This the multi-page printable view of this section. Click here to print.
交易系统
1 - 防止重复支付
业务场景
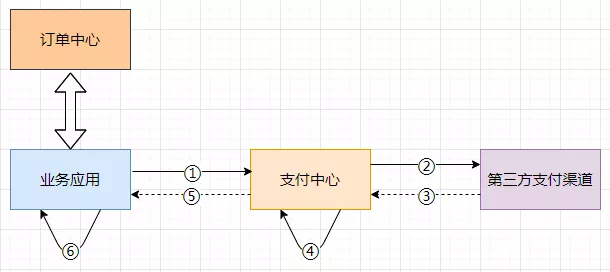
如图是一个简化的下单流程,首先是提交订单,然后是支付。支付的话,一般是走支付网关(支付中心),然后支付中心与第三方支付渠道(微信、支付宝、银联)交互,支付成功以后,异步通知支付中心,支付中心更新自身支付订单状态,再通知业务应用,各业务再更新各自订单状态。
这个过程中经常可能遇到的问题是掉单,无论是超时未收到回调通知也好,还是程序自身报错也好,总之由于各种各样的原因,没有如期收到通知并正确的处理后续逻辑等等,都会造成用户支付成功了,但是服务端这边订单状态没更新,这个时候有可能产生投诉,或者用户重复支付。
由于③⑤造成的掉单称之为外部掉单,由④⑥造成的掉单我们称之为内部掉单。
防止掉单
- 支付订单增加一个中间状态“支付中”,当同一个订单去支付的时候,先检查有没有状态为“支付中”的支付流水,当然支付(prepay)的时候要加个锁。支付完成以后更新支付流水状态的时候再将其改成“支付成功”状态。
- 支付中心这边要自己定义一个超时时间(比如:30秒),在此时间范围内如果没有收到支付成功回调,则应调用接口主动查询支付结果,比如10s、20s、30s查一次,如果在最大查询次数内没有查到结果,应做异常处理
- 支付中心收到支付结果以后,将结果同步给业务系统,可以发MQ,也可以直接调用,直接调用的话要加重试(比如:SpringBoot Retry)
- 无论是支付中心,还是业务应用,在接收支付结果通知时都要考虑接口幂等性,消息只处理一次,其余的忽略
- 业务应用也应做超时主动查询支付结果
对于上面说的超时主动查询可以在发起支付的时候将这些支付订单放到一张表中,用定时任务去扫。
防止重复
创建订单的时候,用订单信息计算一个哈希值,判断 redis 中是否有key,有则不允许重复提交,没有则生成一个新key,放到redis中设置个过期时间,然后创建订单。其实就是在一段时间内不可重复相同的操作。
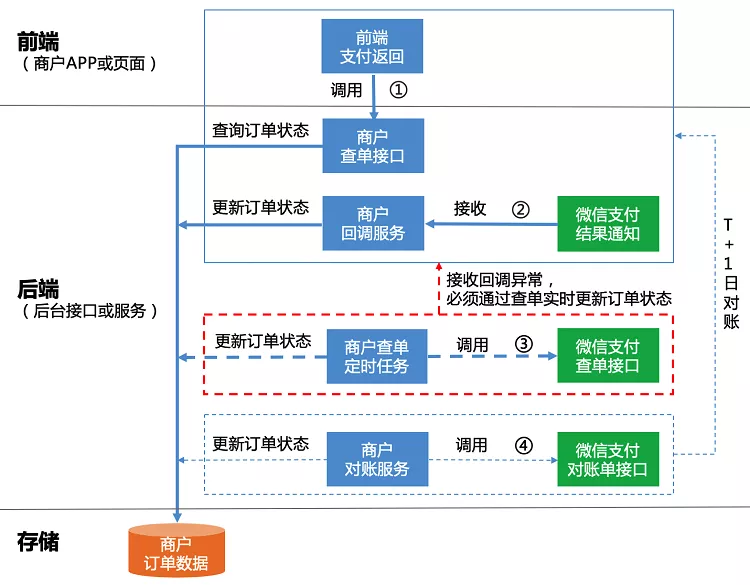
微信支付的支付流程
2 - 千万对账系统
什么是对账
如果你花 10 元钱购物,支付后通过付款记录可以看到 10 元的扣款记录;商家也会在确认收到付款之后交付商品。可以将这样简单的一次购物过程看做一次对账:你说你服了 10 元,商家确认你付了 10 元。
如果我们使用的是微信支付,那么微信支付系统也会产生一条支付记录,第二天它在后台会生成一个账单记录,我们可以通过该账单跟我们的支付记录核对,这就是支付对账。
为什么要对账
正常支付的情况下,我们和第三方支付渠道都会产生交易数据,那么在对账过程中如果两端数据一致则没有问题。但是如果由于网络等其他问题导致双方数据不一致,通过支付对账就可以发现其中的问题。
对账可以说支付系统最后一道安全防线,通过对账我们可及时的对之前支付进行纠错,避免订单差错越积越多,最后财务盘点变成一笔糊涂账。
支付对账系统
整体架构图:
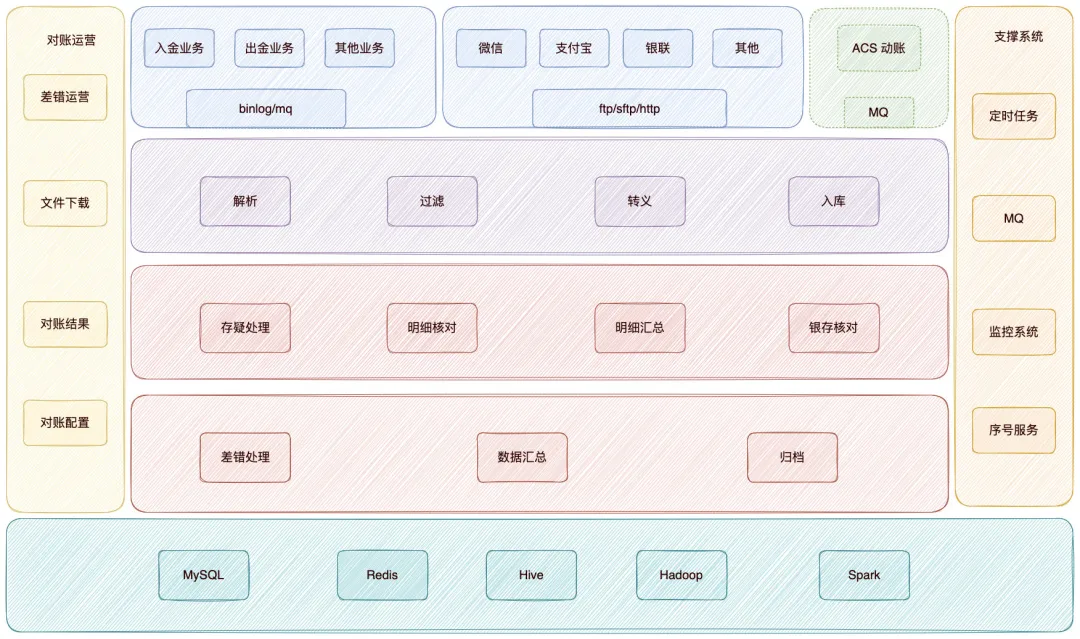
整个对账系统分为两个模块:
- 对账模块:主要负责对账文件拉取、数据解析、数据核对、数据汇总等任务。
- 差错模块:是对账模块后置任务,对账模块核对过程产生无法核对成功的数据,这类数据将会推送给差错系统。
- 差错系统将会根据规则生成差错订单,运营人员可以在后台处理这列数据。
