This the multi-page printable view of this section. Click here to print.
分布式
1 - 基本构成
1.1 - 一致性模型
强一致性
当更新操作完成之后,任何多个后续进程或者线程的访问都会返回最新的更新过的值,直到这个数据被其他数据更新为止。
但是这种实现对性能影响较大,因为这意味着,只要上次的操作没有处理完,就不能让用户读取数据。
弱一致性
系统并不保证进程或者线程的访问都会返回最新更新过的值。系统在数据写入成功之后,不承诺立即可以读到最新写入的值,也不会具体的承诺多久之后可以读到。但会尽可能保证在某个时间级别(比如秒级别)之后,可以让数据达到一致性状态。
最终一致性
最终一致性也是弱一致性的一种,它无法保证数据更新后,所有后续的访问都能看到最新数值,而是需要一个时间,在这个时间之后可以保证这一点,而在这个时间内,数据也许是不一致的,这个系统无法保证强一致性的时间片段被称为“不一致窗口”。不一致窗口的时间长短取决于很多因素,比如备份数据的个数、网络传输延迟速度、系统负载等。
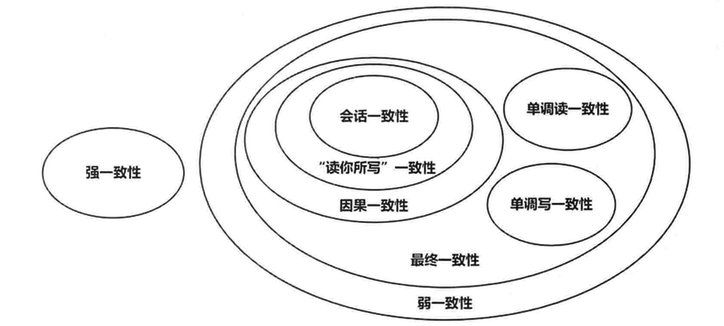
最终一致性在实际应用中又有多种变种:
| 类型 | 说明 |
|---|---|
| 因果一致性 | 如果 A 进程在更新之后向 B 进程通知更新的完成,那么 B 的访问操作将会返回更新的值。而没有因果关系的 C 进程将会遵循最终一致性的规则(C 在不一致窗口内还是看到是旧值)。 |
| 读你所写一致性 | 因果一致性的特定形式。一个进程进行数据更新后,会给自己发送一条通知,该进程后续的操作都会以最新值作为基础,而其他的进程还是只能在不一致窗口之后才能看到最新值。 |
| 会话一致性 | 读你所写一致性的特定形式。进程在访问存储系统同一个会话内,系统保证该进程可以读取到最新之,但如果会话终止,重新连接后,如果此时还在不一致窗口内,还是可能读取到旧值。 |
| 单调读一致性 | 如果一个进程已经读取到一个特定值,那么该进程不会读取到该值以前的任何值。 |
| 单调写一致性 | 系统保证对同一个进程的写操作串行化。 |
它们之间的关系如下图:
1.2 - ACID 隔离级别
强一致性ACID:
单机环境下我们对传统关系型数据库有苛刻的要求,由于存在网络的延迟和消息丢失,ACID 便是保证事务的原则,这四大原则甚至我们都不需要解释出来就耳熟能详了:
- Atomicity:原子性,一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。
- Consistency:一致性,在事务开始之前和事务结束以后,数据库的完整性没有被破坏。
- Isolation:隔离性,数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。
- Durabilit:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
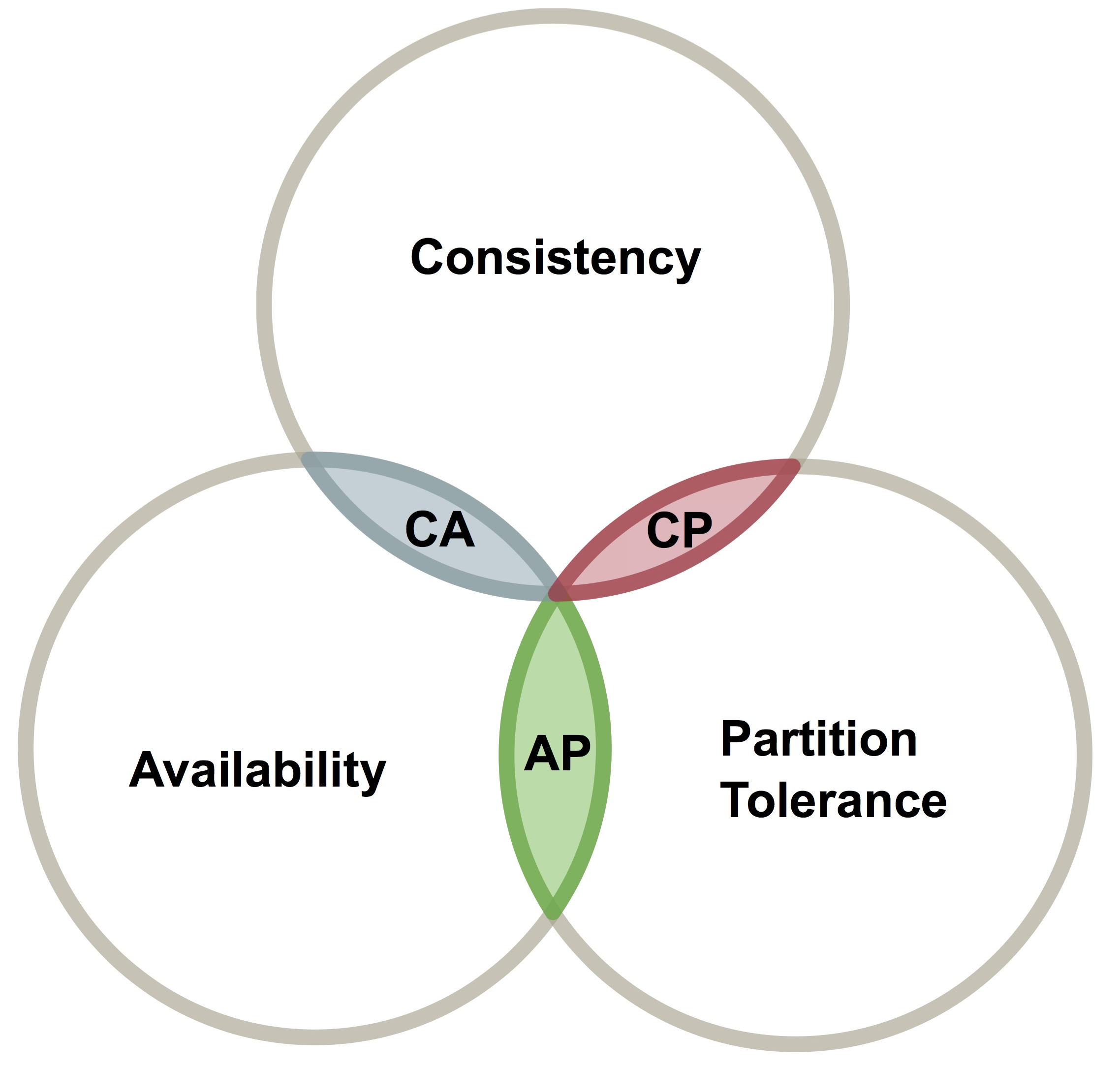
1.3 - CAP
定义
C,Consistency,“all nodes see the same data at the same time”,即更新操作成功并返回客户端之后,所有节点在同一时间的数据完全一致。即所有节点拥有数据的最新版本。
A,Availability,可用性:“Reads and writes always succed”,即服务一直可用,而且是正常响应时间。
对于一个可用性的分布式系统,每个非故障节点必须对每一个请求做出响应。即,该系统使用的任何算法必须最终终止。当同事要求分区容忍性时,这是一个很强的定义:即使是严重的网络错误,每个请求也必须能够终止。
P,Partition Tolerance,分区容忍性:“the system continues to operate despite arbitrary message loss or failure of part of the system”,即系统容忍网络出现分区、分区之间网络不可达的情况。分区容忍性和可扩展性紧密相关。整体来说指的是,在遇到特定节点或网络分区故障时,仍然能够对外提供满足一致性和可用性的服务。
P,分区容忍性
什么是分区容忍性:
- 一个分布式系统中,节点组成的网络本来应该是连通的。然而可能因为一些故障,使得有的节点之间不再连通,整个网络就分成了几块区域。数据就散步在这些不连通的区域中,就成为分区现象。
- 当一个数据项只在一个节点中保存,那么分区出现后,和这个节点不连通的部分就无法访问到该数据项。这时分区是无法容忍的。
- 提高分区容忍性的办法就是将一个数据项复制到多个节点上,那么在出现分区之后,这一数据项就可能分布在各个区域中,容忍性就提高了。
- 然而,要把数据复制到多个节点,就会带来一致性的问题,就是多个节点之上的数据可能是不一致的。
- 要保证一致,每次写操作就要等待所有节点写成功,则这种等待又会带来可用性问题。
- 总的来说就是,数据存在的节点越多,分区容忍性就越高,但是要复制的数据就越多,一致性就越难保证。为了保证一致性,更新所有节点数据的操作就会耗时更长,导致可用性降低。
不能同时满足的证明
假设系统中有 5 个节点,N1~N5,N1/N2/N3 在物理机房 A,N4/N5 在物理机房 B。现在发生了网络分区,机房 A 和机房 B 之间的网络不互通。
保证一致性:此时客户端在 A 机房写入数据,不能同步到 B 机房。写入失败。此时失去了可用性。
保证可用性:数据在 A 机房的 N1~N3 节点都写入成功并返回完成。数据在 B 机房的 N4~N5 节点也写入数据成功并返回完成。同一份数据在 A 和 B 机房出现了不一致的情况。
比如想象 ZK,当一个节点宕机,系统将其踢出集群,然后其他一般以上的节点写入成功即可。是不是 ZK 就满足了 CAP 呢。其实这里有一个误区,系统将其踢出集群,有一个隐含条件,系统引入了一个调度者——一个踢出失败节点的调度者。如果调度者和 ZK 节点出现网络分区时,整个系统是不可用的。
常见场景
在网络分区无法避免的情况下,一致性和可用性必须二选一。而在没有发生网络故障时,即分布式系统正常运行时,一致性和可用性是可以被同时满足的。但是,对于大多数互联网应用来说,因为规模比较大,部署节点分散,网络故障是常态,可用性是必须要保证的,所有只有舍弃一致性来保证服务的 AP。但是对于一些金融相关的行业来说,有很多场景需要保证一致性,这种情况下通常会考虑 CA 和 CP 模型,CA 模型在网络故障时完全不可用,CP 模型具备部分可用性。
CA without P:关注一致性和可用性,需要非常严格的全体一致性协议,比如“2PC”。 CA 系统不能容忍网络错误或节点错误,一旦出现这样的问题,整个系统就会拒绝写请求,因为它并不知道对面的那个节点是否挂掉了,还是只是网络问题。唯一安全的方式就是把自己设置为只读。
CP without A:关注一致性和分区容忍性。关注的是系统中大多数节点的一致性协议,比如 Paxos 算法。这样的系统只需要保证大多数节点数据一致,而少数节点会在没有同步到最新数据版本时变为不可用状态,从而提供部分可用性。
AP without C:关注可用性和分区容忍性。因此,这样的系统不能达成一致性,需要给出数据冲突,给出数据冲突就需要维护数据版本。Dynamo 就是这样的系统。
对于分布式系统分区容忍性是天然具备的要求,否则一旦出现网络分区,系统就拒绝所有写入只允许可读,这对大部分的场景是不可接收的,因此,在设计分布式系统时,更多的情况下是选举 CP 还是 AP,要么选择强一致性弱可用性,要么选择高可用性容忍弱一致性。
1.4 - BASE
弱一致性BASE:
多数情况下,其实我们也并非一定要求强一致性,部分业务可以容忍一定程度的延迟一致,所以为了兼顾效率,发展出来了最终一致性理论BASE,BASE是指基本可用(Basically Available)、软状态( Soft State)、最终一致性( Eventual Consistency)
- 基本可用(Basically Available):基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。
- 软状态(Soft State):软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据至少会有三个副本,允许不同节点间副本同步的延时就是软状态的体现。
- 最终一致性(Eventual Consistency):最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
1.5 - CALM
分布式架构的核心就在一致性的实现和妥协,那么如何设计一套算法来保证不同节点之间的通信和数据达到无限趋向一致性,就非常重要了。保证不同节点在充满不确定性网络环境下能达成相同副本的一致性是非常困难的,业界对该课题也做了大量的研究。
首先我们要了解一致性的大前提原则(CALM):
CALM原则的全称是 Consistency and Logical Monotonicity ,主要描述的是分布式系统中单调逻辑与一致性的关系,它的内容如下,参考consistency as logical monotonicity:
- 在分布式系统中,单调的逻辑都能保证 “最终一致性”,这个过程中不需要依赖中心节点的调度
- 任意分布式系统,如果所有的非单调逻辑都有中心节点调度,那么这个分布式系统就可以实现最终“一致性”
单调逻辑和非单调逻辑
如果一个结论是由单调逻辑根据一系列信息推理出来的,那么这个结论就会一直有效,即使后来又获得了新的信息。简单来说,就是后来的推论永远不会影响到之前推论的有效性。
反之,如果新的信息会导致之前的推论无效,那么这样的逻辑就是非单调逻辑。
一个逻辑非单调的例子
如果T是鸟,那么我们认为T可以飞,这样的逻辑可以表述为:
Bird(T) -> Fly(T)
现在有一只鸟 Tweet,那么 Bird(Tweet) 是成立的,那么是否就有 Fly(Tweet) 呢?根据现在已知的条件,我们可以很容易做出结论:
Bird(Tweet) -> Fly(Tweet)
这样的逻辑看起似乎没什么问题,但是随着我们知识的增长,我们会发现一些特例:
- 如果Tweet是企鹅或者鸡,那么Tweet不能飞
- 如果Tweet的翅膀严重受伤了,那么Tweet不能飞
如果Tweet是上面条件中之一,那么 Fly(Tweet) 的结论就会失效。这样的逻辑就是非单调逻辑。
非单调逻辑的一个特点就是没有考虑全部的知识。
一个逻辑单调的例子
例如数学上常见的逆否命题推论:
如果 P -> Q
那么 -Q -> -P
这个推论无论P和Q的内容是什么都是成立的。单调逻辑的特点就是已经考虑了全部的情况。
非单调逻辑
现实世界中总是有各种特例情况,我们通常无法再下结论之前考虑到所有的情况。所以大部分逻辑通常都是非单调逻辑(基于假设),非单调逻辑一般有5种类型的假设,例如:已知船通常可以用来渡河,现在有一艘船A,船A可以渡河吗?
- 主观认知逻辑(subjective autoepistemic):船A可以渡河,因为我没有得到任何船A无法渡河的信息。
- 原型逻辑(prototical):船A可以渡河,因为已知:船通常可以渡河
- 最低风险逻辑(No-Risk): 如果假设船A不能渡河,并且如果我的假设错误,那么我就浪费这一次渡河的机会(这是无法接受的),所以假设船A可以渡河。(最低风险是依据自己的利益来假设的,也可用类似的逻辑最终推导出“船A不能渡河”,具体的结果依据自身的利益来决定)
- 最优猜测逻辑(Best-Guest):首先我需要渡河,但是除了船A以外我不知道还有没有其他船,所以假设船A可以渡河
- 概率逻辑(Probabilistic): 超过80%的船可以渡河,所以假设船A也可以渡河
Reference
1.6 - Gossip
Gossip是一种去中心化、容错并保证最终一致性的协议。
背景
Gossip是为了解决分布式遇到的问题而设计的。由于服务和数据分布在不同的机器上,节点之间的每次交互都伴随着网络延迟、网络故障等的性能问题。可见,分布式系统会比单机系统遇到更多的难题。
如CAP理论 所描述的,CAP三个因素在分布式的条件下只能满足两个。对于分布式系统来说,分区容忍性是基本要求。因为分布式系统的设计初衷就是利用集群多集的能力去处理单机无法解决的问题。分区容忍性(可扩展性)通过通过scale up和scale out实现的,也就是通过升级硬件或者增加机器来提升分布式系统的性能。这么说,可扩展性和可用性是相关联的。可扩展性好的系统,其可用性一般会比较高。所以分布式系统的所有问题基本都是在一致性和可用性之间进行协调和平衡。在工程实践中的经验如下:
一般来说,交易系统类的业务对一致性的要求比较高,一般会采用ACID模型来保证数据的强一致性,所以其可用性和扩展性就比较差。而其他大多数业务系统一般不需要保证强一致性,只要最终一致就可以了,它们一般采用BASE模型,用最终一致性的思想来设计分布式系统,从而使得系统可以达到很高的可用性和扩展性。
一致性可以通过信息在分布式环境下分发来保证,而分发的方式和速度则决定一致性的程度。从客户端的角度来讲:一致性包含三种状态:强一致性、弱一致性、最终一致性(弱一致性的特例)。在下图的一致性光谱中我们可以看出,弱一致性性是异步冗余,读写操作的响应更加快;而强一致性一般都是同步冗余的,所以伴随着性能的下降。

而最终一致性还有其他变种:因果一致性(有逻辑关系的操作能读到更新值)、读你所写一致性(Read-your-writes Consistency,A用户操作只保证自己的后续操作能读到更新值)、会话一致性(保证整个会话期间的读写一致性)、单调一致性(单用户的操作顺序一致)。
SWIM:最终一致性
前面提到Gossip解决的问题就是在分布式环境下信息高效分发的问题,这个问题的解决决定着系统的一致性程度。而Gossip协议是基于一种叫做SWIM的协议( S calable W eakly-consistent I nfection-style Process Group M embership Protocol)。SWIM是一种无中心的分布式协议,各个节点之间通过 P2P 实现信息交流同步各节点状态的方法。看名字也知道这是一种弱一致性的实现。
SWIM协议给每个进程组成员在本地维护一个成员表,记录该组存活的进程。该协议通过失效检测器(Failure Detector)和传播组件(Dissemination Component)来完成工作。
SWIM的失效检测器会检测失效的节点并将失效节点的更新信息发送给传播组件。SWIM的传播组件通过多播(multicast)的形式将失效信息传播给组内的其他成员。
协议的可扩展性体现在:新成员的加入和退出也以同样的方式进行多播通信。而在基本的时间周期内进行失效检测能够保证在限定的时间范围内完成完备性检查,即每个失效的进程都能最终被检测到(最终一致性)。通过多播方式传输协议消的问题在于效率不好也不可靠,通过在ping和ack消息中捎带成员更新信息能够降低丢包率和减少传输时延。这种传播方式被称为可传导的方式(Infection-style)。
Gossip:办公室八卦
我们的办公室八卦一般都是从一次交谈开始,只要一个人八卦一下,在有限的时间内办公室的的人都会知道该八卦的信息,这种方式也与病毒传播类似。因此 Gossip也有“病毒感染算法”、“谣言传播算法”之称。
Gossip来源于流行病学的研究(括号里就是Gossip协议):
- 在总数为n+1的人群中,被感染(infected)的人数初始化为1,并向周围传播。(一个节点状态发生变化,并向临近节点发送更新信息)
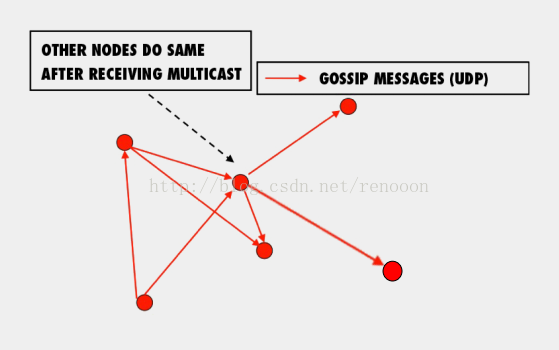
- 在每个周期内总有未被感染(uninfected)的人转变成被感染的人,方式为每个被感染的人随机感染b个人。(对于节点状态变化的信息随机发送给b个节点,图例中的b值为2)
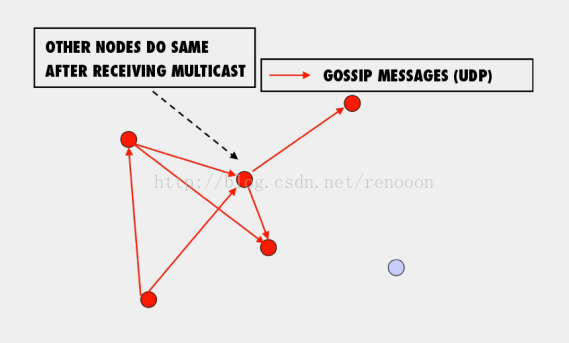
- 经过足够的时间,所有的人都会被感染。(随着时间推移,信息能够传达到所有的节点,下一节会进行简单的证明)

可以看到,协议的核心内容就是节点通过将信息随机发送到b个节点来完成本次信息的传播,其涉及到周期性、配对、交互模式。Gossip的交互模式分为两种:Anti-entropy和Rumor mongering。
- Anti-entropy:每个节点周期性地随机选择其他节点,然后通过相互交换自己的所有数据来消除两者之间的差异。
- Rumor mongering:当一个节点有来新信息后,该节点变成活跃状态,并周期性地联系其他节点向其发送新信息。
每个节点维护一个自己的信息表 <key, (value, version)> ,即属性的值以及版本号;和一个记录其他节点的信息表 <node, <key, (value, version)» 。每个节点和系统中的某个节点相互配对成为peer。而节点的信息交换方式主要有3种。
- Push:拥有状态新信息的节点随机选择联系节点并想起发送自己得到信息。
- Pull:发起信息交换的节点随机选择联系节点并从对方获取信息。
- Push-Pull混合模式:发起信息交换的节点向选择的节点发送信息。
上述Gossip为什么能够完成状态的同步呢?我们对其做一个简单的分析。
Analysis:收敛性证明
我们以上一节的Push模式Gossip协议进行分析。
在n+1个节点的系统中,每个节点每次随机向其他b个节点进行信息通信,即传播速率:β=bn。
在连续时间过程中,x的变化速率dxdt=−βxy
而总时间为 t=clog(n)
那么当c和b都是独立于n的很小的数值时。Gossip协议能够保证:
- 低延迟:在clog(n)内完成一次信息的更新。虽然不是常数级别的,但是其对数级别增长率在程序世界里是实践上可取的。
- 可靠性:n+1−1ncb−2
- 轻量级:每个节点不会发送超过cblog(n)条信息。
这样我们不仅证明了Gossip的可靠性,并可以保证其在分布式系统应用的高可用性。注意的是,即使有的节点因宕机而重启或者有新节点加入,但经过一段时间后,这些节点的状态也会与其他节点达成一致。也就是说,Gossip天然具有分布式容错的优点。
Application:应用
除了改善SWIM协议中的多播方式,Gossip还在很多地方有应用:
- 数据库复制:基于Gossip实现分布数据管理的一般思路是:在一个节点实现数据更新,通过Gossip算法将更新传播导其他节点。
- 聚合计算:在无中心的系统中,没有中心节点存储全局信息。通过Gossip应用导分布环境下的聚合计算中来保证系统的发送消息的容错。
总之,Gossip简单、高效,同时具有很好的可扩展性和鲁棒性,非常适合大规模、动态、资源受限的网络环境。
但Gossip的缺点也很明显,冗余通信会对网路带宽、CPU资源造成很大的负载,而这些负载又受限于通信频率,该频率又影响着算法收敛的速度。
算法样例-脑裂问题
Cassandra内部有一个Gossiper,每隔一秒运行一次(在Gossiper.java的start方法中),按照以下规则向其他节点发送同步消息:
- 随机取一个当前活着的节点,并向它发送同步请求
- 向随机一台不可达的机器发送同步请求
- 如果第一步中所选择的节点不是seed,或者当前活着的节点数少于seed数,则向随意一台seed发送同步请求
如果没有这个判断,考虑这样一种场景,有4台机器,{A, B, C, D},并且配置了它们都是seed,如果它们同时启动,可能会出现这样的情形:
- A节点起来,发现没有活着的节点,走到第三步,和任意一个种子同步,假设选择了B
- B节点和A完成同步,则认为A活着,它将和A同步,由于A是种子,B将不再和其他种子同步
- C节点起来,发现没有活着的节点,同样走到第三步,和任意一个种子同步,假设这次选择了D
- C节点和D完成同步,认为D活着,则它将和D同步,由于D也是种子,所以C也不再和其他种子同步
这时就形成了两个孤岛,A和B互相同步,C和D之间互相同步,但是{A,B}和{C,D}之间将不再互相同步,它们也就不知道对方的存在了。
加入第二个判断后,A和B同步完,发现只有一个节点活着,但是seed有4个,这时会再和任意一个seed通信,从而打破这个孤岛。
Reference
1.7 - CRDT
我们了解到分布式一些规律原则之后,就要着手考虑如何来实现解决方案,一致性算法的前提是数据结构,或者说一切算法的根基都是数据结构,设计良好的数据结构加上精妙的算法可以高效的解决现实的问题。经过前人不断的探索,我们得知分布式系统被广泛采用的数据结构CRDT。
参考《谈谈CRDT》,A comprehensive study of Convergent and Commutative Replicated Data Types
- 基于状态(state-based):即将各个节点之间的CRDT数据直接进行合并,所有节点都能最终合并到同一个状态,数据合并的顺序不会影响到最终的结果。
- 基于操作(operation-based):将每一次对数据的操作通知给其他节点。只要节点知道了对数据的所有操作(收到操作的顺序可以是任意的),就能合并到同一个状态。
什么是 CRDT
CRDT 是 Conflict-Free Replicated Data Type 的缩写,即无冲突的可复制数据类型。
它用于解决分布式系统的最终一致性问题,即,在分布式系统中,应用采用什么样的数据结构来保证最终一致性?而 CRDT 是目前理论界给出的答案,相关论文为 A comprehensive study of Convergent and Commutative Replicated Data Types。
一致性的难题
构建一个分布式系统并不难,而难的是构建一个与单机系统的正确性一样的分布式系统,即 CAP 定理。
CAP 定理告诉我们,在构建分布式系统时,Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性),三者只能同时选取两项。
其中,分区容错性是任何生产环境下的分布式系统所必须的,因此,只有在 C、A 之间做出取舍:
- 选择一致性:构建一个强一致性系统,比如符合 ACID 特性的数据库系统。
- 选择可用性:构建一个最终一致性系统,比如 NoSQL 系统。
选择一致性时数据一旦落地就是一致的,但是可用性不能实时保证,比如系统有时忙于一致性处理,无法对外提供服务。
选择可用性时则时刻都能保证可用,但是各个节点在同一时刻所持有的数据可能并不一致,但经过一段时间后,数据在各节点间会达到一致状态。
因此,现在的分布式系统总是会偏向于选择 AP,以提供一个无单点故障、总是可用且更高吞吐的系统。
使用那些信息能够达到最终一致
在实际应用中,我们需要考虑多种数据类型的应用和场景,设计一个能够保证最终一致性的数据结构会变得很复杂。
而 CRDT 就是这样一些适用于不同场景的、可以保持最终一致性的数据结构的统称。围绕 CRDT 理论,则涵盖了:
- 它们应该具有怎样的基本表现形式
- 满足一些什么样的条件才可以保持最终一致性,毕竟不能每次都穷举所有情况
- 不断寻找一些通用的、有大量应用场景的 CRDT,并努力提高其空间、时间效率
前面提到的 CRDT 相关论文总结了目前为止人们在 CRDT 这件事情上的认识程度,简要总结如下:
- 定义了 CRDT
- 列举了 CRDT 的两种基本形式:
- 基于状态的 CRDT:存储最终值
- 基于操作的 CRDT:存储操作记录
- 界定了 CRDT 能够满足最终一致性的边界条件。比如,设计一个 CRDT,只需要验证它是否满足这些边界条件,即可知道它是否能够保持最终一致性
- 界定了两类 CRDT 在系统中应用时,需要的信息交换的边界条件。即回答怎样才能叫做”收集到足够多的信息“
- 枚举了当前已知的 CRDT,包括计数器(counter)、寄存器(register)、集合(set)、图(graph)等几个种类
- 在现实中应用如何应用 CRDT,尤其是如何回收存储空间的问题
如何在实际系统中应用
最终一致性分布式框架 RiakCore 的应用方式:
- 抛弃自己缩写的数据结构,实现 CRDT,或者使用已有的 CRDT Library
- 参考 CRDT 的一致性可判断条件(即”收集到足够多的信息“),在需要判断最终一致性时收集它们
- 抛弃自己所写的一致性判断算法,实现 CRDT 的一致性合并算法,或者使用已有的 CRDT Library
Riak 是一个由 Erlang 编写的分布式、去中心化的数据存储系统,Riak Core 定义了其数据分发和扩展的形式,可以被认为是一个用于构建分布式、可扩展、高容错应用的工具集。
谁应该使用?
