多处理器调度
过去很多年,多处理器系统只存在于高端服务器中。现在,它们越来越多的出现在个人电脑、笔记本电脑甚至移动设备上。多核处理器将多个 CPU 组装在一块芯片上,是这种扩展的根源。由于计算机的构架师们当时很难让单核 CPU 更快,同时又不增加太多功耗,所以这种多核 CPU 很快就变得流行。
当然,多核 CPU 也带来和很多困难。主要困难是典型的应用程序都只使用一个 CPU,增加更多的 CPU 并没有让这类程序运行的更快。为了解决该问题不得不重新这些程序,使之能够并行执行,或者使用多线程。多线程应用可以将工作分散到多个 CPU 上,因此 CPU 资源越多运行的也就越快。
除了应用程序,操作系统遇到的一个新的问题是多处理器调度。到目前为止,我们讨论了很多单处理器调度的原则,那么如何将这些想法扩展到多处理器上呢?
背景:多处理器架构
为了了解多处理器调度带来的新问题,必须先知道它与单 CPU 之间的基本区别。区别的核心在于对硬件缓存的使用,以及多处理器之间共享数据的方式。
在单 CPU 系统中,存在多级的硬件缓存,一般来说会让处理器更快的执行程序。缓存是很小但很快的存储设备,通常拥有内存中最热数据的备份。相比之下,内存很大且拥有所有的数据,但访问速度较慢。通过将频繁访问的数据放在缓存中,系统似乎拥有又大又快的内存。
举个例子,假设一个程序需要从内存中加载指令并读取一个值,系统只有一个 CPU,拥有较小的缓存和较大的内存。
程序第一次读取数据时,数据在内存中,因此需要花费较长的时间。处理器判断该数据可能被再次使用,因此将其放入 CPU 缓存中。如果之后程序需要再次使用该数据,CPU 会先查找缓存。因为在缓存中找到了数据,所以取数据会快的多,程序则会运行的更快。
缓存是基于局部性的概念,局部性有两种,即时间局部性和空间局部性。时间局部性指当一个数据被访问后,它很有可能在不久的将来被再次访问,比如循环代码中的数据或指令本身。而空间局部性指的是,当程序访问地址为 X 的数据时,很有可能会紧接着访问 X 周围的数据,比如遍历数组或指令的顺序执行。由于这两种局部性存在于大多数程序中,硬件系统可以很好的预测哪些数据可以放入缓存,从而运行的更快。
有趣的是,如果系统有多个处理器,并共享同一个内存,会怎样呢?