先简单的看一下之前的对账系统设计,了解下对账的整体流程。
对账系统设计
业务流程如下:
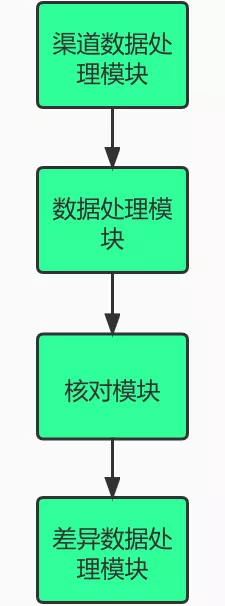
整体流程可以分为三个模块:
- 本端数据处理:本端数据指的是我们应用产生的支付记录,这里根据账期(交易日期)与渠道编号获取单一渠道的所有支付记录。
- 对端数据处理:对端数据指的是第三方支付渠道支付记录,一般通过下载对账文件获取。
- 本端数据与渠道端数据核对
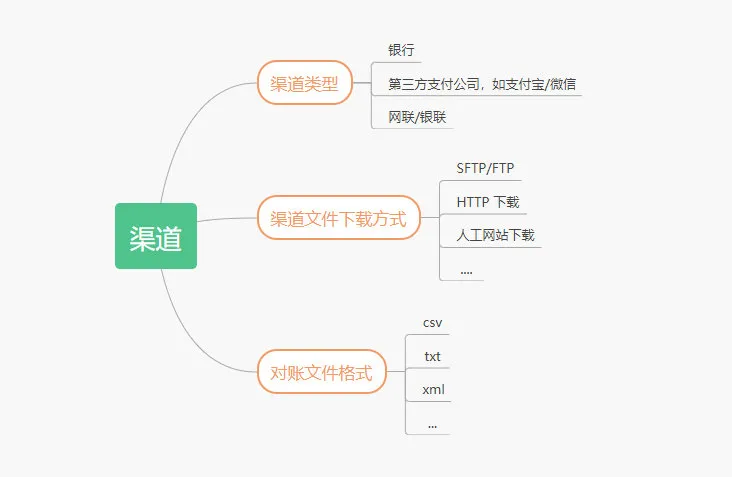
由于每个渠道下载方式,文件格式都不太一样,对端数据处理的时候需要将其转化统一数据格式,标准化后入库存储。
对端数据转化存储之后,在对账流程中,对端数据也需要跟本端数据一样,获取当前账期下所有记录。
两端数据都获取成功之后,接下来就是本地数据逐笔核对。核对内容则主要包括以下部分:
| 字段名 | 字段含义 | 额外说明 |
|---|---|---|
| ID | D 主键 | 账单表唯一主键,如果是 MySQL 可以用自增 ID,如果是 TiDB 或 Hive 则建议用 UUID |
| BILL_DATE | 账单日期 | 即第三方账单的下发日期,对于国内渠道一般为结算日期账单日期 |
| FILE_ID | 账单文件编号 | 文件编号,下载的原始账单文件在完成标准格式转换后会生成一个唯一的文件 ID 便于检索 |
| CHANNEL | 渠道编码 | 渠道编码,可以根据支付平台对对接渠道的内部定义进行转换 |
| CHANNEL_NAME | 渠道名称 | 渠道名称,如支付宝、微信这样 |
| SUBCHANNEL | 二级渠道编码 | 这里是为了适配在使用支付渠道事存在第四方支付的情况,或下级渠道的情况 |
| SUB_CHANNEL_NAME | 二级渠道名称 | 二级渠道名称,如通过 Ping++ 对接了 QQ 支付,这里的二级渠道就是 QQ 支付 |
| ORDER_ID | 平台订单号 | 这里是指,支付平台与第三方渠道交互的系统唯一订单号 |
| TRADE_TYPE | 交易类型 | 支付平台根据交易类型进行的定义,如 charge 表示支付;refund 表示退款 |
| PAY_TYPE | 支付类型 | 第三方渠道对其支付产品的定义在自己系统中的统一转换编码,如微信 APP 支付 |
| TRADE_NO | 渠道支付订单号 | 第三方支付渠道生成的渠道支付订单号 |
| TRADE_TIME | 交易时间 | 交易发生的事件,可以统一格式为“YYYY-MM-DD HH:MM:SS” |
| STATUS | 交易状态 | 交易状态转换,可根据支付平台定义的交易转换对账单中的状态进行映射转换 |
| ORD_AMT | 支付金额 | 支付订单金额,为了统一处理,一律转换为最小单位,如“分” |
| CURRENCY | 币种 | 支付币种,根据国籍支付币种进行统一转换,如 CNYEUR 等 |
| FEE | 支付手续费 | 支付手续费总额 |
| FEE_DETAIL | 手续费明细 | 支付手续费明细,如海外渠道手续费可能分为各种费,这里可以记录费用明细 |
| FEE_RULE | 手续费规则 | 对手续费规则的定义,如果存在计费系统或者对渠道计费有管理,这里可以填充相应标示 |
| CH_MER_ID | 渠道商户号 | 对应的渠道商户号,如同一个渠道可能申请多个商户号,这里可以进行区分 |