所有力求追踪一致性的系统,都应该使用 CRDT。如果一个最终一致性的分布式系统还有没有使用 CRDT,要么是其所使用的数据结构已经实现了 CRDT 的一种或几种,虽然可能很粗糙,要么是这个系统在最终一致性上的保证存在问题。
总结
CRDT 并未给用户层面带来影响,但是从管理员、开发者的角度来看,CRDT 给了我们基于逻辑来判断分布式系统能否保证最终一致性的能力。
Reference
1.8 - 2PC
2PC 是一种非常有影响力的协议,用于确保访问多个分区或分片中的数据的事务的原子性和持久性。它无处不在 – 无论是在旧的“古老的”分布式系统、数据库系统和文件系统,如Oracle,IBM DB2,PostgreSQL 和 Microsoft TxF(支持事务的 NTFS)还是在较年轻的“千禧”系统如 MariaDB、TokuDB、VoltDB、Cloud Spanner、Apache Flink、Apache Kafka 和 Azure SQL 数据库。如果您的系统支持跨分片/分区/数据库的 ACID 事务,那么它很可能会在后台运行 2PC(或其某些变体)。有时它甚至出现在“前台” – 旧版本的 MongoDB 要求用户在应用程序代码中为多文档事务实现 2PC。
在这篇文章中,我们将首先介绍一下 2PC:它是如何工作的以及它解决了什么问题。然后,我们将展示 2PC 的一些主要问题以及现代系统如何试图解决它。不幸的是,这些尝试的解决方案也带来了一些其他问题。在文章最后,我将说明下一代分布式系统应该避免使用 2PC,以及如何实现这一点。
概述
2PC 有很多变种,但基本协议的工作原理如下。
基本假设:一个事务相关的工作已经划分给存储该事务数据的分片节点。我们将在每个分片中执行的工作,称为节点“参与者”的工作。当事务准备好“提交”时,每个参与者都能够独立于彼此完成事务相应的职责。2PC 协议由单个独立的、可协调的节点发起(可能是参与者之一)。
2PC 协议的基本流程如下图所示。(协议从图的顶部开始,然后向下进行。)
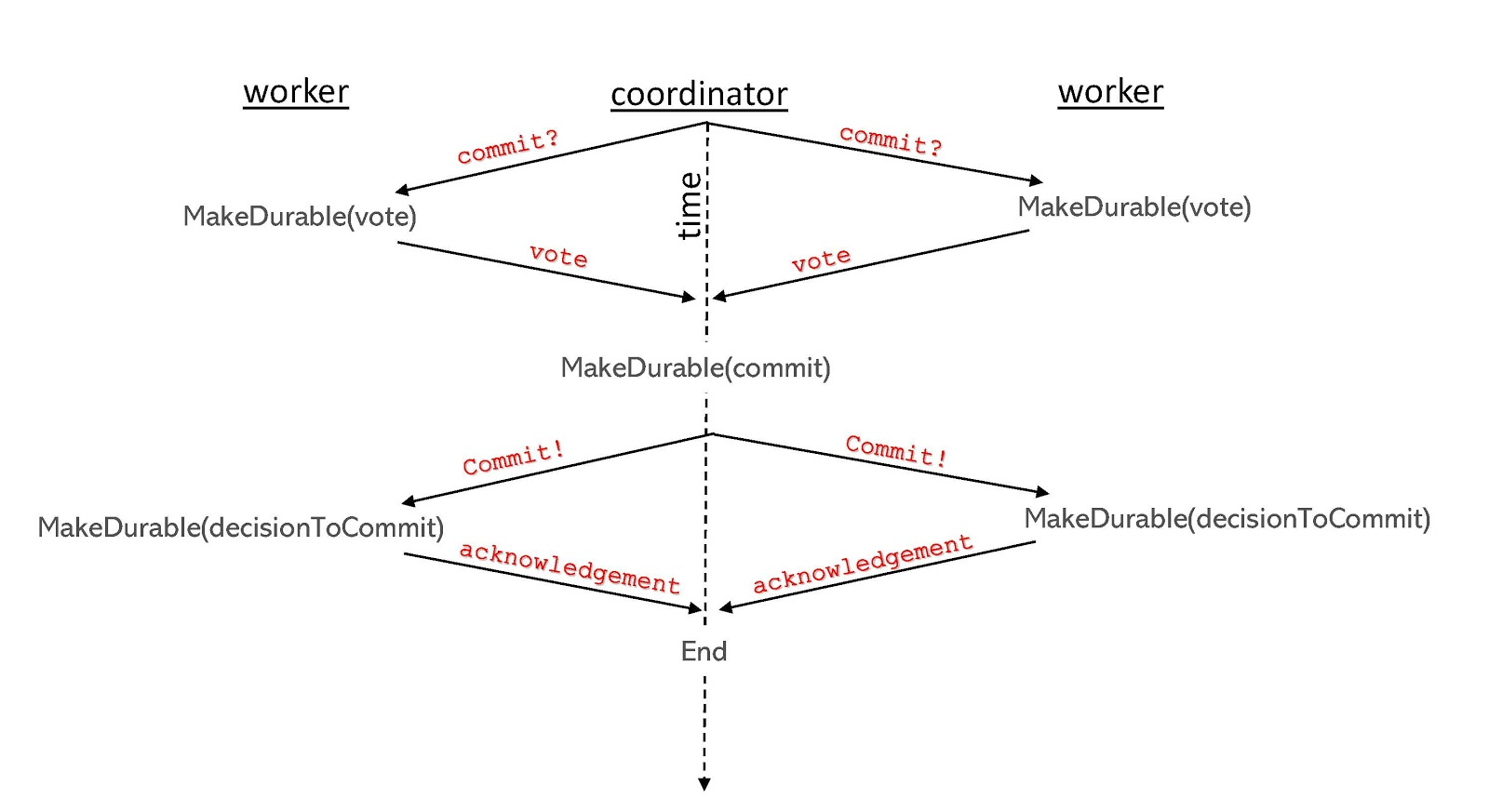
阶段1:协调者询问每个参与者,是否已成功完成其对该事务的职责,并达到可以提交的状态。每个参与者都回答“同意”或“反对”。
阶段2:协调者统计所有回应,如果每个参与者都回答“同意”,那么就提交事务,否则就中止事务。协调者向每个具有提交最终决策权力的参与者发送消息,并接收参与者的确认消息。
此机制确保事务的原子性属性:整个事务将反映在系统的最终状态中,或者不反映在系统的最终状态中。即使只有一个参与者没有提交,那么整个事务将会被中止。换句话说:每个参与者对事务都有“否决权”。
它还确保了事务的持久性。每个参与者确保在阶段1响应“同意”之前,已将所有事务持久地写入存储。这使协调者对事务做出最终决定时,无需担心参与者在投票“同意”之后写入失败。在这篇文章中,当使用术语“持久写入”时,我们有目的地模糊化了两个区别 – 本地临时性存储,或是分布式的写入到多个分片以“持久化”。
除了持久地写入事务相关的数据之外,协议本身还需要额外的写入,在处理消息之前必须使其持久化。例如,一名参与者在第一阶段投票“同意”之前拥有否决权,但在此之后,它不能改变其投票结果。但如果它在投票“同意”后立即崩溃怎么办? 当它恢复时,它可能不知道它投了“同意”,仍然认为它拥有否决权,并继续流程并中止事务。为了防止这种情况,它必须在“同意”投票发给协调者之前,持久化相关投票结果。(除了这个例子,在标准的 2PC 流程中,还有另外两种消息需要发送前持久化操作。)
问题
2PC 存在两个主要问题。第一个是众所周知的,并在所有讲述 2PC 的教科书中都进行了讨论。第二个不太知名,但仍然是一个大的问题。
阻塞问题
众所周知的问题被称为“阻塞(block)问题”。当每个参与者都投了“同意”,但协调者在将最终决定的消息未能发送给至少一参与者之前就挂了,就会出现这种情况。问题的原因是,通过投票“同意”,每个参与者已经取消了否决事务的权力。但是,协调者仍有绝对权力来决定事务的最终状态。如果协调者在向至少一名参与者发送最终决定的消息之前挂了,那么参与者就无法做出最终决定 – 他们不能中止,因为协调者可能会在挂掉之前决定提交,并且他们无法提交,因为协调者可能决定在失败之前中止。因此,他们必须等待—等到协调者恢复—以便得到最终决定。与此同时,他们无法处理与停滞冲突的事务,因为该事务的写入的最终结果尚未确定。
阻塞问题有两种解决方案。方案一是修改核心协议以消除阻塞问题。不幸的是,这些修改降低了性能 – 通常通过添加额外的一轮通信来实现 – 因此很少在实践中使用。
方案二是保持协议不变,但降低协调者失败从而引发阻塞的可能性 – 例如,通过在副本共识协议上运行 2PC 并确保协议的重要状态被复制。不幸的是,这些解决方案再一次降低了性能,因为协议要求这些副本共识轮次按顺序进行,因此它们可能会给协议增加显著的延迟。
拥堵问题
鲜为人知的问题是我称之为“拥堵(cloggage)问题”。在处理事务之后进行 2PC,必然增加事务的等待时间,它等于运行协议所花费的时间。延迟的增加对于许多系统来说已经是一个问题,但更大的问题是,工作节点必须到第二阶段中期才知道事务的最终结果。在他们得到最终结果之前,他们必须为可能中止事务的可能性做好准备,因此在事务得到确认之前,他们通常会暂停其他有冲突的事务进行。这些阻塞的事务同样会进一步阻止其他事务运行,依此类推,直到 2PC 完成,所有被阻止的事务才可以恢复。这些拥堵问题进一步增加了事务平均延迟,并且降低了整体的事务吞吐量。
结论
总结我们上面讨论的问题:2PC 在四个方面污染了系统架构:延迟 (协议的时间加上冲突事务的停顿时间),吞吐量(因为它碰到冲突的事务会停顿),可扩展性 (系统越大,事务更需要多分区的支持,并且必须付出 2PC 的吞吐量和延迟成本以及可用性(前面提到的阻塞问题)。
没有人喜欢 2PC,但几十年来,人们都认为它是一种必要的妥协。
解决方案
三十多年来,业界一直在分布式系统中使用两阶段提交。我们已经意识到引入 2PC 会带来性能、可伸缩性和可用性问题,但在没有更好的替代方案之前,仍需要选择使用它。
真相就是,如果有更好的方案,2PC 就没必要存在了。为了实现这一目标,无论是在学术界(如SIGMOD 2016论文)和工业界都在进行尝试。通常的做法是避免分布式事务,例如通过在提交事务之前将数据重新分片,使得事务不再是分布式事务。不幸的是,这种重新分片的做法降低了系统的性能。
我倡导对分布式系统架构进行更深层次的优化。我坚持认为系统可以使用更简单和高效的提交协议,在保证 ACID 的同时,能够处理分布式事务。
一切问题的根源来自一个存在数十年的假设:事务可能随时以任何理由中止。即使我在相同的初始系统状态下运行相同的事务,在下午 2:00 它可能可以成功提交,但在 3:00 时却会提交失败。
为什么需要该假设?大多数架构师认为有以下几个原因。首先,节点可能在任何时候失败,包括在事务处理过程中。系统故障恢复过程中,由于无法获取故障前的内存状态,因此也无法恢复事务失败之前的现场。因此系统需要中止故障出现时所有相关事务。由于任何时候都可能发生故障,这意味着事务可能随时中止。
其次,大多数并发控制协议都需要能够随时中止事务。乐观协议在处理事务后执行“验证”,如果验证失败,则中止事务。悲观协议通常使用锁来防止并发异常,这种锁的使用可能会导致死锁,然后又需要通过中止(至少)事务的方法来解决死锁问题。由于可能随时出现死锁,因此事务需要保留随时中止的能力。
如果来重新审视两阶段提交协议,您将看到随时中止事务的可能性,是 2PC 协议中复杂和延迟的主要原因。参与者不能轻易地告诉其他方是否同意提交,因为他可能在此之后(在事务提交前)出现故障,然后在故障恢复期间中止此事务。因此,他们必须等到事务结束(当所有重要状态都已经持久化)并且严格按照两个阶段进行处理:在第一阶段,每个参与者公开放弃其控制以中止事务,然后才能进入第二阶段,作出最终决定并进行广播。
在我看来,我们需要从参与者中移除否决权,并且以系统无法在执行期间随时中止事务的假设来进行架构设计。只接受以业务逻辑需要来否决事务的情况。如果在给定数据库当前状态下,理论上可以提交事务情况下,无论发生何种类型的故障,该事务都必须可以提交。此外也不接受由于其他并发运行导致的竞争条件而不能最终提交或中止事务。
消除随意中止事务的灵活性听起来很难。我们将很快讨论如何实现这一目标。但首先让我们观察在不能随意中止事务的情况下,提交协议会如何变化。
当事务不能随意中止时,提交协议是什么样的
我们来看两个例子。
在第一个例子中,假设存储变量 X 的节点需要执行一个任务:将 X 的值更改为 42。假设在 X 上没有定义完整性约束或触发器(这可能会阻止系统将 X 设为 42)。在这种情况下,该参与方永远没有中止事务的权力。无论发生什么,该参与方必须将 X 更改为42,如果修改过程中出现系统故障,则必须在故障恢复后将 X 设成 42。由于参与方没有随意中止事务的能力,因此在提交协议期间,不需要检测参与方是否可以提交。
在第二个例子中,假设存储变量 Y 和 Z 值的节点接收到两个事务任务:从前一个 Y 值中减去 1 并将 Z 设置为 Y 的新值。此外,假设 Y 上存在完整性约束,表明 Y 永远不会低于 0(例如它代表零售应用程序中的库存)。因此,此参与方必须运行以下代码:
IF (Y > 0)
Subtract 1 from Y
ELSE
ABORT the transaction
Z = Y
因为应用程序的逻辑需要这样做,所以必须赋予参与者中止事务的权力。但是这种权力是受限的。只有当 Y 的初始值为 0 时,才能中止该事务,否则必须提交。因此,参与方不必等到完成事务之后才知道它是否需要提交。相反:一旦它完成了事务中第一行代码的执行,它就已经知道了最终需要提交还是中止。这意味着相比于 2PC 而言,提交协议将能够更早地启动。
现在让我们将这两个例子组合成一个例子,其中一个事务由两个参与者执行 – 其中一个参与者正在完成第一个例子中描述的工作,另一个参与者正在完成第二个例子中描述的工作。由于我们保证原子性,第一个参与者不能简单地将 X 设置为 42,相反,它自己的工作依赖于 Y 的值。实际上,第一个参与者的事务代码变为:
temp = Do_Remote_Read(Y)
if (temp > 0)
X = 42
请注意,如果第一个参与者的代码如上的话,那么另一个参与者的代码可以简化为:
IF (Y > 0)
Subtract 1 from Y
Z = Y
通过以这种方式编写事务代码,两个参与方都删除了显式中止逻辑。相反,两个参与方都有 if 语句来检查是否会导致原始事务中止的约束。如果原始事务中止,两个参与方最终都无所作为。否则,两个参与方都会根据事务逻辑更改其本地状态。
此时需要注意的一点是,在上面的代码中完全消除了对提交协议的需求。除了应用程序代码在给定数据状态下定义的条件逻辑以外的任何原因,系统都不允许中止事务。并且所有参与者都在这个相同的条件上调整他们的动作,这样他们就可以独立地决定,在由于当前系统状态而无法完成事务的情况下“什么也不做”。因此,已经消除了事务中止的所有可能性,并且在事务处理结束时不需要任何类型的分布式协议来做出关于事务组合的最终决定。2PC 的所有问题都已消除。因为没有协调者,所以也没有阻塞(block)问题。因为所有必要的检查都与事务处理时候完成,而非在事务完成之后检查,所以没有拥堵(cloggage)问题。
此外,只要不允许系统因应用程序逻辑之外的任何原因而中止事务,总是可以像上面那样重写任何事务以替换代码中的中止逻辑,即 if 语句有条件地检查中止条件。此外,可以在重写应用程序代码的情况下实现此目的。(有关如何执行此操作的详细信息超出了本文的范围,但可以高屋建瓴地总结为:当一个节点执行了导致中止的条件逻辑时,它可以设置特殊的标记,其他节点可以在远程读取这些标记。)
实质上:在事务处理系统中有两种类型中止:(1)由数据状态引起的中止和(2)由系统本身引起的中止(例如故障或死锁)。如上所述,类别(1)总是可以根据数据的条件逻辑来编写。因此,如果您可以消除类别(2)中止,则可以消除提交协议。
所以现在,我们所要做的就是解释如何消除类别(2)中止。
消除系统本身中止
我花了将近十年的时间来设计没有系统引发中止的系统。此类系统的示例是 Calvin,CalvinFS,Orthrus,PVW 以及惰性处理事务系统。这一特性的推动力来自于— Calvin —因为它是一个确定性数据库系统。确定性数据库保证在给定一组定义的输入请求的情况下,数据库中只有一个可能的最终数据状态。因此,如果将相同的输入发送到系统的两份不同的副本,两份副本将独立地处理该输入,并将最终达到一致的结果。
系统本身中止,例如系统故障或并发控制竞态条件,从根本上说是不确定性事件。一个副本很可能碰见系统调用失败或进入竞态条件,而另一个副本则不会。如果允许这些非确定性事件导致事务中止,则一个副本会中止事务而另一个副本将提交事务 – 这是对确定性的违背。因此,我们必须以系统故障和竞态条件不能导致事务中止的方式设计 Calvin。对于并发控制,Calvin 使用了避免死锁技术的悲观锁定,该技术确保系统永远不会陷入由于死锁导致的事务中止的状况。面对系统故障,Calvin 无法从中断的位置重启事务(因为在故障期间失去了内存状态)。尽管如此,通过从相同的原始输入重新启动事务,它依然能够完成该事务的处理而不必中止它。
这些解决方案(包括防止死锁以及故障重启恢复事务),都不局限于在确定性数据库系统中使用。在非确定性系统中,如果失败期间,丢失的事务状态被其他非故障节点侦测到,那么事务重启变得略微棘手。但是也有一些简单的方法来解决这个问题,但这些方法已经超出了本文讨论的范围。实际上,我上面提到的其他系统都是非确定性系统。一旦我们意识到消除系统本身故障所带来的威力,我们就将设计植入到 Calvin 之后构建的每个系统中 – 甚至是非确定性系统。
结论
系统架构师继续在分区系统中使用 2PC 的好处微乎其微。我认为,忽略系统本身中止以及状态写入故障是更好的前进方法。确定性数据库系统(如 Calvin 或 FaunaDB)总是会规避系统本身中止,因此通常可避免 2PC。但是这种优势仅发挥在确定性数据库是一个巨大的浪费。从非确定性系统中消除系统本身引起的中止并不困难。最近的项目表明,甚至可以在不使用悲观并发控制技术的系统中消除系统引起的中止。例如,我们上面链接的 PVW 和惰性事务处理系统都使用多版本并发控制(MVCC)的变体。FaunaDB 使用乐观并发控制的变体。
在我看来,几乎没有理由坚持过时的系统性中止假设,当系统在单台机器上运行时,这种假设是合理的。然而,很多现代系统已经扩展到到多台可以故障隔离的机器上。维持该假设就需要成本高昂类似 2PC 的协调和提交协议。2PC 的性能问题一直是非 ACID 系统兴起的主要推动力,这些系统放弃了强一致性保证,以达到更好的可扩展性、可用性和性能。2PC 太慢了!它增加了所有事务的延迟,不仅仅是协议本身的时间占用,还阻止了访问相同数据的其他事务的并发执行。此外,2PC 还限制了可伸缩性(通过降低并发性)和可用性(我们上面讨论的阻塞问题)。前进的道路已经很明确:我们需要在设计系统时重新审视过时的假设,并对两阶段提交说“再见”!
Reference
1.9 - 3PC
三阶段提交协议最关键要解决的问题就是 Coordinator 和参与者同时挂掉导致数据不一致的问题,所以 3PC 在 2PC 的基础上又添加了一个阶段:CanCommit、PreCommit、DoCommit。
过程
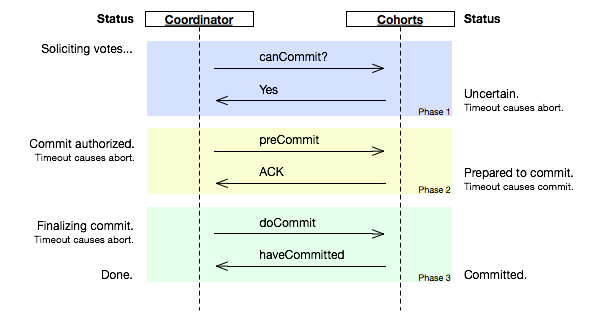
1:CanCommit
- 事务轮序:Coordinator 向各个参与者发送 CanCommit 请求,询问是否可以执行事务提交操作,并开始等待所有参与者的响应。
- 参与者向 Coordinator 反馈询问的响应:参与者收到 CanCommit 请求之后,正常情况下,如果自身认为可以顺利执行事务,那么会返回 Yes 响应并进入预备专题,否则返回 No。
2:PreCommit
执行事务预提交:如果 Coordinator 接收到各个参与者的反馈都是 Yes,那么执行事务预提交:
- 发送预提交请求:Coordinator 向各参与者发送 PreCommit 请求,进入 prepared 阶段。
- 事务预提交:参与者接收到 PreCommit 请求之后,会执行事务操作,并将 Undo 和 Redo 信息记录到事务日志中。
- 参与者向 Coordinator 反馈事务执行的响应:如果各参与者都成功执行了事务操作,那么反馈给 Coordinator ACK 响应,同时开始等待最终指令:提交 commit 或终止 abort,结束流程。
中断事务:如果任何一个参与者向 Coordinator 反馈了 No 响应,或者在等待超时后,Coordinator 无法接收到所有参与者的反馈,那么就会中断事务。
- 发送中断请求:Coordinator 向所有参与者发送 abort 请求。
- 中断事务:无论收到来自 Coordinator 的 abort 请求,还是等待超时,参与者都中断事务。
3:DoCommit
执行提交:
- 发送提交事务:假设 Coordinator 正常工作,接收到了所有参与者的 ACK,那么他将从预提交阶段进入提交阶段,并向所有参与者发送 DoCommit 请求。
- 事务提交:参与者收到 DoCommit 请求之后,正式提交事务,并在完成事务提交之后释放占用的资源。
- 反馈事务提交结果:参与者完成事务提交之后,向 Coordinator 发送 ACK。
- 完成事务:Coordinator 接收到所有参与者的 ACK,完成事务。
中断事务:假设 Coordinator 正常工作,并且有任一参与者反馈 No,或者在等待超时后无法接受到所有参与者的反馈,都会中断事务:
- 发送中断请求:Coordinator 向所有参与者节点发送 abort 请求。
- 事务回滚:参与者收到 abort 请求之后,利用 undo 日志执行事务回滚,并在完成事务回滚后释放占用资源。
- 返回事务回滚结果:参与者在完成事务回滚之后,向 Coordinator 发送 ACK。
- 中断事务:Coordinator 接收到所有参与者反馈的 ACK,中断事务。
分析
3PC 虽然解决了 Coordinator 与参与者均异常情况下导致数据不一致的问题,3PC 依然带来了其他问题。比如,网络分区问题,在 PreCommit 消息发出后突然两个机房断开网络,这时 Coordinator 所在机会会 abort,另外剩余的参与者的机房则会 commit。
而且由于 3PC 的设计过于复杂,在解决 2PC 问题的时候也引入了新的问题,因此实际应用并不广泛。
Reference
1.10 - Paxos
分布式系统除了能提升整个系统的性能外还有一个重要的特性就是提高系统的可靠性,可靠性指的是当分布式系统中一台或N台机器宕掉后都不会导致系统不可用,分布式系统是 “state machine replication” 的,每个节点都可能是其他节点的快照,这是保证分布式系统高可靠性的关键,而存在多个复制节点就会存在数据不一致的问题,这时一致性就成了分布式系统的核心;在分布式系统中必须保证:
加入在分布式系统中初始时各个节点的数据是一致的,每个节点都顺序执行系列操作,然后每个节点最终的数据还是一致的。
一致性算法:用于保证在分布式系统中每个节点都顺序执行相同的操作序列,在每个指令上执行一致性算法就能保证各个节点最终的数据是一致的。
Paxos 就是用于解决一致性问题的算法。有多个节点就会存在节点之间的通信问题,有两种通信模型:共享内存、消息传递。Paxos 是基于消息传递的通信模型。
概述
Paxos 用于解决分布式系统中的一致性问题。在一个 Paxos 过程只批准一个 Value,只有被 Prepare 的 Value 且被多数 Acceptor 接受才能被批准,被批准的 Value 只能被 Learner。
流程简述:
- 有一个 Client、三个 Proposer、三个 Acceptor、一个 Leaner;
- Client 向 Prepare 提交一个 Data 请求入库,Proposer 接收到 Client 请求后生成一个序列号 1 向三个 Acceptor(或最少两个)发送序号 1 请求提案。
- 假如三个 Acceptor 收到 Proposer 申请提交的序号 1 提案,且三个 Acceptor 都是初次接收到该提案,这时向 Proposer 回复 Promise 允许提交的提案。
- Proposer 收到三个 Acceptor(满足过半原则)的 Promise 回复后接着向三个 Acceptor 正式提交提案(序号 1,value 为 data)。
- 三个 Acceptor 都受到该提案,请求期间没有收到其他请求,Acceptor 则接受提案,回复 Proposer 已接受提案,然后向 Learner 提交提案。
- Proposer 收到回复后给 Client 成功处理请求。
- Learner 收到提案后开始学习提案(存储 Data)。
角色划分:
- Proposer:提议者
- Acceptor:决策者
- Learner:提案学习者
阶段划分:
- 准备阶段
- Proposer 向超过半数(n/2+1)的 Acceptor 发起 Prepare 消息(提案编号)。
- 如果 Prepare 符合协议规则,Acceptor 回复 Promise 消息,否则拒绝。
- 决议阶段(投票阶段)
- 如果超过半数 Acceptor 回复 Promise,Proposer 向 Acceptor 发送 Accept 消息。
- Acceptor 检查 Accept 消息是否符合规则,消息符合规则则批准 Accept 请求。
详解
Paxos 保证
- 只有提出的议案才能被选中,没有议案提出就不会被选中。
- 多个被提出的议案中只有一个议案会被选中。
- 议案被选中后 Learner 就可以开始学习该议案。
约束条件
P1-Acceptor 必须接受它接收到的第一个议案。有约束就会出现一个问题:当多个议案被多个 Proposer 同时提出,这时每个 Acceptor 都接收到了它们各自的第一个议案,此时无法选择最终议案。所以就需要另一个约束 P2。
P2-一个议案被选中需要过半的 Acceptor 接受。
假设 A 为整个 Acceptor 集合;B 为超过 A 一半的 Acceptor 集合,B 为 A 的子集;C 也是超过 A 半数的 Acceptor 集合,C 也是 A 的子集。由此可知,任意两个超过半数的子集中必定有一个相同的成员 Acceptor。
此说明了一个 Acceptor 可以接受不止一个议案,此时需要一个编号来标识每个议案,议案的编号格式为:(编号,Value)。编号为不可重复且全序。
因为一个 Paxos 过程只能批准一个 Value,这时退出了约束 P3。
P3-当编号为 K0、Value 为 V0 的议案(K0,V0)被过半的 Acceptor 接受后,今后(同一个 Paxos 或称一个 Round 中),所有比 K0 更高编号且被 Acceptor 接受的议案,其 Value 必须为 V0。
因为每个 Proposer 都可以提出多个议案,每个议案最初都有一个不同的 Value,所有要满足 P3 就又要退出一个新的约束 P4。
P4-只有 Acceptor 没有接受过议案,Proposer 才能采用自己的 Value,否则 Proposer 的 Value 议案为 Acceptor 中编号最大的 Proposer Value。
Paxos 流程
这里具体例子来说明 Paxos 的整个具体流程: 假如有 Server1、Server2、Server3 这样三台服务器,我们要从中选出 leader,这时候 Paxos 派上用场了。整个选举的结构图如下:
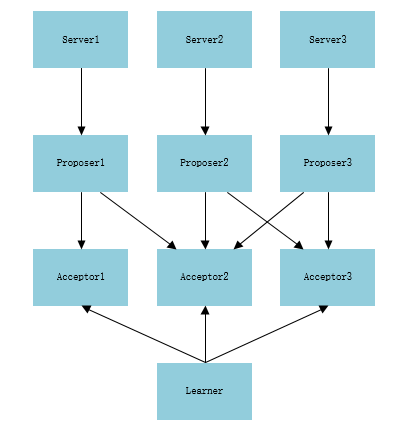
1-准备阶段
- 每个 Server 都向 Proposer 发消息称自己想成为 leader,Server1 往 Proposer1 发、Server2 往 Proposer2 发、Server3 往 Proposer3 发;
- 现在每个 Proposer 都接收到了 Server1 发来的消息但时间不一样, Proposer2 先接收到了,然后是 Proposer1,接着才是 Proposer3;
- Proposer2 首先接收到消息所以他从系统中取得一个编号 1,Proposer2 向 Acceptor2 和 Acceptor3 发送一条,编号为 1 的消息;
- 接着 Proposer1 也接收到了 Server1 发来的消息,取得一个编号 2,Proposer1 向 Acceptor1 和 Acceptor2 发送一条,编号为 2 的消息;
- 最后 Proposer3 也接收到了 Server3 发来的消息,取得一个编号 3,Proposer3 向 Acceptor2 和 Acceptor3 发送一条,编号为 3 的消息;
- 这时 Proposer1 发送的消息先到达 Acceptor1 和 Acceptor2,这两个都没有接收过请求所以接受了请求返回 (2,null) 给 Proposer1,并承诺不接受编号小于 2 的请求;
- 此时 Proposer2 发送的消息到达 Acceptor2 和 Acceptor3,Acceprot3 没有接收过请求则返回 (1,null) 给 Proposer2,并承诺不接受编号小于 1 的请求,但这时 Acceptor2 已经接受过 Proposer1 的请求并承诺不接受编号小于的 2 的请求了,所以 Acceptor2 拒绝 Proposer2 的请求;