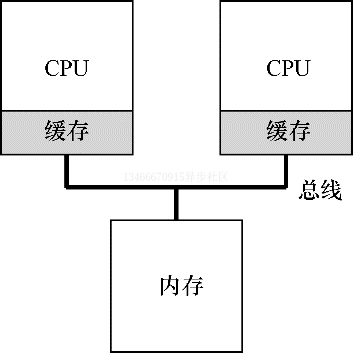
事实证明,多 CPU 的情况下缓存要复杂的多。假设运行一个在 CPU1 上的程序从内存地址 A 读取数据。由于不再 CPU1 的缓存中,所以系统会直接访问内存,得到值 D。程序然后修改了 A 处的值,只是将其缓存更新会新的值 D1。将数据写回内存比较慢,因此系统通常稍后再执行写入操作。假设这时系统中断了该程序的运行,并将其交给 CPU2,重新读取地址 A 的数据,由于 CPU2 的缓存中没有该数据,所以会直接从内存读取,得到了旧的值 D,而不是正确的 D1。
这一普遍的问题被称为缓存一致性问题,有大量的研究文献描述了解决该问题的微妙之处。这里我们仅提几个要点。
硬件提供了该问题的基本解决方案:通过监控内存访问,硬件可以保证获得正确的数据,并保证共享内存的唯一性。在基于总线的系统中,一种方式是使用总线窥探。每个缓存都通过监听链接了所有缓存和内存的总线,来发现内存访问操作。如果 CPU 发现对它放在缓存中的数据的更新,会作废本地副本,或将其更新。而回写缓存,则会让事情变得更加复杂。
同步
跨 CPU 访问(尤其是写入)时共享数据或数据结构,需要使用互斥原语才能保证正确性。比如多 CPU 并发访问一个共享队列。如果没有锁,即使有底层一致性协议,并发的从队列增加或删除元素依然不会得到正确的结果。需要使用锁来保证数据结构状态更新的原子性。
为了更具体,我们设想这样的代码序列,用于删除共享链表的一个元素。
1 typedef struct __Node_t {
2 int value;
3 struct __Node_t *next;
4 } Node_t;
5
6 int List_Pop() {
7 Node_t *tmp = head; // remember old head ...
8 int value = head->value; // ... and its value
9 head = head->next; // advance head to next pointer
10 free(tmp); // free old head
11 return value; // return value at head
12 }
假设两个 CPU 上的不同线程同时进入这个函数。如果线程 1 执行第一行,会将 head 的当前值存入它的 tmp 变量。如果线程 2 接着也执行第一行,他也会将同样的 head 值存入自己的私有 tmp 变量。tmp 变量在栈上分配,两个线程拥有各自的私有存储。因此,两个线程会尝试删除同一个链表头,而不是每个线程各移除一个元素,这导致了各种问题。
当然,让这类函数正确工作的方式是使用锁。这里只需要一个互斥锁,然后在函数开始时调用 lock,在结束时条用 unlock,确保代码的执行符合预期。我们会看到,这里依然会有问题,尤其是性能方面。具体来说,随着 CPU 数量的增加,访问同步共享的数据结构会变得很慢。
缓存亲和度
在设计多处理器调度时遇到的最后一个问题,是所谓的缓存亲和度。这个概念很简单:一个进程在某个 CPU 上运行时,会在该 CPU 的缓存中维护很多状态。下次该进程在相同的 CPU 上运行时,由于缓存中的数据而执行的更快。相反,在不同的 CPU 上执行,会由于需要重新加载数据而变慢。因此多处理器调度应该考虑到这种缓存亲和度,并尽可能将进程保持在相同的 CPU 上执行。
单队列调度
现在我们来讨论如何设计一个多处理器调度程序。最基本的方式是简单的复用单处理器调度的基本结构,将所有需要调度的工作放在一个单独的队列中,我们称之为单队列多处理器调度(SQMS)。该方法最大的优点是简单,不需要做过多的修改,就可以将原有的策略应用于多 CPU,以选择最合适的工作来运行。
然而,SQMS 有几个明显的缺陷。第一个是缺乏扩展性。为了保证在多个 CPU 上正确运行,调度程序的开发者需要在代码中通过加锁来保证原子性。在 SQMS 访问单个队列时,锁能确保得到正确的结果。
然而,锁可能带来巨大的性能损失,尤其是随着系统中的 CPU 数增加时。随着这种单个锁的争用增加,系统花费了越来越多的时间在锁的开销上,较少的时间用于系统应该完成的工作。
SQMS 的第二个主要问题是缓存亲和度。比如,假设我们有 5 个工作 ABCDE 和 4 个 CPU。调度队列如下:

一段时间后,假设每个工作依次执行一个时间片,然后选择另一个工作,下面是每个 CPU 可能的调度队列:

由于每个 CPU 都简单的从全局共享的队列中选取下一个要执行的工作,因此每个工作都不断的在不同 CPU 之间转移,这与缓存亲和度的目标背道而驰。
为了解决该问题,大多数 SQMS 调度程序都引入了一些亲和机制,尽可能让进程在同一个 CPU 上运行。保持一些工作的亲和度的同时,可能需要牺牲其他的亲和度来实现负载均衡。比如,针对同样的 5 个工作的调度如下:
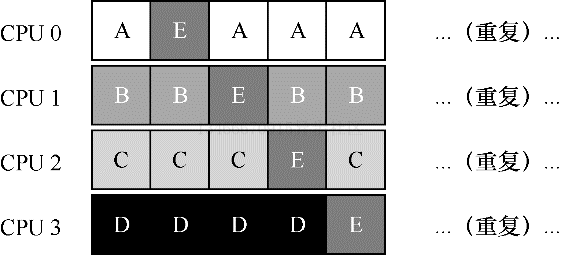
这种情况下,ABCD 都保持在同一个 CPU 上运行,只有工作 E 在不断的来回转移,从而尽可能多的获得缓存亲和度。为了公平起见,之后我们可以选择不同的工作来转移。但实现这种策略可能会很复杂。
我们看到,SQMS 调度方式有优势但也有不足。优势是能够从单 CPU 调度程序很简单的发展而来,根据定义,它只有一个队列。然而,它的扩展性不好(由于同步开销),并且不能很好的保证缓存亲和度。
多队列调度
正是由于但队列调度的这些问题,有些系统使用了多队列方案,比如每个 CPU 一个队列。我们称之为多队列多处理器调度(MQMS)。
在 MQMS 中,基本调度框架包含多个调度队列,每个队列可以使用不同的调度规则,比如轮转或者其他任何可能的算法。当一个工作进入系统后,系统会依靠一些启发性规则将其放入某个队列来调度。这样一来,每个 CPU 调度之间互相独立,就避免了但队列的方式中由于数据共享及同步带来的问题。
例如,假设系统中有两个 CPU。这时一些工作进入系统。由于每个 CPU 都有自己的调度队列,操作系统需要决定每个工作放入哪个队列。可能像下面这样:

根据不同队列的调度侧列,每个 CPU 从两个工作中选择,决定谁将运行。比如利用轮转,调度结果可能如下所示:

MQMS 比 SQMS 有明显的优势,它天生具有可扩展性。队列的数量会随着 CPU 的增加而增加,因此锁和缓存争用的开销不是大问题。此外,MQMS 天生具有良好的缓存亲和度。所有工作都保持在固定的 CPU 上,因而可以很好的利用缓存数据。
但是,如果稍加注意你可能会发现一个新的问题,即负载不均衡。假定和上面的设定一样,但假设一个工作执行完毕,现在的调度队列如下:

如果对系统中每个队列都执行轮转调度策略,会得到如下调度结果:

从上图可以看出,A 获得了 BD 两倍的 CPU 时间,这不是期望的结果。更糟的是,假设 A 和 C 都执行完毕,系统中只有 B 和 D,调度队列看起来如下:

因此 CPU 使用时间线看起来令人难过:

所以可怜的多队列多处理器调度程序应该怎么办呢?最明显的答案是让工作移动,这种技术我们称之为迁移。通过工作的跨 CPU 迁移,可以实现真正的负载均衡。
来看两个例子就更清楚了。同样,一个 CPU 空闲,另一个 CPU 有一些工作:

在这种情况下,期望的迁移很容易理解:操作系统应该讲 B 或 D 迁移到 CPU0。这次工作迁移使得负载均衡,皆大欢喜。
更棘手的情况是较早的一些例子,A 肚子留在 CPU0 上,BD 在 CPU1 上交替执行。

在这种情况下,单次迁移并不能解决问题。应该怎么做呢?答案是不断的迁移一个或多个工作。一种可能的方案是不断切换工作,如下面的时间线所示。可以看到,开始的时候 A 独享 CPU0,BD 在 CPU1。一些时间片后,B 迁移到 CPU0 与 A 竞争,D 则独享 CPU1 一段时间。这样就实现了负载均衡。

当然,还有其他不同的迁移模式。但现在是最棘手的部分:系统如何决定发起这样的迁移?
一个基本的方法是采用一种技术,名为工作窃取。通过这种方法,工作量少的队列不定期的偷看其他队列是不是比自己的工作多。如果目标队列比源队列中的工作显著较多,就从目标队列窃取一个或多个工作,实现负载均衡。
当然,这种方法也有让人抓狂的地方——如果太频繁的检查其他队列就会带来较高的开销,可扩展性不好,而这时多队列调度最初的全部目标。相反,如果检查间隔较长,又可能会带来严重的负载不均。找到合适的阈值仍然是黑魔法,这在系统策略设计中很常见。
Linux 多处理器调度
有趣的是,在构建多处理器调度程序方面,Linux 社区一直没有达成共识。一直以来,存在 3 种不同的调度程序:O(1)调度程序、完全公平调度程序(CFS)、BF 调度程序(BFS)。从 Meehean 的论文中可以找到对这些不同调度程序优缺点的对比总结。
O(1) CFS 采用多队列,而 BFS 采用单队列,这说明两种方法都可以成功。当然它们之间还有很多不同的细节。比如 O(1) 调度程序是基于优先级的,类似之前讲过的 MLFQ,随时间推移改变进程的优先级,然后调度优先级最高的进程,来实现各种调度目标。交互性得到了特别的关注。与之不同,CFS 是确定的比例调度方法,类似之前介绍的步长调度。BFS 作为 3 个算法中唯一采用单队列的算法,也是基于比例调度,但采用了更复杂的方案,称为最早合适虚拟截止时间优先算法(EEVEF)。
小结
本章介绍了多处理器调度程序的不同实现方法。其中单队列的方式比较容易构建,负载均衡较好,但在扩展性和缓存亲和度方面有着天生的缺陷。多队列的方式有很好的扩展性和缓存亲和度,但实现负载均衡却很困难,也更复杂。无论采用哪种方式,都没有简单的答案:构建一个通用的调度程序仍然是一项令人生畏的任务,因为即使很小的代码改动,也有可能导致巨大的行为差异。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.