| COUNTRY | 国家编码 | 根据交易订单中的收单国家情况进行定义,可以设计成统一的国际国家编码,如中国 86 这样 |
| CITY | 城市编码(新增) | 城市,这个字段对于国内渠道来说可能意义不大,但是有些海外渠道则可能会有区别 |
| USER_FLG | 渠道用户标识 | 第三方支付渠道用户公开表示,如微信 Openld 这样,便于检索排查 |
| REFUND_ORIGIN_ORDER | 退款原订单号 | 如果为退款账单数据,这里可以记录其原始的支付订单号 |
| DESC_ | 支付信息描述 | 关于支付备注信息的描述 |
| CHANNEL_TRADE_TYPE | 渠道原始交易类型 | 第三方原始交易类型的表述,之所以加这个在于有些渠道,如银联类型太多,便于排错 |
| META_DATA | 支付原数据 | 对于目前很多支付渠道,都具备传输原数据的功能,即你传什么数据,账单就给你返回什么,可以用于平台自己的一些特殊业务标记 |
| CREATE_TIME | 创建时间 | 数据入库时间 |
| UPDATE_TIME | 更新时间 | 数据最后被更改的时间 |
| EXTEND_1 | 扩展 1 | 扩张字段 1 |
| EXTEND_2 | 扩展 2 | 扩张字段 2 |
| EXTEND_3 | 扩展 3 | 扩张字段 3 |
核对流程其实也比较简单,示例如下:
查找本端数据/对端数据,然后转化存储到 Map 中,其中 key 为订单号,value 为本端/对端订单对象。
然后遍历本端数据 Map 对象,依次去对端数据 Map 查找。如果能查找到,说明对端数据也有这笔。这笔核对成功,对端数据集中移除这笔。
如果查找不到,说明这笔数据为差异数据,它在本端存在,对端不存在,将其移动到差异数据集中。
最后,本端数据遍历结束,如果对端数据集还存在数据,那就证明这些数据也是差异数据,他们在对端存在,本端不存在,将其也移动到差异数据集中。
PS:上述流程存在瑕疵,只能核对出两边订单互有缺失的流程,但是实际情况下还会碰到两边订单都存在,但是订单金额却不一样的差异数据。这种情况有可能发现在系统 Bug,比如渠道端上送金额单位为元,但是实际上送金额单位为分,这就导致对账两端金额不一致。
之前对账系统日均处理的支付数据峰值在几十万,所以上面的流程没什么问题,还可以抗住,正常处理。
但是目前的支付数据日均在千万级,如果还是用这种方式对账,当前系统可能会直接崩了。
千万数据级
查询效率
本端/对端数据通过分页查询业务数据表获取当天所有的数据。随着每天支付数据累计,业务表中数据将会越来越多,这就会导致数据查询变慢。
实际过程我们发现,单个渠道数据量很大的情况下,对账完成需要一两个小时。
虽然说对账是一个离线流程,允许对账完成时间可以久一点。但是对账流程是后续其他任务的前置流程,整个对账流程还是需要在中午之前完成,这样运营同学就可以在下午处理。
OOM
上面流程中,我们把把全部数据加载到内存中,小数据量下没什么问题。
但是在千万级数据情况下,数据都加载到内存中,并且还是加载了两份数据(本端、对端),这就很容易吃完整个应用内存,从而导致 Full GC,甚至还有可能导致应用 OOM。
而且这还会导致级联反应,一个任务引发 Full GC,导致其他渠道对账收到影响。
性能问题
原先系统设计上,单一渠道对账处理流程只能在单个机器上处理,无法并行处理。
这就导致系统设计伸缩性很差,服务器资源也被大量的浪费。
解决方案
实际上还是存在优化空间的,可以利用单机多线程并行处理,但是大数据下其实带来效果不是很好。