- 最后 Proposer3 发送的消息到达 Acceptor2 和 Acceptor3, Acceptor2 接受过提议,但此时编号为 3 大于 Acceptor2 的承诺 2 与 Accetpor3 的承诺 1,所以接受提议返回 (3,null);
- Proposer2 没收到过半的回复所以重新取得编号 4,并发送给 Acceptor2 和 Acceptor3,然后A cceptor2 和 Acceptor3 都收到消息,此时编号 4 大于 Acceptor2 与 Accetpor3 的承诺 3,所以接受提议返回 (4,null);
2-决议阶段
- Proposer3 收到过半的返回,并且返回的 Value 为 null,所以Proposer3 提交了 (3,server3) 的议案;
- Proposer1 收到过半返回,返回的 Value 为 null,所以 Proposer1提交了 (2,server1) 的议案;
- Proposer2 收到过半返回,返回的 Value 为 null,所以 Proposer2 提交了 (4,server2) 的议案;
- Acceptor1、Acceptor2 接收到 Proposer1 的提案 (2,server1) 请求,Acceptor2 承诺编号大于 4 所以拒绝了通过,Acceptor1 通过了请求;
- Proposer2 的提案 (4,server2) 发送到了Acceptor2、Acceptor3,提案编号为 4 所以 Acceptor2、Acceptor3 都通过了提案请求;
- Acceptor2、Acceptor3 接收到 Proposer3 的提案 (3,server3) 请求,Acceptor2、Acceptor3 承诺编号大于 4 所以拒绝了提案;
- 此时过半的 Acceptor 都接受了 Proposer2 的提案 (4,server2),Larner 感知到了提案的通过,Larner 学习提案,server2 成为 Leader;
一个 Paxos 过程只会产生一个议案所以至此这个流程结束,选举结果 Server2 为 Leader。
Reference
1.11 - ZAB
背景
Zookeeper 使用了一种称为 Zab(Zookeeper Atomic Broadcast)的协议作为其一致性复制的核心,据其作者说这是一种新发算法,其特点是充分考虑了 Yahoo 的具体情况:高吞吐量、低延迟、健壮、简单,但不过分要求其扩展性。
Zookeeper 的实现是有 Client、Server 构成,Server 端提供了一个一致性复制、存储服务,Client 端会提供一些具体的语义,比如分布式锁、选举算法、分布式互斥等。从存储内容来说,Server 端更多的是存储一些数据的状态,而非数据内容本身,因此 Zookeeper 可以作为一个小文件系统使用。数据状态的存储量相对不大,完全可以全部加载到内存中,从而极大地消除了通信延迟。
Server 可以 Crash 后重启,考虑到容错性,Server 必须“记住”之前的数据状态,因此数据需要持久化,但吞吐量很高时,磁盘的 IO 便成为系统瓶颈,其解决办法是使用缓存,把随机写变为连续写。
考虑到 Zookeeper 主要操作数据的状态,为了保证状态的一致性, Zookeeper 提出了两个安全属性(Safety Property):
- 全序(total-order),如果消息 A 在消息 B 之前发送,则所有 Server 应该看到相同顺序的结果。
- 因果关系(causal-order),如果消息 A 在消息 B 之前发生(A 导致了 B),并被一起发送,则 A 始终在 B 之前执行。
为了保证上述两个安全属性,Zookeeper 使用了 TCP 协议和 Leader 机制。通过使用 TCP 协议保证了消息的全序特性(先发先到),通过 Leader 机制解决了因果顺序问题:先到 Leader 的先执行。因为有了 Leader,Zookeeper 的架构就变为:Master-Slave 模式,但在该模式中Master(Leader)会 Crash,因此,Zookeeper 引入了 Leader 选举算法,以保证系统的健壮性。归纳起来 Zookeeper 整个工作分两个阶段:
- Atomic Broadcast
- Leader 选举
Atomic Broadcast
同一时刻存在一个 Leader 节点,其他节点称为 Follower。如果是更新请求,如果客户端连接到 Leader 节点,则由 Leader 节点执行其请求;如果连接到 Follower 节点,则需转发到 Leader 节点执行。但对于读请求,Client 可以直接从 Follower 节点读取数据,如果需要读取到最新数据,则需要从 Leader 节点读取,Zookeeper 设计的读写比例是 2:1。
Leader 通过一个简化版的 2PC 模式向其他 Follower 发送请求,但与 2PC 有两个不同之处:
- 因为只有一个 Leader,Leader 提交到 Follower 的请求一定会被接受(没有其他 Leader 干扰)。
- 不需要所有 Follower 都响应成功,只要多数响应即可。
通俗的说,如果有 2f+1 个节点,允许 f 个节点失败。因为任何两个过半数集必要一个交集,当 Leader 切换时,通过这些交集节点可以获得当前系统的最新状态。如果没有一个过半数集存在(存活节点少于 f+1)则算法过程结束。
但又一个特例:如果 ABC 三个节点,A 是 Leader,如果 B 宕机,则 AC 能够正常工作,因为 A 是 Leader,AC 还能构成过半数集;如果 A 宕机则无法继续工作,因为用于 Leader 选举的过半数集无法构成。
Leader Election
Leader 选举主要是依赖 Paxos 算法,具体算法过程请参考其他博文,这里仅考虑 Leader 选举带来的一些问题。
Leader 选举遇到的最大问题是,”新老交互“的问题,新 Leader 是否要继续老 Leader 的状态。这里要按老 Leader Crash 的时机点分几种情况:
- 老 Leader 在 COMMIT 前 Crash(已经提交到本地)。
- 老 Leader 在 COMMIT 后 Crash,但有部分 Follower 接收到了Commit请求。
第一种情况,这些数据只有老 Leader 自己知道,当老 Leader 重启后,需要与新 Leader 同步并把这些数据从本地删除,以维持状态一致。
第二种情况,新 Leader 应该能通过一个多数派获得老 Leader 提交的最新数据。老 Leader 重启后,可能还会认为自己是 Leader,可能会继续发送未完成的请求,从而因为两个 Leader 同时存在导致算法过程失败,解决办法是把 Leader 信息加入每条消息的 id 中,Zookeeper 中称为 zxid,zxid 为一 64 位数字,高 32 位为 leader 信息又称为 epoch,每次 leader 转换时递增;低 32 位为消息编号,Leader 转换时应该从 0 重新开始编号。通过 zxid,Follower 能很容易发现请求是否来自老 Leader,从而拒绝老 Leader 的请求。
因为在老 Leader 中存在着数据删除(情况1),因此 Zookeeper 的数据存储要支持补偿操作,这也就需要像数据库一样记录 log。
ZAB 与 Paxos
Zab 的作者认为 Zab 与 Paxos 并不相同,只所以没有采用 Paxos 是因为 Paxos 保证不了全序顺序:
Because multiple leaders can propose a value for a given instance two problems arise. First, proposals can conflict. Paxos uses ballots to detect and resolve conflicting proposals. Second, it is not enough to know that a given instance number has been committed, processes must also be able to figure out which value has been committed.
Paxos 算法的确是不关心请求之间的逻辑顺序,而只考虑数据之间的全序,但很少有人直接使用 Paxos 算法,都会经过一定的简化、优化。
一般 Paxos 都会有几种简化形式,其中之一便是,在存在 Leader 的情况下,可以简化为 1 个阶段(Leader Election)。仅有一个阶段的场景需要有一个健壮的 Leader,因此工作重点就变为 Leader 选举,在考虑到 Learner 的过程,还需要一个”学习“的阶段,通过这种方式,Paxos 可简化为两个阶段:
- Leader Election
- Learner Learn
如果再考虑多数派要 Learn 成功,这其实就是 Zab 协议。Paxos 算法着重是强调了选举过程的控制,对决议学习考虑的不多,Zab 恰好对此进行了补充。
1.12 - Raft
基本概念
复制状态机
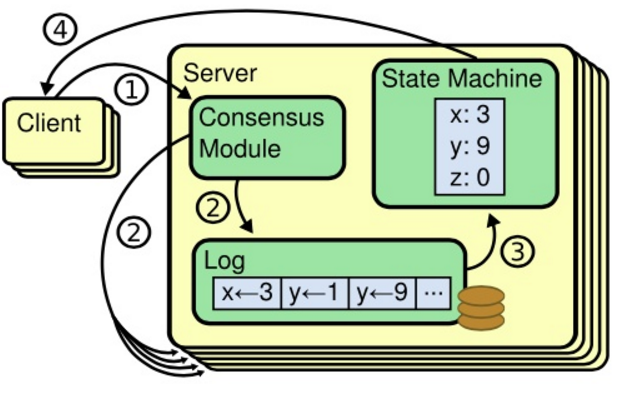
- 复制状态机通过日志复制来实现:
- 日志:每台机器保存一份日志,日志来自客户端的请求,包含一系列命令。
- 状态机:状态机会按序执行这些命令。
- 一致性模型:分布式环境中,保证多机的日志是一致的,这样回放到状态机中得到的状态就是一致的。
- 一致性算法用于一致性模型,一般有以下特性:
- Safety:在非拜占庭问题下(网络延时、网络分区、丢包、重复包、包乱序),结果是正确的。
- Availability:在半数以上机器能正常工作时,服务可用。
- Timing-unindepentent:不依赖于时钟来保持日志一致性,错误的时钟以及极端的消息延时最多会造成可用性问题。
实际的实现中,建议状态机的每个命令曹邹都是幂等的,这样更易于保证一致性。
服务器状态
每台服务器一定会处于三种状态:
- 领导者
- 候选者
- 追随者
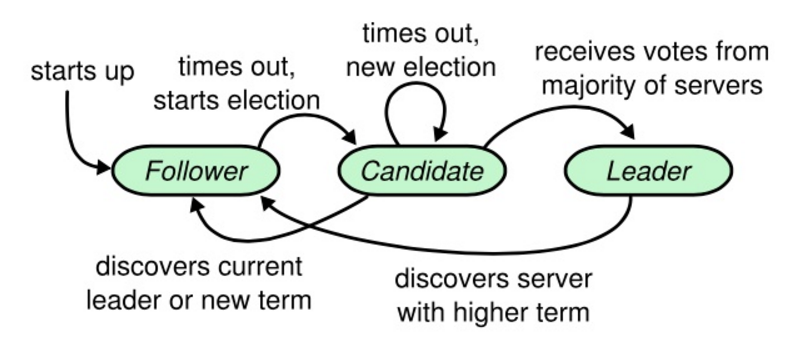
- 追随者只响应其他服务器的请求。如果追随者没有收到任何消息,它会成为一个候选者并开始一次选举。
- 收到大多数服务器投票的候选者将称为新的领导者。
- 领导者在宕机之前会一致保持领导者的状态。
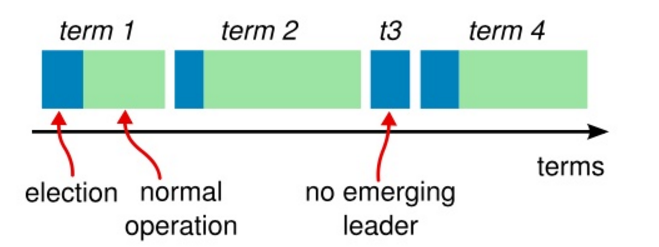
任期
Raft 算法将事件划分为任意不同长度的任期(Term)。任期用连续的数字来表示。每个任期的开始都是一次选举(election),一个或多个候选者会试图称为领导者。如果一个候选者赢得了选举,他就会在该任期的剩余时间内担任领导者。在某些情况下,选票会被瓜分,有可能没有选出领导者。这时将开始另一个任期,并且立刻开始下一次选举。Raft 算法保证在指定的任期内只有一个领导者。
RPC
Raft 算法中服务器节点之间通过 RPC 通信,并且基本的一致性算法只需要两种类型的 RPC。请求投票 RPC 由候选者在选举期间发起,然后附加条目 RPC 由领导者发起,用来复制日志或提供一种心跳机制。为了服务器之间传输快照增加了第三种 RPC。当服务器没有及时收到 RPC 的响应时会尝试重试,并且它们能够并行的发起 RPC 来获得最佳性能。RPC 有三种:
- RequestVote RPC:候选者在选举期间发起。
- AppendEntries RPC:领导者发起的一种心跳机制,或用于日志复制。
- InstallSnapshot RPC:领导者使用该 RPC 来发送快照给过于落后的追随者。
超时设置:
- BroadcastTime:领导者的心跳超时。
- ElectionTimeout:追随者设置的候选超时时间。
- MTBF:指的是单个服务器发生故障的间隔时间的平均值。
BroadcastTime < ElectionTimeout < MTBT 原则:
- BroadcastTime 应该比 ElectionTimeout 小一个数量级,为的是使领导者能够持续发送心跳信息来避免追随者开始发起选举。
- ElectionTimeout 应该比 MTBT 小几个数量级,为的是使系统稳定运行。
一般 BroadcastTime 大约为 0.5 毫秒到 20 毫秒,ElectionTimeout 一般在 10ms 到 500ms 之间。大多数服务器的 MTBF 都在几个月甚至更长。
选举
触发条件:
- 一般情况下,追随者接收到领导者的心跳时,会重置 ElectionTimeout,不会触发。
- 领导者故障,追随者的 ElectionTimeout 发生超时,会转换为候选者,触发选举。
候选操作过程:
追随者自增当前任期,转换为候选者,对自己投票,并发起 RequestVote RPC,等待以下三种情况发生:
- 获得超过半数服务器的投票,赢得选举,称为领导者。
- 另一台服务器赢得选举,并接收到对应的心跳,称为追随者。
- 选举超时,没有任何一台服务器赢得选举,自增当前任期,重新发起选举。
注意事项:
- 服务器在一个任期内,最多只能给一个候选者投票,采用先到先服务原则。
- 候选者等待投票期间,可能会接收到来自其他声明称为领导者的 AppendEntries RPC。如果该领导人的任期(RCP 的内容)比当当前候选者的任期要大,则当前候选者认为该领导者合法,并转换称为追随者;如果 RPC 中的任期小于当前任期,则后选择拒绝此次 RPC,继续保持候选者状态。
- 候选者既没有赢得选举也没有输得选举:如果很多追随者在同一时刻都称为了候选者,选票会被分散,可能没有候选者获得较多的投票。当这种情况发生时,每一个候选者都会超时,并且通过自增任期号和发起另一轮 RequestVote RPC 来开始新的选举。然而,如果没有其他手段来分配选票的话,这种情况可能会无限制的重复下去。所以 Raft 使用的随机方式来设置选举超时时间(150~300ms)来避免这种情况的发生。
问题探讨:
- 候选者已经给自己投票了,一个候选者在一个任期内只会给一个人投票。
- 也有可能算法本身设定候选者就拒绝所有其他服务器的请求。
日志复制
接收命令过程:
- 领导者接受客户端请求。
- 领导者将命令追加到日志。
- 发送 AppendEntries RPC 请求到追随者。
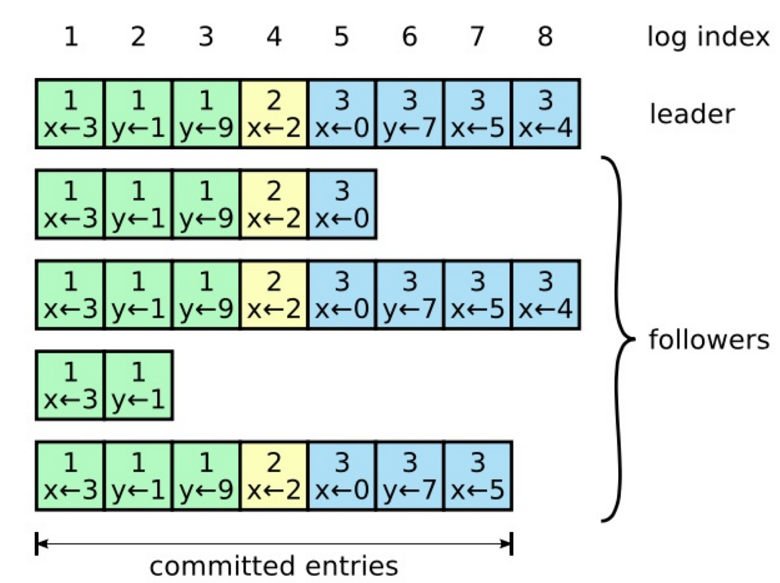
- 领导者收到大多数追随者的确认后,领导者 Commit 日志,将日志在状态机中回放,并返回结果给客户端。
提交过程:
- 在下一个心跳阶段,领导者再次发送 AppendEntries RPC 给追随者,日志已经 Commit 完成。
- 追随者收到 Commit 结果之后,将日志在状态机中回放。
安全性
到目前为止描述的机制并不能充分的保证每一个状态机会按照相同的顺序执行相同的指令,例如:一个跟随者可能会进入不可用状态同时领导人已经提交了若干的日志条目,然后这个跟随者可能会被选举为领导人并且覆盖这些日志条目;因此,不同的状态机可能会执行不同的指令序列。
1. 领导者追加日志
领导者永远不会覆盖已经存在的日志条目;日志永远只有一个流向:从领导者到追随者;
2. 选举限制:投票阻止没有全部日志条目的服务器赢得选举
如果投票者的日志比候选人的新,拒绝投票请求;这意味着要赢得选举,候选者的日志至少和大多数服务器的日志一样新,那么它一定包含全部的已经提交的日志条目。
3. 永远不提交任期之前的日志条目(只提交任期内的日志条目)
在Raft算法中,当一个日志被安全的复制到绝大多数的机器上面,即AppendEntries RPC在绝大多数服务器正确返回了,那么这个日志就是被提交了,然后领导者会更新 “commit index”。
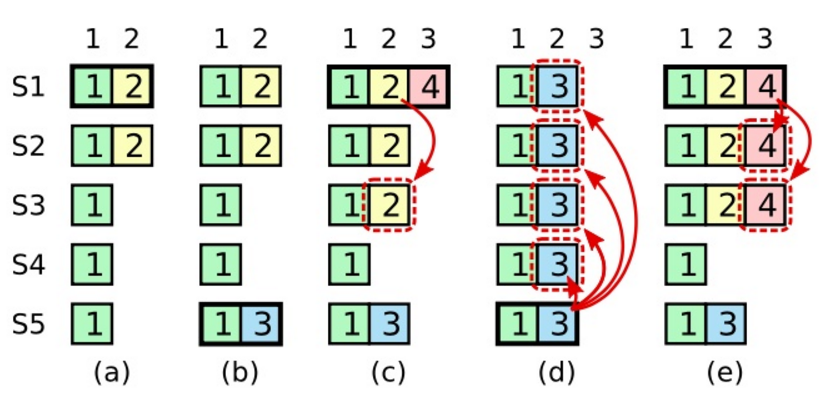
如果允许提交任期之前的日志条目,那么在步骤 c 中,我们就会把之前任期为 2 的日志提交到其他服务器中去,并造成了大多数机器存在了日志为 2 的情况。所以造成了 d 中 S5 中任期为 3 的日志条目会覆盖掉已经提交的日志的情况。
Raft 从来不会通过计算复制的数目来提交之前人气的日志条目。只有领导人当前任期的日志条目才能通过计算数目来进行提交。一旦当前任期的日志条目以这种方式被提交,那么由于日志匹配原则(Log Matching Property),之前的日志条目也都会被间接的提交。
论文中的这段话比较难理解,更加直观的说:由于 Raft 不会提交任期之前的日志条目,那么就不会从 b 过渡到 c 的情况,只能从 b 发生 S5 宕机的情况下直接过渡到 e,这样就产生的更新的任期,这样 S5 就没有机会被选为领导者了。
4. 候选者和追随者崩溃
候选者和追随者崩溃的情况处理要简单的多。如果这类角色崩溃了,那么后续发送给他们的 RequestVote 和 AppendEntries 的所有 RPC 都会失败,Raft 算法中处理这类失败就是简单的无限重试的方式。如果这些服务器重新可用,那么这些 RPC 就会成功返回。如果一个服务器完成了一个 RPC,但是在响应 Leader 前崩溃了,那么当他再次可用的时候还会收到相同的 RPC 请求,此时接收服务器负责检查,比如如果收到了已经包含该条日志的 RPC 请求,可以直接忽略这个请求,确保对系统是无害的。
集群成员变更
集群成员的变更和成员的宕机与重启不同,因为前者会修改成员个数进而影响到领导者的选取和决议过程,因为在分布式系统这对于 majority 这个集群中成员大多数的概念是极为重要的。
简单的做法是,运维人员将系统临时下线,修改配置,重新上线。但是这种做法存在两个缺点:
- 更改时集群不可用
- 认为操作失误风险
直接从一种配置转到新的配置是十分不安全的
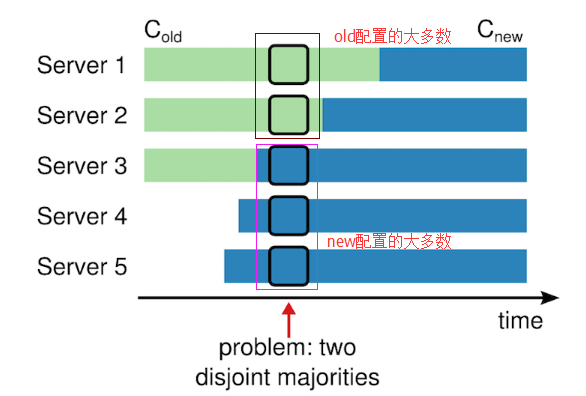
因为各个机器可能在任何的时候进行转换。在这个例子中,集群配额从 3 台机器变成了 5 台。不幸的是,存在这样的一个时间点,两个不同的领导人在同一个任期里都可以被选举成功。一个是通过旧的配置,一个通过新的配置。
两阶段方法保证安全性
为了保证安全性,配置更改必须使用两阶段方法。在 Raft 中,集群先切换到一个过渡的配置,我们称之为共同一致;一旦共同一致已经被提交了,那么系统就切换到新的配置上。共同一致是老配置和新配置的结合。
共同一致允许独立的服务器在不影响安全性的前提下,在不同的时间进行配置转换过程。此外,共同一致可以让集群在配置转换的过程人依然响应服务器请求。
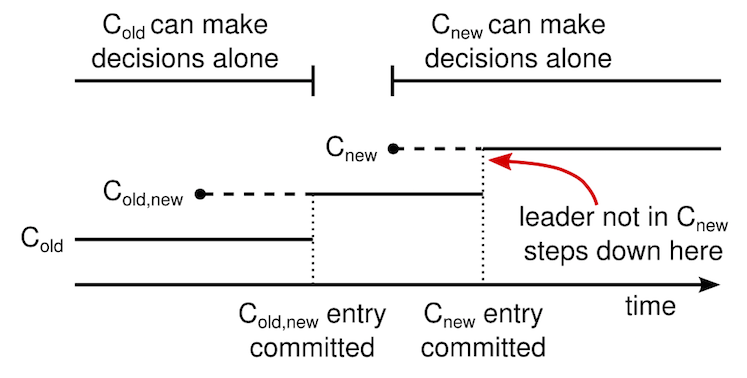
一个领导人接收到一个改变配置从 C-old 到 C-new 的请求,他会为了共同一致存储配置(图中的 C-old,new),以前面描述的日志条目和副本的形式。一旦一个服务器将新的配置日志条目增加到它的日志中,他就会用这个配置来做出未来所有的决定。领导人完全特性保证了只有拥有 C-old,new 日志条目的服务器才有可能被选举为领导人。当 C-old,new 日志条目被提交以后,领导人在使用相同的策略提交 C-new,如下图所示,C-old 和 C-new 没有任何机会同时做出单方面的决定,这就保证了安全性。
上图是一个配置切换的时间线。虚线表示已经被创建但是还没有被提交的条目,实线表示最后被提交的日志条目。领导人首先创建了 C-old,new 的配置条目在自己的日志中,并提交到 C-old,new 中(C-old,new 的大多数和 C-new 的大多数)。然后他创建 C-new 条目并提交到 C-new 中的大多数。这样就不存在 C-new 和 C-old 可以同时做出决定的时间点。
日志压缩
日志会随着系统的不断运行会无限制的增长,这会给存储带来压力,几乎所有的分布式系统(Chubby、ZooKeeper)都采用快照的方式进行日志压缩,做完快照之后快照会在稳定持久存储中保存,而快照之前的日志和快照就可以丢弃掉。
Raft的具体做法如下图所示:
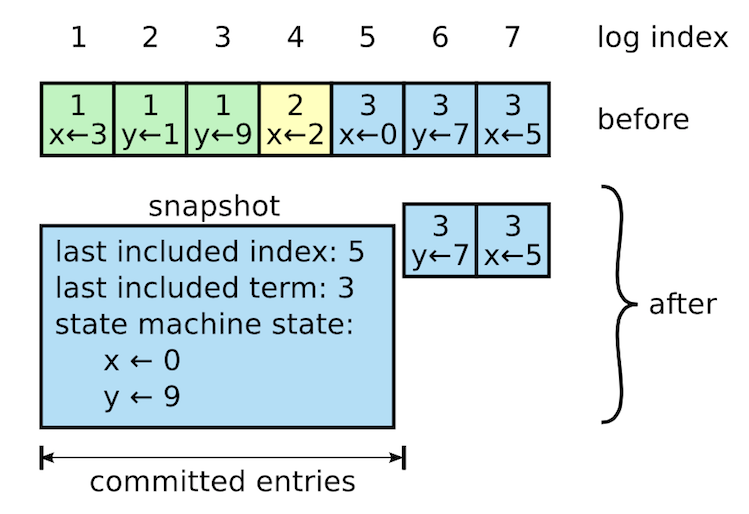
与 Raft 其它操作 Leader-Based 不同,snapshot 是由各个节点独立生成的。除了日志压缩这一个作用之外,snapshot 还可以用于同步状态:slow-follower 以及 new-server,Raft 使用 InstallSnapshot RPC 完成该过程,不再赘述。
Client 交互
- Client 只向领导者发送请求;
- Client 开始会向追随者发送请求,追随者拒绝 Client 的请求,并重定向到领导者;
- Client 请求失败,会超时重新发送请求。
Raft 算法要求 Client 的请求线性化,防止请求被多次执行。有两个解决方案:
- Raft 算法提出要求每个请求有个唯一标识;
- Raft 的请求保持幂等性。
Reference
1.13 - 分布式一致性
什么是一致性问题
以银行 ATM 为例,假设 A 的账户内有 200 存款,某一时刻 A 和其朋友 B 同时在不同的两个 ATM 机执行”取款 200“的操作,此时系统便出现了一致性问题,因为无论系统做出何种回应都会导致不一致的问题:
- 系统接受一方的取款请求,拒绝另一方的取款请求:一方会认为系统不可用
- 系统同时接受两个请求:账户发生透支
- 系统同时拒绝两个请求:双方均认为系统不可用
解决一致性问题的算法
Lamport 面包店算法
每个请求先申请到一个独一无二的号码,然后按照号码小者优先的规则进行办理。即在分布式系统中维护一个全局的”排号系统“。
这要求高质量的硬件环境,参考谷歌利用GPS和原子钟使数据库全球范围信息同步。
Vector Clocks
同样由上面算法的作者 Lamport 提出,算是对上面算法的改进,去除了维护全局排号系统的负担。
该算法通过一系列计数器实现。还是 ATM 的例子,A、B 所用的 ATM 机需要自己维护一个计数器序列,每次操作将这个序列里自己的计数器加一,当 ATM 发送请求到系统时附带上该序列。假设两台 ATM 的计数器一开始都是 0,A 操作后将发送 [{a,1}, {b,0}],B 操作后将发送 [{a,0}, {b,1}],可以发现 A 发送的 b 比 B 发送的 b 要小,说明有冲突,此时按照时间顺序谁先到处理谁,后来的拒绝。假如同时到达则按 ATM 机的字母排号选择,即先 A 后 B。
注意,Vector Clocks 仅用来发现冲突,并不包含冲突的解决过程。Riak 和早期的 Cassandra、Dynamo 应用了该算法。但是该算法需要每次请求前先像其他节点获得对方计数器的最新版本,而且要给 Vector Clocks 预留存储空间,造成性能和资源消耗的加剧,因此效果不佳。
选举算法
首先在系统中通过既定的规则选举出一个 Master,其余节点都是 Slave,外来请求均通过 Master 来处理,Slave 仅需从 Master 节点同步数据即可。常见的算法实现比如 Paxos 和 Raft。
缺点是,当 Master 失效后系统会执行选举过程,这是系统会处于短暂的不可用状态。
Quorum NRW
一种从客户端侧解决一致性问题的投票算法,通过客户端同步操作多个实例来保证一致性,具体冲突解决由客户端实现,其主要数据思想来源于鸽巢原理,可以保证同一份数据对象的多份拷贝不会被超过两个访问对象读写。
分布式系统中的每一份数据对象都被赋予一票,每个操作必须要获得最小的读票数(Vr)或者最小的写票数(Vw),才能进行读写。如果一个系统有 V 票,即一个数据对象有 V 份冗余拷贝,那么最小的读写票数必须满足:
- Vr + Vw > V
- Vw > V/2
第一条规则保证了一个数据库不会被同时读写。当一个写操作请求过来的时候,它必须要获得Vw个冗余拷贝的许可。而剩下的数量是V-Vw 不够Vr,因此不能再有读请求过来了。同理,当读请求已经获得了Vr个冗余拷贝的许可时,写请求就无法获得许可了。
第二条规则保证了数据的串行化修改,一份数据的冗余拷贝不可能同时被两个写请求修改。
比如一个拥有 5 节点的系统,该算法可以让写操作写完 3 台即返回,剩下的由系统进行同步;而读操作则至少需要读 3 台,才能保证读到一个最新的数据。
Rev Tree
类似于 Git 的版本树,对每次操作生成一个 Rev id,将每次操作的 Rev id 都放到上次操作之后形成主分支,当一个拥有不一致的 Rev Tree 的数据想要进行合并时冲突产生,这时会生成一个新的分支,然后两个分支同时工作。默认以最长分支为主分支,其他分支及数据会在一段时间后删除。因此有些场景中并不可行。
CouchDB 中应用了该算法,该算法把冲突的解决交给了时间,活跃度最高的数据被保留下来,适用于没有权威决策要求的去中心化系统。
区块链
这是比特币网络中用于记录交易过程生成总账本的算法,类似于上面的 Rev Tree,同时基于安全性需求增加了非对称加密、计算能力验证等逻辑。参考比特币的原理及运行机制。
CRDT
CRDT 值能够避免冲突的可复制数据结构,力图从数据结构上避免冲突,同时这类数据结构的合并过程都会满足 ACID 2.0:
- 结合律:
f(a,f(b,c)) = f(f(a,b),c) - 交换律:
f(a,b) = f(b,a) - 幂等性:
f(f(x))=f(x)
Reference
1.14 - 分布式事务
什么是事务
将多个不同的命令组装到一起的过程。
核心:锁与并发
称为事务为了更易理解。
性能较低。
容易理解的模型性能都不好,性能好的模型(锁的粒度小,增加了编程难度)都不易理解。
追求平衡。
事务要保证的问题就是一致性。
ACID保证事务完整性、原子性。什么是ACID?
