀疏地址空间。它还很快,因为分段需要的算法很简单,很适合由硬件完成,地址转换的开销极小。分段还有一个附加好处是代码共享。如果代码放在独立的段中,这样段就可以被多个运行的程序共享。
但我们已经知道,在内存中分配不同大小的段会导致一些问题,我们希望客服。首先,是我们上面讨论的外部碎片。由于段的大小不同,空闲内存被割裂成各种奇怪的大小,因此满足内存分配请求可能会很难。用户可以尝试采用聪明的算法,或定义紧凑内存,但问题很根本,难以避免。
第二个问题也许更重要,分段还是不足以支持更一般化的稀疏地址空间。比如,如果有一个很大但是稀疏的堆,都在一个逻辑段中,整个堆仍然必须完整的加载到内存中。换言之,如果使用地址空间的方式不能很好的匹配底层分段的设计目标,分段就不能很好的工作。因此我们需要找到新的解决方案。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.