那主要原因是因为发生在系统架构上,当前系统使用底层使用 MySQL 处理的。
传统的 MySQL 是 OLTP(on-line transaction processing),这个结构决定它适合用于高并发,小事务业务数据处理。
但是对账业务特性动辄就是百万级,千万级数据,数据量处理非常大。但是对账数据处理大多是一次性,不会频繁更新。
上面业务特性决定了,MySQL 这种 OLTP 系统不太适合大数据级对账业务。
那专业的事应该交给专业的人去做,对账业务也一样,这种大数据级业务比较适合由 Hive、Spark SQL 等 OLAP 去做。
核心流程
数据平台
前面提到,千万级数据需要使用 Hive,Spark 等相关大数据技术,这就离不开大数据平台的技术支持。
简单聊下我们这边大数据平台 DP (Data Platform),它提供用户大数据离线任务开发所需要的环境、工具以及数据,具有入口统一性、一站式、简化 Hadoop 本身的复杂性、数据安全等特点。
DP 平台提供功能如下:
- 数据双向离线同步,MySQL 与 Hive 互相同步
- 大数据离线计算,支持SQL(SparkSQL/HiveSQL/Presto)形式处理各类的数据清洗、转化、聚合操作,也支持使用MapReduce、Spark等形式,处理比较复杂的计算场景
- 即时的SQL查询,允许用户即时的执行SQL、查看执行的日志和结果数以及进行结果数据的可视化分析
- 数据报表
那本篇文章不会涉及具体的大数据技术相关的实现细节,相关原理(主要是咱也不会~),主要聊下对账系统如何联合 DP 平台实现完整数据对账方案。
对账系统概览
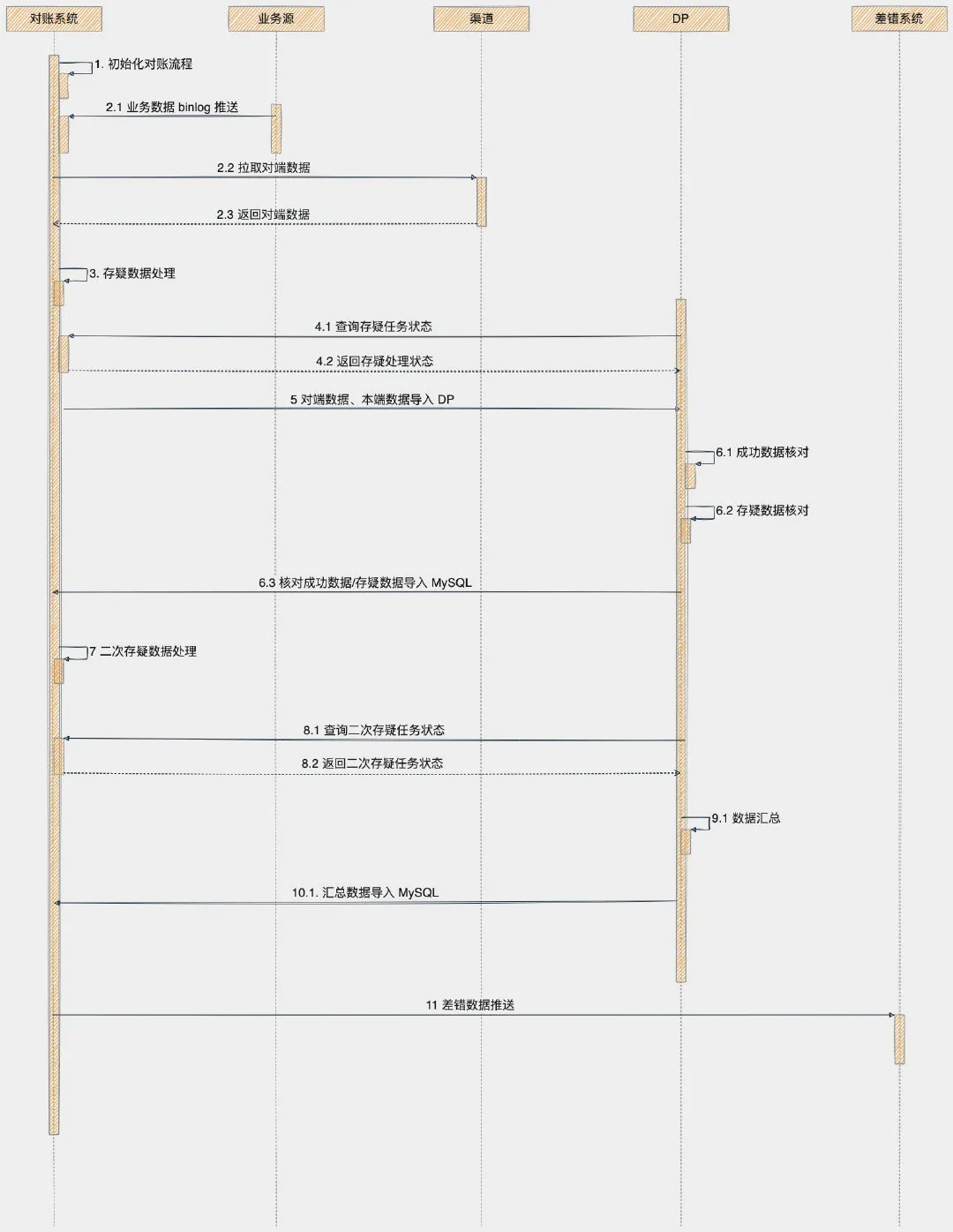
开头的时序图,我们可以看到整个对账过程设计好几个业务流程,那在这里对账系统内部将会维护一个流程状态机,当前一个流程处理结束之后,下一个流程才能被触发。
由于当前对账系统实现方案,涉及对账系统与 DP 平台,对账系统目前没办法调用 DP 平台触发任务,但是 DP 平台可以通过通过 HTTP 接口调用对账系统。
所以当前流程触发的方式使用的是定时任务的方案,每个流程有一个单独的定时任务。
对账系统内的定时任务触发的时候,将会判断当前流程是否已经到达执行条件,即判断一下当前任务的状态。
每个定时任务触发时间人为设置的时候,岔开一两分钟,防止同时运行。
DP 平台使用自带调度任务,对账系统无法控制 DP 任务的运行。
DP 平台定时任务可以通过运行 Scala 脚本代码,调用对账系统提供 HTTP 查询接口,通过这种方式判断当前流程是否已经到达执行条件。
下面详细解释一下每个流程。
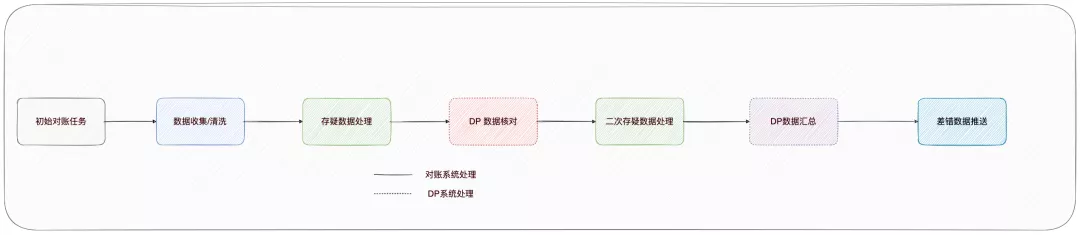
1. 初始化对账任务
对账系统依靠对账任务记录推动流转,目前每天凌晨将会初始化生成对账任务记录,后续任务流转就可以从这里开始。
对账系统维护一张对账核对规则表:

对账核对规则表关键字段含义如下:
- channel_code 渠道编码,每个支付渠道将会分配一个唯一渠道编码,例如微信,支付宝
- biz_type 业务类型,例如支付,退款,提现等
- status 是否生效
每次对接新的支付渠道,对账配置规则需要新增核对规则。
初始化对账定时任务将会查找核对规则表中所有的生效的配置规则,依次生成当天的对账任务记录:

对账任务记录部分字段与核对规则表含义一样,不再赘述,其他字段含义如下:
bill_date 账期,一般 D 日对账任务核对 D-1 数据,所以账期为 D-1 日