建索引、读一行数据、插入一行并建索引、删除整张表….每个操作都是事务。
- two phase lock(2PL):两阶段锁,读(加锁) - 操作 - 提交(解锁)
事务单元
多个事务单元关联时,每个事务单元都不会看到数据的中间状态。
事务单元之间的 happen-before 关系:
- 读写
- 写读
- 读读
- 写写
《事务处理》
如何满足事务关联的同时更快完成(速度)?如何保证上面四种操作的逻辑顺序(正确性)?
- 排队各种操作:串行序列化、不需要冲突控制,但是慢,
- 针对同一个单元的访问进行访问控制,排成多个队,没有冲突的地方进行并行:读写均加锁,
- 针对读场景做优化,读与写锁分离开,读进行并行操作:提升读多写少性能,即读写锁,可重复读
- MVCC,多版本并发控制,写不阻塞读,copy on write,写读场景优化,写的时候可以读,只有写写时冲突,系统实现复杂性变高,日志变多。
ACID 中的 I,隔离级别,但为了并发而破坏了一致性:
- 可序列化
- 可重复读
- 读已提交
事务处理的常见问题
事务顺序
MVCC中,每次数据写入都放入不同版本的数据log,如何保证写写读的顺序。
内存中维持数据自增号,写的时候加1。读的时候根据ID找对应的数据。逻辑时间戳(事务单元先后)、物理时间戳(时钟)。
故障恢复
错误类型:
- 业务属性不匹配,记录操作的反向操作,进行回退
- 系统崩溃,在数据恢复没有完全完成时不对外不服务,防止崩溃时没有完成的事务而造成的中间数据暴露
死锁怎么办
原因:
- 两个线程
- 不同方向
- 相同资源
方法:
- 尽可能不死锁,降低隔离级别
- 碰撞检测,记录各单元持有的锁进行检查,终止一边
- 等锁超时,但是超长事务导致每次死锁释放需要太久时间,2是主流,这个辅助
深入单机事务
ACID
原子性操作:要么同时成功要么同时失败,回滚到事务最初状态。执行每个操作都记录一个回滚段。
一致性:核心为“看”,happen before,一个事务单元保证全部成功以后才可见。对多个事务操作的同一数据加锁,将事务顺序化,排队,同时将锁下推到数据上,将锁分离,而不是一个超级大锁。
隔离性:因为一致性中加锁而带来的性能问题,对强一致性进行破坏。
- 序列化读写,用排他锁,将所有读写操作排队:性能差==不可用
- 读写锁,读锁不能被写锁升级(读的时候不能写):
- 可重复读,读读操作并行
- 读写锁,读已提交,读锁能被写锁升级(读的时候能写):
- 读读并行
- 读写并行
- 读未提交,只加写锁,不加读锁
- 读读并行
- 读写并行
- 写读并行,所有的写是串行的,读都是并行的,可以读到写过程中未提交的数据(因此不建议用)
- MVCC,打脸上面的 SQL92标准。快照隔离级别,核心:copy on write+无锁编程,针对读多写少优化
- 每个事务都有一个版本号
- 新的事务同时进来后生成一个新的版本号,读取上一个版本号事务开始之前的数据
- 在读一致性数据的同时实现读未提交
持久性:事务完成后,所有的提交都要物理存储。延迟与持久性平衡。
(操作 -> 内存 -> 磁盘(块越大越块),如果在内存中攒成一块再写磁盘)
等待多次 commit 之后(group commit)再刷磁盘,攒成一大块,但吞吐变小,需要权衡
RAID 保证持久性:RAID controller 同时写到多个磁盘,同时成功同时失败,这又成为一个新的事务。
典型异常应对策略
业务属性不匹配:
- 原子性
- 一致性
- 回滚:事务单元中的每个操作都记录一个回滚段
系统宕机:重启后进入 recovery 模式,执行回滚段
调优原则
在不影响业务应用的前提下:
- 减少锁的覆盖范围(减小锁粒度)
- myisam 表锁 -> innodb 行锁
- 原位锁 -> mvcc 多版本(将一个大锁拆分到不同版本的数据上)
- 增加锁上可并行的线程数
- 读锁写锁分离、允许并行读取数据
- 选择正确的锁类型,与读写锁是不同层次的概念(共两种锁:排他锁,共享锁)
- 悲观锁,适合并发争抢比较严重的场景
- 乐观锁,适合并发争抢不太严重的场景
数据库中的 U 锁(update 锁):如果事务单元中有写操作,则在进行读操作时直接申请为写锁,而不是读锁。
分布式事务与单机事务
分布式事务的目标:
- 完整的事务支持,和单机一样
- 无限扩展
事务
(对于共享数据,)让多步操作顺序发生,让多线程看上去就像一步操作。
事务优化:尽可能的快,数据又不错乱。
网络
优点:去中心化,网络提供了理论上无限的扩展能力,理论上无线的数据安全性(不丢失),理论上无线的服务可用性。
缺点:共享数据困难(通过消息复制),更多的延迟,确定性丧失,并发编程难度。
基于锁的事务遇到的问题
从 2PL 到 2PC
所有的数据库都会抽象为两阶段锁的操作。在分布式中抽象为两阶段提交。
由第三者-协调器负责跨机提交。
分布式事务异常处理
任何步骤出现状况时全部回滚。但是当一阶段已提交并暴露后,二阶段提交失败则无法再回滚,只能等待直到处理成功。
分布式日志记录
协调者高可用:
- 必须是多机,任意协调者必须知道这个事务运行的状态
- 记录日志,准备阶段需要记录一次日志
- 每个节点的commit 都必须记录日志
分布式事务延迟变大
随着数据、节点增长,延迟越来越大,即分布式事务的最大问题。
基于 MVCC 的事务视线中遇到的问题
分布式顺序问题
逻辑时间戳,所有操作都需要一个时间戳,然后才能知道该操作需要操作的数据版本,以保证操作顺序。
但是分布式中无法再进行时间戳的分配了,单台机器分配的话将成为单点,同时,单位时间内能够分配的时间戳是有限的,比如一台机器为100台机器分配时间戳。多台又无法保证递增性。
分布式事务的主要难题
传统数据库的分布式事务
Google Spanner 赏析
阿里分布式事务模型
DRDS/TDDL 实战
1.15 - 分布式事务
基础理论
在讲解具体方案之前,我们先了解一下分布式事务所涉及到的基础理论知识。
我们拿转账作为例子,A需要转100元给B,那么需要给A的余额-100元,给B的余额+100元,整个转账要保证,A-100和B+100同时成功,或者同时失败。看看在各种场景下,是如何解决这个问题的。
事务
把多条语句作为一个整体进行操作的功能,被称为数据库事务。数据库事务可以确保该事务范围内的所有操作都可以全部成功或者全部失败。
事务具有 4 个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为 ACID 特性。
- Atomicity(原子性):一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复到事务开始前的状态,就像这个事务从来没有执行过一样。
- Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。完整性包括外键约束、应用定义的等约束不会被破坏。
- Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。
- Durability(持久性):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
分布式事务
银行跨行转账业务是一个典型分布式事务场景,假设A需要跨行转账给B,那么就涉及两个银行的数据,无法通过一个数据库的本地事务保证转账的ACID,只能够通过分布式事务来解决。
分布式事务就是指事务的发起者、资源及资源管理器和事务协调者分别位于分布式系统的不同节点之上。在上述转账的业务中,用户A-100操作和用户B+100操作不是位于同一个节点上。本质上来说,分布式事务就是为了保证在分布式场景下,数据操作的正确执行。
分布式事务在分布式环境下,为了满足可用性、性能与降级服务的需要,降低一致性与隔离性的要求,一方面遵循 BASE 理论(BASE相关理论,涉及内容非常多,感兴趣的同学,可以参考BASE理论):
- 基本业务可用性(Basic Availability)
- 柔性状态(Soft state)
- 最终一致性(Eventual consistency)
同样的,分布式事务也部分遵循 ACID 规范:
- 原子性:严格遵循
- 一致性:事务完成后的一致性严格遵循;事务中的一致性可适当放宽
- 隔离性:并行事务间不可影响;事务中间结果可见性允许安全放宽
- 持久性:严格遵循
两阶段提交/XA
XA是由X/Open组织提出的分布式事务的规范,XA规范主要定义了(全局)事务管理器(TM)和(局部)资源管理器(RM)之间的接口。本地的数据库如mysql在XA中扮演的是RM角色
XA一共分为两阶段:
第一阶段(prepare):即所有的参与者RM准备执行事务并锁住需要的资源。参与者ready时,向TM报告已准备就绪。 第二阶段 (commit/rollback):当事务管理者(TM)确认所有参与者(RM)都ready后,向所有参与者发送commit命令。 目前主流的数据库基本都支持XA事务,包括mysql、oracle、sqlserver、postgre
XA 事务由一个或多个资源管理器(RM)、一个事务管理器(TM)和一个应用程序(ApplicationProgram)组成。
把上面的转账作为例子,一个成功完成的XA事务时序图如下:
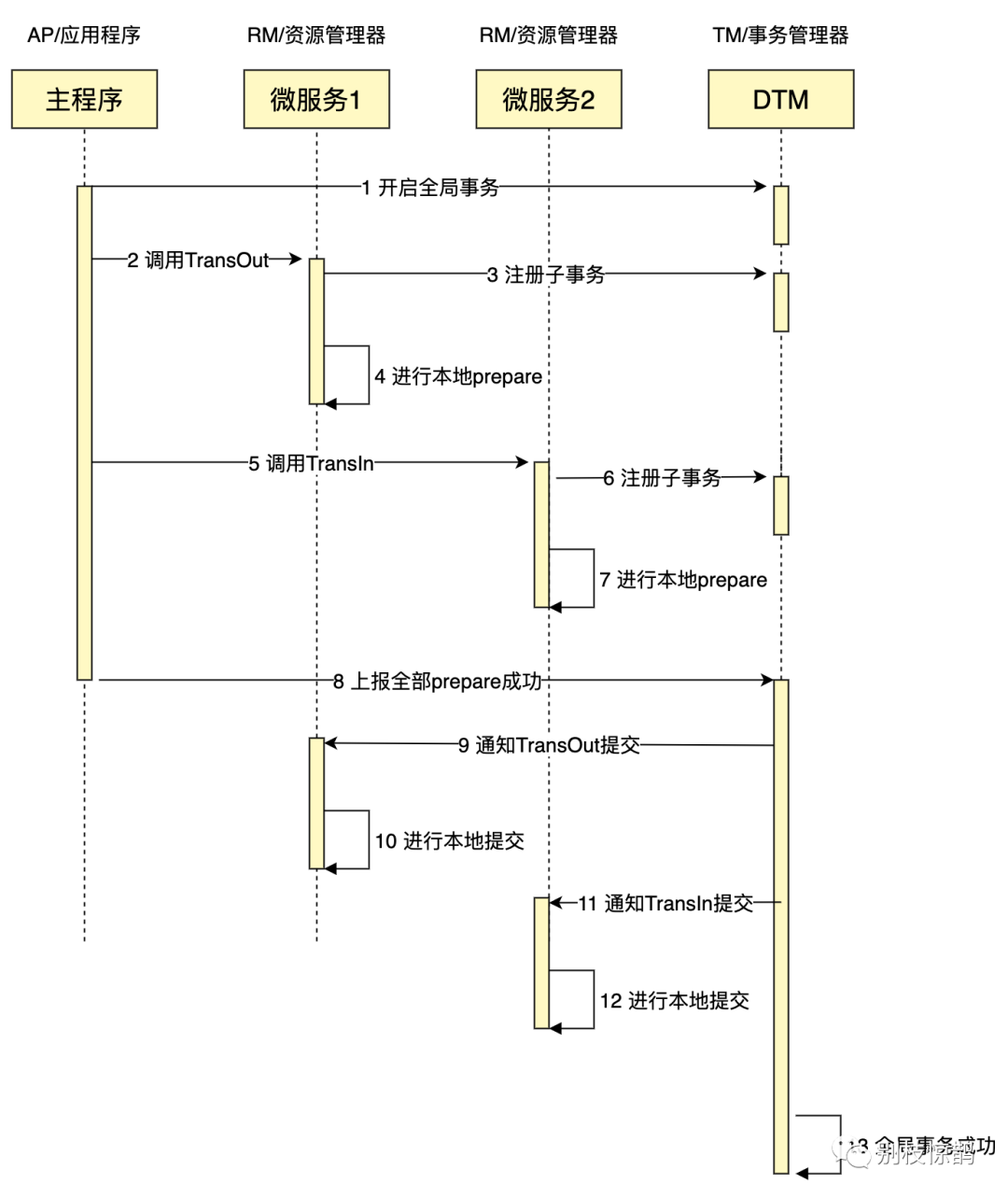
如果有任何一个参与者prepare失败,那么TM会通知所有完成prepare的参与者进行回滚。
XA事务的特点是:
- 简单易理解,开发较容易
- 对资源进行了长时间的锁定,并发度低
如果读者想要进一步研究XA,go语言可参考github.com/yedf/dtm,java语言可参考github.com/seata/seata
SAGA
Saga是这一篇数据库论文saga提到的一个方案。其核心思想是将长事务拆分为多个本地短事务,由Saga事务协调器协调,如果正常结束那就正常完成,如果某个步骤失败,则根据相反顺序一次调用补偿操作。
把上面的转账作为例子,一个成功完成的SAGA事务时序图如下:
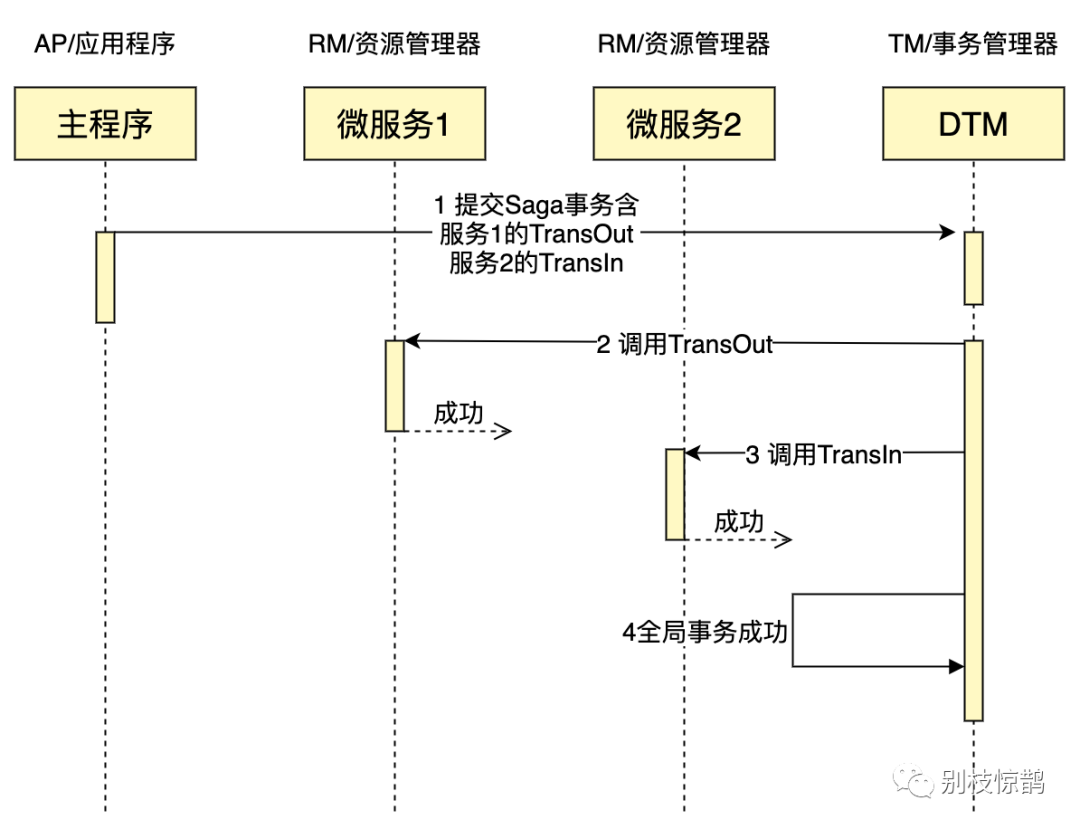
SAGA事务的特点:
- 并发度高,不用像XA事务那样长期锁定资源
- 需要定义正常操作以及补偿操作,开发量比XA大
- 一致性较弱,对于转账,可能发生A用户已扣款,最后转账又失败的情况
论文里面的SAGA内容较多,包括两种恢复策略,包括分支事务并发执行,我们这里的讨论,仅包括最简单的SAGA
SAGA适用的场景较多,长事务适用,对中间结果不敏感的业务场景适用
如果读者想要进一步研究SAGA,go语言可参考DTM,java语言可参考seata
TCC
关于 TCC(Try-Confirm-Cancel)的概念,最早是由 Pat Helland 于 2007 年发表的一篇名为《Life beyond Distributed Transactions:an Apostate’s Opinion》的论文提出。
TCC分为3个阶段
- Try 阶段:尝试执行,完成所有业务检查(一致性), 预留必须业务资源(准隔离性)
- Confirm 阶段:确认执行真正执行业务,不作任何业务检查,只使用 Try 阶段预留的业务资源,Confirm 操作要求具备幂等设计,Confirm 失败后需要进行重试。
- Cancel 阶段:取消执行,释放 Try 阶段预留的业务资源。Cancel 阶段的异常和 Confirm 阶段异常处理方案基本上一致,要求满足幂等设计。
把上面的转账作为例子,通常会在Try里面冻结金额,但不扣款,Confirm里面扣款,Cancel里面解冻金额,一个成功完成的TCC事务时序图如下:
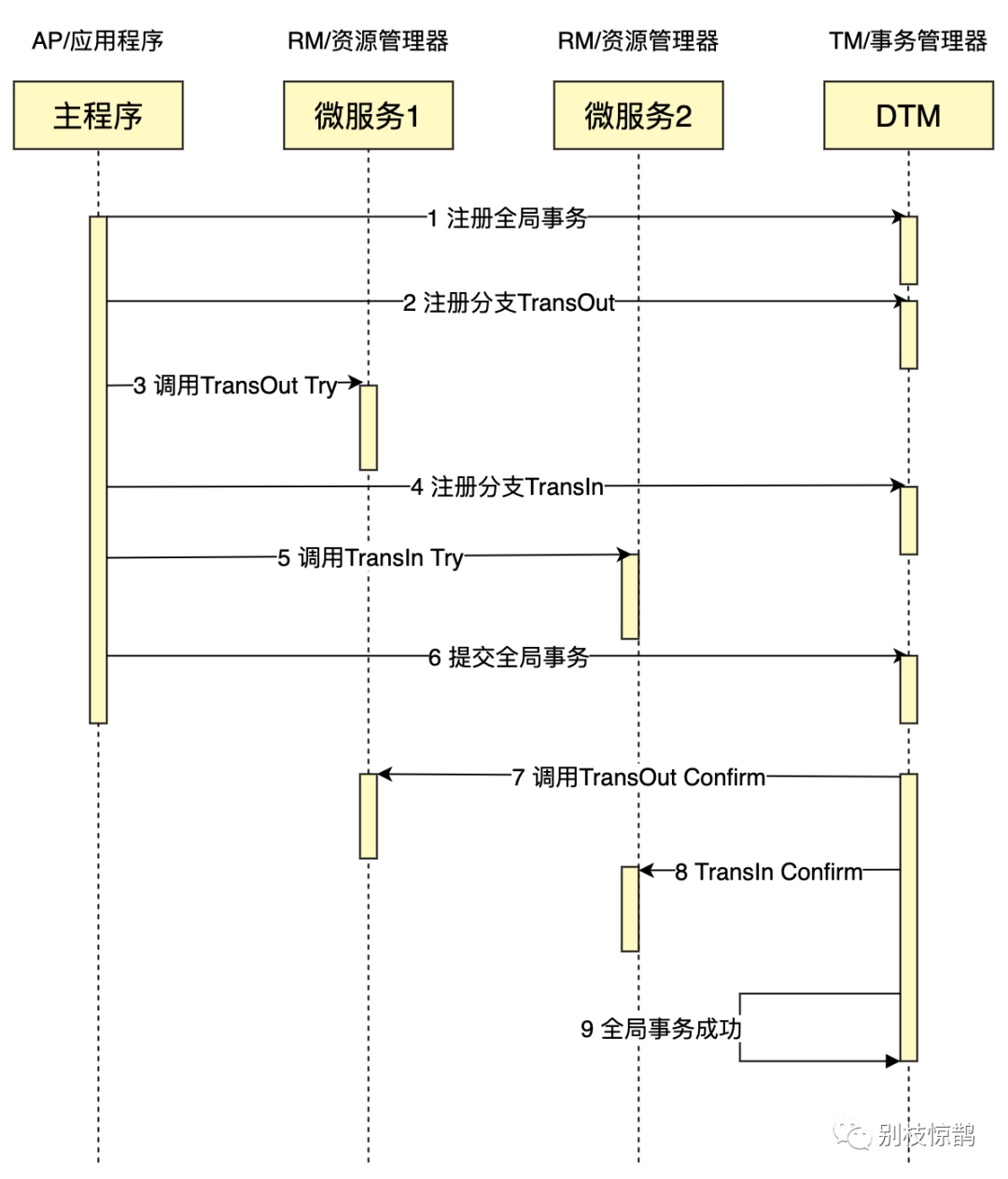
TCC特点如下:
- 并发度较高,无长期资源锁定。
- 开发量较大,需要提供Try/Confirm/Cancel接口。
- 一致性较好,不会发生SAGA已扣款最后又转账失败的情况
- TCC适用于订单类业务,对中间状态有约束的业务
如果读者想要进一步研究TCC,go语言可参考DTM,java语言可参考seata
本地消息表
本地消息表这个方案最初是 ebay 架构师 Dan Pritchett 在 2008 年发表给 ACM 的文章。设计核心是将需要分布式处理的任务通过消息的方式来异步确保执行。
大致流程如下:
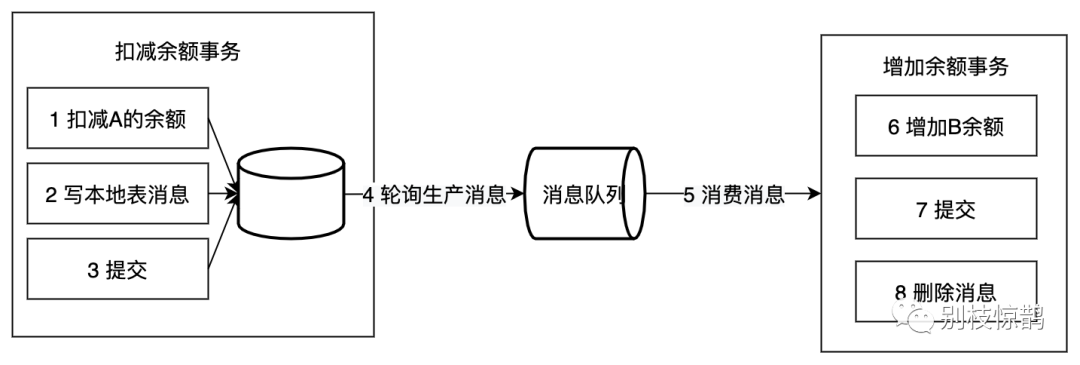
写本地消息和业务操作放在一个事务里,保证了业务和发消息的原子性,要么他们全都成功,要么全都失败。
容错机制:
- 扣减余额事务 失败时,事务直接回滚,无后续步骤
- 轮序生产消息失败, 增加余额事务失败都会进行重试
本地消息表的特点:
- 长事务仅需要分拆成多个任务,使用简单
- 生产者需要额外的创建消息表
- 每个本地消息表都需要进行轮询
- 消费者的逻辑如果无法通过重试成功,那么还需要更多的机制,来回滚操作
适用于可异步执行的业务,且后续操作无需回滚的业务
事务消息
在上述的本地消息表方案中,生产者需要额外创建消息表,还需要对本地消息表进行轮询,业务负担较重。阿里开源的RocketMQ 4.3之后的版本正式支持事务消息,该事务消息本质上是把本地消息表放到RocketMQ上,解决生产端的消息发送与本地事务执行的原子性问题。
事务消息发送及提交:
- 发送消息(half消息)
- 服务端存储消息,并响应消息的写入结果
- 根据发送结果执行本地事务(如果写入失败,此时half消息对业务不可见,本地逻辑不执行)
- 根据本地事务状态执行Commit或者Rollback(Commit操作发布消息,消息对消费者可见)
正常发送的流程图如下:
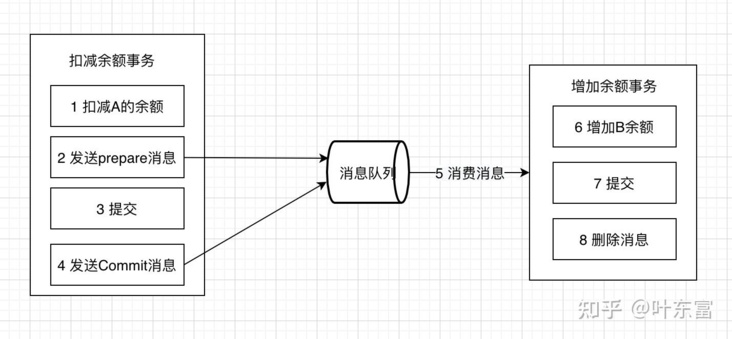
补偿流程:
对没有Commit/Rollback的事务消息(pending状态的消息),从服务端发起一次“回查” Producer收到回查消息,返回消息对应的本地事务的状态,为Commit或者Rollback 事务消息方案与本地消息表机制非常类似,区别主要在于原先相关的本地表操作替换成了一个反查接口
事务消息特点如下:
- 长事务仅需要分拆成多个任务,并提供一个反查接口,使用简单
- 消费者的逻辑如果无法通过重试成功,那么还需要更多的机制,来回滚操作
适用于可异步执行的业务,且后续操作无需回滚的业务
如果读者想要进一步研究事务消息,可参考github.com/apache/rocketmq,为了方便一站式解决分布式事务问题,github.com/yedf/dtm也提供了实现
最大努力通知
发起通知方通过一定的机制最大努力将业务处理结果通知到接收方。具体包括:
有一定的消息重复通知机制。因为接收通知方可能没有接收到通知,此时要有一定的机制对消息重复通知。 消息校对机制。如果尽最大努力也没有通知到接收方,或者接收方消费消息后要再次消费,此时可由接收方主动向通知方查询消息信息来满足需求。 前面介绍的的本地消息表和事务消息都属于可靠消息,与这里介绍的最大努力通知有什么不同?