batch_no 对账批次,生成规则如下:账期+渠道编码+ 001
phase,当前对账任务处于阶段,根据上面对账流程可以分为:
初始化
数据收集
存疑处理
数据核对
二次存疑处理
数据汇总
差错数据推送
error_reason 错误原因
初始化对账任务结束之后,对账任务流程推动到第二阶段,数据收集。
2. 数据收集
数据收集阶段,收集两端待核对的数据,为后面的数据核对任务提供核对数据。
数据收集阶段分为两部分:
- 本端数据收集,即自己方产生的支付数据
- 对端数据收集,即三方渠道产生支付数据
本端数据收集
本端数据,是自己业务产生的支付数据,这些数据原本存在各个业务的数据库中。
对账系统获取这些支付数据,一般有两种方式:
- 查询,对账系统主动拉取
- 推送,对账系统监听获取数据
查询数据方式前面也聊到过,数据量小的情况下,没什么问题。一旦数据量变大,查询效率就会变低。
所以这里我们采用推送的方式,对账系统监听各个业务数据表 binlog,每当业务数据发生变动,对账系统就可以接受到 binlog 消息。
对账系统接受到 binlog 消息,将会判断当前消息是否需要过滤,是否已经支付成功等等,满足条件之后,binlog 消息将会插入本端数据表中,表结构如下:

本端记录表关键字段含义如下:
- channel_code 渠道编码,每个支付渠道将会分配一个唯一渠道编码,例如微信,支付宝
- biz_order_no 本端支付流水号
- bill_date 账期
- status 状态
- is_check 对账状态,0-未核对,1-已核对
- trade_amount 支付金额
- channel_order_no 三方渠道支付单号
- merchant_no 商户号
- sub_merchant_no 子商户号
上面展示的支付记录表结构,根据业务类型不同,本端其实还有退款记录表,提现记录表等。
这里设计的时候,实际上也可以将所有业务数据放在一张表中,然后根据业务类型字段区分。
对端数据收集
对端数据,就是第三方支付渠道产生支付数据,一般 D 日产生交易之后,D+1 日第三方渠道将会生成一个对账文件。
对账系统需要从对端提供的对账文件获取对端数据。
渠道的对账文件,下载方式,文件类型存在很大的差异,每次接入新的支付渠道,这里需要经过新的开发。
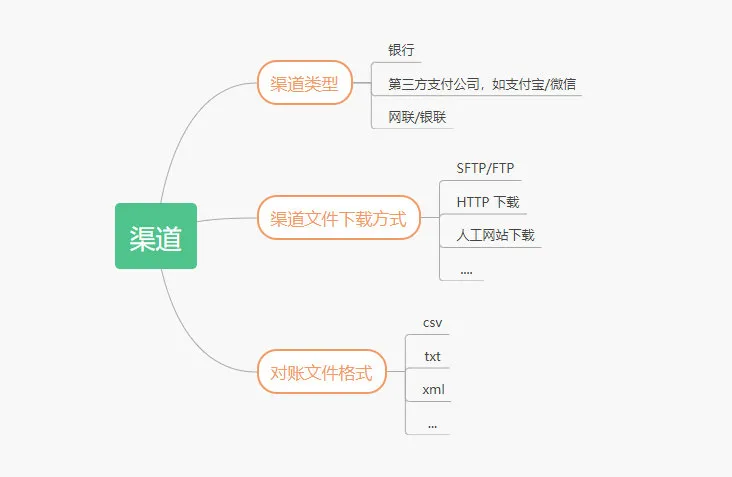
对端数据这里维护了一张渠道下载配置表,对端数据收集的时候将会获取所有可用配置:

渠道下载配置表关键字段含义如下:
mch_id 三方渠道分配的商户号
type 下载类型:
FTP
SFTP
HTTP
download_param 下载的配置参数,比如 FTP 的地址,登录密码,下载地址等。
对账文件下载成功之后,需要根据文件类型进行解析,最后转化自己的需要的对账数据入库。
对端数据表结构如下:

上面关键字段与本端记录表类似,额外新增字段:
channel_fee 渠道手续费,用于统计渠道收的手续费。
同样渠道记录表根据根据业务类型也分为退款渠道记录表,提现渠道记录表等,同样也可以合并成一张表,根据业务类型区分。
对端数据收集阶段,由于拉取三方渠道的对账文件,那有时候渠道端存在异常,将会导致对账文件下载延迟,从而导致其他任务也出现的相应的延迟。
这一点是整个对账流程中,相对不可控的问题。我们需要在对账流程设计中考虑这一点。
对账文件下载解析成功入库之后,对账流程将会流转到下一个流程存疑数据处理。
3. 存疑数据处理
讲解这个流程之前,先给大家解释一下什么是存疑数据?
正常支付过程中,会存在一个两边账期不一致的问题,比如说本端数据支付时间是 2021 年 12 月 28 日 23 点 59 分 59 秒,那么本端认为这笔支付交易账期是 2021 年 12 月 28 日。
然而这笔支付发送给三方渠道之后,三方渠道支付成功的时间已经是 2021 年 12 月 29 日 0 点 0 分 2 秒,三方渠道支付账期记为2021 年 12 月 29 日。
这种情况下我们这边记录账期是 2021 年 12 月 28 日,但是第三方渠道这笔记录是 2021 年 12 月 29 日,所以 2021 年 12 月 28 日对账单上没有这笔支付记录,这就导致一笔差异数据(一端有/一端无)的情况。
上面这种情况就是典型因为日切问题导致差异。
但是我们知道 2021 年 12 月 29 日对账单上肯定会包含这笔,所以我们可以先把这笔差异数据挂起,当做存疑数据,等到 2021 年 12 月 29 日账期对账的时候,对方账单包含这笔,当天就能核对成功,这就解决这笔差异数据。
所以说存疑数据,就跟其字面意思一样,当这笔数据当前处理不了的时候,那就现放着,不做定论,过一天我再尝试处理一下。
除了上面日切问题导致的差异数据以外,还有一些情况:
- 网络问题,导致两边订单状态不一致。
- 测试环境与生产环境共用一个三方渠道商户号,测试环境产生的交易出现在对账单里
存疑数据分为三种类型:
- 本端有,渠道无,即本端存在订单信息,渠道账单记录没有订单信息,可能是日切导致的问题
- 渠道有,本端无,即本端不存在订单信息,渠道端账单记录却有订单信息,可能是测试环境与生产环境共用渠道参数
- 金额不平,即双方都存在订单信息,但是双方订单金额不一致
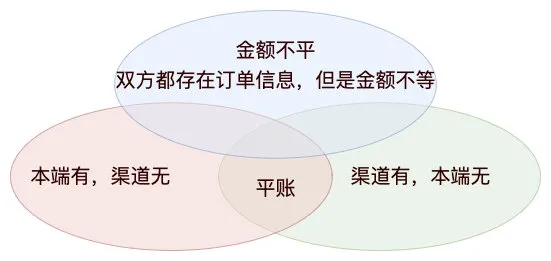
了解完存疑数据的定义,我们再来看下存疑数据处理的流程。
存疑数据将会由下面的流程中产生,这里先来看下存疑表结构:

关键字段如下:
- batch_no 批次号
- biz_id 业务单号
- biz_amount 金额
- status 0-未处理,1-已处理
- biz_date 账期
- biz_type 业务类型
- channel_code 渠道类型
- delayed_times 延迟天数
- merchant_no 商户号
- sub_merchant_no 子商户号
- buffer_type 存疑类型,0-本端存疑,1-渠道存疑
存疑处理过程将会捞起所有存疑表中还未处理的存疑数据,根据存疑类型反向查找对账数据表。例如:
- 渠道存疑(第一天对账,本端有,渠道无),查找对端数据
- 本端存疑(第一天对账,本端无,渠道有),查找本端数据
查找对端/本端数据,都是根据支付流水号加业务类型查找定位。
如果在本端/对端数据中找到,这里还需要再对比一下金额:
- 如果金额不相等,代表单号相同,但是金额不等,将这笔移动到支付差异表
- 如果金额相等,代表这两笔核平,存疑表将这笔数据更新为核对成功,本端/对端数据更新为对账成功
上面这一步比较重要,因为下面对账核对过程主要核对要素是支付流水号+支付金额,通过这种方式收集单片账是无法知道是因为单号不存在,还是因为金额不存在原因,具体流程可以看下下面核对流程。
如果在本端/对端数据还是找不到,那就根据渠道配置的存疑规则,如果当前已经存疑的天数大于配置渠道存疑天数,则将数据直接移动到差错表。
如果存疑天数小于当前渠道配置天数,那就不要管,继续保存在存疑表,等待下一天存疑数据处理。
一般来说,日切导致的数据,存疑一天,就可以解决。但是有些渠道可能是 T+1 在对账,这种情况需要配置的存疑天数就要长一点了。
本地存疑数据处理结束之后,下面就要开始 DP 数据处理。
4. 数据导入 DP
在 DP 核对之前,我们需要将对账系统收集的数据,从 MySQL 导入 DP Hive 表中。
DP 任务调度开始,DP 平台定时检测对账系统提供 HTTP 接口,判断本次存疑流程是否处理完成。
如果完成,自动触发将数据从 MySQL 导入 DP Hive 表中。
数据导入之后,将会开始 DP 核对规程。这个过程就是整个对账流程最关键的部分,这个流程核对两端数据,检查两端是否存在差异数据。
5. DP 核对
数据导入结束,DP 平台开始核对数据,这个过程分为两个核对任务:
成功数据核对
成功数据核对任务,核对的目的是为了核对出本端与对端支付单号与金额一致的数据。
这里的核对任务使用了 Hive SQL,整个 SQL 如下所示:
---- A
CREATE TABLE IF NOT EXISTS dp.pay_check_success (
`batch_no` bigint comment '批次号',
`merchant_no` string comment '三方商户号',
`sub_merchant_no` string comment '三方子商户号',
`biz_id` string comment '对账业务关联字段',
`biz_amount` bigint comment '金额',
`biz_date` string comment '业务日期',
`biz_type` int comment '业务类型',
`status` int comment '状态标识',
`remark` string comment '备注',
`create_time` string comment '创建时间',
`update_time` string comment '修改时间',
`trade_date` int comment '订单交易日期',
`channel_code` int comment '渠道类型'
);
----B
insert
overwrite table dp.pay_check_success
select
tb1.batch_no as batch_no,
tb1.merchant_no as merchant_no,
tb1.sub_merchant_no as sub_merchant_no,
tb1.biz_id as biz_id,
tb1.biz_amount as biz_amount,
tb1.biz_date as biz_date,
tb1.biz_type as biz_type,
tb1.status as status,
tb1.remark as remark,
tb1.trade_date as trade_date,
tb1.channel_code as channel_code
from
(
select
tb2.batch_no as batch_no,
tb1.merchant_no as merchant_no,
tb1.sub_merchant_no as sub_merchant_no,
tb1.biz_order_no as biz_id,
tb1.trader_amount as biz_amount,
'${DP_1_DAYS_AGO_Ymd}' as biz_date,
'0' as status,
'' as remark,
'${DP_1_DAYS_AGO_Ymd}' as trade_date,
tb1.channel_code as channel_code
from
dp.pay_check_record tb1
inner join dp.pay_check_channel_record tb2 on tb1.biz_order_no = tb2.biz_order_no
and tb1.trader_amount = tb2.trader_amount
and tb1.channel_code = tb2.channel_code
where
tb1.is_check = 0
and tb2.is_check = 0
and tb1.bill_date = '${DP_1_DAYS_AGO_Ymd}'
and tb2.bill_date = '${DP_1_DAYS_AGO_Ymd}'
and tb1.is_filter = 0