可靠消息一致性,发起通知方需要保证将消息发出去,并且将消息发到接收通知方,消息的可靠性关键由发起通知方来保证。
最大努力通知,发起通知方尽最大的努力将业务处理结果通知为接收通知方,但是可能消息接收不到,此时需要接收通知方主动调用发起通知方的接口查询业务处理结果,通知的可靠性关键在接收通知方。
解决方案上,最大努力通知需要:
- 提供接口,让接受通知放能够通过接口查询业务处理结果
- 消息队列ACK机制,消息队列按照间隔1min、5min、10min、30min、1h、2h、5h、10h的方式,逐步拉大通知间隔 ,直到达到通知要求的时间窗口上限。之后不再通知
最大努力通知适用于业务通知类型,例如微信交易的结果,就是通过最大努力通知方式通知各个商户,既有回调通知,也有交易查询接口
AT 事务模式
这是阿里开源项目seata中的一种事务模式,在蚂蚁金服也被称为FMT。优点是该事务模式使用方式,类似XA模式,业务无需编写各类补偿操作,回滚由框架自动完成,缺点也类似AT,存在较长时间的锁,不满足高并发的场景。有兴趣的同学可以参考seata-AT
异常处理
在分布式事务的各个环节都有可能出现网络以及业务故障等问题,这些问题需要分布式事务的业务方做到防空回滚,幂等,防悬挂三个特性。
异常情况
下面以TCC事务说明这些异常情况:
空回滚:
在没有调用 TCC 资源 Try 方法的情况下,调用了二阶段的 Cancel 方法,Cancel 方法需要识别出这是一个空回滚,然后直接返回成功。
出现原因是当一个分支事务所在服务宕机或网络异常,分支事务调用记录为失败,这个时候其实是没有执行Try阶段,当故障恢复后,分布式事务进行回滚则会调用二阶段的Cancel方法,从而形成空回滚。
幂等:
由于任何一个请求都可能出现网络异常,出现重复请求,所以所有的分布式事务分支,都需要保证幂等性
悬挂:
悬挂就是对于一个分布式事务,其二阶段 Cancel 接口比 Try 接口先执行。
出现原因是在 RPC 调用分支事务try时,先注册分支事务,再执行RPC调用,如果此时 RPC 调用的网络发生拥堵,RPC 超时以后,TM就会通知RM回滚该分布式事务,可能回滚完成后,RPC 请求才到达参与者真正执行。
下面看一个网络异常的时序图,更好的理解上述几种问题

业务处理请求4的时候,Cancel在Try之前执行,需要处理空回滚 业务处理请求6的时候,Cancel重复执行,需要幂等 业务处理请求8的时候,Try在Cancel后执行,需要处理悬挂
面对上述复杂的网络异常情况,目前看到各家建议的方案都是业务方通过唯一键,去查询相关联的操作是否已完成,如果已完成则直接返回成功。相关的判断逻辑较复杂,易出错,业务负担重。
子事务屏障
在项目https://github.com/yedf/dtm中,首创了一种子事务屏障技术,使用该技术,能够达到这个效果,看示意图:
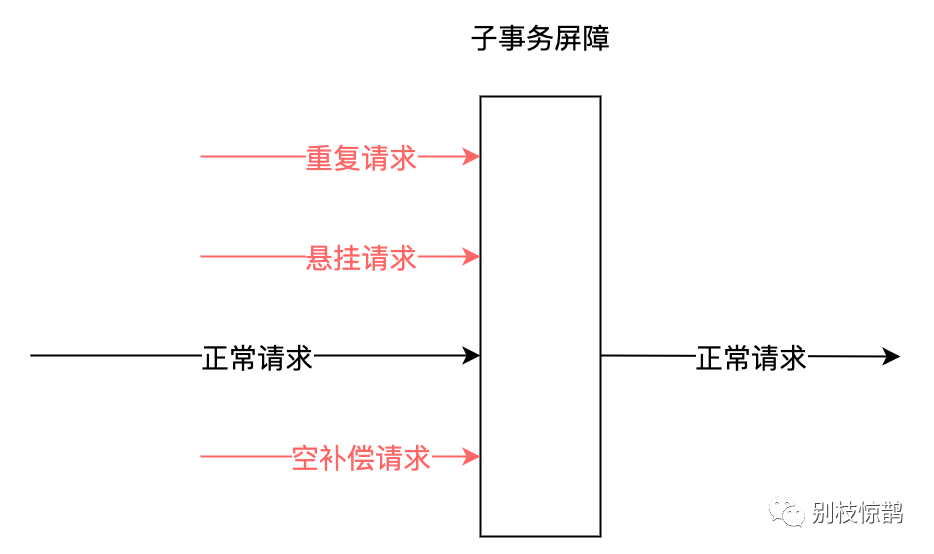
所有这些请求,到了子事务屏障后:不正常的请求,会被过滤;正常请求,通过屏障。开发者使用子事务屏障之后,前面所说的各种异常全部被妥善处理,业务开发人员只需要关注实际的业务逻辑,负担大大降低。 子事务屏障提供了方法ThroughBarrierCall,方法的原型为:
func ThroughBarrierCall(db *sql.DB, transInfo *TransInfo, busiCall BusiFunc)
业务开发人员,在busiCall里面编写自己的相关逻辑,调用该函数。ThroughBarrierCall保证,在空回滚、悬挂等场景下,busiCall不会被调用;在业务被重复调用时,有幂等控制,保证只被提交一次。
子事务屏障会管理TCC、SAGA、XA、事务消息等,也可以扩展到其他领域。
子事务屏障原理
子事务屏障技术的原理是,在本地数据库,建立分支事务状态表sub_trans_barrier,唯一键为全局事务id-子事务id-子事务分支名称(try|confirm|cancel)
- 开启事务
- 如果是Try分支,则那么insert ignore插入gid-branchid-try,如果成功插入,则调用屏障内逻辑
- 如果是Confirm分支,那么insert ignore插入gid-branchid-confirm,如果成功插入,则调用屏障内逻辑
- 如果是Cancel分支,那么insert ignore插入gid-branchid-try,再插入gid-branchid-cancel,如果try未插入并且cancel插入成功,则调用屏障内逻辑
- 屏障内逻辑返回成功,提交事务,返回成功
- 屏障内逻辑返回错误,回滚事务,返回错误
在此机制下,解决了网络异常相关的问题
- 空补偿控制–如果Try没有执行,直接执行了Cancel,那么Cancel插入gid-branchid-try会成功,不走屏障内的逻辑,保证了空补偿控制
- 幂等控制–任何一个分支都无法重复插入唯一键,保证了不会重复执行
- 防悬挂控制–Try在Cancel之后执行,那么插入的gid-branchid-try不成功,就不执行,保证了防悬挂控制
对于SAGA事务,也是类似的机制。
子事务屏障小结
子事务屏障技术,为https://github.com/yedf/dtm首创,它的意义在于设计简单易实现的算法,提供了简单易用的接口,在首创,它的意义在于设计简单易实现的算法,提供了简单易用的接口,在这两项的帮助下,开发人员彻底的从网络异常的处理中解放出来。
该技术目前需要搭配yedf/dtm事务管理器,目前SDK已经提供给go语言的开发者。其他语言的sdk正在规划中。对于其他的分布式事务框架,只要提供了合适的分布式事务信息,能够按照上述原理,快速实现该技术。
1.16 - 一致性与共识算法
分布式一致性
在一个分布式系统中,如何保证集群中所有节点中的数据完全相同,并且能够对某个提案(Proposal)达成一致,是分布式系统正常工作的核心问题,而共识算法就是用来保证分布式系统一致性的方法。
然而分布式系统中由于引入了多个节点,所以系统中会出现各种非常复杂的情况;随着节点数量增加,节点失效、故障或者宕机就变成了非常常见的事情,解决分布式系统中的各种边界条件和意外情况也增加了解决分布式一致性问题的难度。
在一个分布式系统中,除了节点的失效会是会导致一致性不容易达成的主要原因之外,节点之间的网络通信受到干扰甚至阻断,以及分布式系统的运行速度的差异都是解决分布式系统一致性所面临的难题。
CAP
在 1998 年秋,加州伯克利大学的教授 Eric Brewer 第一次发布了 CAP 理论,在 1999 年论文 “Brewer’s Conjecture and the Feasibility of Consitent, Available, Partition-Tolerant Web Service” 正式发布,其中总结了 Eric Brewer 提出的 CAP 理论。
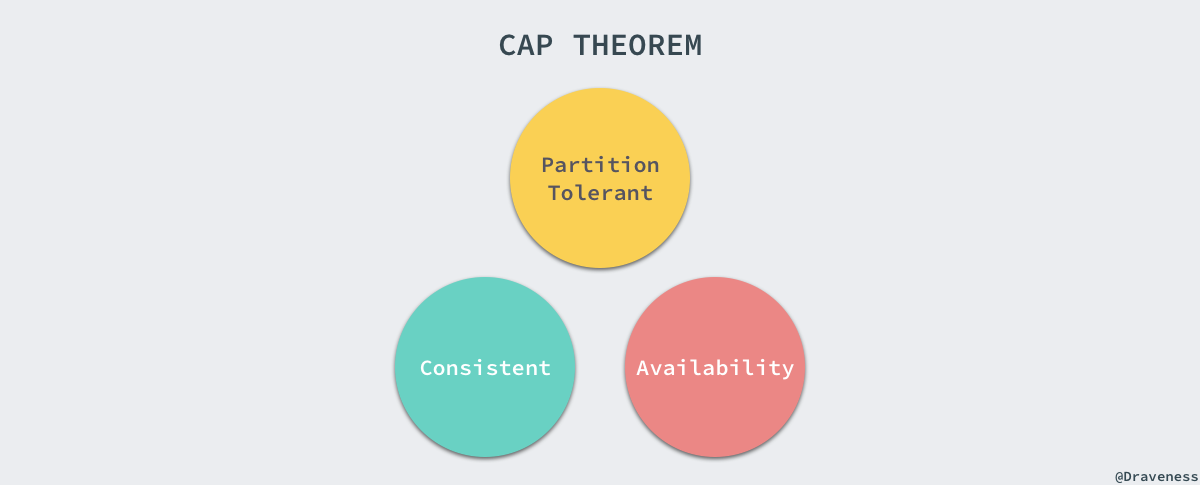
该论文证明了两个非常有意思的理论:首先是在异步网络模型中,所有的节点都是由于没有时钟,仅能根据接收到的消息做出判断,这时完全不能保证一致性、可用性、分区容错性,每个系统仅能在这三种特性中选择两种。
这里讨论的一致性都是强一致性,即所有节点接收到同样的操作时会按照完全相同的顺序执行,被一个节点提交的更新操作会立即反映在其他通过异步或部分同步网络连接的节点上,如果想要同时满足一致性和分区容错性,在异步网络中,我们只能中心化存储所有数据,通过其他节点将请求路由给中心节点达到这两个目的。
但是在现实世界中其实并不存在绝对异步的网络环境,如果我们允许每个节点拥有自己的时钟,这些时钟虽然有着各自不同的时间,但他们的**更新频率是完全相同的,**所以我们可以通过时钟得知接收消息的间隔时间,在这种更宽松的前提下,我们能够得到更加强大的服务。
然而在部分同步的网络环境中,仍然没有办法同时保证三种特性,证明的过程其实非常简单,可以直接阅读 论文的 4.2 节,然而时钟的出现能够让我们知道当前消息有多久没有得到回应,通过超时时间就能在一定程度上解决信息丢失的问题。
由于网络一定会存在延时,所以没有办法在分布式系统中做到强一致性的同时保证可用性,不过我们可以通过降低对一致性的要求,在一致性和可用性之间做出权衡,而这其实也是设计分布式系统首先要考虑的问题,由于强一致性的系统会导致系统的可用性降低,仅仅将接受请求的工作交给其他节点对于高并发的服务并不能解决问题,所以在目前主流的分布式系统中都选择最终一致性。
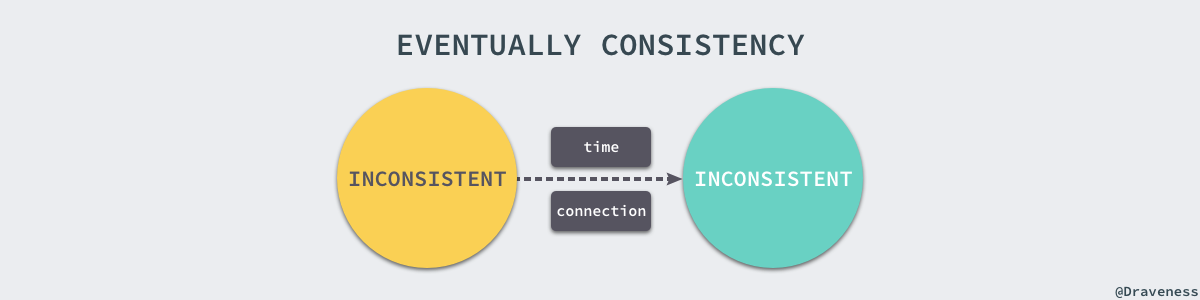
最终一致性允许多个节点间的状态出现冲突,但是所有能够沟通的节点都能够在有限的时间内解决冲突,从不一致的状态恢复到一致。这里列出的两个条件比较重要:一是节点直接可以正常通信,而是冲突需要在有限时间内解决,只有在两个条件均成立时才能达到最终一致性。
拜占庭将军问题
该问题是 Leslie Lamport 在 The Byzantine Generals Problem 论文中提出的分布式领域的容错问题,它是分布式领域中最复杂、最严格的容错模型。
在该模型下,系统不会对集群中的节点做任何的限制,它们可以向其他节点发送随机数据、错误数据,也可以选择不响应其他节点的请求,这些无法预测的行为使得容错这一问题变得更加复杂。
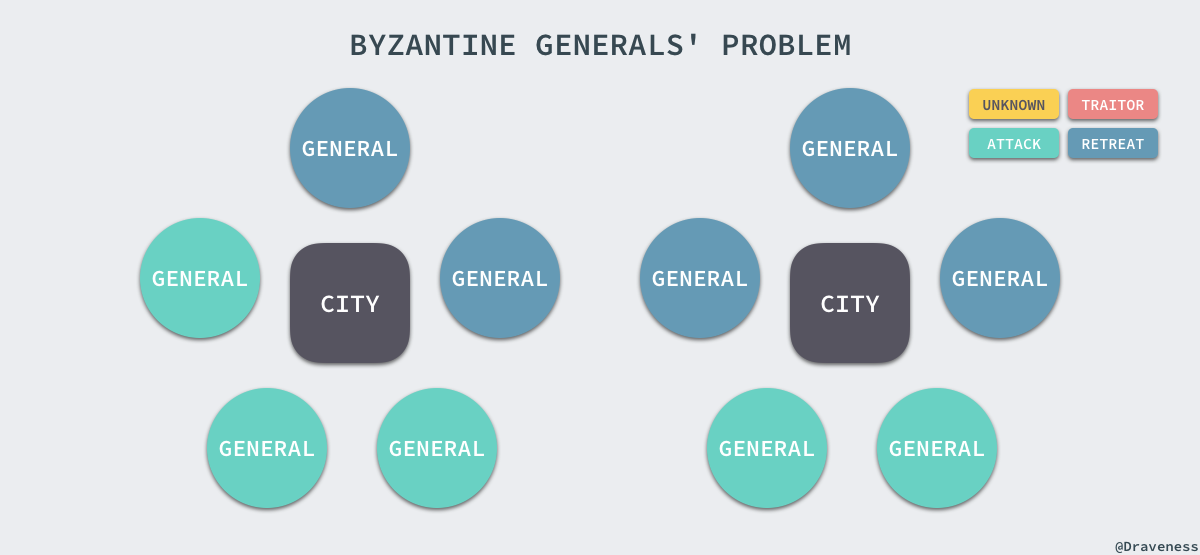
拜占庭将军问题描述了如下的场景,有一组将军分别指挥一部分军队,每个将军都不知道其他将军是否是可靠的,也不知道其他将军传递的信息是否可靠,但是他们需要通过投票选择是否要进攻或撤退:
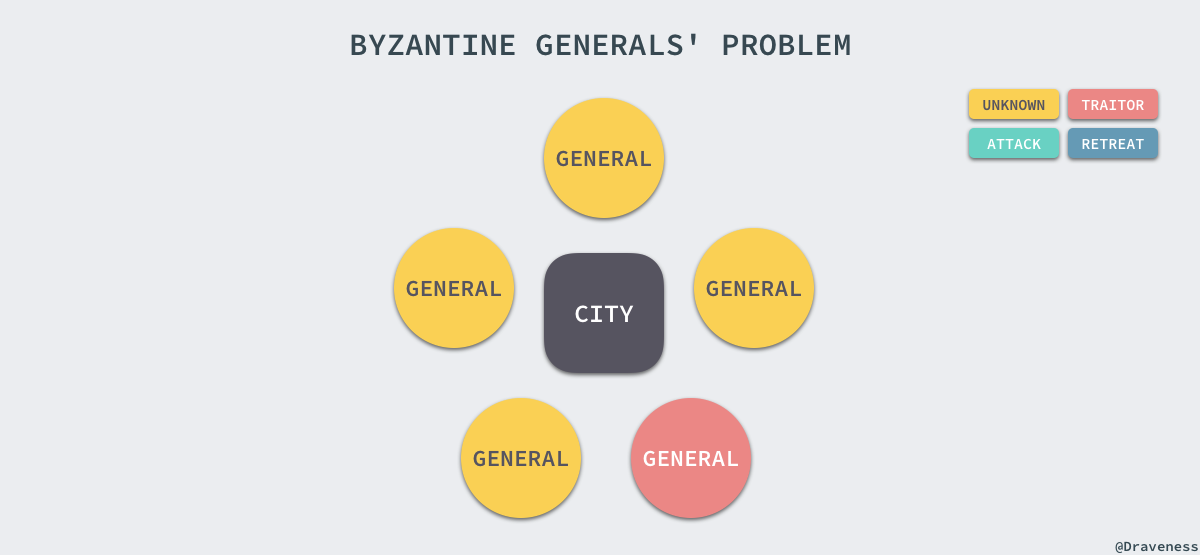
本节中,黄色代表状态未知,绿色代表进攻,蓝色代表撤退,红色代表当前将军的信息不可靠。
这时,无论将军是否可靠,只要所有的将军达成了统一的方案,选择进攻或撤退其实是没有任何问题的:
上述的情况不会对当前的战局造成太大影响,但是如果其中一个将军告诉其中一部分将军选择进攻,告诉另一部分将军选择撤退,就会出现非常严重的问题了。
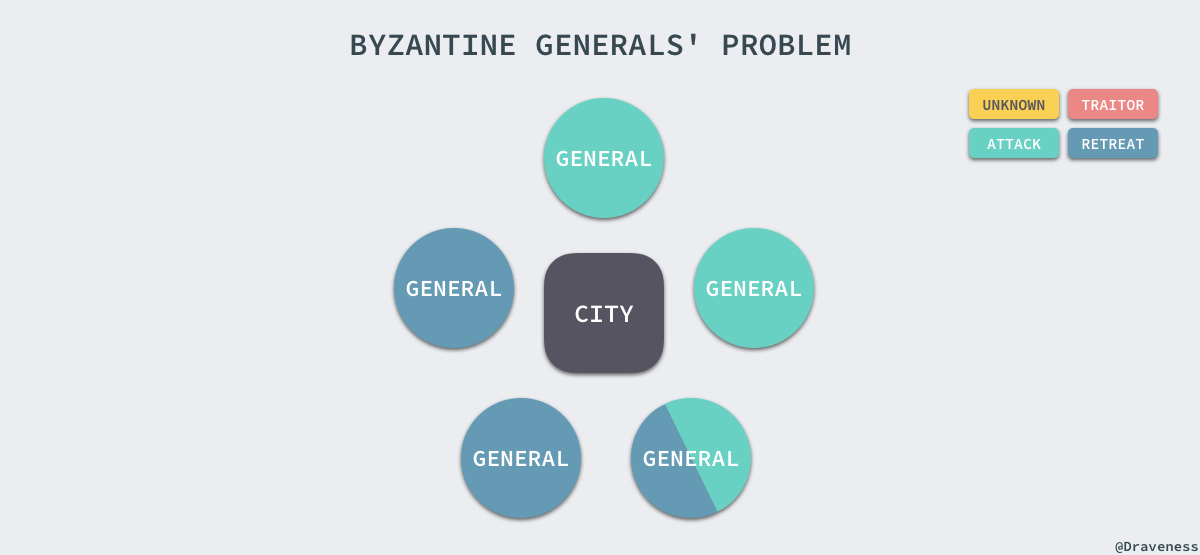
由于将军的队伍中出现了一个叛徒或者信息在传递的过程中被拦截,会导致一部分将军会选择进攻,剩下的一份会选择撤退,他们都认为自己的选择是大多数人的选择,这时会出现严重的不一致问题。
拜占庭将军问题是对分布式系统容错的最高要求,然而这不是日常工作中使用的大多数分布式系统中会面对的问题,我们遇到更多的还是节点故障宕机或者不响应等情况,这就大大简化了系统对容错的要求;不过类似 Bitcoin、Ethereum 等分布式系统确实需要考虑拜占庭容错的问题,我们会在下面介绍它们是如何解决的。
FLP
FLP 不可能定理是分布式系统领域最重要的定理之一,它给出了一个非常重要的结论:在网络可靠且存在节点失效的异步模型系统中,不存在一个可以解决一致性问题的确定性算法。
In this paper, we show the surprising result that no completely asynchronous consensus protocol can tolerate even a single unannounced process death. We do not consider Byzantine failures, and we assume that the message system is reliable it delivers all messages correctly and exactly once.