) tb1
整个 SQL 分为两部分,第一部分将会在 DP 中创建一张 pay_check_success,记录核对成功的数据。
第二部分,将核对成功的数据插入上面创建的 pay_check_success 表中。
查找核对成功的数据 SQL 如下:
select
tb2.batch_no as batch_no,
tb1.merchant_no as merchant_no,
tb1.sub_merchant_no as sub_merchant_no,
tb1.biz_order_no as biz_id,
tb1.trader_amount as biz_amount,
'${DP_1_DAYS_AGO_Ymd}' as biz_date,
'0' as status,
'' as remark,
'${DP_1_DAYS_AGO_Ymd}' as trade_date,
tb1.channel_code as channel_code
from
dp.pay_check_record tb1
inner join dp.pay_check_channel_record tb2 on tb1.biz_order_no = tb2.biz_order_no
and tb1.trader_amount = tb2.trader_amount
and tb1.channel_code = tb2.channel_code
where
tb1.is_check = 0
and tb2.is_check = 0
and tb1.bill_date = '${DP_1_DAYS_AGO_Ymd}'
and tb2.bill_date = '${DP_1_DAYS_AGO_Ymd}'
and tb1.is_filter = 0
上述 SQL 存在一些 DP 平台系统变量。DP_1_DAYS_AGO_Ymd 代表当前日期的前一天
主要逻辑非常简单,利用 SQL 内连接查询的功能,可以查找单号,金额,渠道编码一致的数据。
成功数据核对任务结束,将会把刚才在 DP 中创建的 pay_check_success 同步回对账系统的 MYSQL 数据库中。
存疑数据核对
存疑数据核对任务,核对的目的是为了核对出本端与对端支付单号或金额不一致的数据。
这些数据将会当做存疑数据,这些数据将会在第二阶段存疑数据处理。
这里的核对任务也是使用了 Hive SQL ,整个 SQL 跟上面比较类似,SQL 如下所示:
CREATE TABLE IF NOT EXISTS dp.check_dp_buffer_record (
`biz_id` string comment '订单号',
`order_type` string comment '订单类型 0本端订单 1渠道订单',
`bill_date` int comment '对账日期',
`biz_type` int comment '业务类型',
`channel_code` int comment '渠道类型',
`amount` string comment '金额',
`merchant_no` string comment '商户号',
`sub_merchant_no` string comment '三方子商户号',
`trade_date` int comment '交易日期',
`create_time` string comment '创建时间',
`update_time` string comment '修改时间'
);
insert
overwrite table dp.check_dp_buffer_record
select
tb1.biz_id as biz_id,
tb1.order_type as order_type,
tb1.bill_date as bill_date,
tb1.biz_type as biz_type,
tb1.channel_code as channel_code,
tb1.amount as amount,
tb1.merchant_no as merchant_no,
tb1.sub_merchant_no as sub_merchant_no,
tb1.trade_date as trade_date,
'${DP_0_DAYS_AGO_Y_m_d_HMS}',
'${DP_0_DAYS_AGO_Y_m_d_HMS}'
FROM
(
select
tb1.biz_order_no as biz_id,
0 as order_type,
tb1.bill_date as bill_date,
10 as biz_type,
tb1.channel_code as channel_code,
tb1.trade_amount as amount,
tb1.merchant_no as merchant_no,
tb1.sub_merchant_no as sub_merchant_no,
'${DP_1_DAYS_AGO_Ymd}' as trade_date
FROM
(
select
biz_order_no,
bill_date,
channel_code,
trade_amount,
merchant_no,
sub_merchant_no
from
ods.pay_check_record
where
and bill_date = '${DP_1_DAYS_AGO_Ymd}'
and is_filter = 0
and is_check = 0
) tb1
LEFT JOIN (
select
biz_order_no,
trade_amount,
channel_code
from
ods.pay_check_channel_record
where
and bill_date = '${DP_1_DAYS_AGO_Ymd}'
and is_check = 0
) tb2 ON tb1.biz_order_no = tb2.biz_order_no
and tb1.trade_amount = tb2.trade_amount
and tb1.channel_code = tb2.channel_code
where
tb2.biz_order_no IS NULL
union
select
tb1.biz_order_no as biz_id,
1 as order_type,
tb1.bill_date as bill_date,
10 as biz_type,
tb1.channel_code as channel_code,
tb1.trade_amount as amount,
tb1.merchant_no as merchant_no,
tb1.sub_merchant_no as sub_merchant_no,
'${DP_1_DAYS_AGO_Ymd}' as trade_date
FROM
(
select
biz_order_no,
bill_date,
channel_code,
trade_amount,
merchant_no,
sub_merchant_no
from
ods.pay_check_chnnel_bill
where
and bill_date = '${DP_1_DAYS_AGO_Ymd}'
and is_check = 0
) tb1
LEFT JOIN (
select
biz_order_no,
channel_code,
trade_amount
from
ods.pay_check_record
where
and bill_date = '${DP_1_DAYS_AGO_Ymd}'
and is_filter = 0
and is_check = 0
) tb2 ON tb1.biz_order_no = tb2.biz_order_no
and tb1.trade_amount = tb2.trade_amount
and tb1.channel_code = tb2.channel_code