这个定理其实也就是告诉我们不要浪费时间去为异步分布式系统设计在任意场景上都能实现的共识算法,异步系统完全没办法保证在有限时间内达成一致,在这里作者并不会去尝试证明 FLP 不可能定理,读者可以阅读相关论文 Impossibility of Distributed Consensuswith One Faulty Process 了解更多内容。
共识算法
在上节中,我们已经简单了解了分布式系统中面对的问题与挑战,在这里我们会介绍不同共识算法的实现原理,包括传统分布式领域的 Paxos、Raft,以及加密货币中使用的工作量证明(POW)、权益证明(POS)和委托权益证明(DPOS),通过对这些共识算法原理的介绍和分析,我相信各位读者能对分布式一致性和共识算法有更深的理解。
Paxos 与 Raft
Paxos 和 Raft 是目前分布式系统领域中两种非常著名的解决一致性问题的共识算法,两者都能解决分布式系统中的一致性问题,但是前者的实现与证明非常难以理解,后者的实现比较简洁并且遵循人类的直觉,它的出现就是为了解决 Paxos 难以理解并难以实现的问题。
我们先来简单介绍一下 Paxos 究竟是什么。Paxos 其实是一类能够解决分布式一致性问题的协议,它能够让分布式网络中的节点在出现错误时仍然保持一致;Leslie Lamport 提出的 Paxos 可以在没有恶意节点的前提下保证系统中节点的一致性,也是第一个被证明完备的共识算法,目前完备的共识算法包括 Raft 本质上都是 Paxos 的变种。
作为一类协议,Paxos 中包括 Bais Paxos、Multi-Paxos、Cheap Paxos 和其他变种,这里我们会简单介绍 Basic Paxos 和 Multi-Paxos 这两种协议。
Basic Paxos
Basic Paxos 是 Paxos 中最为基础的协议,每个 Basic Paxos 的协议实例最终都会选择唯一一个结果;使用 Paxos 作为共识算法的分布式系统中,节点都会有三种身份,分别是 Proposer、Acceptor、Learner。
我们在这里会忽略最后一种身份 Learner 以简化协议的运行过程、便于理解;Paxos 的运行过程分为两个阶段,分别是准备阶段(Prepare) 和接受阶段(Accept),当 Proposer 接收到来自客户端的请求时,就会进入如下流程:
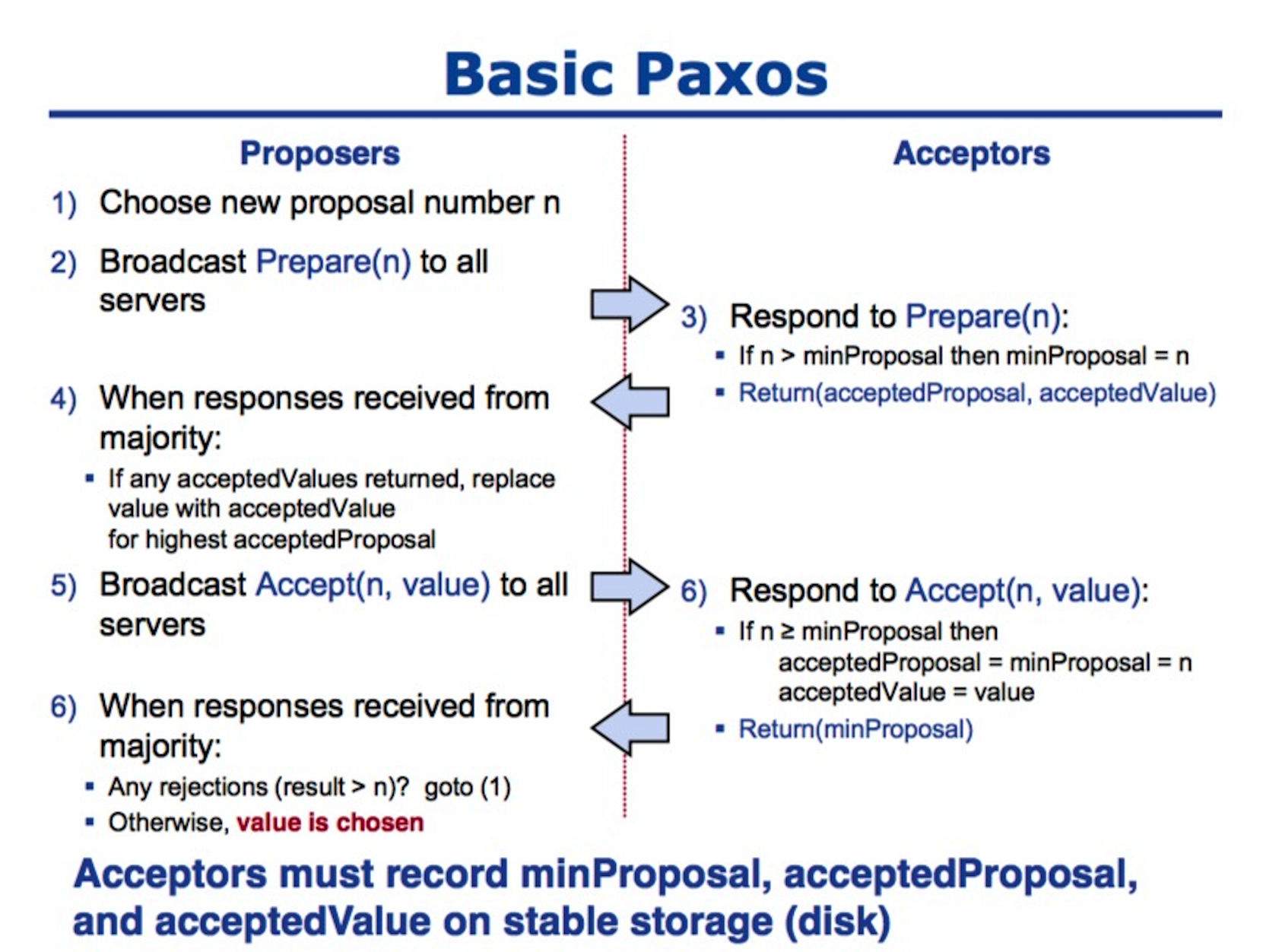
图片来自 Paxos lecture (Raft user study) 第 12 页。
在整个共识算法运行的过程中,Proposer 负责提出提案并向 Acceptor 分别发出两次 RPC 请求,Prepare 和 Accept;Acceptor 会根据其持有的信息 minProposal、acceptedProposal、acceptValue,来选择接受或拒绝当前的提案,当某一个提案被过半数的 Acceptor 接受之后,我们就认为当前提案被整个集群接受了。
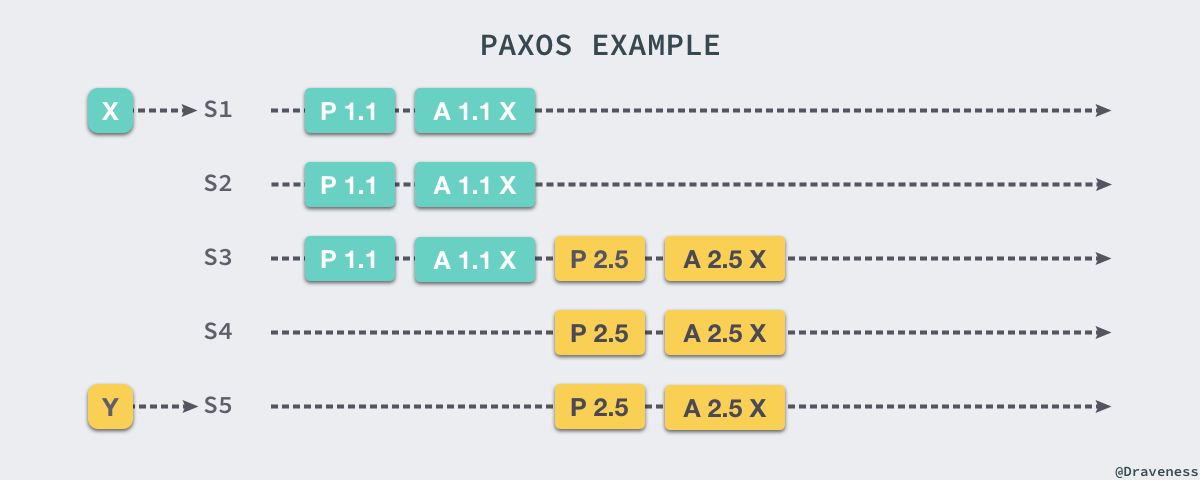
我们简单举一个例子来介绍 Paxos 是如何在多个提案下保证最终能够达到一致性的,上图中 S1 和 S5 分别接收到了来自客户端的请求 X 和 Y,S1 首先向 S2 和 S3 发出 Prepare RPC 和 Accept RPC,三个服务器都接受了 S1 的提案;之后,S5 向 S3 和 S4 服务器发出 Prepare(2.5) 的请求,S3 由于已经接受了 X,所以他会返回接受的提案和值 (1.1, X),这时服务器使用接收到的提案代替自己的提案 Y,重新向其他服务器发送 Accept(2.5 X) 的 RPC,最终所有的服务器会达成一致并选择相同的值。
Multi-Paxos
由于大多数分布式服务器都要接受一系列的值,如果使用 Basic Paxos 来处理数据流,那么就会导致非常明显的性能损失,而 Multi-Paxos 是前者的加强版,如果集群中的 Leader 是非常稳定的,那么我们往往不需要准备阶段的工作,这样就能将 RPC 的次数减少一半。

上图中描述的就是稳定阶段 Multi-Paxos 的处理过程,S1 是整个集群的 Leader,当其他的节点接收到来自客户端的请求时,都会将请求转发给 Leader 进行处理。
当然,Leader 角色的出现自然会带来另一个问题,也就是 Leader 究竟应该如何选举,在 Paxos Made Simple 一文中并没有给出 Multi-Paxos 的具体实现方法和细节,所以不同的 Multi-Paxos 实现会有各种细微的差别。
Raft
Raft 其实就是 Multi-Paxos 的一个变种,Raft 通过简化 Multi-Paxos 模型,实现了一种更易让人理解的共识算法,它们两者都能够对一系列连续的问题达成一致。
Raft 在 Multi-Paxos 的基础上做了两个限制,首先是 Raft 中追加日志的操作必须是连续的,而 Multi-Paxos 中追加日志的操作是并发的,但是对于节点内部的状态机来说两者都是有序的;第二就是 Raft 对 Leader 选举的条件做了限制,只有拥有最新、最全日志的节点才能够当选 Leader,但是 Multi-Paxos 由于任意节点都可以写日志,所以在选择 Leader 上么有什么限制,只是在选择 Leader 之后需要将 Leader 中的日志补全。
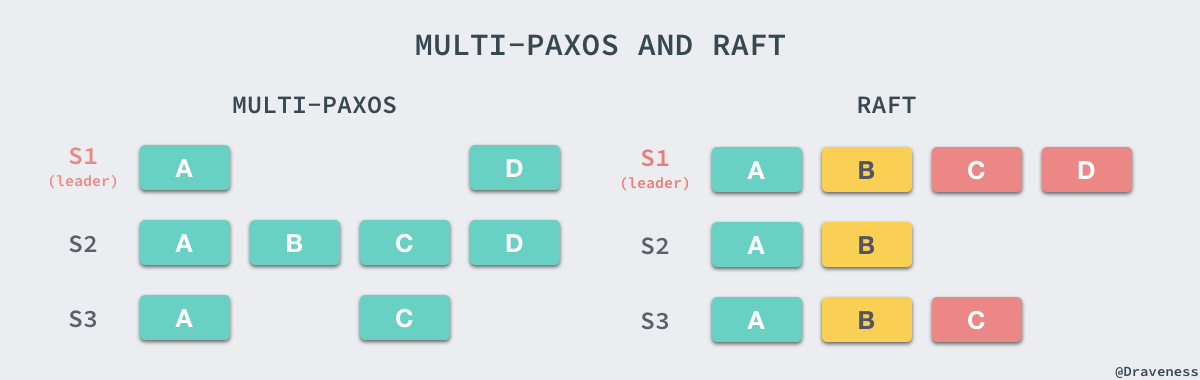
在 Raft 中,所有 Follower 的日志都是 Leader 的子集,而 Multi-Paxos 中的日志并不会做这个保证,由于 Raft 对日志追加的方式和选举过程进行了限制,所以在实现上会更加容易和简单。
从理论上来讲,支持并发日志追加的 Paxos 会比 Raft 拥有更加优秀的性能,不过其理解和实现上还是比较复杂的,很多人都会说 Paxos 是科学,而 Raft 是工程,当作者需要去实现一个共识算法,会选择使用 Raft 和更简洁的实现,避免因为一些边界条件带来的复杂问题。
可以查看 The Raft Consensus Algorithm 了解更多 Raft 的细节。
POW:Proof-of-Work
上一节介绍的共识算法,无论是 Paxos 还是 Raft 其实都只能解决拜占庭将军问题的一致性问题,不能够应对分布式网络中出现的极端情况,但是这在传统的分布式系统都不是什么问题,无论分布式数据库还是消息队列集群,它们内部的节点并不会故意发送错误信息,在类似系统中,最常见的问题就是节点失去响应或失效,所以它们在这种情况下是有效可行的,也是充分的。
这一节介绍的 工作量证明 是一个用于阻止拒绝服务攻击(DDOS)和类似垃圾邮件等服务错误问题的协议,它在 1993 年被 Cynthia Dwork 和 Moni Naor 提出,它能够帮助分布式系统达到拜占庭容错。
工作量证明的关键特点就是,分布式系统中的请求服务的节点必须解决一个一般难度但是可行(feasible)的问题,但是验证问题答案的过程对于服务提供者来说却非常容易,也就是一个不容易解答但是容易验证的问题。
这种问题通常需要消耗一定的 CPU 时间来计算某个问题的答案,目前最大的区块链网络-比特币(Bitcoin) 就使用了工作量证明的分布式一致性算法,在网络中的所有节点计算通过以下的谜题来获得当前区块的记账权:
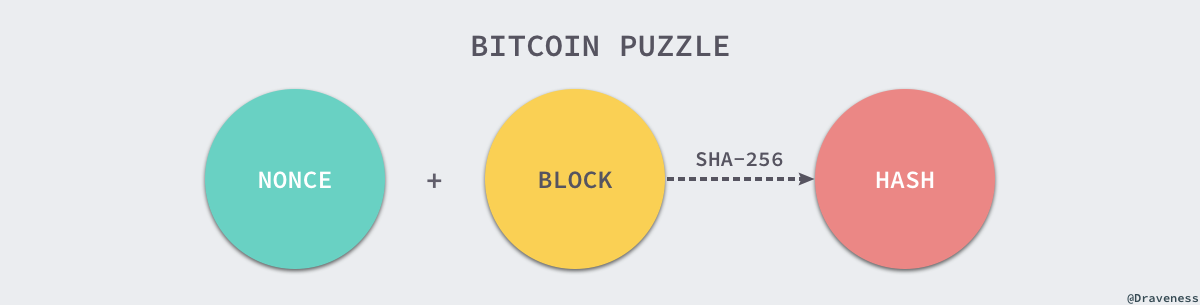
SHA-256 作为一个哈希函数,想要通过 SHA-256 函数的输出推断输入在目前来看可能性是可以忽略不计的,比特币网络就需要每一个及诶单不断改变 NONCE 来得到不同的 HASH,如果得到的 HASH 结果在小于某个范围,目前(2017-12-17)的难度是:
0x0000000000000000000000000000000000000000000000000000017268d8a21a
也就是说如果只计算一次 SHA-256 的值能够小于上述结果的可能性是 1.37 ∗ 10^-65,当前的全网算力也达到了 13,919 PH/s,这是个非常恐怖的数字,随着网络算力的不断改变,比特币也会不断改变当前问题的难度,保证每个区块被发现的时间在 10min 左右;整个比特币网络中,谁先得到当前问题的答案就能获得这个区块的记账权,并将当前区块通过 Gossip 协议发送给尽可能多的比特币节点。
工作量证明的原理其实非常简单,比特币网络选择的谜题非常好的适应了工作量证明定义中的问题,比较难以计算同时又易于验证,我们可以简单理解为工作量证明防止错误或者无效请求的原理就是增加客户端请求服务的工作量,而适合难度的谜题又能保证合法的请求不会受影响。
由于工作量证明需要消耗大量的算力,同时比特币大约 10min 才会产生一个区块,区块的大小也只有 1MB,仅仅能够包含 3-4000 笔交易,平均下来每秒只能够处理 5~7 笔交易,所以比特币网络的拥堵非常严重。
POS:Proof-of-Stake
权益证明是区块链网络中使用的另一种共识算法,在基于权益证明的加密货币中,下一个区块的选择是根据不同节点的股份和时间随机进行的。
由于创造新的区块不会消耗大量的 CPU,如果它不诚实也不会造成什么损失,这也就给了很多节点作弊的理由,每个节点为了最大化利益会在多条链上同时挖矿。
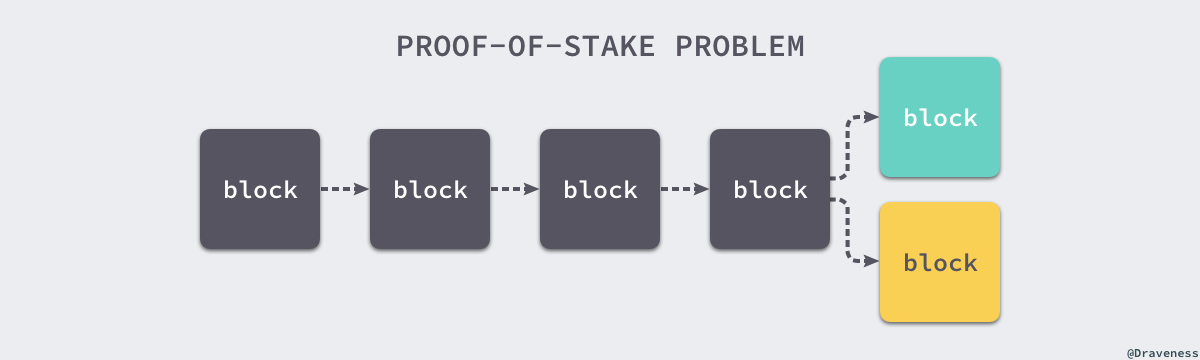
在早期的所有权证明算法中,整个网络只会奖励创建区块的节点,不存在任何惩罚,这时每个节点在创造的多条链上同时投票才能够最大化利益,在这种情况下网络中的节点很难对一条链达成共识。
有两种办法能够解决缺乏厉害关系(nothing-at-stake)造成的问题,一种是使用 Slasher 协议,惩罚同时在多条链上投票的节点;第二种方法是直接惩罚在错误的链上创建块的节点,总而言之就是通过算法之外的手段来解决这个问题,引入激励和惩罚。
与工作量证明相比,权益证明不需要消耗大量的电力就能保证区块链网络的安全性,同时也不需要在每个区块中创建新的货币来激励旷工参与当前网络的运行,这也就在一定程度上缩短了达成共识所需要的时间,基于权益证明的 Ethereum 每秒大概处理 30 笔交易左右。
DPOS:Delegated Proof-of-Stake
前面介绍的权益证明算法可以将整个区块链网络理解为一家公司,出资最多、占比最大的人又更多的机会得到话语权(记账权);对于小股东来说,千分之几甚至万分之几的股份很难有什么作为,只能得到股份带来的分红和收益。
但是在这里介绍的委托权益证明能够让每个人选出可以代表自己利益的人参与到记账权的争夺中,这样多个小股东就能够通过投票选出自己的代理人,保障自己的利益。整个网络中选举出的多个节点能够在 1s 之内对 99.9% 的交易进行确认,使用委托权益证明的 EOS 能够每秒处理几十万笔交易,同时也能够比较监管的干预。
在委托权益证明中,每个参与者都能够选举任意数量的节点生成下一个区块,得票最多的前 N 个节点会被选择成为区块的创建者,下一个区块的创建者就会从这样一组当选者中随机选取,除此之外,N 的数量也是整个网络投票决定的,所以可以尽可能的保证网络的去中心化。
Reference
- Consensus (computer science)
- 区块链共识算法(POW,POS,DPOS,PBFT)介绍和心得
- Paxos 与 Raft
- Proof-of-work system
- Proof-of-stake
- Proof of Stake FAQ · Ethereum Wiki
- Delegated Proof of Stake
- Delegated Proof-of-Stake Consensus
- DPOS共识算法 – 缺失的白皮书
- 共识算法
- CAP theorem
- Paxos Made Simple
- The Raft Consensus Algorithm
- In Search of an Understandable Consensus Algorithm
- 谈谈 paxos, multi-paxos, raft
- Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services
- “Eventual Consistency” vs “Strong Eventual Consistency” vs “Strong Consistency”?
- Impossibility of Distributed Consensuswith One Faulty Process
- The Byzantine Generals Problem
- Byzantine fault tolerance
- A Brief Tour of FLP Impossibility
- Paxos Made Simple
- Neat Algorithms - Paxos
- FLP Impossibility 的证明
- 白话区块链
- Paxos
- Paxos lecture (Raft user study)
- Bitcoin: A Peer-to-Peer Electronic Cash System
- Proof of Stake · Bitcoin Wiki
- Slasher
- Proof of Stake FAQ
1.17 - 分布式锁
前情提要
基于分布式的 CAP (一致性、可用性、容错性)原理,系统在设计之初必须要考虑取舍,在互联网领域的绝大多数场景中,一般会牺牲强一致性来换取高可用性,只需要保证最终一致性即可,而这个最终一致的时间是用户可接受的范围即可。
为了保证最终一致性,一般会使用分布式事务、分布式锁等,分布式锁也有多种实现方案:
- 基于数据库
- 基于缓存
- 基于 zookeeper
分布式锁的实现目标:
- 可以保证在分布式部署的应用集群中,同一个方法在同一时间只能被一台机器上的一个线程执行;
- 必须是可重入锁,以避免死锁
- 可以根据业务决定是不是一个阻塞锁
- 有高可用的加锁解锁功能
- 加锁解锁操作的性能要高
基于数据库
基于表
在数据库中创建表,要锁住某个方法或资源时,在表中增加一条记录,想要释放时删除该记录。
创建表:
CREATE TABLE `methodLock` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`method_name` varchar(64) NOT NULL DEFAULT '' COMMENT '锁定的方法名',
`desc` varchar(1024) NOT NULL DEFAULT '备注信息',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '保存数据时间,自动生成',
PRIMARY KEY (`id`),
UNIQUE KEY `uidx_method_name` (`method_name `) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='锁定中的方法';
加锁操作:
insert into methodLock(method_name,desc) values (‘method_name’,‘desc’);
解锁操作:
delete from methodLock where method_name ='method_name';
缺点:
- 这把锁强依赖于数据库的高可用性;
- 锁没有失效时间,一旦解锁操作失败,将导致其他线程无法再获得锁;
- 这把锁只能是非阻塞的,因为数据的插入操作一旦失败就会返回报错。没有获得锁的线程并不会排队进入队列,想要再次获得锁就要再次出发获得锁操作;
- 这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为表中数据已经存在了。
解决方法:
- 使用分布式数据库;
- 使用定时任务,按时清理超时的锁;
- 通过 while 循环直到插入成功;
- 添加字段,记录当前获得锁的主机的信息和线程信息,然后在下次获取锁时先查询,如果信息匹配则分配锁。
基于数据库排它锁
基于 MySQL 中 InnoDB 自带的排它锁实现加锁:
public boolean lock(){
connection.setAutoCommit(false)
while(true){
try{
result = select * from methodLock where method_name=xxx for update;
if(result==null){
return true;
}
}catch(Exception e){
}
sleep(1000);
}
return false;
}
在查询语句后面增加for update,数据库会在查询过程中给数据库表增加排它锁,当某条记录被加上排它锁之后,其他线程则无法再在该记录上增加排它锁。
InnoDB 引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则会使用表级锁。这里我们希望使用行级锁,就要给
method_name添加索引,同时一定要创建成唯一索引,否则会出现多个重载方法之间无法同时被访问的问题,重载方法的话建议同时保存参数类型。
这时可以认为获得排他锁的线程即获得了分布式锁,当获取到锁之后,可以执行方法的业务逻辑,最后再进行解锁操作:
public void unlock(){
connection.commit();
}
这种方式可以有效解决上面提到的无法解锁和阻塞锁的问题。
- 阻塞锁:
for update语句会在执行成功之后立即返回,在执行失败时一直处于阻塞状态,直到成功; - 锁定之后服务宕机造成的无法释放:这种方式下,服务宕机时数据库会自动释放锁。
但是仍然无法解决单点问题和可重入问题。
另一个问题:虽然对method_name使用了唯一索引,并且显式使用for update来使用行级别锁。但是,MySQL 会对查询进行优化,即便在条件中使用了索引字段,但是否使用索引来检索数据仍然是由 MySQL 通过判断不同执行计划的代价来决定的,如果 MySQL 自认为扫表效率更高,比如对一些很小的表,则不会使用索引,这是将会使用表锁而不是行锁。。。
同时,我们要使用排它锁来进行分布式锁的 lock,那么一个排它锁长时间不提交就会占用数据库连接,连接过多则造成数据库不可用。
基于缓存
基于类似 Redis、Memcached、Tair等缓存时,性能会表现更好。
比如在 Tair 中使用TairManager.put进行加锁和解锁操作:
public boolean trylock(String key) {
ResultCode code = ldbTairManager.put(NAMESPACE, key, "This is a Lock.", 2, 0);
if (ResultCode.SUCCESS.equals(code))
return true;
else
return false;
}
public boolean unlock(String key) {
ldbTairManager.invalid(NAMESPACE, key);
}
同样会存在的问题:
- 锁没有失效时间;
- 只能是非阻塞的,无论成功失败都会直接返回;
- 是非重入的,一个线程获得锁之后,在释放之前,都无法再获得锁,因为使用的 KEY 在 缓存中已存在,无法再次进行 put 操作。
解决方式:
- put 时设置过期时间;
- while 重复执行知道成功;
- 保存主机和线程信息。
但是失效时间设计为多久合适呢?太短的话还没执行完就自动释放了,太久则浪费时间。
基于 ZK
基于 ZK 临时有序节点来实现分布式锁。
每个客户端对某个方法加锁时,在 ZK 中的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。当释放锁的时候,只需要将这个节点删除即可。同时可以避免因宕机而造成的死锁。
是否能解决其他实现遇到的问题:
- 可以有效解决无法释放问题,因为在创建锁的时候,客户端会在 ZK 中创建一个临时节点,一点客户端宕机则 session 连接断开,这时临时节点会自动删除,其他客户端会再次获得锁。
- 阻塞锁:客户端通过在 ZK 中创建顺序节点,并且在节点中绑定监听器,一旦节点有变化,ZK 会通知客户端,客户端可以检查自己创建的节点是不是当前所有节点中需要最小的,如果是,那么自己就获得锁。
- 可重入:客户端在创建节点时同时保存主机与线程信息,下次想要获取时和当前最小节点中的信息进行对比即可,相同则获得锁,不同在创建一个新的节点来进行排队。
- 单点:ZK 本身就作为高可用集群部署。
同时可以直接使用 ZK 的三方库 Curator 客户端,这个客户端中已经封装了一个可重入锁服务:
public boolean tryLock(long timeout, TimeUnit unit) throws InterruptedException{
try{
return interProcessMutex.acquire(timeout, unit);
} catch (Exception e){
e.printStackTrace();
}
return true;
}
public boolean unlock(){
try{
interProcessMutex.release();
}catch(Throwable e){
log.error(e.getMessage(), e)
} finally{
executorService.schedule(new Cleaner(client, path), delayTimeForClean, TimeUnit.MILLISECONDS);
}
return true;
}
只是基于 ZK 的实现在性能上达不到基于缓存的实现,这是由 ZK 的分布式机制决定的(Leader 执行再同步到所有 follower)。
同时可能带来并发问题,只是不常见而已。比如,由于网络抖动,客户端与 ZK 集群的 session 断开了,那么 ZK 会以为客户端挂了,这时删除临时节点,这时其他节点则获得了锁,则可能产生并发问题。不常见是因为 ZK 有重试机制,一旦 ZK 集群检测不到客户端心跳就会进行重试,Curator 客户端支持多种尝试策略,多次重试仍然不行则删除临时节点。
总结
从理解的难以程度(由低到高):数据库 - 缓存 - ZK
从实现复杂度(由低到高):ZK -= 缓存 - 数据库
性能角度(由高到低):缓存 - ZK -= 数据库
可靠性(由高到低):ZK - 缓存 - 数据库
1.18 - 一致性哈希算法
当我们在做数据库分库分表或者是分布式缓存时,不可避免的都会遇到一个问题: 如何将数据均匀的分散到各个节点中,并且尽量的在加减节点时能使受影响的数据最少。
Hash 取模
随机放置就不说了,会带来很多问题。通常最容易想到的方案就是 hash 取模了。
可以将传入的 Key 按照 index = hash(key) % N 这样来计算出需要存放的节点。其中 hash 函数是一个将字符串转换为正整数的哈希映射方法,N 就是节点的数量。
这样可以满足数据的均匀分配,但是这个算法的容错性和扩展性都较差。比如增加或删除了一个节点时,所有的 Key 都需要重新计算,显然这样成本较高,为此需要一个算法满足分布均匀同时也要有良好的容错性和拓展性。
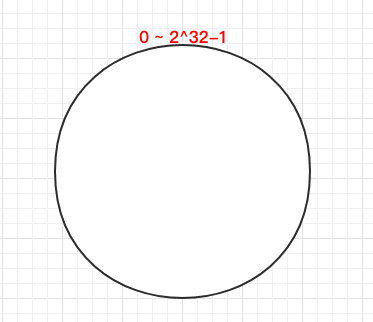
一致 Hash 算法
一致 Hash 算法是将所有的哈希值构成了一个环,其范围在 0 ~ 2^32-1。如下图:
之后将各个节点散列到这个环上,可以用节点的 IP、hostname 这样的唯一性字段作为 Key 进行 hash(key),散列之后如下:
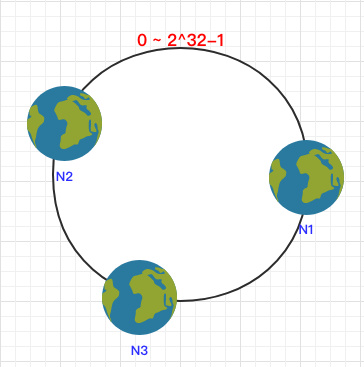
之后需要将数据定位到对应的节点上,使用同样的 hash 函数 将 Key 也映射到这个环上。
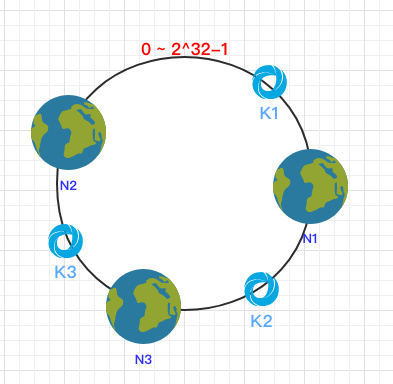
这样按照顺时针方向就可以把 k1 定位到 N1节点,k2 定位到 N3节点,k3 定位到 N2节点。
容错性
这时假设 N1 宕机了:
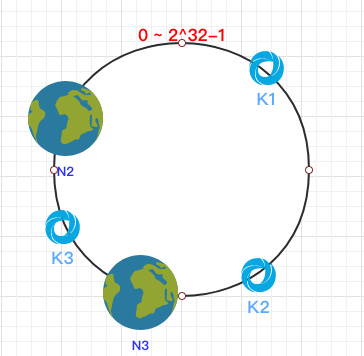
依然根据顺时针方向,k2 和 k3 保持不变,只有 k1 被重新映射到了 N3。这样就很好的保证了容错性,当一个节点宕机时只会影响到少少部分的数据。
拓展性
当新增一个节点时:
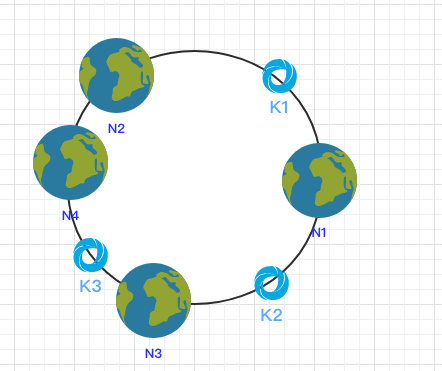
在 N2 和 N3 之间新增了一个节点 N4 ,这时会发现受印象的数据只有 k3,其余数据也是保持不变,所以这样也很好的保证了拓展性。
虚拟节点
到目前为止该算法依然也有点问题。
当节点较少时会出现数据分布不均匀的情况:
这样会导致大部分数据都在 N1 节点,只有少量的数据在 N2 节点。
为了解决这个问题,一致哈希算法引入了虚拟节点。将每一个节点都进行多次 hash,生成多个节点放置在环上称为虚拟节点:
计算时可以在 IP 后加上编号来生成哈希值。
这样只需要在原有的基础上多一步由虚拟节点映射到实际节点的步骤即可让少量节点也能满足均匀性。
1.19 - 全局唯一标识
为什么需要全局唯一ID
传统的单体架构的时候,我们基本是单库然后业务单表的结构。每个业务表的ID一般我们都是从1增,通过AUTO_INCREMENT=1设置自增起始值,但是在分布式服务架构模式下分库分表的设计,使得多个库或多个表存储相同的业务数据。这种情况根据数据库的自增ID就会产生相同ID的情况,不能保证主键的唯一性。

如上图,如果第一个订单存储在 DB1 上则订单 ID 为1,当一个新订单又入库了存储在 DB2 上订单 ID 也为1。我们系统的架构虽然是分布式的,但是在用户层应是无感知的,重复的订单主键显而易见是不被允许的。那么针对分布式系统如何做到主键唯一性呢?
UUID
UUID (Universally Unique Identifier),通用唯一识别码的缩写。UUID是由一组32位数的16进制数字所构成,所以UUID理论上的总数为 16^32=2^128,约等于 3.4 x 10^38。也就是说若每纳秒产生1兆个UUID,要花100亿年才会将所有UUID用完。
生成的UUID是由 8-4-4-4-12格式的数据组成,其中32个字符和4个连字符’ - ‘,一般我们使用的时候会将连字符删除 uuid.toString().replaceAll("-","")。
目前UUID的产生方式有5种版本,每个版本的算法不同,应用范围也不同。
基于时间的UUID- 版本1: 这个一般是通过当前时间,随机数,和本地Mac地址来计算出来,可以通过 org.apache.logging.log4j.core.util包中的 UuidUtil.getTimeBasedUuid()来使用或者其他包中工具。由于使用了MAC地址,因此能够确保唯一性,但是同时也暴露了MAC地址,私密性不够好。DCE安全的UUID- 版本2 DCE(Distributed Computing Environment)安全的UUID和基于时间的UUID算法相同,但会把时间戳的前4位置换为POSIX的UID或GID。这个版本的UUID在实际中较少用到。基于名字的UUID(MD5)- 版本3 基于名字的UUID通过计算名字和名字空间的MD5散列值得到。这个版本的UUID保证了:相同名字空间中不同名字生成的UUID的唯一性;不同名字空间中的UUID的唯一性;相同名字空间中相同名字的UUID重复生成是相同的。随机UUID- 版本4 根据随机数,或者伪随机数生成UUID。这种UUID产生重复的概率是可以计算出来的,但是重复的可能性可以忽略不计,因此该版本也是被经常使用的版本。JDK中使用的就是这个版本。基于名字的UUID(SHA1)- 版本5 和基于名字的UUID算法类似,只是散列值计算使用SHA1(Secure Hash Algorithm 1)算法。
我们 Java中 JDK自带的 UUID产生方式就是版本4根据随机数生成的 UUID 和版本3基于名字的 UUID,有兴趣的可以去看看它的源码。
public static void main(String[] args) {
//获取一个版本4根据随机字节数组的UUID。
UUID uuid = UUID.randomUUID();
System.out.println(uuid.toString().replaceAll("-",""));
//获取一个版本3(基于名称)根据指定的字节数组的UUID。
byte[] nbyte = {10, 20, 30};
UUID uuidFromBytes = UUID.nameUUIDFromBytes(nbyte);
System.out.println(uuidFromBytes.toString().replaceAll("-",""));
}
得到的UUID结果:
59f51e7ea5ca453bbfaf2c1579f09f1d
7f49b84d0bbc38e9a493718013baace6
虽然 UUID 生成方便,本地生成没有网络消耗,但是使用起来也有一些缺点,
- 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,暴露使用者的位置。
- 对MySQL索引不利:如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能,可以查阅 Mysql 索引原理 B+树的知识。
数据库生成
是不是一定要基于外界的条件才能满足分布式唯一ID的需求呢,我们能不能在我们分布式数据库的基础上获取我们需要的ID?
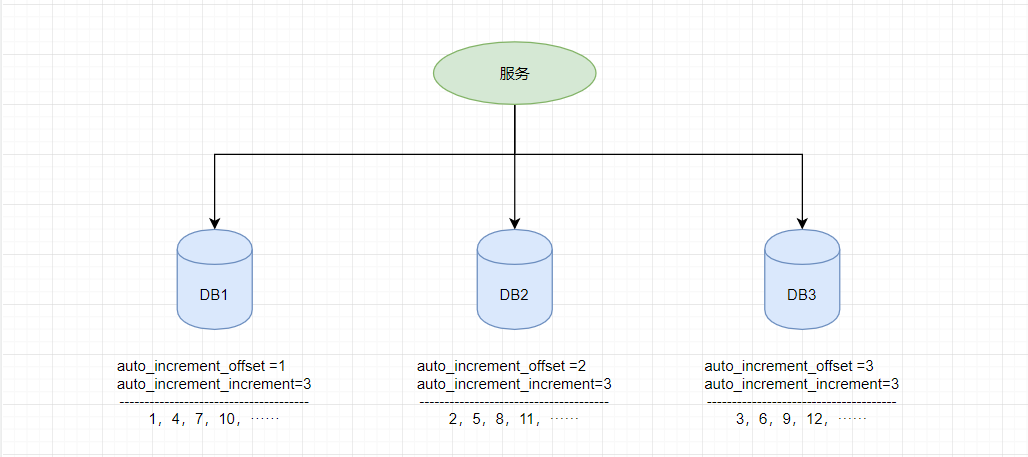
由于分布式数据库的起始自增值一样所以才会有冲突的情况发生,那么我们将分布式系统中数据库的同一个业务表的自增ID设计成不一样的起始值,然后设置固定的步长,步长的值即为分库的数量或分表的数量。
以MySQL举例,利用给字段设置auto_increment_increment和auto_increment_offset来保证ID自增。
auto_increment_offset:表示自增长字段从那个数开始,他的取值范围是1 .. 65535。auto_increment_increment:表示自增长字段每次递增的量,其默认值是1,取值范围是1 .. 65535。
假设有三台机器,则DB1中order表的起始ID值为1,DB2中order表的起始值为2,DB3中order表的起始值为3,它们自增的步长都为3,则它们的ID生成范围如下图所示:
通过这种方式明显的优势就是依赖于数据库自身不需要其他资源,并且ID号单调自增,可以实现一些对ID有特殊要求的业务。
但是缺点也很明显,首先它强依赖DB,当DB异常时整个系统不可用。虽然配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号。还有就是ID发号性能瓶颈限制在单台MySQL的读写性能。
使用redis实现
Redis实现分布式唯一ID主要是通过提供像 INCR 和 INCRBY 这样的自增原子命令,由于Redis自身的单线程的特点所以能保证生成的 ID 肯定是唯一有序的。
但是单机存在性能瓶颈,无法满足高并发的业务需求,所以可以采用集群的方式来实现。集群的方式又会涉及到和数据库集群同样的问题,所以也需要设置分段和步长来实现。
为了避免长期自增后数字过大可以通过与当前时间戳组合起来使用,另外为了保证并发和业务多线程的问题可以采用 Redis + Lua的方式进行编码,保证安全。
Redis 实现分布式全局唯一ID,它的性能比较高,生成的数据是有序的,对排序业务有利,但是同样它依赖于redis,需要系统引进redis组件,增加了系统的配置复杂性。
当然现在Redis的使用性很普遍,所以如果其他业务已经引进了Redis集群,则可以资源利用考虑使用Redis来实现。
雪花算法-Snowflake
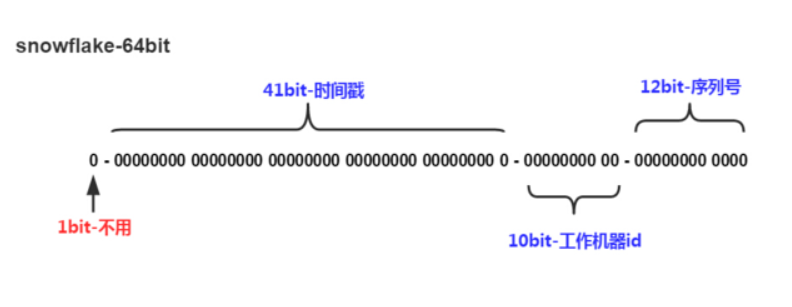
Snowflake,雪花算法是由Twitter开源的分布式ID生成算法,以划分命名空间的方式将 64-bit位分割成多个部分,每个部分代表不同的含义。而 Java中64bit的整数是Long类型,所以在 Java 中 SnowFlake 算法生成的 ID 就是 long 来存储的。
- 第1位占用1bit,其值始终是0,可看做是符号位不使用。
- 第2位开始的41位是时间戳,41-bit位可表示2^41个数,每个数代表毫秒,那么雪花算法可用的时间年限是
(1L<<41)/(1000L360024*365)=69 年的时间。 - 中间的10-bit位可表示机器数,即2^10 = 1024台机器,但是一般情况下我们不会部署这么台机器。如果我们对IDC(互联网数据中心)有需求,还可以将 10-bit 分 5-bit 给 IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,具体的划分可以根据自身需求定义。
- 最后12-bit位是自增序列,可表示2^12 = 4096个数。
这样的划分之后相当于在一毫秒一个数据中心的一台机器上可产生4096个有序的不重复的ID。但是我们 IDC 和机器数肯定不止一个,所以毫秒内能生成的有序ID数是翻倍的。
Snowflake 的Twitter官方原版是用Scala写的,对Scala语言有研究的同学可以去阅读下,以下是 Java 版本的写法。
package com.jajian.demo.distribute;
/**
* Twitter_Snowflake<br>
* SnowFlake的结构如下(每部分用-分开):<br>
* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000 <br>
* 1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0<br>
* 41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截)
* 得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的(如下下面程序IdWorker类的startTime属性)。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69<br>
* 10位的数据机器位,可以部署在1024个节点,包括5位datacenterId和5位workerId<br>
* 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号<br>
* 加起来刚好64位,为一个Long型。<br>
* SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右。
*/
public class SnowflakeDistributeId {
// ==============================Fields===========================================
/**
* 开始时间截 (2015-01-01)
*/
private final long twepoch = 1420041600000L;
/**
* 机器id所占的位数
*/
private final long workerIdBits = 5L;
/**
* 数据标识id所占的位数
*/
private final long datacenterIdBits = 5L;
/**
* 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数)
*/
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/**
* 支持的最大数据标识id,结果是31
*/
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/**
* 序列在id中占的位数
*/
private final long sequenceBits = 12L;
/**
* 机器ID向左移12位
*/
private final long workerIdShift = sequenceBits;
/**
* 数据标识id向左移17位(12+5)
*/
private final long datacenterIdShift = sequenceBits + workerIdBits;
/**
* 时间截向左移22位(5+5+12)
*/
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/**
* 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095)
*/
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/**
* 工作机器ID(0~31)
*/
private long workerId;
/**
* 数据中心ID(0~31)
*/
private long datacenterId;
/**
* 毫秒内序列(0~4095)
*/
private long sequence = 0L;
/**
* 上次生成ID的时间截
*/
private long lastTimestamp = -1L;
//==============================Constructors=====================================
/**
* 构造函数
*
* @param workerId 工作ID (0~31)
* @param datacenterId 数据中心ID (0~31)
*/
public SnowflakeDistributeId(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
// ==============================Methods==========================================
/**
* 获得下一个ID (该方法是线程安全的)
*
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen();
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
}
//时间戳改变,毫秒内序列重置
else {
sequence = 0L;
}
//上次生成ID的时间截
lastTimestamp = timestamp;
//移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift) //
| (datacenterId << datacenterIdShift) //
| (workerId << workerIdShift) //
| sequence;
}
/**
* 阻塞到下一个毫秒,直到获得新的时间戳
*
* @param lastTimestamp 上次生成ID的时间截
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 返回以毫秒为单位的当前时间
*
* @return 当前时间(毫秒)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
}
雪花算法提供了一个很好的设计思想,雪花算法生成的ID是趋势递增,不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的,而且可以根据自身业务特性分配bit位,非常灵活。
但是雪花算法强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。如果恰巧回退前生成过一些ID,而时间回退后,生成的ID就有可能重复。官方对于此并没有给出解决方案,而是简单的抛错处理,这样会造成在时间被追回之前的这段时间服务不可用。
很多其他类雪花算法也是在此思想上的设计然后改进规避它的缺陷,后面介绍的百度 UidGenerator 和 美团分布式ID生成系统 Leaf 中snowflake模式都是在 snowflake 的基础上演进出来的。
百度-UidGenerator
百度的
UidGenerator是百度开源基于Java语言实现的唯一ID生成器,是在雪花算法 snowflake 的基础上做了一些改进。UidGenerator以组件形式工作在应用项目中, 支持自定义workerId位数和初始化策略,适用于docker等虚拟化环境下实例自动重启、漂移等场景。
在实现上,UidGenerator 提供了两种生成唯一ID方式,分别是 DefaultUidGenerator 和 CachedUidGenerator,官方建议如果有性能考虑的话使用 CachedUidGenerator 方式实现。
UidGenerator 依然是以划分命名空间的方式将 64-bit位分割成多个部分,只不过它的默认划分方式有别于雪花算法 snowflake。它默认是由 1-28-22-13 的格式进行划分。可根据你的业务的情况和特点,自己调整各个字段占用的位数。
- 第1位仍然占用1bit,其值始终是0。
- 第2位开始的28位是时间戳,28-bit位可表示2^28个数,这里不再是以毫秒而是以秒为单位,每个数代表秒则可用
(1L<<28)/ (360024365) ≈ 8.51年的时间。 - 中间的 workId (数据中心+工作机器,可以其他组成方式)则由 22-bit位组成,可表示 2^22 = 4194304个工作ID。
- 最后由13-bit位构成自增序列,可表示2^13 = 8192个数。

其中 workId (机器 id),最多可支持约420w次机器启动。内置实现为在启动时由数据库分配(表名为 WORKER_NODE),默认分配策略为用后即弃,后续可提供复用策略。
DROP TABLE IF EXISTS WORKER_NODE;
CREATE TABLE WORKER_NODE
(
ID BIGINT NOT NULL AUTO_INCREMENT COMMENT 'auto increment id',
HOST_NAME VARCHAR(64) NOT NULL COMMENT 'host name',
PORT VARCHAR(64) NOT NULL COMMENT 'port',
TYPE INT NOT NULL COMMENT 'node type: ACTUAL or CONTAINER',
LAUNCH_DATE DATE NOT NULL COMMENT 'launch date',
MODIFIED TIMESTAMP NOT NULL COMMENT 'modified time',
CREATED TIMESTAMP NOT NULL COMMENT 'created time',
PRIMARY KEY(ID)
) COMMENT='DB WorkerID Assigner for UID Generator',ENGINE = INNODB;
DefaultUidGenerator 实现
DefaultUidGenerator 就是正常的根据时间戳和机器位还有序列号的生成方式,和雪花算法很相似,对于时钟回拨也只是抛异常处理。仅有一些不同,如以秒为为单位而不再是毫秒和支持Docker等虚拟化环境。
protected synchronized long nextId() {
long currentSecond = getCurrentSecond();
// Clock moved backwards, refuse to generate uid
if (currentSecond < lastSecond) {
long refusedSeconds = lastSecond - currentSecond;
throw new UidGenerateException("Clock moved backwards. Refusing for %d seconds", refusedSeconds);
}
// At the same second, increase sequence
if (currentSecond == lastSecond) {
sequence = (sequence + 1) & bitsAllocator.getMaxSequence();
// Exceed the max sequence, we wait the next second to generate uid
if (sequence == 0) {
currentSecond = getNextSecond(lastSecond);
}
// At the different second, sequence restart from zero
} else {
sequence = 0L;
}
lastSecond = currentSecond;
// Allocate bits for UID
return bitsAllocator.allocate(currentSecond - epochSeconds, workerId, sequence);
}
如果你要使用 DefaultUidGenerator 的实现方式的话,以上划分的占用位数可通过 spring 进行参数配置。
<bean id="defaultUidGenerator" class="com.baidu.fsg.uid.impl.DefaultUidGenerator" lazy-init="false">
<property name="workerIdAssigner" ref="disposableWorkerIdAssigner"/>
<!-- Specified bits & epoch as your demand. No specified the default value will be used -->
<property name="timeBits" value="29"/>
<property name="workerBits" value="21"/>
<property name="seqBits" value="13"/>
<property name="epochStr" value="2016-09-20"/>
</bean>
CachedUidGenerator 实现
而官方建议的性能较高的 CachedUidGenerator 生成方式,是使用 RingBuffer 缓存生成的id。数组每个元素成为一个slot。RingBuffer容量,默认为Snowflake算法中sequence最大值(2^13 = 8192)。可通过 boostPower 配置进行扩容,以提高 RingBuffer 读写吞吐量。
Tail指针、Cursor指针用于环形数组上读写slot:
- Tail指针 表示Producer生产的最大序号(此序号从0开始,持续递增)。Tail不能超过Cursor,即生产者不能覆盖未消费的slot。当Tail已赶上curosr,此时可通过rejectedPutBufferHandler指定PutRejectPolicy
- Cursor指针 表示Consumer消费到的最小序号(序号序列与Producer序列相同)。Cursor不能超过Tail,即不能消费未生产的slot。当Cursor已赶上tail,此时可通过rejectedTakeBufferHandler指定TakeRejectPolicy
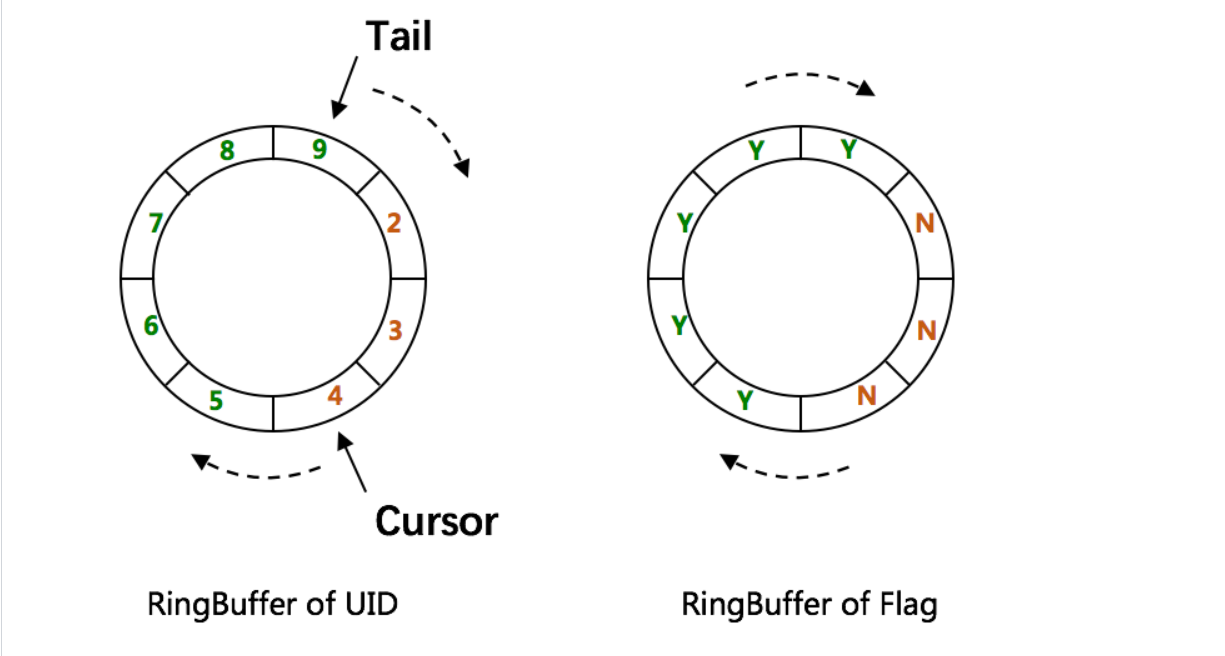
CachedUidGenerator采用了双RingBuffer,Uid-RingBuffer用于存储Uid、Flag-RingBuffer用于存储Uid状态(是否可填充、是否可消费)。
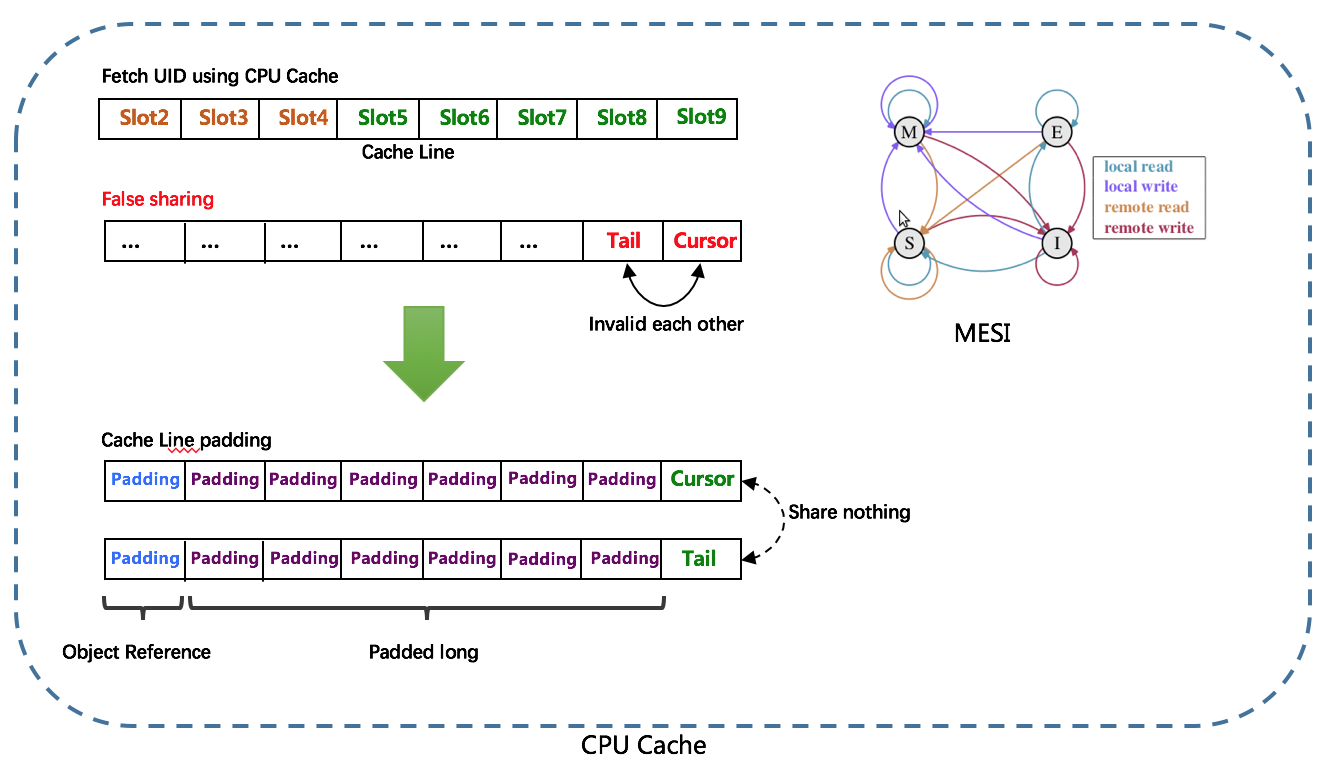
由于数组元素在内存中是连续分配的,可最大程度利用CPU cache以提升性能。但同时会带来「伪共享」FalseSharing问题,为此在Tail、Cursor指针、Flag-RingBuffer中采用了CacheLine 补齐方式。
RingBuffer填充时机
- 初始化预填充 RingBuffer初始化时,预先填充满整个RingBuffer。
- 即时填充 Take消费时,即时检查剩余可用slot量(tail - cursor),如小于设定阈值,则补全空闲slots。阈值可通过paddingFactor来进行配置,请参考Quick Start中CachedUidGenerator配置。
- 周期填充 通过Schedule线程,定时补全空闲slots。可通过scheduleInterval配置,以应用定时填充功能,并指定Schedule时间间隔。
美团Leaf
Leaf是美团基础研发平台推出的一个分布式ID生成服务,名字取自德国哲学家、数学家莱布尼茨的著名的一句话:“There are no two identical leaves in the world”,世间不可能存在两片相同的叶子。
Leaf 也提供了两种ID生成的方式,分别是 Leaf-segment 数据库方案和 Leaf-snowflake 方案。
Leaf-segment 数据库方案
Leaf-segment 数据库方案,是在上文描述的在使用数据库的方案上,做了如下改变:
- 原方案每次获取ID都得读写一次数据库,造成数据库压力大。改为利用proxy server批量获取,每次获取一个segment(step决定大小)号段的值。用完之后再去数据库获取新的号段,可以大大的减轻数据库的压力。
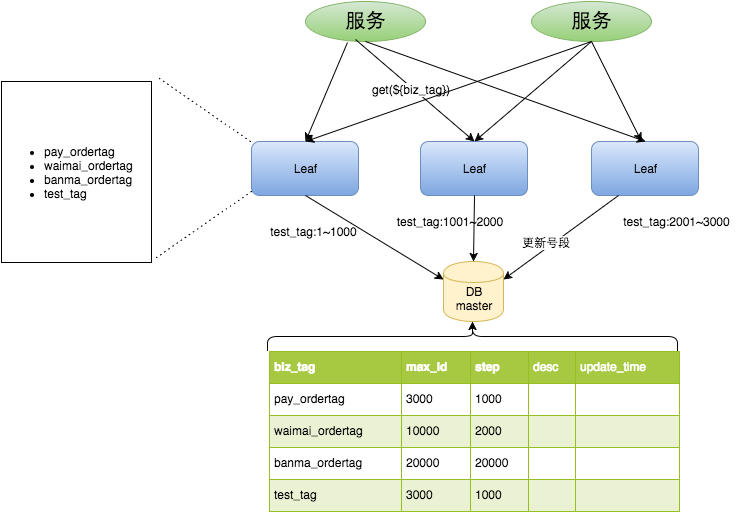
- 各个业务不同的发号需求用
biz_tag字段来区分,每个biz-tag的ID获取相互隔离,互不影响。如果以后有性能需求需要对数据库扩容,不需要上述描述的复杂的扩容操作,只需要对biz_tag分库分表就行。
数据库表设计如下:
CREATE TABLE `leaf_alloc` (
`biz_tag` varchar(128) NOT NULL DEFAULT '' COMMENT '业务key',
`max_id` bigint(20) NOT NULL DEFAULT '1' COMMENT '当前已经分配了的最大id',
`step` int(11) NOT NULL COMMENT '初始步长,也是动态调整的最小步长',
`description` varchar(256) DEFAULT NULL COMMENT '业务key的描述',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB;
原来获取ID每次都需要写数据库,现在只需要把step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从1减小到了1/step,大致架构如下图所示:
同时Leaf-segment 为了解决 TP999(满足千分之九百九十九的网络请求所需要的最低耗时)数据波动大,当号段使用完之后还是会hang在更新数据库的I/O上,TP999 数据会出现偶尔的尖刺的问题,提供了双buffer优化。
简单的说就是,Leaf 取号段的时机是在号段消耗完的时候进行的,也就意味着号段临界点的ID下发时间取决于下一次从DB取回号段的时间,并且在这期间进来的请求也会因为DB号段没有取回来,导致线程阻塞。如果请求DB的网络和DB的性能稳定,这种情况对系统的影响是不大的,但是假如取DB的时候网络发生抖动,或者DB发生慢查询就会导致整个系统的响应时间变慢。
为了DB取号段的过程能够做到无阻塞,不需要在DB取号段的时候阻塞请求线程,即当号段消费到某个点时就异步的把下一个号段加载到内存中,而不需要等到号段用尽的时候才去更新号段。这样做就可以很大程度上的降低系统的 TP999 指标。详细实现如下图所示:
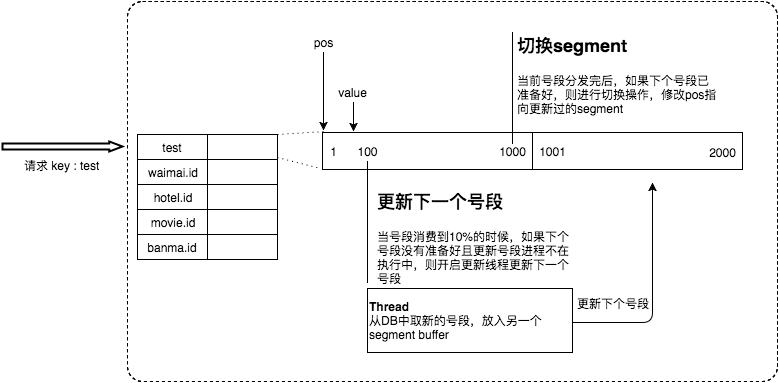
采用双buffer的方式,Leaf服务内部有两个号段缓存区segment。当前号段已下发10%时,如果下一个号段未更新,则另启一个更新线程去更新下一个号段。当前号段全部下发完后,如果下个号段准备好了则切换到下个号段为当前segment接着下发,循环往复。
- 每个biz-tag都有消费速度监控,通常推荐segment长度设置为服务高峰期发号QPS的600倍(10分钟),这样即使DB宕机,Leaf仍能持续发号10-20分钟不受影响。
- 每次请求来临时都会判断下个号段的状态,从而更新此号段,所以偶尔的网络抖动不会影响下个号段的更新。
对于这种方案依然存在一些问题,它仍然依赖 DB的稳定性,需要采用主从备份的方式提高 DB的可用性,还有 Leaf-segment方案生成的ID是趋势递增的,这样ID号是可被计算的,例如订单ID生成场景,通过订单id号相减就能大致计算出公司一天的订单量,这个是不能忍受的。
Leaf-snowflake方案
Leaf-snowflake方案完全沿用 snowflake 方案的bit位设计,对于workerID的分配引入了Zookeeper持久顺序节点的特性自动对snowflake节点配置 wokerID。避免了服务规模较大时,动手配置成本太高的问题。
Leaf-snowflake是按照下面几个步骤启动的:
- 启动Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)。
- 如果有注册过直接取回自己的workerID(zk顺序节点生成的int类型ID号),启动服务。
- 如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerID号,启动服务。
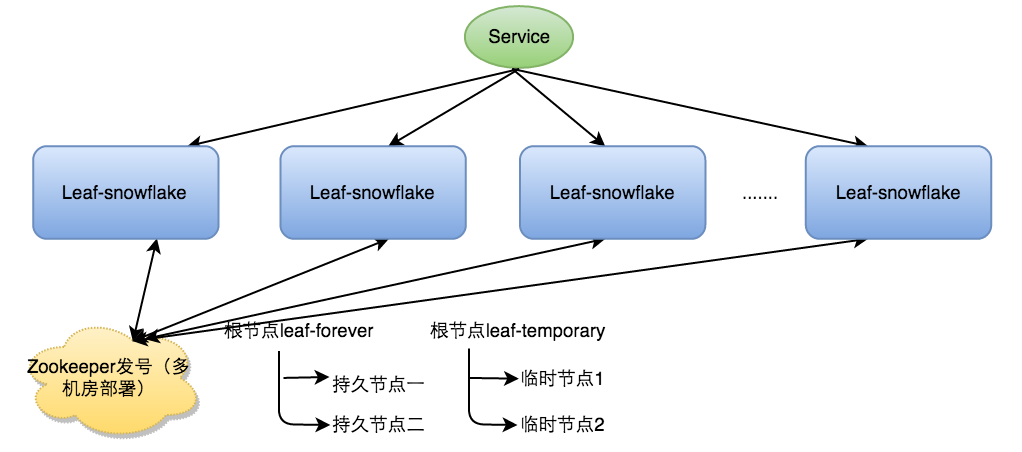
为了减少对 Zookeeper的依赖性,会在本机文件系统上缓存一个workerID文件。当ZooKeeper出现问题,恰好机器出现问题需要重启时,能保证服务能够正常启动。
上文阐述过在类 snowflake算法上都存在时钟回拨的问题,Leaf-snowflake在解决时钟回拨的问题上是通过校验自身系统时间与 leaf_forever/${self}节点记录时间做比较然后启动报警的措施。
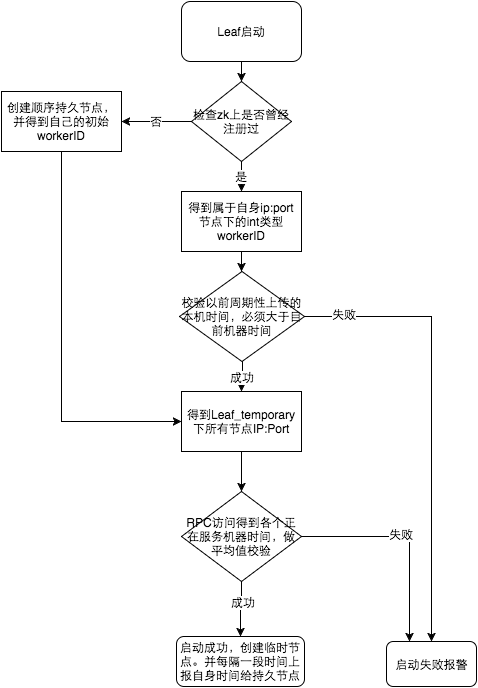
美团官方建议是由于强依赖时钟,对时间的要求比较敏感,在机器工作时NTP同步也会造成秒级别的回退,建议可以直接关闭NTP同步。要么在时钟回拨的时候直接不提供服务直接返回ERROR_CODE,等时钟追上即可。或者做一层重试,然后上报报警系统,更或者是发现有时钟回拨之后自动摘除本身节点并报警。
在性能上官方提供的数据目前 Leaf 的性能在4C8G 的机器上QPS能压测到近5w/s,TP999 1ms。
Mist 薄雾算法
最近有个号称超过snowflake 587倍的ID生成算法,可以参看这里, 如下内容摘自 GitHub中项目README
薄雾算法是不同于 snowflake 的全局唯一 ID 生成算法。相比 snowflake ,薄雾算法具有更高的数值上限和更长的使用期限。
现在薄雾算法拥有比雪花算法更高的性能!