where
tb2.biz_order_no IS NULL
) tb1;
整个 SQL 分为两部分,第一部分将会在 DP 中创建一张 check_dp_buffer_record,记录核对差异的的数据。
第二部分,将核对差异的数据插入上面创建的 check_dp_buffer_record 表中。
查找差异数据较为麻烦,需要分成两部分收集:
- 本端单边账,即本端存在数据,但是对端不存在数据
- 渠道端单边账,即对端存在数据,本端不存在数据
两边数据查找到之后,使用 SQL union 功能,将两端数据联合。
我们先来看下本端单边张的逻辑的:
select
tb1.biz_order_no as biz_id,
0 as order_type,
tb1.bill_date as bill_date,
10 as biz_type,
tb1.channel_code as channel_code,
tb1.trade_amount as amount,
tb1.merchant_no as merchant_no,
tb1.sub_merchant_no as sub_merchant_no,
'${DP_1_DAYS_AGO_Ymd}' as trade_date
FROM
(
select
biz_order_no,
bill_date,
channel_code,
trade_amount,
merchant_no,
sub_merchant_no
from
ods.pay_check_record
where
and bill_date = '${DP_1_DAYS_AGO_Ymd}'
and is_filter = 0
and is_check = 0
) tb1
LEFT JOIN (
select
biz_order_no,
trade_amount,
channel_code
from
ods.pay_check_channel_record
where
and bill_date = '${DP_1_DAYS_AGO_Ymd}'
and is_check = 0
) tb2 ON tb1.biz_order_no = tb2.biz_order_no
and tb1.trade_amount = tb2.trade_amount
and tb1.channel_code = tb2.channel_code
where
tb2.biz_order_no IS NULL
SQL 看起来比较复杂,实际逻辑可以简化为下面 SQL:
select
*
from
innerTab t1
LEFT JOIN channelTab t2 ON t1.biz_order_no = t2.biz_order_no
and t1.trade_amount = t2.trade_amount
and t1.channel_code = t2.channel_code
where
t2.biz_order_no is null;
这里主要利用 SQL 左连接的功能,本端数据 left join 渠道数据,如果渠道单号不存在,则认为本端数据存在,渠道数据不存在,当然也有可能是两端数据都存在,但是金额不相等。
这种情况记为本端数据存疑,orderType 为 0。
渠道端单边账收集逻辑:
select
tb1.biz_order_no as biz_id,
1 as order_type,
tb1.bill_date as bill_date,
10 as biz_type,
tb1.channel_code as channel_code,
tb1.trade_amount as amount,
tb1.merchant_no as merchant_no,
tb1.sub_merchant_no as sub_merchant_no,
'${DP_1_DAYS_AGO_Ymd}' as trade_date
FROM
(
select
biz_order_no,
bill_date,
channel_code,
trade_amount,
merchant_no,
sub_merchant_no
from
ods.pay_check_chnnel_bill
where
and bill_date = '${DP_1_DAYS_AGO_Ymd}'
and is_check = 0
) tb1
LEFT JOIN (
select
biz_order_no,
channel_code,
trade_amount
from
ods.pay_check_record
where
and bill_date = '${DP_1_DAYS_AGO_Ymd}'
and is_filter = 0
and is_check = 0
) tb2 ON tb1.biz_order_no = tb2.biz_order_no
and tb1.trade_amount = tb2.trade_amount
and tb1.channel_code = tb2.channel_code
where
tb2.biz_order_no IS NULL
逻辑与本端单边账收集类似,渠道数据 left join 本端数据,如果本端单号不存在,则为渠道数据存在,本端数据不存在。当然也有可能是两端数据都存在,但是金额不相等。
这里记为渠道存疑数据,orderType 为 1。
成功数据核对以及存疑数据核对结束,DP 平台将会自动把数据从 Hive 表中导入到 MySQL。
数据导出结束,DP 平台将会调用对账系统的相关接口,通知对账系统 DP 核对流程结束。
DP 核对流程是整个对账流程核心流程,目前千万级数据的情况下,大概能在一个小时之内搞定。
DP 核对流程结束之后,对账系统开始下个流程-二次存疑数据处理。
6. 二次存疑数据处理
前面流程我们讲到存疑处理,为什么这里还需要二次存疑数据处理呢?
这因为 DP 核对存疑数据收集的过程,我们使用业务单号与金额去互相匹配,那如果不存在,有可能是因为两端数据有一端不存在,还有可能是因为两端数据数据都存在,但是金额却不相等。
DP 核对过程是无法区分出这两种情况,所以增加一个二次存疑数据处理流程,单独区分出这两类数据。
回到二次存疑数据处理流程,当天产生的所有存疑数据都从 DP 中导入到 check_dp_buffer_record 表。
二次存疑数据处理流程将会查找 check_dp_buffer_record 表所有未核对的记录,然后依次遍历。
遍历过程中将会尝试在 check_dp_buffer_record 表中查找相反方向的存疑数据。
这个可能不好理解,举个例子:
假如有一笔订单,本端是 100 元,渠道端是 10 元。这种情况两笔记录都会出现在 check_dp_buffer_record 表。
遍历到本端这笔的时候,这笔类型是本端存疑,type为 0。使用者本端单号从 check_dp_buffer_record 查找渠道端存疑(type 为 1)的数据。
上面的情况可以找到,证明这笔存疑数据其实是金额不相等,这里需要将数据移动到差错表。
那如果是正常一端缺失的数据,那自然去相反方向查找是找不到的,这种数据是正常存疑数据,移动内部存疑表。
对账系统二次存疑数据处理结束之后,开始下一个阶段数据汇总。
7. 数据汇总
数据汇总阶段就是为了统计当天每个有多少成功功对账数据,多少存疑数据,统计结束通过看板给相关运营人员展示统计数据。
由于数据量大的问题,这里使用的是 DP 平台 Sprak 任务进行任务统计。
这里逻辑简单解释为,就是利用 Scala 脚本代码对数据进行相关求和,这里代码没有普遍性,就不展示具体的逻辑了。
8. 差错数据推送
数据汇总结束之后,开始下一个阶段,差错数据推送给差错系统。
上面存疑数据处理的流程中转化的差错数据,当前存在对账系统内部差错数据表中。
目前我们差错数据是是另外一个差错系统单独处理,所以对账系统需要把差错数据表数据推送给差错系统。
这里的逻辑比较简单,查找所有待处理的差错数据,遍历发送 NSQ 消息给差错系统。