量了什么业务场景和要求呢?
用到全局唯一 ID 的场景不少,这里引用美团 Leaf 的场景介绍:
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。如在美团点评的金融、支付、餐饮、酒店、猫眼电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一 ID 来标识一条数据或消息,数据库的自增 ID 显然不能满足需求;特别一点的如订单、骑手、优惠券也都需要有唯一 ID 做标识。此时一个能够生成全局唯一ID 的系统是非常必要的。
引用微信 seqsvr 的场景介绍:
微信在立项之初,就已确立了利用数据版本号实现终端与后台的数据增量同步机制,确保发消息时消息可靠送达对方手机。
爬虫数据服务的场景介绍:
数据来源各不相同,且并发极大的情况下难以生成统一的数据编号,同时数据编号又将作为爬虫下游整个链路的溯源依据,在爬虫业务链路中十分重要。
这里参考美团 Leaf 的要求:
- 全局唯一性:不能出现重复的 ID 号,既然是唯一标识,这是最基本的要求;
- 趋势递增:在 MySQL InnoDB 引擎中使用的是聚集索引,由于多数 RDBMS 使用 B-tree 的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能;
- 单调递增:保证下一个 ID 一定大于上一个 ID,例如事务版本号、IM 增量消息、排序等特殊需求;
- 信息安全:如果 ID 是连续的,恶意用户的爬取工作就非常容易做了,直接按照顺序下载指定 URL 即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要 ID 无规则、不规则;
可以用“全局不重复,不可猜测且呈递增态势”这句话来概括描述要求。
薄雾算法的设计思路是怎么样的?
薄雾算法采用了与 snowflake 相同的位数——64,在考量业务场景和要求后并没有沿用 1-41-10-12 的占位,而是采用了 1-47-8-8 的占位。即:
* 1 2 48 56 64
* +------+-----------------------------------------------------+----------+----------+
* retain | increas | salt | salt |
* +------+-----------------------------------------------------+----------+----------+
* 0 | 0000000000 0000000000 0000000000 0000000000 0000000 | 00000000 | 00000000 |
* +------+-----------------------------------------------------+------------+--------+
第一段为最高位,占 1 位,保持为 0,使得值永远为正数;
第二段放置自增数,占 47 位,自增数在高位能保证结果值呈递增态势,遂低位可以为所欲为;
第三段放置随机因子一,占 8 位,上限数值 255,使结果值不可预测;
第四段放置随机因子二,占 8 位,上限数值 255,使结果值不可预测;
薄雾算法生成的数值是什么样的?
薄雾自增数为 1~10 的运行结果类似如下:
171671
250611
263582
355598
427749
482010
581550
644278
698636
762474
根据运行结果可知,薄雾算法能够满足“全局不重复,不可猜测且呈递增态势”的场景要求。
薄雾算法 mist 和雪花算法 snowflake 有何区别?
snowflake 是由 Twitter 公司提出的一种全局唯一 ID 生成算法,它具有“递增态势、不依赖数据库、高性能”等特点,自 snowflake 推出以来备受欢迎,算法被应用于大大小小公司的服务中。snowflake 高位为时间戳的二进制,遂完全受到时间戳的影响,倘若时间回拨(当前服务器时间回到之前的某一时刻),那么 snowflake 有极大概率生成与之前同一时刻的重复 ID,这直接影响整个业务。
snowflake 受时间戳影响,使用上限不超过 70 年。
薄雾算法 Mist 由书籍《Python3 反爬虫原理与绕过实战》的作者韦世东综合 百度 UidGenerator、 美团 Leaf 和 微信序列号生成器 seqsvr 中介绍的技术点,同时考虑高性能分布式序列号生成器架构后设计的一款“递增态势、不依赖数据库、高性能且不受时间回拨影响”的全局唯一序列号生成算法。
薄雾算法不受时间戳影响,受到数值大小影响。薄雾算法高位数值上限计算方式为int64(1<<47 - 1),上限数值140737488355327 百万亿级,假设每天消耗 10 亿,薄雾算法能使用 385+ 年。
为什么薄雾算法不受时间回拨影响?
snowflake 受时间回拨影响的根本原因是高位采用时间戳的二进制值,而薄雾算法的高位是按序递增的数值。结果值的大小由高位决定,遂薄雾算法不受时间回拨影响。
为什么说薄雾算法的结果值不可预测?
考虑到“不可预测”的要求,薄雾算法的中间位是 8 位随机值,且末 8 位是也是随机值,两组随机值大大增加了预测难度,因此称为结果值不可预测。
中间位和末位随机值的开闭区间都是 [0, 255],理论上随机值可以出现 256 * 256 种组合。
当程序重启,薄雾算法的值会重复吗?
snowflake 受时间回拨影响,一旦时间回拨就有极大概率生成重复的 ID。薄雾算法中的高位是按序递增的数值,程序重启会造成按序递增数值回到初始值,但由于中间位和末尾随机值的影响,因此不是必定生成(有大概率生成)重复 ID,但递增态势必定受到影响。
薄雾算法的值会重复,那我要它干嘛?
- 无论是什么样的全局唯一 ID 生成算法,都会有优点和缺点。在实际的应用当中,没有人会将全局唯一 ID 生成算法完全托付给程序,而是会用数据库存储关键值或者所有生成的值。全局唯一 ID 生成算法大多都采用分布式架构或者主备架构提供发号服务,这时候就不用担心它的重复问题;
- 生成性能比雪花算法高太多倍;
- 代码少且简单,在大型应用中,单功能越简单越好;
是否提供薄雾算法的工程实践或者架构实践?
是的,作者的另一个项目 Medis 是薄雾算法与 Redis 的结合,实现了“全局不重复”,你再也不用担心程序重启带来的问题。
薄雾算法的分布式架构,推荐 CP 还是 AP?
CAP 是分布式架构中最重要的理论,C 指的是一致性、A 指的是可用性、P 指的是分区容错性。CAP 当中,C 和 A 是互相冲突的,且 P 一定存在,遂我们必须在 CP 和 AP 中选择。实际上这跟具体的业务需求有关,但是对于全局唯一 ID 发号服务来说,大多数时候可用性比一致性更重要,也就是选择 AP 会多过选择 CP。至于你怎么选,还是得结合具体的业务场景考虑。
薄雾算法的性能测试
采用 Golnag(1.14) 自带的 Benchmark 进行测试,测试机硬件环境如下:
内存 16 GB 2133 MHz LPDDR3
处理器 2.3 GHz 双核Intel Core i5
操作系统 macOS Catalina
机器 MacBook Pro (13-inch, 2017, Two Thunderbolt 3 ports)
进行了多轮测试,随机取 3 轮测试结果。以此计算平均值,得 单次执行时间 346 ns/op。以下是随机 3 轮测试的结果:
goos: darwin
goarch: amd64
pkg: mist
BenchmarkMain-4 3507442 339 ns/op
PASS
ok mist 1.345s
goos: darwin
goarch: amd64
pkg: mist
BenchmarkMain-4 3488708 338 ns/op
PASS
ok mist 1.382s
goos: darwin
goarch: amd64
pkg: mist
BenchmarkMain-4 3434936 360 ns/op
PASS
ok mist 1.394s
总结
以上基本列出了所有常用的分布式ID生成方式,其实大致分类的话可以分为两类:
- 一种是类DB型的,根据设置不同起始值和步长来实现趋势递增,需要考虑服务的容错性和可用性。
- 另一种是类snowflake型,这种就是将64位划分为不同的段,每段代表不同的涵义,基本就是时间戳、机器ID和序列数。这种方案就是需要考虑时钟回拨的问题以及做一些 buffer的缓冲设计提高性能。
而且可通过将三者(时间戳,机器ID,序列数)划分不同的位数来改变使用寿命和并发数。
例如对于并发数要求不高、期望长期使用的应用,可增加时间戳位数,减少序列数的位数. 例如配置成{"workerBits":23,"timeBits":31,"seqBits":9}时, 可支持28个节点以整体并发量14400 UID/s的速度持续运行68年。
对于节点重启频率频繁、期望长期使用的应用, 可增加工作机器位数和时间戳位数, 减少序列数位数. 例如配置成{"workerBits":27,"timeBits":30,"seqBits":6}时, 可支持37个节点以整体并发量2400 UID/s的速度持续运行34年。
1.20 - 分布式谬误
20多年前,Peter Deutsch和James Gosling定义了分布式计算的8个谬误。这些是许多开发人员对分布式系统做出的错误假设。从长远来看,这些通常被证明是错误的,导致难以修复错误。
1. 网络可靠
问题
通过网络呼叫将失败。
今天的大多数系统都会调用其他系统。您是否正在与第三方系统(支付网关,会计系统,CRM)集成?你在做网络服务电话吗?如果呼叫失败会发生什么?如果您要查询数据,则可以进行简单的重试。但是如果您发送命令会发生什么?我们举一个简单的例子:
var creditCardProcessor = new CreditCardPaymentService();
creditCardProcessor.Charge(chargeRequest);
如果我们收到HTTP超时异常会怎么样?如果服务器没有处理请求,那么我们可以重试。但是,如果它确实处理了请求,我们需要确保我们不会对客户进行双重收费。您可以通过使服务器具有幂等性来实现此目的。这意味着如果您使用相同的收费请求拨打10次,则客户只需支付一次费用。如果您没有正确处理这些错误,那么您的系统是不确定的。处理所有这些情况可能会非常复杂。
解决方案
因此,如果网络上的呼叫失败,我们能做什么?好吧,我们可以自动重试。排队系统非常擅长这一点。它们通常使用称为存储和转发的模式。它们在将消息转发给收件人之前在本地存储消息。如果收件人处于脱机状态,则排队系统将重试发送邮件。MSMQ是这种排队系统的一个例子。
但是这种变化将对您的系统设计产生重大影响。您正在从请求/响应模型转移到触发并忘记。由于您不再等待响应,因此您需要更改系统中的用户行程。您不能只使用队列发送替换每个Web服务调用。
结论
你可能会说网络现在更可靠 - 而且它们是。但事情发生了。硬件和软件可能会出现故障 - 电源,路由器,更新或补丁失败,无线信号弱,网络拥塞,啮齿动物或鲨鱼。是的,鲨鱼:在一系列鲨鱼叮咬之后,谷歌正在加强与Kevlar的海底数据线。
还有人为因素。人们可以开始DDOS攻击,也可以破坏物理设备。
这是否意味着您需要删除当前的技术堆栈并使用消息传递系统?并不是的!您需要权衡失败的风险与您需要进行的投资。您可以通过投资基础架构和软件来最小化失败的可能性。在许多情况下,失败是一种选择。但在设计分布式系统时,您确实需要考虑失败的问题。
2. 延迟是零
问题
通过网络拨打电话不是即时的。
内存呼叫和互联网呼叫之间存在七个数量级的差异。您的应用程序应该是网络感知。这意味着您应该清楚地将本地呼叫与远程呼叫分开。让我们看看我在代码库中看到的一个例子:
var viewModel = new ViewModel();
var documents = new DocumentsCollection();
foreach (var document in documents)
{
var snapshot = document.GetSnapshot();
viewModel.Add(snapshot);
}
没有进一步检查,这看起来很好。但是,有两个远程呼叫。第2行进行一次调用以获取文档摘要列表。在第5行,还有另一个调用,它检索有关每个文档的更多信息。这是一个经典的Select n + 1问题。为了解决网络延迟问题,您应该在一次调用中返回所有必需的数据。一般的建议是本地调用可以细粒度,但远程调用应该更粗粒度。这就是为什么分布式对象和“网络透明度”的想法死了。但是,即使每个人都同意分布式对象是一个坏主意,有些人仍然认为延迟加载总是一个好主意:
var employee = EmployeeRepository.GetBy(someCriteria)
var department = employee.Department;
var manager = department.Manager;
foreach (var peer in manager.Employees;)
{
// do something
}
您不希望财产获取者进行网络呼叫。但是,每个“。” 在上面的代码中调用实际上可以触发数据库之旅。
解决方案
- 带回您可能需要的所有数据 如果您进行远程呼叫,请确保恢复可能需要的所有数据。网络通信不应该是唠叨的。
- 将Data Closer移动到客户端 另一种可能的解决方案是将数据移近客户端。如果您正在使用云,请根据客户的位置仔细选择可用区。缓存还可以帮助最小化网络呼叫的数量。对于静态内容,内容交付网络(CDN)是另一个不错的选择。
- 反转数据流 删除远程调用的另一个选项是反转数据流。我们可以使用Pub / Sub并在本地存储数据,而不是查询其他服务。这样,我们就可以在需要时获取数据。当然,这会带来一些复杂性,但它可能是工具箱中的一个很好的工具。
结论
虽然延迟可能不是LAN中的问题,但当您转移到WAN或Internet时,您会注意到延迟。这就是为什么将网络呼叫与内存中的呼叫明确分开是很重要的。在采用微服务架构模式时,您应该牢记这一点。您不应该只使用远程调用替换本地呼叫。这可能会使你的系统变成分布式的大泥球。
3. 带宽是无限的
问题
带宽是有限的。
带宽是网络在一段时间内发送数据的容量。到目前为止,我还没有发现它是一个问题,但我可以看到为什么它在某些条件下可能是一个问题。虽然带宽随着时间的推移而有所改善,但我们发送的数据量也有所增加。与通过网络传递简单DTO的应用相比,视频流或VoIP需要更多带宽。带宽对于移动应用程序来说更为重要,因此开发人员在设计后端API时需要考虑它。
错误地使用ORM也会造成伤害。我见过开发人员在查询中过早调用.ToList()的示例,因此在内存中加载整个表。
解决方案
领域驱动的设计模式
那么我们怎样才能确保我们不会带来太多数据呢?域驱动设计模式可以帮助:
- 首先,您不应该争取单一的企业级域模型。您应该将域划分为有界上下文。
- 要避免有界上下文中的大型复杂对象图,可以使用聚合模式。聚合确保一致性并定义事务边界。
命令和查询责任隔离
我们有时会加载复杂的对象图,因为我们需要在屏幕上显示它的一部分。如果我们在很多地方这样做,我们最终会得到一个庞大而复杂的模型,对于写作和阅读来说都是次优的。另一种方法可以是使用命令和查询责任隔离 - CQRS。这意味着将域模型分为两部分:
- 在写模式将确保不变保持真实的数据是一致的。由于写模型不关心视图问题,因此可以保持较小且集中。
- 该读取模型是视图的担忧进行了优化,所以我们可以获取所有所需的特定视图中的数据(例如,我们的应用程序的屏幕)。
结论
在第二个谬误(延迟不是0)和第三个谬误(带宽是无限的)之间有延伸,您应该传输更多数据,以最大限度地减少网络往返次数。您应该传输较少的数据以最小化带宽使用。您需要平衡这两种力量,并找到通过线路发送的正确数据量。
虽然您可能不会经常遇到带宽限制,但考虑传输的数据非常重要。更少的数据更容易理解。数据越少意味着耦合越少。因此,只传输您可能需要的数据。
4. 网络是安全的
问题
网络并不安全。
这是一个比其他人更多的媒体报道的假设。您的系统仅与最薄弱的链接一样安全。坏消息是分布式系统中有很多链接。您正在使用HTTPS,除非与不支持它的第三方遗留系统进行通信。您正在查看自己的代码,寻找安全问题,但正在使用可能存在风险的开源库。一个OpenSSL的漏洞允许人们通过盗取SSL / TLS保护的数据。Apache Struts中的一个错误允许攻击者在服务器上执行代码。即使你正在抵御所有这些,仍然存在人为因素。恶意DBA可能“错放”数据库备份。今天的攻击者掌握着大量的计算能力和耐心。所以问题不在于他们是否会攻击你的系统,而是什么时候。
解决方案
- 深度防御
您应该使用分层方法来保护您的系统。您需要在网络,基础架构和应用程序级别进行不同的安全检查。
- 安全心态
在设计系统时要牢记安全性。十大漏洞列表在过去5年中没有发生太大变化。您应遵循安全软件设计的最佳实践,并检查常见安全漏洞的代码。您应该定期搜索第三方库以查找新漏洞。常见漏洞和暴露列表可以提供帮助。
- 威胁建模
威胁建模是一种识别系统中可能存在的安全威胁的系统方法。首先确定系统中的所有资产(数据库中的用户数据,文件等)以及如何访问它们。之后,您可以识别可能的攻击并开始执行它们。我建议阅读高级API安全性的第2章,以便更好地概述威胁建模。
结论
唯一安全的系统是关闭电源的系统,不连接到任何网络(理想情况下是在一个有形模块中)。它是多么有用的系统!事实是,安全是艰难而昂贵的。分布式系统中有许多组件和链接,每个组件和链接都是恶意用户的可能目标。企业需要平衡攻击的风险和概率与实施预防机制的成本。
攻击者手上有很多耐心和计算能力。我们可以通过使用威胁建模来防止某些类型的攻击,但我们无法保证100%的安全性。因此,向业务部门明确表示这一点是个好主意,共同决定投资安全性的程度,并制定安全漏洞何时发生的计划。
5. 拓扑不会改变
问题
网络拓扑不断变化。
网络拓扑始终在变化。有时它会因意外原因而发生变化 - 当您的应用服务器出现故障并需要更换时。很多时候它是故意的 - 在新服务器上添加新进程。如今,随着云和容器的增加,这一点更加明显。弹性扩展 - 根据工作负载添加或删除服务器的能力 - 需要一定程度的网络灵活性。
解决方案
摘要网络的物理结构
您需要做的第一件事是抽象网络的物理结构。有几种方法可以做到这一点:
- 停止硬编码IP - 您应该更喜欢使用主机名。通过使用URI,我们依靠DNS将主机名解析为IP。
- 当DNS不够时(例如,当您需要映射IP和端口时),则使用发现服务。
- Service Bus框架还可以提供位置透明性。
无价值的,而非重要的
通过将您的服务器视为没有价值的,而不是很重要的,您确保没有服务器是不可替代的。这一点智慧可以帮助您进入正确的思维模式:任何服务器都可能出现故障(从而改变拓扑结构),因此您应该尽可能地自动化。
测试
最后一条建议是测试你的假设。停止服务或关闭服务器,看看您的系统是否仍在运行。像Netflix的Chaos Monkey这样的工具可以通过随机关闭生产环境中的VM或容器来实现这一目标。通过带来痛苦,您更有动力构建一个可以处理拓扑更改的更具弹性的系统。
结论
十年前,大多数拓扑结构并没有经常改变。但是当它发生时,它可能发生在生产中并引入了一些停机时间。如今,随着云和容器的增加,很难忽视这种谬误。你需要为失败做好准备并进行测试。不要等到它在生产中发生!
6. 有一位管理员
问题
这个知道一切的人并不存在。
嗯,这个看起来很明显。当然,没有一个人知道一切。这是一个问题吗?只要应用程序运行顺利,它就不是。但是,当出现问题时,您需要修复它。因为很多人触摸了应用程序,知道如何解决问题的人可能不在那里。
有很多事情可能会出错。一个例子是配置。今天的应用程序在多个商店中存储配置:配置文件,环境变量,数据库,命令行参数。没有人知道每个可能的配置值的影响是什么。
另一件可能出错的事情是系统升级。分布式应用程序有许多移动部件,您需要确保它们是同步的。例如,您需要确保当前版本的代码适用于当前版本的数据库。如今,人们关注DevOps和持续交付。但支持零停机部署并非易事。
但是,至少这些东西都在你的控制之下。许多应用程序与第三方系统交互。这意味着,如果它们失效,你可以做的事情就不多了。因此,即使您的系统有一名管理员,您仍然无法控制第三方系统。
解决方案
每个人都应对释放过程负责
这意味着从一开始就涉及Ops人员或系统管理员。理想情况下,他们将成为团队的一员。尽早让系统管理员了解您的进度可以帮助您发现限制因素。例如,生产环境可能具有与开发环境不同的配置,安全限制,防火墙规则或可用端口。
记录和监控
系统管理员应该拥有用于错误报告和管理问题的正确工具。你应该从一开始就考虑监控。分布式系统应具有集中式日志。访问十个不同服务器上的日志以调查问题是不可接受的方法。
解耦
您应该在系统升级期间争取最少的停机时间。这意味着您应该能够独立升级系统的不同部分。通过使组件向后兼容,您可以在不同时间更新服务器和客户端。
通过在组件之间放置队列,您可以暂时将它们分离。这意味着,例如,即使后端关闭,Web服务器仍然可以接受请求。
隔离第三方依赖关系
您应该以不同于您拥有的组件的方式处理控制之外的系统。这意味着使您的系统更能适应第三方故障。您可以通过引入抽象层来减少外部依赖的影响。这意味着当第三方系统出现故障时,您将找到更少的地方来查找错误。
结论
要解决这个谬论,您需要使系统易于管理。DevOps,日志记录和监控可以提供帮助。您还需要考虑系统的升级过程。如果升级需要数小时的停机时间,则无法部署每个sprint。没有一个管理员,所以每个人都应该对发布过程负责。
7. 运输成本为零
问题
运输成本并不是零。
这种谬论与第二个谬误有关,即 延迟为零。通过网络传输内容在时间和资源上都有代价。如果第二个谬误讨论了时间方面,那么谬误#7就会解决资源消耗问题。
这种谬论有两个不同的方面:
网络基础设施的成本
网络基础设施需要付出代价。服务器,SAN,网络交换机,负载平衡器以及负责此设备的人员 - 所有这些都需要花钱。如果您的系统是在内部部署的,那么您需要预先支付这个价格。如果您正在使用云,那么您只需为您使用的内容付费,但您仍然需要付费。
序列化/反序列化的成本
这种谬误的第二个方面是在传输级别和应用程序级别之间传输数据的成本。序列化和反序列化会消耗CPU时间,因此需要花钱。如果您的应用程序是内部部署的,那么如果您不主动监视资源消耗,则会隐藏此成本。但是,如果您的应用程序部署在云端,那么这笔费用就会非常明显,因为您需要为使用的内容付费。
解决方案
关于基础设施的成本,你无能为力。您只能确保尽可能高效地使用它。SOAP或XML比JSON更昂贵。JSON比像Google的Protocol Buffers这样的二进制协议更昂贵。根据系统的类型,这可能或多或少重要。例如,对于与视频流或VoIP有关的应用,传输成本更为重要。
结论
您应该注意运输成本以及应用程序正在执行的序列化和反序列化程度。这并不意味着您应该优化,除非需要它。您应该对资源消耗进行基准测试和监控,并确定运输成本是否对您有用。
8. 网络是同质的
问题
网络不是同质的。
同质网络是使用类似配置和相同通信协议的计算机网络。拥有类似配置的计算机是一项艰巨的任务。例如,您几乎无法控制哪些移动设备可以连接到您的应用。这就是为什么重点关注标准协议。
解决方案
您应该选择标准格式以避免供应商锁定。这可能意味着XML,JSON或协议缓冲区。有很多选择可供选择。
结论
您需要确保系统的组件可以相互通信。使用专有协议会损害应用程序的互操作性。
总结
设计分布式系统很难。
这些谬论发表于20多年前。但他们今天仍然坚持,其中一些比其他人更多。我认为今天许多开发人员都知道它们,但我们编写的代码并没有显示出来。
我们必须接受这些事实:网络不可靠,不安全并且需要花钱。带宽有限。网络的拓扑结构将发生变化。其组件的配置方式不同。意识到这些限制将有助于我们设计更好的分布式系统。